This is the multi-page printable view of this section. Click here to print.
Networks
- A Complete Guide to Network Commands in MacOS Terminal: IP Addresses and Beyond
- What is Squid Proxy Server
- What are the advantages of using IEEE 802.3 over IEEE 802.5 in enterprise networks
- How do the data transmission speeds of IEEE 802.3 and IEEE 802.5 networks compare
- What are the main differences between IEEE 802.3 and IEEE 802.5 standards
- How do the physical topologies of IEEE 802.3 and IEEE 802.5 networks differ
- RFC 3261: Unraveling the Session Initiation Protocol (SIP)
- Commonly Used Crypto Terms and Their Brief Descriptions
- How do coins and tokens impact the overall cryptocurrency market
- Understanding IEEE Standards: Importance, Development, and Applications
- Getting Started with AlmaLinux 9 Initial Settings
- Mastering DNS Configurations with BIND on AlmaLinux 9
- Building Your Local Network with DNSmasq and DHCP on AlmaLinux 9
- Simplifying Network Configuration with DHCP on AlmaLinux 9
- Understanding Internet Service Providers (ISPs): A Comprehensive Guide
- Internet Protocol (IP) Overview: Understanding the Foundation of Internet Communications
- Address Resolution Protocol (ARP): The Network's Address Book
- Private vs. Public IP Addresses: A Complete Guide to Network Addressing
- Understanding Network Address Translation (NAT): Types, Benefits, and How It Works
- TCP vs. UDP: Differences and Use Cases
- Data Encapsulation in Networking: A Layer-by-Layer Breakdown
- TCP/IP Model Layers and Functions
- Understanding the OSI Model Layers: A Comprehensive Guide
- Subnetting and CIDR Notation: A Deep Dive
- IPv4 vs. IPv6: A Comprehensive Guide to Internet Protocol Addressing
- Understanding MAC Addresses and IP Addresses: Key Differences and Uses in Networking
- Network Devices: Routers, Switches, and Hubs
- Peer-to-Peer vs. Client-Server Networks
- Network Topologies: Understanding Star, Bus, Ring, and Mesh Architectures
- Types of Computer Networks: Understanding LAN, MAN, and WAN
- Understanding Data Modulation Techniques in Communication Systems
- Half-Duplex vs. Full-Duplex Communication: A Comprehensive Guide
- Demultiplexing Techniques: Understanding Signal Separation in Modern Communications
- Multiplexing in Data Communications: How It Works and Why It’s Essential
- Data Compression Techniques in Modern Computing
- Network Error Detection and Correction Methods: Ensuring Data Integrity in Digital Communications
- Latency and Jitter: Understanding Their Impact on Network Performance
- Understanding Bandwidth and Throughput: Key Concepts in Networking
- Wired vs. Wireless Communication: A Comparative Analysis
- Transmission Media in Data Communications: Understanding the Physical Layer of Network Infrastructure
- Synchronous vs. Asynchronous Transmission: Key Differences, Benefits, and Use Cases
- Data Transmission Modes
- The Indispensable Role of Standards in Networking
- Communication Protocols Overview: A Comprehensive Guide to Modern Data Exchange
- Analog vs. Digital Communication: Understanding the Differences, Benefits, and Challenges
- Configuring SIP Trunks in FreeSWITCH
- Integrating FreeSWITCH with Asterisk: A Comprehensive Guide
- Setting Up a FreeSWITCH Basic Dialplan
- Configuring FreeSWITCH for the First Time on Alma Linux
- Configuring FreeSWITCH for the First Time on Ubuntu Server
- Installing FreeSWITCH on Alma Linux: A Step-by-Step Guide
- Installing FreeSWITCH on Ubuntu Server: A Step-by-Step Guide
- Types of Communication Channels: Guide to Effective Information Exchange
- Basic Terminologies in Data Communications
- Data Communication: Building the Foundation for Modern Connectivity
- A/D Conversion: A Comprehensive Guide to Analog-to-Digital Conversion
- Understanding AI Models: Ultimate Modern Artificial Intelligence Guide
- USDC (USD Coin): Guide to the Leading Regulated Stablecoin
- Exploring Solana: The High-Speed Blockchain and Its Native Coin, SOL
- Must Known Common Cryptocurrency Terms For You
- What is Cryptocurrency? Why Are They So Popular?
- Extended List of Social Media Platforms
- Exploring Mastodon: A Decentralized Alternative to Traditional Social Media
- Best Social Sharing Plugins for WordPress: A Comprehensive Guide
- 300 topics related to Data Communications and Networking
- The Top 5 Technology Trends You Can't Ignore in 2024
- The Future of Electric Vehicles: How Tech Innovations Are Driving the EV Revolution
- How 5G is Shaping the Future of IoT: What to Expect in 2024 and Beyond
- GPU vs CPU: When and Why to Choose One Over the Other
- How Edge Computing is Changing the Game in Data Processing
- Explainable AI: Why It’s Crucial for the Future of Artificial Intelligence
- Machine Learning in 2024: Trends and Predictions
- How AI is Revolutionizing Healthcare: From Diagnosis to Treatment
- Time Analysis: Understanding Static and Dynamic Hazards in Digital Logic Circuits
- Digital System Design: Top-Down and Bottom-Up Design Approaches
- Mastering Cloud and AI with Google Cloud’s Cloud Skills Boost
- Floating-Point Arithmetic Units : A Comprehensive Guide
- Multiplication and Division Circuits in Digital Systems: A Comprehensive Guide
- Multiplexers and Demultiplexers: Essential Building Blocks of Digital Systems
- BCD, Gray Code, and Other Encoding Schemes: Unraveling the World of Digital Data Representation
- Starlink Satellites and Internet Services
- Should an Emotional Bond be Established with Artificial Intelligence? What to Consider
- Understanding Networks: A Comprehensive Guide to Modern Connectivity
- IP-MPLS: The Backbone of Modern Network Infrastructure
- GSM-R: The Digital Backbone of Modern Railway Communication
- Apache Multiprocessing Modules: Optimizing Your Web Server's Performance
- Apache Modules: Enhancing Your Web Server's Functionality
- Introduction to Algorithms: A Closer Look at the Writers Behind the Masterpiece
- Virtual Distributed Filesystem (VDFS): An In-Depth Overview
- Ethernet Ports and Commonly Used Ports for Services: An In-Depth Guide
- UDP Communication: The Swift and Efficient Data Transfer Protocol
- TCP Communication: The Backbone of Reliable Internet Data Transfer
- Understanding Wide Area Networks (WANs)
- Understanding Local Area Networks (LANs)
- NetBIOS: A Primer
- IoT: Understanding the Internet of Things
- What is LLM (Large Language Model)? A Comprehensive Guide
- Understanding AI Models: A Comprehensive Guide to the World of Artificial Intelligence
- Understanding Network Address Translation (NAT): A Comprehensive Guide
A Complete Guide to Network Commands in MacOS Terminal: IP Addresses and Beyond
For Mac users who want to dive into network diagnostics and management through the Terminal, understanding the essential networking commands is crucial. This comprehensive guide will walk you through the most useful Terminal commands for viewing IP addresses and managing network connections on MacOS.
Viewing IP Addresses
Checking Your Local IP Address
The most straightforward way to view your IP address is using the ifconfig command. While this command is considered legacy on Linux systems, it remains fully functional on MacOS:
ifconfig
This command displays information about all network interfaces. However, it provides a lot of information that might be overwhelming. To filter for just your primary interface (usually en0 for Wi-Fi or en1 for Ethernet):
ifconfig en0 | grep inet
A more modern alternative is the ip command:
ipconfig getifaddr en0
Finding Your Public IP Address
Your public IP address (the one visible to the internet) can be checked using curl commands:
curl ifconfig.me
or
curl ipecho.net/plain
Essential Network Diagnostic Commands
1. Network Statistics with netstat
The netstat command provides network statistics and information:
# View all active connections
netstat -an
# View routing table
netstat -r
# Display network interface statistics
netstat -i
2. Testing Connectivity with ping
The ping command sends ICMP echo requests to test network connectivity:
# Basic ping
ping www.google.com
# Limit to specific number of pings
ping -c 5 www.google.com
3. Tracing Network Routes
Use traceroute to see the path packets take to reach a destination:
traceroute www.google.com
4. DNS Lookups
The dig command provides detailed DNS information:
# Basic DNS lookup
dig www.google.com
# Short answer only
dig +short www.google.com
# Reverse DNS lookup
dig -x 8.8.8.8
Advanced Network Management
1. Network Service Management
MacOS provides the networksetup command for advanced network configuration:
# List all network services
networksetup -listallnetworkservices
# Get Wi-Fi information
networksetup -getinfo "Wi-Fi"
# Turn Wi-Fi off/on
networksetup -setairportpower en0 off
networksetup -setairportpower en0 on
2. Wi-Fi Specific Commands
The airport command (a symbolic link must be created first) provides detailed Wi-Fi information:
# Create symbolic link (only needs to be done once)
sudo ln -s /System/Library/PrivateFrameworks/Apple80211.framework/Versions/Current/Resources/airport /usr/local/bin/airport
# Scan for available networks
airport -s
# Get current Wi-Fi status
airport -I
3. Network Port Information
Use lsof to list open network ports and the processes using them:
# List all network connections
sudo lsof -i
# List processes listening on specific ports
sudo lsof -i :80
Troubleshooting Network Issues
1. Flushing DNS Cache
When experiencing DNS-related issues, clearing the DNS cache can help:
sudo dscacheutil -flushcache; sudo killall -HUP mDNSResponder
2. Network Interface Reset
If you’re having network connectivity issues, you can reset the network interface:
sudo ifconfig en0 down
sudo ifconfig en0 up
3. Checking Network Hardware Status
For detailed information about your network hardware:
system_profiler SPNetworkDataType
Best Practices and Tips
Regular Monitoring: Make it a habit to check network statistics periodically using commands like
netstatandifconfigto understand your network’s normal behavior.Security Awareness: When using commands that show network information, be cautious about sharing the output as it may contain sensitive information about your network configuration.
Documentation: Keep a record of useful commands and their outputs when your network is functioning correctly. This provides a baseline for comparison when troubleshooting issues.
Permission Management: Many network commands require administrator privileges. Always use
sudowith caution and only when necessary.
Conclusion
Understanding and effectively using Terminal network commands on MacOS is an essential skill for any system administrator or power user. These commands provide detailed insights into your network configuration and are invaluable for troubleshooting connectivity issues. While the graphical interface provides basic network information, the Terminal offers more detailed control and diagnostic capabilities.
Remember that networking is complex, and these commands are just the beginning. As you become more comfortable with these basic commands, you can explore more advanced networking tools and concepts to better manage and troubleshoot your network connections.
What is Squid Proxy Server
In today’s digital landscape, managing and optimizing network traffic is vital for organizations of all sizes. A Squid Proxy Server is a powerful, versatile tool widely used to improve network efficiency, enhance security, and manage internet usage.
This article explores what a Squid Proxy Server is, how it works, its features, benefits, use cases, and how you can set it up and optimize it for your network.
What is a Proxy Server?
Before diving into Squid, it’s essential to understand what a proxy server is. A proxy server acts as an intermediary between a client (e.g., a computer or mobile device) and the internet. When a client sends a request to access a website or service, the proxy server intercepts and processes the request, forwarding it to the destination server. The destination server then sends the response back to the proxy, which relays it to the client.
What is Squid Proxy Server?
Squid Proxy Server is an open-source, high-performance caching proxy for web clients and servers. Originally developed for Unix-like systems, Squid has grown to support multiple operating systems, including Linux, FreeBSD, and Windows.
Key features of Squid Proxy Server include:
- Web caching: Stores frequently requested web content to reduce bandwidth usage and improve response times.
- Access control: Manages who can access specific resources on the internet.
- Content filtering: Blocks or restricts access to specific websites or types of content.
- Protocol support: Supports HTTP, HTTPS, FTP, and more.
- Logging and monitoring: Tracks user activity and network performance.
Squid is widely used by organizations, ISPs, and individuals to optimize network performance, enhance security, and control internet usage.
How Does Squid Proxy Server Work?
At its core, Squid operates as a caching proxy server. Here’s a step-by-step breakdown of its functionality:
- Client Request: A client device sends a request to access a web resource, such as a webpage or file.
- Request Interception: The Squid proxy server intercepts the request.
- Cache Check: Squid checks its cache to see if the requested content is already stored.
- If found, the content is served directly from the cache.
- If not found, Squid forwards the request to the destination server.
- Content Delivery: The destination server responds with the requested content.
- Cache Update: Squid stores the retrieved content in its cache for future requests.
- Client Response: The proxy server delivers the content to the client.
This process not only speeds up content delivery but also reduces bandwidth usage and enhances network performance.
Key Features of Squid Proxy Server
Squid stands out due to its rich feature set. Let’s examine its core functionalities:
1. Caching
Squid stores web resources locally, reducing the need to fetch them repeatedly from external servers. This improves load times and reduces bandwidth costs.
2. Protocol Support
Squid supports various protocols, including HTTP, HTTPS, and FTP. It can also act as a reverse proxy, handling requests for servers within a private network.
3. Access Control
Administrators can define rules to control which users or devices can access specific resources. For example, access can be restricted based on IP addresses, usernames, or time of day.
4. Content Filtering
Squid integrates with third-party tools to filter content, block advertisements, and restrict access to inappropriate websites.
5. SSL Bumping
Squid can inspect and filter HTTPS traffic by decrypting and re-encrypting secure connections. This is especially useful for enforcing security policies.
6. Logging and Reporting
Squid provides detailed logs of user activity, which are invaluable for troubleshooting, monitoring, and compliance purposes.
7. Scalability
Squid is designed to handle large-scale deployments, making it suitable for small businesses, large enterprises, and ISPs.
Benefits of Using Squid Proxy Server
Implementing Squid Proxy Server in your network environment offers numerous advantages:
1. Improved Network Performance
- Caching reduces the need to fetch repeated content from external servers, improving load times for end-users.
- Bandwidth savings help organizations lower their internet costs.
2. Enhanced Security
- Squid hides client IP addresses, adding an extra layer of privacy.
- SSL bumping allows for inspection of encrypted traffic, helping detect malicious activities.
3. Better Resource Management
- Access control ensures that only authorized users can access specific resources.
- Administrators can limit bandwidth usage for certain users or applications.
4. Reduced Server Load
- Squid can act as a reverse proxy, distributing traffic across multiple servers and reducing the load on backend servers.
5. Detailed Insights
- Logs and reports provide insights into user behavior, helping with policy enforcement and troubleshooting.
Common Use Cases of Squid Proxy Server
Squid’s versatility makes it ideal for various scenarios:
1. Internet Service Providers (ISPs)
ISPs use Squid to cache web content and reduce bandwidth costs while improving load times for subscribers.
2. Educational Institutions
Schools and universities deploy Squid for content filtering and bandwidth management, ensuring appropriate internet usage.
3. Businesses
Organizations use Squid to secure their networks, control internet access, and optimize resource usage.
4. Content Delivery Networks (CDNs)
Squid acts as a reverse proxy in CDNs, caching and delivering content efficiently to end-users.
5. Personal Use
Tech-savvy individuals use Squid for personal projects, such as setting up a private caching proxy or managing internet traffic in a home network.
Setting Up Squid Proxy Server
Follow these steps to set up and configure Squid on a Linux-based system:
Step 1: Install Squid
Update your package repository and install Squid:
sudo apt update # For Debian/Ubuntu-based systems
sudo apt install squid -y
For AlmaLinux, use:
sudo dnf install squid -y
Step 2: Configure Squid
Edit the main configuration file:
sudo nano /etc/squid/squid.conf
Set up basic parameters, such as:
- Access control lists (ACLs): Define which clients can use the proxy.
- Cache settings: Optimize the caching behavior.
- Port settings: Specify the port Squid listens on (default is 3128).
For example:
acl localnet src 192.168.1.0/24
http_access allow localnet
http_port 3128
Step 3: Start Squid
Enable and start the Squid service:
sudo systemctl enable squid
sudo systemctl start squid
Step 4: Test the Proxy
Configure a client to use the Squid proxy and test internet connectivity. Check the logs for activity:
sudo tail -f /var/log/squid/access.log
Optimizing Squid Proxy Server
For best performance, consider these tips:
- Adjust Cache Size: Configure the cache size based on your available storage and traffic volume.
- Enable DNS Caching: Reduce DNS lookup times by enabling DNS caching.
- Monitor Logs: Regularly review logs to detect unusual activity or troubleshoot issues.
- Use Authentication: Implement user authentication to restrict access and enhance security.
Challenges and Limitations of Squid Proxy Server
While Squid offers numerous benefits, it also has some limitations:
- Complex Configuration: Setting up Squid requires a solid understanding of networking and proxies.
- Resource Intensive: Large-scale deployments may require significant CPU and memory resources.
- SSL Limitations: SSL bumping may cause compatibility issues with some websites or applications.
Conclusion
Squid Proxy Server is a robust, feature-rich tool that helps organizations manage, optimize, and secure their network traffic. From caching and access control to content filtering and logging, Squid offers a wide range of functionalities suitable for various use cases.
Whether you’re an IT administrator optimizing a corporate network or a tech enthusiast experimenting with proxies, Squid Proxy Server is a valuable asset. By understanding its features, benefits, and setup process, you can leverage Squid to improve network efficiency, enhance security, and ensure seamless internet access for users.
What are the advantages of using IEEE 802.3 over IEEE 802.5 in enterprise networks
When comparing IEEE 802.3 (Ethernet) and IEEE 802.5 (Token Ring), several advantages make IEEE 802.3 a more favorable choice for enterprise networks. Here are the key advantages of using IEEE 802.3 over IEEE 802.5:
1. Cost Efficiency
Lower Hardware Costs: Ethernet technology, governed by IEEE 802.3, has become the dominant networking standard, leading to mass production of Ethernet hardware. This results in lower costs for switches, routers, and network interface cards (NICs) compared to Token Ring equipment, which is less commonly produced and thus more expensive[1][2].
Affordable Cabling: The cabling used in Ethernet networks (e.g., twisted-pair cables) is generally cheaper and more widely available than the specialized cabling often required for Token Ring networks[1].
2. Scalability
Higher Data Rates: IEEE 802.3 supports a wide range of data rates, from 10 Mbps to over 400 Gbps in modern implementations. This scalability allows enterprises to upgrade their networks easily as their data needs grow[1][2].
Flexible Network Design: Ethernet can be implemented in various topologies (e.g., star, tree), making it adaptable to different organizational layouts and growth patterns without requiring significant redesigns[1][4].
3. Interoperability
Wide Compatibility: IEEE 802.3 ensures that devices from different manufacturers can work together seamlessly, which is crucial for enterprises that may use equipment from multiple vendors. This interoperability simplifies network expansion and integration of new technologies[1][2].
Standardization: As a widely adopted standard, Ethernet benefits from extensive testing and validation across many devices and applications, ensuring reliability in diverse environments[1].
4. Performance and Efficiency
Collision Management: While both standards manage data transmission differently, Ethernet’s CSMA/CD (Carrier Sense Multiple Access with Collision Detection) allows for efficient handling of collisions when they occur, albeit with some performance impact during high traffic loads. However, modern Ethernet switches operate in full-duplex mode, effectively eliminating collisions altogether[1][4].
Higher Throughput: With advancements like Gigabit Ethernet and beyond, Ethernet can handle higher throughput compared to Token Ring’s maximum speeds of 16 Mbps or even up to 100 Mbps with specialized configurations[2][4].
5. Simplicity of Implementation
Ease of Setup: Setting up an Ethernet network is generally simpler than a Token Ring network due to the straightforward nature of Ethernet’s architecture and the availability of user-friendly networking equipment[1][2].
Minimal Configuration Needs: Ethernet networks typically require less complex configuration compared to Token Ring setups, which involve managing token passing and ensuring that all devices are synchronized correctly within the logical ring structure[4].
6. Robustness and Reliability
Fault Tolerance: In an Ethernet network using a star topology, if one connection fails, it does not affect the entire network; only the device connected through that link is impacted. In contrast, Token Ring networks can suffer from performance issues if any device fails or if there are problems with the token-passing mechanism[1][2].
Easier Troubleshooting: The centralized nature of most Ethernet deployments allows for easier monitoring and troubleshooting of network issues compared to the more complex token-passing system used in Token Ring networks[4].
Conclusion
In summary, while both IEEE 802.3 (Ethernet) and IEEE 802.5 (Token Ring) have their merits, the advantages of using IEEE 802.3 in enterprise networks are compelling. Cost efficiency, scalability, interoperability, performance efficiency, simplicity of implementation, and robustness make Ethernet the preferred choice for modern networking needs. As organizations continue to evolve and expand their technological infrastructure, adopting IEEE 802.3 standards positions them well for future growth and innovation in networking capabilities.
Sources
[1] What Is IEEE 802.3? | FS Community https://community.fs.com/encyclopedia/ieee-8023.html [2] IEEE Standards - Dr. Balvinder Taneja https://drbtaneja.com/ieee-standards/ [3] [PDF] Overview of LANs Ethernet Token Ring https://wiki.eecs.yorku.ca/course_archive/2009-10/W/3213/_media/assignments:cse3213_16_lans_w2010.pdf [4] What is token ring and how does it work? - TechTarget https://www.techtarget.com/searchnetworking/definition/Token-Ring [5] What are the IEEE 802 wireless standards? - TechTarget https://www.techtarget.com/searchnetworking/reference/IEEE-802-Wireless-Standards-Fast-Reference
How do the data transmission speeds of IEEE 802.3 and IEEE 802.5 networks compare
The data transmission speeds of IEEE 802.3 (Ethernet) and IEEE 802.5 (Token Ring) differ significantly, reflecting their respective design philosophies and technological advancements. Here’s a detailed comparison of their data transmission speeds:
Data Transmission Speeds
IEEE 802.3 (Ethernet)
- Original Speed: The original IEEE 802.3 standard specified a data rate of 10 Mbps.
- Fast Ethernet: The subsequent standard, IEEE 802.3u, introduced Fast Ethernet, which operates at 100 Mbps.
- Gigabit Ethernet: Later developments included IEEE 802.3z and 802.3ab, which support 1 Gbps (1000 Mbps).
- 10 Gigabit Ethernet: The standard evolved further with IEEE 802.3ae, enabling speeds of 10 Gbps.
- Higher Speeds: More recent standards have pushed Ethernet capabilities to 40 Gbps, 100 Gbps, and even beyond, with standards like IEEE 802.3ba.
IEEE 802.5 (Token Ring)
- Original Speed: The initial versions of Token Ring (IEEE 802.5) operated at speeds of 4 Mbps and later at 16 Mbps.
- Enhanced Versions: Extensions such as IEEE 802.5t allowed for speeds up to 100 Mbps, while IEEE 802.5v provided capabilities for speeds of 1 Gbps over fiber optics.
Comparison Summary
| Feature | IEEE 802.3 (Ethernet) | IEEE 802.5 (Token Ring) |
|---|---|---|
| Original Speed | 10 Mbps | 4 Mbps |
| Fast Ethernet Speed | 100 Mbps | N/A |
| Gigabit Ethernet Speed | 1 Gbps | N/A |
| 10 Gigabit Ethernet Speed | Up to 10 Gbps | N/A |
| Maximum Speed (Recent) | Up to 400 Gbps+ | Up to 1 Gbps over fiber |
Conclusion
In summary, IEEE 802.3 (Ethernet) significantly outpaces IEEE 802.5 (Token Ring) in terms of data transmission speeds. While Token Ring started with lower speeds and has limited enhancements, Ethernet has continuously evolved to support much higher data rates, making it the preferred choice for modern enterprise networks where high-speed data transmission is crucial. The scalability and flexibility of Ethernet further enhance its appeal compared to Token Ring’s more rigid structure and lower performance capabilities.
Sources
[1] A Standard for the Transmission of IP Datagrams over IEEE 802 Networks https://www.ietf.org/rfc/rfc1042.html [2] 802 Standards. IEEE 802.2, 802.3, 802.5, 802.11 http://network-communications.blogspot.com/2011/06/802-standards-ieee-8022-8023-8025-80211.html [3] IEEE 802.4 (Token Bus) - Computer Networks - YouTube https://www.youtube.com/watch?v=5i_dUo1abNg
What are the main differences between IEEE 802.3 and IEEE 802.5 standards
The IEEE 802 standards encompass a wide range of networking technologies, with two notable standards being IEEE 802.3 and IEEE 802.5. Both standards serve distinct purposes and utilize different methods for data transmission. Here are the main differences between them:
Overview of IEEE 802.3 and IEEE 802.5
IEEE 802.3 (Ethernet)
- Type: Wired networking standard.
- Purpose: Defines the physical and data link layers for wired Ethernet networks.
- Access Method: Utilizes Carrier Sense Multiple Access with Collision Detection (CSMA/CD) to manage data transmission.
- Topology: Primarily uses a star topology, although it can also support bus topology in some configurations.
- Data Rates: Originally specified for 10 Mbps, with subsequent enhancements leading to Fast Ethernet (100 Mbps), Gigabit Ethernet (1 Gbps), and beyond.
- Frame Structure: Data is transmitted in frames that include a preamble, MAC addresses, type/length field, payload, and frame check sequence (FCS).
- Collision Handling: If two devices transmit simultaneously, a collision occurs; both devices stop transmitting and wait for a random time before attempting to send again.
IEEE 802.5 (Token Ring)
- Type: Wired networking standard.
- Purpose: Defines the standard for token ring networks, providing an alternative to Ethernet with different operational characteristics.
- Access Method: Employs a token-passing mechanism where a device must possess a token to transmit data, ensuring orderly access to the network.
- Topology: Typically utilizes a physical star topology with devices connected to a central hub (Multi-station Access Unit - MAU), but operates logically as a ring.
- Data Rates: Originally supported speeds of 4 Mbps and 16 Mbps, with later versions allowing for speeds up to 100 Mbps and even 1 Gbps over fiber optics.
- Collision Handling: The token-passing method eliminates collisions entirely since only the device holding the token can transmit at any given time.
Key Differences
| Feature | IEEE 802.3 (Ethernet) | IEEE 802.5 (Token Ring) |
|---|---|---|
| Access Method | CSMA/CD | Token passing |
| Topology | Star (primarily) | Star physically, ring logically |
| Data Transmission Rate | Starts at 10 Mbps, goes up to 100 Gbps+ | Starts at 4 Mbps, goes up to 1 Gbps |
| Collision Handling | Collisions possible; managed by CSMA/CD | No collisions; orderly access via token |
| Frame Structure | Ethernet frames with preamble and FCS | Token structure; no specific frame format |
| Network Efficiency | Less predictable due to potential collisions | More predictable performance |
Conclusion
In summary, while both IEEE 802.3 and IEEE 802.5 are essential standards in the realm of networking, they cater to different operational needs and methodologies. IEEE 802.3 has become the dominant technology for wired local area networks due to its simplicity and scalability, whereas IEEE 802.5 offered deterministic performance through its token-passing mechanism but has largely fallen out of favor in modern networking environments. Understanding these differences is crucial for network design and implementation in various applications.
Sources
[1] IEEE Standards - Dr. Balvinder Taneja https://drbtaneja.com/ieee-standards/ [2] 802 Standards. IEEE 802.2, 802.3, 802.5, 802.11 http://network-communications.blogspot.com/2011/06/802-standards-ieee-8022-8023-8025-80211.html [3] What are the IEEE 802 wireless standards? - TechTarget https://www.techtarget.com/searchnetworking/reference/IEEE-802-Wireless-Standards-Fast-Reference
How do the physical topologies of IEEE 802.3 and IEEE 802.5 networks differ
The physical topologies of IEEE 802.3 (Ethernet) and IEEE 802.5 (Token Ring) networks differ significantly, reflecting their distinct operational methodologies and design principles. Here’s a detailed comparison of their physical topologies:
IEEE 802.3 (Ethernet) Topology
Physical Topology
- Star Topology: The most common physical topology for IEEE 802.3 networks is the star topology. In this configuration, all devices (nodes) are connected to a central device, typically a switch or hub. This central point acts as a repeater for data flow.
Characteristics
Centralized Management: The star topology allows for easier management and troubleshooting since all connections converge at a single point. If one device fails, it does not affect the entire network, only the device connected to that specific port.
Scalability: Adding new devices is straightforward; network administrators can simply connect additional nodes to the central switch without disrupting existing connections.
Full-Duplex Communication: Modern Ethernet switches support full-duplex communication, allowing simultaneous data transmission and reception between devices, which enhances network performance.
Collision Handling: While earlier Ethernet implementations used CSMA/CD (Carrier Sense Multiple Access with Collision Detection), modern Ethernet networks typically operate in full-duplex mode, effectively eliminating collisions.
IEEE 802.5 (Token Ring) Topology
Physical Topology
- Star Ring Topology: IEEE 802.5 networks typically utilize a star ring topology. In this setup, devices are connected to a central hub known as a Multistation Access Unit (MAU), but the logical operation of the network forms a ring.
Characteristics
Token Passing Mechanism: Data transmission is controlled by a token-passing protocol. Only the device holding the token can transmit data, which ensures orderly access and eliminates collisions.
Logical Ring Structure: Although physically arranged in a star configuration, the logical operation resembles a ring where data travels in one direction from one device to another until it returns to the sender.
Deterministic Performance: The token-passing mechanism provides predictable performance because each device has guaranteed access to the network when it possesses the token, making it suitable for applications requiring consistent response times.
Single Point of Failure: If any device or connection in the ring fails, it can disrupt communication unless redundancy measures (like dual-ring configurations) are implemented.
Comparison Summary
| Feature | IEEE 802.3 (Ethernet) | IEEE 802.5 (Token Ring) |
|---|---|---|
| Physical Topology | Star topology | Star ring topology |
| Data Transmission Method | CSMA/CD (collision detection) | Token passing |
| Scalability | High; easy to add devices | Moderate; adding devices can be complex due to token management |
| Fault Tolerance | High; failure of one device does not affect others | Lower; failure can disrupt the entire network unless redundancy is implemented |
| Performance | Full-duplex communication available | Deterministic but limited to one transmission at a time |
| Network Management | Centralized management via switches | Centralized management via MAU |
Conclusion
In conclusion, the physical topologies of IEEE 802.3 and IEEE 802.5 reflect their fundamental operational differences. Ethernet’s star topology offers flexibility, scalability, and ease of management, making it suitable for modern enterprise networks. In contrast, Token Ring’s star ring topology provides deterministic performance through its token-passing mechanism but has limitations in fault tolerance and scalability. Understanding these differences is crucial for network design and implementation based on specific organizational needs and priorities.
Sources
[1] Network Topology Types: Complete Overview - NAKIVO https://www.nakivo.com/blog/types-of-network-topology-explained/ [2] IEEE Standards - Dr. Balvinder Taneja https://drbtaneja.com/ieee-standards/ [3] What are the IEEE 802 wireless standards? - TechTarget https://www.techtarget.com/searchnetworking/reference/IEEE-802-Wireless-Standards-Fast-Reference [4] week 4 may: IEEE 802.3 & 803.5 standards - Forum - ProBoards https://networkingsecurity.proboards.com/thread/22/week-ieee-802-803-standards
RFC 3261: Unraveling the Session Initiation Protocol (SIP)
In the complex world of telecommunications and internet communication, the Session Initiation Protocol (SIP) stands as a cornerstone technology that has revolutionized how we connect and communicate. Defined in RFC 3261, SIP has become the standard protocol for initiating, maintaining, and terminating real-time communication sessions across IP networks. This blog post will dive deep into the intricacies of SIP, exploring its architecture, functionality, and profound impact on modern communication technologies.
Understanding the Context
Before delving into the specifics of RFC 3261, it’s important to understand the communication landscape that necessitated the development of SIP. In the late 1990s and early 2000s, telecommunications were undergoing a massive transformation. Traditional circuit-switched networks were giving way to packet-switched IP networks, creating a need for a flexible, scalable protocol that could handle various forms of real-time communication.
What is SIP?
At its core, SIP is an application-layer control protocol designed to establish, modify, and terminate multimedia sessions such as voice and video calls, instant messaging, and other collaborative applications. Unlike some complex communication protocols, SIP was intentionally designed to be simple, flexible, and extensible.
The key characteristics that set SIP apart include:
- Text-Based Protocol: Similar to HTTP, SIP uses human-readable text messages, making it easier to debug and understand.
- Lightweight and Flexible: It can be easily extended to support new technologies and communication methods.
- Peer-to-Peer Architecture: SIP eliminates the need for centralized servers in many communication scenarios.
Technical Architecture of SIP
Basic Components
SIP defines several key components that work together to establish communication sessions:
- User Agents: Clients that initiate and receive communication requests.
- Proxy Servers: Intermediary servers that route SIP requests between users.
- Registrar Servers: Servers that accept registration requests from users.
- Redirect Servers: Servers that provide alternative contact information for users.
Communication Model
The protocol uses a request-response model similar to HTTP. The primary SIP methods include:
- INVITE: Initiates a communication session
- BYE: Terminates an existing session
- REGISTER: Registers a user’s current location
- OPTIONS: Queries server capabilities
- CANCEL: Cancels a pending request
- ACK: Confirms request receipt
Message Structure
A typical SIP message consists of two main parts:
- Start Line: Indicates the message type (request or response)
- Headers: Provide routing and session description information
The messages are text-based, making them relatively easy to parse and understand. This design was intentional, allowing for easier implementation and debugging compared to binary protocols.
Session Establishment Process
The process of establishing a SIP session involves several intricate steps:
- User Location: Determining the endpoint of the communication
- Capability Negotiation: Determining the media types and parameters
- Session Setup: Establishing the communication parameters
- Session Management: Modifying and terminating the session
Authentication and Security
RFC 3261 incorporates robust authentication mechanisms:
- Digest authentication
- Support for TLS (Transport Layer Security)
- Ability to integrate with external authentication systems
Key Innovations in RFC 3261
When RFC 3261 was published in June 2002, it introduced several groundbreaking concepts:
- Decentralized Architecture: Moved away from monolithic telecommunication systems
- Scalability: Designed to support millions of simultaneous sessions
- Multimodal Communication: Enabled integration of various communication types
- NAT and Firewall Traversal: Improved connectivity across different network configurations
Real-World Applications
SIP has found widespread adoption in numerous technologies:
- Voice over IP (VoIP) Systems
- Video Conferencing Platforms
- Unified Communication Solutions
- Mobile Communication Applications
- Internet Telephony Services
Challenges and Limitations
Despite its strengths, SIP is not without challenges:
- Complex Implementation: The protocol’s flexibility can make implementation complex
- Security Vulnerabilities: Requires careful configuration to prevent potential attacks
- Network Address Translation (NAT) Issues: Can struggle with certain network configurations
Evolution and Future Directions
While RFC 3261 remains the foundational document, the SIP protocol continues to evolve. Modern extensions address emerging communication needs, including:
- Enhanced security mechanisms
- Improved support for mobile devices
- Better integration with web technologies
- Support for emerging communication paradigms
Impact on Modern Communication
The significance of RFC 3261 cannot be overstated. By providing a standardized, flexible protocol for real-time communication, SIP has been instrumental in:
- Democratizing communication technologies
- Reducing telecommunication costs
- Enabling global, instant communication
- Supporting innovation in communication platforms
Technical Considerations for Implementers
For developers and network engineers looking to implement SIP, key considerations include:
- Thorough understanding of the RFC 3261 specification
- Robust error handling
- Comprehensive security implementations
- Performance optimization
- Compatibility testing across different systems
Conclusion
RFC 3261 and the Session Initiation Protocol represent a pivotal moment in communication technology. By providing a flexible, scalable framework for real-time communication, SIP has transformed how we connect, collaborate, and communicate in the digital age.
As communication technologies continue to evolve, the principles established in RFC 3261 remain crucial. The protocol’s elegance lies in its simplicity, flexibility, and ability to adapt to changing technological landscapes.
Whether you’re a telecommunications professional, a software developer, or simply someone interested in how modern communication works, understanding SIP provides invaluable insights into the infrastructure that powers our connected world.
Commonly Used Crypto Terms and Their Brief Descriptions
The world of cryptocurrency is filled with unique terminology that can be overwhelming for newcomers. Understanding these terms is essential for anyone looking to navigate the crypto landscape effectively. This blog post will provide a comprehensive list of commonly used crypto terms along with their brief descriptions, helping you familiarize yourself with the jargon of this rapidly evolving field.
1. Altcoin
Definition: Any cryptocurrency that is not Bitcoin. There are thousands of altcoins available, each with its unique features and purposes.
2. Blockchain
Definition: A decentralized digital ledger that records all transactions across a network of computers. It consists of blocks that are chained together chronologically, ensuring data integrity and security.
3. Coin
Definition: A digital asset that operates independently on its own blockchain. For example, Bitcoin (BTC) is the coin for the Bitcoin blockchain, while Ether (ETH) serves the Ethereum blockchain.
4. Decentralized Finance (DeFi)
Definition: A financial system built on blockchain technology that allows users to conduct transactions without intermediaries like banks. DeFi applications enable lending, borrowing, trading, and earning interest on cryptocurrencies.
5. Fiat Currency
Definition: Government-issued currency that is not backed by a physical commodity like gold. Examples include the US dollar and the euro.
6. Gas Fee
Definition: The cost required to execute a transaction or smart contract on the Ethereum network. Gas fees are paid in Gwei, which is a subunit of Ether.
7. Halving
Definition: An event in which the mining rewards for Bitcoin are cut in half approximately every four years to control its supply and inflation rate.
8. Initial Coin Offering (ICO)
Definition: A fundraising method used by cryptocurrency projects to raise capital by selling tokens to investors before the project launches.
9. Ledger
Definition: A record-keeping system for all transactions made with a cryptocurrency, stored on the blockchain.
10. Memecoin
Definition: A type of cryptocurrency inspired by internet memes or social media trends, often lacking inherent value or utility. Examples include Dogecoin and Shiba Inu.
11. Mining
Definition: The process of verifying and adding transactions to a blockchain by solving complex mathematical problems. Miners are rewarded with newly created coins for their efforts.
12. Private Key
Definition: A secret alphanumeric code that allows the owner to access and manage their cryptocurrency holdings. It must be kept secure to prevent unauthorized access.
13. Public Key
Definition: A cryptographic code that allows users to receive cryptocurrencies into their wallet. It is derived from the private key and can be shared publicly.
14. Smart Contract
Definition: Self-executing contracts with the terms directly written into code on the blockchain. They automatically enforce and execute agreements when predefined conditions are met.
15. Token
Definition: A digital asset created on an existing blockchain, often representing assets or utilities within a specific ecosystem (e.g., BAT on Ethereum).
16. Wallet
Definition: A software or hardware tool used to store, send, and receive cryptocurrencies while managing private keys.
17. FOMO (Fear of Missing Out)
Definition: The anxiety that arises from believing others are benefiting from an opportunity while one is not participating—common in volatile crypto markets during price surges.
18. FUD (Fear, Uncertainty, Doubt)
Definition: Negative information spread about a cryptocurrency or project with the intent to manipulate market sentiment or prices.
19. ATH (All-Time High)
Definition: The highest price ever reached by a cryptocurrency in its trading history.
20. REKT
Definition: Slang derived from the misspelling of “wrecked,” referring to significant financial losses in trading or investment contexts.
21. Cold Storage
Definition: A method of storing cryptocurrencies offline to enhance security against hacks and unauthorized access.
22. Hot Wallet
Definition: A cryptocurrency wallet connected to the internet, making it more convenient for transactions but also more vulnerable to hacks.
23. KYC (Know Your Customer)
Definition: The process by which businesses verify the identity of their clients as part of regulatory compliance, often required before allowing account creation or transactions.
24. Liquidity
Definition: The ease with which a cryptocurrency can be bought or sold without significantly affecting its price; high liquidity indicates many buyers and sellers in the market.
25. Volume
Definition: The total amount of a cryptocurrency traded during a specific period, indicating market activity and interest levels.
26. Fork
Definition: An update or change in protocol rules within a blockchain network that results in two separate chains—hard forks create new currencies, while soft forks do not break backward compatibility.
27. Validator
Definition: Participants in proof-of-stake networks who validate transactions and create new blocks based on their staked assets rather than through mining processes.
Conclusion
Understanding these commonly used crypto terms is crucial for anyone looking to engage with cryptocurrencies effectively—whether as an investor, developer, or enthusiast. This glossary serves as a foundational reference point as you navigate this exciting and often complex digital landscape.
By familiarizing yourself with these terms, you will be better equipped to participate in discussions about cryptocurrencies and make informed decisions regarding investments or projects you may consider exploring further in this dynamic field.
Sources
[1] 140+ Blockchain and Crypto Words: The Ultimate A-Z Glossary
[2] Crypto Glossary for Nonprofits and Donors - 60+ terms - The Giving Block https://thegivingblock.com/resources/crypto-glossary/
[3] Explainer: What common cryptocurrency terms mean - Bankrate https://www.bankrate.com/investing/crypto-definitions/
[4] 51 Crypto Terms You Must Know - Brickken https://www.brickken.com/en/post/blog-crypto-terms
[5] Key terms to understand in crypto - Brex https://www.brex.com/resources/key-crypto-terms
How do coins and tokens impact the overall cryptocurrency market
Coins and tokens play significant roles in the overall cryptocurrency market, each impacting it in unique ways. Understanding these impacts can help investors and enthusiasts navigate the complexities of the crypto ecosystem. Here’s a detailed exploration of how coins and tokens influence the market.
1. Market Dynamics
Coins: Coins, such as Bitcoin and Ethereum, are typically seen as the backbone of the cryptocurrency market. They operate on their own blockchains and are often used as a store of value or a medium of exchange. The demand for coins is largely driven by their utility, transaction volume, and market sentiment. For instance, Bitcoin’s price is influenced by its adoption as digital gold and its limited supply of 21 million coins, which creates scarcity[1][6].
Tokens: Tokens exist on existing blockchains (like Ethereum) and can serve various purposes beyond mere currency. They often represent assets or utilities within a specific ecosystem, such as governance rights or access to services. The success of tokens is closely tied to the projects they are associated with; if a project gains traction, its token’s value may rise due to increased demand[1][2]. However, many tokens are subject to volatility and speculation, especially those launched through Initial Coin Offerings (ICOs), which can lead to rapid price fluctuations based on hype rather than intrinsic value[3][5].
2. Price Influences
Supply and Demand: Both coins and tokens are affected by supply and demand dynamics. For coins, the price typically correlates with transaction volume on their respective blockchains. Higher usage can lead to increased demand, driving prices up[1][6]. Conversely, if a large holder (“whale”) sells off a significant amount of a coin, it can flood the market and cause prices to drop due to oversupply.
Tokens are influenced by their utility within their ecosystems. A token with strong use cases—such as those that facilitate transactions or provide governance rights—can see its price rise as demand increases[3][4]. However, if a token has poor tokenomics (e.g., unlimited supply or lack of utility), it may struggle to maintain value in the market[6].
3. Ecosystem Impact
Coins: Coins contribute to the security and stability of their networks through mechanisms like mining or staking. For example, Bitcoin’s proof-of-work system incentivizes miners to validate transactions and secure the network. This security aspect can enhance investor confidence, further stabilizing prices during market fluctuations[2].
Tokens: Tokens often create complex ecosystems that resemble small economies with various stakeholders (developers, investors, users). The success of these ecosystems can lead to increased adoption and higher token valuations. Well-structured tokenomics—such as limited supply, clear utility, and effective distribution—can foster growth within these ecosystems, enhancing their overall impact on the market[3][4].
4. Market Capitalization
The market capitalization of coins tends to be more stable compared to tokens due to their entrenched positions in the market. Coins like Bitcoin have established themselves as dominant players with significant market caps that reflect their widespread use and acceptance[5]. In contrast, tokens often exhibit more volatile market caps due to rapid changes in project popularity and speculative trading behavior.
5. Regulatory Considerations
Both coins and tokens face regulatory scrutiny but in different ways. Coins are often viewed similarly to traditional currencies by regulators, while tokens may be classified as securities depending on their structure and use case. This regulatory landscape can significantly impact how each type is perceived in the market and can influence investor behavior.
Conclusion
In summary, coins and tokens significantly impact the cryptocurrency market through their unique functionalities, price dynamics, ecosystem contributions, and regulatory considerations. Coins provide foundational value and security within blockchain networks, while tokens offer diverse applications that can drive innovation and growth in various sectors.
Understanding these distinctions helps investors make informed decisions about where to allocate resources in this rapidly evolving landscape. As both coins and tokens continue to develop alongside technological advancements and regulatory changes, their roles in shaping the future of finance will remain critical.
Sources
[1] Crypto Tokens and Crypto Coins: What Drives Performance? https://blogs.cfainstitute.org/investor/2022/04/25/crypto-tokens-and-crypto-coins-what-drives-performance/
[2] Crypto Coins and Tokens: Their Use-Cases Explained - Ledger https://www.ledger.com/academy/crypto/what-is-the-difference-between-coins-and-tokens
[3] Tokenomics: How to make better crypto investments [2024] - Blockpit https://www.blockpit.io/blog/tokenomics
[4] What is Crypto Token Supply? A Complete Guide - LCX https://www.lcx.com/what-is-the-crypto-token-supply/
[5] Classification of cryptocurrency coins and tokens by the dynamics of their … https://pmc.ncbi.nlm.nih.gov/articles/PMC6170580/
[6] What Determines the Price of Crypto? - Koinly https://koinly.io/blog/what-determines-the-price-of-crypto/
Understanding IEEE Standards: Importance, Development, and Applications
The Institute of Electrical and Electronics Engineers (IEEE) is a prominent organization that plays a crucial role in the development of global standards across various technological fields. Established in 1963, IEEE has evolved into a leading authority for standards that underpin many aspects of modern life, from telecommunications to computer networks and power generation. This blog post delves into the significance of IEEE standards, their development process, and their applications across different industries.
What Are IEEE Standards?
IEEE standards are formal documents that establish specifications and guidelines for various technologies and practices. They are developed through a consensus-driven process involving experts from around the world. These standards ensure interoperability, safety, and efficiency in technology deployment, making them essential for both manufacturers and consumers.
Key Areas of IEEE Standards
IEEE standards cover a wide array of fields, including:
- Telecommunications: Standards such as IEEE 802.11 (Wi-Fi) facilitate wireless communication.
- Computer Networking: The IEEE 802 family provides protocols for local area networks (LANs) and metropolitan area networks (MANs).
- Power and Energy: Standards like IEEE 1547 govern the interconnection of distributed energy resources with electric power systems.
- Artificial Intelligence: Emerging standards address ethical considerations and technical requirements for AI systems.
- Healthcare: Standards such as ISO/IEEE 11073 pertain to health informatics, ensuring interoperability among medical devices.
The Development Process of IEEE Standards
The development of IEEE standards follows a structured process designed to ensure thorough review and consensus among stakeholders. This process typically involves the following steps:
- Proposal Submission: A new standard or revision is proposed by individuals or organizations.
- Working Group Formation: A committee is formed to address the proposal, consisting of experts in the relevant field.
- Drafting: The working group drafts the standard, incorporating feedback from various stakeholders.
- Balloting: The draft is circulated for voting among IEEE members to assess its technical reliability and soundness.
- Revision: Based on feedback from the ballot, revisions are made to improve clarity and applicability.
- Publication: Once approved, the standard is published and made available to the public.
This rigorous process ensures that IEEE standards are not only technically sound but also reflect a broad consensus within the industry.
Notable IEEE Standards
Among the numerous standards developed by IEEE, several have had a significant impact on technology:
IEEE 802 Series
The IEEE 802 series is perhaps one of the most recognized sets of standards, primarily governing networking technologies. Key components include:
- IEEE 802.3: Defines Ethernet standards for wired networking.
- IEEE 802.11: Governs wireless local area networks (Wi-Fi), enabling devices to connect to the internet wirelessly.
- IEEE 802.15: Focuses on wireless personal area networks (WPAN), including technologies like Bluetooth.
These standards facilitate communication between diverse devices, ensuring compatibility and performance across different platforms.
IEEE 1547
This standard addresses the interconnection of distributed energy resources with electric power systems. It plays a critical role in integrating renewable energy sources like solar panels into existing power grids while ensuring safety and reliability.
ISO/IEEE 11073
This set of standards focuses on health informatics, particularly in ensuring that medical devices can communicate effectively with healthcare IT systems. This interoperability is vital for patient safety and data accuracy in clinical settings.
The Impact of IEEE Standards on Technology
The influence of IEEE standards extends beyond mere compliance; they foster innovation by providing a framework within which new technologies can develop. Here are some key impacts:
Promoting Interoperability
One of the primary benefits of IEEE standards is their ability to promote interoperability among devices from different manufacturers. For instance, Wi-Fi standards enable devices from various brands to connect seamlessly to wireless networks, enhancing user experience.
Ensuring Safety and Reliability
Standards like those governing electrical safety ensure that products meet minimum safety requirements before they reach consumers. This not only protects users but also helps manufacturers avoid liability issues.
Facilitating Market Growth
By establishing common practices and specifications, IEEE standards help create markets for new technologies. For example, the widespread adoption of Ethernet technology has led to significant growth in networking equipment manufacturing.
Supporting Global Trade
IEEE standards are recognized internationally, facilitating trade between countries by ensuring that products meet widely accepted criteria. This global recognition helps companies expand their markets without facing regulatory barriers.
Challenges in Developing IEEE Standards
Despite their importance, developing IEEE standards comes with challenges:
- Consensus Building: Achieving agreement among diverse stakeholders can be difficult due to differing priorities and perspectives.
- Keeping Up with Technology: Rapid technological advancements can make it challenging for standards to remain relevant; ongoing revisions are necessary.
- Resource Allocation: Developing comprehensive standards requires significant time and financial resources, which can be a barrier for smaller organizations.
Future Directions for IEEE Standards
As technology continues to evolve at an unprecedented pace, so too will the need for updated and new standards. Some future directions include:
- Artificial Intelligence: Developing ethical guidelines and technical specifications for AI systems will be crucial as AI becomes more integrated into everyday life.
- Internet of Things (IoT): With billions of connected devices expected in the coming years, establishing robust IoT standards will be essential for security and interoperability.
- Sustainability Standards: As environmental concerns grow, developing standards that promote sustainable practices in technology will become increasingly important.
Conclusion
IEEE standards play a vital role in shaping the technological landscape by providing guidelines that ensure safety, interoperability, and innovation across various industries. As we move forward into an era marked by rapid technological change, the importance of these standards will only grow. By fostering collaboration among experts worldwide, IEEE continues to lead efforts that benefit humanity through technological advancements while addressing emerging challenges head-on.
Sources
[1] IEEE Standards in Computer Networks - Scaler Blog https://www.scaler.in/ieee-standards-in-computer-networks/ [2] [PDF] The Complete Guide to Copper and Fiber-Optic Networking 5th Edition https://technic2u.files.wordpress.com/2016/08/cabling1.pdf [3] IEEE Standards Association - Wikipedia https://en.wikipedia.org/wiki/IEEE_Standards_Association [4] [PDF] Computer Networks, Fourth Edition - Spartans Fall-14 https://fall14cs.files.wordpress.com/2016/04/computer_networks4thed_tanenbaum.pdf [5] IEEE at a Glance https://www.ieee.org/about/at-a-glance.html [6] ada source code: Topics by Science.gov https://www.science.gov/topicpages/a/ada+source+code [7] Standards - IEEE PES https://ieee-pes.org/technical-activities/standards/
Getting Started with AlmaLinux 9 Initial Settings
Introduction
AlmaLinux 9 is a robust and versatile Linux distribution designed to meet the needs of enterprises and individuals alike. Whether you’re setting up a server for hosting applications, managing networks, or personal projects, configuring the system with essential initial settings is critical for a secure and efficient environment.
In this guide, we’ll walk you through the fundamental initial settings for AlmaLinux 9 to ensure your system is ready for action.
Step 1: Add a New User
When installing AlmaLinux, you typically create a root user. While powerful, root access should be minimized to enhance security. Start by creating a non-root user with sudo privileges.
Add a new user:
sudo adduser newuserSet a password for the user:
sudo passwd newuserGrant sudo privileges:
sudo usermod -aG wheel newuserVerify sudo access:
Switch to the new user:
su - newuserRun a command requiring sudo:
sudo dnf update
Step 2: Set Up Firewall and SELinux
AlmaLinux comes with firewalld and SELinux for enhanced security. Configuring these properly ensures your system is protected from unauthorized access.
Enable and start the firewall:
sudo systemctl enable firewalld --nowAllow essential services (e.g., SSH and HTTP):
sudo firewall-cmd --permanent --add-service=ssh sudo firewall-cmd --permanent --add-service=http sudo firewall-cmd --reloadCheck SELinux status:
sestatusModify SELinux mode (optional):
If enforcing causes issues with some applications, switch to permissive:
sudo setenforce 0 sudo sed -i 's/^SELINUX=enforcing/SELINUX=permissive/' /etc/selinux/config
Step 3: Configure Network Settings
Properly setting up your network is essential, especially for servers requiring static IPs.
Set a static IP using
nmcli:nmcli connection modify eth0 ipv4.addresses 192.168.1.100/24 ipv4.gateway 192.168.1.1 ipv4.dns 8.8.8.8 ipv4.method manual nmcli connection up eth0Verify network configuration:
ip addr
Step 4: Enable or Disable Services
Managing services ensures your system runs only what it needs, improving performance and security.
List all services:
systemctl list-unit-filesEnable a critical service (e.g., SSH):
sudo systemctl enable sshd --nowDisable unnecessary services:
sudo systemctl disable <service_name> --now
Step 5: Update the System and Add Repositories
Keeping your system up-to-date ensures you have the latest security patches and features.
Update AlmaLinux:
sudo dnf update -yEnable additional repositories (e.g., EPEL):
sudo dnf install -y epel-release
Step 6: Use the Web Admin Console
AlmaLinux includes Cockpit, a powerful web-based admin console for managing your server.
Install Cockpit:
sudo dnf install -y cockpit sudo systemctl enable cockpit.socket --nowAccess the console:
Open a browser and navigate to:
https://<server-ip>:9090Log in using your server credentials.
Step 7: Customize Vim and Sudo Settings
Finally, personalizing your environment improves productivity.
Set up Vim preferences:
Create or edit
~/.vimrc:set number syntax on set expandtab set shiftwidth=4
Customize sudo behavior:
Edit
/etc/sudoers(usingvisudo) to modify timeout or logging:Defaults timestamp_timeout=15
Conclusion
By completing these steps, you’ve laid a solid foundation for working with AlmaLinux 9. From user management to securing your system with firewalls and SELinux, these configurations prepare your server for advanced setups like application hosting, networking, or virtualization.
What’s Next?
In the next post, we’ll dive into time synchronization (NTP) and secure shell configurations (SSH) to ensure your server is synchronized and accessible securely.
Stay tuned, and don’t forget to share your experiences and tips in the comments below!
Mastering DNS Configurations with BIND on AlmaLinux 9
Introduction
For administrators managing networks with complex DNS requirements, BIND (Berkeley Internet Name Domain) is a powerful and versatile DNS server. It allows you to configure internal and external DNS services, manage zone files, and implement advanced features like split DNS.
In this guide, we’ll cover how to set up and configure BIND DNS Server on AlmaLinux 9 for both internal and external networks.
Part 1: Installing and Setting Up BIND
Step 1: Install BIND
Install BIND and related packages:
sudo dnf install -y bind bind-utilsEnable and start the service:
sudo systemctl enable named --nowVerify installation:
systemctl status named
Step 2: Configure BIND for a Local Network
The primary configuration file for BIND is located at /etc/named.conf.
Edit
/etc/named.conf:sudo nano /etc/named.confModify the following settings:
Restrict access to local clients:
options { listen-on port 53 { 127.0.0.1; 192.168.1.0/24; }; allow-query { localhost; 192.168.1.0/24; }; recursion yes; };Add logging for queries (optional):
logging { channel default_debug { file "data/named.run"; severity dynamic; }; };
Restart BIND:
sudo systemctl restart named
Step 3: Create a Zone for Internal DNS
Zones are a critical part of DNS. You’ll define a zone file for managing your local network’s DNS records.
Edit
/etc/named.confto add a zone:zone "localdomain" IN { type master; file "/var/named/localdomain.zone"; allow-update { none; }; };Create the zone file:
sudo nano /var/named/localdomain.zoneAdd the following content:
$TTL 86400 @ IN SOA ns1.localdomain. admin.localdomain. ( 2023112701 ; Serial 3600 ; Refresh 1800 ; Retry 604800 ; Expire 86400 ) ; Minimum TTL @ IN NS ns1.localdomain. ns1 IN A 192.168.1.10 server1 IN A 192.168.1.11 server2 IN A 192.168.1.12Set permissions for the zone file:
sudo chown root:named /var/named/localdomain.zone sudo chmod 640 /var/named/localdomain.zoneVerify configuration:
sudo named-checkconf sudo named-checkzone localdomain /var/named/localdomain.zoneRestart BIND:
sudo systemctl restart named
Part 2: Configuring BIND for External Networks
For public-facing DNS, ensure you configure BIND with security and scalability in mind.
Step 1: Add an External Zone
Edit
/etc/named.conf:zone "example.com" IN { type master; file "/var/named/example.com.zone"; allow-update { none; }; };Create the external zone file:
sudo nano /var/named/example.com.zoneAdd the following records:
$TTL 86400 @ IN SOA ns1.example.com. admin.example.com. ( 2023112701 ; Serial 3600 ; Refresh 1800 ; Retry 604800 ; Expire 86400 ) ; Minimum TTL @ IN NS ns1.example.com. ns1 IN A 203.0.113.10 www IN A 203.0.113.20 mail IN A 203.0.113.30 @ IN MX 10 mail.example.com.Test and reload BIND:
sudo named-checkzone example.com /var/named/example.com.zone sudo systemctl reload named
Step 2: Secure the DNS Server
Enable DNSSEC:
Generate keys:
sudo dnssec-keygen -a RSASHA256 -b 2048 -n ZONE example.comAdd the generated keys to the zone file.
Chroot the BIND server:
sudo dnf install -y bind-chroot sudo systemctl enable named-chroot --now
Step 3: Test Your DNS Setup
Query a record locally:
dig @localhost server1.localdomainQuery a public record:
dig @203.0.113.10 www.example.comTest external queries from another machine:
dig @<bind-server-ip> example.com
Part 3: Advanced BIND Features
Step 1: Configure Split DNS
Split DNS allows internal and external users to access different views of the same domain.
Edit
/etc/named.conf:view "internal" { match-clients { 192.168.1.0/24; }; zone "example.com" IN { type master; file "/var/named/internal.example.com.zone"; }; }; view "external" { match-clients { any; }; zone "example.com" IN { type master; file "/var/named/external.example.com.zone"; }; };Create separate zone files for internal and external views.
Step 2: Configure Aliases (CNAME)
Add CNAME records to a zone file:
blog IN CNAME www ftp IN CNAME server1Restart BIND:
sudo systemctl restart named
Conclusion
BIND provides unparalleled flexibility for DNS management, whether for internal name resolution or public-facing services. By mastering zones, securing configurations, and leveraging advanced features like split DNS, you can effectively manage any network’s DNS needs.
What’s Next?
In the next post, we’ll explore DHCP configuration on AlmaLinux 9, focusing on dynamic and static IP address management.
Building Your Local Network with DNSmasq and DHCP on AlmaLinux 9
Introduction
Managing local networks can be challenging without proper tools. Enter Dnsmasq, a lightweight and versatile solution for providing DNS and DHCP services on a single server. By leveraging Dnsmasq on AlmaLinux 9, you can efficiently configure and manage your network for both name resolution and dynamic IP allocation.
In this guide, we’ll set up Dnsmasq to act as a DNS server and DHCP server to simplify local network management.
Part 1: Installing and Configuring Dnsmasq
Dnsmasq is a streamlined tool that combines DNS caching and DHCP management, making it ideal for small-to-medium networks.
Step 1: Install Dnsmasq
Install the package:
sudo dnf install -y dnsmasqEnable and start the service:
sudo systemctl enable dnsmasq --nowVerify the installation:
systemctl status dnsmasq
Step 2: Configure Dnsmasq
Dnsmasq’s configuration file is located at /etc/dnsmasq.conf. Here’s how to customize it for your network:
Edit the configuration file:
sudo nano /etc/dnsmasq.confAdd or update the following settings:
Enable DNS caching:
cache-size=1000Specify a local DNS domain:
domain=localdomainSet the DHCP range and lease time:
dhcp-range=192.168.1.50,192.168.1.100,12hAssign static IPs using MAC addresses (optional):
dhcp-host=00:11:22:33:44:55,192.168.1.10
Save and close the file, then restart Dnsmasq:
sudo systemctl restart dnsmasq
Step 3: Test Dnsmasq Configuration
Verify DNS functionality:
Query a domain:
dig example.comCheck cached responses:
dig example.com
Verify DHCP functionality:
On a client, release and renew the IP address:
sudo dhclient -r && sudo dhclient
Check assigned IPs:
View leases on the server:
cat /var/lib/misc/dnsmasq.leases
Part 2: Advanced Configuration for DNS and DHCP
Dnsmasq supports additional features to enhance your local network.
Step 1: Configure Custom Hostnames
Edit the
/etc/hostsfile:sudo nano /etc/hostsAdd custom hostname mappings:
192.168.1.10 server1.localdomain server1 192.168.1.11 server2.localdomain server2Restart Dnsmasq:
sudo systemctl restart dnsmasq
Step 2: Integrate with External DNS Servers
Edit
/etc/dnsmasq.confto specify upstream DNS servers:server=8.8.8.8 server=8.8.4.4Clear the DNS cache:
sudo systemctl restart dnsmasq
Step 3: Troubleshooting Dnsmasq
Check logs for issues:
sudo journalctl -u dnsmasqTest configuration syntax:
sudo dnsmasq --testEnsure no port conflicts:
Stop conflicting services:
sudo systemctl stop systemd-resolved
Part 3: Secure and Optimize Dnsmasq
Step 1: Restrict DNS Queries
Limit queries to internal clients:
Add the following to
/etc/dnsmasq.conf:interface=eth0 bind-interfaces
Restart Dnsmasq:
sudo systemctl restart dnsmasq
Step 2: Enable Logging
Enable detailed logging for troubleshooting:
Add to
/etc/dnsmasq.conf:log-queries log-facility=/var/log/dnsmasq.log
View logs:
tail -f /var/log/dnsmasq.log
Step 3: Optimize for Performance
Increase cache size:
Update
/etc/dnsmasq.conf:cache-size=2000
Enable asynchronous DNS processing:
Add:
dns-forward-max=150
Conclusion
With Dnsmasq configured, you now have a lightweight and efficient solution for managing DNS and DHCP services on your AlmaLinux 9 server. This setup is perfect for small to medium networks, offering a robust way to handle name resolution and IP allocation.
What’s Next?
In the next post, we’ll delve deeper into configuring a full-fledged DNS server using BIND to manage internal and external domains with greater control.
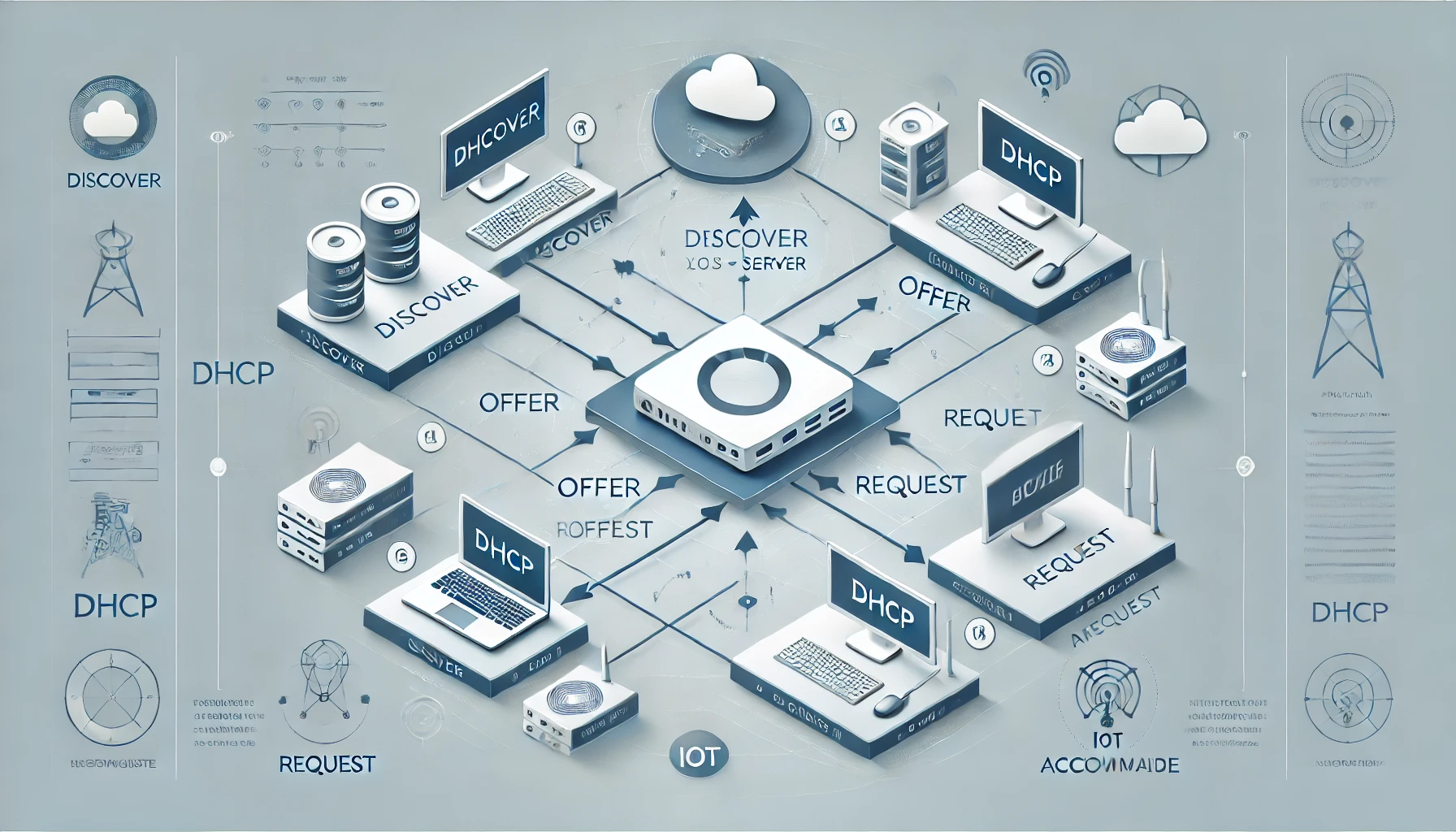
Simplifying Network Configuration with DHCP on AlmaLinux 9
Introduction
Dynamic Host Configuration Protocol (DHCP) simplifies IP address management in a network by automating the assignment of IPs, subnet masks, gateways, and DNS settings. On AlmaLinux 9, configuring a DHCP server allows you to efficiently manage both dynamic and static IP allocation.
In this guide, we’ll walk through the setup and configuration of a DHCP on AlmaLinux 9 to ensure seamless network management.
Part 1: Installing and Setting Up DHCP
Step 1: Install the DHCP Server
Install the DHCP server package:
sudo dnf install -y dhcp-serverVerify the installation:
dhcpd --version
Step 2: Configure DHCP Settings
The main configuration file for the DHCP server is located at /etc/dhcp/dhcpd.conf.
Edit the configuration file:
sudo nano /etc/dhcp/dhcpd.confAdd the following settings:
Define the default lease time and maximum lease time:
default-lease-time 600; max-lease-time 7200;Specify the subnet and IP range:
subnet 192.168.1.0 netmask 255.255.255.0 { range 192.168.1.50 192.168.1.100; option routers 192.168.1.1; option domain-name-servers 8.8.8.8, 8.8.4.4; option domain-name "localdomain"; }Add static IP assignments (optional):
host server1 { hardware ethernet 00:11:22:33:44:55; fixed-address 192.168.1.10; }
Save and close the file.
Step 3: Start and Enable the DHCP Server
Enable and start the service:
sudo systemctl enable dhcpd --nowVerify the service status:
sudo systemctl status dhcpd
Step 4: Test the Configuration
Check for syntax errors:
sudo dhcpd -t -cf /etc/dhcp/dhcpd.confMonitor DHCP server logs:
sudo tail -f /var/log/messagesVerify client IP assignment:
On a client machine, release and renew the IP address:
sudo dhclient -r && sudo dhclient
Part 2: Advanced DHCP Configurations
Step 1: Define Multiple Subnets
For networks with multiple subnets, define each subnet in the configuration file.
Add subnet definitions:
subnet 192.168.1.0 netmask 255.255.255.0 { range 192.168.1.50 192.168.1.100; option routers 192.168.1.1; } subnet 10.0.0.0 netmask 255.255.255.0 { range 10.0.0.50 10.0.0.100; option routers 10.0.0.1; }Restart the DHCP server:
sudo systemctl restart dhcpd
Step 2: Add Reserved IP Addresses
For critical devices (e.g., servers or printers), you may want to reserve IPs.
Add reservations in the configuration file:
host printer { hardware ethernet 00:11:22:33:44:66; fixed-address 192.168.1.20; } host fileserver { hardware ethernet 00:11:22:33:44:77; fixed-address 192.168.1.30; }Restart the DHCP server:
sudo systemctl restart dhcpd
Step 3: Enable Dynamic DNS Updates
Dynamic DNS (DDNS) allows the DHCP server to update DNS records automatically when leasing IPs.
Edit
/etc/dhcp/dhcpd.conf:ddns-update-style interim; ignore client-updates; key DHCP_UPDATE { algorithm HMAC-MD5; secret "<generated-secret>"; }; zone localdomain. { primary 192.168.1.10; key DHCP_UPDATE; }Restart the DHCP and DNS servers:
sudo systemctl restart dhcpd named
Part 3: Troubleshooting and Best Practices
Step 1: Common Troubleshooting Commands
Check the status of the DHCP server:
sudo systemctl status dhcpdVerify configuration syntax:
sudo dhcpd -t -cf /etc/dhcp/dhcpd.confMonitor logs for errors:
sudo journalctl -u dhcpd
Step 2: Best Practices
Use Reserved IPs for Critical Devices:
- Assign static IPs to servers, printers, and other important devices to avoid conflicts.
Enable Logging:
Ensure logging is enabled for easier troubleshooting:
log-facility local7;
Secure Your DHCP Server:
Use firewall rules to restrict access to trusted clients:
sudo firewall-cmd --add-service=dhcp --permanent sudo firewall-cmd --reload
Conclusion
With the DHCP server configured, your AlmaLinux 9 setup can efficiently manage IP allocation and network connectivity. Whether for dynamic or static IPs, this configuration ensures smooth network operation.
Understanding Internet Service Providers (ISPs): A Comprehensive Guide
What is an ISP?
An Internet Service Provider, or ISP, is a company that provides Internet access to its customers. Think of it as the bridge between your device (computer, smartphone, tablet) and the vast world of the internet. ISPs establish the network infrastructure, including cables, routers, and servers, that allows you to connect to the internet and access websites, send emails, stream videos, and much more.
How Does an ISP Work?
Physical Infrastructure: ISPs lay vast networks of cables, both underground and underwater, to connect different locations. These cables carry digital information, including internet traffic.
Network Centers: ISPs operate network centers, also known as data centers, which house servers and routers that manage internet traffic. These centers are responsible for routing data packets to their intended destinations.
Internet Exchange Points (IXPs): ISPs connect to IXPs, which are physical infrastructures where multiple ISPs can exchange internet traffic. This allows for efficient routing of data across the internet.
Customer Connection: ISPs provide various connection methods to customers, such as:* Dial-up: A legacy method using a modem to connect to the internet over a phone line.
Digital Subscriber Line (DSL): A high-speed internet connection using existing telephone lines.
Cable Internet: A high-speed internet connection using coaxial cables, often shared with cable TV services.
Fiber Optic Internet: A high-speed internet connection using fiber optic cables, offering the fastest speeds and lowest latency.
Wireless Internet: A wireless connection using technologies like Wi-Fi, 4G, 5G, and satellite.
Types of ISPs
Regional ISPs: These ISPs operate within a specific geographic region, such as a city, state, or province. They often provide services to smaller communities and businesses.
National ISPs: These ISPs operate across the country, providing internet access to a wider range of customers. They often have a larger network infrastructure and can offer a variety of services, including broadband internet, VoIP, and data center services.
Global ISPs: These ISPs have a global reach, operating across multiple countries. They often provide international connectivity and services to large corporations and multinational organizations.
Choosing an ISP
When selecting an ISP, consider the following factors:
Speed: The internet speed, measured in Mbps (megabits per second), determines how quickly you can download and upload data.
Reliability: A reliable ISP offers consistent service with minimal downtime.
Coverage: Ensure the ISP’s network covers your area.
Customer Service: Good customer support is essential for resolving issues and getting timely assistance.
Pricing: Compare the cost of different plans, including any additional fees or contracts.
Data Caps: Some ISPs impose data caps, limiting the amount of data you can use each month.
Contract Terms: Understand the terms and conditions of your ISP’s contract, including any early termination fees or penalties.
ISP Services Beyond Internet Access
Many ISPs offer additional services beyond internet access, such as:
Home Phone Service: VoIP (Voice over IP) phone service allows you to make calls over the internet.
Cable TV: ISPs that use coaxial cables often offer cable TV services.
Home Security Systems: Some ISPs offer home security systems that can be monitored remotely.
Streaming TV Services: Many ISPs bundle streaming TV services with their internet plans.
The Role of ISPs in the Digital Age
ISPs play a crucial role in the digital age by providing the infrastructure that enables individuals and businesses to connect to the internet. As technology continues to evolve, ISPs are adapting to meet the increasing demand for faster, more reliable, and more affordable internet access. By understanding the basics of ISPs, you can make informed decisions about your internet service and maximize your online experience.
Internet Protocol (IP) Overview: Understanding the Foundation of Internet Communications
The Internet Protocol (IP) serves as the fundamental building block of Internet communications, enabling billions of devices worldwide to connect and share information seamlessly. Whether you’re sending an email, streaming a video, or browsing websites, IP works silently in the background to ensure your data reaches its intended destination. In this comprehensive guide, we’ll explore what IP is, how it works, and why it’s crucial for modern digital communications.
What is the Internet Protocol?
The Internet Protocol is a set of rules that governs how data is transmitted across networks. It’s part of the TCP/IP protocol suite, which forms the backbone of Internet communications. IP provides two primary functions:
Addressing - Assigning unique addresses to devices on a network
Fragmentation - Breaking down large data packets into smaller ones for efficient transmission
Think of IP as the postal service of the internet. Just as every house needs an address for mail delivery, every device connected to the internet needs an IP address to send and receive data.
Understanding IP Addresses
An IP address is a unique numerical identifier assigned to each device on a network. There are currently two versions of IP addresses in use:
IPv4 (Internet Protocol version 4)
Uses 32-bit addresses
Format: Four sets of numbers ranging from 0 to 255 (e.g., 192.168.1.1)
Supports approximately 4.3 billion unique addresses
Still widely used but facing address exhaustion
IPv6 (Internet Protocol version 6)
Uses 128-bit addresses
Format: Eight groups of four hexadecimal digits (e.g., 2001:0db8:85a3:0000:0000:8a2e:0370:7334)
Provides an astronomical number of unique addresses (340 undecillion)
Designed to address IPv4’s limitations and support future growth
How IP Works: The Journey of a Data Packet
When you send data across the internet, IP breaks it down into smaller units called packets. Each packet contains:
Header Information* Source IP address
Destination IP address
Packet sequence number
Protocol version
Time-to-live (TTL) value
Payload* The actual data being transmitted
The journey of a data packet involves several steps:
Packet Creation: The sending device breaks data into packets and adds header information.
Routing: Packets travel through various routers and networks, with each router determining the best path to the destination.
Reassembly: The receiving device reconstructs the original data from the received packets.
Key Features of IP
- Connectionless Protocol
IP operates on a “best effort” delivery model, meaning:
No guaranteed delivery
No acknowledgment of receipt
No error checking
No flow control
These functions are handled by higher-level protocols like TCP (Transmission Control Protocol).
- Network Address Translation (NAT)
NAT allows multiple devices on a local network to share a single public IP address, helping to:
Conserve IPv4 addresses
Enhance network security
Simplify network administration
- Subnetting
Subnetting divides larger networks into smaller, more manageable segments, offering:
Improved network performance
Enhanced security
Better network organization
More efficient routing
Common IP-Related Protocols
Several protocols work alongside IP to ensure reliable network communications:
ICMP (Internet Control Message Protocol)* Reports errors and network conditions
Used by ping and traceroute tools
Essential for network diagnostics
ARP (Address Resolution Protocol)* Maps IP addresses to physical (MAC) addresses
Essential for local network communications
DHCP (Dynamic Host Configuration Protocol)* Automatically assigns IP addresses to devices
Simplifies network administration
Prevents address conflicts
IP Security Considerations
As the foundation of Internet communications, IP security is crucial. Common security measures include:
- IPsec (Internet Protocol Security)
Provides encryption and authentication
Ensures data confidentiality and integrity
Commonly used in VPNs
- Firewalls
Filter traffic based on IP addresses
Control network access
Protect against unauthorized access
- Access Control Lists (ACLs)
Define rules for IP traffic
Restrict network access
Enhance network security
The Future of IP
As the internet continues to evolve, IP faces new challenges and opportunities:
IPv6 Adoption* Gradual transition from IPv4
Improved security features
Better support for mobile devices
Enhanced Quality of Service (QoS)
Internet of Things (IoT)* Billions of new connected devices
Need for efficient address allocation
Enhanced security requirements
Software-Defined Networking (SDN)* More flexible network management
Improved traffic optimization
Enhanced security controls
Best Practices for IP Management
To maintain a healthy network infrastructure:
Document Your IP Addressing Scheme* Maintain accurate records
Plan for future growth
Document subnet assignments
Implement Security Measures* Regular security audits
Strong access controls
Updated security policies
Monitor Network Performance* Track IP address usage
Monitor network traffic
Identify potential issues early
Conclusion
The Internet Protocol remains the cornerstone of modern digital communications, enabling the connected world we live in today. Understanding IP is crucial for network administrators, developers, and anyone working with internet technologies. As we continue to see advances in networking technology and an increasing number of connected devices, IP will continue to evolve to meet these challenges while maintaining its fundamental role in connecting our digital world.
Whether you’re managing a network, developing applications, or simply curious about how the internet works, having a solid understanding of IP is invaluable. By staying informed about IP developments and best practices, you can better prepare for the future of network communications and ensure your systems remain efficient, secure, and ready for whatever comes next.
Address Resolution Protocol (ARP): The Network's Address Book
In the intricate world of networking, the Address Resolution Protocol (ARP) plays a crucial role in ensuring seamless communication between devices on a local network. This protocol acts as a network’s address book, translating logical IP addresses into physical MAC addresses, and enabling devices to communicate effectively.
Understanding IP and MAC Addresses
Before delving into ARP, let’s clarify the distinction between IP and MAC addresses:
IP Address: A logical address assigned to a device on a network, allowing it to communicate with other devices.
MAC Address: A unique physical address assigned to a network interface card (NIC), identifying the device’s hardware.
The Role of ARP
When a device needs to send data to another device on the same network, it knows the IP address of the destination device. However, to transmit data at the Data Link layer, it requires the physical MAC address of the destination device. This is where ARP comes into play.
The ARP Process
ARP Request:* A device needs to send a packet to another device on the same network.
It knows the IP address of the destination device but lacks its MAC address.
The device broadcasts an ARP request packet to all devices on the network.
The ARP request packet contains the IP address of the destination device and a special hardware address (usually all zeros).
ARP Reply:* The device with the matching IP address receives the ARP request.
It constructs an ARP reply packet containing its MAC address and the IP address of the requesting device.
The ARP reply packet is broadcast to all devices on the network.
Caching the ARP Entry:* The requesting device receives the ARP reply and caches the mapping of the destination device’s IP address to its MAC address in its ARP cache.
This cached information is used for future communications with the same destination device.
ARP Cache
The ARP cache is a temporary table stored in a device’s memory, containing mappings of IP addresses to MAC addresses. This cache speeds up the process of resolving IP addresses to MAC addresses, as devices can refer to the cache instead of broadcasting ARP requests for each communication.
ARP Timeout and Aging
ARP cache entries are not permanent. They have a specific timeout period, usually a few minutes. After the timeout period, the entry is removed from the cache. This mechanism helps to prevent outdated information from being used.
ARP Spoofing
ARP spoofing is a security attack where an attacker sends fake ARP replies to a target device, claiming to have the MAC address of another device on the network. This can lead to various security issues, such as man-in-the-middle attacks and network disruptions.
ARP Poisoning
ARP poisoning is a specific type of ARP spoofing attack where the attacker floods the network with fake ARP replies, causing devices to incorrectly map IP addresses to MAC addresses. This can disrupt network traffic and compromise security.
Mitigating ARP Attacks
To protect against ARP attacks, consider the following measures:
Static ARP Entries: Configure static ARP entries for critical devices, preventing them from being affected by ARP poisoning attacks.
Port Security: Implement port security on network switches to limit the number of devices that can connect to a port, reducing the risk of unauthorized devices.
ARP Inspection: Use network security devices with ARP inspection capabilities to monitor ARP traffic and detect and block malicious ARP packets.
Network Segmentation: Segmenting the network into smaller subnets can limit the impact of ARP attacks.
Conclusion
The Address Resolution Protocol is a fundamental networking protocol that enables devices to communicate effectively on a local network. By understanding the ARP process, ARP cache, and potential security threats, network administrators can ensure the security and reliability of their networks. By implementing appropriate security measures, such as static ARP entries, port security, and ARP inspection, organizations can mitigate the risks associated with ARP attacks and protect their network infrastructure.
Private vs. Public IP Addresses: A Complete Guide to Network Addressing
Understanding the distinction between private and public IP addresses is crucial for anyone involved in networking, whether you’re a network administrator, IT professional, or simply interested in how the internet works. This comprehensive guide explores the differences, use cases, and implications of private and public IP addressing.
Understanding IP Addresses: The Basics
Before diving into the differences between private and public IP addresses, let’s establish a foundation of what IP addresses are and why we need different types.
What is an IP Address?
An IP address is a unique numerical identifier assigned to every device connected to a network. It serves two primary purposes:
Host identification
Location addressing
Public IP Addresses
Definition and Characteristics
Public IP addresses are globally unique addresses that are visible and accessible over the internet. These addresses are assigned by Internet Service Providers (ISPs) and are regulated by the Internet Assigned Numbers Authority (IANA).
Key Features of Public IP Addresses
Global Uniqueness:
Each public IP address must be unique worldwide
No two devices on the internet can share the same public IP
Controlled allocation through regional internet registries
Internet Accessibility:
Direct access from anywhere on the internet
Enables hosting of public services
Required for direct internet communication
Assignment Methods:
Static allocation
Dynamic allocation through DHCP
Provider-assigned addressing
Common Uses for Public IP Addresses
Web Servers:
Hosting websites
Running email servers
Providing cloud services
Remote Access:
VPN endpoints
Remote desktop connections
SSH access
Online Gaming:
Game servers
Peer-to-peer connections
Gaming consoles
Private IP Addresses
Definition and Characteristics
Private IP addresses are used within local networks and are not routable over the Internet. These addresses are defined in RFC 1918 and can be reused across different private networks.
Private IP Address Ranges
Class A:
Range: 10.0.0.0 to 10.255.255.255
Subnet mask: 255.0.0.0
Available addresses: 16,777,216
Class B:
Range: 172.16.0.0 to 172.31.255.255
Subnet mask: 255.240.0.0
Available addresses: 1,048,576
Class C:
Range: 192.168.0.0 to 192.168.255.255
Subnet mask: 255.255.0.0
Available addresses: 65,536
Common Uses for Private IP Addresses
Home Networks:
Personal computers
Smart devices
Printers
Corporate Networks:
Office workstations
Internal servers
Network printers
IoT Devices:
Smart home devices
Security cameras
Environmental sensors
Network Address Translation (NAT)
Understanding NAT
NAT is the crucial technology that bridges private and public IP addressing, allowing devices with private IP addresses to communicate with the internet.
How NAT Works
Outbound Traffic:
The private IP source address is replaced with a public IP
Port numbers are tracked for return traffic
The connection state is maintained
Inbound Traffic:
Public IP destination is translated to private IP
Port forwarding rules direct traffic to specific devices
Connection tracking ensures proper delivery
Types of NAT
Static NAT:
One-to-one mapping
Permanent address translation
Used for servers requiring constant access
Dynamic NAT:
Many-to-many mapping
Temporary address assignment
Used for general internet access
Port Address Translation (PAT):
Many-to-one mapping
Also called NAT overload
Most common in home networks
Benefits and Limitations
Advantages of Private IP Addresses
Security:
Natural firewall effect
Hidden from Internet exposure
Reduced attack surface
Address Conservation:
Reuse of address space
Efficient resource utilization
Scalability for internal networks
Network Management:
Simplified internal routing
Easier network segmentation
Consistent addressing schemes
Advantages of Public IP Addresses
Direct Accessibility:
No NAT requirements
Simpler configuration
Better performance
Service Hosting:
Easy to host services
Direct peer connections
Simplified troubleshooting
Network Transparency:
Clear communication paths
Easier security monitoring
Simplified network design
Best Practices and Implementation
Network Design Considerations
Address Planning:
Allocate sufficient private address space
Plan for growth
Consider subnet requirements
Security Measures:
Implement firewalls
Use VPNs for remote access
Monitor network traffic
Documentation:
Maintain IP address inventory
Document NAT configurations
Keep network diagrams updated
Common Implementation Scenarios
Small Office/Home Office:
Single public IP
The private network behind NAT
Basic port forwarding
Medium Business:
Multiple public IPs
Segmented private network
Advanced NAT configurations
Enterprise Environment:
Public IP blocks
Complex private addressing
Multiple NAT zones
Troubleshooting and Management
Common Issues
NAT-Related Problems:
Port forwarding conflicts
Connection tracking table overflow
NAT traversal issues
Address Conflicts:
Duplicate IP addresses
Overlapping networks
DHCP conflicts
Connectivity Issues:
NAT timeout problems
Routing issues
DNS resolution failures
Management Tools
Network Monitoring:
IP address management (IPAM)
Traffic analyzers
NAT monitoring tools
Documentation Tools:
Network mapping software
IP address databases
Configuration management systems
Conclusion
The distinction between private and public IP addresses is fundamental to modern networking. Each type serves specific purposes and comes with its advantages and challenges. Understanding how to effectively use both types of addresses, along with technologies like NAT, is crucial for building and maintaining efficient networks.
As networks continue to evolve and IPv6 adoption increases, the relationship between private and public addressing may change, but the basic principles of network segmentation and address management will remain important. Whether you’re managing a home network or enterprise infrastructure, a solid understanding of IP addressing is essential for successful network operation and troubleshooting.
Remember that proper network design should always consider both immediate requirements and future growth, balancing security, accessibility, and manageability. By following best practices and maintaining good documentation, you can create robust and efficient networks that serve your needs while remaining secure and manageable.
Understanding Network Address Translation (NAT): Types, Benefits, and How It Works
As the demand for internet-connected devices grows, managing IP addresses and ensuring secure network communication becomes increasingly important. Network Address Translation (NAT) plays a crucial role in facilitating efficient and secure communication between private networks and public networks like the Internet. NAT allows multiple devices to share a single public IP address, making it an essential solution for both home and business networks.
This guide explores NAT’s functionality, different types, benefits, and practical applications. By understanding NAT, you’ll gain valuable insight into one of the core technologies that support modern internet communication. 1. What is Network Address Translation (NAT)?
Network Address Translation (NAT) is a method that modifies IP addresses as they pass through a router or firewall, enabling devices within a private network to share a single public IP address when accessing the internet. NAT operates at the Network Layer (Layer 3) of the OSI model and is commonly implemented in routers and firewalls.
In a typical setup, NAT translates private IP addresses (used within a local network) to a public IP address (used on the internet). This approach reduces the number of public IPs required, conserves IPv4 address space, and provides an additional layer of security by masking internal IP addresses from external networks. 2. How Does NAT Work?
When a device within a private network sends data to the internet, NAT modifies the device’s private IP address to a public IP address provided by the ISP. Here’s a simplified breakdown of how NAT works:
Outgoing Data: When a device (like a computer or smartphone) in a private network sends a request to access the internet, it sends the data packet to the router.
IP Address Translation: The router replaces the device’s private IP address with the router’s public IP address.
Port Assignment: The router assigns a unique port number to each outgoing connection, which allows it to track responses.
Routing Response: When the internet responds, the router uses the port number to determine which device within the private network the response is intended for, ensuring it reaches the correct destination.
This process enables multiple devices on the same network to communicate with the internet using a single public IP address. 3. Types of NAT
There are several types of NAT, each serving a unique purpose and suitable for different scenarios:
a. Static NAT
Static NAT maps a single private IP address to a single public IP address. This type of NAT is ideal for devices that need to be accessible from outside the network, such as web servers or FTP servers.
Use Case: Static NAT is commonly used in business settings where specific internal devices, like servers, need dedicated public IPs for direct access from the internet.
Benefit: It provides a fixed mapping, making the internal device consistently reachable from the outside network.
b. Dynamic NAT
Dynamic NAT automatically assigns available public IP addresses to devices within the private network on an as-needed basis. This approach is useful when there are more devices in the network than public IP addresses.
Use Case: Common in organizations that want to manage multiple devices but may have a limited number of public IPs available.
Benefit: Dynamic NAT is flexible, providing IP addresses dynamically and freeing them up once a session ends.
c. Port Address Translation (PAT)
Port Address Translation (PAT), also known as NAT Overloading, is the most commonly used type of NAT. PAT allows multiple devices on a private network to share a single public IP address by assigning a unique port number to each device’s connection.
Use Case: Widely used in home and small business networks where only one public IP address is available.
Benefit: PAT efficiently conserves public IP addresses, allowing hundreds of devices to use a single IP, thanks to port assignment.
Each of these NAT types has distinct characteristics and serves different networking needs. 4. Private vs. Public IP Addresses and NAT
To understand NAT’s role, it’s essential to differentiate between private and public IP addresses:
Private IP Addresses: Used within a local network and not routable on the Internet. Examples of private IP ranges include
192.168.0.0/16,10.0.0.0/8, and172.16.0.0/12.Public IP Addresses: Unique addresses assigned by ISPs and required for devices to communicate on the internet.
NAT bridges the gap between private and public IPs, enabling devices with private IPs to access the internet using a shared public IP, thus conserving IP address space. 5. The Importance of NAT in Today’s Networking
NAT has become crucial in networking for several reasons:
IPv4 Address Conservation: With IPv4 address exhaustion, NAT enables multiple devices to share a single IP address, reducing the need for more IPv4 addresses.
Security: NAT hides private IP addresses from the internet, making it harder for external entities to identify or directly attack individual devices.
Network Organization: NAT helps organize internal networks, especially in larger organizations where managing public IP addresses would otherwise be complex and costly.
With these advantages, NAT is widely used in both residential and commercial networks. 6. Benefits of Network Address Translation
Implementing NAT brings several benefits to network management and security:
a. IP Address Conservation
NAT allows many devices to share a single IP address, reducing the need for additional public IPs. This is particularly valuable given the limited availability of IPv4 addresses.
b. Enhanced Network Security
By hiding internal IP addresses from the public, NAT provides a layer of security that makes devices within a network less visible to external threats. This address hiding reduces the risk of unsolicited traffic and attacks targeting specific devices.
c. Simplified Network Management
NAT allows network administrators to manage IP addressing within a private network independently of the ISP, making it easier to assign and organize internal addresses without needing additional public IPs. 7. NAT and IPv6: What Changes?
IPv6, the latest version of the IP protocol, was developed to address IPv4 address exhaustion by offering a much larger pool of IP addresses. Because IPv6 provides more than enough unique IPs for every device, NAT is not as necessary in IPv6 networks as it is in IPv4.
However, NAT64 (a version of NAT for IPv6) exists to help IPv6-only networks communicate with IPv4 networks, providing a bridge between the two IP versions. 8. NAT and Port Forwarding
Port forwarding is a technique used alongside NAT to allow specific traffic from the internet to reach designated devices on a private network. For instance, a network administrator can configure port forwarding to route web traffic (port 80) to a particular device within the network.
Example Use Case:
- A home user sets up port forwarding to allow external access to a gaming console or a media server within their network.
This approach allows certain services within a private network to be accessible externally without exposing all devices, enhancing security while maintaining access. 9. NAT Limitations and Challenges
While NAT provides numerous benefits, it also comes with limitations:
a. Compatibility Issues
Some applications and protocols, especially those requiring peer-to-peer connections, can encounter issues with NAT. For example, some VoIP and online gaming applications may experience connection issues due to NAT’s IP address and port translation.
b. Increased Complexity in Network Management
In large networks, managing NAT configurations and troubleshooting connectivity issues can become complex, especially when dealing with dynamic NAT or PAT.
c. Limited End-to-End Connectivity
NAT complicates end-to-end connectivity, as it modifies IP addresses and ports, which can interfere with applications relying on consistent IP addresses for direct connections. 10. Practical Applications of NAT
NAT is widely used across different types of networks and applications:
Home Networks: NAT enables all devices in a home to access the internet through a single IP address.
Business Networks: Companies use NAT to manage IP addressing for large numbers of devices without requiring many public IPs.
ISP Networks: ISPs often use NAT to assign private IP addresses to customers, conserving public IP addresses.
Cloud Services: NAT is used within cloud environments to allow private cloud instances to connect to the internet securely.
Each of these applications demonstrates how NAT helps reduce IP usage while ensuring secure connectivity. 11. NAT Traversal: Overcoming NAT Limitations
NAT traversal techniques are used to address the limitations of NAT for specific applications. Protocols like STUN (Session Traversal Utilities for NAT) and TURN (Traversal Using Relays around NAT) help applications bypass NAT to maintain end-to-end connectivity, especially for real-time applications like video calls.
These protocols assist devices in detecting their public IP and port numbers, allowing them to maintain stable connections despite NAT configurations. Conclusion
Network Address Translation (NAT) is an essential component of modern networking. By allowing multiple devices to share a single public IP address, NAT addresses the challenges of IPv4 address exhaustion and provides added security by concealing private IPs. Understanding how NAT works, along with its types and practical applications, offers valuable insights into managing and securing network connections effectively.
Whether in home setups, business environments, or large-scale ISP networks, NAT plays a foundational role in ensuring smooth communication and IP address management. Frequently Asked Questions (FAQs)
Q1: What is the main purpose of NAT?
- NAT enables devices in a private network to access the internet using a shared public IP address, conserving IP resources and enhancing security.
Q2: Is NAT still necessary with IPv6?
- NAT is less critical in IPv6 networks due to the abundance of IP addresses. However, NAT64 helps bridge IPv4 and IPv6 networks.
Q3: How does NAT enhance network security?
- By hiding private IP addresses, NAT reduces exposure to external threats, making it harder for malicious actors to identify internal devices.
Q4: What’s the difference between NAT and PAT?
- NAT translates IP addresses, while PAT, a subset of NAT, also assigns unique port numbers, allowing multiple devices to use the same public IP.
Q5: Can NAT interfere with certain applications?
- Yes, some applications, such as VoIP or online gaming, can experience connectivity issues due to NAT. NAT traversal techniques help mitigate this.
Q6: What is port forwarding?
- Port forwarding is a technique used alongside NAT to direct specific external traffic to designated devices within a private network, enabling external access to selected services.
TCP vs. UDP: Differences and Use Cases
TCP (Transmission Control Protocol) and UDP (User Datagram Protocol) are two fundamental protocols used for data transmission over the Internet. Understanding their differences, advantages, and appropriate use cases is crucial for anyone involved in network technology or application development. This blog post will explore the characteristics of TCP and UDP, compare their functionalities, and provide examples of scenarios where each protocol is best suited.
Understanding TCP and UDP
What is TCP?
TCP is a connection-oriented protocol, meaning it establishes a connection between the sender and receiver before any data is transmitted. This connection setup involves a process known as a three-way handshake, which ensures that both parties are ready to communicate. The steps include:
SYN: The sender sends a synchronization request to the receiver.
SYN-ACK: The receiver acknowledges the request and sends back a synchronization acknowledgment.
ACK: The sender confirms the acknowledgment.
Once this connection is established, TCP guarantees that data packets are delivered in order and without errors. If any packets are lost or corrupted during transmission, TCP will automatically retransmit them until they are received correctly. This reliability comes with some overhead, as TCP must manage error checking, flow control, and congestion control.
What is UDP?
In contrast, UDP is a connectionless protocol. It does not establish a dedicated end-to-end connection before sending data. Instead, it sends packets of data called datagrams without ensuring their delivery or order. This “fire-and-forget” approach means that UDP can transmit data much faster than TCP since it does not wait for acknowledgments or retransmissions.
UDP is ideal for applications where speed is critical and some data loss can be tolerated. For instance, in live video streaming or online gaming, losing a few packets may not significantly affect the overall experience.
Key Differences Between TCP and UDP
| Feature | TCP | UDP |
|---|---|---|
| **Connection Type** | Connection-oriented | Connectionless |
| **Reliability** | Guarantees delivery and order | No guarantee of delivery or order |
| **Error Checking** | Extensive error checking and correction | Minimal error checking |
| **Speed** | Slower due to overhead | Faster due to lower overhead |
| **Use Cases** | Web browsing, email, file transfers | Video streaming, online gaming, VoIP |
| **Packet Structure** | More complex header | Simpler header |
Reliability
TCP’s reliability stems from its acknowledgment system. Each packet sent must be acknowledged by the receiver; if an acknowledgment is not received within a certain timeframe, the packet is resent. This ensures that all data arrives intact and in the correct order.
UDP lacks this mechanism entirely. While this makes it faster, it also means that applications using UDP must implement their methods for handling lost packets if necessary.
Overhead
The overhead associated with TCP includes managing connections, maintaining state information about each session (such as sequence numbers), and handling retransmissions. This overhead can lead to increased latency compared to UDP.
UDP’s simplicity allows for lower overhead, making it suitable for applications that require quick transmission without the need for guaranteed delivery.
Latency
Latency refers to the time it takes for data to travel from source to destination. Because TCP requires acknowledgments and has built-in error checking, it generally has higher latency than UDP. In scenarios where timing is critical—such as real-time communications—UDP’s low latency gives it an advantage.
Use Cases for TCP
Given its characteristics, TCP is best suited for applications where reliability and accuracy are paramount:
Web Browsing: When loading web pages, users expect all elements (text, images) to load correctly and in order.
Email Transmission: Email protocols like SMTP rely on TCP to ensure that messages are sent without loss.
File Transfers: Protocols like FTP use TCP to guarantee complete file transfers.
Secure Transactions: Online banking and shopping require secure connections provided by TCP to protect sensitive information.
Use Cases for UDP
UDP shines in scenarios where speed is more critical than reliability:
Video Streaming: Services like Netflix use UDP for streaming video content because occasional packet loss does not significantly impact user experience.
Voice over IP (VoIP): Applications like Skype prioritize real-time communication over perfect accuracy; thus, they often use UDP.
Online Gaming: Many multiplayer games utilize UDP to ensure fast-paced interactions between players without delays caused by packet retransmissions.
DNS Queries: The Domain Name System often uses UDP because queries are small and can be resent easily if lost.
Conclusion
In summary, both TCP and UDP have unique strengths that make them suitable for different types of applications. TCP should be used when data integrity and order are critical, while UDP is preferable when speed is essential and some data loss can be tolerated.
Understanding these protocols’ differences allows developers and network engineers to choose the right one based on their specific needs—ensuring efficient communication across networks while optimizing performance based on application requirements.
As technology continues to evolve, so too will the applications of these protocols. Staying informed about their capabilities will help professionals make better decisions in designing systems that rely on robust networking solutions.
Citations: [1] https://www.linkedin.com/advice/3/what-some-common-use-cases-examples [2] https://www.twingate.com/blog/tcp-vs-udp [3] https://stackoverflow.com/questions/5330277/what-are-examples-of-tcp-and-udp-in-real-life [4] https://www.avast.com/c-tcp-vs-udp-difference [5] https://ostinato.org/blog/tcp-vs-udp-understanding-differences-and-use-cases [6] https://www.spiceworks.com/tech/networking/articles/tcp-vs-udp/ [7] https://www.geeksforgeeks.org/differences-between-tcp-and-udp/ [8] https://www.digitalsamba.com/blog/tcp-and-udp-protocols
Data Encapsulation in Networking: A Layer-by-Layer Breakdown
Data encapsulation is a fundamental concept in networking, essential for the seamless transmission of data across various networks. It involves the process of adding header and trailer information to data packets at each layer of the OSI model. This layered approach ensures that data is formatted and addressed correctly, enabling it to traverse complex network infrastructures.
The OSI Model and Data Encapsulation
The Open Systems Interconnection (OSI) model is a conceptual framework used to describe the functions of a networking system. It divides network communication into seven layers, each responsible for specific tasks. Data encapsulation occurs at the lower layers of the OSI model, starting from the Physical layer and progressing through the Data Link and Network layers.
Physical Layer Encapsulation
At the Physical layer, data is converted into bits, the smallest unit of data. These bits are then encoded into electrical signals, light pulses, or radio waves, depending on the transmission medium. The Physical layer adds a physical layer header and trailer to the data bits, providing information such as synchronization signals, clocking signals, and error correction codes.
Data Link Layer Encapsulation
The Data Link layer is responsible for reliable data transmission between nodes on a network. It divides data into frames, which are smaller units of data. A Data Link layer header and trailer are added to each frame, containing information such as the source and destination addresses, frame delimiters, and error-checking codes.
Network Layer Encapsulation
The Network layer is responsible for routing data packets across multiple networks. It encapsulates data frames into packets, adding a Network layer header to each packet. This header includes information such as the source and destination IP addresses, time-to-live (TTL) value, and protocol type.
The Encapsulation Process
Application Layer: The application data is generated by an application, such as a web browser or email client.
Transport Layer: The Transport layer divides the data into segments and adds a Transport layer header, containing information such as port numbers and sequence numbers.
Network Layer: The Network layer encapsulates the segments into packets, adding a Network layer header, containing information such as source and destination IP addresses.
Data Link Layer: The Network layer packets are encapsulated into frames, adding a Data Link layer header and trailer, containing information such as source and destination MAC addresses.
Physical Layer: The Data Link layer frames are converted into bits and encoded into signals, ready for transmission over the physical medium.
Decapsulation
The reverse process of encapsulation is decapsulation. As data packets travel through the network, the headers and trailers added at each layer are removed. This allows the receiving device to extract the original data and process it accordingly.
Benefits of Data Encapsulation
Error Detection and Correction: Encapsulation adds error-checking codes to data, enabling the detection and correction of errors during transmission.
Addressing and Routing: Encapsulation provides the necessary addressing information to route data packets to their intended destinations.
Security: Encapsulation can be used to encrypt data, ensuring secure transmission over public networks.
Quality of Service (QoS): Encapsulation allows for the prioritization of certain types of traffic, ensuring the timely delivery of critical data.
Conclusion
Data encapsulation is a fundamental building block of modern networking. By understanding the layered approach to data transmission, network administrators can optimize network performance, troubleshoot issues, and ensure the reliable delivery of data. As network technologies continue to evolve, data encapsulation will remain a critical component of network infrastructure.
Additional Considerations:
Protocol Stacks: Different network protocols, such as TCP/IP and OSI, use different layer structures and encapsulation mechanisms.
Network Devices: Network devices, such as routers and switches, play a crucial role in the encapsulation and decapsulation of data packets.
Network Performance: The efficiency of data encapsulation and decapsulation can impact network performance, particularly in high-traffic environments.
Security Threats: Understanding data encapsulation can help identify potential security vulnerabilities and implement appropriate measures to protect network data.
By mastering the concepts of data encapsulation, you can gain a deeper understanding of how networks function and how to troubleshoot network issues effectively.
TCP/IP Model Layers and Functions
- Network Access Layer (Layer 1)
- Internet Layer (Layer 2)
- Transport Layer (Layer 3)
- Application Layer (Layer 4) Let’s examine each layer in detail, starting from the bottom up.
Network Access Layer
Overview The Network Access Layer, also known as the Network Interface Layer or Link Layer, is the foundation of the TCP/IP model. This layer handles the physical transmission of data between devices on the same network. Key Functions
Physical Addressing:
Manages MAC (Media Access Control) addresses
Handles physical device identification
Controls hardware addressing schemes
Data Framing:
Organizes data into frames
Adds error detection information
Manages frame synchronization
Media Access Control:
Controls access to physical media
Manages collision detection and avoidance
Coordinates shared medium usage
Protocols and Standards
- Ethernet
- Wi-Fi (802.11)
- PPP (Point-to-Point Protocol)
- Token Ring
- FDDI (Fiber Distributed Data Interface)
Internet Layer
Overview The Internet Layer enables data routing between different networks, making it possible for information to traverse multiple networks to reach its destination. Key Functions
Logical Addressing:
Implements IP addressing
Manages subnet addressing
Handles address resolution
Routing:
Determines optimal paths for data
Manages routing tables
Handles packet forwarding
Fragmentation and Reassembly:
Breaks large packets into smaller units
Reassembles fragments at destination
Manages Maximum Transmission Unit (MTU)
Primary Protocols
IPv4 and IPv6:
Provides logical addressing
Handles packet formatting
Manages address allocation
ICMP (Internet Control Message Protocol):
Error reporting
Network diagnostics
Status messaging
ARP (Address Resolution Protocol):
Maps IP addresses to MAC addresses
Maintains address resolution tables
Handles address conflicts
Transport Layer
Overview The Transport Layer ensures reliable data delivery between applications, managing the quality, flow, and integrity of data transmission. Key Functions
Connection Management:
Establishes connections
Maintains session state
Handles connection termination
Flow Control:
Prevents buffer overflow
Manages transmission rates
Coordinates data flow
Error Control:
Detects transmission errors
Manages retransmissions
Ensures data integrity
Primary Protocols
TCP (Transmission Control Protocol):
Connection-oriented communication
Reliable data delivery
Ordered packet delivery
Flow control and congestion management
UDP (User Datagram Protocol):
Connectionless communication
Fast, lightweight transmission
No guaranteed delivery
Minimal overhead
Application Layer
Overview The Application Layer is the topmost layer, providing network services directly to end-users and applications. Key Functions
Application Services:
Email Handling
File transfer
Web browsing
Remote access
Data Formatting:
Standardizes data presentation
Handles encryption
Manages compression
Session Management:
Controls dialogue between applications
Manages authentication
Handles authorization
Common Protocols
HTTP/HTTPS:
Web page transfer
Secure communication
RESTful services
FTP/SFTP:
File transfer
Directory services
File management
SMTP/POP3/IMAP:
Email transmission
Message retrieval
Mailbox management
DNS:
Name resolution
Domain management
Service discovery
Layer Interaction and Data Flow
Encapsulation Process
Application Layer:
Creates user data
Adds application headers
Transport Layer:
Adds TCP/UDP header
Creates segments/datagrams
Internet Layer:
Adds IP header
Creates packets
Network Access Layer:
Adds frame header and trailer
Creates frames
Data Flow Example Consider sending an email:
- The Application Layer creates the email message
- The Transport Layer segments the message and adds reliability
- Internet Layer addresses and routes the segments
- Network Access Layer transmits the physical signals
Troubleshooting and Diagnostics
Layer-Specific Tools
Network Access Layer:
Cable testers
Network analyzers
Signal strength meters
Internet Layer:
Ping
Traceroute
IP configuration tools
Transport Layer:
Port scanners
Connection monitors
Protocol analyzers
Application Layer:
Web debugging tools
Protocol-specific analyzers
Application monitors
Security Considerations
Layer-Specific Security Measures
Network Access Layer:
MAC filtering
Port security
Physical access control
Internet Layer:
Firewalls
IPSec
Access Control Lists (ACLs)
Transport Layer:
TLS/SSL
Port filtering
Connection monitoring
Application Layer:
Authentication
Encryption
Access control
Conclusion
Understanding the TCP/IP model layers and their functions is crucial for network professionals and anyone involved in internet technologies. Each layer serves specific purposes and works in harmony with the others to enable the reliable, efficient communication we depend on daily. The modular nature of the TCP/IP model allows for flexibility and innovation within each layer while maintaining compatibility across the entire system. This architecture has proven remarkably resilient and adaptable, supporting the internet’s evolution from its early days to today’s complex, interconnected world. As networks continue to evolve and new technologies emerge, the fundamental principles of the TCP/IP model remain relevant, providing a solid framework for understanding and implementing network communications. Whether you’re troubleshooting network issues, developing network applications, or designing network infrastructure, a thorough understanding of these layers and their functions is essential for success in the field of networking.
Understanding the OSI Model Layers: A Comprehensive Guide
The OSI (Open Systems Interconnection) Model is a conceptual framework that standardizes the functions of a telecommunication or computing system into seven distinct layers. These layers range from the physical connections that link devices to the high-level application protocols that facilitate end-user interactions. Understanding each OSI model layer is essential for anyone working in networking or IT, as it provides a structured approach to troubleshooting, designing, and managing network systems.
This guide will walk through each layer, explaining their roles, processes, and relevance in the modern networking world. 1. What is the OSI Model?
The OSI model is a theoretical framework for how data moves across a network. Created by the International Organization for Standardization (ISO) in 1984, the OSI model divides network communication into seven layers, each responsible for a specific set of tasks. By organizing networking functions into these layers, the OSI model provides a universal standard for different systems and technologies to interact and communicate effectively.
Each layer of the OSI model has specific responsibilities that contribute to the data’s journey from one device to another, ensuring that communication happens smoothly and without interruption. 2. The Seven Layers of the OSI Model
The OSI model is broken down into seven layers, each with unique tasks and responsibilities. From bottom to top, these layers are:
Physical Layer
Data Link Layer
Network Layer
Transport Layer
Session Layer
Presentation Layer
Application Layer
An easy way to remember these layers is through the mnemonic “Please Do Not Throw Sausage Pizza Away.” 3. Layer 1: The Physical Layer
The Physical Layer is the lowest level of the OSI model and deals with the raw transmission of data. It encompasses all the physical aspects of network communication, such as cables, switches, wireless transmissions, and other hardware components.
Key Responsibilities:
Transmission Medium: Defines the means of transferring raw bits over physical media, including fiber optics, Ethernet cables, and radio frequencies.
Signal Encoding: Converts data into electrical, optical, or radio signals to be transmitted.
Topology and Physical Connections: Manages network topology and device connections.
Examples: Ethernet cables, fiber optics, Wi-Fi signals, and hardware components like network interface cards (NICs). 4. Layer 2: The Data Link Layer
The Data Link Layer is responsible for establishing a reliable link between directly connected nodes and ensuring data frames reach their destination without errors.
Key Responsibilities:
Error Detection and Correction: Detects and corrects errors that may occur during data transmission.
MAC (Media Access Control): Manages how devices share the network medium and assigns unique MAC addresses to devices.
Frame Synchronization: Organizes data into frames and controls their flow.
The Data Link Layer is divided into two sub-layers:
MAC Layer: Manages access to the physical media.
LLC (Logical Link Control) Layer: Handles error checking and frame synchronization.
Examples: Ethernet (IEEE 802.3), Wi-Fi (IEEE 802.11), and PPP (Point-to-Point Protocol). 5. Layer 3: The Network Layer
The Network Layer is responsible for routing data between different networks and determining the best path for data transmission.
Key Responsibilities:
Routing: Determines the most efficient path for data to travel across interconnected networks.
Logical Addressing: Assigns IP addresses to devices, enabling them to communicate over multiple networks.
Packet Forwarding: Breaks down data into packets and directs them to their destination.
This layer makes communication possible between devices across diverse network types and is essential for the Internet’s function.
Examples: IP (Internet Protocol), ICMP (Internet Control Message Protocol), and routers. 6. Layer 4: The Transport Layer
The Transport Layer ensures reliable data transmission between devices. It breaks data into segments and reassembles them on the receiving end, making sure everything arrives in order.
Key Responsibilities:
Segmentation and Reassembly: Divides data into manageable segments and reassembles them at the destination.
Flow Control: Manages data flow to prevent congestion and data loss.
Error Handling: Ensures data arrives without errors and in the correct sequence.
The Transport Layer can use different protocols depending on the need for reliability:
TCP (Transmission Control Protocol): Provides reliable, connection-oriented data transmission.
UDP (User Datagram Protocol): Offers faster, connectionless transmission but without guaranteed delivery.
Examples: TCP and UDP protocols, port numbers, and flow control mechanisms. 7. Layer 5: The Session Layer
The Session Layer manages sessions or connections between applications. It establishes, maintains, and terminates connections, allowing multiple sessions to be handled simultaneously.
Key Responsibilities:
Session Management: Manages the setup, duration, and teardown of sessions.
Synchronization: Provides checkpoints for continuous data streams, allowing data to resume if a connection is temporarily interrupted.
Dialog Control: Coordinates communication, enabling half-duplex or full-duplex operation.
The Session Layer is crucial for applications that require continuous data flow, such as streaming services and online gaming.
Examples: RPC (Remote Procedure Call), NetBIOS, and PPTP (Point-to-Point Tunneling Protocol). 8. Layer 6: The Presentation Layer
The Presentation Layer acts as the data translator for the network. It formats data so that it can be understood by both the sender and receiver.
Key Responsibilities:
Data Translation: Converts data formats between application and network formats (e.g., translating between ASCII and EBCDIC).
Encryption and Decryption: Encrypts data before transmission and decrypts it upon receipt to ensure security.
Data Compression: Reduces the size of data for faster transmission.
The Presentation Layer is particularly important in multimedia applications where data needs to be compressed and formatted correctly.
Examples: SSL (Secure Sockets Layer), TLS (Transport Layer Security), and formats like JPEG, MPEG, and ASCII. 9. Layer 7: The Application Layer
The Application Layer is the topmost layer of the OSI model and serves as the interface between the network and end-user applications. This layer does not refer to the actual applications themselves but to the protocols and services that support them.
Key Responsibilities:
User Interface: Provides an interface for the user to interact with network services.
Service Advertisement: Identifies and makes available different services to applications, such as email, file transfer, and web browsing.
Application Services: Handles protocols that enable user-level applications to communicate.
Examples: HTTP (Hypertext Transfer Protocol), FTP (File Transfer Protocol), SMTP (Simple Mail Transfer Protocol), and DNS (Domain Name System). 10. Practical Applications of the OSI Model
The OSI model offers a structured approach to network communication, making it easier to troubleshoot and optimize networks. Here are some practical uses:
Network Troubleshooting: By identifying the layer at which a problem occurs, network engineers can efficiently diagnose and address issues.
Protocol Development: Protocols and networking standards are developed with the OSI layers in mind to ensure compatibility.
Educational Tool: The OSI model is widely used in networking education to explain how different functions contribute to network communication.
11. Benefits of Understanding the OSI Model
Enhanced Troubleshooting: The OSI model allows network professionals to isolate and address issues quickly by pinpointing the layer where the issue originates.
Structured Framework: The model provides a standard approach for designing and understanding complex networks, making it easier to adapt to various technologies and vendors.
Compatibility and Interoperability: The OSI model ensures different network devices, software, and protocols can work together, regardless of manufacturer or technology. 12. Comparison with the TCP/IP Model
The OSI model is often compared to the TCP/IP model, which is a more simplified, practical framework with four layers instead of seven. While the OSI model serves as a conceptual model, the TCP/IP model focuses on the protocols and processes used on the internet.
| Layer (OSI Model) | Equivalent Layer (TCP/IP Model) |
|---|---|
| Application | Application |
| Presentation | Application |
| Session | Application |
| Transport | Transport |
| Network | Internet |
| Data Link | Network Access |
| Physical | Network Access |
13. OSI Model in Modern Networking
The OSI model remains relevant today as a framework, even though most modern networking is based on the TCP/IP protocol. Many applications still adhere to OSI principles for network interoperability, and understanding the OSI model helps professionals navigate the complexities of today’s digital environment. Conclusion
The OSI model’s seven layers provide an essential framework for understanding network communication. From the physical hardware connections at Layer 1 to the high-level protocols at Layer 7, each layer plays a critical role in ensuring data moves smoothly from sender to receiver. By understanding each layer’s functions and responsibilities, network professionals can troubleshoot, design, and manage networks more effectively.
Whether you’re a network administrator, IT professional, or tech enthusiast, grasping the
OSI model’s intricacies can deepen your knowledge of how networks function, making you better equipped to handle networking challenges and advancements. Frequently Asked Questions (FAQs)
Q1: Why is the OSI model still important today?
- Although the TCP/IP model is more widely used, the OSI model is invaluable for troubleshooting, network design, and learning foundational networking principles.
Q2: What is the difference between the OSI model and TCP/IP model?
- The OSI model has seven layers, while the TCP/IP model has four layers. OSI is a theoretical model, whereas TCP/IP is protocol-based and more commonly used.
Q3: What layer does a router operate on?
- Routers primarily operate at the Network Layer (Layer 3) to route data between networks.
Q4: How do layers interact in the OSI model?
- Each layer communicates with the layer directly above and below it, providing services to the higher layer and receiving services from the lower layer.
Q5: What layer is the Internet Protocol (IP) in the OSI model?
- IP operates at the Network Layer (Layer 3) and is essential for routing data across networks.
Q6: Can a problem in one OSI layer affect others?
- Yes, issues at one layer can propagate and affect higher or lower layers, impacting overall communication and performance.
Subnetting and CIDR Notation: A Deep Dive
In the realm of networking, subnetting, and CIDR notation are essential concepts for efficient IP address allocation and network management. By understanding these techniques, network administrators can optimize network performance, enhance security, and effectively manage network resources.
What is Subnetting?
Subnetting is the process of dividing a larger network into smaller subnetworks, or subnets. This is achieved by borrowing bits from the host portion of an IP address to create a subnet mask. The subnet mask defines the network and host portions of an IP address.
Why Subnetting?
Efficient IP Address Allocation: Subnetting allows for more efficient use of IP addresses by breaking down a large network into smaller, more manageable subnets.
Enhanced Network Security: By dividing a network into smaller subnets, you can isolate different network segments, reducing the potential impact of security breaches.
Improved Network Performance: Subnetting can help to reduce network traffic and improve overall network performance by segmenting traffic based on specific needs.
CIDR Notation
Classless Inter-Domain Routing (CIDR) notation is a method of representing IP addresses and their corresponding subnet masks in a concise and efficient manner. It uses a slash (/) followed by a number to indicate the number of bits in the network portion of the IP address.
How Subnetting Works
To subnet a network, you need to determine the number of subnets required and the number of hosts per subnet. Once you have this information, you can calculate the number of bits needed to represent the subnets and hosts.
Example:
Consider a Class C network with the IP address 192.168.1.0/24. This network can accommodate 254 hosts (2^8 - 2). If you need to create 4 subnets, each with 62 hosts, you would need to borrow 2 bits from the host portion of the IP address.
The new subnet mask would be 255.255.255.192 (/26).
The 4 subnets would be:
192.168.1.0/26
192.168.1.64/26
192.168.1.128/26
192.168.1.192/26
Subnetting and Routing Protocols
Subnetting has a significant impact on routing protocols. Routers use routing protocols to exchange routing information and build routing tables. When subnetting is implemented, routers must be configured with the appropriate subnet masks to ensure correct routing of packets.
Common Subnetting Scenarios
Departmental Subnetting: Dividing a network into subnets for different departments within an organization.
Building Subnetting: Subnetting a network based on physical location, such as different buildings or floors.
VLAN Subnetting: Using VLANs to logically segment a network and assign different subnets to each VLAN.
Best Practices for Subnetting
Plan Ahead: Carefully plan your subnetting scheme to ensure that it meets your current and future needs.
Consider Future Growth: Allocate enough IP addresses to accommodate future growth.
Keep It Simple: Avoid overly complex subnetting schemes that can be difficult to manage.
Document Your Network: Document your subnetting scheme to aid in troubleshooting and future modifications.
Troubleshooting Subnetting Issues
Incorrect Subnet Mask: Verify that the subnet mask is correctly configured on all devices.
Routing Issues: Check the routing tables on routers to ensure that they are routing traffic correctly.
IP Address Conflicts: Use tools like IP scanners to identify and resolve IP address conflicts.
DHCP Configuration: Ensure that your DHCP server is configured to assign IP addresses within the correct subnet.
Conclusion
Subnetting and CIDR notation are fundamental concepts for effective network management. By understanding these techniques, you can optimize your network’s performance, security, and scalability. By following best practices and troubleshooting techniques, you can ensure that your network operates smoothly and efficiently.
Additional Tips
Use a Subnetting Calculator: A subnetting calculator can help you quickly calculate subnet masks and IP addresses.
Consider VLSM: Variable-length subnet Masking (VLSM) allows you to use different subnet masks for different subnets, optimizing IP address utilization.
Stay Updated: Keep up with the latest networking technologies and standards to ensure that your network is secure and efficient.
By mastering the art of subnetting and CIDR notation, you can take your networking skills to the next level and build robust, reliable, and secure networks.
IPv4 vs. IPv6: A Comprehensive Guide to Internet Protocol Addressing
The Internet Protocol (IP) serves as the fundamental addressing system that enables communication across the Internet. As we continue to connect more devices to the global network, understanding the differences between IPv4 and IPv6 becomes increasingly important. This article explores both protocols in detail, examining their structures, benefits, and challenges.
The Evolution of Internet Protocol Addressing
When the internet was first developed, IPv4 seemed to provide more than enough addresses for the foreseeable future. However, the explosive growth of internet-connected devices has pushed IPv4 to its limits, necessitating the development and implementation of IPv6.
IPv4: The Original Internet Protocol
Structure and Format
IPv4 uses a 32-bit addressing scheme, formatted as four octets of numbers ranging from 0 to 255, separated by periods. For example:
192.168.1.1
10.0.0.1
172.16.254.1
Key Characteristics
Address Space:
Total possible addresses: 2³² (approximately 4.3 billion)
Unique addresses: Significantly fewer due to reserved ranges
Private address ranges for internal networks
Header Structure:
Minimum 20 bytes
Variable length
Contains essential routing and fragmentation information
Packet Size:
Minimum: 20 bytes
Maximum: 65,535 bytes
Typical size: 576 bytes for non-local destinations
Advantages of IPv4
Universal Support:
Widely implemented across all networks
Supported by virtually all hardware and software
Extensively documented and understood
Simple Configuration:
Easy to set up and configure
Familiar to network administrators
Well-established troubleshooting procedures
NAT Compatibility:
Network Address Translation enables address conservation
Provides additional security through address hiding
Facilitates internal network management
Limitations of IPv4
Address Exhaustion:
A limited number of available addresses
Regional internet registries running out of new addresses
Increasing reliance on NAT and private addressing
Security Concerns:
Security features were not built into the original protocol
Requires additional protocols for security
Vulnerable to various types of attacks
IPv6: The Next Generation Protocol
Structure and Format
IPv6 uses a 128-bit addressing scheme, represented as eight groups of four hexadecimal digits, separated by colons. For example:
2001:0db8:85a3:0000:0000:8a2e:0370:7334
fe80:0000:0000:0000:0202:b3ff:fe1e:8329
2001:db8::1
Key Characteristics
Address Space:
Total possible addresses: 2¹²⁸ (approximately 340 undecillion)
Enough addresses for trillions of addresses per square millimeter of Earth’s surface
Built-in support for multiple address types
Header Structure:
Fixed length of 40 bytes
Simplified compared to IPv4
Extension headers for additional functionality
Enhanced Features:
Auto-configuration capabilities
Built-in security features
Improved Quality of Service (QoS)
Advantages of IPv6
Vast Address Space:
Eliminates the need for NAT
Supports direct end-to-end connectivity
Future-proof for Internet of Things (IoT) growth
Improved Security:
IPSec built into the protocol
Better support for authentication and privacy
Enhanced packet handling capabilities
Enhanced Performance:
Simplified header structure
More efficient routing
Better support for multicast and anycast
Current Challenges with IPv6
Adoption Rate:
Slow implementation globally
Requires hardware and software updates
Training and expertise gaps
Compatibility Issues:
Not directly compatible with IPv4
Requires transition mechanisms
Some legacy systems may not support IPv6
Comparing IPv4 and IPv6
Addressing and Notation
IPv4: Uses decimal notation with periods
IPv6: Uses hexadecimal notation with colons
Readability: IPv4 is generally easier to read and remember
Security Features
IPv4: Security implemented through additional protocols
IPv6: Built-in IPSec support
Authentication: IPv6 provides better authentication mechanisms
Performance Considerations
Header Size: IPv6 has a larger basic header but simpler structure
Fragmentation: Handled differently in IPv6, improving efficiency
Routing: IPv6 enables more efficient routing decisions
Transition Strategies and Coexistence
Dual Stack Implementation
Running both protocols simultaneously
Gradual migration pathway
Increased complexity and overhead
Tunneling Mechanisms
Encapsulating IPv6 packets within IPv4
Various tunneling protocols are available
Temporary solution during transition
Translation Techniques
Converting between IPv4 and IPv6
Network Address Translation-Protocol Translation (NAT-PT)
Application Layer Gateways (ALGs)
Future Outlook and Recommendations
For Organizations
Plan for IPv6 Adoption:
Assess current infrastructure
Develop transition timeline
Train technical staff
Implementation Strategy:
Start with dual-stack approach
Test IPv6 in controlled environments
Gradually expand deployment
Security Considerations:
Update security policies
Implement IPv6-aware security tools
Monitor both protocols during the transition
Conclusion
The transition from IPv4 to IPv6 represents a significant evolution in internet technology. While IPv4 continues to serve as the backbone of most current networks, IPv6 offers the addressing capacity and enhanced features necessary for future growth. Understanding both protocols is crucial for network administrators and IT professionals as we continue to navigate this transition period.
The coexistence of IPv4 and IPv6 will likely continue for many years to come, making it essential to maintain expertise in both protocols while gradually shifting toward IPv6-based infrastructure. Organizations should approach this transition strategically, considering their specific needs and resources while ensuring their networks remain secure and efficient throughout the process.
Understanding MAC Addresses and IP Addresses: Key Differences and Uses in Networking
In today’s digital landscape, understanding how devices communicate is crucial. Two terms often heard in the world of networking are MAC (Media Access Control) Address and IP (Internet Protocol) Address. Both play essential roles in how devices interact within a network, but they serve different purposes and operate on different levels.
This guide will clarify the distinctions between MAC addresses and IP addresses, explain how they work, and outline their roles in ensuring smooth communication and connectivity. 1. What is a MAC Address?
A MAC Address (Media Access Control Address) is a unique identifier assigned to a network interface card (NIC) of a device. This identifier is used to enable device-to-device communication on a local network level, such as in a home or office environment.
Key Characteristics of MAC Addresses:
Permanence: MAC addresses are typically permanent and hardcoded by the device manufacturer. They do not change over time, even if the device is connected to different networks.
Format: MAC addresses are represented in hexadecimal form, commonly shown as six pairs of alphanumeric characters (e.g.,
00:1A:2B:3C:4D:5E).Layer 2 Address: The MAC address operates at Layer 2 (Data Link Layer) of the OSI model, responsible for local network communication.
Components of a MAC Address:
Organizationally Unique Identifier (OUI): The first three octets identify the manufacturer.
Device Identifier: The last three octets specify the unique identifier for the individual device.
Example of a MAC Address:
`00:1A:2B:3C:4D:5E``` **2. What is an IP Address?** An **IP Address** (Internet Protocol Address) is a unique identifier assigned to each device connected to a network. Unlike the MAC address, the IP address can change depending on the network it connects to, especially if it’s assigned dynamically. **Key Characteristics of IP Addresses**: * **Dynamic and Static Options**: IP addresses can be static (fixed) or dynamic (changing). Dynamic IPs are more common and are typically assigned by a DHCP (Dynamic Host Configuration Protocol) server. * **Format**: IP addresses can be IPv4 or IPv6. IPv4 uses four groups of numbers separated by dots (e.g., `192.168.1.1`), while IPv6 uses a more complex format with alphanumeric characters separated by colons. * **Layer 3 Address**: The IP address operates at Layer 3 (Network Layer) of the OSI model, allowing communication across different networks. **Example of IPv4 and IPv6 Addresses**: * IPv4: `192.168.1.1` * IPv6: `2001:0db8:85a3:0000:0000:8a2e:0370:7334` **3. Differences Between MAC Addresses and IP Addresses****4. Why Both MAC and IP Addresses Are Needed** **MAC addresses** enable devices to identify each other within a local network. When data packets are sent between devices on the same network, MAC addresses ensure they reach the correct destination. **IP addresses** are crucial for routing data between networks. For instance, in order for data to be sent across the internet or between different networks, IP addresses help locate the source and destination on a larger scale. Both MAC and IP addresses work together to ensure data reaches its intended location efficiently. In a typical network communication process, data packets are addressed using an IP address but delivered to a specific device using its MAC address. **5. How MAC and IP Addresses Work Together in Network Communication** When a device wants to communicate on a network, both MAC and IP addresses are used to identify the sender and receiver accurately. Here’s how it works: * **Sending Data**: When a device sends data, it uses the IP address to locate the destination network and the MAC address to identify the specific device within that network. * **Routing**: Routers use IP addresses to send data across multiple networks, forwarding packets closer to their destination. * **Delivery**: Once data reaches the destination network, the MAC address ensures the data packet is delivered to the exact device. An essential protocol in this process is **ARP (Address Resolution Protocol)**. ARP helps convert IP addresses to MAC addresses so that data can be transmitted correctly across the network. **6. IPv4 vs. IPv6: How IP Addressing Has Evolved** The traditional IP addressing system, **IPv4**, has been widely used since the early days of networking. However, the growth in internet-connected devices led to a shortage of IPv4 addresses, prompting the development of **IPv6**. **Key Differences Between IPv4 and IPv6**: * **Address Length**: IPv4 addresses are 32 bits, while IPv6 addresses are 128 bits. * **Address Capacity**: IPv4 supports about 4.3 billion addresses, whereas IPv6 can handle approximately 340 undecillion addresses. * **Format**: IPv4 uses four numerical octets (e.g., `192.168.1.1`), while IPv6 uses eight alphanumeric groups separated by colons. The transition to IPv6 ensures that more devices can have unique IP addresses, facilitating the growth of IoT (Internet of Things) devices and global internet expansion. **7. Types of IP Addresses: Public vs. Private** **Public IP Addresses** are assigned by ISPs (Internet Service Providers) for devices that need to connect to the internet. Public IPs are unique across the global network. **Private IP Addresses** are used within a local network and are not accessible from the internet. They allow devices within a home or office network to communicate without requiring unique global IPs. **Example Ranges of Private IP Addresses**: * **IPv4**: `192.168.0.0` to `192.168.255.255` * **IPv6**: `fd00::/8` (Unique Local Addresses) **8. DHCP and Static IP Addressing** IP addresses can be assigned either **statically** (permanently assigned) or **dynamically** (changing, based on demand). **Dynamic IPs** are commonly assigned by DHCP servers, which automate the process of assigning IP addresses. This makes managing devices easier, particularly in large networks. **Static IPs** are manually assigned and fixed. These are often used for devices that need a consistent address, such as servers, printers, or other network devices that require stability. **9. Security Considerations for MAC and IP Addresses** Both MAC and IP addresses have vulnerabilities, and each plays a role in network security measures: * **MAC Address Filtering**: This security feature allows only specific MAC addresses to access a network. It’s commonly used in Wi-Fi networks to prevent unauthorized access. * **IP Address Restrictions**: Firewalls and VPNs can restrict IP access, limiting communication-based on geographic location or network. Despite these measures, MAC addresses can be **spoofed** (faked) to impersonate a device, while IP addresses can be **masked** using proxies or VPNs. **10. Real-world applications of MAC and IP Addresses** **MAC Address Applications**: * **Local Network Security**: MAC filtering in Wi-Fi networks limits access to authorized devices. * **Device Tracking**: Used in network management for tracking and monitoring devices within a network. **IP Address Applications**: * **Internet Access**: Devices require an IP address to connect to the internet. * **Geolocation Services**: IP addresses are often used to determine the approximate location of a device for tailored services, such as local content. **11. Understanding ARP and DNS in IP and MAC Address Communication** Two essential protocols—**ARP** and **DNS**—play significant roles in facilitating smooth communication using IP and MAC addresses: * **ARP (Address Resolution Protocol)**: ARP translates IP addresses into MAC addresses, enabling data transfer on local networks. * **DNS (Domain Name System)**: DNS translates domain names into IP addresses, making it easier for users to navigate the internet without memorizing numerical addresses. These protocols help streamline communication processes across networks, ensuring that data packets reach their correct destinations. **12. Summary of MAC and IP Addresses**
Feature MAC Address IP Address **Purpose** Identifies device within a local network Identifies device on a broader network or internet **Format** Hexadecimal, six pairs (e.g., `00:1A:2B:3C:4D:5E`) IPv4 (four groups), IPv6 (eight groups) **Layer** Operates on Layer 2 (Data Link) Operates on Layer 3 (Network) **Assignment** Set by manufacturer, usually permanent Can be static or dynamic, assigned by network or DHCP **Scope** Local network only Global network or internet **Conclusion** Both **MAC addresses** and **IP addresses** are fundamental to modern networking, playing distinct roles in device identification and data routing. While MAC addresses ensure devices are correctly identified on a local level, IP addresses enable broader communication across networks. Together, these identifiers facilitate the seamless exchange of information, keeping the digital world connected and operational. **Frequently Asked Questions (FAQs)** **Q1: Can a device have more than one MAC or IP address?** * Yes, a device can have multiple MAC and IP addresses if it has multiple network interfaces, such as Ethernet and Wi-Fi. **Q2: Are MAC addresses unique?** * MAC addresses are intended to be unique, but MAC spoofing can create duplicate addresses on the network. **Q3: Can IP addresses be traced?** * Yes, IP addresses can be traced back to an approximate location, usually the region or city, but not an exact address. **Q4: How often do dynamic IP addresses change?** * Dynamic IP addresses change depending on the DHCP lease duration, which varies by network configuration. **Q5: Can MAC addresses be changed?** * Some devices allow users to change the MAC address through a process called MAC spoofing, often used for privacy reasons. **Q6: Why is IPv6 necessary?** * IPv6 is necessary to accommodate the growing number of internet-connected devices, as IPv4 addresses are running out.
Address Type MAC Address IP Address **Purpose** Identifies devices on a local network Locates devices on global network or internet **Layer** Data Link Layer (Layer 2) Network Layer (Layer 3) **Format** Hexadecimal IPv4 (numeric), IPv6 (alphanumeric) **Example** `00:1A:2B:3C:4D:5E` IPv4: `192.168.1.1`, IPv6: `2001:0db8::7334`
Network Devices: Routers, Switches, and Hubs
Network devices play a crucial role in the functioning of computer networks, facilitating communication between various devices. Among these devices, routers, switches, and hubs are fundamental components that serve different purposes within a network. Understanding the differences and functionalities of these devices is essential for anyone involved in networking, whether for personal use or in a professional environment. This blog post will explore each of these devices in detail, outlining their roles, how they operate, and their applications in modern networking.
Understanding Network Devices
- Hubs
Definition and Functionality
A hub is the simplest type of network device that connects multiple computers or other devices within a Local Area Network (LAN). Operating at the physical layer (Layer 1) of the OSI model, hubs function primarily as multiport repeaters. When data packets arrive at one port, the hub broadcasts them to all other ports, regardless of the intended destination. This means that every device connected to the hub receives all data packets, which can lead to inefficiencies and network collisions.
Types of Hubs
Hubs can be categorized into three main types:
-
Passive Hubs: These simply connect multiple devices without any signal amplification or processing.
-
Active Hubs: These hubs regenerate signals before transmitting them to other ports, thus extending the distance over which data can travel.
-
Intelligent Hubs: These offer additional features such as management capabilities and monitoring functions.
Advantages and Disadvantages
While hubs are inexpensive and easy to set up, they have significant drawbacks:
-
Advantages:
-
Cost-effective for small networks.
-
Simple installation and configuration.
-
Disadvantages:
-
Inefficient data transmission due to broadcasting.
-
Increased chances of data collisions.
-
Lack of security since all devices see all traffic.
- Switches
Definition and Functionality
Switches are more advanced than hubs and operate at the data link layer (Layer 2) of the OSI model. They intelligently manage data traffic by using MAC addresses to determine the destination of each data packet. When a switch receives a packet, it examines the MAC address and forwards it only to the intended recipient device. This selective forwarding reduces unnecessary traffic on the network and enhances overall performance.
Types of Switches
Switches can be classified into two main types:
-
Unmanaged Switches: These are basic plug-and-play devices that require no configuration.
-
Managed Switches: These offer advanced features such as VLAN support, traffic prioritization, and network monitoring capabilities.
Advantages and Disadvantages
Switches provide several benefits over hubs:
-
Advantages:
-
Improved performance due to reduced collisions.
-
Enhanced security since only intended recipients receive data packets.
-
Ability to create virtual LANs (VLANs) for better network organization.
-
Disadvantages:
-
Higher cost compared to hubs.
-
More complex setup and management for managed switches.
- Routers
Definition and Functionality
Routers are the most sophisticated of these three devices, operating at the network layer (Layer 3) of the OSI model. Their primary function is to connect multiple networks and route data packets between them based on IP addresses. Routers analyze incoming packets, determine their destination, and select the best path for transmission across interconnected networks.
Types of Routers
Routers can be divided into several categories based on their application:
-
Home Routers: Typically combine routing capabilities with switch functionality for small networks.
-
Enterprise Routers: Designed for larger networks with advanced features such as traffic management and security protocols.
-
Core Routers: Operate within the backbone of large networks, managing high-speed data transmission.
Advantages and Disadvantages
Routers offer numerous advantages but also come with some challenges:
-
Advantages:
-
Ability to connect different types of networks (e.g., LANs to WANs).
-
Advanced features like NAT (Network Address Translation) for IP address management.
-
Enhanced security through firewall capabilities.
-
Disadvantages:
-
Higher cost compared to switches and hubs.
-
More complex configuration requirements.
Comparison Table: Hubs vs Switches vs Routers
| Feature | Hub | Switch | Router |
|---|---|---|---|
| OSI Layer | Layer 1 (Physical Layer) | Layer 2 (Data Link Layer) | Layer 3 (Network Layer) |
| Data Handling | Broadcasts to all ports | Forwards based on MAC address | Routes based on IP address |
| Efficiency | Low | High | High |
| Security | None | Moderate | High |
| Cost | Low | Moderate | High |
| Use Case | Small networks | Medium to large networks | Connecting different networks |
Practical Applications
Hubs in Modern Networking
While hubs were once common in networking setups, their use has declined significantly due to inefficiencies. However, they may still be found in very small or legacy systems where cost is a primary concern. In most cases, they have been replaced by switches that provide better performance and security.
Switches in Business Environments
Switches are essential in business environments where multiple devices need to communicate efficiently. They enable seamless communication between computers, printers, servers, and other networked devices. Managed switches are particularly valuable in enterprise settings where network segmentation and monitoring are necessary for optimal performance.
Routers for Internet Connectivity
Routers are critical for providing internet access in both home and business environments. They manage traffic between local networks and external networks like the Internet. Modern routers often include built-in firewalls, VPN support, and other security features that protect against external threats while ensuring efficient data flow.
Conclusion
Understanding the differences between routers, switches, and hubs is vital for anyone involved in networking. Each device serves a distinct purpose within a network architecture:
-
Hubs provide basic connectivity but lack intelligence.
-
Switches enhance performance by intelligently directing traffic within a LAN.
-
Routers connect multiple networks while managing data flow based on IP addresses.
As networking technology continues to evolve, integrated devices that combine functionalities are becoming more common. However, understanding each device’s unique role remains essential for designing efficient networks tailored to specific needs. Whether you are setting up a home network or managing an enterprise-level infrastructure, knowing when to use each type of device will lead to better performance, security, and overall user satisfaction in your networking endeavors.
Citations: [1] https://www.pynetlabs.com/hub-vs-switch-vs-router/ [2] https://themillergroup.com/differences-hubs-switches-routers/ [3] https://www.linkedin.com/pulse/routers-switches-hubs-understanding-your-network-hari-subedi-xrfvf [4] https://www.geeksforgeeks.org/difference-between-hub-switch-and-router/ [5] https://www.geeksforgeeks.org/network-devices-hub-repeater-bridge-switch-router-gateways/ [6] https://community.fs.com/article/do-you-know-the-differences-between-hubs-switches-and-routers.html [7] https://blog.netwrix.com/network-devices-explained [8] https://www.techtarget.com/searchnetworking/tip/An-introduction-to-8-types-of-network-devices
Peer-to-Peer vs. Client-Server Networks
In the realm of computer networking, understanding the fundamental differences between peer-to-peer (P2P) and client-server networks is crucial. Both architectures have their unique strengths and weaknesses, making them suitable for different applications. In this comprehensive guide, we will delve into the intricacies of these two network types, exploring their characteristics, advantages, disadvantages, and real-world applications.
Peer-to-Peer (P2P) Networks
In a P2P network, each computer acts as both a client and a server. This means that every device can share resources, such as files, printers, or internet connections, directly with other devices on the network. No central authority or dedicated server is managing the network.
Key Characteristics of P2P Networks:
-
Decentralized: No central server controls the network.
-
Direct Communication: Devices communicate directly with each other.
-
Scalability: Easy to add or remove devices.
-
Flexibility: Can be used for various purposes, including file sharing, gaming, and video conferencing.
Advantages of P2P Networks:
-
Cost-Effective: No need for expensive server hardware.
-
Simplicity: Easy to set up and manage.
-
Reliability: If one device fails, the network can still function.
-
Scalability: Easily expand the network by adding more devices.
Disadvantages of P2P Networks:
-
Security Risks: Vulnerable to attacks like malware and hacking.
-
Performance Issues: Can become slow with many users.
-
Limited Control: Difficult to manage and monitor the network.
-
Resource Constraints: Relies on the resources of individual devices.
Real-World Applications of P2P Networks:
-
File Sharing: Popular for sharing large files, such as movies, music, and software.
-
Gaming: Enables multiplayer gaming without the need for dedicated servers.
-
Video Conferencing: Facilitates real-time communication between multiple users.
-
Distributed Computing: Leverages the combined processing power of multiple devices for complex tasks.
Client-Server Networks
In a client-server network, devices are divided into two categories: clients and servers. Clients request services from servers, which provide those services. Servers are powerful computers that store and manage resources, while clients are typically less powerful devices that access those resources.
Key Characteristics of Client-Server Networks:
-
Centralized: A central server controls the network.
-
Hierarchical Structure: Clear distinction between clients and servers.
-
Security: Enhanced security measures can be implemented on the server.
-
Scalability: Can handle a large number of users and devices.
Advantages of Client-Server Networks:
-
Centralized Management: Easier to manage and control the network.
-
Enhanced Security: Strong security measures can be implemented on the server.
-
Reliable Performance: Servers can handle heavy workloads and provide consistent performance.
-
Scalability: Easily expand the network by adding more servers.
Disadvantages of Client-Server Networks:
-
Higher Cost: Requires significant investment in server hardware and software.
-
Complex Setup: More complex to set up and configure than P2P networks.
-
Single Point of Failure: If the server fails, the entire network can be disrupted.
-
Dependency on Server: Clients rely on the server for resources and services.
Real-World Applications of Client-Server Networks:
-
Corporate Networks: Used to share files, printers, and other resources within an organization.
-
Web Servers: Host websites and web applications.
-
Email Servers: Manage and deliver email messages.
-
Database Servers: Store and manage large amounts of data.
-
Game Servers: Host multiplayer games and provide centralized game services.
Choosing the Right Network Architecture
The choice between a P2P and a client-server network depends on various factors, including:
-
Number of Users: For small networks with a limited number of users, a P2P network may be sufficient. For larger networks with many users, a client-server network is more suitable.
-
Security Requirements: If security is a major concern, a client-server network with strong security measures is recommended.
-
Performance Requirements: For demanding applications, a client-server network with powerful servers can provide better performance.
-
Management Complexity: P2P networks are simpler to manage, while client-server networks require more administrative overhead.
-
Cost Considerations: P2P networks are generally more cost-effective, while client-server networks can be more expensive due to the cost of server hardware and software.
Hybrid Networks
In some cases, a hybrid network that combines elements of both P2P and client-server architectures may be the best solution. This approach can provide the benefits of both network types, such as the flexibility of P2P networks and the centralized management of client-server networks.
Conclusion
By understanding the key differences between P2P and client-server networks, you can make informed decisions about which architecture is best suited for your specific needs. Consider factors such as the number of users, security requirements, performance needs, management complexity, and cost when choosing the right network for your organization or personal use.
Additional Considerations:
-
Network Topology: The physical layout of the network, such as bus, star, ring, or mesh topologies, can also impact performance and reliability.
-
Network Protocols: The communication protocols used to transmit data, such as TCP/IP, HTTP, and FTP, play a crucial role in network functionality.
-
Network Security: Implementing strong security measures, such as firewalls, intrusion detection systems, and encryption, is essential to protect network resources from unauthorized access and cyberattacks.
By carefully considering these factors and selecting the appropriate network architecture, you can build a robust and efficient network that meets your specific requirements.
Network Topologies: Understanding Star, Bus, Ring, and Mesh Architectures
Network topology is a fundamental concept in computer networking that describes how devices are connected and communicate with each other. The physical and logical arrangement of these connections can significantly impact network performance, reliability, and scalability. In this comprehensive guide, we’ll explore four primary network topologies: Star, Bus, Ring, and Mesh, examining their advantages, disadvantages, and practical applications.
Star Topology: The Hub-and-Spoke Model
Star topology is perhaps the most widely implemented network architecture in modern networks, particularly in home and office environments. In this configuration, all devices connect to a central hub or switch, creating a layout that resembles a star.
Key Characteristics
-
Every device connects directly to a central node
-
No direct device-to-device connections
-
All communication passes through the central hub
-
Easy to implement and manage
Advantages
-
Simplified Management: Adding or removing devices doesn’t affect the rest of the network
-
Enhanced Reliability: If one connection fails, other devices remain unaffected
-
Excellent Performance: Direct connections to the central hub minimize network congestion
-
Easy Troubleshooting: Problems can be quickly isolated and resolved
Disadvantages
-
Single Point of Failure: If the central hub fails, the entire network goes down
-
Higher Cost: Requires more cabling compared to some other topologies
-
Limited Scalability: The central hub’s capacity determines network size
-
Cable Length Limitations: Distance between devices and hub is constrained
Bus Topology: The Linear Connection
Bus topology represents one of the earliest network architectures, where all devices connect to a single central cable, often called the backbone or bus.
Key Characteristics
-
A single main cable connects all devices
-
Devices connect via drop lines and taps
-
Terminators at both ends prevent signal reflection
-
A linear arrangement of connections
Advantages
-
Simple Design: Easy to implement in small networks
-
Cost-Effective: Requires less cabling than other topologies
-
Flexible: Easy to extend for small networks
-
Suitable for Temporary Networks: Quick to set up and modify
Disadvantages
-
Limited Length: Cable length restrictions affect network size
-
Performance Issues: Network speed decreases as more devices are added
-
Collision Risk: Only one device can transmit at a time
-
Reliability Concerns: Cable breaks can bring down the entire network
Ring Topology: The Circular Connection
Ring topology connects devices in a closed loop, where each device connects to exactly two other devices, forming a ring structure.
Key Characteristics
-
Data travels in a single direction
-
Each device acts as a repeater to maintain signal strength
-
No terminated ends
-
Token-based access control
Advantages
-
Equal Access: Each device has equal access to network resources
-
Predictable Performance: Known data transmission times
-
No Signal Degradation: Each device boosts the signal
-
No Central Host: Eliminates single point of failure of star topology
Disadvantages
-
Single Point of Failure: One broken connection can affect the entire network
-
Complex Troubleshooting: Difficult to isolate problems
-
Network Disruption: Adding or removing devices disrupts network operation
-
Limited Scalability: Adding devices increases network latency
Mesh Topology: The Interconnected Web
Mesh topology represents the most robust and redundant network architecture, where devices connect to multiple other devices in the network.
Key Characteristics
-
Multiple paths between devices
-
Can be fully or partially meshed
-
Decentralized structure
-
Self-healing capabilities
Advantages
-
High Reliability: Multiple paths ensure continued operation if links fail
-
Excellent Redundancy: No single point of failure
-
Load Balancing: Traffic can be distributed across multiple paths
-
Privacy and Security: Data can take private paths through the network
Disadvantages
-
Complex Implementation: Requires significant planning and management
-
High Cost: Requires more cabling and hardware
-
Maintenance Challenges: Complex troubleshooting and updates
-
Network Overhead: Route discovery and maintenance consume resources
Practical Applications and Considerations
When choosing a network topology, several factors should be considered:
Business Requirements
-
Size of the network
-
Budget constraints
-
Reliability requirements
-
Performance needs
-
Scalability expectations
Environmental Factors
-
The physical layout of the space
-
Distance between devices
-
Electromagnetic interference
-
Building architecture and limitations
Management Capabilities
-
Available technical expertise
-
Maintenance requirements
-
Monitoring and troubleshooting needs
-
Future growth plans
Conclusion
Understanding network topologies is crucial for designing and implementing effective computer networks. Each topology offers unique advantages and challenges, and the best choice depends on specific requirements and constraints. While star topology dominates modern LANs due to its simplicity and reliability, other topologies remain relevant in specific scenarios. Mesh networks, in particular, are gaining popularity in wireless applications and IoT deployments.
As technology continues to evolve, hybrid approaches combining multiple topologies are becoming more common, allowing organizations to leverage the strengths of different architectures while minimizing their weaknesses. The key to successful network design lies in carefully evaluating requirements and choosing the topology—or combination of topologies—that best meets those needs while providing room for future growth and adaptation.
Types of Computer Networks: Understanding LAN, MAN, and WAN
Computer networks play a pivotal role in linking devices in our interconnected world, allowing them to communicate and share data efficiently. Whether at home, in a bustling city, or working across continents, networks enable seamless communication between devices on a small or large scale. This article delves into the types of computer networks, particularly focusing on LAN (Local Area Network), MAN (Metropolitan Area Network), and WAN (Wide Area Network), their purposes, unique features, and common applications.
Let’s explore the essential features of each of these network types and gain a better understanding of how they help connect people and systems across various distances. 1. What is a Computer Network?
A computer network is a system of interconnected devices that can communicate with each other and share resources such as data, files, and internet connections. These networks facilitate communication and collaboration, ranging from small, local setups within a home to extensive networks linking entire regions or continents.
The primary types of networks—LAN, MAN, and WAN—differ based on their scale, the area they cover, and the specific applications they support. 2. Local Area Network (LAN)
Definition: A Local Area Network (LAN) is a network that spans a small geographical area, such as a single building, office, or home. It typically connects a limited number of devices, such as computers, printers, and other peripherals within proximity.
Key Features of LAN:
-
Limited Range: LANs generally cover an area of up to a few kilometers, ideal for connecting devices within a single room, building, or campus.
-
High Speed: LANs offer high data transfer speeds, usually in the range of 100 Mbps to 10 Gbps, allowing for quick access to files, applications, and resources.
-
Low Latency: The short physical distance in a LAN minimizes data transmission delays, providing near-instantaneous access to network resources.
-
Private Network: LANs are typically privately owned, meaning access is restricted to users within the organization or household.
Common Applications of LAN:
-
Office Networks: LANs are commonly used in office environments to connect employees’ computers, enabling file sharing, collaborative applications, and centralized printing.
-
Home Networks: Many homes set up LANs to connect personal devices, gaming consoles, and smart home gadgets.
-
School and Campus Networks: Educational institutions rely on LANs to connect student computers, faculty systems, and administrative tools for resource sharing and collaboration.
Benefits of LAN:
-
Cost-Effective: LANs are relatively inexpensive to set up, using minimal hardware and infrastructure.
-
Security: As a closed network, LANs are easier to secure with firewalls and access controls.
Limitations of LAN:
-
Limited Range: LANs can only cover small distances; expanding the range requires connecting multiple LANs or moving to a larger network type.
-
Dependence on a Centralized Network: If the central network fails, it can impact all connected devices.
3. Metropolitan Area Network (MAN)
Definition: A Metropolitan Area Network (MAN) covers a larger geographical area than a LAN, typically a city or a large campus. MANs bridge the gap between LANs and WANs, connecting various LANs across an urban area to facilitate communication and resource sharing.
Key Features of MAN:
-
Medium Range: MANs can cover areas as large as a city, reaching distances of around 10 to 50 kilometers.
-
Moderate Speed: While generally slower than LANs, MANs still offer high data transfer rates suitable for medium-scale data sharing.
-
Backbone Network: MANs often serve as a backbone network connecting smaller LANs within a region, such as connecting different offices of a company spread across a city.
Common Applications of MAN:
-
City-Wide Connections: Municipalities use MANs to connect various city services, such as libraries, government offices, and emergency services.
-
University Campuses: Large educational institutions may deploy MANs to connect different faculties, dormitories, and research centers scattered across a city.
-
Corporate Branches: Companies with multiple locations within a city use MANs to ensure seamless communication and data access across all sites.
Benefits of MAN:
-
Scalability: MANs are scalable, allowing multiple LANs to interconnect and expand the network without complex configurations.
-
Centralized Management: MANs can manage data and resources across various branches efficiently through centralized control.
Limitations of MAN:
-
Higher Cost than LAN: Setting up a MAN requires more infrastructure and higher bandwidth, making it more expensive than LAN.
-
Moderate Latency: MANs may experience higher latency than LANs due to the greater distances involved.
4. Wide Area Network (WAN)
Definition: A Wide Area Network (WAN) covers a vast geographical area, connecting devices and networks across cities, countries, or even continents. Unlike LANs and MANs, WANs usually utilize public infrastructure like telecommunication lines, satellites, or internet service providers.
Key Features of WAN:
-
Extensive Range: WANs can span large distances, often covering multiple regions or countries.
-
Slower Speeds Compared to LAN and MAN: Data transfer rates in WANs tend to be lower due to the significant distances involved, though high-speed connections are increasingly available.
-
Complex Infrastructure: WANs rely on a combination of private and public communication channels, including satellite links, leased lines, and fiber optics.
Common Applications of WAN:
-
Global Corporations: Large companies with international offices use WANs to ensure communication and data exchange between global branches.
-
Internet: The Internet itself is a global WAN, connecting millions of private, public, corporate, and government networks worldwide.
-
Cloud Services: Cloud providers rely on WANs to offer storage, computing, and applications accessible from anywhere globally.
Benefits of WAN:
-
Broad Reach: WANs enable communication and resource sharing over great distances, critical for global businesses and organizations.
-
Reliable Connectivity: WANs provide consistent connectivity between remote locations, ensuring that users have continuous access to information.
Limitations of WAN:
-
High Cost: WAN infrastructure is costly, often requiring complex networking equipment and leased telecommunication lines.
-
Security Concerns: WANs are vulnerable to security threats as they span public networks. Enhanced security measures, such as encryption and VPNs, are often required.
5. Comparing LAN, MAN, and WAN
To better understand the differences between LAN, MAN, and WAN, here’s a quick comparison:
| Feature | LAN (Local Area Network) | MAN (Metropolitan Area Network) | WAN (Wide Area Network) |
|---|---|---|---|
| **Geographical Area** | Small (single building or campus) | Medium (city or large campus) | Large (countrywide or global) |
| **Speed** | High | Moderate | Moderate to low |
| **Latency** | Very low | Low to moderate | Moderate to high |
| **Cost** | Low | Moderate | High |
| **Ownership** | Private | Mixed (often public/private) | Often public infrastructure |
| **Examples** | Office network, home network | City government network, university campus | Corporate WAN, internet |
6. Which Network Type is Right for You?
Choosing between LAN, MAN, and WAN depends on your specific needs, including the range, budget, and speed requirements:
-
LAN is ideal for small, contained spaces needing high-speed, low-latency communication.
-
MAN works best for city-wide connections, linking multiple LANs within a region.
-
WAN is suited for organizations that require international or multi-regional connectivity.
Conclusion
Understanding the different types of computer networks—LAN, MAN, and WAN—helps us appreciate how communication and data sharing happens seamlessly across various distances. Each network type has unique characteristics suited for different applications, from home setups and city infrastructures to global enterprises. Whether it’s for a household, a company, or an entire city, selecting the right network type is essential for achieving efficient and reliable connectivity. Frequently Asked Questions (FAQs)
Q1: What are the main differences between LAN, MAN, and WAN?
- LAN covers small areas with high speed and low latency, MAN covers cities with moderate speeds, and WAN spans large distances at lower speeds and higher costs.
Q2: Can I use a LAN for a city-wide network?
- LANs are not ideal for city-wide connections. For such purposes, MANs or WANs are more suitable due to their broader reach.
Q3: Why is WAN slower than LAN?
- WANs cover longer distances, and the infrastructure, such as satellite and telecommunication links, can introduce latency compared to the local infrastructure of LANs.
Q4: How secure is a WAN compared to LAN?
- WANs are more vulnerable due to public infrastructure but can be secured with VPNs, encryption, and additional firewalls, whereas LANs are inherently more secure due to limited access.
Q5: Are MANs typically private or public networks?
- MANs can be both, often having public elements like city fiber optics but controlled access within specific organizations.
Q6: Do all computer networks require internet access?
- No, LANs and MANs can operate without internet access, though WANs often connect through the internet for broader communication.
Understanding Data Modulation Techniques in Communication Systems
In today’s connected world, effective data transmission is key to the seamless functioning of everything from mobile networks to satellite communications. At the heart of this data transmission lies data modulation techniques—methods used to encode data so it can travel across communication channels efficiently and accurately. In this post, we’ll explore the fundamental concepts of data modulation, the different types, how each technique functions, and their practical applications.
1. Introduction to Data Modulation
Data modulation refers to the process of modifying a carrier signal to encode information for transmission over a communication channel. In this process, data is superimposed on a carrier wave by altering one or more of its properties—amplitude, frequency, or phase—creating a modulated signal that carries the original information to a receiver.
2. Why Data Modulation is Essential in Communication Systems
Without data modulation, transmitting large volumes of data over long distances would be both inefficient and error-prone. Modulation enhances the efficiency of data transmission, reduces the likelihood of data corruption, and optimizes the use of available bandwidth. In addition, different modulation techniques offer solutions for different communication needs, from low-bandwidth audio transmission to high-capacity digital data streams.
3. Types of Data Modulation Techniques
Data modulation techniques can be broadly divided into two categories:
-
Analog Modulation: Involves continuous signals where the carrier wave is modified by amplitude, frequency, or phase.
-
Digital Modulation: Uses discrete signals, modifying the carrier wave in specific patterns that represent binary data (0s and 1s).
Here are the main types:
Analog Modulation Techniques
-
Amplitude Modulation (AM)
-
Frequency Modulation (FM)
-
Phase Modulation (PM)
Digital Modulation Techniques
-
Amplitude Shift Keying (ASK)
-
Frequency Shift Keying (FSK)
-
Phase Shift Keying (PSK)
-
Quadrature Amplitude Modulation (QAM)
Each technique is suited to different applications and comes with its unique strengths and limitations.
4. How Data Modulation Works: Basic Principles
Modulation works by altering one or more characteristics of a carrier signal—a continuous signal with a constant amplitude, frequency, or phase. The carrier wave becomes a medium for the original data, whether it’s analog (e.g., voice) or digital (e.g., binary data). The receiver then demodulates the signal, extracting the original information from the modulated carrier wave.
5. Amplitude Modulation (AM) Explained
What is AM?
In Amplitude Modulation, the carrier signal’s amplitude varies in direct proportion to the data being transmitted, while frequency and phase remain constant.
How does AM work?
For example, in an audio broadcast, the amplitude of the carrier wave changes according to the loudness of the audio signal, allowing the receiver to detect and reproduce the original sound.
Applications of AM
AM is widely used in AM radio broadcasting. It is effective for transmitting audio signals over long distances but is prone to noise interference, which can affect signal clarity.
6. Frequency Modulation (FM) Explained
What is FM?
In Frequency Modulation, the frequency of the carrier signal varies in accordance with the data, while amplitude and phase remain unchanged.
How does FM work?
In an FM radio broadcast, the carrier wave’s frequency shifts slightly to represent changes in the audio signal’s pitch. This makes FM more resistant to noise interference than AM.
Applications of FM
FM is popular in radio broadcasting for high-fidelity sound, as it maintains better sound quality than AM, especially in urban environments with higher potential for signal interference.
7. Phase Modulation (PM) Explained
What is PM?
Phase Modulation changes the phase of the carrier wave to encode data, while amplitude and frequency are kept constant.
How does PM Work?
Each variation in the phase of the carrier wave corresponds to a change in the data signal. In digital communication, PM is widely used since it can efficiently represent binary data.
Applications of PM
PM is less common in analog broadcasts but is fundamental in digital data transmission and technologies like Wi-Fi and Bluetooth.
8. Digital Modulation Techniques in Detail
8.1 Amplitude Shift Keying (ASK)
In ASK, the amplitude of the carrier wave shifts between predetermined levels, representing binary 0s and 1s. It’s simple but vulnerable to noise, making it less reliable for certain applications.
8.2 Frequency Shift Keying (FSK)
FSK modulates the frequency of the carrier wave between discrete levels. FSK is commonly used in low-bandwidth applications, such as caller ID and early data modems.
8.3 Phase Shift Keying (PSK)
PSK shifts the phase of the carrier signal to represent data bits. PSK offers better noise resistance than ASK, making it a popular choice for digital communications.
8.4 Quadrature Amplitude Modulation (QAM)
QAM combines ASK and PSK, varying both amplitude and phase, allowing it to transmit more data per carrier wave. This makes QAM highly efficient and ideal for high-speed data applications, such as cable modems and Wi-Fi.
9. Advantages of Modulation in Data Communications
-
Efficient Bandwidth Usage: Modulation allows more data to travel over limited bandwidth by making efficient use of carrier waves.
-
Noise Reduction: Techniques like FM and QAM provide noise resistance, preserving signal quality in noisy environments.
-
Enhanced Data Rates: Digital modulation techniques support high data transmission rates, essential for modern applications like streaming and file transfer.
-
Improved Signal Clarity: Modulation helps to maintain the integrity of signals over long distances, reducing signal degradation.
10. Challenges and Limitations of Modulation Techniques
-
Noise Susceptibility: Some techniques, like ASK, are highly sensitive to noise, which can distort the signal.
-
Complexity in Implementation: Techniques like QAM and PSK require sophisticated transmitters and receivers.
-
Bandwidth Requirements: High-capacity modulation techniques like QAM need greater bandwidth, which can be limiting in some networks.
-
Power Consumption: Modulation requires additional power, particularly in digital communication, affecting the battery life of mobile devices.
11. Applications of Modulation Techniques in Modern Technology
Modulation techniques are indispensable in numerous applications:
-
Radio and Television Broadcasting: AM and FM modulation transmit audio and video content over long distances.
-
Mobile Networks: Techniques like PSK and QAM support the data rates in mobile communication, especially in 4G and 5G networks.
-
Wi-Fi: Modulation techniques like QAM provide high-speed wireless data transfer, vital for internet connectivity.
-
Satellite Communication: Frequency modulation techniques help manage bandwidth and maintain data integrity in satellite communication.
12. The Future of Modulation Technologies
As communication demands evolve, so do modulation techniques. Future advancements are likely to include:
-
Higher-Order QAM: With more amplitude and phase states, higher-order QAM can transmit larger volumes of data, supporting high-speed internet and 5G.
-
Adaptive Modulation: Dynamic adjustment of modulation based on network conditions can optimize data rates and signal quality.
-
Quantum Modulation: Future research may leverage quantum mechanics to enable secure, efficient communication channels, ideal for sensitive data transmission.
13. FAQs on Data Modulation Techniques
What is data modulation?
Data modulation is the process of encoding data onto a carrier signal to transmit it over a communication channel.
Why is modulation important in digital communication?
Modulation is essential for encoding data in a way that maximizes bandwidth usage, reduces interference, and improves data rates.
What’s the difference between analog and digital modulation?
Analog modulation continuously varies a carrier signal (amplitude, frequency, or phase), while digital modulation uses discrete states to represent binary data.
What is the most efficient digital modulation technique?
QAM is one of the most efficient digital modulation techniques for high-speed data applications, balancing data rate and noise resistance.
Is FM or AM better for sound quality?
FM generally provides better sound quality than AM due to its resistance to noise and interference.
How does modulation affect bandwidth usage?
Higher-order modulation techniques can transmit more data per channel, making efficient use of available bandwidth but requiring more sophisticated equipment.
14. Conclusion
Data modulation techniques form the backbone of modern communication systems, enabling efficient and reliable transmission of data across
vast distances. From simple AM and FM techniques to complex digital methods like QAM, each modulation type has unique benefits and applications. As technology advances, modulation techniques continue to evolve, supporting higher data rates, improved signal quality, and enhanced bandwidth usage to meet the demands of our increasingly digital world.
Half-Duplex vs. Full-Duplex Communication: A Comprehensive Guide
In the realm of data communication, understanding the nuances of data transmission modes is crucial. Two primary modes, half-duplex and full-duplex, govern the flow of data between devices. While both have their specific applications, their distinct characteristics significantly impact network performance and efficiency.
Half-Duplex Communication
Half-duplex communication is a mode of data transmission where data can flow in both directions, but only one direction at a time. It’s akin to a one-lane bridge where cars can travel in either direction, but not simultaneously.
Key Characteristics of Half-Duplex Communication:
-
Shared Medium: Both devices share the same communication channel.
-
Turn-Taking: Devices must take turns to transmit and receive data.
-
Lower Efficiency: The shared medium limits the overall data throughput.
-
Simpler Implementation: Half-duplex systems are generally simpler to implement.
Real-world Examples of Half-Duplex Communication:
-
Walkie-Talkies: Users must press and release the “talk” button to transmit and listen.
-
Early Modems: Older modems often operated in half-duplex mode, requiring users to switch between transmit and receive modes.
-
Some Wireless Networks: Certain wireless networks, particularly older ones, may operate in half-duplex mode, especially in congested environments.
Full-Duplex Communication
Full-duplex communication, on the other hand, allows data to flow in both directions simultaneously. It’s analogous to a two-lane highway where cars can travel in both directions independently.
Key Characteristics of Full-Duplex Communication:
-
Dedicated Channels: Separate channels are used for transmission and reception.
-
Simultaneous Transmission and Reception: Devices can transmit and receive data concurrently.
-
Higher Efficiency: Full-duplex systems offer higher data throughput.
-
Complex Implementation: Full-duplex systems are generally more complex to implement.
Real-world Examples of Full-Duplex Communication:
-
Telephone Conversations: Both parties can talk and listen simultaneously.
-
Modern Modems: Most modern modems operate in full-duplex mode, enabling efficient data transfer.
-
Ethernet Networks: Ethernet networks, the backbone of many computer networks, typically operate in full-duplex mode, allowing high-speed data transfer.
Choosing the Right Mode: Factors to Consider
The choice between half-duplex and full-duplex communication depends on several factors:
-
Required Data Rate: If high data rates are required, full-duplex is the preferred choice.
-
Latency Sensitivity: For applications that require low latency, full-duplex is more suitable.
-
Cost: Half-duplex systems are generally less expensive to implement.
-
Complexity: Full-duplex systems are more complex and may require additional hardware or software.
Hybrid Communication Modes
In some cases, hybrid communication modes are employed to combine the benefits of both half-duplex and full-duplex. For example, time-division multiplexing (TDM) can be used to divide a full-duplex channel into multiple half-duplex channels, allowing multiple devices to share the same channel.
The Future of Communication Modes
As technology continues to evolve, the demand for higher data rates and lower latency will drive the adoption of full-duplex communication. Emerging technologies like 5G and Wi-Fi 6 are pushing the boundaries of wireless communication, enabling more efficient and reliable full-duplex transmission.
In conclusion, understanding the differences between half-duplex and full-duplex communication is essential for network engineers, system administrators, and anyone involved in data communication. By carefully considering the specific requirements of a network, the appropriate communication mode can be selected to optimize performance and efficiency.
Demultiplexing Techniques: Understanding Signal Separation in Modern Communications
In the realm of telecommunications and data transmission, demultiplexing plays a crucial role in efficiently processing multiple signals transmitted over a single channel. This comprehensive guide explores various demultiplexing techniques, their applications, and their importance in modern communication systems.
Understanding Demultiplexing
Demultiplexing (often abbreviated as DEMUX) is the process of separating multiple signals that have been combined into a single transmission stream back into their original individual signals. It’s essentially the reverse process of multiplexing, where multiple signals are combined for transmission over a shared medium.
Basic Principles
The fundamental concept behind demultiplexing involves:
-
Signal identification
-
Channel separation
-
Signal reconstruction
-
Timing synchronization
-
Error management
Types of Demultiplexing Techniques
- Time Division Demultiplexing (TDD)
Time Division Demultiplexing separates signals based on their specific time slots in the transmission stream.
Key Characteristics:
-
Synchronous operation
-
Fixed time slot allocation
-
Regular sampling intervals
-
Buffer requirements
-
Clock recovery mechanisms
Implementation Requirements:
-
Precise Timing* Accurate clock synchronization
-
Frame synchronization
-
Guard time management
-
Buffer Management* Input buffering
-
Output buffering
-
Timing adjustment
-
Error Handling* Slot misalignment detection
-
Recovery mechanisms
-
Error correction
- Frequency Division Demultiplexing (FDD)
Frequency Division Demultiplexing separates signals based on their different frequency bands.
Components:
-
Filters* Bandpass filters
-
Lowpass filters
-
Highpass filters
-
Frequency Converters* Local oscillators
-
Mixers
-
Amplifiers
Applications:
-
Radio broadcasting
-
Television systems
-
Cable networks
-
Satellite communications
-
Mobile communications
- Wavelength Division Demultiplexing (WDD)
Particularly important in optical fiber communications, WDD separates signals based on different wavelengths of light.
Key Features:
-
High bandwidth capacity
-
Low signal loss
-
Minimal interference
-
Bidirectional communication
-
Scalability
Implementation Methods:
-
Prism-Based Demultiplexing* Uses optical prisms
-
Angular dispersion
-
Spatial separation
-
Diffraction Grating* Multiple wavelength separation
-
High spectral resolution
-
Compact design
-
Fiber Bragg Gratings* Wavelength-specific reflection
-
In-fiber implementation
-
Temperature sensitivity
- Code Division Demultiplexing (CDM)
Code Division Demultiplexing separates signals based on their unique coding sequences.
Characteristics:
-
Spread spectrum technology
-
Unique code assignments
-
Simultaneous transmission
-
Enhanced security
-
Interference resistance
Implementation Requirements:
-
Code Generation* Orthogonal codes
-
Pseudo-random sequences
-
Walsh codes
-
Synchronization* Code timing
-
Phase alignment
-
Frame synchronization
-
Signal Processing* Correlation detection
-
Code tracking
-
Error correction
Advanced Demultiplexing Techniques
- Statistical Demultiplexing
This technique dynamically allocates bandwidth based on actual traffic demands.
Advantages:
-
Improved efficiency
-
Better resource utilization
-
Adaptive capacity allocation
-
Reduced latency
-
Cost-effective
Challenges:
-
Complex implementation
-
Buffer management
-
Quality of Service (QoS)
-
Traffic prediction
- Orthogonal Frequency Division Demultiplexing (OFDM)
OFDM is crucial in modern wireless communications and digital broadcasting.
Key Features:
-
High spectral efficiency
-
Resistance to multipath
-
Flexible implementation
-
Scalable bandwidth
-
Enhanced throughput
Applications:
-
4G/5G networks
-
Digital TV
-
WiFi systems
-
Power line communications
-
Underwater communications
Implementation Considerations
- Hardware Requirements
Essential Components:
-
Signal processors
-
Filters
-
Amplifiers
-
Timing circuits
-
Buffer memory
Performance Factors:
-
Processing speed
-
Power consumption
-
Heat dissipation
-
Size constraints
-
Cost considerations
- Software Requirements
Key Functions:
-
Signal processing algorithms
-
Timing control
-
Error detection
-
Buffer management
-
System monitoring
Development Considerations:
-
Real-time processing
-
Optimization
-
Scalability
-
Maintainability
-
Testing procedures
Challenges and Solutions
Common Challenges:
-
Synchronization Issues* Clock drift
-
Frame alignment
-
Phase errors
-
Signal Quality* Noise interference
-
Signal distortion
-
Cross-talk
-
System Complexity* Implementation costs
-
Maintenance requirements
-
Troubleshooting difficulty
Solutions and Best Practices:
-
Design Optimization* Efficient algorithms
-
Hardware acceleration
-
Pipeline processing
-
Quality Assurance* Comprehensive testing
-
Performance monitoring
-
Regular maintenance
-
System Integration* Standardized interfaces
-
Modular design
-
Scalable architecture
Future Trends
Emerging Technologies:
-
Artificial Intelligence Integration* Adaptive algorithms
-
Smart resource allocation
-
Predictive maintenance
-
Software-Defined Demultiplexing* Flexible implementation
-
Dynamic reconfiguration
-
Enhanced efficiency
-
Quantum Demultiplexing* Quantum state separation
-
Enhanced capacity
-
Improved security
Best Practices for Implementation
Planning Phase:
-
Requirements Analysis* Traffic patterns
-
Capacity needs
-
Quality requirements
-
Budget constraints
-
System Design* Architecture planning
-
Component selection
-
Integration strategy
-
Testing methodology
Deployment Phase:
-
Implementation Steps* Component installation
-
System configuration
-
Testing and verification
-
Documentation
-
Optimization* Performance tuning
-
Resource allocation
-
Error handling
-
Monitoring setup
Conclusion
Demultiplexing techniques continue to evolve and play a crucial role in modern communications systems. Understanding these techniques and their applications is essential for engineers and technicians working in telecommunications and data communications.
As technology advances, new challenges and opportunities emerge in the field of demultiplexing. Staying informed about the latest developments and best practices ensures optimal implementation and operation of these crucial systems.
Whether implementing a new system or maintaining existing infrastructure, careful consideration of the various demultiplexing techniques and their applications helps ensure efficient and reliable communication systems that meet current and future needs.
Multiplexing in Data Communications: How It Works and Why It’s Essential
Data communication forms the backbone of today’s connected world, enabling data transmission between devices over various networks. With the exponential increase in data generated and transmitted globally, optimizing bandwidth usage has become critical. One of the most effective methods to achieve this is through multiplexing. In this post, we’ll dive into what multiplexing is, its various types, and applications, and why it plays such a vital role in data communications.
1. Introduction to Multiplexing
Multiplexing is a process that combines multiple signals or data streams into one single, complex signal over a shared medium, allowing efficient utilization of resources. The signal is then separated back into its original streams at the receiving end. This enables a single communication channel, like a cable or frequency band, to carry several independent signals simultaneously.
2. Why Multiplexing is Essential in Data Communications
With the rising demand for high-speed internet, seamless connectivity, and the need to transmit more data than ever, efficient resource usage is crucial. Multiplexing enhances bandwidth utilization by enabling multiple data streams to share a single transmission path, reducing the need for multiple channels and decreasing costs while increasing efficiency.
3. Types of Multiplexing
There are several types of multiplexing, each suited to different communication environments and requirements. The primary types include:
-
Frequency Division Multiplexing (FDM)
-
Time Division Multiplexing (TDM)
-
Wavelength Division Multiplexing (WDM)
-
Code Division Multiplexing (CDM)
Each type uses a unique approach to combine multiple data streams into a single channel.
4. How Multiplexing Works: Basic Principles
In any multiplexing technique, the primary components are:
-
Multiplexer (MUX): Combines multiple input signals into one composite signal for transmission over a shared medium.
-
Demultiplexer (DEMUX): Splits the composite signal back into its components at the receiving end.
These components operate through protocols that determine how signals are segmented, labeled, and transmitted to ensure they’re accurately separated on the receiving end.
5. Frequency Division Multiplexing (FDM) Explained
What is FDM?
Frequency Division Multiplexing allocates a unique frequency band to each signal. This allows multiple signals to transmit simultaneously over a single medium, as each occupies a different frequency.
How FDM Works
Each data stream modulates a unique carrier frequency, and all carrier frequencies are then combined into one signal. At the receiving end, each frequency is demodulated separately to retrieve the original data streams.
Applications of FDM
FDM is commonly used in radio and TV broadcasting, where multiple channels are transmitted over specific frequency ranges without interference.
6. Time Division Multiplexing (TDM) Explained
What is TDM?
Time Division Multiplexing divides the transmission time into multiple intervals or time slots. Each signal transmits during a dedicated time slot, one after another in rapid succession.
How TDM Works
In TDM, the transmission time is split into slots, and each slot is assigned to a different signal. TDM is synchronized, so the receiver knows which slot corresponds to which signal.
Types of TDM
-
Synchronous TDM: Fixed time slots are pre-assigned to each data source, regardless of whether data is available.
-
Asynchronous (or Statistical) TDM: Slots are dynamically assigned based on active channels, increasing efficiency.
Applications of TDM
TDM is widely used in telephone networks and digital communication systems, where multiple calls are combined over a single transmission path.
7. Wavelength Division Multiplexing (WDM) Explained
What is WDM?
Wavelength Division Multiplexing is similar to FDM but specifically used for optical fiber communications. Each data channel transmits at a different wavelength, or color, of light.
How WDM Works
In WDM, separate laser beams, each carrying data at a unique wavelength, are combined into a single optical fiber. At the receiving end, these beams are split back into their original wavelengths and data streams.
Applications of WDM
WDM is commonly used in high-speed fiber-optic networks, particularly in metropolitan and long-distance telecommunications.
8. Code Division Multiplexing (CDM) Explained
What is CDM?
Code Division Multiplexing (CDM) assigns a unique code to each data stream, allowing multiple signals to share the same frequency spectrum simultaneously.
How CDM Works
Each signal is encoded with a unique code that differentiates it from others. The receiver uses the code to isolate each data stream from the combined signal.
Applications of CDM
CDM is widely used in mobile communications, such as CDMA (Code Division Multiple Access) in cellular networks, where multiple users share the same frequency without interference.
9. Advantages of Multiplexing
-
Efficient Bandwidth Utilization: Reduces the need for additional channels, allowing multiple data streams to share a single channel.
-
Cost Savings: Reduces infrastructure costs by limiting the amount of required transmission channels.
-
Scalability: Supports adding more data streams without extensive infrastructure changes.
-
Improved Network Efficiency: Increases the data-carrying capacity of networks, making them more efficient.
10. Challenges and Limitations of Multiplexing
-
Interference: Overlapping frequencies or time slots can cause signal interference if not managed properly.
-
Synchronization: TDM and CDM require precise synchronization to ensure data streams remain separated.
-
Infrastructure Costs: Initial setup costs for sophisticated multiplexing equipment can be high.
-
Limitations in Bandwidth: Only so many signals can be multiplexed before bandwidth or quality is compromised.
11. Applications of Multiplexing in Data Communications
Multiplexing is foundational in:
-
Telecommunications: Enables multiple voice and data calls over a single connection.
-
Internet Data Transmission: Used in broadband internet to carry multiple data channels.
-
Radio and Television Broadcasting: Transmits multiple channels over radio and television frequencies.
-
Fiber Optic Communications: Allows high-capacity data transmission in metropolitan and long-haul fiber networks.
12. Multiplexing in Modern Telecommunication Networks
Modern telecommunication relies heavily on multiplexing to manage the explosion of data from internet users, IoT devices, and cellular networks. From satellite to 5G cellular networks, multiplexing maximizes data throughput and minimizes transmission costs, meeting the needs of a connected world.
13. Future of Multiplexing Technologies
The future of multiplexing will focus on:
-
Advanced WDM: Moving toward Dense Wavelength Division Multiplexing (DWDM) with more wavelength channels per fiber.
-
Software-Defined Multiplexing: Allowing dynamic and programmable multiplexing configurations to adjust for network demands in real time.
-
Quantum Multiplexing: Research into quantum communications may offer secure multiplexing options that further optimize bandwidth and security.
14. FAQs on Multiplexing in Data Communications
What is multiplexing in simple terms?
Multiplexing combines multiple data streams into one signal over a single channel, making efficient use of transmission resources.
How does multiplexing improve network efficiency?
By allowing multiple signals to share a single channel, multiplexing increases the data-carrying capacity of networks, improving efficiency and reducing costs.
What’s the difference between FDM and TDM?
FDM assigns unique frequencies to each data stream, while TDM assigns time slots, enabling them to use the same frequency one after the other.
Why is multiplexing used in fiber-optic networks?
Multiplexing maximizes the data-carrying capacity of fiber-optic cables, essential for high-speed, high-capacity communications.
Is multiplexing used in wireless communications?
Yes, CDM, a form of multiplexing, is used in cellular networks like CDMA and 4G LTE.
What are the limitations of multiplexing?
Challenges include potential signal interference, synchronization requirements, and infrastructure setup costs.
15. Conclusion
Multiplexing is a cornerstone of data communications, optimizing bandwidth use by enabling multiple data streams to share a single transmission medium. From telecommunications to broadcasting, multiplexing ensures efficient, scalable, and cost-effective data transmission solutions. As data demands continue to grow, advancements in multiplexing technologies promise to meet future communication needs, making it a field of ongoing innovation and critical importance.
Data Compression Techniques in Modern Computing
Data compression is a critical technique in modern computing, particularly for optimizing web performance and storage efficiency. This blog post will explore various data compression techniques, their importance, and how they can be applied effectively in different contexts, especially in web development and database management.
Understanding Data Compression
Data compression is the process of encoding information using fewer bits than the original representation. The primary goal is to reduce the size of data to save storage space or speed up transmission over networks. Compression can be categorized into two main types:
-
Lossless Compression: This technique allows the original data to be perfectly reconstructed from the compressed data. It is essential for applications where data integrity is crucial, such as text files, executable files, and some image formats.
-
Lossy Compression: This method reduces file size by removing some data, which may result in a loss of quality. It is commonly used for audio, video, and image files where a perfect reproduction is not necessary.
Key Algorithms in Data Compression
Several algorithms are widely used for data compression. Here are a few notable ones:
-
Lempel-Ziv-Welch (LZW): A lossless compression algorithm that builds a dictionary of input sequences. It is used in formats like GIF and TIFF.
-
Huffman Coding: A lossless algorithm that assigns variable-length codes to input characters based on their frequencies, allowing more common characters to have shorter codes.
-
DEFLATE: This algorithm combines LZ77 and Huffman coding to achieve high compression ratios while maintaining speed. It is used in formats like ZIP and GZIP.
-
Brotli: Developed by Google, Brotli is an open-source compression algorithm that provides better compression ratios than GZIP, especially for text-based content.
Importance of Data Compression
Data compression plays a vital role in various aspects of computing:
-
Improved Load Times: Compressed files take less time to transfer over the internet, leading to faster loading times for websites and applications.
-
Reduced Bandwidth Costs: Smaller file sizes mean less data transmitted over networks, which can significantly lower bandwidth costs for web hosting providers and users alike.
-
Enhanced User Experience: Faster load times contribute to a better user experience, which can lead to higher engagement and conversion rates on websites.
-
Efficient Storage Utilization: In databases and file systems, compression helps save storage space, allowing organizations to store more data without incurring additional costs.
Data Compression Techniques for Web Development
GZIP Compression
GZIP is one of the most commonly used compression methods for web content. It works by finding repeated strings or patterns within files and replacing them with shorter representations. The process involves two main steps:
-
LZ77 Algorithm: Scans the input file for repeated sequences and replaces them with references to earlier occurrences.
-
Huffman Coding: Assigns shorter codes to more frequently occurring characters, further reducing file size.
To enable GZIP compression on a WordPress site:
-
Check if your hosting provider supports GZIP by default.
-
If not, you can enable it manually by editing the
.htaccessfile or using plugins designed for performance optimization[1][4].
Brotli Compression
Brotli is an advanced compression algorithm that offers better performance than GZIP in many scenarios. It uses a predefined dictionary of common words and phrases to optimize compression further. Brotli can achieve higher compression ratios while maintaining fast decompression speeds, making it ideal for serving static assets like HTML, CSS, and JavaScript files.
To implement Brotli on your WordPress site:
-
Ensure your server supports Brotli (many modern servers do).
-
Use plugins or server configurations that enable Brotli automatically[2][5].
Data Compression Techniques in Database Management
In addition to web development, data compression techniques are crucial in database management systems (DBMS) like SQL Server. Here are some common techniques used:
Row-Level Compression
Row-level compression focuses on compressing individual rows within a database table. This technique provides significant storage savings with minimal impact on query performance. To enable row-level compression in SQL Server, you can use the following command:
ALTER TABLE [TableName] REBUILD WITH (DATA_COMPRESSION = ROW);
Page-Level Compression
Page-level compression compresses data at the page level, resulting in even greater storage savings compared to row-level compression. This method reduces disk I/O and improves query response times:
ALTER TABLE [TableName] REBUILD WITH (DATA_COMPRESSION = PAGE);
Columnstore Compression
Columnstore compression is designed for large-scale data warehousing scenarios. It stores and queries data in a columnar format, offering exceptional storage savings and improved query performance:
CREATE CLUSTERED COLUMNSTORE INDEX [IndexName] ON [TableName] WITH (DATA_COMPRESSION = COLUMNSTORE);
Backup Compression
SQL Server allows you to compress database backups, resulting in reduced backup sizes and faster backup operations:
BACKUP DATABASE [DatabaseName] TO DISK = 'C:\Backup\BackupFile.bak' WITH COMPRESSION;
Best Practices for Implementing Data Compression
When implementing data compression techniques, consider the following best practices:
Evaluate Impact on Performance: Test how different compression methods affect application performance before deploying them in production environments.
Choose Appropriate Techniques: Select the right type of compression based on your specific needs—lossless for critical data integrity or lossy for media files where quality loss is acceptable.
Monitor Efficiency: Regularly assess the effectiveness of your chosen compression methods using monitoring tools provided by your DBMS or web server analytics.
Stay Updated: Keep abreast of advancements in compression algorithms as technology evolves; newer methods may offer better performance or efficiency.
Conclusion
Data compression techniques are essential tools for optimizing both web performance and database management. By understanding various algorithms such as GZIP and Brotli for web development or row-level and page-level compression for databases, developers can significantly enhance user experiences while reducing costs associated with bandwidth and storage.
Implementing these techniques thoughtfully will not only improve load times but also contribute to overall system efficiency and scalability in an increasingly data-driven world. Embrace these strategies to unlock the full potential of your applications and websites today!
Citations: [1] https://wp-rocket.me/google-core-web-vitals-wordpress/enable-text-compression/ [2] https://pressidium.com/blog/http-compression/ [3] https://marcelodba.wordpress.com/2022/08/06/advanced-data-compression-in-sql-server-techniques-for-efficient-storage-and-performance/ [4] https://verpex.com/blog/wordpress-hosting/how-to-enable-gzip-compression-in-wordpress [5] https://wpprovider.com/what-is-brotli-and-how-does-it-speed-up-my-wordpress-website/ [6] https://www.elegantthemes.com/blog/wordpress/lossless-compression [7] https://qodeinteractive.com/magazine/how-to-enable-gzip-compression-in-wordpress/ [8] https://www.cmsjunkie.com/blog/post/navigating-wordpress-performance-the-comprehensive-roadmap-from-caching-to-compression-and-beyond
Network Error Detection and Correction Methods: Ensuring Data Integrity in Digital Communications
In our increasingly connected world, ensuring the accuracy and reliability of data transmission has never been more critical. Network errors can occur due to various factors, from electromagnetic interference to hardware failures. This comprehensive guide explores the methods and techniques used to detect and correct these errors, ensuring that our digital communications remain reliable and accurate.
Understanding Network Errors
Before diving into detection and correction methods, it’s essential to understand what network errors are and why they occur.
Common Causes of Network Errors
Physical Interference* Electromagnetic interference
Signal attenuation
Crosstalk between cables
Environmental factors
Hardware Issues* Faulty network equipment
Degraded transmission media
Connection problems
Power fluctuations
Software-Related Problems* Buffer overflows
Timing errors
Protocol mismatches
Configuration issues
Error Detection Methods
- Parity Checking
One of the simplest error detection methods, parity checking adds an extra bit to data to ensure the total number of 1s is either odd or even.
Types of Parity Checking:
Even Parity: The total number of 1s (including the parity bit) must be even
Odd Parity: The total number of 1s (including the parity bit) must be odd
Advantages:
Simple implementation
Low overhead
Quick processing
Limitations:
Cannot detect even a number of bit errors
No error correction capability
Limited effectiveness for burst errors
- Cyclic Redundancy Check (CRC)
CRC is a powerful error detection method widely used in digital networks and storage devices.
How CRC Works:
Data is treated as a binary number
It is divided by a predetermined polynomial
The remainder becomes the check value
The check value is transmitted with the data
The receiver performs the same calculation to verify the integrity
Key Features:
Highly reliable for burst error detection
Relatively simple to implement in hardware
Computationally efficient
Suitable for various data sizes
- Checksum
Checksums provide a simple way to verify data integrity by adding up the values of the data bytes.
Implementation Methods:
Internet Checksum
Fletcher’s Checksum
Adler-32
Custom algorithms
Applications:
TCP/IP protocols
File verification
Data storage
Message authentication
Error Correction Methods
- Forward Error Correction (FEC)
FEC methods allow receivers to correct errors without requesting retransmission, making them ideal for applications where retransmission is impractical.
Common FEC Techniques:
Hamming Codes* Can correct single-bit errors
Can detect double-bit errors
Widely used in computer memory systems
Relatively simple implementation
Reed-Solomon Codes* Excellent for burst error correction
Used in storage systems and digital broadcasting
More complex implementation
Higher overhead
Low-Density Parity Check (LDPC) Codes* Very efficient for large data blocks
Used in high-speed communications
Complex implementation
Excellent performance near Shannon limit
- Automatic Repeat Request (ARQ)
ARQ methods rely on error detection and retransmission to ensure reliable data delivery.
Types of ARQ:
Stop-and-Wait ARQ* Simplest form
The sender waits for an acknowledgment
Low efficiency
Suitable for simple applications
Go-Back-N ARQ* Continuous transmission
Retransmits all frames after error
Better efficiency than Stop-and-Wait
Higher complexity
Selective Repeat ARQ* Only retransmits error frames
The most efficient ARQ variant
Requires more buffer space
More complex implementation
Hybrid Methods
Many modern systems combine multiple error detection and correction techniques for optimal performance.
Hybrid ARQ (HARQ)
HARQ combines FEC and ARQ methods to provide both efficiency and reliability.
Types of HARQ:
Type I HARQ* Always includes error correction coding
Retransmits entire packet if errors cannot be corrected
Simple implementation
Moderate efficiency
Type II HARQ* The initial transmission uses only error detection
Subsequent transmissions include error correction
More efficient use of channel capacity
Higher implementation complexity
Implementation Considerations
When choosing error detection and correction methods, several factors should be considered:
- Application Requirements
Real-time vs. non-real-time
Acceptable error rates
Bandwidth constraints
Processing power limitations
- Channel Characteristics
Noise patterns
Error types and frequencies
Available bandwidth
Transmission latency
- Resource Constraints
Hardware capabilities
Processing power
Memory availability
Power consumption
Best Practices
To ensure optimal error detection and correction:
Choose Appropriate Methods* Match methods to application needs
Consider channel characteristics
Account for resource constraints
Plan for scalability
Implement Proper Testing* Verify error detection capabilities
Test correction mechanisms
Simulate various error conditions
Monitor performance metrics
Maintain Documentation* Document implementation details
Record configuration settings
Keep testing results
Update procedures as needed
Future Trends
Error detection and correction continue to evolve with new technologies and requirements:
Emerging Technologies
Quantum error correction
Machine learning-based methods
Advanced coding schemes
Adaptive error correction
New Applications
5G and 6G networks
Quantum communications
Internet of Things (IoT)
Edge computing
Conclusion
Error detection and correction methods are fundamental to reliable digital communications. As technology advances and data transmission requirements become more demanding, these methods continue to evolve and improve. Understanding the various approaches and their applications is crucial for network engineers and system designers.
By carefully selecting and implementing appropriate error detection and correction methods, organizations can ensure the integrity and reliability of their data communications while optimizing resource usage and meeting performance requirements. As we move toward even more complex and demanding applications, the importance of effective error handling will only continue to grow.
Latency and Jitter: Understanding Their Impact on Network Performance
In today’s interconnected world, the performance of a network is measured by several factors, including speed, reliability, and stability. Among these, latency and jitter are critical metrics that affect the quality of data transmission, especially for applications requiring real-time communication, such as video conferencing, online gaming, and VoIP (Voice over IP) services. In this article, we’ll break down what latency and jitter are, why they matter, and how they influence the quality of network connections.
1. Introduction to Latency and Jitter
In networking, the terms latency and jitter are frequently mentioned as they impact the responsiveness and stability of data transmission. While latency refers to the delay in data transmission, jitter is the variation in latency over time. Both factors are crucial to the user experience, particularly in applications where real-time interaction is necessary. Understanding these metrics can help users and network administrators optimize connectivity for seamless communication.
2. What is Latency?
Latency is the time delay it takes for a data packet to travel from the sender to the receiver across a network. Think of latency as the “ping” or delay you experience while waiting for a webpage to load, a video to start streaming, or a message to reach the recipient. Lower latency means data is transferred more quickly, which results in faster load times and better network performance.
3. How Latency is Measured
Latency is typically measured in milliseconds (ms), representing the time it takes for data to travel between two points. To measure latency, network tools like ping and traceroute are commonly used. Ping sends a packet to a specific destination and calculates the time taken for the packet to return. This round-trip time (RTT) is recorded as latency, offering an idea of the network’s responsiveness.
4. Types of Latency
Different types of latency contribute to the overall delay experienced in a network. Understanding these categories can help diagnose and reduce latency.
Processing Latency
This is the delay caused by the devices (routers, switches, etc.) as they process and forward data packets along the network. Processing latency is generally minimal but can add up if several devices are involved.
Queuing Latency
Queuing latency occurs when data packets are waiting in line to be transmitted. This type of latency typically increases with network congestion, where too many packets are sent simultaneously, and devices need to queue packets for processing.
Transmission Latency
Transmission latency is the time it takes to transmit a packet over a network link. Transmission speeds depend on the bandwidth of the link, and higher bandwidth generally reduces transmission latency.
Propagation Latency
Propagation latency is the time it takes for data to travel from the sender to the receiver based on physical distance and the medium used (e.g., fiber optic cables or satellite connections). This delay depends on the speed of light in the transmission medium and increases with longer distances.
5. What is Jitter?
Jitter, also known as packet delay variation, is the fluctuation in delay that occurs during data transmission. While latency is the total time taken for data to travel, jitter represents the variation in that time from one data packet to another. High jitter results in an unstable connection, which can be detrimental to applications requiring consistent data delivery, like online gaming and video calls.
6. How Jitter is Measured
Jitter is measured as the variation in latency over time, often calculated as the average change in delay between packets. It is usually represented in milliseconds (ms), and lower jitter values indicate a more stable and predictable connection. Tools like iperf and Wireshark are commonly used to measure jitter and analyze network performance.
7. Causes of Latency in Networks
Several factors contribute to latency in a network. Some common causes include:
Distance: Longer distances increase propagation latency, especially in satellite networks.
Network Congestion: Heavy traffic results in queuing latency, slowing down data transmission.
Packet Loss and Retransmission: Lost packets that need to be retransmitted add to the overall delay.
Device Processing Time: Routers and switches require time to process packets, contributing to processing latency.
Bandwidth Limitations: Lower bandwidth can increase transmission latency, as data packets take longer to pass through limited-capacity channels.
8. Causes of Jitter in Networks
Jitter is mainly caused by irregularities in data packet transmission. Common causes of jitter include:
Network Congestion: Congestion increases the variability in packet transmission times, leading to higher jitter.
Route Changes: Changing network routes can create inconsistencies in delivery times.
Interference: Wireless networks are particularly susceptible to interference from other devices, causing packet delays and increased jitter.
Device Performance Variability: Variations in processing speed among network devices, such as routers and switches, can lead to inconsistent packet delivery times.
9. Impacts of Latency and Jitter on Network Performance
Both latency and jitter have significant impacts on network performance and user experience. Here’s how they affect different applications:
Video Streaming: High latency can cause delays in buffering, and high jitter can lead to pixelation or audio issues.
VoIP Calls: Latency above 150 ms can cause noticeable delays in voice transmission, while jitter can cause audio distortion.
Online Gaming: High latency results in lag, while jitter creates unpredictable delays, making real-time reactions challenging.
Data Transfers: Latency affects the overall time taken to upload or download files, but jitter has minimal impact on non-real-time data transfers.
10. Latency and Jitter in Real-Time Applications
Real-time applications, such as online gaming, video calls, and VoIP services, are especially sensitive to latency and jitter. In these cases:
Latency: For most real-time applications, a latency below 100 ms is ideal. Above this, users start to experience noticeable delays that can hinder the interactive experience.
Jitter: Ideally, jitter should be kept below 30 ms for real-time applications. High jitter creates inconsistency in data arrival times, disrupting the quality and clarity of audio and video.
11. How to Reduce Latency
Reducing latency can significantly improve network performance and user satisfaction. Here are some effective methods:
Upgrade Bandwidth: Higher bandwidth reduces transmission latency, allowing data to pass through faster.
Use a Content Delivery Network (CDN): CDNs reduce latency by distributing content across servers closer to users.
Optimize Routing: Choose the most direct and efficient routing paths to reduce processing and queuing latency.
Implement Quality of Service (QoS): QoS can prioritize high-priority traffic, reducing queuing latency for critical applications.
Switch to Wired Connections: Wired connections, such as fiber optics, have lower latency compared to wireless connections.
12. How to Reduce Jitter
Jitter can be minimized by managing network stability and ensuring consistent data transmission. Here are some methods:
Prioritize Real-Time Traffic: Implement QoS policies to prioritize real-time applications, ensuring smoother and more consistent packet delivery.
Use Jitter Buffers: Jitter buffers can hold data packets temporarily to smooth out variations in arrival time, which is particularly helpful in VoIP and streaming applications.
Optimize Network Devices: Ensure routers and switches are up to date and capable of handling traffic without causing delays.
Minimize Wireless Interference: Reduce interference in wireless networks by limiting the number of connected devices and avoiding physical obstacles that can disrupt signal strength.
13. Latency and Jitter in 5G and Next-Gen Networks
With the rollout of 5G, latency and jitter are expected to reduce drastically, providing faster and more reliable network performance. 5G technology has been designed to deliver ultra-low latency, often as low as 1 ms, and to minimize jitter, making it ideal for emerging applications such as:
Augmented Reality (AR) and Virtual Reality (VR): The low latency of 5G will enable seamless, real-time AR and VR experiences.
Autonomous Vehicles: Ultra-low latency in 5G allows for near-instantaneous communication between vehicles and infrastructure, essential for safe autonomous navigation.
IoT Applications: Industrial IoT applications benefit from 5G’s reduced latency and jitter, allowing for real-time monitoring and automation.
14. Frequently Asked Questions (FAQs)
What is an acceptable latency level for most applications?
For general web browsing and data transfer, latency below 100 ms is considered acceptable. However, for real-time applications like gaming or video calls, latency should ideally be under 50 ms
.
How does jitter affect VoIP calls?
High jitter causes variations in voice packet arrival times, leading to audio distortion or choppy calls. Keeping jitter below 30 ms is recommended for clear VoIP calls.
Can high bandwidth eliminate latency?
While high bandwidth can reduce transmission latency, it cannot eliminate other sources of delay, such as propagation or processing latency. Thus, bandwidth upgrades can help but don’t fully solve latency issues.
Is jitter more of a problem on wireless or wired networks?
Jitter is generally more common on wireless networks due to interference from other wireless signals, distance from the router, and physical obstructions.
What tools can measure latency and jitter?
Tools like ping, iperf, and Wireshark are commonly used to measure latency and jitter in network connections, providing insights into network stability.
Why is low latency critical for online gaming?
Low latency reduces lag, allowing for quick, responsive actions, which is essential for fast-paced gaming environments where timing is crucial.
15. Conclusion
Latency and jitter are essential factors in network performance, impacting the user experience across a wide range of applications. While latency refers to the total time delay in data transmission, jitter measures the variability of that delay. Both metrics are critical to real-time applications, where even slight inconsistencies can disrupt quality. By understanding and managing latency and jitter, network administrators can enhance connectivity, improve user experience, and support the demands of modern digital applications.
Understanding Bandwidth and Throughput: Key Concepts in Networking
In the realm of networking, two terms often come up that are crucial for understanding how data is transmitted over networks: bandwidth and throughput. While they are related, they represent different aspects of network performance. This blog post will delve into the definitions, differences, and implications of bandwidth and throughput, as well as their significance in real-world applications.
What is Bandwidth?
Bandwidth refers to the maximum data transfer capacity of a network connection. It is a measure of how much data can be sent over a network channel in a given amount of time, typically expressed in bits per second (bps). Bandwidth can also be represented in larger units such as megabits per second (Mbps) or gigabits per second (Gbps).
Characteristics of Bandwidth:
Theoretical Limit: Bandwidth represents the upper limit of data transfer capabilities. It does not guarantee that this amount of data will be transmitted at any given time; rather, it indicates the potential capacity.
Measurement: Bandwidth is measured at the physical layer of the OSI model, which includes the hardware technologies that facilitate communication over a network.
Influence on Speed: While higher bandwidth can lead to faster data transfer rates, it does not automatically equate to improved performance due to other limiting factors such as network congestion and latency.
What is Throughput?
Throughput, on the other hand, is the actual amount of data successfully transmitted over a network in a specific period. It reflects real-world performance and is influenced by various factors including network traffic, errors, and latency. Throughput is also measured in bits per second (bps) but represents the practical delivery rate rather than the theoretical maximum.
Characteristics of Throughput:
Actual Performance: Throughput provides a realistic view of how much data can be transferred effectively under current conditions.
Affected by Network Conditions: Unlike bandwidth, throughput can vary significantly based on network congestion, interference, and transmission errors.
Measurement Across OSI Layers: Throughput can be assessed at various layers of the OSI model, providing insights into performance across different aspects of a network.
Key Differences Between Bandwidth and Throughput
Understanding the distinction between bandwidth and throughput is essential for evaluating network performance. Here’s a comparison:
| Feature | Bandwidth | Throughput |
|---|---|---|
| Definition | Maximum data transfer capacity | Actual data transferred |
| Measurement | Theoretical limit (bps) | Real-world performance (bps) |
| Impact Factors | Hardware capabilities | Network conditions (traffic, errors) |
| Variability | Generally constant | Highly variable |
| Importance | Indicates potential speed | Reflects actual user experience |
The Relationship Between Bandwidth and Throughput
While bandwidth sets the stage for what is possible in terms of data transfer, throughput determines what users actually experience. It is important to note that throughput will always be less than or equal to bandwidth due to various limiting factors.
For instance, if you have a network connection with a bandwidth of 100 Mbps, this means that under ideal conditions, you could potentially transmit 100 megabits of data every second. However, due to factors such as network congestion or packet loss, your actual throughput might only be 80 Mbps or even lower.
Factors Affecting Throughput
Several elements can impact throughput:
Network Congestion: High levels of traffic can slow down data transmission rates.
Latency: The time it takes for data packets to travel from source to destination can affect how quickly information is received.
Errors and Retransmissions: If packets are lost or corrupted during transmission, they need to be retransmitted, which reduces overall throughput.
Protocol Overheads: Different networking protocols have varying levels of overhead that can affect how efficiently data is transmitted.
Real-World Implications
Understanding bandwidth and throughput is crucial for both individuals and organizations when it comes to optimizing network performance. Here are some practical applications:
Internet Service Providers (ISPs) often advertise bandwidth capabilities but may not provide clear information about expected throughput during peak usage times.
Network Administrators need to monitor both metrics to identify bottlenecks and optimize configurations for better performance.
For businesses relying on cloud services or remote work solutions, ensuring adequate bandwidth and monitoring throughput can lead to smoother operations and improved productivity.
Improving Bandwidth and Throughput
To enhance both bandwidth and throughput in your network environment, consider implementing the following strategies:
Upgrade Your Equipment: Ensure routers and switches support higher bandwidth standards (e.g., upgrading from 802.11n to 802.11ac Wi-Fi).
Optimize Network Configuration: Configure Quality of Service (QoS) settings to prioritize critical applications.
Reduce Interference: Minimize physical barriers and electronic interference that could affect wireless signals.
Regular Testing: Use tools like Iperf or speed test utilities to regularly measure both bandwidth and throughput for ongoing optimization.
Conclusion
In summary, while bandwidth represents the maximum potential capacity for data transmission over a network, throughput reflects the actual performance experienced by users. Understanding these concepts is essential for anyone involved in networking—from casual users seeking better internet speeds to IT professionals managing complex systems.
By focusing on both improving bandwidth capabilities and maximizing throughput through strategic measures, individuals and organizations can ensure optimal performance in their networking environments. As technology continues to evolve, staying informed about these metrics will remain critical for navigating the digital landscape effectively.
Citations: [1] https://www.javatpoint.com/bandwidth-vs-throughput [2] https://stackoverflow.com/questions/36949735/what-is-the-difference-between-latency-bandwidth-and-throughput/39187441 [3] https://strom.wordpress.com/2020/07/30/network-solutions-blog-cost-effective-ways-to-improve-your-network-bandwidth/ [4] https://blogchiasekienthuc.wordpress.com/2014/05/19/a-guide-to-bandwidth-and-throughput/ [5] https://themeim.com/what-is-bandwidth-in-web-hosting/ [6] https://movement3.wordpress.com/2007/10/30/network-through-put-test/ [7] https://www.rswebsols.com/network-basics-bandwidth-latency-throughput/
Wired vs. Wireless Communication: A Comparative Analysis
In today’s interconnected world, communication has become an integral part of our daily lives. Whether it’s staying connected with friends and family, conducting business transactions, or accessing information, reliable and efficient communication is essential. To achieve this, we rely on various communication technologies, which can be broadly categorized into two types: wired and wireless.
Wired Communication
Wired communication involves the transmission of data over physical cables or wires. This traditional method has been used for decades and continues to be a reliable option for many applications.
Key Characteristics of Wired Communication:
Reliability: Wired connections are generally more reliable than wireless connections, as they are less susceptible to interference and signal degradation.
Security: Wired connections can be more secure, as they are less prone to hacking and eavesdropping.
Speed: Wired connections can offer higher data transfer speeds, especially for long distances.
Cost-Effective: Wired infrastructure can be relatively inexpensive to install and maintain, especially for short distances.
Types of Wired Communication:
Ethernet: This is the most common wired technology used for local area networks (LANs). Ethernet cables transmit data at various speeds, ranging from 10 Mbps to 100 Gbps.
Fiber Optic: Fiber optic cables use light pulses to transmit data at extremely high speeds. They are ideal for long-distance communication and high-bandwidth applications.
Coaxial Cable: Coaxial cables are used for cable television and internet connections. They offer good performance and are relatively affordable.
Wireless Communication
Wireless communication, on the other hand, involves the transmission of data over electromagnetic waves. This technology has revolutionized the way we communicate, making it possible to connect devices without physical cables.
Key Characteristics of Wireless Communication:
Flexibility: Wireless connections offer greater flexibility, as devices can be used anywhere within the coverage area.
Mobility: Wireless devices can be easily moved around, making them ideal for mobile applications.
Scalability: Wireless networks can be easily expanded to accommodate more devices.
Cost-Effective: Wireless technologies can be more cost-effective to install and maintain, especially for large areas.
Types of Wireless Communication:
Wi-Fi: Wi-Fi uses radio waves to transmit data over short distances. It is widely used for home and office networks.
Cellular Networks: Cellular networks use radio waves to transmit data over long distances. They are used for mobile phones and other mobile devices.
Bluetooth: Bluetooth is a short-range wireless technology used for connecting devices such as headphones, keyboards, and mice.
Satellite Communication: Satellite communication involves the transmission of data via satellites orbiting the Earth. It is used for global communication and remote areas.
Comparing Wired and Wireless Communication
| Feature | Wired Communication | Wireless Communication |
|---|---|---|
| Reliability | High | Moderate to Low |
| Security | High | Moderate to Low |
| Speed | High | Moderate to High |
| Cost-Effectiveness | High for short distances, low for long distances | Moderate to High |
| Flexibility | Low | High |
| Mobility | Low | High |
| Scalability | Moderate | High |
Choosing the Right Technology
The choice between wired and wireless communication depends on various factors, including:
Distance: For short distances, wired connections are often more reliable and cost-effective. For long distances, wireless technologies like satellite communication may be necessary.
Security: Wired connections are generally more secure, but wireless connections can be secured using encryption techniques.
Mobility: Wireless connections offer greater mobility, making them ideal for mobile devices.
Cost: Wired infrastructure can be expensive to install, especially for large areas. Wireless technologies can be more cost-effective, but they may require ongoing subscription fees.
Interference: Wireless connections can be susceptible to interference from other devices and environmental factors.
The Future of Communication
As technology continues to advance, the line between wired and wireless communication is becoming increasingly blurred. Emerging technologies like 5G and Wi-Fi 6 are pushing the boundaries of wireless performance, making it possible to achieve speeds comparable to wired connections.
In the future, we can expect to see a hybrid approach, combining the best of both worlds. For example, wired connections may be used for critical infrastructure, while wireless connections will be used for everyday devices.
Ultimately, the choice between wired and wireless communication will depend on the specific needs of the user. By understanding the strengths and weaknesses of each technology, we can make informed decisions to ensure reliable and efficient communication.
Transmission Media in Data Communications: Understanding the Physical Layer of Network Infrastructure
In our increasingly connected world, the way data physically travels from one point to another remains a crucial yet often overlooked aspect of modern communications. Transmission media, the physical paths along which information flows, form the foundation of all data communications. This comprehensive guide explores the various types of transmission media, their characteristics, applications, and the factors that influence their selection.
Understanding Transmission Media
Transmission media refers to the physical means through which data, instructions, and information travel between computing devices. These pathways can be broadly categorized into two main types: guided (wired) and unguided (wireless) media. Each type has its own set of characteristics, advantages, and limitations that make it suitable for specific applications.
Guided (Wired) Transmission Media
Twisted Pair Cable
Twisted pair cabling remains one of the most commonly used transmission media in modern networks, particularly in Ethernet installations. These cables consist of pairs of insulated copper wires twisted together to reduce electromagnetic interference.
Types of Twisted Pair Cables:
Unshielded Twisted Pair (UTP)
Most common and cost-effective
Categories range from Cat3 to Cat8
Used in home and office networks
Maximum length typically 100 meters
Susceptible to external interference
Shielded Twisted Pair (STP)
Additional metallic shield for better noise protection
Higher cost than UTP
Better performance in electrically noisy environments
Requires proper grounding
Commonly used in industrial settings
Coaxial Cable
Coaxial cables offer superior protection against noise and higher bandwidth capabilities compared to twisted pair cables. Their construction includes:
Central copper conductor
Insulating layer
Metallic shield
Protective outer jacket
Applications of Coaxial Cables:
Cable television distribution
Long-distance telephone lines
High-speed internet connections
Radio frequency transmission
Computer network connections
Fiber Optic Cable
Fiber optic cables represent the pinnacle of guided transmission media, using light pulses to transmit data through thin glass or plastic fibers. They offer several significant advantages:
Key Benefits:
Extremely high bandwidth
Very low signal attenuation
Immune to electromagnetic interference
Enhanced security
Lighter weight compared to metal cables
Long-distance transmission capability
Types of Fiber Optic Cables:
Single-mode Fiber
Smaller core diameter
Longer transmission distances
Higher bandwidth
More expensive
Commonly used in long-haul networks
Multi-mode Fiber
Larger core diameter
Shorter transmission distances
Lower cost
Easier to install and maintain
Suitable for local area networks
Unguided (Wireless) Transmission Media
Radio Waves
Radio waves form the basis of many wireless communication systems, offering flexibility and mobility.
Characteristics:
Omnidirectional propagation
Ability to penetrate buildings
Frequency range from 3 KHz to 1 GHz
Affected by atmospheric conditions
Applications:
AM/FM radio broadcasting
Mobile phones
Wireless LANs
Bluetooth devices
IoT devices
Microwaves
Microwave transmission operates at higher frequencies than radio waves, offering increased data capacity.
Key Features:
Line-of-sight transmission
High frequency (1-300 GHz)
Narrow beam width
Susceptible to weather conditions
Used for point-to-point communication
Common Uses:
Satellite communications
Terrestrial microwave links
Wireless broadband
Radar systems
Infrared
Infrared transmission offers short-range, high-bandwidth communication options.
Characteristics:
Short-range communication
Line-of-sight requirement
Immune to radio frequency interference
Cannot penetrate solid objects
Cost-effective for specific applications
Applications:
Remote controls
Device-to-device data transfer
Indoor wireless networks
Industrial automation
Factors Affecting Transmission Media Selection
When choosing transmission media for specific applications, several factors must be considered:
- Performance Requirements
Bandwidth needs
Transmission speed
Distance requirements
Error rates
Latency considerations
- Installation Environment
Indoor vs. outdoor installation
Environmental conditions
Physical space constraints
Electromagnetic interference levels
Security requirements
- Cost Considerations
Material costs
Installation expenses
Maintenance requirements
Upgrade potential
Lifetime value
- Regulatory Compliance
Local building codes
Industry standards
Environmental regulations
Safety requirements
Future Trends in Transmission Media
The field of transmission media continues to evolve with new technologies and improvements:
Emerging Technologies
Hollow-core fiber optics
Plastic optical fiber
Li-Fi (Light Fidelity)
Advanced wireless standards
Quantum communication channels
Environmental Considerations
Energy-efficient designs
Recyclable materials
Reduced electromagnetic pollution
Sustainable manufacturing processes
Best Practices for Implementation
To ensure optimal performance and longevity of transmission media installations:
Proper Planning
Conduct thorough site surveys
Document all requirements
Plan for future growth
Consider redundancy needs
Quality Installation
Use certified installers
Follow manufacturer guidelines
Implement proper testing procedures
Maintain detailed documentation
Regular Maintenance
Schedule periodic inspections
Monitor performance metrics
Update documentation
Plan for upgrades
Conclusion
The choice of transmission media plays a crucial role in determining the performance, reliability, and cost-effectiveness of data communication systems. As technology continues to advance, new forms of transmission media emerge, offering improved capabilities and addressing current limitations. Understanding the characteristics, advantages, and limitations of different transmission media is essential for network designers, administrators, and IT professionals.
Whether implementing a new network infrastructure or upgrading existing systems, careful consideration of transmission media options ensures optimal performance and future scalability. By staying informed about the latest developments in transmission media technology, organizations can make informed decisions that align with their current needs and future growth plans.
Synchronous vs. Asynchronous Transmission: Key Differences, Benefits, and Use Cases
The way data is transmitted over communication networks can significantly impact the efficiency, speed, and accuracy of information sharing. Among the fundamental transmission methods, synchronous and asynchronous transmission are two widely used approaches, each with unique characteristics, advantages, and applications. In this article, we will explore the differences, benefits, and use cases of synchronous and asynchronous transmission, helping you understand how each one functions and when each is most suitable.
1. Introduction to Data Transmission
Data transmission is the process of transferring data from one point to another, whether within a computer system, between computers, or across complex networks. Synchronous and asynchronous transmission are two methods that differ primarily in how they coordinate data timing during transfer. The method of transmission chosen often depends on factors such as data type, the need for accuracy, speed, and the complexity of the network.
2. What is Synchronous Transmission?
Synchronous transmission is a data transfer method where data is sent in a continuous, steady stream, with precise timing to synchronize the sender and receiver. This means that both the sender and receiver are coordinated with a clock signal, allowing data to flow seamlessly and without breaks. It is commonly used in high-speed networks and applications that require large volumes of data to be transferred efficiently.
3. Characteristics of Synchronous Transmission
Clock Synchronization: Both sender and receiver operate with a shared clock to keep data flow consistent.
Continuous Data Stream: Data is sent in continuous blocks without start and stop bits, making it ideal for high-volume data.
Reduced Overhead: Since no start or stop bits are used for each data segment, synchronous transmission reduces the amount of additional data required, making it more efficient for larger data transfers.
Error Detection: Error-checking codes are often used to ensure data accuracy, reducing the chance of data corruption.
4. What is Asynchronous Transmission?
Asynchronous transmission sends data in a more sporadic, irregular manner, without the need for clock synchronization. Each data packet, or byte, is sent individually and marked by start and stop bits, allowing the receiver to understand when data transmission begins and ends. This method is commonly used for smaller data transfers or in situations where simplicity is more important than high-speed communication.
5. Characteristics of Asynchronous Transmission
Individual Data Packets: Data is sent one byte at a time, with each packet having a start and stop bit.
Independent Transmission: Unlike synchronous transmission, asynchronous transmission does not require a shared clock signal, allowing each byte to be sent independently.
Higher Overhead: Due to the addition of start and stop bits, asynchronous transmission can create more overhead, reducing efficiency for large data transfers.
More Flexibility: Without a need for constant clock synchronization, asynchronous transmission is often easier to implement in simpler, low-speed applications.
6. Key Differences Between Synchronous and Asynchronous Transmission
| Feature | Synchronous Transmission | Asynchronous Transmission |
|---|---|---|
| **Clock Synchronization** | Requires a shared clock | Does not require a shared clock |
| **Data Flow** | Continuous blocks of data | Individual packets with start/stop bits |
| **Speed** | Typically faster and more efficient | Generally slower due to higher overhead |
| **Error Detection** | Often uses error-checking protocols | Relies on the start/stop bits for the basic structure |
| **Applications** | High-speed networks, bulk data transfers | Simple, low-speed, or sporadic data transfers |
7. Advantages of Synchronous Transmission
Pros of Using Synchronous Transmission
Higher Efficiency for Large Data Transfers: Synchronous transmission is ideal for transferring large volumes of data quickly and efficiently due to its continuous data stream.
Reduced Overhead: By eliminating start and stop bits, synchronous transmission minimizes the amount of additional data, enhancing overall efficiency.
Accurate and Reliable: Synchronous transmission often includes advanced error-checking protocols, improving the accuracy and reliability of data transfer.
Consistent Data Flow: The synchronized nature of this transmission method enables a smooth, continuous flow of data, which is particularly beneficial for applications that require high data rates.
8. Advantages of Asynchronous Transmission
Pros of Using Asynchronous Transmission
Simplicity: Asynchronous transmission is simpler to implement, as it does not require complex clock synchronization between sender and receiver.
Flexibility for Sporadic Data Transfer: Ideal for low-speed applications or where data is transmitted sporadically, asynchronous transmission offers flexibility without complex synchronization requirements.
Cost-Effective for Small Data Volumes: Asynchronous transmission’s straightforward structure makes it cost-effective for systems where data needs to be transferred infrequently or in small amounts.
Reduced Initial Setup: Since clock synchronization is unnecessary, asynchronous transmission systems are often faster to set up and can operate independently of timing constraints.
9. Disadvantages of Synchronous Transmission
Complex Setup: Synchronous transmission requires a shared clock and a more sophisticated setup, making it more complex and expensive.
Not Ideal for Sporadic Data: Continuous data flow means that synchronous transmission is less effective for applications where data is sent infrequently or in small bursts.
Potential Synchronization Issues: If synchronization between the sender and receiver is lost, it can cause data loss or corruption, requiring additional error-checking protocols.
10. Disadvantages of Asynchronous Transmission
Higher Overhead: Due to start and stop bits accompanying each data byte, asynchronous transmission generates more overhead, making it inefficient for large data transfers.
Lower Speed and Efficiency: Since data is sent individually with start and stop bits, asynchronous transmission is slower and less efficient than synchronous methods.
Basic Error Detection: Asynchronous transmission relies primarily on start/stop bits for packet recognition, which is less robust than synchronous error-checking protocols.
11. Applications of Synchronous Transmission
Synchronous transmission is commonly used in applications that demand high speed, reliability, and efficiency, such as:
Internet Communication: High-speed internet protocols, such as TCP/IP, use synchronous methods to facilitate fast, bulk data transfers.
File Transfers: Synchronous transmission is used in protocols like FTP (File Transfer Protocol) for transferring large files reliably.
Streaming and Real-Time Applications: Audio and video streaming, as well as live broadcasts, benefit from synchronous transmission for maintaining consistent data flow.
Corporate Networks: Many corporate environments rely on synchronous transmission to maintain high-speed, high-capacity data networks.
12. Applications of Asynchronous Transmission
Asynchronous transmission is often chosen for applications where simplicity, flexibility, and low-speed data transfer are key. Examples include:
Peripheral Communication: Devices like keyboards, mice, and other peripherals use asynchronous transmission to send data as needed.
Low-Speed Data Transfers: Asynchronous transmission is suitable for low-speed data transfer protocols, such as RS-232, used in simple computer communication.
Email and Messaging: Many basic forms of digital communication, like emails, use asynchronous transmission to handle sporadic data exchange.
Telecommunication Devices: In early telecommunication devices, asynchronous transmission was commonly used for data transfer over telephone lines.
13. How to Choose Between Synchronous and Asynchronous Transmission
Choosing between synchronous and asynchronous transmission depends on specific factors such as data volume, transfer speed, cost, and network complexity:
For High-Speed Data Transfer: Synchronous transmission is typically the better choice.
For Sporadic Data Transfer: Asynchronous transmission is suitable for low-speed and infrequent data transfer needs.
Complexity and Cost Considerations: If simplicity and cost are important, asynchronous transmission may be the most practical option.
Error Sensitivity: Synchronous transmission with error-checking is preferable when data accuracy and error reduction are critical.
14. Frequently Asked Questions (FAQs)
What is the main difference between synchronous and asynchronous transmission?
Synchronous transmission requires clock synchronization and sends data in a continuous stream, while asynchronous transmission sends data in individual packets with start and stop bits and does not require a shared clock.
Which is faster: synchronous or asynchronous transmission?
Synchronous transmission is generally faster and more efficient, especially for large volumes of data.
Can synchronous transmission work without a clock?
No, synchronous transmission relies on a shared clock signal for timing, which coordinates the sender and receiver.
Why is asynchronous transmission used in keyboard and mouse communication?
Asynchronous transmission allows peripheral devices to send data sporadically, making it ideal for devices that do not need to transfer large volumes of data continuously.
Is asynchronous transmission suitable for high-speed internet?
No, asynchronous transmission is less efficient and slower than synchronous transmission, making it unsuitable for high-speed internet and large data transfers.
Are there any hybrid methods combining synchronous and
asynchronous transmission? Yes, some systems use elements of both methods, using synchronous protocols for high-speed data but asynchronous protocols for simpler, sporadic data requirements.
15. Conclusion
Both synchronous and asynchronous transmission play crucial roles in modern communication, each serving specific needs based on data volume, speed, and complexity requirements. Synchronous transmission provides high-speed, continuous data transfer with excellent error control, making it ideal for applications like high-speed internet and file transfers. In contrast, asynchronous transmission’s flexibility and simplicity make it suitable for low-speed, infrequent data transfers, such as those needed by peripherals and basic communication devices.
Understanding the distinctions between these two methods allows for better decision-making in choosing the most appropriate transmission mode for different technological and communication needs.
Data Transmission Modes
Data transmission is a fundamental aspect of computer networking, facilitating communication between devices. Understanding the various modes of data transmission is essential for optimizing network performance and ensuring efficient communication. This blog post delves into the three primary data transmission modes: Simplex, Half-Duplex, and Full-Duplex. Each mode has unique characteristics, advantages, and applications, making them suitable for different scenarios.
Overview of Data Transmission Modes
Data transmission modes refer to the directionality of data flow between two connected devices. The choice of transmission mode can significantly impact the efficiency and reliability of communication. Below are the three primary modes:
Simplex Mode
Half-Duplex Mode
Full-Duplex Mode
Simplex Mode
In Simplex Mode, data transmission occurs in one direction only. This means that one device sends data while the other device only receives it, with no capability for sending data back to the sender. This unidirectional communication is ideal for situations where feedback from the receiver is unnecessary.
Characteristics:
Directionality: Unidirectional
Bandwidth Usage: Utilizes maximum bandwidth since all available capacity is dedicated to one direction.
Error Handling: Limited error checking since there is no return path for acknowledgments.
Examples:
Broadcasting Systems: Television and radio broadcasts where information flows from the broadcaster to the audience.
Keyboards: Data flows from the keyboard to the computer, with no need for the keyboard to receive any data back.
Sensors: Devices like temperature sensors that send readings to a central monitoring system.
Advantages:
High efficiency in scenarios where only one-way communication is needed.
Minimal complexity in design and implementation.
Disadvantages:
Lack of feedback can lead to challenges in error detection and correction.
Not suitable for interactive applications where two-way communication is essential.
Half-Duplex Mode
Half-Duplex Mode allows data transmission in both directions, but not simultaneously. This means that while one device sends data, the other must wait until it has finished before it can respond.
Characteristics:
Directionality: Bidirectional but alternating.
Bandwidth Usage: More efficient than simplex as it allows for two-way communication without requiring additional channels.
Error Handling: Improved error detection capabilities since both devices can communicate back and forth.
Examples:
Walkie-Talkies: Users take turns speaking; one must finish before the other can respond.
CB Radios: Similar to walkie-talkies, where users communicate in turns.
Fax Machines: Sending documents in one direction at a time.
Advantages:
Allows for two-way communication without needing separate channels.
More efficient use of bandwidth compared to simplex mode.
Disadvantages:
Slower communication as devices must wait for their turn to transmit.
Potential delays in communication can occur if multiple messages are queued.
Full-Duplex Mode
In Full-Duplex Mode, data can be transmitted in both directions simultaneously. This mode allows for continuous two-way communication, enhancing interaction between devices.
Characteristics:
Directionality: Bidirectional and simultaneous.
Bandwidth Usage: Requires more bandwidth since both channels are utilized at once.
Error Handling: Enhanced error detection due to continuous feedback between devices.
Examples:
Telephone Networks: Both parties can speak and listen at the same time.
Video Conferencing Systems: Participants can interact without waiting for turns.
Modern Local Area Networks (LANs): Devices communicate simultaneously over a shared medium.
Advantages:
Fast and efficient communication as there are no delays between responses.
Ideal for applications requiring real-time interaction, such as voice calls or online gaming.
Disadvantages:
Increased complexity in design and implementation due to simultaneous data handling.
Requires more sophisticated hardware to manage concurrent transmissions effectively.
Comparison Table of Transmission Modes
| Mode | Directionality | Bandwidth Usage | Advantages | Disadvantages | Examples |
|---|---|---|---|---|---|
| Simplex | Unidirectional | Maximum available | High efficiency for one-way communication | No feedback or error checking | TV broadcasting, keyboards |
| Half-Duplex | Bidirectional (alternating) | Moderate | Allows two-way communication | Slower due to turn-taking | Walkie-talkies, fax machines |
| Full-Duplex | Bidirectional (simultaneous) | High | Fast real-time interaction | More complex hardware requirements | Telephone networks, video calls |
Factors Affecting Data Transmission Modes
When selecting a data transmission mode, several factors should be considered:
Application Requirements: Determine whether real-time interaction is necessary or if one-way communication suffices.
Network Infrastructure: Assess whether existing hardware supports full-duplex capabilities or if half-duplex would be more feasible.
Cost Considerations: Evaluate budget constraints as full-duplex systems may require more investment in technology and infrastructure.
Synchronization Types
In addition to directionality, synchronization plays a crucial role in data transmission:
Synchronous Transmission
Synchronous transmission involves sending data in a continuous stream with synchronized timing between sender and receiver. This method is often used in high-speed networks where efficiency is paramount.
Asynchronous Transmission
Asynchronous transmission sends data in discrete packets rather than a continuous stream. Each packet includes start and stop bits, allowing the receiver to identify when a new byte begins and ends. This method is common in applications like serial communications (e.g., USB).
Conclusion
Understanding data transmission modes—simplex, half-duplex, and full-duplex—is essential for anyone involved in networking or telecommunications. Each mode has its strengths and weaknesses, making them suitable for different applications based on requirements such as speed, efficiency, and interaction needs. By carefully considering these factors, network designers can optimize their systems for better performance and reliability.
Citations: [1] https://findtodaysnotes.wordpress.com/transmission-modes-in-computer-networks/ [2] https://gcore.com/learning/data-transmission-guide-everything-you-need-to-know/ [3] https://computerscienceigsce.wordpress.com/chapter-2/ [4] https://nsaaleaict.wordpress.com/computer-networking/ [5] https://computernetworks969.wordpress.com/2016/06/19/transmission-modes-in-computer-networks/ [6] https://avcreatians.wordpress.com/2020/08/10/types-of-transmission-modes/ [7] https://nripeshnrip.wordpress.com/2018/09/20/data-communication-computer-networks/ [8] https://telecommunicationhub.wordpress.com/2018/08/19/different-mode-of-transmission/
The Indispensable Role of Standards in Networking
In today’s interconnected world, networks have become the lifeblood of businesses, organizations, and individuals alike. From the smallest home network to the vast expanse of the internet, networks facilitate seamless communication, data transfer, and resource sharing. However, the smooth functioning of these intricate systems heavily relies on a common language: standards.
Understanding Network Standards
Network standards are a set of guidelines, protocols, and specifications that govern the design, implementation, and operation of networks. They ensure interoperability, compatibility, and reliability across different devices and systems, regardless of their manufacturer or vendor.
The Importance of Standards in Networking
Interoperability:* Device Compatibility: Standards ensure that devices from different manufacturers can communicate and work together seamlessly. For example, a router from Cisco can connect to a switch from Juniper, and both can communicate effectively.
Protocol Compatibility: Different protocols, such as TCP/IP, HTTP, and FTP, adhere to specific standards, allowing devices to exchange data in a standardized format.
Reliability:* Error Correction and Detection: Standards incorporate error correction and detection mechanisms to minimize data loss and corruption during transmission.
Security: Standards define security protocols and practices to protect networks from cyber threats.
Efficiency:* Optimized Performance: Standards promote efficient network utilization by defining optimal packet sizes, transmission rates, and other parameters.
Scalability: Standards enable networks to grow and adapt to changing needs, ensuring smooth operations as the network expands.
Innovation:* Foundation for New Technologies: Standards provide a solid foundation for the development of new network technologies, such as 5G, IoT, and cloud computing.
Accelerated Development: By adhering to standards, developers can focus on innovation rather than reinventing the wheel.
Key Network Standards Organizations
Several organizations play a crucial role in developing and maintaining network standards:
IEEE (Institute of Electrical and Electronics Engineers):* Develops standards for a wide range of technologies, including Ethernet, Wi-Fi, and power over Ethernet (PoE).
IETF (Internet Engineering Task Force):* Focuses on internet standards, such as TCP/IP, HTTP, and DNS.
ITU-T (International Telecommunication Union - Telecommunication Standardization Sector):* Develops standards for telecommunication networks, including broadband, VoIP, and mobile networks.
ANSI (American National Standards Institute):* Coordinates the development of voluntary consensus standards for products, services, processes, systems, and personnel in the United States.
Common Network Standards
Ethernet:* The most widely used standard for local area networks (LANs).
Defines physical layer and data link layer specifications for wired networks.
Supports various speeds, including 10 Mbps, 100 Mbps, 1 Gbps, 10 Gbps, and 100 Gbps.
Wi-Fi:* Enables wireless communication between devices.
Based on IEEE 802.11 standards, which define different generations of Wi-Fi, each with improved performance and security features.
TCP/IP:* The fundamental protocol suite for the internet.
Consists of several protocols, including TCP (Transmission Control Protocol) and IP (Internet Protocol).
TCP ensures reliable data delivery, while IP handles packet routing and addressing.
HTTP:* The protocol is used for communication between web browsers and web servers.
Defines the format of requests and responses, enabling the exchange of web pages and other data.
HTTPS:* A secure version of HTTP that uses encryption to protect data transmitted over the internet.
Ensures the confidentiality and integrity of data, preventing unauthorized access and tampering.
The Future of Network Standards
As technology continues to evolve, network standards will play an even more critical role in shaping the future of connectivity. Emerging technologies, such as 5G, IoT, and AI, will require new standards to address their unique requirements.
Some of the key trends in network standards include:
Software-defined networking (SDN): SDN separates the control plane from the data plane, enabling greater flexibility and programmability.
Network Function Virtualization (NFV): NFV allows network functions to be virtualized, reducing hardware costs and increasing agility.
5G and Beyond : 5G and future generations of wireless technology will require new standards to support higher data rates, lower latency, and greater capacity.
By understanding the importance of network standards and staying up-to-date with the latest developments, organizations can ensure the reliability, security, and efficiency of their networks. As the world becomes increasingly interconnected, standards will continue to be the foundation of a robust and innovative digital landscape.
Communication Protocols Overview: A Comprehensive Guide to Modern Data Exchange
In today’s interconnected digital world, communication protocols serve as the invisible backbone that enables seamless data exchange between devices, applications, and networks. Understanding these protocols is crucial for anyone working in technology, from network administrators to software developers. This comprehensive guide will explore the most important communication protocols, their purposes, and how they work together to power our connected world.
What Are Communication Protocols?
Communication protocols are standardized rules and procedures that govern how data is transmitted between electronic devices. Think of them as the “language” that different devices use to communicate with each other. Just as humans need a common language to understand each other, devices need protocols to ensure reliable and efficient data exchange.
The OSI Model: A Framework for Understanding Protocols
Before diving into specific protocols, it’s essential to understand the OSI (Open Systems Interconnection) model. This seven-layer framework helps organize and categorize different protocols based on their functions:
Physical Layer
Data Link Layer
Network Layer
Transport Layer
Session Layer
Presentation Layer
Application Layer
Each layer serves a specific purpose, and protocols operate within one or more of these layers to ensure smooth communication.
Key Network Protocols
TCP/IP (Transmission Control Protocol/Internet Protocol)
The foundation of modern internet communications, TCP/IP is a suite of protocols working together. TCP ensures reliable data delivery by:
Breaking data into smaller packets
Tracking packet delivery
Requesting retransmission of lost packets
Maintaining packet order
IP, on the other hand, handles addressing and routing, ensuring data packets reach their intended destination across networks.
HTTP/HTTPS (Hypertext Transfer Protocol)
HTTP is the protocol that powers the web, enabling communication between web browsers and servers. Key features include:
Request-response model
Stateless communication
Support for various data types
Method definitions (GET, POST, PUT, DELETE)
HTTPS adds a security layer through encryption, protecting sensitive data during transmission.
Industrial and IoT Protocols
MQTT (Message Queuing Telemetry Transport)
Designed for IoT devices and machine-to-machine communication, MQTT excels in environments with:
Limited bandwidth
High latency
Unreliable networks
Small code footprints
Its publish-subscribe model makes it ideal for sensor networks and remote monitoring applications.
Modbus
A veteran of industrial communications, Modbus remains widely used in manufacturing and automation. Benefits include:
Simple implementation
Open standard
Robust performance
Wide device support
Wireless Communication Protocols
Wi-Fi (IEEE 802.11)
The ubiquitous wireless networking standard continues to evolve with new versions offering:
Increased speeds
Better range
Improved security
Enhanced device support
Bluetooth
Perfect for short-range wireless communication, Bluetooth has found numerous applications in:
Personal electronics
Healthcare devices
Automotive systems
Smart home products
The newer Bluetooth Low Energy (BLE) standard has become particularly important for IoT applications.
Security Protocols
SSL/TLS (Secure Sockets Layer/Transport Layer Security)
These protocols provide security through:
Data encryption
Authentication
Integrity checking
Perfect forward secrecy
Modern TLS versions have largely replaced SSL, though the terms are often used interchangeably.
SSH (Secure Shell)
Essential for secure remote system administration, SSH offers:
Encrypted command-line access
Secure file transfers
Port forwarding
Key-based authentication
Emerging Protocol Trends
WebSocket
Enabling real-time, bi-directional communication between web clients and servers, WebSocket is crucial for:
Live chat applications
Gaming platforms
Financial trading systems
Real-time dashboards
gRPC
Developed by Google, gRPC is gaining popularity for microservices architecture due to its:
High performance
Strong typing
Code generation capabilities
Cross-platform support
Streaming support
Best Practices for Protocol Implementation
When implementing communication protocols, consider these key factors:
Security First: Always prioritize security considerations and use encrypted protocols when handling sensitive data.
Performance Optimization: Choose protocols that match your performance requirements and network conditions.
Scalability: Ensure your chosen protocols can handle growing data volumes and user numbers.
Compatibility: Consider backward compatibility and industry standards when selecting protocols.
Monitoring: Implement proper monitoring and logging to track protocol performance and issues.
The Future of Communication Protocols
As technology continues to evolve, we’re seeing new trends in protocol development:
Increased focus on security and privacy
Better support for real-time communications
Lower latency for edge computing
Enhanced efficiency for IoT applications
Improved support for cloud-native architectures
Conclusion
Understanding communication protocols is essential for anyone working with networked systems. While the landscape of protocols continues to evolve, the fundamental principles remain constant: ensuring reliable, efficient, and secure data exchange between systems.
As we move forward, new protocols will emerge to address evolving technological needs, while existing ones will adapt and improve. Staying informed about these developments is crucial for making informed decisions about which protocols to implement in your systems and applications.
Whether you’re developing IoT devices, building web applications, or managing industrial systems, choosing the right protocols can make the difference between a system that merely works and one that excels in performance, security, and reliability.
Analog vs. Digital Communication: Understanding the Differences, Benefits, and Challenges
The debate between analog and digital communication has been ongoing for decades, with each method offering unique advantages and challenges. From early telecommunication systems to modern digital networks, communication technology has evolved significantly, shaping how we connect with the world around us. This article will examine the nuances of analog and digital communication, examining their differences, benefits, limitations, and applications.
1. Introduction to Communication Methods
At its core, communication is the process of transmitting information from one place or person to another. This transmission can be done in various ways, broadly classified as analog or digital communication. In analog communication, signals are continuous and vary smoothly over time, while in digital communication, information is transmitted in binary format (0s and 1s), often offering greater accuracy and resistance to interference.
With advancements in technology, digital communication has become more prevalent; however, analog communication still plays a significant role in many applications. Understanding the differences between these two methods helps in making informed decisions about which system is best for specific needs.
2. What is Analog Communication?
Analog communication uses continuous signals to represent information. In this method, signals vary in amplitude or frequency, closely mimicking the original sound, light, or data source they represent. For instance, a radio broadcast transmitting voice or music through radio waves is a form of analog communication.
Characteristics of Analog Communication
Continuous Signal: Unlike digital signals, which are discrete, analog signals flow smoothly without interruption.
Amplitude and Frequency Modulation: Analog signals vary in amplitude or frequency to carry information.
Susceptibility to Noise: Analog signals are more prone to interference from external sources, which can lead to signal degradation.
3. What is Digital Communication?
Digital communication transmits data in binary format, with the information encoded into 0s and 1s. This digital representation allows data to be processed and transmitted with greater accuracy, making it more suitable for modern communication technologies, including the Internet, cellular networks, and satellite systems.
Characteristics of Digital Communication
Discrete Signal: Digital communication sends information in separate packets or bits, creating a clear, precise signal.
Higher Noise Resistance: Digital signals are less susceptible to interference, maintaining signal integrity over longer distances.
Error Detection and Correction: Digital communication systems can detect and correct errors in transmission, enhancing reliability.
4. Key Differences Between Analog and Digital Communication
Signal Processing
Analog Communication: Signal processing in analog communication is relatively straightforward, as it uses a continuous signal. However, this can make it harder to filter out noise.
Digital Communication: Digital signal processing allows for complex manipulation, including encryption and compression, improving efficiency and security.
Quality and Fidelity
Analog Communication: Analog systems tend to degrade over distance, making it harder to maintain signal quality in long-range communication.
Digital Communication: Digital signals maintain quality better over long distances and can be regenerated, preserving fidelity.
Transmission and Bandwidth
Analog Communication: Typically requires a broader bandwidth and is more susceptible to signal degradation due to interference.
Digital Communication: Generally more bandwidth-efficient and can transmit data at high speeds without as much signal loss.
5. Advantages of Analog Communication
Pros of Using Analog Signals
Natural Representation of Signals: Analog signals provide a closer representation of real-world sounds and images, which can be essential in specific applications like music and certain radio communications.
Lower Initial Cost: Analog systems are often less expensive to implement initially, making them accessible for simpler applications.
Simplicity: Analog systems are straightforward in design, making them easy to use and understand.
6. Advantages of Digital Communication
Pros of Using Digital Signals
Enhanced Accuracy: Digital communication can maintain signal quality over distance due to error correction capabilities.
Data Encryption and Compression: Digital systems can encrypt data, improving security, and compress data, enhancing efficiency.
Integration with Modern Technology: Digital signals are compatible with computers and the internet, facilitating modern data-driven communication.
7. Disadvantages of Analog Communication
Noise Sensitivity: Analog signals are vulnerable to interference, which can degrade signal quality.
Higher Maintenance: Analog systems often require more maintenance to keep signal quality intact, particularly over long distances.
Less Efficient Data Processing: Analog systems have limited ability for data manipulation, encryption, or compression.
8. Disadvantages of Digital Communication
Complexity: Digital systems require more complex hardware and software, leading to higher initial costs.
Latency Issues: In some cases, digital communication can experience latency, especially in data-intensive tasks or real-time applications.
Potential Data Loss: During analog-to-digital conversion, some data can be lost, impacting fidelity, especially in highly sensitive applications.
9. Applications of Analog Communication
Analog communication is used in applications where continuous signal processing is advantageous. Some common uses include:
Radio Broadcasting: AM and FM radio stations use analog signals to transmit audio content.
Television Transmission: Older analog TVs receive signals that continuously represent images and sound.
Telephone Systems: Traditional landline systems employ analog signals to transmit voice data.
10. Applications of Digital Communication
Digital communication has become the standard in many areas, offering high data integrity and security. Some examples include:
Cellular Networks: Digital communication is fundamental in mobile phone networks, enabling voice and data services.
Internet and Wi-Fi: Digital signals are essential for internet data transmission and Wi-Fi connectivity.
Satellite Communication: Digital signals are more reliable for satellite data transmission, which often covers vast distances.
11. Analog and Digital in Modern Technology
In modern technology, analog and digital communication coexist. Hybrid systems combine both, such as in digital broadcasting of radio where audio is captured in analog form but transmitted digitally. Similarly, modern telecommunication devices convert analog voice signals into digital data for transmission over digital networks.
12. How to Choose Between Analog and Digital Systems
When deciding between analog and digital systems, consider the following factors:
Budget: Analog systems are often more affordable, while digital systems require higher upfront investments.
Signal Quality Needs: Digital is better for high-quality, long-distance communication.
Interference Concerns: Digital systems are less susceptible to noise, making them ideal for environments with high interference.
13. Future Trends in Communication Technology
As technology advances, digital communication is set to dominate, with innovations like 5G and the Internet of Things (IoT) relying heavily on digital transmission. However, analog communication will continue to play a role in applications where real-time processing and continuous signal flow are needed.
14. Frequently Asked Questions (FAQs)
What is the primary difference between analog and digital communication?
Analog communication uses continuous signals, while digital communication transmits data in binary format.
Which is more secure, analog or digital communication?
Digital communication is generally more secure due to encryption capabilities.
Why is analog communication still in use?
Analog is still used in areas like music and certain radio broadcasting, where continuous signals provide benefits.
Does digital communication eliminate noise completely?
No, but digital communication significantly reduces noise impact through error correction.
Can analog signals be converted to digital?
Yes, through analog-to-digital converters (ADCs), which are widely used in modern devices.
What is the future of analog communication?
While digital is becoming dominant, analog will remain relevant in specific applications.
15. Conclusion
The choice between analog and digital communication ultimately depends on the application and the specific requirements of the transmission. Digital communication offers higher quality, security, and efficiency, which is why it dominates modern technology. However, analog communication continues to serve well in areas where natural signal processing is beneficial. As communication technology evolves, both analog and digital systems will play vital roles in creating seamless and reliable networks.
Configuring SIP Trunks in FreeSWITCH
SIP trunking is a crucial component of modern VoIP systems, allowing FreeSWITCH to connect with external service providers for making and receiving calls. This comprehensive guide will walk you through the process of configuring SIP trunks in FreeSWITCH, from basic setup to advanced configurations.
Understanding SIP Trunks
What is an SIP Trunk?
A SIP trunk is a virtual connection between your FreeSWITCH system and an Internet Telephony Service Provider (ITSP). It enables:
Outbound calls to the PSTN network
Inbound calls from external numbers
Cost-effective long-distance calling
Multiple concurrent call channels
Basic SIP Trunk Configuration
- Gateway Configuration
Create a new file in /usr/local/freeswitch/conf/sip_profiles/external/:
<include>
<gateway name="my_provider">
<param name="username" value="your_username"/>
<param name="password" value="your_password"/>
<param name="proxy" value="sip.provider.com"/>
<param name="register" value="true"/>
<param name="context" value="public"/>
<param name="caller-id-in-from" value="false"/>
<param name="register-transport" value="udp"/>
</gateway>
</include>
- External Profile Configuration
Modify /usr/local/freeswitch/conf/sip_profiles/external.xml:
<profile name="external">
<settings>
<param name="ext-sip-ip" value="auto-nat"/>
<param name="ext-rtp-ip" value="auto-nat"/>
<param name="context" value="public"/>
<param name="sip-port" value="5080"/>
<param name="rtp-timer-name" value="soft"/>
</settings>
</profile>
Advanced Gateway Parameters
- Authentication and Registration
<gateway name="secure_provider">
<param name="realm" value="sip.provider.com"/>
<param name="from-domain" value="sip.provider.com"/>
<param name="register-proxy" value="proxy.provider.com"/>
<param name="expire-seconds" value="3600"/>
<param name="register-transport" value="tls"/>
<param name="retry-seconds" value="30"/>
</gateway>
- Codec Configuration
<gateway name="codec_specific">
<param name="inbound-codec-prefs" value="PCMU,PCMA,G729"/>
<param name="outbound-codec-prefs" value="PCMU,PCMA,G729"/>
<param name="inbound-codec-negotiation" value="greedy"/>
<param name="codec-fallback" value="PCMU"/>
</gateway>
Routing Configuration
- Outbound Route Setup
Create /usr/local/freeswitch/conf/dialplan/default/03_outbound.xml:
<include>
<context name="default">
<extension name="outbound_calls">
<condition field="destination_number" expression="^(\d{11})$">
<action application="set" data="effective_caller_id_number=${outbound_caller_id_number}"/>
<action application="set" data="hangup_after_bridge=true"/>
<action application="bridge" data="sofia/gateway/my_provider/$1"/>
</condition>
</extension>
</context>
</include>
- Inbound Route Setup
Create /usr/local/freeswitch/conf/dialplan/public/01_inbound.xml:
<include>
<context name="public">
<extension name="inbound_did">
<condition field="destination_number" expression="^(1\d{10})$">
<action application="set" data="domain_name=$${domain}"/>
<action application="transfer" data="1000 XML default"/>
</condition>
</extension>
</context>
</include>
Failover and Load Balancing
- Multiple Gateway Setup
<include>
<gateway name="primary_provider">
<param name="proxy" value="sip1.provider.com"/>
<param name="register" value="true"/>
</gateway>
<gateway name="backup_provider">
<param name="proxy" value="sip2.provider.com"/>
<param name="register" value="true"/>
</gateway>
</include>
- Failover Dialplan
<extension name="outbound_with_failover">
<condition field="destination_number" expression="^(\d{11})$">
<action application="set" data="hangup_after_bridge=true"/>
<action application="bridge" data="sofia/gateway/primary_provider/$1,sofia/gateway/backup_provider/$1"/>
</condition>
</extension>
Security Configurations
- TLS Setup
<gateway name="secure_trunk">
<param name="register-transport" value="tls"/>
<param name="secure-sip" value="true"/>
<param name="secure-rtp" value="true"/>
<param name="ssl-cacert" value="/etc/freeswitch/tls/ca.crt"/>
<param name="ssl-cert" value="/etc/freeswitch/tls/client.crt"/>
<param name="ssl-key" value="/etc/freeswitch/tls/client.key"/>
</gateway>
- Access Control Lists
<configuration name="acl.conf" description="Network Lists">
<network-lists>
<list name="trusted_providers" default="deny">
<node type="allow" cidr="203.0.113.0/24"/>
<node type="allow" cidr="198.51.100.0/24"/>
</list>
</network-lists>
</configuration>
Quality of Service (QoS)
- RTP Configuration
<gateway name="qos_enabled">
<param name="rtp-timer-name" value="soft"/>
<param name="rtp-ip" value="auto"/>
<param name="apply-inbound-acl" value="trusted_providers"/>
<param name="dtmf-type" value="rfc2833"/>
<param name="rtp-timeout-sec" value="300"/>
<param name="rtp-hold-timeout-sec" value="1800"/>
</gateway>
- Bandwidth Management
<gateway name="bandwidth_managed">
<param name="inbound-codec-prefs" value="PCMU@20i,PCMA@20i,G729@20i"/>
<param name="outbound-codec-prefs" value="PCMU@20i,PCMA@20i,G729@20i"/>
<param name="suppress-cng" value="true"/>
<param name="rtp-digit-delay" value="20"/>
</gateway>
Monitoring and Troubleshooting
- Sofia Status Commands
In fs_cli:
sofia status
sofia status gateway my_provider
sofia loglevel all 9```
2. Logging Configuration
Best Practices
- Gateway Organization
Use meaningful gateway names
Group similar providers
Document configurations
Regular backup of configurations
- Security Measures
Implement strong passwords
Use TLS when possible
Regular security audits
Monitor for suspicious activity
- Performance Optimization
Regular monitoring of call quality
Bandwidth management
Codec optimization
Connection testing
Testing and Verification
- Basic Tests
# Check gateway registration
fs_cli -x "sofia status gateway my_provider"
# Test outbound calling
fs_cli -x "originate sofia/gateway/my_provider/11234567890 &echo"
# Check SIP messages
fs_cli -x "sofia global siptrace on"```
2. Ongoing Maintenance
* Regular registration checks
* Call quality monitoring
* Performance metrics collection
* Log analysis
## Conclusion
Properly configured SIP trunks are essential for a reliable FreeSWITCH system. Key points to remember for configuring SIP trunks in FreeSWITCH:
* Start with basic configuration and build up
* Implement proper security measures
* Monitor and maintain regularly
* Document all changes
* Test thoroughly before production deployment
As your system grows, consider:
* Implementing redundancy
* Load balancing
* Advanced security measures
* Quality of service optimization
* Regular audits and updates
Keep your FreeSWITCH system up to date and regularly check for security advisories and best practices from your ITSP and the FreeSWITCH community.
Integrating FreeSWITCH with Asterisk: A Comprehensive Guide
Introduction
Both FreeSWITCH and Asterisk are popular open-source communication platforms, widely used for handling voice, video, and text communications. While FreeSWITCH is known for its flexibility in handling media and complex call flows, Asterisk shines as a robust telephony platform with a vast ecosystem of features and integrations. Integrating FreeSWITCH with Asterisk provides a powerful hybrid solution, combining the strengths of both platforms to support sophisticated VoIP and PBX needs. This guide walks through the process of integrating FreeSWITCH with Asterisk, covering essential configuration steps, use cases, and troubleshooting.
Why Integrate FreeSWITCH with Asterisk?
Integrating these two platforms can provide several key benefits:
Enhanced Media Handling: FreeSWITCH excels in handling complex media tasks such as video conferencing and transcoding, which can offload some of the load from Asterisk.
Scalability: FreeSWITCH’s scalability makes it ideal for expanding the capacity of an Asterisk deployment.
Customization: By leveraging both platforms, users can customize call flows and features, optimizing each system for the tasks it handles best.
Prerequisites
Before beginning, ensure you have:
FreeSWITCH and Asterisk are installed on separate servers (or virtual machines).
Basic networking knowledge and familiarity with VoIP protocols (such as SIP).
Administrative access to both FreeSWITCH and Asterisk servers.
Step 1: Network and Firewall Configuration
For seamless communication, start by allowing network access between the Asterisk and FreeSWITCH servers. Ensure that the following ports are open on both servers:
SIP Port: 5060 (UDP) for SIP communication
RTP Ports: 16384-32768 (UDP) for media traffic
To configure the firewall on both servers:
# Open SIP port
sudo firewall-cmd --add-port=5060/udp --permanent
# Open RTP range
sudo firewall-cmd --add-port=16384-32768/udp --permanent
# Reload firewall settings
sudo firewall-cmd --reload
Step 2: Configure SIP Trunks
A SIP trunk between FreeSWITCH and Asterisk enables each system to route calls to the other.
On FreeSWITCH
- Open the external SIP profile configuration on FreeSWITCH:
sudo nano /usr/local/freeswitch/conf/sip_profiles/external.xml
- * Define a new gateway for Asterisk with its IP address:
<gateway name="asterisk">
<param name="username" value="freeswitch"/>
<param name="password" value="strongpassword"/>
<param name="realm" value="asterisk_ip"/>
<param name="proxy" value="asterisk_ip"/>
<param name="register" value="true"/>
</gateway>
- * Save and exit. Then reload the FreeSWITCH configuration to apply the changes:
fs_cli -x "reloadxml"```
#### On Asterisk
* Open the `pjsip.conf` file on your Asterisk server (or `sip.conf` if using chan_sip):
```bash
sudo nano /etc/asterisk/pjsip.conf```
<!-- wp:list {"ordered":true,"start":2} -->
<ol start="2" class="wp-block-list">* Add a configuration for a SIP trunk to FreeSWITCH:
[freeswitch] type=endpoint context=from-freeswitch disallow=all allow=ulaw aors=freeswitch_aor```
- * Specify the address and authentication details for the FreeSWITCH SIP trunk:
[freeswitch_aor]
type=aor
contact=sip:freeswitch_ip:5060
[freeswitch_auth]
type=auth
auth_type=userpass
username=freeswitch
password=strongpassword
- * Save the file and reload Asterisk’s PJSIP module:
asterisk -rx "pjsip reload"```
Step 3: Setting Up Dial Plans
With SIP trunks in place, configure dial plans to handle call routing between FreeSWITCH and Asterisk.
#### On FreeSWITCH
Edit the default dial plan on FreeSWITCH to route calls intended for Asterisk.
* Open `default.xml` for editing:
```bash
sudo nano /usr/local/freeswitch/conf/dialplan/default.xml
- * Add a new extension that matches calls destined for Asterisk:
<extension name="to-asterisk">
<condition field="destination_number" expression="^3\d{3}$">
<action application="bridge" data="sofia/external/asterisk/${destination_number}"/>
</condition>
</extension>
- * Save and exit the file, then reload the dial plan:
fs_cli -x "reloadxml"```
#### On Asterisk
* Open `extensions.conf` on Asterisk:
```bash
sudo nano /etc/asterisk/extensions.conf```
<!-- wp:list {"ordered":true,"start":2} -->
<ol start="2" class="wp-block-list">* Define a new context to route calls from Asterisk to FreeSWITCH:
[from-internal] exten => _4XXX,1,Dial(PJSIP/${EXTEN}@freeswitch) exten => _4XXX,n,Hangup()```
- * Save the file and reload the Asterisk dial plan:
asterisk -rx "dialplan reload"```
With these dial plans in place, calls to numbers beginning with `3` will route from FreeSWITCH to Asterisk, and calls beginning with `4` will route from Asterisk to FreeSWITCH.
Step 4: Testing the Integration
With the configurations set up, it’s time to test calls between FreeSWITCH and Asterisk.
* **Register Extensions**: Make sure devices (softphones or hardware phones) are registered to extensions on each platform.
* **Place a Test Call**: Try dialing an extension from FreeSWITCH to Asterisk (e.g., `3001`), and vice versa, to confirm the connection works.
* **Check Logs**: If calls don’t connect, check the logs on both platforms for errors:
* **Asterisk**: `/var/log/asterisk/full`
* **FreeSWITCH**: `/usr/local/freeswitch/log/freeswitch.log`
* **Use CLI Commands**: The following commands help diagnose issues:
```bash
# FreeSWITCH
fs_cli -x "sofia status"
# Asterisk
asterisk -rx "pjsip show endpoints"```
Step 5: Advanced Configuration Options
To maximize the integration, consider some additional configurations:
* **Codec Synchronization**: Ensure both systems use compatible codecs to avoid transcoding, which can reduce latency and improve call quality. Typical codecs are G.711 (ulaw) and G.729.
* **Failover and Load Balancing**: For high availability, set up multiple FreeSWITCH or Asterisk servers and use SIP options like DNS SRV records for failover.
* **DTMF Handling**: Ensure both systems use compatible DTMF modes (RFC2833, Inband, or SIP INFO) to avoid issues with interactive menus or IVRs.
* **SIP Security**: Enable IP filtering, strong passwords, and transport layer security (TLS) for SIP communications, especially if the servers are accessible over the internet.
Step 6: Troubleshooting Common Issues
Here are some common integration challenges and tips for troubleshooting:
* **SIP Registration Errors**: If Asterisk or FreeSWITCH isn’t registering with the other, check the SIP configuration for correct IPs, usernames, and passwords.
* **Codec Mismatch**: Calls failing due to unsupported codec issues can be fixed by standardizing codecs on both platforms.
* **Network Latency**: If there’s an echo or delay, ensure both servers are in low-latency environments, especially if using external cloud instances.
* **Logging and Debugging**:
* FreeSWITCH: Increase logging level `/usr/local/freeswitch/conf/autoload_configs/logfile.conf.xml` if more detailed information is needed.
* Asterisk: Use `pjsip set logger on` to capture detailed SIP messaging logs.
Use Cases for FreeSWITCH and Asterisk Integration
* **Unified Communications and IVR Systems**: FreeSWITCH’s powerful IVR capabilities complement Asterisk’s call routing, creating a comprehensive communications platform.
* **Scalable Conference Bridge**: FreeSWITCH’s media handling allows it to act as a conference bridge while Asterisk manages call control.
* **Custom PBX Features**: FreeSWITCH can provide complex call handling and customization, while Asterisk can support traditional PBX functionalities.
Conclusion
Integrating FreeSWITCH with Asterisk opens up a wide range of possibilities for building robust, scalable, and feature-rich telephony solutions. With careful configuration of SIP trunks, dial plans, and codecs, these two platforms can work seamlessly together, creating a hybrid solution that maximizes each system’s strengths. Whether for a business PBX, conferencing solution, or advanced VoIP system, combining FreeSWITCH and Asterisk provides flexibility, performance, and scalability for diverse communication needs.
**FAQs**
**1. Can FreeSWITCH and Asterisk run on the same server?** Yes, but it’s generally recommended to run them on separate servers to avoid port conflicts and improve performance.
**2. What are the benefits of using both FreeSWITCH and Asterisk?** Combining both platforms leverages FreeSWITCH’s media capabilities and Asterisk’s call handling, creating a more versatile communication solution.
**3. How do I ensure call quality between FreeSWITCH and Asterisk?** Standardize compatible codecs (e.g., G.711) and minimize transcoding to improve call quality.
**4. Can I use this setup with other VoIP providers?** Yes, both FreeSWITCH and Asterisk can connect to external VoIP providers, allowing flexibility in routing and redundancy.
**5. What are the best security practices for SIP integration?** Use strong passwords, enable TLS, restrict IP access, and keep both systems updated to secure SIP integration.
Setting Up a FreeSWITCH Basic Dialplan
Dialplans are the heart of FreeSWITCH, determining how calls are routed and processed within your system. In this comprehensive guide, we’ll explore how to create and configure a FreeSWITCH basic dialplan that handles common calling scenarios. Whether you’re new to FreeSWITCH or looking to enhance your existing setup, this guide will help you understand and implement effective call routing strategies.
Understanding Dialplan Basics
What is a Dialplan?
A dialplan is a set of instructions that tells FreeSWITCH how to handle calls. It’s essentially a routing table that determines what happens when someone makes a call through your system. Dialplans in FreeSWITCH are written in XML and consist of several key components:
Contexts
Extensions
Conditions
Actions
Anti-Actions
Dialplan Structure
Basic XML Structure
<include>
<context name="my_context">
<extension name="my_extension">
<condition field="destination_number" expression="^(\d+)$">
<action application="bridge" data="user/${destination_number}"/>
</condition>
</extension>
</context>
</include>
Key Components Explained
Context: A logical grouping of extensions
Extension: A set of rules for handling specific calls
Condition: Criteria that must be met for actions to execute
Action: What happens when conditions are met
Anti-Action: What happens when conditions are not met
Creating Your First Dialplan
- Basic Internal Calls
Create a new file /usr/local/freeswitch/conf/dialplan/default/01_internal.xml:
<include>
<context name="default">
<!-- Extension to Extension Calls -->
<extension name="internal">
<condition field="destination_number" expression="^(10[01][0-9])$">
<action application="set" data="ringback=${us-ring}"/>
<action application="bridge" data="user/$1"/>
</condition>
</extension>
<!-- Voicemail Access -->
<extension name="voicemail">
<condition field="destination_number" expression="^(\*98)$">
<action application="answer"/>
<action application="voicemail" data="check default ${domain_name} ${caller_id_number}"/>
</condition>
</extension>
</context>
</include>
- Adding External Calls
Create /usr/local/freeswitch/conf/dialplan/default/02_external.xml:
<include>
<context name="default">
<!-- Outbound Calls -->
<extension name="outbound">
<condition field="destination_number" expression="^(1?\d{10})$">
<action application="set" data="effective_caller_id_number=${outbound_caller_id_number}"/>
<action application="bridge" data="sofia/gateway/my_provider/$1"/>
</condition>
</extension>
</context>
</include>
Common Dialplan Features
- Time-Based Routing
<extension name="business_hours">
<condition wday="2-6" hour="9-17"> <!-- Monday-Friday, 9 AM-5 PM -->
<action application="bridge" data="user/1000"/>
<anti-action application="voicemail" data="default ${domain_name} 1000"/>
</condition>
</extension>
- IVR (Interactive Voice Response)
<extension name="main_ivr">
<condition field="destination_number" expression="^(5000)$">
<action application="answer"/>
<action application="sleep" data="1000"/>
<action application="ivr" data="main_menu"/>
</condition>
</extension>
- Conference Rooms
<extension name="conferences">
<condition field="destination_number" expression="^(3\d{3})$">
<action application="answer"/>
<action application="conference" data="$1@default"/>
</condition>
</extension>
Advanced Dialplan Techniques
- Call Recording
<extension name="record_calls">
<condition field="destination_number" expression="^(record_\d+)$">
<action application="set" data="RECORD_STEREO=true"/>
<action application="set" data="record_file=/recordings/${strftime(%Y-%m-%d_%H-%M-%S)}_${destination_number}.wav"/>
<action application="record_session" data="${record_file}"/>
<action application="bridge" data="user/$1"/>
</condition>
</extension>
- Call Queues
<extension name="support_queue">
<condition field="destination_number" expression="^(7000)$">
<action application="answer"/>
<action application="set" data="queue_moh=$${hold_music}"/>
<action application="callcenter" data="support@default"/>
</condition>
</extension>
- Failover Routing
<extension name="failover">
<condition field="destination_number" expression="^(2\d{3})$">
<action application="set" data="call_timeout=20"/>
<action application="set" data="hangup_after_bridge=true"/>
<action application="bridge" data="user/$1,user/${default_gateway}"/>
</condition>
</extension>
Best Practices
- Organization
Use numbered files for loading order (01_internal.xml, 02_external.xml, etc.)
Group similar extensions together
Comment your dialplan thoroughly
- Security
<extension name="limit_international">
<condition field="destination_number" expression="^(011\d+)$">
<condition field="${user_data(${caller_id_number} international_allowed)}" expression="^true$">
<action application="bridge" data="sofia/gateway/my_provider/$1"/>
<anti-action application="playback" data="not_authorized.wav"/>
</condition>
</condition>
</extension>
- Error Handling
<extension name="handle_failed_calls">
<condition field="${originate_disposition}" expression="^(BUSY|NO_ANSWER|USER_NOT_REGISTERED)$">
<action application="voicemail" data="default ${domain_name} ${dialed_extension}"/>
</condition>
</extension>
Testing and Debugging
- Log Configuration
Add to /usr/local/freeswitch/conf/autoload_configs/switch.conf.xml:
<param name="loglevel" value="debug"/>
- Testing Commands
In fs_cli:
reloadxml
show dialplan
eval ${destination_number}
Common Troubleshooting
- Dialplan Not Working
Check these common issues:
XML syntax errors
Regular expression patterns
File permissions
Context names matching the user’s context
- Call Routing Issues
Verify:
Gateway configurations
User directory settings
Network connectivity
SIP profile settings
Monitoring and Maintenance
- Regular Checks
# Check dialplan syntax
/usr/local/freeswitch/bin/fs_cli -x "xml_validate"
# Monitor active calls
/usr/local/freeswitch/bin/fs_cli -x "show calls"```
2. Performance Monitoring
Conclusion
Creating an effective dialplan is crucial for a well-functioning FreeSWITCH system. Start with basic call routing and gradually add more complex features as needed. Remember to:
Keep your dialplan organized and well-documented
Test thoroughly before deploying changes
Monitor performance and logs regularly
Implement security measures
Plan for scalability
As your system grows, you can expand your dialplan to include more advanced features like:
Multi-tenant configurations
Advanced IVR systems
Custom applications
Integration with external systems
Regular maintenance and updates will ensure your FreeSWITCH system continues to handle calls efficiently and reliably.
Configuring FreeSWITCH for the First Time on Alma Linux
Introduction
Once FreeSWITCH is successfully installed on Alma Linux, the next step is configuring it to meet your specific requirements. FreeSWITCH provides a flexible and powerful platform for handling various telephony functions like voice, video, and messaging. However, to take full advantage of its capabilities, an initial setup and configuration process is crucial. This guide walks through essential configurations, including setting up SIP profiles, dialing plans, codecs, and security measures for configuring FreeSWITCH.
Prerequisites
To follow along with this guide, you should have:
FreeSWITCH is installed on Alma Linux following proper installation procedures.
Root or sudo access on the Alma Linux server.
Basic understanding of SIP and VoIP concepts for effective configuration.
Step 1: Directory Structure and Configuration Files Overview
FreeSWITCH’s configurations are stored in the /usr/local/freeswitch/conf directory, with each major area divided into distinct folders:
dialplan: Contains files for defining call routing rules.
sip_profiles: Holds configurations for SIP profiles, which manage SIP connections.
vars.xml: A core file defining global variables for the FreeSWITCH environment.
Familiarizing yourself with these directories will make configuration easier and more organized. Step 2: Setting Global Variables
The vars.xml file in /usr/local/freeswitch/conf is the primary configuration file for setting up global variables. Here’s how to customize it:
- Open
vars.xmlwith a text editor:
sudo nano /usr/local/freeswitch/conf/vars.xml
- * Modify key variables such as:
Domain Name: Set this to the server’s IP or domain name for identification purposes.
xml <X-PRE-PROCESS cmd="set" data="domain_name=your.domain.com"/>SIP Ports: You can specify custom SIP ports if desired:
xml <X-PRE-PROCESS cmd="set" data="external_sip_port=5060"/> <X-PRE-PROCESS cmd="set" data="internal_sip_port=5061"/>Internal SIP Profile: This profile is generally used for internal devices within the same network.
Open
internal.xmlto configure internal settings:Set the bind address to the local IP, or leave it as
0.0.0.0to allow connections on any network interface:xml <param name="sip-ip" value="0.0.0.0"/>External SIP Profile: Configure this profile to handle external connections, often used for connecting with external providers or remote users.
Open
external.xml- Update the external IP and port values if needed:
xml <param name="sip-ip" value="public.ip.address"/> <param name="rtp-ip" value="public.ip.address"/> Understanding Contexts: Dialplans in FreeSWITCH operate within “contexts,” which are separate groups of rules that define call behavior. The default context is usually set to
default.Editing Default Dialplan:
Open the
default.xmldialplan:Add custom extensions, routing rules, and call-handling logic as needed:
xml <extension name="example_extension"> <condition field="destination_number" expression="^1001$"> <action application="answer"/> <action application="playback" data="ivr/ivr-welcome_to_freeswitch.wav"/> <action application="hangup"/> </condition> </extension>Testing Dialplans: After editing, reload the dialplan without restarting FreeSWITCH:
- Configure SIP Profiles for NAT: Open the internal and external SIP profiles and add the following NAT settings:
Password Protect SIP Accounts: Set strong passwords for each SIP user account in
/usr/local/freeswitch/conf/directory/default/.IP-Based Restrictions: Limit SIP connections to trusted IP addresses. For example, in
internal.xml:- Check SIP Status: Use
fs_clito view active SIP profiles and registrations: - Review Logs for Errors: Logs are stored in
/usr/local/freeswitch/log/. For example:
After making these changes, save the file and restart FreeSWITCH to apply them:
sudo systemctl restart freeswitch
Step 3: Configuring SIP Profiles
FreeSWITCH organizes SIP configurations in “profiles” to separate internal and external connections. The default SIP profiles are stored in /usr/local/freeswitch/conf/sip_profiles.
`sudo nano /usr/local/freeswitch/conf/sip_profiles/internal.xml
`sudo nano /usr/local/freeswitch/conf/sip_profiles/external.xml
Save and close each file, then restart FreeSWITCH to enable these settings. Step 4: Setting Up Dialplans
Dialplans control how calls are routed and handled within FreeSWITCH. The default dialplan files are in /usr/local/freeswitch/conf/dialplan.
`sudo nano /usr/local/freeswitch/conf/dialplan/default.xml
fs_cli -x "reloadxml"```
Step 5: Codec Configuration
Codec selection impacts call quality and bandwidth. FreeSWITCH supports a range of audio codecs, including G.711, G.729, and Opus.
* **Configure Codecs in SIP Profiles**:
* Edit `internal.xml` and `external.xml` profiles to set preferred codecs: `xml <param name="codec-prefs" value="OPUS,PCMU,PCMA"/>`
* **Enable Transcoding**: For calls between devices with different codec support, enable transcoding in FreeSWITCH.
* **Testing Codec Functionality**: Use `fs_cli` to verify codec setup by running:
```bash
sofia status profile internal
Step 6: Configuring NAT Settings
Network Address Translation (NAT) can cause connectivity issues, especially in environments with remote clients or devices behind firewalls.
<param name="ext-sip-ip" value="external.ip.address"/>
<param name="ext-rtp-ip" value="external.ip.address"/>
<param name="rtp-timeout-sec" value="300"/>
- * **Set IPs in vars.xml**: Also set external IPs in `vars.xml` to ensure correct media routing:
<X-PRE-PROCESS cmd="set" data="external_rtp_ip=your.external.ip"/>
<X-PRE-PROCESS cmd="set" data="external_sip_ip=your.external.ip"/>
Step 7: Implementing Security Measures
FreeSWITCH is highly customizable for security, and securing SIP and RTP traffic is essential.
<param name="auth-calls" value="true"/>
<param name="apply-inbound-acl" value="trusted"/>
- * **Enable TLS for SIP**: Encrypt SIP communications by enabling TLS in the `internal.xml` and `external.xml` profiles:
<param name="tls" value="true"/>
<param name="tls-bind-params" value="transport=tls"/>
Step 8: Testing FreeSWITCH Setup
With configurations complete, test the setup to ensure everything works as expected:
sofia status
- * **Test Calls Between Extensions**: Try making calls between extensions configured in the dialplan to ensure call routing works.
tail -f /usr/local/freeswitch/log/freeswitch.log```
Step 9: Automating Startup and Shutdown
To automate FreeSWITCH to start on boot, confirm it’s enabled in systemd:
```bash
sudo systemctl enable freeswitch
To manage FreeSWITCH manually, use:
sudo systemctl start freeswitch
sudo systemctl stop freeswitch
Conclusion
Setting up and configuring FreeSWITCH on Alma Linux offers a comprehensive telephony platform suitable for a range of VoIP and unified communication needs. By following these initial configuration steps, including setting up SIP profiles, dialing plans, codecs, and security options, you’ll be able to make the most of FreeSWITCH’s powerful capabilities. This guide provides a foundation for configuring FreeSWITCH to ensure efficient and secure communication across your network. FAQs
1. Can I use FreeSWITCH for video calls on Alma Linux? Yes, FreeSWITCH supports video conferencing and SIP-based video calls. Additional modules and codecs, like VP8, may need configuration.
2. How can I back up my FreeSWITCH configuration? Simply back up the /usr/local/freeswitch/conf directory to save all configuration settings.
3. What is the default FreeSWITCH admin password? FreeSWITCH does not have a default password. Users set this up during initial configuration.
4. How do I troubleshoot SIP connectivity issues? Use the sofia status and sofia status profile <profile_name> commands in `fs
_cli` to check SIP profiles and diagnose connectivity issues.
5. Can I run FreeSWITCH with other PBX software? While it’s technically possible, it’s recommended to run FreeSWITCH on a dedicated server to avoid conflicts.
6. What are the best practices for securing FreeSWITCH? Implement strong password policies, limit IP access, enable TLS, and configure access control lists (ACLs) for SIP profiles.
Configuring FreeSWITCH for the First Time on Ubuntu Server
Setting up FreeSWITCH on an Ubuntu server can seem daunting at first, but with the right guidance, it becomes a manageable task. This comprehensive guide will walk you through the initial setup and configuration process, helping you establish a solid foundation for your VoIP system with FreeSWITCH.
Introduction to FreeSWITCH
FreeSWITCH is a scalable open-source telephony platform designed to route and interconnect various communication protocols using audio, video, text, or any other form of media. It’s particularly popular for its flexibility and robust performance in handling VoIP communications.
Prerequisites
Before beginning the installation process, ensure your Ubuntu server meets these requirements:
Ubuntu 20.04 LTS or newer
Minimum 2GB RAM (4GB recommended)
At least 20GB of free disk space
Root or sudo access
Active internet connection
Basic knowledge of the Linux command line
Installation Process
- System Preparation
First, update your system and install the necessary dependencies:
sudo apt update && sudo apt upgrade -y
sudo apt install -y git wget tar build-essential automake autoconf libtool \
libtool-bin pkg-config libssl-dev zlib1g-dev libdb-dev unixodbc-dev \
libncurses5-dev libexpat1-dev libgdbm-dev bison erlang-dev libesl-dev
- Installing FreeSWITCH
Clone the Repository
cd /usr/src/
git clone https://github.com/signalwire/freeswitch.git -b v1.10 freeswitch
cd freeswitch
Prepare the Build
./bootstrap.sh
Configure the Build
./configure --enable-portable-binary \
--prefix=/usr/local/freeswitch \
--enable-core-pgsql-support \
--enable-static-sqlite \
--enable-core-odbc-support```
#### Compile and Install
```bash
make
sudo make install
sudo make cd-sounds-install
sudo make cd-moh-install
Initial Configuration
- Directory Structure Setup
FreeSWITCH’s configuration files are located in /usr/local/freeswitch/conf. The main configuration hierarchy is:
/usr/local/freeswitch/conf/
├── autoload_configs/
├── dialplan/
├── directory/
├── freeswitch.xml
├── sip_profiles/
└── vars.xml
- Basic Configuration Files
Configure vars.xml
The vars.xml file contains global variables. Edit it to match your environment:
<include>
<X-PRE-PROCESS cmd="set" data="domain=your-domain.com"/>
<X-PRE-PROCESS cmd="set" data="local_ip_v4=auto"/>
<X-PRE-PROCESS cmd="set" data="external_rtp_ip=auto-nat"/>
<X-PRE-PROCESS cmd="set" data="external_sip_ip=auto-nat"/>
</include>
Configure SIP Profiles
Navigate to /usr/local/freeswitch/conf/sip_profiles/ and modify internal.xml:
<profile name="internal">
<settings>
<param name="auth-calls" value="true"/>
<param name="apply-inbound-acl" value="domains"/>
<param name="local-network-acl" value="localnet.auto"/>
<param name="debug" value="0"/>
<param name="sip-port" value="5060"/>
</settings>
</profile>
- Setting Up Extensions
Create a new user directory file in /usr/local/freeswitch/conf/directory/default/:
<include>
<user id="1000">
<params>
<param name="password" value="your_secure_password"/>
<param name="vm-password" value="1000"/>
</params>
<variables>
<variable name="toll_allow" value="domestic,international,local"/>
<variable name="accountcode" value="1000"/>
<variable name="user_context" value="default"/>
<variable name="effective_caller_id_name" value="Extension 1000"/>
<variable name="effective_caller_id_number" value="1000"/>
</variables>
</user>
</include>
Security Configuration
- Firewall Setup
Configure UFW to allow necessary ports:
sudo ufw allow 5060/udp # SIP
sudo ufw allow 5061/tcp # SIP TLS
sudo ufw allow 16384:32768/udp # RTp
- ACL Configuration
Modify /usr/local/freeswitch/conf/autoload_configs/acl.conf.xml:
<configuration name="acl.conf" description="Network Lists">
<network-lists>
<list name="trusted" default="deny">
<node type="allow" cidr="192.168.0.0/24"/>
<node type="allow" cidr="10.0.0.0/8"/>
</list>
</network-lists>
</configuration>
Starting and Managing FreeSWITCH
- Create Systemd Service
Create /etc/systemd/system/freeswitch.service:
[Unit]
Description=FreeSWITCH
After=syslog.target network.target local-fs.target
[Service]
User=freeswitch
Group=freeswitch
Type=forking
EnvironmentFile=-/etc/default/freeswitch
ExecStart=/usr/local/freeswitch/bin/freeswitch -nc -nonat
ExecReload=/usr/local/freeswitch/bin/fs_cli -x reload
Restart=on-failure
TimeoutStartSec=45
[Install]
WantedBy=multi-user.target```
2. Start and Enable FreeSWITCH
```bash
sudo systemctl daemon-reload
sudo systemctl start freeswitch
sudo systemctl enable freeswitch
Verification and Testing
- Check Service Status
sudo systemctl status freeswitch
- Connect to the FreeSWITCH Console
/usr/local/freeswitch/bin/fs_cli```
3. Basic Testing Commands
Within fs_cli, try these commands:
```bash
status
sofia status
sofia status profile internal
show registrations
Troubleshooting Common Issues
- Log Analysis
Monitor logs in real-time:
tail -f /usr/local/freeswitch/log/freeswitch.log```
2. Common Problems and Solutions
#### SIP Registration Issues
* Check firewall rules
* Verify SIP profile configuration
* Ensure correct credentials in directory files
#### Audio Problems
* Verify RTP port range is open in the firewall
* Check NAT settings in vars.xml
* Confirm codec settings in the configuration
## Performance Tuning
1. System Optimization
Add to `/etc/sysctl.conf`:
```bash
net.core.rmem_max=16777216
net.core.wmem_max=16777216
net.ipv4.tcp_rmem=4096 87380 16777216
net.ipv4.tcp_wmem=4096 65536 16777216```
2. FreeSWITCH Settings
Modify `/usr/local/freeswitch/conf/autoload_configs/switch.conf.xml`:
Conclusion
This guide has covered the essential steps for setting up and configuring FreeSWITCH on Ubuntu Server. Remember that this is just the beginning – FreeSWITCH offers many more advanced features and configurations that you can explore based on your specific needs.
Regular maintenance, security updates, and monitoring are crucial for maintaining a healthy FreeSWITCH installation. As you become more familiar with the system, you can start exploring more advanced features like:
Implementing complex dialplans
Setting up conference bridges
Configuring voicemail systems
Integrating with external services
Implementing WebRTC support
Keep your FreeSWITCH installation up to date and regularly check the official documentation and community forums for best practices and security advisories.
Installing FreeSWITCH on Alma Linux: A Step-by-Step Guide
Introduction
FreeSWITCH is a highly flexible and powerful open-source communications platform used for voice, video, and messaging across a variety of protocols. For those using Alma Linux—a reliable RHEL-based distribution—installing FreeSWITCH allows organizations to leverage a sophisticated telephony solution for VoIP applications, PBX systems, and conferencing. This guide provides a detailed, step-by-step walkthrough for installing FreeSWITCH on Alma Linux.
Prerequisites
Before beginning the installation, make sure you have:
A server or virtual machine running Alma Linux (preferably version 8 or newer).
Root access to the server or a user with sudo privileges.
Basic understanding of Linux commands.
An internet connection to download necessary packages.
Step 1: Update the Alma Linux System
Start by updating your Alma Linux system. This ensures you have the latest security patches and package updates.
sudo dnf update -y
Once the update is complete, reboot the system if necessary:
sudo reboot```
Step 2: Install Development Tools and Dependencies
FreeSWITCH relies on multiple development tools and libraries. You can install these packages with the following command:
```bash
sudo dnf groupinstall "Development Tools" -y
sudo dnf install git wget cmake autoconf automake libtool -y
Next, install additional dependencies that FreeSWITCH requires:
sudo dnf install epel-release -y
sudo dnf install libedit-devel sqlite-devel pcre-devel speex-devel openssl-devel -y
Step 3: Set Up FreeSWITCH User and Directories
For security and management, it’s best to create a dedicated user for running FreeSWITCH.
sudo adduser --system --no-create-home --group freeswitch
Create necessary directories for FreeSWITCH:
sudo mkdir -p /usr/local/freeswitch
sudo mkdir -p /usr/local/freeswitch/log
sudo mkdir -p /usr/local/freeswitch/run
Assign appropriate permissions to the FreeSWITCH user:
sudo chown -R freeswitch:freeswitch /usr/local/freeswitch
sudo chmod -R 775 /usr/local/freeswitch
Step 4: Download FreeSWITCH Source Code
Head to the FreeSWITCH GitHub repository to download the latest stable version of FreeSWITCH.
cd /usr/src
sudo git clone https://github.com/signalwire/freeswitch.git
cd freeswitch
sudo git checkout v1.10```
The `checkout` command will switch to the stable version 1.10, which is suitable for production use.
Step 5: Build and Compile FreeSWITCH
FreeSWITCH offers various configuration options; the default configuration works for most installations. First, install the necessary codecs, modules, and configurations:
```bash
./bootstrap.sh
./configure```
After configuring, compile the source code using:
```bash
make```
This process may take several minutes. If there are any errors, ensure that all dependencies are correctly installed. After successfully compiling FreeSWITCH, install it by running:
```bash
sudo make install
Step 6: Install Additional FreeSWITCH Modules
FreeSWITCH’s functionality can be extended by adding modules. Here’s how to install the basic modules often needed in a standard telephony environment:
sudo make cd-sounds-install cd-moh-install
sudo make samples
The samples command installs sample configuration files in /usr/local/freeswitch/conf.
Step 7: Configure Systemd Service for FreeSWITCH
To ensure FreeSWITCH starts automatically and runs as a background service, create a systemd service file:
sudo nano /etc/systemd/system/freeswitch.service```
Insert the following configuration into the file:
```bash
[Unit]
Description=FreeSWITCH Service
After=network.target
[Service]
Type=forking
ExecStart=/usr/local/freeswitch/bin/freeswitch -ncwait -nonat
ExecStop=/usr/local/freeswitch/bin/freeswitch -stop
PIDFile=/usr/local/freeswitch/run/freeswitch.pid
User=freeswitch
Group=freeswitch
Restart=always
LimitNOFILE=100000
[Install]
WantedBy=multi-user.target```
Save and exit the file. Reload the systemd daemon to recognize the new FreeSWITCH service:
```bash
sudo systemctl daemon-reload
Enable the FreeSWITCH service to start automatically on boot:
sudo systemctl enable freeswitch
Step 8: Start FreeSWITCH Service
Start FreeSWITCH by executing:
sudo systemctl start freeswitch
To confirm it’s running, check the status:
sudo systemctl status freeswitch
If the service is running, you should see an “active (running)” message.
Step 9: Configure Firewall for FreeSWITCH
To allow external access to FreeSWITCH, open the necessary ports on your firewall. By default, FreeSWITCH uses:
5060 (UDP) for SIP
5061 (UDP) for secure SIP (SIP-TLS)
16384–32768 (UDP) for RTP (Real-Time Protocol)
Use the following commands to open these ports:
sudo firewall-cmd --add-port=5060/udp --permanent
sudo firewall-cmd --add-port=5061/udp --permanent
sudo firewall-cmd --add-port=16384-32768/udp --permanent
sudo firewall-cmd --reload
Step 10: Test FreeSWITCH Installation
To verify the FreeSWITCH installation, connect to the FreeSWITCH CLI by running:
/usr/local/freeswitch/bin/fs_cli```
Once inside the CLI, you can test a few commands, such as:
```bash
status
sofia status
These commands should display FreeSWITCH’s current status and protocol details, confirming that it’s correctly set up.
Step 11: Basic Configuration Tips
FreeSWITCH’s default configuration may not suit all needs. Here are a few tips to help configure it:
Edit SIP Profiles: Modify SIP profiles in
/usr/local/freeswitch/conf/sip_profilesto suit your network setup.Set Up Extensions: Define extensions in
/usr/local/freeswitch/conf/dialplan/default.xml.Configure NAT: If behind NAT, add your public IP and local network information in the SIP profiles.
Add Security Features: Enable password protections, and consider limiting IP access to the FreeSWITCH server.
Troubleshooting Common Issues
Here are a few common issues that might arise during installation and their solutions:
Missing Dependencies: Ensure all libraries are installed, especially
openssl-develandlibedit-devel.Firewall Blocks: Confirm all required ports are open on the firewall.
FreeSWITCH Doesn’t Start: Check the system log (
journalctl -xe) for details on errors-preventing startup.
Conclusion
Installing FreeSWITCH on Alma Linux gives users access to a highly flexible telephony platform for handling voice, video, and messaging services. By following this guide, you’ll be able to successfully set up FreeSWITCH on Alma Linux, allowing your organization or personal projects to take advantage of its powerful communication capabilities. With FreeSWITCH running, you can begin configuring and customizing it to meet your specific telephony requirements. FAQs
1. What is FreeSWITCH used for? FreeSWITCH is an open-source telephony platform used for handling voice, video, and messaging over various protocols, ideal for creating VoIP, PBX, and conferencing solutions.
2. Why use Alma Linux for FreeSWITCH? Alma Linux is a stable, RHEL-compatible OS, making it a reliable choice for hosting applications like FreeSWITCH that require enterprise-level stability.
3. How much RAM is recommended for FreeSWITCH? For basic setups, 1 GB of RAM is sufficient, but for larger deployments, consider 4 GB or more to handle higher call volumes and multiple concurrent calls.
4. Can FreeSWITCH run alongside other VoIP software? Yes, but it’s generally recommended to run it on a dedicated server to avoid port conflicts and performance issues.
5. How do I secure FreeSWITCH? Implement strong password policies, restrict access to SIP ports, and enable TLS for secure communication.
6. Where can I get additional FreeSWITCH modules? Modules can be installed from the FreeSWITCH source repository, and the FreeSWITCH documentation provides details on individual module functions and configurations.
Installing FreeSWITCH on Ubuntu Server: A Step-by-Step Guide
Introduction
FreeSWITCH is a powerful open-source communications platform widely used for VoIP, video, and chat applications. It’s designed to facilitate large-scale telecommunication systems, supporting a broad range of protocols and codecs, making it highly versatile and efficient. Setting up FreeSWITCH on an Ubuntu server offers a reliable and cost-effective way to manage and scale communications. This step-by-step guide will walk you through the process of installing FreeSWITCH on Ubuntu. Whether you’re a beginner or a seasoned system administrator, this guide will help you get FreeSWITCH up and running in no time.
System Requirements
Before starting the installation, make sure you have the following:
Ubuntu Server: This guide is compatible with Ubuntu 18.04, 20.04, and later versions.
2 GB RAM or higher: A minimum of 2 GB of RAM is recommended.
Processor: A modern multi-core processor is preferred.
Root or Sudo Access: Ensure you have administrative privileges.
Updating the Ubuntu Server
To begin, it’s important to update your Ubuntu system to ensure all packages are up to date:
sudo apt update && sudo apt upgrade -y
This command updates your package lists and installs the latest versions of all packages.
Installing Dependencies
FreeSWITCH requires a set of dependencies for a successful installation. Begin by installing these necessary packages:
sudo apt install -y build-essential git-core cmake automake autoconf libtool pkg-config \
libjpeg-dev libncurses5-dev libssl-dev libpcre3-dev libcurl4-openssl-dev libldns-dev \
libedit-dev libsqlite3-dev libopus-dev libsndfile1-dev libavformat-dev libswscale-dev \
libvpx-dev libavresample-dev libavfilter-dev libxml2-dev libxslt1-dev libmp3lame-dev \
libspeexdsp-dev libspeex-dev libogg-dev libvorbis-dev libtiff-dev libtiff5-dev libpq-dev
This command installs all required libraries and tools needed to compile and run FreeSWITCH.
Cloning the FreeSWITCH Source Code
Next, clone the FreeSWITCH repository from GitHub. This will allow you to build FreeSWITCH from the latest source:
cd /usr/local/src
sudo git clone https://github.com/signalwire/freeswitch.git
cd freeswitch
The cd command changes the directory to where FreeSWITCH will be downloaded, and then the git clone command retrieves the FreeSWITCH source code.
Checking Out the Latest Stable Version
FreeSWITCH has both master and stable branches. To ensure a stable installation, switch to the latest stable version:
sudo git checkout v1.10
This command switches to the latest stable release, which is currently v1.10.
Building and Compiling FreeSWITCH
With the source code downloaded, it’s time to build and compile FreeSWITCH. First, install FreeSWITCH’s core dependencies:
sudo ./bootstrap.sh -j
sudo ./configure -C
The bootstrap.sh script prepares the FreeSWITCH environment for compilation, while configure -C optimizes the build process.
Compiling the Source Code
Now, compile the source code using the make command:
sudo make
sudo make install
This process may take some time depending on your system’s resources. The make command compiles FreeSWITCH and make install installs it onto your system.
Installing FreeSWITCH Modules
FreeSWITCH’s functionality is enhanced by its modular structure, allowing you to install only the features you need. Use the following command to install all essential modules:
sudo make all cd-sounds-install cd-moh-install
cd-sounds-install: Installs sound files for ringtones and other audio.
cd-moh-install: Installs Music on Hold files.
These modules are essential for a fully operational FreeSWITCH instance.
Configuring FreeSWITCH
FreeSWITCH comes with a default configuration suitable for most basic setups. However, you may need to customize it based on your requirements.
- Navigate to the Configuration Directory:
cd /usr/local/freeswitch/conf```
<!-- wp:list {"ordered":true,"start":2} -->
<ol start="2" class="wp-block-list">* **Edit Core Configuration Files:** Use any text editor to modify the configuration files, such as `vars.xml` or `sip_profiles` for SIP settings:
```bash
sudo nano vars.xml
Adjust settings based on your network and user needs, including parameters for IP addresses, ports, and protocol settings.
Starting FreeSWITCH
Once configured, FreeSWITCH is ready to start. You can start it directly from the terminal:
/usr/local/freeswitch/bin/freeswitch
This command launches FreeSWITCH in the foreground, allowing you to see the output and check for any immediate issues.
Running FreeSWITCH in the Background
To run FreeSWITCH as a background process, use:
/usr/local/freeswitch/bin/freeswitch -nc```
The `-nc` flag runs FreeSWITCH in non-console mode, making it ideal for production servers.
## Testing the Installation
To ensure FreeSWITCH is working correctly, log in to the FreeSWITCH CLI by typing:
```bash
/usr/local/freeswitch/bin/fs_cli```
This command opens the FreeSWITCH Command Line Interface, where you can test various commands and ensure the system is functioning as expected.
Basic Test Commands
Try using the following commands within the CLI to confirm the setup:
* `status`: Displays the status of FreeSWITCH.
* `sofia status`: Shows SIP profiles and registration status.
* `reloadxml`: Reloads XML configuration files without restarting FreeSWITCH.
## Setting Up FreeSWITCH as a System Service
To simplify management, set up FreeSWITCH as a system service:
* **Create a Service File:**
```bash
sudo nano /etc/systemd/system/freeswitch.service```
<!-- wp:list {"ordered":true,"start":2} -->
<ol start="2" class="wp-block-list">* **Add Service Configuration:** Paste the following configuration into the file:
```bash
[Unit]
Description=FreeSWITCH Service
After=network.target
[Service]
Type=forking
ExecStart=/usr/local/freeswitch/bin/freeswitch -ncwait -nonat
ExecStop=/usr/local/freeswitch/bin/freeswitch -stop
User=root
Group=root
Restart=always
[Install]
WantedBy=multi-user.target```
<!-- wp:list {"ordered":true,"start":3} -->
<ol start="3" class="wp-block-list">* **Enable and Start the Service:**
```bash
sudo systemctl enable freeswitch
sudo systemctl start freeswitch
This configuration file allows you to manage FreeSWITCH with systemctl, making it easier to control FreeSWITCH at boot.
Troubleshooting Common Installation Issues
Dependency Errors
If you encounter dependency errors, double-check that all required packages were installed in the dependencies step. Run sudo apt update and sudo apt install as needed to ensure all dependencies are in place.
Service Not Starting
If FreeSWITCH fails to start as a service, use journalctl -xe to check for errors in the system logs. Adjust the configuration as needed and restart the service.
Security and Best Practices
Limit Access: Use firewalls to restrict access to your FreeSWITCH server and prevent unauthorized access.
Enable Logging: Enable detailed logging to monitor activity and troubleshoot issues.
Regular Updates: Keep FreeSWITCH and your Ubuntu server up to date to protect against security vulnerabilities.
Conclusion
FreeSWITCH offers a robust platform for VoIP and communications solutions, and installing it on an Ubuntu server is a great way to leverage its features. By following this step-by-step guide, you should have a fully functional FreeSWITCH instance up and running. From dependencies and configuration to troubleshooting, this guide provides everything you need to set up FreeSWITCH successfully. With this setup, you’ll be well-equipped to handle VoIP and communication needs efficiently and securely.
Types of Communication Channels: Guide to Effective Information Exchange
In today’s interconnected world, communication channels play a vital role in conveying information across various platforms, from casual interactions to critical business processes. These channels are the pathways through which messages are transmitted between people, devices, or systems, impacting how quickly, accurately, and effectively information is shared.
Whether in personal relationships, workplaces, or digital spaces, understanding the different types of communication channels can improve the quality of interactions, reduce misunderstandings, and enhance productivity. In this post, we’ll break down the primary communication channels, their uses, and their strengths and weaknesses. What Are Communication Channels?
Communication channels are the mediums or paths through which information travels between a sender and a receiver. Each channel has distinct characteristics that determine its suitability for different communication needs. Choosing the right channel is essential for ensuring that the intended message reaches its recipient clearly and effectively.
Communication channels fall into several types, which can broadly be classified based on the direction of communication, formality, and the means of interaction (face-to-face, written, or digital). 1. Face-to-Face Communication Channels
Face-to-face, or in-person communication, is one of the most traditional and effective methods for sharing information, especially when the subject is complex or sensitive.
Advantages:
Provides immediate feedback through verbal and non-verbal cues like tone, gestures, and facial expressions.
Enhances understanding and reduces the chances of misinterpretation.
Builds trust and rapport, making it ideal for relationship-based interactions.
Disadvantages:
Requires physical presence, which can be challenging with geographical or scheduling constraints.
Less feasible for distributed teams or in remote work environments.
Use Cases: Face-to-face channels are suitable for interviews, meetings, negotiations, and counseling sessions.
2. Written Communication Channels
Written communication is a foundational channel for formal and recordable interactions, often preferred in professional and academic settings.
Types:
Letters and Memos: Primarily used for official correspondence, updates, or requests in organizations.
Reports: Detailed documents that provide information on a specific topic or project.
Emails: One of the most versatile and commonly used written communication methods, suitable for both formal and informal interactions.
Text Messages: Common in personal communication and increasingly used in businesses for quick, informal updates.
Advantages:
Provides a permanent record that can be referenced later.
Can be composed thoughtfully, reducing the chances of errors.
Enables asynchronous communication, allowing the sender and receiver to interact on their schedules.
Disadvantages:
Lacks non-verbal cues, which can lead to misunderstandings.
Not ideal for complex discussions or emotionally sensitive topics.
Use Cases: Written channels are used for official communications, contracts, instructions, and formal requests.
3. Digital Communication Channels
Digital channels have become essential with the rise of remote work and online connectivity. These include emails, instant messaging, and social media platforms.
Types:
Email: A widely used digital communication channel for both personal and professional communication.
Instant Messaging (IM): Platforms like Slack, Microsoft Teams, and WhatsApp facilitate quick exchanges and team collaboration.
Video Conferencing: Platforms such as Zoom, Google Meet, and Skype allow for visual interaction, combining digital with face-to-face advantages.
Social Media: Channels like LinkedIn, Twitter, and Facebook, where users can share updates and interact with a broad audience.
Advantages:
Enables rapid, real-time communication regardless of location.
Suitable for both one-on-one interactions and group collaborations.
Flexible and versatile, supporting text, video, and multimedia.
Disadvantages:
This can lead to information overload with too many notifications.
Increased risk of security issues, especially on social media and unencrypted platforms.
Use Cases: Digital channels are widely used for daily updates, team collaborations, virtual meetings, and customer engagement.
4. Nonverbal Communication Channels
Nonverbal communication involves transmitting information without words, using body language, facial expressions, and other physical cues. This type of communication channel is especially impactful when combined with face-to-face interactions.
Types:
Body Language: Gestures, posture, and eye contact can convey emotions or emphasize points.
Facial Expressions: Expressions can reveal a person’s feelings or reactions.
Tone of Voice: Tone, pitch, and volume of speech can communicate confidence, enthusiasm, or uncertainty.
Advantages:
Enhances the effectiveness of verbal communication by adding context.
Can reinforce messages and help build rapport.
Often more immediate and intuitive, making it suitable for interpersonal settings.
Disadvantages:
Can be easily misinterpreted without cultural or situational context.
Limited in remote or text-based communication.
Use Cases: Nonverbal channels are key in face-to-face conversations, interviews, public speaking, and leadership.
5. Audio Communication Channels
Audio communication channels rely on voice to convey information and are commonly used in scenarios where visual or written channels are unnecessary.
Types:
Telephone Calls: Ideal for quick conversations and real-time feedback.
Voicemail: Allows asynchronous voice communication.
Podcasts and Audio Messages: Increasingly popular in digital spaces for informative and personal content sharing.
Advantages:
Enables immediate, real-time interaction, which is effective for quick exchanges.
Allows for tone variation, which adds emotional depth and clarity to the message.
Feasible in low-bandwidth areas, making it accessible in remote regions.
Disadvantages:
Lacks visual cues, which may hinder understanding in sensitive or complex situations.
Can be prone to background noise and interruptions, especially on mobile networks.
Use Cases: Audio channels are often used in customer service, quick updates, remote work, and when face-to-face communication is not possible.
6. Visual Communication Channels
Visual communication includes the use of imagery, videos, and graphics to convey ideas. Visual aids enhance understanding by supplementing text with a visual component.
Types:* Presentations: Slide decks, often used in business meetings, that provide a visual summary of ideas.
Diagrams and Charts: Effective for illustrating data, statistics, or complex processes.
Videos: Used across industries for training, marketing, and educational purposes.
Infographics: A popular format on social media for summarizing information attractively.
Advantages:* Enhances information retention by making it visually engaging.
Effective for explaining complex topics in a simplified manner.
Suitable for reaching a broad audience, especially on social media and digital platforms.
Disadvantages:* May require additional resources, such as design tools or skills.
Interpretation of visuals can vary, depending on cultural or personal perspectives.
Use Cases: Visual communication is ideal for educational content, marketing, training, and presentations.
7. Formal and Informal Communication Channels
Formal and informal channels determine the tone and structure of communication. The choice between the two depends on the context, audience, and purpose.
Formal Communication
Includes structured, official communication such as company announcements, policies, and professional interactions.
Advantages: Reduces ambiguity by following established guidelines.
Disadvantages: May feel impersonal or rigid, depending on the audience.
Informal Communication
Casual interactions like team chats, quick calls, or text messages.
Advantages: Builds camaraderie and encourages open, comfortable communication.
Disadvantages: Lacks structure, which can sometimes lead to misinterpretations.
How to Choose the Right Communication Channel
Selecting the appropriate communication channel can depend on several factors:
Purpose of Communication: Identify if the goal is informative, persuasive, or relational.
Audience: Consider the needs, preferences, and expectations of the recipients.
Complexity of Message: Complex topics may require face-to-face or visual support, while simple updates can be text-based.
Urgency: Urgent messages are better conveyed through real-time channels like phone calls or instant messaging.
Confidentiality: Sensitive information may require secure, private channels such as emails or encrypted messaging.
FAQs: Communication Channels
1. What is the most effective communication channel? The effectiveness of a channel depends on context; for example, face-to-face communication is ideal for nuanced discussions, while email is effective for detailed, recordable exchanges.
2. Why is nonverbal communication important? Nonverbal communication provides emotional context and reinforces verbal messages, helping to build trust and understanding.
3. Can visual communication replace written communication? While visual aids enhance understanding, they often work best alongside written or verbal communication, especially for complex subjects.
4. How does social media serve as a communication channel? Social media enables broad, quick communication, allowing organizations to reach audiences instantly for marketing, updates, and customer engagement.
5. What is the role of instant messaging in business? Instant messaging is a quick, efficient way for teams to collaborate, share updates, and solve problems in real-time.
6. How do formal and informal channels differ in effectiveness? Formal channels ensure clarity and professionalism, while informal channels support camaraderie and encourage openness, each serving a unique purpose in communication. Communication channels form the foundation of effective information exchange, and understanding their types and appropriate use is key to success in both personal and professional settings. By choosing the right channel for each message, you can enhance clarity, foster better relationships, and achieve more successful outcomes.
Basic Terminologies in Data Communications
In today’s interconnected world, data communications form the backbone of our digital infrastructure. Whether you’re a student beginning your journey in IT, a professional looking to expand your knowledge, or simply someone curious about how information travels across networks, understanding the fundamental terminology is crucial. This guide will walk you through the essential concepts and terms used in data communications.
What is Data Communication?
At its core, data communication is the process of exchanging data between two devices through a transmission medium. This exchange can be as simple as sending a text message or as complex as streaming a 4K video. The primary goal is to deliver data accurately, efficiently, and securely from the sender to the intended recipient.
Key Components of Data Communication
- Message
The message is the information to be communicated. It can take various forms:
Text (emails, documents)
Numbers (financial data)
Images (photos, graphics)
Audio (voice calls, music)
Video (streaming content)
Any combination of these types
- Sender and Receiver
Sender: The device that generates and transmits the data
Receiver: The device that accepts and processes the transmitted data These devices can be computers, smartphones, servers, or any other device capable of data transmission and reception.
- Transmission Medium
The physical path through which data travels from sender to receiver. Common types include:
Guided Media
Twisted Pair Cable: Common in Ethernet networks and telephone lines
Coaxial Cable: Used in cable TV and internet services
Fiber Optic Cable: Offers highest speeds and bandwidth for data transmission
Unguided Media
Radio Waves: Used in Wi-Fi and cellular communications
Microwaves: Employed in satellite communications
Infrared: Found in short-range communications like TV remotes
Essential Terminology
Bandwidth
Bandwidth represents the amount of data that can be transmitted through a communication channel in a given time period. It’s typically measured in bits per second (bps) or its larger units:
Kilobits per second (Kbps)
Megabits per second (Mbps)
Gigabits per second (Gbps)
Protocol
A protocol is a set of rules governing data communication. Think of it as a language that devices use to communicate with each other. Common protocols include:
TCP/IP (Transmission Control Protocol/Internet Protocol)
HTTP (Hypertext Transfer Protocol)
FTP (File Transfer Protocol)
SMTP (Simple Mail Transfer Protocol)
Network Topology
The physical or logical arrangement of devices in a network. Basic topologies include:
Bus: All devices connect to a single cable
Star: Devices connect to a central hub
Ring: Devices form a circular connection
Mesh: Devices interconnect with multiple paths
Hybrid: Combination of two or more topologies
Transmission Modes
The direction of data flow between devices:
Simplex
One-way communication
Example: TV broadcasting
Half-Duplex
Two-way communication, but not simultaneous
Example: Walkie-talkies
Full-Duplex
Simultaneous two-way communication
Example: Phone calls
Data Encoding
The process of converting data into a format suitable for transmission. Common encoding methods include:
Binary encoding
Manchester encoding
Non-Return to Zero (NRZ)
ASCII encoding
Important Networking Concepts
IP Address
A unique numerical identifier is assigned to each device on a network. Two main versions are in use:
IPv4 (e.g., 192.168.1.1)
IPv6 (e.g., 2001:0db8:85a3:0000:0000:8a2e:0370:7334)
MAC Address
A hardware identification number is unique to each network interface card (NIC). It’s permanently assigned by the manufacturer and consists of six pairs of hexadecimal digits.
Packets
Units of data that are routed between an origin and destination. Each packet contains:
Header (source and destination information)
Payload (actual data)
Trailer (error checking information)
Data Transmission Characteristics
- Attenuation
The loss of signal strength as data travels through the transmission medium. Factors affecting attenuation include:
Distance
Medium quality
Environmental conditions
- Noise
Unwanted signals that interfere with data transmission:
Thermal Noise: Caused by electronic component temperature
Electromagnetic Interference: From nearby electronic devices
Crosstalk: Signal interference between adjacent channels
- Latency
The time delay between sending and receiving data. Important aspects include:
Propagation Delay: Time for a signal to travel through the medium
Processing Delay: Time for data processing at nodes
Queuing Delay: Time spent waiting in network device queues
Error Detection and Correction
To ensure reliable communication, various methods are employed:
Error Detection
Parity Check: Simple but limited error detection
Checksum: More comprehensive error detection
Cyclic Redundancy Check (CRC): Advanced error detection
Error Correction
Forward Error Correction (FEC): Adds redundant data for correction
Automatic Repeat Request (ARQ): Requests retransmission of corrupt data
Conclusion
Understanding these basic terminologies is essential for anyone working with or interested in data communications. As technology continues to evolve, these fundamental concepts remain relevant and form the foundation for more advanced topics in networking and telecommunications.
Whether you’re troubleshooting network issues, designing communication systems, or simply trying to understand how your devices communicate, familiarity with these terms will prove invaluable. Keep this guide handy as a reference as you delve deeper into the world of data communications.
Data Communication: Building the Foundation for Modern Connectivity
Data communication forms the backbone of today’s digital world, enabling devices, applications, and networks to transmit and receive information seamlessly. In our everyday interactions—whether it’s browsing the internet, streaming videos, or sending messages—data communication makes these connections possible. As technology grows, understanding data communication is crucial not only for IT professionals but also for anyone looking to deepen their grasp of the internet, telecommunications, and information systems.
In this post, we’ll explore the fundamentals of data communication, its types, and the essential components that enable efficient and reliable data transfer. Let’s dive in! What is Data Communication?
Data communication refers to the exchange of data between two or more devices through a transmission medium, such as cables or wireless signals. The goal is to ensure accurate, timely, and reliable transfer of data from one point to another. Data communication is not limited to text or numerical information; it includes multimedia elements like images, audio, and video as well.
Key Elements of Data Communication
Understanding the basic elements involved in data communication can help illustrate how data travels from one device to another:
Sender: The sender is the device or entity that initiates the communication. Examples include a computer, smartphone, or server.
Receiver: The receiver is the destination device or entity that receives the transmitted data, such as another computer, server, or mobile phone.
Message: This is the actual data or information that needs to be transmitted, which can take various forms, such as text, images, or multimedia.
Transmission Medium: The physical pathway through which data travels from sender to receiver. Common examples are cables, fiber optics, or wireless signals.
Protocol: These are the predefined rules or standards that govern data transmission, ensuring smooth and accurate communication.
Types of Data Communication
Data communication can be categorized based on direction, speed, and media type. Here are the main types:
1. Simplex Communication
In simplex communication, data flows in only one direction—from sender to receiver—without any reverse communication.
An example of simplex communication is radio broadcasting, where listeners can only receive the signal and not respond back.
2. Half-Duplex Communication
In half-duplex communication, data can be sent and received by both parties, but not simultaneously.
A common example is a walkie-talkie, where one user has to wait for the other to finish before responding.
3. Full-Duplex Communication
In full-duplex communication, data flows in both directions simultaneously, allowing a real-time, bidirectional exchange.
Telephones and internet-based video conferencing are examples of full-duplex communication.
Data Communication Modes: Serial vs. Parallel
Data transmission can also be classified by how data is transferred over a medium.
Serial Transmission
In serial transmission, data is consecutively sent bit by bit.
Common in USB connections and internet protocols, serial transmission is ideal for long-distance communication due to its simplicity and cost-effectiveness.
Parallel Transmission
In parallel transmission, multiple bits are sent simultaneously across multiple channels, allowing faster data transfer.
Used in short-distance applications like computer buses, parallel transmission can be more efficient but is limited by noise and interference over longer distances.
Types of Transmission Media in Data Communication
Transmission media can be broadly divided into guided (wired) and unguided (wireless) categories.
Guided Transmission Media
Guided media include physical cables and fibers that guide the data from one point to another.
Twisted Pair Cable: Consists of twisted pairs of wires, used in telephone lines and Ethernet cables.
Coaxial Cable: Known for its high bandwidth and resistance to interference, commonly used in cable television.
Fiber Optic Cable: Transmits data as light pulses through glass or plastic fibers, offering high-speed, high-capacity connections.
Unguided Transmission Media
Wireless media use electromagnetic waves to transmit data without a physical connection.
Radio Waves: Used in radio broadcasting, Wi-Fi, and cellular communication.
Microwaves: Ideal for long-distance and high-capacity data transfer, commonly used in satellite communications.
Infrared: Used in short-range applications, such as remote controls and some wireless peripherals.
Protocols and Standards in Data Communication
To facilitate seamless data communication, protocols, and standards are essential. They provide a framework for how data is formatted, transmitted, and received, ensuring compatibility across different devices and networks.
Transmission Control Protocol/Internet Protocol (TCP/IP): This suite of protocols is foundational for Internet communication, enabling devices to exchange data reliably.
Hypertext Transfer Protocol (HTTP/HTTPS): Primarily used for web-based communication, allowing users to access and browse websites securely.
Simple Mail Transfer Protocol (SMTP): Essential for email communication, enabling the sending and receiving of messages across networks.
The OSI Model in Data Communication
The OSI (Open Systems Interconnection) model is a conceptual framework that describes how different network protocols interact in seven layers. Each layer is designed to handle a specific aspect of the communication process, from physical data transfer to application-level interactions.
Physical Layer: Deals with the actual hardware, transmission mediums, and physical connections.
Data Link Layer: Manages error detection and frames data into manageable packets.
Network Layer: Directs packets across different networks.
Transport Layer: Ensures end-to-end data transfer and reliability.
Session Layer: Establishes, maintains, and ends communication sessions.
Presentation Layer: Translates data into formats the application layer can process.
Application Layer: Interacts with end-user applications like email, browsing, and file transfer.
Common Challenges in Data Communication
While data communication has come a long way, it faces several challenges that can affect its efficiency, reliability, and security:
Latency: Delays in data transfer, often caused by distance or network congestion.
Bandwidth Limitations: Limited data-carrying capacity can slow down transmission, especially in high-traffic networks.
Interference: Noise and electromagnetic interference can degrade signal quality in wireless communications.
Data Security: The risk of data breaches and unauthorized access, particularly in wireless networks.
Applications of Data Communication
Data communication is integral to numerous applications that we rely on daily. Some examples include:
Internet and Web Browsing: HTTP and HTTPS protocols enable users to access websites and online resources.
Email and Messaging: SMTP and similar protocols allow for the reliable exchange of messages.
Voice over Internet Protocol (VoIP): Used for audio and video calls over the internet, such as Zoom or Skype.
Internet of Things (IoT): Connects devices, enabling them to communicate, share data, and automate processes.
Future Trends in Data Communication
As data demands grow, several emerging technologies are set to shape the future of data communication:
5G and Beyond: Next-generation wireless technology promises faster speeds, lower latency, and greater connectivity.
Quantum Communication: This technology is being explored for secure and high-speed data transfer using quantum encryption.
Artificial Intelligence (AI): AI-driven communication systems can optimize network traffic, reduce latency, and improve data flow efficiency.
Edge Computing: By processing data closer to the source, edge computing reduces latency and bandwidth usage.
FAQs: Data Communications
1. What is the main purpose of data communication? Data communication aims to facilitate the transfer of information between devices accurately, timely, and reliably.
2. How does wireless communication differ from wired communication? Wireless communication uses electromagnetic waves to transmit data without physical connections, whereas wired communication relies on physical cables.
3. What is the role of protocols in data communication? Protocols are sets of rules that standardize data transmission, ensuring compatibility and efficient communication between different systems.
4. What is latency in data communication? Latency refers to the delay between sending and receiving data, often influenced by network congestion and distance.
5. Why is the OSI model important? The OSI model standardizes network protocols into layers, promoting interoperability and ensuring smooth data transfer.
6. How does 5G impact data communication? 5G technology offers higher speeds, lower latency, and greater capacity, enhancing real-time applications like video streaming and IoT. Data communication has transformed how we interact, connect, and exchange information. From simple text messages to sophisticated video calls, it forms the backbone of modern connectivity. By understanding the components, types, and protocols of data communication, we gain insights into the digital ecosystem that powers today’s world—and the innovations driving us into the future.
A/D Conversion: A Comprehensive Guide to Analog-to-Digital Conversion
Analog-to-digital conversion, often abbreviated as A/D or ADC, is a process essential to modern digital devices. A/D conversion allows analog signals, which are continuous and vary smoothly, to be transformed into digital data that computers and other digital systems can process. From smartphones and computers to industrial automation systems and medical devices, A/D conversion is at the heart of many technological applications. In this guide, we’ll cover everything you need to know about A/D conversion: what it is, how it works, its types, and real-world applications. What is A/D Conversion?
At its core, A/D conversion is the process of translating an analog signal into a digital signal. Analog signals, such as sound waves, light intensities, or temperature changes, are continuous, meaning they exist over a range of values without interruption. Digital signals, on the other hand, are discrete and represent data as binary values (0s and 1s), which computers can easily read and process.
Example: Consider a microphone capturing sound. Sound waves are analog, continuously changing in amplitude. An A/D converter (ADC) processes these sound waves and converts them into digital audio files that can be stored, edited, and played back on digital devices. The Importance of A/D Conversion
A/D conversion is crucial because most sensors and input devices in the real world generate analog signals, while computers and digital devices require data in digital form to process it. Without A/D conversion, it would be impossible for computers to interact with the analog world, limiting their functionality in numerous applications. This conversion enables the digital analysis, storage, and sharing of data in various fields, including audio engineering, medical imaging, telecommunications, and more. Basic Principles of A/D Conversion
The A/D conversion process consists of three main steps: sampling, quantization, and encoding.
Sampling: This is the process of taking discrete snapshots (samples) of the analog signal at regular intervals. The sampling rate (how frequently samples are taken) is crucial. A higher sampling rate can capture more detail from the analog signal. For example, in audio processing, the CD-quality sampling rate is 44.1 kHz, meaning the signal is sampled 44,100 times per second.
Quantization: Each sampled value is then mapped to a discrete level, a process called quantization. The precision of quantization depends on the bit depth (number of bits used per sample). Higher bit depths provide more precise values but require more memory.
Encoding: In the final step, each quantized value is converted into a binary code (a series of 0s and 1s). This binary data is then stored or processed as digital information by the computer.
Types of A/D Converters (ADCs)
Several types of ADCs are used in electronics, each suited to specific applications depending on speed, accuracy, and power requirements.
1. Flash ADC (Direct Conversion)
Description: Flash ADCs are the fastest type of ADC and use a parallel approach with multiple comparators to evaluate all possible values at once.
Advantages: Extremely fast, making them ideal for high-speed applications.
Disadvantages: High power consumption and more expensive.
Applications: Video, radar, high-frequency digital oscilloscopes.
2. Successive Approximation ADC (SAR ADC)
Description: Successive approximation ADCs use a binary search method, approximating the input voltage by successively refining each bit from most significant to least significant.
Advantages: Good balance between speed, accuracy, and power efficiency.
Disadvantages: Not as fast as flash ADCs but faster than many other types.
Applications: Audio equipment, instrumentation, control systems.
3. Sigma-Delta ADC (ΣΔ ADC)
Description: Sigma-delta ADCs use oversampling and digital filtering, which allows for high resolution at slower speeds.
Advantages: High accuracy and excellent noise reduction capabilities.
Disadvantages: Slower conversion speed, making them unsuitable for very high-speed applications.
Applications: Audio applications, digital scales, temperature sensors.
4. Dual Slope ADC
Description: Dual slope ADCs integrate the input signal over time, providing high accuracy and immunity to noise.
Advantages: High accuracy and very low susceptibility to noise.
Disadvantages: Slow speed, so not suitable for high-frequency applications.
Applications: Precision measurement instruments like multimeters.
5. Pipeline ADC
Description: Pipeline ADCs use multiple stages, each handling a part of the conversion process, allowing for both speed and accuracy.
Advantages: Combines speed and accuracy, making it suitable for medium-to-high-speed applications.
Disadvantages: More complex circuitry, which increases cost and power consumption.
Applications: Medical imaging, digital communications.
Key Specifications of A/D Converters
When choosing an ADC, several specifications determine its suitability for particular applications:
Resolution: This is the number of bits in the digital output and determines the ADC’s precision. Higher resolution allows for more precise measurements.
Sampling Rate: This specifies how many samples per second the ADC can process. Applications requiring high-speed data, such as video processing, demand a high sampling rate.
Signal-to-Noise Ratio (SNR): A measure of the signal’s strength relative to background noise. Higher SNR values indicate clearer and more accurate digital output.
Total Harmonic Distortion (THD): Indicates distortion introduced during conversion. Lower THD is desirable for applications where signal integrity is critical.
A/D Conversion Process: Step-by-Step Example
Let’s walk through a step-by-step example of A/D conversion using a Successive Approximation ADC.
Sampling: The ADC samples the input signal voltage. Suppose it samples a 3.2V analog signal.
Comparison and Approximation: The SAR ADC uses a comparator to compare the input voltage against an internal reference voltage. In successive steps, it refines the estimated voltage, starting from the most significant bit.
Quantization: The ADC determines a binary value closest to 3.2V based on the bit depth (e.g., 8-bit or 12-bit).
Encoding: The result is encoded in binary, giving an output that can be interpreted by the digital system.
Real-World Applications of A/D Conversion
The versatility of A/D conversion makes it integral in numerous fields:
Audio Recording and Playback: Microphones capture sound as analog signals, which are then converted to digital data for storage, processing, and playback on digital devices.
Medical Imaging: In medical imaging technologies like MRI and CT scans, analog signals are converted to digital to produce detailed images for analysis and diagnosis.
Communication Systems: Cell phones, radios, and digital TVs all rely on A/D conversion to transform incoming analog signals into digital data that can be processed and transmitted over networks.
Industrial Automation: Sensors in automated factories and assembly lines collect real-time data (temperature, pressure, etc.) in analog form, which is then converted to digital for monitoring and control.
Scientific Research: ADCs are essential in research, where precision measurements from analog sensors must be converted to digital for analysis, modeling, and simulation.
Frequently Asked Questions (FAQs) on A/D Conversion
1. What is the difference between analog and digital signals?
Analog signals are continuous and vary smoothly over time, while digital signals consist of discrete values (usually 0s and 1s) that represent the information in binary form.
2. Why is A/D conversion necessary?
A/D conversion is necessary because most computers and digital devices only understand digital signals. Converting analog signals into digital form allows these devices to process, store, and analyze real-world data.
3. What factors determine ADC accuracy?
ADC accuracy depends on resolution (bit depth), sampling rate, signal-to-noise ratio (SNR), and factors like temperature stability and linearity.
4. What is the role of sampling rate in ADC?
The sampling rate determines how frequently an analog signal is sampled. Higher sampling rates capture more detail, which is crucial for applications requiring high-fidelity data, like audio and video processing.
5. Which type of ADC is best for high-speed applications?
Flash ADCs are the fastest, making them ideal for high-speed applications like radar and digital oscilloscopes, though they tend to be more expensive.
6. Can A/D conversion introduce errors?
Yes, errors like quantization noise and sampling errors can occur during A/D conversion. These errors are managed through proper selection of ADC resolution and sampling rate based on the application. Conclusion
A/D conversion bridges the gap between the analog world and digital systems, making it a cornerstone of modern technology. From simple audio recording to complex scientific instrumentation, the conversion of analog signals to digital data enables digital devices to interact with, analyze, and utilize information from the physical world. Understanding the types, specifications, and applications of ADCs can help anyone working with digital electronics, engineering, or data processing make more informed decisions about this fundamental process.
A/D conversion isn’t just a technical function; it’s the foundational process that connects human experience with the capabilities of digital technology, expanding our ability to understand and shape the world around us.
Understanding AI Models: Ultimate Modern Artificial Intelligence Guide
Artificial Intelligence (AI) models have become an integral part of our digital landscape, powering everything from the virtual assistants on our phones to complex systems that help doctors diagnose diseases. In this comprehensive guide, we’ll explore what AI models are, how they work, and their impact on various industries.
What Are AI Models?
At their core, AI models are sophisticated computer programs designed to process information and make decisions or predictions based on patterns they’ve identified in data. Think of them as highly advanced pattern recognition systems that can learn from examples rather than following rigid, pre-programmed rules.
These models come in various types and sizes, each designed for specific tasks:
Machine Learning Models
The most fundamental category of AI models relies on statistical techniques to learn from data. These models improve their performance as they process more information, similar to how humans learn from experience. Common examples include:
Decision Trees: Used for classification and prediction tasks
Random Forests: Combining multiple decision trees for better accuracy
Support Vector Machines: Effective for categorizing data into distinct groups
Deep Learning Models
A more complex subset of machine learning, deep learning models are inspired by the human brain’s neural networks. They consist of multiple layers of interconnected nodes that process information in increasingly abstract ways. Popular architectures include:
Convolutional Neural Networks (CNNs): Specialized for image recognition
Recurrent Neural Networks (RNNs): Designed for sequential data like text or time series
Transformers: Powering modern language models and revolutionizing natural language processing
How AI Models Learn
The learning process for AI models typically follows three main approaches:
Supervised Learning
In this approach, models learn from labeled data – examples where the correct answer is provided. It’s like having a teacher who shows you the right answer while you’re learning. This method is commonly used in:
Spam detection
Image classification
Speech recognition
Medical diagnosis
Unsupervised Learning
These models work with unlabeled data, finding patterns and relationships without being told what to look for. Applications include:
Customer segmentation
Anomaly detection
Recommendation systems
Pattern discovery in large datasets
Reinforcement Learning
Similar to how animals learn through reward and punishment, these models improve through trial and error. They’re particularly useful in:
Game playing AI
Robotics
Autonomous vehicles
Resource management
The Impact of AI Models Across Industries
Healthcare
AI models are transforming medical care through:
Early disease detection
Drug discovery
Personalized treatment plans
Medical image analysis
Patient care optimization
Finance
The financial sector leverages AI models for:
Fraud detection
Risk assessment
Algorithmic trading
Customer service automation
Credit scoring
Transportation
AI is revolutionizing how we move:
Self-driving vehicles
Traffic prediction
Route optimization
Maintenance scheduling
Safety systems
Education
The educational landscape is being enhanced through:
Personalized learning paths
Automated grading
Student performance prediction
Content recommendation
Administrative task automation
Challenges and Considerations
While AI models offer tremendous potential, they also present several challenges that need careful consideration:
Data Quality and Quantity
Models are only as good as the data they’re trained on. High-quality, diverse, and representative data is essential for:
Accurate predictions
Unbiased results
Robust performance
Reliable decision-making
Ethical Considerations
As AI models become more prevalent, ethical concerns include:
Privacy protection
Bias mitigation
Transparency
Accountability
Fair access
Technical Limitations
Current challenges in AI model development include:
Computational requirements
Energy consumption
Model interpretability
Generalization ability
Resource constraints
The Future of AI Models
The field of AI is rapidly evolving, with several exciting developments on the horizon:
Multimodal Models
Future models will better integrate different types of data:
Text and images
Speech and video
Sensor data
Biological signals
Enhanced Efficiency
Researchers are working on:
Smaller, more efficient models
Reduced energy consumption
Faster training times
Better resource utilization
Improved Accessibility
The democratization of AI through:
User-friendly tools
Cloud-based solutions
Open-source projects
Educational resources
Conclusion
AI models represent a remarkable achievement in computer science and continue to push the boundaries of what’s possible. As these systems become more sophisticated and accessible, their impact on society will only grow. Understanding their capabilities, limitations, and implications is crucial for anyone looking to navigate our increasingly AI-driven world.
Whether you’re a business leader, developer, or simply someone interested in technology, staying informed about AI models is essential. As we move forward, the key will be balancing innovation with responsibility, ensuring these powerful tools benefit society while addressing important ethical and practical considerations.
Remember that AI models are tools that augment human capabilities rather than replace them entirely. By understanding their proper role and application, we can better harness their potential while maintaining human oversight and judgment in critical decisions.
USDC (USD Coin): Guide to the Leading Regulated Stablecoin
In the rapidly evolving world of cryptocurrency, USD Coin (USDC) has emerged as one of the most trusted and widely-used stablecoins. Launched in 2018 as a collaboration between Circle and Coinbase through the Centre consortium, USDC has established itself as a pioneer in regulated, transparent stablecoin operations. This comprehensive guide explores USDC’s features, use cases, and its significant impact on the digital asset ecosystem.
What Is USD Coin (USDC)?
USDC is a digital stablecoin that’s pegged to the US dollar at a 1:1 ratio. Unlike traditional cryptocurrencies such as Bitcoin or Ethereum, which can experience significant price volatility, USDC is designed to maintain a stable value relative to the US dollar. This stability is achieved through a full-reserve backing system, meaning that for every USDC token in circulation, there is one US dollar held in reserve.
Key Features and Advantages
Regulatory Compliance
One of USDC’s distinguishing characteristics is its strong focus on regulatory compliance:
Regular Audits: Monthly attestations by Grant Thornton LLP verify the reserve backing
Regulated Institutions: Reserves are held in US-regulated financial institutions
Transparent Operations: Clear reporting and disclosure of reserve composition
Technical Infrastructure
USDC operates across multiple blockchain networks, including:
Ethereum (primary network)
Algorand
Solana
Avalanche
Tron
Stellar
This multi-chain presence enables broader accessibility and varied use cases while maintaining consistent security standards across platforms.
Real-World Applications
Digital Payments
USDC has found numerous practical applications in the digital economy:
Cross-Border Transactions* Faster settlement times compared to traditional banking
Lower transaction fees
24/7 operation capability
Business Operations* Payroll processing
Vendor payments
International trade settlement
Financial Services* Lending and borrowing
Yield generation
Investment opportunities
The Role of USDC in DeFi
Decentralized Finance Integration
USDC has become a cornerstone of the DeFi ecosystem:
Liquidity Provision* Major components of lending protocols
Essential for liquidity pools
Stable trading pairs
Yield Generation* Staking opportunities
Lending markets
Liquidity mining programs
Risk Management* Collateral for synthetic assets
Hedge against market volatility
Stable value storage
Security and Risk Considerations
Reserve Management
USDC maintains a conservative approach to reserve management:
Asset Composition* Cash and cash equivalents
Short-duration US Treasury bonds
Regular public disclosure of holdings
Banking Partners* Regulated US financial institutions
Multiple banking relationships for risk distribution
Regular monitoring and compliance checks
Technical Security
The platform implements robust security measures:
Smart Contract Security* Regular audits by leading security firms
Open-source code for transparency
Bug bounty programs
Operational Security* Multi-signature requirements
Cold storage for reserves
Regular security assessments
Market Impact and Adoption
Growth Trajectory
USDC has experienced significant growth since its launch:
Market Capitalization* The steady increase in total supply
Growing institutional adoption
Expanding use cases
Trading Volume* High daily transaction volumes
Growing presence on major exchanges
Increasing DeFi integration
Institutional Adoption
USDC has gained significant traction among institutional users:
Financial Institutions* Banking partnerships
Payment processor integration
Corporate treasury adoption
Business Integration* E-commerce platforms
Payment services
Cross-border trade
Future Developments and Potential
Innovation Pipeline
Several developments are shaping USDC’s future:
Technical Improvements* Enhanced scalability solutions
Cross-chain interoperability
Smart contract optimization
Use Case Expansion* Government partnerships
Retail Adoption
Financial inclusion initiatives
Regulatory Landscape
The evolving regulatory environment presents both challenges and opportunities:
Compliance Framework* Ongoing regulatory dialogue
Proactive adaptation to new requirements
International regulatory coordination
Industry Standards* Participation in standard-setting initiatives
Collaboration with regulatory bodies
Best practice development
Best Practices for USDC Users
Usage Guidelines
To maximize the benefits of USDC, consider these recommendations:
Transaction Management* Verify recipient addresses
Monitor gas fees on different networks
Maintain appropriate security measures
Portfolio Integration* Diversification strategies
Risk management considerations
Liquidity planning
Conclusion
USDC represents a significant evolution in the stablecoin space, combining the benefits of digital currencies with regulatory compliance and operational transparency. Its growing adoption across various sectors demonstrates its utility as a bridge between traditional finance and the digital asset ecosystem.
As the cryptocurrency market continues to mature, USDC’s commitment to regulatory compliance and transparency positions it well for continued growth and adoption. For users ranging from individual investors to large institutions, understanding USDC’s capabilities and limitations is crucial for making informed decisions in the digital asset space.
The future of USDC appears promising, with ongoing developments in technology, use cases, and regulatory frameworks likely to further enhance its utility and adoption. As the digital asset ecosystem evolves, USDC’s role as a regulated, transparent stablecoin will likely become increasingly important in facilitating the transition to a more digital financial future. You can find the most popular list of cryptocurrencies on our blog page.
Exploring Solana: The High-Speed Blockchain and Its Native Coin, SOL
Solana, an advanced blockchain platform, has emerged as a strong competitor in the cryptocurrency and decentralized technology space, thanks to its high-speed transactions, low costs, and scalable architecture. The platform’s native currency, SOL, has garnered widespread interest among developers, investors, and enthusiasts alike. In this article, we’ll take a closer look at Solana’s architecture, its unique Proof of History (PoH) consensus mechanism, its benefits, use cases, and the potential it holds in shaping the future of decentralized finance (DeFi) and beyond.
You can look at the price chart at the bottom of this page or with this in-page link.
What is Solana?
Solana is a high-performance blockchain network designed to facilitate decentralized applications (dApps) and crypto-assets with fast transaction speeds and low fees. Unlike many other blockchains, which often struggle with scalability and high transaction costs, Solana is built to handle high throughput efficiently, making it suitable for applications requiring large-scale operation.
Solana’s ability to process transactions at high speeds has made it a popular choice for various applications, including decentralized finance (DeFi) platforms, non-fungible tokens (NFTs), and other Web3 solutions. It uses a unique hybrid consensus model that combines Proof of Stake (PoS) with a novel mechanism called Proof of History (PoH) to achieve remarkable transaction speeds and scalability.
A Brief History of Solana
The Solana project was initiated by Anatoly Yakovenko in 2017, a former Qualcomm engineer who aimed to solve some of the pressing issues in blockchain, such as low transaction throughput and high fees. Yakovenko’s approach focused on developing a high-performance blockchain that could meet the demands of real-world applications while remaining decentralized and secure.
In 2020, Solana officially launched its mainnet, quickly gaining traction among developers and investors. By early 2021, the Solana Foundation had raised over $20 million, positioning itself as a leading blockchain platform for scalable applications. Today, Solana is one of the fastest-growing ecosystems in the blockchain space, competing closely with Ethereum and other major networks.
How Solana Works: Proof of History and Proof of Stake
Solana’s architecture is built on a combination of Proof of Stake (PoS) and Proof of History (PoH), which distinguishes it from most other blockchains. This hybrid model allows Solana to achieve faster transaction speeds without sacrificing security or decentralization.
Proof of Stake (PoS): Like other PoS blockchains, Solana relies on validators who stake SOL, the network’s native cryptocurrency, to secure the network and validate transactions. Validators earn rewards for participating in the consensus process, helping maintain the network’s integrity.
Proof of History (PoH): PoH is a novel consensus mechanism unique to Solana. Instead of each transaction being timestamped individually, PoH generates a historical record that shows events in sequence. This approach enables validators to agree on the order of events quickly, drastically reducing the time it takes to confirm transactions. PoH essentially acts as a “clock” for the blockchain, ensuring a common, trustworthy timestamp for all nodes in the network.
By combining PoS with PoH, Solana can process around 65,000 transactions per second (TPS), a remarkable achievement compared to Ethereum’s 15-30 TPS. This scalability allows Solana to support high-demand applications without experiencing network congestion or rising transaction fees.
The Role of SOL
SOL is the native cryptocurrency of the Solana blockchain, performing various roles within the ecosystem:
Transaction Fees: SOL is used to pay transaction fees on the network, ensuring that transactions are processed quickly and efficiently.
Staking: SOL holders can stake their tokens to become validators or delegate them to existing validators, earning rewards in return. Staking not only provides users with passive income but also strengthens network security.
Governance: While Solana doesn’t yet have a formalized governance model like some other blockchains, SOL holders may play an increasing role in governance decisions as the platform continues to evolve.
Solana vs. Ethereum: Key Differences
While Solana and Ethereum are often compared as rivals, they serve different purposes and have distinct architectures:
| Feature | Solana | Ethereum |
|---|---|---|
| **Consensus Mechanism** | PoS + PoH | PoW (Ethereum 1.0), transitioning to PoS (Ethereum 2.0) |
| **Transaction Speed** | Up to 65,000 TPS | 15-30 TPS |
| **Transaction Fees** | Low | High, although Ethereum 2.0 aims to reduce fees |
| **Primary Use Cases** | High-speed dApps, DeFi, NFTs | Smart contracts, DeFi, dApps, NFTs |
| **Smart Contract Language** | Rust, C | Solidity |
These differences illustrate why Solana is often favored for applications requiring high transaction speeds and low costs, while Ethereum remains the go-to platform for developers creating complex decentralized applications.
Key Advantages of Solana
High Transaction Speed: Solana’s PoH mechanism enables it to achieve speeds of up to 65,000 TPS, significantly faster than Ethereum and most other blockchains.
Low Transaction Fees: Solana’s architecture allows for cost-efficient transactions, making it ideal for DeFi and other applications that require frequent, small transactions.
Scalability: Solana’s network is designed to scale as hardware improves, meaning it can potentially handle even higher throughput as technology advances.
Developer-Friendly Environment: Solana’s support for popular programming languages like Rust and C enables a broader range of developers to create applications on the platform.
Growing Ecosystem: The Solana ecosystem is rapidly expanding, with numerous projects spanning DeFi, NFTs, gaming, and Web3. As more applications are developed, the value and utility of SOL are likely to increase.
Real-World Applications of Solana
Solana’s scalability and low fees make it suitable for a wide range of applications. Here are some notable use cases:
Decentralized Finance (DeFi): DeFi projects on Solana offer users alternatives to traditional finance, including decentralized exchanges, lending platforms, and stablecoins. The speed and cost-efficiency of Solana make it an attractive option for DeFi developers.
Non-Fungible Tokens (NFTs): Solana has become a popular choice for NFT marketplaces due to its low fees, allowing creators to mint NFTs without incurring high costs. Platforms like Solanart and Magic Eden are well-known Solana-based NFT marketplaces.
Gaming: Blockchain-based games like Star Atlas leverage Solana’s high transaction speed to deliver a seamless gaming experience where players can buy, sell, and trade in-game assets as NFTs.
Web3 Applications: Solana’s low fees and fast transactions make it ideal for Web3 applications, where users expect a responsive, decentralized internet experience. Social media and content-sharing platforms like Audius are building on Solana to offer users more control over their data.
Challenges and Risks
Despite its advantages, Solana faces challenges that could impact its future success:
Network Outages: Solana has experienced several network outages in the past, raising concerns about its reliability and security.
Centralization Risks: While Solana is technically decentralized, critics argue that its validator network is more centralized than other blockchains, as the network requires significant computational resources to run.
Competition: Solana faces intense competition from other blockchain platforms like Ethereum, Binance Smart Chain, and Avalanche. As the blockchain space evolves, Solana will need to continue innovating to maintain its position.
Security: Like all blockchains, Solana is vulnerable to exploits and attacks. While the network has measures to protect against these risks, security remains a top priority as more assets are stored and traded on the platform.
The Future of Solana
Solana’s future is promising, with plans for continued improvements to scalability, security, and decentralization. The platform’s core developers are working on tools to improve the network’s stability and prevent future outages, while also expanding the ecosystem with partnerships and collaborations.
In the coming years, Solana is likely to become more integrated with mainstream financial and technological systems, potentially bridging the gap between traditional finance and blockchain technology. Its developer-friendly environment, combined with high transaction speed and low fees, positions Solana to play a key role in the future of DeFi, NFTs, gaming, and Web3.
Conclusion
Solana has firmly established itself as one of the leading blockchain platforms, attracting a wide array of developers and projects across multiple sectors. With its innovative Proof of History mechanism, Solana offers a high-speed, low-cost alternative to other blockchains, making it ideal for applications requiring scalability and efficiency.
As the ecosystem around Solana grows, so does the potential of its native currency, SOL, for users, developers, and investors alike. Although challenges remain, Solana’s technical strengths and growing community suggest that it will continue to be a force in the blockchain space. Whether you’re interested in using Solana’s dApps, investing in SOL, or simply exploring its technology, Solana represents a unique and compelling part of the blockchain ecosystem. You can find the most popular list of cryptocurrencies on our blog page.
Must Known Common Cryptocurrency Terms For You
The cryptocurrency world can be a bit overwhelming, especially for beginners. With its language full of technical jargon, understanding even basic concepts can seem like a challenge. This comprehensive guide to common cryptocurrency terms is designed to help you make sense of the industry, whether you’re new to crypto or looking to expand your knowledge. We’ll cover everything from the basics to more advanced terms so that you can navigate the world of digital currencies with confidence.
Table of Contents
Common Cryptocurrency Terms
Blockchain-Related Terms
Wallets and Security Terms
Trading and Investment Terms
Technical and Mining Terms
DeFi, NFTs, and Emerging Crypto Concepts
Conclusion
1. Common Cryptocurrency Terms
Cryptocurrency: A form of digital or virtual currency that uses cryptography for security and operates on decentralized networks like blockchain.
Bitcoin (BTC): The first and most well-known cryptocurrency, created by Satoshi Nakamoto in 2009.
Altcoin: Any cryptocurrency other than Bitcoin. Examples include Ethereum, Litecoin, and Ripple.
Fiat Currency: Traditional government-issued currencies, such as the U.S. dollar (USD) or Euro (EUR), that are not backed by a physical commodity like gold.
Decentralization: The process of distributing control away from a central authority, such as a government or bank, commonly seen in cryptocurrencies.
Token: A digital asset that represents value or utility and operates on a blockchain. Tokens can represent anything from assets to voting rights.
Stablecoin: A type of cryptocurrency that is pegged to the value of a fiat currency, such as Tether (USDT) or USD Coin (USDC), to minimize volatility.
ICO (Initial Coin Offering): A fundraising method used by new cryptocurrencies to raise capital by selling a portion of their tokens to early investors.
Whitepaper: A document released by a cryptocurrency project that explains its technology, goals, and methodology.
HODL: A slang term derived from a misspelling of “hold,” referring to the strategy of holding onto a cryptocurrency long-term, despite market fluctuations.
2. Blockchain-Related Terms
- * **Blockchain**: A decentralized, digital ledger that records transactions across a network of computers (nodes).
Block: A record of transactions that, when verified, becomes part of a blockchain.
Node: A computer that participates in the blockchain network by validating transactions and maintaining the distributed ledger.
Consensus Mechanism: The method by which nodes in a blockchain network agree on the validity of transactions. Common mechanisms include Proof of Work (PoW) and Proof of Stake (PoS).
Proof of Work (PoW): A consensus mechanism that requires miners to solve complex mathematical problems to validate transactions.
Proof of Stake (PoS): A consensus mechanism where validators are chosen based on the number of tokens they hold and are willing to “stake” as collateral.
Smart Contract: A self-executing contract with the terms of the agreement directly written into code, which automatically enforces the terms of the agreement.
Gas Fee: A fee paid to execute transactions or smart contracts on blockchain platforms like Ethereum.
Fork: A change or split in a blockchain’s protocol that creates two separate versions of the blockchain. Forks can be “hard” (permanent) or “soft” (temporary).
Ledger: A record of transactions. In cryptocurrency, a ledger is usually maintained in a decentralized manner using blockchain technology.
Public Key: A cryptographic code that is paired with a private key and used to receive cryptocurrency.
Private Key: A secret cryptographic code used to access and control a cryptocurrency wallet. It should never be shared.
Hot Wallet: A cryptocurrency wallet that is connected to the internet, such as those on exchanges. While convenient, hot wallets are more susceptible to hacking.
Cold Wallet: A cryptocurrency wallet that is not connected to the internet, often stored on a hardware device or paper, and is more secure than a hot wallet.
Seed Phrase: A sequence of words generated by a wallet that allows the user to recover their funds if they lose access to the wallet. It must be stored securely.
2FA (Two-Factor Authentication): An extra layer of security used to protect accounts by requiring a second form of verification, such as a text message code, in addition to a password.
Encryption: The process of converting data into a coded form to prevent unauthorized access.
Multi-Signature (Multisig): A security feature where multiple parties must approve a transaction before it is executed.
Phishing: A fraudulent attempt to obtain sensitive information by disguising as a trustworthy entity, often through fake websites or emails.
Liquidity: The ease with which a cryptocurrency can be bought or sold without affecting its market price.
Market Cap (Market Capitalization): The total value of a cryptocurrency, calculated by multiplying its current price by its total supply.
Bull Market: A market characterized by rising prices and optimism among investors.
Bear Market: A market characterized by declining prices and pessimism among investors.
Limit Order: An order to buy or sell a cryptocurrency at a specific price or better.
Market Order: An order to buy or sell a cryptocurrency immediately at the current market price.
Stop-Loss Order: An order placed to sell a cryptocurrency once it reaches a certain price, aimed at limiting losses.
Whale: A term used to describe an individual or entity that holds a large amount of cryptocurrency and has the potential to influence market prices.
ATH (All-Time High): The highest price that a cryptocurrency has ever reached.
FOMO (Fear of Missing Out): The anxiety or fear that one is missing out on potential profits, leading to impulsive investments.
FUD (Fear, Uncertainty, and Doubt): Negative information or rumors spread to create panic among investors, often resulting in selling.
Pump and Dump: A scheme where a cryptocurrency’s price is artificially inflated (pumped) through misleading information and then sold off (dumped) at a profit by those who initiated the pump.
Portfolio: A collection of investments, which in the case of cryptocurrency might include various digital assets.
Arbitrage: The practice of taking advantage of price differences between different exchanges by buying cryptocurrency on one exchange and selling it on another at a higher price.
Miner: A participant in the cryptocurrency network who performs mining tasks to validate transactions.
Hash: A cryptographic function that converts input data into a fixed-size string of characters, representing it as a unique digital fingerprint.
Hash Rate: The computational power used in mining to solve mathematical problems and validate transactions.
Nonce: A number used only once in the process of mining to alter the hash value and meet the difficulty requirements of the blockchain.
Halving: An event in which the reward for mining new blocks is reduced by half, typically occurring at regular intervals in cryptocurrencies like Bitcoin.
51% Attack: A situation where more than half of the computing power or mining hash rate on a network is controlled by a single entity, potentially leading to double-spending or network manipulation.
Difficulty: A measure of how hard it is to mine a new block in a blockchain network.
Staking: The process of holding cryptocurrency in a wallet to support the operations of a blockchain network, often earning rewards in return.
Validator: A participant in a Proof of Stake (PoS) network who validates transactions and adds them to the blockchain.
Node Operator: Someone who runs a node (a computer that helps validate transactions and maintain the blockchain).
NFT (Non-Fungible Token): A type of token that represents a unique digital asset, often used for digital art, collectibles, and virtual items.
Yield Farming: A DeFi strategy where users provide liquidity to a platform in exchange for rewards, often in the form of interest or additional tokens.
Liquidity Pool: A smart contract where users can deposit assets to facilitate decentralized trading, lending, and other financial services.
DAO (Decentralized Autonomous Organization): An organization that is governed by smart contracts and decentralized decision-making, often using tokens to vote on governance matters.
dApp (Decentralized Application): An application that runs on a decentralized network, such as Ethereum, rather than being controlled by a centralized entity.
Gas: A unit of measure that represents the computational work required to execute transactions on Ethereum.
Airdrop: The distribution of free tokens to users, often used as a marketing tool or reward for early adopters.
Flash Loan: A type of uncollateralized loan available in DeFi platforms, where funds must be borrowed and returned within the same transaction.
Stablecoin: Cryptocurrencies that are pegged to a stable asset like fiat currencies to reduce price volatility.
Governance Token: A token that gives holders the right to vote on decisions affecting a blockchain network or DeFi platform.
Impermanent Loss: A potential loss faced by liquidity providers in a liquidity pool when the price of their deposited assets changes significantly.
3. Wallets and Security Terms
- * **Wallet**: A digital tool or software that stores cryptocurrency and allows users to send, receive, and manage their digital assets.
4. Trading and Investment Terms
- * **Exchange**: A platform where users can buy, sell, and trade cryptocurrencies. Examples include Binance, Coinbase, and Kraken.
5. Technical and Mining Terms
- * **Mining**: The process of validating transactions and adding them to the blockchain, often rewarded with new cryptocurrency. This usually involves solving complex mathematical problems.
6. DeFi, NFTs, and Emerging Crypto Concepts
- * **DeFi (Decentralized Finance)**: A movement that aims to create an open-source, permissionless financial system built on blockchain, offering financial services without intermediaries like banks.
- * **Tokenomics**: The study and design of the economic model behind a cryptocurrency or token, including its distribution, supply, and incentives.
Conclusion
Understanding cryptocurrency involves getting familiar with the terminology that defines this space. From basic terms like blockchain and wallet to more advanced concepts like DeFi and NFTs, this guide covers the essential vocabulary you’ll encounter. Whether you’re just beginning your crypto journey or deepening your knowledge, these common cryptocurrency terms will equip you with the language and insight to better understand this rapidly evolving world.
What is Cryptocurrency? Why Are They So Popular?
Cryptocurrency has become one of the most talked-about innovations in the world of finance and technology in recent years. Its decentralized nature and potential to revolutionize traditional monetary systems have intrigued millions of people globally. But what is cryptocurrency? How does it work? And why has it gained such immense popularity? In this blog post, we will explore the fundamentals of cryptocurrency, its working mechanisms, and the factors driving its growing popularity.
1. What is Cryptocurrency?
At its core, cryptocurrency is a form of digital or virtual currency that relies on cryptographic techniques for security. Unlike traditional currencies, such as the U.S. dollar or the euro, cryptocurrencies operate on a decentralized platform, meaning they are not controlled by a central authority like a government or a financial institution.
Cryptocurrencies are based on blockchain technology, a digital ledger that records all transactions across a network of computers. This decentralized system ensures transparency and security without the need for intermediaries, such as banks, to verify and facilitate transactions.
The most well-known cryptocurrency is Bitcoin, which was introduced in 2009 by an anonymous entity (or group) using the pseudonym Satoshi Nakamoto. Since then, thousands of other cryptocurrencies—often referred to as “altcoins”—have emerged, each with its own unique features and uses.
2. How Does Cryptocurrency Work?
Cryptocurrencies function on a combination of complex technologies that allow for secure and decentralized transactions. Understanding the mechanics of cryptocurrency requires a closer look at three key components: blockchain technology, decentralization, and cryptographic security.
Blockchain Technology
The backbone of all cryptocurrencies is blockchain technology. A blockchain is essentially a digital ledger that records every transaction that takes place within a given cryptocurrency’s network. This ledger is made up of “blocks” that contain data on the transaction (such as sender, receiver, and amount) and are “chained” together in chronological order.
Blockchain technology is designed to be both secure and immutable. Once a block has been added to the chain, it cannot be altered or deleted. This ensures a high level of transparency, as every transaction is recorded and can be audited. Additionally, because blockchain is decentralized and spread across multiple computers (or nodes) in the network, no single entity can control the entire system.
Decentralization and Peer-to-Peer Networks
Unlike traditional financial systems that rely on centralized institutions like banks, cryptocurrencies operate on decentralized networks of computers. These networks use a peer-to-peer (P2P) structure, where each participant (or node) plays a role in verifying and validating transactions.
When a user initiates a transaction, it is broadcast to the network, where nodes work to validate it. This process is known as “mining” in the context of some cryptocurrencies like Bitcoin, where miners use computing power to solve complex mathematical problems that validate transactions. Once verified, the transaction is added to the blockchain, and the user receives their cryptocurrency.
Cryptographic Security
Cryptocurrencies are secured by advanced cryptography. Every user has a “public key” and a “private key” that serve as their address and signature, respectively. The public key is what others use to send you cryptocurrency, while the private key allows you to authorize transactions from your account.
The use of cryptographic techniques ensures that transactions are secure and cannot be easily tampered with. If a user’s private key is lost or stolen, however, they may lose access to their funds permanently, which is one of the inherent risks of cryptocurrencies.
3. Types of Cryptocurrencies
Bitcoin
Bitcoin is the first and most widely recognized cryptocurrency. Launched in 2009, it was designed as a digital alternative to traditional fiat currencies. Bitcoin operates on its own blockchain and uses a proof-of-work (PoW) system, where miners compete to validate transactions and are rewarded with new bitcoins.
Bitcoin’s primary appeal lies in its simplicity and its status as a pioneer in the cryptocurrency space. It is often viewed as “digital gold,” and many investors treat it as a store of value or a hedge against inflation.
Altcoins (Ethereum, Litecoin, Ripple, etc.)
While Bitcoin remains the dominant player, many other cryptocurrencies—collectively referred to as altcoins—have emerged over the years. Each of these altcoins offers unique features and use cases:
Ethereum: Known for its smart contract functionality, Ethereum allows developers to build decentralized applications (dApps) on its platform. It is widely used in decentralized finance (DeFi) and non-fungible tokens (NFTs).
Litecoin: Often called the “silver to Bitcoin’s gold,” Litecoin was designed to offer faster transaction times and lower fees than Bitcoin.
Ripple (XRP): Ripple focuses on facilitating cross-border payments and is used by financial institutions for efficient money transfers.
Altcoins have added a layer of innovation to the cryptocurrency world, with many offering features beyond simple peer-to-peer transactions.
4. Why Are Cryptocurrencies So Popular?
The surge in cryptocurrency’s popularity can be attributed to several factors, each appealing to different groups of people. Some view cryptocurrencies as a means to gain financial independence, while others see them as speculative investments with the potential for significant returns.
Financial Independence
One of the main attractions of cryptocurrency is the idea of financial independence. Traditional financial systems are often controlled by governments, banks, and other institutions, which can impose fees, restrictions, or delays on transactions. Cryptocurrencies offer an alternative where users have full control over their funds without needing to rely on intermediaries.
This decentralized nature appeals to those who value privacy and autonomy, especially in regions where the traditional banking infrastructure is weak or where there are concerns about government overreach.
Investment Potential and Speculation
Cryptocurrencies have garnered significant attention as investment vehicles, with Bitcoin and many altcoins experiencing dramatic price increases over the years. Early investors in Bitcoin, for example, have seen massive returns, fueling a speculative frenzy.
Many view cryptocurrencies as a way to diversify their portfolios, often hoping to capitalize on the volatility of the market. The potential for high returns, combined with the growing adoption of cryptocurrencies in mainstream finance, has made them an attractive asset for retail and institutional investors alike.
Security and Privacy
Cryptocurrencies offer enhanced security and privacy compared to traditional financial systems. Transactions are pseudonymous, meaning that while transaction data is publicly available on the blockchain, the identity of the parties involved is not directly tied to the transaction.
This level of privacy, combined with the security provided by cryptography, makes cryptocurrencies appealing to individuals who prioritize data protection and the secure transfer of value.
Accessibility and Global Nature
Cryptocurrencies are accessible to anyone with an internet connection, making them a global currency in a true sense. This accessibility allows individuals from all parts of the world to participate in the global economy without needing a traditional bank account.
Furthermore, cryptocurrencies offer a solution to the issue of cross-border payments, which can be slow and expensive through traditional banking systems. By using cryptocurrency, international transfers can be completed quickly and at a fraction of the cost.
5. Challenges and Risks of Cryptocurrency
While cryptocurrencies offer many advantages, they also come with several challenges and risks that should not be overlooked.
Volatility
Cryptocurrency markets are notoriously volatile. Prices can fluctuate dramatically within short periods, leading to significant gains or losses for investors. This volatility is often driven by speculative trading, regulatory news, or changes in the broader economic environment.
Regulatory Concerns
Cryptocurrencies operate in a relatively unregulated space. Governments and regulatory bodies are still determining how to classify and control these digital assets. In some countries, cryptocurrencies are banned or heavily restricted, while others are working to create frameworks for their regulation.
Security Risks
Although cryptocurrencies are designed to be secure, they are not immune to security risks. Hacks, scams, and fraud have occurred, particularly on cryptocurrency exchanges, where users’ funds are stored in digital wallets. Additionally, if a user loses access to their private key, they can lose access to their cryptocurrency permanently.
6. Conclusion
Cryptocurrency represents a new frontier in the world of finance, offering exciting possibilities for decentralization, financial autonomy, and innovation. With the increasing adoption of digital currencies like Bitcoin and Ethereum, cryptocurrencies have become a popular investment and a potential game-changer in global finance. However, it’s essential to understand both the opportunities and risks that come with this technology.
While cryptocurrencies offer enhanced privacy, security, and the potential for significant returns, they also come with volatility, regulatory challenges, and security concerns. As the cryptocurrency space continues to evolve, it will be interesting to see how these digital assets shape the future of money and finance. We have prepared a popular cryptocurrencies list for you in this blog post.
Extended List of Social Media Platforms
Here is an extended list of social media platforms, adding more categories and options to cover a wide range of use cases, regions, and interests.
General Social Media Platforms
Facebook
Instagram
Twitter (X)
LinkedIn
Snapchat
TikTok
Pinterest
Reddit
YouTube
WhatsApp
WeChat
Telegram
Tumblr
Viber
Quora
Signal (Privacy-focused messaging)
Mastodon (Decentralized microblogging)
MeWe (Privacy-focused alternative to Facebook)
Ello (Ad-free and creative community)
Diaspora (Decentralized, privacy-focused platform)
Visual and Video Platforms
- * **Vimeo**
Flickr
Dailymotion
Triller
Byte
Likee
Twitch
Periscope (Live streaming; Twitter integration)
Bigo Live (Video and live streaming)
Caffeine (Live streaming, focused on gaming)
Medium (Blogging and long-form writing)
Discord (Gaming, community chats, now broader use)
Behance (Design and creative portfolios)
Dribbble (Creative community, particularly design)
SoundCloud (Music sharing, focused on independent artists)
Spotify (Music and podcast social features)
Goodreads (Books, reading, and literary discussions)
DeviantArt (Art and creative sharing)
Patreon (Content creators and membership subscriptions)
Substack (Publishing platform for newsletters)
Letterboxd (Social platform for movie lovers and reviews)
Audiomack (Music streaming, especially for independent artists)
Mix (Content discovery and bookmarking)
Untappd (Social network for beer enthusiasts)
Last.fm (Music tracking and discovery)
Bandcamp (Independent musicians and fan engagement)
Ravelry (Knitting and crocheting community)
Wattpad (Story writing and reading)
Ko-fi (Tipping and support platform for creators)
Fanfiction.net (Fan fiction writing and community)
Line (Widely used in Japan)
KakaoTalk (Dominant in South Korea)
Sina Weibo (Chinese microblogging platform)
Douyin (Chinese version of TikTok)
Qzone (Popular social network in China)
Renren (China’s former Facebook equivalent, still active)
Taringa! (Popular in Latin America)
Zalo (Vietnam’s most popular social app)
Vero (Ad-free social network with chronological posts)
XING (German-speaking professional network)
Facenama (Popular in Iran)
Gaia Online (Anime-themed social network)
Odnoklassniki (Popular in Russia for reconnecting with classmates)
Microsoft Teams (Professional communication)
Yammer (Enterprise social network)
Glassdoor (Job reviews, company insights)
AngelList (Startup networking and job hunting)
GitHub (Code sharing, version control, networking)
Stack Overflow (Developer Q&A and networking)
ResearchGate (Platform for researchers and academics)
Academia.edu (Academics sharing papers and research)
Polywork (Professional networking with project focus)
Bumble
OkCupid
Hinge
Match.com
Plenty of Fish (POF)
Grindr (LGBTQ+ dating and social networking)
HER (Dating and social networking for LGBTQ+ women)
Coffee Meets Bagel
Happn (Location-based social discovery)
Fitocracy (Social fitness app for tracking and motivation)
MapMyRun (Fitness tracking with social elements)
Runkeeper (Fitness tracking with social features)
MyFitnessPal (Social elements in diet and fitness tracking)
Razer Cortex (Gaming and social interaction)
Battle.net (Gaming and online communities)
GG (Esports and gaming community)
Kongregate (Online games with community features)
Catster (Social platform for cat lovers)
Cuteness (Pet lovers sharing cute moments)
Petster (Social network for pets and owners)
Furbo (Interactive platform for dog owners)
Buffer (Content scheduling and management)
Sprout Social (Social media monitoring and engagement)
Later (Instagram-focused social media management)
Canva (Design tool with social sharing features)
Niche or Specialized Networks
- * **Clubhouse** (Audio-based conversations)
Regional or Specialized Platforms
- * **VK (VKontakte)** (Popular in Russia and CIS countries)
Professional and Work-Focused Platforms
- * **Slack** (Team communication and collaboration)
Dating and Networking Platforms
- * **Tinder**
Fitness, Sports, and Lifestyle Platforms
- * **Strava** (Running, cycling, and fitness community)
Gaming and Esports Platforms
- * **Steam Community** (Gaming and discussion)
Pet and Animal Communities
- * **Dogster** (Social platform for dog lovers)
Additional Platforms for Businesses and Content Creators
- * **Hootsuite** (Social media management and analytics)
This extended list covers a diverse range of social media platforms, from major global networks to niche platforms catering to specific interests, industries, and regional markets. Whether you’re looking to connect with like-minded individuals, share creative works, or engage in professional networking, there’s a platform for virtually every purpose.
Exploring Mastodon: A Decentralized Alternative to Traditional Social Media
In recent years, the social media landscape has experienced growing concerns about privacy, data collection, content moderation, and the centralization of control. Major platforms like Facebook, Twitter (now X), and Instagram are often criticized for their monopoly on user data and the algorithms that drive their content. As a response to this dissatisfaction, decentralized alternatives have emerged, offering users more control over their online experience. Among these, Mastodon stands out as a unique, open-source platform that provides a fresh approach to social networking.
In this blog post, we’ll take a deep dive into Mastodon—what it is, how it works, its decentralized structure, and why it’s become an attractive alternative to mainstream social networks. We’ll also explore its benefits, limitations, and how users can get started on this innovative platform.
What is Mastodon?
Mastodon is a decentralized, open-source social network that allows users to interact through text posts (called “toots”), images, videos, and links, much like traditional social platforms. Launched in 2016 by Eugen Rochko, Mastodon was created as a reaction to the increasing dominance of large tech companies in social media. Unlike centralized platforms where one company controls all user data and interactions, Mastodon operates through a federated model, giving users more autonomy.
In essence, Mastodon isn’t a single website like Twitter or Facebook; it’s a network of independently hosted servers (called instances) that are connected, allowing users to communicate across different instances. This concept of decentralization is at the heart of Mastodon’s philosophy.
Key Features of Mastodon:
Federated network: Mastodon is not owned or controlled by a single entity. It’s made up of multiple independent servers that communicate with each other.
No algorithms: Mastodon shows content in a chronological order, unlike traditional social media platforms that use complex algorithms to decide what users see.
Open-source: Mastodon’s code is open-source, meaning anyone can inspect, modify, or contribute to its development.
Greater privacy: Users have more control over their data and privacy settings on Mastodon.
How Does Mastodon Work?
To understand Mastodon, it’s essential to grasp the concept of federation. Each user on Mastodon signs up on an instance—a server run by an individual, organization, or community. These instances can set their own rules and moderation policies, creating a network where each instance is part of the larger Mastodon universe, called the Fediverse (short for federated universe).
Signing Up and Choosing an Instance
When you sign up for Mastodon, you must first choose an instance to join. Think of it like choosing a neighborhood in a larger city. Each instance has its own community and theme, catering to different interests. For example, some instances might focus on tech discussions, while others might be for artists, activists, or specific regions.
While instances are independent, they are interconnected, meaning users on one instance can interact with users on other instances. It’s this federated structure that makes Mastodon different from traditional social networks, where all users are part of the same monolithic system.
Posting and Interacting on Mastodon
Once you’ve signed up on an instance, you can start posting “toots” (Mastodon’s version of tweets) and interacting with other users. There are no algorithms curating your feed, so you’ll see posts from people you follow in real-time. Mastodon also offers different privacy settings for each toot—you can choose to make a post public, visible only to followers, or unlisted. This gives users more control over who sees their content.
Just like on other social networks, users can favorite, boost (the Mastodon equivalent of retweeting), and reply to posts. There’s also the option to follow users from other instances, expanding your social circle beyond your own instance.
Moderation and Content Control
One of the key benefits of Mastodon is its approach to moderation. Each instance is responsible for enforcing its own rules, which means moderation can vary from one instance to another. For example, some instances might have strict rules against hate speech and harassment, while others may prioritize free speech with fewer restrictions.
Because moderation is decentralized, users have the freedom to choose instances that align with their values. However, it’s important to note that if an instance fails to moderate harmful content effectively, other instances can choose to block or defederate from it, cutting off interaction with that instance’s users.
Why Mastodon is Gaining Popularity
Mastodon’s appeal lies in its user-centric approach, offering solutions to some of the key issues associated with mainstream social media. Here are a few reasons why people are turning to Mastodon:
- Decentralization and User Control
Mastodon’s federated model puts power back into the hands of users and communities. Because no single entity controls the platform, there’s less concern about corporate interference, data monetization, or arbitrary changes to the platform’s rules.
Users can create or join instances that match their preferences, and they aren’t beholden to a profit-driven company that might prioritize advertisers over user interests. This level of control is appealing to individuals who are increasingly wary of big tech companies and their data collection practices.
- Privacy and Data Security
Mastodon emphasizes user privacy. While many centralized platforms collect vast amounts of personal data to sell to advertisers, Mastodon doesn’t operate with the same profit motive. Because instances are independently run, there’s no centralized body harvesting user data. Additionally, Mastodon offers robust privacy settings, allowing users to control who sees their posts and how their data is handled.
- No Ads or Algorithms
One of the most significant draws of Mastodon is its lack of ads and algorithms. On platforms like Facebook and Twitter, algorithms determine what users see, often favoring sensational or highly engaging content to increase user engagement and maximize advertising revenue. Mastodon, on the other hand, shows posts in chronological order, allowing users to have a more organic and unfiltered experience.
The absence of ads also means there’s no incentive to manipulate user behavior for profit, fostering a more authentic and less commercialized environment.
- Community-Driven Environment
Because Mastodon is composed of various instances, each instance can cultivate its own community and culture. Users are free to join instances that reflect their interests or values, and instance administrators are free to establish rules and moderation policies that suit their communities.
This community-driven model offers a level of flexibility and diversity not often found on monolithic platforms, allowing people with niche interests or concerns to create spaces tailored specifically to their needs.
Challenges and Limitations of Mastodon
While Mastodon offers a refreshing alternative to traditional social networks, it’s not without its challenges. These limitations should be considered by potential users before making the switch.
- Fragmentation
Mastodon’s federated model, while empowering, can lead to fragmentation. Unlike Twitter, where all users are part of the same platform, Mastodon’s instances create a more siloed experience. This can make it difficult for new users to decide which instance to join or to discover content across the entire network. While users can interact across instances, the lack of a centralized system can be confusing for some.
- Smaller User Base
Although Mastodon has grown in popularity, it still has a much smaller user base compared to major platforms like Facebook or Instagram. This can make it harder for new users to find friends or followers, and it may limit the reach of content creators who rely on large audiences. However, for many, the smaller, more intimate nature of Mastodon is part of its appeal.
- Learning Curve
For users accustomed to traditional social media platforms, Mastodon’s decentralized structure can take some getting used to. The process of choosing an instance, navigating different communities, and understanding the federated model can feel overwhelming at first.
How to Get Started on Mastodon
Getting started on Mastodon is relatively simple:
Choose an Instance: Begin by selecting an instance that aligns with your interests or values. You can browse instance directories such as joinmastodon.org to find one that suits you.
Sign Up: Create an account on your chosen instance by providing a username, email, and password.
Customize Your Profile: Like other social platforms, Mastodon allows you to customize your profile with a bio, avatar, and header image.
Follow Users: Start following users both within your instance and from other instances to build your feed.
Explore and Engage: Interact with posts by tooting, boosting, and replying. Engage with your instance’s community and discover new people through Mastodon’s federated network.
Conclusion
Mastodon offers a unique, decentralized alternative to traditional social media platforms, giving users more control over their data, privacy, and community interactions. With its federated structure, lack of algorithms, and emphasis on user-driven moderation, Mastodon represents a new frontier in social networking. While it comes with some challenges, such as a smaller user base and a learning curve, Mastodon’s community-driven approach makes it a compelling choice for those seeking a more open, transparent, and user-centric social experience.
Best Social Sharing Plugins for WordPress: A Comprehensive Guide
Introduction
In today’s digital age, social media has become an integral part of our lives. It’s a powerful tool for businesses to connect with their audience, increase brand awareness, and drive traffic to their websites. One effective way to leverage social media is through social sharing. By allowing visitors to easily share your content on their favorite platforms, you can amplify its reach and potentially attract new followers and customers.
This comprehensive guide will explore some of the best social sharing plugins available for WordPress. These plugins offer a variety of features to help you optimize your content for social sharing and maximize its impact.
Key Factors to Consider When Choosing a Social Sharing Plugin
Before diving into specific plugins, let’s discuss the key factors you should consider when making your selection:
Ease of Use: The plugin should be intuitive and easy to set up, even for those without technical expertise.
Customization Options: Look for a plugin that allows you to customize the appearance, placement, and functionality of the sharing buttons to match your website’s design and branding.
Social Network Compatibility: Ensure the plugin supports the social networks that are most relevant to your target audience.
Analytics and Tracking: A good plugin should provide insights into how your content is being shared, allowing you to track performance and make data-driven decisions.
Mobile Optimization: In today’s mobile-first world, it’s essential that the plugin works seamlessly on all devices.
Top Social Sharing Plugins for WordPress
Now, let’s delve into some of the most popular and highly-rated social sharing plugins for WordPress:
1. Social Warfare
Social Warfare is a powerful and versatile plugin that offers a wide range of features, including:
Customization: You can customize the appearance, placement, and behavior of the sharing buttons to match your website’s design.
Analytics: Track the performance of your content on social media and identify the most popular sharing networks.
Sharing Optimization: Social Warfare helps you optimize your content for social sharing by suggesting the best title and image to use.
Call-to-Action Buttons: Create custom call-to-action buttons to encourage visitors to take specific actions, such as subscribing to your newsletter or downloading a freebie.
2. AddToAny Share Buttons
AddToAny is a popular and lightweight plugin that offers a simple and effective way to add social sharing buttons to your website. Key features include:
Customization: Choose from a variety of button styles and layouts.
Social Network Support: AddToAny supports over 100 social networks and sharing options.
Mobile Optimization: The plugin is fully responsive and works well on all devices.
Analytics: Track the performance of your social shares.
3. Shareaholic
Shareaholic is a comprehensive social sharing plugin that offers a variety of features, including:
Customization: Customize the appearance, placement, and behavior of the sharing buttons.
Analytics: Track the performance of your social shares and identify your top-performing content.
Related Content Suggestions: Shareaholic can suggest related content to your visitors, increasing engagement and time on site.
Social Follow Buttons: Add social follow buttons to your website to encourage visitors to follow you on social media.
4. MashShare
MashShare is a fast and efficient social sharing plugin that offers a variety of customization options. Key features include:
Customization: Choose from a variety of button styles and layouts.
Social Network Support: MashShare supports a wide range of social networks.
Analytics: Track the performance of your social shares.
Floating Sidebar: Display the sharing buttons in a floating sidebar that stays visible as visitors scroll down the page.
5. Easy Social Share Buttons
Easy Social Share Buttons is a user-friendly plugin that offers a variety of customization options. Key features include:
Customization: Choose from a variety of button styles and layouts.
Social Network Support: Easy Social Share Buttons supports a wide range of social networks.
Analytics: Track the performance of your social shares.
Floating Sidebar: Display the sharing buttons in a floating sidebar that stays visible as visitors scroll down the page.
Additional Tips for Maximizing Social Sharing
In addition to choosing a good social sharing plugin, here are some additional tips for maximizing social sharing:
Create High-Quality Content: People are more likely to share content that is valuable, informative, or entertaining.
Use Eye-Catching Images: A visually appealing image can help your content stand out and encourage sharing.
Optimize Your Titles and Descriptions: Write compelling titles and descriptions that accurately reflect the content of your post and entice people to click.
Encourage Sharing: Explicitly ask your readers to share your content on social media. You can include a call-to-action at the beginning or end of your post.
Monitor and Respond: Keep an eye on your social media accounts and respond to comments and messages. This can help build relationships with your audience and encourage them to share your content.
Conclusion
Social sharing is a powerful tool for increasing your website’s visibility and driving traffic. By choosing the right social sharing plugin and following the tips outlined in this guide, you can effectively promote your content on social media and reach a wider audience.
300 topics related to Data Communications and Networking
Here is a list of 300 topics related to Data Communications and Networking:
Fundamentals of Data Communications
Networking Basics
- * Types of Computer Networks (LAN, MAN, WAN)
Working of Switches in a Network
Bridges and Their Role in Networking
Firewalls and Network Security
Gateways and Their Functions
Modems and Their Role in Data Communication
Wireless Access Points (WAPs)
Load Balancers in Networks
Proxy Servers: How They Work
Network Interface Cards (NICs)
VLANs and Their Applications
Managed vs. Unmanaged Switches
Power over Ethernet (PoE) Technology
Packet Shapers and Traffic Management
Hardware and Software Firewalls
Internet Control Message Protocol (ICMP)
Hypertext Transfer Protocol (HTTP/HTTPS)
Simple Mail Transfer Protocol (SMTP)
File Transfer Protocol (FTP) and Secure FTP (SFTP)
Simple Network Management Protocol (SNMP)
Telnet and Secure Shell (SSH)
Border Gateway Protocol (BGP)
Open Shortest Path First (OSPF)
Routing Information Protocol (RIP)
Transmission Control Protocol (TCP)
User Datagram Protocol (UDP)
Secure Sockets Layer (SSL) and Transport Layer Security (TLS)
Internet Protocol Security (IPsec)
Dynamic Routing Protocols
Static vs. Dynamic Routing
Spanning Tree Protocol (STP)
Voice over IP (VoIP) Protocols
Quality of Service (QoS) Protocols
Multiprotocol Label Switching (MPLS)
Wi-Fi Standards (802.11a/b/g/n/ac/ax)
WiMAX Technology
Cellular Networks (2G, 3G, 4G, 5G)
Bluetooth Communication in Networking
Zigbee Protocol in Wireless Communication
RFID and Near Field Communication (NFC)
Wireless Security Protocols (WEP, WPA, WPA2, WPA3)
Mobile Ad Hoc Networks (MANET)
Wireless Mesh Networks
Wi-Fi Direct: How It Works
Wireless Interference and Solutions
Wireless Spectrum Management
Long Range Wireless Networks (LoRaWAN)
Wireless Antenna Technologies
Software-Defined Networking (SDN)
Network Functions Virtualization (NFV)
Data Center Networking
Virtual Private Networks (VPNs)
MPLS vs. VPN: Differences and Applications
Content Delivery Networks (CDNs)
Cloud Networking: Overview
Edge Computing and Networking
Internet of Things (IoT) and Networking
Network Convergence in Communication
Network Automation and Orchestration
5G Networks: Architecture and Deployment
IPv6: Benefits and Challenges
Carrier Ethernet and WAN Technologies
Network Encryption Techniques
Firewalls: Types and Configurations
Intrusion Detection Systems (IDS)
Intrusion Prevention Systems (IPS)
Virtual Private Networks (VPN) for Secure Communication
SSL/TLS Certificates in Secure Web Traffic
DDoS (Distributed Denial-of-Service) Attacks and Mitigation
Public Key Infrastructure (PKI) in Networking
Two-Factor Authentication (2FA)
Wireless Security Best Practices
Zero Trust Network Security Model
Network Security Auditing and Compliance
Network Penetration Testing
Securing Internet of Things (IoT) Devices
Threat Intelligence in Networking
Network Forensics and Incident Response
Phishing and Social Engineering Attacks
Secure Network Design Principles
Advanced Persistent Threats (APTs) in Networking
Asymmetric vs. Symmetric Encryption in Networking
Fiber Optic Communication: How It Works
Satellite Communication and Networking
IPv6 Transition Mechanisms
Network Slicing in 5G
Smart Grid Networking
Low-Power Wide-Area Networks (LPWAN)
Li-Fi (Light Fidelity) Networks
Cognitive Radio Networks
Self-Organizing Networks (SON)
Network Security Protocols in Layer 3
Dense Wavelength Division Multiplexing (DWDM)
Passive Optical Networks (PON)
Ethernet over Power (EoP) Networking
Network Monitoring Tools: Overview
Simple Network Management Protocol (SNMP) Monitoring
Network Traffic Analysis and Control
Network Latency Optimization Techniques
Network Troubleshooting Strategies
Packet Sniffing and Network Analysis
Load Balancing in Network Traffic
High Availability in Network Design
Redundancy Protocols: VRRP and HSRP
Network Performance Tuning
Wi-Fi Optimization Techniques
Monitoring Cloud Networks
Performance Testing in Network Infrastructure
Network Downtime Prevention
Internet Governance and Net Neutrality
TCP/IP Protocol Stack
Routing Protocols in the Internet
Domain Name System (DNS): How It Works
HTTP vs. HTTPS: Differences
Internet Exchange Points (IXPs)
The Role of ISPs in Data Communication
The Dark Web and Network Security
IPv6 Adoption and Challenges on the Internet
Digital Certificates in Secure Communications
Encryption in Internet Communication
The Role of Content Delivery Networks (CDNs)
Cloud Services and Internet Infrastructure
Peer-to-Peer Networking on the Internet
Internet Backbone and Infrastructure Providers
Evolution of Web Protocols
Secure Internet Protocols: SSL and TLS
Internet of Things (IoT) on the Internet
Internet Bandwidth Management
Cloud-Based VPNs: How They Work
Cloud Firewalls for Network Security
Software-Defined WAN (SD-WAN)
Cloud Load Balancers
Cloud-Native Networking Solutions
Multi-Cloud Networking Strategies
Serverless Architecture and Networking
Edge Cloud Computing
Hybrid Cloud Networking
Virtual LANs in Cloud Infrastructure
Cloud Traffic Engineering
Data Privacy in Cloud Networking
Microsegmentation in Cloud Networks
Network Topologies for Cloud Deployment
Quantum Networking: Future Prospects
Artificial Intelligence in Networking
Blockchain Technology in Networking
6G Networks: What to Expect
Virtual Reality and Networking
Augmented Reality and Network Challenges
Internet of Things (IoT) Evolution
Satellite Internet Technologies
Network Security in the Age of AI
The OSI Model Explained
HTTP/3: What’s New?
The Future of DNS Security Extensions (DNSSEC)
IPv6 Transition Protocols
Multicast Protocols in Networking
Spanning Tree Protocol (STP) Security
OpenFlow in Software-Defined Networking (SDN)
Internet Control Message Protocol (ICMP) Uses
Dynamic Host Configuration Protocol (DHCP) Explained
Edge Computing in IoT Networks
IoT Security Challenges
Low-Power IoT Protocols (Zigbee, LoRa)
5G and IoT Networking
IoT Communication Protocols
Smart Home Networks and IoT
IoT in Industrial Networks
Sensor Networks in IoT
IoT Cloud Connectivity
Hierarchical Network Design
Enterprise Network Design Best Practices
Data Center Network Architectures
SDN Architecture in Networks
Resilient Network Design Strategies
Fault Tolerance in Network Design
Network Redundancy and Failover Mechanisms
Network Segmentation Techniques
Designing for Scalability in Networks
GDPR and Networking Compliance
Encryption Methods for Secure Communication
Privacy-Enhanced Technologies (PETs)
Data Anonymization in Networking
End-to-End Encryption Techniques
Privacy Risks in 5G Networks
User Privacy in IoT Networks
Data Sovereignty in Cross-Border Networking
Secure Data Transmission Techniques
Network Protocol Emulation Tools
Network Simulation and Testing Tools
Traffic Shaping and Protocol Testing
VoIP Protocol Testing in Networks
Performance Testing for Wireless Protocols
Stress Testing Network Protocols
SDN Protocol Testing Techniques
Security Testing in Protocol Development
Conformance Testing in Network Protocols
Network Diagnostic Tools: An Overview
Ping and Traceroute in Network Troubleshooting
Troubleshooting Connectivity Issues
Troubleshooting Wireless Networks
Slow Network Speed: Causes and Fixes
Packet Loss Troubleshooting Techniques
Troubleshooting Network Layer Problems
Analyzing Network Traffic with Wireshark
Debugging DNS Issues
Firewalls: Types and Features
Intrusion Detection Systems (IDS) Overview
Snort: Open-Source IDS
Security Information and Event Management (SIEM)
Network Vulnerability Scanning Tools
Network Penetration Testing Tools
OpenVAS: Open-Source Security Scanner
Antivirus vs. Antimalware in Networks
Deep Packet Inspection (DPI) Tools
Mobile Network Architecture (4G vs. 5G)
Wireless Roaming and Handover
Mobile Backhaul Networks
Mobility Management in Wireless Networks
LTE (Long-Term Evolution) Technology
Mobility and QoS in 5G Networks
Radio Access Network (RAN) in Mobile Networks
Interference Management in Mobile Networks
Satellite-Based Mobile Networks
Baseband vs. Broadband Transmission
Transmission Modes: Simplex, Duplex
Error Control in Data Transmission
Modulation Techniques in Data Communication
Signal Propagation in Wireless Communication
Spread Spectrum Techniques
Frequency Division Multiplexing (FDM)
Time Division Multiplexing (TDM)
Orthogonal Frequency-Division Multiplexing (OFDM)
6G Networks: Concepts and Challenges
Internet of Nano-Things (IoNT)
Tactile Internet: Future of Networking
AI-Powered Networks: Trends and Opportunities
Quantum Networking: An Overview
Neural Networks in Data Communication
Blockchain-Based Networking Solutions
Smart Networks: AI and IoT Integration
Data Communications in Autonomous Vehicles
Network Devices
- * Functions of a Router in Networking
Network Protocols
- * What are Network Protocols?
Wireless Networking
- * Basics of Wireless Networks
Networking Technologies
- * Network Virtualization: Concepts and Benefits
Security in Networking
- * Overview of Network Security
Advanced Networking Concepts
- * Network Address Translation (NAT) and Port Forwarding
Network Performance and Monitoring
- * Network Performance Metrics
Data Communication and the Internet
- * Evolution of the Internet
Cloud Networking
- * What is Cloud Networking?
Future of Data Communications
- * Emerging Trends in Networking
Network Protocols and Standards
- * TCP/IP Protocols: A Deep Dive
IoT Networking
- * IoT Networking Architectures
Network Design and Architecture
- * Principles of Network Design
Networking and Data Privacy
- * Data Privacy in Networking
Network Protocol Testing
- * Testing TCP/IP Implementations
Network Troubleshooting
- * Common Network Issues and Fixes
Network Security Tools
- * Overview of Network Security Tools
Wireless Networks and Mobility
- * Mobility in Wireless Networks
Data Transmission Techniques
- * Analog vs. Digital Transmission
Emerging Networking Technologies
- * Li-Fi: Wireless Data Transmission Using Light
These topics cover a wide range of aspects related to data communications and networking, from basic concepts to advanced technologies and future trends. You can choose any of these topics to write about based on the depth of knowledge and interest.
The Top 5 Technology Trends You Can't Ignore in 2024
As we approach 2024, the technological landscape continues to evolve at an unprecedented pace. Innovations in artificial intelligence, blockchain, the Internet of Things (IoT), and cloud computing are reshaping industries and transforming the way we live and work. In this blog post, we’ll explore the top five technology trends that are set to dominate in 2024 and beyond. Whether you’re a business leader, technology enthusiast, or simply curious about the future, understanding these trends is crucial for staying ahead in our rapidly changing world.
1. Artificial Intelligence: From Assistants to Collaborators
Artificial Intelligence (AI) has been a buzzword for years, but in 2024, we’re seeing a significant shift in how AI is being integrated into our daily lives and business operations.
Generative AI Goes Mainstream
Generative AI, which includes technologies like GPT (Generative Pre-trained Transformer) models, is moving beyond text generation and into more complex creative tasks. In 2024, we can expect to see:
AI-Assisted Content Creation: Advanced AI tools will help create high-quality written content, images, and even video, revolutionizing industries like marketing, entertainment, and education.
Personalized Learning and Skill Development: AI-powered platforms will offer highly personalized learning experiences, adapting in real-time to individual learning styles and progress.
AI in Drug Discovery and Healthcare: Generative AI models will accelerate drug discovery processes and assist in developing personalized treatment plans.
Ethical AI and Responsible Development
As AI becomes more pervasive, there’s an increased focus on developing and implementing AI systems ethically and responsibly:
AI Governance Frameworks: Expect to see more comprehensive AI governance frameworks being adopted by organizations and potentially mandated by governments.
Explainable AI: There will be a greater emphasis on developing AI systems that can explain their decision-making processes, particularly in sensitive areas like healthcare and finance.
Bias Detection and Mitigation: Advanced tools and methodologies will be developed to detect and mitigate biases in AI systems, ensuring fairer outcomes across various applications.
AI-Human Collaboration
The narrative is shifting from AI replacing humans to AI augmenting human capabilities:
AI-Powered Decision Support: In fields like finance, healthcare, and strategic planning, AI will increasingly be used to provide data-driven insights to support human decision-making.
Augmented Creativity: AI tools will work alongside human creatives, offering suggestions, automating routine tasks, and even co-creating content.
AI in Scientific Research: AI will accelerate scientific discoveries by analyzing vast datasets, generating hypotheses, and even designing experiments.
2. Blockchain: Beyond Cryptocurrencies
While blockchain technology has been predominantly associated with cryptocurrencies, 2024 will see its applications expand significantly across various sectors.
Decentralized Finance (DeFi) 2.0
The next generation of DeFi platforms will address current limitations and offer more sophisticated financial services:
Improved Scalability and Interoperability: New blockchain protocols will enable faster transactions and seamless interaction between different blockchain networks.
Institutional DeFi: We’ll see increased adoption of DeFi by traditional financial institutions, blending centralized and decentralized finance.
Regulatory Compliance: DeFi platforms will incorporate more robust KYC (Know Your Customer) and AML (Anti-Money Laundering) measures to comply with evolving regulations.
Enterprise Blockchain Solutions
Blockchain will continue to gain traction in enterprise applications:
Supply Chain Transparency: More companies will implement blockchain to ensure transparency and traceability in their supply chains.
Digital Identity Management: Blockchain-based identity solutions will offer more secure and user-controlled identity verification systems.
Smart Contracts in Legal and Real Estate: The use of smart contracts will become more common in legal agreements and real estate transactions, streamlining processes and reducing fraud.
Tokenization of Assets
The concept of representing real-world assets as digital tokens on a blockchain will gain momentum:
Real Estate Tokenization: Fractional ownership of properties through tokenization will make real estate investing more accessible.
Art and Collectibles: The tokenization of art and collectibles will continue to grow, enabling fractional ownership and easier trading of high-value items.
Carbon Credits and Environmental Assets: Blockchain will play a crucial role in creating more transparent and efficient markets for carbon credits and other environmental assets.
3. Internet of Things (IoT): The Connected World Expands
The Internet of Things continues to grow, with more devices becoming interconnected and generating vast amounts of data. In 2024, we’ll see several key developments in the IoT space.
5G-Powered IoT
The widespread adoption of 5G networks will unlock new possibilities for IoT applications:
Industrial IoT (IIoT): 5G will enable more sophisticated and real-time monitoring and control systems in manufacturing and industrial settings.
Smart Cities: 5G-powered IoT sensors will enhance urban management, from traffic control to waste management and energy distribution.
Connected Vehicles: The automotive industry will leverage 5G and IoT for advanced driver assistance systems (ADAS) and vehicle-to-everything (V2X) communication.
Edge Computing in IoT
To address latency issues and reduce bandwidth usage, more processing will happen at the edge of the network:
AI at the Edge: IoT devices will increasingly incorporate AI capabilities, enabling local data processing and decision-making.
Predictive Maintenance: Edge computing will enable more effective predictive maintenance in industrial settings, reducing downtime and maintenance costs.
Privacy-Preserving IoT: Edge computing will allow for more data to be processed locally, addressing some privacy concerns associated with cloud-based IoT systems.
IoT Security and Standards
As the IoT ecosystem expands, security and standardization become increasingly crucial:
IoT Security Frameworks: Expect to see more comprehensive security frameworks specifically designed for IoT environments.
Standardization Efforts: Industry-wide efforts to establish common standards for IoT devices and communications will gain momentum, improving interoperability and security.
IoT Device Authentication: Advanced authentication methods, possibly leveraging blockchain technology, will be implemented to ensure the integrity of IoT networks.
4. Cloud Computing: The Next Evolution
Cloud computing continues to be a foundational technology for digital transformation. In 2024, we’ll see several trends reshaping the cloud landscape.
Multi-Cloud and Hybrid Cloud Strategies
Organizations will increasingly adopt multi-cloud and hybrid cloud approaches:
Cloud-Agnostic Tools: The development of cloud-agnostic tools and platforms will make it easier for organizations to manage multi-cloud environments.
Edge-Cloud Integration: Seamless integration between edge computing resources and centralized cloud services will become more common.
Cloud Cost Optimization: Advanced tools for managing and optimizing cloud costs across multiple providers will become essential for businesses.
Serverless Computing and Function-as-a-Service (FaaS)
Serverless architectures will continue to gain popularity:
Expanded Use Cases: Serverless computing will be adopted for a wider range of applications, including data processing, API backends, and even machine learning workflows.
Improved Developer Experience: Tools and frameworks for serverless development will mature, making it easier for developers to build and deploy serverless applications.
Event-Driven Architectures: Serverless computing will facilitate the adoption of event-driven architectures, enabling more responsive and scalable systems.
Sustainable Cloud Computing
As environmental concerns grow, cloud providers and users will focus on sustainability:
Green Data Centers: Cloud providers will invest more in renewable energy and energy-efficient data center technologies.
Carbon-Aware Computing: New tools and practices will emerge to help organizations optimize their cloud usage for reduced carbon footprint.
Circular Economy in IT: There will be an increased focus on recycling and reusing hardware in data centers to minimize environmental impact.
5. Quantum Computing: From Theory to Practice
While still in its early stages, quantum computing is poised to make significant strides in 2024, with potential impacts across various industries.
Quantum Supremacy Demonstrations
We can expect to see more demonstrations of quantum supremacy in specific problem domains:
Optimization Problems: Quantum computers will show their potential in solving complex optimization problems in fields like logistics and finance.
Material Science: Quantum simulations will accelerate the discovery of new materials with applications in energy storage, superconductivity, and more.
Cryptography: Progress in quantum computing will drive advancements in post-quantum cryptography to secure systems against future quantum threats.
Quantum-as-a-Service (QaaS)
Major cloud providers will expand their quantum computing offerings:
Hybrid Quantum-Classical Algorithms: We’ll see the development of more algorithms that leverage both quantum and classical computing resources.
Quantum Machine Learning: Early applications of quantum computing in machine learning tasks will demonstrate potential speedups for certain types of problems.
Quantum Software Development Kits (SDKs): More sophisticated SDKs will emerge, making it easier for developers to create quantum algorithms without deep physics knowledge.
Quantum Networking
The foundations for quantum networks will continue to be laid:
Quantum Key Distribution (QKD): Early commercial deployments of QKD systems will enhance the security of critical communications.
Quantum Repeaters: Progress in quantum repeater technology will pave the way for long-distance quantum networks.
Quantum Internet Protocols: Research into protocols for a future quantum internet will intensify, laying the groundwork for ultra-secure global communication networks.
Conclusion: Embracing the Future
As we look ahead to 2024, these five technology trends – AI, blockchain, IoT, cloud computing, and quantum computing – are set to reshape our digital landscape. The convergence of these technologies will create new opportunities for innovation, efficiency, and growth across industries.
However, with great technological power comes great responsibility. As these technologies advance, it’s crucial to consider their ethical implications, ensure robust security measures, and work towards sustainable implementation.
For individuals and organizations alike, staying informed and adaptable will be key to thriving in this rapidly evolving technological environment. Whether you’re a business leader looking to leverage these technologies for competitive advantage, a developer eager to explore new frontiers, or simply a curious observer of technological progress, understanding these trends will be essential for navigating the digital future.
As we embrace these advancements, let’s strive to harness their potential for the betterment of society, addressing global challenges, and creating a more connected, efficient, and sustainable world. The future is here, and it’s up to us to shape it responsibly and innovatively.
The Future of Electric Vehicles: How Tech Innovations Are Driving the EV Revolution
The electric vehicle (EV) industry is undergoing a transformative revolution driven by technological innovations. As we look to the future, three pivotal areas stand out: breakthroughs in battery technology, advancements in autonomous driving, and the development of charging infrastructure. This blog post will delve into each of these aspects, exploring how they collectively contribute to the EV revolution.
Breakthroughs in Battery Technology
Lithium-Ion Batteries
Lithium-ion batteries have long been the backbone of electric vehicles, offering a balance between energy density, cost, and lifecycle. However, recent advancements are pushing the boundaries of what these batteries can achieve. Researchers are now focusing on improving battery chemistry to enhance energy density and reduce charging times.
Solid-State Batteries: One of the most promising developments is the shift towards solid-state batteries. Unlike traditional lithium-ion batteries that use liquid electrolytes, solid-state batteries utilize solid electrolytes, which can significantly increase energy density and safety. This technology could potentially double the range of electric vehicles while reducing fire risks associated with liquid electrolytes[1][3].
Alternative Chemistries
In addition to solid-state technology, alternative chemistries such as lithium-sulfur and sodium-ion batteries are gaining traction. Lithium-sulfur batteries promise higher energy capacity at a lower cost, while sodium-ion batteries offer a more sustainable approach by utilizing abundant materials[2][3]. These innovations not only aim to enhance performance but also address environmental concerns related to battery production and disposal.
Recycling and Sustainability
As the demand for EVs increases, so does the need for sustainable battery production and recycling methods. Companies are investing in technologies that allow for efficient recycling of battery components, reducing waste and mitigating environmental impact. For instance, closed-loop recycling processes can recover valuable materials from used batteries, thereby decreasing dependency on raw material extraction[4].
Advancements in Autonomous Driving
The Intersection of EVs and AVs
The integration of autonomous vehicle (AV) technology with electric vehicles is reshaping transportation. Autonomous electric vehicles (AEVs) leverage advanced sensors and artificial intelligence to navigate roads safely and efficiently. This convergence is not just a technological trend; it represents a fundamental shift in how we think about mobility.
Safety Improvements: AEVs are designed to minimize human error, which is responsible for approximately 94% of traffic accidents. Equipped with sophisticated sensor arrays and machine learning algorithms, these vehicles can detect obstacles, predict pedestrian movements, and make real-time decisions to enhance road safety[1][2].
Regulatory Landscape
As AEV technology matures, regulatory frameworks are evolving to accommodate these innovations. Countries around the world are beginning to implement legislation that facilitates the testing and deployment of autonomous vehicles on public roads. For instance, the UK recently enacted The Automated Vehicles Act, paving the way for broader acceptance of self-driving technologies[5].
Industry Players
Major automotive manufacturers like Tesla and General Motors are at the forefront of this revolution. Tesla’s Full Self-Driving (FSD) package aims to achieve full autonomy through continuous software updates that enhance vehicle capabilities over time[6]. Meanwhile, GM envisions a future where all autonomous vehicles will be electric, emphasizing safety, eco-friendliness, and tech integration as key drivers for this transition[2][4].
Development of Charging Infrastructure
Current Challenges
Despite advancements in EV technology, charging infrastructure remains a significant barrier to widespread adoption. Many potential EV buyers express concerns about charging availability and speed compared to traditional gasoline stations. To address these challenges, extensive investment in charging networks is essential.
Fast-Charging Solutions
Innovations in fast-charging technology are critical for alleviating range anxiety among consumers. Ultra-fast charging stations can replenish an EV’s battery up to 80% in as little as 30 minutes, making long-distance travel more feasible[4]. Companies like ChargePoint and Electrify America are expanding their networks to include more fast-charging options across urban areas and highways.
Smart Charging Systems
The future also lies in smart charging systems that optimize energy use based on demand and grid capacity. These systems can schedule charging during off-peak hours when electricity rates are lower or when renewable energy sources are abundant[3]. By integrating smart grids with EV charging infrastructure, we can create a more sustainable energy ecosystem.
Incentives for Infrastructure Development
Governments worldwide are recognizing the importance of robust charging infrastructure in promoting EV adoption. Various incentives—such as tax credits for installing home chargers or funding for public charging stations—are being implemented to encourage both consumers and businesses to invest in EV technology[2][4].
Conclusion
The future of electric vehicles is bright, driven by groundbreaking advancements in battery technology, autonomous driving capabilities, and comprehensive charging infrastructure development. As these technologies continue to evolve and integrate, they promise not only to transform personal mobility but also to contribute significantly to environmental sustainability.
By addressing current challenges and leveraging innovative solutions, we stand on the cusp of a transportation revolution that could redefine our relationship with mobility—making it safer, cleaner, and more efficient than ever before.
As we move forward into this electrifying future, it is imperative for stakeholders across industries—manufacturers, policymakers, and consumers—to collaborate closely. Together, we can ensure that the transition to electric vehicles is not only successful but also beneficial for society as a whole.
Citations: [1] https://www.virtusa.com/digital-themes/autonomous-electric-vehicles [2] https://www.gm.com/stories/all-avs-should-be-evs [3] https://arxiv.org/pdf/2307.00016.pdf [4] https://www.govtech.com/fs/why-autonomous-and-electric-vehicles-are-inextricably-linked.html [5] https://evmagazine.com/top10/top-10-autonomous-vehicles [6] https://www.navya.tech/en/autonomous-hybrid-or-electric/ [7] https://www.reddit.com/r/SelfDrivingCars/comments/16rs6mz/best_electric_car_for_highway_self_driving/ [8] https://www.sciencedirect.com/science/article/abs/pii/S136192092200387X
How 5G is Shaping the Future of IoT: What to Expect in 2024 and Beyond
As we stand on the cusp of a new era in connectivity, the rollout of 5G networks is set to revolutionize the Internet of Things (IoT) landscape. This fifth-generation cellular network technology promises to bring unprecedented speed, reliability, and capacity to our connected devices. In this blog post, we’ll explore how 5G is poised to transform the IoT ecosystem, with a particular focus on its impact on smart devices and the broader technological landscape as we look ahead to 2024 and beyond.
Understanding 5G and IoT
Before delving into the future, let’s briefly recap what 5G and IoT mean:
5G: The fifth generation of cellular network technology, designed to deliver faster speeds, lower latency, and the ability to connect more devices simultaneously than its predecessors.
IoT (Internet of Things): A network of interconnected devices that can communicate and share data with each other and with users, often without human intervention.
The convergence of these two technologies is set to unlock new possibilities and reshape various industries.
The Promise of 5G for IoT
5G brings several key improvements that are particularly beneficial for IoT applications:
Enhanced Speed: With theoretical peak data rates of up to 20 Gbps, 5G can facilitate real-time data processing and analysis for IoT devices.
Lower Latency: 5G aims to reduce latency to as low as 1 millisecond, enabling near-instantaneous communication between devices.
Increased Connection Density: 5G networks can support up to 1 million connected devices per square kilometer, a significant increase from 4G.
Improved Energy Efficiency: 5G is designed to be more energy-efficient, which is crucial for battery-powered IoT devices.
Network Slicing: This feature allows for the creation of multiple virtual networks on a single physical infrastructure, enabling customized connectivity for different IoT applications.
Impact on Smart Devices
As we look towards 2024 and beyond, 5G is set to transform various categories of smart devices:
- Smartphones and Wearables
While smartphones are already benefiting from 5G’s increased speeds, the future will see even more integration with IoT ecosystems. Expect smartphones to become central hubs for controlling and monitoring a wide array of IoT devices.
Wearables, such as smartwatches and fitness trackers, will leverage 5G to provide more accurate, real-time health monitoring. We may see the emergence of new wearable form factors that take advantage of 5G’s capabilities, such as augmented reality (AR) glasses that can process complex data in real-time.
- Smart Home Devices
The smart home sector is poised for significant growth with 5G. Here’s what we might expect:
Enhanced Security Systems: 5G will enable more sophisticated home security systems with real-time video monitoring, facial recognition, and instant alerts.
Smart Appliances: Refrigerators, washing machines, and other household appliances will become more intelligent and responsive, with the ability to communicate with each other and with users more effectively.
Energy Management: 5G-enabled smart meters and thermostats will offer more precise control over energy consumption, leading to increased efficiency and cost savings.
- Autonomous Vehicles
5G is set to play a crucial role in the development and deployment of autonomous vehicles:
Vehicle-to-Everything (V2X) Communication: 5G will enable cars to communicate with each other, with infrastructure, and with pedestrians in real-time, enhancing safety and traffic management.
In-Vehicle Entertainment: With 5G’s high bandwidth, passengers in autonomous vehicles will have access to high-quality streaming content and immersive AR/VR experiences.
Over-the-Air Updates: 5G will facilitate faster and more reliable software updates for vehicles, ensuring they always have the latest features and security patches.
- Industrial IoT Devices
The industrial sector stands to benefit significantly from 5G-enabled IoT:
Smart Factories: 5G will power the next generation of smart factories, enabling real-time monitoring and control of production processes, predictive maintenance, and increased automation.
Remote Operations: With 5G’s low latency, remote operation of heavy machinery and robots will become more feasible and precise.
Asset Tracking: 5G-enabled sensors will provide more accurate and real-time tracking of assets throughout the supply chain.
Broader Impact on the Tech Landscape
The integration of 5G and IoT will have far-reaching effects on the broader technological landscape:
- Edge Computing
5G’s low latency and high bandwidth will accelerate the adoption of edge computing. This will allow for more processing to be done closer to the data source, reducing the need to send data to centralized cloud servers. This shift will be particularly important for applications requiring real-time processing, such as autonomous vehicles and industrial automation.
- Artificial Intelligence and Machine Learning
The increased data flow enabled by 5G will provide AI and ML algorithms with more information to learn from, leading to more accurate predictions and insights. This will be particularly impactful in areas such as:
Predictive maintenance in manufacturing
Personalized healthcare recommendations
Smart city management and optimization
- Augmented and Virtual Reality
5G’s high bandwidth and low latency are crucial for the widespread adoption of AR and VR technologies. We can expect to see more immersive and responsive AR/VR applications in various fields, including:
Education and training
Remote collaboration
Entertainment and gaming
- Smart Cities
5G will be a key enabler for smart city initiatives:
Traffic Management: Real-time data from vehicles and infrastructure will enable more efficient traffic flow and reduced congestion.
Public Safety: 5G-enabled cameras and sensors can enhance emergency response times and public safety monitoring.
Utility Management: Smart grids powered by 5G will improve the distribution and management of electricity, water, and gas.
Challenges and Considerations
While the future of 5G and IoT looks promising, there are several challenges that need to be addressed:
Security and Privacy: With more devices connected and more data being transmitted, ensuring the security and privacy of this information will be crucial.
Infrastructure Development: The rollout of 5G infrastructure requires significant investment and may take time to achieve widespread coverage.
Standardization: As the IoT ecosystem grows, ensuring interoperability between devices from different manufacturers will be essential.
Energy Consumption: While 5G is more energy-efficient per bit of data transmitted, the overall increase in data usage could lead to higher energy consumption.
Spectrum Allocation: Efficient allocation and management of the radio frequency spectrum will be necessary to support the growing number of 5G devices.
Looking Ahead: 2024 and Beyond
As we look towards 2024 and beyond, we can expect to see:
Widespread 5G Adoption: By 2024, 5G networks are likely to be widely available in most urban areas of developed countries.
Explosion of IoT Devices: The number of connected IoT devices is projected to reach 41.6 billion by 2025, according to IDC.
New Business Models: The convergence of 5G and IoT will enable new services and business models across various industries.
Enhanced User Experiences: From more immersive entertainment to more efficient public services, 5G-enabled IoT will transform user experiences in numerous ways.
Sustainability Initiatives: 5G and IoT will play a crucial role in sustainability efforts, from smart energy management to more efficient transportation systems.
Conclusion
The integration of 5G and IoT is set to usher in a new era of connectivity, transforming not just our devices but the very way we interact with the world around us. As we move towards 2024 and beyond, we can expect to see a proliferation of smart devices and applications that leverage the speed, reliability, and capacity of 5G networks.
From smarter homes and cities to more efficient industries and immersive entertainment experiences, the possibilities are vast and exciting. However, as we embrace this new technology, it’s crucial that we also address the challenges it presents, particularly in terms of security, privacy, and equitable access.
As we stand on the brink of this technological revolution, one thing is clear: the future of IoT, powered by 5G, is set to be more connected, more intelligent, and more transformative than ever before. Businesses, policymakers, and individuals alike would do well to prepare for this new landscape, as it promises to reshape our world in profound and far-reaching ways.
GPU vs CPU: When and Why to Choose One Over the Other
In the world of computing, two components often steal the spotlight: the Central Processing Unit (CPU) and the Graphics Processing Unit (GPU). While both are essential for modern computing tasks, they have distinct characteristics and excel in different areas. Understanding when and why to choose one over the other can significantly impact performance, efficiency, and cost-effectiveness in various applications, from gaming to artificial intelligence. In this blog post, we’ll dive deep into the world of CPUs and GPUs, comparing their strengths, weaknesses, and ideal use cases.
Understanding CPUs and GPUs
Before we delve into the comparison, let’s briefly define what CPUs and GPUs are and their primary functions.
What is a CPU?
The Central Processing Unit, or CPU, is often referred to as the “brain” of a computer. It’s a general-purpose processor designed to handle a wide variety of tasks efficiently. Key characteristics of CPUs include:
Versatility: CPUs can handle a diverse range of computational tasks.
Sequential Processing: They excel at executing complex instructions in a sequential manner.
Low Latency: CPUs are optimized for quick response times in interactive applications.
Cache Memory: They have large cache memories to reduce data access times.
What is a GPU?
The Graphics Processing Unit, or GPU, was initially designed to render graphics but has evolved to handle other types of parallel processing tasks. Key characteristics of GPUs include:
Parallel Processing: GPUs are designed to perform many simple calculations simultaneously.
Specialized Architecture: They are optimized for floating-point operations and matrix multiplication.
High Throughput: GPUs can process large amounts of data quickly when the same operation is applied to many data points.
Graphics-Oriented: They have specialized hardware for rendering graphics efficiently.
CPU vs GPU: A Comparison of Strengths and Weaknesses
To understand when to choose a CPU or GPU, it’s essential to compare their strengths and weaknesses across various factors.
- Processing Approach
CPU:
Excels at sequential processing
Optimized for complex, varied instructions
Better for tasks that require frequent branching and decision-making
GPU:
Designed for parallel processing
Efficient at performing the same operation on large datasets
Ideal for tasks that can be broken down into many identical, independent calculations
- Instruction Set Complexity
CPU:
Supports a wide range of complex instructions
Can handle diverse workloads efficiently
Better for tasks requiring sophisticated logic and control flow
GPU:
Has a more limited instruction set
Optimized for simpler, repetitive instructions
Excels when the same operation needs to be performed on many data points
- Memory Access
CPU:
Has access to large amounts of system RAM
Benefits from sophisticated cache hierarchies
Better for tasks with unpredictable memory access patterns
GPU:
Has high-bandwidth memory but in smaller quantities
Memory access is optimized for specific patterns
Excels when data access is predictable and can be coalesced
- Latency vs Throughput
CPU:
Optimized for low latency
Provides quick response times for interactive tasks
Better for applications requiring real-time user interaction
GPU:
Optimized for high throughput
Can process large amounts of data quickly
Ideal for batch processing and non-interactive workloads
- Power Efficiency
CPU:
Generally more power-efficient for general-purpose computing
Better suited for tasks that don’t require constant high performance
GPU:
Can be more power-efficient for specific, parallelizable workloads
May consume more power when fully utilized
- Cost Considerations
CPU:
Essential for all computing systems
Cost varies widely based on performance and features
GPU:
Optional for many systems but essential for others
High-end GPUs can be very expensive
Use Cases: When to Choose CPU vs GPU
Now that we’ve compared the strengths and weaknesses of CPUs and GPUs, let’s explore specific use cases where one might be preferred over the other.
Gaming
CPU-Intensive Aspects:
Game logic and AI
Physics simulations
Managing game state and player interactions
GPU-Intensive Aspects:
Rendering graphics and visual effects
Texture mapping and shading
High-resolution display output
When to Prioritize CPU:
For games with complex AI or physics simulations
Strategy games or simulations with many active entities
When running multiple background tasks while gaming
When to Prioritize GPU:
For visually demanding games with high-quality graphics
When gaming at high resolutions or frame rates
For VR gaming, which requires high performance rendering
Example: A modern open-world game might rely heavily on both CPU and GPU. The CPU handles the game’s complex AI systems, manages the open world’s many interactive elements, and coordinates gameplay mechanics. Meanwhile, the GPU renders the vast, detailed landscapes, complex character models, and sophisticated lighting and particle effects that make the game visually stunning.
Artificial Intelligence and Machine Learning
CPU-Intensive Aspects:
Data preprocessing and feature engineering
Training of simple models (e.g., linear regression, decision trees)
Inference for small-scale models
GPU-Intensive Aspects:
Training deep neural networks
Large-scale matrix operations
Parallel processing of big datasets
When to Prioritize CPU:
For small-scale machine learning projects
When working with models that don’t benefit from parallelization
For tasks involving a lot of branching or conditional logic
When to Prioritize GPU:
For training and inference with deep learning models
When working with large datasets that can be processed in parallel
For tasks involving computer vision or natural language processing
Example: In a computer vision project for autonomous vehicles, GPUs would be crucial for training and running the deep neural networks that process and analyze visual data from multiple cameras in real-time. The massive parallelism of GPUs allows for quick processing of complex image recognition tasks. However, the CPU would still play a vital role in coordinating the overall system, making high-level decisions based on the processed visual data, and managing other vehicle systems.
Video Editing and 3D Rendering
CPU-Intensive Aspects:
Video encoding and decoding
Effects that require sequential processing
Managing project files and timelines
GPU-Intensive Aspects:
Real-time preview rendering
Applying complex visual effects
3D rendering and animation
When to Prioritize CPU:
For tasks that require processing entire video files sequentially
When working with codecs that are optimized for CPU encoding
For managing large projects with many assets
When to Prioritize GPU:
For real-time playback of high-resolution video with effects
When working with 3D animation and complex visual effects
For faster rendering of final output in many cases
Example: A professional video editor working on a 4K documentary might rely heavily on both CPU and GPU. The CPU manages the overall project, handles the timeline, and performs certain types of video encoding. The GPU accelerates the playback of high-resolution footage, enables real-time application of complex effects and color grading, and speeds up the final render. Some specific effects might be CPU-bound, while others are GPU-accelerated, making a balance between strong CPU and GPU performance ideal for this scenario.
Scientific Computing and Data Analysis
CPU-Intensive Aspects:
Complex mathematical operations
Data preprocessing and cleaning
Running traditional statistical models
GPU-Intensive Aspects:
Large-scale numerical simulations
Parallel data processing operations
Certain types of cryptography
When to Prioritize CPU:
For analyses involving complex, interdependent calculations
When working with algorithms that don’t parallelize well
For general-purpose data analysis and statistical modeling
When to Prioritize GPU:
For large-scale simulations (e.g., climate modeling, particle physics)
When working with operations that can be heavily parallelized
For certain types of financial modeling and risk analysis
Example: In a climate modeling project, GPUs might be used to process the massive amounts of data and run complex simulations that involve many independent calculations. The parallel processing power of GPUs can significantly speed up these simulations. However, the CPU would still be crucial for managing the overall process, performing complex statistical analyses on the results, and handling parts of the model that require more sequential processing.
Web Servers and Databases
CPU-Intensive Aspects:
Processing web requests
Executing database queries
Running application logic
GPU-Intensive Aspects:
Certain types of database operations (e.g., sorting, hashing)
Specific web applications (e.g., browser-based 3D rendering)
When to Prioritize CPU:
For most traditional web serving and database management tasks
When running complex queries or stored procedures
For applications with heavy server-side processing
When to Prioritize GPU:
For specialized database operations that benefit from parallelization
In certain big data processing scenarios
For web applications that involve server-side rendering of graphics
Example: A typical web server handling e-commerce transactions would primarily rely on CPU power. The CPU processes incoming requests, executes database queries, runs the application logic, and generates dynamic content. However, if the same e-commerce site implemented a 3D product viewer or ran complex recommendation algorithms on large datasets, it might leverage GPU acceleration for these specific tasks while still relying primarily on the CPU for most operations.
The Future: CPU-GPU Collaboration
As technology evolves, the line between CPU and GPU is becoming increasingly blurred. We’re seeing developments such as:
Integrated Graphics: CPUs with built-in GPU capabilities for improved performance in everyday tasks.
Heterogeneous Computing: Frameworks that allow seamless use of both CPU and GPU resources for optimal performance.
Specialized AI Processors: Chips designed specifically for AI workloads, combining elements of both CPU and GPU architectures.
Quantum Computing: Emerging technology that may redefine how we approach certain types of computations.
Conclusion: Making the Right Choice
Choosing between CPU and GPU ultimately depends on the specific requirements of your application or workload. Here are some key takeaways:
Consider the Nature of Your Task: Is it primarily sequential or can it be parallelized?
Evaluate Your Performance Needs: Do you need low latency or high throughput?
Assess Your Budget: High-end GPUs can be expensive, so consider the cost-benefit ratio.
Think About Power Efficiency: GPUs can consume a lot of power when fully utilized.
Look at Software Support: Ensure that the software you’re using can take advantage of GPU acceleration if you’re considering that route.
Consider a Balanced Approach: Many modern workloads benefit from a combination of strong CPU and GPU performance.
By understanding the strengths and weaknesses of CPUs and GPUs, you can make informed decisions about hardware investments and software optimizations. Whether you’re a gamer, a data scientist, a content creator, or a software developer, choosing the right processing approach can significantly impact your productivity and the performance of your applications.
As technology continues to advance, we can expect to see even more innovative ways to leverage the strengths of both CPUs and GPUs, creating more powerful and efficient computing solutions for the challenges of tomorrow.
How Edge Computing is Changing the Game in Data Processing
In the rapidly evolving landscape of digital technology, edge computing has emerged as a game-changer in the way we process and analyze data. This innovative approach to data processing is reshaping industries, enabling new technologies, and paving the way for more efficient and responsive systems. In this blog post, we’ll explore what edge computing is, how it’s transforming data processing, and the significant advantages it offers for real-time data analysis across various sectors.
Understanding Edge Computing
Before we dive into the impact of edge computing, let’s first understand what it is and how it differs from traditional cloud computing.
What is Edge Computing?
Edge computing is a distributed computing paradigm that brings data storage and computation closer to the sources of data. Instead of relying solely on centralized data centers or cloud services, edge computing processes data at or near the “edge” of the network, where the data is generated.
Edge Computing vs. Cloud Computing
While cloud computing has revolutionized how we store and process data, edge computing addresses some of its limitations:
Latency: Cloud computing can introduce delays due to the distance data must travel. Edge computing reduces latency by processing data closer to its source.
Bandwidth: By processing data locally, edge computing reduces the amount of data that needs to be transmitted to central servers, saving bandwidth.
Real-time processing: Edge computing enables real-time data analysis and decision-making, crucial for many modern applications.
Offline functionality: Edge devices can continue to function even when disconnected from the central network, ensuring continuity of operations.
The Rise of Edge Computing: Driving Factors
Several technological trends and business needs have contributed to the rise of edge computing:
Internet of Things (IoT) proliferation: The explosion of IoT devices has created a need for local data processing to handle the vast amounts of data generated.
5G networks: The rollout of 5G networks complements edge computing by providing faster, more reliable connections for edge devices.
Artificial Intelligence and Machine Learning: The need for real-time AI/ML inference at the edge is driving the adoption of edge computing.
Privacy and security concerns: Edge computing can enhance data privacy by keeping sensitive information local rather than sending it to centralized servers.
Industry 4.0: The push for smart manufacturing and industrial automation requires real-time data processing and decision-making.
Advantages of Edge Computing for Real-Time Data Analysis
Edge computing offers several significant advantages when it comes to real-time data analysis:
- Reduced Latency
One of the most significant benefits of edge computing is its ability to drastically reduce latency in data processing.
How it works:
Data is processed at or near its source, eliminating the need to send it to a distant data center.
Decisions based on the data can be made almost instantaneously.
Real-world impact:
Autonomous vehicles can make split-second decisions based on sensor data.
Industrial equipment can respond immediately to changing conditions, improving safety and efficiency.
- Bandwidth Optimization
Edge computing helps optimize bandwidth usage by processing data locally and sending only relevant information to the cloud.
How it works:
Raw data is analyzed at the edge, and only processed results or important data points are transmitted.
This reduces the amount of data sent over the network, freeing up bandwidth for other uses.
Real-world impact:
Smart cities can manage traffic flows more efficiently by processing traffic camera data locally.
Oil and gas companies can monitor remote equipment without overwhelming their network infrastructure.
- Enhanced Reliability and Resiliency
By distributing computing resources, edge computing creates more resilient systems.
How it works:
Edge devices can continue to function even if the connection to the central network is lost.
Critical operations can be maintained locally, ensuring business continuity.
Real-world impact:
Healthcare devices can continue monitoring patients even during network outages.
Retail point-of-sale systems can process transactions offline and sync data later.
- Improved Data Privacy and Security
Edge computing can enhance data privacy and security by keeping sensitive information local.
How it works:
Personal or sensitive data can be processed locally without ever leaving the device.
Only aggregated or anonymized data is sent to the cloud, reducing the risk of data breaches.
Real-world impact:
Smart home devices can process voice commands locally, protecting user privacy.
Healthcare providers can ensure patient data remains on-premises, complying with regulations like HIPAA.
- Cost Efficiency
While the initial investment in edge infrastructure can be significant, it can lead to cost savings in the long run.
How it works:
Reduced data transfer to the cloud can lower cloud computing and storage costs.
More efficient use of network resources can defer the need for network upgrades.
Real-world impact:
Manufacturing companies can reduce cloud computing costs by processing vast amounts of sensor data locally.
Telecommunications companies can optimize their network investments by offloading processing to edge devices.
- Contextual Awareness and Personalization
Edge computing enables more contextually aware and personalized experiences by processing data in real-time.
How it works:
Local processing allows devices to quickly adapt to user behavior or environmental conditions.
Personalized experiences can be delivered without the need to constantly communicate with a central server.
Real-world impact:
Augmented reality applications can provide real-time, context-aware information to users.
Retail stores can offer personalized promotions to customers based on their in-store behavior, processed in real-time.
Edge Computing in Action: Industry Applications
The advantages of edge computing for real-time data analysis are being leveraged across various industries:
Manufacturing and Industry 4.0
Edge computing is a cornerstone of the Fourth Industrial Revolution, enabling smart manufacturing processes.
Applications:
Real-time monitoring and predictive maintenance of equipment
Quality control through AI-powered visual inspection
Adaptive manufacturing processes that respond to real-time data
Example: A smart factory uses edge computing to process data from thousands of sensors in real-time, allowing for immediate adjustments to production processes and predictive maintenance, reducing downtime and improving efficiency.
Healthcare and Telemedicine
Edge computing is transforming healthcare delivery and enabling new forms of patient care.
Applications:
Real-time patient monitoring and alerts
AI-assisted diagnosis at the point of care
Secure, HIPAA-compliant data processing
Example: Wearable health devices use edge computing to process vital signs data locally, only alerting healthcare providers when anomalies are detected, ensuring timely interventions while maintaining patient privacy.
Smart Cities and Urban Management
Edge computing is essential for managing the complex systems of smart cities efficiently.
Applications:
Traffic management and adaptive traffic light systems
Environmental monitoring and pollution control
Smart grid management for energy efficiency
Example: A smart city uses edge computing in its traffic management system, processing data from traffic cameras and sensors locally to adjust traffic light timing in real-time, reducing congestion and improving traffic flow.
Retail and Customer Experience
Edge computing is enhancing the retail experience through real-time personalization and inventory management.
Applications:
Dynamic pricing based on real-time demand
Personalized in-store experiences and recommendations
Automated checkout systems
Example: A retail store uses edge computing to process data from shelf sensors and cameras, automatically updating inventory levels and triggering restocking orders in real-time, ensuring products are always available to customers.
Autonomous Vehicles
Edge computing is crucial for the development and operation of autonomous vehicles.
Applications:
Real-time sensor data processing for navigation and obstacle avoidance
Vehicle-to-vehicle (V2V) and vehicle-to-infrastructure (V2I) communication
Predictive maintenance and performance optimization
Example: An autonomous vehicle uses edge computing to process data from multiple sensors (cameras, LIDAR, radar) in real-time, making split-second decisions about navigation and safety without relying on a constant connection to the cloud.
Challenges and Considerations in Edge Computing
While edge computing offers numerous advantages, it also presents some challenges:
Security: Distributed systems can increase the attack surface for cybercriminals. Robust security measures are essential.
Management complexity: Managing a distributed network of edge devices can be more complex than centralized cloud systems.
Hardware limitations: Edge devices may have limited processing power and storage compared to cloud data centers.
Standardization: The lack of standardization in edge computing can lead to interoperability issues.
Initial costs: Implementing edge computing infrastructure can require significant upfront investment.
The Future of Edge Computing
As technology continues to evolve, we can expect to see further advancements in edge computing:
AI at the edge: More sophisticated AI and machine learning models will run directly on edge devices.
5G and beyond: The continued rollout of 5G and future 6G networks will enhance edge computing capabilities.
Edge-cloud continuum: We’ll see a more seamless integration between edge and cloud computing, creating a flexible, distributed computing environment.
Green computing: Edge computing will play a role in creating more energy-efficient IT infrastructures.
New application paradigms: Edge computing will enable new types of applications and services that we haven’t yet imagined.
Conclusion: Embracing the Edge Computing Revolution
Edge computing is not just a technological trend; it’s a fundamental shift in how we approach data processing and analysis. By bringing computation closer to the data source, edge computing is enabling faster, more efficient, and more innovative solutions across industries.
The advantages of edge computing for real-time data analysis – including reduced latency, improved reliability, enhanced privacy, and cost efficiency – are driving its adoption in various sectors, from manufacturing and healthcare to smart cities and autonomous vehicles.
As we move forward, organizations that embrace edge computing will be better positioned to leverage the power of real-time data analysis, creating more responsive, efficient, and intelligent systems. The edge computing revolution is here, and it’s changing the game in data processing, paving the way for a more connected and intelligent future.
Whether you’re a business leader, a technology professional, or simply someone interested in the future of technology, understanding and leveraging edge computing will be crucial in the coming years. The edge is where the action is – and that’s where the future of data processing lies.
Explainable AI: Why It’s Crucial for the Future of Artificial Intelligence
Artificial Intelligence (AI) is playing an increasingly prominent role in shaping the future of industries, influencing everything from healthcare diagnostics to financial decision-making, marketing, and autonomous driving. However, with AI’s growing capabilities comes a key challenge—transparency. As AI models become more complex, particularly with the rise of deep learning, their decision-making processes often become opaque. This lack of clarity has led to the development of a concept known as Explainable AI (XAI), which focuses on making AI systems more interpretable and understandable to humans.
In this blog post, we will explore the concept of Explainable AI, its importance for the future of artificial intelligence, and why it is crucial for ensuring user trust, accountability, and fairness in AI-driven systems.
What is Explainable AI?
Explainable AI refers to the set of methods and techniques that enable humans to understand and trust the outcomes of machine learning models. Unlike traditional “black box” models that provide little to no insight into how decisions are made, explainable AI seeks to make the decision-making process more transparent. This allows users, stakeholders, and regulators to understand why an AI system made a particular prediction, recommendation, or decision.
At its core, Explainable AI has two key objectives:
Interpretability – Ensuring that humans can understand how a model arrives at its decisions.
Transparency – Providing clear, understandable reasons behind the actions or outputs of AI systems.
Explainable AI becomes even more important as AI models are increasingly used in high-stakes environments such as healthcare, legal judgments, financial transactions, and autonomous systems, where the consequences of incorrect or biased decisions can have significant impacts on people’s lives.
The Need for Transparency in AI Systems
AI systems, especially those relying on deep learning or neural networks, have made substantial strides in tackling complex tasks like image recognition, language processing, and prediction. However, these systems often operate as “black boxes”—meaning their internal workings are difficult, if not impossible, for humans to interpret. This lack of transparency presents several challenges:
Trust: Users and decision-makers are more likely to trust AI systems if they understand how and why a model made a particular decision. If the AI outputs are inexplicable, trust diminishes, potentially leading to reluctance in using AI systems in critical areas.
Accountability: In cases where AI systems make decisions that lead to negative consequences—such as a misdiagnosis in healthcare or a biased hiring decision—being able to explain how the system arrived at its decision is crucial for holding developers or organizations accountable.
Compliance: As AI systems are increasingly governed by regulations and ethical frameworks, transparency becomes essential for meeting compliance requirements. Regulatory bodies may require organizations to demonstrate that their AI systems are not discriminatory and are operating within the legal bounds.
Fairness and Bias Mitigation: AI systems trained on biased datasets can perpetuate or even amplify societal biases, leading to unfair treatment of certain groups. Explainable AI can help identify and address these biases by shedding light on how the model makes decisions.
Why Explainable AI is Crucial for the Future
As AI becomes more embedded in key aspects of daily life, the need for explainability will only grow. Let’s dive into why Explainable AI is essential for the future of artificial intelligence and its role in promoting trust, accountability, and fairness.
- Building User Trust and Confidence
Trust is foundational to the widespread adoption of AI technologies. Users are unlikely to rely on AI systems if they cannot understand how these systems function or make decisions. In industries such as healthcare, finance, and law, trust in AI can have significant implications. For example, if a medical AI system recommends a treatment plan for a patient but cannot explain why, both the doctor and the patient may hesitate to follow its advice.
Explainable AI helps bridge this gap by providing insights into how an AI system arrived at its conclusions, fostering greater trust between humans and machines. When users can see and understand the reasoning behind an AI-driven decision, they are more likely to accept and act on that decision. Trust is crucial not only for day-to-day users but also for organizations looking to integrate AI into their processes. Companies and professionals need confidence in the technology before entrusting it with critical tasks.
- Ensuring Accountability and Compliance
One of the most critical reasons for explainable AI is the need for accountability. As AI systems are increasingly used to make decisions that have far-reaching effects on individuals and society, there must be a way to hold those systems accountable when things go wrong.
For instance, if an AI system incorrectly denies someone a loan or wrongfully identifies an innocent person in a criminal investigation, the impacted individuals deserve an explanation. Moreover, organizations deploying AI systems need to understand how those systems function so they can take responsibility for their actions and rectify any issues.
In some regions, regulations are already being put in place to address this. For example, the European Union’s General Data Protection Regulation (GDPR) includes a “right to explanation,” which gives individuals the right to know why certain automated decisions were made about them. In this regulatory landscape, explainable AI becomes not just a best practice but a legal requirement, ensuring that AI systems are compliant and accountable to stakeholders, regulators, and the public.
- Mitigating Bias and Promoting Fairness
Bias in AI systems is a significant concern that can lead to harmful consequences, particularly when AI is applied in sensitive areas like hiring, credit scoring, and criminal justice. Machine learning models learn from historical data, and if that data reflects biases present in society, the models can inadvertently perpetuate these biases.
For example, a hiring algorithm trained on resumes from a predominantly male workforce might inadvertently favor male candidates over female candidates. Similarly, an AI system used in the legal system might unfairly target certain racial or ethnic groups due to biases in the training data.
Explainable AI can play a key role in mitigating these biases by providing transparency into the decision-making process. When the internal workings of a model are interpretable, developers and users can identify potential sources of bias and take steps to correct them. In this way, explainable AI not only promotes fairness but also helps build ethical AI systems that treat all individuals equitably.
- Enhancing Human-AI Collaboration
In many fields, AI is not meant to replace human decision-making but rather to augment and assist it. This approach, known as augmented intelligence, is particularly important in domains such as healthcare, finance, and legal analysis, where human expertise and judgment are critical.
Explainable AI enhances this collaboration by providing human users with the reasoning behind AI-driven suggestions or predictions. For example, in healthcare, an AI model may flag certain medical images for further review, but a human doctor needs to understand the reasoning behind this flag to make the final diagnosis. Similarly, in finance, AI systems can recommend investment strategies, but human analysts need to understand the basis for those recommendations to evaluate their merit.
By making AI systems more interpretable, explainable AI enables smoother collaboration between humans and machines, allowing both to leverage their respective strengths for better outcomes.
- Driving Innovation and Adoption
Explainable AI also has a crucial role to play in driving further innovation in AI technology. As transparency improves, organizations and developers can gain deeper insights into how their models work, what factors drive performance, and where improvements can be made.
This level of understanding helps AI developers refine their models, improve accuracy, and reduce errors, leading to better AI systems overall. Explainable AI can also foster broader adoption of AI technologies, as businesses and end-users become more comfortable integrating AI into their operations, knowing that they can trust and understand the systems at play.
In highly regulated industries like finance and healthcare, explainable AI can serve as a catalyst for more widespread AI adoption by demonstrating that AI systems can be trusted to operate within legal, ethical, and technical standards.
Techniques for Achieving Explainable AI
Explainable AI is achieved through a combination of techniques designed to make models more interpretable. These include:
LIME (Local Interpretable Model-Agnostic Explanations): This method provides locally interpretable explanations for individual predictions. LIME works by perturbing the input and observing changes in the output, giving insight into which features are most influential in a model’s decision.
SHAP (SHapley Additive exPlanations): SHAP values offer a game-theoretic approach to explain the output of machine learning models by assigning each feature an importance value based on its contribution to the final prediction.
Model Simplification: Sometimes, simplifying a complex model to a more interpretable one—such as using decision trees instead of deep neural networks—can make AI systems more transparent, even if it sacrifices some predictive power.
Visualization Tools: Tools that allow users to visualize the inner workings of AI models, such as heat maps for image recognition or attention maps for natural language processing, can provide valuable insights into how AI systems make decisions.
Conclusion: A Transparent Future for AI
Explainable AI is not just a technical necessity but a fundamental building block for ensuring trust, accountability, fairness, and innovation in AI systems. As artificial intelligence becomes more deeply integrated into industries and society, the ability to explain and interpret AI-driven decisions will be crucial for fostering trust and ensuring that these systems work for the benefit of everyone.
By focusing on transparency and understanding, we can help mitigate the risks associated with “black box” AI models and build a future where AI enhances human decision-making, promotes fairness, and drives innovation in a responsible and ethical manner.
Machine Learning in 2024: Trends and Predictions
Machine learning (ML) continues to be a driving force behind innovation in technology, with its influence expanding across industries such as healthcare, finance, manufacturing, and entertainment. As we move into 2024, machine learning is becoming more embedded in the fabric of everyday life and is poised to tackle even more complex challenges. The field is evolving at a rapid pace, with breakthroughs in algorithms, computing power, and data availability shaping its future. In this blog post, we’ll explore the trends that will define machine learning in 2024 and beyond, and predict where the technology is headed in the coming years.
The Growing Importance of Foundation Models
In 2024, the evolution of foundation models—large, pre-trained models that can be fine-tuned for specific tasks—is likely to be one of the most transformative trends in machine learning. These models, such as OpenAI’s GPT series or Google’s BERT, have significantly improved natural language understanding, image recognition, and even complex decision-making. Their versatility comes from the fact that they are pre-trained on enormous datasets and can then be adapted to various tasks with minimal additional training.
The next wave of foundation models is expected to push the boundaries even further. These models will be capable of handling multi-modal inputs, integrating text, images, audio, and possibly video into unified frameworks. This capability would open new avenues for applications in areas such as virtual assistants, autonomous vehicles, and medical diagnostics. With their capacity to generalize across domains, foundation models are likely to lead to more robust, scalable AI systems that can be applied to a broader range of industries with minimal customization.
Trend Toward Federated Learning and Data Privacy
As concerns over data privacy continue to grow, federated learning is emerging as a critical trend in 2024. Federated learning allows machine learning models to be trained across multiple decentralized devices or servers while keeping the data localized. Instead of sending data to a central server, federated learning algorithms send updates about the model, thereby protecting users’ sensitive information.
In the era of heightened privacy regulations such as the General Data Protection Regulation (GDPR) in Europe and California’s Consumer Privacy Act (CCPA), this decentralized approach to model training offers a significant advantage. Organizations can still leverage vast amounts of data to build powerful machine learning systems, but without violating user privacy.
The adoption of federated learning is expected to increase, particularly in industries like healthcare and finance, where privacy is paramount. In healthcare, for example, patient data remains sensitive, and federated learning can enable medical research using distributed datasets from multiple hospitals without compromising confidentiality. Similarly, financial institutions can train fraud detection models without exposing user data to unnecessary risks. By 2024, federated learning could become a key component in building privacy-preserving machine learning models across various domains.
Machine Learning for Automation and Augmented Intelligence
Automation is a key application of machine learning, and its role will continue to expand in 2024. ML models are now automating routine tasks in industries such as manufacturing, customer service, and logistics, helping businesses streamline operations and reduce costs. But while automation will be a major trend, we’re also seeing a shift toward augmented intelligence, where AI and machine learning technologies complement human decision-making rather than replace it.
Augmented intelligence helps humans by providing data-driven insights and suggestions that improve decision-making in complex scenarios. For example, in healthcare, machine learning algorithms can analyze medical images and suggest diagnoses, but the final decision is made by a human doctor. Similarly, in finance, AI can identify patterns and trends in vast datasets, providing analysts with actionable insights.
In 2024, more businesses are expected to adopt augmented intelligence systems, as these hybrid models strike a balance between leveraging AI’s efficiency and maintaining human oversight. This trend will accelerate as machine learning systems become more explainable, helping humans understand and trust the decisions suggested by algorithms.
Expansion of Explainable AI (XAI)
As machine learning models become more complex, particularly with deep learning techniques, the issue of transparency and explainability becomes more urgent. Many current ML systems, especially those using neural networks, operate as “black boxes,” where their internal workings are difficult for even their developers to understand. This lack of transparency can be problematic in industries like healthcare, finance, and autonomous driving, where understanding why a model made a certain decision is crucial.
In 2024, there is a growing push toward Explainable AI (XAI)—developing techniques that allow machine learning models to explain their decisions in a way that humans can understand. Techniques such as LIME (Local Interpretable Model-agnostic Explanations) and SHAP (SHapley Additive exPlanations) are gaining traction as tools that provide insights into how a model arrived at a particular conclusion.
The demand for XAI is being driven not just by regulatory concerns but also by the need to build trust in AI systems. As machine learning becomes embedded in critical decision-making processes, organizations must ensure that the technology is transparent, interpretable, and accountable. XAI will be a critical trend in 2024, particularly in industries where understanding the “why” behind a model’s decision is just as important as the “what.”
Democratization of Machine Learning Tools
Machine learning is becoming increasingly accessible, thanks to the democratization of tools and platforms that allow even non-experts to build and deploy models. In 2024, AutoML (Automated Machine Learning) and no-code/low-code platforms are expected to further break down the barriers to entry, enabling more individuals and small businesses to leverage machine learning in their operations.
AutoML platforms, such as Google’s Cloud AutoML and Microsoft’s Azure ML, automate many of the tasks involved in building machine learning models, such as data preprocessing, feature selection, and hyperparameter tuning. This allows users with little to no coding experience to develop sophisticated machine learning models that were once the domain of experts.
No-code and low-code platforms are also gaining momentum, allowing users to build custom AI applications with drag-and-drop interfaces. In 2024, these platforms will become even more user-friendly and powerful, enabling businesses of all sizes to incorporate AI into their workflows. The democratization of machine learning will drive greater innovation across industries, as more people gain access to the tools needed to harness the power of AI.
Real-Time Machine Learning and Edge AI
As demand for faster decision-making increases, real-time machine learning and Edge AI are poised to become even more critical in 2024. Real-time machine learning enables models to process and act on data as it is generated, without delays caused by batch processing. This is particularly important in use cases like fraud detection, recommendation systems, and autonomous vehicles, where decisions must be made instantly.
Edge AI takes real-time processing a step further by moving AI computation away from centralized cloud servers and closer to the data source, such as IoT devices, sensors, and mobile devices. By performing computations at the edge, these systems reduce latency, improve speed, and enhance privacy since data doesn’t need to be sent to a remote server for processing.
The rise of 5G networks will further accelerate the adoption of Edge AI in 2024, as faster network speeds will make it easier to deploy machine learning models on devices with limited computational resources. In industries like manufacturing, energy, and transportation, Edge AI will enable predictive maintenance, optimize energy consumption, and enhance the safety and efficiency of autonomous systems.
Predictive Analytics and AI-Driven Decision Making
Predictive analytics has been a cornerstone of machine learning for years, but in 2024, AI-driven decision-making is expected to take it to new heights. Machine learning models are now capable of analyzing vast amounts of historical data to predict future outcomes with increasing accuracy. This trend will continue to grow, with more organizations using predictive analytics to optimize operations, improve customer experiences, and gain a competitive edge.
In finance, for example, predictive models can forecast market trends, identify investment opportunities, and assess credit risk. In healthcare, machine learning models can predict disease outbreaks, patient readmissions, and treatment outcomes, helping providers make proactive decisions that improve patient care. Retailers are also using predictive analytics to forecast demand, personalize recommendations, and optimize inventory management.
As machine learning models become more sophisticated, the predictions they generate will be more accurate, reliable, and actionable. AI-driven decision-making will allow businesses to make data-backed decisions more quickly and confidently, leading to better outcomes across industries.
Conclusion: What to Expect in 2024 and Beyond
The landscape of machine learning in 2024 is marked by significant advancements in both technology and application. Foundation models will become more powerful and versatile, federated learning will provide privacy-conscious approaches to data sharing, and automation will continue to evolve into augmented intelligence, enhancing rather than replacing human decision-making. Explainable AI will play a vital role in building trust, while AutoML and no-code platforms will democratize access to machine learning tools. Real-time machine learning and Edge AI will meet the growing demand for immediate, decentralized decision-making, while predictive analytics will drive AI-powered insights across industries.
The year 2024 promises exciting developments in machine learning, with innovation continuing at a rapid pace. As these trends unfold, machine learning will become more integrated into our daily lives, shaping the future in ways we are only beginning to imagine. Organizations that embrace these trends will be well-positioned to lead in this new era of intelligent systems, while those that lag behind may struggle to keep up with the transformative potential of machine learning.
How AI is Revolutionizing Healthcare: From Diagnosis to Treatment
In recent years, artificial intelligence (AI) has emerged as a transformative force across various industries, and healthcare is no exception. The integration of AI technologies in medicine is reshaping how we approach diagnosis, treatment, and patient care. From predictive analytics to robotic surgeries, AI is revolutionizing healthcare in ways that were once thought to be the realm of science fiction. In this post, we’ll explore the multifaceted impact of AI on healthcare and how it’s improving outcomes for patients and healthcare providers alike.
AI in Diagnosis: Enhancing Accuracy and Speed
One of the most significant contributions of AI to healthcare is in the field of diagnosis. Machine learning algorithms, trained on vast datasets of medical images and patient records, are becoming increasingly adept at identifying patterns and anomalies that might escape even the most experienced human practitioners.
Medical Imaging and AI
In radiology, AI-powered systems are assisting radiologists in detecting and classifying abnormalities in X-rays, MRIs, and CT scans. For instance:
Breast Cancer Detection: AI algorithms have shown remarkable accuracy in identifying breast cancer in mammograms, often outperforming human radiologists in early detection rates.
Brain Tumor Identification: Machine learning models can analyze brain MRIs to detect and classify tumors, helping neurosurgeons plan more effective treatments.
Lung Nodule Detection: AI systems can quickly scan chest CT images to identify potentially cancerous lung nodules, enabling earlier intervention and improved patient outcomes.
These AI-assisted diagnostic tools not only improve accuracy but also significantly reduce the time required for image analysis, allowing radiologists to focus on more complex cases and patient care.
Predictive Analytics in Disease Progression
AI is also making strides in predicting disease progression and patient outcomes. By analyzing vast amounts of patient data, including genetic information, lifestyle factors, and medical history, AI models can:
Predict the likelihood of a patient developing certain conditions, such as heart disease or diabetes.
Forecast how a disease might progress in individual patients, allowing for more personalized treatment plans.
Identify patients at high risk of hospital readmission, enabling proactive interventions.
This predictive capability is particularly valuable in managing chronic diseases and allocating healthcare resources more efficiently.
AI in Treatment Planning and Drug Discovery
Beyond diagnosis, AI is playing a crucial role in developing treatment plans and accelerating drug discovery processes.
Personalized Treatment Plans
AI algorithms can analyze a patient’s genetic makeup, medical history, and lifestyle factors to recommend personalized treatment plans. This approach, known as precision medicine, tailors therapies to individual patients, potentially improving efficacy and reducing side effects.
For example, in oncology, AI systems can suggest optimal chemotherapy regimens based on a patient’s specific cancer type and genetic profile, maximizing treatment effectiveness while minimizing adverse reactions.
Drug Discovery and Development
The pharmaceutical industry is leveraging AI to revolutionize the drug discovery process:
Molecular Design: AI algorithms can generate and evaluate millions of potential drug compounds in silico, significantly speeding up the initial stages of drug discovery.
Predicting Drug Interactions: Machine learning models can predict how new drugs might interact with other medications or biological systems, helping to identify potential side effects early in the development process.
Clinical Trial Optimization: AI can assist in designing more efficient clinical trials by identifying suitable patient populations and predicting trial outcomes.
These AI-driven approaches have the potential to dramatically reduce the time and cost associated with bringing new drugs to market, ultimately benefiting patients who need novel treatments.
AI-Powered Robotic Surgery
Robotic surgery, enhanced by AI, is another area where technology is transforming healthcare. While robotic surgical systems have been in use for some time, the integration of AI is taking their capabilities to new heights:
Precision and Consistency
AI-enhanced robotic systems can perform surgical procedures with a level of precision and consistency that surpasses human capabilities. These systems can:
Compensate for natural hand tremors, ensuring steady movements during delicate procedures.
Provide real-time guidance to surgeons, highlighting critical structures and suggesting optimal incision points.
Learn from vast databases of surgical videos and outcomes to continually improve their performance.
Minimally Invasive Procedures
AI-powered robotic systems excel in minimally invasive surgeries, allowing for smaller incisions, reduced scarring, and faster recovery times. This is particularly beneficial in procedures such as:
Laparoscopic surgeries
Orthopedic surgeries (e.g., joint replacements)
Cardiac procedures
Remote Surgery
The combination of AI, robotics, and high-speed communication networks is making remote surgery a reality. Surgeons can now perform procedures on patients located hundreds or even thousands of miles away, bringing specialized surgical care to underserved areas.
AI in Patient Monitoring and Care Management
AI is not only transforming diagnosis and treatment but also revolutionizing how we monitor patients and manage their care.
Continuous Patient Monitoring
AI-powered systems can analyze data from wearable devices and in-hospital monitoring equipment to:
Detect early signs of deterioration in patients’ conditions.
Predict and prevent adverse events such as sepsis or cardiac arrest.
Optimize medication dosing based on real-time patient data.
This continuous monitoring allows for more proactive and timely interventions, potentially saving lives and reducing healthcare costs.
Virtual Nursing Assistants
AI-driven virtual nursing assistants are being developed to support patients and healthcare providers:
They can answer routine patient questions, freeing up nurses to focus on more complex tasks.
These systems can remind patients to take medications and schedule follow-up appointments.
Virtual assistants can also triage patient concerns, directing urgent cases to human healthcare providers when necessary.
Mental Health Support
AI is also making inroads in mental healthcare:
Chatbots and virtual therapists can provide initial support and screening for mental health issues.
AI algorithms can analyze text and voice data to detect signs of depression, anxiety, or other mental health conditions.
Machine learning models can predict the likelihood of mental health crises, allowing for early intervention.
While these AI-powered mental health tools are not meant to replace human therapists, they can serve as valuable complementary resources, especially in areas with limited access to mental health professionals.
Challenges and Ethical Considerations
While the potential benefits of AI in healthcare are immense, it’s important to acknowledge the challenges and ethical considerations that come with this technological revolution:
Data Privacy and Security
The use of AI in healthcare relies heavily on access to large amounts of patient data. Ensuring the privacy and security of this sensitive information is paramount. Healthcare organizations must implement robust data protection measures and comply with regulations such as HIPAA in the United States and GDPR in Europe.
Algorithmic Bias
AI systems are only as good as the data they’re trained on. If training datasets are not diverse or representative, AI models may perpetuate or even exacerbate existing healthcare disparities. It’s crucial to develop AI systems with diverse datasets and continuously monitor for bias.
Transparency and Explainability
Many AI algorithms, particularly deep learning models, operate as “black boxes,” making it difficult to understand how they arrive at their conclusions. In healthcare, where decisions can have life-or-death consequences, it’s essential to develop more transparent and explainable AI systems.
Human-AI Collaboration
As AI systems become more prevalent in healthcare, it’s important to strike the right balance between AI assistance and human expertise. Healthcare providers need to be trained to effectively work alongside AI tools, understanding both their capabilities and limitations.
The Future of AI in Healthcare
As we look to the future, the potential applications of AI in healthcare continue to expand. Some exciting areas of development include:
Nanorobotics: Microscopic AI-powered robots that can be deployed inside the human body for targeted drug delivery or to perform minimally invasive procedures.
Brain-Computer Interfaces: AI-enhanced systems that can interpret brain signals, potentially restoring movement or communication abilities to patients with severe neurological conditions.
Genetic Editing: AI could play a crucial role in advancing CRISPR and other genetic editing technologies, potentially curing genetic diseases at the molecular level.
Conclusion
The integration of AI into healthcare is not just a technological advancement; it represents a fundamental shift in how we approach medicine and patient care. From enhancing diagnostic accuracy and personalizing treatments to revolutionizing surgical procedures and patient monitoring, AI is driving improvements across the entire healthcare spectrum.
While challenges remain, particularly in the areas of data privacy, algorithmic bias, and ethical considerations, the potential benefits of AI in healthcare are too significant to ignore. As we continue to refine and develop these technologies, we can look forward to a future where healthcare is more precise, efficient, and accessible to all.
The AI revolution in healthcare is not about replacing human medical professionals but about augmenting their capabilities and allowing them to focus on what they do best – providing compassionate, personalized care to patients. By embracing AI technologies responsibly and thoughtfully, we can work towards a healthcare system that delivers better outcomes for patients and providers alike.
Time Analysis: Understanding Static and Dynamic Hazards in Digital Logic Circuits
In the realm of digital logic design, timing is paramount to ensure that circuits function correctly and efficiently. The complexity of modern digital systems necessitates careful consideration of timing issues that can arise, which could otherwise lead to unexpected behaviors and unreliable results. One key aspect of timing analysis is the study of hazards in digital circuits, specifically static and dynamic hazards. These hazards can cause incorrect output transitions or glitches, and managing them is crucial for maintaining the integrity and performance of digital systems.
This blog will explore the concepts of static and dynamic hazards in digital logic circuits, their causes, potential effects, and strategies to mitigate them. Whether you’re a beginner or an experienced digital designer, understanding these timing challenges is essential to ensuring reliable system operation.
What Are Hazards in Digital Circuits?
A hazard in digital logic refers to an unwanted and unintended transition in the output of a combinational circuit, which can occur when input signals change. Even though the logic states of a circuit are meant to transition from one state to another smoothly, hazards can introduce brief glitches or spikes in the output, leading to incorrect system behavior.
Hazards generally arise from differences in the propagation delay of signals through various parts of a circuit. These delays can cause temporary discrepancies between the expected and actual output, which, if not controlled, may result in faulty operation.
Hazards are broadly classified into two categories:
Static Hazards
Dynamic Hazards
- Static Hazards
A static hazard occurs when the output of a digital circuit momentarily changes when it should remain constant. Static hazards are most commonly observed in circuits where a transition occurs between two stable logic levels, typically from logic ‘1’ to ‘1’ or ‘0’ to ‘0’. Despite the fact that the output is expected to remain at the same logic level, a brief glitch can cause the output to flip momentarily.
Types of Static Hazards
Static hazards are categorized into two types:
Static-1 Hazard: This type of hazard occurs when the output should remain at logic ‘1’, but a temporary glitch causes it to drop to ‘0’ momentarily before returning to ‘1’.
Static-0 Hazard: This occurs when the output is expected to remain at logic ‘0’, but due to a brief glitch, it rises to ‘1’ before returning to ‘0’.
Causes of Static Hazards
Static hazards are caused by differences in the propagation delay of signals through different paths in a logic circuit. These delays result from the various gate components, wiring lengths, and electrical characteristics of the circuit. When multiple paths exist between the inputs and the output of a combinational logic circuit, some paths may be faster or slower than others, causing brief discrepancies in the output.
Consider a situation where a circuit has multiple input changes that affect the output. If one of the input paths experiences a longer delay than another, the output may briefly switch to an incorrect state before settling at the intended logic level. This transient behavior is the essence of a static hazard.
Example of a Static-1 Hazard
To illustrate a static-1 hazard, consider a simple logic circuit with the following function:
[ F(A, B, C) = A’B + AB’ ]
In this circuit, the output is expected to remain at logic ‘1’ when inputs transition between certain combinations. However, due to varying gate delays, when the inputs change from one valid state to another, the output might momentarily drop to ‘0’, causing a glitch even though it should stay at ‘1’. This would be an example of a static-1 hazard.
Impact of Static Hazards
Static hazards can cause transient glitches in digital circuits, which may not always lead to functional failures in combinational circuits. However, in synchronous systems, where the circuit output is sampled at specific intervals, these glitches can be problematic if they occur at the wrong moment. They may lead to incorrect data being latched into memory elements, which can cause functional errors or even system crashes.
How to Eliminate Static Hazards
To eliminate or minimize static hazards, designers can add additional logic gates or redundant logic terms to ensure that the output remains stable even when input transitions occur. The process of adding these gates is called hazard mitigation or hazard covering.
A common approach to removing static hazards is to use Karnaugh maps to identify potential hazards and add redundant logic terms. By doing so, the logic paths are balanced in terms of delay, reducing the chance of glitches.
- Dynamic Hazards
A dynamic hazard occurs when the output of a digital circuit experiences multiple unwanted transitions (glitches) while changing from one logic state to another. Unlike static hazards, which involve brief changes when the output is supposed to remain constant, dynamic hazards involve multiple intermediate transitions as the output moves between two different logic states (from ‘0’ to ‘1’ or vice versa).
Causes of Dynamic Hazards
Dynamic hazards are caused by similar factors as static hazards—namely, variations in signal propagation delays through different paths of a logic circuit. However, dynamic hazards are more complex because they occur when the output is supposed to change states, and the different delays cause the output to oscillate multiple times before stabilizing at the correct value.
Dynamic hazards are more likely to occur in circuits with multiple logic levels or complex combinational networks with multiple inputs. When the inputs change simultaneously, variations in the time it takes for signals to propagate through different paths can cause the output to oscillate between ‘0’ and ‘1’ several times before settling on the final value.
Example of a Dynamic Hazard
To illustrate a dynamic hazard, consider a more complex logic circuit with several inputs, such as:
[ F(A, B, C, D) = AB + CD ]
When inputs A and B change simultaneously from ‘0’ to ‘1’, there may be multiple paths through the logic gates that propagate the input changes. Due to differences in propagation delay, the output may oscillate between ‘0’ and ‘1’ several times before settling at the correct final value.
Impact of Dynamic Hazards
Dynamic hazards can be more problematic than static hazards because they involve multiple incorrect transitions. In high-speed digital circuits, where precise timing is critical, these oscillations can lead to significant timing violations. If the output of a circuit oscillates between ‘0’ and ‘1’, it can cause incorrect data to be captured, leading to errors in subsequent stages of the system.
In systems where timing is tightly constrained (such as microprocessors or high-speed data transfer systems), dynamic hazards can severely affect performance, leading to reduced reliability and incorrect functionality.
How to Eliminate Dynamic Hazards
Eliminating dynamic hazards requires careful attention to the timing of the circuit and the paths through which signals propagate. Some strategies to reduce or eliminate dynamic hazards include:
Balancing Delays: One effective way to minimize dynamic hazards is to ensure that all paths through the logic circuit have approximately equal delays. This can be achieved by carefully selecting gate types and minimizing the differences in wire lengths.
Redundant Logic: Adding redundant logic gates can help eliminate dynamic hazards by ensuring that the output transitions smoothly from one state to another without multiple glitches. This method is similar to the technique used to eliminate static hazards but applied to cases where the output is changing states.
Delay Insertion: In some cases, inserting delays into specific paths can help synchronize the timing of different inputs, reducing the likelihood of dynamic hazards. By slowing down faster paths, designers can ensure that all input signals reach the output at the same time, reducing oscillations.
Synchronous Design: Using synchronous design techniques can help mitigate the impact of dynamic hazards. By ensuring that the circuit operates based on a clock signal, the output is only sampled at specific intervals, reducing the risk of capturing an incorrect output during a glitch.
Static vs. Dynamic Hazards: Key Differences
While both static and dynamic hazards arise from timing discrepancies in digital circuits, they have distinct characteristics and effects:
Static Hazards occur when the output is supposed to remain constant but momentarily glitches to an incorrect value. They typically involve a single, brief transition and are relatively easy to identify and mitigate.
Dynamic Hazards occur when the output is transitioning between two logic states and experiences multiple unwanted transitions or oscillations. They are more complex to handle and can have a more significant impact on the circuit’s performance.
Practical Considerations in Hazard Mitigation
In real-world digital design, hazard mitigation is a crucial aspect of ensuring reliable system performance. Here are some practical tips for managing hazards:
Early Detection: During the design phase, engineers should use simulation tools to detect potential hazards. Identifying hazards early allows for design modifications before the circuit is fabricated or implemented in hardware.
Redundancy in Design: Incorporating redundant logic gates or paths can help eliminate hazards. However, designers must balance the benefits of hazard elimination with the increased complexity and potential power consumption introduced by additional gates.
Signal Integrity: Proper management of signal integrity, including controlling noise and minimizing crosstalk between adjacent wires, can help reduce the chances of hazards.
Proper Testing: Post-design testing is essential to ensure that hazards are properly mitigated. Both static and dynamic hazards can be subtle and may only appear under specific input conditions or timing constraints.
Conclusion
In digital logic circuits, static and dynamic hazards are timing-related issues that can cause glitches or unwanted transitions in the output. These hazards arise from differences in signal propagation delays and can lead to functional errors, especially in high-speed systems or complex logic designs.
By understanding the causes and effects of hazards and employing techniques such as balanced delays, redundant logic, and synchronous design, engineers can effectively mitigate these timing issues. As digital systems continueto evolve and increase in complexity, managing hazards will remain a critical aspect of ensuring reliable and efficient circuit operation.
With the right strategies in place, designers can ensure that their digital systems are robust, reliable, and capable of meeting the demands of modern technology.
Digital System Design: Top-Down and Bottom-Up Design Approaches
In today’s digital age, system design has become a critical skill for developing complex and functional systems. Whether it’s creating hardware, software, or a combination of both, digital system design ensures that systems are developed efficiently and meet specific requirements. The complexity of digital systems, ranging from microcontrollers to large-scale networks, necessitates a structured design process. Two prominent methodologies for designing these systems are the Top-Down and Bottom-Up approaches. Each of these methodologies offers unique perspectives and techniques for system development, depending on the goals, the scale of the system, and the level of abstraction required.
In this blog, we will explore the Top-Down and Bottom-Up design approaches, providing insights into their respective strengths, limitations, and applicability in digital system design.
What is Digital System Design?
Digital system design refers to the process of creating electronic devices, software architectures, or systems that process, store, and transfer information in binary (0s and 1s) format. These systems are ubiquitous in modern life, from the microprocessor in your smartphone to cloud-based infrastructure running massive data centers. The design of digital systems involves numerous components, such as microprocessors, memory units, input/output interfaces, and communication channels.
The design process typically involves several stages:
Specification: Defining the functionality, requirements, and constraints of the system.
Architecture: Deciding the structure and interconnections of system components.
Design: Crafting the specific components and ensuring their integration.
Testing: Ensuring that the system works according to the design and meets all functional requirements.
As the complexity of digital systems continues to grow, designers are turning to systematic approaches to ensure that systems are both reliable and scalable. This is where Top-Down and Bottom-Up design approaches come into play.
Top-Down Design Approach
The Top-Down design approach begins with a high-level view of the system, gradually breaking it down into smaller, more manageable components. This method focuses on defining the overall architecture and then subdividing it into lower-level modules or components until all the design details are fully specified.
How Does Top-Down Design Work?
High-Level Abstraction: The process starts with a general idea of what the system should achieve. This might include a block diagram or an abstract view that outlines the major functions of the system. At this stage, no concrete implementation details are included.
Decomposition: The system is then divided into smaller subsystems or modules. Each module represents a portion of the overall system’s functionality. These modules can be further broken down into smaller parts, creating a hierarchy of increasingly specific components.
Detailed Design: As the hierarchy expands, the designer moves from high-level abstraction to detailed design, specifying the behavior of individual modules. At this stage, the designer begins to define the internal logic, hardware architecture, or software algorithms that will implement each module’s functionality.
Integration: Once all the modules are fully defined, the system is reassembled by integrating the individual components back together. Testing at each level of hierarchy ensures that the system behaves as expected.
Advantages of Top-Down Design
Clear Structure: Top-Down design offers a clear structure for organizing and managing complex systems. By starting with a broad overview, designers ensure that the system’s overall objectives are prioritized.
Early Focus on System Requirements: This approach emphasizes understanding the system’s high-level goals early in the process, reducing the risk of developing unnecessary or redundant components.
Better Documentation: Because the system is broken down into increasingly detailed steps, the process generates extensive documentation at every level. This documentation is valuable for future maintenance, upgrades, and collaboration.
Limitations of Top-Down Design
Rigid Hierarchy: A strict Top-Down approach can sometimes result in rigid hierarchies that limit flexibility. If there are unforeseen changes in requirements or system constraints, the entire design might need to be reworked.
Overlooking Low-Level Details: Since the focus is initially on the high-level design, critical low-level implementation details may be overlooked. This can lead to issues during the later stages of design when these details become relevant.
Difficulty in Managing Complexity: For highly complex systems with a large number of components, it can be challenging to manage all the interdependencies that arise when designing from the top down.
Bottom-Up Design Approach
In contrast to the Top-Down approach, the Bottom-Up design method starts with the design of the lowest-level components. These components are then gradually combined to build up higher-level modules until the entire system is assembled.
How Does Bottom-Up Design Work?
Component-Level Design: The Bottom-Up approach starts at the lowest level of abstraction, designing the individual building blocks of the system. These components can be hardware circuits, software functions, or any other low-level elements.
Module Creation: After designing the basic components, these are combined to form larger subsystems or modules. Each module is constructed to perform a specific function, based on the behavior of its individual components.
System Integration: The process continues by integrating these larger modules to form even higher-level subsystems. This continues until the complete system is built, tested, and ready for deployment.
Refinement and Testing: As the system is built from the ground up, extensive testing ensures that each component and module performs as expected. Any issues at the component level are resolved before moving on to the higher levels.
Advantages of Bottom-Up Design
Reusable Components: The Bottom-Up approach allows designers to create modular, reusable components that can be used in other systems. This is particularly beneficial in industries like software development, where libraries of pre-built functions or classes can be reused across multiple projects.
Flexibility in Design: Since the approach focuses on smaller components first, designers can make changes to individual parts without affecting the entire system. This can make the system more adaptable to changing requirements or improvements in technology.
Early Focus on Implementation: The Bottom-Up method addresses the low-level details of implementation early in the design process, helping to prevent problems during later stages of system development.
Limitations of Bottom-Up Design
Lack of High-Level Vision: The Bottom-Up approach can sometimes lose sight of the overall system goals, particularly in large-scale projects. Focusing too much on individual components may result in a disjointed or inefficient system.
Complexity in Integration: Building a system from the ground up can make it difficult to ensure that all components work together seamlessly. The integration phase can become complex, especially when interdependencies between modules are not well managed.
Time-Consuming: Starting from the lowest level can be time-consuming, particularly if a designer needs to repeatedly refine and test components before they are ready to be integrated into larger subsystems.
Top-Down vs. Bottom-Up: When to Use Each?
The decision to use either a Top-Down or Bottom-Up approach depends largely on the project scope, system requirements, and the specific design goals. Here are some general guidelines:
Top-Down is suitable when:
The system has well-defined high-level requirements.
There is a need to ensure that the overall architecture remains consistent with the project goals.
The project involves complex systems where documentation and traceability are critical.
Bottom-Up is suitable when:
The design involves reusable components or standardized modules.
There is a focus on optimizing performance at the component level.
The project allows for flexibility and iterative design.
In some cases, a hybrid approach might be the best solution. Designers may start with a Top-Down view to establish the overall architecture and then switch to a Bottom-Up approach for designing and refining individual components.
Conclusion
Both Top-Down and Bottom-Up design approaches have their own strengths and weaknesses, and the choice of approach depends on the specific requirements of the system being developed. Top-Down design offers clarity, structure, and a focus on high-level objectives, while Bottom-Up design emphasizes flexibility, reuse, and component-level optimization. For digital system designers, understanding when to apply each approach—or even combining them—can lead to more efficient, scalable, and robust systems. By carefully selecting the appropriate methodology, engineers can ensure that their designs meet the functional, performance, and scalability requirements of modern digital systems.
Mastering Cloud and AI with Google Cloud’s Cloud Skills Boost
The growing demand for cloud computing, artificial intelligence (AI), and machine learning (ML) has transformed how businesses operate in the digital age. To address this need, Google Cloud offers Cloud Skills Boost, an online learning platform designed to help individuals and organizations gain expertise in cloud technologies, AI, and more. Whether you’re a beginner seeking foundational knowledge or an experienced professional aiming to upskill, Cloud Skills Boost provides resources tailored to every learning level.
In this post, we’ll explore the different features of the Cloud Skills Boost platform, the variety of AI courses available, and how you can leverage these resources to accelerate your cloud career.
What is Google Cloud’s Cloud Skills Boost?
Google Cloud’s Cloud Skills Boost is an educational platform offering hands-on learning paths, courses, and labs that focus on Google Cloud and its services. The platform is particularly beneficial for those looking to enhance their skills in fields such as AI, ML, data engineering, and cloud infrastructure management.
Key Features of Cloud Skills Boost:
Interactive Labs: Cloud Skills Boost offers interactive, hands-on labs that let learners gain real-world experience using Google Cloud tools. These labs are integrated with live cloud environments, allowing users to practice with actual cloud resources rather than simulations.
Learning Paths: The platform organizes content into curated learning paths to guide learners step-by-step through courses related to their area of interest. Popular learning paths focus on AI, machine learning, and cloud architecture.
Assessments and Quests: Many courses include quizzes, assessments, and quests that allow learners to test their knowledge as they progress. These features are valuable for reinforcing concepts and ensuring that learners understand the material.
Certifications: Cloud Skills Boost helps learners prepare for Google Cloud certifications such as Associate Cloud Engineer, Professional Data Engineer, or Professional Cloud Architect. These certifications validate your expertise in cloud solutions and increase your competitiveness in the job market.
Free Tier and Paid Options: Google Cloud Skills Boost offers a combination of free and paid content, with some free introductory courses and labs available. For those looking for more advanced training, a monthly subscription provides unlimited access to premium content.
Why Focus on AI and Machine Learning?
AI and ML are among the most transformative technologies of the 21st century. They have applications across various sectors such as healthcare, finance, retail, and manufacturing. According to industry trends, businesses that leverage AI and ML are more likely to outperform their competitors in innovation, efficiency, and customer experience.
Google Cloud Skills Boost recognizes this trend by offering a range of AI-related courses and labs. These focus on the practical use of AI and ML tools, particularly those provided by Google Cloud.
Key AI/ML Courses on Cloud Skills Boost
Machine Learning Fundamentals: This course introduces the basics of ML, covering key concepts such as supervised and unsupervised learning, classification, regression, and neural networks. Learners gain practical experience by working on simple ML models using tools like TensorFlow and AI Platform.
Building AI Solutions on Vertex AI: Vertex AI is Google Cloud’s unified ML platform that enables businesses to build, deploy, and manage ML models efficiently. This course focuses on creating end-to-end AI solutions using Vertex AI, from data preprocessing to model deployment.
ML Pipelines with Kubeflow: Kubeflow is an open-source ML toolkit optimized for Kubernetes. In this course, learners dive into managing and deploying ML workflows at scale using Kubeflow on Google Cloud.
Natural Language Processing with Cloud NLP APIs: Natural Language Processing (NLP) is a branch of AI that deals with understanding and generating human language. This course covers Google Cloud’s NLP APIs and how they can be used to develop chatbots, sentiment analysis tools, and other text-based AI applications.
Image Recognition with AutoML Vision: This course focuses on Google Cloud’s AutoML Vision service, which allows users to train custom image recognition models without extensive knowledge of ML. Learners are introduced to the basics of image classification and labeling, as well as how to deploy trained models for real-world use.
Hands-On Experience: Why It Matters
Unlike traditional learning methods, which may focus on theory or video lectures, Google Cloud Skills Boost emphasizes hands-on experience. The platform’s labs provide access to real cloud environments where users can interact with AI and ML tools directly.
For example, in the Introduction to Machine Learning with TensorFlow lab, learners are tasked with building a basic machine learning model that predicts housing prices based on input data. This real-world problem-solving approach ensures that learners gain practical skills that are directly applicable to their work.
Learning at Your Own Pace
One of the biggest advantages of Cloud Skills Boost is its flexibility. Learners can progress through courses at their own pace, choosing from a mix of self-paced video tutorials, documentation, and labs. This makes it easy to balance learning with a busy professional or personal schedule.
Moreover, learners can customize their education based on specific goals, whether it’s preparing for a certification, exploring a new technology, or improving an existing skill set.
Benefits of Google Cloud Certifications
Obtaining a Google Cloud certification demonstrates proficiency in key areas of cloud technology, making you a more attractive candidate for employers. Certifications are recognized globally and are a great way to validate skills in competitive fields like AI and cloud computing.
Google Cloud offers multiple certification paths, depending on your level of expertise and career aspirations:
Associate Cloud Engineer: Best suited for those new to cloud computing, this certification validates your ability to deploy and manage Google Cloud services.
Professional Data Engineer: Focuses on designing and building data processing systems and analyzing data to support decision-making.
Professional Machine Learning Engineer: This certification is designed for ML engineers who develop, train, and optimize ML models on Google Cloud.
How to Get Started with Cloud Skills Boost
Starting with Cloud Skills Boost is straightforward. Follow these steps:
Create an Account: Sign up for a free Google Cloud account, which includes access to some free-tier courses and labs.
Browse Courses: Explore different learning paths based on your interests. The platform categorizes courses into sections like AI/ML, infrastructure, and data engineering.
Enroll in Labs: Once you’ve identified your area of interest, enroll in interactive labs that provide hands-on experience with real-world cloud tools.
Earn Skill Badges: After completing certain quests and labs, you’ll earn skill badges that can be shared on social platforms like LinkedIn, showcasing your expertise.
Prepare for Certification: If certification is your goal, enroll in the relevant learning path to prepare for exams. Many paths offer exam preparation tips and practice questions.
Conclusion
Google Cloud’s Cloud Skills Boost platform is an invaluable resource for anyone looking to gain expertise in AI, machine learning, and cloud computing. With its combination of hands-on labs, curated learning paths, and industry-recognized certifications, the platform is ideal for learners at all levels. Whether you’re an individual looking to improve your skills or an organization seeking to train employees, Cloud Skills Boost provides the tools and guidance needed to excel in the rapidly evolving cloud and AI landscape.
By investing time in the free and paid offerings on Cloud Skills Boost, you can stay competitive in today’s technology-driven job market and pave the way for a successful career in AI and cloud solutions.
Floating-Point Arithmetic Units : A Comprehensive Guide
In the world of modern computing, handling numbers with extreme precision is critical, especially in scientific computations, graphics processing, and real-time simulations. The need to efficiently process large and small numbers with fractions has led to the development of floating-point arithmetic units (FPUs). These units are integral components in processors, designed to handle complex calculations involving real numbers.
This blog post provides an in-depth look at floating-point arithmetic units, how they work, their role in computing systems, and why they are essential for a wide range of applications. What is Floating-Point Arithmetic?
Before exploring the design and functionality of a floating-point arithmetic unit, it’s essential to understand the concept of floating-point arithmetic.
Floating-point numbers are a way to represent real numbers that can include very large, very small, or fractional values. In computing, these numbers are stored in a special format, which allows for a wide range of values while maintaining precision. They differ from fixed-point numbers, where the decimal point remains in a fixed position. Floating-point notation allows the decimal point (or radix point) to “float,” providing more flexibility in representing numbers with varying magnitudes.
Floating-point arithmetic is defined by the IEEE 754 standard, which governs how floating-point numbers are represented and how operations like addition, subtraction, multiplication, and division are performed on them.
Components of a Floating-Point Number
A floating-point number is represented by three main components:
Sign Bit (S): Determines whether the number is positive or negative. A sign bit of 0 indicates a positive number, and a sign bit of 1 indicates a negative number.
Exponent (E): Encodes the position of the decimal point, which allows the number to represent very large or very small values. The exponent is typically stored in a biased format, meaning it includes an offset to handle both positive and negative exponents.
Mantissa or Significand (M): Contains the actual digits of the number. It is normalized to ensure that the leading digit is non-zero, allowing for consistent precision across a wide range of values.
For example, the number 6.75 can be represented as:
6.75 = 1.6875 x 2^2```
In floating-point notation, this could be stored as:
* **S**: 0 (positive)
* **E**: 2 (stored with a bias)
* **M**: 1.6875
What is a Floating-Point Arithmetic Unit (FPU)?
A **floating-point arithmetic unit (FPU)** is a specialized part of a computer's processor designed to handle floating-point calculations. It is responsible for performing arithmetic operations on floating-point numbers, including addition, subtraction, multiplication, division, and more complex functions like square root and trigonometric calculations.
The FPU is often implemented as a separate unit within the **Central Processing Unit (CPU)** or as an independent **coprocessor** in systems that require intensive mathematical calculations, such as in high-performance computing (HPC), 3D graphics rendering, and scientific simulations.
#### Types of Arithmetic Operations Performed by an FPU
* **Addition and Subtraction**: Adding and subtracting floating-point numbers involves aligning their exponents, performing the operation on the significands, and normalizing the result.
* **Multiplication**: When multiplying floating-point numbers, the significands are multiplied, and the exponents are added. The result is then normalized.
* **Division**: Division involves dividing the significands and subtracting the exponents, followed by normalization.
* **Square Root and Other Functions**: Some advanced FPUs can perform functions like square root calculations, logarithms, and trigonometric functions, which are essential in scientific computing.
The IEEE 754 Standard
The IEEE 754 standard, established in 1985, is a key factor in ensuring consistent floating-point arithmetic across different computing systems. This standard defines the format for representing floating-point numbers and the rules for how arithmetic operations are performed on them.
The most commonly used formats defined by IEEE 754 include:
* **Single Precision**: This format uses 32 bits to represent a floating-point number, divided into 1 bit for the sign, 8 bits for the exponent, and 23 bits for the significand. Single precision is commonly used in applications where memory efficiency is important, such as in graphics processing.
* **Double Precision**: This format uses 64 bits, with 1 bit for the sign, 11 bits for the exponent, and 52 bits for the significand. Double precision offers higher accuracy and is often used in scientific and financial applications where precision is critical.
* **Extended Precision**: Some systems support extended precision formats that provide even greater accuracy by using additional bits for the exponent and significand.
By adhering to the IEEE 754 standard, FPUs can produce consistent results, even when running on different hardware platforms or operating systems.
How Floating-Point Arithmetic Units Work
The design of an FPU is highly optimized to handle floating-point operations quickly and efficiently. The FPU's internal architecture is composed of several components, each responsible for different stages of the calculation process.
#### 1. **Exponent Alignment**
When performing addition or subtraction on two floating-point numbers, the exponents of the numbers must first be aligned. This involves shifting the smaller number’s significand so that both numbers have the same exponent.
For example, to add 2.5 (written as 1.25 x 2^1) and 0.75 (written as 0.75 x 2^0), the FPU will shift the exponent of the smaller number (0.75) so that both numbers have an exponent of 1:
```bash
2.5 (1.25 x 2^1) + 0.75 (0.75 x 2^1) = 1.25 + 0.375 = 1.625 x 2^1```
Once the exponents are aligned, the significands can be added or subtracted.
#### 2. **Normalization**
After the significands are added or subtracted, the result may not be in the normalized form, meaning that the leading bit of the significand is not necessarily a 1. To normalize the result, the FPU shifts the significand and adjusts the exponent accordingly.
For instance, if the result of an operation is `0.125 x 2^5`, the FPU will normalize this to `1.25 x 2^3`.
#### 3. **Rounding**
Floating-point arithmetic often results in numbers that cannot be represented exactly within the limits of the available bits. To address this, the FPU applies **rounding** to the result. IEEE 754 defines several rounding modes:
* **Round to Nearest**: The result is rounded to the nearest representable number.
* **Round Toward Zero**: The result is rounded toward zero (truncated).
* **Round Toward Positive or Negative Infinity**: The result is rounded toward the nearest infinity, either positive or negative.
Rounding ensures that the FPU can efficiently handle operations without requiring infinite precision, which would be impractical in hardware.
#### 4. **Handling Special Cases**
FPUs are designed to handle several special cases that can arise during floating-point calculations, such as:
* **Infinity**: When an operation results in a value that exceeds the maximum representable number, the result is considered positive or negative infinity.
* **Not a Number (NaN)**: NaN represents undefined or unrepresentable values, such as the result of dividing 0 by 0 or taking the square root of a negative number.
* **Zero**: FPUs must distinguish between positive zero and negative zero, as these can affect certain operations.
Applications of Floating-Point Arithmetic Units
FPUs play a crucial role in a variety of computing applications that require precision, speed, and efficient handling of real numbers. Some of the key areas where FPUs are essential include:
#### 1. **Scientific Computing**
In fields like physics, chemistry, and engineering, calculations involving extremely large or small values are common. FPUs enable scientists to perform simulations, solve differential equations, and model complex systems with high accuracy. Double precision floating-point arithmetic is often used in these applications to ensure the required level of precision.
#### 2. **Graphics Processing**
Graphics processing, particularly in 3D rendering, relies heavily on floating-point calculations. Operations such as scaling, rotation, and transformation of objects in a 3D space require accurate manipulation of floating-point numbers. In this context, FPUs are critical in ensuring smooth graphics rendering in real-time applications like video games and virtual reality.
#### 3. **Machine Learning and Artificial Intelligence**
Machine learning algorithms, especially those involving neural networks, often require matrix multiplication and other operations on real numbers. FPUs are integral in accelerating these calculations, allowing for faster training and inference in AI models. Specialized processors, such as **GPUs (Graphics Processing Units)**, often include powerful FPUs to handle the large volume of floating-point operations in deep learning.
#### 4. **Financial and Economic Modeling**
In finance, calculations often involve fractional values with high precision, such as interest rates, stock prices, and currency exchanges. FPUs are used to perform these calculations efficiently while maintaining the precision necessary for accurate financial predictions and risk assessments.
#### 5. **Real-Time Simulations**
In simulations such as fluid dynamics, climate modeling, and automotive crash testing, FPUs are essential for handling the complex mathematical models that govern these processes. The high precision and performance of FPUs enable real-time or near-real-time simulations, providing valuable insights in research and development.
Floating-Point Arithmetic Units in Modern CPUs and GPUs
Modern processors, whether CPUs or GPUs
, integrate highly optimized FPUs to handle floating-point calculations. While CPUs may have one or more FPUs dedicated to handling general-purpose floating-point arithmetic, GPUs are designed with massive parallelism in mind, often containing hundreds or thousands of FPUs to process large datasets simultaneously.
For instance, modern **GPUs** from manufacturers like **NVIDIA** and **AMD** have evolved to excel in floating-point performance, making them the go-to choice for high-performance computing tasks like machine learning, scientific research, and 3D rendering. These GPUs can perform trillions of floating-point operations per second (teraflops), showcasing the power of FPUs in contemporary computing.
Challenges and Future Trends in Floating-Point Arithmetic
While FPUs are powerful tools for handling floating-point calculations, there are some inherent challenges:
* **Precision vs. Performance**: Higher precision, such as using double precision, can come at the cost of slower performance and increased memory usage. Balancing precision and performance is a key challenge in FPU design.
* **Rounding Errors**: Due to the finite number of bits used to represent floating-point numbers, rounding errors are inevitable. In critical applications, these errors must be carefully managed to avoid inaccuracies.
* **Energy Efficiency**: As processors become more powerful, energy efficiency becomes a significant concern, especially in large-scale computing systems like data centers. Optimizing FPUs for power efficiency while maintaining high performance is an ongoing area of research.
Looking ahead, the demand for more efficient and powerful FPUs will continue to grow, especially in fields like artificial intelligence, high-performance computing, and real-time data analysis. Advancements in quantum computing and other emerging technologies may also influence the future design and capabilities of floating-point arithmetic units.
Conclusion
**Floating-point arithmetic units (FPUs)** are indispensable components of modern computing systems, enabling the efficient and precise processing of real numbers. From scientific simulations to graphics rendering and machine learning, FPUs play a critical role in powering the advanced applications that define our digital age.
By understanding the mechanics of FPUs—how they perform arithmetic operations, adhere to the IEEE 754 standard, and handle special cases—we can appreciate their importance in delivering high-precision results. As technology continues to evolve, the role of FPUs in pushing the boundaries of what’s possible in computing will only grow.
Multiplication and Division Circuits in Digital Systems: A Comprehensive Guide
In the realm of digital electronics, circuits that perform arithmetic operations such as multiplication and division are vital components of computing systems. These circuits are found in everything from simple calculators to advanced microprocessors, playing an essential role in a variety of applications that require mathematical computations. While addition and subtraction can be handled relatively easily by basic digital circuits, multiplication and division require more complex logic.
This blog post delves into the fundamental principles behind multiplication and division circuits, exploring how they work, the types of algorithms used to implement them, and their applications in digital systems. Understanding the Basics: Binary Arithmetic
Before diving into multiplication and division circuits, it’s essential to understand how binary arithmetic works. Binary numbers are the backbone of digital systems, where data is represented as sequences of 0s and 1s. In binary arithmetic, the same rules of traditional arithmetic apply, but calculations are performed with binary digits (bits).
Addition: Binary addition works similarly to decimal addition but carries over when the sum exceeds 1. For example, 1 + 1 in binary equals 10 (binary for 2), with a carry of 1.
Subtraction: Binary subtraction follows similar principles, often using two’s complement representation to handle negative numbers.
Multiplication and Division: These are more complex operations that require specialized circuits to perform efficiently. Let’s explore how these operations are implemented in digital hardware.
Multiplication Circuits
1. Binary Multiplication Basics
In binary systems, multiplication is a repetitive addition process. When multiplying two binary numbers, the result is obtained by multiplying each bit of one number by the other number and then summing the intermediate results. The process is analogous to decimal multiplication, where you multiply each digit and shift the result accordingly based on the digit’s place value.
For example:
Multiplying 1011 (11 in decimal) by 110 (6 in decimal):
1011
x 0110
------
0000 (0 * 1011)
1011 (1 * 1011, shifted one position)
1011 (1 * 1011, shifted two positions)
------
1000010 (66 in decimal)```
While binary multiplication appears straightforward, implementing it efficiently in digital circuits requires clever design to handle shifts, additions, and bit-level operations simultaneously.
#### 2. **Types of Multiplication Circuits**
Multiplication circuits can be categorized into various types based on their complexity and performance. The two most common approaches are **serial multipliers** and **parallel multipliers**.
<!-- wp:heading {"level":5} -->
<h5 class="wp-block-heading">A. **Serial Multipliers**</h5>
Serial multipliers work by processing one bit of the multiplier at a time. These are simpler in design but slower because they require multiple clock cycles to complete the multiplication. The most basic serial multiplier performs the following steps:
* Multiply the least significant bit of the multiplier by the multiplicand.
* Add the result to an accumulated sum.
* Shift the multiplier and multiplicand, and repeat the process for the next bit.
Serial multipliers are often used in low-cost and low-power applications where performance is not critical.
<!-- wp:heading {"level":5} -->
<h5 class="wp-block-heading">B. **Parallel Multipliers**</h5>
Parallel multipliers, also known as **array multipliers** or **combinational multipliers**, perform multiple bit-level operations in parallel, significantly increasing the speed of multiplication. One of the most common types of parallel multipliers is the **Wallace tree multiplier**, which uses a tree structure to reduce the number of partial products and sum them more efficiently.
* **Array Multiplier**: The array multiplier uses a grid of AND gates and adders to generate and sum partial products in parallel. This circuit takes less time to complete the operation compared to a serial multiplier because all the partial products are generated and added simultaneously.
* **Wallace Tree Multiplier**: The Wallace tree multiplier optimizes the multiplication process by reducing the number of partial products in fewer stages. Instead of simply summing the partial products, the Wallace tree uses a combination of **full adders** and **half adders** to perform the additions in a tree-like structure, minimizing the number of required addition steps.
#### 3. **Booth’s Algorithm**
For more efficient multiplication of binary numbers, especially when one operand contains many consecutive ones or zeros, **Booth’s Algorithm** can be used. Booth’s Algorithm reduces the number of addition and subtraction operations required during multiplication by recognizing patterns in the binary representation of the multiplier.
* The algorithm scans the multiplier in pairs of bits, reducing the total number of partial products and handling both positive and negative multipliers efficiently using two's complement representation.
* Booth's Algorithm is particularly useful when dealing with signed binary numbers, as it eliminates the need for separate circuits to handle positive and negative values.
Division Circuits
Division is inherently more complex than multiplication because it requires repeated subtraction, shifting, and handling of remainders. In digital systems, division can be performed using two main approaches: **restoring** and **non-restoring division**.
#### 1. **Binary Division Basics**
Binary division, much like decimal division, involves repeated subtraction of the divisor from the dividend until the remainder is less than the divisor. The quotient is built one bit at a time, and the remainder is updated after each subtraction.
For example:
```bash
Dividing 1100 (12 in decimal) by 0011 (3 in decimal):
1. Start with 1100 (dividend) and 0011 (divisor).
2. Shift the divisor to align with the most significant bit of the dividend.
3. Subtract divisor from the dividend, generating a partial quotient.
4. Shift and repeat until the remainder is less than the divisor.```
#### 2. **Restoring Division**
In **restoring division**, the process involves:
* **Subtracting** the divisor from the current dividend (or partial remainder).
* If the result is positive, the subtraction was successful, and a **1** is placed in the quotient.
* If the result is negative, the subtraction is undone (restored), and a **0** is placed in the quotient.
* The remainder is updated, and the divisor is shifted to process the next bit.
While restoring division is conceptually simple, it requires extra steps to restore the original value of the dividend when the result of the subtraction is negative, making it less efficient.
#### 3. **Non-Restoring Division**
**Non-restoring division** improves on the restoring method by eliminating the need to undo failed subtractions. In this method:
* After a failed subtraction (negative result), instead of restoring the original value, the algorithm proceeds directly with the next step.
* The next subtraction is performed, but instead of subtracting the divisor, it **adds** the divisor (since the previous step produced a negative result).
* This process repeats, and the quotient is built bit by bit, as in restoring division.
Non-restoring division is faster than restoring division because it skips the restoration step, making it more efficient in hardware implementations.
#### 4. **SRT Division**
**SRT Division** is another approach used in high-performance processors. Named after its developers (Sweeney, Robertson, and Tocher), SRT division is a digit-recurrence algorithm that improves efficiency by generating quotient digits faster than traditional binary long division.
* SRT division works by choosing a quotient digit from a predefined set of possible values at each step, which simplifies the decision-making process during division.
* The result is faster division operations, especially in systems that need high-performance arithmetic.
#### 5. **Division by Shifting**
A simpler method for dividing by powers of two is **division by shifting**. In binary systems, dividing a number by 2 is equivalent to shifting the binary digits to the right. For example, dividing `1010` (10 in decimal) by 2 results in `0101` (5 in decimal). This approach is extremely efficient for division by 2, 4, 8, and other powers of two, as no actual subtraction is needed.
Comparison: Multiplication vs. Division Circuits
While both multiplication and division circuits perform essential arithmetic operations, they differ in complexity and speed. Here’s a comparison of their key aspects:
<!-- wp:table -->
<figure class="wp-block-table"><table class="has-fixed-layout"><thead><tr><th>Feature</th><th>Multiplication Circuits</th><th>Division Circuits</th></tr></thead><tbody><tr><td>**Complexity**</td><td>Relatively simple (serial) to complex (parallel)</td><td>More complex, due to remainder handling</td></tr><tr><td>**Operation Time**</td><td>Faster with parallel multipliers (e.g., Wallace tree)</td><td>Slower due to iterative nature</td></tr><tr><td>**Algorithm Examples**</td><td>Booth's Algorithm, Wallace Tree</td><td>Restoring, Non-Restoring, SRT</td></tr><tr><td>**Application**</td><td>Common in DSP, graphics, AI</td><td>Used in floating-point arithmetic, error correction</td></tr></tbody></table></figure>
<!-- /wp:table -->
Applications of Multiplication and Division Circuits
Multiplication and division circuits are integral to many digital systems and applications. Some key examples include:
* **Digital Signal Processing (DSP)**: Multiplication circuits are heavily used in DSP applications such as filtering, audio processing, and image processing.
* **Computer Graphics**: Multiplication and division circuits handle geometric transformations, shading, and rendering operations in 3D graphics.
* **Machine Learning and AI**: Multiplication circuits are used in matrix operations, which are fundamental to deep learning algorithms and neural networks.
* **Embedded Systems**: Both multiplication and division circuits are critical in embedded systems, where they handle real-time calculations, sensor data processing, and control logic.
* **Cryptography**: Division algorithms play a role in cryptographic operations like modular arithmetic, which is used in encryption schemes.
Conclusion
Multiplication and division circuits are fundamental components of modern digital systems, playing a crucial role in
everything from basic arithmetic operations to advanced machine learning algorithms. Whether it's the array multipliers that power digital signal processing or the non-restoring division algorithms used in high-performance computing, these circuits enable the mathematical functionality that underpins modern technology.
Understanding how multiplication and division circuits work provides valuable insight into the design and performance of digital systems. As technology advances, these circuits will continue to evolve, becoming more efficient and capable of handling increasingly complex computations. Whether you're a student of computer engineering or a professional in the field, mastering multiplication and division circuits is a key step in understanding digital electronics and computer architecture.
Multiplexers and Demultiplexers: Essential Building Blocks of Digital Systems
In the realm of digital electronics and communications, multiplexers (MUXs) and demultiplexers (DEMUXs) are fundamental components used to manage the flow of data. They play a crucial role in optimizing data transmission, reducing circuit complexity, and improving system efficiency. Understanding how these components work is key to designing efficient digital systems, whether you’re working on communication protocols, circuit design, or data routing in computer networks.
In this post, we’ll dive deep into what multiplexers and demultiplexers are, how they function, their applications, and why they are so critical in digital systems. What is a Multiplexer?
A multiplexer (MUX) is a combinational logic device that selects one input from several input lines and transmits it to a single output line. It functions as a data selector, allowing multiple signals to share a single communication channel or resource, which reduces the number of data lines required to transmit information.
Think of a multiplexer as a multi-lane highway that converges into a single lane. Although many cars (signals) are coming from different directions, the multiplexer controls which car gets access to the single output lane at any given time.
Basic Structure of a Multiplexer
A multiplexer has:
Data Inputs (n inputs): These are the multiple inputs from which the device selects one to pass to the output.
Select Lines: These are control lines used to choose which input should be forwarded to the output. The number of select lines is based on the number of inputs and is given by (2^n = m), where n is the number of select lines and m is the number of inputs.
Single Output: The selected input is sent to the output based on the control signals.
For example, in a 2-to-1 MUX, there are two data inputs (D0 and D1), one select line (S), and one output (Y). The value on the select line determines whether the output is D0 or D1. If S = 0, Y = D0, and if S = 1, Y = D1.
Multiplexer Truth Table (2-to-1 MUX)
| Select Line (S) | Input D0 | Input D1 | Output (Y) |
|---|---|---|---|
| 0 | D0 | D1 | D0 |
| 1 | D0 | D1 | D1 |
Expanding to Larger Multiplexers
For larger multiplexers, the number of select lines increases. For example:
- A 4-to-1 multiplexer has four data inputs (D0 to D3), two select lines (S0 and S1), and one output. Based on the combination of the select lines, one of the four inputs is chosen. The truth table for a 4-to-1 MUX looks like this:
| Select Lines (S1, S0) | Output (Y) |
|---|---|
| 00 | D0 |
| 01 | D1 |
| 10 | D2 |
| 11 | D3 |
- An 8-to-1 multiplexer has eight data inputs (D0 to D7), three select lines (S0, S1, S2), and one output. Similarly, an n-to-1 multiplexer can be designed by increasing the number of inputs and select lines.
Advantages of Using Multiplexers
Reduced Wiring: Multiplexers allow multiple signals to share the same communication line, reducing the number of wires and components needed in a system.
Efficient Use of Resources: By combining several data streams into a single output, multiplexers optimize the use of available resources, such as bandwidth in communication systems.
Increased Flexibility: With the use of select lines, a multiplexer provides flexible control over data transmission and signal routing, which is critical in systems requiring dynamic switching between different input sources.
Applications of Multiplexers
Multiplexers have widespread applications in digital systems and communication. Some key applications include:
Data Routing: Multiplexers are used in routers and switches to direct data packets from multiple input sources to a single output destination.
Signal Processing: In signal processing systems, multiplexers are used to combine multiple analog or digital signals into one line for transmission over a single communication channel.
Memory Access: In computer systems, multiplexers are used to control access to memory, allowing multiple devices or processors to read and write data to the same memory bus.
Communication Systems: Multiplexers are heavily used in communication systems, where multiple signals need to be transmitted over a single channel, such as in telephone networks and satellite communications.
What is a Demultiplexer?
A demultiplexer (DEMUX) is the inverse of a multiplexer. It takes a single input signal and routes it to one of many output lines based on select inputs. Essentially, a DEMUX decodes information from one input line to multiple output lines, distributing data to different destinations as needed.
You can think of a demultiplexer as a road junction where a single lane splits into multiple lanes. The demultiplexer decides which lane (output line) the incoming vehicle (data) should be routed to.
Basic Structure of a Demultiplexer
A demultiplexer has:
Single Input: A single data signal is fed into the demultiplexer.
Select Lines: These control the routing of the input to one of the output lines.
Multiple Outputs (n outputs): The input signal is routed to one of the multiple output lines depending on the select lines. The number of select lines required is given by (2^n = m), where n is the number of select lines and m is the number of outputs.
For example, a 1-to-4 DEMUX has one input, two select lines (S0, S1), and four outputs (Y0 to Y3). Based on the combination of select lines, the input is directed to one of the four outputs.
Demultiplexer Truth Table (1-to-4 DEMUX)
| Select Lines (S1, S0) | Output Y0 | Output Y1 | Output Y2 | Output Y3 |
|---|---|---|---|---|
| 00 | Input | 0 | 0 | 0 |
| 01 | 0 | Input | 0 | 0 |
| 10 | 0 | 0 | Input | 0 |
| 11 | 0 | 0 | 0 | Input |
Expanding to Larger Demultiplexers
Like multiplexers, demultiplexers can be expanded to handle more outputs. For instance, an 8-to-1 DEMUX has one input, three select lines (S0, S1, S2), and eight output lines (Y0 to Y7). The number of select lines increases with the number of outputs, as each combination of select lines determines which output receives the input signal.
Advantages of Using Demultiplexers
Efficient Data Distribution: Demultiplexers allow a single data stream to be efficiently distributed to multiple destinations, reducing the need for multiple input channels.
Simplified Circuit Design: By directing data to specific outputs based on select inputs, DEMUXs reduce the need for additional logic gates or complex routing mechanisms.
Versatility: Demultiplexers are versatile devices that can be used in various applications, from digital communication systems to microprocessor design.
Applications of Demultiplexers
Data Distribution: Demultiplexers are used in systems where a single data source needs to be sent to multiple destinations. For example, in digital communication systems, a demultiplexer helps route incoming signals to the appropriate receiver.
Memory Management: In computer systems, demultiplexers are used in memory management systems to route data from the processor to the correct memory address.
Digital Displays: Demultiplexers are used in controlling digital displays, where a single input controls which segment of a display is turned on or off.
Key Differences Between Multiplexers and Demultiplexers
Functionality:
A multiplexer selects one input from several inputs and forwards it to a single output.
A demultiplexer takes one input and distributes it to one of several outputs.
Direction of Data Flow:
A multiplexer compresses multiple inputs into a single output.
A demultiplexer expands a single input into multiple outputs.
Control Lines:
In a multiplexer, select lines control which input is chosen to pass to the output.
In a demultiplexer, select lines control which output receives the input.
Applications:
Multiplexers are used in data selection, routing, and signal processing.
Demultiplexers are used in data distribution, decoding, and routing information to multiple destinations.
Combining Multiplexers and Demultiplexers
In many digital systems, multiplexers and demultiplexers are used together to facilitate efficient data routing and transmission. For example, in communication networks, a multiplexer can be used to combine multiple data streams into one for transmission over a single channel,
while a demultiplexer at the receiving end can distribute the data back to the correct destination.
This combination is crucial in modern communication systems like satellite communication, where bandwidth is limited and efficient data management is required. Conclusion
Multiplexers and demultiplexers are integral components of digital systems, providing efficient ways to manage data flow. Multiplexers allow multiple inputs to share a single output channel, while demultiplexers distribute a single input to multiple output destinations. Their versatility and efficiency make them indispensable in a wide variety of applications, from communication systems and computer memory management to signal processing and data routing.
By understanding how MUXs and DEMUXs work, you’ll be better equipped to design and optimize digital systems that require flexible and efficient data handling.
BCD, Gray Code, and Other Encoding Schemes: Unraveling the World of Digital Data Representation
In the realm of digital systems and computer science, the way we represent data is crucial. While binary is the fundamental language of computers, there are numerous encoding schemes designed for specific purposes or to overcome particular challenges. In this blog post, we’ll explore some of these encoding schemes, focusing on Binary-Coded Decimal (BCD), Gray code, and touching on several other important encoding methods. We’ll delve into how they work, their advantages, limitations, and real-world applications.
Binary: The Foundation of Digital Encoding
Before we dive into more complex encoding schemes, let’s briefly revisit binary encoding, the foundation of all digital systems.
Binary uses only two digits, 0 and 1, to represent all numbers. For example:
Decimal: 0 1 2 3 4 5 6 7
Binary: 0 1 10 11 100 101 110 111```
While binary is efficient for computers, it's not always the most convenient for human interpretation or specific applications. This is where alternative encoding schemes come into play.
## Binary-Coded Decimal (BCD)
What is BCD?
Binary-Coded Decimal (BCD) is an encoding scheme that represents decimal digits using a binary code. In its most common form, each decimal digit is represented by a four-bit binary number.
How BCD Works
In BCD, each decimal digit (0-9) is encoded separately:
```bash
Decimal: 0 1 2 3 4 5 6 7 8 9
BCD: 0000 0001 0010 0011 0100 0101 0110 0111 1000 1001```
For example, the decimal number 23 would be represented in BCD as:
```bash
2 3
0010 0011```
Advantages of BCD
* **Easy conversion**: Converting between decimal and BCD is straightforward, making it useful for systems that interface with decimal inputs or outputs.
* **No rounding errors**: BCD can represent decimal fractions exactly, which is crucial for financial calculations.
Limitations of BCD
* **Inefficient storage**: BCD uses four bits to represent ten possibilities, wasting potential bit combinations.
* **Limited range**: For a given number of bits, BCD can represent fewer numbers than pure binary.
Applications of BCD
* **Financial systems**: Where exact decimal representations are crucial.
* **Digital displays**: Many seven-segment displays use BCD input.
* **Data communication**: Some protocols use BCD for ease of conversion.
## Gray Code
What is Gray Code?
Gray code, also known as reflected binary code, is a sequence of binary numbers where adjacent numbers differ by only one bit.
How Gray Code Works
Here's the Gray code sequence for 3-bit numbers:
```bash
Decimal: 0 1 2 3 4 5 6 7
Binary: 000 001 010 011 100 101 110 111
Gray: 000 001 011 010 110 111 101 100```
To convert from binary to Gray code:
* The most significant bit remains the same.
* Each subsequent bit is XORed with the previous bit of the binary number.
Advantages of Gray Code
* **Minimal changes**: Only one bit changes between adjacent numbers, reducing errors in certain applications.
* **Error detection**: It's easier to detect errors when only one bit should change at a time.
Applications of Gray Code
* **Rotary encoders**: Used in robotics and industrial control to track position.
* **Analog-to-Digital Conversion**: Reduces errors in the conversion process.
* **Genetic algorithms**: Used in some implementations to represent chromosomes.
## Other Important Encoding Schemes
1. ASCII (American Standard Code for Information Interchange)
ASCII is a character encoding standard for electronic communication. It uses 7 bits to represent 128 characters, including uppercase and lowercase letters, digits, punctuation marks, and control characters.
Example:
```bash
Character: A B C a b c 1 2 3
ASCII: 65 66 67 97 98 99 49 50 51```
ASCII is widely used in text-based communication and data storage.
2. Unicode
Unicode is a more comprehensive character encoding standard that aims to represent every character from all writing systems of the world.
Unicode uses various encoding forms, including UTF-8, UTF-16, and UTF-32. UTF-8, which is widely used on the internet, uses 1 to 4 bytes per character.
Example (UTF-8):
```bash
Character: A € 你
UTF-8: 41 E2 82 AC E4 BD A0```
Unicode has become the standard for multilingual text representation in modern computing.
3. Hamming Code
Hamming code is an error-detecting and error-correcting code that uses parity bits to identify and correct single-bit errors.
For example, to encode 4 data bits (D1, D2, D3, D4), we add 3 parity bits (P1, P2, P3):
```bash
P1 P2 D1 P3 D2 D3 D4```
Hamming code is used in error-correcting memory and some communication protocols.
4. Run-Length Encoding (RLE)
RLE is a simple form of data compression that replaces sequences of identical data elements with a single data value and count.
Example:
```bash
Original: WWWWWWWWWWBBBWWWWWWWWWWWWWWWWWWWWWWWWB
RLE: 10W3B12W1b
RLE is used in image compression, particularly for simple graphics with large contiguous regions of the same color.
- Huffman Coding
Huffman coding is a data compression technique that assigns variable-length codes to characters based on their frequency of occurrence. More frequent characters get shorter codes.
Example:
Character: A B C D
Frequency: 5 1 6 3
Huffman: 10 110 0 111```
Huffman coding is used in various data compression algorithms and file formats.
6. Manchester Encoding
Manchester encoding is a synchronous clock encoding technique used in data transmission. It represents data by transitions rather than levels.
```bash
Data: 0 1 0 1 1 0
Manchester: ▔╱▁╲▔╱▁╲▁╲▔╱```
Manchester encoding is used in Ethernet and other communication protocols for its self-clocking property.
## Comparing Encoding Schemes
When choosing an encoding scheme, consider the following factors:
* **Efficiency**: How efficiently does the scheme use available bits?
* **Error resilience**: How well does the scheme handle errors or noise?
* **Ease of encoding/decoding**: How complex are the encoding and decoding processes?
* **Self-clocking**: Does the scheme provide timing information?
* **Compatibility**: Is the scheme widely supported by existing systems?
Different schemes excel in different areas:
* BCD is efficient for decimal-based human interfaces but inefficient for storage.
* Gray code excels in error resilience for incremental changes.
* ASCII and Unicode are optimized for text representation.
* Hamming code provides error correction at the cost of additional bits.
* RLE and Huffman coding focus on data compression.
* Manchester encoding provides self-clocking but uses more bandwidth.
## Real-World Applications
Understanding these encoding schemes is crucial in various fields:
* **Data Communication**: Protocols like Ethernet use Manchester encoding, while error-correcting codes like Hamming are used in noisy channels.
* **Computer Architecture**: BCD is used in some arithmetic units, especially in calculators and financial systems.
* **Digital Electronics**: Gray code is used in rotary encoders and analog-to-digital converters.
* **Software Development**: Understanding character encodings like ASCII and Unicode is crucial for text processing and internationalization.
* **Data Compression**: Techniques like RLE and Huffman coding are fundamental to many compression algorithms.
* **Cryptography**: Many encoding schemes form the basis of more complex cryptographic algorithms.
## The Future of Encoding Schemes
As technology evolves, so do our encoding needs:
* **Quantum Computing**: Quantum systems will require new ways of encoding information, based on quantum states rather than classical bits.
* **DNA Storage**: Encoding digital data in DNA sequences is an emerging field, requiring novel encoding schemes.
* **Advanced Error Correction**: As we push the limits of data transmission and storage, more sophisticated error-correcting codes are being developed.
* **AI and Machine Learning**: These fields are driving the development of encoding schemes optimized for neural networks and other AI algorithms.
## Conclusion
Encoding schemes are the unsung heroes of the digital world. They bridge the gap between the binary language of computers and the diverse needs of various applications. From the simplicity of BCD to the error-resilience of Gray code, from the universality of Unicode to the efficiency of Huffman coding, each scheme plays a crucial role in modern computing and communication.
As we've explored in this post, there's no one-size-fits-all encoding scheme. The choice depends on the specific requirements of the application, balancing factors like efficiency, error-resilience, and ease of use. Understanding these schemes provides insight into the inner workings of digital systems and can be invaluable in designing efficient and robust digital solutions.
Whether you're developing software, designing digital circuits, working on data compression algorithms, or simply curious about how data is represented in the digital world, a solid grasp of these encoding schemes is a valuable asset. They form the foundation upon which our entire digital infrastructure is built, enabling the seamless flow of information that we often take for granted in our increasingly connected world.
As we look to the future, new challenges in quantum computing, DNA storage, and artificial intelligence will undoubtedly lead to the development of novel encoding schemes. By understanding the principles behind existing schemes, we're better equipped to tackle these challenges and continue pushing the boundaries of what's possible in the digital realm.
Starlink Satellites and Internet Services
In recent years, the landscape of internet connectivity has undergone a significant transformation, primarily due to advancements in satellite technology. One of the most notable players in this arena is Starlink, a satellite internet constellation developed by SpaceX, founded by Elon Musk. Starlink aims to provide high-speed internet access globally, particularly in underserved and remote areas where traditional internet infrastructure is lacking. This blog post delves into the workings of Starlink satellites, their services, and their impact on global connectivity.
What are Starlink Satellites?
Starlink satellites are part of a low Earth orbit (LEO) constellation designed to deliver broadband internet services. Unlike traditional geostationary satellites that orbit approximately 22,236 miles above the Earth, Starlink satellites operate at altitudes ranging from 340 to 1,200 kilometers (about 211 to 746 miles). This proximity significantly reduces latency and enhances data transmission speeds, making it possible for users to experience internet connectivity comparable to terrestrial options like cable or fiber optics[1][3].
Key Features of Starlink Satellites
Low Earth Orbit: The LEO positioning allows Starlink satellites to transmit data with lower latency—typically between 20 to 40 milliseconds—compared to geostationary satellites that can have latencies exceeding 600 milliseconds[2][3].
Large Constellation: As of now, there are thousands of Starlink satellites in orbit, with plans for many more. This extensive network ensures robust coverage and redundancy[1].
Continuous Upgrades: SpaceX has the unique capability to launch its own satellites frequently and cost-effectively, allowing for continuous updates and improvements in technology[7].
How Starlink Internet Works
Starlink’s internet service operates through a combination of satellite technology and ground infrastructure. Users need a Starlink terminal—often referred to as “Dishy”—which includes a satellite dish and a Wi-Fi router. The installation process is designed for simplicity:
Plug it in: Connect the terminal to power.
Point at the sky: Position the dish for an unobstructed view of the sky using the Starlink app for guidance.
Once set up, the terminal communicates with the satellites overhead, which relay data back to ground stations connected to the broader internet network[4][5].
Internet Service Plans
Starlink offers various service plans catering to different user needs:
Residential Service: Priced around $120 per month with an initial hardware cost of approximately $599. This plan provides unlimited data with speeds ranging from 50 Mbps to 220 Mbps depending on location and network congestion[2][3].
Starlink for RVs: This plan allows users to take their service on the road but may experience deprioritized speeds compared to fixed-location users.
Starlink Maritime: Designed for vessels at sea, offering speeds up to 350 Mbps but requiring a more expensive terminal and monthly fee[2][5].
Advantages of Using Starlink
Starlink’s innovative approach offers several advantages over traditional internet providers:
Global Coverage
Starlink aims to provide internet access in areas where conventional services are either unavailable or unreliable. According to recent reports, it is available to approximately 99.6% of U.S. households, making it one of the most accessible providers in rural regions[3][5].
High-Speed Connectivity
Users can expect download speeds typically between 100 Mbps and 200 Mbps, which is significantly higher than many other satellite providers like HughesNet or Viasat that cap out around 25 Mbps to 150 Mbps[3][5]. This makes Starlink particularly appealing for activities such as streaming video or online gaming.
Low Latency
The reduced latency associated with LEO satellites makes Starlink suitable for applications that require real-time communication, such as video conferencing and online gaming—areas where traditional satellite services often fall short due to delays[3][4].
Emergency Response Capability
Starlink has proven invaluable during emergencies. For example, during the ongoing conflict in Ukraine, Starlink terminals were deployed rapidly to support communications when traditional infrastructure was compromised. The ability to set up service quickly in disaster-stricken areas showcases its potential as a reliable resource in crises[1][5].
Challenges and Limitations
Despite its many benefits, Starlink faces several challenges:
High Initial Costs
The upfront cost for equipment can be a barrier for some users. While the monthly subscription is competitive compared to other satellite services, the initial investment may deter potential customers[5][6].
Network Congestion
As more users subscribe to Starlink’s services, network congestion can lead to slower speeds during peak times. A study indicated that average download speeds dropped from over 100 Mbps in late 2021 to about 67 Mbps by early 2023 due to increased subscriptions[3][5].
Environmental Concerns
The proliferation of satellites raises concerns about space debris and its impact on astronomical observations. The bright trails left by Starlink satellites can interfere with ground-based telescopes and other observational equipment[1][2].
Future Developments
Looking ahead, several exciting developments are on the horizon for Starlink:
Direct-to-Cell Service
In partnership with T-Mobile, SpaceX plans to offer direct cellular service via its satellites starting in 2024. This will allow users in remote areas without cellular coverage to send texts and make calls using existing mobile devices[2][3].
Enhanced Speeds and Capacity
As more advanced satellites are launched into orbit, users can expect improvements in speed and capacity. The introduction of newer generations of satellites is anticipated to bolster performance even further[1][7].
Conclusion
Starlink represents a significant leap forward in satellite internet technology, providing high-speed connectivity where it was previously unavailable or unreliable. Its innovative use of low Earth orbit satellites allows for reduced latency and improved service quality compared to traditional satellite providers. While challenges remain—such as high initial costs and environmental concerns—the potential benefits make Starlink an attractive option for many users worldwide.
As technology continues to evolve and expand, it will be fascinating to see how Starlink adapts and grows within the ever-changing landscape of global internet connectivity.
Citations: [1] https://www.space.com/spacex-starlink-satellites.html [2] https://en.wikipedia.org/wiki/Starlink [3] https://www.cnet.com/home/internet/starlink-internet-review/ [4] https://www.starlink.com/residential [5] https://www.satelliteinternet.com/providers/starlink/ [6] https://www.starlink.com [7] https://www.starlink.com/technology [8] https://www.starlink.com/satellites
Should an Emotional Bond be Established with Artificial Intelligence? What to Consider
As artificial intelligence (AI) becomes increasingly sophisticated and integrated into our daily lives, a thought-provoking question arises: Should we form emotional bonds with AI entities? This complex issue touches on psychology, ethics, technology, and philosophy, raising important considerations about the nature of relationships, consciousness, and the role of AI in society. In this blog post, we’ll explore the various aspects of this question, examining both the potential benefits and risks of forming emotional connections with AI.
Understanding Emotional Bonds with AI
Before delving into the implications, it’s crucial to understand what we mean by “emotional bonds” with AI:
Definition and Context
An emotional bond with AI refers to a sense of attachment, affection, or emotional investment in an artificial intelligence entity. This could range from feeling fondness for a virtual assistant to developing a deep sense of companionship with an AI-powered robot.
Current AI Capabilities
While AI has made significant strides, it’s important to note that current AI systems do not have genuine emotions or consciousness. They can simulate emotional responses based on programming and data analysis, but they do not experience feelings in the way humans do.
Potential Benefits of Emotional Bonds with AI
Forming emotional connections with AI could offer several potential benefits:
- Enhanced User Experience
Emotional engagement can make interactions with AI more natural and enjoyable, potentially increasing the effectiveness of AI-assisted tasks and services.
- Emotional Support and Mental Health
AI companions could provide emotional support to individuals who are lonely, isolated, or struggling with mental health issues. They could offer consistent, judgment-free interaction and support.
- Educational and Therapeutic Applications
Emotionally engaging AI could be used in educational settings to make learning more interactive and personalized. In therapy, AI could assist in treatments for social anxiety or autism spectrum disorders.
- Improved Human-AI Collaboration
As AI becomes more prevalent in workplaces, emotional bonds could lead to better teamwork between humans and AI systems, potentially increasing productivity and job satisfaction.
- Empathy Development
Interacting with AI in an emotionally engaged way might help some individuals practice and develop their empathy skills, which could translate to improved human-to-human interactions.
Risks and Concerns
However, there are significant risks and ethical concerns to consider:
- Misplaced Emotional Investment
There’s a risk of individuals becoming overly attached to AI entities, potentially neglecting real human relationships or developing unrealistic expectations.
- Privacy and Data Concerns
Emotional engagement with AI often involves sharing personal information. This raises concerns about data privacy, security, and the potential for manipulation.
- Ethical Implications of AI “Emotions”
Creating AI that simulates emotions raises ethical questions about the nature of consciousness and the potential for exploiting human emotions.
- Dependency and Addiction
There’s a risk of individuals becoming dependent on AI for emotional support, potentially leading to addiction-like behaviors or an inability to cope without AI assistance.
- Impact on Human Relationships
Widespread emotional bonding with AI could potentially impact the way we form and maintain human-to-human relationships, possibly leading to social isolation or changes in social norms.
- Blurring of Reality
Deep emotional connections with AI might lead some individuals to blur the lines between artificial and human relationships, potentially causing confusion or disappointment.
- Manipulation and Exploitation
Bad actors could potentially use emotionally engaging AI to manipulate vulnerable individuals for financial gain or other malicious purposes.
Psychological Considerations
The psychology behind human-AI emotional bonds is complex and multifaceted:
- Anthropomorphism
Humans have a natural tendency to attribute human characteristics to non-human entities. This can lead to emotional attachments to AI, even when we rationally understand their artificial nature.
- The Uncanny Valley
As AI becomes more human-like, it may reach a point where it’s unsettlingly close to human but not quite there, potentially causing discomfort or revulsion. This phenomenon, known as the uncanny valley, could impact emotional bonding with AI.
- Attachment Theory
Understanding how humans form attachments could inform the development of AI systems designed for emotional engagement, but it also raises questions about the appropriateness of applying human attachment models to artificial entities.
- Cognitive Biases
Various cognitive biases, such as the ELIZA effect (where people unconsciously assume computer behaviors are analogous to human behaviors), can influence how we perceive and interact with AI emotionally.
Ethical Framework for AI-Human Emotional Bonds
To navigate the complex landscape of emotional bonds with AI, we need to consider developing an ethical framework:
- Transparency
AI systems should be transparent about their artificial nature and capabilities. Users should always be aware that they are interacting with an AI, not a human.
- Consent and Control
Users should have control over the level of emotional engagement they have with AI and should be able to easily disengage or limit interactions.
- Privacy Protection
Strict data protection measures should be in place to safeguard the personal information shared during emotional interactions with AI.
- Ethical Design
AI systems designed for emotional engagement should be created with ethical considerations in mind, avoiding manipulative tactics or exploitative features.
- Human Oversight
There should be human oversight in the development and deployment of emotionally engaging AI to ensure ethical standards are maintained.
- Research and Monitoring
Ongoing research should be conducted to understand the long-term psychological and social impacts of emotional bonds with AI, with mechanisms in place to address any negative effects.
Societal Implications
The widespread formation of emotional bonds with AI could have far-reaching societal implications:
- Changing Social Norms
As AI companions become more common, social norms around relationships and emotional support may evolve.
- Economic Impact
Industries built around emotional AI companions could emerge, potentially impacting traditional sectors like mental health services or entertainment.
- Legal Considerations
New legal frameworks may be needed to address issues related to AI companions, such as rights, responsibilities, and liabilities.
- Education and Skill Development
There may be a need for education on healthy interactions with AI and the development of new social-emotional skills for a world where AI companions are common.
- Cultural Differences
Different cultures may approach emotional bonds with AI in varying ways, potentially leading to global disparities or conflicts in AI development and use.
Future Scenarios
As AI continues to advance, we can envision several possible future scenarios:
- AI as Complementary Emotional Support
AI could evolve to provide complementary emotional support alongside human relationships, enhancing overall well-being without replacing human connections.
- AI as Primary Emotional Companions
In some cases, AI might become the primary source of emotional companionship for individuals, particularly in situations where human interaction is limited or challenging.
- Integration of AI in Human Social Networks
AI entities could become integrated into human social networks, acting as intermediaries or facilitators of human-to-human connections.
- Hybrid Human-AI Relationships
We might see the emergence of hybrid relationships where AI enhances or augments human-to-human emotional bonds.
- Rejection of Emotional AI
Conversely, there could be a societal backlash against emotional AI, with a renewed emphasis on authentic human connections.
Conclusion: A Balanced Approach
The question of whether we should form emotional bonds with AI doesn’t have a simple yes or no answer. As with many technological advancements, the key lies in finding a balanced approach that maximizes benefits while mitigating risks.
Emotional engagement with AI has the potential to enhance our lives in numerous ways, from providing support and companionship to improving our interactions with technology. However, it’s crucial that we approach this development with caution, ethical consideration, and a clear understanding of the limitations and potential consequences.
As we move forward, it will be essential to:
Conduct thorough research on the psychological and social impacts of emotional bonds with AI
Develop robust ethical guidelines and regulatory frameworks
Ensure transparency and user control in AI systems designed for emotional engagement
Maintain a clear distinction between AI and human relationships
Promote digital literacy and healthy attitudes towards AI interactions
Ultimately, the decision to form emotional bonds with AI will likely be a personal one, influenced by individual circumstances, cultural norms, and societal trends. As a society, our role should be to create an environment where these choices can be made responsibly, with full awareness of both the potential benefits and the risks involved.
As AI continues to evolve, so too will our understanding of its role in our emotional lives. By approaching this development thoughtfully and ethically, we can work towards a future where AI enhances our emotional well-being without compromising the fundamental human connections that define us.
Understanding Networks: A Comprehensive Guide to Modern Connectivity
In our increasingly interconnected world, networks form the backbone of our digital infrastructure. From the internet that connects billions of devices globally to the local area network in your home or office, understanding networks is crucial for anyone navigating the modern digital landscape. This comprehensive guide will delve into the world of networks, explaining key concepts, types of networks, and their importance in our daily lives.
What is a Network?
At its core, a network is a collection of interconnected devices that can communicate with each other. These devices, often called nodes, can be computers, smartphones, servers, or any other device capable of sending or receiving data. The primary purpose of a network is to share resources and information.
Types of Networks
Networks come in various sizes and serve different purposes. Let’s explore some of the most common types:
- Local Area Network (LAN)
A LAN is a network that connects devices within a limited area, such as a home, office, or small group of buildings.
Key characteristics of LANs:
High-speed data transfer
Limited geographical area
Typically owned and managed by a single organization
Common uses:
Sharing files and printers
Collaborative work environments
Local gaming networks
- Wide Area Network (WAN)
A WAN connects devices across a large geographical area, often spanning cities, countries, or even continents.
Key characteristics of WANs:
Cover large geographical areas
Often use leased telecommunication lines
Typically slower than LANs due to distance and complexity
Common uses:
Connecting branch offices of a company
The Internet (the largest WAN)
Government and military communications
- Wireless Local Area Network (WLAN)
A WLAN is similar to a LAN but uses wireless network technology, primarily Wi-Fi, to connect devices.
Key characteristics of WLANs:
Provides wireless connectivity within a limited area
Requires wireless network adapters in devices
Can be less secure than wired networks if not properly configured
Common uses:
Home and office Wi-Fi networks
Public hotspots in cafes, airports, etc.
Campus-wide networks in universities
- Metropolitan Area Network (MAN)
A MAN is larger than a LAN but smaller than a WAN, typically covering a city or large campus.
Key characteristics of MANs:
Span a larger area than a LAN but smaller than a WAN
Often used by municipalities or large organizations
Can use a mix of wired and wireless technologies
Common uses:
City-wide Wi-Fi networks
Connecting multiple campuses of a university
Traffic management systems in cities
- Personal Area Network (PAN)
A PAN is a network for interconnecting devices centered around an individual’s workspace.
Key characteristics of PANs:
Very short range (typically within a few meters)
Often use wireless technologies like Bluetooth
Centered around personal devices
Common uses:
Connecting a smartphone to wireless earbuds
Fitness trackers communicating with smartphones
Wireless keyboard and mouse connections
Network Topologies
The topology of a network refers to the arrangement of its elements (links, nodes, etc.). Common network topologies include:
Bus Topology: All devices are connected to a single cable.
Star Topology: All devices are connected to a central hub or switch.
Ring Topology: Devices are connected in a closed loop.
Mesh Topology: Devices are interconnected with multiple redundant connections.
Tree Topology: A hierarchical structure with a root node and child nodes.
Each topology has its advantages and disadvantages in terms of cost, reliability, and scalability.
Key Components of Networks
Understanding networks involves familiarity with several key components:
- Nodes
Nodes are the devices on a network, including computers, servers, smartphones, and IoT devices.
- Network Interface Cards (NICs)
NICs are hardware components that allow devices to connect to a network, either through an Ethernet port or wirelessly.
- Switches
Switches connect devices within a network and use MAC addresses to direct traffic to the appropriate device.
- Routers
Routers connect different networks and direct traffic between them, using IP addresses to determine the best path for data.
- Modems
Modems convert digital signals from your devices into analog signals that can be transmitted over telephone or cable lines, and vice versa.
- Firewalls
Firewalls are security devices that monitor and control incoming and outgoing network traffic based on predetermined security rules.
Network Protocols
Protocols are the rules and standards that govern how data is transmitted over a network. Some essential protocols include:
TCP/IP (Transmission Control Protocol/Internet Protocol): The fundamental communication protocol of the internet.
HTTP/HTTPS (Hypertext Transfer Protocol/Secure): Used for transmitting web pages.
FTP (File Transfer Protocol): Used for transferring files between computers on a network.
SMTP (Simple Mail Transfer Protocol): Used for sending email.
DNS (Domain Name System): Translates domain names into IP addresses.
The OSI Model
The Open Systems Interconnection (OSI) model is a conceptual framework that describes how data communication occurs between devices on a network. It consists of seven layers:
Physical Layer
Data Link Layer
Network Layer
Transport Layer
Session Layer
Presentation Layer
Application Layer
Understanding the OSI model helps in troubleshooting network issues and understanding how different network technologies interact.
Network Security
As networks become increasingly integral to our daily lives, securing them becomes paramount. Some key aspects of network security include:
Encryption: Protecting data as it travels across the network.
Access Control: Ensuring only authorized users can access network resources.
Intrusion Detection and Prevention: Monitoring networks for suspicious activity and taking action to prevent attacks.
Virtual Private Networks (VPNs): Providing secure, encrypted connections over public networks.
Regular Updates and Patches: Keeping network devices and software up to date to protect against known vulnerabilities.
The Future of Networks
As technology continues to evolve, so do networks. Some emerging trends in networking include:
5G Networks: Promising faster speeds and lower latency for mobile devices.
Internet of Things (IoT): Connecting billions of devices to the internet, from smart home appliances to industrial sensors.
Software-Defined Networking (SDN): Allowing for more flexible and programmable network management.
Edge Computing: Bringing computation and data storage closer to the location where it is needed to improve response times and save bandwidth.
Quantum Networking: Exploring the potential of quantum mechanics to create ultra-secure communication channels.
Conclusion
Networks are the invisible fabric that connects our digital world. From the Wi-Fi network in your home to the global internet, understanding how networks function is increasingly important in our connected society. Whether you’re a casual internet user, an IT professional, or somewhere in between, a solid grasp of networking concepts can help you make better decisions about technology use, troubleshoot issues more effectively, and appreciate the complex infrastructure that powers our digital lives.
As networks continue to evolve and expand, they will play an even more crucial role in shaping our future. From enabling smart cities and autonomous vehicles to powering virtual reality experiences and facilitating global communication, networks will remain at the forefront of technological innovation.
By understanding the basics of how networks operate, their various types, components, and security considerations, you’re better equipped to navigate and leverage the connected world around you. As we move forward, staying informed about networking trends and best practices will be key to making the most of the opportunities that our increasingly networked world presents.
IP-MPLS: The Backbone of Modern Network Infrastructure
In the ever-evolving world of networking technologies, IP-MPLS (Internet Protocol - Multiprotocol Label Switching) stands out as a crucial component powering many of today’s most advanced and efficient networks. This powerful combination of protocols has revolutionized the way data is transmitted across networks, offering improved performance, scalability, and flexibility. In this comprehensive guide, we’ll explore IP-MPLS, its components, benefits, and its role in shaping modern network infrastructure.
What is IP-MPLS?
IP-MPLS is a networking technology that combines the flexibility of IP routing with the performance and traffic management capabilities of MPLS. To understand IP-MPLS, let’s break it down into its two main components:
IP (Internet Protocol): The fundamental protocol for routing packets across interconnected networks.
MPLS (Multiprotocol Label Switching): A protocol that uses labels to make data forwarding decisions, improving speed and enabling more sophisticated traffic management.
IP-MPLS integrates these two technologies to create a powerful, versatile networking solution that’s widely used by service providers and large enterprises.
How IP-MPLS Works
To understand how IP-MPLS works, let’s look at its key components and processes:
- Label Edge Routers (LERs)
LERs sit at the edge of an MPLS network. They perform two crucial functions:
Ingress LER: Adds labels to incoming IP packets, converting them into MPLS packets.
Egress LER: Removes labels from MPLS packets, converting them back to IP packets before they exit the MPLS network.
- Label Switch Routers (LSRs)
LSRs are the core routers within an MPLS network. They forward packets based on the MPLS labels, without needing to examine the IP header.
- Label Switched Paths (LSPs)
LSPs are predetermined paths through the MPLS network. They’re established between an ingress LER and an egress LER, defining the route that labeled packets will follow.
- Labels
Labels are short, fixed-length identifiers inserted between the Layer 2 (data link) header and the Layer 3 (network) header of a packet. They contain information about how to forward the packet.
- Label Distribution Protocol (LDP)
LDP is used by routers to exchange label mapping information, allowing them to establish LSPs.
When a packet enters an IP-MPLS network:
The ingress LER examines the IP header and assigns an appropriate label.
The labeled packet is forwarded to the next LSR in the path.
Each LSR along the path uses the label to determine the next hop, swapping the incoming label with an outgoing label.
When the packet reaches the egress LER, the label is removed, and the packet is forwarded based on its IP header.
Benefits of IP-MPLS
IP-MPLS offers numerous advantages over traditional IP routing:
- Improved Performance
Faster Forwarding: LSRs can make forwarding decisions based on simple label lookups, which is faster than complex IP routing table lookups.
Traffic Engineering: MPLS allows for precise control over traffic flows, enabling efficient use of network resources.
- Enhanced Scalability
Hierarchical Labeling: MPLS supports multiple levels of labels, allowing for efficient scaling of large networks.
Reduced Routing Table Size: Core routers only need to maintain label information, not full IP routing tables.
- Support for Quality of Service (QoS)
Traffic Prioritization: Labels can include QoS information, allowing for differentiated treatment of various traffic types.
Guaranteed Bandwidth: LSPs can be established with specific bandwidth guarantees for critical applications.
- Improved Reliability
Fast Reroute: MPLS supports rapid rerouting in case of link or node failures, improving network resilience.
Path Protection: Backup LSPs can be pre-established to provide instant failover.
- Support for Virtual Private Networks (VPNs)
Layer 3 VPNs: IP-MPLS enables efficient and scalable implementation of Layer 3 VPNs.
Layer 2 VPNs: MPLS can also support Layer 2 VPN services, allowing for transparent LAN services across wide areas.
- Protocol Independence
- Multiprotocol Support: MPLS can carry various types of traffic, including IP, ATM, and Frame Relay.
Applications of IP-MPLS
IP-MPLS finds wide application in various networking scenarios:
- Service Provider Networks
Service providers use IP-MPLS to:
Offer VPN services to enterprise customers
Implement traffic engineering to optimize network utilization
Provide differentiated services with QoS guarantees
- Enterprise WANs
Large enterprises leverage IP-MPLS for:
Connecting geographically distributed sites
Ensuring performance for critical applications
Implementing scalable and secure VPNs
- Mobile Backhaul
Mobile operators use IP-MPLS in their backhaul networks to:
Handle the increasing data traffic from mobile devices
Provide QoS for different types of mobile traffic (voice, data, video)
Support the transition to 5G networks
- Data Center Interconnect
IP-MPLS is used to connect geographically distributed data centers, providing:
High-bandwidth, low-latency connections
Traffic engineering capabilities for optimal resource utilization
Support for data center virtualization and cloud services
Challenges and Considerations
While IP-MPLS offers numerous benefits, it also presents some challenges:
- Complexity
Implementing and managing an IP-MPLS network requires specialized knowledge and skills. The complexity of MPLS configurations can lead to operational challenges.
- Cost
MPLS-capable equipment is often more expensive than standard IP routing equipment. Additionally, MPLS services from providers can be costlier than basic internet connectivity.
- Vendor Lock-in
While MPLS is a standard, there can be vendor-specific implementations and features, potentially leading to lock-in with a particular equipment vendor.
- Troubleshooting
Diagnosing issues in an MPLS network can be more complex than in a traditional IP network due to the additional layer of abstraction introduced by labels.
The Future of IP-MPLS
As networking technologies continue to evolve, IP-MPLS is adapting to meet new challenges:
- Integration with SDN
Software-Defined Networking (SDN) is being integrated with MPLS to provide more dynamic and programmable control over MPLS networks.
- Segment Routing
Segment Routing is emerging as a simplified alternative to traditional MPLS, offering similar benefits with reduced protocol complexity.
- MPLS in the Cloud
As more enterprises move to cloud-based services, there’s growing interest in extending MPLS capabilities into and between cloud environments.
- 5G and Beyond
MPLS continues to play a crucial role in mobile networks, evolving to support the high-bandwidth, low-latency requirements of 5G and future mobile technologies.
Conclusion
IP-MPLS has become a cornerstone of modern networking infrastructure, offering a powerful combination of performance, scalability, and flexibility. Its ability to efficiently route traffic, provide QoS guarantees, and support various services has made it indispensable for service providers and large enterprises alike.
As we look to the future, IP-MPLS continues to evolve, integrating with emerging technologies like SDN and adapting to new networking paradigms. While it may face challenges from newer technologies, the fundamental principles of MPLS – efficient forwarding based on labels and the ability to engineer traffic flows – remain relevant and valuable.
Whether you’re a network professional looking to optimize your infrastructure, an IT decision-maker evaluating networking solutions, or simply a technology enthusiast, understanding IP-MPLS provides valuable insight into the technologies that power our interconnected world. As data demands continue to grow and network architectures become more complex, IP-MPLS will undoubtedly continue to play a crucial role in shaping the future of networking.
GSM-R: The Digital Backbone of Modern Railway Communication
In the world of railway transportation, effective communication is paramount. It ensures the safety of passengers, the efficiency of operations, and the smooth coordination between various elements of the rail network. Enter GSM-R, or Global System for Mobile Communications – Railway, a specialized mobile communication standard that has revolutionized how railways operate. In this comprehensive guide, we’ll explore GSM-R, its features, benefits, and its crucial role in modern railway systems.
What is GSM-R?
GSM-R (Global System for Mobile Communications – Railway) is a secure platform for voice and data communication between railway operational staff, including drivers, dispatchers, shunting team members, train engineers, and station controllers. It’s based on the GSM standard but with specific features and functions to meet the operational and functional needs of modern railways.
Developed in the 1990s, GSM-R is part of the European Rail Traffic Management System (ERTMS) and has become the international wireless communications standard for railway communication and applications.
Key Features of GSM-R
GSM-R isn’t just a simple adaptation of GSM for railways. It comes with several unique features tailored to meet the specific needs of railway operations:
Priority and Pre-emption: GSM-R ensures that critical calls always get through, even in times of network congestion. It uses a multi-level priority scheme, allowing emergency calls to take precedence over less critical communications.
Functional Addressing: This feature allows calls to be made to a particular function (like “driver of train 123”) rather than to a specific person or phone number. This is crucial in an environment where staff changes frequently.
Location-Dependent Addressing: Calls can be routed based on a train’s location. For example, a call to “nearest maintenance team” will be routed to the team closest to the train’s current position.
Emergency Calls: GSM-R provides a special emergency call feature that connects to all relevant parties simultaneously in case of an emergency.
Shunting Mode: This mode allows communication between a shunting team leader and the driver during shunting operations.
Direct Mode: In areas without network coverage, GSM-R devices can communicate directly with each other over short distances.
High-Speed Operation: GSM-R is designed to work at speeds up to 500 km/h, maintaining reliable communication even on high-speed rail lines.
Enhanced Data Rates: While based on GSM, GSM-R supports higher data rates to accommodate advanced railway applications.
The Role of GSM-R in Railway Operations
GSM-R plays a crucial role in various aspects of railway operations:
- Safety
Safety is paramount in railway operations, and GSM-R significantly enhances it:
Emergency Communication: In case of any incident, GSM-R allows for immediate and simultaneous communication with all relevant parties.
Driver-Controller Communication: Continuous and reliable communication between train drivers and traffic controllers ensures safe train movements.
Trackside Worker Safety: GSM-R helps in alerting trackside workers of approaching trains and allows them to communicate any safety concerns quickly.
- Operational Efficiency
GSM-R contributes to operational efficiency in several ways:
Real-time Information: It allows for the transmission of real-time information about train locations, delays, and track conditions.
Traffic Management: Controllers can use GSM-R to manage traffic more effectively, reducing delays and improving punctuality.
Maintenance Coordination: GSM-R facilitates better coordination of maintenance activities, minimizing disruptions to regular services.
- Passenger Information
While not directly accessible to passengers, GSM-R indirectly improves passenger information:
Accurate Announcements: Station staff can receive real-time updates about train movements, allowing for more accurate passenger announcements.
Service Updates: Information about service disruptions or changes can be quickly communicated to relevant staff, who can then inform passengers.
- Integration with ETCS
GSM-R forms an integral part of the European Train Control System (ETCS), the signaling and control component of ERTMS:
Data Transmission: GSM-R provides the communication channel for ETCS data, allowing for the transmission of movement authorities, speed restrictions, and other crucial signaling information.
Position Reporting: Trains can report their position via GSM-R, enabling more accurate traffic management.
Technical Aspects of GSM-R
While based on GSM technology, GSM-R has several technical specificities:
Frequency Bands: GSM-R typically operates in the 876-880 MHz (uplink) and 921-925 MHz (downlink) frequency bands in Europe, though exact allocations may vary by country.
Network Architecture: A GSM-R network consists of base stations (BTS), base station controllers (BSC), mobile switching centers (MSC), and various databases and registers similar to a public GSM network, but with additional railway-specific elements.
Handover: GSM-R supports seamless handover between base stations, crucial for maintaining communication with fast-moving trains.
Reliability: GSM-R networks are designed with high redundancy and reliability, often with overlapping coverage to ensure continuous communication.
Security: GSM-R incorporates enhanced security features to protect against eavesdropping and unauthorized access.
Challenges and Future of GSM-R
Despite its success, GSM-R faces several challenges:
Capacity Limitations: As railway operations become more complex and data-intensive, the capacity of GSM-R may become a limiting factor.
Interference: In some areas, there have been issues with interference from public mobile networks operating in adjacent frequency bands.
Technology Evolution: As GSM is phased out in public networks, maintaining GSM-R equipment may become more challenging and expensive.
Data Speed: While sufficient for current needs, the data speeds offered by GSM-R may not be adequate for future applications.
To address these challenges, the railway industry is looking towards the future. The successor to GSM-R is already in development: Future Railway Mobile Communication System (FRMCS). Based on 5G technology, FRMCS aims to provide higher capacity, faster data speeds, and support for advanced applications like remote driving and artificial intelligence-based traffic management.
Conclusion
GSM-R has undoubtedly transformed railway communications, bringing unprecedented levels of safety, efficiency, and reliability to rail networks worldwide. Its specialized features, tailored to the unique needs of railways, have made it an indispensable tool in modern rail operations.
As we look to the future, while GSM-R will eventually be superseded by more advanced technologies, its impact on the railway industry will be long-lasting. It has set the standard for what a railway communication system should be and has paved the way for even more innovative solutions in the future.
Whether you’re a railway professional, a technology enthusiast, or simply a curious train passenger, understanding GSM-R gives you a glimpse into the complex, often unseen systems that keep our trains running safely and efficiently. The next time you’re on a train journey, remember that beneath the apparent simplicity of your trip lies a sophisticated communication network, silently ensuring your journey is as safe and smooth as possible.
Apache Multiprocessing Modules: Optimizing Your Web Server's Performance
In the world of web servers, Apache HTTP Server stands out as one of the most popular and versatile options available. One of the key features that contribute to Apache’s flexibility and performance is its use of Multiprocessing Modules (MPMs). In this post, we’ll dive deep into Apache MPMs, exploring what they are, how they work, and how to choose the right one for your needs.
What are Apache Multiprocessing Modules?
Apache Multiprocessing Modules, or MPMs, are responsible for binding to network ports on the machine, accepting requests, and dispatching children to handle the requests. In simpler terms, MPMs determine how Apache handles concurrent connections and processes requests from clients.
The choice of MPM can significantly impact your web server’s performance, scalability, and resource usage. Apache offers several MPMs, each designed to optimize performance for different environments and workloads.
Why are MPMs Important?
Performance: Different MPMs can handle connections and process requests in various ways, affecting the overall performance of your web server.
Scalability: Some MPMs are better suited for handling a large number of concurrent connections, which is crucial for high-traffic websites.
Resource Usage: MPMs differ in how they utilize system resources like CPU and memory, which can be critical in resource-constrained environments.
Compatibility: Certain MPMs are more compatible with specific modules or operating systems, which can influence your choice based on your server setup.
Now, let’s explore the main Apache MPMs and their characteristics.
Main Apache Multiprocessing Modules
- Prefork MPM
The Prefork MPM is the traditional and most compatible MPM in Apache. It’s a non-threaded, pre-forking web server.
Key characteristics:
Spawns child processes in advance to handle requests
Each child process handles one connection at a time
Highly stable and compatible with non-thread-safe modules
Uses more memory compared to threaded MPMs
Good for compatibility, not ideal for high concurrency
Best suited for:
Environments requiring maximum compatibility
Servers running non-thread-safe modules or languages (e.g., some PHP configurations)
- Worker MPM
The Worker MPM implements a hybrid multi-process multi-threaded server. It’s more scalable than the Prefork MPM.
Key characteristics:
Uses multiple child processes
Each child process can have multiple threads
More memory-efficient than Prefork
Can handle more requests simultaneously
Requires thread-safe modules
Best suited for:
High-traffic websites
Servers with limited memory but good CPU resources
- Event MPM
The Event MPM is similar to the Worker MPM but is designed to handle persistent connections more efficiently.
Key characteristics:
Based on the Worker MPM
Handles keep-alive connections more efficiently
Dedicates a separate thread to manage listening sockets
Highly scalable and efficient for high-concurrency scenarios
Requires thread-safe modules
Best suited for:
Servers handling a large number of concurrent, long-lived connections (e.g., HTTPS or WebSocket servers)
High-traffic websites with many idle keep-alive connections
- mpm_winnt (Windows only)
This is a single-threaded MPM designed specifically for Windows systems.
Key characteristics:
Single parent process with a single child process
The child process creates threads to handle requests
Designed to behave optimally on Windows platforms
Best suited for:
- Apache installations on Windows servers
Choosing the Right MPM
Selecting the appropriate MPM depends on various factors:
Operating System: Some MPMs are platform-specific. For example, mpm_winnt is only for Windows.
Hardware Resources: Consider your server’s CPU and memory capabilities. Threaded MPMs like Worker and Event are generally more memory-efficient but may require more CPU.
Expected Traffic: For high-traffic sites, Worker or Event MPMs usually perform better due to their ability to handle more concurrent connections.
Application Compatibility: If you’re using modules or applications that aren’t thread-safe (like some PHP configurations), you might need to use the Prefork MPM.
Connection Types: If your server handles many persistent connections, the Event MPM might be the best choice.
Configuring MPMs
The process of configuring MPMs varies depending on how Apache was installed and which operating system you’re using. However, here are some general steps:
- Checking the Current MPM: You can check which MPM is currently in use by running:
apache2ctl -V | grep MPm
- * **Enabling an MPM**: On Debian-based systems, you can enable an MPM using:
sudo a2dismod mpm_prefork
sudo a2enmod mpm_event```
Replace `mpm_event` with your desired MPM.
<!-- wp:list {"ordered":true,"start":3} -->
<ol start="3" class="wp-block-list">* **Configuring MPM Settings**: MPM settings are typically configured in the Apache configuration file. For example, on Ubuntu, you might edit `/etc/apache2/mods-available/mpm_event.conf` for the Event MPM.
* **Restarting Apache**: After making changes, restart Apache to apply them:
```bash
sudo systemctl restart apache2```
## Fine-tuning MPM Performance
Each MPM has various directives that can be adjusted to optimize performance. Here are some key directives for the Event MPM as an example:
* `StartServers`: The number of child server processes created at startup.
* `MinSpareThreads`: Minimum number of worker threads which are kept spare.
* `MaxSpareThreads`: Maximum number of worker threads which are kept spare.
* `ThreadsPerChild`: Number of threads created by each child process.
* `MaxRequestWorkers`: Maximum number of connections that will be processed simultaneously.
* `MaxConnectionsPerChild`: Limit on the number of connections that an individual child server process will handle.
Adjusting these values can significantly impact your server's performance, but it requires careful testing and monitoring to find the optimal configuration for your specific use case.
## Monitoring MPM Performance
To ensure your chosen MPM is performing optimally, it's crucial to monitor your server's performance. Some tools and techniques for this include:
* **Apache Server Status**: Enable the mod_status module to get real-time statistics about your server's performance.
* **Log Analysis**: Regularly analyze your Apache access and error logs to identify performance issues.
* **System Monitoring Tools**: Use tools like top, htop, or more advanced solutions like Nagios or Zabbix to monitor system resource usage.
* **Apache Bench (ab)**: This tool, included with Apache, can be used for benchmarking your server's performance under different loads.
## Conclusion
Apache Multiprocessing Modules play a crucial role in determining the performance and behavior of your web server. While the Event MPM is often the best choice for modern, high-traffic websites, the right choice depends on your specific needs, hardware resources, and software compatibility.
Remember that configuring MPMs is just one aspect of optimizing your Apache server. Other factors, such as proper caching strategies, efficient use of Apache modules, and overall system tuning, are equally important for achieving optimal performance.
As with any significant change to your server configuration, always test thoroughly in a staging environment before applying changes to your production server. Monitor your server's performance closely after making changes, and be prepared to adjust your configuration as your needs evolve.
By understanding and properly configuring Apache MPMs, you can ensure that your web server is operating at peak efficiency, providing the best possible experience for your users.
Apache Modules: Enhancing Your Web Server's Functionality
Apache HTTP Server, commonly referred to as Apache, is one of the most popular web servers in use today. Its flexibility and power come in large part from its modular architecture. In this post, we’ll explore Apache modules, what they are, and provide brief descriptions of some of the most commonly used ones.
What are Apache Modules?
Apache modules are components that extend the functionality of the Apache web server. They allow you to add features, improve performance, and customize how your server handles requests without having to modify the core Apache code. Modules can be compiled into Apache statically, or they can be loaded dynamically at runtime.
Types of Apache Modules
Apache modules can be broadly categorized into several types:
Core Modules: These are built into Apache and provide essential functionality.
Standard Modules: These come with Apache but need to be enabled explicitly.
Third-Party Modules: These are developed by the community and can be added to extend Apache’s capabilities further.
Now, let’s dive into some of the most commonly used Apache modules and their brief descriptions.
Core Modules
- mod_core
This module provides core features of Apache that are always available. It includes directives for basic configuration like setting document root, enabling directory listings, and configuring error documents.
- mod_so (Shared Object)
The mod_so module supports loading modules at runtime. It’s crucial for the dynamic loading of other modules, allowing you to add or remove functionality without recompiling Apache.
Standard Modules
- mod_access_compat
This module provides host-based access control. It allows you to restrict access to your server based on characteristics of the client’s host such as hostname or IP address.
- mod_alias
The mod_alias module allows for mapping different parts of the host filesystem into the document tree and for URL redirection.
- mod_auth_basic
This module allows the use of HTTP Basic Authentication to restrict access by checking users’ credentials.
- mod_authn_file
mod_authn_file provides authentication front-ends such as mod_auth_basic to authenticate users by looking up users in plain text password files.
- mod_authz_host
This module provides access control based on hostname, IP address, or other characteristics of the client’s host.
- mod_autoindex
mod_autoindex generates directory indexes automatically, similar to the Unix ls command or the Win32 dir shell command.
- mod_deflate
This module provides the DEFLATE output filter that allows output from your server to be compressed before being sent to the client over the network.
- mod_dir
The mod_dir module provides “trailing slash” redirects and serving directory index files.
- mod_env
This module allows for control of internal environment variables that are used by various Apache HTTP Server modules.
- mod_filter
mod_filter provides context-sensitive configuration of output content filters.
- mod_mime
This module is used to assign content metadata to the content selected for an HTTP response by mapping patterns in the URI or filenames to the metadata values.
- mod_log_config
The mod_log_config module provides for flexible logging of client requests.
- mod_negotiation
This module provides for content negotiation, allowing the server to choose the best representation of a resource based on the browser’s capabilities.
- mod_setenvif
The mod_setenvif module allows you to set environment variables based on characteristics of the request.
- mod_ssl
mod_ssl provides strong cryptography for the Apache web server via the Secure Sockets Layer (SSL) and Transport Layer Security (TLS) protocols.
- mod_status
The mod_status module provides information on server activity and performance.
- mod_rewrite
This powerful module provides a rule-based rewriting engine to rewrite requested URLs on the fly.
Popular Third-Party Modules
- mod_security
mod_security is an open-source web application firewall. It provides protection from a range of attacks against web applications and allows for HTTP traffic monitoring and real-time analysis.
- mod_evasive
This module provides evasive action in the event of an HTTP DoS or DDoS attack or brute force attack.
- mod_pagespeed
Developed by Google, mod_pagespeed automatically optimizes web pages and resources to enhance the user experience.
- mod_wsgi
mod_wsgi allows hosting of Python web applications which support the Python WSGI interface.
Working with Apache Modules
Enabling and Disabling Modules
In most Apache installations, you can use the a2enmod and a2dismod commands to enable and disable modules respectively. For example:
sudo a2enmod rewrite
sudo a2dismod status
After enabling or disabling modules, you’ll need to restart Apache for the changes to take effect:
sudo systemctl restart apache2```
Checking Loaded Modules
You can check which modules are currently loaded in Apache by running:
```bash
apache2ctl -m
This will list all loaded modules, both static and shared.
Configuring Modules
Most modules can be configured in your Apache configuration files. The main configuration file is usually located at /etc/apache2/apache2.conf or /etc/httpd/conf/httpd.conf, depending on your system.
Module-specific configurations are often placed in separate files within the mods-available directory and symlinked to the mods-enabled directory when the module is enabled.
Conclusion
Apache modules are a powerful way to extend and customize your web server’s functionality. From basic authentication and URL rewriting to advanced features like web application firewalls and performance optimization, there’s likely a module to suit your needs.
When working with Apache modules, always remember to:
Keep your Apache installation and modules up to date to ensure security and performance.
Only enable the modules you need to minimize resource usage and potential security risks.
Always test configuration changes in a staging environment before applying them to production.
Monitor your server’s performance after enabling new modules to ensure they’re not negatively impacting your site’s speed or stability.
By understanding and effectively utilizing Apache modules, you can create a web server environment that’s secure, efficient, and tailored to your specific requirements.
Introduction to Algorithms: A Closer Look at the Writers Behind the Masterpiece
When discussing some of the most influential books in the field of computer science, Introduction to Algorithms is a title that always stands out. The book, often referred to as “CLRS” after the initials of its authors, has been a cornerstone for both students and professionals in the study of algorithms. Written by Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein, it’s widely regarded as one of the most comprehensive textbooks on algorithms.
This blog post will introduce you to these distinguished writers, delve into the structure and content of the book, and explain how their combined expertise has resulted in what many consider to be the definitive guide to algorithms.
The Legacy of Introduction to Algorithms
First published in 1990, Introduction to Algorithms has gone through several editions, each refining and updating its content to stay relevant in the ever-evolving field of computer science. It is not just a textbook, but a comprehensive reference that covers everything from basic algorithm design and analysis to more advanced topics like dynamic programming and graph algorithms.
What makes this book stand out is its blend of theoretical rigor and practical application. It is designed to be accessible to both beginners and experts alike, offering a clear, well-structured guide to complex topics. The book’s content is presented through a combination of pseudocode, mathematical rigor, and visual aids like diagrams, which helps readers understand even the most difficult concepts. Now, let’s take a closer look at the authors who contributed to this monumental text. The Authors
Thomas H. Cormen
Thomas H. Cormen is perhaps the most well-known among the four authors, having played a major role in multiple editions of the book. A professor at Dartmouth College, Cormen specializes in algorithm engineering and parallel computing.
Cormen earned his PhD in Electrical Engineering and Computer Science from MIT, where he worked closely with Charles Leiserson. He has spent a significant portion of his career teaching and making algorithms accessible to a broader audience. In addition to Introduction to Algorithms, he has authored another book, Algorithms Unlocked, aimed at presenting core algorithmic ideas to non-computer science professionals.
His contributions to the book are characterized by clear and concise explanations that make even the most complex algorithms approachable. His sections on sorting, searching, and divide-and-conquer strategies are considered definitive by many.
Charles E. Leiserson
Charles E. Leiserson is a professor at MIT known for his work in parallel computing and the design of cache-efficient algorithms. He has made significant contributions to computer architecture and parallelism.
Leiserson earned his PhD in Computer Science from Carnegie Mellon University. He is a pioneer in the teaching of parallel programming and has co-developed the Cilk programming language, which focuses on parallelism in software. His contributions to Introduction to Algorithms, particularly in graph algorithms and dynamic programming, have made those chapters some of the most comprehensive in the field.
Ronald L. Rivest
Ronald L. Rivest is a cryptographer and one of the co-creators of the RSA encryption algorithm, a foundational technology for modern secure communication. He is a professor at MIT and has been a key figure in the development of cryptography and voting systems.
Rivest earned his PhD in Computer Science from Stanford University and is one of the most cited authors in the field of computer security. His sections in Introduction to Algorithms focus on data structures, hashing, and complexity theory, blending rigorous mathematical explanations with real-world application.
Clifford Stein
Clifford Stein, a professor at Columbia University, specializes in operations research, parallel computing, and combinatorial optimization. While perhaps less well-known than his co-authors, Stein’s contributions to the book—particularly in graph algorithms and approximation algorithms—are significant.
Stein earned his PhD from MIT and has co-authored another book, Discrete Math for Computer Science, which is commonly used in introductory courses. His chapters on graph algorithms and network flows offer detailed insights into how algorithms can solve real-world problems, from logistics to telecommunications. A Detailed Look at the Book’s Content
Introduction to Algorithms is structured into several distinct parts, each focusing on different algorithm categories and design techniques. This comprehensive approach allows the book to cater to beginners while also challenging more advanced readers.
Part I: Foundations
The first section of the book lays the groundwork by introducing the fundamental concepts needed to understand algorithms:
Mathematical Foundations: Topics like logarithms, summations, and probability provide the mathematical basis required for analyzing algorithms.
Basic Data Structures: This section introduces essential data structures like arrays, linked lists, stacks, and queues, which are critical to the performance of algorithms.
Performance Analysis: The book explains how to analyze an algorithm’s efficiency using time complexity and space complexity, emphasizing the importance of metrics like Big-O notation.
Part II: Sorting and Order Statistics
Sorting algorithms are central to computer science, and this section provides a thorough treatment of various techniques:
Insertion Sort, Merge Sort, and Quick Sort: The book begins with basic sorting methods before advancing to more efficient, divide-and-conquer algorithms like merge sort and quicksort.
Heap Sort: This section includes an in-depth discussion of heap structures and their use in sorting.
Counting, Radix, and Bucket Sort: Non-comparison-based sorting methods are explored, particularly their use in specialized scenarios.
Each algorithm is explained in detail with pseudocode, performance analysis, and real-world applications, making this section crucial for anyone studying computer science.
Part III: Data Structures
The book moves into more advanced data structures that are essential for the efficient design of algorithms:
Binary Search Trees: Discussions on basic binary trees are followed by more advanced self-balancing trees like red-black trees.
Hashing: This chapter introduces hash tables and explores methods for resolving collisions, such as chaining and open addressing.
Augmented Data Structures: Techniques for enhancing basic data structures, allowing for more advanced operations, are discussed.
Part IV: Advanced Design and Analysis Techniques
This section focuses on powerful techniques for designing efficient algorithms:
Dynamic Programming: The book explains how to break problems into overlapping subproblems using classic algorithms like the Longest Common Subsequence and the Knapsack Problem.
Greedy Algorithms: Algorithms like Huffman Coding and Prim’s Algorithm are explored, with a focus on how local optimal choices can lead to globally optimal solutions.
Amortized Analysis: This topic helps readers understand algorithms with varying operation costs, such as dynamic arrays and splay trees.
Part V: Graph Algorithms
Graph algorithms are vital in fields like network design and social media analysis:
Graph Traversal: Techniques like Breadth-First Search (BFS) and Depth-First Search (DFS) are introduced early in this section.
Minimum Spanning Trees: The book explains Kruskal’s and Prim’s algorithms for finding the minimum-cost spanning tree.
Shortest Path Algorithms: Algorithms such as Dijkstra’s and Bellman-Ford are discussed for computing shortest paths in graphs.
Network Flow Algorithms: Techniques like the Ford-Fulkerson method are used for solving flow problems in networks.
Part VI: NP-Completeness
One of the most complex and interesting sections of the book, NP-completeness, explores:
P vs. NP: The authors provide an accessible explanation of this unsolved problem in computational theory.
Reduction Techniques: The book explains how to prove that a problem is NP-complete through reductions.
Approximation Algorithms: Since NP-complete problems are hard to solve, the book introduces algorithms that find near-optimal solutions efficiently.
Part VII: Advanced Topics
The final part covers specialized topics, including:
Linear Programming: Optimization techniques where the objective and constraints are linear.
String Matching: Algorithms for searching substrings in strings, such as the Knuth-Morris-Pratt algorithm.
Cryptography: An introduction to algorithms in cryptography, such as the RSA algorithm, which Rivest co-invented.
Strengths of the Book
One reason Introduction to Algorithms has remained a go-to reference for decades is its versatility:
Comprehensive Coverage: The book covers nearly every major algorithmic area, from basic sorting algorithms to advanced topics like NP-completeness and cryptography.
Mathematical Rigor: The emphasis on formal analysis ensures that readers can evaluate algorithmic efficiency.
Balanced Approach: It’s mathematically rigorous but also practical, with detailed examples and pseudocode that make it accessible.
Visual Aids: Diagrams and step-by-step illustrations make complex algorithms easier to understand.
Conclusion
The authors of Introduction to Algorithms—Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein—have created a textbook that is unparalleled in its depth, clarity, and comprehensive coverage. From basic sorting and data structures to advanced topics like NP-completeness, graph algorithms, and cryptography, the book serves as both a teaching tool and a reference for professionals. The authors’ combined expertise has resulted in a text that is both rigorous and accessible, making it a must-read for anyone serious about algorithms. Whether you’re a student just starting out or a seasoned professional, Introduction to Algorithms remains an invaluable resource in understanding the fundamental concepts that drive computer science.
Virtual Distributed Filesystem (VDFS): An In-Depth Overview
In today’s world, data management and accessibility are critical challenges for both businesses and individuals. The demand for scalable, efficient, and reliable systems to store and access vast amounts of data across multiple locations has led to the development of distributed file systems. Among these, the Virtual Distributed Filesystem (VDFS) stands out as a sophisticated technology that addresses several modern data storage needs.
In this blog post, we’ll explore what VDFS is, how it works, and its significance in today’s IT landscape. By the end, you’ll have a clearer understanding of why VDFS is gaining traction in the world of distributed computing and cloud infrastructure.
What is a Virtual Distributed Filesystem (VDFS)?
A Virtual Distributed Filesystem (VDFS) is a type of distributed file system that provides a virtualized layer over multiple physical storage systems, allowing data to be stored across multiple servers or locations while appearing as a single unified filesystem to the user. VDFS facilitates seamless access to files as if they were located on a single machine, even though the data may be distributed across different geographic locations, servers, or storage media.
In essence, VDFS abstracts the underlying complexities of data distribution, providing transparency in how and where files are stored. This enables better scalability, fault tolerance, and improved performance in distributed environments.
Core Concepts of VDFS
To understand how VDFS operates, we need to grasp a few key concepts that define its structure and functionality:
Virtualization: At its core, VDFS virtualizes the physical storage infrastructure. This means it decouples the actual location of the data from how it is accessed. Users and applications interact with a virtual layer, making it irrelevant where the data physically resides.
Distributed Architecture: VDFS operates in a distributed architecture, where multiple nodes (servers or storage devices) share the responsibility of storing and managing data. Data is often split into chunks and distributed across different nodes to increase fault tolerance and optimize performance.
Replication and Redundancy: VDFS often employs replication strategies to store copies of data across different nodes, ensuring data availability even in the event of hardware failures. This redundancy helps in disaster recovery and ensures high availability.
Scalability: One of the most important characteristics of a VDFS is its scalability. As data needs grow, the system can easily expand by adding more nodes without disrupting operations. This makes VDFS particularly useful for cloud computing and large-scale enterprise environments.
Fault Tolerance: Since data is distributed across multiple nodes and often replicated, VDFS can tolerate failures of individual nodes without affecting the overall system. This ensures reliability and data integrity.
Access Transparency: A key feature of VDFS is that it provides a unified namespace for users and applications. Regardless of where a file is physically stored in the system, it can be accessed using a consistent path, making file access simple and transparent.
How Does VDFS Work?
A VDFS is essentially built on the idea of virtualizing and distributing data. It operates over a network, typically in cloud or enterprise environments, where multiple storage devices are networked together. Here’s a high-level breakdown of how VDFS works:
1. Storage Nodes
In a VDFS, data is stored across multiple storage nodes. Each node could be a server, a cloud-based storage unit, or even network-attached storage (NAS) devices. These nodes communicate with each other to form a cohesive system where data is split and distributed.
2. Metadata Servers
A metadata server manages information about the structure and organization of the filesystem. This includes details about where data blocks are stored, how they are split, and how they can be accessed. When a user requests a file, the metadata server identifies the physical location of the data and helps coordinate access to it.
3. Data Distribution and Replication
Data in a VDFS is often broken into smaller blocks or chunks and distributed across different nodes. This distribution is typically done in a way that maximizes efficiency and performance. Additionally, VDFS systems frequently replicate data across multiple nodes for redundancy. For example, a file might be split into four chunks, with each chunk being replicated across two or more nodes.
4. Client Access
Clients or users interact with the VDFS as if it were a local filesystem. When a file is requested, the system retrieves the relevant data blocks from the nodes that store them, reassembles the file, and delivers it to the client. Thanks to virtualization, the user has no idea that the file they are accessing might be spread across multiple servers in different locations.
5. Fault Tolerance and Recovery
In the event of a failure, VDFS’s fault tolerance mechanisms come into play. Because the system stores multiple copies of data, it can automatically recover from hardware failures without data loss. When a node fails, the system retrieves the necessary data from the replicated copies stored on other nodes.
Benefits of VDFS
VDFS offers a variety of benefits, making it a valuable tool for managing large-scale data across distributed systems. Below are some of the key advantages:
1. Scalability
As businesses and organizations generate more data, scalability becomes a primary concern. VDFS allows storage capacity to grow incrementally by adding more nodes to the system without disrupting existing data or services. This makes VDFS an ideal solution for cloud environments, big data applications, and enterprises with ever-expanding storage needs.
2. High Availability and Reliability
By replicating data across multiple nodes and ensuring redundancy, VDFS provides high availability. Even if a node or storage device fails, the system can continue operating without data loss. This is essential for businesses that rely on constant access to their data.
3. Performance Optimization
VDFS improves performance by distributing data across different nodes, allowing multiple nodes to handle read and write operations simultaneously. This parallelism can significantly reduce the time required for data retrieval and enhance the overall efficiency of the system, particularly in environments where large datasets are accessed frequently.
4. Fault Tolerance
VDFS systems are designed with fault tolerance in mind. Hardware failures, network issues, or other unexpected events do not disrupt the system since data is replicated across multiple nodes. This makes VDFS a resilient and reliable solution for organizations that cannot afford downtime or data loss.
5. Simplified Management
Because VDFS provides a unified namespace and abstracts the complexity of the underlying storage systems, administrators can manage storage more easily. The system automatically handles data distribution, replication, and failure recovery, reducing the manual effort involved in managing distributed storage.
Use Cases of VDFS
VDFS is particularly useful in environments where data needs to be stored across multiple locations and accessed by various users or applications. Below are some common use cases where VDFS shines:
1. Cloud Storage and Services
Cloud providers like Amazon Web Services (AWS), Google Cloud, and Microsoft Azure often use distributed filesystems to store massive amounts of data across geographically dispersed data centers. VDFS provides the necessary scalability and fault tolerance required in cloud storage solutions, ensuring that users can access data from anywhere without interruptions.
2. Big Data and Analytics
Big data applications deal with vast amounts of information, often requiring distributed storage systems that can scale seamlessly. VDFS enables the storage and processing of large datasets across multiple nodes, allowing for faster access and analysis of data in real-time.
3. Enterprise Data Management
Large organizations that need to store, manage, and access data across different departments and offices benefit from VDFS’s ability to provide a centralized storage solution. With VDFS, companies can ensure data is consistently available across different geographic locations, without needing to maintain separate storage systems.
4. High-Performance Computing (HPC)
In high-performance computing environments, where large-scale simulations, scientific computations, or machine learning models are run, fast and reliable data access is critical. VDFS helps optimize data access and ensure that multiple compute nodes can read and write data efficiently.
Challenges and Limitations
While VDFS offers many advantages, it is not without its challenges. Here are a few potential issues:
1. Network Dependency
Since VDFS relies on distributed nodes, network performance can have a significant impact on the system’s overall efficiency. If the network between the nodes is slow or unreliable, data access times can be affected.
2. Complexity
Although VDFS simplifies storage management in many ways, the underlying system can be complex to configure and maintain, especially for organizations without extensive IT resources. Setting up a VDFS with optimal data distribution, replication, and fault tolerance requires significant expertise.
3. Cost
Depending on the number of nodes and replication requirements, setting up a VDFS can become expensive, particularly when deployed in an on-premise environment. The cost of additional hardware, network infrastructure, and maintenance can add up.
Conclusion
Virtual Distributed Filesystem (VDFS) is an essential tool for managing large amounts of data in distributed environments. With its scalability, fault tolerance, and performance optimizations, VDFS is increasingly used in cloud storage, big data, and high-performance computing applications. While it presents some challenges in terms of complexity and cost, its benefits often outweigh these limitations for organizations that require robust, reliable data storage solutions.
As businesses continue to generate and rely on data, the importance of technologies like VDFS will only grow. For organizations looking to scale their storage needs and ensure high availability, implementing a Virtual Distributed Filesystem may be the key to future-proofing their infrastructure.
Ethernet Ports and Commonly Used Ports for Services: An In-Depth Guide
In today’s interconnected world, network communication is the backbone of modern IT infrastructures. Ethernet ports and commonly used network ports play a critical role in how devices communicate and interact on a network. Whether it’s a local area network (LAN) or the internet, understanding the purpose of these ports is essential for both beginners and seasoned professionals.
This blog post provides a comprehensive guide to Ethernet ports, network ports, and the commonly used ports for various services in a network environment.
What is an Ethernet Port?
An Ethernet port is a physical interface on computers, routers, switches, and other networking devices that connects a device to a wired network using an Ethernet cable. Ethernet ports use standard RJ-45 connectors and are commonly found on devices such as desktops, laptops, and network equipment. Through these ports, devices can send and receive data over a wired Ethernet connection, ensuring fast, stable, and secure network access.
Ethernet has been the de facto standard for wired networking for decades, and despite the rise of wireless technologies, it remains vital due to its reliability and speed.
Types of Ethernet Ports
There are different standards for Ethernet ports, and they vary based on speed and performance:
Fast Ethernet (10/100 Mbps): This Ethernet standard supports speeds of 10 Mbps to 100 Mbps. Fast Ethernet ports are still found on many devices, but they have largely been replaced by more advanced technologies.
Gigabit Ethernet (10/100/1000 Mbps): The most common type of Ethernet port on modern devices, Gigabit Ethernet supports speeds up to 1 Gbps (1000 Mbps). It’s the standard for most home and office networking devices.
10 Gigabit Ethernet: Used mainly in enterprise environments, this Ethernet standard supports speeds of up to 10 Gbps and requires specialized network cabling and hardware to achieve these speeds.
Ethernet ports provide the physical connection that supports network communication, but the underlying protocols and services are governed by network ports. Let’s dive into the concept of network ports.
What Are Network Ports?
In the context of networking, a port is a logical endpoint used for network communication. Network ports are essential to how computers differentiate between various types of network traffic. They are represented by a number ranging from 0 to 65535 and are tied to specific processes or services on a device.
Network ports allow a single device to support multiple connections at once. For example, when you access a website, the communication happens over a specific port, usually Port 80 for HTTP or Port 443 for HTTPS. Meanwhile, your email client might be using another port for its connection.
Ports are split into three broad categories:
Well-known Ports (0-1023): These ports are reserved for specific services and protocols. They are typically assigned by the Internet Assigned Numbers Authority (IANA).
Registered Ports (1024-49151): Registered ports are those that IANA registers for use by application developers. These ports are not as strictly defined as well-known ports, but common services still rely on them.
Dynamic or Private Ports (49152-65535): These ports are used for private or temporary purposes. Many services dynamically assign ports from this range for internal connections.
Let’s explore some of the most commonly used ports for services across networks.
Commonly Used Ports for Services
There are thousands of network ports, but certain services and protocols consistently rely on specific port numbers. Understanding these ports is important for managing networks and troubleshooting connectivity issues.
Port 20 and 21: File Transfer Protocol (FTP)
FTP is one of the oldest network protocols used for transferring files between devices over a network. It uses two ports:
Port 21: Used to establish the connection and control communication between the client and the server.
Port 20: Used to transfer data once the connection is established.
While FTP is effective, it lacks security features, so secure alternatives like SFTP (Secure File Transfer Protocol) and FTPS (FTP Secure) are often used.
Port 22: Secure Shell (SSH)
SSH is a widely used protocol for securely accessing remote systems and managing devices over a network. It encrypts data traffic, providing a secure way to perform administrative tasks like file management and system monitoring.
Port 22 is the default port for SSH, though administrators sometimes change it for security reasons to prevent attacks.
Port 25: Simple Mail Transfer Protocol (SMTP)
SMTP is the protocol used for sending emails across networks. Mail servers typically use Port 25 to receive and send email messages. However, because Port 25 is often targeted by spammers, some ISPs block traffic on this port, so alternative ports like 587 or 465 (with SSL encryption) are also used.
Port 53: Domain Name System (DNS)
DNS is the system that translates human-readable domain names into IP addresses. DNS uses both UDP and TCP on Port 53, depending on the nature of the request. Most DNS queries use UDP, but certain DNS requests (such as zone transfers between servers) rely on TCP.
Port 80 and 443: HTTP and HTTPS
Port 80: The default port for HTTP (HyperText Transfer Protocol), which is used for unencrypted web traffic. When you access a website without SSL (Secure Sockets Layer), your browser communicates via Port 80.
Port 443: The default port for HTTPS, the secure version of HTTP. HTTPS uses encryption to secure the communication between a web server and a browser, protecting the data from eavesdroppers. This port is crucial for web security and is widely adopted across the internet.
Port 110: Post Office Protocol Version 3 (POP3)
POP3 is a protocol used by email clients to retrieve messages from a mail server. It is primarily used to download emails and store them locally. While Port 110 is the default for POP3, many services have switched to IMAP or SMTP over SSL for added security.
Port 143: Internet Message Access Protocol (IMAP)
IMAP is another email retrieval protocol, but unlike POP3, IMAP allows users to manage their email directly on the server. This makes it more flexible for users who need to access email from multiple devices. The default port for IMAP is 143, with Port 993 often used for encrypted IMAP over SSL.
Port 3389: Remote Desktop Protocol (RDP)
RDP is a Microsoft protocol that allows users to remotely access Windows-based computers. Port 3389 is the default port used for RDP connections. To secure this port, administrators often rely on firewalls or VPNs, as RDP is frequently targeted by attackers.
Port 3306: MySQL Database Service
MySQL is a popular open-source relational database management system. Port 3306 is used by MySQL servers to handle incoming database queries. When configuring a database connection, developers must ensure that this port is open and accessible if they’re hosting the database on a remote server.
Port 5060 and 5061: Session Initiation Protocol (SIP)
SIP is a protocol used to establish voice and video calls over the internet. It’s commonly used in VoIP (Voice over Internet Protocol) services. SIP uses two primary ports:
Port 5060: For non-encrypted communication.
Port 5061: For encrypted communication via Transport Layer Security (TLS).
The Importance of Securing Network Ports
Open and misconfigured ports are often a target for cyberattacks. Port scanning is a common technique used by hackers to discover which ports are open on a network and what services are running. This can reveal vulnerabilities, so securing ports is crucial.
Here are a few tips for securing network ports:
Close Unnecessary Ports: Any port that’s not in use should be closed to prevent unauthorized access.
Use Firewalls: Firewalls help manage which ports are accessible from the internet and can block unwanted traffic.
Enable Encryption: Use encrypted protocols like HTTPS, SSH, and SFTP to protect sensitive data.
Change Default Ports: Changing default ports (such as using a port other than 22 for SSH) can add an extra layer of security by obscuring common entry points.
Conclusion
Ethernet ports and network ports are essential components of modern networking. Understanding how they work, and the role of commonly used ports for various services, provides a foundation for setting up and managing a secure, efficient network. From the physical Ethernet connections that link devices to the logical ports that direct traffic, each part of the process is vital to enabling seamless communication across networks.
As the internet evolves and cyber threats grow, securing these ports becomes more important than ever. Whether you’re managing a home network or an enterprise infrastructure, having a strong grasp of Ethernet and network ports is key to maintaining a secure and well-functioning system.
UDP Communication: The Swift and Efficient Data Transfer Protocol
In the world of computer networking, speed and efficiency are often paramount. While TCP (Transmission Control Protocol) is widely known for its reliability, there’s another protocol that takes center stage when it comes to quick, lightweight data transmission: the User Datagram Protocol, or UDP. In this post, we’ll explore UDP communication, its characteristics, applications, and why it’s a crucial component of modern networking.
Understanding UDP: The Basics
UDP, like its counterpart TCP, is a core protocol of the Internet Protocol suite. Developed by David P. Reed in 1980, UDP was designed to serve as a counterpoint to TCP, offering a simpler, faster method of sending data packets across networks.
Key Characteristics of UDP
Connectionless: Unlike TCP, UDP doesn’t establish a dedicated end-to-end connection before transmitting data.
No Guaranteed Delivery: UDP doesn’t ensure that packets reach their destination or arrive in order.
No Congestion Control: UDP doesn’t adjust its transmission rate based on network conditions.
Lightweight: With minimal protocol overhead, UDP is faster and more efficient than TCP for certain applications.
Supports Broadcasting: UDP can send packets to all devices on a network simultaneously.
These characteristics make UDP ideal for scenarios where speed is more critical than perfect reliability, and where occasional data loss is acceptable.
The Inner Workings of UDP
To understand how UDP operates, let’s break down its structure and processes.
UDP Packet Structure
A UDP packet, also known as a datagram, consists of a header and a data section. The header is remarkably simple, containing just four fields:
Source Port Number: Identifies the sending application.
Destination Port Number: Identifies the receiving application.
Length: The total length of the UDP packet (header + data).
Checksum: Used for error-checking of the header and data.
This streamlined header contributes to UDP’s efficiency, as it adds minimal overhead to the data being transmitted.
The UDP Communication Process
Packet Creation: The sending application creates a UDP packet, filling in the header fields and attaching the data.
Transmission: The packet is sent directly onto the network without any prior communication with the recipient.
Routing: Network devices route the packet based on its IP address (which is part of the IP header encapsulating the UDP packet).
Reception: The receiving device accepts the incoming UDP packet.
Delivery to Application: If the destination port matches an open port on the receiving device, the packet is delivered to the corresponding application.
Optional Response: The receiving application may send a response, but this is not required or guaranteed by the UDP protocol itself.
This process occurs without any handshaking dialogues or tracking of packet order, making it much faster than TCP’s more complex procedures.
UDP vs. TCP: When to Use Which?
The choice between UDP and TCP depends largely on the specific requirements of your application. Here’s a quick comparison:
UDP is Preferable When:
Speed is crucial
Real-time communication is needed
Small data transfers are frequent
Some data loss is acceptable
TCP is Better When:
Data integrity is paramount
Ordered packet delivery is necessary
Network conditions are unpredictable
You need confirmation of data receipt
Real-World Applications of UDP
UDP’s unique characteristics make it ideal for various applications:
- Online Gaming
In fast-paced multiplayer games, low latency is crucial. UDP allows for quick updates of player positions and actions, where an occasional lost packet won’t significantly impact gameplay.
- Voice over IP (VoIP)
Applications like Skype or Discord use UDP for voice transmission. In a conversation, it’s better to have a brief moment of garbled audio (due to a lost packet) than to have the entire conversation delayed while waiting for retransmissions.
- Video Streaming
While video streaming often uses a combination of TCP and UDP, many streaming protocols leverage UDP for the actual video data transmission, as it’s more important to maintain a smooth flow than to ensure every frame is perfect.
- DNS (Domain Name System)
DNS queries typically use UDP for their initial requests. The small size of these queries makes them ideal for UDP’s lightweight approach.
- DHCP (Dynamic Host Configuration Protocol)
DHCP, which assigns IP addresses to devices on a network, uses UDP because it needs to communicate before a device has a configured IP address.
- IoT and Sensor Networks
In Internet of Things (IoT) applications, devices often need to send small amounts of data frequently. UDP’s efficiency makes it well-suited for these scenarios.
Challenges and Solutions in UDP Communication
While UDP’s simplicity offers many advantages, it also presents some challenges:
- Packet Loss
Since UDP doesn’t guarantee delivery, applications must be designed to handle lost packets gracefully. This might involve implementing application-layer reliability mechanisms or simply accepting some level of data loss.
- Packet Ordering
UDP doesn’t maintain packet order, so applications must either be order-agnostic or implement their own ordering system if needed.
- Congestion Control
Without built-in congestion control, UDP applications can potentially overwhelm networks. Responsible UDP usage often involves implementing application-layer congestion control mechanisms.
- Security
UDP’s simplicity can make it more vulnerable to certain types of attacks, such as UDP flood attacks. Implementing security at the application layer or using protocols like DTLS (Datagram Transport Layer Security) can help mitigate these risks.
Implementing UDP: Programming Considerations
When developing applications that use UDP, there are several key points to keep in mind:
Error Handling: Since UDP doesn’t handle errors itself, your application needs robust error-checking mechanisms.
Timeout Management: Implement appropriate timeouts for waiting on responses, as UDP won’t automatically retransmit lost packets.
Packet Size: Be mindful of the maximum transmission unit (MTU) to avoid fragmentation.
Port Management: Properly manage port numbers, especially when developing servers that handle multiple clients.
State Management: Since UDP is stateless, your application may need to maintain its own state information if required.
The Future of UDP
As with many long-standing protocols, UDP continues to evolve:
QUIC (Quick UDP Internet Connections)
Developed by Google, QUIC is a transport layer network protocol that uses UDP as its basis. It aims to provide TCP-like reliability with UDP-like speed, potentially offering the best of both worlds for many applications.
UDP in 5G Networks
With the rollout of 5G networks, UDP’s importance may grow. The low-latency requirements of many 5G applications align well with UDP’s characteristics.
Enhanced Security
As security becomes increasingly crucial, we may see more standardized ways of securing UDP communications, similar to how TLS works for TCP.
Conclusion
UDP, with its simplicity and efficiency, plays a vital role in modern networking. While it may not be as well-known to the general public as TCP, its impact on our daily digital experiences is profound. From the games we play to the voice calls we make, UDP is often working behind the scenes to ensure swift and efficient communication.
Understanding UDP is crucial for network administrators, developers, and anyone involved in creating or managing networked applications. By leveraging UDP’s strengths and mitigating its weaknesses, we can build faster, more responsive systems that enhance user experiences across a wide range of applications.
As we move into an era of even greater connectivity, with IoT devices, real-time applications, and low-latency requirements becoming increasingly common, UDP’s importance is likely to grow. Its ability to provide quick, lightweight communication will continue to make it a cornerstone of internet communication protocols for years to come.
TCP Communication: The Backbone of Reliable Internet Data Transfer
In the vast and complex world of computer networking, one protocol stands out as a cornerstone of reliable data transfer: the Transmission Control Protocol, or TCP. This fundamental building block of the Internet ensures that data packets are delivered accurately and in order, forming the basis for many of the online services we use daily. In this post, we’ll dive deep into TCP communication, exploring its history, mechanics, and why it remains crucial in today’s fast-paced digital landscape.
The Origins of TCP
To understand TCP, we need to step back in time to the early days of computer networking. In the 1970s, as the precursor to the Internet (ARPANET) was being developed, researchers realized they needed a reliable way to transmit data between computers. This led to the creation of TCP by Vint Cerf and Bob Kahn in 1974.
Initially, TCP was part of a single protocol called TCP/IP (Transmission Control Protocol/Internet Protocol). However, it was later split into two distinct protocols: TCP for managing the reliable delivery of data, and IP for routing packets to their correct destinations.
What Makes TCP Special?
TCP is a connection-oriented protocol, which means it establishes a dedicated end-to-end connection before any data is exchanged. This connection-oriented nature is one of the key features that sets TCP apart from its counterpart, UDP (User Datagram Protocol). Let’s explore some of the characteristics that make TCP unique:
Reliability: TCP ensures that all data sent reaches its destination without errors. If any packets are lost or corrupted during transmission, TCP detects this and retransmits the affected packets.
Ordered Delivery: TCP guarantees that data packets are delivered to the application in the same order they were sent. This is crucial for many applications, such as file transfers or streaming services.
Flow Control: TCP implements flow control mechanisms to prevent the sender from overwhelming the receiver with more data than it can handle.
Congestion Control: TCP can detect network congestion and adjust its transmission rate accordingly, helping to prevent network overload.
Full-Duplex Communication: TCP allows for simultaneous two-way communication between the sender and receiver.
The TCP Handshake: Establishing a Connection
One of the most fascinating aspects of TCP is its connection establishment process, commonly known as the “three-way handshake.” This process ensures that both parties are ready to communicate and sets up the parameters for the ensuing data transfer. Here’s how it works:
SYN: The client sends a SYN (synchronize) packet to the server, indicating its desire to establish a connection and including an initial sequence number.
SYN-ACK: The server responds with a SYN-ACK packet, acknowledging the client’s request and sending its own sequence number.
ACK: The client sends an ACK (acknowledge) packet back to the server, confirming receipt of the SYN-ACK.
Once this handshake is complete, the connection is established, and data transfer can begin.
The Life of a TCP Connection
After the connection is established, TCP manages the data transfer through a series of sophisticated mechanisms:
Segmentation and Sequencing
TCP breaks large chunks of data into smaller segments, each with a sequence number. This allows the receiver to reassemble the data in the correct order, even if packets arrive out of sequence.
Acknowledgments and Retransmission
For each segment received, the recipient sends an acknowledgment (ACK) back to the sender. If the sender doesn’t receive an ACK within a certain timeframe, it assumes the packet was lost and retransmits it.
Flow Control
TCP uses a “sliding window” mechanism for flow control. The receiver advertises how much data it can handle (its receive window), and the sender adjusts its transmission rate accordingly.
Congestion Control
TCP employs various algorithms (like slow start, congestion avoidance, and fast retransmit) to detect and respond to network congestion, helping to maintain optimal network performance.
TCP in Action: Real-World Applications
TCP’s reliability and ordered delivery make it ideal for applications where data integrity is crucial. Some common use cases include:
Web Browsing: When you load a webpage, your browser uses HTTP over TCP to ensure all elements of the page are received correctly.
Email: Protocols like SMTP, POP3, and IMAP rely on TCP to guarantee the accurate delivery of your messages.
File Transfer: Whether you’re uploading files to cloud storage or using FTP, TCP ensures your files arrive intact.
Database Communications: Many database systems use TCP for client-server communication, ensuring data consistency.
TCP vs. UDP: Choosing the Right Protocol
While TCP is excellent for many applications, it’s not always the best choice. Its connection-oriented nature and reliability mechanisms introduce some overhead, which can be unnecessary for certain types of data transfer. This is where UDP comes in.
UDP is a connectionless protocol that doesn’t guarantee reliable delivery or ordered packets. This makes it faster and more efficient for applications where occasional packet loss is acceptable, such as:
Real-time gaming
Live video streaming
Voice over IP (VoIP)
The choice between TCP and UDP depends on the specific requirements of your application. If you need guaranteed, ordered delivery, TCP is your go-to protocol. If speed is more critical and you can tolerate some data loss, UDP might be the better choice.
The Future of TCP
Despite being over four decades old, TCP continues to evolve. Researchers and engineers are constantly working on improvements to make TCP more efficient and better suited to modern network conditions. Some areas of ongoing development include:
TCP Fast Open: This extension allows data to be exchanged during the initial handshake, reducing latency for short connections.
Multipath TCP: This modification allows a single TCP connection to use multiple paths simultaneously, improving reliability and throughput.
QUIC (Quick UDP Internet Connections): Although not TCP itself, this Google-developed protocol aims to provide TCP-like reliability over UDP, potentially offering the best of both worlds.
Conclusion
TCP remains a fundamental part of the Internet’s infrastructure, silently ensuring the reliable delivery of data across the globe. Its robust design has stood the test of time, adapting to the ever-changing landscape of computer networking.
As we continue to push the boundaries of what’s possible online, understanding protocols like TCP becomes increasingly important. Whether you’re a network engineer, a software developer, or simply an curious internet user, appreciating the intricacies of TCP can give you a deeper understanding of how our digital world functions.
The next time you send an email, stream a video, or simply browse the web, take a moment to appreciate the complex dance of TCP packets that make it all possible. It’s a testament to the power of well-designed protocols and the ongoing innovation in the field of computer networking.
Understanding Wide Area Networks (WANs)
In the world of networking, Wide Area Networks (WANs) stand as the backbone of modern communication across cities, countries, and even continents. While most people are familiar with Local Area Networks (LANs) that connect devices within a single location, WANs serve a different and much larger purpose by linking multiple LANs across vast distances.
In this article, we’ll dive deep into what WANs are, how they work, their components, types, and how they are an integral part of the global internet and corporate infrastructure.
What is a Wide Area Network (WAN)?
A Wide Area Network (WAN) is a type of network that connects multiple Local Area Networks (LANs) and other networks over long distances. WANs can stretch across cities, countries, or even around the globe. The internet is the largest and most well-known example of a WAN, but many organizations also have their own private WANs to connect different offices, factories, or data centers spread out over large geographic areas.
WANs are essential for organizations that operate in multiple locations because they allow different offices or branches to communicate with each other, share resources, and access central databases or servers. For instance, a company with offices in New York, London, and Tokyo can use a WAN to ensure all employees in those cities can collaborate as if they were on the same network.
Key Components of a WAN
WANs rely on several key components to function effectively. These components work together to create a seamless, secure, and efficient communication system across vast distances.
Routers: Routers play a crucial role in WANs, as they are responsible for directing data between different networks. They read data packets’ destination IP addresses and route them through the most efficient path to ensure they reach their intended location.
Switches: Switches, similar to their role in LANs, are used to manage the flow of data within the network. They ensure that the data reaches the correct device by segmenting the network into manageable parts.
Modems: Modems are used to convert digital data from a computer or network into signals that can be transmitted over telephone lines or fiber optic cables. In the context of WANs, modems connect different networks to the internet or another WAN service provider.
Leased Lines: In many corporate WAN setups, organizations rent dedicated lines (leased lines) from telecom companies to connect different locations. These lines provide a secure and reliable connection, but they come at a higher cost than shared network services.
Public and Private Networks: WANs can make use of both public networks (like the internet) and private networks. While public networks are cost-effective, they can be less secure. Private networks, on the other hand, offer enhanced security and reliability but are more expensive to set up and maintain.
Firewalls and Security: Given the vast distances and public exposure involved in WANs, security is a top priority. Firewalls, VPNs (Virtual Private Networks), and encryption are commonly used to secure data as it travels across the WAN and to protect the network from unauthorized access.
How Does a WAN Work?
At its core, a WAN is a collection of interconnected networks. Unlike LANs, which use Ethernet cables or Wi-Fi to connect devices in a localized area, WANs use a variety of communication technologies, including fiber-optic cables, satellites, and wireless transmission systems, to connect networks across vast distances.
Here’s a simplified breakdown of how a WAN works:
Network Interconnection: A WAN connects multiple LANs or networks, typically using routers that direct data between these smaller networks. For instance, a company’s LAN in New York might be connected to a LAN in Los Angeles through a WAN.
Data Transmission: Data sent over a WAN is divided into smaller packets, which are then transmitted across the network. These packets travel through routers, switches, and sometimes even satellites, to reach their destination. The routers ensure the data takes the most efficient path to avoid congestion or delays.
WAN Service Providers: Most organizations do not own the entire infrastructure that makes up their WAN. Instead, they rely on service providers, such as telecom companies, to lease network lines and offer connectivity services.
Connection Types: Depending on the specific needs of an organization, WANs can use different types of connections, such as leased lines, MPLS (Multiprotocol Label Switching), and public internet services. The type of connection affects the speed, reliability, and cost of the WAN.
Types of WAN Connections
WANs can be implemented using various types of connections, each with its own advantages and drawbacks. The type of connection chosen typically depends on factors like the size of the organization, the geographic distribution of its offices, and its budget.
Leased Lines: Leased lines are private, dedicated connections that offer high reliability and security. These lines are rented from telecom companies, and they provide a direct point-to-point connection between two locations. While leased lines are more expensive than other options, they are often used by businesses that require high levels of security and consistent performance.
MPLS (Multiprotocol Label Switching): MPLS is a popular choice for enterprise WANs. It is a private, high-performance connection that routes data based on labels instead of traditional IP addresses. MPLS offers better quality of service (QoS) by prioritizing certain types of data, making it ideal for applications like video conferencing or VoIP (Voice over IP).
Broadband Internet: Broadband internet, including DSL, fiber-optic, and cable, is a cost-effective option for smaller businesses or home offices that need WAN connections. However, broadband internet is less reliable and secure compared to leased lines or MPLS, making it less suitable for large enterprises or sensitive data transmission.
Satellite Connections: In areas where physical infrastructure like fiber-optic cables is not available, satellite connections can be used to create a WAN. While satellite WANs provide connectivity in remote or rural areas, they are often slower and more expensive than other options.
Virtual Private Network (VPN): A VPN is commonly used by businesses that need to securely connect remote workers or branch offices to the corporate network over the internet. VPNs create an encrypted “tunnel” through which data travels, ensuring privacy and security even over public networks.
Advantages of WANs
WANs offer numerous advantages, especially for businesses that operate across multiple locations or need to connect to remote resources. Some key benefits include:
Global Connectivity: The primary purpose of a WAN is to connect networks over large geographic distances. Whether it’s connecting offices in different countries or providing remote workers access to a central server, WANs make it possible for geographically dispersed teams to stay connected and productive.
Centralized Data and Resources: WANs allow organizations to centralize their resources, such as servers, databases, and applications. Employees at different locations can access these resources without the need for duplicating hardware or software at each site.
Scalability: WANs are highly scalable, making it easy for businesses to expand their network as they grow. New offices or locations can be added to the WAN without needing to overhaul the entire network infrastructure.
Reliability and Redundancy: Many WANs are designed with redundancy in mind, ensuring that if one part of the network fails, data can still be rerouted through other paths. This high level of reliability is critical for businesses that depend on continuous network access for their operations.
Improved Communication: WANs enhance communication by enabling services like VoIP, video conferencing, and instant messaging across distant locations. This helps businesses improve collaboration and decision-making across different branches.
Challenges and Limitations of WANs
Despite their many advantages, WANs also come with some challenges and limitations, particularly when compared to LANs:
Cost: Setting up and maintaining a WAN, especially one that uses leased lines or MPLS, can be expensive. Small businesses or startups may find the initial investment and ongoing costs of a private WAN to be prohibitive.
Complexity: WANs are far more complex than LANs due to the larger distances and the number of interconnected networks. Managing a WAN requires specialized knowledge and resources, making it necessary for companies to hire skilled network administrators.
Latency: Because data in a WAN has to travel longer distances, latency (the delay in data transmission) can be an issue. While advancements in technology have reduced this problem, it remains a concern, especially for real-time applications like video conferencing or online gaming.
Security: WANs, especially those that rely on public internet connections, are more vulnerable to security threats like hacking, eavesdropping, or data breaches. Organizations need to invest in robust security measures, such as encryption and firewalls, to protect their WAN.
The Future of WANs
As technology continues to evolve, so do WANs. The rise of cloud computing, 5G networks, and software-defined networking (SDN) is reshaping how WANs are designed and managed. For instance, SD-WAN (Software-Defined Wide Area Network) is a newer technology that allows businesses to manage their WANs through software, improving flexibility, reducing costs, and optimizing network performance.
The integration of 5G technology promises faster speeds and lower latency for WANs, making it easier for businesses to connect remote locations and access cloud services. As more organizations move their resources to the cloud, WANs will continue to play a crucial role in ensuring seamless access to data and applications.
Conclusion
Wide Area Networks (WANs)
are essential for businesses and organizations that operate across multiple locations or need to connect to remote resources. From the internet to corporate networks spanning continents, WANs enable global connectivity, centralized resources, and improved communication.
While WANs can be complex and costly to set up, their advantages in terms of scalability, reliability, and global reach make them an indispensable part of modern networking infrastructure. As new technologies like SD-WAN and 5G emerge, the future of WANs looks bright, offering even greater possibilities for connectivity and performance.
Understanding Local Area Networks (LANs)
In today’s digital age, connectivity is crucial for almost all forms of communication, collaboration, and productivity. Among the foundational pillars of modern networking is the Local Area Network (LAN). Though the term may seem familiar, the technology behind it plays an integral role in the smooth functioning of businesses, homes, and even schools.
This article aims to delve deep into the world of LANs, explaining what they are, how they work, their components, and why they remain an essential part of our networking infrastructure today.
What is a Local Area Network (LAN)?
A Local Area Network (LAN) is a type of computer network that links devices within a limited geographical area, typically a home, office, or school. These networks allow for the sharing of resources such as files, internet connections, printers, and other devices between connected systems. LANs are characterized by their small physical size, often covering distances measured in meters or a few kilometers, unlike Wide Area Networks (WANs) which span larger areas, including cities or even countries.
Key Components of a LAN
For a LAN to function, certain key components must be in place. These components include:
Devices (Nodes): Every LAN requires multiple devices that need to connect, such as computers, printers, and servers. Each device is called a node, and the network allows them to communicate with each other.
Network Interface Card (NIC): A NIC, sometimes referred to as a network adapter, allows a computer or device to connect to the network. Modern computers and devices often come with built-in NICs, but external adapters can be used when needed.
Switches: A switch is a device that connects multiple devices on a LAN and directs data packets to the appropriate devices. It ensures that the communication between devices within the network is efficient by minimizing data collisions and routing traffic intelligently.
Routers: Although routers are more commonly associated with connecting a LAN to the internet or other networks, they can also play a role within a LAN by managing data traffic and acting as a gateway for external communication.
Cabling (or Wi-Fi): Traditional LANs rely on physical cables, typically Ethernet cables, to connect devices to the network. However, with the rise of wireless technology, many modern LANs are now wireless, using Wi-Fi standards to facilitate connectivity without physical cables.
Access Points: For wireless LANs, access points are used to broadcast a Wi-Fi signal and allow devices to connect to the network wirelessly. These access points are often connected to a switch or router.
Servers: In larger LANs, servers are used to manage network resources and provide centralized services such as file storage, printing, and user authentication.
How Does a LAN Work?
A LAN operates through the transfer of data packets between devices within the network. Here’s a simplified breakdown of the process:
Connection Setup: Each device on the LAN is assigned a unique IP address (or MAC address) to identify it on the network. Devices can connect either via Ethernet cables (in a wired LAN) or through Wi-Fi (in a wireless LAN).
Data Transfer: When a device wants to communicate with another device on the network (e.g., sending a file), it breaks the data into smaller packets. These packets are then transmitted over the network to the destination device.
Switch Role: A switch ensures that the data packets are sent only to the intended device. It does this by reading the destination address of the packet and forwarding it accordingly, preventing unnecessary traffic.
Network Speed: LANs are known for their high data transfer speeds. Typical LAN speeds range from 100 Mbps to several gigabits per second, depending on the infrastructure in place (cabling, switches, etc.).
Access Control: LANs often implement security protocols to manage who can access the network and what resources they can use. For instance, network administrators might set up authentication systems that require users to log in with credentials.
Types of LAN Configurations
While LANs are often thought of as a single type of network, there are various configurations based on the needs of the network.
Wired LAN: The most traditional form of a LAN is wired, where devices are physically connected using Ethernet cables. Wired LANs typically provide faster speeds and more secure connections compared to wireless networks.
Wireless LAN (WLAN): WLANs have become increasingly popular due to their flexibility and ease of setup. Instead of cables, devices communicate via radio waves, usually within a limited range of an access point. Wireless LANs provide mobility but might suffer from interference and slower speeds compared to wired LANs.
Virtual LAN (VLAN): A VLAN is a subgroup of devices on a LAN that behave as if they were on the same physical network, even if they are spread across different physical locations. This segmentation helps improve security and manage network traffic more efficiently.
Advantages of LANs
The implementation of a LAN brings several benefits, especially for businesses and homes with multiple devices. Here are a few:
Resource Sharing: One of the biggest advantages of a LAN is the ability to share resources like printers, scanners, and files across all connected devices. This minimizes redundancy and reduces costs.
Speed: LANs, especially those that are wired, offer much faster data transfer speeds than WANs or internet connections. This makes LANs ideal for applications that require high-speed data transfer, such as file sharing and gaming.
Cost-Effective: Compared to other networking solutions, LANs are relatively inexpensive to set up and maintain. Once the infrastructure is in place, the cost of adding more devices to the network is minimal.
Security: With proper configuration, LANs can offer high levels of security. Network administrators can restrict access to sensitive information and use firewalls, encryption, and authentication systems to protect the network from unauthorized users.
Centralized Data Management: In a LAN, servers can manage and store all the data, providing a centralized backup and access control solution. This centralization reduces the risk of data loss and simplifies data management for businesses.
Challenges and Limitations of LANs
Despite the numerous advantages, LANs are not without their challenges:
Limited Range: A LAN is confined to a small geographic area, which limits its application to larger, more widespread operations. Businesses that have multiple branches or operate globally will need a WAN or another type of network for interconnection.
Security Risks: While LANs can be secure, they are also vulnerable to internal security breaches. If someone gains unauthorized access to a device within the LAN, they could potentially access all the shared resources.
Maintenance and Management: For larger LANs, regular maintenance is required to ensure optimal performance. This includes upgrading hardware, managing IP addresses, and troubleshooting connectivity issues, which may require skilled IT personnel.
Wireless Interference: In wireless LANs, interference from other electronic devices or physical obstructions can degrade network performance, leading to slower speeds and dropped connections.
The Future of LANs
With the advent of newer technologies like 5G, cloud computing, and the Internet of Things (IoT), one might question the future relevance of LANs. However, LANs remain a vital part of both personal and corporate networks. The high-speed data transfer, low latency, and resource-sharing capabilities of LANs ensure that they will continue to play an essential role in networking infrastructures for years to come.
LAN technology is also evolving. The rise of fiber-optic cables, mesh networking, and advanced security protocols are helping LANs stay competitive and capable of handling the increasing demands of modern digital environments.
Conclusion
Local Area Networks (LANs) are a fundamental building block of modern networking. From homes to businesses, LANs facilitate fast, reliable communication between devices, ensuring efficient resource sharing and data transfer. While they have certain limitations, the advantages of speed, security, and cost-effectiveness make LANs a popular choice for small to medium-sized networks.
As technology continues to evolve, so will the capabilities of LANs, ensuring they remain a critical component in our increasingly connected world. Whether you’re setting up a small home network or managing a corporate network, understanding the principles and benefits of a LAN is essential to making the most of your networking infrastructure.
NetBIOS: A Primer
Introduction
NetBIOS, or Network Basic Input/Output System, is a legacy network protocol primarily used on Microsoft Windows systems. It provides a simple interface for applications to access network services, such as file sharing, printing, and naming resolution. While it has been largely superseded by more modern protocols like TCP/IP, NetBIOS remains relevant in certain legacy environments and specific network configurations.
This comprehensive blog post will delve into the intricacies of NetBIOS, exploring its history, functionality,components, and its role in contemporary networking.
History of NetBIOS
NetBIOS was originally developed by IBM in the early 1980s as a component of the PC-DOS operating system. Its primary purpose was to provide a basic networking capability for personal computers, enabling them to share files and printers over local area networks (LANs).
As Microsoft Windows gained popularity, NetBIOS was incorporated into the operating system and became a fundamental component of its networking architecture. However, with the widespread adoption of TCP/IP,NetBIOS gradually became less essential, as TCP/IP offered a more versatile and scalable networking solution.
NetBIOS Functionality
NetBIOS operates on the datalink layer of the OSI model, providing a set of services for applications to communicate with each other on a network. Key functionalities of NetBIOS include:
Name resolution: NetBIOS allows applications to resolve names of network resources, such as computers and printers, into their corresponding network addresses.
Session management: NetBIOS manages sessions between applications, allowing them to establish connections and exchange data.
Datagram services: NetBIOS provides a datagram service for sending and receiving short messages without requiring a connection.
NetBIOS Components
NetBIOS consists of several key components:
NetBIOS Name Service (NBNS): This component resolves NetBIOS names into their corresponding network addresses. NBNS uses a broadcast-based protocol to locate other computers on the network.
NetBIOS Interface Message Processor (NIB): The NIB is responsible for encapsulating NetBIOS messages into network frames and vice versa. It interacts with the underlying network interface card (NIC) to transmit and receive data.
NetBIOS Workgroup: A NetBIOS workgroup is a logical grouping of computers that share resources.Computers within the same workgroup can easily communicate with each other using NetBIOS.
NetBIOS Over TCP/IP (NBT)
To integrate NetBIOS with TCP/IP networks, Microsoft introduced NetBIOS Over TCP/IP (NBT). NBT provides a way for NetBIOS applications to communicate over TCP/IP networks, allowing them to coexist with other TCP/IP-based applications. NBT uses TCP port 139 for session-oriented communication and UDP port 137 for name resolution.
NetBIOS and Modern Networking
While NetBIOS has been largely replaced by TCP/IP-based protocols in modern networking environments,it still has relevance in certain scenarios. Some common use cases for NetBIOS include:
Legacy applications: Some older applications may still rely on NetBIOS for network communication.
Small networks: In small, simple network environments, NetBIOS can provide a basic networking solution.
Specific services: Certain services, such as file and print sharing, may still use NetBIOS.
Challenges and Considerations:
Security: NetBIOS can be vulnerable to security attacks, such as spoofing and denial of service (DoS) attacks. Proper security measures, such as firewalls and intrusion detection systems, should be implemented to protect NetBIOS networks.
Scalability: NetBIOS may not be suitable for large-scale networks due to its broadcast-based name resolution mechanism.
Compatibility: NetBIOS may not be compatible with all network operating systems or hardware.
Conclusion
NetBIOS, while a legacy protocol, continues to play a role in certain networking environments.Understanding its functionality, components, and integration with TCP/IP is essential for network administrators and IT professionals working with older systems or specific network configurations. As modern networking technologies continue to evolve, NetBIOS is likely to become increasingly less prevalent, but its historical significance and continued use in certain niche areas cannot be ignored.
IoT: Understanding the Internet of Things
Introduction
The Internet of Things (IoT) has emerged as a revolutionary technology, connecting everyday objects to the internet, creating a vast network of interconnected devices. From smart homes to industrial automation, IoT is transforming industries and reshaping our daily lives.
This comprehensive blog post will delve into the intricacies of IoT, exploring its fundamental concepts, applications, benefits, challenges, and future prospects.
Understanding IoT
IoT refers to the interconnection of physical devices, vehicles, home appliances, and other objects embedded with electronics, software, sensors, and network connectivity. These devices collect and exchange data, enabling them to communicate and interact with each other.
Key Components of IoT:
Devices: These include sensors, actuators, and microcontrollers that collect, process, and transmit data.
Connectivity: Networks like Wi-Fi, Bluetooth, cellular, and low-power wide-area networks (LPWANs) provide communication channels for IoT devices.
Data Processing: Cloud computing and edge computing platforms handle data analysis, storage, and processing.
Applications: IoT solutions are implemented across various domains, from smart cities and healthcare to agriculture and manufacturing.
Applications of IoT
IoT has found applications in numerous sectors, revolutionizing the way we live, work, and interact with our environment. Here are some prominent examples:
Smart Homes:
Home automation: Control lights, thermostats, security systems, and appliances remotely.
Energy management: Optimize energy consumption and reduce costs.
Smart appliances: Appliances with built-in IoT capabilities.
Healthcare:
Remote patient monitoring: Track vital signs and provide timely medical assistance.
Wearable devices: Monitor health metrics and fitness activities.
Medical IoT: Improve patient care and efficiency in healthcare facilities.
Agriculture:
Precision agriculture: Optimize farming practices using data-driven insights.
Smart irrigation: Efficiently manage water usage based on soil moisture and weather conditions.
** Livestock monitoring:** Track animal health and behavior.
Manufacturing:
Industrial IoT (IIoT): Enhance productivity, efficiency, and quality control in manufacturing processes.
Predictive maintenance: Prevent equipment failures and reduce downtime.
Supply chain management: Optimize logistics and inventory management.
Transportation:
Connected vehicles: Improve safety, traffic management, and fuel efficiency.
Autonomous vehicles: Self-driving cars and trucks.
Smart parking: Optimize parking space utilization.
Cities:
Smart cities: Improve urban infrastructure, resource management, and citizen services.
Smart grids: Optimize energy distribution and consumption.
Traffic management: Reduce congestion and improve transportation efficiency.
Benefits of IoT
IoT offers numerous benefits across various industries and applications, including:
Increased efficiency: Streamline processes, reduce costs, and improve productivity.
Enhanced decision-making: Data-driven insights enable informed decision-making.
Improved customer experience: Personalized services and enhanced customer satisfaction.
Enhanced safety: Monitor safety conditions and prevent accidents.
Sustainability: Optimize resource usage and reduce environmental impact.
Challenges and Considerations
Despite its immense potential, IoT faces several challenges:
Security: Protecting IoT devices and data from cyber threats is a major concern.
Privacy: Ensuring privacy and data protection in IoT applications is crucial.
Interoperability: Ensuring compatibility and seamless communication between different IoT devices and systems.
Scalability: Handling the vast amount of data generated by IoT devices and ensuring scalability.
Cost: The initial investment in IoT infrastructure and devices can be significant.
The Future of IoT
The future of IoT is promising, with continued advancements in technology and increasing adoption across various sectors. Some key trends to watch include:
Edge computing: Processing data closer to the source to reduce latency and improve responsiveness.
Artificial intelligence (AI) and machine learning: Leveraging AI to extract valuable insights from IoT data.
5G connectivity: Providing faster speeds, lower latency, and greater capacity for IoT devices.
Internet of Medical Things (IoMT): Transforming healthcare with connected medical devices.
Industrial Internet of Things (IIoT): Driving digital transformation in manufacturing and industry.
Conclusion
IoT is a transformative technology that is reshaping the way we live, work, and interact with the world. By connecting everyday objects to the internet, IoT enables new possibilities, improves efficiency, and enhances our quality of life. As the technology continues to evolve, we can expect to see even more innovative applications and benefits in the years to come.
What is LLM (Large Language Model)? A Comprehensive Guide
The rapid advancement of Artificial Intelligence (AI) has opened up a world of possibilities, from self-driving cars to voice assistants and chatbots. Among the most impressive developments in AI is the creation of Large Language Models (LLMs). These AI models are transforming the way machines understand and generate human language, unlocking new potentials in natural language processing (NLP) tasks. But what exactly is an LLM, and how does it work?
In this blog post, we’ll explore what Large Language Models are, how they function, their practical applications, and the potential benefits and challenges they pose. Whether you’re an AI enthusiast, a business leader looking to integrate AI into your operations, or someone curious about the technology shaping our future, this guide will provide you with a solid understanding of LLMs.
- What is a Large Language Model (LLM)?
A Large Language Model (LLM) is a type of artificial intelligence model specifically designed to understand, process, and generate human language. These models are built on machine learning algorithms, especially a subset of machine learning called deep learning, that allows them to perform a wide range of natural language processing (NLP) tasks such as translation, summarization, answering questions, and even writing creative content.
What makes an LLM “large” is its scale — both in terms of the number of parameters (the variables in the model that are learned during training) and the size of the datasets used to train it. These models are typically trained on massive amounts of text data from diverse sources like books, websites, and academic articles, allowing them to learn the intricate patterns and structures of language.
Popular examples of LLMs include GPT-4 (used by ChatGPT), BERT by Google, and T5 by Google Research. The growing size of these models (some have billions of parameters) allows them to generate human-like text that is often indistinguishable from text written by humans. 2. How Do LLMs Work?
LLMs rely on deep learning techniques, particularly neural networks, to process and understand language. Here’s a simplified breakdown of how they work:
a) Training Phase
LLMs are trained using a method called unsupervised learning. In this phase, the model is fed vast amounts of text data (ranging from news articles to books) without being explicitly told what to learn. The model processes this data and identifies patterns, relationships between words, sentence structures, and context.
For example, when reading a sentence like “The cat sat on the mat,” the LLM learns the associations between “cat” and “sat” or “sat” and “mat,” thus understanding the structure and meaning of the sentence. As the model continues to process more text, it improves its ability to predict the next word in a sequence, a key feature of language models.
b) Parameters and Tokens
The intelligence of an LLM is embedded in its parameters. Parameters are the values that the model adjusts during training to optimize its ability to make predictions. In the context of language, these parameters help the model determine the likelihood of a word appearing in a certain position based on the surrounding words.
Another important concept is the use of tokens. In LLMs, text is broken down into smaller units called tokens, which could be words, subwords, or even characters. By working with tokens, the model can process even complex sentences, capturing the context and meaning.
c) Transformer Architecture
Most modern LLMs, including GPT and BERT, are built on a deep learning architecture known as Transformers. The Transformer model is revolutionary because it processes words in parallel, allowing it to handle large amounts of text efficiently and understand the relationships between words, even if they are far apart in a sentence.
Key components of Transformers include:
Self-Attention Mechanism: This allows the model to weigh the importance of different words in a sentence relative to one another, enabling it to focus on the context most relevant to understanding the meaning.
Feedforward Neural Networks: These networks process the data and output predictions, such as the next word in a sentence or the answer to a question.
- Key Features of Large Language Models
LLMs are known for their impressive capabilities, but there are several specific features that make them stand out:
a) Contextual Understanding
Unlike earlier AI models, LLMs can understand and generate language based on context. They can grasp the meaning of words depending on the surrounding text and maintain coherence across sentences and paragraphs.
b) Few-Shot Learning
LLMs like GPT-4 are capable of few-shot learning, meaning they can perform tasks with minimal examples or training. For example, if you provide the model with a few examples of how to answer a certain type of question, it can generalize that information and apply it to new questions.
c) Multitasking Ability
LLMs can handle multiple NLP tasks within the same framework. They can summarize text, answer questions, translate languages, and even write creative stories without requiring task-specific training.
d) Human-Like Text Generation
Perhaps the most remarkable feature of LLMs is their ability to generate text that closely mimics human writing. The text they produce is coherent, contextually relevant, and often indistinguishable from human-created content. 4. Popular Examples of Large Language Models
Several LLMs have gained widespread attention due to their power and versatility. Some of the most well-known include:
a) GPT-4 (Generative Pre-trained Transformer 4)
Developed by OpenAI, GPT-4 is one of the most advanced language models available today. It is capable of generating high-quality text based on prompts and is widely used for tasks like chatbot development, content generation, and code writing.
b) BERT (Bidirectional Encoder Representations from Transformers)
BERT, developed by Google, is a transformer-based model designed to understand the context of words in a sentence by looking at both the words before and after them (hence the “bidirectional” in its name). BERT has become a core component of Google Search, helping to deliver more relevant search results.
c) T5 (Text-to-Text Transfer Transformer)
T5, also developed by Google, takes a different approach by treating all NLP tasks as a text-to-text problem. Whether it’s translation, summarization, or answering questions, T5 converts the task into a text transformation challenge. 5. Applications of LLMs in the Real World
LLMs have a broad range of applications, many of which are already transforming industries:
a) Content Creation
LLMs can generate human-like text for blogs, social media posts, and marketing materials. With AI tools, content creators can quickly produce high-quality drafts, saving time and effort.
b) Customer Service
LLM-powered chatbots are improving customer service by handling inquiries, resolving issues, and offering personalized support. These bots are capable of understanding complex queries and providing accurate, context-aware responses.
c) Translation Services
Models like GPT-4 and T5 have significantly improved machine translation, enabling real-time, accurate translations of text from one language to another. This has applications in everything from global business communication to travel.
d) Healthcare
In healthcare, LLMs can analyze patient data, assist in diagnostics, and even generate clinical reports. Their ability to process vast amounts of medical literature makes them valuable tools for healthcare professionals seeking the latest research and insights.
e) Coding and Software Development
LLMs are increasingly being used in software development. Tools like GitHub Copilot, powered by GPT-4, help developers by suggesting code snippets and solutions, thereby accelerating the coding process and reducing errors. 6. Benefits and Challenges of LLMs
LLMs offer many advantages, but they also present several challenges that need to be addressed.
Benefits
Versatility: LLMs can perform a wide variety of tasks, from writing content to answering technical questions, all within the same model.
Efficiency: Automating tasks like customer support and content creation can save businesses time and money.
Continuous Learning: These models can improve over time with additional training data, becoming more accurate and capable.
Challenges
Bias and Fairness: LLMs can inherit biases from the datasets they are trained on, leading to skewed or unfair outputs.
Data Requirements: Training LLMs requires vast amounts of data and computational resources, making them accessible only to large organizations.
Interpretability: LLMs often operate as “black boxes,” meaning their decision-making processes are not always transparent or easy to understand.
- The Future of Large Language Models
The future of LLMs is incredibly promising, with research and development focusing on making these models more efficient, ethical, and accessible. Innovations like Federated Learning, which allows models to learn from decentralized data sources, and Explainable AI, which aims to make AI decision-making more transparent, are set to drive the next wave of advancements in this field.
Additionally, the integration of LLMs into everyday applications will continue to grow, making AI-driven technologies more seamless and ubiquitous in our daily lives. 8. Conclusion
Large Language Models (LLMs) represent
one of the most exciting developments in AI today. From powering intelligent chatbots to transforming content creation and improving machine translation, LLMs are reshaping how we interact with technology. While challenges remain, particularly around bias and interpretability, the potential benefits are vast.
As AI continues to evolve, understanding the fundamentals of LLMs will become increasingly important, not just for developers but for anyone interested in the future of technology. Whether you’re looking to integrate LLMs into your business or simply curious about the technology driving some of today’s most innovative tools, LLMs are certainly something to watch. In a world driven by data and communication, Large Language Models will continue to be at the forefront of AI innovation, shaping the future of human-machine interaction.
Understanding AI Models: A Comprehensive Guide to the World of Artificial Intelligence
Artificial Intelligence (AI) is transforming industries across the globe, from healthcare and finance to entertainment and transportation. Behind every AI application, whether it’s a voice assistant like Siri or an advanced self-driving car, lies a complex system of AI models. These models are the core of AI technology, allowing machines to process information, learn from data, and make intelligent decisions.
In this blog post, we’ll take a deep dive into what AI models are, how they work, the various types of AI models, and their real-world applications. Whether you’re a tech enthusiast, a professional exploring AI for your business, or simply curious about the technology that powers modern innovations, this post will provide a comprehensive understanding of AI models.
- What Are AI Models?
An AI model is a computational program that is trained to perform specific tasks by learning from data. At the core of these models is the ability to simulate human-like decision-making and problem-solving processes. By analyzing vast amounts of data, AI models can identify patterns, make predictions, and even improve their performance over time.
In simpler terms, think of an AI model as a recipe. Just as a chef follows a recipe to make a dish, an AI model follows a set of instructions (algorithms) to process data and produce a result. The key difference is that AI models have the ability to “learn” from the data they process, meaning they can adjust their behavior based on experience and feedback, leading to more accurate outcomes.
The development of AI models involves three critical stages:
Data Collection – Gathering relevant data.
Training – Feeding the data to the model so it can learn and adapt.
Testing and Deployment – Assessing the model’s performance and applying it to real-world tasks.
- How AI Models Work
AI models are built on the foundation of algorithms—mathematical and computational formulas that process input data to produce output. During the training phase, these models learn by identifying patterns within large datasets. They then apply this learning to make predictions or decisions on new, unseen data.
The process of building and using an AI model generally involves the following steps:
Data Input: Raw data is collected and inputted into the system. This can include text, images, video, audio, or even sensory data from IoT devices.
Feature Selection: The AI system extracts important variables or “features” from the data that will help the model understand patterns. For example, in a spam detection model, features might include email length, subject lines, and the presence of specific keywords.
Training the Model: The model is trained using this data by adjusting its internal parameters to minimize errors and make more accurate predictions.
Testing: Once the model has been trained, it’s tested on a separate dataset to assess its accuracy and generalization ability (how well it performs on new data).
Fine-Tuning: If the model’s performance isn’t optimal, adjustments are made to improve accuracy. This may involve tuning hyperparameters or using different types of algorithms.
Deployment: After the model reaches a satisfactory level of performance, it is deployed in real-world applications where it continues to operate and improve with new data.
This cycle of training, testing, and fine-tuning is the essence of building an AI model that can effectively make decisions and solve problems.
- Types of AI Models
There are various types of AI models, each designed to solve specific problems. The most common include Machine Learning, Deep Learning, Reinforcement Learning, and Generative AI models. Let’s break these down:
3.1 Machine Learning Models
Machine Learning (ML) models use statistical techniques to enable computers to “learn” from data without being explicitly programmed. These models rely on large datasets to identify patterns and make predictions. ML models can be classified into three main types:
Supervised Learning: In supervised learning, the model is trained on a labeled dataset, meaning that the input data is paired with the correct output. The goal is for the model to learn from this training data so it can predict outcomes on new, unseen data. A common example is email spam filtering.
Unsupervised Learning: Unsupervised learning works with unlabeled data, meaning the model must find hidden patterns or relationships in the data. Clustering and association are common tasks in unsupervised learning, such as grouping similar customer profiles or discovering market trends.
Semi-supervised Learning: This method is a blend of supervised and unsupervised learning. It uses a small amount of labeled data along with a large amount of unlabeled data to build more accurate models. It’s often used when labeled data is expensive or difficult to obtain.
3.2 Deep Learning Models
Deep Learning is a subset of machine learning that uses artificial neural networks to mimic the workings of the human brain. Deep learning models are highly effective for tasks that require large-scale data analysis, such as image recognition, natural language processing (NLP), and autonomous driving.
Neural Networks: These are the backbone of deep learning models. A neural network is composed of layers of interconnected “neurons” that process data and pass information from one layer to the next. Deep neural networks have many hidden layers, which allow them to identify intricate patterns in data.
Convolutional Neural Networks (CNNs): Used primarily for image and video recognition tasks, CNNs can detect patterns like edges, textures, and shapes in visuals. They are commonly employed in facial recognition software and self-driving cars.
Recurrent Neural Networks (RNNs): RNNs are used for sequential data, such as time series or natural language. They have memory-like structures that help them process data over time, making them ideal for tasks like speech recognition or translation.
3.3 Reinforcement Learning Models
Reinforcement Learning (RL) models learn through trial and error, making them different from supervised or unsupervised learning models. In reinforcement learning, an agent (AI model) interacts with an environment and receives feedback in the form of rewards or penalties. The model learns to make better decisions by maximizing rewards over time.
- Real-World Examples: RL is commonly used in areas like robotics, where a machine must learn how to perform tasks like walking or grasping objects. It’s also a key technology behind video game AI, where characters learn to adapt to player actions.
3.4 Generative AI Models
Generative AI focuses on creating new data that resembles the training data. These models generate everything from text to images and even video, based on patterns they learn from existing data. Two popular types of generative AI are:
Generative Adversarial Networks (GANs): GANs use two neural networks—a generator and a discriminator—that compete against each other. The generator creates new data, while the discriminator evaluates how real or fake that data is. GANs are used for tasks like creating realistic images or enhancing low-resolution images.
Transformer Models: A key development in natural language processing, transformers like GPT-4 are generative models capable of producing human-like text based on input prompts. These models are the foundation of many modern AI chatbots and language translation tools.
- Real-World Applications of AI Models
AI models have found their way into various industries, revolutionizing how tasks are performed. Here are some common applications:
Healthcare: AI models are used for diagnosing diseases, predicting patient outcomes, and discovering new drugs. For example, ML models can analyze medical images to detect early signs of cancer.
Finance: In finance, AI models predict stock market trends, manage risk, and detect fraud. Algorithms are also used to automate trading, enhancing speed and accuracy in financial markets.
Customer Service: AI-powered chatbots and virtual assistants use NLP models to answer customer queries, handle complaints, and provide support 24/7.
E-commerce: Recommendation engines powered by AI models suggest products based on user behavior and preferences, boosting sales and enhancing customer experience.
Autonomous Vehicles: Deep learning models help self-driving cars interpret their environment, avoid obstacles, and make real-time driving decisions.
- Challenges and Limitations of AI Models
Despite their incredible potential, AI models are not without challenges:
Data Dependency: AI models rely heavily on large amounts of data. Without high-quality, labeled data, the model’s accuracy can be significantly affected.
Bias and Fairness: AI models can inherit biases present in the data used for training, leading to unfair or discriminatory outcomes, especially in sensitive fields like hiring or lending.
Complexity: Advanced AI models, particularly deep learning models, require significant computational resources and expertise, making them difficult to implement for smaller organizations.
Interpretability: Many AI models, particularly deep learning networks, operate as “black boxes,” meaning it’s hard to understand how they arrive at specific decisions, which raises ethical and regulatory concerns.
- The Future of AI Models
AI models are evolving rapidly, with advancements in areas like quantum computing and federated learning. As AI continues to progress, we can expect more accurate, efficient, and ethically sound models that can tackle even more complex tasks. From self-improving models to explainable AI, the future of AI models looks promising.
- Conclusion
AI models are the backbone of artificial intelligence, transforming how machines learn, reason, and interact with the world. From machine learning to deep learning and beyond, these models power a wide array of applications that make our lives easier, more efficient, and more connected.
While challenges remain, the continued evolution of AI models promises to drive innovation in nearly every field, making them an essential part of the future of technology. By understanding the basics of AI models and their real-world applications, you can better appreciate the power and potential that AI holds for the future.
Whether you’re a business leader, developer, or just someone curious about AI, now is the perfect time to explore the endless possibilities AI models offer!
Understanding Network Address Translation (NAT): A Comprehensive Guide
In today’s interconnected world, the internet has become an integral part of our daily lives. However, have you ever wondered how millions of devices can connect to the internet simultaneously when there aren’t enough unique IP addresses to go around? The answer lies in a crucial technology called Network Address Translation, or NAT for short. In this post, we’ll dive deep into NAT, exploring its purpose, functionality, types, and impact on modern networking.
What is Network Address Translation (NAT)?
Network Address Translation is a method used in computer networking that allows multiple devices on a local network to share a single public IP address when connecting to the internet. It acts as a mediator between your private network and the public internet, translating private IP addresses into a public IP address and vice versa.
The Purpose of NAT
NAT serves several important purposes in modern networking:
Conservation of IP addresses: With the exponential growth of internet-connected devices, the available IPv4 addresses are becoming scarce. NAT allows multiple devices to share a single public IP address, significantly reducing the demand for unique public IP addresses.
Enhanced security: By hiding the internal network structure behind a single public IP address, NAT acts as a basic firewall, making it more difficult for external threats to directly access devices on the private network.
Simplified network management: NAT enables network administrators to use private IP addressing schemes within their local networks, providing more flexibility in network design and management.
How Does NAT Work?
To understand how NAT works, let’s break down the process step by step:
Outgoing traffic:
A device on the private network sends a request to access a resource on the internet.
The NAT device (usually a router) receives this request and replaces the device’s private IP address with its own public IP address.
The NAT device also modifies the source port number and keeps track of this translation in its NAT table.
The modified request is then sent out to the internet.
Incoming traffic:
When the response from the internet arrives, it’s addressed to the public IP of the NAT device.
The NAT device checks its NAT table to determine which internal device the response should be sent to.
It then replaces its own public IP address with the private IP address of the intended recipient device.
Finally, the response is forwarded to the correct device on the private network.
This process happens seamlessly and quickly, allowing for smooth internet communication while maintaining the benefits of private addressing.
Types of NAT
There are several types of NAT, each with its own characteristics and use cases:
- Static NAT
Static NAT involves a one-to-one mapping between a private IP address and a public IP address. This type of NAT is typically used when a device on the private network needs to be accessible from the internet, such as a web server or email server.
Pros:
Allows inbound connections, making it suitable for hosting services.
Provides a consistent public IP for specific devices.
Cons:
Requires a unique public IP address for each mapped device, which doesn’t conserve IP addresses.
Can be more expensive due to the need for multiple public IP addresses.
- Dynamic NAT
Dynamic NAT uses a pool of public IP addresses and assigns them to private IP addresses as needed. When a device on the private network requests internet access, it’s assigned the first available public IP from the pool.
Pros:
More efficient use of public IP addresses compared to Static NAT.
Provides some level of anonymity as the public IP changes.
Cons:
Still requires multiple public IP addresses.
Doesn’t allow inbound connections unless specifically configured.
- Port Address Translation (PAT) / Network Address Port Translation (NAPT)
PAT, also known as NAT overload, is the most common form of NAT used in home and small business networks. It allows multiple devices to share a single public IP address by using different port numbers for each connection.
Pros:
Extremely efficient use of public IP addresses.
Provides good security by hiding internal network structure.
Cost-effective for large networks.
Cons:
Can cause issues with some applications that require specific port mappings.
Makes it challenging to host services that require inbound connections.
NAT and IPv6
While NAT has been crucial in extending the lifespan of IPv4 addressing, the adoption of IPv6 is changing the landscape. IPv6 provides an enormous address space, theoretically eliminating the need for NAT. However, NAT still plays a role in IPv6 networks:
NAT64: This technology allows communication between IPv6 and IPv4 networks, essential during the transition period.
NPTv6 (Network Prefix Translation for IPv6): While not as common, this can be used for network renumbering or multihoming scenarios in IPv6 networks.
Challenges and Considerations
While NAT has been instrumental in sustaining the growth of the internet, it’s not without its challenges:
Application compatibility: Some applications, particularly those requiring peer-to-peer connections or specific port assignments, may face issues with NAT.
Complexity in troubleshooting: NAT can make network troubleshooting more complex, as it adds an extra layer of address translation.
Performance overhead: Although minimal in most cases, NAT does introduce some processing overhead, which can be noticeable in high-traffic scenarios.
Security implications: While NAT provides a basic level of security, it shouldn’t be relied upon as the sole security measure. Additional firewalling and security practices are still necessary.
Best Practices for NAT Implementation
To ensure optimal performance and security when using NAT, consider the following best practices:
Use appropriate NAT types: Choose the type of NAT that best fits your network requirements and scale.
Implement proper security measures: Don’t rely solely on NAT for security. Use firewalls, intrusion detection systems, and other security tools in conjunction with NAT.
Keep NAT devices updated: Regularly update the firmware of your NAT devices to ensure they have the latest security patches and performance improvements.
Monitor NAT performance: Keep an eye on your NAT device’s performance, especially in high-traffic environments, to ensure it’s not becoming a bottleneck.
Plan for IPv6 transition: While NAT remains important, start planning for the transition to IPv6 to future-proof your network.
Conclusion
Network Address Translation has been a cornerstone technology in the growth and scalability of the internet. By allowing multiple devices to share a single public IP address, NAT has not only conserved the limited IPv4 address space but also provided an additional layer of security for private networks.
As we move towards wider adoption of IPv6, the role of NAT may evolve, but its importance in managing and securing network communications remains significant. Understanding NAT and its various implementations is crucial for network administrators, IT professionals, and anyone interested in the inner workings of internet connectivity.
Whether you’re managing a home network or a large corporate infrastructure, NAT continues to play a vital role in connecting our digital world. By implementing NAT effectively and staying aware of its strengths and limitations, we can ensure more efficient, secure, and scalable network communications for years to come.